mirror of
https://github.com/riba2534/TCP-IP-NetworkNote.git
synced 2026-06-29 17:36:05 +08:00
docs: 全面审查并修正所有章节文档内容
- 修正各章节中的错别字和术语错误(如 IPv4 大写规范、接收/接受区分等) - 补充和完善部分习题答案 - 优化技术描述的准确性和专业性 - 合并所有章节内容到根 README.md 新增文件: - CLAUDE.md: 项目开发指南 - .claude/agents/content-reviewer.md: 内容审查 subagent - .claude/agents/merger.md: 文档合并 subagent 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude Opus 4.5 <noreply@anthropic.com>
This commit is contained in:
@@ -16,7 +16,7 @@ web服务器端就是要基于 HTTP 协议,将网页对应文件传输给客
|
||||
|
||||
|
||||
|
||||
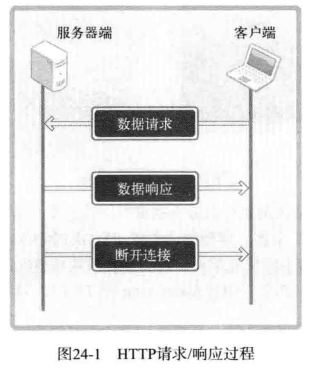
从上图可以看出,服务器端相应客户端请求后立即断开连接。换言之,服务器端不会维持客户端状态。即使同一客户端再次发送请求,服务器端也无法辨认出是原先那个,而会以相同方式处理新请求。因此,HTTP 又称「无状态的 Stateless 协议」
|
||||
从上图可以看出,服务器端响应客户端请求后立即断开连接。换言之,服务器端不会维持客户端状态。即使同一客户端再次发送请求,服务器端也无法辨认出是原先那个,而会以相同方式处理新请求。因此,HTTP 又称「无状态的 Stateless 协议」。
|
||||
|
||||
#### 24.1.3 请求消息(Request Message)的结构
|
||||
|
||||
@@ -24,17 +24,17 @@ web服务器端就是要基于 HTTP 协议,将网页对应文件传输给客
|
||||
|
||||
|
||||
|
||||
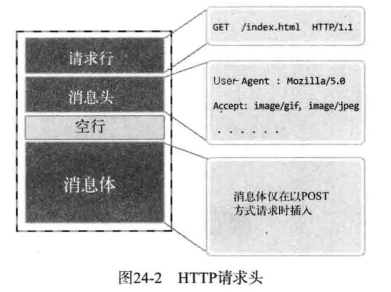
从图中可以看出,请求消息可以分为请求头、消息头、消息体 3 个部分。其中,请求行含有请求方式(请求目的)信息。典型的请求方式有 GET 和 POST ,GET 主要用于请求数据,POST 主要用于传输数据。为了降低复杂度,我们实现只能响应 GET 请求的 Web 服务器端,下面解释图中的请求行信息。其中「GET/index.html HTTP/1.1」 具有如下含义:
|
||||
从图中可以看出,请求消息可以分为请求行、消息头、消息体 3 个部分。其中,请求行含有请求方式(请求目的)信息。典型的请求方式有 GET 和 POST ,GET 主要用于请求数据,POST 主要用于传输数据。为了降低复杂度,我们实现只能响应 GET 请求的 Web 服务器端,下面解释图中的请求行信息。其中「GET/index.html HTTP/1.1」 具有如下含义:
|
||||
|
||||
> 请求(GET)index.html 文件,通常以 1.1 版本的 HTTP 协议进行通信。
|
||||
|
||||
请求行只能通过 1 行(line)发送,因此,服务器端很容易从 HTTP 请求中提取第一行,并分别分析请求行中的信息。
|
||||
请求行只能通过 1 行(line)发送,因此,服务器端很容易从 HTTP 请求中提取第一行,并分别分析请求行中的信息。
|
||||
|
||||
请求行下面的消息头中包含发送请求的浏览器信息、用户认证信息等关于 HTTP 消息的附加信息。最后的消息体中装有客户端向服务端传输的数据,为了装入数据,需要以 POST 方式发送请求。但是我们的目标是实现 GET 方式的服务器端,所以可以忽略这部分内容。另外,消息体和消息头与之间以空行隔开,因此不会发生边界问题
|
||||
请求行下面的消息头中包含发送请求的浏览器信息、用户认证信息等关于 HTTP 消息的附加信息。最后的消息体中装有客户端向服务端传输的数据,为了装入数据,需要以 POST 方式发送请求。但是我们的目标是实现 GET 方式的服务器端,所以可以忽略这部分内容。另外,消息体和消息头之间以空行隔开,因此不会发生边界问题。
|
||||
|
||||
#### 24.1.4 响应消息(Response Message)的结构
|
||||
|
||||
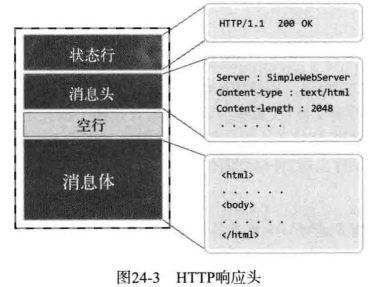
下面是 Web 服务器端向客户端传递的响应信息的结构。从图中可以看出,该响应消息由状态行、头信息、消息体等 3 个部分组成。状态行中有关于请求的状态信息,这是与请求消息相比最为显著地区别。
|
||||
下面是 Web 服务器端向客户端传递的响应信息的结构。从图中可以看出,该响应消息由状态行、头信息、消息体等 3 个部分组成。状态行中有关于请求的状态信息,这是与请求消息相比最为显著的区别。
|
||||
|
||||
|
||||
|
||||
@@ -173,7 +173,7 @@ void send_data(FILE *fp, char *ct, char *file_name)
|
||||
fputs(cnt_len, fp);
|
||||
fputs(cnt_type, fp);
|
||||
|
||||
//传输请求数据
|
||||
//传输响应体数据
|
||||
while (fgets(buf, BUF_SIZE, send_file) != NULL)
|
||||
{
|
||||
fputs(buf, fp);
|
||||
@@ -239,19 +239,19 @@ gcc webserv_linux.c -D_REENTRANT -o web_serv -lpthread
|
||||
|
||||
1. **下列关于 Web 服务器端和 Web 浏览器端的说法错误的是**?
|
||||
|
||||
答:以下加粗选项代表正确。
|
||||
答:**选项 5 是错误的**。
|
||||
|
||||
1. **Web 浏览器并不是通过自身创建的套接字连接服务端的客户端**
|
||||
1. Web 浏览器是通过自身创建的套接字连接服务端的客户端
|
||||
2. Web 服务器端通过 TCP 套接字提供服务,因为它将保持较长的客户端连接并交换数据
|
||||
3. 超文本与普通文本的最大区别是其具有可跳转的特性
|
||||
4. Web 浏览器可视为向浏览器提供请求文件的文件传输服务器端
|
||||
5. 除 Web 浏览器外,其他客户端都无法访问 Web 服务器端。
|
||||
5. **除 Web 浏览器外,其他客户端都无法访问 Web 服务器端。(错误:任何能发起 HTTP 请求的客户端都可以访问 Web 服务器端,如 curl、wget、编程实现的 HTTP 客户端等)**
|
||||
|
||||
2. **下列关于 HTTP 协议的描述错误的是**?
|
||||
|
||||
答:以下加粗选项代表正确。
|
||||
答:**选项 1 是错误的**。
|
||||
|
||||
1. HTTP 协议是无状态的 Stateless 协议,不仅可以通过 TCP 实现,还可以通过 UDP 来实现
|
||||
2. **HTTP 协议是无状态的 Stateless 协议,因为其在 1 次请求和响应过程完成后立即断开连接。因此,如果同一服务器端和客户端需要 3 次请求及响应,则意味着需要经过 3 次套接字的创建过程**。
|
||||
3. **服务端向客户端传递的状态码中含有请求处理结果的信息**。
|
||||
4. **HTTP 协议是基于因特网的协议,因此,为了同时向大量客户端提供服务,HTTP 协议被设计为 Stateless 协议**。
|
||||
1. **HTTP 协议是无状态的 Stateless 协议,不仅可以通过 TCP 实现,还可以通过 UDP 来实现。(错误:标准 HTTP 协议是基于 TCP 的,HTTP/3 基于 QUIC 协议即 UDP 实现,但传统意义上 HTTP 是基于 TCP 的)**
|
||||
2. HTTP 协议是无状态的 Stateless 协议,因为其在 1 次请求和响应过程完成后立即断开连接。因此,如果同一服务器端和客户端需要 3 次请求及响应,则意味着需要经过 3 次套接字的创建过程。
|
||||
3. 服务端向客户端传递的状态码中含有请求处理结果的信息。
|
||||
4. HTTP 协议是基于因特网的协议,因此,为了同时向大量客户端提供服务,HTTP 协议被设计为 Stateless 协议。
|
||||
|
||||
Reference in New Issue
Block a user