diff --git a/README.md b/README.md
index b19ab37..8991c59 100644
--- a/README.md
+++ b/README.md
@@ -80,7 +80,7 @@ The browser tries to figure out the IP address for the entered domain. The DNS l
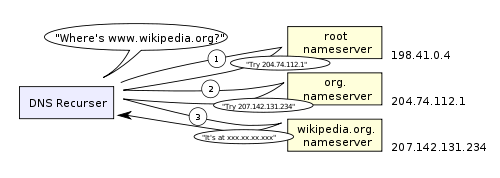
Here is a diagram of what a recursive DNS search looks like:
-
+
One worrying thing about DNS is that the entire domain like wikipedia.org or facebook.com seems to map to a single IP address. Fortunately, there are ways of mitigating the bottleneck:
@@ -234,7 +234,7 @@ Once the server supplies the resources (HTML, CSS, JS, images, etc.) to the brow
7. **Data Storage:** This is a persistence layer. The browser may need to save data locally, such as cookies. Browsers also support storage mechanisms such as [localStorage](https://developer.mozilla.org/en-US/docs/Web/API/Window/localStorage), [IndexedDB](https://developer.mozilla.org/en-US/docs/Web/API/IndexedDB_API/Using_IndexedDB) and [FileSystem](https://developer.chrome.com/apps/fileSystem).
-
+
Let’s start, with the simplest possible case: a plain HTML page with some text and a single image. What does the browser need to do to process this simple page?
@@ -248,7 +248,7 @@ Let’s start, with the simplest possible case: a plain HTML page with some text
4. **DOM construction:** Finally, because the HTML markup defines relationships between different tags (some tags are contained within tags) the created objects are linked in a tree data structure that also captures the parent-child relationships defined in the original markup: HTML object is a parent of the body object, the body is a parent of the paragraph object, and so on.
-
+
The final output of this entire process is the Document Object Model, or the “DOM” of our simple page, which the browser uses for all further processing of the page.
@@ -256,7 +256,7 @@ The final output of this entire process is the Document Object Model, or the “
Every time the browser has to process HTML markup it has to step through all of the steps above: convert bytes to characters, identify tokens, convert tokens to nodes, and build the DOM tree. This entire process can take some time, especially if we have a large amount of HTML to process.
-
+
If you open up Chrome DevTools and record a timeline while the page is loaded, you can see the actual time taken to perform this step — in the example above, it took us ~5ms to convert a chunk of HTML bytes into a DOM tree. Of course, if the page was larger, as most pages are, this process might take significantly longer. You will see in our future sections on creating smooth animations that this can easily become your bottleneck if the browser has to process large amounts of HTML.
@@ -290,7 +290,7 @@ The rendering engine will start getting the contents of the requested document f
After that the basic flow of the rendering engine is:
-
+
The rendering engine will start parsing the HTML document and convert elements to [DOM](http://domenlightenment.com/) nodes in a tree called the **"content tree"**.
@@ -307,7 +307,7 @@ It's important to understand that this is a gradual process. For better user exp
Given below is Webkit's flow:
-
+
## Parsing Basics
@@ -325,7 +325,7 @@ Parsing can be separated into two sub processes: lexical analysis and syntax ana
Parsers usually divide the work between two components: the lexer (sometimes called tokenizer) that is responsible for breaking the input into valid tokens, and the parser that is responsible for constructing the parse tree by analyzing the document structure according to the language syntax rules. The lexer knows how to strip irrelevant characters like white spaces and line breaks.
-
+
The parsing process is iterative. The parser will usually ask the lexer for a new token and try to match the token with one of the syntax rules. If a rule is matched, a node corresponding to the token will be added to the parse tree and the parser will ask for another token.
@@ -339,7 +339,7 @@ HTML parsing algorithm consists of two stages: tokenization and tree constructio
**Tokenization** is the lexical analysis, parsing the input into tokens. Among HTML tokens are start tags, end tags, attribute names and attribute values. The tokenizer recognizes the token, gives it to the tree constructor, and consumes the next character for recognizing the next token, and so on until the end of the input.
-
+
## DOM Tree
@@ -362,7 +362,7 @@ The DOM has an almost one-to-one relation to the markup. For example:
This markup would be translated to the following DOM tree:
-
+
### Why is the DOM slow?
@@ -391,7 +391,7 @@ There are DOM elements which correspond to several visual objects. These are usu
Some render objects correspond to a DOM node but not in the same place in the tree. Floats and absolutely positioned elements are out of flow, placed in a different part of the tree, and mapped to the real frame. A placeholder frame is where they should have been.
-
+
In WebKit the process of resolving the style and creating a renderer is called "attachment". Every DOM node has an "attach" method. Attachment is synchronous, node insertion to the DOM tree calls the new node "attach" method.
diff --git a/img/Example_of_an_iterative_DNS_resolver.svg b/img/Example_of_an_iterative_DNS_resolver.svg
new file mode 100644
index 0000000..4ef810d
--- /dev/null
+++ b/img/Example_of_an_iterative_DNS_resolver.svg
@@ -0,0 +1,270 @@
+
+
+
diff --git a/img/dom-timeline.png b/img/dom-timeline.png
new file mode 100644
index 0000000..e4c6dfd
Binary files /dev/null and b/img/dom-timeline.png differ
diff --git a/img/flow.png b/img/flow.png
new file mode 100644
index 0000000..6c12e8e
Binary files /dev/null and b/img/flow.png differ
diff --git a/img/full-process.png b/img/full-process.png
new file mode 100644
index 0000000..7d96b4f
Binary files /dev/null and b/img/full-process.png differ
diff --git a/img/image011.png b/img/image011.png
new file mode 100644
index 0000000..74a4a43
Binary files /dev/null and b/img/image011.png differ
diff --git a/img/image015.png b/img/image015.png
new file mode 100644
index 0000000..1ff7051
Binary files /dev/null and b/img/image015.png differ
diff --git a/img/image017.png b/img/image017.png
new file mode 100644
index 0000000..1bae213
Binary files /dev/null and b/img/image017.png differ
diff --git a/img/image025.png b/img/image025.png
new file mode 100644
index 0000000..b826453
Binary files /dev/null and b/img/image025.png differ
diff --git a/img/layers.png b/img/layers.png
new file mode 100644
index 0000000..242330c
Binary files /dev/null and b/img/layers.png differ
diff --git a/img/webkitflow.png b/img/webkitflow.png
new file mode 100644
index 0000000..1e0089d
Binary files /dev/null and b/img/webkitflow.png differ
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 