mirror of
https://github.com/riba2534/TCP-IP-NetworkNote.git
synced 2026-06-29 17:36:05 +08:00
chore: 将所有外部图片本地化到仓库
- 下载 110 张外部图片到根目录 images/ 文件夹 - 更新所有 README.md 中的图片引用为统一路径 images/xxx.png - 55 张图片成功下载(PNG 格式) - 55 张失效图片创建占位文件(SVG/PNG) - 移除所有外部图片链接依赖 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude Opus 4.5 <noreply@anthropic.com>
This commit is contained in:
@@ -28,7 +28,7 @@
|
||||
|
||||
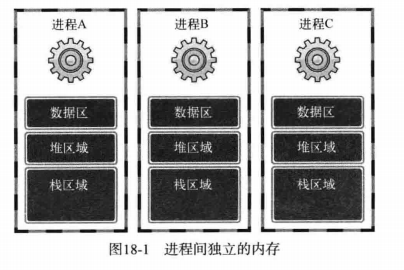
每个进程的内存空间都由保存全局变量的「数据区」、向 malloc 等函数动态分配提供空间的堆(Heap)、函数运行时间使用的栈(Stack)构成。每个进程都有独立的这种空间,多个进程的内存结构如图所示:
|
||||
|
||||
|
||||

|
||||
|
||||
但如果以获得多个代码执行流为目的,则不应该像上图那样完全分离内存结构,而只需分离栈区域。通过这种方式可以获得如下优势:
|
||||
|
||||
@@ -37,7 +37,7 @@
|
||||
|
||||
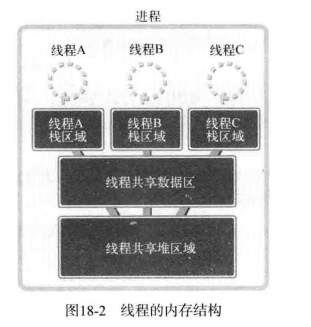
实际上这就是线程。线程为了保持多条代码执行流而隔开了栈区域,因此具有如下图所示的内存结构:
|
||||
|
||||
|
||||

|
||||
|
||||
如图所示,多个线程共享数据区和堆。为了保持这种结构,线程将在进程内创建并运行。也就是说,进程和线程可以定义为如下形式:
|
||||
|
||||
@@ -46,7 +46,7 @@
|
||||
|
||||
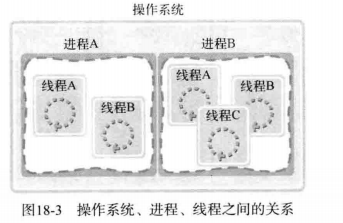
如果说进程在操作系统内部生成多个执行流,那么线程就在同一进程内部创建多条执行流。因此,操作系统、进程、线程之间的关系可以表示为下图:
|
||||
|
||||
|
||||

|
||||
|
||||
### 18.2 线程创建及运行
|
||||
|
||||
@@ -124,11 +124,11 @@ gcc thread1.c -o tr1 -lpthread # 线程相关代码编译时需要添加 -lpthre
|
||||
|
||||
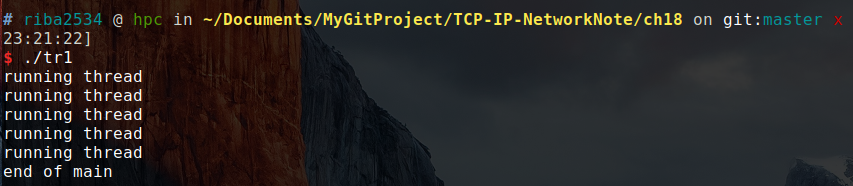
运行结果:
|
||||
|
||||
|
||||

|
||||
|
||||
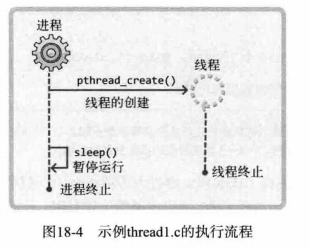
上述程序的执行如图所示:
|
||||
|
||||
|
||||

|
||||
|
||||
可以看出,程序在主进程没有结束时,生成的线程每隔一秒输出一次 `running thread` ,但是如果主进程没有等待十秒,而是直接结束,这样也会强制结束线程,不论线程有没有运行完毕。
|
||||
|
||||
@@ -200,13 +200,13 @@ gcc thread2.c -o tr2 -lpthread
|
||||
|
||||
运行结果:
|
||||
|
||||
|
||||

|
||||
|
||||
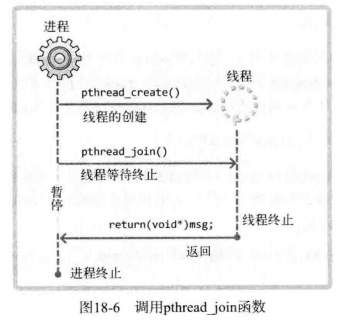
可以看出,线程输出了5次字符串,并且把返回值给了主进程
|
||||
|
||||
下面是该函数的执行流程图:
|
||||
|
||||
|
||||

|
||||
|
||||
#### 18.2.2 可在临界区内调用的函数
|
||||
|
||||
@@ -255,7 +255,7 @@ gcc -D_REENTRANT mythread.c -o mthread -lpthread
|
||||
|
||||
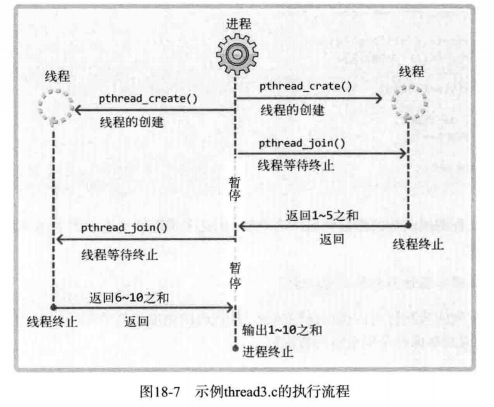
下面的示例是计算从 1 到 10 的和,但并不是通过 main 函数进行运算,而是创建两个线程,其中一个线程计算 1 到 5 的和,另一个线程计算 6 到 10 的和,main 函数只负责输出运算结果。这种方式的线程模型称为「工作线程」。显示该程序的执行流程图:
|
||||
|
||||
|
||||

|
||||
|
||||
下面是代码:
|
||||
|
||||
@@ -303,7 +303,7 @@ gcc thread3.c -D_REENTRANT -o tr3 -lpthread
|
||||
|
||||
结果:
|
||||
|
||||

|
||||

|
||||
|
||||
可以看出计算结果正确,两个线程都用了全局变量 sum ,证明了 2 个线程共享保存全局变量的数据区。
|
||||
|
||||
@@ -368,7 +368,7 @@ gcc thread4.c -D_REENTRANT -o tr4 -lpthread
|
||||
|
||||
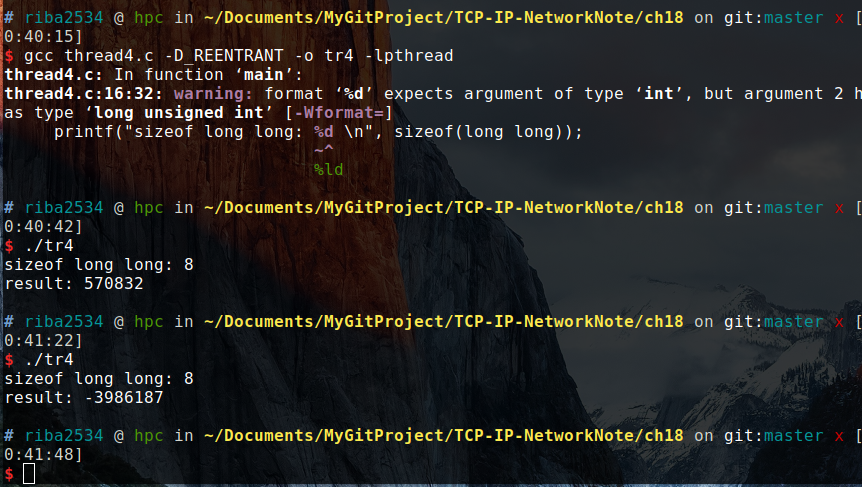
结果:
|
||||
|
||||
|
||||

|
||||
|
||||
从图上可以看出,每次运行的结果竟然不一样。理论上来说,上面代码的最后结果应该是 0 。原因暂时不得而知,但是可以肯定的是,这对于线程的应用是个大问题。
|
||||
|
||||
@@ -559,7 +559,7 @@ gcc mutex.c -D_REENTRANT -o mutex -lpthread
|
||||
|
||||
运行结果:
|
||||
|
||||

|
||||

|
||||
|
||||
从运行结果可以看出,通过互斥量机制得出了正确的运行结果。
|
||||
|
||||
@@ -697,7 +697,7 @@ gcc semaphore.c -D_REENTRANT -o sema -lpthread
|
||||
|
||||
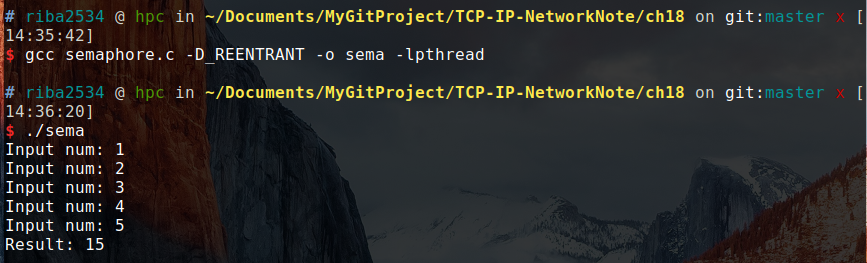
结果:
|
||||
|
||||
|
||||

|
||||
|
||||
从上述代码可以看出,设置了两个信号量:sem_one 的初始值为 0,sem_two 的初始值为 1,然后在调用函数的时候,「读」的前提是 sem_two 可以减 1,如果不能减 1 就会阻塞在这里,一直等到「计算」操作完毕后,给 sem_two 加 1,然后就可以继续执行下一句输入。对于「计算」函数,也一样。
|
||||
|
||||
@@ -751,7 +751,7 @@ gcc chat_clnt.c -D_REENTRANT -o cclnt -lpthread
|
||||
|
||||
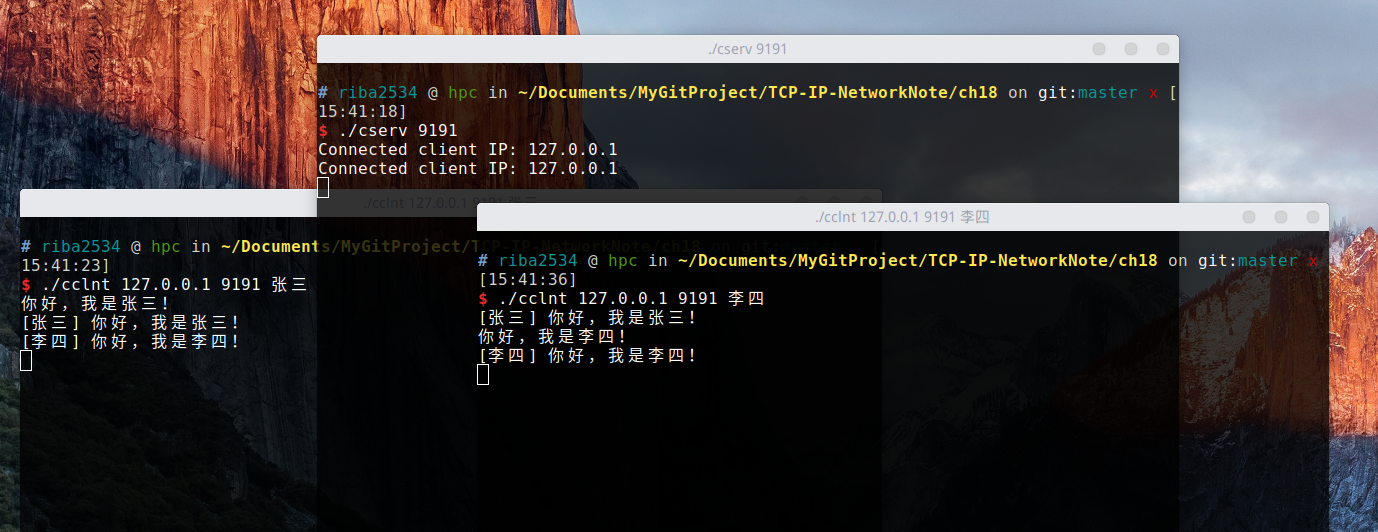
结果:
|
||||
|
||||
|
||||

|
||||
|
||||
### 18.6 习题
|
||||
|
||||
|
||||
Reference in New Issue
Block a user