mirror of
https://github.com/riba2534/TCP-IP-NetworkNote.git
synced 2026-06-30 01:46:15 +08:00
docs: 全面审查并修正所有章节文档内容
- 修正各章节中的错别字和术语错误(如 IPv4 大写规范、接收/接受区分等) - 补充和完善部分习题答案 - 优化技术描述的准确性和专业性 - 合并所有章节内容到根 README.md 新增文件: - CLAUDE.md: 项目开发指南 - .claude/agents/content-reviewer.md: 内容审查 subagent - .claude/agents/merger.md: 文档合并 subagent 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude Opus 4.5 <noreply@anthropic.com>
This commit is contained in:
@@ -21,9 +21,9 @@ select 性能上最大的弱点是:每次传递监视对象信息,准确的
|
||||
|
||||
这样就无需每次调用 select 函数时都向操作系统传递监视对象信息,但是前提操作系统支持这种处理方式。Linux 的支持方式是 epoll ,Windows 的支持方式是 IOCP。
|
||||
|
||||
#### 17.1.2 select 也有有点
|
||||
#### 17.1.2 select 也有优点
|
||||
|
||||
select 的兼容性比较高,这样就可以支持很多的操作系统,不受平台的限制,满足以下两个条件使可以使用 select 函数:
|
||||
select 的兼容性比较高,这样就可以支持很多的操作系统,不受平台的限制,满足以下两个条件时可以使用 select 函数:
|
||||
|
||||
- 服务器接入者少
|
||||
- 程序应该具有兼容性
|
||||
@@ -83,7 +83,7 @@ size:epoll 实例的大小
|
||||
|
||||
调用 epoll_create 函数时创建的文件描述符保存空间称为「epoll 例程」,但有些情况下名称不同,需要稍加注意。通过参数 size 传递的值决定 epoll 例程的大小,但该值只是向操作系统提出的建议。换言之,size 并不用来决定 epoll 的大小,而仅供操作系统参考。
|
||||
|
||||
> Linux 2.6.8 之后的内核将完全忽略传入 epoll_create 函数的 size 函数,因此内核会根据情况调整 epoll 例程大小。但是本书程序并没有忽略 size
|
||||
> Linux 2.6.8 之后的内核将完全忽略传入 epoll_create 函数的 size 参数,因此内核会根据情况调整 epoll 例程大小。但是本书程序并没有忽略 size
|
||||
|
||||
epoll_create 函数创建的资源与套接字相同,也由操作系统管理。因此,该函数和创建套接字的情况相同,也会返回文件描述符,也就是说返回的文件描述符主要用于区分 epoll 例程。需要终止时,与其他文件描述符相同,也要调用 close 函数
|
||||
|
||||
@@ -105,13 +105,13 @@ event:监视对象的事件类型
|
||||
|
||||
与其他 epoll 函数相比,该函数看起来有些复杂,但通过调用语句就很容易理解,假设按照如下形式调用 epoll_ctl 函数:
|
||||
|
||||
```CQL
|
||||
epoll_ctl(A,EPOLL_CTL_ADD,B,C);
|
||||
```c
|
||||
epoll_ctl(A, EPOLL_CTL_ADD, B, C);
|
||||
```
|
||||
|
||||
第二个参数 EPOLL_CTL_ADD 意味着「添加」,上述语句有如下意义:
|
||||
|
||||
> epoll 例程 A 中注册文件描述符 B ,主要目的是为了监视参数 C 中的事件
|
||||
> epoll 例程 A 中注册文件描述符 B,主要目的是为了监视参数 C 中的事件
|
||||
|
||||
再介绍一个调用语句。
|
||||
|
||||
@@ -142,7 +142,7 @@ epoll_ctl(epfd,EPOLL_CTL_ADD,sockfd,&event);
|
||||
...
|
||||
```
|
||||
|
||||
上述代码将 epfd 注册到 epoll 例程 epfd 中,并在需要读取数据的情况下产生相应事件。接下来给出 epoll_event 的成员 events 中可以保存的常量及所指的事件类型。
|
||||
上述代码将 sockfd 注册到 epoll 例程 epfd 中,并在需要读取数据的情况下产生相应事件。接下来给出 epoll_event 的成员 events 中可以保存的常量及所指的事件类型。
|
||||
|
||||
- EPOLLIN:需要读取数据的情况
|
||||
- EPOLLOUT:输出缓冲为空,可以立即发送数据的情况
|
||||
@@ -207,7 +207,7 @@ gcc echo_epollserv.c -o serv
|
||||
|
||||
总结一下 epoll 的流程:
|
||||
|
||||
1. epoll_create 创建一个保存 epoll 文件描述符的空间,可以没有参数
|
||||
1. epoll_create 创建一个保存 epoll 文件描述符的空间(size 参数仅作为建议传递)
|
||||
2. 动态分配内存,给将要监视的 epoll_wait
|
||||
3. 利用 epoll_ctl 控制 添加 删除,监听事件
|
||||
4. 利用 epoll_wait 来获取改变的文件描述符,来执行程序
|
||||
@@ -290,7 +290,7 @@ Linux 套接字相关函数一般通过 -1 通知发生了错误。虽然知道
|
||||
int errno;
|
||||
```
|
||||
|
||||
为了访问该变量,需要引入 `error.h` 头文件,因此此头文件有上述变量的 extren 声明。另外,每种函数发生错误时,保存在 errno 变量中的值都不同。
|
||||
为了访问该变量,需要引入 `errno.h` 头文件,因此此头文件有上述变量的 extern 声明。另外,每种函数发生错误时,保存在 errno 变量中的值都不同。
|
||||
|
||||
> read 函数发现输入缓冲中没有数据可读时返回 -1,同时在 errno 中保存 EAGAIN 常量
|
||||
|
||||
@@ -298,7 +298,7 @@ int errno;
|
||||
|
||||
```c
|
||||
#include <fcntl.h>
|
||||
int fcntl(int fields, int cmd, ...);
|
||||
int fcntl(int filedes, int cmd, ...);
|
||||
/*
|
||||
成功时返回 cmd 参数相关值,失败时返回 -1
|
||||
filedes : 属性更改目标的文件描述符
|
||||
@@ -306,14 +306,14 @@ cmd : 表示函数调用目的
|
||||
*/
|
||||
```
|
||||
|
||||
从上述声明可以看出 fcntl 有可变参数的形式。如果向第二个参数传递 F_GETFL ,可以获得第一个参数所指的文件描述符属性(int 型)。反之,如果传递 F_SETFL ,可以更改文件描述符属性。若希望将文件(套接字)改为非阻塞模式,需要如下 2 条语句。
|
||||
从上述声明可以看出 fcntl 有可变参数的形式。如果向第二个参数传递 F_GETFL ,可以获得第一个参数所指的文件描述符属性(int 型)。反之,如果传递 F_SETFL ,可以更改文件描述符属性。若希望将文件(套接字)改为非阻塞模式,需要如下 2 条语句。
|
||||
|
||||
```C
|
||||
int flag = fcntl(fd,F_GETFL,0);
|
||||
```c
|
||||
int flag = fcntl(fd, F_GETFL, 0);
|
||||
fcntl(fd, F_SETFL, flag | O_NONBLOCK);
|
||||
```
|
||||
|
||||
通过第一条语句,获取之前设置的属性信息,通过第二条语句在此基础上添加非阻塞 O_NONBLOCK 标志。调用 read/write 函数时,无论是否存在数据,都会形成非阻塞文件(套接字)。fcntl 函数的适用范围很广。
|
||||
通过第一条语句获取之前设置的属性信息,通过第二条语句在此基础上添加非阻塞 O_NONBLOCK 标志。调用 read/write 函数时,无论是否存在数据,都会形成非阻塞文件(套接字)。fcntl 函数的适用范围很广。
|
||||
|
||||
#### 17.2.4 实现边缘触发回声服务器端
|
||||
|
||||
@@ -346,25 +346,25 @@ gcc echo_EPETserv.c -o serv
|
||||
|
||||
> 可以分离接收数据和处理数据的时间点!
|
||||
|
||||
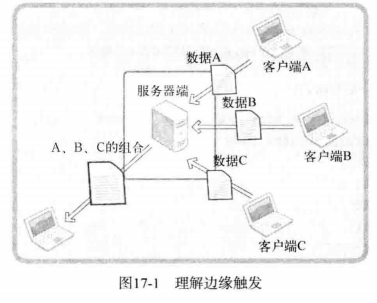
下面是边缘触发的图
|
||||
下面是边缘触发的图:
|
||||
|
||||
|
||||
|
||||
运行流程如下:
|
||||
|
||||
- 服务器端分别从 A B C 接收数据
|
||||
- 服务器端按照 A B C 的顺序重新组合接收到的数据
|
||||
- 服务器端分别从 A、B、C 接收数据
|
||||
- 服务器端按照 A、B、C 的顺序重新组合接收到的数据
|
||||
- 组合的数据将发送给任意主机。
|
||||
|
||||
为了完成这个过程,如果可以按照如下流程运行,服务端的实现并不难:
|
||||
|
||||
- 客户端按照 A B C 的顺序连接服务器,并且按照次序向服务器发送数据
|
||||
- 需要接收数据的客户端应在客户端 A B C 之前连接到服务器端并等待
|
||||
- 客户端按照 A、B、C 的顺序连接服务器,并且按照次序向服务器发送数据
|
||||
- 需要接收数据的客户端应在客户端 A、B、C 之前连接到服务器端并等待
|
||||
|
||||
但是实际情况中可能是下面这样:
|
||||
|
||||
- 客户端 C 和 B 正在向服务器发送数据,但是 A 并没有连接到服务器
|
||||
- 客户端 A B C 乱序发送数据
|
||||
- 客户端 A、B、C 乱序发送数据
|
||||
- 服务端已经接收到数据,但是要接收数据的目标客户端并没有连接到服务器端。
|
||||
|
||||
因此,即使输入缓冲收到数据,服务器端也能决定读取和处理这些数据的时间点,这样就给服务器端的实现带来很大灵活性。
|
||||
|
||||
Reference in New Issue
Block a user