java 多线程并发
@@ -1,4 +1,6 @@
|
||||
|
||||
> 参考文献
|
||||
> * [java nio一篇博客](https://blog.csdn.net/forezp/article/details/88414741)
|
||||
> * [java nio并发编程网](http://ifeve.com/overview/)
|
||||
|
||||
# NIO
|
||||
|
||||
|
||||
61
Java基础教程/Java实用技巧/01 Java模板变量替换.md
Normal file
@@ -0,0 +1,61 @@
|
||||
## 1 org.apache.commons.text
|
||||
|
||||
变量默认前缀是`${`,后缀是`}`
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>org.apache.commons</groupId>
|
||||
<artifactId>commons-lang3</artifactId>
|
||||
<version>3.12.0</version>
|
||||
</dependency>
|
||||
```
|
||||
```java
|
||||
Map valuesMap = new HashMap();
|
||||
valuesMap.put("code", 1234);
|
||||
String templateString = "验证码:${code},您正在登录管理后台,5分钟内输入有效。";
|
||||
StringSubstitutor sub = new StringSubstitutor(valuesMap);
|
||||
String content= sub.replace(templateString);
|
||||
System.out.println(content);
|
||||
验证码:1234,您正在登录管理后台,5分钟内输入有效。
|
||||
```
|
||||
### 修改前缀、后缀
|
||||
```java
|
||||
Map valuesMap = new HashMap();
|
||||
valuesMap.put("code", 1234);
|
||||
String templateString = "验证码:[code],您正在登录管理后台,5分钟内输入有效。";
|
||||
StringSubstitutor sub = new StringSubstitutor(valuesMap);
|
||||
//修改前缀、后缀
|
||||
sub.setVariablePrefix("[");
|
||||
sub.setVariableSuffix("]");
|
||||
String content= sub.replace(templateString);
|
||||
System.out.println(content);
|
||||
```
|
||||
|
||||
## 2 org.springframework.expression
|
||||
```java
|
||||
String smsTemplate = "验证码:#{[code]},您正在登录管理后台,5分钟内输入有效。";
|
||||
Map<String, Object> params = new HashMap<>();
|
||||
params.put("code", 12345);;
|
||||
|
||||
ExpressionParser parser = new SpelExpressionParser();
|
||||
TemplateParserContext parserContext = new TemplateParserContext();
|
||||
String content = parser.parseExpression(smsTemplate,parserContext).getValue(params, String.class);
|
||||
|
||||
System.out.println(content);
|
||||
验证码:12345,您正在登录管理后台,5分钟内输入有效。
|
||||
```
|
||||
ExpressionParser是简单的用java编写的表达式解析器,官方文档:
|
||||
|
||||
http://docs.spring.io/spring/docs/current/spring-framework-reference/html/expressions.html
|
||||
|
||||
## 3 java.text.MessageFormat
|
||||
```java
|
||||
Object[] params = new Object[]{"1234", "5"};
|
||||
String msg = MessageFormat.format("验证码:{0},您正在登录管理后台,{1}分钟内输入有效。", params);
|
||||
System.out.println(msg);
|
||||
验证码:1234,您正在登录管理后台,10分钟内输入有效。
|
||||
```
|
||||
## 4 java.lang.String
|
||||
```java
|
||||
String s = String.format("My name is %s. I am %d.", "Tom", 18);
|
||||
System.out.println(s);
|
||||
```
|
||||
413
Java基础教程/Java并发编程/01 Java并发实现.md
Normal file
@@ -0,0 +1,413 @@
|
||||
# java并发实现
|
||||
|
||||
## 1 并发实现
|
||||
|
||||
3中基本方法和4中拓展方法。
|
||||
|
||||
使用线程的3中基本方法
|
||||
|
||||
- 实现 Runnable 接口;
|
||||
- 实现 Callable 接口;
|
||||
- 继承 Thread 类。
|
||||
|
||||
|
||||
使用四种拓展的方法
|
||||
* 匿名内部类
|
||||
* ThreadPool&Executor
|
||||
* 定时器timer
|
||||
* stream
|
||||
|
||||
|
||||
实现 Runnable 和 Callable 接口的类只能当做一个可以在线程中运行的任务,不是真正意义上的线程,因此最后还需要通过 Thread 来调用。
|
||||
|
||||
通过线程驱动执行线程任务
|
||||
|
||||
|
||||
### 实现 Runnable 接口
|
||||
|
||||
需要实现接口中的 run() 方法。
|
||||
|
||||
```java
|
||||
public class MyRunnable implements Runnable {
|
||||
@Override
|
||||
public void run() {
|
||||
// ...
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
使用 Runnable 实例再创建一个 Thread 实例,然后调用 Thread 实例的 start() 方法来启动线程。
|
||||
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
MyRunnable instance = new MyRunnable();
|
||||
Thread thread = new Thread(instance);
|
||||
thread.start();
|
||||
}
|
||||
```
|
||||
|
||||
### 实现 Callable 接口
|
||||
|
||||
与 Runnable 相比,Callable 可以有返回值,返回值通过 FutureTask 进行封装。
|
||||
|
||||
```java
|
||||
public class MyCallable implements Callable<Integer> {
|
||||
public Integer call() {
|
||||
return 123;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
public static void main(String[] args) throws ExecutionException, InterruptedException {
|
||||
MyCallable mc = new MyCallable();
|
||||
FutureTask<Integer> ft = new FutureTask<>(mc);
|
||||
Thread thread = new Thread(ft);
|
||||
thread.start();
|
||||
System.out.println(ft.get());
|
||||
}
|
||||
```
|
||||
|
||||
### 继承 Thread 类
|
||||
|
||||
同样也是需要实现 run() 方法,因为 Thread 类也实现了 Runable 接口。
|
||||
|
||||
当调用 start() 方法启动一个线程时,虚拟机会将该线程放入就绪队列中等待被调度,当一个线程被调度时会执行该线程的 run() 方法。
|
||||
|
||||
```java
|
||||
public class MyThread extends Thread {
|
||||
public void run() {
|
||||
// ...
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
MyThread mt = new MyThread();
|
||||
mt.start();
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 通过内部类的方式实现多线程
|
||||
直接可以通过Thread类的start()方法进行实现,因为Thread类实现了Runnable接口,并重写了run方法,在run方法中实现自己的逻辑,例如:
|
||||
|
||||
```java
|
||||
//这里通过了CountDownLatch,来进行阻塞,来观察两个线程的启动,这样更加体现的明显一些:
|
||||
public static CountDownLatch countDownLatch=new CountDownLatch(2);
|
||||
|
||||
public static void main(String[] args) {
|
||||
new Thread(()->{
|
||||
countDownLatch.countDown();
|
||||
try {
|
||||
countDownLatch.await();
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.println("T1");
|
||||
}).start();
|
||||
|
||||
new Thread(()->{
|
||||
countDownLatch.countDown();
|
||||
try {
|
||||
countDownLatch.await();
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.println("T2");
|
||||
}).start();
|
||||
}
|
||||
```
|
||||
|
||||
### 通过线程池来实现多线程
|
||||
线程池可以根据不同的场景来选择不同的线程池来进行实现
|
||||
```java
|
||||
//实现代码如下:
|
||||
public class Demo5 {
|
||||
|
||||
public static void main(String[] args) {
|
||||
ExecutorService executorService = Executors.newFixedThreadPool(5);
|
||||
for(int i=0;i<5;i++){
|
||||
int finalI = i;
|
||||
executorService.execute(()-> {
|
||||
System.out.println(finalI);
|
||||
});
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 通过Timer定时器来实现多线程
|
||||
就Timer来讲就是一个调度器,而TimerTask呢只是一个实现了run方法的一个类,而具体的TimerTask需要由你自己来实现,同样根据参数得不同存在多种执行方式,例如其中延迟定时任务这样:
|
||||
|
||||
```java
|
||||
//具体代码如下:
|
||||
public class Demo6 {
|
||||
|
||||
public static void main(String[] args) {
|
||||
Timer timer=new Timer();
|
||||
timer.schedule(new TimerTask(){
|
||||
@Override
|
||||
public void run() {
|
||||
System.out.println(1);
|
||||
}
|
||||
},2000l,1000l);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 通过stream实现多线程
|
||||
jdk1.8 API添加了一个新的抽象称为流Stream,可以让你以一种声明的方式处理数据。
|
||||
Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。
|
||||
具体简单代码实现如下:
|
||||
|
||||
```java
|
||||
//代码实现:
|
||||
public class Demo7 {
|
||||
|
||||
//为了更形象体现并发,通过countDownLatch进行阻塞
|
||||
static CountDownLatch countDownLatch=new CountDownLatch(6);
|
||||
public static void main(String[] args) {
|
||||
List list=new ArrayList<>();
|
||||
list.add(1);
|
||||
list.add(2);
|
||||
list.add(3);
|
||||
list.add(4);
|
||||
list.add(5);
|
||||
list.add(6);
|
||||
|
||||
list.parallelStream().forEach(p->{
|
||||
//将所有请求在打印之前进行阻塞,方便观察
|
||||
countDownLatch.countDown();
|
||||
try {
|
||||
System.out.println("线程执行到这里啦");
|
||||
Thread.sleep(10000);
|
||||
countDownLatch.await();
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.println(p);
|
||||
});
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## 2 线程基础设置
|
||||
|
||||
### Daemon
|
||||
|
||||
守护线程是程序运行时在后台提供服务的线程,不属于程序中不可或缺的部分。
|
||||
|
||||
当所有非守护线程结束时,程序也就终止,同时会杀死所有守护线程。
|
||||
|
||||
main() 属于非守护线程。
|
||||
|
||||
在线程启动之前使用 setDaemon() 方法可以将一个线程设置为守护线程。
|
||||
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
Thread thread = new Thread(new MyRunnable());
|
||||
thread.setDaemon(true);
|
||||
}
|
||||
```
|
||||
|
||||
### sleep
|
||||
|
||||
Thread.sleep(millisec) 方法会休眠当前正在执行的线程,millisec 单位为毫秒。
|
||||
|
||||
sleep() 可能会抛出 InterruptedException,因为异常不能跨线程传播回 main() 中,因此必须在本地进行处理。线程中抛出的其它异常也同样需要在本地进行处理。
|
||||
|
||||
```java
|
||||
public void run() {
|
||||
try {
|
||||
Thread.sleep(3000);
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### yield
|
||||
|
||||
对静态方法 Thread.yield() 的调用声明了当前线程已经完成了生命周期中最重要的部分,可以切换给其它线程来执行。该方法只是对线程调度器的一个建议,而且也只是建议具有相同优先级的其它线程可以运行。
|
||||
|
||||
```java
|
||||
public void run() {
|
||||
Thread.yield();
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## 3 中断
|
||||
|
||||
一个线程执行完毕之后会自动结束,如果在运行过程中发生异常也会提前结束。
|
||||
|
||||
### InterruptedException
|
||||
|
||||
通过调用一个线程的 interrupt() 来中断该线程,如果该线程处于阻塞、限期等待或者无限期等待状态,那么就会抛出 InterruptedException,从而提前结束该线程。但是不能中断 I/O 阻塞和 synchronized 锁阻塞。
|
||||
|
||||
对于以下代码,在 main() 中启动一个线程之后再中断它,由于线程中调用了 Thread.sleep() 方法,因此会抛出一个 InterruptedException,从而提前结束线程,不执行之后的语句。
|
||||
|
||||
```java
|
||||
public class InterruptExample {
|
||||
|
||||
private static class MyThread1 extends Thread {
|
||||
@Override
|
||||
public void run() {
|
||||
try {
|
||||
Thread.sleep(2000);
|
||||
System.out.println("Thread run");
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
Thread thread1 = new MyThread1();
|
||||
thread1.start();
|
||||
thread1.interrupt();
|
||||
System.out.println("Main run");
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
Main run
|
||||
java.lang.InterruptedException: sleep interrupted
|
||||
at java.lang.Thread.sleep(Native Method)
|
||||
at InterruptExample.lambda$main$0(InterruptExample.java:5)
|
||||
at InterruptExample$$Lambda$1/713338599.run(Unknown Source)
|
||||
at java.lang.Thread.run(Thread.java:745)
|
||||
```
|
||||
|
||||
### interrupted()
|
||||
|
||||
如果一个线程的 run() 方法执行一个无限循环,并且没有执行 sleep() 等会抛出 InterruptedException 的操作,那么调用线程的 interrupt() 方法就无法使线程提前结束。
|
||||
|
||||
但是调用 interrupt() 方法会设置线程的中断标记,此时调用 interrupted() 方法会返回 true。因此可以在循环体中使用 interrupted() 方法来判断线程是否处于中断状态,从而提前结束线程。
|
||||
|
||||
```java
|
||||
public class InterruptExample {
|
||||
|
||||
private static class MyThread2 extends Thread {
|
||||
@Override
|
||||
public void run() {
|
||||
while (!interrupted()) {
|
||||
// ..
|
||||
}
|
||||
System.out.println("Thread end");
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
Thread thread2 = new MyThread2();
|
||||
thread2.start();
|
||||
thread2.interrupt();
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
Thread end
|
||||
```
|
||||
|
||||
### Executor 的中断操作
|
||||
|
||||
调用 Executor 的 shutdown() 方法会等待线程都执行完毕之后再关闭,但是如果调用的是 shutdownNow() 方法,则相当于调用每个线程的 interrupt() 方法。
|
||||
|
||||
以下使用 Lambda 创建线程,相当于创建了一个匿名内部线程。
|
||||
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
ExecutorService executorService = Executors.newCachedThreadPool();
|
||||
executorService.execute(() -> {
|
||||
try {
|
||||
Thread.sleep(2000);
|
||||
System.out.println("Thread run");
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
});
|
||||
executorService.shutdownNow();
|
||||
System.out.println("Main run");
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
Main run
|
||||
java.lang.InterruptedException: sleep interrupted
|
||||
at java.lang.Thread.sleep(Native Method)
|
||||
at ExecutorInterruptExample.lambda$main$0(ExecutorInterruptExample.java:9)
|
||||
at ExecutorInterruptExample$$Lambda$1/1160460865.run(Unknown Source)
|
||||
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
|
||||
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
|
||||
at java.lang.Thread.run(Thread.java:745)
|
||||
```
|
||||
|
||||
如果只想中断 Executor 中的一个线程,可以通过使用 submit() 方法来提交一个线程,它会返回一个 Future\<?\> 对象,通过调用该对象的 cancel(true) 方法就可以中断线程。
|
||||
|
||||
```java
|
||||
Future<?> future = executorService.submit(() -> {
|
||||
// ..
|
||||
});
|
||||
future.cancel(true);
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 4 线程状态转换
|
||||
|
||||
一个线程只能处于一种状态,并且这里的线程状态特指 Java 虚拟机的线程状态,不能反映线程在特定操作系统下的状态。
|
||||
|
||||
### 新建(NEW)
|
||||
|
||||
创建后尚未启动。
|
||||
|
||||
### 可运行(RUNABLE)
|
||||
|
||||
正在 Java 虚拟机中运行。但是在操作系统层面,它可能处于运行状态,也可能等待资源调度(例如处理器资源),资源调度完成就进入运行状态。所以该状态的可运行是指可以被运行,具体有没有运行要看底层操作系统的资源调度。
|
||||
|
||||
### 阻塞(BLOCKED)
|
||||
|
||||
请求获取 monitor lock 从而进入 synchronized 函数或者代码块,但是其它线程已经占用了该 monitor lock,所以出于阻塞状态。要结束该状态进入从而 RUNABLE 需要其他线程释放 monitor lock。
|
||||
|
||||
### 无限期等待(WAITING)
|
||||
|
||||
等待其它线程显式地唤醒。
|
||||
|
||||
阻塞和等待的区别在于,阻塞是被动的,它是在等待获取 monitor lock。而等待是主动的,通过调用 Object.wait() 等方法进入。
|
||||
|
||||
| 进入方法 | 退出方法 |
|
||||
| --- | --- |
|
||||
| 没有设置 Timeout 参数的 Object.wait() 方法 | Object.notify() / Object.notifyAll() |
|
||||
| 没有设置 Timeout 参数的 Thread.join() 方法 | 被调用的线程执行完毕 |
|
||||
| LockSupport.park() 方法 | LockSupport.unpark(Thread) |
|
||||
|
||||
### 限期等待(TIMED_WAITING)
|
||||
|
||||
无需等待其它线程显式地唤醒,在一定时间之后会被系统自动唤醒。
|
||||
|
||||
| 进入方法 | 退出方法 |
|
||||
| --- | --- |
|
||||
| Thread.sleep() 方法 | 时间结束 |
|
||||
| 设置了 Timeout 参数的 Object.wait() 方法 | 时间结束 / Object.notify() / Object.notifyAll() |
|
||||
| 设置了 Timeout 参数的 Thread.join() 方法 | 时间结束 / 被调用的线程执行完毕 |
|
||||
| LockSupport.parkNanos() 方法 | LockSupport.unpark(Thread) |
|
||||
| LockSupport.parkUntil() 方法 | LockSupport.unpark(Thread) |
|
||||
|
||||
调用 Thread.sleep() 方法使线程进入限期等待状态时,常常用“使一个线程睡眠”进行描述。调用 Object.wait() 方法使线程进入限期等待或者无限期等待时,常常用“挂起一个线程”进行描述。睡眠和挂起是用来描述行为,而阻塞和等待用来描述状态。
|
||||
|
||||
### 死亡(TERMINATED)
|
||||
|
||||
可以是线程结束任务之后自己结束,或者产生了异常而结束。
|
||||
|
||||
[Java SE 9 Enum Thread.State](https://docs.oracle.com/javase/9/docs/api/java/lang/Thread.State.html)
|
||||
|
||||
445
Java基础教程/Java并发编程/02 Java互斥同步.md
Normal file
@@ -0,0 +1,445 @@
|
||||
|
||||
## 1 互斥同步
|
||||
|
||||
Java 提供了两种锁机制来控制多个线程对共享资源的互斥访问,第一个是 JVM 实现的 synchronized,而另一个是 JDK 实现的 ReentrantLock。
|
||||
|
||||
### synchronized
|
||||
|
||||
**1. 同步一个代码块**
|
||||
|
||||
```java
|
||||
public void func() {
|
||||
synchronized (this) {
|
||||
// ...
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
它只作用于同一个对象,如果调用两个对象上的同步代码块,就不会进行同步。
|
||||
|
||||
对于以下代码,使用 ExecutorService 执行了两个线程,由于调用的是同一个对象的同步代码块,因此这两个线程会进行同步,当一个线程进入同步语句块时,另一个线程就必须等待。
|
||||
|
||||
```java
|
||||
public class SynchronizedExample {
|
||||
|
||||
public void func1() {
|
||||
synchronized (this) {
|
||||
for (int i = 0; i < 10; i++) {
|
||||
System.out.print(i + " ");
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
SynchronizedExample e1 = new SynchronizedExample();
|
||||
ExecutorService executorService = Executors.newCachedThreadPool();
|
||||
executorService.execute(() -> e1.func1());
|
||||
executorService.execute(() -> e1.func1());
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9
|
||||
```
|
||||
|
||||
对于以下代码,两个线程调用了不同对象的同步代码块,因此这两个线程就不需要同步。从输出结果可以看出,两个线程交叉执行。
|
||||
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
SynchronizedExample e1 = new SynchronizedExample();
|
||||
SynchronizedExample e2 = new SynchronizedExample();
|
||||
ExecutorService executorService = Executors.newCachedThreadPool();
|
||||
executorService.execute(() -> e1.func1());
|
||||
executorService.execute(() -> e2.func1());
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
0 0 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9
|
||||
```
|
||||
|
||||
|
||||
**2. 同步一个方法**
|
||||
* 编写同步方法的一般语法如下。 这里的lockObject是对对象的引用,该对象的锁与同步语句表示的监视器相关联。
|
||||
* '.class' object -如果方法是静态的。
|
||||
* this' object -如果方法不是静态的。 “ this”是指对其中调用同步方法的当前对象的引用。
|
||||
|
||||
```java
|
||||
public synchronized void func () {
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
它和同步代码块一样,作用于同一个对象。
|
||||
|
||||
**3. 同步一个类**
|
||||
|
||||
```java
|
||||
public void func() {
|
||||
synchronized (SynchronizedExample.class) {
|
||||
// ...
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
作用于整个类,也就是说两个线程调用同一个类的不同对象上的这种同步语句,也会进行同步。
|
||||
|
||||
```java
|
||||
public class SynchronizedExample {
|
||||
|
||||
public void func2() {
|
||||
synchronized (SynchronizedExample.class) {
|
||||
for (int i = 0; i < 10; i++) {
|
||||
System.out.print(i + " ");
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
SynchronizedExample e1 = new SynchronizedExample();
|
||||
SynchronizedExample e2 = new SynchronizedExample();
|
||||
ExecutorService executorService = Executors.newCachedThreadPool();
|
||||
executorService.execute(() -> e1.func2());
|
||||
executorService.execute(() -> e2.func2());
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9
|
||||
```
|
||||
|
||||
**4. 同步一个静态方法**
|
||||
|
||||
```java
|
||||
public synchronized static void fun() {
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
作用于整个类。
|
||||
|
||||
### 对象级别和类级别的同步
|
||||
|
||||
|
||||
* 当我们要同步non-static method non-static code block时, Object level lock是一种机制,这样,只有一个线程将能够在给定的类实例上执行代码块。 应该始终这样做, 以确保实例级数据线程安全 。
|
||||
|
||||
|
||||
```java
|
||||
public class DemoClass
|
||||
{
|
||||
public synchronized void demoMethod(){}
|
||||
}
|
||||
|
||||
or
|
||||
|
||||
public class DemoClass
|
||||
{
|
||||
public void demoMethod(){
|
||||
synchronized (this)
|
||||
{
|
||||
//other thread safe code
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
or
|
||||
|
||||
public class DemoClass
|
||||
{
|
||||
private final Object lock = new Object();
|
||||
public void demoMethod(){
|
||||
synchronized (lock)
|
||||
{
|
||||
//other thread safe code
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
* Class level lock可防止多个线程在运行时在该类的所有可用实例中的任何一个中进入synchronized块。 这意味着,如果在运行时有100个demoMethod()实例,则一次只能在一个实例中的任何一个线程上执行demoMethod() ,而所有其他实例将被其他线程锁定。
|
||||
|
||||
```java
|
||||
public class DemoClass
|
||||
{
|
||||
//Method is static
|
||||
public synchronized static void demoMethod(){
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
or
|
||||
|
||||
public class DemoClass
|
||||
{
|
||||
public void demoMethod()
|
||||
{
|
||||
//Acquire lock on .class reference
|
||||
synchronized (DemoClass.class)
|
||||
{
|
||||
//other thread safe code
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
or
|
||||
|
||||
public class DemoClass
|
||||
{
|
||||
private final static Object lock = new Object();
|
||||
|
||||
public void demoMethod()
|
||||
{
|
||||
//Lock object is static
|
||||
synchronized (lock)
|
||||
{
|
||||
//other thread safe code
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
注意事项
|
||||
* Java中的同步保证了没有两个线程可以同时或并发执行需要相同锁的同步方法。
|
||||
* synchronized关键字只能与方法和代码块一起使用。 这些方法或块可以是static也可以non-static 。
|
||||
* 每当线程进入Java synchronized方法或块时,它都会获取一个锁,而当线程离开同步方法或块时,它将释放该锁。 即使线程在完成后或由于任何错误或异常而离开同步方法时,也会释放锁定。
|
||||
* Java synchronized关键字本质上是可re-entrant ,这意味着如果一个同步方法调用另一个需要相同锁的同步方法,则持有锁的当前线程可以进入该方法而无需获取锁。
|
||||
* 如果在同步块中使用的对象为null,则Java同步将引发NullPointerException 。 例如,在上面的代码示例中,如果将锁初始化为null,则“ synchronized (lock) ”将抛出NullPointerException 。
|
||||
* Java中的同步方法使您的应用程序性能降低。 因此,在绝对需要时使用同步。 另外,请考虑使用同步的代码块仅同步代码的关键部分。
|
||||
* 静态同步方法和非静态同步方法都可能同时或同时运行,因为它们锁定在不同的对象上。
|
||||
* 根据Java语言规范,您不能在构造函数中使用synchronized关键字。 这是非法的,并导致编译错误。
|
||||
* 不要在Java中的同步块上的非final字段上进行同步。 因为非最终字段的引用可能随时更改,然后不同的线程可能会在不同的对象上进行同步,即完全没有同步。
|
||||
* 不要使用String文字,因为它们可能在应用程序中的其他地方被引用,并且可能导致死锁。 使用new关键字创建的字符串对象可以安全使用。 但作为最佳实践,请在我们要保护的共享变量本身上创建一个新的private作用域Object实例OR锁。
|
||||
|
||||
|
||||
### ReentrantLock
|
||||
|
||||
ReentrantLock 是 java.util.concurrent(J.U.C)包中的锁。
|
||||
|
||||
```java
|
||||
public class LockExample {
|
||||
|
||||
private Lock lock = new ReentrantLock();
|
||||
|
||||
public void func() {
|
||||
lock.lock();
|
||||
try {
|
||||
for (int i = 0; i < 10; i++) {
|
||||
System.out.print(i + " ");
|
||||
}
|
||||
} finally {
|
||||
lock.unlock(); // 确保释放锁,从而避免发生死锁。
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
LockExample lockExample = new LockExample();
|
||||
ExecutorService executorService = Executors.newCachedThreadPool();
|
||||
executorService.execute(() -> lockExample.func());
|
||||
executorService.execute(() -> lockExample.func());
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9
|
||||
```
|
||||
|
||||
|
||||
### 比较
|
||||
除非需要使用 ReentrantLock 的高级功能,否则优先使用 synchronized。这是因为 synchronized 是 JVM 实现的一种锁机制,JVM 原生地支持它,而 ReentrantLock 不是所有的 JDK 版本都支持。并且使用 synchronized 不用担心没有释放锁而导致死锁问题,因为 JVM 会确保锁的释放。
|
||||
|
||||
|
||||
**1. 锁的实现**
|
||||
|
||||
synchronized 是 JVM 实现的,而 ReentrantLock 是 JDK 实现的。
|
||||
|
||||
**2. 性能**
|
||||
|
||||
新版本 Java 对 synchronized 进行了很多优化,例如自旋锁等,synchronized 与 ReentrantLock 大致相同。
|
||||
|
||||
**3. 等待可中断**
|
||||
|
||||
当持有锁的线程长期不释放锁的时候,正在等待的线程可以选择放弃等待,改为处理其他事情。
|
||||
|
||||
ReentrantLock 可中断,而 synchronized 不行。
|
||||
|
||||
**4. 公平锁**
|
||||
|
||||
公平锁是指多个线程在等待同一个锁时,必须按照申请锁的时间顺序来依次获得锁。
|
||||
|
||||
synchronized 中的锁是非公平的,ReentrantLock 默认情况下也是非公平的,但是也可以是公平的。
|
||||
|
||||
**5. 锁绑定多个条件**
|
||||
|
||||
一个 ReentrantLock 可以同时绑定多个 Condition 对象。
|
||||
|
||||
|
||||
|
||||
|
||||
## 2 线程之间的协作
|
||||
|
||||
当多个线程可以一起工作去解决某个问题时,如果某些部分必须在其它部分之前完成,那么就需要对线程进行协调。
|
||||
|
||||
### Thread:join
|
||||
|
||||
在线程中调用另一个线程的 join() 方法,会将当前线程挂起,而不是忙等待,直到目标线程结束。
|
||||
|
||||
对于以下代码,虽然 b 线程先启动,但是因为在 b 线程中调用了 a 线程的 join() 方法,b 线程会等待 a 线程结束才继续执行,因此最后能够保证 a 线程的输出先于 b 线程的输出。
|
||||
|
||||
```java
|
||||
public class JoinExample {
|
||||
|
||||
private class A extends Thread {
|
||||
@Override
|
||||
public void run() {
|
||||
System.out.println("A");
|
||||
}
|
||||
}
|
||||
|
||||
private class B extends Thread {
|
||||
|
||||
private A a;
|
||||
|
||||
B(A a) {
|
||||
this.a = a;
|
||||
}
|
||||
|
||||
@Override
|
||||
public void run() {
|
||||
try {
|
||||
a.join();
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.println("B");
|
||||
}
|
||||
}
|
||||
|
||||
public void test() {
|
||||
A a = new A();
|
||||
B b = new B(a);
|
||||
b.start();
|
||||
a.start();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
JoinExample example = new JoinExample();
|
||||
example.test();
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
A
|
||||
B
|
||||
```
|
||||
|
||||
### Object:wait、notify、notifyAll
|
||||
|
||||
调用 wait() 使得线程等待某个条件满足,线程在等待时会被挂起,当其他线程的运行使得这个条件满足时,其它线程会调用 notify() 或者 notifyAll() 来唤醒挂起的线程。
|
||||
|
||||
它们都属于 Object 的一部分,而不属于 Thread。
|
||||
|
||||
只能用在同步方法或者同步控制块中使用,否则会在运行时抛出 IllegalMonitorStateException。
|
||||
|
||||
使用 wait() 挂起期间,线程会释放锁。这是因为,如果没有释放锁,那么其它线程就无法进入对象的同步方法或者同步控制块中,那么就无法执行 notify() 或者 notifyAll() 来唤醒挂起的线程,造成死锁。
|
||||
|
||||
```java
|
||||
public class WaitNotifyExample {
|
||||
|
||||
public synchronized void before() {
|
||||
System.out.println("before");
|
||||
notifyAll();
|
||||
}
|
||||
|
||||
public synchronized void after() {
|
||||
try {
|
||||
wait();
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.println("after");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
ExecutorService executorService = Executors.newCachedThreadPool();
|
||||
WaitNotifyExample example = new WaitNotifyExample();
|
||||
executorService.execute(() -> example.after());
|
||||
executorService.execute(() -> example.before());
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
before
|
||||
after
|
||||
```
|
||||
|
||||
**wait() 和 sleep() 的区别**
|
||||
|
||||
- wait() 是 Object 的方法,而 sleep() 是 Thread 的静态方法;
|
||||
- wait() 会释放锁,sleep() 不会。
|
||||
|
||||
### Condition:await、signal、signalAll
|
||||
|
||||
java.util.concurrent 类库中提供了 Condition 类来实现线程之间的协调,可以在 Condition 上调用 await() 方法使线程等待,其它线程调用 signal() 或 signalAll() 方法唤醒等待的线程。
|
||||
|
||||
相比于 wait() 这种等待方式,await() 可以指定等待的条件,因此更加灵活。
|
||||
|
||||
使用 Lock 来获取一个 Condition 对象。
|
||||
|
||||
```java
|
||||
public class AwaitSignalExample {
|
||||
|
||||
private Lock lock = new ReentrantLock();
|
||||
private Condition condition = lock.newCondition();
|
||||
|
||||
public void before() {
|
||||
lock.lock();
|
||||
try {
|
||||
System.out.println("before");
|
||||
condition.signalAll();
|
||||
} finally {
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
|
||||
public void after() {
|
||||
lock.lock();
|
||||
try {
|
||||
condition.await();
|
||||
System.out.println("after");
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
} finally {
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
ExecutorService executorService = Executors.newCachedThreadPool();
|
||||
AwaitSignalExample example = new AwaitSignalExample();
|
||||
executorService.execute(() -> example.after());
|
||||
executorService.execute(() -> example.before());
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
before
|
||||
after
|
||||
```
|
||||
166
Java基础教程/Java并发编程/03 Java进程通信.md
Normal file
@@ -0,0 +1,166 @@
|
||||
## 1 Pipe
|
||||
|
||||
|
||||
PipedReader是Reader类的扩展,用于读取字符流。 它的read()方法读取连接的PipedWriter的流。 同样, PipedWriter是Writer类的扩展,它完成Reader类所收缩的所有工作。
|
||||
|
||||
|
||||
* 读线程
|
||||
|
||||
```java
|
||||
public class PipeReaderThread implements Runnable
|
||||
{
|
||||
PipedReader pr;
|
||||
String name = null;
|
||||
|
||||
public PipeReaderThread(String name, PipedReader pr)
|
||||
{
|
||||
this.name = name;
|
||||
this.pr = pr;
|
||||
}
|
||||
|
||||
public void run()
|
||||
{
|
||||
try {
|
||||
// continuously read data from stream and print it in console
|
||||
while (true) {
|
||||
char c = (char) pr.read(); // read a char
|
||||
if (c != -1) { // check for -1 indicating end of file
|
||||
System.out.print(c);
|
||||
}
|
||||
}
|
||||
} catch (Exception e) {
|
||||
System.out.println(" PipeThread Exception: " + e);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
* 写线程
|
||||
|
||||
```java
|
||||
public class PipeWriterThread implements Runnable
|
||||
{
|
||||
PipedWriter pw;
|
||||
String name = null;
|
||||
|
||||
public PipeWriterThread(String name, PipedWriter pw) {
|
||||
this.name = name;
|
||||
this.pw = pw;
|
||||
}
|
||||
|
||||
public void run() {
|
||||
try {
|
||||
while (true) {
|
||||
// Write some data after every two seconds
|
||||
pw.write("Testing data written...n");
|
||||
pw.flush();
|
||||
Thread.sleep(2000);
|
||||
}
|
||||
} catch (Exception e) {
|
||||
System.out.println(" PipeThread Exception: " + e);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
* 测试代码
|
||||
|
||||
```java
|
||||
package multiThread;
|
||||
|
||||
import java.io.*;
|
||||
|
||||
public class PipedCommunicationTest
|
||||
{
|
||||
public static void main(String[] args)
|
||||
{
|
||||
new PipedCommunicationTest();
|
||||
}
|
||||
|
||||
public PipedCommunicationTest()
|
||||
{
|
||||
try
|
||||
{
|
||||
// Create writer and reader instances
|
||||
PipedReader pr = new PipedReader();
|
||||
PipedWriter pw = new PipedWriter();
|
||||
|
||||
// Connect the writer with reader
|
||||
pw.connect(pr);
|
||||
|
||||
// Create one writer thread and one reader thread
|
||||
Thread thread1 = new Thread(new PipeReaderThread("ReaderThread", pr));
|
||||
|
||||
Thread thread2 = new Thread(new PipeWriterThread("WriterThread", pw));
|
||||
|
||||
// start both threads
|
||||
thread1.start();
|
||||
thread2.start();
|
||||
|
||||
}
|
||||
catch (Exception e)
|
||||
{
|
||||
System.out.println("PipeThread Exception: " + e);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 2 BlockQueue(新的最佳实践)
|
||||
|
||||
|
||||
```java
|
||||
package corejava.thread;
|
||||
|
||||
import java.util.concurrent.ArrayBlockingQueue;
|
||||
import java.util.concurrent.BlockingQueue;
|
||||
import java.util.concurrent.RejectedExecutionHandler;
|
||||
import java.util.concurrent.ThreadPoolExecutor;
|
||||
import java.util.concurrent.TimeUnit;
|
||||
|
||||
public class DemoExecutor
|
||||
{
|
||||
public static void main(String[] args)
|
||||
{
|
||||
Integer threadCounter = 0;
|
||||
BlockingQueue<Runnable> blockingQueue = new ArrayBlockingQueue<Runnable>(50);
|
||||
|
||||
CustomThreadPoolExecutor executor = new CustomThreadPoolExecutor(10,
|
||||
20, 5000, TimeUnit.MILLISECONDS, blockingQueue);
|
||||
|
||||
executor.setRejectedExecutionHandler(new RejectedExecutionHandler() {
|
||||
@Override
|
||||
public void rejectedExecution(Runnable r,
|
||||
ThreadPoolExecutor executor) {
|
||||
System.out.println("DemoTask Rejected : "
|
||||
+ ((DemoTask) r).getName());
|
||||
System.out.println("Waiting for a second !!");
|
||||
try {
|
||||
Thread.sleep(1000);
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.println("Lets add another time : "
|
||||
+ ((DemoTask) r).getName());
|
||||
executor.execute(r);
|
||||
}
|
||||
});
|
||||
// Let start all core threads initially
|
||||
executor.prestartAllCoreThreads();
|
||||
while (true) {
|
||||
threadCounter++;
|
||||
// Adding threads one by one
|
||||
System.out.println("Adding DemoTask : " + threadCounter);
|
||||
executor.execute(new DemoTask(threadCounter.toString()));
|
||||
|
||||
if (threadCounter == 100)
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 3 共享数据(最基本的通信方式)
|
||||
448
Java基础教程/Java并发编程/04 Java线程池.md
Normal file
@@ -0,0 +1,448 @@
|
||||
|
||||
## 1 Executor概述
|
||||
|
||||
### 概述
|
||||
Executor framework框架由三个主要接口(以及许多子接口)组成,即Executor , ExecutorService和ThreadPoolExecutor 。
|
||||
* 该框架主要将任务创建和执行分开。 任务创建主要是样板代码,并且很容易替换。
|
||||
* 对于执行者,我们必须创建实现Runnable或Callable接口的任务,并将其发送给执行者。
|
||||
* 执行程序在内部维护一个(可配置的)线程池,以通过避免连续产生线程来提高应用程序性能。
|
||||
* 执行程序负责执行任务,并使用池中的必要线程运行它们。
|
||||
|
||||
|
||||
|
||||
### 分类
|
||||
|
||||
Executor 管理多个异步任务的执行,而无需程序员显式地管理线程的生命周期。这里的异步是指多个任务的执行互不干扰,不需要进行同步操作。
|
||||
|
||||
- CachedThreadPool:缓存线程池执行程序 –创建一个线程池,该线程池可根据需要创建新线程,但在可用时将重用以前构造的线程。 如果任务长时间运行,请勿使用此线程池。 如果线程数超出系统可以处理的范围,则可能导致系统崩溃。
|
||||
- FixedThreadPool:固定线程池执行程序 –创建一个线程池,该线程池可重用固定数量的线程来执行任意数量的任务。 如果在所有线程都处于活动状态时提交了其他任务,则它们将在队列中等待,直到某个线程可用为止。 最适合现实生活中的大多数用例。
|
||||
- SingleThreadExecutor:相当于大小为 1 的 FixedThreadPool,单线程池执行程序 –创建单线程以执行所有任务。 当您只有一个任务要执行时,请使用它。
|
||||
- ScheduledThreadPool:调度线程池执行程序 –创建一个线程池,该线程池可以调度命令以在给定延迟后运行或定期执行。
|
||||
- ForkJoinPool:分支合并线程池,适合用于处理复杂任务。初始化线程容量与 CPU 核心数相关。线程池中运行的内容必须是 ForkJoinTask 的子类型(RecursiveTask,RecursiveAction)。
|
||||
- WorkStealingPool:JDK1.8 新增的线程池。工作窃取线程池。当线程池中有空闲连接时,自动到等待队列中窃取未完成任务,自动执行。初始化线程容量与 CPU 核心数相关。此线程池中维护的是精灵线程。ExecutorService.newWorkStealingPool();
|
||||
|
||||
|
||||
ThreadPoolExecutor类具有四个不同的构造函数,但是由于它们的复杂性,Java并发API提供了Executors类来构造执行程序和其他相关对象。 尽管我们可以使用其构造函数之一直接创建ThreadPoolExecutor ,但是建议使用Executors类。
|
||||
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
ExecutorService executorService = Executors.newCachedThreadPool();
|
||||
for (int i = 0; i < 5; i++) {
|
||||
executorService.execute(new MyRunnable());
|
||||
}
|
||||
executorService.shutdown();
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### 使用
|
||||
|
||||
|
||||
1. 通过executors工具类创建.Executors是一个实用程序类,它提供用于创建接口实现的工厂方法。
|
||||
|
||||
```java
|
||||
//Executes only one thread
|
||||
ExecutorService es = Executors.newSingleThreadExecutor();
|
||||
|
||||
//Internally manages thread pool of 2 threads
|
||||
ExecutorService es = Executors.newFixedThreadPool(2);
|
||||
|
||||
//Internally manages thread pool of 10 threads to run scheduled tasks
|
||||
ExecutorService es = Executors.newScheduledThreadPool(10);
|
||||
```
|
||||
|
||||
2. 创建ExecutorService。我们可以选择ExecutorService接口的实现类,然后直接创建它的实例。 下面的语句创建一个线程池执行程序,该线程池执行程序的最小线程数为10,最大线程数为100,存活时间为5毫秒,并且有一个阻塞队列来监视将来的任务。
|
||||
|
||||
|
||||
|
||||
```java
|
||||
import java.util.concurrent.ExecutorService;
|
||||
import java.util.concurrent.LinkedBlockingQueue;
|
||||
import java.util.concurrent.ThreadPoolExecutor;
|
||||
import java.util.concurrent.TimeUnit;
|
||||
|
||||
ExecutorService executorService = new ThreadPoolExecutor(10, 100, 5L, TimeUnit.MILLISECONDS,
|
||||
new LinkedBlockingQueue<Runnable>());
|
||||
```
|
||||
|
||||
3. Execute Runnable tasks
|
||||
1. void execute(Runnable task) –在将来的某个时间执行给定命令。
|
||||
2. Future submit(Runnable task)可运行Future submit(Runnable task) –提交要执行的可运行任务,并返回代表该任务的Future 。 Future的get()方法成功完成后将返回null 。
|
||||
3. 提交可运行任务以执行并返回代表该任务的Future 。 Future的get()方法将在成功完成后返回给定的result
|
||||
|
||||
```java
|
||||
|
||||
import java.time.LocalDateTime;
|
||||
import java.util.concurrent.ExecutionException;
|
||||
import java.util.concurrent.ExecutorService;
|
||||
import java.util.concurrent.Executors;
|
||||
import java.util.concurrent.Future;
|
||||
import java.util.concurrent.TimeUnit;
|
||||
|
||||
public class Main
|
||||
{
|
||||
public static void main(String[] args)
|
||||
{
|
||||
//Demo task
|
||||
Runnable runnableTask = () -> {
|
||||
try {
|
||||
TimeUnit.MILLISECONDS.sleep(1000);
|
||||
System.out.println("Current time :: " + LocalDateTime.now());
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
};
|
||||
|
||||
//Executor service instance
|
||||
ExecutorService executor = Executors.newFixedThreadPool(10);
|
||||
|
||||
//1. execute task using execute() method
|
||||
executor.execute(runnableTask);
|
||||
|
||||
//2. execute task using submit() method
|
||||
Future<String> result = executor.submit(runnableTask, "DONE");
|
||||
|
||||
while(result.isDone() == false)
|
||||
{
|
||||
try
|
||||
{
|
||||
System.out.println("The method return value : " + result.get());
|
||||
break;
|
||||
}
|
||||
catch (InterruptedException | ExecutionException e)
|
||||
{
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
//Sleep for 1 second
|
||||
try {
|
||||
Thread.sleep(1000L);
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
|
||||
//Shut down the executor service
|
||||
executor.shutdownNow();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
4. Execute Callable tasks
|
||||
1. Future submit(callableTask) –提交一个执行返回值的任务,并返回代表该任务的未决结果的未来。
|
||||
2. List<Future> invokeAll(Collection tasks) –执行给定的任务,并when all complete返回保存其状态和结果的Future列表。 注意,仅当所有任务完成时结果才可用。请注意,已完成的任务可能已正常终止,也可能引发异常。
|
||||
3. List <Future> invokeAll(Collection task,timeOut,timeUnit) –执行给定的任务,并在所有完成或超时到期时返回保存其状态和结果的Future列表。
|
||||
|
||||
|
||||
```java
|
||||
|
||||
import java.time.LocalDateTime;
|
||||
import java.util.Arrays;
|
||||
import java.util.List;
|
||||
import java.util.concurrent.Callable;
|
||||
import java.util.concurrent.ExecutionException;
|
||||
import java.util.concurrent.ExecutorService;
|
||||
import java.util.concurrent.Executors;
|
||||
import java.util.concurrent.Future;
|
||||
import java.util.concurrent.TimeUnit;
|
||||
|
||||
public class Main
|
||||
{
|
||||
public static void main(String[] args) throws ExecutionException
|
||||
{
|
||||
//Demo Callable task
|
||||
Callable<String> callableTask = () -> {
|
||||
TimeUnit.MILLISECONDS.sleep(1000);
|
||||
return "Current time :: " + LocalDateTime.now();
|
||||
};
|
||||
|
||||
//Executor service instance
|
||||
ExecutorService executor = Executors.newFixedThreadPool(1);
|
||||
|
||||
List<Callable<String>> tasksList = Arrays.asList(callableTask, callableTask, callableTask);
|
||||
|
||||
//1. execute tasks list using invokeAll() method
|
||||
try
|
||||
{
|
||||
List<Future<String>> results = executor.invokeAll(tasksList);
|
||||
|
||||
for(Future<String> result : results) {
|
||||
System.out.println(result.get());
|
||||
}
|
||||
}
|
||||
catch (InterruptedException e1)
|
||||
{
|
||||
e1.printStackTrace();
|
||||
}
|
||||
|
||||
//2. execute individual tasks using submit() method
|
||||
Future<String> result = executor.submit(callableTask);
|
||||
|
||||
while(result.isDone() == false)
|
||||
{
|
||||
try
|
||||
{
|
||||
System.out.println("The method return value : " + result.get());
|
||||
break;
|
||||
}
|
||||
catch (InterruptedException | ExecutionException e)
|
||||
{
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
//Sleep for 1 second
|
||||
try {
|
||||
Thread.sleep(1000L);
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
|
||||
//Shut down the executor service
|
||||
executor.shutdownNow();
|
||||
}
|
||||
}
|
||||
```
|
||||
## 2 FixedThreadPool
|
||||
* 如果有任何任务引发异常,则应用程序将捕获该异常并重新启动该任务。
|
||||
* 如果有任何任务运行完毕,应用程序将注意到并重新启动任务。
|
||||
```java
|
||||
package com.howtodoinjava.multiThreading.executors;
|
||||
|
||||
import java.util.concurrent.ExecutorService;
|
||||
import java.util.concurrent.Executors;
|
||||
import java.util.concurrent.Future;
|
||||
|
||||
public class DemoExecutorUsage {
|
||||
|
||||
private static ExecutorService executor = null;
|
||||
private static volatile Future taskOneResults = null;
|
||||
private static volatile Future taskTwoResults = null;
|
||||
|
||||
public static void main(String[] args) {
|
||||
executor = Executors.newFixedThreadPool(2);
|
||||
while (true)
|
||||
{
|
||||
try
|
||||
{
|
||||
checkTasks();
|
||||
Thread.sleep(1000);
|
||||
} catch (Exception e) {
|
||||
System.err.println("Caught exception: " + e.getMessage());
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
private static void checkTasks() throws Exception {
|
||||
if (taskOneResults == null
|
||||
|| taskOneResults.isDone()
|
||||
|| taskOneResults.isCancelled())
|
||||
{
|
||||
taskOneResults = executor.submit(new TestOne());
|
||||
}
|
||||
|
||||
if (taskTwoResults == null
|
||||
|| taskTwoResults.isDone()
|
||||
|| taskTwoResults.isCancelled())
|
||||
{
|
||||
taskTwoResults = executor.submit(new TestTwo());
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
class TestOne implements Runnable {
|
||||
public void run() {
|
||||
while (true)
|
||||
{
|
||||
System.out.println("Executing task one");
|
||||
try
|
||||
{
|
||||
Thread.sleep(1000);
|
||||
} catch (Throwable e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
class TestTwo implements Runnable {
|
||||
public void run() {
|
||||
while (true)
|
||||
{
|
||||
System.out.println("Executing task two");
|
||||
try
|
||||
{
|
||||
Thread.sleep(1000);
|
||||
} catch (Throwable e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 3 ForkJoinPool
|
||||
|
||||
主要用于并行计算中,和 MapReduce 原理类似,都是把大的计算任务拆分成多个小任务并行计算。
|
||||
|
||||
```java
|
||||
public class ForkJoinExample extends RecursiveTask<Integer> {
|
||||
|
||||
private final int threshold = 5;
|
||||
private int first;
|
||||
private int last;
|
||||
|
||||
public ForkJoinExample(int first, int last) {
|
||||
this.first = first;
|
||||
this.last = last;
|
||||
}
|
||||
|
||||
@Override
|
||||
protected Integer compute() {
|
||||
int result = 0;
|
||||
if (last - first <= threshold) {
|
||||
// 任务足够小则直接计算
|
||||
for (int i = first; i <= last; i++) {
|
||||
result += i;
|
||||
}
|
||||
} else {
|
||||
// 拆分成小任务
|
||||
int middle = first + (last - first) / 2;
|
||||
ForkJoinExample leftTask = new ForkJoinExample(first, middle);
|
||||
ForkJoinExample rightTask = new ForkJoinExample(middle + 1, last);
|
||||
leftTask.fork();
|
||||
rightTask.fork();
|
||||
result = leftTask.join() + rightTask.join();
|
||||
}
|
||||
return result;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
public static void main(String[] args) throws ExecutionException, InterruptedException {
|
||||
ForkJoinExample example = new ForkJoinExample(1, 10000);
|
||||
ForkJoinPool forkJoinPool = new ForkJoinPool();
|
||||
Future result = forkJoinPool.submit(example);
|
||||
System.out.println(result.get());
|
||||
}
|
||||
```
|
||||
|
||||
ForkJoin 使用 ForkJoinPool 来启动,它是一个特殊的线程池,线程数量取决于 CPU 核数。
|
||||
|
||||
```java
|
||||
public class ForkJoinPool extends AbstractExecutorService
|
||||
```
|
||||
|
||||
ForkJoinPool 实现了工作窃取算法来提高 CPU 的利用率。每个线程都维护了一个双端队列,用来存储需要执行的任务。工作窃取算法允许空闲的线程从其它线程的双端队列中窃取一个任务来执行。窃取的任务必须是最晚的任务,避免和队列所属线程发生竞争。例如下图中,Thread2 从 Thread1 的队列中拿出最晚的 Task1 任务,Thread1 会拿出 Task2 来执行,这样就避免发生竞争。但是如果队列中只有一个任务时还是会发生竞争。
|
||||
|
||||

|
||||
|
||||
## 4 ScheduledThreadPool
|
||||
|
||||
而是您可能要在一段时间后执行任务或定期执行任务。 为此,Executor框架提供ScheduledThreadPoolExecutor类。
|
||||
|
||||
1. 实现一个任务
|
||||
```java
|
||||
class Task implements Runnable
|
||||
{
|
||||
private String name;
|
||||
|
||||
public Task(String name) {
|
||||
this.name = name;
|
||||
}
|
||||
|
||||
public String getName() {
|
||||
return name;
|
||||
}
|
||||
|
||||
@Override
|
||||
public void run()
|
||||
{
|
||||
try {
|
||||
System.out.println("Doing a task during : " + name + " - Time - " + new Date());
|
||||
}
|
||||
catch (Exception e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
2. Execute a task after a period of time.
|
||||
|
||||
```java
|
||||
|
||||
package com.howtodoinjava.demo.multithreading;
|
||||
|
||||
import java.util.Date;
|
||||
import java.util.concurrent.Executors;
|
||||
import java.util.concurrent.ScheduledExecutorService;
|
||||
import java.util.concurrent.TimeUnit;
|
||||
|
||||
public class ScheduledThreadPoolExecutorExample
|
||||
{
|
||||
public static void main(String[] args)
|
||||
{
|
||||
ScheduledExecutorService executor = Executors.newScheduledThreadPool(2);
|
||||
Task task1 = new Task ("Demo Task 1");
|
||||
Task task2 = new Task ("Demo Task 2");
|
||||
|
||||
System.out.println("The time is : " + new Date());
|
||||
|
||||
executor.schedule(task1, 5 , TimeUnit.SECONDS);
|
||||
executor.schedule(task2, 10 , TimeUnit.SECONDS);
|
||||
|
||||
try {
|
||||
executor.awaitTermination(1, TimeUnit.DAYS);
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
executor.shutdown();
|
||||
}
|
||||
}
|
||||
|
||||
Output:
|
||||
|
||||
The time is : Wed Mar 25 16:14:07 IST 2015
|
||||
Doing a task during : Demo Task 1 - Time - Wed Mar 25 16:14:12 IST 2015
|
||||
Doing a task during : Demo Task 2 - Time - Wed Mar 25 16:14:17 IST 2015
|
||||
```
|
||||
|
||||
|
||||
3. Execute a task periodically
|
||||
|
||||
```java
|
||||
public class ScheduledThreadPoolExecutorExample
|
||||
{
|
||||
public static void main(String[] args)
|
||||
{
|
||||
ScheduledExecutorService executor = Executors.newScheduledThreadPool(1);
|
||||
Task task1 = new Task ("Demo Task 1");
|
||||
|
||||
System.out.println("The time is : " + new Date());
|
||||
|
||||
ScheduledFuture<?> result = executor.scheduleAtFixedRate(task1, 2, 5, TimeUnit.SECONDS);
|
||||
|
||||
try {
|
||||
TimeUnit.MILLISECONDS.sleep(20000);
|
||||
}
|
||||
catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
executor.shutdown();
|
||||
}
|
||||
}
|
||||
|
||||
Output:
|
||||
|
||||
The time is : Wed Mar 25 16:20:12 IST 2015
|
||||
Doing a task during : Demo Task 1 - Time - Wed Mar 25 16:20:14 IST 2015
|
||||
Doing a task during : Demo Task 1 - Time - Wed Mar 25 16:20:19 IST 2015
|
||||
Doing a task during : Demo Task 1 - Time - Wed Mar 25 16:20:24 IST 2015
|
||||
Doing a task during : Demo Task 1 - Time - Wed Mar 25 16:20:29 IST 2015
|
||||
```
|
||||
286
Java基础教程/Java并发编程/05 JUC并发组件.md
Normal file
@@ -0,0 +1,286 @@
|
||||
## 1 J.U.C - AQS
|
||||
|
||||
java.util.concurrent(J.U.C)大大提高了并发性能,AQS 被认为是 J.U.C 的核心。
|
||||
|
||||
### CountDownLatch
|
||||
|
||||
用来控制一个或者多个线程等待多个线程。
|
||||
|
||||
维护了一个计数器 cnt,每次调用 countDown() 方法会让计数器的值减 1,减到 0 的时候,那些因为调用 await() 方法而在等待的线程就会被唤醒。
|
||||
|
||||

|
||||
|
||||
```java
|
||||
public class CountdownLatchExample {
|
||||
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
final int totalThread = 10;
|
||||
CountDownLatch countDownLatch = new CountDownLatch(totalThread);
|
||||
ExecutorService executorService = Executors.newCachedThreadPool();
|
||||
for (int i = 0; i < totalThread; i++) {
|
||||
executorService.execute(() -> {
|
||||
System.out.print("run..");
|
||||
countDownLatch.countDown();
|
||||
});
|
||||
}
|
||||
countDownLatch.await();
|
||||
System.out.println("end");
|
||||
executorService.shutdown();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
run..run..run..run..run..run..run..run..run..run..end
|
||||
```
|
||||
|
||||
### CyclicBarrier
|
||||
|
||||
用来控制多个线程互相等待,只有当多个线程都到达时,这些线程才会继续执行。
|
||||
|
||||
和 CountdownLatch 相似,都是通过维护计数器来实现的。线程执行 await() 方法之后计数器会减 1,并进行等待,直到计数器为 0,所有调用 await() 方法而在等待的线程才能继续执行。
|
||||
|
||||
CyclicBarrier 和 CountdownLatch 的一个区别是,CyclicBarrier 的计数器通过调用 reset() 方法可以循环使用,所以它才叫做循环屏障。
|
||||
|
||||
CyclicBarrier 有两个构造函数,其中 parties 指示计数器的初始值,barrierAction 在所有线程都到达屏障的时候会执行一次。
|
||||
|
||||
```java
|
||||
public CyclicBarrier(int parties, Runnable barrierAction) {
|
||||
if (parties <= 0) throw new IllegalArgumentException();
|
||||
this.parties = parties;
|
||||
this.count = parties;
|
||||
this.barrierCommand = barrierAction;
|
||||
}
|
||||
|
||||
public CyclicBarrier(int parties) {
|
||||
this(parties, null);
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
```java
|
||||
public class CyclicBarrierExample {
|
||||
|
||||
public static void main(String[] args) {
|
||||
final int totalThread = 10;
|
||||
CyclicBarrier cyclicBarrier = new CyclicBarrier(totalThread);
|
||||
ExecutorService executorService = Executors.newCachedThreadPool();
|
||||
for (int i = 0; i < totalThread; i++) {
|
||||
executorService.execute(() -> {
|
||||
System.out.print("before..");
|
||||
try {
|
||||
cyclicBarrier.await();
|
||||
} catch (InterruptedException | BrokenBarrierException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.print("after..");
|
||||
});
|
||||
}
|
||||
executorService.shutdown();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
before..before..before..before..before..before..before..before..before..before..after..after..after..after..after..after..after..after..after..after..
|
||||
```
|
||||
|
||||
### Semaphore
|
||||
|
||||
Semaphore 类似于操作系统中的信号量,可以控制对互斥资源的访问线程数。
|
||||
|
||||
以下代码模拟了对某个服务的并发请求,每次只能有 3 个客户端同时访问,请求总数为 10。
|
||||
|
||||
```java
|
||||
public class SemaphoreExample {
|
||||
|
||||
public static void main(String[] args) {
|
||||
final int clientCount = 3;
|
||||
final int totalRequestCount = 10;
|
||||
Semaphore semaphore = new Semaphore(clientCount);
|
||||
ExecutorService executorService = Executors.newCachedThreadPool();
|
||||
for (int i = 0; i < totalRequestCount; i++) {
|
||||
executorService.execute(()->{
|
||||
try {
|
||||
semaphore.acquire();
|
||||
System.out.print(semaphore.availablePermits() + " ");
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
} finally {
|
||||
semaphore.release();
|
||||
}
|
||||
});
|
||||
}
|
||||
executorService.shutdown();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
2 1 2 2 2 2 2 1 2 2
|
||||
```
|
||||
|
||||
|
||||
### FutureTask
|
||||
|
||||
在介绍 Callable 时我们知道它可以有返回值,返回值通过 Future\<V\> 进行封装。FutureTask 实现了 RunnableFuture 接口,该接口继承自 Runnable 和 Future\<V\> 接口,这使得 FutureTask 既可以当做一个任务执行,也可以有返回值。
|
||||
|
||||
```java
|
||||
public class FutureTask<V> implements RunnableFuture<V>
|
||||
```
|
||||
|
||||
```java
|
||||
public interface RunnableFuture<V> extends Runnable, Future<V>
|
||||
```
|
||||
|
||||
FutureTask 可用于异步获取执行结果或取消执行任务的场景。当一个计算任务需要执行很长时间,那么就可以用 FutureTask 来封装这个任务,主线程在完成自己的任务之后再去获取结果。
|
||||
|
||||
```java
|
||||
public class FutureTaskExample {
|
||||
|
||||
public static void main(String[] args) throws ExecutionException, InterruptedException {
|
||||
FutureTask<Integer> futureTask = new FutureTask<Integer>(new Callable<Integer>() {
|
||||
@Override
|
||||
public Integer call() throws Exception {
|
||||
int result = 0;
|
||||
for (int i = 0; i < 100; i++) {
|
||||
Thread.sleep(10);
|
||||
result += i;
|
||||
}
|
||||
return result;
|
||||
}
|
||||
});
|
||||
|
||||
Thread computeThread = new Thread(futureTask);
|
||||
computeThread.start();
|
||||
|
||||
Thread otherThread = new Thread(() -> {
|
||||
System.out.println("other task is running...");
|
||||
try {
|
||||
Thread.sleep(1000);
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
});
|
||||
otherThread.start();
|
||||
System.out.println(futureTask.get());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
other task is running...
|
||||
4950
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
## 2 J.U.C -并发容器
|
||||
|
||||
并发集合是指使用了最新并发能力的集合,在JUC包下。而同步集合指之前用同步锁实现的集合
|
||||
|
||||
### CopyOnWrite
|
||||
|
||||
CopyOnWriteArrayList在写的时候会复制一个副本,对副本写,写完用副本替换原值,读的时候不需要同步,适用于写少读多的场合。
|
||||
|
||||
|
||||
CopyOnWriteArraySet基于CopyOnWriteArrayList来实现的,只是在不允许存在重复的对象这个特性上遍历处理了一下。
|
||||
|
||||
|
||||
|
||||
### BlockingQueue
|
||||
|
||||
在并发队列上JDK提供了两套实现,
|
||||
* 一个是以ConcurrentLinkedQueue为代表的高性能队列
|
||||
* 一个是以BlockingQueue接口为代表的阻塞队列。
|
||||
|
||||
ConcurrentLinkedQueue适用于高并发场景下的队列,通过无锁的方式实现,通常ConcurrentLinkedQueue的性能要优于BlockingQueue。BlockingQueue的典型应用场景是生产者-消费者模式中,如果生产快于消费,生产队列装满时会阻塞,等待消费。
|
||||
|
||||
|
||||
|
||||
java.util.concurrent.BlockingQueue 接口有以下阻塞队列的实现:
|
||||
|
||||
- **FIFO 队列** :LinkedBlockingQueue、ArrayBlockingQueue(固定长度)
|
||||
- **优先级队列** :PriorityBlockingQueue
|
||||
|
||||
提供了阻塞的 take() 和 put() 方法:如果队列为空 take() 将阻塞,直到队列中有内容;如果队列为满 put() 将阻塞,直到队列有空闲位置。
|
||||
|
||||
**使用 BlockingQueue 实现生产者消费者问题**
|
||||
|
||||
```java
|
||||
public class ProducerConsumer {
|
||||
|
||||
private static BlockingQueue<String> queue = new ArrayBlockingQueue<>(5);
|
||||
|
||||
private static class Producer extends Thread {
|
||||
@Override
|
||||
public void run() {
|
||||
try {
|
||||
queue.put("product");
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.print("produce..");
|
||||
}
|
||||
}
|
||||
|
||||
private static class Consumer extends Thread {
|
||||
|
||||
@Override
|
||||
public void run() {
|
||||
try {
|
||||
String product = queue.take();
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.print("consume..");
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
for (int i = 0; i < 2; i++) {
|
||||
Producer producer = new Producer();
|
||||
producer.start();
|
||||
}
|
||||
for (int i = 0; i < 5; i++) {
|
||||
Consumer consumer = new Consumer();
|
||||
consumer.start();
|
||||
}
|
||||
for (int i = 0; i < 3; i++) {
|
||||
Producer producer = new Producer();
|
||||
producer.start();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
produce..produce..consume..consume..produce..consume..produce..consume..produce..consume..
|
||||
```
|
||||
|
||||
|
||||
### Concurrent
|
||||
* ConcurrentLinkedQueue
|
||||
* ConcurrentLinkedDeque
|
||||
|
||||
* ConcurrentHashMap
|
||||
|
||||
是专用于高并发的Map实现,内部实现进行了锁分离,get操作是无锁的。
|
||||
|
||||
* ConcurrentSkipListMap
|
||||
|
||||
java api也提供了一个实现ConcurrentSkipListMap接口的类,ConcurrentSkipListMap接口实现了与ConcurrentNavigableMap接口有相同行为的一个非阻塞式列表。从内部实现机制来讲,它使用了一个Skip List来存放数据。Skip List是基于并发列表的数据结构,效率与二叉树相近。
|
||||
当插入元素到映射中时,ConcurrentSkipListMap接口类使用键值来排序所有元素。除了提供返回一个具体元素的方法外,这个类也提供获取子映射的方法。
|
||||
|
||||
ConcurrentSkipListMap类提供的常用方法:
|
||||
```java
|
||||
1.headMap(K toKey):K是在ConcurrentSkipListMap对象的 泛型参数里用到的键。这个方法返回映射中所有键值小于参数值toKey的子映射。
|
||||
2.tailMap(K fromKey):K是在ConcurrentSkipListMap对象的 泛型参数里用到的键。这个方法返回映射中所有键值大于参数值fromKey的子映射。
|
||||
3.putIfAbsent(K key,V value):如果映射中不存在键key,那么就将key和value保存到映射中。
|
||||
4.pollLastEntry():返回并移除映射中的最后一个Map.Entry对象。
|
||||
5.replace(K key,V value):如果映射中已经存在键key,则用参数中的value替换现有的值。
|
||||
```
|
||||
365
Java基础教程/Java并发编程/06 Java线程安全.md
Normal file
@@ -0,0 +1,365 @@
|
||||
# Java 并发
|
||||
|
||||
## 1 线程安全概述
|
||||
|
||||
### 线程不安全示例
|
||||
|
||||
如果多个线程对同一个共享数据进行访问而不采取同步操作的话,那么操作的结果是不一致的。
|
||||
|
||||
以下代码演示了 1000 个线程同时对 cnt 执行自增操作,操作结束之后它的值有可能小于 1000。
|
||||
|
||||
```java
|
||||
public class ThreadUnsafeExample {
|
||||
|
||||
private int cnt = 0;
|
||||
|
||||
public void add() {
|
||||
cnt++;
|
||||
}
|
||||
|
||||
public int get() {
|
||||
return cnt;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
final int threadSize = 1000;
|
||||
ThreadUnsafeExample example = new ThreadUnsafeExample();
|
||||
final CountDownLatch countDownLatch = new CountDownLatch(threadSize);
|
||||
ExecutorService executorService = Executors.newCachedThreadPool();
|
||||
for (int i = 0; i < threadSize; i++) {
|
||||
executorService.execute(() -> {
|
||||
example.add();
|
||||
countDownLatch.countDown();
|
||||
});
|
||||
}
|
||||
countDownLatch.await();
|
||||
executorService.shutdown();
|
||||
System.out.println(example.get());
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
997
|
||||
```
|
||||
|
||||
|
||||
### 线程安全
|
||||
|
||||
多个线程不管以何种方式访问某个类,并且在主调代码中不需要进行同步,都能表现正确的行为。
|
||||
|
||||
线程安全有以下几种实现方式:
|
||||
* 不可变对象
|
||||
* 无同步方案
|
||||
* 互斥同步
|
||||
* 非阻塞同步
|
||||
|
||||
## 2 不可变对象
|
||||
|
||||
不可变(Immutable)的对象一定是线程安全的,不需要再采取任何的线程安全保障措施。只要一个不可变的对象被正确地构建出来,永远也不会看到它在多个线程之中处于不一致的状态。多线程环境下,应当尽量使对象成为不可变,来满足线程安全。
|
||||
|
||||
不可变的类型:
|
||||
|
||||
- final 关键字修饰的基本数据类型
|
||||
- String
|
||||
- 枚举类型
|
||||
- Number 部分子类,如 Long 和 Double 等数值包装类型,BigInteger 和 BigDecimal 等大数据类型。但同为 Number 的原子类 AtomicInteger 和 AtomicLong 则是可变的。
|
||||
|
||||
对于集合类型,可以使用 Collections.unmodifiableXXX() 方法来获取一个不可变的集合。
|
||||
|
||||
```java
|
||||
public class ImmutableExample {
|
||||
public static void main(String[] args) {
|
||||
Map<String, Integer> map = new HashMap<>();
|
||||
Map<String, Integer> unmodifiableMap = Collections.unmodifiableMap(map);
|
||||
unmodifiableMap.put("a", 1);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
Exception in thread "main" java.lang.UnsupportedOperationException
|
||||
at java.util.Collections$UnmodifiableMap.put(Collections.java:1457)
|
||||
at ImmutableExample.main(ImmutableExample.java:9)
|
||||
```
|
||||
|
||||
Collections.unmodifiableXXX() 先对原始的集合进行拷贝,需要对集合进行修改的方法都直接抛出异常。
|
||||
|
||||
```java
|
||||
public V put(K key, V value) {
|
||||
throw new UnsupportedOperationException();
|
||||
}
|
||||
```
|
||||
|
||||
## 3 无同步方案
|
||||
|
||||
要保证线程安全,并不是一定就要进行同步。如果一个方法本来就不涉及共享数据,那它自然就无须任何同步措施去保证正确性。
|
||||
|
||||
### 3.1 栈封闭
|
||||
|
||||
多个线程访问同一个方法的局部变量时,不会出现线程安全问题,因为局部变量存储在虚拟机栈中,属于线程私有的。
|
||||
|
||||
```java
|
||||
public class StackClosedExample {
|
||||
public void add100() {
|
||||
int cnt = 0;
|
||||
for (int i = 0; i < 100; i++) {
|
||||
cnt++;
|
||||
}
|
||||
System.out.println(cnt);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
StackClosedExample example = new StackClosedExample();
|
||||
ExecutorService executorService = Executors.newCachedThreadPool();
|
||||
executorService.execute(() -> example.add100());
|
||||
executorService.execute(() -> example.add100());
|
||||
executorService.shutdown();
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
100
|
||||
100
|
||||
```
|
||||
|
||||
### 3.2 线程本地存储(Thread Local Storage)
|
||||
|
||||
如果一段代码中所需要的数据必须与其他代码共享,那就看看这些共享数据的代码是否能保证在同一个线程中执行。如果能保证,我们就可以把共享数据的可见范围限制在同一个线程之内,这样,无须同步也能保证线程之间不出现数据争用的问题。
|
||||
|
||||
符合这种特点的应用并不少见,大部分使用消费队列的架构模式(如“生产者-消费者”模式)都会将产品的消费过程尽量在一个线程中消费完。其中最重要的一个应用实例就是经典 Web 交互模型中的“一个请求对应一个服务器线程”(Thread-per-Request)的处理方式,这种处理方式的广泛应用使得很多 Web 服务端应用都可以使用线程本地存储来解决线程安全问题。
|
||||
|
||||
可以使用 java.lang.ThreadLocal 类来实现线程本地存储功能。
|
||||
|
||||
对于以下代码,thread1 中设置 threadLocal 为 1,而 thread2 设置 threadLocal 为 2。过了一段时间之后,thread1 读取 threadLocal 依然是 1,不受 thread2 的影响。
|
||||
|
||||
```java
|
||||
public class ThreadLocalExample {
|
||||
public static void main(String[] args) {
|
||||
ThreadLocal threadLocal = new ThreadLocal();
|
||||
Thread thread1 = new Thread(() -> {
|
||||
threadLocal.set(1);
|
||||
try {
|
||||
Thread.sleep(1000);
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.println(threadLocal.get());
|
||||
threadLocal.remove();
|
||||
});
|
||||
Thread thread2 = new Thread(() -> {
|
||||
threadLocal.set(2);
|
||||
threadLocal.remove();
|
||||
});
|
||||
thread1.start();
|
||||
thread2.start();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
1
|
||||
```
|
||||
|
||||
为了理解 ThreadLocal,先看以下代码:
|
||||
|
||||
```java
|
||||
public class ThreadLocalExample1 {
|
||||
public static void main(String[] args) {
|
||||
ThreadLocal threadLocal1 = new ThreadLocal();
|
||||
ThreadLocal threadLocal2 = new ThreadLocal();
|
||||
Thread thread1 = new Thread(() -> {
|
||||
threadLocal1.set(1);
|
||||
threadLocal2.set(1);
|
||||
});
|
||||
Thread thread2 = new Thread(() -> {
|
||||
threadLocal1.set(2);
|
||||
threadLocal2.set(2);
|
||||
});
|
||||
thread1.start();
|
||||
thread2.start();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
它所对应的底层结构图为:
|
||||
|
||||

|
||||
|
||||
每个 Thread 都有一个 ThreadLocal.ThreadLocalMap 对象。
|
||||
|
||||
```java
|
||||
/* ThreadLocal values pertaining to this thread. This map is maintained
|
||||
* by the ThreadLocal class. */
|
||||
ThreadLocal.ThreadLocalMap threadLocals = null;
|
||||
```
|
||||
|
||||
当调用一个 ThreadLocal 的 set(T value) 方法时,先得到当前线程的 ThreadLocalMap 对象,然后将 ThreadLocal-\>value 键值对插入到该 Map 中。
|
||||
|
||||
```java
|
||||
public void set(T value) {
|
||||
Thread t = Thread.currentThread();
|
||||
ThreadLocalMap map = getMap(t);
|
||||
if (map != null)
|
||||
map.set(this, value);
|
||||
else
|
||||
createMap(t, value);
|
||||
}
|
||||
```
|
||||
|
||||
get() 方法类似。
|
||||
|
||||
```java
|
||||
public T get() {
|
||||
Thread t = Thread.currentThread();
|
||||
ThreadLocalMap map = getMap(t);
|
||||
if (map != null) {
|
||||
ThreadLocalMap.Entry e = map.getEntry(this);
|
||||
if (e != null) {
|
||||
@SuppressWarnings("unchecked")
|
||||
T result = (T)e.value;
|
||||
return result;
|
||||
}
|
||||
}
|
||||
return setInitialValue();
|
||||
}
|
||||
```
|
||||
|
||||
ThreadLocal 从理论上讲并不是用来解决多线程并发问题的,因为根本不存在多线程竞争。
|
||||
|
||||
在一些场景 (尤其是使用线程池) 下,由于 ThreadLocal.ThreadLocalMap 的底层数据结构导致 ThreadLocal 有内存泄漏的情况,应该尽可能在每次使用 ThreadLocal 后手动调用 remove(),以避免出现 ThreadLocal 经典的内存泄漏甚至是造成自身业务混乱的风险。
|
||||
|
||||
### 3.3 可重入代码(Reentrant Code)
|
||||
|
||||
这种代码也叫做纯代码(Pure Code),可以在代码执行的任何时刻中断它,转而去执行另外一段代码(包括递归调用它本身),而在控制权返回后,原来的程序不会出现任何错误。
|
||||
|
||||
可重入代码有一些共同的特征,例如不依赖存储在堆上的数据和公用的系统资源、用到的状态量都由参数中传入、不调用非可重入的方法等。
|
||||
|
||||
|
||||
A Stateless Servlet
|
||||
|
||||
```java
|
||||
public class StatelessFactorizer implements Servlet
|
||||
{
|
||||
public void service(ServletRequest req, ServletResponse resp)
|
||||
{
|
||||
BigInteger i = extractFromRequest(req);
|
||||
BigInteger[] factors = factor(i);
|
||||
encodeIntoResponse(resp, factors);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 4 互斥同步
|
||||
|
||||
悲观同步,损失性能
|
||||
|
||||
### 4.1 synchronized 和 ReentrantLock。
|
||||
|
||||
### 4.2 Object.wait/notify
|
||||
|
||||
### 4.3 Condition.await/signal
|
||||
|
||||
## 5 非阻塞同步
|
||||
|
||||
互斥同步最主要的问题就是线程阻塞和唤醒所带来的性能问题,因此这种同步也称为阻塞同步。
|
||||
|
||||
互斥同步属于一种悲观的并发策略,总是认为只要不去做正确的同步措施,那就肯定会出现问题。无论共享数据是否真的会出现竞争,它都要进行加锁(这里讨论的是概念模型,实际上虚拟机会优化掉很大一部分不必要的加锁)、用户态核心态转换、维护锁计数器和检查是否有被阻塞的线程需要唤醒等操作。
|
||||
|
||||
随着硬件指令集的发展,我们可以使用基于冲突检测的乐观并发策略:先进行操作,如果没有其它线程争用共享数据,那操作就成功了,否则采取补偿措施(不断地重试,直到成功为止)。这种乐观的并发策略的许多实现都不需要将线程阻塞,因此这种同步操作称为非阻塞同步。
|
||||
|
||||
### 5.1 CAS(Compare and Swap Algorithm)
|
||||
|
||||
乐观锁需要操作和冲突检测这两个步骤具备原子性,这里就不能再使用互斥同步来保证了,只能靠硬件来完成。硬件支持的原子性操作最典型的是:比较并交换(Compare-and-Swap,CAS)。CAS 指令需要有 3 个操作数,分别是
|
||||
* 内存地址 V、
|
||||
* 旧的预期值 A
|
||||
* 新值 B。
|
||||
|
||||
当执行操作时,只有当 V 的值等于 A,才将 V 的值更新为 B。
|
||||
|
||||
让我们通过一个例子来了解整个过程。 假设V是存储值“ 10”的存储位置。 有多个线程想要递增此值并将递增的值用于其他操作,这是一种非常实际的方案。 让我们分步分解整个CAS操作:
|
||||
|
||||
1. 线程1和2想要增加它,它们都读取值并将其增加到11。
|
||||
```
|
||||
V = 10, A = 0, B = 0
|
||||
```
|
||||
2. 现在线程1首先出现,并将V与它的最后一个读取值进行比较:
|
||||
```
|
||||
V = 10, A = 10, B = 11
|
||||
|
||||
if A = V
|
||||
V = B
|
||||
else
|
||||
operation failed
|
||||
return V
|
||||
显然,V的值将被覆盖为11,即操作成功。
|
||||
```
|
||||
3. 线程2到来并尝试与线程1相同的操作
|
||||
```
|
||||
V = 11, A = 10, B = 11
|
||||
|
||||
if A = V
|
||||
V = B
|
||||
else
|
||||
operation failed
|
||||
return V
|
||||
```
|
||||
4. 在这种情况下,V不等于A,因此不替换值,并返回V的当前值,即11。 现在,线程2再次使用值重试此操作:
|
||||
```
|
||||
V = 11, A = 11, B = 12
|
||||
```
|
||||
|
||||
而这一次,条件得到满足,增量值12返回线程2。
|
||||
|
||||
总而言之,当多个线程尝试使用CAS同时更新同一变量时,一个将获胜并更新该变量的值,而其余则将丢失。 但是失败者并不会因为线程中断而受到惩罚。 他们可以自由地重试该操作,或者什么也不做。
|
||||
|
||||
|
||||
### 5.2 AtomicInteger
|
||||
|
||||
J.U.C 包里面的整数原子类 AtomicInteger 的方法调用了 Unsafe 类的 CAS 操作。
|
||||
|
||||
以下代码使用了 AtomicInteger 执行了自增的操作。
|
||||
|
||||
```java
|
||||
private AtomicInteger cnt = new AtomicInteger();
|
||||
|
||||
public void add() {
|
||||
cnt.incrementAndGet();
|
||||
}
|
||||
```
|
||||
|
||||
以下代码是 incrementAndGet() 的源码,它调用了 Unsafe 的 getAndAddInt() 。
|
||||
|
||||
```java
|
||||
public final int incrementAndGet() {
|
||||
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
|
||||
}
|
||||
```
|
||||
|
||||
以下代码是 getAndAddInt() 源码,var1 指示对象内存地址,var2 指示该字段相对对象内存地址的偏移,var4 指示操作需要加的数值,这里为 1。通过 getIntVolatile(var1, var2) 得到旧的预期值,通过调用 compareAndSwapInt() 来进行 CAS 比较,如果该字段内存地址中的值等于 var5,那么就更新内存地址为 var1+var2 的变量为 var5+var4。
|
||||
|
||||
可以看到 getAndAddInt() 在一个循环中进行,发生冲突的做法是不断的进行重试。
|
||||
|
||||
```java
|
||||
public final int getAndAddInt(Object var1, long var2, int var4) {
|
||||
int var5;
|
||||
do {
|
||||
var5 = this.getIntVolatile(var1, var2);
|
||||
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
|
||||
|
||||
return var5;
|
||||
}
|
||||
```
|
||||
|
||||
### 5.3 ABA
|
||||
|
||||
如果一个变量初次读取的时候是 A 值,它的值被改成了 B,后来又被改回为 A,那 CAS 操作就会误认为它从来没有被改变过。
|
||||
|
||||
J.U.C 包提供了一个带有标记的原子引用类 AtomicStampedReference 来解决这个问题,它可以通过控制变量值的版本来保证 CAS 的正确性。大部分情况下 ABA 问题不会影响程序并发的正确性,如果需要解决 ABA 问题,改用传统的互斥同步可能会比原子类更高效。
|
||||
211
Java基础教程/Java并发编程/07 Java内存模型.md
Normal file
@@ -0,0 +1,211 @@
|
||||
# 内存模型
|
||||
|
||||
|
||||
## 1 Java 内存模型
|
||||
|
||||
Java 内存模型试图屏蔽各种硬件和操作系统的内存访问差异,以实现让 Java 程序在各种平台下都能达到一致的内存访问效果。
|
||||
|
||||
### 主内存与工作内存
|
||||
|
||||
处理器上的寄存器的读写的速度比内存快几个数量级,为了解决这种速度矛盾,在它们之间加入了高速缓存。
|
||||
|
||||
加入高速缓存带来了一个新的问题:缓存一致性。如果多个缓存共享同一块主内存区域,那么多个缓存的数据可能会不一致,需要一些协议来解决这个问题。
|
||||
|
||||

|
||||
|
||||
所有的变量都存储在主内存中,每个线程还有自己的工作内存,工作内存存储在高速缓存或者寄存器中,保存了该线程使用的变量的主内存副本拷贝。
|
||||
|
||||
线程只能直接操作工作内存中的变量,不同线程之间的变量值传递需要通过主内存来完成。
|
||||
|
||||

|
||||
|
||||
### 内存间交互操作
|
||||
|
||||
Java 内存模型定义了 8 个操作来完成主内存和工作内存的交互操作。
|
||||
|
||||

|
||||
|
||||
- read:把一个变量的值从主内存传输到工作内存中
|
||||
- load:在 read 之后执行,把 read 得到的值放入工作内存的变量副本中
|
||||
- use:把工作内存中一个变量的值传递给执行引擎
|
||||
- assign:把一个从执行引擎接收到的值赋给工作内存的变量
|
||||
- store:把工作内存的一个变量的值传送到主内存中
|
||||
- write:在 store 之后执行,把 store 得到的值放入主内存的变量中
|
||||
- lock:作用于主内存的变量
|
||||
- unlock
|
||||
|
||||
## 2 内存模型三大特性
|
||||
|
||||
### 1 原子性
|
||||
|
||||
Java 内存模型保证了 read、load、use、assign、store、write、lock 和 unlock 操作具有原子性,例如对一个 int 类型的变量执行 assign 赋值操作,这个操作就是原子性的。但是 Java 内存模型允许虚拟机将没有被 volatile 修饰的 64 位数据(long,double)的读写操作划分为两次 32 位的操作来进行,即 load、store、read 和 write 操作可以不具备原子性。
|
||||
|
||||
有一个错误认识就是,int 等原子性的类型在多线程环境中不会出现线程安全问题。前面的线程不安全示例代码中,cnt 属于 int 类型变量,1000 个线程对它进行自增操作之后,得到的值为 997 而不是 1000。
|
||||
|
||||
为了方便讨论,将内存间的交互操作简化为 3 个:load、assign、store。
|
||||
|
||||
下图演示了两个线程同时对 cnt 进行操作,load、assign、store 这一系列操作整体上看不具备原子性,那么在 T1 修改 cnt 并且还没有将修改后的值写入主内存,T2 依然可以读入旧值。可以看出,这两个线程虽然执行了两次自增运算,但是主内存中 cnt 的值最后为 1 而不是 2。因此对 int 类型读写操作满足原子性只是说明 load、assign、store 这些单个操作具备原子性。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/2797a609-68db-4d7b-8701-41ac9a34b14f.jpg" width="300px"> </div><br>
|
||||
|
||||
AtomicInteger 能保证多个线程修改的原子性。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/dd563037-fcaa-4bd8-83b6-b39d93a12c77.jpg" width="300px"> </div><br>
|
||||
|
||||
使用 AtomicInteger 重写之前线程不安全的代码之后得到以下线程安全实现:
|
||||
|
||||
```java
|
||||
public class AtomicExample {
|
||||
private AtomicInteger cnt = new AtomicInteger();
|
||||
|
||||
public void add() {
|
||||
cnt.incrementAndGet();
|
||||
}
|
||||
|
||||
public int get() {
|
||||
return cnt.get();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
final int threadSize = 1000;
|
||||
AtomicExample example = new AtomicExample(); // 只修改这条语句
|
||||
final CountDownLatch countDownLatch = new CountDownLatch(threadSize);
|
||||
ExecutorService executorService = Executors.newCachedThreadPool();
|
||||
for (int i = 0; i < threadSize; i++) {
|
||||
executorService.execute(() -> {
|
||||
example.add();
|
||||
countDownLatch.countDown();
|
||||
});
|
||||
}
|
||||
countDownLatch.await();
|
||||
executorService.shutdown();
|
||||
System.out.println(example.get());
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
1000
|
||||
```
|
||||
|
||||
除了使用原子类之外,也可以使用 synchronized 互斥锁来保证操作的原子性。它对应的内存间交互操作为:lock 和 unlock,在虚拟机实现上对应的字节码指令为 monitorenter 和 monitorexit。
|
||||
|
||||
```java
|
||||
public class AtomicSynchronizedExample {
|
||||
private int cnt = 0;
|
||||
|
||||
public synchronized void add() {
|
||||
cnt++;
|
||||
}
|
||||
|
||||
public synchronized int get() {
|
||||
return cnt;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
final int threadSize = 1000;
|
||||
AtomicSynchronizedExample example = new AtomicSynchronizedExample();
|
||||
final CountDownLatch countDownLatch = new CountDownLatch(threadSize);
|
||||
ExecutorService executorService = Executors.newCachedThreadPool();
|
||||
for (int i = 0; i < threadSize; i++) {
|
||||
executorService.execute(() -> {
|
||||
example.add();
|
||||
countDownLatch.countDown();
|
||||
});
|
||||
}
|
||||
countDownLatch.await();
|
||||
executorService.shutdown();
|
||||
System.out.println(example.get());
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
1000
|
||||
```
|
||||
|
||||
### 2. 可见性
|
||||
|
||||
可见性指当一个线程修改了共享变量的值,其它线程能够立即得知这个修改。Java 内存模型是通过在变量修改后将新值同步回主内存,在变量读取前从主内存刷新变量值来实现可见性的。
|
||||
|
||||
主要有三种实现可见性的方式:
|
||||
|
||||
- volatile
|
||||
- synchronized,对一个变量执行 unlock 操作之前,必须把变量值同步回主内存。
|
||||
- final,被 final 关键字修饰的字段在构造器中一旦初始化完成,并且没有发生 this 逃逸(其它线程通过 this 引用访问到初始化了一半的对象),那么其它线程就能看见 final 字段的值。
|
||||
|
||||
对前面的线程不安全示例中的 cnt 变量使用 volatile 修饰,不能解决线程不安全问题,因为 volatile 并不能保证操作的原子性。
|
||||
|
||||
### 3. 有序性
|
||||
|
||||
有序性是指:在本线程内观察,所有操作都是有序的。在一个线程观察另一个线程,所有操作都是无序的,无序是因为发生了指令重排序。在 Java 内存模型中,允许编译器和处理器对指令进行重排序,重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性。
|
||||
|
||||
volatile 关键字通过添加内存屏障的方式来禁止指令重排,即重排序时不能把后面的指令放到内存屏障之前。
|
||||
|
||||
也可以通过 synchronized 来保证有序性,它保证每个时刻只有一个线程执行同步代码,相当于是让线程顺序执行同步代码。
|
||||
|
||||
## 3 先行发生原则
|
||||
|
||||
上面提到了可以用 volatile 和 synchronized 来保证有序性。除此之外,JVM 还规定了先行发生原则,让一个操作无需控制就能先于另一个操作完成。
|
||||
|
||||
### 1. 单一线程原则
|
||||
|
||||
> Single Thread rule
|
||||
|
||||
在一个线程内,在程序前面的操作先行发生于后面的操作。
|
||||
|
||||

|
||||
|
||||
### 2. 管程锁定规则
|
||||
|
||||
> Monitor Lock Rule
|
||||
|
||||
一个 unlock 操作先行发生于后面对同一个锁的 lock 操作。
|
||||
|
||||

|
||||
|
||||
### 3. volatile 变量规则
|
||||
|
||||
> Volatile Variable Rule
|
||||
|
||||
对一个 volatile 变量的写操作先行发生于后面对这个变量的读操作。
|
||||
|
||||

|
||||
|
||||
### 4. 线程启动规则
|
||||
|
||||
> Thread Start Rule
|
||||
|
||||
Thread 对象的 start() 方法调用先行发生于此线程的每一个动作。
|
||||
|
||||

|
||||
|
||||
### 5. 线程加入规则
|
||||
|
||||
> Thread Join Rule
|
||||
|
||||
Thread 对象的结束先行发生于 join() 方法返回。
|
||||
|
||||

|
||||
|
||||
### 6. 线程中断规则
|
||||
|
||||
> Thread Interruption Rule
|
||||
|
||||
对线程 interrupt() 方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过 interrupted() 方法检测到是否有中断发生。
|
||||
|
||||
### 7. 对象终结规则
|
||||
|
||||
> Finalizer Rule
|
||||
|
||||
一个对象的初始化完成(构造函数执行结束)先行发生于它的 finalize() 方法的开始。
|
||||
|
||||
### 8. 传递性
|
||||
|
||||
> Transitivity
|
||||
|
||||
如果操作 A 先行发生于操作 B,操作 B 先行发生于操作 C,那么操作 A 先行发生于操作 C。
|
||||
113
Java基础教程/Java并发编程/08 Java锁优化.md
Normal file
@@ -0,0 +1,113 @@
|
||||
|
||||
## 1 锁优化
|
||||
|
||||
这里的锁优化主要是指 JVM 对 synchronized 的优化。
|
||||
|
||||
### 自旋锁
|
||||
|
||||
互斥同步进入阻塞状态的开销都很大,应该尽量避免。在许多应用中,共享数据的锁定状态只会持续很短的一段时间。自旋锁的思想是让一个线程在请求一个共享数据的锁时执行忙循环(自旋)一段时间,如果在这段时间内能获得锁,就可以避免进入阻塞状态。
|
||||
|
||||
自旋锁虽然能避免进入阻塞状态从而减少开销,但是它需要进行忙循环操作占用 CPU 时间,它只适用于共享数据的锁定状态很短的场景。
|
||||
|
||||
在 JDK 1.6 中引入了自适应的自旋锁。自适应意味着自旋的次数不再固定了,而是由前一次在同一个锁上的自旋次数及锁的拥有者的状态来决定。
|
||||
|
||||
### 锁消除
|
||||
|
||||
锁消除是指对于被检测出不可能存在竞争的共享数据的锁进行消除。
|
||||
|
||||
锁消除主要是通过逃逸分析来支持,如果堆上的共享数据不可能逃逸出去被其它线程访问到,那么就可以把它们当成私有数据对待,也就可以将它们的锁进行消除。
|
||||
|
||||
对于一些看起来没有加锁的代码,其实隐式的加了很多锁。例如下面的字符串拼接代码就隐式加了锁:
|
||||
|
||||
```java
|
||||
public static String concatString(String s1, String s2, String s3) {
|
||||
return s1 + s2 + s3;
|
||||
}
|
||||
```
|
||||
|
||||
String 是一个不可变的类,编译器会对 String 的拼接自动优化。在 JDK 1.5 之前,会转化为 StringBuffer 对象的连续 append() 操作:
|
||||
|
||||
```java
|
||||
public static String concatString(String s1, String s2, String s3) {
|
||||
StringBuffer sb = new StringBuffer();
|
||||
sb.append(s1);
|
||||
sb.append(s2);
|
||||
sb.append(s3);
|
||||
return sb.toString();
|
||||
}
|
||||
```
|
||||
|
||||
每个 append() 方法中都有一个同步块。虚拟机观察变量 sb,很快就会发现它的动态作用域被限制在 concatString() 方法内部。也就是说,sb 的所有引用永远不会逃逸到 concatString() 方法之外,其他线程无法访问到它,因此可以进行消除。
|
||||
|
||||
### 锁粗化
|
||||
|
||||
如果一系列的连续操作都对同一个对象反复加锁和解锁,频繁的加锁操作就会导致性能损耗。
|
||||
|
||||
上一节的示例代码中连续的 append() 方法就属于这类情况。如果虚拟机探测到由这样的一串零碎的操作都对同一个对象加锁,将会把加锁的范围扩展(粗化)到整个操作序列的外部。对于上一节的示例代码就是扩展到第一个 append() 操作之前直至最后一个 append() 操作之后,这样只需要加锁一次就可以了。
|
||||
|
||||
### 轻量级锁
|
||||
|
||||
JDK 1.6 引入了偏向锁和轻量级锁,从而让锁拥有了四个状态:无锁状态(unlocked)、偏向锁状态(biasble)、轻量级锁状态(lightweight locked)和重量级锁状态(inflated)。
|
||||
|
||||
以下是 HotSpot 虚拟机对象头的内存布局,这些数据被称为 Mark Word。其中 tag bits 对应了五个状态,这些状态在右侧的 state 表格中给出。除了 marked for gc 状态,其它四个状态已经在前面介绍过了。
|
||||
|
||||

|
||||
|
||||
下图左侧是一个线程的虚拟机栈,其中有一部分称为 Lock Record 的区域,这是在轻量级锁运行过程创建的,用于存放锁对象的 Mark Word。而右侧就是一个锁对象,包含了 Mark Word 和其它信息。
|
||||
|
||||

|
||||
|
||||
轻量级锁是相对于传统的重量级锁而言,它使用 CAS 操作来避免重量级锁使用互斥量的开销。对于绝大部分的锁,在整个同步周期内都是不存在竞争的,因此也就不需要都使用互斥量进行同步,可以先采用 CAS 操作进行同步,如果 CAS 失败了再改用互斥量进行同步。
|
||||
|
||||
当尝试获取一个锁对象时,如果锁对象标记为 0 01,说明锁对象的锁未锁定(unlocked)状态。此时虚拟机在当前线程的虚拟机栈中创建 Lock Record,然后使用 CAS 操作将对象的 Mark Word 更新为 Lock Record 指针。如果 CAS 操作成功了,那么线程就获取了该对象上的锁,并且对象的 Mark Word 的锁标记变为 00,表示该对象处于轻量级锁状态。
|
||||
|
||||

|
||||
|
||||
如果 CAS 操作失败了,虚拟机首先会检查对象的 Mark Word 是否指向当前线程的虚拟机栈,如果是的话说明当前线程已经拥有了这个锁对象,那就可以直接进入同步块继续执行,否则说明这个锁对象已经被其他线程线程抢占了。如果有两条以上的线程争用同一个锁,那轻量级锁就不再有效,要膨胀为重量级锁。
|
||||
|
||||
### 偏向锁
|
||||
|
||||
偏向锁的思想是偏向于让第一个获取锁对象的线程,这个线程在之后获取该锁就不再需要进行同步操作,甚至连 CAS 操作也不再需要。
|
||||
|
||||
当锁对象第一次被线程获得的时候,进入偏向状态,标记为 1 01。同时使用 CAS 操作将线程 ID 记录到 Mark Word 中,如果 CAS 操作成功,这个线程以后每次进入这个锁相关的同步块就不需要再进行任何同步操作。
|
||||
|
||||
当有另外一个线程去尝试获取这个锁对象时,偏向状态就宣告结束,此时撤销偏向(Revoke Bias)后恢复到未锁定状态或者轻量级锁状态。
|
||||
|
||||

|
||||
|
||||
## 2 多线程开发良好的实践
|
||||
|
||||
- 给线程起个有意义的名字,这样可以方便找 Bug。
|
||||
|
||||
- 缩小同步范围,从而减少锁争用。例如对于 synchronized,应该尽量使用同步块而不是同步方法。
|
||||
|
||||
- 多用同步工具少用 wait() 和 notify()。首先,CountDownLatch, CyclicBarrier, Semaphore 和 Exchanger 这些同步类简化了编码操作,而用 wait() 和 notify() 很难实现复杂控制流;其次,这些同步类是由最好的企业编写和维护,在后续的 JDK 中还会不断优化和完善。
|
||||
|
||||
- 使用 BlockingQueue 实现生产者消费者问题。
|
||||
|
||||
- 多用并发集合少用同步集合,例如应该使用 ConcurrentHashMap 而不是 Hashtable。
|
||||
|
||||
- 使用本地变量和不可变类来保证线程安全。
|
||||
|
||||
- 使用线程池而不是直接创建线程,这是因为创建线程代价很高,线程池可以有效地利用有限的线程来启动任务。
|
||||
|
||||
## 参考资料
|
||||
|
||||
- BruceEckel. Java 编程思想: 第 4 版 [M]. 机械工业出版社, 2007.
|
||||
- 周志明. 深入理解 Java 虚拟机 [M]. 机械工业出版社, 2011.
|
||||
- [Threads and Locks](https://docs.oracle.com/javase/specs/jvms/se6/html/Threads.doc.html)
|
||||
- [线程通信](http://ifeve.com/thread-signaling/#missed_signal)
|
||||
- [Java 线程面试题 Top 50](http://www.importnew.com/12773.html)
|
||||
- [BlockingQueue](http://tutorials.jenkov.com/java-util-concurrent/blockingqueue.html)
|
||||
- [thread state java](https://stackoverflow.com/questions/11265289/thread-state-java)
|
||||
- [CSC 456 Spring 2012/ch7 MN](http://wiki.expertiza.ncsu.edu/index.php/CSC_456_Spring_2012/ch7_MN)
|
||||
- [Java - Understanding Happens-before relationship](https://www.logicbig.com/tutorials/core-java-tutorial/java-multi-threading/happens-before.html)
|
||||
- [6장 Thread Synchronization](https://www.slideshare.net/novathinker/6-thread-synchronization)
|
||||
- [How is Java's ThreadLocal implemented under the hood?](https://stackoverflow.com/questions/1202444/how-is-javas-threadlocal-implemented-under-the-hood/15653015)
|
||||
- [Concurrent](https://sites.google.com/site/webdevelopart/21-compile/06-java/javase/concurrent?tmpl=%2Fsystem%2Fapp%2Ftemplates%2Fprint%2F&showPrintDialog=1)
|
||||
- [JAVA FORK JOIN EXAMPLE](http://www.javacreed.com/java-fork-join-example/ "Java Fork Join Example")
|
||||
- [聊聊并发(八)——Fork/Join 框架介绍](http://ifeve.com/talk-concurrency-forkjoin/)
|
||||
- [Eliminating SynchronizationRelated Atomic Operations with Biased Locking and Bulk Rebiasing](http://www.oracle.com/technetwork/java/javase/tech/biasedlocking-oopsla2006-preso-150106.pdf)
|
||||
|
||||
|
||||
## 死锁问题
|
||||
BIN
Java基础教程/Java并发编程/image/2022-12-16-16-18-55.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 41 KiB |
BIN
Java基础教程/Java并发编程/image/2022-12-16-18-02-06.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 40 KiB |
BIN
Java基础教程/Java并发编程/image/2022-12-16-19-59-39.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 42 KiB |
BIN
Java基础教程/Java并发编程/image/2022-12-16-19-59-48.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 28 KiB |
BIN
Java基础教程/Java并发编程/image/2022-12-16-20-01-57.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 21 KiB |
BIN
Java基础教程/Java并发编程/image/2022-12-16-20-02-05.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 26 KiB |
BIN
Java基础教程/Java并发编程/image/2022-12-16-20-02-13.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 28 KiB |
BIN
Java基础教程/Java并发编程/image/2022-12-16-20-02-23.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 30 KiB |
BIN
Java基础教程/Java并发编程/image/2022-12-16-20-02-33.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 32 KiB |
BIN
Java基础教程/Java并发编程/image/2022-12-16-20-24-02.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 38 KiB |
BIN
Java基础教程/Java并发编程/image/2022-12-16-20-24-06.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 38 KiB |
BIN
Java基础教程/Java并发编程/image/2022-12-16-20-24-10.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 38 KiB |
BIN
Java基础教程/Java并发编程/image/2022-12-16-20-24-15.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 38 KiB |
BIN
Java基础教程/Java并发编程/image/2022-12-16-20-53-47.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 22 KiB |
BIN
Java基础教程/Java并发编程/image/2022-12-19-11-10-40.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 30 KiB |
BIN
Java基础教程/Java并发编程/image/2022-12-19-14-45-38.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 36 KiB |
BIN
Java基础教程/Java并发编程/image/2022-12-19-14-45-52.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 29 KiB |
@@ -1,370 +0,0 @@
|
||||
**引**
|
||||
|
||||
如果对什么是线程、什么是进程仍存有疑惑,请先Google之,因为这两个概念不在本文的范围之内。
|
||||
|
||||
用多线程只有一个目的,那就是更好的利用cpu的资源,因为所有的多线程代码都可以用单线程来实现。说这个话其实只有一半对,因为反应“多角色”的程序代码,最起码每个角色要给他一个线程吧,否则连实际场景都无法模拟,当然也没法说能用单线程来实现:比如最常见的“生产者,消费者模型”。
|
||||
|
||||
很多人都对其中的一些概念不够明确,如同步、并发等等,让我们先建立一个数据字典,以免产生误会。
|
||||
|
||||
- 多线程:指的是这个程序(一个进程)运行时产生了不止一个线程
|
||||
|
||||
- 并行与并发:
|
||||
|
||||
- 并行:多个cpu实例或者多台机器同时执行一段处理逻辑,是真正的同时。
|
||||
|
||||
- 并发:通过cpu调度算法,让用户看上去同时执行,实际上从cpu操作层面不是真正的同时。并发往往在场景中有公用的资源,那么针对这个公用的资源往往产生瓶颈,我们会用TPS或者QPS来反应这个系统的处理能力。
|
||||
|
||||

|
||||
|
||||
并发与并行
|
||||
|
||||
- 线程安全:经常用来描绘一段代码。指在并发的情况之下,该代码经过多线程使用,线程的调度顺序不影响任何结果。这个时候使用多线程,我们只需要关注系统的内存,cpu是不是够用即可。反过来,线程不安全就意味着线程的调度顺序会影响最终结果,如不加事务的转账代码:
|
||||
|
||||
void transferMoney(User from, User to, float amount){
|
||||
to.setMoney(to.getBalance() + amount); from.setMoney(from.getBalance() -
|
||||
amount); }
|
||||
|
||||
- 同步:Java中的同步指的是通过人为的控制和调度,保证共享资源的多线程访问成为线程安全,来保证结果的准确。如上面的代码简单加入@synchronized关键字。在保证结果准确的同时,提高性能,才是优秀的程序。线程安全的优先级高于性能。
|
||||
|
||||
好了,让我们开始吧。我准备分成几部分来总结涉及到多线程的内容:
|
||||
|
||||
1. 扎好马步:线程的状态
|
||||
|
||||
2. 内功心法:每个对象都有的方法(机制)
|
||||
|
||||
3. 太祖长拳:基本线程类
|
||||
|
||||
4. 九阴真经:高级多线程控制类
|
||||
|
||||
**扎好马步:线程的状态**
|
||||
|
||||
先来两张图:
|
||||
|
||||

|
||||
|
||||
线程状态
|
||||
|
||||

|
||||
|
||||
线程状态转换
|
||||
|
||||
各种状态一目了然,值得一提的是"blocked"这个状态:
|
||||
|
||||
线程在Running的过程中可能会遇到阻塞(Blocked)情况
|
||||
|
||||
1. 调用join()和sleep()方法,sleep()时间结束或被打断,join()中断,IO完成都会回到Runnable状态,等待JVM的调度。
|
||||
|
||||
2. 调用wait(),使该线程处于等待池(wait blocked
|
||||
pool),直到notify()/notifyAll(),线程被唤醒被放到锁定池(lock blocked pool
|
||||
),释放同步锁使线程回到可运行状态(Runnable)
|
||||
|
||||
3. 对Running状态的线程加同步锁(Synchronized)使其进入(lock blocked pool
|
||||
),同步锁被释放进入可运行状态(Runnable)。
|
||||
|
||||
此外,在runnable状态的线程是处于被调度的线程,此时的调度顺序是不一定的。Thread类中的yield方法可以让一个running状态的线程转入runnable。
|
||||
|
||||
**内功心法:每个对象都有的方法(机制)**
|
||||
|
||||
synchronized, wait, notify 是任何对象都具有的同步工具。让我们先来了解他们
|
||||
|
||||

|
||||
|
||||
monitor
|
||||
|
||||
他们是应用于同步问题的人工线程调度工具。讲其本质,首先就要明确monitor的概念,Java中的每个对象都有一个监视器,来监测并发代码的重入。在非多线程编码时该监视器不发挥作用,反之如果在synchronized
|
||||
范围内,监视器发挥作用。
|
||||
|
||||
wait/notify必须存在于synchronized块中。并且,这三个关键字针对的是同一个监视器(某对象的监视器)。这意味着wait之后,其他线程可以进入同步块执行。
|
||||
|
||||
当某代码并不持有监视器的使用权时(如图中5的状态,即脱离同步块)去wait或notify,会抛出java.lang.IllegalMonitorStateException。也包括在synchronized块中去调用另一个对象的wait/notify,因为不同对象的监视器不同,同样会抛出此异常。
|
||||
|
||||
再讲用法:
|
||||
|
||||
- synchronized单独使用:
|
||||
|
||||
- 代码块:如下,在多线程环境下,synchronized块中的方法获取了lock实例的monitor,如果实例相同,那么只有一个线程能执行该块内容
|
||||
|
||||

|
||||
|
||||
复制代码
|
||||
|
||||
public class Thread1 implements Runnable { Object lock; public void run() {
|
||||
synchronized(lock){ ..do something } } }
|
||||
|
||||

|
||||
|
||||
复制代码
|
||||
|
||||
- 直接用于方法:
|
||||
相当于上面代码中用lock来锁定的效果,实际获取的是Thread1类的monitor。更进一步,如果修饰的是static方法,则锁定该类所有实例。
|
||||
|
||||
public class Thread1 implements Runnable { public synchronized void run() { ..do
|
||||
something } }
|
||||
|
||||
- synchronized, wait, notify结合:典型场景生产者消费者问题
|
||||
|
||||

|
||||
|
||||
复制代码
|
||||
|
||||
/\*\* \* 生产者生产出来的产品交给店员 \*/ public synchronized void produce() {
|
||||
if(this.product \>= MAX_PRODUCT) { try { wait();
|
||||
System.out.println("产品已满,请稍候再生产"); } catch(InterruptedException e) {
|
||||
e.printStackTrace(); } return; } this.product++;
|
||||
System.out.println("生产者生产第" + this.product + "个产品."); notifyAll();
|
||||
//通知等待区的消费者可以取出产品了 } /\*\* \* 消费者从店员取产品 \*/ public
|
||||
synchronized void consume() { if(this.product \<= MIN_PRODUCT) { try { wait();
|
||||
System.out.println("缺货,稍候再取"); } catch (InterruptedException e) {
|
||||
e.printStackTrace(); } return; } System.out.println("消费者取走了第" +
|
||||
this.product + "个产品."); this.product--; notifyAll();
|
||||
//通知等待去的生产者可以生产产品了}
|
||||
|
||||

|
||||
|
||||
复制代码
|
||||
|
||||
**volatile**
|
||||
|
||||
多线程的内存模型:main memory(主存)、working
|
||||
memory(线程栈),在处理数据时,线程会把值从主存load到本地栈,完成操作后再save回去(volatile关键词的作用:每次针对该变量的操作都激发一次load
|
||||
and save)。
|
||||
|
||||

|
||||
|
||||
volatile
|
||||
|
||||
针对多线程使用的变量如果不是volatile或者final修饰的,很有可能产生不可预知的结果(另一个线程修改了这个值,但是之后在某线程看到的是修改之前的值)。其实道理上讲同一实例的同一属性本身只有一个副本。但是多线程是会缓存值的,本质上,volatile就是不去缓存,直接取值。在线程安全的情况下加volatile会牺牲性能。
|
||||
|
||||
**太祖长拳:基本线程类**
|
||||
|
||||
基本线程类指的是Thread类,Runnable接口,Callable接口
|
||||
|
||||
Thread 类实现了Runnable接口,启动一个线程的方法:
|
||||
|
||||
MyThread my = new MyThread(); my.start();
|
||||
|
||||
**Thread类相关方法:**
|
||||
|
||||

|
||||
|
||||
复制代码
|
||||
|
||||
//当前线程可转让cpu控制权,让别的就绪状态线程运行(切换)public static
|
||||
Thread.yield() //暂停一段时间public static Thread.sleep()
|
||||
//在一个线程中调用other.join(),将等待other执行完后才继续本线程。 public join()
|
||||
//后两个函数皆可以被打断public interrupte()
|
||||
|
||||

|
||||
|
||||
复制代码
|
||||
|
||||
**关于中断**:它并不像stop方法那样会中断一个正在运行的线程。线程会不时地检测中断标识位,以判断线程是否应该被中断(中断标识值是否为true)。终端只会影响到wait状态、sleep状态和join状态。被打断的线程会抛出InterruptedException。
|
||||
|
||||
Thread.interrupted()检查当前线程是否发生中断,返回boolean
|
||||
|
||||
synchronized在获锁的过程中是不能被中断的。
|
||||
|
||||
中断是一个状态!interrupt()方法只是将这个状态置为true而已。所以说正常运行的程序不去检测状态,就不会终止,而wait等阻塞方法会去检查并抛出异常。如果在正常运行的程序中添加while(!Thread.interrupted())
|
||||
,则同样可以在中断后离开代码体
|
||||
|
||||
**Thread类最佳实践**:
|
||||
|
||||
写的时候最好要设置线程名称 Thread.name,并设置线程组
|
||||
ThreadGroup,目的是方便管理。在出现问题的时候,打印线程栈 (jstack -pid)
|
||||
一眼就可以看出是哪个线程出的问题,这个线程是干什么的。
|
||||
|
||||
**如何获取线程中的异常**
|
||||
|
||||

|
||||
|
||||
不能用try,catch来获取线程中的异常
|
||||
|
||||
**Runnable**
|
||||
|
||||
与Thread类似
|
||||
|
||||
**Callable**
|
||||
|
||||
future模式:并发模式的一种,可以有两种形式,即无阻塞和阻塞,分别是isDone和get。其中Future对象用来存放该线程的返回值以及状态
|
||||
|
||||
ExecutorService e = Executors.newFixedThreadPool(3);
|
||||
//submit方法有多重参数版本,及支持callable也能够支持runnable接口类型.Future
|
||||
future = e.submit(new myCallable()); future.isDone() //return true,false 无阻塞
|
||||
future.get() // return 返回值,阻塞直到该线程运行结束
|
||||
|
||||
**九阴真经:高级多线程控制类**
|
||||
|
||||
以上都属于内功心法,接下来是实际项目中常用到的工具了,Java1.5提供了一个非常高效实用的多线程包:*java.util.concurrent*,
|
||||
提供了大量高级工具,可以帮助开发者编写高效、易维护、结构清晰的Java多线程程序。
|
||||
|
||||
**1.ThreadLocal类**
|
||||
|
||||
用处:保存线程的独立变量。对一个线程类(继承自Thread)
|
||||
|
||||
当使用ThreadLocal维护变量时,ThreadLocal为每个使用该变量的线程提供独立的变量副本,所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。常用于用户登录控制,如记录session信息。
|
||||
|
||||
实现:每个Thread都持有一个TreadLocalMap类型的变量(该类是一个轻量级的Map,功能与map一样,区别是桶里放的是entry而不是entry的链表。功能还是一个map。)以本身为key,以目标为value。
|
||||
|
||||
主要方法是get()和set(T a),set之后在map里维护一个threadLocal -\>
|
||||
a,get时将a返回。ThreadLocal是一个特殊的容器。
|
||||
|
||||
**2.原子类(AtomicInteger、AtomicBoolean……)**
|
||||
|
||||
如果使用atomic wrapper
|
||||
class如atomicInteger,或者使用自己保证原子的操作,则等同于synchronized
|
||||
|
||||
//返回值为booleanAtomicInteger.compareAndSet(int expect,int update)
|
||||
|
||||
该方法可用于实现乐观锁,考虑文中最初提到的如下场景:a给b付款10元,a扣了10元,b要加10元。此时c给b2元,但是b的加十元代码约为:
|
||||
|
||||

|
||||
|
||||
复制代码
|
||||
|
||||
if(b.value.compareAndSet(old, value)){ return ; }else{ //try again // if that
|
||||
fails, rollback and log}
|
||||
|
||||

|
||||
|
||||
复制代码
|
||||
|
||||
**AtomicReference**
|
||||
|
||||
对于AtomicReference 来讲,也许对象会出现,属性丢失的情况,即oldObject ==
|
||||
current,但是oldObject.getPropertyA != current.getPropertyA。
|
||||
|
||||
这时候,AtomicStampedReference就派上用场了。这也是一个很常用的思路,即加上版本号
|
||||
|
||||
**3.Lock类**
|
||||
|
||||
lock: 在java.util.concurrent包内。共有三个实现:
|
||||
|
||||
ReentrantLock ReentrantReadWriteLock.ReadLock ReentrantReadWriteLock.WriteLock
|
||||
|
||||
主要目的是和synchronized一样,
|
||||
两者都是为了解决同步问题,处理资源争端而产生的技术。功能类似但有一些区别。
|
||||
|
||||
区别如下:
|
||||
|
||||

|
||||
|
||||
复制代码
|
||||
|
||||
lock更灵活,可以自由定义多把锁的枷锁解锁顺序(synchronized要按照先加的后解顺序)
|
||||
提供多种加锁方案,lock 阻塞式, trylock 无阻塞式, lockInterruptily 可打断式,
|
||||
还有trylock的带超时时间版本。 本质上和监视器锁(即synchronized是一样的)
|
||||
能力越大,责任越大,必须控制好加锁和解锁,否则会导致灾难。 和Condition类的结合。
|
||||
性能更高,对比如下图:
|
||||
|
||||

|
||||
|
||||
复制代码
|
||||
|
||||

|
||||
|
||||
synchronized和Lock性能对比
|
||||
|
||||
**ReentrantLock**
|
||||
|
||||
可重入的意义在于持有锁的线程可以继续持有,并且要释放对等的次数后才真正释放该锁。
|
||||
|
||||
使用方法是:
|
||||
|
||||
1.先new一个实例
|
||||
|
||||
static ReentrantLock r=new ReentrantLock();
|
||||
|
||||
2.加锁
|
||||
|
||||
r.lock()或r.lockInterruptibly();
|
||||
|
||||
此处也是个不同,后者可被打断。当a线程lock后,b线程阻塞,此时如果是lockInterruptibly,那么在调用b.interrupt()之后,b线程退出阻塞,并放弃对资源的争抢,进入catch块。(如果使用后者,必须throw
|
||||
interruptable exception 或catch)
|
||||
|
||||
3.释放锁
|
||||
|
||||
r.unlock()
|
||||
|
||||
必须做!何为必须做呢,要放在finally里面。以防止异常跳出了正常流程,导致灾难。这里补充一个小知识点,finally是可以信任的:经过测试,哪怕是发生了OutofMemoryError,finally块中的语句执行也能够得到保证。
|
||||
|
||||
**ReentrantReadWriteLock**
|
||||
|
||||
可重入读写锁(读写锁的一个实现)
|
||||
|
||||
ReentrantReadWriteLock lock = new ReentrantReadWriteLock() ReadLock r =
|
||||
lock.readLock(); WriteLock w = lock.writeLock();
|
||||
|
||||
两者都有lock,unlock方法。写写,写读互斥;读读不互斥。可以实现并发读的高效线程安全代码
|
||||
|
||||
**4.容器类**
|
||||
|
||||
这里就讨论比较常用的两个:
|
||||
|
||||
BlockingQueue ConcurrentHashMap
|
||||
|
||||
**BlockingQueue**
|
||||
|
||||
阻塞队列。该类是java.util.concurrent包下的重要类,通过对Queue的学习可以得知,这个queue是单向队列,可以在队列头添加元素和在队尾删除或取出元素。类似于一个管
|
||||
道,特别适用于先进先出策略的一些应用场景。普通的queue接口主要实现有PriorityQueue(优先队列),有兴趣可以研究
|
||||
|
||||
BlockingQueue在队列的基础上添加了多线程协作的功能:
|
||||
|
||||

|
||||
|
||||
BlockingQueue
|
||||
|
||||
除了传统的queue功能(表格左边的两列)之外,还提供了阻塞接口put和take,带超时功能的阻塞接口offer和poll。put会在队列满的时候阻塞,直到有空间时被唤醒;take在队
|
||||
列空的时候阻塞,直到有东西拿的时候才被唤醒。用于生产者-消费者模型尤其好用,堪称神器。
|
||||
|
||||
常见的阻塞队列有:
|
||||
|
||||
ArrayListBlockingQueue LinkedListBlockingQueue DelayQueue SynchronousQueue
|
||||
|
||||
**ConcurrentHashMap**
|
||||
|
||||
高效的线程安全哈希map。请对比hashTable , concurrentHashMap, HashMap
|
||||
|
||||
**5.管理类**
|
||||
|
||||
管理类的概念比较泛,用于管理线程,本身不是多线程的,但提供了一些机制来利用上述的工具做一些封装。
|
||||
|
||||
了解到的值得一提的管理类:ThreadPoolExecutor和 JMX框架下的系统级管理类
|
||||
ThreadMXBean
|
||||
|
||||
**ThreadPoolExecutor**
|
||||
|
||||
如果不了解这个类,应该了解前面提到的ExecutorService,开一个自己的线程池非常方便:
|
||||
|
||||

|
||||
|
||||
复制代码
|
||||
|
||||
ExecutorService e = Executors.newCachedThreadPool(); ExecutorService e =
|
||||
Executors.newSingleThreadExecutor(); ExecutorService e =
|
||||
Executors.newFixedThreadPool(3); //
|
||||
第一种是可变大小线程池,按照任务数来分配线程, //
|
||||
第二种是单线程池,相当于FixedThreadPool(1) // 第三种是固定大小线程池。 //
|
||||
然后运行e.execute(new MyRunnableImpl());
|
||||
|
||||

|
||||
|
||||
复制代码
|
||||
|
||||
该类内部是通过ThreadPoolExecutor实现的,掌握该类有助于理解线程池的管理,本质上,他们都是ThreadPoolExecutor类的各种实现版本。请参见javadoc:
|
||||
|
||||

|
||||
|
||||
ThreadPoolExecutor参数解释
|
||||
|
||||
翻译一下:
|
||||
|
||||

|
||||
|
||||
复制代码
|
||||
|
||||
corePoolSize:池内线程初始值与最小值,就算是空闲状态,也会保持该数量线程。
|
||||
maximumPoolSize:线程最大值,线程的增长始终不会超过该值。
|
||||
keepAliveTime:当池内线程数高于corePoolSize时,经过多少时间多余的空闲线程才会被回收。回收前处于wait状态
|
||||
unit: 时间单位,可以使用TimeUnit的实例,如TimeUnit.MILLISECONDS
|
||||
workQueue:待入任务(Runnable)的等待场所,该参数主要影响调度策略,如公平与否,是否产生饿死(starving)
|
||||
threadFactory:线程工厂类,有默认实现,如果有自定义的需要则需要自己实现ThreadFactory接口并作为参数传入。
|
||||
@@ -1,5 +0,0 @@
|
||||
# 底层事件处理
|
||||
|
||||
-----
|
||||
|
||||
* 在java.awt学习的时候,将监听器绑定到事件源上,当指定事件发生时监听器会自动匹配到相应的动作,执行相应的处理方式。但在底层事件处理过程中,不许要监听器,能够直接获取当前发生的底层事件,然后进行匹配处理。
|
||||
@@ -1,117 +0,0 @@
|
||||
## 新的事件监听机制
|
||||
|
||||
-----
|
||||
|
||||
* 之前是定义一个组件对象(事件源),队组建对象绑定一个监听器对象,在监听器对象中有监听同一事件不同动作的函数,函数内部对事件进行处理。从监听器的角度对事件和动作进行处理。
|
||||
* 现在是直接将静态事件绑定到事件源上,通过process函数运行运行事件发生时的处理方式。而且这些静态事件是已经存在于awtEvent类中的。
|
||||
|
||||
```
|
||||
|
||||
package EventHandle;
|
||||
|
||||
import java.awt.*;
|
||||
import java.awt.event.ComponentEvent;
|
||||
import java.awt.event.MouseEvent;
|
||||
import java.awt.event.WindowEvent;
|
||||
|
||||
/**
|
||||
* @author 宙斯
|
||||
* 准确的说这并不是先前的事件监听机制吧。它不存在指明的监听器。
|
||||
* 应该更像一种组件自带的事件匹配功能。
|
||||
* 具体步骤:
|
||||
* 打开某一类型的事件匹配功能。
|
||||
* 使用process函数运行某个事件
|
||||
* 当事件发生时通过事件的ID匹配具体的动作。
|
||||
* 匹配后设置相应的处理方式。
|
||||
*/
|
||||
|
||||
public class baseEvent extends Frame{
|
||||
private int x = 0,y = 0,flag = 0;
|
||||
private Image img;
|
||||
private int dx = 0,dy = 0;
|
||||
|
||||
public static void main(String[] args) {
|
||||
baseEvent bE = new baseEvent();
|
||||
}
|
||||
public baseEvent(){
|
||||
super();
|
||||
setSize(500,500);
|
||||
this.setVisible(true);
|
||||
|
||||
Toolkit tk = Toolkit.getDefaultToolkit();
|
||||
img = tk.getImage("first.png");
|
||||
|
||||
//相当于添加了对Component事件的监听器,似乎监听器类在底层已经直接绑定。
|
||||
enableEvents(AWTEvent.COMPONENT_EVENT_MASK);
|
||||
enableEvents(AWTEvent.WINDOW_EVENT_MASK);
|
||||
enableEvents(AWTEvent.MOUSE_EVENT_MASK);
|
||||
|
||||
repaint();
|
||||
|
||||
}
|
||||
|
||||
//直接调用底层的事件处理函数
|
||||
public void processComponentEvent(ComponentEvent e){
|
||||
if(e.getID() == ComponentEvent.COMPONENT_MOVED){
|
||||
System.out.println(e.getSource());
|
||||
System.out.println(e.getID());
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
public void processWindowEvent(WindowEvent e){
|
||||
if(e.getID() == WindowEvent.WINDOW_CLOSING){
|
||||
System.exit(0);
|
||||
}
|
||||
}
|
||||
/*
|
||||
public void processMouseEvent(MouseEvent e){
|
||||
if(e.getID() == MouseEvent.MOUSE_PRESSED){
|
||||
System.out.println("pressed");
|
||||
if((e.getX()>= x)&&(e.getX()<=x+100)&&(e.getY()>=y)&&(e.getY()<=y+100)){
|
||||
flag = 1;
|
||||
System.out.println(e.getX()+"..."+e.getY());
|
||||
|
||||
}
|
||||
}
|
||||
if((e.getID()==MouseEvent.MOUSE_RELEASED)&&(flag == 1)){
|
||||
x = e.getX();
|
||||
y = e.getY();
|
||||
repaint();
|
||||
flag = 0;
|
||||
}
|
||||
}
|
||||
*/
|
||||
public void processMouseEvent(MouseEvent e){
|
||||
if(e.getID() == MouseEvent.MOUSE_PRESSED){
|
||||
System.out.println("pressed");
|
||||
if((e.getX()>= x)&&(e.getX()<=x+100)&&(e.getY()>=y)&&(e.getY()<=y+100)){
|
||||
dx = e.getX()-x;
|
||||
dy = e.getY()-y;
|
||||
flag = 1;
|
||||
System.out.println(e.getX()+"..."+e.getY());
|
||||
|
||||
}
|
||||
}
|
||||
if(e.getID()== MouseEvent.MOUSE_MOVED&&flag ==1){
|
||||
x = e.getX()-dx;
|
||||
y = e.getY()-dy;
|
||||
System.out.println(e.getX()+"..."+e.getY());
|
||||
|
||||
repaint();
|
||||
|
||||
}
|
||||
if((e.getID()==MouseEvent.MOUSE_RELEASED)&&(flag == 1)){
|
||||
flag = 0;
|
||||
}
|
||||
|
||||
}
|
||||
public void paint(Graphics g){
|
||||
g.drawImage(img, x, y,100,100, this);
|
||||
}
|
||||
|
||||
|
||||
}
|
||||
|
||||
|
||||
```
|
||||
@@ -1,14 +0,0 @@
|
||||
# 多线程共享受限资源
|
||||
|
||||
----
|
||||
|
||||
## >多线程共享受限资源存在的问题
|
||||
|
||||
|
||||
----
|
||||
|
||||
* **这个描述???**
|
||||
当你坐在桌子旁边时,手里有有一把叉子,准备插起盘子里最后一块十五,当叉子碰到十五的时候,它忽然消失了。
|
||||
|
||||
* **解决方法**
|
||||
给这个资源加锁,每个线程访问这个资源时上锁,访问结束后开锁。
|
||||
@@ -1,14 +0,0 @@
|
||||
# 多线程共享受限资源
|
||||
|
||||
----
|
||||
|
||||
## >多线程共享受限资源存在的问题
|
||||
|
||||
|
||||
----
|
||||
|
||||
* **这个描述???**
|
||||
当你坐在桌子旁边时,手里有有一把叉子,准备插起盘子里最后一块十五,当叉子碰到十五的时候,它忽然消失了。
|
||||
|
||||
* **解决方法**
|
||||
给这个资源加锁,每个线程访问这个资源时上锁,访问结束后开锁。
|
||||
@@ -1,48 +0,0 @@
|
||||
# 多线程理论补充
|
||||
|
||||
------
|
||||
|
||||
## >让步机制
|
||||
|
||||
-----
|
||||
|
||||
* **yield()**
|
||||
thread.yield()线程执行这个函数会主动放弃执行的优先级,但只是暗示别的线程能够抢到更多的资源,没有确定的机制保证cpu资源一定被其他线程使用。
|
||||
|
||||
## >休眠机制
|
||||
|
||||
---
|
||||
|
||||
* **sleep()**
|
||||
thread.sleep(30)线程停止执行30ms,可能会跑出异常,此线程调用interrupt()方法,中断了线程的执行。
|
||||
|
||||
## >优先权机制
|
||||
|
||||
----
|
||||
|
||||
* **setPriority()**
|
||||
thread.setPriority()通过thread类中的常量对优先级进行设定。thread.getPriority()能够获取当前线程的优先级。
|
||||
|
||||
## >后台进程
|
||||
|
||||
-----
|
||||
|
||||
* **后台线程(守护线程)thread.setDaemon()**
|
||||
程序运行时,在后台提供的一种通用的线程,当所有的非后台线程结束时,后台线程(守护线程)自动终止。必须在线程启动之前,调用方法setDaemon(),将线程设置成后台线程。isDeamon()判断是否为后台线程。
|
||||
|
||||
## >加入线程
|
||||
|
||||
----
|
||||
|
||||
* **t.join(a)**
|
||||
t线程此时将被挂起,直到a线程结束才会被执行。当a线程结束时,t.isAlive()返回为假,线程恢复。
|
||||
|
||||
## >编码变体
|
||||
|
||||
-----
|
||||
|
||||
* **implements Runnable**
|
||||
通过实现接口Runnable来达到作为线程类的方法。必须实现run方法。
|
||||
|
||||
* **建立有响应的用户界面**
|
||||
让运算作为一个独立的线程在后台独立运行。
|
||||
@@ -1,48 +0,0 @@
|
||||
# 多线程理论补充
|
||||
|
||||
------
|
||||
|
||||
## >让步机制
|
||||
|
||||
-----
|
||||
|
||||
* **yield()**
|
||||
thread.yield()线程执行这个函数会主动放弃执行的优先级,但只是暗示别的线程能够抢到更多的资源,没有确定的机制保证cpu资源一定被其他线程使用。
|
||||
|
||||
## >休眠机制
|
||||
|
||||
---
|
||||
|
||||
* **sleep()**
|
||||
thread.sleep(30)线程停止执行30ms,可能会跑出异常,此线程调用interrupt()方法,中断了线程的执行。
|
||||
|
||||
## >优先权机制
|
||||
|
||||
----
|
||||
|
||||
* **setPriority()**
|
||||
thread.setPriority()通过thread类中的常量对优先级进行设定。thread.getPriority()能够获取当前线程的优先级。
|
||||
|
||||
## >后台进程
|
||||
|
||||
-----
|
||||
|
||||
* **后台线程(守护线程)thread.setDaemon()**
|
||||
程序运行时,在后台提供的一种通用的线程,当所有的非后台线程结束时,后台线程(守护线程)自动终止。必须在线程启动之前,调用方法setDaemon(),将线程设置成后台线程。isDeamon()判断是否为后台线程。
|
||||
|
||||
## >加入线程
|
||||
|
||||
----
|
||||
|
||||
* **t.join(a)**
|
||||
t线程此时将被挂起,直到a线程结束才会被执行。当a线程结束时,t.isAlive()返回为假,线程恢复。
|
||||
|
||||
## >编码变体
|
||||
|
||||
-----
|
||||
|
||||
* **implements Runnable**
|
||||
通过实现接口Runnable来达到作为线程类的方法。必须实现run方法。
|
||||
|
||||
* **建立有响应的用户界面**
|
||||
让运算作为一个独立的线程在后台独立运行。
|
||||
@@ -1,40 +0,0 @@
|
||||
# 多线程的应用
|
||||
|
||||
------
|
||||
|
||||
## 多线程停止线程
|
||||
|
||||
----
|
||||
|
||||
* stop方法已经过时不能使用,只能当run方法结束时,才能终止线程。开启多线程程运行时,代码通常是循环结构,只要控制住线程,通常可以让run方法结束。
|
||||
* 应当设计可以修改的无限循环标志。跳出无限循环,则会终止线程。
|
||||
* 当线程在循环内进入等待状态时,及时线程的循环条件不满足,必须终止线程,但是无法执行到判断语句进行线程的终止,此时,必须使用interrupt()函数来达到要求。
|
||||
* interrupt将处于冻结状态的线程强制转换到运行状态。此时wait()就会跑出我们处理已久的中断异常。
|
||||
* 当没有指定的方式让冻结的线程回复到运行状态时,这是需要对冻结进行清除。Thread提供了interrupt方法。
|
||||
|
||||
|
||||
## 多线程 守护线程
|
||||
|
||||
-----
|
||||
|
||||
* 守护线程就是后台线程,也是一种依赖线程
|
||||
* 特点:
|
||||
当前台线程结束后,后台线程会自动终止,作为依赖线程,守护线程,不用强调结束。
|
||||
* 方法:
|
||||
setDemon()设置某个线程为守护线程
|
||||
|
||||
## 多线程join方法
|
||||
|
||||
----
|
||||
|
||||
* t1.join() t1抢夺cpu执行权,主线程处于冻结状态,t1优先执行。相当于顺序执行两个线程。主线程碰到谁的join就会等谁执行。
|
||||
* 当A线程执行到了B线程的Join方法时,A线程就会等待,等B线程都执行完成,A才会执行。join才会临时加入线程执行。当B线程进入wait时,A线程也能继续执行。
|
||||
* toString 方法能够显示线程的名称,线程的优先级,线程当前的分组(线程组谁调用就是谁的线程组的)
|
||||
* 所有线程包括主线程,默认是5。数越大优先级越高。MAX_PRIORITY,MIN_PRIORITY,
|
||||
* yield()方法,当线程读到这里是,会释放执行权。这样会使所有的线程都有平均执行的效果。
|
||||
|
||||
## 什么时候会使用到多线程
|
||||
|
||||
----
|
||||
|
||||
* 当程序独立运算相互之间不相关的时候,可以用多线程封装一下,提高程序执行的速度
|
||||
@@ -1,40 +0,0 @@
|
||||
# 多线程的应用
|
||||
|
||||
------
|
||||
|
||||
## 多线程停止线程
|
||||
|
||||
----
|
||||
|
||||
* stop方法已经过时不能使用,只能当run方法结束时,才能终止线程。开启多线程程运行时,代码通常是循环结构,只要控制住线程,通常可以让run方法结束。
|
||||
* 应当设计可以修改的无限循环标志。跳出无限循环,则会终止线程。
|
||||
* 当线程在循环内进入等待状态时,及时线程的循环条件不满足,必须终止线程,但是无法执行到判断语句进行线程的终止,此时,必须使用interrupt()函数来达到要求。
|
||||
* interrupt将处于冻结状态的线程强制转换到运行状态。此时wait()就会跑出我们处理已久的中断异常。
|
||||
* 当没有指定的方式让冻结的线程回复到运行状态时,这是需要对冻结进行清除。Thread提供了interrupt方法。
|
||||
|
||||
|
||||
## 多线程 守护线程
|
||||
|
||||
-----
|
||||
|
||||
* 守护线程就是后台线程,也是一种依赖线程
|
||||
* 特点:
|
||||
当前台线程结束后,后台线程会自动终止,作为依赖线程,守护线程,不用强调结束。
|
||||
* 方法:
|
||||
setDemon()设置某个线程为守护线程
|
||||
|
||||
## 多线程join方法
|
||||
|
||||
----
|
||||
|
||||
* t1.join() t1抢夺cpu执行权,主线程处于冻结状态,t1优先执行。相当于顺序执行两个线程。主线程碰到谁的join就会等谁执行。
|
||||
* 当A线程执行到了B线程的Join方法时,A线程就会等待,等B线程都执行完成,A才会执行。join才会临时加入线程执行。当B线程进入wait时,A线程也能继续执行。
|
||||
* toString 方法能够显示线程的名称,线程的优先级,线程当前的分组(线程组谁调用就是谁的线程组的)
|
||||
* 所有线程包括主线程,默认是5。数越大优先级越高。MAX_PRIORITY,MIN_PRIORITY,
|
||||
* yield()方法,当线程读到这里是,会释放执行权。这样会使所有的线程都有平均执行的效果。
|
||||
|
||||
## 什么时候会使用到多线程
|
||||
|
||||
----
|
||||
|
||||
* 当程序独立运算相互之间不相关的时候,可以用多线程封装一下,提高程序执行的速度
|
||||
@@ -1,166 +0,0 @@
|
||||
# 多线程间的通讯
|
||||
|
||||
-----
|
||||
|
||||
## 多线程通讯的定义:
|
||||
|
||||
----
|
||||
|
||||
- 多个不同的线程对共同的数据进行不同的操作。
|
||||
|
||||
## 多线程通讯间的安全问题
|
||||
|
||||
-----
|
||||
|
||||
* 安全问题的原因
|
||||
例如当多个线程对同一个数据进行不同操作时,导致各种操作的先后顺序出现混乱。
|
||||
* 安全问题的解决方式
|
||||
对这些线程操作数据的部分进行同步处理,使用相同的锁,将不同的部分锁起。
|
||||
|
||||
## 线程间通讯等待唤醒机制
|
||||
|
||||
-----
|
||||
|
||||
* 可以模仿锁的工作原理(设置标志位,记录当前是够线程占用锁内的程序,实现只能有一个线程执行锁内代码的现象)
|
||||
* 步骤:
|
||||
1. 设置标志位flag
|
||||
2. 当标志位处于输入状态时,执行输入程序,执行完成后修改为输出状态。
|
||||
3. 当标志位处于输出状态时,执行输出程序,执行完成后修改为输入状态。
|
||||
## 等待唤醒机制的具体实现
|
||||
|
||||
----
|
||||
|
||||
* wait()和notify()函数必须在同步代码块或者同步函数当中使用。注意wait()会抛出中断异常。对持有监视器(锁)的线程进行操作。
|
||||
* wait()和notify()的操作对象是同步中持有当前锁的线程。
|
||||
* 线程的等待唤醒机制必须制定一把确定的锁。锁是任意的对象,任意对象都能成为锁,成为锁之后都能调用wait和notify的方法。而且这些方法都定义在Object类中。只有同一个锁上的被等待线程可以被同一个notify唤醒。等待唤醒必须是同一个锁。
|
||||
|
||||
## 使用新的工具类实现程序锁定和解锁
|
||||
|
||||
----
|
||||
|
||||
package painting;
|
||||
|
||||
import java.util.concurrent.locks.Condition;
|
||||
import java.util.concurrent.locks.Lock;
|
||||
import java.util.concurrent.locks.ReentrantLock;
|
||||
|
||||
/**
|
||||
* @author 宙斯
|
||||
*
|
||||
*/
|
||||
public class LockerUsing {
|
||||
|
||||
/**
|
||||
* @param args
|
||||
*/
|
||||
public static void main(String[] args) {
|
||||
Resource2 r = new Resource2();
|
||||
Produce2 pro = new Produce2(r);
|
||||
Consumer2 con = new Consumer2(r);
|
||||
|
||||
Thread t1 = new Thread(pro);
|
||||
Thread t2 = new Thread(con);
|
||||
Thread t3 = new Thread(pro);
|
||||
Thread t4 = new Thread(con);
|
||||
t1.start();
|
||||
t2.start();
|
||||
t3.start();
|
||||
t4.start();
|
||||
}
|
||||
|
||||
}
|
||||
class Resource2{
|
||||
private String name;
|
||||
private int count =1;
|
||||
private boolean flag = false;
|
||||
private Lock lock = new ReentrantLock();//新建了一个锁对象
|
||||
private Condition condition_con = lock.newCondition();//生成了一个与锁相关的控制对象
|
||||
private Condition condition_pro = lock.newCondition();
|
||||
public void set(String name) throws InterruptedException{
|
||||
lock.lock();
|
||||
try{
|
||||
while(flag)
|
||||
condition_pro.await();
|
||||
|
||||
this.name= name+"..."+count++;
|
||||
System.out.println(Thread.currentThread().getName()+"生产者:"+this.name);
|
||||
flag = true;
|
||||
condition_con.signal();
|
||||
}
|
||||
finally{
|
||||
lock.unlock();//异常处理当中释放锁的动过一定要被执行
|
||||
|
||||
}
|
||||
}
|
||||
public void out() throws InterruptedException{
|
||||
lock.lock();
|
||||
try{
|
||||
while(!flag)
|
||||
condition_con.await();
|
||||
System.out.println(Thread.currentThread().getName()+"消费者:"+this.name);
|
||||
flag = false;
|
||||
condition_pro.signalAll();
|
||||
}
|
||||
finally{
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
}
|
||||
class Produce2 implements Runnable{
|
||||
private Resource2 res;
|
||||
Produce2(Resource2 res){
|
||||
this.res = res;
|
||||
|
||||
}
|
||||
public void run()
|
||||
{
|
||||
while(true){
|
||||
try {
|
||||
res.set("商品");
|
||||
} catch (InterruptedException e) {
|
||||
// TODO Auto-generated catch block
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
class Consumer2 implements Runnable{
|
||||
private Resource2 res;
|
||||
Consumer2(Resource2 res){
|
||||
this.res = res;
|
||||
|
||||
}
|
||||
public void run()
|
||||
{
|
||||
while(true){
|
||||
try {
|
||||
res.out();
|
||||
} catch (InterruptedException e) {
|
||||
// TODO Auto-generated catch block
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
* 代码的解释:
|
||||
|
||||
1. 单线程 -----多线程-----多线程操作同一个数据源的时候实行同步机制------带有满足条件的同步机制(睡眠唤醒机制)
|
||||
2. 实现了多线程不同操作相同的程序,这个类具有模板的价值.对资源的不同操作写到资源类中,并使用this资源类的锁,对各种不同的操作进行上锁
|
||||
3. 而非写到其他操作类中,这样能够将同步和冲突解决都封装到资源类中便于理解和操作。
|
||||
4. 当线程数多于两个,比如此程序中有两个在生产两个在消费,那么标准的方式应该是通过循环判断标志位是否合格,
|
||||
因为当某个线程判断满足后,但在进入之前肯能被其他线程修改标志位。
|
||||
而且必须使用notifyAll()唤醒所有的线程。
|
||||
5. 使用Locker及其相关类的好处
|
||||
一个Locker上可以有很多condition对象执行操作,也就是只唤醒对方的condition
|
||||
jdk1.5实现了多线程的升级解决方案
|
||||
将同步设置Synchronize替换成Lock操作,可见
|
||||
将Object中wait,notify,notifyAll替换成Condition对象。该对象可以Locker锁进行获取
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -1,166 +0,0 @@
|
||||
# 多线程间的通讯
|
||||
|
||||
-----
|
||||
|
||||
## 多线程通讯的定义:
|
||||
|
||||
----
|
||||
|
||||
- 多个不同的线程对共同的数据进行不同的操作。
|
||||
|
||||
## 多线程通讯间的安全问题
|
||||
|
||||
-----
|
||||
|
||||
* 安全问题的原因
|
||||
例如当多个线程对同一个数据进行不同操作时,导致各种操作的先后顺序出现混乱。
|
||||
* 安全问题的解决方式
|
||||
对这些线程操作数据的部分进行同步处理,使用相同的锁,将不同的部分锁起。
|
||||
|
||||
## 线程间通讯等待唤醒机制
|
||||
|
||||
-----
|
||||
|
||||
* 可以模仿锁的工作原理(设置标志位,记录当前是够线程占用锁内的程序,实现只能有一个线程执行锁内代码的现象)
|
||||
* 步骤:
|
||||
1. 设置标志位flag
|
||||
2. 当标志位处于输入状态时,执行输入程序,执行完成后修改为输出状态。
|
||||
3. 当标志位处于输出状态时,执行输出程序,执行完成后修改为输入状态。
|
||||
## 等待唤醒机制的具体实现
|
||||
|
||||
----
|
||||
|
||||
* wait()和notify()函数必须在同步代码块或者同步函数当中使用。注意wait()会抛出中断异常。对持有监视器(锁)的线程进行操作。
|
||||
* wait()和notify()的操作对象是同步中持有当前锁的线程。
|
||||
* 线程的等待唤醒机制必须制定一把确定的锁。锁是任意的对象,任意对象都能成为锁,成为锁之后都能调用wait和notify的方法。而且这些方法都定义在Object类中。只有同一个锁上的被等待线程可以被同一个notify唤醒。等待唤醒必须是同一个锁。
|
||||
|
||||
## 使用新的工具类实现程序锁定和解锁
|
||||
|
||||
----
|
||||
|
||||
package painting;
|
||||
|
||||
import java.util.concurrent.locks.Condition;
|
||||
import java.util.concurrent.locks.Lock;
|
||||
import java.util.concurrent.locks.ReentrantLock;
|
||||
|
||||
/**
|
||||
* @author 宙斯
|
||||
*
|
||||
*/
|
||||
public class LockerUsing {
|
||||
|
||||
/**
|
||||
* @param args
|
||||
*/
|
||||
public static void main(String[] args) {
|
||||
Resource2 r = new Resource2();
|
||||
Produce2 pro = new Produce2(r);
|
||||
Consumer2 con = new Consumer2(r);
|
||||
|
||||
Thread t1 = new Thread(pro);
|
||||
Thread t2 = new Thread(con);
|
||||
Thread t3 = new Thread(pro);
|
||||
Thread t4 = new Thread(con);
|
||||
t1.start();
|
||||
t2.start();
|
||||
t3.start();
|
||||
t4.start();
|
||||
}
|
||||
|
||||
}
|
||||
class Resource2{
|
||||
private String name;
|
||||
private int count =1;
|
||||
private boolean flag = false;
|
||||
private Lock lock = new ReentrantLock();//新建了一个锁对象
|
||||
private Condition condition_con = lock.newCondition();//生成了一个与锁相关的控制对象
|
||||
private Condition condition_pro = lock.newCondition();
|
||||
public void set(String name) throws InterruptedException{
|
||||
lock.lock();
|
||||
try{
|
||||
while(flag)
|
||||
condition_pro.await();
|
||||
|
||||
this.name= name+"..."+count++;
|
||||
System.out.println(Thread.currentThread().getName()+"生产者:"+this.name);
|
||||
flag = true;
|
||||
condition_con.signal();
|
||||
}
|
||||
finally{
|
||||
lock.unlock();//异常处理当中释放锁的动过一定要被执行
|
||||
|
||||
}
|
||||
}
|
||||
public void out() throws InterruptedException{
|
||||
lock.lock();
|
||||
try{
|
||||
while(!flag)
|
||||
condition_con.await();
|
||||
System.out.println(Thread.currentThread().getName()+"消费者:"+this.name);
|
||||
flag = false;
|
||||
condition_pro.signalAll();
|
||||
}
|
||||
finally{
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
}
|
||||
class Produce2 implements Runnable{
|
||||
private Resource2 res;
|
||||
Produce2(Resource2 res){
|
||||
this.res = res;
|
||||
|
||||
}
|
||||
public void run()
|
||||
{
|
||||
while(true){
|
||||
try {
|
||||
res.set("商品");
|
||||
} catch (InterruptedException e) {
|
||||
// TODO Auto-generated catch block
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
class Consumer2 implements Runnable{
|
||||
private Resource2 res;
|
||||
Consumer2(Resource2 res){
|
||||
this.res = res;
|
||||
|
||||
}
|
||||
public void run()
|
||||
{
|
||||
while(true){
|
||||
try {
|
||||
res.out();
|
||||
} catch (InterruptedException e) {
|
||||
// TODO Auto-generated catch block
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
* 代码的解释:
|
||||
|
||||
1. 单线程 -----多线程-----多线程操作同一个数据源的时候实行同步机制------带有满足条件的同步机制(睡眠唤醒机制)
|
||||
2. 实现了多线程不同操作相同的程序,这个类具有模板的价值.对资源的不同操作写到资源类中,并使用this资源类的锁,对各种不同的操作进行上锁
|
||||
3. 而非写到其他操作类中,这样能够将同步和冲突解决都封装到资源类中便于理解和操作。
|
||||
4. 当线程数多于两个,比如此程序中有两个在生产两个在消费,那么标准的方式应该是通过循环判断标志位是否合格,
|
||||
因为当某个线程判断满足后,但在进入之前肯能被其他线程修改标志位。
|
||||
而且必须使用notifyAll()唤醒所有的线程。
|
||||
5. 使用Locker及其相关类的好处
|
||||
一个Locker上可以有很多condition对象执行操作,也就是只唤醒对方的condition
|
||||
jdk1.5实现了多线程的升级解决方案
|
||||
将同步设置Synchronize替换成Lock操作,可见
|
||||
将Object中wait,notify,notifyAll替换成Condition对象。该对象可以Locker锁进行获取
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -1,321 +0,0 @@
|
||||
# java并发控制
|
||||
|
||||
> 参考文献
|
||||
> * [并发编程](https://www.cnblogs.com/flashsun/p/10776168.html)
|
||||
> * [java高并发编程](https://blog.csdn.net/cx105200/article/details/80220937)
|
||||
|
||||
|
||||
synchronized 关键字
|
||||
可用来给对象和方法或者代码块加锁,当它锁定一个方法或者一个代码块的时候,同一时刻最多只有一个线程执行这段代码。可能锁对象包括: this, 临界资源对象,Class 类对象
|
||||
|
||||
同步方法
|
||||
同步方法锁定的是当前对象。当多线程通过同一个对象引用多次调用当前同步方法时, 需同步执行。
|
||||
|
||||
public synchronized void test(){
|
||||
System.out.println("测试一下");
|
||||
}
|
||||
1
|
||||
2
|
||||
3
|
||||
同步代码块
|
||||
同步代码块的同步粒度更加细致,是商业开发中推荐的编程方式。可以定位到具体的同步位置,而不是简单的将方法整体实现同步逻辑。在效率上,相对更高。
|
||||
锁定临界对象
|
||||
同步代码块在执行时,是锁定 object 对象。当多个线程调用同一个方法时,锁定对象不变的情况下,需同步执行。
|
||||
|
||||
public void test(){
|
||||
synchronized(o){
|
||||
System.out.println("测试一下");
|
||||
}
|
||||
}
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
锁定当前对象
|
||||
|
||||
public void test(){
|
||||
synchronized(this){
|
||||
System.out.println("测试一下");
|
||||
}
|
||||
}
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
锁的底层实现
|
||||
Java 虚拟机中的同步(Synchronization)基于进入和退出管程(Monitor)对象实现。同步方法 并不是由 monitor enter 和 monitor exit 指令来实现同步的,而是由方法调用指令读取运行时常量池中方法的 ACC_SYNCHRONIZED 标志来隐式实现的。
|
||||
对象内存简图
|
||||
|
||||
对象头:存储对象的 hashCode、锁信息或分代年龄或 GC 标志,类型指针指向对象的类元数据,JVM 通过这个指针确定该对象是哪个类的实例等信息。
|
||||
实例变量:存放类的属性数据信息,包括父类的属性信息
|
||||
填充数据:由于虚拟机要求对象起始地址必须是 8 字节的整数倍。填充数据不是必须存在的,仅仅是为了字节对齐
|
||||
当在对象上加锁时,数据是记录在对象头中。当执行 synchronized 同步方法或同步代码块时,会在对象头中记录锁标记,锁标记指向的是 monitor 对象(也称为管程或监视器锁) 的起始地址。每个对象都存在着一个 monitor 与之关联,对象与其 monitor 之间的关系有存在多种实现方式,如 monitor 可以与对象一起创建销毁或当线程试图获取对象锁时自动生成,但当一个 monitor 被某个线程持有后,它便处于锁定状态。
|
||||
在 Java 虚拟机(HotSpot)中,monitor 是由 ObjectMonitor 实现的。
|
||||
ObjectMonitor 中有两个队列,_WaitSet 和 _EntryList,以及_Owner 标记。其中_WaitSet 是用于管理等待队列(wait)线程的,_EntryList 是用于管理锁池阻塞线程的,_Owner 标记用于记录当前执行线程。线程状态图如下:
|
||||
|
||||
这里写图片描述
|
||||
|
||||
当多线程并发访问同一个同步代码时,首先会进入_EntryList,当线程获取锁标记后,
|
||||
monitor 中的_Owner 记录此线程,并在 monitor 中的计数器执行递增计算(+1),代表锁定,其他线程在_EntryList 中继续阻塞。若执行线程调用 wait 方法,则 monitor 中的计数器执行赋值为 0 计算,并将_Owner 标记赋值为 null,代表放弃锁,执行线程进如_WaitSet 中阻塞。若执行线程调用 notify/notifyAll 方法,_WaitSet 中的线程被唤醒,进入_EntryList 中阻塞,等待获取锁标记。若执行线程的同步代码执行结束,同样会释放锁标记,monitor 中的_Owner 标记赋值为 null,且计数器赋值为 0 计算。
|
||||
|
||||
锁的种类
|
||||
Java 中锁的种类大致分为偏向锁,自旋锁,轻量级锁,重量级锁。
|
||||
锁的使用方式为:先提供偏向锁,如果不满足的时候,升级为轻量级锁,再不满足,升级为重量级锁。自旋锁是一个过渡的锁状态,不是一种实际的锁类型。
|
||||
锁只能升级,不能降级。
|
||||
|
||||
重量级锁
|
||||
|
||||
在锁的底层实现中解释的就是重量级锁。
|
||||
|
||||
偏向锁
|
||||
|
||||
是一种编译解释锁。如果代码中不可能出现多线程并发争抢同一个锁的时候,JVM 编译代码,解释执行的时候,会自动的放弃同步信息。消除 synchronized 的同步代码结果。使用锁标记的形式记录锁状态。在 Monitor 中有变量 ACC_SYNCHRONIZED。当变量值使用的时候, 代表偏向锁锁定。可以避免锁的争抢和锁池状态的维护。提高效率。
|
||||
|
||||
轻量级锁
|
||||
过渡锁。当偏向锁不满足,也就是有多线程并发访问,锁定同一个对象的时候,先提升为轻量级锁。也是使用标记 ACC_SYNCHRONIZED 标记记录的。ACC_UNSYNCHRONIZED 标记记录未获取到锁信息的线程。就是只有两个线程争抢锁标记的时候,优先使用轻量级锁。
|
||||
两个线程也可能出现重量级锁。
|
||||
|
||||
自旋锁
|
||||
是一个过渡锁,是偏向锁和轻量级锁的过渡。
|
||||
当获取锁的过程中,未获取到。为了提高效率,JVM 自动执行若干次空循环,再次申请锁,而不是进入阻塞状态的情况。称为自旋锁。自旋锁提高效率就是避免线程状态的变更。
|
||||
|
||||
volatile 关键字
|
||||
变量的线程可见性。在 CPU 计算过程中,会将计算过程需要的数据加载到 CPU 计算缓存中,当 CPU 计算中断时,有可能刷新缓存,重新读取内存中的数据。在线程运行的过程中,如果某变量被其他线程修改,可能造成数据不一致的情况,从而导致结果错误。而 volatile 修饰的变量是线程可见的,当 JVM 解释 volatile 修饰的变量时,会通知 CPU,在计算过程中, 每次使用变量参与计算时,都会检查内存中的数据是否发生变化,而不是一直使用 CPU 缓存中的数据,可以保证计算结果的正确。
|
||||
volatile 只是通知底层计算时,CPU 检查内存数据,而不是让一个变量在多个线程中同步。
|
||||
|
||||
volatile int count = 0;
|
||||
1
|
||||
wait¬ify
|
||||
AtomicXxx 类型组
|
||||
原子类型。
|
||||
在 concurrent.atomic 包中定义了若干原子类型,这些类型中的每个方法都是保证了原子操作的。多线程并发访问原子类型对象中的方法,不会出现数据错误。在多线程开发中,如果某数据需要多个线程同时操作,且要求计算原子性,可以考虑使用原子类型对象。
|
||||
|
||||
AtomicInteger count = new AtomicInteger(0);
|
||||
void m(){
|
||||
count.incrementAndGet();
|
||||
}
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
注意:原子类型中的方法是保证了原子操作,但多个方法之间是没有原子性的。如:
|
||||
|
||||
AtomicInteger i = new AtomicInteger(0);
|
||||
if(i.get() != 5){
|
||||
i.incrementAndGet();
|
||||
}
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
在上述代码中,get 方法和 incrementAndGet 方法都是原子操作,但复合使用时,无法保证原子性,仍旧可能出现数据错误。
|
||||
|
||||
CountDownLatch 门闩
|
||||
门闩是 concurrent 包中定义的一个类型,是用于多线程通讯的一个辅助类型。
|
||||
门闩相当于在一个门上加多个锁,当线程调用 await 方法时,会检查门闩数量,如果门
|
||||
|
||||
闩数量大于 0,线程会阻塞等待。当线程调用 countDown 时,会递减门闩的数量,当门闩数量为 0 时,await 阻塞线程可执行。
|
||||
|
||||
CountDownLatch latch = new CountDownLatch(5);
|
||||
|
||||
void m1(){
|
||||
try {
|
||||
latch.await();// 等待门闩开放。
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.println("m1() method");
|
||||
}
|
||||
|
||||
void m2(){
|
||||
for(int i = 0; i < 10; i++){
|
||||
if(latch.getCount() != 0){
|
||||
System.out.println("latch count : " + latch.getCount());
|
||||
latch.countDown(); // 减门闩上的锁。
|
||||
}
|
||||
try {
|
||||
TimeUnit.MILLISECONDS.sleep(500);
|
||||
} catch (InterruptedException e) {
|
||||
// TODO Auto-generated catch block
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.println("m2() method : " + i);
|
||||
}
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
10
|
||||
11
|
||||
12
|
||||
13
|
||||
14
|
||||
15
|
||||
16
|
||||
17
|
||||
18
|
||||
19
|
||||
20
|
||||
21
|
||||
22
|
||||
23
|
||||
24
|
||||
25
|
||||
锁的重入
|
||||
在 Java 中,同步锁是可以重入的。只有同一线程调用同步方法或执行同步代码块,对同一个对象加锁时才可重入。
|
||||
当线程持有锁时,会在 monitor 的计数器中执行递增计算,若当前线程调用其他同步代码,且同步代码的锁对象相同时,monitor 中的计数器继续递增。每个同步代码执行结束,
|
||||
monitor 中的计数器都会递减,直至所有同步代码执行结束,monitor 中的计数器为 0 时,释放锁标记,_Owner 标记赋值为 null。
|
||||
|
||||
ReentrantLock
|
||||
重入锁,建议应用的同步方式。相对效率比 synchronized 高。量级较轻。
|
||||
synchronized 在 JDK1.5 版本开始,尝试优化。到 JDK1.7 版本后,优化效率已经非常好了。在绝对效率上,不比 reentrantLock 差多少。
|
||||
使用重入锁,必须必须必须手工释放锁标记。一般都是在 finally 代码块中定义释放锁标记的 unlock 方法。
|
||||
|
||||
公平锁
|
||||
|
||||
这里写图片描述
|
||||
|
||||
private static ReentrantLock lock = new ReentrantLock(true);
|
||||
public void run(){
|
||||
for(int i = 0; i < 5; i++){
|
||||
lock.lock();
|
||||
try{
|
||||
System.out.println(Thread.currentThread().getName() + " get lock");
|
||||
}finally{
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
}
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
10
|
||||
11
|
||||
8ThreadLocal
|
||||
|
||||
remove 问题
|
||||
这里写图片描述
|
||||
|
||||
同步容器
|
||||
解决并发情况下的容器线程安全问题的。给多线程环境准备一个线程安全的容器对象。线程安全的容器对象: Vector, Hashtable。线程安全容器对象,都是使用 synchronized
|
||||
方法实现的。
|
||||
concurrent 包中的同步容器,大多数是使用系统底层技术实现的线程安全。类似 native。
|
||||
Java8 中使用 CAS。
|
||||
|
||||
Map/Set
|
||||
ConcurrentHashMap/ConcurrentHashSet
|
||||
|
||||
底层哈希实现的同步 Map(Set)。效率高,线程安全。使用系统底层技术实现线程安全。量级较 synchronized 低。key 和 value 不能为 null。
|
||||
|
||||
ConcurrentSkipListMap/ConcurrentSkipListSet
|
||||
|
||||
底层跳表(SkipList)实现的同步 Map(Set)。有序,效率比 ConcurrentHashMap 稍低。
|
||||
|
||||
这里写图片描述
|
||||
|
||||
List
|
||||
CopyOnWriteArrayList
|
||||
|
||||
写时复制集合。写入效率低,读取效率高。每次写入数据,都会创建一个新的底层数组。
|
||||
|
||||
Queue
|
||||
ConcurrentLinkedQueue
|
||||
|
||||
基础链表同步队列。
|
||||
|
||||
LinkedBlockingQueue
|
||||
阻塞队列,队列容量不足自动阻塞,队列容量为 0 自动阻塞。
|
||||
|
||||
ArrayBlockingQueue
|
||||
底层数组实现的有界队列。自动阻塞。根据调用 API(add/put/offer)不同,有不同特性。
|
||||
当容量不足的时候,有阻塞能力。
|
||||
add 方法在容量不足的时候,抛出异常。
|
||||
put 方法在容量不足的时候,阻塞等待。
|
||||
offer 方法,
|
||||
单参数 offer 方法,不阻塞。容量不足的时候,返回 false。当前新增数据操作放弃。三参数 offer 方法(offer(value,times,timeunit)),容量不足的时候,阻塞 times 时长(单
|
||||
位为 timeunit),如果在阻塞时长内,有容量空闲,新增数据返回 true。如果阻塞时长范围
|
||||
内,无容量空闲,放弃新增数据,返回 false。
|
||||
|
||||
DelayQueue
|
||||
延时队列。根据比较机制,实现自定义处理顺序的队列。常用于定时任务。如:定时关机。
|
||||
|
||||
LinkedTransferQueue
|
||||
转移队列,使用 transfer 方法,实现数据的即时处理。没有消费者,就阻塞。
|
||||
|
||||
SynchronusQueue
|
||||
同步队列,是一个容量为 0 的队列。是一个特殊的 TransferQueue。必须现有消费线程等待,才能使用的队列。
|
||||
add 方法,无阻塞。若没有消费线程阻塞等待数据,则抛出异常。
|
||||
put 方法,有阻塞。若没有消费线程阻塞等待数据,则阻塞。
|
||||
|
||||
ThreadPool&Executor
|
||||
Executor
|
||||
线程池顶级接口。
|
||||
常用方法 - void execute(Runnable)
|
||||
作用是: 启动线程任务的。
|
||||
|
||||
ExecutorService
|
||||
Executor 接口的子接口。
|
||||
常见方法 - Future submit(Callable), Future submit(Runnable)
|
||||
|
||||
Future
|
||||
未来结果,代表线程任务执行结束后的结果。
|
||||
|
||||
Callable
|
||||
可执行接口。
|
||||
接口方法 : Object call();相当于 Runnable 接口中的 run 方法。区别为此方法有返回值。不能抛出已检查异常。
|
||||
和 Runnable 接口的选择 - 需要返回值或需要抛出异常时,使用 Callable,其他情况可任意选择。
|
||||
|
||||
Executors
|
||||
工具类型。为 Executor 线程池提供工具方法。类似 Arrays,Collections 等工具类型的功用。
|
||||
|
||||
FixedThreadPool
|
||||
容量固定的线程池
|
||||
queued tasks - 任务队列
|
||||
completed tasks - 结束任务队列
|
||||
|
||||
CachedThreadPool
|
||||
缓存的线程池。容量不限(Integer.MAX_VALUE)。自动扩容。默认线程空闲 60 秒,自动销毁。
|
||||
|
||||
ScheduledThreadPool
|
||||
计划任务线程池。可以根据计划自动执行任务的线程池。
|
||||
|
||||
SingleThreadExceutor
|
||||
单一容量的线程池。
|
||||
|
||||
ForkJoinPool
|
||||
分支合并线程池(mapduce 类似的设计思想)。适合用于处理复杂任务。初始化线程容量与 CPU 核心数相关。
|
||||
线程池中运行的内容必须是 ForkJoinTask 的子类型(RecursiveTask,RecursiveAction)。
|
||||
|
||||
WorkStealingPool
|
||||
JDK1.8 新增的线程池。工作窃取线程池。当线程池中有空闲连接时,自动到等待队列中窃取未完成任务,自动执行。
|
||||
初始化线程容量与 CPU 核心数相关。此线程池中维护的是精灵线程。
|
||||
ExecutorService.newWorkStealingPool();
|
||||
|
||||
ThreadPoolExecutor
|
||||
线程池底层实现。除 ForkJoinPool 外,其他常用线程池底层都是使用 ThreadPoolExecutor
|
||||
实现的。
|
||||
public ThreadPoolExecutor
|
||||
(int corePoolSize, // 核心容量
|
||||
|
||||
int maximumPoolSize, // 最大容量
|
||||
long keepAliveTime, // 生命周期,0 为永久
|
||||
TimeUnit unit, // 生命周期单位
|
||||
BlockingQueue workQueue // 任务队列,阻塞队列。
|
||||
);
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -1,125 +0,0 @@
|
||||
# java并发机制与底层实现原理
|
||||
## 1 volatile
|
||||
volatile是轻量级的synchronize,它在多处理器开发中保证了共享变量的“可见性”,因为它不会引起线程上下文的切换和调度,所以比synchronize的使用和执行成本更底。
|
||||
为了提高处理速度,处理器不直接和内存进行通信,而是先将系统内存的数据读到内部缓存(L1,L2或其他)后再进行操作,但操作完不知道何时会写到内存。使用volatile变量,在操作后,JVM会发出lock指令
|
||||
|
||||
将当前处理器缓存行的数据写回到系统内存
|
||||
这个写回内存的操作会使在其他cpu里缓存了该内存地址的数据无效
|
||||
|
||||
|
||||
|
||||
## 2 synchronize
|
||||
### 同步基础
|
||||
synchronize实现同步的基础,具体表现为三种形式
|
||||
|
||||
* 对于普通同步方法,锁是当前实例对象
|
||||
* 对于静态同步方法,锁是当前类的class对象
|
||||
* 对于同步方法块,锁是Synchronize括号里配置的对象
|
||||
* 当一个线程试图访问同步代码块时,它首先必须得到锁,退出或抛出异常时必须释放锁。那么锁到底存在那里,锁里会存储什么信息。
|
||||
|
||||
### java对象头
|
||||
synchonize用的锁是存在java对象头里的。如果对象是数组类型,则JVM用三个字宽存储对象头,如果对象为非数组类型,则用二个字宽存储对象头。32位中,一字宽等于四字节(32bit)
|
||||
|
||||
<table>
|
||||
<tbody><tr>
|
||||
<td>长度</td>
|
||||
<td>内容</td>
|
||||
<td>说明</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>32/64bit</td>
|
||||
<td>Mark Word</td>
|
||||
<td>存储对象的hashCode或锁信息等。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>32/64bit</td>
|
||||
<td>Class Metadata Address</td>
|
||||
<td>存储到对象类型数据的指针</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>32/64bit</td>
|
||||
<td>Array length</td>
|
||||
<td>数组的长度(如果当前对象是数组)</td>
|
||||
</tr>
|
||||
</tbody></table>
|
||||
|
||||
在运行期间Mark Word里存存储的数据会随着锁标志位的变化而变化。会成为下面的一种
|
||||
|
||||

|
||||
|
||||
|
||||
## 3 锁类型
|
||||
为了减少获得锁与释放锁所带来的性能消耗,引入“偏向锁”和“轻量级锁'.所以在java中存在四种状态
|
||||
|
||||
* 无锁状态
|
||||
* 偏向锁状态
|
||||
* 轻量级锁状态
|
||||
* 自旋锁
|
||||
* 重量级锁状态
|
||||
|
||||
|
||||
它会随着竞争情况逐渐升级。锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后不能降级成偏向锁
|
||||
|
||||
### 偏向锁
|
||||
Hotspot的作者经过以往的研究发现大多数情况下锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁。当一个线程访问同步块并获取锁时,会在对象头和栈帧中的锁记录里存储锁偏向的线程ID,以后该线程在进入和退出同步块时不需要花费CAS操作来加锁和解锁。
|
||||
|
||||
流程图中展示偏向锁的获取释放以及升级至轻量锁
|
||||
|
||||

|
||||
|
||||
### 轻量级锁
|
||||
1. 轻量级锁加锁:
|
||||
线程在执行同步块之前,JVM会先在当前线程的栈桢中创建用于存储锁记录的空间,并将对象头中的Mark Word复制到锁记录中,官方称为Displaced Mark Word。然后线程尝试使用CAS将对象头中的Mark Word替换为指向锁记录的指针。如果成功,当前线程获得锁,如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁。
|
||||
|
||||
2. 轻量级锁解锁
|
||||
轻量级解锁时,会使用原子的CAS操作来将Displaced Mark Word替换回到对象头,如果成功,则表示没有竞争发生。如果失败,表示当前锁存在竞争,锁就会膨胀成重量级锁。下图是两个线程同时争夺锁,导致锁膨胀的流程图。
|
||||
|
||||
|
||||
借用网上流程图如下:
|
||||

|
||||
|
||||
### 自旋锁
|
||||
当竟争存在时,如果线程可以很快获得锁,那么可以不在OS层挂起线程(线程切换平均消耗8K个时钟周期),让线程多做几个空操作(自旋)
|
||||
|
||||
1. 如果同步块过长,自旋失败,会降低系统性能
|
||||
2. 如果同步块很短,自旋成功,节省线程挂起切换时间,担升系统性能
|
||||
|
||||
## 4 锁对比
|
||||
|
||||
|
||||
<table>
|
||||
<tbody><tr>
|
||||
<td>锁</td>
|
||||
<td align="center">优点</td>
|
||||
<td align="center">缺点</td>
|
||||
<td align="center">适用场景</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>偏向锁</td>
|
||||
<td>加锁和解锁不需要额外的消耗,和执行非同步方法比仅存在纳秒级的差距。</td>
|
||||
<td>如果线程间存在锁竞争,会带来额外的锁撤销的消耗。</td>
|
||||
<td>适用于只有一个线程访问同步块场景。</td</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>轻量级锁</td>
|
||||
<td>竞争的线程不会阻塞,提高了程序的响应速度。</td>
|
||||
<td>如果始终得不到锁竞争的线程使用自旋会消耗CPU</td>
|
||||
<td>追求响应时间。同步块执行速度非常快。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>重量级锁</td>
|
||||
<td>线程竞争不使用自旋,不会消耗CPU。</td>
|
||||
<td>线程阻塞,响应时间缓慢。</td>
|
||||
<td>追求吞吐量。同步块执行速度较长。</td>
|
||||
</tr>
|
||||
</tbody></table>
|
||||
|
||||
|
||||
|
||||
总结
|
||||
* 偏向锁,轻量级锁,自旋锁不是JAVA语言层上的优化方法
|
||||
* 内置于JVM中的获取锁的优化方法与获取锁的步骤
|
||||
* 偏向锁可用可先尝试偏向锁
|
||||
* 轻量级锁可用可先尝试轻量级锁
|
||||
* 1与2都失败,则尝试自旋锁
|
||||
* 再失败,尝试普通锁,使用OS互斥量在操作系统层挂起
|
||||
@@ -1,284 +0,0 @@
|
||||
# java并发机制
|
||||
|
||||
|
||||
|
||||
## java多线程
|
||||
|
||||
### 继承Thread类
|
||||
Thread类本质上是实现了Runnable接口的一个实例,代表一个线程的实例。启动方法就是通过继承了Thread类的start()实例方法。执行run()方法(重写的)。就可以启动新线程并执行自己定义。例如:
|
||||
```java
|
||||
//实现方法的类
|
||||
public class Demo1 extends Thread {
|
||||
|
||||
public void run(){
|
||||
System.out.println("继承Thread类");
|
||||
}
|
||||
}
|
||||
|
||||
//执行的方法
|
||||
public static void main(String[] args) {
|
||||
|
||||
Demo1 demo1=new Demo1();
|
||||
demo1.start();
|
||||
}
|
||||
```
|
||||
|
||||
### 实现Runnable接口
|
||||
由于java是单继承的,那么在平时开发中就提倡使用接口的方式实现。则需要实现多线程的类通过实现Runnable接口的run方法。通过Thread的start()方法进行启动,例如:
|
||||
|
||||
```java
|
||||
//实现的方法类:
|
||||
public class Demo2 implements Runnable {
|
||||
|
||||
@Override
|
||||
public void run() {
|
||||
System.out.println("实现runnable接口");
|
||||
}
|
||||
|
||||
//执行方法:
|
||||
public static void main(String[] args) {
|
||||
|
||||
Demo2 demo2=new Demo2();
|
||||
Thread thread=new Thread(demo2);
|
||||
thread.start();
|
||||
}
|
||||
```
|
||||
### 通过内部类的方式实现多线程
|
||||
直接可以通过Thread类的start()方法进行实现,因为Thread类实现了Runnable接口,并重写了run方法,在run方法中实现自己的逻辑,例如:
|
||||
|
||||
```java
|
||||
//这里通过了CountDownLatch,来进行阻塞,来观察两个线程的启动,这样更加体现的明显一些:
|
||||
public static CountDownLatch countDownLatch=new CountDownLatch(2);
|
||||
|
||||
public static void main(String[] args) {
|
||||
new Thread(()->{
|
||||
countDownLatch.countDown();
|
||||
try {
|
||||
countDownLatch.await();
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.println("T1");
|
||||
}).start();
|
||||
|
||||
new Thread(()->{
|
||||
countDownLatch.countDown();
|
||||
try {
|
||||
countDownLatch.await();
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.println("T2");
|
||||
}).start();
|
||||
}
|
||||
```
|
||||
|
||||
### 通过实现Callable接口
|
||||
通过实现Callable接口的call方法,可以通过FutureTask的get()方法来获取call方法中的返回值,具体实现如下:
|
||||
|
||||
```java
|
||||
//实现类方法:
|
||||
public class Demo3 implements Callable {
|
||||
|
||||
@Override
|
||||
public Object call() {
|
||||
return "1";
|
||||
}
|
||||
}
|
||||
|
||||
//执行方法:
|
||||
public static void main(String[] args) {
|
||||
|
||||
//创建实现类对象
|
||||
Callable demo3=new Demo3();
|
||||
FutureTask oneTask = new FutureTask(demo3);
|
||||
Thread thread=new Thread(oneTask);
|
||||
thread.start();
|
||||
Object o = null;
|
||||
try {
|
||||
//获取返回值
|
||||
o = oneTask.get();
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
} catch (ExecutionException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.println(o);
|
||||
}
|
||||
```
|
||||
|
||||
### 通过线程池来实现多线程
|
||||
线程池可以根据不同的场景来选择不同的线程池来进行实现,这里我仅使用其中之一进行演示,后续会单独写一个线程池相关的单独介绍:
|
||||
|
||||
```java
|
||||
//实现代码如下:
|
||||
public class Demo5 {
|
||||
|
||||
public static void main(String[] args) {
|
||||
ExecutorService executorService = Executors.newFixedThreadPool(5);
|
||||
for(int i=0;i<5;i++){
|
||||
int finalI = i;
|
||||
executorService.execute(()-> {
|
||||
System.out.println(finalI);
|
||||
});
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 通过Timer定时器来实现多线程
|
||||
就Timer来讲就是一个调度器,而TimerTask呢只是一个实现了run方法的一个类,而具体的TimerTask需要由你自己来实现,同样根据参数得不同存在多种执行方式,例如其中延迟定时任务这样:
|
||||
|
||||
```
|
||||
//具体代码如下:
|
||||
public class Demo6 {
|
||||
|
||||
public static void main(String[] args) {
|
||||
Timer timer=new Timer();
|
||||
timer.schedule(new TimerTask(){
|
||||
@Override
|
||||
public void run() {
|
||||
System.out.println(1);
|
||||
}
|
||||
},2000l,1000l);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 通过stream实现多线程
|
||||
jdk1.8 API添加了一个新的抽象称为流Stream,可以让你以一种声明的方式处理数据。
|
||||
Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。
|
||||
具体简单代码实现如下:
|
||||
|
||||
```
|
||||
//代码实现:
|
||||
public class Demo7 {
|
||||
|
||||
//为了更形象体现并发,通过countDownLatch进行阻塞
|
||||
static CountDownLatch countDownLatch=new CountDownLatch(6);
|
||||
public static void main(String[] args) {
|
||||
List list=new ArrayList<>();
|
||||
list.add(1);
|
||||
list.add(2);
|
||||
list.add(3);
|
||||
list.add(4);
|
||||
list.add(5);
|
||||
list.add(6);
|
||||
|
||||
list.parallelStream().forEach(p->{
|
||||
//将所有请求在打印之前进行阻塞,方便观察
|
||||
countDownLatch.countDown();
|
||||
try {
|
||||
System.out.println("线程执行到这里啦");
|
||||
Thread.sleep(10000);
|
||||
countDownLatch.await();
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.println(p);
|
||||
});
|
||||
}
|
||||
}
|
||||
```
|
||||
## java异步IO
|
||||
|
||||
|
||||
### java NIO
|
||||
> 参考文献
|
||||
> * [java nio一篇博客](https://blog.csdn.net/forezp/article/details/88414741)
|
||||
> * [java nio并发编程网](http://ifeve.com/overview/)
|
||||
|
||||
|
||||
|
||||
### java akka
|
||||
|
||||
1. 前情提要
|
||||
面向对象编程理论中,对象之间通信,依赖的是消息,但java里,对象之间通信,用的是对象方法
|
||||
|
||||
2. Actor模型
|
||||
计算模型,计算单位Actor,所有的计算都在Actor中执行。Actor中一切都是actor,actor之间完全隔离,不共享任何变量。不共享变量,就不会有并发问题。java本身不支持actor模型,需要引入第三方类库Akka
|
||||
|
||||
3. 代码范例
|
||||
```
|
||||
//该Actor当收到消息message后,
|
||||
//会打印Hello message
|
||||
static class HelloActor
|
||||
extends UntypedActor {
|
||||
@Override
|
||||
public void onReceive(Object message) {
|
||||
System.out.println("Hello " + message);
|
||||
}
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
//创建Actor系统
|
||||
ActorSystem system = ActorSystem.create("HelloSystem");
|
||||
//创建HelloActor
|
||||
ActorRef helloActor =
|
||||
system.actorOf(Props.create(HelloActor.class));
|
||||
//发送消息给HelloActor
|
||||
helloActor.tell("Actor", ActorRef.noSender());
|
||||
}
|
||||
```
|
||||
actor之间通信完美遵循了消息机制。而不是通过调用对象的方式
|
||||
|
||||
4. 消息和对象方法的区别
|
||||
actor内部有一个邮箱mailbox,接受到的消息先放到邮箱,如果有积压,新消息不会马上得到处理。actor是单线程处理消息。所以不会有并发问题
|
||||
说白了,就是消费者线程的生产者-消费者模式
|
||||
|
||||
5. 区别
|
||||
对相关的方法调用,一般是同步的,而actor的消息机制是异步的。
|
||||
|
||||
6. Actor规范定义
|
||||
1. 处理能力,处理接收到的消息
|
||||
2. 存储能力,actor可以存储自己的内部状态
|
||||
3. 通信能力,actor可以和其他actor之间通信
|
||||
7. actor实现线程安全的累加器
|
||||
无锁算法,因为只有1个线程在消费,不会存在并发问题
|
||||
|
||||
```
|
||||
//累加器
|
||||
static class CounterActor extends UntypedActor {
|
||||
private int counter = 0;
|
||||
@Override
|
||||
public void onReceive(Object message){
|
||||
//如果接收到的消息是数字类型,执行累加操作,
|
||||
//否则打印counter的值
|
||||
if (message instanceof Number) {
|
||||
counter += ((Number) message).intValue();
|
||||
} else {
|
||||
System.out.println(counter);
|
||||
}
|
||||
}
|
||||
}
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
//创建Actor系统
|
||||
ActorSystem system = ActorSystem.create("HelloSystem");
|
||||
//4个线程生产消息
|
||||
ExecutorService es = Executors.newFixedThreadPool(4);
|
||||
//创建CounterActor
|
||||
ActorRef counterActor =
|
||||
system.actorOf(Props.create(CounterActor.class));
|
||||
//生产4*100000个消息
|
||||
for (int i=0; i<4; i++) {
|
||||
es.execute(()->{
|
||||
for (int j=0; j<100000; j++) {
|
||||
counterActor.tell(1, ActorRef.noSender());
|
||||
}
|
||||
});
|
||||
}
|
||||
//关闭线程池
|
||||
es.shutdown();
|
||||
//等待CounterActor处理完所有消息
|
||||
Thread.sleep(1000);
|
||||
//打印结果
|
||||
counterActor.tell("", ActorRef.noSender());
|
||||
//关闭Actor系统
|
||||
system.shutdown();
|
||||
}
|
||||
```
|
||||
8. 总结
|
||||
actor计算模型,基本计算单元。消息通信。
|
||||
|
||||
9. 应用
|
||||
spark,filink,play
|
||||
@@ -1,5 +0,0 @@
|
||||
# 底层事件处理
|
||||
|
||||
-----
|
||||
|
||||
* 在java.awt学习的时候,将监听器绑定到事件源上,当指定事件发生时监听器会自动匹配到相应的动作,执行相应的处理方式。但在底层事件处理过程中,不许要监听器,能够直接获取当前发生的底层事件,然后进行匹配处理。
|
||||
@@ -133,12 +133,17 @@ s[1][2] = new String("!");
|
||||
|
||||
|
||||
### 具体方法
|
||||
|
||||
* public static int binarySearch(Object[] a, Object key)
|
||||
```java
|
||||
public static int binarySearch(Object[] a, Object key)
|
||||
用二分查找算法在给定数组中搜索给定值的对象(Byte,Int,double等)。数组在调用前必须排序好的。如果查找值包含在数组中,则返回搜索键的索引;否则返回 (-(插入点) - 1)。
|
||||
* public static boolean equals(long[] a, long[] a2)
|
||||
public static boolean equals(long[] a, long[] a2)
|
||||
如果两个指定的 long 型数组彼此相等,则返回 true。如果两个数组包含相同数量的元素,并且两个数组中的所有相应元素对都是相等的,则认为这两个数组是相等的。换句话说,如果两个数组以相同顺序包含相同的元素,则两个数组是相等的。同样的方法适用于所有的其他基本数据类型(Byte,short,Int等)。
|
||||
* public static void fill(int[] a, int val)
|
||||
public static void fill(int[] a, int val)
|
||||
将指定的 int 值分配给指定 int 型数组指定范围中的每个元素。同样的方法适用于所有的其他基本数据类型(Byte,short,Int等)。
|
||||
* public static void sort(Object[] a)
|
||||
对指定对象数组根据其元素的自然顺序进行升序排列。同样的方法适用于所有的其他基本数据类型(Byte,short,Int等)。
|
||||
public static void sort(Object[] a)
|
||||
对指定对象数组根据其元素的自然顺序进行升序排列。同样的方法适用于所有的其他基本数据类型(Byte,short,Int等)。
|
||||
public static void toString(array[])
|
||||
依次打印元素
|
||||
public static void stream()
|
||||
转化成一个流
|
||||
```
|
||||
@@ -1 +0,0 @@
|
||||
Builder & StreamOf & Optional
|
||||
@@ -19,18 +19,31 @@ C++中的容器分为(都是线性的)
|
||||
* queue 队列
|
||||
|
||||
|
||||
Java中的容器分为(都是线性的)
|
||||
* 集合collection
|
||||
* List
|
||||
* Queue
|
||||
* Set
|
||||
* Map
|
||||
Java中的容器分为(都是线性的)集合collection。除了一下基本集合类型,还有多个特殊的类型,后续补充
|
||||
* List
|
||||
* Arraylist,有序,插入序
|
||||
* vector
|
||||
* stack
|
||||
* Queue
|
||||
* linkedlist,双端队列有序,插入序
|
||||
* arrayqueue,有序,插入序
|
||||
* priorityQueue,有序,自然序
|
||||
* Set
|
||||
* hashset,无序
|
||||
* linkedhashset,有序,插入序
|
||||
* treeSet,有序,自然序
|
||||
* Map
|
||||
* hashmap,无序
|
||||
* linkedhashmap,有序,插入序
|
||||
* treemap 有序,自然序
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
## 体系
|
||||
|
||||
+ [Java 集合 - `List`](2.md)
|
||||
@@ -61,4 +74,24 @@ Java中的容器分为(都是线性的)
|
||||
6. `List`内部存储一系列**可重复**的对象,是一个**有序**集合,对象按插入顺序排列
|
||||
7. `Queue`是一个**队列**容器,其特性与`List`相同,但只能从`队头`和`队尾`操作元素
|
||||
8. JDK 为集合的各种操作提供了两个工具类`Collections`和`Arrays`,之后会讲解工具类的常用方法
|
||||
9. 四种抽象集合类型内部也会衍生出许多具有不同特性的集合类,**不同场景下择优使用,没有最佳的集合**
|
||||
9. 四种抽象集合类型内部也会衍生出许多具有不同特性的集合类,**不同场景下择优使用,没有最佳的集合**
|
||||
|
||||
|
||||
## 对比
|
||||
|
||||
|
||||
章节结束各集合总结:(以 JDK1.8 为例)
|
||||
|
||||
| 数据类型 | 插入、删除时间复杂度 | 查询时间复杂度 | 底层数据结构 | 是否线程安全 |
|
||||
| :------------ | :------------------- | :------------- | :------------------- | :----------- |
|
||||
| Vector | O(N) | O(1) | 数组 | 是(已淘汰) |
|
||||
| ArrayList | O(N) | O(1) | 数组 | 否 |
|
||||
| LinkedList | O(1) | O(N) | 双向链表 | 否 |
|
||||
| HashSet | O(1) | O(1) | 数组+链表+红黑树 | 否 |
|
||||
| TreeSet | O(logN) | O(logN) | 红黑树 | 否 |
|
||||
| LinkedHashSet | O(1) | O(1)~O(N) | 数组 + 链表 + 红黑树 | 否 |
|
||||
| ArrayDeque | O(N) | O(1) | 数组 | 否 |
|
||||
| PriorityQueue | O(logN) | O(logN) | 堆(数组实现) | 否 |
|
||||
| HashMap | O(1) ~ O(N) | O(1) ~ O(N) | 数组+链表+红黑树 | 否 |
|
||||
| TreeMap | O(logN) | O(logN) | 数组+红黑树 | 否 |
|
||||
| HashTable | O(1) / O(N) | O(1) / O(N) | 数组+链表 | 是(已淘汰) |
|
||||
@@ -1,6 +1,6 @@
|
||||
# List 接口
|
||||
|
||||
## 1 概述
|
||||
## 0 概述
|
||||
|
||||
### 简介
|
||||
List 接口和 Set 接口齐头并进,是我们日常开发中接触的很多的一种集合类型了。整个 List 集合的组成部分如下图
|
||||
@@ -27,9 +27,9 @@ AbstractSequentialList 抽象类继承了 AbstractList,在原基础上限制
|
||||
|
||||
|
||||
|
||||
## 2 ArrayList
|
||||
## 1 ArrayList
|
||||
|
||||
### 概述
|
||||
### 底层原理
|
||||
ArrayList 以**数组**作为存储结构,它是**线程不安全**的集合;具有**查询快、在数组中间或头部增删慢**的特点,所以它除了线程不安全这一点,其余可以替代`Vector`,而且线程安全的 ArrayList 可以使用 `CopyOnWriteArrayList`代替 Vector。
|
||||
|
||||

|
||||
@@ -539,51 +539,10 @@ public class ArrayListExample
|
||||
}
|
||||
```
|
||||
|
||||
## 3 LinkedList
|
||||
## 2 Vector
|
||||
### 底层原理
|
||||
|
||||
LinkedList 底层采用`双向链表`数据结构存储元素,由于链表的内存地址`非连续`,所以它不具备随机访问的特点,但由于它利用指针连接各个元素,所以插入、删除元素只需要`操作指针`,不需要`移动元素`,故具有**增删快、查询慢**的特点。它也是一个非线程安全的集合。
|
||||
|
||||
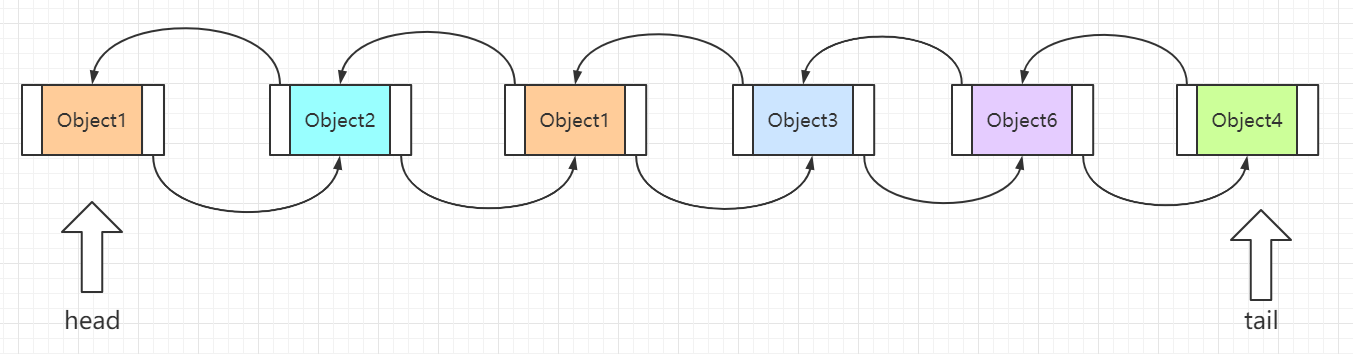
|
||||
|
||||
由于以双向链表作为数据结构,它是**线程不安全**的集合;存储的每个节点称为一个`Node`,下图可以看到 Node 中保存了`next`和`prev`指针,`item`是该节点的值。在插入和删除时,时间复杂度都保持为 `O(1)`
|
||||
|
||||
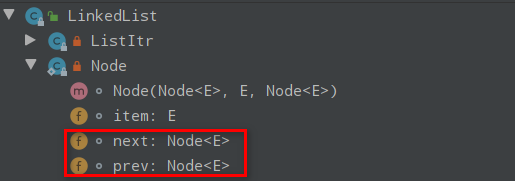
|
||||
|
||||
关于 LinkedList,除了它是以链表实现的集合外,还有一些特殊的特性需要注意的。
|
||||
|
||||
- 优势:LinkedList 底层没有`扩容机制`,使用`双向链表`存储元素,所以插入和删除元素效率较高,适用于频繁操作元素的场景
|
||||
- 劣势:LinkedList 不具备`随机访问`的特点,查找某个元素只能从 `head` 或 `tail` 指针一个一个比较,所以**查找中间的元素时效率很低**
|
||||
- 查找优化:LinkedList 查找某个下标 `index` 的元素时**做了优化**,若 `index > (size / 2)`,则从 `head` 往后查找,否则从 `tail` 开始往前查找,代码如下所示:
|
||||
|
||||
```Java
|
||||
LinkedList.Node<E> node(int index) {
|
||||
LinkedList.Node x;
|
||||
int i;
|
||||
if (index < this.size >> 1) { // 查找的下标处于链表前半部分则从头找
|
||||
x = this.first;
|
||||
for(i = 0; i < index; ++i) { x = x.next; }
|
||||
return x;
|
||||
} else { // 查找的下标处于数组的后半部分则从尾开始找
|
||||
x = this.last;
|
||||
for(i = this.size - 1; i > index; --i) { x = x.prev; }
|
||||
return x;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
- 双端队列:使用双端链表实现,并且实现了 `Deque` 接口,使得 LinkedList 可以用作**双端队列**。下图可以看到 Node 是集合中的元素,提供了前驱指针和后继指针,还提供了一系列操作`头结点`和`尾结点`的方法,具有双端队列的特性。
|
||||
|
||||
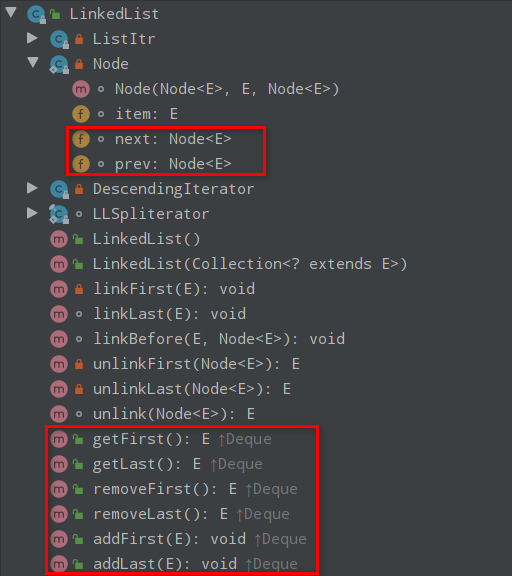
|
||||
|
||||
LinkedList 集合最让人树枝的是它的链表结构,但是我们同时也要注意它是一个双端队列型的集合。
|
||||
|
||||
```java
|
||||
Deque<Object> deque = new LinkedList<>();
|
||||
```
|
||||
|
||||
### Vector
|
||||
|
||||
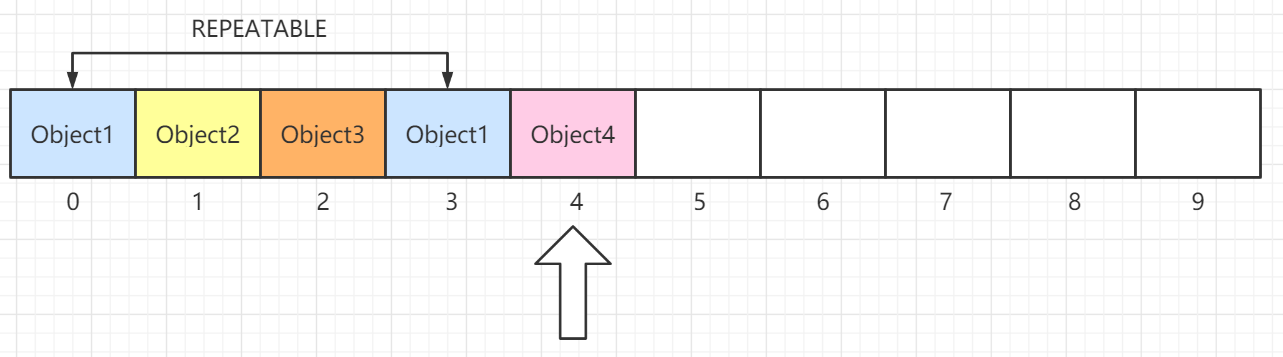
|
||||

|
||||
|
||||
`Vector` 在现在已经是一种过时的集合了,包括继承它的 `Stack` 集合也如此,它们被淘汰的原因都是因为**性能**低下。
|
||||
|
||||
@@ -598,8 +557,9 @@ public synchronized E get(int index);
|
||||
|
||||
现在,在**线程安全**的情况下,不需要选用 Vector 集合,取而代之的是 **ArrayList** 集合;在并发环境下,出现了 `CopyOnWriteArrayList`,Vector 完全被弃用了。
|
||||
|
||||
### Stack
|
||||
|
||||
## 3 Stack
|
||||
### 底层原理
|
||||
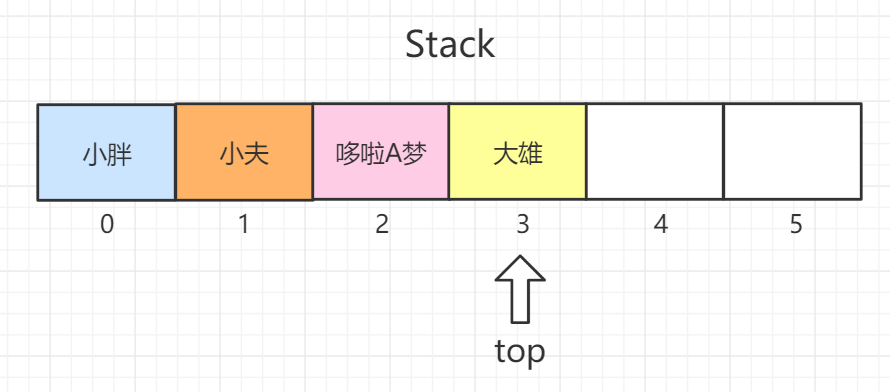
|
||||
|
||||
`Stack`是一种`后入先出(LIFO)`型的集合容器,如图中所示,`大雄`是最后一个进入容器的,top指针指向大雄,那么弹出元素时,大雄也是第一个被弹出去的。
|
||||
@@ -613,4 +573,57 @@ Deque<Integer> stack = new ArrayDeque<Integer>();
|
||||
```
|
||||
|
||||
ArrayDeque 的数据结构是:`数组`,并提供**头尾指针下标**对数组元素进行操作。本文也会讲到哦,客官请继续往下看,莫着急!:smile:
|
||||
|
||||
|
||||
|
||||
## 4 CopyOnWriteArrayList
|
||||
> 用来替代vector,提供现成安全的list
|
||||
### 底层原理
|
||||
|
||||
Java CopyOnWriteArrayList是ArrayList的thread-safe变体,其中所有可变操作(添加,设置等)都通过对基础array进行全新复制来实现。
|
||||
|
||||
* CopyOnWriteArrayList类实现List和RandomAccess接口,因此提供ArrayList类中可用的所有功能。
|
||||
* 使用CopyOnWriteArrayList进行更新操作的成本很高,因为每个突变都会创建基础数组的克隆副本,并为其添加/更新元素。
|
||||
* 它是ArrayList的线程安全版本。 每个访问列表的线程在初始化此列表的迭代器时都会看到自己创建的后备阵列快照版本。
|
||||
* 因为它在创建迭代器时获取基础数组的快照,所以它不会抛出ConcurrentModificationException 。
|
||||
* 不支持对迭代器的删除操作(删除,设置和添加)。 这些方法抛出UnsupportedOperationException 。
|
||||
* CopyOnWriteArrayList是synchronized List的并发替代,当迭代的次数超过突变次数时,CopyOnWriteArrayList可以提供更好的并发性。
|
||||
* 它允许重复的元素和异构对象(使用泛型来获取编译时错误)。因为它每次创建迭代器时都会创建一个新的数组副本,所以performance is slower比ArrayList performance is slower 。
|
||||
|
||||
|
||||
### 实例
|
||||
|
||||
```java
|
||||
CopyOnWriteArrayList<Integer> list = new CopyOnWriteArrayList<>(new Integer[] {1,2,3});
|
||||
|
||||
System.out.println(list); //[1, 2, 3]
|
||||
|
||||
//Get iterator 1
|
||||
Iterator<Integer> itr1 = list.iterator();
|
||||
|
||||
//Add one element and verify list is updated
|
||||
list.add(4);
|
||||
|
||||
System.out.println(list); //[1, 2, 3, 4]
|
||||
|
||||
//Get iterator 2
|
||||
Iterator<Integer> itr2 = list.iterator();
|
||||
|
||||
System.out.println("====Verify Iterator 1 content====");
|
||||
|
||||
itr1.forEachRemaining(System.out :: println); //1,2,3
|
||||
|
||||
System.out.println("====Verify Iterator 2 content====");
|
||||
|
||||
itr2.forEachRemaining(System.out :: println); //1,2,3,4
|
||||
```
|
||||
|
||||
### 主要方法
|
||||
|
||||
```java
|
||||
CopyOnWriteArrayList() :创建一个空列表。
|
||||
CopyOnWriteArrayList(Collection c) :创建一个列表,该列表包含指定集合的元素,并按集合的迭代器返回它们的顺序。
|
||||
CopyOnWriteArrayList(object[] array) :创建一个保存给定数组副本的列表。
|
||||
boolean addIfAbsent(object o) :如果不存在则追加元素。
|
||||
int addAllAbsent(Collection c) :以指定集合的迭代器返回的顺序,将指定集合中尚未包含在此列表中的所有元素追加到此列表的末尾。
|
||||
```
|
||||
|
||||
531
Java基础教程/Java集合类/04 Queue.md
Normal file
@@ -0,0 +1,531 @@
|
||||
# Queue
|
||||
|
||||
|
||||
## 0 Queue介绍
|
||||
|
||||
### 主要方法
|
||||
`Queue`队列,在 JDK 中有两种不同类型的集合实现:**单向队列**(AbstractQueue) 和 **双端队列**(Deque)
|
||||
|
||||
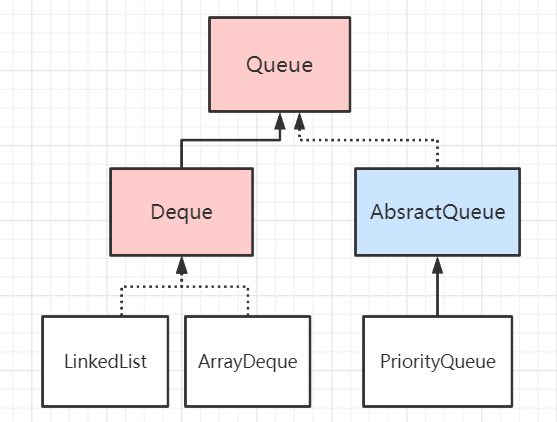
|
||||
|
||||
Queue 中提供了两套增加、删除元素的 API,当插入或删除元素失败时,会有**两种不同的失败处理策略**。
|
||||
|
||||
| 方法及失败策略 | 插入方法 | 删除方法 | 查找方法 |
|
||||
| :------------- | :------- | :------- | -------- |
|
||||
| 抛出异常 | add() | remove() | get() |
|
||||
| 返回失败默认值 | offer() | poll() | peek() |
|
||||
|
||||
选取哪种方法的决定因素:插入和删除元素失败时,希望`抛出异常`还是返回`布尔值`
|
||||
|
||||
`add()` 和 `offer()` 对比:
|
||||
|
||||
在队列长度大小确定的场景下,队列放满元素后,添加下一个元素时,add() 会抛出 `IllegalStateException`异常,而 `offer()` 会返回 `false` 。
|
||||
|
||||
但是它们两个方法在插入**某些不合法的元素**时都会抛出三个相同的异常。
|
||||
|
||||
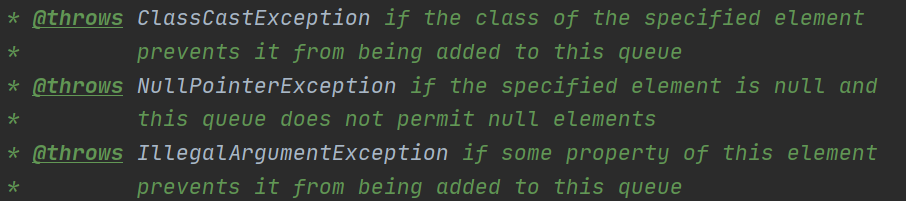
|
||||
|
||||
`remove()` 和 `poll()` 对比:
|
||||
|
||||
在**队列为空**的场景下, `remove()` 会抛出 `NoSuchElementException`异常,而 `poll()` 则返回 `null` 。
|
||||
|
||||
`get()`和`peek()`对比:
|
||||
|
||||
在队列为空的情况下,`get()`会抛出`NoSuchElementException`异常,而`peek()`则返回`null`。
|
||||
|
||||
|
||||
### Deque 接口
|
||||
|
||||
`Deque` 接口的实现非常好理解:从**单向**队列演变为**双向**队列,内部额外提供**双向队列的操作方法**即可:
|
||||
|
||||
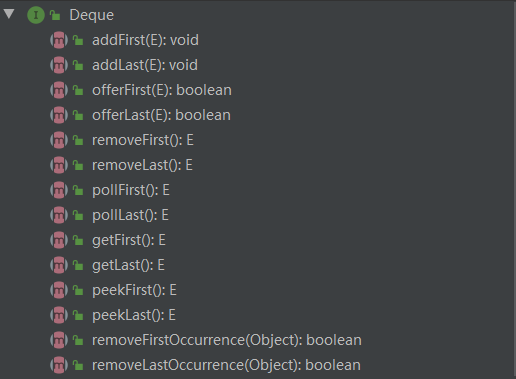
|
||||
|
||||
Deque 接口额外提供了**针对队列的头结点和尾结点**操作的方法,而**插入、删除方法同样也提供了两套不同的失败策略**。除了`add()`和`offer()`,`remove()`和`poll()`以外,还有`get()`和`peek()`出现了不同的策略
|
||||
|
||||
### AbstractQueue 抽象类
|
||||
|
||||
AbstractQueue 类中提供了各个 API 的基本实现,主要针对各个不同的处理策略给出基本的方法实现,定义在这里的作用是让`子类`根据其`方法规范`(操作失败时抛出异常还是返回默认值)实现具体的业务逻辑。
|
||||
|
||||
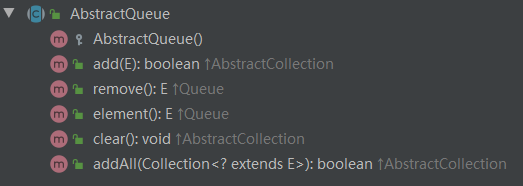
|
||||
|
||||
|
||||
## 1 LinkedList
|
||||
|
||||
### 继承关系
|
||||
|
||||

|
||||
|
||||
### 底层实现
|
||||
|
||||
LinkedList 底层采用`双向链表`数据结构存储元素,由于链表的内存地址`非连续`,所以它不具备随机访问的特点,但由于它利用指针连接各个元素,所以插入、删除元素只需要`操作指针`,不需要`移动元素`,故具有**增删快、查询慢**的特点。它也是一个非线程安全的集合。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
由于以双向链表作为数据结构,它是**线程不安全**的集合;存储的每个节点称为一个`Node`,下图可以看到 Node 中保存了`next`和`prev`指针,`item`是该节点的值。在插入和删除时,时间复杂度都保持为 `O(1)`
|
||||
|
||||

|
||||
|
||||
关于 LinkedList,除了它是以链表实现的集合外,还有一些特殊的特性需要注意的。
|
||||
|
||||
- 优势:LinkedList 底层没有`扩容机制`,使用`双向链表`存储元素,所以插入和删除元素效率较高,适用于频繁操作元素的场景
|
||||
- 劣势:LinkedList 不具备`随机访问`的特点,查找某个元素只能从 `head` 或 `tail` 指针一个一个比较,所以**查找中间的元素时效率很低**
|
||||
- 查找优化:LinkedList 查找某个下标 `index` 的元素时**做了优化**,若 `index > (size / 2)`,则从 `head` 往后查找,否则从 `tail` 开始往前查找,代码如下所示:
|
||||
|
||||
```Java
|
||||
LinkedList.Node<E> node(int index) {
|
||||
LinkedList.Node x;
|
||||
int i;
|
||||
if (index < this.size >> 1) { // 查找的下标处于链表前半部分则从头找
|
||||
x = this.first;
|
||||
for(i = 0; i < index; ++i) { x = x.next; }
|
||||
return x;
|
||||
} else { // 查找的下标处于数组的后半部分则从尾开始找
|
||||
x = this.last;
|
||||
for(i = this.size - 1; i > index; --i) { x = x.prev; }
|
||||
return x;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
- 双端队列:使用双端链表实现,并且实现了 `Deque` 接口,使得 LinkedList 可以用作**双端队列**。下图可以看到 Node 是集合中的元素,提供了前驱指针和后继指针,还提供了一系列操作`头结点`和`尾结点`的方法,具有双端队列的特性。
|
||||
|
||||

|
||||
|
||||
LinkedList 集合最让人树枝的是它的链表结构,但是我们同时也要注意它是一个双端队列型的集合。
|
||||
|
||||
```java
|
||||
Deque<Object> deque = new LinkedList<>();
|
||||
```
|
||||
|
||||
### 常用方法
|
||||
|
||||
|
||||
```java
|
||||
LinkedList() :初始化一个空的LinkedList实现。
|
||||
LinkedListExample(Collection c) :初始化一个LinkedList,该LinkedList包含指定集合的元素,并按集合的迭代器返回它们的顺序。
|
||||
boolean add(Object o) :将指定的元素追加到列表的末尾。
|
||||
void add(int index,Object element) :将指定的元素插入列表中指定位置的索引处。
|
||||
void addFirst(Object o) :将给定元素插入列表的开头。
|
||||
void addLast(Object o) :将给定元素附加到列表的末尾。
|
||||
int size() :返回列表中的元素数
|
||||
boolean contains(Object o) :如果列表包含指定的元素,则返回true ,否则返回false 。
|
||||
boolean remove(Object o) :删除列表中指定元素的第一次出现。
|
||||
Object getFirst() :返回列表中的第一个元素。
|
||||
Object getLast() :返回列表中的最后一个元素。
|
||||
int indexOf(Object o) :返回指定元素首次出现的列表中的索引;如果列表不包含指定元素,则返回-1。
|
||||
lastIndexOf(Object o) :返回指定元素最后一次出现的列表中的索引;如果列表不包含指定元素,则返回-1。
|
||||
Iterator iterator() :以适当的顺序返回对该列表中的元素进行迭代的迭代器。
|
||||
Object[] toArray() :以正确的顺序返回包含此列表中所有元素的数组。
|
||||
List subList(int fromIndex,int toIndex) :返回此列表中指定的fromIndex(包括)和toIndex(不包括)之间的视图。
|
||||
```
|
||||
|
||||
### LinkedList与ArrayList
|
||||
|
||||
* ArrayList是使用动态可调整大小的数组的概念实现的。 而LinkedList是双向链表实现。
|
||||
* ArrayList允许随机访问其元素,而LinkedList则不允许。
|
||||
* LinkedList还实现了Queue接口,该接口添加了比ArrayList更多的方法,例如offer(),peek(),poll()等。
|
||||
* 与LinkedList相比, ArrayList添加和删除速度较慢,但在获取时却较快,因为如果LinkedList中的array已满,则无需调整数组大小并将内容复制到新数组。
|
||||
* LinkedList比ArrayList具有更多的内存开销,因为在ArrayList中,每个索引仅保存实际对象,但是在LinkedList的情况下,每个节点都保存下一个和上一个节点的数据和地址。
|
||||
|
||||
|
||||
## 2 ArrayDeque
|
||||
|
||||
使用**数组**实现的双端队列,它是**无界**的双端队列,最小的容量是`8`(JDK 1.8)。在 JDK 11 看到它默认容量已经是 `16`了。
|
||||
|
||||
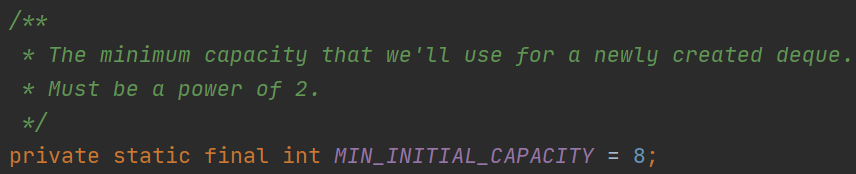
|
||||
|
||||
`ArrayDeque` 在日常使用得不多,值得注意的是它与 `LinkedList` 的对比:`LinkedList` 采用**链表**实现双端队列,而 `ArrayDeque` 使用**数组**实现双端队列。
|
||||
|
||||
> 在文档中作者写到:**ArrayDeque 作为栈时比 Stack 性能好,作为队列时比 LinkedList 性能好**
|
||||
|
||||
由于双端队列**只能在头部和尾部**操作元素,所以删除元素和插入元素的时间复杂度大部分都稳定在 `O(1)` ,除非在扩容时会涉及到元素的批量复制操作。但是在大多数情况下,使用它时应该指定一个大概的数组长度,避免频繁的扩容。
|
||||
|
||||
|
||||
## 3 PriorityQueue
|
||||
### 底层原理
|
||||
PriorityQueue 基于**优先级堆实现**的优先级队列,而堆是采用**数组**实现:
|
||||
|
||||

|
||||
|
||||
文档中的描述告诉我们:该数组中的元素通过传入 `Comparator` 进行定制排序,如果不传入`Comparator`时,则按照元素本身`自然排序`,但要求元素实现了`Comparable`接口,所以 PriorityQueue **不允许存储 NULL 元素**。
|
||||
|
||||
PriorityQueue 应用场景:元素本身具有优先级,需要按照**优先级处理元素**
|
||||
|
||||
- 例如游戏中的VIP玩家与普通玩家,VIP 等级越高的玩家越先安排进入服务器玩耍,减少玩家流失。
|
||||
|
||||
```Java
|
||||
public static void main(String[] args) {
|
||||
Student vip1 = new Student("张三", 1);
|
||||
Student vip3 = new Student("洪七", 2);
|
||||
Student vip4 = new Student("老八", 4);
|
||||
Student vip2 = new Student("李四", 1);
|
||||
Student normal1 = new Student("王五", 0);
|
||||
Student normal2 = new Student("赵六", 0);
|
||||
// 根据玩家的 VIP 等级进行降序排序
|
||||
PriorityQueue<Student> queue = new PriorityQueue<>((o1, o2) -> o2.getScore().compareTo(o1.getScore()));
|
||||
queue.add(vip1);queue.add(vip4);queue.add(vip3);
|
||||
queue.add(normal1);queue.add(normal2);queue.add(vip2);
|
||||
while (!queue.isEmpty()) {
|
||||
Student s1 = queue.poll();
|
||||
System.out.println(s1.getName() + "进入游戏; " + "VIP等级: " + s1.getScore());
|
||||
}
|
||||
}
|
||||
public static class Student implements Comparable<Student> {
|
||||
private String name;
|
||||
private Integer score;
|
||||
public Student(String name, Integer score) {
|
||||
this.name = name;
|
||||
this.score = score;
|
||||
}
|
||||
@Override
|
||||
public int compareTo(Student o) {
|
||||
return this.score.compareTo(o.getScore());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
执行上面的代码可以得到下面这种有趣的结果,可以看到`氪金`使人带来快乐。
|
||||
|
||||
|
||||
|
||||
VIP 等级越高(优先级越高)就越优先安排进入游戏(优先处理),类似这种有优先级的场景还有非常多,各位可以发挥自己的想象力。
|
||||
|
||||
PriorityQueue 总结:
|
||||
|
||||
- PriorityQueue 是基于**优先级堆**实现的优先级队列,而堆是用**数组**维护的
|
||||
|
||||
- PriorityQueue 适用于**元素按优先级处理**的业务场景,例如用户在请求人工客服需要排队时,根据用户的**VIP等级**进行 `插队` 处理,等级越高,越先安排客服。
|
||||
|
||||
|
||||
### 主要方法
|
||||
```java
|
||||
boolean add(object) :将指定的元素插入此优先级队列。
|
||||
boolean offer(object) :将指定的元素插入此优先级队列。
|
||||
boolean remove(object) :从此队列中移除指定元素的单个实例(如果存在)。
|
||||
Object poll() :检索并删除此队列的头部;如果此队列为空,则返回null。
|
||||
Object element() :获取但不删除此队列的头部,如果此队列为空,则抛出NoSuchElementException 。
|
||||
Object peek() :检索但不删除此队列的头部;如果此队列为空,则返回null。
|
||||
void clear() :从此优先级队列中删除所有元素。
|
||||
Comparator comparator() :返回用于对此队列中的元素进行排序的Comparator comparator()如果此队列是根据其元素的自然顺序排序的,则返回null。
|
||||
boolean contains(Object o) :如果此队列包含指定的元素,则返回true。
|
||||
Iterator iterator() :返回对该队列中的元素进行迭代的迭代器。
|
||||
int size() :返回此队列中的元素数。
|
||||
Object[] toArray() :返回一个包含此队列中所有元素的数组。
|
||||
```
|
||||
|
||||
|
||||
## 4 PriorityBlockingQueue
|
||||
|
||||
### 底层原理
|
||||
Java PriorityBlockingQueue类是concurrent阻塞队列数据结构的实现,其中根据对象的priority对其进行处理。 名称的“阻塞”部分已添加,表示线程将阻塞等待,直到队列上有可用的项目为止 。
|
||||
|
||||
在priority blocking queue ,添加的对象根据其优先级进行排序。 默认情况下,优先级由对象的自然顺序决定。 队列构建时提供的Comparator器可以覆盖默认优先级。
|
||||
* PriorityBlockingQueue是一个无界队列,并且会动态增长。 默认初始容量为'11' ,可以在适当的构造函数中使用initialCapacity参数覆盖此初始容量。
|
||||
* 它**提供了阻塞检索操作**。
|
||||
* 它不允许使用NULL对象。
|
||||
* 添加到PriorityBlockingQueue的对象必须具有可比性,否则它将引发ClassCastException 。
|
||||
* 默认情况下,优先级队列的对象以自然顺序排序 。
|
||||
* 比较器可用于队列中对象的自定义排序。
|
||||
* 优先级队列的head是基于自然排序或基于比较器排序的least元素。 当我们轮询队列时,它从队列中返回头对象。
|
||||
* 如果存在多个具有相同优先级的对象,则它可以随机轮询其中的任何一个。
|
||||
* PriorityBlockingQueue是thread safe 。
|
||||
|
||||
### 主要方法
|
||||
|
||||
```java
|
||||
boolean add(object) :将指定的元素插入此优先级队列。
|
||||
boolean offer(object) :将指定的元素插入此优先级队列。
|
||||
boolean remove(object) :从此队列中移除指定元素的单个实例(如果存在)。
|
||||
Object poll() :检索并删除此队列的头部,并在必要时等待指定的等待时间,以使元素可用。
|
||||
Object poll(timeout, timeUnit) :检索并删除此队列的头部,如果有必要,直到指定的等待时间,元素才可用。
|
||||
Object take() :检索并删除此队列的头部,如有必要,请等待直到元素可用。
|
||||
void put(Object o) :将指定的元素插入此优先级队列。
|
||||
void clear() :从此优先级队列中删除所有元素。
|
||||
Comparator comparator() :返回用于对此队列中的元素进行排序的Comparator comparator()如果此队列是根据其元素的自然顺序排序的,则返回null。
|
||||
boolean contains(Object o) :如果此队列包含指定的元素,则返回true。
|
||||
Iterator iterator() :返回对该队列中的元素进行迭代的迭代器。
|
||||
int size() :返回此队列中的元素数。
|
||||
int drainTo(Collection c) :从此队列中删除所有可用元素,并将它们添加到给定的collection中。
|
||||
intrainToTo(Collection c,int maxElements) :从此队列中最多移除给定数量的可用元素,并将它们添加到给定的collection中。
|
||||
int remainingCapacity() Integer.MAX_VALUE int remainingCapacity() :总是返回Integer.MAX_VALUE因为PriorityBlockingQueue不受容量限制。
|
||||
Object[] toArray() :返回一个包含此队列中所有元素的数组。
|
||||
```
|
||||
### 实例
|
||||
```java
|
||||
import java.util.concurrent.PriorityBlockingQueue;
|
||||
import java.util.concurrent.TimeUnit;
|
||||
|
||||
public class PriorityQueueExample
|
||||
{
|
||||
public static void main(String[] args) throws InterruptedException
|
||||
{
|
||||
PriorityBlockingQueue<Integer> priorityBlockingQueue = new PriorityBlockingQueue<>();
|
||||
|
||||
new Thread(() ->
|
||||
{
|
||||
System.out.println("Waiting to poll ...");
|
||||
|
||||
try
|
||||
{
|
||||
while(true)
|
||||
{
|
||||
Integer poll = priorityBlockingQueue.take();
|
||||
System.out.println("Polled : " + poll);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(1));
|
||||
}
|
||||
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}).start();
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(2));
|
||||
priorityBlockingQueue.add(1);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(2));
|
||||
priorityBlockingQueue.add(2);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(2));
|
||||
priorityBlockingQueue.add(3);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 5 ArrayBlockingQueue
|
||||
|
||||
### 底层原理
|
||||
|
||||
ArrayBlockingQueue类是由数组支持的Java concurrent和bounded阻塞队列实现。 它对元素FIFO(先进先出)进行排序。
|
||||
|
||||
ArrayBlockingQueue的head是一直在队列中最长时间的那个元素。 ArrayBlockingQueue的tail是最短时间进入队列的元素。 新元素插入到队列的尾部 ,并且队列检索操作在队列的开头获取元素 。
|
||||
|
||||
* ArrayBlockingQueue是由数组支持的固定大小的有界队列。
|
||||
* 它对元素FIFO(先进先出)进行排序。
|
||||
* 元素插入到尾部,并从队列的开头检索。
|
||||
* 创建后,队列的容量无法更改。
|
||||
* 它提供阻塞的插入和检索操作 。
|
||||
* 它不允许使用NULL对象。
|
||||
* ArrayBlockingQueue是thread safe 。
|
||||
* 方法iterator()提供的Iterator按从第一个(头)到最后一个(尾部)的顺序遍历元素。
|
||||
* ArrayBlockingQueue支持可选的fairness policy用于订购等待的生产者线程和使用者线程。 将fairness设置为true ,队列按FIFO顺序授予线程访问权限。
|
||||
|
||||
|
||||
|
||||
|
||||
### 生产消费者实例
|
||||
使用阻塞插入和检索从ArrayBlockingQueue中放入和取出元素的Java示例。
|
||||
|
||||
* 当队列已满时,生产者线程将等待。 一旦从队列中取出一个元素,它就会将该元素添加到队列中。
|
||||
* 如果队列为空,使用者线程将等待。 队列中只有一个元素时,它将取出该元素。
|
||||
```java
|
||||
import java.util.concurrent.ArrayBlockingQueue;
|
||||
import java.util.concurrent.TimeUnit;
|
||||
|
||||
public class ArrayBlockingQueueExample
|
||||
{
|
||||
public static void main(String[] args) throws InterruptedException
|
||||
{
|
||||
ArrayBlockingQueue<Integer> priorityBlockingQueue = new ArrayBlockingQueue<>(5);
|
||||
|
||||
//Producer thread
|
||||
new Thread(() ->
|
||||
{
|
||||
int i = 0;
|
||||
try
|
||||
{
|
||||
while (true)
|
||||
{
|
||||
priorityBlockingQueue.put(++i);
|
||||
System.out.println("Added : " + i);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(1));
|
||||
}
|
||||
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}).start();
|
||||
|
||||
//Consumer thread
|
||||
new Thread(() ->
|
||||
{
|
||||
try
|
||||
{
|
||||
while (true)
|
||||
{
|
||||
Integer poll = priorityBlockingQueue.take();
|
||||
System.out.println("Polled : " + poll);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(2));
|
||||
}
|
||||
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}).start();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 主要方法
|
||||
|
||||
```java
|
||||
ArrayBlockingQueue(int capacity) :构造具有给定(固定)容量和默认访问策略的空队列。
|
||||
ArrayBlockingQueue(int capacity,boolean fair) :构造具有给定(固定)容量和指定访问策略的空队列。 如果公允值为true ,则按FIFO顺序处理在插入或移除时阻塞的线程的队列访问; 如果为false,则未指定访问顺序。
|
||||
ArrayBlockingQueue(int capacity,boolean fair,Collection c) :构造一个队列,该队列具有给定(固定)的容量,指定的访问策略,并最初包含给定集合的元素,并以集合迭代器的遍历顺序添加。
|
||||
void put(Object o) :将指定的元素插入此队列的尾部,如果队列已满,则等待空间变为可用。
|
||||
boolean add(object) : Inserts the specified element at the tail of this queue if it is possible to do so immediately without exceeding the queue’s capacity, returning true upon success and throwing an IllegalStateException if this queue is full.
|
||||
boolean offer(object) :如果可以在不超出队列容量的情况下立即执行此操作,则在此队列的尾部插入指定的元素,如果成功,则返回true,如果此队列已满,则抛出IllegalStateException。
|
||||
boolean remove(object) :从此队列中移除指定元素的单个实例(如果存在)。
|
||||
Object peek() :检索但不删除此队列的头部;如果此队列为空,则返回null。
|
||||
Object poll() :检索并删除此队列的头部;如果此队列为空,则返回null。
|
||||
Object poll(timeout, timeUnit) :检索并删除此队列的头部,如果有必要,直到指定的等待时间,元素才可用。
|
||||
Object take() :检索并删除此队列的头部,如有必要,请等待直到元素可用。
|
||||
void clear() :从队列中删除所有元素。
|
||||
boolean contains(Object o) :如果此队列包含指定的元素,则返回true。
|
||||
Iterator iterator() :以适当的顺序返回对该队列中的元素进行迭代的迭代器。
|
||||
int size() :返回此队列中的元素数。
|
||||
int drainTo(Collection c) :从此队列中删除所有可用元素,并将它们添加到给定的collection中。
|
||||
intrainToTo(Collection c,int maxElements) :从此队列中最多移除给定数量的可用元素,并将它们添加到给定的collection中。
|
||||
int remainingCapacity() :返回该队列理想情况下(在没有内存或资源限制的情况下)可以接受而不阻塞的其他元素的数量。
|
||||
Object[] toArray() :以适当的顺序返回一个包含此队列中所有元素的数组。
|
||||
```
|
||||
|
||||
|
||||
## 6 LinkedTransferQueue
|
||||
|
||||
### 底层原理
|
||||
|
||||
直接消息队列。也就是说,生产者生产后,必须等待消费者来消费才能继续执行。
|
||||
|
||||
Java TransferQueue是并发阻塞队列的实现,生产者可以在其中等待使用者使用消息。 LinkedTransferQueue类是Java中TransferQueue的实现。
|
||||
|
||||
|
||||
* LinkedTransferQueue是链接节点上的unbounded队列。
|
||||
* 此队列针对任何给定的生产者对元素FIFO(先进先出)进行排序。
|
||||
* 元素插入到尾部,并从队列的开头检索。
|
||||
* 它提供阻塞的插入和检索操作 。
|
||||
* 它不允许使用NULL对象。
|
||||
* LinkedTransferQueue是thread safe 。
|
||||
* 由于异步性质,size()方法不是固定时间操作,因此,如果在遍历期间修改此集合,则可能会报告不正确的结果。
|
||||
* 不保证批量操作addAll,removeAll,retainAll,containsAll,equals和toArray是原子执行的。 例如,与addAll操作并发操作的迭代器可能仅查看某些添加的元素。
|
||||
|
||||
|
||||
|
||||
### 实例
|
||||
非阻塞实例
|
||||
|
||||
```java
|
||||
LinkedTransferQueue<Integer> linkedTransferQueue = new LinkedTransferQueue<>();
|
||||
|
||||
linkedTransferQueue.put(1);
|
||||
|
||||
System.out.println("Added Message = 1");
|
||||
|
||||
Integer message = linkedTransferQueue.poll();
|
||||
|
||||
System.out.println("Recieved Message = " + message);
|
||||
```
|
||||
|
||||
阻塞插入实例,用于现成状态同步通信
|
||||
使用阻塞插入和检索从LinkedTransferQueue放入和取出元素的Java示例。
|
||||
|
||||
* 生产者线程将等待,直到有消费者准备从队列中取出项目为止。
|
||||
* 如果队列为空,使用者线程将等待。 队列中只有一个元素时,它将取出该元素。 只有在消费者接受了消息之后,生产者才可以再发送一条消息。
|
||||
|
||||
|
||||
|
||||
|
||||
```java
|
||||
import java.util.Random;
|
||||
import java.util.concurrent.LinkedTransferQueue;
|
||||
import java.util.concurrent.TimeUnit;
|
||||
|
||||
public class LinkedTransferQueueExample
|
||||
{
|
||||
public static void main(String[] args) throws InterruptedException
|
||||
{
|
||||
LinkedTransferQueue<Integer> linkedTransferQueue = new LinkedTransferQueue<>();
|
||||
|
||||
new Thread(() ->
|
||||
{
|
||||
Random random = new Random(1);
|
||||
try
|
||||
{
|
||||
while (true)
|
||||
{
|
||||
System.out.println("Producer is waiting to transfer message...");
|
||||
|
||||
Integer message = random.nextInt();
|
||||
boolean added = linkedTransferQueue.tryTransfer(message);
|
||||
if(added) {
|
||||
System.out.println("Producer added the message - " + message);
|
||||
}
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(3));
|
||||
}
|
||||
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}).start();
|
||||
|
||||
new Thread(() ->
|
||||
{
|
||||
try
|
||||
{
|
||||
while (true)
|
||||
{
|
||||
System.out.println("Consumer is waiting to take message...");
|
||||
|
||||
Integer message = linkedTransferQueue.take();
|
||||
|
||||
System.out.println("Consumer recieved the message - " + message);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(3));
|
||||
}
|
||||
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}).start();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### 主要方法
|
||||
|
||||
```java
|
||||
LinkedTransferQueue() :构造一个初始为空的LinkedTransferQueue。
|
||||
LinkedTransferQueue(Collection c) :构造一个LinkedTransferQueue,最初包含给定集合的元素,并以该集合的迭代器的遍历顺序添加。
|
||||
Object take() :检索并删除此队列的头部,如有必要,请等待直到元素可用。
|
||||
void transfer(Object o) :将元素传输给使用者,如有必要,请等待。
|
||||
boolean tryTransfer(Object o) :如果可能,立即将元素传输到等待的使用者。
|
||||
boolean tryTransfer(Object o,long timeout,TimeUnit unit) :如果有可能,则在超时之前将元素传输给使用者。
|
||||
int getWaitingConsumerCount() :返回等待通过BlockingQueue.take()或定时轮询接收元素的使用者数量的估计值。
|
||||
boolean hasWaitingConsumer() :如果至少有一个使用者正在等待通过BlockingQueue.take()或定时轮询接收元素,则返回true。
|
||||
void put(Object o) :将指定的元素插入此队列的尾部。
|
||||
boolean add(object) : Inserts the specified element at the tail of this queue.
|
||||
boolean offer(object) :将指定的元素插入此队列的尾部。
|
||||
boolean remove(object) :从此队列中移除指定元素的单个实例(如果存在)。
|
||||
Object peek() :检索但不删除此队列的头部;如果此队列为空,则返回null。
|
||||
Object poll() :检索并删除此队列的头部;如果此队列为空,则返回null。
|
||||
Object poll(timeout, timeUnit) :检索并删除此队列的头部,如果有必要,直到指定的等待时间,元素才可用。
|
||||
void clear() :从队列中删除所有元素。
|
||||
boolean contains(Object o) :如果此队列包含指定的元素,则返回true。
|
||||
Iterator iterator() :以适当的顺序返回对该队列中的元素进行迭代的迭代器。
|
||||
int size() :返回此队列中的元素数。
|
||||
int drainTo(Collection c) :从此队列中删除所有可用元素,并将它们添加到给定的collection中。
|
||||
intrainToTo(Collection c,int maxElements) :从此队列中最多移除给定数量的可用元素,并将它们添加到给定的collection中。
|
||||
int remainingCapacity() :返回该队列理想情况下(在没有内存或资源限制的情况下)可以接受而不阻塞的其他元素的数量。
|
||||
Object[] toArray() :以适当的顺序返回一个包含此队列中所有元素的数组。
|
||||
```
|
||||
|
||||
344
Java基础教程/Java集合类/05 Set.md
Normal file
@@ -0,0 +1,344 @@
|
||||
## 0 Set 接口
|
||||
|
||||
### Set接口
|
||||
`Set`接口继承了`Collection`接口,是一个不包括重复元素的集合,更确切地说,Set 中任意两个元素不会出现 `o1.equals(o2)`,而且 Set **至多**只能存储一个 `NULL` 值元素,Set 集合的组成部分可以用下面这张图概括:
|
||||
|
||||
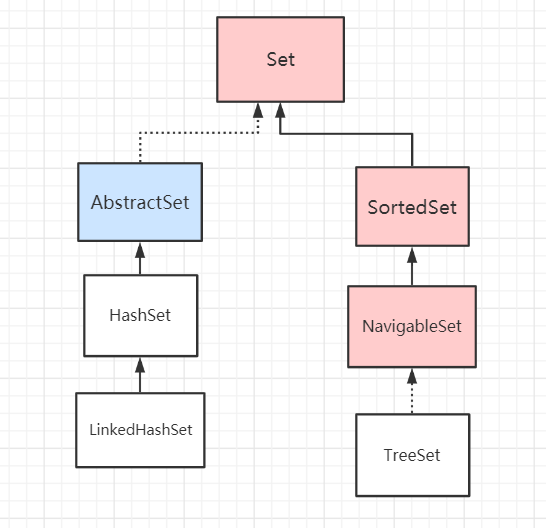
|
||||
|
||||
在 Set 集合体系中,我们需要着重关注两点:
|
||||
|
||||
- 存入**可变元素**时,必须非常小心,因为任意时候元素状态的改变都有可能使得 Set 内部出现两个**相等**的元素,即 `o1.equals(o2) = true`,所以一般不要更改存入 Set 中的元素,否则将会破坏了 `equals()` 的作用!
|
||||
|
||||
- Set 的最大作用就是判重,在项目中最大的作用也是**判重**!
|
||||
|
||||
接下来我们去看它的实现类和子类: `AbstractSet` 和 `SortedSet`
|
||||
|
||||
### AbstractSet 抽象类
|
||||
|
||||
`AbstractSet` 是一个实现 Set 的一个抽象类,定义在这里可以将所有具体 Set 集合的**相同行为**在这里实现,**避免子类包含大量的重复代码**
|
||||
|
||||
所有的 Set 也应该要有相同的 `hashCode()` 和 `equals()` 方法,所以使用抽象类把该方法重写后,子类无需关心这两个方法。
|
||||
|
||||
```Java
|
||||
public abstract class AbstractSet<E> implements Set<E> {
|
||||
// 判断两个 set 是否相等
|
||||
public boolean equals(Object o) {
|
||||
if (o == this) { // 集合本身
|
||||
return true;
|
||||
} else if (!(o instanceof Set)) { // 集合不是 set
|
||||
return false;
|
||||
} else {
|
||||
// 比较两个集合的元素是否全部相同
|
||||
}
|
||||
}
|
||||
// 计算所有元素的 hashcode 总和
|
||||
public int hashCode() {
|
||||
int h = 0;
|
||||
Iterator i = this.iterator();
|
||||
while(i.hasNext()) {
|
||||
E obj = i.next();
|
||||
if (obj != null) {
|
||||
h += obj.hashCode();
|
||||
}
|
||||
}
|
||||
return h;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### SortedSet 接口
|
||||
|
||||
`SortedSet` 是一个接口,它在 Set 的基础上扩展了**排序**的行为,所以所有实现它的子类都会拥有排序功能。
|
||||
|
||||
```Java
|
||||
public interface SortedSet<E> extends Set<E> {
|
||||
// 元素的比较器,决定元素的排列顺序
|
||||
Comparator<? super E> comparator();
|
||||
// 获取 [var1, var2] 之间的 set
|
||||
SortedSet<E> subSet(E var1, E var2);
|
||||
// 获取以 var1 开头的 Set
|
||||
SortedSet<E> headSet(E var1);
|
||||
// 获取以 var1 结尾的 Set
|
||||
SortedSet<E> tailSet(E var1);
|
||||
// 获取首个元素
|
||||
E first();
|
||||
// 获取最后一个元素
|
||||
E last();
|
||||
}
|
||||
```
|
||||
|
||||
## 1 HashSet
|
||||
|
||||
### 底层实现
|
||||
|
||||
HashSet 底层借助 `HashMap` 实现,我们可以观察它的多个构造方法,本质上都是 new 一个 HashMap
|
||||
|
||||
|
||||
```Java
|
||||
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, Serializable {
|
||||
public HashSet() {
|
||||
this.map = new HashMap();
|
||||
}
|
||||
public HashSet(int initialCapacity, float loadFactor) {
|
||||
this.map = new HashMap(initialCapacity, loadFactor);
|
||||
}
|
||||
public HashSet(int initialCapacity) {
|
||||
this.map = new HashMap(initialCapacity);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
我们可以观察 `add()` 方法和`remove()`方法是如何将 HashSet 的操作嫁接到 HashMap 的。
|
||||
|
||||
```Java
|
||||
private static final Object PRESENT = new Object();
|
||||
|
||||
public boolean add(E e) {
|
||||
return this.map.put(e, PRESENT) == null;
|
||||
}
|
||||
public boolean remove(Object o) {
|
||||
return this.map.remove(o) == PRESENT;
|
||||
}
|
||||
```
|
||||
|
||||
我们看到 `PRESENT` 就是一个**静态常量**:使用 PRESENT 作为 HashMap 的 value 值,使用HashSet的开发者只需**关注**于需要插入的 `key`,**屏蔽**了 HashMap 的 `value`
|
||||
|
||||

|
||||
|
||||
上图可以观察到每个`Entry`的`value`都是 PRESENT 空对象,我们就不用再理会它了。
|
||||
|
||||
HashSet 在 HashMap 基础上实现,所以很多地方可以联系到 HashMap:
|
||||
|
||||
- 底层数据结构:HashSet 也是采用`数组 + 链表 + 红黑树`实现
|
||||
- 线程安全性:由于采用 HashMap 实现,而 HashMap 本身线程不安全,在HashSet 中没有添加额外的同步策略,所以 HashSet 也**线程不安全**
|
||||
- 存入 HashSet 的对象的状态**最好不要发生变化**,因为有可能改变状态后,在集合内部出现两个元素`o1.equals(o2)`,破坏了 `equals()`的语义。
|
||||
|
||||
|
||||
### 继承结构
|
||||
|
||||
* 实现了Set接口。
|
||||
* HashSet中不允许重复的值。
|
||||
* HashSet中允许一个NULL元素。
|
||||
* 无序集合,并且不保证集合的迭代顺序。
|
||||
* 为基本操作(添加,删除,包含和调整大小)提供恒定的时间性能。
|
||||
* HashSet不同步。 如果多个线程同时访问哈希集,并且至少有一个线程修改了哈希集,则必须在外部对其进行同步。使用Collections.synchronizedSet(new HashSet())方法获取同步的哈希集。
|
||||
|
||||
|
||||

|
||||
|
||||
### 基本使用
|
||||
|
||||
* 默认初始容量为16 。 我们可以通过在构造函数HashSet(int initialCapacity)传递默认容量来覆盖此默认容量。
|
||||
|
||||
|
||||
|
||||
```java
|
||||
public boolean add(E e) :如果指定的元素不存在,则将其添加到Set中。 此方法在内部使用equals()方法检查重复项。 如果元素重复,则元素被拒绝,并且不替换值。
|
||||
public void clear() :从哈希集中删除所有元素。
|
||||
public boolean contains(Object o) :如果哈希集包含指定的元素othrweise false ,则返回false 。
|
||||
public boolean isEmpty() :如果哈希集不包含任何元素,则返回true ,否则返回false 。
|
||||
public int size() :返回哈希集中的元素数量。
|
||||
public Iterator<E> iterator() :返回对此哈希集中的元素的迭代器。 从迭代器返回的元素没有特定的顺序。
|
||||
public boolean remove(Object o) :从哈希集中删除指定的元素(如果存在)并返回true ,否则返回false 。
|
||||
public boolean removeAll(Collection <?> c) :删除哈希集中属于指定集合的所有元素。
|
||||
public Object clone() :返回哈希集的浅表副本。
|
||||
public Spliterator<E> spliterator() :在此哈希集中的元素上创建后绑定和故障快速的Spliterator。
|
||||
```
|
||||
|
||||
## 2 LinkedHashSet
|
||||
|
||||
### 底层原理
|
||||
LinkedHashSet 的代码少的可怜,不信我给你我粘出来
|
||||
|
||||

|
||||
|
||||
少归少,还是不能闹,`LinkedHashSet`继承了`HashSet`,我们跟随到父类 HashSet 的构造方法看看
|
||||
|
||||
```java
|
||||
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
|
||||
this.map = new LinkedHashMap(initialCapacity, loadFactor);
|
||||
}
|
||||
```
|
||||
|
||||
发现父类中 map 的实现采用`LinkedHashMap`,这里注意不是`HashMap`,而 LinkedHashMap 底层又采用 HashMap + 双向链表 实现的,所以本质上 LinkedHashSet 还是使用 HashMap 实现的。
|
||||
|
||||
> LinkedHashSet -> LinkedHashMap -> HashMap + 双向链表
|
||||
|
||||
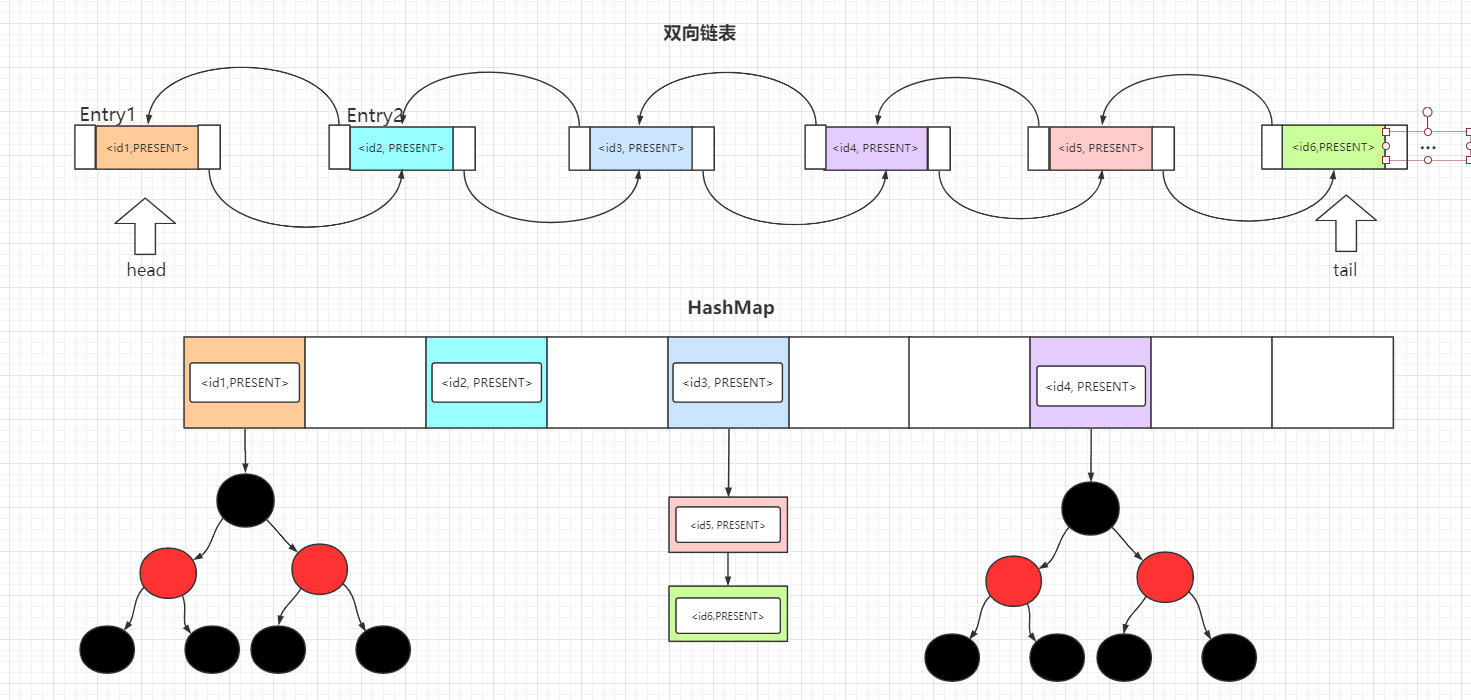
|
||||
|
||||
而 LinkedHashMap 是采用 `HashMap`和`双向链表`实现的,这条双向链表中保存了元素的插入顺序。所以 LinkedHashSet 可以按照元素的插入顺序遍历元素,如果你熟悉`LinkedHashMap`,那 LinkedHashSet 也就更不在话下了。
|
||||
|
||||
关于 LinkedHashSet 需要注意几个地方:
|
||||
|
||||
- 它继承了 `HashSet`,而 HashSet 默认是采用 HashMap 存储数据的,但是 LinkedHashSet 调用父类构造方法初始化 map 时是 LinkedHashMap 而不是 HashMap,这个要额外注意一下
|
||||
- 由于 LinkedHashMap 不是线程安全的,且在 LinkedHashSet 中没有添加额外的同步策略,所以 LinkedHashSet 集合**也不是线程安全**的
|
||||
|
||||
### 继承关系
|
||||
|
||||

|
||||
|
||||
* 它扩展了HashSet类,后者扩展了AbstractSet类。
|
||||
* 它实现Set接口。
|
||||
* LinkedHashSet中不允许重复的值 。
|
||||
* LinkedHashSet中允许一个NULL元素。
|
||||
* 它是一个ordered collection ,它是元素插入到集合中insertion-order ( insertion-order )。
|
||||
* 像HashSet一样,此类为基本操作(添加,删除,包含和调整大小)提供constant time performance 。
|
||||
* LinkedHashSet not synchronized 。 如果多个线程同时访问哈希集,并且至少有一个线程修改了哈希集,则必须在外部对其进行同步。
|
||||
* 使用Collections.synchronizedSet(new LinkedHashSet())方法来获取同步的LinkedHashSet。
|
||||
|
||||
|
||||
### 使用方法
|
||||
|
||||
```java
|
||||
public boolean add(E e) :如果指定的元素不存在,则将其添加到Set中。 此方法在内部使用equals()方法检查重复项。 如果元素重复,则元素被拒绝,并且不替换值。
|
||||
public void clear() :从LinkedHashSet中删除所有元素。
|
||||
public boolean contains(Object o) :如果LinkedHashSet包含指定的元素othrweise false ,则返回false 。
|
||||
public boolean isEmpty() :如果LinkedHashSet不包含任何元素,则返回true ,否则返回false 。
|
||||
public int size() :返回LinkedHashSet中的元素数。
|
||||
public Iterator<E> iterator() :返回对此LinkedHashSet中的元素的迭代器。 从迭代器返回的元素没有特定的顺序。
|
||||
public boolean remove(Object o) :从LinkedHashSet中移除指定的元素(如果存在)并返回true ,否则返回false 。
|
||||
public boolean removeAll(Collection <?> c) :删除LinkedHashSet中属于指定集合的所有元素。
|
||||
public Object clone() :返回LinkedHashSet的浅表副本。
|
||||
public Spliterator<E> spliterator() :在此LinkedHashSet中的元素上创建后绑定和故障快速的Spliterator。 它具有以下初始化属性Spliterator.DISTINCT , Spliterator.ORDERED 。
|
||||
```
|
||||
## 3 TreeSet
|
||||
|
||||
### 底层原理
|
||||
TreeSet 是基于 TreeMap 的实现,所以存储的元素是**有序**的,底层的数据结构是`数组 + 红黑树`。
|
||||
|
||||
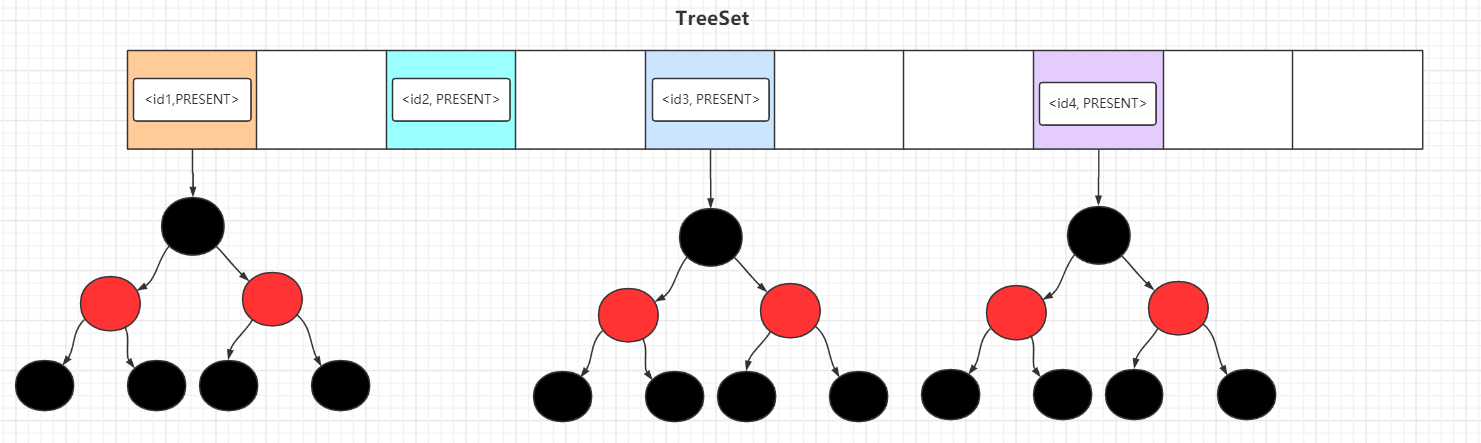
|
||||
|
||||
而元素的排列顺序有`2`种,和 TreeMap 相同:自然排序和定制排序,常用的构造方法已经在下面展示出来了,TreeSet 默认按照自然排序,如果需要定制排序,需要传入`Comparator`。
|
||||
|
||||
```Java
|
||||
public TreeSet() {
|
||||
this(new TreeMap<E,Object>());
|
||||
}
|
||||
public TreeSet(Comparator<? super E> comparator) {
|
||||
this(new TreeMap<>(comparator));
|
||||
}
|
||||
```
|
||||
|
||||
TreeSet 应用场景有很多,像在游戏里的玩家战斗力排行榜
|
||||
|
||||
```Java
|
||||
public class Player implements Comparable<Integer> {
|
||||
public String name;
|
||||
public int score;
|
||||
@Override
|
||||
public int compareTo(Student o) {
|
||||
return Integer.compareTo(this.score, o.score);
|
||||
}
|
||||
}
|
||||
public static void main(String[] args) {
|
||||
Player s1 = new Player("张三", 100);
|
||||
Player s2 = new Player("李四", 90);
|
||||
Player s3 = new Player("王五", 80);
|
||||
TreeSet<Player> set = new TreeSet();
|
||||
set.add(s2); set.add(s1); set.add(s3);
|
||||
System.out.println(set);
|
||||
}
|
||||
// [Student{name='王五', score=80}, Student{name='李四', score=90}, Student{name='张三', score=100}]
|
||||
```
|
||||
|
||||
对 TreeSet 介绍了它的主要实现方式和应用场景,有几个值得注意的点。
|
||||
|
||||
- TreeSet 的所有操作都会转换为对 TreeMap 的操作,TreeMap 采用**红黑树**实现,任意操作的平均时间复杂度为 `O(logN)`
|
||||
- TreeSet 是一个**线程不安全**的集合
|
||||
- TreeSet 常应用于对**不重复**的元素**定制排序**,例如玩家战力排行榜
|
||||
|
||||
> 注意:TreeSet判断元素是否重复的方法是判断compareTo()方法是否返回0,而不是调用 hashcode() 和 equals() 方法,如果返回 0 则认为集合内已经存在相同的元素,不会再加入到集合当中。
|
||||
|
||||
### 继承关系
|
||||
|
||||

|
||||
|
||||
* 它扩展了AbstractSet类,该类扩展了AbstractCollection类。
|
||||
* 它实现了NavigableSet接口,该接口扩展了SortedSet接口。
|
||||
* TreeSet中不允许重复的值。
|
||||
* 在TreeSet中不允许NULL。
|
||||
* 它是一个ordered collection ,按排序顺序存储元素。
|
||||
* 与HashSet一样,此类为基本操作(添加,删除,包含和调整大小)提供恒定的时间性能。
|
||||
* TreeSet不允许插入异构对象,因为它必须比较对象以确定排序顺序。
|
||||
* TreeSet不synchronized 。 如果多个线程同时访问哈希集,并且至少有一个线程修改了哈希集,则必须在外部对其进行同步。
|
||||
* 使用Collections.synchronizedSortedSet(new TreeSet())方法获取同步的TreeSet。
|
||||
|
||||
|
||||
|
||||
### 使用方法
|
||||
```java
|
||||
boolean add(E e) :将指定的元素添加到Set中(如果尚不存在)。
|
||||
Comparator comparator() :返回用于对该集合中的元素进行排序的Comparator comparator()如果此集合使用其元素的自然排序,则返回null。
|
||||
Object first() :返回当前在此集合中的第一个(最低)元素。
|
||||
Object last() :返回当前在此集合中的最后一个(最大)元素。
|
||||
void clear() :从TreeSet中删除所有元素。
|
||||
boolean contains(Object o) :如果TreeSet包含指定的元素,则返回true否则返回false 。
|
||||
boolean isEmpty() :如果TreeSet不包含任何元素,则返回true ,否则返回false 。
|
||||
int size() :返回TreeSet中的元素数。
|
||||
Iterator<E> iterator() :以ascending order返回此集合中元素的迭代器。
|
||||
Iterator<E> descendingIterator() :以Iterator<E> descendingIterator()返回此集合中元素的迭代器。
|
||||
NavigableSet<E> descendingSet() :返回此集合中包含的元素的逆序视图。
|
||||
boolean remove(Object o) :从TreeSet中移除指定的元素(如果存在)并返回true ,否则返回false 。
|
||||
Object clone() :返回TreeSet的浅表副本。
|
||||
Spliterator<E> spliterator() :在此TreeSet中的元素上创建后绑定和故障快速的Spliterator。 它与树集提供的顺序相同。
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 4 CopyOnWriteArraySet
|
||||
|
||||
### 底层原理
|
||||
HashSet的thread-safe变体,它对所有操作都使用基础CopyOnWriteArrayList
|
||||
|
||||
与CopyOnWriteArrayList相似,它的immutable snapshot样式iterator方法在创建iterator使用对数组状态(在后备列表内)的引用。 这在遍历操作远远超过集合更新操作且我们不想同步遍历并且在更新集合时仍希望线程安全的用例中很有用。
|
||||
|
||||
* 作为正常设置的数据结构,它不允许重复。
|
||||
* CopyOnWriteArraySet类实现Serializable接口并扩展AbstractSet类。
|
||||
* 使用CopyOnWriteArraySet进行更新操作成本很高,因为每个突变都会创建基础数组的克隆副本并向其添加/更新元素。
|
||||
* 它是HashSet的线程安全版本。 每个访问该集合的线程在初始化此集合的迭代器时都会看到自己创建的后备阵列快照版本。
|
||||
* 因为它在创建迭代器时获取基础数组的快照,所以它不会抛出ConcurrentModificationException 。不支持迭代器上的变异操作。 这些方法抛出UnsupportedOperationException 。
|
||||
* CopyOnWriteArraySet是synchronized Set的并发替代,当迭代的次数超过突变次数时,CopyOnWriteArraySet提供更好的并发性。
|
||||
* 它允许重复的元素和异构对象(使用泛型来获取编译时错误)。
|
||||
* 由于每次创建迭代器时都会创建基础数组的新副本,因此performance is slower HashSet
|
||||
|
||||
### 主要方法
|
||||
|
||||
```java
|
||||
CopyOnWriteArraySet() :创建一个空集。
|
||||
CopyOnWriteArraySet(Collection c) :创建一个包含指定集合元素的集合,其顺序由集合的迭代器返回。
|
||||
boolean add(object o) :将指定的元素添加到此集合(如果尚不存在)。
|
||||
boolean addAll(collection c) :将指定集合中的所有元素(如果尚不存在boolean addAll(collection c)添加到此集合中。
|
||||
void clear() :从此集合中删除所有元素。
|
||||
boolean contains(Object o) :如果此集合包含指定的元素,则返回true。
|
||||
boolean isEmpty() :如果此集合不包含任何元素,则返回true。
|
||||
Iterator iterator() :以添加这些元素的顺序在此集合中包含的元素上返回一个迭代器。
|
||||
boolean remove(Object o) :从指定的集合中删除指定的元素(如果存在)。
|
||||
int size() :返回此集合中的元素数
|
||||
```
|
||||
|
||||
|
||||
### 实例
|
||||
|
||||
```java
|
||||
CopyOnWriteArraySet<Integer> set = new CopyOnWriteArraySet<>(Arrays.asList(1,2,3));
|
||||
|
||||
System.out.println(set); //[1, 2, 3]
|
||||
|
||||
//Get iterator 1
|
||||
Iterator<Integer> itr1 = set.iterator();
|
||||
|
||||
//Add one element and verify set is updated
|
||||
set.add(4);
|
||||
System.out.println(set); //[1, 2, 3, 4]
|
||||
|
||||
//Get iterator 2
|
||||
Iterator<Integer> itr2 = set.iterator();
|
||||
|
||||
System.out.println("====Verify Iterator 1 content====");
|
||||
|
||||
itr1.forEachRemaining(System.out :: println); //1,2,3
|
||||
|
||||
System.out.println("====Verify Iterator 2 content====");
|
||||
|
||||
itr2.forEachRemaining(System.out :: println); //1,2,3,4
|
||||
```
|
||||
425
Java基础教程/Java集合类/06 Map.md
Normal file
@@ -0,0 +1,425 @@
|
||||
|
||||
## 0 Map 集合体系详解
|
||||
|
||||
`Map`接口是由`<key, value>`组成的集合,由`key`映射到**唯一**的`value`,所以`Map`不能包含重复的`key`,每个键**至多**映射一个值。下图是整个 Map 集合体系的主要组成部分,我将会按照日常使用频率从高到低一一讲解。
|
||||
|
||||
不得不提的是 Map 的设计理念:**定位元素**的时间复杂度优化到 `O(1)`
|
||||
|
||||
Map 体系下主要分为 AbstractMap 和 SortedMap两类集合
|
||||
|
||||
`AbstractMap`是对 Map 接口的扩展,它定义了普通的 Map 集合具有的**通用行为**,可以避免子类重复编写大量相同的代码,子类继承 AbstractMap 后可以重写它的方法,**实现额外的逻辑**,对外提供更多的功能。
|
||||
|
||||
`SortedMap` 定义了该类 Map 具有 `排序`行为,同时它在内部定义好有关排序的抽象方法,当子类实现它时,必须重写所有方法,对外提供排序功能。
|
||||
|
||||

|
||||
|
||||
## 1 HashMap
|
||||
|
||||
### 底层原理
|
||||
HashMap 是一个**最通用的**利用哈希表存储元素的集合,将元素放入 HashMap 时,将`key`的哈希值转换为数组的`索引`下标**确定存放位置**,查找时,根据`key`的哈希地址转换成数组的`索引`下标**确定查找位置**。
|
||||
|
||||
HashMap 底层是用数组 + 链表 + 红黑树这三种数据结构实现,它是**非线程安全**的集合。
|
||||
|
||||

|
||||
|
||||
发送哈希冲突时,HashMap 的解决方法是将相同映射地址的元素连成一条`链表`,如果链表的长度大于`8`时,且数组的长度大于`64`则会转换成`红黑树`数据结构。
|
||||
|
||||
关于 HashMap 的简要总结:
|
||||
|
||||
1. 它是集合中最常用的`Map`集合类型,底层由`数组 + 链表 + 红黑树`组成
|
||||
2. HashMap不是线程安全的
|
||||
3. 插入元素时,通过计算元素的`哈希值`,通过**哈希映射函数**转换为`数组下标`;查找元素时,同样通过哈希映射函数得到数组下标`定位元素的位置`
|
||||
|
||||
### 继承关系
|
||||
|
||||

|
||||
|
||||
* HashMap不能包含重复的键。
|
||||
* HashMap允许多个null值,但只允许一个null键。
|
||||
* HashMap是一个unordered collection 。 它不保证元素的任何特定顺序。
|
||||
* HashMap not thread-safe 。 您必须显式同步对HashMap的并发修改。 或者,您可以使用Collections.synchronizedMap(hashMap)来获取HashMap的同步版本。
|
||||
* 只能使用关联的键来检索值。
|
||||
* HashMap仅存储对象引用。 因此,必须将原语与其对应的包装器类一起使用。 如int将存储为Integer 。
|
||||
|
||||
|
||||
### 主要方法
|
||||
|
||||
```java
|
||||
void clear() :从HashMap中删除所有键-值对。
|
||||
Object clone() :返回指定HashMap的浅表副本。
|
||||
boolean containsKey(Object key) :根据是否在地图中找到指定的键,返回true或false 。
|
||||
boolean containsValue(Object Value) :类似于containsKey()方法,它查找指定的值而不是键。
|
||||
Object get(Object key) :返回HashMap中指定键的值。
|
||||
boolean isEmpty() :检查地图是否为空。
|
||||
Set keySet() :返回存储在HashMap中的所有密钥的Set 。
|
||||
Object put(Key k,Value v) :将键值对插入HashMap中。
|
||||
int size() :返回地图的大小,该大小等于存储在HashMap中的键值对的数量。
|
||||
Collection values() :返回地图中所有值的集合。
|
||||
Value remove(Object key) :删除指定键的键值对。
|
||||
void putAll(Map m) :将地图的所有元素复制到另一个指定的地图。
|
||||
```
|
||||
|
||||
|
||||
|
||||
合并两个hashmap
|
||||
* 使用HashMap.putAll(HashMap)方法,即可将所有映射从第二张地图复制到第一张地图。hashmap不允许重复的键 。 因此,当我们以这种方式合并map时,对于map1的重复键,其值会被map2相同键的值覆盖。
|
||||
|
||||
```java
|
||||
//map 1
|
||||
HashMap<Integer, String> map1 = new HashMap<>();
|
||||
|
||||
map1.put(1, "A");
|
||||
map1.put(2, "B");
|
||||
map1.put(3, "C");
|
||||
map1.put(5, "E");
|
||||
|
||||
//map 2
|
||||
HashMap<Integer, String> map2 = new HashMap<>();
|
||||
|
||||
map2.put(1, "G"); //It will replace the value 'A'
|
||||
map2.put(2, "B");
|
||||
map2.put(3, "C");
|
||||
map2.put(4, "D"); //A new pair to be added
|
||||
|
||||
//Merge maps
|
||||
map1.putAll(map2);
|
||||
|
||||
System.out.println(map1);
|
||||
```
|
||||
* merge()函数如果我们要处理在地图中存在重复键的情况,并且我们不想丢失任何地图和任何键的数据。HashMap.merge()函数3个参数。 键,值,并使用用户提供的BiFunction合并重复键的值。跟put一样,实现了重复key的处理。
|
||||
|
||||
```java
|
||||
Merge HashMaps Example
|
||||
//map 1
|
||||
HashMap<Integer, String> map1 = new HashMap<>();
|
||||
|
||||
map1.put(1, "A");
|
||||
map1.put(2, "B");
|
||||
map1.put(3, "C");
|
||||
map1.put(5, "E");
|
||||
|
||||
//map 2
|
||||
HashMap<Integer, String> map2 = new HashMap<>();
|
||||
|
||||
map2.put(1, "G"); //It will replace the value 'A'
|
||||
map2.put(2, "B");
|
||||
map2.put(3, "C");
|
||||
map2.put(4, "D"); //A new pair to be added
|
||||
|
||||
//Merge maps
|
||||
map2.forEach(
|
||||
(key, value) -> map1.merge( key, value, (v1, v2) -> v1.equalsIgnoreCase(v2) ? v1 : v1 + "," + v2)
|
||||
);
|
||||
|
||||
System.out.println(map1);
|
||||
```
|
||||
|
||||
### 遍历方法
|
||||
|
||||
通过不同的set遍历呗。包括EntrySet遍历、keyset遍历
|
||||
|
||||
```java
|
||||
1)在每个循环中使用enrtySet()
|
||||
for (Map.Entry<String,Integer> entry : testMap.entrySet()) {
|
||||
entry.getKey();
|
||||
entry.getValue();
|
||||
}
|
||||
2)在每个循环中使用keySet()
|
||||
for (String key : testMap.keySet()) {
|
||||
testMap.get(key);
|
||||
}
|
||||
3)使用enrtySet()和迭代器
|
||||
Iterator<Map.Entry<String,Integer>> itr1 = testMap.entrySet().iterator();
|
||||
while(itr1.hasNext())
|
||||
{
|
||||
Map.Entry<String,Integer> entry = itr1.next();
|
||||
entry.getKey();
|
||||
entry.getValue();
|
||||
}
|
||||
4)使用keySet()和迭代器
|
||||
Iterator itr2 = testMap.keySet().iterator();
|
||||
while(itr2.hasNext())
|
||||
{
|
||||
String key = itr2.next();
|
||||
testMap.get(key);
|
||||
}
|
||||
```
|
||||
|
||||
## 2 LinkedHashMap
|
||||
|
||||
### 底层原理
|
||||
|
||||
LinkedHashMap 可以看作是 `HashMap` 和 `LinkedList` 的结合:它在 HashMap 的基础上添加了一条双向链表,`默认`存储各个元素的插入顺序,但由于这条双向链表,使得 LinkedHashMap 可以实现 `LRU`缓存淘汰策略,因为我们可以设置这条双向链表按照`元素的访问次序`进行排序
|
||||
|
||||

|
||||
|
||||
LinkedHashMap 是 HashMap 的子类,所以它具备 HashMap 的所有特点,其次,它在 HashMap 的基础上维护了一条`双向链表`,该链表存储了**所有元素**,`默认`元素的顺序与插入顺序**一致**。若`accessOrder`属性为`true`,则遍历顺序按元素的访问次序进行排序。
|
||||
|
||||
```java
|
||||
// 头节点
|
||||
transient LinkedHashMap.Entry<K, V> head;
|
||||
// 尾结点
|
||||
transient LinkedHashMap.Entry<K, V> tail;
|
||||
```
|
||||
|
||||
利用 LinkedHashMap 可以实现 `LRU` 缓存淘汰策略,因为它提供了一个方法:
|
||||
|
||||
```java
|
||||
protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) {
|
||||
return false;
|
||||
}
|
||||
```
|
||||
|
||||
该方法可以移除`最靠近链表头部`的一个节点,而在`get()`方法中可以看到下面这段代码,其作用是挪动结点的位置:
|
||||
|
||||
```java
|
||||
if (this.accessOrder) {
|
||||
this.afterNodeAccess(e);
|
||||
}
|
||||
```
|
||||
|
||||
只要调用了`get()`且`accessOrder = true`,则会将该节点更新到链表`尾部`,具体的逻辑在`afterNodeAccess()`中,感兴趣的可翻看源码,篇幅原因这里不再展开。
|
||||
|
||||
现在如果要实现一个`LRU`缓存策略,则需要做两件事情:
|
||||
|
||||
- 指定`accessOrder = true`可以设定链表按照访问顺序排列,通过提供的构造器可以设定`accessOrder`
|
||||
|
||||
```java
|
||||
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
|
||||
super(initialCapacity, loadFactor);
|
||||
this.accessOrder = accessOrder;
|
||||
}
|
||||
```
|
||||
|
||||
- 重写`removeEldestEntry()`方法,内部定义逻辑,通常是判断`容量`是否达到上限,若是则执行淘汰。
|
||||
|
||||
这里就要贴出一道大厂面试必考题目:[146. LRU缓存机制](https://leetcode-cn.com/problems/lru-cache/),只要跟着我的步骤,就能顺利完成这道大厂题了。
|
||||
|
||||
关于 LinkedHashMap 主要介绍两点:
|
||||
|
||||
1. 它底层维护了一条`双向链表`,因为继承了 HashMap,所以它也不是线程安全的
|
||||
2. LinkedHashMap 可实现`LRU`缓存淘汰策略,其原理是通过设置`accessOrder`为`true`并重写`removeEldestEntry`方法定义淘汰元素时需满足的条件
|
||||
|
||||
## 3 TreeMap
|
||||
|
||||
### 底层原理
|
||||
TreeMap 是 `SortedMap` 的子类,所以它具有**排序**功能。它是基于`红黑树`数据结构实现的,每一个键值对`<key, value>`都是一个结点,默认情况下按照`key`自然排序,另一种是可以通过传入定制的`Comparator`进行自定义规则排序。
|
||||
|
||||
```java
|
||||
// 按照 key 自然排序,Integer 的自然排序是升序
|
||||
TreeMap<Integer, Object> naturalSort = new TreeMap<>();
|
||||
// 定制排序,按照 key 降序排序
|
||||
TreeMap<Integer, Object> customSort = new TreeMap<>((o1, o2) -> Integer.compare(o2, o1));
|
||||
```
|
||||
|
||||
TreeMap 底层使用了数组+红黑树实现,所以里面的存储结构可以理解成下面这幅图哦。
|
||||
|
||||
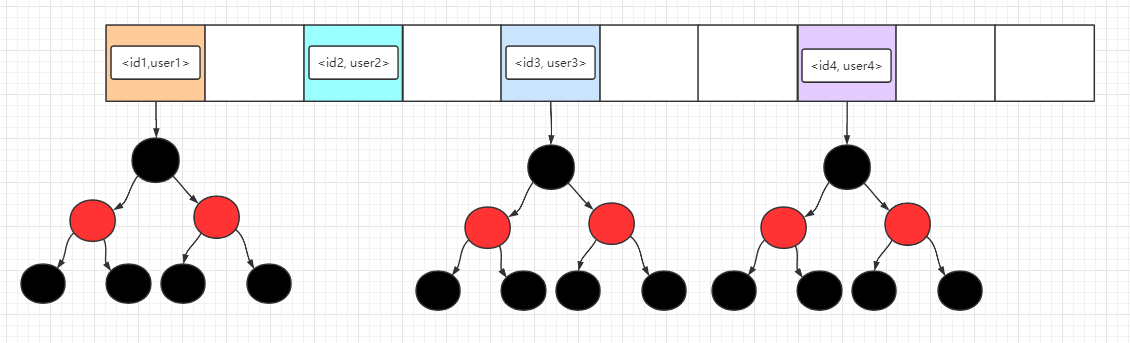
|
||||
|
||||
图中红黑树的每一个节点都是一个`Entry`,在这里为了图片的简洁性,就不标明 key 和 value 了,注意这些元素都是已经按照`key`排好序了,整个数据结构都是保持着`有序` 的状态!
|
||||
|
||||
关于`自然`排序与`定制`排序:
|
||||
|
||||
- 自然排序:要求`key`必须实现`Comparable`接口。
|
||||
|
||||
由于`Integer`类实现了 Comparable 接口,按照自然排序规则是按照`key`从小到大排序。
|
||||
|
||||
```java
|
||||
TreeMap<Integer, String> treeMap = new TreeMap<>();
|
||||
treeMap.put(2, "TWO");
|
||||
treeMap.put(1, "ONE");
|
||||
System.out.print(treeMap);
|
||||
// {1=ONE, 2=TWO}
|
||||
```
|
||||
|
||||
- 定制排序:在初始化 TreeMap 时传入新的`Comparator`,**不**要求`key`实现 Comparable 接口
|
||||
|
||||
```java
|
||||
TreeMap<Integer, String> treeMap = new TreeMap<>((o1, o2) -> Integer.compare(o2, o1));
|
||||
treeMap.put(1, "ONE");
|
||||
treeMap.put(2, "TWO");
|
||||
treeMap.put(4, "FOUR");
|
||||
treeMap.put(3, "THREE");
|
||||
System.out.println(treeMap);
|
||||
// {4=FOUR, 3=THREE, 2=TWO, 1=ONE}
|
||||
```
|
||||
|
||||
通过传入新的`Comparator`比较器,可以覆盖默认的排序规则,上面的代码按照`key`降序排序,在实际应用中还可以按照其它规则自定义排序。
|
||||
|
||||
`compare()`方法的返回值有三种,分别是:`0`,`-1`,`+1`
|
||||
|
||||
(1)如果返回`0`,代表两个元素相等,不需要调换顺序
|
||||
|
||||
(2)如果返回`+1`,代表前面的元素需要与后面的元素调换位置
|
||||
|
||||
(3)如果返回`-1`,代表前面的元素不需要与后面的元素调换位置
|
||||
|
||||
而何时返回`+1`和`-1`,则由我们自己去定义,JDK默认是按照**自然排序**,而我们可以根据`key`的不同去定义降序还是升序排序。
|
||||
|
||||
关于 TreeMap 主要介绍了两点:
|
||||
|
||||
1. 它底层是由`红黑树`这种数据结构实现的,所以操作的时间复杂度恒为`O(logN)`
|
||||
2. TreeMap 可以对`key`进行自然排序或者自定义排序,自定义排序时需要传入`Comparator`,而自然排序要求`key`实现了`Comparable`接口
|
||||
3. TreeMap 不是线程安全的。它不synchronized 。 使用Collections.synchronizedSortedMap(new TreeMap())在并发环境中工作。
|
||||
4. 它不能具有null键,但可以具有多个null值。
|
||||
5. 它以排序顺序(自然顺序)或地图创建时提供的Comparator来存储键。
|
||||
6. 它为containsKey , get , put和remove操作提供了保证的log(n)时间成本。
|
||||
|
||||
### 主要方法
|
||||
|
||||
```java
|
||||
void clear():从地图中删除所有键/值对。
|
||||
void size():返回此映射中存在的键值对的数量。
|
||||
void isEmpty():如果此映射不包含键值映射,则返回true。
|
||||
boolean containsKey(Object key):如果地图中存在指定的键,则返回'true' 。
|
||||
boolean containsValue(Object key):如果将指定值映射到映射中的至少一个键,则返回'true' 。
|
||||
Object get(Object key):检索由指定key映射的值;如果此映射不包含key映射关系,则返回null。
|
||||
Object remove(Object key):如果存在,则从映射中删除指定键的键值对。
|
||||
Comparator comparator():它返回用于对该映射中的键进行排序的比较器;如果此映射使用其键的自然排序,则返回null。
|
||||
Object firstKey():返回树图中当前的第一个(最小)键。
|
||||
Object lastKey():返回树图中当前的最后一个(最大)键。
|
||||
Object ceilingKey(Object key):返回大于或等于给定键的最小键;如果没有这样的键,则返回null。
|
||||
Object higherKey(Object key):返回严格大于指定键的最小键。
|
||||
NavigableMap descendingMap():它返回此地图中包含的映射的reverse order view 。
|
||||
```
|
||||
|
||||
## 4 WeakHashMap
|
||||
|
||||
WeakHashMap 日常开发中比较少见,它是基于普通的`Map`实现的,而里面`Entry`中的键在每一次的`垃圾回收`都会被清除掉,所以非常适合用于**短暂访问、仅访问一次**的元素,缓存在`WeakHashMap`中,并尽早地把它回收掉。
|
||||
|
||||
当`Entry`被`GC`时,WeakHashMap 是如何感知到某个元素被回收的呢?
|
||||
|
||||
在 WeakHashMap 内部维护了一个引用队列`queue`
|
||||
|
||||
```java
|
||||
private final ReferenceQueue<Object> queue = new ReferenceQueue<>();
|
||||
```
|
||||
|
||||
这个 queue 里包含了所有被`GC`掉的键,当JVM开启`GC`后,如果回收掉 WeakHashMap 中的 key,会将 key 放入queue 中,在`expungeStaleEntries()`中遍历 queue,把 queue 中的所有`key`拿出来,并在 WeakHashMap 中删除掉,以达到**同步**。
|
||||
|
||||
```java
|
||||
private void expungeStaleEntries() {
|
||||
for (Object x; (x = queue.poll()) != null; ) {
|
||||
synchronized (queue) {
|
||||
// 去 WeakHashMap 中删除该键值对
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
再者,需要注意 WeakHashMap 底层存储的元素的数据结构是`数组 + 链表`,**没有红黑树**哦,可以换一个角度想,如果还有红黑树,那干脆直接继承 HashMap ,然后再扩展就完事了嘛,然而它并没有这样做:
|
||||
|
||||
```java
|
||||
public class WeakHashMap<K, V> extends AbstractMap<K, V> implements Map<K, V> {
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
所以,WeakHashMap 的数据结构图我也为你准备好啦。
|
||||
|
||||
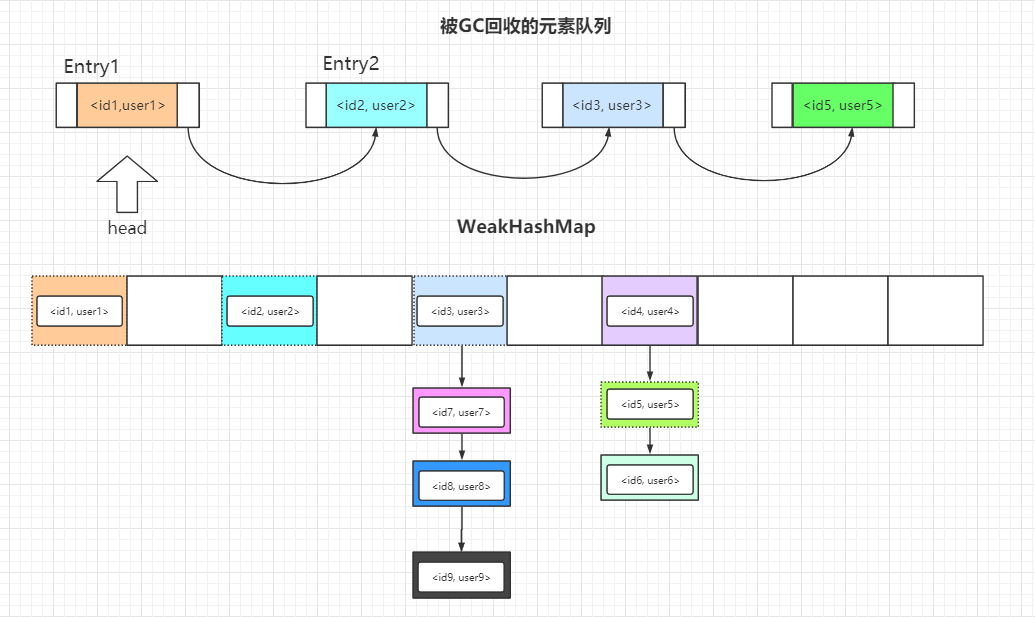
|
||||
|
||||
图中被虚线标识的元素将会在下一次访问 WeakHashMap 时被删除掉,WeakHashMap 内部会做好一系列的调整工作,所以记住队列的作用就是标志那些已经被`GC`回收掉的元素。
|
||||
|
||||
关于 WeakHashMap 需要注意两点:
|
||||
|
||||
1. 它的键是一种**弱键**,放入 WeakHashMap 时,随时会被回收掉,所以不能确保某次访问元素一定存在
|
||||
2. 它依赖普通的`Map`进行实现,是一个非线程安全的集合
|
||||
3. WeakHashMap 通常作为**缓存**使用,适合存储那些**只需访问一次**、或**只需保存短暂时间**的键值对
|
||||
|
||||
## 5 Hashtable
|
||||
### 底层原理
|
||||
Hashtable 底层的存储结构是`数组 + 链表`,而它是一个**线程安全**的集合,但是因为这个线程安全,它就被淘汰掉了。
|
||||
|
||||
下面是Hashtable存储元素时的数据结构图,它只会存在数组+链表,当链表过长时,查询的效率过低,而且会长时间**锁住** Hashtable。
|
||||
|
||||

|
||||
|
||||
> 本质上就是 WeakHashMap 的底层存储结构了。你千万别问为什么 WeakHashMap 不继承 Hashtable 哦,Hashtable 的`性能`在并发环境下非常差,在非并发环境下可以用`HashMap`更优。
|
||||
|
||||
HashTable 本质上是 HashMap 的前辈,它被淘汰的原因也主要因为两个字:**性能**
|
||||
|
||||
HashTable 是一个 **线程安全** 的 Map,它所有的方法都被加上了 **synchronized** 关键字,也是因为这个关键字,它注定成为了时代的弃儿。
|
||||
|
||||
HashTable 底层采用 **数组+链表** 存储键值对,由于被弃用,后人也没有对它进行任何改进
|
||||
|
||||
HashTable 默认长度为 `11`,负载因子为 `0.75F`,即元素个数达到数组长度的 75% 时,会进行一次扩容,每次扩容为原来数组长度的 `2` 倍
|
||||
|
||||
HashTable 所有的操作都是线程安全的。
|
||||
|
||||
### 方法
|
||||
跟hashtable一样
|
||||
|
||||
## 6 ConcurrentHashMap
|
||||
|
||||
### 底层原理
|
||||
oncurrentHashMap通过设计支持并发访问其键值对。
|
||||
|
||||
|
||||
|
||||
### 使用方法
|
||||
|
||||
创建和读写
|
||||
```java
|
||||
import java.util.Iterator;
|
||||
import java.util.concurrent.ConcurrentHashMap;
|
||||
|
||||
public class HashMapExample
|
||||
{
|
||||
public static void main(String[] args) throws CloneNotSupportedException
|
||||
{
|
||||
ConcurrentHashMap<Integer, String> concurrHashMap = new ConcurrentHashMap<>();
|
||||
|
||||
//Put require no synchronization
|
||||
concurrHashMap.put(1, "A");
|
||||
concurrHashMap.put(2, "B");
|
||||
|
||||
//Get require no synchronization
|
||||
concurrHashMap.get(1);
|
||||
|
||||
Iterator<Integer> itr = concurrHashMap.keySet().iterator();
|
||||
|
||||
//Using synchronized block is advisable
|
||||
synchronized (concurrHashMap)
|
||||
{
|
||||
while(itr.hasNext()) {
|
||||
System.out.println(concurrHashMap.get(itr.next()));
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
使用Collection.synchronizedMap也有同样的方法
|
||||
|
||||
```java
|
||||
import java.util.Collections;
|
||||
import java.util.HashMap;
|
||||
import java.util.Iterator;
|
||||
import java.util.Map;
|
||||
|
||||
public class HashMapExample
|
||||
{
|
||||
public static void main(String[] args) throws CloneNotSupportedException
|
||||
{
|
||||
Map<Integer, String> syncHashMap = Collections.synchronizedMap(new HashMap<>());
|
||||
|
||||
//Put require no synchronization
|
||||
syncHashMap.put(1, "A");
|
||||
syncHashMap.put(2, "B");
|
||||
|
||||
//Get require no synchronization
|
||||
syncHashMap.get(1);
|
||||
|
||||
Iterator<Integer> itr = syncHashMap.keySet().iterator();
|
||||
|
||||
//Using synchronized block is advisable
|
||||
synchronized (syncHashMap)
|
||||
{
|
||||
while(itr.hasNext()) {
|
||||
System.out.println(syncHashMap.get(itr.next()));
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
175
Java基础教程/Java集合类/07 Iterable&Ieterator.md
Normal file
@@ -0,0 +1,175 @@
|
||||
# Iterator Iterable ListIterator
|
||||
|
||||
## 1 Iterator
|
||||
所有Java集合类都提供iterator()方法,该方法返回Iterator的实例以遍历该集合中的元素。
|
||||
|
||||
```java
|
||||
public interface Iterator<E> {
|
||||
boolean hasNext();
|
||||
E next();
|
||||
void remove();
|
||||
}
|
||||
```
|
||||
|
||||
提供的API接口含义如下:
|
||||
|
||||
- `hasNext()`:判断集合中是否存在下一个对象
|
||||
- `next()`:返回集合中的下一个对象,并将访问指针移动一位
|
||||
- `remove()`:删除集合中调用`next()`方法返回的对象.每次调用next()只能调用一次此方法。
|
||||
|
||||
在早期,遍历集合的方式只有一种,通过`Iterator`迭代器操作
|
||||
|
||||
```java
|
||||
List<Integer> list = new ArrayList<>();
|
||||
list.add(1);
|
||||
list.add(2);
|
||||
list.add(3);
|
||||
Iterator iter = list.iterator();
|
||||
while (iter.hasNext()) {
|
||||
Integer next = iter.next();
|
||||
System.out.println(next);
|
||||
if (next == 2) { iter.remove(); }
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
## 2 `Iterable`
|
||||
|
||||
```java
|
||||
public interface Iterable<T> {
|
||||
Iterator<T> iterator();
|
||||
// JDK 1.8
|
||||
default void forEach(Consumer<? super T> action) {
|
||||
Objects.requireNonNull(action);
|
||||
for (T t : this) {
|
||||
action.accept(t);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
可以看到`Iterable`接口里面提供了`Iterator`接口,所以实现了`Iterable`接口的集合依旧可以使用`迭代器`遍历和操作集合中的对象;
|
||||
|
||||
而在 `JDK 1.8`中,`Iterable`提供了一个新的方法`forEach()`,它允许使用增强 for 循环遍历对象。
|
||||
|
||||
```java
|
||||
List<Integer> list = new ArrayList<>();
|
||||
for (Integer num : list) {
|
||||
System.out.println(num);
|
||||
}
|
||||
```
|
||||
|
||||
我们通过命令:`javap -c`反编译上面的这段代码后,发现它只是 Java 中的一个`语法糖`,本质上还是调用`Iterator`去遍历。
|
||||
|
||||

|
||||
|
||||
翻译成代码,就和一开始的`Iterator`迭代器遍历方式基本相同了。
|
||||
|
||||
```java
|
||||
Iterator iter = list.iterator();
|
||||
while (iter.hasNext()) {
|
||||
Integer num = iter.next();
|
||||
System.out.println(num);
|
||||
}
|
||||
```
|
||||
|
||||
> 还有更深层次的探讨:为什么要设计两个接口`Iterable`和`Iterator`,而不是保留其中一个就可以了。
|
||||
>
|
||||
> 简单讲解:`Iterator`的保留可以让子类去**实现自己的迭代器**,而`Iterable`接口更加关注于`for-each`的增强语法。具体可参考:[Java中的Iterable与Iterator详解](https://www.cnblogs.com/litexy/p/9744241.html)
|
||||
|
||||
## 3 Iterator 和Iterable
|
||||
|
||||
关于`Iterator`和`Iterable`的讲解告一段落,下面来总结一下它们的重点:
|
||||
|
||||
1. `Iterator`是提供集合操作内部对象的一个迭代器,它可以**遍历、移除**对象,且只能够**单向移动**
|
||||
2. `Iterable`是对`Iterator`的封装,在`JDK 1.8`时,实现了`Iterable`接口的集合可以使用**增强 for 循环**遍历集合对象,我们通过**反编译**后发现底层还是使用`Iterator`迭代器进行遍历
|
||||
|
||||
等等,这一章还没完,还有一个`ListIterator`。它继承 Iterator 接口,在遍历`List`集合时可以从**任意索引下标**开始遍历,而且支持**双向遍历**。
|
||||
|
||||
ListIterator 存在于 List 集合之中,通过调用方法可以返回**起始下标**为 `index`的迭代器
|
||||
|
||||
```java
|
||||
List<Integer> list = new ArrayList<>();
|
||||
// 返回下标为0的迭代器
|
||||
ListIterator<Integer> listIter1 = list.listIterator();
|
||||
// 返回下标为5的迭代器
|
||||
ListIterator<Integer> listIter2 = list.listIterator(5);
|
||||
```
|
||||
|
||||
ListIterator 中有几个重要方法,大多数方法与 Iterator 中定义的含义相同,但是比 Iterator 强大的地方是可以在**任意一个下标位置**返回该迭代器,且可以实现**双向遍历**。
|
||||
|
||||
```java
|
||||
public interface ListIterator<E> extends Iterator<E> {
|
||||
boolean hasNext();
|
||||
E next();
|
||||
boolean hasPrevious();
|
||||
E previous();
|
||||
int nextIndex();
|
||||
int previousIndex();
|
||||
void remove();
|
||||
// 替换当前下标的元素,即访问过的最后一个元素
|
||||
void set(E e);
|
||||
void add(E e);
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## 4 ListIterator
|
||||
### 简介
|
||||
* ListIterator支持在元素列表上的所有CRUD操作(CREATE,READ,UPDATE和DELETE)。
|
||||
* 与Iterator不同,ListIterator是bi-directional 。 它支持正向和反向迭代。
|
||||
* 它没有当前元素; 它的光标位置始终位于通过调用previous()返回的元素和通过调用next()返回的元素之间。
|
||||
|
||||
### 实例
|
||||
|
||||
```java
|
||||
ArrayList<String> list = new ArrayList<>();
|
||||
|
||||
list.add("A");
|
||||
list.add("B");
|
||||
list.add("C");
|
||||
list.add("D");
|
||||
list.add("E");
|
||||
list.add("F");
|
||||
|
||||
ListIterator<String> listIterator = list.listIterator();
|
||||
|
||||
System.out.println("Forward iteration");
|
||||
|
||||
//Forward iterator
|
||||
while(listIterator.hasNext()) {
|
||||
System.out.print(listIterator.next() + ",");
|
||||
}
|
||||
|
||||
System.out.println("Backward iteration");
|
||||
|
||||
//Backward iterator
|
||||
while(listIterator.hasPrevious()) {
|
||||
System.out.print(listIterator.previous() + ",");
|
||||
}
|
||||
|
||||
System.out.println("Iteration from specified position");
|
||||
|
||||
//Start iterating from index 2
|
||||
listIterator = list.listIterator(2);
|
||||
|
||||
while(listIterator.hasNext()) {
|
||||
System.out.print(listIterator.next() + ",");
|
||||
```
|
||||
|
||||
|
||||
### 主要方法
|
||||
|
||||
```java
|
||||
void add(Object o) :将指定的元素插入列表(可选操作)。
|
||||
boolean hasNext() :如果在向前遍历列表时此列表迭代器包含更多元素,则返回true 。
|
||||
boolean hasPrevious() :如果在反向遍历列表时此列表迭代器包含更多元素,则返回true 。
|
||||
Object next() :返回列表中的下一个元素并前进光标位置。
|
||||
int nextIndex() :返回元素的索引,该元素的索引将由对next()的后续调用返回。
|
||||
Object previous() :返回列表中的上一个元素,并将光标位置向后移动。
|
||||
int previousIndex() :返回元素的索引,该元素的索引将由对next()的后续调用返回。
|
||||
void remove() :从列表中移除next()或previous()返回的最后一个元素(可选操作)。
|
||||
void set(Object o) :将next()或previous()返回的最后一个元素替换为指定的元素(可选操作)。
|
||||
```
|
||||
186
Java基础教程/Java集合类/08 Comparable&Comparator.md
Normal file
@@ -0,0 +1,186 @@
|
||||
|
||||
## Comparable
|
||||
|
||||
### 概述
|
||||
Java Comparable接口,用于根据对象的natural order对array或对象list进行natural order 。 元素的自然排序是通过在对象中实现其compareTo()方法来实现的。
|
||||
```java
|
||||
public interface Comparable<T>
|
||||
{
|
||||
public int compareTo(T o);
|
||||
}
|
||||
```
|
||||
|
||||
### 使用
|
||||
```java
|
||||
import java.time.LocalDate;
|
||||
|
||||
public class Employee implements Comparable<Employee> {
|
||||
|
||||
private Long id;
|
||||
private String name;
|
||||
private LocalDate dob;
|
||||
|
||||
@Override
|
||||
public int compareTo(Employee o)
|
||||
{
|
||||
return this.getId().compareTo( o.getId() );
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
* 使用Collections.sort()方法对对象list进行排序。
|
||||
* 使用Arrays.sort()方法对对象array进行排序。
|
||||
* Collections.reverseOrder()
|
||||
|
||||
|
||||
## 2 Comparator比较器
|
||||
|
||||
我们还是先研究这个方法
|
||||
|
||||
`public static <T> void sort(List<T> list)`:将集合中元素按照默认规则排序。
|
||||
|
||||
不过这次存储的是字符串类型。
|
||||
|
||||
```java
|
||||
public class CollectionsDemo2 {
|
||||
public static void main(String[] args) {
|
||||
ArrayList<String> list = new ArrayList<String>();
|
||||
list.add("cba");
|
||||
list.add("aba");
|
||||
list.add("sba");
|
||||
list.add("nba");
|
||||
//排序方法
|
||||
Collections.sort(list);
|
||||
System.out.println(list);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
结果:
|
||||
|
||||
```
|
||||
[aba, cba, nba, sba]
|
||||
```
|
||||
|
||||
|
||||
* 使用Collections.sort(list, Comparator)方法按提供的比较器实例施加的顺序对对象list进行排序。
|
||||
* 使用Arrays.sort(array, Comparator)方法按提供的比较器实例施加的顺序对对象array进行排序。
|
||||
|
||||
### Comparator.compare()
|
||||
|
||||
* ` public int compare(String o1, String o2)`:比较其两个参数的顺序。
|
||||
|
||||
> 两个对象比较的结果有三种:大于,等于,小于。
|
||||
>
|
||||
> 如果要按照升序排序,
|
||||
> 则o1 小于o2,返回(负数),相等返回0,01大于02返回(正数)
|
||||
> 如果要按照降序排序
|
||||
> 则o1 小于o2,返回(正数),相等返回0,01大于02返回(负数)
|
||||
|
||||
操作如下:
|
||||
|
||||
```java
|
||||
public class CollectionsDemo3 {
|
||||
public static void main(String[] args) {
|
||||
ArrayList<String> list = new ArrayList<String>();
|
||||
list.add("cba");
|
||||
list.add("aba");
|
||||
list.add("sba");
|
||||
list.add("nba");
|
||||
//排序方法 按照第一个单词的降序
|
||||
Collections.sort(list, new Comparator<String>() {
|
||||
@Override
|
||||
public int compare(String o1, String o2) {
|
||||
return o2.charAt(0) - o1.charAt(0);
|
||||
}
|
||||
});
|
||||
System.out.println(list);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
结果如下:
|
||||
|
||||
```
|
||||
[sba, nba, cba, aba]
|
||||
```
|
||||
|
||||
### Collections.comparing()
|
||||
该实用程序方法接受一个为类提取排序键的函数。 本质上,这是一个将对类对象进行排序的字段。
|
||||
|
||||
```java
|
||||
//Order by name
|
||||
Comparator.comparing(Employee::getName);
|
||||
|
||||
//Order by name in reverse order
|
||||
Comparator.comparing(Employee::getName).reversed();
|
||||
|
||||
//Order by id field
|
||||
Comparator.comparing(Employee::getId);
|
||||
|
||||
//Order by employee age
|
||||
Comparator.comparing(Employee::getDate);
|
||||
|
||||
ArrayList<Employee> list = new ArrayList<>();
|
||||
|
||||
list.add(new Employee(22l, "Lokesh", LocalDate.now()));
|
||||
list.add(new Employee(30l, "Bob", LocalDate.now()));
|
||||
list.add(new Employee(18l, "Alex", LocalDate.now()));
|
||||
list.add(new Employee(5l, "David", LocalDate.now()));
|
||||
list.add(new Employee(600l, "Charles", LocalDate.now()));
|
||||
|
||||
Collections.sort(list, Comparator.comparing( Employee::getName ).reversed());
|
||||
|
||||
System.out.println(list);
|
||||
```
|
||||
|
||||
### Collections.thenComparing()
|
||||
此实用程序方法用于group by sort 。
|
||||
|
||||
```java
|
||||
//Order by name and then by age
|
||||
Comparator.comparing(Employee::getName)
|
||||
.thenComparing(Employee::getDob);
|
||||
|
||||
//Order by name -> date of birth -> id
|
||||
Comparator.comparing(Employee::getName)
|
||||
.thenComparing(Employee::getDob)
|
||||
.thenComparing(Employee::getId);
|
||||
|
||||
ArrayList<Employee> list = new ArrayList<>();
|
||||
|
||||
list.add(new Employee(22l, "Lokesh", LocalDate.now()));
|
||||
list.add(new Employee(30l, "Lokesh", LocalDate.now()));
|
||||
list.add(new Employee(18l, "Alex", LocalDate.now()));
|
||||
list.add(new Employee(5l, "Lokesh", LocalDate.now()));
|
||||
list.add(new Employee(600l, "Charles", LocalDate.now()));
|
||||
|
||||
Comparator<Employee> groupByComparator = Comparator.comparing(Employee::getName)
|
||||
.thenComparing(Employee::getDob)
|
||||
.thenComparing(Employee::getId);
|
||||
|
||||
Collections.sort(list, groupByComparator);
|
||||
|
||||
System.out.println(list);
|
||||
|
||||
```
|
||||
### Collections.reverseOrder()
|
||||
此实用程序方法返回一个比较器,该比较器对实现Comparable接口的对象集合强加natural ordering或total ordering的逆序。
|
||||
|
||||
```java
|
||||
//Reverse of natural order as specified in
|
||||
//Comparable interface's compareTo() method
|
||||
|
||||
Comparator.reversed();
|
||||
|
||||
//Reverse of order by name
|
||||
|
||||
Comparator.comparing(Employee::getName).reversed();
|
||||
|
||||
```
|
||||
|
||||
## 3 简述Comparable和Comparator两个接口的区别
|
||||
|
||||
**Comparable**:强行对实现它的每个类的对象进行整体排序。这种排序被称为类的自然排序,类的compareTo方法被称为它的自然比较方法。只能在类中实现compareTo()一次,不能经常修改类的代码实现自己想要的排序。实现此接口的对象列表(和数组)可以通过Collections.sort(和Arrays.sort)进行自动排序,对象可以用作有序映射中的键或有序集合中的元素,无需指定比较器。
|
||||
|
||||
**Comparator**:强行对某个对象进行整体排序。可以将Comparator 传递给sort方法(如Collections.sort或 Arrays.sort),从而允许在排序顺序上实现精确控制。还可以使用Comparator来控制某些数据结构(如有序set或有序映射)的顺序,或者为那些没有自然顺序的对象collection提供排序。
|
||||
159
Java基础教程/Java集合类/09 Sort.md
Normal file
@@ -0,0 +1,159 @@
|
||||
## 1 数组排序Arrays.sort
|
||||
Java程序使用Arrays.sort()方法升序排序
|
||||
```java
|
||||
import java.util.Arrays;
|
||||
|
||||
public class JavaSortExample
|
||||
{
|
||||
public static void main(String[] args)
|
||||
{
|
||||
//Unsorted array
|
||||
Integer[] numbers = new Integer[] { 15, 11, 9, 55, 47, 18, 520, 1123, 366, 420 };
|
||||
|
||||
//Sort the array
|
||||
Arrays.sort(numbers);
|
||||
|
||||
//Print array to confirm
|
||||
System.out.println(Arrays.toString(numbers));
|
||||
}
|
||||
}
|
||||
```
|
||||
### 逆序
|
||||
|
||||
```java
|
||||
Integer[] numbers = new Integer[] { 15, 11, 9, 55, 47, 18, 520, 1123, 366, 420 };
|
||||
|
||||
//Sort the array in reverse order
|
||||
Arrays.sort(numbers, Collections.reverseOrder());
|
||||
|
||||
//Print array to confirm
|
||||
System.out.println(Arrays.toString(numbers));
|
||||
```
|
||||
|
||||
### 部分排序
|
||||
|
||||
```java
|
||||
//Unsorted array
|
||||
Integer[] numbers = new Integer[] { 15, 11, 9, 55, 47, 18, 1123, 520, 366, 420 };
|
||||
|
||||
//Sort the array
|
||||
Arrays.sort(numbers, 2, 6);
|
||||
|
||||
//Print array to confirm
|
||||
System.out.println(Arrays.toString(numbers));
|
||||
```
|
||||
|
||||
### 并发排序
|
||||
|
||||
它将数组分解为不同的子数组,并且每个子数组在different threads使用Arrays.sort()进行排序。 最终,所有排序的子数组将合并为一个数组。
|
||||
|
||||
```java
|
||||
Arrays.parallelSort(numbers);
|
||||
|
||||
Arrays.parallelSort(numbers, 2, 6);
|
||||
|
||||
Arrays.parallelSort(numbers, Collections.reverseOrder());
|
||||
```
|
||||
|
||||
|
||||
> 不支持集合排序。转换为列表,然后排序,然后转换为集合。
|
||||
> 不支持map排序。获取keyset,然后排序访问。
|
||||
> 但是treeSet和TreeMap本身都是排序好的。
|
||||
|
||||
## 2 字符串排序方法
|
||||
|
||||
### Stream API
|
||||
使用Stream.sorted() API对字符串的字符进行排序的示例。
|
||||
|
||||
```java
|
||||
String randomString = "adcbgekhs";
|
||||
|
||||
String sortedChars = Stream.of( randomString.split("") )
|
||||
.sorted()
|
||||
.collect(Collectors.joining());
|
||||
|
||||
System.out.println(sortedChars); // abcdeghks
|
||||
```
|
||||
|
||||
### Arrays.sort()
|
||||
使用Arrays.sort()方法对字符串排序的示例。
|
||||
|
||||
```java
|
||||
String randomString = "adcbgekhs";
|
||||
|
||||
//Convert string to char array
|
||||
char[] chars = randomString.toCharArray();
|
||||
|
||||
//Sort char array
|
||||
Arrays.sort(chars);
|
||||
|
||||
//Convert char array to string
|
||||
String sortedString = String.valueOf(chars);
|
||||
|
||||
System.out.println(sortedChars); // abcdeghks
|
||||
```
|
||||
|
||||
|
||||
## 3 ArraysList排序
|
||||
|
||||
### 自带的sort方法
|
||||
|
||||
```java
|
||||
//Unsorted list
|
||||
List<String> names = Arrays.asList("Alex", "Charles", "Brian", "David");
|
||||
|
||||
//1. Natural order
|
||||
names.sort( Comparator.comparing( String::toString ) );
|
||||
|
||||
System.out.println(names);
|
||||
|
||||
//2. Reverse order
|
||||
names.sort( Comparator.comparing( String::toString ).reversed() );
|
||||
|
||||
System.out.println(names);
|
||||
```
|
||||
|
||||
### Collections.sort
|
||||
|
||||
```java
|
||||
//Unsorted list
|
||||
List<String> names = Arrays.asList("Alex", "Charles", "Brian", "David");
|
||||
|
||||
//1. Natural order
|
||||
Collections.sort(names);
|
||||
|
||||
System.out.println(names);
|
||||
|
||||
//2. Reverse order
|
||||
Collections.sort(names, Collections.reverseOrder());
|
||||
|
||||
System.out.println(names);
|
||||
```
|
||||
|
||||
### Stream
|
||||
|
||||
```java
|
||||
//Unsorted list
|
||||
List<String> names = Arrays.asList("Alex", "Charles", "Brian", "David");
|
||||
|
||||
//1. Natural order
|
||||
List<String> sortedNames = names
|
||||
.stream()
|
||||
.sorted(Comparator.comparing(String::toString))
|
||||
.collect(Collectors.toList());
|
||||
|
||||
System.out.println(sortedNames);
|
||||
|
||||
//2. Reverse order
|
||||
List<String> reverseSortedNames = names
|
||||
.stream()
|
||||
.sorted(Comparator.comparing(String::toString).reversed())
|
||||
.collect(Collectors.toList());
|
||||
|
||||
System.out.println(reverseSortedNames);
|
||||
```
|
||||
|
||||
## 4 ObjectSort
|
||||
|
||||
将Comparable&Comparator
|
||||
|
||||
771
Java基础教程/Java集合类/09 Stream.md
Normal file
@@ -0,0 +1,771 @@
|
||||
# Java 8 数据流教程
|
||||
|
||||
|
||||
## 1 数据流原理
|
||||
### 基本原理
|
||||
|
||||
> 数据流和输入输出流不同
|
||||
这个示例驱动的教程是Java8**数据流**(Stream)的深入总结。当我第一次看到`Stream`API时,我非常疑惑,因为它听起来和Java IO的`InputStream` 和 `OutputStream`一样。但是Java8的数据流是完全不同的东西。
|
||||
|
||||
|
||||
> 在函数式编程中,单体是一个结构,表示定义为步骤序列的计算。单体结构的类型定义了它对链式操作,或具有相同类型的嵌套函数的含义。
|
||||
|
||||
### 数据流的链式操作
|
||||
数据流表示元素的序列,并支持不同种类的操作来执行元素上的计算:
|
||||
|
||||
```java
|
||||
List<String> myList =
|
||||
Arrays.asList("a1", "a2", "b1", "c2", "c1");
|
||||
|
||||
myList
|
||||
.stream()
|
||||
.filter(s -> s.startsWith("c"))
|
||||
.map(String::toUpperCase)
|
||||
.sorted()
|
||||
.forEach(System.out::println);
|
||||
```
|
||||
* 这种数据流的链式操作也叫作操作流水线。
|
||||
* 多数数据流操作都接受一些lambda表达式参数,函数式接口用来指定操作的具体行为。这些操作的大多数必须是无干扰而且是无状态的。
|
||||
* 当一个函数不修改数据流的底层数据源,它就是**无干扰的**。例如,在上面的例子中,没有任何lambda表达式通过添加或删除集合元素修改`myList`。
|
||||
* 当一个函数的操作的执行是确定性的,它就是**无状态的**。例如,在上面的例子中,没有任何lambda表达式依赖于外部作用域中任何在操作过程中可变的变量或状态。
|
||||
|
||||
## 2 数据流的不同类型
|
||||
数据流可以从多种数据源创建,
|
||||
### 从集合创建
|
||||
`List`和`Set`支持新方法`stream()` 和 `parallelStream()`,来创建串行流或并行流。并行流能够在多个线程上执行操作。我们现在来看看串行流:
|
||||
|
||||
```java
|
||||
Arrays.asList("a1", "a2", "a3")
|
||||
.stream()
|
||||
.findFirst()
|
||||
.ifPresent(System.out::println); // a1
|
||||
```
|
||||
|
||||
### Stream类创建
|
||||
在对象列表上调用`stream()`方法会返回一个通常的对象流。但是我们不需要创建一个集合来创建数据流,就像下面那样:
|
||||
|
||||
```java
|
||||
Stream.of("a1", "a2", "a3")
|
||||
.findFirst()
|
||||
.ifPresent(System.out::println); // a1
|
||||
```
|
||||
|
||||
只要使用`Stream.of()`,就可以从一系列对象引用中创建数据流。
|
||||
|
||||
### 基本数据流
|
||||
Java8还自带了特殊种类的流,用于处理基本数据类型`int`、`long` 和 `double`。`IntStream`、`LongStream` 和 `DoubleStream`。
|
||||
|
||||
`IntStream`可以使用`IntStream.range()`替换通常的`for`循环:
|
||||
|
||||
```java
|
||||
IntStream.range(1, 4)
|
||||
.forEach(System.out::println);
|
||||
// 1
|
||||
// 2
|
||||
// 3
|
||||
```
|
||||
|
||||
所有这些基本数据流都像通常的对象数据流一样,但有一些不同。基本的数据流使用特殊的lambda表达式,例如,`IntFunction`而不是`Function`,`IntPredicate`而不是`Predicate`。而且基本数据流支持额外的聚合终止操作`sum()`和`average()`:
|
||||
|
||||
```java
|
||||
Arrays.stream(new int[] {1, 2, 3})
|
||||
.map(n -> 2 * n + 1)
|
||||
.average()
|
||||
.ifPresent(System.out::println); // 5.0
|
||||
```
|
||||
|
||||
有时需要将通常的对象数据流转换为基本数据流,或者相反。出于这种目的,对象数据流支持特殊的映射操作`mapToInt()`、`mapToLong()` 和 `mapToDouble()`:
|
||||
|
||||
```java
|
||||
Stream.of("a1", "a2", "a3")
|
||||
.map(s -> s.substring(1))
|
||||
.mapToInt(Integer::parseInt)
|
||||
.max()
|
||||
.ifPresent(System.out::println); // 3
|
||||
```
|
||||
|
||||
基本数据流可以通过`mapToObj()`转换为对象数据流:
|
||||
|
||||
```java
|
||||
IntStream.range(1, 4)
|
||||
.mapToObj(i -> "a" + i)
|
||||
.forEach(System.out::println);
|
||||
|
||||
// a1
|
||||
// a2
|
||||
// a3
|
||||
```
|
||||
|
||||
下面是组合示例:浮点数据流首先映射为整数数据流,之后映射为字符串的对象数据流:
|
||||
|
||||
```java
|
||||
Stream.of(1.0, 2.0, 3.0)
|
||||
.mapToInt(Double::intValue)
|
||||
.mapToObj(i -> "a" + i)
|
||||
.forEach(System.out::println);
|
||||
|
||||
// a1
|
||||
// a2
|
||||
// a3
|
||||
```
|
||||
|
||||
## 3 处理顺序
|
||||
|
||||
### 衔接操作和终止操作
|
||||
衔接操作的一个重要特性就是延迟性。观察下面没有终止操作的例子:
|
||||
|
||||
```java
|
||||
Stream.of("d2", "a2", "b1", "b3", "c")
|
||||
.filter(s -> {
|
||||
System.out.println("filter: " + s);
|
||||
return true;
|
||||
});
|
||||
```
|
||||
|
||||
执行这段代码时,不向控制台打印任何东西。这是因为衔接操作只在终止操作调用时被执行。
|
||||
|
||||
### 垂直执行
|
||||
让我们通过添加终止操作`forEach`来扩展这个例子:
|
||||
|
||||
```java
|
||||
Stream.of("d2", "a2", "b1", "b3", "c")
|
||||
.filter(s -> {
|
||||
System.out.println("filter: " + s);
|
||||
return true;
|
||||
})
|
||||
.forEach(s -> System.out.println("forEach: " + s));
|
||||
```
|
||||
|
||||
执行这段代码会得到如下输出:
|
||||
|
||||
```
|
||||
filter: d2
|
||||
forEach: d2
|
||||
filter: a2
|
||||
forEach: a2
|
||||
filter: b1
|
||||
forEach: b1
|
||||
filter: b3
|
||||
forEach: b3
|
||||
filter: c
|
||||
forEach: c
|
||||
```
|
||||
|
||||
结果的顺序可能出人意料。原始的方法会在数据流的所有元素上,一个接一个地水平执行所有操作。但是每个元素在调用链上垂直移动。第一个字符串`"d2"`首先经过`filter`然后是`forEach`,执行完后才开始处理第二个字符串`"a2"`。
|
||||
|
||||
这种行为可以减少每个元素上所执行的实际操作数量,就像我们在下个例子中看到的那样:
|
||||
|
||||
```java
|
||||
Stream.of("d2", "a2", "b1", "b3", "c")
|
||||
.map(s -> {
|
||||
System.out.println("map: " + s);
|
||||
return s.toUpperCase();
|
||||
})
|
||||
.anyMatch(s -> {
|
||||
System.out.println("anyMatch: " + s);
|
||||
return s.startsWith("A");
|
||||
});
|
||||
|
||||
// map: d2
|
||||
// anyMatch: D2
|
||||
// map: a2
|
||||
// anyMatch: A2
|
||||
```
|
||||
|
||||
只要提供的数据元素满足了谓词,`anyMatch`操作就会返回`true`。对于第二个传递`"A2"`的元素,它的结果为真。由于数据流的链式调用是垂直执行的,`map`这里只需要执行两次。所以`map`会执行尽可能少的次数,而不是把所有元素都映射一遍。
|
||||
|
||||
### 先过滤排除
|
||||
|
||||
下面的例子由两个衔接操作`map`和`filter`,以及一个终止操作`forEach`组成。让我们再来看看这些操作如何执行:
|
||||
|
||||
```java
|
||||
Stream.of("d2", "a2", "b1", "b3", "c")
|
||||
.map(s -> {
|
||||
System.out.println("map: " + s);
|
||||
return s.toUpperCase();
|
||||
})
|
||||
.filter(s -> {
|
||||
System.out.println("filter: " + s);
|
||||
return s.startsWith("A");
|
||||
})
|
||||
.forEach(s -> System.out.println("forEach: " + s));
|
||||
|
||||
// map: d2
|
||||
// filter: D2
|
||||
// map: a2
|
||||
// filter: A2
|
||||
// forEach: A2
|
||||
// map: b1
|
||||
// filter: B1
|
||||
// map: b3
|
||||
// filter: B3
|
||||
// map: c
|
||||
// filter: C
|
||||
```
|
||||
|
||||
就像你可能猜到的那样,`map`和`filter`会对底层集合的每个字符串调用五次,而`forEach`只会调用一次。
|
||||
|
||||
如果我们调整操作顺序,将`filter`移动到调用链的顶端,就可以极大减少操作的执行次数:
|
||||
|
||||
```java
|
||||
Stream.of("d2", "a2", "b1", "b3", "c")
|
||||
.filter(s -> {
|
||||
System.out.println("filter: " + s);
|
||||
return s.startsWith("a");
|
||||
})
|
||||
.map(s -> {
|
||||
System.out.println("map: " + s);
|
||||
return s.toUpperCase();
|
||||
})
|
||||
.forEach(s -> System.out.println("forEach: " + s));
|
||||
|
||||
// filter: d2
|
||||
// filter: a2
|
||||
// map: a2
|
||||
// forEach: A2
|
||||
// filter: b1
|
||||
// filter: b3
|
||||
// filter: c
|
||||
```
|
||||
|
||||
## 4 复用数据流
|
||||
|
||||
Java8的数据流不能被复用。一旦你调用了任何终止操作,数据流就关闭了:
|
||||
|
||||
```java
|
||||
Stream<String> stream =
|
||||
Stream.of("d2", "a2", "b1", "b3", "c")
|
||||
.filter(s -> s.startsWith("a"));
|
||||
|
||||
stream.anyMatch(s -> true); // ok
|
||||
stream.noneMatch(s -> true); // exception
|
||||
```
|
||||
|
||||
在相同数据流上,在`anyMatch`之后调用`noneMatch`会产生下面的异常:
|
||||
|
||||
```
|
||||
java.lang.IllegalStateException: stream has already been operated upon or closed
|
||||
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:229)
|
||||
at java.util.stream.ReferencePipeline.noneMatch(ReferencePipeline.java:459)
|
||||
at com.winterbe.java8.Streams5.test7(Streams5.java:38)
|
||||
at com.winterbe.java8.Streams5.main(Streams5.java:28)
|
||||
```
|
||||
|
||||
要克服这个限制,我们需要为每个我们想要执行的终止操作创建新的数据流调用链。例如,我们创建一个数据流供应器,来构建新的数据流,并且设置好所有衔接操作:
|
||||
|
||||
```java
|
||||
Supplier<Stream<String>> streamSupplier =
|
||||
() -> Stream.of("d2", "a2", "b1", "b3", "c")
|
||||
.filter(s -> s.startsWith("a"));
|
||||
|
||||
streamSupplier.get().anyMatch(s -> true); // ok
|
||||
streamSupplier.get().noneMatch(s -> true); // ok
|
||||
```
|
||||
|
||||
每次对`get()`的调用都构造了一个新的数据流,我们将其保存来调用终止操作。
|
||||
|
||||
## 5 高级操作
|
||||
|
||||
数据流执行大量的不同操作。我们已经了解了一些最重要的操作,例如`filter`和`map`。我将它们留给你来探索所有其他的可用操作。下面让我们深入了解一些更复杂的操作:`collect`、`flatMap`和`reduce`。
|
||||
|
||||
这一节的大部分代码示例使用下面的`Person`列表来演示:
|
||||
|
||||
```java
|
||||
class Person {
|
||||
String name;
|
||||
int age;
|
||||
|
||||
Person(String name, int age) {
|
||||
this.name = name;
|
||||
this.age = age;
|
||||
}
|
||||
|
||||
@Override
|
||||
public String toString() {
|
||||
return name;
|
||||
}
|
||||
}
|
||||
|
||||
List<Person> persons =
|
||||
Arrays.asList(
|
||||
new Person("Max", 18),
|
||||
new Person("Peter", 23),
|
||||
new Person("Pamela", 23),
|
||||
new Person("David", 12));
|
||||
```
|
||||
|
||||
### `collect`
|
||||
|
||||
`collect`是非常有用的终止操作,将流中的元素存放在不同类型的结果中,例如`List`、`Set`或者`Map`。`collect`接受收集器(Collector),它由四个不同的操作组成:供应器(supplier)、累加器(accumulator)、组合器(combiner)和终止器(finisher)。这在开始听起来十分复杂,但是Java8通过内置的`Collectors`类支持多种内置的收集器。所以对于大部分常见操作,你并不需要自己实现收集器。
|
||||
|
||||
让我们以一个非常常见的用例来开始:
|
||||
|
||||
```java
|
||||
List<Person> filtered =
|
||||
persons
|
||||
.stream()
|
||||
.filter(p -> p.name.startsWith("P"))
|
||||
.collect(Collectors.toList());
|
||||
|
||||
System.out.println(filtered); // [Peter, Pamela]
|
||||
```
|
||||
|
||||
就像你看到的那样,它非常简单,只是从流的元素中构造了一个列表。如果需要以`Set`来替代`List`,只需要使用`Collectors.toSet()`就好了。
|
||||
|
||||
下面的例子按照年龄对所有人进行分组:
|
||||
|
||||
```java
|
||||
Map<Integer, List<Person>> personsByAge = persons
|
||||
.stream()
|
||||
.collect(Collectors.groupingBy(p -> p.age));
|
||||
|
||||
personsByAge
|
||||
.forEach((age, p) -> System.out.format("age %s: %s\n", age, p));
|
||||
|
||||
// age 18: [Max]
|
||||
// age 23: [Peter, Pamela]
|
||||
// age 12: [David]
|
||||
```
|
||||
|
||||
收集器十分灵活。你也可以在流的元素上执行聚合,例如,计算所有人的平均年龄:
|
||||
|
||||
```java
|
||||
Double averageAge = persons
|
||||
.stream()
|
||||
.collect(Collectors.averagingInt(p -> p.age));
|
||||
|
||||
System.out.println(averageAge); // 19.0
|
||||
```
|
||||
|
||||
如果你对更多统计学方法感兴趣,概要收集器返回一个特殊的内置概要统计对象,所以我们可以简单计算最小年龄、最大年龄、算术平均年龄、总和和数量。
|
||||
|
||||
```java
|
||||
IntSummaryStatistics ageSummary =
|
||||
persons
|
||||
.stream()
|
||||
.collect(Collectors.summarizingInt(p -> p.age));
|
||||
|
||||
System.out.println(ageSummary);
|
||||
// IntSummaryStatistics{count=4, sum=76, min=12, average=19.000000, max=23}
|
||||
```
|
||||
|
||||
下面的例子将所有人连接为一个字符串:
|
||||
|
||||
```java
|
||||
String phrase = persons
|
||||
.stream()
|
||||
.filter(p -> p.age >= 18)
|
||||
.map(p -> p.name)
|
||||
.collect(Collectors.joining(" and ", "In Germany ", " are of legal age."));
|
||||
|
||||
System.out.println(phrase);
|
||||
// In Germany Max and Peter and Pamela are of legal age.
|
||||
```
|
||||
|
||||
连接收集器接受分隔符,以及可选的前缀和后缀。
|
||||
|
||||
既然我们知道了一些最强大的内置收集器,让我们来尝试构建自己的特殊收集器吧。我们希望将流中的所有人转换为一个字符串,包含所有大写的名称,并以`|`分割。为了完成它,我们通过`Collector.of()`创建了一个新的收集器。我们需要传递一个收集器的四个组成部分:供应器、累加器、组合器和终止器。
|
||||
|
||||
```java
|
||||
Collector<Person, StringJoiner, String> personNameCollector =
|
||||
Collector.of(
|
||||
() -> new StringJoiner(" | "), // supplier
|
||||
(j, p) -> j.add(p.name.toUpperCase()), // accumulator
|
||||
(j1, j2) -> j1.merge(j2), // combiner
|
||||
StringJoiner::toString); // finisher
|
||||
|
||||
String names = persons
|
||||
.stream()
|
||||
.collect(personNameCollector);
|
||||
|
||||
System.out.println(names); // MAX | PETER | PAMELA | DAVID
|
||||
```
|
||||
|
||||
由于Java中的字符串是不可变的,我们需要一个助手类`StringJointer`。让收集器构造我们的字符串。供应器最开始使用相应的分隔符构造了这样一个`StringJointer`。累加器用于将每个人的大写名称加到`StringJointer`中。组合器知道如何把两个`StringJointer`合并为一个。最后一步,终结器从`StringJointer`构造出预期的字符串。
|
||||
|
||||
### `flatMap`
|
||||
|
||||
我们已经了解了如何通过使用`map`操作,将流中的对象转换为另一种类型。`map`有时十分受限,因为每个对象只能映射为一个其它对象。但如何我希望将一个对象转换为多个或零个其他对象呢?`flatMap`这时就会派上用场。
|
||||
|
||||
`flatMap`将流中的每个元素,转换为其它对象的流。所以每个对象会被转换为零个、一个或多个其它对象,以流的形式返回。这些流的内容之后会放进`flatMap`所返回的流中。
|
||||
|
||||
在我们了解`flatMap`如何使用之前,我们需要相应的类型体系:
|
||||
|
||||
```java
|
||||
class Foo {
|
||||
String name;
|
||||
List<Bar> bars = new ArrayList<>();
|
||||
|
||||
Foo(String name) {
|
||||
this.name = name;
|
||||
}
|
||||
}
|
||||
|
||||
class Bar {
|
||||
String name;
|
||||
|
||||
Bar(String name) {
|
||||
this.name = name;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
下面,我们使用我们自己的关于流的知识来实例化一些对象:
|
||||
|
||||
```java
|
||||
List<Foo> foos = new ArrayList<>();
|
||||
|
||||
// create foos
|
||||
IntStream
|
||||
.range(1, 4)
|
||||
.forEach(i -> foos.add(new Foo("Foo" + i)));
|
||||
|
||||
// create bars
|
||||
foos.forEach(f ->
|
||||
IntStream
|
||||
.range(1, 4)
|
||||
.forEach(i -> f.bars.add(new Bar("Bar" + i + " <- " + f.name))));
|
||||
```
|
||||
|
||||
现在我们拥有了含有三个`foo`的列表,每个都含有三个`bar`。
|
||||
|
||||
`flatMap`接受返回对象流的函数。所以为了处理每个`foo`上的`bar`对象,我们需要传递相应的函数:
|
||||
|
||||
```java
|
||||
foos.stream()
|
||||
.flatMap(f -> f.bars.stream())
|
||||
.forEach(b -> System.out.println(b.name));
|
||||
|
||||
// Bar1 <- Foo1
|
||||
// Bar2 <- Foo1
|
||||
// Bar3 <- Foo1
|
||||
// Bar1 <- Foo2
|
||||
// Bar2 <- Foo2
|
||||
// Bar3 <- Foo2
|
||||
// Bar1 <- Foo3
|
||||
// Bar2 <- Foo3
|
||||
// Bar3 <- Foo3
|
||||
```
|
||||
|
||||
像你看到的那样,我们成功地将含有三个`foo`对象中的流转换为含有九个`bar`对象的流。
|
||||
|
||||
最后,上面的代码示例可以简化为流式操作的单一流水线:
|
||||
|
||||
```java
|
||||
IntStream.range(1, 4)
|
||||
.mapToObj(i -> new Foo("Foo" + i))
|
||||
.peek(f -> IntStream.range(1, 4)
|
||||
.mapToObj(i -> new Bar("Bar" + i + " <- " + f.name))
|
||||
.forEach(f.bars::add))
|
||||
.flatMap(f -> f.bars.stream())
|
||||
.forEach(b -> System.out.println(b.name));
|
||||
```
|
||||
|
||||
`flatMap`也可用于Java8引入的`Optional`类。`Optional`的`flatMap`操作返回一个`Optional`或其他类型的对象。所以它可以用于避免烦人的`null`检查。
|
||||
|
||||
考虑像这样更复杂的层次结构:
|
||||
|
||||
```java
|
||||
class Outer {
|
||||
Nested nested;
|
||||
}
|
||||
|
||||
class Nested {
|
||||
Inner inner;
|
||||
}
|
||||
|
||||
class Inner {
|
||||
String foo;
|
||||
}
|
||||
```
|
||||
|
||||
为了处理外层示例上的内层字符串`foo`,你需要添加多个`null`检查来避免潜在的`NullPointerException`:
|
||||
|
||||
```java
|
||||
Outer outer = new Outer();
|
||||
if (outer != null && outer.nested != null && outer.nested.inner != null) {
|
||||
System.out.println(outer.nested.inner.foo);
|
||||
}
|
||||
```
|
||||
|
||||
可以使用`Optional`的`flatMap`操作来完成相同的行为:
|
||||
|
||||
```java
|
||||
Optional.of(new Outer())
|
||||
.flatMap(o -> Optional.ofNullable(o.nested))
|
||||
.flatMap(n -> Optional.ofNullable(n.inner))
|
||||
.flatMap(i -> Optional.ofNullable(i.foo))
|
||||
.ifPresent(System.out::println);
|
||||
```
|
||||
|
||||
如果存在的话,每个`flatMap`的调用都会返回预期对象的`Optional`包装,否则为`null`的`Optional`包装。
|
||||
|
||||
### `reduce`
|
||||
|
||||
归约操作将所有流中的元素组合为单一结果。Java8支持三种不同类型的`reduce`方法。第一种将流中的元素归约为流中的一个元素。让我们看看我们如何使用这个方法来计算出最老的人:
|
||||
|
||||
```java
|
||||
persons
|
||||
.stream()
|
||||
.reduce((p1, p2) -> p1.age > p2.age ? p1 : p2)
|
||||
.ifPresent(System.out::println); // Pamela
|
||||
```
|
||||
|
||||
`reduce`方法接受`BinaryOperator`积累函数。它实际上是两个操作数类型相同的`BiFunction`。`BiFunction`就像是`Function`,但是接受两个参数。示例中的函数比较两个人的年龄,来返回年龄较大的人。
|
||||
|
||||
第二个`reduce`方法接受一个初始值,和一个`BinaryOperator`累加器。这个方法可以用于从流中的其它`Person`对象中构造带有聚合后名称和年龄的新`Person`对象。
|
||||
|
||||
```java
|
||||
Person result =
|
||||
persons
|
||||
.stream()
|
||||
.reduce(new Person("", 0), (p1, p2) -> {
|
||||
p1.age += p2.age;
|
||||
p1.name += p2.name;
|
||||
return p1;
|
||||
});
|
||||
|
||||
System.out.format("name=%s; age=%s", result.name, result.age);
|
||||
// name=MaxPeterPamelaDavid; age=76
|
||||
```
|
||||
|
||||
第三个`reduce`对象接受三个参数:初始值,`BiFunction`累加器和`BinaryOperator`类型的组合器函数。由于初始值的类型不一定为`Person`,我们可以使用这个归约函数来计算所有人的年龄总和。:
|
||||
|
||||
```java
|
||||
Integer ageSum = persons
|
||||
.stream()
|
||||
.reduce(0, (sum, p) -> sum += p.age, (sum1, sum2) -> sum1 + sum2);
|
||||
|
||||
System.out.println(ageSum); // 76
|
||||
```
|
||||
|
||||
你可以看到结果是76。但是背后发生了什么?让我们通过添加一些调试输出来扩展上面的代码:
|
||||
|
||||
```java
|
||||
Integer ageSum = persons
|
||||
.stream()
|
||||
.reduce(0,
|
||||
(sum, p) -> {
|
||||
System.out.format("accumulator: sum=%s; person=%s\n", sum, p);
|
||||
return sum += p.age;
|
||||
},
|
||||
(sum1, sum2) -> {
|
||||
System.out.format("combiner: sum1=%s; sum2=%s\n", sum1, sum2);
|
||||
return sum1 + sum2;
|
||||
});
|
||||
|
||||
// accumulator: sum=0; person=Max
|
||||
// accumulator: sum=18; person=Peter
|
||||
// accumulator: sum=41; person=Pamela
|
||||
// accumulator: sum=64; person=David
|
||||
```
|
||||
|
||||
你可以看到,累加器函数做了所有工作。它首先使用初始值`0`和第一个人Max来调用累加器。接下来的三步中`sum`会持续增加,直到76。
|
||||
|
||||
等一下。好像组合器从来没有调用过?以并行方式执行相同的流会揭开这个秘密:
|
||||
|
||||
```java
|
||||
Integer ageSum = persons
|
||||
.parallelStream()
|
||||
.reduce(0,
|
||||
(sum, p) -> {
|
||||
System.out.format("accumulator: sum=%s; person=%s\n", sum, p);
|
||||
return sum += p.age;
|
||||
},
|
||||
(sum1, sum2) -> {
|
||||
System.out.format("combiner: sum1=%s; sum2=%s\n", sum1, sum2);
|
||||
return sum1 + sum2;
|
||||
});
|
||||
|
||||
// accumulator: sum=0; person=Pamela
|
||||
// accumulator: sum=0; person=David
|
||||
// accumulator: sum=0; person=Max
|
||||
// accumulator: sum=0; person=Peter
|
||||
// combiner: sum1=18; sum2=23
|
||||
// combiner: sum1=23; sum2=12
|
||||
// combiner: sum1=41; sum2=35
|
||||
```
|
||||
|
||||
这个流的并行执行行为会完全不同。现在实际上调用了组合器。由于累加器被并行调用,组合器需要用于计算部分累加值的总和。
|
||||
|
||||
下一节我们会深入了解并行流。
|
||||
|
||||
## 6 并行流
|
||||
|
||||
流可以并行执行,在大量输入元素上可以提升运行时的性能。并行流使用公共的`ForkJoinPool`,由`ForkJoinPool.commonPool()`方法提供。底层线程池的大小最大为五个线程 -- 取决于CPU的物理核数。
|
||||
|
||||
```java
|
||||
ForkJoinPool commonPool = ForkJoinPool.commonPool();
|
||||
System.out.println(commonPool.getParallelism()); // 3
|
||||
```
|
||||
|
||||
在我的机器上,公共池默认初始化为3。这个值可以通过设置下列JVM参数来增减:
|
||||
|
||||
```
|
||||
-Djava.util.concurrent.ForkJoinPool.common.parallelism=5
|
||||
```
|
||||
|
||||
集合支持`parallelStream()`方法来创建元素的并行流。或者你可以在已存在的数据流上调用衔接方法`parallel()`,将串行流转换为并行流。
|
||||
|
||||
为了描述并行流的执行行为,下面的例子向`sout`打印了当前线程的信息。
|
||||
|
||||
```java
|
||||
Arrays.asList("a1", "a2", "b1", "c2", "c1")
|
||||
.parallelStream()
|
||||
.filter(s -> {
|
||||
System.out.format("filter: %s [%s]\n",
|
||||
s, Thread.currentThread().getName());
|
||||
return true;
|
||||
})
|
||||
.map(s -> {
|
||||
System.out.format("map: %s [%s]\n",
|
||||
s, Thread.currentThread().getName());
|
||||
return s.toUpperCase();
|
||||
})
|
||||
.forEach(s -> System.out.format("forEach: %s [%s]\n",
|
||||
s, Thread.currentThread().getName()));
|
||||
```
|
||||
|
||||
通过分析调试输出,我们可以对哪个线程用于执行流式操作拥有更深入的理解:
|
||||
|
||||
```
|
||||
filter: b1 [main]
|
||||
filter: a2 [ForkJoinPool.commonPool-worker-1]
|
||||
map: a2 [ForkJoinPool.commonPool-worker-1]
|
||||
filter: c2 [ForkJoinPool.commonPool-worker-3]
|
||||
map: c2 [ForkJoinPool.commonPool-worker-3]
|
||||
filter: c1 [ForkJoinPool.commonPool-worker-2]
|
||||
map: c1 [ForkJoinPool.commonPool-worker-2]
|
||||
forEach: C2 [ForkJoinPool.commonPool-worker-3]
|
||||
forEach: A2 [ForkJoinPool.commonPool-worker-1]
|
||||
map: b1 [main]
|
||||
forEach: B1 [main]
|
||||
filter: a1 [ForkJoinPool.commonPool-worker-3]
|
||||
map: a1 [ForkJoinPool.commonPool-worker-3]
|
||||
forEach: A1 [ForkJoinPool.commonPool-worker-3]
|
||||
forEach: C1 [ForkJoinPool.commonPool-worker-2]
|
||||
```
|
||||
|
||||
就像你看到的那样,并行流使用了所有公共的`ForkJoinPool`中的可用线程来执行流式操作。在连续的运行中输出可能有所不同,因为所使用的特定线程是非特定的。
|
||||
|
||||
让我们通过添加额外的流式操作`sort`来扩展这个示例:
|
||||
|
||||
```java
|
||||
Arrays.asList("a1", "a2", "b1", "c2", "c1")
|
||||
.parallelStream()
|
||||
.filter(s -> {
|
||||
System.out.format("filter: %s [%s]\n",
|
||||
s, Thread.currentThread().getName());
|
||||
return true;
|
||||
})
|
||||
.map(s -> {
|
||||
System.out.format("map: %s [%s]\n",
|
||||
s, Thread.currentThread().getName());
|
||||
return s.toUpperCase();
|
||||
})
|
||||
.sorted((s1, s2) -> {
|
||||
System.out.format("sort: %s <> %s [%s]\n",
|
||||
s1, s2, Thread.currentThread().getName());
|
||||
return s1.compareTo(s2);
|
||||
})
|
||||
.forEach(s -> System.out.format("forEach: %s [%s]\n",
|
||||
s, Thread.currentThread().getName()));
|
||||
```
|
||||
|
||||
结果起初可能比较奇怪:
|
||||
|
||||
```
|
||||
filter: c2 [ForkJoinPool.commonPool-worker-3]
|
||||
filter: c1 [ForkJoinPool.commonPool-worker-2]
|
||||
map: c1 [ForkJoinPool.commonPool-worker-2]
|
||||
filter: a2 [ForkJoinPool.commonPool-worker-1]
|
||||
map: a2 [ForkJoinPool.commonPool-worker-1]
|
||||
filter: b1 [main]
|
||||
map: b1 [main]
|
||||
filter: a1 [ForkJoinPool.commonPool-worker-2]
|
||||
map: a1 [ForkJoinPool.commonPool-worker-2]
|
||||
map: c2 [ForkJoinPool.commonPool-worker-3]
|
||||
sort: A2 <> A1 [main]
|
||||
sort: B1 <> A2 [main]
|
||||
sort: C2 <> B1 [main]
|
||||
sort: C1 <> C2 [main]
|
||||
sort: C1 <> B1 [main]
|
||||
sort: C1 <> C2 [main]
|
||||
forEach: A1 [ForkJoinPool.commonPool-worker-1]
|
||||
forEach: C2 [ForkJoinPool.commonPool-worker-3]
|
||||
forEach: B1 [main]
|
||||
forEach: A2 [ForkJoinPool.commonPool-worker-2]
|
||||
forEach: C1 [ForkJoinPool.commonPool-worker-1]
|
||||
```
|
||||
|
||||
`sort`看起来只在主线程上串行执行。实际上,并行流上的`sort`在背后使用了Java8中新的方法`Arrays.parallelSort()`。如[javadoc](https://docs.oracle.com/javase/8/docs/api/java/util/Arrays.html#parallelSort-T:A-)所说,这个方法会参照数据长度来决定以串行或并行来执行。
|
||||
|
||||
> 如果指定数据的长度小于最小粒度,它使用相应的`Arrays.sort`方法来排序。
|
||||
|
||||
返回上一节中`reduce`的例子。我们已经发现了组合器函数只在并行流中调用,而不在串行流中调用。让我们来观察实际上涉及到哪个线程:
|
||||
|
||||
```java
|
||||
List<Person> persons = Arrays.asList(
|
||||
new Person("Max", 18),
|
||||
new Person("Peter", 23),
|
||||
new Person("Pamela", 23),
|
||||
new Person("David", 12));
|
||||
|
||||
persons
|
||||
.parallelStream()
|
||||
.reduce(0,
|
||||
(sum, p) -> {
|
||||
System.out.format("accumulator: sum=%s; person=%s [%s]\n",
|
||||
sum, p, Thread.currentThread().getName());
|
||||
return sum += p.age;
|
||||
},
|
||||
(sum1, sum2) -> {
|
||||
System.out.format("combiner: sum1=%s; sum2=%s [%s]\n",
|
||||
sum1, sum2, Thread.currentThread().getName());
|
||||
return sum1 + sum2;
|
||||
});
|
||||
```
|
||||
|
||||
控制台的输出表明,累加器和组合器都在所有可用的线程上并行执行:
|
||||
|
||||
```
|
||||
accumulator: sum=0; person=Pamela; [main]
|
||||
accumulator: sum=0; person=Max; [ForkJoinPool.commonPool-worker-3]
|
||||
accumulator: sum=0; person=David; [ForkJoinPool.commonPool-worker-2]
|
||||
accumulator: sum=0; person=Peter; [ForkJoinPool.commonPool-worker-1]
|
||||
combiner: sum1=18; sum2=23; [ForkJoinPool.commonPool-worker-1]
|
||||
combiner: sum1=23; sum2=12; [ForkJoinPool.commonPool-worker-2]
|
||||
combiner: sum1=41; sum2=35; [ForkJoinPool.commonPool-worker-2]
|
||||
```
|
||||
|
||||
总之,并行流对拥有大量输入元素的数据流具有极大的性能提升。但是要记住一些并行流的操作,例如`reduce`和`collect`需要额外的计算(组合操作),这在串行执行时并不需要。
|
||||
|
||||
此外我们已经了解,所有并行流操作都共享相同的JVM相关的公共`ForkJoinPool`。所以你可能需要避免实现又慢又卡的流式操作,因为它可能会拖慢你应用中严重依赖并行流的其它部分。
|
||||
|
||||
|
||||
|
||||
## 7 功能列表
|
||||
|
||||
|
||||
### 中间管道
|
||||

|
||||
|
||||
|
||||
### 终止管道
|
||||
|
||||

|
||||
|
||||
|
||||
### map&flatmap
|
||||
|
||||
map与flatMap都是用于转换已有的元素为其它元素,区别点在于:
|
||||
* map 必须是一对一的,即每个元素都只能转换为1个新的元素
|
||||
* flatMap 可以是一对多的,即每个元素都可以转换为1个或者多个新的元素
|
||||
|
||||

|
||||
|
||||
|
||||
### peek和foreach方法
|
||||
peek和foreach,都可以用于对元素进行遍历然后逐个的进行处理。
|
||||
|
||||
但根据前面的介绍,peek属于中间方法,而foreach属于终止方法。这也就意味着peek只能作为管道中途的一个处理步骤,而没法直接执行得到结果,其后面必须还要有其它终止操作的时候才会被执行;而foreach作为无返回值的终止方法,则可以直接执行相关操作。
|
||||
BIN
Java基础教程/Java集合类/image/2022-12-15-16-54-49.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 45 KiB |
BIN
Java基础教程/Java集合类/image/2022-12-15-16-54-56.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 45 KiB |
BIN
Java基础教程/Java集合类/image/2022-12-15-16-55-23.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 24 KiB |
BIN
Java基础教程/Java集合类/image/2022-12-15-17-11-05.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 77 KiB |
BIN
Java基础教程/Java集合类/image/2022-12-15-17-14-17.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 43 KiB |
BIN
Java基础教程/Java集合类/image/2022-12-15-19-08-19.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 96 KiB |
BIN
Java基础教程/Java集合类/image/2022-12-15-19-08-34.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 46 KiB |
BIN
Java基础教程/Java集合类/image/2022-12-15-19-16-20.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 87 KiB |
BIN
Java基础教程/Java集合类/image/2022-12-15-19-17-09.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 76 KiB |
BIN
Java基础教程/Java集合类/image/2022-12-15-19-28-47.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 23 KiB |
BIN
Java基础教程/Java集合类/image/2022-12-15-19-35-52.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 34 KiB |
BIN
Java基础教程/Java集合类/image/2022-12-15-19-38-24.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 41 KiB |
BIN
Java基础教程/Java集合类/image/2022-12-15-19-39-03.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 11 KiB |
BIN
Java基础教程/Java集合类/image/2022-12-15-20-19-36.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 22 KiB |
BIN
Java基础教程/Java集合类/image/2022-12-15-21-12-52.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 79 KiB |
BIN
Java基础教程/Java集合类/image/2022-12-15-21-53-10.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 483 KiB |
BIN
Java基础教程/Java集合类/image/2022-12-15-22-45-56.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 127 KiB |
BIN
Java基础教程/Java集合类/image/2022-12-15-22-46-12.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 147 KiB |
BIN
Java基础教程/Java集合类/image/2022-12-15-22-46-59.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 67 KiB |
66
test.csv
Normal file
@@ -0,0 +1,66 @@
|
||||
+------+--------------+---------------+-----------------------+-----------+----------+---------------------+---------------------+
|
||||
| id | instance_id | instance_name | workspace_id | tenant_id | operator | gmt_create | gmt_modified |
|
||||
+------+--------------+---------------+-----------------------+-----------+----------+---------------------+---------------------+
|
||||
| 4936 | BGAUH89M7MFH | default | acgatewayshpre | CZKZJVCN | NULL | 2022-06-14 20:52:09 | 2022-06-14 20:52:09 |
|
||||
| 4935 | V6LFHIUEDCLA | default | acgatewayshprod | CZKZJVCN | NULL | 2022-06-14 20:21:17 | 2022-06-14 20:21:17 |
|
||||
| 4675 | ALAZYISSVVQQ | default | aicontainerpre | CZKZJVCN | NULL | 2022-02-15 16:16:17 | 2022-02-15 16:16:17 |
|
||||
| 4705 | UWHIWDYOIAPU | default | aicontainerprod | CZKZJVCN | NULL | 2022-02-25 20:12:14 | 2022-02-25 20:12:14 |
|
||||
| 4773 | TR2M3AOT2HA5 | default | AIotPRE | CZKZJVCN | NULL | 2022-03-16 20:49:59 | 2022-03-16 20:49:59 |
|
||||
| 4836 | GMIKNNQTZJXD | default | AIotPROD | CZKZJVCN | NULL | 2022-03-30 20:15:36 | 2022-03-30 20:15:36 |
|
||||
| 4653 | FZTPEGUAEYOX | default | baascontainerpre | CZKZJVCN | NULL | 2022-01-27 10:14:57 | 2022-01-27 10:14:57 |
|
||||
| 4629 | DPPSMO0CDA8V | default | baascontainerprod | CZKZJVCN | NULL | 2022-01-17 16:29:35 | 2022-01-17 16:29:35 |
|
||||
| 282 | WDBAHQRYFC4U | default | BaasDev | CZKZJVCN | NULL | 2018-09-19 11:39:03 | 2018-09-19 11:39:03 |
|
||||
| 132 | DPPSMO0CDA8V | default | BaaSProduction | CZKZJVCN | NULL | 2018-04-25 18:46:39 | 2018-04-25 18:46:39 |
|
||||
| 1157 | HVKV1C2MB9LA | default | BAIProd | CZKZJVCN | NULL | 2019-11-27 16:34:05 | 2019-11-27 16:34:05 |
|
||||
| 1135 | YXMF6VJQZEEE | default | BAITest | CZKZJVCN | NULL | 2019-11-15 15:23:48 | 2019-11-15 15:23:48 |
|
||||
| 1297 | S4J83OOBBVY5 | default | bamboo | CZKZJVCN | NULL | 2020-02-05 11:32:39 | 2020-02-05 11:32:39 |
|
||||
| 4572 | K9OZTUJSIG29 | default | BaseService | CZKZJVCN | NULL | 2021-12-28 12:01:08 | 2021-12-28 12:01:08 |
|
||||
| 549 | UZLS24IJMMYU | default | BillProd | CZKZJVCN | NULL | 2019-01-23 17:11:13 | 2019-01-23 17:11:13 |
|
||||
| 864 | KZER0YOOPS76 | default | BillTest | CZKZJVCN | NULL | 2019-06-06 17:34:54 | 2019-06-06 17:34:54 |
|
||||
| 4172 | Q5HGURE3PPIW | default | carbonchain | CZKZJVCN | NULL | 2021-07-29 10:18:46 | 2021-07-29 10:18:46 |
|
||||
| 1001 | UIYU2EXZALCN | default | chainfin | CZKZJVCN | NULL | 2019-09-16 14:12:18 | 2019-09-16 14:12:18 |
|
||||
| 4909 | H3SHOYMMCR7U | default | commoncontainerpre | CZKZJVCN | NULL | 2022-05-18 15:30:00 | 2022-05-18 15:30:00 |
|
||||
| 4888 | TMOA3W40FD8A | default | commoncontainerprod | CZKZJVCN | NULL | 2022-05-10 20:09:15 | 2022-05-10 20:09:15 |
|
||||
| 4477 | BVABJWRJQVNO | default | customertechprod | CZKZJVCN | NULL | 2021-12-06 11:17:38 | 2021-12-06 11:17:38 |
|
||||
| 320 | CHSNHYPZOPWT | default | default | CZKZJVCN | NULL | 2018-09-29 11:30:34 | 2018-09-29 11:30:34 |
|
||||
| 554 | SVDWJXSAF27G | default | dev | CZKZJVCN | NULL | 2019-01-25 19:49:51 | 2019-01-25 19:49:51 |
|
||||
| 2920 | IJZ8UB2Z6ERB | default | EWTPProd | CZKZJVCN | NULL | 2020-09-03 10:02:04 | 2020-09-03 10:02:04 |
|
||||
| 501 | 0TFGMHCWK7DU | default | FinanceSystem | CZKZJVCN | NULL | 2019-01-04 14:23:16 | 2019-01-04 14:23:16 |
|
||||
| 4207 | 7MHKQPIQVBRT | default | govchain | CZKZJVCN | NULL | 2021-08-10 20:38:01 | 2021-08-10 20:38:01 |
|
||||
| 1492 | 9CHDLAFI2SHI | default | gvtprod | CZKZJVCN | NULL | 2020-04-02 18:02:31 | 2020-04-02 18:02:31 |
|
||||
| 4739 | MVEEOWVWRRYZ | default | horizontalbusinesspre | CZKZJVCN | NULL | 2022-03-08 16:37:03 | 2022-03-08 16:37:03 |
|
||||
| 1141 | W6472KEGAD1G | default | IoTFinanceIntTest | CZKZJVCN | NULL | 2019-11-19 15:46:10 | 2019-11-19 15:46:10 |
|
||||
| 988 | WAORB2A5FDUF | default | IoTFinanceProd | CZKZJVCN | NULL | 2019-09-05 11:23:33 | 2019-09-05 11:23:33 |
|
||||
| 960 | QVHRUKXBHAI3 | default | iotfinancetest | CZKZJVCN | NULL | 2019-08-12 17:20:00 | 2019-08-12 17:20:00 |
|
||||
| 1563 | NVL9APRD97BX | default | liangfanshanghai | CZKZJVCN | NULL | 2020-04-16 10:18:46 | 2020-04-16 10:18:46 |
|
||||
| 5014 | 8JL0ZHQWSPFL | default | MainsetCommunication | CZKZJVCN | NULL | 2022-08-17 10:41:47 | 2022-08-17 10:41:47 |
|
||||
| 1063 | RZV9KY3PZW8K | default | miniappprodworkspace | CZKZJVCN | NULL | 2019-09-26 22:18:49 | 2019-09-26 22:18:49 |
|
||||
| 751 | UNI0HI3CMNUM | default | miniapptestworkspace | CZKZJVCN | NULL | 2019-04-08 16:19:08 | 2019-04-08 16:19:08 |
|
||||
| 280 | 2NP8RKLV1LXK | default | miniProgramProd | CZKZJVCN | NULL | 2018-09-19 11:12:11 | 2018-09-19 11:12:11 |
|
||||
| 659 | NCVTGS0C3DPG | default | miniProgramTest | CZKZJVCN | NULL | 2019-03-12 20:42:38 | 2019-03-12 20:42:38 |
|
||||
| 4764 | KD46PEF7BIVK | default | morsecontainerpre | CZKZJVCN | NULL | 2022-03-14 16:21:20 | 2022-03-14 16:21:20 |
|
||||
| 4844 | WKURV3M5KPME | default | morsecontainerprod | CZKZJVCN | NULL | 2022-04-01 16:54:45 | 2022-04-01 16:54:45 |
|
||||
| 907 | TOHZIGDSAHMP | default | morseprod | CZKZJVCN | NULL | 2019-06-27 11:40:12 | 2019-06-27 11:40:12 |
|
||||
| 909 | XGJ4W5MUZYYT | default | MPC | CZKZJVCN | NULL | 2019-06-27 15:21:56 | 2019-06-27 15:21:56 |
|
||||
| 944 | KIQNASVQAHCS | default | mychain10dev | CZKZJVCN | NULL | 2019-07-31 15:10:56 | 2019-07-31 15:10:56 |
|
||||
| 1245 | AXA7KOKPTQXS | default | mychaingldev | CZKZJVCN | NULL | 2020-01-14 09:53:49 | 2020-01-14 09:53:49 |
|
||||
| 875 | LDKQGMOXC52B | default | mychaintest | CZKZJVCN | NULL | 2019-06-13 19:22:11 | 2019-06-13 19:22:11 |
|
||||
| 846 | PDYQG1XD12FN | default | mykmsprod | CZKZJVCN | NULL | 2019-05-31 10:23:36 | 2019-05-31 10:23:36 |
|
||||
| 905 | 5ALUQZ5BOWGN | default | myshellprod | CZKZJVCN | NULL | 2019-06-26 15:24:26 | 2019-06-26 15:24:26 |
|
||||
| 841 | FJDNJYCYDAEM | default | myshelltest | CZKZJVCN | NULL | 2019-05-29 13:58:47 | 2019-05-29 13:58:47 |
|
||||
| 977 | FZTPEGUAEYOX | default | pre | CZKZJVCN | NULL | 2019-08-27 15:42:19 | 2019-08-27 15:42:19 |
|
||||
| 3921 | QTLRCLZWQ9QA | default | prodmetrics | CZKZJVCN | NULL | 2021-05-13 20:34:38 | 2021-05-13 20:34:38 |
|
||||
| 717 | 4QOFZUYOFA52 | default | QABaasNotary | CZKZJVCN | NULL | 2019-03-28 11:04:37 | 2019-03-28 11:04:37 |
|
||||
| 1384 | S3EFEM0YDTOD | default | SitDigitalLogistics | CZKZJVCN | NULL | 2020-03-02 20:00:00 | 2020-03-02 20:00:00 |
|
||||
| 692 | IHPNO7LQ3AEO | default | SoftSeaturtleProd | CZKZJVCN | NULL | 2019-03-21 22:40:10 | 2019-03-21 22:40:10 |
|
||||
| 879 | FQVQPQ8YEHK4 | default | SoftSeaturtleTest | CZKZJVCN | NULL | 2019-06-14 23:13:54 | 2019-06-14 23:13:54 |
|
||||
| 513 | J1WZ89RSAYIB | default | sslab1online | CZKZJVCN | NULL | 2019-01-08 16:39:06 | 2019-01-08 16:39:06 |
|
||||
| 4889 | 0ZODETAPWWVB | default | taascontainerpre | CZKZJVCN | NULL | 2022-05-11 11:23:53 | 2022-05-11 11:23:53 |
|
||||
| 4943 | WRHL3ERZXO7I | default | taascontainerprod | CZKZJVCN | NULL | 2022-06-20 11:29:27 | 2022-06-20 11:29:27 |
|
||||
| 4209 | ARX5RQMCTPTE | default | tianyandev | CZKZJVCN | NULL | 2021-08-11 19:38:58 | 2021-08-11 19:38:58 |
|
||||
| 4807 | ZYS49OKF7FO3 | default | TrusplePre | CZKZJVCN | NULL | 2022-03-25 11:44:58 | 2022-03-25 11:44:58 |
|
||||
| 4677 | XKNG9BHAL2VZ | default | trustedindustrypre | CZKZJVCN | NULL | 2022-02-16 10:00:14 | 2022-02-16 10:00:14 |
|
||||
| 4683 | ZJANF6TCHYXE | default | trustedindustryprod | CZKZJVCN | NULL | 2022-02-17 15:21:25 | 2022-02-17 15:21:25 |
|
||||
| 4791 | MBS1OXWDVBHV | default | TWCPre | CZKZJVCN | NULL | 2022-03-23 10:10:13 | 2022-03-23 10:10:13 |
|
||||
| 4849 | IHPNO7LQ3AEO | default | TWCProd | CZKZJVCN | NULL | 2022-04-08 16:08:31 | 2022-04-08 16:08:31 |
|
||||
+------+--------------+---------------+-----------------------+-----------+----------+---------------------+---------------------+
|
||||
|
223
test.log
@@ -1,222 +1,3 @@
|
||||
2-11-30T15:54:15.676+0800: [GC (Allocation Failure) 2022-11-30T15:54:15.676+0800: [ParNew: 449594K->47213K(471872K), 0.0761273 secs] 517409K->120073K(3019584K), 0.0762392 secs] [Times: user=0.13 sys=0.00, real=0.08 secs]
|
||||
15:54:16.419 INFO c.a.antcloud.dsrconsole.core.service.dispatcher.impl.CASecuritySigmaDispatcher - MeshSecurityDispatchModel is init and active.
|
||||
15:54:16.630 ERROR druid.sql.Statement - {conn-110001, pstmt-120004} execute error. DELETE FROM menu_settings WHERE menu_id NOT IN
|
||||
java.sql.SQLSyntaxErrorException: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '' at line 1
|
||||
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:120)
|
||||
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:97)
|
||||
at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:122)
|
||||
at com.mysql.cj.jdbc.ClientPreparedStatement.executeInternal(ClientPreparedStatement.java:953)
|
||||
at com.mysql.cj.jdbc.ClientPreparedStatement.execute(ClientPreparedStatement.java:370)
|
||||
at com.alibaba.druid.filter.FilterChainImpl.preparedStatement_execute(FilterChainImpl.java:3409)
|
||||
at com.alibaba.druid.filter.FilterEventAdapter.preparedStatement_execute(FilterEventAdapter.java:440)
|
||||
at com.alibaba.druid.filter.FilterChainImpl.preparedStatement_execute(FilterChainImpl.java:3407)
|
||||
at com.alibaba.druid.filter.FilterEventAdapter.preparedStatement_execute(FilterEventAdapter.java:440)
|
||||
at com.alibaba.druid.filter.FilterChainImpl.preparedStatement_execute(FilterChainImpl.java:3407)
|
||||
at com.alibaba.druid.proxy.jdbc.PreparedStatementProxyImpl.execute(PreparedStatementProxyImpl.java:167)
|
||||
at com.alibaba.druid.pool.DruidPooledPreparedStatement.execute(DruidPooledPreparedStatement.java:498)
|
||||
at org.apache.ibatis.executor.statement.PreparedStatementHandler.update(PreparedStatementHandler.java:47)
|
||||
at org.apache.ibatis.executor.statement.RoutingStatementHandler.update(RoutingStatementHandler.java:74)
|
||||
at org.apache.ibatis.executor.SimpleExecutor.doUpdate(SimpleExecutor.java:50)
|
||||
at org.apache.ibatis.executor.BaseExecutor.update(BaseExecutor.java:117)
|
||||
at org.apache.ibatis.executor.CachingExecutor.update(CachingExecutor.java:76)
|
||||
at org.apache.ibatis.session.defaults.DefaultSqlSession.update(DefaultSqlSession.java:194)
|
||||
at org.apache.ibatis.session.defaults.DefaultSqlSession.delete(DefaultSqlSession.java:209)
|
||||
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
|
||||
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
|
||||
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
|
||||
at java.lang.reflect.Method.invoke(Method.java:498)
|
||||
at org.mybatis.spring.SqlSessionTemplate$SqlSessionInterceptor.invoke(SqlSessionTemplate.java:434)
|
||||
at com.sun.proxy.$Proxy141.delete(Unknown Source)
|
||||
at org.mybatis.spring.SqlSessionTemplate.delete(SqlSessionTemplate.java:311)
|
||||
at org.apache.ibatis.binding.MapperMethod.execute(MapperMethod.java:72)
|
||||
at org.apache.ibatis.binding.MapperProxy$PlainMethodInvoker.invoke(MapperProxy.java:145)
|
||||
at org.apache.ibatis.binding.MapperProxy.invoke(MapperProxy.java:86)
|
||||
at com.sun.proxy.$Proxy336.deleteNotInIds(Unknown Source)
|
||||
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
|
||||
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
|
||||
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
|
||||
at java.lang.reflect.Method.invoke(Method.java:498)
|
||||
at org.springframework.aop.support.AopUtils.invokeJoinpointUsingReflection(AopUtils.java:344)
|
||||
at org.springframework.aop.framework.ReflectiveMethodInvocation.invokeJoinpoint(ReflectiveMethodInvocation.java:198)
|
||||
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:163)
|
||||
at com.alipay.antcloud.dsrconsole.core.service.interceptor.DAOInterceptor.invoke(DAOInterceptor.java:45)
|
||||
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186)
|
||||
at org.springframework.aop.framework.JdkDynamicAopProxy.invoke(JdkDynamicAopProxy.java:212)
|
||||
at com.sun.proxy.$Proxy337.deleteNotInIds(Unknown Source)
|
||||
at com.alipay.antcloud.dsrconsole.core.service.system.service.impl.SystemSettingsServiceImpl.saveMenus(SystemSettingsServiceImpl.java:67)
|
||||
at com.alipay.antcloud.dsrconsole.endpoint.webui.WebUIConfig.setMenus(WebUIConfig.java:112)
|
||||
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
|
||||
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
|
||||
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
|
||||
at java.lang.reflect.Method.invoke(Method.java:498)
|
||||
at com.alipay.drm.client.update.ResourceAttributeUpdater.updateResource(ResourceAttributeUpdater.java:102)
|
||||
at com.alipay.drm.client.update.ResourceAttributeUpdater.updateStringValueForAttributeV3(ResourceAttributeUpdater.java:194)
|
||||
at com.alipay.drm.client.update.ResourceAttributeUpdater.updateStringValueForAttribute(ResourceAttributeUpdater.java:167)
|
||||
at com.alipay.drm.client.assembly.ResourceInitializer.doUpdate(ResourceInitializer.java:200)
|
||||
at com.alipay.drm.client.assembly.ResourceInitializer.initForAttribute(ResourceInitializer.java:174)
|
||||
at com.alipay.drm.client.assembly.ResourceInitializer.initAttribute(ResourceInitializer.java:93)
|
||||
at com.alipay.drm.client.assembly.register.RegisterAssembly.assembly(RegisterAssembly.java:96)
|
||||
at com.alipay.drm.client.manager.DistributedResourceManagerImpl.realRegister(DistributedResourceManagerImpl.java:240)
|
||||
at com.alipay.drm.client.manager.DistributedResourceManagerImpl.register(DistributedResourceManagerImpl.java:117)
|
||||
at com.alipay.antcloud.dsrconsole.endpoint.webui.WebUIConfig.init(WebUIConfig.java:124)
|
||||
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
|
||||
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
|
||||
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
|
||||
at java.lang.reflect.Method.invoke(Method.java:498)
|
||||
at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor$LifecycleElement.invoke(InitDestroyAnnotationBeanPostProcessor.java:389)
|
||||
at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor$LifecycleMetadata.invokeInitMethods(InitDestroyAnnotationBeanPostProcessor.java:333)
|
||||
at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor.postProcessBeforeInitialization(InitDestroyAnnotationBeanPostProcessor.java:157)
|
||||
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.applyBeanPostProcessorsBeforeInitialization(AbstractAutowireCapableBeanFactory.java:415)
|
||||
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.initializeBean(AbstractAutowireCapableBeanFactory.java:1791)
|
||||
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:594)
|
||||
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:516)
|
||||
at org.springframework.beans.factory.support.AbstractBeanFactory.lambda$doGetBean$0(AbstractBeanFactory.java:324)
|
||||
at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:234)
|
||||
at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:322)
|
||||
at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:202)
|
||||
at org.springframework.beans.factory.support.DefaultListableBeanFactory.preInstantiateSingletons(DefaultListableBeanFactory.java:897)
|
||||
at org.springframework.context.support.AbstractApplicationContext.finishBeanFactoryInitialization(AbstractApplicationContext.java:879)
|
||||
at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:551)
|
||||
at org.springframework.boot.web.servlet.context.ServletWebServerApplicationContext.refresh(ServletWebServerApplicationContext.java:143)
|
||||
at org.springframework.boot.SpringApplication.refresh(SpringApplication.java:758)
|
||||
at org.springframework.boot.SpringApplication.refresh(SpringApplication.java:750)
|
||||
at org.springframework.boot.SpringApplication.refreshContext(SpringApplication.java:405)
|
||||
at org.springframework.boot.SpringApplication.run(SpringApplication.java:315)
|
||||
at org.springframework.boot.SpringApplication.run(SpringApplication.java:1237)
|
||||
at org.springframework.boot.SpringApplication.run(SpringApplication.java:1226)
|
||||
at com.alipay.antcloud.dsrconsole.endpoint.SpringBootSOFALite2DsrconsoleApplication.main(SpringBootSOFALite2DsrconsoleApplication.java:26)
|
||||
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
|
||||
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
|
||||
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
|
||||
at java.lang.reflect.Method.invoke(Method.java:498)
|
||||
at org.springframework.boot.loader.MainMethodRunner.run(MainMethodRunner.java:49)
|
||||
at org.springframework.boot.loader.Launcher.launch(Launcher.java:107)
|
||||
at org.springframework.boot.loader.Launcher.launch(Launcher.java:58)
|
||||
at org.springframework.boot.loader.JarLauncher.main(JarLauncher.java:88)
|
||||
15:54:16.665 WARN o.s.boot.web.servlet.context.AnnotationConfigServletWebServerApplicationContext - Exception encountered during context initialization - cancelling refresh attempt: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'webUIConfig': Invocation of init method failed; nested exception is java.lang.RuntimeException: Assembly drm attribute[menus] exception
|
||||
15:54:16.674 INFO org.springframework.scheduling.concurrent.ThreadPoolTaskScheduler - Shutting down ExecutorService 'changeServiceCheckScheduler'
|
||||
15:54:16.675 INFO org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor - Shutting down ExecutorService 'changeServiceCheckThreadPool'
|
||||
15:54:16.687 INFO com.alibaba.druid.pool.DruidDataSource - {dataSource-1} closed
|
||||
15:54:16.688 INFO com.alibaba.druid.pool.DruidDataSource - {dataSource-2} closed
|
||||
15:54:16.709 INFO org.apache.catalina.core.StandardService - Stopping service [Tomcat]
|
||||
15:54:16.747 INFO o.s.boot.autoconfigure.logging.ConditionEvaluationReportLoggingListener -
|
||||
Alipay.jsbkclcore:name=com.antgroup.creditloan.clcore.common.util.drm.CommonGrayControlDrm.feeSubsidyQuerySwicthDrm.controlRule,version=3.0@DRM
|
||||
|
||||
Error starting ApplicationContext. To display the conditions report re-run your application with 'debug' enabled.
|
||||
15:54:16.750 ERROR org.springframework.boot.SpringApplication - Application run failed
|
||||
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'webUIConfig': Invocation of init method failed; nested exception is java.lang.RuntimeException: Assembly drm attribute[menus] exception
|
||||
at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor.postProcessBeforeInitialization(InitDestroyAnnotationBeanPostProcessor.java:160)
|
||||
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.applyBeanPostProcessorsBeforeInitialization(AbstractAutowireCapableBeanFactory.java:415)
|
||||
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.initializeBean(AbstractAutowireCapableBeanFactory.java:1791)
|
||||
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:594)
|
||||
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:516)
|
||||
at org.springframework.beans.factory.support.AbstractBeanFactory.lambda$doGetBean$0(AbstractBeanFactory.java:324)
|
||||
at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:234)
|
||||
at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:322)
|
||||
at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:202)
|
||||
at org.springframework.beans.factory.support.DefaultListableBeanFactory.preInstantiateSingletons(DefaultListableBeanFactory.java:897)
|
||||
at org.springframework.context.support.AbstractApplicationContext.finishBeanFactoryInitialization(AbstractApplicationContext.java:879)
|
||||
at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:551)
|
||||
at org.springframework.boot.web.servlet.context.ServletWebServerApplicationContext.refresh(ServletWebServerApplicationContext.java:143)
|
||||
at org.springframework.boot.SpringApplication.refresh(SpringApplication.java:758)
|
||||
at org.springframework.boot.SpringApplication.refresh(SpringApplication.java:750)
|
||||
at org.springframework.boot.SpringApplication.refreshContext(SpringApplication.java:405)
|
||||
at org.springframework.boot.SpringApplication.run(SpringApplication.java:315)
|
||||
at org.springframework.boot.SpringApplication.run(SpringApplication.java:1237)
|
||||
at org.springframework.boot.SpringApplication.run(SpringApplication.java:1226)
|
||||
at com.alipay.antcloud.dsrconsole.endpoint.SpringBootSOFALite2DsrconsoleApplication.main(SpringBootSOFALite2DsrconsoleApplication.java:26)
|
||||
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
|
||||
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
|
||||
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
|
||||
at java.lang.reflect.Method.invoke(Method.java:498)
|
||||
at org.springframework.boot.loader.MainMethodRunner.run(MainMethodRunner.java:49)
|
||||
at org.springframework.boot.loader.Launcher.launch(Launcher.java:107)
|
||||
at org.springframework.boot.loader.Launcher.launch(Launcher.java:58)
|
||||
at org.springframework.boot.loader.JarLauncher.main(JarLauncher.java:88)
|
||||
Caused by: java.lang.RuntimeException: Assembly drm attribute[menus] exception
|
||||
at com.alipay.drm.client.assembly.register.RegisterAssembly.assembly(RegisterAssembly.java:108)
|
||||
at com.alipay.drm.client.manager.DistributedResourceManagerImpl.realRegister(DistributedResourceManagerImpl.java:240)
|
||||
at com.alipay.drm.client.manager.DistributedResourceManagerImpl.register(DistributedResourceManagerImpl.java:117)
|
||||
at com.alipay.antcloud.dsrconsole.endpoint.webui.WebUIConfig.init(WebUIConfig.java:124)
|
||||
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
|
||||
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
|
||||
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
|
||||
at java.lang.reflect.Method.invoke(Method.java:498)
|
||||
at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor$LifecycleElement.invoke(InitDestroyAnnotationBeanPostProcessor.java:389)
|
||||
at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor$LifecycleMetadata.invokeInitMethods(InitDestroyAnnotationBeanPostProcessor.java:333)
|
||||
at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor.postProcessBeforeInitialization(InitDestroyAnnotationBeanPostProcessor.java:157)
|
||||
... 27 common frames omitted
|
||||
Caused by: java.lang.RuntimeException: Update drm attribute failed! app = dsrconsole, attribute = menus
|
||||
at com.alipay.drm.client.update.ResourceAttributeUpdater.updateStringValueForAttributeV3(ResourceAttributeUpdater.java:205)
|
||||
at com.alipay.drm.client.update.ResourceAttributeUpdater.updateStringValueForAttribute(ResourceAttributeUpdater.java:167)
|
||||
at com.alipay.drm.client.assembly.ResourceInitializer.doUpdate(ResourceInitializer.java:200)
|
||||
at com.alipay.drm.client.assembly.ResourceInitializer.initForAttribute(ResourceInitializer.java:174)
|
||||
at com.alipay.drm.client.assembly.ResourceInitializer.initAttribute(ResourceInitializer.java:93)
|
||||
at com.alipay.drm.client.assembly.register.RegisterAssembly.assembly(RegisterAssembly.java:96)
|
||||
... 37 common frames omitted
|
||||
Caused by: java.lang.reflect.InvocationTargetException: null
|
||||
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
|
||||
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
|
||||
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
|
||||
at java.lang.reflect.Method.invoke(Method.java:498)
|
||||
at com.alipay.drm.client.update.ResourceAttributeUpdater.updateResource(ResourceAttributeUpdater.java:102)
|
||||
at com.alipay.drm.client.update.ResourceAttributeUpdater.updateStringValueForAttributeV3(ResourceAttributeUpdater.java:194)
|
||||
... 42 common frames omitted
|
||||
Caused by: org.springframework.jdbc.BadSqlGrammarException:
|
||||
### Error updating database. Cause: java.sql.SQLSyntaxErrorException: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '' at line 1
|
||||
### The error may exist in com/alipay/antcloud/dsrconsole/common/dal/dao/MenuSettingDAO.java (best guess)
|
||||
### The error may involve com.alipay.antcloud.dsrconsole.common.dal.dao.MenuSettingDAO.deleteNotInIds-Inline
|
||||
### The error occurred while setting parameters
|
||||
### SQL: DELETE FROM menu_settings WHERE menu_id NOT IN
|
||||
### Cause: java.sql.SQLSyntaxErrorException: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '' at line 1
|
||||
; bad SQL grammar []; nested exception is java.sql.SQLSyntaxErrorException: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '' at line 1
|
||||
at org.springframework.jdbc.support.SQLErrorCodeSQLExceptionTranslator.doTranslate(SQLErrorCodeSQLExceptionTranslator.java:239)
|
||||
at org.springframework.jdbc.support.AbstractFallbackSQLExceptionTranslator.translate(AbstractFallbackSQLExceptionTranslator.java:72)
|
||||
at org.mybatis.spring.MyBatisExceptionTranslator.translateExceptionIfPossible(MyBatisExceptionTranslator.java:75)
|
||||
at org.mybatis.spring.SqlSessionTemplate$SqlSessionInterceptor.invoke(SqlSessionTemplate.java:447)
|
||||
at com.sun.proxy.$Proxy141.delete(Unknown Source)
|
||||
at org.mybatis.spring.SqlSessionTemplate.delete(SqlSessionTemplate.java:311)
|
||||
at org.apache.ibatis.binding.MapperMethod.execute(MapperMethod.java:72)
|
||||
at org.apache.ibatis.binding.MapperProxy$PlainMethodInvoker.invoke(MapperProxy.java:145)
|
||||
at org.apache.ibatis.binding.MapperProxy.invoke(MapperProxy.java:86)
|
||||
at com.sun.proxy.$Proxy336.deleteNotInIds(Unknown Source)
|
||||
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
|
||||
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
|
||||
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
|
||||
at java.lang.reflect.Method.invoke(Method.java:498)
|
||||
at org.springframework.aop.support.AopUtils.invokeJoinpointUsingReflection(AopUtils.java:344)
|
||||
at org.springframework.aop.framework.ReflectiveMethodInvocation.invokeJoinpoint(ReflectiveMethodInvocation.java:198)
|
||||
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:163)
|
||||
at com.alipay.antcloud.dsrconsole.core.service.interceptor.DAOInterceptor.invoke(DAOInterceptor.java:45)
|
||||
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186)
|
||||
at org.springframework.aop.framework.JdkDynamicAopProxy.invoke(JdkDynamicAopProxy.java:212)
|
||||
at com.sun.proxy.$Proxy337.deleteNotInIds(Unknown Source)
|
||||
at com.alipay.antcloud.dsrconsole.core.service.system.service.impl.SystemSettingsServiceImpl.saveMenus(SystemSettingsServiceImpl.java:67)
|
||||
at com.alipay.antcloud.dsrconsole.endpoint.webui.WebUIConfig.setMenus(WebUIConfig.java:112)
|
||||
... 48 common frames omitted
|
||||
Caused by: java.sql.SQLSyntaxErrorException: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '' at line 1
|
||||
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:120)
|
||||
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:97)
|
||||
at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:122)
|
||||
at com.mysql.cj.jdbc.ClientPreparedStatement.executeInternal(ClientPreparedStatement.java:953)
|
||||
at com.mysql.cj.jdbc.ClientPreparedStatement.execute(ClientPreparedStatement.java:370)
|
||||
at com.alibaba.druid.filter.FilterChainImpl.preparedStatement_execute(FilterChainImpl.java:3409)
|
||||
at com.alibaba.druid.filter.FilterEventAdapter.preparedStatement_execute(FilterEventAdapter.java:440)
|
||||
at com.alibaba.druid.filter.FilterChainImpl.preparedStatement_execute(FilterChainImpl.java:3407)
|
||||
at com.alibaba.druid.filter.FilterEventAdapter.preparedStatement_execute(FilterEventAdapter.java:440)
|
||||
at com.alibaba.druid.filter.FilterChainImpl.preparedStatement_execute(FilterChainImpl.java:3407)
|
||||
at com.alibaba.druid.proxy.jdbc.PreparedStatementProxyImpl.execute(PreparedStatementProxyImpl.java:167)
|
||||
at com.alibaba.druid.pool.DruidPooledPreparedStatement.execute(DruidPooledPreparedStatement.java:498)
|
||||
at org.apache.ibatis.executor.statement.PreparedStatementHandler.update(PreparedStatementHandler.java:47)
|
||||
at org.apache.ibatis.executor.statement.RoutingStatementHandler.update(RoutingStatementHandler.java:74)
|
||||
at org.apache.ibatis.executor.SimpleExecutor.doUpdate(SimpleExecutor.java:50)
|
||||
at org.apache.ibatis.executor.BaseExecutor.update(BaseExecutor.java:117)
|
||||
at org.apache.ibatis.executor.CachingExecutor.update(CachingExecutor.java:76)
|
||||
at org.apache.ibatis.session.defaults.DefaultSqlSession.update(DefaultSqlSession.java:194)
|
||||
at org.apache.ibatis.session.defaults.DefaultSqlSession.delete(DefaultSqlSession.java:209)
|
||||
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
|
||||
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
|
||||
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
|
||||
at java.lang.reflect.Method.invoke(Method.java:498)
|
||||
at org.mybatis.spring.SqlSessionTemplate$SqlSessionInterceptor.invoke(SqlSessionTemplate.java:434)
|
||||
... 67 common frames omitted
|
||||
2022-11-30T15:54:21.079+0800: [GC (Allocation Failure) 2022-11-30T15:54:21.079+0800: [ParNew: 466669K->33016K(471872K), 0.0560081 secs] 539529K->108523K(3019584K), 0.0561194 secs] [Times: user=0.11 sys=0.00, real=0.05 secs]
|
||||
Alipay.jsbkclcore:name=com.antgroup.creditloan.clcore.common.util.drm.CommonGrayControlDrm.feeSubsidyQuerySwicthDrm.controlRule,version=3.0@DRM
|
||||