mirror of
https://github.com/huggingface/deep-rl-class.git
synced 2026-06-17 15:38:07 +08:00
@@ -29,11 +29,11 @@ This course is **self-paced** you can start when you want 🥳.
|
||||
| [Published 🥳](https://github.com/huggingface/deep-rl-class/blob/main/unit3/bonus.md)| [Bonus: Automatic Hyperparameter Tuning using Optuna](https://github.com/huggingface/deep-rl-class/blob/main/unit3/bonus.md)| | | |
|
||||
| [Published 🥳](https://medium.com/@thomassimonini/an-introduction-to-unity-ml-agents-with-hugging-face-efbac62c8c80) | [🎁 Learn to train your first Unity MLAgent](https://medium.com/@thomassimonini/an-introduction-to-unity-ml-agents-with-hugging-face-efbac62c8c80) | |
|
||||
| [Published 🥳](https://github.com/huggingface/deep-rl-class/tree/main/unit5#unit-5-policy-gradient-with-pytorch) | [Policy Gradient with PyTorch](https://huggingface.co/blog/deep-rl-pg) | [Code a Reinforce agent from scratch using PyTorch and train it to play Pong 🎾, CartPole and Pixelcopter 🚁](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/unit5/unit5.ipynb) |
|
||||
| July the 7th | 🎁 A new library integration | 🏗️ |
|
||||
| July the 14th | Actor-Critic Methods | 🏗️ |
|
||||
| [Published 🥳](https://github.com/huggingface/deep-rl-class/tree/main/unit6#towards-better-explorations-methods-with-curiosity) | [Towards better explorations methods with Curiosity](https://github.com/huggingface/deep-rl-class/tree/main/unit6#towards-better-explorations-methods-with-curiosity)| |
|
||||
| July the 15th | Actor-Critic Methods | 🏗️ |
|
||||
| July the 21th | Proximal Policy Optimization (PPO) | 🏗️ |
|
||||
| July the 28th | Decision Transformers and offline Reinforcement Learning | 🏗️ |
|
||||
| August the 5th | Towards better explorations methods | 🏗️ |
|
||||
|
||||
|
||||
|
||||
## The library you'll learn during this course
|
||||
|
||||
61
unit6/README.md
Normal file
61
unit6/README.md
Normal file
@@ -0,0 +1,61 @@
|
||||
# Towards better explorations methods with Curiosity
|
||||
|
||||
In this Unit, we'll study in theory **Curiosity in Deep Reinforcement Learning**, a technique used to push our agent to better explore its environment and solve two majors flaws in Deep Reinforcement Learning:
|
||||
|
||||
1️⃣ **Sparse rewards environments: environments were most rewards do not contain information, and hence are set to zero.**
|
||||
|
||||
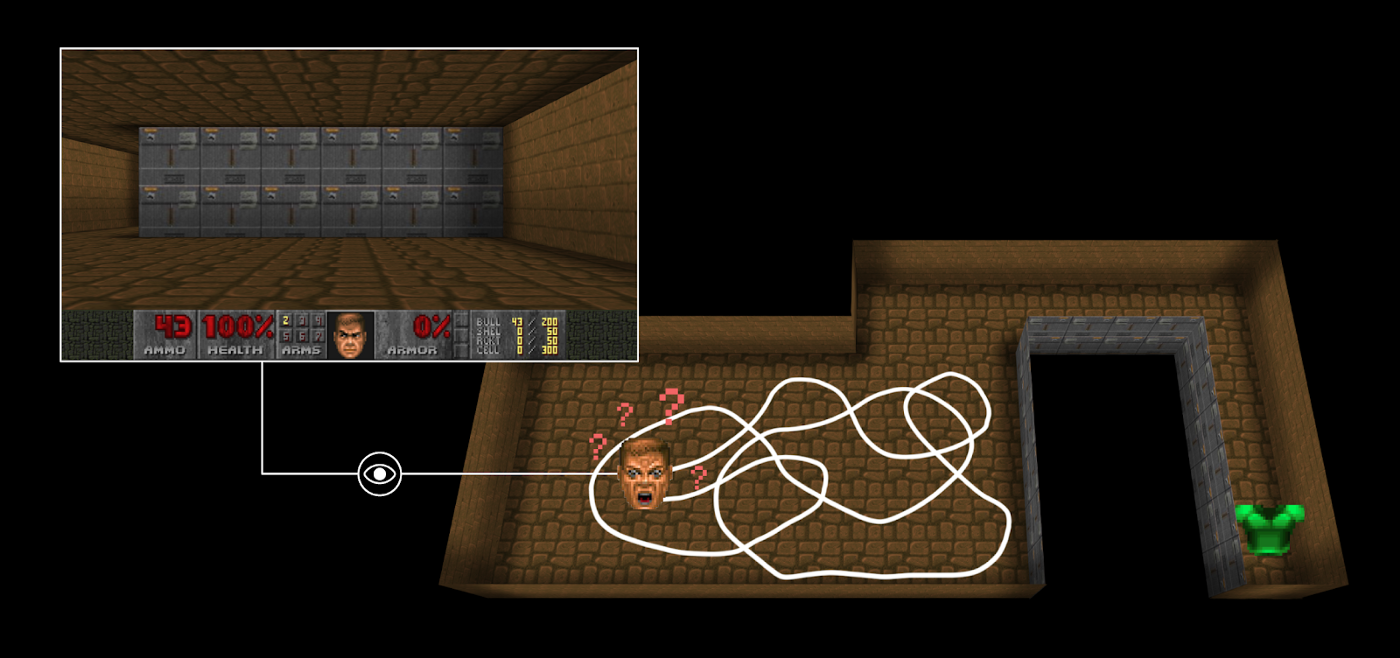
For instance, in [Vizdoom environment](https://github.com/mwydmuch/ViZDoom) “DoomMyWayHome,” your agent is only rewarded if it finds the vest. However, the vest is
|
||||
**far away from your starting point, so most of your rewards will be zero**. Therefore, if our agent does not receive useful feedback (dense rewards), it will take much longer to learn an optimal policy and it **can spend time turning around without finding the goal**.
|
||||
|
||||
|
||||
|
||||
2️⃣ **The extrinsic reward function (environment reward function) is handmade, that is in each environment, a human has to implement a reward function. But how we can scale that in big and complex environments?**
|
||||
|
||||
Therefore, a solution to these problems is to develop a reward function that is intrinsic to the agent, i.e., generated by the agent itself. The agent will act as a self-learner since it will be the student, but also its own feedback master.
|
||||
|
||||
This intrinsic reward mechanism is known as curiosity because this reward push to explore states that are novel/unfamiliar. **In order to achieve that, our agent will receive a high reward when exploring new trajectories.**
|
||||
|
||||
We'll see two techniques to create this curiosity, both of them are based on a Paper.
|
||||
|
||||
## Required time ⏱️
|
||||
The required time for this unit is, approximately:
|
||||
- One hour for the first paper study
|
||||
- One hour for the second paper study
|
||||
|
||||
## Start this Unit 🚀
|
||||
1️⃣ 📖 Read [Curiosity-Driven Learning through Next State Prediction](https://medium.com/data-from-the-trenches/curiosity-driven-learning-through-next-state-prediction-f7f4e2f592fa)
|
||||
|
||||
2️⃣ In addition, you should read the paper 👉 https://pathak22.github.io/noreward-rl/
|
||||
|
||||
3️⃣ 📖 Read [Random Network Distillation: a new take on Curiosity-Driven Learning](https://medium.com/data-from-the-trenches/curiosity-driven-learning-through-random-network-distillation-488ffd8e5938)
|
||||
|
||||
4️⃣ In addition, you should read the paper 👉 https://arxiv.org/abs/1810.12894
|
||||
|
||||
## Additional readings 📚
|
||||
- [Curiosity and Procrastination in Reinforcement Learning, Google Brain](https://ai.googleblog.com/2018/10/curiosity-and-procrastination-in.html)
|
||||
- [ML-Agents, Curiosity for Sparse-reward Environments](https://github.com/Unity-Technologies/ml-agents/blob/main/docs/ML-Agents-Overview.md#curiosity-for-sparse-reward-environments)
|
||||
|
||||
## How to make the most of this course
|
||||
|
||||
To make the most of the course, my advice is to:
|
||||
|
||||
- **Participate in Discord** and join a study group.
|
||||
- **Read multiple times** the theory part and takes some notes
|
||||
- Don’t just do the colab. When you learn something, try to change the environment, change the parameters and read the libraries' documentation. Have fun 🥳
|
||||
- Struggling is **a good thing in learning**. It means that you start to build new skills. Deep RL is a complex topic and it takes time to understand. Try different approaches, use our additional readings, and exchange with classmates on discord.
|
||||
|
||||
## This is a course built with you 👷🏿♀️
|
||||
|
||||
We want to improve and update the course iteratively with your feedback. **If you have some, please fill this form** 👉 https://forms.gle/3HgA7bEHwAmmLfwh9
|
||||
|
||||
## Don’t forget to join the Community 📢
|
||||
|
||||
We have a discord server where you **can exchange with the community and with us, create study groups to grow each other and more**
|
||||
|
||||
👉🏻 [https://discord.gg/aYka4Yhff9](https://discord.gg/aYka4Yhff9).
|
||||
|
||||
Don’t forget to **introduce yourself when you sign up 🤗**
|
||||
|
||||
❓If you have other questions, [please check our FAQ](https://github.com/huggingface/deep-rl-class#faq)
|
||||
|
||||
### Keep learning, stay awesome,
|
||||
Reference in New Issue
Block a user