mirror of
https://github.com/hairrrrr/C-CrashCourse.git
synced 2026-06-29 10:06:46 +08:00
5-16
This commit is contained in:
@@ -1,930 +0,0 @@
|
||||
## 二:指针进阶
|
||||
|
||||
|
||||
|
||||
> 码字不易,对你有帮助 **点赞/转发/关注** 支持一下作者
|
||||
>
|
||||
> 微信搜公众号:**不会编程的程序圆**
|
||||
>
|
||||
> **看更多干货,获取第一时间更新**
|
||||
|
||||
|
||||
|
||||
## 思维导图
|
||||
|
||||
***
|
||||
|
||||
|
||||
|
||||
## 目录
|
||||
|
||||
***
|
||||
|
||||
[TOC]
|
||||
|
||||
|
||||
|
||||
@[toc]
|
||||
### 前言
|
||||
|
||||
***
|
||||
|
||||
#### 指针的概念
|
||||
|
||||
>1. 指针就是个变量,用来存放地址,地址唯一标识一块内存空间。
|
||||
>2. 指针的大小是固定的4/8个字节(32位平台/64位平台)。
|
||||
>3. 指针是有类型,指针的类型决定了指针的+-整数的步长,指针解引用操作的时候的权限。
|
||||
|
||||
|
||||
|
||||
### 1、字符指针
|
||||
|
||||
#### 字符串的 数组 与 指针 表示的区别
|
||||
|
||||
请看下面这段代码,猜测会输出什么:
|
||||
|
||||
**1-1.c**
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
char str1[] = "Hello";
|
||||
char str2[] = "Hello";
|
||||
|
||||
const char* str3 = "Hello";
|
||||
const char* str4 = "Hello";
|
||||
|
||||
//查看str1与str2 ,str3与str4 的地址是否相同
|
||||
|
||||
if (str1 == str2)
|
||||
printf("str1 == str2\n");
|
||||
|
||||
if (str3 == str4)
|
||||
printf("str3 == str4\n");
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```c
|
||||
str3 == str4
|
||||
```
|
||||
|
||||
我们不着急解释原因,我们再来看一下下面这个例子:
|
||||
|
||||
**1-2.c**
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void){
|
||||
char str1[] = "hello";
|
||||
str1[0] = 'a';
|
||||
printf("%s\n", str1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
**1-3.c**
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void){
|
||||
char* str2 = "hello";
|
||||
str2[0] = 'a';
|
||||
printf("%s\n", str2);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
**试着思考:**
|
||||
1-2.c 和 1-3.c 输出的结果一样吗?
|
||||
为什么 1-3.c 程序会直接崩溃呢?
|
||||
|
||||
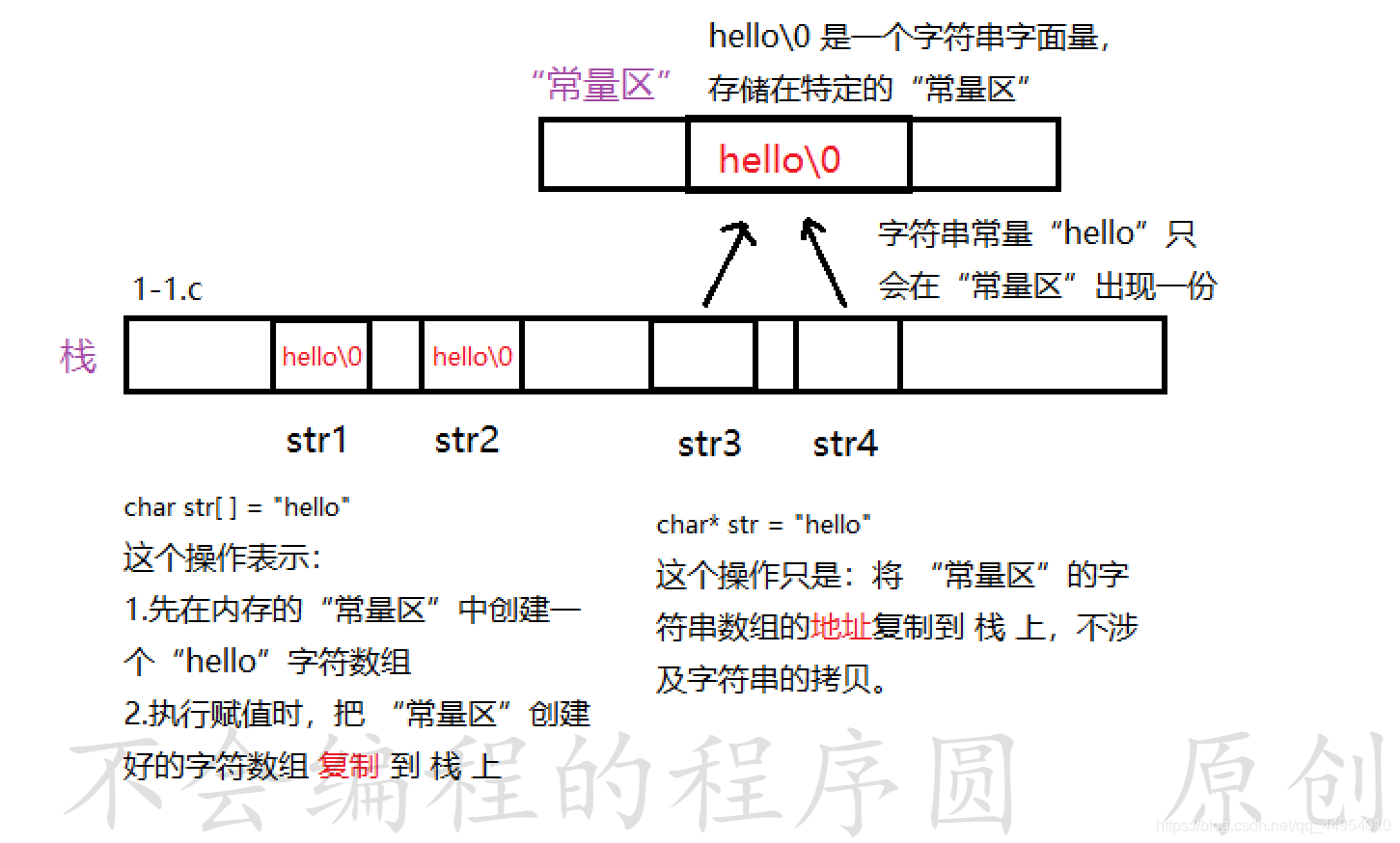
这是因为字符串字面量 "hello" 存储在 **常量区** ,该区域内的常量是**只读**的,不能被修改。
|
||||
|
||||
为了更加清楚的了解上面三个程序的原理,不妨看看下图:
|
||||
|
||||
|
||||
|
||||
<br>
|
||||
|
||||
### 2、指针数组
|
||||
|
||||
```c
|
||||
int* arr1[10]; //整形指针的数组
|
||||
char *arr2[4]; //一级字符指针的数组
|
||||
char **arr3[5];//二级字符指针的数组
|
||||
```
|
||||
|
||||
<br>
|
||||
|
||||
### 3、数组指针
|
||||
|
||||
#### Ⅰ:定义
|
||||
|
||||
数组指针是**指针**。
|
||||
|
||||
```c
|
||||
int *p1[10];//这是一个数组,里面放的都是 int型的指针
|
||||
int (*p2)[10];//这是一个指针,指向一个大小为 10个 int 的数组
|
||||
```
|
||||
|
||||
**`[]`的优先级高于 `*`,所以 `()`不能省略**
|
||||
|
||||
|
||||
|
||||
#### Ⅱ:数组名 与 &数组名
|
||||
|
||||
**3-1.c**
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main(void){
|
||||
|
||||
int arr[10] = { 0 };
|
||||
printf("arr = %p\n", arr);
|
||||
printf("&arr= %p\n", &arr);
|
||||
|
||||
printf("arr+1 = %p\n", arr+1);
|
||||
printf("&arr+1= %p\n", &arr+1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```c
|
||||
arr = 012FFE48
|
||||
&arr= 012FFE48
|
||||
arr+1 = 012FFE4C
|
||||
&arr+1= 012FFE70
|
||||
```
|
||||
|
||||
|
||||
|
||||
实际上: **&arr 表示的是数组的地址**,而不是数组首元素的地址。
|
||||
数组的地址+1,跳过整个数组的大小,所以 &arr+1 相对于 &arr 的差值是40.
|
||||
|
||||
|
||||
|
||||
#### Ⅲ:数组指针的使用
|
||||
|
||||
**3-2.c**
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
void printArr1(int arr[][4], int row, int col) {
|
||||
|
||||
int i, j;
|
||||
printf("\nint arr[][4]\n");
|
||||
for (i = 0; i < row; i++) {
|
||||
for (j = 0; j < col; j++)
|
||||
printf("%d ", arr[i][j]);
|
||||
printf("\n");
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
void printArr2(int (*arr)[4], int row, int col) {
|
||||
|
||||
int i, j;
|
||||
printf("\n int (*arr)[]\n");
|
||||
for (i = 0; i < row; i++) {
|
||||
for (j = 0; j < col; j++)
|
||||
printf("%d ", arr[i][j]);
|
||||
printf("\n");
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
int main(void) {
|
||||
|
||||
int arr[3][4] = { 0 };
|
||||
|
||||
printArr1(arr, 3, 4);
|
||||
printArr2(arr, 3, 4);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```c
|
||||
int arr[][4]
|
||||
0 0 0 0
|
||||
0 0 0 0
|
||||
0 0 0 0
|
||||
|
||||
int (*arr)[]
|
||||
0 0 0 0
|
||||
0 0 0 0
|
||||
0 0 0 0
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 4、数组参数 & 指针参数
|
||||
|
||||
#### Ⅰ:一维数组传参
|
||||
|
||||
**4-1.c**
|
||||
|
||||
我们先来看一下 main 函数
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
int arr[10] = { 0 };
|
||||
int* arr2[20] = { 0 };
|
||||
|
||||
test1(arr);
|
||||
test2(arr);
|
||||
test3(arr);
|
||||
|
||||
test4(arr2);
|
||||
test5(arr2);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
请判断以下五个函数的参数写法是否正确:
|
||||
|
||||
```c
|
||||
void test1(int arr[]) {
|
||||
|
||||
}
|
||||
|
||||
void test2(int arr[10]) {
|
||||
|
||||
}
|
||||
|
||||
void test3(int* arr) {
|
||||
|
||||
}
|
||||
|
||||
void test4(int* arr[20]) {
|
||||
|
||||
}
|
||||
|
||||
void test5(int** arr) {
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
这五种写法都是可以的。
|
||||
|
||||
|
||||
|
||||
#### Ⅱ:二维数组传参
|
||||
|
||||
**4-2.c**
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
void test(int arr[3][5])
|
||||
{}
|
||||
void test(int arr[][])// error
|
||||
{}
|
||||
void test(int arr[][5])
|
||||
{}
|
||||
void test(int *arr) // error
|
||||
{}
|
||||
void test(int* arr[5])
|
||||
{}
|
||||
void test(int (*arr)[5])
|
||||
{}
|
||||
void test(int **arr) // error
|
||||
{}
|
||||
int main(void)
|
||||
{
|
||||
int arr[3][5] = {0};
|
||||
test(arr)
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
**二维数组传参,只有第一个 [] 内的数字可以省略,其他的都不能省略**
|
||||
|
||||
|
||||
|
||||
### 5、函数指针
|
||||
|
||||
#### Ⅰ:定义
|
||||
|
||||
**5-1.c**
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
printf("%p\n", main);
|
||||
printf("%p\n", &main);//输出函数地址 用不用 & 都可以
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```c
|
||||
008A129E
|
||||
008A129E
|
||||
```
|
||||
|
||||
输出的两个地址是 main 函数的地址。
|
||||
|
||||
|
||||
|
||||
如何理解函数指针?
|
||||
|
||||
> 当你写完并保存一个 .c 文件后,这个文件是存储在计算机硬盘中的。编译 c文件后生成的 .exe(可执行文件)也是在硬盘上。
|
||||
>
|
||||
> 当你双击 .exe 文件时,操作系统就会把这个文件加载到**内存中**,并创建一个对应的 进程。
|
||||
|
||||
对于函数指针来说,最大的用处就是可以直接调用函数。
|
||||
|
||||
|
||||
|
||||
如何保存函数地址呢?
|
||||
**5-2.c**
|
||||
```c
|
||||
void test()
|
||||
{
|
||||
printf("hehe\n");
|
||||
}
|
||||
|
||||
void (*pfun1)();
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### Ⅱ:函数指针数组
|
||||
|
||||
我们要将函数的地址存放到一个数组中去,这个数组就叫 函数指针数组。
|
||||
|
||||
> 定义方法:`int (*parr[10])();`
|
||||
>
|
||||
> parr 先与 [] 结合,说明 parr 是数组,数组的内容是 int (*)() 类型的函数指针。
|
||||
|
||||
|
||||
|
||||
##### 应用:转移表
|
||||
|
||||
**5-3.c** 计算器
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int add(int x, int y) {
|
||||
return (x + y);
|
||||
}
|
||||
|
||||
int sub(int x, int y) {
|
||||
return (x - y);
|
||||
}
|
||||
|
||||
int mul(int x, int y) {
|
||||
return (x * y);
|
||||
}
|
||||
|
||||
int div(int x, int y) {
|
||||
return (x / y);
|
||||
}
|
||||
|
||||
|
||||
|
||||
int main(void) {
|
||||
|
||||
int x, y;
|
||||
int input = 1;
|
||||
int (*p[5])(int, int) = { 0, add, sub, mul, div };
|
||||
|
||||
while (input) {
|
||||
|
||||
printf("**********************\n");
|
||||
printf(" 1: ADD \n");
|
||||
printf(" 2: SUB \n");
|
||||
printf(" 3: MUL \n");
|
||||
printf(" 4: DIV \n");
|
||||
printf(" 0: EXIT \n");
|
||||
printf("**********************\n");
|
||||
|
||||
printf("Enter a choice: ");
|
||||
scanf("%d", &input);
|
||||
|
||||
if (input == 0)
|
||||
break;
|
||||
else if (input < 1 || input > 4) {
|
||||
printf("wrong input!\n");
|
||||
}
|
||||
else {
|
||||
printf("Enter two numbers: ");
|
||||
scanf("%d %d", &x, &y);
|
||||
printf("result = %d\n", (*p[input])(x, y));
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
##### 应用:回调函数
|
||||
|
||||
|
||||
|
||||
### 6.指针和数组笔试题
|
||||
|
||||
环境:**32 位机器**
|
||||
|
||||
#### 第一组
|
||||
|
||||
```c
|
||||
int a[] = {1,2,3,4};
|
||||
printf("%d\n",sizeof(a));
|
||||
printf("%d\n",sizeof(a+0));
|
||||
printf("%d\n",sizeof(*a));
|
||||
printf("%d\n",sizeof(a+1));
|
||||
printf("%d\n",sizeof(a[1]));
|
||||
printf("%d\n",sizeof(&a));
|
||||
printf("%d\n",sizeof(*&a));
|
||||
printf("%d\n",sizeof(&a+1));
|
||||
printf("%d\n",sizeof(&a[0]));
|
||||
printf("%d\n",sizeof(&a[0]+1));
|
||||
```
|
||||
|
||||
答案:
|
||||
|
||||
```c
|
||||
printf("%d\n",sizeof(a));// 16
|
||||
printf("%d\n",sizeof(a+0));// 4 (a + 0 这个操作使得编译器将 a 看为指针)
|
||||
printf("%d\n",sizeof(*a));// 4
|
||||
printf("%d\n",sizeof(a+1));// 4
|
||||
printf("%d\n",sizeof(a[1]));// 4
|
||||
printf("%d\n",sizeof(&a));// 4
|
||||
printf("%d\n",sizeof(*&a));// 16 (&a 是数组指针。再次用 * 解引用,是从这个地址开始取 int(*)[4] 类型对应的字节数)
|
||||
printf("%d\n",sizeof(&a+1));// 4 (&a 得到的是 int(*)[4] 类型的指针,只要是指针大小就是 4)
|
||||
printf("%d\n",sizeof(&a[0]));// 4
|
||||
printf("%d\n",sizeof(&a[0]+1));// 4
|
||||
```
|
||||
|
||||
#### 第二组
|
||||
|
||||
```c
|
||||
char arr[] = {'a','b','c','d','e','f'};
|
||||
printf("%d\n", sizeof(arr));
|
||||
printf("%d\n", sizeof(arr+0));
|
||||
printf("%d\n", sizeof(*arr));
|
||||
printf("%d\n", sizeof(arr[1]));
|
||||
printf("%d\n", sizeof(&arr));
|
||||
printf("%d\n", sizeof(&arr+1));
|
||||
printf("%d\n", sizeof(&arr[0]+1));
|
||||
|
||||
printf("%d\n", strlen(arr));
|
||||
printf("%d\n", strlen(arr+0));
|
||||
printf("%d\n", strlen(*arr));
|
||||
printf("%d\n", strlen(arr[1]));
|
||||
printf("%d\n", strlen(&arr));
|
||||
printf("%d\n", strlen(&arr+1));
|
||||
printf("%d\n", strlen(&arr[0]+1));
|
||||
```
|
||||
|
||||
答案:
|
||||
|
||||
```c
|
||||
printf("%d\n", sizeof(arr));// 6
|
||||
printf("%d\n", sizeof(arr+0));// 4
|
||||
printf("%d\n", sizeof(*arr));// 1
|
||||
printf("%d\n", sizeof(arr[1]));// 1
|
||||
printf("%d\n", sizeof(&arr));// 4 (char (*)[6] 类型的指针)
|
||||
printf("%d\n", sizeof(&arr+1));// 4
|
||||
printf("%d\n", sizeof(&arr[0]+1));//4
|
||||
|
||||
printf("%d\n", strlen(arr));// 未定义 (arr 字符数组没有 '\0',有可能会出现一个随机值,程序也有可能会崩溃。)
|
||||
printf("%d\n", strlen(arr+0));// 未定义
|
||||
printf("%d\n", strlen(*arr)); // 错误的参数类型 (strlen 要的是 char* 类型,但是 *arr 是 char类型。*arr 是字符 a,也就是 97,编译器有可能将 97 当成一个 16 进制的地址。所以,这样的代码一定是不对的)
|
||||
printf("%d\n", strlen(arr[1]));//同上
|
||||
printf("%d\n", strlen(&arr));// 未定义
|
||||
printf("%d\n", strlen(&arr+1)); // 未定义
|
||||
printf("%d\n", strlen(&arr[0]+1));// 未定义
|
||||
```
|
||||
|
||||
#### 第三组
|
||||
|
||||
```c
|
||||
char arr[] = "abcdef";
|
||||
printf("%d\n", sizeof(arr));
|
||||
printf("%d\n", sizeof(arr+0));
|
||||
printf("%d\n", sizeof(*arr));
|
||||
printf("%d\n", sizeof(arr[1]));
|
||||
printf("%d\n", sizeof(&arr));
|
||||
printf("%d\n", sizeof(&arr+1));
|
||||
printf("%d\n", sizeof(&arr[0]+1));
|
||||
|
||||
printf("%d\n", strlen(arr));
|
||||
printf("%d\n", strlen(arr+0));
|
||||
printf("%d\n", strlen(*arr));
|
||||
printf("%d\n", strlen(arr[1]));
|
||||
printf("%d\n", strlen(&arr));
|
||||
printf("%d\n", strlen(&arr+1));
|
||||
printf("%d\n", strlen(&arr[0]+1));
|
||||
```
|
||||
|
||||
答案:
|
||||
|
||||
```c
|
||||
char arr[] = "abcdef";
|
||||
printf("%d\n", sizeof(arr));//7
|
||||
printf("%d\n", sizeof(arr+0));//7
|
||||
printf("%d\n", sizeof(*arr));//1
|
||||
printf("%d\n", sizeof(arr[1]));//1
|
||||
printf("%d\n", sizeof(&arr));//4 (char (*)[7])
|
||||
printf("%d\n", sizeof(&arr+1));//4 (char (*)[7])
|
||||
printf("%d\n", sizeof(&arr[0]+1));//4 (char*)
|
||||
|
||||
printf("%d\n", strlen(arr));// 6
|
||||
printf("%d\n", strlen(arr+0));// 6
|
||||
printf("%d\n", strlen(*arr));// 错误的参数类型
|
||||
printf("%d\n", strlen(arr[1]));// 同上
|
||||
printf("%d\n", strlen(&arr));// 6 (&arr 的类型是 char (*)[7] 与 char* 类型不一致,但是 &arr 与 arr 是相同的,所以恰巧能得出正确结果,但是这是错误的写法。)
|
||||
printf("%d\n", strlen(&arr+1)); // 未定义 (&arr + 1,跳过了整个数组,访问数组后面的空间,非法内存访问)
|
||||
printf("%d\n", strlen(&arr[0]+1)); // 5 (&arr[0] -> char* ,加以跳过一个数组元素)
|
||||
```
|
||||
|
||||
#### 第四组
|
||||
|
||||
```c
|
||||
char *p = "abcdef";
|
||||
printf("%d\n", sizeof(p));
|
||||
printf("%d\n", sizeof(p+1));
|
||||
printf("%d\n", sizeof(*p));
|
||||
printf("%d\n", sizeof(p[0]));
|
||||
printf("%d\n", sizeof(&p));
|
||||
printf("%d\n", sizeof(&p+1));
|
||||
printf("%d\n", sizeof(&p[0]+1));
|
||||
|
||||
printf("%d\n", strlen(p));
|
||||
printf("%d\n", strlen(p+1));
|
||||
printf("%d\n", strlen(*p));
|
||||
printf("%d\n", strlen(p[0]));
|
||||
printf("%d\n", strlen(&p));
|
||||
printf("%d\n", strlen(&p+1));
|
||||
printf("%d\n", strlen(&p[0]+1));
|
||||
```
|
||||
|
||||
答案:
|
||||
|
||||
```c
|
||||
char *p = "abcdef";
|
||||
printf("%d\n", sizeof(p));// 4
|
||||
printf("%d\n", sizeof(p+1));// 4
|
||||
printf("%d\n", sizeof(*p));// 1
|
||||
printf("%d\n", sizeof(p[0]));// 1
|
||||
printf("%d\n", sizeof(&p));// 4 (char**)
|
||||
printf("%d\n", sizeof(&p+1));// 4 (char**)
|
||||
printf("%d\n", sizeof(&p[0]+1));// 4
|
||||
|
||||
printf("%d\n", strlen(p));// 6
|
||||
printf("%d\n", strlen(p+1));// 5
|
||||
printf("%d\n", strlen(*p));// 错误的参数类型
|
||||
printf("%d\n", strlen(p[0]));// 错误的参数类型
|
||||
printf("%d\n", strlen(&p));// 同上 (&p 的类型是 char**,将char** 强转成的 char* 并不是一个字符串)
|
||||
printf("%d\n", strlen(&p+1));// 未定义
|
||||
printf("%d\n", strlen(&p[0]+1));// 5 (对于 &p[0] 来说,p 先与 [] 结合)
|
||||
```
|
||||
|
||||
|
||||
|
||||
> 指针为什么也可以用 `[]`运算符?
|
||||
>
|
||||
> 对于指针 int* p = "abc";
|
||||
>
|
||||
> `p[1]` 等价于 `*(p + 1)`
|
||||
>
|
||||
> 这是因为数组很多时候可以隐式转换成指针。
|
||||
|
||||
|
||||
|
||||
重点注意:`printf("%d\n", strlen(&p));`
|
||||
|
||||
`&p`的类型是 `char**`,但是C语言会将其隐式类型转换成 `char*`,但是 strlen 访问的是地址p的内存空间,那这其实是未定义行为。
|
||||
|
||||
|
||||
|
||||
#### 第五组
|
||||
|
||||
```c
|
||||
int a[3][4] = {0};
|
||||
printf("%d\n",sizeof(a));
|
||||
printf("%d\n",sizeof(a[0][0]));
|
||||
printf("%d\n",sizeof(a[0]));
|
||||
printf("%d\n",sizeof(a[0]+1));
|
||||
printf("%d\n",sizeof(*(a[0]+1)));
|
||||
printf("%d\n",sizeof(a+1));
|
||||
printf("%d\n",sizeof(*(a+1)));
|
||||
printf("%d\n",sizeof(&a[0]+1));
|
||||
printf("%d\n",sizeof(*(&a[0]+1)));
|
||||
printf("%d\n",sizeof(*a));
|
||||
printf("%d\n",sizeof(a[3]));
|
||||
```
|
||||
|
||||
答案:
|
||||
|
||||
```c
|
||||
int a[3][4] = {0};
|
||||
//所谓二维数组本质是一维数组。里面的每个元素又是一个一维数组。
|
||||
//本例是一个长度为 3 的一维数组,每个元素又是长度为 4 的一维数组。(VS 中可以用调试来测试)
|
||||
printf("%d\n",sizeof(a));// 48
|
||||
printf("%d\n",sizeof(a[0][0]));// 4
|
||||
printf("%d\n",sizeof(a[0]));// 16 (a[0] 的类型是 int[4])
|
||||
printf("%d\n",sizeof(a[0]+1));// 4 (a[0]->int[4]相当于一个一维数组,a[0] + 1 隐式转换为指针 int*)
|
||||
printf("%d\n",sizeof(*(a[0]+1)));// 4 (a[0] + 1 -> a[0][1])
|
||||
printf("%d\n",sizeof(a+1));// 4
|
||||
printf("%d\n",sizeof(*(a+1)));// 4
|
||||
printf("%d\n",sizeof(&a[0]+1));// 4 (a[0] -> int[4],&a[0] -> int (*)[4],再加1还是数组指针)
|
||||
printf("%d\n",sizeof(*(&a[0]+1)));// 16 (int (*)[4] 解引用变为 int[4])
|
||||
printf("%d\n",sizeof(*a));// 16 (*a -> *(a + 0) -> a[0])
|
||||
printf("%d\n",sizeof(a[3]));// 16
|
||||
```
|
||||
|
||||
重点注意:
|
||||
|
||||
`printf("%d\n",sizeof(a[0]+1))`
|
||||
|
||||
`printf("%d\n",sizeof(&a[0]+1))`
|
||||
|
||||
a[0] 与 &a[0] 的差异比较:
|
||||
|
||||
```c
|
||||
int a[3][4] = {
|
||||
{1, 2, 3, 4},
|
||||
{5, 6, 7, 8},
|
||||
{5, 10, 11, 12},
|
||||
};
|
||||
|
||||
printf("%d\n", *(a[0] + 1));// 2
|
||||
printf("%d\n", **(&a[0] + 1));//5
|
||||
```
|
||||
|
||||
|
||||
|
||||
`printf("%d\n",sizeof(*(&a[0]+1)));`
|
||||
|
||||
我们来一步一步分析:
|
||||
|
||||
`a[0] -> int[4] ; &a[0] -> int (\*)[4] ; &a[0] + 1 -> int (\*)[4] ; *(&a[0] + 1) -> int[4]`
|
||||
|
||||
|
||||
|
||||
`printf("%d\n",sizeof(a[3]))`
|
||||
|
||||
`sizeof`是一个运算符,并不是函数。它在预编译时期替换。而我们说的“数组下标访问越界”前提条件是 **内存**访问越界,这个时期是程序运行时。a[3] 就是 int[4] 类型,所以就是 16。哪怕你写 a[100]都可以。
|
||||
|
||||
`printf("%d\n", 16)`是程序运行时执行的语句。
|
||||
|
||||
#### 关于 const
|
||||
|
||||
```c
|
||||
int num;
|
||||
const int* p = #
|
||||
int const* p = #// 这样的写法不科学,int* 应该当成一个整体,不过它的含义与上面的相同。
|
||||
int* const p = #
|
||||
```
|
||||
|
||||
对于第一种写法,*p 是不能改变的;对于第三种写法,地址 p 是不能被改变的。
|
||||
|
||||
|
||||
|
||||
### 7. 指针笔试题
|
||||
|
||||
#### Ⅰ
|
||||
|
||||
```c
|
||||
int main(void)
|
||||
{
|
||||
int a[5] = { 1, 2, 3, 4, 5 };
|
||||
int *ptr = (int *)(&a + 1);
|
||||
printf( "%d,%d", *(a + 1), *(ptr - 1));
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
`a + 1`:a 隐式转换成 指针,指向 首地址后移 4 个字节。(a 隐式转换后是 int* 类型,它指向的 int 大小是 4 个字节,所以后移 4 个字节)
|
||||
|
||||
`&a` 的类型是 `int(*)[5]` ,所以 `&a + 1` 后移 int[5] 的长度
|
||||
|
||||
|
||||
|
||||
所以最后输出的是:2,5
|
||||
|
||||
#### Ⅱ
|
||||
|
||||
```c
|
||||
//由于还没学习结构体,这里告知结构体的大小是20个字节
|
||||
struct Test
|
||||
{
|
||||
int Num;
|
||||
char *pcName;
|
||||
short sDate;
|
||||
char cha[2];
|
||||
short sBa[4];
|
||||
}*p;
|
||||
//假设p 的值为0x100000。 如下表表达式的值分别为多少?
|
||||
int main(void)
|
||||
{
|
||||
printf("%p\n", p + 0x1);
|
||||
printf("%p\n", (unsigned long)p + 0x1);
|
||||
printf("%p\n", (unsigned int*)p + 0x1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
`p + 0x1`: p 加十六进制的 1,p 所指向的结构体大小是 20,所以 p 会增加 20 。但是注意 `%p` 输出的是 16 进制的地址,所以输出的是 0x100014
|
||||
|
||||
`(unsigned long)p + 0x1`: p 被强转成了一个数,所以输出的就是 0x100001
|
||||
|
||||
`(unsigned int*)p + 0x1`: p 被强转成了一个 int* 类型的指针,所以输出的是 0x100004
|
||||
|
||||
#### Ⅲ
|
||||
|
||||
```c
|
||||
int main(void)
|
||||
{
|
||||
int a[4] = { 1, 2, 3, 4 };
|
||||
int *ptr1 = (int *)(&a + 1);
|
||||
int *ptr2 = (int *)((int)a + 1);
|
||||
printf( "%x,%x", ptr1[-1], *ptr2);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
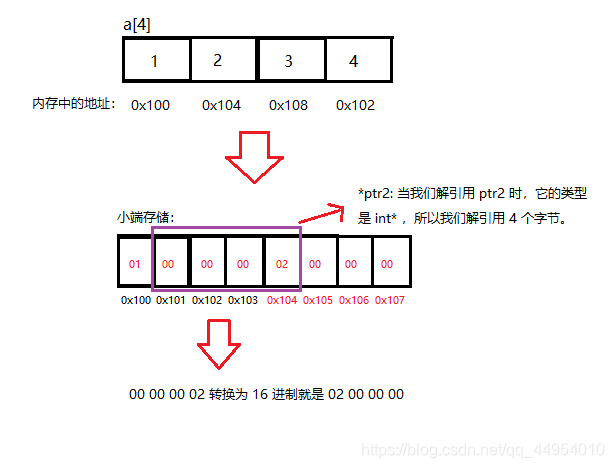
`ptr1[-1]`: 前面我们说过,这个操作相当于 `*(ptr1 - 1)`
|
||||
|
||||
`(int)a + 1`: 是将 a 先强转为 int 然后再加 1,所以 a 仅仅增加了 1 个字节
|
||||
|
||||
|
||||
|
||||
#### Ⅳ
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
int main(void)
|
||||
{
|
||||
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
|
||||
int *p;
|
||||
p = a[0];
|
||||
printf( "%d", p[0]);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
p[0] -> a[0] [0] ,所以输出的是 0 吗?
|
||||
|
||||
并不是,注意看 a[3] [2]大括号内的内容,里面是圆括号而不是大括号,这是**逗号表达式**。
|
||||
|
||||
所以,a[0] [0] == 1
|
||||
|
||||
|
||||
|
||||
#### Ⅴ
|
||||
|
||||
```c
|
||||
int main(void){
|
||||
int a[5][5];
|
||||
int(*p)[4];
|
||||
p = a;
|
||||
printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
指针(同类型)相减的意义是**两个指针之间间隔的元素个数**
|
||||
|
||||
`&p[4][2]` -> 数组中的第 19 个元素(4 * 4 + 3)
|
||||
|
||||
`&a[4][2]` -> 数组中的第 23 个元素 (4 * 5 + 3)
|
||||
|
||||
|
||||
|
||||
答案:FFFFFFFC,-4
|
||||
|
||||
|
||||
|
||||
#### Ⅵ
|
||||
|
||||
```c
|
||||
int main(void)
|
||||
{
|
||||
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
|
||||
int *ptr1 = (int *)(&aa + 1);
|
||||
int *ptr2 = (int *)(*(aa + 1));
|
||||
printf( "%d,%d", *(ptr1 - 1), *(ptr2 - 1));
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
`&aa` 的类型是 `int(*)[2][5]`,所以 `&aa + 1` 指向的是整个数组后面的内存 。所以 `*(ptr1 - 1)` 的值是 10
|
||||
|
||||
`aa` aa + 1 让 aa 隐式转换为 `int(*)[5]` ,所以 `aa + 1` 指向的是元素 6 所在的地址。所以 `*(ptr2 - 1)` 的值是 5
|
||||
|
||||
|
||||
|
||||
#### Ⅶ
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
int main(void)
|
||||
{
|
||||
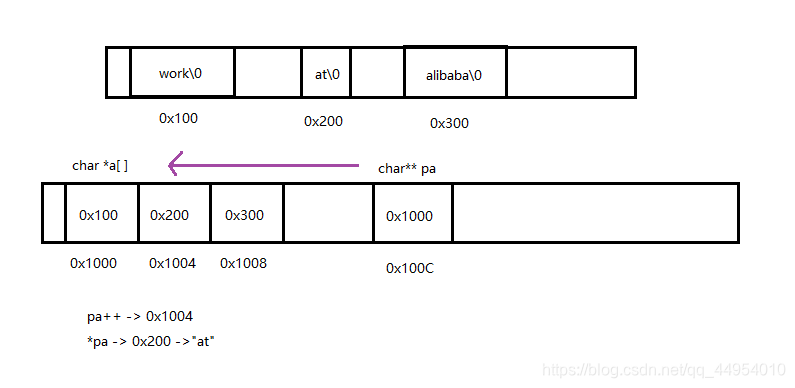
char *a[] = {"work","at","alibaba"};
|
||||
char**pa = a;
|
||||
pa++;
|
||||
printf("%s\n", *pa);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
<br>
|
||||
|
||||
|
||||
|
||||
#### Ⅷ
|
||||
|
||||
```c
|
||||
int main(void)
|
||||
{
|
||||
char *c[] = {"ENTER","NEW","POINT","FIRST"};
|
||||
char** cp[] = {c+3,c+2,c+1,c};
|
||||
char***cpp = cp;
|
||||
printf("%s\n", **++cpp);// ++cpp 会改变 cpp 的值
|
||||
printf("%s\n", *--*++cpp+3);//
|
||||
printf("%s\n", *cpp[-2]+3);//-2 并没有改变 cpp
|
||||
printf("%s\n", cpp[-1][-1]+1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
<br>
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
单目运算符从右向左依次运算。
|
||||
|
||||
```c
|
||||
char* p = "ENTER";
|
||||
printf("%s", p + 3);// 输出 ER,p + 3 增加 3 个字节,因为 p 指向的类型是 char 大小是 1 个字节。
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
***
|
||||
|
||||
以上就是本次的内容。
|
||||
|
||||
如果文章有错误欢迎指正和补充,感谢!
|
||||
|
||||
最后,如果你还有什么问题或者想知道到的,可以在评论区告诉我呦,我可以在后面的文章加上你们的真知灼见。
|
||||
|
||||
**关注我**,看更多干货!
|
||||
|
||||
我是程序圆,我们下次再见。
|
||||
@@ -1,102 +0,0 @@
|
||||
|
||||
>码字不易,对你有帮助 **点赞/转发/关注** 支持一下作者
|
||||
|
||||
#### 1.打印杨辉三角
|
||||
|
||||
|
||||
1
|
||||
1 1
|
||||
1 2 1
|
||||
1 3 3 1
|
||||
1 4 6 4 1
|
||||
...
|
||||
|
||||
***
|
||||
#### 2. 字符串旋转
|
||||
|
||||
|
||||
写一个函数,判断一个字符串是否为另外一个字符串旋转之后的字符串。
|
||||
|
||||
例如:给定s1 =AABCD和s2 = BCDAA,返回1
|
||||
给定s1=abcd和s2=ACBD,返回0.
|
||||
|
||||
AABCD左旋一个字符得到ABCDA
|
||||
AABCD左旋两个字符得到BCDAA
|
||||
AABCD右旋一个字符得到DAABC
|
||||
|
||||
***
|
||||
|
||||
|
||||
|
||||
|
||||
#### 3. 字符串左旋
|
||||
|
||||
|
||||
实现一个函数,可以左旋字符串中的k个字符。
|
||||
|
||||
例如:
|
||||
ABCD左旋一个字符得到BCDA
|
||||
ABCD左旋两个字符得到CDAB
|
||||
|
||||
***
|
||||
|
||||
|
||||
|
||||
|
||||
#### 4. 杨氏矩阵
|
||||
|
||||
有一个数字矩阵,矩阵的每行从左到右是递增的,矩阵从上到下是递增的,请编写程序在这样的矩阵中查找某个数字是否存在。
|
||||
|
||||
|
||||
|
||||
要求:时间复杂度小于O(N);
|
||||
|
||||
*可以先不去管复杂度问题,这里给出一种方便理解的算法。[参考文章](https://blog.csdn.net/sgbfblog/article/details/7745450?depth_1-utm_source=distribute.pc_relevant_right.none-task&utm_source=distribute.pc_relevant_right.none-task)*
|
||||
|
||||
|
||||
***
|
||||
|
||||
#### 5. 实现qsort
|
||||
|
||||
***
|
||||
|
||||
#### 6. 猜凶手日本某地发生了一件谋杀案,警察通过排查确定杀人凶手必为4个嫌疑犯的一个。
|
||||
|
||||
以下为4个嫌疑犯的供词:
|
||||
|
||||
|
||||
|
||||
A说:不是我。
|
||||
|
||||
B说:是C。
|
||||
|
||||
C说:是D。
|
||||
|
||||
D说:C在胡说
|
||||
|
||||
已知3个人说了真话,1个人说的是假话。
|
||||
|
||||
|
||||
|
||||
现在请根据这些信息,写一个程序来确定到底谁是凶手。
|
||||
|
||||
***
|
||||
#### 7. 猜名次
|
||||
|
||||
5位运动员参加了10米台跳水比赛,有人让他们预测比赛结果:
|
||||
|
||||
A选手说:B第二,我第三;
|
||||
|
||||
B选手说:我第二,E第四;
|
||||
|
||||
C选手说:我第一,D第二;
|
||||
|
||||
D选手说:C最后,我第三;
|
||||
|
||||
E选手说:我第四,A第一;
|
||||
|
||||
比赛结束后,每位选手都说对了一半,请编程确定比赛的名次。
|
||||
|
||||
***
|
||||
答案在我的 github 上,欢迎 star !以后的代码都会上传的这里。
|
||||
[点击查看答案](https://github.com/hairrrrr/C-CrashCourse)
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1,4 +0,0 @@
|
||||
### 第二章 C语言基础概念
|
||||
2.1[第一节](https://github.com/hairrrrr/C-CrashCourse/blob/master/C%20Crash%20Course/02%20Basic%20Conception/text/01.md)
|
||||
|
||||
2.2[第二节](https://github.com/hairrrrr/C-CrashCourse/blob/master/C%20Crash%20Course/02%20Basic%20Conception/text/02.md)
|
||||
@@ -1,430 +0,0 @@
|
||||
## C语言基本概念
|
||||
|
||||
*Syntactic sugar causes cancer of the semi-colons.*[^0]
|
||||
|
||||
|
||||
|
||||
> 码字不易,对你有帮助 **点赞/转发/关注** 支持一下作者
|
||||
> 微信搜公众号:**不会编程的程序圆**
|
||||
> **看更多干货,获取第一时间更新**
|
||||
|
||||
|
||||
|
||||
### :earth_asia:思维导图
|
||||
|
||||
***
|
||||
|
||||
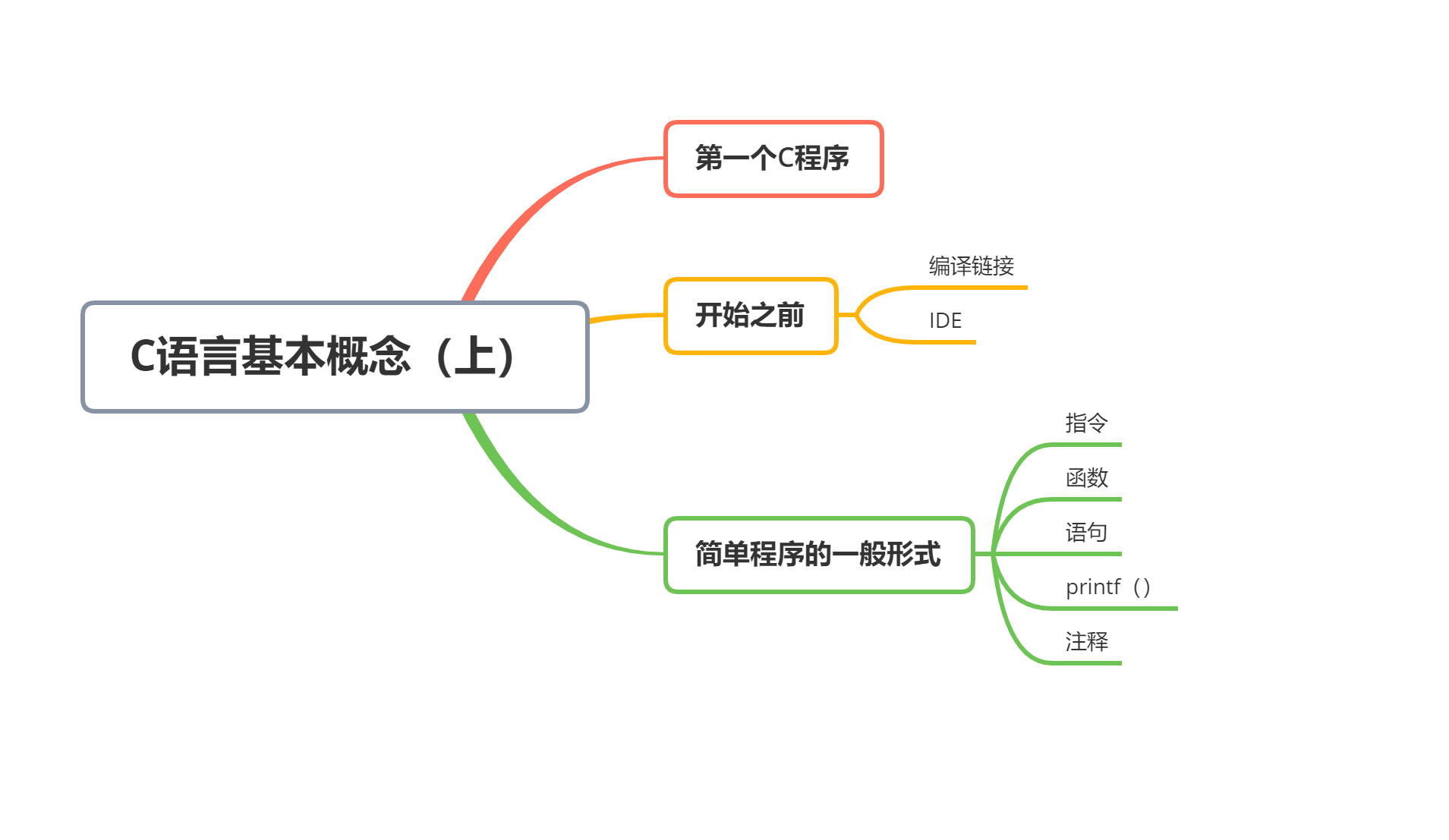
|
||||
|
||||
### :globe_with_meridians:目录
|
||||
|
||||
***
|
||||
|
||||
[TOC]
|
||||
|
||||
### :email:写在前面
|
||||
|
||||
***
|
||||
|
||||
如果只是写个人学习总结的博客很容易,简单写一些感悟然后贴上代码走人就可以了,甚至不用校审。但是我命名本系列为【C语言必知必会】帮助你从入门到精通 C语言,那势必要“事无巨细”一些:既要考虑到没有基础的初学者,又不能止于基础。所以本教程适合各类人群学习,只要你看就一定会有帮助。
|
||||
|
||||
本教程是本人纯手打并排版,校审由我与我的搭档汤圆君一起完成的。你们看这一篇文章我要写好几个小时。如果文章对你有帮助,请不要“白嫖”。支持一下作者,作者会发更多干货好文。
|
||||
|
||||
特别鸣谢:汤圆君(公众号:【Cc听香水榭】 长期更新高质量英语教学)关注她表示对她工作的认可吧!
|
||||
|
||||
### :books:教学
|
||||
|
||||
***
|
||||
|
||||
### 第一个C程序
|
||||
|
||||
**main.c**
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void){
|
||||
|
||||
printf("Hello,World\n");//a simple C program
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
将上述程序写在你的编译器里。
|
||||
|
||||
然后给文件命名,并以`.c`作为扩展名,例如`main.c`。
|
||||
|
||||
现在,编译并运行该程序。如果一切正常,输出的应该是:
|
||||
|
||||
```c
|
||||
Hello,World
|
||||
```
|
||||
|
||||
|
||||
|
||||
恭喜你,你已经是一名C程序员了!:laughing:
|
||||
|
||||
|
||||
|
||||
*Hello,World 是伟大的。它像着一个呱呱坠地的婴儿对世界的问好,它憧憬着美好的世界,一切事物都是新鲜的。*
|
||||
|
||||
——不会编程的程序圆
|
||||
|
||||
现在,让我们看看这个程序到底是什么意思。
|
||||
|
||||
### 正式开始之前
|
||||
|
||||
#### 编译和链接
|
||||
|
||||
C程序编译链接的过程:(知道即可)
|
||||
|
||||
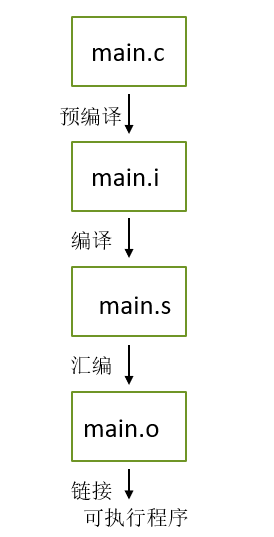
|
||||
|
||||
#### 集成开发环境
|
||||
|
||||
> 集成开发环境(integrated development enviroment,IDE):集成开发环境是一个软件包,我们可以在其中编辑,编译,链接,执行和调试程序。
|
||||
|
||||
IDE推荐:
|
||||
|
||||
CodeBlock(本教学中的简单的程序会用这个软件来完成)
|
||||
|
||||
VS2019(编写需要调试的程序用它来完成)
|
||||
|
||||
### 简单程序的一般形式
|
||||
|
||||
#### 1. 指令
|
||||
|
||||
示例程序第一行`#include<stdio.h>`就是一条指令。
|
||||
|
||||
在程序**编译之前**,C编译器的**预处理器**(preprocessor)会首先对源代码进行一些准备工作,即预处理(preprocessing)。
|
||||
|
||||
> **指令(directive):**我们把 预处理器 执行的命令称为 预处理器指令(preprocessor directive),简称指令。
|
||||
>
|
||||
> 指令的结尾不需要添加分号
|
||||
|
||||
`#include<stdio.h>`的作用相当于把 **头文件** `stdio.h` 中的所有内容都输入到该行所在的位置。
|
||||
|
||||
实际上,这是一种**复制+粘贴**的操作。
|
||||
|
||||
**include 文件提供了一种方便的途径共享许多程序共有的信息**。
|
||||
|
||||
`stdio.h`文件中包含了供编译器使用的输入和输出函数(如 `printf()`)信息。
|
||||
|
||||
该文件名的含义为**标准输入/输出**头文件(stadard input&output .header)
|
||||
|
||||
> **头文件(header):**在C程序顶部的信息集合。
|
||||
|
||||
每个头文件都包含一些标准库的内容。
|
||||
|
||||
示例程序引入stdio.h头文件的原因:C语言不同于其他编程语言,它没有内置的“读/写”命令。输入/输出功能由标准库中的函数实现。[^1]
|
||||
|
||||
**每次用到库函数,必须用#include指令包含相关的头文件。**省略必要的头文件可能不会对某一个特定程序造成影响,但是最好不要这样做。
|
||||
|
||||
[^1]: 为何不内置输入/输出? 原因之一是并非所有程序都会用到I/O(输入输出)包 。简洁高效表现了C语言的哲学。
|
||||
|
||||
|
||||
|
||||
#### 2.函数
|
||||
|
||||
`int main(void)`
|
||||
|
||||
> **函数:**类似于其他编程语言的“过程”或“子例程”,它们是用来构建程序的构建块。
|
||||
|
||||
事实上,C语言就是函数的集合。
|
||||
|
||||
函数分两大类:第一种是程序员自己编写的函数;另一类则是C作为语言实现的一部分提供的函数,即**库函数**(library function)。因为它们属于一个由编译器提供的函数“库”。
|
||||
|
||||
**main函数**:C程序都是从`main()`函数“开始”执行。`main()`函数是程序的唯一入口。**可以理解为程序是从main函数开始运行到main函数结尾结束。**
|
||||
|
||||
**返回类型**:`int`是main函数的 返回类型。这表明 main函数返回的值是整型。
|
||||
|
||||
*返回给哪里?返回给操作系统,我们后面再来讲解*
|
||||
|
||||
**参数**:`()`内包含的信息为函数的参数。示例中的`void`表示该例中没有传入任何参数。
|
||||
|
||||
> **请注意**
|
||||
>
|
||||
> 有背景颜色的地方都是重要的知识,但是在这里不管你是初学者/学了一段时间了,我都建议你遵守以下规范:
|
||||
>
|
||||
> **main函数到底应该怎么写?**我在这里不详细展开说。
|
||||
>
|
||||
> **正确的形式**:`int main(int argc, char* argv[])`
|
||||
>
|
||||
> **可以接受的形式:**`int main(void)`
|
||||
>
|
||||
> **错误的写法**:`int main()` 谭老师书中的写法。跟我学,不要用这种写法
|
||||
>
|
||||
> **脑瘫的写法**:`void main()` `void main(void)`所有C语言的标准都未认可这种写法,你在赣神魔?
|
||||
|
||||
|
||||
|
||||
`return 0`
|
||||
|
||||
**返回值**:前面我们讲到了*返回类型*,那么就应该有个返回值。示例中 `return `就代表返回,`0`是这个main函数的返回值。
|
||||
|
||||
> **main函数中return的作用**:
|
||||
>
|
||||
> 1.**使main函数终止**。mian函数在这里结束。
|
||||
>
|
||||
> 2.main函数返回值是0,**表示程序正常终止**。
|
||||
|
||||
**所以,`return 0`在main函数中是不可省略的**
|
||||
|
||||
虽然即使你不写,可能也可以通过编译,但是不写是不对的。
|
||||
|
||||
|
||||
|
||||
#### 3.语句
|
||||
|
||||
> 语句是程序运行时执行的命令
|
||||
>
|
||||
> 语句是带顺序执行的 C 程序段。任何函数体都是一条复合语句,继而为语句或声明的序列
|
||||
|
||||
例如:
|
||||
|
||||
```c
|
||||
int main(void)
|
||||
{ // 复合语句的开始
|
||||
int n = 1; // 声明(非语句)
|
||||
n = n+1; // 表达式语句
|
||||
printf("n = %d\n", n); // 表达式语句
|
||||
return 0; // 返回语句
|
||||
} // 复合语句之结尾,函数体之结尾
|
||||
```
|
||||
|
||||
|
||||
|
||||
**C语言中的六种语句**
|
||||
|
||||
1. **标号语句**
|
||||
|
||||
1) [goto](https://zh.cppreference.com/w/c/language/goto) 语句的目标。 (*标识符* **:** *语句*)
|
||||
|
||||
2) [switch](https://zh.cppreference.com/w/c/language/switch) 语句的 `case` 标号。(**case** *常量表达式* **:** *语句*)
|
||||
|
||||
3) [switch](https://zh.cppreference.com/w/c/language/switch) 语句的默认标号。 (**default** **:** *语句*)
|
||||
|
||||
2. **复合语句**
|
||||
|
||||
复合语句,或称**块**,是**花括号**所包围的语句与声明的序列。
|
||||
|
||||
`{声明(可选)| 语句 }`
|
||||
|
||||
3. **表达式语句**
|
||||
|
||||
典型的 C 程序中大多数语句是表达式语句,例如赋值或函数调用。
|
||||
|
||||
无表达式的表达式语句被称作*空语句*。它通常用于提供空循环体给 [for](https://zh.cppreference.com/w/c/language/for) 或 [while](https://zh.cppreference.com/w/c/language/while) 循环。
|
||||
|
||||
4. **选择语句**
|
||||
|
||||
选择语句根据表达式的值,选择数条语句之一执行。
|
||||
|
||||
1) [if](https://zh.cppreference.com/w/c/language/if) 语句
|
||||
|
||||
2) [if](https://zh.cppreference.com/w/c/language/if) 语句带 `else` 子句
|
||||
|
||||
3) [switch](https://zh.cppreference.com/w/c/language/switch) 语句
|
||||
|
||||
5. **迭代语句**
|
||||
|
||||
迭代语句重复执行一条语句。
|
||||
|
||||
1) [while](https://zh.cppreference.com/w/c/language/while) 循环
|
||||
|
||||
2) [do-while](https://zh.cppreference.com/w/c/language/do) 循环
|
||||
|
||||
3) [for](https://zh.cppreference.com/w/c/language/for) 循环
|
||||
|
||||
6. **跳转语句**
|
||||
|
||||
跳转语句无条件地转移控制流。
|
||||
|
||||
1) [break](https://zh.cppreference.com/w/c/language/break) 语句
|
||||
|
||||
2) [continue](https://zh.cppreference.com/w/c/language/continue) 语句
|
||||
|
||||
3) [return](https://zh.cppreference.com/w/c/language/return) 语句带可选的表达式
|
||||
|
||||
4) [goto](https://zh.cppreference.com/w/c/language/goto) 语句
|
||||
|
||||
|
||||
|
||||
**为什么需要分号?**
|
||||
|
||||
由于语句可以连续占用多行,有时很难确定它结束的位置,因此需要用分号来向编译器表示语句结束的位置。但预处理指令通常只用占一行,因此**不需要**分号结尾
|
||||
|
||||
|
||||
|
||||
#### 4.打印字符串 printf() 函数
|
||||
|
||||
`printf("Hello,World\n");`
|
||||
|
||||
`printf()`是一个功能十分强大的函数。*后面我们会进一步介绍*
|
||||
|
||||
示例中我们只是用printf函数打印了出了一条**字符串字面量(string literal)** —— 用一对双引号引起来的一系列字符。
|
||||
|
||||
**字符串**,顾名思义就是一串字符。
|
||||
|
||||
printf函数不会自动换行到下一行打印,它只会在它最开始那一行一直打印直到程序迫使它换行。
|
||||
|
||||
`\n`表示printf函数打印完成后跳转到下一行
|
||||
|
||||
|
||||
|
||||
请看如下程序,思考它的效果与示例中有何不同?
|
||||
|
||||
```c
|
||||
printf("Hello,");
|
||||
printf("World\n");
|
||||
```
|
||||
|
||||
答案[^2](点击或到文章尾查看)
|
||||
|
||||
|
||||
|
||||
如果想输出下面的结果,请考虑一下,应该如何写程序呢?
|
||||
|
||||
```c
|
||||
Hello,
|
||||
World
|
||||
```
|
||||
|
||||
答案:
|
||||
|
||||
```c
|
||||
printf("Hello,\n");
|
||||
printf("World\n");
|
||||
```
|
||||
|
||||
对于这个问题,第二个printf函数的 \n 可以省略。简单来说,printf函数会在 \n 出现的地方换行。
|
||||
|
||||
|
||||
|
||||
#### 5.注释
|
||||
|
||||
`//a simple C program`
|
||||
|
||||
> 写注释可以让自己和别人更容易明白你写的程序。
|
||||
>
|
||||
> C语言注释的好处是:可以写在任何地方。注释的部分会被编译器忽略。
|
||||
|
||||
我们试想一件事你昨天吃了什么饭,记性好是吧?上周五吃的什么饭?如果连上周 一天三顿的饭都不能记住,何况你自己查看你很久之前写的代码呢?
|
||||
|
||||
##### 两种注释符号
|
||||
|
||||
第一种:`/* */`
|
||||
|
||||
单行注释
|
||||
|
||||
```c
|
||||
/* 关注微信公众号:不会编程的程序圆 */
|
||||
/* 看更多干货,获取第一时间更新 */
|
||||
/* 码字不易,对你有帮助 点赞/转发/关注,鼓励一下作者 */
|
||||
```
|
||||
|
||||
多行注释
|
||||
|
||||
```c
|
||||
/* 关注微信公众号:不会编程的程序圆
|
||||
看更多干货,获取第一时间更新
|
||||
码字不易,对你有帮助 点赞/转发/关注,鼓励一下作者 */
|
||||
```
|
||||
|
||||
但是,上面这一种注释方式可能难以阅读,因为人不不容易发现注释结束的位置。
|
||||
|
||||
改进:
|
||||
|
||||
```c
|
||||
/*关注微信公众号:不会编程的程序圆
|
||||
看更多干货,获取第一时间更新
|
||||
码字不易,对你有帮助 点赞/转发/关注,鼓励一下作者
|
||||
*/
|
||||
```
|
||||
|
||||
更好的方法:将注释部分围起来
|
||||
|
||||
```c
|
||||
/*************************************************
|
||||
* 关注微信公众号:不会编程的程序圆 *
|
||||
* 看更多干货,获取第一时间更新 *
|
||||
* 码字不易,对你有帮助 点赞/转发/关注,鼓励一下作者 *
|
||||
*************************************************/
|
||||
```
|
||||
|
||||
当然如果你嫌麻烦,也可以简化一下:
|
||||
|
||||
```c
|
||||
/*
|
||||
* 关注微信公众号:不会编程的程序圆
|
||||
* 看更多干货,获取第一时间更新
|
||||
* 码字不易,对你有帮助 点赞/转发/关注,鼓励一下作者
|
||||
*/
|
||||
```
|
||||
|
||||
简短的注释可以放在同一行
|
||||
|
||||
```c
|
||||
printf("Hello World\n");/* 不会编程的程序圆 */
|
||||
```
|
||||
|
||||
|
||||
|
||||
但是,如果你忘记了终止注释可能会导致你的编译器跳过程序的一部分,请思考下列:
|
||||
|
||||
```c
|
||||
printf("不会"); /* 关注我的公众号呦~
|
||||
printf("编程");
|
||||
printf("的"); /* 更多鼓励,更多干货!*/
|
||||
printf("程序圆");
|
||||
```
|
||||
|
||||
你可以在自己的编译器上自己敲一下,看看会输出什么。
|
||||
|
||||
由于第一条注释忘记输入结束标志,导致编译器将直到找到结束标志之前的程序都当成了注释!
|
||||
|
||||
|
||||
|
||||
第二种:`//`
|
||||
|
||||
C99提供的新的注释方式。
|
||||
|
||||
```C
|
||||
//关注微信公众号:不会编程的程序圆
|
||||
//看更多干货,获取第一时间更新
|
||||
//码字不易,对你有帮助 点赞/转发/关注,鼓励一下作者
|
||||
```
|
||||
|
||||
> 新的注释风格有两大优点:
|
||||
>
|
||||
> 1. 这种注释会在行末自动终结,所以不用担心会出现未终止的注释意外吞噬部分程序的情况
|
||||
> 2. 每行前都有 // ,所以多行的注释更加醒目
|
||||
|
||||
综上所述,建议采用 `//` 这种注释方式
|
||||
|
||||
|
||||
|
||||
[^0]: *语法糖导致分号癌。摘自《epigrams-on-programming》*
|
||||
[^2]: 相同。
|
||||
|
||||
*参考资料:《C Primer Plus》《C语言程序设计:现代方法》 网上资料:cppreference.com*
|
||||
|
||||
***
|
||||
|
||||
> 本文GitHub已更新,文中代码都可以在上面对应的目录下找到,欢迎 star !
|
||||
> https://github.com/hairrrrr/C-CrashCourse
|
||||
|
||||
|
||||
|
||||
以上就是本次的内容。
|
||||
|
||||
如果文章有错误欢迎指正和补充,感谢!
|
||||
|
||||
最后,如果你还有什么问题或者想知道到的,可以在评论区告诉我呦,我在后面的文章可以加上。
|
||||
|
||||
**关注我**,看更多干货!
|
||||
|
||||
我是程序圆,我们下次再见。
|
||||
@@ -1,365 +0,0 @@
|
||||
## C语言基本结构(下)
|
||||
|
||||
*Every program is a part of some other program and rarely fits.*[^0]
|
||||
|
||||
|
||||
|
||||
> 码字不易,对你有帮助 **点赞/转发/关注** 支持一下作者
|
||||
|
||||
> 微信搜公众号:**不会编程的程序圆**
|
||||
|
||||
> **看更多干货,获取第一时间更新**
|
||||
|
||||
### 思维导图
|
||||
|
||||
***
|
||||
|
||||
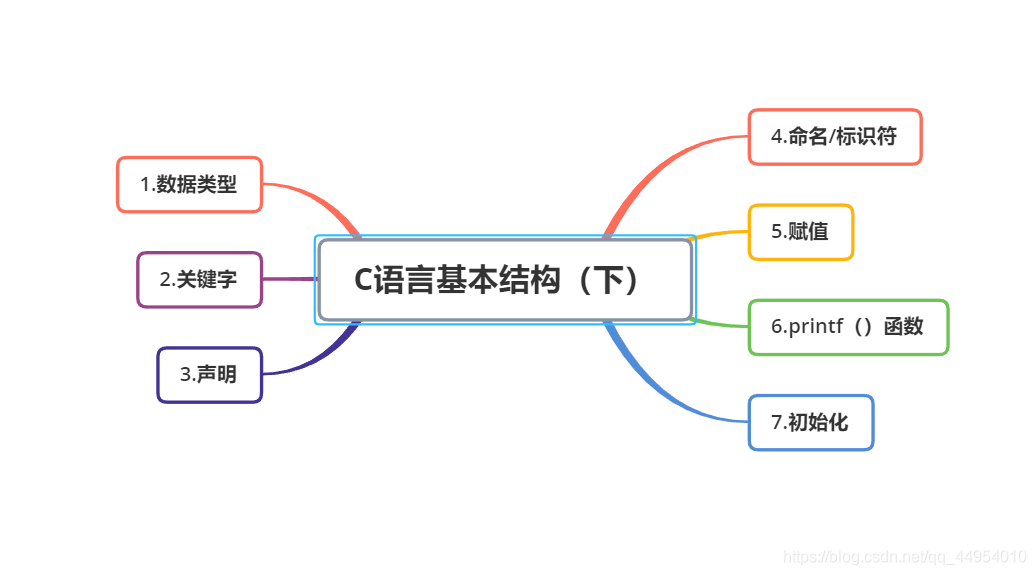
|
||||
|
||||
###
|
||||
|
||||
***
|
||||
|
||||
|
||||
|
||||
### :email:写在前面
|
||||
|
||||
***
|
||||
|
||||
如果只是写个人学习总结的博客很容易,简单写一些感悟然后贴上代码走人就可以了,甚至不用校审。但是我命名本系列为【C语言必知必会】帮助你从入门到精通 C语言,那势必要“事无巨细”一些:既要考虑到没有基础的初学者,又不能止于基础。所以本教程适合各类人群学习,只要你看就一定会有帮助。
|
||||
|
||||
本教程是本人纯手打并排版,校审由我与我的搭档汤圆君一起完成的。你们看这一篇文章我要写好几个小时。如果文章对你有帮助,请不要“白嫖”。支持一下作者,作者会发更多干货好文。
|
||||
|
||||
特别鸣谢:汤圆君(公众号:【Cc听香水榭】 长期更新高质量英语教学)关注她表示对她工作的认可吧!
|
||||
|
||||
》 此符号表示该内容以后的章节会讲解,此章节内不要求理解。
|
||||
|
||||
|
||||
|
||||
### 简单的程序结构
|
||||
|
||||
***
|
||||
|
||||
下面是一个简单的程序,身高是给出的,体重是在程序中得到的,我们输出的是体重与身高/体重的值。
|
||||
|
||||
这里我们更注重的是**程序的结构**而非程序本身。
|
||||
|
||||
|
||||
|
||||
示例
|
||||
|
||||

|
||||
|
||||
|
||||
#### 1. 类型
|
||||
|
||||
> 每一个变量都有**类型**(type)。类型用来描述变量的数据的种类,也称**数据类型**。
|
||||
|
||||
数值型变量的类型决定了变量所能存储的最大值与最小值,以及是否允许小数点后出现数字。
|
||||
|
||||
示例中只有一种数据类型:`int`
|
||||
|
||||
> **int**(integer):即整型,表示整数。
|
||||
|
||||
数据类型还有很多,目前除了 int 以外,我们只再使用另一种:
|
||||
|
||||
> **float**(floating-point): 浮点型,可以表示小数
|
||||
|
||||
**注意**:虽然 float 型可以带小数,但是进行**算术运算**时,float 型要比 int 型慢,而且 float 通常只是一个值的近似值。(比如在一个float 型变量中存储 0.1, 但其实可能这个变量的值为 0.09999987,这是舍入造成的误差)
|
||||
|
||||
*题外话:我当时学的时候,就没有人告诉我这些知识,你们如果现在是初学,我都感觉到羡慕,你们要少走多少弯路啊!*
|
||||
|
||||
|
||||
|
||||
#### 2. 关键字
|
||||
|
||||
> int 与float 都是C语言的**关键字**(keyword),关键字是语言定义的单词,**不能用做其他用途**。比如不能用作命名函数名与变量名。
|
||||
|
||||
关键字:*斜体代表C99新增关键字*
|
||||
|
||||
| auto | enum | unsigned | break | extern |
|
||||
| ---------- | -------- | -------- | ---------- | ------------ |
|
||||
| return | void | case | float | short |
|
||||
| volatile | char | for | signed | while |
|
||||
| const | goto | sizeof | continue | if |
|
||||
| static | default | struct | do | int |
|
||||
| switch | double | long | typedef | else |
|
||||
| register | union | | | |
|
||||
| *restrict* | *inline* | *_Bool* | *_Complex* | *_Imaginary* |
|
||||
|
||||
如果关键字使用不当(关键字作为变量名),编译器会将其视为语法错误。
|
||||
|
||||
|
||||
|
||||
> 保留标识符(reserved identifier):下划线开头的标识符和标准库函数名(如:printf())
|
||||
|
||||
C语言已经指定了这些标识符的用途或保留了它们的使用权,如果你使用它们作为变量名,即使没有语法错误,也不能随便使用。
|
||||
|
||||
#### 3. 声明
|
||||
|
||||
> **声明**(declaration):在使用变量(variable)之前,必须对其进行声明(为编译器所作的描述)。
|
||||
>
|
||||
> 声明的方式为:数据类型 + 变量名(程序员自己决定变量名,命名规则后面会讲)
|
||||
|
||||
示例中的 `int weight`完成了两件事情。第一,函数中有个变量名为 weight。第二,int 表明这个变量是整型。
|
||||
|
||||
编译器用这些信息为变量 weight 在内存中分配空间。
|
||||
|
||||
|
||||
|
||||
**C99** 前,如果有声明,声明一定要在语句之前。(就像示例那样,函数体中第一块是声明,第二块才是语句。)
|
||||
|
||||
C99 和 C11 遵循 C++ 的惯例,可以把声明放在任何位置。即可以使用时再声明变量。以后C程序中这种做法可能会很流行。**但是目前不建议这样。**
|
||||
|
||||
|
||||
|
||||
就**书写格式**而言,我建议将声明全部放在**函数体头部**,声明与语句之间**空出一行**。
|
||||
|
||||
|
||||
|
||||
#### 4. 命名
|
||||
|
||||
> weight,height 都是**标识符**,也就是一个变量,函数或其他实体的名称。因此,声明将特定标识符与计算机内存的特定位置联系起来,同时也就确定了存储在某位置的信息类型或数据类型。
|
||||
|
||||
|
||||
|
||||
给变量命名时要使用有意义的变量名或标识符。如果变量名无法清楚的表达自身的用途,可以在注释中进一步说明,这是一种良好的编程习惯与编程技巧。
|
||||
|
||||
C99 与 C11 允许使用更长的标识符,但是编译器只识别前 63个字符。*对于外部标识符,只允许 31 个字符*。事实上,你可以使用更长的字符,但是编译器可能忽略超出的部分。(比如有两个标识符都是 64 个字符,但只有最后一个字符不同。编译器可能会视其为同一个名字,也可能不会。标准并未定义在这种情况下会发生什么。)
|
||||
|
||||
|
||||
|
||||
> 命名规则:可以用小写字母,大写字母,数字和下划线(_)来命名。**名称的第一个字符必须是字符或下划线,不能是数字**
|
||||
|
||||
**操作系统和C库经常使用一个下划线或两个下划线开始的标识符(如:_kcab),因此最好避免在自己的程序中使用这种名称。(避免与操作系统和c库的标识符重复)**
|
||||
|
||||
C语言的名称区分大小写。即:star,Star,STAR 是不同的。
|
||||
|
||||
|
||||
|
||||
**声明变量的理由**:
|
||||
|
||||
1. 把所有变量放在一处,方便读者查找和理解程序的用途。
|
||||
2. 声明变量可以促使你在编写程序之前做好计划(比如你的程序要用什么变量,你可以提前规划)。
|
||||
3. 声明变量有助于发现程序中的小错误,如拼写错误。
|
||||
4. **不提前声明变量,C程序编译将无法通过**
|
||||
|
||||
|
||||
|
||||
#### 5. 赋值
|
||||
|
||||
> 赋值(assignment):变量通过赋值的方式获得值。
|
||||
|
||||
示例中,`weight = 160; `是一个 **赋值表达式语句**。意思是“把值 160 赋给 变量 weight”。
|
||||
|
||||
在执行 `int weight;`时,编译器在计算机内存中为变量 weight 预留的空间,然后在执行这行代码时,把值存储在之前预留的位置。可以给 weight 赋不同的值,这就是 weight 之所以被称为变量的原因。
|
||||
|
||||
**注意:**
|
||||
|
||||
- 该行表达式将值从右侧赋到左侧。
|
||||
|
||||
- 该语句以分号结尾。
|
||||
- `=` 在计算机中不是相等的意思,而是赋值。我们在读 `weight = 160; `时,我们应该这么读:“将 160 赋给 weight”
|
||||
- `==`表示相等
|
||||
|
||||
|
||||
|
||||
#### 6. printf() 函数
|
||||
|
||||
`printf(“我的体重是:%d斤\n,身高与体重的比为:%d”, weight, height / weight);`
|
||||
|
||||
这是我们示例中的 printf 函数,我们来看两个不那么复杂的:
|
||||
|
||||
```c
|
||||
main(void);
|
||||
printf("Hi");
|
||||
```
|
||||
|
||||
|
||||
|
||||
首先,printf() 的 **圆括号**是不是很像 main() ?这表示 printf 是一个函数名,它也是一个函数。圆括号内的内容是从 main() 函数传递给 printf() 函数的信息。该信息被称为**参数**,更确切的说,是**实际参数**(actual argument),简称**实参**。
|
||||
|
||||
既然是函数,它其实也是像我们看到的 main函数一样,也有函数头和函数体。
|
||||
|
||||
printf() 函数是一个库函数,库函数我们上一节讲函数种类时说过,这是一种不需要程序员去写的,只需要引用头文件 `stdio.h`就可以直接使用的。但是我们应该知道这一点,详细情况我们后面会说讲。
|
||||
|
||||
**当程序运行到 printf() 函数这一行时,控制权被转给了printf()函数。函数执行结束后,控制权被返回至主调函数(calling function),该例中是 main()** 。
|
||||
|
||||
|
||||
|
||||
printf() 函数的作用是向我们的显示器输出内容。
|
||||
|
||||
此例中,printf() 函数的括号内 分为两部分,一部分在双引号内,另一部分在双引号外,它们中间以逗号隔开。双引号外有两个参数 weight 和 height / weight ,他们分别是变量和**表达式**(含有常量,变量和运算符的式子),也是指定要被打印的参数(打印到你的屏幕上)。
|
||||
|
||||
我们发现,最终我们屏幕上看到的是引号内的内容。我们可以来看一下输出的内容:
|
||||
|
||||
```c
|
||||
我的体重是:160斤
|
||||
身高与体重的比为:1
|
||||
```
|
||||
|
||||
|
||||
|
||||
我们发现:首先引号内的 `%d` 和`\n`并没有被输出,`%d`的位置被替换成了一个整数。为什么会这样呢?
|
||||
|
||||
> `\n`代表**一个换行符(newline character)**。对于 printf 函数来说,它的意思是:“**在下一行的最左边开始新的一行**”。
|
||||
>
|
||||
> 也就是说换行符和在键盘上按下 Enter按键相同。
|
||||
>既然如此,为何不在键入 printf() 参数时直接使用 Enter键呢?因为编辑器可能认为这是直接的命令,而不是存储在源代码中的指令。换句话说,如果直接按下 Enter键,编辑器会退出当前行并开始新的一行。但是,换行符会影响程序输出的(显示)格式。
|
||||
|
||||
换行符是一个**转义序列**(escape sequence)。转义序列用于难以表示或无法输入的字符。如,`\t`代表 Tab键,即制表符。`\b`代表 Backspace键,即退格键。我们在后面会继续讨论。
|
||||
|
||||
这样就解释了为何一行的printf() 函数会输出两行。
|
||||
|
||||
|
||||
|
||||
*以下这部分不能理解可以只看结论,能理解更好。*
|
||||
|
||||
在解释 %d 之前我们先来看一下,weight 和 height / weight 所代表的值。
|
||||
|
||||
weight 是被赋值为 160 的,所以 weight 的值就是 160
|
||||
|
||||
C语言中,`/`表示除法, `*` 表示乘法。
|
||||
|
||||
那么 height / weight 的值是多少呢?我们现在不知道这个表达式的值是多少,但是我们知道这个它肯定代表 180 / 160
|
||||
|
||||
而最终输出的值是 1 ,这和我们想的不一样,我们知道结果应该是个小数,那么这是为什么呢?
|
||||
|
||||
我想可能的原因有两个:
|
||||
|
||||
1. %d 将小数转换为整数
|
||||
2. 180 / 160 本身在C语言中的值就是整数
|
||||
|
||||
我们来测试一下:
|
||||
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
int a = 3;
|
||||
int b = 2;
|
||||
float c = 1.1f;//f 表示1.1是浮点数
|
||||
|
||||
printf("%d\n", c);//%d 用来输出整型
|
||||
printf("%f\n", a / b);//%f 用来输出浮点型
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```c
|
||||
-1717986918
|
||||
0.000000
|
||||
```
|
||||
|
||||
输出并不是我们想要的内容,我们来看一下编译器的警告:
|
||||
|
||||
编译器警告:
|
||||
|
||||
```c
|
||||
“printf”: 格式字符串“%d”需要类型“int”的参数,但可变参数 1 拥有了类型“double”
|
||||
“printf”: 格式字符串“%f”需要类型“double”的参数,但可变参数 1 拥有了类型“int”
|
||||
```
|
||||
|
||||
可以不去理解报错的内容。输出与报错至少说明了一点:
|
||||
|
||||
**%d 在我的编译器上无法输出浮点型;整型 / 整型 不是浮点型。**
|
||||
|
||||
那就说明了原因2是对的,即:**180 / 160 的值就是 1**
|
||||
|
||||
|
||||
|
||||
为什么 `180 / 160 == 1 `(180 / 160 的值是 1)呢?
|
||||
|
||||
因为 weight 和 height 都整数,它们相除结果取整数(向下取整)。
|
||||
|
||||
|
||||
|
||||
如何输出 float 类型的浮点数?
|
||||
|
||||
```c
|
||||
printf("%f", 2.0f);
|
||||
```
|
||||
|
||||
|
||||
|
||||
>`%d`是一个占位符,其作用是指明 num 值的位置。d 代表 以十进制的格式。
|
||||
|
||||
|
||||
|
||||
还有一点要注意的是,在示例中,第二个输出的整数的参数(height / weight )是一个表达式,我们也可以在程序中添加一个新的变量,然后用这个变量代替上面的表达式作为 printf() 的参数。如:
|
||||
|
||||
```c
|
||||
int main(void)
|
||||
{
|
||||
int height = 180;
|
||||
int weight, scale;//scale:比例
|
||||
weight = 160;
|
||||
scale = height / weight;
|
||||
printf(“我的体重是:%d斤\n,身高与体重的比为:%d”, weight, scale);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
合理的使用表达式作为函数的参数可以简化程序。
|
||||
|
||||
也说明**在任何需要数值的地方,都可以使用具有相同类型的表达式**。
|
||||
|
||||
|
||||
|
||||
#### 7. 初始化
|
||||
|
||||
当程序开始执行时,某些变量会被自动设置为0,而大多数不会。没有默认值并且尚未在程序中被赋值的变量时未初始化的(uninitialized)。
|
||||
|
||||
如果试图访问未初始化的变量,可能会得到不可预知的值。在某些编译器中,可能会发生更坏的情况(甚至程序崩溃)。
|
||||
|
||||
|
||||
|
||||
我们可以用赋值的办法给变量赋初值,但还有更简洁的做法:在变量声明中加入初始值。
|
||||
|
||||
例如示例中的 `int height = 180`数值 180 就是一个**初始化式**(initializer)。
|
||||
|
||||
|
||||
|
||||
同一个声明中可以对任意数量的变量进行初始化。如:
|
||||
|
||||
```c
|
||||
int a = 10, b = 15, c = 20;
|
||||
```
|
||||
|
||||
上述每个变量都拥有属于自己的初始化式。接下来的例子,只有 c 有初始化式,a,b没有。
|
||||
|
||||
```c
|
||||
int a, b, c = 20;
|
||||
```
|
||||
|
||||
|
||||
|
||||
***
|
||||
|
||||
[^0]: 每个程序都是其他程序不合适的一部分。
|
||||
|
||||
*参考资料:《C Primer Plus》《C语言程序设计:现代方法》*
|
||||
|
||||
|
||||
|
||||
> 本文GitHub已更新,所有教学和练习代码都会上传上去,欢迎 star !
|
||||
>
|
||||
> https://github.com/hairrrrr/C-CrashCourse
|
||||
|
||||
|
||||
|
||||
***
|
||||
以上就是本次的内容。
|
||||
|
||||
如果文章有错误欢迎指正和补充,感谢!
|
||||
|
||||
最后,如果你还有什么问题或者想知道到的,可以在评论区告诉我呦,我可以在后面的文章加上你们的真知灼见。
|
||||
|
||||
**关注我**,看更多干货!
|
||||
|
||||
我是程序圆,我们下次再见。
|
||||
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1,764 +0,0 @@
|
||||
>看下去一定对你有帮助!有帮助就点个赞吧
|
||||
|
||||
字符串函数 指的是头文件 ` stdio.h ` 中的输入输出函数 和 头文件`string.h`里定义的我们平时直接使用的函数。
|
||||
一下是本节重点讲解的 10 个函数。对于生僻点的字符串函数我们以后再讲。
|
||||
|
||||
- putchar & getchar
|
||||
- strlen & strnlen_s
|
||||
- strcmp & strncmp
|
||||
- strcpy & strncpy
|
||||
- strcat & strncat
|
||||
|
||||
这些函数我们到处在用,可你有没有想过,究竟这些函数是怎么声明和定义的?他们远没有你想的那么简单。
|
||||
|
||||
**以下被划掉的部分如果你理解,那是最好。不理解不可以不用纠结,~~慢慢来~~**
|
||||
|
||||

|
||||
|
||||
### (一)putchar & getchar
|
||||
#### putchar
|
||||
>`int putchar( int ch )`
|
||||
>**头文件**:stdio.h
|
||||
>
|
||||
**定义**:写字符 ch 到 stdout 。在内部,字符于写入前被转换到 unsigned char 。
|
||||
>*stdout:标准输出 我们后面会单独讲*
|
||||
>意思就是:向标准输出写入一个字符
|
||||
~~等价于 putc(ch, stdout) 。~~
|
||||
|
||||
>**参数**: `ch` 要被写入的字符串
|
||||
|
||||
>**返回值**:
|
||||
>成功时返回写入的字符。
|
||||
失败时返回 EOF ~~并设置 stdout 上的错误指示器~~
|
||||
*EOF(end of file)是一个宏,值为 -1*
|
||||
|
||||
|
||||
第一次看到这个函数的 返回类型 和 参数类型 我其实很懵:
|
||||
|
||||
嗯?
|
||||
|
||||
我输入的不是 char 类型的吗? 怎么参数类型是 int ?
|
||||
|
||||
我看到的不是 char 类型的 `A` 吗?怎么返回类型是 int?
|
||||
|
||||

|
||||
|
||||
其实,输出是什么不代表返回就是什么。scanf还返回整数呢,照样可以输出汉字。
|
||||
|
||||
下面的程序帮助大家理解:
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
char ch = 'A';
|
||||
|
||||
int a = 0;
|
||||
|
||||
a = putchar(ch);
|
||||
|
||||
printf("\n%d", a);
|
||||
|
||||
return 0;
|
||||
|
||||
}
|
||||
```
|
||||
输出:
|
||||
```c
|
||||
A
|
||||
65
|
||||
```
|
||||
|
||||
上面我说慢慢来的时候也许有同学不屑:“这还用慢慢来?早会了!”
|
||||
|
||||
那好吧,`putchar` 的上面的定义中说它等价于 `putc`
|
||||
|
||||
要不我们再来看看 putc 是怎么定义的?与 putc 类似的还有个 `fputc`
|
||||
|
||||
要想真正理解它们还得看看 `ferror`,一个个来呗?
|
||||
|
||||

|
||||
|
||||
A watched pot never boils —— 心急吃不了热豆腐
|
||||
|
||||
#### getchar
|
||||
>`int getchar(void)`
|
||||
|
||||
>**头文件**:stdio.h
|
||||
|
||||
>**定义**:
|
||||
>从 stdin 读取下一个字符。
|
||||
~~等价于 getc(stdin) 。~~
|
||||
也就是 从标准输入读入一个字符
|
||||
|
||||
>**参数**:无
|
||||
|
||||
>**返回值**:
|
||||
成功时为获得的字符
|
||||
失败时为 EOF 。
|
||||
|
||||
#### getchar的返回值有什么用?
|
||||
如何退出下面程序中的 while循环?
|
||||
|
||||
可以自己打出来先测试一下。
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
int ch;
|
||||
|
||||
while ((ch = getchar()) != EOF) {
|
||||
putchar(ch);
|
||||
}
|
||||
|
||||
printf("EOF\n");
|
||||
//退出循环的方式可能有两种:
|
||||
//1.程序被关闭。EOF不会输出
|
||||
//2.退出了循环,程序继续向下运行。EOF会被输出
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
后面还会继续详细讲解 这部分知识。可以自行思考一下,也可以查阅资料看看。
|
||||
|
||||
我做了一个便于理解的图示,如果现在就想看,在公众号回复[0206]查看。
|
||||
|
||||
*为了减少冗余,下面的程序我只写 main 函数部分,
|
||||
|
||||
但是在你写程序到时候你要记得引用头文件 string.h*
|
||||
|
||||
### (二)strlen & strnlen_s
|
||||
帮你理解:
|
||||
strlen: string lenth
|
||||
#### strlen
|
||||
>`size_t strlen( const char *str )`
|
||||
|
||||
>**头文件**:`string.h`
|
||||
|
||||
>**参数**:str - 指向要检测的空终止字符串的指针
|
||||
|
||||
>**返回值**: 空终止字节字符串 str 的长度。
|
||||
>***
|
||||
|
||||
>**定义**:返回给定空终止字符串的长度,即首元素为 str 所指,且不包含首个空字符的字符数组中的字符数。
|
||||
若 str 不是指向空终止字节字符串的指针则行为未定义。
|
||||
|
||||
*什么是 空终止字节字符串?
|
||||
空终止字节字符串( NTBS )是尾随零值字节(空终止字符)的非零字节序列。字节字符串中的每个字节都是一些字符集的编码。例如,字符数组 {'\x63','\x61','\x74','\0'} 是一个以 ASCII 编码表示字符串 "cat" 的 NTBS 。*
|
||||
|
||||
#### strnlen_s
|
||||
>`size_t strnlen_s( const char *str, size_t strsz )`
|
||||
|
||||
>**头文件**:`string.h`
|
||||
|
||||
>**参数**:
|
||||
>str - 指向要检测的空终止字符串的指针
|
||||
strsz - 要检测的最大字符数量
|
||||
|
||||
>**返回值**:
|
||||
>成功时为空终止字节字符串 str 的长度,若 str 是空指针则为零,若找不到空字符则为 strsz 。
|
||||
>***
|
||||
|
||||
>**定义**:
|
||||
>除了若 str 为空指针则返回零,而若在 str 的首 strsz 个字节找不到空字符则返回 strsz 。
|
||||
> 若 str 指向缺少空字符的字符数组且该字符数组的大小 < strsz 则行为未定义;~~换言之, strsz 的错误值不会暴露行将来临的缓冲区溢出。~~
|
||||
|
||||
#### strlen 与 strnlen_s 的区别与用法
|
||||
|
||||
**1.空指针**
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char* str = NULL;
|
||||
|
||||
//str为空指针,行为未定义。程序会崩溃
|
||||
printf("%d\n", strlen(str));
|
||||
|
||||
//str为空指针,返回 0
|
||||
printf("%d\n", strnlen_s(str, 1));
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
**2.没有终止符的字符串数组当作函数参数**
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char str[] = { 'H', 'E', 'L', 'L', 'O', };
|
||||
|
||||
printf("%d\n", strlen(str));
|
||||
|
||||
printf("%d\n", strnlen_s(str, (size_t)sizeof(str)));
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
猜一猜会输出什么?
|
||||
```c
|
||||
19
|
||||
5
|
||||
```
|
||||
**当我们不清楚字符串中有没有 '\0' 时,我们要小心使用 strlen**
|
||||
|
||||
strlen 只有遇到 '\0' 才会停止,这造成的潜在的数组越界风险。
|
||||
|
||||
**3. 当 strsz > str的大小 时**
|
||||
1)若 str 有终止符
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char str[] = { 'H', 'I', '!', 0 };
|
||||
|
||||
printf("%d\n", strnlen_s(str, 5));
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
```c
|
||||
3
|
||||
```
|
||||
2) 若 str 无终止符, 行为未定义
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char str[] = { 'H', 'I', '!'};
|
||||
|
||||
printf("%d\n", strnlen_s(str, 5));
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
```c
|
||||
5
|
||||
```
|
||||
最后,对于 `strnlen_s `来说**如果 strsz < str数组大小**,直接返回 strsz
|
||||
|
||||
#### strlen 详解
|
||||
###### const的作用
|
||||
`size_t strlen( const char *str )`
|
||||
|
||||
const 的作用是什么?
|
||||
|
||||
简单来说,如果你不希望这个函数改变你传入的数组,const 具有保护作用,使得 strlen 函数内部无法改变 str 数组每个元素的值。
|
||||
|
||||
const详解可以参考这篇文章:
|
||||
|
||||
[点击查看](https://mp.weixin.qq.com/s/Fc-sAgpXmJ1eVKufZCvN8A)
|
||||
|
||||
#### mystrlen
|
||||
mystrlen 的写法有很多,如果你的编译器是 VS,你甚至可以直接看编译器是如何去写的。
|
||||
|
||||
一下提供一种比较简洁的写法供大家参考:
|
||||
|
||||
不难(你细品
|
||||
|
||||
```c
|
||||
int mystrlen(const char* str) {
|
||||
|
||||
char* end = str;
|
||||
|
||||
while ( *end++ );
|
||||
|
||||
//退出while循环时,多加了一次 1
|
||||
return (end - start - 1);
|
||||
|
||||
}
|
||||
|
||||
int main() {
|
||||
|
||||
char* str = "Hello World!";
|
||||
|
||||
printf("%d\n", mystrlen(str));
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||

|
||||
### (三) strcmp & strncmp
|
||||
如何记忆?
|
||||
strcmp:string compare
|
||||
|
||||
lhs:left-hand side
|
||||
|
||||
rhs:right-hand side
|
||||
#### strcmp
|
||||
>`int strcmp( const char *lhs, const char *rhs )`
|
||||
>**头文件**:`string.h`
|
||||
|
||||
>**参数**:
|
||||
lhs, rhs - 指向要比较的空终止字节字符串的指针
|
||||
|
||||
>**返回值**:
|
||||
>若字典序中 lhs 先出现于 rhs 则为负值。
|
||||
|
||||
>若 lhs 与 rhs 比较相等则为零。
|
||||
|
||||
>若字典序中 lhs 后出现于 rhs 则为正值。
|
||||
>***
|
||||
>*什么是字典序?*
|
||||
>*简单理解就是在字母表中出现的顺序。*
|
||||
>*记法小窍门:*
|
||||
|
||||
>*lhs ASCII码值大 就为正 否则为负*
|
||||
>*解释:ASCII值大在字典序中肯定靠后,是后出现的*
|
||||
>***
|
||||
>**定义**:
|
||||
>以字典序比较二个空终止字节字符串。
|
||||
|
||||
>结果的符号是被比较的字符串中首对不同字符(都转译成 unsigned char )的值间的差的符号。
|
||||
|
||||
>若 lhs 或 rhs 不是指向空终止字节字符串的指针,则行为未定义。
|
||||
|
||||
### strncmp
|
||||
>`int strncmp( const char *lhs, const char *rhs, size_t count )`
|
||||
>**头文件**:`string.h`
|
||||
|
||||
>**参数**:
|
||||
|
||||
>lhs, rhs - 指向要比较的可能空终止的数组的指针
|
||||
|
||||
>count - 要比较的最大字符数
|
||||
|
||||
>**返回值**:
|
||||
>若字典序中 lhs 先出现于 rhs 则为负值。
|
||||
|
||||
>若 lhs 与 rhs 比较相等,或若 count 为零,则为零。
|
||||
|
||||
>若字典序中 lhs 后出现于 rhs 则为正值。
|
||||
>***
|
||||
>**定义**:
|
||||
|
||||
>比较二个可能空终止的数组的至多 count 个字符。按字典序进行比较。不比较后随空字符的字符。
|
||||
|
||||
>结果的符号是被比较的数组中首对字符(都转译成 unsigned char )的值间的差的符号。
|
||||
|
||||
>若出现越过 lhs 或 rhs 结尾的访问,则行为未定义。若 lhs 或 rhs 为空指针,则行为未定义。
|
||||
#### strcmp 与 strncmp 比较
|
||||
**1. lhs 或 rhs 为非空终止字符字符串**
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char str2[3] = { 'J', 'I', 'M' };
|
||||
//'M' 后的字符是不可预测的。但是肯定都比0大,所以输出 0 或 1
|
||||
//你可以试试将 str1 也改为 str2 的数组形式, 试试结果会不会为 -1
|
||||
char str1[3] = "JIM";
|
||||
|
||||
printf("%d\n", strcmp(str1, str2));
|
||||
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
**2. count 的作用**
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char* str1 = "Helloa";
|
||||
char* str2 = "HelloA";
|
||||
|
||||
printf("%d\n", strcmp(str1, str2));
|
||||
//输出 1, str1 > str2
|
||||
|
||||
printf("%d\n", strncmp(str1, str2, 5));
|
||||
//输出 0, str1 = str2
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
**3. "Hello" 与 "Hello " 的区别?**
|
||||
字符串 "Hello" 是小于字符串 "Hello " 的。(用strcmp函数检测)
|
||||
因为最后一次字符比较是 '\0' 与 ' '比较,
|
||||
'\0' ASCII码值为 0, ' ' ASCII码值为 32
|
||||
如图:
|
||||

|
||||
```c
|
||||
int main() {
|
||||
|
||||
char* str1 = "Hello";
|
||||
char* str2 = "Hello ";
|
||||
|
||||
printf("%d\n", strcmp(str1, str2));
|
||||
printf("%d\n", strncmp(str1, str2, 10));
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
输出:
|
||||
```c
|
||||
-1
|
||||
-1
|
||||
```
|
||||
|
||||
#### mystrcmp
|
||||
先想后做,事半功倍:
|
||||
1. 按字符比较,都相等返回0;
|
||||
出现不相等,返回 *lhs - *rhs 的差值
|
||||
2. *lhs 或 *rhs 遇到 '\0' 退出循环返回 差值
|
||||
|
||||
```c
|
||||
int mystrcmp(char* str1, char* str2) {
|
||||
|
||||
while (1) {
|
||||
if (*str1 != *str2)
|
||||
break;
|
||||
else if (*str1 == 0)
|
||||
break;
|
||||
else
|
||||
++str1, ++str2;
|
||||
}
|
||||
|
||||
return (*str1 - *str2);
|
||||
}
|
||||
|
||||
int main() {
|
||||
|
||||
char* str1 = "Hello";
|
||||
char* str2 = "Hello";
|
||||
|
||||
printf("%d\n", mystrcmp(str1, str2));
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
上面的 mystrcmp 看着很笨,当然是可以改进的。
|
||||
自己思考一下。
|
||||
答案放在了我的GitHub上。[点击查看](https://github.com/hairrrrr/C-CrashCourse/tree/master/C%20Crash%20Course/13%20String/Prelesson/code/mystrcmp)
|
||||
对你有帮助,麻烦给我点个小星星哦,方便下次查看。
|
||||
如果你有更好的解法,欢迎 pull request !
|
||||
|
||||

|
||||
### (四) strcpy & strncpy
|
||||
帮助理解:
|
||||
strcpy:string copy
|
||||
|
||||
dest:destination
|
||||
|
||||
src:source
|
||||
#### strcpy
|
||||
>`char *strcpy( char *dest, const char *src )`
|
||||
>**头文件**:`string.h`
|
||||
|
||||
>**参数**:
|
||||
|
||||
>dest - 指向要写入的字符数组的指针
|
||||
|
||||
>src - 指向要复制的空终止字节字符串的指针
|
||||
|
||||
>**返回值**:
|
||||
|
||||
>返回 dest 的副本
|
||||
|
||||
>***
|
||||
|
||||
>**定义**:
|
||||
|
||||
>复制 src 所指向的空终止字节字符串,包含空终止符,到首元素为 dest 所指的字符数组。
|
||||
若 dest 数组长度不足则行为未定义。
|
||||
若字符串覆盖则行为未定义。
|
||||
若 dest 不是指向字符数组的指针或 src 不是指向空终止字节字符串的指针则行为未定义。
|
||||
|
||||
#### strncpy
|
||||
>`char *strncpy( char *dest, const char *src, size_t count )`
|
||||
|
||||
>**头文件**:`string.h`
|
||||
|
||||
>**参数**:
|
||||
|
||||
>dest - 指向要复制到的字符数组的指针
|
||||
|
||||
>src - 指向复制来源的字符数组的指针
|
||||
|
||||
>count - 要复制的最大字符数
|
||||
|
||||
>**返回值**:
|
||||
|
||||
> 返回 dest 的副本
|
||||
>
|
||||
>***
|
||||
|
||||
>**定义**:
|
||||
|
||||
>复制 src 所指向的字符数组的至多 count 个字符(包含空终止字符,但不包含后随空字符的任何字符)到 dest 所指向的字符数组。
|
||||
|
||||
>**若在完全复制整个 src 数组前抵达 count ,则结果的字符数组不是空终止的。**
|
||||
若在复制来自 src 的空终止字符后未抵达 count ,则写入额外的空字符到 dest ,直至写入总共 count 个字符。
|
||||
若字符数组重叠,
|
||||
若 dest 或 src 不是指向字符数组的指针(包含若 dest 或 src 为空指针),
|
||||
若 dest 所指向的数组大小小于 count ,
|
||||
或若 src 所指向的数组大小小于 count 且它不含空字符,
|
||||
则行为未定义。
|
||||
|
||||
#### strcpy 与 strncpy 的未定义行为
|
||||
**1. dest 和 src 一定不能是空终止字节字符串, 且要指向字符串**
|
||||
**2. dest 与 src 覆盖**
|
||||
|
||||
从 C99起 strcpy函数原型变成了这样:
|
||||
`char *strcpy( char *restrict dest, const char *restrict src )`
|
||||
|
||||
`restrict` 表示两个字符串是不重叠的
|
||||
|
||||
重叠并不是重复一样的意思。这一点我们目前不去深入。
|
||||
|
||||
**3. dest 长度小于 src**
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char* str1 = "Hello";
|
||||
char* str2 = "Hello World";
|
||||
|
||||
strcpy(str1, str2);
|
||||
strncpy(str1, str2, 12);
|
||||
|
||||
puts(str1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
这样写是可以通过编译的,但是你要知道这样做实际上已经越界了。
|
||||
|
||||
如果用数组的形式定义字符串,编译器才会报错。
|
||||
|
||||
可以看出,在这种情况下。编译器对数组更为敏感,数组的写法也更加安全。
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char str1[] = "hello";
|
||||
char str2[] = "hello world";
|
||||
|
||||
//两个函数都会报错
|
||||
strcpy(str1, str2);
|
||||
//strncpy(str1, str2, 12);
|
||||
|
||||
puts(str1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
**4. strncpy:dest 大小小于 count**
|
||||
|
||||
这点其实 3 也说明了。
|
||||
|
||||
对于 strcpy 来说, dest 的大小不能小于 src
|
||||
|
||||
而 strncpy 只需要 dest 的大小不小于 count 即可
|
||||
|
||||
**5. src 大小小于 count 且 src 不含空字符**
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char str1[] = "Hello World";
|
||||
char str2[] = { 'H', 'e', 'l','l', 'o' };
|
||||
|
||||
strncpy(str1, str2, 10);
|
||||
|
||||
puts(str1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
输出:
|
||||
```c
|
||||
Hello烫烫蘢
|
||||
```
|
||||
其实这也不难理解,strncpy 需要 '\0' 来判断 src 是否写完。
|
||||
|
||||
如果有 src 结尾有'\0' ,这时如果 count 还没有写满
|
||||
|
||||
函数会向 dest 中写入 '\0' 直到写满 count
|
||||
|
||||
但是如果 src 没有 '\0' 那么函数不知道 src 已经结束,而继续写入后面的内容,结果可想而知,是不可预测的。
|
||||
|
||||
#### mystrcpy
|
||||
```c
|
||||
#include<assert.h>
|
||||
|
||||
char* mystrcpy(char* str1, char* str2) {
|
||||
|
||||
assert(str1 != NULL && str2 != NULL);
|
||||
assert(strlen(str1) >= strlen(str2));
|
||||
|
||||
//核心代码从这里开始, 上面的不懂可以加QQ群问我(群在我公众号关注回复的消息里)
|
||||
char* after = str1;
|
||||
|
||||
while (*str1++ = *str2++);
|
||||
|
||||
return after;
|
||||
}
|
||||
|
||||
int main() {
|
||||
|
||||
char* str1 = "HI!!!";
|
||||
char* str2 = "Hello";
|
||||
|
||||
mystrcpy(str1, str2);
|
||||
puts(str1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
### (五)strcat & strncat
|
||||
帮你理解:
|
||||
strcat:string catenate 字符串连接
|
||||
|
||||
#### strcat
|
||||
>`char *strcat( char *dest, const char *src )`
|
||||
|
||||
>**头文件**:`string.h`
|
||||
|
||||
>**参数**:
|
||||
|
||||
>dest - 指向要后附到的空终止字节字符串的指针
|
||||
|
||||
>src - 指向作为复制来源的空终止字节字符串的指针
|
||||
|
||||
>**返回值**:
|
||||
|
||||
>返回 dest 的副本
|
||||
|
||||
>***
|
||||
|
||||
>**定义**:
|
||||
|
||||
>后附 src 所指向的空终止字节字符串的副本到 dest 所指向的空终止字节字符串的结尾。字符 src[0] 替换 dest 末尾的空终止符。产生的字节字符串是空终止的。
|
||||
若目标数组对于 src 和 dest 的内容以及空终止符不够大,则行为未定义。
|
||||
若字符串重叠,则行为未定义。
|
||||
若 dest 或 src 不是指向空终止字节字符串的指针,则行为未定义。
|
||||
|
||||
#### strncat
|
||||
>`char *strncat( char *dest, const char *src, size_t count )`
|
||||
|
||||
>**头文件**:`string.h`
|
||||
|
||||
>**参数**:
|
||||
|
||||
>dest - 指向要后附到的空终止字节字符串的指针
|
||||
|
||||
>src - 指向作为复制来源的字符数组的指针
|
||||
|
||||
>count - 要复制的最大字符数
|
||||
>**反回值**:
|
||||
|
||||
>返回 dest 的副本
|
||||
>***
|
||||
|
||||
>**定义**:
|
||||
|
||||
>后附来自 src 所指向的字符数组的至多 count 个字符,到 dest 所指向的空终止字节字符串的末尾,若找到空字符则停止。字符 src[0] 替换位于 dest 末尾的空终止符。始终后附终止空字符到末尾(故函数可写入的最大字节数是 count+1 )。
|
||||
若目标数组没有对于 dest 和 src 的首 count 个字符加上终止空字符的足够空间,则行为未定义。
|
||||
若源与目标对象重叠,则行为未定义。
|
||||
若 dest 不是指向空终止字节字符串的指针,或 src 不是指向字符数组的指针,则行为未定义。
|
||||
|
||||
|
||||
#### strcat 与 strncat 用法解读
|
||||
**1. strcat:dest >= dest + src + '\0'**
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char str1[11] = "Hello";
|
||||
char* str2 = " World";
|
||||
|
||||
//11刚好可以放下"Hello World",但是因为没有'\0' 的位置,程序崩溃。
|
||||
strcat(str1, str2);
|
||||
puts(str1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
**2. strcpy:dest 或 src 不是 空终止字节字符串**
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char str1[11] = "Hello";
|
||||
char str2[3] = {'J', 'I', 'M'};//程序崩溃
|
||||
|
||||
strcat(str1, str2);
|
||||
puts(str1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
**3. strncpy:dest 不是空终止字节字符串?**
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char str1[11] = {'H', 'I'};
|
||||
char str2[3] = { 'J', 'I', 'M' };
|
||||
|
||||
strncat(str1, str2, 3);
|
||||
puts(str1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
正确地输出了:
|
||||
```c
|
||||
HIJIM
|
||||
```
|
||||
可以看出 strncpy 具有某种优化,即使 dest 没有空字符,它也能正确找到正确的后缀位置
|
||||
|
||||
即使 src 没有空字符,也可以在新的 dest 后加上空字符
|
||||
|
||||
|
||||
#### mystrcat
|
||||
```c
|
||||
char* mystrcat(char* str1, char* str2) {
|
||||
//这一步请细品
|
||||
while (str1[strlen(str1)] = *str2++);
|
||||
|
||||
return str1;
|
||||
}
|
||||
|
||||
int main() {
|
||||
|
||||
char str1[8] = "Hi";
|
||||
char str2[4] = "YOU";
|
||||
|
||||
mystrcat(str1, str2);
|
||||
puts(str1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
***
|
||||
|
||||
### 写在后面
|
||||

|
||||
|
||||
说了半天,其实就是想带大家过一遍我们常用的字符串函数。
|
||||
|
||||
里面肯定有你忽略的知识点,希望大家**一定不要放过一些细节**,**一定要多想**,**一定要多写代码**。
|
||||
|
||||
|
||||
重要的事说三遍。
|
||||
|
||||
再有就是,不要嫌麻烦。
|
||||
|
||||
毕竟你看完可能只要 10 分钟,我写要写好几个小时。
|
||||
|
||||
其实这也只是入门的基础概念,真的要学会还是要拿来用。
|
||||
|
||||
具体使用有机会再总结吧。
|
||||
|
||||
***
|
||||
**更多精彩内容:**
|
||||
|
||||
[指针入门](https://mp.weixin.qq.com/s/0DD10hQQ4411ycbKSpghTw)
|
||||
|
||||
[你不知道的素数判断方法](https://mp.weixin.qq.com/s/T-ovU-PIunKFrgH1ZVLOLw)
|
||||
|
||||
***
|
||||
|
||||
如果你找到了文章的错误,请一定留言/评论/QQ群 告诉我,如果你给的建议好,我会在文中加上你的内容并且加上你的ID。
|
||||
|
||||
你也可以在 GitHub 上提交请求,这样也会让你上榜留名哦!
|
||||
|
||||
Github会在 **公众号上发布 1~2天后**发布。
|
||||
|
||||
**喜欢就点个小星星吧**,下次方便查看
|
||||
|
||||
关注我的公众号,获取第一时间更新:
|
||||
|
||||

|
||||
|
||||
|
||||
以上,感谢观看!
|
||||
|
||||
|
||||
参考资料:cppreference.com
|
||||
@@ -1,2 +0,0 @@
|
||||
## string
|
||||
## 字符串
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1,234 +0,0 @@
|
||||
#define _CRT_SECURE_NO_WARNINGS 1
|
||||
|
||||
#include<stdio.h>
|
||||
|
||||
////全局变量
|
||||
|
||||
//int f(void);
|
||||
//
|
||||
//int gAll = 12;
|
||||
//
|
||||
//int main(void){
|
||||
//
|
||||
// //__func__ 可以打印出当前函数的函数名,下划线一边是两个
|
||||
// printf("in %s gAll = %d\n", __func__, gAll);
|
||||
// f();
|
||||
// printf("again in %s gAll = %d\n", __func__, gAll);
|
||||
//
|
||||
// return 0;
|
||||
//}
|
||||
//
|
||||
//int f(void) {
|
||||
//
|
||||
// printf("in %s gAll = %d\n", __func__, gAll);
|
||||
// gAll += 2;
|
||||
// printf("again in %s gAll = %d\n", __func__, gAll);
|
||||
//
|
||||
// return gAll;
|
||||
//}
|
||||
|
||||
//int gAll = 12;
|
||||
//int g = gAll;
|
||||
//
|
||||
//int main(void) {
|
||||
//
|
||||
// return 0;
|
||||
//}
|
||||
|
||||
//const int gAll = 12;
|
||||
//int g = gAll;
|
||||
//
|
||||
//int main(void) {
|
||||
//
|
||||
// return 0;
|
||||
//}
|
||||
|
||||
//int f(void);
|
||||
//
|
||||
//int gAll = 12;
|
||||
//
|
||||
//int main(void) {
|
||||
//
|
||||
// int gAll = 2;
|
||||
//
|
||||
// printf("in %s gAll = %d\n", __func__, gAll);
|
||||
//
|
||||
// f();
|
||||
//
|
||||
// printf("again in %s gAll = %d\n", __func__, gAll);
|
||||
//
|
||||
// return 0;
|
||||
//}
|
||||
//
|
||||
//int f(void) {
|
||||
//
|
||||
// printf("in %s gAll = %d\n", __func__, gAll);
|
||||
// gAll += 2;
|
||||
// printf("again in %s gAll = %d\n", __func__, gAll);
|
||||
//
|
||||
// return gAll;
|
||||
//}
|
||||
|
||||
//int f(void);
|
||||
//
|
||||
//int main(void) {
|
||||
//
|
||||
// f();
|
||||
// f();
|
||||
// f();
|
||||
//
|
||||
// return 0;
|
||||
//}
|
||||
//
|
||||
//int f(void) {
|
||||
//
|
||||
// static int All = 1;
|
||||
// printf("in %s All = %d\n", __func__, All);
|
||||
// All += 2;
|
||||
// printf("again in %s All = %d\n", __func__, All);
|
||||
//
|
||||
// return All;
|
||||
//}
|
||||
|
||||
//int f(void);
|
||||
//
|
||||
//int gAll = 12;
|
||||
//
|
||||
//int main(void) {
|
||||
//
|
||||
// printf("1 st\n");
|
||||
// f();
|
||||
// printf("2 nd\n");
|
||||
// f();
|
||||
//
|
||||
// return 0;
|
||||
//}
|
||||
//
|
||||
//int f(void) {
|
||||
//
|
||||
// int a = 0;
|
||||
// int b = 0;
|
||||
// static int All = 1;
|
||||
//
|
||||
// printf("&All : %p\n", &All);
|
||||
// printf("&gAll: %p\n", &gAll);
|
||||
// printf("&a : %p\n", &a);
|
||||
// printf("&b : %p\n", &b);
|
||||
//
|
||||
// return All;
|
||||
//}
|
||||
|
||||
//int* f(void);
|
||||
//void g(void);
|
||||
//
|
||||
//int main(void) {
|
||||
//
|
||||
// int* p = f();
|
||||
// printf("*p = %d\n", *p);
|
||||
// g();
|
||||
// printf("*p = %d\n", *p);
|
||||
//
|
||||
// return 0;
|
||||
//}
|
||||
//
|
||||
//int* f(void) {
|
||||
//
|
||||
// int i = 12;
|
||||
//
|
||||
// return &i;
|
||||
//}
|
||||
//void g(void) {
|
||||
//
|
||||
// int k = 24;
|
||||
//
|
||||
// printf("k = %d\n", k);
|
||||
//
|
||||
// return k;
|
||||
//}
|
||||
|
||||
//编译预处理 与 宏
|
||||
|
||||
//#include<stdio.h>
|
||||
//
|
||||
//const double PI = 3.14159;
|
||||
//
|
||||
//int main(void) {
|
||||
//
|
||||
// printf("%f\n", 2 * PI * 3.0);
|
||||
// return 0;
|
||||
//}
|
||||
|
||||
//#include<stdio.h>
|
||||
//
|
||||
//#define PI 3.14159
|
||||
////注意:不写分号 不写等于号
|
||||
//
|
||||
//int main(void) {
|
||||
//
|
||||
// printf("%f\n", 2 * PI * 3.0);
|
||||
// return 0;
|
||||
//}
|
||||
|
||||
//int main(void) {
|
||||
//
|
||||
// printf("%s : %d\n", __FILE__, __LINE__);
|
||||
// printf("%s %s\n", __DATE__, __TIME__);
|
||||
//
|
||||
// return 0;
|
||||
//}
|
||||
|
||||
//#define cube(x) ((x) * (x) * (x))
|
||||
//
|
||||
//int main(void) {
|
||||
//
|
||||
// printf("%d\n", cube(5));
|
||||
// return 0;
|
||||
//}
|
||||
//
|
||||
//#define ERROR1(x) (x * 57)
|
||||
//#define ERROR2(x) (x) * 57
|
||||
//
|
||||
//int main(void) {
|
||||
//
|
||||
// int i = 1;
|
||||
// printf("%d\n", ERROR1(i + 2));
|
||||
// printf("%d\n", 300 / ERROR2(1));
|
||||
//
|
||||
// return 0;
|
||||
//}
|
||||
|
||||
//#define PRETTY_PRINT(msg) printf(msg);
|
||||
//
|
||||
//int main(void) {
|
||||
//
|
||||
// int n = 0;
|
||||
//
|
||||
// printf("Input an number\n");
|
||||
// scanf("%d", &n);
|
||||
//
|
||||
// if (n < 10)
|
||||
// PRETTY_PRINT("less than 10\n");
|
||||
// else
|
||||
// PRETTY_PRINT("more than 10\n");
|
||||
//
|
||||
// return 0;
|
||||
//}
|
||||
|
||||
//#include<stdio.h>
|
||||
//#include<string.h>
|
||||
//
|
||||
//#define TOUPPER(c) ('a' <= (c) && (c) <= 'z' ? (c) - 'a' + 'A' : (c))
|
||||
//
|
||||
//int main(void) {
|
||||
//
|
||||
// int i = 0;
|
||||
// char s[1000];
|
||||
// strcpy(s, "abcd");
|
||||
// putchar(TOUPPER(s[++i]));
|
||||
//
|
||||
// return 0;
|
||||
//}
|
||||
|
||||
//大程序结构
|
||||
|
||||
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1,17 +0,0 @@
|
||||
#ifndef _ARRAY_H_
|
||||
#define _ARRAY_H_
|
||||
|
||||
#define BLOCK_SIZE 20
|
||||
|
||||
typedef struct {
|
||||
int* array;
|
||||
int size;
|
||||
}Array;
|
||||
|
||||
Array array_creat(int init_size);//初始化数组
|
||||
void array_free(Array* a);//释放堆上空间
|
||||
int array_size(const Array* a);//查看数组的大小
|
||||
int* array_at(Array* a, int index);
|
||||
void array_inflate(Array* a, int more_size);
|
||||
|
||||
#endif
|
||||
@@ -1,108 +0,0 @@
|
||||
#define _CRT_SECURE_NO_WARNINGS 1
|
||||
|
||||
#include"Array.h"
|
||||
#include<stdio.h>
|
||||
#include<stdlib.h>
|
||||
//typedef struct {
|
||||
// int* array;
|
||||
// int size;
|
||||
//}Array;
|
||||
|
||||
Array array_creat(int init_size) {
|
||||
|
||||
Array a;
|
||||
|
||||
a.array = (int*)malloc(sizeof(int) * init_size);
|
||||
a.size = init_size;
|
||||
|
||||
return a;
|
||||
}
|
||||
//为何不传入指针?
|
||||
//比如:Array array_creat(Array* a, int init_size)
|
||||
//问题如下:
|
||||
//1.如果a == NULL?
|
||||
//2.如果a指向的是已经malloc过的空间,那样还要再free一次
|
||||
|
||||
void array_free(Array* a) {
|
||||
|
||||
free(a->array);
|
||||
a->array = NULL;//防止此函数被调用两次。free(NULL)是可以的
|
||||
a->size = 0;
|
||||
}
|
||||
|
||||
int array_size(const Array* a) {
|
||||
|
||||
return a->size;
|
||||
}
|
||||
|
||||
int* array_at(Array* a, int index) {
|
||||
|
||||
if (index >= a->size)
|
||||
array_inflate(&a, (index / BLOCK_SIZE + 1) * BLOCK_SIZE - a->size);
|
||||
//为什么不直接加上一个 BLOCK_SIZE?而是用 index / BLOCK_SIZE + 1) * BLOCK_SIZE - a->size) 这么复杂的公式?
|
||||
//这样加强了程序的可变性,如果某一次数组增加的大小你不清楚,比如从 100 增加到 150
|
||||
//直接加 BLOCL_SIZE 可能并不够用,用着个公式增加的大小一定 大于等于 需要增加的大小。
|
||||
//为什么引入 BLOCKJ_SIZE ?
|
||||
//一方面 增加了程序的扩展性(可以方便更改)和可读性,另一方面
|
||||
//如果你设置的 BLICK_SIZE 过大,数组大小这时就增加 1,这样太浪费内存
|
||||
//如果设置的过小就不能数组满足大幅的更改
|
||||
//拿本题 BLOCK_SIZE = 20 为例,一次最多多增加 19 个 int 的大小,这也就意味着
|
||||
//这种方法浪费的内存最多只有 19*sizeof(int) 个字节
|
||||
|
||||
return &(a->array[index]);
|
||||
}
|
||||
|
||||
////输出数组元素
|
||||
//int array_get(const Array a, int index) {
|
||||
//
|
||||
// return a.array[index];
|
||||
//}
|
||||
////修改数组元素
|
||||
//int array_set(Array* a, int index, int value) {
|
||||
//
|
||||
// return (a->array[index] = value);
|
||||
//}
|
||||
|
||||
void array_inflate(Array* a, int more_size) {
|
||||
|
||||
int* p = (int*)malloc(sizeof(int) * (a->size + more_size));
|
||||
int i = 0;
|
||||
|
||||
//可换成memcpy
|
||||
for (i = 0; i < a->size; i++) {
|
||||
p[i] = a->array[i];
|
||||
}
|
||||
free(a->array);
|
||||
|
||||
a->array = p;
|
||||
a->size += more_size;
|
||||
}
|
||||
|
||||
|
||||
int main(void) {
|
||||
|
||||
Array a;
|
||||
int size = 0;
|
||||
|
||||
printf("初始化数组大小,请输入:\n");
|
||||
scanf("%d", &size);
|
||||
|
||||
a = array_creat(size);
|
||||
|
||||
printf("%d members in array\n", array_size(&a));
|
||||
//为什么不直接用 a.size 输出数组的大小?
|
||||
//这样用函数来返回数组大小的方式就叫做 封装
|
||||
//日后如果有版本更新,算法优化等等,可以用函数来实现,将实现的代码保护起来
|
||||
|
||||
//array_at(&a, 1) 返回 &(a.array[1]) 解引用即使这个变量 array[1]
|
||||
//当然这个函数可以拆开,实现在array_at 后
|
||||
*array_at(&a, 1) = 10;
|
||||
printf("a.array[1] = %d\n", *array_at(&a, 1));
|
||||
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -1,13 +0,0 @@
|
||||
#ifndef _LINK_LIST_
|
||||
#define _LINK_LIST_
|
||||
|
||||
typedef struct _node {
|
||||
|
||||
char Name[20];
|
||||
char Gender[5];
|
||||
int Age;
|
||||
long long ID;
|
||||
struct _node* next;
|
||||
}node;
|
||||
|
||||
#endif
|
||||
@@ -1,59 +0,0 @@
|
||||
#define _CRT_SECURE_NO_WARNINGS 1
|
||||
|
||||
#include<stdio.h>
|
||||
#include<stdlib.h>
|
||||
#include"Array.h"
|
||||
|
||||
//typedef struct _node {
|
||||
//
|
||||
// char name[20];
|
||||
// char gender[5];
|
||||
// int age;
|
||||
// long long ID;
|
||||
//}node;
|
||||
|
||||
int main(void) {
|
||||
|
||||
node* head = NULL;
|
||||
int count = 1;
|
||||
int Exit = 0;
|
||||
|
||||
do {
|
||||
printf("是否继续?输入 0 退出\n");
|
||||
scanf("%d", &Exit);
|
||||
|
||||
if (Exit) {
|
||||
printf("请输入第 %d 个学生信息\n", count++);
|
||||
node* p = (node*)malloc(sizeof(node));
|
||||
printf("\t\t姓名: ");
|
||||
scanf("%s", p->Name);
|
||||
printf("\t\t性别: ");
|
||||
scanf("%s", p->Gender);
|
||||
printf("\t\t年龄: ");
|
||||
scanf("%d", &(p->Age));
|
||||
printf("\t\t学号: ");
|
||||
scanf("%lld", &(p->ID));
|
||||
|
||||
p->next = NULL;
|
||||
|
||||
node* last = head;//创建新的节点需要寻找最后一个放 NULL 的节点
|
||||
|
||||
//如果表头是空指针
|
||||
if (last) {
|
||||
//节点 指针域为NULL 找到了
|
||||
while (last->next)
|
||||
last = last->next;
|
||||
last->next = p;
|
||||
}
|
||||
else
|
||||
head = p;
|
||||
}
|
||||
} while (Exit);
|
||||
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -1,3 +0,0 @@
|
||||
翁恺MOOC
|
||||
|
||||
main 函数中的链表创建
|
||||
@@ -1,2 +0,0 @@
|
||||
翁恺老师 MOOC
|
||||
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
@@ -1 +0,0 @@
|
||||
上传文件夹
|
||||
276
Coding/Advanced_C/01 Examples/Address_Book/AddressBook.c
Normal file
276
Coding/Advanced_C/01 Examples/Address_Book/AddressBook.c
Normal file
@@ -0,0 +1,276 @@
|
||||
#include<stdio.h>
|
||||
#include<string.h>
|
||||
|
||||
#define Max_SIZE 50 //定义通讯录的大小
|
||||
|
||||
typedef struct PersonInfo {
|
||||
char name[100];
|
||||
char phone[100];
|
||||
}PersonInfo;
|
||||
|
||||
typedef struct AddressBook {
|
||||
PersonInfo all_address[Max_SIZE];
|
||||
int size;
|
||||
}AddressBook;
|
||||
//size 的含义是:
|
||||
//数组 all_address 下标范围在 [0,size) 内的元素是有意义的
|
||||
// [size, 200) 是我们没有用到的
|
||||
|
||||
//初始化
|
||||
void init(AddressBook* address_book) {
|
||||
|
||||
address_book->size = 0;
|
||||
//尽量少用 magic number(不明含义的数字)
|
||||
for (int i = 0; i < Max_SIZE; i++) {
|
||||
strcpy(address_book->all_address->name, " ");
|
||||
strcpy(address_book->all_address->phone, " ");
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
int Menu(void) {
|
||||
|
||||
printf("======================\n");
|
||||
printf("*** 0.退出 ***\n");
|
||||
printf("*** 1.新增联系人 ***\n");
|
||||
printf("*** 2.删除联系人 ***\n");
|
||||
printf("*** 3.查找联系人 ***\n");
|
||||
printf("*** 4.修改联系人 ***\n");
|
||||
printf("*** 5.打印联系人 ***\n");
|
||||
printf("*** 6.清除联系人 ***\n");
|
||||
printf("*** 7.排序联系人 ***\n");
|
||||
printf("======================\n");
|
||||
|
||||
printf("请输入你的选择:");
|
||||
int choice;
|
||||
scanf("%d", &choice);
|
||||
|
||||
return choice;
|
||||
}
|
||||
|
||||
void AddPersonInfo(AddressBook* address_book) {
|
||||
|
||||
printf("新增联系人\n");
|
||||
|
||||
if (address_book->size >= Max_SIZE) {
|
||||
printf("通讯录已满,请先清除!\n");
|
||||
return;
|
||||
//虽然函数类型是 void 但是也是可以用 return 滴
|
||||
}
|
||||
PersonInfo* info = &address_book->all_address[address_book->size];
|
||||
|
||||
printf("请输入联系人姓名:");
|
||||
scanf("%s", info->name);
|
||||
printf("请输入联系人电话:");
|
||||
scanf("%s", info->phone);
|
||||
|
||||
address_book->size++;
|
||||
}
|
||||
|
||||
void DelPersonInfo(AddressBook* address_book) {
|
||||
|
||||
//删除的方法很多,可以根据姓名,电话,序号等等来删除,
|
||||
//这里我们就用我个人比较常用的 搜索名字的删除方法
|
||||
|
||||
char search_name[100] = { 0 };
|
||||
|
||||
printf("删除联系人\n");
|
||||
printf("请输入联系人姓名:");
|
||||
scanf("%s", search_name);
|
||||
|
||||
int name_exist = FindName(address_book, search_name);
|
||||
|
||||
//这里注意 FindName 返回值设定,要被删除的元素下标可能是 0,这种情况下会返回 0
|
||||
if (name_exist == -1) {
|
||||
printf("该联系人不存在!\n");
|
||||
return;
|
||||
}
|
||||
|
||||
//删除了相同姓名的第一个后,继续寻找改名字,如果找到了,重复上面的操作,如果没找到,退出循环
|
||||
//相同的姓名的情况比较复杂,在修改,查找,排序等等场景都会带来麻烦,
|
||||
//而且平时你的通讯录中难道会将两个相同姓名的人的备注写成一样的吗?
|
||||
//所以,我仅仅在删除功能中实现一种针对相同姓名的情况的设计思路,后面的其他功能默认没有重复姓名的情况。
|
||||
while (name_exist != -1) {
|
||||
|
||||
//将 all_address 数组的最后一个元素赋值给要删除的元素,完成删除
|
||||
//结构体类型是可以直接赋值的
|
||||
address_book->all_address[name_exist] = address_book->all_address[address_book->size - 1];
|
||||
address_book->size--;
|
||||
name_exist = FindName(address_book, search_name);
|
||||
}
|
||||
|
||||
printf("删除成功!\n");
|
||||
|
||||
}
|
||||
|
||||
int FindName(AddressBook* address_book, char search_name[100]) {
|
||||
|
||||
for (int i = 0; i < address_book->size; i++) {
|
||||
//找到返回数组下标
|
||||
if (strcmp(address_book->all_address->name, search_name) == 0) {
|
||||
return i;
|
||||
}
|
||||
}
|
||||
//没有找到,返回 -1
|
||||
return -1;
|
||||
}
|
||||
|
||||
void FindPersonInfo(AddressBook* address_book) {
|
||||
|
||||
char search_name[100] = { 0 };
|
||||
|
||||
//搜索人的方式也很多,我们这里用搜索名字的方法
|
||||
printf("更新联系人\n");
|
||||
printf("请输入人名:");
|
||||
scanf("%s", search_name);
|
||||
|
||||
for (int i = 0; i < address_book->size; i++) {
|
||||
PersonInfo* info = &address_book->all_address[i];// 创建一个 PersonInfo 类型的变量简化程序,不然下面的姓名访问就太长了
|
||||
if (strcmp(info->name, search_name) == 0) {
|
||||
printf("[%d] %s %s\n", i, info->name, info->phone);
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
}
|
||||
|
||||
void ModifyPersonInfo(AddressBook* address_book) {
|
||||
|
||||
char search_name[100] = { 0 };
|
||||
int isjump = 1;
|
||||
|
||||
printf("删除联系人\n");
|
||||
printf("请输入联系人姓名:");
|
||||
scanf("%s", search_name);
|
||||
|
||||
int name_exist = FindName(address_book, search_name);
|
||||
|
||||
if (name_exist == -1) {
|
||||
printf("该联系人不存在!\n");
|
||||
return;
|
||||
}
|
||||
|
||||
//优化以下用户的体验
|
||||
printf("请输入新的姓名,输入 0 跳过:");
|
||||
scanf("%d", &isjump);
|
||||
if (isjump) {
|
||||
scanf("%s", address_book->all_address[name_exist].name);
|
||||
}
|
||||
printf("请输入新的电话,输入 0 跳过:");
|
||||
scanf("%d", &isjump);
|
||||
if (isjump) {
|
||||
scanf("%s", address_book->all_address[name_exist].phone);
|
||||
}
|
||||
|
||||
printf("更新成功!\n");
|
||||
|
||||
}
|
||||
|
||||
void PrintPersonInfo(AddressBook* address_book) {
|
||||
|
||||
PersonInfo* info;
|
||||
|
||||
if (address_book->size == 0) {
|
||||
printf("当前没有联系人!\n");
|
||||
return;
|
||||
}
|
||||
|
||||
printf("所有联系人信息如下:\n");
|
||||
|
||||
for (int i = 0; i < address_book->size; i++) {
|
||||
info = &address_book->all_address[i];
|
||||
printf("[%2d]%4s %s\n", i, info->name, info->phone);
|
||||
}
|
||||
}
|
||||
|
||||
void ClearPersonInfo(AddressBook* address_book) {
|
||||
|
||||
//清除所有信息是一种 危险的行为,我们最好让用户确认一次
|
||||
//相比你应该在自己的手机上回复过出厂设置,系统应该会让你确认不止一次!
|
||||
int is_continue = 0;
|
||||
|
||||
printf("清除所有联系人,你确定吗?输入 0 继续: ");
|
||||
scanf("%d", &is_continue);
|
||||
if(is_continue == 0) {
|
||||
//将 size 置为 0 即可,不过你也可以将数组的每个元素都进行重置
|
||||
address_book->size = 0;
|
||||
}
|
||||
printf("清除完成!\n");
|
||||
}
|
||||
|
||||
void SortPersonInfo(AddressBook* address_book) {
|
||||
|
||||
printf("排序通讯录\n");
|
||||
|
||||
for (int i = 0; i < address_book->size - 1; i++) {
|
||||
for (int j = 0; j < address_book->size - 1 - i; j++) {
|
||||
PersonInfo* info = &address_book->all_address[j];
|
||||
PersonInfo* info_next = &address_book->all_address[j + 1];
|
||||
//简单的用 strcmp 进行排序,不过排序的行为感觉是“未定义”的,
|
||||
//看着有规律,但再多试试会发现很多情况并没有规律。
|
||||
//也还有很多可以排血的函数。比如:strcoll,wcsscoll,wcscmp 这些只要你能弄懂,我想你也可以用。
|
||||
//或者有其他更好的实现办法,但这并不是我们在这里的重点。
|
||||
if (strcmp(info->name, info_next) > 0) {
|
||||
PersonInfo tmp;
|
||||
tmp = *info;
|
||||
*info = *info_next;
|
||||
*info_next = tmp;
|
||||
}
|
||||
}
|
||||
}
|
||||
printf("排序成功!\n");
|
||||
}
|
||||
|
||||
int main(int argc, char* argv[]) {
|
||||
|
||||
AddressBook address_book;
|
||||
|
||||
//声明一个函数指针类型
|
||||
typedef void (*Func)(AddressBook*);
|
||||
Func func_table[] = {
|
||||
NULL,
|
||||
AddPersonInfo,
|
||||
DelPersonInfo,
|
||||
FindPersonInfo,
|
||||
ModifyPersonInfo,
|
||||
PrintPersonInfo,
|
||||
ClearPersonInfo,
|
||||
SortPersonInfo,
|
||||
};
|
||||
//或者你也可以这么做:
|
||||
//声明一个函数类型:
|
||||
//typedef void (Func)(AddressBook*);
|
||||
//我们用的是指针数组,数组类型必须是指针类型,所以应该加上 *
|
||||
//Func* func_table[] = {
|
||||
//NULL,
|
||||
//AddPersonInfo,
|
||||
//DelPersonInfo,
|
||||
//FindPersonInfo,
|
||||
//ModifyPersonInfo,
|
||||
//PrintPersonInfo,
|
||||
//ClearPersonInfo,
|
||||
//SortPersonInfo,
|
||||
//};
|
||||
|
||||
init(&address_book);
|
||||
|
||||
|
||||
while (1) {
|
||||
int choice = Menu();
|
||||
|
||||
if (choice < 0 || choice > 7) {
|
||||
printf("输入错误!\n");
|
||||
continue;
|
||||
}
|
||||
|
||||
if (choice == 0) {
|
||||
printf("再见!\n");
|
||||
break;
|
||||
}
|
||||
|
||||
func_table[choice](&address_book);
|
||||
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
5
Coding/Advanced_C/01 Examples/Address_Book/readme.md
Normal file
5
Coding/Advanced_C/01 Examples/Address_Book/readme.md
Normal file
@@ -0,0 +1,5 @@
|
||||
## 简易版通讯录
|
||||
|
||||
第一版通讯录的实现是定义一个结构体里面包含一个数组。技巧不高,其实就是结构体的一个应用
|
||||
|
||||
后面可能会优化,可能不会。。
|
||||
{kind=link}
|
Before Width: | Height: | Size: 65 KiB After Width: | Height: | Size: 65 KiB |
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user