diff --git a/CMakeLists.txt b/CMakeLists.txt
index 95c09d8e2..5030f3bb1 100644
--- a/CMakeLists.txt
+++ b/CMakeLists.txt
@@ -59,6 +59,7 @@ add_subdirectory(search)
add_subdirectory(strings)
add_subdirectory(sorting)
add_subdirectory(probability)
+add_subdirectory(machine_learning)
add_subdirectory(computer_oriented_statistical_methods)
if(USE_OPENMP)
diff --git a/DIRECTORY.md b/DIRECTORY.md
index 919fae165..79589f90c 100644
--- a/DIRECTORY.md
+++ b/DIRECTORY.md
@@ -101,6 +101,9 @@
* [Linear Probing Hash Table](https://github.com/TheAlgorithms/C-Plus-Plus/blob/master/hashing/linear_probing_hash_table.cpp)
* [Quadratic Probing Hash Table](https://github.com/TheAlgorithms/C-Plus-Plus/blob/master/hashing/quadratic_probing_hash_table.cpp)
+## Machine Learning
+ * [Adaline Learning](https://github.com/TheAlgorithms/C-Plus-Plus/blob/master/machine_learning/adaline_learning.cpp)
+
## Math
* [Binary Exponent](https://github.com/TheAlgorithms/C-Plus-Plus/blob/master/math/binary_exponent.cpp)
* [Double Factorial](https://github.com/TheAlgorithms/C-Plus-Plus/blob/master/math/double_factorial.cpp)
diff --git a/machine_learning/CMakeLists.txt b/machine_learning/CMakeLists.txt
new file mode 100644
index 000000000..e6d8a9af4
--- /dev/null
+++ b/machine_learning/CMakeLists.txt
@@ -0,0 +1,18 @@
+# If necessary, use the RELATIVE flag, otherwise each source file may be listed
+# with full pathname. RELATIVE may makes it easier to extract an executable name
+# automatically.
+file( GLOB APP_SOURCES RELATIVE ${CMAKE_CURRENT_SOURCE_DIR} *.cpp )
+# file( GLOB APP_SOURCES ${CMAKE_SOURCE_DIR}/*.c )
+# AUX_SOURCE_DIRECTORY(${CMAKE_CURRENT_SOURCE_DIR} APP_SOURCES)
+foreach( testsourcefile ${APP_SOURCES} )
+ # I used a simple string replace, to cut off .cpp.
+ string( REPLACE ".cpp" "" testname ${testsourcefile} )
+ add_executable( ${testname} ${testsourcefile} )
+
+ set_target_properties(${testname} PROPERTIES LINKER_LANGUAGE CXX)
+ if(OpenMP_CXX_FOUND)
+ target_link_libraries(${testname} OpenMP::OpenMP_CXX)
+ endif()
+ install(TARGETS ${testname} DESTINATION "bin/machine_learning")
+
+endforeach( testsourcefile ${APP_SOURCES} )
diff --git a/machine_learning/adaline_learning.cpp b/machine_learning/adaline_learning.cpp
new file mode 100644
index 000000000..a58b59cca
--- /dev/null
+++ b/machine_learning/adaline_learning.cpp
@@ -0,0 +1,269 @@
+/**
+ * \file
+ * \brief [Adaptive Linear Neuron
+ * (ADALINE)](https://en.wikipedia.org/wiki/ADALINE) implementation
+ *
+ * 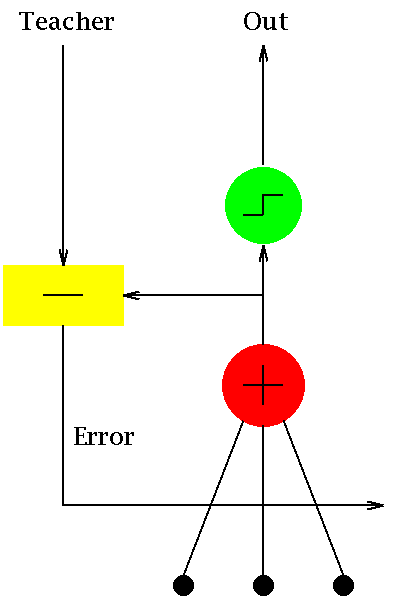 + * [source](https://commons.wikimedia.org/wiki/File:Adaline_flow_chart.gif)
+ * ADALINE is one of the first and simplest single layer artificial neural
+ * network. The algorithm essentially implements a linear function
+ * \f[ f\left(x_0,x_1,x_2,\ldots\right) =
+ * \sum_j x_jw_j+\theta
+ * \f]
+ * where \f$x_j\f$ are the input features of a sample, \f$w_j\f$ are the
+ * coefficients of the linear function and \f$\theta\f$ is a constant. If we
+ * know the \f$w_j\f$, then for any given set of features, \f$y\f$ can be
+ * computed. Computing the \f$w_j\f$ is a supervised learning algorithm wherein
+ * a set of features and their corresponding outputs are given and weights are
+ * computed using stochastic gradient descent method.
+ */
+
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+
+#define MAX_ITER 500 // INT_MAX ///< Maximum number of iterations to learn
+
+class adaline {
+ public:
+ /**
+ * Default constructor
+ * \param[in] num_features number of features present
+ * \param[in] eta learning rate (optional, default=0.1)
+ * \param[in] convergence accuracy (optional, default=\f$1\times10^{-5}\f$)
+ */
+ adaline(int num_features, const double eta = 0.01f,
+ const double accuracy = 1e-5)
+ : eta(eta), accuracy(accuracy) {
+ if (eta <= 0) {
+ std::cerr << "learning rate should be positive and nonzero"
+ << std::endl;
+ std::exit(EXIT_FAILURE);
+ }
+
+ weights = std::vector(
+ num_features +
+ 1); // additional weight is for the constant bias term
+
+ // initialize with random weights in the range [-50, 49]
+ for (int i = 0; i < weights.size(); i++)
+ weights[i] = (static_cast(std::rand() % 100) - 50);
+ }
+
+ /**
+ * Operator to print the weights of the model
+ */
+ friend std::ostream &operator<<(std::ostream &out, const adaline &ada) {
+ out << "<";
+ for (int i = 0; i < ada.weights.size(); i++) {
+ out << ada.weights[i];
+ if (i < ada.weights.size() - 1)
+ out << ", ";
+ }
+ out << ">";
+ return out;
+ }
+
+ /**
+ * predict the output of the model for given set of features
+ * \param[in] x input vector
+ * \returns model prediction output
+ */
+ int predict(const std::vector &x) {
+ if (!check_size_match(x))
+ return 0;
+
+ double y = weights.back(); // assign bias value
+
+ for (int i = 0; i < x.size(); i++) y += x[i] * weights[i];
+
+ return y >= 0 ? 1 : -1; // quantizer: apply ADALINE threshold function
+ }
+
+ /**
+ * Update the weights of the model using supervised learning for one feature
+ * vector
+ * \param[in] x feature vector
+ * \param[in] y known output value
+ * \returns correction factor
+ */
+ double fit(const std::vector &x, const int &y) {
+ if (!check_size_match(x))
+ return 0;
+
+ /* output of the model with current weights */
+ int p = predict(x);
+ int prediction_error = y - p; // error in estimation
+ double correction_factor = eta * prediction_error;
+
+ /* update each weight, the last weight is the bias term */
+ for (int i = 0; i < x.size(); i++) {
+ weights[i] += correction_factor * x[i];
+ }
+ weights[x.size()] += correction_factor; // update bias
+
+ return correction_factor;
+ }
+
+ /**
+ * Update the weights of the model using supervised learning for an array of
+ * vectors.
+ * \param[in] X array of feature vector
+ * \param[in] y known output value for each feature vector
+ */
+ template
+ void fit(std::vector const (&X)[N], const int *y) {
+ double avg_pred_error = 1.f;
+
+ int iter;
+ for (iter = 0; (iter < MAX_ITER) && (avg_pred_error > accuracy);
+ iter++) {
+ avg_pred_error = 0.f;
+
+ // perform fit for each sample
+ for (int i = 0; i < N; i++) {
+ double err = fit(X[i], y[i]);
+ avg_pred_error += std::abs(err);
+ }
+ avg_pred_error /= N;
+
+ // Print updates every 200th iteration
+ // if (iter % 100 == 0)
+ std::cout << "\tIter " << iter << ": Training weights: " << *this
+ << "\tAvg error: " << avg_pred_error << std::endl;
+ }
+
+ if (iter < MAX_ITER)
+
+ std::cout << "Converged after " << iter << " iterations."
+ << std::endl;
+ else
+ std::cout << "Did not converge after " << iter << " iterations."
+ << std::endl;
+ }
+
+ private:
+ /**
+ * convenient function to check if input feature vector size matches the
+ * model weights size
+ * \param[in] x fecture vector to check
+ * \returns `true` size matches
+ * \returns `false` size does not match
+ */
+ bool check_size_match(const std::vector &x) {
+ if (x.size() != (weights.size() - 1)) {
+ std::cerr << __func__ << ": "
+ << "Number of features in x does not match the feature "
+ "dimension in model!"
+ << std::endl;
+ return false;
+ }
+ return true;
+ }
+
+ const double eta; ///< learning rate of the algorithm
+ const double accuracy; ///< model fit convergence accuracy
+ std::vector weights; ///< weights of the neural network
+};
+
+/**
+ * test function to predict points in a 2D coordinate system above the line
+ * \f$x=y\f$ as +1 and others as -1.
+ * Note that each point is defined by 2 values or 2 features.
+ * \param[in] eta learning rate (optional, default=0.01)
+ */
+void test1(double eta = 0.01) {
+ adaline ada(2, eta); // 2 features
+
+ const int N = 10; // number of sample points
+
+ std::vector X[N] = {{0, 1}, {1, -2}, {2, 3}, {3, -1},
+ {4, 1}, {6, -5}, {-7, -3}, {-8, 5},
+ {-9, 2}, {-10, -15}};
+ int y[] = {1, -1, 1, -1, -1, -1, 1, 1, 1, -1}; // corresponding y-values
+
+ std::cout << "------- Test 1 -------" << std::endl;
+ std::cout << "Model before fit: " << ada << std::endl;
+
+ ada.fit(X, y);
+ std::cout << "Model after fit: " << ada << std::endl;
+
+ int predict = ada.predict({5, -3});
+ std::cout << "Predict for x=(5,-3): " << predict;
+ assert(predict == -1);
+ std::cout << " ...passed" << std::endl;
+
+ predict = ada.predict({5, 8});
+ std::cout << "Predict for x=(5,8): " << predict;
+ assert(predict == 1);
+ std::cout << " ...passed" << std::endl;
+}
+
+/**
+ * test function to predict points in a 2D coordinate system above the line
+ * \f$x+y=-1\f$ as +1 and others as -1.
+ * Note that each point is defined by 2 values or 2 features.
+ * The function will create random sample points for training and test purposes.
+ * \param[in] eta learning rate (optional, default=0.01)
+ */
+void test2(double eta = 0.01) {
+ adaline ada(2, eta); // 2 features
+
+ const int N = 50; // number of sample points
+
+ std::vector X[N];
+ int Y[N]; // corresponding y-values
+
+ int range = 500; // sample points range
+ int range2 = range >> 1;
+ for (int i = 0; i < N; i++) {
+ double x0 = ((std::rand() % range) - range2) / 100.f;
+ double x1 = ((std::rand() % range) - range2) / 100.f;
+ X[i] = {x0, x1};
+ Y[i] = (x0 + x1) > -1 ? 1 : -1;
+ }
+
+ std::cout << "------- Test 1 -------" << std::endl;
+ std::cout << "Model before fit: " << ada << std::endl;
+
+ ada.fit(X, Y);
+ std::cout << "Model after fit: " << ada << std::endl;
+
+ int N_test_cases = 5;
+ for (int i = 0; i < N_test_cases; i++) {
+ double x0 = ((std::rand() % range) - range2) / 100.f;
+ double x1 = ((std::rand() % range) - range2) / 100.f;
+
+ int predict = ada.predict({x0, x1});
+
+ std::cout << "Predict for x=(" << x0 << "," << x1 << "): " << predict;
+
+ int expected_val = (x0 + x1) > -1 ? 1 : -1;
+ assert(predict == expected_val);
+ std::cout << " ...passed" << std::endl;
+ }
+}
+
+/** Main function */
+int main(int argc, char **argv) {
+ std::srand(std::time(nullptr)); // initialize random number generator
+
+ double eta = 0.2; // default value of eta
+ if (argc == 2) // read eta value from commandline argument if present
+ eta = strtof(argv[1], nullptr);
+
+ test1(eta);
+
+ std::cout << "Press ENTER to continue..." << std::endl;
+ std::cin.get();
+
+ test2(eta);
+
+ return 0;
+}
+ * [source](https://commons.wikimedia.org/wiki/File:Adaline_flow_chart.gif)
+ * ADALINE is one of the first and simplest single layer artificial neural
+ * network. The algorithm essentially implements a linear function
+ * \f[ f\left(x_0,x_1,x_2,\ldots\right) =
+ * \sum_j x_jw_j+\theta
+ * \f]
+ * where \f$x_j\f$ are the input features of a sample, \f$w_j\f$ are the
+ * coefficients of the linear function and \f$\theta\f$ is a constant. If we
+ * know the \f$w_j\f$, then for any given set of features, \f$y\f$ can be
+ * computed. Computing the \f$w_j\f$ is a supervised learning algorithm wherein
+ * a set of features and their corresponding outputs are given and weights are
+ * computed using stochastic gradient descent method.
+ */
+
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+
+#define MAX_ITER 500 // INT_MAX ///< Maximum number of iterations to learn
+
+class adaline {
+ public:
+ /**
+ * Default constructor
+ * \param[in] num_features number of features present
+ * \param[in] eta learning rate (optional, default=0.1)
+ * \param[in] convergence accuracy (optional, default=\f$1\times10^{-5}\f$)
+ */
+ adaline(int num_features, const double eta = 0.01f,
+ const double accuracy = 1e-5)
+ : eta(eta), accuracy(accuracy) {
+ if (eta <= 0) {
+ std::cerr << "learning rate should be positive and nonzero"
+ << std::endl;
+ std::exit(EXIT_FAILURE);
+ }
+
+ weights = std::vector(
+ num_features +
+ 1); // additional weight is for the constant bias term
+
+ // initialize with random weights in the range [-50, 49]
+ for (int i = 0; i < weights.size(); i++)
+ weights[i] = (static_cast(std::rand() % 100) - 50);
+ }
+
+ /**
+ * Operator to print the weights of the model
+ */
+ friend std::ostream &operator<<(std::ostream &out, const adaline &ada) {
+ out << "<";
+ for (int i = 0; i < ada.weights.size(); i++) {
+ out << ada.weights[i];
+ if (i < ada.weights.size() - 1)
+ out << ", ";
+ }
+ out << ">";
+ return out;
+ }
+
+ /**
+ * predict the output of the model for given set of features
+ * \param[in] x input vector
+ * \returns model prediction output
+ */
+ int predict(const std::vector &x) {
+ if (!check_size_match(x))
+ return 0;
+
+ double y = weights.back(); // assign bias value
+
+ for (int i = 0; i < x.size(); i++) y += x[i] * weights[i];
+
+ return y >= 0 ? 1 : -1; // quantizer: apply ADALINE threshold function
+ }
+
+ /**
+ * Update the weights of the model using supervised learning for one feature
+ * vector
+ * \param[in] x feature vector
+ * \param[in] y known output value
+ * \returns correction factor
+ */
+ double fit(const std::vector &x, const int &y) {
+ if (!check_size_match(x))
+ return 0;
+
+ /* output of the model with current weights */
+ int p = predict(x);
+ int prediction_error = y - p; // error in estimation
+ double correction_factor = eta * prediction_error;
+
+ /* update each weight, the last weight is the bias term */
+ for (int i = 0; i < x.size(); i++) {
+ weights[i] += correction_factor * x[i];
+ }
+ weights[x.size()] += correction_factor; // update bias
+
+ return correction_factor;
+ }
+
+ /**
+ * Update the weights of the model using supervised learning for an array of
+ * vectors.
+ * \param[in] X array of feature vector
+ * \param[in] y known output value for each feature vector
+ */
+ template
+ void fit(std::vector const (&X)[N], const int *y) {
+ double avg_pred_error = 1.f;
+
+ int iter;
+ for (iter = 0; (iter < MAX_ITER) && (avg_pred_error > accuracy);
+ iter++) {
+ avg_pred_error = 0.f;
+
+ // perform fit for each sample
+ for (int i = 0; i < N; i++) {
+ double err = fit(X[i], y[i]);
+ avg_pred_error += std::abs(err);
+ }
+ avg_pred_error /= N;
+
+ // Print updates every 200th iteration
+ // if (iter % 100 == 0)
+ std::cout << "\tIter " << iter << ": Training weights: " << *this
+ << "\tAvg error: " << avg_pred_error << std::endl;
+ }
+
+ if (iter < MAX_ITER)
+
+ std::cout << "Converged after " << iter << " iterations."
+ << std::endl;
+ else
+ std::cout << "Did not converge after " << iter << " iterations."
+ << std::endl;
+ }
+
+ private:
+ /**
+ * convenient function to check if input feature vector size matches the
+ * model weights size
+ * \param[in] x fecture vector to check
+ * \returns `true` size matches
+ * \returns `false` size does not match
+ */
+ bool check_size_match(const std::vector &x) {
+ if (x.size() != (weights.size() - 1)) {
+ std::cerr << __func__ << ": "
+ << "Number of features in x does not match the feature "
+ "dimension in model!"
+ << std::endl;
+ return false;
+ }
+ return true;
+ }
+
+ const double eta; ///< learning rate of the algorithm
+ const double accuracy; ///< model fit convergence accuracy
+ std::vector weights; ///< weights of the neural network
+};
+
+/**
+ * test function to predict points in a 2D coordinate system above the line
+ * \f$x=y\f$ as +1 and others as -1.
+ * Note that each point is defined by 2 values or 2 features.
+ * \param[in] eta learning rate (optional, default=0.01)
+ */
+void test1(double eta = 0.01) {
+ adaline ada(2, eta); // 2 features
+
+ const int N = 10; // number of sample points
+
+ std::vector X[N] = {{0, 1}, {1, -2}, {2, 3}, {3, -1},
+ {4, 1}, {6, -5}, {-7, -3}, {-8, 5},
+ {-9, 2}, {-10, -15}};
+ int y[] = {1, -1, 1, -1, -1, -1, 1, 1, 1, -1}; // corresponding y-values
+
+ std::cout << "------- Test 1 -------" << std::endl;
+ std::cout << "Model before fit: " << ada << std::endl;
+
+ ada.fit(X, y);
+ std::cout << "Model after fit: " << ada << std::endl;
+
+ int predict = ada.predict({5, -3});
+ std::cout << "Predict for x=(5,-3): " << predict;
+ assert(predict == -1);
+ std::cout << " ...passed" << std::endl;
+
+ predict = ada.predict({5, 8});
+ std::cout << "Predict for x=(5,8): " << predict;
+ assert(predict == 1);
+ std::cout << " ...passed" << std::endl;
+}
+
+/**
+ * test function to predict points in a 2D coordinate system above the line
+ * \f$x+y=-1\f$ as +1 and others as -1.
+ * Note that each point is defined by 2 values or 2 features.
+ * The function will create random sample points for training and test purposes.
+ * \param[in] eta learning rate (optional, default=0.01)
+ */
+void test2(double eta = 0.01) {
+ adaline ada(2, eta); // 2 features
+
+ const int N = 50; // number of sample points
+
+ std::vector X[N];
+ int Y[N]; // corresponding y-values
+
+ int range = 500; // sample points range
+ int range2 = range >> 1;
+ for (int i = 0; i < N; i++) {
+ double x0 = ((std::rand() % range) - range2) / 100.f;
+ double x1 = ((std::rand() % range) - range2) / 100.f;
+ X[i] = {x0, x1};
+ Y[i] = (x0 + x1) > -1 ? 1 : -1;
+ }
+
+ std::cout << "------- Test 1 -------" << std::endl;
+ std::cout << "Model before fit: " << ada << std::endl;
+
+ ada.fit(X, Y);
+ std::cout << "Model after fit: " << ada << std::endl;
+
+ int N_test_cases = 5;
+ for (int i = 0; i < N_test_cases; i++) {
+ double x0 = ((std::rand() % range) - range2) / 100.f;
+ double x1 = ((std::rand() % range) - range2) / 100.f;
+
+ int predict = ada.predict({x0, x1});
+
+ std::cout << "Predict for x=(" << x0 << "," << x1 << "): " << predict;
+
+ int expected_val = (x0 + x1) > -1 ? 1 : -1;
+ assert(predict == expected_val);
+ std::cout << " ...passed" << std::endl;
+ }
+}
+
+/** Main function */
+int main(int argc, char **argv) {
+ std::srand(std::time(nullptr)); // initialize random number generator
+
+ double eta = 0.2; // default value of eta
+ if (argc == 2) // read eta value from commandline argument if present
+ eta = strtof(argv[1], nullptr);
+
+ test1(eta);
+
+ std::cout << "Press ENTER to continue..." << std::endl;
+ std::cin.get();
+
+ test2(eta);
+
+ return 0;
+}