mirror of
https://github.com/apachecn/ailearning.git
synced 2026-04-13 18:01:04 +08:00
1
.gitignore
vendored
1
.gitignore
vendored
@@ -3,6 +3,7 @@ __pycache__/
|
||||
*.py[cod]
|
||||
*$py.class
|
||||
.vscode
|
||||
data/*
|
||||
|
||||
# C extensions
|
||||
*.so
|
||||
|
||||
@@ -5,21 +5,33 @@
|
||||
'''
|
||||
|
||||
class TextNER(object):
|
||||
DEBUG = False
|
||||
path_root = "/home/apachecn/jiangzhonglian"
|
||||
DEBUG = True
|
||||
if DEBUG:
|
||||
path_root = "/Users/jiangzhonglian/data/nlp/命名实体识别/data"
|
||||
path_root = "data/NER3"
|
||||
chunk_tags = ['O', 'B-ORG', 'I-ORG',
|
||||
'B-Po_VIEW', 'I-Po_VIEW',
|
||||
'B-Mi_VIEW', 'I-Mi_VIEW',
|
||||
'B-Ne_VIEW', 'I-Ne_VIEW'
|
||||
]
|
||||
# chunk_tags = ['O', 'B-TIME', 'I-TIME', 'B-LOCATION', 'I-LOCATION',
|
||||
# "B-PERSON_NAME", "I-PERSON_NAME", "B-ORG_NAME", "I-ORG_NAME",
|
||||
# "B-COMPANY_NAME", "I-COMPANY_NAME", "B-PRODUCT_NAME", "I-PRODUCT_NAME"]
|
||||
# chunk_tags = ['O', 'B-PER', 'I-PER', 'B-LOC', 'I-LOC', "B-ORG", "I-ORG"]
|
||||
else:
|
||||
path_root = "data/NER"
|
||||
chunk_tags = ['O', 'B-PER', 'I-PER', 'B-LOC', 'I-LOC', "B-ORG", "I-ORG"]
|
||||
|
||||
path_train = '%s/train_data.data' % path_root
|
||||
path_test = '%s/test_data.data' % path_root
|
||||
path_config = '%s/config.pkl' % path_root
|
||||
path_model = '%s/model.h5' % path_root
|
||||
path_origin = '%s/origin.txt' % path_root
|
||||
path_train = '%s/train.txt' % path_root
|
||||
path_test = '%s/test.txt' % path_root
|
||||
path_config = '%s/config.pkl' % path_root
|
||||
path_model = '%s/model.h5' % path_root
|
||||
|
||||
# 迭代次数
|
||||
EPOCHS = 3
|
||||
# embedding的列数
|
||||
EPOCHS = 10
|
||||
# embedding的维度数
|
||||
EMBED_DIM = 128
|
||||
# LSTM的列数
|
||||
# LSTM的维度数
|
||||
BiLSTM_UNITS = 128
|
||||
|
||||
|
||||
|
||||
@@ -47,12 +47,12 @@
|
||||
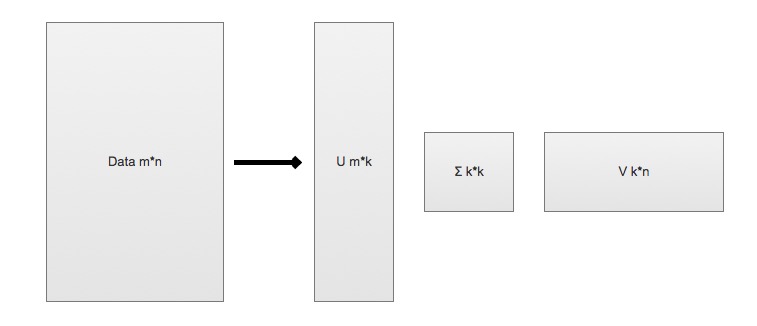
> SVD 是矩阵分解的一种类型,也是矩阵分解最常见的技术
|
||||
|
||||
* SVD 将原始的数据集矩阵 Data 分解成三个矩阵 U、∑、V
|
||||
* 举例: 如果原始矩阵 \\(Data_{m*n}\\) 是m行n列,
|
||||
* \\(U_{m * k}\\) 表示m行k列
|
||||
* \\(∑_{k * k}\\) 表示k行k列
|
||||
* \\(V_{k * n}\\) 表示k行n列。
|
||||
* 举例: 如果原始矩阵 $$Data_{m*n}$$ 是m行n列,
|
||||
* $$U_{m * k}$$ 表示m行k列
|
||||
* $$∑_{k * k}$$ 表示k行k列
|
||||
* $$V_{k * n}$$ 表示k行n列。
|
||||
|
||||
\\(Data_{m*n} = U_{m\*k} \* ∑_{k\*k} \* V_{k\*n}\\)
|
||||
$$Data_{m*n} = U_{m\*k} \* ∑_{k\*k} \* V_{k\*n}$$
|
||||
|
||||
|
||||
|
||||
@@ -61,7 +61,7 @@
|
||||

|
||||
|
||||
* 上述分解中会构建出一个矩阵∑,该矩阵只有对角元素,其他元素均为0(近似于0)。另一个惯例就是,∑的对角元素是从大到小排列的。这些对角元素称为奇异值。
|
||||
* 奇异值与特征值(PCA 数据中重要特征)是有关系的。这里的奇异值就是矩阵 \\(Data * Data^T\\) 特征值的平方根。
|
||||
* 奇异值与特征值(PCA 数据中重要特征)是有关系的。这里的奇异值就是矩阵 $$Data * Data^T$$ 特征值的平方根。
|
||||
* 普遍的事实: 在某个奇异值的数目(r 个=>奇异值的平方和累加到总值的90%以上)之后,其他的奇异值都置为0(近似于0)。这意味着数据集中仅有 r 个重要特征,而其余特征则都是噪声或冗余特征。
|
||||
|
||||
### SVD 算法特点
|
||||
|
||||
@@ -61,44 +61,44 @@ Support Vector Machines: Slide 12 Copyright © 2001, 2003, Andrew W. Moore Why M
|
||||
|
||||
> 点到超平面的距离
|
||||
|
||||
* 分隔超平面`函数间距`: \\(y(x)=w^Tx+b\\)
|
||||
* 分类的结果: \\(f(x)=sign(w^Tx+b)\\) (sign表示>0为1,<0为-1,=0为0)
|
||||
* 点到超平面的`几何间距`: \\(d(x)=(w^Tx+b)/||w||\\) (||w||表示w矩阵的二范数=> \\(\sqrt{w^T*w}\\), 点到超平面的距离也是类似的)
|
||||
* 分隔超平面`函数间距`: $$y(x)=w^Tx+b$$
|
||||
* 分类的结果: $$f(x)=sign(w^Tx+b)$$ (sign表示>0为1,<0为-1,=0为0)
|
||||
* 点到超平面的`几何间距`: $$d(x)=(w^Tx+b)/||w||$$ (||w||表示w矩阵的二范数=> $$\sqrt{w^T*w}$$, 点到超平面的距离也是类似的)
|
||||
|
||||

|
||||
|
||||
> 拉格朗日乘子法
|
||||
|
||||
* 类别标签用-1、1,是为了后期方便 \\(label*(w^Tx+b)\\) 的标识和距离计算;如果 \\(label*(w^Tx+b)>0\\) 表示预测正确,否则预测错误。
|
||||
* 类别标签用-1、1,是为了后期方便 $$label*(w^Tx+b)$$ 的标识和距离计算;如果 $$label*(w^Tx+b)>0$$ 表示预测正确,否则预测错误。
|
||||
* 现在目标很明确,就是要找到`w`和`b`,因此我们必须要找到最小间隔的数据点,也就是前面所说的`支持向量`。
|
||||
* 也就说,让最小的距离取最大.(最小的距离: 就是最小间隔的数据点;最大: 就是最大间距,为了找出最优超平面--最终就是支持向量)
|
||||
* 目标函数: \\(arg: max_{关于w, b} \left( min[label*(w^Tx+b)]*\frac{1}{||w||} \right) \\)
|
||||
1. 如果 \\(label*(w^Tx+b)>0\\) 表示预测正确,也称`函数间隔`,\\(||w||\\) 可以理解为归一化,也称`几何间隔`。
|
||||
2. 令 \\(label*(w^Tx+b)>=1\\), 因为0~1之间,得到的点是存在误判的可能性,所以要保障 \\(min[label*(w^Tx+b)]=1\\),才能更好降低噪音数据影响。
|
||||
3. 所以本质上是求 \\(arg: max_{关于w, b} \frac{1}{||w||} \\);也就说,我们约束(前提)条件是: \\(label*(w^Tx+b)=1\\)
|
||||
* 新的目标函数求解: \\(arg: max_{关于w, b} \frac{1}{||w||} \\)
|
||||
* => 就是求: \\(arg: min_{关于w, b} ||w|| \\) (求矩阵会比较麻烦,如果x只是 \\(\frac{1}{2}*x^2\\) 的偏导数,那么。。同样是求最小值)
|
||||
* => 就是求: \\(arg: min_{关于w, b} (\frac{1}{2}*||w||^2)\\) (二次函数求导,求极值,平方也方便计算)
|
||||
* 目标函数: $$arg: max_{关于w, b} \left( min[label*(w^Tx+b)]*\frac{1}{||w||} \right) $$
|
||||
1. 如果 $$label*(w^Tx+b)>0$$ 表示预测正确,也称`函数间隔`,$$||w||$$ 可以理解为归一化,也称`几何间隔`。
|
||||
2. 令 $$label*(w^Tx+b)>=1$$, 因为0~1之间,得到的点是存在误判的可能性,所以要保障 $$min[label*(w^Tx+b)]=1$$,才能更好降低噪音数据影响。
|
||||
3. 所以本质上是求 $$arg: max_{关于w, b} \frac{1}{||w||} $$;也就说,我们约束(前提)条件是: $$label*(w^Tx+b)=1$$
|
||||
* 新的目标函数求解: $$arg: max_{关于w, b} \frac{1}{||w||} $$
|
||||
* => 就是求: $$arg: min_{关于w, b} ||w|| $$ (求矩阵会比较麻烦,如果x只是 $$\frac{1}{2}*x^2$$ 的偏导数,那么。。同样是求最小值)
|
||||
* => 就是求: $$arg: min_{关于w, b} (\frac{1}{2}*||w||^2)$$ (二次函数求导,求极值,平方也方便计算)
|
||||
* 本质上就是求线性不等式的二次优化问题(求分隔超平面,等价于求解相应的凸二次规划问题)
|
||||
* 通过拉格朗日乘子法,求二次优化问题
|
||||
* 假设需要求极值的目标函数 (objective function) 为 f(x,y),限制条件为 φ(x,y)=M # M=1
|
||||
* 设g(x,y)=M-φ(x,y) # 临时φ(x,y)表示下文中 \\(label*(w^Tx+b)\\)
|
||||
* 设g(x,y)=M-φ(x,y) # 临时φ(x,y)表示下文中 $$label*(w^Tx+b)$$
|
||||
* 定义一个新函数: F(x,y,λ)=f(x,y)+λg(x,y)
|
||||
* a为λ(a>=0),代表要引入的拉格朗日乘子(Lagrange multiplier)
|
||||
* 那么: \\(L(w,b,\alpha)=\frac{1}{2} * ||w||^2 + \sum_{i=1}^{n} \alpha_i * [1 - label * (w^Tx+b)]\\)
|
||||
* 因为: \\(label*(w^Tx+b)>=1, \alpha>=0\\) , 所以 \\(\alpha*[1-label*(w^Tx+b)]<=0\\) , \\(\sum_{i=1}^{n} \alpha_i * [1-label*(w^Tx+b)]<=0\\)
|
||||
* 当 \\(label*(w^Tx+b)>1\\) 则 \\(\alpha=0\\) ,表示该点为<font color=red>非支持向量</font>
|
||||
* 相当于求解: \\(max_{关于\alpha} L(w,b,\alpha) = \frac{1}{2} *||w||^2\\)
|
||||
* 如果求: \\(min_{关于w, b} \frac{1}{2} *||w||^2\\) , 也就是要求: \\(min_{关于w, b} \left( max_{关于\alpha} L(w,b,\alpha)\right)\\)
|
||||
* 那么: $$L(w,b,\alpha)=\frac{1}{2} * ||w||^2 + \sum_{i=1}^{n} \alpha_i * [1 - label * (w^Tx+b)]$$
|
||||
* 因为: $$label*(w^Tx+b)>=1, \alpha>=0$$ , 所以 $$\alpha*[1-label*(w^Tx+b)]<=0$$ , $$\sum_{i=1}^{n} \alpha_i * [1-label*(w^Tx+b)]<=0$$
|
||||
* 当 $$label*(w^Tx+b)>1$$ 则 $$\alpha=0$$ ,表示该点为<font color=red>非支持向量</font>
|
||||
* 相当于求解: $$max_{关于\alpha} L(w,b,\alpha) = \frac{1}{2} *||w||^2$$
|
||||
* 如果求: $$min_{关于w, b} \frac{1}{2} *||w||^2$$ , 也就是要求: $$min_{关于w, b} \left( max_{关于\alpha} L(w,b,\alpha)\right)$$
|
||||
* 现在转化到对偶问题的求解
|
||||
* \\(min_{关于w, b} \left(max_{关于\alpha} L(w,b,\alpha) \right) \\) >= \\(max_{关于\alpha} \left(min_{关于w, b}\ L(w,b,\alpha) \right) \\)
|
||||
* $$min_{关于w, b} \left(max_{关于\alpha} L(w,b,\alpha) \right) $$ >= $$max_{关于\alpha} \left(min_{关于w, b}\ L(w,b,\alpha) \right) $$
|
||||
* 现在分2步
|
||||
* 先求: \\(min_{关于w, b} L(w,b,\alpha)=\frac{1}{2} * ||w||^2 + \sum_{i=1}^{n} \alpha_i * [1 - label * (w^Tx+b)]\\)
|
||||
* 先求: $$min_{关于w, b} L(w,b,\alpha)=\frac{1}{2} * ||w||^2 + \sum_{i=1}^{n} \alpha_i * [1 - label * (w^Tx+b)]$$
|
||||
* 就是求`L(w,b,a)`关于[w, b]的偏导数, 得到`w和b的值`,并化简为: `L和a的方程`。
|
||||
* 参考: 如果公式推导还是不懂,也可以参考《统计学习方法》李航-P103<学习的对偶算法>
|
||||

|
||||
* 终于得到课本上的公式: \\(max_{关于\alpha} \left( \sum_{i=1}^{m} \alpha_i - \frac{1}{2} \sum_{i, j=1}^{m} label_i·label_j·\alpha_i·\alpha_j·<x_i, x_j> \right) \\)
|
||||
* 约束条件: \\(a>=0\\) 并且 \\(\sum_{i=1}^{m} a_i·label_i=0\\)
|
||||
* 终于得到课本上的公式: $$max_{关于\alpha} \left( \sum_{i=1}^{m} \alpha_i - \frac{1}{2} \sum_{i, j=1}^{m} label_i·label_j·\alpha_i·\alpha_j·<x_i, x_j> \right) $$
|
||||
* 约束条件: $$a>=0$$ 并且 $$\sum_{i=1}^{m} a_i·label_i=0$$
|
||||
|
||||
> 松弛变量(slack variable)
|
||||
|
||||
@@ -107,13 +107,13 @@ Support Vector Machines: Slide 12 Copyright © 2001, 2003, Andrew W. Moore Why M
|
||||
|
||||
|
||||
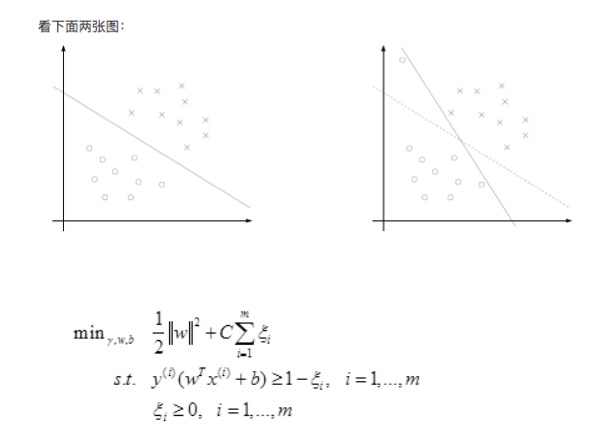
* 我们知道几乎所有的数据都不那么干净, 通过引入松弛变量来 `允许数据点可以处于分隔面错误的一侧`。
|
||||
* 约束条件: \\(C>=a>=0\\) 并且 \\(\sum_{i=1}^{m} a_i·label_i=0\\)
|
||||
* 约束条件: $$C>=a>=0$$ 并且 $$\sum_{i=1}^{m} a_i·label_i=0$$
|
||||
* 总的来说:
|
||||
* 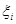 表示 `松弛变量`
|
||||
* 常量C是 `惩罚因子`, 表示离群点的权重(用于控制“最大化间隔”和“保证大部分点的函数间隔小于1.0” )
|
||||
* \\(label*(w^Tx+b) > 1\\) and alpha = 0 (在边界外,就是非支持向量)
|
||||
* \\(label*(w^Tx+b) = 1\\) and 0< alpha < C (在分割超平面上,就支持向量)
|
||||
* \\(label*(w^Tx+b) < 1\\) and alpha = C (在分割超平面内,是误差点 -> C表示它该受到的惩罚因子程度)
|
||||
* $$label*(w^Tx+b) > 1$$ and alpha = 0 (在边界外,就是非支持向量)
|
||||
* $$label*(w^Tx+b) = 1$$ and 0< alpha < C (在分割超平面上,就支持向量)
|
||||
* $$label*(w^Tx+b) < 1$$ and alpha = C (在分割超平面内,是误差点 -> C表示它该受到的惩罚因子程度)
|
||||
* 参考地址: https://www.zhihu.com/question/48351234/answer/110486455
|
||||
* C值越大,表示离群点影响越大,就越容易过度拟合;反之有可能欠拟合。
|
||||
* 我们看到,目标函数控制了离群点的数目和程度,使大部分样本点仍然遵守限制条件。
|
||||
@@ -137,7 +137,7 @@ Support Vector Machines: Slide 12 Copyright © 2001, 2003, Andrew W. Moore Why M
|
||||
* 这里指的合适必须要符合一定的条件
|
||||
1. 这两个 alpha 必须要在间隔边界之外
|
||||
2. 这两个 alpha 还没有进行过区间化处理或者不在边界上。
|
||||
* 之所以要同时改变2个 alpha;原因是我们有一个约束条件: \\(\sum_{i=1}^{m} a_i·label_i=0\\);如果只是修改一个 alpha,很可能导致约束条件失效。
|
||||
* 之所以要同时改变2个 alpha;原因是我们有一个约束条件: $$\sum_{i=1}^{m} a_i·label_i=0$$;如果只是修改一个 alpha,很可能导致约束条件失效。
|
||||
|
||||
> SMO 伪代码大致如下:
|
||||
|
||||
|
||||
@@ -1,5 +1,9 @@
|
||||
# 【入门须知】必须了解
|
||||
|
||||
实体: 抽取
|
||||
关系: 图谱
|
||||
意图: 分类
|
||||
|
||||
* **【入门须知】必须了解**: <https://github.com/apachecn/AiLearning/tree/master/docs/nlp>
|
||||
* **【入门教程】强烈推荐: PyTorch 自然语言处理**: <https://github.com/apachecn/NLP-with-PyTorch>
|
||||
* Python 自然语言处理 第二版: <https://usyiyi.github.io/nlp-py-2e-zh>
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
numpy
|
||||
pandas
|
||||
sklearn
|
||||
keras
|
||||
tensorflow
|
||||
keras==2.3.1
|
||||
tensorflow==2.0.0
|
||||
git+https://www.github.com/keras-team/keras-contrib.git
|
||||
121
tutorials/keras/brat_tag.py
Normal file
121
tutorials/keras/brat_tag.py
Normal file
@@ -0,0 +1,121 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
"""
|
||||
数据格式转化
|
||||
"""
|
||||
import os
|
||||
import emoji
|
||||
from middleware.utils import get_catalog_files
|
||||
from config.setting import Config
|
||||
|
||||
tag_dic = {"实体对象": "ORG",
|
||||
"正向观点": "Po_VIEW",
|
||||
"中性观点": "Mi_VIEW",
|
||||
"负向观点": "Ne_VIEW"}
|
||||
|
||||
|
||||
# 转换成可训练的格式,最后以"END O"结尾
|
||||
def from_ann2dic(r_ann_path, r_txt_path, w_path):
|
||||
q_dic = {}
|
||||
print("开始读取文件:%s" % r_ann_path)
|
||||
with open(r_ann_path, "r", encoding="utf-8") as f:
|
||||
lines = f.readlines()
|
||||
for line in lines:
|
||||
line_arr = line.split()
|
||||
# print(">>> ", line_arr)
|
||||
cls = tag_dic[line_arr[1]]
|
||||
start_index = int(line_arr[2])
|
||||
end_index = int(line_arr[3])
|
||||
length = end_index - start_index
|
||||
for r in range(length):
|
||||
q_dic[start_index+r] = ("B-%s" % cls) if r == 0 else ("I-%s" % cls)
|
||||
|
||||
# 存储坐标和对应的列名: {23: 'B-Ne_VIEW', 24: 'I-Ne_VIEW', 46: 'B-ORG', 47: 'I-ORG'}
|
||||
print("q_dic: ", q_dic)
|
||||
|
||||
print("开始读取文件内容: %s" % r_txt_path)
|
||||
with open(r_txt_path, "r", encoding="utf-8") as f:
|
||||
content_str = f.read()
|
||||
|
||||
print("开始写入文本%s" % w_path)
|
||||
with open(w_path, "w", encoding="utf-8") as w:
|
||||
for i, strA in enumerate(content_str):
|
||||
# print(">>> %s-%s" % (i, strA))
|
||||
if strA == "\n":
|
||||
w.write("\n")
|
||||
else:
|
||||
if i in q_dic:
|
||||
tag = q_dic[i]
|
||||
else:
|
||||
tag = "O" # 大写字母O
|
||||
w.write('%s %s\n' % (strA, tag))
|
||||
w.write('%s\n' % "END O")
|
||||
|
||||
|
||||
# 生成train.txt、dev.txt、test.txt
|
||||
# 除8,9-new.txt分别用于dev和test外,剩下的合并成train.txt
|
||||
def create_train_data(data_root_dir, w_path):
|
||||
if os.path.exists(w_path):
|
||||
os.remove(w_path)
|
||||
for file in os.listdir(data_root_dir):
|
||||
path = os.path.join(data_root_dir, file)
|
||||
if file.endswith("8-new.txt"):
|
||||
# 重命名为dev.txt
|
||||
os.rename(path, os.path.join(data_root_dir, "dev.txt"))
|
||||
continue
|
||||
if file.endswith("9-new.txt"):
|
||||
# 重命名为test.txt
|
||||
os.rename(path, os.path.join(data_root_dir, "test.txt"))
|
||||
continue
|
||||
q_list = []
|
||||
print("开始读取文件:%s" % file)
|
||||
with open(path, "r", encoding="utf-8") as f:
|
||||
lines = f.readlines()
|
||||
for line in lines:
|
||||
line = line.rstrip()
|
||||
if line == "END O":
|
||||
break
|
||||
q_list.append(line)
|
||||
|
||||
# 获取list 列表: ['美 O', '! O', '气 O', '质 O', '特 O', '别 O', '好 O', '', '造 O', '型 O', '独 O', '特 O', ', O', '尺 B-ORG', '码 I-ORG', '偏 B-Ne_VIEW', '大 I-Ne_VIEW', ', O']
|
||||
# print("q_list: ", q_list)
|
||||
print("开始写入文本: %s" % w_path)
|
||||
with open(w_path, "a", encoding="utf-8") as f:
|
||||
for item in q_list:
|
||||
f.write('%s\n' % item)
|
||||
|
||||
|
||||
def brat_1_format_origin(catalog):
|
||||
"""
|
||||
格式化原始文件(去除表情符号的影响,brat占2个字符,但是python占1个字符)
|
||||
"""
|
||||
with open('%s/origin/origin.txt' % path_root, "r", encoding="utf-8") as f:
|
||||
lines = f.readlines()
|
||||
with open('%s/tag_befer/befer.txt' % path_root, "w", encoding="utf-8") as f:
|
||||
# 转换原始文件
|
||||
for line in lines:
|
||||
text = emoji.demojize(line)
|
||||
f.write('%s' % text)
|
||||
# 创建标注的新文件
|
||||
with open('%s/tag_befer/befer.ann' % path_root, "w", encoding="utf-8") as f:
|
||||
pass
|
||||
|
||||
def brat_2_create_train_data(catalog):
|
||||
file_list = get_catalog_files("%s/tag_after" % catalog, status=-1, str1=".DS_Store")
|
||||
file_list = list(set([i.split("/")[-1].split(".")[0] for i in file_list]))
|
||||
print(file_list)
|
||||
for filename in file_list:
|
||||
r_ann_path = os.path.join(catalog, "tag_after/%s.ann" % filename)
|
||||
r_txt_path = os.path.join(catalog, "tag_after/%s.txt" % filename)
|
||||
w_path = os.path.join(catalog, "new/%s-new.txt" % filename)
|
||||
print("filename", r_ann_path, r_txt_path, w_path)
|
||||
from_ann2dic(r_ann_path, r_txt_path, w_path)
|
||||
# 生成train.txt、dev.txt、test.txt
|
||||
create_train_data("%s/new" % catalog, "%s/new/train.txt" % catalog)
|
||||
|
||||
|
||||
def main():
|
||||
catalog = Config.nlp_ner.path_root
|
||||
|
||||
# brat_1_format_origin(catalog)
|
||||
brat_2_create_train_data(catalog)
|
||||
@@ -3,9 +3,12 @@ import numpy as np
|
||||
import pandas as pd
|
||||
import platform
|
||||
from collections import Counter
|
||||
import keras
|
||||
from keras.models import Sequential
|
||||
from keras.layers import Embedding, Bidirectional, LSTM
|
||||
from keras.layers import Embedding, Bidirectional, LSTM, Dropout
|
||||
from keras_contrib.layers import CRF
|
||||
from keras_contrib.losses import crf_loss
|
||||
from keras_contrib.metrics import crf_viterbi_accuracy
|
||||
"""
|
||||
# padding: pre(默认) 向前补充0 post 向后补充0
|
||||
# truncating: 文本超过 pad_num, pre(默认) 删除前面 post 删除后面
|
||||
@@ -31,7 +34,7 @@ def load_data():
|
||||
# Counter({'的': 8, '中': 7, '致': 7, '党': 7})
|
||||
word_counts = Counter(row[0].lower() for sample in train for row in sample)
|
||||
vocab = [w for w, f in iter(word_counts.items()) if f >= 2]
|
||||
chunk_tags = ['O', 'B-PER', 'I-PER', 'B-LOC', 'I-LOC', "B-ORG", "I-ORG"]
|
||||
chunk_tags = Config.nlp_ner.chunk_tags
|
||||
|
||||
# 存储保留的有效个数的 vovab 和 对应 chunk_tags
|
||||
with open(Config.nlp_ner.path_config, 'wb') as outp:
|
||||
@@ -57,7 +60,10 @@ def _parse_data(filename):
|
||||
# 主要是分句: split_text 默认每个句子都是一行,所以原来换行就需要 两个split_text
|
||||
texts = fn.read().decode('utf-8').strip().split(split_text + split_text)
|
||||
# 对于每个字需要 split_text, 而字的内部需要用空格分隔
|
||||
data = [[row.split() for row in text.split(split_text)] for text in texts]
|
||||
# len(row) > 0 避免连续2个换行,导致 row 数据为空
|
||||
# row.split() 会删除空格或特殊符号,导致空格数据缺失!
|
||||
data = [[[" ", "O"] if len(row.split()) != 2 else row.split() for row in text.split(split_text) if len(row) > 0] for text in texts]
|
||||
# data = [[row.split() for row in text.split(split_text) if len(row.split()) == 2] for text in texts]
|
||||
return data
|
||||
|
||||
|
||||
@@ -96,10 +102,17 @@ def create_model(len_vocab, len_chunk_tags):
|
||||
model = Sequential()
|
||||
model.add(Embedding(len_vocab, Config.nlp_ner.EMBED_DIM, mask_zero=True)) # Random embedding
|
||||
model.add(Bidirectional(LSTM(Config.nlp_ner.BiLSTM_UNITS // 2, return_sequences=True)))
|
||||
model.add(Dropout(0.25))
|
||||
crf = CRF(len_chunk_tags, sparse_target=True)
|
||||
model.add(crf)
|
||||
model.summary()
|
||||
model.compile('adam', loss=crf.loss_function, metrics=[crf.accuracy])
|
||||
model.compile('adam', loss=crf_loss, metrics=[crf_viterbi_accuracy])
|
||||
# model.compile('rmsprop', loss=crf_loss, metrics=[crf_viterbi_accuracy])
|
||||
|
||||
# from keras.optimizers import Adam
|
||||
# adam_lr = 0.0001
|
||||
# adam_beta_1 = 0.5
|
||||
# model.compile(optimizer=Adam(lr=adam_lr, beta_1=adam_beta_1), loss=crf_loss, metrics=[crf_viterbi_accuracy])
|
||||
return model
|
||||
|
||||
|
||||
@@ -115,29 +128,38 @@ def test():
|
||||
with open(Config.nlp_ner.path_config, 'rb') as inp:
|
||||
(vocab, chunk_tags) = pickle.load(inp)
|
||||
model = create_model(len(vocab), len(chunk_tags))
|
||||
predict_text = '中华人民共和国国务院总理周恩来在外交部长陈毅的陪同下,连续访问了埃塞俄比亚等非洲10国以及阿尔巴尼亚'
|
||||
text_EMBED, length = process_data(predict_text, vocab)
|
||||
model.load_weights(Config.nlp_ner.path_model)
|
||||
raw = model.predict(text_EMBED)[0][-length:]
|
||||
result = [np.argmax(row) for row in raw]
|
||||
result_tags = [chunk_tags[i] for i in result]
|
||||
# predict_text = '造型独特,尺码偏大,估计是钉子头圆的半径的缘故'
|
||||
with open(Config.nlp_ner.path_origin, "r", encoding="utf-8") as f:
|
||||
lines = f.readlines()
|
||||
for predict_text in lines:
|
||||
content = predict_text.strip()
|
||||
text_EMBED, length = process_data(content, vocab)
|
||||
model.load_weights(Config.nlp_ner.path_model)
|
||||
raw = model.predict(text_EMBED)[0][-length:]
|
||||
pre_result = [np.argmax(row) for row in raw]
|
||||
result_tags = [chunk_tags[i] for i in pre_result]
|
||||
|
||||
per, loc, org = '', '', ''
|
||||
|
||||
for s, t in zip(predict_text, result_tags):
|
||||
if t in ('B-PER', 'I-PER'):
|
||||
per += ' ' + s if (t == 'B-PER') else s
|
||||
if t in ('B-ORG', 'I-ORG'):
|
||||
org += ' ' + s if (t == 'B-ORG') else s
|
||||
if t in ('B-LOC', 'I-LOC'):
|
||||
loc += ' ' + s if (t == 'B-LOC') else s
|
||||
|
||||
print(['person:' + per, 'location:' + loc, 'organzation:' + org])
|
||||
# 保存每句话的 实体和观点
|
||||
result = {}
|
||||
tag_list = [i for i in chunk_tags if i not in ["O"]]
|
||||
for word, t in zip(content, result_tags):
|
||||
# print(word, t)
|
||||
if t not in tag_list:
|
||||
continue
|
||||
for i in range(0, len(tag_list), 2):
|
||||
if t in tag_list[i:i+2]:
|
||||
# print("\n>>> %s---%s==%s" % (word, t, tag_list[i:i+2]))
|
||||
tag = tag_list[i].split("-")[-1]
|
||||
if tag not in result:
|
||||
result[tag] = ""
|
||||
result[tag] += ' '+word if t==tag_list[i] else word
|
||||
print(result)
|
||||
|
||||
|
||||
def main():
|
||||
# print("--")
|
||||
train()
|
||||
test()
|
||||
|
||||
# if __name__ == "__main__":
|
||||
# train()
|
||||
|
||||
Reference in New Issue
Block a user