mirror of
https://github.com/Estom/notes.git
synced 2026-07-27 08:51:46 +08:00
优化java部分结构
This commit is contained in:
2
.vscode/settings.json
vendored
2
.vscode/settings.json
vendored
@@ -203,4 +203,6 @@
|
||||
"markdown.copyFiles.destination": {
|
||||
"**/*": "image/"
|
||||
},
|
||||
"trae.tab.enableRename": false,
|
||||
"trae.tab.enableAutoImport": false,
|
||||
}
|
||||
File diff suppressed because it is too large
Load Diff
@@ -1,97 +0,0 @@
|
||||
## 准备知识
|
||||
数据结构分为
|
||||
|
||||
* 线性数据结构
|
||||
* 树型数据结构
|
||||
* 图型数据结构
|
||||
|
||||
|
||||
C++中的容器分为(都是线性的)
|
||||
* 顺序容器
|
||||
* array 数组
|
||||
* vector向量
|
||||
* list 链表
|
||||
* 关联容器
|
||||
* map 映射
|
||||
* set 集合
|
||||
* 容器适配器
|
||||
* stack 栈
|
||||
* queue 队列
|
||||
|
||||
|
||||
Java中的集合容器分为单列集合collection和双列映射Map。除了一下基本集合类型,还有多个特殊的类型,后续补充
|
||||
* List
|
||||
* Arraylist,有序,插入序
|
||||
* vector
|
||||
* stack
|
||||
* Queue
|
||||
* linkedlist,双端队列有序,插入序
|
||||
* arrayqueue,有序,插入序
|
||||
* priorityQueue,有序,自然序
|
||||
* Set
|
||||
* hashset,无序
|
||||
* linkedhashset,有序,插入序
|
||||
* treeSet,有序,自然序
|
||||
* Map
|
||||
* hashmap,无序
|
||||
* linkedhashmap,有序,插入序
|
||||
* treemap 有序,自然序
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
## 体系
|
||||
|
||||
+ [Java 集合 - `List`](2.md)
|
||||
+ [`ArrayList`](3.md)
|
||||
+ [链表](47.md)
|
||||
+ [`Vector`](81.md)
|
||||
+ [Java 集合 - `Set`](102.md)
|
||||
+ [`HashSet`](103.md)
|
||||
+ [`LinkedHashSet`](111.md)
|
||||
+ [`TreeSet`](114.md)
|
||||
+ [Java 集合 - `Map`](117.md)
|
||||
+ [`HashMap`](118.md)
|
||||
+ [`TreeMap`](142.md)
|
||||
+ [`LinkedHashMap`](148.md)
|
||||
+ [Java 集合 - `Iterator`/`ListIterator`](152.md)
|
||||
+ [`Comparable`和`Comparator`接口](155.md)
|
||||
+ [集合面试问题](158.md)
|
||||
|
||||
|
||||
## 集合框架总览
|
||||
|
||||
|
||||
1. 集合框架提供了两个遍历接口:`Iterator`和`ListIterator`,其中后者是前者的`优化版`,支持在任意一个位置进行**前后双向遍历**。注意图中的`Collection`应当继承的是`Iterable`而不是`Iterator`,后面会解释`Iterable`和`Iterator`的区别
|
||||
2. 整个集合框架分为两个门派(类型):`Collection`和`Map`,前者是一个容器,存储一系列的**对象**;后者是键值对`<key, value>`,存储一系列的**键值对**
|
||||
3. 在集合框架体系下,衍生出四种具体的集合类型:`Map`、`Set`、`List`、`Queue`
|
||||
4. `Map`存储`<key,value>`键值对,查找元素时通过`key`查找`value`
|
||||
5. `Set`内部存储一系列**不可重复**的对象,且是一个**无序**集合,对象排列顺序不一
|
||||
6. `List`内部存储一系列**可重复**的对象,是一个**有序**集合,对象按插入顺序排列
|
||||
7. `Queue`是一个**队列**容器,其特性与`List`相同,但只能从`队头`和`队尾`操作元素
|
||||
8. JDK 为集合的各种操作提供了两个工具类`Collections`和`Arrays`,之后会讲解工具类的常用方法
|
||||
9. 四种抽象集合类型内部也会衍生出许多具有不同特性的集合类,**不同场景下择优使用,没有最佳的集合**
|
||||
|
||||
|
||||
## 对比
|
||||
|
||||
|
||||
章节结束各集合总结:(以 JDK1.8 为例)
|
||||
|
||||
| 数据类型 | 插入、删除时间复杂度 | 查询时间复杂度 | 底层数据结构 | 是否线程安全 |
|
||||
| :------------ | :------------------- | :------------- | :------------------- | :----------- |
|
||||
| Vector | O(N) | O(1) | 数组 | 是(已淘汰) |
|
||||
| ArrayList | O(N) | O(1) | 数组 | 否 |
|
||||
| LinkedList | O(1) | O(N) | 双向链表 | 否 |
|
||||
| HashSet | O(1) | O(1) | 数组+链表+红黑树 | 否 |
|
||||
| TreeSet | O(logN) | O(logN) | 红黑树 | 否 |
|
||||
| LinkedHashSet | O(1) | O(1)~O(N) | 数组 + 链表 + 红黑树 | 否 |
|
||||
| ArrayDeque | O(N) | O(1) | 数组 | 否 |
|
||||
| PriorityQueue | O(logN) | O(logN) | 堆(数组实现) | 否 |
|
||||
| HashMap | O(1) ~ O(N) | O(1) ~ O(N) | 数组+链表+红黑树 | 否 |
|
||||
| TreeMap | O(logN) | O(logN) | 数组+红黑树 | 否 |
|
||||
| HashTable | O(1) / O(N) | O(1) / O(N) | 数组+链表 | 是(已淘汰) |
|
||||
181
Java/03Java标准集合类/02 集合底层结构.md
Normal file
181
Java/03Java标准集合类/02 集合底层结构.md
Normal file
@@ -0,0 +1,181 @@
|
||||
# Java 容器
|
||||
|
||||
## 一、概览
|
||||
|
||||
容器主要包括 Collection 和 Map 两种,Collection 存储着对象的集合,而 Map 存储着键值对(两个对象)的映射表。
|
||||
|
||||
### Collection单列集合
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208220948084.png"/> </div><br>
|
||||
|
||||
#### 1. Set
|
||||
|
||||
- TreeSet:基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)。
|
||||
|
||||
- HashSet:基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
|
||||
|
||||
- LinkedHashSet:具有 HashSet 的查找效率,并且内部使用双向链表维护元素的插入顺序。
|
||||
|
||||
#### 2. List
|
||||
|
||||
- ArrayList:基于动态数组实现,支持随机访问。
|
||||
|
||||
- Vector:和 ArrayList 类似,但它是线程安全的。
|
||||
|
||||
- LinkedList:基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列和双向队列。
|
||||
|
||||
#### 3. Queue & Deque
|
||||
- ArrayDeque:基于数组实现,和 ArrayList 类似,但是 ArrayDeque 不支持随机访问。
|
||||
|
||||
- LinkedList:可以用它来实现双向队列。
|
||||
|
||||
- PriorityQueue:基于堆结构实现,可以用它来实现优先队列。
|
||||
|
||||
### Map双列映射
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20201101234335837.png"/> </div><br>
|
||||
|
||||
- TreeMap:基于红黑树实现。
|
||||
|
||||
- HashMap:基于哈希表实现。
|
||||
|
||||
- HashTable:和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程同时写入 HashTable 不会导致数据不一致。它是遗留类,不应该去使用它,而是使用 ConcurrentHashMap 来支持线程安全,ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
|
||||
|
||||
- LinkedHashMap:使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
|
||||
|
||||
|
||||
## 二、容器中的设计模式
|
||||
|
||||
### 迭代器模式
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208225301973.png"/> </div><br>
|
||||
|
||||
Collection 继承了 Iterable 接口,其中的 iterator() 方法能够产生一个 Iterator 对象,通过这个对象就可以迭代遍历 Collection 中的元素。
|
||||
|
||||
从 JDK 1.5 之后可以使用 foreach 方法来遍历实现了 Iterable 接口的聚合对象。
|
||||
|
||||
```java
|
||||
List<String> list = new ArrayList<>();
|
||||
list.add("a");
|
||||
list.add("b");
|
||||
for (String item : list) {
|
||||
System.out.println(item);
|
||||
}
|
||||
```
|
||||
|
||||
### 适配器模式
|
||||
|
||||
java.util.Arrays#asList() 可以把数组类型转换为 List 类型。
|
||||
|
||||
```java
|
||||
@SafeVarargs
|
||||
public static <T> List<T> asList(T... a)
|
||||
```
|
||||
|
||||
应该注意的是 asList() 的参数为泛型的变长参数,不能使用基本类型数组作为参数,只能使用相应的包装类型数组。
|
||||
|
||||
```java
|
||||
Integer[] arr = {1, 2, 3};
|
||||
List list = Arrays.asList(arr);
|
||||
```
|
||||
|
||||
也可以使用以下方式调用 asList():
|
||||
|
||||
```java
|
||||
List list = Arrays.asList(1, 2, 3);
|
||||
```
|
||||
|
||||
## 集合框架总览
|
||||
数据结构分为
|
||||
|
||||
* 线性数据结构
|
||||
* 树型数据结构
|
||||
* 图型数据结构
|
||||
|
||||
|
||||
C++中的容器分为(都是线性的)
|
||||
* 顺序容器
|
||||
* array 数组
|
||||
* vector向量
|
||||
* list 链表
|
||||
* 关联容器
|
||||
* map 映射
|
||||
* set 集合
|
||||
* 容器适配器
|
||||
* stack 栈
|
||||
* queue 队列
|
||||
|
||||
|
||||
Java中的集合容器分为单列集合collection和双列映射Map。除了一下基本集合类型,还有多个特殊的类型,后续补充
|
||||
* List
|
||||
* Arraylist,有序,插入序
|
||||
* vector
|
||||
* stack
|
||||
* Queue
|
||||
* linkedlist,双端队列有序,插入序
|
||||
* arrayqueue,有序,插入序
|
||||
* priorityQueue,有序,自然序
|
||||
* Set
|
||||
* hashset,无序
|
||||
* linkedhashset,有序,插入序
|
||||
* treeSet,有序,自然序
|
||||
* Map
|
||||
* hashmap,无序
|
||||
* linkedhashmap,有序,插入序
|
||||
* treemap 有序,自然序
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
1. 集合框架提供了两个遍历接口:`Iterator`和`ListIterator`,其中后者是前者的`优化版`,支持在任意一个位置进行**前后双向遍历**。注意图中的`Collection`应当继承的是`Iterable`而不是`Iterator`,后面会解释`Iterable`和`Iterator`的区别
|
||||
2. 整个集合框架分为两个门派(类型):`Collection`和`Map`,前者是一个容器,存储一系列的**对象**;后者是键值对`<key, value>`,存储一系列的**键值对**
|
||||
3. 在集合框架体系下,衍生出四种具体的集合类型:`Map`、`Set`、`List`、`Queue`
|
||||
4. `Map`存储`<key,value>`键值对,查找元素时通过`key`查找`value`
|
||||
5. `Set`内部存储一系列**不可重复**的对象,且是一个**无序**集合,对象排列顺序不一
|
||||
6. `List`内部存储一系列**可重复**的对象,是一个**有序**集合,对象按插入顺序排列
|
||||
7. `Queue`是一个**队列**容器,其特性与`List`相同,但只能从`队头`和`队尾`操作元素
|
||||
8. JDK 为集合的各种操作提供了两个工具类`Collections`和`Arrays`,之后会讲解工具类的常用方法
|
||||
9. 四种抽象集合类型内部也会衍生出许多具有不同特性的集合类,**不同场景下择优使用,没有最佳的集合**
|
||||
|
||||
|
||||
## 集合概要对比
|
||||
|
||||
|
||||
章节结束各集合总结:(以 JDK1.8 为例)
|
||||
|
||||
| 数据类型 | 插入、删除时间复杂度 | 查询时间复杂度 | 底层数据结构 | 是否线程安全 |
|
||||
| :------------ | :------------------- | :------------- | :------------------- | :----------- |
|
||||
| Vector | O(N) | O(1) | 数组 | 是(已淘汰) |
|
||||
| ArrayList | O(N) | O(1) | 数组 | 否 |
|
||||
| LinkedList | O(1) | O(N) | 双向链表 | 否(已淘汰) |
|
||||
| HashSet | O(1) | O(1) | 数组+链表+红黑树 | 否 |
|
||||
| TreeSet | O(logN) | O(logN) | 红黑树 | 否 |
|
||||
| LinkedHashSet | O(1) | O(1)~O(N) | 数组 + 链表 + 红黑树 | 否 |
|
||||
| ArrayDeque | O(N) | O(1) | 数组 | 否 |
|
||||
| PriorityQueue | O(logN) | O(logN) | 堆(数组实现) | 否 |
|
||||
| HashMap | O(1) ~ O(N) | O(1) ~ O(N) | 数组+链表+红黑树 | 否 |
|
||||
| TreeMap | O(logN) | O(logN) | 数组+红黑树 | 否 |
|
||||
| HashTable | O(1) / O(N) | O(1) / O(N) | 数组+链表 | 是(已淘汰) |
|
||||
|
||||
|
||||
## 参考资料
|
||||
|
||||
- Eckel B. Java 编程思想 [M]. 机械工业出版社, 2002.
|
||||
- [Java Collection Framework](https://www.w3resource.com/java-tutorial/java-collections.php)
|
||||
- [Iterator 模式](https://openhome.cc/Gossip/DesignPattern/IteratorPattern.htm)
|
||||
- [Java 8 系列之重新认识 HashMap](https://tech.meituan.com/java_hashmap.html)
|
||||
- [What is difference between HashMap and Hashtable in Java?](http://javarevisited.blogspot.hk/2010/10/difference-between-hashmap-and.html)
|
||||
- [Java 集合之 HashMap](http://www.zhangchangle.com/2018/02/07/Java%E9%9B%86%E5%90%88%E4%B9%8BHashMap/)
|
||||
- [The principle of ConcurrentHashMap analysis](http://www.programering.com/a/MDO3QDNwATM.html)
|
||||
- [探索 ConcurrentHashMap 高并发性的实现机制](https://www.ibm.com/developerworks/cn/java/java-lo-concurrenthashmap/)
|
||||
- [HashMap 相关面试题及其解答](https://www.jianshu.com/p/75adf47958a7)
|
||||
- [Java 集合细节(二):asList 的缺陷](http://wiki.jikexueyuan.com/project/java-enhancement/java-thirtysix.html)
|
||||
- [Java Collection Framework – The LinkedList Class](http://javaconceptoftheday.com/java-collection-framework-linkedlist-class/)
|
||||
|
||||
@@ -29,7 +29,27 @@ AbstractSequentialList 抽象类继承了 AbstractList,在原基础上限制
|
||||
|
||||
## 1 ArrayList
|
||||
|
||||
### 底层原理
|
||||
|
||||
### ArrayList底层原理
|
||||
|
||||
|
||||
#### 1. 概览
|
||||
|
||||
因为 ArrayList 是基于数组实现的,所以支持快速随机访问。RandomAccess 接口标识着该类支持快速随机访问。
|
||||
|
||||
```java
|
||||
public class ArrayList<E> extends AbstractList<E>
|
||||
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
|
||||
```
|
||||
|
||||
数组的默认大小为 10。
|
||||
|
||||
```java
|
||||
private static final int DEFAULT_CAPACITY = 10;
|
||||
```
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208232221265.png"/> </div><br>
|
||||
|
||||
ArrayList 以**数组**作为存储结构,它是**线程不安全**的集合;具有**查询快、在数组中间或头部增删慢**的特点,所以它除了线程不安全这一点,其余可以替代`Vector`,而且线程安全的 ArrayList 可以使用 `CopyOnWriteArrayList`代替 Vector。
|
||||
|
||||

|
||||
@@ -69,6 +89,136 @@ private static int calculateCapacity(Object[] elementData, int minCapacity) {
|
||||
|
||||

|
||||
|
||||
#### 2. 扩容
|
||||
|
||||
添加元素时使用 ensureCapacityInternal() 方法来保证容量足够,如果不够时,需要使用 grow() 方法进行扩容,新容量的大小为 `oldCapacity + (oldCapacity >> 1)`,即 oldCapacity+oldCapacity/2。其中 oldCapacity >> 1 需要取整,所以新容量大约是旧容量的 1.5 倍左右。(oldCapacity 为偶数就是 1.5 倍,为奇数就是 1.5 倍-0.5)
|
||||
|
||||
扩容操作需要调用 `Arrays.copyOf()` 把原数组整个复制到新数组中,这个操作代价很高,因此最好在创建 ArrayList 对象时就指定大概的容量大小,减少扩容操作的次数。
|
||||
|
||||
```java
|
||||
public boolean add(E e) {
|
||||
ensureCapacityInternal(size + 1); // Increments modCount!!
|
||||
elementData[size++] = e;
|
||||
return true;
|
||||
}
|
||||
|
||||
private void ensureCapacityInternal(int minCapacity) {
|
||||
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
|
||||
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
|
||||
}
|
||||
ensureExplicitCapacity(minCapacity);
|
||||
}
|
||||
|
||||
private void ensureExplicitCapacity(int minCapacity) {
|
||||
modCount++;
|
||||
// overflow-conscious code
|
||||
if (minCapacity - elementData.length > 0)
|
||||
grow(minCapacity);
|
||||
}
|
||||
|
||||
private void grow(int minCapacity) {
|
||||
// overflow-conscious code
|
||||
int oldCapacity = elementData.length;
|
||||
int newCapacity = oldCapacity + (oldCapacity >> 1);
|
||||
if (newCapacity - minCapacity < 0)
|
||||
newCapacity = minCapacity;
|
||||
if (newCapacity - MAX_ARRAY_SIZE > 0)
|
||||
newCapacity = hugeCapacity(minCapacity);
|
||||
// minCapacity is usually close to size, so this is a win:
|
||||
elementData = Arrays.copyOf(elementData, newCapacity);
|
||||
}
|
||||
```
|
||||
|
||||
#### 3. 删除元素
|
||||
|
||||
需要调用 System.arraycopy() 将 index+1 后面的元素都复制到 index 位置上,该操作的时间复杂度为 O(N),可以看到 ArrayList 删除元素的代价是非常高的。
|
||||
|
||||
```java
|
||||
public E remove(int index) {
|
||||
rangeCheck(index);
|
||||
modCount++;
|
||||
E oldValue = elementData(index);
|
||||
int numMoved = size - index - 1;
|
||||
if (numMoved > 0)
|
||||
System.arraycopy(elementData, index+1, elementData, index, numMoved);
|
||||
elementData[--size] = null; // clear to let GC do its work
|
||||
return oldValue;
|
||||
}
|
||||
```
|
||||
|
||||
#### 4. 序列化
|
||||
|
||||
ArrayList 基于数组实现,并且具有动态扩容特性,因此保存元素的数组不一定都会被使用,那么就没必要全部进行序列化。
|
||||
|
||||
保存元素的数组 elementData 使用 transient 修饰,该关键字声明数组默认不会被序列化。
|
||||
|
||||
```java
|
||||
transient Object[] elementData; // non-private to simplify nested class access
|
||||
```
|
||||
|
||||
ArrayList 实现了 writeObject() 和 readObject() 来控制只序列化数组中有元素填充那部分内容。
|
||||
|
||||
```java
|
||||
private void readObject(java.io.ObjectInputStream s)
|
||||
throws java.io.IOException, ClassNotFoundException {
|
||||
elementData = EMPTY_ELEMENTDATA;
|
||||
|
||||
// Read in size, and any hidden stuff
|
||||
s.defaultReadObject();
|
||||
|
||||
// Read in capacity
|
||||
s.readInt(); // ignored
|
||||
|
||||
if (size > 0) {
|
||||
// be like clone(), allocate array based upon size not capacity
|
||||
ensureCapacityInternal(size);
|
||||
|
||||
Object[] a = elementData;
|
||||
// Read in all elements in the proper order.
|
||||
for (int i=0; i<size; i++) {
|
||||
a[i] = s.readObject();
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
private void writeObject(java.io.ObjectOutputStream s)
|
||||
throws java.io.IOException{
|
||||
// Write out element count, and any hidden stuff
|
||||
int expectedModCount = modCount;
|
||||
s.defaultWriteObject();
|
||||
|
||||
// Write out size as capacity for behavioural compatibility with clone()
|
||||
s.writeInt(size);
|
||||
|
||||
// Write out all elements in the proper order.
|
||||
for (int i=0; i<size; i++) {
|
||||
s.writeObject(elementData[i]);
|
||||
}
|
||||
|
||||
if (modCount != expectedModCount) {
|
||||
throw new ConcurrentModificationException();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
序列化时需要使用 ObjectOutputStream 的 writeObject() 将对象转换为字节流并输出。而 writeObject() 方法在传入的对象存在 writeObject() 的时候会去反射调用该对象的 writeObject() 来实现序列化。反序列化使用的是 ObjectInputStream 的 readObject() 方法,原理类似。
|
||||
|
||||
```java
|
||||
ArrayList list = new ArrayList();
|
||||
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(file));
|
||||
oos.writeObject(list);
|
||||
```
|
||||
|
||||
#### 5. Fail-Fast
|
||||
|
||||
modCount 用来记录 ArrayList 结构发生变化的次数。结构发生变化是指添加或者删除至少一个元素的所有操作,或者是调整内部数组的大小,仅仅只是设置元素的值不算结构发生变化。
|
||||
|
||||
在进行序列化或者迭代等操作时,需要比较操作前后 modCount 是否改变,如果改变了需要抛出 ConcurrentModificationException。代码参考上节序列化中的 writeObject() 方法。
|
||||
|
||||
|
||||
|
||||
### 构造函数
|
||||
|
||||
* 没有逐个元素初始化的方法,使用Arrays.asList能够添加对象初始化。
|
||||
@@ -539,7 +689,90 @@ public class ArrayListExample
|
||||
}
|
||||
```
|
||||
|
||||
## 2 Vector
|
||||
## 2 Vector :warning: 已弃用
|
||||
|
||||
|
||||
### 同步
|
||||
|
||||
它的实现与 ArrayList 类似,但是使用了 synchronized 进行同步。
|
||||
|
||||
```java
|
||||
public synchronized boolean add(E e) {
|
||||
modCount++;
|
||||
ensureCapacityHelper(elementCount + 1);
|
||||
elementData[elementCount++] = e;
|
||||
return true;
|
||||
}
|
||||
|
||||
public synchronized E get(int index) {
|
||||
if (index >= elementCount)
|
||||
throw new ArrayIndexOutOfBoundsException(index);
|
||||
|
||||
return elementData(index);
|
||||
}
|
||||
```
|
||||
|
||||
### 扩容
|
||||
|
||||
Vector 的构造函数可以传入 capacityIncrement 参数,它的作用是在扩容时使容量 capacity 增长 capacityIncrement。如果这个参数的值小于等于 0,扩容时每次都令 capacity 为原来的两倍。
|
||||
|
||||
```java
|
||||
public Vector(int initialCapacity, int capacityIncrement) {
|
||||
super();
|
||||
if (initialCapacity < 0)
|
||||
throw new IllegalArgumentException("Illegal Capacity: "+
|
||||
initialCapacity);
|
||||
this.elementData = new Object[initialCapacity];
|
||||
this.capacityIncrement = capacityIncrement;
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
private void grow(int minCapacity) {
|
||||
// overflow-conscious code
|
||||
int oldCapacity = elementData.length;
|
||||
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
|
||||
capacityIncrement : oldCapacity);
|
||||
if (newCapacity - minCapacity < 0)
|
||||
newCapacity = minCapacity;
|
||||
if (newCapacity - MAX_ARRAY_SIZE > 0)
|
||||
newCapacity = hugeCapacity(minCapacity);
|
||||
elementData = Arrays.copyOf(elementData, newCapacity);
|
||||
}
|
||||
```
|
||||
|
||||
调用没有 capacityIncrement 的构造函数时,capacityIncrement 值被设置为 0,也就是说默认情况下 Vector 每次扩容时容量都会翻倍。
|
||||
|
||||
```java
|
||||
public Vector(int initialCapacity) {
|
||||
this(initialCapacity, 0);
|
||||
}
|
||||
|
||||
public Vector() {
|
||||
this(10);
|
||||
}
|
||||
```
|
||||
|
||||
### 与 ArrayList 的比较
|
||||
|
||||
- Vector 是同步的,因此开销就比 ArrayList 要大,访问速度更慢。最好使用 ArrayList 而不是 Vector,因为同步操作完全可以由程序员自己来控制;
|
||||
- Vector 每次扩容请求其大小的 2 倍(也可以通过构造函数设置增长的容量),而 ArrayList 是 1.5 倍。
|
||||
|
||||
### 替代方案
|
||||
|
||||
可以使用 `Collections.synchronizedList();` 得到一个线程安全的 ArrayList。
|
||||
|
||||
```java
|
||||
List<String> list = new ArrayList<>();
|
||||
List<String> synList = Collections.synchronizedList(list);
|
||||
```
|
||||
|
||||
也可以使用 concurrent 并发包下的 CopyOnWriteArrayList 类。
|
||||
|
||||
```java
|
||||
List<String> list = new CopyOnWriteArrayList<>();
|
||||
```
|
||||
|
||||
### 底层原理
|
||||
|
||||

|
||||
@@ -558,7 +791,7 @@ public synchronized E get(int index);
|
||||
现在,在**线程安全**的情况下,不需要选用 Vector 集合,取而代之的是 **ArrayList** 集合;在并发环境下,出现了 `CopyOnWriteArrayList`,Vector 完全被弃用了。
|
||||
|
||||
|
||||
## 3 Stack
|
||||
## 3 Stack :warning: 已弃用
|
||||
### 底层原理
|
||||
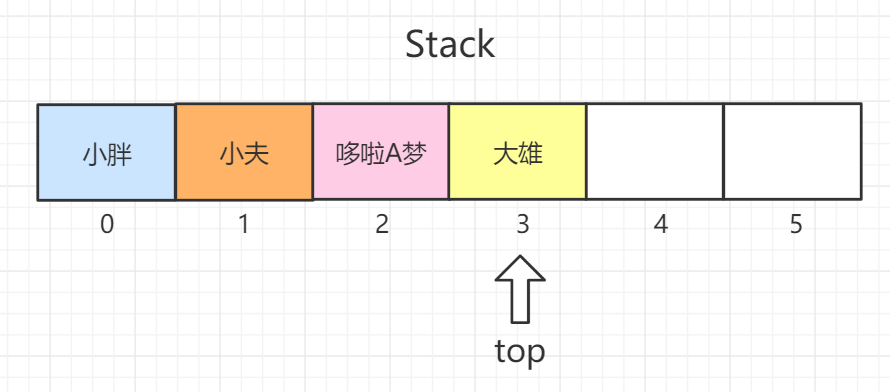
|
||||
|
||||
@@ -575,55 +808,38 @@ Deque<Integer> stack = new ArrayDeque<Integer>();
|
||||
ArrayDeque 的数据结构是:`数组`,并提供**头尾指针下标**对数组元素进行操作。本文也会讲到哦,客官请继续往下看,莫着急!:smile:
|
||||
|
||||
|
||||
## 4 CopyOnWriteArrayList
|
||||
> 用来替代vector,提供现成安全的list
|
||||
### 底层原理
|
||||
## 4 LinkedList :warning: 已弃用
|
||||
|
||||
Java CopyOnWriteArrayList是ArrayList的thread-safe变体,其中所有可变操作(添加,设置等)都通过对基础array进行全新复制来实现。
|
||||
### 1. 概览
|
||||
|
||||
* CopyOnWriteArrayList类实现List和RandomAccess接口,因此提供ArrayList类中可用的所有功能。
|
||||
* 使用CopyOnWriteArrayList进行更新操作的成本很高,因为每个突变都会创建基础数组的克隆副本,并为其添加/更新元素。
|
||||
* 它是ArrayList的线程安全版本。 每个访问列表的线程在初始化此列表的迭代器时都会看到自己创建的后备阵列快照版本。
|
||||
* 因为它在创建迭代器时获取基础数组的快照,所以它不会抛出ConcurrentModificationException 。
|
||||
* 不支持对迭代器的删除操作(删除,设置和添加)。 这些方法抛出UnsupportedOperationException 。
|
||||
* CopyOnWriteArrayList是synchronized List的并发替代,当迭代的次数超过突变次数时,CopyOnWriteArrayList可以提供更好的并发性。
|
||||
* 它允许重复的元素和异构对象(使用泛型来获取编译时错误)。因为它每次创建迭代器时都会创建一个新的数组副本,所以performance is slower比ArrayList performance is slower 。
|
||||
|
||||
|
||||
### 实例
|
||||
基于双向链表实现,使用 Node 存储链表节点信息。
|
||||
|
||||
```java
|
||||
CopyOnWriteArrayList<Integer> list = new CopyOnWriteArrayList<>(new Integer[] {1,2,3});
|
||||
|
||||
System.out.println(list); //[1, 2, 3]
|
||||
|
||||
//Get iterator 1
|
||||
Iterator<Integer> itr1 = list.iterator();
|
||||
|
||||
//Add one element and verify list is updated
|
||||
list.add(4);
|
||||
|
||||
System.out.println(list); //[1, 2, 3, 4]
|
||||
|
||||
//Get iterator 2
|
||||
Iterator<Integer> itr2 = list.iterator();
|
||||
|
||||
System.out.println("====Verify Iterator 1 content====");
|
||||
|
||||
itr1.forEachRemaining(System.out :: println); //1,2,3
|
||||
|
||||
System.out.println("====Verify Iterator 2 content====");
|
||||
|
||||
itr2.forEachRemaining(System.out :: println); //1,2,3,4
|
||||
private static class Node<E> {
|
||||
E item;
|
||||
Node<E> next;
|
||||
Node<E> prev;
|
||||
}
|
||||
```
|
||||
|
||||
### 主要方法
|
||||
每个链表存储了 first 和 last 指针:
|
||||
|
||||
```java
|
||||
CopyOnWriteArrayList() :创建一个空列表。
|
||||
CopyOnWriteArrayList(Collection c) :创建一个列表,该列表包含指定集合的元素,并按集合的迭代器返回它们的顺序。
|
||||
CopyOnWriteArrayList(object[] array) :创建一个保存给定数组副本的列表。
|
||||
boolean addIfAbsent(object o) :如果不存在则追加元素。
|
||||
int addAllAbsent(Collection c) :以指定集合的迭代器返回的顺序,将指定集合中尚未包含在此列表中的所有元素追加到此列表的末尾。
|
||||
transient Node<E> first;
|
||||
transient Node<E> last;
|
||||
```
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208233940066.png"/> </div><br>
|
||||
|
||||
### 2. 与 ArrayList 的比较
|
||||
|
||||
ArrayList 基于动态数组实现,LinkedList 基于双向链表实现。ArrayList 和 LinkedList 的区别可以归结为数组和链表的区别:
|
||||
|
||||
- 数组支持随机访问,但插入删除的代价很高,需要移动大量元素;移动元素已经有内核级的优化。
|
||||
- 链表不支持随机访问,但插入删除只需要改变指针。需要提前进行大量O(n)的查找,性能并没有优势。
|
||||
|
||||
|
||||
在大多数场景下,已经没有使用价值。
|
||||
1. 元素索引的操作,ArrayList的随机访问更高。
|
||||
2. 元素收尾插入删除的操作,ArrayDeque循环数组具有更快的优势。
|
||||
3. 对于队列内部插入删除操作,虽然只有O(1),不需要移动元素,但是需要事先查找元素O(n),导致在实际使用中性能极其低下。
|
||||
@@ -49,7 +49,7 @@ AbstractQueue 类中提供了各个 API 的基本实现,主要针对各个不
|
||||
|
||||
|
||||
|
||||
## 1 LinkedList
|
||||
## 1 LinkedList :warning: 已废弃
|
||||
|
||||
### 继承关系
|
||||
|
||||
@@ -214,318 +214,3 @@ Iterator iterator() :返回对该队列中的元素进行迭代的迭代器。
|
||||
int size() :返回此队列中的元素数。
|
||||
Object[] toArray() :返回一个包含此队列中所有元素的数组。
|
||||
```
|
||||
|
||||
|
||||
## 4 PriorityBlockingQueue
|
||||
|
||||
### 底层原理
|
||||
Java PriorityBlockingQueue类是concurrent阻塞队列数据结构的实现,其中根据对象的priority对其进行处理。 名称的“阻塞”部分已添加,表示线程将阻塞等待,直到队列上有可用的项目为止 。
|
||||
|
||||
在priority blocking queue ,添加的对象根据其优先级进行排序。 默认情况下,优先级由对象的自然顺序决定。 队列构建时提供的Comparator器可以覆盖默认优先级。
|
||||
* PriorityBlockingQueue是一个无界队列,并且会动态增长。 默认初始容量为'11' ,可以在适当的构造函数中使用initialCapacity参数覆盖此初始容量。
|
||||
* 它**提供了阻塞检索操作**。
|
||||
* 它不允许使用NULL对象。
|
||||
* 添加到PriorityBlockingQueue的对象必须具有可比性,否则它将引发ClassCastException 。
|
||||
* 默认情况下,优先级队列的对象以自然顺序排序 。
|
||||
* 比较器可用于队列中对象的自定义排序。
|
||||
* 优先级队列的head是基于自然排序或基于比较器排序的least元素。 当我们轮询队列时,它从队列中返回头对象。
|
||||
* 如果存在多个具有相同优先级的对象,则它可以随机轮询其中的任何一个。
|
||||
* PriorityBlockingQueue是thread safe 。
|
||||
|
||||
### 主要方法
|
||||
|
||||
```java
|
||||
boolean add(object) :将指定的元素插入此优先级队列。
|
||||
boolean offer(object) :将指定的元素插入此优先级队列。
|
||||
boolean remove(object) :从此队列中移除指定元素的单个实例(如果存在)。
|
||||
Object poll() :检索并删除此队列的头部,并在必要时等待指定的等待时间,以使元素可用。
|
||||
Object poll(timeout, timeUnit) :检索并删除此队列的头部,如果有必要,直到指定的等待时间,元素才可用。
|
||||
Object take() :检索并删除此队列的头部,如有必要,请等待直到元素可用。
|
||||
void put(Object o) :将指定的元素插入此优先级队列。
|
||||
void clear() :从此优先级队列中删除所有元素。
|
||||
Comparator comparator() :返回用于对此队列中的元素进行排序的Comparator comparator()如果此队列是根据其元素的自然顺序排序的,则返回null。
|
||||
boolean contains(Object o) :如果此队列包含指定的元素,则返回true。
|
||||
Iterator iterator() :返回对该队列中的元素进行迭代的迭代器。
|
||||
int size() :返回此队列中的元素数。
|
||||
int drainTo(Collection c) :从此队列中删除所有可用元素,并将它们添加到给定的collection中。
|
||||
intrainToTo(Collection c,int maxElements) :从此队列中最多移除给定数量的可用元素,并将它们添加到给定的collection中。
|
||||
int remainingCapacity() Integer.MAX_VALUE int remainingCapacity() :总是返回Integer.MAX_VALUE因为PriorityBlockingQueue不受容量限制。
|
||||
Object[] toArray() :返回一个包含此队列中所有元素的数组。
|
||||
```
|
||||
### 实例
|
||||
```java
|
||||
import java.util.concurrent.PriorityBlockingQueue;
|
||||
import java.util.concurrent.TimeUnit;
|
||||
|
||||
public class PriorityQueueExample
|
||||
{
|
||||
public static void main(String[] args) throws InterruptedException
|
||||
{
|
||||
PriorityBlockingQueue<Integer> priorityBlockingQueue = new PriorityBlockingQueue<>();
|
||||
|
||||
new Thread(() ->
|
||||
{
|
||||
System.out.println("Waiting to poll ...");
|
||||
|
||||
try
|
||||
{
|
||||
while(true)
|
||||
{
|
||||
Integer poll = priorityBlockingQueue.take();
|
||||
System.out.println("Polled : " + poll);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(1));
|
||||
}
|
||||
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}).start();
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(2));
|
||||
priorityBlockingQueue.add(1);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(2));
|
||||
priorityBlockingQueue.add(2);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(2));
|
||||
priorityBlockingQueue.add(3);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 5 ArrayBlockingQueue
|
||||
|
||||
### 底层原理
|
||||
|
||||
ArrayBlockingQueue类是由数组支持的Java concurrent和bounded阻塞队列实现。 它对元素FIFO(先进先出)进行排序。
|
||||
|
||||
ArrayBlockingQueue的head是一直在队列中最长时间的那个元素。 ArrayBlockingQueue的tail是最短时间进入队列的元素。 新元素插入到队列的尾部 ,并且队列检索操作在队列的开头获取元素 。
|
||||
|
||||
* ArrayBlockingQueue是由数组支持的固定大小的有界队列。
|
||||
* 它对元素FIFO(先进先出)进行排序。
|
||||
* 元素插入到尾部,并从队列的开头检索。
|
||||
* 创建后,队列的容量无法更改。
|
||||
* 它提供阻塞的插入和检索操作 。
|
||||
* 它不允许使用NULL对象。
|
||||
* ArrayBlockingQueue是thread safe 。
|
||||
* 方法iterator()提供的Iterator按从第一个(头)到最后一个(尾部)的顺序遍历元素。
|
||||
* ArrayBlockingQueue支持可选的fairness policy用于订购等待的生产者线程和使用者线程。 将fairness设置为true ,队列按FIFO顺序授予线程访问权限。
|
||||
|
||||
|
||||
|
||||
|
||||
### 生产消费者实例
|
||||
使用阻塞插入和检索从ArrayBlockingQueue中放入和取出元素的Java示例。
|
||||
|
||||
* 当队列已满时,生产者线程将等待。 一旦从队列中取出一个元素,它就会将该元素添加到队列中。
|
||||
* 如果队列为空,使用者线程将等待。 队列中只有一个元素时,它将取出该元素。
|
||||
```java
|
||||
import java.util.concurrent.ArrayBlockingQueue;
|
||||
import java.util.concurrent.TimeUnit;
|
||||
|
||||
public class ArrayBlockingQueueExample
|
||||
{
|
||||
public static void main(String[] args) throws InterruptedException
|
||||
{
|
||||
ArrayBlockingQueue<Integer> priorityBlockingQueue = new ArrayBlockingQueue<>(5);
|
||||
|
||||
//Producer thread
|
||||
new Thread(() ->
|
||||
{
|
||||
int i = 0;
|
||||
try
|
||||
{
|
||||
while (true)
|
||||
{
|
||||
priorityBlockingQueue.put(++i);
|
||||
System.out.println("Added : " + i);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(1));
|
||||
}
|
||||
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}).start();
|
||||
|
||||
//Consumer thread
|
||||
new Thread(() ->
|
||||
{
|
||||
try
|
||||
{
|
||||
while (true)
|
||||
{
|
||||
Integer poll = priorityBlockingQueue.take();
|
||||
System.out.println("Polled : " + poll);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(2));
|
||||
}
|
||||
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}).start();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 主要方法
|
||||
|
||||
```java
|
||||
ArrayBlockingQueue(int capacity) :构造具有给定(固定)容量和默认访问策略的空队列。
|
||||
ArrayBlockingQueue(int capacity,boolean fair) :构造具有给定(固定)容量和指定访问策略的空队列。 如果公允值为true ,则按FIFO顺序处理在插入或移除时阻塞的线程的队列访问; 如果为false,则未指定访问顺序。
|
||||
ArrayBlockingQueue(int capacity,boolean fair,Collection c) :构造一个队列,该队列具有给定(固定)的容量,指定的访问策略,并最初包含给定集合的元素,并以集合迭代器的遍历顺序添加。
|
||||
void put(Object o) :将指定的元素插入此队列的尾部,如果队列已满,则等待空间变为可用。
|
||||
boolean add(object) : Inserts the specified element at the tail of this queue if it is possible to do so immediately without exceeding the queue’s capacity, returning true upon success and throwing an IllegalStateException if this queue is full.
|
||||
boolean offer(object) :如果可以在不超出队列容量的情况下立即执行此操作,则在此队列的尾部插入指定的元素,如果成功,则返回true,如果此队列已满,则抛出IllegalStateException。
|
||||
boolean remove(object) :从此队列中移除指定元素的单个实例(如果存在)。
|
||||
Object peek() :检索但不删除此队列的头部;如果此队列为空,则返回null。
|
||||
Object poll() :检索并删除此队列的头部;如果此队列为空,则返回null。
|
||||
Object poll(timeout, timeUnit) :检索并删除此队列的头部,如果有必要,直到指定的等待时间,元素才可用。
|
||||
Object take() :检索并删除此队列的头部,如有必要,请等待直到元素可用。
|
||||
void clear() :从队列中删除所有元素。
|
||||
boolean contains(Object o) :如果此队列包含指定的元素,则返回true。
|
||||
Iterator iterator() :以适当的顺序返回对该队列中的元素进行迭代的迭代器。
|
||||
int size() :返回此队列中的元素数。
|
||||
int drainTo(Collection c) :从此队列中删除所有可用元素,并将它们添加到给定的collection中。
|
||||
intrainToTo(Collection c,int maxElements) :从此队列中最多移除给定数量的可用元素,并将它们添加到给定的collection中。
|
||||
int remainingCapacity() :返回该队列理想情况下(在没有内存或资源限制的情况下)可以接受而不阻塞的其他元素的数量。
|
||||
Object[] toArray() :以适当的顺序返回一个包含此队列中所有元素的数组。
|
||||
```
|
||||
|
||||
|
||||
## 6 LinkedTransferQueue
|
||||
|
||||
### 底层原理
|
||||
|
||||
直接消息队列。也就是说,生产者生产后,必须等待消费者来消费才能继续执行。
|
||||
|
||||
Java TransferQueue是并发阻塞队列的实现,生产者可以在其中等待使用者使用消息。 LinkedTransferQueue类是Java中TransferQueue的实现。
|
||||
|
||||
|
||||
* LinkedTransferQueue是链接节点上的unbounded队列。
|
||||
* 此队列针对任何给定的生产者对元素FIFO(先进先出)进行排序。
|
||||
* 元素插入到尾部,并从队列的开头检索。
|
||||
* 它提供阻塞的插入和检索操作 。
|
||||
* 它不允许使用NULL对象。
|
||||
* LinkedTransferQueue是thread safe 。
|
||||
* 由于异步性质,size()方法不是固定时间操作,因此,如果在遍历期间修改此集合,则可能会报告不正确的结果。
|
||||
* 不保证批量操作addAll,removeAll,retainAll,containsAll,equals和toArray是原子执行的。 例如,与addAll操作并发操作的迭代器可能仅查看某些添加的元素。
|
||||
|
||||
|
||||
|
||||
### 实例
|
||||
非阻塞实例
|
||||
|
||||
```java
|
||||
LinkedTransferQueue<Integer> linkedTransferQueue = new LinkedTransferQueue<>();
|
||||
|
||||
linkedTransferQueue.put(1);
|
||||
|
||||
System.out.println("Added Message = 1");
|
||||
|
||||
Integer message = linkedTransferQueue.poll();
|
||||
|
||||
System.out.println("Recieved Message = " + message);
|
||||
```
|
||||
|
||||
阻塞插入实例,用于现成状态同步通信
|
||||
使用阻塞插入和检索从LinkedTransferQueue放入和取出元素的Java示例。
|
||||
|
||||
* 生产者线程将等待,直到有消费者准备从队列中取出项目为止。
|
||||
* 如果队列为空,使用者线程将等待。 队列中只有一个元素时,它将取出该元素。 只有在消费者接受了消息之后,生产者才可以再发送一条消息。
|
||||
|
||||
|
||||
|
||||
|
||||
```java
|
||||
import java.util.Random;
|
||||
import java.util.concurrent.LinkedTransferQueue;
|
||||
import java.util.concurrent.TimeUnit;
|
||||
|
||||
public class LinkedTransferQueueExample
|
||||
{
|
||||
public static void main(String[] args) throws InterruptedException
|
||||
{
|
||||
LinkedTransferQueue<Integer> linkedTransferQueue = new LinkedTransferQueue<>();
|
||||
|
||||
new Thread(() ->
|
||||
{
|
||||
Random random = new Random(1);
|
||||
try
|
||||
{
|
||||
while (true)
|
||||
{
|
||||
System.out.println("Producer is waiting to transfer message...");
|
||||
|
||||
Integer message = random.nextInt();
|
||||
boolean added = linkedTransferQueue.tryTransfer(message);
|
||||
if(added) {
|
||||
System.out.println("Producer added the message - " + message);
|
||||
}
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(3));
|
||||
}
|
||||
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}).start();
|
||||
|
||||
new Thread(() ->
|
||||
{
|
||||
try
|
||||
{
|
||||
while (true)
|
||||
{
|
||||
System.out.println("Consumer is waiting to take message...");
|
||||
|
||||
Integer message = linkedTransferQueue.take();
|
||||
|
||||
System.out.println("Consumer recieved the message - " + message);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(3));
|
||||
}
|
||||
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}).start();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### 主要方法
|
||||
|
||||
```java
|
||||
LinkedTransferQueue() :构造一个初始为空的LinkedTransferQueue。
|
||||
LinkedTransferQueue(Collection c) :构造一个LinkedTransferQueue,最初包含给定集合的元素,并以该集合的迭代器的遍历顺序添加。
|
||||
Object take() :检索并删除此队列的头部,如有必要,请等待直到元素可用。
|
||||
void transfer(Object o) :将元素传输给使用者,如有必要,请等待。
|
||||
boolean tryTransfer(Object o) :如果可能,立即将元素传输到等待的使用者。
|
||||
boolean tryTransfer(Object o,long timeout,TimeUnit unit) :如果有可能,则在超时之前将元素传输给使用者。
|
||||
int getWaitingConsumerCount() :返回等待通过BlockingQueue.take()或定时轮询接收元素的使用者数量的估计值。
|
||||
boolean hasWaitingConsumer() :如果至少有一个使用者正在等待通过BlockingQueue.take()或定时轮询接收元素,则返回true。
|
||||
void put(Object o) :将指定的元素插入此队列的尾部。
|
||||
boolean add(object) : Inserts the specified element at the tail of this queue.
|
||||
boolean offer(object) :将指定的元素插入此队列的尾部。
|
||||
boolean remove(object) :从此队列中移除指定元素的单个实例(如果存在)。
|
||||
Object peek() :检索但不删除此队列的头部;如果此队列为空,则返回null。
|
||||
Object poll() :检索并删除此队列的头部;如果此队列为空,则返回null。
|
||||
Object poll(timeout, timeUnit) :检索并删除此队列的头部,如果有必要,直到指定的等待时间,元素才可用。
|
||||
void clear() :从队列中删除所有元素。
|
||||
boolean contains(Object o) :如果此队列包含指定的元素,则返回true。
|
||||
Iterator iterator() :以适当的顺序返回对该队列中的元素进行迭代的迭代器。
|
||||
int size() :返回此队列中的元素数。
|
||||
int drainTo(Collection c) :从此队列中删除所有可用元素,并将它们添加到给定的collection中。
|
||||
intrainToTo(Collection c,int maxElements) :从此队列中最多移除给定数量的可用元素,并将它们添加到给定的collection中。
|
||||
int remainingCapacity() :返回该队列理想情况下(在没有内存或资源限制的情况下)可以接受而不阻塞的其他元素的数量。
|
||||
Object[] toArray() :以适当的顺序返回一个包含此队列中所有元素的数组。
|
||||
```
|
||||
|
||||
|
||||
@@ -283,62 +283,3 @@ Object clone() :返回TreeSet的浅表副本。
|
||||
Spliterator<E> spliterator() :在此TreeSet中的元素上创建后绑定和故障快速的Spliterator。 它与树集提供的顺序相同。
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 4 CopyOnWriteArraySet
|
||||
|
||||
### 底层原理
|
||||
HashSet的thread-safe变体,它对所有操作都使用基础CopyOnWriteArrayList
|
||||
|
||||
与CopyOnWriteArrayList相似,它的immutable snapshot样式iterator方法在创建iterator使用对数组状态(在后备列表内)的引用。 这在遍历操作远远超过集合更新操作且我们不想同步遍历并且在更新集合时仍希望线程安全的用例中很有用。
|
||||
|
||||
* 作为正常设置的数据结构,它不允许重复。
|
||||
* CopyOnWriteArraySet类实现Serializable接口并扩展AbstractSet类。
|
||||
* 使用CopyOnWriteArraySet进行更新操作成本很高,因为每个突变都会创建基础数组的克隆副本并向其添加/更新元素。
|
||||
* 它是HashSet的线程安全版本。 每个访问该集合的线程在初始化此集合的迭代器时都会看到自己创建的后备阵列快照版本。
|
||||
* 因为它在创建迭代器时获取基础数组的快照,所以它不会抛出ConcurrentModificationException 。不支持迭代器上的变异操作。 这些方法抛出UnsupportedOperationException 。
|
||||
* CopyOnWriteArraySet是synchronized Set的并发替代,当迭代的次数超过突变次数时,CopyOnWriteArraySet提供更好的并发性。
|
||||
* 它允许重复的元素和异构对象(使用泛型来获取编译时错误)。
|
||||
* 由于每次创建迭代器时都会创建基础数组的新副本,因此performance is slower HashSet
|
||||
|
||||
### 主要方法
|
||||
|
||||
```java
|
||||
CopyOnWriteArraySet() :创建一个空集。
|
||||
CopyOnWriteArraySet(Collection c) :创建一个包含指定集合元素的集合,其顺序由集合的迭代器返回。
|
||||
boolean add(object o) :将指定的元素添加到此集合(如果尚不存在)。
|
||||
boolean addAll(collection c) :将指定集合中的所有元素(如果尚不存在boolean addAll(collection c)添加到此集合中。
|
||||
void clear() :从此集合中删除所有元素。
|
||||
boolean contains(Object o) :如果此集合包含指定的元素,则返回true。
|
||||
boolean isEmpty() :如果此集合不包含任何元素,则返回true。
|
||||
Iterator iterator() :以添加这些元素的顺序在此集合中包含的元素上返回一个迭代器。
|
||||
boolean remove(Object o) :从指定的集合中删除指定的元素(如果存在)。
|
||||
int size() :返回此集合中的元素数
|
||||
```
|
||||
|
||||
|
||||
### 实例
|
||||
|
||||
```java
|
||||
CopyOnWriteArraySet<Integer> set = new CopyOnWriteArraySet<>(Arrays.asList(1,2,3));
|
||||
|
||||
System.out.println(set); //[1, 2, 3]
|
||||
|
||||
//Get iterator 1
|
||||
Iterator<Integer> itr1 = set.iterator();
|
||||
|
||||
//Add one element and verify set is updated
|
||||
set.add(4);
|
||||
System.out.println(set); //[1, 2, 3, 4]
|
||||
|
||||
//Get iterator 2
|
||||
Iterator<Integer> itr2 = set.iterator();
|
||||
|
||||
System.out.println("====Verify Iterator 1 content====");
|
||||
|
||||
itr1.forEachRemaining(System.out :: println); //1,2,3
|
||||
|
||||
System.out.println("====Verify Iterator 2 content====");
|
||||
|
||||
itr2.forEachRemaining(System.out :: println); //1,2,3,4
|
||||
```
|
||||
@@ -30,6 +30,381 @@ HashMap 底层是用数组 + 链表 + 红黑树这三种数据结构实现,它
|
||||
2. HashMap不是线程安全的
|
||||
3. 插入元素时,通过计算元素的`哈希值`,通过**哈希映射函数**转换为`数组下标`;查找元素时,同样通过哈希映射函数得到数组下标`定位元素的位置`
|
||||
|
||||
|
||||
#### 1. 存储结构
|
||||
|
||||
内部包含了一个 Entry 类型的数组 table。Entry 存储着键值对。它包含了四个字段,从 next 字段我们可以看出 Entry 是一个链表。即数组中的每个位置被当成一个桶,一个桶存放一个链表。HashMap 使用拉链法来解决冲突,同一个链表中存放哈希值和散列桶取模运算结果相同的 Entry。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208234948205.png"/> </div><br>
|
||||
|
||||
```java
|
||||
transient Entry[] table;
|
||||
```
|
||||
|
||||
```java
|
||||
static class Entry<K,V> implements Map.Entry<K,V> {
|
||||
final K key;
|
||||
V value;
|
||||
Entry<K,V> next;
|
||||
int hash;
|
||||
|
||||
Entry(int h, K k, V v, Entry<K,V> n) {
|
||||
value = v;
|
||||
next = n;
|
||||
key = k;
|
||||
hash = h;
|
||||
}
|
||||
|
||||
public final K getKey() {
|
||||
return key;
|
||||
}
|
||||
|
||||
public final V getValue() {
|
||||
return value;
|
||||
}
|
||||
|
||||
public final V setValue(V newValue) {
|
||||
V oldValue = value;
|
||||
value = newValue;
|
||||
return oldValue;
|
||||
}
|
||||
|
||||
public final boolean equals(Object o) {
|
||||
if (!(o instanceof Map.Entry))
|
||||
return false;
|
||||
Map.Entry e = (Map.Entry)o;
|
||||
Object k1 = getKey();
|
||||
Object k2 = e.getKey();
|
||||
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
|
||||
Object v1 = getValue();
|
||||
Object v2 = e.getValue();
|
||||
if (v1 == v2 || (v1 != null && v1.equals(v2)))
|
||||
return true;
|
||||
}
|
||||
return false;
|
||||
}
|
||||
|
||||
public final int hashCode() {
|
||||
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
|
||||
}
|
||||
|
||||
public final String toString() {
|
||||
return getKey() + "=" + getValue();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 2. 拉链法的工作原理
|
||||
|
||||
```java
|
||||
HashMap<String, String> map = new HashMap<>();
|
||||
map.put("K1", "V1");
|
||||
map.put("K2", "V2");
|
||||
map.put("K3", "V3");
|
||||
```
|
||||
|
||||
- 新建一个 HashMap,默认大小为 16;
|
||||
- 插入 <K1,V1\> 键值对,先计算 K1 的 hashCode 为 115,使用除留余数法得到所在的桶下标 115%16=3。
|
||||
- 插入 <K2,V2\> 键值对,先计算 K2 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6。
|
||||
- 插入 <K3,V3\> 键值对,先计算 K3 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6,插在 <K2,V2\> 前面。
|
||||
|
||||
应该注意到链表的插入是以头插法方式进行的,例如上面的 <K3,V3\> 不是插在 <K2,V2\> 后面,而是插入在链表头部。
|
||||
|
||||
查找需要分成两步进行:
|
||||
|
||||
- 计算键值对所在的桶;
|
||||
- 在链表上顺序查找,时间复杂度显然和链表的长度成正比。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208235258643.png"/> </div><br>
|
||||
|
||||
#### 3. put 操作
|
||||
|
||||
```java
|
||||
public V put(K key, V value) {
|
||||
if (table == EMPTY_TABLE) {
|
||||
inflateTable(threshold);
|
||||
}
|
||||
// 键为 null 单独处理
|
||||
if (key == null)
|
||||
return putForNullKey(value);
|
||||
int hash = hash(key);
|
||||
// 确定桶下标
|
||||
int i = indexFor(hash, table.length);
|
||||
// 先找出是否已经存在键为 key 的键值对,如果存在的话就更新这个键值对的值为 value
|
||||
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
|
||||
Object k;
|
||||
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
|
||||
V oldValue = e.value;
|
||||
e.value = value;
|
||||
e.recordAccess(this);
|
||||
return oldValue;
|
||||
}
|
||||
}
|
||||
|
||||
modCount++;
|
||||
// 插入新键值对
|
||||
addEntry(hash, key, value, i);
|
||||
return null;
|
||||
}
|
||||
```
|
||||
|
||||
HashMap 允许插入键为 null 的键值对。但是因为无法调用 null 的 hashCode() 方法,也就无法确定该键值对的桶下标,只能通过强制指定一个桶下标来存放。HashMap 使用第 0 个桶存放键为 null 的键值对。
|
||||
|
||||
```java
|
||||
private V putForNullKey(V value) {
|
||||
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
|
||||
if (e.key == null) {
|
||||
V oldValue = e.value;
|
||||
e.value = value;
|
||||
e.recordAccess(this);
|
||||
return oldValue;
|
||||
}
|
||||
}
|
||||
modCount++;
|
||||
addEntry(0, null, value, 0);
|
||||
return null;
|
||||
}
|
||||
```
|
||||
|
||||
使用链表的头插法,也就是新的键值对插在链表的头部,而不是链表的尾部。
|
||||
|
||||
```java
|
||||
void addEntry(int hash, K key, V value, int bucketIndex) {
|
||||
if ((size >= threshold) && (null != table[bucketIndex])) {
|
||||
resize(2 * table.length);
|
||||
hash = (null != key) ? hash(key) : 0;
|
||||
bucketIndex = indexFor(hash, table.length);
|
||||
}
|
||||
|
||||
createEntry(hash, key, value, bucketIndex);
|
||||
}
|
||||
|
||||
void createEntry(int hash, K key, V value, int bucketIndex) {
|
||||
Entry<K,V> e = table[bucketIndex];
|
||||
// 头插法,链表头部指向新的键值对
|
||||
table[bucketIndex] = new Entry<>(hash, key, value, e);
|
||||
size++;
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
Entry(int h, K k, V v, Entry<K,V> n) {
|
||||
value = v;
|
||||
next = n;
|
||||
key = k;
|
||||
hash = h;
|
||||
}
|
||||
```
|
||||
|
||||
#### 4. 确定桶下标
|
||||
|
||||
很多操作都需要先确定一个键值对所在的桶下标。
|
||||
|
||||
```java
|
||||
int hash = hash(key);
|
||||
int i = indexFor(hash, table.length);
|
||||
```
|
||||
|
||||
**4.1 计算 hash 值**
|
||||
|
||||
```java
|
||||
final int hash(Object k) {
|
||||
int h = hashSeed;
|
||||
if (0 != h && k instanceof String) {
|
||||
return sun.misc.Hashing.stringHash32((String) k);
|
||||
}
|
||||
|
||||
h ^= k.hashCode();
|
||||
|
||||
// This function ensures that hashCodes that differ only by
|
||||
// constant multiples at each bit position have a bounded
|
||||
// number of collisions (approximately 8 at default load factor).
|
||||
h ^= (h >>> 20) ^ (h >>> 12);
|
||||
return h ^ (h >>> 7) ^ (h >>> 4);
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
public final int hashCode() {
|
||||
return Objects.hashCode(key) ^ Objects.hashCode(value);
|
||||
}
|
||||
```
|
||||
|
||||
**4.2 取模**
|
||||
|
||||
令 x = 1\<\<4,即 x 为 2 的 4 次方,它具有以下性质:
|
||||
|
||||
```
|
||||
x : 00010000
|
||||
x-1 : 00001111
|
||||
```
|
||||
|
||||
令一个数 y 与 x-1 做与运算,可以去除 y 位级表示的第 4 位以上数:
|
||||
|
||||
```
|
||||
y : 10110010
|
||||
x-1 : 00001111
|
||||
y&(x-1) : 00000010
|
||||
```
|
||||
|
||||
这个性质和 y 对 x 取模效果是一样的:
|
||||
|
||||
```
|
||||
y : 10110010
|
||||
x : 00010000
|
||||
y%x : 00000010
|
||||
```
|
||||
|
||||
我们知道,位运算的代价比求模运算小的多,因此在进行这种计算时用位运算的话能带来更高的性能。
|
||||
|
||||
确定桶下标的最后一步是将 key 的 hash 值对桶个数取模:hash%capacity,如果能保证 capacity 为 2 的 n 次方,那么就可以将这个操作转换为位运算。
|
||||
|
||||
```java
|
||||
static int indexFor(int h, int length) {
|
||||
return h & (length-1);
|
||||
}
|
||||
```
|
||||
|
||||
#### 5. 扩容-基本原理
|
||||
|
||||
设 HashMap 的 table 长度为 M,需要存储的键值对数量为 N,如果哈希函数满足均匀性的要求,那么每条链表的长度大约为 N/M,因此查找的复杂度为 O(N/M)。
|
||||
|
||||
为了让查找的成本降低,应该使 N/M 尽可能小,因此需要保证 M 尽可能大,也就是说 table 要尽可能大。HashMap 采用动态扩容来根据当前的 N 值来调整 M 值,使得空间效率和时间效率都能得到保证。
|
||||
|
||||
和扩容相关的参数主要有:capacity、size、threshold 和 load_factor。
|
||||
|
||||
| 参数 | 含义 |
|
||||
| :--: | :-- |
|
||||
| capacity | table 的容量大小,默认为 16。需要注意的是 capacity 必须保证为 2 的 n 次方。|
|
||||
| size | 键值对数量。 |
|
||||
| threshold | size 的临界值,当 size 大于等于 threshold 就必须进行扩容操作。 |
|
||||
| loadFactor | 装载因子,table 能够使用的比例,threshold = (int)(capacity* loadFactor)。 |
|
||||
|
||||
```java
|
||||
static final int DEFAULT_INITIAL_CAPACITY = 16;
|
||||
|
||||
static final int MAXIMUM_CAPACITY = 1 << 30;
|
||||
|
||||
static final float DEFAULT_LOAD_FACTOR = 0.75f;
|
||||
|
||||
transient Entry[] table;
|
||||
|
||||
transient int size;
|
||||
|
||||
int threshold;
|
||||
|
||||
final float loadFactor;
|
||||
|
||||
transient int modCount;
|
||||
```
|
||||
|
||||
从下面的添加元素代码中可以看出,当需要扩容时,令 capacity 为原来的两倍。
|
||||
|
||||
```java
|
||||
void addEntry(int hash, K key, V value, int bucketIndex) {
|
||||
Entry<K,V> e = table[bucketIndex];
|
||||
table[bucketIndex] = new Entry<>(hash, key, value, e);
|
||||
if (size++ >= threshold)
|
||||
resize(2 * table.length);
|
||||
}
|
||||
```
|
||||
|
||||
扩容使用 resize() 实现,需要注意的是,扩容操作同样需要把 oldTable 的所有键值对重新插入 newTable 中,因此这一步是很费时的。
|
||||
|
||||
```java
|
||||
void resize(int newCapacity) {
|
||||
Entry[] oldTable = table;
|
||||
int oldCapacity = oldTable.length;
|
||||
if (oldCapacity == MAXIMUM_CAPACITY) {
|
||||
threshold = Integer.MAX_VALUE;
|
||||
return;
|
||||
}
|
||||
Entry[] newTable = new Entry[newCapacity];
|
||||
transfer(newTable);
|
||||
table = newTable;
|
||||
threshold = (int)(newCapacity * loadFactor);
|
||||
}
|
||||
|
||||
void transfer(Entry[] newTable) {
|
||||
Entry[] src = table;
|
||||
int newCapacity = newTable.length;
|
||||
for (int j = 0; j < src.length; j++) {
|
||||
Entry<K,V> e = src[j];
|
||||
if (e != null) {
|
||||
src[j] = null;
|
||||
do {
|
||||
Entry<K,V> next = e.next;
|
||||
int i = indexFor(e.hash, newCapacity);
|
||||
e.next = newTable[i];
|
||||
newTable[i] = e;
|
||||
e = next;
|
||||
} while (e != null);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 6. 扩容-重新计算桶下标
|
||||
|
||||
在进行扩容时,需要把键值对重新计算桶下标,从而放到对应的桶上。在前面提到,HashMap 使用 hash%capacity 来确定桶下标。HashMap capacity 为 2 的 n 次方这一特点能够极大降低重新计算桶下标操作的复杂度。
|
||||
|
||||
假设原数组长度 capacity 为 16,扩容之后 new capacity 为 32:
|
||||
|
||||
```html
|
||||
capacity : 00010000
|
||||
new capacity : 00100000
|
||||
```
|
||||
|
||||
对于一个 Key,它的哈希值 hash 在第 5 位:
|
||||
|
||||
- 为 0,那么 hash%00010000 = hash%00100000,桶位置和原来一致;
|
||||
- 为 1,hash%00010000 = hash%00100000 + 16,桶位置是原位置 + 16。
|
||||
|
||||
#### 7. 计算数组容量
|
||||
|
||||
HashMap 构造函数允许用户传入的容量不是 2 的 n 次方,因为它可以自动地将传入的容量转换为 2 的 n 次方。
|
||||
|
||||
先考虑如何求一个数的掩码,对于 10010000,它的掩码为 11111111,可以使用以下方法得到:
|
||||
|
||||
```
|
||||
mask |= mask >> 1 11011000
|
||||
mask |= mask >> 2 11111110
|
||||
mask |= mask >> 4 11111111
|
||||
```
|
||||
|
||||
mask+1 是大于原始数字的最小的 2 的 n 次方。
|
||||
|
||||
```
|
||||
num 10010000
|
||||
mask+1 100000000
|
||||
```
|
||||
|
||||
以下是 HashMap 中计算数组容量的代码:
|
||||
|
||||
```java
|
||||
static final int tableSizeFor(int cap) {
|
||||
int n = cap - 1;
|
||||
n |= n >>> 1;
|
||||
n |= n >>> 2;
|
||||
n |= n >>> 4;
|
||||
n |= n >>> 8;
|
||||
n |= n >>> 16;
|
||||
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
|
||||
}
|
||||
```
|
||||
|
||||
#### 8. 链表转红黑树
|
||||
|
||||
从 JDK 1.8 开始,一个桶存储的链表长度大于等于 8 时会将链表转换为红黑树。
|
||||
|
||||
#### 9. 与 Hashtable 的比较
|
||||
|
||||
- Hashtable 使用 synchronized 来进行同步。
|
||||
- HashMap 可以插入键为 null 的 Entry。
|
||||
- HashMap 的迭代器是 fail-fast 迭代器。
|
||||
- HashMap 不能保证随着时间的推移 Map 中的元素次序是不变的。
|
||||
|
||||
|
||||
### 继承关系
|
||||
|
||||

|
||||
@@ -200,6 +575,137 @@ public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
|
||||
1. 它底层维护了一条`双向链表`,因为继承了 HashMap,所以它也不是线程安全的
|
||||
2. LinkedHashMap 可实现`LRU`缓存淘汰策略,其原理是通过设置`accessOrder`为`true`并重写`removeEldestEntry`方法定义淘汰元素时需满足的条件
|
||||
|
||||
|
||||
#### 存储结构
|
||||
|
||||
继承自 HashMap,因此具有和 HashMap 一样的快速查找特性。
|
||||
|
||||
```java
|
||||
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>
|
||||
```
|
||||
|
||||
内部维护了一个双向链表,用来维护插入顺序或者 LRU 顺序。
|
||||
|
||||
```java
|
||||
/**
|
||||
* The head (eldest) of the doubly linked list.
|
||||
*/
|
||||
transient LinkedHashMap.Entry<K,V> head;
|
||||
|
||||
/**
|
||||
* The tail (youngest) of the doubly linked list.
|
||||
*/
|
||||
transient LinkedHashMap.Entry<K,V> tail;
|
||||
```
|
||||
|
||||
accessOrder 决定了顺序,默认为 false,此时维护的是插入顺序。
|
||||
|
||||
```java
|
||||
final boolean accessOrder;
|
||||
```
|
||||
|
||||
LinkedHashMap 最重要的是以下用于维护顺序的函数,它们会在 put、get 等方法中调用。
|
||||
|
||||
```java
|
||||
void afterNodeAccess(Node<K,V> p) { }
|
||||
void afterNodeInsertion(boolean evict) { }
|
||||
```
|
||||
|
||||
#### afterNodeAccess()
|
||||
|
||||
当一个节点被访问时,如果 accessOrder 为 true,则会将该节点移到链表尾部。也就是说指定为 LRU 顺序之后,在每次访问一个节点时,会将这个节点移到链表尾部,保证链表尾部是最近访问的节点,那么链表首部就是最近最久未使用的节点。
|
||||
|
||||
```java
|
||||
void afterNodeAccess(Node<K,V> e) { // move node to last
|
||||
LinkedHashMap.Entry<K,V> last;
|
||||
if (accessOrder && (last = tail) != e) {
|
||||
LinkedHashMap.Entry<K,V> p =
|
||||
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
|
||||
p.after = null;
|
||||
if (b == null)
|
||||
head = a;
|
||||
else
|
||||
b.after = a;
|
||||
if (a != null)
|
||||
a.before = b;
|
||||
else
|
||||
last = b;
|
||||
if (last == null)
|
||||
head = p;
|
||||
else {
|
||||
p.before = last;
|
||||
last.after = p;
|
||||
}
|
||||
tail = p;
|
||||
++modCount;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### afterNodeInsertion()
|
||||
|
||||
在 put 等操作之后执行,当 removeEldestEntry() 方法返回 true 时会移除最晚的节点,也就是链表首部节点 first。
|
||||
|
||||
evict 只有在构建 Map 的时候才为 false,在这里为 true。
|
||||
|
||||
```java
|
||||
void afterNodeInsertion(boolean evict) { // possibly remove eldest
|
||||
LinkedHashMap.Entry<K,V> first;
|
||||
if (evict && (first = head) != null && removeEldestEntry(first)) {
|
||||
K key = first.key;
|
||||
removeNode(hash(key), key, null, false, true);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
removeEldestEntry() 默认为 false,如果需要让它为 true,需要继承 LinkedHashMap 并且覆盖这个方法的实现,这在实现 LRU 的缓存中特别有用,通过移除最近最久未使用的节点,从而保证缓存空间足够,并且缓存的数据都是热点数据。
|
||||
|
||||
```java
|
||||
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
|
||||
return false;
|
||||
}
|
||||
```
|
||||
|
||||
#### LRU 缓存
|
||||
|
||||
以下是使用 LinkedHashMap 实现的一个 LRU 缓存:
|
||||
|
||||
- 设定最大缓存空间 MAX_ENTRIES 为 3;
|
||||
- 使用 LinkedHashMap 的构造函数将 accessOrder 设置为 true,开启 LRU 顺序;
|
||||
- 覆盖 removeEldestEntry() 方法实现,在节点多于 MAX_ENTRIES 就会将最近最久未使用的数据移除。
|
||||
|
||||
```java
|
||||
class LRUCache<K, V> extends LinkedHashMap<K, V> {
|
||||
private static final int MAX_ENTRIES = 3;
|
||||
|
||||
protected boolean removeEldestEntry(Map.Entry eldest) {
|
||||
return size() > MAX_ENTRIES;
|
||||
}
|
||||
|
||||
LRUCache() {
|
||||
super(MAX_ENTRIES, 0.75f, true);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
LRUCache<Integer, String> cache = new LRUCache<>();
|
||||
cache.put(1, "a");
|
||||
cache.put(2, "b");
|
||||
cache.put(3, "c");
|
||||
cache.get(1);
|
||||
cache.put(4, "d");
|
||||
System.out.println(cache.keySet());
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
[3, 1, 4]
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 3 TreeMap
|
||||
|
||||
### 底层原理
|
||||
@@ -283,7 +789,7 @@ Object higherKey(Object key):返回严格大于指定键的最小键。
|
||||
NavigableMap descendingMap():它返回此地图中包含的映射的reverse order view 。
|
||||
```
|
||||
|
||||
## 4 WeakHashMap
|
||||
## 4 WeakHashMap
|
||||
|
||||
WeakHashMap 日常开发中比较少见,它是基于普通的`Map`实现的,而里面`Entry`中的键在每一次的`垃圾回收`都会被清除掉,所以非常适合用于**短暂访问、仅访问一次**的元素,缓存在`WeakHashMap`中,并尽早地把它回收掉。
|
||||
|
||||
@@ -327,7 +833,65 @@ public class WeakHashMap<K, V> extends AbstractMap<K, V> implements Map<K, V> {
|
||||
2. 它依赖普通的`Map`进行实现,是一个非线程安全的集合
|
||||
3. WeakHashMap 通常作为**缓存**使用,适合存储那些**只需访问一次**、或**只需保存短暂时间**的键值对
|
||||
|
||||
## 5 Hashtable
|
||||
|
||||
### 存储结构
|
||||
|
||||
WeakHashMap 的 Entry 继承自 WeakReference,被 WeakReference 关联的对象在下一次垃圾回收时会被回收。
|
||||
|
||||
WeakHashMap 主要用来实现缓存,通过使用 WeakHashMap 来引用缓存对象,由 JVM 对这部分缓存进行回收。
|
||||
|
||||
```java
|
||||
private static class Entry<K,V> extends WeakReference<Object> implements Map.Entry<K,V>
|
||||
```
|
||||
|
||||
### ConcurrentCache
|
||||
|
||||
Tomcat 中的 ConcurrentCache 使用了 WeakHashMap 来实现缓存功能。
|
||||
|
||||
ConcurrentCache 采取的是分代缓存:
|
||||
|
||||
- 经常使用的对象放入 eden 中,eden 使用 ConcurrentHashMap 实现,不用担心会被回收(伊甸园);
|
||||
- 不常用的对象放入 longterm,longterm 使用 WeakHashMap 实现,这些老对象会被垃圾收集器回收。
|
||||
- 当调用 get() 方法时,会先从 eden 区获取,如果没有找到的话再到 longterm 获取,当从 longterm 获取到就把对象放入 eden 中,从而保证经常被访问的节点不容易被回收。
|
||||
- 当调用 put() 方法时,如果 eden 的大小超过了 size,那么就将 eden 中的所有对象都放入 longterm 中,利用虚拟机回收掉一部分不经常使用的对象。
|
||||
|
||||
```java
|
||||
public final class ConcurrentCache<K, V> {
|
||||
|
||||
private final int size;
|
||||
|
||||
private final Map<K, V> eden;
|
||||
|
||||
private final Map<K, V> longterm;
|
||||
|
||||
public ConcurrentCache(int size) {
|
||||
this.size = size;
|
||||
this.eden = new ConcurrentHashMap<>(size);
|
||||
this.longterm = new WeakHashMap<>(size);
|
||||
}
|
||||
|
||||
public V get(K k) {
|
||||
V v = this.eden.get(k);
|
||||
if (v == null) {
|
||||
v = this.longterm.get(k);
|
||||
if (v != null)
|
||||
this.eden.put(k, v);
|
||||
}
|
||||
return v;
|
||||
}
|
||||
|
||||
public void put(K k, V v) {
|
||||
if (this.eden.size() >= size) {
|
||||
this.longterm.putAll(this.eden);
|
||||
this.eden.clear();
|
||||
}
|
||||
this.eden.put(k, v);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## 5 Hashtable :warning: 已废弃
|
||||
### 底层原理
|
||||
Hashtable 底层的存储结构是`数组 + 链表`,而它是一个**线程安全**的集合,但是因为这个线程安全,它就被淘汰掉了。
|
||||
|
||||
@@ -349,77 +913,3 @@ HashTable 所有的操作都是线程安全的。
|
||||
|
||||
### 方法
|
||||
跟hashtable一样
|
||||
|
||||
## 6 ConcurrentHashMap
|
||||
|
||||
### 底层原理
|
||||
oncurrentHashMap通过设计支持并发访问其键值对。
|
||||
|
||||
|
||||
|
||||
### 使用方法
|
||||
|
||||
创建和读写
|
||||
```java
|
||||
import java.util.Iterator;
|
||||
import java.util.concurrent.ConcurrentHashMap;
|
||||
|
||||
public class HashMapExample
|
||||
{
|
||||
public static void main(String[] args) throws CloneNotSupportedException
|
||||
{
|
||||
ConcurrentHashMap<Integer, String> concurrHashMap = new ConcurrentHashMap<>();
|
||||
|
||||
//Put require no synchronization
|
||||
concurrHashMap.put(1, "A");
|
||||
concurrHashMap.put(2, "B");
|
||||
|
||||
//Get require no synchronization
|
||||
concurrHashMap.get(1);
|
||||
|
||||
Iterator<Integer> itr = concurrHashMap.keySet().iterator();
|
||||
|
||||
//Using synchronized block is advisable
|
||||
synchronized (concurrHashMap)
|
||||
{
|
||||
while(itr.hasNext()) {
|
||||
System.out.println(concurrHashMap.get(itr.next()));
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
使用Collection.synchronizedMap也有同样的方法
|
||||
|
||||
```java
|
||||
import java.util.Collections;
|
||||
import java.util.HashMap;
|
||||
import java.util.Iterator;
|
||||
import java.util.Map;
|
||||
|
||||
public class HashMapExample
|
||||
{
|
||||
public static void main(String[] args) throws CloneNotSupportedException
|
||||
{
|
||||
Map<Integer, String> syncHashMap = Collections.synchronizedMap(new HashMap<>());
|
||||
|
||||
//Put require no synchronization
|
||||
syncHashMap.put(1, "A");
|
||||
syncHashMap.put(2, "B");
|
||||
|
||||
//Get require no synchronization
|
||||
syncHashMap.get(1);
|
||||
|
||||
Iterator<Integer> itr = syncHashMap.keySet().iterator();
|
||||
|
||||
//Using synchronized block is advisable
|
||||
synchronized (syncHashMap)
|
||||
{
|
||||
while(itr.hasNext()) {
|
||||
System.out.println(syncHashMap.get(itr.next()));
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
0
Java/03Java标准集合类/11 Arrays和Collections.md
Normal file
0
Java/03Java标准集合类/11 Arrays和Collections.md
Normal file
@@ -294,13 +294,112 @@ other task is running...
|
||||
|
||||
并发集合是指使用了最新并发能力的集合,在JUC包下。而同步集合指之前用同步锁实现的集合
|
||||
|
||||
### CopyOnWrite
|
||||
### CopyOnWriteArrayList
|
||||
|
||||
CopyOnWriteArrayList在写的时候会复制一个副本,对副本写,写完用副本替换原值,读的时候不需要同步,适用于写少读多的场合。
|
||||
|
||||
|
||||
CopyOnWriteArraySet基于CopyOnWriteArrayList来实现的,只是在不允许存在重复的对象这个特性上遍历处理了一下。
|
||||
|
||||
#### 读写分离
|
||||
|
||||
写操作在一个复制的数组上进行,读操作还是在原始数组中进行,读写分离,互不影响。
|
||||
|
||||
写操作需要加锁,防止并发写入时导致写入数据丢失。
|
||||
|
||||
写操作结束之后需要把原始数组指向新的复制数组。
|
||||
|
||||
```java
|
||||
public boolean add(E e) {
|
||||
final ReentrantLock lock = this.lock;
|
||||
lock.lock();
|
||||
try {
|
||||
Object[] elements = getArray();
|
||||
int len = elements.length;
|
||||
Object[] newElements = Arrays.copyOf(elements, len + 1);
|
||||
newElements[len] = e;
|
||||
setArray(newElements);
|
||||
return true;
|
||||
} finally {
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
|
||||
final void setArray(Object[] a) {
|
||||
array = a;
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
@SuppressWarnings("unchecked")
|
||||
private E get(Object[] a, int index) {
|
||||
return (E) a[index];
|
||||
}
|
||||
```
|
||||
|
||||
#### 适用场景
|
||||
|
||||
CopyOnWriteArrayList 在写操作的同时允许读操作,大大提高了读操作的性能,因此很适合读多写少的应用场景。
|
||||
|
||||
但是 CopyOnWriteArrayList 有其缺陷:
|
||||
|
||||
- 内存占用:在写操作时需要复制一个新的数组,使得内存占用为原来的两倍左右;
|
||||
- 数据不一致:读操作不能读取实时性的数据,因为部分写操作的数据还未同步到读数组中。
|
||||
|
||||
所以 CopyOnWriteArrayList 不适合内存敏感以及对实时性要求很高的场景。
|
||||
|
||||
|
||||
> 用来替代vector,提供现成安全的list
|
||||
#### 底层原理
|
||||
|
||||
Java CopyOnWriteArrayList是ArrayList的thread-safe变体,其中所有可变操作(添加,设置等)都通过对基础array进行全新复制来实现。
|
||||
|
||||
* CopyOnWriteArrayList类实现List和RandomAccess接口,因此提供ArrayList类中可用的所有功能。
|
||||
* 使用CopyOnWriteArrayList进行更新操作的成本很高,因为每个突变都会创建基础数组的克隆副本,并为其添加/更新元素。
|
||||
* 它是ArrayList的线程安全版本。 每个访问列表的线程在初始化此列表的迭代器时都会看到自己创建的后备阵列快照版本。
|
||||
* 因为它在创建迭代器时获取基础数组的快照,所以它不会抛出ConcurrentModificationException 。
|
||||
* 不支持对迭代器的删除操作(删除,设置和添加)。 这些方法抛出UnsupportedOperationException 。
|
||||
* CopyOnWriteArrayList是synchronized List的并发替代,当迭代的次数超过突变次数时,CopyOnWriteArrayList可以提供更好的并发性。
|
||||
* 它允许重复的元素和异构对象(使用泛型来获取编译时错误)。因为它每次创建迭代器时都会创建一个新的数组副本,所以performance is slower比ArrayList performance is slower 。
|
||||
|
||||
|
||||
#### 实例
|
||||
|
||||
```java
|
||||
CopyOnWriteArrayList<Integer> list = new CopyOnWriteArrayList<>(new Integer[] {1,2,3});
|
||||
|
||||
System.out.println(list); //[1, 2, 3]
|
||||
|
||||
//Get iterator 1
|
||||
Iterator<Integer> itr1 = list.iterator();
|
||||
|
||||
//Add one element and verify list is updated
|
||||
list.add(4);
|
||||
|
||||
System.out.println(list); //[1, 2, 3, 4]
|
||||
|
||||
//Get iterator 2
|
||||
Iterator<Integer> itr2 = list.iterator();
|
||||
|
||||
System.out.println("====Verify Iterator 1 content====");
|
||||
|
||||
itr1.forEachRemaining(System.out :: println); //1,2,3
|
||||
|
||||
System.out.println("====Verify Iterator 2 content====");
|
||||
|
||||
itr2.forEachRemaining(System.out :: println); //1,2,3,4
|
||||
```
|
||||
|
||||
#### 主要方法
|
||||
|
||||
```java
|
||||
CopyOnWriteArrayList() :创建一个空列表。
|
||||
CopyOnWriteArrayList(Collection c) :创建一个列表,该列表包含指定集合的元素,并按集合的迭代器返回它们的顺序。
|
||||
CopyOnWriteArrayList(object[] array) :创建一个保存给定数组副本的列表。
|
||||
boolean addIfAbsent(object o) :如果不存在则追加元素。
|
||||
int addAllAbsent(Collection c) :以指定集合的迭代器返回的顺序,将指定集合中尚未包含在此列表中的所有元素追加到此列表的末尾。
|
||||
```
|
||||
|
||||
|
||||
|
||||
### BlockingQueue
|
||||
@@ -376,6 +475,322 @@ produce..produce..consume..consume..produce..consume..produce..consume..produce.
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 4 PriorityBlockingQueue
|
||||
|
||||
### 底层原理
|
||||
Java PriorityBlockingQueue类是concurrent阻塞队列数据结构的实现,其中根据对象的priority对其进行处理。 名称的“阻塞”部分已添加,表示线程将阻塞等待,直到队列上有可用的项目为止 。
|
||||
|
||||
在priority blocking queue ,添加的对象根据其优先级进行排序。 默认情况下,优先级由对象的自然顺序决定。 队列构建时提供的Comparator器可以覆盖默认优先级。
|
||||
* PriorityBlockingQueue是一个无界队列,并且会动态增长。 默认初始容量为'11' ,可以在适当的构造函数中使用initialCapacity参数覆盖此初始容量。
|
||||
* 它**提供了阻塞检索操作**。
|
||||
* 它不允许使用NULL对象。
|
||||
* 添加到PriorityBlockingQueue的对象必须具有可比性,否则它将引发ClassCastException 。
|
||||
* 默认情况下,优先级队列的对象以自然顺序排序 。
|
||||
* 比较器可用于队列中对象的自定义排序。
|
||||
* 优先级队列的head是基于自然排序或基于比较器排序的least元素。 当我们轮询队列时,它从队列中返回头对象。
|
||||
* 如果存在多个具有相同优先级的对象,则它可以随机轮询其中的任何一个。
|
||||
* PriorityBlockingQueue是thread safe 。
|
||||
|
||||
### 主要方法
|
||||
|
||||
```java
|
||||
boolean add(object) :将指定的元素插入此优先级队列。
|
||||
boolean offer(object) :将指定的元素插入此优先级队列。
|
||||
boolean remove(object) :从此队列中移除指定元素的单个实例(如果存在)。
|
||||
Object poll() :检索并删除此队列的头部,并在必要时等待指定的等待时间,以使元素可用。
|
||||
Object poll(timeout, timeUnit) :检索并删除此队列的头部,如果有必要,直到指定的等待时间,元素才可用。
|
||||
Object take() :检索并删除此队列的头部,如有必要,请等待直到元素可用。
|
||||
void put(Object o) :将指定的元素插入此优先级队列。
|
||||
void clear() :从此优先级队列中删除所有元素。
|
||||
Comparator comparator() :返回用于对此队列中的元素进行排序的Comparator comparator()如果此队列是根据其元素的自然顺序排序的,则返回null。
|
||||
boolean contains(Object o) :如果此队列包含指定的元素,则返回true。
|
||||
Iterator iterator() :返回对该队列中的元素进行迭代的迭代器。
|
||||
int size() :返回此队列中的元素数。
|
||||
int drainTo(Collection c) :从此队列中删除所有可用元素,并将它们添加到给定的collection中。
|
||||
intrainToTo(Collection c,int maxElements) :从此队列中最多移除给定数量的可用元素,并将它们添加到给定的collection中。
|
||||
int remainingCapacity() Integer.MAX_VALUE int remainingCapacity() :总是返回Integer.MAX_VALUE因为PriorityBlockingQueue不受容量限制。
|
||||
Object[] toArray() :返回一个包含此队列中所有元素的数组。
|
||||
```
|
||||
### 实例
|
||||
```java
|
||||
import java.util.concurrent.PriorityBlockingQueue;
|
||||
import java.util.concurrent.TimeUnit;
|
||||
|
||||
public class PriorityQueueExample
|
||||
{
|
||||
public static void main(String[] args) throws InterruptedException
|
||||
{
|
||||
PriorityBlockingQueue<Integer> priorityBlockingQueue = new PriorityBlockingQueue<>();
|
||||
|
||||
new Thread(() ->
|
||||
{
|
||||
System.out.println("Waiting to poll ...");
|
||||
|
||||
try
|
||||
{
|
||||
while(true)
|
||||
{
|
||||
Integer poll = priorityBlockingQueue.take();
|
||||
System.out.println("Polled : " + poll);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(1));
|
||||
}
|
||||
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}).start();
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(2));
|
||||
priorityBlockingQueue.add(1);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(2));
|
||||
priorityBlockingQueue.add(2);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(2));
|
||||
priorityBlockingQueue.add(3);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 5 ArrayBlockingQueue
|
||||
|
||||
### 底层原理
|
||||
|
||||
ArrayBlockingQueue类是由数组支持的Java concurrent和bounded阻塞队列实现。 它对元素FIFO(先进先出)进行排序。
|
||||
|
||||
ArrayBlockingQueue的head是一直在队列中最长时间的那个元素。 ArrayBlockingQueue的tail是最短时间进入队列的元素。 新元素插入到队列的尾部 ,并且队列检索操作在队列的开头获取元素 。
|
||||
|
||||
* ArrayBlockingQueue是由数组支持的固定大小的有界队列。
|
||||
* 它对元素FIFO(先进先出)进行排序。
|
||||
* 元素插入到尾部,并从队列的开头检索。
|
||||
* 创建后,队列的容量无法更改。
|
||||
* 它提供阻塞的插入和检索操作 。
|
||||
* 它不允许使用NULL对象。
|
||||
* ArrayBlockingQueue是thread safe 。
|
||||
* 方法iterator()提供的Iterator按从第一个(头)到最后一个(尾部)的顺序遍历元素。
|
||||
* ArrayBlockingQueue支持可选的fairness policy用于订购等待的生产者线程和使用者线程。 将fairness设置为true ,队列按FIFO顺序授予线程访问权限。
|
||||
|
||||
|
||||
|
||||
|
||||
### 生产消费者实例
|
||||
使用阻塞插入和检索从ArrayBlockingQueue中放入和取出元素的Java示例。
|
||||
|
||||
* 当队列已满时,生产者线程将等待。 一旦从队列中取出一个元素,它就会将该元素添加到队列中。
|
||||
* 如果队列为空,使用者线程将等待。 队列中只有一个元素时,它将取出该元素。
|
||||
```java
|
||||
import java.util.concurrent.ArrayBlockingQueue;
|
||||
import java.util.concurrent.TimeUnit;
|
||||
|
||||
public class ArrayBlockingQueueExample
|
||||
{
|
||||
public static void main(String[] args) throws InterruptedException
|
||||
{
|
||||
ArrayBlockingQueue<Integer> priorityBlockingQueue = new ArrayBlockingQueue<>(5);
|
||||
|
||||
//Producer thread
|
||||
new Thread(() ->
|
||||
{
|
||||
int i = 0;
|
||||
try
|
||||
{
|
||||
while (true)
|
||||
{
|
||||
priorityBlockingQueue.put(++i);
|
||||
System.out.println("Added : " + i);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(1));
|
||||
}
|
||||
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}).start();
|
||||
|
||||
//Consumer thread
|
||||
new Thread(() ->
|
||||
{
|
||||
try
|
||||
{
|
||||
while (true)
|
||||
{
|
||||
Integer poll = priorityBlockingQueue.take();
|
||||
System.out.println("Polled : " + poll);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(2));
|
||||
}
|
||||
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}).start();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 主要方法
|
||||
|
||||
```java
|
||||
ArrayBlockingQueue(int capacity) :构造具有给定(固定)容量和默认访问策略的空队列。
|
||||
ArrayBlockingQueue(int capacity,boolean fair) :构造具有给定(固定)容量和指定访问策略的空队列。 如果公允值为true ,则按FIFO顺序处理在插入或移除时阻塞的线程的队列访问; 如果为false,则未指定访问顺序。
|
||||
ArrayBlockingQueue(int capacity,boolean fair,Collection c) :构造一个队列,该队列具有给定(固定)的容量,指定的访问策略,并最初包含给定集合的元素,并以集合迭代器的遍历顺序添加。
|
||||
void put(Object o) :将指定的元素插入此队列的尾部,如果队列已满,则等待空间变为可用。
|
||||
boolean add(object) : Inserts the specified element at the tail of this queue if it is possible to do so immediately without exceeding the queue’s capacity, returning true upon success and throwing an IllegalStateException if this queue is full.
|
||||
boolean offer(object) :如果可以在不超出队列容量的情况下立即执行此操作,则在此队列的尾部插入指定的元素,如果成功,则返回true,如果此队列已满,则抛出IllegalStateException。
|
||||
boolean remove(object) :从此队列中移除指定元素的单个实例(如果存在)。
|
||||
Object peek() :检索但不删除此队列的头部;如果此队列为空,则返回null。
|
||||
Object poll() :检索并删除此队列的头部;如果此队列为空,则返回null。
|
||||
Object poll(timeout, timeUnit) :检索并删除此队列的头部,如果有必要,直到指定的等待时间,元素才可用。
|
||||
Object take() :检索并删除此队列的头部,如有必要,请等待直到元素可用。
|
||||
void clear() :从队列中删除所有元素。
|
||||
boolean contains(Object o) :如果此队列包含指定的元素,则返回true。
|
||||
Iterator iterator() :以适当的顺序返回对该队列中的元素进行迭代的迭代器。
|
||||
int size() :返回此队列中的元素数。
|
||||
int drainTo(Collection c) :从此队列中删除所有可用元素,并将它们添加到给定的collection中。
|
||||
intrainToTo(Collection c,int maxElements) :从此队列中最多移除给定数量的可用元素,并将它们添加到给定的collection中。
|
||||
int remainingCapacity() :返回该队列理想情况下(在没有内存或资源限制的情况下)可以接受而不阻塞的其他元素的数量。
|
||||
Object[] toArray() :以适当的顺序返回一个包含此队列中所有元素的数组。
|
||||
```
|
||||
|
||||
|
||||
## 6 LinkedTransferQueue
|
||||
|
||||
### 底层原理
|
||||
|
||||
直接消息队列。也就是说,生产者生产后,必须等待消费者来消费才能继续执行。
|
||||
|
||||
Java TransferQueue是并发阻塞队列的实现,生产者可以在其中等待使用者使用消息。 LinkedTransferQueue类是Java中TransferQueue的实现。
|
||||
|
||||
|
||||
* LinkedTransferQueue是链接节点上的unbounded队列。
|
||||
* 此队列针对任何给定的生产者对元素FIFO(先进先出)进行排序。
|
||||
* 元素插入到尾部,并从队列的开头检索。
|
||||
* 它提供阻塞的插入和检索操作 。
|
||||
* 它不允许使用NULL对象。
|
||||
* LinkedTransferQueue是thread safe 。
|
||||
* 由于异步性质,size()方法不是固定时间操作,因此,如果在遍历期间修改此集合,则可能会报告不正确的结果。
|
||||
* 不保证批量操作addAll,removeAll,retainAll,containsAll,equals和toArray是原子执行的。 例如,与addAll操作并发操作的迭代器可能仅查看某些添加的元素。
|
||||
|
||||
|
||||
|
||||
### 实例
|
||||
非阻塞实例
|
||||
|
||||
```java
|
||||
LinkedTransferQueue<Integer> linkedTransferQueue = new LinkedTransferQueue<>();
|
||||
|
||||
linkedTransferQueue.put(1);
|
||||
|
||||
System.out.println("Added Message = 1");
|
||||
|
||||
Integer message = linkedTransferQueue.poll();
|
||||
|
||||
System.out.println("Recieved Message = " + message);
|
||||
```
|
||||
|
||||
阻塞插入实例,用于现成状态同步通信
|
||||
使用阻塞插入和检索从LinkedTransferQueue放入和取出元素的Java示例。
|
||||
|
||||
* 生产者线程将等待,直到有消费者准备从队列中取出项目为止。
|
||||
* 如果队列为空,使用者线程将等待。 队列中只有一个元素时,它将取出该元素。 只有在消费者接受了消息之后,生产者才可以再发送一条消息。
|
||||
|
||||
|
||||
|
||||
|
||||
```java
|
||||
import java.util.Random;
|
||||
import java.util.concurrent.LinkedTransferQueue;
|
||||
import java.util.concurrent.TimeUnit;
|
||||
|
||||
public class LinkedTransferQueueExample
|
||||
{
|
||||
public static void main(String[] args) throws InterruptedException
|
||||
{
|
||||
LinkedTransferQueue<Integer> linkedTransferQueue = new LinkedTransferQueue<>();
|
||||
|
||||
new Thread(() ->
|
||||
{
|
||||
Random random = new Random(1);
|
||||
try
|
||||
{
|
||||
while (true)
|
||||
{
|
||||
System.out.println("Producer is waiting to transfer message...");
|
||||
|
||||
Integer message = random.nextInt();
|
||||
boolean added = linkedTransferQueue.tryTransfer(message);
|
||||
if(added) {
|
||||
System.out.println("Producer added the message - " + message);
|
||||
}
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(3));
|
||||
}
|
||||
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}).start();
|
||||
|
||||
new Thread(() ->
|
||||
{
|
||||
try
|
||||
{
|
||||
while (true)
|
||||
{
|
||||
System.out.println("Consumer is waiting to take message...");
|
||||
|
||||
Integer message = linkedTransferQueue.take();
|
||||
|
||||
System.out.println("Consumer recieved the message - " + message);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(3));
|
||||
}
|
||||
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}).start();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### 主要方法
|
||||
|
||||
```java
|
||||
LinkedTransferQueue() :构造一个初始为空的LinkedTransferQueue。
|
||||
LinkedTransferQueue(Collection c) :构造一个LinkedTransferQueue,最初包含给定集合的元素,并以该集合的迭代器的遍历顺序添加。
|
||||
Object take() :检索并删除此队列的头部,如有必要,请等待直到元素可用。
|
||||
void transfer(Object o) :将元素传输给使用者,如有必要,请等待。
|
||||
boolean tryTransfer(Object o) :如果可能,立即将元素传输到等待的使用者。
|
||||
boolean tryTransfer(Object o,long timeout,TimeUnit unit) :如果有可能,则在超时之前将元素传输给使用者。
|
||||
int getWaitingConsumerCount() :返回等待通过BlockingQueue.take()或定时轮询接收元素的使用者数量的估计值。
|
||||
boolean hasWaitingConsumer() :如果至少有一个使用者正在等待通过BlockingQueue.take()或定时轮询接收元素,则返回true。
|
||||
void put(Object o) :将指定的元素插入此队列的尾部。
|
||||
boolean add(object) : Inserts the specified element at the tail of this queue.
|
||||
boolean offer(object) :将指定的元素插入此队列的尾部。
|
||||
boolean remove(object) :从此队列中移除指定元素的单个实例(如果存在)。
|
||||
Object peek() :检索但不删除此队列的头部;如果此队列为空,则返回null。
|
||||
Object poll() :检索并删除此队列的头部;如果此队列为空,则返回null。
|
||||
Object poll(timeout, timeUnit) :检索并删除此队列的头部,如果有必要,直到指定的等待时间,元素才可用。
|
||||
void clear() :从队列中删除所有元素。
|
||||
boolean contains(Object o) :如果此队列包含指定的元素,则返回true。
|
||||
Iterator iterator() :以适当的顺序返回对该队列中的元素进行迭代的迭代器。
|
||||
int size() :返回此队列中的元素数。
|
||||
int drainTo(Collection c) :从此队列中删除所有可用元素,并将它们添加到给定的collection中。
|
||||
intrainToTo(Collection c,int maxElements) :从此队列中最多移除给定数量的可用元素,并将它们添加到给定的collection中。
|
||||
int remainingCapacity() :返回该队列理想情况下(在没有内存或资源限制的情况下)可以接受而不阻塞的其他元素的数量。
|
||||
Object[] toArray() :以适当的顺序返回一个包含此队列中所有元素的数组。
|
||||
```
|
||||
|
||||
|
||||
|
||||
### Concurrent
|
||||
* ConcurrentLinkedQueue
|
||||
* ConcurrentLinkedDeque
|
||||
|
||||
792
Java/04Java并发编程/06 JUC并发容器.md
Normal file
792
Java/04Java并发编程/06 JUC并发容器.md
Normal file
@@ -0,0 +1,792 @@
|
||||
# 2 J.U.C -并发容器
|
||||
|
||||
并发集合是指使用了最新并发能力的集合,在JUC包下。而同步集合指之前用同步锁实现的集合。
|
||||
|
||||
其对应的基础集合类的接口并没有发生太大变化,主要是针对并发场景进行优化,使用各种方式保证并发集合的安全性。
|
||||
|
||||
## 1 CopyOnWrite
|
||||
|
||||
### CopyOnWriteArrayList
|
||||
|
||||
CopyOnWriteArrayList在写的时候会复制一个副本,对副本写,写完用副本替换原值,读的时候不需要同步,适用于写少读多的场合。
|
||||
|
||||
|
||||
CopyOnWriteArraySet基于CopyOnWriteArrayList来实现的,只是在不允许存在重复的对象这个特性上遍历处理了一下。
|
||||
|
||||
#### 读写分离
|
||||
|
||||
写操作在一个复制的数组上进行,读操作还是在原始数组中进行,读写分离,互不影响。
|
||||
|
||||
写操作需要加锁,防止并发写入时导致写入数据丢失。
|
||||
|
||||
写操作结束之后需要把原始数组指向新的复制数组。
|
||||
|
||||
```java
|
||||
public boolean add(E e) {
|
||||
final ReentrantLock lock = this.lock;
|
||||
lock.lock();
|
||||
try {
|
||||
Object[] elements = getArray();
|
||||
int len = elements.length;
|
||||
Object[] newElements = Arrays.copyOf(elements, len + 1);
|
||||
newElements[len] = e;
|
||||
setArray(newElements);
|
||||
return true;
|
||||
} finally {
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
|
||||
final void setArray(Object[] a) {
|
||||
array = a;
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
@SuppressWarnings("unchecked")
|
||||
private E get(Object[] a, int index) {
|
||||
return (E) a[index];
|
||||
}
|
||||
```
|
||||
|
||||
#### 适用场景
|
||||
|
||||
CopyOnWriteArrayList 在写操作的同时允许读操作,大大提高了读操作的性能,因此很适合读多写少的应用场景。
|
||||
|
||||
但是 CopyOnWriteArrayList 有其缺陷:
|
||||
|
||||
- 内存占用:在写操作时需要复制一个新的数组,使得内存占用为原来的两倍左右;
|
||||
- 数据不一致:读操作不能读取实时性的数据,因为部分写操作的数据还未同步到读数组中。
|
||||
|
||||
所以 CopyOnWriteArrayList 不适合内存敏感以及对实时性要求很高的场景。
|
||||
|
||||
|
||||
> 用来替代vector,提供现成安全的list
|
||||
#### 底层原理
|
||||
|
||||
Java CopyOnWriteArrayList是ArrayList的thread-safe变体,其中所有可变操作(添加,设置等)都通过对基础array进行全新复制来实现。
|
||||
|
||||
* CopyOnWriteArrayList类实现List和RandomAccess接口,因此提供ArrayList类中可用的所有功能。
|
||||
* 使用CopyOnWriteArrayList进行更新操作的成本很高,因为每个突变都会创建基础数组的克隆副本,并为其添加/更新元素。
|
||||
* 它是ArrayList的线程安全版本。 每个访问列表的线程在初始化此列表的迭代器时都会看到自己创建的后备阵列快照版本。
|
||||
* 因为它在创建迭代器时获取基础数组的快照,所以它不会抛出ConcurrentModificationException 。
|
||||
* 不支持对迭代器的删除操作(删除,设置和添加)。 这些方法抛出UnsupportedOperationException 。
|
||||
* CopyOnWriteArrayList是synchronized List的并发替代,当迭代的次数超过突变次数时,CopyOnWriteArrayList可以提供更好的并发性。
|
||||
* 它允许重复的元素和异构对象(使用泛型来获取编译时错误)。因为它每次创建迭代器时都会创建一个新的数组副本,所以performance is slower比ArrayList performance is slower 。
|
||||
|
||||
|
||||
#### 实例
|
||||
|
||||
```java
|
||||
CopyOnWriteArrayList<Integer> list = new CopyOnWriteArrayList<>(new Integer[] {1,2,3});
|
||||
|
||||
System.out.println(list); //[1, 2, 3]
|
||||
|
||||
//Get iterator 1
|
||||
Iterator<Integer> itr1 = list.iterator();
|
||||
|
||||
//Add one element and verify list is updated
|
||||
list.add(4);
|
||||
|
||||
System.out.println(list); //[1, 2, 3, 4]
|
||||
|
||||
//Get iterator 2
|
||||
Iterator<Integer> itr2 = list.iterator();
|
||||
|
||||
System.out.println("====Verify Iterator 1 content====");
|
||||
|
||||
itr1.forEachRemaining(System.out :: println); //1,2,3
|
||||
|
||||
System.out.println("====Verify Iterator 2 content====");
|
||||
|
||||
itr2.forEachRemaining(System.out :: println); //1,2,3,4
|
||||
```
|
||||
|
||||
#### 主要方法
|
||||
|
||||
```java
|
||||
CopyOnWriteArrayList() :创建一个空列表。
|
||||
CopyOnWriteArrayList(Collection c) :创建一个列表,该列表包含指定集合的元素,并按集合的迭代器返回它们的顺序。
|
||||
CopyOnWriteArrayList(object[] array) :创建一个保存给定数组副本的列表。
|
||||
boolean addIfAbsent(object o) :如果不存在则追加元素。
|
||||
int addAllAbsent(Collection c) :以指定集合的迭代器返回的顺序,将指定集合中尚未包含在此列表中的所有元素追加到此列表的末尾。
|
||||
```
|
||||
|
||||
|
||||
|
||||
### CopyOnWriteArraySet
|
||||
|
||||
#### 底层原理
|
||||
HashSet的thread-safe变体,它对所有操作都使用基础CopyOnWriteArrayList
|
||||
|
||||
与CopyOnWriteArrayList相似,它的immutable snapshot样式iterator方法在创建iterator使用对数组状态(在后备列表内)的引用。 这在遍历操作远远超过集合更新操作且我们不想同步遍历并且在更新集合时仍希望线程安全的用例中很有用。
|
||||
|
||||
* 作为正常设置的数据结构,它不允许重复。
|
||||
* CopyOnWriteArraySet类实现Serializable接口并扩展AbstractSet类。
|
||||
* 使用CopyOnWriteArraySet进行更新操作成本很高,因为每个突变都会创建基础数组的克隆副本并向其添加/更新元素。
|
||||
* 它是HashSet的线程安全版本。 每个访问该集合的线程在初始化此集合的迭代器时都会看到自己创建的后备阵列快照版本。
|
||||
* 因为它在创建迭代器时获取基础数组的快照,所以它不会抛出ConcurrentModificationException 。不支持迭代器上的变异操作。 这些方法抛出UnsupportedOperationException 。
|
||||
* CopyOnWriteArraySet是synchronized Set的并发替代,当迭代的次数超过突变次数时,CopyOnWriteArraySet提供更好的并发性。
|
||||
* 它允许重复的元素和异构对象(使用泛型来获取编译时错误)。
|
||||
* 由于每次创建迭代器时都会创建基础数组的新副本,因此performance is slower HashSet
|
||||
|
||||
#### 主要方法
|
||||
|
||||
```java
|
||||
CopyOnWriteArraySet() :创建一个空集。
|
||||
CopyOnWriteArraySet(Collection c) :创建一个包含指定集合元素的集合,其顺序由集合的迭代器返回。
|
||||
boolean add(object o) :将指定的元素添加到此集合(如果尚不存在)。
|
||||
boolean addAll(collection c) :将指定集合中的所有元素(如果尚不存在boolean addAll(collection c)添加到此集合中。
|
||||
void clear() :从此集合中删除所有元素。
|
||||
boolean contains(Object o) :如果此集合包含指定的元素,则返回true。
|
||||
boolean isEmpty() :如果此集合不包含任何元素,则返回true。
|
||||
Iterator iterator() :以添加这些元素的顺序在此集合中包含的元素上返回一个迭代器。
|
||||
boolean remove(Object o) :从指定的集合中删除指定的元素(如果存在)。
|
||||
int size() :返回此集合中的元素数
|
||||
```
|
||||
|
||||
|
||||
#### 实例
|
||||
|
||||
```java
|
||||
CopyOnWriteArraySet<Integer> set = new CopyOnWriteArraySet<>(Arrays.asList(1,2,3));
|
||||
|
||||
System.out.println(set); //[1, 2, 3]
|
||||
|
||||
//Get iterator 1
|
||||
Iterator<Integer> itr1 = set.iterator();
|
||||
|
||||
//Add one element and verify set is updated
|
||||
set.add(4);
|
||||
System.out.println(set); //[1, 2, 3, 4]
|
||||
|
||||
//Get iterator 2
|
||||
Iterator<Integer> itr2 = set.iterator();
|
||||
|
||||
System.out.println("====Verify Iterator 1 content====");
|
||||
|
||||
itr1.forEachRemaining(System.out :: println); //1,2,3
|
||||
|
||||
System.out.println("====Verify Iterator 2 content====");
|
||||
|
||||
itr2.forEachRemaining(System.out :: println); //1,2,3,4
|
||||
```
|
||||
|
||||
## 2 BlockingQueue
|
||||
|
||||
在并发队列上JDK提供了两套实现,
|
||||
* 一个是以ConcurrentLinkedQueue为代表的高性能队列
|
||||
* 一个是以BlockingQueue接口为代表的阻塞队列。
|
||||
|
||||
ConcurrentLinkedQueue适用于高并发场景下的队列,通过无锁的方式实现,通常ConcurrentLinkedQueue的性能要优于BlockingQueue。BlockingQueue的典型应用场景是生产者-消费者模式中,如果生产快于消费,生产队列装满时会阻塞,等待消费。
|
||||
|
||||
|
||||
|
||||
java.util.concurrent.BlockingQueue 接口有以下阻塞队列的实现:
|
||||
|
||||
- **FIFO 队列** :LinkedBlockingQueue、LinkedBlockingDeque、ArrayBlockingQueue(固定长度)
|
||||
- **优先级队列** :PriorityBlockingQueue
|
||||
- TransferQueue
|
||||
- DelayQueue
|
||||
|
||||
提供了阻塞的 take() 和 put() 方法:如果队列为空 take() 将阻塞,直到队列中有内容;如果队列为满 put() 将阻塞,直到队列有空闲位置。
|
||||
|
||||
**使用 BlockingQueue 实现生产者消费者问题**
|
||||
|
||||
```java
|
||||
public class ProducerConsumer {
|
||||
|
||||
private static BlockingQueue<String> queue = new ArrayBlockingQueue<>(5);
|
||||
|
||||
private static class Producer extends Thread {
|
||||
@Override
|
||||
public void run() {
|
||||
try {
|
||||
queue.put("product");
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.print("produce..");
|
||||
}
|
||||
}
|
||||
|
||||
private static class Consumer extends Thread {
|
||||
|
||||
@Override
|
||||
public void run() {
|
||||
try {
|
||||
String product = queue.take();
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.print("consume..");
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
for (int i = 0; i < 2; i++) {
|
||||
Producer producer = new Producer();
|
||||
producer.start();
|
||||
}
|
||||
for (int i = 0; i < 5; i++) {
|
||||
Consumer consumer = new Consumer();
|
||||
consumer.start();
|
||||
}
|
||||
for (int i = 0; i < 3; i++) {
|
||||
Producer producer = new Producer();
|
||||
producer.start();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```html
|
||||
produce..produce..consume..consume..produce..consume..produce..consume..produce..consume..
|
||||
```
|
||||
|
||||
|
||||
|
||||
### PriorityBlockingQueue
|
||||
|
||||
#### 底层原理
|
||||
Java PriorityBlockingQueue类是concurrent阻塞队列数据结构的实现,其中根据对象的priority对其进行处理。 名称的“阻塞”部分已添加,表示线程将阻塞等待,直到队列上有可用的项目为止 。
|
||||
|
||||
在priority blocking queue ,添加的对象根据其优先级进行排序。 默认情况下,优先级由对象的自然顺序决定。 队列构建时提供的Comparator器可以覆盖默认优先级。
|
||||
* PriorityBlockingQueue是一个无界队列,并且会动态增长。 默认初始容量为'11' ,可以在适当的构造函数中使用initialCapacity参数覆盖此初始容量。
|
||||
* 它**提供了阻塞检索操作**。
|
||||
* 它不允许使用NULL对象。
|
||||
* 添加到PriorityBlockingQueue的对象必须具有可比性,否则它将引发ClassCastException 。
|
||||
* 默认情况下,优先级队列的对象以自然顺序排序 。
|
||||
* 比较器可用于队列中对象的自定义排序。
|
||||
* 优先级队列的head是基于自然排序或基于比较器排序的least元素。 当我们轮询队列时,它从队列中返回头对象。
|
||||
* 如果存在多个具有相同优先级的对象,则它可以随机轮询其中的任何一个。
|
||||
* PriorityBlockingQueue是thread safe 。
|
||||
|
||||
#### 主要方法
|
||||
|
||||
```java
|
||||
boolean add(object) :将指定的元素插入此优先级队列。
|
||||
boolean offer(object) :将指定的元素插入此优先级队列。
|
||||
boolean remove(object) :从此队列中移除指定元素的单个实例(如果存在)。
|
||||
Object poll() :检索并删除此队列的头部,并在必要时等待指定的等待时间,以使元素可用。
|
||||
Object poll(timeout, timeUnit) :检索并删除此队列的头部,如果有必要,直到指定的等待时间,元素才可用。
|
||||
Object take() :检索并删除此队列的头部,如有必要,请等待直到元素可用。
|
||||
void put(Object o) :将指定的元素插入此优先级队列。
|
||||
void clear() :从此优先级队列中删除所有元素。
|
||||
Comparator comparator() :返回用于对此队列中的元素进行排序的Comparator comparator()如果此队列是根据其元素的自然顺序排序的,则返回null。
|
||||
boolean contains(Object o) :如果此队列包含指定的元素,则返回true。
|
||||
Iterator iterator() :返回对该队列中的元素进行迭代的迭代器。
|
||||
int size() :返回此队列中的元素数。
|
||||
int drainTo(Collection c) :从此队列中删除所有可用元素,并将它们添加到给定的collection中。
|
||||
intrainToTo(Collection c,int maxElements) :从此队列中最多移除给定数量的可用元素,并将它们添加到给定的collection中。
|
||||
int remainingCapacity() Integer.MAX_VALUE int remainingCapacity() :总是返回Integer.MAX_VALUE因为PriorityBlockingQueue不受容量限制。
|
||||
Object[] toArray() :返回一个包含此队列中所有元素的数组。
|
||||
```
|
||||
#### 实例
|
||||
```java
|
||||
import java.util.concurrent.PriorityBlockingQueue;
|
||||
import java.util.concurrent.TimeUnit;
|
||||
|
||||
public class PriorityQueueExample
|
||||
{
|
||||
public static void main(String[] args) throws InterruptedException
|
||||
{
|
||||
PriorityBlockingQueue<Integer> priorityBlockingQueue = new PriorityBlockingQueue<>();
|
||||
|
||||
new Thread(() ->
|
||||
{
|
||||
System.out.println("Waiting to poll ...");
|
||||
|
||||
try
|
||||
{
|
||||
while(true)
|
||||
{
|
||||
Integer poll = priorityBlockingQueue.take();
|
||||
System.out.println("Polled : " + poll);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(1));
|
||||
}
|
||||
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}).start();
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(2));
|
||||
priorityBlockingQueue.add(1);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(2));
|
||||
priorityBlockingQueue.add(2);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(2));
|
||||
priorityBlockingQueue.add(3);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### ArrayBlockingQueue
|
||||
|
||||
#### 底层原理
|
||||
|
||||
ArrayBlockingQueue类是由数组支持的Java concurrent和bounded阻塞队列实现。 它对元素FIFO(先进先出)进行排序。
|
||||
|
||||
ArrayBlockingQueue的head是一直在队列中最长时间的那个元素。 ArrayBlockingQueue的tail是最短时间进入队列的元素。 新元素插入到队列的尾部 ,并且队列检索操作在队列的开头获取元素 。
|
||||
|
||||
* ArrayBlockingQueue是由数组支持的固定大小的有界队列。
|
||||
* 它对元素FIFO(先进先出)进行排序。
|
||||
* 元素插入到尾部,并从队列的开头检索。
|
||||
* 创建后,队列的容量无法更改。
|
||||
* 它提供阻塞的插入和检索操作 。
|
||||
* 它不允许使用NULL对象。
|
||||
* ArrayBlockingQueue是thread safe 。
|
||||
* 方法iterator()提供的Iterator按从第一个(头)到最后一个(尾部)的顺序遍历元素。
|
||||
* ArrayBlockingQueue支持可选的fairness policy用于订购等待的生产者线程和使用者线程。 将fairness设置为true ,队列按FIFO顺序授予线程访问权限。
|
||||
|
||||
|
||||
|
||||
|
||||
#### 生产消费者实例
|
||||
使用阻塞插入和检索从ArrayBlockingQueue中放入和取出元素的Java示例。
|
||||
|
||||
* 当队列已满时,生产者线程将等待。 一旦从队列中取出一个元素,它就会将该元素添加到队列中。
|
||||
* 如果队列为空,使用者线程将等待。 队列中只有一个元素时,它将取出该元素。
|
||||
```java
|
||||
import java.util.concurrent.ArrayBlockingQueue;
|
||||
import java.util.concurrent.TimeUnit;
|
||||
|
||||
public class ArrayBlockingQueueExample
|
||||
{
|
||||
public static void main(String[] args) throws InterruptedException
|
||||
{
|
||||
ArrayBlockingQueue<Integer> priorityBlockingQueue = new ArrayBlockingQueue<>(5);
|
||||
|
||||
//Producer thread
|
||||
new Thread(() ->
|
||||
{
|
||||
int i = 0;
|
||||
try
|
||||
{
|
||||
while (true)
|
||||
{
|
||||
priorityBlockingQueue.put(++i);
|
||||
System.out.println("Added : " + i);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(1));
|
||||
}
|
||||
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}).start();
|
||||
|
||||
//Consumer thread
|
||||
new Thread(() ->
|
||||
{
|
||||
try
|
||||
{
|
||||
while (true)
|
||||
{
|
||||
Integer poll = priorityBlockingQueue.take();
|
||||
System.out.println("Polled : " + poll);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(2));
|
||||
}
|
||||
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}).start();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 主要方法
|
||||
|
||||
```java
|
||||
ArrayBlockingQueue(int capacity) :构造具有给定(固定)容量和默认访问策略的空队列。
|
||||
ArrayBlockingQueue(int capacity,boolean fair) :构造具有给定(固定)容量和指定访问策略的空队列。 如果公允值为true ,则按FIFO顺序处理在插入或移除时阻塞的线程的队列访问; 如果为false,则未指定访问顺序。
|
||||
ArrayBlockingQueue(int capacity,boolean fair,Collection c) :构造一个队列,该队列具有给定(固定)的容量,指定的访问策略,并最初包含给定集合的元素,并以集合迭代器的遍历顺序添加。
|
||||
void put(Object o) :将指定的元素插入此队列的尾部,如果队列已满,则等待空间变为可用。
|
||||
boolean add(object) : Inserts the specified element at the tail of this queue if it is possible to do so immediately without exceeding the queue’s capacity, returning true upon success and throwing an IllegalStateException if this queue is full.
|
||||
boolean offer(object) :如果可以在不超出队列容量的情况下立即执行此操作,则在此队列的尾部插入指定的元素,如果成功,则返回true,如果此队列已满,则抛出IllegalStateException。
|
||||
boolean remove(object) :从此队列中移除指定元素的单个实例(如果存在)。
|
||||
Object peek() :检索但不删除此队列的头部;如果此队列为空,则返回null。
|
||||
Object poll() :检索并删除此队列的头部;如果此队列为空,则返回null。
|
||||
Object poll(timeout, timeUnit) :检索并删除此队列的头部,如果有必要,直到指定的等待时间,元素才可用。
|
||||
Object take() :检索并删除此队列的头部,如有必要,请等待直到元素可用。
|
||||
void clear() :从队列中删除所有元素。
|
||||
boolean contains(Object o) :如果此队列包含指定的元素,则返回true。
|
||||
Iterator iterator() :以适当的顺序返回对该队列中的元素进行迭代的迭代器。
|
||||
int size() :返回此队列中的元素数。
|
||||
int drainTo(Collection c) :从此队列中删除所有可用元素,并将它们添加到给定的collection中。
|
||||
intrainToTo(Collection c,int maxElements) :从此队列中最多移除给定数量的可用元素,并将它们添加到给定的collection中。
|
||||
int remainingCapacity() :返回该队列理想情况下(在没有内存或资源限制的情况下)可以接受而不阻塞的其他元素的数量。
|
||||
Object[] toArray() :以适当的顺序返回一个包含此队列中所有元素的数组。
|
||||
```
|
||||
|
||||
|
||||
### LinkedTransferQueue
|
||||
|
||||
#### 底层原理
|
||||
|
||||
直接消息队列。也就是说,生产者生产后,必须等待消费者来消费才能继续执行。
|
||||
|
||||
Java TransferQueue是并发阻塞队列的实现,生产者可以在其中等待使用者使用消息。 LinkedTransferQueue类是Java中TransferQueue的实现。
|
||||
|
||||
|
||||
* LinkedTransferQueue是链接节点上的unbounded队列。
|
||||
* 此队列针对任何给定的生产者对元素FIFO(先进先出)进行排序。
|
||||
* 元素插入到尾部,并从队列的开头检索。
|
||||
* 它提供阻塞的插入和检索操作 。
|
||||
* 它不允许使用NULL对象。
|
||||
* LinkedTransferQueue是thread safe 。
|
||||
* 由于异步性质,size()方法不是固定时间操作,因此,如果在遍历期间修改此集合,则可能会报告不正确的结果。
|
||||
* 不保证批量操作addAll,removeAll,retainAll,containsAll,equals和toArray是原子执行的。 例如,与addAll操作并发操作的迭代器可能仅查看某些添加的元素。
|
||||
|
||||
|
||||
|
||||
#### 实例
|
||||
非阻塞实例
|
||||
|
||||
```java
|
||||
LinkedTransferQueue<Integer> linkedTransferQueue = new LinkedTransferQueue<>();
|
||||
|
||||
linkedTransferQueue.put(1);
|
||||
|
||||
System.out.println("Added Message = 1");
|
||||
|
||||
Integer message = linkedTransferQueue.poll();
|
||||
|
||||
System.out.println("Recieved Message = " + message);
|
||||
```
|
||||
|
||||
阻塞插入实例,用于现成状态同步通信
|
||||
使用阻塞插入和检索从LinkedTransferQueue放入和取出元素的Java示例。
|
||||
|
||||
* 生产者线程将等待,直到有消费者准备从队列中取出项目为止。
|
||||
* 如果队列为空,使用者线程将等待。 队列中只有一个元素时,它将取出该元素。 只有在消费者接受了消息之后,生产者才可以再发送一条消息。
|
||||
|
||||
|
||||
|
||||
|
||||
```java
|
||||
import java.util.Random;
|
||||
import java.util.concurrent.LinkedTransferQueue;
|
||||
import java.util.concurrent.TimeUnit;
|
||||
|
||||
public class LinkedTransferQueueExample
|
||||
{
|
||||
public static void main(String[] args) throws InterruptedException
|
||||
{
|
||||
LinkedTransferQueue<Integer> linkedTransferQueue = new LinkedTransferQueue<>();
|
||||
|
||||
new Thread(() ->
|
||||
{
|
||||
Random random = new Random(1);
|
||||
try
|
||||
{
|
||||
while (true)
|
||||
{
|
||||
System.out.println("Producer is waiting to transfer message...");
|
||||
|
||||
Integer message = random.nextInt();
|
||||
boolean added = linkedTransferQueue.tryTransfer(message);
|
||||
if(added) {
|
||||
System.out.println("Producer added the message - " + message);
|
||||
}
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(3));
|
||||
}
|
||||
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}).start();
|
||||
|
||||
new Thread(() ->
|
||||
{
|
||||
try
|
||||
{
|
||||
while (true)
|
||||
{
|
||||
System.out.println("Consumer is waiting to take message...");
|
||||
|
||||
Integer message = linkedTransferQueue.take();
|
||||
|
||||
System.out.println("Consumer recieved the message - " + message);
|
||||
|
||||
Thread.sleep(TimeUnit.SECONDS.toMillis(3));
|
||||
}
|
||||
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
}).start();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### 主要方法
|
||||
|
||||
```java
|
||||
LinkedTransferQueue() :构造一个初始为空的LinkedTransferQueue。
|
||||
LinkedTransferQueue(Collection c) :构造一个LinkedTransferQueue,最初包含给定集合的元素,并以该集合的迭代器的遍历顺序添加。
|
||||
Object take() :检索并删除此队列的头部,如有必要,请等待直到元素可用。
|
||||
void transfer(Object o) :将元素传输给使用者,如有必要,请等待。
|
||||
boolean tryTransfer(Object o) :如果可能,立即将元素传输到等待的使用者。
|
||||
boolean tryTransfer(Object o,long timeout,TimeUnit unit) :如果有可能,则在超时之前将元素传输给使用者。
|
||||
int getWaitingConsumerCount() :返回等待通过BlockingQueue.take()或定时轮询接收元素的使用者数量的估计值。
|
||||
boolean hasWaitingConsumer() :如果至少有一个使用者正在等待通过BlockingQueue.take()或定时轮询接收元素,则返回true。
|
||||
void put(Object o) :将指定的元素插入此队列的尾部。
|
||||
boolean add(object) : Inserts the specified element at the tail of this queue.
|
||||
boolean offer(object) :将指定的元素插入此队列的尾部。
|
||||
boolean remove(object) :从此队列中移除指定元素的单个实例(如果存在)。
|
||||
Object peek() :检索但不删除此队列的头部;如果此队列为空,则返回null。
|
||||
Object poll() :检索并删除此队列的头部;如果此队列为空,则返回null。
|
||||
Object poll(timeout, timeUnit) :检索并删除此队列的头部,如果有必要,直到指定的等待时间,元素才可用。
|
||||
void clear() :从队列中删除所有元素。
|
||||
boolean contains(Object o) :如果此队列包含指定的元素,则返回true。
|
||||
Iterator iterator() :以适当的顺序返回对该队列中的元素进行迭代的迭代器。
|
||||
int size() :返回此队列中的元素数。
|
||||
int drainTo(Collection c) :从此队列中删除所有可用元素,并将它们添加到给定的collection中。
|
||||
intrainToTo(Collection c,int maxElements) :从此队列中最多移除给定数量的可用元素,并将它们添加到给定的collection中。
|
||||
int remainingCapacity() :返回该队列理想情况下(在没有内存或资源限制的情况下)可以接受而不阻塞的其他元素的数量。
|
||||
Object[] toArray() :以适当的顺序返回一个包含此队列中所有元素的数组。
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 3 Concurrent
|
||||
* ConcurrentLinkedQueue
|
||||
* ConcurrentLinkedDeque
|
||||
|
||||
* ConcurrentHashMap
|
||||
* ConcurrentHashSet
|
||||
|
||||
|
||||
|
||||
* ConcurrentSkipListMap
|
||||
* ConcurrentSkipListSet
|
||||
|
||||
ConcurrentHashMap是专用于高并发的Map实现,内部实现进行了锁分离,get操作是无锁的。
|
||||
|
||||
java api也提供了一个实现ConcurrentSkipListMap接口的类,ConcurrentSkipListMap接口实现了与ConcurrentNavigableMap接口有相同行为的一个非阻塞式列表。从内部实现机制来讲,它使用了一个Skip List来存放数据。Skip List是基于并发列表的数据结构,效率与二叉树相近。
|
||||
当插入元素到映射中时,ConcurrentSkipListMap接口类使用键值来排序所有元素。除了提供返回一个具体元素的方法外,这个类也提供获取子映射的方法。
|
||||
|
||||
ConcurrentSkipListMap类提供的常用方法:
|
||||
```java
|
||||
1.headMap(K toKey):K是在ConcurrentSkipListMap对象的 泛型参数里用到的键。这个方法返回映射中所有键值小于参数值toKey的子映射。
|
||||
2.tailMap(K fromKey):K是在ConcurrentSkipListMap对象的 泛型参数里用到的键。这个方法返回映射中所有键值大于参数值fromKey的子映射。
|
||||
3.putIfAbsent(K key,V value):如果映射中不存在键key,那么就将key和value保存到映射中。
|
||||
4.pollLastEntry():返回并移除映射中的最后一个Map.Entry对象。
|
||||
5.replace(K key,V value):如果映射中已经存在键key,则用参数中的value替换现有的值。
|
||||
```
|
||||
|
||||
|
||||
|
||||
### ConcurrentHashMap
|
||||
|
||||
#### 底层原理
|
||||
|
||||
#### 1. 存储结构
|
||||
|
||||

|
||||
```java
|
||||
static final class HashEntry<K,V> {
|
||||
final int hash;
|
||||
final K key;
|
||||
volatile V value;
|
||||
volatile HashEntry<K,V> next;
|
||||
}
|
||||
```
|
||||
|
||||
ConcurrentHashMap 和 HashMap 实现上类似,最主要的差别是 ConcurrentHashMap 采用了分段锁(Segment),每个分段锁维护着几个桶(HashEntry),多个线程可以同时访问不同分段锁上的桶,从而使其并发度更高(并发度就是 Segment 的个数)。
|
||||
|
||||
Segment 继承自 ReentrantLock。
|
||||
|
||||
```java
|
||||
static final class Segment<K,V> extends ReentrantLock implements Serializable {
|
||||
|
||||
private static final long serialVersionUID = 2249069246763182397L;
|
||||
|
||||
static final int MAX_SCAN_RETRIES =
|
||||
Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
|
||||
|
||||
transient volatile HashEntry<K,V>[] table;
|
||||
|
||||
transient int count;
|
||||
|
||||
transient int modCount;
|
||||
|
||||
transient int threshold;
|
||||
|
||||
final float loadFactor;
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
final Segment<K,V>[] segments;
|
||||
```
|
||||
|
||||
默认的并发级别为 16,也就是说默认创建 16 个 Segment。
|
||||
|
||||
```java
|
||||
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
|
||||
```
|
||||
|
||||
#### 2. size 操作
|
||||
|
||||
每个 Segment 维护了一个 count 变量来统计该 Segment 中的键值对个数。
|
||||
|
||||
```java
|
||||
/**
|
||||
* The number of elements. Accessed only either within locks
|
||||
* or among other volatile reads that maintain visibility.
|
||||
*/
|
||||
transient int count;
|
||||
```
|
||||
|
||||
在执行 size 操作时,需要遍历所有 Segment 然后把 count 累计起来。
|
||||
|
||||
ConcurrentHashMap 在执行 size 操作时先尝试不加锁,如果连续两次不加锁操作得到的结果一致,那么可以认为这个结果是正确的。
|
||||
|
||||
尝试次数使用 RETRIES_BEFORE_LOCK 定义,该值为 2,retries 初始值为 -1,因此尝试次数为 3。
|
||||
|
||||
如果尝试的次数超过 3 次,就需要对每个 Segment 加锁。
|
||||
|
||||
```java
|
||||
|
||||
/**
|
||||
* Number of unsynchronized retries in size and containsValue
|
||||
* methods before resorting to locking. This is used to avoid
|
||||
* unbounded retries if tables undergo continuous modification
|
||||
* which would make it impossible to obtain an accurate result.
|
||||
*/
|
||||
static final int RETRIES_BEFORE_LOCK = 2;
|
||||
|
||||
public int size() {
|
||||
// Try a few times to get accurate count. On failure due to
|
||||
// continuous async changes in table, resort to locking.
|
||||
final Segment<K,V>[] segments = this.segments;
|
||||
int size;
|
||||
boolean overflow; // true if size overflows 32 bits
|
||||
long sum; // sum of modCounts
|
||||
long last = 0L; // previous sum
|
||||
int retries = -1; // first iteration isn't retry
|
||||
try {
|
||||
for (;;) {
|
||||
// 超过尝试次数,则对每个 Segment 加锁
|
||||
if (retries++ == RETRIES_BEFORE_LOCK) {
|
||||
for (int j = 0; j < segments.length; ++j)
|
||||
ensureSegment(j).lock(); // force creation
|
||||
}
|
||||
sum = 0L;
|
||||
size = 0;
|
||||
overflow = false;
|
||||
for (int j = 0; j < segments.length; ++j) {
|
||||
Segment<K,V> seg = segmentAt(segments, j);
|
||||
if (seg != null) {
|
||||
sum += seg.modCount;
|
||||
int c = seg.count;
|
||||
if (c < 0 || (size += c) < 0)
|
||||
overflow = true;
|
||||
}
|
||||
}
|
||||
// 连续两次得到的结果一致,则认为这个结果是正确的
|
||||
if (sum == last)
|
||||
break;
|
||||
last = sum;
|
||||
}
|
||||
} finally {
|
||||
if (retries > RETRIES_BEFORE_LOCK) {
|
||||
for (int j = 0; j < segments.length; ++j)
|
||||
segmentAt(segments, j).unlock();
|
||||
}
|
||||
}
|
||||
return overflow ? Integer.MAX_VALUE : size;
|
||||
}
|
||||
```
|
||||
|
||||
#### 3. JDK 1.8 的改动
|
||||
|
||||
JDK 1.7 使用分段锁机制来实现并发更新操作,核心类为 Segment,它继承自重入锁 ReentrantLock,并发度与 Segment 数量相等。
|
||||
|
||||
JDK 1.8 使用了 CAS 操作来支持更高的并发度,在 CAS 操作失败时使用内置锁 synchronized。
|
||||
|
||||
并且 JDK 1.8 的实现也在链表过长时会转换为红黑树。
|
||||
|
||||
|
||||
|
||||
#### 使用方法
|
||||
|
||||
创建和读写
|
||||
```java
|
||||
import java.util.Iterator;
|
||||
import java.util.concurrent.ConcurrentHashMap;
|
||||
|
||||
public class HashMapExample
|
||||
{
|
||||
public static void main(String[] args) throws CloneNotSupportedException
|
||||
{
|
||||
ConcurrentHashMap<Integer, String> concurrHashMap = new ConcurrentHashMap<>();
|
||||
|
||||
//Put require no synchronization
|
||||
concurrHashMap.put(1, "A");
|
||||
concurrHashMap.put(2, "B");
|
||||
|
||||
//Get require no synchronization
|
||||
concurrHashMap.get(1);
|
||||
|
||||
Iterator<Integer> itr = concurrHashMap.keySet().iterator();
|
||||
|
||||
//Using synchronized block is advisable
|
||||
synchronized (concurrHashMap)
|
||||
{
|
||||
while(itr.hasNext()) {
|
||||
System.out.println(concurrHashMap.get(itr.next()));
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
使用Collection.synchronizedMap也有同样的方法
|
||||
|
||||
```java
|
||||
import java.util.Collections;
|
||||
import java.util.HashMap;
|
||||
import java.util.Iterator;
|
||||
import java.util.Map;
|
||||
|
||||
public class HashMapExample
|
||||
{
|
||||
public static void main(String[] args) throws CloneNotSupportedException
|
||||
{
|
||||
Map<Integer, String> syncHashMap = Collections.synchronizedMap(new HashMap<>());
|
||||
|
||||
//Put require no synchronization
|
||||
syncHashMap.put(1, "A");
|
||||
syncHashMap.put(2, "B");
|
||||
|
||||
//Get require no synchronization
|
||||
syncHashMap.get(1);
|
||||
|
||||
Iterator<Integer> itr = syncHashMap.keySet().iterator();
|
||||
|
||||
//Using synchronized block is advisable
|
||||
synchronized (syncHashMap)
|
||||
{
|
||||
while(itr.hasNext()) {
|
||||
System.out.println(syncHashMap.get(itr.next()));
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
BIN
Java/04Java并发编程/image/image.png
Normal file
BIN
Java/04Java并发编程/image/image.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 72 KiB |
@@ -343,6 +343,7 @@ G1(垃圾优先)垃圾收集器已在Java 7中提供,旨在长期替代CMS
|
||||
|
||||
1. 每个对象都有年龄计数器,在对象头中。每熬过一次minorGC年龄就会增加1
|
||||
2. 当年龄增加到15时,就会被晋升到老年代。可以通过-XX:MaxTenuringThreshold=15设置。
|
||||
3. 大量对象在young gc后任然存活。survivor空间不够,在 Young GC 时,JVM 会检查 目标 Survivor 区(通常是 S1)是否足够容纳 Eden 区中存活的对象。如果 S1 区空间不足(比如 S1 当前使用率已经是 100%),JVM 会绕过 Survivor 区,直接将存活对象晋升到老年代。
|
||||
|
||||
### 动态对象年龄判断
|
||||
1. 当Survior区中低于或等于某年龄的所有对象总和大于Survivor空间的一半,大于等于该年龄的对象就可以直接进入老年代。
|
||||
|
||||
@@ -2,6 +2,14 @@
|
||||
https://cloud.tencent.com/developer/article/2177482
|
||||
|
||||
## 问题排查工具有哪些
|
||||
给一个系统定位问题的时候,知识、经验是关键基础,数据是依据,工具是运用知识处理数据的手段。这里说的数据主要包括以下几种,当运行的程序出现问题的时候,你首先也应该找到相关的数据进行分析。
|
||||
* 异常堆栈
|
||||
* 虚拟机运行日志
|
||||
* 垃圾收集器日志
|
||||
* 线程快照(threaddump文件)
|
||||
* 堆转存快照(heapdump文件)
|
||||
|
||||
|
||||
如果是在生产环境中直接排查 JVM 的话,最简单的做法就是使用 JDK 自带的 6 个非常实用的命令行工具来排查。它们分别是:jps、jstat、jinfo、jmap、jhat 和 jstack,它们都位于 JDK 的 bin 目录下,可以使用命令行工具直接运行,其目录如下图所示:
|
||||
|
||||

|
||||
|
||||
317
MARKDOWN.md
317
MARKDOWN.md
@@ -1,5 +1,7 @@
|
||||
## markdonw绘图
|
||||
> 参考文档
|
||||
> https://github.github.com/gfm/#precedence
|
||||
|
||||
## markdonw绘图
|
||||
### 时序图
|
||||
```sequence
|
||||
A->B:因果关系
|
||||
@@ -39,3 +41,316 @@ pie
|
||||
"原因三" : 188
|
||||
```
|
||||
|
||||
## 图标速查表
|
||||
|
||||
People
|
||||
|
||||
| :bowtie: `:bowtie:` | :smile: `:smile:` | :laughing: `:laughing:` |
|
||||
|---|---|---|
|
||||
| :blush: `:blush:` | :smiley: `:smiley:` | :relaxed: `:relaxed:` |
|
||||
| :smirk: `:smirk:` | :heart_eyes: `:heart_eyes:` | :kissing_heart: `:kissing_heart:` |
|
||||
| :kissing_closed_eyes: `:kissing_closed_eyes:` | :flushed: `:flushed:` | :relieved: `:relieved:` |
|
||||
| :satisfied: `:satisfied:` | :grin: `:grin:` | :wink: `:wink:` |
|
||||
| :stuck_out_tongue_winking_eye: `:stuck_out_tongue_winking_eye:` | :stuck_out_tongue_closed_eyes: `:stuck_out_tongue_closed_eyes:` | :grinning: `:grinning:` |
|
||||
| :kissing: `:kissing:` | :kissing_smiling_eyes: `:kissing_smiling_eyes:` | :stuck_out_tongue: `:stuck_out_tongue:` |
|
||||
| :sleeping: `:sleeping:` | :worried: `:worried:` | :frowning: `:frowning:` |
|
||||
| :anguished: `:anguished:` | :open_mouth: `:open_mouth:` | :grimacing: `:grimacing:` |
|
||||
| :confused: `:confused:` | :hushed: `:hushed:` | :expressionless: `:expressionless:` |
|
||||
| :unamused: `:unamused:` | :sweat_smile: `:sweat_smile:` | :sweat: `:sweat:` |
|
||||
| :disappointed_relieved: `:disappointed_relieved:` | :weary: `:weary:` | :pensive: `:pensive:` |
|
||||
| :disappointed: `:disappointed:` | :confounded: `:confounded:` | :fearful: `:fearful:` |
|
||||
| :cold_sweat: `:cold_sweat:` | :persevere: `:persevere:` | :cry: `:cry:` |
|
||||
| :sob: `:sob:` | :joy: `:joy:` | :astonished: `:astonished:` |
|
||||
| :scream: `:scream:` | :neckbeard: `:neckbeard:` | :tired_face: `:tired_face:` |
|
||||
| :angry: `:angry:` | :rage: `:rage:` | :triumph: `:triumph:` |
|
||||
| :sleepy: `:sleepy:` | :yum: `:yum:` | :mask: `:mask:` |
|
||||
| :sunglasses: `:sunglasses:` | :dizzy_face: `:dizzy_face:` | :imp: `:imp:` |
|
||||
| :smiling_imp: `:smiling_imp:` | :neutral_face: `:neutral_face:` | :no_mouth: `:no_mouth:` |
|
||||
| :innocent: `:innocent:` | :alien: `:alien:` | :yellow_heart: `:yellow_heart:` |
|
||||
| :blue_heart: `:blue_heart:` | :purple_heart: `:purple_heart:` | :heart: `:heart:` |
|
||||
| :green_heart: `:green_heart:` | :broken_heart: `:broken_heart:` | :heartbeat: `:heartbeat:` |
|
||||
| :heartpulse: `:heartpulse:` | :two_hearts: `:two_hearts:` | :revolving_hearts: `:revolving_hearts:` |
|
||||
| :cupid: `:cupid:` | :sparkling_heart: `:sparkling_heart:` | :sparkles: `:sparkles:` |
|
||||
| :star: `:star:` | :star2: `:star2:` | :dizzy: `:dizzy:` |
|
||||
| :boom: `:boom:` | :collision: `:collision:` | :anger: `:anger:` |
|
||||
| :exclamation: `:exclamation:` | :question: `:question:` | :grey_exclamation: `:grey_exclamation:` |
|
||||
| :grey_question: `:grey_question:` | :zzz: `:zzz:` | :dash: `:dash:` |
|
||||
| :sweat_drops: `:sweat_drops:` | :notes: `:notes:` | :musical_note: `:musical_note:` |
|
||||
| :fire: `:fire:` | :hankey: `:hankey:` | :poop: `:poop:` |
|
||||
| :shit: `:shit:` | :+1: `:+1:` | :thumbsup: `:thumbsup:` |
|
||||
| :-1: `:-1:` | :thumbsdown: `:thumbsdown:` | :ok_hand: `:ok_hand:` |
|
||||
| :punch: `:punch:` | :facepunch: `:facepunch:` | :fist: `:fist:` |
|
||||
| :v: `:v:` | :wave: `:wave:` | :hand: `:hand:` |
|
||||
| :raised_hand: `:raised_hand:` | :open_hands: `:open_hands:` | :point_up: `:point_up:` |
|
||||
| :point_down: `:point_down:` | :point_left: `:point_left:` | :point_right: `:point_right:` |
|
||||
| :raised_hands: `:raised_hands:` | :pray: `:pray:` | :point_up_2: `:point_up_2:` |
|
||||
| :clap: `:clap:` | :muscle: `:muscle:` | :metal: `:metal:` |
|
||||
| :fu: `:fu:` | :walking: `:walking:` | :runner: `:runner:` |
|
||||
| :running: `:running:` | :couple: `:couple:` | :family: `:family:` |
|
||||
| :two_men_holding_hands: `:two_men_holding_hands:` | :two_women_holding_hands: `:two_women_holding_hands:` | :dancer: `:dancer:` |
|
||||
| :dancers: `:dancers:` | :ok_woman: `:ok_woman:` | :no_good: `:no_good:` |
|
||||
| :information_desk_person: `:information_desk_person:` | :raising_hand: `:raising_hand:` | :bride_with_veil: `:bride_with_veil:` |
|
||||
| :person_with_pouting_face: `:person_with_pouting_face:` | :person_frowning: `:person_frowning:` | :bow: `:bow:` |
|
||||
| :couplekiss: `:couplekiss:` | :couple_with_heart: `:couple_with_heart:` | :massage: `:massage:` |
|
||||
| :haircut: `:haircut:` | :nail_care: `:nail_care:` | :boy: `:boy:` |
|
||||
| :girl: `:girl:` | :woman: `:woman:` | :man: `:man:` |
|
||||
| :baby: `:baby:` | :older_woman: `:older_woman:` | :older_man: `:older_man:` |
|
||||
| :person_with_blond_hair: `:person_with_blond_hair:` | :man_with_gua_pi_mao: `:man_with_gua_pi_mao:` | :man_with_turban: `:man_with_turban:` |
|
||||
| :construction_worker: `:construction_worker:` | :cop: `:cop:` | :angel: `:angel:` |
|
||||
| :princess: `:princess:` | :smiley_cat: `:smiley_cat:` | :smile_cat: `:smile_cat:` |
|
||||
| :heart_eyes_cat: `:heart_eyes_cat:` | :kissing_cat: `:kissing_cat:` | :smirk_cat: `:smirk_cat:` |
|
||||
| :scream_cat: `:scream_cat:` | :crying_cat_face: `:crying_cat_face:` | :joy_cat: `:joy_cat:` |
|
||||
| :pouting_cat: `:pouting_cat:` | :japanese_ogre: `:japanese_ogre:` | :japanese_goblin: `:japanese_goblin:` |
|
||||
| :see_no_evil: `:see_no_evil:` | :hear_no_evil: `:hear_no_evil:` | :speak_no_evil: `:speak_no_evil:` |
|
||||
| :guardsman: `:guardsman:` | :skull: `:skull:` | :feet: `:feet:` |
|
||||
| :lips: `:lips:` | :kiss: `:kiss:` | :droplet: `:droplet:` |
|
||||
| :ear: `:ear:` | :eyes: `:eyes:` | :nose: `:nose:` |
|
||||
| :tongue: `:tongue:` | :love_letter: `:love_letter:` | :bust_in_silhouette: `:bust_in_silhouette:` |
|
||||
| :busts_in_silhouette: `:busts_in_silhouette:` | :speech_balloon: `:speech_balloon:` | :thought_balloon: `:thought_balloon:` |
|
||||
| :feelsgood: `:feelsgood:` | :finnadie: `:finnadie:` | :goberserk: `:goberserk:` |
|
||||
| :godmode: `:godmode:` | :hurtrealbad: `:hurtrealbad:` | :rage1: `:rage1:` |
|
||||
| :rage2: `:rage2:` | :rage3: `:rage3:` | :rage4: `:rage4:` |
|
||||
| :suspect: `:suspect:` | :trollface: `:trollface:` |
|
||||
|
||||
Nature
|
||||
|
||||
| :sunny: `:sunny:` | :umbrella: `:umbrella:` | :cloud: `:cloud:` |
|
||||
|---|---|---|
|
||||
| :snowflake: `:snowflake:` | :snowman: `:snowman:` | :zap: `:zap:` |
|
||||
| :cyclone: `:cyclone:` | :foggy: `:foggy:` | :ocean: `:ocean:` |
|
||||
| :cat: `:cat:` | :dog: `:dog:` | :mouse: `:mouse:` |
|
||||
| :hamster: `:hamster:` | :rabbit: `:rabbit:` | :wolf: `:wolf:` |
|
||||
| :frog: `:frog:` | :tiger: `:tiger:` | :koala: `:koala:` |
|
||||
| :bear: `:bear:` | :pig: `:pig:` | :pig_nose: `:pig_nose:` |
|
||||
| :cow: `:cow:` | :boar: `:boar:` | :monkey_face: `:monkey_face:` |
|
||||
| :monkey: `:monkey:` | :horse: `:horse:` | :racehorse: `:racehorse:` |
|
||||
| :camel: `:camel:` | :sheep: `:sheep:` | :elephant: `:elephant:` |
|
||||
| :panda_face: `:panda_face:` | :snake: `:snake:` | :bird: `:bird:` |
|
||||
| :baby_chick: `:baby_chick:` | :hatched_chick: `:hatched_chick:` | :hatching_chick: `:hatching_chick:` |
|
||||
| :chicken: `:chicken:` | :penguin: `:penguin:` | :turtle: `:turtle:` |
|
||||
| :bug: `:bug:` | :honeybee: `:honeybee:` | :ant: `:ant:` |
|
||||
| :beetle: `:beetle:` | :snail: `:snail:` | :octopus: `:octopus:` |
|
||||
| :tropical_fish: `:tropical_fish:` | :fish: `:fish:` | :whale: `:whale:` |
|
||||
| :whale2: `:whale2:` | :dolphin: `:dolphin:` | :cow2: `:cow2:` |
|
||||
| :ram: `:ram:` | :rat: `:rat:` | :water_buffalo: `:water_buffalo:` |
|
||||
| :tiger2: `:tiger2:` | :rabbit2: `:rabbit2:` | :dragon: `:dragon:` |
|
||||
| :goat: `:goat:` | :rooster: `:rooster:` | :dog2: `:dog2:` |
|
||||
| :pig2: `:pig2:` | :mouse2: `:mouse2:` | :ox: `:ox:` |
|
||||
| :dragon_face: `:dragon_face:` | :blowfish: `:blowfish:` | :crocodile: `:crocodile:` |
|
||||
| :dromedary_camel: `:dromedary_camel:` | :leopard: `:leopard:` | :cat2: `:cat2:` |
|
||||
| :poodle: `:poodle:` | :paw_prints: `:paw_prints:` | :bouquet: `:bouquet:` |
|
||||
| :cherry_blossom: `:cherry_blossom:` | :tulip: `:tulip:` | :four_leaf_clover: `:four_leaf_clover:` |
|
||||
| :rose: `:rose:` | :sunflower: `:sunflower:` | :hibiscus: `:hibiscus:` |
|
||||
| :maple_leaf: `:maple_leaf:` | :leaves: `:leaves:` | :fallen_leaf: `:fallen_leaf:` |
|
||||
| :herb: `:herb:` | :mushroom: `:mushroom:` | :cactus: `:cactus:` |
|
||||
| :palm_tree: `:palm_tree:` | :evergreen_tree: `:evergreen_tree:` | :deciduous_tree: `:deciduous_tree:` |
|
||||
| :chestnut: `:chestnut:` | :seedling: `:seedling:` | :blossom: `:blossom:` |
|
||||
| :ear_of_rice: `:ear_of_rice:` | :shell: `:shell:` | :globe_with_meridians: `:globe_with_meridians:` |
|
||||
| :sun_with_face: `:sun_with_face:` | :full_moon_with_face: `:full_moon_with_face:` | :new_moon_with_face: `:new_moon_with_face:` |
|
||||
| :new_moon: `:new_moon:` | :waxing_crescent_moon: `:waxing_crescent_moon:` | :first_quarter_moon: `:first_quarter_moon:` |
|
||||
| :waxing_gibbous_moon: `:waxing_gibbous_moon:` | :full_moon: `:full_moon:` | :waning_gibbous_moon: `:waning_gibbous_moon:` |
|
||||
| :last_quarter_moon: `:last_quarter_moon:` | :waning_crescent_moon: `:waning_crescent_moon:` | :last_quarter_moon_with_face: `:last_quarter_moon_with_face:` |
|
||||
| :first_quarter_moon_with_face: `:first_quarter_moon_with_face:` | :moon: `:moon:` | :earth_africa: `:earth_africa:` |
|
||||
| :earth_americas: `:earth_americas:` | :earth_asia: `:earth_asia:` | :volcano: `:volcano:` |
|
||||
| :milky_way: `:milky_way:` | :partly_sunny: `:partly_sunny:` | :octocat: `:octocat:` |
|
||||
| :squirrel: `:squirrel:` |
|
||||
|
||||
Objects
|
||||
|
||||
| :bamboo: `:bamboo:` | :gift_heart: `:gift_heart:` | :dolls: `:dolls:` |
|
||||
|---|---|---|
|
||||
| :school_satchel: `:school_satchel:` | :mortar_board: `:mortar_board:` | :flags: `:flags:` |
|
||||
| :fireworks: `:fireworks:` | :sparkler: `:sparkler:` | :wind_chime: `:wind_chime:` |
|
||||
| :rice_scene: `:rice_scene:` | :jack_o_lantern: `:jack_o_lantern:` | :ghost: `:ghost:` |
|
||||
| :santa: `:santa:` | :christmas_tree: `:christmas_tree:` | :gift: `:gift:` |
|
||||
| :bell: `:bell:` | :no_bell: `:no_bell:` | :tanabata_tree: `:tanabata_tree:` |
|
||||
| :tada: `:tada:` | :confetti_ball: `:confetti_ball:` | :balloon: `:balloon:` |
|
||||
| :crystal_ball: `:crystal_ball:` | :cd: `:cd:` | :dvd: `:dvd:` |
|
||||
| :floppy_disk: `:floppy_disk:` | :camera: `:camera:` | :video_camera: `:video_camera:` |
|
||||
| :movie_camera: `:movie_camera:` | :computer: `:computer:` | :tv: `:tv:` |
|
||||
| :iphone: `:iphone:` | :phone: `:phone:` | :telephone: `:telephone:` |
|
||||
| :telephone_receiver: `:telephone_receiver:` | :pager: `:pager:` | :fax: `:fax:` |
|
||||
| :minidisc: `:minidisc:` | :vhs: `:vhs:` | :sound: `:sound:` |
|
||||
| :speaker: `:speaker:` | :mute: `:mute:` | :loudspeaker: `:loudspeaker:` |
|
||||
| :mega: `:mega:` | :hourglass: `:hourglass:` | :hourglass_flowing_sand: `:hourglass_flowing_sand:` |
|
||||
| :alarm_clock: `:alarm_clock:` | :watch: `:watch:` | :radio: `:radio:` |
|
||||
| :satellite: `:satellite:` | :loop: `:loop:` | :mag: `:mag:` |
|
||||
| :mag_right: `:mag_right:` | :unlock: `:unlock:` | :lock: `:lock:` |
|
||||
| :lock_with_ink_pen: `:lock_with_ink_pen:` | :closed_lock_with_key: `:closed_lock_with_key:` | :key: `:key:` |
|
||||
| :bulb: `:bulb:` | :flashlight: `:flashlight:` | :high_brightness: `:high_brightness:` |
|
||||
| :low_brightness: `:low_brightness:` | :electric_plug: `:electric_plug:` | :battery: `:battery:` |
|
||||
| :calling: `:calling:` | :email: `:email:` | :mailbox: `:mailbox:` |
|
||||
| :postbox: `:postbox:` | :bath: `:bath:` | :bathtub: `:bathtub:` |
|
||||
| :shower: `:shower:` | :toilet: `:toilet:` | :wrench: `:wrench:` |
|
||||
| :nut_and_bolt: `:nut_and_bolt:` | :hammer: `:hammer:` | :seat: `:seat:` |
|
||||
| :moneybag: `:moneybag:` | :yen: `:yen:` | :dollar: `:dollar:` |
|
||||
| :pound: `:pound:` | :euro: `:euro:` | :credit_card: `:credit_card:` |
|
||||
| :money_with_wings: `:money_with_wings:` | :e-mail: `:e-mail:` | :inbox_tray: `:inbox_tray:` |
|
||||
| :outbox_tray: `:outbox_tray:` | :envelope: `:envelope:` | :incoming_envelope: `:incoming_envelope:` |
|
||||
| :postal_horn: `:postal_horn:` | :mailbox_closed: `:mailbox_closed:` | :mailbox_with_mail: `:mailbox_with_mail:` |
|
||||
| :mailbox_with_no_mail: `:mailbox_with_no_mail:` | :door: `:door:` | :smoking: `:smoking:` |
|
||||
| :bomb: `:bomb:` | :gun: `:gun:` | :hocho: `:hocho:` |
|
||||
| :pill: `:pill:` | :syringe: `:syringe:` | :page_facing_up: `:page_facing_up:` |
|
||||
| :page_with_curl: `:page_with_curl:` | :bookmark_tabs: `:bookmark_tabs:` | :bar_chart: `:bar_chart:` |
|
||||
| :chart_with_upwards_trend: `:chart_with_upwards_trend:` | :chart_with_downwards_trend: `:chart_with_downwards_trend:` | :scroll: `:scroll:` |
|
||||
| :clipboard: `:clipboard:` | :calendar: `:calendar:` | :date: `:date:` |
|
||||
| :card_index: `:card_index:` | :file_folder: `:file_folder:` | :open_file_folder: `:open_file_folder:` |
|
||||
| :scissors: `:scissors:` | :pushpin: `:pushpin:` | :paperclip: `:paperclip:` |
|
||||
| :black_nib: `:black_nib:` | :pencil2: `:pencil2:` | :straight_ruler: `:straight_ruler:` |
|
||||
| :triangular_ruler: `:triangular_ruler:` | :closed_book: `:closed_book:` | :green_book: `:green_book:` |
|
||||
| :blue_book: `:blue_book:` | :orange_book: `:orange_book:` | :notebook: `:notebook:` |
|
||||
| :notebook_with_decorative_cover: `:notebook_with_decorative_cover:` | :ledger: `:ledger:` | :books: `:books:` |
|
||||
| :bookmark: `:bookmark:` | :name_badge: `:name_badge:` | :microscope: `:microscope:` |
|
||||
| :telescope: `:telescope:` | :newspaper: `:newspaper:` | :football: `:football:` |
|
||||
| :basketball: `:basketball:` | :soccer: `:soccer:` | :baseball: `:baseball:` |
|
||||
| :tennis: `:tennis:` | :8ball: `:8ball:` | :rugby_football: `:rugby_football:` |
|
||||
| :bowling: `:bowling:` | :golf: `:golf:` | :mountain_bicyclist: `:mountain_bicyclist:` |
|
||||
| :bicyclist: `:bicyclist:` | :horse_racing: `:horse_racing:` | :snowboarder: `:snowboarder:` |
|
||||
| :swimmer: `:swimmer:` | :surfer: `:surfer:` | :ski: `:ski:` |
|
||||
| :spades: `:spades:` | :hearts: `:hearts:` | :clubs: `:clubs:` |
|
||||
| :diamonds: `:diamonds:` | :gem: `:gem:` | :ring: `:ring:` |
|
||||
| :trophy: `:trophy:` | :musical_score: `:musical_score:` | :musical_keyboard: `:musical_keyboard:` |
|
||||
| :violin: `:violin:` | :space_invader: `:space_invader:` | :video_game: `:video_game:` |
|
||||
| :black_joker: `:black_joker:` | :flower_playing_cards: `:flower_playing_cards:` | :game_die: `:game_die:` |
|
||||
| :dart: `:dart:` | :mahjong: `:mahjong:` | :clapper: `:clapper:` |
|
||||
| :memo: `:memo:` | :pencil: `:pencil:` | :book: `:book:` |
|
||||
| :art: `:art:` | :microphone: `:microphone:` | :headphones: `:headphones:` |
|
||||
| :trumpet: `:trumpet:` | :saxophone: `:saxophone:` | :guitar: `:guitar:` |
|
||||
| :shoe: `:shoe:` | :sandal: `:sandal:` | :high_heel: `:high_heel:` |
|
||||
| :lipstick: `:lipstick:` | :boot: `:boot:` | :shirt: `:shirt:` |
|
||||
| :tshirt: `:tshirt:` | :necktie: `:necktie:` | :womans_clothes: `:womans_clothes:` |
|
||||
| :dress: `:dress:` | :running_shirt_with_sash: `:running_shirt_with_sash:` | :jeans: `:jeans:` |
|
||||
| :kimono: `:kimono:` | :bikini: `:bikini:` | :ribbon: `:ribbon:` |
|
||||
| :tophat: `:tophat:` | :crown: `:crown:` | :womans_hat: `:womans_hat:` |
|
||||
| :mans_shoe: `:mans_shoe:` | :closed_umbrella: `:closed_umbrella:` | :briefcase: `:briefcase:` |
|
||||
| :handbag: `:handbag:` | :pouch: `:pouch:` | :purse: `:purse:` |
|
||||
| :eyeglasses: `:eyeglasses:` | :fishing_pole_and_fish: `:fishing_pole_and_fish:` | :coffee: `:coffee:` |
|
||||
| :tea: `:tea:` | :sake: `:sake:` | :baby_bottle: `:baby_bottle:` |
|
||||
| :beer: `:beer:` | :beers: `:beers:` | :cocktail: `:cocktail:` |
|
||||
| :tropical_drink: `:tropical_drink:` | :wine_glass: `:wine_glass:` | :fork_and_knife: `:fork_and_knife:` |
|
||||
| :pizza: `:pizza:` | :hamburger: `:hamburger:` | :fries: `:fries:` |
|
||||
| :poultry_leg: `:poultry_leg:` | :meat_on_bone: `:meat_on_bone:` | :spaghetti: `:spaghetti:` |
|
||||
| :curry: `:curry:` | :fried_shrimp: `:fried_shrimp:` | :bento: `:bento:` |
|
||||
| :sushi: `:sushi:` | :fish_cake: `:fish_cake:` | :rice_ball: `:rice_ball:` |
|
||||
| :rice_cracker: `:rice_cracker:` | :rice: `:rice:` | :ramen: `:ramen:` |
|
||||
| :stew: `:stew:` | :oden: `:oden:` | :dango: `:dango:` |
|
||||
| :egg: `:egg:` | :bread: `:bread:` | :doughnut: `:doughnut:` |
|
||||
| :custard: `:custard:` | :icecream: `:icecream:` | :ice_cream: `:ice_cream:` |
|
||||
| :shaved_ice: `:shaved_ice:` | :birthday: `:birthday:` | :cake: `:cake:` |
|
||||
| :cookie: `:cookie:` | :chocolate_bar: `:chocolate_bar:` | :candy: `:candy:` |
|
||||
| :lollipop: `:lollipop:` | :honey_pot: `:honey_pot:` | :apple: `:apple:` |
|
||||
| :green_apple: `:green_apple:` | :tangerine: `:tangerine:` | :lemon: `:lemon:` |
|
||||
| :cherries: `:cherries:` | :grapes: `:grapes:` | :watermelon: `:watermelon:` |
|
||||
| :strawberry: `:strawberry:` | :peach: `:peach:` | :melon: `:melon:` |
|
||||
| :banana: `:banana:` | :pear: `:pear:` | :pineapple: `:pineapple:` |
|
||||
| :sweet_potato: `:sweet_potato:` | :eggplant: `:eggplant:` | :tomato: `:tomato:` |
|
||||
| :corn: `:corn:` |
|
||||
|
||||
Places
|
||||
|
||||
| :house: `:house:` | :house_with_garden: `:house_with_garden:` | :school: `:school:` |
|
||||
|---|---|---|
|
||||
| :office: `:office:` | :post_office: `:post_office:` | :hospital: `:hospital:` |
|
||||
| :bank: `:bank:` | :convenience_store: `:convenience_store:` | :love_hotel: `:love_hotel:` |
|
||||
| :hotel: `:hotel:` | :wedding: `:wedding:` | :church: `:church:` |
|
||||
| :department_store: `:department_store:` | :european_post_office: `:european_post_office:` | :city_sunrise: `:city_sunrise:` |
|
||||
| :city_sunset: `:city_sunset:` | :japanese_castle: `:japanese_castle:` | :european_castle: `:european_castle:` |
|
||||
| :tent: `:tent:` | :factory: `:factory:` | :tokyo_tower: `:tokyo_tower:` |
|
||||
| :japan: `:japan:` | :mount_fuji: `:mount_fuji:` | :sunrise_over_mountains: `:sunrise_over_mountains:` |
|
||||
| :sunrise: `:sunrise:` | :stars: `:stars:` | :statue_of_liberty: `:statue_of_liberty:` |
|
||||
| :bridge_at_night: `:bridge_at_night:` | :carousel_horse: `:carousel_horse:` | :rainbow: `:rainbow:` |
|
||||
| :ferris_wheel: `:ferris_wheel:` | :fountain: `:fountain:` | :roller_coaster: `:roller_coaster:` |
|
||||
| :ship: `:ship:` | :speedboat: `:speedboat:` | :boat: `:boat:` |
|
||||
| :sailboat: `:sailboat:` | :rowboat: `:rowboat:` | :anchor: `:anchor:` |
|
||||
| :rocket: `:rocket:` | :airplane: `:airplane:` | :helicopter: `:helicopter:` |
|
||||
| :steam_locomotive: `:steam_locomotive:` | :tram: `:tram:` | :mountain_railway: `:mountain_railway:` |
|
||||
| :bike: `:bike:` | :aerial_tramway: `:aerial_tramway:` | :suspension_railway: `:suspension_railway:` |
|
||||
| :mountain_cableway: `:mountain_cableway:` | :tractor: `:tractor:` | :blue_car: `:blue_car:` |
|
||||
| :oncoming_automobile: `:oncoming_automobile:` | :car: `:car:` | :red_car: `:red_car:` |
|
||||
| :taxi: `:taxi:` | :oncoming_taxi: `:oncoming_taxi:` | :articulated_lorry: `:articulated_lorry:` |
|
||||
| :bus: `:bus:` | :oncoming_bus: `:oncoming_bus:` | :rotating_light: `:rotating_light:` |
|
||||
| :police_car: `:police_car:` | :oncoming_police_car: `:oncoming_police_car:` | :fire_engine: `:fire_engine:` |
|
||||
| :ambulance: `:ambulance:` | :minibus: `:minibus:` | :truck: `:truck:` |
|
||||
| :train: `:train:` | :station: `:station:` | :train2: `:train2:` |
|
||||
| :bullettrain_front: `:bullettrain_front:` | :bullettrain_side: `:bullettrain_side:` | :light_rail: `:light_rail:` |
|
||||
| :monorail: `:monorail:` | :railway_car: `:railway_car:` | :trolleybus: `:trolleybus:` |
|
||||
| :ticket: `:ticket:` | :fuelpump: `:fuelpump:` | :vertical_traffic_light: `:vertical_traffic_light:` |
|
||||
| :traffic_light: `:traffic_light:` | :warning: `:warning:` | :construction: `:construction:` |
|
||||
| :beginner: `:beginner:` | :atm: `:atm:` | :slot_machine: `:slot_machine:` |
|
||||
| :busstop: `:busstop:` | :barber: `:barber:` | :hotsprings: `:hotsprings:` |
|
||||
| :checkered_flag: `:checkered_flag:` | :crossed_flags: `:crossed_flags:` | :izakaya_lantern: `:izakaya_lantern:` |
|
||||
| :moyai: `:moyai:` | :circus_tent: `:circus_tent:` | :performing_arts: `:performing_arts:` |
|
||||
| :round_pushpin: `:round_pushpin:` | :triangular_flag_on_post: `:triangular_flag_on_post:` | :jp: `:jp:` |
|
||||
| :kr: `:kr:` | :cn: `:cn:` | :us: `:us:` |
|
||||
| :fr: `:fr:` | :es: `:es:` | :it: `:it:` |
|
||||
| :ru: `:ru:` | :gb: `:gb:` | :uk: `:uk:` |
|
||||
| :de: `:de:` |
|
||||
|
||||
Symbols
|
||||
|
||||
| :one: `:one:` | :two: `:two:` | :three: `:three:` |
|
||||
|---|---|---|
|
||||
| :four: `:four:` | :five: `:five:` | :six: `:six:` |
|
||||
| :seven: `:seven:` | :eight: `:eight:` | :nine: `:nine:` |
|
||||
| :keycap_ten: `:keycap_ten:` | :1234: `:1234:` | :zero: `:zero:` |
|
||||
| :hash: `:hash:` | :symbols: `:symbols:` | :arrow_backward: `:arrow_backward:` |
|
||||
| :arrow_down: `:arrow_down:` | :arrow_forward: `:arrow_forward:` | :arrow_left: `:arrow_left:` |
|
||||
| :capital_abcd: `:capital_abcd:` | :abcd: `:abcd:` | :abc: `:abc:` |
|
||||
| :arrow_lower_left: `:arrow_lower_left:` | :arrow_lower_right: `:arrow_lower_right:` | :arrow_right: `:arrow_right:` |
|
||||
| :arrow_up: `:arrow_up:` | :arrow_upper_left: `:arrow_upper_left:` | :arrow_upper_right: `:arrow_upper_right:` |
|
||||
| :arrow_double_down: `:arrow_double_down:` | :arrow_double_up: `:arrow_double_up:` | :arrow_down_small: `:arrow_down_small:` |
|
||||
| :arrow_heading_down: `:arrow_heading_down:` | :arrow_heading_up: `:arrow_heading_up:` | :leftwards_arrow_with_hook: `:leftwards_arrow_with_hook:` |
|
||||
| :arrow_right_hook: `:arrow_right_hook:` | :left_right_arrow: `:left_right_arrow:` | :arrow_up_down: `:arrow_up_down:` |
|
||||
| :arrow_up_small: `:arrow_up_small:` | :arrows_clockwise: `:arrows_clockwise:` | :arrows_counterclockwise: `:arrows_counterclockwise:` |
|
||||
| :rewind: `:rewind:` | :fast_forward: `:fast_forward:` | :information_source: `:information_source:` |
|
||||
| :ok: `:ok:` | :twisted_rightwards_arrows: `:twisted_rightwards_arrows:` | :repeat: `:repeat:` |
|
||||
| :repeat_one: `:repeat_one:` | :new: `:new:` | :top: `:top:` |
|
||||
| :up: `:up:` | :cool: `:cool:` | :free: `:free:` |
|
||||
| :ng: `:ng:` | :cinema: `:cinema:` | :koko: `:koko:` |
|
||||
| :signal_strength: `:signal_strength:` | :u5272: `:u5272:` | :u5408: `:u5408:` |
|
||||
| :u55b6: `:u55b6:` | :u6307: `:u6307:` | :u6708: `:u6708:` |
|
||||
| :u6709: `:u6709:` | :u6e80: `:u6e80:` | :u7121: `:u7121:` |
|
||||
| :u7533: `:u7533:` | :u7a7a: `:u7a7a:` | :u7981: `:u7981:` |
|
||||
| :sa: `:sa:` | :restroom: `:restroom:` | :mens: `:mens:` |
|
||||
| :womens: `:womens:` | :baby_symbol: `:baby_symbol:` | :no_smoking: `:no_smoking:` |
|
||||
| :parking: `:parking:` | :wheelchair: `:wheelchair:` | :metro: `:metro:` |
|
||||
| :baggage_claim: `:baggage_claim:` | :accept: `:accept:` | :wc: `:wc:` |
|
||||
| :potable_water: `:potable_water:` | :put_litter_in_its_place: `:put_litter_in_its_place:` | :secret: `:secret:` |
|
||||
| :congratulations: `:congratulations:` | :m: `:m:` | :passport_control: `:passport_control:` |
|
||||
| :left_luggage: `:left_luggage:` | :customs: `:customs:` | :ideograph_advantage: `:ideograph_advantage:` |
|
||||
| :cl: `:cl:` | :sos: `:sos:` | :id: `:id:` |
|
||||
| :no_entry_sign: `:no_entry_sign:` | :underage: `:underage:` | :no_mobile_phones: `:no_mobile_phones:` |
|
||||
| :do_not_litter: `:do_not_litter:` | :non-potable_water: `:non-potable_water:` | :no_bicycles: `:no_bicycles:` |
|
||||
| :no_pedestrians: `:no_pedestrians:` | :children_crossing: `:children_crossing:` | :no_entry: `:no_entry:` |
|
||||
| :eight_spoked_asterisk: `:eight_spoked_asterisk:` | :eight_pointed_black_star: `:eight_pointed_black_star:` | :heart_decoration: `:heart_decoration:` |
|
||||
| :vs: `:vs:` | :vibration_mode: `:vibration_mode:` | :mobile_phone_off: `:mobile_phone_off:` |
|
||||
| :chart: `:chart:` | :currency_exchange: `:currency_exchange:` | :aries: `:aries:` |
|
||||
| :taurus: `:taurus:` | :gemini: `:gemini:` | :cancer: `:cancer:` |
|
||||
| :leo: `:leo:` | :virgo: `:virgo:` | :libra: `:libra:` |
|
||||
| :scorpius: `:scorpius:` | :sagittarius: `:sagittarius:` | :capricorn: `:capricorn:` |
|
||||
| :aquarius: `:aquarius:` | :pisces: `:pisces:` | :ophiuchus: `:ophiuchus:` |
|
||||
| :six_pointed_star: `:six_pointed_star:` | :negative_squared_cross_mark: `:negative_squared_cross_mark:` | :a: `:a:` |
|
||||
| :b: `:b:` | :ab: `:ab:` | :o2: `:o2:` |
|
||||
| :diamond_shape_with_a_dot_inside: `:diamond_shape_with_a_dot_inside:` | :recycle: `:recycle:` | :end: `:end:` |
|
||||
| :on: `:on:` | :soon: `:soon:` | :clock1: `:clock1:` |
|
||||
| :clock130: `:clock130:` | :clock10: `:clock10:` | :clock1030: `:clock1030:` |
|
||||
| :clock11: `:clock11:` | :clock1130: `:clock1130:` | :clock12: `:clock12:` |
|
||||
| :clock1230: `:clock1230:` | :clock2: `:clock2:` | :clock230: `:clock230:` |
|
||||
| :clock3: `:clock3:` | :clock330: `:clock330:` | :clock4: `:clock4:` |
|
||||
| :clock430: `:clock430:` | :clock5: `:clock5:` | :clock530: `:clock530:` |
|
||||
| :clock6: `:clock6:` | :clock630: `:clock630:` | :clock7: `:clock7:` |
|
||||
| :clock730: `:clock730:` | :clock8: `:clock8:` | :clock830: `:clock830:` |
|
||||
| :clock9: `:clock9:` | :clock930: `:clock930:` | :heavy_dollar_sign: `:heavy_dollar_sign:` |
|
||||
| :copyright: `:copyright:` | :registered: `:registered:` | :tm: `:tm:` |
|
||||
| :x: `:x:` | :heavy_exclamation_mark: `:heavy_exclamation_mark:` | :bangbang: `:bangbang:` |
|
||||
| :interrobang: `:interrobang:` | :o: `:o:` | :heavy_multiplication_x: `:heavy_multiplication_x:` |
|
||||
| :heavy_plus_sign: `:heavy_plus_sign:` | :heavy_minus_sign: `:heavy_minus_sign:` | :heavy_division_sign: `:heavy_division_sign:` |
|
||||
| :white_flower: `:white_flower:` | :100: `:100:` | :heavy_check_mark: `:heavy_check_mark:` |
|
||||
| :ballot_box_with_check: `:ballot_box_with_check:` | :radio_button: `:radio_button:` | :link: `:link:` |
|
||||
| :curly_loop: `:curly_loop:` | :wavy_dash: `:wavy_dash:` | :part_alternation_mark: `:part_alternation_mark:` |
|
||||
| :trident: `:trident:` | :black_square: `:black_square:` | :white_square: `:white_square:` |
|
||||
| :white_check_mark: `:white_check_mark:` | :black_square_button: `:black_square_button:` | :white_square_button: `:white_square_button:` |
|
||||
| :black_circle: `:black_circle:` | :white_circle: `:white_circle:` | :red_circle: `:red_circle:` |
|
||||
| :large_blue_circle: `:large_blue_circle:` | :large_blue_diamond: `:large_blue_diamond:` | :large_orange_diamond: `:large_orange_diamond:` |
|
||||
| :small_blue_diamond: `:small_blue_diamond:` | :small_orange_diamond: `:small_orange_diamond:` | :small_red_triangle: `:small_red_triangle:` |
|
||||
| :small_red_triangle_down: `:small_red_triangle_down:` | :shipit: `:shipit:` |
|
||||
|
||||
@@ -373,4 +373,62 @@ let a = [1, 2, 3, 4, 5];
|
||||
let slice = &a[1..3];
|
||||
```
|
||||
|
||||
这个 slice 的类型是 &[i32]。它跟字符串 slice 的工作方式一样,通过存储第一个集合元素的引用和一个集合总长度。你可以对其他所有集合使用这类 slice。
|
||||
这个 slice 的类型是 &[i32]。它跟字符串 slice 的工作方式一样,通过存储第一个集合元素的引用和一个集合总长度。你可以对其他所有集合使用这类 slice。
|
||||
|
||||
|
||||
|
||||
## 所有权深入理解
|
||||
|
||||
人生就是用代价换好处,跟咒术回战中的天与咒缚一样,牺牲的东西越多,能换到的能力就越多,都是等价交换。
|
||||
|
||||
Rust中的所有权机制,就是牺牲灵活性换取安全性。
|
||||
|
||||
### 值语义和引用语义
|
||||
|
||||
值语义会发生拷贝
|
||||
引用语义会发生移动
|
||||
|
||||
### 表达式规则
|
||||
|
||||
1. 左值,在Rust中又称为,位置表达式
|
||||
2. 右值,在Rust中又称为,值表达式
|
||||
3. 左值一定是右值,因为位置表达式可以独立作为一个值表达式,被赋值语句使用。
|
||||
4. 函数的返回值一定是右值。
|
||||
|
||||
### 规则一:所有权规则:何时发生移动
|
||||
|
||||
1. 左值出现在右值表达式中,或者说,位置表达式出现在值表达式中。
|
||||
2. 左值没有实现Copy trait。
|
||||
1. 如果左值实现了Copy trait,那么左值就是发生复制,因为Copy trait表明左值可以复制,而不是移动。
|
||||
2. 如果左值实现了Drop trait,那么左值就是发生移动,因为Drop trait表明左值可以移动,而不是销毁。
|
||||
3. 这两个trait必须且仅能存在一个。
|
||||
|
||||
|
||||
### 规则二:生命周期规则:变量与数据生命周期一致
|
||||
|
||||
RAII销毁变量的同时销毁资源
|
||||
|
||||
basically, RAII is a design pattern that guarantees that resources are cleaned up in the right way.
|
||||
1. 一个数据只能被一个变量所拥有。
|
||||
2. 只有持有数据所有权的变量才会释放它的资源
|
||||
|
||||
### 规则三:借用规则
|
||||
简单理解为一个代码层面的读写锁。写独占,读共享
|
||||
1. 一个变量允许存在多个不可变借用,或一个可变借用。(写写互斥)
|
||||
2. 如果存在不可变借用,所有者暂时失去写权限,只能读取。(读读共享)
|
||||
3. 如果存在可变借用,所有者暂时失去读写权限。(读写互斥)
|
||||
4. 只要存在任意借用,所有者暂时失去了释放与移动的权限。(写写、读写互斥)
|
||||
|
||||
|
||||
另外有一点很重要,借用是C++中的指针,是取地址操作运算符!可以解引用。
|
||||
|
||||
|
||||
### 重新借用
|
||||
|
||||
遵循规则一:所有权规则。重新借用后所有权转移到新的借用中。
|
||||
|
||||
|
||||
### 复合类型的所有权
|
||||
|
||||
1. 聚合所有权,整体共享一套所有权规则。数组
|
||||
2. 字段所有类型,复合类型的字段独享所有权。结构体
|
||||
|
||||
11
Script/connect
Normal file
11
Script/connect
Normal file
@@ -0,0 +1,11 @@
|
||||
# 查看连接名称
|
||||
nmcli connection show
|
||||
|
||||
# 修改连接为静态IP(假设连接名为"Wired connection 1")
|
||||
sudo nmcli connection modify "Wired connection 1" ipv4.addresses 192.168.1.17/24
|
||||
sudo nmcli connection modify "Wired connection 1" ipv4.gateway 192.168.1.1
|
||||
sudo nmcli connection modify "Wired connection 1" ipv4.dns "8.8.8.8"
|
||||
sudo nmcli connection modify "Wired connection 1" ipv4.method manual
|
||||
|
||||
# 重启连接
|
||||
sudo nmcli connection down "Wired connection 1" && sudo nmcli connection up "Wired connection 1"
|
||||
0
基金股票/a.xmind
Normal file
0
基金股票/a.xmind
Normal file
Reference in New Issue
Block a user