pipelinse and istio
4
.vscode/settings.json
vendored
@@ -199,4 +199,8 @@
|
||||
],
|
||||
"java.configuration.updateBuildConfiguration": "disabled",
|
||||
"java.compile.nullAnalysis.mode": "automatic",
|
||||
"markdown.editor.filePaste.enabled": "always",
|
||||
"markdown.copyFiles.destination": {
|
||||
"**/*": "image/"
|
||||
},
|
||||
}
|
||||
28
kubenets/04-12port-forward.md
Normal file
@@ -0,0 +1,28 @@
|
||||
kubectl port-forward 允许使用资源名称 (例如 Pod 名称)来选择匹配的 Pod 来进行端口转发
|
||||
|
||||
# 将 mongo-75f59d57f4-4nd6q 改为 Pod 的名称
|
||||
kubectl port-forward mongo-75f59d57f4-4nd6q 28015:27017
|
||||
|
||||
这相当于
|
||||
|
||||
kubectl port-forward pods/mongo-75f59d57f4-4nd6q 28015:27017
|
||||
或者
|
||||
|
||||
kubectl port-forward deployment/mongo 28015:27017
|
||||
或者
|
||||
|
||||
kubectl port-forward replicaset/mongo-75f59d57f4 28015:27017
|
||||
或者
|
||||
|
||||
kubectl port-forward service/mongo 28015:27017
|
||||
|
||||
以上所有命令都有效。输出类似于:
|
||||
|
||||
Forwarding from 127.0.0.1:28015 -> 27017
|
||||
Forwarding from [::1]:28015 -> 27017
|
||||
|
||||
|
||||
与本地 28015 端口建立的连接将被转发到运行 MongoDB 服务器的 Pod 的 27017 端口。 通过此连接,你可以使用本地工作站来调试在 Pod 中运行的数据库。
|
||||
|
||||
kubectl port-forward 仅实现了 TCP 端口 支持。 在 issue 47862 中跟踪了对 UDP 协议的支持。
|
||||
|
||||
326
kubenets/12 RBAC鉴权.md
Normal file
@@ -0,0 +1,326 @@
|
||||
## 鉴权说明
|
||||
|
||||
### 简介
|
||||
|
||||
启用RBAC,需要在 apiserver 中添加参数--authorization-mode=RBAC
|
||||
|
||||
API Server目前支持以下几种授权策略:
|
||||
|
||||
* AlwaysDeny:表示拒绝所有请求,一般用于测试。
|
||||
* AlwaysAllow:允许接收所有请求。
|
||||
* 如果集群不需要授权流程,则可以采用该策略,这也是Kubernetes的默认配置。
|
||||
* ABAC(Attribute-Based Access Control):基于属性的访问控制。
|
||||
* 表示使用用户配置的授权规则对用户请求进行匹配和控制。
|
||||
* Webhook:通过调用外部REST服务对用户进行授权。
|
||||
* RBAC:Role-Based Access Control,基于角色的访问控制(本章讲解)。
|
||||
* Node:是一种专用模式,用于对kubelet发出的请求进行访问控制。
|
||||
|
||||
### 概念
|
||||
|
||||
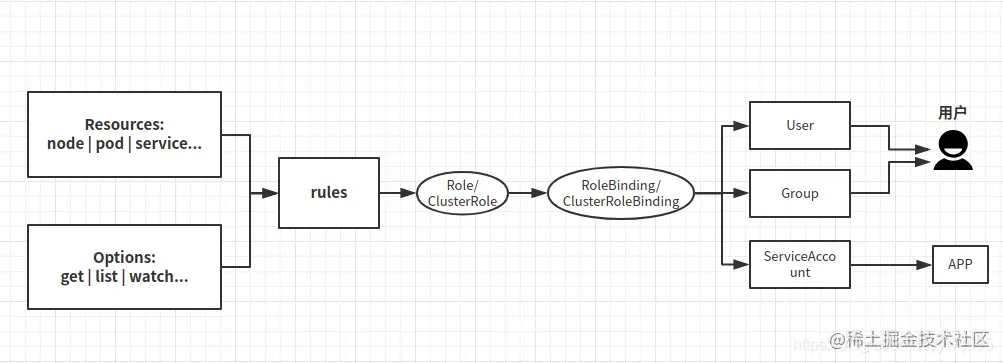
K8s的用户分两种,一种是普通用户,一种是ServiceAccount(服务账户)。
|
||||
|
||||
普通用户
|
||||
|
||||
普通用户是假定被外部或独立服务管理的。管理员分配私钥。平时常用的kubectl命令都是普通用户执行的。
|
||||
如果是用户需求权限,则将Role与User(或Group)绑定(这需要创建User/Group),是给用户使用的。
|
||||
|
||||
ServiceAccount(服务账户)
|
||||
|
||||
ServiceAccount(服务帐户)是由Kubernetes API管理的用户。它们绑定到特定的命名空间,并由API服务器自动创建或通过API调用手动创建。服务帐户与存储为Secrets的一组证书相关联,这些凭据被挂载到pod中,以便集群进程与Kubernetes API通信。
|
||||
如果是程序需求权限,将Role与ServiceAccount指定(这需要创建ServiceAccount并且在deployment中指定ServiceAccount),是给程序使用的。
|
||||
|
||||
|
||||
|
||||
|
||||
## 操作步骤
|
||||
|
||||
### 步骤
|
||||
|
||||
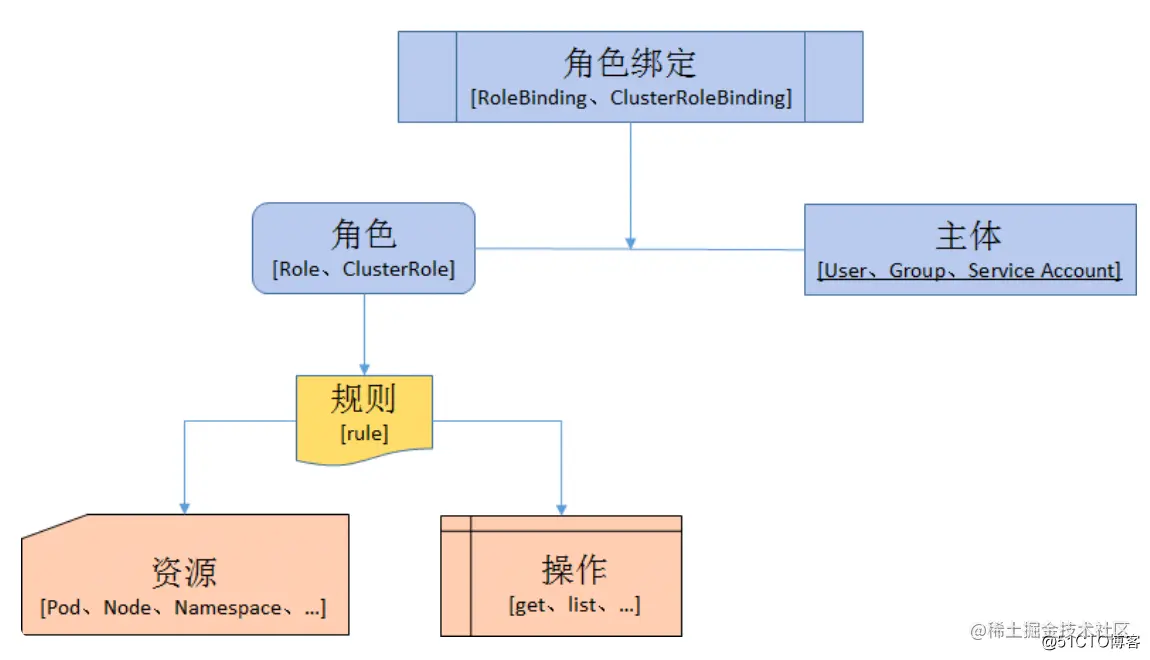
在RABC API中,通过如下的步骤进行授权:
|
||||
|
||||
1. **定义角色** :在定义角色时会指定此角色对于资源的访问控制的规则。
|
||||
2. **绑定角色** :将主体与角色进行绑定,对用户进行访问授权。
|
||||
|
||||
|
||||
|
||||
**角色**
|
||||
|
||||
* Role:授权特定命名空间的访问权限
|
||||
* ClusterRole:授权所有命名空间的访问权限
|
||||
|
||||
**角色绑定**
|
||||
|
||||
* RoleBinding:将角色绑定到主体(即subject)
|
||||
* ClusterRoleBinding:将集群角色绑定到主体
|
||||
|
||||
**主体(subject)**
|
||||
|
||||
* User:用户
|
||||
* Group:用户组
|
||||
* ServiceAccount:服务账号
|
||||
|
||||
### 核心资源
|
||||
|
||||
#### Role
|
||||
|
||||
1. Role关联资源、操作的权限
|
||||
|
||||
```
|
||||
kind: Role
|
||||
apiVersion: rbac.authorization.k8s.io/v1
|
||||
metadata:
|
||||
namespace: default
|
||||
name: pod-role
|
||||
rules:
|
||||
- apiGroups: [""] # "" indicates the core API group
|
||||
resources: ["pods"]
|
||||
verbs: ["get", "watch", "list"]
|
||||
```
|
||||
|
||||
2. clusterRole关联集群资源的资源、操作权限
|
||||
|
||||
```
|
||||
apiVersion: rbac.authorization.k8s.io/v1
|
||||
kind: ClusterRole
|
||||
metadata:
|
||||
name: pod-clusterrole
|
||||
rules:
|
||||
- apiGroups: [""]
|
||||
resources: ["pods"]
|
||||
verbs: ["get", "watch", "list"]
|
||||
```
|
||||
|
||||
常用的资源类型有
|
||||
|
||||
```
|
||||
"services", "endpoints", "pods","secrets","configmaps","crontabs","deployments","jobs","nodes","rolebindings","clusterroles","daemonsets","replicasets","statefulsets","horizontalpodautoscalers","replicationcontrollers","cronjobs"
|
||||
```
|
||||
|
||||
常用的操作语义有
|
||||
|
||||
```
|
||||
"get", "list", "watch", "create", "update", "patch", "delete", "exec"
|
||||
```
|
||||
|
||||
#### 角色绑定
|
||||
|
||||
RoleBinding
|
||||
|
||||
```
|
||||
kind: RoleBinding
|
||||
apiVersion: rbac.authorization.k8s.io/v1
|
||||
metadata:
|
||||
name: rb
|
||||
namespace: default
|
||||
subjects:
|
||||
- kind: ServiceAccount
|
||||
name: zhangsan
|
||||
namespace: default
|
||||
roleRef:
|
||||
kind: Role
|
||||
name: pod-role
|
||||
apiGroup: rbac.authorization.k8s.io
|
||||
```
|
||||
|
||||
ClusterRoleBinding
|
||||
|
||||
```
|
||||
kind: ClusterRoleBinding
|
||||
apiVersion: rbac.authorization.k8s.io/v1
|
||||
metadata:
|
||||
name: crb
|
||||
subjects:
|
||||
- kind: ServiceAccount
|
||||
name: mark
|
||||
namespace: default
|
||||
roleRef:
|
||||
kind: ClusterRole
|
||||
name: pod-clusterrole
|
||||
apiGroup: rbac.authorization.k8s.io
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: ServiceAccount
|
||||
metadata:
|
||||
name: mark
|
||||
namespace: default
|
||||
```
|
||||
|
||||
### User&Group
|
||||
|
||||
|
||||
```
|
||||
kind: Role
|
||||
apiVersion: rbac.authorization.k8s.io/v1
|
||||
metadata:
|
||||
namespace: dev
|
||||
name: devuser-role
|
||||
rules:
|
||||
- apiGroups: [""]
|
||||
resources: ["pods"]
|
||||
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
|
||||
---
|
||||
kind: RoleBinding 绑定
|
||||
apiVersion: rbac.authorization.k8s.io/v1
|
||||
metadata:
|
||||
name: devuser-rolebinding
|
||||
namespace: dev
|
||||
subjects:
|
||||
- kind: User
|
||||
name: devuser
|
||||
apiGroup: rbac.authorization.k8s.io
|
||||
roleRef:
|
||||
kind: Role
|
||||
name: devuser-role
|
||||
apiGroup: rbac.authorization.k8s.io
|
||||
```
|
||||
|
||||
## 3 具体实例
|
||||
|
||||
### 创建用户
|
||||
|
||||
1. 创建k8s用户,首先使用ssl生成本地证书的私钥*.key和整数签名请求*.csr
|
||||
|
||||
```
|
||||
# 创建私钥
|
||||
$ openssl genrsa -out devuser.key 2048
|
||||
|
||||
# 用此私钥创建一个csr(证书签名请求)文件
|
||||
$ openssl req -new -key devuser.key -subj "/CN=devuser" -out devuser.csr
|
||||
```
|
||||
|
||||
2. 然后使用k8s的证书ca.crt和私钥ca.key对客户端的证书签名请求*.csr进行签名,颁发客户端证书*.crt
|
||||
|
||||
```
|
||||
|
||||
# 拿着私钥和请求文件生成证书
|
||||
$ openssl x509 -req -in devuser.csr -CA /etc/kubernetes/pki/ca.crt -CAkey /etc/kubernetes/pki/ca.key -CAcreateserial -out devuser.crt -days 365
|
||||
```
|
||||
|
||||
3. 生成账号
|
||||
|
||||
```
|
||||
$ kubectl config set-credentials devuser --client-certificate=./devuser.crt --client-key=./devuser.key --embed-certs=true
|
||||
|
||||
```
|
||||
|
||||
4. 设置用户的上下文参数
|
||||
|
||||
```
|
||||
# # 设置上下文, 默认会保存在 $HOME/.kube/config
|
||||
$ kubectl config set-context devuser@kubernetes --cluster=kubernetes --user=devuser --namespace=dev
|
||||
|
||||
# 查看
|
||||
$ kubectl config get-contexts
|
||||
|
||||
```
|
||||
|
||||
5. 切换用户上下文。可以看到新建的用户还没有授权访问nodes资源鉴权失败。
|
||||
|
||||
```
|
||||
$ kubectl config use-context devuser@kubernetes
|
||||
# 查看
|
||||
$ kubectl config get-contexts
|
||||
$ kubectl get nodes
|
||||
|
||||
|
||||
Error from server (Forbidden): nodes is forbidden: User "devuser" cannot list resource "nodes" in API group "" at the cluster scope
|
||||
```
|
||||
|
||||
#### 对用户授权
|
||||
|
||||
1. 接下来就是对账号进行授权。这里需要先把用切回来,要不然就无法进行下一步授权了。
|
||||
|
||||
```
|
||||
$ kubectl config use-context kubernetes-admin@kubernetes
|
||||
$ kubectl get nodes
|
||||
```
|
||||
|
||||
2. 部署下列文件。创建一个角色devuser-role具有dev命名空间的pods的所有权限。并绑定devuser用户。
|
||||
|
||||
```
|
||||
kind: Role # 角色
|
||||
apiVersion: rbac.authorization.k8s.io/v1
|
||||
metadata:
|
||||
namespace: dev
|
||||
name: devuser-role
|
||||
rules:
|
||||
- apiGroups: [""] # ""代表核心api组
|
||||
resources: ["pods"]
|
||||
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
|
||||
---
|
||||
kind: RoleBinding # 角色绑定
|
||||
apiVersion: rbac.authorization.k8s.io/v1
|
||||
metadata:
|
||||
name: devuser-rolebinding
|
||||
namespace: dev
|
||||
subjects:
|
||||
- kind: User
|
||||
name: devuser # 目标用户
|
||||
apiGroup: rbac.authorization.k8s.io
|
||||
roleRef:
|
||||
kind: Role
|
||||
name: devuser-role # 角色信息
|
||||
apiGroup: rbac.authorization.k8s.io
|
||||
```
|
||||
|
||||
3. 进行验证。用devuser,已经可以管理dev命名空间下的pod资源了,也只能管理dev命名空间下的pod资源,无法管理dev以外的资源类型,验证ok。ClusterRoleBinding绑定类似,这里就不重复了。有兴趣的小伙伴可以试试。
|
||||
|
||||
```
|
||||
$ kubectl apply -f devuser-role-bind
|
||||
$ kubectl config use-context devuser@kubernetes
|
||||
$ kubectl get pods # 不带命名空间,这里默认dev,也只能查看dev上面限制的命名空间的pods资源,从而也验证了role是针对命名空间的权限限制
|
||||
#查看其它命名空间的资源
|
||||
$ kubectl get pods -n default
|
||||
$ kubectl get pods -n kube-system
|
||||
$ kubectl get nodes
|
||||
```
|
||||
|
||||
#### 为ServiceAccount授权
|
||||
|
||||
1. 创建serviceAccount并绑定到ClusterRole
|
||||
|
||||
```
|
||||
kind: ClusterRoleBinding
|
||||
apiVersion: rbac.authorization.k8s.io/v1
|
||||
metadata:
|
||||
name: admin
|
||||
annotations:
|
||||
rbac.authorization.kubernetes.io/autoupdate: "true"
|
||||
roleRef:
|
||||
kind: ClusterRole
|
||||
name: cluster-admin
|
||||
apiGroup: rbac.authorization.k8s.io
|
||||
subjects:
|
||||
- kind: ServiceAccount
|
||||
name: sa001
|
||||
namespace: kube-system
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: ServiceAccount
|
||||
metadata:
|
||||
name: sa001
|
||||
namespace: kube-system
|
||||
```
|
||||
|
||||
2. 创建授权后就可以通过k8s的serviceAccount的token访问集群了。
|
||||
|
||||
```
|
||||
$ kubectl -n kube-system get secret|grep sa001
|
||||
$ kubectl -n kube-system describe secret sa001-token-c2klg
|
||||
# 也可以使用 jsonpath 的方式直接获取 token 的值,如:
|
||||
$ kubectl -n kube-system get secret sa001-token-c2klg -o jsonpath={.data.token}|base64 -d
|
||||
```
|
||||
|
||||
|
||||
## 总结
|
||||
|
||||
|
||||
**RoleBinding 和 ClusterRoleBinding** :角色绑定和集群角色绑定,简单来说就是把声明的 Subject 和我们的 Role 进行绑定的过程(给某个用户绑定上操作的权限),二者的区别也是作用范围的区别:RoleBinding 只会影响到当前namespace 下面的资源操作权限,而 ClusterRoleBinding 会影响到所有的namespace。
|
||||
|
||||
* **Rule** :规则,规则是一组属于不同 API Group 资源上的一组操作的集合
|
||||
* **Role 和 ClusterRole** :角色和集群角色,这两个对象都包含上面的 Rules 元素,二者的区别在于,在 Role 中,定义的规则只适用于单个命名空间,也就是和namespace 关联的,而 ClusterRole 是集群范围内的,因此定义的规则不受命名空间的约束。另外 Role 和 ClusterRole 在Kubernetes中都被定义为集群内部的 API 资源,和我们前面学习过的 Pod、ConfigMap 这些类似,都是我们集群的资源对象,所以同样的可以使用我们前面的kubectl相关的命令来进行操作
|
||||
* **Subject** :主题,对应在集群中尝试操作的对象,集群中定义了3种类型的主题资源:
|
||||
|
||||
1. **User** :用户,这是有外部独立服务进行管理的,管理员进行私钥的分配,用户可以使用 KeyStone或者 Goolge 帐号,甚至一个用户名和密码的文件列表也可以。对于用户的管理集群内部没有一个关联的资源对象,所以用户不能通过集群内部的 API 来进行管理
|
||||
2. **Group** :组,这是用来关联多个账户的,集群中有一些默认创建的组,比如cluster-admin
|
||||
3. **ServiceAccount** :服务帐号,通过Kubernetes API 来管理的一些用户帐号,和namespace 进行关联的,适用于集群内部运行的应用程序,需要通过 API 来完成权限认证,所以在集群内部进行权限操作,我们都需要使用到 ServiceAccount,这也是我们这节课的重点
|
||||
244
kubenets/istio/01 Istio快速开始.md
Normal file
@@ -0,0 +1,244 @@
|
||||
## 1 简介
|
||||
|
||||
### 服务网格
|
||||
|
||||
如果用一句话来解释什么是服务网格,可以将它比作是应用程序或者说微服务间的 TCP/IP,负责服务之间的网络调用、限流、熔断和监控。对于编写应用程序来说一般无须关心 TCP/IP 这一层(比如通过 HTTP 协议的 RESTful 应用),同样使用服务网格也就无须关系服务之间的那些原来是通过应用程序或者其他框架实现的事情,比如 Spring Cloud、OSS,现在只要交给服务网格就可以了。
|
||||
|
||||
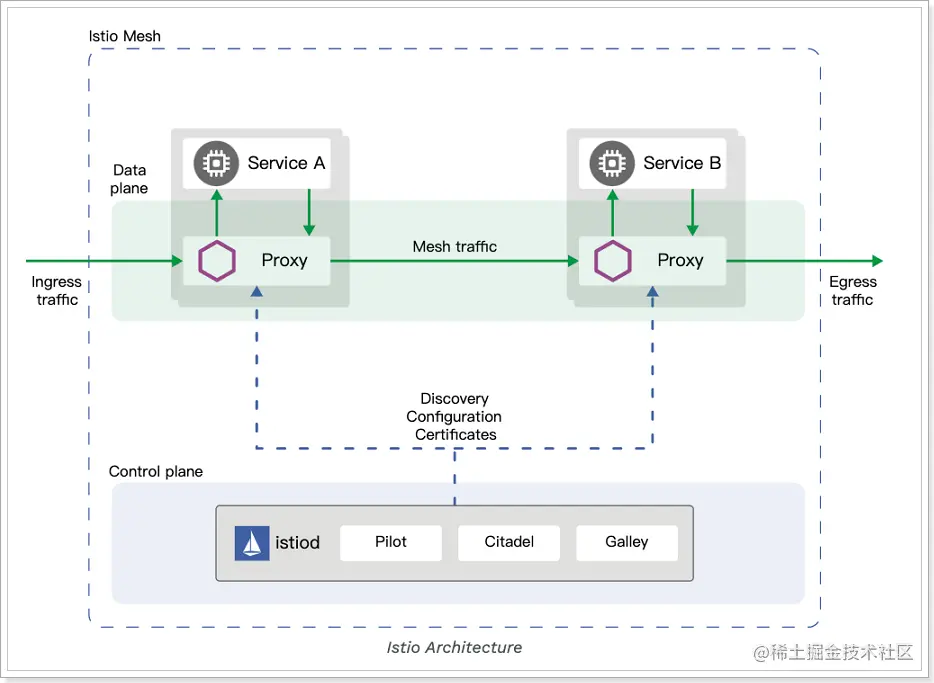
服务网格中分为控制平面和数据平面,当前流行的两款开源的服务网格 Istio 和 Linkerd 实际上都是这种构造,只不过 Istio 的划分更清晰,而且部署更零散,很多组件都被拆分,控制平面中包括 Mixer(Istio 1.5 之前版本)、Pilot、Citadel,数据平面默认是用 Envoy;而 Linkerd 中只分为 Linkerd 做数据平面,namerd 作为控制平面。
|
||||
|
||||
控制平面的特点:
|
||||
|
||||
* 不直接解析数据包
|
||||
* 与控制平面中的代理通信,下发策略和配置
|
||||
* 负责网络行为的可视化
|
||||
* 通常提供 API 或者命令行工具可用于配置版本化管理,便于持续集成和部署
|
||||
|
||||
数据平面的特点:
|
||||
|
||||
* 通常是按照无状态目标设计的,但实际上为了提高流量转发性能,需要缓存一些数据,因此无状态也是有争议的
|
||||
* 直接处理入站和出站数据包,转发、路由、健康检查、负载均衡、认证、鉴权、产生监控数据等
|
||||
* 对应用来说透明,即可以做到无感知部署
|
||||
|
||||

|
||||
|
||||
服务网格是七层网络架构中的第五层
|
||||
|
||||

|
||||
|
||||
|
||||
### Istio
|
||||
|
||||
实际上Istio 就是 Service Mesh 架构的一种实现,服务之间的通信(比如这里的 Service A 访问 Service B)会通过代理(默认是 Envoy)来进行。将微服务下沉到了云原生的层面。
|
||||
|
||||
> 发现上层应用的一系列技术,都在向云原生的方式靠拢,即k8s定义的一套部署运维机制。曾经服务的发布和订阅还是通过专门的中间件注册中心来实现的,现在k8s提供了云原生的方式进行服务的发布和订阅。服务治理曾经是中间件的能力,现在也下沉到了云原生的方式,通过istio来实现容器切面,进行服务治理
|
||||
|
||||
控制平面做了进一步的细分,分成了 Pilot、Citadel 和 Galley,它们的各自功能如下:
|
||||
|
||||
* Pilot:为 Envoy 提供了服务发现,流量管理和智能路由(AB 测试、金丝雀发布等),以及错误处理(超时、重试、熔断)功能。
|
||||
* Citadel:为服务之间提供认证和证书管理,可以让服务自动升级成 TLS 协议。
|
||||
* Galley:Galley 是 Istio 的配置验证、提取、处理和分发组件。它负责将其余的 Istio 组件与从底层平台(例如 Kubernetes)获取用户配置的细节隔离开来。
|
||||
|
||||
|
||||
|
||||
### 优势
|
||||
|
||||
通过负载均衡、服务间的身份验证、监控等方法,Istio 可以轻松地创建一个已经部署了服务的网络,而服务的代码只需很少更改甚至无需更改。通过在整个环境中部署一个特殊的 sidecar 代理为服务添加 Istio 的支持,而代理会拦截微服务之间的所有网络通信,然后使用其控制平面的功能来配置和管理 Istio,这包括:
|
||||
|
||||
* 为 HTTP、gRPC、WebSocket 和 TCP 流量自动负载均衡。
|
||||
* 通过丰富的路由规则、重试、故障转移和故障注入对流量行为进行细粒度控制。
|
||||
* 可插拔的策略层和配置 API,支持访问控制、速率限制和配额。
|
||||
* 集群内(包括集群的入口和出口)所有流量的自动化度量、日志记录和追踪。
|
||||
* 在具有强大的基于身份验证和授权的集群中实现安全的服务间通信。
|
||||
|
||||
### 能力
|
||||
|
||||

|
||||
|
||||
#### 流量管理
|
||||
|
||||
Istio 简单的规则配置和流量路由允许您控制服务之间的流量和 API 调用过程。
|
||||
|
||||
Istio 简化了服务级属性(如熔断器、超时和重试)的配置,并且让它轻而易举的执行重要的任务(如 A/B 测试、金丝雀发布和按流量百分比划分的分阶段发布)。
|
||||
|
||||
有了更好的对流量的可视性和开箱即用的故障恢复特性,就可以在问题产生之前捕获它们,无论面对什么情况都可以使调用更可靠,网络更健壮。
|
||||
|
||||
#### 安全
|
||||
|
||||
Istio 的安全特性解放了开发人员,使其只需要专注于应用程序级别的安全。
|
||||
|
||||
Istio 提供了底层的安全通信通道,并为大规模的服务通信管理认证、授权和加密。有了 Istio,服务通信在默认情况下就是受保护的,可以让您在跨不同协议和运行时的情况下实施一致的策略——而所有这些都只需要很少甚至不需要修改应用程序。
|
||||
|
||||
Istio 是独立于平台的,可以与 Kubernetes(或基础设施)的网络策略一起使用。但它更强大,能够在网络和应用层面保护pod到 pod 或者服务到服务之间的通信。
|
||||
|
||||
#### 可观察性
|
||||
|
||||
Istio 健壮的追踪、监控和日志特性让您能够深入的了解服务网格部署。
|
||||
|
||||
通过 Istio 的监控能力,可以真正的了解到服务的性能是如何影响上游和下游的;而它的定制 Dashboard 提供了对所有服务性能的可视化能力,并让您看到它如何影响其他进程。
|
||||
|
||||
Istio 的 Mixer 组件负责策略控制和遥测数据收集。它提供了后端抽象和中介,将一部分 Istio 与后端的基础设施实现细节隔离开来,并为运维人员提供了对网格与后端基础实施之间交互的细粒度控制。
|
||||
|
||||
所有这些特性都使您能够更有效地设置、监控和加强服务的 SLO。当然,底线是您可以快速有效地检测到并修复出现的问题。
|
||||
|
||||
## 2 最佳实践
|
||||
|
||||
### 应用需要改造
|
||||
|
||||
服务通信和治理相关的功能迁移到 [sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 进程中后, 应用中的 SDK 通常需要作出一些对应的改变。
|
||||
|
||||
比如 SDK 需要关闭一些功能,例如重试。一个典型的场景是,SDK 重试 m 次,[sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 重试 n 次,这会导致 m * n 的重试风暴,从而引发风险。
|
||||
|
||||
此外,诸如 trace header 的透传,也需要 SDK 进行升级改造。如果你的 SDK 中还有其它特殊逻辑和功能,这些可能都需要小心处理才能和 Isito [sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 完美配合。
|
||||
|
||||
## 只有 HTTP 协议是一等公民
|
||||
|
||||
> 这也是Istio在落地过程中一个重要的改造点。将企业内部的私有通信协议适配到自身的sidecar上。
|
||||
|
||||
Istio 原生对 HTTP 协议提供了完善的全功能支持,但在真实的业务场景中,私有化协议却非常普遍,而 Istio 却并未提供原生支持。
|
||||
|
||||
这导致使用私有协议的一些服务可能只能被迫使用 TCP 协议来进行基本的请求路由,这会导致很多功能的缺失,这其中包括 Istio 非常强大的基于内容的消息路由,如基于 header、 path 等进行权重路由。
|
||||
|
||||
## Istio 在集群规模较大时的性能问题
|
||||
|
||||
> 这一世istio的优势之一,不依赖单独集中式的注册中心,而是从k8s的etcd注册中心订阅全量的服务。而不是等待访问发生时进行订阅和路由。
|
||||
|
||||
Istio 默认的工作模式下,每个 [sidecar]() 都会收到全集群所有服务的信息。如果你部署过 Istio 官方的 Bookinfo 示例应用,并使用 Envoy 的 config dump 接口进行观察,你会发现,仅仅几个服务,Envoy 所收到的配置信息就有将近 20w 行。
|
||||
|
||||
可以想象,在稍大一些的集群规模,Envoy 的内存开销、Istio 的 CPU 开销、XDS 的下发时效性等问题,一定会变得尤为突出。
|
||||
|
||||
Istio 这么做一是考虑这样可以开箱即用,用户不用进行过多的配置,另外在一些场景,可能也无法梳理出准确的服务之间的调用关系,因此直接给每个 [sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 下发了全量的服务配置,即使这个 [sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 只会访问其中很小一部分服务。
|
||||
|
||||
当然这个问题也有解法,你可以通过 [sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") [CRD](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#crd "CRD,全称 Custom Resource Definition(自定义资源定义)是默认的 Kubernetes API 扩展。") 来显示定义服务调用关系,使 Envoy 只得到他需要的服务信息,从而大幅降低 Envoy 的资源开销,但前提是在你的业务线中能梳理出这些调用关系。
|
||||
|
||||
## XDS 分发没有分级发布机制
|
||||
|
||||
当你对一个服务的策略配置进行变更的时候,XDS 不具备分级发布的能力,所有访问这个服务的 Envoy 都会立即收到变更后的最新配置。这在一些对变更敏感的严苛生产环境,可能是有很高风险甚至不被允许的。
|
||||
|
||||
如果你的生产环境严格要求任何变更都必须有分级发布流程,那你可能需要考虑自己实现一套这样的机制
|
||||
|
||||
## Istio 组件故障时是否有退路?
|
||||
|
||||
以 Istio 为代表的 [sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 架构的特殊性在于,[sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 直接承接了业务流量,而不像一些其他的基础设施那样,只是整个系统的**旁路组件**(比如 Kubernetes)。
|
||||
|
||||
因此在 Isito 落地初期,你必须考虑,如果 [sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 进程挂掉,服务怎么办?是否有退路?是否能 fallback 到直连模式?
|
||||
|
||||
在 Istio 落地过程中,是否能无损 fallback,通常决定了核心业务能否接入服务网格。
|
||||
|
||||
## Istio 目前解决的问题域还很有限
|
||||
|
||||
> Sidecar是一种设计模型,能够将应用和基础架构解耦。Istio只是使用这种模式实现服务发布和订阅,时Sidecar设计模式的一种应用场景。
|
||||
|
||||
Istio 目前主要解决的是分布式系统之间服务调用的问题,但还有一些分布式系统的复杂语义和功能并未纳入到 Istio 的 [sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 运行时之中,比如消息发布和订阅、状态管理、资源绑定等等。
|
||||
|
||||
云原生应用将会朝着多 [sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 运行时或将更多分布式能力纳入单 [sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 运行时的方向继续发展,以使服务本身变得更为轻量,**让应用和基础架构彻底解耦**。
|
||||
|
||||
如果你的生产环境中,业务系统对接了非常多和复杂的分布式系系统中间件,Istio 目前可能并不能完全解决你的应用的云原生化诉求。
|
||||
|
||||
## 3 实践
|
||||
|
||||
### 安装
|
||||
|
||||
1. 下载istioctl工具https://gcsweb.istio.io/gcs/istio-release/releases/1.21.2/ 下载对应操作系统的版本。
|
||||
|
||||
```
|
||||
wget https://github.com/istio/istio/releases/download/1.18.1/istio-1.18.1-linux-amd64.tar.gz
|
||||
tar -zxvf istio-1.18.1-linux-amd64.tar.gz
|
||||
cp /bin/istioctl /usr/bin/ctl
|
||||
```
|
||||
|
||||
2. 将istio安装到环境中。安装后会出现以下资源。
|
||||
|
||||
```shell
|
||||
➜ istio-1.21.2 istioctl install --set profile=demo -y
|
||||
WARNING: Istio is being upgraded from 1.18.0 to 1.21.2.
|
||||
Running this command will overwrite it; use revisions to upgrade alongside the existing version.
|
||||
Before upgrading, you may wish to use 'istioctl x precheck' to check for upgrade warnings.
|
||||
This installation will make default injection and validation pointing to the default revision, and originally it was pointing to the revisioned one.
|
||||
✔ Istio core installed
|
||||
✔ Istiod installed
|
||||
✔ Egress gateways installed
|
||||
✔ Ingress gateways installed
|
||||
✔ Installation complete Made this installation the default for injection and validation.
|
||||
➜ istio-1.21.2 cd ..
|
||||
➜ kubetest kubectl get all -n istio-system
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
pod/istio-egressgateway-8c547cdc-27s94 1/1 Running 0 73s
|
||||
pod/istio-ingressgateway-cd9c7b79-2gsr5 1/1 Running 0 73s
|
||||
pod/istiod-868c79fcc6-tl9g7 1/1 Running 0 89s
|
||||
|
||||
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
service/istio-egressgateway ClusterIP 192.168.241.8 <none> 80/TCP,443/TCP 73s
|
||||
service/istio-ingressgateway LoadBalancer 192.168.23.245 123.57.172.74 15021:30965/TCP,80:32501/TCP,443:30930/TCP,31400:31622/TCP,15443:32480/TCP 73s
|
||||
service/istiod ClusterIP 192.168.35.184 <none> 15010/TCP,15012/TCP,443/TCP,15014/TCP 15d
|
||||
|
||||
NAME READY UP-TO-DATE AVAILABLE AGE
|
||||
deployment.apps/istio-egressgateway 1/1 1 1 73s
|
||||
deployment.apps/istio-ingressgateway 1/1 1 1 73s
|
||||
deployment.apps/istiod 1/1 1 1 15d
|
||||
|
||||
NAME DESIRED CURRENT READY AGE
|
||||
replicaset.apps/istio-egressgateway-8c547cdc 1 1 1 74s
|
||||
replicaset.apps/istio-ingressgateway-cd9c7b79 1 1 1 74s
|
||||
replicaset.apps/istiod-6b56fd6ddd 0 0 0 15d
|
||||
replicaset.apps/istiod-868c79fcc6 1 1 1 90s
|
||||
|
||||
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
|
||||
horizontalpodautoscaler.autoscaling/istiod Deployment/istiod 10%/80% 1 5 1 15d
|
||||
|
||||
NAME AGE
|
||||
containernetworkfilesystem.storage.alibabacloud.com/cnfs-nas-c3225ec7463fe4ba9816186be4d2eb7f7 16d
|
||||
```
|
||||
|
||||
3. 给制定明敏个空间开启istio注入。
|
||||
|
||||
```shell
|
||||
kubectl label namespace bookinfo istio-injection=enabled
|
||||
```
|
||||
|
||||
```shell
|
||||
[root@vela istio-1.18.1]# kubectl get crds |grep istio
|
||||
authorizationpolicies.security.istio.io 2023-07-23T04:42:38Z
|
||||
destinationrules.networking.istio.io 2023-07-23T04:42:38Z
|
||||
envoyfilters.networking.istio.io 2023-07-23T04:42:38Z
|
||||
gateways.networking.istio.io 2023-07-23T04:42:38Z
|
||||
istiooperators.install.istio.io 2023-07-23T04:42:39Z
|
||||
peerauthentications.security.istio.io 2023-07-23T04:42:39Z
|
||||
proxyconfigs.networking.istio.io 2023-07-23T04:42:39Z
|
||||
requestauthentications.security.istio.io 2023-07-23T04:42:39Z
|
||||
serviceentries.networking.istio.io 2023-07-23T04:42:39Z
|
||||
sidecars.networking.istio.io 2023-07-23T04:42:39Z
|
||||
telemetries.telemetry.istio.io 2023-07-23T04:42:39Z
|
||||
virtualservices.networking.istio.io 2023-07-23T04:42:39Z
|
||||
wasmplugins.extensions.istio.io 2023-07-23T04:42:40Z
|
||||
workloadentries.networking.istio.io 2023-07-23T04:42:40Z
|
||||
workloadgroups.networking.istio.io 2023-07-23T04:42:40Z
|
||||
```
|
||||
|
||||
4. 部署测试应用
|
||||
|
||||
```shell
|
||||
kubectl apply -f samples/bookinfo/platform/kube/bookinfo.yaml -n bookinfo
|
||||
|
||||
istio-1.21.2 kubectl apply -f samples/bookinfo/platform/kube/bookinfo.yaml -n bookinfo
|
||||
service/details created
|
||||
serviceaccount/bookinfo-details created
|
||||
deployment.apps/details-v1 created
|
||||
service/ratings created
|
||||
serviceaccount/bookinfo-ratings created
|
||||
deployment.apps/ratings-v1 created
|
||||
service/reviews created
|
||||
serviceaccount/bookinfo-reviews created
|
||||
deployment.apps/reviews-v1 created
|
||||
deployment.apps/reviews-v2 created
|
||||
deployment.apps/reviews-v3 created
|
||||
service/productpage created
|
||||
serviceaccount/bookinfo-productpage created
|
||||
|
||||
```
|
||||
|
||||
5. 测试引用是否启动成功
|
||||
|
||||
```shell
|
||||
kubectl exec -n bookinfo "$(kubectl get -n bookinfo pod -l app=ratings -o jsonpath='{.items[0].metadata.name}')" -c ratings -- curl -sS productpage:9080/productpage | grep -o "<title>.*</title>"
|
||||
<title>Simple Bookstore App</title>
|
||||
```
|
||||
20
kubenets/istio/02 Sidecar.md
Normal file
@@ -0,0 +1,20 @@
|
||||
## 简介
|
||||
|
||||
### Sidecar模式
|
||||
|
||||
将应用程序的功能划分为单独的进程运行在同一个最小调度单元中(例如 Kubernetes 中的 Pod)可以被视为 sidecar 模式。如下图所示,sidecar 模式允许您在应用程序旁边添加更多功能,而无需额外第三方组件配置或修改应用程序代码。
|
||||
|
||||
就像连接了 [Sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 的三轮摩托车一样,在软件架构中, [Sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 连接到父应用并且为其添加扩展或者增强功能。[Sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 应用与主应用程序松散耦合。它可以屏蔽不同编程语言的差异,统一实现微服务的可观察性、监控、日志记录、配置、断路器等功能。
|
||||
|
||||

|
||||
|
||||
|
||||
### 使用 Sidecar 模式的优势
|
||||
|
||||
使用 [sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 模式部署服务网格时,无需在节点上运行代理,但是集群中将运行多个相同的 [sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 副本。在 [sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 部署方式中,每个应用的容器旁都会部署一个伴生容器,这个容器称之为 [sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 容器。[Sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 接管进出应用容器的所有流量。在 Kubernetes 的 Pod 中,在原有的应用容器旁边注入一个 [Sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 容器,两个容器共享存储、网络等资源,可以广义的将这个包含了 [sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 容器的 Pod 理解为一台主机,两个容器共享主机资源。
|
||||
|
||||
因其独特的部署结构,使得 [sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 模式具有以下优势:
|
||||
|
||||
* 将与应用业务逻辑无关的功能抽象到共同基础设施,降低了微服务代码的复杂度。
|
||||
* 因为不再需要编写相同的第三方组件配置文件和代码,所以能够降低微服务架构中的代码重复度。
|
||||
* [Sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 可独立升级,降低应用程序代码和底层平台的耦合度。
|
||||
136
kubenets/istio/03 Istio注入原理.md
Normal file
@@ -0,0 +1,136 @@
|
||||
## 规范
|
||||
|
||||
### Pod Spec 中需满足的条件
|
||||
|
||||
为了成为 服务网格中的一部分,Kubernetes 集群中的每个 Pod 都必须满足如下条件,这些规范不是由 Istio 自动注入的,而需要 生成 Kubernetes 应用部署的 YAML 文件时需要遵守的:
|
||||
|
||||
Service 关联:每个 pod 都必须只属于某一个 Kubernetes Service (当前不支持一个 pod 同时属于多个 service)。
|
||||
命名的端口:Service 的端口必须命名。端口的名字必须遵循如下格式 `<protocol>`[-`<suffix>`],可以是 http、http2、 grpc、 mongo、 或者 redis 作为 `<protocol>` ,这样才能使用 Istio 的路由功能。例如 name: http2-foo 和 name: http 都是有效的端口名称,而 name: http2foo 不是。如果端口的名称是不可识别的前缀或者未命名,那么该端口上的流量就会作为普通的 TCP 流量来处理(除非使用 Protocol: UDP 明确声明使用 UDP 端口)。
|
||||
带有 app label 的 Deployment:我们建议 Kubernetes 的Deploymenet 资源的配置文件中为 Pod 明确指定 applabel。每个 Deployment 的配置中都需要有个与其他 Deployment 不同的含有意义的 app label。app label 用于在分布式追踪中添加上下文信息。
|
||||
Mesh 中的每个 pod 里都有一个 Sidecar:最后,网格中的每个 pod 都必须运行与 Istio 兼容的 sidecar。以下部分介绍了将 sidecar 注入到 pod 中的两种方法:使用istioctl 命令行工具手动注入,或者使用 Istio Initializer 自动注入。注意 sidecar 不涉及到流量,因为它们与容器位于同一个 pod 中。
|
||||
|
||||
## 原理
|
||||
|
||||
### 注入方式
|
||||
|
||||
1. istioctl手动注入
|
||||
2. 自动注入
|
||||
|
||||
Sidecar 容器注入的流程,每个注入了 Sidecar 的 Pod 中除了原先应用的应用本身的容器外,都会多出来这样两个容器:
|
||||
|
||||
* istio-init:用于给 Sidecar 容器即 Envoy 代理做初始化,设置 iptables 端口转发
|
||||
* istio-proxy:Envoy 代理容器,运行 Envoy 代理
|
||||
|
||||
### Init容器
|
||||
|
||||
一个 Pod 中可以指定多个 Init 容器,如果指定了多个,那么 Init 容器将会按顺序依次运行。只有当前面的 Init 容器必须运行成功后,才可以运行下一个 Init 容器。当所有的 Init 容器运行完成后,Kubernetes 才初始化 Pod 和运行应用容器。
|
||||
|
||||
Init 容器使用 Linux Namespace,所以相对应用程序容器来说具有不同的文件系统视图。因此,它们能够具有访问 Secret 的权限,而应用程序容器则不能。
|
||||
|
||||
Istio 在 Pod 中注入的 Init 容器名为 istio-init,如果你查看 reviews Deployment 配置,你将看到其中 initContaienrs 的启动参数:
|
||||
|
||||
```
|
||||
initContainers:
|
||||
- name: istio-init
|
||||
image: docker.io/istio/proxyv2:1.13.1
|
||||
args:
|
||||
- istio-iptables
|
||||
- '-p'
|
||||
- '15001'
|
||||
- '-z'
|
||||
- '15006'
|
||||
- '-u'
|
||||
- '1337'
|
||||
- '-m'
|
||||
- REDIRECT
|
||||
- '-i'
|
||||
- '*'
|
||||
- '-x'
|
||||
- ''
|
||||
- '-b'
|
||||
- '*'
|
||||
- '-d'
|
||||
- 15090,15021,15020
|
||||
```
|
||||
|
||||
参数解释
|
||||
|
||||
```
|
||||
$ istio-iptables -p PORT -u UID -g GID [-m mode] [-b ports] [-d ports] [-i CIDR] [-x CIDR] [-h]
|
||||
-p: 指定重定向所有 TCP 流量的 Envoy 端口(默认为 $ENVOY_PORT = 15001)
|
||||
-u: 指定未应用重定向的用户的 UID。通常,这是代理容器的 UID(默认为 $ENVOY_USER 的 uid,istio_proxy 的 uid 或 1337)
|
||||
-g: 指定未应用重定向的用户的 GID。(与 -u param 相同的默认值)
|
||||
-m: 指定入站连接重定向到 Envoy 的模式,“REDIRECT” 或 “TPROXY”(默认为 $ISTIO_INBOUND_INTERCEPTION_MODE)
|
||||
-b: 逗号分隔的入站端口列表,其流量将重定向到 Envoy(可选)。使用通配符 “*” 表示重定向所有端口。为空时表示禁用所有入站重定向(默认为 $ISTIO_INBOUND_PORTS)
|
||||
-d: 指定要从重定向到 Envoy 中排除(可选)的入站端口列表,以逗号格式分隔。使用通配符“*” 表示重定向所有入站流量(默认为 $ISTIO_LOCAL_EXCLUDE_PORTS)
|
||||
-i: 指定重定向到 Envoy(可选)的 IP 地址范围,以逗号分隔的 CIDR 格式列表。使用通配符 “*” 表示重定向所有出站流量。空列表将禁用所有出站重定向(默认为 $ISTIO_SERVICE_CIDR)
|
||||
-x: 指定将从重定向中排除的 IP 地址范围,以逗号分隔的 CIDR 格式列表。使用通配符 “*” 表示重定向所有出站流量(默认为 $ISTIO_SERVICE_EXCLUDE_CIDR)。
|
||||
-z: 所有入站 TCP 流量重定向端口(默认为 $INBOUND_CAPTURE_PORT 15006)
|
||||
```
|
||||
|
||||
这条启动命令的作用是:
|
||||
|
||||
* 将应用容器的所有流量都转发到 Envoy 的 15006 端口。
|
||||
* 使用 istio-proxy 用户身份运行, UID 为 1337,即 Envoy 所处的用户空间,这也是 istio-proxy 容器默认使用的用户,见 YAML 配置中的 runAsUser 字段。
|
||||
* 使用默认的 REDIRECT 模式来重定向流量。
|
||||
* 将所有出站流量都重定向到 Envoy 代理。
|
||||
* 将除了 15090、15201、15020 端口以外的所有端口的流量重定向到 Envoy 代理。
|
||||
|
||||
该容器存在的意义就是让 Envoy 代理可以拦截所有的进出 Pod 的流量,即将入站流量重定向到 Sidecar,再拦截应用容器的出站流量经过 Sidecar 处理后再出站
|
||||
|
||||
## 3 流量路由
|
||||
|
||||
本文以 Istio 官方的 bookinfo 示例来讲解在进入 Pod 的流量被 iptables 转交给 Envoy [sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 后,Envoy 是如何做路由转发的,详述了 Inbound 和 Outbound 处理过程。
|
||||
|
||||

|
||||
|
||||
|
||||
### Envoy的架构
|
||||
|
||||

|
||||
|
||||
每个 host 上都可能运行多个 service,Envoy 中也可能有多个 Listener,每个 Listener 中可能会有多个 filter 组成了 chain。
|
||||
|
||||
|
||||
**Host** :能够进行网络通信的实体(在手机或服务器等上的应用程序)。在 Envoy 中主机是指逻辑网络应用程序。只要每台主机都可以独立寻址,一块物理硬件上就运行多个主机。
|
||||
|
||||
**Downstream** :下游(downstream)主机连接到 Envoy,发送请求并或获得响应。
|
||||
|
||||
**Upstream** :上游(upstream)主机获取来自 Envoy 的链接请求和响应。
|
||||
|
||||
**Cluster** : 集群(cluster)是 Envoy 连接到的一组逻辑上相似的上游主机。Envoy 通过服务发现发现集群中的成员。Envoy 可以通过主动运行状况检查来确定集群成员的健康状况。Envoy 如何将请求路由到集群成员由负载均衡策略确定。
|
||||
|
||||
**Mesh** :一组互相协调以提供一致网络拓扑的主机。Envoy mesh 是指一组 Envoy 代理,它们构成了由多种不同服务和应用程序平台组成的分布式系统的消息传递基础。
|
||||
|
||||
**运行时配置** :与 Envoy 一起部署的带外实时配置系统。可以在无需重启 Envoy 或 更改 Envoy 主配置的情况下,通过更改设置来影响操作。
|
||||
|
||||
**Listener** : 侦听器(listener)是可以由下游客户端连接的命名网络位置(例如,端口、unix域套接字等)。Envoy 公开一个或多个下游主机连接的侦听器。一般是每台主机运行一个 Envoy,使用单进程运行,但是每个进程中可以启动任意数量的 Listener(监听器),目前只监听 TCP,每个监听器都独立配置一定数量的(L3/L4)网络过滤器。Listenter 也可以通过 Listener Discovery Service( **LDS** )动态获取。
|
||||
|
||||
**Listener filter** :Listener 使用 listener filter(监听器过滤器)来操作链接的元数据。它的作用是在不更改 Envoy 的核心功能的情况下添加更多的集成功能。Listener filter 的 API 相对简单,因为这些过滤器最终是在新接受的套接字上运行。在链中可以互相衔接以支持更复杂的场景,例如调用速率限制。Envoy 已经包含了多个监听器过滤器。
|
||||
|
||||
**Http Route Table** :HTTP 的路由规则,例如请求的域名,Path 符合什么规则,转发给哪个 Cluster。
|
||||
|
||||
**Health checking** :健康检查会与SDS服务发现配合使用。但是,即使使用其他服务发现方式,也有相应需要进行主动健康检查的情况。
|
||||
|
||||
|
||||
|
||||
## xDS
|
||||
|
||||
xDS 是一个关键概念,它是一类发现服务的统称,其包括如下几类:
|
||||
|
||||
* CDS:Cluster Discovery Service
|
||||
* EDS:Endpoint Discovery Service
|
||||
* SDS:Service Discovery Service
|
||||
* RDS:Route Discovery Service
|
||||
* LDS:Listener Discovery Service
|
||||
|
||||
正是通过对 xDS 的请求来动态更新 Envoy 配置。
|
||||
|
||||
## Envoy Mesh
|
||||
|
||||
Envoy Mesh 指的是由 envoy 做负载均衡和代理的 mesh。该 Mesh 中会包含两类 envoy:
|
||||
|
||||
* Edge envoy:即流量进出 mesh 时候的 envoy,相当于 kubernetes 中的 ingress。
|
||||
* Service envoy:服务 envoy 是跟每个 serivce 实例一起运行的,应用程序无感知的进程外工具,在 kubernetes 中会与应用容器以 [sidecar](https://jimmysong.io/kubernetes-handbook/GLOSSARY.html#sidecar "Sidecar,全称 Sidecar proxy,为在应用程序旁运行的单独的进程,它可以为应用程序添加许多功能,而无需在应用程序中添加额外的第三方组件,或修改应用程序的代码或配置。") 形式运行在同一个 pod 中。
|
||||
|
||||
Envoy 即可以单独作为 edge envoy,也可以仅做 service envoy 使用,也可以两者同时使用。Mesh 中的所有 envoy 会共享路由信息。
|
||||
BIN
kubenets/istio/image/01Istio快速开始/1714031946432.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 180 KiB |
BIN
kubenets/istio/image/01Istio快速开始/1714032043713.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 356 KiB |
BIN
kubenets/istio/image/01Istio快速开始/1714033236237.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 684 KiB |
BIN
kubenets/istio/image/02Sidecar/1714030026950.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 70 KiB |
BIN
kubenets/istio/image/03Istio注入原理/1714031349157.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 109 KiB |
BIN
kubenets/istio/image/03Istio注入原理/1714032179003.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 131 KiB |
BIN
kubenets/istio/image/04Istio/1714028930185.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 268 KiB |
243
人工智能/kubeflow/01 kubeflow.md
Normal file
@@ -0,0 +1,243 @@
|
||||
## MLOps
|
||||
|
||||
机器学习开发迭代
|
||||
3. 数据收集
|
||||
a. 大数据量下的文件存储与读取 —— HDFS,NFS 等分布式文件存储系统;
|
||||
b. 非结构化数据 —— S3 等对象存储;
|
||||
c. 向量数据存储 —— milvus 等向量数据库;
|
||||
d. 数据的持续采集与入库 —— Kafka,RabbitMQ 等流式处理工具 ;
|
||||
4. 数据预处理
|
||||
a. 清洗、格式化、规范化、脱敏 —— Python Pandas;
|
||||
b. 人工标记;
|
||||
c. 特征工程,“数据和特征决定了模型的上限,算法只是在帮忙逼近这个上限”
|
||||
5. 框架选择
|
||||
a. 训练框架:PyTorch,TensorFlow,PaddlePaddle,……;
|
||||
6. 模型训练
|
||||
a. 代码开发 —— Python IDE,Notebook;
|
||||
ⅰ. 开发阶段会采集小量的数据,经过小次数的迭代,用于正确性验证, Notebook 可以辅助验证;
|
||||
b. 训练
|
||||
ⅰ. 本地/单节点/单机单卡/单机多卡/多机多卡 —— GPU 管理与调度
|
||||
ⅱ. 任务调度/故障转移/checkpoint —— 分布式 AI 任务调度框架
|
||||
ⅲ. 任务调度 —— CoScheduling/GangScheduling
|
||||
c. 向量数据库 —— milvus,pinecone
|
||||
d. 调参,根据训练情况与经验调整模型的超参数 (HyperParameter)
|
||||
ⅰ. 神经网络输出的结果是当前网络架构下每个节点函数的系数,其它参数都为超参数,如每个节点使用的函数、权重、输入/输出的节点,甚至网络本身的架构;
|
||||
ⅱ. 随着模型复杂度增加,有多种超参自动调优算法(基于网格/贝叶斯/梯度/种群)
|
||||
e. 模型生成与版本管理
|
||||
ⅰ. 模型文件存储 —— NFS,对象存储,huggingface;
|
||||
ⅱ. 模型镜像存储 —— docker 镜像仓库;
|
||||
|
||||
7. 模型部署 —— 运行中的模型服务是标准的无状态应用
|
||||
a. 模型的拉取,转化与处理(转化存储格式,单个模型的剪枝,多个模型集成);
|
||||
b. 选择模型运行框架:TensorFlow,Triton server,Seldon Serving,paddlepaddle;
|
||||
c. 声明资源配置(如要求 Nvidia 显卡,CUDA 12.2+,40GiB 显存) —— GPU 管理与调度;
|
||||
d. 监控(模型服务的流量、模型服务资源使用率、集群资源使用率、推理请求耗时) —— prometheus,grafana;
|
||||
e. 自动弹性伸缩 —— 配合指标采集 + hpa 策略;
|
||||
f. 版本管理、滚动更新、发布管理 —— 应用发布策略与流量管理策略;
|
||||
|
||||
## kubeflow核心组件
|
||||
|
||||
### 架构
|
||||
|
||||

|
||||
|
||||
Central Dashboard:Kubeflow的dashboard看板页面
|
||||
Metadata:用于跟踪各数据集、作业与模型
|
||||
Jupyter Notebooks:一个交互式业务IDE编码环境
|
||||
Frameworks for Training:支持的ML框架
|
||||
Chainer
|
||||
MPI
|
||||
MXNet
|
||||
PyTorch
|
||||
TensorFlow
|
||||
Hyperparameter Tuning:Katib,超参数服务器
|
||||
Pipelines:一个ML的工作流组件,用于定义复杂的ML工作流
|
||||
Tools for Serving:提供在Kubernetes上对机器学习模型的部署
|
||||
KFServing
|
||||
Seldon Core Serving
|
||||
TensorFlow Serving(TFJob):提供对Tensorflow模型的在线部署,支持版本控制及无需停止线上服务、切换模型等
|
||||
NVIDIA Triton Inference Server(Triton以前叫TensorRT)
|
||||
TensorFlow Batch Prediction
|
||||
Multi-Tenancy in Kubeflow:Kubeflow中的多租户
|
||||
Fairing:一个将code打包构建image的组件 Kubeflow中大多数组件的实现都是通过定义CRD来工作。目前Kubeflow主要的组件有:
|
||||
Operator是针对不同的机器学习框架提供资源调度和分布式训练的能力(TF-Operator,PyTorch-Operator,Caffe2-Operator,MPI-Operator,MXNet-Operator);
|
||||
Pipelines是一个基于Argo实现了面向机器学习场景的流水线项目,提供机器学习流程的创建、编排调度和管理,还提供了一个Web UI。
|
||||
Katib是基于各个Operator实现的超参数搜索和简单的模型结构搜索的系统,支持并行搜索和分布式训练等。超参优化在实际的工作中还没有被大规模的应用,所以这部分的技术还需要一些时间来成熟;
|
||||
Serving支持部署各个框架训练好的模型的服务化部署和离线预测。Kubeflow提供基于TFServing,KFServing,Seldon等好几种方案。由于机器学习框架很多,算法模型也各种各样。工业界一直缺少一种能真正统一的部署框架和方案。这方面Kubeflow也仅仅是把常见的都集成了进来,但是并没有做更多的抽象和统一。
|
||||
|
||||
## 2.1. **JupyterLab Notebook**
|
||||
|
||||
**JupyterLab 是一个基于Web的交互式开发环境,它是 Project Jupyter 的一部分,旨在为科学计算、数据科学和机器学习等领域提供强大的工作空间。JupyterLab 是 Jupyter Notebook 的下一代用户界面,它不仅支持笔记本,还支持代码编辑器、终端、数据文件查看器以及其他自定义组件。JupyterLab 的优势和特点如下:**
|
||||
|
||||
1. **交互式开发环境** **:J**upyterLab 提供了一个交互式的环境,让用户可以写代码、运行代码、查看结果,并立即获取反馈,这对于数据分析和模型原型设计来说非常有用。
|
||||
2. **支持多种编程语言:**虽然最初是为 Python 设计的,但 JupyterLab 内核(kernels)支持多种编程语言,包括 R、Julia 和 Scala,满足不同领域研究人员的需求。
|
||||
3. **数据可视化** **:**JupyterLab 支持丰富的数据可视化库,如 Matplotlib、Seaborn、Plotly 等,这些工具对于理解数据和展示机器学习模型的结果至关重要。
|
||||
4. **模型原型与实验** **:**机器学习研究者和工程师使用 JupyterLab 来构建、测试和评估模型原型,它提供了一个灵活的环境来实验不同的算法和参数。
|
||||
5. **可扩展性:**JupyterLab 是高度可扩展的,可以通过安装第三方扩展来增强其功能,例如调试器、版本控制和云服务集成。
|
||||
6. **生态系统集成:**JupyterLab 可以集成到更广泛的数据科学和 AI 生态系统中,比如可以与大数据处理平台(如 Apache Spark)和机器学习平台(如 TensorFlow、PyTorch)配合使用。
|
||||
|
||||
## 2.2. **Pipelines**
|
||||
|
||||
**Pipelines 基于 Argo 实现了面向机器学习场景的工作流,提供机器学习流程的创建、编排调度和管理,还提供了一个Web UI。**
|
||||

|
||||
|
||||
**流水线执行过程:**
|
||||
|
||||
1. **Python SDK:使用 Kubeflow Pipelines 领域特定语言 (DSL) 创建组件或指定管道。**
|
||||
2. **DSL 编译器:DSL 编译器将pipeline的 Python 代码转换为静态配置 (YAML)。**
|
||||
3. **Pipeline Service:调用服务,从静态配置运行流水线。**
|
||||
4. **Kubernetes APIServer:流水线服务调用APIServer,创建运行所需的CRD**
|
||||
5. **Orchestration Controllers:一组控制器,如Argo用于编排工作流**
|
||||
6. **Artifact storage:pod存储两种数据,元数据和中间产物**
|
||||
|
||||
1. **Metadata:实验、作业等聚合指标,存储在MySQL中**
|
||||
2. **Artifacts:存储大规模时序指标,如Minio或云存储**
|
||||
7. **常驻代理和ML元数据服务:**
|
||||
|
||||
1. **agent 监听流水线服务创建的k8s资源,并将资源的状态持久化存储至ML META 服务**
|
||||
2. **agent负责记录有哪些容器参与执行,并记录其输入和输出(容器参数和URI)**
|
||||
8. **Pipeline Web Server :收集数据并显示相关视图**
|
||||
|
||||
## 2.3. **Training Operator**
|
||||
|
||||
**Kubeflow Training Operator 是一个 Kubernetes 原生项目,针对不同的机器学习框架提供资源调度和****分布式训练**的能力。比如,用户可以使用 Training Operator 和 MPIJob 运行高性能计算 (HPC) 任务,因为它支持在大量用于 HPC 的 Kubernetes 上运行消息传递接口 (MPI)。
|
||||
|
||||
|
||||
* Central Dashboard:`Kubeflow`的 `dashboard`看板页面
|
||||
* Metadata:用于跟踪各数据集、作业与模型
|
||||
* **Jupyter Notebooks** :一个交互式业务IDE编码环境
|
||||
* Frameworks for Training:支持的ML框架
|
||||
* Chainer
|
||||
* MPI
|
||||
* MXNet
|
||||
* [PyTorch](https://aigc.luomor.com/tag/pytorch/ "PyTorch")
|
||||
* TensorFlow
|
||||
* Hyperparameter Tuning:`Katib`,超参数服务器
|
||||
* **Pipelines** :一个ML的工作流组件,用于定义复杂的ML工作流
|
||||
* Tools for Serving:提供在 `Kubernetes`上对机器学习模型的部署
|
||||
* KFServing
|
||||
* Seldon Core Serving
|
||||
* TensorFlow Serving(TFJob):提供对 `<a href="https://aigc.luomor.com/tag/tensorflow/" target="_blank" title="Tensorflow">Tensorflow</a>`模型的在线部署,支持版本控制及无需停止线上服务、切换模型等
|
||||
* NVIDIA Triton Inference Server(Triton以前叫TensorRT)
|
||||
* TensorFlow Batch Prediction
|
||||
* Multi-Tenancy in Kubeflow:Kubeflow中的多租户
|
||||
* **Fairing** :一个将 `code`打包构建 `image`的组件 `Kubeflow`中大多数组件的实现都是通过定义 `CRD`来工作。目前 `Kubeflow`主要的组件有:
|
||||
* **Operator**是针对不同的机器学习框架提供资源调度和分布式训练的能力(`TF-Operator`,`PyTorch-Operator`,`Caffe2-Operator`,`MPI-Operator`,`MXNet-Operator`);
|
||||
* **Pipelines**是一个基于 `Argo`实现了面向机器学习场景的流水线项目,提供机器学习流程的创建、编排调度和管理,还提供了一个 `<a href="https://aigc.luomor.com/tag/web/" target="_blank" title="Web">Web</a><span> </span>UI`。
|
||||
* **Katib**是基于各个 `Operator`实现的超参数搜索和简单的模型结构搜索的系统,支持并行搜索和分布式训练等。超参优化在实际的工作中还没有被大规模的应用,所以这部分的技术还需要一些时间来成熟;
|
||||
* **Serving**支持部署各个框架训练好的模型的服务化部署和离线预测。`Kubeflow`提供基于 `TFServing`,`KFServing`,`Seldon`等好几种方案。由于机器学习框架很多,算法模型也各种各样。工业界一直缺少一种能真正统一的部署框架和方案。这方面 `Kubeflow`也仅仅是把常见的都集成了进来,但是并没有做更多的抽象和统一。
|
||||
|
||||
**针对不同的ML框架,Training Operator创建了不同的自定义资源:**
|
||||
|
||||
| **ML Framework** | **Custom Resource** |
|
||||
| ---------------------- | ------------------------------------------------------------------------- |
|
||||
| **PyTorch** | [PyTorchJob](https://www.kubeflow.org/docs/components/training/pytorch/) |
|
||||
| **Tensorflow** | [TFJob](https://www.kubeflow.org/docs/components/training/tftraining/) |
|
||||
| **XGBoost** | [XGBoostJob](https://www.kubeflow.org/docs/components/training/xgboost/) |
|
||||
| **MPI** | [MPIJob](https://www.kubeflow.org/docs/components/training/mpi/) |
|
||||
| **PaddlePaddle** | [PaddleJob](https://www.kubeflow.org/docs/components/training/paddlepaddle/) |
|
||||
|
||||
**示例:**
|
||||
|
||||
```yaml
|
||||
apiVersion: "kubeflow.org/v1"
|
||||
kind: "TFJob"
|
||||
metadata:
|
||||
name: "tf-smoke-gpu"
|
||||
spec:
|
||||
tfReplicaSpecs:
|
||||
PS: # 参数服务器
|
||||
replicas: 1
|
||||
template:
|
||||
metadata:
|
||||
creationTimestamp: null
|
||||
spec:
|
||||
containers:
|
||||
- args:
|
||||
- python
|
||||
- tf_cnn_benchmarks.py
|
||||
- --batch_size=32
|
||||
- --model=resnet50
|
||||
- --variable_update=parameter_server
|
||||
- --flush_stdout=true
|
||||
- --num_gpus=1
|
||||
- --local_parameter_device=cpu
|
||||
- --device=cpu
|
||||
- --data_format=NHWC
|
||||
image: gcr.io/kubeflow/tf-benchmarks-cpu:v20171202-bdab599-dirty-284af3
|
||||
name: tensorflow # pod中必须有一个命名为tensorflow的容器
|
||||
ports:
|
||||
- containerPort: 2222
|
||||
name: tfjob-port
|
||||
resources:
|
||||
limits:
|
||||
cpu: "1"
|
||||
workingDir: /opt/tf-benchmarks/scripts/tf_cnn_benchmarks
|
||||
restartPolicy: OnFailure
|
||||
Worker: # 工作节点
|
||||
replicas: 1
|
||||
template:
|
||||
metadata:
|
||||
creationTimestamp: null
|
||||
spec:
|
||||
containers:
|
||||
- args:
|
||||
- python
|
||||
- tf_cnn_benchmarks.py
|
||||
- --batch_size=32
|
||||
- --model=resnet50
|
||||
- --variable_update=parameter_server
|
||||
- --flush_stdout=true
|
||||
- --num_gpus=1 # gpu个数
|
||||
- --local_parameter_device=cpu
|
||||
- --device=gpu # gpu
|
||||
- --data_format=NHWC
|
||||
image: gcr.io/kubeflow/tf-benchmarks-gpu:v20171202-bdab599-dirty-284af3
|
||||
name: tensorflow
|
||||
ports:
|
||||
- containerPort: 2222
|
||||
name: tfjob-port
|
||||
resources:
|
||||
limits:
|
||||
nvidia.com/gpu: 1 # 使用gpu
|
||||
workingDir: /opt/tf-benchmarks/scripts/tf_cnn_benchmarks
|
||||
restartPolicy: OnFailure
|
||||
```
|
||||
|
||||
在分布式TensorFlow有多个角色协同工作以训练和评估模型,以下是每个进程的基本职责:
|
||||
|
||||
1. **Chief** **(主节点):**
|
||||
|
||||
* **Chief节点负责协调训练过程,包括初始化任务、保存检查点、编写TensorBoard日志等。**
|
||||
* **在训练开始时,Chief节点负责初始化参数。**
|
||||
* **它通常也是负责恢复训练状态(如果需要的话)和执行最终的同步工作。**
|
||||
|
||||
2. **PS** **(Parameter Server,参数服务器):**
|
||||
|
||||
* **参数服务器主要负责管理模型的参数,即存储和更新训练过程中的权重和偏差。**
|
||||
* **在训练过程中,Worker节点会计算梯度,并将这些梯度发送到参数服务器上进行应用(即更新模型参数)。**
|
||||
|
||||
3. **Worker** **:**
|
||||
|
||||
* **Worker节点主要负责执行模型的前向和反向传播计算,即计算损失函数和梯度。**
|
||||
* **Worker节点在接收到最新的模型参数后也负责对它们进行本地更新。**
|
||||
|
||||
4. **Evaluator** **:**
|
||||
|
||||
* **Evaluator节点负责评估训练好的模型的性能。这是通过对验证集数据的评估来完成的。**
|
||||
* **Evaluator节点通常在训练过程中独立运行,不参与模型的训练更新过程**
|
||||
|
||||
## 2.4. [Katib](https://github.com/kubeflow/katib)
|
||||
|
||||
**Katib 是一个用于自动化机器学习 (** **AutoML** **) 的 Kubernetes 原生项目, Katib 支持超参数调整、Early Stopping 和神经架构搜索 (NAS)。**
|
||||
|
||||
* **Katib 与机器学习 (ML) 框架无关,它可以调整任何语言编写的应用程序的超参数,并原生支持多种机器学习框架,例如 TensorFlow、MXNet、PyTorch、XGBoost 等。**
|
||||
* **Katib 支持多种 AutoML 算法,例如贝叶斯优化、Parzen 估计树、随机搜索、协方差矩阵适应进化策略、Hyperband、高效神经架构搜索、可微架构搜索等等。**
|
||||
|
||||

|
||||
|
||||
## 2.5 KServ
|
||||
|
||||
## 3 安装教程
|
||||
|
||||
https://cloud.tencent.com/developer/article/2317882
|
||||
9
人工智能/kubeflow/02 Notebook.md
Normal file
@@ -0,0 +1,9 @@
|
||||
## kubeflow 简介
|
||||
|
||||
### 是什么
|
||||
|
||||
Kubeflow 项目致力于使 Kubernetes 上的机器学习 (ML) 工作流程部署变得简单、可移植且可扩展。
|
||||
|
||||
### 组件架构
|
||||
|
||||

|
||||
488
人工智能/kubeflow/03 Pipelines原理.md
Normal file
@@ -0,0 +1,488 @@
|
||||
****## Kubeflow Pipelines
|
||||
|
||||
## 1 PipeLines介绍
|
||||
|
||||
安装教程
|
||||
https://cloud.tencent.com/developer/article/1674948
|
||||
|
||||
使用教程
|
||||
https://juejin.cn/post/6844904195301064712
|
||||
|
||||
详细说明
|
||||
|
||||
https://blog.csdn.net/qq_45808700/article/details/132188234
|
||||
|
||||
### 1.1 Kubeflow Pipelines介绍
|
||||
|
||||
kubeflow/kubeflow 是一个胶水项目,pipelines 是基于 kubeflow 实现的工作流系统,它的目标是借助 kubeflow 的底层支持,实现出一套工作流,支持数据准备,模型训练,模型部署,可以通过代码提交等等方式触发
|
||||
|
||||
Kubeflow 是一个基于云原生的Machine Learning Platform,它把诸多对机器学习的支持,比如模型训练,超参数训练,模型部署等等结合在了一起,部署了 kubeflow 用户就可以利用它进行不同的机器学习任务,旨于快速在kubernetes环境中构建一套开箱即用的机器学习平台,它将机器学习的代码像构建应用一样打包,使其他人也能够重复使用。
|
||||
|
||||
Pipelines是Kubeflow社区开源的一个端到端工作流项目,工作流的原理是每一个组件都定义好自己的输入和输出,然后根据输入和输出关系确定工作流的流程。所以工作流的方式对于组件的复用可以起到很好的作用。Pipelines基于 kubeflow 实现工作流系统,它的目标是借助 kubeflow 的底层支持,实现出一套工作流,支持数据准备,模型训练,模型部署,可以通过代码提交等等方式触发
|
||||
|
||||
|
||||
Kubeflow pipeline(简称KFP) 通过定义一个有向无环图DAG描述流水线系统(pipeline),流水线中每一步流程是由容器定义组成的组件(component),将机器学习中的应用代码按照流水线的方式编排,形成可重复的工作流,并提供平台,帮助编排,部署,管理,这些端到端机器学习工作流,同时提供了下述能力
|
||||
|
||||
任务编排:KFP通过argo提供workflow的能力,能够实现丰富多样的DAG 工作流,用户可以根据的业务需求定义、管理和复用自己工作流;
|
||||
实验管理:KFP通过Experiments的能力,能够展示和对比不同实验参数(例如:模型超参)下Pipeline的运行结果,用户可以根据结果来对工作流任务进行调优;
|
||||
模型追溯:KFP通过Tracking的能力,能够记录每一次Pipeline运行中每个step的输入和输出信息,用户可以根据记录的内容进行问题排查或模型调优;
|
||||
|
||||
### 1.2 Kubeflow pipelines(KFP) 基本概念
|
||||
|
||||
当我们想要发起一次机器学习的试验时,需要创建一个experiment,在experiment中发起运行任务(run)。Experiment 是一个抽象概念,用于分组管理运行任务。
|
||||
|
||||
Pipeline:定义一组操作的工作流,其中每一步都由component组成。 背后是一个Argo的模板配置。
|
||||
Component: 一个容器操作,可以通过pipeline的sdk 定义。每一个component 可以定义输出(output)和产物(artifact), 输出可以通过设置下一步的环境变量,作为下一步的输入, artifact 是组件运行完成后写入一个约定格式文件,在界面上可以被渲染展示。
|
||||
Experiment: 可以看做一个工作空间,在其中可以针对工作流尝试不同的配置,管理一组运行任务。
|
||||
Run: pipeline 的运行任务实例,这些任务会对应一个工作流实例。由Argo统一管理运行顺序和前后依赖关系。工作流的一次执行,用户在执行的过程中可以看到每一步的输出文件,以及日志
|
||||
Recurring run: 定时任务,定义运行周期,Pipeline 组件会定期拉起对应的Pipeline Run。
|
||||
|
||||
## 2 Argo Workflows
|
||||
|
||||
之前提到Kubeflow pipelines很大程度上依赖Argo来进行任务编排,Argo Workflows是一个开源的本地容器工作流引擎,用于在Kubernetes上编排并行作业。Argo工作流是作为Kubernetes CRD(自定义资源定义)实现的。
|
||||
|
||||
定义工作流,其中工作流中的每个步骤都是一个容器。
|
||||
将多步骤工作流建模为一系列任务,或者使用有向无环图(DAG)捕获任务之间的依赖关系。
|
||||
使用Kubernetes上的Argo工作流,在很短的时间内轻松运行用于机器学习或数据处理的计算密集型作业。
|
||||
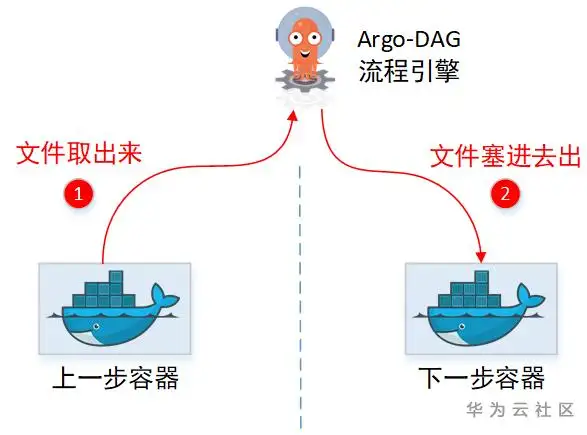
Argo的步骤间可以通过管理面中转传递信息,即下一步(容器)可以获取上一步(容器)的结果。结果传递有2种:
|
||||
文件:上一步容器新生成的文件,会直接出现在下一步容器里面。
|
||||
结果信息:上一步的执行结果信息(如某文件内容),下一步也可以拿到。
|
||||
|
||||
### 2.2.1 Argo传递文件
|
||||
|
||||
|
||||
|
||||
没有共享目录,那中转文件,只能是通过先取出来,再塞回去的方式喽。实际上Argo也确实这么做的,只是实现上还有些约束。
|
||||
|
||||
(1)“临时中转仓库”需要引入第三方软件(Minio)
|
||||
|
||||
(2)文件不能太大
|
||||
|
||||
(3)需要在用户容器侧,增加“代理”帮忙上传&下载文件。
|
||||
|
||||
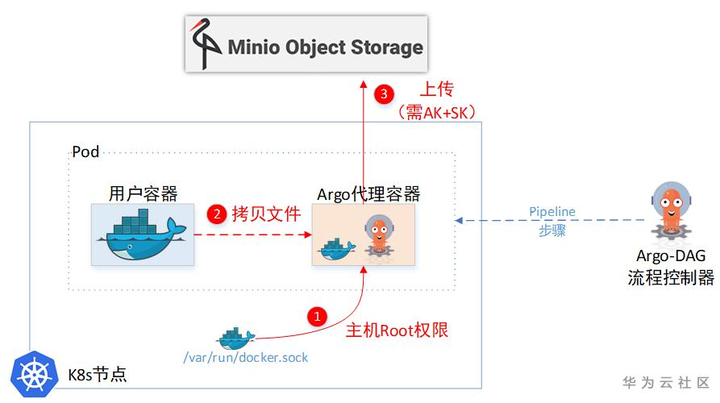
|
||||
|
||||
(1)Argo给用户容器设置了一个SideCar容器,通过这个SideCar去读取用户的文件,然后上传到临时仓库。
|
||||
|
||||
(2) 一个Pod里面的两个Container,文件系统也是独立的,并不能直接取到另一个Container的文件。所以Sidecar容器为了取另一个容器里的文件,又把主机上面的docker.sock挂载进来了。这样就相当于拿到了主机Root权限,可以任意cp主机上任意容器里面的文件。
|
||||
|
||||
### 2.2.2 Argo传递结果信息
|
||||
|
||||
Argo自己没有存储Information的临时仓库,所以它需要记录这些临时待中转的information(Argo使用了Minio对象存储用来暂存中转文件,但Minio只能存文件,没有存Metadata元数据功能)。于是Argo使用Pod里面的Annotation字段即ETCD中(ETCD的单个对象不能超过1M大小),当做临时中转仓库。先把信息记这里,下一步容器想要,就来这里取。
|
||||
|
||||
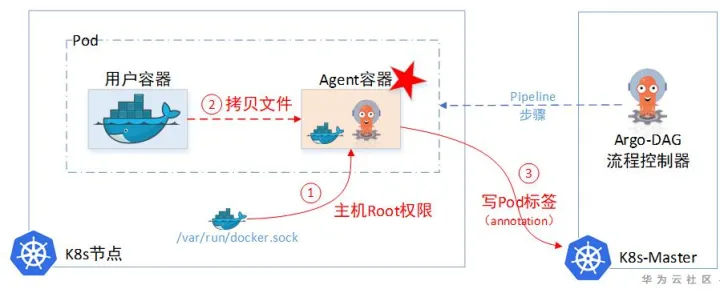
|
||||
|
||||
### 2.2.3 Argo缺陷
|
||||
|
||||
Argo是基于K8s云原生这套理念,即ETCD充当“数据库”来运行的,导致约束比较大。像:流程模板,历史执行记录,这些大量的信息很明显需要一个持久化层(数据库)来记录的,单纯依赖ETCD会有单条记录不能超过1M,总记录大小不能超过8G的约束。
|
||||
|
||||
所以一个完整的流程引擎,包含一个数据库也都是很常规的。因此KFP在这一层做了较大的增强。
|
||||
|
||||
另外,在ML领域的用户界面层,KFP也做了较多的用户体验改进。包括可以查看每一步的训练输出结果,直接通过UI进行可视化的图形展示。
|
||||
|
||||
## 3查看Pipeline
|
||||
|
||||
|
||||
|
||||
## 4 Pipeline 架构
|
||||
|
||||
|
||||
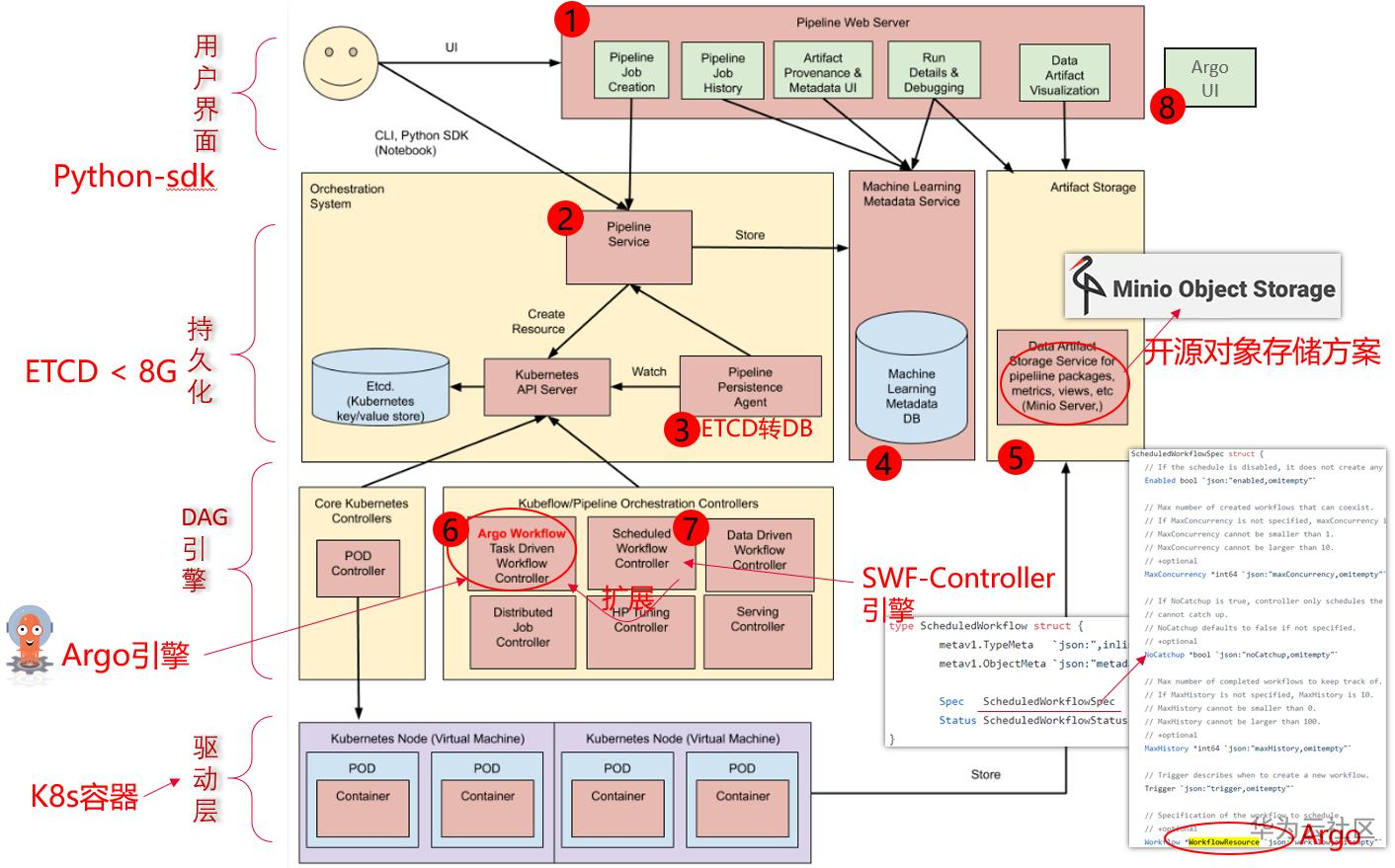
|
||||
|
||||
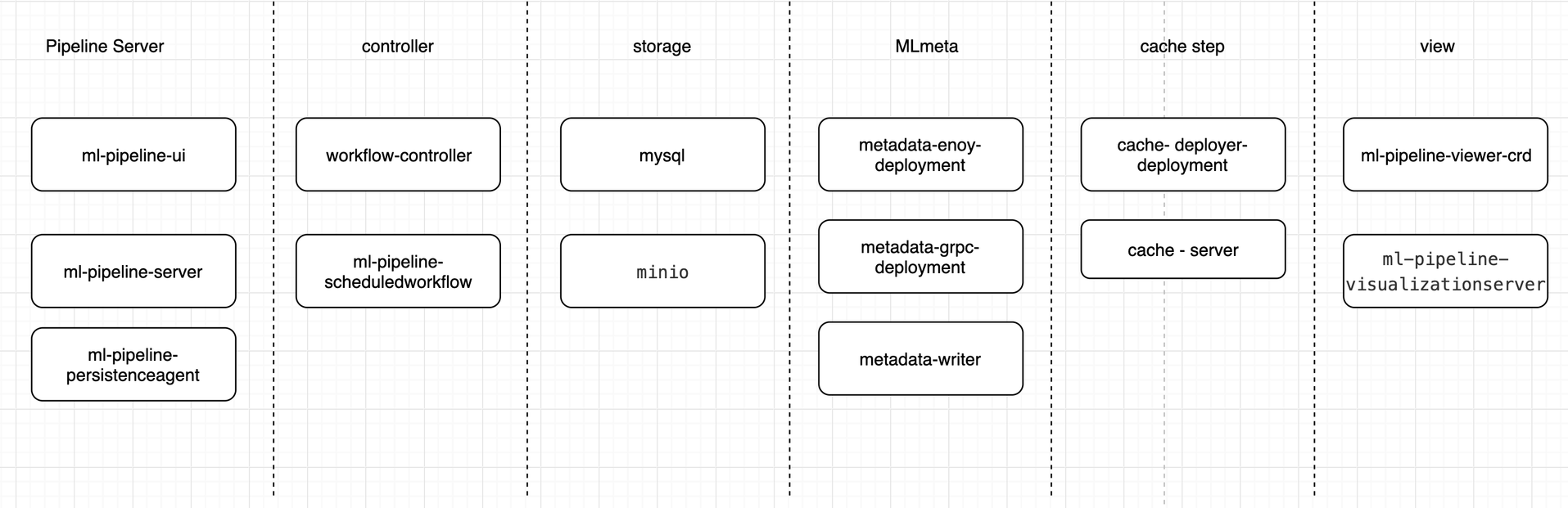
上图为Kubeflow Pipelines的架构图,主要分为八个部分:
|
||||
|
||||
* Python SDK: 负责构造出工作流,并且根据工作流构造出 ScheduledWorkflow 的 YAML 定义,随后将其作为参数传递给工作流系统的后端服务。
|
||||
* DSL Compiler: 将Python代码转换成YAML静态配置文件(DSL编译器);
|
||||
* Pipeline Web Server: Pipeline的前端服务,可视化整个工作流的过程,以及获取日志,发起新的运行等,显示当前正在运行的Pipeline列表、Pipeline执行的历史记录,有关各个Pipeline运行的调试信息和执行状态等;
|
||||
* Pipeline Service:Pipeline的后端服务,调用K8S服务,从YAML创建 Pipeline运行;依赖关系存储数据库(如 MySQL)和对象存储(如 Amazon S3),处理所有工作流中的 CRUD 请求。
|
||||
* Kubernetes Resources:创建CRDs运行Pipeline;
|
||||
* Machine Learning Metadata Service: 用于监视由Pipeline Service创建的Kubernetes资源,并可以将这些资源的状态持久在保留ML元数据服务中(存储任务流容器之间的input/output数据交互);
|
||||
* Artifact Storage:用于存储Metadata和Artifact。Kubeflow Pipelines可以将元数据存储在MySQL数据库中,也可以将工件制品存储在Minio服务器或S3等工件存储中;
|
||||
* Orchestration controllers:对任务的编排,比如Argo Workflow控制器,可以协调任务驱动的工作流。
|
||||
|
||||
从功能上划分可以分为以下6类:
|
||||
|
||||
|
||||
|
||||
|
||||
## 5 Kubeflow Pipelines SDK
|
||||
|
||||
pipeline sdk是使用python配合kubeflow pipelines功能的工具包。为了简化用户使用kubeflow pipelines功能,Kubeflow Pipelines SDK 提供了许多API,以下是一些常用的包:
|
||||
|
||||
kfp.components:该子包提供了一系列可重用的组件的实现,这些组件可以在不同的流程中重复使用。组件可以是定义了输入和输出的容器化软件,也可以是表示命令行工具的Python函数。
|
||||
|
||||
kfp.components.func_to_container_op:调用将函数构建为 apipeline task(ContainerOp) 实例,在容器中运行原始函数。
|
||||
kfp.components.load_component_from_file: kfp.components.load_component_from_file是一个函数,用于从本地文件系统中加载 Kubeflow 组件。使用此函数,您可以在运行时加载和使用预编译的 Kubeflow 组件。这使得组件的共享和重用变得更加容易。
|
||||
kfp.dsl:该子包提供了一组构建块,可用于创建KFP编排定义。DSL提供了可用于编写和组合步骤、输入输出和流程的代码库。
|
||||
|
||||
kfp.dsl.component: kfp.dsl.component 是一个装饰器,允许您将一个函数转换为 Kubeflow 组件。使用这个装饰器,您可以通过编写 Python 函数来定义 Kubeflow 流水线中的任务。一旦定义了组件,您可以在多个 Kubeflow 流水线中重复使用它。
|
||||
kfp.dsl.Pipeline: kfp.dsl.Pipeline是一个用于定义 Kubeflow 流水线的类。您可以使用此类来定义流水线的所有组件,以及它们之间的依赖关系。一旦定义了流水线,您可以使用 kfp.compiler将其编译为可在 Kubeflow 上运行的格式。
|
||||
kfp.dsl.ContainerOp: kfp.dsl.ContainerOp是一个用于定义容器操作的类。这个类允许您定义一个容器镜像,并指定容器启动时应该执行的命令。容器操作可以被组合成一个流水线,并在 Kubeflow 上执行。
|
||||
kfp.compiler:该子包提供了编译器的实现,用于编译和导出 Kubeflow Pipelines 流水线,您可以使用此 API 将 Kubeflow 流水线定义编译为 YAML 或 JSON 格式,以便在 Kubeflow 上执行它将KFP编排定义编译为Kubernetes的自定义资源(CRD)以部署和执行。
|
||||
|
||||
kfp.compiler.Compiler.compile:将您的Python DSL代码编译成Kubeflow Pipelines服务可以处理的单一静态配置(YAML格式)。Kubeflow Pipelines服务将staticconfiguration转换成一组用于执行的Kubernetes资源。
|
||||
kfp.compiler.build_docker_image:根据 Dockerfile 构建容器镜像,并将镜像推送到 URI。在参数中,您需要提供包含映像规范的 Dockerfile 的路径,以及目标映像(例如容器注册表)的 URI。
|
||||
kfp.Client:该子包为KFP服务提供了Python客户端库。它允许您通过API与KFP服务器进行交互,例如对运行中的流程进行操作。
|
||||
|
||||
kfp.Client.create_experiment:创建一个工作流实验环境并返回
|
||||
kfp.Client.run_pipeline:创建一个运行任务实例
|
||||
kfp.Notebook:该子包为Jupyter Notebook提供了扩展,使其能够与KFP服务进行交互。它包含了KFP的Web UI和其它可视化工具。
|
||||
总之,Kubeflow Pipelines SDK 提供了一些用于定义和构建 Kubeflow 流水线的强大的 API。使用这些 API,可以快速开发和管理复杂的机器学习工作流。
|
||||
|
||||
|
||||
|
||||
## 6 Pipeline实践
|
||||
|
||||
流水线的定义可以分为两步,
|
||||
|
||||
1. 首先是定义组件,组件可以从镜像开始完全自定义。这里介绍一下自定义的方式:首先需要打包一个Docker镜像,这个镜像是组件的依赖,每一个组件的运行,就是一个Docker容器。其次需要为其定义一个python函数,描述组件的输入输出等信息,这一定义是为了能够让流水线理解组件在流水线中的结构,有几个输入节点,几个输出节点等。接下来组件的使用就与普通的组件并无二致了。
|
||||
2. 实现流水线的第二步,就是根据定义好的组件组成流水线,在流水线中,由输入输出关系会确定图上的边以及方向。在定义好流水线后,可以通过 python中实现好的流水线客户端提交到系统中运行。
|
||||
|
||||
|
||||
虽然kubeflow/pipelines的使用略显复杂,但它的实现其实并不麻烦。整个的架构可以分为五个部分,分别是ScheduledWorkflow CRD以及其operator,流水线前端,流水线后端,Python SDK和persistence agent。
|
||||
|
||||
* ScheduledWorkflow CRD扩展了argoproj/argo的Workflow定义。这也是流水线项目中的核心部分,它负责真正地在Kubernetes上按照拓扑序创建出对应的容器完成流水线的逻辑。
|
||||
* Python SDK负责构造出流水线,并且根据流水线构造出 ScheduledWorkflow的YAML定义,随后将其作为参数传递给流水线系统的后端服务。
|
||||
* 后端服务依赖关系存储数据库(如MySQL)和对象存储(如S3),处理所有流水线中的CRUD请求。
|
||||
* 前端负责可视化整个流水线的过程,以及获取日志,发起新的运行等。
|
||||
* Persistence agent负责把数据从Kubernetes Master的etcd中sync到后端服务的关系型数据库中,其实现的方式与CRD operator类似,通过informer来监听 Kubernetes apiserver对应资源实现。
|
||||
|
||||
Pipelines提供机器学习流程的创建、编排调度和管理,还提供了一个Web UI。这部分主要基于Argo Workflow。
|
||||
|
||||
### 6.1 构造Pipeline
|
||||
|
||||
Kubeflow Pipelines提供了Python的SDK让用户来快速构建符合自己业务场景的Pipeline。通过Kubeflow Pipelines,您可以使用KFP Python SDK创作组件和Pipeline,将Pipeline编译为中间表示YAML,并提交管道以在符合KFP标准的后端上运行。
|
||||
|
||||
以下代码来自官网:https://www.kubeflow.org/docs/components/pipelines/v2/installation/quickstart/
|
||||
|
||||
```
|
||||
from kfp import dsl
|
||||
from kfp import client
|
||||
|
||||
@dsl.component
|
||||
def addition_component(num1: int, num2: int) -> int:
|
||||
return num1 + num2
|
||||
|
||||
@dsl.pipeline(name='addition-pipeline')
|
||||
def my_pipeline(a: int, b: int, c: int = 10):
|
||||
add_task_1 = addition_component(num1=a, num2=b)
|
||||
add_task_2 = addition_component(num1=add_task_1.output, num2=c)
|
||||
|
||||
endpoint = '<KFP_ENDPOINT>'
|
||||
kfp_client = client.Client(host=endpoint)
|
||||
run = kfp_client.create_run_from_pipeline_func(
|
||||
my_pipeline,
|
||||
arguments={
|
||||
'a': 1,
|
||||
'b': 2
|
||||
},
|
||||
)
|
||||
url = f'{endpoint}/#/runs/details/{run.run_id}'
|
||||
print(url)
|
||||
```
|
||||
|
||||
|
||||
以上代码包括以下几个部分:
|
||||
|
||||
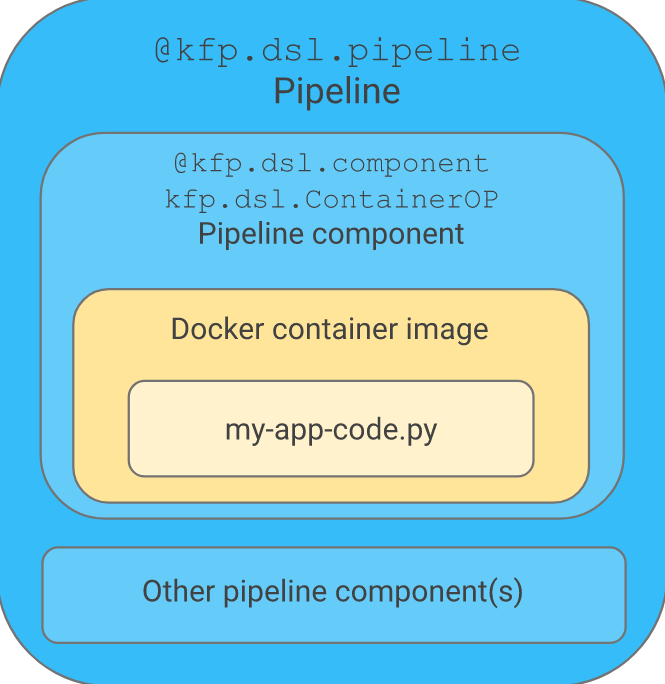
第一部分中,使用@dsl.component装饰器创建了一个轻量级的Python组件:
|
||||
|
||||
```
|
||||
@dsl.component
|
||||
def addition_component(num1: int, num2: int) -> int:
|
||||
return num1 + num2
|
||||
```
|
||||
|
||||
|
||||
@dsl.component装饰器将Python函数转化为可在工作流中使用的组件。在参数上需要指定类型注释和返回值,这样可以告诉KFP执行器如何序列化和反序列化组件之间传递的数据。类型注释和返回值还使得KFP编译器能够对工作流任务之间传递的数据进行类型检查。
|
||||
|
||||
第二部分中,使用@dsl.pipeline装饰器创建了一个工作流:
|
||||
|
||||
```
|
||||
@dsl.pipeline(name=’addition-pipeline’)
|
||||
def my_pipeline(a: int, b: int, c: int = 10):
|
||||
…
|
||||
|
||||
```
|
||||
|
||||
|
||||
第三部分中,以下代码在工作流函数中将组件连接起来形成一个计算有向无环图(DAG):
|
||||
|
||||
```
|
||||
add_task_1 = addition_component(num1=a, num2=b)
|
||||
add_task_2 = addition_component(num1=add_task_1.output, num2=c)
|
||||
```
|
||||
|
||||
|
||||
这个例子中通过为每个任务传递不同的参数,从同一个名为addition_component的组件中实例化了两个不同的加法任务,必须始终使用关键字参数传递组件参数,具体如下:
|
||||
|
||||
第一个任务将工作流参数a和b作为输入参数。
|
||||
第二个任务将add_task_1.output(即add_task_1的输出)作为第一个输入参数,并将工作流参数c作为第二个输入参数。
|
||||
|
||||
|
||||
第四部分中,以下代码使用部署步骤中获取的端点实例化了一个KFP客户端,并将工作流与所需的工作流参数提交给KFP后端:
|
||||
|
||||
|
||||
```
|
||||
endpoint = ‘<KFP_ENDPOINT>’
|
||||
kfp_client = client.Client(host=endpoint)
|
||||
run = kfp_client.create_run_from_pipeline_func(
|
||||
my_pipeline,
|
||||
arguments={
|
||||
'a’: 1,
|
||||
‘b’: 2
|
||||
},
|
||||
)
|
||||
url = f’{endpoint}/#/runs/details/{run.run_id}’
|
||||
print(url)
|
||||
```
|
||||
|
||||
|
||||
在这个例子中,将工作流的endpoint替换为在部署步骤中获取的KFP端点URL。或者,还可以将工作流编译为IR YAML以供以后使用:
|
||||
|
||||
```
|
||||
from kfp import compiler
|
||||
compiler.Compiler().compile(pipeline_func=my_pipeline, package_path=’pipe
|
||||
```
|
||||
|
||||
|
||||
目前提交运行pipelines有2种方法,二者本质都是使用sdk编译pipelines组件
|
||||
|
||||
* 在notebook中使用sdk提交pipelines至服务中心,直接可以在ui中查看pipelines实验运行进度。
|
||||
* 将pipelines组件打成zip包通过ui上传至服务中心,同样可以在ui查看实验运行进度。
|
||||
|
||||
### 6.2 启动Pytorch工作流实例
|
||||
|
||||
```
|
||||
import json
|
||||
from typing import NamedTuple
|
||||
from collections import namedtuple
|
||||
import kfp
|
||||
import kfp.dsl as dsl
|
||||
from kfp import components
|
||||
from kfp.dsl.types import Integer
|
||||
|
||||
|
||||
def get_current_namespace():
|
||||
"""Returns current namespace if available, else kubeflow"""
|
||||
try:
|
||||
current_namespace = open(
|
||||
"/var/run/secrets/kubernetes.io/serviceaccount/namespace"
|
||||
).read()
|
||||
except:
|
||||
current_namespace = "kubeflow"
|
||||
return current_namespace
|
||||
|
||||
|
||||
def create_worker_spec(
|
||||
worker_num: int = 0
|
||||
) -> NamedTuple(
|
||||
"CreatWorkerSpec", [("worker_spec", dict)]
|
||||
):
|
||||
"""
|
||||
Creates pytorch-job worker spec
|
||||
"""
|
||||
worker = {}
|
||||
if worker_num > 0:
|
||||
worker = {
|
||||
"replicas": worker_num,
|
||||
"restartPolicy": "OnFailure",
|
||||
"template": {
|
||||
"metadata": {
|
||||
"annotations": {
|
||||
"sidecar.istio.io/inject": "false"
|
||||
}
|
||||
},
|
||||
"spec": {
|
||||
"containers": [
|
||||
{
|
||||
"args": [
|
||||
"--backend",
|
||||
"gloo",
|
||||
],
|
||||
"image": "public.ecr.aws/pytorch-samples/pytorch_dist_mnist:latest",
|
||||
"name": "pytorch",
|
||||
"resources": {
|
||||
"requests": {
|
||||
"memory": "4Gi",
|
||||
"cpu": "2000m",
|
||||
# Uncomment for GPU
|
||||
# "nvidia.com/gpu": 1,
|
||||
},
|
||||
"limits": {
|
||||
"memory": "4Gi",
|
||||
"cpu": "2000m",
|
||||
# Uncomment for GPU
|
||||
# "nvidia.com/gpu": 1,
|
||||
},
|
||||
},
|
||||
}
|
||||
]
|
||||
},
|
||||
},
|
||||
}
|
||||
|
||||
worker_spec_output = namedtuple(
|
||||
"MyWorkerOutput", ["worker_spec"]
|
||||
)
|
||||
return worker_spec_output(worker)
|
||||
|
||||
|
||||
worker_spec_op = components.func_to_container_op(
|
||||
create_worker_spec,
|
||||
base_image="python:slim",
|
||||
)
|
||||
|
||||
|
||||
@dsl.pipeline(
|
||||
name="launch-kubeflow-pytorchjob",
|
||||
description="An example to launch pytorch.",
|
||||
)
|
||||
def mnist_train(
|
||||
namespace: str = get_current_namespace(),
|
||||
worker_replicas: int = 1,
|
||||
ttl_seconds_after_finished: int = -1,
|
||||
job_timeout_minutes: int = 600,
|
||||
delete_after_done: bool = False,
|
||||
):
|
||||
pytorchjob_launcher_op = components.load_component_from_file(
|
||||
"./component.yaml"
|
||||
)
|
||||
|
||||
master = {
|
||||
"replicas": 1,
|
||||
"restartPolicy": "OnFailure",
|
||||
"template": {
|
||||
"metadata": {
|
||||
"annotations": {
|
||||
# See https://github.com/kubeflow/website/issues/2011
|
||||
"sidecar.istio.io/inject": "false"
|
||||
}
|
||||
},
|
||||
"spec": {
|
||||
"containers": [
|
||||
{
|
||||
# To override default command
|
||||
# "command": [
|
||||
# "python",
|
||||
# "/opt/mnist/src/mnist.py"
|
||||
# ],
|
||||
"args": [
|
||||
"--backend",
|
||||
"gloo",
|
||||
],
|
||||
# Or, create your own image from
|
||||
# https://github.com/kubeflow/pytorch-operator/tree/master/examples/mnist
|
||||
"image": "public.ecr.aws/pytorch-samples/pytorch_dist_mnist:latest",
|
||||
"name": "pytorch",
|
||||
"resources": {
|
||||
"requests": {
|
||||
"memory": "4Gi",
|
||||
"cpu": "2000m",
|
||||
# Uncomment for GPU
|
||||
# "nvidia.com/gpu": 1,
|
||||
},
|
||||
"limits": {
|
||||
"memory": "4Gi",
|
||||
"cpu": "2000m",
|
||||
# Uncomment for GPU
|
||||
# "nvidia.com/gpu": 1,
|
||||
},
|
||||
},
|
||||
}
|
||||
],
|
||||
# If imagePullSecrets required
|
||||
# "imagePullSecrets": [
|
||||
# {"name": "image-pull-secret"},
|
||||
# ],
|
||||
},
|
||||
},
|
||||
}
|
||||
|
||||
worker_spec_create = worker_spec_op(
|
||||
worker_replicas
|
||||
)
|
||||
|
||||
# Launch and monitor the job with the launcher
|
||||
pytorchjob_launcher_op(
|
||||
# Note: name needs to be a unique pytorchjob name in the namespace.
|
||||
# Using RUN_ID_PLACEHOLDER is one way of getting something unique.
|
||||
name=f"name-{kfp.dsl.RUN_ID_PLACEHOLDER}",
|
||||
namespace=namespace,
|
||||
master_spec=master,
|
||||
# pass worker_spec as a string because the JSON serializer will convert
|
||||
# the placeholder for worker_replicas (which it sees as a string) into
|
||||
# a quoted variable (eg a string) instead of an unquoted variable
|
||||
# (number). If worker_replicas is quoted in the spec, it will break in
|
||||
# k8s. See https://github.com/kubeflow/pipelines/issues/4776
|
||||
worker_spec=worker_spec_create.outputs[
|
||||
"worker_spec"
|
||||
],
|
||||
ttl_seconds_after_finished=ttl_seconds_after_finished,
|
||||
job_timeout_minutes=job_timeout_minutes,
|
||||
delete_after_done=delete_after_done,
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import kfp.compiler as compiler
|
||||
|
||||
pipeline_file = "test.tar.gz"
|
||||
print(
|
||||
f"Compiling pipeline as {pipeline_file}"
|
||||
)
|
||||
compiler.Compiler().compile(
|
||||
mnist_train, pipeline_file
|
||||
)
|
||||
|
||||
# # To run:
|
||||
# client = kfp.Client()
|
||||
# run = client.create_run_from_pipeline_package(
|
||||
# pipeline_file,
|
||||
# arguments={},
|
||||
# run_name="test pytorchjob run"
|
||||
# )
|
||||
# print(f"Created run {run}")
|
||||
```
|
||||
|
||||
### 6.3 kfp-kubernetes库
|
||||
|
||||
kfp-kubernetes Python库支持创作具有kubernetes特定功能的Kubeflow工作流。具体来说,kfp-kubernetes库支持使用以下创作工作流:
|
||||
|
||||
* Secrets
|
||||
|
||||
* PersistentVolumeClaims
|
||||
|
||||
首先安装该库
|
||||
|
||||
```pip
|
||||
pip install kfp-kubernetes
|
||||
```
|
||||
|
||||
Secret: As environment variable
|
||||
|
||||
```
|
||||
from kfp import dsl
|
||||
from kfp import kubernetes@dsl.component
|
||||
def print_secret():
|
||||
import os
|
||||
print(os.environ['my-secret'])@dsl.pipeline
|
||||
def pipeline():
|
||||
task = print_secret()
|
||||
kubernetes.use_secret_as_env(task,
|
||||
secret_name='my-secret',
|
||||
secret_key_to_env={'password': 'SECRET_VAR'})
|
||||
```
|
||||
|
||||
## 7 Kubeflow-Pipeline后续演进点
|
||||
|
||||
Kubeflow-Pipeline是Kubeflow的一个组件,用于构建和部署机器学习工作流程。目前,Kubeflow-Pipeline已经具备了很多强大的功能,如批量数据预处理、模型训练、模型推理等。未来,它可以在以下几个方面进行进一步演进:
|
||||
|
||||
支持更广泛的机器学习应用场景:目前Kubeflow-Pipeline主要支持传统的机器学习应用场景,但未来可以进一步支持深度学习、强化学习等更广泛的应用场景。
|
||||
|
||||
更好的可视化和调试支持:Kubeflow-Pipeline已经具备一些可视化和调试功能,但未来可以进一步提高其易用性和可扩展性,以便更好地支持大规模机器学习工作流程。
|
||||
|
||||
更好的集成和生态系统支持:目前Kubeflow-Pipeline已经与Kubernetes和其他一些工具进行了集成,但未来可以进一步提高其与其他机器学习和数据科学工具的集成和生态系统支持。
|
||||
|
||||
更好的安全性和可靠性支持:随着Kubeflow-Pipeline被越来越多地用于生产环境中,其安全性和可靠性将变得越来越重要。使用权限过于高的Sidecar容器作为其实现步骤之间元数据传递的途径,也会是KFP生产级使用的一道门槛。未来可以进一步提高其安全性和可靠性支持,以满足生产环境的需求。
|
||||
|
||||
Dag引擎组件的水平扩展(HPA)是其重要的一个特性,也是要成为一个成熟引擎所必要的能力。当前KFP在稳定性以及组件的水平扩展上都还有待改进,因此商业使用还需要一段时间,这将是KFP未来的一个重要目标.
|
||||
324
人工智能/kubeflow/04 pipelines快速开始.md
Normal file
@@ -0,0 +1,324 @@
|
||||
## 1 如何创建一个pipelines
|
||||
|
||||
### 部署pipelines
|
||||
|
||||
### 安装pipelines sdk
|
||||
安装kfp的python组件
|
||||
```
|
||||
$ pip install kfp --upgrade
|
||||
```
|
||||
导入kfp相关的包
|
||||
```
|
||||
import kfp
|
||||
import kfp.components as comp
|
||||
```
|
||||
|
||||
### 创建管道
|
||||
1. 创建合并数据的业务组件
|
||||
1. 函数的参数用 kfp.components.InputPath和 kfp.components.OutputPath注释进行修饰。这些注释让 Kubeflow Pipelines 知道提供压缩 tar 文件的路径并创建函数存储合并的 CSV 文件的路径。
|
||||
2. 用于kfp.components.create_component_from_func 返回可用于创建管道步骤的工厂函数。此示例还指定了运行此函数的基础容器映像、保存组件规范的路径以及运行时需要在容器中安装的 PyPI 包的列表。
|
||||
```py
|
||||
def merge_csv(file_path: comp.InputPath('Tarball'),
|
||||
output_csv: comp.OutputPath('CSV')):
|
||||
import glob
|
||||
import pandas as pd
|
||||
import tarfile
|
||||
|
||||
tarfile.open(name=file_path, mode="r|gz").extractall('data')
|
||||
df = pd.concat(
|
||||
[pd.read_csv(csv_file, header=None)
|
||||
for csv_file in glob.glob('data/*.csv')])
|
||||
df.to_csv(output_csv, index=False, header=False)
|
||||
|
||||
|
||||
create_step_merge_csv = kfp.components.create_component_from_func(
|
||||
func=merge_csv,
|
||||
output_component_file='component.yaml', # This is optional. It saves the component spec for future use.
|
||||
base_image='python:3.7',
|
||||
packages_to_install=['pandas==1.1.4'])
|
||||
```
|
||||
|
||||
2. 创建下载组件
|
||||
1. kfp.components.create_component_from_func使用和 创建的工厂函数来 kfp.components.load_component_from_url创建管道的任务。
|
||||
```py
|
||||
web_downloader_op = kfp.components.load_component_from_url(
|
||||
'https://raw.githubusercontent.com/kubeflow/pipelines/master/components/contrib/web/Download/component.yaml')
|
||||
```
|
||||
|
||||
3. 将两个组件构成pipelines
|
||||
```py
|
||||
# Define a pipeline and create a task from a component:
|
||||
def my_pipeline(url):
|
||||
web_downloader_task = web_downloader_op(url=url)
|
||||
merge_csv_task = create_step_merge_csv(file=web_downloader_task.outputs['data'])
|
||||
# The outputs of the merge_csv_task can be referenced using the
|
||||
# merge_csv_task.outputs dictionary: merge_csv_task.outputs['output_csv']
|
||||
```
|
||||
|
||||
### 编译运行管道
|
||||
|
||||
1. 运行以下命令来编译您的管道并将其另存为pipeline.yaml.pipeline.yaml使用 Kubeflow Pipelines 用户界面上传并运行您的文件。
|
||||
```
|
||||
kfp.compiler.Compiler().compile(
|
||||
pipeline_func=my_pipeline,
|
||||
package_path='pipeline.yaml')
|
||||
```
|
||||
2. 创建Client连接到pipelines服务端
|
||||
```py
|
||||
client = kfp.Client("http://") # change arguments accordingly
|
||||
|
||||
client.create_run_from_pipeline_func(
|
||||
my_pipeline,
|
||||
arguments={
|
||||
'url': 'https://storage.googleapis.com/ml-pipeline-playground/iris-csv-files.tar.gz'
|
||||
})
|
||||
```
|
||||
|
||||
|
||||
## 2 创建构建
|
||||
|
||||
### 2.1设计管道组件
|
||||
首先定义一段业务相关的python脚本。例如
|
||||
```py
|
||||
#!/usr/bin/env python3
|
||||
import argparse
|
||||
from pathlib import Path
|
||||
|
||||
# Function doing the actual work (Outputs first N lines from a text file)
|
||||
def do_work(input1_file, output1_file, param1):
|
||||
for x, line in enumerate(input1_file):
|
||||
if x >= param1:
|
||||
break
|
||||
_ = output1_file.write(line)
|
||||
|
||||
# Defining and parsing the command-line arguments
|
||||
parser = argparse.ArgumentParser(description='My program description')
|
||||
# Paths must be passed in, not hardcoded
|
||||
parser.add_argument('--input1-path', type=str,
|
||||
help='Path of the local file containing the Input 1 data.')
|
||||
parser.add_argument('--output1-path', type=str,
|
||||
help='Path of the local file where the Output 1 data should be written.')
|
||||
parser.add_argument('--param1', type=int, default=100,
|
||||
help='The number of lines to read from the input and write to the output.')
|
||||
args = parser.parse_args()
|
||||
|
||||
# Creating the directory where the output file is created (the directory
|
||||
# may or may not exist).
|
||||
Path(args.output1_path).parent.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
with open(args.input1_path, 'r') as input1_file:
|
||||
with open(args.output1_path, 'w') as output1_file:
|
||||
do_work(input1_file, output1_file, args.param1)
|
||||
|
||||
```
|
||||
其执行方式如下
|
||||
```py
|
||||
python3 program.py --input1-path <path-to-the-input-file> \
|
||||
--param1 <number-of-lines-to-read> \
|
||||
--output1-path <path-to-write-the-output-to>
|
||||
```
|
||||
|
||||
|
||||
### 2.2 将组件容器化
|
||||
|
||||
1. 创建一个Dockerfile 。 Dockerfile 指定:
|
||||
|
||||
基础容器镜像。例如,您的代码运行的操作系统。
|
||||
需要安装代码才能运行的任何依赖项。
|
||||
要复制到容器中的文件,例如该组件的可运行代码。
|
||||
以下是 Dockerfile 示例。
|
||||
```
|
||||
FROM python:3.7
|
||||
RUN python3 -m pip install keras
|
||||
COPY ./src /pipelines/component/src
|
||||
```
|
||||
|
||||
### 2.3 定义组件的实现
|
||||
|
||||
创建一个名为 的文件component.yaml并在文本编辑器中打开它。
|
||||
|
||||
创建组件的实现部分并指定容器映像的严格名称。运行build_image.sh脚本时会提供严格的图像名称。
|
||||
|
||||
```yaml
|
||||
implementation:
|
||||
container:
|
||||
# The strict name of a container image that you've pushed to a container registry.
|
||||
image: gcr.io/my-org/my-image@sha256:a172..752f
|
||||
```
|
||||
command为您的组件的实现定义一个。此字段指定用于在容器中运行程序的命令行参数。
|
||||
|
||||
```py
|
||||
implementation:
|
||||
container:
|
||||
image: gcr.io/my-org/my-image@sha256:a172..752f
|
||||
# command is a list of strings (command-line arguments).
|
||||
# The YAML language has two syntaxes for lists and you can use either of them.
|
||||
# Here we use the "flow syntax" - comma-separated strings inside square brackets.
|
||||
command: [
|
||||
python3,
|
||||
# Path of the program inside the container
|
||||
/pipelines/component/src/program.py,
|
||||
--input1-path,
|
||||
{inputPath: Input 1},
|
||||
--param1,
|
||||
{inputValue: Parameter 1},
|
||||
--output1-path,
|
||||
{outputPath: Output 1},
|
||||
]
|
||||
```
|
||||
|
||||
### 2.4 定义组件的接口
|
||||
|
||||
1. 定义输入,请将具有以下属性的component.yaml项目添加到 列表中:inputs
|
||||
|
||||
* name:此输入的人类可读名称。每个输入的名称必须是唯一的。
|
||||
* description:(可选。)人类可读的输入描述。
|
||||
* default:(可选。)指定此输入的默认值。
|
||||
* type:(可选。)指定输入的类型。详细了解 Kubeflow Pipelines SDK 中定义的类型以及类型检查在管道和组件中的工作原理。
|
||||
* optional:指定此输入是否可选。该属性的值的类型为Bool,默认为False。
|
||||
在此示例中,Python 程序有两个输入:
|
||||
|
||||
Input 1包含String数据。
|
||||
Parameter 1包含一个Integer.
|
||||
```py
|
||||
inputs:
|
||||
- {name: Input 1, type: String, description: 'Data for input 1'}
|
||||
- {name: Parameter 1, type: Integer, default: '100', description: 'Number of lines to copy'}
|
||||
```
|
||||
|
||||
1. 组件的输出将作为路径传递到您的管道。在运行时,Kubeflow Pipelines 为每个组件的输出创建一个路径。这些路径作为输入传递到组件的实现。
|
||||
|
||||
要在组件规范 YAML 中定义输出,请将outputs具有以下属性的项目添加到列表中:
|
||||
|
||||
* name:此输出的人类可读名称。每个输出的名称必须是唯一的。
|
||||
* description:(可选。)人类可读的输出描述。
|
||||
* type:(可选。)指定输出的类型。详细了解 Kubeflow Pipelines SDK 中定义的类型以及类型检查在管道和组件中的工作原理。
|
||||
|
||||
在此示例中,Python 程序返回一个输出。输出已命名 Output 1并且包含String数据。
|
||||
|
||||
```py
|
||||
outputs:
|
||||
- {name: Output 1, type: String, description: 'Output 1 data.'}
|
||||
|
||||
```
|
||||
3. 定义组件的接口后,应该component.yaml类似于以下内容:
|
||||
```yaml
|
||||
name: Get Lines
|
||||
description: Gets the specified number of lines from the input file.
|
||||
|
||||
inputs:
|
||||
- {name: Input 1, type: String, description: 'Data for input 1'}
|
||||
- {name: Parameter 1, type: Integer, default: '100', description: 'Number of lines to copy'}
|
||||
|
||||
outputs:
|
||||
- {name: Output 1, type: String, description: 'Output 1 data.'}
|
||||
|
||||
implementation:
|
||||
container:
|
||||
image: gcr.io/my-org/my-image@sha256:a172..752f
|
||||
# command is a list of strings (command-line arguments).
|
||||
# The YAML language has two syntaxes for lists and you can use either of them.
|
||||
# Here we use the "flow syntax" - comma-separated strings inside square brackets.
|
||||
command: [
|
||||
python3,
|
||||
# Path of the program inside the container
|
||||
/pipelines/component/src/program.py,
|
||||
--input1-path,
|
||||
{inputPath: Input 1},
|
||||
--param1,
|
||||
{inputValue: Parameter 1},
|
||||
--output1-path,
|
||||
{outputPath: Output 1},
|
||||
]
|
||||
```
|
||||
|
||||
### 2.5 运行组件
|
||||
|
||||
```py
|
||||
import kfp
|
||||
import kfp.components as comp
|
||||
|
||||
create_step_get_lines = comp.load_component_from_text("""
|
||||
name: Get Lines
|
||||
description: Gets the specified number of lines from the input file.
|
||||
|
||||
inputs:
|
||||
- {name: Input 1, type: Data, description: 'Data for input 1'}
|
||||
- {name: Parameter 1, type: Integer, default: '100', description: 'Number of lines to copy'}
|
||||
|
||||
outputs:
|
||||
- {name: Output 1, type: Data, description: 'Output 1 data.'}
|
||||
|
||||
implementation:
|
||||
container:
|
||||
image: gcr.io/my-org/my-image@sha256:a172..752f
|
||||
# command is a list of strings (command-line arguments).
|
||||
# The YAML language has two syntaxes for lists and you can use either of them.
|
||||
# Here we use the "flow syntax" - comma-separated strings inside square brackets.
|
||||
command: [
|
||||
python3,
|
||||
# Path of the program inside the container
|
||||
/pipelines/component/src/program.py,
|
||||
--input1-path,
|
||||
{inputPath: Input 1},
|
||||
--param1,
|
||||
{inputValue: Parameter 1},
|
||||
--output1-path,
|
||||
{outputPath: Output 1},
|
||||
]""")
|
||||
|
||||
# create_step_get_lines is a "factory function" that accepts the arguments
|
||||
# for the component's inputs and output paths and returns a pipeline step
|
||||
# (ContainerOp instance).
|
||||
#
|
||||
# To inspect the get_lines_op function in Jupyter Notebook, enter
|
||||
# "get_lines_op(" in a cell and press Shift+Tab.
|
||||
# You can also get help by entering `help(get_lines_op)`, `get_lines_op?`,
|
||||
# or `get_lines_op??`.
|
||||
|
||||
# Create a simple component using only bash commands. The output of this component
|
||||
# can be passed to a downstream component that accepts an input with the same type.
|
||||
create_step_write_lines = comp.load_component_from_text("""
|
||||
name: Write Lines
|
||||
description: Writes text to a file.
|
||||
|
||||
inputs:
|
||||
- {name: text, type: String}
|
||||
|
||||
outputs:
|
||||
- {name: data, type: Data}
|
||||
|
||||
implementation:
|
||||
container:
|
||||
image: busybox
|
||||
command:
|
||||
- sh
|
||||
- -c
|
||||
- |
|
||||
mkdir -p "$(dirname "$1")"
|
||||
echo "$0" > "$1"
|
||||
args:
|
||||
- {inputValue: text}
|
||||
- {outputPath: data}
|
||||
""")
|
||||
|
||||
# Define your pipeline
|
||||
def my_pipeline():
|
||||
write_lines_step = create_step_write_lines(
|
||||
text='one\ntwo\nthree\nfour\nfive\nsix\nseven\neight\nnine\nten')
|
||||
|
||||
get_lines_step = create_step_get_lines(
|
||||
# Input name "Input 1" is converted to pythonic parameter name "input_1"
|
||||
input_1=write_lines_step.outputs['data'],
|
||||
parameter_1='5',
|
||||
)
|
||||
|
||||
# If you run this command on a Jupyter notebook running on Kubeflow,
|
||||
# you can exclude the host parameter.
|
||||
# client = kfp.Client()
|
||||
client = kfp.Client(host='<your-kubeflow-pipelines-host-name>')
|
||||
|
||||
# Compile, upload, and submit this pipeline for execution.
|
||||
client.create_run_from_pipeline_func(my_pipeline, arguments={})
|
||||
```
|
||||
|
||||
{kind=link}
|
After Width: | Height: | Size: 143 KiB |
BIN
人工智能/kubeflow/image/01kubeflow/1714036812492.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 60 KiB |
BIN
人工智能/kubeflow/image/01kubeflow/1714036889421.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 143 KiB |
BIN
人工智能/kubeflow/image/01kubeflow/1714036983488.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 95 KiB |
BIN
人工智能/kubeflow/image/01kubeflow/1714037030721.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 72 KiB |
BIN
人工智能/kubeflow/image/image-1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 101 KiB |
BIN
人工智能/kubeflow/image/image-2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 101 KiB |
BIN
人工智能/kubeflow/image/image.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 101 KiB |
75
人工智能/入门工具.md
Normal file
@@ -0,0 +1,75 @@
|
||||
## 主流
|
||||
|
||||
### 文本生成
|
||||
|
||||
**chatgpt4(openAI)**
|
||||
|
||||
* 强
|
||||
|
||||
claude3(Amazon)
|
||||
|
||||
* 长文本,读书读论文总结
|
||||
gemini(Google)
|
||||
|
||||
**poe(Quora)**
|
||||
|
||||
* 机器学习综合
|
||||
|
||||
Gemini(Google)
|
||||
|
||||
* 后发优势
|
||||
|
||||
### 图片生成
|
||||
|
||||
stable diffusion(开源本地部署)
|
||||
|
||||
**midjourney**
|
||||
|
||||
**dall-e3(OpenAI)**
|
||||
|
||||
canva
|
||||
|
||||
### 视频生成工具
|
||||
|
||||
stable vide diffusion(开源本地部署)
|
||||
|
||||
**sora(openAI)**
|
||||
|
||||
RunWay
|
||||
|
||||
Pika(动画)
|
||||
|
||||
Haiper
|
||||
|
||||
### 音乐生成
|
||||
|
||||
Suno(中英文可唱歌)
|
||||
|
||||
Stable Audio(纯音乐)
|
||||
|
||||
### 工具
|
||||
|
||||
**perplexity 浏览器**
|
||||
|
||||
**copilot(Github) 编程工具**
|
||||
|
||||
Heygen/DID/SadTalk 数字人
|
||||
|
||||
## 国内
|
||||
|
||||
通义千问系列
|
||||
|
||||
文心一言系列
|
||||
|
||||
## 使用计划
|
||||
|
||||
核心:IdeaTalk(工作环境)、POE(居家环境)
|
||||
|
||||
重点:openai全家桶、通义千问全家桶、midjouney、plexity、copilot
|
||||
|
||||
付费体验:poe 20/openai 20 /midjourney 20/copilot 10
|
||||
|
||||
|
||||
## 本地大模型
|
||||
|
||||
### ollama
|
||||
0
人工智能/大模型学习路线.md
Normal file
35
加密/8 SSL证书认证.md
Normal file
@@ -0,0 +1,35 @@
|
||||
### 认证流程
|
||||
|
||||
SSL证书认证的流程可以概括为以下几个主要步骤:
|
||||
|
||||
1. **准备与申请** :
|
||||
|
||||
* **确定域名/IP地址** :首先确定需要为哪个域名或公网IP地址申请SSL证书。
|
||||
* **生成CSR** :创建一个Certificate Signing Request(CSR)文件。这个过程中,会在服务器上生成一对公钥和私钥。公钥将包含在CSR中,而私钥则需安全地保存在服务器上。CSR还包含了申请者的详细信息(如组织名称、域名、联系人信息等),这些信息将被包含在最终签发的SSL证书中。
|
||||
|
||||
2. **提交与审核** :
|
||||
|
||||
* **提交CSR** :将生成的CSR文件提交给选定的SSL证书颁发机构(CA)。
|
||||
* **身份验证** :根据所申请的SSL证书类型(DV、OV、EV),CA进行相应的身份验证:
|
||||
* **DV(Domain Validation)** :仅验证域名所有权,通常通过添加指定的DNS记录、回复电子邮件至注册邮箱或上传特定文件至指定位置等方式完成。
|
||||
* **OV(Organization Validation)** :除域名验证外,还需验证申请组织的真实性和合法性,可能需要提供企业注册信息、电话验证等。
|
||||
* **EV(Extended Validation)** :最严格的验证级别,除了OV要求的所有信息外,还会进行更深入的企业身份核实,包括法律状态、运营状况等,并可能需要电话验证。
|
||||
|
||||
3. **颁发与安装** :
|
||||
|
||||
* **证书签发** :CA在完成身份验证后,使用其私钥对包含申请者信息和公钥的证书数据进行签名,生成正式的SSL证书(CRT文件)。
|
||||
* **接收与部署** :申请者收到签发的SSL证书后,将其安装到服务器上,与之前生成的私钥关联。在Web服务器配置中启用SSL并指向正确的证书和私钥文件。
|
||||
|
||||
4. **客户端验证** :
|
||||
|
||||
* **发起HTTPS连接** :用户访问受SSL保护的网站时,浏览器发起HTTPS请求。
|
||||
* **证书传输** :服务器响应请求时,随同其他握手信息一起发送其SSL证书(CRT文件)给客户端。
|
||||
* **证书验证** :
|
||||
* **链验证** :客户端检查证书的有效期、CA的可信性以及证书链的完整性(如有中间证书,需验证其有效性并构建完整的信任链至根证书)。
|
||||
* **域名匹配** :确认证书中的域名与正在访问的域名一致。
|
||||
* **公钥加密** :客户端使用接收到的服务器公钥加密一个随机生成的对称会话密钥,用于后续的加密通信。
|
||||
* **身份确认与加密通信** :如果所有验证步骤均通过,客户端认为服务器身份可信,开始使用协商的对称密钥进行加密通信。反之,若验证失败,浏览器会显示警告,提示用户连接可能不安全。
|
||||
|
||||
以上就是SSL证书从申请到客户端验证的完整流程,旨在确保网络通信的安全性和数据的机密性。
|
||||
|
||||

|
||||
BIN
加密/image.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 242 KiB |