-### C 语言基础
+### 学习 C 语言
***
@@ -140,7 +140,7 @@
-### 代码练习
+### C 经典练习题
***
@@ -175,6 +175,8 @@
+
+
### 读书笔记
***
@@ -202,7 +204,7 @@
-### C 语言小游戏
+### 用 C 实现的小游戏
***
@@ -218,7 +220,7 @@
-### C 语言课程设计作业
+### C 课程设计作业
***
diff --git a/content/c-notes/你不知道的几种素数判断方法,由浅入深,详解.md b/content/c-notes/你不知道的几种素数判断方法,由浅入深,详解.md
new file mode 100644
index 0000000..e7993c4
--- /dev/null
+++ b/content/c-notes/你不知道的几种素数判断方法,由浅入深,详解.md
@@ -0,0 +1,252 @@
+我们要判断素数,首先要知道素数的定义。
+
+> 素数:质数又称素数。一个大于1的自然数,除了1和它自身外,不能被其他自然数整除的数叫做质数;否则称为合数。
+
+知道了素数的定义,那么我们应该想一下,如何去判断一个数是否为素数?
+
+> 一种思路是,我们在每次得到一个数后,都去计算,去尝试因式分解它,看它除了1和自身之外还有没有其他因子
+> 另一种是,我们去查阅素数表,看这个数在不在素数表上。那我们就要先得到素数表。
+
+以下除了第一种方法,第2~4种方法都是用第二种思路做的
+当要判断的目标数很少时,第一种高效。但是当给定的目标数组很多,数也很大时。后面的思路配上高效的查找算法,显然更高效
+
+------
+
+### 方法1:暴力求解
+
+1-1:稍微动动脑
+
+> **思想**:
+> 根据素数的定义思考。素数是大于1的自然数,除了1和自身外,其他数都不是它的因子。
+> 那我们就可以用一个循环,从2开始遍历到这个数减去1,如果这个数都不能被整除,那么这个数就是素数。
+> 也就是说:
+> 给定一个数 n , i 从 2 开始取值,直到 n - 1(取整数),如果 n % i != 0 , n 就是素数
+> 进一步思考,有必要遍历到 n - 1 吗?
+> 除了1以外,任何合数最小的因子就是2,那最大的因子就是 n/2
+> 那我们就遍历到 n/2就足够了
+
+这样我们就可以写出这个算法的核心代码:
+
+```
+int isPrime(int target) {
+
+ int i = 0;
+
+ if (target <= 1) {
+ printf("illegal input!\n");//素数定义
+ return -1;
+ }
+
+ for (i = 2; i <= target / 2; i++) {
+ if (target % i == 0)
+ return 0;//不是素数直接返回0
+ }
+
+ return 1;//是素数返回1
+}
+```
+
+
+
+1-2:再进一步
+
+> **思想**:
+>
+> 在上面的基础上,其实不需要遍历到 n/2,只需要到 根号n(包含根号n) 就可以了。为什么呢?这是个数学问题,大家自行思考一下。
+
+核心代码:
+
+```
+int isPrime(int target) {
+
+ int i = 0;
+
+ if (target <= 1) {
+ printf("illegal input!\n");//素数定义
+ return -1;
+ }
+
+ for (i = 2; i <= (int)sqrt(target); i++) {
+ if (target % i == 0)
+ return 0;
+ }
+
+ return 1;
+}
+```
+
+
+
+------
+
+> 从第二种方法开始,我们都是先完成判断素数数组,然后用二分法去查找判断数组
+>
+> 这里说一下以下三种方法牵扯的概念:
+>
+> - 范围:1 ~ 范围上限N
+> - 范围上限N:判断素数需要用户输入随机素数,这个随机素数的范围是1 ~ N
+> - 判断素数数组:将数组的`下标`与`1 ~ N`的自然数一一对应起来。
+> 判断 1到N 的自然数是否为素数,其实就是判断数组的下标是否为素数,如果是 给这个下标所对应的判断素数数组元素赋1,否则赋0
+> 比如:我要判断3是否为素数,我们就找到`判断素数数组isPrime`中的下标为3的元素,即:`isPrime[3]`
+> 如果 `3` 是素数 , 赋值1,即`isPrime[3] = 1`
+> `如果 3 不是素数,赋值0 ,即isPrime[3] = 0`
+> 这样我们在用二分法查找时,查找数组下标就可以,找到下标后返回下标对应的判断素数数组的值。
+> 如果是1说明下标对应的自然数是素数,否则不是
+
+------
+
+### 方法2:用素数表来判断素数
+
+> **思路**:
+> 如果一个数不能整除比它小的任何素数,那么这个数就是素数
+> 这种“打印”素数表的方法效率很低,不推荐使用,可以学习思想
+
+核心代码:
+
+```
+//target:输入的要查找的数
+//count:当前已知的素数个数
+//PrimeArray:存放素数的数组
+int isPrime(int target, int count, int* PrimeArray) {
+
+ int i = 0;
+ for (i = 0; i < count; i++) {
+ if (target % PrimeArray[i] == 0)
+ return 0;
+ }
+
+ return 1;
+}
+```
+
+
+
+------
+
+### 方法3:普通筛法——埃拉托斯特尼(Eratosthenes)筛法
+
+> **思路**:
+> \1. 我们的想法是,创建一个比范围上限大1的数组,我们只关注下标为 1 ~ N(要求的上限) 的数组元素与数组下标(一一对应)。
+> \2. 将数组初始化为1。然后用for循环,遍历范围为:【2 ~ sqrt(N)】。如果数组元素为1,则说明这个数组元素的下标所对应的数是素数。
+> \3. 随后我们将这个下标(除1以外)的整数倍所对应的数组元素全部置为0,也就是判断其为非素数。
+> 这样,我们就知道了范围内(1 ~ 范围上限N)所有数是素数(下标对应的数组元素值为1)或不是素数(下标对应的数组元素值为0)
+
+> 用百度百科对埃拉托斯特尼筛法简单描述:**要得到自然数n以内的全部素数,必须把不大于 的所有素数的倍数剔除,剩下的就是素数。**
+
+核心代码:
+
+```
+// 判断素数的数组 范围上限N
+void Eratprime(int* isprime, int upper_board) {
+
+ int i = 0;
+ int j = 0;
+ //初始化isprime
+ for (i = 2; i <= upper_board; i++)
+ isprime[i] = 1;
+
+
+ for (i = 2; i < (int)sqrt(upper_board); i++) {
+ if (isprime[i]) {
+ isprime[i] = 1;
+ }
+ for (j = 2; i * j <= upper_board; j++) {//素数的n倍(n >= 2)不是素数
+ isprime[i * j] = 0;
+ }
+ }
+
+}
+```
+
+
+
+------
+
+### 方法4:线性筛法——欧拉筛法
+
+> **思路**:
+> 我们再思考一下上面的埃拉托斯特尼筛法,会发现,在“剔除“非素数时,有些合数会重复赋值。这样就会增加复杂度,降低效率。
+> 比如:范围上限N = 16时
+>
+> ```
+> 2是素数,剔除”2 的倍数“,它们是:4,6, 8,10, 12, 14, 16
+> 3是素数,剔除”3 的倍数”,它们是,6,9,12,15
+> ```
+>
+> 
+>
+> 6,12是重复的。如何减少重复呢?
+
+核心代码:
+
+```
+void PrimeList(int* Prime, bool* isPrime, int n) {
+
+ int i = 0;
+ int j = 0;
+ int count = 0;
+
+ if (isPrime != NULL) {//确保isPrime不是空指针
+ //将isPrime数组初始化为 1
+ for (i = 2; i <= N; i++) {
+ isPrime[i] = true;
+ }
+ }
+
+ if (isPrime != NULL && Prime != NULL) {
+ //从2遍历到范围上限N
+ for (i = 2; i <= N; i++) {
+ if (isPrime[i])//如果下标(下标对应着1 ~ 范围上限N)对应的isPrime值没有被置为false,说明这个数是素数,将下标放入素数数组
+ Prime[count++] = i;
+ //循环控制表达式的意义:j小于等于素数数组的个数 或 素数数组中的每一个素数与 i 的积小于范围上限N
+ for (j = 0; (j < count) && (Prime[j] * (long long)i) <= N; j++)//将i强制转换是因为vs上有warning,要求转换为宽类型防止算术溢出。数据上不产生影响
+ {
+ isPrime[i * Prime[j]] = false;//每一个素数的 i 倍(i >= 2)都不是素数,置为false
+
+ //这个是欧拉筛法的核心,它可以减少非素数置false的重复率
+ //意义是将每一个合数(非素数)拆成 2(最小因数)与最大因数 的乘积
+ if (i % Prime[j] == 0)
+ break;
+ }
+ }
+ }
+}
+```
+
+
+
+如果你没有理解,可以参考下例
+
+
+
+
+
+
+
+[以上四种算法的完整代码在我的github上,帮助到你了不妨给我点个star哦~](https://github.com/hairrrrr/win.ccode/tree/master/Pactise/2020WinterVacation/Prime/Prime Judgement)
+
+------
+
+
+
+
+
+------
+
+感谢指出我错误的微信网友: 大异小同 。
+
+本次修改内容:
+
+\1. 1-1中的代码,for循环的循环控制 i < target / 2 改为 i <= target
+
+错误情况:当 target == 4 时,target / 2 的值是 2,i 从 2开始,如果 循环控制是:i < target / 2, 则不会进入 for 循环,所以会将 4 误判为素数
+
+\2. sqrt 函数的返回值是 double 类型。
+
+将 i <= sqrt(target) 改为 i <= (int)sqrt(target)
+
+sqrt 函数的函数原型:double sqrt(double arg);
+
+
+
+2020 - 2 - 24 日修改:
\ No newline at end of file
diff --git a/content/c-notes/小端和整型存储.md b/content/c-notes/小端和整型存储.md
new file mode 100644
index 0000000..ce06201
--- /dev/null
+++ b/content/c-notes/小端和整型存储.md
@@ -0,0 +1,290 @@
+
+
+### 1.如何用程序判断自己的机器是大端还是小端?
+
+***
+
+通常情况下,我们的计算机都是小端存储模式。
+
+> 小端:数字的低位存储到内存的低地址上。
+>
+> 大端:数字的低位存储到内存的高地址上。
+
+我们在 VS 中创建一个临时变脸
+
+```c
+int a = 0x11223344;// 十六进制数
+```
+
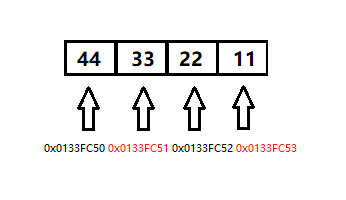
+然后打开调试器,看到变量 a 在内存中是这样存储的:
+
+```c
+0x0133FC50 44 33 22 11
+```
+
+对于 Vs 调试中内存窗口的这行信息应该如何理解呢?它就表示:
+
+
+
+十六进制数每两位表示一个字节,地址也是十六进制数;int 类型在 32 位机器上大小为 4 个字节。
+
+
+
+**如何理解十六进制数每两位表示一个字节?**
+
+十六进制数每一位的取值范围是 0 ~ 15,表示 16 种不同可能,对应 4 个二进制位(0000 ~ 1111),所以每一位十六进制可以表示 4 个二进制位,那么两个十六进制位就表示 8 个二进制位,也就是 1 个字节。
+
+
+
+可以看到,在我的机器上,低位 44 存储在 低地址(0x0133FC50)上,所以我的机器是 小端存储模式。
+
+
+
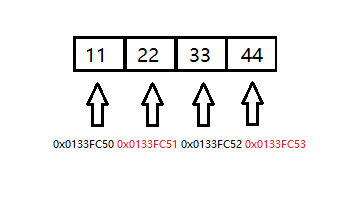
+如果是大端存储模式,变量 a 在内存中的存储应该如下图所示:
+
+
+
+
+
+现在,让我们用程序来验证一下我们的机器到底是大端还是小端。
+
+
+
+#### 方法一
+
+```c
+#include
+
+int main(void) {
+
+ int a = 0x11223344;
+ int* pi = &a;
+ char* pc = (char*)pi;//指针强转
+
+ printf("%x\n", *pc);//输出 44 ,得到证实
+
+ return 0;
+}
+```
+
+
+
+#### 方法二
+
+```c
+#include
+
+typedef union {
+ int a;
+ char ch[sizeof(int)];
+}BOS;//big or small
+
+int main(void) {
+
+ BOS bos;
+ bos.a = 0x11223344;
+
+ printf("%x", (unsigned int)bos.ch[0]);//输出 44
+
+ return 0;
+}
+```
+
+
+
+### 2.关于整数类型存储的面试问题
+
+***
+
+以下问题大家可以先独立思考一下,看看如果真的面试官问你,你能不能正确的回答并清晰的讲出其中的原理。
+
+#### 1
+
+请问,printf 函数会打印出什么内容?并解释原因。
+
+```c
+char a = -1;
+signed char b = -1;
+unsigned char c = -1;
+printf("a = %d, b = %d, c = %d\n", a, b, c);
+```
+
+```c
+a = -1, b = -1, c = 255
+```
+
+
+
+**signed char 与 char 表示同一种类型,原理一样**
+
+
+
+
+
+#### 2
+
+请问,printf 函数会打印出什么内容?并解释原因。
+
+```c
+char a = -128;
+printf("%u\n", a);
+```
+
+```c
+4294967168
+```
+
+你想到了吗?
+
+
+
+我们还是按照上面的思路分析:
+
+
+
+#### 3
+
+请问,printf 函数会打印出什么内容?并解释原因。
+
+```c
+char a = 128;
+printf("%u\n", a);
+```
+
+```c
+4294967168
+```
+
+神奇吗?并不神奇。
+
+
+
+原因就在于“截断”时得到的二进制序列是一模一样的,后面的操做是相同的。
+
+
+
+另外说一句,char 的范围是 -128 ~ 127,所以上面的 char 型变量 a 溢出了。
+
+
+
+试着想想下面的 printf 函数又会输出什么呢?
+
+```c
+unsigned char a = -128;
+unsigned char b = 128;
+printf("a = %u, b = %u\n", a, b);
+```
+
+
+
+#### 4
+
+```c
+int i = -20;
+unsigned int j = 10;
+printf("%d\n", i + j);
+```
+
+首先,i 与 j 相加时,**int 转换为 unsigned int** 。
+
+
+
+#### 5
+
+请问:下面的程序会输出什么?
+
+```c
+unsigned int i;
+for(i = 9; i >= 0; i--){
+ printf("%u\n", i);
+}
+```
+
+
+
+这个问题的关键点就是在 i == 0 时。如果 i 的类型是 int ,毫无疑问,for 循环会在这里结束。可是,现在 i 的类型是 unsigned int。
+
+我们知道,`i--`等同于 `i -= 1`,也就是 `i = i - 1` 。对于编译器来说,其实这个操作是 `i = i + (-1)`,我们知道, -1 的补码是:
+
+ 11111111 11111111 11111111 11111111
+
+当它与 0(i)相加时,i 的补码就变成了全 1。问题就在于,这时候 i 是 unsigned int 类型,这个全 1 的补码的含义并不是 -1 而是 unsigned int 的最大值。所以循环条件 `i >= 0 `依然满足。
+
+
+
+换句话说,对于 unsigned int 类型的 i 来说,`i >= 0`是恒成立的。
+
+
+
+所以答案是无限循环。
+
+
+
+#### 6
+
+ ```c
+int main(void)
+{
+ char a[1000];
+ int i;
+
+ for(i=0; i<1000; i++){
+ a[i] = -1-i;
+ }
+
+ printf("%d",strlen(a));
+
+ return 0;
+}
+ ```
+
+
+
+#### 7
+
+```c
+7.
+#include
+unsigned char i = 0;
+int main(void){
+ for(i = 0;i<=255;i++){
+ printf("hello world\n");
+ }
+
+ return 0;
+}
+
+```
+
+这个情况与例5相同。
+
+
+
+### 3.浮点数
+
+浮点数我们不做过多说明,详情我们在【C入门到精通】讲过。
+
+我们着重强调一下,对于 **2 个浮点数的比较** 来说,不能像整型那样直接比较,应该引入一个误差范围,比如:
+
+```c
+#define E 1e-4 //定义一个精度
+
+ float i = 19.0;
+ float j = i / 7.0;
+
+ if (j * 7.0 - i < E && j * 7.0 - i > -E) {
+ printf("相等!\n");
+ } else {
+ printf("不相等!\n");
+ }
+```
+
+
+
+**如果本文你有地方没有看懂,推荐阅读以下文章,可以帮助你理解**:
+
+- [一文看懂枚举&结构&联合](https://mp.weixin.qq.com/s/NkXZSdM-gnAuG7_jAM8ZiA)
+
+
+
+
diff --git a/content/c-notes/指针进阶.md b/content/c-notes/指针进阶.md
new file mode 100644
index 0000000..8b20962
--- /dev/null
+++ b/content/c-notes/指针进阶.md
@@ -0,0 +1,943 @@
+## 指针进阶
+
+
+
+## 目录
+
+***
+
+[TOC]
+
+
+
+### 前言
+
+***
+
+#### 指针的概念
+
+>1. 指针就是个变量,用来存放地址,地址唯一标识一块内存空间。
+>2. 指针的大小是固定的4/8个字节(32位平台/64位平台)。
+>3. 指针是有类型,指针的类型决定了指针的+-整数的步长,指针解引用操作的时候的权限。
+
+
+
+### 1、字符指针
+
+#### 字符串的 数组 与 指针 表示的区别
+
+请看下面这段代码,猜测会输出什么:
+
+**1-1.c**
+
+```c
+#include
+
+int main(void) {
+
+ char str1[] = "Hello";
+ char str2[] = "Hello";
+
+ const char* str3 = "Hello";
+ const char* str4 = "Hello";
+
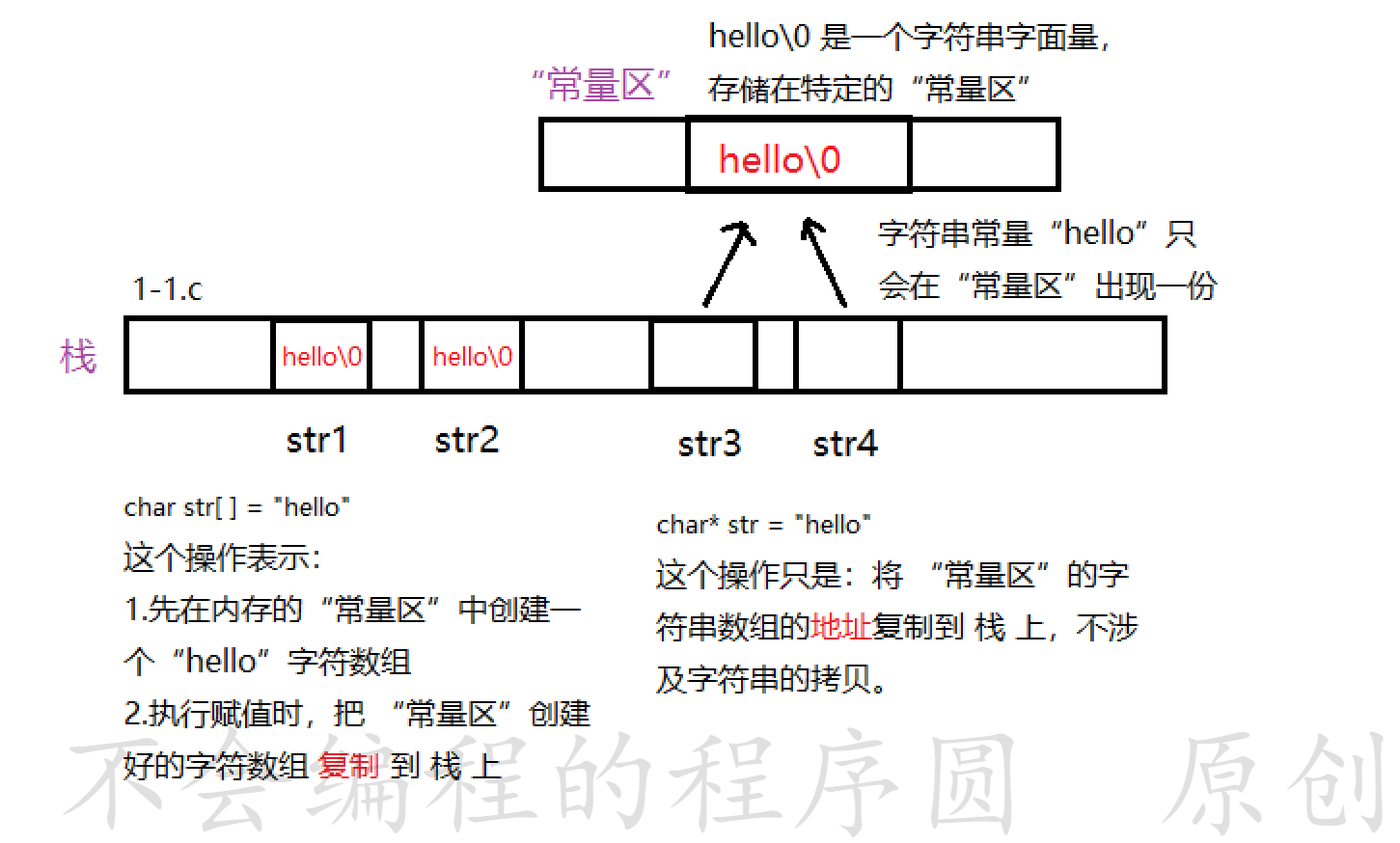
+ //查看str1与str2 ,str3与str4 的地址是否相同
+
+ if (str1 == str2)
+ printf("str1 == str2\n");
+
+ if (str3 == str4)
+ printf("str3 == str4\n");
+
+ return 0;
+}
+```
+
+输出:
+
+```c
+str3 == str4
+```
+
+我们不着急解释原因,我们再来看一下下面这个例子:
+
+**1-2.c**
+
+```c
+#include
+
+int main(void){
+ char str1[] = "hello";
+ str1[0] = 'a';
+ printf("%s\n", str1);
+
+ return 0;
+}
+```
+
+**1-3.c**
+
+```c
+#include
+
+int main(void){
+ char* str2 = "hello";
+ str2[0] = 'a';
+ printf("%s\n", str2);
+
+ return 0;
+}
+```
+
+试着思考:1-2.c 和 1-3.c 输出的结果一样吗?
+
+
+
+为什么 1-3.c 程序会直接崩溃呢?
+
+这是因为字符串字面量 "hello" 存储在 **常量区** ,该区域内的常量是**只读**的,不能被修改。
+
+
+
+为了更加清楚的了解上面三个程序的原理,不妨看看下图:
+
+
+
+
+
+### 2、指针数组
+
+```c
+int* arr1[10]; //整形指针的数组
+char *arr2[4]; //一级字符指针的数组
+char **arr3[5];//二级字符指针的数组
+```
+
+
+
+### 3、数组指针
+
+#### Ⅰ:定义
+
+数组指针是**指针**。
+
+```c
+int *p1[10];//这是一个数组,里面放的都是 int型的指针
+int (*p2)[10];//这是一个指针,指向一个大小为 10个 int 的数组
+```
+
+**`[]`的优先级高于 `*`,所以 `()`不能省略 **
+
+
+
+#### Ⅱ:数组名 与 &数组名
+
+**3-1.c**
+
+```c
+#include
+
+int main(void){
+
+int arr[10] = { 0 };
+ printf("arr = %p\n", arr);
+ printf("&arr= %p\n", &arr);
+
+ printf("arr+1 = %p\n", arr+1);
+ printf("&arr+1= %p\n", &arr+1);
+
+ return 0;
+}
+```
+
+输出:
+
+```c
+arr = 012FFE48
+&arr= 012FFE48
+arr+1 = 012FFE4C
+&arr+1= 012FFE70
+```
+
+
+
+实际上: **&arr 表示的是数组的地址**,而不是数组首元素的地址。
+数组的地址+1,跳过整个数组的大小,所以 &arr+1 相对于 &arr 的差值是40.
+
+
+
+#### Ⅲ:数组指针的使用
+
+**3-2.c**
+
+```c
+#include
+
+void printArr1(int arr[][4], int row, int col) {
+
+ int i, j;
+ printf("\nint arr[][4]\n");
+ for (i = 0; i < row; i++) {
+ for (j = 0; j < col; j++)
+ printf("%d ", arr[i][j]);
+ printf("\n");
+ }
+
+}
+
+void printArr2(int (*arr)[4], int row, int col) {
+
+ int i, j;
+ printf("\n int (*arr)[]\n");
+ for (i = 0; i < row; i++) {
+ for (j = 0; j < col; j++)
+ printf("%d ", arr[i][j]);
+ printf("\n");
+ }
+
+}
+
+int main(void) {
+
+ int arr[3][4] = { 0 };
+
+ printArr1(arr, 3, 4);
+ printArr2(arr, 3, 4);
+
+ return 0;
+}
+```
+
+输出:
+
+```c
+int arr[][4]
+0 0 0 0
+0 0 0 0
+0 0 0 0
+
+ int (*arr)[]
+0 0 0 0
+0 0 0 0
+0 0 0 0
+```
+
+
+
+### 4、数组参数 & 指针参数
+
+#### Ⅰ:一维数组传参
+
+**4-1.c**
+
+我们先来看一下 main 函数
+
+```c
+#include
+
+int main(void) {
+
+ int arr[10] = { 0 };
+ int* arr2[20] = { 0 };
+
+ test1(arr);
+ test2(arr);
+ test3(arr);
+
+ test4(arr2);
+ test5(arr2);
+
+ return 0;
+}
+```
+
+请判断以下五个函数的参数写法是否正确:
+
+```c
+void test1(int arr[]) {
+
+}
+
+void test2(int arr[10]) {
+
+}
+
+void test3(int* arr) {
+
+}
+
+void test4(int* arr[20]) {
+
+}
+
+void test5(int** arr) {
+
+}
+```
+
+这五种写法都是可以的。
+
+
+
+#### Ⅱ:二维数组传参
+
+**4-2.c**
+
+```c
+#include
+
+void test(int arr[3][5])
+{}
+void test(int arr[][])// error
+{}
+void test(int arr[][5])
+{}
+void test(int *arr) // error
+{}
+void test(int* arr[5])
+{}
+void test(int (*arr)[5])
+{}
+void test(int **arr) // error
+{}
+int main(void)
+{
+ int arr[3][5] = {0};
+ test(arr)
+
+ return 0;
+}
+```
+
+**二维数组传参,只有第一个 [] 内的数字可以省略,其他的都不能省略**
+
+
+
+### 5、函数指针
+
+#### Ⅰ:定义
+
+**5-1.c**
+
+```c
+#include
+
+int main(void) {
+
+ printf("%p\n", main);
+ printf("%p\n", &main);//输出函数地址 用不用 & 都可以
+
+ return 0;
+}
+```
+
+输出:
+
+```c
+008A129E
+008A129E
+```
+
+输出的两个地址是 main 函数的地址。
+
+
+
+如何理解函数指针?
+
+> 当你写完并保存一个 .c 文件后,这个文件是存储在计算机硬盘中的。编译 c文件后生成的 .exe(可执行文件)也是在硬盘上。
+>
+> 当你双击 .exe 文件时,操作系统就会把这个文件加载到**内存中**,并创建一个对应的 进程。
+
+对于函数指针来说,最大的用处就是可以直接调用函数。
+
+
+
+如何保存函数地址呢?
+**5-2.c**
+
+```c
+void test()
+{
+printf("hehe\n");
+}
+
+void (*pfun1)();
+
+```
+
+
+
+#### Ⅱ:函数指针数组
+
+我们要将函数的地址存放到一个数组中去,这个数组就叫 函数指针数组。
+
+> 定义方法:`int (*parr[10])();`
+>
+> parr 先与 [] 结合,说明 parr 是数组,数组的内容是 int (*)() 类型的函数指针。
+
+
+
+##### 应用:转移表
+
+**5-3.c** 计算器
+
+```c
+#include
+
+int add(int x, int y) {
+ return (x + y);
+}
+
+int sub(int x, int y) {
+ return (x - y);
+}
+
+int mul(int x, int y) {
+ return (x * y);
+}
+
+int div(int x, int y) {
+ return (x / y);
+}
+
+
+
+int main(void) {
+
+ int x, y;
+ int input = 1;
+ int (*p[5])(int, int) = { 0, add, sub, mul, div };
+
+ while (input) {
+
+ printf("**********************\n");
+ printf(" 1: ADD \n");
+ printf(" 2: SUB \n");
+ printf(" 3: MUL \n");
+ printf(" 4: DIV \n");
+ printf(" 0: EXIT \n");
+ printf("**********************\n");
+
+ printf("Enter a choice: ");
+ scanf("%d", &input);
+
+ if (input == 0)
+ break;
+ else if (input < 1 || input > 4) {
+ printf("wrong input!\n");
+ }
+ else {
+ printf("Enter two numbers: ");
+ scanf("%d %d", &x, &y);
+ printf("result = %d\n", (*p[input])(x, y));
+ }
+
+ }
+
+ return 0;
+}
+```
+
+##### 应用:回调函数
+
+帮助理解:
+
+```c
+int add(int a, int b)
+{
+ return a + b;
+}
+
+int main(void)
+{
+ // 定义一个函数指针
+ int (*p)(int, int) = add;
+
+ p(1, 2);
+ (*p)(1, 2);
+
+ // 定义一个函数指针类型
+ typedef int (*func)(int, int);
+ func p2 = add;
+
+ // 直接定义一个函数指针数组
+ int (*Array[3])(int, int);
+
+ // 利用函数指针类型定义一个函数指针数组
+ func Array2[3];
+
+ Array2[0] = add;
+
+ return 0;
+}
+```
+
+
+
+### 6、指针和数组笔试题
+
+环境:**32 位机器**
+
+#### 第一组
+
+```c
+int a[] = {1,2,3,4};
+printf("%d\n",sizeof(a));
+printf("%d\n",sizeof(a+0));
+printf("%d\n",sizeof(*a));
+printf("%d\n",sizeof(a+1));
+printf("%d\n",sizeof(a[1]));
+printf("%d\n",sizeof(&a));
+printf("%d\n",sizeof(*&a));
+printf("%d\n",sizeof(&a+1));
+printf("%d\n",sizeof(&a[0]));
+printf("%d\n",sizeof(&a[0]+1));
+```
+
+答案:
+
+```c
+printf("%d\n",sizeof(a));// 16
+printf("%d\n",sizeof(a+0));// 4 (a + 0 这个操作使得编译器将 a 看为指针)
+printf("%d\n",sizeof(*a));// 4
+printf("%d\n",sizeof(a+1));// 4
+printf("%d\n",sizeof(a[1]));// 4
+printf("%d\n",sizeof(&a));// 4
+printf("%d\n",sizeof(*&a));// 16 (&a 是数组指针。再次用 * 解引用,是从这个地址开始取 int(*)[4] 类型对应的字节数)
+printf("%d\n",sizeof(&a+1));// 4 (&a 得到的是 int(*)[4] 类型的指针,只要是指针大小就是 4)
+printf("%d\n",sizeof(&a[0]));// 4
+printf("%d\n",sizeof(&a[0]+1));// 4
+```
+
+#### 第二组
+
+```c
+char arr[] = {'a','b','c','d','e','f'};
+printf("%d\n", sizeof(arr));
+printf("%d\n", sizeof(arr+0));
+printf("%d\n", sizeof(*arr));
+printf("%d\n", sizeof(arr[1]));
+printf("%d\n", sizeof(&arr));
+printf("%d\n", sizeof(&arr+1));
+printf("%d\n", sizeof(&arr[0]+1));
+
+printf("%d\n", strlen(arr));
+printf("%d\n", strlen(arr+0));
+printf("%d\n", strlen(*arr));
+printf("%d\n", strlen(arr[1]));
+printf("%d\n", strlen(&arr));
+printf("%d\n", strlen(&arr+1));
+printf("%d\n", strlen(&arr[0]+1));
+```
+
+答案:
+
+```c
+printf("%d\n", sizeof(arr));// 6
+printf("%d\n", sizeof(arr+0));// 4
+printf("%d\n", sizeof(*arr));// 1
+printf("%d\n", sizeof(arr[1]));// 1
+printf("%d\n", sizeof(&arr));// 4 (char (*)[6] 类型的指针)
+printf("%d\n", sizeof(&arr+1));// 4
+printf("%d\n", sizeof(&arr[0]+1));//4
+
+printf("%d\n", strlen(arr));// 未定义 (arr 字符数组没有 '\0',有可能会出现一个随机值,程序也有可能会崩溃。)
+printf("%d\n", strlen(arr+0));// 未定义
+printf("%d\n", strlen(*arr)); // 错误的参数类型 (strlen 要的是 char* 类型,但是 *arr 是 char类型。*arr 是字符 a,也就是 97,编译器有可能将 97 当成一个 16 进制的地址。所以,这样的代码一定是不对的)
+printf("%d\n", strlen(arr[1]));//同上
+printf("%d\n", strlen(&arr));// 未定义
+printf("%d\n", strlen(&arr+1)); // 未定义
+printf("%d\n", strlen(&arr[0]+1));// 未定义
+```
+
+#### 第三组
+
+```c
+char arr[] = "abcdef";
+printf("%d\n", sizeof(arr));
+printf("%d\n", sizeof(arr+0));
+printf("%d\n", sizeof(*arr));
+printf("%d\n", sizeof(arr[1]));
+printf("%d\n", sizeof(&arr));
+printf("%d\n", sizeof(&arr+1));
+printf("%d\n", sizeof(&arr[0]+1));
+
+printf("%d\n", strlen(arr));
+printf("%d\n", strlen(arr+0));
+printf("%d\n", strlen(*arr));
+printf("%d\n", strlen(arr[1]));
+printf("%d\n", strlen(&arr));
+printf("%d\n", strlen(&arr+1));
+printf("%d\n", strlen(&arr[0]+1));
+```
+
+答案:
+
+```c
+char arr[] = "abcdef";
+printf("%d\n", sizeof(arr));//7
+printf("%d\n", sizeof(arr+0));//7
+printf("%d\n", sizeof(*arr));//1
+printf("%d\n", sizeof(arr[1]));//1
+printf("%d\n", sizeof(&arr));//4 (char (*)[7])
+printf("%d\n", sizeof(&arr+1));//4 (char (*)[7])
+printf("%d\n", sizeof(&arr[0]+1));//4 (char*)
+
+printf("%d\n", strlen(arr));// 6
+printf("%d\n", strlen(arr+0));// 6
+printf("%d\n", strlen(*arr));// 错误的参数类型
+printf("%d\n", strlen(arr[1]));// 同上
+printf("%d\n", strlen(&arr));// 6 (&arr 的类型是 char (*)[7] 与 char* 类型不一致,但是 &arr 与 arr 是相同的,所以恰巧能得出正确结果,但是这是错误的写法。)
+printf("%d\n", strlen(&arr+1)); // 未定义 (&arr + 1,跳过了整个数组,访问数组后面的空间,非法内存访问)
+printf("%d\n", strlen(&arr[0]+1)); // 5 (&arr[0] -> char* ,加以跳过一个数组元素)
+```
+
+#### 第四组
+
+```c
+char *p = "abcdef";
+printf("%d\n", sizeof(p));
+printf("%d\n", sizeof(p+1));
+printf("%d\n", sizeof(*p));
+printf("%d\n", sizeof(p[0]));
+printf("%d\n", sizeof(&p));
+printf("%d\n", sizeof(&p+1));
+printf("%d\n", sizeof(&p[0]+1));
+
+printf("%d\n", strlen(p));
+printf("%d\n", strlen(p+1));
+printf("%d\n", strlen(*p));
+printf("%d\n", strlen(p[0]));
+printf("%d\n", strlen(&p));
+printf("%d\n", strlen(&p+1));
+printf("%d\n", strlen(&p[0]+1));
+```
+
+答案:
+
+```c
+char *p = "abcdef";
+printf("%d\n", sizeof(p));// 4
+printf("%d\n", sizeof(p+1));// 4
+printf("%d\n", sizeof(*p));// 1
+printf("%d\n", sizeof(p[0]));// 1
+printf("%d\n", sizeof(&p));// 4 (char**)
+printf("%d\n", sizeof(&p+1));// 4 (char**)
+printf("%d\n", sizeof(&p[0]+1));// 4
+
+printf("%d\n", strlen(p));// 6
+printf("%d\n", strlen(p+1));// 5
+printf("%d\n", strlen(*p));// 错误的参数类型
+printf("%d\n", strlen(p[0]));// 错误的参数类型
+printf("%d\n", strlen(&p));// 同上 (&p 的类型是 char**,将char** 强转成的 char* 并不是一个字符串)
+printf("%d\n", strlen(&p+1));// 未定义
+printf("%d\n", strlen(&p[0]+1));// 5 (对于 &p[0] 来说,p 先与 [] 结合)
+```
+
+
+
+> 指针为什么也可以用 `[]`运算符?
+>
+> 对于指针 int* p = "abc";
+>
+> `p[1]` 等价于 `*(p + 1)`
+>
+> 这是因为数组很多时候可以隐式转换成指针。
+
+
+
+重点注意:`printf("%d\n", strlen(&p));`
+
+`&p`的类型是 `char**`,但是C语言会将其隐式类型转换成 `char*`,但是 strlen 访问的是地址p的内存空间,那这其实是未定义行为。
+
+
+
+#### 第五组
+
+```c
+int a[3][4] = {0};
+printf("%d\n",sizeof(a));
+printf("%d\n",sizeof(a[0][0]));
+printf("%d\n",sizeof(a[0]));
+printf("%d\n",sizeof(a[0]+1));
+printf("%d\n",sizeof(*(a[0]+1)));
+printf("%d\n",sizeof(a+1));
+printf("%d\n",sizeof(*(a+1)));
+printf("%d\n",sizeof(&a[0]+1));
+printf("%d\n",sizeof(*(&a[0]+1)));
+printf("%d\n",sizeof(*a));
+printf("%d\n",sizeof(a[3]));
+```
+
+答案:
+
+```c
+int a[3][4] = {0};
+//所谓二维数组本质是一维数组。里面的每个元素又是一个一维数组。
+//本例是一个长度为 3 的一维数组,每个元素又是长度为 4 的一维数组。(VS 中可以用调试来测试)
+printf("%d\n",sizeof(a));// 48
+printf("%d\n",sizeof(a[0][0]));// 4
+printf("%d\n",sizeof(a[0]));// 16 (a[0] 的类型是 int[4])
+printf("%d\n",sizeof(a[0]+1));// 4 (a[0]->int[4]相当于一个一维数组,a[0] + 1 隐式转换为指针 int*)
+printf("%d\n",sizeof(*(a[0]+1)));// 4 (a[0] + 1 -> a[0][1])
+printf("%d\n",sizeof(a+1));// 4
+printf("%d\n",sizeof(*(a+1)));// 4
+printf("%d\n",sizeof(&a[0]+1));// 4 (a[0] -> int[4],&a[0] -> int (*)[4],再加1还是数组指针)
+printf("%d\n",sizeof(*(&a[0]+1)));// 16 (int (*)[4] 解引用变为 int[4])
+printf("%d\n",sizeof(*a));// 16 (*a -> *(a + 0) -> a[0])
+printf("%d\n",sizeof(a[3]));// 16
+```
+
+重点注意:
+
+`printf("%d\n",sizeof(a[0]+1))`
+
+`printf("%d\n",sizeof(&a[0]+1))`
+
+a[0] 与 &a[0] 的差异比较:
+
+```c
+ int a[3][4] = {
+ {1, 2, 3, 4},
+ {5, 6, 7, 8},
+ {5, 10, 11, 12},
+ };
+
+ printf("%d\n", *(a[0] + 1));// 2
+ printf("%d\n", **(&a[0] + 1));//5
+```
+
+
+
+`printf("%d\n",sizeof(*(&a[0]+1)));`
+
+我们来一步一步分析:
+
+a[0] -> int[4] ; &a[0] -> int (\*)[4] ; &a[0] + 1 -> int (\*)[4] ; *(&a[0] + 1) -> int[4]
+
+
+
+`printf("%d\n",sizeof(a[3]))`
+
+`sizeof`是一个运算符,并不是函数。它在预编译时期替换。而我们说的“数组下标访问越界”前提条件是 **内存**访问越界,这个时期是程序运行时。a[3] 就是 int[4] 类型,所以就是 16。哪怕你写 a[100]都可以。
+
+`printf("%d\n", 16)`是程序运行时执行的语句。
+
+#### 关于 const
+
+```c
+int num;
+const int* p = #
+int const* p = #// 这样的写法不科学,int* 应该当成一个整体,不过它的含义与上面的相同。
+int* const p = #
+```
+
+对于第一种写法,*p 是不能改变的;对于第三种写法,地址 p 是不能被改变的。
+
+
+
+### 7、指针笔试题
+
+#### Ⅰ
+
+```c
+int main(void)
+{
+int a[5] = { 1, 2, 3, 4, 5 };
+int *ptr = (int *)(&a + 1);
+printf( "%d,%d", *(a + 1), *(ptr - 1));
+return 0;
+}
+```
+
+
+
+`a + 1`:a 隐式转换成 指针,指向 首地址后移 4 个字节。(a 隐式转换后是 int* 类型,它指向的 int 大小是 4 个字节,所以后移 4 个字节)
+
+`&a` 的类型是 `int(*)[5]` ,所以 `&a + 1` 后移 int[5] 的长度
+
+
+
+所以最后输出的是:2,5
+
+#### Ⅱ
+
+```c
+//由于还没学习结构体,这里告知结构体的大小是20个字节
+struct Test
+{
+int Num;
+char *pcName;
+short sDate;
+char cha[2];
+short sBa[4];
+}*p;
+//假设p 的值为0x100000。 如下表表达式的值分别为多少?
+int main(void)
+{
+ printf("%p\n", p + 0x1);
+ printf("%p\n", (unsigned long)p + 0x1);
+ printf("%p\n", (unsigned int*)p + 0x1);
+
+ return 0;
+}
+```
+
+
+
+`p + 0x1` p 加十六进制的 1,p 所指向的结构体大小是 20,所以 p 会增加 20 。但是注意 `%p` 输出的是 16 进制的地址,所以输出的是 0x100014
+
+`(unsigned long)p + 0x1` p 被强转成了一个数,所以输出的就是 0x100001
+
+`(unsigned int*)p + 0x1` p 被强转成了一个 int* 类型的指针,所以输出的是 0x100004
+
+#### Ⅲ
+
+```c
+int main(void)
+{
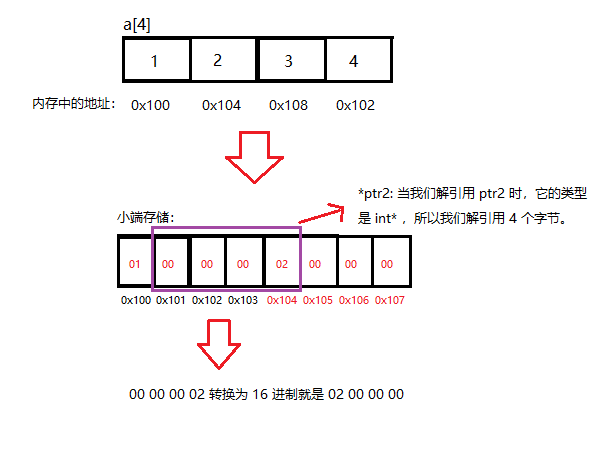
+ int a[4] = { 1, 2, 3, 4 };
+ int *ptr1 = (int *)(&a + 1);
+ int *ptr2 = (int *)((int)a + 1);
+ printf( "%x,%x", ptr1[-1], *ptr2);
+
+ return 0;
+}
+```
+
+
+
+`ptr1[-1]`: 前面我们说过,这个操作相当于 `*(ptr1 - 1)`
+
+`(int)a + 1` 是将 a 先强转为 int 然后再加 1,所以 a 仅仅增加了 1 个字节
+
+
+
+#### Ⅳ
+
+```c
+#include
+int main(void)
+{
+ int a[3][2] = { (0, 1), (2, 3), (4, 5) };
+ int *p;
+ p = a[0];
+ printf( "%d", p[0]);
+
+ return 0;
+}
+```
+
+
+
+p[0] -> a[0] [0] ,所以输出的是 0 吗?
+
+并不是,注意看 a[3] [2]大括号内的内容,里面是圆括号而不是大括号,这是**逗号表达式**。
+
+所以,a[0] [0] == 1
+
+
+
+#### Ⅴ
+
+```c
+int main(void){
+ int a[5][5];
+ int(*p)[4];
+ p = a;
+ printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
+
+ return 0;
+}
+```
+
+
+
+指针(同类型)相减的意义是**两个指针之间间隔的元素个数**
+
+`&p[4][2]` -> 数组中的第 19 个元素(4 * 4 + 3)
+
+`&a[4][2]` -> 数组中的第 23 个元素 (4 * 5 + 3)
+
+
+
+答案:FFFFFFFC,-4
+
+
+
+#### Ⅵ
+
+```c
+int main(void)
+{
+ int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
+ int *ptr1 = (int *)(&aa + 1);
+ int *ptr2 = (int *)(*(aa + 1));
+ printf( "%d,%d", *(ptr1 - 1), *(ptr2 - 1));
+
+ return 0;
+}
+
+```
+
+`&aa` 的类型是 `int(*)[2][5]`,所以 `&aa + 1` 指向的是整个数组后面的内存 。所以 `*(ptr1 - 1)` 的值是 10
+
+`aa` aa + 1 让 aa 隐式转换为 `int(*)[5]` ,所以 `aa + 1` 指向的是元素 6 所在的地址。所以 `*(ptr2 - 1)` 的值是 5
+
+
+
+#### Ⅶ
+
+```c
+#include
+int main(void)
+{
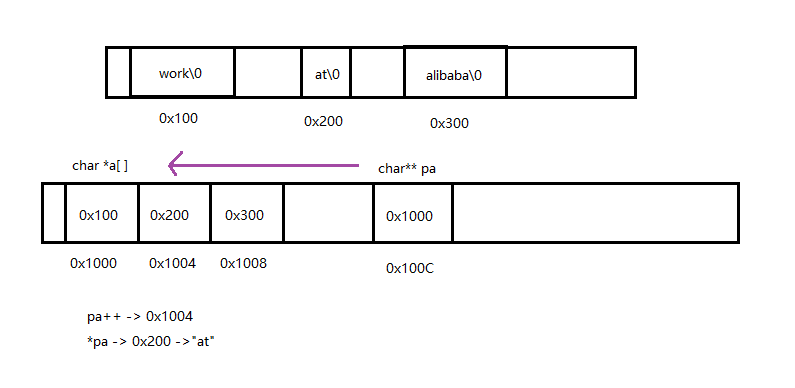
+ char *a[] = {"work","at","alibaba"};
+ char**pa = a;
+ pa++;
+ printf("%s\n", *pa);
+
+ return 0;
+}
+```
+
+
+
+
+
+#### Ⅷ
+
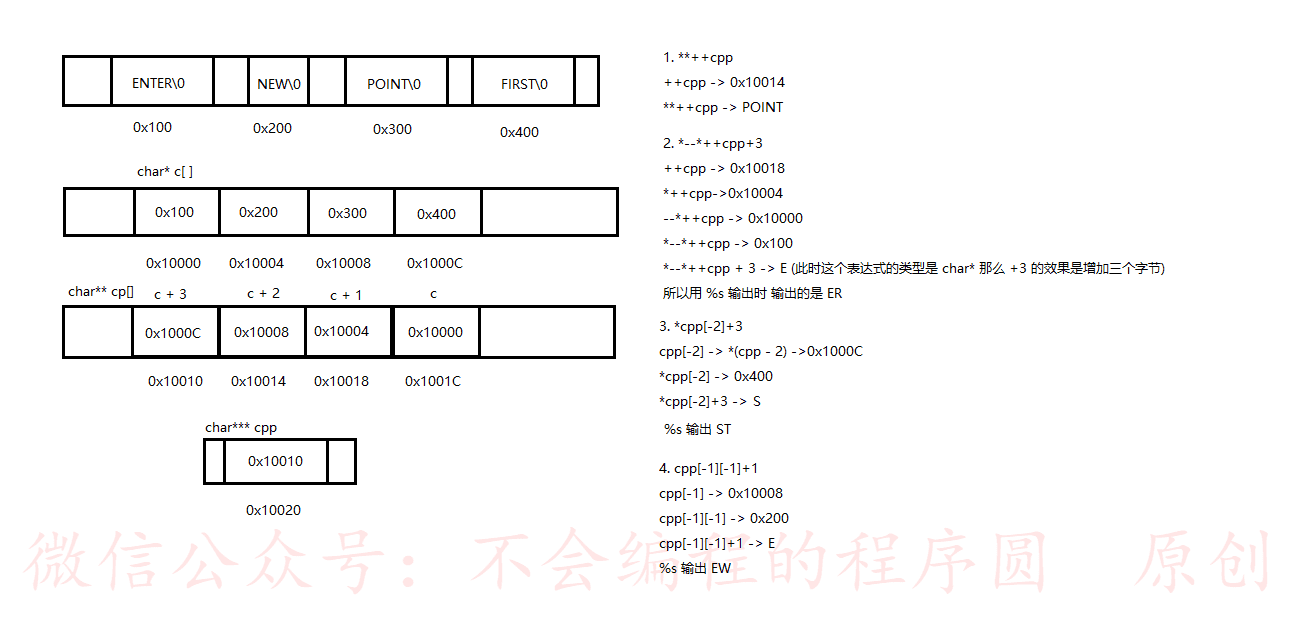
+```c
+int main(void)
+{
+ char *c[] = {"ENTER","NEW","POINT","FIRST"};
+ char** cp[] = {c+3,c+2,c+1,c};
+ char***cpp = cp;
+ printf("%s\n", **++cpp);// ++cpp 会改变 cpp 的值
+ printf("%s\n", *--*++cpp+3);//
+ printf("%s\n", *cpp[-2]+3);//-2 并没有改变 cpp
+ printf("%s\n", cpp[-1][-1]+1);
+
+ return 0;
+}
+```
+
+
+
+
+
+
+
+单目运算符从右向左依次运算。
+
+```c
+char* p = "ENTER";
+printf("%s", p + 3);// 输出 ER,p + 3 增加 3 个字节,因为 p 指向的类型是 char 大小是 1 个字节。
+```
+
+
+
+cpp[-1] [-1] 可以理解为:(cpp[-1])[-1],即:从左向右依次计算。
+
+
+