mirror of
https://github.com/0voice/kernel_new_features.git
synced 2026-07-04 18:36:10 +08:00
Create eBPF详解.md
This commit is contained in:
289
ebpf/文章/eBPF详解.md
Normal file
289
ebpf/文章/eBPF详解.md
Normal file
@@ -0,0 +1,289 @@
|
|||||||
|
## 前言
|
||||||
|
|
||||||
|
Linux系统分为内核空间和用户空间,内核空间是操作系统的核心,对所有硬件具备不受限制的完整访问能力,而用户空间运行的这是非内核进程,即用户的程序,这些进程仅能通过内核开放的系统调用,实现对硬件的有限访问,即用户空间的程序一定会经过内核空间的过滤。
|
||||||
|
|
||||||
|
在之前大多程序,例如网络监控器,都是作为用户级进程运行的。为了分析只在内核空间运行的数据,它们必须将这些数据从内核空间复制到用户空间的内存中去,并进行上下文切换,这与直接在内核空间分析数据相比,性能开销巨大。
|
||||||
|
|
||||||
|
随着近些年网路速度和流量的疯涨,一些应用程序必须处理大量的数据(如音频、流媒体数据)。要在用户空间监控分析那么多流量数据已经不可行了。
|
||||||
|
|
||||||
|
## BPF
|
||||||
|
|
||||||
|
> BPF全称是Berkeley Packet Filter,是类Unix上数据链路层的一种原始接口,提供原始链路层封包的收发。
|
||||||
|
|
||||||
|
- 一个新的VM设计,可以有效的工作在基于寄存器结构的CPU之上
|
||||||
|
- 应用程序使用缓存只复制与过滤数据包相关的数据,不会复制数据包的所有信息,最大程度地减少了BPF处理的数据,提高处理效率
|
||||||
|
|
||||||
|
tcpdump的底层采用了BPF作为底层包过滤技术
|
||||||
|
|
||||||
|
[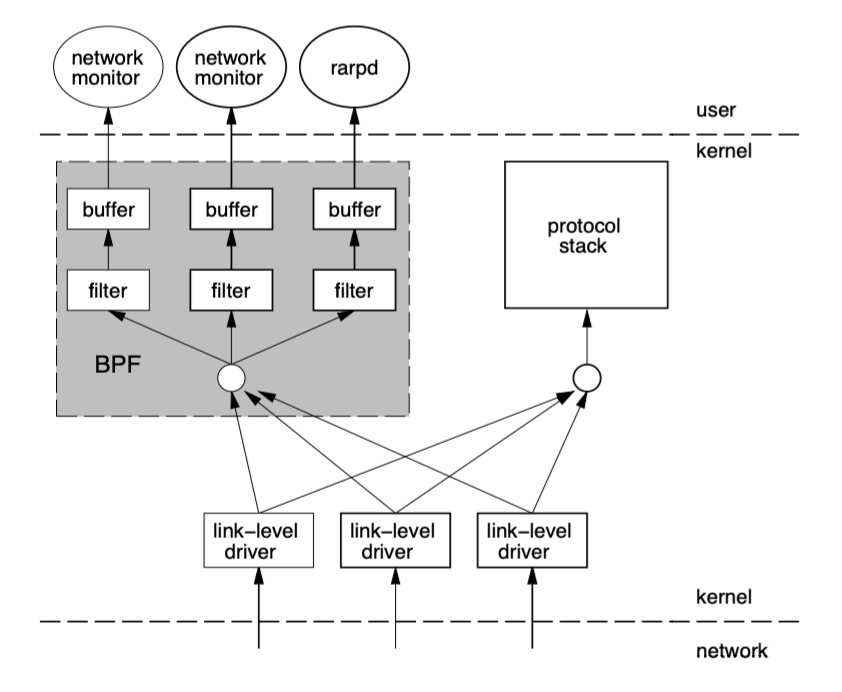](https://cdn.jsdelivr.net/gh/edgarding77/images@latest/cloudnative/ebpf1.png)
|
||||||
|
|
||||||
|
发展到现在升级为**eBPF(extented Berkeley Packet Filter)**,演进成一套通用执行引擎,提供可基于系统或程序事件高效安全执行特定代码的通用能力。
|
||||||
|
|
||||||
|
## 内核技术的挑战
|
||||||
|
|
||||||
|
从操作系统内核的角度来看,面临很多的挑战。
|
||||||
|
|
||||||
|
1. 复杂性不断增加,性能和可拓展性新需求:
|
||||||
|
内核(general kernel),必须在子系统复杂度不断增长的前提下,满足这些性能和可拓展性的需求。
|
||||||
|
2. 永远保持向后兼容:
|
||||||
|
Linus torvalds:“never break user spcae”,这对用户来说是好事,但是对于内核开发者来说,必须保证引入新的代码时,仍然需要兼容数年前的老代码,这会使得原本复杂的内核更加复杂,对于网络来说,这意味着快速收发包路径(fast path)将会收到影响。
|
||||||
|
3. [Feature creeping normality](https://en.wikipedia.org/w/index.php?title=Death_by_a_thousand_cuts_(psychology)):
|
||||||
|
内核不允许一次性引入非常大的改动,只能拆分为数量众多的小patch,每次合并的patch保证系统的向后兼容,并且对系统的影响非常小。
|
||||||
|
|
||||||
|
首先,eBPF带来的好处从长期来说会减少未来的**Feature creeping normality**,因为用户希望内核实现的功能不再需要通过内核去提供,只需要一段eBPF代码,动态加载到内核即可。
|
||||||
|
|
||||||
|
其次,因为eBPF,内核也不再去引入一些影响fast path的代码,避免性能的下降。
|
||||||
|
|
||||||
|
同时,eBPF使得内核完全可编程,安全的可编程。
|
||||||
|
|
||||||
|
## eBPF基础
|
||||||
|
|
||||||
|
**「What」eBPF是一个用于访问Linux内核服务和硬件的方法。**
|
||||||
|
|
||||||
|
> Linux内核一直是实现监视/可观察性,网络和安全性的理想场所。不幸的是,这通常是不切实际的,因为它需要更改内核源代码或加载内核模块,并导致彼此堆叠的抽象层。eBPF是一项革命性的技术,可以在Linux内核中运行沙盒程序,而无需更改内核源代码或加载内核模块。通过使Linux内核可编程,基础架构软件可以利用现有的层,使它们更加智能和功能丰富,而无需继续为系统增加额外的复杂性层。
|
||||||
|
|
||||||
|
1. 将eBPF指令映射到平台原生指令时开销尽可能小(对x86和arm64平台进行了许多优化)
|
||||||
|
2. 内核加载eBPF代码时要验证代码的安全性(限制为一个最小指令集的原因,这样来确保时可验证的,进而确定是安全的)
|
||||||
|
|
||||||
|
但内核模块中引入 bug 是一件极度危险的事情 —— 它会导致内核 crash。 此时 **BPF 的优势**就体现出来了:**校验器(verifier)**会检查是否有越界内存访问 、无限循环等问题,一旦发现就会拒绝加载,而非将这些问题留到运行时(导致 内核 crash 等破坏系统稳定性的行为)。
|
||||||
|
|
||||||
|
[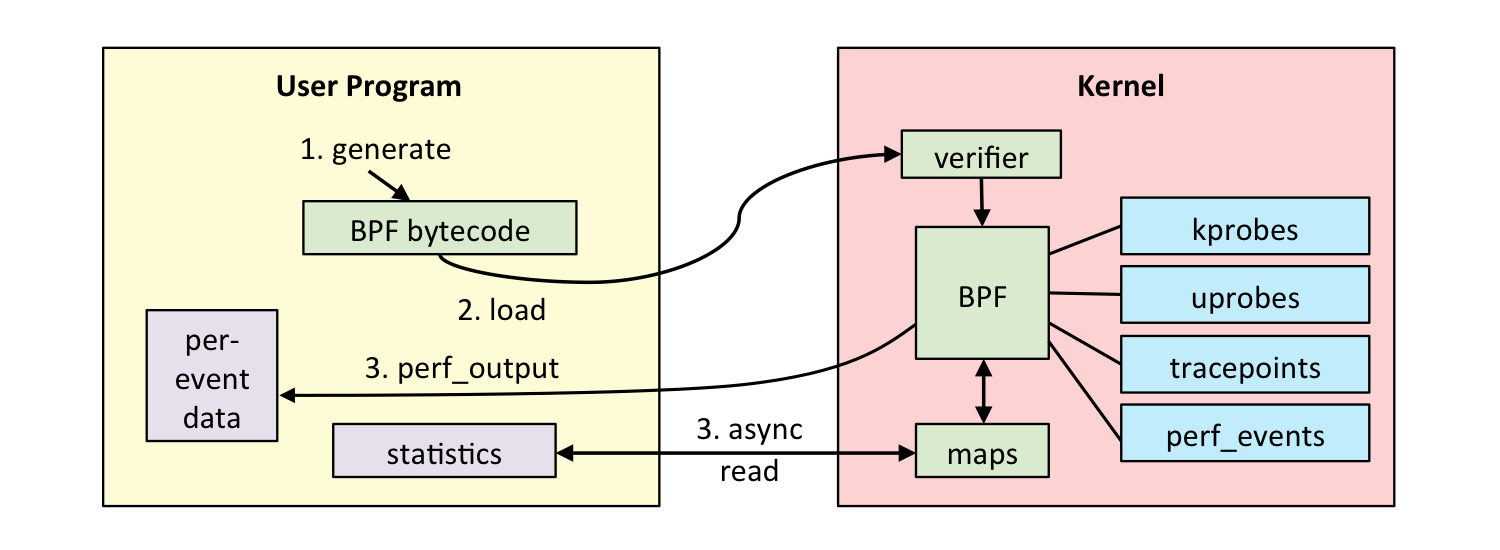](https://cdn.jsdelivr.net/gh/edgarding77/images@latest/cloudnative/ebpf2.png)
|
||||||
|
|
||||||
|
### **版本**
|
||||||
|
|
||||||
|
| version | 功能 |
|
||||||
|
| ------- | ------------------- |
|
||||||
|
| 4.1 | kprobe support |
|
||||||
|
| 4.4 | Perf events |
|
||||||
|
| 4.7 | Tracepoints support |
|
||||||
|
| 4.8 | XDP core |
|
||||||
|
| 4.10 | cgroups support |
|
||||||
|
|
||||||
|
*具体支持情况:*[*https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md*](https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md)
|
||||||
|
|
||||||
|
### 工作流程
|
||||||
|
|
||||||
|
eBPF提供的基本模块(building blocks)和程序附着点(attachment points),可以通过编写eBPF来attach到这些hook来完成某些高级功能,这是eBPF的主要工作方式。
|
||||||
|
|
||||||
|
1. 将eBPF程序编译成字节码
|
||||||
|
2. 在载入到Hook之前,需要进入到虚拟机中进行程序校验eBPF verifier(通过沙盒机制来检查每个程序是否能够安全运行在内核中)
|
||||||
|
|
||||||
|
- 一定是一个有向无环图
|
||||||
|
- 没有不可达代码
|
||||||
|
- 大小限制
|
||||||
|
- 不能不检查间接引用
|
||||||
|
- eBPF 堆栈大小被限制在 MAX_BPF_STACK,截止到内核 Linux 5.8 版本,被设置为 512。目前没有计划增加这个限制,解决方法是改用 BPF Map,它的大小是无限的。
|
||||||
|
- eBPF 字节码大小最初被限制为 4096 条指令,截止到内核 Linux 5.8 版本, 当前已将放宽至 100 万指令( BPF_COMPLEXITY_LIMIT_INSNS),对于无权限的BPF程序,仍然保留4096条限制 ( BPF_MAXINSNS )
|
||||||
|
|
||||||
|
1. JIT编译(保证程序本地运行的高性能)
|
||||||
|
2. 通过JIT编译后,将编译后的程序附加到内核中各种系统调用的hook上
|
||||||
|
3. 在程序被触发时,调用辅助函数处理数据
|
||||||
|
4. 在用户空间和内核空间之间使用键值对共享数据
|
||||||
|
|
||||||
|
### eBPF vs BPF
|
||||||
|
|
||||||
|
eBPF相比于BPF优势:
|
||||||
|
|
||||||
|
1. eBPF能被更多的事件触发,而BPF只能由包到达触发
|
||||||
|
2. 能在内核中运行任意eBPF代码,而BPF只能实现包过滤
|
||||||
|
3. eBPF能够trace很多数据,比如监控系统调用来进行安全监管
|
||||||
|
4. eBPF可用于很多方面:网络性能、防火墙、安全、tracing和设备驱动
|
||||||
|
|
||||||
|
## eBPF核心概念
|
||||||
|
|
||||||
|
通常情况下,eBPF程序由两部分组成:
|
||||||
|
|
||||||
|
1. 内核空间部分:**内核事件触发执行**,如网卡收到一个包、系统调用创建了一个shell进程。
|
||||||
|
2. 用户空间部分:通过某种**共享数据的方式**(BPF maps),来读取内核中产生的数据。
|
||||||
|
|
||||||
|
[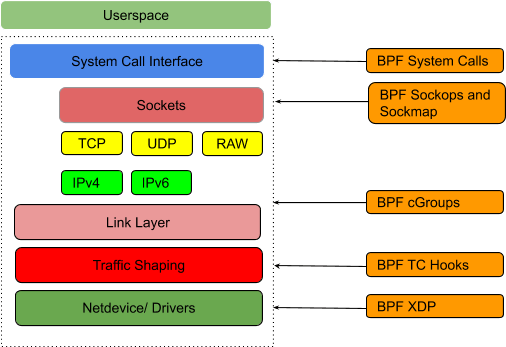](https://cdn.jsdelivr.net/gh/edgarding77/images@latest/cloudnative/ebpf3.png)
|
||||||
|
|
||||||
|
### BPF Hooks
|
||||||
|
|
||||||
|
即哪些地方可以加载BPF程序,在目前的Linux内核中已有的hook类型如下:
|
||||||
|
|
||||||
|
- kernel functions (kprobes)
|
||||||
|
- userspace functions (uprobes)
|
||||||
|
- system calls
|
||||||
|
- fentry/fexit
|
||||||
|
- Tracepoints
|
||||||
|
- network devices (tc/xdp)
|
||||||
|
- network routes
|
||||||
|
- TCP congestion algorithms
|
||||||
|
- sockets (data level)
|
||||||
|
|
||||||
|
从文件打开、创建TCP连接、Socket连接到发送系统消息几乎所有的系统调用,加上用户空间的各种动态信息,都能加载BPF程序。在内核中形成不同的BPF程序类型,在加载时会有类型判断。
|
||||||
|
|
||||||
|
如下图内核代码片段是用来判断BPF程序类型:
|
||||||
|
|
||||||
|
```C
|
||||||
|
static int load_and_attach(const char *event, struct bpf_insn *prog, int size) {
|
||||||
|
bool is_socket = strncmp(event, "socket",6)=0;
|
||||||
|
bool is_kprobe = strncmp(event, "kprobe/", 7-o;
|
||||||
|
bool is_kretprobe = strncmp(event, "kretprobe/",10)==0;
|
||||||
|
bool is tracepoint = strncmp(event, "tracepoint/", 11)==0
|
||||||
|
bool is raw tracepoint = strncmp(event, "rawtracepoint/",15)=0; bool is_xdp = strncmp(event,"xdp",3)==0;
|
||||||
|
bool is perf event - strncmp(event, "perf event",10) ==0;
|
||||||
|
bool is_cgroup skb = strncmp(event, "cgroup/skb",10)==0;
|
||||||
|
bool is_cgroup_sk = strncmp(event, "cgroup/sock",11)==0;
|
||||||
|
bool is_sockops = strncmp(event, "sockops",7)==0;
|
||||||
|
bool is_sk_skb =strncmp(event,"sk_skb",6)==0;
|
||||||
|
boolis sk msg = strncmp(event, "skmsg",6)==0;
|
||||||
|
size_t insns_cnt = size/ sizeof(struct bpf_insn);
|
||||||
|
enum bpf_prog_type prog_type;
|
||||||
|
char buf[256];
|
||||||
|
intfa,efd, err, id;
|
||||||
|
struct perf_event_attr attr ={};
|
||||||
|
attr.type = PERF_TYPE_TRACEPOINT:
|
||||||
|
attr.sample_type = PERF_SAMPLE_RAW;
|
||||||
|
attr.sample_period =1;
|
||||||
|
attr.wakeup _events =1;
|
||||||
|
// 判断语句
|
||||||
|
if(is_socket) {
|
||||||
|
}...
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
### BPF Map
|
||||||
|
|
||||||
|
BPF程序本身只有指令,不会包含实际数据以及状态,可以在BPF程序上创建BPF Map来存储数据状态、统计信息和指标信息等。
|
||||||
|
|
||||||
|
### BPF Helper Funcation
|
||||||
|
|
||||||
|
操作BPF程序和BPF Map的工具类函数;直接调用内核模块接口会与内核版本强耦合,因此提供BPF辅助函数作为稳定API进行跨内核版本移植。
|
||||||
|
|
||||||
|
- 内核helper:定义在bpf/bpf_helpers.h,直接通过变量指针访问
|
||||||
|
- 用户态helper:定义在tools/lib/bpf/bpf.h,需要通过fd向内核发送消息来访问
|
||||||
|
|
||||||
|
### BPF Tracing
|
||||||
|
|
||||||
|
Tracing视为profiling和debuggin收集数据的方法,目标是在运行时提供有用的信息,BPF相比其他tracing技术只在系统中增加少量的性能和时延开销。
|
||||||
|
|
||||||
|
传统Linux使用probes的方法是写程序并编译到内核模块,BPF piggybakc在tracing probes来收集信息。
|
||||||
|
|
||||||
|
### 常用Probes
|
||||||
|
|
||||||
|
- Kernel probes:没有稳定的ABI,会随着内核版本变更也改变;kprobe —— 允许在任意内核指令之前插入BPF程序,kretprobe —— 允许在内核指令执行完成返回时插入BPF程序
|
||||||
|
- Tracepoints:内核代码中的静态marker,能用于在运行的内核中附加代码,具有稳定的API
|
||||||
|
- User-Space Probes:允许在用户空间运行的程序中设置动态flag;定义一个uprobe后,内核会在附加的指令附加创建一个trap(INT3中断进入内核态), 应用到达指令后内核会触发一个事件,该事件将probe函数作为callback
|
||||||
|
- User Statically Defifined Tracepoints(USDTs):在用户态为应用提供静态tracepoints
|
||||||
|
|
||||||
|
## XDP
|
||||||
|
|
||||||
|
> XDP(eXpress Data Path)提供了一个**内核态、高性能、可编程 BPF 包处理框架**(a framework for BPF that enables high-performance programmable packet processing in the Linux kernel)。这个框架在软件中最早可以处理包的位置(即网卡驱动收到包的 时刻)运行 BPF 程序。
|
||||||
|
|
||||||
|
XDP Hook位于网络驱动的[fast path](https://en.wikipedia.org/wiki/Fast_path)(用来描述一个程序中与正常路径相比指令路径长度较短的路径)上,XDP程序直接从接受缓冲区(receive ring)中将包获取,无需执行任何耗时操作,如分配`skb`然后将包推送到网络协议栈等,因此只要又CPU资源,XDP BPF程序就能够在最早的位置执行处理。
|
||||||
|
|
||||||
|
### 基本概念
|
||||||
|
|
||||||
|
**概述:**
|
||||||
|
|
||||||
|
- 为接收的包做决定,可以编辑接收的包的内容或返回一个结果码(包括:丢弃、从原接口发出、放行到后续协议栈等)
|
||||||
|
- XDP可以push或pull包头(比如:如果内核不支持封装格式或协议,XDP能够进行解封装或翻译,并把结果发送给内核处理)
|
||||||
|
- XDP通过bpf syscall来控制,类型为BPF_PROG_TYPE_XDP
|
||||||
|
|
||||||
|
**「What」定义:**
|
||||||
|
|
||||||
|
- 在网络data path上一个安全、可编程、高性能、内核综合的包处理器
|
||||||
|
- 能够在当NIC驱动接收到一个数据包时就执行BPF程序
|
||||||
|
- 运行XDP程序在很早的点就对接收的包进行丢弃、修改或放行处理
|
||||||
|
|
||||||
|
**特点:**
|
||||||
|
|
||||||
|
- XDP和Linux内核以及基础设施协同工作,不向一些运行在用户空间的网络框架(DPDK)是绕过内核的,可以带来几方面的好处:
|
||||||
|
- XDP可以**复用所有上游开发的内核网络驱动、用户空间工具,以及其他一些可用的内核 基础设施**,例如 BPF 辅助函数在调用自身时可以使用系统路由表、socket 等等。
|
||||||
|
- 因为驻留在内核空间,因此 XDP 在访问硬件时与内核其他部分有相同的安全模型。
|
||||||
|
- 将包从 XDP 送到内核中非常简单,可以**复用内核**中这个健壮、高效、使用广泛的 TCP/IP **协议栈**,而不是像一些用户态框架一样需要自己维护一个独立的 TCP/IP 协 议栈。
|
||||||
|
- **无需跨内核/用户空间边界**,因为正在被处理的包已经在内核中,因此可以灵活地将 其转发到内核内的其他实体,例如容器的命名空间或内核网络栈自身。
|
||||||
|
- 用XDP做包处理时没有内存分配
|
||||||
|
- XDP程序只能操作线性的非分片包,具有包的开始和结束指针
|
||||||
|
- 无法访问整个包的metadata,所以输入的context为xdp_buff
|
||||||
|
- 由于是eBPF程序,XDP程序有受限的执行时间,所以在网络pipeline中有固定的使用开销
|
||||||
|
|
||||||
|
### XDP工作模式
|
||||||
|
|
||||||
|
XDP有三种工作模式,默认是native模式:
|
||||||
|
|
||||||
|
- **Native XDP**
|
||||||
|
|
||||||
|
默认模式,在这种模式中,XDP BPF 程序直接运行在网络驱动的早期接收路径上( early receive path)。大部分广泛使用的 10G 及更高速的网卡都已经支持这种模式 。
|
||||||
|
|
||||||
|
- **Offloaded XDP**
|
||||||
|
|
||||||
|
在这种模式中,XDP BPF 程序直接 offload 到网卡,而不是在主机的 CPU 上执行。 因此,本来就已经很低的 per-packet 开销完全从主机下放到网卡,能够比运行在 native XDP 模式取得更高的性能。这种 offload 通常由智能网卡实现,这些网卡有多 线程、多核流处理器(flow processors),一个位于内核中的 JIT 编译器( in-kernel JIT compiler)将 BPF 翻译成网卡的原生指令。
|
||||||
|
|
||||||
|
支持 offloaded XDP 模式的驱动通常也支持 native XDP 模式,因为 BPF 辅助函数可 能目前还只支持后者。
|
||||||
|
|
||||||
|
- **Generic XDP**
|
||||||
|
|
||||||
|
对于还没有实现 native 或 offloaded XDP 的驱动,内核提供了一个 generic XDP 选 项,这种模式不需要任何驱动改动,因为相应的 XDP 代码运行在网络栈很后面的一个 位置(a much later point)。
|
||||||
|
|
||||||
|
这种设置主要面向的是用内核的 XDP API 来编写和测试程序的开发者,并且无法达到 前面两种模式能达到的性能。对于在生产环境使用 XDP,推荐要么选择 native 要么选择 offloaded 模式。
|
||||||
|
|
||||||
|
### 带来的变化
|
||||||
|
|
||||||
|
原本包的路径如下:
|
||||||
|
|
||||||
|
NIC设备 → Driver → Traffic Control → Netfilter → TCP Stack → Socket
|
||||||
|
|
||||||
|
offloaded模式工作在NIC上,而native模式工作在Driver上。
|
||||||
|
|
||||||
|
### 使用案例
|
||||||
|
|
||||||
|
- **DDoS 防御、防火墙**
|
||||||
|
|
||||||
|
XDP BPF 的一个基本特性就是用 `XDP_DROP` 命令驱动将包丢弃,由于这个丢弃的位置 非常早,因此这种方式可以实现高效的网络策略,平均到每个包的开销非常小( per-packet cost)。这对于那些需要处理任何形式的 DDoS 攻击的场景来说是非常理 想的,而且由于其通用性,使得它能够在 BPF 内实现任何形式的防火墙策略,开销几乎为零, 例如,作为 standalone 设备(例如通过 `XDP_TX` 清洗流量);或者广泛部署在节点 上,保护节点的安全(通过 `XDP_PASS` 或 cpumap `XDP_REDIRECT` 允许“好流量”经 过)。
|
||||||
|
|
||||||
|
Offloaded XDP 更进一步,将本来就已经很小的 per-packet cost 全部下放到网卡以 线速(line-rate)进行处理。
|
||||||
|
|
||||||
|
- **转发和负载均衡**
|
||||||
|
|
||||||
|
XDP 的另一个主要使用场景是包转发和负载均衡,这是通过 `XDP_TX` 或 `XDP_REDIRECT` 动作实现的。
|
||||||
|
|
||||||
|
XDP 层运行的 BPF 程序能够任意修改(mangle)数据包,即使是 BPF 辅助函数都能增 加或减少包的 headroom,这样就可以在将包再次发送出去之前,对包进行任何的封装/解封装。
|
||||||
|
|
||||||
|
利用 `XDP_TX` 能够实现 hairpinned(发卡)模式的负载均衡器,这种均衡器能够 在接收到包的网卡再次将包发送出去,而 `XDP_REDIRECT` 动作能够将包转发到另一个 网卡然后发送出去。
|
||||||
|
|
||||||
|
`XDP_REDIRECT` 返回码还可以和 BPF cpumap 一起使用,对那些目标是本机协议栈、 将由 non-XDP 的远端(remote)CPU 处理的包进行负载均衡。
|
||||||
|
|
||||||
|
- **栈前(Pre-stack)过滤/处理**
|
||||||
|
|
||||||
|
除了策略执行,XDP 还可以用于加固内核的网络栈,这是通过 `XDP_DROP` 实现的。 这意味着,XDP 能够在可能的最早位置丢弃那些与本节点不相关的包,这个过程发生在 内核网络栈看到这些包之前。例如假如我们已经知道某台节点只接受 TCP 流量,那任 何 UDP、SCTP 或其他四层流量都可以在发现后立即丢弃。
|
||||||
|
|
||||||
|
这种方式的好处是包不需要再经过各种实体(例如 GRO 引擎、内核的 flow dissector 以及其他的模块),就可以判断出是否应该丢弃,因此减少了内核的 受攻击面。正是由于 XDP 的早期处理阶段,这有效地对内核网络栈“假装”这些包根本 就没被网络设备看到。
|
||||||
|
|
||||||
|
另外,如果内核接收路径上某个潜在 bug 导致 ping of death 之类的场景,那我们能 够利用 XDP 立即丢弃这些包,而不用重启内核或任何服务。而且由于能够原子地替换 程序,这种方式甚至都不会导致宿主机的任何流量中断。
|
||||||
|
|
||||||
|
栈前处理的另一个场景是:在内核分配 `skb` 之前,XDP BPF 程序可以对包进行任意 修改,而且对内核“假装”这个包从网络设备收上来之后就是这样的。对于某些自定义包 修改(mangling)和封装协议的场景来说比较有用,在这些场景下,包在进入 GRO 聚 合之前会被修改和解封装,否则 GRO 将无法识别自定义的协议,进而无法执行任何形 式的聚合。
|
||||||
|
|
||||||
|
XDP 还能够在包的前面 push 元数据(非包内容的数据)。这些元数据对常规的内核栈 是不可见的(invisible),但能被 GRO 聚合(匹配元数据),稍后可以和 tc ingress BPF 程 序一起处理,tc BPF 中携带了 `skb` 的某些上下文,例如,设置了某些 skb 字段。
|
||||||
|
|
||||||
|
- **流抽样(Flow sampling)和监控**
|
||||||
|
|
||||||
|
XDP 还可以用于包监控、抽样或其他的一些网络分析,例如作为流量路径中间节点 的一部分;或运行在终端节点上,和前面提到的场景相结合。对于复杂的包分析,XDP 提供了设施来高效地将网络包(截断的或者是完整的 payload)或自定义元数据 push 到 perf 提供的一个快速、无锁、per-CPU 内存映射缓冲区,或者是一 个用户空间应用。
|
||||||
|
|
||||||
|
这还可以用于流分析和监控,对每个流的初始数据进行分析,一旦确定是正常流量,这个流随 后的流量就会跳过这个监控。感谢 BPF 带来的灵活性,这使得我们可以实现任何形式 的自定义监控或采用。
|
||||||
|
|
||||||
|
## eBPF工具
|
||||||
|
|
||||||
|
- bbc:利用python开发自己工具,但上手较难
|
||||||
|
https://github.com/iovisor/bcc/blob/master/docs/tutorial.md
|
||||||
|
- bpftrace:可以使用高级语言开发,更容易学
|
||||||
|
bpftrace利用LLVM作为后端来将脚本编译为BPF字节码,利用BCC来和linux BPF系统以及已有的linux tracing能力(内核tracing (kprobes)、用户级动态tracing (uprobes)、以及tracepoints)进行交互
|
||||||
|
https://github.com/iovisor/bpftrace
|
||||||
|
- bpftool :一个用来检查 BPF 程序和映射的内核工具
|
||||||
|
https://lwn.net/Articles/739357/https://man.archlinux.org/man/bpftool.8.en源码在 tools/bpf/bpftool 中
|
||||||
|
bpftool prog 可以用来检查系统中运行程序的情况
|
||||||
|
执行 bpf prog dump 来获取整个程序的数据,能够看到由编译器生成的字节码
|
||||||
|
- gobpf:基于bbc框架的go工具
|
||||||
|
https://github.com/iovisor/gobpf
|
||||||
|
|
||||||
|
## 参考
|
||||||
|
|
||||||
|
- http://arthurchiao.art/blog/ebpf-and-k8s-zh/
|
||||||
|
- http://arthurchiao.art/blog/cilium-bpf-xdp-reference-guide-zh/#prog_type_xdp
|
||||||
|
- https://davidlovezoe.club/wordpress/archives/1122
|
||||||
|
- [eBPF是什么?](https://blog.fleeto.us/post/what-is-ebpf/)
|
||||||
|
- 版本支持情况:https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md
|
||||||
|
- https://github.com/zoidbergwill/awesome-ebpf#the-code
|
||||||
|
|
||||||
Reference in New Issue
Block a user