mirror of
https://github.com/riba2534/TCP-IP-NetworkNote.git
synced 2026-06-30 18:06:04 +08:00
完成了第 18 章 多线程服务器端的实现
This commit is contained in:
443
README.md
443
README.md
@@ -1239,7 +1239,7 @@ while (1)
|
||||
|
||||
例:
|
||||
|
||||
1. 向服务器传递3,5,9的同事请求加法运算,服务器返回3+5+9的结果
|
||||
1. 向服务器传递3,5,9的同时请求加法运算,服务器返回3+5+9的结果
|
||||
2. 请求做乘法运算,客户端会收到`3*5*9`的结果
|
||||
3. 如果向服务器传递4,3,2的同时要求做减法,则返回4-3-2的运算结果。
|
||||
|
||||
@@ -1804,7 +1804,7 @@ struct hostent
|
||||
};
|
||||
```
|
||||
|
||||
从上述结构体可以看出,不止返回IP信息,同事还带着其他信息一起返回。域名转换成IP时只需要关注 h_addr_list 。下面简要说明上述结构体的成员:
|
||||
从上述结构体可以看出,不止返回IP信息,同时还带着其他信息一起返回。域名转换成IP时只需要关注 h_addr_list 。下面简要说明上述结构体的成员:
|
||||
|
||||
- h_name:该变量中存有官方域名(Official domain name)。官方域名代表某一主页,但实际上,一些著名公司的域名并没有用官方域名注册。
|
||||
- h_aliases:可以通过多个域名访问同一主页。同一IP可以绑定多个域名,因此,除官方域名外还可以指定其他域名。这些信息可以通过 h_aliases 获得。
|
||||
@@ -2799,7 +2799,7 @@ wait
|
||||
|
||||
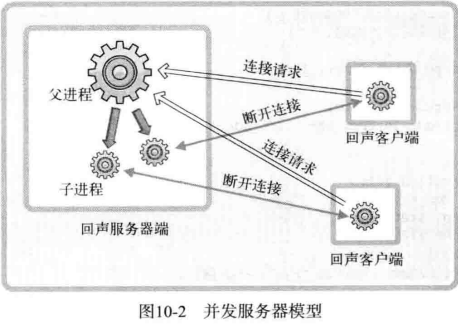
#### 10.4.1 基于进程的并发服务器模型
|
||||
|
||||
之前的回声服务器每次只能同事向 1 个客户端提供服务。因此,需要扩展回声服务器,使其可以同时向多个客户端提供服务。下图是基于多进程的回声服务器的模型。
|
||||
之前的回声服务器每次只能同时向 1 个客户端提供服务。因此,需要扩展回声服务器,使其可以同时向多个客户端提供服务。下图是基于多进程的回声服务器的模型。
|
||||
|
||||
|
||||
|
||||
@@ -3171,7 +3171,7 @@ I/O 复用技术可以解决这个问题。
|
||||
|
||||

|
||||
|
||||
上图是一个纸杯电话系统,为了使得三人同时通话,说话时要同事对着两个纸杯,接听时也需要耳朵同时对准两个纸杯。为了完成 3 人通话,可以进行如下图的改进:
|
||||
上图是一个纸杯电话系统,为了使得三人同时通话,说话时要同时对着两个纸杯,接听时也需要耳朵同时对准两个纸杯。为了完成 3 人通话,可以进行如下图的改进:
|
||||
|
||||

|
||||
|
||||
@@ -4364,7 +4364,7 @@ epoll_ctl(epfd,EPOLL_CTL_ADD,sockfd,&event);
|
||||
- EPOLLET:以边缘触发的方式得到事件通知
|
||||
- EPOLLONESHOT:发生一次事件后,相应文件描述符不再收到事件通知。因此需要向 epoll_ctl 函数的第二个参数传递 EPOLL_CTL_MOD ,再次设置事件。
|
||||
|
||||
可通过位运算同事传递多个上述参数。
|
||||
可通过位运算同时传递多个上述参数。
|
||||
|
||||
#### 17.1.6 epoll_wait
|
||||
|
||||
@@ -4989,7 +4989,440 @@ gcc thread4.c -D_REENTRANT -o tr4 -lpthread
|
||||
|
||||
#### 18.3.1 多个线程访问同一变量是问题
|
||||
|
||||
[thread4.c](https://github.com/riba2534/TCP-IP-NetworkNote/blob/master/ch18/thread4.c) 的问题如下:
|
||||
|
||||
> 2 个线程正在同时访问全局变量 num
|
||||
|
||||
任何内存空间,只要被同时访问,都有可能发生问题。
|
||||
|
||||
因此,线程访问变量 num 时应该阻止其他线程访问,直到线程 1 运算完成。这就是同步(Synchronization)
|
||||
|
||||
#### 18.3.2 临界区位置
|
||||
|
||||
那么在刚才代码中的临界区位置是:
|
||||
|
||||
> 函数内同时运行多个线程时引发问题的多条语句构成的代码块
|
||||
|
||||
全局变量 num 不能视为临界区,因为他不是引起问题的语句,只是一个内存区域的声明。下面是刚才代码的两个 main 函数
|
||||
|
||||
```c
|
||||
void *thread_inc(void *arg)
|
||||
{
|
||||
int i;
|
||||
for (i = 0; i < 50000000; i++)
|
||||
num += 1;//临界区
|
||||
return NULL;
|
||||
}
|
||||
void *thread_des(void *arg)
|
||||
{
|
||||
int i;
|
||||
for (i = 0; i < 50000000; i++)
|
||||
num -= 1;//临界区
|
||||
return NULL;
|
||||
}
|
||||
```
|
||||
|
||||
由上述代码可知,临界区并非 num 本身,而是访问 num 的两条语句,这两条语句可能由多个线程同时运行,也是引起这个问题的直接原因。产生问题的原因可以分为以下三种情况:
|
||||
|
||||
- 2 个线程同时执行 thread_inc 函数
|
||||
- 2 个线程同时执行 thread_des 函数
|
||||
- 2 个线程分别执行 thread_inc 和 thread_des 函数
|
||||
|
||||
比如发生以下情况:
|
||||
|
||||
> 线程 1 执行 thread_inc 的 num+=1 语句的同时,线程 2 执行 thread_des 函数的 num-=1 语句
|
||||
|
||||
也就是说,两条不同的语句由不同的线程执行时,也有可能构成临界区。前提是这 2 条语句访问同一内存空间。
|
||||
|
||||
### 18.4 线程同步
|
||||
|
||||
前面讨论了线程中存在的问题,下面就是解决方法,线程同步。
|
||||
|
||||
#### 18.4.1 同步的两面性
|
||||
|
||||
线程同步用于解决线程访问顺序引发的问题。需要同步的情况可以从如下两方面考虑。
|
||||
|
||||
- 同时访问同一内存空间时发生的情况
|
||||
- 需要指定访问同一内存空间的线程顺序的情况
|
||||
|
||||
情况一之前已经解释过,下面讨论情况二。这是「控制线程执行的顺序」的相关内容。假设有 A B 两个线程,线程 A 负责向指定的内存空间内写入数据,线程 B 负责取走该数据。所以这是有顺序的,不按照顺序就可能发生问题。所以这种也需要进行同步。
|
||||
|
||||
#### 18.4.2 互斥量
|
||||
|
||||
互斥锁(英语:英语:Mutual exclusion,缩写 Mutex)是一种用于多线程编程中,防止两条线程同时对同一公共资源(比如全域变量)进行读写的机制。该目的通过将代码切片成一个一个的临界区域(critical section)达成。临界区域指的是一块对公共资源进行访问的代码,并非一种机制或是算法。一个程序、进程、线程可以拥有多个临界区域,但是并不一定会应用互斥锁。
|
||||
|
||||
通俗的说就互斥量就是一把优秀的锁,当临界区被占据的时候就上锁,等占用完毕然后再放开。
|
||||
|
||||
下面是互斥量的创建及销毁函数。
|
||||
|
||||
```c
|
||||
#include <pthread.h>
|
||||
int pthread_mutex_init(pthread_mutex_t *mutex,
|
||||
const pthread_mutexattr_t *attr);
|
||||
int pthread_mutex_destroy(pthread_mutex_t *mutex);
|
||||
/*
|
||||
成功时返回 0,失败时返回其他值
|
||||
mutex : 创建互斥量时传递保存互斥量的变量地址值,销毁时传递需要销毁的互斥量地址
|
||||
attr : 传递即将创建的互斥量属性,没有特别需要指定的属性时传递 NULL
|
||||
*/
|
||||
```
|
||||
|
||||
从上述函数声明中可以看出,为了创建相当于锁系统的互斥量,需要声明如下 pthread_mutex_t 型变量:
|
||||
|
||||
```c
|
||||
pthread_mutex_t mutex
|
||||
```
|
||||
|
||||
该变量的地址值传递给 pthread_mutex_init 函数,用来保存操作系统创建的互斥量(锁系统)。调用 pthread_mutex_destroy 函数时同样需要该信息。如果不需要配置特殊的互斥量属性,则向第二个参数传递 NULL 时,可以利用 PTHREAD_MUTEX_INITIALIZER 进行如下声明:
|
||||
|
||||
```c
|
||||
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
|
||||
```
|
||||
|
||||
推荐尽可能的使用 pthread_mutex_init 函数进行初始化,因为通过宏进行初始化时很难发现发生的错误。
|
||||
|
||||
下面是利用互斥量锁住或释放临界区时使用的函数。
|
||||
|
||||
```c
|
||||
#include <pthread.h>
|
||||
int pthread_mutex_lock(pthread_mutex_t *mutex);
|
||||
int pthread_mutex_unlock(pthread_mutex_t *mutex);
|
||||
/*
|
||||
成功时返回 0 ,失败时返回其他值
|
||||
*/
|
||||
```
|
||||
|
||||
函数本身含有 lock unlock 等词汇,很容易理解其含义。进入临界区前调用的函数就是 pthread_mutex_lock 。调用该函数时,发现有其他线程已经进入临界区,则 pthread_mutex_lock 函数不会返回,直到里面的线程调用 pthread_mutex_unlock 函数退出临界区位置。也就是说,其他线程让出临界区之前,当前线程一直处于阻塞状态。接下来整理一下代码的编写方式:
|
||||
|
||||
```c
|
||||
pthread_mutex_lock(&mutex);
|
||||
//临界区开始
|
||||
//...
|
||||
//临界区结束
|
||||
pthread_mutex_unlock(&mutex);
|
||||
```
|
||||
|
||||
简言之,就是利用 lock 和 unlock 函数围住临界区的两端。此时互斥量相当于一把锁,阻止多个线程同时访问,还有一点要注意,线程退出临界区时,如果忘了调用 pthread_mutex_unlock 函数,那么其他为了进入临界区而调用 pthread_mutex_lock 的函数无法摆脱阻塞状态。这种情况称为「死锁」。需要格外注意,下面是利用互斥量解决示例 [thread4.c](https://github.com/riba2534/TCP-IP-NetworkNote/blob/master/ch18/thread4.c) 中遇到的问题代码:
|
||||
|
||||
- [mutex.c](https://github.com/riba2534/TCP-IP-NetworkNote/blob/master/ch18/mutex.c)
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <unistd.h>
|
||||
#include <stdlib.h>
|
||||
#include <pthread.h>
|
||||
#define NUM_THREAD 100
|
||||
void *thread_inc(void *arg);
|
||||
void *thread_des(void *arg);
|
||||
|
||||
long long num = 0;
|
||||
pthread_mutex_t mutex; //保存互斥量读取值的变量
|
||||
|
||||
int main(int argc, char *argv[])
|
||||
{
|
||||
pthread_t thread_id[NUM_THREAD];
|
||||
int i;
|
||||
|
||||
pthread_mutex_init(&mutex, NULL); //创建互斥量
|
||||
|
||||
for (i = 0; i < NUM_THREAD; i++)
|
||||
{
|
||||
if (i % 2)
|
||||
pthread_create(&(thread_id[i]), NULL, thread_inc, NULL);
|
||||
else
|
||||
pthread_create(&(thread_id[i]), NULL, thread_des, NULL);
|
||||
}
|
||||
|
||||
for (i = 0; i < NUM_THREAD; i++)
|
||||
pthread_join(thread_id[i], NULL);
|
||||
|
||||
printf("result: %lld \n", num);
|
||||
pthread_mutex_destroy(&mutex); //销毁互斥量
|
||||
return 0;
|
||||
}
|
||||
|
||||
void *thread_inc(void *arg)
|
||||
{
|
||||
int i;
|
||||
pthread_mutex_lock(&mutex); //上锁
|
||||
for (i = 0; i < 50000000; i++)
|
||||
num += 1;
|
||||
pthread_mutex_unlock(&mutex); //解锁
|
||||
return NULL;
|
||||
}
|
||||
void *thread_des(void *arg)
|
||||
{
|
||||
int i;
|
||||
pthread_mutex_lock(&mutex);
|
||||
for (i = 0; i < 50000000; i++)
|
||||
num -= 1;
|
||||
pthread_mutex_unlock(&mutex);
|
||||
return NULL;
|
||||
}
|
||||
```
|
||||
|
||||
编译运行:
|
||||
|
||||
```shell
|
||||
gcc mutex.c -D_REENTRANT -o mutex -lpthread
|
||||
./mutex
|
||||
```
|
||||
|
||||
运行结果:
|
||||
|
||||

|
||||
|
||||
从运行结果可以看出,通过互斥量机制得出了正确的运行结果。
|
||||
|
||||
在代码中:
|
||||
|
||||
```c
|
||||
void *thread_inc(void *arg)
|
||||
{
|
||||
int i;
|
||||
pthread_mutex_lock(&mutex); //上锁
|
||||
for (i = 0; i < 50000000; i++)
|
||||
num += 1;
|
||||
pthread_mutex_unlock(&mutex); //解锁
|
||||
return NULL;
|
||||
}
|
||||
```
|
||||
|
||||
以上代码的临界区划分范围较大,但这是考虑如下优点所做的决定:
|
||||
|
||||
> 最大限度减少互斥量 lock unlock 函数的调用次数
|
||||
|
||||
#### 18.4.3 信号量
|
||||
|
||||
信号量(英语:Semaphore)又称为信号标,是一个同步对象,用于保持在0至指定最大值之间的一个计数值。当线程完成一次对该semaphore对象的等待(wait)时,该计数值减一;当线程完成一次对semaphore对象的释放(release)时,计数值加一。当计数值为0,则线程等待该semaphore对象不再能成功直至该semaphore对象变成signaled状态。semaphore对象的计数值大于0,为signaled状态;计数值等于0,为nonsignaled状态.
|
||||
|
||||
semaphore对象适用于控制一个仅支持有限个用户的共享资源,是一种不需要使用忙碌等待(busy waiting)的方法。
|
||||
|
||||
信号量的概念是由荷兰计算机科学家艾兹赫尔·戴克斯特拉(Edsger W. Dijkstra)发明的,广泛的应用于不同的操作系统中。在系统中,给予每一个进程一个信号量,代表每个进程当前的状态,未得到控制权的进程会在特定地方被强迫停下来,等待可以继续进行的信号到来。如果信号量是一个任意的整数,通常被称为计数信号量(Counting semaphore),或一般信号量(general semaphore);如果信号量只有二进制的0或1,称为二进制信号量(binary semaphore)。在linux系统中,二进制信号量(binary semaphore)又称互斥锁(Mutex)。
|
||||
|
||||
下面介绍信号量,在互斥量的基础上,很容易理解信号量。此处只涉及利用「二进制信号量」(只用 0 和 1)完成「控制线程顺序」为中心的同步方法。下面是信号量的创建及销毁方法:
|
||||
|
||||
```c
|
||||
#include <semaphore.h>
|
||||
int sem_init(sem_t *sem, int pshared, unsigned int value);
|
||||
int sem_destroy(sem_t *sem);
|
||||
/*
|
||||
成功时返回 0 ,失败时返回其他值
|
||||
sem : 创建信号量时保存信号量的变量地址值,销毁时传递需要销毁的信号量变量地址值
|
||||
pshared : 传递其他值时,创建可由多个继承共享的信号量;传递 0 时,创建只允许 1 个进程内部使用的信号量。需要完成同一进程的线程同步,故为0
|
||||
value : 指定创建信号量的初始值
|
||||
*/
|
||||
```
|
||||
|
||||
上述的 shared 参数超出了我们的关注范围,故默认向其传递为 0 。下面是信号量中相当于互斥量 lock unlock 的函数。
|
||||
|
||||
```c
|
||||
#include <semaphore.h>
|
||||
int sem_post(sem_t *sem);
|
||||
int sem_wait(sem_t *sem);
|
||||
/*
|
||||
成功时返回 0 ,失败时返回其他值
|
||||
sem : 传递保存信号量读取值的变量地址值,传递给 sem_post 的信号量增1,传递给 sem_wait 时信号量减一
|
||||
*/
|
||||
```
|
||||
|
||||
调用 sem_init 函数时,操作系统将创建信号量对象,此对象中记录这「信号量值」(Semaphore Value)整数。该值在调用 sem_post 函数时增加 1 ,调用 wait_wait 函数时减一。但信号量的值不能小于 0 ,因此,在信号量为 0 的情况下调用 sem_wait 函数时,调用的线程将进入阻塞状态(因为函数未返回)。当然,此时如果有其他线程调用 sem_post 函数,信号量的值将变为 1 ,而原本阻塞的线程可以将该信号重新减为 0 并跳出阻塞状态。实际上就是通过这种特性完成临界区的同步操作,可以通过如下形式同步临界区(假设信号量的初始值为 1)
|
||||
|
||||
```c
|
||||
sem_wait(&sem);//信号量变为0...
|
||||
// 临界区的开始
|
||||
//...
|
||||
//临界区的结束
|
||||
sem_post(&sem);//信号量变为1...
|
||||
```
|
||||
|
||||
上述代码结构中,调用 sem_wait 函数进入临界区的线程在调用 sem_post 函数前不允许其他线程进入临界区。信号量的值在 0 和 1 之间跳转,因此,具有这种特性的机制称为「二进制信号量」。接下来的代码是信号量机制的代码。下面代码并非是同时访问的同步,而是关于控制访问顺序的同步,该场景为:
|
||||
|
||||
> 线程 A 从用户输入得到值后存入全局变量 num ,此时线程 B 将取走该值并累加。该过程一共进行 5 次,完成后输出总和并退出程序。
|
||||
|
||||
下面是代码:
|
||||
|
||||
- [semaphore.c](https://github.com/riba2534/TCP-IP-NetworkNote/blob/master/ch18/semaphore.c)
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <pthread.h>
|
||||
#include <semaphore.h>
|
||||
|
||||
void *read(void *arg);
|
||||
void *accu(void *arg);
|
||||
static sem_t sem_one;
|
||||
static sem_t sem_two;
|
||||
static int num;
|
||||
|
||||
int main(int argc, char const *argv[])
|
||||
{
|
||||
pthread_t id_t1, id_t2;
|
||||
sem_init(&sem_one, 0, 0);
|
||||
sem_init(&sem_two, 0, 1);
|
||||
|
||||
pthread_create(&id_t1, NULL, read, NULL);
|
||||
pthread_create(&id_t2, NULL, accu, NULL);
|
||||
|
||||
pthread_join(id_t1, NULL);
|
||||
pthread_join(id_t2, NULL);
|
||||
|
||||
sem_destroy(&sem_one);
|
||||
sem_destroy(&sem_two);
|
||||
return 0;
|
||||
}
|
||||
|
||||
void *read(void *arg)
|
||||
{
|
||||
int i;
|
||||
for (i = 0; i < 5; i++)
|
||||
{
|
||||
fputs("Input num: ", stdout);
|
||||
|
||||
sem_wait(&sem_two);
|
||||
scanf("%d", &num);
|
||||
sem_post(&sem_one);
|
||||
}
|
||||
return NULL;
|
||||
}
|
||||
void *accu(void *arg)
|
||||
{
|
||||
int sum = 0, i;
|
||||
for (i = 0; i < 5; i++)
|
||||
{
|
||||
sem_wait(&sem_one);
|
||||
sum += num;
|
||||
sem_post(&sem_two);
|
||||
}
|
||||
printf("Result: %d \n", sum);
|
||||
return NULL;
|
||||
}
|
||||
```
|
||||
|
||||
编译运行:
|
||||
|
||||
```shell
|
||||
gcc semaphore.c -D_REENTRANT -o sema -lpthread
|
||||
./sema
|
||||
```
|
||||
|
||||
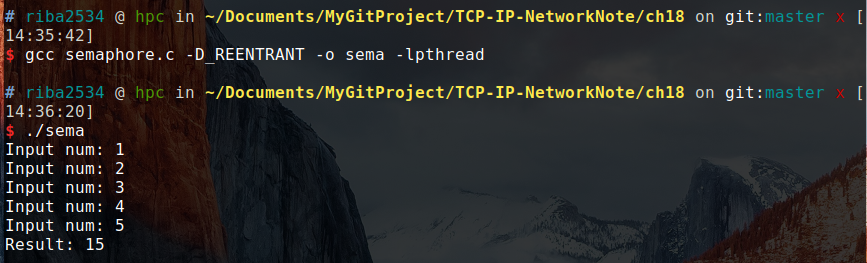
结果:
|
||||
|
||||
|
||||
|
||||
从上述代码可以看出,设置了两个信号量 one 的初始值为 0 ,two 的初始值为 1,然后在调用函数的时候,「读」的前提是 two 可以减一,如果不能减一就会阻塞在这里,一直等到「计算」操作完毕后,给 two 加一,然后就可以继续执行下一句输入。对于「计算」函数,也一样。
|
||||
|
||||
### 18.5 线程的销毁和多线程并发服务器端的实现
|
||||
|
||||
先介绍线程的销毁,然后再介绍多线程服务端
|
||||
|
||||
#### 18.5.1 销毁线程的 3 种方法
|
||||
|
||||
Linux 的线程并不是在首次调用的线程 main 函数返回时自动销毁,所以利用如下方法之一加以明确。否则由线程创建的内存空间将一直存在。
|
||||
|
||||
- 调用 pthread_join 函数
|
||||
- 调用 pthread_detach 函数
|
||||
|
||||
之前调用过 pthread_join 函数。调用该函数时,不仅会等待线程终止,还会引导线程销毁。但该函数的问题是,线程终止前,调用该函数的线程将进入阻塞状态。因此,通过如下函数调用引导线程销毁。
|
||||
|
||||
```c
|
||||
#include <pthread.h>
|
||||
int pthread_detach(pthread_t th);
|
||||
/*
|
||||
成功时返回 0 ,失败时返回其他值
|
||||
thread : 终止的同时需要销毁的线程 ID
|
||||
*/
|
||||
```
|
||||
|
||||
调用上述函数不会引起线程终止或进入阻塞状态,可以通过该函数引导销毁线程创建的内存空间。调用该函数后不能再针对相应线程调用 pthread_join 函数。
|
||||
|
||||
#### 18.5.2 多线程并发服务器端的实现
|
||||
|
||||
下面是多个客户端之间可以交换信息的简单聊天程序。
|
||||
|
||||
- [chat_server.c](https://github.com/riba2534/TCP-IP-NetworkNote/blob/master/ch18/chat_server.c)
|
||||
- [chat_clnt.c](https://github.com/riba2534/TCP-IP-NetworkNote/blob/master/ch18/chat_clnt.c)
|
||||
|
||||
上面的服务端示例中,需要掌握临界区的构成,访问全局变量 clnt_cnt 和数组 clnt_socks 的代码将构成临界区,添加和删除客户端时,变量 clnt_cnt 和数组 clnt_socks 将同时发生变化。因此下列情形会导致数据不一致,从而引发错误:
|
||||
|
||||
- 线程 A 从数组 clnt_socks 中删除套接字信息,同时线程 B 读取 clnt_cnt 变量
|
||||
- 线程 A 读取变量 clnt_cnt ,同时线程 B 将套接字信息添加到 clnt_socks 数组
|
||||
|
||||
编译运行:
|
||||
|
||||
```shell
|
||||
gcc chat_server.c -D_REENTRANT -o cserv -lpthread
|
||||
gcc chat_clnt.c -D_REENTRANT -o cclnt -lpthread
|
||||
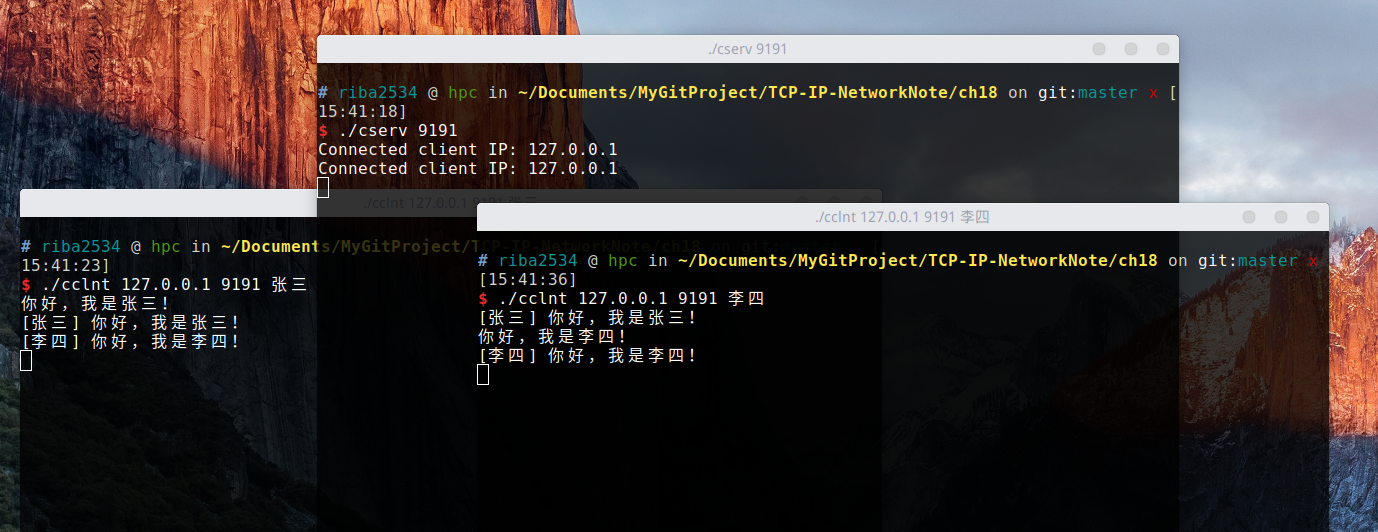
./cserv 9191
|
||||
./cclnt 127.0.0.1 9191 张三
|
||||
./cclnt 127.0.0.1 9191 李四
|
||||
```
|
||||
|
||||
结果:
|
||||
|
||||
|
||||
|
||||
### 18.6 习题
|
||||
|
||||
> 以下答案仅代表本人个人观点,可能不是正确答案。
|
||||
|
||||
1. **单 CPU 系统中如何同时执行多个进程?请解释该过程中发生的上下文切换**。
|
||||
|
||||
答:系统将 CPU 时间分成多个微笑的块后分配给了多个进程。为了分时使用 CPU ,需要「上下文切换」过程。运行程序前需要将相应进程信息读入内存,如果运行进程 A 后需要紧接着运行进程 B ,就应该将进程 A 相关今夕移出内存,并读入进程 B 的信息。这就是上下文切换
|
||||
|
||||
2. **为何线程的上下文切换速度相对更快?线程间数据交换为何不需要类似 IPC 特别技术**。
|
||||
|
||||
答:线程上下文切换过程不需要切换数据区和堆。可以利用数据区和堆交换数据。
|
||||
|
||||
3. **请从执行流角度说明进程和线程的区别**。
|
||||
|
||||
答:进程:在操作系统构成单独执行流的单位。线程:在进程内部构成单独执行流的单位。线程为了保持多条代码执行流而隔开了栈区域。
|
||||
|
||||
4. **下面关于临界区的说法错误的是**?
|
||||
|
||||
答:下面加粗的选项为说法正确。(全错)
|
||||
|
||||
1. 临界区是多个线程同时访问时发生问题的区域
|
||||
2. 线程安全的函数中不存在临界区,即便多个线程同时调用也不会发生问题
|
||||
3. 1 个临界区只能由 1 个代码块,而非多个代码块构成。换言之,线程 A 执行的代码块 A 和线程 B 执行的代码块 B 之间绝对不会构成临界区。
|
||||
4. 临界区由访问全局变量的代码构成。其他变量中不会发生问题。
|
||||
|
||||
5. **下列关于线程同步的说法错误的是**?
|
||||
|
||||
答:下面加粗的选项为说法正确。
|
||||
|
||||
1. 线程同步就是限制访问临界区
|
||||
2. **线程同步也具有控制线程执行顺序的含义**
|
||||
3. **互斥量和信号量是典型的同步技术**
|
||||
4. 线程同步是代替进程 IPC 的技术。
|
||||
|
||||
6. **请说明完全销毁 Linux 线程的 2 种办法**
|
||||
|
||||
答:①调用 pthread_join 函数②调用 pthread_detach 函数。第一个会阻塞调用的线程,而第二个不阻塞。都可以引导线程销毁。
|
||||
|
||||
## 第 19 章 Windows 平台下线程的使用
|
||||
|
||||
暂略
|
||||
|
||||
## 第 20 章 Windows 中的线程同步
|
||||
|
||||
暂略
|
||||
|
||||
## 第 21 章 异步通知 I/O 模型
|
||||
|
||||
暂略
|
||||
|
||||
## 第 22 章 重叠 I/O 模型
|
||||
|
||||
暂略
|
||||
|
||||
## 第 23 章 IOCP
|
||||
|
||||
暂略
|
||||
|
||||
## 第 24 章 制作 HTTP 服务器端
|
||||
|
||||
本章代码,在[TCP-IP-NetworkNote](https://github.com/riba2534/TCP-IP-NetworkNote)中可以找到。
|
||||
|
||||
## License
|
||||
|
||||
|
||||
Reference in New Issue
Block a user