mirror of
https://github.com/youngyangyang04/leetcode-master.git
synced 2026-05-06 21:34:10 +08:00
替换图片链接
This commit is contained in:
@@ -46,13 +46,13 @@
|
||||
|
||||
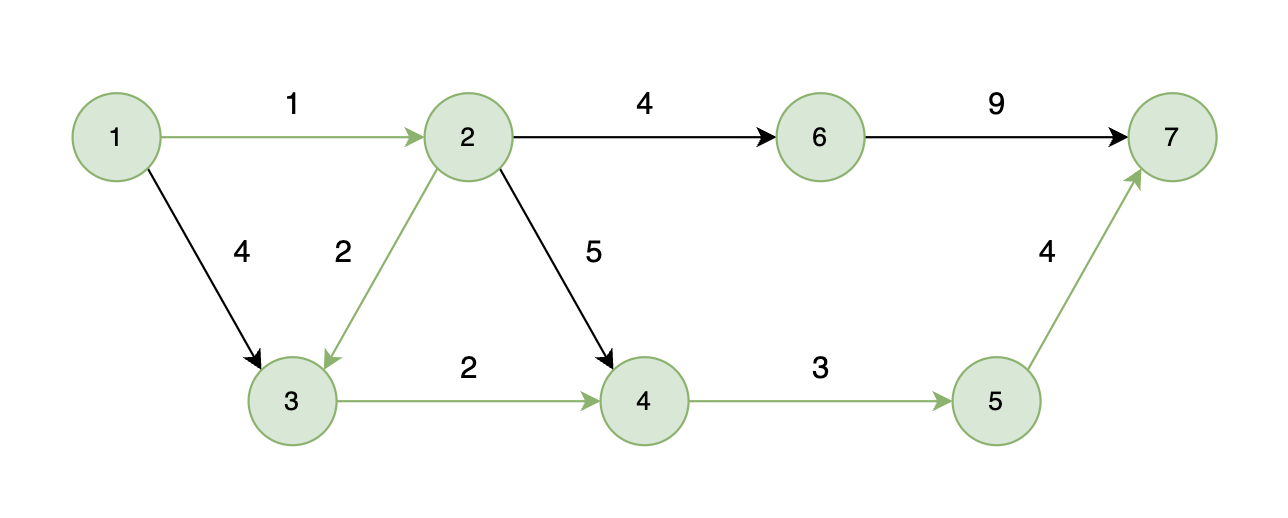
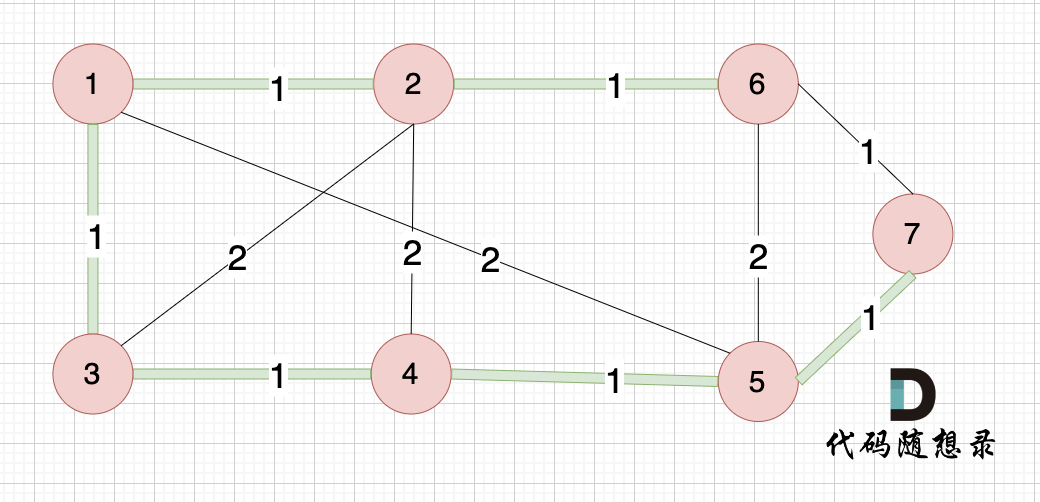
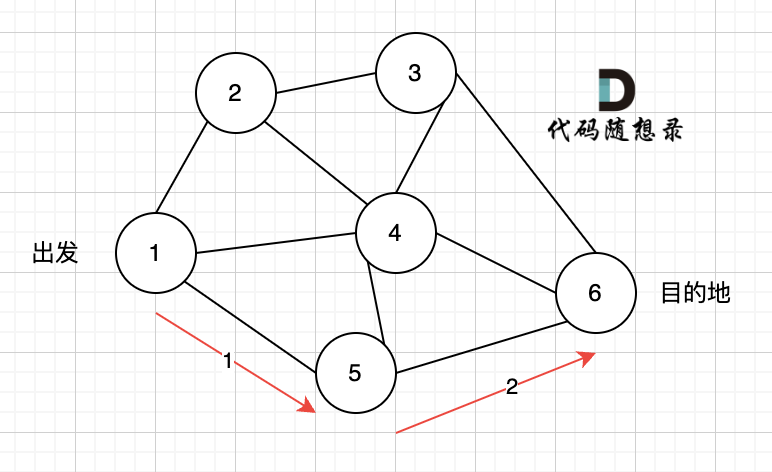
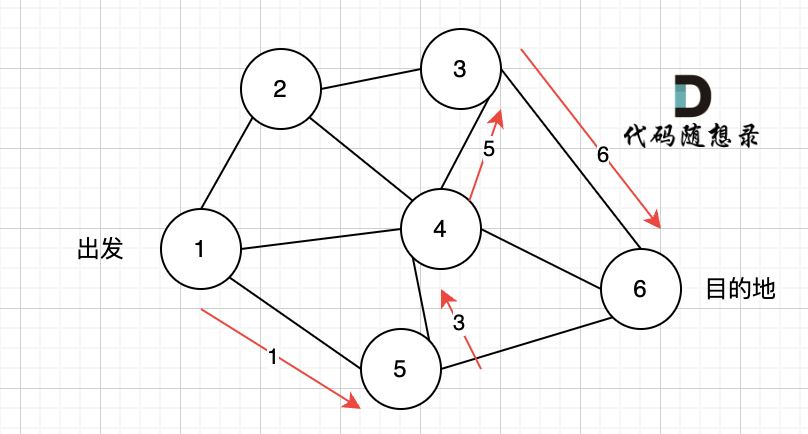
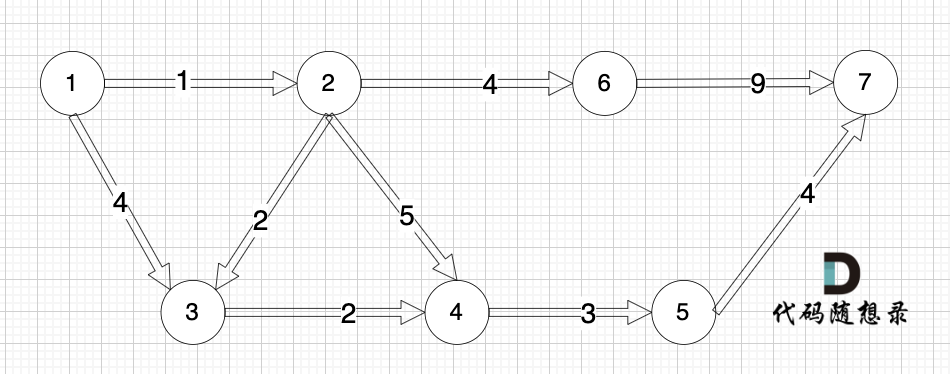
如下图所示,起始车站为 1 号车站,终点车站为 7 号车站,绿色路线为最短的路线,路线总长度为 12,则输出 12。
|
||||
|
||||

|
||||
|
||||
|
||||
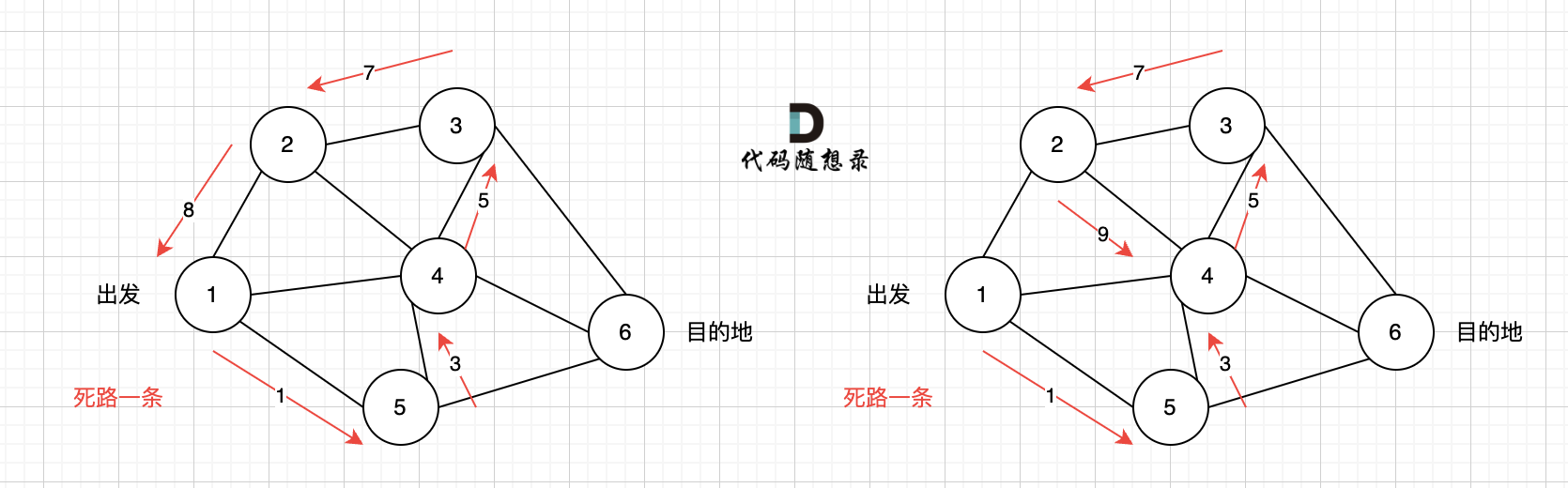
不能到达的情况:
|
||||
|
||||
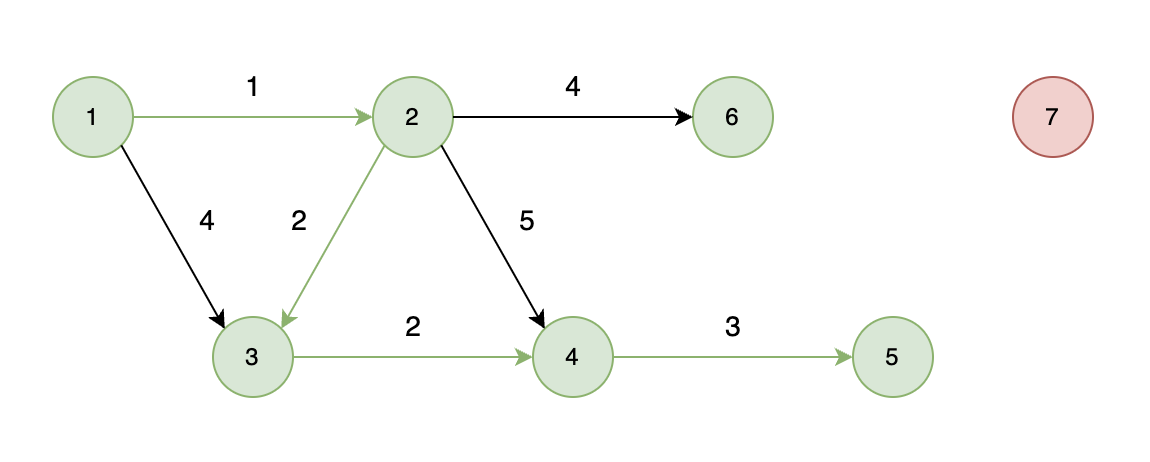
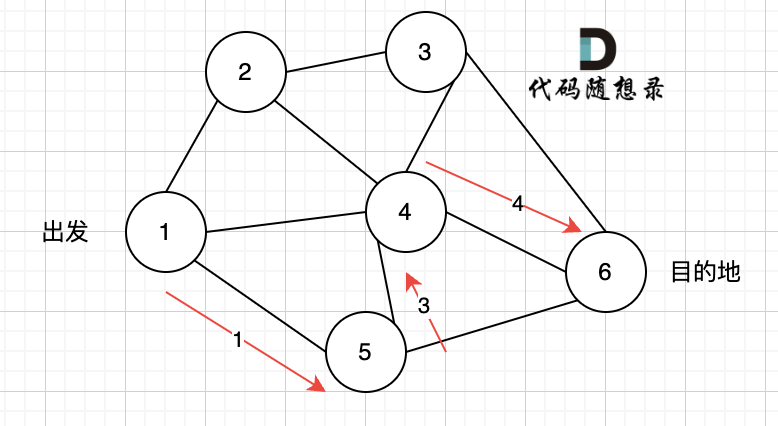
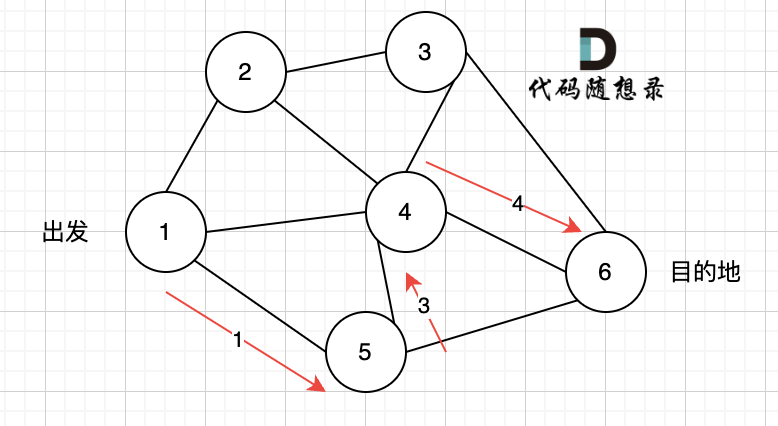
如下图所示,当从起始车站不能到达终点车站时,则输出 -1。
|
||||
|
||||

|
||||
|
||||
|
||||
数据范围:
|
||||
|
||||
@@ -101,7 +101,7 @@
|
||||
|
||||
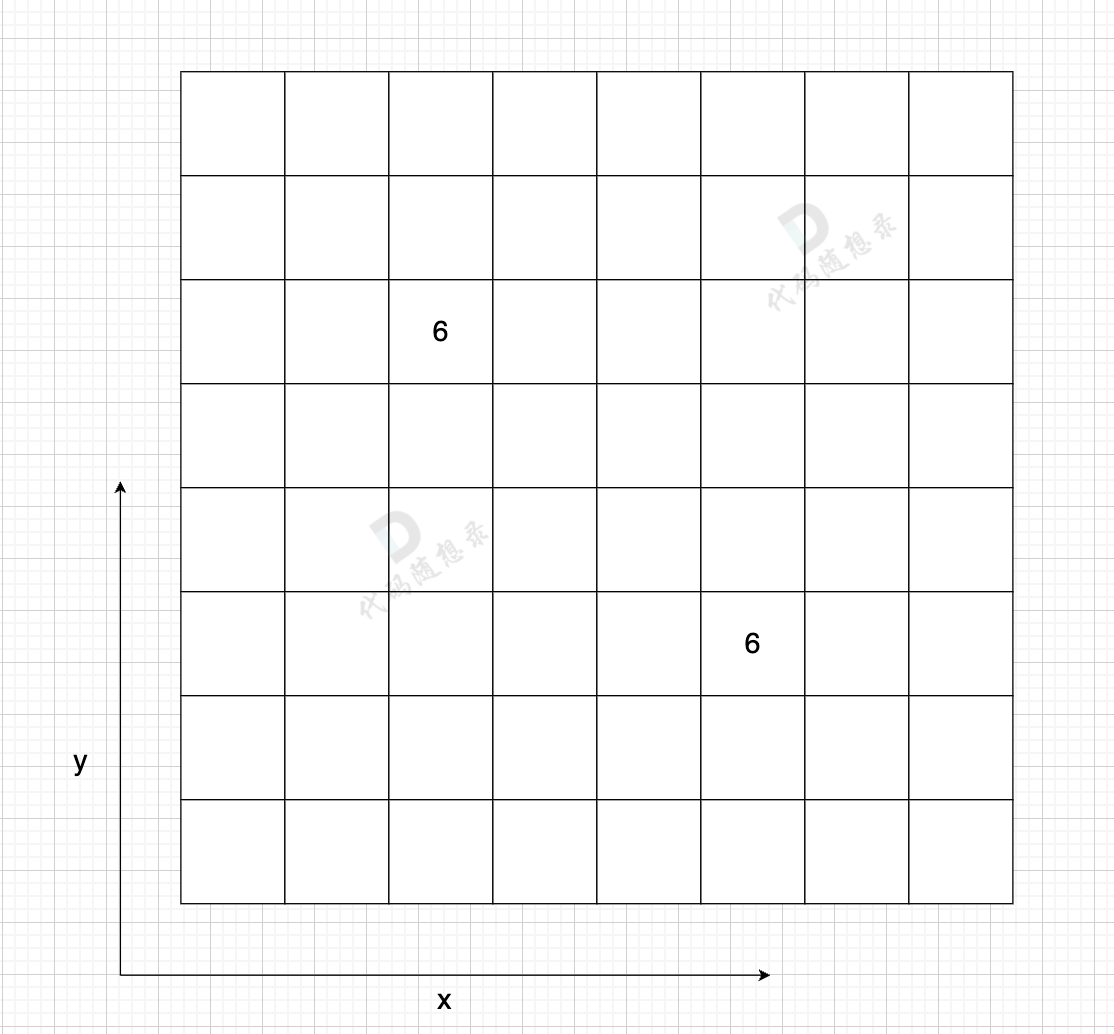
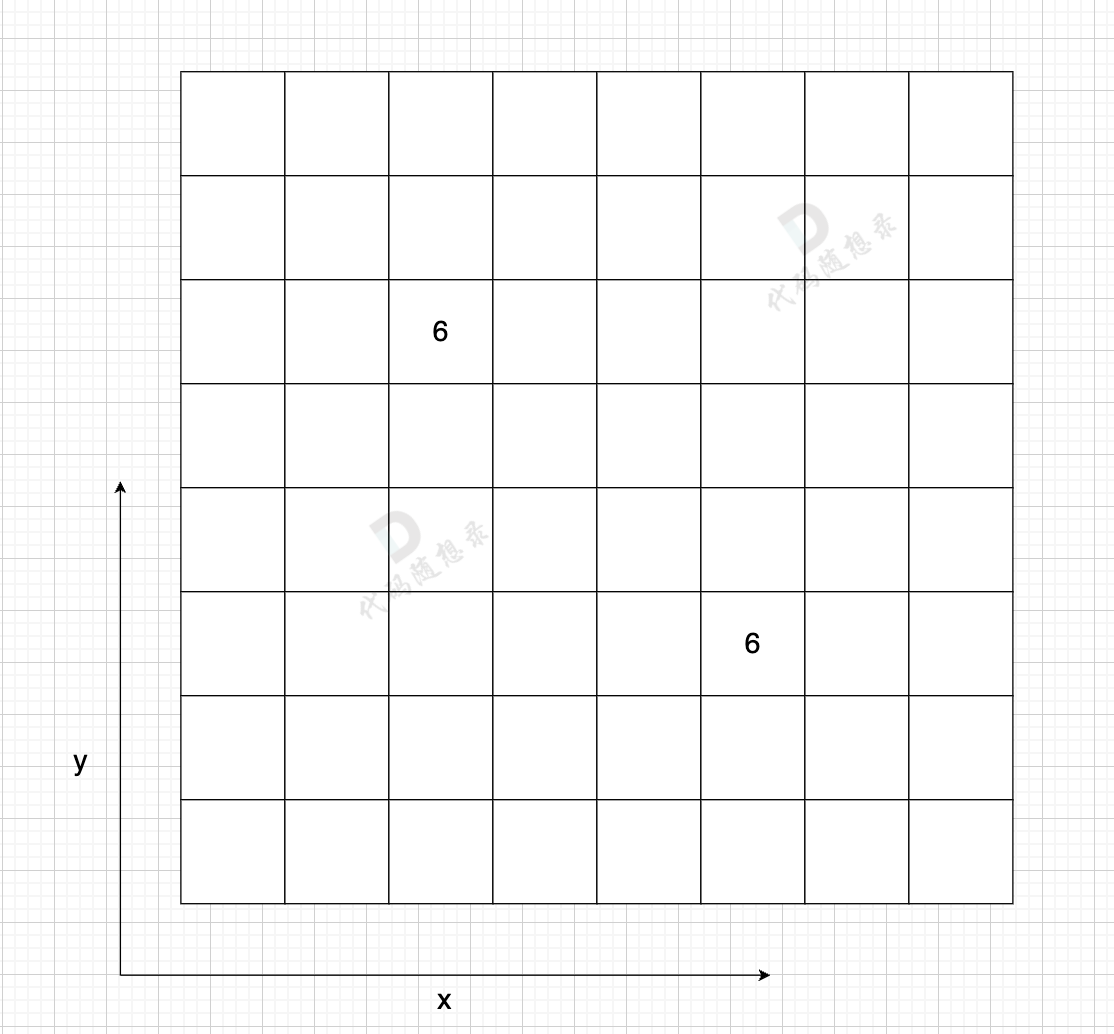
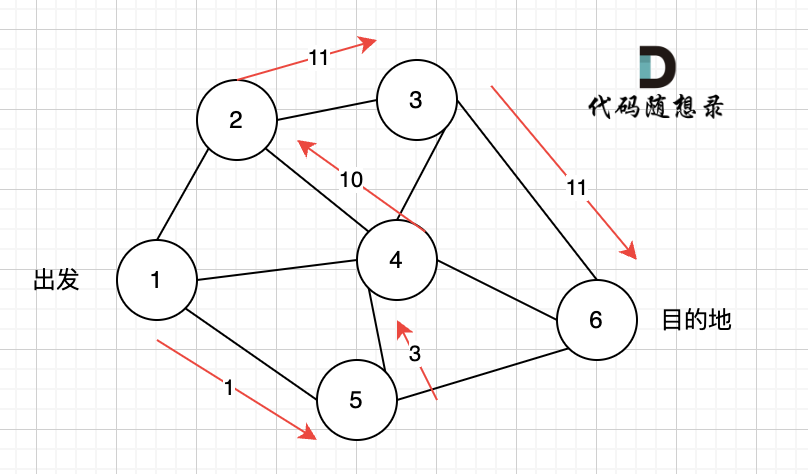
如图:
|
||||
|
||||
|
||||
|
||||
|
||||
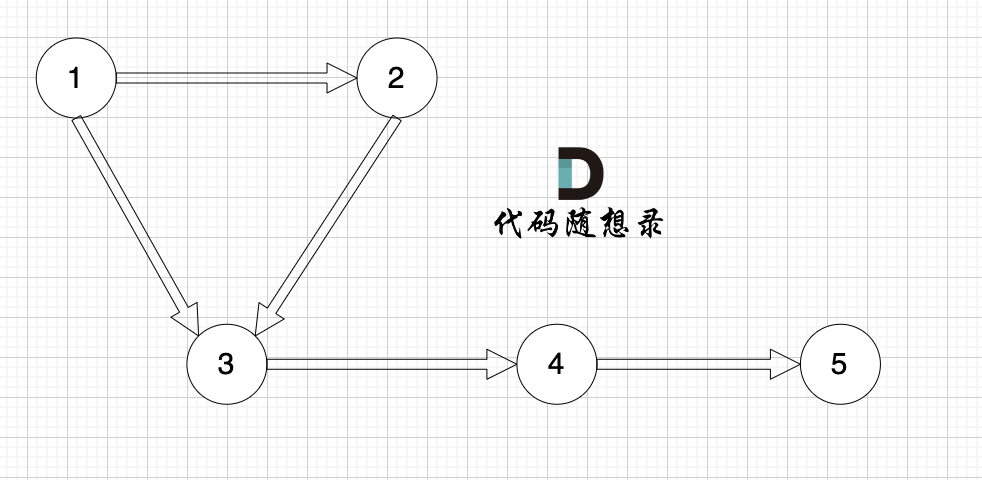
在一个 n (节点数)为8 的图中,就需要申请 8 * 8 这么大的空间,有一条双向边,即:grid[2][5] = 6,grid[5][2] = 6
|
||||
|
||||
@@ -125,7 +125,7 @@
|
||||
|
||||
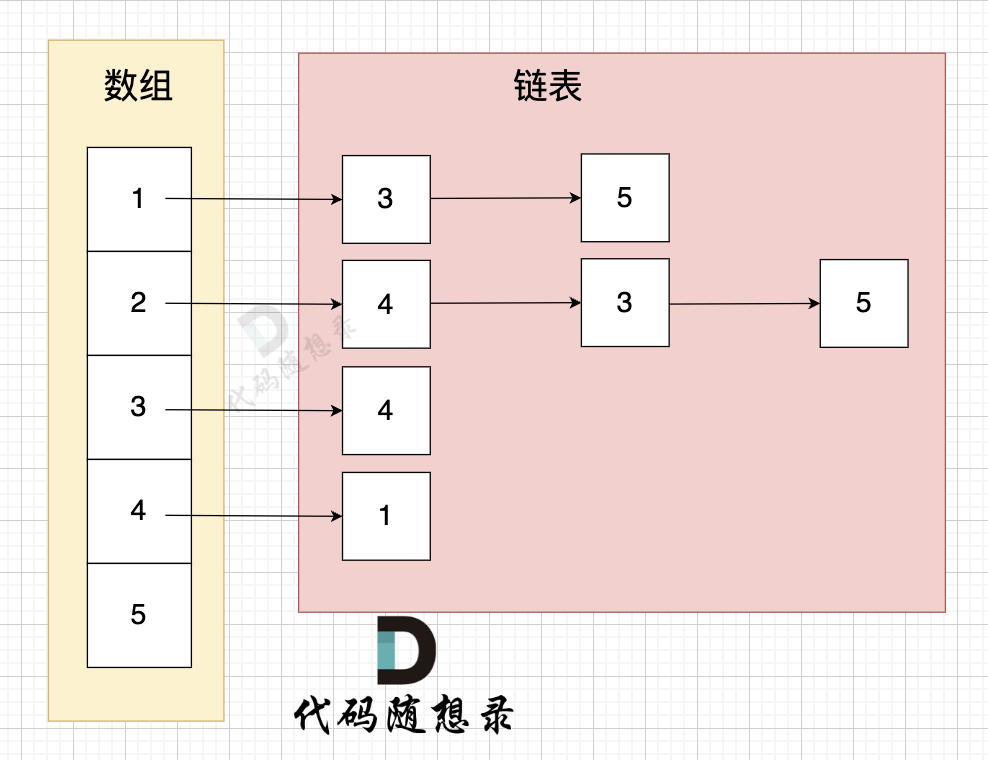
邻接表的构造如图:
|
||||
|
||||

|
||||
|
||||
|
||||
这里表达的图是:
|
||||
|
||||
@@ -210,7 +210,7 @@ vector<list<int>> grid(n + 1);
|
||||
|
||||
不少录友,不知道 如何定义的数据结构,怎么表示邻接表的,我来给大家画一个图:
|
||||
|
||||

|
||||

|
||||
|
||||
图中邻接表表示:
|
||||
|
||||
@@ -231,7 +231,7 @@ vector<list<pair<int,int>>> grid(n + 1);
|
||||
|
||||
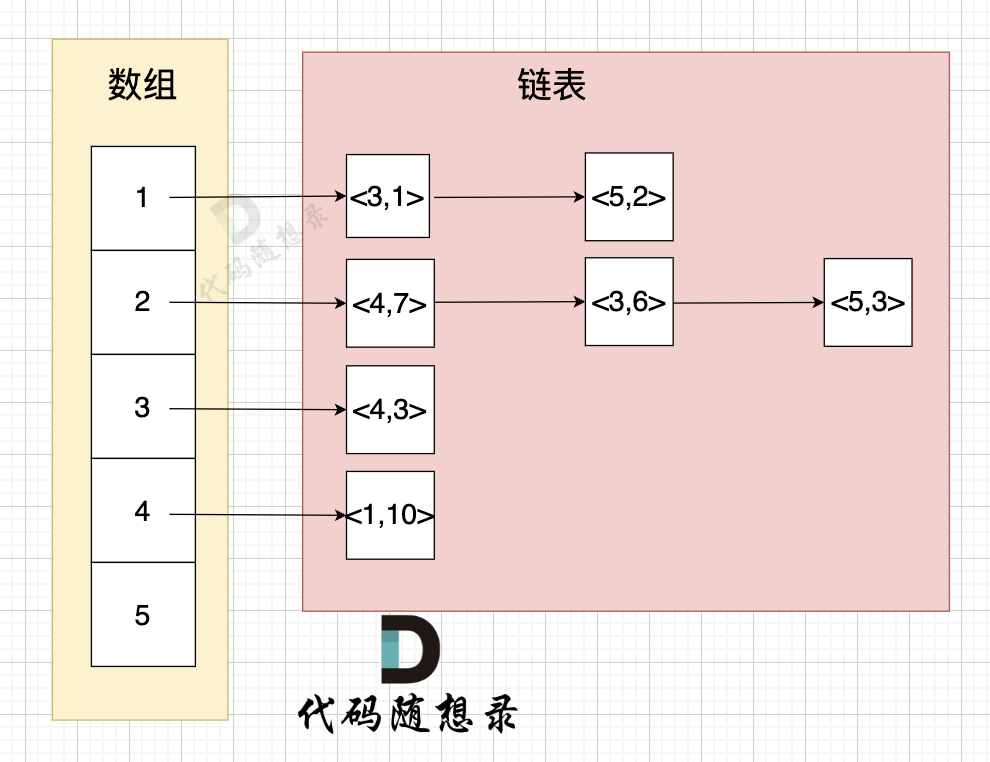
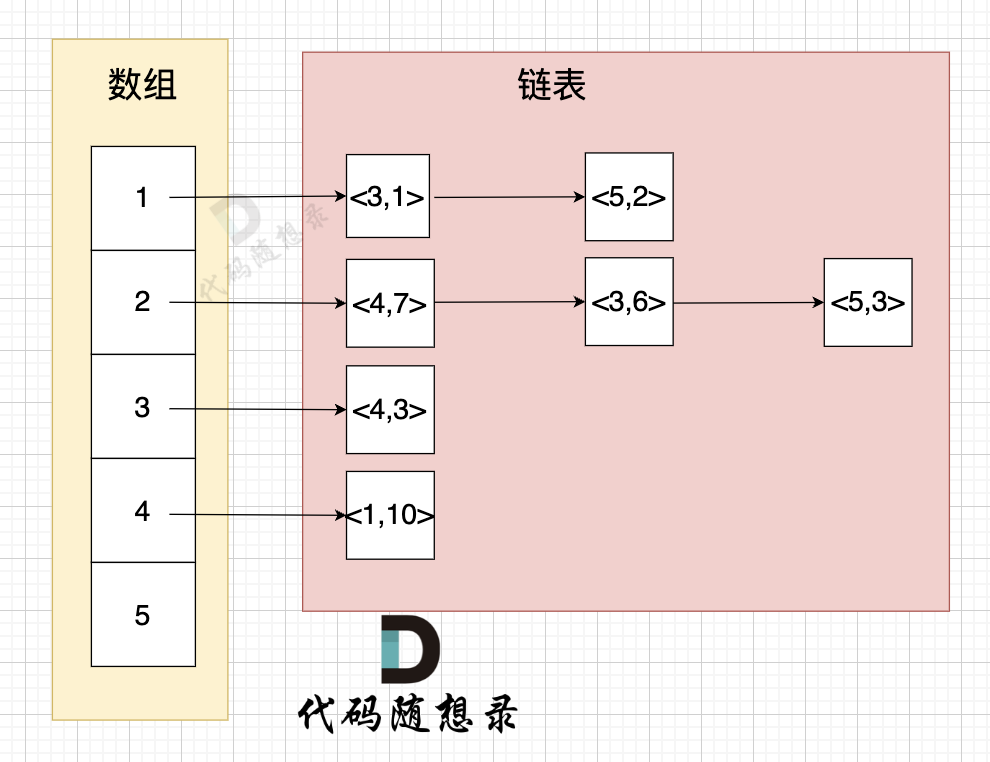
举例来给大家展示 该代码表达的数据 如下:
|
||||
|
||||
|
||||
|
||||
|
||||
* 节点1 指向 节点3 权值为 1
|
||||
* 节点1 指向 节点5 权值为 2
|
||||
@@ -354,7 +354,7 @@ for (int v = 1; v <= n; v++) {
|
||||
|
||||
再回顾一下邻接表的构造(数组 + 链表):
|
||||
|
||||

|
||||

|
||||
|
||||
假如 加入的cur 是节点 2, 那么 grid[2] 表示的就是图中第二行链表。 (grid数组的构造我们在 上面 「图的存储」中讲过)
|
||||
|
||||
|
||||
@@ -46,13 +46,13 @@
|
||||
|
||||
如下图所示,起始车站为 1 号车站,终点车站为 7 号车站,绿色路线为最短的路线,路线总长度为 12,则输出 12。
|
||||
|
||||

|
||||

|
||||
|
||||
不能到达的情况:
|
||||
|
||||
如下图所示,当从起始车站不能到达终点车站时,则输出 -1。
|
||||
|
||||

|
||||

|
||||
|
||||
数据范围:
|
||||
|
||||
@@ -76,7 +76,7 @@ dijkstra算法:在有权图(权值非负数)中求从起点到其他节点
|
||||
|
||||
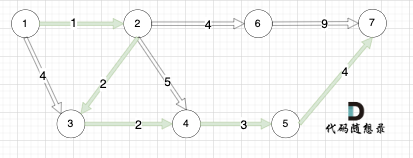
如本题示例中的图:
|
||||
|
||||
|
||||

|
||||
|
||||
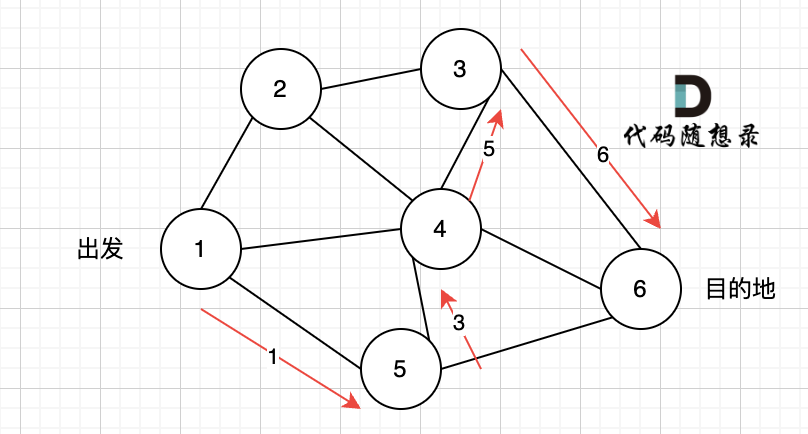
起点(节点1)到终点(节点7) 的最短路径是 图中 标记绿线的部分。
|
||||
|
||||
@@ -122,7 +122,7 @@ minDist数组数值初始化为int最大值。
|
||||
|
||||
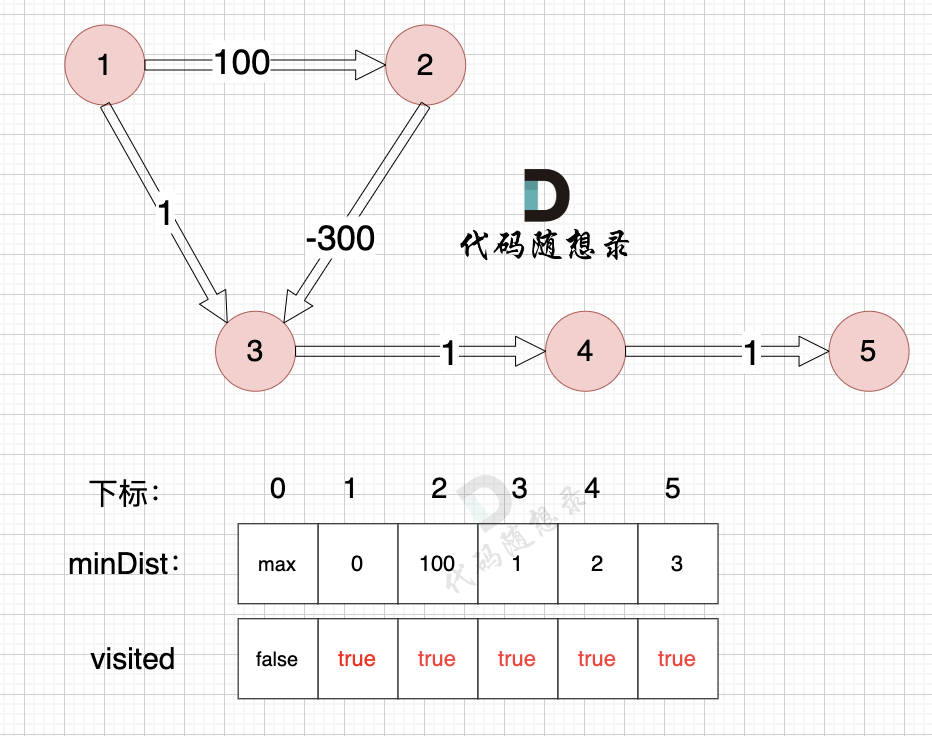
这里在强点一下 **minDist数组的含义:记录所有节点到源点的最短路径**,那么初始化的时候就应该初始为最大值,这样才能在后续出现最短路径的时候及时更新。
|
||||
|
||||

|
||||

|
||||
|
||||
(图中,max 表示默认值,节点0 不做处理,统一从下标1 开始计算,这样下标和节点数值统一, 方便大家理解,避免搞混)
|
||||
|
||||
@@ -144,7 +144,7 @@ minDist数组数值初始化为int最大值。
|
||||
|
||||
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
更新 minDist数组,即:源点(节点1) 到 节点2 和 节点3的距离。
|
||||
@@ -170,7 +170,7 @@ minDist数组数值初始化为int最大值。
|
||||
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
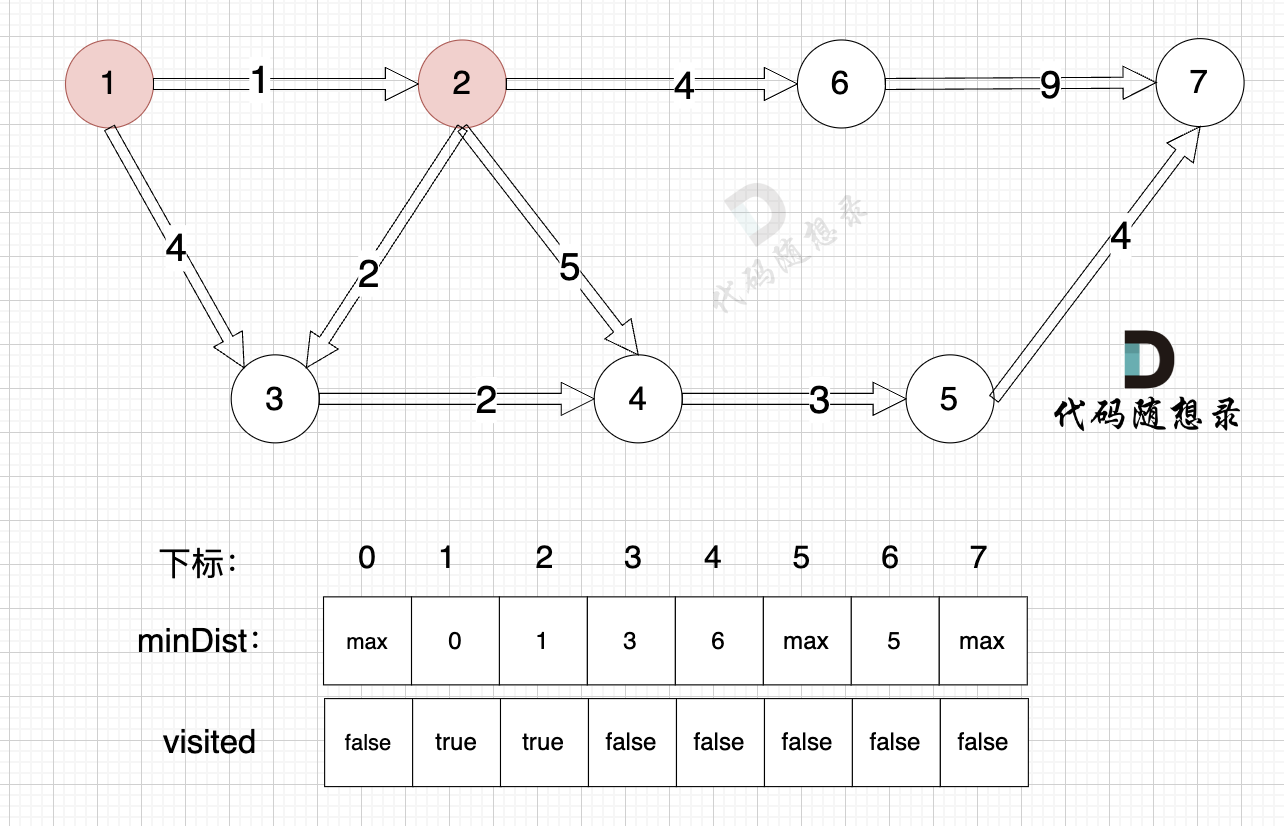
更新 minDist数组,即:源点(节点1) 到 节点6 、 节点3 和 节点4的距离。
|
||||
|
||||
@@ -204,7 +204,7 @@ minDist数组数值初始化为int最大值。
|
||||
|
||||
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||

|
||||

|
||||
|
||||
由于节点3的加入,那么源点可以有新的路径链接到节点4 所以更新minDist数组:
|
||||
|
||||
@@ -224,7 +224,7 @@ minDist数组数值初始化为int最大值。
|
||||
|
||||
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||
|
||||

|
||||
|
||||
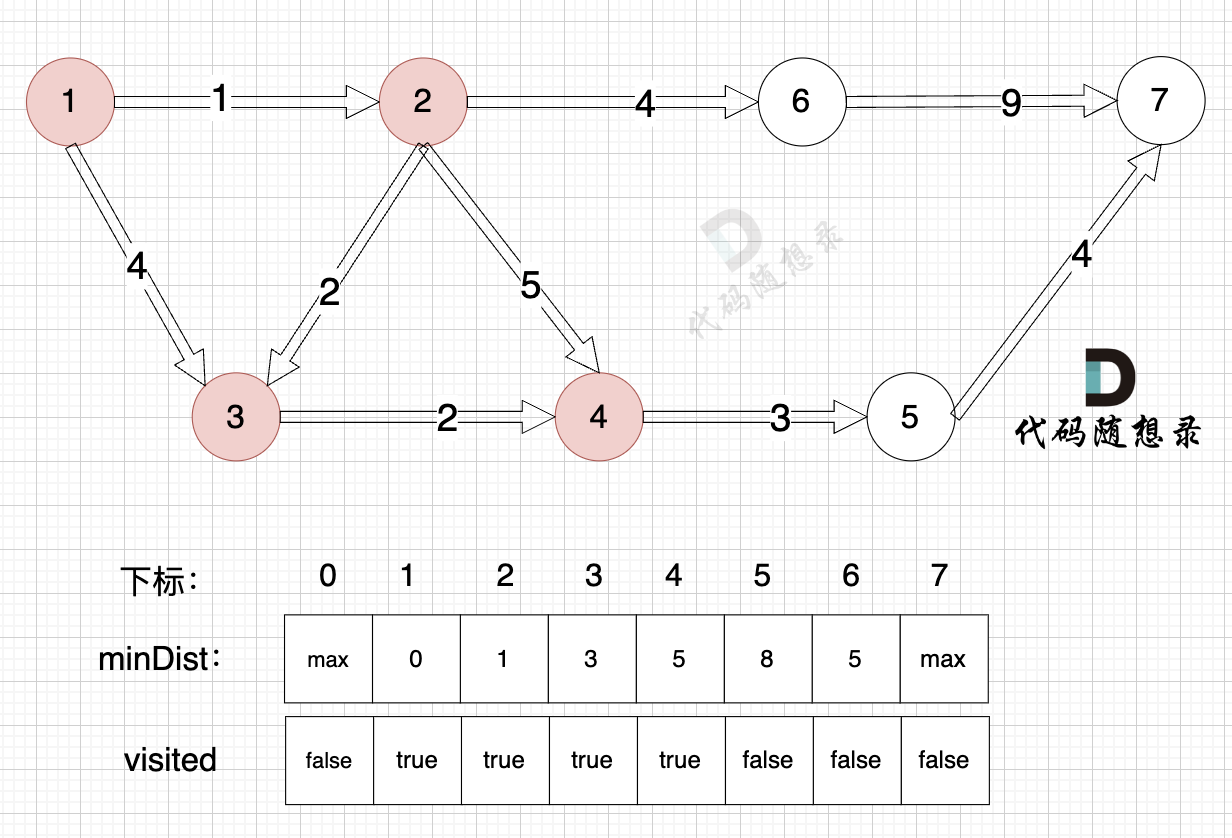
由于节点4的加入,那么源点可以链接到节点5 所以更新minDist数组:
|
||||
|
||||
@@ -244,7 +244,7 @@ minDist数组数值初始化为int最大值。
|
||||
|
||||
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||
|
||||

|
||||
|
||||
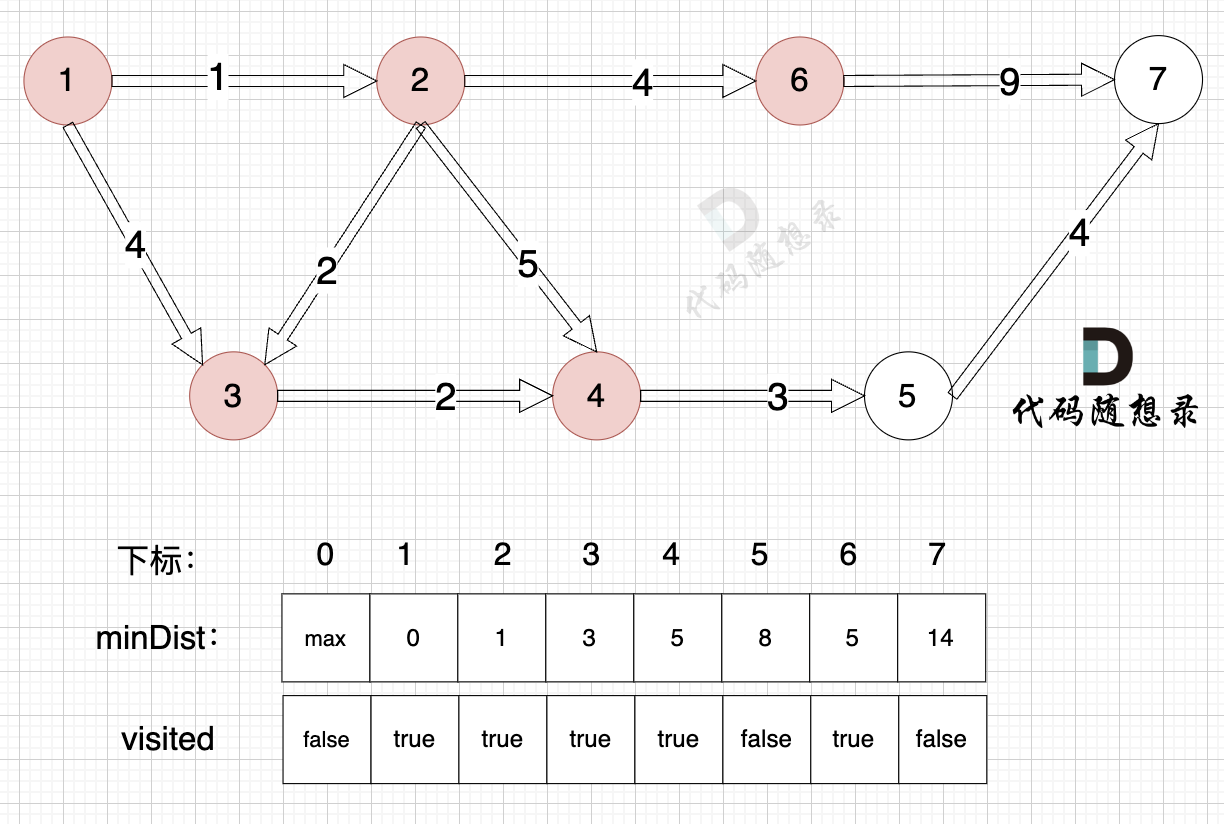
由于节点6的加入,那么源点可以链接到节点7 所以 更新minDist数组:
|
||||
|
||||
@@ -264,7 +264,7 @@ minDist数组数值初始化为int最大值。
|
||||
|
||||
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||
|
||||

|
||||
|
||||
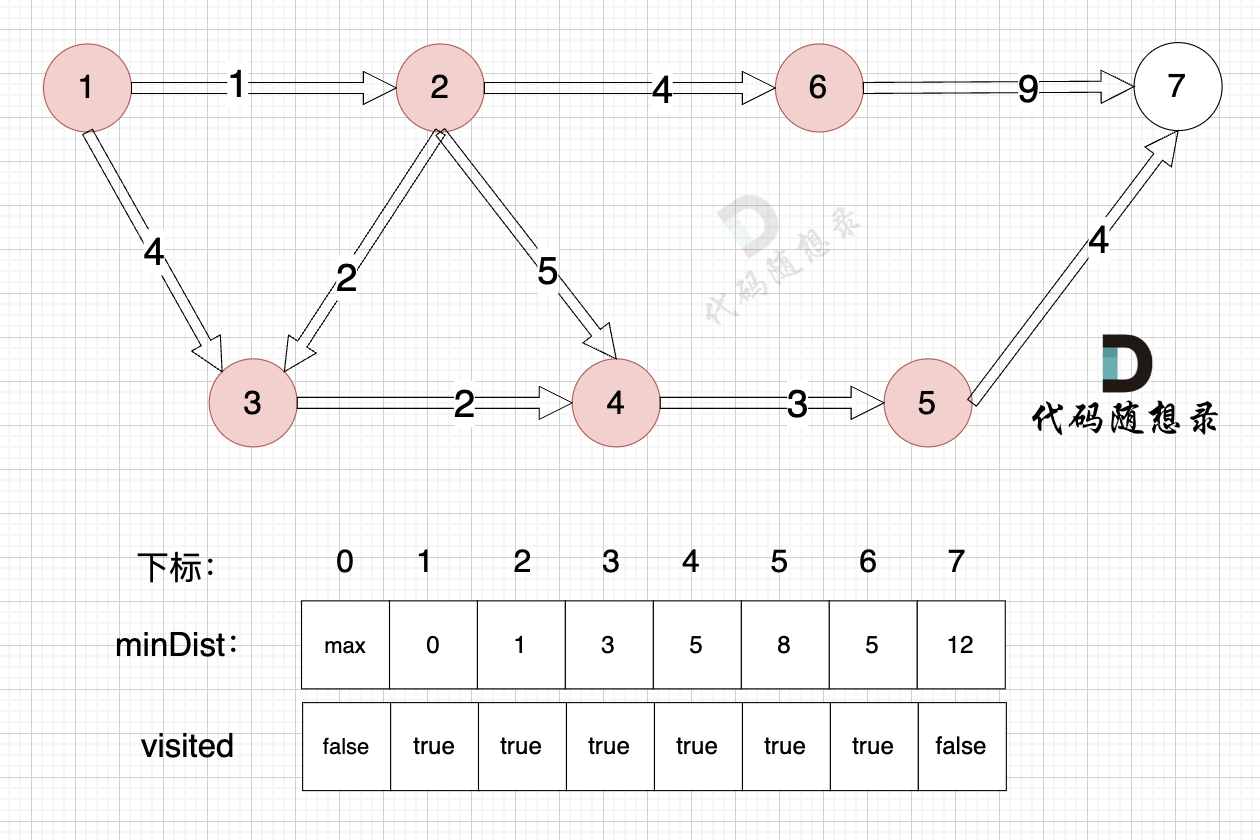
由于节点5的加入,那么源点有新的路径可以链接到节点7 所以 更新minDist数组:
|
||||
|
||||
@@ -282,7 +282,7 @@ minDist数组数值初始化为int最大值。
|
||||
|
||||
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||
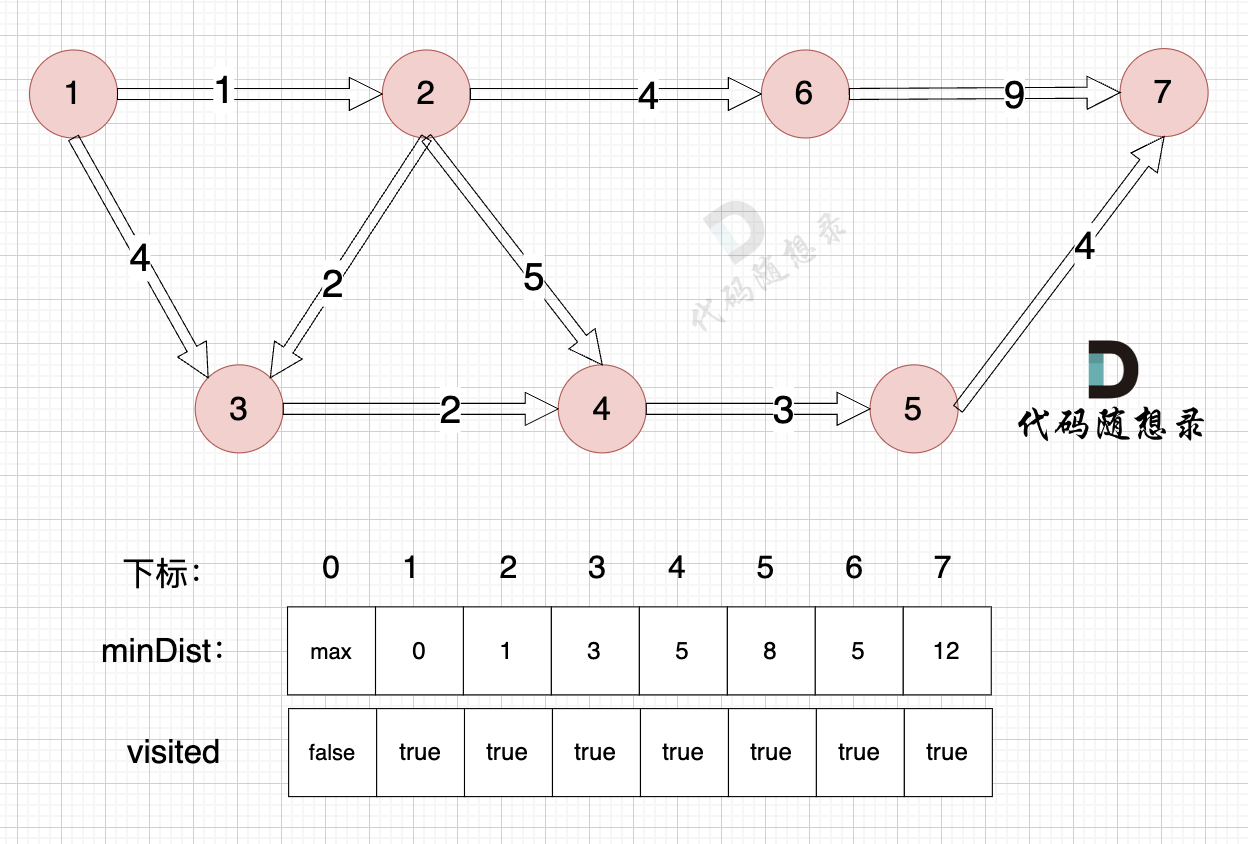
|
||||

|
||||
|
||||
节点7加入,但节点7到节点7的距离为0,所以 不用更新minDist数组
|
||||
|
||||
@@ -296,7 +296,7 @@ minDist数组数值初始化为int最大值。
|
||||
|
||||
路径如图:
|
||||
|
||||
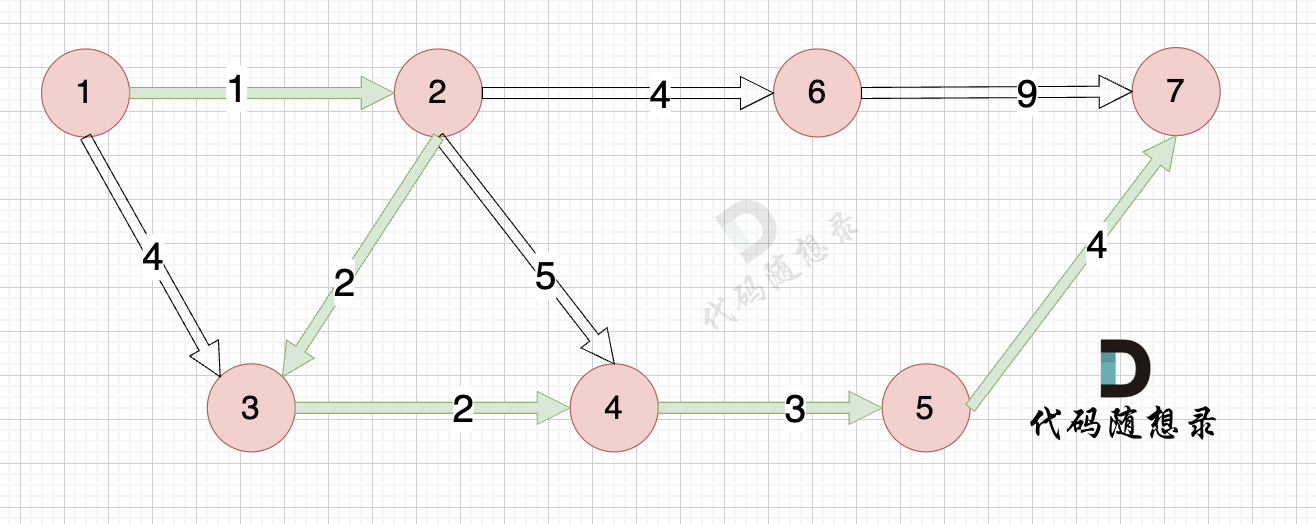
|
||||

|
||||
|
||||
在上面的讲解中,每一步 我都是按照 dijkstra 三部曲来讲解的,理解了这三部曲,代码也就好懂的。
|
||||
|
||||
@@ -541,7 +541,7 @@ int main() {
|
||||
|
||||
对应如图:
|
||||
|
||||

|
||||

|
||||
|
||||
### 出现负数
|
||||
|
||||
@@ -549,7 +549,7 @@ int main() {
|
||||
|
||||
看一下这个图: (有负权值)
|
||||
|
||||
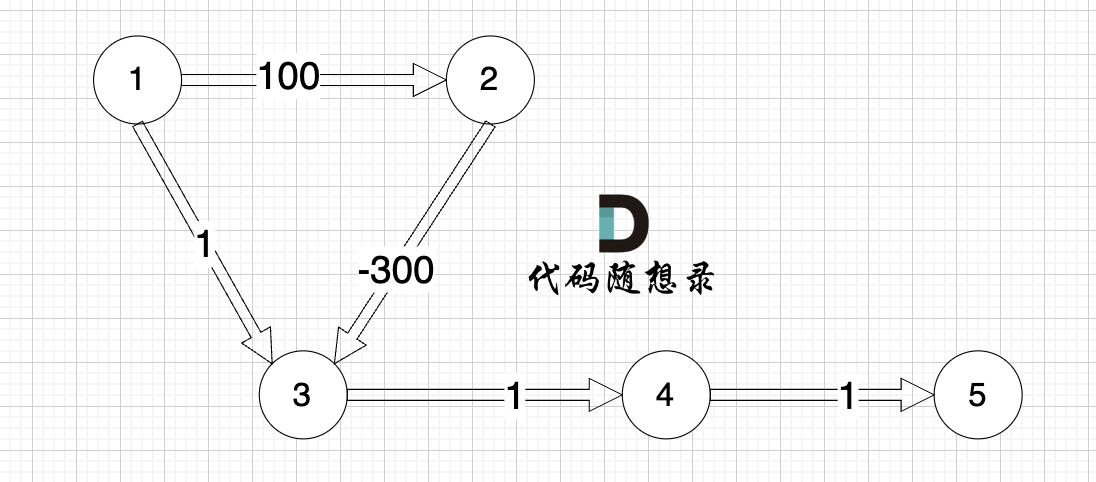
|
||||

|
||||
|
||||
节点1 到 节点5 的最短路径 应该是 节点1 -> 节点2 -> 节点3 -> 节点4 -> 节点5
|
||||
|
||||
@@ -559,7 +559,7 @@ int main() {
|
||||
|
||||
初始化:
|
||||
|
||||
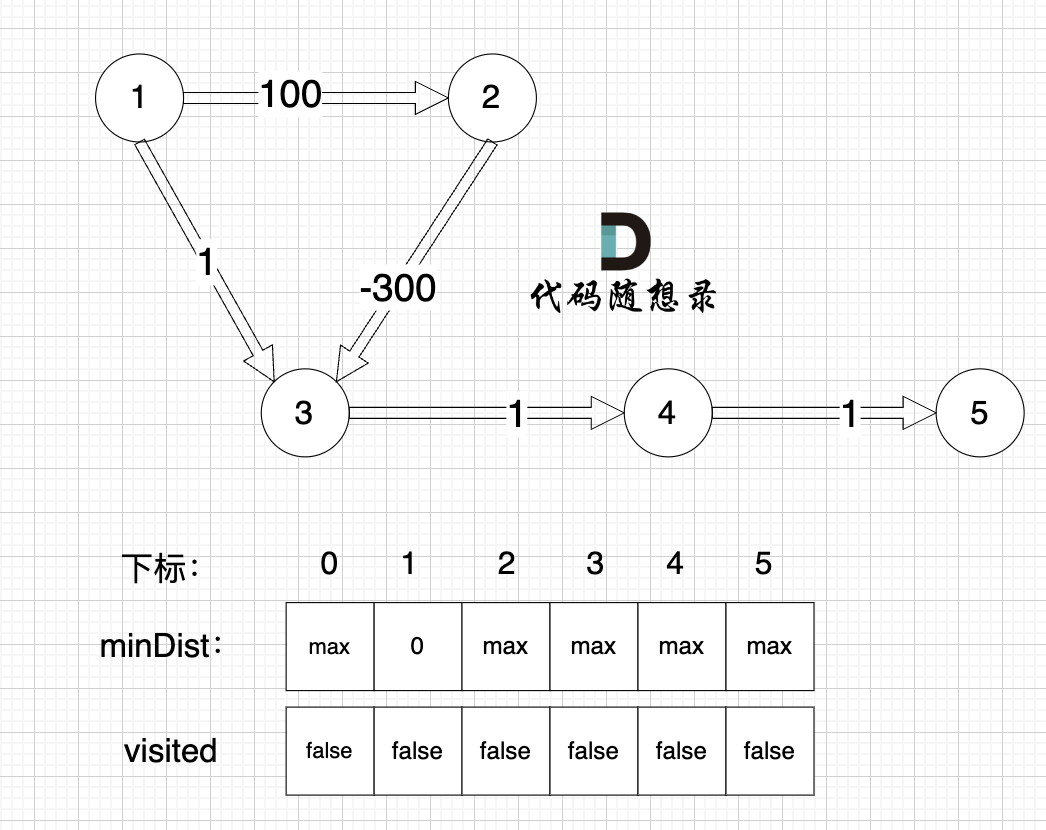
|
||||

|
||||
|
||||
---------------
|
||||
|
||||
@@ -573,7 +573,7 @@ int main() {
|
||||
|
||||
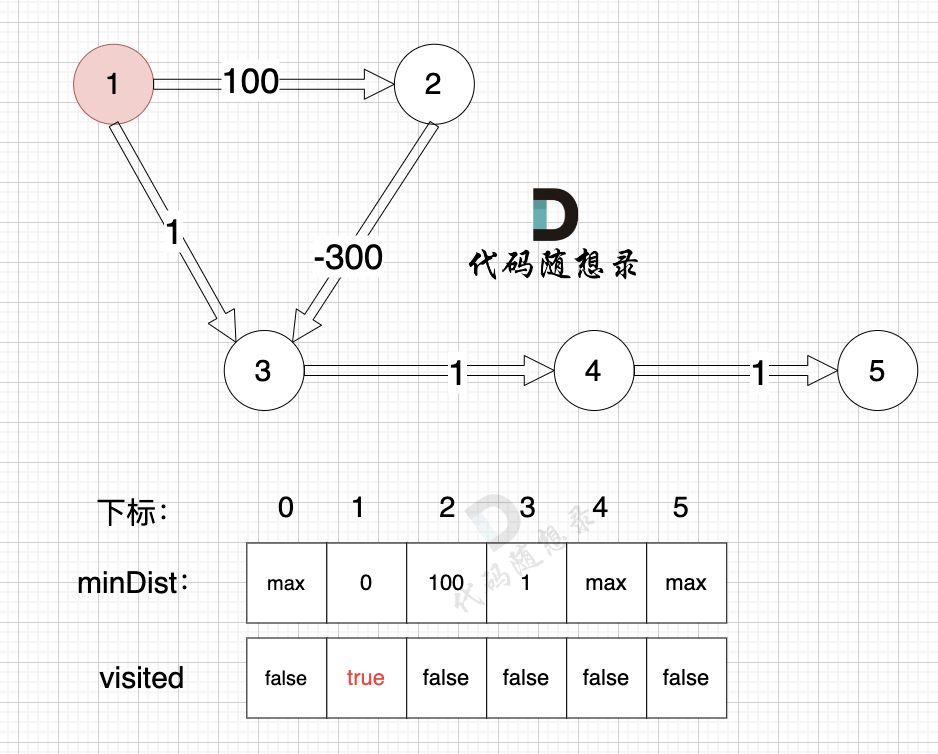
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||
|
||||

|
||||
|
||||
更新 minDist数组,即:源点(节点1) 到 节点2 和 节点3的距离。
|
||||
|
||||
@@ -592,7 +592,7 @@ int main() {
|
||||
|
||||
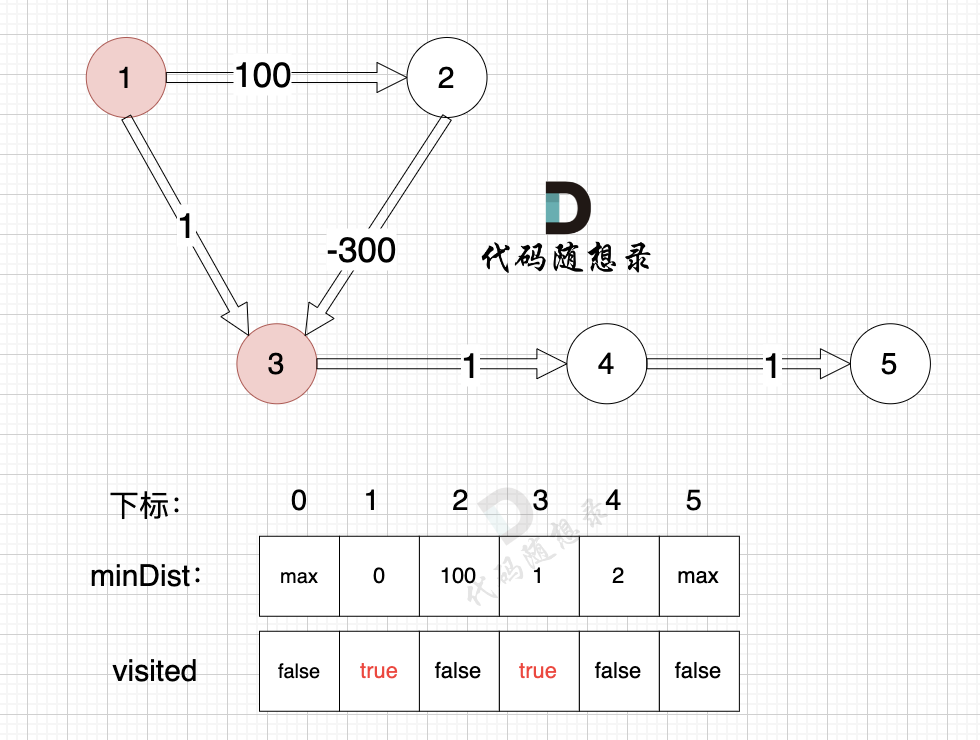
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||
|
||||

|
||||
|
||||
由于节点3的加入,那么源点可以有新的路径链接到节点4 所以更新minDist数组:
|
||||
|
||||
@@ -610,7 +610,7 @@ int main() {
|
||||
|
||||
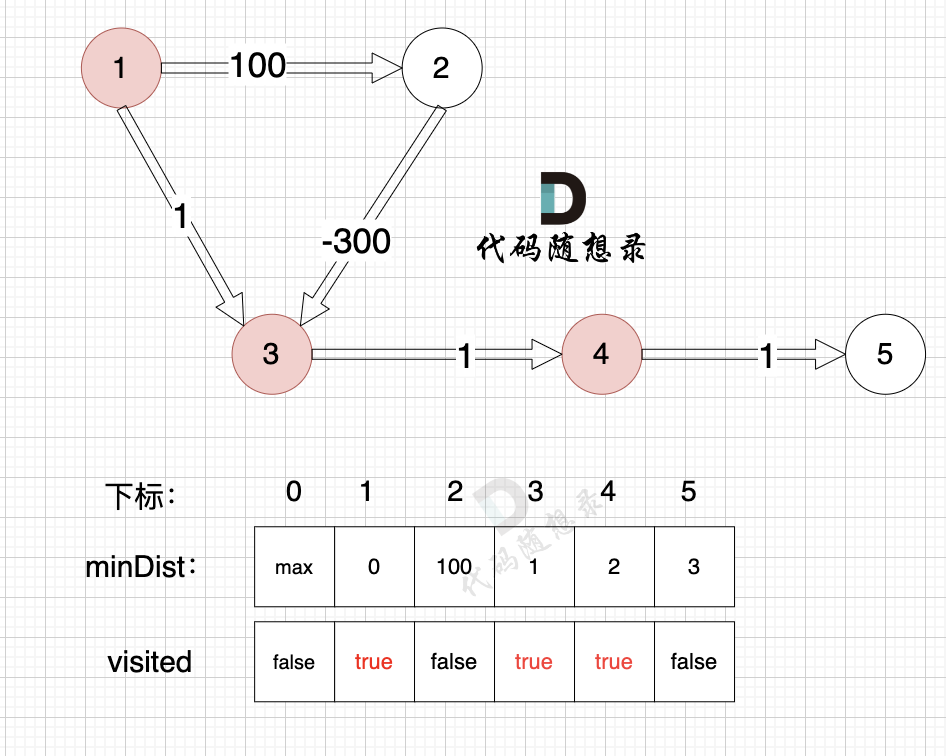
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||
|
||||

|
||||
|
||||
由于节点4的加入,那么源点可以有新的路径链接到节点5 所以更新minDist数组:
|
||||
|
||||
@@ -628,7 +628,7 @@ int main() {
|
||||
|
||||
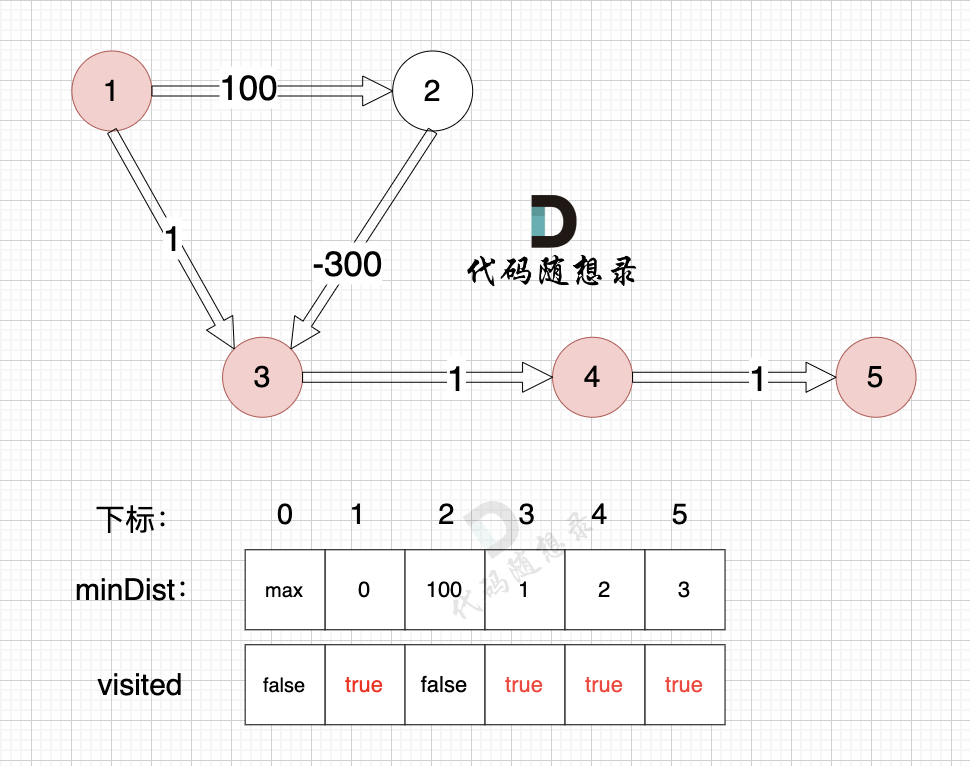
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||
|
||||

|
||||
|
||||
节点5的加入,而节点5 没有链接其他节点, 所以不用更新minDist数组,仅标记节点5被访问过了
|
||||
|
||||
@@ -644,7 +644,7 @@ int main() {
|
||||
|
||||
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||
|
||||

|
||||
|
||||
--------------
|
||||
|
||||
|
||||
@@ -63,7 +63,7 @@ kruscal的思路:
|
||||
|
||||
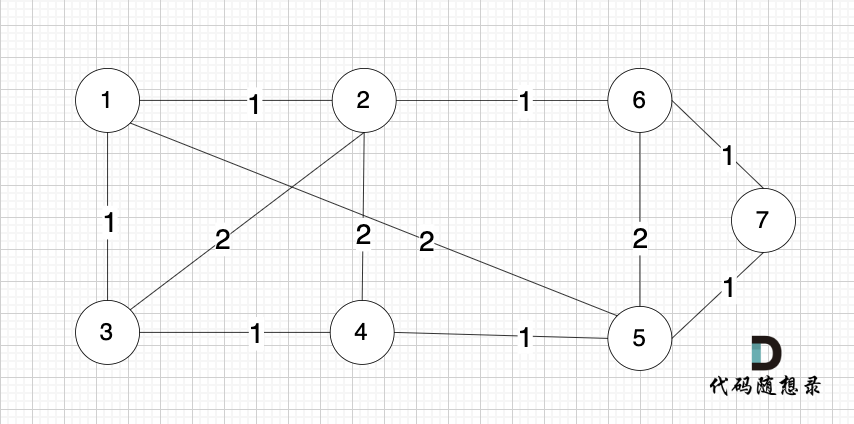
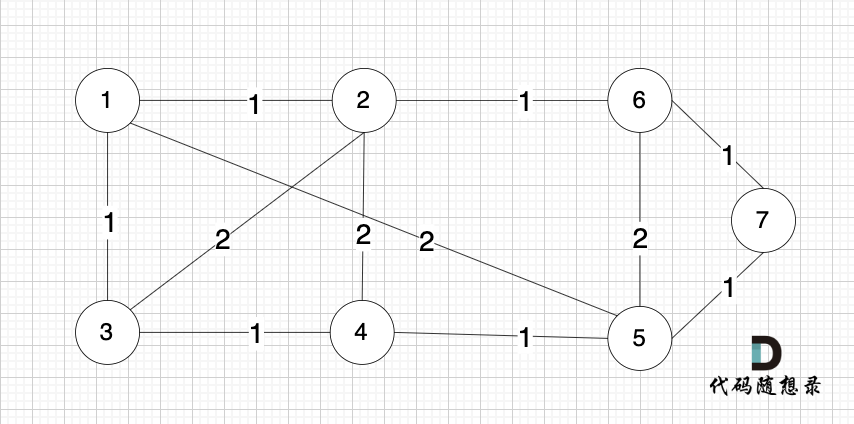
依然以示例中,如下这个图来举例。
|
||||
|
||||
|
||||
|
||||
|
||||
将图中的边按照权值有小到大排序,这样从贪心的角度来说,优先选 权值小的边加入到 最小生成树中。
|
||||
|
||||
@@ -77,13 +77,13 @@ kruscal的思路:
|
||||
|
||||
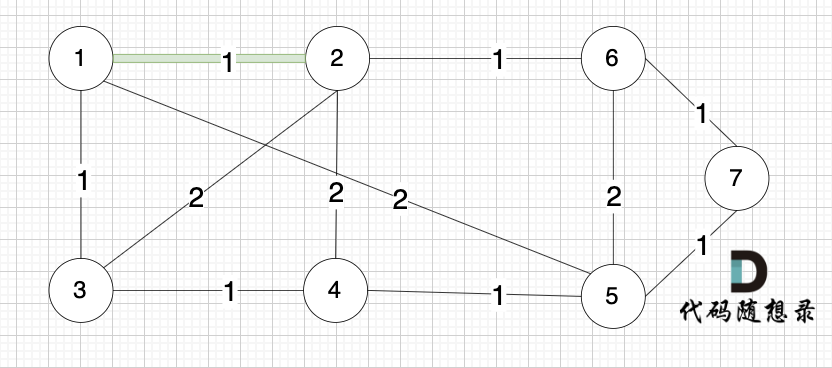
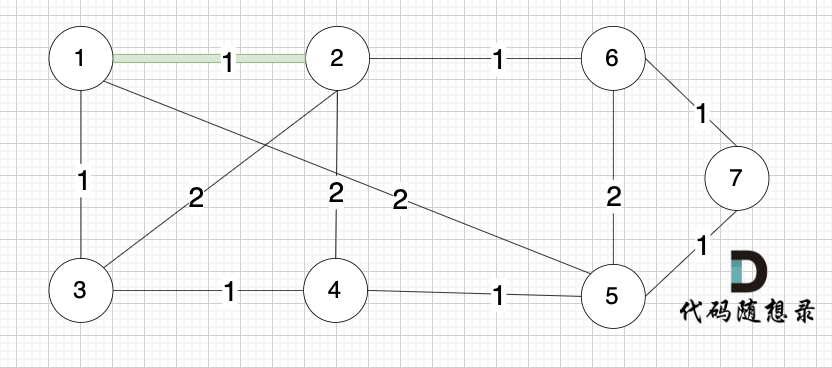
选边(1,2),节点1 和 节点2 不在同一个集合,所以生成树可以添加边(1,2),并将 节点1,节点2 放在同一个集合。
|
||||
|
||||
|
||||
|
||||
|
||||
--------
|
||||
|
||||
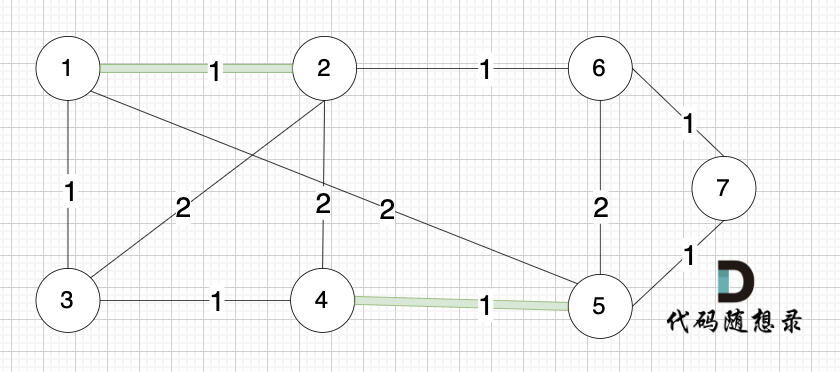
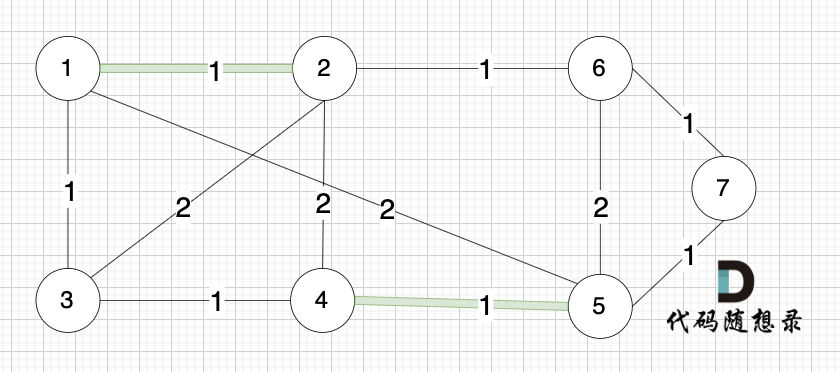
选边(4,5),节点4 和 节点 5 不在同一个集合,生成树可以添加边(4,5) ,并将节点4,节点5 放到同一个集合。
|
||||
|
||||
|
||||
|
||||
|
||||
**大家判断两个节点是否在同一个集合,就看图中两个节点是否有绿色的粗线连着就行**
|
||||
|
||||
@@ -93,25 +93,25 @@ kruscal的思路:
|
||||
|
||||
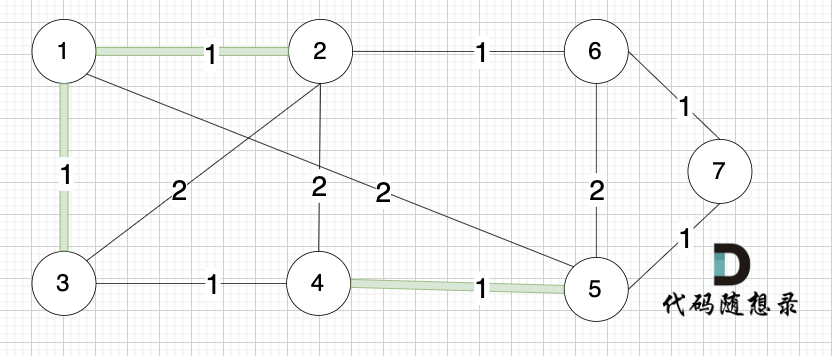
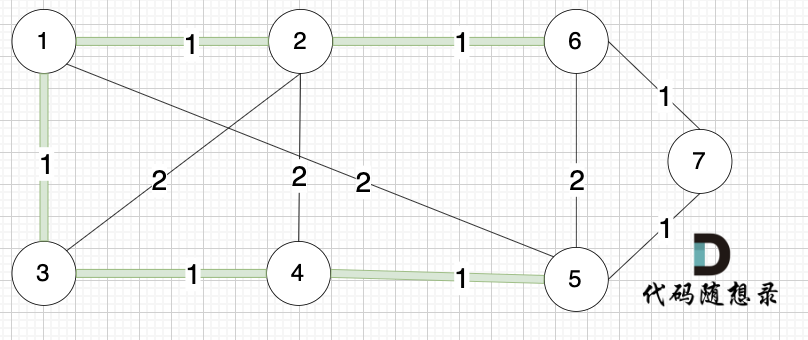
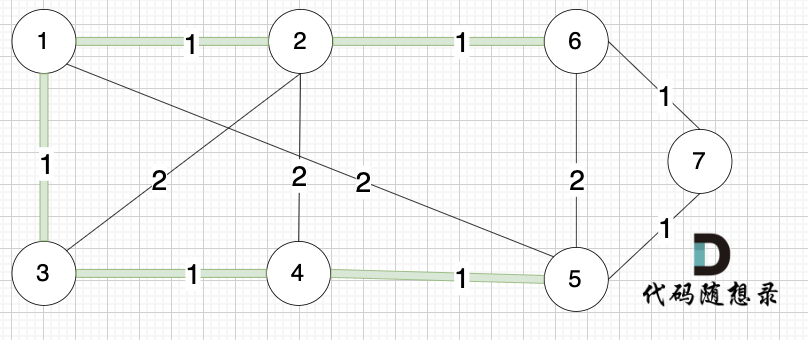
选边(1,3),节点1 和 节点3 不在同一个集合,生成树添加边(1,3),并将节点1,节点3 放到同一个集合。
|
||||
|
||||
|
||||
|
||||
|
||||
---------
|
||||
|
||||
选边(2,6),节点2 和 节点6 不在同一个集合,生成树添加边(2,6),并将节点2,节点6 放到同一个集合。
|
||||
|
||||
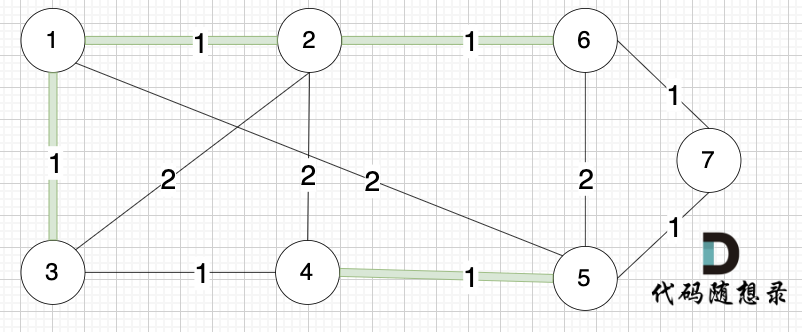
|
||||

|
||||
|
||||
--------
|
||||
|
||||
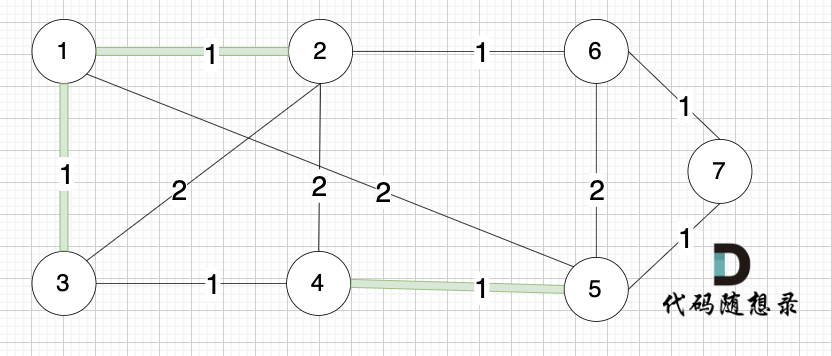
选边(3,4),节点3 和 节点4 不在同一个集合,生成树添加边(3,4),并将节点3,节点4 放到同一个集合。
|
||||
|
||||
|
||||
|
||||
|
||||
----------
|
||||
|
||||
选边(6,7),节点6 和 节点7 不在同一个集合,生成树添加边(6,7),并将 节点6,节点7 放到同一个集合。
|
||||
|
||||
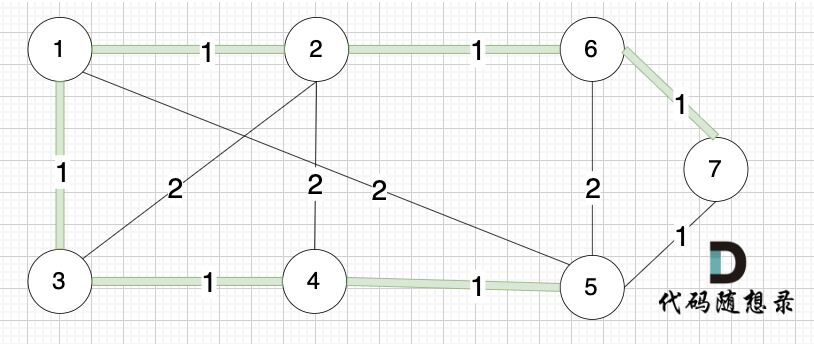
|
||||
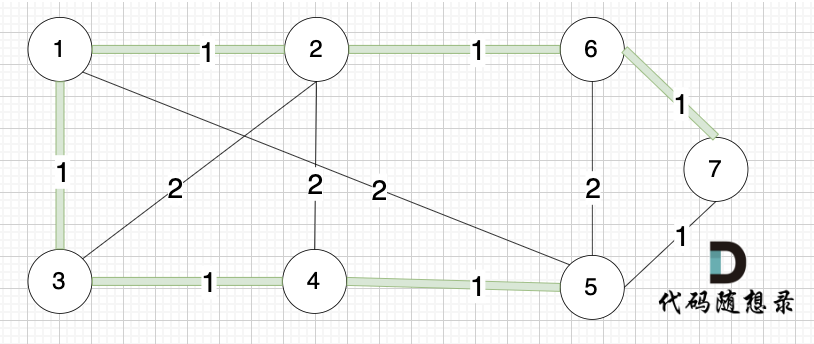
|
||||
|
||||
-----------
|
||||
|
||||
@@ -126,7 +126,7 @@ kruscal的思路:
|
||||
|
||||
此时 我们就已经生成了一个最小生成树,即:
|
||||
|
||||

|
||||

|
||||
|
||||
在上面的讲解中,看图的话 大家知道如何判断 两个节点 是否在同一个集合(是否有绿色的线连在一起),以及如何把两个节点加入集合(就在图中把两个节点连上)
|
||||
|
||||
@@ -346,7 +346,7 @@ int main() {
|
||||
|
||||
大家可能发现 怎么和我们 模拟画的图不一样,差别在于 代码生成的最小生成树中 节点5 和 节点7相连的。
|
||||
|
||||
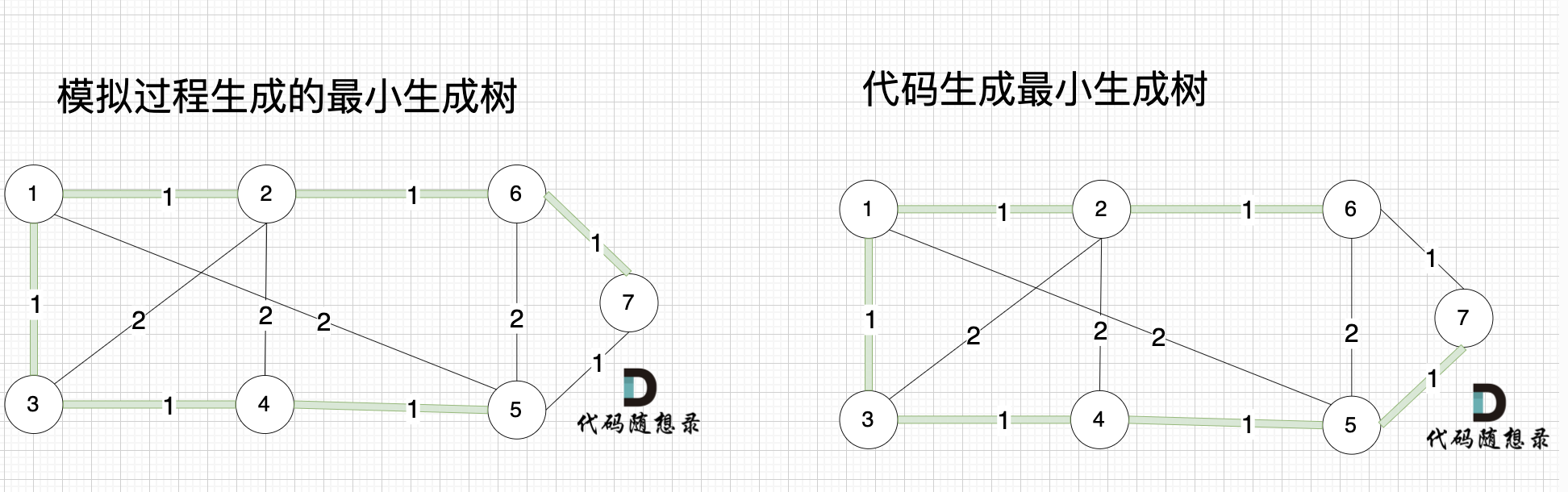
|
||||
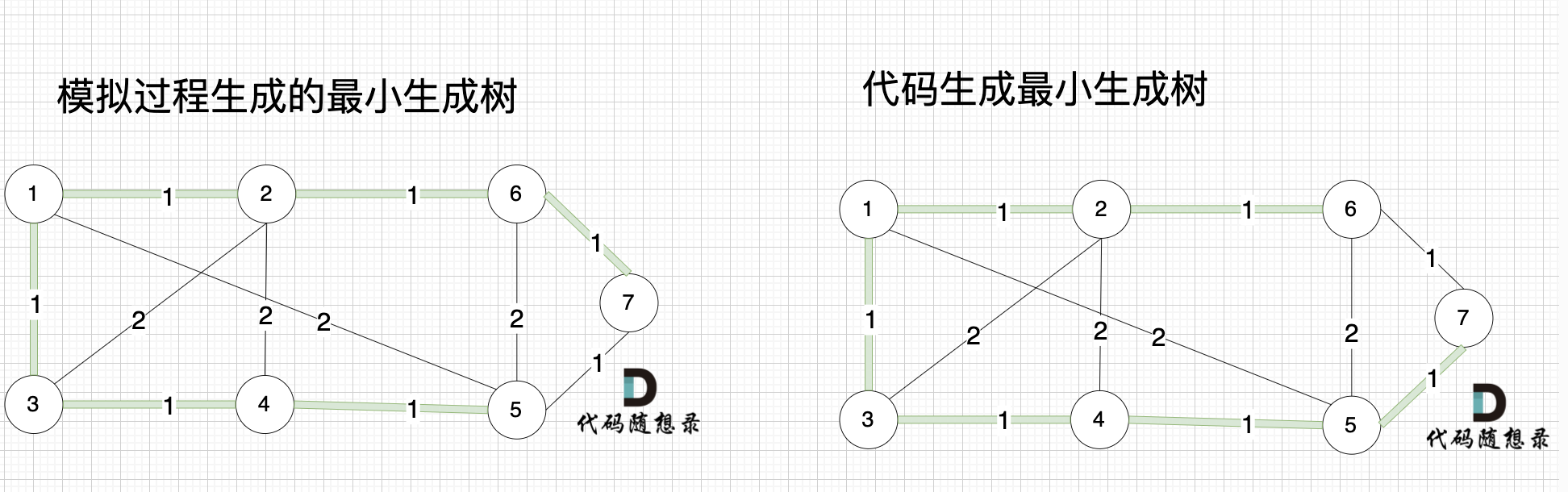
|
||||
|
||||
|
||||
其实造成这个差别 是对边排序的时候 权值相同的边先后顺序的问题导致的,无论相同权值边的顺序是什么样的,最后都能得出最小生成树。
|
||||
@@ -366,7 +366,7 @@ Kruskal 与 prim 的关键区别在于,prim维护的是节点的集合,而 K
|
||||
|
||||
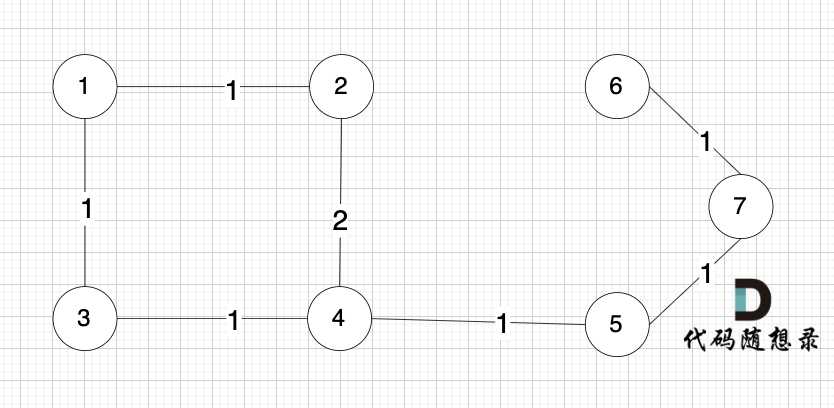
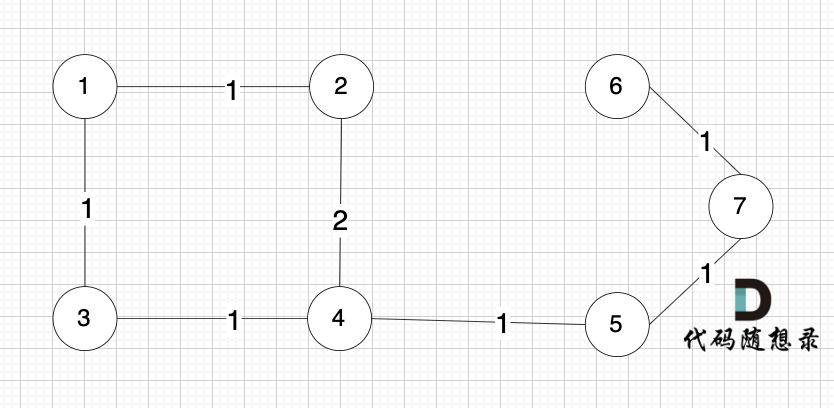
节点未必一定要连着边那, 例如 这个图,大家能明显感受到边没有那么多对吧,但节点数量 和 上述我们讲的例子是一样的。
|
||||
|
||||
|
||||
|
||||
|
||||
为什么边少的话,使用 Kruskal 更优呢?
|
||||
|
||||
|
||||
@@ -61,7 +61,7 @@
|
||||
|
||||
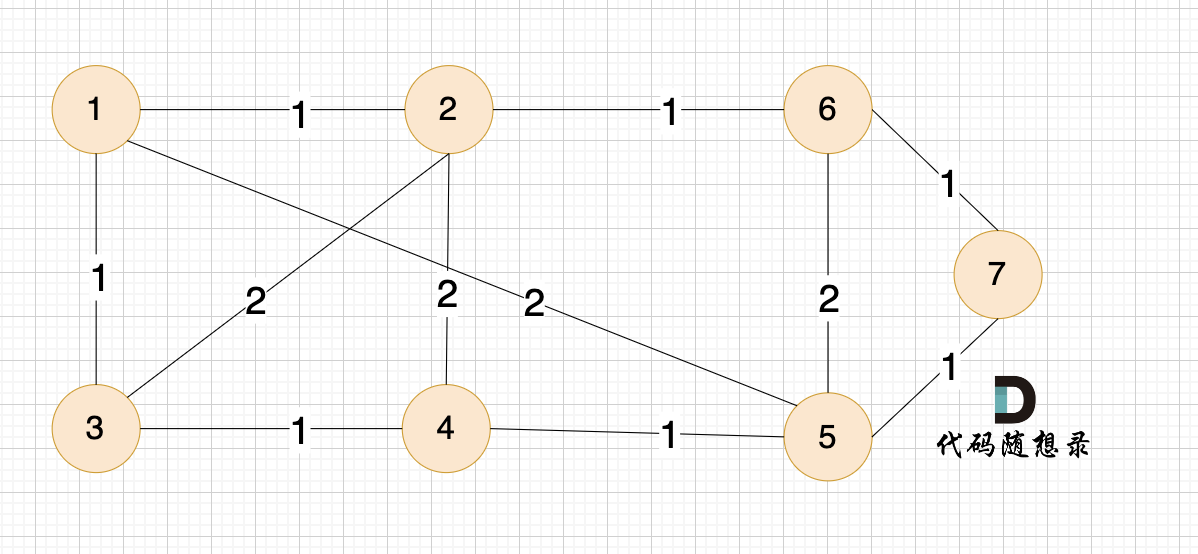
例如本题示例中的无向有权图为:
|
||||
|
||||
|
||||

|
||||
|
||||
那么在这个图中,如何选取n-1条边使得图中所有节点连接到一起,并且边的权值和最小呢?
|
||||
|
||||
@@ -100,7 +100,7 @@ minDist数组里的数值初始化为最大数,因为本题节点距离不会
|
||||
|
||||
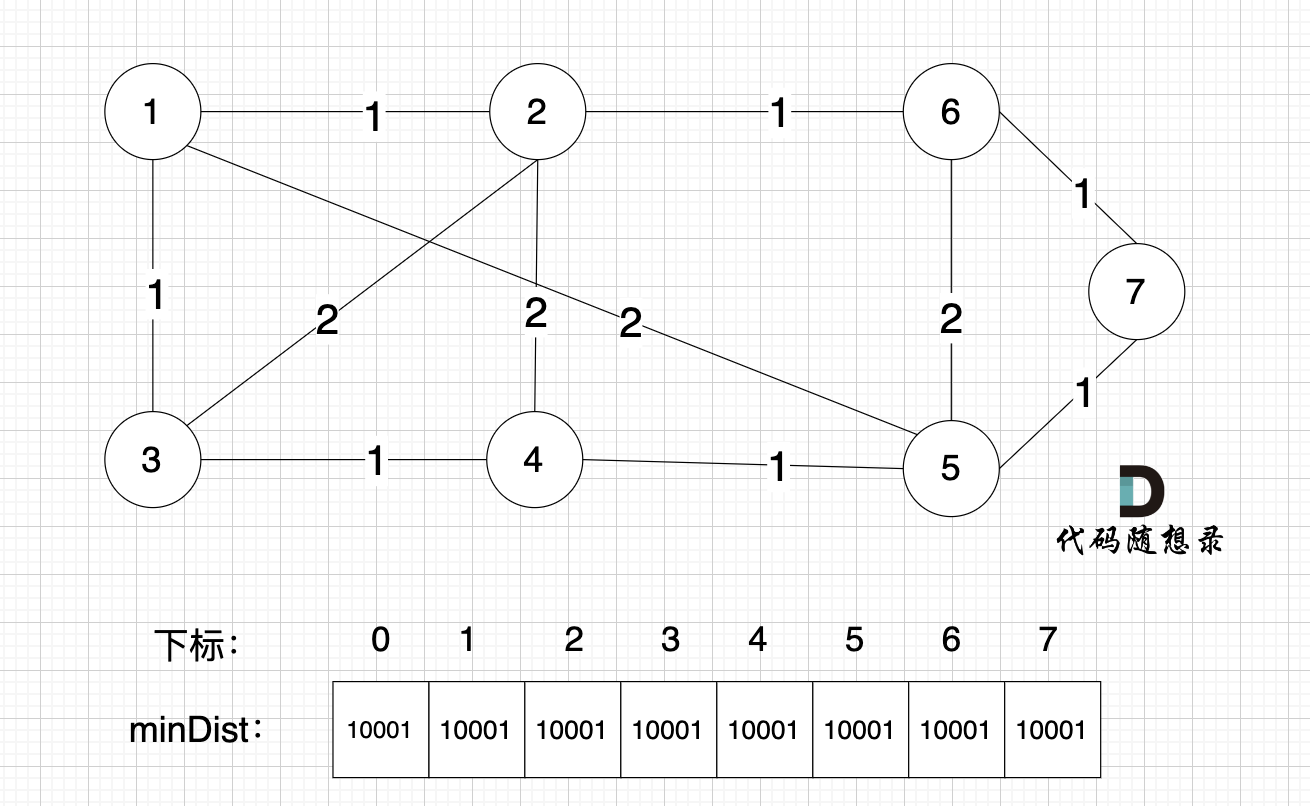
如图:
|
||||
|
||||
|
||||
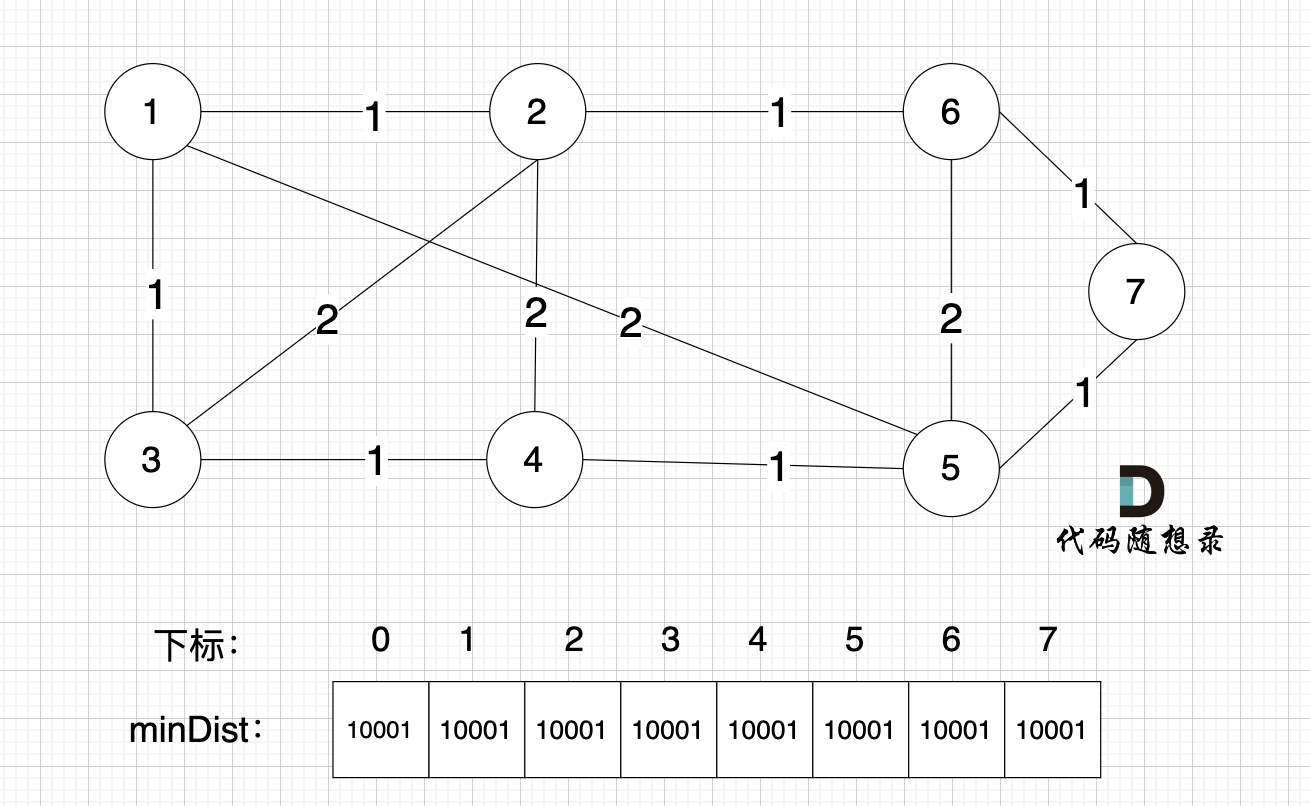
|
||||
|
||||
开始构造最小生成树
|
||||
|
||||
@@ -118,7 +118,7 @@ minDist数组里的数值初始化为最大数,因为本题节点距离不会
|
||||
|
||||
接下来,我们要更新所有节点距离最小生成树的距离,如图:
|
||||
|
||||
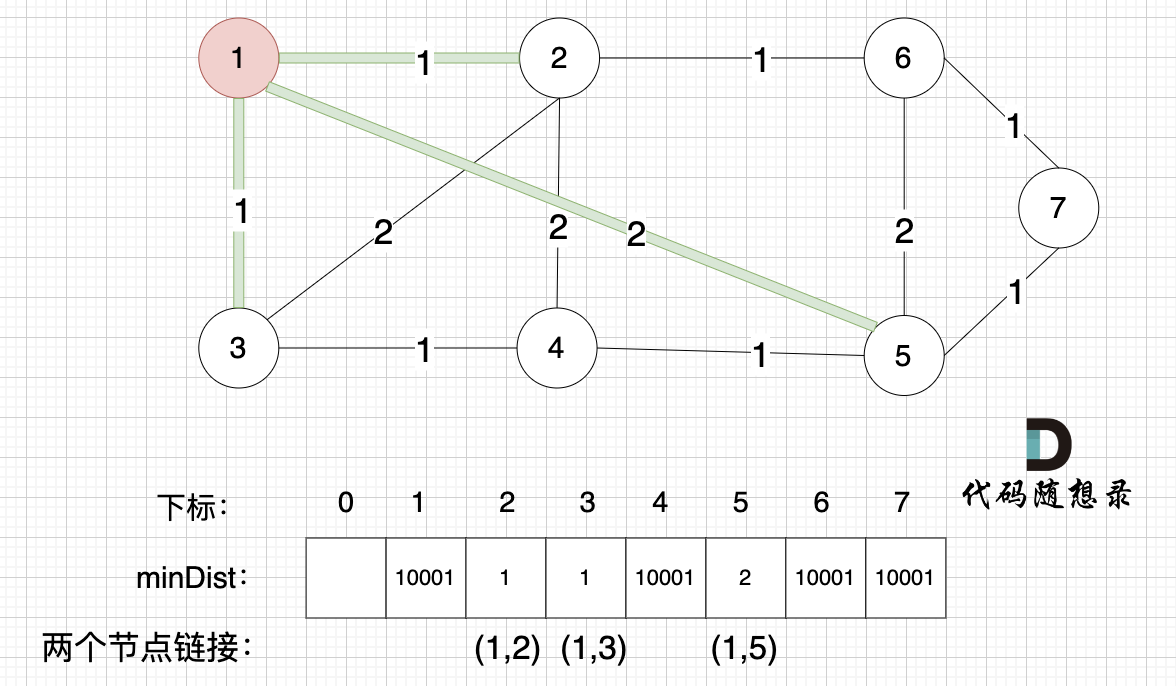
|
||||
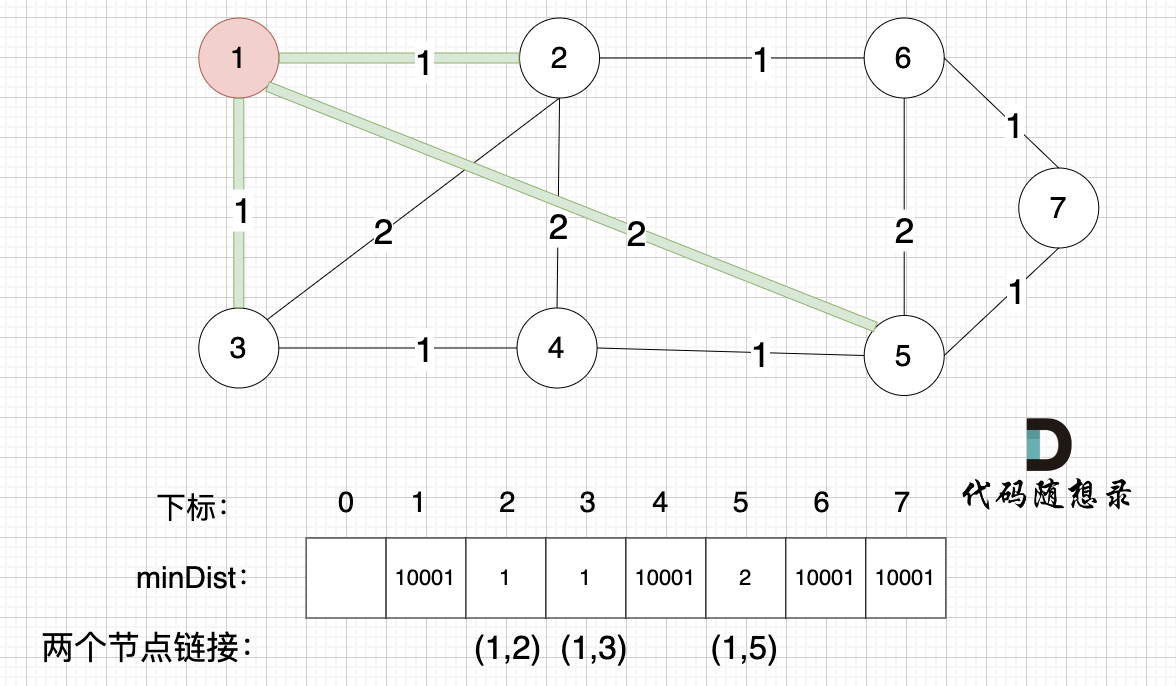
|
||||
|
||||
|
||||
注意下标0,我们就不管它了,下标1与节点1对应,这样可以避免大家把节点搞混。
|
||||
@@ -148,7 +148,7 @@ minDist数组里的数值初始化为最大数,因为本题节点距离不会
|
||||
|
||||
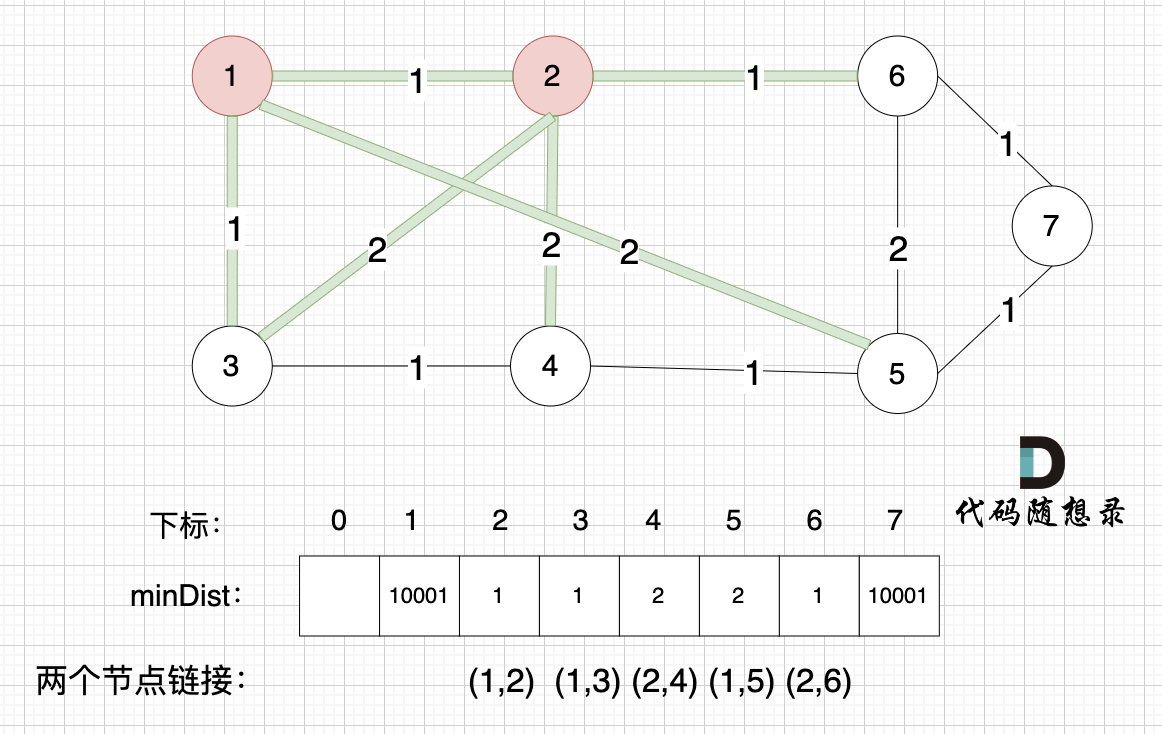
接下来,我们要更新节点距离最小生成树的距离,如图:
|
||||
|
||||
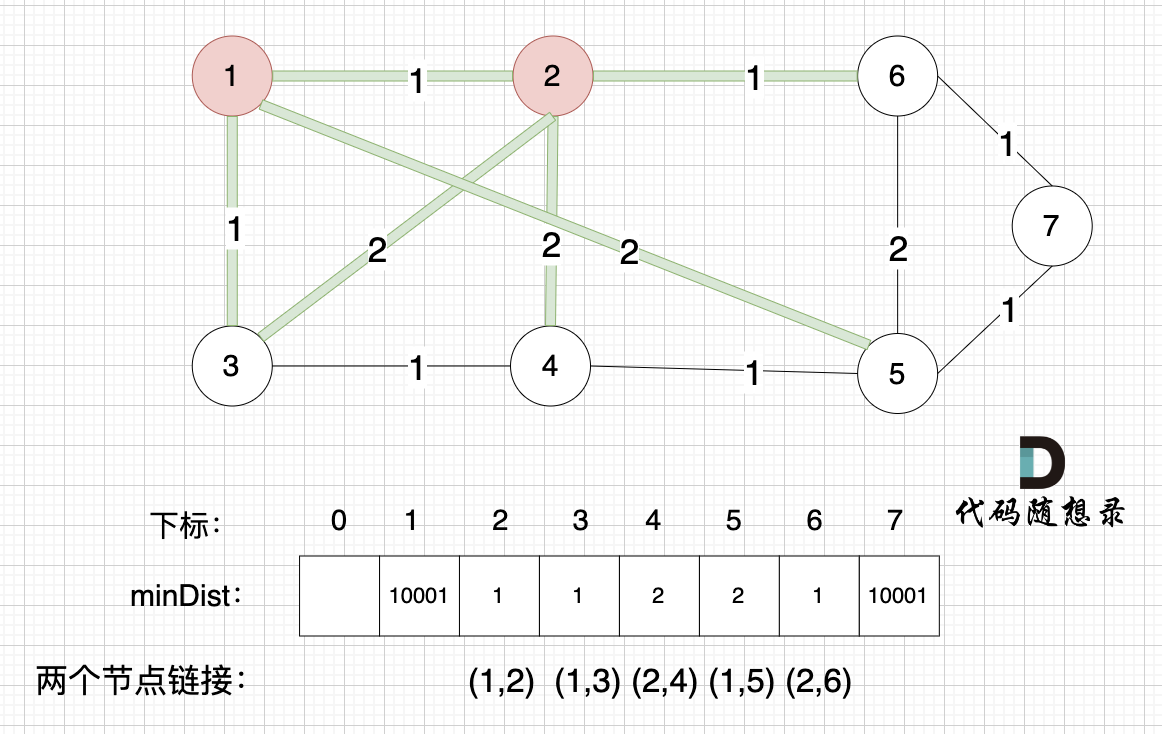
|
||||
|
||||
|
||||
此时所有非生成树的节点距离最小生成树(节点1、节点2)的距离都已经跟新了。
|
||||
|
||||
@@ -172,7 +172,7 @@ minDist数组里的数值初始化为最大数,因为本题节点距离不会
|
||||
|
||||
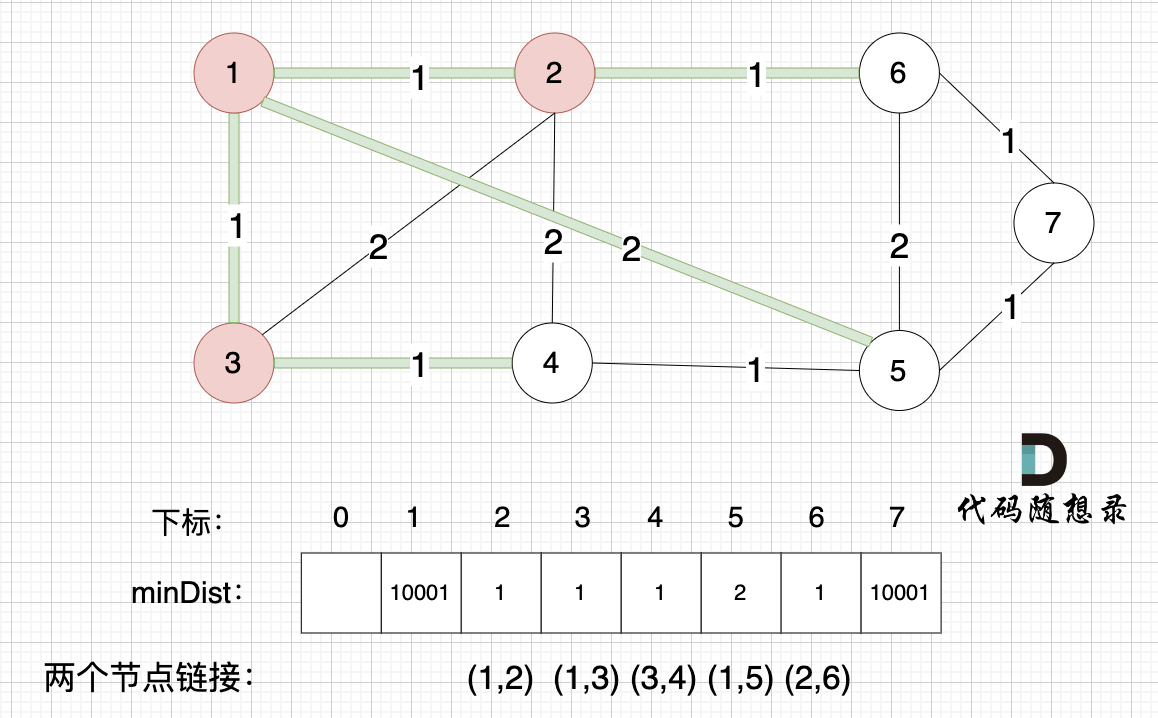
接下来更新节点距离最小生成树的距离,如图:
|
||||
|
||||

|
||||
|
||||
|
||||
所有非生成树的节点距离最小生成树(节点1、节点2、节点3)的距离都已经跟新了。
|
||||
|
||||
@@ -188,7 +188,7 @@ minDist数组里的数值初始化为最大数,因为本题节点距离不会
|
||||
|
||||
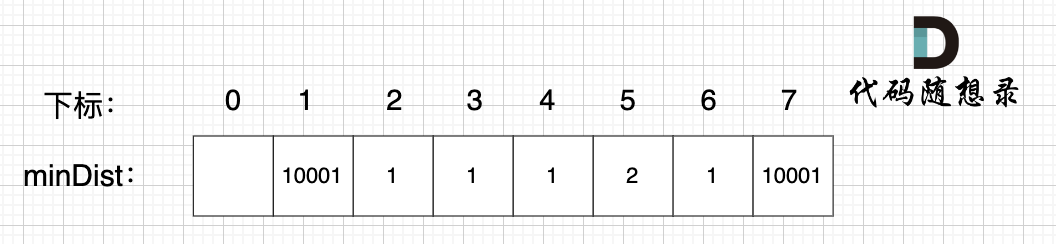
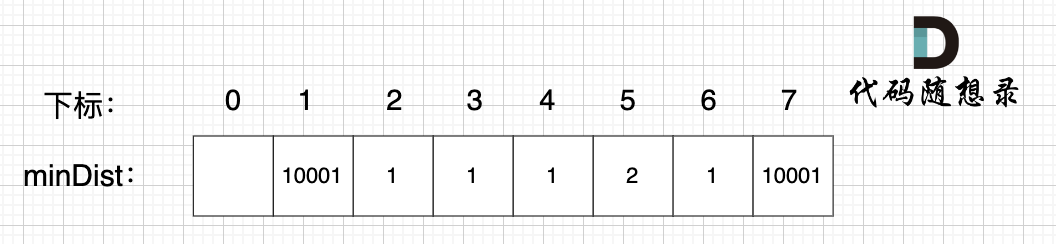
继续选择一个距离最小生成树(节点1、节点2、节点3)最近的非生成树里的节点,为了巩固大家对minDist数组的理解,这里我再啰嗦一遍:
|
||||
|
||||
|
||||
|
||||
|
||||
**minDist数组是记录了所有非生成树节点距离生成树的最小距离**,所以从数组里我们能看出来,非生成树节点4和节点6距离生成树最近。
|
||||
|
||||
@@ -209,7 +209,7 @@ minDist数组里的数值初始化为最大数,因为本题节点距离不会
|
||||
|
||||
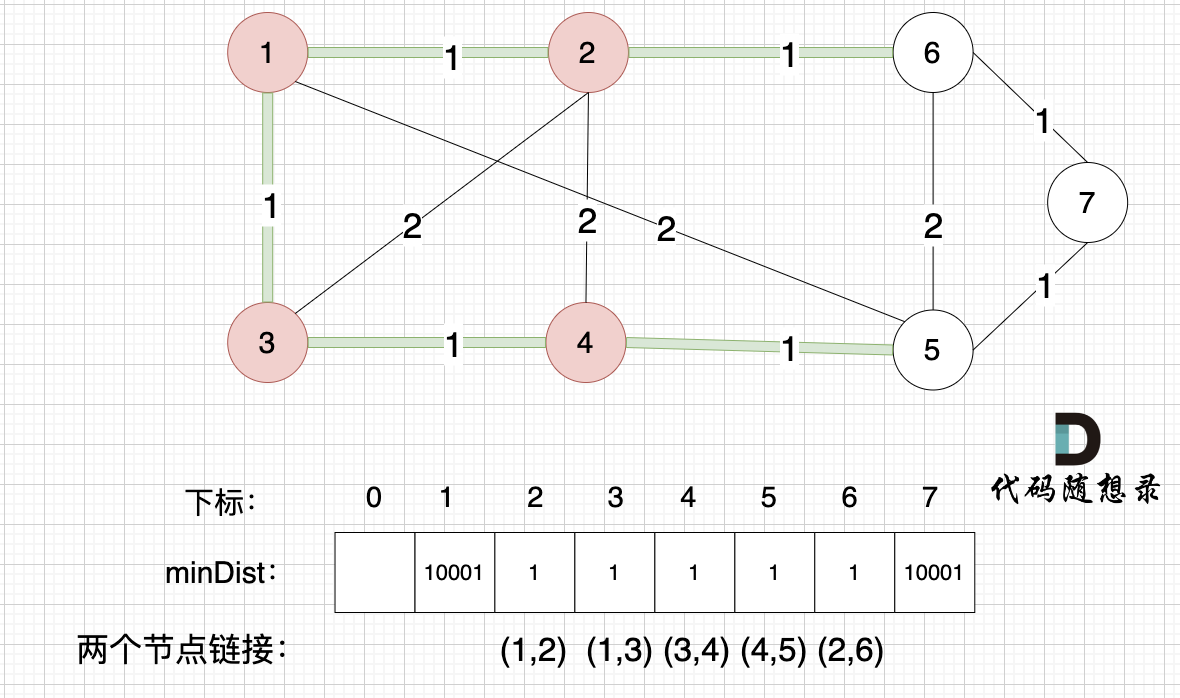
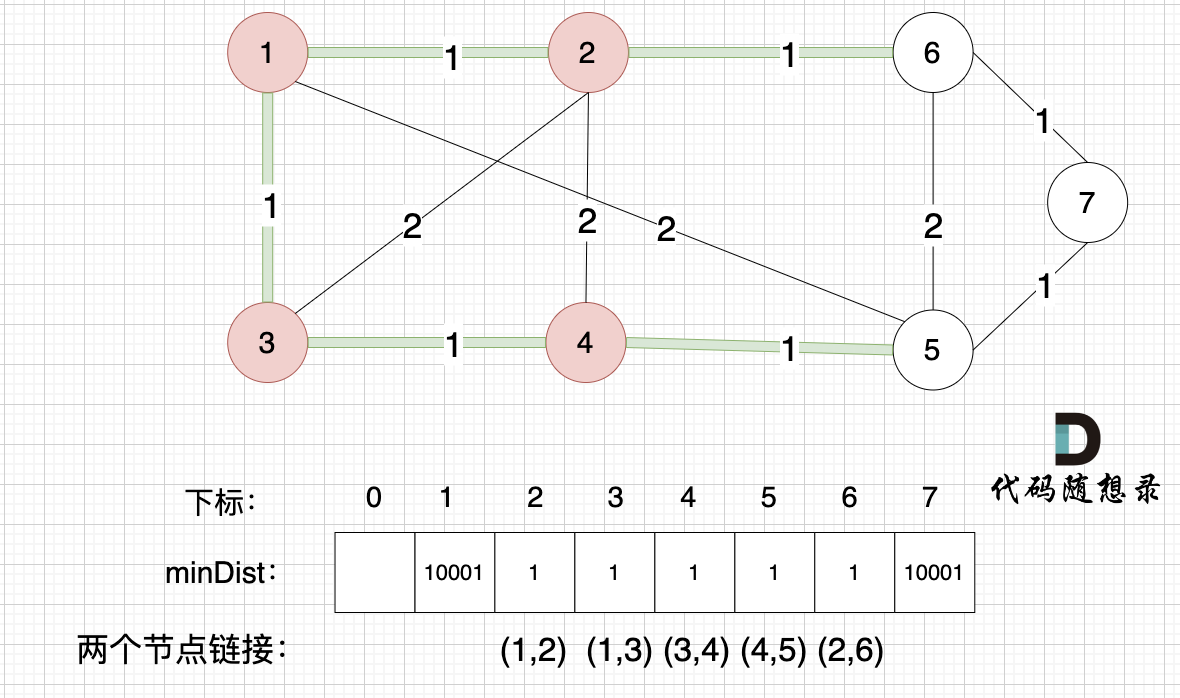
接下来更新节点距离最小生成树的距离,如图:
|
||||
|
||||
|
||||
|
||||
|
||||
minDist数组已经更新了所有非生成树的节点距离最小生成树(节点1、节点2、节点3、节点4)的距离。
|
||||
|
||||
@@ -232,7 +232,7 @@ minDist数组已经更新了所有非生成树的节点距离最小生成树(
|
||||
|
||||
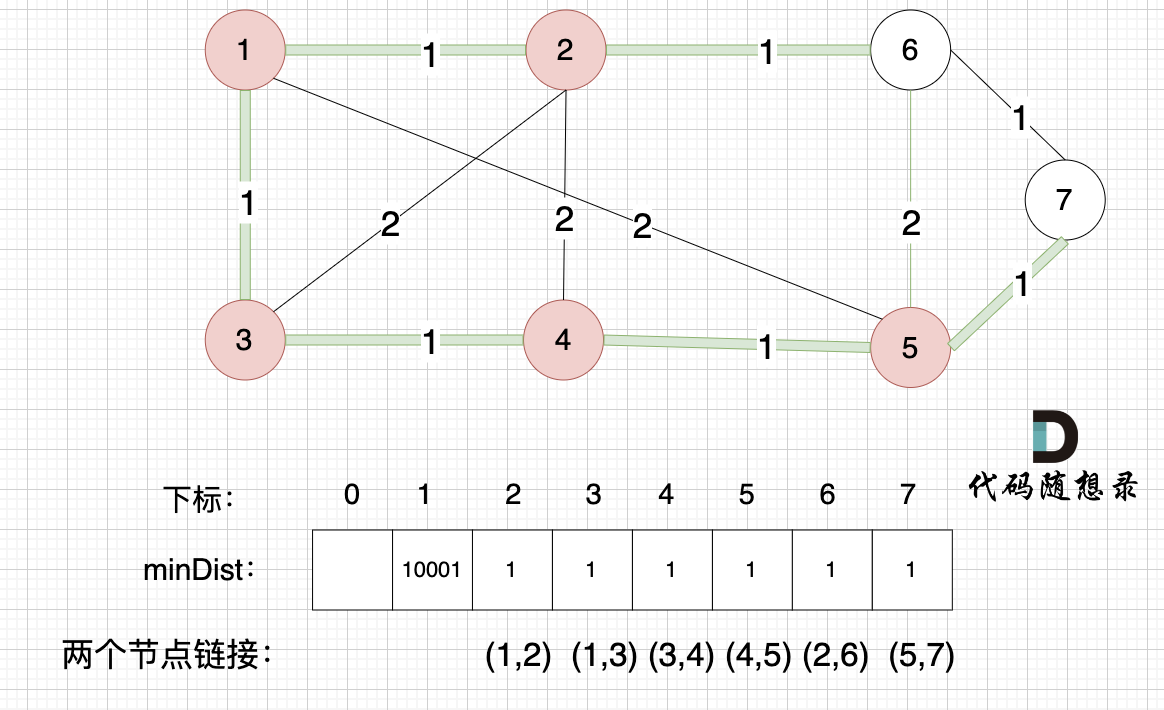
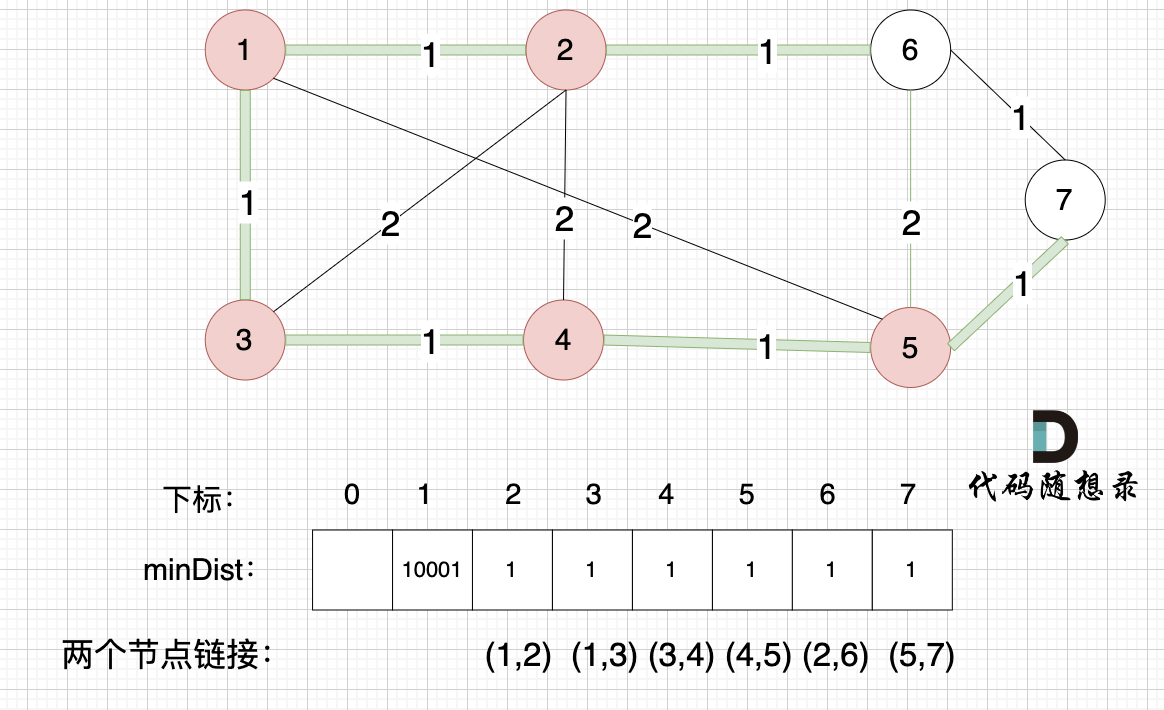
接下来更新节点距离最小生成树的距离,如图:
|
||||
|
||||
|
||||
|
||||
|
||||
minDist数组已经更新了所有非生成树的节点距离最小生成树(节点1、节点2、节点3、节点4、节点5)的距离。
|
||||
|
||||
@@ -253,11 +253,11 @@ minDist数组已经更新了所有非生成树的节点距离最小生成树(
|
||||
|
||||
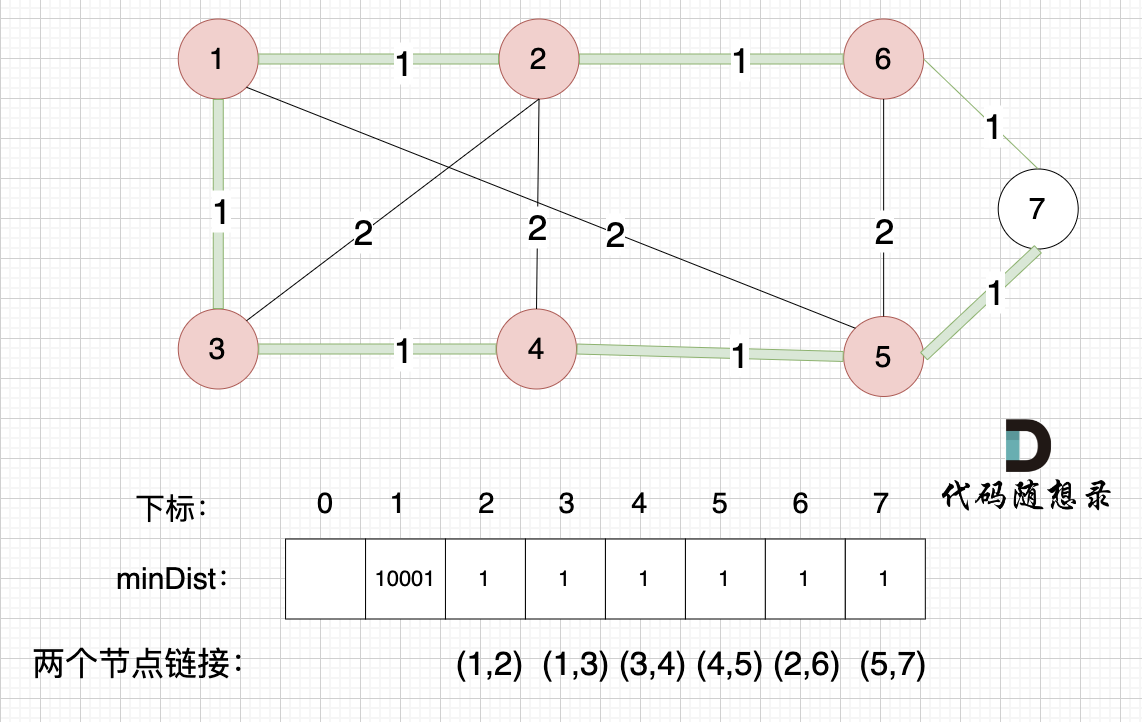
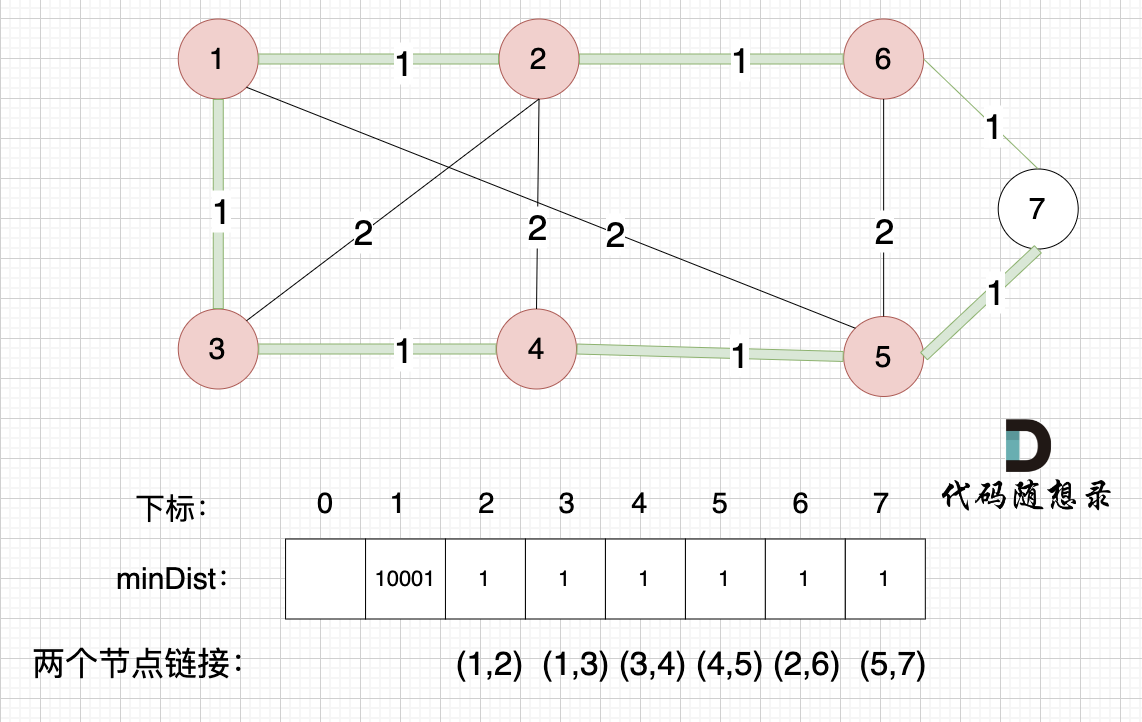
节点1、节点2、节点3、节点4、节点5、节点6算是最小生成树的节点,接下来更新节点距离最小生成树的距离,如图:
|
||||
|
||||
|
||||
|
||||
|
||||
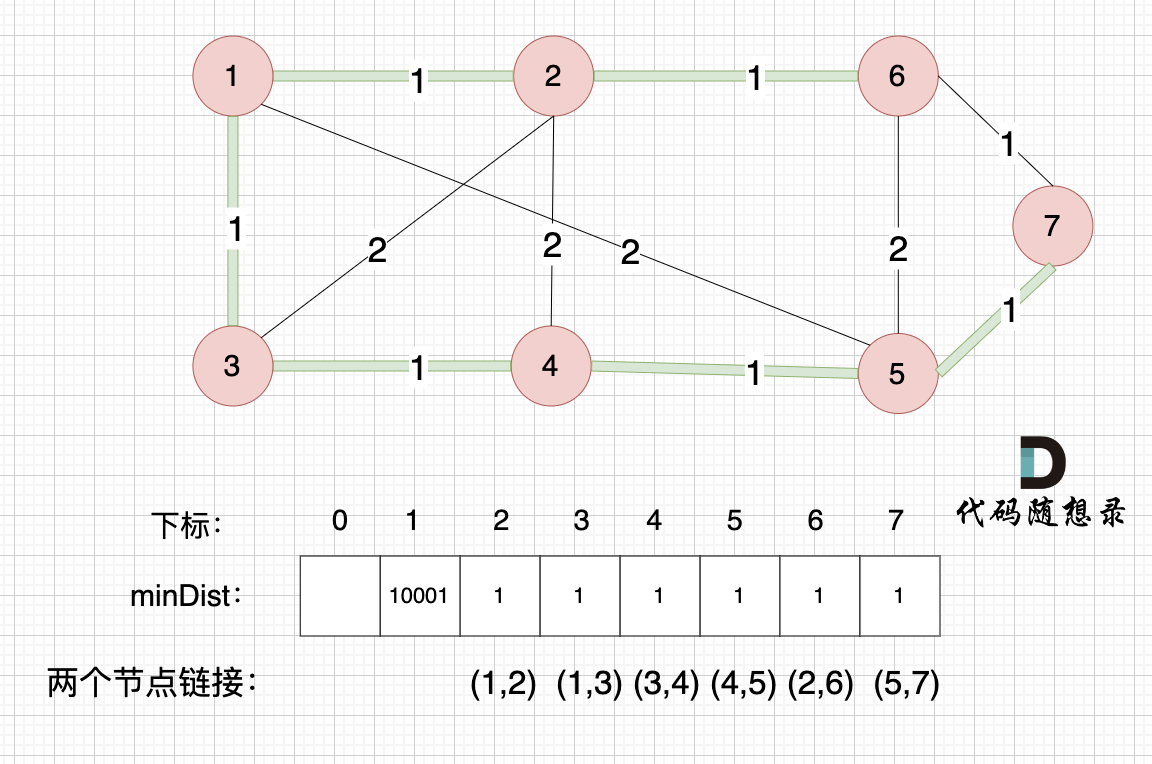
这里就不在重复描述了,大家类推,最后,节点7加入生成树,如图:
|
||||
|
||||
|
||||

|
||||
|
||||
### 最后
|
||||
|
||||
@@ -478,7 +478,7 @@ int main() {
|
||||
|
||||
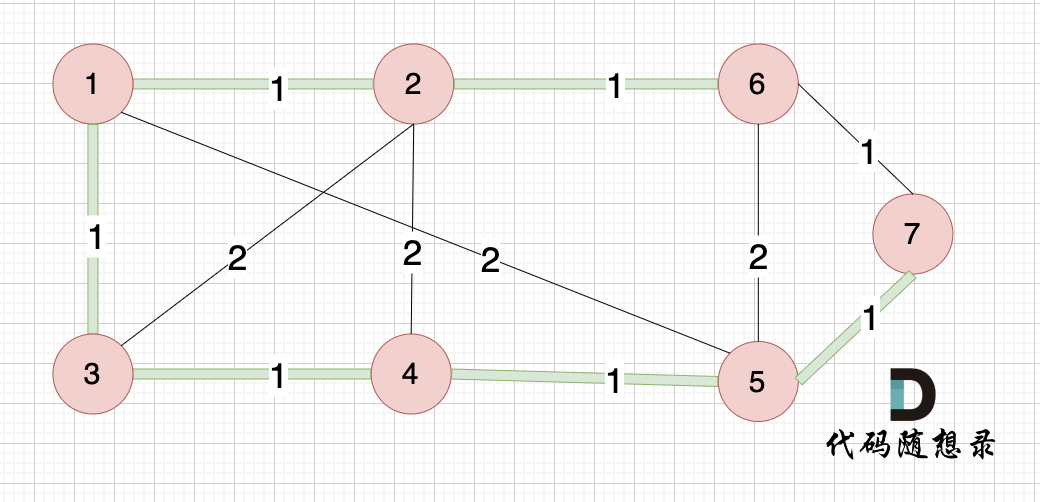
大家可以和我们本题最后生成的最小生成树的图去对比一下边的链接情况:
|
||||
|
||||
|
||||
|
||||
|
||||
绿色的边是最小生成树,和我们的输出完全一致。
|
||||
|
||||
|
||||
@@ -29,11 +29,11 @@
|
||||
|
||||
如图:
|
||||
|
||||
|
||||
|
||||
|
||||
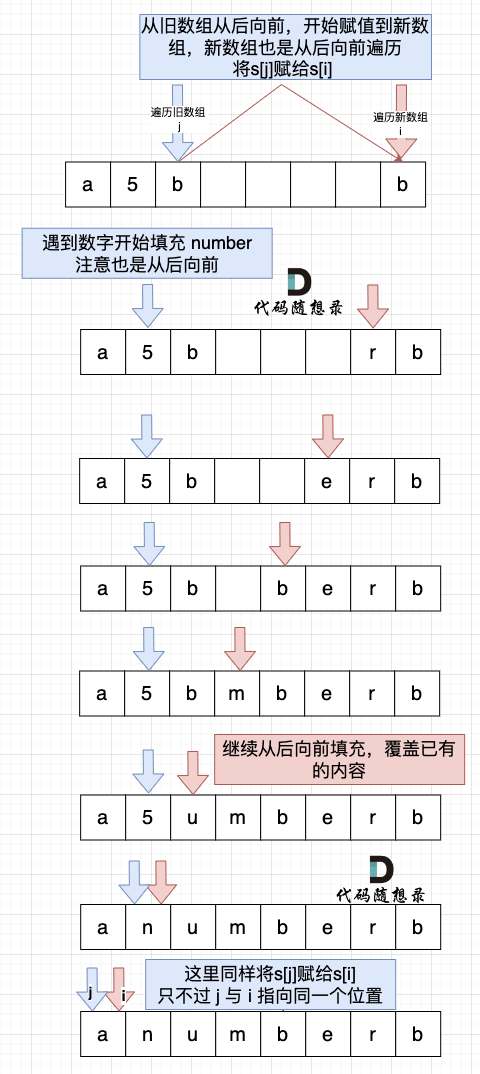
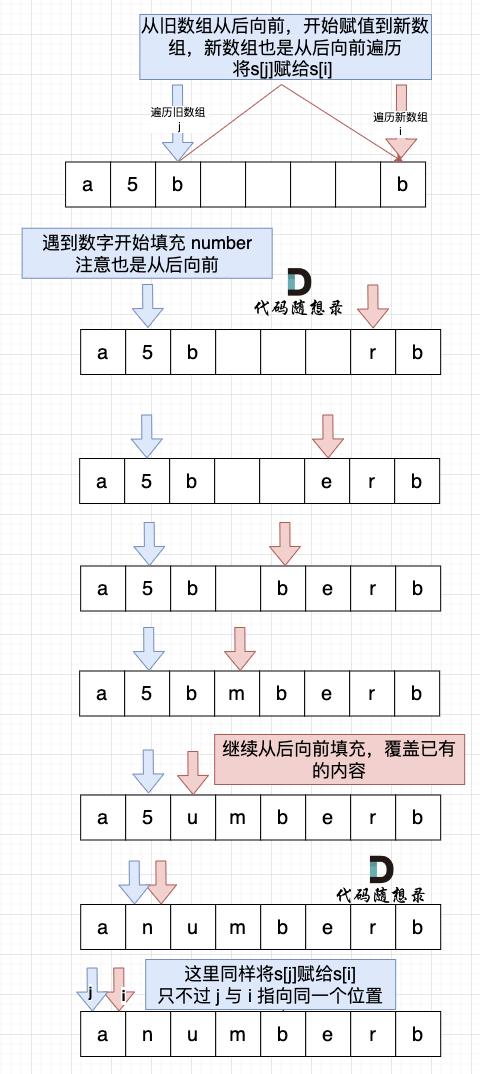
然后从后向前替换数字字符,也就是双指针法,过程如下:i指向新长度的末尾,j指向旧长度的末尾。
|
||||
|
||||
|
||||
|
||||
|
||||
有同学问了,为什么要从后向前填充,从前向后填充不行么?
|
||||
|
||||
|
||||
@@ -40,16 +40,16 @@ fgabcde
|
||||
|
||||
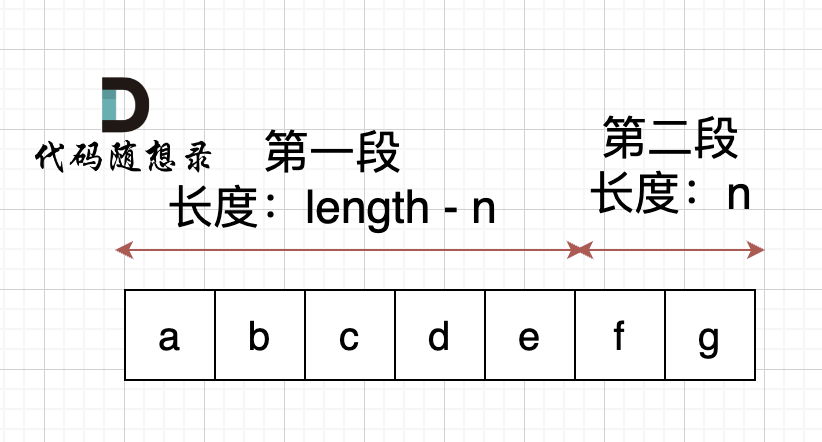
本题中,我们需要将字符串右移n位,字符串相当于分成了两个部分,如果n为2,符串相当于分成了两个部分,如图: (length为字符串长度)
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
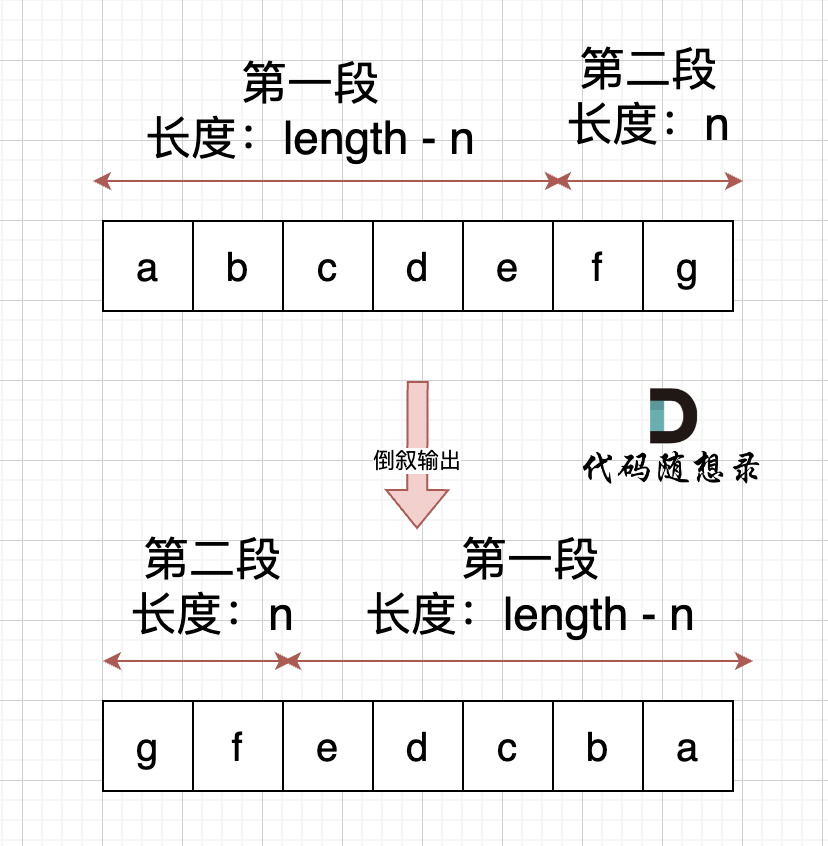
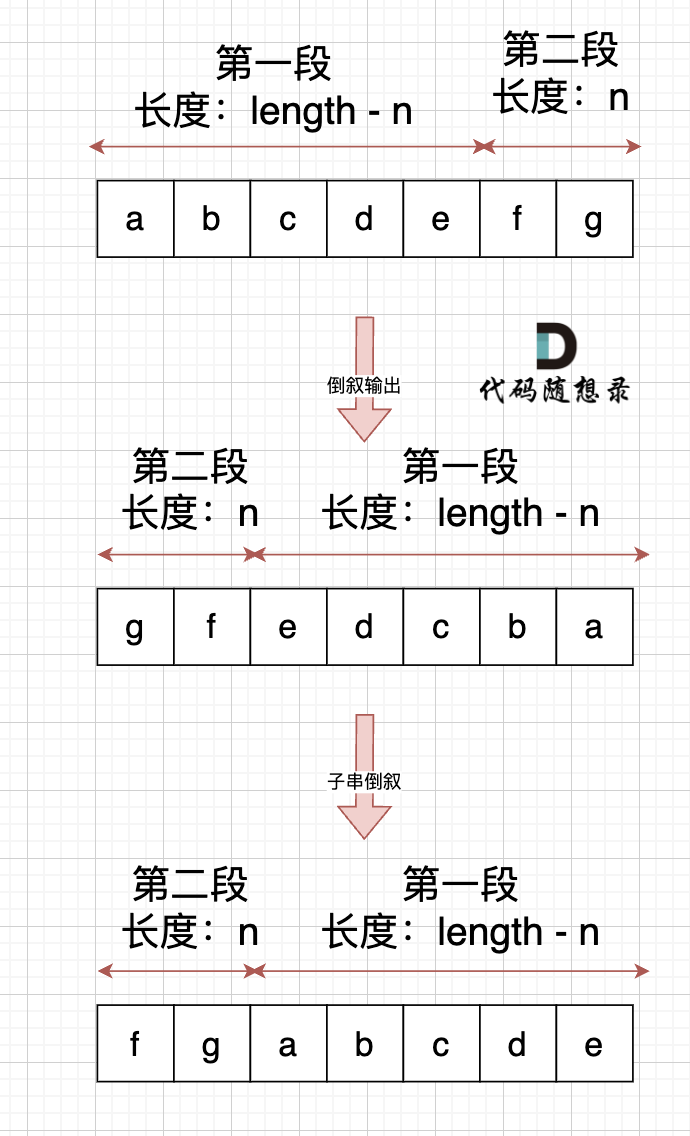
右移n位, 就是将第二段放在前面,第一段放在后面,先不考虑里面字符的顺序,是不是整体倒叙不就行了。如图:
|
||||
|
||||
|
||||

|
||||
|
||||
此时第一段和第二段的顺序是我们想要的,但里面的字符位置被我们倒叙,那么此时我们在把 第一段和第二段里面的字符再倒叙一把,这样字符顺序不就正确了。 如果:
|
||||
|
||||
|
||||

|
||||
|
||||
其实,思路就是 通过 整体倒叙,把两段子串顺序颠倒,两个段子串里的的字符在倒叙一把,**负负得正**,这样就不影响子串里面字符的顺序了。
|
||||
|
||||
@@ -80,7 +80,7 @@ int main() {
|
||||
|
||||
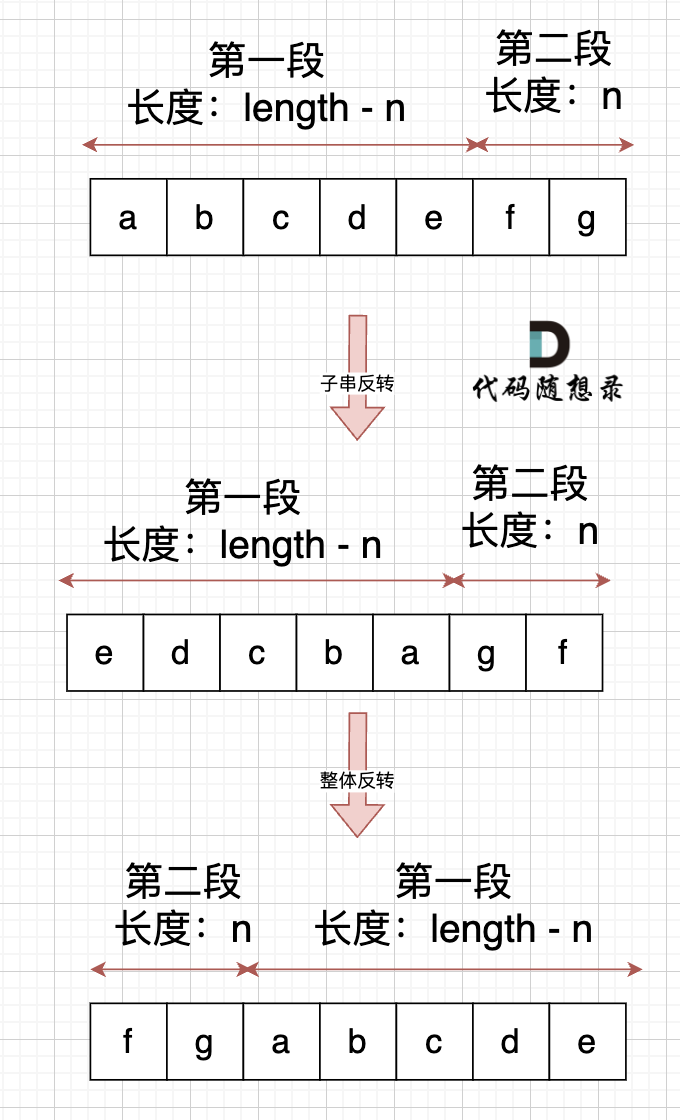
可以的,不过,要记得 控制好 局部反转的长度,如果先局部反转,那么先反转的子串长度就是 len - n,如图:
|
||||
|
||||
|
||||

|
||||
|
||||
代码如下:
|
||||
|
||||
|
||||
@@ -93,7 +93,7 @@ int main() {
|
||||
|
||||
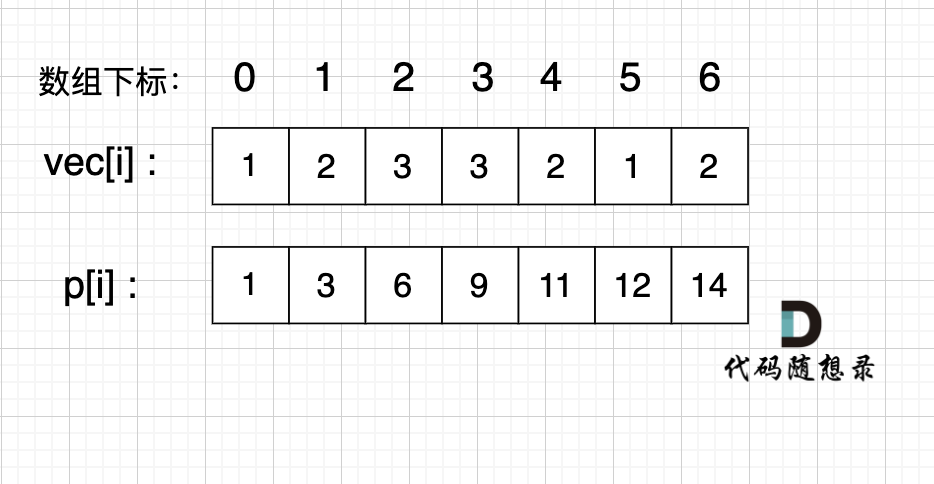
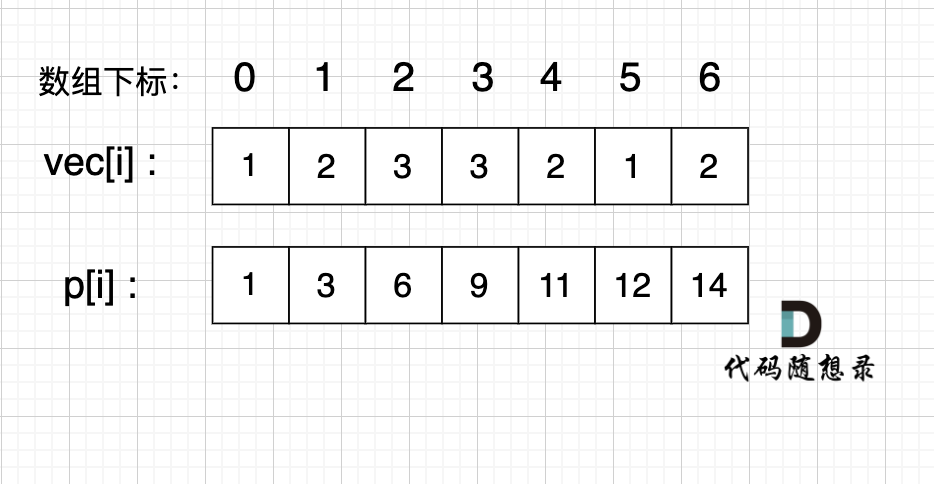
如图:
|
||||
|
||||
|
||||
|
||||
|
||||
如果,我们想统计,在vec数组上 下标 2 到下标 5 之间的累加和,那是不是就用 p[5] - p[1] 就可以了。
|
||||
|
||||
@@ -109,7 +109,7 @@ int main() {
|
||||
|
||||
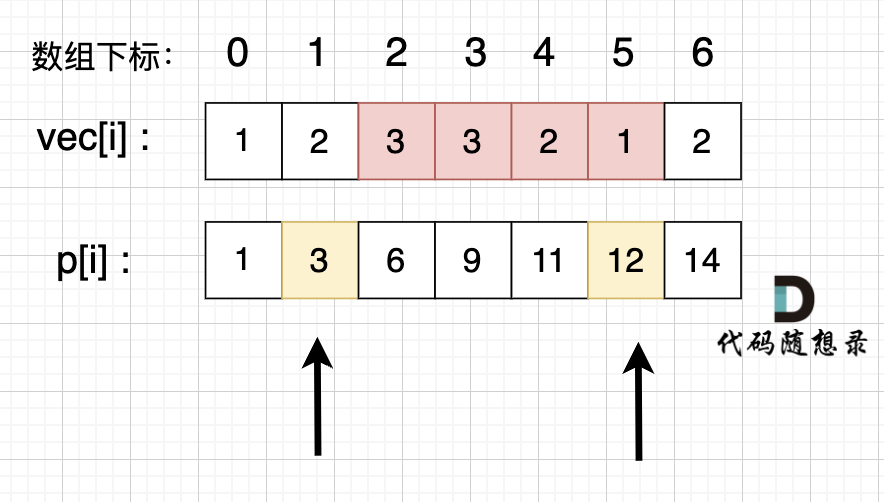
如图所示:
|
||||
|
||||

|
||||
|
||||
|
||||
`p[5] - p[1]` 就是 红色部分的区间和。
|
||||
|
||||
|
||||
@@ -62,7 +62,7 @@
|
||||
|
||||
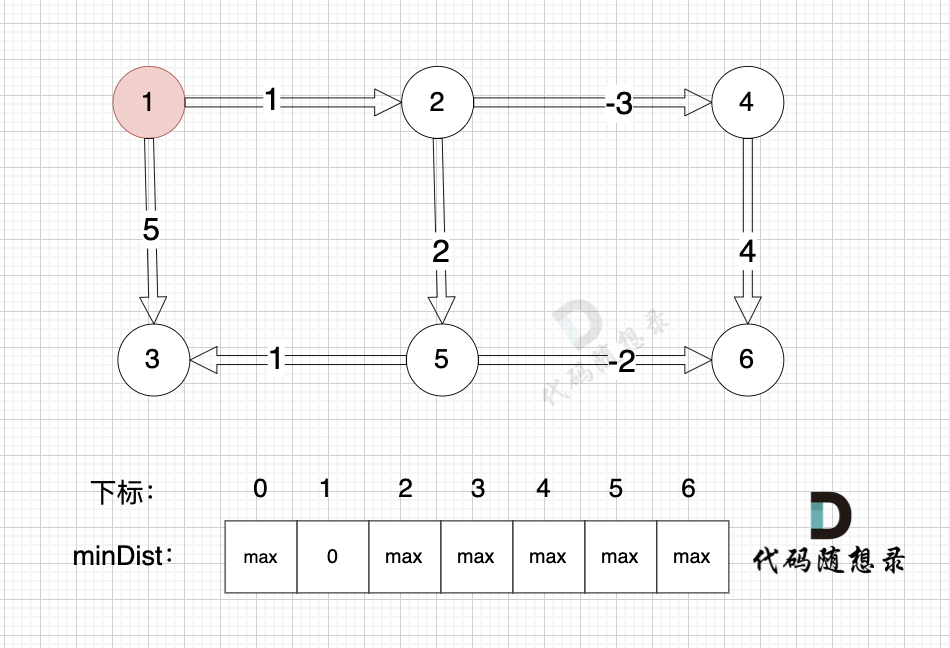
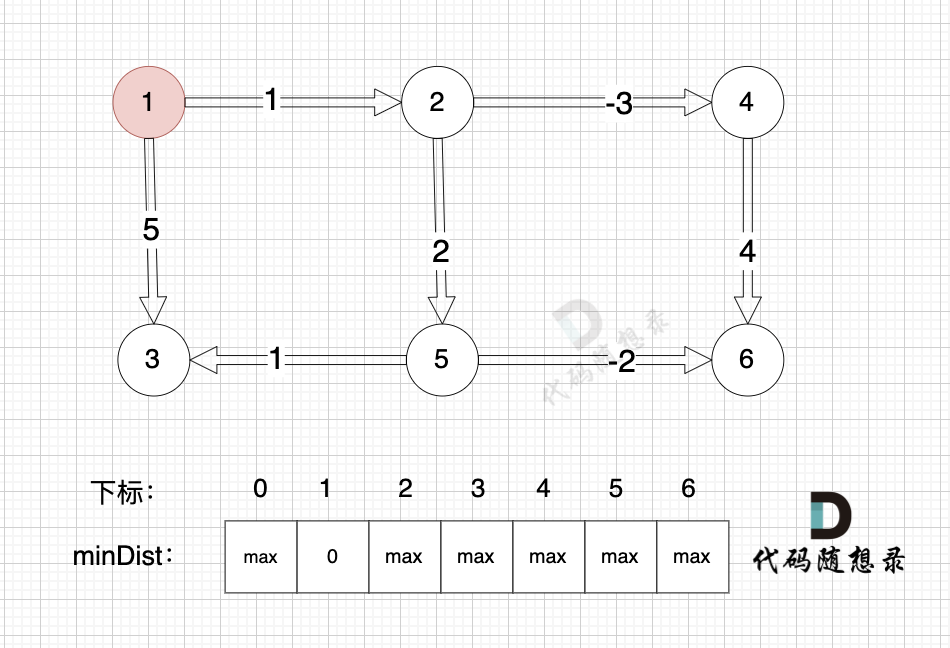
给大家举一个例子:
|
||||
|
||||
|
||||
|
||||
|
||||
本图中,对所有边进行松弛,真正有效的松弛,只有松弛 边(节点1->节点2) 和 边(节点1->节点3) 。
|
||||
|
||||
@@ -97,7 +97,7 @@
|
||||
|
||||
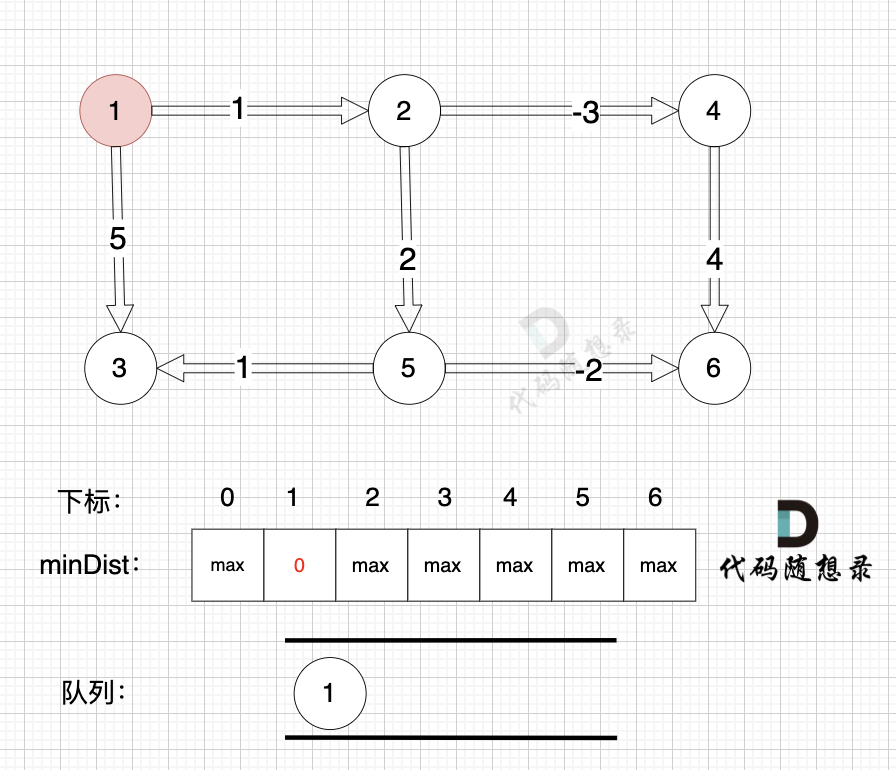
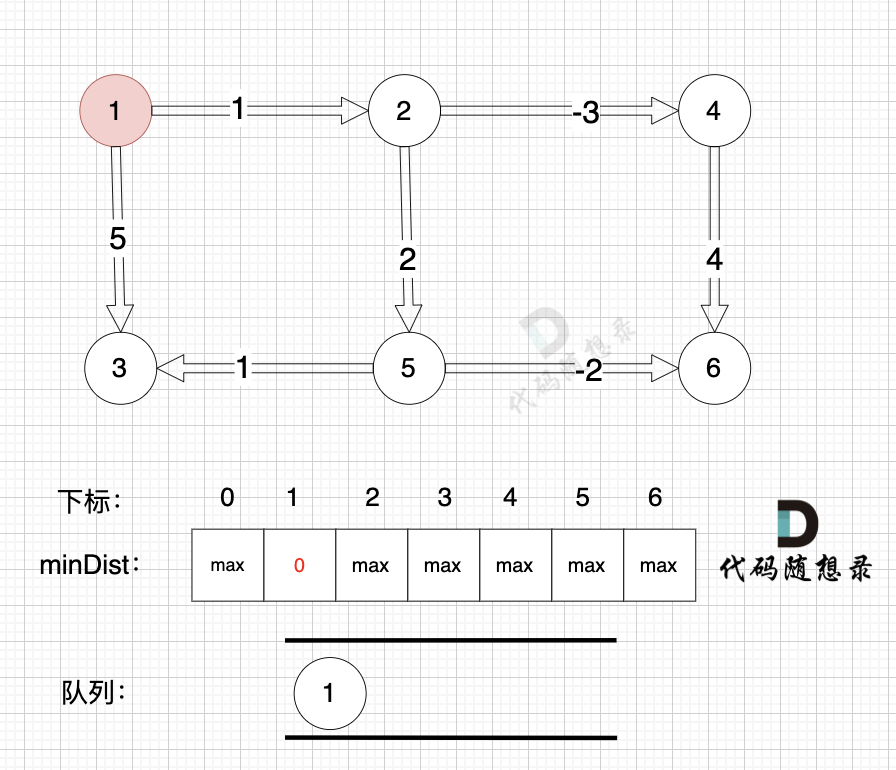
初始化,起点为节点1, 起点到起点的最短距离为0,所以minDist[1] 为 0。 将节点1 加入队列 (下次松弛从节点1开始)
|
||||
|
||||
|
||||
|
||||
|
||||
------------
|
||||
|
||||
@@ -109,7 +109,7 @@
|
||||
|
||||
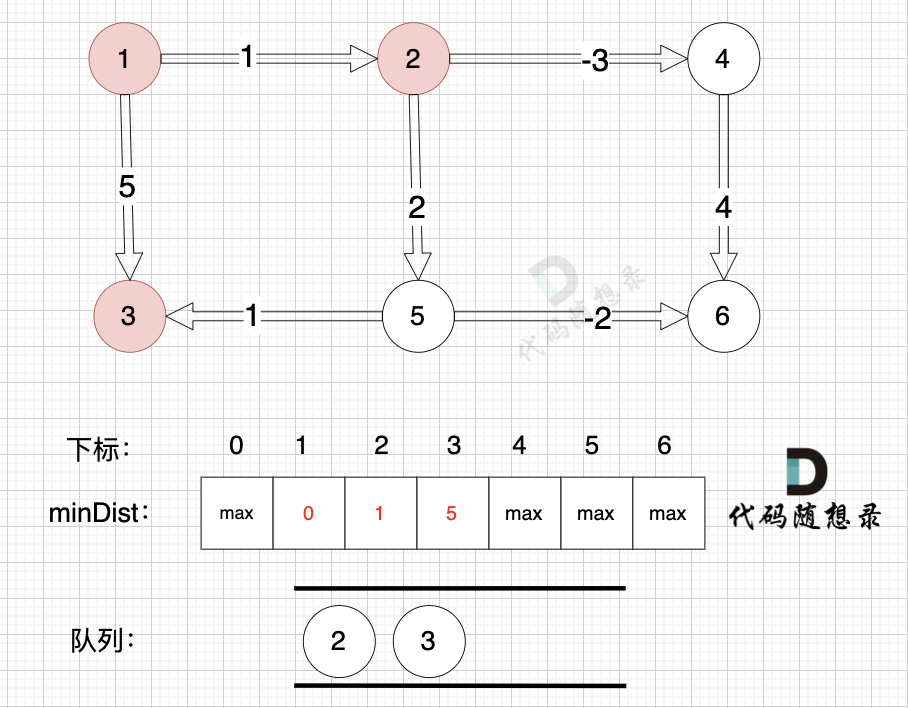
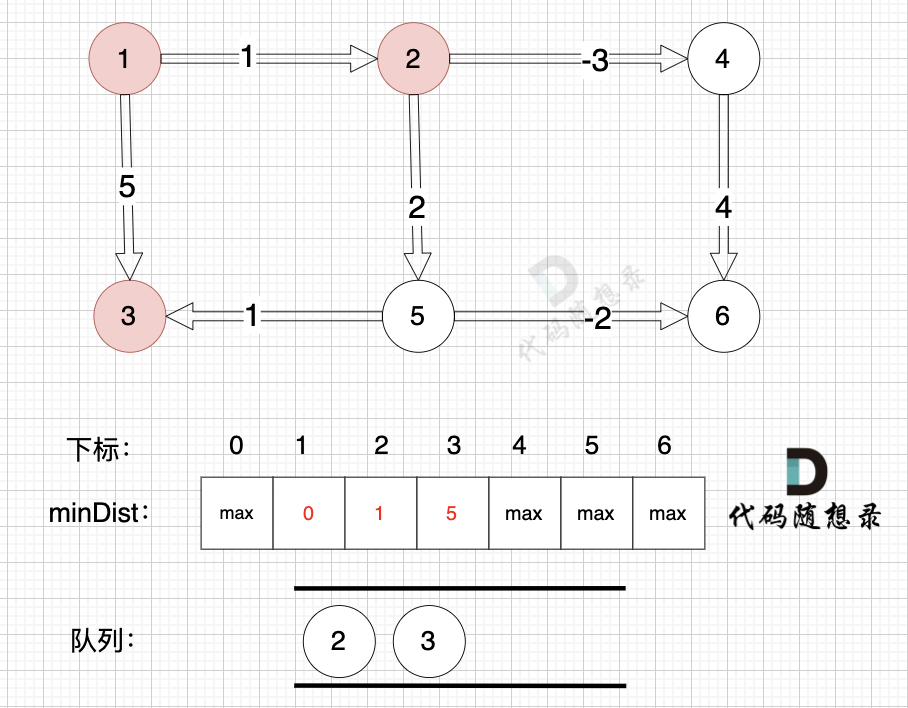
将节点2、节点3 加入队列,如图:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------
|
||||
@@ -124,7 +124,7 @@
|
||||
|
||||
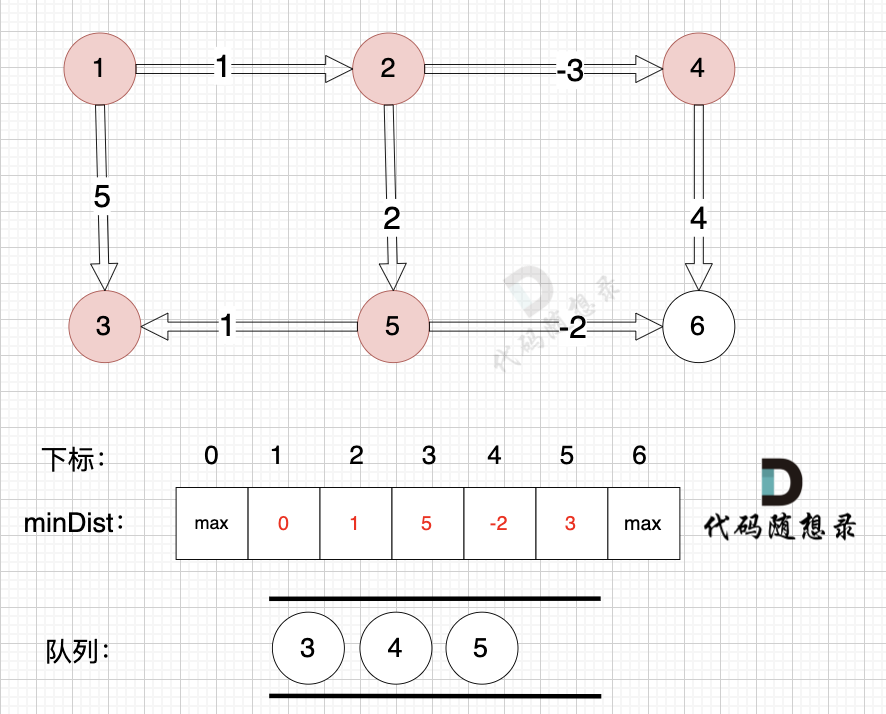
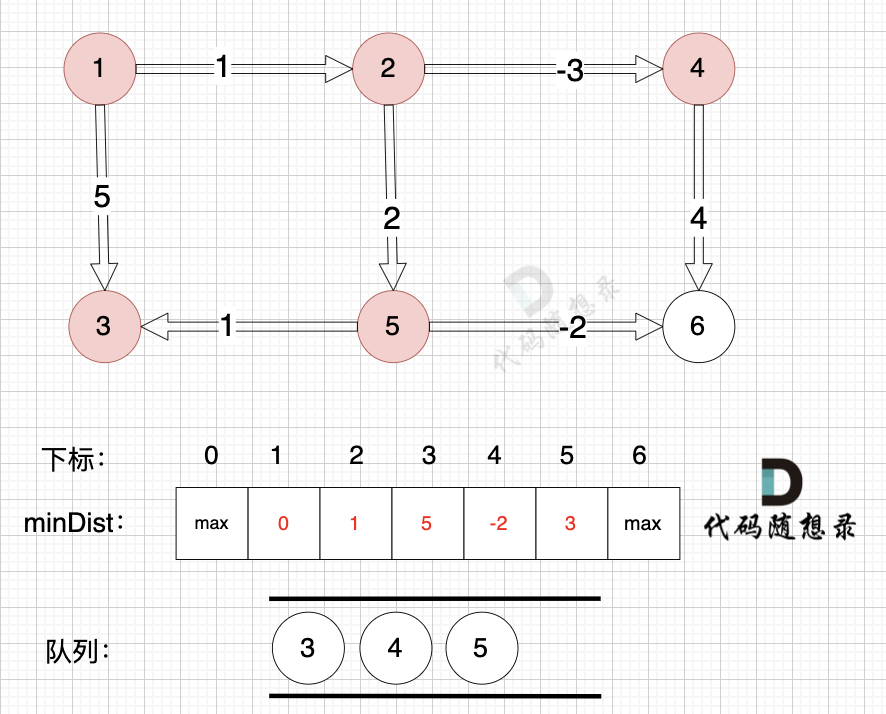
将节点4,节点5 加入队列,如图:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------
|
||||
@@ -134,7 +134,7 @@
|
||||
|
||||
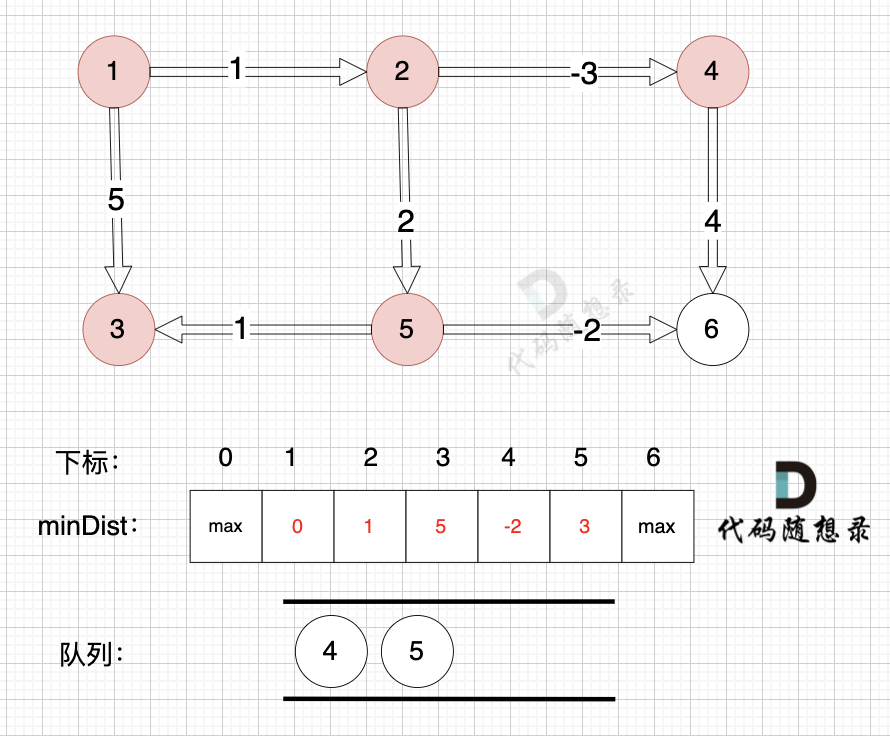
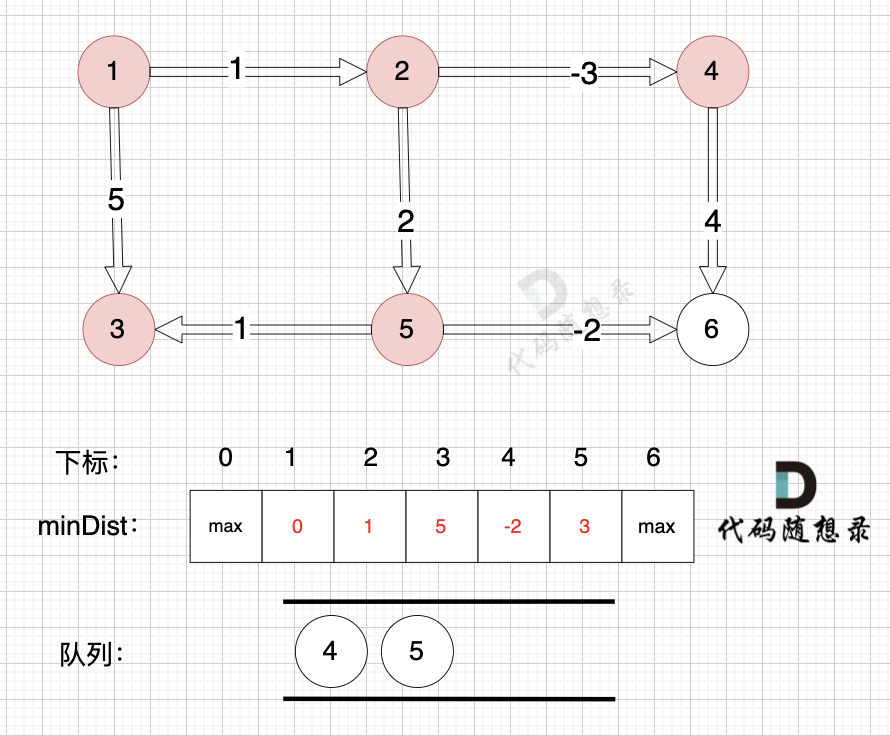
因为没有从节点3作为出发点的边,所以这里就从队列里取出节点3就好,不用做其他操作,如图:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
------------
|
||||
@@ -147,7 +147,7 @@
|
||||
|
||||
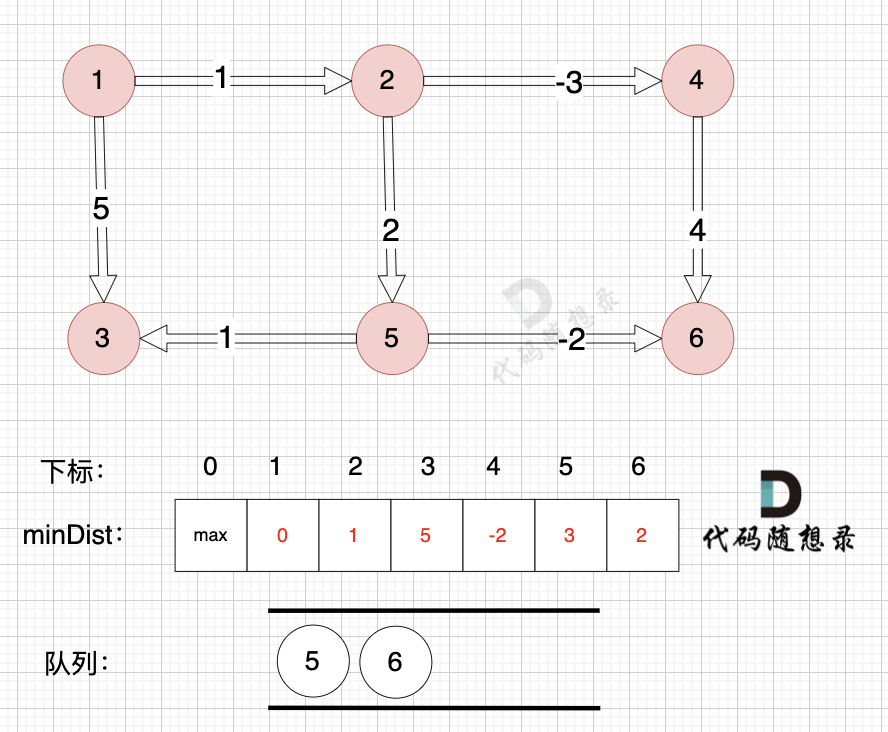
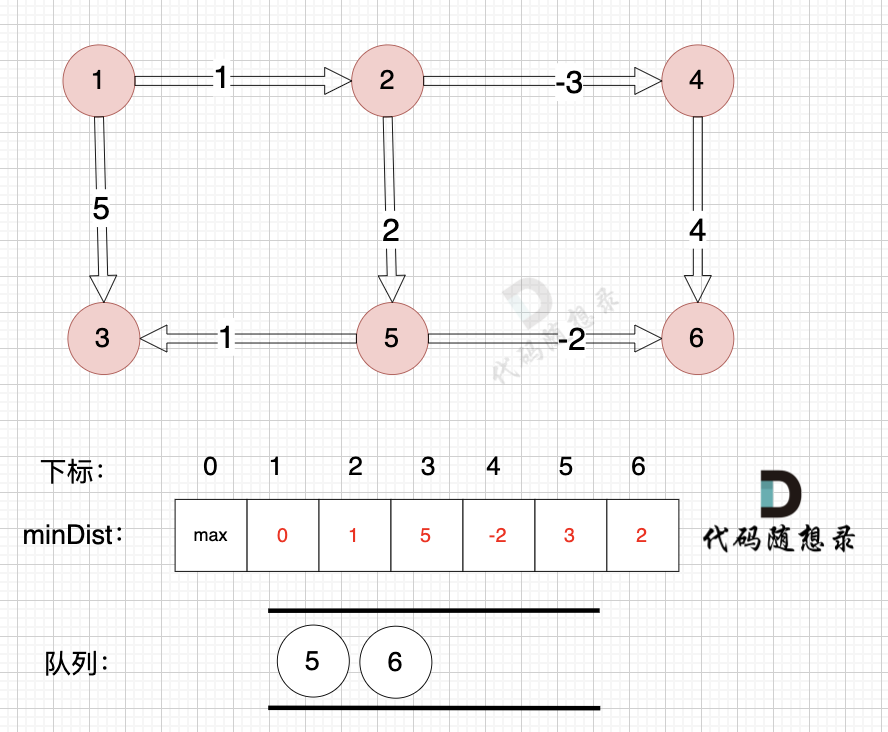
如图:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
---------------
|
||||
@@ -160,7 +160,7 @@
|
||||
|
||||
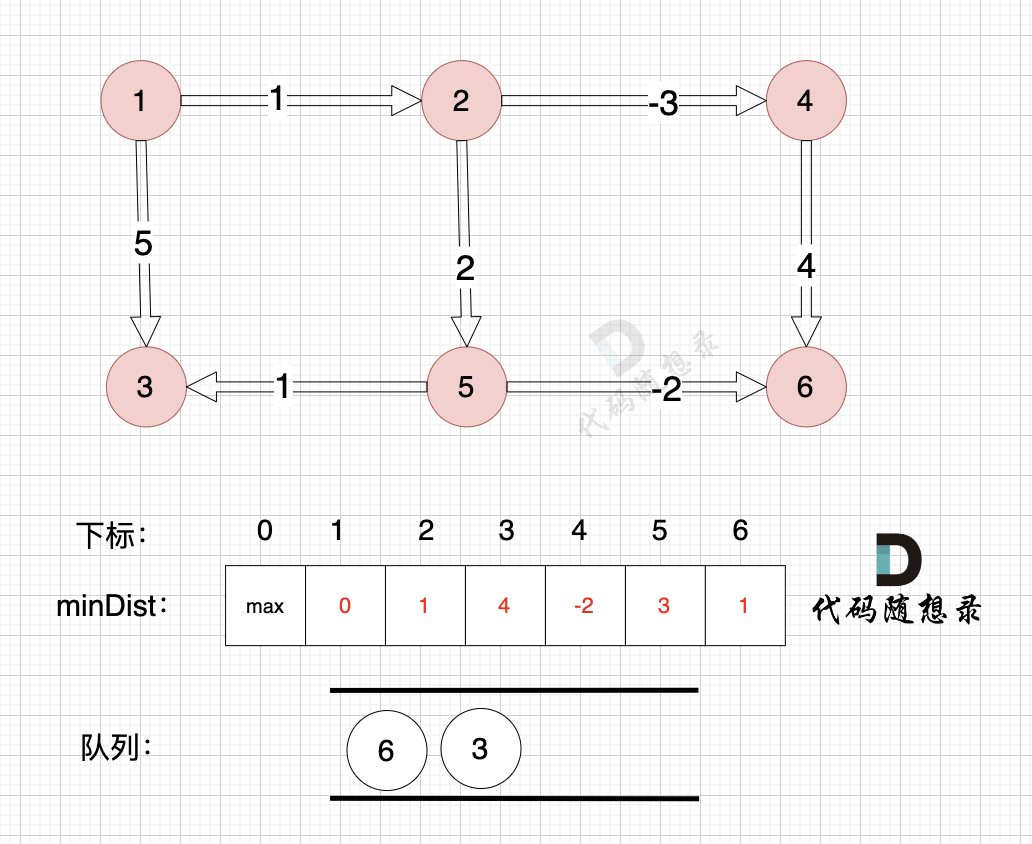
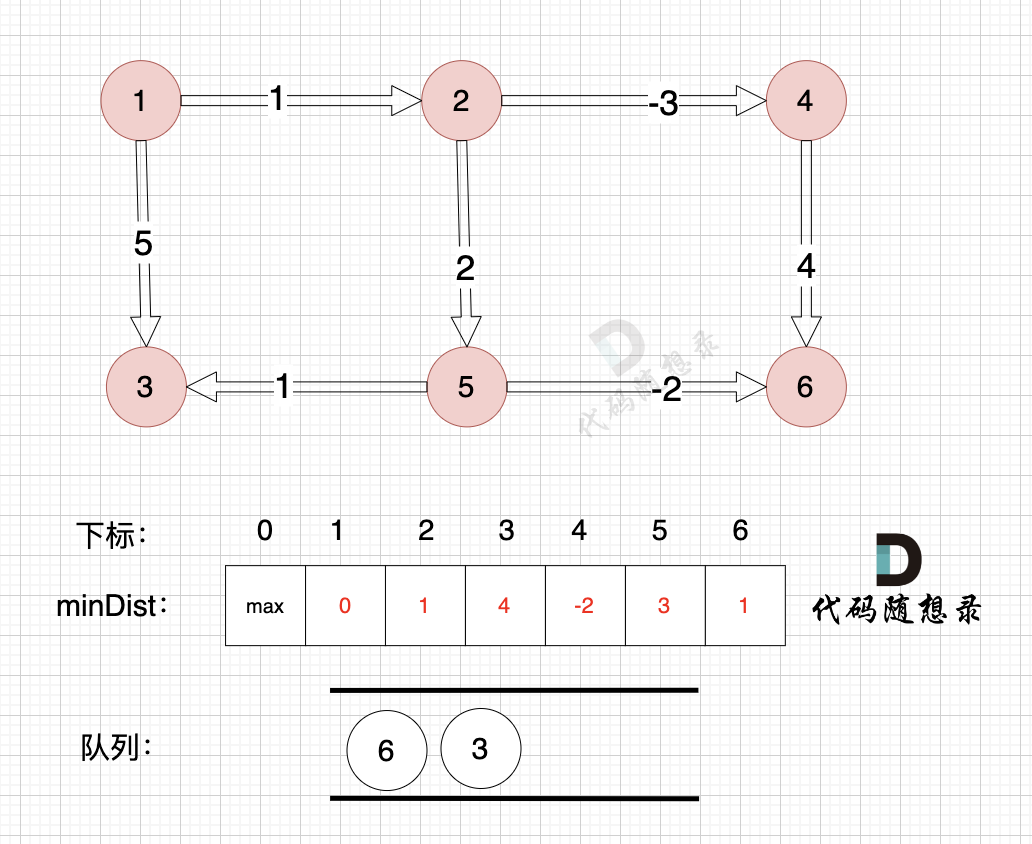
如图,将节点3加入队列,因为节点6已经在队列里,所以不用重复添加
|
||||
|
||||
|
||||
|
||||
|
||||
所以我们在加入队列的过程可以有一个优化,**用visited数组记录已经在队列里的元素,已经在队列的元素不用重复加入**
|
||||
|
||||
@@ -174,7 +174,7 @@
|
||||
|
||||
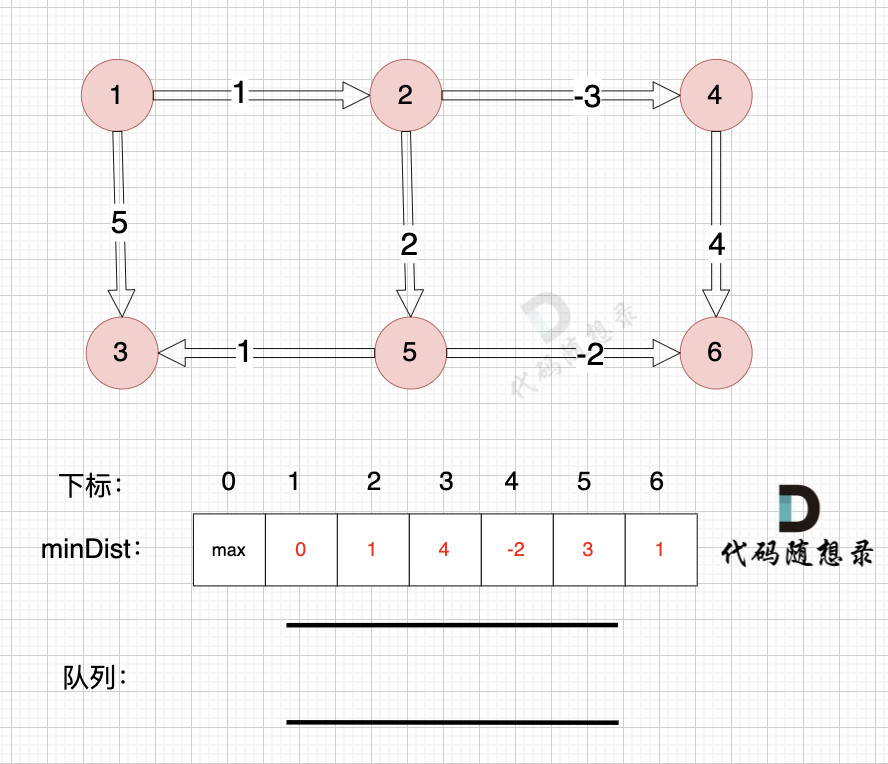
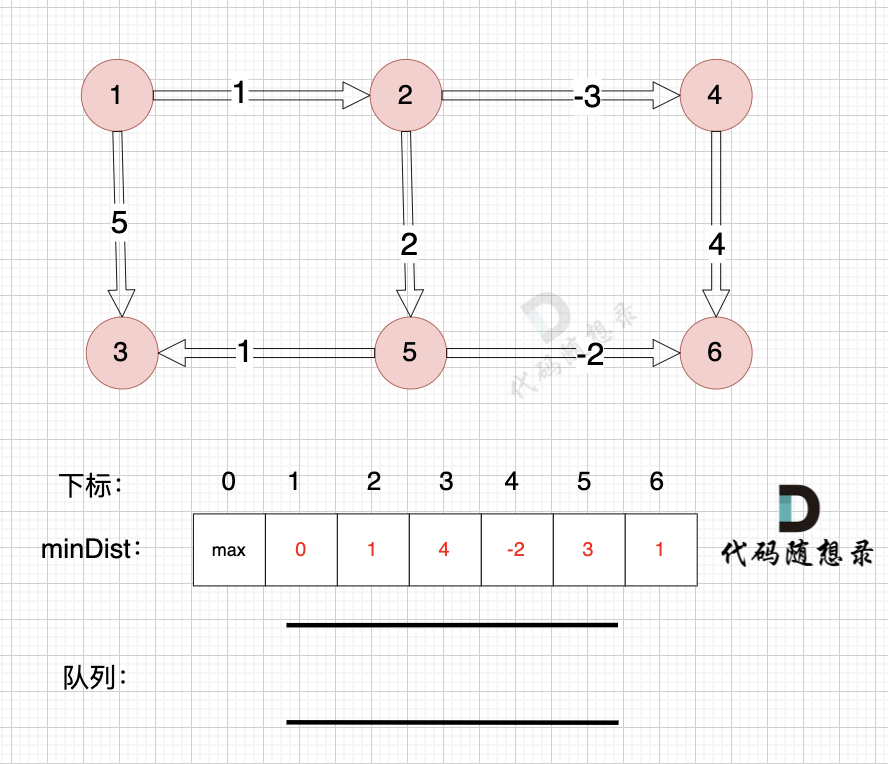
所以直接从队列中取出,如图:
|
||||
|
||||
|
||||
|
||||
|
||||
----------
|
||||
|
||||
@@ -264,7 +264,7 @@ int main() {
|
||||
|
||||
至于为什么 双向图且每一个节点和所有其他节点都相连的话,每个节点 都有 n-1 条指向该节点的边, 我再来举个例子,如图:
|
||||
|
||||
[](https://code-thinking-1253855093.file.myqcloud.com/pics/20240416104138.png)
|
||||
[](https://file.kamacoder.com/pics/20240416104138.png)
|
||||
|
||||
图中 每个节点都与其他所有节点相连,节点数n 为 4,每个节点都有3条指向该节点的边,即入度为3。
|
||||
|
||||
@@ -329,7 +329,7 @@ SPFA(队列优化版Bellman_ford) 在理论上 时间复杂度更胜一筹
|
||||
|
||||
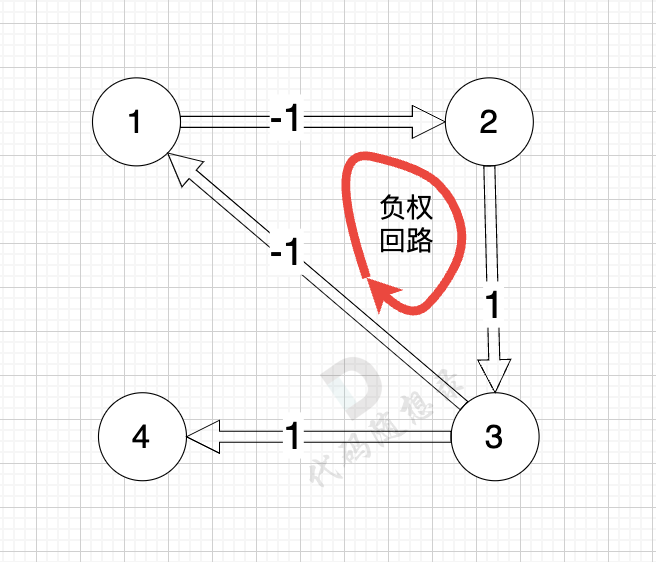
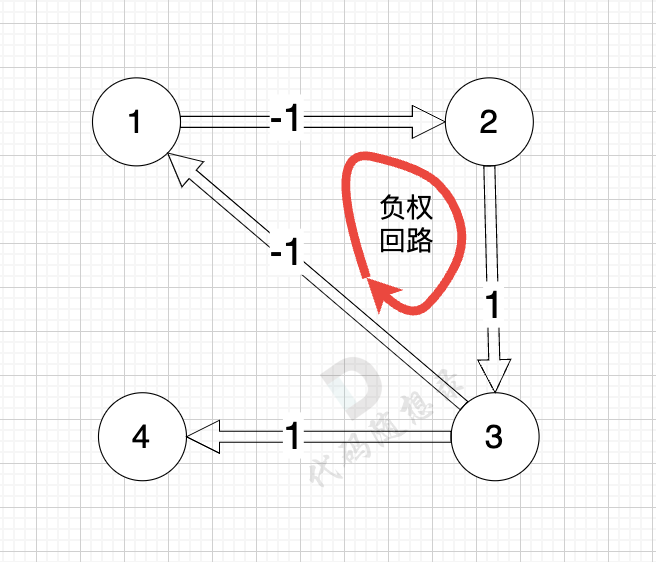
如图:
|
||||
|
||||
|
||||
|
||||
|
||||
正权回路 就是有环,但环的总权值为正数。
|
||||
|
||||
|
||||
@@ -46,7 +46,7 @@
|
||||
1 3 5
|
||||
```
|
||||
|
||||

|
||||

|
||||
|
||||
## 思路
|
||||
|
||||
@@ -78,7 +78,7 @@
|
||||
|
||||
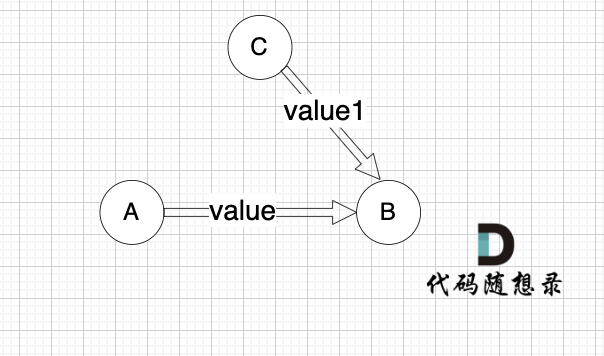
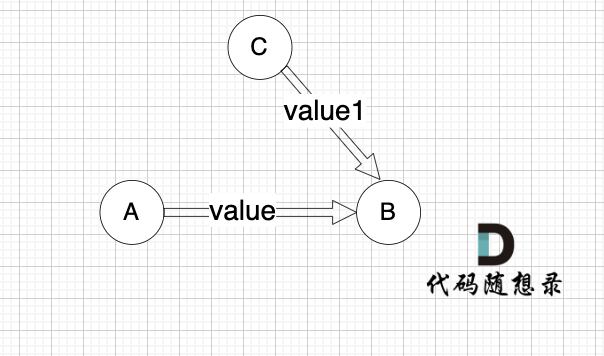
这里我给大家举一个例子,每条边有起点、终点和边的权值。例如一条边,节点A 到 节点B 权值为value,如图:
|
||||
|
||||
|
||||
|
||||
|
||||
minDist[B] 表示 到达B节点 最小权值,minDist[B] 有哪些状态可以推出来?
|
||||
|
||||
@@ -127,7 +127,7 @@ if (minDist[B] > minDist[A] + value) minDist[B] = minDist[A] + value
|
||||
|
||||
如图:
|
||||
|
||||

|
||||

|
||||
|
||||
其他节点对应的minDist初始化为max,因为我们要求最小距离,那么还没有计算过的节点 默认是一个最大数,这样才能更新最小距离。
|
||||
|
||||
@@ -150,36 +150,36 @@ if (minDist[B] > minDist[A] + value) minDist[B] = minDist[A] + value
|
||||
|
||||
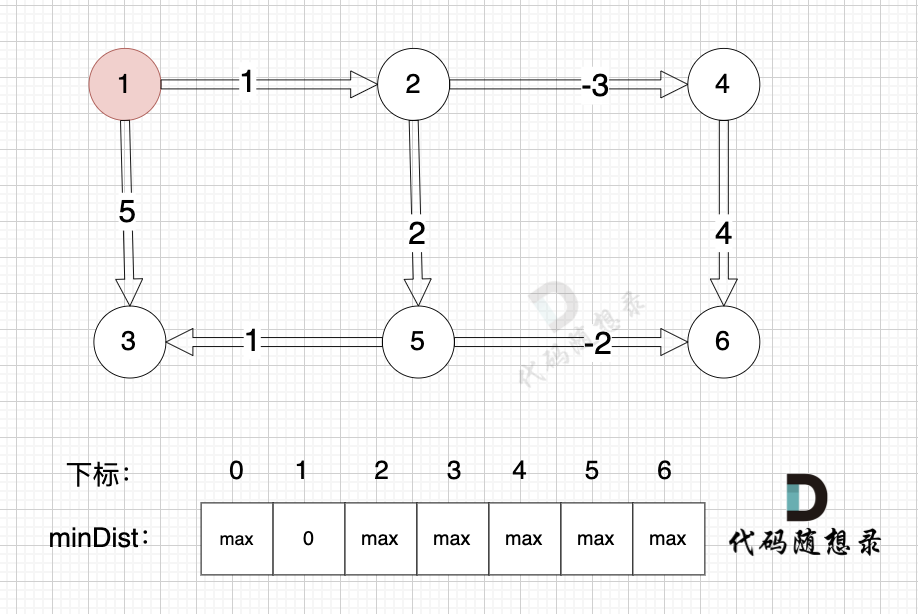
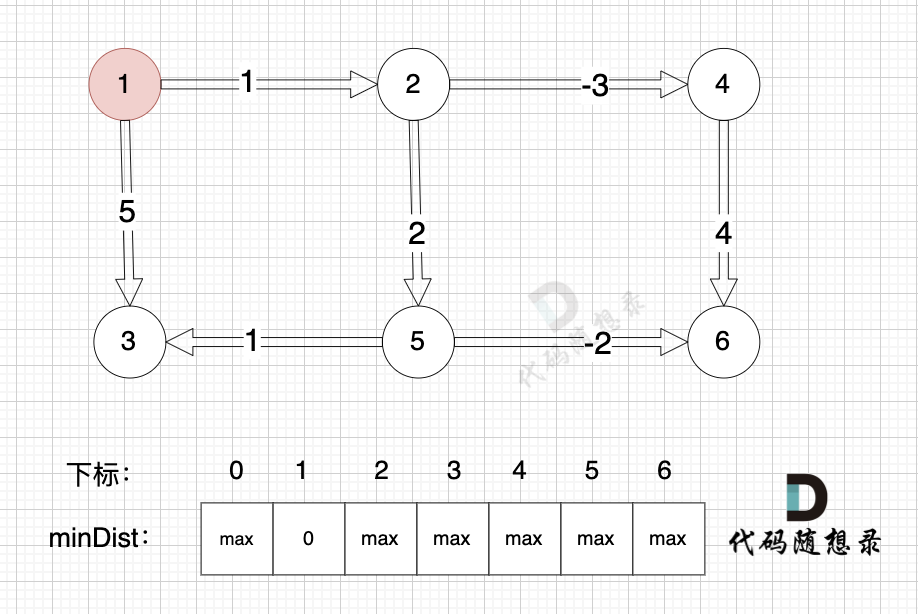
边:节点5 -> 节点6,权值为-2 ,minDist[5] 还是默认数值max,所以不能基于 节点5 去更新节点6,如图:
|
||||
|
||||
|
||||
|
||||
|
||||
(在复习一下,minDist[5] 表示起点到节点5的最短距离)
|
||||
|
||||
|
||||
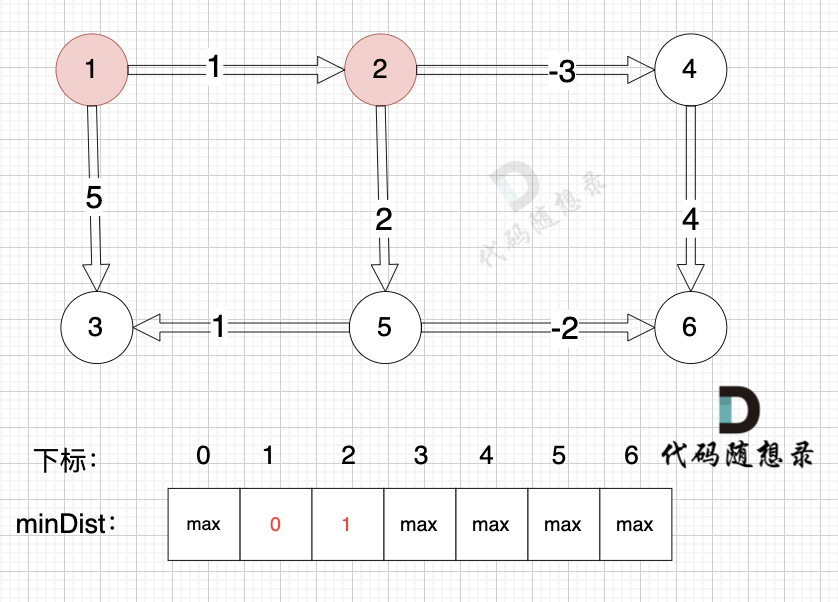
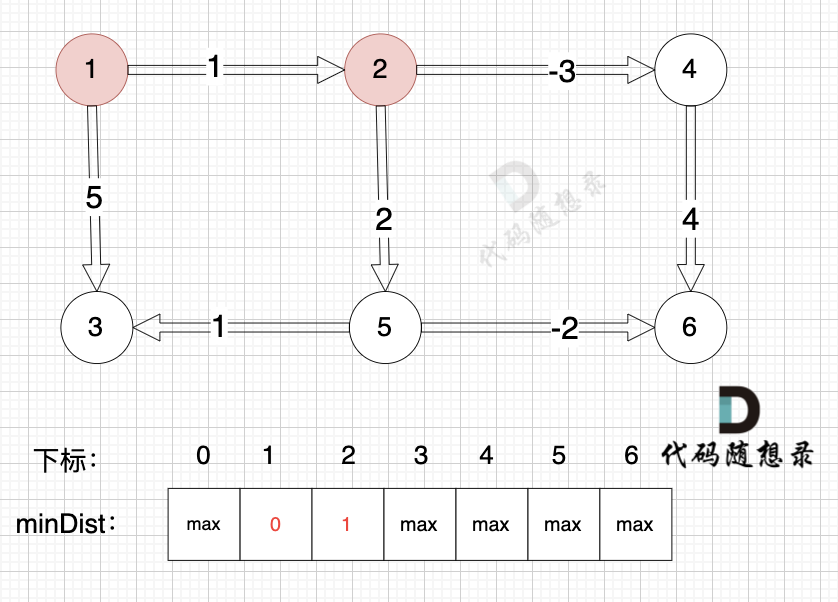
边:节点1 -> 节点2,权值为1 ,minDist[2] > minDist[1] + 1 ,更新 minDist[2] = minDist[1] + 1 = 0 + 1 = 1 ,如图:
|
||||
|
||||
|
||||
|
||||
|
||||
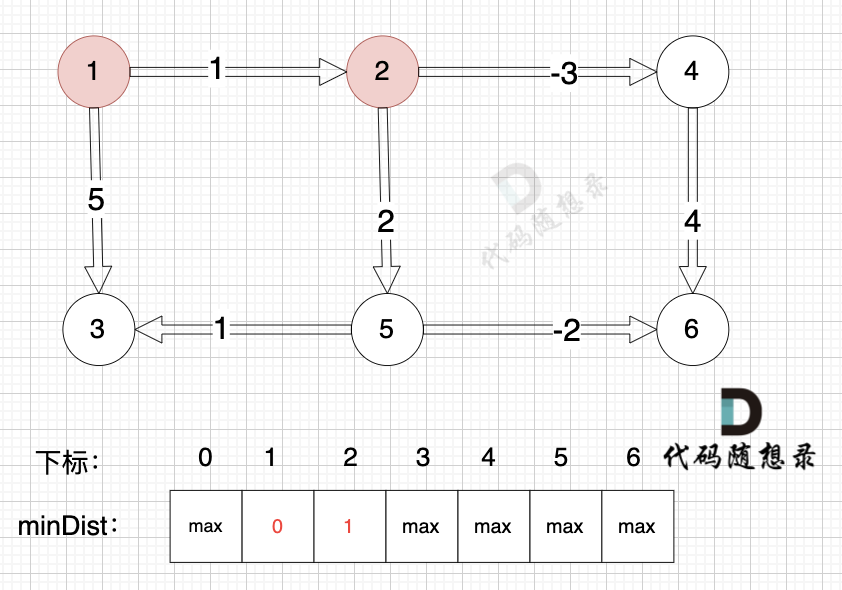
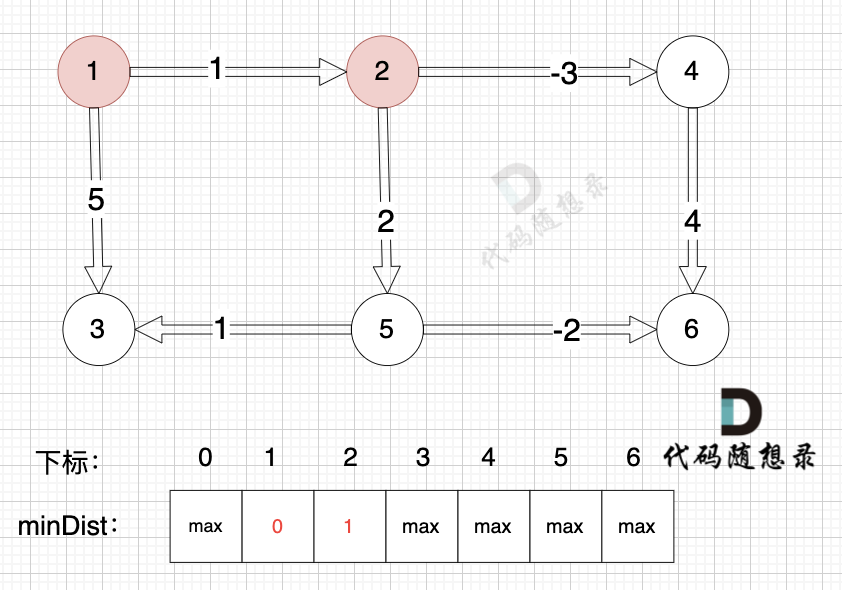
边:节点5 -> 节点3,权值为1 ,minDist[5] 还是默认数值max,所以不能基于节点5去更新节点3 如图:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
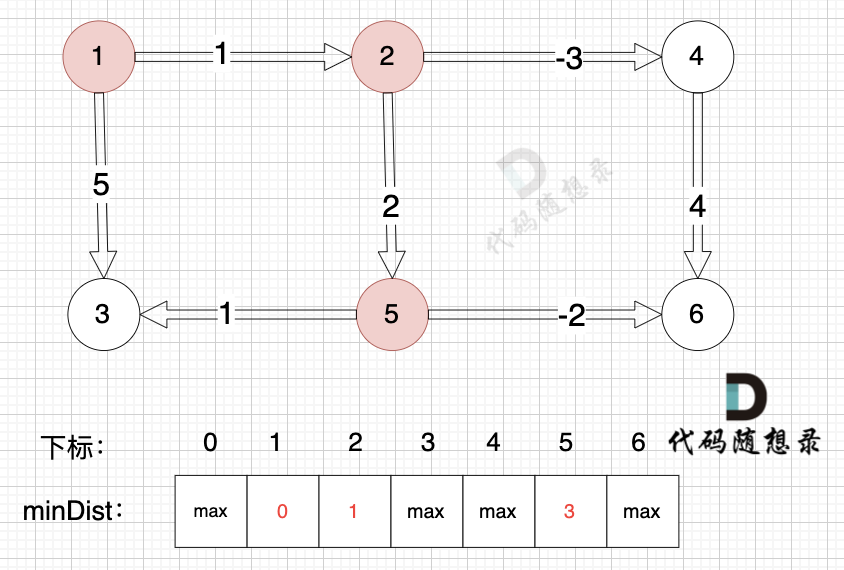
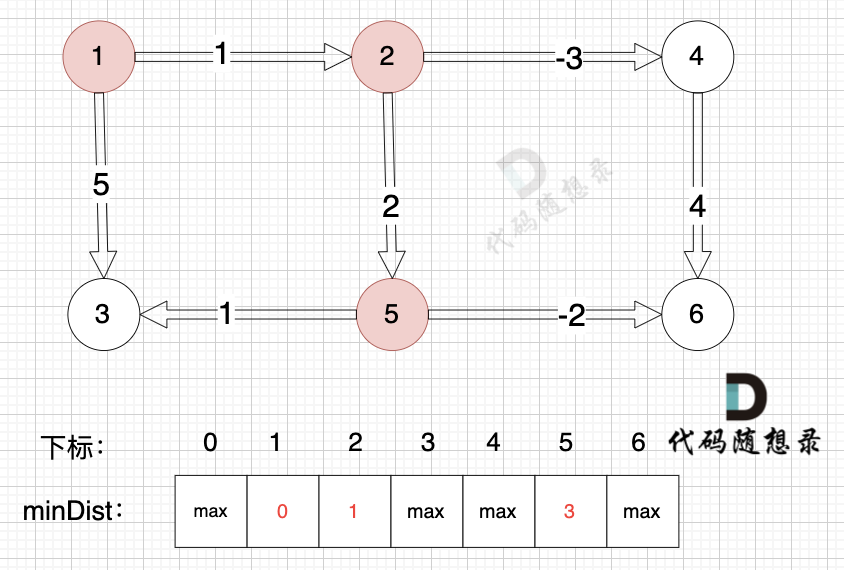
边:节点2 -> 节点5,权值为2 ,minDist[5] > minDist[2] + 2 (经过上面的计算minDist[2]已经不是默认值,而是 1),更新 minDist[5] = minDist[2] + 2 = 1 + 2 = 3 ,如图:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
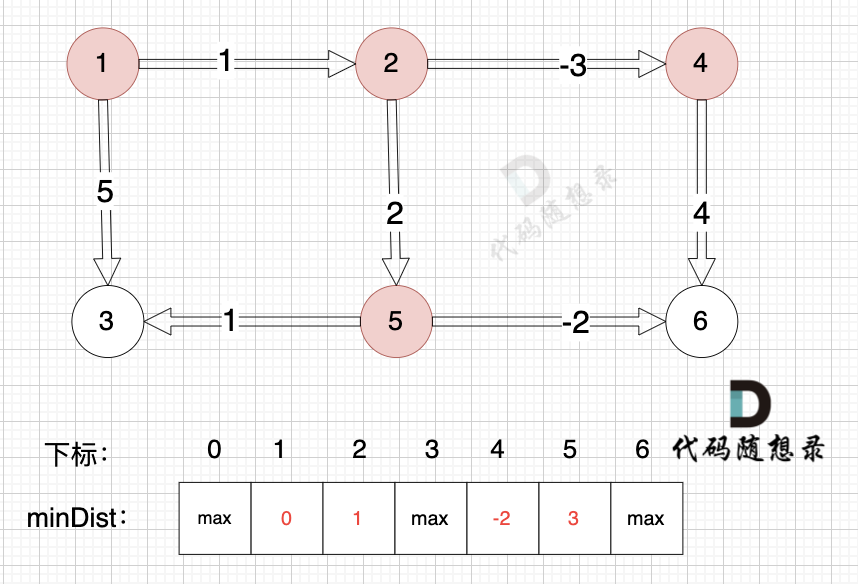
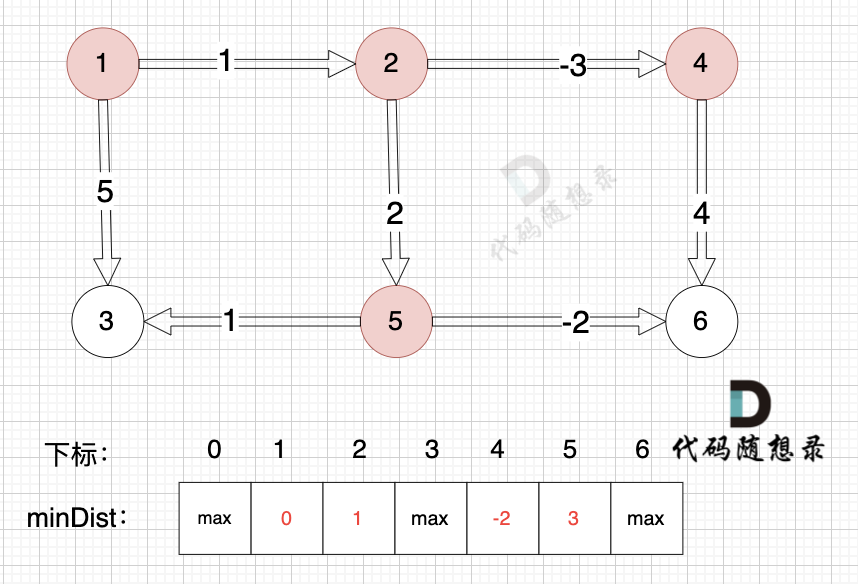
边:节点2 -> 节点4,权值为-3 ,minDist[4] > minDist[2] + (-3),更新 minDist[4] = minDist[2] + (-3) = 1 + (-3) = -2 ,如图:
|
||||
|
||||
|
||||
|
||||
|
||||
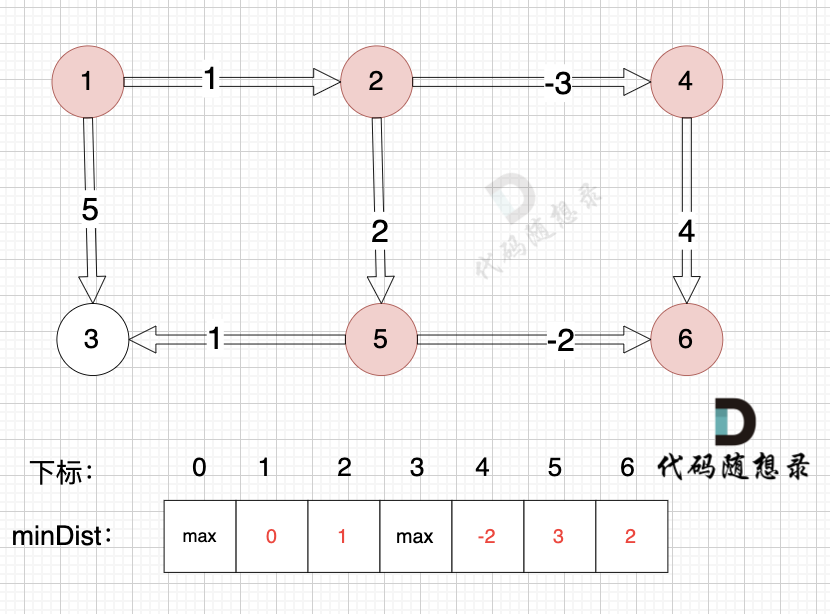
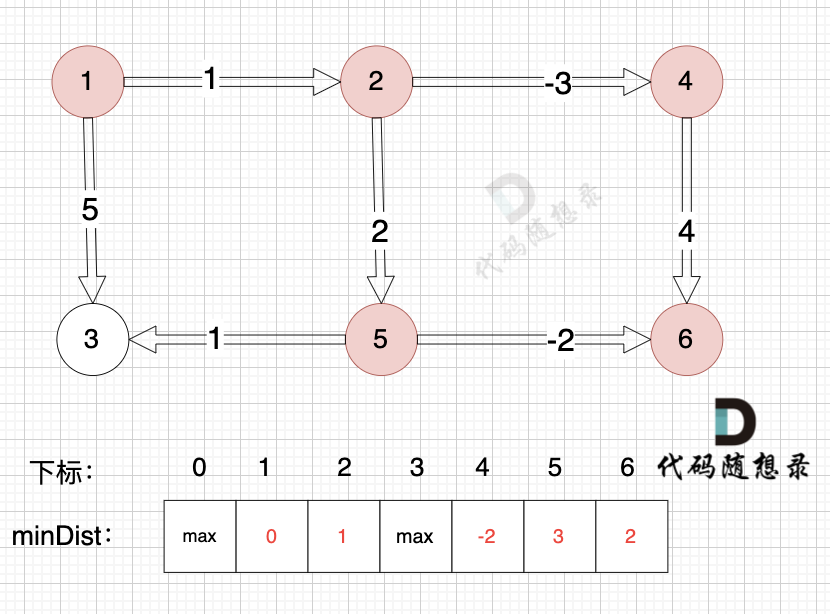
边:节点4 -> 节点6,权值为4 ,minDist[6] > minDist[4] + 4,更新 minDist[6] = minDist[4] + 4 = -2 + 4 = 2
|
||||
|
||||
|
||||
|
||||
|
||||
边:节点1 -> 节点3,权值为5 ,minDist[3] > minDist[1] + 5,更新 minDist[3] = minDist[1] + 5 = 0 + 5 = 5 ,如图:
|
||||
|
||||
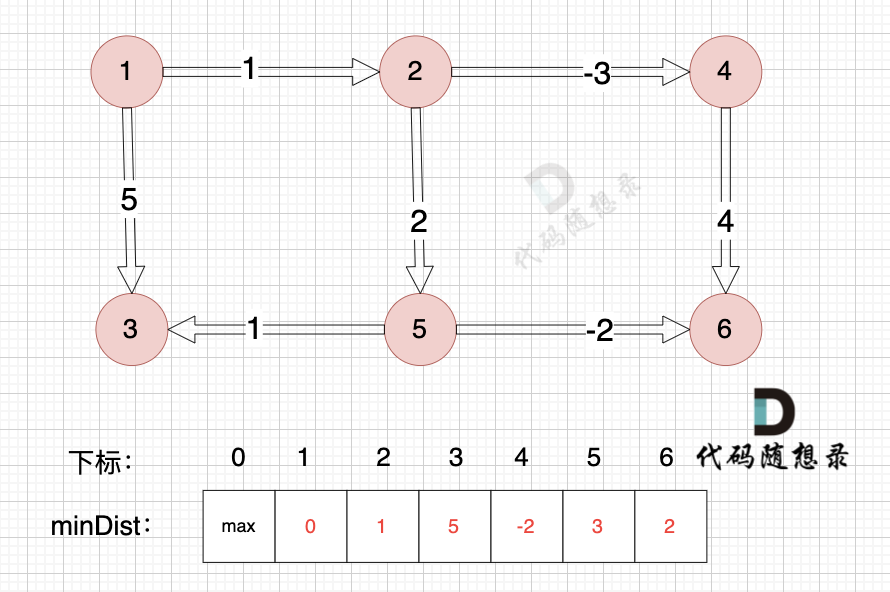
|
||||
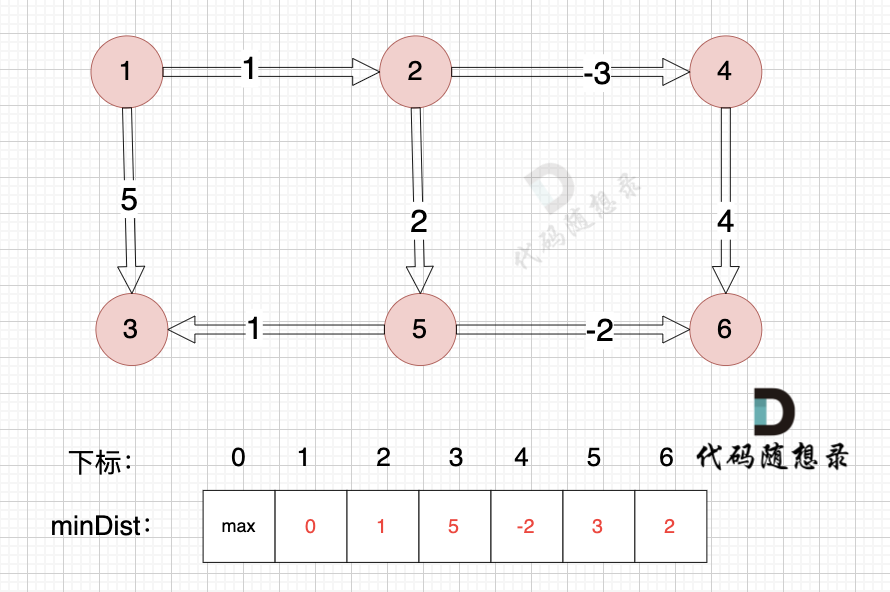
|
||||
|
||||
--------
|
||||
|
||||
|
||||
@@ -78,7 +78,7 @@ circle
|
||||
|
||||
我们拿题目中示例来画一个图:
|
||||
|
||||
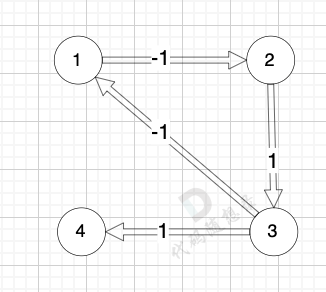
|
||||
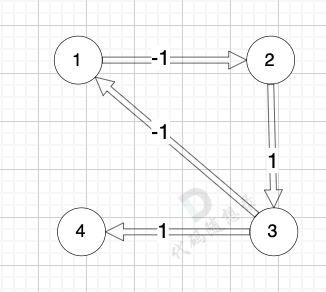
|
||||
|
||||
图中 节点1 到 节点4 的最短路径是多少(题目中的最低运输成本) (注意边可以为负数的)
|
||||
|
||||
@@ -86,7 +86,7 @@ circle
|
||||
|
||||
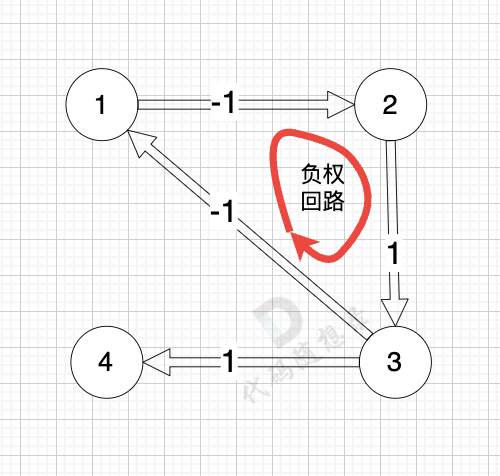
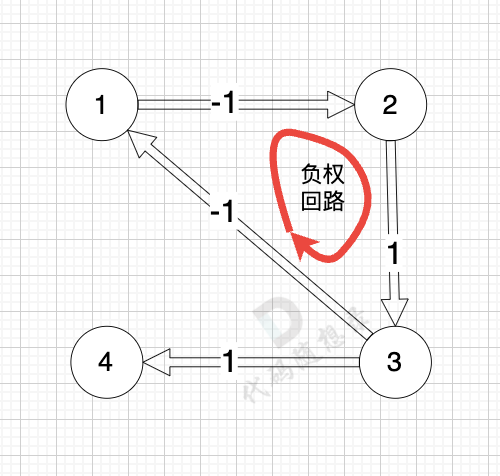
而图中有负权回路:
|
||||
|
||||
|
||||
|
||||
|
||||
那么我们在负权回路中多绕一圈,我们的最短路径 是不是就更小了 (也就是更低的运输成本)
|
||||
|
||||
|
||||
@@ -63,7 +63,7 @@
|
||||
|
||||
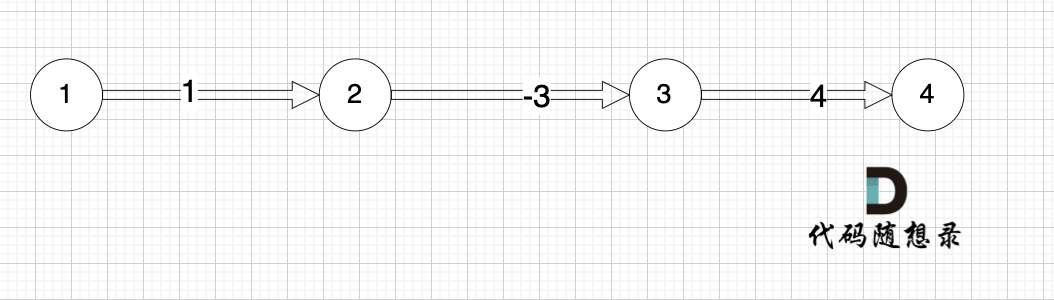
本题是最多经过 k 个城市, 那么是 k + 1条边相连的节点。 这里可能有录友想不懂为什么是k + 1,来看这个图:
|
||||
|
||||
|
||||

|
||||
|
||||
图中,节点1 最多已经经过2个节点 到达节点4,那么中间是有多少条边呢,是 3 条边对吧。
|
||||
|
||||
@@ -195,7 +195,7 @@ int main() {
|
||||
|
||||
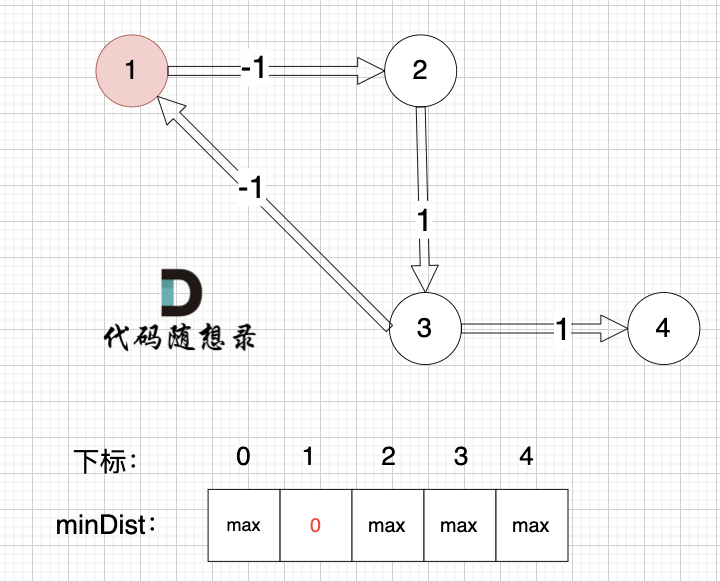
起点为节点1, 起点到起点的距离为0,所以 minDist[1] 初始化为0 ,如图:
|
||||
|
||||
|
||||

|
||||
|
||||
其他节点对应的minDist初始化为max,因为我们要求最小距离,那么还没有计算过的节点 默认是一个最大数,这样才能更新最小距离。
|
||||
|
||||
@@ -203,21 +203,21 @@ int main() {
|
||||
|
||||
边:节点1 -> 节点2,权值为-1 ,minDist[2] > minDist[1] + (-1),更新 minDist[2] = minDist[1] + (-1) = 0 - 1 = -1 ,如图:
|
||||
|
||||
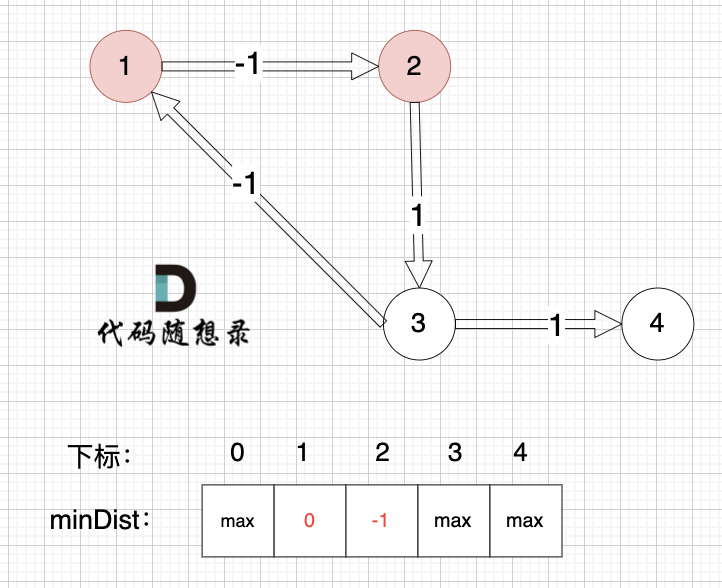
|
||||

|
||||
|
||||
|
||||
边:节点2 -> 节点3,权值为1 ,minDist[3] > minDist[2] + 1 ,更新 minDist[3] = minDist[2] + 1 = -1 + 1 = 0 ,如图:
|
||||
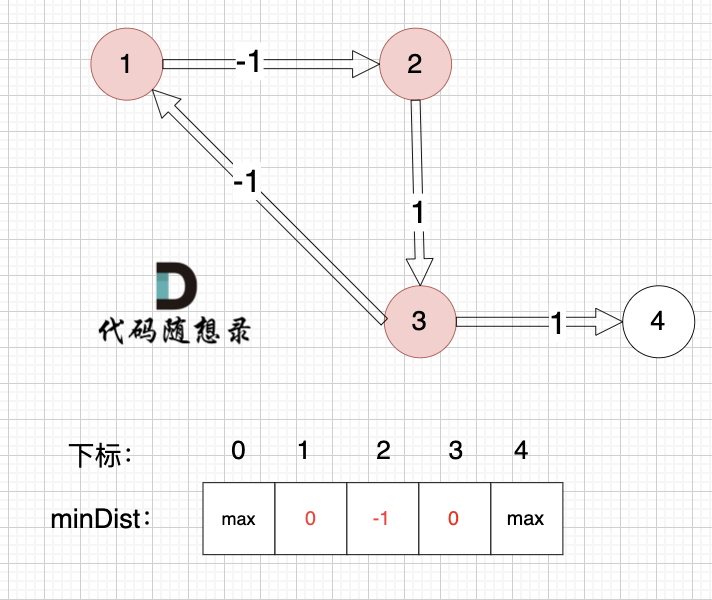
|
||||

|
||||
|
||||
|
||||
边:节点3 -> 节点1,权值为-1 ,minDist[1] > minDist[3] + (-1),更新 minDist[1] = 0 + (-1) = -1 ,如图:
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
边:节点3 -> 节点4,权值为1 ,minDist[4] > minDist[3] + 1,更新 minDist[4] = 0 + 1 = 1 ,如图:
|
||||
|
||||
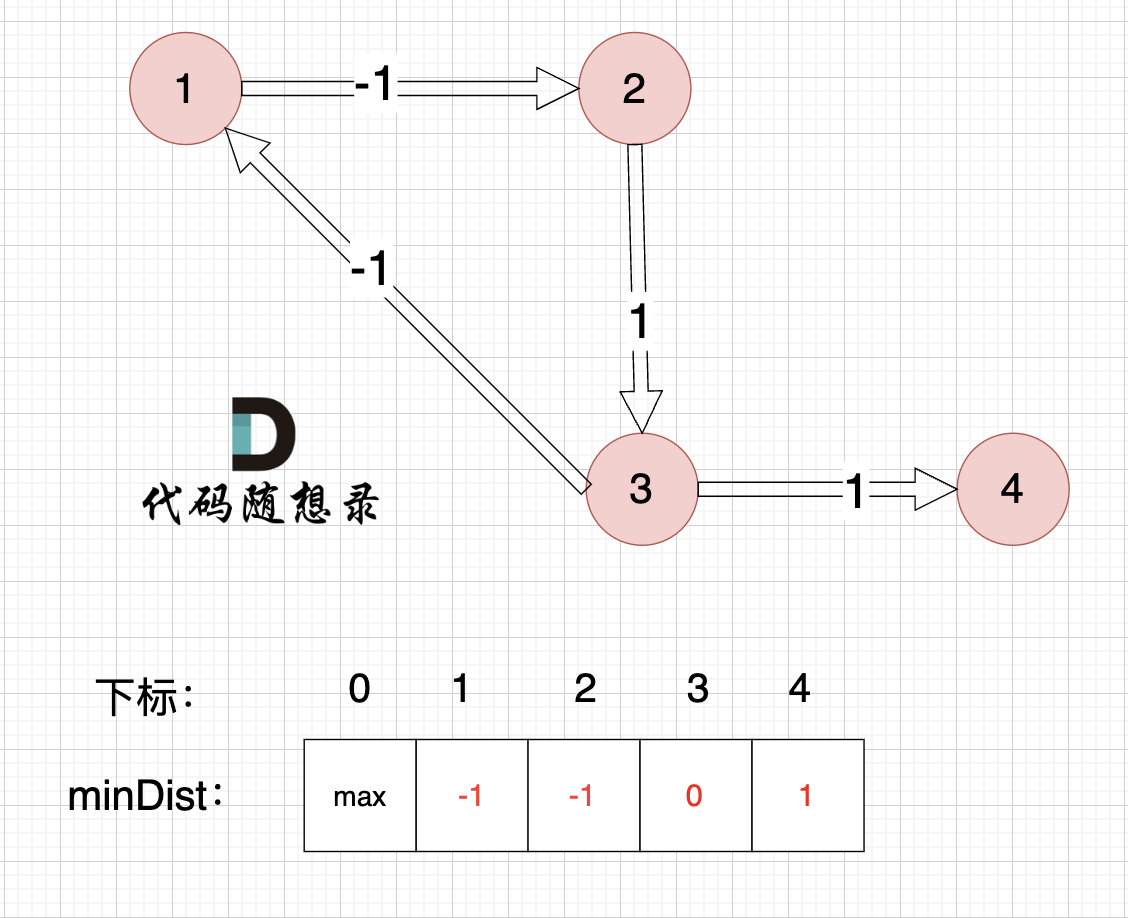
|
||||

|
||||
|
||||
|
||||
以上是对所有边进行的第一次松弛,最后 minDist数组为 :-1 -1 0 1 ,(从下标1算起)
|
||||
@@ -244,7 +244,7 @@ int main() {
|
||||
|
||||
在上面画图距离中,对所有边进行第一次松弛,在计算 边(节点2 -> 节点3) 的时候,更新了 节点3。
|
||||
|
||||

|
||||

|
||||
|
||||
理论上来说节点3 应该在对所有边第二次松弛的时候才更新。 这因为当时是基于已经计算好的 节点2(minDist[2])来做计算了。
|
||||
|
||||
@@ -331,11 +331,11 @@ int main() {
|
||||
|
||||
所构成是图是一样的,都是如下的这个图,但给出的边的顺序是不一样的。
|
||||
|
||||
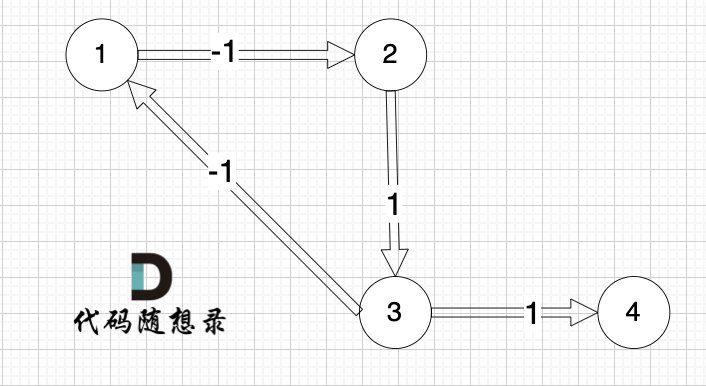
|
||||

|
||||
|
||||
再用版本一的代码是运行一下,发现结果输出是 1, 是对的。
|
||||
|
||||

|
||||

|
||||
|
||||
分明刚刚输出的结果是 -2,是错误的,怎么 一样的图,这次输出的结果就对了呢?
|
||||
|
||||
@@ -345,7 +345,7 @@ int main() {
|
||||
|
||||
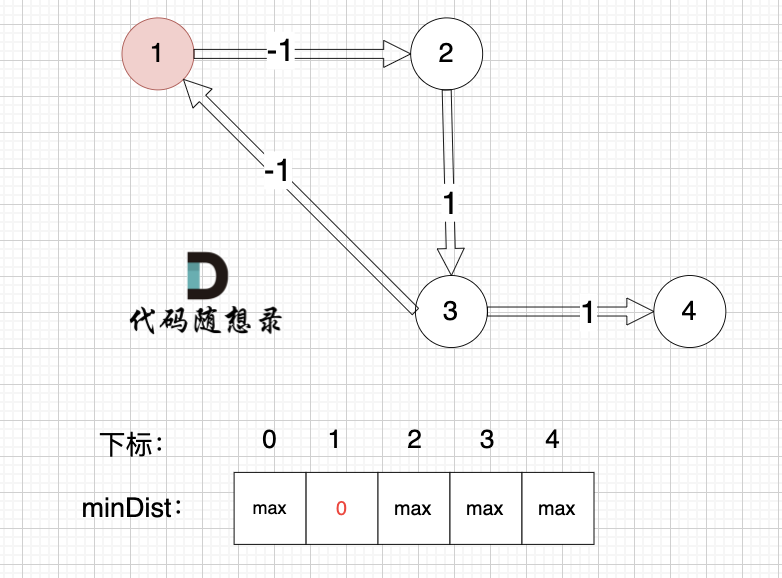
初始化:
|
||||
|
||||
|
||||

|
||||
|
||||
边:节点3 -> 节点1,权值为-1 ,节点3还没有被计算过,节点1 不更新。
|
||||
|
||||
@@ -355,7 +355,7 @@ int main() {
|
||||
|
||||
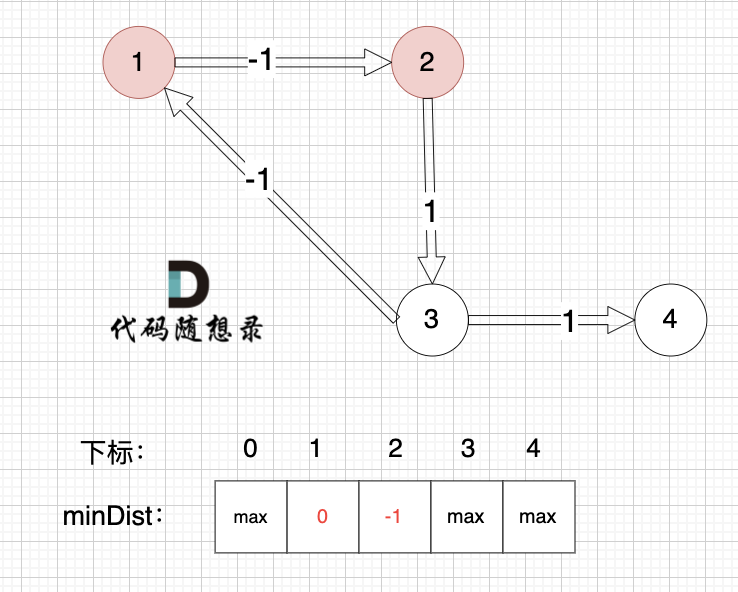
边:节点1 -> 节点2,权值为 -1 ,minDist[2] > minDist[1] + (-1),更新 minDist[2] = 0 + (-1) = -1 ,如图:
|
||||
|
||||
|
||||

|
||||
|
||||
以上是对所有边 松弛一次的状态。
|
||||
|
||||
@@ -472,7 +472,7 @@ int main() {
|
||||
|
||||
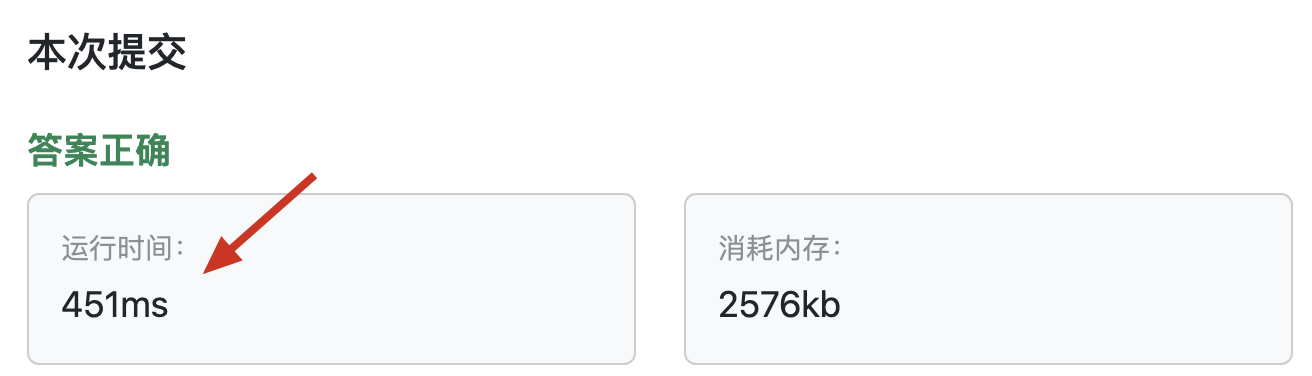
但大家会发现,以上代码大家提交后,怎么耗时这么多?
|
||||
|
||||
|
||||

|
||||
|
||||
理论上,SPFA的时间复杂度不是要比 bellman_ford 更优吗?
|
||||
|
||||
@@ -554,7 +554,7 @@ int main() {
|
||||
|
||||
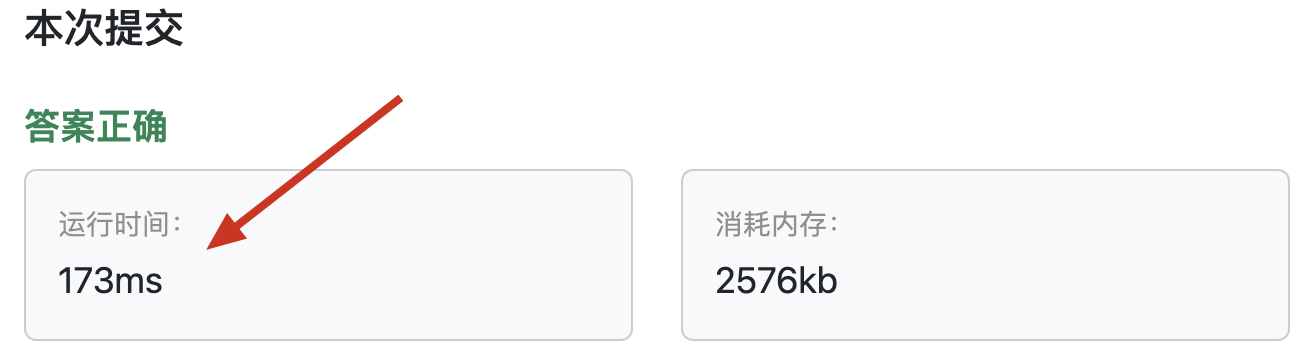
以上代码提交后,耗时情况:
|
||||
|
||||
|
||||

|
||||
|
||||
大家发现 依然远比 bellman_ford 的代码版本 耗时高。
|
||||
|
||||
@@ -579,11 +579,11 @@ dijkstra 是贪心的思路 每一次搜索都只会找距离源点最近的非
|
||||
|
||||
在以下这个图中,求节点1 到 节点7 最多经过2个节点 的最短路是多少呢?
|
||||
|
||||

|
||||

|
||||
|
||||
最短路显然是:
|
||||
|
||||

|
||||

|
||||
|
||||
最多经过2个节点,也就是3条边相连的路线:节点1 -> 节点2 -> 节点6-> 节点7
|
||||
|
||||
@@ -591,24 +591,24 @@ dijkstra 是贪心的思路 每一次搜索都只会找距离源点最近的非
|
||||
|
||||
初始化如图所示:
|
||||
|
||||

|
||||

|
||||
|
||||
找距离源点最近且没有被访问过的节点,先找节点1
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
距离源点最近且没有被访问过的节点,找节点2:
|
||||
|
||||

|
||||

|
||||
|
||||
距离源点最近且没有被访问过的节点,找到节点3:
|
||||
|
||||

|
||||

|
||||
|
||||
距离源点最近且没有被访问过的节点,找到节点4:
|
||||
|
||||

|
||||

|
||||
|
||||
此时最多经过2个节点的搜索就完毕了,但结果中minDist[7] (即节点7的结果)并没有被更。
|
||||
|
||||
|
||||
@@ -155,7 +155,7 @@ grid[i][j][k] = m,表示 节点i 到 节点j 以[1...k] 集合为中间节点
|
||||
|
||||
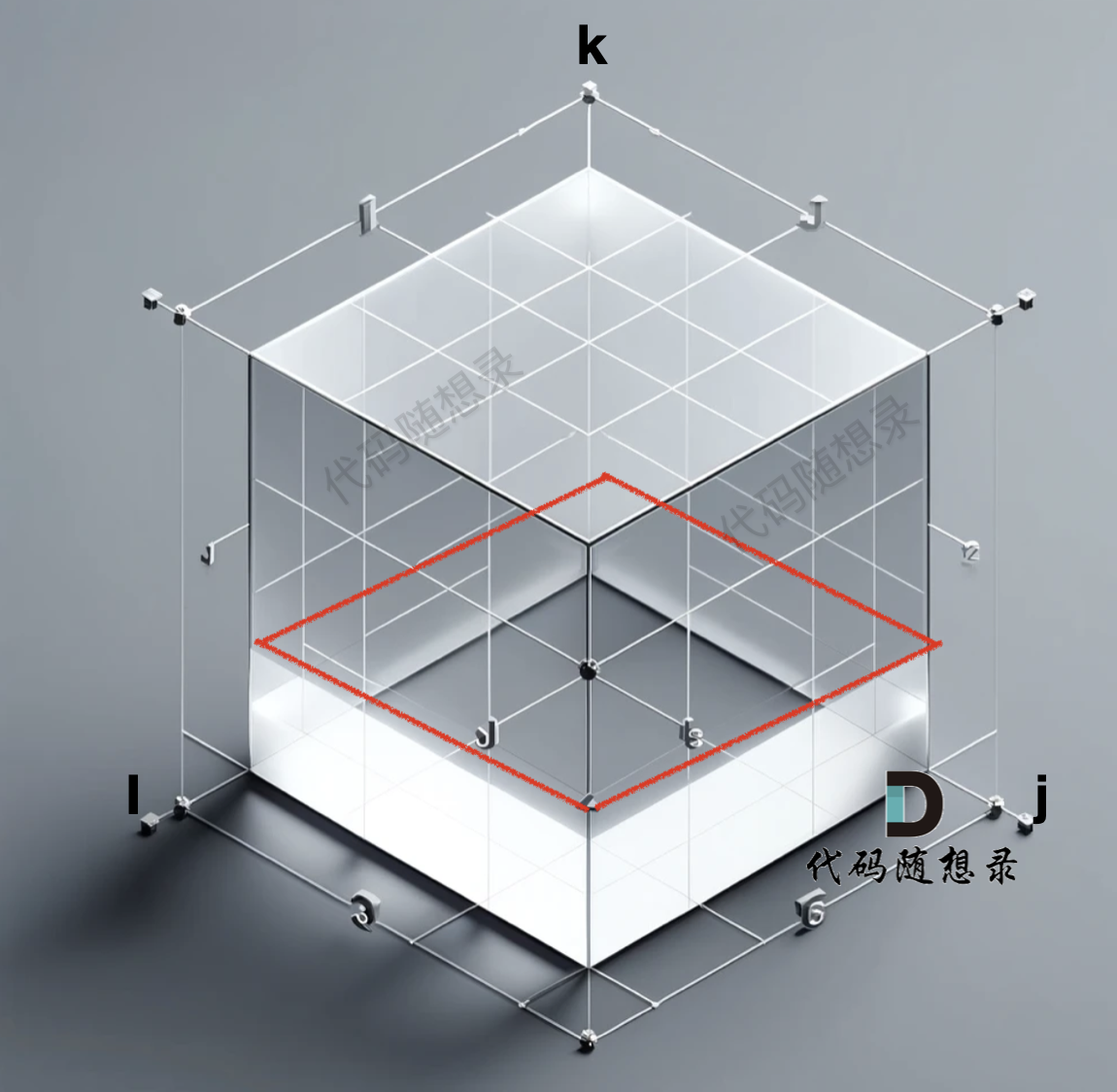
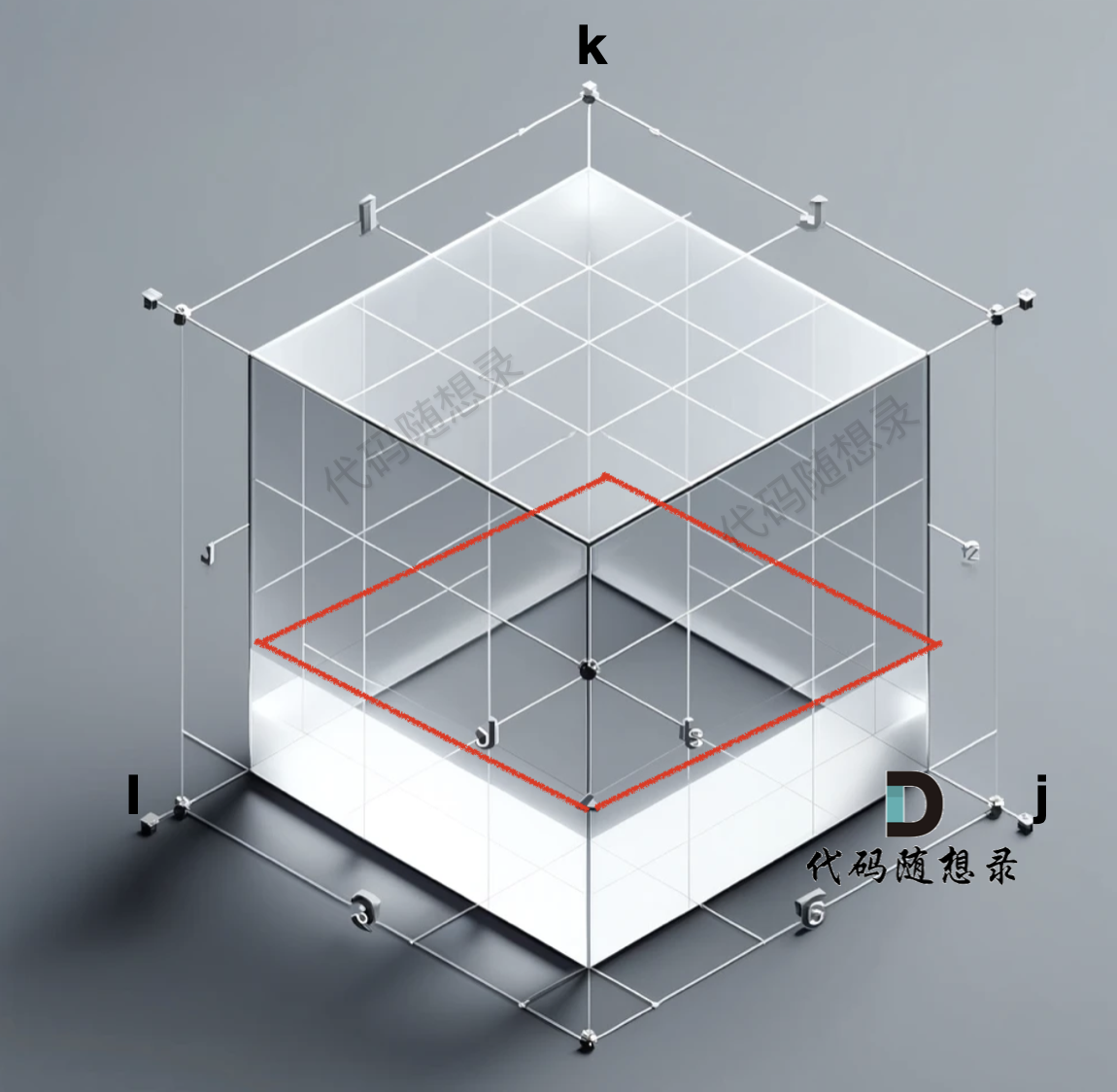
grid数组是一个三维数组,那么我们初始化的数据在 i 与 j 构成的平层,如图:
|
||||
|
||||
|
||||
|
||||
|
||||
红色的 底部一层是我们初始化好的数据,注意:从三维角度去看初始化的数据很重要,下面我们在聊遍历顺序的时候还会再讲。
|
||||
|
||||
@@ -202,7 +202,7 @@ vector<vector<vector<int>>> grid(n + 1, vector<vector<int>>(n + 1, vector<int>(n
|
||||
|
||||
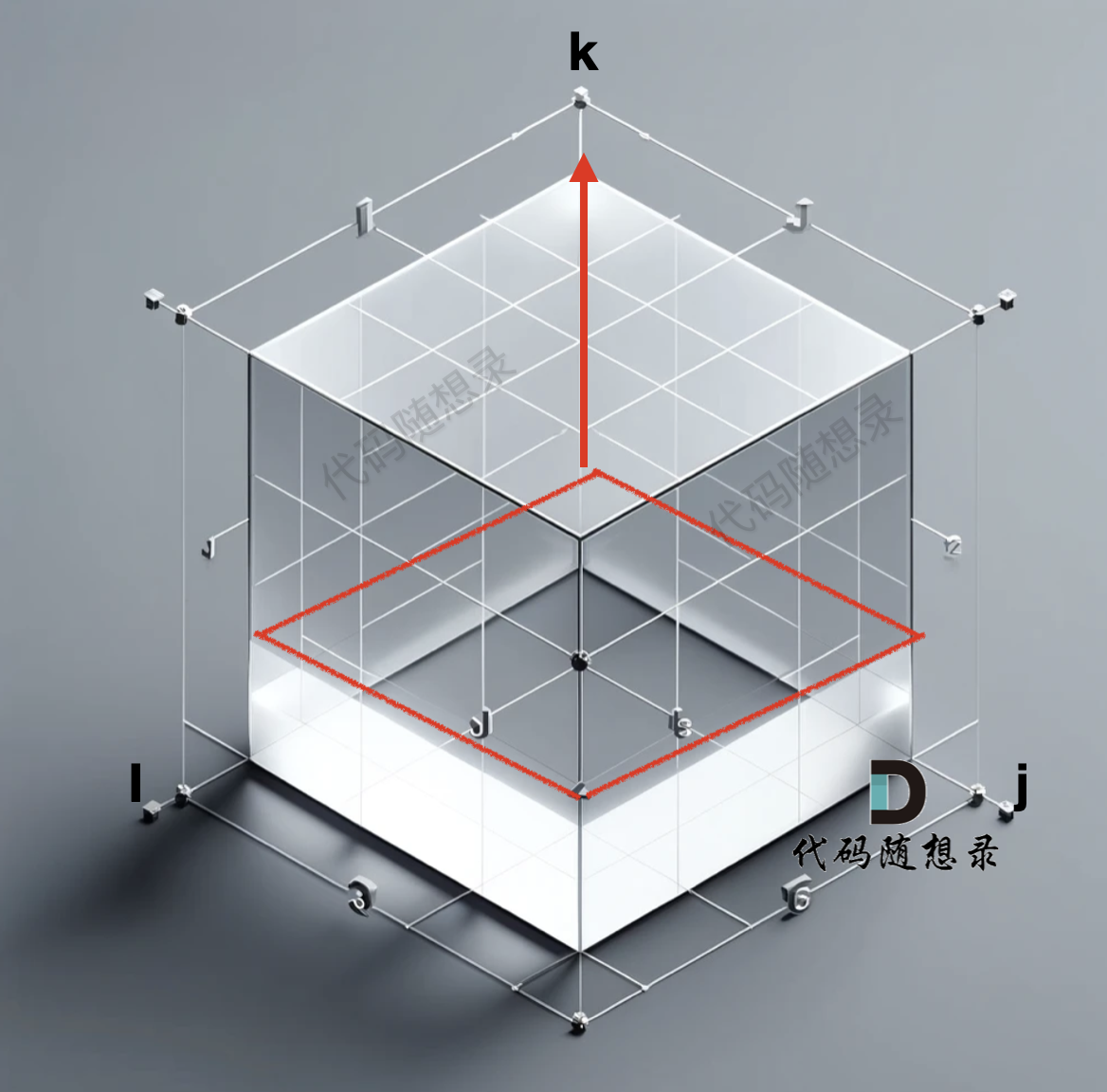
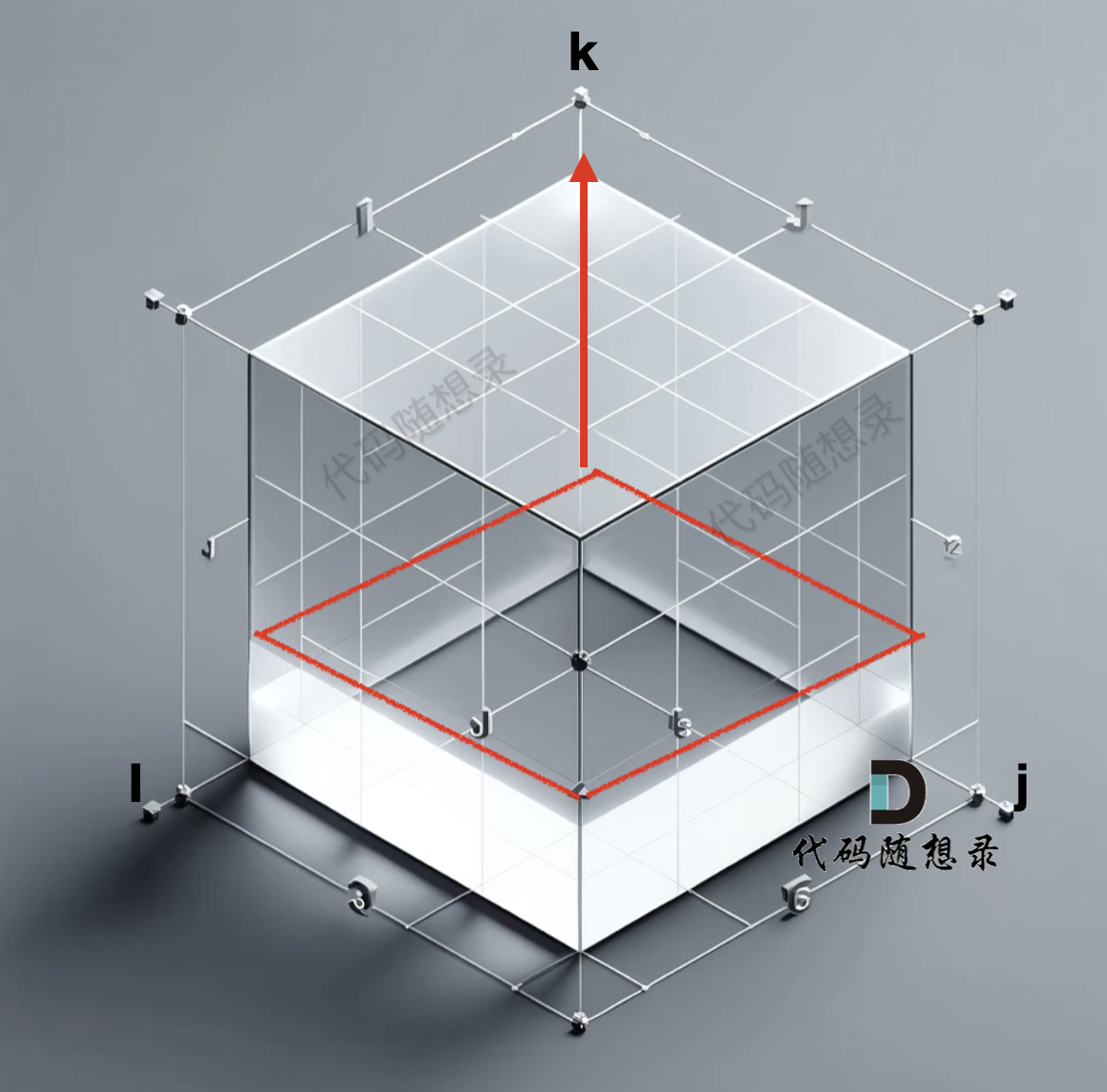
所以遍历k 的for循环一定是在最外面,这样才能一层一层去遍历。如图:
|
||||
|
||||
|
||||
|
||||
|
||||
至于遍历 i 和 j 的话,for 循环的先后顺序无所谓。
|
||||
|
||||
@@ -234,7 +234,7 @@ for (int i = 1; i <= n; i++) {
|
||||
|
||||
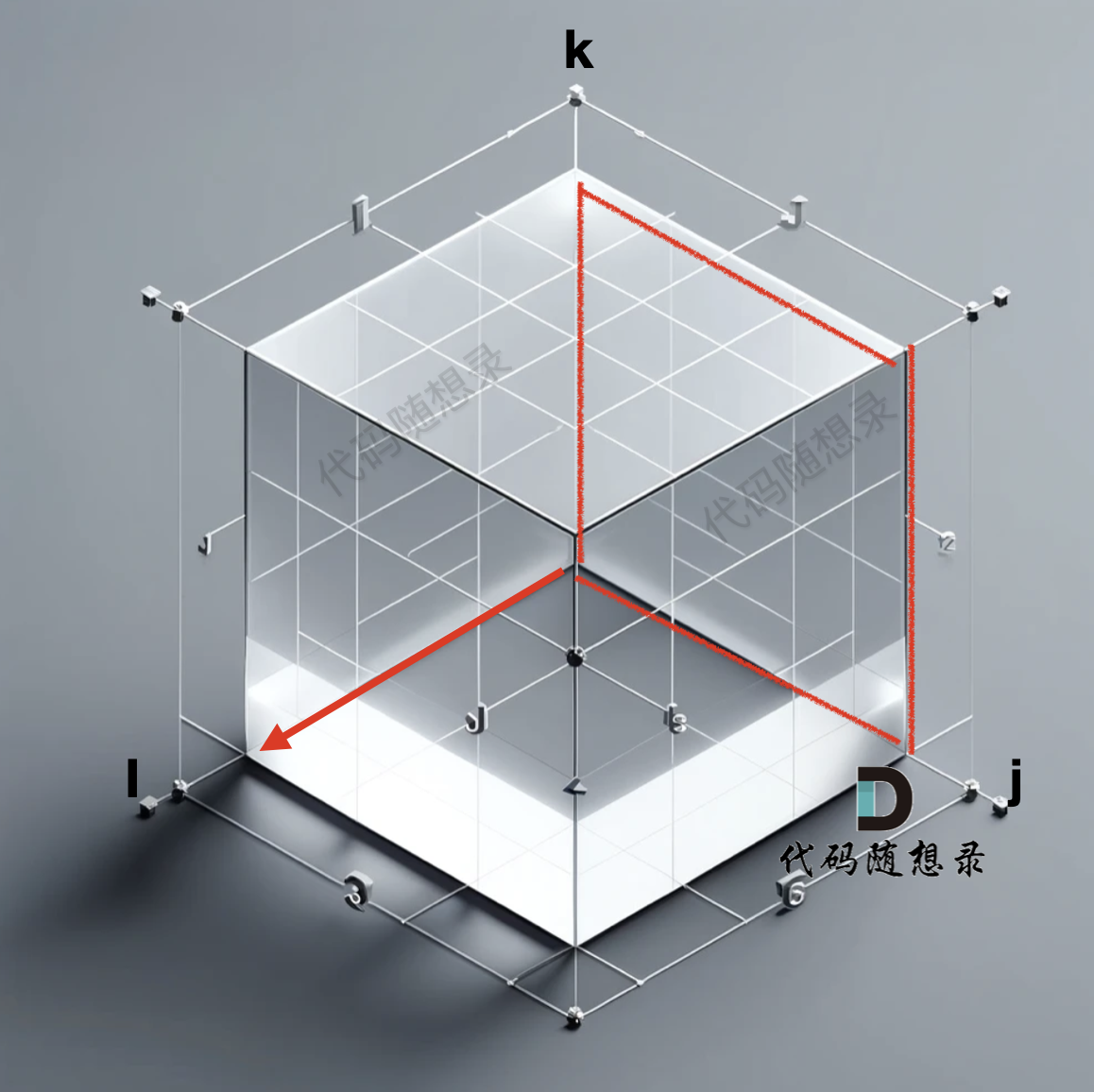
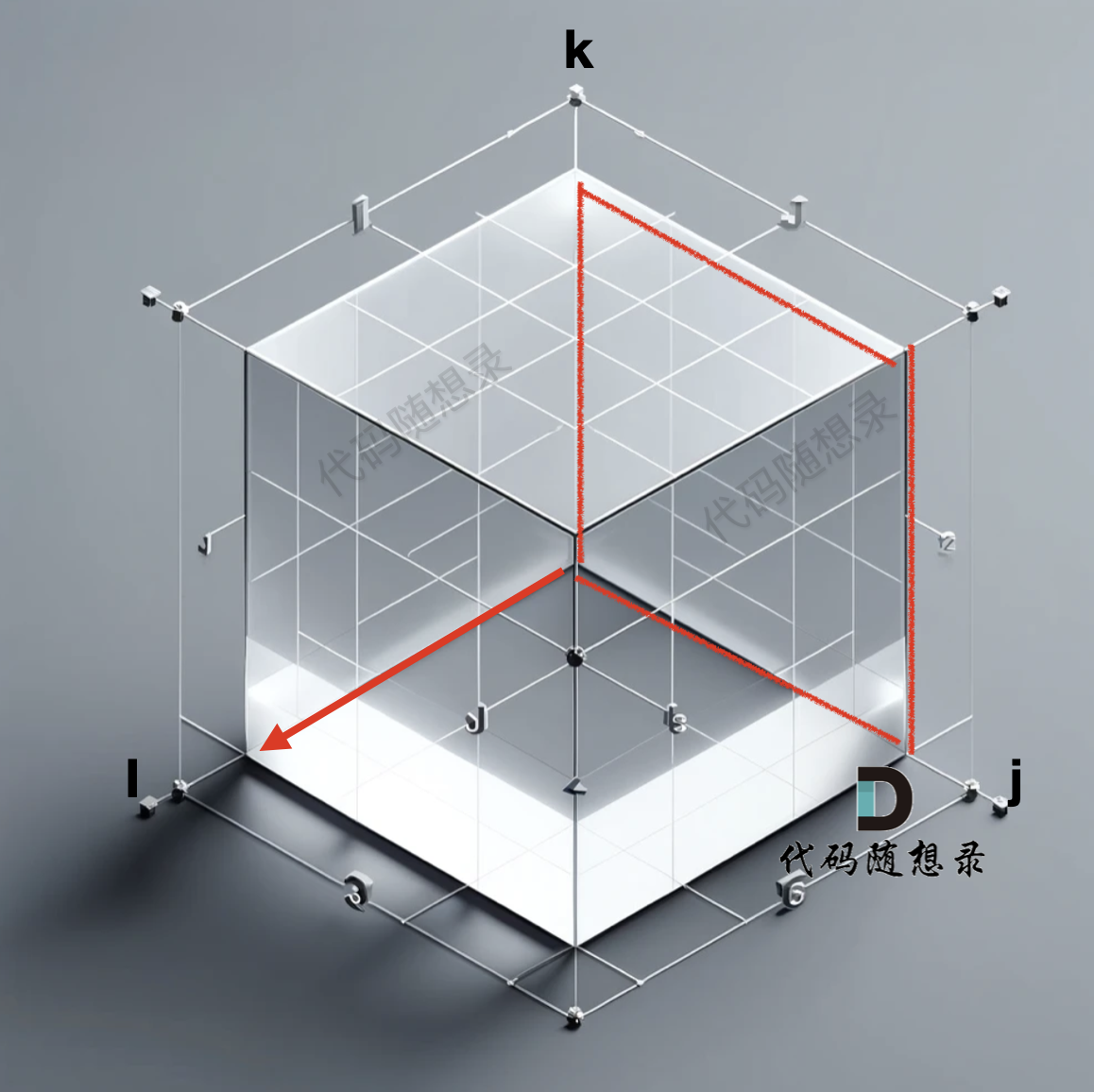
此时就遍历了 j 与 k 形成一个平面,i 则是纵面,那遍历 就是这样的:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
而我们初始化的数据 是 k 为0, i 和 j 形成的平面做初始化,如果以 k 和 j 形成的平面去一层一层遍历,就造成了 递推公式 用不上上一轮计算的结果,从而导致结果不对(初始化的部分是 i 与j 形成的平面,在初始部分有讲过)。
|
||||
@@ -253,7 +253,7 @@ for (int i = 1; i <= n; i++) {
|
||||
|
||||
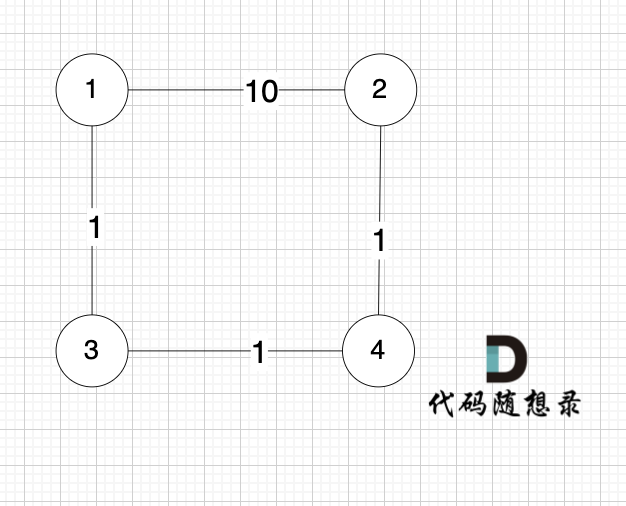
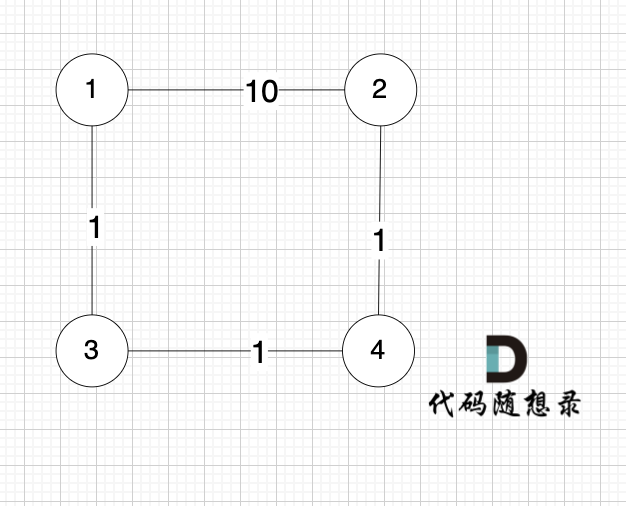
就是图:
|
||||
|
||||
|
||||
|
||||
|
||||
求节点1 到 节点 2 的最短距离,运行结果是 10 ,但正确的结果很明显是3。
|
||||
|
||||
@@ -267,7 +267,7 @@ for (int i = 1; i <= n; i++) {
|
||||
|
||||
而遍历k 的for循环如果放在中间呢,同样是 j 与k 行程一个平面,i 是纵面,遍历的也是这样:
|
||||
|
||||

|
||||

|
||||
|
||||
同样不能完全用上初始化 和 上一层计算的结果。
|
||||
|
||||
@@ -283,7 +283,7 @@ for (int i = 1; i <= n; i++) {
|
||||
|
||||
图:
|
||||
|
||||
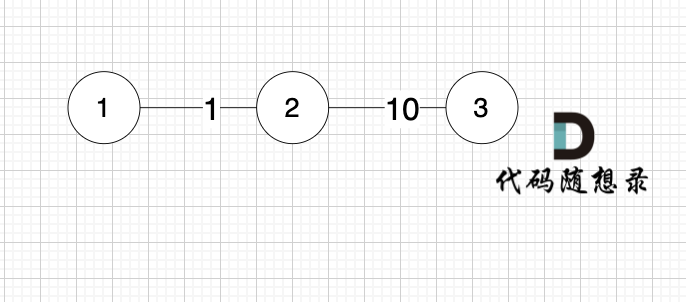
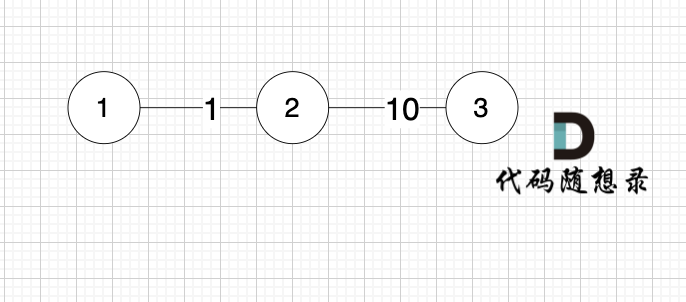
|
||||
|
||||
|
||||
求 节点1 到节点3 的最短距离,如果k循环放中间,程序的运行结果是 -1,也就是不能到达节点3。
|
||||
|
||||
|
||||
@@ -43,7 +43,7 @@
|
||||
|
||||
提示信息
|
||||
|
||||
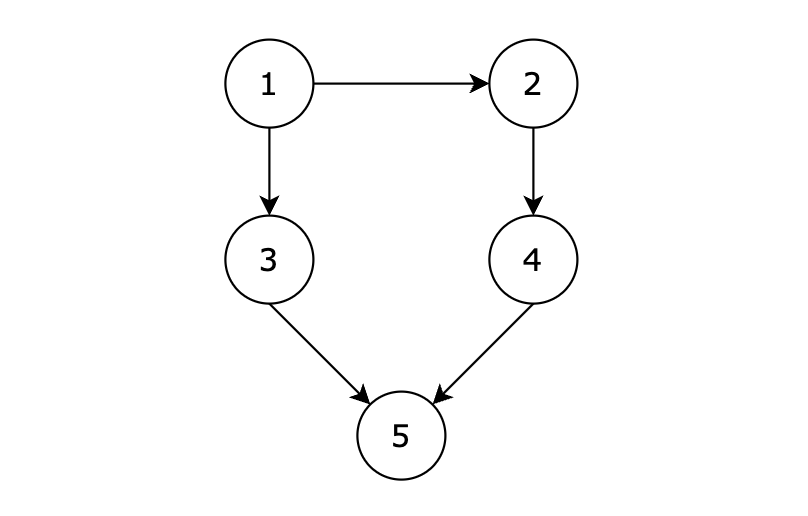
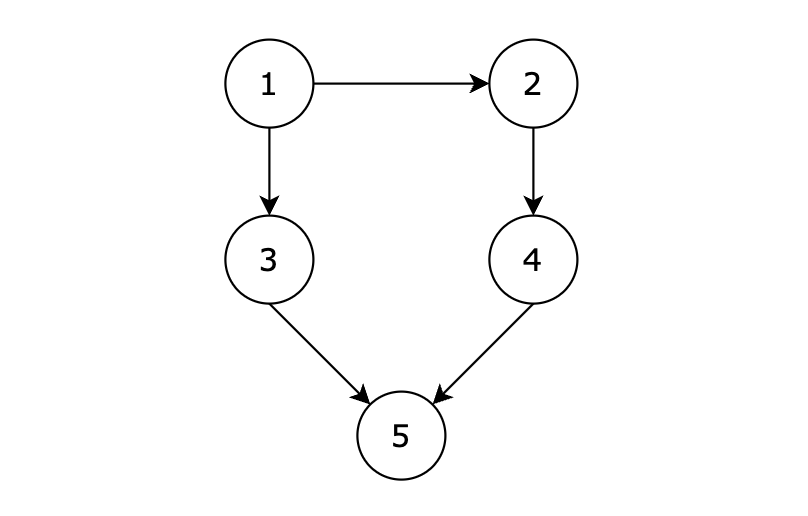
|
||||
|
||||
|
||||
用例解释:
|
||||
|
||||
@@ -141,7 +141,7 @@ while (m--) {
|
||||
我在 [图论理论基础篇](./图论理论基础.md) 举了一个例子:
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
这里表达的图是:
|
||||
|
||||
|
||||
@@ -35,7 +35,7 @@
|
||||
|
||||
提示信息
|
||||
|
||||
|
||||
|
||||
|
||||
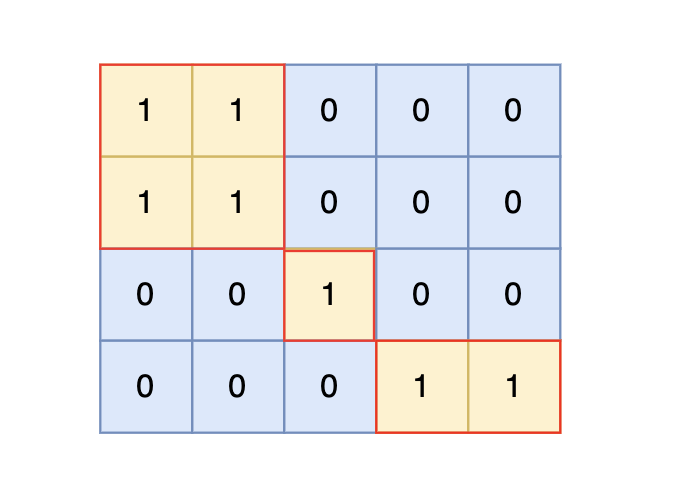
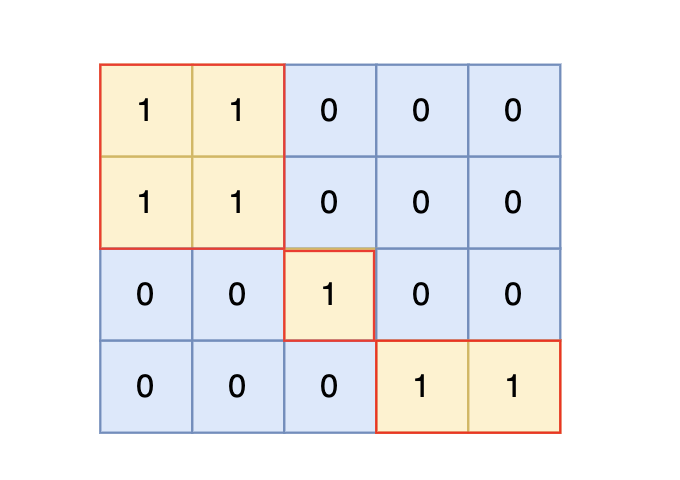
根据测试案例中所展示,岛屿数量共有 3 个,所以输出 3。
|
||||
|
||||
@@ -50,7 +50,7 @@
|
||||
|
||||
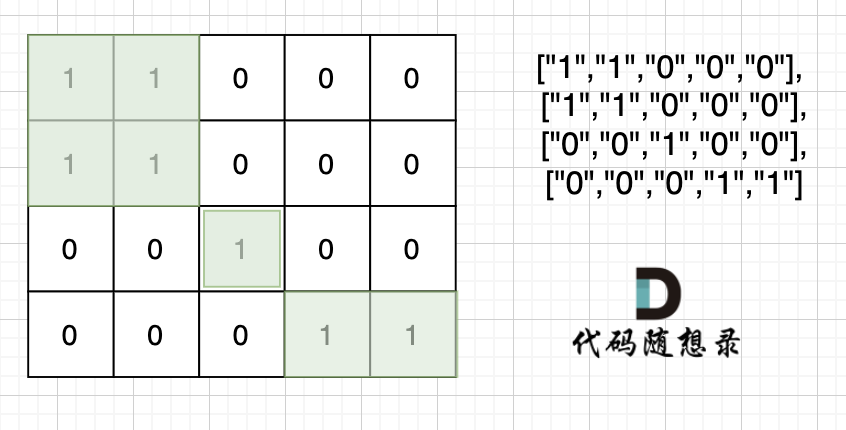
也就是说斜角度链接是不算了, 例如示例二,是三个岛屿,如图:
|
||||
|
||||

|
||||
|
||||
|
||||
这道题题目是 DFS,BFS,并查集,基础题目。
|
||||
|
||||
@@ -72,7 +72,7 @@
|
||||
|
||||
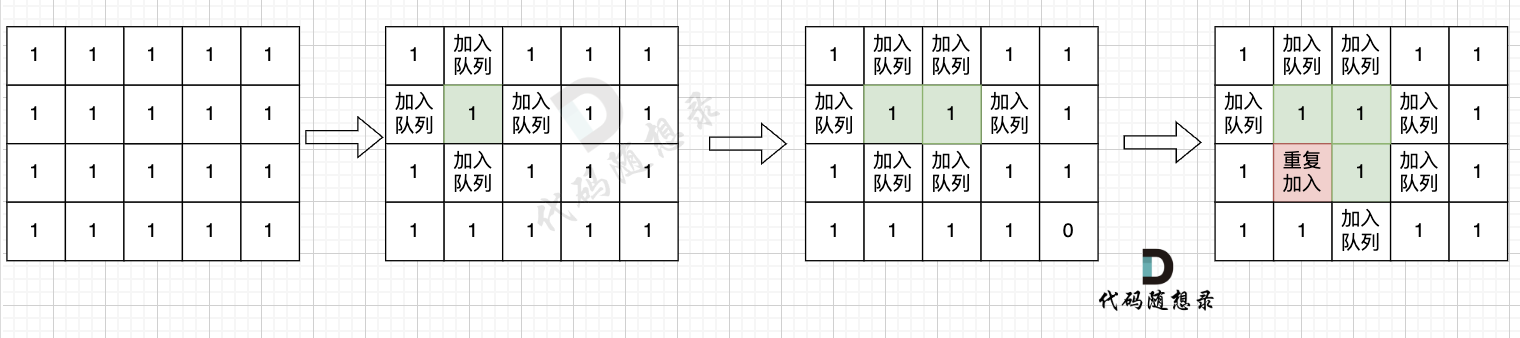
如果从队列拿出节点,再去标记这个节点走过,就会发生下图所示的结果,会导致很多节点重复加入队列。
|
||||
|
||||

|
||||
|
||||
|
||||
超时写法 (从队列中取出节点再标记,注意代码注释的地方)
|
||||
|
||||
|
||||
@@ -36,7 +36,7 @@
|
||||
|
||||
提示信息
|
||||
|
||||

|
||||

|
||||
|
||||
根据测试案例中所展示,岛屿数量共有 3 个,所以输出 3。
|
||||
|
||||
@@ -50,7 +50,7 @@
|
||||
|
||||
也就是说斜角度链接是不算了, 例如示例二,是三个岛屿,如图:
|
||||
|
||||

|
||||

|
||||
|
||||
这道题题目是 DFS,BFS,并查集,基础题目。
|
||||
|
||||
|
||||
@@ -33,7 +33,7 @@
|
||||
|
||||
提示信息
|
||||
|
||||

|
||||
|
||||
|
||||
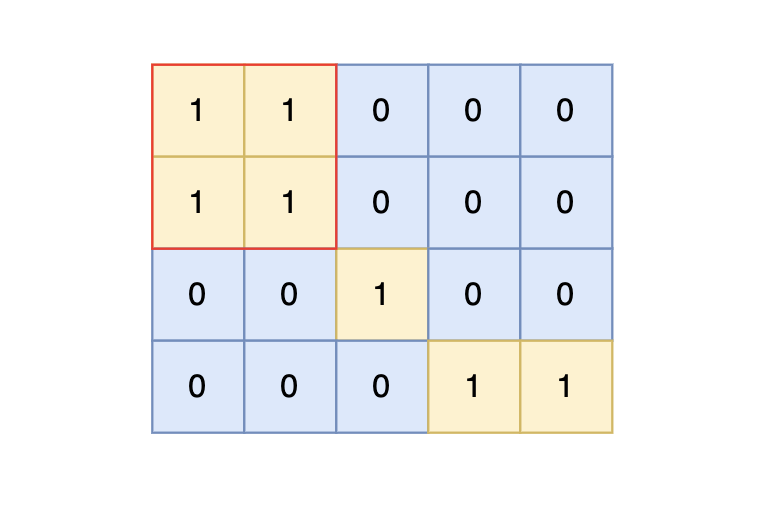
样例输入中,岛屿的最大面积为 4。
|
||||
|
||||
@@ -48,7 +48,7 @@
|
||||
|
||||
也就是说斜角度链接是不算了, 例如示例二,是三个岛屿,如图:
|
||||
|
||||

|
||||

|
||||
|
||||
这道题目也是 dfs bfs基础类题目,就是搜索每个岛屿上“1”的数量,然后取一个最大的。
|
||||
|
||||
|
||||
@@ -37,7 +37,7 @@
|
||||
|
||||
提示信息:
|
||||
|
||||
|
||||
|
||||
|
||||
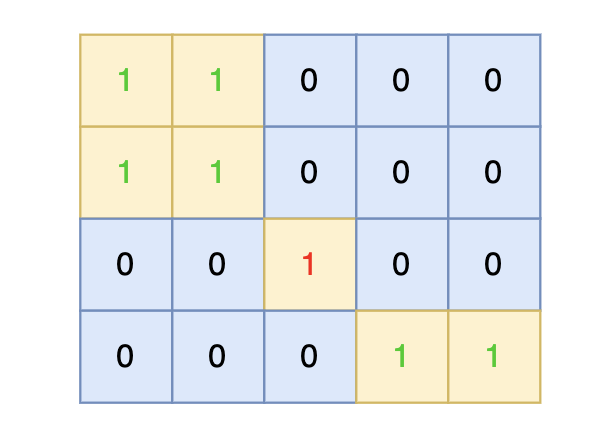
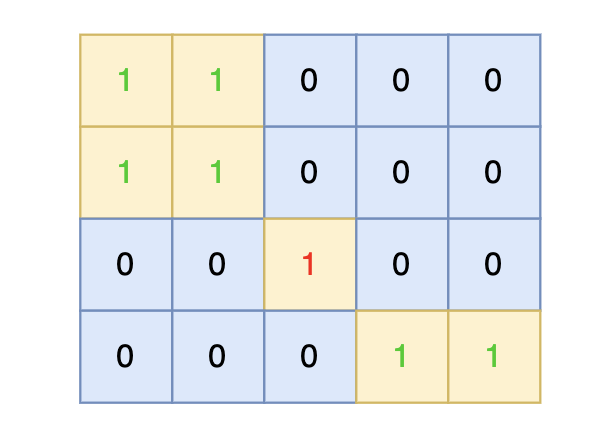
在矩阵中心部分的岛屿,因为没有任何一个单元格接触到矩阵边缘,所以该岛屿属于孤岛,总面积为 1。
|
||||
|
||||
@@ -54,11 +54,11 @@
|
||||
|
||||
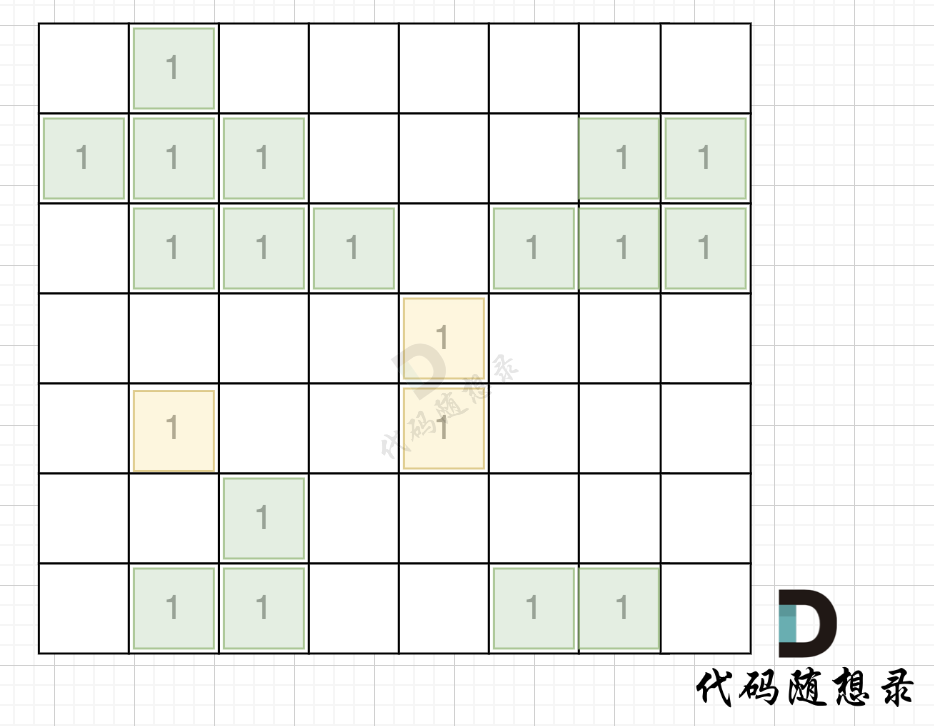
如图,在遍历地图周围四个边,靠地图四边的陆地,都为绿色,
|
||||
|
||||
|
||||
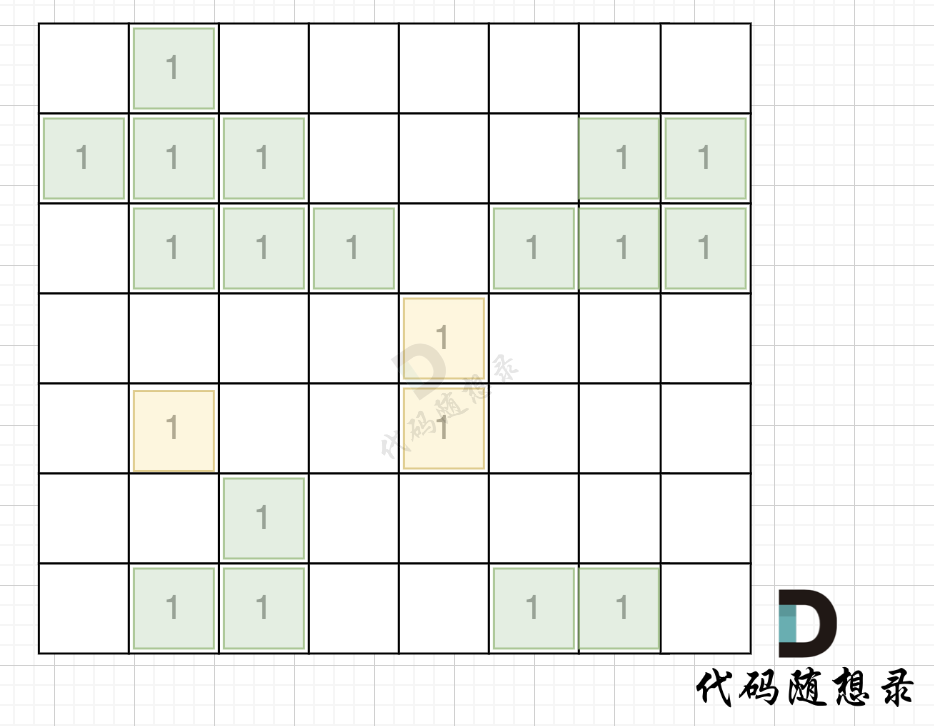
|
||||
|
||||
在遇到地图周边陆地的时候,将1都变为0,此时地图为这样:
|
||||
|
||||
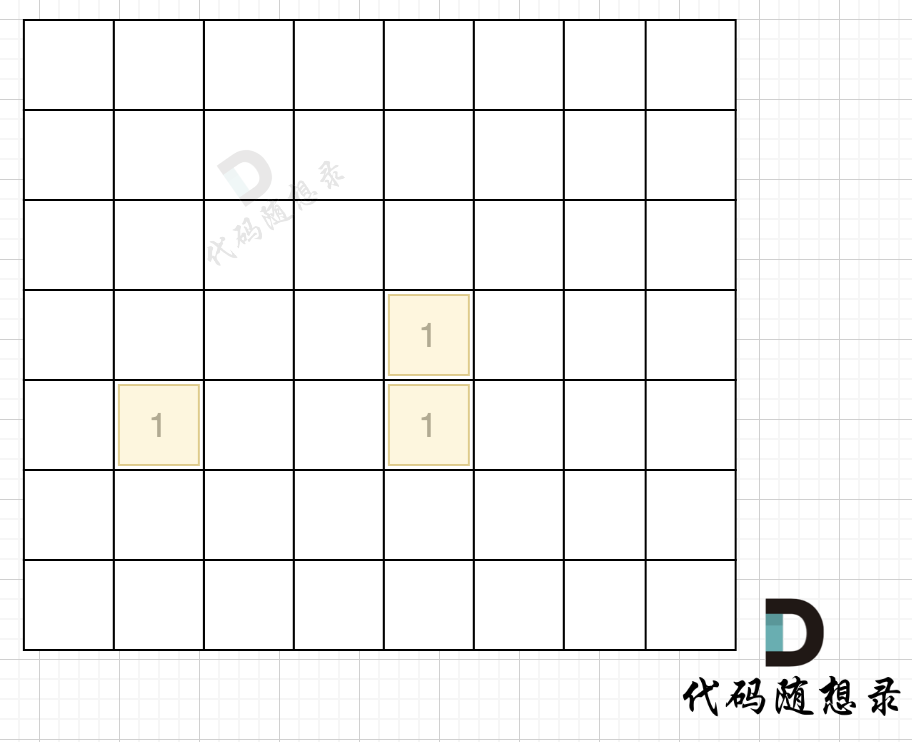
|
||||
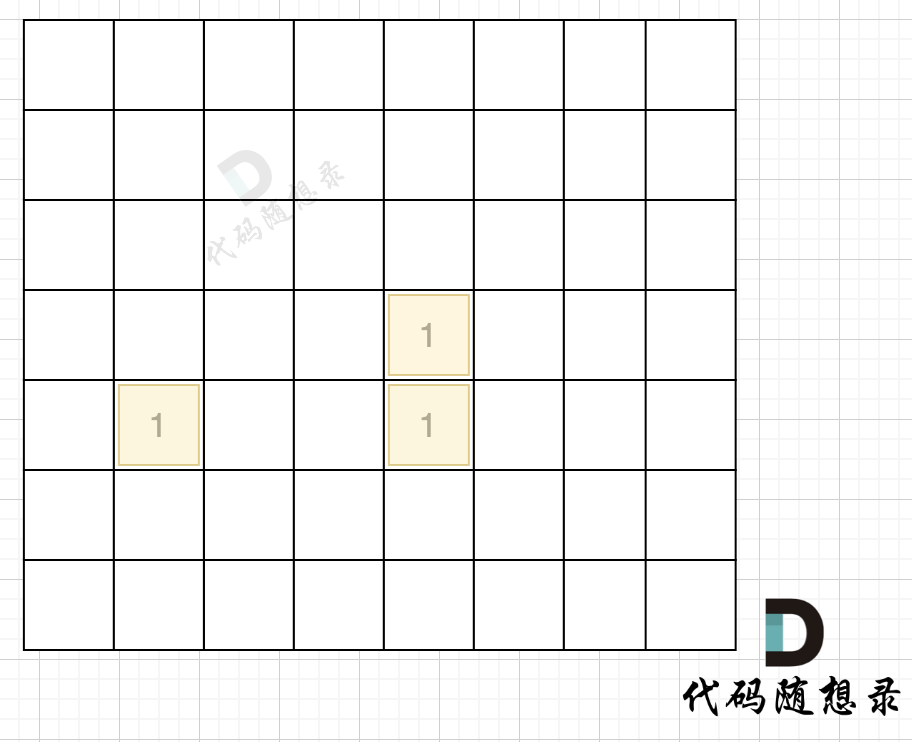
|
||||
|
||||
然后我们再去遍历这个地图,遇到有陆地的地方,去采用深搜或者广搜,边统计所有陆地。
|
||||
|
||||
|
||||
@@ -43,11 +43,11 @@
|
||||
|
||||
提示信息:
|
||||
|
||||
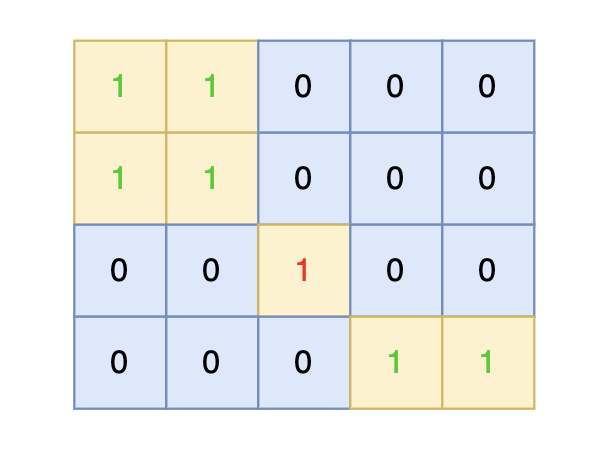
|
||||
|
||||
|
||||
将孤岛沉没:
|
||||
|
||||
|
||||
|
||||
|
||||
数据范围:
|
||||
|
||||
@@ -73,7 +73,7 @@
|
||||
|
||||
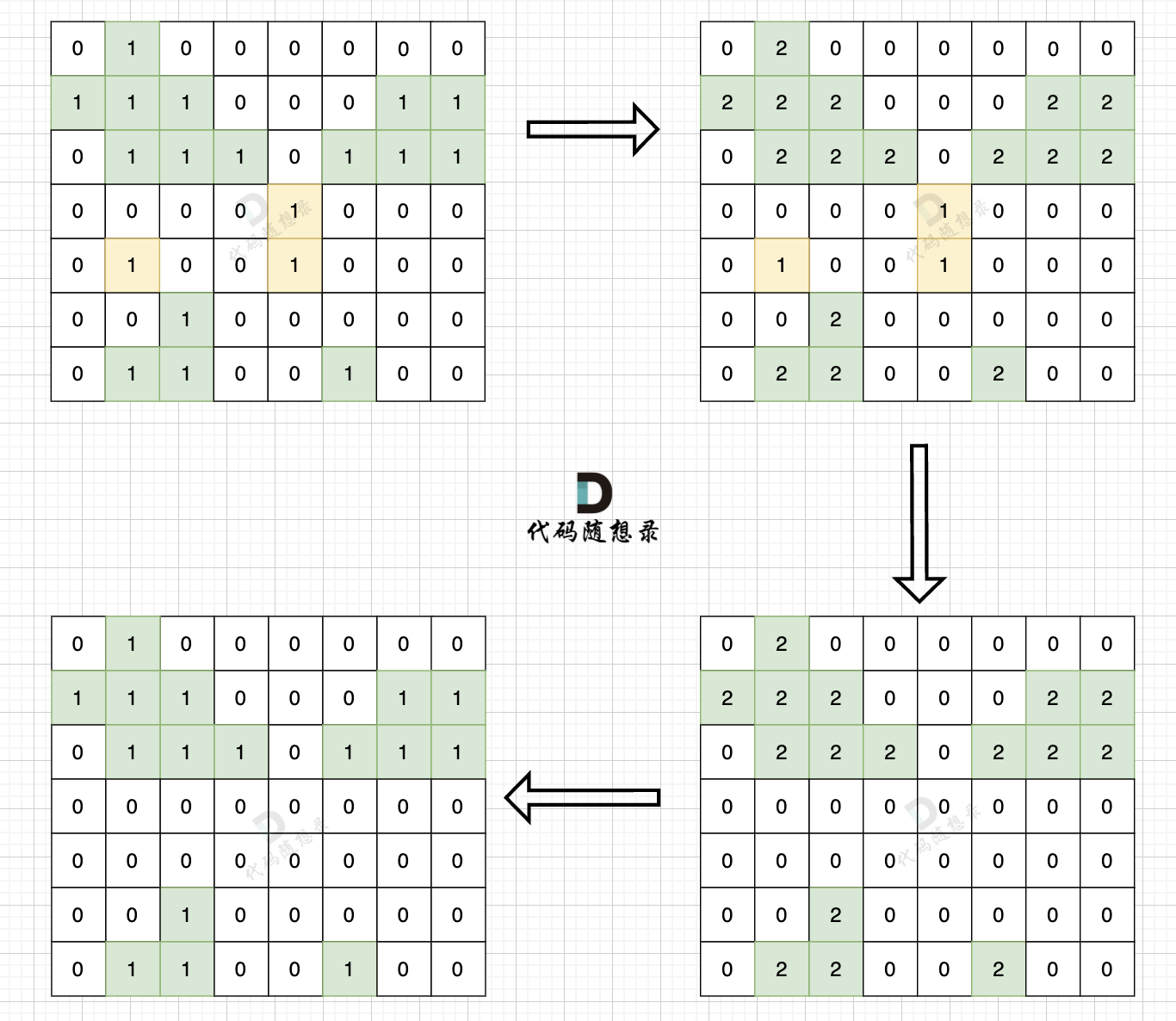
如图:
|
||||
|
||||
|
||||
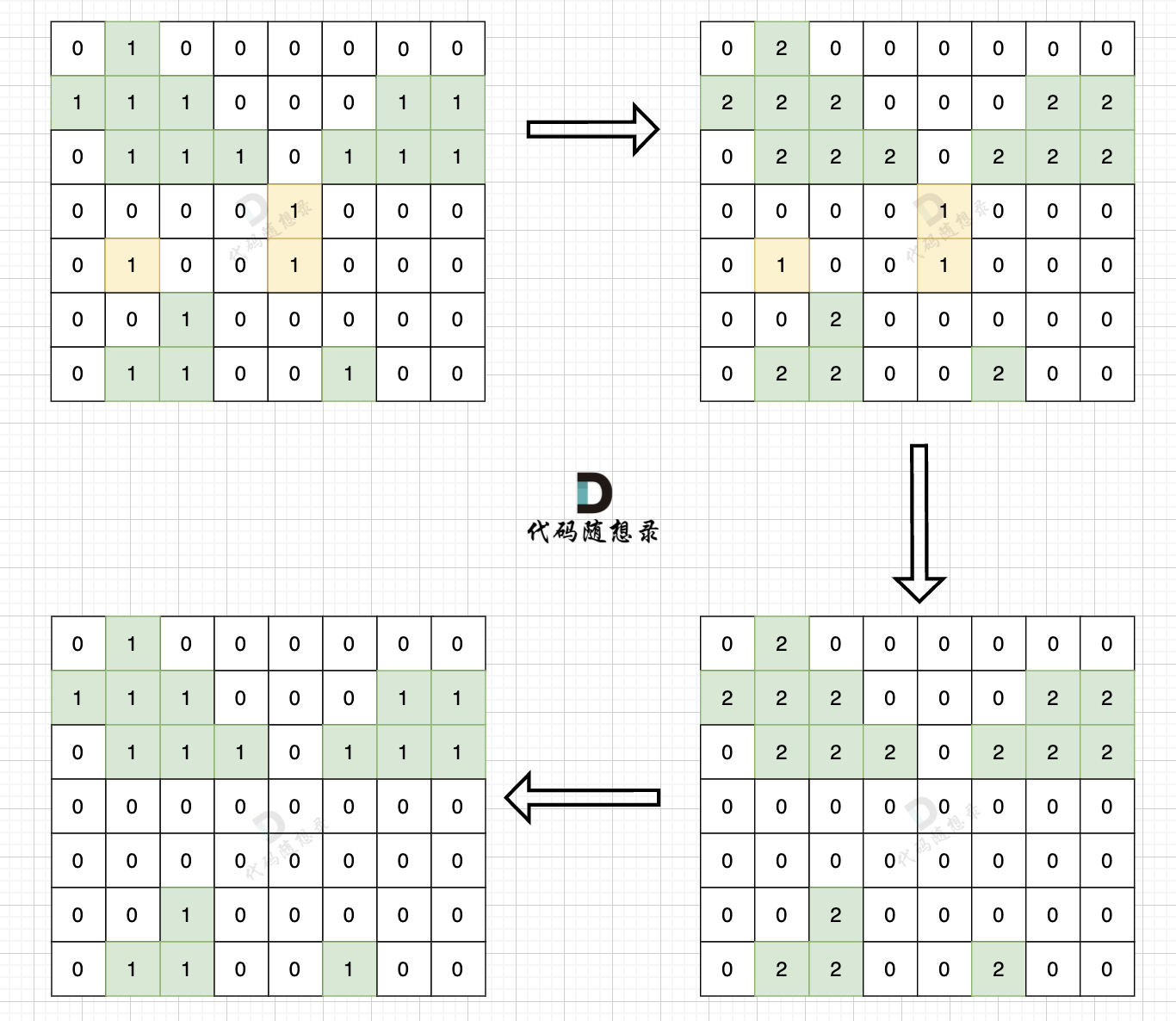
|
||||
|
||||
整体C++代码如下,以下使用dfs实现,其实遍历方式dfs,bfs都是可以的。
|
||||
|
||||
|
||||
@@ -48,7 +48,7 @@
|
||||
|
||||
提示信息:
|
||||
|
||||
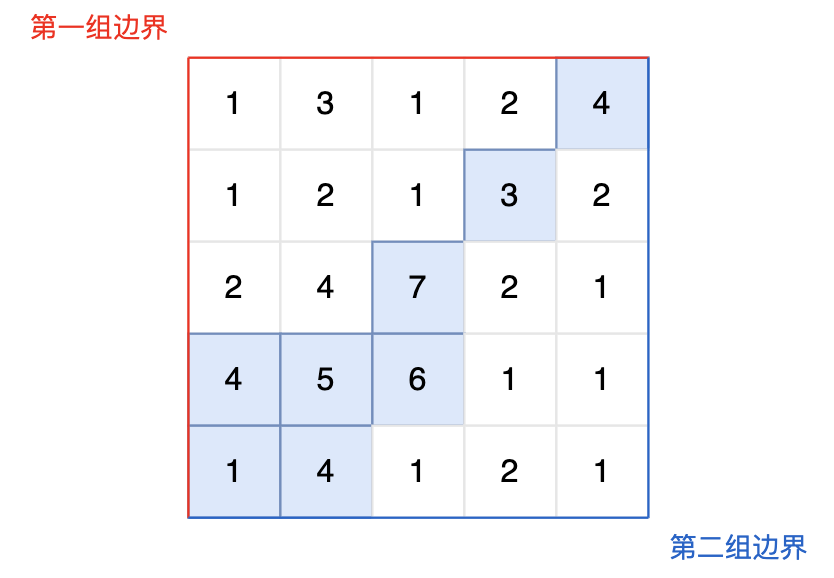
|
||||
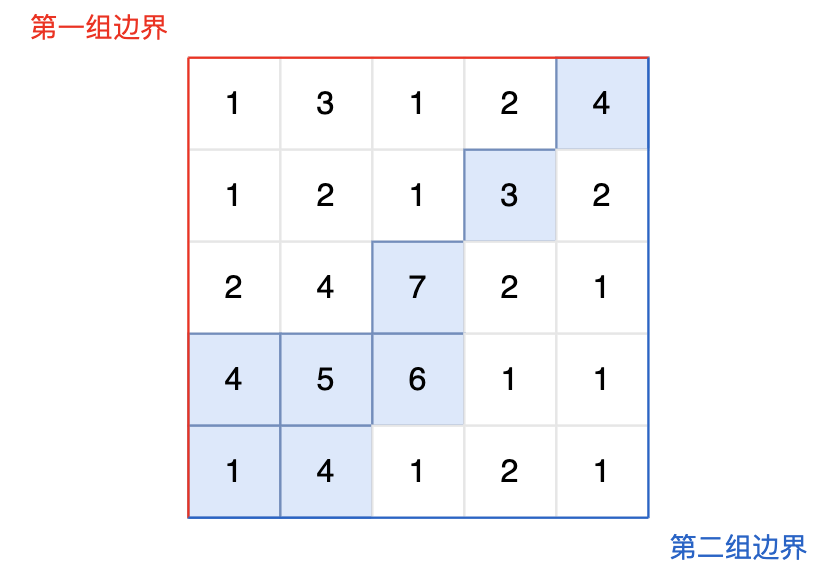
|
||||
|
||||
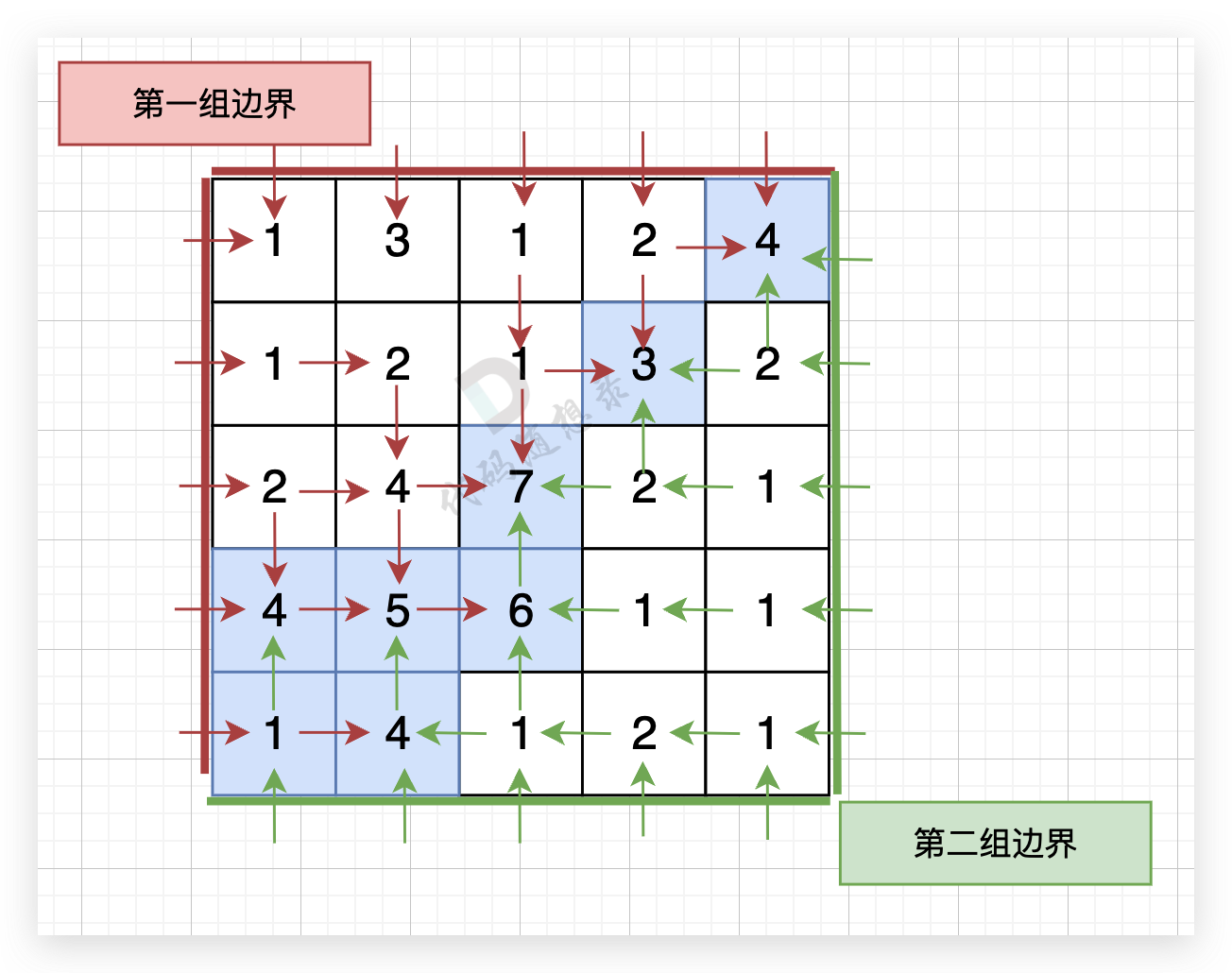
图中的蓝色方块上的雨水既能流向第一组边界,也能流向第二组边界。所以最终答案为所有蓝色方块的坐标。
|
||||
|
||||
@@ -166,11 +166,11 @@ int main() {
|
||||
|
||||
从第一组边界边上节点出发,如图: (图中并没有把所有遍历的方向都画出来,只画关键部分)
|
||||
|
||||

|
||||
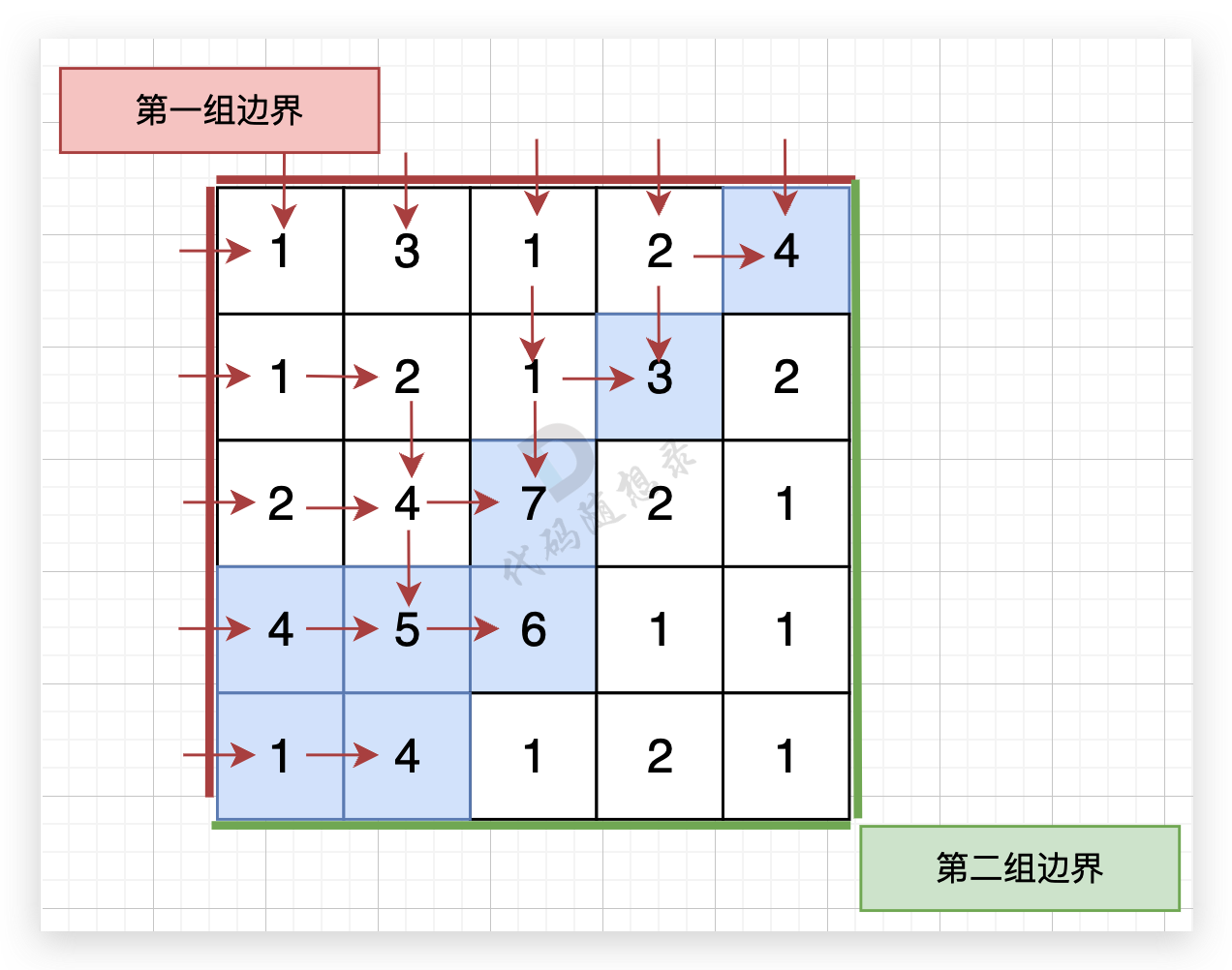
|
||||
|
||||
从第二组边界上节点出发,如图: (图中并没有把所有遍历的方向都画出来,只画关键部分)
|
||||
|
||||

|
||||
|
||||
|
||||
最后,我们得到两个方向交界的这些节点,就是我们最后要求的节点。
|
||||
|
||||
|
||||
@@ -35,12 +35,12 @@
|
||||
|
||||
提示信息
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
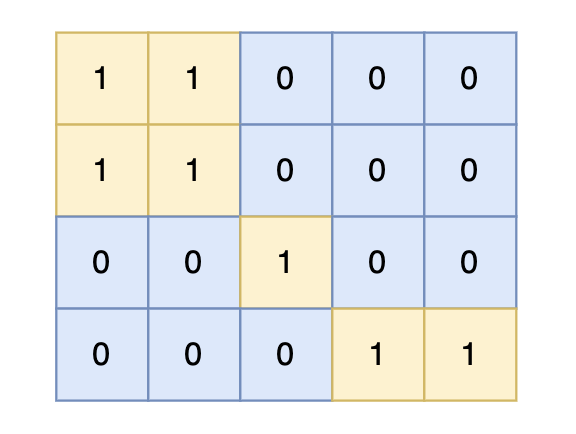
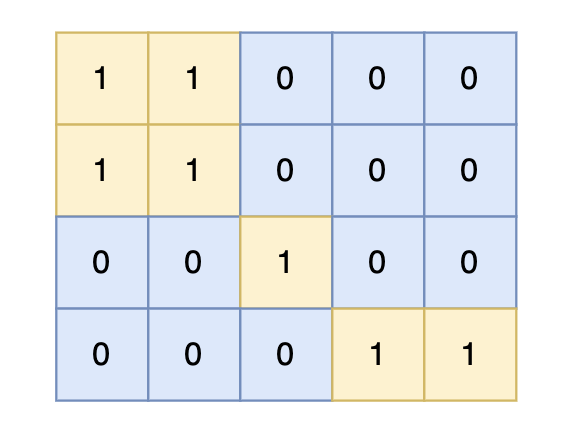
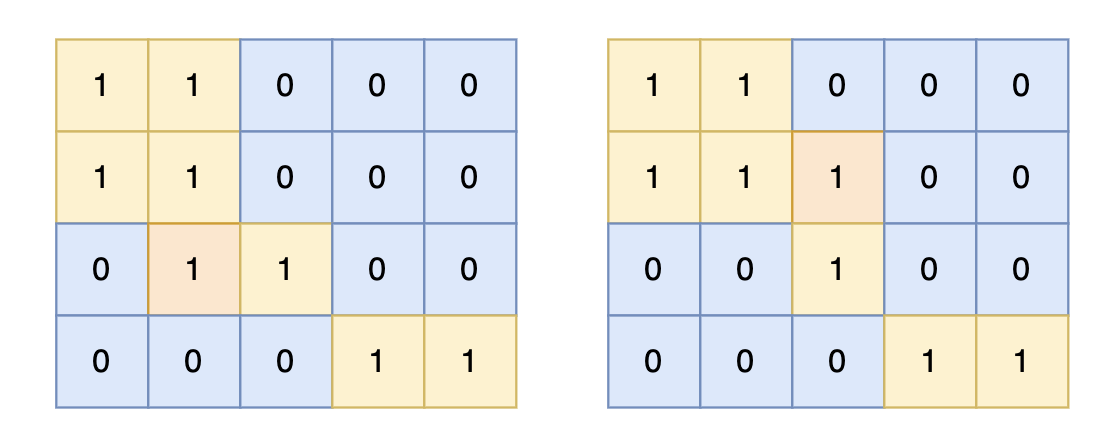
对于上面的案例,有两个位置可将 0 变成 1,使得岛屿的面积最大,即 6。
|
||||
|
||||
|
||||
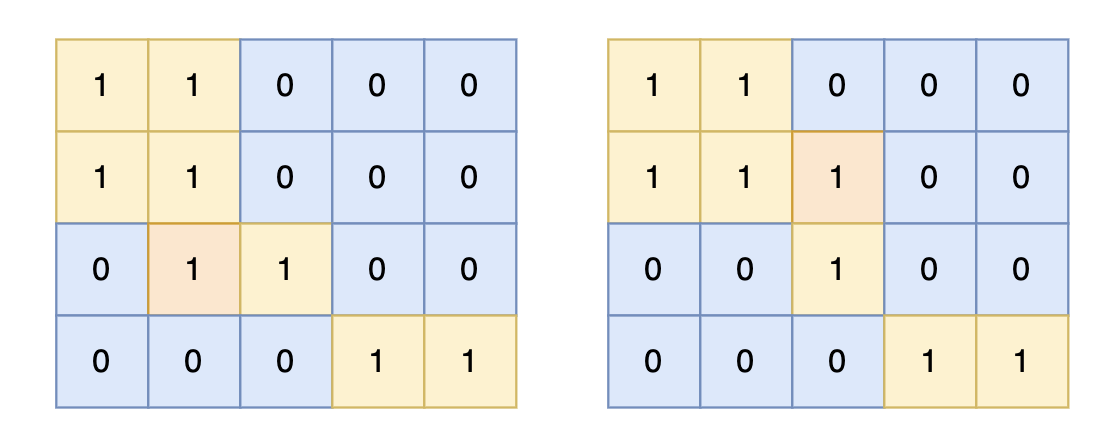
|
||||
|
||||
|
||||
数据范围:
|
||||
@@ -70,11 +70,11 @@
|
||||
|
||||
拿如下地图的岛屿情况来举例: (1为陆地)
|
||||
|
||||
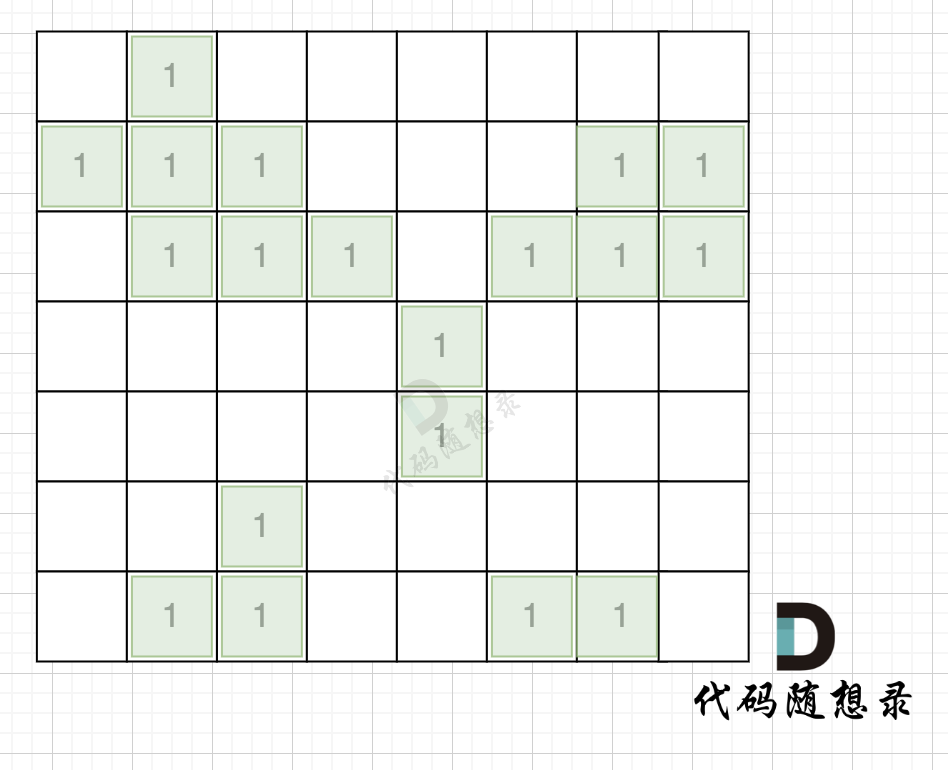
|
||||
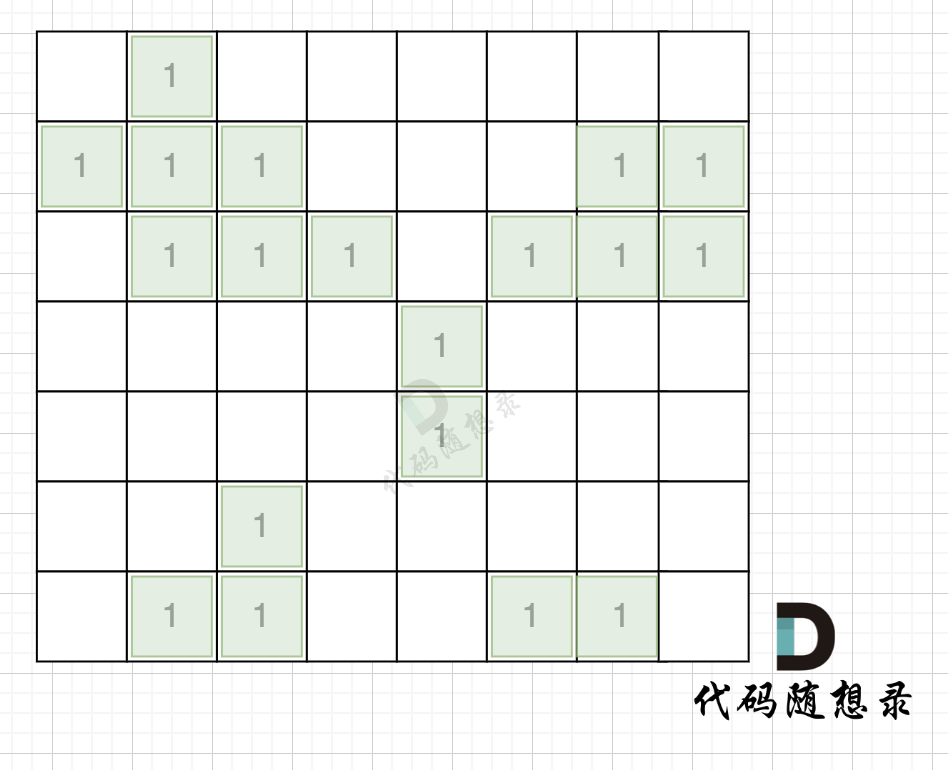
|
||||
|
||||
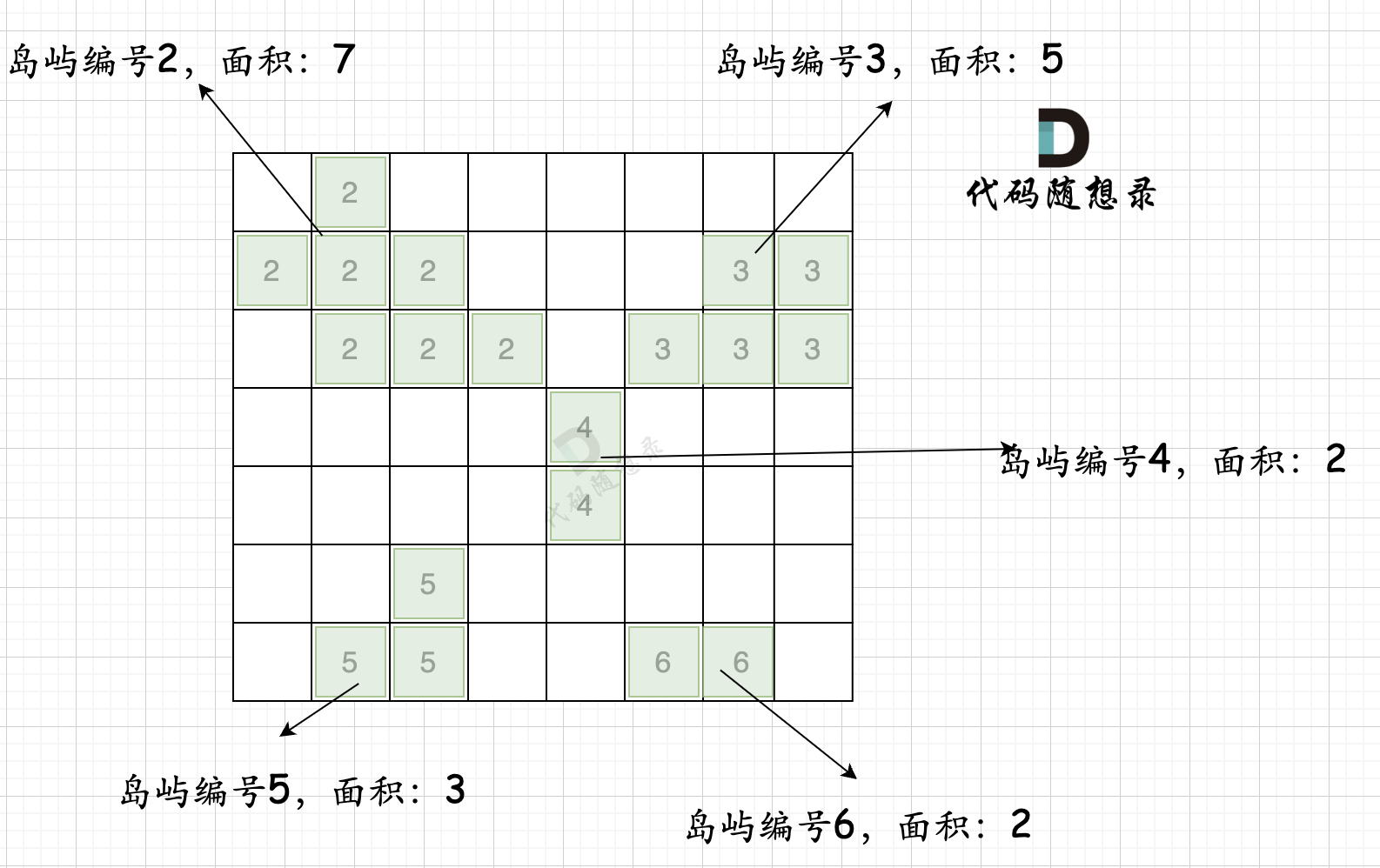
第一步,则遍历地图,并将岛屿的编号和面积都统计好,过程如图所示:
|
||||
|
||||
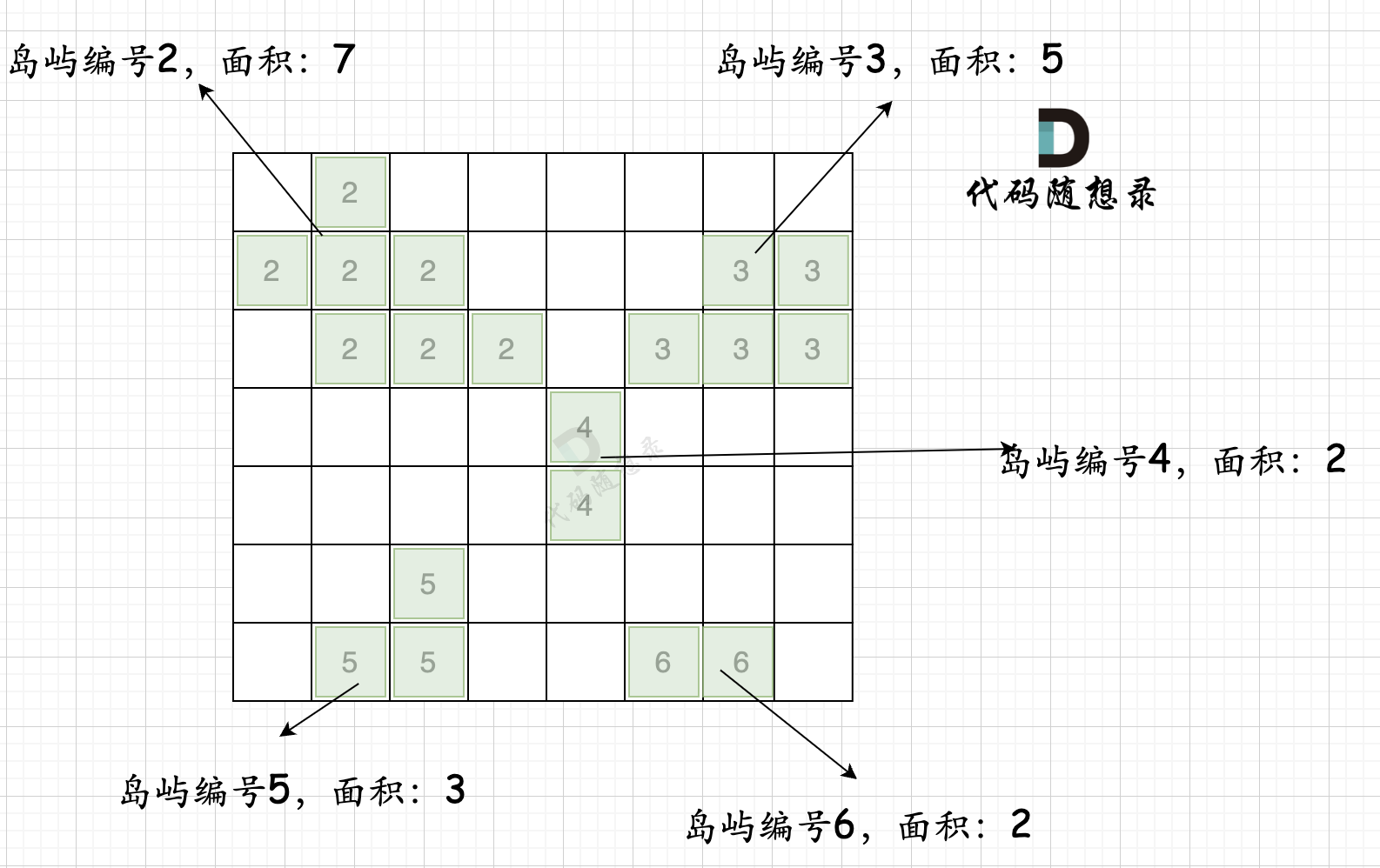
|
||||
|
||||
|
||||
|
||||
本过程代码如下:
|
||||
@@ -121,7 +121,7 @@ int largestIsland(vector<vector<int>>& grid) {
|
||||
|
||||
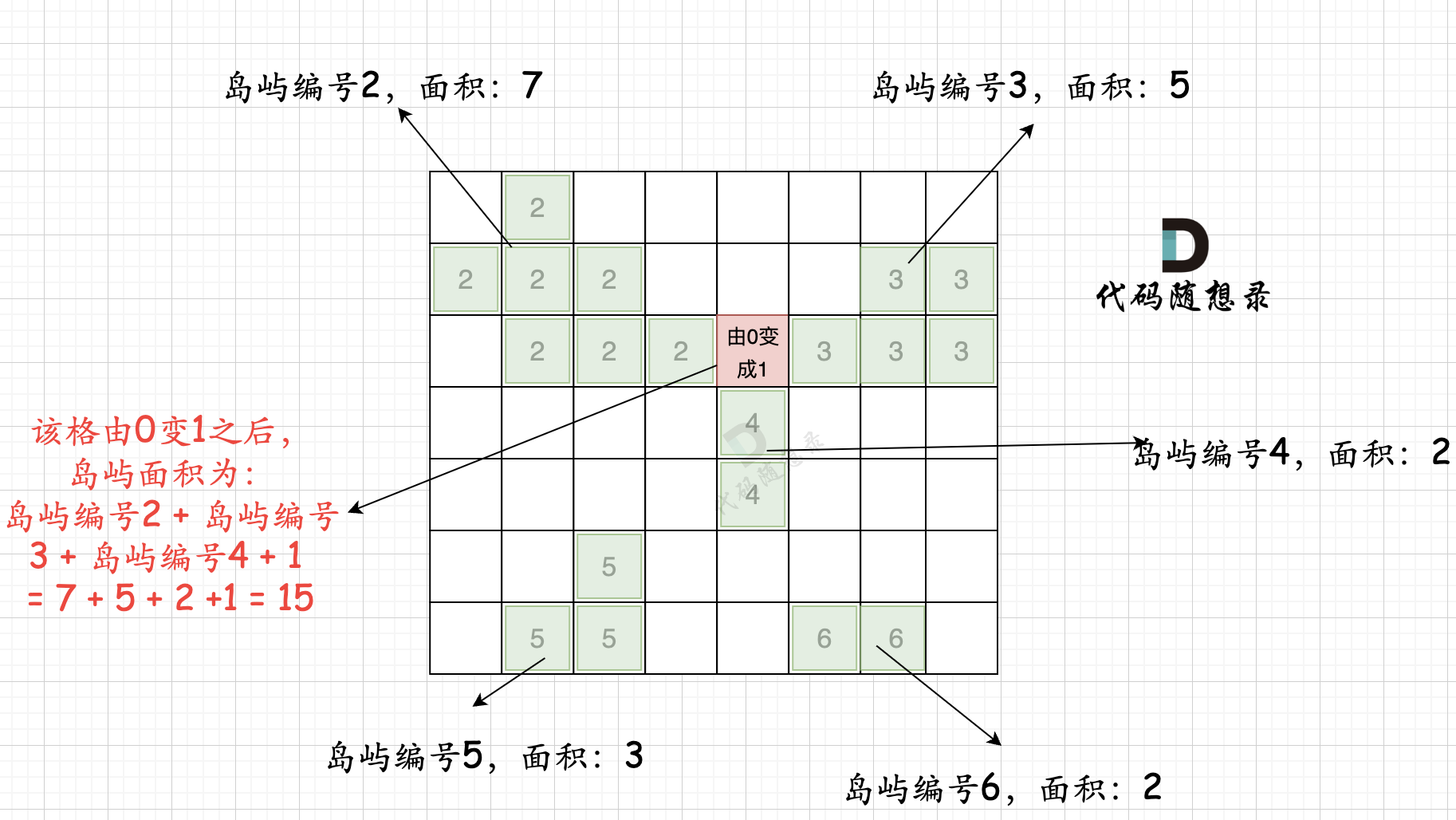
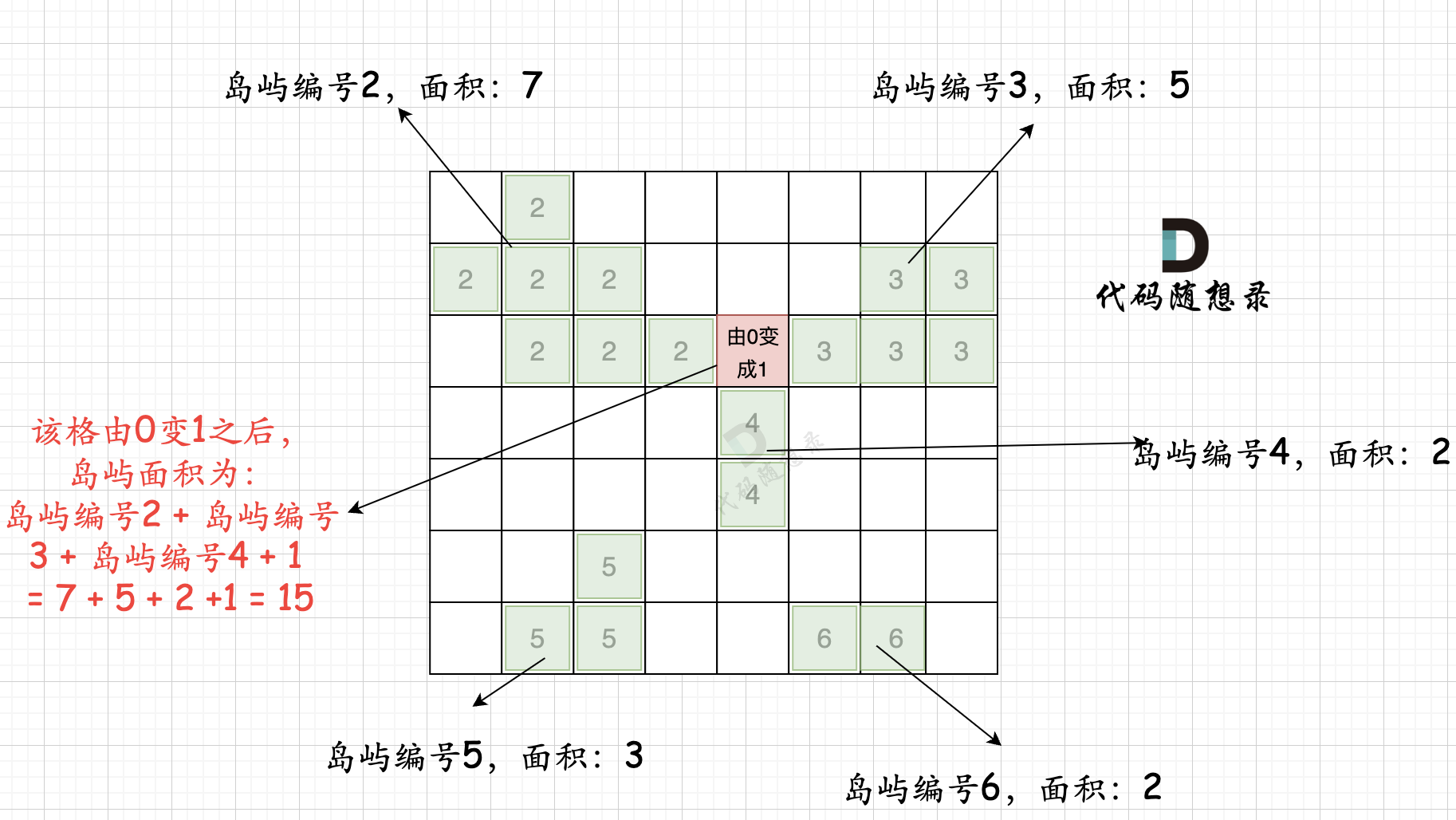
第二步过程如图所示:
|
||||
|
||||
|
||||
|
||||
|
||||
也就是遍历每一个0的方格,并统计其相邻岛屿面积,最后取一个最大值。
|
||||
|
||||
|
||||
@@ -33,7 +33,7 @@
|
||||
|
||||
【提示信息】
|
||||
|
||||
|
||||
|
||||
|
||||
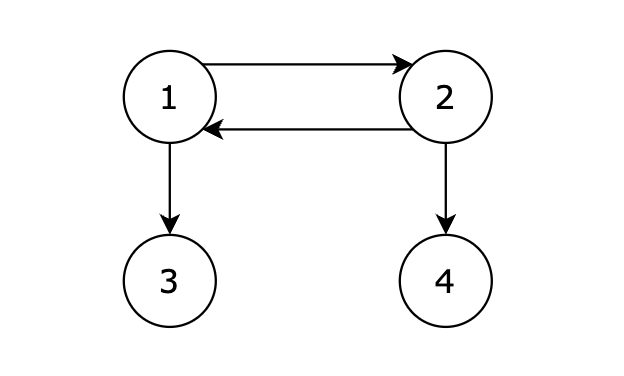
从 1 号节点可以到达任意节点,输出 1。
|
||||
|
||||
@@ -48,7 +48,7 @@
|
||||
|
||||
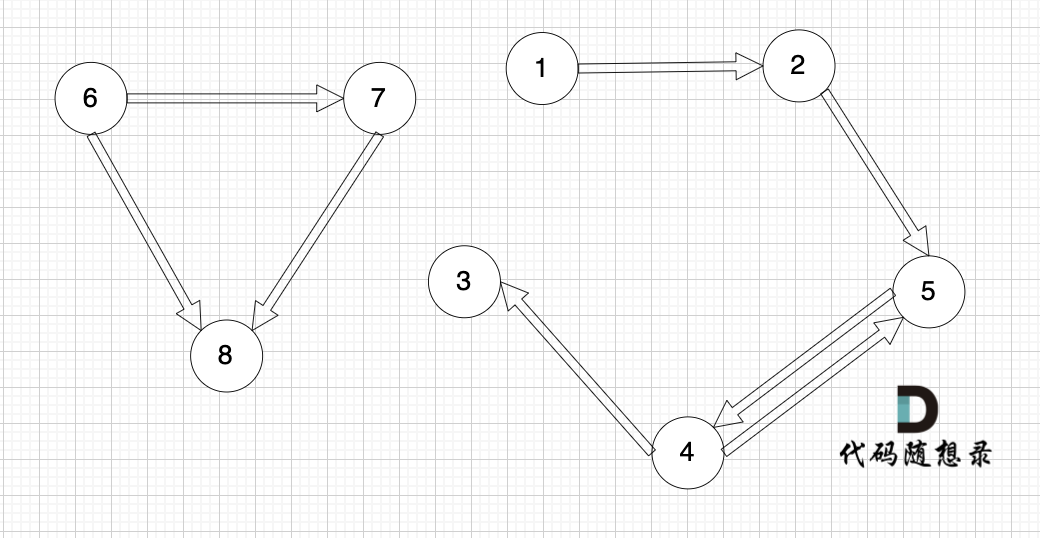
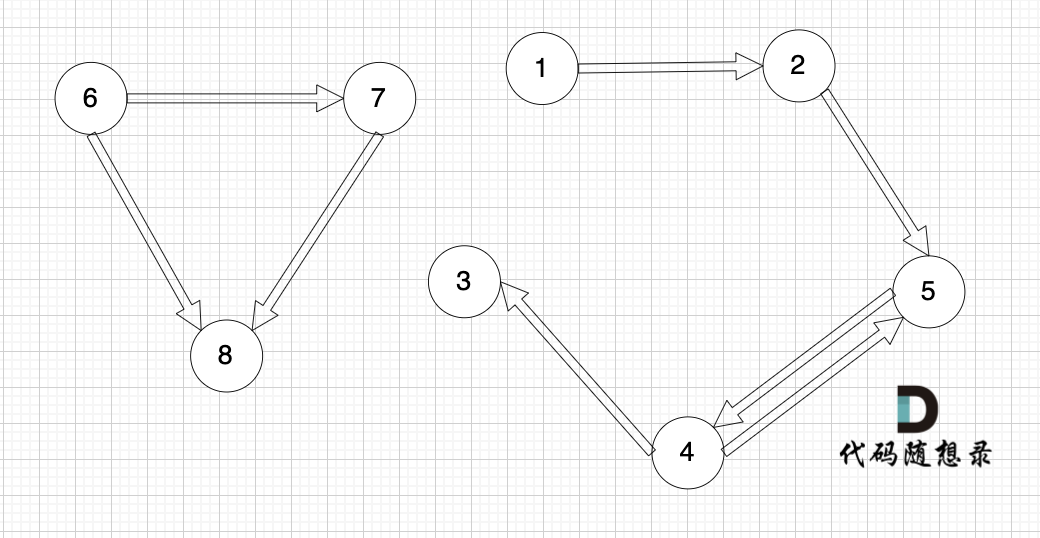
接下来我们再画一个图,从图里可以直观看出来,节点6 是 不能到达节点1 的
|
||||
|
||||
|
||||
|
||||
|
||||
这就很容易让我们想起岛屿问题,只要发现独立的岛,就是不可到达的。
|
||||
|
||||
|
||||
@@ -37,7 +37,7 @@
|
||||
|
||||
提示信息
|
||||
|
||||
|
||||
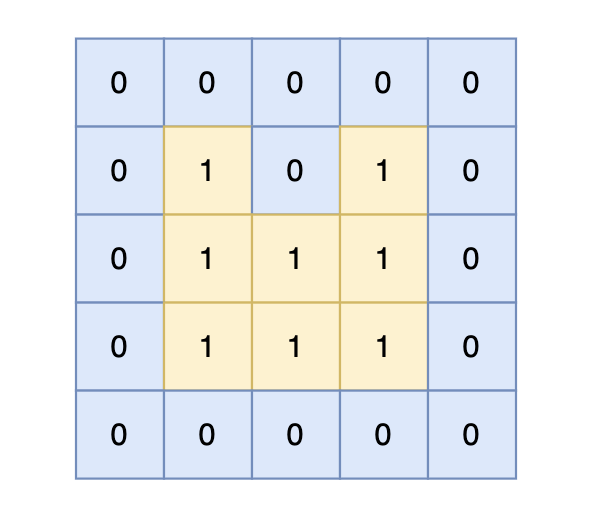
|
||||
|
||||
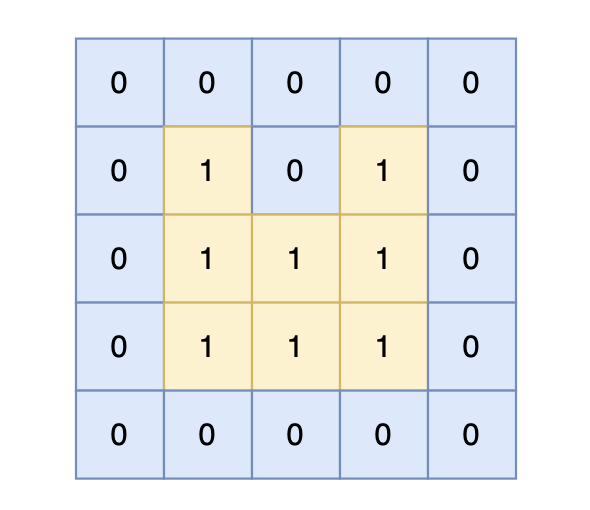
岛屿的周长为 14。
|
||||
|
||||
@@ -57,14 +57,14 @@
|
||||
|
||||
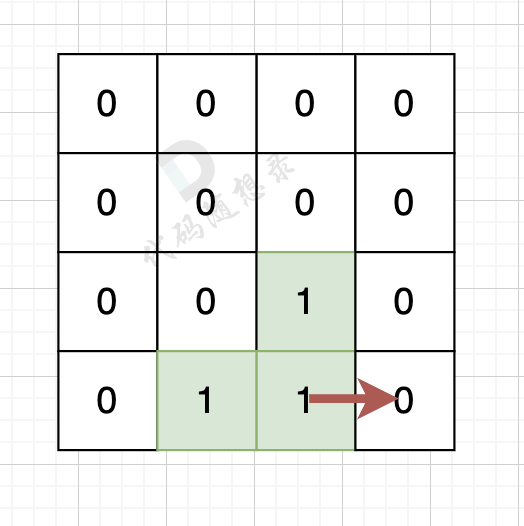
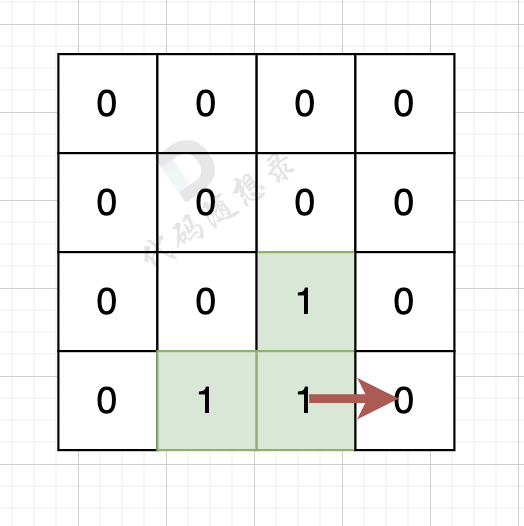
如果该陆地上下左右的空格是有水域,则说明是一条边,如图:
|
||||
|
||||
|
||||
|
||||
|
||||
陆地的右边空格是水域,则说明找到一条边。
|
||||
|
||||
|
||||
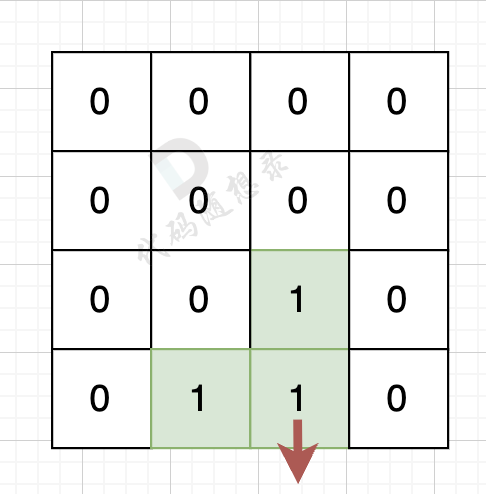
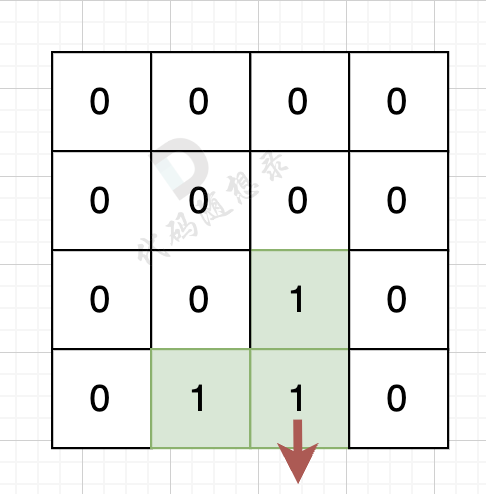
如果该陆地上下左右的空格出界了,则说明是一条边,如图:
|
||||
|
||||
|
||||
|
||||
|
||||
该陆地的下边空格出界了,则说明找到一条边。
|
||||
|
||||
@@ -114,7 +114,7 @@ int main() {
|
||||
|
||||
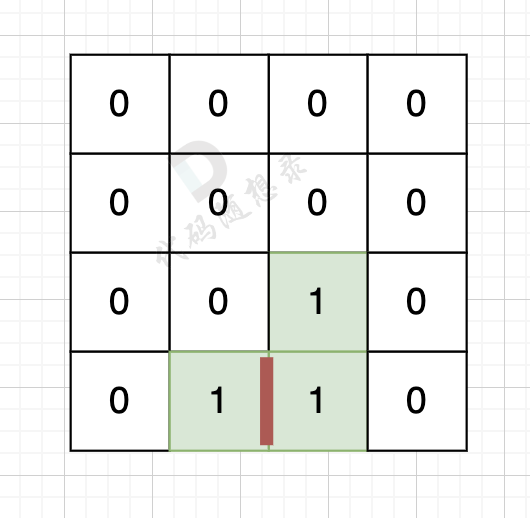
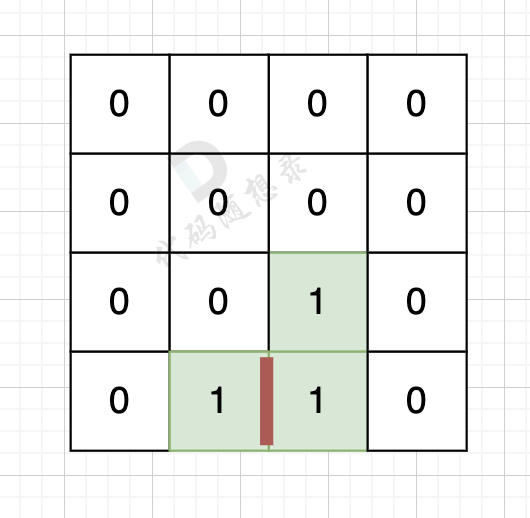
因为有一对相邻两个陆地,边的总数就要减2,如图红线部分,有两个陆地相邻,总边数就要减2
|
||||
|
||||
|
||||
|
||||
|
||||
那么只需要在计算出相邻岛屿的数量就可以了,相邻岛屿数量为cover。
|
||||
|
||||
|
||||
@@ -40,7 +40,7 @@
|
||||
|
||||
提示信息
|
||||
|
||||

|
||||
|
||||
|
||||
数据范围:
|
||||
|
||||
|
||||
@@ -9,11 +9,11 @@
|
||||
|
||||
有一个图,它是一棵树,他是拥有 n 个节点(节点编号1到n)和 n - 1 条边的连通无环无向图(其实就是一个线形图),如图:
|
||||
|
||||

|
||||
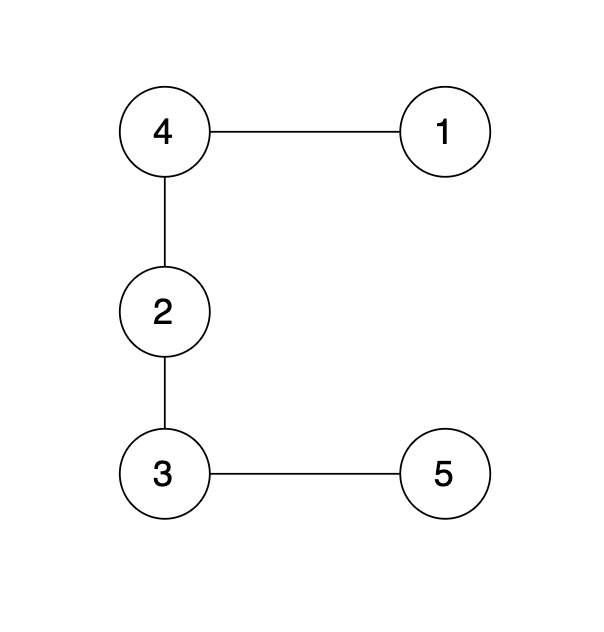
|
||||
|
||||
现在在这棵树上的基础上,添加一条边(依然是n个节点,但有n条边),使这个图变成了有环图,如图
|
||||
|
||||
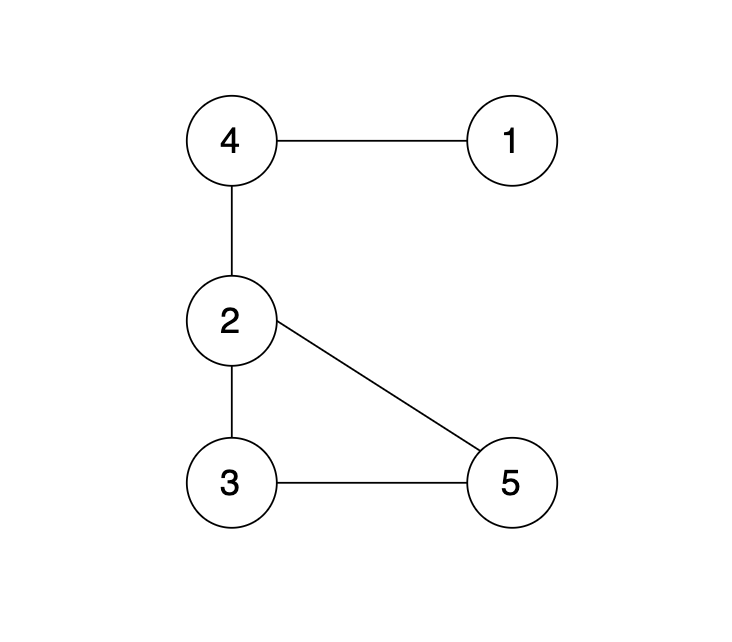
|
||||
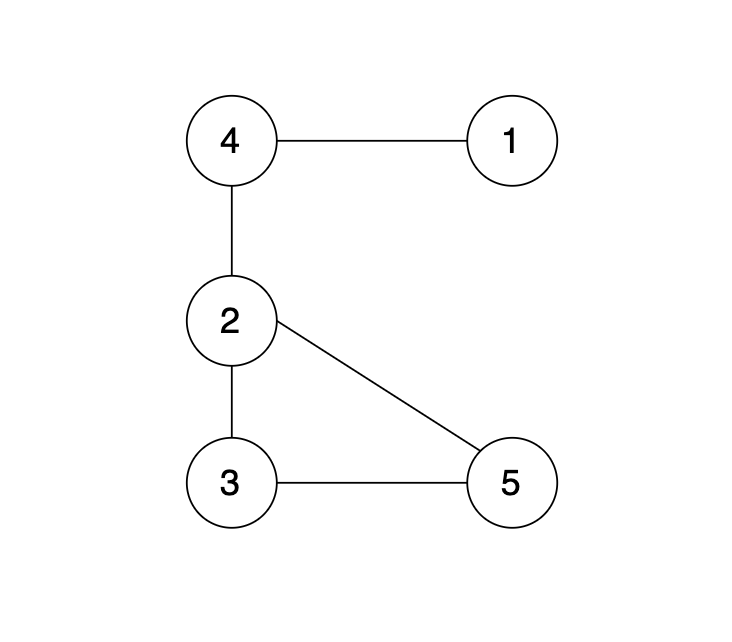
|
||||
|
||||
先请你找出冗余边,删除后,使该图可以重新变成一棵树。
|
||||
|
||||
@@ -42,7 +42,7 @@
|
||||
|
||||
提示信息
|
||||
|
||||
|
||||
|
||||
|
||||
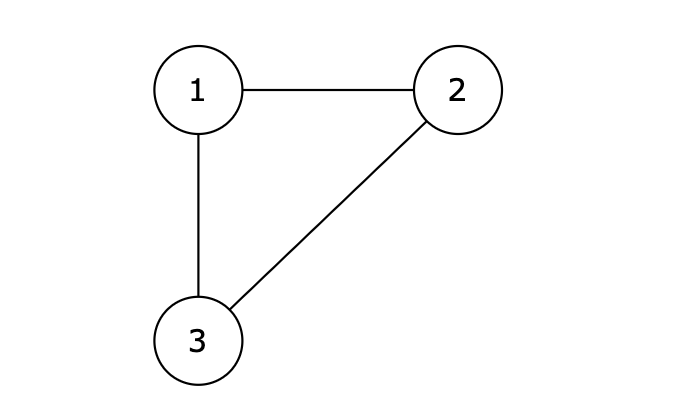
图中的 1 2,2 3,1 3 等三条边在删除后都能使原图变为一棵合法的树。但是 1 3 由于是标准输入里最后出现的那条边,所以输出结果为 1 3
|
||||
|
||||
@@ -69,13 +69,13 @@
|
||||
|
||||
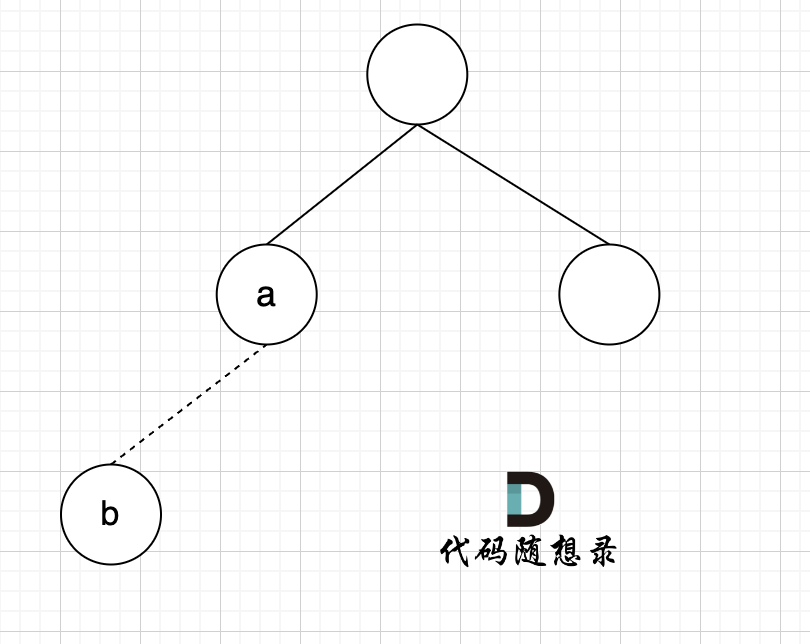
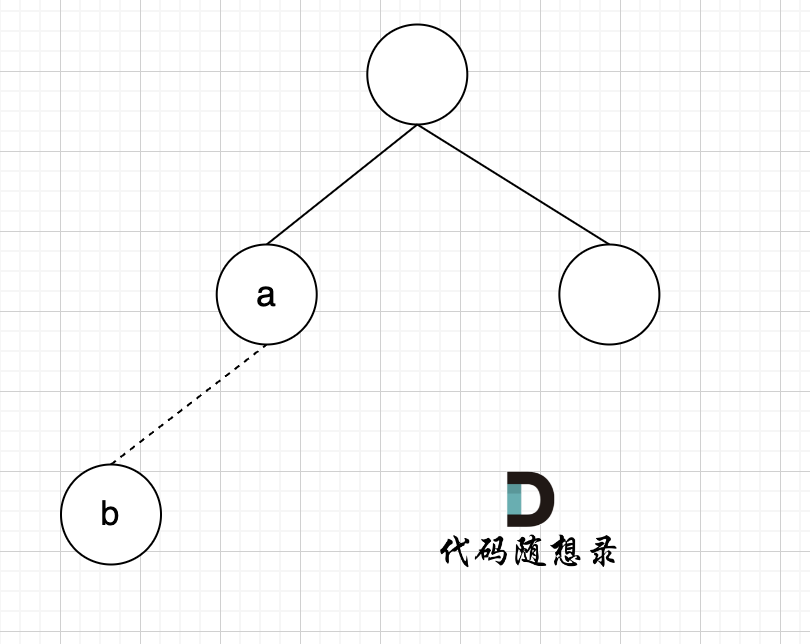
如图所示,节点A 和节点 B 不在同一个集合,那么就可以将两个 节点连在一起。
|
||||
|
||||
|
||||
|
||||
|
||||
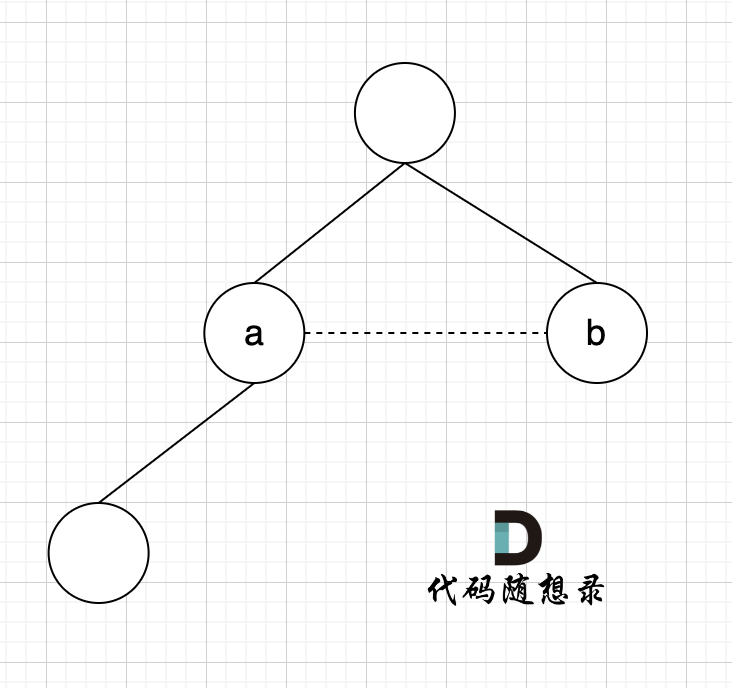
如果边的两个节点已经出现在同一个集合里,说明着边的两个节点已经连在一起了,再加入这条边一定就出现环了。
|
||||
|
||||
如图所示:
|
||||
|
||||
|
||||
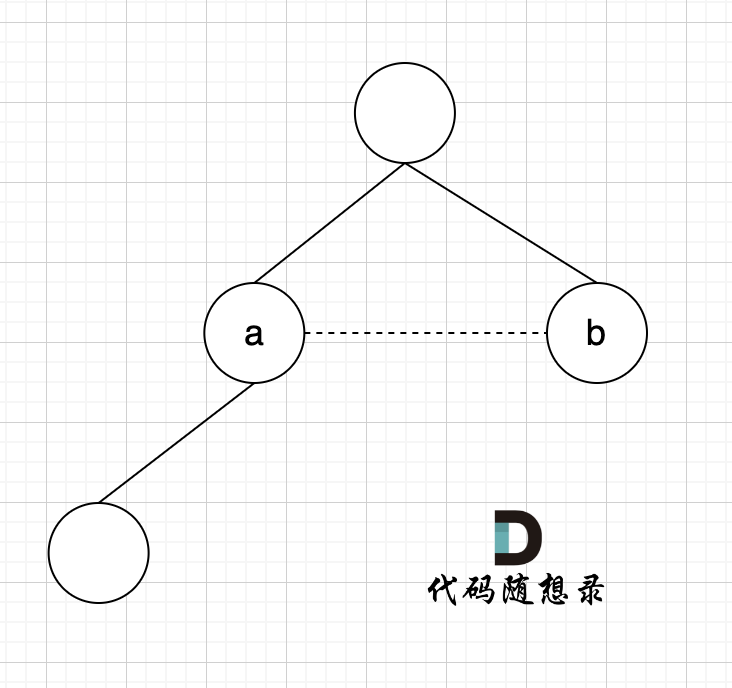
|
||||
|
||||
已经判断 节点A 和 节点B 在在同一个集合(同一个根),如果将 节点A 和 节点B 连在一起就一定会出现环。
|
||||
|
||||
@@ -157,7 +157,7 @@ int main() {
|
||||
|
||||
图:
|
||||
|
||||

|
||||

|
||||
|
||||
输出示例
|
||||
|
||||
|
||||
@@ -9,11 +9,11 @@
|
||||
|
||||
有一种有向树,该树只有一个根节点,所有其他节点都是该根节点的后继。该树除了根节点之外的每一个节点都有且只有一个父节点,而根节点没有父节点。有向树拥有 n 个节点和 n - 1 条边。如图:
|
||||
|
||||
<img src="https://code-thinking-1253855093.file.myqcloud.com/pics/20240827152106.png" alt="" width="50%" />
|
||||
<img src="https://file.kamacoder.com/pics/20240827152106.png" alt="" width="50%" />
|
||||
|
||||
现在有一个有向图,有向图是在有向树中的两个没有直接链接的节点中间添加一条有向边。如图:
|
||||
|
||||
<img src="https://code-thinking-1253855093.file.myqcloud.com/pics/20240827152134.png" alt="" width="50%" />
|
||||
<img src="https://file.kamacoder.com/pics/20240827152134.png" alt="" width="50%" />
|
||||
|
||||
输入一个有向图,该图由一个有着 n 个节点(节点编号 从 1 到 n),n 条边,请返回一条可以删除的边,使得删除该条边之后该有向图可以被当作一颗有向树。
|
||||
|
||||
@@ -42,7 +42,7 @@
|
||||
|
||||
提示信息
|
||||
|
||||
<img src="https://code-thinking-1253855093.file.myqcloud.com/pics/20240527112633.png" alt="" width="50%" />
|
||||
<img src="https://file.kamacoder.com/pics/20240527112633.png" alt="" width="50%" />
|
||||
|
||||
在删除 2 3 后有向图可以变为一棵合法的有向树,所以输出 2 3
|
||||
|
||||
@@ -64,13 +64,13 @@
|
||||
|
||||
如图:
|
||||
|
||||
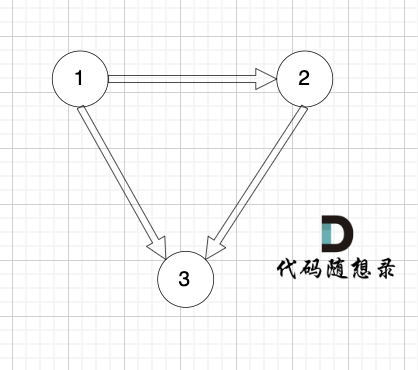
|
||||
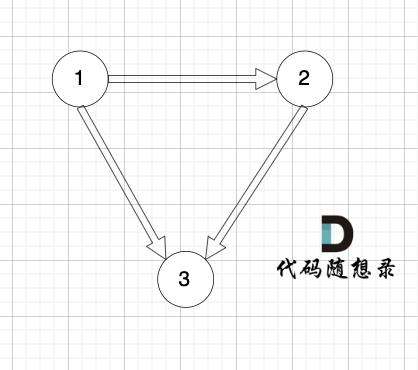
|
||||
|
||||
找到了节点3 的入度为2,删 1 -> 3 或者 2 -> 3 。选择删顺序靠后便可。
|
||||
|
||||
但 入度为2 还有一种情况,情况二,只能删特定的一条边,如图:
|
||||
|
||||
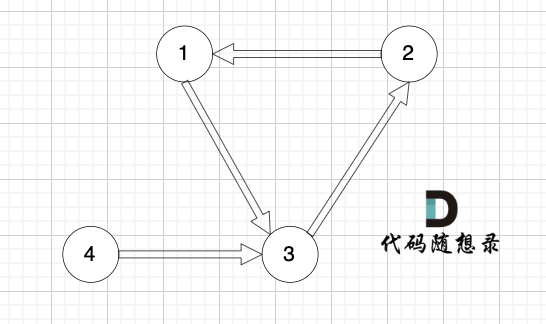
|
||||
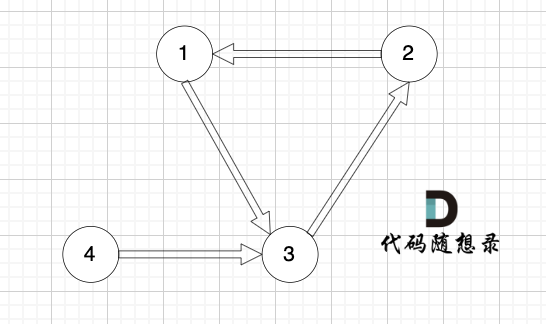
|
||||
|
||||
节点3 的入度为 2,但在删除边的时候,只能删 这条边(节点1 -> 节点3),如果删这条边(节点4 -> 节点3),那么删后本图也不是有向树了(因为找不到根节点)。
|
||||
|
||||
@@ -81,7 +81,7 @@
|
||||
|
||||
如图:
|
||||
|
||||
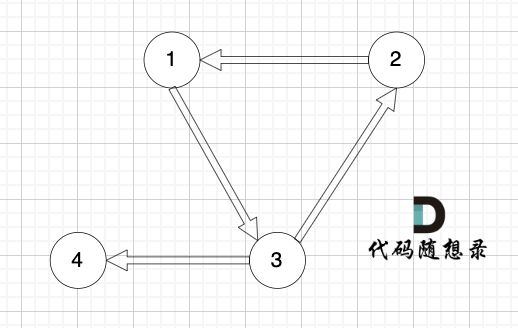
|
||||

|
||||
|
||||
对于情况三,删掉构成环的边就可以了。
|
||||
|
||||
|
||||
@@ -57,7 +57,7 @@ yhn
|
||||
2 <= N <= 500
|
||||
|
||||
<p>
|
||||
<img src="https://code-thinking-1253855093.file.myqcloud.com/pics/20250317105155.png" alt="" width="50%" />
|
||||
<img src="https://file.kamacoder.com/pics/20250317105155.png" alt="" width="50%" />
|
||||
</p>
|
||||
|
||||
|
||||
@@ -65,7 +65,7 @@ yhn
|
||||
|
||||
以示例1为例,从这个图中可以看出 abc 到 def的路线 不止一条,但最短的一条路径上是4个节点。
|
||||
|
||||

|
||||
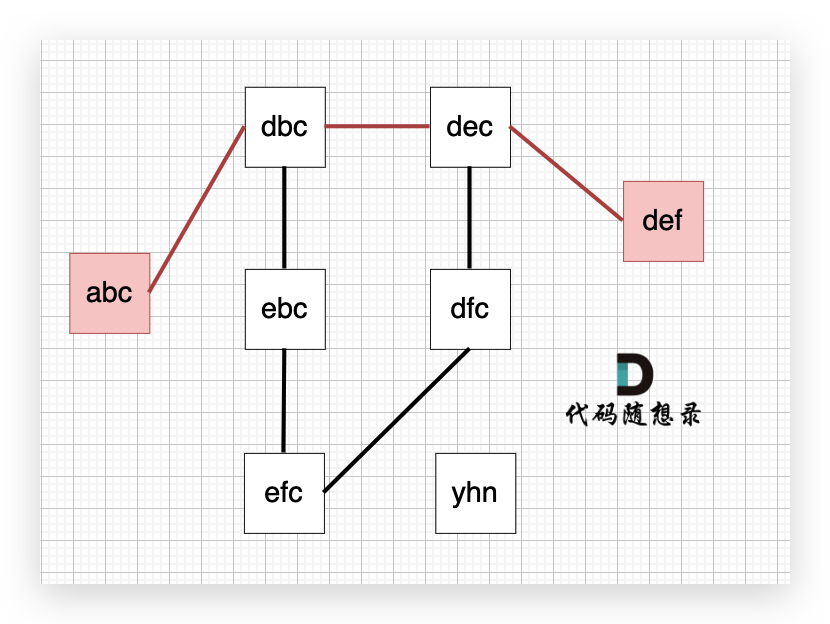
|
||||
|
||||
|
||||
本题只需要求出最短路径的长度就可以了,不用找出具体路径。
|
||||
|
||||
@@ -39,7 +39,7 @@
|
||||
|
||||
文件依赖关系如下:
|
||||
|
||||
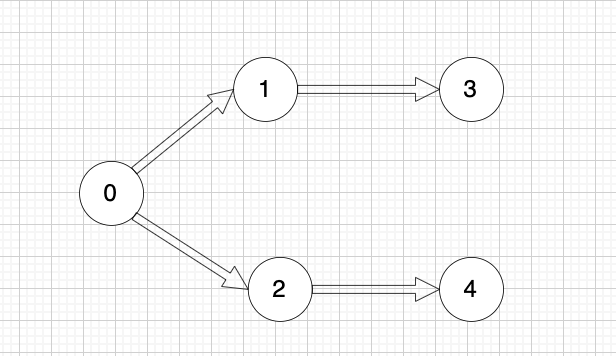
|
||||
|
||||
|
||||
所以,文件处理的顺序除了示例中的顺序,还存在
|
||||
|
||||
@@ -104,7 +104,7 @@
|
||||
|
||||
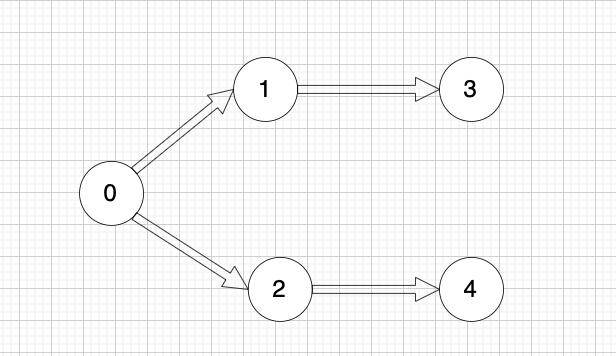
以题目中示例为例如图:
|
||||
|
||||
|
||||
|
||||
|
||||
做拓扑排序的话,如果肉眼去找开头的节点,一定能找到 节点0 吧,都知道要从节点0 开始。
|
||||
|
||||
@@ -135,17 +135,17 @@
|
||||
|
||||
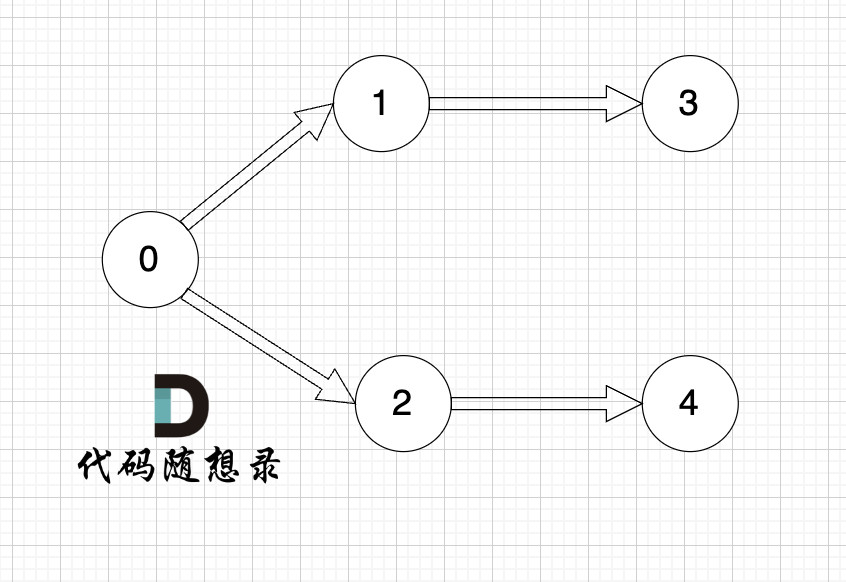
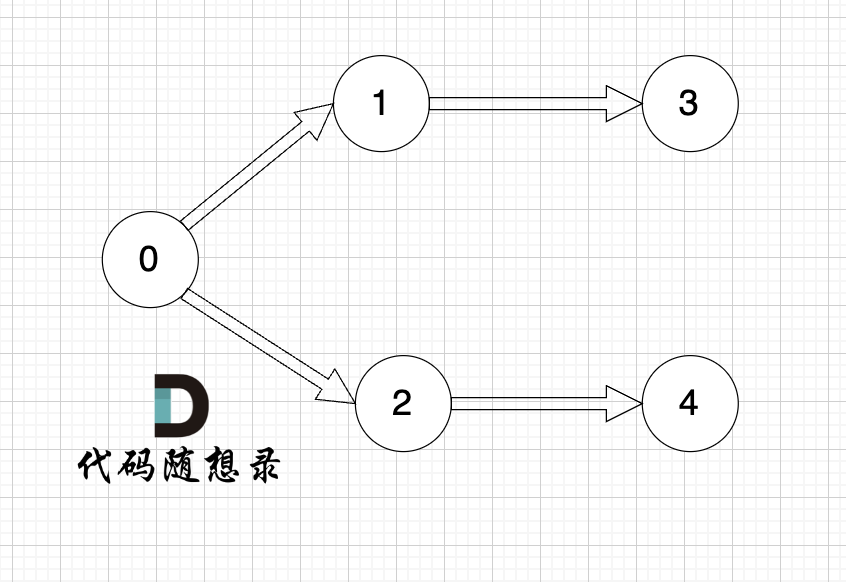
1、找到入度为0 的节点,加入结果集
|
||||
|
||||
|
||||
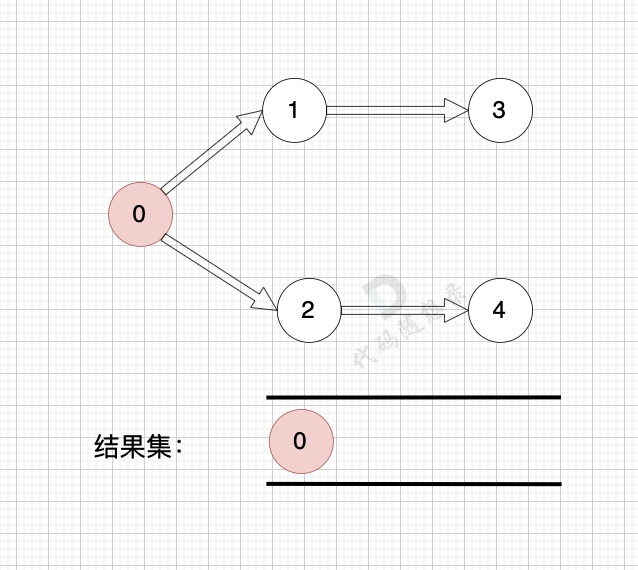
|
||||
|
||||
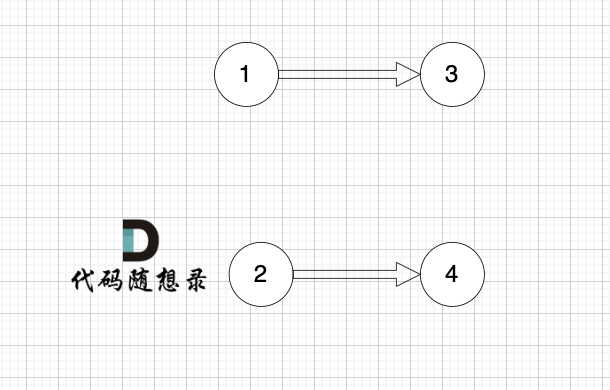
2、将该节点从图中移除
|
||||
|
||||
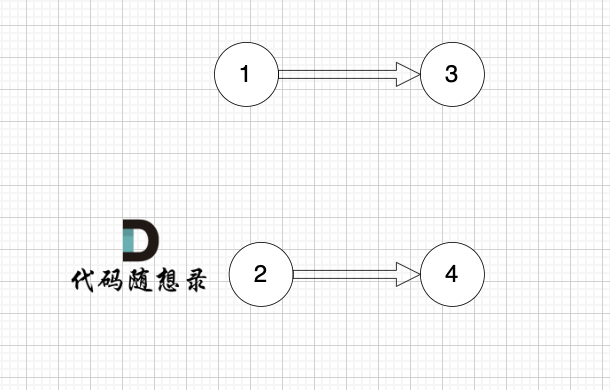
|
||||
|
||||
|
||||
----------------
|
||||
|
||||
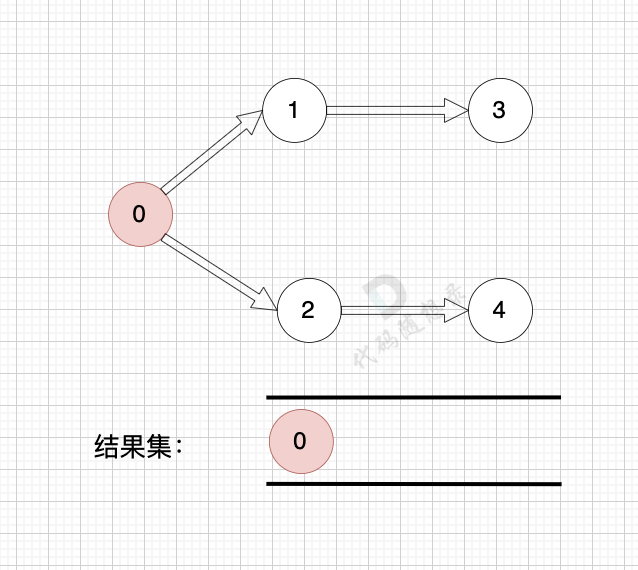
1、找到入度为0 的节点,加入结果集
|
||||
|
||||
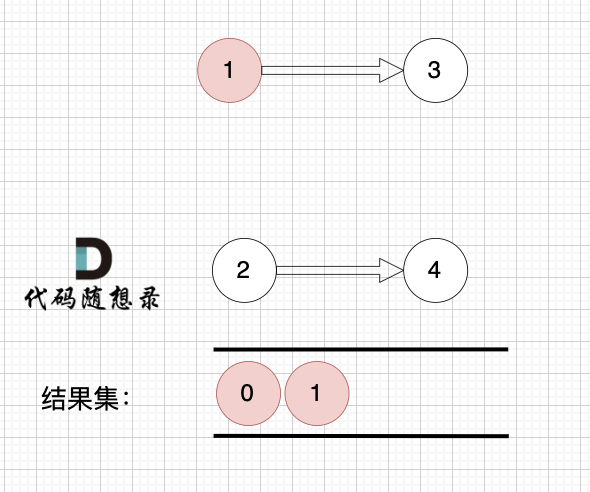
|
||||
|
||||
|
||||
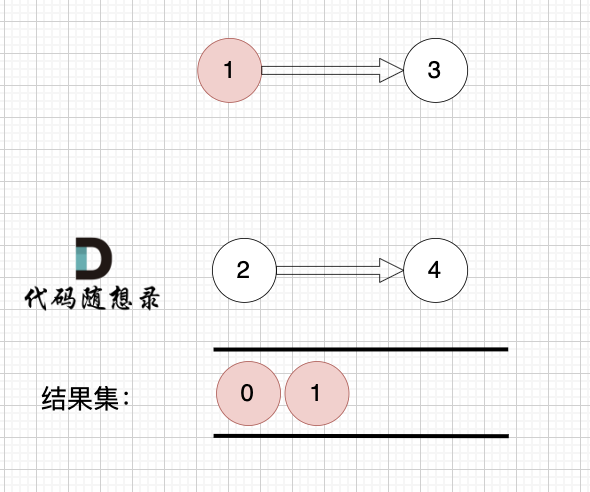
这里大家会发现,节点1 和 节点2 入度都为0, 选哪个呢?
|
||||
|
||||
@@ -153,19 +153,19 @@
|
||||
|
||||
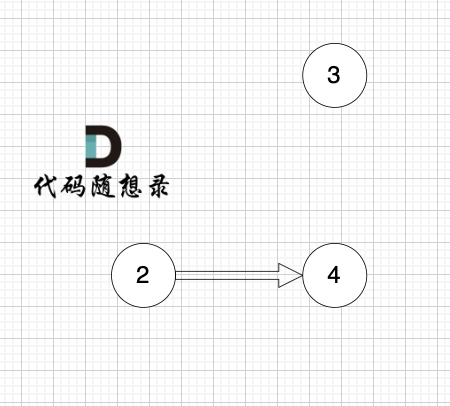
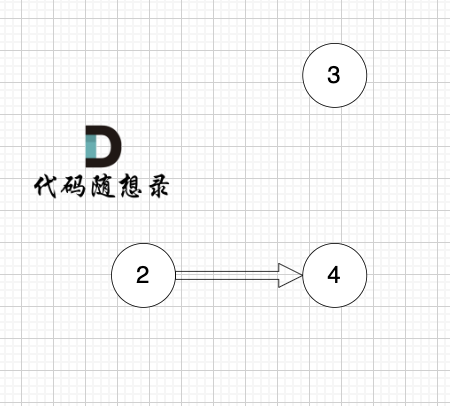
2、将该节点从图中移除
|
||||
|
||||
|
||||
|
||||
|
||||
---------------
|
||||
|
||||
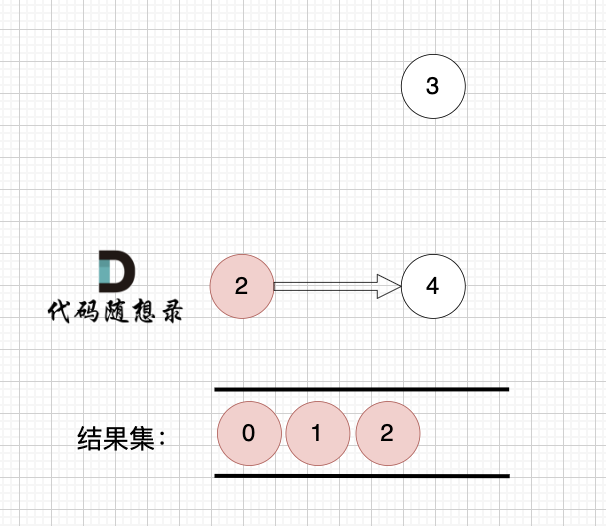
1、找到入度为0 的节点,加入结果集
|
||||
|
||||
|
||||
|
||||
|
||||
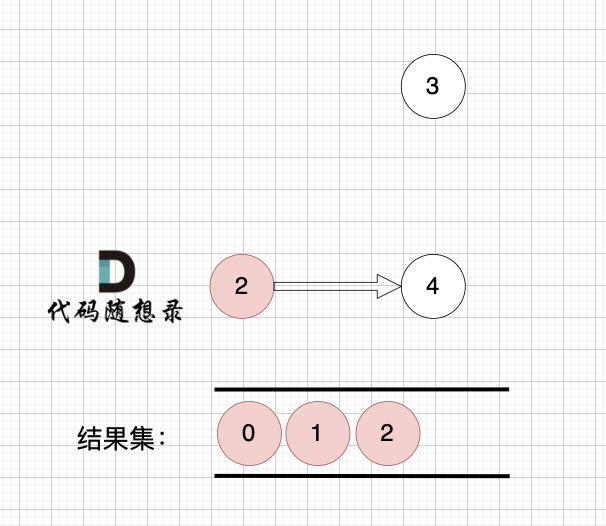
节点2 和 节点3 入度都为0,选哪个都行,这里选节点2
|
||||
|
||||
2、将该节点从图中移除
|
||||
|
||||

|
||||
|
||||
|
||||
--------------
|
||||
|
||||
@@ -177,7 +177,7 @@
|
||||
|
||||
如果有 有向环怎么办呢?例如这个图:
|
||||
|
||||
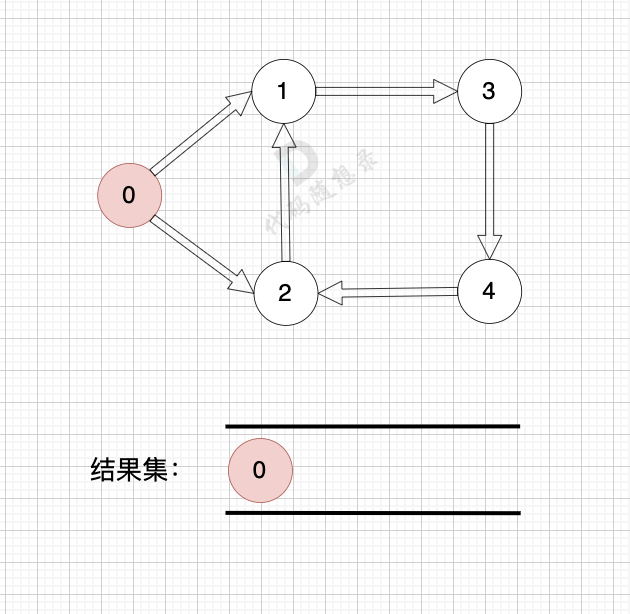
|
||||
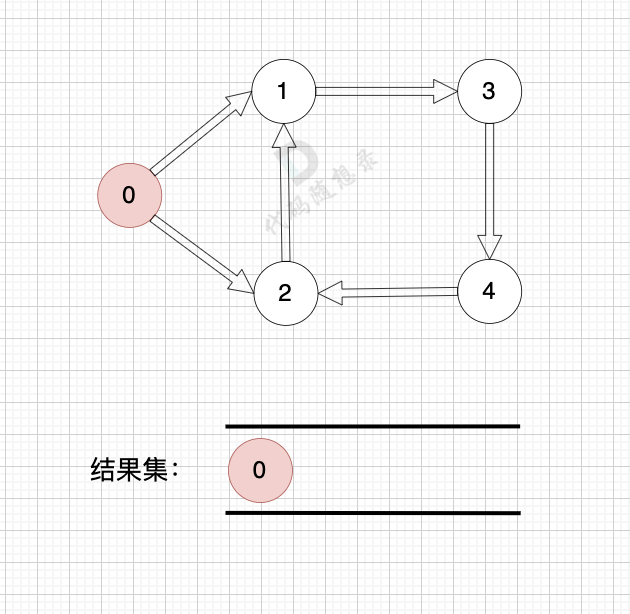
|
||||
|
||||
这个图,我们只能将入度为0 的节点0 接入结果集。
|
||||
|
||||
@@ -252,13 +252,13 @@ while (que.size()) {
|
||||
|
||||
如果这里不理解,看上面的模拟过程第一步:
|
||||
|
||||

|
||||

|
||||
|
||||
这事节点1 和 节点2 的入度为 1。
|
||||
|
||||
将节点0删除后,图为这样:
|
||||
|
||||

|
||||

|
||||
|
||||
那么 节点0 作为出发点 所连接的节点的入度 就都做了 减一 的操作。
|
||||
|
||||
|
||||
@@ -9,7 +9,7 @@
|
||||
|
||||
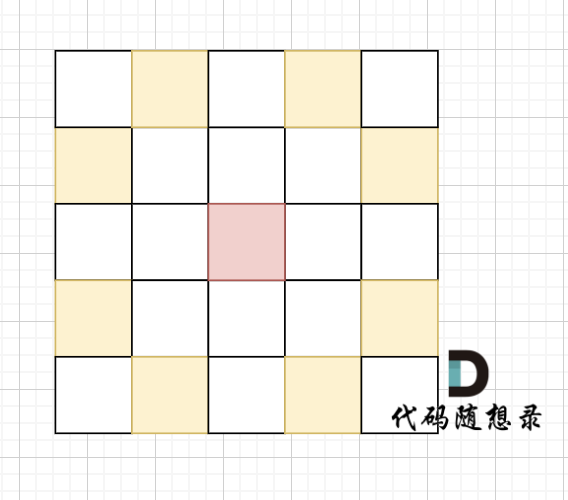
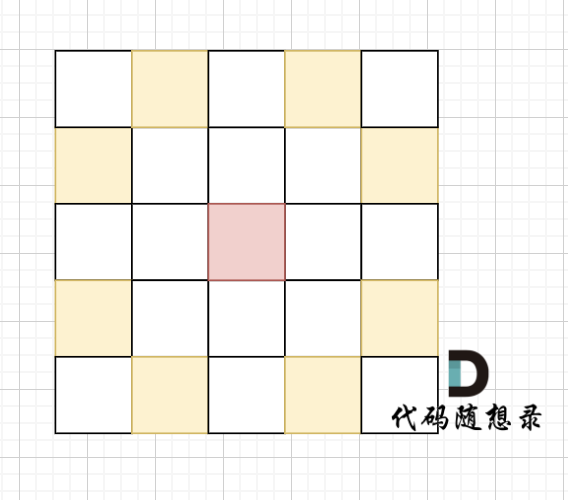
骑士移动规则如图,红色是起始位置,黄色是骑士可以走的地方。
|
||||
|
||||
|
||||
|
||||
|
||||
棋盘大小 1000 x 1000(棋盘的 x 和 y 坐标均在 [1, 1000] 区间内,包含边界)
|
||||
|
||||
@@ -108,7 +108,7 @@ int main()
|
||||
|
||||
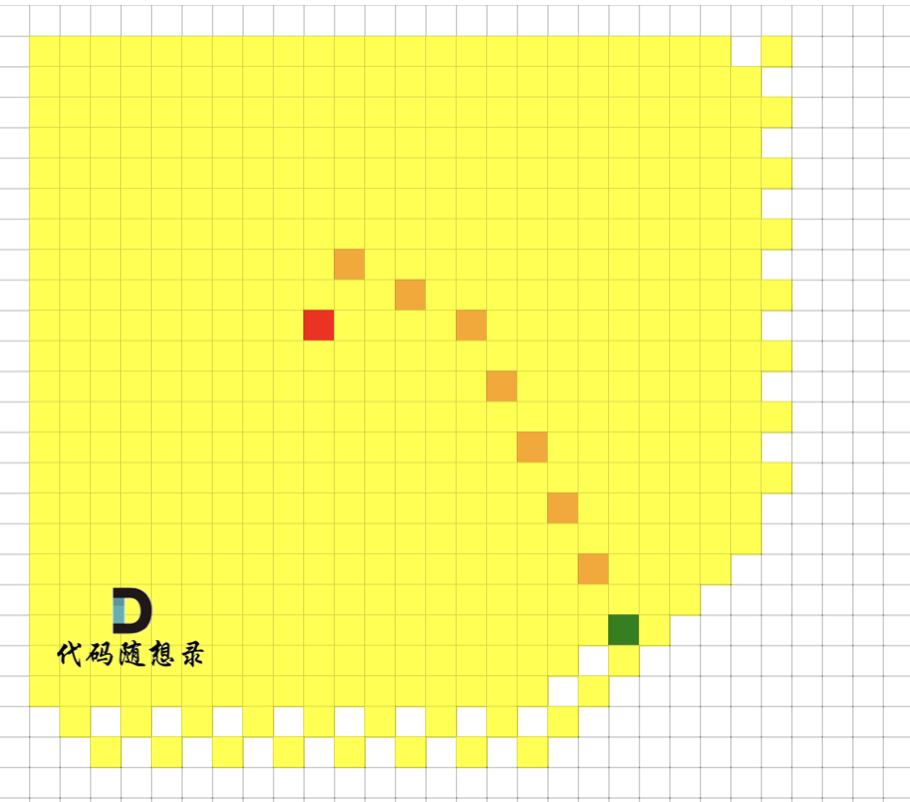
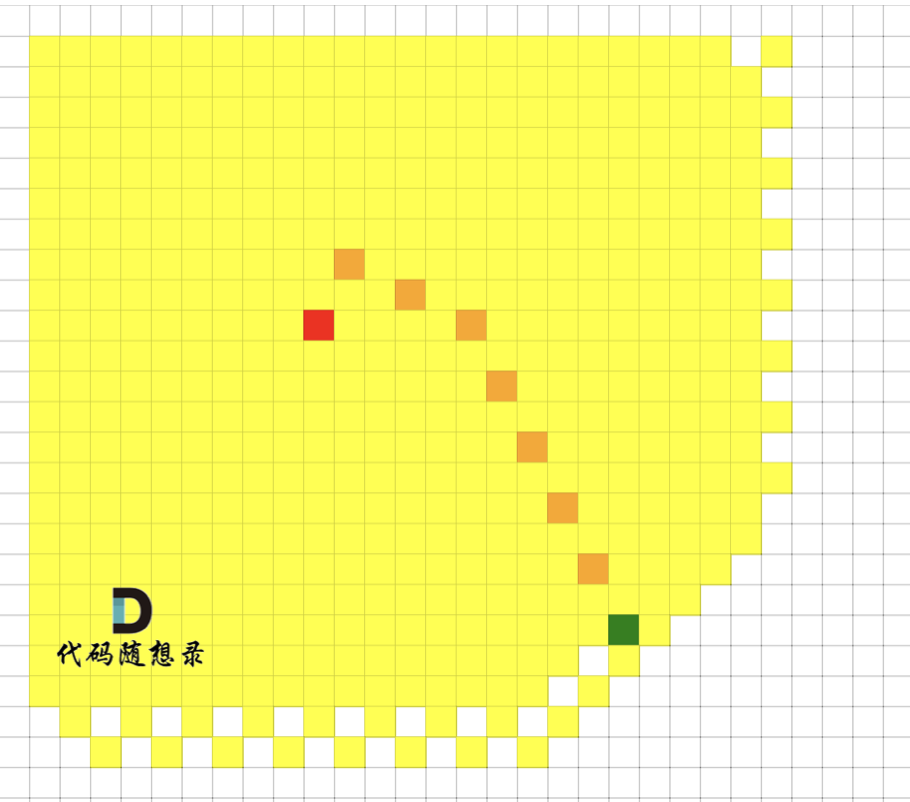
我们来看一下广搜的搜索过程,如图,红色是起点,绿色是终点,黄色是要遍历的点,最后从 起点 找到 达到终点的最短路径是棕色。
|
||||
|
||||
|
||||
|
||||
|
||||
可以看出 广搜中,做了很多无用的遍历, 黄色的格子是广搜遍历到的点。
|
||||
|
||||
@@ -131,11 +131,11 @@ Astar 是一种 广搜的改良版。 有的是 Astar是 dijkstra 的改良版
|
||||
|
||||
在BFS中,我们想搜索,从起点到终点的最短路径,要一层一层去遍历。
|
||||
|
||||

|
||||

|
||||
|
||||
如果 使用A * 的话,其搜索过程是这样的,如图,图中着色的都是我们要遍历的点。
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
(上面两图中 最短路长度都是8,只是走的方式不同而已)
|
||||
|
||||
@@ -105,13 +105,13 @@ bool isSame(int u, int v) {
|
||||
|
||||
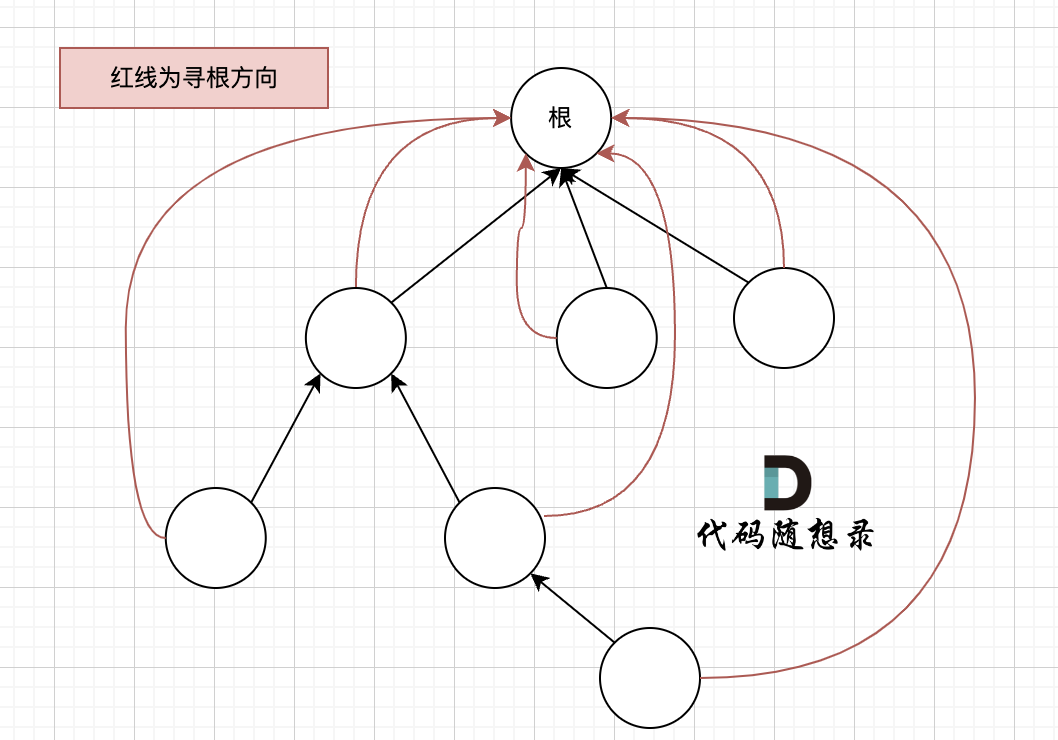
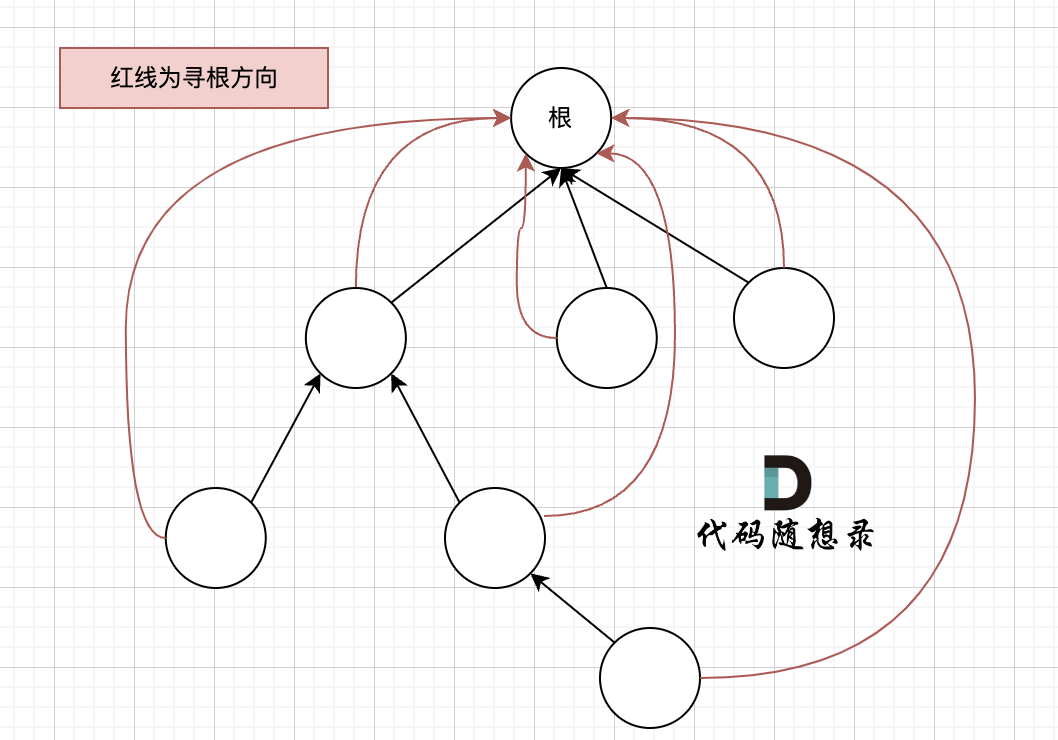
搜索过程像是一个多叉树中从叶子到根节点的过程,如图:
|
||||
|
||||
|
||||
|
||||
|
||||
如果这棵多叉树高度很深的话,每次find函数 去寻找根的过程就要递归很多次。
|
||||
|
||||
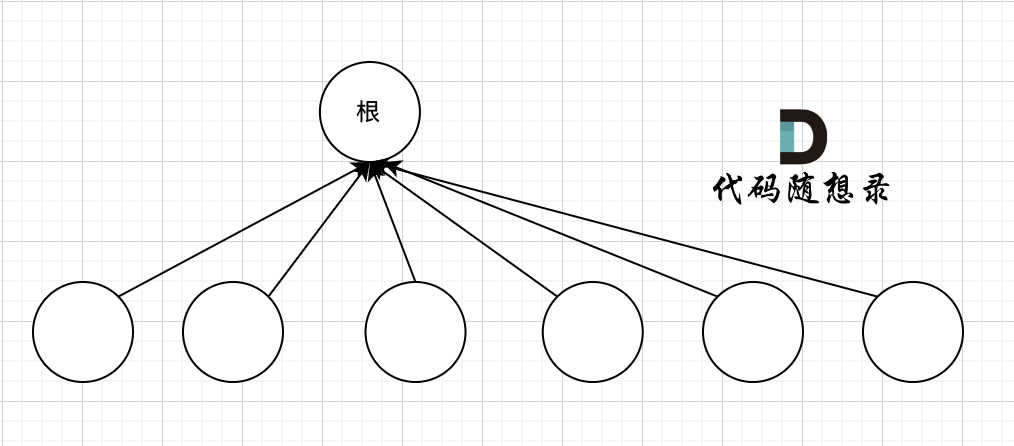
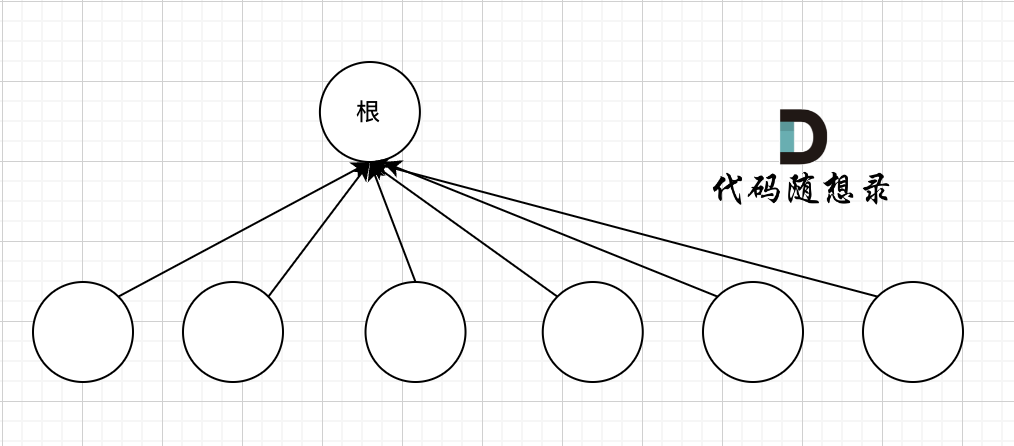
我们的目的只需要知道这些节点在同一个根下就可以,所以对这棵多叉树的构造只需要这样就可以了,如图:
|
||||
|
||||
|
||||
|
||||
|
||||
除了根节点其他所有节点都挂载根节点下,这样我们在寻根的时候就很快,只需要一步,
|
||||
|
||||
@@ -226,7 +226,7 @@ join(3, 2);
|
||||
|
||||
此时构成的图是这样的:
|
||||
|
||||
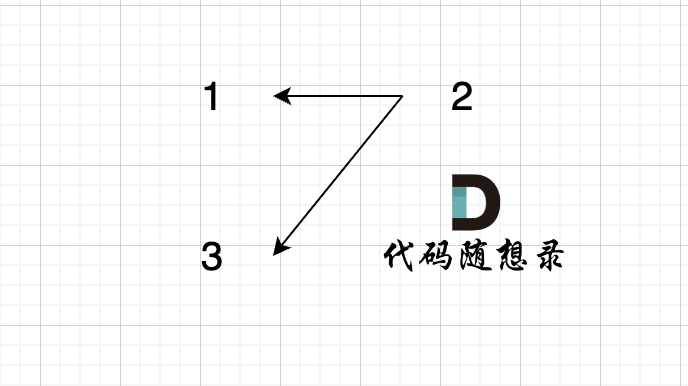
|
||||

|
||||
|
||||
此时问 1,3是否在同一个集合,我们调用 `join(1, 2); join(3, 2);` 很明显本意要表示 1,3是在同一个集合。
|
||||
|
||||
@@ -256,7 +256,7 @@ join(3, 2);
|
||||
|
||||
构成的图是这样的:
|
||||
|
||||
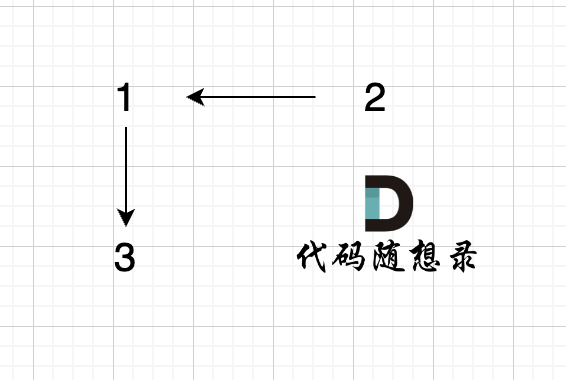
|
||||
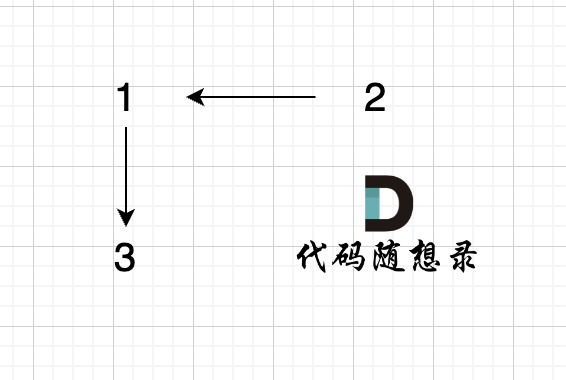
|
||||
|
||||
因为在join函数里,我们有find函数进行寻根的过程,这样就保证元素 1,2,3在这个有向图里是强连通的。
|
||||
|
||||
@@ -275,12 +275,12 @@ join(3, 2);
|
||||
|
||||
1、`join(1, 8);`
|
||||
|
||||
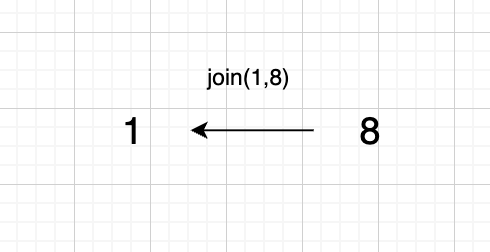
|
||||
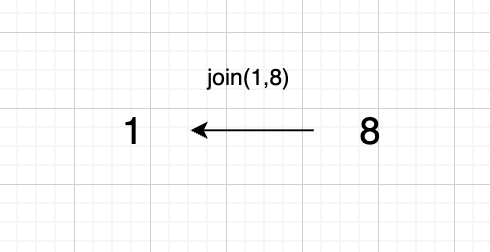
|
||||
|
||||
|
||||
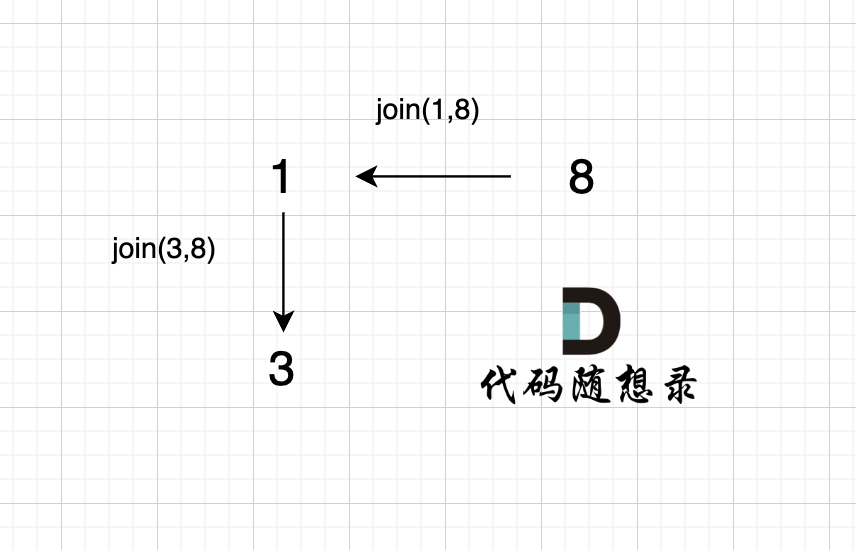
2、`join(3, 8);`
|
||||
|
||||
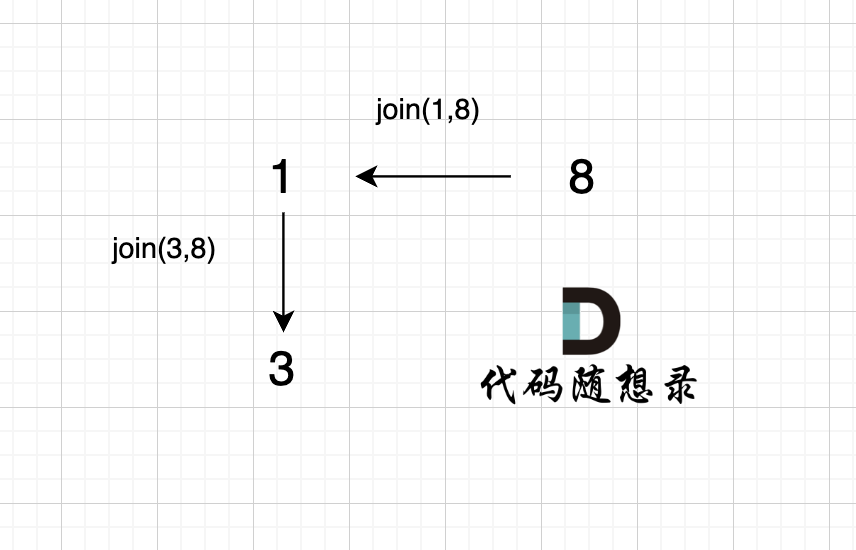
|
||||
|
||||
|
||||
有录友可能想,`join(3, 8)` 在图中为什么 将 元素1 连向元素 3 而不是将 元素 8 连向 元素 3 呢?
|
||||
|
||||
@@ -288,12 +288,12 @@ join(3, 2);
|
||||
|
||||
3、`join(1, 7);`
|
||||
|
||||
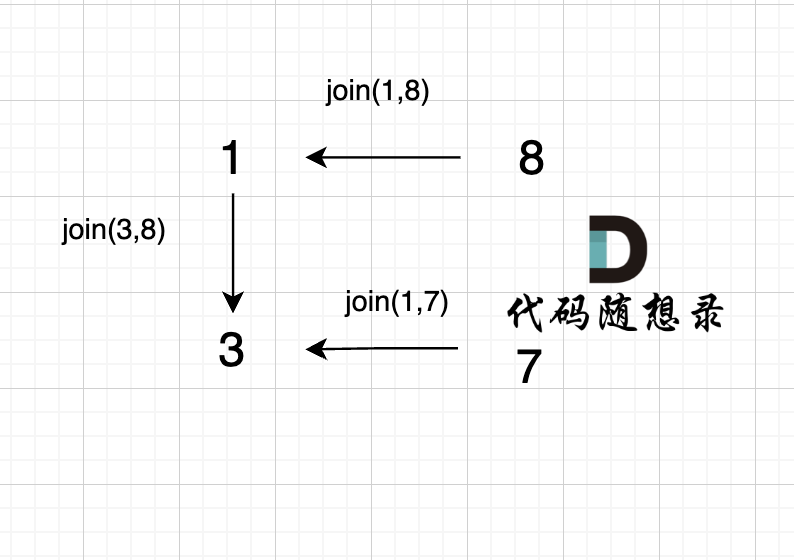
|
||||
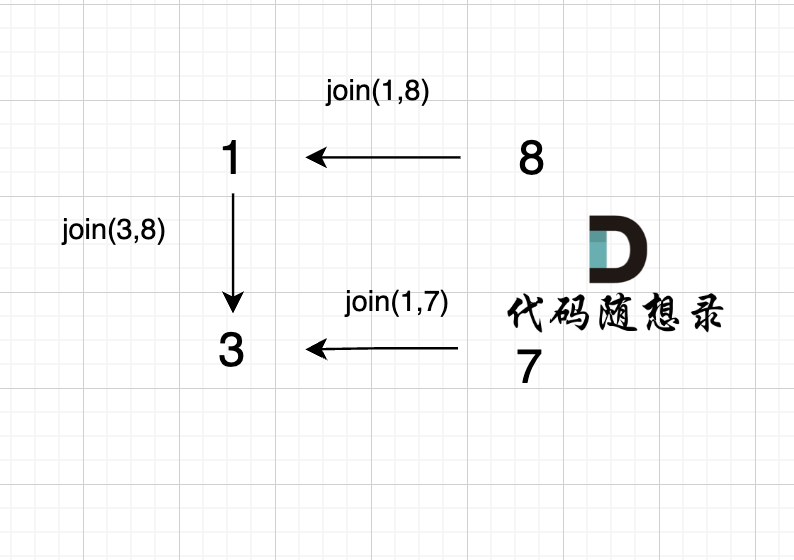
|
||||
|
||||
|
||||
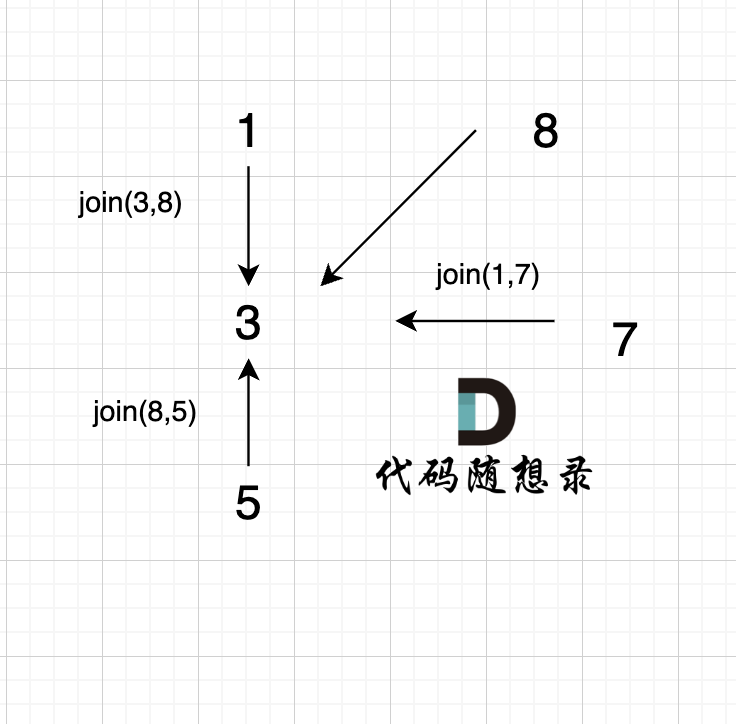
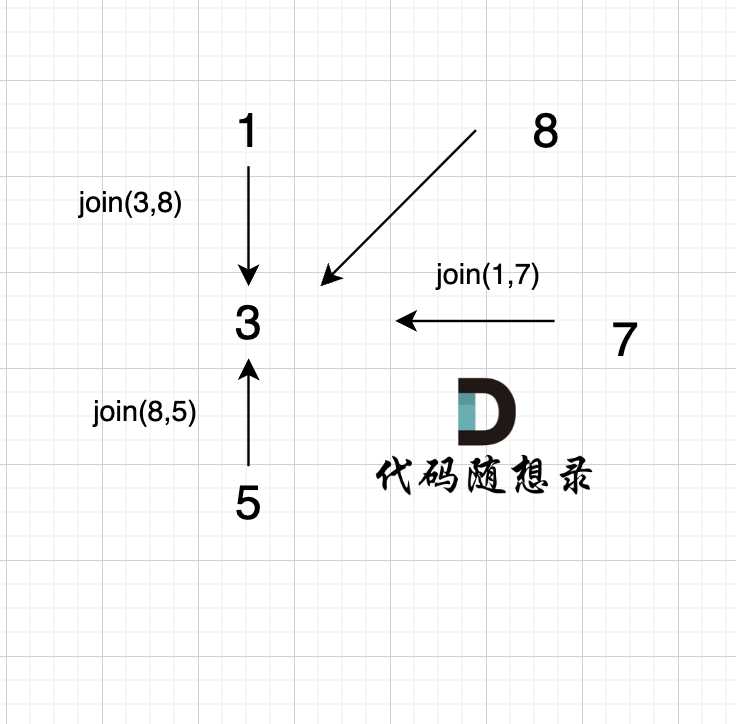
4、`join(8, 5);`
|
||||
|
||||
|
||||
|
||||
|
||||
这里8的根是3,那么 5 应该指向 8 的根 3,这里的原因,我们在上面「常见误区」已经讲过了。 但 为什么 图中 8 又直接指向了 3 了呢?
|
||||
|
||||
@@ -310,11 +310,11 @@ int find(int u) {
|
||||
|
||||
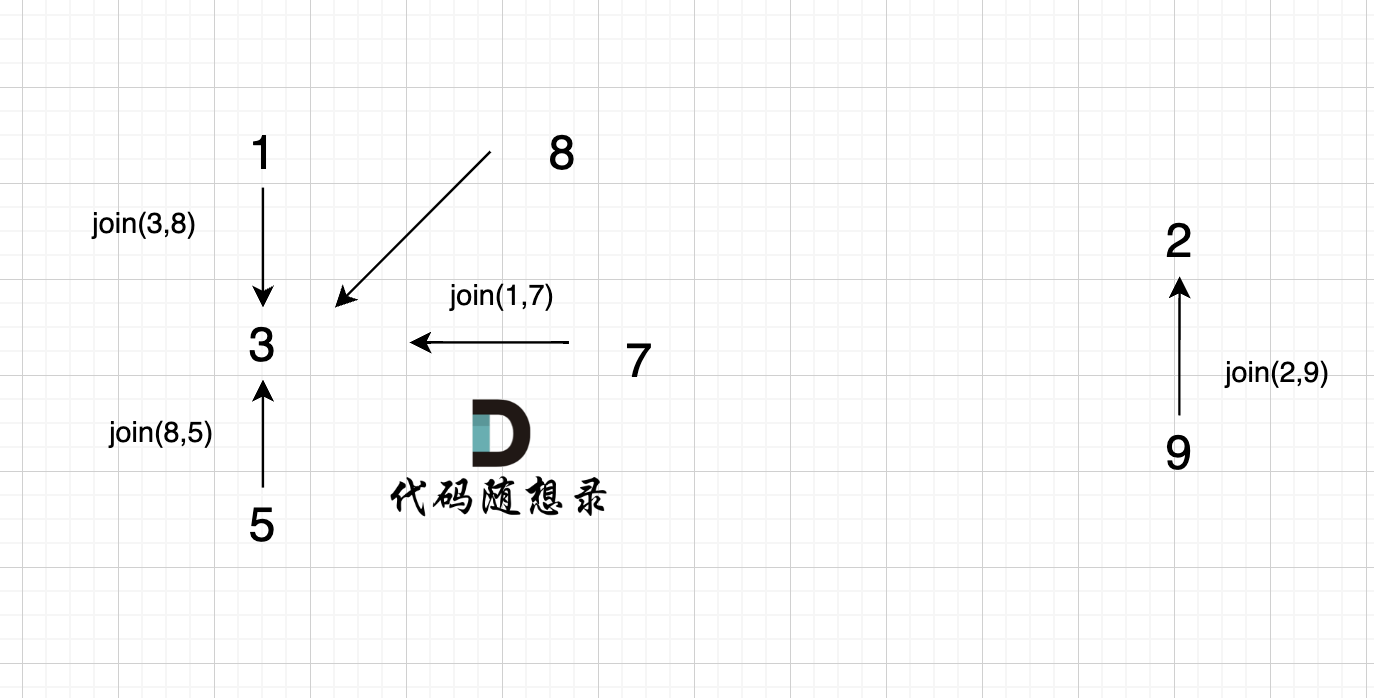
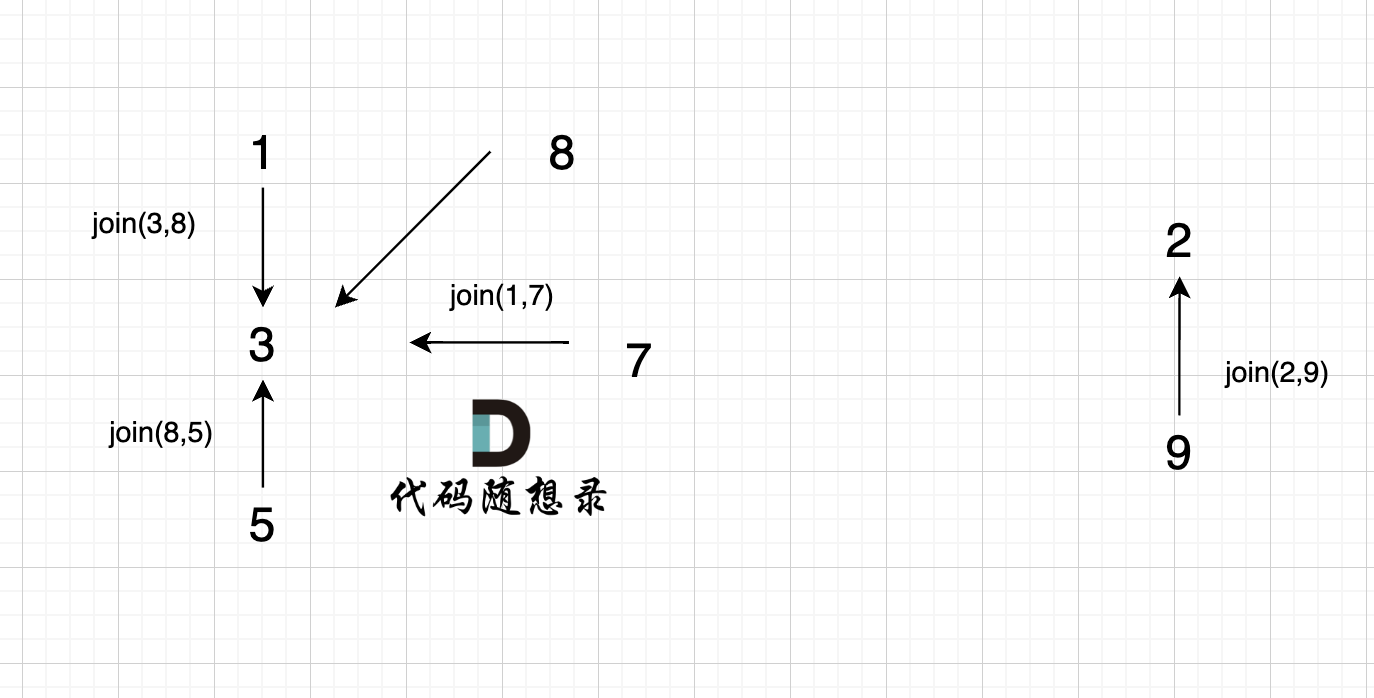
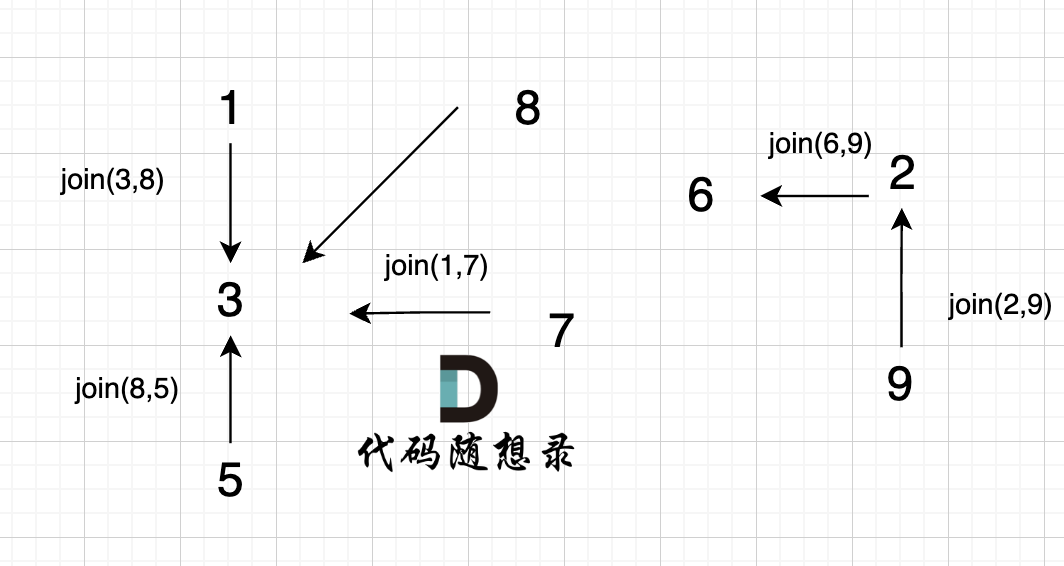
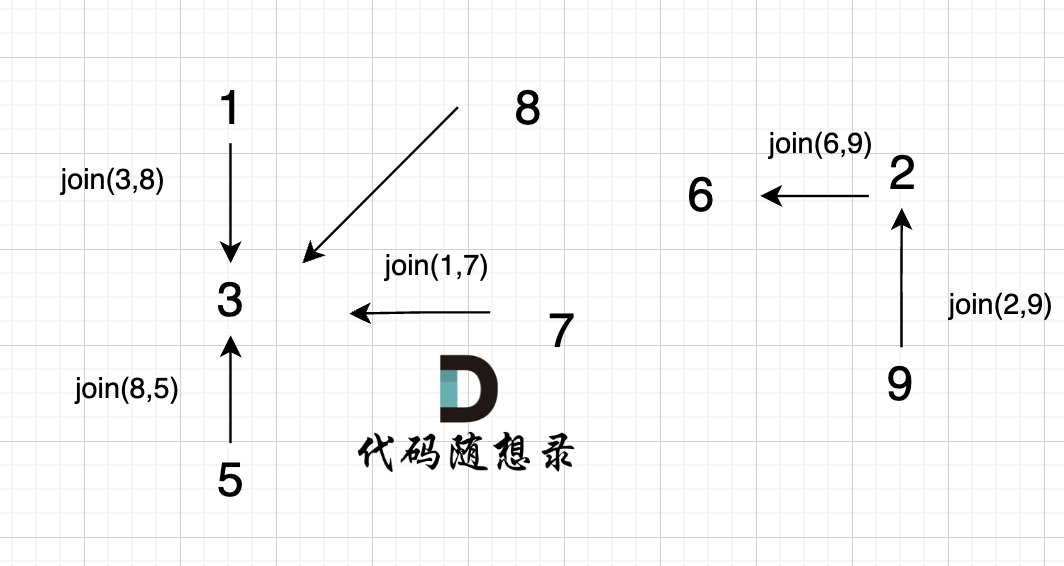
5、`join(2, 9);`
|
||||
|
||||
|
||||
|
||||
|
||||
6、`join(6, 9);`
|
||||
|
||||
|
||||
|
||||
|
||||
这里为什么是 2 指向了 6,因为 9的根为 2,所以用2指向6。
|
||||
|
||||
@@ -347,13 +347,13 @@ rank表示树的高度,即树中结点层次的最大值。
|
||||
|
||||
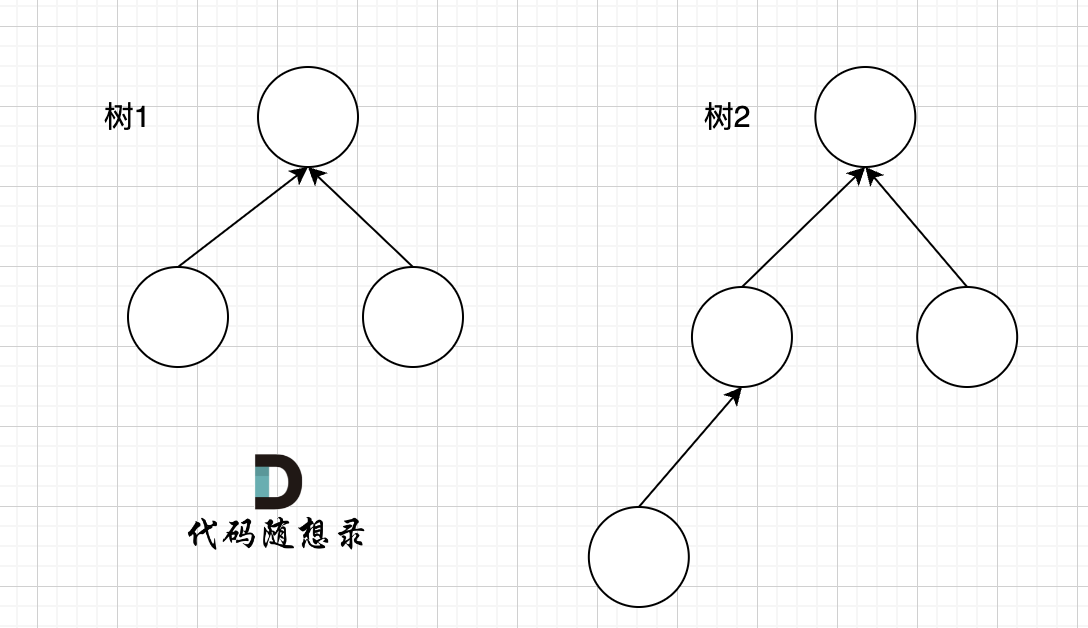
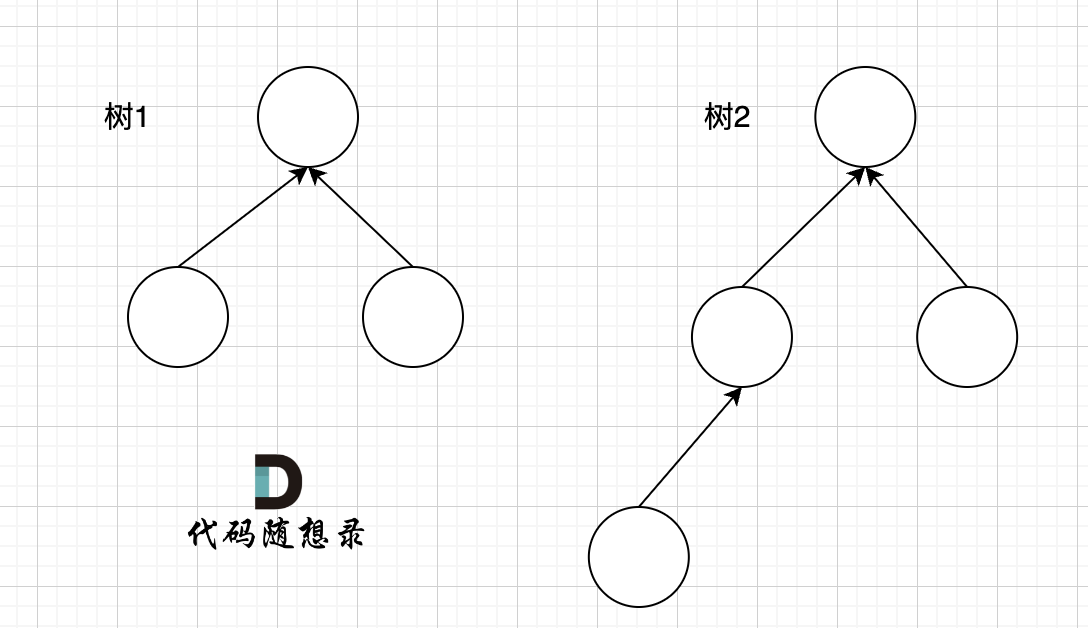
例如两个集合(多叉树)需要合并,如图所示:
|
||||
|
||||
|
||||
|
||||
|
||||
树1 rank 为2,树2 rank 为 3。那么合并两个集合,是 树1 合入 树2,还是 树2 合入 树1呢?
|
||||
|
||||
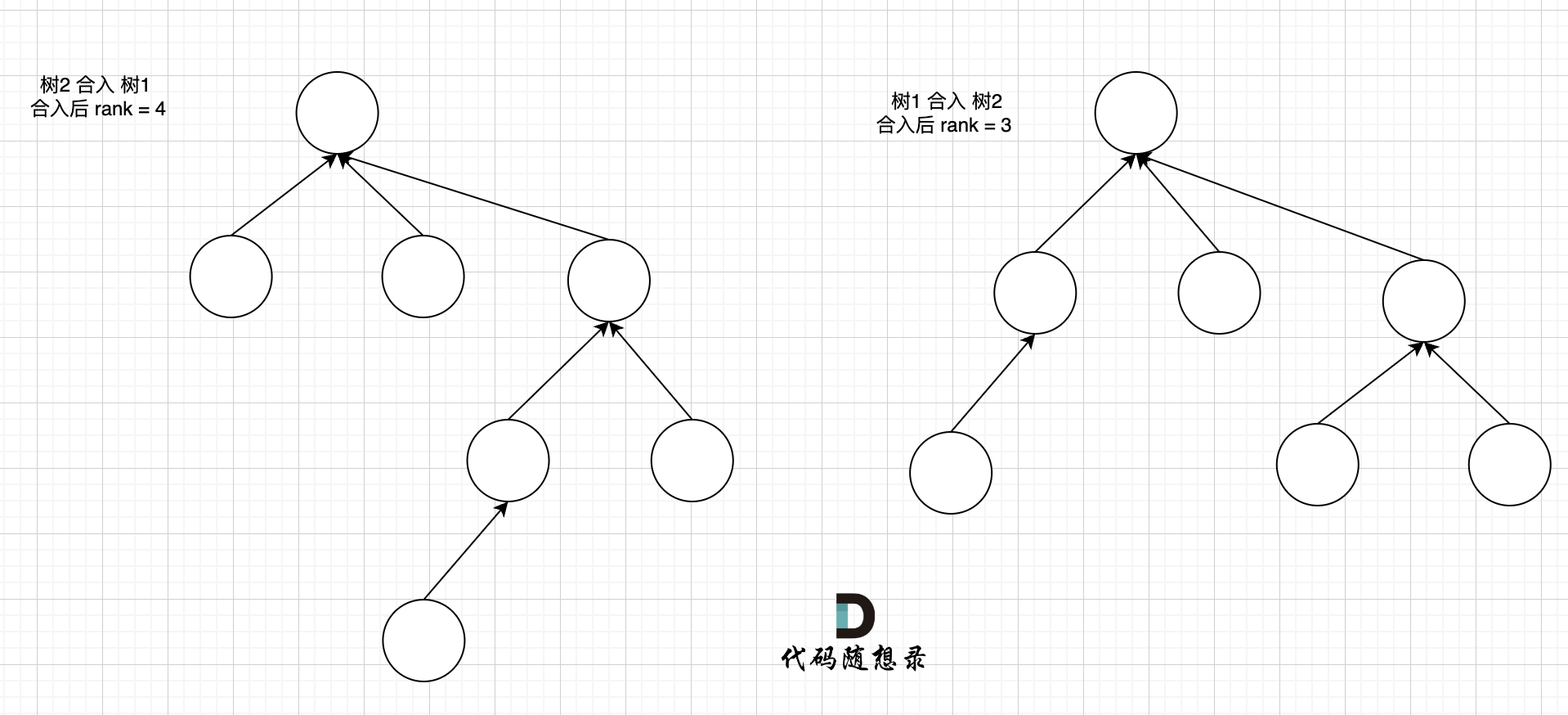
我们来看两个不同方式合入的效果。
|
||||
|
||||
|
||||
|
||||
|
||||
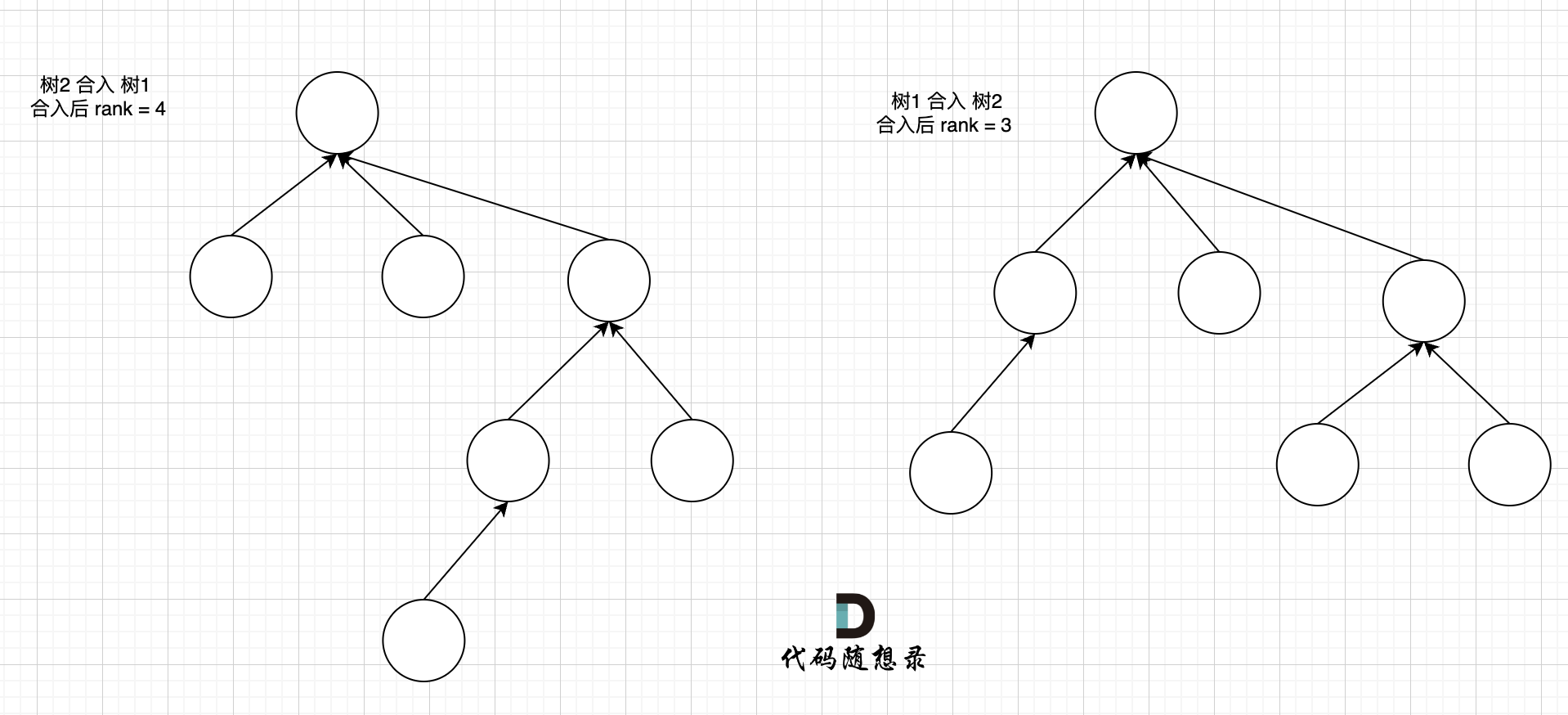
这里可以看出,树2 合入 树1 会导致整棵树的高度变的更高,而 树1 合入 树2 整棵树的高度 和 树2 保持一致。
|
||||
|
||||
|
||||
@@ -18,11 +18,11 @@
|
||||
|
||||
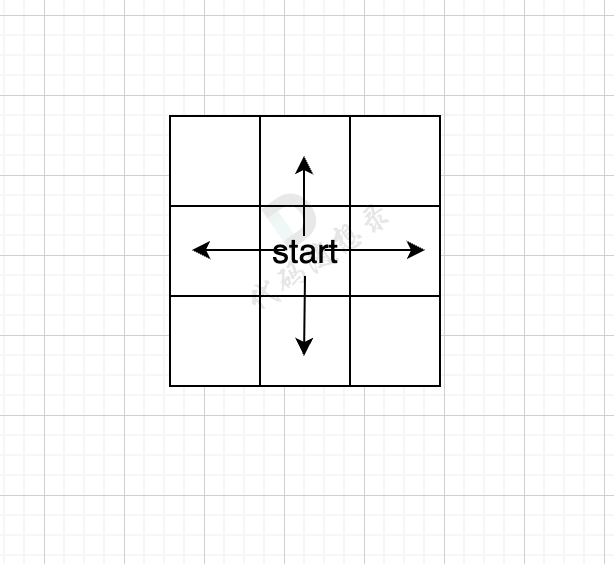
我们用一个方格地图,假如每次搜索的方向为 上下左右(不包含斜上方),那么给出一个start起始位置,那么BFS就是从四个方向走出第一步。
|
||||
|
||||
|
||||
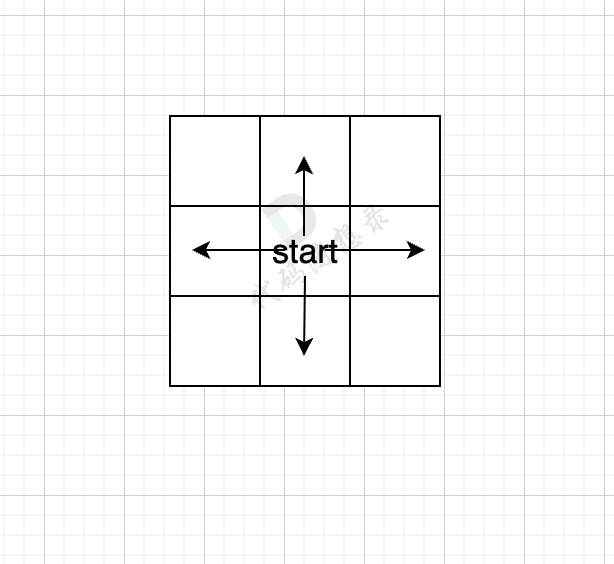
|
||||
|
||||
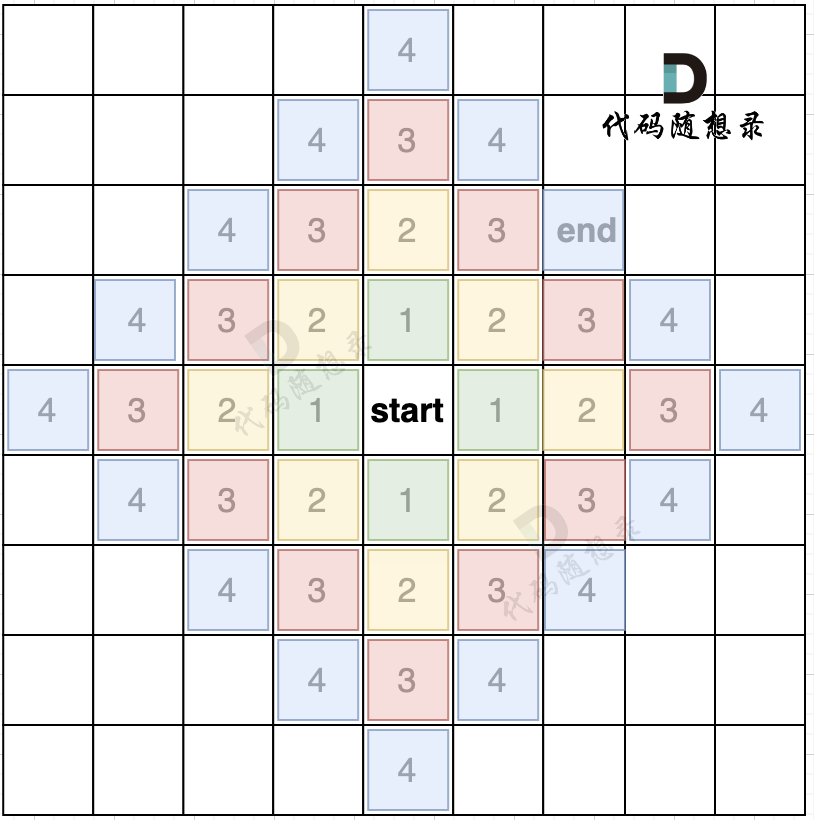
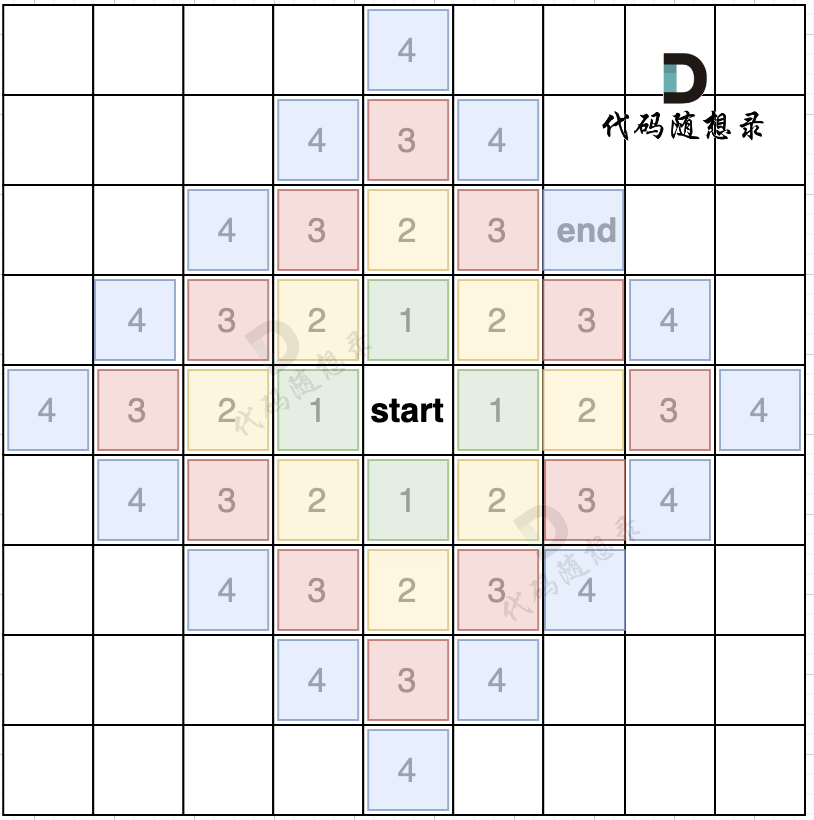
如果加上一个end终止位置,那么使用BFS的搜索过程如图所示:
|
||||
|
||||
|
||||
|
||||
|
||||
我们从图中可以看出,从start起点开始,是一圈一圈,向外搜索,方格编号1为第一步遍历的节点,方格编号2为第二步遍历的节点,第四步的时候我们找到终止点end。
|
||||
|
||||
@@ -30,7 +30,7 @@
|
||||
|
||||
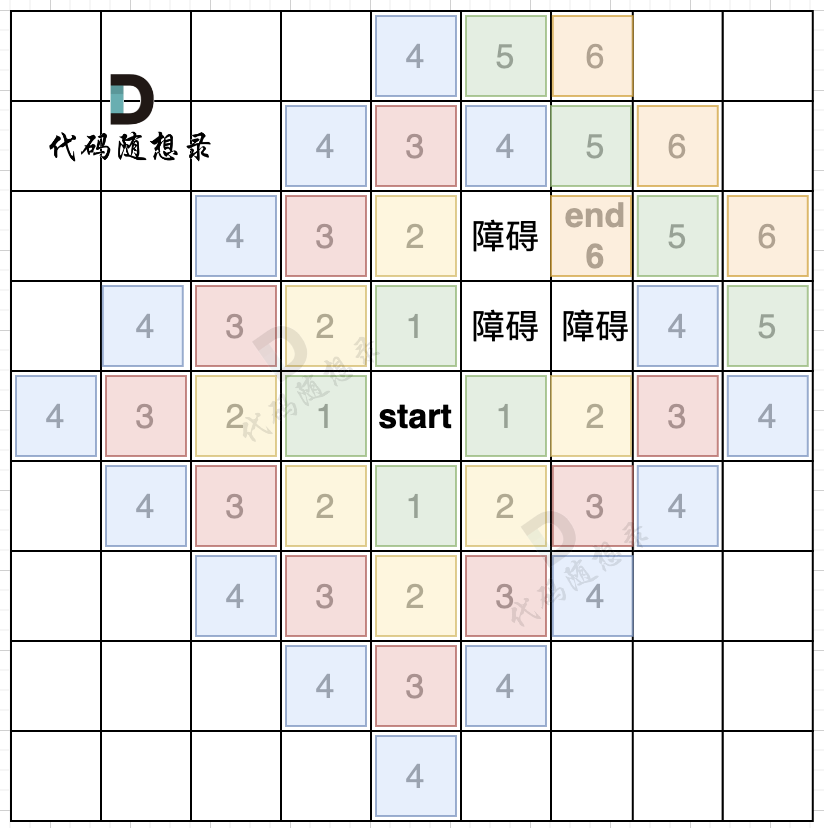
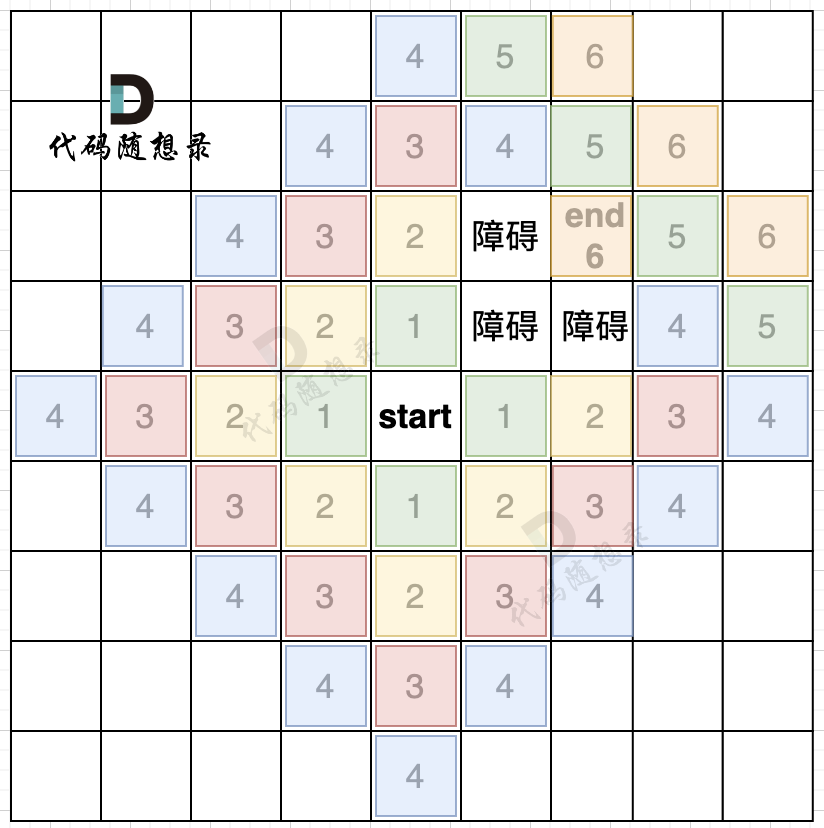
而且地图还可以有障碍,如图所示:
|
||||
|
||||
|
||||
|
||||
|
||||
在第五步,第六步 我只把关键的节点染色了,其他方向周边没有去染色,大家只要关注关键地方染色的逻辑就可以。
|
||||
|
||||
|
||||
@@ -28,29 +28,29 @@
|
||||
|
||||
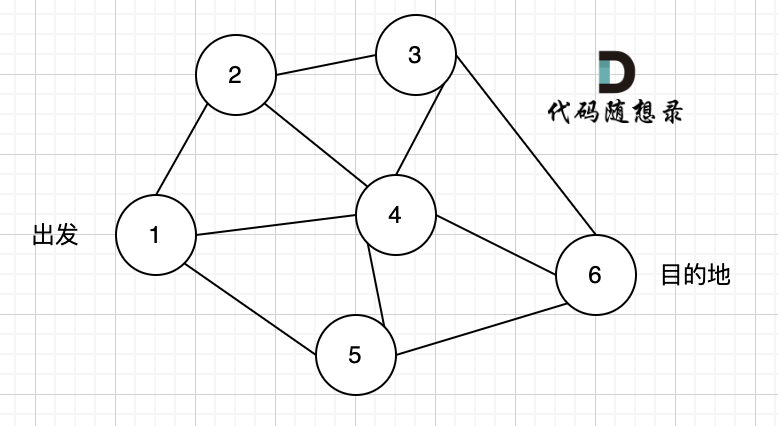
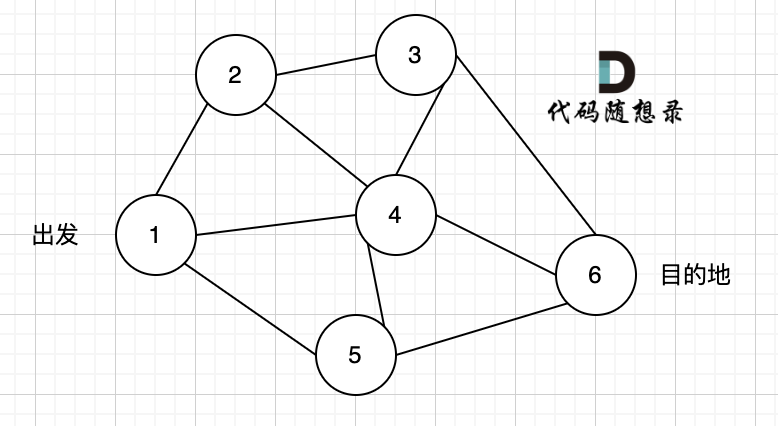
如图一,是一个无向图,我们要搜索从节点1到节点6的所有路径。
|
||||
|
||||
|
||||
|
||||
|
||||
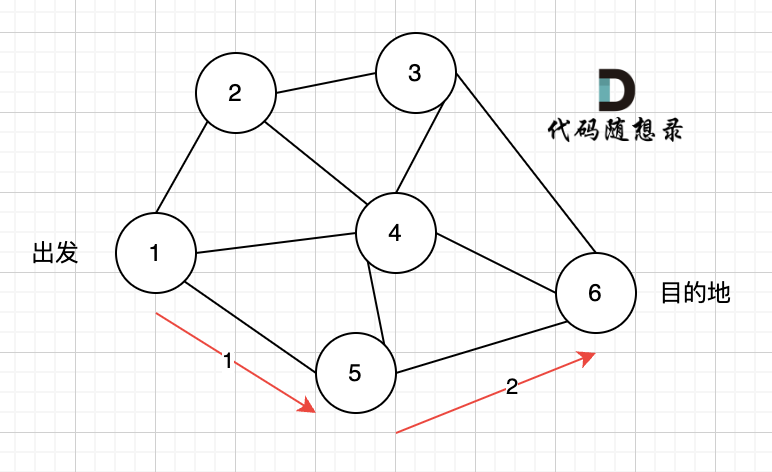
那么dfs搜索的第一条路径是这样的: (假设第一次延默认方向,就找到了节点6),图二
|
||||
|
||||
|
||||
|
||||
|
||||
此时我们找到了节点6,(遇到黄河了,是不是应该回头了),那么应该再去搜索其他方向了。 如图三:
|
||||
|
||||
|
||||
|
||||
|
||||
路径2撤销了,改变了方向,走路径3(红色线), 接着也找到终点6。 那么撤销路径2,改为路径3,在dfs中其实就是回溯的过程(这一点很重要,很多录友不理解dfs代码中回溯是用来干什么的)
|
||||
|
||||
又找到了一条从节点1到节点6的路径,又到黄河了,此时再回头,下图图四中,路径4撤销(回溯的过程),改为路径5。
|
||||
|
||||
|
||||
|
||||
|
||||
又找到了一条从节点1到节点6的路径,又到黄河了,此时再回头,下图图五,路径6撤销(回溯的过程),改为路径7,路径8 和 路径7,路径9, 结果发现死路一条,都走到了自己走过的节点。
|
||||
|
||||
|
||||
|
||||
|
||||
那么节点2所连接路径和节点3所链接的路径 都走过了,撤销路径只能向上回退,去选择撤销当初节点4的选择,也就是撤销路径5,改为路径10 。 如图图六:
|
||||
|
||||
|
||||
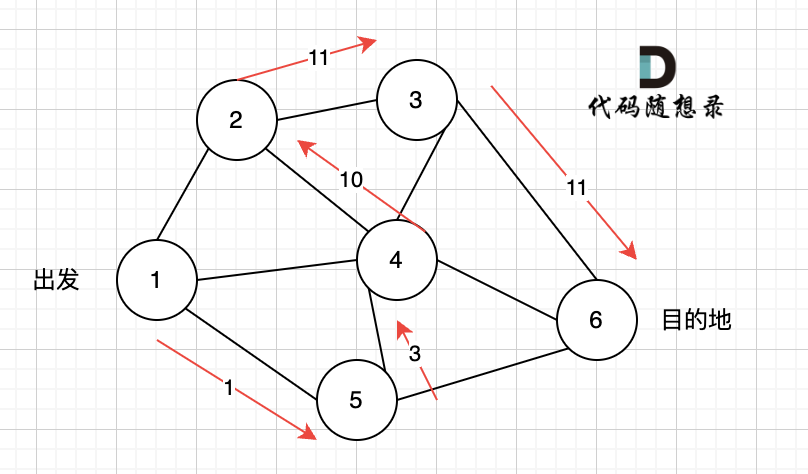
|
||||
|
||||
|
||||
上图演示中,其实我并没有把 所有的 从节点1 到节点6的dfs(深度优先搜索)的过程都画出来,那样太冗余了,但 已经把dfs 关键的地方都涉及到了,关键就两点:
|
||||
@@ -180,7 +180,7 @@ for (选择:本节点所连接的其他节点) {
|
||||
|
||||
如图七所示, 路径2 已经走到了 目的地节点6,那么 路径2 是如何撤销,然后改为 路径3呢? 其实这就是 回溯的过程,撤销路径2,走换下一个方向。
|
||||
|
||||
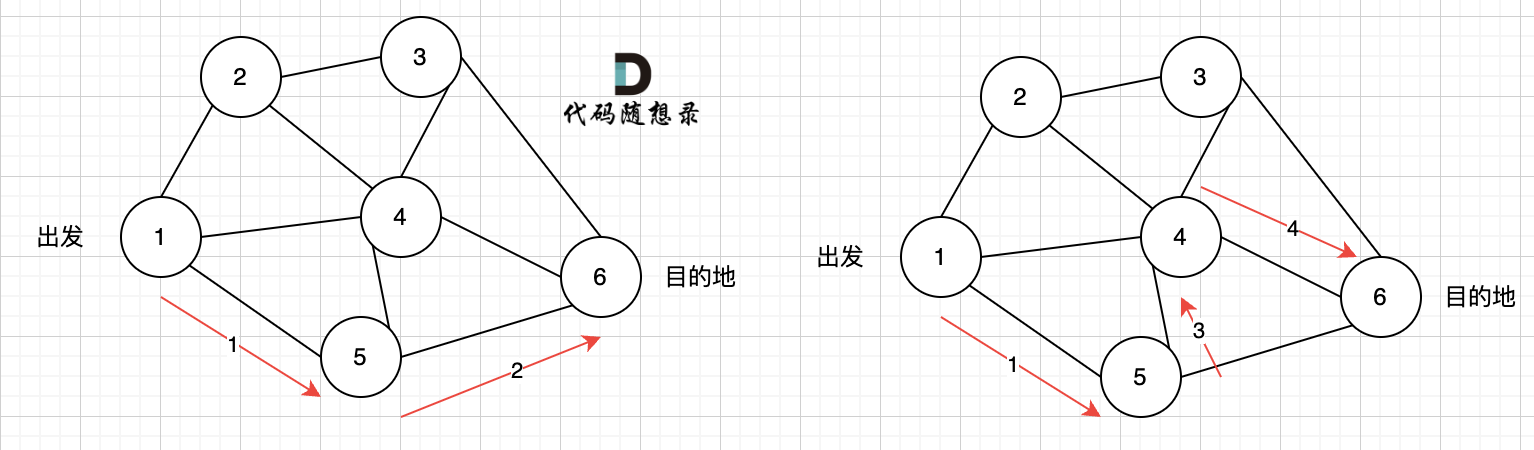
|
||||
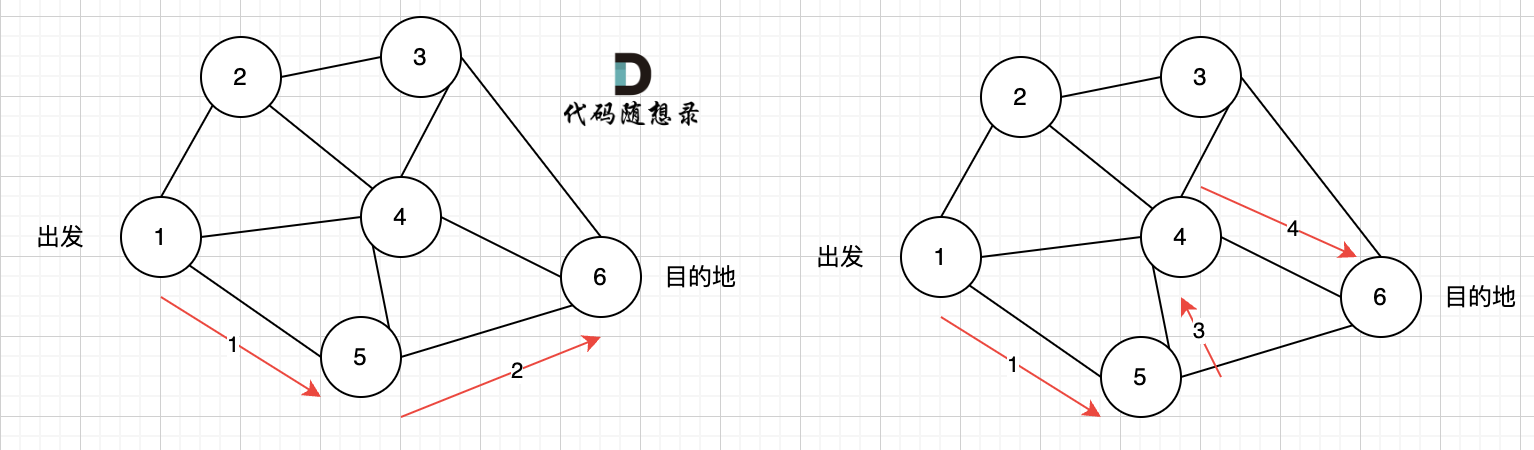
|
||||
|
||||
|
||||
## 总结
|
||||
|
||||
@@ -17,15 +17,15 @@
|
||||
|
||||
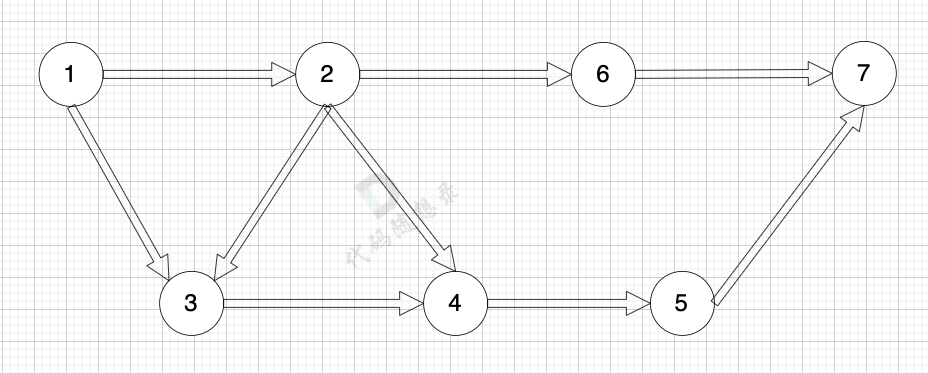
有向图是指 图中边是有方向的:
|
||||
|
||||
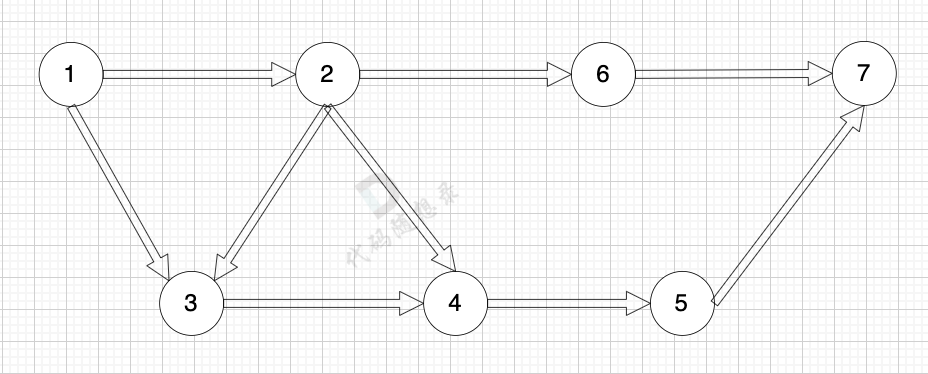
|
||||
|
||||
|
||||
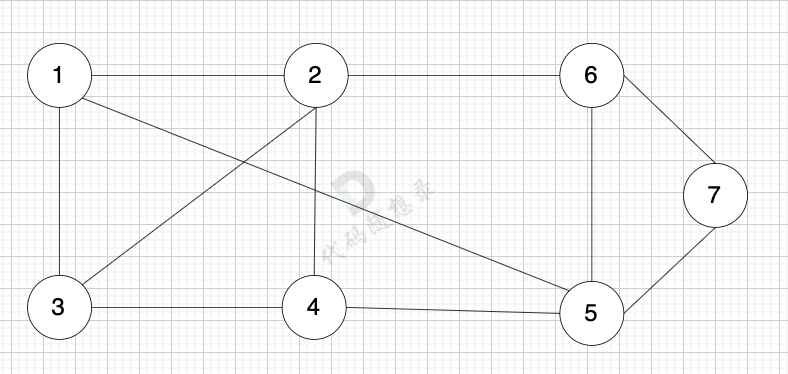
无向图是指 图中边没有方向:
|
||||
|
||||
|
||||
|
||||
|
||||
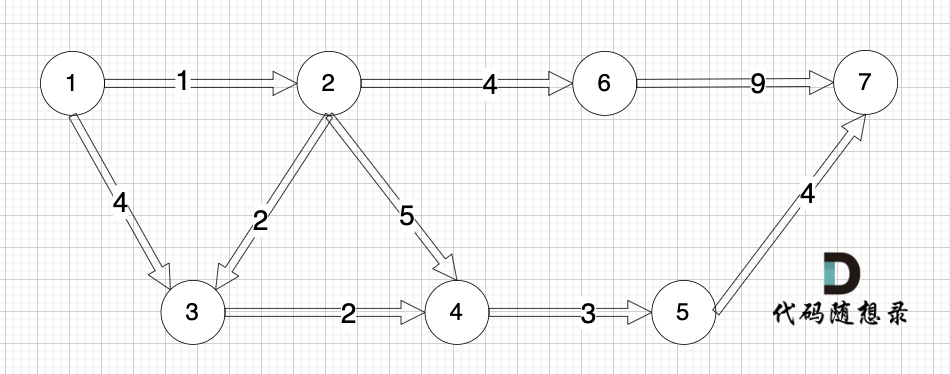
加权有向图,就是图中边是有权值的,例如:
|
||||
|
||||
|
||||
|
||||
|
||||
加权无向图也是同理。
|
||||
|
||||
@@ -35,7 +35,7 @@
|
||||
|
||||
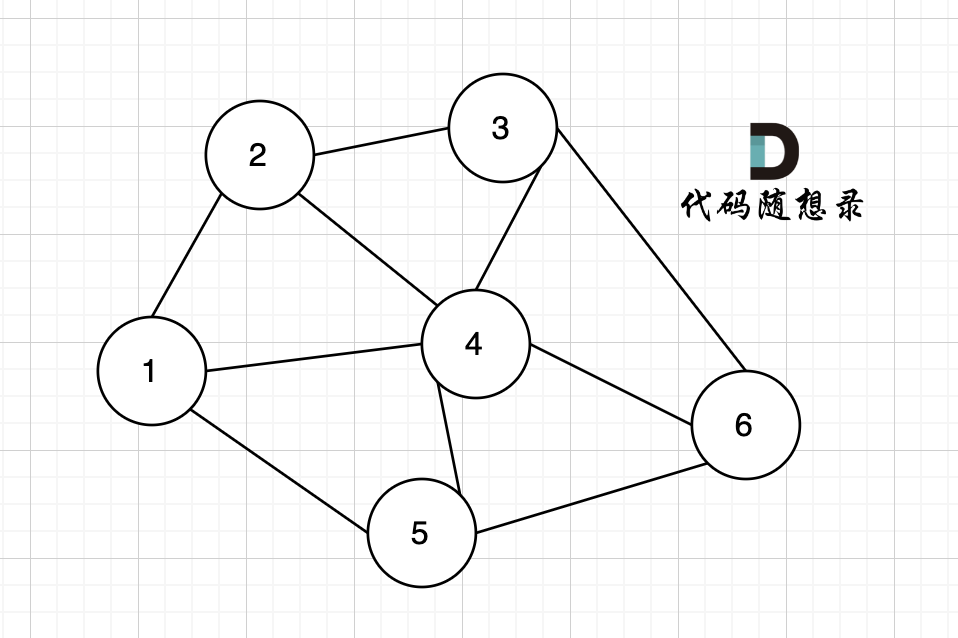
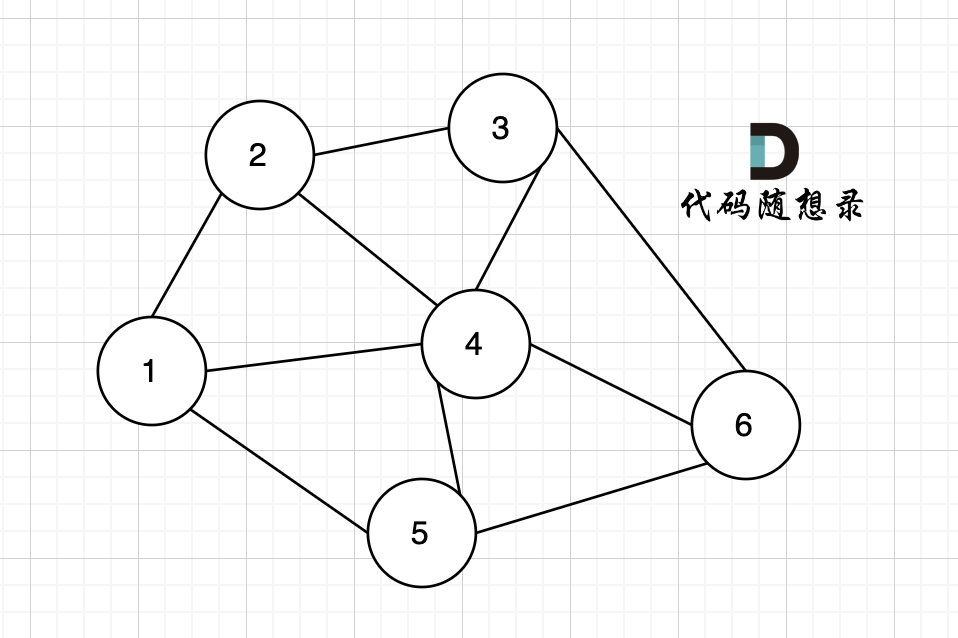
例如,该无向图中,节点4的度为5,节点6的度为3。
|
||||
|
||||
|
||||
|
||||
|
||||
在有向图中,每个节点有出度和入度。
|
||||
|
||||
@@ -45,7 +45,7 @@
|
||||
|
||||
例如,该有向图中,节点3的入度为2,出度为1,节点1的入度为0,出度为2。
|
||||
|
||||
|
||||
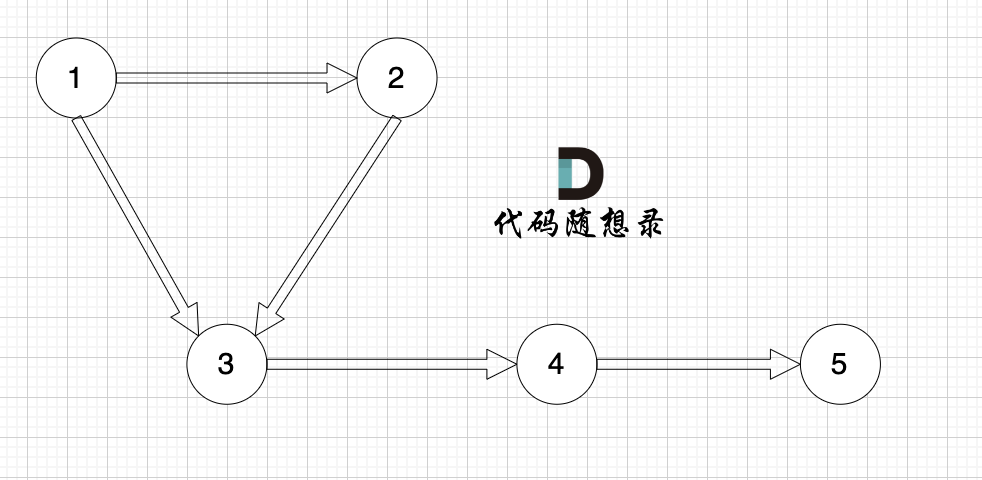
|
||||
|
||||
|
||||
## 连通性
|
||||
@@ -56,11 +56,11 @@
|
||||
|
||||
在无向图中,任何两个节点都是可以到达的,我们称之为连通图 ,如图:
|
||||
|
||||
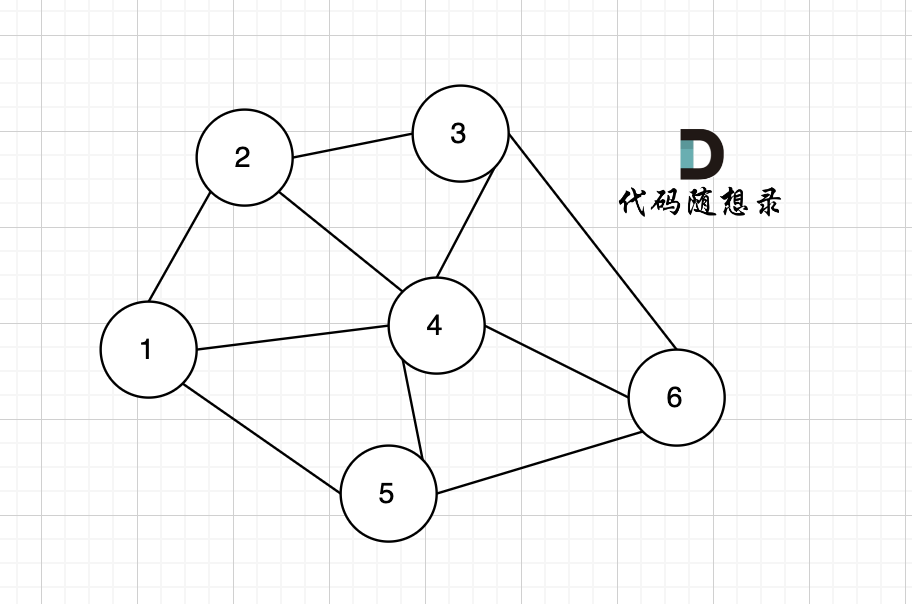
|
||||
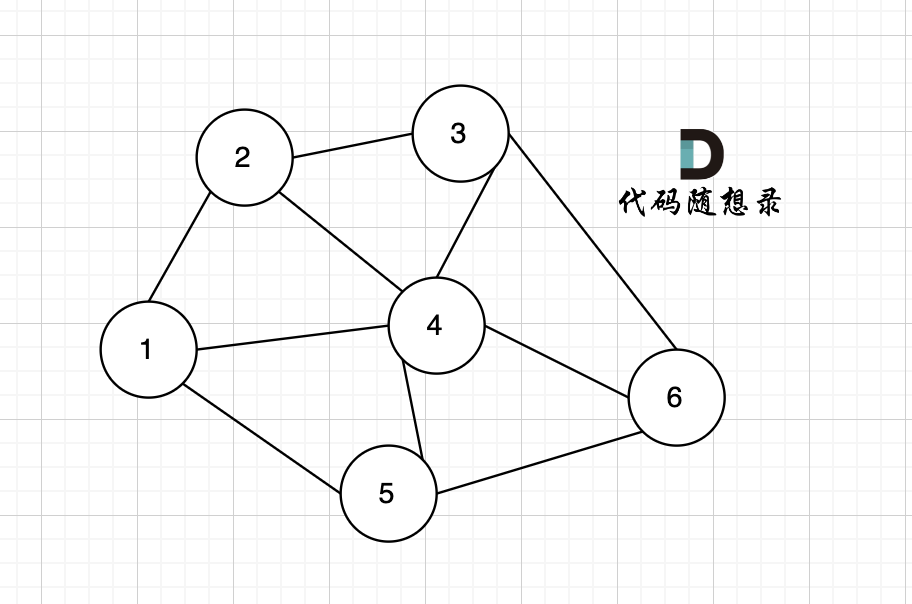
|
||||
|
||||
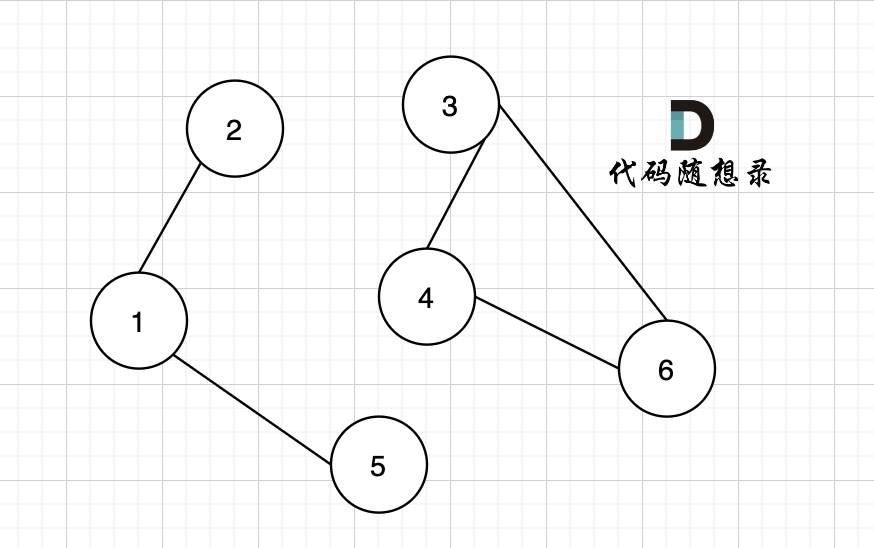
如果有节点不能到达其他节点,则为非连通图,如图:
|
||||
|
||||
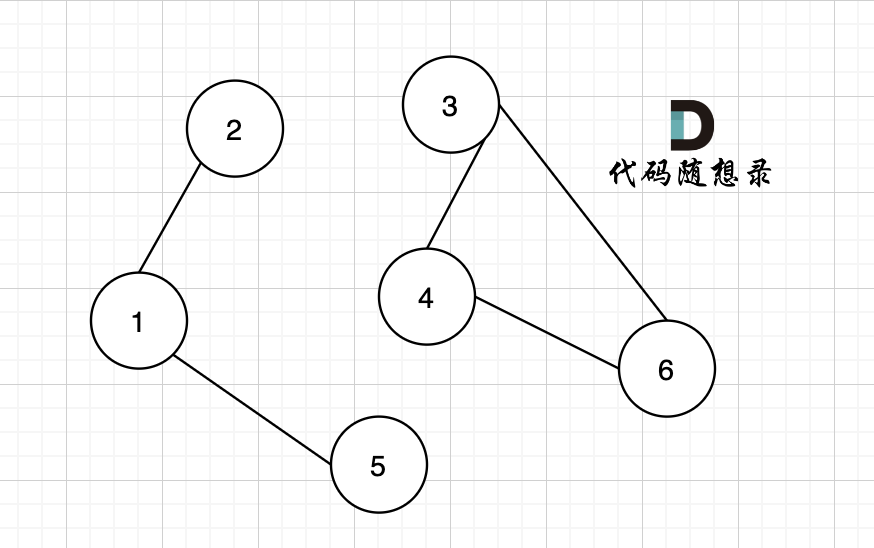
|
||||
|
||||
|
||||
节点1 不能到达节点4。
|
||||
|
||||
@@ -72,7 +72,7 @@
|
||||
|
||||
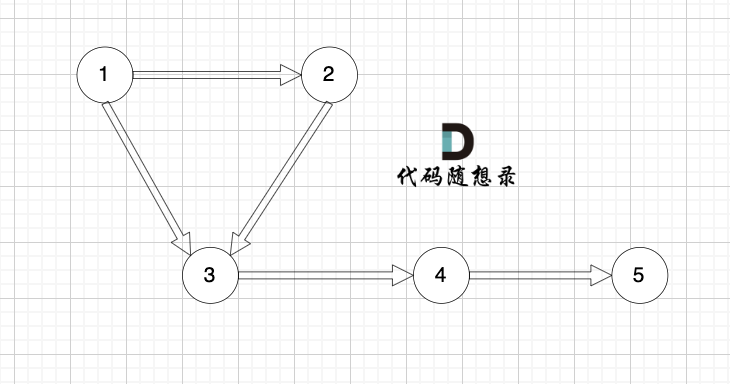
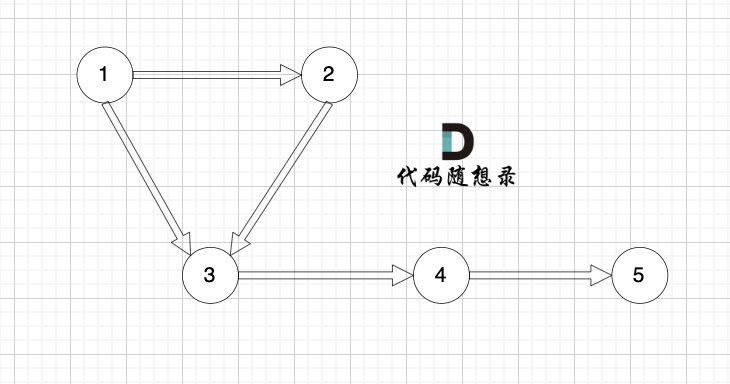
我们来看这个有向图:
|
||||
|
||||
|
||||
|
||||
|
||||
这个图是强连通图吗?
|
||||
|
||||
@@ -82,7 +82,7 @@
|
||||
|
||||
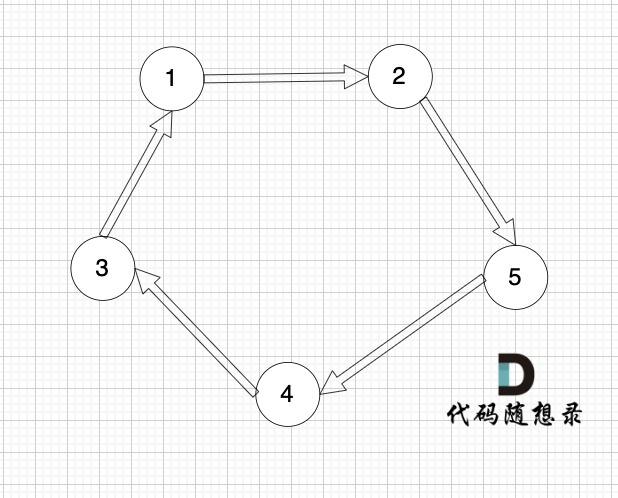
下面这个有向图才是强连通图:
|
||||
|
||||
|
||||
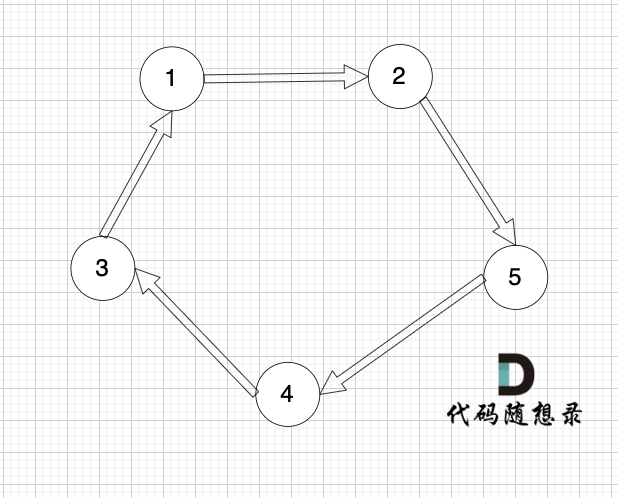
|
||||
|
||||
|
||||
### 连通分量
|
||||
@@ -91,7 +91,7 @@
|
||||
|
||||
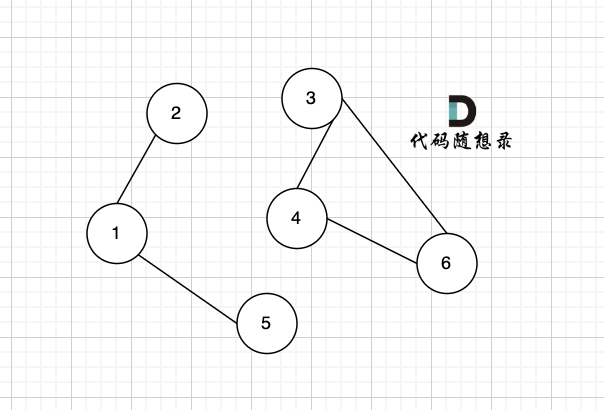
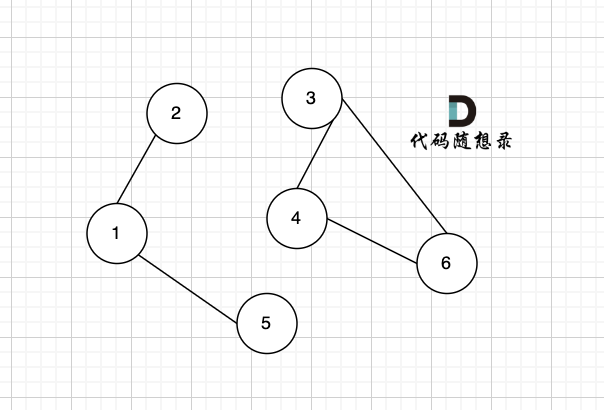
只看概念大家可能不理解,我来画个图:
|
||||
|
||||
|
||||
|
||||
|
||||
该无向图中 节点1、节点2、节点5 构成的子图就是 该无向图中的一个连通分量,该子图所有节点都是相互可达到的。
|
||||
|
||||
@@ -111,7 +111,7 @@
|
||||
|
||||
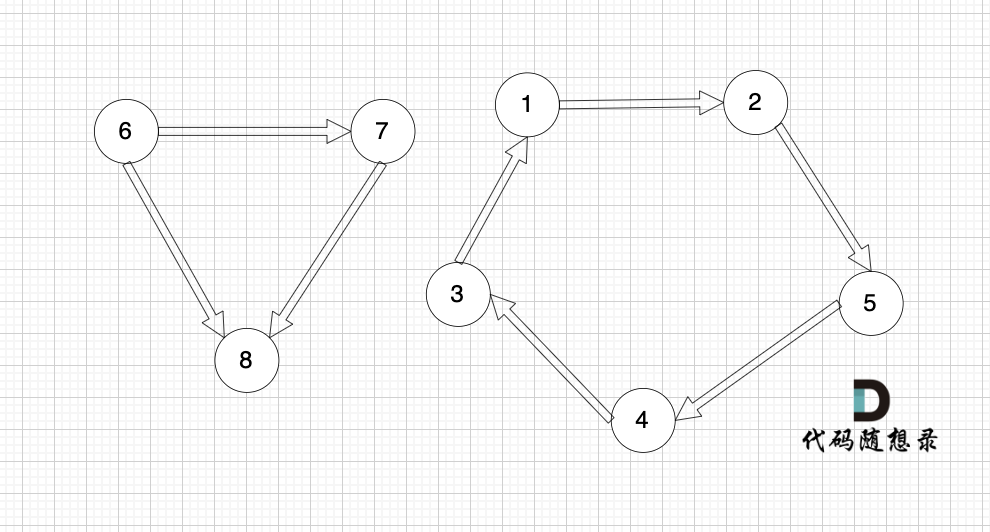
如图:
|
||||
|
||||

|
||||
|
||||
|
||||
节点1、节点2、节点3、节点4、节点5 构成的子图是强连通分量,因为这是强连通图,也是极大图。
|
||||
|
||||
@@ -132,11 +132,11 @@
|
||||
|
||||
例如图:
|
||||
|
||||

|
||||

|
||||
|
||||
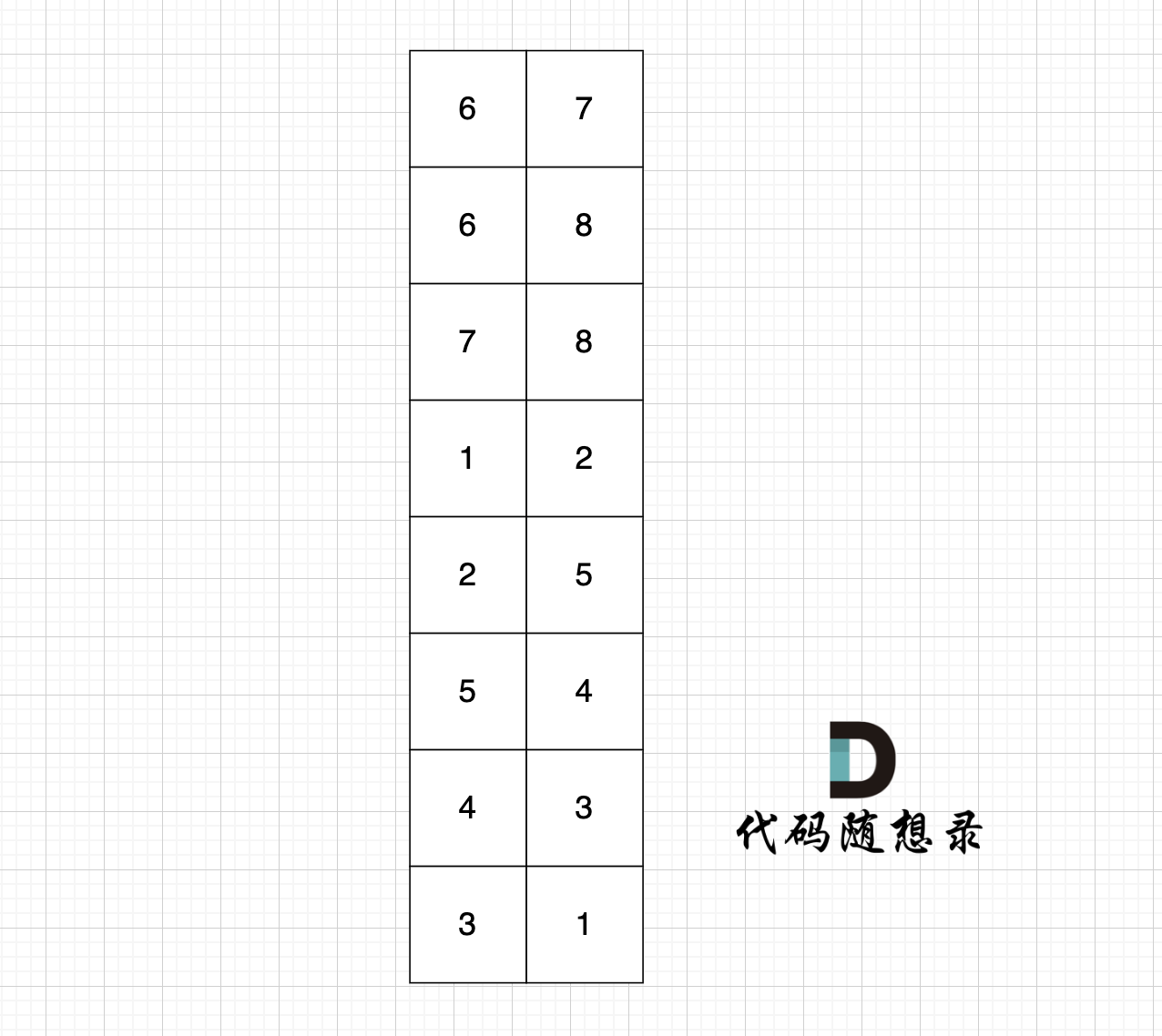
图中有8条边,我们就定义 8 * 2的数组,即有n条边就申请n * 2,这么大的数组:
|
||||
|
||||

|
||||
|
||||
|
||||
数组第一行:6 7,就表示节点6 指向 节点7,以此类推。
|
||||
|
||||
@@ -162,7 +162,7 @@
|
||||
|
||||
如图:
|
||||
|
||||

|
||||

|
||||
|
||||
在一个 n (节点数)为8 的图中,就需要申请 8 * 8 这么大的空间。
|
||||
|
||||
@@ -188,7 +188,7 @@
|
||||
|
||||
邻接表的构造如图:
|
||||
|
||||

|
||||

|
||||
|
||||
这里表达的图是:
|
||||
|
||||
|
||||
@@ -17,7 +17,7 @@
|
||||
|
||||
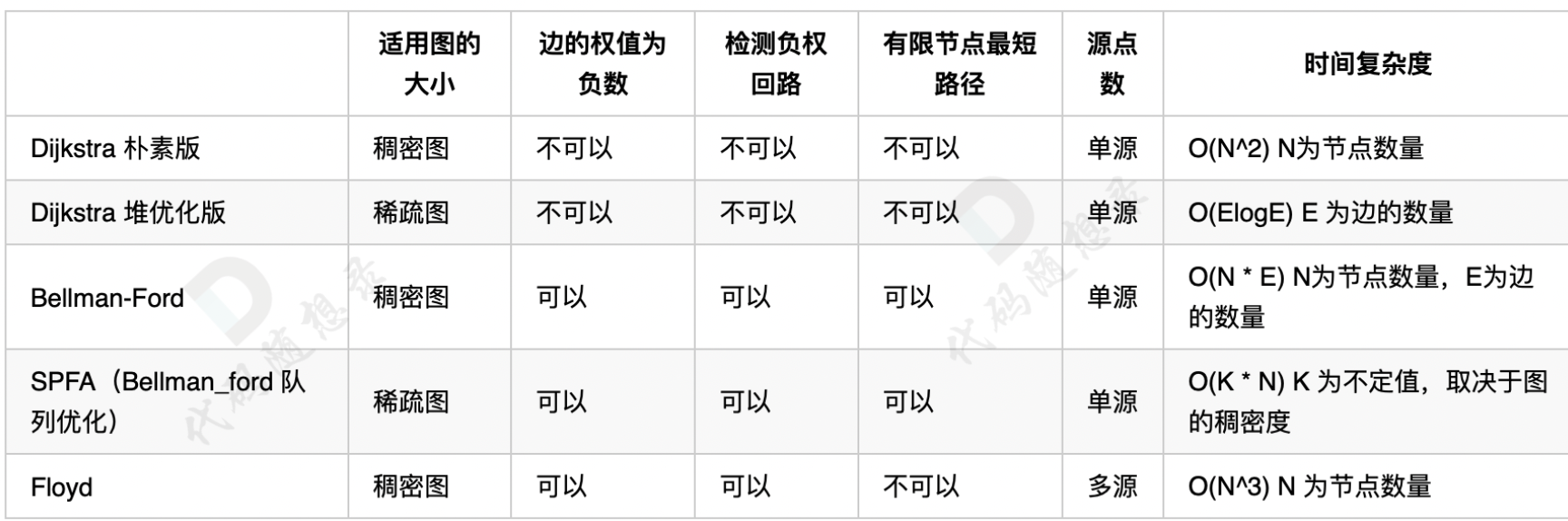
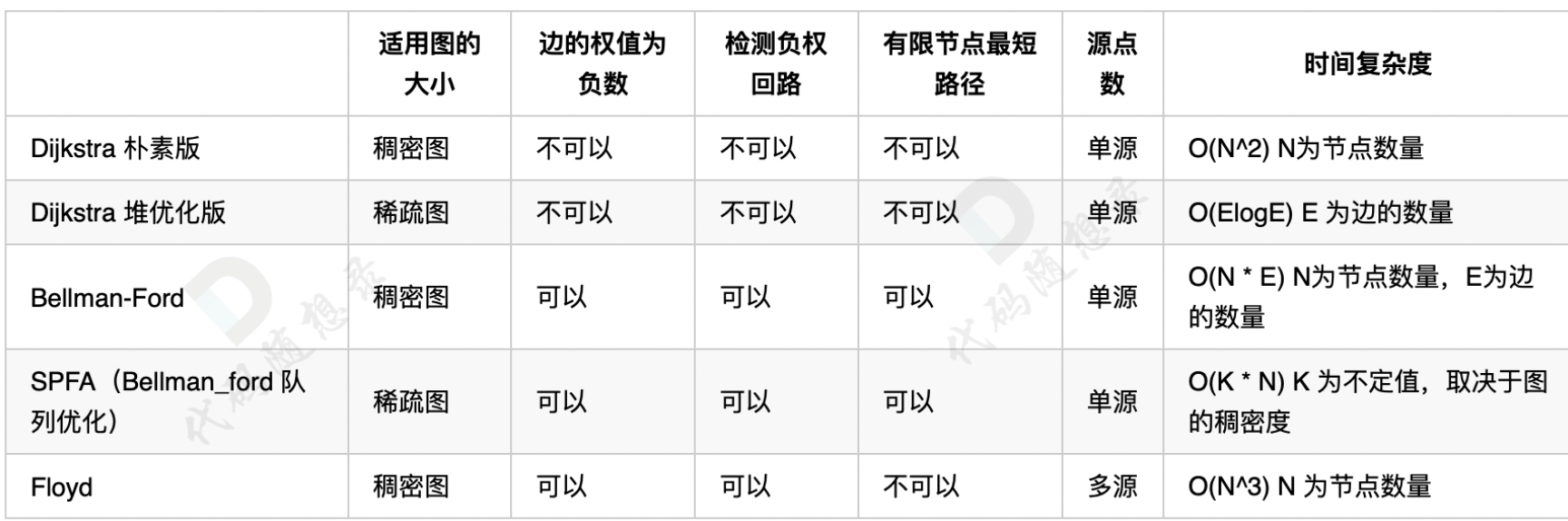
最短路算法比较复杂,而且各自有各自的应用场景,我来用一张表把讲过的最短路算法的使用场景都展现出来:
|
||||
|
||||
|
||||
|
||||
|
||||
(因为A * 属于启发式搜索,和上面最短路算法并不是一类,不适合一起对比,所以没有放在一起)
|
||||
|
||||
|
||||
Reference in New Issue
Block a user