mirror of
https://github.com/apachecn/ailearning.git
synced 2026-06-29 01:36:13 +08:00
更新链接信息
This commit is contained in:
@@ -86,12 +86,20 @@
|
||||
* 相似度计算: 前牌照怎么装(0.762) 如何办理北京牌照(0.486)
|
||||
* 向量化表示: (-0.333, 0.1223 .. ) (0.333, 0.3333, .. )
|
||||
|
||||
### 案例6(机器翻译)
|
||||
### 案例6(篇章分析)
|
||||
|
||||
**机器翻译技术(Machine Translating)**: 基于互联网大数据,融合深度神经网络、统计、规则多种翻译方法,帮助用户跨越语言鸿沟,与世界自由沟通
|
||||
**篇章分析(Document Analysis)**: 分析篇章级文本的内在结构,进而分析文本情感倾向,提取评论性观点,并生成反映文本关键信息的标签与摘要
|
||||
|
||||
例如:
|
||||
|
||||
* 今天我很高兴
|
||||
* I am very happy today
|
||||
* 讲中文编码,然后得到编码值,再去和正确编码值比较并优化
|
||||

|
||||
|
||||
### 案例7(机器翻译)
|
||||
|
||||
**机器翻译技术(Machine Translating)**: 基于互联网大数据,融合深度神经网络、统计、规则多种翻译方法,帮助用户跨越语言鸿沟,与世界自由沟通
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
* 参考百度科普课程: <http://bit.baidu.com/product>
|
||||
|
||||
@@ -27,4 +27,4 @@
|
||||
|
||||
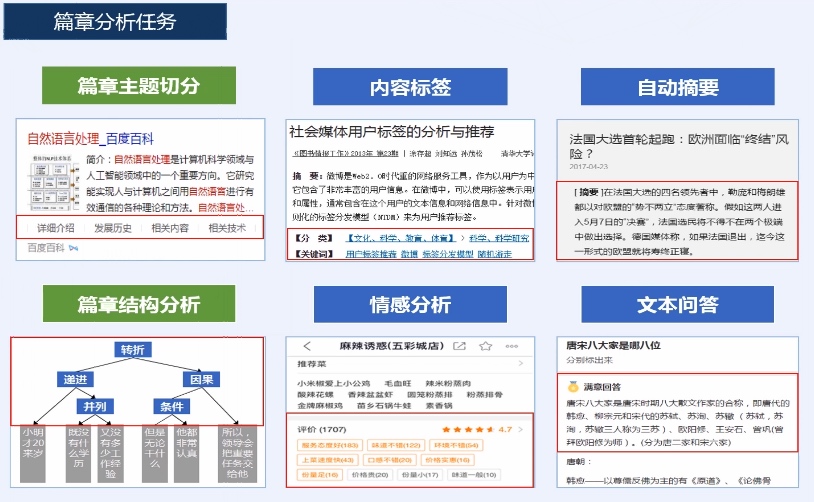
## 篇章分析任务
|
||||
|
||||
|
||||

|
||||
|
||||
@@ -30,7 +30,7 @@
|
||||
|
||||
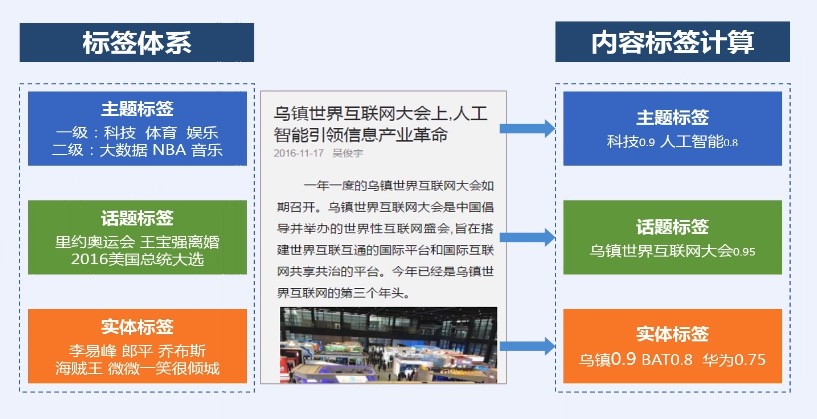
## 百度内容标签
|
||||
|
||||
|
||||

|
||||
|
||||
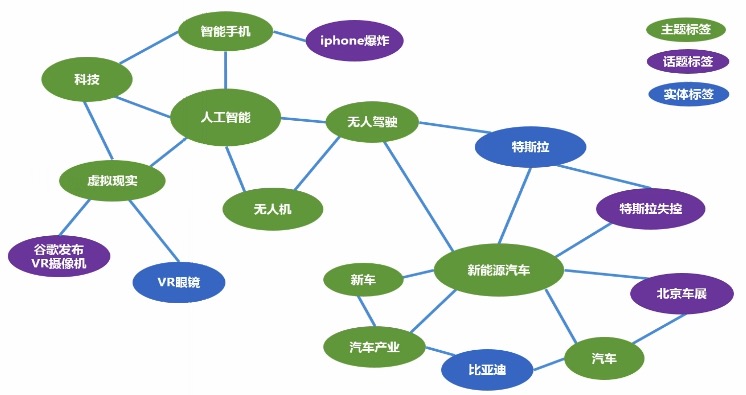
## 标签体系:面向推荐的标签图谱
|
||||
|
||||
@@ -39,14 +39,14 @@
|
||||
* 包括3种节点:主题标签-绿色,话题标签-紫色,实体标签-蓝色。
|
||||
* 有了关联关系,我们可以进行一定程度的探索和泛化。(例如:无人驾驶和人工智能关联很强,如果有人看了无人驾驶,我们就给他推荐人工智能)
|
||||
|
||||
|
||||

|
||||
|
||||
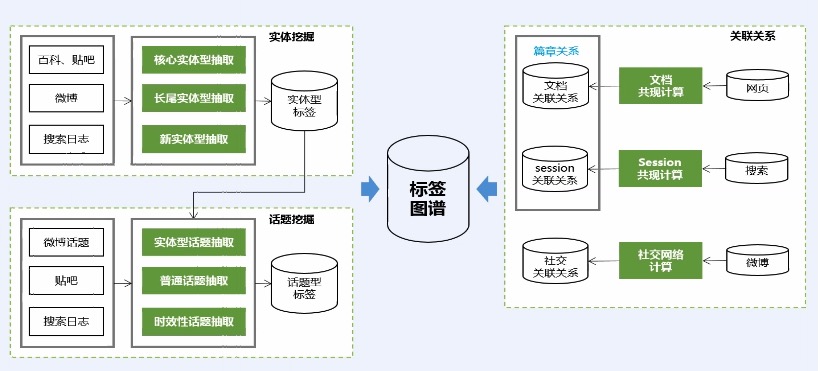
## 标签体系:基于大数据分析的图谱构建
|
||||
|
||||
* 用户信息来源:贴吧、微博
|
||||
* 标签的相关性分析:通过关联规则,发现2个标签总同时出现,我们觉得这是高相关的。
|
||||
|
||||
|
||||

|
||||
|
||||
## 标签计算
|
||||
|
||||
@@ -59,7 +59,7 @@
|
||||
* 第二层 表示层:通过一些 embedding的算法、CNN、LSTM的方法
|
||||
* 第三层 排序层:计算文章与主题之间的相似度,具体会计算每个主题与文章的相似度,并将相似度作为最终的一个主题分类的结果。这种计算的好处能够天然的支持多标记,也就是一篇文章可以同时计算出多个主题标签。
|
||||
|
||||
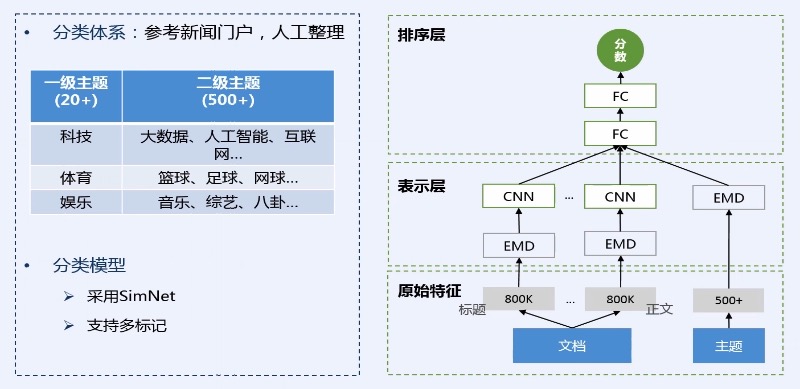
|
||||

|
||||
|
||||
> 通用标签
|
||||
|
||||
@@ -72,11 +72,11 @@
|
||||
* 比如:这个标签在文章中出现的频率 或 出现的位置;如果出现在标题,那么它可能就会比较重要。
|
||||
* 通过融合这2种策略,形成我们通用标签的结果。
|
||||
|
||||
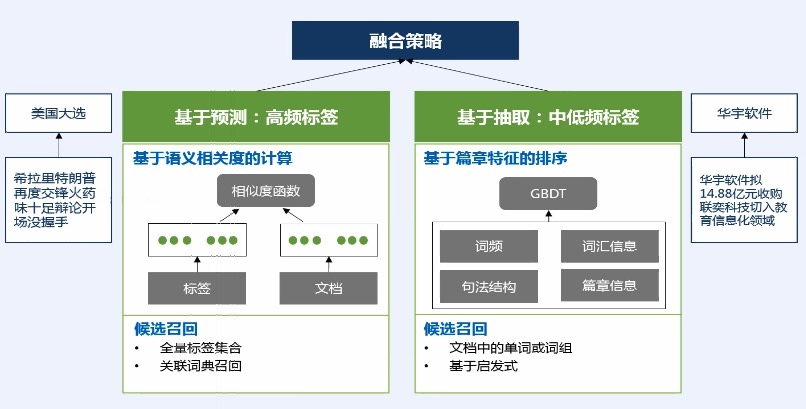
|
||||

|
||||
|
||||
## 内容标签在Feed流中的应用
|
||||
|
||||
1. 标签可以用来话题聚合:比如表示人工智能的标签全部都会集合到同一个话题下面。这样用户可以对人工智能这个话题进行非常充分的浏览。
|
||||
2. 话题频道划分:比如我们在手机百度上面就可以看到,Feed流上面有多个栏目,用户可以点击 `体育` `时尚`等频道
|
||||
|
||||
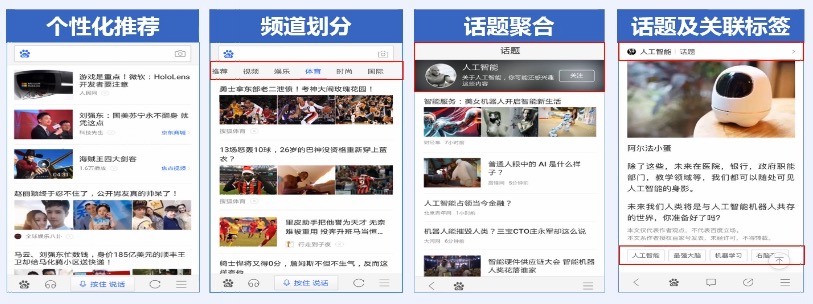
|
||||

|
||||
|
||||
@@ -12,14 +12,14 @@
|
||||
|
||||
* 对(文本的)观点、情感、情绪和评论进行分析计算
|
||||
|
||||
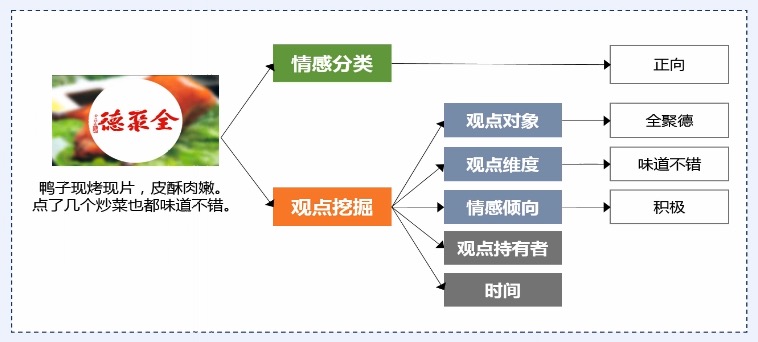
|
||||

|
||||
|
||||
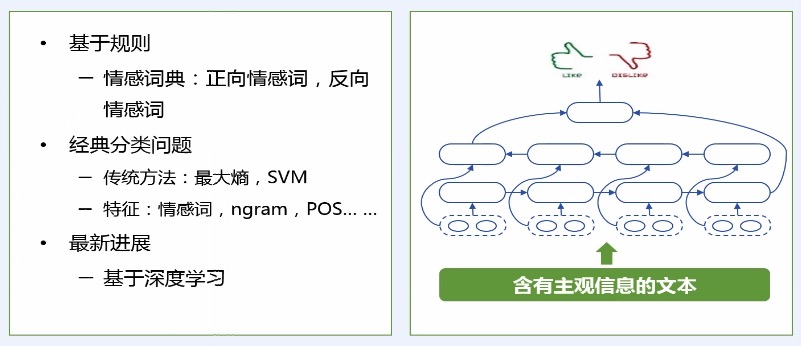
> 情感分类
|
||||
|
||||
* 给定一个文本判断其情感的极性,包括积极、中性、消极。
|
||||
* LSTM 对文本进行语义表示,进而基于语义表示进行情感分类。
|
||||
|
||||
|
||||

|
||||
|
||||
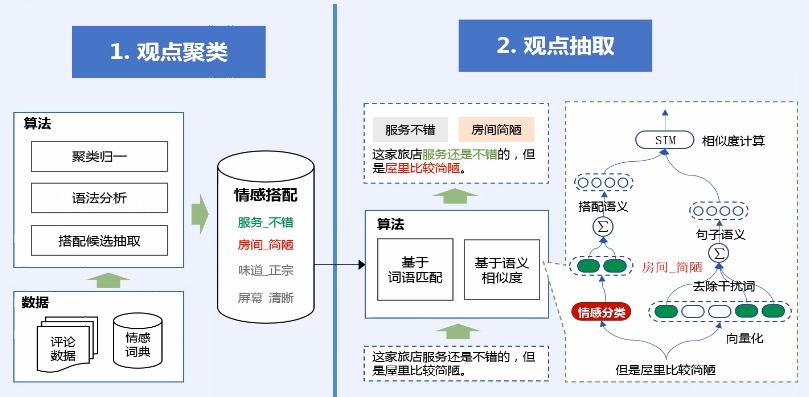
> 观点挖掘
|
||||
|
||||
@@ -28,18 +28,18 @@
|
||||
* 观点抽取一种简单的做法是直接通过标签匹配的方式得到,比如:服务不错这个情感搭配,恰好在文本中出现,我们就可以把它抽取出来。
|
||||
* 但是这种简单的抽取方法,其实上只能从字面上抽取情感搭配,而无法解决字面不一致的,但是意思一样的情感搭配抽取,因此我们还引入了语义相似度的方法。这种方法主要是通过神经网络进行计算的。它能解决这种字面不一致,语义一样的抽取问题。
|
||||
|
||||
|
||||

|
||||
|
||||
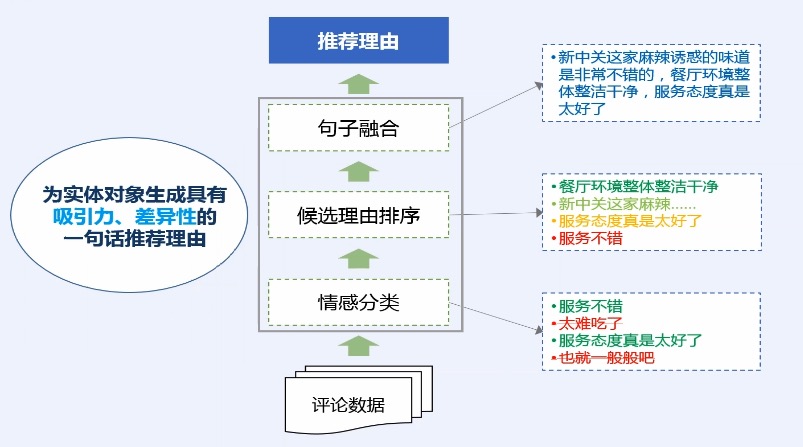
> 观点摘要
|
||||
|
||||
综合了情感分类和观点挖掘的一些技术,而获得的一个整体的应用技术
|
||||
|
||||
|
||||

|
||||
|
||||
## 百度应用:评论观点
|
||||
|
||||
|
||||

|
||||
|
||||
## 百度应用:推荐理由
|
||||
|
||||
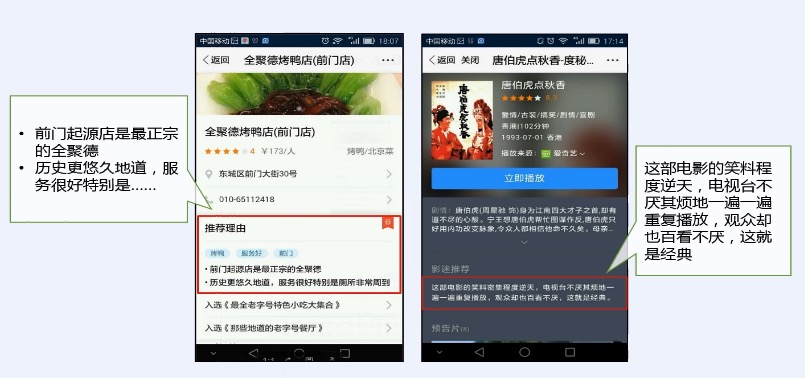
|
||||

|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
## 信息爆炸与移动化
|
||||
|
||||

|
||||

|
||||
|
||||
## 自动摘要应用
|
||||
|
||||
@@ -21,42 +21,42 @@
|
||||
* 以简洁、直观的摘要来概括用户所关注的主要内容
|
||||
* 方便用户快速了解与浏览海量内容
|
||||
|
||||
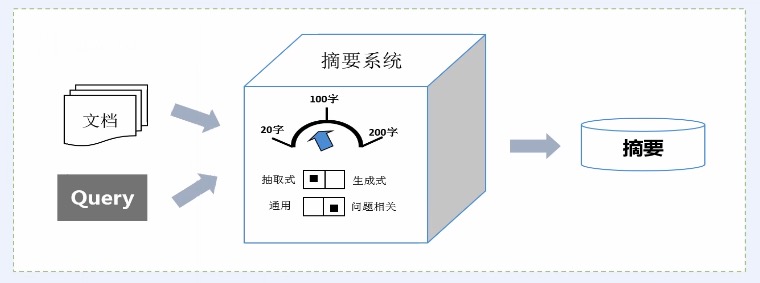
|
||||

|
||||
|
||||
* 自动摘要分类
|
||||
|
||||

|
||||

|
||||
|
||||
* 典型摘要计算流程
|
||||
|
||||
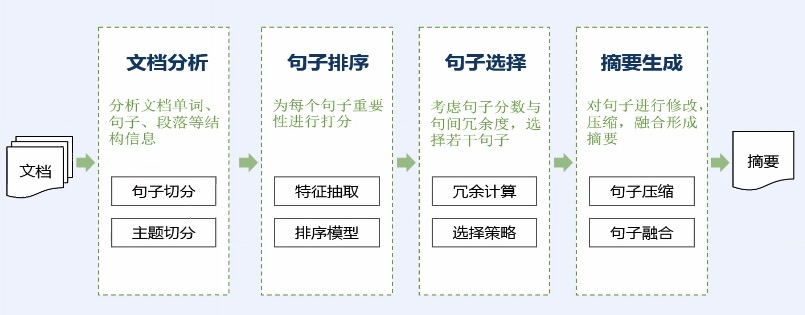
|
||||

|
||||
|
||||
> 基于篇章信息的通用新闻摘要
|
||||
|
||||
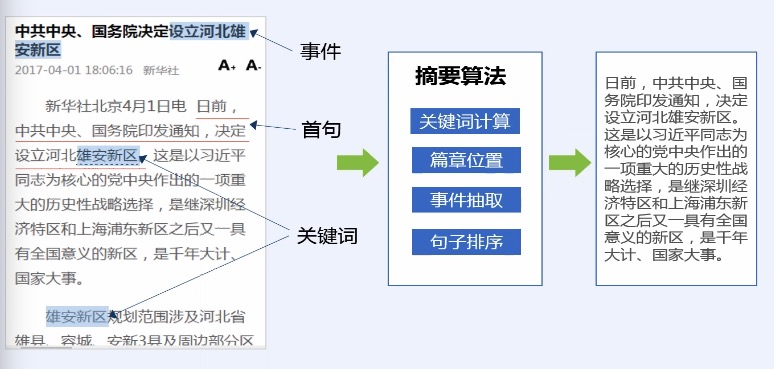
|
||||

|
||||
|
||||
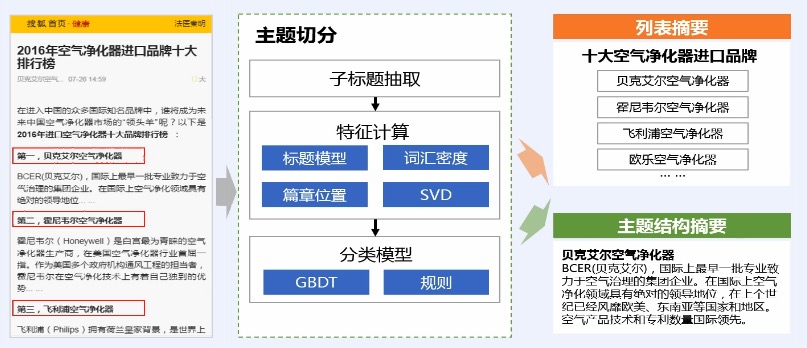
> 篇章主题摘要
|
||||
|
||||
|
||||

|
||||
|
||||
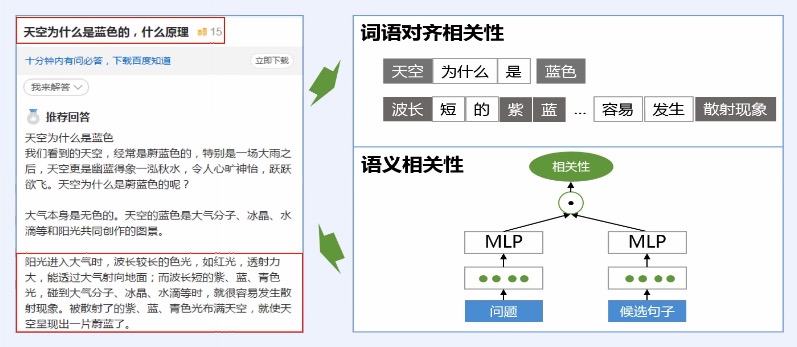
> 问答摘要
|
||||
|
||||
|
||||

|
||||
|
||||
## 百度应用
|
||||
|
||||
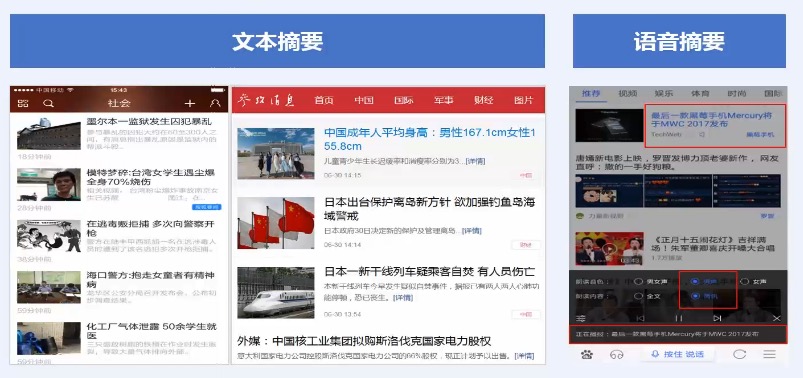
> 文本和语言摘要
|
||||
|
||||
|
||||

|
||||
|
||||
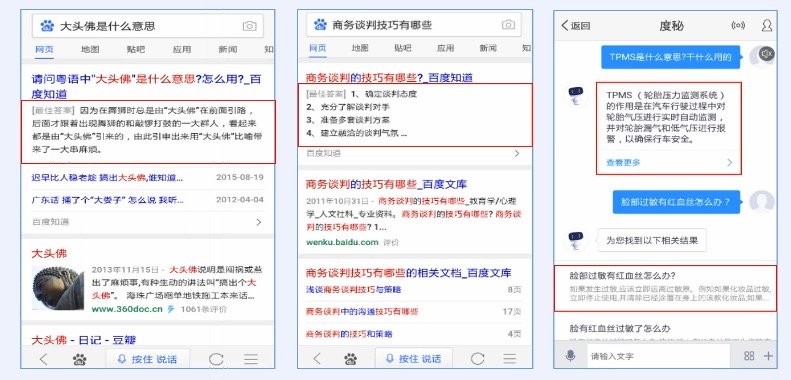
> 问答摘要
|
||||
|
||||
|
||||

|
||||
|
||||
> 搜索播报摘要和图像摘要
|
||||
|
||||
|
||||

|
||||
|
||||
## 总结
|
||||
|
||||

|
||||

|
||||
|
||||
BIN
img/nlp/1.自然语言处理入门介绍/机器翻译.png
Normal file
BIN
img/nlp/1.自然语言处理入门介绍/机器翻译.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 689 KiB |
BIN
img/nlp/1.自然语言处理入门介绍/篇章分析.jpg
Normal file
BIN
img/nlp/1.自然语言处理入门介绍/篇章分析.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 172 KiB |
Reference in New Issue
Block a user