合并
@@ -1,23 +1,23 @@
|
||||
https://commons.apache.org/
|
||||
引入依赖
|
||||
|
||||
|
||||
### 引入依赖
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>commons-beanutils</groupId>
|
||||
<artifactId>commons-beanutils</artifactId>
|
||||
<version>1.9.4</version>
|
||||
</dependency>
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
BeanUtils/BeanUtilsBean
|
||||
```
|
||||
### BeanUtils/BeanUtilsBean
|
||||
```java
|
||||
拷贝: cloneBean/copyProperties/copyProperty
|
||||
获取:getArrayProperty/getSimpleProperty/getProperty
|
||||
其他操作:setProperty设置属性 populate将Bean设置到Map中 describe将Bean转成Map
|
||||
1
|
||||
2
|
||||
3
|
||||
PropertyUtils类
|
||||
```
|
||||
|
||||
### PropertyUtils类
|
||||
```java
|
||||
判断:isReadable/isWriteable
|
||||
获取:
|
||||
getProperty/getSimpleProperty/getPropertyType
|
||||
@@ -25,6 +25,4 @@ PropertyUtils类
|
||||
getMappedProperty/setMappedProperty/getNestedProperty/setNestedProperty
|
||||
getPropertyDescriptor/getPropertyEditorClass
|
||||
拷贝和设置:copyProperties/setProperty/setSimpleProperty /clearDescriptors
|
||||
————————————————
|
||||
版权声明:本文为CSDN博主「white camel」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
|
||||
原文链接:https://blog.csdn.net/m0_37989980/article/details/126396868
|
||||
```
|
||||
68
Java基础教程/Java实用技巧/06 协变返回类型.md
Normal file
@@ -0,0 +1,68 @@
|
||||
|
||||
Java 协变返回类型是指在子类中重写一个方法时,该方法的返回类型可以是父类中该方法返回类型的子类。这意味着子类可以返回更具体的类型,而无需强制转换为父类类型。
|
||||
|
||||
例如,假设有一个父类 Animal 和一个子类 Dog,它们都有一个返回类型为 Animal 的方法 getAnimal。在 Dog 类中重写该方法时,可以将返回类型更改为 Dog,因为 Dog 是 Animal 的子类。这样一来,当调用 Dog 的 getAnimal 方法时,会返回一个 Dog 对象而不是 Animal 对象。
|
||||
|
||||
导出类(子类)覆盖(即重写)基类(父类)方法时,返回的类型可以是基类方法返回类型的子类。
|
||||
```java
|
||||
package com.evada.de;
|
||||
/**
|
||||
* @Author 云析学院
|
||||
* Created by Ay on 2016/12/4.
|
||||
*/
|
||||
public class Ay {
|
||||
|
||||
public static void main(String[] args) {
|
||||
Person person = new Boy();
|
||||
Flower flower = person.buy();
|
||||
flower.like();
|
||||
//! flower.love(); 编译错误
|
||||
//因为是协变返回类型,所以可以向下转型
|
||||
RoseFlower roseFlower = (RoseFlower) person.buy();
|
||||
//可以调用like方法
|
||||
roseFlower.like();
|
||||
//可以调用love方法
|
||||
roseFlower.love();
|
||||
}
|
||||
}
|
||||
class Person{
|
||||
public Flower buy(){
|
||||
System.out.println("Flower...");
|
||||
return new Flower();
|
||||
}
|
||||
}
|
||||
/**
|
||||
* 男孩
|
||||
*/
|
||||
class Boy extends Person{
|
||||
|
||||
/**
|
||||
* 这里覆盖Person类的buy
|
||||
* @return
|
||||
*/
|
||||
@Override
|
||||
public RoseFlower buy(){
|
||||
System.out.println("RoseFlower...");
|
||||
//注意这里,这里就是协变返回类型
|
||||
//导出类**(子类)覆盖(即重写)**基类**(父类)方法时,
|
||||
// 返回的类型可以是基类方法返回类型的子类
|
||||
return new RoseFlower();
|
||||
}
|
||||
}
|
||||
class Flower{
|
||||
/**
|
||||
* 让普通人喜欢
|
||||
*/
|
||||
public void like(){
|
||||
System.out.println("like");
|
||||
}
|
||||
}
|
||||
class RoseFlower extends Flower{
|
||||
/**
|
||||
* 让程序员喜欢
|
||||
*/
|
||||
public void love(){
|
||||
System.out.println("love....");
|
||||
}
|
||||
}
|
||||
```
|
||||
7
Java基础教程/Java实用技巧/07 内省.md
Normal file
@@ -0,0 +1,7 @@
|
||||
在计算机科学中,内省是指计算机程序在运行时(Run time)检查对象(Object)类型的一种能力,通常也可以称作运行时类型检查。
|
||||
不应该将内省和反射混淆。相对于内省,反射更进一步,是指计算机程序在运行时(Run time)可以访问、检测和修改它本身状态或行为的一种能力。
|
||||
|
||||
|
||||
内省(Introspector)是Java语言对Bean类属性、事件的一种缺省处理方法。例如A类中有属性name,那么我们可以通过getName和setName来得到当前值或设置新的值。通过getName/setName来访问name属性,这就是默认规则。
|
||||
|
||||
https://blog.csdn.net/weixin_43726137/article/details/122924821
|
||||
@@ -186,7 +186,13 @@ CloneExample e1 = new CloneExample();
|
||||
```
|
||||
|
||||
重写 clone() 得到以下实现:
|
||||
重写clone()方法,一般会先调用super.clone()进行浅复制,然后再复制那些易变对象,从而达到深复制的效果.也就是说JavaDoc指明了Object.clone()有特殊的语义,他就是能把当前对象的整个结构完全浅拷贝一份出来,至于如何实现的,可以把JVM原生实现的Object.clone()的语义想象成拿到this引用后通过反射去找到该对象实例的所有字段,然后逐一字段拷贝。。(不是作用域object类的方法,而是当前对象this的方法)
|
||||
|
||||
|
||||
HotSpot vm中,Object.clone()在不同的优化层级上有不同的实现。在其中最不优化的版本是这样做的:拿到this引用,通过对象头里记录的Klass信息去找出这个对象有多大,然后直接分配一个新的同样大的空对象并且把Klass信息塞进对象头(这样就已经实现了x.clone.getClass() == x.getClass()这部分语义),然后直接把对象体 的内容看作数组拷贝一样从源对象“盲”拷贝到目标对象,bitwise copy。然后就完事啦。
|
||||
|
||||
我的理解是super.clone() 的调用就是沿着继承树不断网上递归调用直到Object 的clone方法,而跟据JavaDoc所说Object.clone()根据当前对象的类型创建一个新的同类型的空对象,然后把当前对象的字段的值逐个拷贝到新对象上,然后返回给上一层clone() 调用。
|
||||
也就是说super.clone() 的浅复制效果是通过Object.clone()实现的。
|
||||
```java
|
||||
public class CloneExample {
|
||||
private int a;
|
||||
|
||||
@@ -26,6 +26,9 @@ public class ExceptionTest{
|
||||
} finally{
|
||||
System.out.println("finnaly清理工作");
|
||||
}
|
||||
// print some test cases
|
||||
System.out.println("hello world");
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
@@ -33,6 +33,12 @@ Java 泛型(generics)是 JDK 5 中引入的一个新特性, 泛型提供了
|
||||
|
||||
与 C#中的泛型相比,Java 的泛型可以算是“伪泛型”了。在 C#中,不论是在程序源码中、在编译后的中间语言,还是在运行期泛型都是真实存在的。Java 则不同,Java 的泛型只在源代码存在,只供编辑器检查使用,编译后的字节码文件已擦除了泛型类型,同时在必要的地方插入了强制转型的代码。
|
||||
|
||||
泛型的第一作用:起到约束和规范的作用,约束类型属于某一个,规范使用只能用某一种类型。可以让我们业务变得更加清晰和明了并得到了编译时期的语法检查。
|
||||
|
||||
泛型的第二作用:使用泛型的类型或者返回值的方法,自动进行数据类型转换。
|
||||
|
||||
泛型类、泛型方法、泛型接口提供的功能与泛型的类型无关。泛型至于输入输出的类型有关。
|
||||
|
||||
### 泛型的基本用法
|
||||
|
||||
```java
|
||||
|
||||
@@ -12,7 +12,14 @@ SPI就是一种将服务接口与服务实现分离以达到解耦、大大提
|
||||
|
||||
> 为了实现在模块装配的时候不用在程序里动态指明,这就需要一种本地**服务发现机制**。Java spi就是提供这样的一个机制:为某个接口寻找服务实现的机制。
|
||||
|
||||
> JavaSpi起本身也是一种**控制反转思想**。通过额外的程序注入类的实现。包括控制反转和依赖注入两个过程。“Service Provider”和相应的工具”ServiceLoader”。其声明文件相当于Spring的Bean配置文件,实现控制反转,ServiceLoader类实现了依赖的注入。
|
||||
> JavaSpi起本身也是一种**控制反转思想和依赖注入框架**。通过额外的程序注入类的实现。包括控制反转和依赖注入两个过程。“Service Provider”和相应的工具”ServiceLoader”。其声明文件相当于Spring的Bean配置文件,实现控制反转,ServiceLoader类实现了依赖的注入。
|
||||
|
||||
|
||||
### 服务提供者框架
|
||||
1. 他是一种**服务提供者框架**。可以理解为包括以下四个部分:服务接口、服务注册API(服务提供者注册自身的服务)、服务访问API(服务客户端获取服务实例)、服务提供接口(约定服务的接口)
|
||||
2. 在java的ServiceLoader和各种**SPI机制**中,通过约定实现了服务注册API、服务访问API。
|
||||
3. 在Spring中是**控制反转和依赖注入框架**。@Autowired就是服务方位API、@Component是服务注册API。
|
||||
4. 在分布式应用场景中,是基于注册中心的**服务注册和发现机制**。
|
||||
|
||||
|
||||
### 底层原理
|
||||
|
||||
15
Java基础教程/Java语言基础/17 控制灵活性.md
Normal file
@@ -0,0 +1,15 @@
|
||||
## 控制的灵活性
|
||||
### 应用控制的灵活性
|
||||
控制的灵活性总共分为一下几种
|
||||
1. 代码:开发时控制。代码写死,版本固定后无法变更。
|
||||
2. 参数和环境变量:发布时控制。通过参数和环境变量,控制应用的不同表现行为
|
||||
3. 动态配置:运行时控制。通过动态配置灵活调整行为。
|
||||
4. 接口和界面:运行时控制。需要开发运行时接口和界面,控制应用的不同表现行为。
|
||||
|
||||
|
||||
### spi机制中控制的灵活性
|
||||
|
||||
在spi机制中。
|
||||
1. 编译时spi,java sdk提供的ServiceLoader机制通过反射,在编译时查找具体的实现。
|
||||
2. 启动时spi,tomcat、jdbc驱动加载、spring依赖注入都是在启动时根据当前的运行环境查找具体实现。
|
||||
3. 运行时spi,注册中心是在运行时进行服务发现的,可能在运行时进行动态变化。
|
||||
@@ -1,4 +1,5 @@
|
||||
# 生产环境如何排除和优化 JVM?
|
||||
https://cloud.tencent.com/developer/article/2177482
|
||||
|
||||
通过前面几个课时的学习,相信你对 JVM 的理论及实践等相关知识有了一个大体的印象。而本课时将重点讲解 JVM 的排查与优化,这样就会对 JVM 的知识点有一个完整的认识,从而可以更好地应用于实际工作或者面试了。
|
||||
|
||||
@@ -95,6 +96,7 @@ VM Flags:
|
||||
### 4. jmap(堆快照生成工具)
|
||||
jmap(Memory Map for Java)用于查询堆的快照信息。
|
||||
|
||||
#### jmap -heap
|
||||
查询堆信息示例如下:
|
||||
|
||||
```bash
|
||||
@@ -152,6 +154,146 @@ Dumping heap to /Users/admin/Documents/2020.dump ...
|
||||
Heap dump file created
|
||||
```
|
||||
|
||||
#### jmap -histo
|
||||
```
|
||||
jmap -histo:live pid
|
||||
```
|
||||
jmap -histo 命令用于显示 Java 进程中的对象统计信息。该命令将会输出一份对象统计报告,其中包含了对象数量、对象占用的内存大小、对象类名等信息。以下是 jmap -histo 命令输出的结果说明:
|
||||
```
|
||||
num #instances #bytes class name
|
||||
----------------------------------------------
|
||||
1: 10002 10002000 [B
|
||||
2: 1000 900000 [Ljava.lang.Object;
|
||||
3: 100 200000 [C
|
||||
4: 2 1200104 [I
|
||||
5: 1020 53040 java.lang.String
|
||||
6: 5 32712 java.lang.Object
|
||||
7: 384 20736 java.lang.Class
|
||||
8: 1 15664 [Ljava.util.HashMap$Node;
|
||||
9: 102 7344 java.util.HashMap$Node
|
||||
10: 10 4000 [Ljava.util.Hashtable$Entry;
|
||||
11: 101 3636 java.util.Hashtable$Entry
|
||||
12: 22 3432 java.lang.ref.SoftReference
|
||||
13: 101 2424 java.util.HashMap
|
||||
14: 22 1408 java.util.concurrent.ConcurrentHashMap$Node
|
||||
15: 22 1320 java.lang.ref.WeakReference
|
||||
16: 22 528 java.util.concurrent.ConcurrentHashMap
|
||||
17: 11 440 [Ljava.lang.String;
|
||||
18: 23 368 java.util.concurrent.ConcurrentHashMap$TreeBin
|
||||
19: 11 352 java.io.ObjectStreamClass$WeakClassKey
|
||||
20: 2 320 [Ljava.util.concurrent.ConcurrentHashMap$Node;
|
||||
...
|
||||
```
|
||||
其中,每一行包含了以下信息:
|
||||
|
||||
* num:对象的序号。
|
||||
* #instances:对象的数量。
|
||||
* #bytes:对象占用的内存大小,单位为字节。
|
||||
* class name:对象的类名。这个列表按照对象占用的内存从大到小进行排序。在这个示例中,对象的数量、类型和大小都是不同的。其中,[B 表示字节数组,[Ljava.lang.Object; 表示对象数组,[C 表示字符数组,[I 表示整数数组,java.lang.String 和其他对象类型都是 Java 标准库中的类。
|
||||
|
||||
使用 jmap -histo 命令可以帮助您了解 Java 进程中哪些对象占用了大量的内存,从而更好地进行内存分析和优化。
|
||||
|
||||
#### jmap 的使用教程:
|
||||
|
||||
1. 查看进程 ID
|
||||
首先,您需要查看 Java 应用程序的进程 ID(PID)。您可以使用 jps 命令来查看运行的 Java 进程,例如:
|
||||
```sh
|
||||
jps -l
|
||||
```
|
||||
这将显示当前系统中所有运行的 Java 进程的 PID 和类名。
|
||||
|
||||
2. 生成堆转储快照
|
||||
使用 jmap 命令来生成 JVM 的堆转储快照。例如,要生成 PID 为 1234 的 Java 进程的堆转储快照,您可以使用以下命令:
|
||||
```
|
||||
jmap -dump:file=heapdump.bin 1234
|
||||
```
|
||||
|
||||
这将生成一个名为 heapdump.bin 的二进制文件,其中包含了 Java 进程的堆转储快照。
|
||||
|
||||
3. 分析堆转储快照
|
||||
使用 jhat 和 jvisualvm 命令来分析堆转储快照。jhat 命令用于启动一个基于浏览器的分析器,jvisualvm 命令用于启动一个图形用户界面(GUI)分析器。
|
||||
|
||||
例如,要使用 jhat 命令启动分析器,您可以使用以下命令:
|
||||
```
|
||||
jhat heapdump.bin
|
||||
```
|
||||
这将启动一个 Web 服务器,您可以使用浏览器访问 URL http://localhost:7000/ 来查看分析结果。
|
||||
|
||||
要使用 jvisualvm 命令启动分析器,您可以使用以下命令:
|
||||
```
|
||||
jvisualvm
|
||||
```
|
||||
这将启动一个 GUI 分析器,在界面中打开堆转储快照文件进行分析。
|
||||
|
||||
#### jmap的参数和含义
|
||||
jmap 是 Java 自带的一个命令行工具,可以生成 JVM 的堆转储快照,并用于分析和诊断 Java 应用程序的内存使用情况。以下是 jmap 命令的各个参数和结果的含义说明:
|
||||
|
||||
-dump
|
||||
生成 JVM 的堆转储快照。
|
||||
```
|
||||
jmap -dump:file=<filename> <PID>
|
||||
```
|
||||
参数:
|
||||
file:指定输出文件的名称,可以包含路径。
|
||||
PID:Java 进程的进程 ID。
|
||||
|
||||
结果:
|
||||
生成一个名为 filename 的二进制文件,其中包含了 Java 进程的堆转储快照。
|
||||
|
||||
-heap
|
||||
显示 Java 进程的堆信息。
|
||||
```
|
||||
jmap -heap <PID>
|
||||
```
|
||||
参数:
|
||||
PID:Java 进程的进程 ID。
|
||||
结果:
|
||||
显示 Java 进程的堆信息,包括堆内存容量、已使用的堆内存、最大堆内存、新生代和老年代的容量等。
|
||||
|
||||
-histo
|
||||
显示 Java 进程中的对象统计信息。
|
||||
```
|
||||
jmap -histo[:live] <PID>
|
||||
```
|
||||
参数:
|
||||
PID:Java 进程的进程 ID。
|
||||
live:指定只显示当前处于活动状态的对象。
|
||||
结果:
|
||||
显示 Java 进程中的对象统计信息,包括对象数量、对象占用的内存大小、对象类名等。
|
||||
|
||||
-finalizerinfo
|
||||
显示 Java 进程中的 finalize 队列信息。
|
||||
```
|
||||
jmap -finalizerinfo <PID>
|
||||
```
|
||||
参数:
|
||||
PID:Java 进程的进程 ID。
|
||||
结果:
|
||||
显示 Java 进程中的 finalize 队列信息,包括队列中对象的数量、finalize 线程的数量等。
|
||||
|
||||
-permstat
|
||||
显示 Java 进程中的永久代信息。
|
||||
```
|
||||
jmap -permstat <PID>
|
||||
```
|
||||
参数:
|
||||
PID:Java 进程的进程 ID。
|
||||
结果:
|
||||
显示 Java 进程中的永久代信息,包括永久代内存容量、已使用的永久代内存等。
|
||||
|
||||
-F
|
||||
在无法通过正常通道生成堆转储快照时,强制生成堆转储快照。
|
||||
```
|
||||
jmap -dump:file=<filename> -F <PID>
|
||||
```
|
||||
参数:
|
||||
file:指定输出文件的名称,可以包含路径。
|
||||
PID:Java 进程的进程 ID。
|
||||
结果:
|
||||
生成一个名为 filename 的二进制文件,其中包含了 Java 进程的堆转储快照。
|
||||
|
||||
总之,jmap 命令提供了多个参数,可以用于分析和诊断 Java 应用程序的内存使用情况。不同的参数可以生成不同的输出结果,您可以根据需要选择合适的参数来使用 jmap 命令。
|
||||
|
||||
### 5. jhat(堆快照分析功能)
|
||||
jhat(JVM Heap Analysis Tool,堆快照分析工具)和 jmap 搭配使用,用于启动一个 web 站点来分析 jmap 生成的快照文件。
|
||||
|
||||
@@ -328,6 +470,70 @@ Found 1 deadlock.
|
||||
|
||||
从上述信息可以看出使用 jstack ,可以很方便地排查出代码中出现“deadlock”(死锁)的问题。
|
||||
|
||||
|
||||
### 补充jcmd
|
||||
|
||||
用来分析java进程的内存占用
|
||||
1. 添加参数
|
||||
```
|
||||
-XX:NativeMemoryTracking=summary
|
||||
```
|
||||
2. 执行命令
|
||||
```
|
||||
jcmd 6948 VM.native_memory
|
||||
```
|
||||
1. 返回结果
|
||||
|
||||
```
|
||||
➜ ~ jcmd 6948 VM.native_memory
|
||||
6948:
|
||||
|
||||
Native Memory Tracking:
|
||||
|
||||
Total: reserved=6083099KB, committed=1964315KB
|
||||
- Java Heap (reserved=4194304KB, committed=1337344KB)
|
||||
(mmap: reserved=4194304KB, committed=1337344KB)
|
||||
|
||||
- Class (reserved=1167036KB, committed=133476KB)
|
||||
(classes #21170)
|
||||
(malloc=14012KB #34318)
|
||||
(mmap: reserved=1153024KB, committed=119464KB)
|
||||
|
||||
- Thread (reserved=201622KB, committed=201622KB)
|
||||
(thread #197)
|
||||
(stack: reserved=200704KB, committed=200704KB)
|
||||
(malloc=624KB #992)
|
||||
(arena=295KB #389)
|
||||
|
||||
- Code (reserved=257311KB, committed=39431KB)
|
||||
(malloc=7711KB #16415)
|
||||
(mmap: reserved=249600KB, committed=31720KB)
|
||||
|
||||
- GC (reserved=165959KB, committed=155575KB)
|
||||
(malloc=12715KB #865)
|
||||
(mmap: reserved=153244KB, committed=142860KB)
|
||||
|
||||
- Compiler (reserved=172KB, committed=172KB)
|
||||
(malloc=41KB #1192)
|
||||
(arena=131KB #7)
|
||||
|
||||
- Internal (reserved=61345KB, committed=61345KB)
|
||||
(malloc=61313KB #29568)
|
||||
(mmap: reserved=32KB, committed=32KB)
|
||||
|
||||
- Symbol (reserved=29660KB, committed=29660KB)
|
||||
(malloc=25752KB #266545)
|
||||
(arena=3908KB #1)
|
||||
|
||||
- Native Memory Tracking (reserved=5508KB, committed=5508KB)
|
||||
(malloc=28KB #315)
|
||||
(tracking overhead=5480KB)
|
||||
|
||||
- Arena Chunk (reserved=181KB, committed=181KB)
|
||||
(malloc=181KB)
|
||||
|
||||
```
|
||||
|
||||
## 考点分析
|
||||
Java 虚拟机的排查工具是一个合格程序员必备的技能,使用它我们可以很方便地定位出问题的所在,尤其在团队合作的今天,每个人各守一摊很容易出现隐藏的 bug(缺陷)。因此使用这些排查功能可以帮我们快速地定位并解决问题,所以它也是面试中常问的问题之一。
|
||||
|
||||
|
||||
@@ -291,3 +291,14 @@ Hi,Java.
|
||||
|
||||
# 小结
|
||||
本课时我们讲了 8 种实现单例的方式,包括线程安全但可能会造成系统资源浪费的饿汉模式,以及懒汉模式和懒汉模式变种的 5 种实现方式。其中包含了两种双重检测锁的懒汉变种模式,还有最后两种线程安全且可以实现延迟加载的静态内部类的实现方式和枚举类的实现方式,其中比较推荐使用的是后两种单例模式的实现方式。
|
||||
|
||||
|
||||
|
||||
### 是否可以用原子操作
|
||||
|
||||
|
||||
```
|
||||
if(BooleanAtom.checkOrUpdate(false,true)){
|
||||
return new Instance();
|
||||
}
|
||||
```
|
||||
16
Java基础教程/Java面试原理/模块化历程.md
Normal file
@@ -0,0 +1,16 @@
|
||||
不同的隔离级别。
|
||||
|
||||
|
||||
### 编译时隔离:
|
||||
> 具备独立的命名空间,防止代码中的命名冲突,方便合作开发。
|
||||
|
||||
1. 命令脚本
|
||||
2. 函数
|
||||
3. 类
|
||||
4. 包和模块(package/jar/lib/dll)
|
||||
|
||||
### 运行时隔离:
|
||||
1. 框架上下文隔离(现成隔离,运行时对象隔离,可以解决对象冲突)
|
||||
2. JVM隔离(sofaArk热部署/合并部署,虚拟机隔离,运行时类隔离,可以解决包类冲突。)
|
||||
3. 面向服务SOA(进程隔离)
|
||||
4. 微服务docker(进程隔离)
|
||||
@@ -29,7 +29,7 @@ less(选项)(参数)
|
||||
-S:在单行显示较长的内容,而不换行显示;
|
||||
-x<数字>:将TAB字符显示为指定个数的空格字符。
|
||||
```
|
||||
|
||||
### 交互命令
|
||||
less 命令执行的快捷键
|
||||
搜索快捷键总结
|
||||
* /字符串:向下搜索“字符串”的功能
|
||||
@@ -56,10 +56,25 @@ less 命令执行的快捷键
|
||||
* 'a - 导航到标记 a 处
|
||||
|
||||
多文件浏览更换文件(:命令 底行模式)
|
||||
:n newx file
|
||||
:p previous file
|
||||
= :f 打印文件的名字
|
||||
### 参数
|
||||
* :n newx file
|
||||
* :p previous file
|
||||
* = :f 打印文件的名字
|
||||
|
||||
### 正则支持搜索
|
||||
```
|
||||
[abc]a或b或c .任意单个字符 a?零个或一个a
|
||||
[^abc]任意不是abc的字符 \s空格 a*零个或多个a
|
||||
[a-z]a-z的任意字符 \S非空格 a+一个或多个a
|
||||
[a-zA-Z]a-z或A-Z \d任意数字 a{n}正好出现n次a
|
||||
^一行开头 \D任意非数字 a{n,}至少出现n次a
|
||||
$一行末尾 \w任意字母数字或下划线 a{n,m}出现n-m次a
|
||||
(...)括号用于分组 \W任意非字母数字或下划线 a*?零个或多个a(非贪婪)
|
||||
(a|b)a或b \b单词边界 (a)...\1引用分组
|
||||
(?=a)前面有a (?!a)前面没有a \B非单词边界
|
||||
```
|
||||
|
||||
|
||||
### 参数
|
||||
|
||||
文件:指定要分屏显示内容的文件。
|
||||
|
||||
|
||||
@@ -1,6 +1,10 @@
|
||||
supervisord
|
||||
===
|
||||
|
||||
https://blog.csdn.net/weixin_40680612/article/details/124422102
|
||||
|
||||
Supervisor是用Python开发的一套通用的进程管理程序,能将一个普通的命令行进程变为后台daemon,并监控进程状态,异常退出时能自动重启。它是通过fork/exec的方式把这些被管理的进程当作supervisor的子进程来启动,这样只要在supervisor的配置文件中,把要管理的进程的可执行文件的路径写进去即可。也实现当子进程挂掉的时候,父进程可以准确获取子进程挂掉的信息的,可以选择是否自己启动和报警。supervisor还提供了一个功能,可以为supervisord或者每个子进程,设置一个非root的user,这个user就可以管理它对应的进
|
||||
|
||||
配置后台服务/常驻进程的进程管家工具。
|
||||
supervisord的出现,可以用来管理后台运行的程序。通过supervisorctl客户端来控制supervisord守护进程服务,真正进行进程监听的是supervisorctl客户端,而运行supervisor服务时是需要制定相应的supervisor配置文件的。
|
||||
|
||||
@@ -11,6 +15,17 @@ supervisord的出现,可以用来管理后台运行的程序。通过superviso
|
||||
apt-get install supervisor
|
||||
```
|
||||
|
||||
```
|
||||
启动
|
||||
systemctl start supervisord.service
|
||||
停止
|
||||
systemctl start supervisord.service
|
||||
重启
|
||||
systemctl restart supervisord.service
|
||||
查看状态
|
||||
systemctl status supervisord.service
|
||||
```
|
||||
|
||||
## 使用
|
||||
|
||||
Supervisord工具的整个使用流程:
|
||||
@@ -36,6 +51,17 @@ supervisorctl stop app
|
||||
supervisorctl reload # 修改/添加配置文件需要执行这个
|
||||
supervisorctl status
|
||||
webserver RUNNING pid 1120, uptime 0:08:07
|
||||
supervisorctl status 查看进程运行状态
|
||||
supervisorctl start 进程名 启动进程
|
||||
supervisorctl stop 进程名 关闭进程
|
||||
supervisorctl restart 进程名 重启进程
|
||||
supervisorctl update 重新载入配置文件
|
||||
supervisorctl shutdown 关闭supervisord
|
||||
supervisorctl clear 进程名 清空进程日志
|
||||
supervisorctl 进入到交互模式下。使用help查看所有命令。
|
||||
start stop restart + all 表示启动,关闭,重启所有进程进程名 清空进程日志
|
||||
supervisorctl 进入到交互模式下。使用help查看所有命令。
|
||||
start stop restart + all 表示启动,关闭,重启所有进程
|
||||
```
|
||||
|
||||
启动supervisor程序
|
||||
@@ -117,3 +143,56 @@ numprocs 启动几个进程
|
||||
autostart supervisor启动的时候是否随着同时启动
|
||||
autorestart 当程序over的时候,这个program会自动重启,一定要选上
|
||||
```
|
||||
|
||||
|
||||
```shell
|
||||
配置监控应用
|
||||
cd /etc/supervisord.d
|
||||
vim frpserver.conf
|
||||
[program:frpServer] ; 程序名称,可以通过ctl指定名称进行控制
|
||||
#directory = /home/kangaroo/build/CIServer ; 程序的启动目录
|
||||
command = /root/frp/frps -c /root/frp/frps.ini
|
||||
# ; 启动命令,可以看出与手动在命令行启动的命令是一样的
|
||||
autostart = true ; 在 supervisord 启动的时候也自动启动
|
||||
startsecs = 20 ; 启动 5 秒后没有异常退出,就当作已经正常启动了
|
||||
autorestart = true ; 程序异常退出后自动重启
|
||||
startretries = 3 ; 启动失败自动重试次数,默认是 3
|
||||
user = root ; 用哪个用户启动
|
||||
redirect_stderr = true ; 把 stderr 重定向到 stdout,默认 false
|
||||
stdout_logfile = /home/supervisor/log/frps.log
|
||||
stdout_logfile_maxbytes = 20MB ; stdout 日志文件大小,默认 50MB
|
||||
stdout_logfile_backups = 20 ; stdout 日志文件备份数
|
||||
|
||||
tomcat配置:
|
||||
|
||||
cd /etc/supervisord.d
|
||||
vim frpserver.conf
|
||||
[program:tomcat]
|
||||
command=/apache-tomcat-8.5.55/bin/catalina.sh run
|
||||
environment=JAVA_HOME="/java/jdk1.8.0_191/",JAVA_BIN="/java/jdk1.8.0_191/bin"
|
||||
directory=/apache-tomcat-8.5.55/
|
||||
autostart = true
|
||||
autorestart=true
|
||||
redirect_stderr=true
|
||||
stdout_logfile=/dev/stdout
|
||||
stdout_logfile_maxbytes=20MB
|
||||
|
||||
nginx配置
|
||||
|
||||
cd /etc/supervisord.d
|
||||
vim frpserver.conf
|
||||
[program:nginxServer] ; 程序名称,可以通过ctl指定名称进行控制
|
||||
#directory = /home/kangaroo/build/CIServer ; 程序的启动目录
|
||||
command = /usr/sbin/nginx -g 'daemon off;'
|
||||
# ; 启动命令,可以看出与手动在命令行启动的命令是一样的
|
||||
autostart = true ; 在 supervisord 启动的时候也自动启动
|
||||
startsecs = 20 ; 启动 5 秒后没有异常退出,就当作已经正常启动了
|
||||
autorestart = true ; 程序异常退出后自动重启
|
||||
startretries = 3 ; 启动失败自动重试次数,默认是 3
|
||||
user = root ; 用哪个用户启动
|
||||
redirect_stderr = true ; 把 stderr 重定向到 stdout,默认 false
|
||||
stdout_logfile = /home/supervisor/log/nginx.log
|
||||
stdout_logfile_maxbytes = 20MB ; stdout 日志文件大小,默认 50MB
|
||||
stdout_logfile_backups = 20 ; stdout 日志文件备份数
|
||||
```
|
||||
|
||||
|
||||
@@ -154,9 +154,9 @@ home is a writable directory
|
||||
```
|
||||
数字测试: -eq -ne -lt -le -gt -ge,[[ ]]同 [ ]一致
|
||||
文件测试: -r、-l、-w、-x、-f、-d、-s、-nt、-ot,[[ ]]同 [ ]一致
|
||||
字符串测试: > < =(同==) != -n -z,不可使用“<=”和“>=”,[[ ]]同 [ ]<
|
||||
字符串测试: > < =(同==) != -n -z,不可使用“<=”和“>=”,[[ ]]同 [ ]
|
||||
|
||||
SPAN style="COLOR: rgb(0,1,2)">一致,但在[]中,>和<必须使用\进行转义,即\>和\<
|
||||
< >一致,但在[]中,>和<必须使用\进行转义,即\>和\<
|
||||
逻辑测试: []为 -a -o ! [[ ]] 为&& || !
|
||||
数学运算: [] 不可以使用 [[ ]]可以使用+ - */ %
|
||||
组合: 均可用各自逻辑符号连接的数字(运算)测试、文件测试、字符测试
|
||||
|
||||
219
MySQL/15 排序和校验规则.md
Normal file
@@ -0,0 +1,219 @@
|
||||
|
||||
## 1 基本概念
|
||||
mysql数据库在做查询时候,有时候是英文字母大小写敏感的,有时候又不是的,主要是由mysql的字符校验规则的设置决定的,通常默认是不支持的大小写字母敏感的。
|
||||
### 什么是字符集和校验规则?
|
||||
字符集是一套符号和编码。校对规则是在字符集内用于比较字符的一套规则。任何一个给定的字符集至少有一个校对规则,它可能有几个校对规则。要想列出一个字符集的校对规则,使用SHOW COLLATION语句。
|
||||

|
||||
校对规则一般有这些特征:
|
||||
1. 两个不同的字符集不能有相同的校对规则。
|
||||
2. 每个字符集有一个默认校对规则。例如,utf8默认校对规则是utf8_general_ci。
|
||||
|
||||
### 命名规定
|
||||
存在校对规则命名约定:它们以其相关的字符集名开始,通常包括一个语言名,并且以_ci(大小写不敏感)、_cs(大小写敏感)或_bin(二元)结束。不同级别的字符集和校验规则可控制大小写敏感
|
||||
|
||||
MySQL5.1在同一台服务器、同一个数据库或甚至在同一个表中使用不同字符集或校对规则来混合定义字符串。字符集和校对规则有4个级别的默认设置:服务器级、数据库级、表级和连接级。
|
||||
## 2 服务器级
|
||||
### 修改配置文件
|
||||
MySQL按照如下方法确定服务器字符集和服务器校对规则:
|
||||
|
||||
1. 修改配置文件/etc/my.cnf。
|
||||
2. 在[mysqld]下添加:collation_server = utf8_bin。
|
||||
3. 重启实例
|
||||
|
||||
更改服务器级的校验规则(collation_server )后,数据库校验规则(collation_collation)默认会继承服务器级的。
|
||||
> 注意:
|
||||
> 这个只适用于在重新启动之后, 新建的库,已存在的库不受影响.
|
||||
> 同样的, 即使库的校验规则改了,已经存在的表不受修改影响;
|
||||
> 同理与已经存在的列...
|
||||
```sql
|
||||
mysql> create databaseyutest0;
|
||||
Query OK,1 row affected (0.00sec)
|
||||
mysql> useyutest0;Databasechanged
|
||||
mysql> create table t1 (name varchar(10));
|
||||
Query OK,0 rows affected (0.01sec)
|
||||
mysql> insert into t1 values('AAA');
|
||||
Query OK,1 row affected (0.00sec)
|
||||
mysql> insert into t1 values('aaa');
|
||||
Query OK,1 row affected (0.01sec)
|
||||
mysql> select * fromt1;
|
||||
+------+
|
||||
| name |
|
||||
+------+
|
||||
| AAA |
|
||||
| aaa |
|
||||
+------+
|
||||
2 rows in set (0.00sec)
|
||||
mysql> select * from t1 where name='aaa';
|
||||
+------+
|
||||
| name |
|
||||
+------+
|
||||
| aaa |
|
||||
+------+
|
||||
1 row in set (0.00 sec)
|
||||
```
|
||||
可以看出,在服务器级进行相应的校对规则设置,查询大小写敏感。
|
||||
### 当服务器启动时根据有效的选项设置
|
||||
当启动mysqld时,根据使用的初始选项设置来确定服务器字符集和校对规则。
|
||||
```sql
|
||||
shell> mysqld --character-set-server=latin1 --collation-server=latin1_swedish_ci
|
||||
```
|
||||
更改设定值的一个方法是通过重新编译。如果希望在从源程序构建时更改默认服务器字符集和校对规则,使用:--with-charset和--with-collation作为configure的参量。例如:
|
||||
```sql
|
||||
shell> ./configure --with-charset=latin1 --with-collation=latin1_german1_ci
|
||||
```
|
||||
mysqld和configure都验证字符集/校对规则组合是否有效。如果无效,每个程序都显示一个错误信息,然后终止。
|
||||
|
||||
## 3 数据库级
|
||||
### 规则说明
|
||||
MySQL这样选择数据库字符集和数据库校对规则:
|
||||
1. 如果指定了character set X和collate Y,那么采用字符集X和校对规则Y。
|
||||
2. 如果指定了character set X而没有指定collate Y,那么采用character set X和character set X的默认校对规则。
|
||||
3. 否则,采用服务器字符集和服务器校对规则。
|
||||
### 测试验证
|
||||
1. 创建数据库时设置数据库校验规则
|
||||
```sql
|
||||
mysql> create database yutest default character setutf8 collate utf8_bin;
|
||||
Query OK,1 row affected (0.00sec)
|
||||
mysql> show variables like 'collation_%';
|
||||
+----------------------+-----------------+
|
||||
| Variable_name | Value |
|
||||
+----------------------+-----------------+
|
||||
| collation_connection | utf8_general_ci |
|
||||
| collation_database | utf8_bin |
|
||||
| collation_server | utf8_general_ci |
|
||||
+----------------------+-----------------+
|
||||
3 rows in set (0.00sec)
|
||||
mysql> select * fromt1;
|
||||
+------+
|
||||
| name |
|
||||
+------+
|
||||
| ABC |
|
||||
| abc |
|
||||
+------+
|
||||
2 rows in set (0.00sec)
|
||||
mysql> select * from t1 where name='abc';
|
||||
+------+
|
||||
| name |
|
||||
+------+
|
||||
| abc |
|
||||
+------+
|
||||
1 row in set (0.01 sec)
|
||||
```
|
||||
可以看出,在数据库级进行相应的校对规则设置,查询大小写敏感。
|
||||
|
||||
## 4 表级
|
||||
### 规则说明
|
||||
MySQL按照下面的方式选择表字符集和校对规则:
|
||||
1. 如果指定了character set X和collate Y,那么采用character set X和collate Y。
|
||||
2. 如果指定了character set X而没有指定collate Y,那么采用character set X和character set X的默认校对规则。
|
||||
3. 否则,采用数据库字符集和服务器校对规则。
|
||||
### 测试验证
|
||||
在创建表时设置表级校验规则:
|
||||
```sql
|
||||
mysql> create databaseyutest2;
|
||||
Query OK,1 row affected (0.01sec)
|
||||
mysql> useyutest2;Databasechanged
|
||||
mysql> create table t1(name varchar(10))-> default character setutf8 collate utf8_bin;
|
||||
Query OK,0 rows affected (0.01sec)
|
||||
mysql> insert into t1 values('ABC');
|
||||
Query OK,1 row affected (0.00sec)
|
||||
mysql> insert into t1 values('abc');
|
||||
Query OK,1 row affected (0.00sec)
|
||||
mysql> show variables like 'collation_%';+----------------------+-----------------+
|
||||
| Variable_name | Value |
|
||||
+----------------------+-----------------+
|
||||
| collation_connection | utf8_general_ci |
|
||||
| collation_database | utf8_general_ci |
|
||||
| collation_server | utf8_general_ci |
|
||||
+----------------------+-----------------+
|
||||
3 rows in set (0.00sec)
|
||||
mysql> select * fromt1;+------+
|
||||
| name |
|
||||
+------+
|
||||
| ABC |
|
||||
| abc |
|
||||
+------+
|
||||
2 rows in set (0.00sec)
|
||||
mysql> select * from t1 where name='abc';+------+
|
||||
| name |
|
||||
+------+
|
||||
| abc |
|
||||
+------+
|
||||
1 row in set (0.00 sec)
|
||||
```
|
||||
可以看出,在表级进行相应的校对规则设置,查询大小写敏感。
|
||||
### 5 连接级
|
||||
|
||||
### 连接字符集
|
||||
考虑什么是一个“连接”:它是连接服务器时所作的事情。客户端发送SQL语句,例如查询,通过连接发送到服务器。服务器通过连接发送响应给客户端,例如结果集。对于客户端连接,这样会导致一些关于连接的字符集和校对规则的问题,这些问题均能够通过系统变量来解决:
|
||||
```sql
|
||||
mysql> show variables like 'character%';
|
||||
+--------------------------+----------------------------+
|
||||
| Variable_name | Value |
|
||||
+--------------------------+----------------------------+
|
||||
| character_set_client | utf8 |
|
||||
| character_set_connection | utf8 |
|
||||
| character_set_database | utf8 |
|
||||
| character_set_filesystem | binary |
|
||||
| character_set_results | utf8 |
|
||||
| character_set_server | utf8 |
|
||||
| character_set_system | utf8 |
|
||||
| character_sets_dir | /usr/share/mysql/charsets/ |
|
||||
+--------------------------+----------------------------+
|
||||
8 rows in set (0.00 sec)
|
||||
```
|
||||
1. 当查询离开客户端后,在查询中使用哪种字符集?
|
||||
1. 服务器使用character_set_client变量作为客户端发送的查询中使用的字符集。
|
||||
2. 服务器接收到查询后应该转换为哪种字符集?
|
||||
1. 转换时,服务器使用character_set_connection和collation_connection系统变量。它将客户端发送的查询从character_set_client系统变量转换到character_set_connection。
|
||||
3. 服务器发送结果集或返回错误信息到客户端之前应该转换为哪种字符集?
|
||||
1. character_set_results变量指示服务器返回查询结果到客户端使用的字符集。包括结果数据,例如列值和结果元数据(如列名)。
|
||||
|
||||
|
||||
### 在SQL语句中使用collate
|
||||
创建数据库表时大小写不敏感,仍然有方法在查询时区分大小写
|
||||
|
||||
使用collate子句,能够为一个比较覆盖任何默认校对规则。collate可以用于多种SQL语句中,比如where,having,group by,order by,as,聚合函数。
|
||||
```sql
|
||||
mysql> select * from t1 where name collate utf8_bin = 'ABC';+------+
|
||||
| name |
|
||||
+------+
|
||||
| ABC |
|
||||
+------+
|
||||
1 row in set (0.00sec)
|
||||
mysql> select * from t1 where name = 'ABC';+------+
|
||||
| name |
|
||||
+------+
|
||||
| ABC |
|
||||
| Abc |
|
||||
| abc |
|
||||
+------+
|
||||
3 rows in set (0.00sec)
|
||||
mysql> select * fromt1;+------+
|
||||
| name |
|
||||
+------+
|
||||
| ABC |
|
||||
| Abc |
|
||||
| abc |
|
||||
+------+
|
||||
3 rows in set (0.00 sec)
|
||||
```
|
||||
### binary操作符
|
||||
binary操作符是collate子句的一个速记符。binary 'x'等价与'x' collate y,这里y是字符集'x'二元校对规则的名字。每一个字符集有一个二元校对规则。例如,latin1字符集的二元校对规则是latin1_bin,因此,如果列a是字符集latin1,以下两个语句有相同效果:
|
||||
```sql
|
||||
select * from t1 order by binarya;select * from t1 order by a collate latin1_bin;
|
||||
mysql> select * from t1 where binary name = 'ABC';+------+
|
||||
| name |
|
||||
+------+
|
||||
| ABC |
|
||||
+------+
|
||||
1 row in set (0.00sec)
|
||||
mysql>mysql> select * from t1 where name = 'ABC';+------+
|
||||
| name |
|
||||
+------+
|
||||
| ABC |
|
||||
| Abc |
|
||||
| abc |
|
||||
+------+
|
||||
3 rows in set (0.00 sec)
|
||||
```
|
||||
67
MySQL/16 explain性能分析.md
Normal file
@@ -0,0 +1,67 @@
|
||||
|
||||
## 1 简介
|
||||
在MySQL中,EXPLAIN命令的返回值是一个表格,包含了查询语句的执行计划。表格中的每一行代表了一个访问方式,每一列代表了一个属性,例如:
|
||||
```sql
|
||||
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
|
||||
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|
||||
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
|
||||
| 1 | SIMPLE | users | const | PRIMARY | PRIMARY | 4 | const| 1 | |
|
||||
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
|
||||
```
|
||||
下面是表格中各个属性的含义:
|
||||
|
||||
* id: 查询的标识符,每个查询都有一个唯一的标识符。如果是子查询,id的序号会递增,id值越大优先级越高,优先被执行
|
||||
* 
|
||||
* 
|
||||
* select_type: 查询的类型,共有以下几种类型:
|
||||
* SIMPLE:简单select查询,查询中不包含子查询或者UNION
|
||||
* PRIMARY:查询中若包含任何复杂的子查询,最外层查询则被标记为primary
|
||||
* SUBQUERY:在select或where中包含了子查询
|
||||
* DERIVED:在from列表中包含的子查询被标记为derived(衍生)把结果放在临时表当
|
||||
* UNION:若第二个select出现的union之后,则被标记为union。若union包含在from子句的子查询中,外层select将被标记为deriver
|
||||
* UNION RESULT:从union表获取结果select,两个UNION合并的结果集在最后
|
||||
|
||||
* table: 此行正在访问的表。
|
||||
* type: 表示访问类型,包括以下几种类型:
|
||||
* ALL: 全表扫描,将访问表的每一行数据。将全表进行扫描,从硬盘当中读取数据,如果出现了All 切数据量非常大, 一定要去做优化
|
||||
* index: 全索引扫描,将访问索引的每一行数据。index与All区别为index类型只遍历索引树,通常比All要快,
|
||||
因为索引文件通常比数据文件要小all和index都是读全表,
|
||||
但index是从索引中读取,all是从硬盘当中读取
|
||||
* range: 只检索给定范围的行,使用一个索引来选择行 一般就是在你的where语句中出现between<>\ in等查询,这种范围扫描索引比全表扫描要好,因为它只需要开始于索引的某一点.而结束语另一点,不用扫描全部索引。
|
||||
* ref: 非唯一性索引扫描。出现在一对多关系中,例如部门和员工。ref 非唯一性索引扫描,返回匹配某个单独值的所有行,本质上也是一种索引访问,它返回所有匹配某个单独值的行可能会找到多个符合条件的行,所以它应该属于查找和扫描的混合体
|
||||
* eq_ref: 唯一索引引用,类似于ref,但使用的是唯一索引。eq_ref 唯一性索引扫描 对于每个索引键,表中只有一条记录与之匹配, 常见于主键或唯一索引扫描
|
||||
* const: 表示通过索引一次就找到了。常量复杂度
|
||||
* system: 表中有一行记录(系统表) 这是const类型的特例,平时不会出现
|
||||
* partitions:如果查询是基于分区表的话, 会显示查询访问的分区
|
||||
* possible_keys: 可能使用的索引列表。
|
||||
* key: 实际使用的索引。
|
||||
* 实际使用的索引,如果为NULL,则没有使用索引,查询中若使用了覆盖索引 ,则该索引仅出现在key列表possible_keys与key关系,理论应该用到哪些索引实际用到了哪些索引覆盖索引 查询的字段和建立的字段刚好吻合,
|
||||
这种我们称为覆盖索引
|
||||
* key_len: 索引键使用的字节数。
|
||||
* ref: 列与索引之间的匹配。索引是否被引入到, 到底引用到了哪几个索引
|
||||
* rows: 表示MySQL估计需要扫描的行数。语句中出现了Using Filesort 和 Using Temporary说明没有使用到索引。出现 impossible where说明条件永远不成立
|
||||
* Extra: 额外的信息,包括以下几种类型:
|
||||
* Using filesort: MySQL需要额外排序。
|
||||
* Using temporary: MySQL需要创建临时表。
|
||||
* Using index: 查询使用了覆盖索引。
|
||||
* Using where: MySQL需要过滤部分数据。
|
||||
* Using join buffer: MySQL正在使用连接缓冲区。
|
||||
* filtered满足查询的记录数量的比例,注意是百分比,不是具体记录数 . 值越大越好,filtered列的值依赖统计信息,并不十分准确
|
||||
|
||||
|
||||
|
||||
通过分析执行计划,可以发现哪些地方需要优化,例如是否可以添加索引、是否可以缩小查询范围等等。
|
||||
|
||||
|
||||
## 2 实例
|
||||
|
||||
### id值与执行顺序
|
||||
* id值相同
|
||||

|
||||
|
||||
|
||||
* id值不同
|
||||

|
||||
|
||||
* id值
|
||||

|
||||
BIN
MySQL/image/2023-04-17-10-41-31.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 24 KiB |
BIN
MySQL/image/2023-04-17-19-43-59.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 13 KiB |
BIN
MySQL/image/2023-04-19-09-44-09.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 46 KiB |
BIN
MySQL/image/2023-04-19-09-47-56.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 42 KiB |
BIN
MySQL/image/2023-04-19-09-48-33.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 110 KiB |
BIN
MySQL/image/2023-04-19-09-59-39.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 29 KiB |
BIN
MySQL/image/2023-04-19-09-59-52.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 43 KiB |
BIN
MySQL/image/2023-04-19-10-00-39.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 39 KiB |
BIN
MySQL/image/2023-04-19-10-01-08.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 60 KiB |
BIN
MySQL/image/2023-04-19-10-02-16.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 62 KiB |
BIN
MySQL/image/2023-04-19-10-02-32.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 50 KiB |
BIN
MySQL/image/2023-04-19-10-03-35.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 34 KiB |
BIN
MySQL/image/2023-04-19-10-03-55.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 35 KiB |
BIN
MySQL/image/2023-04-19-10-04-23.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 42 KiB |
BIN
MySQL/image/2023-04-19-10-04-39.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 46 KiB |
@@ -9,7 +9,7 @@
|
||||
* 设计模式中的观察者模式
|
||||
* jdk中的observable和observer
|
||||
* ui中事件监听机制
|
||||
* 注册中心和消息队列的订阅发布机制
|
||||
* 消息队列的订阅发布机制
|
||||
|
||||
先是一种对象间的一对多的关系;最简单的如交通信号灯,信号灯是目标(一方),行人注视着信号灯(多方)。当目标发送改变(发布),观察者(订阅者)就可以接收到改变。 观察者如何处理(如行人如何走,是快走/慢走/不走,目标不会管的), 目标无需干涉;所以就松散耦合了它们之间的关系。
|
||||
|
||||
|
||||
33
Spring/Springboot/spring创建的方式.md
Normal file
@@ -0,0 +1,33 @@
|
||||
# springApplication创建的方法
|
||||
|
||||
### 1.通过类的静态方法直接创建
|
||||
|
||||
```java
|
||||
SpringApplication.run(ApplicationConfiguration.class,args);
|
||||
```
|
||||
|
||||
### 2.通过自定义SpringApplication创建
|
||||
|
||||
```java
|
||||
SpringApplication springApplication = new SpringApplication(ApplicationConfiguration.class); //这里也是传入配置源,但也可以不传
|
||||
springApplication.setWebApplicationType(WebApplicationType.NONE); //指定服务类型 可以指定成非Web应用和SERVLET应用以及REACTIVE应用
|
||||
springApplication.setAdditionalProfiles("prod"); //prodFiles配置
|
||||
Set<String> sources = new HashSet<>(); //创建配置源
|
||||
sources.add(ApplicationConfiguration.class.getName()); //指定配置源
|
||||
springApplication.setSources(sources); //设置配置源,注意配置源可以多个
|
||||
ConfigurableApplicationContext context = springApplication.run(args); //运行SpringApplication 返回值为服务上下文对象
|
||||
context.close(); //上下文关闭
|
||||
```
|
||||
|
||||
|
||||
### 3.通过Builder工厂模式
|
||||
> 只是一种初始化对象的方法。
|
||||
|
||||
```java
|
||||
ConfigurableApplicationContext context = new SpringApplicationBuilder(ApplicationConfiguration.class)//这里也是传入配置源,但也可以不传
|
||||
.web(WebApplicationType.REACTIVE)
|
||||
.profiles("java7")
|
||||
.sources(ApplicationConfiguration.class) //可以多个Class
|
||||
.run();
|
||||
context.close(); //上下文关闭
|
||||
```
|
||||
199
Spring/Springboot/生命周期回调方法.md
Normal file
@@ -0,0 +1,199 @@
|
||||
对于spring的bean来讲,我们默认可以指定两个生命周期回调方法。一个是在ApplicationContext将bean初始化完全完成后,包括注入对应的依赖(例如属性注入)后的回调方法;另一个是在ApplicationContext准备销毁之前的回调方法。
|
||||
|
||||
要实现这种回调主要有三种方式:
|
||||
|
||||
实现特定的接口。
|
||||
在XML配置文件中指定回调方法。
|
||||
使用JSR-250标准的注解。
|
||||
|
||||
为什么要调用生命周期回调函数
|
||||
|
||||
因为如果在构造方法中执行一些操作,实际上spring并没有完成依赖注入,调用过程中会报错。因为在spring bean的实例化过程中,是先单独实例化PersonService和EvanService的。然后再完成对EvanService的注入。如果不这么做的话,而选择在PersonService的构造方法里用EvanService做一些事的话,此时的EvanService是还没有完成注入的。
|
||||
|
||||
调用构造函数初始化一个对象--> 进行依赖注入 --> 调用生命周期回调函数init方法
|
||||
|
||||
|
||||
## 1 实现特定的接口
|
||||
|
||||
针对bean初始化后的回调和ApplicationContext销毁前的回调,Spring分别为我们了提供了InitializingBean和DisposableBean接口供用户实现,这样Spring在需要进行回调时就会调用对应接口提供的回调方法。
|
||||
|
||||
### InitializingBean
|
||||
|
||||
InitializingBean是用来定义ApplicationContext在完全初始化一个bean以后需要需要回调的方法的,其中只定义了一个afterPropertiesSet()方法。如其名称所描述的那样,该方法将在ApplicationContext将一个bean完全初始化,包括将对应的依赖项都注入以后才会被调用。InitializingBean的完全定义如下。
|
||||
|
||||
```java
|
||||
public interface InitializingBean {
|
||||
|
||||
void afterPropertiesSet() throws Exception;
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
由于InitializingBean的afterPropertiesSet()方法会在依赖项都进行注入以后再回调,所以该方法通常会用来检查必要的依赖注入,以使我们能够在bean被初始化时就发现其中的错误,而不是在很长时间使用以后才发现。如果你去看Spring的源码,你就会发现源码中有很多InitializingBean的使用,而且基本都是用来检查必要的依赖项是否为空的。
|
||||
```java
|
||||
public class Hello implements InitializingBean {
|
||||
|
||||
private World world;
|
||||
|
||||
/**
|
||||
* 该方法将在当前bean被完全初始化后被调用
|
||||
*/
|
||||
public void afterPropertiesSet() throws Exception {
|
||||
Assert.notNull(world, "world should not be null.");
|
||||
}
|
||||
|
||||
public void setWorld(World world) {
|
||||
this.world = world;
|
||||
}
|
||||
}
|
||||
```
|
||||
### DisposableBean
|
||||
DisposableBean是用来定义在ApplicationContext销毁之前需要回调的方法的。DisposableBean接口中只定义了一个destroy()方法,在ApplicationContext被销毁前,Spring将依次调用bean容器中实现了DisposableBean接口的destroy()方法。所以,我们可以通过实现该接口的destroy()方法来达到在ApplicationContext销毁前释放某些特定资源的目的。
|
||||
```
|
||||
public interface DisposableBean {
|
||||
|
||||
void destroy() throws Exception;
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
在Spring的源码中,也有很多实现了DisposableBean接口的类,如我们熟悉的ApplicationContext实现类、SingleConnectionDataSource等。
|
||||
|
||||
|
||||
## 2 在XML中配置回调方法
|
||||
在XML配置文件中通过bean元素定义一个bean时,我们可以通过bean元素的init-method属性和destroy-method属性来指定当前bean在初始化以后和ApplicationContext销毁前的回调方法。需要注意的是所指定的回调方法必须是没有参数的。
|
||||
通过init-method属性来指定初始化方法时所对应的方法必须是该bean中所拥有的方法,所以首先我们需要在对应的bean中定义对应的初始化方法,这里假设我们需要在bean中定义一个init()方法作为该bean的初始化方法,那么我们可以对我们的bean进行类似如下定义。
|
||||
|
||||
```java
|
||||
public class Hello {
|
||||
|
||||
private World world;
|
||||
|
||||
/**
|
||||
* 该方法将被用来作为初始化方法,在当前bean被完全初始化后被调用
|
||||
*/
|
||||
public void init() {
|
||||
Assert.notNull(world, "world should not be null.");
|
||||
}
|
||||
|
||||
public void setWorld(World world) {
|
||||
this.world = world;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
接下来就是在XML配置文件中定义该bean时通过init-method属性定义对应的初始化方法为init()方法,init-method属性的属性值就对应初始化方法的名称,所以我们的bean应该是如下定义。
|
||||
|
||||
```xml
|
||||
<bean name="world" class="com.app.World"/>
|
||||
<!-- 通过init-method属性指定初始化方法名称 -->
|
||||
<bean id="hello" class="com.app.Hello" init-method="init">
|
||||
<property name="world" ref="world"/>
|
||||
</bean>
|
||||
```
|
||||
|
||||
init-method和destroy-method的用法和配置等基本上都是一样的,所以对于使用destroy-method来指定ApplicationContext销毁前的回调方法的用法就不再赘述了。
|
||||
|
||||
如果我们的初始化方法或销毁方法的名称大都是一样的,在通过init-method和destroy-method进行指定的时候我们就没有必要一个个bean都去指定了,Spring允许我们在最顶级的beans元素上指定默认的初始化后回调方法和销毁前的回调方法名称,这样对于没有指定init-method或destroy-method的bean将默认将其中default-init-method或default-destroy-method属性值对应名称的方法(如果存在的话)视为初始化后的回调方法或销毁前的回调方法。这是通过default-init-method和default-destroy-method属性来定义的。
|
||||
|
||||
```java
|
||||
<beans xmlns="http://www.springframework.org/schema/beans"
|
||||
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
|
||||
xsi:schemaLocation="http://www.springframework.org/schema/beans
|
||||
http://www.springframework.org/schema/beans/spring-beans.xsd"
|
||||
default-init-method="init" default-destroy-method="destroy">
|
||||
|
||||
</beans>
|
||||
```
|
||||
|
||||
以上表示定义默认的初始化后回调方法名称为init,默认的销毁前回调方法名称为destroy。
|
||||
当定义了default-init-method或default-destroy-method以后,如果我们的某个bean对应的初始化后回调方法名称或销毁前的回调方法名称与默认定义的不一样,则我们可以在对应的bean上通过init-method或destroy-method指定该bean自身的回调方法名称,即bean上定义的回调方法名称将会比默认定义拥有更高的优先级。
|
||||
|
||||
## 3 使用JSR-250标准的注解
|
||||
关于bean的生命周期回调方法,Spring也会JSR-250标准注解做了支持,即在bean完全初始化后将回调使用@PostConstruct标注的方法,在销毁ApplicationContext前将回调使用@PreDestroy标注的方法。
|
||||
针对之前的示例,如果我们现在把定义的bean定义成如下这样,即没有在bean上通过init-method和destroy-method指定初始化方法和销毁方法。
|
||||
|
||||
```xml
|
||||
|
||||
<bean name="world" class="com.app.World"/>
|
||||
<bean id="hello" class="com.app.Hello">
|
||||
<property name="world" ref="world"/>
|
||||
</bean>
|
||||
```
|
||||
|
||||
|
||||
当然,这里也不考虑全局性的init-method和destroy-method方法,如果我们希望在id为“hello”的bean被初始化后回调其中的init()方法,在销毁前回调其中的destroy()方法,我们就可以通过@PostConstruct和@PreDestroy进行如下定义。
|
||||
```
|
||||
public class Hello {
|
||||
|
||||
private World world;
|
||||
|
||||
/**
|
||||
* 该方法将被用来作为初始化方法,在当前bean被完全初始化后被调用
|
||||
*/
|
||||
@PostConstruct
|
||||
public void init() {
|
||||
Assert.notNull(world, "world should not be null.");
|
||||
}
|
||||
|
||||
@PreDestroy
|
||||
public void destroy() {
|
||||
System.out.println("---------destroy-----------");
|
||||
}
|
||||
|
||||
public void setWorld(World world) {
|
||||
this.world = world;
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
使用JSR-250标准指定初始化后的回调方法以及销毁前的回调方法时,如果我们希望将多个方法都作为对应的回调方法进行回调,则可以在多个方法上同时使用对应的注解进行标注,Spring将依次执行对应的方法。
|
||||
```java
|
||||
public class Hello {
|
||||
|
||||
private World world;
|
||||
|
||||
@PostConstruct
|
||||
public void init() {
|
||||
System.out.println("-----------init-------------");
|
||||
}
|
||||
|
||||
/**
|
||||
* 该方法将被用来作为初始化方法,在当前bean被完全初始化后被调用
|
||||
*/
|
||||
@PostConstruct
|
||||
public void init2() {
|
||||
Assert.notNull(world, "world should not be null.");
|
||||
}
|
||||
|
||||
@PreDestroy
|
||||
public void destroy() {
|
||||
System.out.println("------------destroy----------------");
|
||||
}
|
||||
|
||||
@PreDestroy
|
||||
public void destroy2() {
|
||||
System.out.println("---------destroy2-----------");
|
||||
}
|
||||
|
||||
public void setWorld(World world) {
|
||||
this.world = world;
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
## 4 混合使用三种方式
|
||||
依据:spring官方文档
|
||||
|
||||
Spring允许我们混合使用上述介绍的三种方式来指定对应的回调方法。当对于同一个bean使用三种方式指定了同一个方法作为初始化后的回调方法或销毁前的回调方法,则对应的回调方法只会被执行一次。然而,当对于同一个bean使用两种或三种方式指定的回调方法不是同一个方法时,Spring将依次执行使用不同的方式指定的回调方法。对于初始化后的回调方法而言,具体规则如下:
|
||||
|
||||
使用@PostConstruct标注的方法。
|
||||
实现InitializingBean接口后的回调方法afterPropertiesSet()方法。
|
||||
通过init-method或default-init-method指定的方法。
|
||||
|
||||
对于销毁前的回调方法而言,其规则是一样的:
|
||||
|
||||
使用@PreDestroy标注的方法。
|
||||
实现DisposableBean接口后的回调方法destroy()方法。
|
||||
通过destroy-method或default-destroy-method指定的方法。
|
||||
@@ -89,8 +89,7 @@ k8s.gcr.io/etcd:3.5.3-0=gotok8s/etcd:3.5.3-0
|
||||
```
|
||||
|
||||
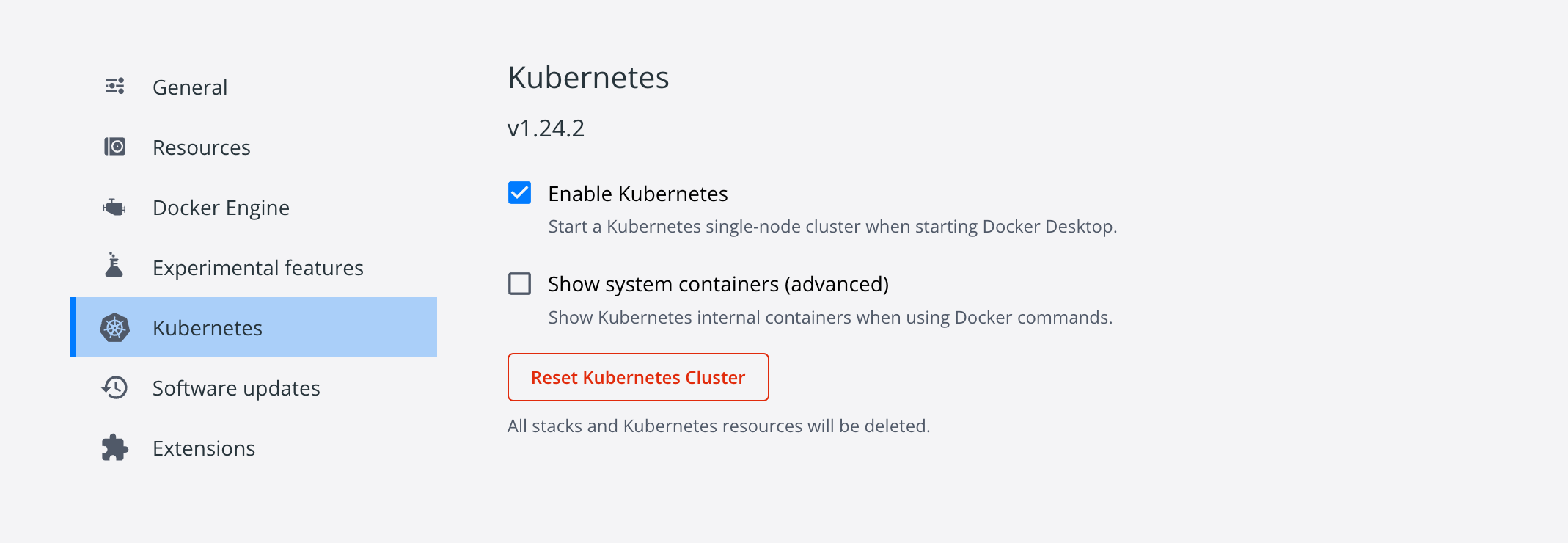
然后执行`./load_images.sh `即可下载k8s依赖的镜像,随后打开`Docker`,进入设置界面,勾选`Enable Kubernetes`即可:
|
||||
|
||||
|
||||

|
||||
|
||||
不出意外,界面左下角会出现`Kubernetes running`的提示,这样就安装成功了。
|
||||
|
||||
@@ -540,6 +539,9 @@ kubectl expose po hello --port=5000 --target-port=5000 --type=NodePort --name h
|
||||
kubectl get services
|
||||
```
|
||||
|
||||
## MINIKUBE
|
||||
|
||||
https://minikube.sigs.k8s.io/docs/start/
|
||||
## 参考
|
||||
|
||||
本部分内容有参考如下文章:
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
cd# 基础概念介绍
|
||||
# 基础概念介绍
|
||||
|
||||

|
||||
|
||||
|
||||
@@ -178,7 +178,7 @@ switched to db test_data
|
||||
|
||||
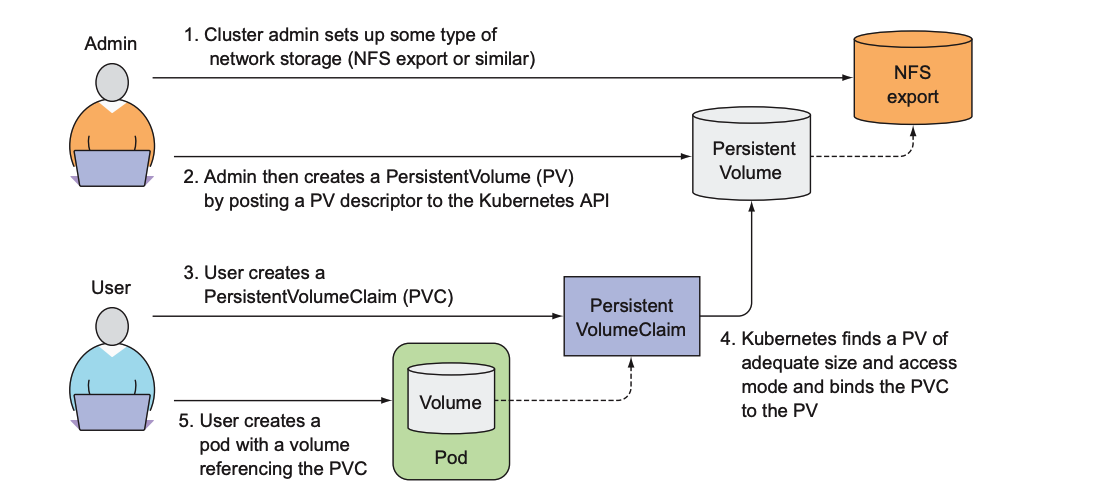
持久卷由管理员创建(各种配置信息),然后用户创建持久卷声明,提交后`k8s`就会找到匹配的持久卷并将其绑定到持久卷声明。
|
||||
|
||||
|
||||

|
||||
|
||||
这样做的好处在于,对于用户只需要关注声明一下需要多大的存储、需要什么权限(读写)等,然后pod通过其中一个卷的名称来引用声明就可以了,将细节完美地进行了隐藏。
|
||||
|
||||
|
||||
@@ -121,7 +121,7 @@ root 1634 1607 0 06:31 pts/0 00:00:00 ps -ef
|
||||
|
||||
我们直接使用书中的例子:`vim fortune-pod-env.yaml`:
|
||||
|
||||
```shell
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
@@ -200,7 +200,7 @@ PWD=/
|
||||
|
||||
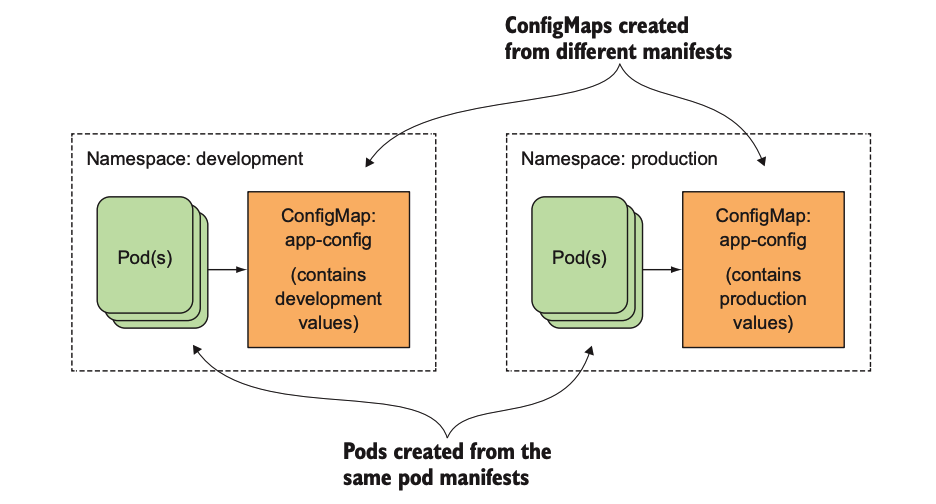
`ConfigMap`是不需要被读取的,它映射的内容通过环境变量或者卷文件的形式传给容器。一般直接在`pod`的定义里面就可以声明`ConfigMap`,这样就可以根据不同的环境创建不同的配置,流程交互如下图所示:
|
||||
|
||||
|
||||

|
||||
|
||||
### 创建
|
||||
|
||||
|
||||
@@ -280,17 +280,22 @@ kubectl attach -it nginx -c shell
|
||||
-t tty表示窗口链接
|
||||
-c 容器container名称
|
||||
● 进入指定的容器中执行特定的命令
|
||||
```sh
|
||||
kubectl exec -it mongodb mongo
|
||||
kubectl exec -it pod_name -c container_name -- /bin/sh
|
||||
```
|
||||
● 暂时服务化一个容器,将本机的端口映射到容器中某个服务的端口。
|
||||
kubectl port-forward fortune 8080:80
|
||||
● 永久服务化,创建一个持久化的服务
|
||||
```sh
|
||||
# 创建一个服务对象
|
||||
# NodePort 在所有节点(虚拟机)上开放一个特定端口,任何发送到该端口的流量都被转发到对应服务
|
||||
kubectl expose pod nginx --port=80 --target-port=80 --type=NodePort --name nginx-http
|
||||
```
|
||||
● 删除所有的pod和所有的资源
|
||||
```
|
||||
kubectl delete pod --all -n custom-namespace
|
||||
kubectl delete all --all -n custom-namespace2
|
||||
kubectl delete ns --all
|
||||
|
||||
```
|
||||
## kubectl错误排查的步骤
|
||||
BIN
kubenets/image/2023-08-09-14-11-04.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 115 KiB |
BIN
kubenets/image/2023-08-09-16-49-09.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 98 KiB |
BIN
kubenets/image/2023-08-09-16-55-18.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 72 KiB |
@@ -37,6 +37,7 @@ scope的取值用来定义依赖生效的空间(main目录、test目录)和
|
||||
* runtime编译时不需要,但是运行时需要的jar。实际运行时需要接口的实现类。JDBC接口标准提供了一系列借口,能够进行编译。但是运行时需要JDBC的具体实现。
|
||||

|
||||
|
||||
<table><thead><tr><th>值</th><th>解释</th></tr></thead><tbody><tr><td>compile</td><td><code>默认的scope</code>,表示 dependency 都可以在生命周期中使用。而且,这些dependencies 会传递到依赖的项目中。适用于所有阶段,会随着项目一起发布。</td></tr><tr><td>provided</td><td>跟compile相似,但是表明了dependency 由JDK或者容器提供,例如Servlet AP和一些Java EE APIs。这个scope 只能作用在编译和测试时,同时没有传递性。</td></tr><tr><td>runtime</td><td>表示dependency不作用在编译时,但会作用在运行和测试时,如JDBC驱动,适用运行和测试阶段。</td></tr><tr><td>test</td><td>表示dependency作用在测试时,不作用在运行时。 只在测试时使用,用于编译和运行测试代码。不会随项目发布。</td></tr><tr><td><code>system </code></td><td>与provided类似,但是它不会去maven仓库寻找依赖,而是在本地找;而<code>systemPath</code>标签将提供本地路径</td></tr><tr><td>import</td><td>这个标签就是 引入该dependency的pom中定义的所有dependency定义</td></tr></tbody></table>
|
||||
### optional可选依赖
|
||||
|
||||
在开发阶段需要的类,但是在运行阶段可能不需要的类,就不需要再打包的时候导入到其中。
|
||||
|
||||
557
maven/02 mavenSetting.md
Normal file
@@ -0,0 +1,557 @@
|
||||
# Maven的settings.xml配置详解
|
||||
|
||||
|
||||
1 基本介绍
|
||||
maven的两大配置文件:settings.xml和pom.xml。其中settings.xml是maven的全局配置文件,pom.xml则是文件所在项目的局部配置。
|
||||
|
||||
1.1 settings.xml文件位置
|
||||
①全局配置文件:${M2_HOME}/conf/settings.xml,对操作系统所有者生效
|
||||
|
||||
②用户配置:user.home/.m2/settings.xml,只对当前操作系统的使用者生效
|
||||
|
||||
1.2 配置文件优先级
|
||||
局部配置优先于全局配置。
|
||||
|
||||
配置优先级从高到低:pom.xml> user settings > global settings
|
||||
|
||||
如果这些文件同时存在,在应用配置时,会合并它们的内容,如果有重复的配置,优先级高的配置会覆盖优先级低的。如果全局配置和用户配置都存在,它们的内容将被合并,并且用户范围的settings.xml会覆盖全局的settings.xml。
|
||||
|
||||
1.3 注意事项
|
||||
note1: Maven安装后,用户目录下不会自动生成settings.xml,只有全局配置文件。如果需要创建用户范围的settings.xml,可以将安装路径下的settings复制到目录${user.home}/.m2/。Maven默认的settings.xml是一个包含了注释和例子的模板,可以快速的修改它来达到你的要求。
|
||||
note2: 全局配置一旦更改,所有的用户都会受到影响,而且如果maven进行升级,所有的配置都会被清除,所以要提前复制和备份${M2_HOME}/conf/settings.xml文件,一般情况下不推荐配置全局的settings.xml。
|
||||
2 标签详解
|
||||
2.1 顶级元素概览
|
||||
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
|
||||
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
|
||||
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0
|
||||
https://maven.apache.org/xsd/settings-1.0.0.xsd">
|
||||
|
||||
<!-- 该值表示构建系统本地仓库的路径,默认值:~/.m2/repository -->
|
||||
<localRepository/>
|
||||
|
||||
<!--
|
||||
作用:表示maven是否需要和用户交互以获得输入
|
||||
如果maven需要和用户交互以获得输入,则设置成true,反之则应为false。默认为true。
|
||||
-->
|
||||
<interactiveMode/>
|
||||
|
||||
<!--
|
||||
作用:maven是否需要使用plugin-registry.xml文件来管理插件版本。
|
||||
如果需要让maven使用文件~/.m2/plugin-registry.xml来管理插件版本,则设为true。默认为false。
|
||||
-->
|
||||
<usePluginRegistry/>
|
||||
|
||||
<!--
|
||||
作用:表示maven是否需要在离线模式下运行。
|
||||
如果构建系统需要在离线模式下运行,则为true,默认为false。
|
||||
当由于网络设置原因或者安全因素,构建服务器不能连接远程仓库的时候,该配置就十分有用。
|
||||
-->
|
||||
<offline/>
|
||||
|
||||
<!--
|
||||
作用:当插件的组织id(groupId)没有显式提供时,供搜寻插件组织Id(groupId)的列表。
|
||||
该元素包含一个pluginGroup元素列表,每个子元素包含了一个组织Id(groupId)。
|
||||
当我们使用某个插件,并且没有在命令行为其提供组织Id(groupId)的时候,Maven就会使用该列表。
|
||||
默认情况下该列表包含了org.apache.maven.plugins和org.codehaus.mojo。
|
||||
<pluginGroups>
|
||||
<pluginGroup>plugin的组织Id(groupId):org.codehaus.mojo</pluginGroup>
|
||||
</pluginGroups>
|
||||
-->
|
||||
<pluginGroups/>
|
||||
|
||||
<!-- 下面几个标签详细介绍 -->
|
||||
<servers/>
|
||||
<mirrors/>
|
||||
<proxies/>
|
||||
<profiles/>
|
||||
<activeProfiles/>
|
||||
</settings>
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
10
|
||||
11
|
||||
12
|
||||
13
|
||||
14
|
||||
15
|
||||
16
|
||||
17
|
||||
18
|
||||
19
|
||||
20
|
||||
21
|
||||
22
|
||||
23
|
||||
24
|
||||
25
|
||||
26
|
||||
27
|
||||
28
|
||||
29
|
||||
30
|
||||
31
|
||||
32
|
||||
33
|
||||
34
|
||||
35
|
||||
36
|
||||
37
|
||||
38
|
||||
39
|
||||
40
|
||||
41
|
||||
42
|
||||
43
|
||||
44
|
||||
45
|
||||
2.2 标签servers
|
||||
作用:一般,仓库的下载和部署是在pom.xml文件中的repositories和distributionManagement元素中定义的。
|
||||
|
||||
然而,一般类似用户名、密码(有些仓库访问是需要安全认证的)等信息不应该在pom.xml文件中配置,
|
||||
|
||||
这些信息可以配置在settings.xml中。
|
||||
|
||||
<servers>
|
||||
<server>
|
||||
<!-- server的id,不是用户登录的id,该id与distributionManagement中repository元素的id相匹配 -->
|
||||
<id>serverId</id>
|
||||
|
||||
<!-- 鉴权用户名和鉴权密码表示服务器认证所需要的登录名和密码 -->
|
||||
<username>username</username>
|
||||
<password>password</password>
|
||||
|
||||
<!-- 鉴权时使用的私钥位置 -->
|
||||
<privateKey>${usr.home}/.ssh/id_dsa</privateKey>
|
||||
<!-- 鉴权时使用的私钥密码 -->
|
||||
<passphrase>passphrase</passphrase>
|
||||
|
||||
<!-- 文件被创建时的权限 -->
|
||||
<filePermissions>664</filePermissions>
|
||||
<!-- 目录被创建时的权限 -->
|
||||
<directoryPermissions>775</directoryPermissions>
|
||||
</server>
|
||||
</servers>
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
10
|
||||
11
|
||||
12
|
||||
13
|
||||
14
|
||||
15
|
||||
16
|
||||
17
|
||||
18
|
||||
19
|
||||
20
|
||||
2.3 标签mirrors
|
||||
<mirrors>
|
||||
<mirror>
|
||||
<!-- 该镜像的唯一标识符 -->
|
||||
<id>mirrorId</id>
|
||||
|
||||
<!-- 镜像名称 -->
|
||||
<name>name</name>
|
||||
|
||||
<!-- 该镜像的URL,构建系统会优先考虑使用该URL,而非使用默认的服务器URL -->
|
||||
<url>url</url>
|
||||
|
||||
<!-- 被镜像的服务器的id。例如,如果我们要设置了一个Maven中央仓库(http://repo.maven.apache.org/maven2/)的镜像,就需要将该元素设置成central。这必须和中央仓库的id central完全一致。 -->
|
||||
<mirrorOf>central</mirrorOf>
|
||||
</mirror>
|
||||
</mirrors>
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
10
|
||||
11
|
||||
12
|
||||
13
|
||||
14
|
||||
15
|
||||
2.4 标签profiles
|
||||
作用:根据环境参数来调整构建配置的列表。
|
||||
|
||||
settings.xml中的profile元素是pom.xml中profile元素的裁剪版本。
|
||||
|
||||
它包含了id、activation、repositories、pluginRepositories和 properties元素。这里的profile元素只包含这五个子元素是因为这里只关心构建系统这个整体(这正是settings.xml文件的角色定位),而非单独的项目对象模型设置。如果一个settings.xml中的profile被激活,它的值会覆盖任何其它定义在pom.xml中带有相同id的profile。
|
||||
|
||||
<profiles>
|
||||
<profile>
|
||||
<id>test</id> <!-- profile的唯一标识 -->
|
||||
<activation /> <!-- 自动触发profile的条件逻辑 -->
|
||||
<properties /> <!-- 扩展属性列表 -->
|
||||
<repositories /> <!-- 远程仓库列表 -->
|
||||
<pluginRepositories /> <!-- 插件仓库列表 -->
|
||||
</profile>
|
||||
</profiles>
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
2.4.1 activation
|
||||
作用:自动触发profile的条件逻辑。
|
||||
|
||||
如pom.xml中的profile一样,profile的作用在于它能够在某些特定的环境中自动使用某些特定的值;这些环境通过activation元素指定。
|
||||
|
||||
activation元素并不是激活profile的唯一方式。settings.xml文件中的activeProfile元素可以包含profile的id。profile也可以通过在命令行,使用-P标记和逗号分隔的列表来显式的激活(如,-P test)。
|
||||
|
||||
<activation>
|
||||
<!--profile默认是否激活的标识 -->
|
||||
<activeByDefault>false</activeByDefault>
|
||||
|
||||
<!--当匹配的jdk被检测到,profile被激活。例如,1.4激活JDK1.4,1.4.0_2,而!1.4激活所有版本不是以1.4开头的JDK。 -->
|
||||
<jdk>1.5</jdk>
|
||||
|
||||
<!--当匹配的操作系统属性被检测到,profile被激活。os元素可以定义一些操作系统相关的属性。 -->
|
||||
<os>
|
||||
<!--激活profile的操作系统的名字 -->
|
||||
<name>Windows XP</name>
|
||||
<!--激活profile的操作系统所属家族(如 'windows') -->
|
||||
<family>Windows</family>
|
||||
<!--激活profile的操作系统体系结构 -->
|
||||
<arch>x86</arch>
|
||||
<!--激活profile的操作系统版本 -->
|
||||
<version>5.1.2600</version>
|
||||
</os>
|
||||
|
||||
<!--如果Maven检测到某一个属性(其值可以在POM中通过${name}引用),其拥有对应的name = 值,Profile就会被激活。如果值字段是空的,那么存在属性名称字段就会激活profile,否则按区分大小写方式匹配属性值字段 -->
|
||||
<property>
|
||||
<!--激活profile的属性的名称 -->
|
||||
<name>mavenVersion</name>
|
||||
<!--激活profile的属性的值 -->
|
||||
<value>2.0.3</value>
|
||||
</property>
|
||||
|
||||
<!--提供一个文件名,通过检测该文件的存在或不存在来激活profile。missing检查文件是否存在,如果不存在则激活profile。另一方面,exists则会检查文件是否存在,如果存在则激活profile。 -->
|
||||
<file>
|
||||
<!--如果指定的文件存在,则激活profile。 -->
|
||||
<exists>${basedir}/file2.properties</exists>
|
||||
<!--如果指定的文件不存在,则激活profile。 -->
|
||||
<missing>${basedir}/file1.properties</missing>
|
||||
</file>
|
||||
</activation>
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
10
|
||||
11
|
||||
12
|
||||
13
|
||||
14
|
||||
15
|
||||
16
|
||||
17
|
||||
18
|
||||
19
|
||||
20
|
||||
21
|
||||
22
|
||||
23
|
||||
24
|
||||
25
|
||||
26
|
||||
27
|
||||
28
|
||||
29
|
||||
30
|
||||
31
|
||||
32
|
||||
33
|
||||
34
|
||||
35
|
||||
注:在maven工程的pom.xml所在目录下执行mvn help:active-profiles命令可以查看中央仓储的profile是否在工程中生效。
|
||||
|
||||
2.4.2 properties
|
||||
作用:对应profile的扩展属性列表。
|
||||
|
||||
maven属性和ant中的属性一样,可以用来存放一些值。这些值可以在pom.xml中的任何地方使用标记${X}来使用,这里X是指属性的名称。属性有五种不同的形式,并且都能在settings.xml文件中访问。
|
||||
|
||||
<!--
|
||||
1. env.X: 在一个变量前加上"env."的前缀,会返回一个shell环境变量。例如,"env.PATH"指代了$path环境变量(在Windows上是%PATH%)。
|
||||
2. project.x:指代了POM中对应的元素值。例如: <project><version>1.0</version></project>通过${project.version}获得version的值。
|
||||
3. settings.x: 指代了settings.xml中对应元素的值。例如:<settings><offline>false</offline></settings>通过 ${settings.offline}获得offline的值。
|
||||
4. Java System Properties: 所有可通过java.lang.System.getProperties()访问的属性都能在POM中使用该形式访问,例如 ${java.home}。
|
||||
5. x: 在<properties/>元素中,或者外部文件中设置,以${someVar}的形式使用。
|
||||
-->
|
||||
<properties>
|
||||
<user.install>${user.home}/our-project</user.install>
|
||||
</properties>
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
10
|
||||
注:如果该profile被激活,则可以在pom.xml中使用${user.install}。
|
||||
|
||||
2.4.3 repositories
|
||||
作用:远程仓库列表,它是maven用来填充构建系统本地仓库所使用的一组远程仓库。
|
||||
|
||||
<repositories>
|
||||
<!--包含需要连接到远程仓库的信息 -->
|
||||
<repository>
|
||||
<!--远程仓库唯一标识 -->
|
||||
<id>codehausSnapshots</id>
|
||||
<!--远程仓库名称 -->
|
||||
<name>Codehaus Snapshots</name>
|
||||
|
||||
<!--远程仓库URL,按protocol://hostname/path形式 -->
|
||||
<url>http://snapshots.maven.codehaus.org/maven2</url>
|
||||
|
||||
<!--如何处理远程仓库里发布版本的下载 -->
|
||||
<releases>
|
||||
<!--true或者false表示该仓库是否为下载某种类型构件(发布版,快照版)开启。 -->
|
||||
<enabled>false</enabled>
|
||||
<!--该元素指定更新发生的频率。Maven会比较本地POM和远程POM的时间戳。这里的选项是:always(一直),daily(默认,每日),interval:X(这里X是以分钟为单位的时间间隔),或者never(从不)。 -->
|
||||
<updatePolicy>always</updatePolicy>
|
||||
<!--当Maven验证构件校验文件失败时该怎么做-ignore(忽略),fail(失败),或者warn(警告)。 -->
|
||||
<checksumPolicy>warn</checksumPolicy>
|
||||
</releases>
|
||||
|
||||
<!--如何处理远程仓库里快照版本的下载。有了releases和snapshots这两组配置,POM就可以在每个单独的仓库中,为每种类型的构件采取不同的策略。例如,可能有人会决定只为开发目的开启对快照版本下载的支持。参见repositories/repository/releases元素 -->
|
||||
<snapshots>
|
||||
<enabled />
|
||||
<updatePolicy />
|
||||
<checksumPolicy />
|
||||
</snapshots>
|
||||
|
||||
<!--用于定位和排序构件的仓库布局类型-可以是default(默认)或者legacy(遗留)。Maven 2为其仓库提供了一个默认的布局;然而,Maven 1.x有一种不同的布局。我们可以使用该元素指定布局是default(默认)还是legacy(遗留)。 -->
|
||||
<layout>default</layout>
|
||||
</repository>
|
||||
</repositories>
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
10
|
||||
11
|
||||
12
|
||||
13
|
||||
14
|
||||
15
|
||||
16
|
||||
17
|
||||
18
|
||||
19
|
||||
20
|
||||
21
|
||||
22
|
||||
23
|
||||
24
|
||||
25
|
||||
26
|
||||
27
|
||||
28
|
||||
29
|
||||
30
|
||||
31
|
||||
32
|
||||
2.4.4 pluginRepositories
|
||||
作用:发现插件的远程仓库列表。
|
||||
|
||||
和repository类似,只是repository是管理jar包依赖的仓库,pluginRepositories则是管理插件的仓库。
|
||||
|
||||
maven插件是一种特殊类型的构件。由于这个原因,插件仓库独立于其它仓库。pluginRepositories元素的结构和repositories元素的结构类似。每个pluginRepository元素指定一个Maven可以用来寻找新插件的远程地址。
|
||||
|
||||
<pluginRepositories>
|
||||
<!-- 包含需要连接到远程插件仓库的信息 -->
|
||||
<!-- 参见profiles/profile/repositories/repository元素的说明 -->
|
||||
<pluginRepository>
|
||||
<id />
|
||||
<name />
|
||||
<url />
|
||||
|
||||
<releases>
|
||||
<enabled />
|
||||
<updatePolicy />
|
||||
<checksumPolicy />
|
||||
</releases>
|
||||
|
||||
<snapshots>
|
||||
<enabled />
|
||||
<updatePolicy />
|
||||
<checksumPolicy />
|
||||
</snapshots>
|
||||
|
||||
<layout />
|
||||
</pluginRepository>
|
||||
</pluginRepositories>
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
10
|
||||
11
|
||||
12
|
||||
13
|
||||
14
|
||||
15
|
||||
16
|
||||
17
|
||||
18
|
||||
19
|
||||
20
|
||||
21
|
||||
22
|
||||
23
|
||||
2.5 activeProfiles
|
||||
作用:手动激活profiles的列表,按照profile被应用的顺序定义activeProfile。
|
||||
|
||||
该元素包含了一组activeProfile元素,每个activeProfile都含有一个profile id。任何在activeProfile中定义的profile id,不论环境设置如何,其对应的 profile都会被激活。如果没有匹配的profile,则什么都不会发生。 例如,env-test是一个activeProfile,则在pom.xml(或者profile.xml)中对应id的profile会被激活。如果运行过程中找不到这样一个profile,Maven则会像往常一样运行。
|
||||
|
||||
<activeProfiles>
|
||||
<!-- 要激活的profile id -->
|
||||
<activeProfile>env</activeProfile>
|
||||
</activeProfiles>
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
3 番外篇:mirror和repository区别
|
||||
简单点来说,repository就是个仓库。maven里有两种仓库,本地仓库和远程仓库。远程仓库相当于公共的仓库,大家都能看到。本地仓库是你本地的一个山寨版,只有你看的到,主要起缓存作用。当你向仓库请求插件或依赖的时候,会先检查本地仓库里是否有。如果有则直接返回,否则会向远程仓库请求,并做缓存。你也可以把你做的东西上传到本地仓库给你本地自己用,或上传到远程仓库,供大家使用。 internal repository是指在局域网内部搭建的repository,它跟central repository, jboss repository等的区别仅仅在于其URL是一个内部网址。
|
||||
|
||||
远程仓库可以在工程的pom.xml文件里指定。如果没指定,默认就会把下面这地方做远程仓库,即默认会到 http://repo1.maven.org/maven2 这个地方去请求插件和依赖包。
|
||||
|
||||
<repository>
|
||||
<snapshots>
|
||||
<enabled>false</enabled>
|
||||
</snapshots>
|
||||
<id>central</id>
|
||||
<name>Maven Repository Switchboard</name>
|
||||
<url>http://repo1.maven.org/maven2</url>
|
||||
</repository>
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
镜像是仓库的镜子,保存了被镜像仓库的所有的内容,主要针对远程仓库而言。配置mirror的目的一般是出于网速考虑。如果仓库X可以提供仓库Y存储的所有内容,那么就可以认为X是Y的一个镜像。换句话说,任何一个可以从仓库Y获得的构件,都能够从它的镜像中获取。举个例子,http://maven.NET.cn/content/groups/public/ 是中央仓库 http://repo1.maven.org/maven2/ 在中国的镜像,由于地理位置的因素,该镜像往往能够提供比中央仓库更快的服务。
|
||||
|
||||
id的值为central,表示该配置为中央仓库的镜像,任何对于中央仓库的请求都会转至该镜像,用户也可以使用同样的方法配置其他仓库的镜像。
|
||||
|
||||
关于镜像的一个更为常见的用法是结合私服。由于私服可以代理任何外部的公共仓库(包括中央仓库),因此,对于组织内部的Maven用户来说,使用一个私服地址就等于使用了所有需要的外部仓库,这可以将配置集中到私服,从而简化Maven本身的配置。在这种情况下,任何需要的构件都可以从私服获得,私服就是所有仓库的镜像。这时,可以配置这样的一个镜像,如例:
|
||||
|
||||
<settings>
|
||||
...
|
||||
<mirrors>
|
||||
<mirror>
|
||||
<id>internal-repository</id>
|
||||
<name>Internal Repository Manager</name>
|
||||
<url>http://192.168.1.100/maven2</url>
|
||||
<mirrorOf>*</mirrorOf>
|
||||
</mirror>
|
||||
</mirrors>
|
||||
...
|
||||
</settings>
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
10
|
||||
11
|
||||
12
|
||||
该例中的值为星号,表示该配置是所有Maven仓库的镜像,任何对于远程仓库的请求都会被转至http://192.168.1.100/maven2/。
|
||||
|
||||
如果该镜像仓库需要认证,则配置一个Id为internal-repository的即可。
|
||||
|
||||
为了满足一些复杂的需求,Maven还支持更高级的镜像配置:
|
||||
|
||||
*\
|
||||
|
||||
匹配所有远程仓库。
|
||||
|
||||
\external:*\
|
||||
|
||||
匹配所有远程仓库,使用localhost的除外,使用file://协议的除外。也就是说,匹配所有不在本机上的远程仓库。
|
||||
|
||||
\repo1,repo2\
|
||||
|
||||
匹配仓库repo1和repo2,使用逗号分隔多个远程仓库。
|
||||
|
||||
*,!repo1\
|
||||
|
||||
匹配所有远程仓库,repo1除外,使用感叹号将仓库从匹配中排除。
|
||||
|
||||
需要注意的是,由于镜像仓库完全屏蔽了被镜像仓库,当镜像仓库不稳定或者停止服务的时候,Maven仍将无法访问被镜像仓库,因而将无法下载构件
|
||||
|
||||
一般远程仓库的镜像配置为阿里云的镜像:
|
||||
|
||||
<mirrors>
|
||||
<mirror>
|
||||
<id>alimaven</id>
|
||||
<name>aliyun maven</name>
|
||||
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
|
||||
<mirrorOf>central</mirrorOf>
|
||||
</mirror>
|
||||
</mirrors>
|
||||
|
||||
|
||||
### 多版本
|
||||
|
||||
由于在多maven版本,多仓库环境下,某些项目开发的时候需要特殊指定对应的仓库地址。
|
||||
|
||||
```sh
|
||||
mvn package install -DskipTests docker:build -s /home/xxx/.m2/settings.xml -Dmaven.repo.local=/home/xxx/.m2/repository
|
||||
```
|
||||
|
||||
命令说明:
|
||||
* package:打包
|
||||
* install:保存到本地仓库
|
||||
* -DskipTests:忽略测试类
|
||||
* docker:build:生成docker镜像
|
||||
* -s:指定settings文件
|
||||
* -Dmaven.repo.local:指定本地仓库地址
|
||||
13
maven/maven继承关系.md
Normal file
@@ -0,0 +1,13 @@
|
||||
https://blog.csdn.net/xiaoheihai666/article/details/125936493
|
||||
|
||||
|
||||
今天想的是做一个springcloud项目,再导入父依赖的时候,发现有的 包爆红,显示不能找到包,我以为是maven问题,结果去setting.xml文件中看配置,确实都配置完了,也添加了阿里云镜像。又因为是maven与idea本版不相容的问题,结果发现不是。于是我新建一个项目在中加了一个本地仓库没有的包,结果发现可以进行自动导入包。
|
||||
|
||||
因此,问题就很明显了,在我新建的项目springcloud项目中pom文件的问题
|
||||
然后,想到这是一个父工程,找到原因是中只是声明依赖,而不实现引入。所以在声明前,应该确保对应版本的依赖已经下载到了本地仓库。
|
||||
|
||||
|
||||
|
||||
1. dependencyManagement中只是声明包,如果包没有使用到,且没有下载到本地,则包会飘红。也就是说dependencyMangement中声明的GAV不会触发下载。
|
||||
|
||||
2. 不经dependency是树状关系,dependencymanagement出了继承的线性关系,也可以引入其他的pom构建成树状关系。所以继承关系和依赖关系都可以是很复杂的结构!。
|
||||
1
start.sh
@@ -10,3 +10,4 @@ find . -name "*.java" -exec wc -l {} \; | awk 'BEGIN{num=0} {num+=$1;print $1;}
|
||||
|
||||
# 查看今天的日志
|
||||
find . -name "*.log" | xargs grep "wrod"
|
||||
n
|
||||
414
test5.csv
@@ -1,414 +0,0 @@
|
||||
10.111.51.108,24
|
||||
10.111.67.138,24
|
||||
10.111.67.137,24
|
||||
10.111.50.3,24
|
||||
10.111.67.70,24
|
||||
10.111.67.71,24
|
||||
10.111.164.139,24
|
||||
10.111.67.132,24
|
||||
10.111.67.131,24
|
||||
10.111.164.137,24
|
||||
10.111.67.75,24
|
||||
10.111.67.72,24
|
||||
10.111.164.135,24
|
||||
10.111.164.136,24
|
||||
10.111.67.73,24
|
||||
10.111.51.101,24
|
||||
10.111.51.103,24
|
||||
10.111.51.104,24
|
||||
10.111.51.100,24
|
||||
10.111.68.171,24
|
||||
10.111.51.116,24
|
||||
10.111.164.2,24
|
||||
10.111.68.172,24
|
||||
10.111.51.119,24
|
||||
10.111.67.56,24
|
||||
10.111.67.57,24
|
||||
10.111.67.54,24
|
||||
10.111.67.55,24
|
||||
10.111.67.145,24
|
||||
10.111.164.9,24
|
||||
10.111.67.147,24
|
||||
10.111.67.58,24
|
||||
10.111.67.146,24
|
||||
10.111.67.59,24
|
||||
10.111.164.128,24
|
||||
10.111.67.143,24
|
||||
10.111.67.142,24
|
||||
10.111.67.63,24
|
||||
10.111.67.64,24
|
||||
10.111.164.127,24
|
||||
10.111.67.62,24
|
||||
10.111.164.123,24
|
||||
10.111.51.113,24
|
||||
10.111.51.114,24
|
||||
10.111.164.121,24
|
||||
10.111.68.160,24
|
||||
10.111.67.46,24
|
||||
10.111.67.49,24
|
||||
10.111.67.47,24
|
||||
10.111.67.48,24
|
||||
10.111.164.118,24
|
||||
10.111.67.52,24
|
||||
10.111.164.115,24
|
||||
10.111.164.116,24
|
||||
10.111.67.53,24
|
||||
10.111.67.51,24
|
||||
10.111.164.114,24
|
||||
10.111.68.167,24
|
||||
10.111.68.166,24
|
||||
10.111.68.153,24
|
||||
10.111.68.152,24
|
||||
10.111.68.151,24
|
||||
10.111.67.34,24
|
||||
10.111.67.35,24
|
||||
10.111.67.32,24
|
||||
10.111.67.33,24
|
||||
10.111.67.38,24
|
||||
10.111.67.39,24
|
||||
10.111.67.36,24
|
||||
10.111.67.37,24
|
||||
10.111.164.107,24
|
||||
10.111.67.42,24
|
||||
10.111.67.40,24
|
||||
10.111.68.157,24
|
||||
10.111.164.100,24
|
||||
10.111.68.156,24
|
||||
10.111.68.155,24
|
||||
10.111.68.154,24
|
||||
10.111.68.159,24
|
||||
10.111.68.158,24
|
||||
10.111.66.254,24
|
||||
10.111.164.180,24
|
||||
10.111.66.253,24
|
||||
10.111.67.29,24
|
||||
10.111.66.251,24
|
||||
10.111.67.23,24
|
||||
10.111.67.24,24
|
||||
10.111.67.21,24
|
||||
10.111.67.22,24
|
||||
10.111.67.27,24
|
||||
10.111.67.28,24
|
||||
10.111.67.25,24
|
||||
10.111.67.26,24
|
||||
10.111.67.174,24
|
||||
10.111.67.170,24
|
||||
10.111.65.217,24
|
||||
10.111.67.30,24
|
||||
10.111.65.216,24
|
||||
10.111.67.31,24
|
||||
10.111.67.171,24
|
||||
10.111.66.255,24
|
||||
10.111.50.236,24
|
||||
10.111.50.235,24
|
||||
10.111.67.16,24
|
||||
10.111.65.222,24
|
||||
10.111.65.221,24
|
||||
10.111.67.15,24
|
||||
10.111.65.224,24
|
||||
10.111.65.223,24
|
||||
10.111.67.184,24
|
||||
10.111.65.226,24
|
||||
10.111.67.186,24
|
||||
10.111.65.225,24
|
||||
10.111.65.228,24
|
||||
10.111.65.227,24
|
||||
10.111.67.183,24
|
||||
10.111.65.229,24
|
||||
10.111.67.182,24
|
||||
10.111.51.129,24
|
||||
10.111.67.156,24
|
||||
10.111.67.155,24
|
||||
10.111.67.157,24
|
||||
10.111.67.154,24
|
||||
10.111.51.123,24
|
||||
10.111.51.124,24
|
||||
10.111.51.125,24
|
||||
10.111.68.196,24
|
||||
10.111.68.195,24
|
||||
10.111.67.167,24
|
||||
10.111.67.166,24
|
||||
10.111.67.169,24
|
||||
10.111.67.168,24
|
||||
10.111.67.163,24
|
||||
10.111.67.165,24
|
||||
10.111.67.164,24
|
||||
10.111.65.206,24
|
||||
10.111.65.205,24
|
||||
10.111.65.208,24
|
||||
10.111.65.207,24
|
||||
10.111.164.145,24
|
||||
10.111.164.140,24
|
||||
10.111.51.130,24
|
||||
10.111.51.131,24
|
||||
10.111.164.141,24
|
||||
10.111.51.132,24
|
||||
10.111.164.47,24
|
||||
10.111.164.46,24
|
||||
10.111.169.246,24
|
||||
10.111.169.242,24
|
||||
10.111.68.109,24
|
||||
10.111.68.108,24
|
||||
10.111.68.107,24
|
||||
10.111.169.248,24
|
||||
10.111.68.228,24
|
||||
10.111.68.102,24
|
||||
10.111.68.225,24
|
||||
10.111.68.101,24
|
||||
10.111.68.226,24
|
||||
10.111.68.227,24
|
||||
10.111.68.220,24
|
||||
10.111.68.106,24
|
||||
10.111.68.221,24
|
||||
10.111.68.105,24
|
||||
10.111.68.222,24
|
||||
10.111.68.104,24
|
||||
10.111.68.103,24
|
||||
10.111.68.223,24
|
||||
10.111.164.58,24
|
||||
10.111.164.59,24
|
||||
10.111.169.251,24
|
||||
10.111.169.252,24
|
||||
10.111.169.253,24
|
||||
10.111.68.217,24
|
||||
10.111.68.218,24
|
||||
10.111.68.219,24
|
||||
10.111.68.213,24
|
||||
10.111.68.215,24
|
||||
10.111.68.216,24
|
||||
10.111.68.210,24
|
||||
10.111.68.211,24
|
||||
10.111.68.212,24
|
||||
10.111.164.22,24
|
||||
10.111.164.23,24
|
||||
10.111.68.206,24
|
||||
10.111.68.207,24
|
||||
10.111.68.208,24
|
||||
10.111.164.29,24
|
||||
10.111.51.94,24
|
||||
10.111.164.197,24
|
||||
10.111.51.95,24
|
||||
10.111.164.198,24
|
||||
10.111.68.205,24
|
||||
10.111.164.195,24
|
||||
10.111.164.196,24
|
||||
10.111.51.97,24
|
||||
10.111.68.201,24
|
||||
10.111.164.191,24
|
||||
10.111.164.32,24
|
||||
10.111.164.190,24
|
||||
10.111.164.31,24
|
||||
10.111.164.34,24
|
||||
10.111.164.185,24
|
||||
10.111.96.155,24
|
||||
10.111.96.153,24
|
||||
10.111.6.8,24
|
||||
10.111.51.81,24
|
||||
10.111.96.150,24
|
||||
10.111.169.201,24
|
||||
10.111.68.145,24
|
||||
10.111.68.144,24
|
||||
10.111.68.143,24
|
||||
10.111.96.159,24
|
||||
10.111.96.145,24
|
||||
10.111.164.14,24
|
||||
10.111.51.90,24
|
||||
10.111.68.131,24
|
||||
10.111.96.143,24
|
||||
10.111.68.130,24
|
||||
10.111.164.13,24
|
||||
10.111.169.213,24
|
||||
10.111.67.101,24
|
||||
10.111.67.100,24
|
||||
10.111.169.218,24
|
||||
10.111.68.135,24
|
||||
10.111.68.134,24
|
||||
10.111.51.82,24
|
||||
10.111.68.133,24
|
||||
10.111.68.132,24
|
||||
10.111.68.139,24
|
||||
10.111.68.138,24
|
||||
10.111.96.148,24
|
||||
10.111.51.89,24
|
||||
10.111.68.137,24
|
||||
10.111.96.149,24
|
||||
10.111.68.136,24
|
||||
10.111.68.241,24
|
||||
10.111.68.120,24
|
||||
10.111.68.129,24
|
||||
10.111.68.124,24
|
||||
10.111.68.246,24
|
||||
10.111.68.247,24
|
||||
10.111.68.121,24
|
||||
10.111.96.137,24
|
||||
10.111.96.138,24
|
||||
10.111.68.245,24
|
||||
10.111.163.24,24
|
||||
10.111.67.209,24
|
||||
10.111.67.202,24
|
||||
10.111.68.119,24
|
||||
10.111.68.118,24
|
||||
10.111.68.235,24
|
||||
10.111.68.113,24
|
||||
10.111.68.112,24
|
||||
10.111.68.236,24
|
||||
10.111.68.237,24
|
||||
10.111.68.111,24
|
||||
10.111.68.238,24
|
||||
10.111.68.110,24
|
||||
10.111.68.117,24
|
||||
10.111.68.231,24
|
||||
10.111.68.116,24
|
||||
10.111.68.115,24
|
||||
10.111.68.114,24
|
||||
10.111.68.234,24
|
||||
10.111.23.212,24
|
||||
10.111.6.74,24
|
||||
10.111.167.232,24
|
||||
10.111.23.213,24
|
||||
10.111.167.235,24
|
||||
10.111.23.215,24
|
||||
10.111.96.194,24
|
||||
10.111.96.191,24
|
||||
10.111.96.190,24
|
||||
10.111.167.230,24
|
||||
10.111.96.188,24
|
||||
10.111.96.185,24
|
||||
10.111.167.229,24
|
||||
10.111.96.179,24
|
||||
10.111.96.177,24
|
||||
10.111.96.178,24
|
||||
10.111.96.174,24
|
||||
10.111.169.185,24
|
||||
10.111.23.202,24
|
||||
10.111.169.194,24
|
||||
10.111.162.186,24
|
||||
10.111.169.195,24
|
||||
10.111.96.164,24
|
||||
10.111.167.248,24
|
||||
10.111.23.203,24
|
||||
10.111.96.163,24
|
||||
10.111.169.191,24
|
||||
10.111.23.204,24
|
||||
10.111.96.160,24
|
||||
10.111.96.161,24
|
||||
10.111.23.207,24
|
||||
10.111.23.208,24
|
||||
10.111.164.88,24
|
||||
10.111.164.83,24
|
||||
10.111.164.84,24
|
||||
10.111.164.98,24
|
||||
10.111.164.99,24
|
||||
10.111.164.96,24
|
||||
10.111.164.97,24
|
||||
10.111.164.91,24
|
||||
10.111.164.94,24
|
||||
10.111.164.95,24
|
||||
10.111.164.92,24
|
||||
10.111.67.0,24
|
||||
10.111.67.4,24
|
||||
10.111.67.6,24
|
||||
10.111.67.5,24
|
||||
10.111.67.8,24
|
||||
10.111.67.7,24
|
||||
10.111.67.9,24
|
||||
10.111.167.210,24
|
||||
10.111.167.213,24
|
||||
10.111.167.214,24
|
||||
10.111.164.67,24
|
||||
10.111.167.216,24
|
||||
10.111.164.60,24
|
||||
10.111.167.218,24
|
||||
10.111.167.219,24
|
||||
10.111.164.76,24
|
||||
10.111.164.74,24
|
||||
10.111.167.200,24
|
||||
10.111.167.201,24
|
||||
10.111.167.202,24
|
||||
10.111.164.78,24
|
||||
10.111.167.204,24
|
||||
10.111.164.73,24
|
||||
10.111.167.206,24
|
||||
10.111.167.207,24
|
||||
10.111.167.208,24
|
||||
10.111.167.209,24
|
||||
10.111.167.198,24
|
||||
10.111.170.44,24
|
||||
10.111.167.190,24
|
||||
10.111.167.196,24
|
||||
10.111.167.197,24
|
||||
10.111.170.42,24
|
||||
10.111.170.43,24
|
||||
10.111.167.187,24
|
||||
10.111.167.188,24
|
||||
10.111.167.189,24
|
||||
10.111.170.27,24
|
||||
10.111.50.247,24
|
||||
10.111.50.248,24
|
||||
10.111.50.246,24
|
||||
10.111.65.231,24
|
||||
10.111.50.243,24
|
||||
10.111.50.244,24
|
||||
10.111.65.230,24
|
||||
10.111.50.242,24
|
||||
10.111.65.234,24
|
||||
10.111.50.249,24
|
||||
client_address,24
|
||||
10.111.50.250,24
|
||||
10.111.170.35,24
|
||||
10.111.170.33,24
|
||||
10.111.170.34,24
|
||||
10.111.68.88,24
|
||||
10.111.68.89,24
|
||||
10.111.68.94,24
|
||||
10.111.68.95,24
|
||||
10.111.68.96,24
|
||||
10.111.68.90,24
|
||||
10.111.68.77,24
|
||||
10.111.68.82,24
|
||||
10.111.68.83,24
|
||||
10.111.22.81,24
|
||||
10.111.68.87,24
|
||||
10.111.22.80,24
|
||||
10.111.68.84,24
|
||||
10.111.170.13,24
|
||||
10.111.170.11,24
|
||||
10.111.68.67,24
|
||||
10.111.68.71,24
|
||||
10.111.22.73,24
|
||||
10.111.68.72,24
|
||||
10.111.68.75,24
|
||||
10.111.68.76,24
|
||||
10.111.164.201,24
|
||||
10.111.68.74,24
|
||||
10.111.164.202,24
|
||||
10.111.164.200,24
|
||||
10.111.167.176,24
|
||||
10.111.167.177,24
|
||||
10.111.23.199,24
|
||||
10.111.68.57,24
|
||||
10.111.68.58,24
|
||||
10.111.68.56,24
|
||||
10.111.167.173,24
|
||||
10.111.68.59,24
|
||||
10.111.167.174,24
|
||||
10.111.167.175,24
|
||||
10.111.68.60,24
|
||||
10.111.68.61,24
|
||||
10.111.68.64,24
|
||||
10.111.68.65,24
|
||||
10.111.68.62,24
|
||||
10.111.67.78,24
|
||||
10.111.68.46,24
|
||||
10.111.67.79,24
|
||||
10.111.68.47,24
|
||||
10.111.67.76,24
|
||||
10.111.67.77,24
|
||||
10.111.68.45,24
|
||||
10.111.68.48,24
|
||||
10.111.67.80,24
|
||||
10.111.68.53,24
|
||||
10.111.68.54,24
|
||||
10.111.67.175,23
|
||||
10.111.164.3,20
|
||||
10.111.164.33,1
|
||||
|