mirror of
https://github.com/riba2534/TCP-IP-NetworkNote.git
synced 2026-06-29 17:36:05 +08:00
docs: 全面审查并修正所有章节文档内容
- 修正各章节中的错别字和术语错误(如 IPv4 大写规范、接收/接受区分等) - 补充和完善部分习题答案 - 优化技术描述的准确性和专业性 - 合并所有章节内容到根 README.md 新增文件: - CLAUDE.md: 项目开发指南 - .claude/agents/content-reviewer.md: 内容审查 subagent - .claude/agents/merger.md: 文档合并 subagent 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude Opus 4.5 <noreply@anthropic.com>
This commit is contained in:
137
ch03/README.md
137
ch03/README.md
@@ -12,12 +12,12 @@ IP 是 Internet Protocol(网络协议)的简写,是为收发网络数据
|
||||
|
||||
为使计算机连接到网络并收发数据,必须为其分配 IP 地址。IP 地址分为两类。
|
||||
|
||||
- IPV4(Internet Protocol version 4)4 字节地址族
|
||||
- IPV6(Internet Protocol version 6)16 字节地址族
|
||||
- IPv4(Internet Protocol version 4)4 字节地址族
|
||||
- IPv6(Internet Protocol version 6)16 字节地址族
|
||||
|
||||
两者之间的主要差别是 IP 地址所用的字节数,目前通用的是 IPV4 , IPV6 的普及还需要时间。
|
||||
两者之间的主要差别是 IP 地址所用的字节数,目前通用的是 IPv4,IPv6 的普及还需要时间。
|
||||
|
||||
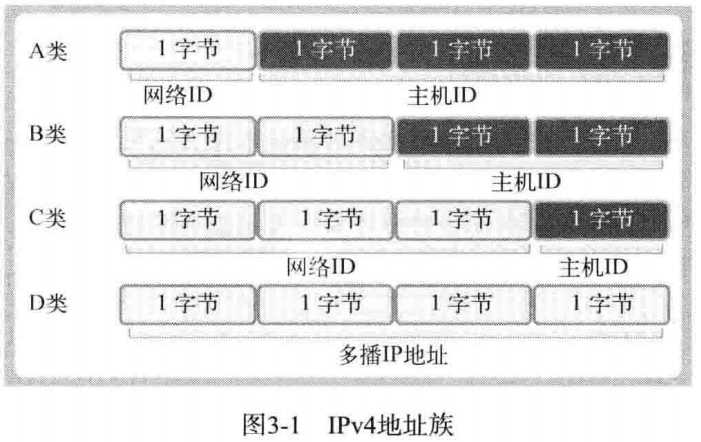
IPV4 标准的 4 字节 IP 地址分为网络地址和主机(指计算机)地址,且分为 A、B、C、D、E 等类型。
|
||||
IPv4 标准的 4 字节 IP 地址分为网络地址和主机(指计算机)地址,且分为 A、B、C、D、E 等类型。
|
||||
|
||||
|
||||
|
||||
@@ -29,7 +29,7 @@ IPV4 标准的 4 字节 IP 地址分为网络地址和主机(指计算机)
|
||||
|
||||
#### 3.1.2 网络地址分类与主机地址边界
|
||||
|
||||
只需通过IP地址的第一个字节即可判断网络地址占用的总字节数,因为我们根据IP地址的边界区分网络地址,如下所示:
|
||||
只需通过 IP 地址的第一个字节即可判断网络地址占用的总字节数,因为我们根据 IP 地址的边界区分网络地址,如下所示:
|
||||
|
||||
- A 类地址的首字节范围为:0~127
|
||||
- B 类地址的首字节范围为:128~191
|
||||
@@ -38,28 +38,28 @@ IPV4 标准的 4 字节 IP 地址分为网络地址和主机(指计算机)
|
||||
还有如下这种表示方式:
|
||||
|
||||
- A 类地址的首位以 0 开始
|
||||
- B 类地址的前2位以 10 开始
|
||||
- C 类地址的前3位以 110 开始
|
||||
- B 类地址的前 2 位以 10 开始
|
||||
- C 类地址的前 3 位以 110 开始
|
||||
|
||||
因此套接字收发数据时,数据传到网络后即可轻松找到主机。
|
||||
|
||||
#### 3.1.3 用于区分套接字的端口号
|
||||
|
||||
IP地址用于区分计算机,只要有IP地址就能向目标主机传输数据,但是只有这些还不够,我们需要把信息传输给具体的应用程序。
|
||||
IP 地址用于区分计算机,只要有 IP 地址就能向目标主机传输数据,但是只有这些还不够,我们需要把信息传输给具体的应用程序。
|
||||
|
||||
所以计算机一般有 NIC(网络接口卡)数据传输设备。通过 NIC 接收的数据内有端口号,操作系统参考端口号把信息传给相应的应用程序。
|
||||
|
||||
端口号由 16 位构成,可分配的端口号范围是 0~65535 。但是 0~1023 是知名端口,一般分配给特定的应用程序,所以应当分配给此范围之外的值。
|
||||
端口号由 16 位构成,可分配的端口号范围是 0~65535。但是 0~1023 是知名端口,一般分配给特定的应用程序,所以应当分配给此范围之外的值。
|
||||
|
||||
虽然端口号不能重复,但是 TCP 套接字和 UDP 套接字不会共用端口号,所以允许重复。如果某 TCP 套接字使用了 9190 端口号,其他 TCP 套接字就无法使用该端口号,但是 UDP 套接字可以使用。
|
||||
|
||||
总之,数据传输目标地址同时包含IP地址和端口号,只有这样,数据才会被传输到最终的目的应用程序。
|
||||
总之,数据传输目标地址同时包含 IP 地址和端口号,只有这样,数据才会被传输到最终的目的应用程序。
|
||||
|
||||
### 3.2 地址信息的表示
|
||||
|
||||
应用程序中使用的IP地址和端口号以结构体的形式给出了定义。本节围绕结构体讨论目标地址的表示方法。
|
||||
应用程序中使用的 IP 地址和端口号以结构体的形式给出了定义。本节围绕结构体讨论目标地址的表示方法。
|
||||
|
||||
#### 3.2.1 表示 IPV4 地址的结构体
|
||||
#### 3.2.1 表示 IPv4 地址的结构体
|
||||
|
||||
结构体的定义如下
|
||||
|
||||
@@ -73,20 +73,20 @@ struct sockaddr_in
|
||||
};
|
||||
```
|
||||
|
||||
该结构体中提到的另一个结构体 in_addr 定义如下,它用来存放 32 位IP地址
|
||||
该结构体中提到的另一个结构体 in_addr 定义如下,它用来存放 32 位 IP 地址
|
||||
|
||||
```c
|
||||
struct in_addr
|
||||
{
|
||||
in_addr_t s_addr; //32位IPV4地址
|
||||
}
|
||||
in_addr_t s_addr; //32位IPv4地址
|
||||
};
|
||||
```
|
||||
|
||||
关于以上两个结构体的一些数据类型:
|
||||
|
||||
| 数据类型名称 | 数据类型说明 | 声明的头文件 |
|
||||
| :----------: | :----------------------------------: | :----------: |
|
||||
| int 8_t | signed 8-bit int | sys/types.h |
|
||||
| int8_t | signed 8-bit int | sys/types.h |
|
||||
| uint8_t | unsigned 8-bit int (unsigned char) | sys/types.h |
|
||||
| int16_t | signed 16-bit int | sys/types.h |
|
||||
| uint16_t | unsigned 16-bit int (unsigned short) | sys/types.h |
|
||||
@@ -94,23 +94,23 @@ struct in_addr
|
||||
| uint32_t | unsigned 32-bit int (unsigned long) | sys/types.h |
|
||||
| sa_family_t | 地址族(address family) | sys/socket.h |
|
||||
| socklen_t | 长度(length of struct) | sys/socket.h |
|
||||
| in_addr_t | IP地址,声明为 uint_32_t | netinet/in.h |
|
||||
| in_port_t | 端口号,声明为 uint_16_t | netinet/in.h |
|
||||
| in_addr_t | IP地址,声明为 uint32_t | netinet/in.h |
|
||||
| in_port_t | 端口号,声明为 uint16_t | netinet/in.h |
|
||||
|
||||
为什么要额外定义这些数据类型呢?这是考虑扩展性的结果
|
||||
为什么要额外定义这些数据类型呢?这是考虑扩展性的结果。
|
||||
|
||||
#### 3.2.2 结构体 sockaddr_in 的成员分析
|
||||
|
||||
- 成员 sin_family
|
||||
|
||||
每种协议适用的地址族不同,比如,IPV4 使用 4 字节的地址族,IPV6 使用 16 字节的地址族。
|
||||
每种协议适用的地址族不同,比如,IPv4 使用 4 字节的地址族,IPv6 使用 16 字节的地址族。
|
||||
|
||||
> 地址族
|
||||
|
||||
| 地址族(Address Family) | 含义 |
|
||||
| ------------------------ | ---------------------------------- |
|
||||
| AF_INET | IPV4用的地址族 |
|
||||
| AF_INET6 | IPV6用的地址族 |
|
||||
| AF_INET | IPv4 用的地址族 |
|
||||
| AF_INET6 | IPv6 用的地址族 |
|
||||
| AF_LOCAL | 本地通信中采用的 Unix 协议的地址族 |
|
||||
|
||||
AF_LOCAL 只是为了说明具有多种地址族而添加的。
|
||||
@@ -121,7 +121,7 @@ AF_LOCAL 只是为了说明具有多种地址族而添加的。
|
||||
|
||||
- 成员 sin_addr
|
||||
|
||||
该成员保存 32 位 IP 地址信息,且也以网络字节序保存
|
||||
该成员保存 32 位 IP 地址信息,且也以网络字节序保存。
|
||||
|
||||
- 成员 sin_zero
|
||||
|
||||
@@ -134,21 +134,21 @@ AF_LOCAL 只是为了说明具有多种地址族而添加的。
|
||||
error_handling("bind() error");
|
||||
```
|
||||
|
||||
此处 bind 第二个参数期望得到的是 sockaddr 结构体变量的地址值,包括地址族、端口号、IP地址等。
|
||||
此处 bind 第二个参数期望得到的是 sockaddr 结构体变量的地址值,包括地址族、端口号、IP 地址等。
|
||||
|
||||
```c
|
||||
struct sockaddr
|
||||
{
|
||||
sa_family_t sin_family; //地址族
|
||||
char sa_data[14]; //地址信息
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
此结构体 sa_data 保存的地址信息中需要包含IP地址和端口号,剩余部分应该填充 0 ,但是这样对于包含地址的信息非常麻烦,所以出现了 sockaddr_in 结构体,然后强制转换成 sockaddr 类型,则生成符合 bind 条件的参数。
|
||||
此结构体 sa_data 保存的地址信息中需要包含 IP 地址和端口号,剩余部分应该填充 0,但是这样对于包含地址的信息非常麻烦,所以出现了 sockaddr_in 结构体,然后强制转换成 sockaddr 类型,则生成符合 bind 条件的参数。
|
||||
|
||||
### 3.3 网络字节序与地址变换
|
||||
|
||||
不同的 CPU 中,4 字节整数值1在内存空间保存方式是不同的。
|
||||
不同的 CPU 中,4 字节整数值 1 在内存空间保存方式是不同的。
|
||||
|
||||
有些 CPU 这样保存:
|
||||
|
||||
@@ -162,14 +162,14 @@ AF_LOCAL 只是为了说明具有多种地址族而添加的。
|
||||
00000001 00000000 00000000 00000000
|
||||
```
|
||||
|
||||
两种一种是顺序保存,一种是倒序保存 。
|
||||
两种一种是顺序保存,一种是倒序保存。
|
||||
|
||||
#### 3.3.1 字节序(Order)与网络字节序
|
||||
|
||||
CPU 保存数据的方式有两种,这意味着 CPU 解析数据的方式也有 2 种:
|
||||
|
||||
- 大端序(Big Endian):高位字节存放到低位地址
|
||||
- 小端序(Little Endian):高位字节存放到高位地址
|
||||
- 小端序(Little Endian):低位字节存放到低位地址
|
||||
|
||||

|
||||

|
||||
@@ -195,14 +195,14 @@ unsigned long ntohl(unsigned long);
|
||||
|
||||
- htons 的 h 代表主机(host)字节序。
|
||||
- htons 的 n 代表网络(network)字节序。
|
||||
- s 代表两个字节的 short 类型,因此以 s 为后缀的函数用于端口转换
|
||||
- l 代表四个字节的 long 类型,所以以 l 为后缀的函数用于 IP 地址转换
|
||||
- s 代表两个字节的 short 类型,因此以 s 为后缀的函数用于端口转换。
|
||||
- l 代表四个字节的 long 类型,所以以 l 为后缀的函数用于 IP 地址转换。
|
||||
|
||||
下面的代码是示例,说明以上函数调用过程:
|
||||
|
||||
[endian_conv.c](https://github.com/riba2534/TCP-IP-NetworkNote/blob/master/ch03/endian_conv.c)
|
||||
|
||||
```cpp
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <arpa/inet.h>
|
||||
int main(int argc, char *argv[])
|
||||
@@ -246,9 +246,9 @@ Network ordered address: 0x78563412
|
||||
|
||||
#### 3.4.1 将字符串信息转换为网络字节序的整数型
|
||||
|
||||
sockaddr_in 中需要的是 32 位整数型,但是我们只熟悉点分十进制表示法,那么改如何把类似于 201.211.214.36 转换为 4 字节的整数类型数据呢 ?幸运的是,有一个函数可以帮助我们完成它,该函数将字符串形式的 IP 地址转换为网络字节序形式的 32 位整数型数据。
|
||||
sockaddr_in 中需要的是 32 位整数型,但是我们只熟悉点分十进制表示法,那么该如何把类似于 201.211.214.36 转换为 4 字节的整数类型数据呢?幸运的是,有一个函数可以帮助我们完成它,该函数将字符串形式的 IP 地址转换为网络字节序形式的 32 位整数型数据。
|
||||
|
||||
```C
|
||||
```c
|
||||
#include <arpa/inet.h>
|
||||
in_addr_t inet_addr(const char *string);
|
||||
//成功时返回 32 位大端序整数型值,失败时返回 INADDR_NONE
|
||||
@@ -295,9 +295,9 @@ Network ordered integer addr: 0x4030201
|
||||
Error occured!
|
||||
```
|
||||
|
||||
1个字节能表示的最大整数是255,所以代码中 addr2 是错误的IP地址。从运行结果看,inet_addr 不仅可以转换地址,还可以检测有效性。
|
||||
1 个字节能表示的最大整数是 255,所以代码中 addr2 是错误的 IP 地址。从运行结果看,inet_addr 不仅可以转换地址,还可以检测有效性。
|
||||
|
||||
inet_aton 函数与 inet_addr 函数在功能上完全相同,也是将字符串形式的IP地址转换成整数型的IP地址。只不过该函数用了 in_addr 结构体,且使用频率更高。
|
||||
inet_aton 函数与 inet_addr 函数在功能上完全相同,也是将字符串形式的 IP 地址转换成整数型的 IP 地址。只不过该函数用了 in_addr 结构体,且使用频率更高。
|
||||
|
||||
```c
|
||||
#include <arpa/inet.h>
|
||||
@@ -341,7 +341,7 @@ void error_handling(char *message)
|
||||
|
||||
编译运行:
|
||||
|
||||
```c
|
||||
```shell
|
||||
gcc inet_aton.c -o aton
|
||||
./aton
|
||||
```
|
||||
@@ -354,7 +354,7 @@ Network ordered integer addr: 0x4f7ce87f
|
||||
|
||||
可以看出,已经成功的把转换后的地址放进了 addr_inet.sin_addr.s_addr 中。
|
||||
|
||||
还有一个函数,与 inet_aton() 正好相反,它可以把网络字节序整数型IP地址转换成我们熟悉的字符串形式,函数原型如下:
|
||||
还有一个函数,与 inet_aton() 正好相反,它可以把网络字节序整数型 IP 地址转换成我们熟悉的字符串形式,函数原型如下:
|
||||
|
||||
```c
|
||||
#include <arpa/inet.h>
|
||||
@@ -362,7 +362,7 @@ char *inet_ntoa(struct in_addr adr);
|
||||
//成功时返回保存转换结果的字符串地址值,失败时返回 NULL 空指针
|
||||
```
|
||||
|
||||
该函数将通过参数传入的整数型IP地址转换为字符串格式并返回。但要小心,返回值为 char 指针,返回字符串地址意味着字符串已经保存在内存空间,但是该函数未向程序员要求分配内存,而是再内部申请了内存保存了字符串。也就是说调用了该函数后要立即把信息复制到其他内存空间。因为,若再次调用 inet_ntoa 函数,则有可能覆盖之前保存的字符串信息。总之,再次调用 inet_ntoa 函数前返回的字符串地址是有效的。若需要长期保存,则应该将字符串复制到其他内存空间。
|
||||
该函数将通过参数传入的整数型 IP 地址转换为字符串格式并返回。但要小心,返回值为 char 指针,返回字符串地址意味着字符串已经保存在内存空间,但是该函数未向程序员要求分配内存,而是在内部申请了内存保存了字符串。也就是说调用了该函数后要立即把信息复制到其他内存空间。因为,若再次调用 inet_ntoa 函数,则有可能覆盖之前保存的字符串信息。总之,再次调用 inet_ntoa 函数前返回的字符串地址是有效的。若需要长期保存,则应该将字符串复制到其他内存空间。
|
||||
|
||||
示例:
|
||||
|
||||
@@ -400,9 +400,9 @@ gcc inet_ntoa.c -o ntoa
|
||||
./ntoa
|
||||
```
|
||||
|
||||
输出:
|
||||
输出:
|
||||
|
||||
```c
|
||||
```
|
||||
Dotted-Decimal notation1: 1.2.3.4
|
||||
Dotted-Decimal notation2: 1.1.1.1
|
||||
Dotted-Decimal notation3: 1.2.3.4
|
||||
@@ -414,7 +414,7 @@ Dotted-Decimal notation3: 1.2.3.4
|
||||
|
||||
```c
|
||||
struct sockaddr_in addr;
|
||||
char *serv_ip = "211.217,168.13"; //声明IP地址族
|
||||
char *serv_ip = "211.217.168.13"; //声明IP地址族
|
||||
char *serv_port = "9190"; //声明端口号字符串
|
||||
memset(&addr, 0, sizeof(addr)); //结构体变量 addr 的所有成员初始化为0
|
||||
addr.sin_family = AF_INET; //制定地址族
|
||||
@@ -430,33 +430,35 @@ addr.sin_port = htons(atoi(serv_port)); //基于字符串的IP地址端口号
|
||||
|
||||
> 答案仅代表本人个人观点,不一定正确
|
||||
|
||||
1. **IP地址族 IPV4 与 IPV6 有什么区别?在何种背景下诞生了 IPV6?**
|
||||
1. **IP 地址族 IPv4 与 IPv6 有什么区别?在何种背景下诞生了 IPv6?**
|
||||
|
||||
答:主要差别是IP地址所用的字节数,目前通用的是IPV4,目前IPV4的资源已耗尽,所以诞生了IPV6,它具有更大的地址空间。
|
||||
答:主要差别是 IP 地址所用的字节数,IPv4 使用 4 字节地址(约 43 亿个地址),IPv6 使用 16 字节地址(约 3.4×10^38 个地址)。目前通用的是 IPv4,但由于 IPv4 地址资源已近枯竭,所以诞生了 IPv6,它具有巨大的地址空间,可以满足未来互联网发展的需求。
|
||||
|
||||
2. **通过 IPV4 网络 ID 、主机 ID 及路由器的关系说明公司局域网的计算机传输数据的过程**
|
||||
2. **通过 IPv4 网络 ID、主机 ID 及路由器的关系说明公司局域网的计算机传输数据的过程。**
|
||||
|
||||
答:网络ID是为了区分网络而设置的一部分IP地址,假设向`www.baidu.com`公司传输数据,该公司内部构建了局域网。因为首先要向`baidu.com`传输数据,也就是说并非一开始就浏览所有四字节IP地址,首先找到网络地址,进而由`baidu.com`(构成网络的路由器)接收到数据后,传输到主机地址。比如向 203.211.712.103 传输数据,那就先找到 203.211.172 ,然后由这个网络的网关找主机号为 172 的机器传输数据。
|
||||
答:网络 ID 是为了区分网络而设置的一部分 IP 地址,主机 ID 是为了区分网络内的主机而设置的部分。假设向某公司传输数据,该公司内部构建了局域网。数据传输时首先根据网络 ID 找到目标网络(由路由器或网关接收),然后由该网络的路由器根据主机 ID 将数据转发给具体的主机。
|
||||
|
||||
3. **套接字地址分为IP地址和端口号,为什么需要IP地址和端口号?或者说,通过IP地址可以区分哪些对象?通过端口号可以区分哪些对象?**
|
||||
例如向 IP 地址 203.211.172.103 传输数据,其中 203.211.172 是网络 ID,103 是主机 ID。数据首先被路由到网络 203.211.172(由该网络的网关路由器接收),然后路由器根据主机 ID 103 将数据传递给局域网内对应的主机。
|
||||
|
||||
答:有了IP地址和端口号,才能把数据准确的传送到某个应用程序中。通过IP地址可以区分具体的主机,通过端口号可以区分主机上的应用程序。
|
||||
3. **套接字地址分为 IP 地址和端口号,为什么需要 IP 地址和端口号?或者说,通过 IP 地址可以区分哪些对象?通过端口号可以区分哪些对象?**
|
||||
|
||||
4. **请说明IP地址的分类方法,并据此说出下面这些IP的分类。**
|
||||
答:有了 IP 地址和端口号,才能把数据准确地传送到某个应用程序中。通过 IP 地址可以区分网络中不同的主机(计算机),通过端口号可以区分同一主机上不同的应用程序(套接字)。
|
||||
|
||||
- 214.121.212.102(C类)
|
||||
- 120.101.122.89(A类)
|
||||
- 129.78.102.211(B类)
|
||||
4. **请说明 IP 地址的分类方法,并据此说出下面这些 IP 的分类。**
|
||||
|
||||
分类方法:A 类地址的首字节范围为:0~127、B 类地址的首字节范围为:128~191、C 类地址的首字节范围为:192~223
|
||||
- 214.121.212.102(C 类)
|
||||
- 120.101.122.89(A 类)
|
||||
- 129.78.102.211(B 类)
|
||||
|
||||
分类方法:A 类地址的首字节范围为:0~127、B 类地址的首字节范围为:128~191、C 类地址的首字节范围为:192~223。
|
||||
|
||||
5. **计算机通过路由器和交换机连接到互联网,请说出路由器和交换机的作用。**
|
||||
|
||||
答:路由器表示连接到互联网的网络 ID,用于在不同网络间转发数据。交换机用于组织一个局域网内部的主机,局域网内部的主机可以通过交换机直接通信。如果局域网内的主机想要和其他网络的主机通信,需要通过路由器转发到目的网络,接收到的其他网络发来的数据先通过路由器接收,再由路由器根据主机号转发到交换机寻找具体的主机。
|
||||
答:路由器用于连接不同的网络,负责在不同网络间转发数据包,根据 IP 地址的网络 ID 进行路由选择。交换机用于组织局域网内部的主机连接,局域网内部的主机可以通过交换机直接通信(基于 MAC 地址)。如果局域网内的主机想要和其他网络的主机通信,需要通过路由器转发到目的网络;接收到的其他网络发来的数据先由路由器接收,再由路由器转发到交换机,最终找到具体的主机。
|
||||
|
||||
6. **什么是知名端口?其范围是多少?知名端口中具有代表性的 HTTP 和 FTP 的端口号各是多少?**
|
||||
|
||||
答:知名端口是要把该端口分配给特定的应用程序,范围是 0~1023 ,HTTP 的端口号是 80 ,FTP 的端口号是20和21
|
||||
答:知名端口(Well-Known Ports)是保留给特定应用程序使用的端口,范围是 0~1023。HTTP 的默认端口号是 80,FTP 的默认端口号是 20(数据连接)和 21(控制连接)。
|
||||
|
||||
7. **向套接字分配地址的 bind 函数原型如下:**
|
||||
|
||||
@@ -467,22 +469,33 @@ addr.sin_port = htons(atoi(serv_port)); //基于字符串的IP地址端口号
|
||||
**而调用时则用:**
|
||||
|
||||
```c
|
||||
bind(serv_sock, (struct sockaddr *)&serv_addr, sizeof(serv_addr)
|
||||
bind(serv_sock, (struct sockaddr *)&serv_addr, sizeof(serv_addr));
|
||||
```
|
||||
|
||||
**此处 serv_addr 为 sockaddr_in 结构体变量。与函数原型不同,传入的是 sockaddr_in 结构体变量,请说明原因。**
|
||||
|
||||
答:因为对于详细的地址信息使用 sockaddr 类型传递特别麻烦,进而有了 sockaddr_in 类型,其中基本与前面的类型保持一致,还有 sa_sata[4] 来保存地址信息,剩余全部填 0,所以强制转换后,不影响程序运行。
|
||||
答:sockaddr 结构体的 sa_data 成员是一个 14 字节的数组,需要手动填充 IP 地址、端口号等信息,使用起来非常麻烦。因此设计了 sockaddr_in 结构体,它将地址信息分成了 sin_family、sin_port、sin_addr 等独立的成员,便于使用。由于 sockaddr_in 和 sockaddr 在内存布局上是兼容的(大小相同,前两个字段偏移一致),且 bind 函数需要的是 sockaddr 类型的指针,所以可以将 sockaddr_in 结构体变量的地址强制转换为 sockaddr* 类型传入,不影响程序的正确运行。
|
||||
|
||||
8. **请解释大端序,小端序、网络字节序,并说明为何需要网络字节序。**
|
||||
8. **请解释大端序、小端序、网络字节序,并说明为何需要网络字节序。**
|
||||
|
||||
答:CPU 向内存保存数据有两种方式,大端序是高位字节存放低位地址,小端序是高位字节存放高位地址,网络字节序是为了方便传输的信息统一性,统一成了大端序。
|
||||
答:
|
||||
- 大端序(Big Endian):高位字节存放在低位地址
|
||||
- 小端序(Little Endian):低位字节存放在低位地址
|
||||
- 网络字节序:为了在网络上统一传输数据的格式,约定使用大端序作为网络字节序
|
||||
|
||||
需要网络字节序的原因:不同的 CPU 架构采用不同的字节序(如 x86 是小端序,PowerPC 是大端序),如果两台字节序不同的计算机直接传输数据,接收方会错误解析数据。因此约定网络传输统一使用大端序,发送前将主机字节序转换为网络字节序,接收后再转换回主机字节序。
|
||||
|
||||
9. **大端序计算机希望把 4 字节整数型 12 传递到小端序计算机。请说出数据传输过程中发生的字节序变换过程。**
|
||||
|
||||
答:0x12->0x21
|
||||
答:整数 12 的十六进制表示为 0x0000000C。
|
||||
|
||||
10. **怎样表示回送地址?其含义是什么?如果向会送地址处传输数据将会发生什么情况?**
|
||||
- 在大端序计算机上,内存表示为:`00 00 00 0C`(从低地址到高地址)
|
||||
- 发送时已经是网络字节序(大端序),无需转换,直接发送 `00 00 00 0C`
|
||||
- 小端序计算机接收到 `00 00 00 0C` 后,通过 ntohl() 函数转换为小端序
|
||||
- 转换后在小端序计算机内存中为:`0C 00 00 00`(从低地址到高地址)
|
||||
|
||||
答:127.0.0.1 表示回送地址,指的是计算机自身的IP地址,无论什么程序,一旦使用回送地址发送数据,协议软件立即返回,不进行任何网络传输。
|
||||
注意:字节序转换函数处理的是整个 4 字节整数,而非单字节。对于单字节值 12(0x0C),无论在大端序还是小端序机器上,其值都是 0x0C,不会变成 0x21。
|
||||
|
||||
10. **怎样表示回送地址?其含义是什么?如果向回送地址处传输数据将会发生什么情况?**
|
||||
|
||||
答:回送地址表示为 127.0.0.1(IPv4)或 ::1(IPv6),指的是计算机自身的 IP 地址,也称为本地环回地址。无论什么程序,一旦使用回送地址发送数据,数据不会真正发送到网络上,而是在本机协议栈内循环,协议软件立即将数据返回给本机的接收端,不进行任何网络传输。回送地址常用于本地服务测试和网络程序调试。
|
||||
|
||||
Reference in New Issue
Block a user