mirror of
https://github.com/Estom/notes.git
synced 2026-04-14 10:21:08 +08:00
java 教程又编辑了一会
This commit is contained in:
8
.vscode/settings.json
vendored
8
.vscode/settings.json
vendored
@@ -190,7 +190,11 @@
|
||||
],
|
||||
"java.format.settings.url": ".vscode/java-formatter.xml",
|
||||
"java.project.sourcePaths": [
|
||||
"Java源代码/Java1",
|
||||
"Java源代码/Code1"
|
||||
"Java源代码/Lesson01",
|
||||
"Java源代码/Lesson02",
|
||||
"Java源代码/Lesson03",
|
||||
"Java源代码/Lesson04",
|
||||
"Java源代码/Lesson05",
|
||||
"Java源代码/Lesson06"
|
||||
],
|
||||
}
|
||||
7
JavaScript/Bower/概述.md
Normal file
7
JavaScript/Bower/概述.md
Normal file
@@ -0,0 +1,7 @@
|
||||
Bower是一款优秀的包管理器,它由Twitter公司开发,支持以命令行的方式来对包进行搜索、下载、更新和卸载。
|
||||
|
||||
基于nodejs的模块化思想,把功能分散到各个模块中,让模块和模块之间存在联系,通过 Bower 来管理模块间的这种联系。
|
||||
|
||||
bower ,从一开始,就是专门为前端表现设计的包管理器,一切全部为前端考虑的。npm 和bower 的最大区别,就是 npm 支持嵌套地依赖管理,而 bower只能支持扁平的依赖(嵌套的依赖,由程序员自己解决)。
|
||||
|
||||
当然,bower 是运行在node.js 基础上,所以你的当前环境确保已经安装 node.js .一般来说,npm管理后台的包,bower管理前台的包
|
||||
@@ -1,8 +0,0 @@
|
||||
package com.ykl;
|
||||
public class Java01HelloWorld {
|
||||
public static void main(String[] args) {
|
||||
System.out.println("Hello");
|
||||
// System.exit(0);
|
||||
|
||||
}
|
||||
}
|
||||
@@ -1,28 +0,0 @@
|
||||
// package com.ykl.innerclass;
|
||||
import java.lang.Thread;
|
||||
/**
|
||||
* AnonymousClass
|
||||
*/
|
||||
public class AnonymousClass {
|
||||
|
||||
private int a;
|
||||
|
||||
public static void main(String[] args){
|
||||
new AnonymousClass().test(2);
|
||||
}
|
||||
|
||||
//事实证明匿名内部类
|
||||
public void test(final int a){
|
||||
int b =10;
|
||||
int c =11;
|
||||
new Thread(){
|
||||
public void run() {
|
||||
System.out.println(a);
|
||||
System.out.println(b);
|
||||
}
|
||||
}.start();
|
||||
b = 12;
|
||||
System.out.print(b);
|
||||
}
|
||||
|
||||
}
|
||||
@@ -1,5 +1,7 @@
|
||||
package com.ykl;
|
||||
|
||||
/**
|
||||
* 整个项目的启动程序
|
||||
*/
|
||||
public class HelloWorld {
|
||||
/*
|
||||
* 多行注释,可以注释一段文字
|
||||
@@ -3,6 +3,7 @@ package com.ykl;
|
||||
* @author ykl
|
||||
* @since 2022
|
||||
* @version 1.0
|
||||
* 验证前置类型转换的有效性
|
||||
*/
|
||||
public class Demo5 {
|
||||
/**
|
||||
@@ -1,5 +1,9 @@
|
||||
// package com.ykl.exceptions;
|
||||
|
||||
/**
|
||||
* Java工程目录结构
|
||||
* * src下的内容才能被识别
|
||||
*/
|
||||
public class ExceptionTest{
|
||||
public static void main(String[] args) {
|
||||
System.out.println("Hello World!");
|
||||
@@ -0,0 +1,20 @@
|
||||
package com.ykl.extentions;
|
||||
|
||||
/**
|
||||
* 验证静态变量能够被类的实例访问
|
||||
*/
|
||||
|
||||
class Book{
|
||||
private String name;
|
||||
private int price;
|
||||
static final String id="BOOK";
|
||||
public static void main(String[] args) {
|
||||
Book book = new Book();
|
||||
System.out.println(book.name);
|
||||
System.out.println(book.price);
|
||||
// 事实证明这三种方法都能够访问到类变量
|
||||
System.out.println(id);
|
||||
System.out.println(Book.id);
|
||||
System.out.println(book.id);
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,45 @@
|
||||
|
||||
import java.lang.Thread;
|
||||
/**
|
||||
* AnonymousClass
|
||||
*/
|
||||
public class AnonymousClass {
|
||||
|
||||
private int a;
|
||||
|
||||
public static void main(String[] args){
|
||||
new AnonymousClass().test(2);
|
||||
// 成员内部类需要创建对象
|
||||
AnonymousClass ac = new AnonymousClass();
|
||||
ac.new Inner().getName();
|
||||
//静态内部类可以直接访问
|
||||
new AnonymousClass.StaticInner().getName();
|
||||
}
|
||||
|
||||
public class Inner{
|
||||
public void getName(){
|
||||
System.out.println("成员内部类");
|
||||
}
|
||||
}
|
||||
|
||||
public static class StaticInner{
|
||||
public void getName(){
|
||||
System.out.println("静态内部类");
|
||||
}
|
||||
}
|
||||
|
||||
//事实证明匿名内部类必须访问final类型的变量,或者事实上final类型的变量。
|
||||
public void test(final int a){
|
||||
int b =10;
|
||||
int c =11;
|
||||
new Thread(){
|
||||
public void run() {
|
||||
System.out.println(a);
|
||||
System.out.println(b);
|
||||
}
|
||||
}.start();
|
||||
// b = 12;
|
||||
System.out.print(b);
|
||||
}
|
||||
|
||||
}
|
||||
@@ -0,0 +1,31 @@
|
||||
package com.ykl.innerclass;
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
public class PartialDemo {
|
||||
static String name = "王五";
|
||||
String name2 = "周七";
|
||||
public void demo() {
|
||||
String name = "张三";
|
||||
class Inner{
|
||||
String name = "李四";
|
||||
public void showInner(String name) {
|
||||
System.out.println("这是外部类变量:"+PartialDemo.this.name2);
|
||||
System.out.println("这是外部类变量(静态变量可以):"+PartialDemo.name);
|
||||
System.out.println("这是方法中局部变量变量:"+name);
|
||||
System.out.println("这是局部内部类中的变量:"+this.name);
|
||||
|
||||
}
|
||||
}
|
||||
Inner inner=new Inner();
|
||||
inner.showInner(name);
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
PartialDemo partialDemo = new PartialDemo();
|
||||
partialDemo.demo();
|
||||
}
|
||||
|
||||
}
|
||||
@@ -1,5 +1,7 @@
|
||||
package com.ykl;
|
||||
|
||||
/**
|
||||
* 验证函数重载和类型转换的优先级
|
||||
*/
|
||||
|
||||
import java.sql.Array;
|
||||
|
||||
@@ -2,6 +2,9 @@ package com.ykl;
|
||||
|
||||
import java.util.Scanner;
|
||||
|
||||
/**
|
||||
* 验证scanner输入输出的有效性
|
||||
*/
|
||||
public class ScannerTest {
|
||||
public static void main(String[] args) {
|
||||
Scanner s = new Scanner(System.in);
|
||||
@@ -0,0 +1,23 @@
|
||||
package com.ykl.wrapper;
|
||||
|
||||
/**
|
||||
* 用来验证拆箱装箱的有效性
|
||||
*/
|
||||
public class WrapperTest {
|
||||
public static void main(String[] args) {
|
||||
int a=1;
|
||||
int b=2;
|
||||
|
||||
Integer c =1;
|
||||
Integer d =2;
|
||||
Integer e =new Integer(1);
|
||||
System.out.println(a==b);
|
||||
System.out.println(a==c);
|
||||
System.out.println(c==d);
|
||||
System.out.println(c==e);//不拆箱
|
||||
System.out.println(c.equals(d));
|
||||
System.out.println(c.equals(e));
|
||||
System.out.println(e.equals(a));//类型不转换
|
||||
|
||||
}
|
||||
}
|
||||
3
Java基础教程/Java源代码/Lesson02/.idea/.gitignore
generated
vendored
3
Java基础教程/Java源代码/Lesson02/.idea/.gitignore
generated
vendored
@@ -1,3 +0,0 @@
|
||||
# Default ignored files
|
||||
/shelf/
|
||||
/workspace.xml
|
||||
12
Java基础教程/Java源代码/Lesson02/.idea/basicLesson/pom.xml
generated
12
Java基础教程/Java源代码/Lesson02/.idea/basicLesson/pom.xml
generated
@@ -1,12 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<project xmlns="http://maven.apache.org/POM/4.0.0"
|
||||
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
|
||||
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
|
||||
<modelVersion>4.0.0</modelVersion>
|
||||
|
||||
<groupId>org.example</groupId>
|
||||
<artifactId>basicLesson</artifactId>
|
||||
<version>1.0-SNAPSHOT</version>
|
||||
|
||||
|
||||
</project>
|
||||
@@ -1,24 +0,0 @@
|
||||
/**
|
||||
* Alipay.com Inc.
|
||||
* Copyright (c) 2004-2022 All Rights Reserved.
|
||||
*/
|
||||
package com.ykl;
|
||||
|
||||
/**
|
||||
* @author yinkanglong
|
||||
* @version : Application, v 0.1 2022-07-11 09:20 yinkanglong Exp $
|
||||
*/
|
||||
public class Application {
|
||||
public static void main(String[] args) {
|
||||
String a = "test";
|
||||
String b = "test";
|
||||
String c = new String("test");
|
||||
String d = new String("test");
|
||||
|
||||
System.out.println(a==b);
|
||||
System.out.println(c==d);
|
||||
System.out.println("hello world");
|
||||
|
||||
|
||||
}
|
||||
}
|
||||
@@ -1,38 +0,0 @@
|
||||
/**
|
||||
* Alipay.com Inc.
|
||||
* Copyright (c) 2004-2022 All Rights Reserved.
|
||||
*/
|
||||
package com.ykl.annotationtest;
|
||||
|
||||
import java.lang.reflect.Field;
|
||||
import java.lang.reflect.Method;
|
||||
|
||||
/**
|
||||
* @author yinkanglong
|
||||
* @version : AnnotationTest, v 0.1 2022-07-12 09:50 yinkanglong Exp $
|
||||
*/
|
||||
public class AnnotationTest {
|
||||
|
||||
public static void main(String[] args) throws Exception {
|
||||
// 获取类上的注解
|
||||
Class<Demo> clazz = Demo.class;
|
||||
MyAnnotation annotationOnClass = clazz.getAnnotation(MyAnnotation.class);
|
||||
System.out.println(annotationOnClass.getValue());
|
||||
|
||||
// 获取成员变量上的注解
|
||||
Field name = clazz.getField("name");
|
||||
MyAnnotation annotationOnField = name.getAnnotation(MyAnnotation.class);
|
||||
System.out.println(annotationOnField.getValue());
|
||||
|
||||
// 获取hello方法上的注解
|
||||
Method hello = clazz.getMethod("hello", (Class<?>[]) null);
|
||||
MyAnnotation annotationOnMethod = hello.getAnnotation(MyAnnotation.class);
|
||||
System.out.println(annotationOnMethod.getValue());
|
||||
|
||||
// 获取defaultMethod方法上的注解
|
||||
Method defaultMethod = clazz.getMethod("defaultMethod", (Class<?>[]) null);
|
||||
MyAnnotation annotationOnDefaultMethod = defaultMethod.getAnnotation(MyAnnotation.class);
|
||||
System.out.println(annotationOnDefaultMethod.getValue());
|
||||
|
||||
}
|
||||
}
|
||||
@@ -1,25 +0,0 @@
|
||||
/**
|
||||
* Alipay.com Inc.
|
||||
* Copyright (c) 2004-2022 All Rights Reserved.
|
||||
*/
|
||||
package com.ykl.annotationtest;
|
||||
|
||||
/**
|
||||
* @author yinkanglong
|
||||
* @version : Demo, v 0.1 2022-07-12 09:49 yinkanglong Exp $
|
||||
*/
|
||||
/**
|
||||
* @author qiyu
|
||||
*/
|
||||
@MyAnnotation(getValue = "annotation on class")
|
||||
public class Demo {
|
||||
|
||||
@MyAnnotation(getValue = "annotation on field")
|
||||
public String name;
|
||||
|
||||
@MyAnnotation(getValue = "annotation on method")
|
||||
public void hello() {}
|
||||
|
||||
@MyAnnotation() // 故意不指定getValue
|
||||
public void defaultMethod() {}
|
||||
}
|
||||
@@ -1,17 +0,0 @@
|
||||
/**
|
||||
* Alipay.com Inc.
|
||||
* Copyright (c) 2004-2022 All Rights Reserved.
|
||||
*/
|
||||
package com.ykl.annotationtest;
|
||||
|
||||
import java.lang.annotation.Retention;
|
||||
import java.lang.annotation.RetentionPolicy;
|
||||
|
||||
/**
|
||||
* @author yinkanglong
|
||||
* @version : MyAnnotation, v 0.1 2022-07-12 09:48 yinkanglong Exp $
|
||||
*/
|
||||
@Retention(RetentionPolicy.RUNTIME)
|
||||
public @interface MyAnnotation {
|
||||
String getValue() default "no description";
|
||||
}
|
||||
@@ -1,27 +0,0 @@
|
||||
/**
|
||||
* Alipay.com Inc.
|
||||
* Copyright (c) 2004-2022 All Rights Reserved.
|
||||
*/
|
||||
package com.ykl.eceptiontest;
|
||||
|
||||
/**
|
||||
* @author yinkanglong
|
||||
* @version : ExceptionTest, v 0.1 2022-07-11 19:45 yinkanglong Exp $
|
||||
*/
|
||||
public class ExceptionTest {
|
||||
|
||||
public static void main(String args[]) {
|
||||
int a[] = new int[2];
|
||||
try {
|
||||
System.out.println("Access element three :" + a[3]);
|
||||
} catch (ArrayIndexOutOfBoundsException e) {
|
||||
System.out.println("Exception thrown :" + e);
|
||||
return ;
|
||||
} finally {
|
||||
a[0] = 6;
|
||||
System.out.println("First element value: " + a[0]);
|
||||
System.out.println("The finally statement is executed");
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
15
Java基础教程/Java源代码/Lesson02/.idea/misc.xml
generated
15
Java基础教程/Java源代码/Lesson02/.idea/misc.xml
generated
@@ -1,15 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<project version="4">
|
||||
<component name="JavadocGenerationManager">
|
||||
<option name="OUTPUT_DIRECTORY" value="$PROJECT_DIR$/.." />
|
||||
<option name="OPTION_SCOPE" value="private" />
|
||||
<option name="OPTION_DOCUMENT_TAG_USE" value="true" />
|
||||
<option name="OPTION_DOCUMENT_TAG_AUTHOR" value="true" />
|
||||
<option name="OPTION_DOCUMENT_TAG_VERSION" value="true" />
|
||||
<option name="OTHER_OPTIONS" value="-encoding utf-8 -charset utf-8" />
|
||||
<option name="LOCALE" value="zh_CN" />
|
||||
</component>
|
||||
<component name="ProjectRootManager" version="2" languageLevel="JDK_1_8" project-jdk-name="1.8" project-jdk-type="JavaSDK">
|
||||
<output url="file://$PROJECT_DIR$/out" />
|
||||
</component>
|
||||
</project>
|
||||
9
Java基础教程/Java源代码/Lesson02/.idea/modules.xml
generated
9
Java基础教程/Java源代码/Lesson02/.idea/modules.xml
generated
@@ -1,9 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<project version="4">
|
||||
<component name="ProjectModuleManager">
|
||||
<modules>
|
||||
<module fileurl="file://$PROJECT_DIR$/BasicLanguage/BasicLanguage.iml" filepath="$PROJECT_DIR$/BasicLanguage/BasicLanguage.iml" />
|
||||
<module fileurl="file://$PROJECT_DIR$/Lesson02.iml" filepath="$PROJECT_DIR$/Lesson02.iml" />
|
||||
</modules>
|
||||
</component>
|
||||
</project>
|
||||
124
Java基础教程/Java源代码/Lesson02/.idea/uiDesigner.xml
generated
124
Java基础教程/Java源代码/Lesson02/.idea/uiDesigner.xml
generated
@@ -1,124 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<project version="4">
|
||||
<component name="Palette2">
|
||||
<group name="Swing">
|
||||
<item class="com.intellij.uiDesigner.HSpacer" tooltip-text="Horizontal Spacer" icon="/com/intellij/uiDesigner/icons/hspacer.svg" removable="false" auto-create-binding="false" can-attach-label="false">
|
||||
<default-constraints vsize-policy="1" hsize-policy="6" anchor="0" fill="1" />
|
||||
</item>
|
||||
<item class="com.intellij.uiDesigner.VSpacer" tooltip-text="Vertical Spacer" icon="/com/intellij/uiDesigner/icons/vspacer.svg" removable="false" auto-create-binding="false" can-attach-label="false">
|
||||
<default-constraints vsize-policy="6" hsize-policy="1" anchor="0" fill="2" />
|
||||
</item>
|
||||
<item class="javax.swing.JPanel" icon="/com/intellij/uiDesigner/icons/panel.svg" removable="false" auto-create-binding="false" can-attach-label="false">
|
||||
<default-constraints vsize-policy="3" hsize-policy="3" anchor="0" fill="3" />
|
||||
</item>
|
||||
<item class="javax.swing.JScrollPane" icon="/com/intellij/uiDesigner/icons/scrollPane.svg" removable="false" auto-create-binding="false" can-attach-label="true">
|
||||
<default-constraints vsize-policy="7" hsize-policy="7" anchor="0" fill="3" />
|
||||
</item>
|
||||
<item class="javax.swing.JButton" icon="/com/intellij/uiDesigner/icons/button.svg" removable="false" auto-create-binding="true" can-attach-label="false">
|
||||
<default-constraints vsize-policy="0" hsize-policy="3" anchor="0" fill="1" />
|
||||
<initial-values>
|
||||
<property name="text" value="Button" />
|
||||
</initial-values>
|
||||
</item>
|
||||
<item class="javax.swing.JRadioButton" icon="/com/intellij/uiDesigner/icons/radioButton.svg" removable="false" auto-create-binding="true" can-attach-label="false">
|
||||
<default-constraints vsize-policy="0" hsize-policy="3" anchor="8" fill="0" />
|
||||
<initial-values>
|
||||
<property name="text" value="RadioButton" />
|
||||
</initial-values>
|
||||
</item>
|
||||
<item class="javax.swing.JCheckBox" icon="/com/intellij/uiDesigner/icons/checkBox.svg" removable="false" auto-create-binding="true" can-attach-label="false">
|
||||
<default-constraints vsize-policy="0" hsize-policy="3" anchor="8" fill="0" />
|
||||
<initial-values>
|
||||
<property name="text" value="CheckBox" />
|
||||
</initial-values>
|
||||
</item>
|
||||
<item class="javax.swing.JLabel" icon="/com/intellij/uiDesigner/icons/label.svg" removable="false" auto-create-binding="false" can-attach-label="false">
|
||||
<default-constraints vsize-policy="0" hsize-policy="0" anchor="8" fill="0" />
|
||||
<initial-values>
|
||||
<property name="text" value="Label" />
|
||||
</initial-values>
|
||||
</item>
|
||||
<item class="javax.swing.JTextField" icon="/com/intellij/uiDesigner/icons/textField.svg" removable="false" auto-create-binding="true" can-attach-label="true">
|
||||
<default-constraints vsize-policy="0" hsize-policy="6" anchor="8" fill="1">
|
||||
<preferred-size width="150" height="-1" />
|
||||
</default-constraints>
|
||||
</item>
|
||||
<item class="javax.swing.JPasswordField" icon="/com/intellij/uiDesigner/icons/passwordField.svg" removable="false" auto-create-binding="true" can-attach-label="true">
|
||||
<default-constraints vsize-policy="0" hsize-policy="6" anchor="8" fill="1">
|
||||
<preferred-size width="150" height="-1" />
|
||||
</default-constraints>
|
||||
</item>
|
||||
<item class="javax.swing.JFormattedTextField" icon="/com/intellij/uiDesigner/icons/formattedTextField.svg" removable="false" auto-create-binding="true" can-attach-label="true">
|
||||
<default-constraints vsize-policy="0" hsize-policy="6" anchor="8" fill="1">
|
||||
<preferred-size width="150" height="-1" />
|
||||
</default-constraints>
|
||||
</item>
|
||||
<item class="javax.swing.JTextArea" icon="/com/intellij/uiDesigner/icons/textArea.svg" removable="false" auto-create-binding="true" can-attach-label="true">
|
||||
<default-constraints vsize-policy="6" hsize-policy="6" anchor="0" fill="3">
|
||||
<preferred-size width="150" height="50" />
|
||||
</default-constraints>
|
||||
</item>
|
||||
<item class="javax.swing.JTextPane" icon="/com/intellij/uiDesigner/icons/textPane.svg" removable="false" auto-create-binding="true" can-attach-label="true">
|
||||
<default-constraints vsize-policy="6" hsize-policy="6" anchor="0" fill="3">
|
||||
<preferred-size width="150" height="50" />
|
||||
</default-constraints>
|
||||
</item>
|
||||
<item class="javax.swing.JEditorPane" icon="/com/intellij/uiDesigner/icons/editorPane.svg" removable="false" auto-create-binding="true" can-attach-label="true">
|
||||
<default-constraints vsize-policy="6" hsize-policy="6" anchor="0" fill="3">
|
||||
<preferred-size width="150" height="50" />
|
||||
</default-constraints>
|
||||
</item>
|
||||
<item class="javax.swing.JComboBox" icon="/com/intellij/uiDesigner/icons/comboBox.svg" removable="false" auto-create-binding="true" can-attach-label="true">
|
||||
<default-constraints vsize-policy="0" hsize-policy="2" anchor="8" fill="1" />
|
||||
</item>
|
||||
<item class="javax.swing.JTable" icon="/com/intellij/uiDesigner/icons/table.svg" removable="false" auto-create-binding="true" can-attach-label="false">
|
||||
<default-constraints vsize-policy="6" hsize-policy="6" anchor="0" fill="3">
|
||||
<preferred-size width="150" height="50" />
|
||||
</default-constraints>
|
||||
</item>
|
||||
<item class="javax.swing.JList" icon="/com/intellij/uiDesigner/icons/list.svg" removable="false" auto-create-binding="true" can-attach-label="false">
|
||||
<default-constraints vsize-policy="6" hsize-policy="2" anchor="0" fill="3">
|
||||
<preferred-size width="150" height="50" />
|
||||
</default-constraints>
|
||||
</item>
|
||||
<item class="javax.swing.JTree" icon="/com/intellij/uiDesigner/icons/tree.svg" removable="false" auto-create-binding="true" can-attach-label="false">
|
||||
<default-constraints vsize-policy="6" hsize-policy="6" anchor="0" fill="3">
|
||||
<preferred-size width="150" height="50" />
|
||||
</default-constraints>
|
||||
</item>
|
||||
<item class="javax.swing.JTabbedPane" icon="/com/intellij/uiDesigner/icons/tabbedPane.svg" removable="false" auto-create-binding="true" can-attach-label="false">
|
||||
<default-constraints vsize-policy="3" hsize-policy="3" anchor="0" fill="3">
|
||||
<preferred-size width="200" height="200" />
|
||||
</default-constraints>
|
||||
</item>
|
||||
<item class="javax.swing.JSplitPane" icon="/com/intellij/uiDesigner/icons/splitPane.svg" removable="false" auto-create-binding="false" can-attach-label="false">
|
||||
<default-constraints vsize-policy="3" hsize-policy="3" anchor="0" fill="3">
|
||||
<preferred-size width="200" height="200" />
|
||||
</default-constraints>
|
||||
</item>
|
||||
<item class="javax.swing.JSpinner" icon="/com/intellij/uiDesigner/icons/spinner.svg" removable="false" auto-create-binding="true" can-attach-label="true">
|
||||
<default-constraints vsize-policy="0" hsize-policy="6" anchor="8" fill="1" />
|
||||
</item>
|
||||
<item class="javax.swing.JSlider" icon="/com/intellij/uiDesigner/icons/slider.svg" removable="false" auto-create-binding="true" can-attach-label="false">
|
||||
<default-constraints vsize-policy="0" hsize-policy="6" anchor="8" fill="1" />
|
||||
</item>
|
||||
<item class="javax.swing.JSeparator" icon="/com/intellij/uiDesigner/icons/separator.svg" removable="false" auto-create-binding="false" can-attach-label="false">
|
||||
<default-constraints vsize-policy="6" hsize-policy="6" anchor="0" fill="3" />
|
||||
</item>
|
||||
<item class="javax.swing.JProgressBar" icon="/com/intellij/uiDesigner/icons/progressbar.svg" removable="false" auto-create-binding="true" can-attach-label="false">
|
||||
<default-constraints vsize-policy="0" hsize-policy="6" anchor="0" fill="1" />
|
||||
</item>
|
||||
<item class="javax.swing.JToolBar" icon="/com/intellij/uiDesigner/icons/toolbar.svg" removable="false" auto-create-binding="false" can-attach-label="false">
|
||||
<default-constraints vsize-policy="0" hsize-policy="6" anchor="0" fill="1">
|
||||
<preferred-size width="-1" height="20" />
|
||||
</default-constraints>
|
||||
</item>
|
||||
<item class="javax.swing.JToolBar$Separator" icon="/com/intellij/uiDesigner/icons/toolbarSeparator.svg" removable="false" auto-create-binding="false" can-attach-label="false">
|
||||
<default-constraints vsize-policy="0" hsize-policy="0" anchor="0" fill="1" />
|
||||
</item>
|
||||
<item class="javax.swing.JScrollBar" icon="/com/intellij/uiDesigner/icons/scrollbar.svg" removable="false" auto-create-binding="true" can-attach-label="false">
|
||||
<default-constraints vsize-policy="6" hsize-policy="0" anchor="0" fill="2" />
|
||||
</item>
|
||||
</group>
|
||||
</component>
|
||||
</project>
|
||||
6
Java基础教程/Java源代码/Lesson02/.idea/vcs.xml
generated
6
Java基础教程/Java源代码/Lesson02/.idea/vcs.xml
generated
@@ -1,6 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<project version="4">
|
||||
<component name="VcsDirectoryMappings">
|
||||
<mapping directory="$PROJECT_DIR$/../.." vcs="Git" />
|
||||
</component>
|
||||
</project>
|
||||
@@ -1,11 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<module type="JAVA_MODULE" version="4">
|
||||
<component name="NewModuleRootManager" inherit-compiler-output="true">
|
||||
<exclude-output />
|
||||
<content url="file://$MODULE_DIR$">
|
||||
<sourceFolder url="file://$MODULE_DIR$/src" isTestSource="false" />
|
||||
</content>
|
||||
<orderEntry type="jdk" jdkName="1.8" jdkType="JavaSDK" />
|
||||
<orderEntry type="sourceFolder" forTests="false" />
|
||||
</component>
|
||||
</module>
|
||||
@@ -41,25 +41,50 @@ public class Dog {
|
||||
|
||||
- 成员变量Field:描述类或者对象的属性信息的。
|
||||
- 成员方法Method:描述类或者对象的行为的。
|
||||
- 构造器(构造方法,Constructor): 初始化类的一个对象返回。
|
||||
- 代码块:代码块按照有无static可以分为静态代码块和实例代码块。
|
||||
- 内部类:将一个类定义在另一个类里面或者一个方法里面,这样的类称为内部类。
|
||||
- 构造器(构造方法)Constructor: 初始化类的一个对象返回。
|
||||
- 代码块Block:代码块按照有无static可以分为静态代码块和实例代码块。
|
||||
- 内部类InnerClass:将一个类定义在另一个类里面或者一个方法里面,这样的类称为内部类。
|
||||
|
||||
|
||||
### 访问权限修饰符
|
||||
|
||||
* 如果一个类的成员变量或成员方法被修饰为private,则只能在本类中使用,在子类中不可使用,并且在其他包的类中是不可见的。
|
||||
一个类的成员变量或成员方法
|
||||
* 如果被修饰为private,则只能在本类中使用,在子类中不可使用,并且在其他包的类中是不可见的。
|
||||
* 如果被修饰为public,则在子类和其他包的类中可以使用。
|
||||
* 如果被修饰为protect,则仅在子类中可以使用。
|
||||
* 如果没有权限修饰符,默认访问权限为整个包。
|
||||
|
||||
|
||||
|
||||
## 2 成员变量Field
|
||||
### 变量类型
|
||||
|
||||
* 局部变量:在方法、构造方法或者语句块中定义的变量被称为局部变量。变量声明和初始化都是在方法中,方法结束后,变量就会自动销毁。
|
||||
* 成员变量:成员变量是定义在类中,方法体之外的变量。这种变量在创建对象的时候实例化。成员变量可以被类中方法、构造方法和特定类的语句块访问。只能通过实例化的对象进行访问
|
||||
* 成员变量:成员变量是定义在类中,方法体之外的变量。这种变量在创建对象的时候实例化。成员变量可以被类中的成员方法、构造方法和特定类的语句块访问。只能通过实例化的对象进行访问
|
||||
* 类变量:类变量也声明在类中,方法体之外,但必须声明为 static 类型。只能通过类名进行访问
|
||||
|
||||
```java
|
||||
package com.ykl.extentions;
|
||||
|
||||
/**
|
||||
* 验证静态变量能够被类的实例访问
|
||||
*/
|
||||
|
||||
class Book{
|
||||
private String name;
|
||||
private int price;
|
||||
static final String id="BOOK";
|
||||
public static void main(String[] args) {
|
||||
Book book = new Book();
|
||||
System.out.println(book.name);
|
||||
System.out.println(book.price);
|
||||
// 事实证明这三种方法都能够访问到类变量
|
||||
System.out.println(id);
|
||||
System.out.println(Book.id);
|
||||
System.out.println(book.id);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 成员变量
|
||||
|
||||
在Java中对象的属性称为成员变量。为了了解成员变量,在下面的代码中首先定义一个图书类,成员变量对应于类**对象的属性**,在Book类中设置3个成员变量,分别为id,name和category,分别对应于图书编号,图书名称和图书类别3个图书属性。
|
||||
|
||||
@@ -22,6 +22,53 @@
|
||||
|
||||
## 2 使用
|
||||
|
||||
```java
|
||||
|
||||
import java.lang.Thread;
|
||||
/**
|
||||
* AnonymousClass
|
||||
*/
|
||||
public class AnonymousClass {
|
||||
|
||||
private int a;
|
||||
|
||||
public static void main(String[] args){
|
||||
new AnonymousClass().test(2);
|
||||
// 成员内部类需要创建对象
|
||||
AnonymousClass ac = new AnonymousClass();
|
||||
ac.new Inner().getName();
|
||||
//静态内部类可以直接访问
|
||||
new AnonymousClass.StaticInner().getName();
|
||||
}
|
||||
|
||||
public class Inner{
|
||||
public void getName(){
|
||||
System.out.println("成员内部类");
|
||||
}
|
||||
}
|
||||
|
||||
public static class StaticInner{
|
||||
public void getName(){
|
||||
System.out.println("静态内部类");
|
||||
}
|
||||
}
|
||||
|
||||
//事实证明匿名内部类必须访问final类型的变量,或者事实上final类型的变量。
|
||||
public void test(final int a){
|
||||
int b =10;
|
||||
int c =11;
|
||||
new Thread(){
|
||||
public void run() {
|
||||
System.out.println(a);
|
||||
System.out.println(b);
|
||||
}
|
||||
}.start();
|
||||
// b = 12;
|
||||
System.out.print(b);
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
### 成员内部类
|
||||
|
||||
在类的内部方法的外部编写的类就是成员内部类。
|
||||
@@ -430,7 +477,7 @@ final com.cxh.test2.Outter this$0;
|
||||
public com.cxh.test2.Outter$Inner(com.cxh.test2.Outter);
|
||||
```
|
||||
|
||||
从这里可以看出,虽然我们在定义的内部类的构造器是无参构造器,编译器还是会默认添加一个参数,该参数的类型为指向外部类对象的一个引用,所以成员内部类中的Outter this&0 指针便指向了外部类对象,因此可以在成员内部类中随意访问外部类的成员。从这里也间接说明了成员内部类是依赖于外部类的,如果没有创建外部类的对象,则无法对Outter this&0引用进行初始化赋值,也就无法创建成员内部类的对象了。、
|
||||
从这里可以看出,虽然我们在定义的内部类的构造器是无参构造器,编译器还是会默认添加一个参数,该参数的类型为指向外部类对象的一个引用,所以成员内部类中的Outter this&0 指针便指向了外部类对象,因此可以在成员内部类中随意访问外部类的成员。从这里也间接说明了成员内部类是依赖于外部类的,如果没有创建外部类的对象,则无法对Outter this&0引用进行初始化赋值,也就无法创建成员内部类的对象了。
|
||||
|
||||
|
||||
### 局部内部类和匿名内部类只能访问局部final变量
|
||||
@@ -515,3 +562,124 @@ public class Test {
|
||||
|
||||
|
||||
> 如果局部变量的值在编译期间就可以确定,则直接在匿名内部里面创建一个拷贝。如果局部变量的值无法在编译期间确定,则通过构造器传参的方式来对拷贝进行初始化赋值。
|
||||
|
||||
### 静态内部类有特殊的地方吗?
|
||||
|
||||
从前面可以知道,静态内部类是不依赖于外部类的,也就说可以在不创建外部类对象的情况下创建内部类的对象。另外,静态内部类是不持有指向外部类对象的引用的,这个读者可以自己尝试反编译class文件看一下就知道了,是没有Outter this&0引用的。
|
||||
|
||||
|
||||
## 4 常见的与内部类相关的笔试面试题
|
||||
|
||||
### 根据注释填写(1),(2),(3)处的代码
|
||||
|
||||
```java
|
||||
public class Test{
|
||||
public static void main(String[] args){
|
||||
// 初始化Bean1
|
||||
(1)
|
||||
bean1.I++;
|
||||
// 初始化Bean2
|
||||
(2)
|
||||
bean2.J++;
|
||||
//初始化Bean3
|
||||
(3)
|
||||
bean3.k++;
|
||||
}
|
||||
class Bean1{
|
||||
public int I = 0;
|
||||
}
|
||||
|
||||
static class Bean2{
|
||||
public int J = 0;
|
||||
}
|
||||
}
|
||||
|
||||
class Bean{
|
||||
class Bean3{
|
||||
public int k = 0;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
从前面可知,对于成员内部类,必须先产生外部类的实例化对象,才能产生内部类的实例化对象。而静态内部类不用产生外部类的实例化对象即可产生内部类的实例化对象。
|
||||
|
||||
**创建静态内部类对象的一般形式为: 外部类类名.内部类类名 xxx = new 外部类类名.内部类类名()**
|
||||
|
||||
**创建成员内部类对象的一般形式为: 外部类类名.内部类类名 xxx = 外部类对象名.new 内部类类名()**
|
||||
|
||||
因此,(1),(2),(3)处的代码分别为:
|
||||
|
||||
```java
|
||||
Test test = new Test();
|
||||
|
||||
Test.Bean1 bean1 = test.new Bean1();
|
||||
```
|
||||
|
||||
```java
|
||||
Test.Bean2 b2 = new Test.Bean2();
|
||||
```
|
||||
|
||||
```java
|
||||
Bean bean = new Bean();
|
||||
|
||||
Bean.Bean3 bean3 = bean.new Bean3();
|
||||
```
|
||||
|
||||
### 下面这段代码的输出结果是什么?
|
||||
|
||||
```java
|
||||
public class Test {
|
||||
public static void main(String[] args) {
|
||||
Outter outter = new Outter();
|
||||
outter.new Inner().print();
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
class Outter
|
||||
{
|
||||
private int a = 1;
|
||||
class Inner {
|
||||
private int a = 2;
|
||||
public void print() {
|
||||
int a = 3;
|
||||
System.out.println("局部变量:" + a);
|
||||
System.out.println("内部类变量:" + this.a);
|
||||
System.out.println("外部类变量:" + Outter.this.a);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```shell
|
||||
3
|
||||
2
|
||||
1
|
||||
```
|
||||
|
||||
最后补充一点知识:关于成员内部类的继承问题。一般来说,内部类是很少用来作为继承用的。但是当用来继承的话,要注意两点:
|
||||
|
||||
1)成员内部类的引用方式必须为 Outter.Inner.
|
||||
|
||||
2)构造器中必须有指向外部类对象的引用,并通过这个引用调用super()。这段代码摘自《Java编程思想》
|
||||
|
||||
```java
|
||||
class WithInner {
|
||||
class Inner{
|
||||
|
||||
}
|
||||
}
|
||||
class InheritInner extends WithInner.Inner {
|
||||
|
||||
// InheritInner() 是不能通过编译的,一定要加上形参
|
||||
InheritInner(WithInner wi) {
|
||||
wi.super(); //必须有这句调用
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
WithInner wi = new WithInner();
|
||||
InheritInner obj = new InheritInner(wi);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
@@ -9,7 +9,7 @@ Java 泛型(generics)是 JDK 5 中引入的一个新特性, 泛型提供了
|
||||
|
||||

|
||||
|
||||
|
||||
与C#中的泛型相比,Java的泛型可以算是“伪泛型”了。在C#中,不论是在程序源码中、在编译后的中间语言,还是在运行期泛型都是真实存在的。Java则不同,Java的泛型只在源代码存在,只供编辑器检查使用,编译后的字节码文件已擦除了泛型类型,同时在必要的地方插入了强制转型的代码。
|
||||
### 泛型的基本用法
|
||||
|
||||
```java
|
||||
|
||||
95
Java基础教程/Java语言基础/15 Java编译原理.md
Normal file
95
Java基础教程/Java语言基础/15 Java编译原理.md
Normal file
@@ -0,0 +1,95 @@
|
||||
> https://www.cnblogs.com/qingshanli/p/9281760.html
|
||||
## 1 Java编译流程
|
||||
|
||||
### 基本流程
|
||||
|
||||
* 前端编译主要指与源语言有关但与目标机无关的部分,包括词法分析、语法分析、语义分析与中间代码生成。把*.java文件转变成*.class文件
|
||||
* 后端编译主要指与目标机有关的部分,包括代码优化和目标代码生成等。指把字节码转变成机器码
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
关键工具:词法分析器、语法分析器、语义分析器和代码生成器
|
||||
|
||||
1. 读取源码,进行词法分析。也就是找出源码字节中的关键字,识别出合法的关键字,最后得出一些规范化的Token(中文意思是“标记“、”象征”等)流。
|
||||
2. 对Token流进行语法分析,检查关键词的组合是否符合语法,最后得到抽象的语法树(语法树是吧语言的主要此法用一个结构化的形式组合在一起)
|
||||
3. 进行语法分析,把难懂的,复杂的语法转化成更加简单的的语法(对计算机来说),最后得到一个注解过后的抽象语法树
|
||||
4. 通过字节码生成器将经过注解的抽象语法树生成字节码
|
||||
## 2 Java前端编译
|
||||
|
||||
java的前端编译(即javac编译)可分为解析与填充符号表、插入式注解处理器的注解处理、分析与字节码生成等三个过程。
|
||||
|
||||

|
||||
|
||||
|
||||
1. 解析与填充符号表。解析步骤包括词法分析和语法分析两个阶段。词法分析是将源代码的字符流转变为标记(Token)集合, 单个字符是程序编写过程的最小单位, 而标记则是编译过程的最小单位, 关键字、变量名、字面量、运算符都可以成为标记。语法分析是根据Token序列构造抽象语法树的过程, 抽象语法树(AST)是一种用来描述程序代码语法结构的树形表示方式, 语法树的每一个节点都代表着程序代码中的一个语法结构, 如包、类型、修饰符、运算符、接口、返回值都可以是一个语法结构。 符号表是由一组符号地址和符号信息构成的表格。在语法分析中, 符号表所登记的内容将用于语义检查和产生中间代码。在目标代码生成阶段, 符号表是当对符号名进行地址分配时的依据。
|
||||
|
||||
2. 插入式注解处理器。插入式注解处理器可以看做是一组编译器的插件, 在这些插件里面, 可以读取、修改、添加抽象语法树中的任意元素。如果这些插件在处理注解期间对语法数进行了修改, 编译器将回到解析与填充符号表的过程重新处理, 直到所有插入式注解处理器都没有再对语法数进行修改为止, 每一次循环称为一个Round。
|
||||
3. 语义分析与字节码生成。语法分析后, 编译器获得了程序代码的抽象语法树表示, 语法数能表示一个结构正确的源程序的抽象, 但无法保证源程序是符合逻辑的。而语义分析的主要任务是对结构正确的源程序进行上下文有关性质的审查。Javac的编译过程中, 语义分析过程分为标注检查、数据及控制流分析两个步骤。
|
||||
1. 标注检查的内容包括诸如变量使用前是否已被声明、变量与赋值之间的数据类型是否能够匹配等。另外在标注检查步骤中, 还有一个重要的动作称为常量折叠。
|
||||
2. 数据及控制流分析是对程序上下文逻辑更进一步的验证, 他可以检查出诸如程序局部变量在使用前是否有赋值、方法的每条路径是否都有返回值、是否所有的受查异常都被正确处理等问题。
|
||||
|
||||
|
||||
Java中常用的语法糖有泛型、变长参数、自动装箱/拆箱、遍历循环、条件编译等等。虚拟机运行时并不支持这些语法, 它们在编译阶段还原回简单的基础语法结构, 这个过程称为解语法糖。
|
||||
|
||||
字节码生成是Javac编译过程的最后一个阶段, 它将前面各个步骤所生成的信息(语法数、符号表)转化成字节码写到磁盘中, 另外还进行少量的代码添加(如实例构造器)和转换工作。
|
||||
|
||||
## 3 Java中的后端编译
|
||||
在部分商用虚拟机中, Java程序最初是通过解释器进行解释执行的, 当虚拟机发现某个方法或代码块的运行特别频繁时, 就会把这些代码认定为"热点代码"。为了提高热点代码的执行效率, 在运行时, 虚拟机将会把这些代码编译成与本地平台相关的机器码, 并进行各种层析的优化, 完成这个任务的编译器称为即时编译器(JIT编译器)。
|
||||
|
||||
### 编译器与解释器
|
||||
HotSpot虚拟机中内置了两个即时编译器, 分别称为Client Compiler(C1编译器)和Server Compiler(C2编译器)。在HotSpot虚拟机中, 默认采用解释器与其中一个编译器直接配合的方式工作, 程序使用哪个编译器, 取决于虚拟机运行的模式, HotSpot虚拟机会根据自身版本与宿主机器的硬件性能自动选择运行模式, 这种解释器与编译器搭配使用的方式在虚拟机中称为"混合模式"(Mixed Mode)。在个人机器上, 通过java -version命令可查看自己安装的JDK中是哪种模式。
|
||||
|
||||
```sh
|
||||
➜ ~ java -version
|
||||
java version "1.8.0_291"
|
||||
Java(TM) SE Runtime Environment (build 1.8.0_291-b10)
|
||||
Java HotSpot(TM) 64-Bit Server VM (build 25.291-b10, mixed mode)
|
||||
```
|
||||
|
||||
### 分层编译
|
||||
在JDK 1.7的Server模式虚拟机中, 默认开启分层编译的策略。分层编译根据编译器编译、优化的规模与耗时, 划分出不同的编译层次:
|
||||
|
||||
1. 第0层, 程序解释执行, 解释器不开启性能监控功能, 可触发第1层编译。
|
||||
2. 第1层, 也称为C1编译, 将字节码编译为本地代码, 进行简单可靠的优化, 如有必要将加入性能性能监控的逻辑。
|
||||
3. 第2层(或2层以上), 也称为C2编译, 也是将字节码编译为本地代码, 但是会启用一些编译耗时较长的优化, 甚至会根据性能监控信息进行一些不可靠的激进优化。
|
||||
|
||||
实施分层编译后, C1编译器和C2编译器将会同时工作, 用C1编译器获取更高的编译速度, 用C2编译器获取更好的编译质量。
|
||||
|
||||
### 编译对象与触发条件
|
||||
在运行过程中会被即时编译器编译的"热点代码"有如下两类:
|
||||
* 被多次调用的方法。
|
||||
* 被多次执行的循环体。
|
||||
|
||||
对于第一种情况, 编译器会以整个方法作为编译对象, 这种编译也是虚拟机中标准的JIT编译方式。而对于第二种, 尽管编译动作是由循环体所触发的, 但编译器依然会以整个方法(而不是单独的循环体)作为编译对象, 这种编译方式因为编译发生在方法执行过程之中, 因此形象的称之为栈上替换(即OSR编译)。
|
||||
|
||||
### 热点探测
|
||||
|
||||
判断是否需要触发即时编译, 需要先识别出热点代码, 这个行为称之为热点探测。目前主要的热点探测判定方式有以下两种:
|
||||
|
||||
基于采样的热点探测: 虚拟机周期性地检查各个线程的栈顶, 如发现某个方法经常出现在栈顶, 它就是"热点方法"。好处是简单高效, 还可以获取方法调用关系; 缺点是很难精确的确认一个方法的热点, 容易受到线程阻塞或别的外界因素干扰。
|
||||
基于计数器的热点探测: 虚拟机会为每个方法(甚至是代码块)建立计数器, 统计方法的执行次数, 如果执行次数超过一定的阈值就认为是"热点方法"。
|
||||
在HotSpot虚拟机中使用的是第二种————基于计数器的热点探测, 它为每个方法准备了两类计数器: 方法调用计数器和回边计数器。在确定虚拟机运行参数的前提下, 这两个计数器都有一个的确定的阈值, 当计数器超过阈值溢出, 就会触发JIT编译。
|
||||
|
||||
方法调用计数器用于统计方法被调用的次数; 回边计数器用于统计一个方法中循环体代码执行的次数, 在字节码中遇到控制流向后跳转的指令称为"回边"。关于这两种计数器, 读者可参阅<<深入理解Java虚拟机>>, 这里不多做深入分析。
|
||||
|
||||
|
||||
### 编译过程
|
||||
在默认设置下, 无论是方法调用产生的标准JIT编译请求, 还是OSR编译请求, 虚拟机在代码编译器还未完成之前, 都仍然将按照解释方式继续执行, 而编译动作则在后台的编译线程中进行。
|
||||
|
||||
## 4 Java的后端编译优化技术
|
||||
### 公共子表达式消除
|
||||
如果一个表达式E已经计算过了,并且从先前的计算到现在E中所有变量的值都没有发生变化,那E的这次出现就成为了公共子表达式。对于这种表达式, 没必要花时间再对它进行计算, 只需要直接用前面计算过的表达式结果替代E就可以了。
|
||||
|
||||
### 数组边界检查消除
|
||||
顾名思义就是如果编译器根据数据流分析, 访问数组的下标没有越界, 那么就可以消除数组的边界检查, 这样能节省很多的条件判断操作, 提升程序性能。
|
||||
|
||||
### 方法内联
|
||||
内联函数就是在程序编译时,编译器将程序中出现的内联函数的调用表达式用内联函数的函数体来直接进行替换。
|
||||
|
||||
### 逃逸分析
|
||||
逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他地方中,称为方法逃逸。甚至还有可能被外部线程访问到,譬如赋值给类变量或可以在其他线程中访问的实例变量,称为线程逃逸。
|
||||
|
||||
如果能证明一个对象不会逃逸到方法或线程外,则可能为这个变量进行一些高效的优化, 如栈上替换、同步消除、标量替换。
|
||||
|
||||
162
Java基础教程/Java语言基础/17 语法糖.md
Normal file
162
Java基础教程/Java语言基础/17 语法糖.md
Normal file
@@ -0,0 +1,162 @@
|
||||
> 参考文献
|
||||
> [](https://blog.csdn.net/ol_beta/article/details/6787234)
|
||||
## 1 Java语法糖
|
||||
|
||||
语法糖(Syntactic Sugar),也叫糖衣语法,是英国计算机科学家彼得·约翰·兰达(Peter J. Landin)发明的一个术语。指的是,在计算机语言中添加某种语法,这种语法能使程序员更方便的使用语言开发程序,同时增强程序代码的可读性,避免出错的机会;但是这种语法对语言的功能并没有影响。
|
||||
|
||||
Java中的泛型,变长参数,自动拆箱/装箱,条件编译等都是语法糖。
|
||||
|
||||
### 泛型
|
||||
|
||||
|
||||
与C#中的泛型相比,Java的泛型可以算是“伪泛型”了。在C#中,不论是在程序源码中、在编译后的中间语言,还是在运行期泛型都是真实存在的。Java则不同,Java的泛型只在源代码存在,只供编辑器检查使用,编译后的字节码文件已擦除了泛型类型,同时在必要的地方插入了强制转型的代码。
|
||||
泛型代码:
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
List<String> stringList = new ArrayList<String>();
|
||||
stringList.add("oliver");
|
||||
System.out.println(stringList.get(0));
|
||||
}
|
||||
```
|
||||
将上面的代码的字节码反编译后:
|
||||
```java
|
||||
public static void main(String args[])
|
||||
{
|
||||
List stringList = new ArrayList();
|
||||
stringList.add("oliver");
|
||||
System.out.println((String)stringList.get(0));
|
||||
}
|
||||
```
|
||||
|
||||
### 自动拆箱装箱
|
||||
|
||||
自动拆箱/装箱是在编译期,依据代码的语法,决定是否进行拆箱和装箱动作。
|
||||
* 装箱过程:把基本类型用它们对应的包装类型进行包装,使基本类型具有对象特征。
|
||||
* 拆箱过程:与装箱过程相反,把包装类型转换成基本类型。
|
||||
|
||||
|
||||
需要注意的是:
|
||||
1. 包装类型的“==”运算在没有遇到算数运算符的情况下不会自动拆箱,
|
||||
2. 而其包装类型的equals()方法不会处理数据类型转换
|
||||
|
||||
```java
|
||||
Integer a = 1;
|
||||
Integer b = 1;
|
||||
Long c = 1L;
|
||||
System.out.println(a == b);
|
||||
System.out.println(c.equals(a));
|
||||
```
|
||||
|
||||
|
||||
### 循环历遍(foreach)
|
||||
语法:
|
||||
```java
|
||||
List<Integer> list = new ArrayList<Integer>();
|
||||
for(Integer num : list){
|
||||
System.out.println(num);
|
||||
}
|
||||
```
|
||||
Foreach要求被历遍的对象要实现Iterable接口,由此可想而知,foreach迭代也是调用底层的迭代器实现的。反编译上面源码的字节码:
|
||||
```java
|
||||
List list = new ArrayList();
|
||||
Integer num;
|
||||
Integer num;
|
||||
for (Iterator iterator = list.iterator(); iterator.hasNext(); System.out.println(num)){
|
||||
num = (Integer) iterator.next();
|
||||
}
|
||||
```
|
||||
|
||||
### 条件编辑
|
||||
很多编程语言都提供了条件编译的途径,C,C++中使用#ifdef。Java语言并没有提供这种预编译功能,但是Java也能实现预编译。
|
||||
```java
|
||||
if(true){
|
||||
System.out.println("oliver");
|
||||
}else{
|
||||
System.out.println("lee");
|
||||
}
|
||||
```
|
||||
这段代码的字节码反编译后只有一条语句:
|
||||
```java
|
||||
System.out.println("oliver");
|
||||
```
|
||||
在编译器中,将会把分支不成立的代码消除,这一动作发生在编译器解除语法糖阶段。
|
||||
所以说,可以利用条件语句来实现预编译。
|
||||
|
||||
|
||||
|
||||
### 枚举
|
||||
枚举类型其实并不复杂,在JVM字节码文件结构中,并没有“枚举”这个类型。
|
||||
其实源程序的枚举类型,会在编译期被编译成一个普通了类。利用继承和反射,这是完全可以做到的。
|
||||
看下面一个枚举类:
|
||||
|
||||
```java
|
||||
public enum EnumTest {
|
||||
OLIVER,LEE;
|
||||
}
|
||||
```
|
||||
反编译字节码后:
|
||||
```java
|
||||
public final class EnumTest extends Enum {
|
||||
|
||||
private EnumTest(String s, int i) {
|
||||
super(s, i);
|
||||
}
|
||||
|
||||
public static EnumTest[] values() {
|
||||
EnumTest aenumtest[];
|
||||
int i;
|
||||
EnumTest aenumtest1[];
|
||||
System.arraycopy(aenumtest = ENUM$VALUES, 0,
|
||||
aenumtest1 = new EnumTest[i = aenumtest.length], 0, i);
|
||||
return aenumtest1;
|
||||
}
|
||||
|
||||
public static EnumTest valueOf(String s) {
|
||||
return (EnumTest) Enum.valueOf(EnumTest, s);
|
||||
}
|
||||
|
||||
public static final EnumTest OLIVER;
|
||||
public static final EnumTest LEE;
|
||||
private static final EnumTest ENUM$VALUES[];
|
||||
|
||||
static {
|
||||
OLIVER = new EnumTest("OLIVER", 0);
|
||||
LEE = new EnumTest("LEE", 1);
|
||||
ENUM$VALUES = (new EnumTest[] { OLIVER, LEE });
|
||||
}
|
||||
}
|
||||
```
|
||||
至于更多细节,可以参考父类Enum
|
||||
|
||||
|
||||
|
||||
### 变长参数
|
||||
变长参数允许我们传入到方法的参数是不固定个数。
|
||||
对于这个方法:
|
||||
```java
|
||||
public void foo(String str,Object...args){
|
||||
|
||||
}
|
||||
```
|
||||
我们可以这样调用:
|
||||
```java
|
||||
foo("oliver");
|
||||
foo("oliver",new Object());
|
||||
foo("oliver",new Integer(1),"sss");
|
||||
foo("oliver",new ArrayList(),new Object(),true,1);
|
||||
```
|
||||
参数args可以是任意多个。
|
||||
其实,在编译阶段,args是会被编译成Object [] args。
|
||||
```java
|
||||
public transient void foo(String s, Object aobj[])
|
||||
{
|
||||
}
|
||||
```
|
||||
这样,变长参数就可以实现了。
|
||||
但是要注意的是,变长参数必须是方法参数的最后一项。
|
||||
|
||||
|
||||
### 补充
|
||||
除了上面介绍的语法糖,还有内部类,断言以及JDK7的switch支持字符串,自动关闭资源(在try中定义和关闭)等。
|
||||
|
||||
感兴趣的同学可以反编译字节码了解它们的本质。
|
||||
BIN
Java基础教程/Java语言基础/image/2022-08-15-21-55-14.png
Normal file
BIN
Java基础教程/Java语言基础/image/2022-08-15-21-55-14.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 63 KiB |
BIN
Java基础教程/Java语言基础/image/2022-08-15-22-21-05.png
Normal file
BIN
Java基础教程/Java语言基础/image/2022-08-15-22-21-05.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 49 KiB |
529
kubenets/01.走进Kubernetes.md
Normal file
529
kubenets/01.走进Kubernetes.md
Normal file
@@ -0,0 +1,529 @@
|
||||
# 走进Kubernetes
|
||||
|
||||
|
||||
## 什么是Kubernetes
|
||||
|
||||
随着微服务架构被越来越多的公司使用,大部分单体应用正逐步被拆解成小的、独立运行的微服务。微服务的优势这里不做探讨,但是其带来的服务维护问题大大增加,若想要在管理大量微服务的情况下同时还做到以下几点:
|
||||
|
||||
- 让资源利用率更高
|
||||
|
||||
- 让硬件成本相对更低
|
||||
|
||||
于是就自然而然地就产生了基于容器自动化部署微服务的需求,在容器编排这块的纷争,各大巨头参与,战况惨烈,但最终胜出的是谷歌的Kubernetes[^1],其提供的特性有:
|
||||
|
||||
- **服务发现和负载均衡**
|
||||
- **存储编排**
|
||||
- **自动发布和回滚**
|
||||
- **自愈**
|
||||
- **密钥及配置管理**
|
||||
|
||||
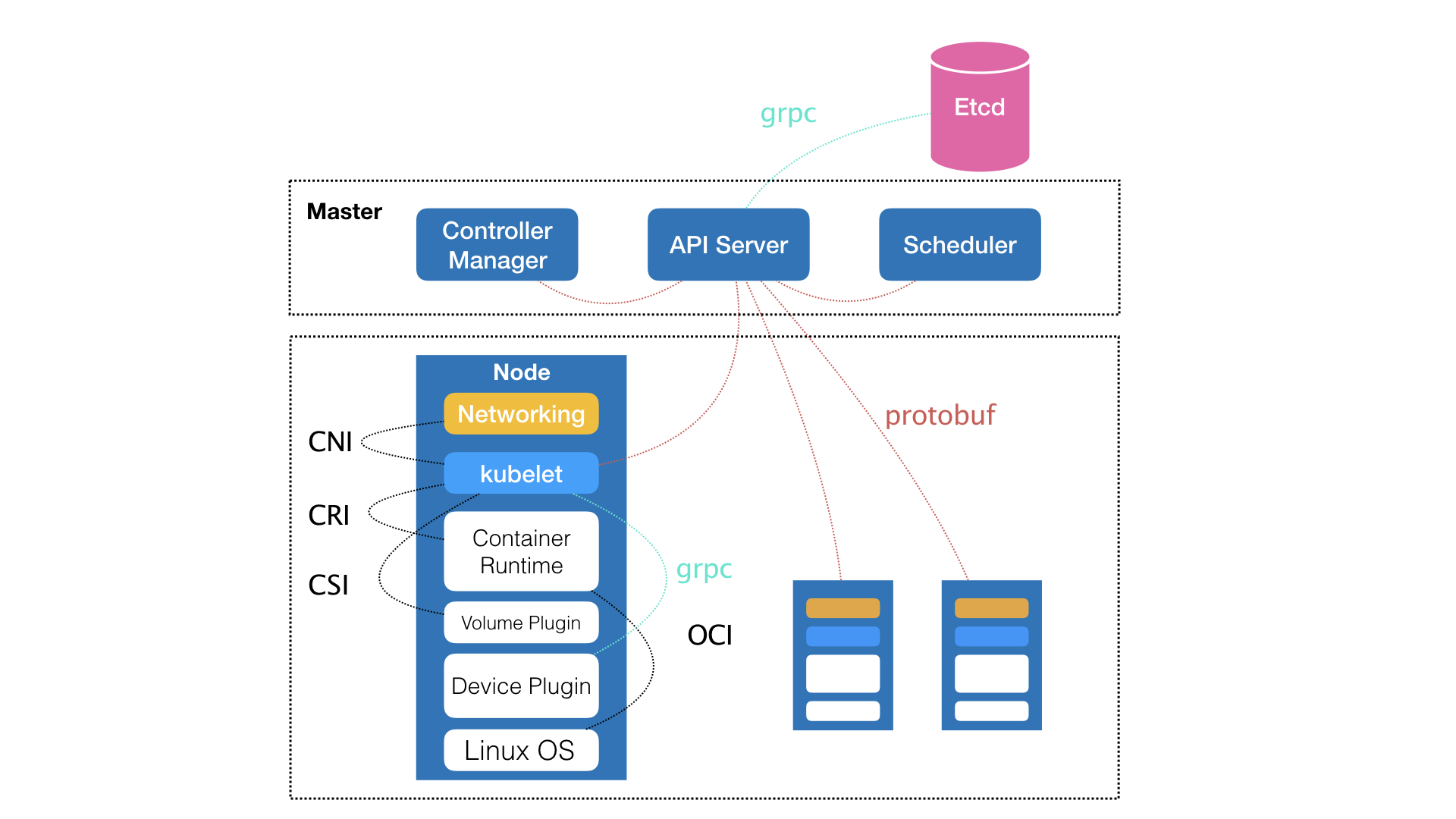
通过下面架构图可以看到其有上下两部分对应的`Master&Node`节点构成,这两种角色分别对应着控制节点和计算节点。
|
||||
|
||||
|
||||
|
||||
> Master控制节点主要出发点在于如何编排、管理、调度用户提交的作业
|
||||
|
||||
Kubernetes控制节点主要由以下几个核心组件组成:
|
||||
|
||||
- etcd保存了整个集群的状态
|
||||
- apiserver提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制
|
||||
- controller manager负责维护集群的状态,比如故障检测、自动扩展、滚动更新等
|
||||
- scheduler负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上
|
||||
|
||||
对于计算节点:
|
||||
|
||||
- kubelet负责维护容器的生命周期,同时也负责Volume(CSI)和网络(CNI)的管理
|
||||
- Container runtime负责镜像管理以及Pod和容器的真正运行(CRI)
|
||||
- kube-proxy负责为Service提供cluster内部的服务发现和负载均衡
|
||||
|
||||
## 安装
|
||||
|
||||
### 单机安装
|
||||
|
||||
关于单机安装`k8s`,我使用的相关环境如下(于2022-08-13更新):
|
||||
|
||||
- macOS:Monterey 12.4
|
||||
- Docker Desktop Vesion:4.11.1
|
||||
- Kubernetes:v1.24.2
|
||||
|
||||
由于镜像的下载涉及到网络原因,因此这里使用了开源项目[k8s-docker-desktop-for-mac](https://github.com/gotok8s/k8s-docker-desktop-for-mac)来解决这个问题,需要注意的是要修改`images`的相关镜像的版本,要和此时`Kubernetes`配对上才行,比如我设置的是:
|
||||
|
||||
```txt
|
||||
k8s.gcr.io/kube-proxy:v1.24.2=gotok8s/kube-proxy:v1.24.2
|
||||
k8s.gcr.io/kube-controller-manager:v1.24.2=gotok8s/kube-controller-manager:v1.24.2
|
||||
k8s.gcr.io/kube-scheduler:v1.24.2=gotok8s/kube-scheduler:v1.24.2
|
||||
k8s.gcr.io/kube-apiserver:v1.24.2=gotok8s/kube-apiserver:v1.24.2
|
||||
k8s.gcr.io/pause:3.7=gotok8s/pause:3.7
|
||||
k8s.gcr.io/coredns/coredns:v1.8.6=gotok8s/coredns:v1.8.6
|
||||
k8s.gcr.io/etcd:3.5.3-0=gotok8s/etcd:3.5.3-0
|
||||
```
|
||||
|
||||
然后执行`./load_images.sh `即可下载k8s依赖的镜像,随后打开`Docker`,进入设置界面,勾选`Enable Kubernetes`即可:
|
||||
|
||||
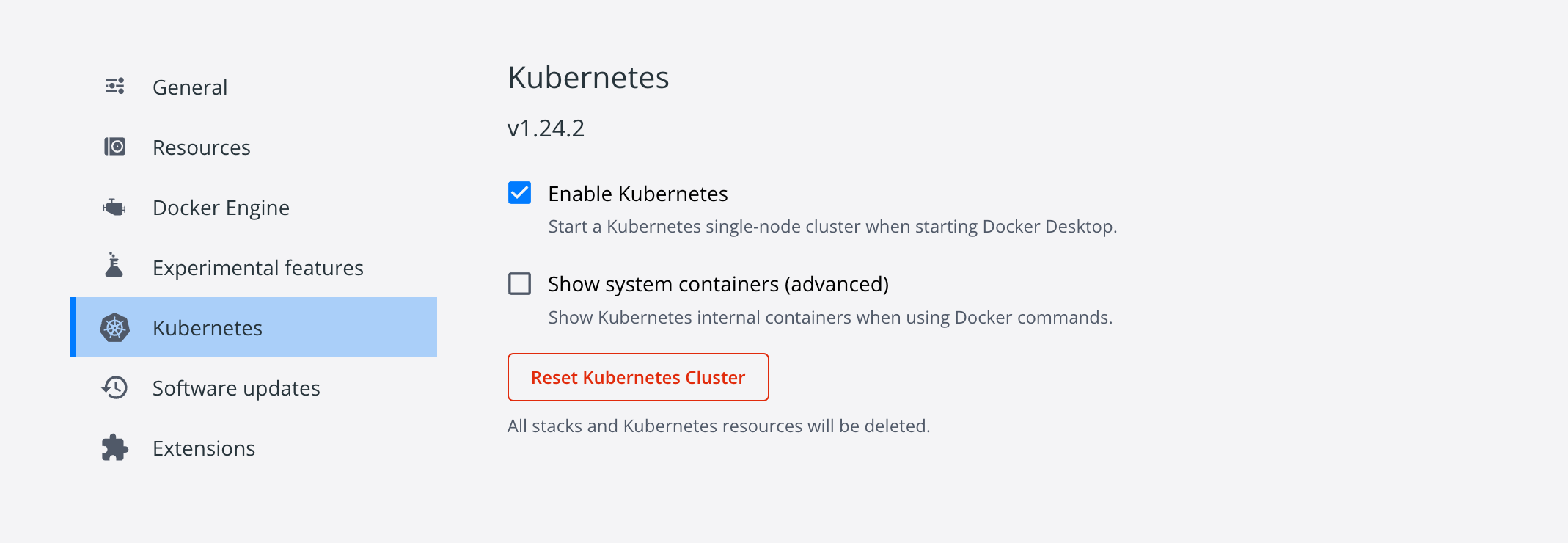
|
||||
|
||||
不出意外,界面左下角会出现`Kubernetes running`的提示,这样就安装成功了。
|
||||
|
||||
每个人的 `Docker` 版本都有差别,不同版本如何查找各个依赖容器对应的版本呢?参考一下命令:
|
||||
|
||||
```shell
|
||||
KUBERNETES_VERSION=v1.24.2
|
||||
# Linux 下执行
|
||||
curl -O -L https://storage.googleapis.com/kubernetes-release/release/${KUBERNETES_VERSION}/bin/linux/amd64/kubeadm
|
||||
chmod +x kubeadm
|
||||
./kubeadm config images list --kubernetes-version=${KUBERNETES_VERSION}
|
||||
```
|
||||
|
||||
版本号那里填写你自己的当前版本即可,不出意外可以得到如下输出:
|
||||
|
||||
```shell
|
||||
k8s.gcr.io/kube-apiserver:v1.24.2
|
||||
k8s.gcr.io/kube-controller-manager:v1.24.2
|
||||
k8s.gcr.io/kube-scheduler:v1.24.2
|
||||
k8s.gcr.io/kube-proxy:v1.24.2
|
||||
k8s.gcr.io/pause:3.7
|
||||
k8s.gcr.io/etcd:3.5.3-0
|
||||
k8s.gcr.io/coredns/coredns:v1.8.6
|
||||
```
|
||||
|
||||
查看集群信息:
|
||||
|
||||
```shell
|
||||
kubectl cluster-info
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```shell
|
||||
Kubernetes control plane is running at https://kubernetes.docker.internal:6443
|
||||
CoreDNS is running at https://kubernetes.docker.internal:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
|
||||
|
||||
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
|
||||
```
|
||||
|
||||
```shell
|
||||
kubectl get nodes
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
查看节点信息:
|
||||
|
||||
```shell
|
||||
kubectl get nodes
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```shell
|
||||
NAME STATUS ROLES AGE VERSION
|
||||
docker-desktop Ready control-plane 11m v1.24.2
|
||||
```
|
||||
|
||||
单机版本的`k8s`安装成功!接下来介绍集群安装。
|
||||
|
||||
### 集群安装
|
||||
|
||||
#### 准备
|
||||
|
||||
- 准备三台机器,比如(使用的配置是4核8G,IP换成你自己的):
|
||||
- 192.168.5.91:Master:
|
||||
- 执行:
|
||||
- `hostnamectl set-hostname master`
|
||||
- `echo "127.0.0.1 $(hostname)" >> /etc/hosts`
|
||||
- 192.168.5.92:Node01
|
||||
- 执行:
|
||||
- `hostnamectl set-hostname node01`
|
||||
- `echo "127.0.0.1 $(hostname)" >> /etc/hosts`
|
||||
- 192.168.5.93:Node02
|
||||
- 执行:
|
||||
- `hostnamectl set-hostname node02`
|
||||
- `echo "127.0.0.1 $(hostname)" >> /etc/hosts`
|
||||
|
||||
- Kubernetes版本:v1.19.3
|
||||
- Docker版本:19.03.12
|
||||
|
||||
开始前请检查以下事项:
|
||||
|
||||
- **CentOS 版本**:>= 7.6
|
||||
- **CPU**:>=2
|
||||
- *IP*:互通
|
||||
- 关闭**swap**:`swapoff -a`
|
||||
|
||||
配置国内kubernetes源:
|
||||
|
||||
```shell
|
||||
cat > /etc/yum.repos.d/kubernetes.repo <<EOF
|
||||
[kubernetes]
|
||||
name=Kubernetes
|
||||
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
|
||||
enabled=1
|
||||
gpgcheck=1
|
||||
repo_gpgcheck=1
|
||||
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
|
||||
EOF
|
||||
```
|
||||
|
||||
安装相关依赖工具:
|
||||
|
||||
```shell
|
||||
yum install -y kubelet-1.19.3 kubeadm-1.19.3 kubectl-1.19.3
|
||||
# 设置开机启动
|
||||
systemctl enable kubelet.service && systemctl start kubelet.service
|
||||
# 查看状态
|
||||
systemctl status kubelet.service
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 初始化Master
|
||||
|
||||
在主节点(`192.168.5.91`)执行以下命令:
|
||||
|
||||
```sh
|
||||
export MASTER_IP=192.168.5.91
|
||||
export APISERVER_NAME=apiserver.demo
|
||||
export POD_SUBNET=10.100.0.1/16
|
||||
echo "${MASTER_IP} ${APISERVER_NAME}" >> /etc/hosts
|
||||
```
|
||||
|
||||
新建脚本`init_master.sh`:
|
||||
|
||||
```shell
|
||||
vim init_master.sh
|
||||
```
|
||||
|
||||
添加:
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
|
||||
# 只在 master 节点执行
|
||||
|
||||
# 脚本出错时终止执行
|
||||
set -e
|
||||
|
||||
if [ ${#POD_SUBNET} -eq 0 ] || [ ${#APISERVER_NAME} -eq 0 ]; then
|
||||
echo -e "\033[31;1m请确保您已经设置了环境变量 POD_SUBNET 和 APISERVER_NAME \033[0m"
|
||||
echo 当前POD_SUBNET=$POD_SUBNET
|
||||
echo 当前APISERVER_NAME=$APISERVER_NAME
|
||||
exit 1
|
||||
fi
|
||||
|
||||
|
||||
# 查看完整配置选项 https://godoc.org/k8s.io/kubernetes/cmd/kubeadm/app/apis/kubeadm/v1beta2
|
||||
rm -f ./kubeadm-config.yaml
|
||||
cat <<EOF > ./kubeadm-config.yaml
|
||||
apiVersion: kubeadm.k8s.io/v1beta2
|
||||
kind: ClusterConfiguration
|
||||
# k8s 版本
|
||||
kubernetesVersion: v1.19.3
|
||||
imageRepository: registry.aliyuncs.com/k8sxio
|
||||
controlPlaneEndpoint: "${APISERVER_NAME}:6443"
|
||||
networking:
|
||||
serviceSubnet: "10.96.0.0/16"
|
||||
podSubnet: "${POD_SUBNET}"
|
||||
dnsDomain: "cluster.local"
|
||||
EOF
|
||||
|
||||
# kubeadm init
|
||||
# 根据您服务器网速的情况,您需要等候 3 - 10 分钟
|
||||
kubeadm config images pull --config=kubeadm-config.yaml
|
||||
kubeadm init --config=kubeadm-config.yaml --upload-certs
|
||||
|
||||
# 配置 kubectl
|
||||
rm -rf /root/.kube/
|
||||
mkdir /root/.kube/
|
||||
cp -i /etc/kubernetes/admin.conf /root/.kube/config
|
||||
|
||||
# 安装 calico 网络插件
|
||||
# 参考文档 https://docs.projectcalico.org/v3.13/getting-started/kubernetes/self-managed-onprem/onpremises
|
||||
echo "安装calico-3.13.1"
|
||||
rm -f calico-3.13.1.yaml
|
||||
wget https://kuboard.cn/install-script/calico/calico-3.13.1.yaml
|
||||
kubectl apply -f calico-3.13.1.yaml
|
||||
```
|
||||
|
||||
如果出错:
|
||||
|
||||
```shell
|
||||
# issue 01
|
||||
# [ERROR FileContent--proc-sys-net-bridge-bridge-nf-call-iptables]: /proc/sys/net/bridge/bridge-nf-call-iptables contents are not set to 1
|
||||
# 所有机器执行
|
||||
echo 1 > /proc/sys/net/bridge/bridge-nf-call-iptables
|
||||
echo 1 > /proc/sys/net/bridge/bridge-nf-call-ip6tables
|
||||
```
|
||||
|
||||
|
||||
|
||||
检查`master`初始化结果:
|
||||
|
||||
```shell
|
||||
# 直到所有的容器组处于 Running 状态
|
||||
watch kubectl get pod -n kube-system -o wide
|
||||
# 查看 master 节点初始化结果
|
||||
kubectl get nodes -o wide
|
||||
```
|
||||
|
||||
如下图:
|
||||
|
||||

|
||||
|
||||
#### 获得join命令参数
|
||||
|
||||
直接在`master`执行:
|
||||
|
||||
```shell
|
||||
kubeadm token create --print-join-command
|
||||
```
|
||||
|
||||
比如此时输出:
|
||||
|
||||
```shell
|
||||
# 有效期两小时
|
||||
kubeadm join apiserver.demo:6443 --token vh5hl9.9fccw1mzfsmsp4gh --discovery-token-ca-cert-hash sha256:6970397fdc6de5020df76de950c9df96349ca119f127551d109430c114b06f40
|
||||
```
|
||||
|
||||
#### 初始化Node
|
||||
|
||||
在所有`node`执行:
|
||||
|
||||
```shell
|
||||
export MASTER_IP=192.168.5.91
|
||||
export APISERVER_NAME=apiserver.demo
|
||||
echo "${MASTER_IP} ${APISERVER_NAME}" >> /etc/hosts
|
||||
|
||||
# 替换为 master 节点上 kubeadm token create 命令的输出
|
||||
kubeadm join apiserver.demo:6443 --token vh5hl9.9fccw1mzfsmsp4gh --discovery-token-ca-cert-hash sha256:6970397fdc6de5020df76de950c9df96349ca119f127551d109430c114b06f40
|
||||
```
|
||||
|
||||
#### 检查初始化结果
|
||||
|
||||
在`master`节点执行:
|
||||
|
||||
```shell
|
||||
kubectl get nodes -o wide
|
||||
```
|
||||
|
||||
输出结果如下:
|
||||
|
||||

|
||||
|
||||
### sealos 快速安装
|
||||
|
||||
经过上面的流程,相信你也能体会到集群部署的麻烦,为了简化这个流程,`Github`上诞生了不少优秀的项目来简化安装流程,接下来以[sealos](https://github.com/fanux/sealos)为例进行命令行一键安装。
|
||||
|
||||
#### 准备
|
||||
|
||||
资源相关以集群安装配置为主,其中集群安装的准备工作也一样做,其他要求如下:
|
||||
|
||||
- ssh 可以访问各安装节点
|
||||
- 各节点主机名不相同,并满足kubernetes的主机名要求。
|
||||
- 各节点时间同步
|
||||
- 网卡名称如果是不常见的,建议修改成规范的网卡名称, 如(eth.*|en.*|em.*)
|
||||
- kubernetes1.20+ 使用containerd作为cri. 不需要用户安装docker/containerd. sealos会安装1.3.9版本containerd。
|
||||
- kubernetes1.19及以下 使用docker作为cri。 也不需要用户安装docker。 sealos会安装1.19.03版本docker
|
||||
|
||||
依赖包:
|
||||
|
||||
```shell
|
||||
yum install socat -y
|
||||
yum remove docker-ce containerd.io -y
|
||||
rm /etc/containerd/config.toml
|
||||
```
|
||||
|
||||
#### 安装
|
||||
|
||||
选一台服务器,我选择安装`v1.22.0`版本,执行命令即可:
|
||||
|
||||
```shell
|
||||
sealos init --passwd 'pwd' --master 192.168.5.91 --node 192.168.5.92 --node 192.168.5.93 --pkg-url /root/kube1.22.0.tar.gz --version v1.22.0
|
||||
```
|
||||
|
||||
#### 检查初始化结果
|
||||
|
||||
在`master`节点执行:
|
||||
|
||||
```shell
|
||||
kubectl get nodes -o wide
|
||||
```
|
||||
|
||||
输出结果如下:
|
||||
|
||||
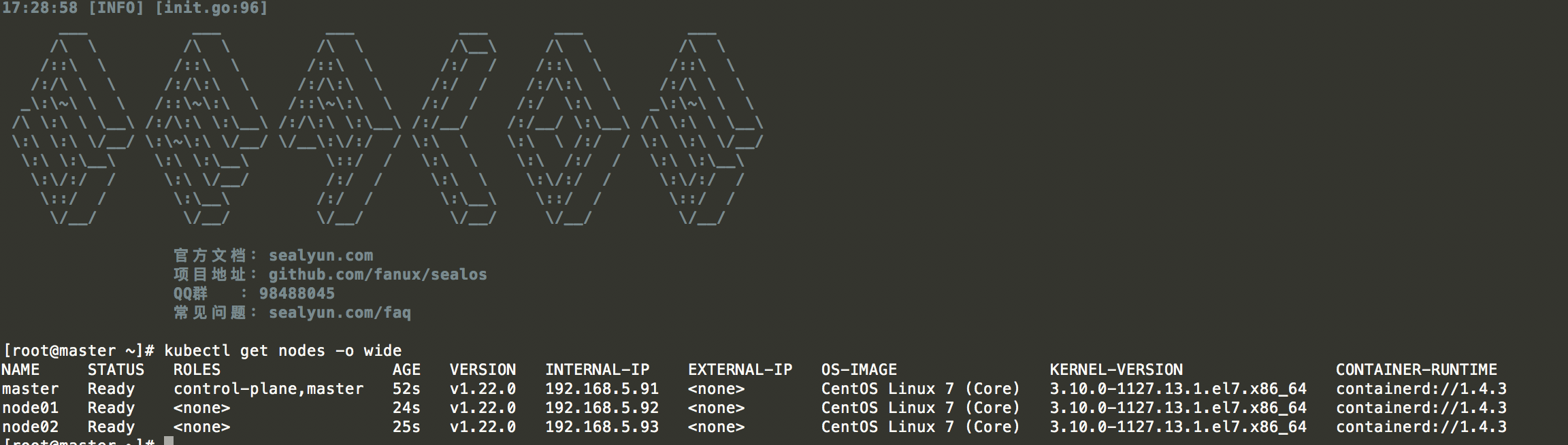
|
||||
|
||||
## UI
|
||||
|
||||
### Kubernetes Dashboard
|
||||
|
||||
[Dashboard](https://github.com/kubernetes/dashboard)可以将容器化应用程序部署到`Kubernetes`集群,对容器化应用程序进行故障排除,以及管理集群资源。
|
||||
|
||||
#### 安装
|
||||
|
||||
安装命令如下:
|
||||
|
||||
```shell
|
||||
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.6.1/aio/deploy/recommended.yaml -O dashboard.yaml
|
||||
|
||||
kubectl apply -f dashboard.yaml
|
||||
kubectl -n kubernetes-dashboard get pods -o wide
|
||||
```
|
||||
|
||||
查看是否成功:
|
||||
|
||||
```shell
|
||||
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
|
||||
dashboard-metrics-scraper-8c47d4b5d-mfb6d 1/1 Running 0 83s 10.1.0.7 docker-desktop <none> <none>
|
||||
kubernetes-dashboard-6c75475678-bdwtn 1/1 Running 0 83s 10.1.0.6 docker-desktop <none> <none>
|
||||
```
|
||||
|
||||
如果执行完发现`STATUS`有`ContainerCreating`,可以查看日志找找原因(注意NAME):
|
||||
|
||||
```shell
|
||||
kubectl describe pod dashboard-metrics-scraper-8c47d4b5d-mfb6d --namespace=kubernetes-dashboard
|
||||
```
|
||||
|
||||
一般都是因为`metrics-scraper:v1.0.8`镜像下载不下来,可以手动执行下载:
|
||||
|
||||
```shell
|
||||
docker pull kubernetesui/metrics-scraper:v1.0.8
|
||||
```
|
||||
|
||||
拉下来之后就妥了,还有一个问题就是选用的服务类型是`ClusterIP`(默认类型,服务只能够在集群内部可以访问),所以我们需要将访问形式改为`NodePort`(通过每个 Node 上的 IP 和静态端口访问):
|
||||
|
||||
```shell
|
||||
kubectl --namespace=kubernetes-dashboard edit service kubernetes-dashboard
|
||||
# 将里面的 type: ClusterIP 改为 type: NodePort
|
||||
```
|
||||
|
||||
保存后,执行:
|
||||
|
||||
```shell
|
||||
kubectl --namespace=kubernetes-dashboard get service kubernetes-dashboard
|
||||
```
|
||||
|
||||
终端输出:
|
||||
|
||||
```shell
|
||||
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
kubernetes-dashboard NodePort 10.110.197.167 <none> 443:32171/TCP 7m32s
|
||||
```
|
||||
|
||||
#### Token
|
||||
|
||||
在浏览器访问[https://0.0.0.0:32171/](https://0.0.0.0:32171/):
|
||||
|
||||
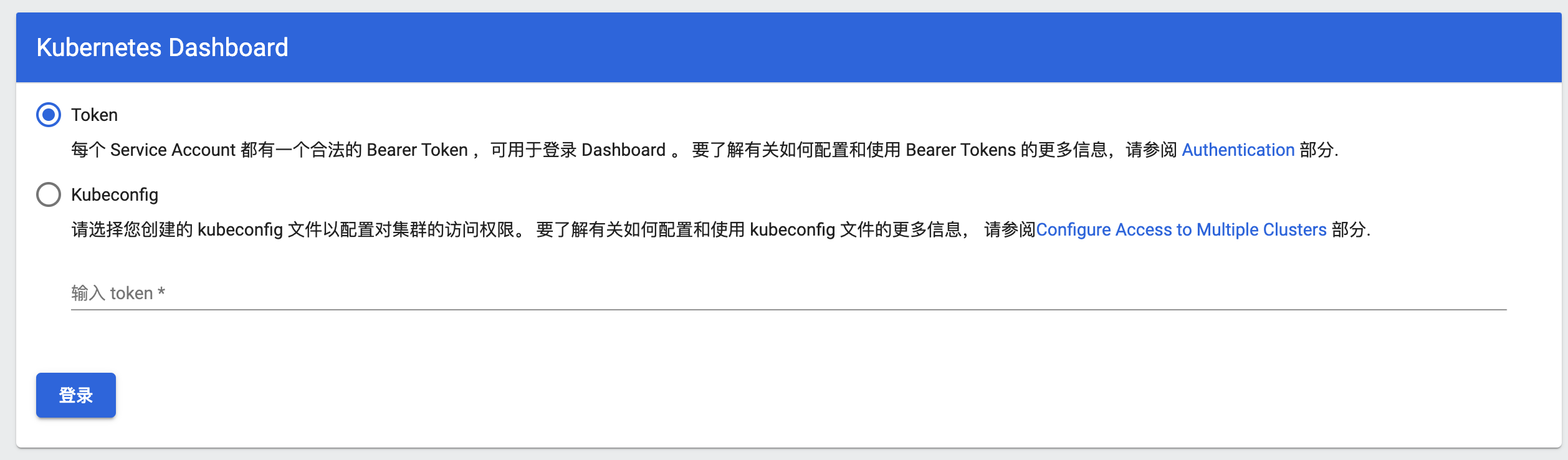
|
||||
|
||||
看界面需要生成`Token`:
|
||||
|
||||
```shell
|
||||
vim admin-user.yaml
|
||||
# 输入
|
||||
apiVersion: v1
|
||||
kind: ServiceAccount
|
||||
metadata:
|
||||
name: admin-user
|
||||
namespace: kubernetes-dashboard
|
||||
# 保存退出
|
||||
vim admin-user-role-binding.yaml
|
||||
# 输入
|
||||
apiVersion: rbac.authorization.k8s.io/v1
|
||||
kind: ClusterRoleBinding
|
||||
metadata:
|
||||
name: admin-user
|
||||
roleRef:
|
||||
apiGroup: rbac.authorization.k8s.io
|
||||
kind: ClusterRole
|
||||
name: cluster-admin
|
||||
subjects:
|
||||
- kind: ServiceAccount
|
||||
name: admin-user
|
||||
namespace: kubernetes-dashboard
|
||||
# 保存退出
|
||||
|
||||
# 执行命令加载配置
|
||||
kubectl -n kubernetes-dashboard create -f admin-user.yaml
|
||||
kubectl -n kubernetes-dashboard create -f admin-user-role-binding.yaml
|
||||
|
||||
# 若出现已存在
|
||||
# 执行:kubectl -n kubernetes-dashboard delete -f xxx.yaml 即可
|
||||
```
|
||||
|
||||
获取令牌:
|
||||
|
||||
```shell
|
||||
kubectl -n kubernetes-dashboard create token admin-user
|
||||
```
|
||||
|
||||
复制`token`到刚才的界面登录即可,登录后界面如下:
|
||||
|
||||
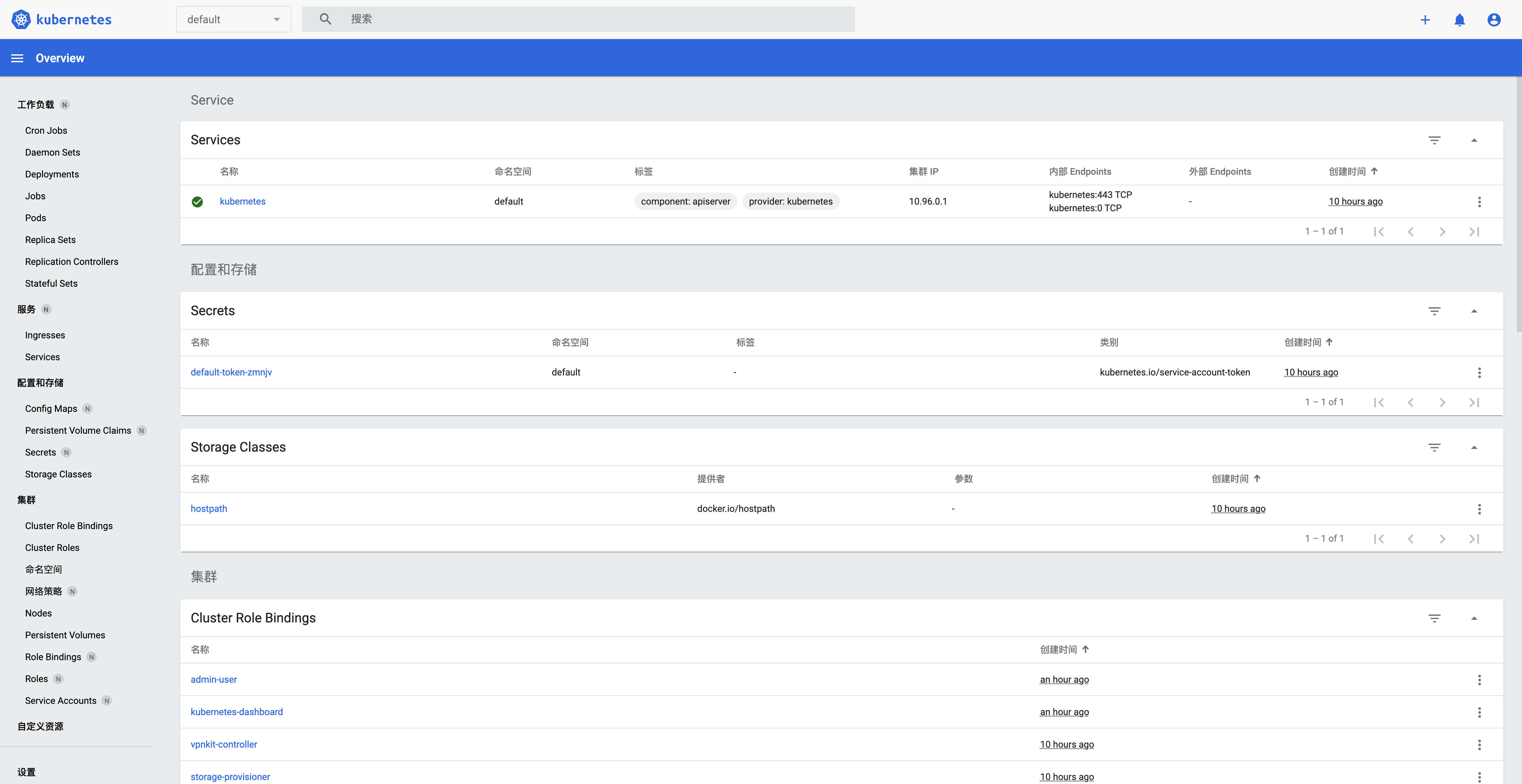
|
||||
|
||||
如果想延长`Token`的有效时间:
|
||||
|
||||
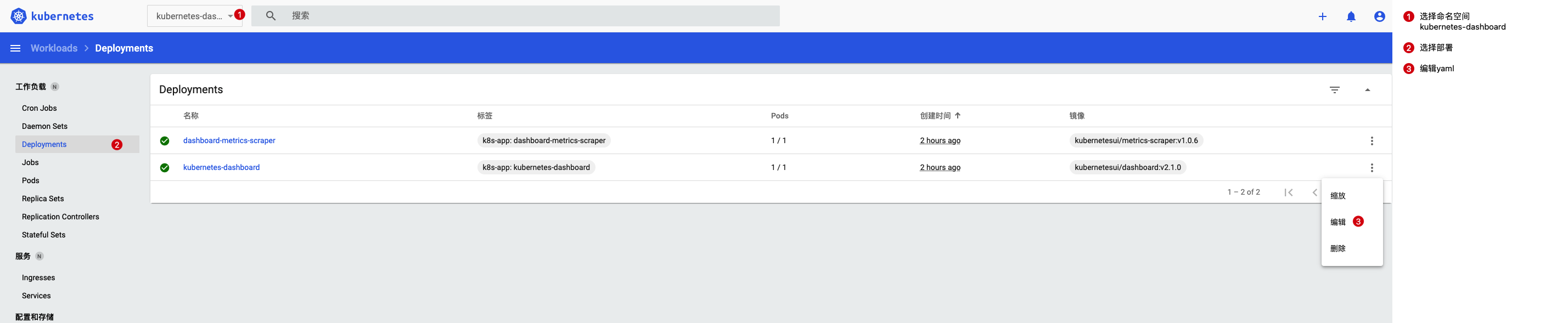
|
||||
|
||||
然后在`containners->args`加上`--token-ttl=43200`:
|
||||
|
||||
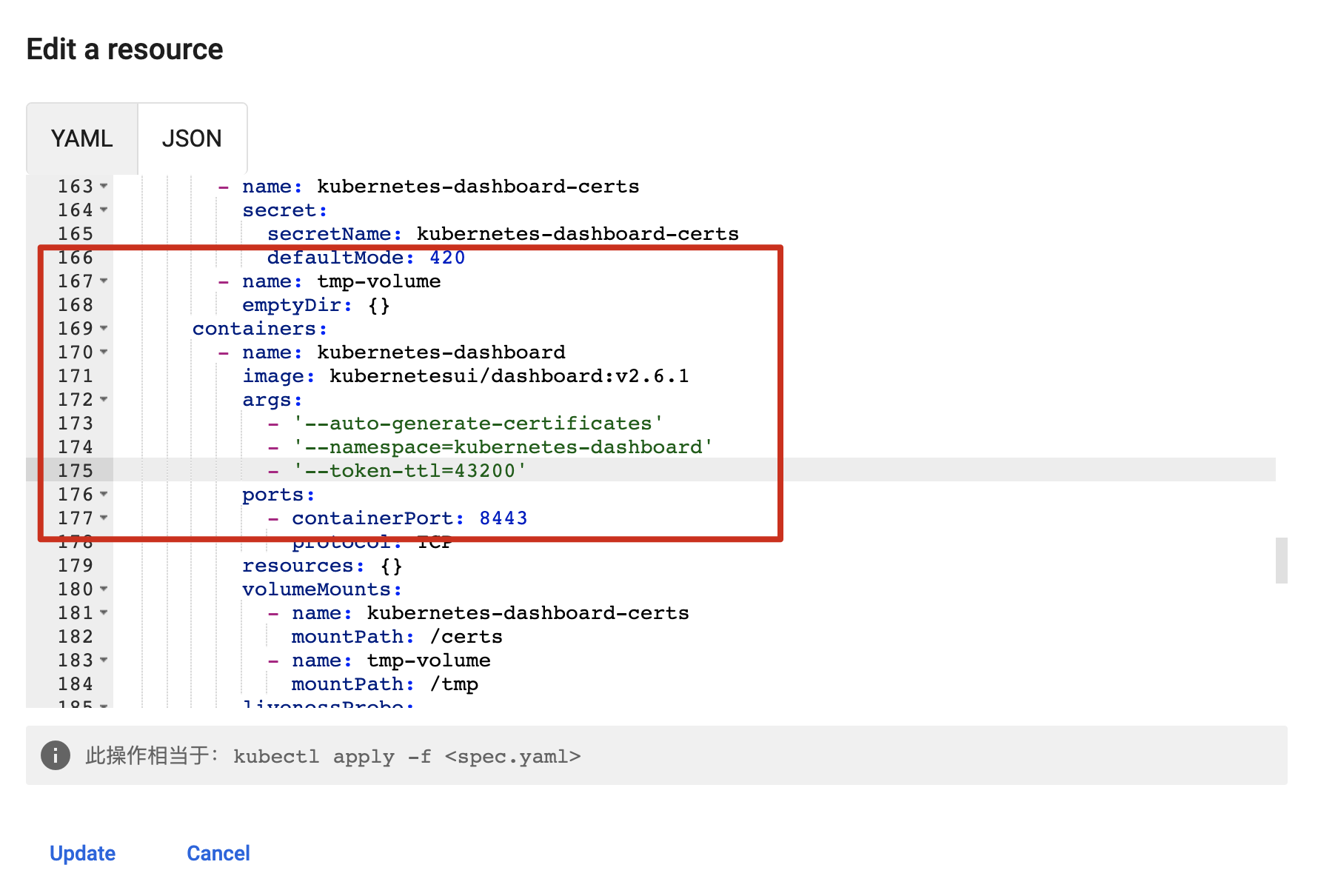
|
||||
|
||||
通过`kubectl edit deployment kubernetes-dashboard -n kubernetes-dashboard `修改也行。
|
||||
|
||||
### KubePi
|
||||
|
||||
> KubePi 是一个现代化的 K8s 面板,其允许管理员导入多个 Kubernetes 集群,并且通过权限控制,将不同 Cluster、Namespace 的权限分配给指定用户。
|
||||
|
||||
使用`Docker`安装如下:
|
||||
|
||||
```shell
|
||||
docker run --privileged -d --restart always -v "`pwd`:/var/lib/kubepi" --name=kubepi --restart=unless-stopped -p 8080:80 kubeoperator/kubepi-server
|
||||
```
|
||||
|
||||
然后打开[KubePi地址](http://localhost:8080/),输入用户名@密码`admin@kubepi`登录,登陆成功后设置`k8s`配置(集群列表->导入):
|
||||
|
||||
|
||||
|
||||
其中配置获取方式如下:
|
||||
|
||||
```shell
|
||||
cat ~/.kube/config
|
||||
```
|
||||
|
||||
确认后,进入集群就可以开始进行管理:
|
||||
|
||||
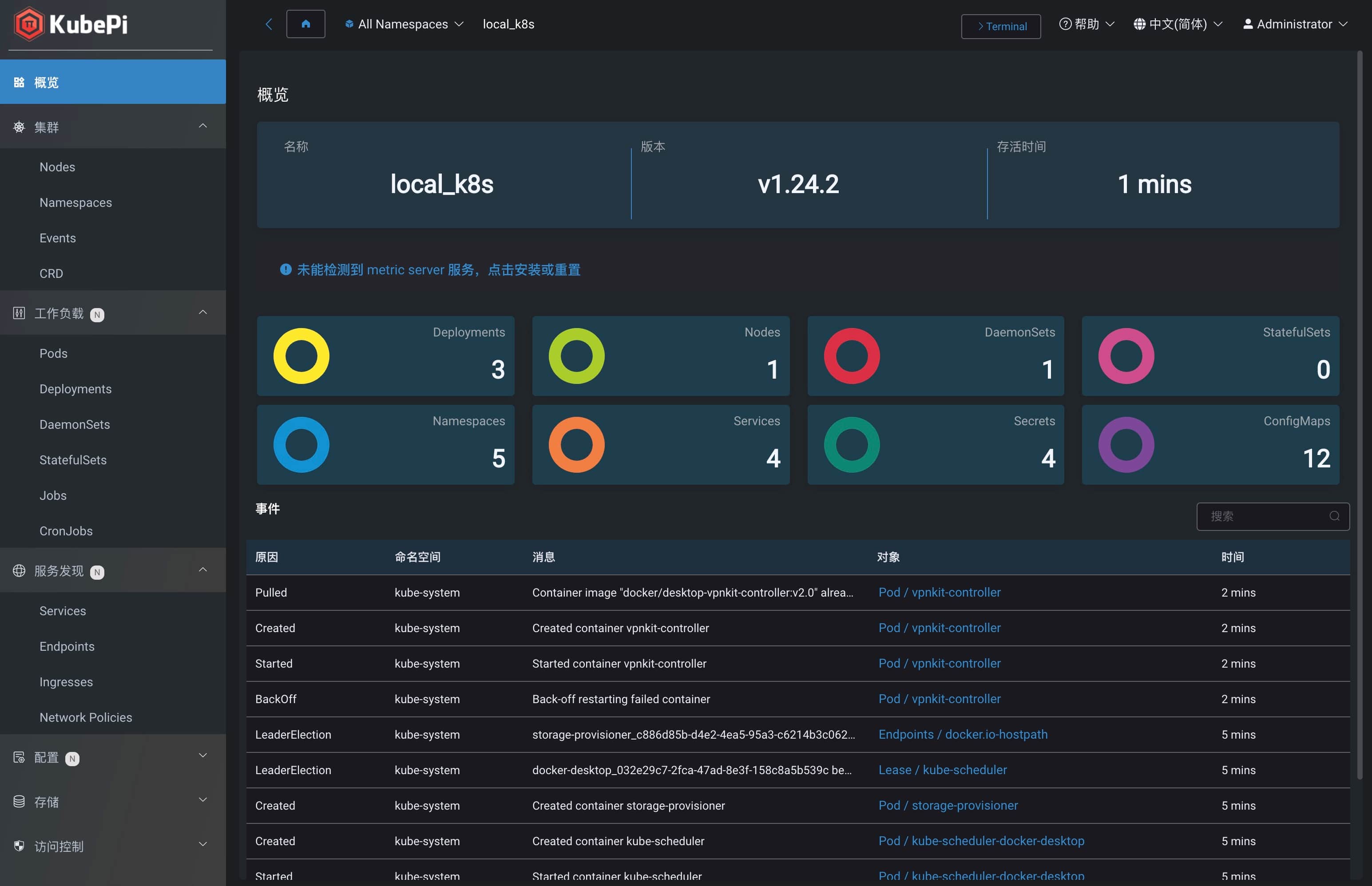
|
||||
|
||||
## 部署镜像
|
||||
|
||||
下拉一个你自己想部署的镜像,具体命令如下(主节点执行):
|
||||
|
||||
```shell
|
||||
# 部署
|
||||
kubectl run hello --image=xxx/hello --port=5000
|
||||
# 列出 pod
|
||||
kubectl get pods
|
||||
# 创建一个服务对象
|
||||
# NodePort 在所有节点(虚拟机)上开放一个特定端口,任何发送到该端口的流量都被转发到对应服务
|
||||
kubectl expose po hello --port=5000 --target-port=5000 --type=NodePort --name hello-http
|
||||
# 列出服务
|
||||
kubectl get services
|
||||
```
|
||||
|
||||
## 参考
|
||||
|
||||
本部分内容有参考如下文章:
|
||||
|
||||
- [使用kubeadm安装kubernetes_v1.19.x](https://kuboard.cn/install/install-k8s.html#%E6%A3%80%E6%9F%A5-centos-hostname)
|
||||
- [Web基础配置篇(十六): Kubernetes集群的安装使用](https://www.pomit.cn/p/2366402025269761#1010602)
|
||||
- [Kubernetes架构](https://jimmysong.io/kubernetes-handbook/concepts/)
|
||||
- [深入剖析Kubernetes](https://time.geekbang.org/column/intro/100015201?code=UhApqgxa4VLIA591OKMTemuH1%2FWyLNNiHZ2CRYYdZzY%3D):入门篇以及集群搭建部分
|
||||
- Kubernetes in Action中文版:第1、2章
|
||||
|
||||
`k8s`开源安装方案:
|
||||
|
||||
- [kubeasz](https://github.com/easzlab/kubeasz):使用Ansible脚本安装K8S集群,介绍组件交互原理,方便直接,不受国内网络环境影响
|
||||
- [sealos](https://github.com/fanux/sealos):一条命令离线安装高可用kubernetes,3min装完,700M,100年证书,生产环境稳如老狗
|
||||
- [follow-me-install-kubernetes-cluster](https://github.com/opsnull/follow-me-install-kubernetes-cluster):和我一步步部署 kubernetes 集群
|
||||
|
||||
[^1]:k8s项目的基础特性是 Google 公司在容器化基础设施领域多年来实践经验的沉淀与升华,`k8s`和`Swarm&Mesos`的竞争有兴趣可自行查询详细看看。
|
||||
437
kubenets/02.概念介绍.md
Normal file
437
kubenets/02.概念介绍.md
Normal file
@@ -0,0 +1,437 @@
|
||||
# 基础概念介绍
|
||||
|
||||

|
||||
|
||||
俗话说,磨刀不误砍柴工。上一章,我们成功搭建了k8s集群,接下来我们主要花时间了解一下k8s的相关概念,为后续掌握更高级的知识提前做好准备。
|
||||
|
||||
本文主要讲解以下四个概念:
|
||||
|
||||
- `Pod`
|
||||
- `Deployment`
|
||||
- `Service`
|
||||
- `Namespace`
|
||||
|
||||
## 引入
|
||||
|
||||
让我们使用`Deployment`运行一个无状态应用来开启此章节吧,比如运行一个`nginx Deployment`(创建文件:`nginx-deployment.yaml`):
|
||||
|
||||
```yaml
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: nginx-deployment
|
||||
labels:
|
||||
app: nginx
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: nginx
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: nginx
|
||||
spec:
|
||||
containers:
|
||||
- name: nginx
|
||||
image: nginx:latest
|
||||
ports:
|
||||
- containerPort: 80
|
||||
```
|
||||
|
||||
配置文件第二行,有个`kind`字段,表示的是此时`yaml`配置的类型,即`Deployment`。什么是`Deployment`?这里我先不做解释,让我们先实践,看能不能在使用过程中体会出这个类型的概念意义。
|
||||
|
||||
在终端执行:
|
||||
|
||||
```shell
|
||||
kubectl apply -f ./nginx-deployment.yaml
|
||||
# 输出
|
||||
deployment.apps/nginx-deployment created
|
||||
```
|
||||
|
||||
然后通过以下命令分别查看集群中创建的 Deployment 和 Pod 的状态:
|
||||
|
||||
```shell
|
||||
# 查看 Deployment
|
||||
kubectl get deployments
|
||||
# 输出
|
||||
NAME READY UP-TO-DATE AVAILABLE AGE
|
||||
nginx-deployment 1/1 1 1 2m29s
|
||||
|
||||
# 查看 Pod
|
||||
kubectl get pods
|
||||
# 输出
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
nginx-deployment-585449566-qslv5 1/1 Running 0 2m38s
|
||||
|
||||
# 查看 Deployment 的信息
|
||||
kubectl describe deployment nginx
|
||||
|
||||
# 删除 Deployment
|
||||
kubectl delete deployment nginx-deployment
|
||||
|
||||
# 查看 Pod 的信息
|
||||
# kubectl describe pod <pod-name>
|
||||
# 这里的 <pod-name> 是某一 Pod 的名称
|
||||
kubectl describe pod nginx-deployment-585449566-qslv5
|
||||
|
||||
# 进入容器
|
||||
kubectl exec -it nginx-deployment-585449566-qslv5 -- /bin/bash
|
||||
```
|
||||
|
||||
此时我们已经成功在k8s上部署了一个实例的nginx应用程序。但是,等等!我们好像又看到了一个新的名词`Pod`,这又是什么?让我们带着疑问继续往下看吧。
|
||||
|
||||
## Pod
|
||||
|
||||
> 在Kubernetes中,最小的管理元素不是一个个独立的容器,而是pod(目的在于解决容器间**紧密协作**关系的难题)
|
||||
|
||||

|
||||
|
||||
`Pod`是一组并置的容器,代表了`Kubernetes`中的基本构建模块:
|
||||
|
||||
- 一个`Pod`包含:
|
||||
- 一个或多个容器(container)
|
||||
- 容器(container)的一些共享资源:存储、网络等
|
||||
- 一个`Pod`的所有容器都运行在同一个节点
|
||||
|
||||
容器可以被管理,但是容器里面的多个进程实际上是不好被管理的,所以**容器被设计为每个容器只运行一个进程**。
|
||||
|
||||
容器的本质实际上就是一个进程,**Namespace 做隔离,Cgroups 做限制,rootfs 做文件系统**。在一个容器只能运行一个进程的前提下,实际开发过程中一个应用是由多个容器紧密协作才可以成功地运行起来。因此,我们需要另一种更高级的结构来将容器绑定在一起,并将它们作为一个单元进行管理,这就是`Pod`出现的目的。
|
||||
|
||||
`Pod`另一个重要意义就是容器设计模式,这对传统虚拟机服务迁移起到了关键性的指导作用,`Kubernetes` 社区把**容器设计模**这个理论整理成了一篇小论文[《Design Patterns for Container-based Distributed Systems》](https://www.usenix.org/conference/hotcloud16/workshop-program/presentation/burns),我也将这篇论文做了一个翻译,阅读地址[《设计模式——基于容器的分布式系统》](https://www.howie6879.cn/k8s/docs/03_appendix/00.%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F%E5%9F%BA%E4%BA%8E%E5%AE%B9%E5%99%A8%E7%9A%84%E5%88%86%E5%B8%83%E5%BC%8F%E7%B3%BB%E7%BB%9F/)。
|
||||
|
||||
### 如何定义并创建一个Pod
|
||||
|
||||
创建文件`nginx-pod.yaml`:
|
||||
|
||||
```shell
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
name: nginx
|
||||
labels:
|
||||
name: nginx
|
||||
spec:
|
||||
shareProcessNamespace: true
|
||||
containers:
|
||||
- name: nginx
|
||||
image: nginx
|
||||
- name: shell
|
||||
image: busybox
|
||||
stdin: true
|
||||
tty: true
|
||||
```
|
||||
|
||||
相关字段解释如下:
|
||||
|
||||
- kind: 该配置的类型,这里是 Pod
|
||||
- metadata:元数据
|
||||
- name:Pod的名称
|
||||
- labels:标签
|
||||
- spec:期望Pod实现的功能
|
||||
- containers:容器相关配置
|
||||
- name:container名称
|
||||
- image:镜像
|
||||
- ports:容器端口
|
||||
- containerPort:应用监听的端口
|
||||
|
||||
运行:
|
||||
|
||||
```shell
|
||||
# 创建
|
||||
kubectl create -f nginx-pod.yaml
|
||||
# 输出
|
||||
pod/nginx created
|
||||
|
||||
# 查看
|
||||
kubectl get pods
|
||||
# 输出
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
nginx 1/1 Running 0 43s
|
||||
|
||||
# 查看 Pod 完整的描述性文件
|
||||
# yaml 是你想看的格式 也可以是 json
|
||||
kubectl get po nginx -o yaml
|
||||
|
||||
# 连接 shell 容器
|
||||
kubectl attach -it nginx -c shell
|
||||
# 在容器执行 ps ax
|
||||
# 会发现 pause 以及 niginx 等进程
|
||||
# 这意味着整个 Pod 里的每个容器的进程对所有容器来说都是可见的,它们共享了同一个 PID Namespace。
|
||||
|
||||
# 删除 Pod
|
||||
kubectl delete -f nginx-pod.yaml
|
||||
```
|
||||
|
||||
这里简单介绍了用声明式API怎么创建`Pod`,但从技术角度看,`Pod`又是怎样被创建的呢?实际上`Pod`只是一个逻辑概念,`Pod`里的所有容器,共享的是同一个`Network Namespace`,并且可以声明共享同一个`Volume`。
|
||||
|
||||
`Pod`除了启动你定义的容器,还会启动一个`Infra`容器,这个容器使用的就是`k8s.gcr.io/pause`镜像,它的作用就是整一个`Network Namespace`方便用户容器加入,这就意味着`Pod`有以下特性:
|
||||
|
||||
- 内部直接使用`127.0.0.1`通信,网络设备一致(`Infra`容器决定)
|
||||
- 只有一个IP地址
|
||||
- `Pod`的生命周期只跟`Infra`容器一致,而与用户容器无关
|
||||
|
||||
### 标签
|
||||
|
||||
现在我们的集群里面只运行了一个`Pod`,但在实际环境中,我们运行数十上百个`Pod`也是一件很正常的事情,这样就引出了`Pod`管理上的问题,我们可以通过标签来组织`Pod`和所有其他`Kubernetes`对象。
|
||||
|
||||
前面`nginx-pod.yaml`里面就声明了`labels`字段,标签为`name`,相关操作记录如下:
|
||||
|
||||
```shell
|
||||
# 查看标签
|
||||
kubectl get pods --show-labels
|
||||
# 输出
|
||||
NAME READY STATUS RESTARTS AGE LABELS
|
||||
nginx 1/1 Running 0 17m name=nginx
|
||||
|
||||
# 增加标签
|
||||
kubectl label pods nginx version=latest
|
||||
# 输出
|
||||
pod/nginx labeled
|
||||
|
||||
# 查看特定标签
|
||||
kubectl get pods -l "version=latest" --show-labels
|
||||
|
||||
# 更新标签
|
||||
kubectl label pods nginx version=1 --overwrite
|
||||
|
||||
# 删除标签
|
||||
kubectl label pods nginx version-
|
||||
```
|
||||
|
||||
### 命名空间
|
||||
|
||||
利用标签,我们可以将`Pod`和其他对象组织成一个组,这是最小粒度的分类,当我们需要将对象分割成完全独立且不重叠的组时,比如我想单独基于`k8s`搭建一套`Flink`集群,我不想让我的`Flink`和前面搭建的`Nginx`放在一起,这个时候,命名空间(namespace)的作用就体现出来了。
|
||||
|
||||
```shell
|
||||
# 列出所有的命名空间
|
||||
kubectl get ns
|
||||
# 输出,我们目前都是在 default 命名空间中进行操作
|
||||
NAME STATUS AGE
|
||||
default Active 20d
|
||||
kube-node-lease Active 20d
|
||||
kube-public Active 20d
|
||||
kube-system Active 20d
|
||||
kubernetes-dashboard Active 19d
|
||||
```
|
||||
|
||||
让我们创建一个命名空间`vim cus-ns.yaml`,输入:
|
||||
|
||||
```shell
|
||||
apiVersion: v1
|
||||
kind: Namespace
|
||||
metadata:
|
||||
name: cus-ns
|
||||
```
|
||||
|
||||
让我们在终端实践一番:
|
||||
|
||||
```shell
|
||||
# 开始创建命名空间 or kubectl create ns cus-ns
|
||||
kubectl create -f cus-ns.yaml
|
||||
# 输出
|
||||
NAME STATUS AGE
|
||||
cus-ns Active 6s
|
||||
|
||||
# 切换命名空间【可选】
|
||||
kubectl config set-context --current --namespace=cus-ns
|
||||
|
||||
# 为新建资源选择命名空间
|
||||
kubectl create -f nginx-pod.yaml -n cus-ns
|
||||
|
||||
kubectl delete ns cus-ns
|
||||
```
|
||||
|
||||
这里我们可以暂时先做一个总结,如前面所说,`Pod`可以表示`k8s`中的基本部署单元。经过前面的讲解,你应该知道以下一些知识点:
|
||||
|
||||
- 手动增删改查`Pod`
|
||||
- 让其服务化(`Service`)
|
||||
|
||||
但是在实际使用中,我们并不会直接人工干预来管理`Pod`,为什么呢?当`Pod`健康出问题或者需要进行更新等操作时,人是没有精力来做这种维护管理工作的,但我们擅长创造工具来自动化这些繁琐的事情,所以我们可以使用后面介绍的`Deployment`。
|
||||
|
||||
### 外部访问
|
||||
|
||||
此时我们已经启动了一个`nginx`,我们有哪些方法可以对`Pod`进行连接测试呢?
|
||||
|
||||
可以使用如下命令:
|
||||
|
||||
```shell
|
||||
kubectl port-forward nginx 8088:80
|
||||
# 输出
|
||||
Forwarding from 127.0.0.1:8088 -> 80
|
||||
Forwarding from [::1]:8088 -> 80
|
||||
|
||||
# 再开一个终端访问测试或者打开浏览器
|
||||
curl http://0.0.0.0:8088/
|
||||
```
|
||||
|
||||
|
||||
|
||||
显然,成功访问,但是这个有个问题就是此端口不会长期开放,一旦一定时间内没有访问,就会自动断掉,我们需要其他的方式来进行访问,比如后面会提到的`Service`,这里就简单运行个命令,大家感受一下:
|
||||
|
||||
```shell
|
||||
# 创建一个服务对象
|
||||
# NodePort 在所有节点(虚拟机)上开放一个特定端口,任何发送到该端口的流量都被转发到对应服务
|
||||
kubectl expose po nginx --port=80 --target-port=80 --type=NodePort --name nginx-http
|
||||
# 输出
|
||||
service/nginx-http exposed
|
||||
|
||||
# 查看服务
|
||||
kubectl get svc
|
||||
# 输出
|
||||
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 16d
|
||||
nginx-http NodePort 10.102.141.232 <none> 80:32220/TCP 1s
|
||||
|
||||
# 终端访问测试
|
||||
curl http://0.0.0.0:32220/
|
||||
# 输出 html, 表示成功端口成功开放给外部
|
||||
```
|
||||
|
||||
## Service
|
||||
|
||||
> Service 服务的主要作用就是替代 Pod 对外暴露一个不变的访问地址
|
||||
|
||||
在本文第二节`Pod`部分的`外部访问`小节,就已经提到并演示了`Service`,它很方便地将我们的服务端口成功开放给外部访问。
|
||||
|
||||
### 介绍
|
||||
|
||||
我们的`Pod`是有生命周期的,它们可以被创建、销毁,但是一旦被销毁,这个对象的相关痕迹就没有了,哪怕我们用`ReplicaSet`让他又*复生*了,但是新`Pod` 的`IP`我们是没法管控的。
|
||||
|
||||
很显然,如果我们的后端服务的接口地址总是在变,我们的前端人员心中定然大骂,怎么办?这就轮到`Service`出场了。
|
||||
|
||||
### 定义 Service
|
||||
|
||||
前面我们创建了一个名为`nginx-http`的`Services`,用的是命令行;接下来我们介绍一下配置文件的形式,在`nginx-deployment.yaml`后面增加以下配置:
|
||||
|
||||
```yaml
|
||||
---
|
||||
kind: Service
|
||||
apiVersion: v1
|
||||
metadata:
|
||||
name: nginx
|
||||
spec:
|
||||
selector:
|
||||
app: nginx
|
||||
type: NodePort
|
||||
ports:
|
||||
- nodePort: 30068
|
||||
port: 8068
|
||||
protocol: TCP
|
||||
targetPort: 80
|
||||
```
|
||||
|
||||
相信上述配置,大部分的字段看起来都没什么问题了吧,先说一下端口这块的含义:
|
||||
|
||||
- nodePort:通过任意节点的`30068`端口来访问`Service`
|
||||
- port:集群内的其他容器组可通过`8068`端口访问`Service`
|
||||
- targetPort:`Pod`内容器的开发端口
|
||||
|
||||
这里我想强调的是`type`字段,说明如下:
|
||||
|
||||
- ClusterIP:默认类型,服务只能够在集群内部可以访问
|
||||
- NodePort:通过每个 Node 上的 IP 和静态端口(`NodePort`)暴露服务
|
||||
- LoadBalancer:使用云提供商的负载均衡器,可以向外部暴露服务。
|
||||
|
||||
关于`LoadBalancer`,基本上是云商会提供此类型,如果是我们自行搭建的,就没有此类型可选,但是很多开源项目默认是启用这种类型,我们可以自行打一个补丁来解决这个问题:
|
||||
|
||||
```shell
|
||||
kubectl patch svc {your-svc-name} -n default -p '{"spec": {"type": "LoadBalancer", "externalIPs":["0.0.0.0"]}}'
|
||||
```
|
||||
|
||||
执行生效命令:
|
||||
|
||||
```shell
|
||||
kubectl apply -f ./nginx-deployment.yaml
|
||||
# 输出
|
||||
deployment.apps/nginx-deployment unchanged
|
||||
service/nginx created
|
||||
|
||||
# 查看服务
|
||||
kubectl get services -o wide
|
||||
# 输出
|
||||
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
|
||||
nginx NodePort 10.110.245.214 <none> 8068:30068/TCP 11m app=nginx
|
||||
|
||||
# 终端测试
|
||||
curl http://0.0.0.0:30068/
|
||||
```
|
||||
|
||||
除了前面提的两种方法(`NodePort`、`LoadBalancer`),还有另外一种方法——`Ingress`资源。我们为什么需要引入`Ingress`,最主要的原因是`LoadBalancer`需要公有的IP地址,自行搭建的就不要考虑了。
|
||||
|
||||
而`Ingress`非常强大,它位于多个服务之前,充当集群中的**智能路由器**或入口点:
|
||||
|
||||
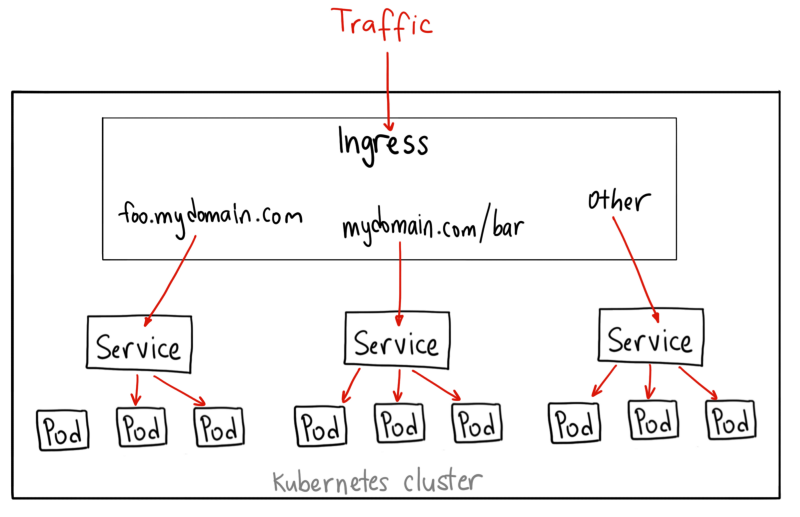
|
||||
|
||||
## Deployment
|
||||
|
||||
窥一斑而知全豹,好好了解完`Pod`之后,再继续了解`k8s`的概念也就水到渠成了。我们一般不会直接创建`Pod`,毕竟通过创建`Deployment`资源可以很方便的创建管理`Pod`(水平扩展、伸缩),并支持声明式地更新应用程序。
|
||||
|
||||
### 介绍
|
||||
|
||||
本章第一小节**引入**部分就是以`Deployment`举例,当时启动配置文件我们看到了一个`Deployment`资源和一个`Pod`,查看命令如下:
|
||||
|
||||
```shell
|
||||
kubectl get deployments
|
||||
# 输出
|
||||
NAME READY UP-TO-DATE AVAILABLE AGE
|
||||
nginx-deployment 0/1 1 0 4s
|
||||
|
||||
kubectl get pods
|
||||
# 输出 如果名字有变化不用在意,只是我重新创建了一个 Deployment
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
nginx-deployment-585449566-mnrtn 1/1 Running 0 2m1s
|
||||
```
|
||||
|
||||
这里我们再增加一条命令:
|
||||
|
||||
```shell
|
||||
kubectl get replicasets.apps
|
||||
# 输出
|
||||
NAME DESIRED CURRENT READY AGE
|
||||
nginx-deployment-585449566 1 1 1 10m
|
||||
```
|
||||
|
||||
嗯嗯~,让我们捋一捋,当我们创建一个`Deployment`对象时,`k8s`不会只创建一个`Deployment`资源,还会创建另外的`ReplicaSet `以及1个`Pod `对象。所以问题来了, `ReplicaSet`又是个是什么东西?
|
||||
|
||||
### ReplicaSet
|
||||
|
||||
如果你更新了`Deployment`的`Pod`模板,那么`Deployment`就需要通过滚动更新(rolling update)的方式进行更新。
|
||||
|
||||
而滚动更新,离不开`ReplicaSet`,说到`ReplicaSet`就得说到`ReplicationController`(弃用)。
|
||||
|
||||
> `ReplicationController`是一种`k8s`资源,其会持续监控正在运行的pod列表,从而保证`Pod`的稳定(在现有`Pod`丢失时启动一个新`Pod`),也能轻松实现`Pod`的水平伸缩
|
||||
|
||||
`ReplicaSet`的行为与`ReplicationController`完全相同,但`Pod`选择器的表达能力更强(允许匹配缺少某个标签的Pod,或包含特定标签名的Pod)。所以我们可以将`Deployment`当成一种更高阶的资源,用于部署应用程序,并以声明的方式管理应用,而不是通过`ReplicaSet`进行部署,上述命令的创建关系如下图:
|
||||
|
||||

|
||||
|
||||
如上图,`Deployment`的控制器,实际上控制的是`ReplicaSet`的数目,以及每个`ReplicaSet`的属性。我们可以说`Deployment`是一个两层控制器:
|
||||
|
||||
> Deployment-->ReplicaSet-->Pod
|
||||
|
||||
这种形式下滚动更新是极好的,但这里有个前提条件那就是`Pod`是无状态的,如果运行的容器必须依赖此时的相关运行数据,那么回滚后这些存在于容器的数据或者一些相关运行状态值就不存在了,对于这种情况,该怎么办?此时需要的就是`StatefulSet`(部署有状态的多副本应用)。
|
||||
|
||||
## StatefulSet
|
||||
|
||||
如果通过`ReplicaSet`创建多个`Pod`副本(其中描述了关联到特定持久卷声明的数据卷),那么这些副本都将共享这个持久卷声明的数据卷。
|
||||
|
||||
|
||||
|
||||
那如何运行一个pod的多个副本,让每个pod都有独立的存储卷呢?对于这个问题,之前学习的相关知识都不能提供比较好的解决方案。`k8s`提供了`Statefulset`资源来运行这类Pod,它是专门定制的一类应用,这类应用中每一个实例都是不可替代的个体,都拥有稳定的名字和状态。
|
||||
|
||||
对于有状态的应用(实例之间有不对等的关系或者依赖外部数据),主要需要对以下两种类型的状态进行复刻:
|
||||
|
||||
- 存储状态:应用的多个实例分别绑定了不同的存储数据,也就是让每个Pod都有自己独立的存储卷
|
||||
- 拓扑状态:应用的多个实例之间不是完全对等的关系,各个Pod需要按照一定的顺序启动
|
||||
|
||||
## 参考
|
||||
|
||||
本章的基本概念就介绍到这里了,谢谢!本部分内容有参考如下文章:
|
||||
|
||||
- [学习Kubernetes基础知识](https://kuboard.cn/learning/k8s-basics/kubernetes-basics.html)
|
||||
- [详解 Kubernetes Deployment 的实现原理](https://draveness.me/kubernetes-deployment/)
|
||||
- [Kubernetes 中文指南](https://jimmysong.io/kubernetes-handbook/concepts/deployment.html):Deployment
|
||||
- [Kubernetes 中文指南](https://jimmysong.io/kubernetes-handbook/concepts/service.html):Service
|
||||
- [深入剖析Kubernetes](https://time.geekbang.org/column/intro/100015201?code=UhApqgxa4VLIA591OKMTemuH1%2FWyLNNiHZ2CRYYdZzY%3D):容器编排部分
|
||||
- Kubernetes in Action中文版:第3、4、5、9章
|
||||
328
kubenets/03.容器持久化存储.md
Normal file
328
kubenets/03.容器持久化存储.md
Normal file
@@ -0,0 +1,328 @@
|
||||
# 容器持久化存储
|
||||
|
||||
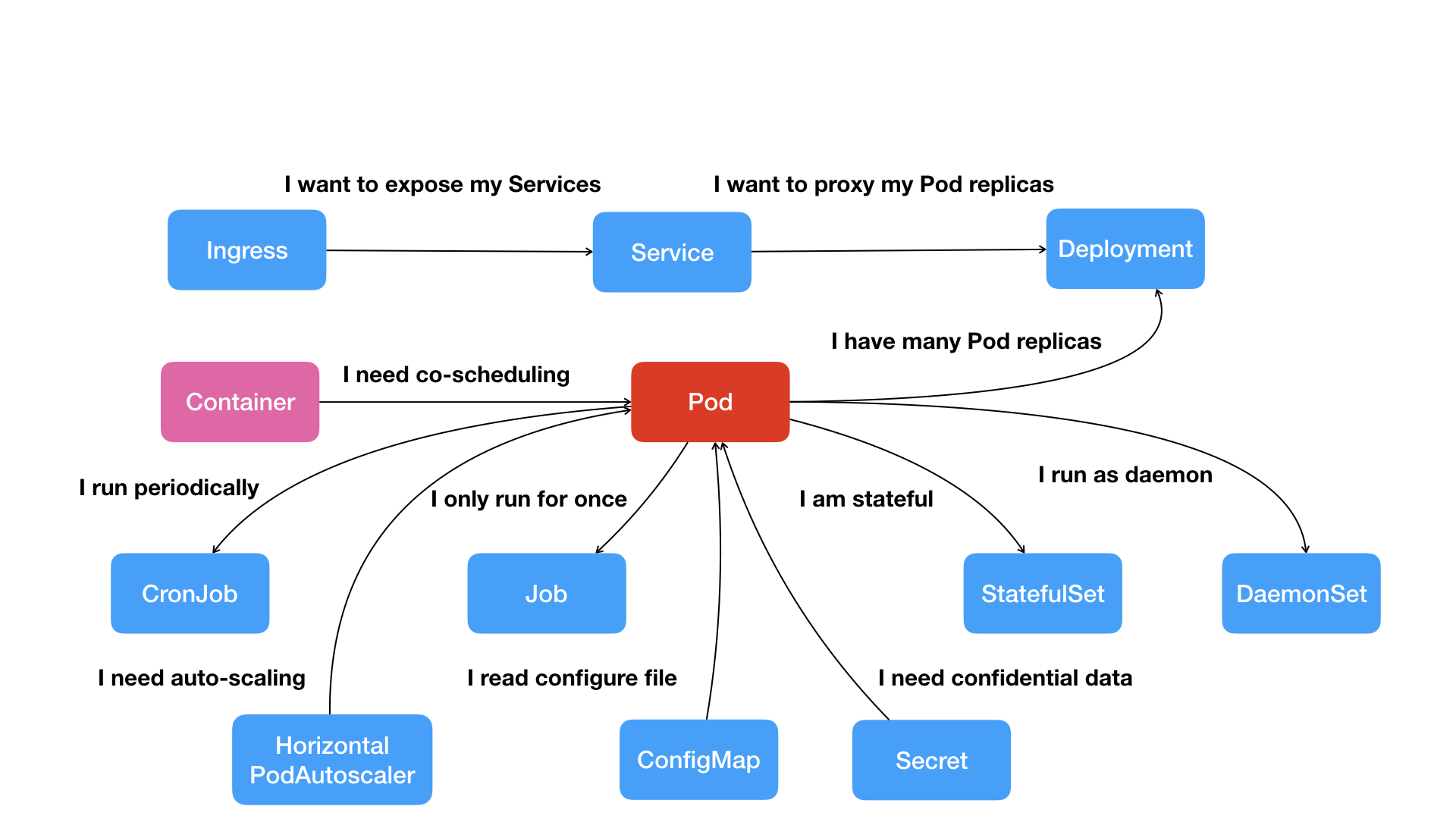
|
||||
|
||||
容器的本质是进程,对于进程,`Linux`系统有进程组的概念来将其组织在一起。在`k8s`里面,使用`Pod`这个逻辑概念来维护容器间的关系。
|
||||
|
||||
有了`Pod`后,我们的应用程序需要被创建和管理,这就引出了`ReplicaSet`和`Deployment`;然后需要将部署好的应用暴露给外部进行访问,`Service`可以提供一个固定的ip和端口让外部访问。
|
||||
|
||||
对于有状态的应用,可以使用`StatefulSet`来进行状态的恢复,在上一节[概念介绍](https://www.howie6879.cn/p/k8s%E5%AD%A6%E4%B9%A0%E4%B9%8B%E8%B7%AF.02.%E6%A6%82%E5%BF%B5%E4%BB%8B%E7%BB%8D/)里面有提到,有状态的应用是离不开**持久化存储**的。
|
||||
|
||||
## 引子
|
||||
|
||||
在`Docker`中,如果一个容器在运行过程中会产生数据并写入到文件系统,当关闭这个容器,用镜像再启动一个容器的时候,你就会意识到新容器并不会识别前一个容器写入文件系统内的任何内容。
|
||||
|
||||
对于有状态的应用,我们希望下次启动的应用可以保持住上次的状态;在`k8s`里面可以通过定义**存储卷**来满足这个需求,它们不像`Pod`这样的顶级资源,而是被定义为`Pod`的一部分,并和`Pod`共享相同的生命周期。因此在`Pod`里面容器重新启动期间,卷的内容是不变的,
|
||||
|
||||
## 卷
|
||||
|
||||
### emptyDir
|
||||
|
||||
在`Pod`中如何定义卷?让我们从`emptyDir`开始。设想一个这样的例子,一个`Pod`应用由两个容器,容器A不断产生数据,容器B将A产生的数据作为输出。此时,这两个容器就需要使用同一个卷。
|
||||
|
||||
让我们实际操作一下,`vim fortune-pod.yaml`:
|
||||
|
||||
```yaml
|
||||
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
name: fortune
|
||||
spec:
|
||||
containers:
|
||||
- image: luksa/fortune
|
||||
name: html-generator
|
||||
volumeMounts:
|
||||
- name: html
|
||||
mountPath: /var/htdocs
|
||||
- image: nginx:alpine
|
||||
name: web-server
|
||||
volumeMounts:
|
||||
- name: html
|
||||
mountPath: /usr/share/nginx/html
|
||||
readOnly: true
|
||||
ports:
|
||||
- containerPort: 80
|
||||
protocol: TCP
|
||||
volumes:
|
||||
- name: html
|
||||
emptyDir: {}
|
||||
```
|
||||
|
||||
说明一下上述配置文件的含义:`fortune`镜像是`k8s in action`书中示例打包的镜像,相当于上面说的不断产生数据的容器A,其中名为`html`的容器挂载在`var/htdocs`中;而`nginx`也挂载了相同的`html`卷,不过位置在`/usr/share/nginx/html`,上面两个容器共用的卷就是`emptyDir: {}`。
|
||||
|
||||
启动来感受一下:
|
||||
|
||||
```shell
|
||||
kubectl create -f fortune-pod.yaml
|
||||
# 输出
|
||||
pod/fortune created
|
||||
|
||||
# 查看状态
|
||||
kubectl get pods
|
||||
# 输出
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
fortune 2/2 Running 0 2m27s
|
||||
|
||||
# 暂时服务化
|
||||
kubectl port-forward fortune 8080:80
|
||||
```
|
||||
|
||||
此时服务就处于可用状态了,在终端输入`curl http://localhost:8080/`,基本上每隔`10s`,都会返回不同的响应,如下图:
|
||||
|
||||

|
||||
|
||||
`emptyDir`卷是最简单的卷类型,但是其他类型的卷都是在它的基础上构建的,在创建空目录后,相应的容器会将数据写入。
|
||||
|
||||
### gitRepo
|
||||
|
||||
假设你有在`github`上开发项目,`gitRepo`卷允许你定义好相关配置然后直接从`github`上下拉项目将数据共享给其他容器使用。
|
||||
|
||||
### hostPath
|
||||
|
||||
前面说的卷都是停留在共享同一个`Pod`的文件,当其需要读取节点文件的时候,就需要`hostPath`卷出场了。和之前介绍的卷最大的不同之处是,`hostPath`是一个持久性存储的卷,其目录存在于对应节点主机的目录。
|
||||
|
||||
所以,`hostPath`仅仅适用于在节点上读取数据,如果你的需求是跨`Pod`,那么`NAS`才是你的解决方案。
|
||||
|
||||
### NFS
|
||||
|
||||
目前相关的云商都会有一套自己的持久化方式,我目前是自己搭建的`k8s`,所以我只能实践一下`NAS`方案,新建文件`vim mongodb-pod-nfs.yaml`,输入以下内容:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
name: mongodb-nfs
|
||||
spec:
|
||||
volumes:
|
||||
- name: mongodb-data
|
||||
nfs:
|
||||
server: 1.2.3.4
|
||||
path: /some/path
|
||||
containers:
|
||||
- image: mongo
|
||||
name: mongodb
|
||||
volumeMounts:
|
||||
- name: mongodb-data
|
||||
mountPath: /data/db
|
||||
ports:
|
||||
- containerPort: 27017
|
||||
protocol: TCP
|
||||
```
|
||||
|
||||
启动:
|
||||
|
||||
```shell
|
||||
kubectl create -f mongodb-pod-nfs.yaml
|
||||
|
||||
# 查看状态
|
||||
kubectl get pods
|
||||
# 输出
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
mongodb-nfs 1/1 Running 0 3m13s
|
||||
```
|
||||
|
||||
我们来验证一下数据持久化是否生效,输入命令`kubectl exec -it mongodb-nfs mongo`进入:
|
||||
|
||||
```shell
|
||||
> use test_data
|
||||
switched to db test_data
|
||||
|
||||
# 插入
|
||||
> db.test.insert({"name": "howie"})
|
||||
WriteResult({ "nInserted" : 1 })
|
||||
|
||||
# 查询
|
||||
> db.test.find({})
|
||||
{ "_id" : ObjectId("6041f5bc0c893dc3bb362e75"), "name" : "howie" }
|
||||
```
|
||||
|
||||
接下来重新创建`Pod`看一下数据是不是还在:
|
||||
|
||||
```shell
|
||||
kubectl delete pod mongodb-nfs
|
||||
|
||||
# 重新创建
|
||||
kubectl create -f mongodb-pod-nfs.yaml
|
||||
# 输出
|
||||
pod/mongodb-nfs created
|
||||
|
||||
# 查看
|
||||
kubectl get pods
|
||||
# 输出
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
mongodb-nfs 1/1 Running 0 28s
|
||||
```
|
||||
|
||||
进入`Pod`内的`mongo`容器,输入命令`kubectl exec -it mongodb-nfs mongo`进入:
|
||||
|
||||
```shell
|
||||
> use test_data
|
||||
switched to db test_data
|
||||
|
||||
# 查询
|
||||
> db.test.find({})
|
||||
{ "_id" : ObjectId("6041f5bc0c893dc3bb362e75"), "name" : "howie" }
|
||||
```
|
||||
|
||||
虽然我们成功让多个`Pod`享用了同一份数据,但这样做法有点问题,让开发人员在配置里面写具体`NFS`地址是很不友好的事情,我们可以使用**持久卷**来解决此问题。
|
||||
|
||||
## 持久卷&持久卷声明
|
||||
|
||||
### 介绍
|
||||
|
||||
前面`NFS`用来做持久化存储是一个反面的例子,对于真实的基础设施,其详细配置应该是被隐藏的;但是`k8s`又实实在在需要对一些基础设施进行访问,怎么办?引入新的资源:
|
||||
|
||||
- 持久卷(PersistentVolume)
|
||||
- 持久卷声明(PersistentVolumeClaim)
|
||||
|
||||
持久卷由管理员创建(各种配置信息),然后用户创建持久卷声明,提交后`k8s`就会找到匹配的持久卷并将其绑定到持久卷声明。
|
||||
|
||||
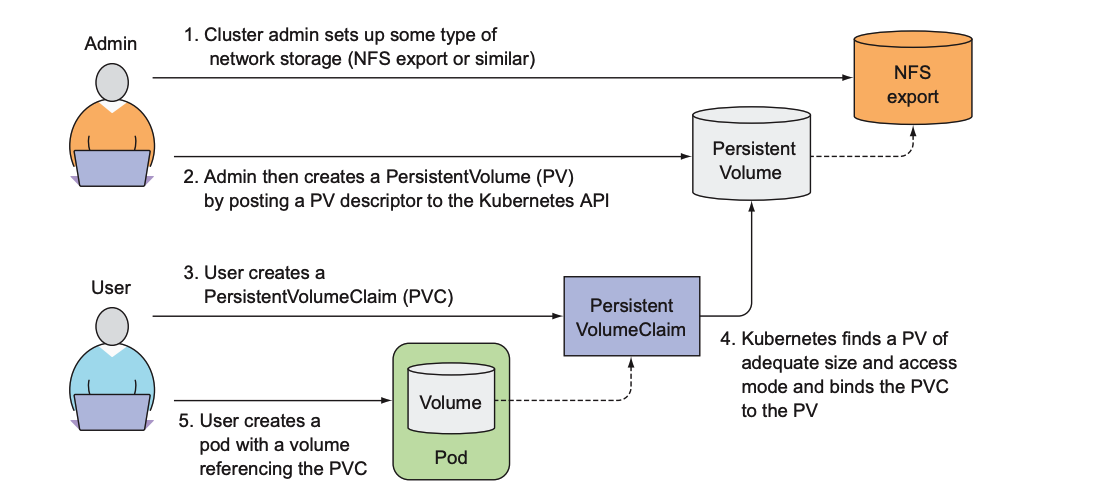
|
||||
|
||||
这样做的好处在于,对于用户只需要关注声明一下需要多大的存储、需要什么权限(读写)等,然后pod通过其中一个卷的名称来引用声明就可以了,将细节完美地进行了隐藏。
|
||||
|
||||
### 实践
|
||||
|
||||
首先建立一个`NFS`类型的`PV`(一般是管理员进行创建),在终端输入`vim mongodb-pv-nfs.yaml`:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: PersistentVolume
|
||||
metadata:
|
||||
name: nfs-pv
|
||||
spec:
|
||||
capacity:
|
||||
storage: 10Mi
|
||||
accessModes:
|
||||
- ReadWriteMany
|
||||
nfs:
|
||||
server: 1.2.3.4
|
||||
path: "/"
|
||||
```
|
||||
|
||||
接下来创建持久卷:
|
||||
|
||||
```shell
|
||||
kubectl create -f mongodb-pv-nfs.yaml
|
||||
# 输出
|
||||
persistentvolume/nfs created
|
||||
|
||||
# 查看
|
||||
kubectl get pv
|
||||
# 输出
|
||||
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
|
||||
nfs-pv 10Mi RWX Retain Available 6s
|
||||
|
||||
# 关于删除
|
||||
# kubectl delete pv nfs-pv
|
||||
```
|
||||
|
||||
可以看到状态已经生效。
|
||||
|
||||
接下来就轮到使用者随意使用`PV`了,如果作为使用者,部署的`Pod`需要持久化存储,那么其需要做的就是创建`PVC`,在终端输入`vim mongodb-pvc-nfs.yaml`:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: PersistentVolumeClaim
|
||||
metadata:
|
||||
name: nfs-pvc
|
||||
spec:
|
||||
accessModes:
|
||||
- ReadWriteMany
|
||||
resources:
|
||||
requests:
|
||||
storage: 10Mi
|
||||
storageClassName: ""
|
||||
```
|
||||
|
||||
然后创建持久化声明:
|
||||
|
||||
```shell
|
||||
kubectl create -f mongodb-pvc-nfs.yaml
|
||||
# 输出
|
||||
persistentvolumeclaim/nfs created
|
||||
|
||||
# 查看 pvc
|
||||
kubectl get pvc
|
||||
# 输出,注意状态是绑定
|
||||
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
|
||||
nfs-pvc Bound nfs-pv 10Mi RWX 6s
|
||||
|
||||
# 查看 pv
|
||||
kubectl get pv
|
||||
# 输出,状态是绑定
|
||||
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
|
||||
nfs-pv 10Mi RWX Retain Bound default/nfs-pvc 3m6s
|
||||
# 关于删除
|
||||
# kubectl delete pvc nfs-pvc
|
||||
```
|
||||
|
||||
对于`ACCESS MODES`,主要分为以下几种:
|
||||
|
||||
- RWO:ReadWriteOnce(仅允许单个节点挂载读写)
|
||||
- ROX:ReadOnlyMany(允许多个节点挂载只读)
|
||||
- RWX:ReadWriteMany(允许多个节点挂载读写这个卷)
|
||||
|
||||
现在,准备工作就绪,在`Pod`中使用持久卷就是引用持久卷名称,在终端输入`vim mongo-pod-pvc.yaml`:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
name: mongodb
|
||||
spec:
|
||||
containers:
|
||||
- image: mongo
|
||||
name: mongodb
|
||||
volumeMounts:
|
||||
- name: mongodb-data
|
||||
mountPath: /data/db
|
||||
ports:
|
||||
- containerPort: 27017
|
||||
protocol: TCP
|
||||
volumes:
|
||||
- name: mongodb-data
|
||||
persistentVolumeClaim:
|
||||
claimName: nfs-pvc
|
||||
```
|
||||
|
||||
创建`Pod`:
|
||||
|
||||
```shell
|
||||
# 先删除原先创建的 mongo Pod
|
||||
kubectl delete pod mongodb-nfs
|
||||
# 创建引用持久卷声明的 Pod
|
||||
kubectl create -f mongodb-pod-pvc.yaml
|
||||
# 输出
|
||||
pod/mongodb created
|
||||
```
|
||||
|
||||
进入`Pod`内的`mongo`容器,输入命令`kubectl exec -it mongodb mongo`进入:
|
||||
|
||||
```shell
|
||||
> use test_data
|
||||
switched to db test_data
|
||||
|
||||
# 查询
|
||||
> db.test.find({})
|
||||
{ "_id" : ObjectId("6041f5bc0c893dc3bb362e75"), "name" : "howie" }
|
||||
```
|
||||
|
||||
没问题,引用了之前的`NFS`下的对应目录。
|
||||
|
||||
## 动态卷
|
||||
|
||||
前面提到,`PV`需要管理人员进行创建,在实际生产环境下,这个`PV`的需求量可能是非常大的,所以这种协调方式是不合理的。所以,`k8s`提供了一套可以自动创建`PV`的机制——**动态卷**。
|
||||
|
||||
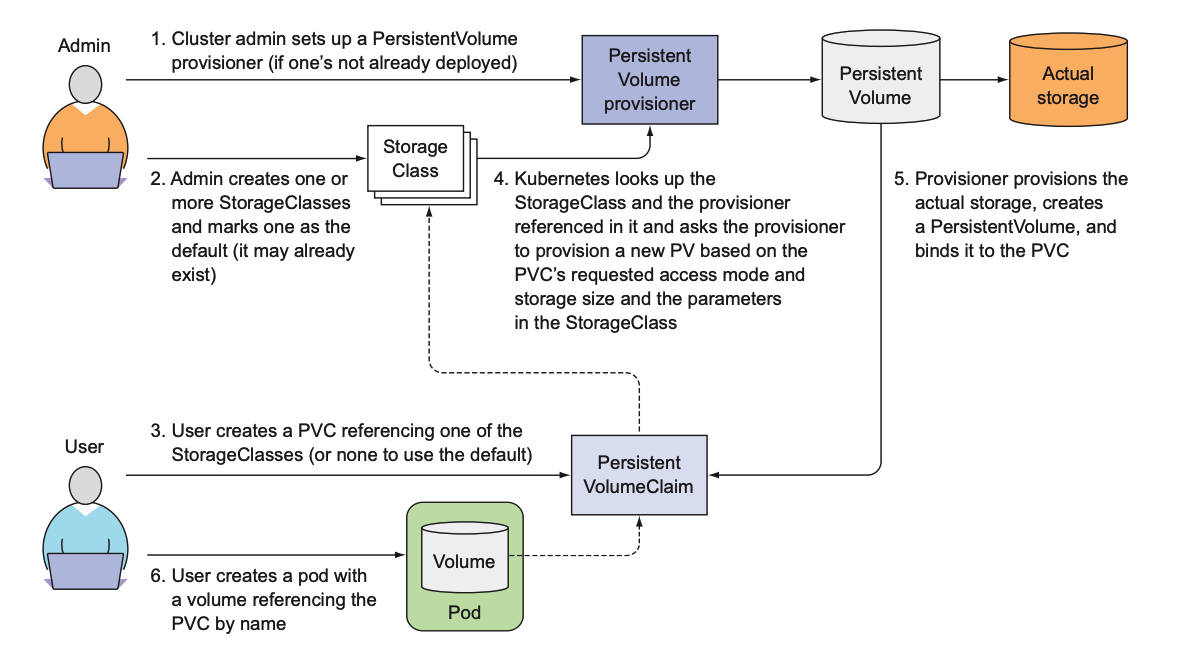
|
||||
|
||||
这张图将使用`StorageClass`的流程描述地很清楚,管理员创建一个或多个`StorageClass`,用户创建`Pod`引用`PVC`声明相关的`storageClassName`就会通过管理员创建的`StorageClass`自动创建`PV`。
|
||||
|
||||
## 参考
|
||||
|
||||
本章关于容器持久化就介绍到这里了,谢谢!本部分内容有参考如下文章:
|
||||
|
||||
- [深入剖析Kubernetes](https://time.geekbang.org/column/intro/100015201?code=UhApqgxa4VLIA591OKMTemuH1%2FWyLNNiHZ2CRYYdZzY%3D):持久化存储部分
|
||||
- [Kubernetes in Action](https://github.com/luksa/kubernetes-in-action)中文版:可以算是第6章的读书笔记
|
||||
|
||||
509
kubenets/04.配置应用程序.md
Normal file
509
kubenets/04.配置应用程序.md
Normal file
@@ -0,0 +1,509 @@
|
||||
# 配置应用程序
|
||||
|
||||

|
||||
|
||||
使用`Docker`部署应用程序时,一般常用的配置方式有:
|
||||
|
||||
- 配置内嵌
|
||||
- 启动传参配置
|
||||
- 环境变量
|
||||
|
||||
经过前面容器持久化存储的介绍,我们很容易能想到是以挂载卷的形式,比如:
|
||||
|
||||
- gitRepo
|
||||
- hostPath
|
||||
- NFS
|
||||
|
||||
再结合边车模式来进行配置文件的管控是可行的,然而有一种更加简便的方法能将配置数据置于`Kubernetes`的顶级资源对象中,那就是`ConfigMap`。
|
||||
|
||||
## 传递命令行参数
|
||||
|
||||
在上一节**容器持久化存储**的`emptyDir`概念介绍部分,我们引入了一个`fortune-pod`的例子,再回顾一下之前的配置文件吧,如下:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
name: fortune
|
||||
spec:
|
||||
containers:
|
||||
- image: luksa/fortune
|
||||
name: html-generator
|
||||
volumeMounts:
|
||||
- name: html
|
||||
mountPath: /var/htdocs
|
||||
- image: nginx:alpine
|
||||
name: web-server
|
||||
volumeMounts:
|
||||
- name: html
|
||||
mountPath: /usr/share/nginx/html
|
||||
readOnly: true
|
||||
ports:
|
||||
- containerPort: 80
|
||||
protocol: TCP
|
||||
volumes:
|
||||
- name: html
|
||||
emptyDir: {}
|
||||
```
|
||||
|
||||
此应用程序设定了每隔`10s`就会自动生成输出到`html`,现在我们要做的是通过命令行参数,自行设定隔多少秒自动生成内容。
|
||||
|
||||
创建文件`fortune-pod-args.yaml`,输入以下内容:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
name: fortune2s
|
||||
spec:
|
||||
containers:
|
||||
- image: luksa/fortune:args
|
||||
args: ["2"]
|
||||
name: html-generator
|
||||
volumeMounts:
|
||||
- name: html
|
||||
mountPath: /var/htdocs
|
||||
- image: nginx:alpine
|
||||
name: web-server
|
||||
volumeMounts:
|
||||
- name: html
|
||||
mountPath: /usr/share/nginx/html
|
||||
readOnly: true
|
||||
ports:
|
||||
- containerPort: 80
|
||||
protocol: TCP
|
||||
volumes:
|
||||
- name: html
|
||||
emptyDir: {}
|
||||
```
|
||||
|
||||
看到配置文件中的`args`字段了么?这个就是传给镜像`luksa/fortune:args`控制时间的参数,让我们启动看看吧。
|
||||
|
||||
```shell
|
||||
kubectl create -f fortune-pod-args.yaml
|
||||
# 输出
|
||||
pod/fortune2s created
|
||||
|
||||
# 查看状态
|
||||
kubectl get pods
|
||||
# 输出
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
fortune 2/2 Running 0 2m27s
|
||||
|
||||
# 暂时服务化
|
||||
kubectl port-forward fortune2s 8080:80
|
||||
```
|
||||
|
||||
访问`127.0.0.1:8080`就会发现输出的频率变成了`2s`:
|
||||
|
||||
```shell
|
||||
> curl 127.0.0.1:8080
|
||||
Stay away from flying saucers today.
|
||||
```
|
||||
|
||||
## 设置环境变量
|
||||
|
||||
> 与容器的命令和参数设置相同,环境变量列表无法在pod创建后被修改
|
||||
|
||||
设置环境变量非常简单,我们只需要在`pod`中指定环境变量即可;当然,这里有个前提是你需要将修改镜像让其支持读取环境变量。
|
||||
|
||||
我们直接使用书中的例子:`vim fortune-pod-env.yaml`:
|
||||
|
||||
```shell
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
name: fortune-env
|
||||
spec:
|
||||
containers:
|
||||
- image: luksa/fortune:env
|
||||
env:
|
||||
- name: INTERVAL
|
||||
value: "30"
|
||||
name: html-generator
|
||||
volumeMounts:
|
||||
- name: html
|
||||
mountPath: /var/htdocs
|
||||
- image: nginx:alpine
|
||||
name: web-server
|
||||
volumeMounts:
|
||||
- name: html
|
||||
mountPath: /usr/share/nginx/html
|
||||
readOnly: true
|
||||
ports:
|
||||
- containerPort: 80
|
||||
protocol: TCP
|
||||
volumes:
|
||||
- name: html
|
||||
emptyDir: {}
|
||||
```
|
||||
|
||||
可以看到配置中声明了`INTERVAL`环境变量值为`30`,在终端中实践一下:
|
||||
|
||||
```shell
|
||||
kubectl create -f fortune-pod-env.yaml
|
||||
# 输出
|
||||
pod/fortune-env created
|
||||
|
||||
# 查看状态
|
||||
kubectl get pods
|
||||
# 输出
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
fortune-env 2/2 Running 0 10s
|
||||
|
||||
# 暂时服务化
|
||||
kubectl port-forward fortune-env 8080:80
|
||||
```
|
||||
|
||||
访问`127.0.0.1:8080`就会发现输出的频率变成了`30s`。
|
||||
|
||||
现在应用程序的所有配置基本上可以说是硬编码的形式进行配置,并且`yaml`配置文件总是有配置相关的字段,有没有办法让镜像和配置文件解耦呢?
|
||||
|
||||
`k8s`提供了名为`ConfigMap`的资源对象解决这个问题。
|
||||
|
||||
## ConfigMap
|
||||
|
||||
资源对象`ConfigMap`提供了向容器中注入配置信息的机制,它本质上就是一个键/值对映射,可以用来保存单个值或者配置文件。
|
||||
|
||||
`ConfigMap`是不需要被读取的,它映射的内容通过环境变量或者卷文件的形式传给容器。一般直接在`pod`的定义里面就可以声明`ConfigMap`,这样就可以根据不同的环境创建不同的配置,流程交互如下图所示:
|
||||
|
||||
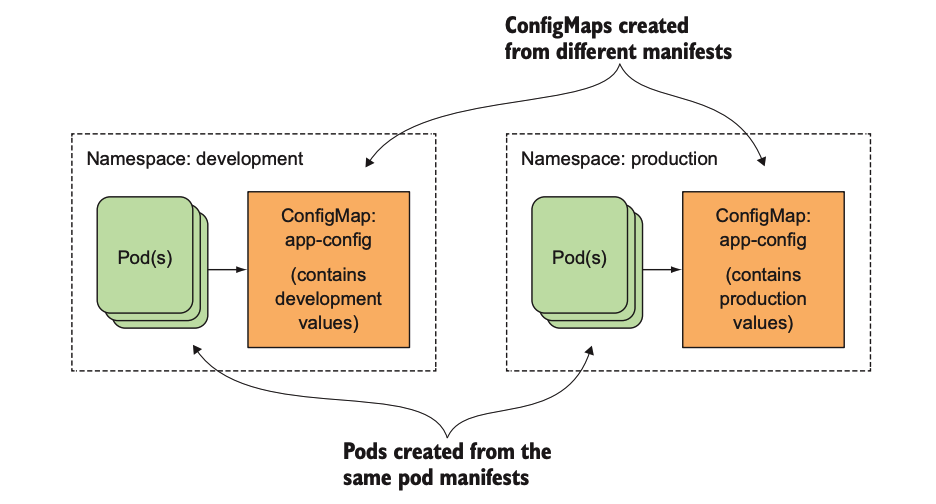
|
||||
|
||||
### 创建
|
||||
|
||||
还是用之前应用程序为例,配置专注于环境变量`INTERVAL`,创建命令如下所示:
|
||||
|
||||
```shell
|
||||
kubectl create configmap fortune-config --from-literal=sleep-interval=25
|
||||
# 输出
|
||||
configmap/fortune-config created
|
||||
|
||||
# 获取相关描述
|
||||
kubectl get configmap fortune-config -o yaml
|
||||
|
||||
# 查看 configmap
|
||||
kubectl get configmap
|
||||
|
||||
# 删除
|
||||
kubectl delete configmap fortune-config
|
||||
```
|
||||
|
||||
此外,`k8s`还可以直接填写配置文件来进行创建`vim fortune-config.yaml`,输入如下内容:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: ConfigMap
|
||||
metadata:
|
||||
name: fortune-config
|
||||
data:
|
||||
sleep-interval: "25"
|
||||
```
|
||||
|
||||
然后执行:
|
||||
|
||||
```shell
|
||||
kubectl create -f fortune-config.yaml
|
||||
# 输出
|
||||
configmap/fortune-config created
|
||||
```
|
||||
|
||||
其实还有更多的创建方式,大概提一下:
|
||||
|
||||
```shell
|
||||
# 从文件内容创建ConfigMap条目
|
||||
kubectl create configmap my-config --from-file=config-file.conf
|
||||
# 从文件夹创建ConfigMap
|
||||
kubectl create configmap my-config --from-file=/path/to/dir
|
||||
# 合并不同选项
|
||||
kubectl create configmap my-config
|
||||
--from-file=foo.json
|
||||
--from-file=bar=foobar.conf
|
||||
--from-file=config-opts/
|
||||
--from-literal=some=thing
|
||||
```
|
||||
|
||||
### 作为环境变量传入容器
|
||||
|
||||
如何将映射中的值传递给`pod`的容器?最简单的方法是给容器设置环境变量,通过在配置中声明`valueFrom`,具体操作`vim fortune-pod-env-configmap.yaml`:
|
||||
|
||||
```shell
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
name: fortune-env-from-configmap
|
||||
spec:
|
||||
containers:
|
||||
- image: luksa/fortune:env
|
||||
env:
|
||||
- name: INTERVAL
|
||||
valueFrom:
|
||||
configMapKeyRef:
|
||||
name: fortune-config
|
||||
key: sleep-interval
|
||||
name: html-generator
|
||||
volumeMounts:
|
||||
- name: html
|
||||
mountPath: /var/htdocs
|
||||
- image: nginx:alpine
|
||||
name: web-server
|
||||
volumeMounts:
|
||||
- name: html
|
||||
mountPath: /usr/share/nginx/html
|
||||
readOnly: true
|
||||
ports:
|
||||
- containerPort: 80
|
||||
protocol: TCP
|
||||
volumes:
|
||||
- name: html
|
||||
emptyDir: {}
|
||||
|
||||
```
|
||||
|
||||
让我们启动`pod`实践看看:
|
||||
|
||||
```shell
|
||||
kubectl create -f fortune-pod-env-configmap.yaml
|
||||
# 输出
|
||||
pod/fortune-env-from-configmap created
|
||||
|
||||
# 查看状态
|
||||
kubectl get pods
|
||||
# 输出
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
fortune-env-from-configmap 2/2 Running 0 19s
|
||||
|
||||
# 暂时服务化
|
||||
kubectl port-forward fortune-env-from-configmap 8080:80
|
||||
|
||||
# 删除pod
|
||||
kubectl delete pods fortune-env-from-configmap
|
||||
```
|
||||
|
||||
现在我们已经成功在`pod`中使用了`ConfigMap`资源,不过这种使用方式是比较低效的,考虑这样一个情况:如果环境变量比较多,这样单独一个个环境变量的设置方式是个程序员都没法忍受的,一般在框架里面加载一些环境变量都会利用前缀机制来进行批量加载。
|
||||
|
||||
`k8s`也提供了这样类似的机制,配置声明如下图示:
|
||||
|
||||
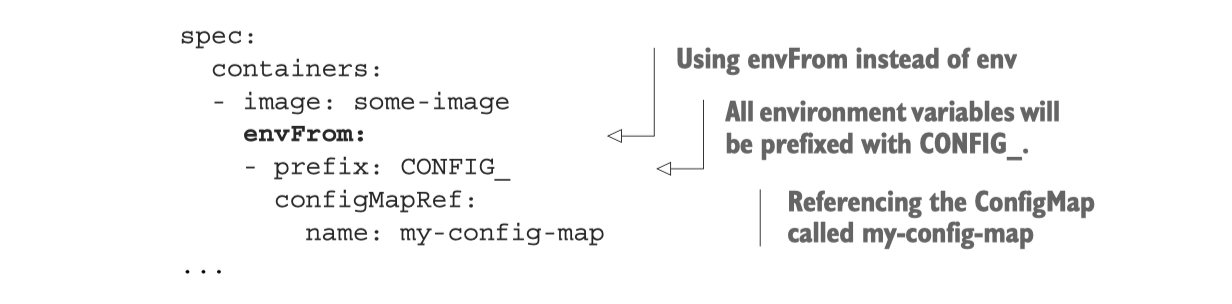
|
||||
|
||||
### ConfigMap卷
|
||||
|
||||
> 环境变量或者命令行参数值作为配置值通常适用于变量值较短的场景。由于ConfigMap中可以包含完整的配置文件内容,当你想要将其暴露给容器时,可以借助前面章节提到过的一种称为configMap卷的特殊卷格式。
|
||||
|
||||
首先删除前面声明建立的`cf`资源:`kubectl delete configmap fortune-config`。然后建立文件夹`configmap-files`,首先建立`Nginx`配置文件:`vim my-nginx-config.conf`:
|
||||
|
||||
```shell
|
||||
server {
|
||||
listen 80;
|
||||
server_name www.kubia-example.com;
|
||||
|
||||
gzip on;
|
||||
gzip_types text/plain application/xml;
|
||||
|
||||
location / {
|
||||
root /usr/share/nginx/html;
|
||||
index index.html index.htm;
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
另外在该文件夹中添加一个名为`sleep-interval`的文本文件,输入`25`,类似前面声明环境变量。
|
||||
|
||||
接下来从文件夹创建`ConfigMap`:
|
||||
|
||||
```shell
|
||||
kubectl create configmap fortune-config --from-file=configmap-files
|
||||
# 输出
|
||||
configmap/fortune-config created
|
||||
|
||||
# 验证
|
||||
kubectl get configmap fortune-config -o yaml
|
||||
```
|
||||
|
||||
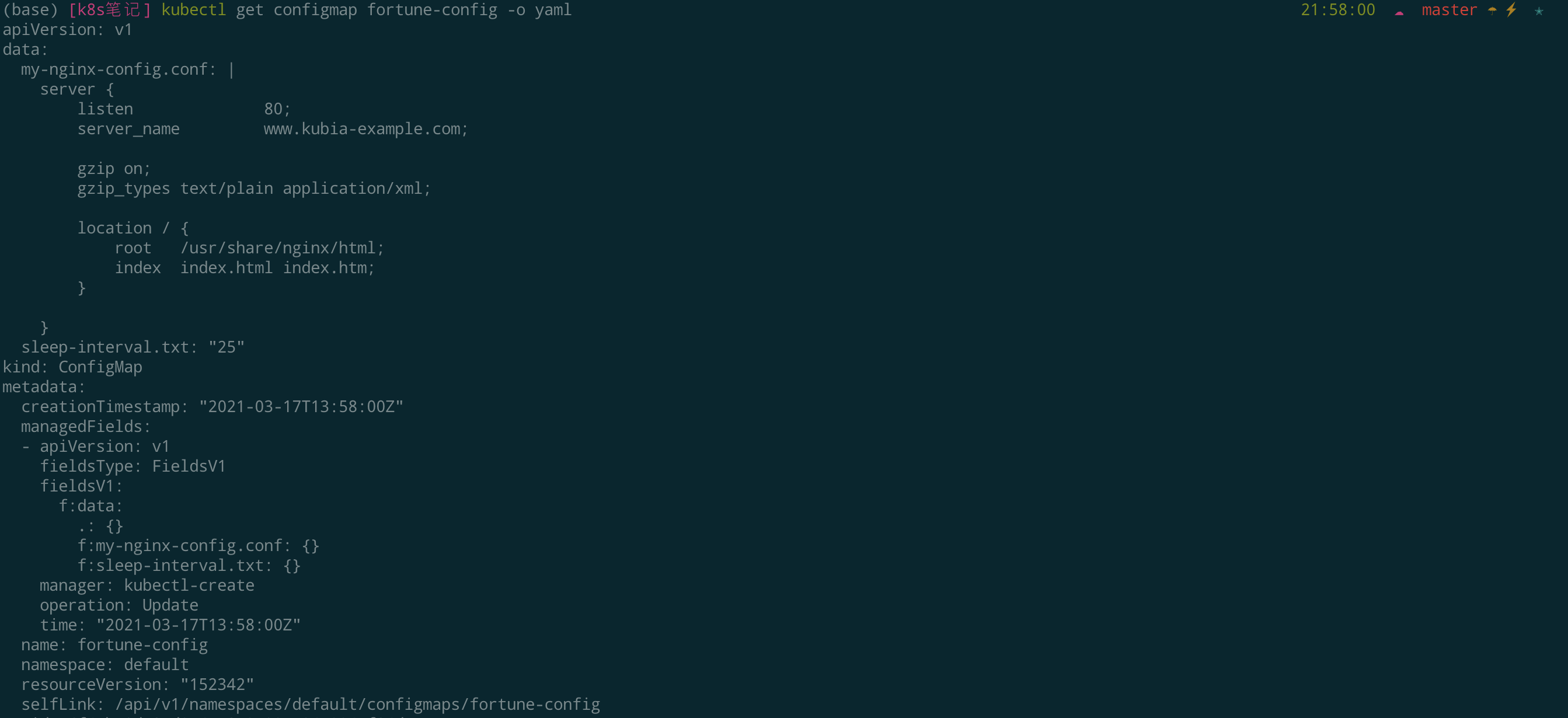
|
||||
|
||||
创建包含`ConfigMap`条目内容的卷只需要创建一个引用`ConfigMap`名称的卷并挂载到容器中:
|
||||
|
||||
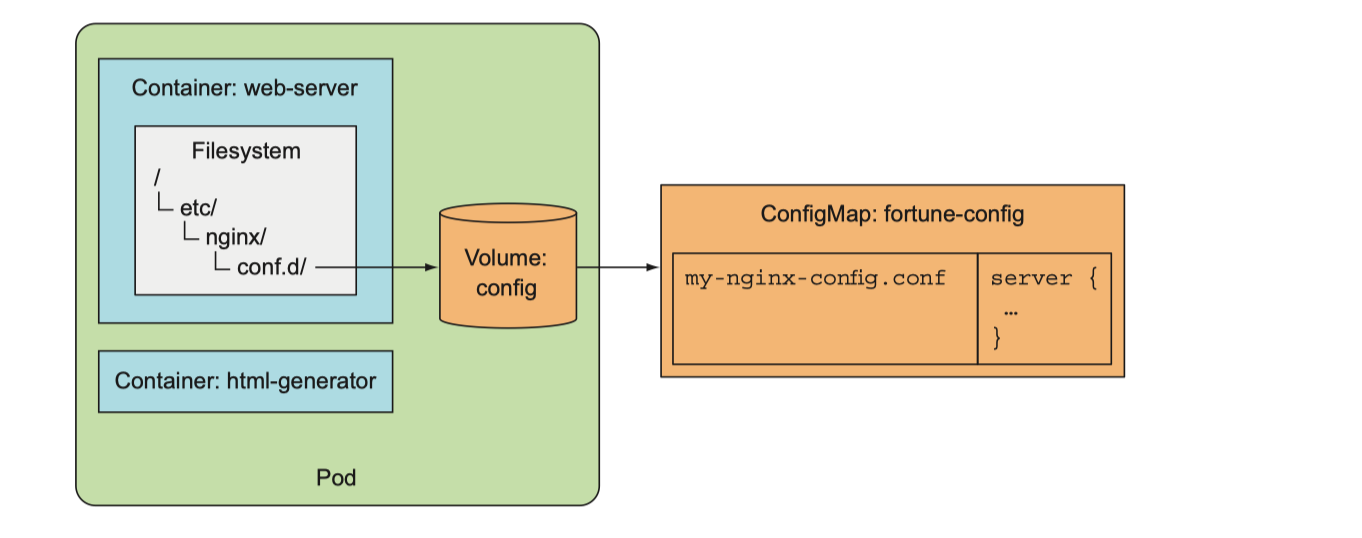
|
||||
|
||||
创建配置文件:`vim fortune-pod-configmap-volume.yaml`,输入如下内容:
|
||||
|
||||
```shell
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
name: fortune-configmap-volume
|
||||
spec:
|
||||
containers:
|
||||
- image: luksa/fortune:env
|
||||
env:
|
||||
- name: INTERVAL
|
||||
valueFrom:
|
||||
configMapKeyRef:
|
||||
name: fortune-config
|
||||
key: sleep-interval
|
||||
name: html-generator
|
||||
volumeMounts:
|
||||
- name: html
|
||||
mountPath: /var/htdocs
|
||||
- image: nginx:alpine
|
||||
name: web-server
|
||||
volumeMounts:
|
||||
- name: html
|
||||
mountPath: /usr/share/nginx/html
|
||||
readOnly: true
|
||||
- name: config
|
||||
mountPath: /etc/nginx/conf.d
|
||||
readOnly: true
|
||||
- name: config
|
||||
mountPath: /tmp/whole-fortune-config-volume
|
||||
readOnly: true
|
||||
ports:
|
||||
- containerPort: 80
|
||||
name: http
|
||||
protocol: TCP
|
||||
volumes:
|
||||
- name: html
|
||||
emptyDir: {}
|
||||
- name: config
|
||||
configMap:
|
||||
name: fortune-config
|
||||
```
|
||||
|
||||
## Secret
|
||||
|
||||
前面说的,都是针对非敏感信息的配置数据,对于一些敏感数据,例如:密码、OAuth token、ssh 密钥等,就可以使用`Secret`资源了。
|
||||
|
||||
`Secret`结构和使用方法都与`ConfigMap`类似,其作用就是将加密数据放到`etcd`中,然后`k8s`将`Secret`分发到对应`pod`所在机器节点来保障其安全性。另外,`Secret`只会存储在节点的内存中,永不写入物理存储。
|
||||
|
||||
### 创建
|
||||
|
||||
以创建一个包含用户名密码的`secret`资源为例:
|
||||
|
||||
```shell
|
||||
# 创建文件
|
||||
echo -n 'admin' > ./username.txt
|
||||
echo -n '1f2d1e2e67df' > ./password.txt
|
||||
|
||||
# 单独创建
|
||||
kubectl create secret generic user --from-file=./username.txt
|
||||
kubectl create secret generic pass --from-file=./password.txt
|
||||
|
||||
# 批量创建资源
|
||||
kubectl create secret generic db-user-pass --from-file=./username.txt --from-file=./password.txt
|
||||
|
||||
# 输出
|
||||
secret/db-user-pass created
|
||||
|
||||
# 查看
|
||||
kubectl get secrets
|
||||
|
||||
# 输出
|
||||
NAME TYPE DATA AGE
|
||||
db-user-pass Opaque 2 6h48m
|
||||
default-token-nlxkq kubernetes.io/service-account-token 3 2d
|
||||
pass Opaque 1 7s
|
||||
user Opaque 1 10s
|
||||
```
|
||||
|
||||
`db-user-pass`很好理解,就是刚才创建的`secret`资源,`default-token-nlxkq`是什么呢?这是一种默认被挂载至所有容器的`Secret`。
|
||||
|
||||
这里同样也可以是用`yaml`文件形式创建,先将用户名密码进行基础的`Base64`转码:
|
||||
|
||||
```shell
|
||||
echo -n 'admin' | base64
|
||||
echo -n '1f2d1e2e67df' | base64
|
||||
```
|
||||
|
||||
`vim db-user-pass-secret.yaml`:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: Secret
|
||||
metadata:
|
||||
name: db-user-pass
|
||||
type: Opaque
|
||||
data:
|
||||
user: YWRtaW4=
|
||||
pass: MWYyZDFlMmU2N2Rm
|
||||
```
|
||||
|
||||
终端执行:
|
||||
|
||||
```shell
|
||||
# 启动
|
||||
kubectl create -f db-user-pass-secret.yaml
|
||||
|
||||
# 查看
|
||||
kubectl get secrets
|
||||
|
||||
# 输出
|
||||
NAME TYPE DATA AGE
|
||||
db-user-pass Opaque 2 15s
|
||||
default-token-ds2lv kubernetes.io/service-account-token 3 41h
|
||||
|
||||
# 删除
|
||||
kubectl delete secrets db-user-pass
|
||||
```
|
||||
|
||||
### 使用
|
||||
|
||||
利用投射数据卷在`Pod`中使用`Secret`,编辑配置文件`vim test-projected-volume.yaml`:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
name: test-projected-volume
|
||||
spec:
|
||||
containers:
|
||||
- name: test-secret-volume
|
||||
image: busybox
|
||||
args:
|
||||
- sleep
|
||||
- "86400"
|
||||
volumeMounts:
|
||||
- name: mysql-cred
|
||||
mountPath: "/projected-volume"
|
||||
readOnly: true
|
||||
volumes:
|
||||
- name: mysql-cred
|
||||
projected:
|
||||
sources:
|
||||
- secret:
|
||||
name: user
|
||||
- secret:
|
||||
name: pass
|
||||
```
|
||||
|
||||
终端执行:
|
||||
|
||||
```shell
|
||||
# 启动
|
||||
kubectl create -f test-projected-volume.yaml
|
||||
|
||||
# 查看
|
||||
kubectl get pods -o wide
|
||||
|
||||
# 输出
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
test-projected-volume 1/1 Running 0 37s
|
||||
|
||||
# 查看数据
|
||||
kubectl exec -it test-projected-volume -- /bin/sh
|
||||
|
||||
> ls /projected-volume/
|
||||
> cat /projected-volume/username.txt
|
||||
|
||||
# 删除
|
||||
kubectl delete pods test-projected-volume
|
||||
```
|
||||
|
||||
|
||||
## 参考
|
||||
|
||||
本章关于配置应用程序就介绍到这里了,谢谢!本部分内容有参考如下文章:
|
||||
|
||||
- [配置 Pod 使用 ConfigMap](https://kubernetes.io/zh/docs/tasks/configure-pod-container/configure-pod-configmap/)
|
||||
- [Secret概述](https://kuboard.cn/learning/k8s-intermediate/config/secrets/)
|
||||
- [Kubernetes in Action](https://github.com/luksa/kubernetes-in-action)中文版:可以算是第7章的读书笔记
|
||||
2
kubenets/05.容器网络.md
Normal file
2
kubenets/05.容器网络.md
Normal file
@@ -0,0 +1,2 @@
|
||||
# 容器网络
|
||||
|
||||
202
kubenets/06.设计模式——基于容器的分布式系统.md
Normal file
202
kubenets/06.设计模式——基于容器的分布式系统.md
Normal file
@@ -0,0 +1,202 @@
|
||||
# 设计模式——基于容器的分布式系统
|
||||
|
||||

|
||||
|
||||
20世纪80年代末至90年代初,面向对象编程思想给软件开发带来了一轮技术革新,就像润物细无声的春雨那般,向全世界的程序员们快速普及了模块化构建应用程序的方法,一直流行至今。
|
||||
|
||||
当下,我们可以看到类似的革新出现在了分布式系统开发,具体特点如下:
|
||||
|
||||
- 基于容器的微服务架构体系日益流行
|
||||
- 容器天然隔离的属性非常适合作为分布式系统中的**基本对象**
|
||||
|
||||
基于面向对象,**四人帮**基于经验提出和总结了对于一些常见软件设计问题的标准解决方案,其描述了一系列基于接口的模式,可以在各种环境中重用,这被称之为软件设计模式。历史一定程度上来说是重复的,随着这种架构模式的成熟,基于容器的分布式系统的设计模式也就自然而然地浮现了。
|
||||
|
||||
本篇主要阐述的是`Brendan Burns`在基于容器的分布式系统中发现的三种设计模式:
|
||||
|
||||
- single-container patterns for container management:容器管理之单容器模式
|
||||
- single-node patterns of closely cooperating containers:容器协调之单节点(多容器)模式
|
||||
- multi-node patterns for distributed algorithms:分布式算法之多节点模式
|
||||
|
||||
基于容器分布式系统的设计模式会给分布式计算编码带来以下优势:
|
||||
|
||||
- 最佳实践,给没有经验的程序员带来相对正确的使用方式
|
||||
- 简化开发
|
||||
- 提升系统可靠性
|
||||
|
||||
## 模式的价值
|
||||
|
||||
模式的目的是提供一般建议或结构来指导设计,这样做的好处有以下三点:
|
||||
|
||||
- 站在巨人的肩膀上,对于经验不怎么丰富的开发者,可以通过模式来指引走在正确的道路上,从而少踩坑,提升项目质量
|
||||
- 提供通用的名称和定义,有共同的领域语言进行交流是一件很重要的事情
|
||||
- 方便识别并构建共享的通用组件
|
||||
|
||||
## 单容器模式
|
||||
|
||||
就像对象会定义边界一样,容器为定义接口提供了天然的边界;它不仅可以暴露特定应用的功能,还可以通过钩子函数来管理系统。传统的容器管理接口是极其有限的,如:
|
||||
|
||||
- run
|
||||
- pause
|
||||
- stop
|
||||
|
||||
这些接口只能说满足基础的使用需求,但是就目前的现状来看,更丰富的接口可以为系统开发者与操作者提供更多的功能。鉴于`HTTP`和`JSON`的普及程度,可以考虑通过容器在特定的节点托管一个`Web`服务来实现。这样做的目的是什么,可以从下面两个角度来看待:
|
||||
|
||||
- upward:容器可以暴露丰富的应用信息,比如:
|
||||
- 各类监控指标(QPS、应用健康等)
|
||||
- 一些开发人员感兴趣的信息如(线程、堆栈、锁、网络消息统计等)
|
||||
- 组件配置、日志等
|
||||
- downward:任何开发者在编写软件组件的时候,都可以使用容器原生支持的生命周期接口来进行管控。比如一个集群管理系统通常会给任务分配对应的**优先级**,高优先级的任务即使在集群被超额订阅的情况下也能保证运行,这种保证是通过逐出已经运行的低优先级任务来实现的,然后这些低优先级任务能否运行取决于后面是否还有资源分配过来;但是这样有个问题就是开发者需要承担一些没必要的复返,比如处理一些优先级比较低的任务被*抛弃*的情况。相反,如果在应用程序和管理系统之间定义了正式的生命周期,那么应用程序组件将变得更易于管理,比如`k8s`使用`Docker` 的`graceful deletion`功能,这就允许应用程序通过完成当前任务,把状态写入磁盘等等操作之后再终止,将这个功能扩展一下就可以使使有状态的分布式系统的状态管理更加容易。
|
||||
|
||||
## 单节点(多容器)模式
|
||||
|
||||
上面提到了单容器的接口,我们稍稍延伸一下,对于一个多容器组成的应用,会有怎样的设计模式呢?当然,此时我们仍旧有些限制条件需要讲清楚:
|
||||
|
||||
- 容器都处于**单节点**下
|
||||
- 容器管理系统需要支持将多容器作为原子单元协调编排,这也侧面印证为什么`k8s`需要有`Pod`这个逻辑概念
|
||||
|
||||
### 边车模式(Sidecar pattern)
|
||||
|
||||
> 扩展和增强现有的应用容器
|
||||
|
||||
目前最常见的多容器部署模式就是边车模式,边车模式就是由两个容器组成的单节点模式:
|
||||
|
||||
- 核心是应用程序容器,这个就是应用程序的轴心
|
||||
- 其次就是边车容器,作用就是改进和增强应用程序容器
|
||||
|
||||
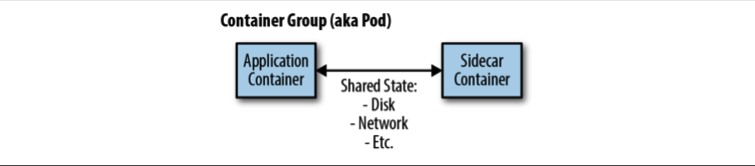
|
||||
|
||||
边车模式的一般方式如上图所示,可以看到应用程序容器和边车容器共享了许多资源:
|
||||
|
||||
- 部分文件系统
|
||||
- 主机名
|
||||
- 网络
|
||||
- 其他
|
||||
|
||||
我们通过下面的例子来看一下边车容器存在的必要性以及好处,图示如下:
|
||||
|
||||
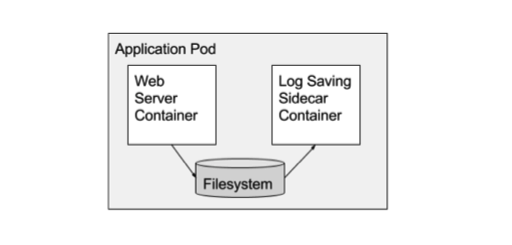
|
||||
|
||||
其中主容器是一个`web`服务,而`日志处理`边车容器的工作就是收集本地磁盘的服务器日志,并将其流式传输至存储集群,这样做的好处有:
|
||||
|
||||
- 容器是资源计算和调度的基本单位,所以可以优先配置主`Web`服务器的`cgroup`使得其处理延时降低,而日志处理容器则在`web`服务器空闲时使用`cpu`时间片进行日志处理
|
||||
- 将模块化和可重用的组件封装成边车,可达到功能内聚,应用可被划分明确的边界进行解耦(方便接入、测试调试、状态处理等),最重要的是可以被不同主容器作为边车容器复用
|
||||
|
||||
### 大使模式(Ambassadors pattern)
|
||||
|
||||
> 改变和管理应用容器与外部世界的通信方式
|
||||
|
||||
第一次看大使模式,很可能会想这不就是另一种形式的边车模式吗?其实不然,首先第一点,大使模式下所有的请求响应信息交换全部是大使容器来完成的,应用程序容器只能和大使容器进行*交流*。
|
||||
|
||||
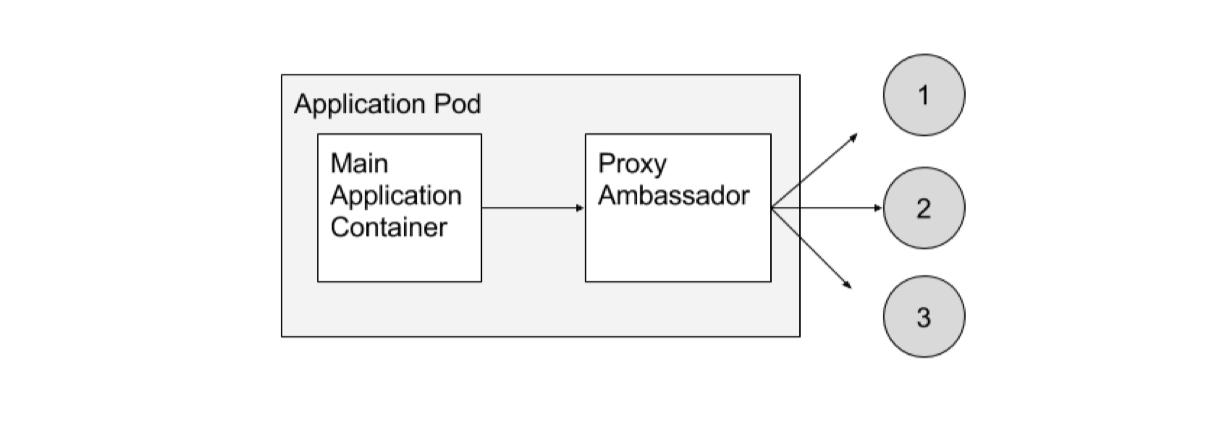
|
||||
|
||||
这种模式主要利用的特性是**同一`Pod`中的容器可以共享相同的`localhost`网络接口**,而且可以从两个角度看大使容器:
|
||||
|
||||
- 内到外:让我们以访问一个存储区域为例,假设该存储区域的大小不断增长,必须分成更多的子系统。在这种情况下,为了不干预主容器并且必须对所有受影响的服务实施相同的新访问逻辑,创建一个大使容器来调解对存储区域的访问是个不错的选择
|
||||
- 外到内:让我们设想一下,我们要测试微服务的新版本,可以通过大使容器控制请求量到相关部署
|
||||
|
||||
<img src="https://images-1252557999.file.myqcloud.com/uPic/1*-aeeNrASuzA8SMkOxyhmcw.png" alt="Image for post" style="zoom: 50%;" />
|
||||
|
||||
### 适配器模式(Adapter pattern)
|
||||
|
||||
> 确保应用程序实现统一的监控接口
|
||||
|
||||
真实世界的应用程序大概率会有出现下面列出的几种情况:
|
||||
|
||||
- 一部分服务自行开发(可能有新老标准差异),一部分使用开源项目
|
||||
- 服务的编写语言多样,日志记录、监控也多样
|
||||
|
||||
假设我们需要有效地监控和运维应用程序,这就要求应用程序可以提供统一的通用接口来进行指标收集。这就是适配器发挥作用的场景了,对于不同应用容器提供的不同接口,可以使用适配器适配这种异构性并转化为一致的接口且原有服务代码不需要做任何改动。
|
||||
|
||||
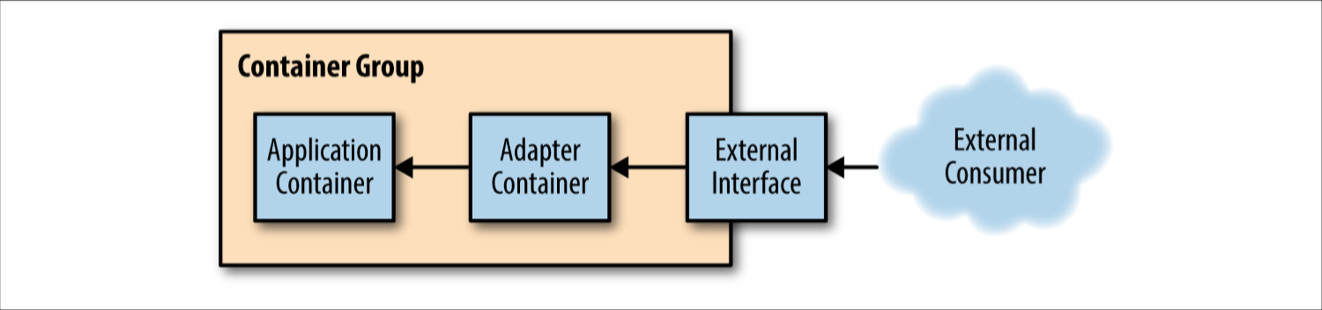
|
||||
|
||||
主应用程序通过`localhost`或者`volume`与适配器容器通信,适配器经过一层处理提供统一的输出给外部使用者,一些常用的使用场景如下:
|
||||
|
||||
- 监控:适配器将应用程序容器公开的监控接口转换为通用监控系统所期望的接口
|
||||
- 日志:适配器提供统一的日志记录输出
|
||||
|
||||
## 多节点模式
|
||||
|
||||
不要将模块化容器局限于单机容器协调上,其实模块化容器还可以使构建协调的多节点分布式应用程序变得更加容易。接下来将描述其中的三种分布式系统模,与前一节中的模式一样,这些模式也需要对 `Pod` 这个逻辑概念的支持。
|
||||
|
||||
### 领导选举模式(Leader election pattern)
|
||||
|
||||
分布式系统中最常见的问题就是领导选举问题,副本被普遍使用在一个组件的多个相同的实例之间共享负载,副本的另一个更加复杂的作用就是使得某一特定副本作为整个部署集的**leader**,其他副本作为热备(这个区分过程比较复杂),当原本Leader宕机时可以快速被选举为新的Leader,以恢复系统功能。系统甚至可以并行地进行领导者选举,例如多个分片均需要确定领导者。
|
||||
|
||||
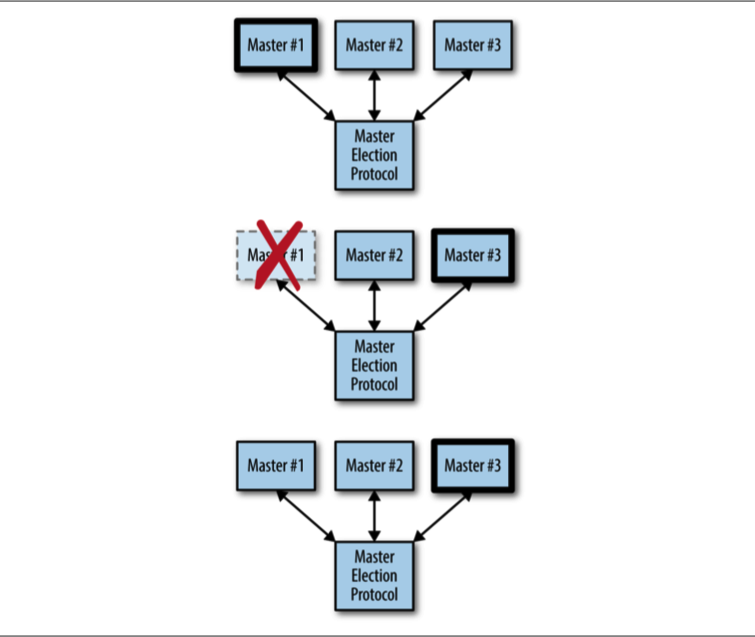
|
||||
|
||||
上图介绍了一个简单的分布式选举的例子:图中三个副本,任何一个副本都有可能成为主副本,首先第一个副本为主,若其不巧发生故障,第二阶段就会通过选举将第三个副本变成主副本,最后,第一个副本回复,重新加入集群,第三副本依旧作为主节点运行调度。
|
||||
|
||||
现在确实有许多类库可以进行领导者选举,但它们通常比较复杂并且难以被正确理解和使用,此外,它们还受到特定编程语言实现的限制。
|
||||
|
||||
所以本部分探讨的就是将领导者选举机制从应用程序中剥离至领导者选举专属容器中,我们可以考虑提供一组领导者选举容器,每个容器都与需要进行领导者选举的应用程序共同调度,这样就可以在这些领导者选举容器之间执行选举。
|
||||
|
||||
同时,它们可以在`localhost `上为需要进行领导者选举的应用程序容器提供一个简化的`HTTP API` (例如`becomeLeader`、`renewLeadership` 等)。
|
||||
|
||||
这些领导者选举容器只需要由这个复杂领域的专家进行一次性构建即可,然后不管应用程序开发人员选择何种编程语言,都可以复用其简化的接口。这种方式代表了软件工程中最好的抽象和封装过程。
|
||||
|
||||
### 工作队列模式(Work queue pattern)
|
||||
|
||||
一个简单通用的容器化工作队列图示如下:
|
||||
|
||||
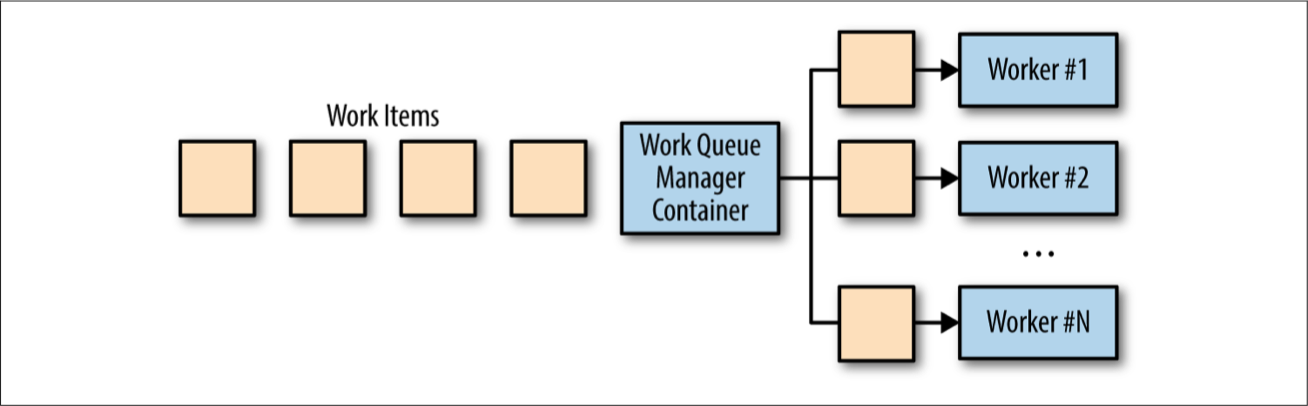
|
||||
|
||||
最左侧提供了一组需要被执行的工作项,然后工作队列管理容器接受输入工作项,将其分发给多个执行器进行消费,并且多个执行器中间没有任何交互,这样的好处是可以根据实际运行情况增加执行器数量来赢取时间。
|
||||
|
||||
虽然工作队列和领导者选举一样,是一个研究得很透彻的课题并且有很多框架对它们进行了很好的实现,但这些分布式系统设计模式仍然是可以在面向容器的架构中获益。在以前的系统中,框架将程序限制在单一的语言环境中(如`Python`中的`Celery`)。
|
||||
|
||||
对于一个容器,由于`run()&mount()`接口的实现,使得实现一个通用的工作队列框架变得简单直接,可以将任意的处理代码打包成一个容器,再结合任意数据就构建成了一个完整的工作队列系统。开发完整工作队列所涉及的所有其他工作都可以由通用工作队列框架处理,并且可以被任何有相同需求的系统复用,用户代码集成等细节让我们看看下面的图示:
|
||||
|
||||
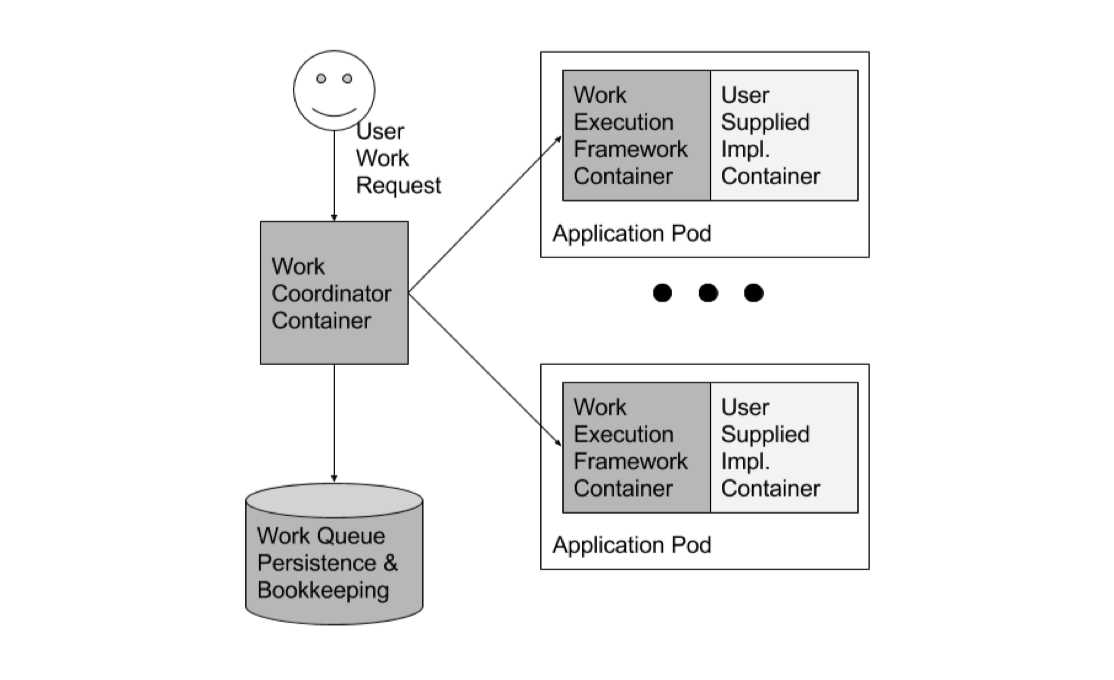
|
||||
|
||||
> 通用工作队列的图示,可重用框架容器以深灰色显示,而开发人员容器以浅灰色显示。
|
||||
|
||||
让我们结合上面的两张图一起看看,在我看来这就是一个从第一张图抽象出用户自定义代码从而形成第二张图的过程,且看我详细列出关键点。
|
||||
|
||||
#### 源容器接口
|
||||
|
||||
用户定义的工作项由工作队列管理容器接收,此时涉及到一个论文中没有描述的点就是队列管理容器对于接收的工作项是默认进行了标准定义的,也就是说工作项都是定义好的标准输入。但实际情况并不可能让所有的输入项都有相同的输入标准,必须由一段用户自定义的处理代码来将输入标准化,不知机智的你是否想到了**大使模式**:
|
||||
|
||||
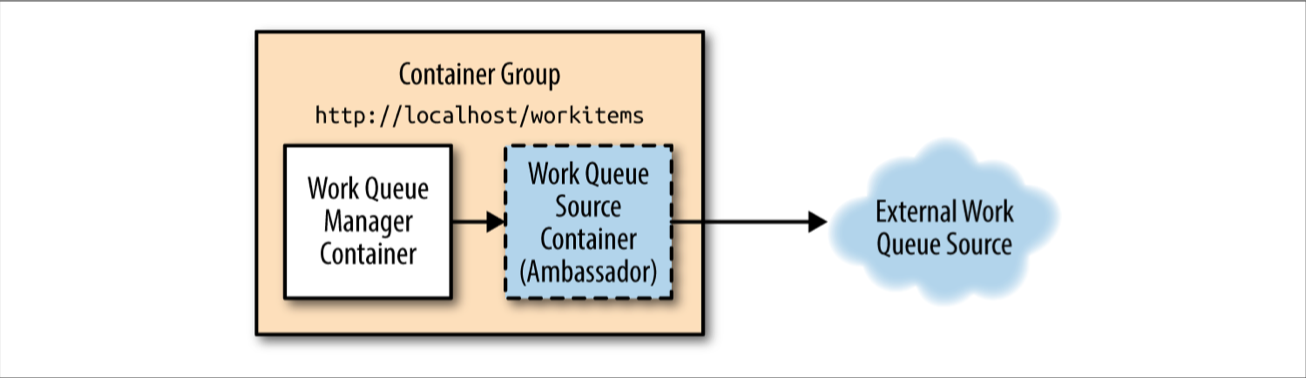
|
||||
|
||||
|
||||
|
||||
#### 执行器容器接口
|
||||
|
||||
当工作队列管理容器获取了对应的工作项,接下来的工作就是下发给执行器进行处理,具体做法是调用一次性`API`触发工作流,并且在工作容器的整个生命周期是不会有其他调用产生的。
|
||||
|
||||
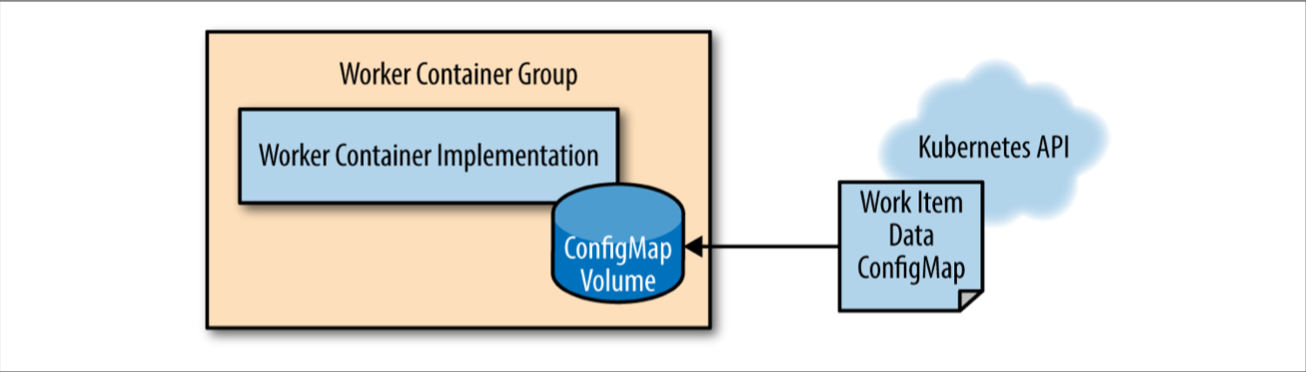
|
||||
|
||||
### 分散/聚集模式(Scatter/gather pattern)
|
||||
|
||||
最后一个我们要着重介绍的设计模式是**分散/收集模式**(终于是最后一个:face_with_thermometer:),首先简单介绍一下这个模式:
|
||||
|
||||
> 分散/收集模式是一个树形模式,当外部客户端向根节点发送一个初始请求,根节点会将这个请求分发给大量服务器,每个服务器分片均返回部分数据,然后跟节点将这些部分结果组合起来形成一个针对原始请求的完整响应。
|
||||
|
||||
对于上面这样一个流程,实际上可以抽象出以下几个标准出来:
|
||||
|
||||
- 分散请求(fanning out the requests)
|
||||
- 收集响应(gathering the responses)
|
||||
- 与客户端交互(interacting with the client)
|
||||
- ...
|
||||
|
||||
上述流程的大部分代码都是通用的,就像面向对象编程中一样,我们可以将这个一个个拆分实现并进行容器化。
|
||||
|
||||
|
||||
|
||||
值得一提的是要实现一个分散/收集系统,需要一个用户提供两个容器:
|
||||
|
||||
- 第一种容器实现叶子节点计算,该容器执行部分计算并返回相应的结果
|
||||
- 第二种容器是合并容器,该容器需要汇总所有叶子容器的计算结果,并组织成一个单一的响应后输出给用户
|
||||
|
||||
## 说明
|
||||
|
||||
主体内容来自:
|
||||
|
||||
- 论文《[Design patterns for container-based distributed systems](https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45406.pdf)》
|
||||
- 书籍《[Designing Distributed Systems](https://book.douban.com/subject/34844678/)》
|
||||
|
||||
不错的同类型资料:
|
||||
|
||||
- [【译】基于容器的分布式系统设计模式](https://www.cnblogs.com/gaochundong/p/design-patterns-for-container-based-distributed-systems.html)
|
||||
|
||||
最近一直在了解低代码开发平台相关知识,就是前面提到的[一站式机器学习云研发平台](https://www.howie6879.cn/post/2021/04_ml_cloud_dev_platform/),其中关于资源管理这块离不开`k8s`的使用,因此花了不少精力在这上面,不出意外会出一个系列的学习笔记,而且在学习分布式设计模式的同时也对分布式系统产生了一些兴趣,这一块后续会一起好好研究研究。
|
||||
76
kubenets/07.图解OSI七层网络模型.md
Normal file
76
kubenets/07.图解OSI七层网络模型.md
Normal file
@@ -0,0 +1,76 @@
|
||||
# 简单图解OSI七层网络模型
|
||||
|
||||
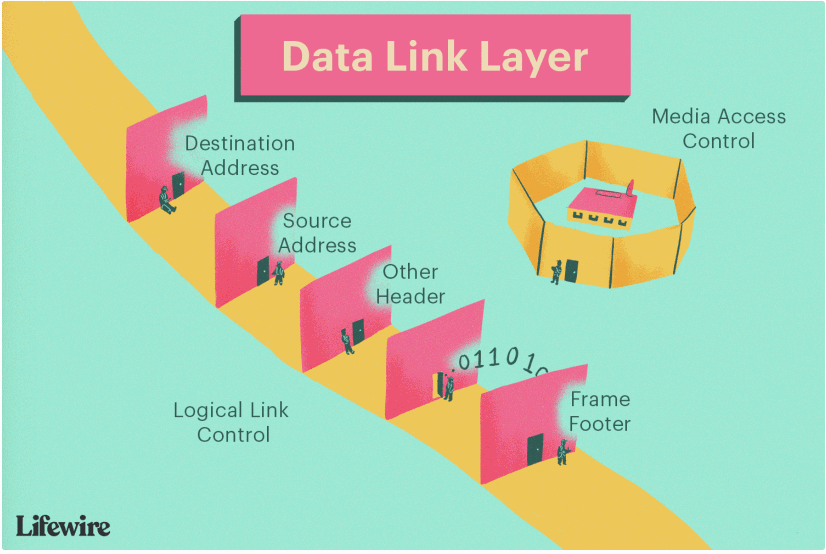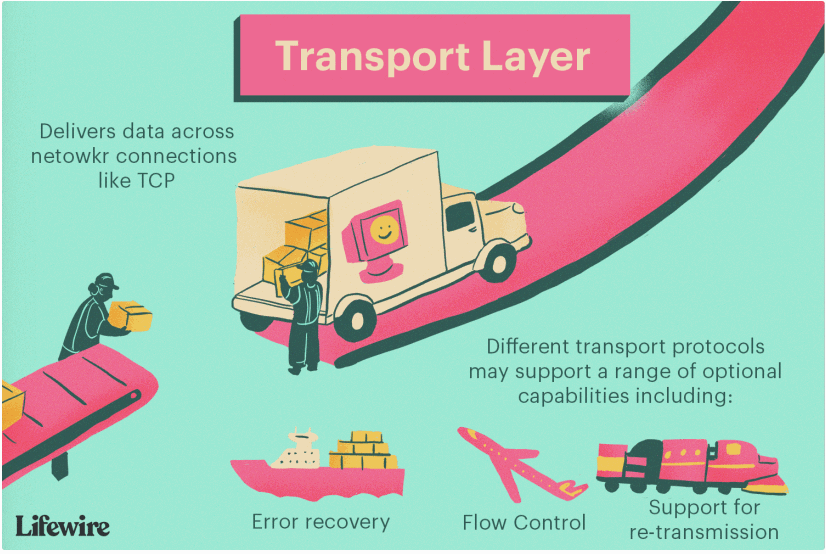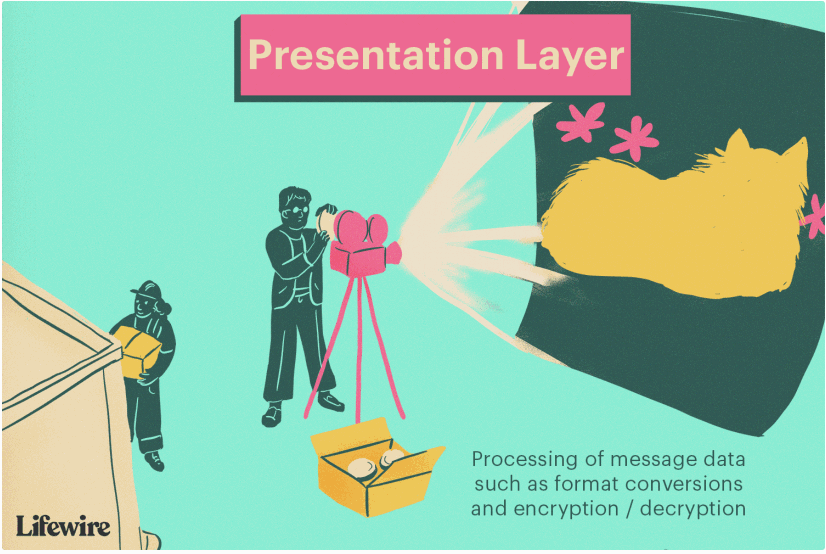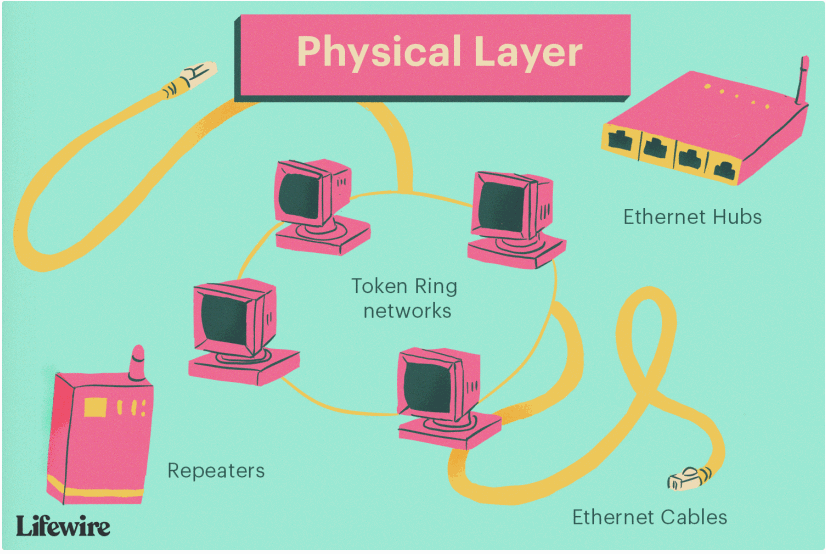
|
||||
|
||||
> 翻译自[Bradley Mitchell](https://www.lifewire.com/bradley-mitchell-816228)的《[The Layers of the OSI Model Illustrated](https://www.lifewire.com/layers-of-the-osi-model-illustrated-818017)》
|
||||
|
||||
Open Systems Interconnection(OSI)定义了一个网络框架,其以层为单位实现了各种协议,同时会将控制权逐层传递。目前`OSI`主要作为教学工具被使用,其在概念上将计算机网络结构按逻辑顺序划分为7层。
|
||||
|
||||
较低层处理电信号、二进制数据块以及路由这些数据以便在网络中的穿梭;从用户的角度来看,更高的层次包括网络请求和响应、数据的表示和网络协议。
|
||||
|
||||
`OSI`模型最初被认为是构建网络系统的标准体系结构,今天许多流行的网络技术都可以看出`OSI`的分层设计。
|
||||
|
||||
## 物理层(Physical Layer)
|
||||
|
||||
物理层是`OSI`模型的第一层,其职责在于通过网络通信媒介将比特流数据从发送(源)设备的物理层传输到接收(终)设备的物理层。
|
||||
|
||||
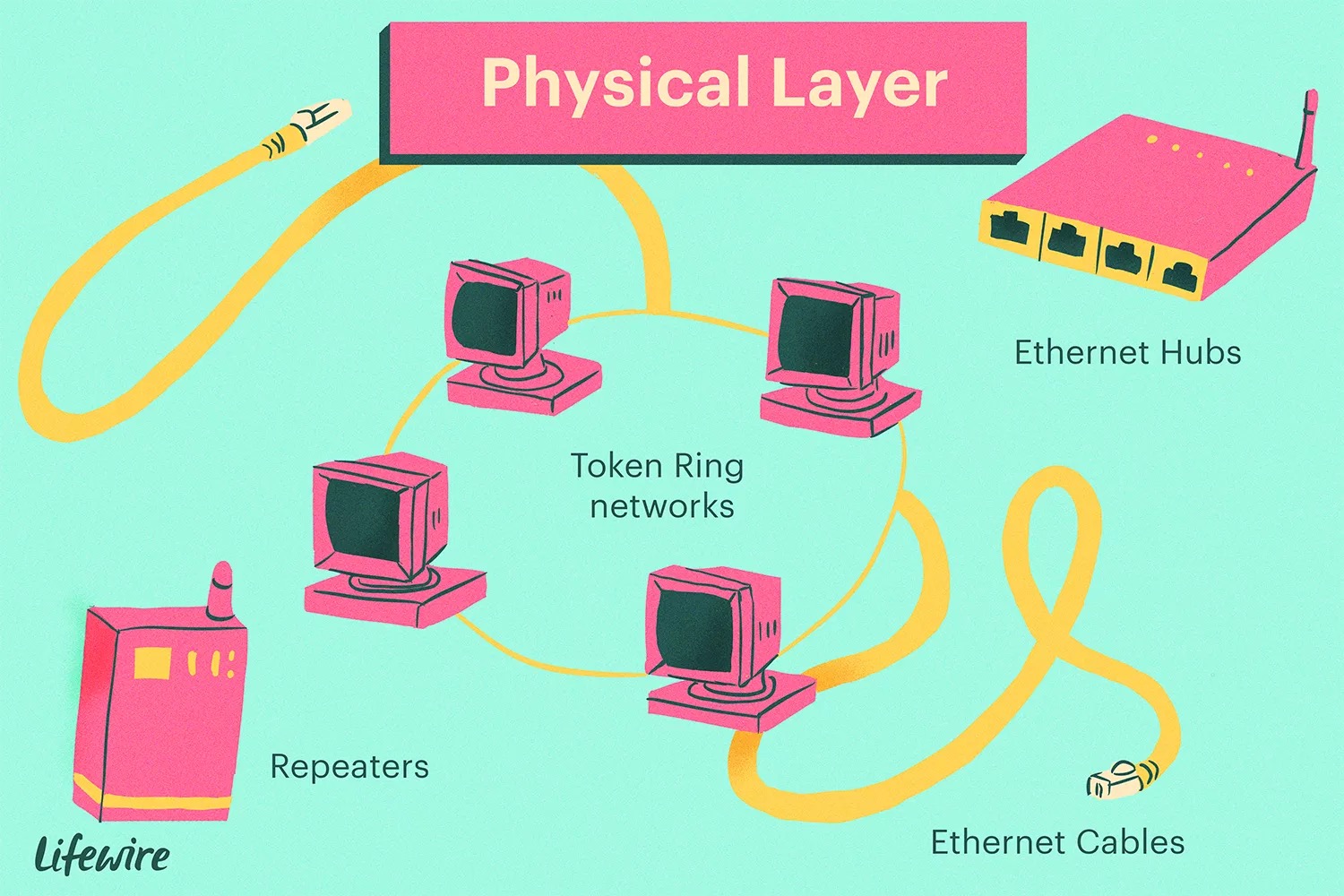
|
||||
|
||||
第一层技术的例子包括以太网电缆和集线器。此外,集线器和其他中继器是在物理层起作用的标准网络设备,电缆连接器也是如此。
|
||||
|
||||
在物理层,数据通过物理介质支持的以下信号类型进行传输:
|
||||
|
||||
- 电压
|
||||
- 无线电频率
|
||||
- 红外脉冲
|
||||
- 普通光
|
||||
|
||||
## 数据链路层(Data Link Layer)
|
||||
|
||||
当从物理层获取数据时,数据链路层会检查物理传输错误,并将比特数据打包成数据帧。数据链路层还管理着物理寻址方案,例如以太网的`MAC`地址,用于控制网络设备对物理介质的访问。
|
||||
|
||||
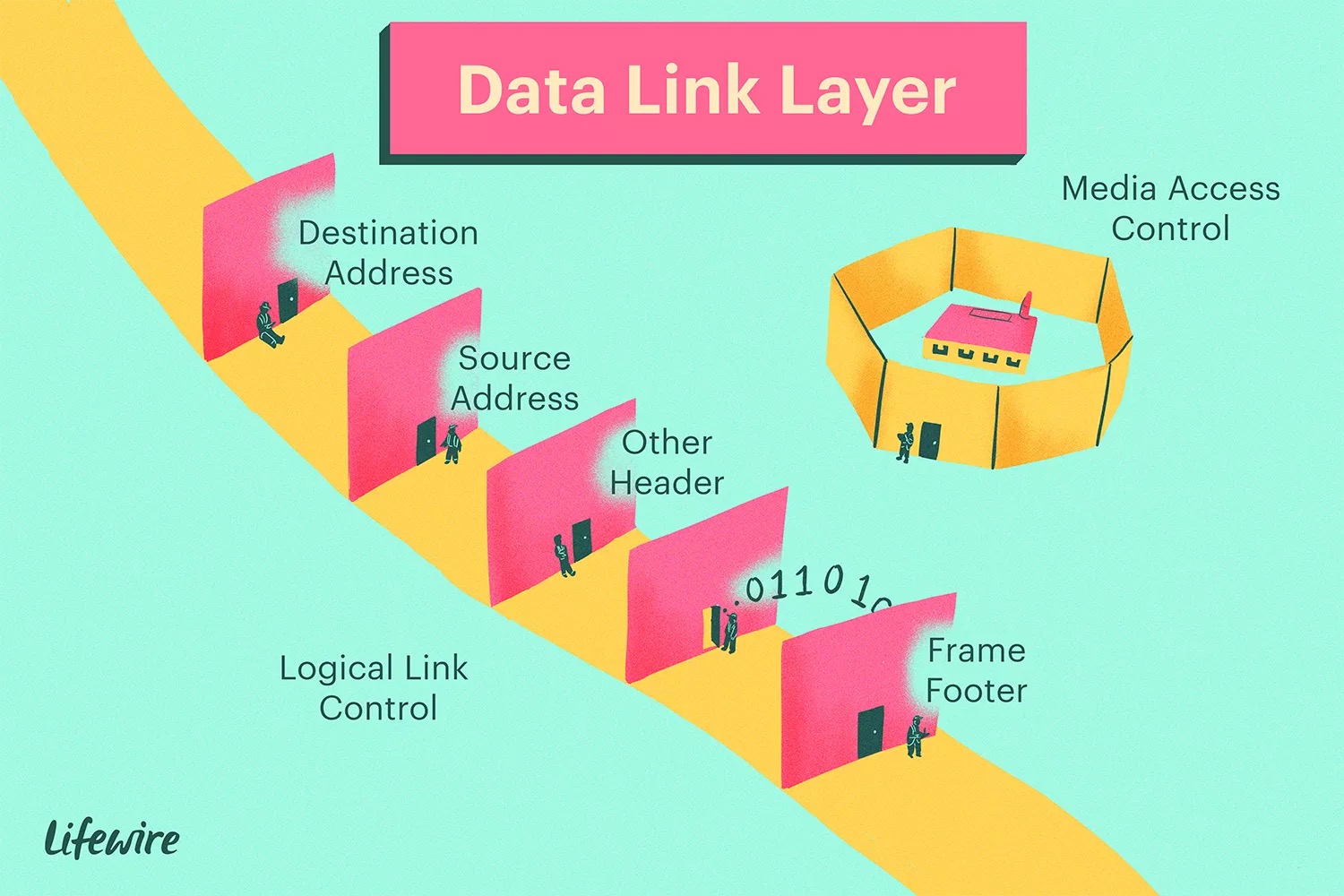
|
||||
|
||||
因为数据链路层是 OSI 模型中最复杂的一层,所以它通常被分成两部分: 媒体访问控制子层和逻辑链路控制子层。
|
||||
|
||||
## 网络层(Network Layer)
|
||||
|
||||
网络层在数据链路层之上增加了路由的概念。每当数据抵达网络层时,就会检查每个帧中包含的源地址和目标地址,以确定数据是否已到达其最终目的地。如果数据已经到达最终目的地,第3层就会将数据格式化并打包为数据包交付给运输层,否则网络层会更新目的地址并将帧推送到下层。
|
||||
|
||||
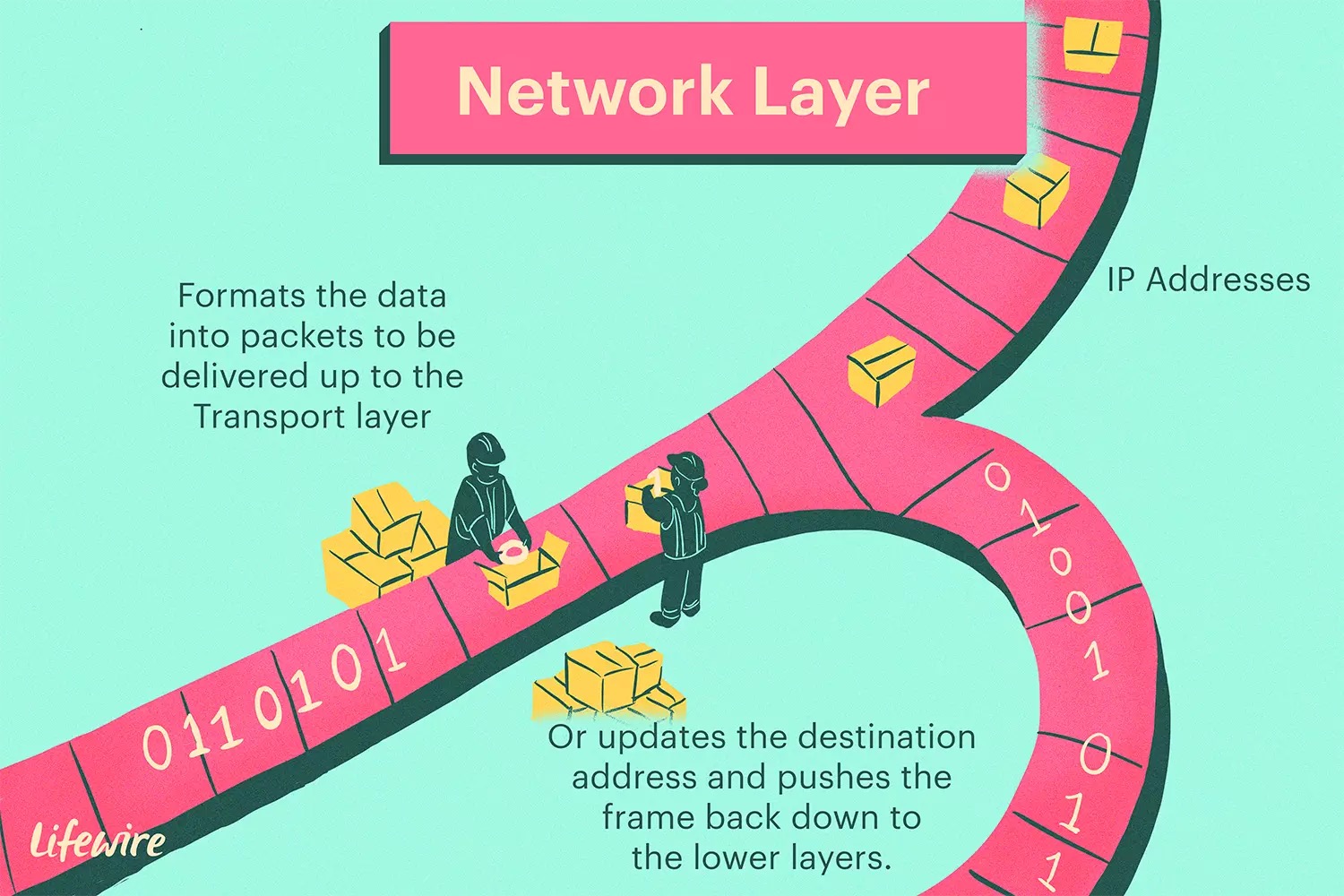
|
||||
|
||||
为了支持路由,网络层需要一个维护逻辑地址,比如网络设备的`IP`地址。网络层还管理着这些逻辑地址和物理地址之间的映射,在`IPv4`网络中,这种映射通过地址解析协议(`ARP`)完成,`IPv6`使用邻居发现协议(`NDP`)。
|
||||
|
||||
## 运输层(Transport Layer)
|
||||
|
||||
传输层通过网络连接传输数据。`TCP` (传输控制协议)和 `UDP (用户数据报协议)是传输层比较常见且有代表性的协议。不同的传输协议可能支持一系列可选功能,包括错误恢复、流控制和支持重新传输。
|
||||
|
||||
|
||||
|
||||
## 会话层(Session Layer)
|
||||
|
||||
会话层位于第五层,其管理着网络连接事件顺序和流程的启动和关闭。它支持多种类型的连接,这些连接可以动态地创建并在单个网络上运行。
|
||||
|
||||
|
||||
|
||||
## 表示层(Presentation Layer)
|
||||
|
||||
表示层位于第六层,就功能相对来说是OSI模型各层中最简单的。其着力于消息数据的语法处理,如格式转换和支持其上一层(应用层)所需的加密/解密。
|
||||
|
||||
|
||||
|
||||
## 应用层(Application Layer)
|
||||
|
||||
应用层为终端用户使用的应用提供**网络服务**(处理用户数据的协议)。举个例子,在Web浏览器应用程序中,应用层协议HTTP打包发送和接收网页内容所需的数据。同时应用层也会向表示层提供或获取数据。
|
||||
|
||||
|
||||
|
||||
## 说明
|
||||
|
||||
本文主体内容来翻译自[Bradley Mitchell](https://www.lifewire.com/bradley-mitchell-816228)的《[The Layers of the OSI Model Illustrated](https://www.lifewire.com/layers-of-the-osi-model-illustrated-818017)》,衍生开的话还有以下不错的书籍资料:
|
||||
|
||||
- [计算机网络-第7版-谢希仁](https://book.douban.com/subject/26960678/)
|
||||
- [趣谈网络协议](https://time.geekbang.org/column/intro/100007101?code=B0w8OmhZXXkMkJ5PSXpY9KNeN4%2FvjOXNDvtHpaRlbK8%3D)
|
||||
- [图解TCP/IP](https://book.douban.com/subject/24737674/)
|
||||
|
||||
大家有兴趣的可以看一看。
|
||||
7
kubenets/08.低配置也有春天👉K3s.md
Normal file
7
kubenets/08.低配置也有春天👉K3s.md
Normal file
@@ -0,0 +1,7 @@
|
||||
# 低配置也有春天👉K3s
|
||||
|
||||
|
||||
> 史上最轻量级Kubernetes,易于安装,只需512MB RAM即可运行。
|
||||
|
||||
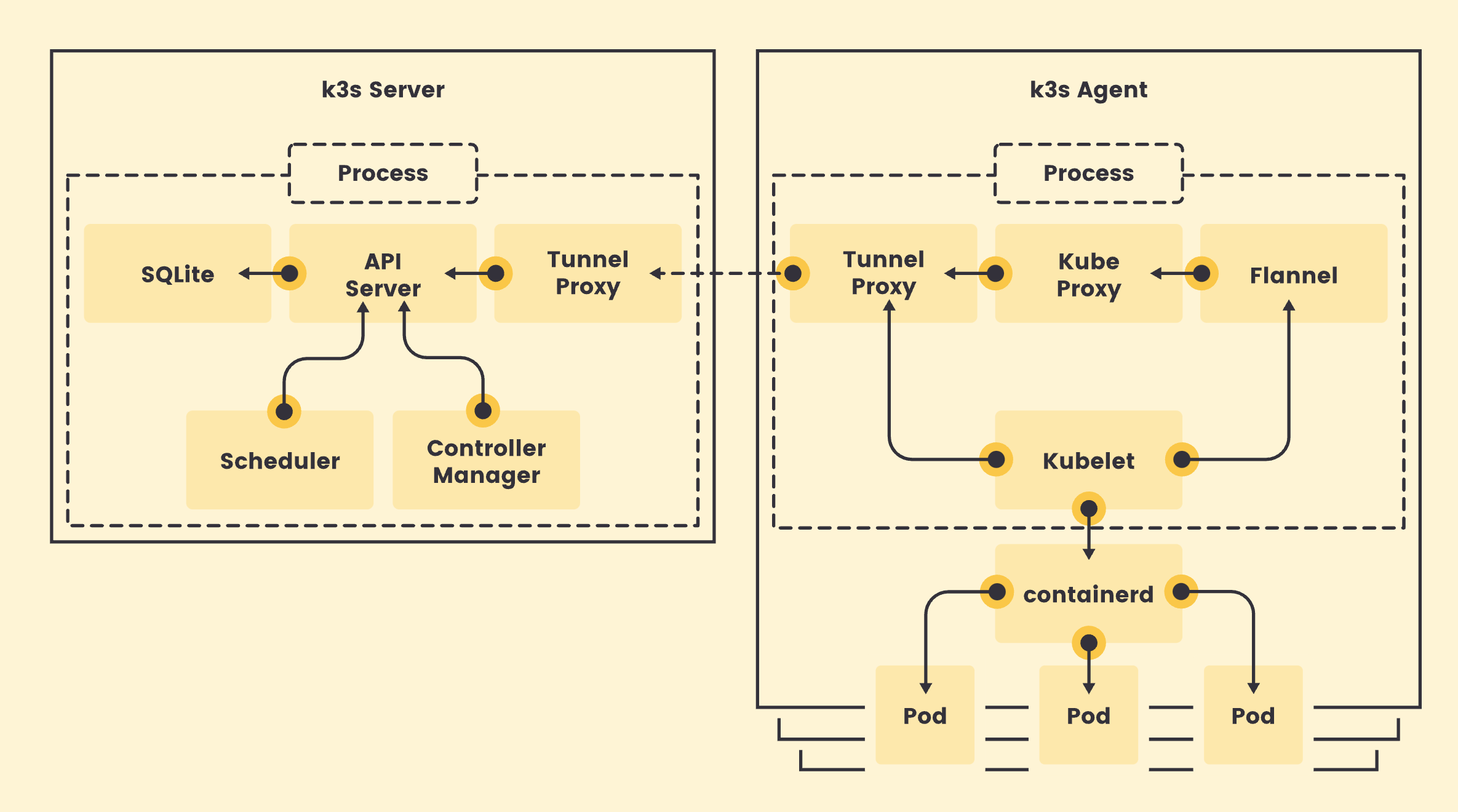
|
||||
|
||||
Reference in New Issue
Block a user