mirror of
https://github.com/hairrrrr/C-CrashCourse.git
synced 2026-06-28 17:46:24 +08:00
1
This commit is contained in:
@@ -1,16 +1,11 @@
|
||||
## 介绍 Introduce
|
||||
|
||||
C语言必知必会系列教程。
|
||||
|
||||
C 语言详细教学。
|
||||
|
||||
欢迎关注我的公众号:【不会编程的程序圆】,看更多干货。
|
||||
帮助 C 语言初学者的从入门到“精通”
|
||||
|
||||
<br>
|
||||
|
||||
<div align="center">
|
||||
<a href="#"> <img src="https://img.shields.io/badge/language-C-orange"></a>
|
||||
<a href="#weixin"> <img src="https://img.shields.io/badge/QQ%E7%BE%A4%E5%8F%B7-1040522517-blue"></a>
|
||||
<a href="#weixin"> <img src="https://img.shields.io/badge/%E5%BE%AE%E4%BF%A1%E5%85%AC%E4%BC%97%E5%8F%B7-%E4%B8%8D%E4%BC%9A%E7%BC%96%E7%A8%8B%E7%9A%84%E7%A8%8B%E5%BA%8F%E5%9C%86-blue"></a>
|
||||
</div>
|
||||
|
||||
@@ -26,7 +21,7 @@ C 语言详细教学。
|
||||
|
||||
本仓库内容除了少部分引用书籍和技术文档的部分内容(均在文中末尾指出),其余都是我的原创。在您引用本仓库内容或者对内容进行修改演绎时,请署名并以相同方式共享,谢谢。
|
||||
|
||||
转载文章请在开头明显处标明该页面地址。公众号等其它盈利性质的转载请联系 2823666460@qq.com。
|
||||
转载文章请在开头明显处标明该页面地址。
|
||||
|
||||
<br>
|
||||
|
||||
|
||||
174
content/c-mordern-approch/01-C语言概论.md
Normal file
174
content/c-mordern-approch/01-C语言概论.md
Normal file
@@ -0,0 +1,174 @@
|
||||
# C语言概述
|
||||
|
||||
*One man's constant is another man's variable。*[^1]
|
||||
|
||||
|
||||
|
||||
:arrow_forward: 此符号表示该内容以后的章节会讲解,此章节内不要求理解。
|
||||
|
||||
|
||||
|
||||
### 本节内容
|
||||
|
||||
***
|
||||
|
||||
C语言的历史,C语言的优缺点以及如何高效的使用C语言
|
||||
|
||||
C语言还值得学习吗?C语言查错的工具
|
||||
|
||||
|
||||
|
||||
### C语言的历史
|
||||
***
|
||||
#### 起源
|
||||
|
||||
C语言是贝尔实验室的 Ken Thompson, Dennis Ritchie 等人开发的 UNIX 操作系统的“副产品”。
|
||||
|
||||
与同时代的其他操作系统一样,UNIX 系统最初也是用汇编语言写的。用汇编语言编写的程序往往难以调试和改进,UNIX 操作系统也不例外。Thompson 意识到需要用一种高级的编程语言来完成 UNIX 系统未来的开发,于是他设计了一种小型的 B语言。Thompson 的 B语言是在 BCPL语言(20世纪60年代中期产生的一种系统编程语言)的基础上开发的,而 BCPL语言又可以追溯到最早(且影响深远)的语言之一——Algol 60语言。
|
||||
|
||||
1970年,贝尔实验室为 UNIX 项目争取到了一台 PDP-11 计算机。当 B语言经过改进并能够在 PDP-11 计算机上成功运行后,Thompson 用 B语言重新编写了部分 UNIX 代码。
|
||||
|
||||
到了1971年,B语言已经明显不适合 PDP-11 计算机了,于是 Ritchie 着手开发 B语言的升级版。最初他将新开发的语言命名为 NB语言(意味New B),但是后来新语言越来越偏离 B语言,于是他将其改名为 C语言。
|
||||
|
||||
到1973年,C语言已经足够稳定,可以用来重新编写 UNIX 系统了。
|
||||
|
||||
#### 标准化
|
||||
|
||||
C语言在20世纪七十年代(尤其是1977年到1979)持续发展。这一时期出现了第一本有关 C语言的书。Brian Kernighan 和 Dennis Ritchie 合作编写的 *The C Programming Language* 于1978年出版,并迅速成为 C程序员必读的“圣经”。由于当时没有 C语言的正式标准,这本书就成为了事实上的标准,编程爱好者把它称为“K&R”或者“白皮书”。(公众号后台回复:【KR】即可获得)
|
||||
|
||||
随着C语言的迅速普及,一系列问题也接踵而至。首先, K&R 对一些语言特性描述得非常模糊,以至于不同编译器对这些特性会做出不同的处理。而且,K&R 也没有对属于 C语言的特性和属于 UNIX 系统的的特性进行明确的区分。更糟糕的是,K&R 出版后 C语言仍然在不断变化,增加了一些新特性并除去了一些旧特性。很快,C语言需要一个全面,准确的最新描述开始成为共识。
|
||||
|
||||
##### C89/C90
|
||||
|
||||
1983年,在美国国家标准协会(ANSI)的推动下(ANSI 于此年组建了一个委员会称为 X3Jll),美国开始制定本国的 C语言标准。
|
||||
|
||||
1988年完成并于1989年12月正式通过的 C语言标准成为 ANSI 标准 X3.159-1989。
|
||||
|
||||
1990年,国际标准化组织(ISO)通过了此项标准,将其作为 ISO/IEC 9899:1990 国际标准(中国国家标准为 GB/T 15272—1994)。
|
||||
|
||||
我们把这一C语言版本称为 **C89** 或 **C90**,以区别原始的 C语言版本。
|
||||
|
||||
委员会在制定的指导原则中的一条写道:保持 C 的精神。委员会在描述这一精神时列出了一下几点:
|
||||
|
||||
- 信任程序员
|
||||
- 不要妨碍程序员做需要做的事
|
||||
- 保持语言精炼简单
|
||||
- 只提供一种方法执行一项操作
|
||||
- 让程序运行更快,即使不能保持其可移植性
|
||||
|
||||
在最后一点上,标准委员会的用意是:作为实现,应该针对目标计算机来定义最合适的某特定操作,而不是强加一个抽象,统一的定义。在学习 C语言的过程中,许多方面都反映了这一哲学思想。
|
||||
|
||||
##### C99
|
||||
|
||||
1995 年,C语言发生了一些改变。
|
||||
|
||||
1999年通过的 ISO/IEC 9899:1999 新标准中包含了一些更重要的改变,这一标准所描述的语言通常称为 **C99**
|
||||
|
||||
此次改变,委员会的用意不是在C语言中添加新的特性,而是为了达到新的目标。
|
||||
|
||||
1. **支持国际化编程**。如:提供多种方法处理国际字符集
|
||||
2. **调整现有实践致力于解决明显的缺陷**。因此,在遇到需要将 C移至64位处理器时,委员会根据现实生活中处理问题的经验来添加标准。
|
||||
3. 为**适应科学和工程项目中的关键计算**,提高 C 的适应性,让 C 比 FORTRAN 更有竞争力。
|
||||
|
||||
其他方面的改变则更为保守,如,尽量让C90,C++兼容,让语言在概念上保持简单。
|
||||
|
||||
虽然改标准已经发布了很长时间,但**并非所有编译器都完全支持C99**的所有改动。因此,你有可能发现 C99 的一些改动在自己的系统中不可用,或者需要改变编译器的设置才可用。
|
||||
|
||||
##### C11
|
||||
|
||||
2011年,**C11**标准问世。
|
||||
|
||||
#### 基于C的语言
|
||||
|
||||
- C++:包含所有C的特性
|
||||
- Java:基于C++,所以也继承了C的许多特性
|
||||
- C#:由C++于java发展起来的较新的语言
|
||||
- Perl:最初是一种简单的脚本语言,在发展过程中采用了C的许多特性
|
||||
|
||||
### C语言还值得学吗?
|
||||
|
||||
答案是肯定的。
|
||||
|
||||
第一,学习C有助于更好的理解C++,Java,C#,Perl以及其他基于C的特性的语言。第一开始就学习其他语言的程序员往往不能很好的掌握继承自C语言的基本特性。
|
||||
|
||||
第二,目前仍有许多C程序,我们需要读懂并维护这些代码。
|
||||
|
||||
第三,C语言仍广泛应用于新软件的开发,特别是在内存或处理能力受限的情况下以及需要使用C语言简单特性的地方。
|
||||
|
||||
### C语言的优缺点
|
||||
***
|
||||
|
||||
与其他任何一种编程语言一样,C语言也有自己的优缺点。这些优缺点都源于该语言的最初用途(编写操作系统和其它系统软件)和它自身的基础理论体系。
|
||||
|
||||
- **C语言是一种底层语言** 为了适应系统编程的需要,C语言提供了对机器级概念(例如,字节和地址)的访问,而这些都是其他编程语言试图隐藏的内容。
|
||||
- **C语言是一种小型语言** 与许多其他编程语言相比,C语言提供了一套更有限特性集合。(在K&R第二版的参考手册中仅用49页就描述了整个C语言。)为了使特性较少,C语言在很大程度上依赖一个标准函数的“库”。
|
||||
- **C是一种包容性语言** C假设用户知道自己在干什么,因此它提供了比其他许多语言更广阔的自由度。此外,C语言不像其他语言那样强制进行详细的错误检查。
|
||||
|
||||
#### C语言的优点
|
||||
|
||||
C语言的众多优点解释了C语言为何如此流行。
|
||||
|
||||
- **高效** 高效性是C语言与生俱来的优点之一。发明C语言就是为了编写那些以往由汇编语言编写的程序,所以对C语言来说,能够在有限的内存空间快速运行就显得至关重要。
|
||||
|
||||
- **可移植** 当程序必须在多种机型(从个人计算机到超级计算机)上运行时,常常会用C语言来编写。
|
||||
|
||||
原因一:C语言没有分裂成不兼容的多种分支。这主要归功于C语言早期与UNIX系统的结合以及后来的ANSI/ISO标准。
|
||||
|
||||
原因二:C语言编译器规模小且容易编写,这使得它们得以广泛应用。
|
||||
|
||||
原因三:C语言的自身特性也支持可移植性(尽管它没有阻止程序员编写不可移植的程序)。
|
||||
|
||||
- **功能强大** C语言拥有一个庞大的数据类型和运算符集合,这个集合使得C语言具有强大的表达能力,往往寥寥几行代码就可以实现许多功能。
|
||||
|
||||
- **灵活** C语言最初设计是为了系统编程,但没有固有的约束将其限制在此范围内。C语言现在可以用于编写从嵌入式系统到商业数据处理的各种应用程序。
|
||||
|
||||
- **标准库** C语言的突出优点就是它具有标准库,该标准库包括了数百个可以用于输入/输出,字符串处理,储存分配以及其他实用操作的函数。
|
||||
|
||||
- **与UNIX的集成** C语言在与UNIX系统(包括Linux)结合方面特别强大。事实上,一些UNIX工具甚至假设用户是了解C语言的。
|
||||
|
||||
#### C语言的缺点
|
||||
|
||||
- **C语言容易隐藏错误** C语言的灵活性使得用它编程出错的概率极高。在用其他语言时可以发现的错误,C语言的编译器却无法检查到。更糟糕的是,C语言还包含大量不易察觉的隐患。
|
||||
- **C程序可能难以理解** C程序的简明扼要与灵活性,可能导致程序员编写出除了自己别人无法读懂的代码。
|
||||
- **C程序可能难以修改** 如果在设计中没有考虑到维护的问题,那么C编写的大型程序可能很难修改。现代的编程语言通常提供“类”和“包”之类的语言特性,这样的特性可以把大的程序分解成许多更容易管理的模块。遗憾的是,C语言恰恰缺少这样的特性。
|
||||
|
||||
### 高效的使用C语言
|
||||
|
||||
要高效的使用C语言,就需要利用C语言优点的同时尽量避免它的缺点,一下给出一些建议。
|
||||
|
||||
- **学习如何规避C语言的缺陷**
|
||||
- **使用软件工具使程序更可靠**(详细见下文)
|
||||
- **利用现有的代码库** 使用C语言的一个好处是其他许多人也在使用C。把别人编写好的代码用于自己的程序是一个非常好多主意。C代码通常被打包成库(函数的集合)。获取适当的库既可以大大减少错误,也可以节省很多编程工作。
|
||||
- **采用一套切合实际的编码规范** 良好的编码习惯和规范易于自己和他人对自己代码的阅读和修改。(公众号回复:【编码规范】,让你学会如何写出规范的代码。)
|
||||
- **避免“投机取巧”和极度复杂的代码**。C语言鼓励使用编程技巧。但是,过犹不及,不要对技巧毫无节制,最简单的解决方案往往也是最难理解的。
|
||||
- **紧贴标准** 大多数编译器都提供不属于 C89/C99 标准的特征和库函数。为了程序的可移植性,若非确有必要,最好避免这些特性和库函数。
|
||||
|
||||
### 怎么让程序更加安全可靠?
|
||||
|
||||
- 分析错误工具——lint
|
||||
- 越界检查工具——bounds-checker
|
||||
- 内存泄漏监测工具——leak-finder
|
||||
- 调高你的编译器的“警告级别”
|
||||
|
||||
|
||||
|
||||
***
|
||||
|
||||
以上就是本次的内容,感谢观看。
|
||||
|
||||
如果文章有错误欢迎指正和补充,感谢!
|
||||
|
||||
最后,如果你还有什么问题或者想知道到的,可以在评论区告诉我呦,我在后面的文章可以加上。
|
||||
|
||||
最后,**关注我**,看更多干货!
|
||||
|
||||
我是程序圆,我们下次再见。
|
||||
|
||||
|
||||
|
||||
[^1]:*吾之常量,彼之变量。摘自《epigrams-on-programming》*
|
||||
|
||||
*参考资料:《C Primer Plus》《C语言程序设计:现代方法》*
|
||||
|
||||
|
||||
|
||||
394
content/c-mordern-approch/02-C语言基本概念.md
Normal file
394
content/c-mordern-approch/02-C语言基本概念.md
Normal file
@@ -0,0 +1,394 @@
|
||||
## C语言基本概念
|
||||
|
||||
*Syntactic sugar causes cancer of the semi-colons.*[^0]
|
||||
|
||||
|
||||
|
||||
### :globe_with_meridians:目录
|
||||
|
||||
***
|
||||
|
||||
[TOC]
|
||||
|
||||
### :books:教学
|
||||
|
||||
***
|
||||
|
||||
### 第一个C程序
|
||||
|
||||
**main.c**
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void){
|
||||
|
||||
printf("Hello,World\n");//a simple C program
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
将上述程序写在你的编译器里。
|
||||
|
||||
然后给文件命名,并以`.c`作为扩展名,例如`main.c`。
|
||||
|
||||
现在,编译并运行该程序。如果一切正常,输出的应该是:
|
||||
|
||||
```c
|
||||
Hello,World
|
||||
```
|
||||
|
||||
|
||||
|
||||
恭喜你,你已经是一名C程序员了!:laughing:
|
||||
|
||||
|
||||
|
||||
*Hello,World 是伟大的。它像着一个呱呱坠地的婴儿对世界的问好,它憧憬着美好的世界,一切事物都是新鲜的。*
|
||||
|
||||
——不会编程的程序圆
|
||||
|
||||
现在,让我们看看这个程序到底是什么意思。
|
||||
|
||||
### 正式开始之前
|
||||
|
||||
#### 编译和链接
|
||||
|
||||
C程序编译链接的过程:(知道即可)
|
||||
|
||||

|
||||
|
||||
#### 集成开发环境
|
||||
|
||||
> 集成开发环境(integrated development enviroment,IDE):集成开发环境是一个软件包,我们可以在其中编辑,编译,链接,执行和调试程序。
|
||||
|
||||
IDE推荐:
|
||||
|
||||
CodeBlock(本教学中的简单的程序会用这个软件来完成)
|
||||
|
||||
VS2019(编写需要调试的程序用它来完成)
|
||||
|
||||
### 简单程序的一般形式
|
||||
|
||||
#### 1. 指令
|
||||
|
||||
示例程序第一行`#include<stdio.h>`就是一条指令。
|
||||
|
||||
在程序**编译之前**,C编译器的**预处理器**(preprocessor)会首先对源代码进行一些准备工作,即预处理(preprocessing)。
|
||||
|
||||
> **指令(directive):**我们把 预处理器 执行的命令称为 预处理器指令(preprocessor directive),简称指令。
|
||||
>
|
||||
> 指令的结尾不需要添加分号
|
||||
|
||||
`#include<stdio.h>`的作用相当于把 **头文件** `stdio.h` 中的所有内容都输入到该行所在的位置。
|
||||
|
||||
实际上,这是一种**复制+粘贴**的操作。
|
||||
|
||||
**include 文件提供了一种方便的途径共享许多程序共有的信息**。
|
||||
|
||||
`stdio.h`文件中包含了供编译器使用的输入和输出函数(如 `printf()`)信息。
|
||||
|
||||
该文件名的含义为**标准输入/输出**头文件(stadard input&output .header)
|
||||
|
||||
> **头文件(header):**在C程序顶部的信息集合。
|
||||
|
||||
每个头文件都包含一些标准库的内容。
|
||||
|
||||
示例程序引入stdio.h头文件的原因:C语言不同于其他编程语言,它没有内置的“读/写”命令。输入/输出功能由标准库中的函数实现。[^1]
|
||||
|
||||
**每次用到库函数,必须用#include指令包含相关的头文件。**省略必要的头文件可能不会对某一个特定程序造成影响,但是最好不要这样做。
|
||||
|
||||
[^1]:为何不内置输入/输出? 原因之一是并非所有程序都会用到I/O(输入输出)包 。简洁高效表现了C语言的哲学。
|
||||
|
||||
|
||||
|
||||
#### 2.函数
|
||||
|
||||
`int main(void)`
|
||||
|
||||
> **函数:**类似于其他编程语言的“过程”或“子例程”,它们是用来构建程序的构建块。
|
||||
|
||||
事实上,C语言就是函数的集合。
|
||||
|
||||
函数分两大类:第一种是程序员自己编写的函数;另一类则是C作为语言实现的一部分提供的函数,即**库函数**(library function)。因为它们属于一个由编译器提供的函数“库”。
|
||||
|
||||
**main函数**:C程序都是从`main()`函数“开始”执行。`main()`函数是程序的唯一入口。**可以理解为程序是从main函数开始运行到main函数结尾结束。**
|
||||
|
||||
**返回类型**:`int`是main函数的 返回类型。这表明 main函数返回的值是整型。
|
||||
|
||||
*返回给哪里?返回给操作系统,我们后面再来讲解*
|
||||
|
||||
**参数**:`()`内包含的信息为函数的参数。示例中的`void`表示该例中没有传入任何参数。
|
||||
|
||||
> **请注意**
|
||||
>
|
||||
> 有背景颜色的地方都是重要的知识,但是在这里不管你是初学者/学了一段时间了,我都建议你遵守以下规范:
|
||||
>
|
||||
> **main函数到底应该怎么写?**我在这里不详细展开说。
|
||||
>
|
||||
> **正确的形式**:`int main(int argc, char* argv[])`
|
||||
>
|
||||
> **可以接受的形式:**`int main(void)`
|
||||
>
|
||||
> **错误的写法**:`int main()` 谭老师书中的写法。跟我学,不要用这种写法
|
||||
>
|
||||
> **脑瘫的写法**:`void main()` `void main(void)`所有C语言的标准都未认可这种写法,你在赣神魔?
|
||||
|
||||
|
||||
|
||||
`return 0`
|
||||
|
||||
**返回值**:前面我们讲到了*返回类型*,那么就应该有个返回值。示例中 `return `就代表返回,`0`是这个main函数的返回值。
|
||||
|
||||
> **main函数中return的作用**:
|
||||
>
|
||||
> 1.**使main函数终止**。mian函数在这里结束。
|
||||
>
|
||||
> 2.main函数返回值是0,**表示程序正常终止**。
|
||||
|
||||
**所以,`return 0`在main函数中是不可省略的**
|
||||
|
||||
虽然即使你不写,可能也可以通过编译,但是不写是不对的。
|
||||
|
||||
|
||||
|
||||
#### 3.语句
|
||||
|
||||
> 语句是程序运行时执行的命令
|
||||
>
|
||||
> 语句是带顺序执行的 C 程序段。任何函数体都是一条复合语句,继而为语句或声明的序列
|
||||
|
||||
例如:
|
||||
|
||||
```c
|
||||
int main(void)
|
||||
{ // 复合语句的开始
|
||||
int n = 1; // 声明(非语句)
|
||||
n = n+1; // 表达式语句
|
||||
printf("n = %d\n", n); // 表达式语句
|
||||
return 0; // 返回语句
|
||||
} // 复合语句之结尾,函数体之结尾
|
||||
```
|
||||
|
||||
|
||||
|
||||
**C语言中的六种语句**
|
||||
|
||||
1. **标号语句**
|
||||
|
||||
1) [goto](https://zh.cppreference.com/w/c/language/goto) 语句的目标。 (*标识符* **:** *语句*)
|
||||
|
||||
2) [switch](https://zh.cppreference.com/w/c/language/switch) 语句的 `case` 标号。(**case** *常量表达式* **:** *语句*)
|
||||
|
||||
3) [switch](https://zh.cppreference.com/w/c/language/switch) 语句的默认标号。 (**default** **:** *语句*)
|
||||
|
||||
2. **复合语句**
|
||||
|
||||
复合语句,或称**块**,是**花括号**所包围的语句与声明的序列。
|
||||
|
||||
`{声明(可选)| 语句 }`
|
||||
|
||||
3. **表达式语句**
|
||||
|
||||
典型的 C 程序中大多数语句是表达式语句,例如赋值或函数调用。
|
||||
|
||||
无表达式的表达式语句被称作*空语句*。它通常用于提供空循环体给 [for](https://zh.cppreference.com/w/c/language/for) 或 [while](https://zh.cppreference.com/w/c/language/while) 循环。
|
||||
|
||||
4. **选择语句**
|
||||
|
||||
选择语句根据表达式的值,选择数条语句之一执行。
|
||||
|
||||
1) [if](https://zh.cppreference.com/w/c/language/if) 语句
|
||||
|
||||
2) [if](https://zh.cppreference.com/w/c/language/if) 语句带 `else` 子句
|
||||
|
||||
3) [switch](https://zh.cppreference.com/w/c/language/switch) 语句
|
||||
|
||||
5. **迭代语句**
|
||||
|
||||
迭代语句重复执行一条语句。
|
||||
|
||||
1) [while](https://zh.cppreference.com/w/c/language/while) 循环
|
||||
|
||||
2) [do-while](https://zh.cppreference.com/w/c/language/do) 循环
|
||||
|
||||
3) [for](https://zh.cppreference.com/w/c/language/for) 循环
|
||||
|
||||
6. **跳转语句**
|
||||
|
||||
跳转语句无条件地转移控制流。
|
||||
|
||||
1) [break](https://zh.cppreference.com/w/c/language/break) 语句
|
||||
|
||||
2) [continue](https://zh.cppreference.com/w/c/language/continue) 语句
|
||||
|
||||
3) [return](https://zh.cppreference.com/w/c/language/return) 语句带可选的表达式
|
||||
|
||||
4) [goto](https://zh.cppreference.com/w/c/language/goto) 语句
|
||||
|
||||
|
||||
|
||||
**为什么需要分号?**
|
||||
|
||||
由于语句可以连续占用多行,有时很难确定它结束的位置,因此需要用分号来向编译器表示语句结束的位置。但预处理指令通常只用占一行,因此**不需要**分号结尾
|
||||
|
||||
|
||||
|
||||
#### 4.打印字符串 printf() 函数
|
||||
|
||||
`printf("Hello,World\n");`
|
||||
|
||||
`printf()`是一个功能十分强大的函数。*后面我们会进一步介绍*
|
||||
|
||||
示例中我们只是用printf函数打印了出了一条**字符串字面量(string literal)** —— 用一对双引号引起来的一系列字符。
|
||||
|
||||
**字符串**,顾名思义就是一串字符。
|
||||
|
||||
printf函数不会自动换行到下一行打印,它只会在它最开始那一行一直打印直到程序迫使它换行。
|
||||
|
||||
`\n`表示printf函数打印完成后跳转到下一行
|
||||
|
||||
|
||||
|
||||
请看如下程序,思考它的效果与示例中有何不同?
|
||||
|
||||
```c
|
||||
printf("Hello,");
|
||||
printf("World\n");
|
||||
```
|
||||
|
||||
答案[^2](点击或到文章尾查看)
|
||||
|
||||
|
||||
|
||||
如果想输出下面的结果,请考虑一下,应该如何写程序呢?
|
||||
|
||||
```c
|
||||
Hello,
|
||||
World
|
||||
```
|
||||
|
||||
答案:
|
||||
|
||||
```c
|
||||
printf("Hello,\n");
|
||||
printf("World\n");
|
||||
```
|
||||
|
||||
对于这个问题,第二个printf函数的 \n 可以省略。简单来说,printf函数会在 \n 出现的地方换行。
|
||||
|
||||
|
||||
|
||||
#### 5.注释
|
||||
|
||||
`//a simple C program`
|
||||
|
||||
> 写注释可以让自己和别人更容易明白你写的程序。
|
||||
>
|
||||
> C语言注释的好处是:可以写在任何地方。注释的部分会被编译器忽略。
|
||||
|
||||
我们试想一件事你昨天吃了什么饭,记性好是吧?上周五吃的什么饭?如果连上周 一天三顿的饭都不能记住,何况你自己查看你很久之前写的代码呢?
|
||||
|
||||
##### 两种注释符号
|
||||
|
||||
第一种:`/* */`
|
||||
|
||||
单行注释
|
||||
|
||||
``` c
|
||||
/* 关注微信公众号:不会编程的程序圆 */
|
||||
/* 看更多干货,获取第一时间更新 */
|
||||
/* 码字不易,对你有帮助 点赞/转发/关注,鼓励一下作者 */
|
||||
```
|
||||
|
||||
多行注释
|
||||
|
||||
```c
|
||||
/* 关注微信公众号:不会编程的程序圆
|
||||
看更多干货,获取第一时间更新
|
||||
码字不易,对你有帮助 点赞/转发/关注,鼓励一下作者 */
|
||||
```
|
||||
|
||||
但是,上面这一种注释方式可能难以阅读,因为人不不容易发现注释结束的位置。
|
||||
|
||||
改进:
|
||||
|
||||
```c
|
||||
/*关注微信公众号:不会编程的程序圆
|
||||
看更多干货,获取第一时间更新
|
||||
码字不易,对你有帮助 点赞/转发/关注,鼓励一下作者
|
||||
*/
|
||||
```
|
||||
|
||||
更好的方法:将注释部分围起来
|
||||
|
||||
```c
|
||||
/*************************************************
|
||||
* 关注微信公众号:不会编程的程序圆 *
|
||||
* 看更多干货,获取第一时间更新 *
|
||||
* 码字不易,对你有帮助 点赞/转发/关注,鼓励一下作者 *
|
||||
*************************************************/
|
||||
```
|
||||
|
||||
当然如果你嫌麻烦,也可以简化一下:
|
||||
|
||||
```c
|
||||
/*
|
||||
* 关注微信公众号:不会编程的程序圆
|
||||
* 看更多干货,获取第一时间更新
|
||||
* 码字不易,对你有帮助 点赞/转发/关注,鼓励一下作者
|
||||
*/
|
||||
```
|
||||
|
||||
简短的注释可以放在同一行
|
||||
|
||||
```c
|
||||
printf("Hello World\n");/* 不会编程的程序圆 */
|
||||
```
|
||||
|
||||
|
||||
|
||||
但是,如果你忘记了终止注释可能会导致你的编译器跳过程序的一部分,请思考下列:
|
||||
|
||||
```c
|
||||
printf("不会"); /* 关注我的公众号呦~
|
||||
printf("编程");
|
||||
printf("的"); /* 更多鼓励,更多干货!*/
|
||||
printf("程序圆");
|
||||
```
|
||||
|
||||
你可以在自己的编译器上自己敲一下,看看会输出什么。
|
||||
|
||||
由于第一条注释忘记输入结束标志,导致编译器将直到找到结束标志之前的程序都当成了注释!
|
||||
|
||||
|
||||
|
||||
第二种:`//`
|
||||
|
||||
C99提供的新的注释方式。
|
||||
|
||||
```C
|
||||
//关注微信公众号:不会编程的程序圆
|
||||
//看更多干货,获取第一时间更新
|
||||
//码字不易,对你有帮助 点赞/转发/关注,鼓励一下作者
|
||||
```
|
||||
|
||||
> 新的注释风格有两大优点:
|
||||
>
|
||||
> 1. 这种注释会在行末自动终结,所以不用担心会出现未终止的注释意外吞噬部分程序的情况
|
||||
> 2. 每行前都有 // ,所以多行的注释更加醒目
|
||||
|
||||
综上所述,建议采用 `//` 这种注释方式
|
||||
|
||||
|
||||
|
||||
[^0]:*语法糖导致分号癌。摘自《epigrams-on-programming》*
|
||||
[^2]:相同。
|
||||
|
||||
*参考资料:《C Primer Plus》《C语言程序设计:现代方法》 网上资料:cppreference.com*
|
||||
|
||||
***
|
||||
|
||||
324
content/c-mordern-approch/03-C语言基本概念.md
Normal file
324
content/c-mordern-approch/03-C语言基本概念.md
Normal file
@@ -0,0 +1,324 @@
|
||||
## C语言基本结构(下)
|
||||
|
||||
*Every program is a part of some other program and rarely fits.*[^0]
|
||||
|
||||
|
||||
|
||||
### :globe_with_meridians:目录
|
||||
|
||||
***
|
||||
|
||||
[TOC]
|
||||
|
||||
|
||||
|
||||
### :apple:简单的程序结构
|
||||
|
||||
***
|
||||
|
||||
下面是一个简单的程序,身高是给出的,体重是在程序中得到的,我们输出的是体重与身高/体重的值。
|
||||
|
||||
这里我们更注重的是**程序的结构**而非程序本身。
|
||||
|
||||
|
||||
|
||||
示例
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
#### 1. 类型
|
||||
|
||||
> 每一个变量都有**类型**(type)。类型用来描述变量的数据的种类,也称**数据类型**。
|
||||
|
||||
数值型变量的类型决定了变量所能存储的最大值与最小值,以及是否允许小数点后出现数字。
|
||||
|
||||
示例中只有一种数据类型:`int`
|
||||
|
||||
> **int**(integer):即整型,表示整数。
|
||||
|
||||
数据类型还有很多,目前除了 int 以外,我们只再使用另一种:
|
||||
|
||||
> **float**(floating-point): 浮点型,可以表示小数
|
||||
|
||||
**注意**:虽然 float 型可以带小数,但是进行**算术运算**时,float 型要比 int 型慢,而且 float 通常只是一个值的近似值。(比如在一个float 型变量中存储 0.1, 但其实可能这个变量的值为 0.09999987,这是舍入造成的误差)
|
||||
|
||||
*题外话:我当时学的时候,就没有人告诉我这些知识,你们如果现在是初学,我都感觉到羡慕,你们要少走多少弯路啊!*
|
||||
|
||||
|
||||
|
||||
#### 2. 关键字
|
||||
|
||||
> int 与float 都是C语言的**关键字**(keyword),关键字是语言定义的单词,**不能用做其他用途**。比如不能用作命名函数名与变量名。
|
||||
|
||||
关键字:*斜体代表C99新增关键字*
|
||||
|
||||
| auto | enum | unsigned | break | extern |
|
||||
| ---------- | -------- | -------- | ---------- | ------------ |
|
||||
| return | void | case | float | short |
|
||||
| volatile | char | for | signed | while |
|
||||
| const | goto | sizeof | continue | if |
|
||||
| static | default | struct | do | int |
|
||||
| switch | double | long | typedef | else |
|
||||
| register | union | | | |
|
||||
| *restrict* | *inline* | *_Bool* | *_Complex* | *_Imaginary* |
|
||||
|
||||
如果关键字使用不当(关键字作为变量名),编译器会将其视为语法错误。
|
||||
|
||||
|
||||
|
||||
> 保留标识符(reserved identifier):下划线开头的标识符和标准库函数名(如:printf())
|
||||
|
||||
C语言已经指定了这些标识符的用途或保留了它们的使用权,如果你使用它们作为变量名,即使没有语法错误,也不能随便使用。
|
||||
|
||||
#### 3. 声明
|
||||
|
||||
> **声明**(declaration):在使用变量(variable)之前,必须对其进行声明(为编译器所作的描述)。
|
||||
>
|
||||
> 声明的方式为:数据类型 + 变量名(程序员自己决定变量名,命名规则后面会讲)
|
||||
|
||||
示例中的 `int weight`完成了两件事情。第一,函数中有个变量名为 weight。第二,int 表明这个变量是整型。
|
||||
|
||||
编译器用这些信息为变量 weight 在内存中分配空间。
|
||||
|
||||
|
||||
|
||||
**C99** 前,如果有声明,声明一定要在语句之前。(就像示例那样,函数体中第一块是声明,第二块才是语句。)
|
||||
|
||||
C99 和 C11 遵循 C++ 的惯例,可以把声明放在任何位置。即可以使用时再声明变量。以后C程序中这种做法可能会很流行。**但是目前不建议这样。**
|
||||
|
||||
|
||||
|
||||
就**书写格式**而言,我建议将声明全部放在**函数体头部**,声明与语句之间**空出一行**。
|
||||
|
||||
|
||||
|
||||
#### 4. 命名
|
||||
|
||||
> weight,height 都是**标识符**,也就是一个变量,函数或其他实体的名称。因此,声明将特定标识符与计算机内存的特定位置联系起来,同时也就确定了存储在某位置的信息类型或数据类型。
|
||||
|
||||
|
||||
|
||||
给变量命名时要使用有意义的变量名或标识符。如果变量名无法清楚的表达自身的用途,可以在注释中进一步说明,这是一种良好的编程习惯与编程技巧。
|
||||
|
||||
C99 与 C11 允许使用更长的标识符,但是编译器只识别前 63个字符。*对于外部标识符,只允许 31 个字符*。事实上,你可以使用更长的字符,但是编译器可能忽略超出的部分。(比如有两个标识符都是 64 个字符,但只有最后一个字符不同。编译器可能会视其为同一个名字,也可能不会。标准并未定义在这种情况下会发生什么。)
|
||||
|
||||
|
||||
|
||||
> 命名规则:可以用小写字母,大写字母,数字和下划线(_)来命名。**名称的第一个字符必须是字符或下划线,不能是数字**
|
||||
|
||||
**操作系统和C库经常使用一个下划线或两个下划线开始的标识符(如:_kcab),因此最好避免在自己的程序中使用这种名称。(避免与操作系统和c库的标识符重复)**
|
||||
|
||||
C语言的名称区分大小写。即:star,Star,STAR 是不同的。
|
||||
|
||||
|
||||
|
||||
**声明变量的理由**:
|
||||
|
||||
1. 把所有变量放在一处,方便读者查找和理解程序的用途。
|
||||
2. 声明变量可以促使你在编写程序之前做好计划(比如你的程序要用什么变量,你可以提前规划)。
|
||||
3. 声明变量有助于发现程序中的小错误,如拼写错误。
|
||||
4. **不提前声明变量,C程序编译将无法通过**
|
||||
|
||||
|
||||
|
||||
#### 5. 赋值
|
||||
|
||||
> 赋值(assignment):变量通过赋值的方式获得值。
|
||||
|
||||
示例中,`weight = 160; `是一个 **赋值表达式语句**。意思是“把值 160 赋给 变量 weight”。
|
||||
|
||||
在执行 `int weight;`时,编译器在计算机内存中为变量 weight 预留的空间,然后在执行这行代码时,把值存储在之前预留的位置。可以给 weight 赋不同的值,这就是 weight 之所以被称为变量的原因。
|
||||
|
||||
**注意:**
|
||||
|
||||
- 该行表达式将值从右侧赋到左侧。
|
||||
|
||||
- 该语句以分号结尾。
|
||||
- `=` 在计算机中不是相等的意思,而是赋值。我们在读 `weight = 160; `时,我们应该这么读:“将 160 赋给 weight”
|
||||
- `==`表示相等
|
||||
|
||||
|
||||
|
||||
#### 6. printf() 函数
|
||||
|
||||
`printf(“我的体重是:%d斤\n,身高与体重的比为:%d”, weight, height / weight);`
|
||||
|
||||
这是我们示例中的 printf 函数,我们来看两个不那么复杂的:
|
||||
|
||||
```c
|
||||
main(void);
|
||||
printf("Hi");
|
||||
```
|
||||
|
||||
|
||||
|
||||
首先,printf() 的 **圆括号**是不是很像 main() ?这表示 printf 是一个函数名,它也是一个函数。圆括号内的内容是从 main() 函数传递给 printf() 函数的信息。该信息被称为**参数**,更确切的说,是**实际参数**(actual argument),简称**实参**。
|
||||
|
||||
既然是函数,它其实也是像我们看到的 main函数一样,也有函数头和函数体。
|
||||
|
||||
printf() 函数是一个库函数,库函数我们上一节讲函数种类时说过,这是一种不需要程序员去写的,只需要引用头文件 `stdio.h`就可以直接使用的。但是我们应该知道这一点,详细情况我们后面会说讲。
|
||||
|
||||
**当程序运行到 printf() 函数这一行时,控制权被转给了printf()函数。函数执行结束后,控制权被返回至主调函数(calling function),该例中是 main()** 。
|
||||
|
||||
|
||||
|
||||
printf() 函数的作用是向我们的显示器输出内容。
|
||||
|
||||
此例中,printf() 函数的括号内 分为两部分,一部分在双引号内,另一部分在双引号外,它们中间以逗号隔开。双引号外有两个参数 weight 和 height / weight ,他们分别是变量和**表达式**(含有常量,变量和运算符的式子),也是指定要被打印的参数(打印到你的屏幕上)。
|
||||
|
||||
我们发现,最终我们屏幕上看到的是引号内的内容。我们可以来看一下输出的内容:
|
||||
|
||||
```c
|
||||
我的体重是:160斤
|
||||
身高与体重的比为:1
|
||||
```
|
||||
|
||||
|
||||
|
||||
我们发现:首先引号内的 `%d` 和`\n`并没有被输出,`%d`的位置被替换成了一个整数。为什么会这样呢?
|
||||
|
||||
> `\n`代表**一个换行符(newline character)**。对于 printf 函数来说,它的意思是:“**在下一行的最左边开始新的一行**”。
|
||||
>
|
||||
> 也就是说换行符和在键盘上按下 Enter按键相同。既然如此,为何不在键入 printf() 参数时直接使用 Enter键呢?因为编辑器可能认为这是直接的命令,而不是存储在源代码中的指令。换句话说,如果直接按下 Enter键,编辑器会退出当前行并开始新的一行。但是,换行符会影响程序输出的(显示)格式。
|
||||
|
||||
换行符是一个**转义序列**(escape sequence)。转义序列用于难以表示或无法输入的字符。如,`\t`代表 Tab键,即制表符。`\b`代表 Backspace键,即退格键。我们在后面会继续讨论。
|
||||
|
||||
这样就解释了为何一行的printf() 函数会输出两行。
|
||||
|
||||
|
||||
|
||||
*以下这部分不能理解可以只看结论,能理解更好。*
|
||||
|
||||
在解释 %d 之前我们先来看一下,weight 和 height / weight 所代表的值。
|
||||
|
||||
weight 是被赋值为 160 的,所以 weight 的值就是 160
|
||||
|
||||
C语言中,`/`表示除法, `*` 表示乘法。
|
||||
|
||||
那么 height / weight 的值是多少呢?我们现在不知道这个表达式的值是多少,但是我们知道这个它肯定代表 180 / 160
|
||||
|
||||
而最终输出的值是 1 ,这和我们想的不一样,我们知道结果应该是个小数,那么这是为什么呢?
|
||||
|
||||
我想可能的原因有两个:
|
||||
|
||||
1. %d 将小数转换为整数
|
||||
2. 180 / 160 本身在C语言中的值就是整数
|
||||
|
||||
我们来测试一下:
|
||||
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
int a = 3;
|
||||
int b = 2;
|
||||
float c = 1.1f;//f 表示1.1是浮点数
|
||||
|
||||
printf("%d\n", c);//%d 用来输出整型
|
||||
printf("%f\n", a / b);//%f 用来输出浮点型
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```c
|
||||
-1717986918
|
||||
0.000000
|
||||
```
|
||||
|
||||
输出并不是我们想要的内容,我们来看一下编译器的警告:
|
||||
|
||||
编译器警告:
|
||||
|
||||
```c
|
||||
“printf”: 格式字符串“%d”需要类型“int”的参数,但可变参数 1 拥有了类型“double”
|
||||
“printf”: 格式字符串“%f”需要类型“double”的参数,但可变参数 1 拥有了类型“int”
|
||||
```
|
||||
|
||||
可以不去理解报错的内容。输出与报错至少说明了一点:
|
||||
|
||||
**%d 在我的编译器上无法输出浮点型;整型 / 整型 不是浮点型。**
|
||||
|
||||
那就说明了原因2是对的,即:**180 / 160 的值就是 1**
|
||||
|
||||
|
||||
|
||||
为什么 `180 / 160 == 1 `(180 / 160 的值是 1)呢?
|
||||
|
||||
因为 weight 和 height 都整数,它们相除结果取整数(向下取整)。
|
||||
|
||||
|
||||
|
||||
如何输出 float 类型的浮点数?
|
||||
|
||||
```c
|
||||
printf("%f", 2.0f);
|
||||
```
|
||||
|
||||
|
||||
|
||||
>`%d`是一个占位符,其作用是指明 num 值的位置。d 代表 以十进制的格式。
|
||||
|
||||
|
||||
|
||||
还有一点要注意的是,在示例中,第二个输出的整数的参数(height / weight )是一个表达式,我们也可以在程序中添加一个新的变量,然后用这个变量代替上面的表达式作为 printf() 的参数。如:
|
||||
|
||||
```c
|
||||
int main(void)
|
||||
{
|
||||
int height = 180;
|
||||
int weight, scale;//scale:比例
|
||||
weight = 160;
|
||||
scale = height / weight;
|
||||
printf(“我的体重是:%d斤\n,身高与体重的比为:%d”, weight, scale);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
合理的使用表达式作为函数的参数可以简化程序。
|
||||
|
||||
也说明**在任何需要数值的地方,都可以使用具有相同类型的表达式**。
|
||||
|
||||
|
||||
|
||||
#### 7. 初始化
|
||||
|
||||
当程序开始执行时,某些变量会被自动设置为0,而大多数不会。没有默认值并且尚未在程序中被赋值的变量时未初始化的(uninitialized)。
|
||||
|
||||
如果试图访问未初始化的变量,可能会得到不可预知的值。在某些编译器中,可能会发生更坏的情况(甚至程序崩溃)。
|
||||
|
||||
|
||||
|
||||
我们可以用赋值的办法给变量赋初值,但还有更简洁的做法:在变量声明中加入初始值。
|
||||
|
||||
例如示例中的 `int height = 180`数值 180 就是一个**初始化式**(initializer)。
|
||||
|
||||
|
||||
|
||||
同一个声明中可以对任意数量的变量进行初始化。如:
|
||||
|
||||
```c
|
||||
int a = 10, b = 15, c = 20;
|
||||
```
|
||||
|
||||
上述每个变量都拥有属于自己的初始化式。接下来的例子,只有 c 有初始化式,a,b没有。
|
||||
|
||||
```c
|
||||
int a, b, c = 20;
|
||||
```
|
||||
|
||||
|
||||
|
||||
***
|
||||
|
||||
[^0]:每个程序都是其他程序不合适的一部分。
|
||||
|
||||
*参考资料:《C Primer Plus》《C语言程序设计:现代方法》*
|
||||
|
||||
|
||||
|
||||
732
content/c-mordern-approch/04-格式化输入输出.md
Normal file
732
content/c-mordern-approch/04-格式化输入输出.md
Normal file
@@ -0,0 +1,732 @@
|
||||
## 格式化输入/输出
|
||||
|
||||
*A programming language is low level when its programs require attention to the irrelevant.*[^0]
|
||||
|
||||
|
||||
|
||||
请将本片与下一节《数据类型》 联系起来一起“食用”。
|
||||
|
||||
**注:本教程含有超纲内容!!!如果你看不懂,不要丧失信心,可以“不求甚解”一些,关键是要多写代码!然后继续学习下面的内容!**
|
||||
|
||||
|
||||
|
||||
:arrow_forward: 此符号表示该内容以后的章节会讲解,此章节内不要求理解。
|
||||
|
||||
|
||||
|
||||
### :globe_with_meridians:目录
|
||||
|
||||
***
|
||||
|
||||
[TOC]
|
||||
|
||||
### printf 函数
|
||||
|
||||
`printf()`函数打印数据的指令要与待打印数据的类型相匹配。例如,打印整数时使用 `%d`,打印字符时使用 `%c` 。这些符号被称为**转换说明**(conversion specification),它们指定了如何把数据(以2进制形式)转换成可显示的形式。
|
||||
|
||||
例如:
|
||||
|
||||
```c
|
||||
printf("I am %d years old", 18);
|
||||
```
|
||||
|
||||
|
||||
|
||||
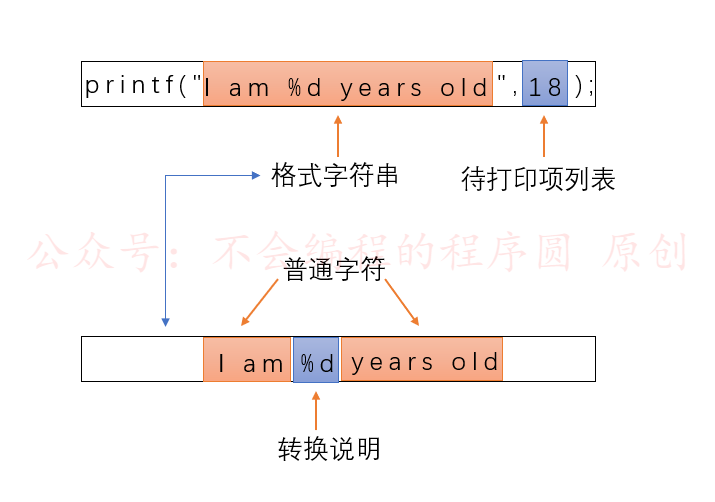
|
||||
|
||||
这是 printf()的格式:
|
||||
|
||||
`printf(格式字符串,待打印项1,待打印项2,...);`
|
||||
|
||||
**待打印项**都是要打印的的项。它们可以是**变量,常量**,甚至是在打印之前计算的**表达式**。上例中,只有一个待打印项: 18 。
|
||||
|
||||
**格式字符串**包含两种不同信息:
|
||||
|
||||
- **普通字符**:以字符串中出现的形式打印出来。上例中,"I am" 与 " years old" 为普通字符
|
||||
- **转换说明**:用待打印项的值来替换。上例中,"%d" 为转换说明
|
||||
|
||||
|
||||
|
||||
***
|
||||
|
||||
#### :warning:
|
||||
|
||||
C语言的编译器不会检测格式字符串中转换说明中的数量与待打印项总个数是否相匹配。
|
||||
|
||||
**1.缺少参数**
|
||||
|
||||
```c
|
||||
printf("%d %d\n", i); // wrong
|
||||
```
|
||||
|
||||
printf 会正确显示 i 的值,然后显示一个无意义的整数值。
|
||||
|
||||
**2.参数过多**
|
||||
|
||||
```c
|
||||
printf("%d\n", i, j);// wrong
|
||||
```
|
||||
|
||||
而在这种情况下,printf 函数会显示变量 i 的值,但是不会显示变量 j 的值
|
||||
|
||||
***
|
||||
|
||||
#### printf 转换说明
|
||||
|
||||
转换说明这部分我做了很久,比较详细,配合下一章**数据类型**才能看懂大部分,剩下的就需要你在不断使用的过程中领悟了。
|
||||
|
||||
|
||||
|
||||
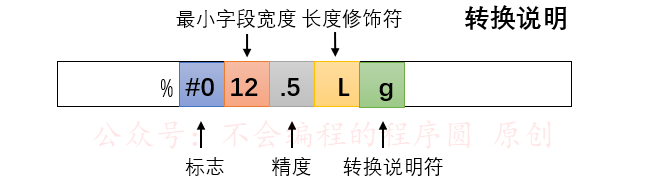
|
||||
|
||||
|
||||
|
||||
- **标志**(可选,允许出现多于一个)
|
||||
|
||||
| - | 字段内左对齐(默认右对齐) |
|
||||
| ---- | ------------------------------------------------------------ |
|
||||
| + | 在打印的数前加上 + 或 - (通常只有负数前面附上减号)*例1* |
|
||||
| 空格 | 在打印的非负数前前面加空格( + 标志优先于空格标志)*例2* |
|
||||
| # | 对象:八进制数,十六进制数,以g/G 转换输出的数 *例3* |
|
||||
| 0 | 用前导 0 在字段宽度内对输出进行填充。如果转换格式为d,i,o,u,x(X),而且指定了精度,可以忽略 0 *例4* |
|
||||
|
||||
例 1:
|
||||
|
||||
```c
|
||||
printf("%d\n", 123);
|
||||
printf("%d\n", -123);
|
||||
printf("%+d\n", 123);
|
||||
printf("%+d\n", -123);
|
||||
```
|
||||
|
||||
```c
|
||||
123
|
||||
-123
|
||||
+123
|
||||
-123
|
||||
```
|
||||
|
||||
例 2:
|
||||
|
||||
```c
|
||||
printf("% d\n", 123);
|
||||
printf("% d\n", -123);
|
||||
printf("% +d\n", 123);
|
||||
```
|
||||
|
||||
```c
|
||||
123
|
||||
-123
|
||||
+123
|
||||
```
|
||||
|
||||
例 3:
|
||||
|
||||
```c
|
||||
printf("%o\n", 0123);
|
||||
printf("%x\n", 0x123);
|
||||
printf("%#o\n", 0123);
|
||||
printf("%#x\n", 0x123);
|
||||
printf("%#g\n", 123.0);
|
||||
printf("%g\n", 123.0);
|
||||
```
|
||||
|
||||
```c
|
||||
123
|
||||
123
|
||||
0123
|
||||
0x123
|
||||
123.000
|
||||
123
|
||||
```
|
||||
|
||||
例 4:
|
||||
|
||||
```c
|
||||
printf("%5d\n", 123);
|
||||
printf("%05d\n", 123);
|
||||
printf("%5.3d\n", 123);
|
||||
```
|
||||
|
||||
```c
|
||||
123
|
||||
00123
|
||||
123
|
||||
```
|
||||
|
||||
- **最小字段宽度**(可选)
|
||||
|
||||
> 如果数据项太小无法达到这个宽度,那么会对字段进行填充。(默认情况下会在数据项左侧添加空格,从而使字段宽度内右对齐)。
|
||||
>
|
||||
> 如果数据项过大以至于超过了这个宽度,那么会完整的显示数据项。
|
||||
>
|
||||
> 字段宽度可以是整数也可以是字符 `*`。如果是字符 * ,那么字段宽度由下一个参数决定。如果这个参数为负,它会被视为前面带 - 标志的正数。*例5*
|
||||
|
||||
例 5:
|
||||
|
||||
```c
|
||||
printf("%5d\n", 123);
|
||||
printf("%2d\n", 123);
|
||||
printf("%*d\n", 5, 123);
|
||||
printf("%*d\n", -5, 123);
|
||||
```
|
||||
|
||||
```c
|
||||
123
|
||||
123
|
||||
123
|
||||
123
|
||||
```
|
||||
|
||||
|
||||
|
||||
- **精度**(可选项)
|
||||
|
||||
> 如果转换说明是:
|
||||
>
|
||||
> d,i,o,u,x,X, 那么精度表示最少位数(如果位数不够,则添加前导 0 )
|
||||
>
|
||||
> a,A,e,E,f,F ,那么精度表示小数点后的位数
|
||||
>
|
||||
> g,G,那么精度表示有效数字个数
|
||||
>
|
||||
> s,那么精度表示最大字节数
|
||||
>
|
||||
> 精度是由小数点(.)后跟一个整数或 * 字符构成的。如果是 * ,那么精度由下一个参数决定(如果这个参数为负,效果与不指定精度一样。)如果只有小数点,那么精度为0 。*例 6*
|
||||
|
||||
例 6:
|
||||
|
||||
```c
|
||||
printf("%.4d\n", 123);
|
||||
|
||||
printf("\n");
|
||||
|
||||
printf("%f\n", 123.0);
|
||||
printf("%.1f\n", 123.0);
|
||||
|
||||
printf("\n");
|
||||
|
||||
printf("%g\n", 123.0);
|
||||
printf("%.5g\n", 123.0);
|
||||
|
||||
printf("\n");
|
||||
|
||||
printf("%s\n", "Hello");
|
||||
printf("%.2s\n", "Hello");
|
||||
|
||||
printf("\n");
|
||||
|
||||
printf("%.*d\n", 4, 123);
|
||||
printf("%.*d\n", -4, 123);
|
||||
```
|
||||
|
||||
```c
|
||||
0123
|
||||
|
||||
123.000000
|
||||
123.0
|
||||
|
||||
123
|
||||
123
|
||||
|
||||
Hello
|
||||
He
|
||||
|
||||
0123
|
||||
123
|
||||
```
|
||||
|
||||
- **长度修饰符**(可选)。
|
||||
|
||||
> 长度修饰符表明待显示的数据项的长度**大于或小于**特定转换说明中的正常值。*例7*
|
||||
|
||||
| 长度修饰符 | 转换说明符 | 含义 |
|
||||
| ---------- | ---------------------- | ----------------------------- |
|
||||
| hh (C99) | d,i,o,u,x,X | signed char, unsigned char |
|
||||
| h | d,i,o,u,x,X | short, unsigned short |
|
||||
| l | d,i,o,u,x,X | long, unsigned long |
|
||||
| ll (C99) | d,i,o,u,x,X | long long, unsigned long long |
|
||||
| L | a,A,e,E,f,F,g,G | long double |
|
||||
| z (C99) | d,i,o,u,x,X | size_t |
|
||||
| j (C99) | d,i,o,u,x,X | ptrdiff_t |
|
||||
|
||||
例 7:
|
||||
|
||||
```c
|
||||
printf("%#hhX\n", 0xAABBCCDDEEFF1122);//这是一个占用内存为 8 个字节的十六进制数
|
||||
printf("%#hX\n", 0xAABBCCDDEEFF1122);
|
||||
printf("%#X\n", 0xAABBCCDDEEFF1122);
|
||||
printf("%#lX\n", 0xAABBCCDDEEFF1122);
|
||||
printf("%#llX\n", 0xAABBCCDDEEFF1122);
|
||||
```
|
||||
|
||||
```c
|
||||
0X22
|
||||
0X1122
|
||||
0XEEFF1122
|
||||
0XEEFF1122
|
||||
0XAABBCCDDEEFF1122
|
||||
```
|
||||
|
||||
- 转换说明符
|
||||
|
||||
由于参数提升(:arrow_forward:),在实参传递给可变数量实参函数时,float 会转换为 double ,char 会转换为 int。*例8*
|
||||
|
||||
| 转换说明符 | 含义 |
|
||||
| -------------- | ------------------------------------------------------------ |
|
||||
| d,i | 把 int 类型转换为 十进制形式 |
|
||||
| o,u,x,X | 把无符号整型转换为八进制(o),十进制(u),十六进制形式(x,X)。 |
|
||||
| f,F (F C99) | 把 double 类型转换为 十进制形式,并把小数点放置在正确位置上。如果没有指定精度,那么小数点后显示6个数字。 |
|
||||
| e,E | 把 double 类型转换为 科学计数法形式。如果没有指定精度,那么小数点后显示6个数字。 |
|
||||
| g,G | 把double 类型转换为 f 形式或 e 形式。当数值的指数部分小于 -4,或大于等于精度时,会选择以 e 的形式显示。尾部的 0 不显示(除非用#标志),且小数点后跟有数字才会显示出来。 |
|
||||
| a,A (C99) | 把 double 类型转换为十六进制科学计数法(p计数法)。 |
|
||||
| c | 显示无符号字符的 int 类型值。 |
|
||||
| s | 写出由实参指向的字符串。 |
|
||||
| p | 把 void* 类型转换为可打印的形式。 |
|
||||
| n | 相应的实参必须是指向 int 型对象的指针。在该对象中存储 ...printf 函数已经输出的字符数量,不产生输出。 |
|
||||
| % | 写字符 % |
|
||||
|
||||
例 8:
|
||||
|
||||
```c
|
||||
printf("%i\n", 123);
|
||||
printf("%d\n", 123);
|
||||
|
||||
printf("%o\n", 123);
|
||||
printf("%u\n", 123);
|
||||
printf("%x\n", 123);
|
||||
printf("%X\n", 123);
|
||||
|
||||
printf("%f\n", 123.0);
|
||||
|
||||
printf("%e\n", 123.0);
|
||||
|
||||
printf("%g\n", 123.0);
|
||||
|
||||
printf("%a\n", 123);
|
||||
|
||||
printf("%c\n", 65);
|
||||
|
||||
printf("%s\n", "123");
|
||||
|
||||
int* a = 2;
|
||||
printf("%p\n", a);
|
||||
|
||||
printf("%%\n");
|
||||
```
|
||||
|
||||
输出:为了方便大家观看我已经将输出中的换行删除了
|
||||
|
||||
```c
|
||||
123
|
||||
123
|
||||
|
||||
173
|
||||
123
|
||||
7b
|
||||
7B
|
||||
|
||||
123.000000
|
||||
|
||||
1.230000e+02
|
||||
|
||||
123
|
||||
|
||||
0x1.e13430000007bp-1021
|
||||
|
||||
A
|
||||
|
||||
123
|
||||
|
||||
00000002
|
||||
|
||||
%
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### printf() 返回值
|
||||
|
||||
> 返回值:**传输到输出流(显示器)的字符数**,若出现输出错误或编码错误(对于字符串和字符转换指定符)则为**负值**。
|
||||
>
|
||||
> 返回类型:`int`
|
||||
>
|
||||
> 使用场景:检查输出错误。(看输出的字符数是否正确)
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
int count;
|
||||
|
||||
count = printf("Hello!\n");
|
||||
|
||||
printf("%d\n", count);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
Hello!
|
||||
7
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 打印较长字符串
|
||||
|
||||
允许的换行方式:
|
||||
|
||||
```c
|
||||
printf("Hello %s\n",
|
||||
XiaoHuang);//为了让读者知道该行未完,可以使用缩进
|
||||
```
|
||||
|
||||
错误的换行方式:
|
||||
|
||||
```c
|
||||
printf("Hello
|
||||
%s\n", XiaoHuang);
|
||||
```
|
||||
|
||||
如果想在双引号括起来的格式字符串中换行,应该这样写:
|
||||
|
||||
1. ```c
|
||||
printf("Hello");
|
||||
printf (" %s\n", XiaoHuang);
|
||||
```
|
||||
|
||||
2. ```c
|
||||
printf("Hello\
|
||||
%s\n", XiaoHuang);
|
||||
```
|
||||
|
||||
3. ```c
|
||||
printf("Hello"
|
||||
" %s\n", XiaoHuang);// ANSI C
|
||||
```
|
||||
|
||||
方法1:使用多个 printf 语句
|
||||
|
||||
方法2:在要换行的地方加上反斜杠( \ )来断行。但是,下一行的代码必须从该行最左端开始,不然输出会包含你所缩进的空白字符。
|
||||
|
||||
方法3:ANSI C 引入的字符串连接。C 编译器会将多个字符串看作一个字符串。
|
||||
|
||||
### scanf() 函数
|
||||
|
||||
我们从键盘输入的都是文本,因为键盘只能生成文本字符:字符,数字和标点符号。如果要输入整数 2014,就要键入2,0,1,4.如果要将其存储为数值而不是字符串,程序就必须要把字符依次转换成数值,这就是 scanf() 要做的。
|
||||
|
||||
scanf() 把输入的字符串转换成整数,浮点数,字符和字符串,而 printf() 正好与之相反,把整数,浮点数,字符,字符串转换成显示在屏幕上的文本。
|
||||
|
||||
scanf() 与 printf() 类似,也要使用 格式字符串 和 参数列表。scanf() 中的格式字符串表明字符输入流的目标数据类型。两个函数的主要区别在于参数列表中。printf() 函数使用变量,常量和表达式,而 scanf() 函数使用指向变量的指针(:arrow_forward:)。这里不需要了解指针,只需要记住一下简单的两条:
|
||||
|
||||
用 scanf 读取
|
||||
|
||||
- 基本变量类型的值,在变量名前加上一个` &`
|
||||
- 把字符串读入数组中,不要使用 `&`
|
||||
|
||||
下面的程序演示了这两条规则:
|
||||
|
||||
**input.c** —— 何时使用 &
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
int main(void){
|
||||
|
||||
int age;
|
||||
float assets;
|
||||
char pets[30];//字符数组,存放字符串
|
||||
|
||||
printf("Enter you age, assets and you favorite pet.\n");
|
||||
scanf("%d %f", &age, &assets); // 这里要用 &
|
||||
scanf("%s", pets);// 字符数组不使用 &
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
***
|
||||
|
||||
#### :warning:
|
||||
|
||||
初学者在使用 scanf 时,在应该写 & 的时候容易忽略 & ,所以每次使用 scanf 的时候一定要格外小心。通常情况下,必要的地方缺少 & 会让程序崩溃(编译器没有警告),但是也有时候程序并不会崩溃,这时候找 bug 可能会让你头痛。
|
||||
|
||||
***
|
||||
|
||||
scanf 的 长度修饰符 和 转换说明符 与 printf 几乎相同。主要的区别如下:
|
||||
|
||||
- **长度修饰符** :(可选项)对于 float 与 double 类型,printf() 的转换说明都用 `f`; 而对于 scanf() ,float 保持不变,double 要在 f 前加长度修饰符 l ,即:`lf`。*例 1*
|
||||
|
||||
例 1:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
double a = 3.0;
|
||||
|
||||
scanf("%lf", &a);
|
||||
printf("%lf", a);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
- **转换说明符** :`%[集合]`匹配集合中的任意序列;`%[^集合]`匹配非集合中的任意序列。*例 2*
|
||||
|
||||
例 2:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
char str[10];//字符串数组
|
||||
|
||||
scanf("%[123]", str);
|
||||
printf("%s", str);
|
||||
|
||||
return 0;
|
||||
}
|
||||
//输入:123456abc123
|
||||
//输出:123
|
||||
```
|
||||
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
char str[10];//字符串数组
|
||||
|
||||
scanf("%[^123]", str);
|
||||
printf("%s", str);
|
||||
|
||||
return 0;
|
||||
}
|
||||
//输入:abc4123a
|
||||
//输出:abc4
|
||||
```
|
||||
|
||||
|
||||
|
||||
- **字符 `*`**:(可选项)字符 * 出现意味着**赋值屏蔽**(assignment suppression): 读入此数据项,但是不会将其赋值给对象。用 * 匹配的数据项不包含在 ...scanf 函数返回的计数中。*例 3*
|
||||
|
||||
例 3:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
int a = 0;
|
||||
|
||||
scanf("%*d%d", &a);
|
||||
printf("%d", a);
|
||||
|
||||
return 0;
|
||||
}
|
||||
输入:1 2
|
||||
输出:2
|
||||
```
|
||||
|
||||
|
||||
|
||||
- **最大字段宽度**:(可选项)最大字段宽度限制了输入项中的字符数量。如果达到最大值,那么次数据项的转换结束。转换开始跳过的空白不计。*例 4*
|
||||
|
||||
```c
|
||||
//输入:1234 Hello
|
||||
//先猜测一下输出
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
int a = 0;
|
||||
char str[10];
|
||||
|
||||
scanf("%2d%3s", &a, str);
|
||||
printf("%d %s", a, str);
|
||||
|
||||
return 0;
|
||||
}
|
||||
//输出:12 34
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 进一步思探究 scanf()
|
||||
|
||||
在上面了解了 scanf 的基本情况后,我们进一步探究 scanf 函数。
|
||||
|
||||
|
||||
|
||||
上面的例 2,为何只是输出了 "123", 我们明明还输入了一组 123,为什么没有输出呢?
|
||||
|
||||
> scanf 函数如果发生了 **输入失败**(没有字符输入)或 **匹配失败** (即输入字符和格式串不匹配),那么...scanf 会提前返回。返回就意味着这个 scanf 的读入结束。
|
||||
|
||||
|
||||
|
||||
scanf 返回的又是什么呢?
|
||||
|
||||
> 成功赋值的接收参数的数量(可以为零,在首个接收用参数赋值前匹配失败的情况下),或者若输入在首个接收用参数赋值前发生失败,则为EOF(EOF 的值是 -1)。
|
||||
|
||||
在C程序中测试 scanf 函数的返回值的循环很普遍。例如,下面的循环逐一读取一串整数,在首个遇到问题的符号处停止:
|
||||
|
||||
```c
|
||||
while(scanf("%d", &i) == 1){
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
对于 scanf 部分最开始的程序 input.c
|
||||
|
||||
如果我们这样先输入:
|
||||
|
||||
```c
|
||||
18 98.5
|
||||
diandian
|
||||
```
|
||||
|
||||
再这样输入:
|
||||
|
||||
```c
|
||||
18
|
||||
98.5
|
||||
|
||||
|
||||
diandian
|
||||
```
|
||||
|
||||
如果你添加上 printf 语句输出这三项,会发现,这两种输入的输出是一样的。
|
||||
|
||||
**在寻找起始位置时,scanf 函数会忽略空白字符**(white-space character,包括空格符,水平和垂直制表符,换页符和换行符),但是`%[ , %c, %n`除外。*例 5*
|
||||
|
||||
例 5:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
int main(void) {
|
||||
|
||||
char ch = 'a';
|
||||
char str[10] = "hi";
|
||||
|
||||
scanf("%c", &ch);
|
||||
scanf("%[123]", str);
|
||||
|
||||
printf("%c %s", ch, str);
|
||||
|
||||
|
||||
return 0;
|
||||
}
|
||||
//输入: b (输入的是:空格 + b,然后按下回车键想接着输入下一个 scanf)
|
||||
//输出: hi
|
||||
```
|
||||
|
||||
这个例子除了证明了上面的结论,还说明了:
|
||||
|
||||
但是 **scanf 函数会忽略最后的换行符**,实际上它没有读取它,这个换行符时下一次 scanf 函数读入的第一个字符。
|
||||
|
||||
|
||||
|
||||
**scanf 函数遵循什么规则来识别整数或浮点数呢?**
|
||||
|
||||
在要读入整数时,scanf 函数首先会寻找正号或负号,然后从读入一个数字开始直到读入一个非数字为止。
|
||||
|
||||
当要求读入浮点数时,scanf 函数首先会寻找正号或负号(可选),然后是一串数字(可能含有小数点),再后是一个指数(可选)。指数由一个字母e,可选的符号,一个或多个数字组成。
|
||||
|
||||
**当 scanf 函数遇到一个不可能输入当前项的字符时,它会把此字符“放回原处”**,以便在扫描下一项或下一次调用 scanf 时再次读入。思考下面(公认有问题的)4个数的排列:
|
||||
|
||||
```c
|
||||
1-20.3-4.0e3回车
|
||||
```
|
||||
|
||||
然后我们用这个 scanf 函数来读入:
|
||||
|
||||
```c
|
||||
scanf("%d%d%f%f", &i, &j, &x, &y);
|
||||
```
|
||||
|
||||
scanf 会如何处理这组输入呢?
|
||||
|
||||
- %d :读入 1
|
||||
- %d :读入 -20
|
||||
- %f :读入 .3 (当作 0.3 处理)
|
||||
- %f:读入 剩下的输入。但是不读入最后的回车
|
||||
|
||||
|
||||
|
||||
**使用 %s 转换说明**,scanf 会读取除了空白字符以外的所以字符。scanf 跳过空白字符并开始读入第一个非空白字符,保存非空白字符直到再遇到空白字符结束。这意味着,scanf 最多只能读取一个单词。无法利用字段宽度使得 scanf 读取多个单词,scanf 会在字段宽度结束或遇到空白字符处停止。scanf 将字符串放入数组时,会在字符串序列末尾加上一个 `\0`。
|
||||
|
||||
|
||||
|
||||
**格式串中的普通字符**
|
||||
|
||||
- **空白字符**:...scanf 函数格式串中的一个或多个连续的空白字符与输入流中的零个或多个空白字符匹配。
|
||||
|
||||
简单说一下就是,格式串中有空格,输入时你可以不写空格或写多个;格式串中有多个空格,输入时你可以只写一个空格。
|
||||
|
||||
- **非空白字符**:看个程序就明白了:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
int main(void) {
|
||||
|
||||
int i, j, k;
|
||||
|
||||
printf("Enter a date: ");
|
||||
scanf("%d - %d - %d", &i, &j, &k);
|
||||
printf("date: %d - %d - %d", i, j, k);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
```c
|
||||
//输入:
|
||||
Enter a date: 2020 - 2-22
|
||||
//输出:
|
||||
date: 2020 - 2 - 22
|
||||
```
|
||||
|
||||
|
||||
**空格你可以随便空,换行都可以随便换,但是一定要打 ''-'' 符号。**
|
||||
|
||||
|
||||
|
||||
#### 易混淆的 printf() 与 scanf()
|
||||
|
||||
1. ```c
|
||||
printf("%d", &i);
|
||||
```
|
||||
|
||||
输出的并不是 i 的值 (而是 i 的地址的十进制数值)
|
||||
|
||||
2. ```c
|
||||
scanf("%d, %d", &i, &j);
|
||||
```
|
||||
|
||||
scanf 在第一个 %d 读入一个整数后,试图把逗号与输入流中的下一个字符相匹配,如果这个字符不是 `,`,那 scanf 就会终操作,而不再读取变量 j 的值。
|
||||
|
||||
3. ```c
|
||||
scanf("%d\n", &i);
|
||||
```
|
||||
|
||||
printf 函数中经常有 `\n` ,但是如果在 scanf 格式串结尾放一个 \n 通常会引发你预期之外的问题。
|
||||
|
||||
对于 scanf 函数来说,\n 等同于空格,那么 scanf 就会在流中寻找空白字符,但是我们上面说过,scanf 格式串中的空白字符会与 输入流中的零个或多个空白字符匹配。所以当你输入完成后按下回车,这个回车会与 scanf 中的 \n 匹配,之后你无论打多少回车都不会使 scanf 结束,除非你输入一个非空字符,使 scanf 因匹配失败而退出。
|
||||
|
||||
|
||||
|
||||
[^0]:*任何编程语言在处理无关事务时都是低级语言。*
|
||||
|
||||
*参考资料:《C Primer Plus》《C语言程序设计:现代方法》*
|
||||
|
||||
|
||||
1083
content/c-mordern-approch/05-基本类型.md
Normal file
1083
content/c-mordern-approch/05-基本类型.md
Normal file
File diff suppressed because it is too large
Load Diff
408
content/c-mordern-approch/06-表达式.md
Normal file
408
content/c-mordern-approch/06-表达式.md
Normal file
@@ -0,0 +1,408 @@
|
||||
# 表达式
|
||||
|
||||
*Symmetry is a complexity reducing concept (co-routines include sub-routines); seek it everywhere.* [^1]
|
||||
|
||||
|
||||
|
||||
## 目录
|
||||
|
||||
***
|
||||
|
||||
[TOC]
|
||||
|
||||
|
||||
|
||||
### 一 算术运算符
|
||||
|
||||
#### 1.概念
|
||||
|
||||
| 一元运算符(只需要 1 个操作数) |
|
||||
| ------------------------------- |
|
||||
| + 一元正号运算符 |
|
||||
| - 一元负号运算符 |
|
||||
|
||||
|
||||
|
||||
**二元运算符**
|
||||
|
||||
| 加法类 | 乘法类 |
|
||||
| ---------------- | --------------- |
|
||||
| + 加法运算符 | * 乘法运算符 |
|
||||
| - 减法运算符 | / 除法运算符 |
|
||||
| | % 求余运算符 |
|
||||
|
||||
|
||||
|
||||
**注意:**
|
||||
|
||||
- int 型与 float 型混合在一起时,运算结果是 float 型。
|
||||
|
||||
比如,9 + 2.5f 的值为 11.5;6.7f / 2 的值为 3.35。
|
||||
|
||||
- 运算符 `/`:当两个操作数都是整型时,结果会**向下取整**。如,1 / 2 的值是 0,而不是 0.5 。
|
||||
|
||||
- 运算符 `%`要求两个操作数都是**整型**。
|
||||
|
||||
- 把 0 作为 `/` 或 `%` 的右操作数会导致未定义行为。
|
||||
|
||||
- 当运算符 `/` 和 `%` 用于负操作数时,其结果难以确定。
|
||||
|
||||
根据 C89 的标准,如果两个操作数中有一个是负数,那么除法结果**既可以向上取整也可以向下取整**(例如,-9 / 7 的结果既可以是 -1 也可以是 -2);i % j 的符号与具体实现有关(例如,-9 % 7 可以是 -2 也可以是 5)。
|
||||
|
||||
在 C99 中,除法的结果总是**向零取整**(因此,-9 / 7 的结果是 -1);i % j 的符号与 i 相同(因此,-9 % 7 的结果是 -2;我特意测试了以下,9 % -7 的值是 2,-9 % -7 的值还是 2)。
|
||||
|
||||
|
||||
|
||||
> **“由实现定义”**的行为:
|
||||
>
|
||||
> 术语由实现定义(implementation-defined)指的是 C标准对 C语言的部分内容未加指定,并认为其细节可有“实现”来具体定义。所谓实现是指程序在特定平台上编译,链接和执行所需要的软件。因此,根据实现的不同,程序的行为可能稍微有差异。
|
||||
>
|
||||
> 这样做的可能很奇怪甚至危险。但是这正是 C语言的目标之一——高效,这常常意味着与硬件相匹配。
|
||||
>
|
||||
> 对于我们来说,我们要**尽量避免编写这种由实现定义的行为的程序**。如果不能做到,起码要仔细查阅手册。
|
||||
|
||||
|
||||
|
||||
#### 2. 运算符的优先级和结合性
|
||||
|
||||
当表达式包含多个运算符时,其含义可能不是一目了然的。我们的解决方法是:
|
||||
|
||||
- 用括号进行分组
|
||||
- 了解运算符的优先级和结合性
|
||||
|
||||
##### 运算符优先级
|
||||
|
||||
(operator precedence)
|
||||
|
||||
| 最高优先级 | + | - | (一元运算符) |
|
||||
| ---------- | ---- | ---- | -------------- |
|
||||
| | * | / | % |
|
||||
| 最低优先级 | + | - | (二元运算符) |
|
||||
|
||||
**例 1-1:**
|
||||
|
||||
```c
|
||||
i + j * k 等价于 i + (j * k)
|
||||
-i + -j 等价于 (-i) + (-j)
|
||||
```
|
||||
|
||||
<br>
|
||||
|
||||
##### 运算符的结合性
|
||||
|
||||
当表达式包含两个或更多相同优先级的运算符时,仅有运算符优先级规则是不够的。这种情况下,运算符的**结合性**(associativity)开始发挥作用。
|
||||
|
||||
> 如果运算符是从左向右开始结合的,那么称这种运算符是左结合的。
|
||||
|
||||
二元运算符即:`*,/,%,+,-`都是左结合的。所以:
|
||||
|
||||
**例 1-2:**
|
||||
|
||||
```c
|
||||
i - j - k 等价于 (i - j) - k
|
||||
```
|
||||
|
||||
|
||||
|
||||
运算符是右结合的,如一元运算符:`+,-`。
|
||||
|
||||
**例 1-3:**
|
||||
|
||||
```c
|
||||
- + i 等价于 -(+i)
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 3.总结
|
||||
|
||||
>在许多语言(特别是 C 语言)中,优先级和结合性规则都是十分重要的。然而 C 语言的运算符太多了(差不多 50 种)。**为了自己和他人理解代码的方便,请最好加上足够多的圆括号。**
|
||||
|
||||
|
||||
|
||||
### 二 赋值运算符
|
||||
|
||||
> 求出表达式的值后往往需要将其存储在变量中,以便将来使用。C语言的 = (简单赋值 simple assignment)运算符可以用于此目的。为了更新已经存储在变量中的值,C语言还提供了一种复合赋值(compound assignment)。
|
||||
|
||||
|
||||
|
||||
#### 1. 简单赋值
|
||||
|
||||
表达式 `v = e`的赋值效果是求出表达式 e 的值,然后将此值赋值给 v。
|
||||
|
||||
**例 2-1:**
|
||||
|
||||
```c
|
||||
i = 5;// i is now 5
|
||||
j = i;// j is now 5
|
||||
k = 10 * i + j;// k is now 55
|
||||
```
|
||||
|
||||
如果 v 与 e 的类型不同,那么赋值运算发生时会将 e 的值转化为 v 的类型:
|
||||
|
||||
**例 2-2:**
|
||||
|
||||
```c
|
||||
int i;
|
||||
double j;
|
||||
i = 72.99f;// i is now 72
|
||||
f = 136;// f is now 136.0
|
||||
```
|
||||
|
||||
|
||||
|
||||
在很多编程语言中,赋值是**语句**;然而在 C语言中,赋值就像 + 那样是**运算符**。
|
||||
|
||||
既然赋值是运算符,那么多个赋值语句可以串联在一起:
|
||||
|
||||
**例 2-3:**
|
||||
|
||||
```c
|
||||
i = j = k = m = 0;
|
||||
```
|
||||
|
||||
**运算符 = 是右结合的**,所以,上面的语句等价于:
|
||||
|
||||
```c
|
||||
i = (j = (k = (m = 0)));
|
||||
```
|
||||
|
||||
作用是先将 0 赋值给 m,再将 m 赋值给 k,再将 k 赋值给 j,再将 j 赋值给 i 。
|
||||
|
||||
|
||||
|
||||
<br>
|
||||
|
||||
###### ! 注意
|
||||
|
||||
因为赋值运算符存在**类型转换**(本节后面会讲),串在一起赋值运算的结果可能不是预期的结果:
|
||||
|
||||
```c
|
||||
int i;
|
||||
float j;
|
||||
|
||||
j = i = 33.3f;
|
||||
//先将 33 赋值给 i,然后将 33.0 赋值给 j
|
||||
```
|
||||
|
||||
#### 2. 左值
|
||||
|
||||
赋值运算要求它的左操作数必须是**左值**(lvalue)。左值表示在计算机中的存储对象,而不是常量或计算的结果。**左值是变量。**
|
||||
|
||||
**例 2-4:**
|
||||
|
||||
```c
|
||||
12 = i;
|
||||
i + j = 0;
|
||||
-i = j;
|
||||
```
|
||||
|
||||
以上三种表达式都是错误的。
|
||||
|
||||
#### 3. 复合赋值
|
||||
|
||||
```c
|
||||
i = i + 2;
|
||||
//等同于
|
||||
i += 2;
|
||||
```
|
||||
|
||||
上面的例子中 += 就是一种符合运算符,表示:将自身表示的数增加 2 后再赋值给自己。
|
||||
|
||||
<br>
|
||||
|
||||
与加法相似,所有赋值运算符的工作原理大体相同。
|
||||
|
||||
> `+=`
|
||||
>
|
||||
> `-=`
|
||||
>
|
||||
> `*=`
|
||||
>
|
||||
> `/=`
|
||||
>
|
||||
> `%=`
|
||||
|
||||
**注意:**
|
||||
|
||||
1. `i *= j + k` 和 `i = i * j + k` 是不一样的。
|
||||
|
||||
2. 使用复合赋值运算符时,注意不要交换组成运算符的两个字符的位置。如:
|
||||
|
||||
`i += j`写成了`i =+ j` 后者等价于:`i = (+j)`
|
||||
|
||||
复合运算符有着和 `=`运算符一样的特性。它们也是右结合的,所以:
|
||||
|
||||
`i += j += k`等价于`i += (j += k)`
|
||||
|
||||
|
||||
|
||||
#### 4. 自增运算符和自减运算符
|
||||
|
||||
> `++`
|
||||
>
|
||||
> `--`
|
||||
|
||||
“自增”(加1)和“自减”(减1)也可以通过下面的方式完成:
|
||||
|
||||
```c
|
||||
i = i + 1;
|
||||
j = j - 1;
|
||||
```
|
||||
|
||||
复合赋值运算符可以简化上面的语句:
|
||||
|
||||
```c
|
||||
i += 1;
|
||||
j -= 1;
|
||||
```
|
||||
|
||||
而 C语言 允许用 ++ 和 -- 运算符将这些语句缩的更短。比如:
|
||||
|
||||
```c
|
||||
i++;
|
||||
j--;
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```c
|
||||
++i;
|
||||
--j;
|
||||
```
|
||||
|
||||
这两种形式的写法的意义不同的:
|
||||
|
||||
- `++i` (前缀(prefix)自增),意味着“立即自增 i ”
|
||||
|
||||
```c
|
||||
int i = 1;
|
||||
printf("%d\n", ++i);
|
||||
printf("%d\n", i);
|
||||
//输出
|
||||
2
|
||||
2
|
||||
```
|
||||
|
||||
- `i++`(后缀(postfix)自增),意味着“先使用 i 的原始值,稍后再自增”。稍后是多久?C语言标准没有给出精确的时间,但是可以放心的假设 i 再下一条语句执行之前进行自增。
|
||||
|
||||
```c
|
||||
int i = 1;
|
||||
printf("%d\n", i++);
|
||||
printf("%d\n", i);
|
||||
//输出
|
||||
1
|
||||
2
|
||||
```
|
||||
|
||||
`--`运算符具有相同的特性。
|
||||
|
||||
|
||||
|
||||
> 后缀的 ++ 和 -- 比一元的正号,负号优先级高,而且都是左结合的。
|
||||
>
|
||||
> 前缀的 ++ 和 -- 与一元的正号,负号优先级相同,并且是右结合的。
|
||||
|
||||
比如:
|
||||
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
int i = 1;
|
||||
|
||||
printf("%d", -i++);
|
||||
printf("%d", i);
|
||||
}
|
||||
//输出:
|
||||
-1
|
||||
2
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 5.表达式求值
|
||||
|
||||
**部分C语言运算符表**
|
||||
|
||||
| 优先级 | 类型名称 | 符号 | 结合性 |
|
||||
| ------ | ------------ | ---------------- | ------ |
|
||||
| 1 | (后缀)自增 | ++ | 左结合 |
|
||||
| | (后缀)自减 | -- | |
|
||||
| 2 | (前缀)自增 | ++ | 右结合 |
|
||||
| | (前缀)自减 | -- | |
|
||||
| | 一元正号 | + | |
|
||||
| | 一元符号 | - | |
|
||||
| 3 | 乘法类 | `* / %` | 左结合 |
|
||||
| 4 | 加法类 | `+ -` | 左结合 |
|
||||
| 5 | 赋值 | `= *= /= -= +=` | 右结合 |
|
||||
|
||||
能理解下面这个表达式的意义,就算掌握了这一部分的表达式求值规则:
|
||||
|
||||
```c
|
||||
a = b += c++ - d + --e / -f
|
||||
```
|
||||
|
||||
等价于:
|
||||
|
||||
```c
|
||||
a = ( b += ( (c++) - d + (--e) / (-f) ) )
|
||||
```
|
||||
|
||||
##### 子表达式的求值顺序
|
||||
|
||||
C语言没有定义子表达式的求值顺序(除了含有 逻辑与,逻辑或 或 逗号运算符的表达式(后面会讲))。
|
||||
|
||||
但是不管子表达式的计算顺序如何,大多数表达式都有相同的值。但是,当子表达式改变了某个操作数的值时,产生的值就可能不一致了。思考下面的例子:
|
||||
|
||||
```c
|
||||
a = 5;
|
||||
c = (b = a + 2) + (a = 1);
|
||||
```
|
||||
|
||||
第二条语句的执行结果是未定义的。对大多数编译器而言,c 的值是 6 或者 2。取决于 子表达式 b = a + 2 和 a = 1 的求值顺序。
|
||||
|
||||
像上例那样,**在表达式中,既在某处访问变量的值,又在别处修改它的值是不可取的。**
|
||||
|
||||
为了避免出现此类情况,我们可以将子表达式分离:
|
||||
|
||||
```c
|
||||
a = 5;
|
||||
b = a + 2;
|
||||
a = 1;
|
||||
c = b - a;
|
||||
```
|
||||
|
||||
执行完这些语句后,c 的值将始终是 6
|
||||
|
||||
除此之外,自增自减运算符也要小心使用。如下例:
|
||||
|
||||
```c
|
||||
i = 2;
|
||||
j = i * i++;
|
||||
```
|
||||
|
||||
j 有两种可能:4 或 6
|
||||
|
||||
我们很自然的认为结果是 4 。但是其实该语句的执行结果是未定义的。
|
||||
|
||||
j 的值为 6 的情况:
|
||||
|
||||
1. 取出第二个操作数(i 的原始值),然后 i 自增
|
||||
2. 取出第一个操作数(i 的新值)
|
||||
3. 将取除的两个操作数相乘(2 和 3),结果是 6
|
||||
|
||||
“取出”变量意味着从内存中获取它们的值。变量后续变化不会影响已经取出的值,因为取出的值通常存储在 CPU 中称为**寄存器**的一个特殊位置。
|
||||
|
||||
##### 未定义行为
|
||||
|
||||
> 未定义行为(undefined behavior): 类似上面两个例子中的语句会导致 未定义行为,这和我们前面讲的**由实现定义**的行为是不同的。当程序中出现未定义行为时,后果是不可预料的。不同的编译器给出的结果可能是不同的。也就是说,程序可能无法通过编译,也可能运行时崩溃,不稳定或者产生无意义的结果。**换句话说,我们应该像躲避“新冠”一样避免未定义行为**。
|
||||
|
||||
|
||||
|
||||
*参考资料:《C Primer Plus》《C语言程序设计:现代方法》*
|
||||
|
||||
[^1]: 对称性有助于减少复杂度(协程包含例程)。对称性无处不在。[Epigrams on Programming 编程警句 ](https://epigrams-on-programming.readthedocs.io/zh_CN/latest/epigrams.html)
|
||||
|
||||
|
||||
|
||||
|
||||
623
content/c-mordern-approch/07-选择语句.md
Normal file
623
content/c-mordern-approch/07-选择语句.md
Normal file
@@ -0,0 +1,623 @@
|
||||
|
||||
|
||||
# 选择语句
|
||||
|
||||
*It is easier to write an incorrect program than understand a correct one.* [^1]
|
||||
|
||||
|
||||
|
||||
## 目录
|
||||
|
||||
***
|
||||
|
||||
[TOC]
|
||||
|
||||
|
||||
|
||||
## 选择语句
|
||||
|
||||
***
|
||||
|
||||
前面已经讲过C语言的语句主要分为 6 大类。本节我们主要探讨 选择语句:if 语句 和 switch 语句
|
||||
|
||||
### 一 逻辑表达式
|
||||
|
||||
包括 if 语句在内的某些 C 语句(while,for 等)都必须测试表达式的值是“真”还是“假”。
|
||||
|
||||
许多编程语言中,类似 `i < j` 这样的表达式都具有特殊的“布尔”类型或者“逻辑”类型(C++ 的 bool 和 Java 的 boolean)。这样的类型只有两个值,即真(true)和假(false)。
|
||||
|
||||
而在 C 语言中,诸如 `i < j` 这样的比较会产生整数:0(假)1(真)。
|
||||
|
||||
**但是,非 0 的其他数也可以表示 真**。在今天看来,这是 C 语言设计的弊端,它将布尔类型与整型混为一谈,让我们在变成过程中可能稍不小心就会给自己挖一个坑。
|
||||
|
||||
#### 1. 关系运算符
|
||||
|
||||
> C 语言的关系运算符(relational operator)和数学上的 `>,<,≤,≥`相对应,只是用在 C 语言的表达式中时产生的结果是 0 或 1 。
|
||||
>
|
||||
> 例如,表达式 10 < 11 的值是 1,11 < 10 的值是 0 。
|
||||
|
||||
关系运算符也可以用于比较整数和浮点数,也允许比较不同类型的操作数。如:5.6 < 5 的值为 0 。
|
||||
|
||||
| 符号 | 含义 |
|
||||
| ---- | -------- |
|
||||
| < | 小于 |
|
||||
| > | 大于 |
|
||||
| <= | 小于等于 |
|
||||
| \>= | 大于等于 |
|
||||
|
||||
关系运算符的优先级**低于**算数运算符。例如:`i + j < k - 1` 的意思是 `(i + j) < (k - 1)`
|
||||
|
||||
关系运算符都是**左结合**的。
|
||||
|
||||
**注意:** 表达式 `i < j < k` 在 C 语言中是合法的,但是可能不是你所期望的含义。因为 < 运算符是左结合的,所以这个表达式等价于:`(i < j) < k`
|
||||
|
||||
表达式会先检测 i 是否小于 j,然后用比较后产生的结果(1 或 0 )来和 k 进行比较。这个表达式并不是测试 j 是否位于 i 和 k 之间。(正确的写法是:`j > i && j < k`)
|
||||
|
||||
#### 2. 判等运算符
|
||||
|
||||
> **判等运算符(equality operator):**相等用`==`表示 。注意不是 `=` ,`=`表示赋值。
|
||||
|
||||
**注意:**
|
||||
|
||||
一定要注意不要将 `==` 写成 `=` ,编译器可能会给你报错,但是如果没有,在你查错的时候,注意是不是 `==` 写错了的问题。
|
||||
|
||||
| 符号 | 含义 |
|
||||
| ---- | ------ |
|
||||
| == | 等于 |
|
||||
| != | 不等于 |
|
||||
|
||||
和关系运算符一样,判等运算符是**左结合**的,也是产生 0(假) 或 1(真) 作为结果。
|
||||
|
||||
判等运算符的优先级**低于**关系运算符。例如:
|
||||
|
||||
`i < j == j < k` 等价于:`(i < j) == (j < k)`,含义是:如果 i < j 和 j < k 同真或同假 这个表达式的结果为真。
|
||||
|
||||
**利用 关系运算符 和 判等运算符**:
|
||||
|
||||
```c
|
||||
(i >= j) + (i == j)
|
||||
```
|
||||
|
||||
上面表达式的值为 0,1 或者 2 分别代表 i < j, i > j, i == j
|
||||
|
||||
#### 3. 逻辑运算符
|
||||
|
||||
> **逻辑运算符(logical operator)**
|
||||
|
||||
| 符号 | 含义 |
|
||||
| ---- | -------------------- |
|
||||
| ! | 逻辑非(一元运算符) |
|
||||
| && | 逻辑与(二元运算符) |
|
||||
| \|\| | 逻辑或(二元运算符) |
|
||||
|
||||
其实 && 就是 数学中的 且 ,|| 就是数学的的 或
|
||||
|
||||
逻辑运算符产生的结果仍然是 0 或 1,操作数经常也是 0 或 1,但这不是必需的。逻辑运算符将任何 **非0**值操作数当作真来处理,任何**0**值操作数当作假来处理。
|
||||
|
||||
- 如果表达式的值为 0,那么 `!表达式`的结果为 1
|
||||
- 如果 表达式1 和 表达式2 的值都是非零值,那么`表达式1 && 表达式2` 的结果为 1
|
||||
- 如果 表达式1 和 表达式2 的值 中的任意一个是(或者两个都是)非零值,那么`表达式1 || 表达式2` 的结果为 1
|
||||
|
||||
所有其他情况下,这些运算符产生的结果都为 0
|
||||
|
||||
**“短路”计算**
|
||||
|
||||
&& 和 || 运算符都遵循“短路”原则。也就是说,这些运算符首先计算出左操作数的值,然后计算右操作数;**如果表达式的值可以仅由左操作数推导出来,那么将不计算右操作数的值**。如:
|
||||
|
||||
```c
|
||||
int i = 0, j = 1;
|
||||
|
||||
if (i && i++) {
|
||||
; // 空语句
|
||||
}
|
||||
printf("%d\n", i); // i 的值没有增加,说明 i++ 没有计算
|
||||
|
||||
if (j || j++) {
|
||||
;
|
||||
}
|
||||
printf("%d\n", j); // j 的值没有增加, 说明 j++ 没有计算
|
||||
// 输出:
|
||||
0
|
||||
1
|
||||
```
|
||||
|
||||
|
||||
|
||||
运算符 !的优先级和一元正负号优先级**相同**,运算符 && 和 || 的优先级**低于**判等运算符。
|
||||
|
||||
例如:`i < j && k == m` 等价于 `(i < j) && (k == m)`
|
||||
|
||||
运算符 ! 是**右结合**的,&& 和 || 是**左结合**的。
|
||||
|
||||
|
||||
|
||||
#### 二 if 语句
|
||||
|
||||
#### 1. if
|
||||
|
||||
if 语句允许程序通过测试表达式的值从两种选项中选择一种。if 语句的简单格式如下:
|
||||
|
||||
```c
|
||||
if(表达式){
|
||||
语句
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
如果语句部分只有一条语句,也可以写成
|
||||
|
||||
```c
|
||||
if(表达式)
|
||||
语句;
|
||||
```
|
||||
|
||||
|
||||
|
||||
执行 if 语句时,先计算圆括号内表达式的值。如果表达式的值**非零**(C语言将非零值解释为真值),那么接着执行大括号内的语句。例如:
|
||||
|
||||
```c
|
||||
if(i > 0)
|
||||
printf("正数\n");
|
||||
```
|
||||
|
||||
|
||||
|
||||
为了判定 k < i < j,可以这样写:
|
||||
```c
|
||||
if(i > k && i < j)
|
||||
```
|
||||
|
||||
为了判定相反的情况,可以写成:
|
||||
|
||||
```c
|
||||
if(i <= k || i >= j)
|
||||
```
|
||||
|
||||
|
||||
|
||||
**例2-1:**程序:为了判定一个数是不是大于零的,如果是,我们就输出提示语,然后让这个数加 1
|
||||
|
||||
```
|
||||
if(i > 0){
|
||||
printf("是正数\n");
|
||||
i++;
|
||||
}
|
||||
```
|
||||
|
||||
#### 2. else 子句
|
||||
|
||||
```c
|
||||
if(表达式)
|
||||
语句;
|
||||
else
|
||||
语句;
|
||||
```
|
||||
|
||||
如果是**复合语句**(compound statement),需要加上花括号
|
||||
|
||||
**加上花括号是一种好习惯。建议不管是不是复合语句,尽量都加上花括号。**
|
||||
|
||||
**例2-2**:增加需求:如果这个数不是正数,那么输出提示语,然后让这个数减 1
|
||||
|
||||
```c
|
||||
if(i > 0){
|
||||
printf("是正数\n");
|
||||
i++;
|
||||
}else{
|
||||
printf("不是正数\n");
|
||||
i--;
|
||||
}
|
||||
```
|
||||
|
||||
#### 3. 嵌套的 if 语句
|
||||
|
||||
**例2-3**:找出 i,j,k 中的最大值,并将其保存到 max 中
|
||||
|
||||
```c
|
||||
if(i > j){
|
||||
if(i > k){
|
||||
max = i;
|
||||
}else{
|
||||
max = k;
|
||||
}
|
||||
}else{
|
||||
if(j > k){
|
||||
max = j;
|
||||
}else{
|
||||
max = k;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 4. 级联式 if 语句
|
||||
|
||||
> 编程时常常需要判定一系列的条件,一旦其中某个条件为真就立刻停止。
|
||||
|
||||
如何做到呢?
|
||||
|
||||
**例2-4** 程序:判断 n 是大于 0 还是 等于 0 还是小于 0
|
||||
|
||||
使用 if else
|
||||
|
||||
```c
|
||||
if(n < 0){
|
||||
printf("n < 0");
|
||||
}else{
|
||||
if(n == 0){
|
||||
printf("n = 0");
|
||||
}
|
||||
else{
|
||||
printf("n > 0");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
使用 else if
|
||||
|
||||
```c
|
||||
if(n < 0){
|
||||
printf("n < 0");
|
||||
}
|
||||
else if(n == 0){
|
||||
printf("n == 0");
|
||||
}
|
||||
else{
|
||||
printf("n > 0");
|
||||
}
|
||||
```
|
||||
|
||||
这样写可以避免 if else 嵌套,从而提高了书写和理解的难易度。
|
||||
|
||||
**级联式 if 语句书写形式:**
|
||||
|
||||
```c
|
||||
if(表达式){
|
||||
语句;
|
||||
}
|
||||
else(表达式){
|
||||
语句;
|
||||
}
|
||||
else{
|
||||
语句;
|
||||
}
|
||||
```
|
||||
|
||||
#### 5. “悬空 else”问题
|
||||
|
||||
请看下面的程序,思考 else 与 那个 if 匹配
|
||||
|
||||
```c
|
||||
if(y != 0)
|
||||
if(x != 0)
|
||||
printf("%.2f", x / y);
|
||||
else
|
||||
printf("Error: y is zero!");
|
||||
```
|
||||
|
||||
如果此时 y = 0, x = 2 会输出什么?
|
||||
|
||||
如果 y = 2, x = 0 会输出什么?
|
||||
|
||||
虽然缩进格式按时 else 属于外层 if,但是 C 语言遵循的规则是**else 子句应该属于离它最近且还未和其他 else 匹配的 if 语句**。
|
||||
|
||||
所以,此例中 else 属于内层的 if 语句。为了避免这种问题,最好的办法就是**加括号**。
|
||||
|
||||
```c
|
||||
if(y != 0){
|
||||
if(x != 0)
|
||||
printf("%.2f", x / y);
|
||||
}
|
||||
else
|
||||
printf("Error: y is zero!");
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 6. 条件表达式
|
||||
|
||||
> **条件运算符(conditional operator):**C 语言运算符中唯一一个三元(ternary)(三个操作数)运算符。
|
||||
|
||||
格式:
|
||||
|
||||
```c
|
||||
[条件表达式]表达式 1 ? 表达式2 :表达式3 ;
|
||||
```
|
||||
|
||||
**例2-6**
|
||||
|
||||
```c
|
||||
if(x > 0){
|
||||
x++;
|
||||
}
|
||||
else{
|
||||
x--;
|
||||
}
|
||||
```
|
||||
|
||||
上面的程序我们用条件运算符可以这么写:
|
||||
|
||||
```c
|
||||
x > 0 ? x++ : x--;
|
||||
```
|
||||
|
||||
|
||||
|
||||
判断 k 的值
|
||||
|
||||
```c
|
||||
i = 1;
|
||||
j = 2;
|
||||
k = i > j ? i : j; // k is 2 now
|
||||
k = (i >= 0 ? i : 0) + j; // k is now 3
|
||||
```
|
||||
|
||||
|
||||
|
||||
条件运算符使程序**更短小但也更难以阅读**,所以最好避免使用。然而有的情况会常常使用条件表达式。比如:
|
||||
|
||||
1)判断返回:
|
||||
|
||||
```c
|
||||
return i > j ? i : j;
|
||||
```
|
||||
|
||||
2)printf
|
||||
|
||||
```c
|
||||
printf("%d\n", i > j ? i : j);
|
||||
```
|
||||
|
||||
条件表达式也普遍应用于某些类型的宏定义中。
|
||||
|
||||
#### 7. 布尔值
|
||||
|
||||
##### C89
|
||||
|
||||
多年以来,C语言一直缺乏适当的布尔类型。
|
||||
|
||||
一种解决方法是,先声明一个 int 型变量,让后将其赋值为 0 或 1:
|
||||
|
||||
```c
|
||||
int flag;
|
||||
flag = 0; // 表示 flag 为 false
|
||||
...
|
||||
flag = 1; // 表示 flag 为 true
|
||||
```
|
||||
|
||||
虽然这种方法可行,但是对于程序的可读性没有多大贡献,因为没有明确的表示 flag 的赋值只能是布尔型,并没有明确指出 0 和 1就是表示真和假。
|
||||
|
||||
|
||||
|
||||
为了使得程序更加便于理解,C89 程序员通常使用 TRUE 和 FALSE 这样的名字定义宏:
|
||||
|
||||
```c
|
||||
#define TRUE 1
|
||||
#define FALSE 0
|
||||
```
|
||||
|
||||
现在对 flag 的赋值就有了更加自然的形式:
|
||||
|
||||
```c
|
||||
flag = FALSE;
|
||||
...
|
||||
flag = TRUE;
|
||||
```
|
||||
|
||||
为了判定 flag 是否为真,可以用:
|
||||
|
||||
```c
|
||||
if(flag == TRUE){
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
或者只写:
|
||||
|
||||
```c
|
||||
if(flag){
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
为了发扬这一思想,我们可以进一步定义一个用作布尔类型的宏:
|
||||
|
||||
```c
|
||||
#define BOOL int;
|
||||
```
|
||||
|
||||
声明布尔类型变量时可以用 BOOL 替代 int
|
||||
|
||||
```c
|
||||
BOOL flag;
|
||||
```
|
||||
|
||||
现在我们就非常清楚了:flag 不是一个普通的整型变量,而是表示布尔条件。(当然编译器还是将 flag 当作 int 类型的变量。)
|
||||
|
||||
##### C99
|
||||
|
||||
C99 中提供了 _Bool 类型:
|
||||
|
||||
```c
|
||||
_Bool flag;
|
||||
```
|
||||
|
||||
> `_Bool`是无符号整型。但是和一般的整形不同,_Bool 只能被赋值为 0 或 1 。一般来说,向 \_Bool 类型变量中储存非零值会导致变量赋值为 1 。
|
||||
|
||||
```c
|
||||
_Bool flag = 5;
|
||||
printf("%u", flag);
|
||||
|
||||
// 输出:
|
||||
1
|
||||
```
|
||||
|
||||
C99 还提供了一个新的头文件`<stdbool.h>`,改头提供了 bool 宏,用来代表 _Bool ;还提供了 true 和 false 两个宏,分别代表 1 和 0 。于是可以写:
|
||||
|
||||
```c
|
||||
#include<stdbool.h>
|
||||
|
||||
bool flag;
|
||||
flag = true;
|
||||
...
|
||||
flag = false;
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 三 switch 语句
|
||||
|
||||
> 日常的编程中,常常需要把表达式和一系列值进行比较,从而找出当前匹配的值。
|
||||
|
||||
使用级联式 if 语句可以达到这个目的:
|
||||
|
||||
```c
|
||||
if(grade == 4)
|
||||
printf("Excellent");
|
||||
else if(grade == 3)
|
||||
printf("Good");
|
||||
else if(grade == 2)
|
||||
printf("Average");
|
||||
else if(grade == 1)
|
||||
printf("Poor");
|
||||
else if(grade == 0)
|
||||
printf("Failing");
|
||||
else
|
||||
printf("Illegal grade");
|
||||
```
|
||||
|
||||
C 语言提供了 switch 语句作为这类级联式 if 语句的替换。使用 switch 语句改写上面的程序:
|
||||
|
||||
```c
|
||||
switch(grade){
|
||||
case 4: printf("Excellent");
|
||||
break;
|
||||
case 3: printf("Good");
|
||||
break;
|
||||
case 2: printf("Average");
|
||||
break;
|
||||
case 1: printf("Poor");
|
||||
break;
|
||||
case 0: printf("Failing");
|
||||
break;
|
||||
default:printf("Illegal grade");
|
||||
break;
|
||||
}
|
||||
```
|
||||
|
||||
**switch 语句常用格式:**
|
||||
|
||||
```c
|
||||
switch(控制表达式){
|
||||
case 常量表达式 : 语句
|
||||
...
|
||||
case 常量表达式 : 语句
|
||||
default : 语句
|
||||
}
|
||||
```
|
||||
|
||||
- **控制表达式:**控制表达式只能用:整型,字符型的变量(C 语言把字符当成整数来处理),不能用浮点数 和 字符串。
|
||||
|
||||
- **分支标号:**每一个分支的开头都有一个标号,格式如下:
|
||||
|
||||
`case 常量表达式;`
|
||||
|
||||
常量表达式(constant expression): 必须是**整数或字符型**,不能包含**变量和函数调用**。
|
||||
|
||||
5 是常量表达式,5 + 10 也是常量表达式;但是 10 + n 不是常量表达式(除非 n 是表示常量的宏)。
|
||||
|
||||
- **语句:**每个分支标号后可以跟任意数量的语句。不需要用花括号把这些语句括起来。每组语句的最后一条通常是 break 语句。
|
||||
|
||||
- **break 的作用:** 本节后面会详细讨论。
|
||||
|
||||
- **default 语句的作用:** 控制表达式的值和所有的标号语句都不匹配的话,会执行 default 后面的语句。(default :默认的意思)
|
||||
|
||||
|
||||
|
||||
C 语言**不允许有重复的分支标号,但对分支的顺序没有要求**,特别是 default 分支不一定要放在最后。
|
||||
|
||||
case 后**只可以跟随一个常量表达式**。但是,**多个分支标号可以放置在同一组语句前面** 。如:
|
||||
|
||||
```c
|
||||
switch(grade){
|
||||
case 4:
|
||||
case 3:
|
||||
case 2:
|
||||
case 1: printf("Passing");
|
||||
break;
|
||||
case 0: printf("Failing");
|
||||
break;
|
||||
default:printf("Illegal grade");
|
||||
break;
|
||||
}
|
||||
```
|
||||
|
||||
为了节省空间,可以将拥有相同语句的分支标号放在同一行:
|
||||
|
||||
```c
|
||||
switch(grade){
|
||||
case 4: case 3: case 2: case 1:
|
||||
printf("Passing");
|
||||
break;
|
||||
case 0: printf("Failing");
|
||||
break;
|
||||
default:printf("Illegal grade");
|
||||
break;
|
||||
}
|
||||
```
|
||||
|
||||
switch 语句**不要求一定有 default 分支**。如果 default 不存在,而且控制表达式的值和所有的标号语句都不匹配的话,控制会直接传给 switch 语句后面的语句。
|
||||
|
||||
#### break 语句的作用
|
||||
|
||||
break 会使程序“跳出” switch 语句,继续执行 switch 后面的语句。
|
||||
|
||||
对控制表达式求值的时,控制会跳转到与 switch 表达式相匹配的分支标号处。分支标号只是说明 switch 内部位置的标记。在执行完分支的最后一句后,程序控制“向下跳转”到下一个分支的第一条语句上,而忽略下一个分支的分支标号。如果没有 break 语句(或者其他某种跳转语句),控制将会从一个分支继续到下一个分支。思考下面的 switch 语句:
|
||||
|
||||
```c
|
||||
switch(grade){
|
||||
case 4: printf("Excellent");
|
||||
case 3: printf("Good");
|
||||
case 2: printf("Average");
|
||||
case 1: printf("Poor");
|
||||
case 0: printf("Failing");
|
||||
default:printf("Illegal grade");
|
||||
}
|
||||
```
|
||||
|
||||
如果 grade 的值为 3,那么显示的信息是:
|
||||
|
||||
```c
|
||||
GoodAveragePoorFailingIllegal grade
|
||||
```
|
||||
|
||||
|
||||
|
||||
**注意:**忘记 break 是编程时常见的错误。虽然有时候会故意忽略 break 以便多个分支共享代码,但是通常情况下省略 break 是因为忽略。
|
||||
|
||||
如果有需要,**明确指出**故意省略 break 语句是一个好主意:
|
||||
|
||||
```c
|
||||
switch(grade){
|
||||
case 4: case 3: case 2: case 1:
|
||||
num_passing++;
|
||||
// Fail Through
|
||||
case 0: total_grades++;
|
||||
break;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
最然 switch 语句最后一个分支不需要 break 语句,但是通常还是会加上一个 break 语句在那里,**以防止将来增加分支时出现“丢失” break 的问题**。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
*参考资料:《C Primer Plus》《C语言程序设计:现代方法》*
|
||||
|
||||
[^1]: 写错误的程序比理解正确的程序简单。[Epigrams on Programming 编程警句 ](https://epigrams-on-programming.readthedocs.io/zh_CN/latest/epigrams.html)
|
||||
|
||||
978
content/c-mordern-approch/08-循环.md
Normal file
978
content/c-mordern-approch/08-循环.md
Normal file
@@ -0,0 +1,978 @@
|
||||
# 循环
|
||||
|
||||
*It is better to have 100 functions operate on one data structure than 10 functions on 10 data structures.* [^1]
|
||||
|
||||
|
||||
|
||||
## 目录
|
||||
|
||||
***
|
||||
|
||||
[TOC]
|
||||
|
||||
|
||||
|
||||
## 循环
|
||||
|
||||
***
|
||||
|
||||
本章将介绍 C 语言的**重复语句(迭代语句)**,这种语句允许用户设置循环。
|
||||
|
||||
**循环**(loop)时重复的执行其他语句(**循环体**)的一种语句。在 C 语言中,每个循环都有自己的**控制表达式**(controlling expression)。循环每执行一次,都要对控制表达式求值。如果表达式为真(表达式的值非 0),那么循环继续执行;否则,退出循环。
|
||||
|
||||
C 提供了三种迭代语句:
|
||||
|
||||
- **while** 语句
|
||||
- **do** 语句(do while 语句)
|
||||
- **for** 语句
|
||||
|
||||
其中以 for 语句最为常用。
|
||||
|
||||
本节后面还会讨论循环相关的 C 语言特性。如 **break,continue,goto**语句
|
||||
|
||||
|
||||
|
||||
### 一 while 语句
|
||||
|
||||
#### 1. while 的基本用法
|
||||
|
||||
while 的基本格式如下:
|
||||
|
||||
```c
|
||||
while(控制表达式){
|
||||
循环体
|
||||
}
|
||||
```
|
||||
|
||||
> 执行 while 语句时,首先计算控制表达式的值。如果值不为零,那么执行循环体,接着再次判定 控制表达式的真值,如果为真,再次执行循环体。直到控制表达式的真值为假,才会结束 while 语句。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**例1-1:**倒计数程序
|
||||
|
||||
```c
|
||||
int i = 10;
|
||||
while(i > 0){
|
||||
printf("%d\n", i);
|
||||
i--;
|
||||
}
|
||||
```
|
||||
|
||||
关于这个例子,我们可以对 while 进行深度思考:
|
||||
|
||||
- **while 循环终止时,控制表达式的值一定为假**。
|
||||
|
||||
```c
|
||||
int i = 10;
|
||||
while(i > 0){
|
||||
printf("%d\n", i);
|
||||
i--;
|
||||
}
|
||||
printf("%d", i); // i is now 0
|
||||
```
|
||||
|
||||
- **可能根本不执行 while 循环体**。
|
||||
|
||||
```c
|
||||
int i = 0;
|
||||
while(i > 0){
|
||||
printf("%d\n", i);
|
||||
i--;
|
||||
}
|
||||
// Nothing is printed.
|
||||
```
|
||||
|
||||
- **while 语句常有多种写法**
|
||||
|
||||
```c
|
||||
int i = 10;
|
||||
while(i > 0){
|
||||
printf("%d\n", i--); // 将 i-- 写在 printf 内,简化循环
|
||||
}
|
||||
```
|
||||
|
||||
#### 2. 无限循环
|
||||
|
||||
> 如果控制表达式的值始终非零,while 循环将无法终止。
|
||||
|
||||
```c
|
||||
while(1){
|
||||
printf("Hello World\n");
|
||||
}
|
||||
```
|
||||
|
||||
除非循环体内有控制循环的语句(break,return,goto)或者调用了导致程序终止的函数,非则上面的循环永远不会结束。
|
||||
|
||||
#### 程序 1:显示平方表
|
||||
|
||||
现编写一个程序来显示平方表。首先程序提示用户输入一个数 n,然后显示出 n 行的输出,每行包含 一个 1 ~ n 的数及其平方值。
|
||||
|
||||
```c
|
||||
This program prints a table of squares.
|
||||
Enter number of entries in table: 5
|
||||
1 1
|
||||
2 4
|
||||
3 9
|
||||
4 16
|
||||
5 25
|
||||
```
|
||||
参考答案:
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void){
|
||||
|
||||
int n;
|
||||
int i = 1;
|
||||
|
||||
printf("This program prints a table of squares.\n");
|
||||
printf("Enter number of entries in table: ");
|
||||
scanf("%d", &n);
|
||||
|
||||
while(i <= n){
|
||||
printf("\t%d\t%d\n", i, i * i);
|
||||
i++;
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
#### 程序 2:数列求和
|
||||
|
||||
```c
|
||||
This program sums a series of integers.
|
||||
Enter integers(0 to terminate):8 23 71 5 0
|
||||
The sum is:107
|
||||
```
|
||||
|
||||
参考答案:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void){
|
||||
|
||||
int n, sum = 0;
|
||||
|
||||
printf("This program sums a series of integers.\n");
|
||||
printf("Enter integers(0 to terminate): ");
|
||||
|
||||
scanf("%d", &n);
|
||||
while(n != 0){
|
||||
sum += n;
|
||||
scanf("%d", &n);
|
||||
}
|
||||
|
||||
printf("The sum is:%d\n", sum);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
我写的,仅供参考:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void){
|
||||
|
||||
int n, sum = 0;
|
||||
|
||||
printf("This program sums a series of integers.\n");
|
||||
printf("Enter integers(0 to terminate): ");
|
||||
|
||||
while(scanf("%d", &n) && n){
|
||||
sum += n;
|
||||
}
|
||||
|
||||
printf("The sum is:%d\n", sum);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
或者 while 循环可以这样写:
|
||||
|
||||
```c
|
||||
int n = 1, sum = 0;
|
||||
|
||||
while(n != 0){
|
||||
scanf("%d", &n);
|
||||
sum += n;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 二 do 语句
|
||||
|
||||
#### 1. do while 基本用法
|
||||
|
||||
> do 语句 和 while 语句其实本质上是相同的。只不过 do 语句**至少会执行一次**循环体。
|
||||
|
||||
**基本形式:**
|
||||
|
||||
```c
|
||||
do{
|
||||
循环体
|
||||
}while(控制表达式);
|
||||
```
|
||||
|
||||
|
||||
|
||||
**例2-1**倒计数程序
|
||||
|
||||
```c
|
||||
int i = 10;
|
||||
do{
|
||||
printf("%d\n", i);
|
||||
i--;
|
||||
}while(i > 0);
|
||||
```
|
||||
|
||||
|
||||
|
||||
顺便一提,**do 语句最好都加上花括号**。
|
||||
|
||||
虽然 do while 没有 while 语句使用的那么多,但是前者对于**至少需要执行一次**的循环来说是十分方便的。
|
||||
|
||||
|
||||
|
||||
#### 程序 3:编写一个程序计算用户输入的整数的位数
|
||||
|
||||
```c
|
||||
Enter a integer: 60
|
||||
The number has 2 digit(s).
|
||||
```
|
||||
|
||||
参考答案:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void){
|
||||
|
||||
int n, count = 0;
|
||||
|
||||
printf("Enter a nonnegative integer:");
|
||||
scanf("%d", &n);
|
||||
|
||||
do{
|
||||
count++;
|
||||
n /= 10; // 除法 10 的次数就是 n 的位数
|
||||
}while(n != 0);
|
||||
|
||||
printf("The number has %d digit(s).\n", count);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
如果我们用 while 循环:
|
||||
|
||||
```c
|
||||
while(n != 0){
|
||||
count++;
|
||||
n /= 10;
|
||||
}
|
||||
```
|
||||
|
||||
如果你输入的是 0 ,这个循环会直接退出。这不符合我们的预期,0 也是整数啊,而且它有 1 位数。
|
||||
|
||||
|
||||
|
||||
### 三 for 循环
|
||||
|
||||
现在开始介绍 C 语言最后一种循环,也是**功能最强大**的一种循环:for 语句。它是我们用的最多的一种循环,一定要熟练掌握。
|
||||
|
||||
#### 1. for 语句的基本用法
|
||||
|
||||
```c
|
||||
for(表达式1; 表达式2; 表达式3){
|
||||
循环体
|
||||
}
|
||||
```
|
||||
|
||||
**例3-1** 倒计数程序
|
||||
|
||||
```c
|
||||
for(i = 10; i > 0; i--){
|
||||
printf("%d\n", i);
|
||||
}
|
||||
```
|
||||
|
||||
在执行上面这个 for 语句时,i 先初始化为 10;然后判定 i 是否大于 0 ;因为结果为真,执行循环体;然后对变量 i 进行自减操作;然后再次判断 i 是否大于 0 ... 直到最后一次 i 自减后,i > 0 不成立了,退出循环。
|
||||
|
||||
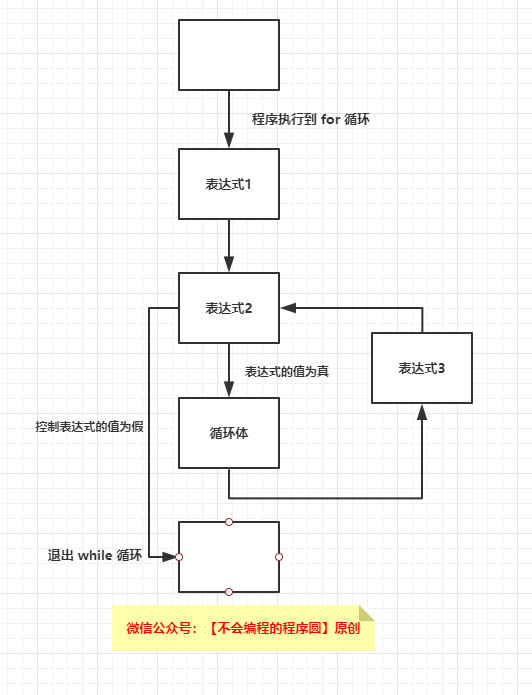
|
||||
|
||||
|
||||
|
||||
for 循环如果我们用 while 语句 也可以模拟:
|
||||
|
||||
```c
|
||||
i = 10;
|
||||
while(i > 0){
|
||||
printf("%d\n", i);
|
||||
i--;
|
||||
}
|
||||
```
|
||||
|
||||
抽象一下即为:
|
||||
|
||||
```c
|
||||
表达式1;
|
||||
while(表达式2){
|
||||
循环体;
|
||||
表达式3;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
**for 循环中的 `i--` 可以写成 `--i` 吗?**
|
||||
|
||||
即:
|
||||
|
||||
```c
|
||||
for(i = 10; i > 0; --i){
|
||||
printf("%d\n", i);
|
||||
}
|
||||
```
|
||||
|
||||
这种做法对循环没有任何影响。`i++` 和 `i--` 在 for 循环的 表达式3 中是完全等价的。
|
||||
|
||||
#### 2. 在 for 语句中省略表达式
|
||||
|
||||
**1.省略第一个表达式**
|
||||
|
||||
```c
|
||||
i = 10;
|
||||
for(; i > 0; --i){
|
||||
printf("%d\n", i);
|
||||
}
|
||||
```
|
||||
|
||||
**注意:**
|
||||
|
||||
- 省略第一个表达式相当于不初始化 i
|
||||
- 即便 第一个表达式省略了,也**不能省略后面的分号**
|
||||
|
||||
**2. 省略第三个表达式**
|
||||
|
||||
```c
|
||||
for(i = 10; i > 0;){
|
||||
printf("%d\n", i);
|
||||
--i
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
**3. 省略第一个和第三个表达式**
|
||||
|
||||
```c
|
||||
i = 10;
|
||||
for(; i > 0; ){
|
||||
printf("%d\n", i);
|
||||
--i
|
||||
}
|
||||
```
|
||||
|
||||
是不是很像我们的 while 语句?
|
||||
|
||||
|
||||
|
||||
**4. 省略第二个表达式**
|
||||
|
||||
```c
|
||||
for (; ;) {
|
||||
printf("Hello\n");
|
||||
}
|
||||
```
|
||||
|
||||
省去控制表达式,**默认为真**,因此 for 语句会不断循环下去。
|
||||
|
||||
它相当于:
|
||||
|
||||
```c
|
||||
while (1) {
|
||||
printf("Hello\n");
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 3. C99 中的 for 语句
|
||||
|
||||
C99 中第一个表达式可以替换成一个声明:
|
||||
|
||||
```c
|
||||
for(int i = 0; i < 10; i++){
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
变量 i 不需要在该句之前进行声明。事实上,如果变量 i 在之前已经声明了,这个语句会创建一个新的 i 且该值**仅用于循环内**。(新的 i 会覆盖之前的 i 。for 语句的花括号相当于一个块,新 i 的作用域仅在这个块内。)
|
||||
|
||||
例如:
|
||||
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
int i = 20;
|
||||
|
||||
for (int i = 0; i < 10; i++) {
|
||||
printf("%d\n", i);
|
||||
}
|
||||
// 循环结束新的 i 应该等于 10
|
||||
|
||||
printf("%d\n", i);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```c
|
||||
0
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
20
|
||||
```
|
||||
|
||||
最后输出的 20 不符合我们的预期,这说明了一个问题:
|
||||
|
||||
旧的 i 始终存在,只不过在 for 语句内,新的 i 相对旧的 i 显“显性”(可以用高中生物的基因来理解一下;或者你就理解为覆盖,但是新的 i 开辟的是新的内存,它不会真的覆盖旧的 i )。
|
||||
|
||||
|
||||
|
||||
for 语句声明的变量不可以在循环外访问(生存期仅在 for 语句内)。例如:
|
||||
|
||||
```c
|
||||
for (int i = 0; i < 10; i++) {
|
||||
printf("%d\n", i);
|
||||
}
|
||||
|
||||
printf("%d\n", i);// 在这里编译会报错,"未定义标识符 i"
|
||||
```
|
||||
|
||||
|
||||
|
||||
> 让 for 语句声明自己的循环控制变量通常是一个好办法:这样**方便且程序的可读性更强**,但是如果**在 for 循环退出后还要使用该变量**,则只能使用以前的 for 语句格式。
|
||||
|
||||
|
||||
|
||||
另外,for 语句可以**声明多个变量**,只要它们的**类型相同**:
|
||||
|
||||
```c
|
||||
for(int i = 0, j = 10; i < j; i++, j--){
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### 4. 逗号表达式
|
||||
|
||||
> 逗号表达式(comma expression)
|
||||
|
||||
##### 基本用法
|
||||
|
||||
```c
|
||||
表达式1,表达式2,表达式3,...,表达式n;
|
||||
```
|
||||
|
||||
- 逗号表达式的优先级低于所有其他运算符
|
||||
- 从左向右依次执行:先计算表达式1,然后是表达式2 ...
|
||||
- 最终整个逗号表达式的值为最后一个表达式的值
|
||||
|
||||
例如:
|
||||
|
||||
```c
|
||||
i = 1, j = 2, k = i + j;
|
||||
```
|
||||
|
||||
相当于是:
|
||||
|
||||
```c
|
||||
((i = 1), (j = 2), (k = i + j));
|
||||
```
|
||||
|
||||
整个逗号表达式的值为 k = i + j 的值,也就是 3
|
||||
|
||||
##### 应用
|
||||
|
||||
假如在进入 for 语句时希望初始化两个变量
|
||||
|
||||
``` c
|
||||
sum = 0;
|
||||
for(i = 1; i <= N; i++){
|
||||
sum += i;
|
||||
}
|
||||
```
|
||||
|
||||
改写为:
|
||||
|
||||
```c
|
||||
for(sum = 0, i = 1; i <= N; i++){
|
||||
sum += i;
|
||||
}
|
||||
```
|
||||
|
||||
#### 程序 4:显示平方表(for)
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void){
|
||||
|
||||
int n;
|
||||
|
||||
printf("This program prints a table of squares.\n");
|
||||
printf("Enter number of entries in table: ");
|
||||
scanf("%d", &n);
|
||||
|
||||
for(int i = 1; i <= n; i++){
|
||||
printf("\t%d\t%d\n", i, i * i);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
#### 程序 5:不用乘法,实现程序“显示平方表”
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void){
|
||||
|
||||
int n;
|
||||
|
||||
printf("This program prints a table of squares.\n");
|
||||
printf("Enter number of entries in table: ");
|
||||
scanf("%d", &n);
|
||||
|
||||
for(int i = 1, square = 1, odd = 3; i <= n; i++){
|
||||
printf("\t%d\t%d\n", i, square);
|
||||
square += odd;
|
||||
odd += 2;
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 四 退出循环
|
||||
|
||||
有时,**循环还没有结束,但我们需要在循环的中间设置退出点**,甚至可能需要对循环设置多个退出点。break 语句可以满足这种需求。
|
||||
|
||||
continue 语句用来跳过某次迭代的部分内容,但是不会跳过整个循环。
|
||||
|
||||
goto 语句允许程序从一条语句直接跳到另一条语句。
|
||||
|
||||
#### 1. break 语句
|
||||
|
||||
> break 语句不但可以把程序控制从 switch 语句中转移出来;还可以用于跳出 while,do while,和 for 循环。
|
||||
|
||||
#### 程序 6:判断素数
|
||||
|
||||
假如要编写一个程序判断 n 是否为素数。我们计划是编写一个 for 语句用 n 除以 2 到 n - 1 之间的所有数。一旦发现有约数就跳出循环,没不需要继续尝试下去。循环终止后,可以用 if 判断循环是提前终止(不是素数)还是正常终止(是素数)。
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void){
|
||||
|
||||
int n, i;
|
||||
|
||||
printf("Enter a number:");
|
||||
scanf("%d", &n);
|
||||
|
||||
for(i = 2; i < n; i++){
|
||||
if(n % i == 0){
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
if(i < n){
|
||||
printf("%d is not a prime\n", n);
|
||||
}else{
|
||||
printf("%d is a prime\n", n);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
#### 程序 7:程序2 重写
|
||||
|
||||
程序 2 中,要求我们当用户输入 0 时,结束求和。我们用很多中方法去实现了,我们可以用 break 语句让程序的意图更加直观。
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void){
|
||||
|
||||
int n, sum = 0;
|
||||
|
||||
printf("This program sums a series of integers.\n");
|
||||
printf("Enter integers(0 to terminate): ");
|
||||
|
||||
|
||||
while(1){
|
||||
scanf("%d", &n);
|
||||
if(n == 0){
|
||||
break;
|
||||
}else{
|
||||
sum += n;
|
||||
}
|
||||
}
|
||||
|
||||
printf("The sum is:%d\n", sum);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
**一个 break 只能跳出一个循环**,如果循环嵌套,那么可能需要多个 break 才能从里层的循环跳出。
|
||||
|
||||
```c
|
||||
int i;
|
||||
while(1){
|
||||
for(i = 1; i < 10; i++){
|
||||
if(i == 5){
|
||||
printf("%d\n", i);
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
运行一下这个程序,发现,屏幕上一直在输出 5,说明外层的循环没有跳出。
|
||||
|
||||
|
||||
|
||||
#### 2. continue 语句
|
||||
|
||||
> break 语句刚好将程序控制转移到循环体的**末尾之后**;而 continue 语句刚好将程序控制转移到循环体**末尾之前**。
|
||||
|
||||
break 语句会跳出循环;而 continue 语句会将程序控制留在循环体之内。
|
||||
|
||||
其实 continue 的作用就是跳过本次循环点剩下内容,重新开始下一轮循环。
|
||||
|
||||
#### 程序 8:计算奇数和
|
||||
|
||||
编写一个程序。先提示用户输入一个数 n,然后将 1 ~ n 的所有奇数相加,然后输出最终的和
|
||||
|
||||
**不使用 continue**
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void){
|
||||
|
||||
int n, sum = 0;
|
||||
|
||||
printf("Enter a number:");
|
||||
scanf("%d", &n);
|
||||
|
||||
for(int i = 1; i <= n; i++){
|
||||
if(i % 2 != 0){
|
||||
sum += i;
|
||||
}
|
||||
}
|
||||
|
||||
printf("Sum of odds is :%d\n", sum);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
**使用 continue**
|
||||
|
||||
只需要改变 for 循环即可
|
||||
|
||||
```c
|
||||
for(int i = 1; i <=n; i++){
|
||||
if(i % 2 == 0){
|
||||
continue;
|
||||
}
|
||||
sum += i;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 3. goto 语句
|
||||
|
||||
> break 和 continue 语句都是跳转语句:它们可以把控制从程序的一个位置转移到另一个位置。然而,这两者都是受限制的。
|
||||
>
|
||||
> goto 语句则可以跳转到函数中任何有标号的语句处。(C99 增加了一条限制:goto 不能用于绕过*变长数组*(后面的章节会讲)的声明。)
|
||||
|
||||
|
||||
|
||||
```c
|
||||
标识符:语句;
|
||||
goto 标识符;
|
||||
```
|
||||
|
||||
#### 程序:程序 6 重写
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void){
|
||||
|
||||
int n, i;
|
||||
|
||||
printf("Enter a number:");
|
||||
scanf("%d", &n);
|
||||
|
||||
for(i = 2; i < n; i++){
|
||||
if(n % i == 0){
|
||||
goto done;
|
||||
}
|
||||
}
|
||||
done:
|
||||
if(i < n){
|
||||
printf("%d is not a prime\n", n);
|
||||
}else{
|
||||
printf("%d is a prime\n", n);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
goto 语句在早期的编程语言中很常见,但是日常 C 语言编程却很少使用它了。break,continue,return 语句(本质上都是受限制的goto 语句)和 exit 函数足以应付大多数需要使用 goto 的情况。
|
||||
|
||||
而且 goto 语句**不建议滥用,能不用就不用**,因为 goto 语句可以打乱程序原本的执行顺序,这大大降低了程序的可读性,提高了改错成本。(这里程序圆是有切身体会的,大一 做C语言的课设的时候,那时候对 C 掌握的并不是很好。我在一个函数内大量的使用 goto 语句,导致我最后都不知道我的 goto 跳到哪里了。)
|
||||
|
||||
|
||||
|
||||
但是 goto 语句偶尔还是有用的,比如上面的例子:循环嵌套的情况,使用goto 语句就很好跳出多重循环了:
|
||||
|
||||
```c
|
||||
int i;
|
||||
while(1){
|
||||
for(i = 1; i < 10; i++){
|
||||
if(i == 5){
|
||||
printf("%d\n", i);
|
||||
goto find;
|
||||
}
|
||||
}
|
||||
}
|
||||
find:
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 程序:账薄结算
|
||||
|
||||
这个程序帮你理解一种简单的交互式程序设计,我们可以通过这种方式设计菜单。
|
||||
|
||||
题目:
|
||||
|
||||
开发一个程序用来维护账簿的余额。程序将为用户提供选择菜单:清空余额账户,向账户存钱,从账户取钱,显示当前余额,退出程序。选项用 0,1,2,3,4表示。程序的会话类似这样:
|
||||
|
||||
```c
|
||||
**** ACME checkbook-balancing program ****
|
||||
Comands: 0 = clear, 1 = credit, 2 = debit, 3 = balance, 4 = exit
|
||||
|
||||
Enter command: 1
|
||||
Enter amount of credit: 1042.56
|
||||
Enter command: 2
|
||||
Enter amount of debit : 133.56
|
||||
Enter command: 3
|
||||
Current balance: 909
|
||||
Ener command: 4
|
||||
Goodbye~
|
||||
```
|
||||
|
||||
参考程序:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
double balance = 0; // 余额
|
||||
double credit, debit;
|
||||
|
||||
// 菜单,形式可以自己设计,尽量美观一点嘛,不过不用纠结这种界面,不要舍本逐末。
|
||||
|
||||
printf("**** ACME checkbook-balancing program ****\n");
|
||||
printf(" Comands: \n");
|
||||
printf(" 0 = clear \n");
|
||||
printf(" 1 = credit \n");
|
||||
printf(" 2 = debit \n");
|
||||
printf(" 3 = balance \n");
|
||||
printf(" 4 = exit \n");
|
||||
|
||||
// 题目中已经规定了这些功能用 0,1,2,3,4 代替,其实是想让我们用 switch
|
||||
// 如果你想用 if else 也完全 ok
|
||||
|
||||
// 死循环让用户可以重复选择
|
||||
while (1) {
|
||||
int choice;
|
||||
printf("Enter command: ");
|
||||
scanf("%d", &choice);
|
||||
|
||||
switch (choice) {
|
||||
|
||||
// 清除账户是一种很“危险”的举动,可以让用户确认一次
|
||||
|
||||
case 0: printf("Are you sure to clear your balance?\n");
|
||||
printf("1 = yes, 0 = no\n");
|
||||
int isClear;
|
||||
scanf("%d", &isClear);
|
||||
if (isClear == 1) {
|
||||
balance = 0;
|
||||
printf("clear successfully!\n");
|
||||
}
|
||||
break;
|
||||
|
||||
case 1: printf("Enter amount of credit: ");
|
||||
scanf("%lf", &credit);
|
||||
balance += credit;
|
||||
break;
|
||||
|
||||
case 2: printf("Enter amount of debit : ");
|
||||
scanf("%lf", &debit);
|
||||
balance -= debit;
|
||||
break;
|
||||
|
||||
case 3: printf("Current balance: %.2f\n", balance);
|
||||
break;
|
||||
|
||||
case 4: printf("Are you sure to quit?\n");
|
||||
printf("1 = yes, 0 = no\n");
|
||||
int isQuit;
|
||||
scanf("%d", &isQuit);
|
||||
if (isQuit == 1) {
|
||||
printf("Goodbye~\n");
|
||||
return 0;
|
||||
}
|
||||
else {
|
||||
break;
|
||||
}
|
||||
default: printf("Illeagl option!\n");
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 五 空语句
|
||||
|
||||
```c
|
||||
i = 0; ; j = 1;
|
||||
```
|
||||
|
||||
第二个语句就是一个空语句:**除了末尾的分号,什么符号也没有。**
|
||||
|
||||
空语句主要有一个好处:**编写空循环体的循环。**
|
||||
|
||||
判断素数的循环我们可以这样改写:
|
||||
|
||||
```c
|
||||
for(d = 2; d <= n && n % d != 0; d++)
|
||||
;
|
||||
```
|
||||
|
||||
注意不要写成:
|
||||
|
||||
```c
|
||||
for(d = 2; d <= n && n % d != 0; d++) ;
|
||||
```
|
||||
|
||||
**程序员习惯将空语句单独放在一行**,否则,一般人阅读程序时可能会混淆后面的语句是否是其循环体。
|
||||
|
||||
```c
|
||||
for(d = 2; d <= n && n % d != 0; d++) ;
|
||||
if(d < n)
|
||||
printf("%d is divisible by %d", n, d);
|
||||
```
|
||||
|
||||
|
||||
|
||||
> 一般情况下,将普通循环转化为带空循环体的语句**不会提高效率**,但是会让程序更加简洁。
|
||||
>
|
||||
> 但是在一些情况下,可能带空循环体的循环会更加高效。如:读取字符数据时(后面会讲)。
|
||||
|
||||
|
||||
|
||||
#### 空语句可能会造成的情况
|
||||
|
||||
**1.if 语句**
|
||||
|
||||
```c
|
||||
if(d == 0);
|
||||
printf("Error: division by zero\n");
|
||||
```
|
||||
|
||||
如果输入的 d 不是 0,后面的这条消息一样会被打印。
|
||||
|
||||
**2.while 语句**
|
||||
|
||||
```c
|
||||
i = 10;
|
||||
while(i > 0);{
|
||||
printf("%d\n", i);
|
||||
i--;
|
||||
}
|
||||
```
|
||||
|
||||
程序会进入死循环,因为 while 没有循环体,而 i 的的值不会减小。
|
||||
|
||||
```c
|
||||
i = 11;
|
||||
while(--i > 0);{
|
||||
printf("%d\n", i);
|
||||
i--;
|
||||
}
|
||||
```
|
||||
|
||||
循环终止,但是花括号内的语句只被执行一次。
|
||||
|
||||
输出:0
|
||||
|
||||
**3. for 语句**
|
||||
|
||||
```c
|
||||
for(i = 10; i > 0; i--);
|
||||
printf("%d\n", i);
|
||||
```
|
||||
|
||||
printf 语句被执行一次
|
||||
|
||||
输出:0
|
||||
|
||||
|
||||
|
||||
*参考资料:《C Primer Plus》《C语言程序设计:现代方法》*
|
||||
|
||||
[^1]: 用100个函数操作一个数据结构比仅用10个函数但是操作10个不同的数据结构要好。[Epigrams on Programming 编程警句 ](https://epigrams-on-programming.readthedocs.io/zh_CN/latest/epigrams.html)
|
||||
691
content/c-mordern-approch/09-数组.md
Normal file
691
content/c-mordern-approch/09-数组.md
Normal file
@@ -0,0 +1,691 @@
|
||||
## 数组
|
||||
|
||||
*Get into a rut early: Do the same processes the same way. Accumulate idioms. Standardize. The only difference (!) between Shakespeare and you was the size of his idiom list - not the size of his vocabulary.* [^1]
|
||||
|
||||
## 目录
|
||||
|
||||
***
|
||||
|
||||
[TOC]
|
||||
|
||||
## 数组
|
||||
|
||||
***
|
||||
|
||||
到目前为止,我们所见的变量都只是**标量**(scalar):标量具有保存单一数据项的能力。
|
||||
|
||||
C 语言也支持**聚合**(aggregate)变量,这类变量可以存储一组数值。C 语言一共有两种聚合类型:**数组**(array)和 **结构**(structure)。
|
||||
|
||||
其中,数组是本节的主角。它只能存储**相同类型**的变量集合。
|
||||
|
||||
### 一 一维数组
|
||||
|
||||
> 数组是含有**多个**数据值的**数据结构**,并且每个数据具有**相同的数据类型**。这些数据值称为**元素**(element)。
|
||||
|
||||
最简单的数组是**一维数组**。一维数组中的每个元素一个接一个的排列。
|
||||
|
||||
为了声明数组,需要指明数组元素的**类型和数量**。
|
||||
|
||||
```c
|
||||
int a[10];// 一个含有 10 个 int 类型变量的数组
|
||||
```
|
||||
|
||||
数组的元素可以是任意类型,数组的长度可以是任何**(整数)常量表达式**指定。
|
||||
|
||||
```c
|
||||
#define N 10
|
||||
|
||||
int a[N];
|
||||
```
|
||||
|
||||
但是不能使用变量(C89)
|
||||
|
||||
```c
|
||||
n = 10;
|
||||
int a[n];
|
||||
```
|
||||
|
||||
尽管 C99 已经允许这种做法,但是,很多编译器并不完全支持 C99 。
|
||||
|
||||
#### 1. 数组下标
|
||||
|
||||
> 对数组**取下标(subscripting)**或进行**索引(indexing)**:为了取特定的数组元素,可以在写数组名的同时在后面加上一个用方括号围绕的整数值。
|
||||
>
|
||||
> 数组元素始终**从 0 开始**,所以长度为 n 的数组元素的索引时 0 ~ n - 1
|
||||
|
||||
例如,a 是含有 10 个元素的数组:
|
||||
|
||||
|
||||
|
||||
`a[i]`是左值,所以数组元素可以像不同变量一样使用:
|
||||
|
||||
```c
|
||||
a[0] = 1;
|
||||
printf("%d\n", a[5]);
|
||||
++a[i];
|
||||
```
|
||||
|
||||
#### 2. 数组和 for 循环
|
||||
|
||||
许多程序包含的 for 循环都是为了对数组的每个元素执行一些操作。下面给出了长度为 N 的数组 a 的一些常见操作。
|
||||
|
||||
```c
|
||||
for(i = 0; i < N; i++){
|
||||
a[i] = 0; // clears a
|
||||
}
|
||||
|
||||
for(i = 0; i < N; i++){
|
||||
scanf("%d", &a[i]); // reads data into a
|
||||
}
|
||||
|
||||
for(i = 0; i < N; i++){
|
||||
sum += a[i]; // sums the elements of a
|
||||
}
|
||||
```
|
||||
|
||||
**注意:在调用 scanf 函数读取数组元素时,就像对待普通变量一样,必须使用取地址符号 `&`**
|
||||
|
||||
|
||||
|
||||
> C 语言不要求检查下标的范围。当下标超出范围时,程序可能执行不可预知的行为。
|
||||
|
||||
|
||||
|
||||
数组下标可以是任何整数表达式:
|
||||
|
||||
```
|
||||
a[i + j*10] = 0;
|
||||
```
|
||||
|
||||
下标可以自增自减:
|
||||
|
||||
```c
|
||||
i = 0;
|
||||
while(i < N)
|
||||
printf("%d\n", a[i++]);
|
||||
```
|
||||
|
||||
i = 0 时进入循环,打印 a[0] 后 i 的值增加 1 ,这样不断重复;当 i = N - 1 时,打印 a[N - 1] 然后 i 的值加 1 变为 N 不满足 控制表达式 退出循环。
|
||||
|
||||
**这类问题可以使用 VS 进行调试,从而判断数组下标的变化情况,如果你不会调试可以留言告诉我,不会的人多的话,我可以出一期教程。以后能调试解决的问题不再赘述。**
|
||||
|
||||
|
||||
|
||||
使用自增自减运算符的时候一定要注意,如果这样子写:
|
||||
|
||||
```c
|
||||
i = 0;
|
||||
while(i < N)
|
||||
a[i] = b[i++]; // 访问并修改 i 的值,会导致未定义行为
|
||||
```
|
||||
|
||||
将自增自减从下标中移走即可:
|
||||
|
||||
```c
|
||||
for(i = 0; i < N; i++){
|
||||
a[i] = b[i];
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 程序:数列反向
|
||||
|
||||
要求录入一串数据,然后按反向顺序输出这些数:
|
||||
|
||||
```c
|
||||
Enter 10 numbers: 1 2 3 4 5
|
||||
In reverse order: 5 4 3 2 1
|
||||
```
|
||||
参考程序:
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
#define N 5
|
||||
|
||||
int main(void){
|
||||
|
||||
int a[N];
|
||||
int i;
|
||||
|
||||
printf("Enter %d numbers: ", N);
|
||||
for(i = 0; i < N; i++){
|
||||
scanf("%d", &a[i]);
|
||||
}
|
||||
|
||||
printf("In reverse order: ");
|
||||
for(i = N - 1; i >= 0; i--){
|
||||
printf("%d ", a[i]);
|
||||
}
|
||||
printf("\n");
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
这个程序使用宏的思想可以借鉴。
|
||||
|
||||
|
||||
|
||||
#### 3. 数组初始化
|
||||
|
||||
> 数组初始化(array initializer)
|
||||
|
||||
一般的初始化方法:
|
||||
|
||||
```c
|
||||
int a[5] = {1, 2, 3, 4, 5};
|
||||
```
|
||||
|
||||
**如果初始化式子比数组短,那么剩余的元素被赋值为 0**
|
||||
|
||||
```c
|
||||
int a[5] = {1, 2, 3};
|
||||
// initial value of a is {1, 2, 3, 0, 0}
|
||||
```
|
||||
|
||||
利用这一特性,可以很容易的将数组全部初始化为 0:
|
||||
|
||||
```c
|
||||
int a[5] = {0};
|
||||
```
|
||||
|
||||
如果给定了数组的初始化式,可以省略数组长度:
|
||||
|
||||
```c
|
||||
int a[] = {1, 2, 3, 4, 5};
|
||||
```
|
||||
|
||||
编译器利用初始化式的长度来确定数组大小。数组仍有固定数量的元素。
|
||||
|
||||
#### 4. 指定初始化(C99)
|
||||
|
||||
> 经常有这样的情况:数组中只有相对较少的元素需要进行显示的初始化,而其他元素可以进行默认赋值。
|
||||
|
||||
比如:
|
||||
|
||||
```c
|
||||
int a[10] = {0, 2, 0, 0, 0, 0, 0, 0, 2, 0};
|
||||
```
|
||||
|
||||
对于更大的数组,如果使用这种方式赋值,将是**冗长**而**容易出错**的。
|
||||
|
||||
C99 中的指定初始化可以用于解决这一问题:
|
||||
|
||||
```c
|
||||
int a[10] = {[1] = 2, [8] = 2};
|
||||
```
|
||||
|
||||
括号中的数组称为**指示符**。
|
||||
|
||||
**注意:**
|
||||
|
||||
- 赋值顺序不是问题。
|
||||
|
||||
```c
|
||||
int a[10] = {[8] = 2, [1] = 2};
|
||||
```
|
||||
|
||||
写成这样也是 ok 的。
|
||||
|
||||
- 指示符必须是**常量表达式**。
|
||||
|
||||
- 如果待初始化的数组长度为 n ,那么指示符的取值为:[0, n-1];如果数组长度是省略的,指示符可以是任意非负数,编译器将根据**最大的指示符**推断出数组长度。
|
||||
|
||||
```c
|
||||
int a[] = {[10] = 10, [1] = 2, [8] = 2,};
|
||||
```
|
||||
|
||||
最大的指示符为 10,数组长度为 11
|
||||
|
||||
- 初始化式中新旧方法可以混用
|
||||
|
||||
```c
|
||||
int a[10] = {1, 2, 3, [4] = 5, 6, 7, [9] = 9};
|
||||
// a[0] = 1, a[1] = 2, a[2] = 3, a[4] = 5, a[5] = 6, a[6] = 7, a[9] = 9 其余都为 0
|
||||
```
|
||||
|
||||
指示符后如果使用旧的方法初始化,那么初始化的元素应该紧邻指示符之后。
|
||||
|
||||
```c
|
||||
int a[] = { [9] = 9, 10, 11 };
|
||||
```
|
||||
|
||||
数组 a 的元素个数为 12 个
|
||||
|
||||
如果新旧初始化方法混用,此时,数组 a 的大小就要看情况:如果最大的指示符后有旧的初始化方法,那么数组长度应该加上直到下一个指示符前的所有元素个数。
|
||||
|
||||
|
||||
|
||||
#### 程序:检查数中重复出现的元素
|
||||
|
||||
检查数中是否有出现多于 1 次的数字。
|
||||
|
||||
1 )判断是否存在重复出现的数字。
|
||||
|
||||
2)输出所有重复出现的数字。
|
||||
|
||||
参考答案:
|
||||
|
||||
1)
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<stdbool.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
bool digit_seen[10] = { false };
|
||||
int digit;
|
||||
unsigned int n;
|
||||
|
||||
printf("Enter a number: ");
|
||||
scanf("%u", &n);
|
||||
|
||||
// 求整数每一位:先 % 在 /
|
||||
while (n > 0) {
|
||||
digit = n % 10;
|
||||
n /= 10;
|
||||
if (digit_seen[digit] == true) {
|
||||
break;
|
||||
}
|
||||
digit_seen[digit] = true;
|
||||
}
|
||||
|
||||
// n > 0 说明 while 循环是 break 退出的,所以就有重复数字
|
||||
if (n > 0) {
|
||||
printf("Repeated digit\n");
|
||||
}
|
||||
else {
|
||||
printf("No repeated digit\n");
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
2)
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
int digit_seen[10] = { 0 };
|
||||
int digit;
|
||||
unsigned int n;
|
||||
|
||||
printf("Enter a number: ");
|
||||
scanf("%u", &n);
|
||||
|
||||
while (n > 0) {
|
||||
digit = n % 10;
|
||||
n /= 10;
|
||||
digit_seen[digit] += 1;// 计算每个数字出现的次数
|
||||
}
|
||||
|
||||
for (int i = 0; i < 10; i++) {
|
||||
if (digit_seen[i] > 1) { // 多于 1 次视为重复
|
||||
printf("%d ", i);
|
||||
}
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
对于第一个程序,如果你的编译器不支持头 <stdbool.h>,你可以自己定义宏,这个我们之前说过。或者就用 0 1 也可以。
|
||||
|
||||
|
||||
|
||||
#### 5. 对数组使用 sizeof 运算符
|
||||
|
||||
```c
|
||||
int a[10];
|
||||
printf("%zu", sizeof(a));
|
||||
```
|
||||
|
||||
数组的大小是数组每个元素大小的总和,也就是:数组元素个数 x 数组数据类型的大小
|
||||
|
||||
上例数组大小为 4 x 10 = 40 (int 大小为 4 的机器上)。
|
||||
|
||||
也可以用 sizeof 计算数组元素的大小:
|
||||
|
||||
```c
|
||||
int a[10];
|
||||
printf("%zu", sizeof(a[0]));
|
||||
// 4
|
||||
```
|
||||
|
||||
此外还有我们经常使用的:**计算数组长度:**用数组的大小除以每个元素的大小
|
||||
|
||||
```c
|
||||
int a[] = {1, 2, 3};
|
||||
printf("%zu", sizeof(a) / sizeof(a[0]));
|
||||
```
|
||||
|
||||
细心的你可能已经发现,为什么我用的 printf 的转换说明都是 `%zu` 这是因为 sizeof 的返回值类型是 size_t 类型(unsigned int),`%zu` 是专门为这种类型设置的转换说明。
|
||||
|
||||
所以,有时候当你这样写程序时,可能会有报错:
|
||||
|
||||
```c
|
||||
for(int i = 0; i < sizeof(a) / sizeof(a[0]); i++){
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
这时因为 i 和 sizeof(a) / sizeof(a[0]) 类型不一样,可以强制类型转换一下:
|
||||
|
||||
```c
|
||||
for(int i = 0; i < (int)sizeof(a) / sizeof(a[0]); i++){
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
如果你嫌麻烦,可以使用宏定义数组长度,但是如果两个数组大小不一样,你就要定义两个宏。
|
||||
|
||||
这时候我们可以使用带参数的宏:
|
||||
|
||||
```c
|
||||
#define ARRAY_LENGTH(a) (int)sizeof(a) / sizeof(a[0])
|
||||
|
||||
int b[5];
|
||||
printf("%d", ARRAY_LENGTH(b));
|
||||
```
|
||||
|
||||
如果不懂,也没有关系,后面我们会详细讲解。
|
||||
|
||||
|
||||
|
||||
#### 程序:计算利息
|
||||
|
||||
编写一个程序显示一个表格。这个表格显示了几年时间内 100 美元投资在不同利率下的价值。用户输入利率和要投资的年数。投资总价值一年算一次,表格将显示输入的利率和紧随其后的 4 个更高的利率下投资的总价值。程序会话如下:
|
||||
|
||||
```c
|
||||
Enter intrest rate: 6
|
||||
Enter number of years: 2
|
||||
|
||||
Years 6% 7% 8% 9% 10%
|
||||
1 106.00 107.00 108.00 109.00 110.00
|
||||
2 112.36 114.49 116.64 118.81 121.00
|
||||
```
|
||||
|
||||
第一行用一个 for 语句来显示。
|
||||
|
||||
我们在计算第一年的价值的时候将结果存放到数组中,然后使用数组中的结果继续计算下一年的价值。
|
||||
|
||||
在这一过程中我们将需要两个 for 语句,一个控制年份,一个控制不同的利率。
|
||||
|
||||
程序示例:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
#define NUM_RATES (int)sizeof(value) / sizeof(value[0])
|
||||
#define INITIAL_BALANCE 100.00
|
||||
|
||||
|
||||
int main(void) {
|
||||
|
||||
int rate;
|
||||
int year;
|
||||
double value[5];
|
||||
|
||||
printf("Enter intrest rate: ");
|
||||
scanf("%d", &rate);
|
||||
printf("Enter number of years: ");
|
||||
scanf("%d", &year);
|
||||
|
||||
printf("\nYears");
|
||||
for (int i = 0; i < NUM_RATES; i++) {
|
||||
printf("%7d%%", rate + i);
|
||||
value[i] = INITIAL_BALANCE; // 初始化
|
||||
}
|
||||
printf("\n");
|
||||
|
||||
for (int i = 0; i < year; i++) {
|
||||
printf("%3d ", i); // 补空格,让第一行和下面的行对齐
|
||||
for (int j = 0; j < NUM_RATES; j++) {
|
||||
value[j] += value[j] * (rate + j) / 100; // 注意这里不要写错
|
||||
printf("%8.2f", value[j]);
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 二 多维数组
|
||||
|
||||
数组可以有任意维数。不过多维数组我们一般只使用**二维数组**。
|
||||
|
||||
二维数组的声明:
|
||||
|
||||
```c
|
||||
int a[3][3];
|
||||
```
|
||||
|
||||
|
||||
|
||||
`a[i][j]`访问的时 第 i 行 第 j 列的元素。
|
||||
|
||||
虽然我们以表格的形式显示二维数组,但是实际上它们在计算机的内存中是按照**行主序**线性存储的,也就是从第 0 行开始。
|
||||
|
||||
所以上面的数组实际是这样存储的:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
基于这个特性,我们一般用嵌套的 for 循环遍历二维数组:
|
||||
|
||||
```c
|
||||
int a[3][3];
|
||||
for(int row = 0; row < 3; row++){
|
||||
for(int col = 0; col < 3; col++){
|
||||
a[row][col] = 0;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 1. 多维数组初始化
|
||||
|
||||
嵌套的一维数组初始化式:
|
||||
|
||||
```c
|
||||
int a[3][3] = {
|
||||
{1, 2, 3},
|
||||
{4, 5, 6},
|
||||
{7, 8, 9}
|
||||
};
|
||||
```
|
||||
|
||||
缺省:
|
||||
|
||||
```c
|
||||
int a[3][3] = {
|
||||
{1},
|
||||
{2, 3}
|
||||
}
|
||||
```
|
||||
|
||||
我们只初始化了第 1 行第 1 个元素,第 2 行第 1,2 个元素,其余的元素初始化为 0
|
||||
|
||||
甚至可以不写内层的大括号:
|
||||
|
||||
```c
|
||||
int a[3][3] = {
|
||||
1, 2, 3,
|
||||
4, 5, 6,
|
||||
7, 8, 9
|
||||
};
|
||||
```
|
||||
|
||||
一旦编译器填满一行,就开始填充下一行。
|
||||
|
||||
试思考,如果这样初始化二维数组,结果会是怎样:
|
||||
|
||||
```c
|
||||
int a[3][3] = {
|
||||
1,
|
||||
2, 3,
|
||||
};
|
||||
```
|
||||
|
||||
第一行被初始化为 1,2,3 其余都为 0
|
||||
|
||||
|
||||
|
||||
C99 的指定初始化对多维数组也有效。例如:
|
||||
|
||||
|
||||
```c
|
||||
int a[3][3]{
|
||||
[0][0] = 0,
|
||||
[1][1] = 1,
|
||||
}
|
||||
```
|
||||
|
||||
像通常一样,没有指定值的元素默认置 0
|
||||
|
||||
|
||||
|
||||
多维数组的初始化可以省去第一维(二位数组中的行),其他维度不能省略。
|
||||
|
||||
```c
|
||||
int a[][3] = { {0}, {0}, {0} };
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### 2. 常量数组
|
||||
|
||||
> 用 `const` 修饰的数组,数组元素无法被改写(只读)。
|
||||
|
||||
```c
|
||||
const char bin_chars[] = {'0','1'};
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 程序:发牌
|
||||
|
||||
下面这个程序说明了二维数组和常量数组的用法。
|
||||
|
||||
**要求:**
|
||||
|
||||
程序负责发一副标准纸牌。每张标准指派都有一个花色(梅花,方块,红桃,黑桃)和一个点数(2 ~ 10, J, Q, K, A)。用户需要指明发多少张牌:
|
||||
|
||||
```c
|
||||
Enter number of cards in hand: 5
|
||||
Your card(s): S8 SA D7 H8 SK
|
||||
```
|
||||
|
||||
**程序说明: **
|
||||
|
||||
- 创建两个常量数组,分别放置 4 中花色 和 13 个点数
|
||||
|
||||
- 程序要可以生成 随机数 。我们需要三个函数:
|
||||
|
||||
time <time.h>
|
||||
|
||||
srand <stdlib.h>
|
||||
|
||||
rand <stdlib.h>
|
||||
|
||||
这三个函数组合就可以完成这一功能,原理在我另一篇文章:【随机数发生器】 中讲解过。
|
||||
|
||||
- 生成的随机数必须在:0 ~ 3 和 0 ~ 13 之间:
|
||||
|
||||
只需要让 `rand() % 4` 那么随机数就在 0 ~ 3 之间,另一个同理。
|
||||
|
||||
- 两次拿到的牌不能是一样的。创建一个 bool 类型的数组,开始时全部初始化 false。每次拿到两个随机数后,如果数组对应的值为 false 那么将该元素置为 true 然后将此牌“发”给用户;否则,重新生成随机数。
|
||||
|
||||
参考程序:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<time.h>
|
||||
#include<stdbool.h>
|
||||
#include<stdlib.h>
|
||||
|
||||
#define NUM_SUIT 4
|
||||
#define NUM_RANK 13
|
||||
|
||||
int main(void) {
|
||||
|
||||
int suit, rank, num_cards;
|
||||
|
||||
const char suit_code[] = {'H', 'D', 'C', 'S'}; // heart红桃 diamand方片 club梅花 spade黑桃
|
||||
const char rank_code[] = { '2', '3', '4', '5', '6', '7', '8', '9', 'T', 'J', 'Q', 'K', 'A' };
|
||||
bool in_hand[NUM_SUIT][NUM_RANK] = { false };
|
||||
|
||||
srand((unsigned)time(NULL));
|
||||
|
||||
printf("Enter number of cards in hand: ");
|
||||
scanf("%d", &num_cards);
|
||||
|
||||
|
||||
printf("Your card(s): ");
|
||||
while (num_cards > 0) {
|
||||
suit = rand() % NUM_SUIT;
|
||||
rank = rand() % NUM_RANK;
|
||||
|
||||
if (!in_hand[suit][rank]) {
|
||||
in_hand[suit][rank] = true;
|
||||
num_cards--;
|
||||
printf("%c%c ", suit_code[suit], rank_code[rank]);
|
||||
}
|
||||
}
|
||||
printf("\n");
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 三 变长数组(C99)
|
||||
|
||||
前面我们说到,数组变量的长度必须用**常量表达式**进行定义。但是 C99 中,可以使用**变量**作为数组长度。
|
||||
|
||||
例如:
|
||||
|
||||
```c
|
||||
scanf("%d", &n);
|
||||
int a[n];
|
||||
```
|
||||
|
||||
>**变长数组**(variable-length array,简称VLA):变长数组的长度时**程序执行时**计算的,而**不是在编译时**计算的。
|
||||
|
||||
如果不用变长数组,我们需要指定一个固定的长度。往往我们必须要给足大小,避免数组太小存放不下,导致程序出错。如果某一次程序只需要很少的空间,那么势必会造成巨大的内存浪费。
|
||||
|
||||
VS 2019 不换其他的编译器的情况下,是不支持 C99 这一特性的。所以,当时我写程序的时候,往往会开辟一个比较大的数组,每次都感觉很呆板。
|
||||
|
||||
作为开始学习的新手,建议就用 define 定义的宏来规定数组长度,这样使得程序更加易度和专业。
|
||||
|
||||
如果你学有余力,那么可以去学习一下动态内存分配函数 ,使用`malloc`来达到程序运行时创建合适大小的数组。我的文章也写过多次**动态内存分配**函数,有兴趣可以去看看。
|
||||
|
||||
|
||||
|
||||
变长数组的限制:
|
||||
|
||||
- 没有静态存储期限
|
||||
- **不能初始化**
|
||||
|
||||
变长数组常见于除了 main 函数以外的其他函数。对于函数 f 而言,变长数组最大的优势就是每次调用 f 时 数组的长度可以不同。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
*参考资料:《C Primer Plus》《C语言程序设计:现代方法》*
|
||||
|
||||
[^1]: 早立规矩:同样方式做的同样处理。积累固定用法(idiom)。标准化。你和莎士比亚的唯一区别是成语(idiom)量——不是词汇量 [Epigrams on Programming 编程警句 ](https://epigrams-on-programming.readthedocs.io/zh_CN/latest/epigrams.html)
|
||||
818
content/c-mordern-approch/10-函数.md
Normal file
818
content/c-mordern-approch/10-函数.md
Normal file
@@ -0,0 +1,818 @@
|
||||
## 函数
|
||||
|
||||
*If you have a procedure with 10 parameters, you probably missed some.* [^1]
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 目录
|
||||
|
||||
***
|
||||
|
||||
[TOC]
|
||||
|
||||
|
||||
|
||||
## 函数
|
||||
|
||||
***
|
||||
|
||||
### 零 前言
|
||||
|
||||
函数这个概念源自数学。在其他语言中,函数也叫方法,过程等。所以,编程中函数与数学中的函数是不同的。
|
||||
|
||||
我们早在第二章就接触到函数这一概念—— main 函数。当时我煞费苦心的尝试用通俗的话向你们解释 main 函数的构成以及各部分的功能。但我们刚开始学编程,对函数一定不能有一个比较深刻的认识。这一节,我将带领大家走进函数,仔细推敲品味函数。从这一节开始,使用函数的思想将会伴随我们今后的编程生涯。
|
||||
|
||||
一个程序可以实现很多复杂的功能,然而如果将所有的功能写在一个 main 函数中,显然是不科学的。大型程序的代码肯定不是几十行的事情,如果这样做,会让你在写代码和修改 bug 时崩溃。退一步说,对于一个项目来说,肯定时多人合作共同编写,都写在 main 函数内,就很僵硬了。
|
||||
|
||||
所以,函数就是一个子程序,它可以将我们的程序**模块化**,不同的函数实现不同的功能,然后再通过一定的方法让它们有机结合起来。将程序模块化,还可以减少不必要的重复——不用重复编写功能相同的代码。
|
||||
|
||||
这一章,会教你如何编写函数,并且更加深入的理解 main 函数本身。
|
||||
|
||||
### 一 函数的定义和调用
|
||||
|
||||
在介绍函数的定义之前,让我们先来看 3 个简单定义的函数。
|
||||
|
||||
这三个函数我就不详细分析了,你可以打开我之前讲 main 函数的构成那篇文章,和 main 函数对比着看。
|
||||
|
||||
#### 1. 3 个 简单的函数
|
||||
|
||||
##### ① 计算平均值
|
||||
|
||||
假设计算两个 double 类型的数值的平均值。
|
||||
|
||||
```c
|
||||
double average(double x, double y){
|
||||
return (x + y) / 2;
|
||||
}
|
||||
|
||||
int main(void){
|
||||
|
||||
double x = 1.0, y = 2.0;
|
||||
printf("%f", average(x, y));
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
##### ② 显示倒计数
|
||||
|
||||
不是每一个函数都有返回值:
|
||||
|
||||
```c
|
||||
void print_count(int n){
|
||||
printf("T minus %d and counting\n", n);
|
||||
}
|
||||
|
||||
int main(void){
|
||||
|
||||
for(int i = 10; i > 0; i--){
|
||||
print_count(i);
|
||||
}
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
##### ③ 显示双关语
|
||||
|
||||
不是每个函数都有参数:
|
||||
|
||||
```c
|
||||
void print_pun(){
|
||||
printf("To C or not to C: that is a question\n");
|
||||
}
|
||||
|
||||
int main(void){
|
||||
|
||||
print_pun();
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 2. 函数定义
|
||||
|
||||
```c
|
||||
返回类型 函数名(形式参数){
|
||||
声明
|
||||
语句
|
||||
}
|
||||
```
|
||||
|
||||
##### 返回类型
|
||||
|
||||
函数的返回类型是函数返回值的类型。
|
||||
|
||||
- 函数**不能返回数组**
|
||||
- 返回类型是**void**表示**没有**返回值
|
||||
- 如果省略返回值,C89 会**假设函数返回的是 int 类型**;C99 中这是不合法的。
|
||||
|
||||
一些程序员喜欢将返回类型放在函数名的**上边**:
|
||||
|
||||
```c
|
||||
double
|
||||
average(double x, double y){
|
||||
return (x + y) / 2;
|
||||
}
|
||||
```
|
||||
|
||||
如果**返回类型很长**,比如 `unsigned long int` 类型,那么这样写是非常有用的。
|
||||
|
||||
##### 形式参数
|
||||
|
||||
每个形式参数前需要写明其类型,形参之间用逗号隔开。
|
||||
|
||||
> 【C语言程序设计——现代方法】这本书中写到:“如果函数没有形式参数,那么圆括号内应该出现 void ”
|
||||
|
||||
**注意**:即使几个形参具有相同的数据类型,也必须对每个形参分别进行类型说明。
|
||||
|
||||
```c
|
||||
double average(double a, b){// error
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
##### 函数体
|
||||
|
||||
C89 中,变量声明必须出现在语句之前。
|
||||
|
||||
C99 中,允许声明和语句混在一起,只要在第一次使用之前进行声明即可。
|
||||
|
||||
**C89**
|
||||
|
||||
```c
|
||||
// 声明
|
||||
int a, b, c;
|
||||
// 语句
|
||||
printf("请输入两个数:");
|
||||
scanf("%d %d", &a, &b);
|
||||
c = a + b;
|
||||
printf("%d\n", c);
|
||||
```
|
||||
|
||||
**C99**
|
||||
|
||||
```c
|
||||
// 语句
|
||||
printf("请输入两个数:");
|
||||
// 声明
|
||||
int a, b;
|
||||
// 语句
|
||||
scanf("%d %d", &a, &b);
|
||||
// 声明
|
||||
int c = a + b;
|
||||
// 语句
|
||||
printf("%d\n", c);
|
||||
```
|
||||
|
||||
##### 块
|
||||
|
||||
> 块(block):一对花括号内就是一个块
|
||||
|
||||
我们在讲循环时说过,如果你这样写 for 语句:
|
||||
|
||||
```c
|
||||
for(int i = 0; ; ){
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
在 for 语句内定义变量 i ,那么当 for 循环结束后,后面的程序没有办法再去使用 i 了,因为 i 已经不存在了。
|
||||
|
||||
for 语句的大括号其实就是一个块。
|
||||
|
||||
在块内定义的变量只属于这一个块,块外的程序是没有办法访问和修改块内定义的变量的。
|
||||
|
||||
如果你还是不理解,可以看看下一章内容中的**作用域和生存期**。
|
||||
|
||||
#### 3. 函数调用
|
||||
|
||||
> 函数调用由函数名和实参列表组成,实参列表用圆括号括起来:
|
||||
|
||||
```c
|
||||
average(x, y);
|
||||
print_count(i);
|
||||
print_pun();
|
||||
```
|
||||
|
||||
返回值非 void 的函数会产生一个值,该值可以存储在变量中,还可以进行测试,显示或者其他用途。
|
||||
```c
|
||||
avg = average(x, y);
|
||||
if(avg > 0){
|
||||
printf("Average is positive\n");
|
||||
}
|
||||
```
|
||||
|
||||
如果不需要非 void 函数返回的值,总可以将其丢弃:
|
||||
|
||||
```c
|
||||
average(x, y); // discard return value
|
||||
```
|
||||
|
||||
average 函数的这个调用就是一个表达式语句的例子:计算出结果,但是不保存它
|
||||
|
||||
|
||||
|
||||
有时候我们可以直接将函数调用产生的结果当做 printf 函数的参数:
|
||||
|
||||
```c
|
||||
printf("%f", average(x, y));
|
||||
```
|
||||
|
||||
这种做法其实也是丢弃了 average 的返回值。
|
||||
|
||||
|
||||
|
||||
说到丢弃返回值,我们最常用的两个函数 `printf` 和 `scanf`也是有返回值的:
|
||||
|
||||
```c
|
||||
num_chars = printf("Hello World!\n"); // num_chars is now 13
|
||||
```
|
||||
|
||||
我们看看 MSDN 中对 printf 返回值的描述:
|
||||
|
||||
>The function returns **the number of characters** printed, or a negative value if an error occurs.
|
||||
|
||||
|
||||
|
||||
```c
|
||||
num = scanf("%d", &i);
|
||||
printf("%d\n", num); // 1
|
||||
|
||||
num = scanf("%s", str);
|
||||
printf("%d\n", num); // 1
|
||||
```
|
||||
|
||||
我们看看 MSDN 中对 scanf 返回值的描述:
|
||||
|
||||
> **scanf** return **the number of fields** successfully converted and assigned; the return value does not include fields that were read but not assigned. A return value of 0 indicates that no fields were assigned.
|
||||
|
||||
<br>
|
||||
|
||||
为了清楚的表明函数的返回值是被故意丢弃的,C 语言通常允许在函数调用前加上 `void`:
|
||||
|
||||
```c
|
||||
(void)printf("Hello World!\n");
|
||||
```
|
||||
|
||||
如此一来,printf 函数的返回值强制类型转换成 void 类型。
|
||||
|
||||
但是,C 语言库中大量函数的返回值通常都会被丢掉;在调用它们时都使用 (void) 会很麻烦,所以我们一般不这么写。
|
||||
|
||||
#### 程序:判断素数
|
||||
|
||||
编写程序提示用户录入数,然后给出一条信息说明此数是否为素数。
|
||||
|
||||
```c
|
||||
Enter a number: 24
|
||||
Not prime
|
||||
```
|
||||
|
||||
把判断素数的实现写到另外一个函数中,此函数返回值为 true 就表示是素数,返回 false 表示不是素数。
|
||||
|
||||
参考程序:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<stdbool.h>
|
||||
|
||||
bool is_prime(int n) {
|
||||
|
||||
int divisor;
|
||||
|
||||
if (n <= 1)
|
||||
return false;
|
||||
|
||||
for (divisor = 2; divisor * divisor <= n; divisor++) {
|
||||
if (n % divisor == 0)
|
||||
return false;
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
|
||||
int main(void) {
|
||||
|
||||
int n;
|
||||
|
||||
printf("Enter a number: ");
|
||||
scanf("%d", &n);
|
||||
|
||||
if (is_prime(n))
|
||||
printf("Prime\n");
|
||||
else
|
||||
printf("Not Prime\n");
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
main 函数中包含一个叫 n 的变量,is_prime 函数中也有一个叫 n 的变量。这两个变量是虽然同名,但是在内存中的地址不同,是完全不相同的。所以给其中一个变量赋新值不会影响另一个变量。下一章我们还会详细的讨论这个问题。
|
||||
|
||||
is_prime 函数中有多条 return 语句。但是任何一次函数调用只能执行其中一条 return 语句,这是因为执行 return 语句后函数就会返回到调用点。本节后面还会深入的学习 return 。
|
||||
|
||||
|
||||
|
||||
### 二 函数声明
|
||||
|
||||
在本节前面的程序中,函数的定义总是放置在调用点的上面。C 语言并没有要求函数的定义必须在调用点之前,如果我们这样写:
|
||||
|
||||
```c
|
||||
int main(void){
|
||||
|
||||
double x = 1.0, y = 2.0;
|
||||
printf("%f", average(x, y));
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
double average(double x, double y){
|
||||
return (x + y) / 2;
|
||||
}
|
||||
```
|
||||
|
||||
当程序执行到 main 函数中的 average 函数调用时,编译器没有任何关于 average 函数的信息:编译器不知道 average 函数有多少形式参数,形式参数的类型是什么,也不知道函数的返回值类型是什么。但是,编译器不会给出出错消息,而是假设 average 函数返回 int 型的值。我们可以说编译器为该函数创建了一个**隐式声明**(implicit declaration)。编译器无法检查传递欸 average 函数的参数个数和类型,只能进行默认的**实际参数提升**(见第三部分)并期待最好的情况发生。当编译器遇到后面的 average 函数时发现函数的返回类型是 double 而不是 int ,从而我们得到一个出错消息。
|
||||
|
||||
比如:
|
||||
|
||||
```c
|
||||
int average(int x, int y);// average 函数的隐式声明
|
||||
```
|
||||
|
||||
|
||||
|
||||
为了避免这种定义前调用的问题,一种方法是使每个函数的定义都出现在其被调用之前。然而这种方法不够灵活,那么如何可以让函数的定义的位置可以自定义呢?
|
||||
|
||||
> **函数声明:**(function declaration)在调用前声明每个函数使得编译器可以先对函数进行概要浏览,而函数的定义可以以后再给出。
|
||||
|
||||
函数的声明类似函数的第一行:
|
||||
|
||||
```c
|
||||
返回类型 函数名(形式参数列表);
|
||||
```
|
||||
|
||||
为 average 函数添加声明后程序的样子:
|
||||
|
||||
```c
|
||||
double average(double x, double y);
|
||||
|
||||
int main(void){
|
||||
|
||||
double x = 1.0, y = 2.0;
|
||||
printf("%f", average(x, y));
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
double average(double x, double y){
|
||||
return (x + y) / 2;
|
||||
}
|
||||
```
|
||||
|
||||
为了和过去的那种圆括号内为空的函数声明风格相区别,我们把这种函数声明称为**函数原型**(function prototype)。函数原型为如何调用函数提供了完整的描述:返回值类型,实参个数和类型。
|
||||
|
||||
***
|
||||
|
||||
上面这句中“和过去的那种....”这里应该如何理解?我们用过去的方法对 average 函数的声明可以是这样的:
|
||||
|
||||
```c
|
||||
double average();
|
||||
```
|
||||
|
||||
也就是可以不用写形参列表。
|
||||
|
||||
*参考文章:https://www.cnblogs.com/pmer/archive/2011/09/04/2166579.html*
|
||||
|
||||
***
|
||||
|
||||
函数原型 不需要说明函数形式参数的名称,只要显示类型即可:
|
||||
|
||||
```c
|
||||
double average(double, double);
|
||||
```
|
||||
|
||||
**通常最好不要省略形参名称**,因为这些名字可以说明每个形参的目的,并且提示程序员再函数调用时实际参数的顺序。
|
||||
|
||||
|
||||
|
||||
> C99中遵循这样的规则:再调用一个函数之前,必须先对其进行声明或定义。如果没有声明而直接调用,会导致出错。
|
||||
|
||||
### 三 实际参数
|
||||
|
||||
> **形式参数:**(parameter) 出现再函数的定义中
|
||||
>
|
||||
> **实际参数:**(argument)出现在函数调用中的表达式。
|
||||
|
||||
在 C语言中,实际参数是通过**值传递**的:调用函数时,计算出每个实际参数的值并将它赋值给相应的形式参数。在函数执行的过程中,形式参数的改变**不会**影响实参的值,这是因为**形式参数是实参的副本**。从效果上来讲,每个形式参数初始化为相应的实参的值。
|
||||
|
||||
实际参数按值传递有利有弊。
|
||||
|
||||
- 利:可以直接修改形参的值
|
||||
|
||||
比如:计算 x 的 n 次方
|
||||
|
||||
```c
|
||||
int power(int x, int n){
|
||||
int i = n;
|
||||
int ret = 1;
|
||||
for(i = 1; i <= n; i++){
|
||||
ret *= x;
|
||||
}
|
||||
return ret;
|
||||
}
|
||||
```
|
||||
|
||||
我们可以在函数内直接修改 n 来减少引入的变量:
|
||||
|
||||
```c
|
||||
int power(int x, int n){
|
||||
int ret = 1;
|
||||
|
||||
while(n--){
|
||||
ret *= x;
|
||||
}
|
||||
|
||||
return ret;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
- 弊:如果我们需要函数返回一个以上的值,那么按值传递显然是无法直接做到的
|
||||
|
||||
例如:我们需要设计一个函数,将 double 类型的值分解成整数和小数部分。因为无法返回两个数,所以通过返回值返回我们计算出的整数部分和小数部分是不现实的。所以可以尝试传入两个变量给函数并修改它们:
|
||||
|
||||
```c
|
||||
void decompose(double x, long int_part, double frac_part){
|
||||
int_part = (long)x; // drops the fractional part of x
|
||||
frac_part = x - int_part;
|
||||
}
|
||||
```
|
||||
|
||||
前面我们也说了,这显然也是不现实的。因为形参的改变无法修改实参。
|
||||
|
||||
如果你感到困惑,我们可以来测试一下:我们在 main 函数中调用这个函数:
|
||||
|
||||
```c
|
||||
int main(void){
|
||||
|
||||
double x = 3.1415926;
|
||||
int i;
|
||||
int d;
|
||||
|
||||
decompose(x, i, d);
|
||||
|
||||
printf("%d %f", i, d); // 编译应该会报错,提示 i,d 未初始化,总之,不是我们想要的结果
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 1. 实际参数转换
|
||||
|
||||
C 语言允许实际参数类型和形式参数类型不匹配的情况下进行函数调用。
|
||||
|
||||
- **编译器在调用前遇到原型:**就像赋值一样,将实际参数隐式转换为相应的形式参数的类型。
|
||||
|
||||
```c
|
||||
double average(double x, double y);
|
||||
|
||||
int main(void){
|
||||
|
||||
int a = 2, b = 3;
|
||||
|
||||
average(a, b);// a, b 被隐式类型转换为 double 类型然后赋值给形参
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
- **编译器在调用前没有遇到原型:**编译器执行**默认的实际参数提升**:1)把 float 类型的实参转换为 double类型。2)把 char,short 类型的实参转换为 int 类型。
|
||||
|
||||
默认的实际参数提升可能无法产生期望的结果。思考下例:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void){
|
||||
|
||||
double x = 3.0;
|
||||
|
||||
printf("Square: %d", square(x));
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
int square(int n){
|
||||
|
||||
return n * n;
|
||||
}
|
||||
```
|
||||
|
||||
double 类型的 x 被执行了没有效果的实际参数提升,square 实际期望 int 类型,但是却得到的是 double 类型,所以 square 将产生无效的结果。通过把 square 实参强转为正确类型可以解决这个问题:
|
||||
|
||||
```c
|
||||
printf("Square: %d", square((int)x));
|
||||
```
|
||||
|
||||
**更好的方案是在函数调用前提供函数原型。**C99中,调用前不提供没有声明或定义是错误的。
|
||||
|
||||
#### 2. 数组型实际参数
|
||||
|
||||
数组经常被当作实际参数。当形式参数为一维数组时,可以(而且是通常情况下)不说明数组长度:
|
||||
|
||||
```c
|
||||
int f(int a[]){
|
||||
...;
|
||||
}
|
||||
```
|
||||
|
||||
C 语言没有为函数提供任何简便的方法来确定传递给它的数组的长度,所以通常情况下,我们必须**把数组长度作为额外的参数提供出来**
|
||||
|
||||
##### 示例:数组求和
|
||||
|
||||
```c
|
||||
int sum_array(int a[], int n);
|
||||
|
||||
int main(void){
|
||||
|
||||
int a[] = {1, 2, 3, 4, 5};
|
||||
int len = sizeof(a) / sizeof(a[0]);
|
||||
int sum;
|
||||
|
||||
sum = sum_array(a, len);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
int sum_array(int a[], int len){
|
||||
|
||||
int ret = 0;
|
||||
|
||||
for(int i = 0; i < len; i++){
|
||||
ret += a[i];
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
**注意:**虽然可以用运算符 `sizeof`计算出数组变量的长度,但是它无法给出数组类型的形式参数参数的正确答案:
|
||||
|
||||
```c
|
||||
int f(int a[]){
|
||||
|
||||
int len = sizeof(a) / sizeof(a[0]);
|
||||
...;
|
||||
}
|
||||
```
|
||||
|
||||
原因在后面的章节会详细讨论。
|
||||
|
||||
上例中 `sum_array` 函数的函数原型可以省略形式参数的名称:
|
||||
|
||||
```c
|
||||
int sum_array(int [], int);
|
||||
```
|
||||
|
||||
在调用 sum_array 函数时,不要将顺序写反。
|
||||
|
||||
**注意:**把数组名传递给函数时,不要在数组名的后面放置方括号:
|
||||
|
||||
```c
|
||||
sum_array(a[], len); //error
|
||||
```
|
||||
|
||||
|
||||
|
||||
##### 数组变量作为函数参数的特性
|
||||
|
||||
**1)数组无法检测传入的数组长度是否正确**,所以:
|
||||
|
||||
- 一个数组有 100 个元素,但是实际仅仅使用 50 个元素,实参可以只写 50:
|
||||
|
||||
```c
|
||||
sum_array(a, 50);
|
||||
```
|
||||
|
||||
函数甚至不会知道数组还有 50 个元素存在!
|
||||
|
||||
- 如果实际参数给的比数组还要大,会造成数组越界,从而导致未定义行为
|
||||
|
||||
```c
|
||||
sum_array(a, 150);// wrong
|
||||
```
|
||||
|
||||
**2)在函数中改变数组型形式参数的元素,同时会改变实际参数的数组元素。**
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
void store_zero(int a[], int len){
|
||||
|
||||
for(int i = 0; i < len; i++){
|
||||
a[i] = 0;
|
||||
}
|
||||
}
|
||||
int main(void){
|
||||
|
||||
int a[3] = {1, 2, 3};
|
||||
|
||||
store_zero(a, sizeof(a) / sizeof(a[0]));
|
||||
|
||||
for(int i = 0; i < 3; i++){
|
||||
printf("%d ", a[i]);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
//输出:
|
||||
0 0 0
|
||||
```
|
||||
|
||||
##### 多维数组
|
||||
|
||||
多维数组的形式参数可以省略第一维的长度,比如`a[][3]`
|
||||
|
||||
但是,这样的方式不能传递**具有任意列数**的多维数组。幸运的是,我们通常可以通过使用指针数组的方式解决这一问题。
|
||||
|
||||
#### 3. 变长数组形式参数 (C99)
|
||||
|
||||
#### 4. 在数组参数声明中使用 static (C99)
|
||||
|
||||
#### 5. 复合字面量(C99)
|
||||
|
||||
以上 3 种 C99 特性这里不做展开,因为我们不常用到,如果你有兴趣,可以自己查询。
|
||||
|
||||
|
||||
|
||||
### 四 return 语句
|
||||
|
||||
> 非 void 类型的函数必须使用 `return `语句来指定将要返回的值。
|
||||
|
||||
```c
|
||||
return 表达式;
|
||||
```
|
||||
|
||||
表达式可以是
|
||||
|
||||
- **常量:** `return 0`
|
||||
- **变量:** `return a`
|
||||
- **复杂的表达式:**`return n >= 0 ? n : 0`
|
||||
|
||||
|
||||
|
||||
如果 return 语句表达式的值和返回类型不匹配,那么系统将把表达式的类型隐式转换为返回类型。
|
||||
|
||||
return 也可以出现在返回值类型为 `void` 的函数中:我们可以直接使用`return;`(没有表达式)来让函数结束。
|
||||
|
||||
|
||||
|
||||
下面的例子中,如果 i 是负数,return 语句会让函数立即返回
|
||||
|
||||
```c
|
||||
void print_int(int i){
|
||||
if(i < 0)
|
||||
return;
|
||||
printf("%d", i);
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
return 语句可以出现在 void 函数的末尾:
|
||||
|
||||
```c
|
||||
void print_pun(){
|
||||
printf("To C or not to C: that is a question\n");
|
||||
return; // Ok,but not needed.
|
||||
}
|
||||
```
|
||||
|
||||
但是 return 语句不是必须的,因为在执行完最后一条语句后函数会自动返回。
|
||||
|
||||
<br>
|
||||
|
||||
如果非 void 函数到达了函数体的末尾(也就是没有 return 语句),那么程序会试图使用函数的返回值,其行为是未定义的。
|
||||
|
||||
有的编译器会有“control reaches end of non-void function” 这样的警告信息。
|
||||
|
||||
|
||||
|
||||
### 五 程序终止
|
||||
|
||||
既然 main 是函数,那么它必须拥有返回类型。正常情况下,main 函数的返回类型是 int 类型,因此我们见到的 main 函数都是这样定义的:
|
||||
|
||||
```c
|
||||
int main(void){
|
||||
...;
|
||||
}
|
||||
```
|
||||
|
||||
以往的 C程序常常省略 main 函数的返回类型,这其实是利用了返回类型默认为 int 类型的传统:
|
||||
|
||||
```c
|
||||
main(){
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
省略 main 函数的参数列表中的 void 是合法的。但是,从编程风格的角度来看,最好显式地表明 main 函数没有参数。后面将会看到,main 函数是有参数的(`int main(int argc, char* argv[])`)
|
||||
|
||||
main 函数返回的值是状态码,在某些操作系统中程序终止时可以检测到状态码。如果程序正常终止,main 函数应该返回 0;为了表示异常终止,main 函数返回非 0 的值。(实际上,这一返回值也可以用于其他用途。)
|
||||
|
||||
|
||||
|
||||
#### 1. exit 函数
|
||||
|
||||
在 main 函数中执行 return 语句时终止程序的一种办法,另一种方法是调用 exit 函数,此函数属于 `<stdlib.h>`头。
|
||||
|
||||
`exit(0)`表示程序正常终止。
|
||||
|
||||
使用 0 可能让人理解比较模糊,在 stdlib.h 头中定义了两个宏:
|
||||
|
||||
`EXIT_SUCCESS` -> 0
|
||||
|
||||
`EXIT_FAILURE` -> 1
|
||||
|
||||
所以我们可以写作:
|
||||
|
||||
`exit(EXIT_SUCCESS);`
|
||||
|
||||
其实 main 函数中使用 return 来终止程序时,return 本身回去调用 exit 函数,所以程序终止这件事最终是由 exit 函数实现的。
|
||||
|
||||
所以我们不去理解,不管那个函数调用 exit 函数都会使得程序终止,return 语句仅仅由 main 函数调用时才会让程序终止。
|
||||
|
||||
所以,一些程序员只是用 exit 函数表示程序终止,以便更容易定位程序中的全部退出点。
|
||||
|
||||
|
||||
|
||||
### 六 递归
|
||||
|
||||
> 如果一个函数调用它本身,那么此函数就是**递归**的(recursive)。
|
||||
|
||||
有些编程语言极度依赖递归,而有些编程语言甚至不允许使用递归。C语言介于中间:它允许递归,但是大多数 C 程序员并不经常使用递归。
|
||||
|
||||
用递归计算 n! 的结果:
|
||||
|
||||
```c
|
||||
int fact(int n){
|
||||
if(n <= 1){
|
||||
return 1;
|
||||
}
|
||||
else{
|
||||
return n * fact(n - 1);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
为了了解递归的工作原理,一起来追踪下面这个语句的执行:
|
||||
|
||||
```c
|
||||
i = fact(3);
|
||||
```
|
||||
|
||||
```c
|
||||
fact(3) 发现 3 不是小于等于 1 的,fact(3) 调用
|
||||
fact(2),此函数发现 2 不是小于等于 1 的,fact(2) 调用
|
||||
fact(1) ,此函数发现 1 是小于等于 1 的,所以 fact(1) 返回 1,从而导致
|
||||
fact(2) 返回 2 * 1 = 2,从而导致
|
||||
fact(3) 返回 3 * 2 = 6
|
||||
```
|
||||
|
||||
**注意:**要理解 fact 函数最终传递 1 之前,未完成的 fact 函数是如何“堆积”的。在最终传递 1 的那一点上,fact 函数逐个解开,直到 fact(3) 的原始调用返回 6 为止。
|
||||
|
||||
上面的程序也可以简化为:
|
||||
|
||||
```c
|
||||
int fact(int n){
|
||||
return n <= 1 ? 1 : n * fact(n - 1);
|
||||
}
|
||||
```
|
||||
|
||||
**注意:** `n <= 1` 就是终止条件,为了放置无限递归,所有的递归都应该有终止条件。
|
||||
|
||||
如果你能理解下面两个程序,那么当前阶段的递归问题已经难不倒你了。
|
||||
|
||||
#### 程序:快速排序
|
||||
|
||||
|
||||
|
||||
#### 程序:归并排序
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
*参考资料:《C语言程序设计:现代方法》*
|
||||
|
||||
[^1]: 如果你写了一个需要10个参数的函数,你或许还漏了什么。[Epigrams on Programming 编程警句 ](https://epigrams-on-programming.readthedocs.io/zh_CN/latest/epigrams.html)
|
||||
|
||||
|
||||
847
content/c-mordern-approch/11-程序结构.md
Normal file
847
content/c-mordern-approch/11-程序结构.md
Normal file
@@ -0,0 +1,847 @@
|
||||
## 程序结构
|
||||
|
||||
*Recursion is the root of computation since it trades description for time.* [^1]
|
||||
|
||||
## 目录
|
||||
|
||||
***
|
||||
|
||||
[TOC]
|
||||
|
||||
## 程序结构
|
||||
|
||||
***
|
||||
|
||||
### 零 前言
|
||||
|
||||
《C 语言程序设计——现代方法》一书中,将此章节安排在了函数之后。在我看来,这样安排不是很合理。在函数一章中,在解释形参和实参可以同名时,没有这部分知识确实很难去阐述原理。
|
||||
|
||||
书中本章开篇第一句话就是“本章来讨论一个程序有多个函数时所产生的几个问题”,其实变量的**作用域**和**生存期**并不是在只有函数的时候才会应用到,举一个很简单的例子:for 循环。 其实这就是我们前面说到的**块**(block)的问题。
|
||||
|
||||
学习过程中,【C 必知必会】系列中的【CMOOC】篇中的相关文章大家可以参考一下。
|
||||
|
||||
本节的内容不局限于 作用域 和 生存期。废话不多说,我们开始吧。
|
||||
|
||||
### 一 局部变量
|
||||
|
||||
> 函数体内声明的变量称为该函数的**局部变量**。
|
||||
|
||||
比如:
|
||||
|
||||
```c
|
||||
int main(void){
|
||||
|
||||
int i;
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
变量 i 就是局部变量。
|
||||
|
||||
##### 局部变量的性质:
|
||||
|
||||
- **自动存储期限**。变量的**存储期限**(生存期)(storage duration)(或存储长度)。局部变量的存储单元在函数被调用时“自动”分配,函数返回时自动回收,所以称这种变量具有自动的存储期限。包含局部变量的函数返回时,局部变量的值无法保留。当再次调用该函数时,无法保证变量仍拥有原先的值。
|
||||
- **块作用域**。变量的**作用域**是可以引用该变量的程序文本部分。局部变量拥有块作用域:从变量声明的点开始一直到所在函数体的末尾。因为变量的作用域不能延伸到其所属的函数之外,所以其他函数可以把同名变量用于其他用途。
|
||||
|
||||
这一段介绍写的太书面化了。其实上面说的无非就是生存期和作用域问题。
|
||||
|
||||
##### 关于生存期和作用域的程序演示
|
||||
|
||||
下面的程序计算数组元素的和:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
void sum_array(int a[], int len) {
|
||||
|
||||
int sum = 0;
|
||||
|
||||
for (int i = 0; i < len; i++) {
|
||||
sum += a[i];
|
||||
}
|
||||
|
||||
printf("sum is %d, length of array is %d", sum, len);
|
||||
}
|
||||
|
||||
int main(void) {
|
||||
|
||||
int len = 10;
|
||||
int a[5];
|
||||
|
||||
for (int i = 0; i < 5; i++) {
|
||||
scanf("%d", &a[i]);
|
||||
}
|
||||
|
||||
sum_array(a, len / 2);
|
||||
|
||||
return 0;
|
||||
}
|
||||
// 我们输入:1 2 3 4 5
|
||||
// 输出: sum is 15, length of array is 5
|
||||
```
|
||||
|
||||
我们将上面的程序改写为:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
void sum_array(int a[], int i) {
|
||||
|
||||
int len = i;
|
||||
int sum = 0;
|
||||
|
||||
for (int i = 0; i < len; i++) {
|
||||
sum += a[i];
|
||||
if (i == len - 1) {
|
||||
i += 5;
|
||||
}
|
||||
}
|
||||
|
||||
printf("sum is %d, length of array is %d", sum, i);
|
||||
}
|
||||
|
||||
int main(void) {
|
||||
|
||||
int i = 10;
|
||||
int a[5];
|
||||
|
||||
for (int i = 0; i < 5; i++) {
|
||||
scanf("%d", &a[i]);
|
||||
}
|
||||
|
||||
sum_array(a, i / 2);
|
||||
|
||||
return 0;
|
||||
}
|
||||
// 我们输入:1 2 3 4 5
|
||||
// 输出: sum is 15, length of array is 5
|
||||
```
|
||||
|
||||
用简单的描述一下作用域和生存期:
|
||||
|
||||
> 作用域:限定某个名字的可用性的代码范围就是该名字的作用域
|
||||
>
|
||||
> 生存期:变量值存在的时间
|
||||
>
|
||||
> 块:一个花括号`{}`就是一个块。
|
||||
>
|
||||
> 通常来说,变量的作用域和生存期都是在一个块内。
|
||||
|
||||
上面第二个程序的执行结果和第一个完全一样,我们现在来一步一步分析一下:
|
||||
|
||||
```c
|
||||
// 新的块(函数)中,i 是一个新的变量,mian 函数中的 i 在这里不再生效(作用域和生存期失效)
|
||||
// 这个 i 就是实参的值,也就是 5
|
||||
void sum_array(int a[], int i) {
|
||||
|
||||
int len = i;
|
||||
int sum = 0;
|
||||
|
||||
// for 语句内 i 的情况和 mian 函数中的一样
|
||||
for (int i = 0; i < len; i++) {
|
||||
sum += a[i];
|
||||
// 为了证明 for 语句内的 i 和外面形参 i 完全不同,在即将退出循环时,我将 i 增加了 5,
|
||||
// 所以退出循环时里面的 i 的值为 10
|
||||
if (i == len - 1) {
|
||||
i += 5;
|
||||
}
|
||||
}
|
||||
// 最后输出的 i 依然是形参 5
|
||||
printf("sum is %d, length of array is %d", sum, i);
|
||||
}
|
||||
|
||||
int main(void) {
|
||||
|
||||
int i = 10;
|
||||
int a[5];
|
||||
|
||||
//在 for 语句这个块内重新声明的 i ,这个 i 和上面的 i 是完全不同的变量。
|
||||
// 修改 for 语句内的 i 不会影响外面的 i ,虽然外面的 i 在 for 语句内依然生效,但是可以理解为里面的 i 将其覆盖了
|
||||
// 正所谓谁的地盘谁做主
|
||||
for (int i = 0; i < 5; i++) {
|
||||
scanf("%d", &a[i]);
|
||||
}
|
||||
// for 语句执行结束后,里面的 i 被自动回收了。i 不再生效。
|
||||
// 所以下面的 i 就是外部的 i,也就是 10
|
||||
|
||||
sum_array(a, i / 2);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
**C99 不要求函数在一开始的位置进行变量声明。所以局部变量的作用域可能会很小**。
|
||||
|
||||
|
||||
|
||||
#### 1. 静态局部变量
|
||||
|
||||
在局部变量中放置单词 static 可以使变量具有**静态存储期限**而不再是自动存储期限。
|
||||
|
||||
因为具有静态存储期限的变量拥有永久的存储单元,所以在整个程序的执行期间都会保留变量的值。比如:
|
||||
|
||||
```c
|
||||
void func(){
|
||||
int static n; // static locol variable
|
||||
}
|
||||
```
|
||||
|
||||
在函数 func 返回时,变量 n 的值不会丢失。
|
||||
|
||||
静态局部变量虽然生存期是整个程序,但是作用域尽在其所定义的块内。也就是说,上例中函数 func 返回后,func 内的 n 就不再可用。
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
void func() {
|
||||
|
||||
int static n = 0;
|
||||
|
||||
printf("%d\n", ++n);
|
||||
|
||||
}
|
||||
|
||||
int main(void) {
|
||||
|
||||
func();
|
||||
func();
|
||||
func();
|
||||
|
||||
return 0;
|
||||
}
|
||||
//输出:
|
||||
1
|
||||
2
|
||||
3
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 二 全局变量
|
||||
|
||||
> 全局变量(外部变量 external variable)声明在所有函数体之外。
|
||||
|
||||
##### 全局变量的性质
|
||||
|
||||
- **静态存储期限**。
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int i = 0;
|
||||
|
||||
void func() {
|
||||
|
||||
printf("%d\n", ++i);
|
||||
}
|
||||
|
||||
int main(void) {
|
||||
|
||||
func();
|
||||
func();
|
||||
func();
|
||||
|
||||
return 0;
|
||||
}
|
||||
//输出:
|
||||
1
|
||||
2
|
||||
3
|
||||
```
|
||||
|
||||
|
||||
|
||||
- **文件作用域**。全局变量的作用域:从变量被声明的点开始一直到所在文件的末尾。外部变量声明之后的函数都可以访问(并修改)它。
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int i = 0;
|
||||
|
||||
void func() {
|
||||
|
||||
printf("%d\n", ++i);
|
||||
}
|
||||
|
||||
void func1() {
|
||||
|
||||
printf("%d\n", ++i);
|
||||
}
|
||||
|
||||
int main(void) {
|
||||
|
||||
func();
|
||||
func1();
|
||||
func();
|
||||
|
||||
return 0;
|
||||
}
|
||||
//输出:
|
||||
1
|
||||
2
|
||||
3
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 程序:全局变量实现栈
|
||||
|
||||
**栈**是一种只能从一端“进出”的数据结构。这一端被称为栈顶。
|
||||
|
||||
我们可以用数组来模拟这种数据结构。用一个变量 top 标记当前栈顶的位置。如果数据压栈,则将 top 自增;如果数据出栈,则将 top 自减。我们需要写很多函数来实现这种数据结构,比如 压栈,出栈,判满,判空等等。我们可以将 表示栈顶的变量 top 和 表示栈的数组定义为全局变量。这里有一段代码(不是完整的程序):
|
||||
|
||||
```c
|
||||
#include<stdbool.h> // C99 only
|
||||
|
||||
#define STACK_SIZE 100
|
||||
int stack[STACK_SIZE];
|
||||
int top = -1;
|
||||
|
||||
void make_empty(){
|
||||
top = -1;
|
||||
}
|
||||
|
||||
bool is_empty(){
|
||||
return top == -1;
|
||||
}
|
||||
|
||||
bool is_full(){
|
||||
return top == STACK_SIZE - 1;
|
||||
}
|
||||
//压栈
|
||||
void push(int i){
|
||||
if(is_full()){
|
||||
printf("栈满!增加数据失败!");
|
||||
return;
|
||||
}
|
||||
else{
|
||||
stack[++top] = i;
|
||||
}
|
||||
}
|
||||
//出栈
|
||||
int pop(){
|
||||
if(is_empty()){
|
||||
printf("栈空!出栈失败!");
|
||||
return;
|
||||
}
|
||||
else{
|
||||
return stack[top--];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 全局变量的利与弊
|
||||
|
||||
**利:**多个函数共享一个变量时或者少数几个函数共享大量变量时,外部变量很有用。
|
||||
|
||||
然而在大多数情况下,对于函数而言,**传参比共享变量更好**。原因如下:
|
||||
|
||||
**弊:**
|
||||
|
||||
- 在程序维护期间,如果改变全局变量(比方说改变其类型),那么将需要检查同一文件中的每个函数,以确认该变化如何对函数产生影响。
|
||||
- 如果全局变量被赋了错误的值,可能很难确定出错的函数。
|
||||
- 很难在其他程序中复用依赖于全局变量的函数。依赖全局变量的函数不是“独立”的。为了在另一个程序中使用该函数,必须带上此函数需要的全局变量。
|
||||
- 如果全局变量在多个函数中使用(比如 for 循环的控制变量 i),让人误认为变量的使用彼此关联,而实际可能并非如此。
|
||||
|
||||
**注意:**使用全局变量时,要确保它们的名字都有意义。如果你发现全局变量的名字就像 `i`,`temp`一样,这可能意味着这些变量其实应该是局部变量。
|
||||
|
||||
**将局部变量声明为全局变量可能会导致一些问题**。思考下例:
|
||||
|
||||
```c
|
||||
int i;
|
||||
|
||||
void print_one_row(void){
|
||||
for(i = 1; i <= 10; i++)
|
||||
printf("*");
|
||||
}
|
||||
|
||||
void print_all_row(void){
|
||||
for(i = 1; i <= 10; i++){
|
||||
print_one_row();
|
||||
printf("\n");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
此时,print_all_row 打印的不是 10 行,而是 1 行。第一次调用 print_one_row 函数返回时, i 的值将为 11 ,不满足 for 的控制表达式,循环退出。
|
||||
|
||||
所以,**全局变量建议不要使用。**
|
||||
|
||||
|
||||
|
||||
#### 程序:猜数
|
||||
|
||||
程序产生一个 1 ~ 100 的随机数,用户尝试用尽可能少的次数猜出这个数。程序运行如下:
|
||||
|
||||
```c
|
||||
Guess the secret number between 1 and 100.
|
||||
|
||||
A new number has been chosen.
|
||||
Enter guess:55
|
||||
Too low; try again.
|
||||
Enter guess:65
|
||||
Too high; try again.
|
||||
Enter guess: 60
|
||||
You won in 3 guesses!
|
||||
|
||||
Play again?(Y/N) n
|
||||
```
|
||||
|
||||
程序示例:
|
||||
|
||||
**使用全局变量**
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<stdlib.h>
|
||||
#include<time.h>
|
||||
|
||||
#define MAX_NUMBER 100
|
||||
|
||||
int secret_number;// 要猜的数
|
||||
|
||||
void generate_secret_number();// 随机数生成
|
||||
void read_guesses(); // 猜的实现
|
||||
|
||||
int main(void) {
|
||||
|
||||
char command;
|
||||
|
||||
printf("Guess the secret number between 1 and 100.\n");
|
||||
|
||||
do {
|
||||
generate_secret_number();
|
||||
printf("A new number has been chosen.\n");
|
||||
read_guesses();
|
||||
printf("Play again?(Y/N)");
|
||||
scanf(" %c", &command);// 注意 %c 前的空格,这很重要
|
||||
printf("\n");
|
||||
} while (command == 'y' || command == 'Y');
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
// 可以用这样的注释将函数的功能写在函数的定义的上方
|
||||
// 我个人比较喜欢将简单的注释写在函数原型处
|
||||
|
||||
/****************************************************************************
|
||||
*
|
||||
* generate_secret_number: Initilizes the random number generator using the
|
||||
* time of day.Randomly selects a number between
|
||||
* 1 and MAX_NUMBER and stores it in secret_number
|
||||
*
|
||||
*****************************************************************************/
|
||||
|
||||
void generate_secret_number() {
|
||||
|
||||
srand((unsigned)time(NULL));
|
||||
|
||||
secret_number = rand() % MAX_NUMBER + 1;
|
||||
}
|
||||
|
||||
/*****************************************************************
|
||||
*
|
||||
* read_guesses:Repeatedly reads user guesses and gives hints
|
||||
* When guess is right,prints the total number of
|
||||
* guesses and returns
|
||||
*
|
||||
******************************************************************/
|
||||
|
||||
void read_guesses() {
|
||||
|
||||
int guess, count = 0;
|
||||
|
||||
for (;;) {
|
||||
printf("Enter guess: ");
|
||||
scanf("%d", &guess);
|
||||
count++;
|
||||
if (guess > secret_number) {
|
||||
printf("Too high; try again\n");
|
||||
}
|
||||
else if (guess < secret_number) {
|
||||
printf("Too low; try again.\n");
|
||||
}
|
||||
else {
|
||||
printf("You won in %d guesses!\n\n", count);
|
||||
return;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**不用全局变量**
|
||||
|
||||
不用全局变量我们就需要让产生随机数的函数返回产生的随机数,然后将随机数当作参数传给 read_guesses() 函数。
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<stdlib.h>
|
||||
#include<time.h>
|
||||
|
||||
#define MAX_NUMBER 100
|
||||
|
||||
int generate_secret_number();// 随机数生成
|
||||
void read_guesses(int secret_number); // 猜的实现
|
||||
|
||||
int main(void) {
|
||||
|
||||
char command;
|
||||
int secret_number;
|
||||
|
||||
printf("Guess the secret number between 1 and 100.\n");
|
||||
|
||||
do {
|
||||
secret_number = generate_secret_number();
|
||||
printf("A new number has been chosen.\n");
|
||||
read_guesses(secret_number);
|
||||
printf("Play again?(Y/N)");
|
||||
scanf(" %c", &command);
|
||||
printf("\n");
|
||||
} while (command == 'y' || command == 'Y');
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
|
||||
int generate_secret_number() {
|
||||
|
||||
srand((unsigned)time(NULL));
|
||||
|
||||
int secret_number = rand() % MAX_NUMBER + 1;
|
||||
|
||||
return secret_number;
|
||||
}
|
||||
|
||||
void read_guesses(int secret_number) {
|
||||
|
||||
int guess, count = 0;
|
||||
|
||||
for (;;) {
|
||||
printf("Enter guess: ");
|
||||
scanf("%d", &guess);
|
||||
count++;
|
||||
if (guess > secret_number) {
|
||||
printf("Too high; try again\n");
|
||||
}
|
||||
else if (guess < secret_number) {
|
||||
printf("Too low; try again.\n");
|
||||
}
|
||||
else {
|
||||
printf("You won in %d guesses!\n\n", count);
|
||||
return;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 三 构建 C 程序
|
||||
|
||||
从 猜数 的程序中你应该大体可以感受到如何从头到尾去写一个 c 程序。我们这里给出比较好的编排顺序:
|
||||
|
||||
1. `#include`指令
|
||||
2. `#define`指令
|
||||
3. 类型定义
|
||||
4. 全局变量声明
|
||||
5. 函数原型
|
||||
6. main 函数定义
|
||||
7. 其他函数定义
|
||||
|
||||
多写写程序自然会领略到其中的道理。
|
||||
|
||||
#### 程序:手牌分类
|
||||
|
||||
编写程序对手牌进行读取和分类。手中的每张牌都有花色(方块,梅花,红桃和黑桃)和等级(2,3,4,5,6,7,8,9,T,J,Q,K 和 A)。不允许使用王牌,并且假设 A 是最高等级的。一手 5 张牌,然后把手中的牌分为下列某一类(列出的顺序从好到坏)。
|
||||
|
||||
- 同花顺(顺序连续且同花色)
|
||||
- 四张(4 张牌等级相同)
|
||||
- 葫芦(3 张牌等级一样,另外2 张等级一样)
|
||||
- 同花(5 张牌同花色)
|
||||
- 顺子(5 张牌等级顺序连续)
|
||||
- 三张(3 张牌等级连续)
|
||||
- 两对
|
||||
- 一对(2 张牌等级一样)
|
||||
- 其他牌
|
||||
|
||||
如果一手牌可以分为两种或多种类别,程序将选择最好的一种。
|
||||
|
||||
为了便于输入,将牌的等级和花色简化如下:
|
||||
|
||||
- 等级: 2,3,4,5,6,7,8,9,t,j,q,k ,a
|
||||
- 花色:c d h s
|
||||
|
||||
如果用户输入非法牌或者输入同一张牌两次,程序将此牌忽略掉,产生错误信息,然后要求输入另一张牌。如果输入为 0 而不是一张牌,就会导致程序终止。
|
||||
|
||||
与程序的会话如下:
|
||||
|
||||
```c
|
||||
|
||||
Enter a card : 2s
|
||||
Enter a card : 5s
|
||||
Enter a card : 4s
|
||||
Enter a card : 3s
|
||||
Enter a card : 6s
|
||||
Straight flush
|
||||
|
||||
Enter a card : 8c
|
||||
Enter a card : as
|
||||
Enter a card : 8c
|
||||
Duplicated card; ignored.
|
||||
Enter a card : 7c
|
||||
Enter a card : ad
|
||||
Enter a card : 3h
|
||||
Pair
|
||||
|
||||
Enter a card : 6s
|
||||
Enter a card : d2
|
||||
Bad card; ignored.
|
||||
Enter a card : 2d
|
||||
Enter a card : 9c
|
||||
Enter a card : 4h
|
||||
Enter a card : ts
|
||||
High card
|
||||
|
||||
Enter a card: 0
|
||||
```
|
||||
|
||||
程序示例:
|
||||
|
||||
```c
|
||||
/*
|
||||
* 程序难点思路:
|
||||
* 1)为了判定手中的牌是否重复,我们需要一个布尔类型数组存储整副牌,初始化整个数组为 false。如果一张牌已经在我们手上,那么我们将数组对应的元素置为 true
|
||||
* 2)用两个分别数组来存储每个点数和花色的个数,这样方便我们后面判断牌的类型
|
||||
* 3)8 种牌的类型,我们可拆成 同花,顺子,4张,3张,对子(值为 0,1,2)这五种基础类型的组合。
|
||||
*
|
||||
* 程序结构:
|
||||
* 通过上面的分析,我们发现:这个程序需要 3 个数组和 5 个变量,如果都作为函数参数传参,显得有些笨。
|
||||
* 而且,前面我们说过,函数只能返回一个值,那如果要将函数分离, 5 种基础类型就得放进数组;或者使用指针,而指针我们没有学习,而且指针还是逃不开传参
|
||||
* 这样一分析,貌似使用全局变量是最好的做法了。对于初学者来说,这样可能确实是最好的。
|
||||
* 但是,使用大量的全局变量是很不好的习惯,我不能让自己去写这样的代码。我认为:宁可这道题不做,也不能有坏的代码风格去写!
|
||||
* 后面我们会学习自定义类型:结构体,它可能是这种问题最好的解决方法。
|
||||
*
|
||||
* 下面是这个问题的 4 种解决方法:
|
||||
* 1)应用全局变量
|
||||
* 2)应用指针作为函数参数
|
||||
* 3)将判断卡牌类型的函数与打印函数合并
|
||||
* 4)使用结构体
|
||||
*
|
||||
* 在这里,我坚持使用结构体来解决这类问题。全局变量大家只要知道概念即可,对于这道题来说,比起方法,可能设计程序的模块化思路更值得学习。
|
||||
* 即使使用结构体,程序的主要逻辑也不会变。如果你非要用全局变量写,那你可以改写一下。
|
||||
*/
|
||||
|
||||
#include<stdio.h>
|
||||
#include<stdbool.h>
|
||||
|
||||
#define RANK 13
|
||||
#define SUIT 4
|
||||
#define CARD 5
|
||||
|
||||
typedef struct CardType {
|
||||
bool flush; //同花
|
||||
bool straight; //顺子
|
||||
bool four; //四张
|
||||
bool three; //三张
|
||||
int pair; // 对子
|
||||
// 0 表示不是 1 表示 1个对子 2 表示两个对子
|
||||
bool cardInHand[SUIT][RANK]; // 判断此牌是否已在手中
|
||||
int numRank[RANK]; // 每个点数的个数
|
||||
int numSuit[SUIT]; // 每个花色的个数
|
||||
}CardType;
|
||||
|
||||
|
||||
void initCardType(CardType* card); // 初始化
|
||||
void readCard(CardType* card); // 读取输入
|
||||
void analyseCard(CardType* card); // 分析手牌
|
||||
void printResult(CardType* card); //打印结果
|
||||
|
||||
int main(void) {
|
||||
|
||||
CardType card;
|
||||
|
||||
for (; ;) {
|
||||
initCardType(&card);
|
||||
readCard(&card);
|
||||
analyseCard(&card);
|
||||
printResult(&card);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
|
||||
void initCardType(CardType* card) {
|
||||
|
||||
card->flush = false;
|
||||
card->straight = false;
|
||||
card->four = false;
|
||||
card->three = false;
|
||||
card->pair = 0;
|
||||
|
||||
int i, j;
|
||||
|
||||
for (i = 0; i < SUIT; i++) {
|
||||
card->numSuit[i] = 0;
|
||||
for (j = 0; j < RANK; j++) {
|
||||
card->cardInHand[i][j] = false;
|
||||
}
|
||||
}
|
||||
|
||||
for (i = 0; i < RANK; i++) {
|
||||
card->numRank[i] = 0;
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
|
||||
void readCard(CardType* card) {
|
||||
|
||||
int card_read = CARD, rank, suit;
|
||||
bool bad_card;
|
||||
char ch;
|
||||
|
||||
while (card_read) {
|
||||
|
||||
bad_card = false; // 不要忘记重置坏牌的标记
|
||||
|
||||
printf("Enter a card : ");
|
||||
|
||||
// 判断点数
|
||||
ch = getchar();
|
||||
switch (ch) {
|
||||
case '0': exit(0); break;
|
||||
case '2': rank = 0; break;
|
||||
case '3': rank = 1; break;
|
||||
case '4': rank = 2; break;
|
||||
case '5': rank = 3; break;
|
||||
case '6': rank = 4; break;
|
||||
case '7': rank = 5; break;
|
||||
case '8': rank = 6; break;
|
||||
case '9': rank = 7; break;
|
||||
case 't':case 'T': rank = 8; break;
|
||||
case 'j':case 'J': rank = 9; break;
|
||||
case 'q':case 'Q': rank = 10; break;
|
||||
case 'k':case 'K': rank = 11; break;
|
||||
case 'a':case 'A': rank = 12; break;
|
||||
default:bad_card = true; break;
|
||||
}
|
||||
|
||||
ch = getchar();
|
||||
switch (ch) {
|
||||
case 'c': case 'C': suit = 0; break;
|
||||
case 'd': case 'D': suit = 1; break;
|
||||
case 'h': case 'H': suit = 2; break;
|
||||
case 's': case 'S': suit = 3; break;
|
||||
default: bad_card = true; break;
|
||||
}
|
||||
|
||||
// 检测输入是否多于两个字符
|
||||
while ((ch = getchar()) != '\n') {
|
||||
if (ch != ' ')
|
||||
bad_card = true;
|
||||
}
|
||||
|
||||
if (bad_card)
|
||||
printf("Bad card; ignored.\n");
|
||||
else if (card->cardInHand[suit][rank])
|
||||
printf("Duplicated card; ignored.\n");
|
||||
else {
|
||||
++card->numRank[rank];
|
||||
++card->numSuit[suit];
|
||||
card->cardInHand[suit][rank] = true;
|
||||
card_read--;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
void analyseCard(CardType* card) {
|
||||
|
||||
int i, count;
|
||||
|
||||
// 同花是五张牌相同花色
|
||||
for (i = 0; i < SUIT; i++) {
|
||||
if (card->numSuit[i] == 5)
|
||||
card->flush = true;
|
||||
}
|
||||
|
||||
// 顺子是五张连续的牌,中间不能隔断
|
||||
|
||||
i = 0;
|
||||
// 找到数组种第一张存在的牌
|
||||
while (card->numRank[i] == 0)
|
||||
i++;
|
||||
count = 0;
|
||||
for (; i < RANK && card->numRank[i] != 0; i++) {
|
||||
count++;
|
||||
}
|
||||
// 顺子必须是五张
|
||||
if (count == CARD) {
|
||||
card->straight = true;
|
||||
return; // 顺子肯定不是对子
|
||||
}
|
||||
|
||||
for (i = 0; i < RANK; i++) {
|
||||
if (card->numRank[i] == 4)
|
||||
card->four = true;
|
||||
if (card->numRank[i] == 3)
|
||||
card->three = true;
|
||||
if (card->numRank[i] == 2)
|
||||
++card->pair;
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
void printResult(CardType* card) {
|
||||
|
||||
if (card->flush && card->straight)
|
||||
printf("Stright flush\n");
|
||||
else if (card->four)
|
||||
printf("Four of a kind\n");
|
||||
else if (card->three && card->pair == 1)
|
||||
printf("Full house\n");
|
||||
else if (card->flush)
|
||||
printf("flush\n");
|
||||
else if (card->straight)
|
||||
printf("straight\n");
|
||||
else if (card->three)
|
||||
printf("Three of a kind\n");
|
||||
else if (card->pair == 2)
|
||||
printf("Two pairs\n");
|
||||
else if (card->pair == 1)
|
||||
printf("pair\n");
|
||||
else
|
||||
printf("High card\n");
|
||||
|
||||
printf("\n\n");
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
*参考资料:《C语言程序设计:现代方法》*
|
||||
|
||||
[^1]: 递归是计算之母。她用描述换取时间。 [Epigrams on Programming 编程警句 ](https://epigrams-on-programming.readthedocs.io/zh_CN/latest/epigrams.html)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
450
content/c-mordern-approch/12-指针.md
Normal file
450
content/c-mordern-approch/12-指针.md
Normal file
@@ -0,0 +1,450 @@
|
||||
## 指针
|
||||
|
||||
*If two people write exactly the same program, each should be put in micro-code and then they certainly won't be the same.*
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 目录
|
||||
|
||||
***
|
||||
|
||||
[TOC]
|
||||
|
||||
## 指针
|
||||
|
||||
***
|
||||
|
||||
### 零 前言
|
||||
|
||||
指针是 C 语言最重要——也是最常被误解——的特性之一。本节重点介绍指针的基础内容。
|
||||
|
||||
|
||||
|
||||
### 一 指针变量
|
||||
|
||||
现代大多数计算机将内存分割为**字节**(byte),每个字节可以存储 8 位的信息:`0000 0001`。
|
||||
|
||||
每个字节都有唯一的**地址**(address),用来和内存种的其他字节相区别。如果内存中有 n 个字节,那么可以把地址看作 0 ~ n - 1的数。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
可执行程序由**代码**(原始 C 程序中于语句对应的机器指令)和 **数据**(原始程序中的变量)两部分构成。程序中的每个变量占有一个或多个字节,把**第一个字节的地址**称为是变量的地址。
|
||||
|
||||
|
||||
|
||||
上图中,i 占有的字节是 2000 ~ 2003 4 个字节,2000 就是 i 的地址。
|
||||
|
||||
虽然用数表示地址,但是地址的取值范围可能不同于整数的取值范围,所以一定不能用普通的整型变量存储地址。
|
||||
|
||||
但是,我们可以用特殊的**指针变量**(pointer variable)存储地址。在用指针变量存储 p 存储变量 i 的地址时,我们说 p “指向” i 。换句话说,指针就是地址,而指针变量就是存储地址的变量。
|
||||
|
||||
|
||||
|
||||
#### 1. 指针变量的声明
|
||||
|
||||
```c
|
||||
int* p;
|
||||
```
|
||||
|
||||
上述声明说明**p 是指向 int 类型对象的指针变量**。这里我们用术语**对象**代替**变量**,这是因为 p 可以指向不属于变量的内存区域。(后面会讲)
|
||||
|
||||
指针变量可以与其他变量一起出现在声明中:
|
||||
```c
|
||||
int a, b[10], *p, *q;
|
||||
```
|
||||
|
||||
C 语言要求每个指针变量**只能指向一种**特定类型(引用类型)的对象。
|
||||
|
||||
```c
|
||||
int* p;
|
||||
double* q;
|
||||
char* r;
|
||||
```
|
||||
|
||||
***
|
||||
|
||||
**关于指针变量声明中 * 与谁挨着的问题**:
|
||||
|
||||
请看下面的声明:
|
||||
|
||||
```c
|
||||
int* p,q;
|
||||
```
|
||||
|
||||
请问,上面的声明中 p 和 q 都是指针变量吗?
|
||||
|
||||
小黄:我觉得是,如果你写成这样:
|
||||
|
||||
```c
|
||||
int *p, q;
|
||||
```
|
||||
|
||||
那就是只有 p 是指针变量了。
|
||||
|
||||
程序圆:你这样想就大错特错啦,上面这两种写法是**等价的**。都是声明 p 为指针变量而 q 是一个普通的 int 类型变量。
|
||||
|
||||
小黄:哦~那我们平时应该选择那种写法呢?
|
||||
|
||||
程序圆:通常情况下我们都是选择第一种写法,即:`int* p`。但是这样确实容易造成误解,所以我们通常一行只声明一个指针变量就可以了。
|
||||
|
||||
***
|
||||
|
||||
### 二 取地址运算符和间接寻址运算符
|
||||
|
||||
#### 1. 取地址运算符
|
||||
|
||||
声明指针变量时我们没有将它指向任何对象:
|
||||
|
||||
```c
|
||||
int* p;
|
||||
```
|
||||
|
||||
在使用之前初始化 p 是至关重要的。使用**取地址运算符**`&`把某个变量的地址赋值给它。
|
||||
|
||||
```c
|
||||
int i;
|
||||
p = &i; //&i 就是 i 在内存中的地址
|
||||
```
|
||||
|
||||
现在 p 就指向了整型变量 i
|
||||
|
||||
我们也可以声明的同时初始化:
|
||||
|
||||
```c
|
||||
int i;
|
||||
int* p = &i;
|
||||
```
|
||||
|
||||
甚至可以这样:
|
||||
|
||||
```c
|
||||
int i, *p = &i;
|
||||
```
|
||||
|
||||
但是需要先声明 i
|
||||
|
||||
#### 2. 间接寻址运算符
|
||||
|
||||
间接寻址运算符也叫**解引用**运算符,我个人还是喜欢叫它用解引用运算符。
|
||||
|
||||
```c
|
||||
int i;
|
||||
int* p = &i;
|
||||
```
|
||||
|
||||
指针变量 p 指向 i,使用`*`运算符可以访问存储在对对象中的内容(访问存储在指针变量指向的地址上的内容)。
|
||||
|
||||
```c
|
||||
printf("%d", *p); // (*p == i)
|
||||
```
|
||||
|
||||
**“`*`和`&`互为逆运算”:**
|
||||
|
||||
```c
|
||||
j = *&i;// same as j = i;
|
||||
```
|
||||
|
||||
只要 p 指向 i,\*p 就是 i 的**别名**。***p 不仅拥有和 i 相同的值,而且 *p 的改变也会改变 i 的值。**
|
||||
|
||||
```c
|
||||
int i = 0;
|
||||
int* p = &i;
|
||||
printf("i = %d\n", i);
|
||||
printf("p = %d\n", *p);
|
||||
// 输出:0 0
|
||||
*p = 1;
|
||||
printf("now i = %d\n", i);
|
||||
printf("now p = %d\n", *p);
|
||||
//输出:1 1
|
||||
```
|
||||
|
||||
**注意:**
|
||||
|
||||
解引用**未初始化**的指针变量会导致**未定义行为**:
|
||||
|
||||
```c
|
||||
int* p;
|
||||
printf("%d", *p);
|
||||
```
|
||||
|
||||
给 **`*p`赋值尤为危险**。如果 p 恰好具有有效的内存地址,程序会试图修改存储在该地址的数据:
|
||||
|
||||
```c
|
||||
int* p;
|
||||
*p = 1; // wrong
|
||||
```
|
||||
|
||||
这是极度不安全的行为。好在我们的编译器会给出警告。即使这样使用了,编译器不会真的让你去修改其他地方(比如操作系统等)的数据。
|
||||
|
||||
所以如果你定义的指针特别多,你也不知道那个会被用上,可以这样初始化指针变量:
|
||||
|
||||
```c
|
||||
int* p = NULL; // NULL 表示空指针,该处的内存无法修改
|
||||
```
|
||||
|
||||
然后在需要对 p 解引用的地方添加一个判断:
|
||||
|
||||
```c
|
||||
if(p != NULL){
|
||||
...;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 三 指针赋值
|
||||
|
||||
C 语言允许**相同类型**的指针变量进行赋值。
|
||||
|
||||
```c
|
||||
int i;
|
||||
int* p = &i;
|
||||
int* q;
|
||||
q = p;
|
||||
```
|
||||
|
||||
或者直接初始化并赋值:
|
||||
|
||||
```c
|
||||
int* q = p;
|
||||
```
|
||||
|
||||
|
||||
|
||||
现在可以通过改变 *p 的值来改变 i :
|
||||
```c
|
||||
int i = 0;
|
||||
int* p = &i;
|
||||
int* q = p;
|
||||
printf("now i = %d\n", i);
|
||||
printf("now p = %d\n", *q);
|
||||
// 输出:0 0
|
||||
*q = 2;
|
||||
printf("now i = %d\n", i);
|
||||
printf("now p = %d\n", *q);
|
||||
//输出:2 2
|
||||
```
|
||||
|
||||
不要将 `*q = *p` 和 `q = p` 搞混,前者是将 p 指向的对象的值(变量 i 的值)赋值给 q 指向的对象(变量 j)中。
|
||||
|
||||
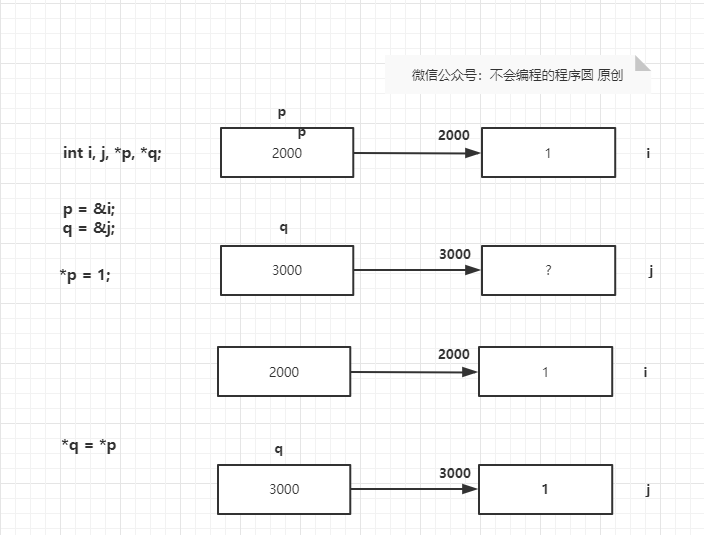
|
||||
|
||||
|
||||
|
||||
### 四 指针作为参数
|
||||
|
||||
还记得之前分解小数的函数 decompose 吗?我们曾将想在这个函数中通过改变形参来改变实参,但是我们失败了,今天我们再来重新看一下如何用指针作为参数完成这一任务:
|
||||
|
||||
将 decompose 函数定义中的形参 int_part 和 frac_part 声明成指针类型。
|
||||
|
||||
```c
|
||||
void decompose(double x, long* int_part; double* frac_part){
|
||||
*int_part = (long)x;
|
||||
*frac_part = x - *int_part;
|
||||
}
|
||||
```
|
||||
|
||||
调用该函数:
|
||||
|
||||
```c
|
||||
int i;
|
||||
double x, d;
|
||||
decompose(x, &i, &d);
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
当函数调用完成,实参 i 和 d 的值也修改了。你可以再 main 函数中输出一下 i 和 d 测试一下。
|
||||
|
||||
|
||||
|
||||
用指针作为参数其实并不新鲜:
|
||||
|
||||
```c
|
||||
int i;
|
||||
scanf("%d", &i);
|
||||
```
|
||||
|
||||
必须将 & 放在 i 前以便传给 scanf 函数指向 i 的指针,指针会告诉 scanf 函数将读取的值放在那里。如果没有 & 传递给 scanf 的将是 i 的值。
|
||||
|
||||
虽然 scanf 函数的实参必须是指针,但是并不是总需要 & 运算符:
|
||||
|
||||
```c
|
||||
int i;
|
||||
int* p = &i;
|
||||
scanf("%d", p);
|
||||
```
|
||||
|
||||
p 已经包含了 i 的地址,所以不需要 &。使用 & 是错误的:
|
||||
|
||||
```c
|
||||
scanf("%d", &p);
|
||||
```
|
||||
|
||||
scanf 函数将把读入的整数放在 p 中而不是 i 中。
|
||||
|
||||
**注意:**
|
||||
|
||||
向函数传递需要的指针却失败了可能会造成严重后果。比如,如果我们在调用 decompose 函数时没有在 i 和 d 前加上 & :
|
||||
|
||||
```c
|
||||
decompose(x, i, d);
|
||||
```
|
||||
|
||||
函数期望的第二和第三个参数是指针,但传入的却是 i 和 d 的值。decompose 函数没有办法区分,所以它会把 i 和 d 的值当作指针来使用(指针本身是整数)。当函数修改 *int_part 和 *frac_part 时,它会修改未知的内存地址,而不是修改 i 和 d。
|
||||
|
||||
如果已经提供了函数原型,那么编译器将告诉我们实参类型不对。然而对于 scanf 来说,编译器通常不会检查出传递指针失败,因此 scanf 函数特别容易出错。
|
||||
|
||||
#### 程序:找出数组中的最大元素和最小元素
|
||||
|
||||
与程序的交互如下:
|
||||
|
||||
```c
|
||||
Enter 5 numbers:9 5 2 7 8
|
||||
Largest: 9
|
||||
Smallest: 2
|
||||
```
|
||||
|
||||
参考程序:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
#define SIZE 5
|
||||
|
||||
void max_min(int a[], int len, int* max, int* min);
|
||||
|
||||
int main(void) {
|
||||
|
||||
int a[SIZE];
|
||||
int max, min, i;
|
||||
|
||||
printf("Enter 5 numbers: ");
|
||||
for (i = 0; i < SIZE; i++)
|
||||
scanf("%d", &a[i]);
|
||||
|
||||
max_min(a, SIZE, &max, &min);
|
||||
|
||||
printf("Largest: %d\n", max);
|
||||
printf("Smallest: %d\n", min);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
void max_min(int a[], int len, int* max, int* min) {
|
||||
|
||||
int i;
|
||||
|
||||
*max = *min = a[0];
|
||||
for (i = 1; i < len; i++) {
|
||||
// a[i] 如果比 *max 大 那肯定不会比 *min 小,反之也成立
|
||||
if (a[i] > * max)
|
||||
*max = a[i];
|
||||
else if (a[i] < *min)
|
||||
*min = a[i];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 用 const 保护参数
|
||||
|
||||
指针传参时,可以使用 `const`来表明函数不会改变指针参数所指向的对象。 const 应放于形参中:
|
||||
|
||||
```c
|
||||
void f(const int* p){
|
||||
...;
|
||||
}
|
||||
```
|
||||
|
||||
试图改变 *p 时编译器会报错。
|
||||
|
||||
***
|
||||
|
||||
小黄:const 一定只能放在 int 之前吗?这样写合不合法:
|
||||
|
||||
```c
|
||||
int* const p;
|
||||
```
|
||||
|
||||
程序圆:合法。但是和上面那种声明方式的含义不同。上面的 const 修饰的是 *p,使得 *p 不能被修改;而这一种 const 修饰的 p,使得 p 的指向不能发生改变:
|
||||
|
||||
```c
|
||||
int i,j;
|
||||
const int* p = &i;
|
||||
int* const q = &j;
|
||||
|
||||
*p = 0; // wrong
|
||||
p = q; // ok
|
||||
|
||||
*q = 0; // ok
|
||||
q = p; // wrong
|
||||
```
|
||||
|
||||
你甚至可以这样写:
|
||||
|
||||
```c
|
||||
int const *p;
|
||||
```
|
||||
|
||||
这和第一中写法是同一个意思:使得 *p 不能被修改。
|
||||
|
||||
***
|
||||
|
||||
|
||||
|
||||
### 五 指针作为返回值
|
||||
|
||||
请看返回值类型为 `int*`类型的函数 max:
|
||||
|
||||
```c
|
||||
int* max(int* a, int* b){
|
||||
if(*a > *b)
|
||||
return a;
|
||||
else
|
||||
return b;
|
||||
}
|
||||
```
|
||||
|
||||
max 返回较大数的指针。
|
||||
|
||||
调用:
|
||||
|
||||
```c
|
||||
int a,b;
|
||||
int* p = max(&a, &b);
|
||||
```
|
||||
|
||||
需要使用相同的指针类型接收返回值。
|
||||
|
||||
**注意:**
|
||||
|
||||
永远不要返回指向**自动局部变量**的指针:
|
||||
|
||||
```c
|
||||
int* f(){
|
||||
int i;
|
||||
...
|
||||
return i;
|
||||
}
|
||||
```
|
||||
|
||||
一旦 f 返回,i 就不存在了,所以指向 i 的指针是无效的。有的编译器可能给出警告:“function returns address of local variable”
|
||||
|
||||
|
||||
|
||||
*参考资料:《C语言程序设计:现代方法》*
|
||||
|
||||
[^1]: 如果两个人用低级语言写同一个程序,它们显然不会相同。[Epigrams on Programming 编程警句 ](https://epigrams-on-programming.readthedocs.io/zh_CN/latest/epigrams.html)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
541
content/c-mordern-approch/13-指针和数组.md
Normal file
541
content/c-mordern-approch/13-指针和数组.md
Normal file
@@ -0,0 +1,541 @@
|
||||
## 指针和数组
|
||||
|
||||
*In the long run every program becomes rococo - then rubble.* [^1]
|
||||
|
||||
|
||||
|
||||
## 目录
|
||||
|
||||
***
|
||||
|
||||
|
||||
|
||||
## 指针与数组
|
||||
|
||||
***
|
||||
|
||||
### 零 前言
|
||||
|
||||
C 语言中指针和数组的关系是非常紧密的。当指针指向数组元素时,C 语言允许对指针进行算术运算(加减),通过这种运算我们可以用指针取代数组下标对数组进行处理。
|
||||
|
||||
|
||||
|
||||
### 一 指针的算数运算
|
||||
|
||||
```c
|
||||
int a[10] = {0};
|
||||
int* p = &a[0];
|
||||
```
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
我们可以通过 p 访问 a[0]:
|
||||
|
||||
```c
|
||||
*p = 5;
|
||||
printf("%d", a[0]); // 5
|
||||
```
|
||||
|
||||
|
||||
|
||||
C 语言只支持 3 种格式的指针算数运算:
|
||||
|
||||
- 指针加上整数
|
||||
- 指针减去整数
|
||||
- 两个指针相减
|
||||
|
||||
|
||||
|
||||
#### 1. 指针加整数
|
||||
|
||||
指针 p 加上整数 j 产生指向特定元素的指针,这个特定元素是 p 原先指向的元素的后的 j 个位置。也就是说如果 p 指向 a[i],那么 p + j 指向 a[i + j],前提是 a[i + j] 存在。如图:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### 2. 指针减整数
|
||||
|
||||
如果指针 p 指向数组元素 a[i],那么 p - j 指向 a[i - j] 。例如:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### 3. 两个指针相减
|
||||
|
||||
两个指针相减结果是指针之间的距离(用数组元素个数来度量)。
|
||||
|
||||
如果 p 指向 a[i],q 指向 a[j],q - p 等于 j - i 。例如:
|
||||
|
||||
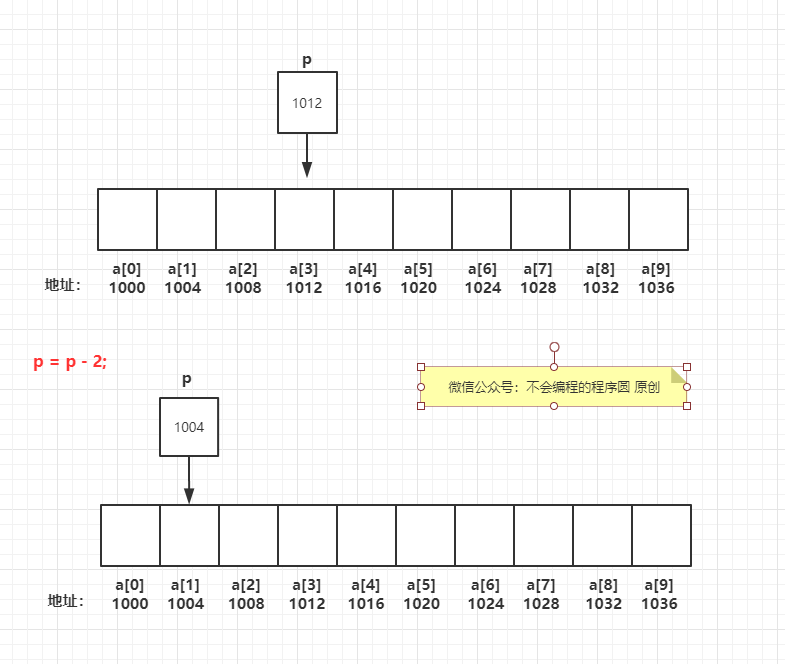
|
||||
|
||||
**注意:**
|
||||
|
||||
在一个不指向任何数组元素的指针上执行算数运算会导致未定义行为。此外,只有在两个指针指向同一个数组时,把他们相减才有意义。
|
||||
|
||||
|
||||
|
||||
#### 4. 指针比较
|
||||
|
||||
可以用关系运算符(`<`,`>`,`<=`,`>=`)和判等运算符(`==`和 `!=`)进行指针比较。只有在两个指针指向同一数组时,用关系运算符进行指针比较才有意义。比较的结果依赖于数组种两个元素的相对位置。如图:
|
||||
|
||||
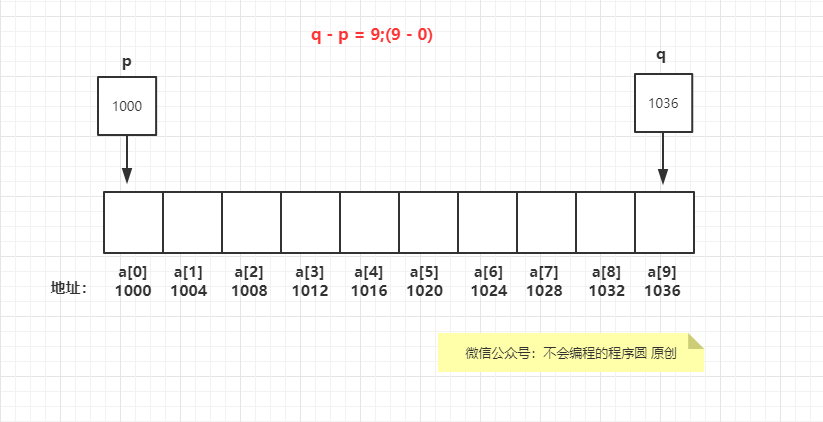
|
||||
|
||||
|
||||
|
||||
#### 5. 指向复合常量的指针(C99)
|
||||
|
||||
略。
|
||||
|
||||
|
||||
|
||||
### 二 指针用于数组处理
|
||||
|
||||
通过对指针变量进行重复自增来访问数组元素。
|
||||
|
||||
```c
|
||||
#define N 10
|
||||
|
||||
int a[N], sum, *p;
|
||||
sum = 0;
|
||||
for(p = &a[0]; p < &a[N]; p++)
|
||||
sum += *p;
|
||||
```
|
||||
|
||||
|
||||
|
||||
for 语句中的条件 `p < &a[N]`值得特别说一下。尽管 a[N] 元素不存在(数组下标是 a[0] 到 a[N - 1]),但是对它使用取地址运算符是合法的。因为循环不会检查 a[N] 的值,所以使用 &a[N] 是十分安全的。执行循环体时,p 依次等于 &a[0], &a[1], ..., &a[N - 1],但是当 p 等于 &a[N] 时,循环终止。
|
||||
|
||||
当然,改用下标可以很容易写出不使用指针的循环。支持采用指针算术运算的最常见论调是,这样作可以节省执行时间。但是这依赖于具体实现——对于有的编译器来说,实际上依靠下标的循环会产生更好的代码。
|
||||
|
||||
|
||||
|
||||
#### 解引用 与 自增自减 的组合
|
||||
|
||||
对于语句:
|
||||
|
||||
```c
|
||||
a[i++] = j;
|
||||
```
|
||||
|
||||
我们可以用指针改写为:
|
||||
|
||||
```c
|
||||
*p++ = j;
|
||||
```
|
||||
|
||||
因为后缀 ++ 的优先级高于 * ,所以上面的语句等同于:
|
||||
|
||||
```c
|
||||
*(p++) = j;
|
||||
```
|
||||
|
||||
先将 j 赋值给 p 指向的对象,然后 p 指向数组下一个元素。
|
||||
|
||||
| 表达式 | 含义 |
|
||||
| --------------- | -------------------- |
|
||||
| (*p)++ | *p 自增(后置) |
|
||||
| *++p 或 *(++p) | 先自增 p,然后解引用 |
|
||||
| ++*p 或 ++(\*p) | *p 自增 (前置) |
|
||||
|
||||
我们最常用到的就是 `*p++` 。
|
||||
|
||||
对数组元素求和时,我们可以将前面写的 for 循环改写为:
|
||||
|
||||
```c
|
||||
p = &a[0];
|
||||
sum = 0;
|
||||
while(p < &a[N])
|
||||
sum += *p++;
|
||||
```
|
||||
|
||||
|
||||
|
||||
\* 和 -- 的组合和 ++ 类似。
|
||||
|
||||
#### 程序:栈实现程序修改
|
||||
|
||||
之前我们用整型变量 top 记录栈顶的位置。现在我们用一个指针变量替换 top ,这个指针变量初始为 NULL(不指向任何对象)。
|
||||
```c
|
||||
int* top_ptr = &stack[0];
|
||||
```
|
||||
|
||||
下面是新的 push 和 pop 函数:
|
||||
|
||||
```c
|
||||
void push(int* top_ptr, int i){
|
||||
if(is_full())
|
||||
stack_overflow();
|
||||
else
|
||||
*++top_ptr = i;
|
||||
}
|
||||
int pop(int* top_ptr){
|
||||
if(is_empty())
|
||||
stack_underflow();
|
||||
else
|
||||
return *top_ptr--;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 三 数组名作为指针
|
||||
|
||||
可以用数组名作为指向数组第一个元素的指针
|
||||
|
||||
```c
|
||||
int a[5] = {1, 2, 3, 4, 5};
|
||||
printf("%d\n", *a); // 1
|
||||
printf("%d\n", *(a + 4)); // 5
|
||||
*(a + 1) = 1; // a[1] is now 1
|
||||
```
|
||||
|
||||
明白了这个原理,我们可以改写 for 语句求和数组元素的程序:
|
||||
|
||||
```c
|
||||
for(p = a; p < a + N; p++)
|
||||
sum += *p;
|
||||
```
|
||||
|
||||
**注意:**数组名是被 const 保护的指针:
|
||||
|
||||
```c
|
||||
int a[5];
|
||||
// 类似于:
|
||||
int* const a;
|
||||
```
|
||||
|
||||
所以,数组名 a 的指向不能被改变。
|
||||
|
||||
```c
|
||||
int a[5], b[10];
|
||||
a = b; // wrong
|
||||
a++; // wrong
|
||||
```
|
||||
|
||||
这一限制不会给我们造成什么损失:我们可以把 a 赋值给一个指针变量,然后改变该指针变量:
|
||||
|
||||
```c
|
||||
p = a;
|
||||
p++;
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 程序:数列反向(改进版)
|
||||
|
||||
前面我们讲过一个逆序输出数列的程序。
|
||||
|
||||
原来的程序利用下标来访问数组中的元素。我们用指针的算数运算取代数组的取下标操作:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
#define SIZE 5
|
||||
|
||||
int main(void) {
|
||||
|
||||
int a[SIZE];
|
||||
int* p;
|
||||
|
||||
printf("Enter %d numbers: ", SIZE);
|
||||
for (p = a; p < a + SIZE; p++)
|
||||
scanf("%d", p);
|
||||
|
||||
printf("Reverse array: ");
|
||||
for (p = a + SIZE - 1; p >= a; p--)
|
||||
printf("%d ", *p);
|
||||
printf("\n");
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 1. 数组型实际参数
|
||||
|
||||
数组名在传递给函数时,总是被视为指针。
|
||||
|
||||
- 在给函数传递普通变量时,变量的值会被复制;任何对形参的改变都不会影响到实参。
|
||||
|
||||
在给函数传递数组时,数组本身没有复制,而是将首元素的指针赋值给形参;所以对数组形参的改变是可以改变实参的。
|
||||
|
||||
比如我们之前写的将数组的每个元素赋值为 0
|
||||
|
||||
```c
|
||||
void store_zero(int a[], int n){
|
||||
int i;
|
||||
|
||||
for(i = 0; i < n; i++)
|
||||
a[i] = 0;
|
||||
}
|
||||
```
|
||||
|
||||
为了指明数组形参不能被改变,可以在其声明中包含单词 const :
|
||||
|
||||
```c
|
||||
void find_largest(const int a[], int n){
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
如果参数有 const,编译器会核实 find_largest 函数体中确实没有对 a 中元素的赋值。
|
||||
|
||||
- 因为向函数传递数组没有对数组进行复制,所以传递大数组不会降低效率,浪费空间。
|
||||
|
||||
- 可以把数组型形参声明为指针。例如:
|
||||
|
||||
```c
|
||||
void find_largest(int* a, int n){
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
声明 a 是指针就相当于声明它是数组。编译器把这两类声明看作是完全一样的。
|
||||
|
||||
**注意:**
|
||||
|
||||
对形参而言,声明为数组和指针是一样的;但是对变量而言,这是不同的。声明
|
||||
|
||||
```c
|
||||
int a[10];
|
||||
```
|
||||
|
||||
编译器会预留 10 个整数的空间,但声明
|
||||
|
||||
```c
|
||||
int* a;
|
||||
```
|
||||
|
||||
编译器只会预留一个指针变量的空间。在后一种情况下,a 不是数组,试图把它当作数组来使用可能会导致糟糕的后果。例如:
|
||||
|
||||
```c
|
||||
*a = 0;
|
||||
```
|
||||
|
||||
因为我们不知道 a 指向哪里,修改 a 指向的对象的结果是无法预料的。
|
||||
|
||||
- 可以给向形参传递数组“片段”。比如:
|
||||
|
||||
```c
|
||||
largest = find_largest(&a[5], 10);
|
||||
```
|
||||
|
||||
上面函数调用的含义就是:从 a[5] 开始检查,检查 10 个元素,从中找出最大值。
|
||||
|
||||
#### 2. 用指针作为数组名
|
||||
|
||||
既然数组名可以作为指针,指针也是可以看作数组名进行取下标操作的。
|
||||
|
||||
```c
|
||||
#define N 10
|
||||
int a[N], *p = a,sum = 0, i;
|
||||
|
||||
for(i = 0; i < N; i++)
|
||||
sum += p[i];
|
||||
```
|
||||
|
||||
编译器将 p[i] 看作是 *(p + i) 。后面我们会进一步讨论它的其他用法。
|
||||
|
||||
|
||||
|
||||
### 四 指针和多维数组
|
||||
|
||||
指针可以指向多维数组的元素。简单起见,我们在这里只讨论二维数组,但所有内容可以应用于更高维的数组。
|
||||
|
||||
#### 1. 处理多维数组的元素
|
||||
|
||||
如果把多维数组看作一维数组,可以这样遍历数组:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
#define ROW 2
|
||||
#define COL 3
|
||||
|
||||
int main(void) {
|
||||
|
||||
int a[ROW][COL] = {
|
||||
{1, 2, 3},
|
||||
{4, 5, 6}
|
||||
};
|
||||
|
||||
for (int* p = &a[0][0]; p <= &a[ROW - 1][COL - 1]; p++)
|
||||
printf("%d ", *p);
|
||||
printf("\n");
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
p 从数组的第一个元素地址开始遍历到数组的最后一个元素的地址。
|
||||
|
||||
|
||||
|
||||
虽然这种写法对大多数 C 的编译器都是合法的。但是明显破坏了程序的可读性,对一些老的编译器来说这种方法提高了效率。但是对许多现代编译器这样所获得的速度优势往往极少甚至没有。
|
||||
|
||||
|
||||
|
||||
**以下内容初学者可以仅作了解即可**
|
||||
|
||||
#### 2. 处理多维数组的行
|
||||
|
||||
为了访问到二维数组的第 i 行的元素,需要初始化 p 使其指向第 i 行的首元素:
|
||||
|
||||
```c
|
||||
p = &a[i][0];
|
||||
```
|
||||
|
||||
等价于:
|
||||
|
||||
```c
|
||||
p = a[i];
|
||||
```
|
||||
|
||||
原理:对于任意数组 a 来说,`a[i]`等价于 `*(a + i)`。因此,对于二维数组来说,`&a[i][0]`等同于 `&(*(a[i] + 0))`,因为 & 和 * 可以抵消,所以该表达式等价于`a[i]`
|
||||
|
||||
对上面的二维数组第一行的遍历可以这样写:
|
||||
|
||||
```c
|
||||
for (int* p = a[0]; p < a[0] + COL; p++)
|
||||
printf("%d ", *p);
|
||||
```
|
||||
|
||||
对于 find_largest 函数来说,我们可以传入某一行的首元素地址,然后让它帮我们计算该行的最大元素:
|
||||
|
||||
```c
|
||||
find_largest(a[i], COL);
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 3. 处理多维数组的列
|
||||
|
||||
处理列就要复杂一些。下面的循环遍历数组第 i 列:
|
||||
|
||||
```c
|
||||
int (*p)[COL];
|
||||
|
||||
for (p = &a[0]; p < &a[ROW]; p++)
|
||||
printf("%d ", (*p)[i]);
|
||||
```
|
||||
|
||||
这里把 p 声明为指向长度为 COL 的整型数组的指针。在声明 int (*p)[COL] 中 *p 是需要带括号的,如果没有括号,编译器将认为 p 是**指针数组**,而不是指向数组的指针。表达式 p++ 将 p 移动到下一行开始的位置。表达式 (\*p)[i] 中,\*p 代表 a 的一整行,因此 (\*p)[i] 选中了该行第 i 列那个元素;括号也是必要的,因为编译器会将 *p[i] 解释为 *(p[i])
|
||||
|
||||
|
||||
|
||||
#### 4. 多维数组名作为指针
|
||||
|
||||
对于多维数组 `int a[ROW][COL]` 来说,a 不是指向 `a[0][0]` 的指针而是指向 `a[0]`的指针。从 C 语言的观点来看,这样是有意义的。C 语言不认为 a 是二维数组而是一维数组,且这个一维数组每个元素又是一个一维数组。用作指针时,a 的类型是 `int (*)[COL]`(指向长度为 COL 的整型数组的指针) 。
|
||||
|
||||
了解 a 指向的是 a[0] 有助于简化处理二维数组元素的循环。例如,简化上面的遍历数组第 i 列的循环:
|
||||
|
||||
```c
|
||||
int (*p)[COL];
|
||||
|
||||
for (p = a; p < a + ROW; p++)
|
||||
printf("%d ", (*p)[2]);
|
||||
```
|
||||
|
||||
调用 find_largest 找到数组最大的元素时,如果我们这样写:
|
||||
|
||||
```c
|
||||
find_largest(a, ROW * COL);
|
||||
```
|
||||
|
||||
这条语句不能通过编译,因为 find_largest 函数期望的实际类型是 `int*` 而 a 的类型是 `int (*)[COL]` 。正确的调用写法是:
|
||||
|
||||
```c
|
||||
find_largest(a[0], ROW * COL);
|
||||
```
|
||||
|
||||
`a[0]`指向 0 行的第 0 个元素。
|
||||
|
||||
***
|
||||
|
||||
程序圆寄语:
|
||||
|
||||
以上部分可以说是到目前为止我们接触到的指针的最难的层面了。如果你看不懂,那请往下看:
|
||||
|
||||
如果你是初学者,那这部分内容对你太过于深了。不建议你现在着急去搞懂它,你需要大量的应用指针编程练习才能对指针有一个比较立体的认识。你只需要掌握前 3 部分内容即可。
|
||||
|
||||
如果你在看这篇文章之前已经学过了指针,并且想搞懂这部分内容,那可以去我的【C 进阶】系列查看相关的文章。
|
||||
|
||||
后面很快我们就会回过头来继续深挖指针,敬请期待!
|
||||
|
||||
***
|
||||
|
||||
### 五 C99 中的指针和变长数组
|
||||
|
||||
略。
|
||||
|
||||
|
||||
|
||||
*参考资料:《C语言程序设计:现代方法》*
|
||||
|
||||
[^1]: 程序终将成为洛可可,然后是碎石。[Epigrams on Programming 编程警句 ](https://epigrams-on-programming.readthedocs.io/zh_CN/latest/epigrams.html)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
969
content/c-mordern-approch/14-字符串.md
Normal file
969
content/c-mordern-approch/14-字符串.md
Normal file
@@ -0,0 +1,969 @@
|
||||
## 字符串
|
||||
|
||||
*Everything should be built top-down, except the first time.* [^1]
|
||||
|
||||
|
||||
|
||||
## 目录
|
||||
|
||||
***
|
||||
|
||||
[TOC]
|
||||
|
||||
## 字符串
|
||||
|
||||
***
|
||||
|
||||
### 零 前言
|
||||
|
||||
前几章虽然我们用过 char 类型变量和 char 类型数组,但我们始终没有谈到处理字符序列(C 的术语是**字符串**)的便捷方法。
|
||||
|
||||
本章将介绍**字符串常量**(C 标准中称为**字符串字面量**)和**字符串变量**(可以在程序运行时修改)。
|
||||
|
||||
|
||||
|
||||
### 一 字符串字面量
|
||||
|
||||
> 字符串字面量(string literal)是一对用双引号括起来的字符序列。
|
||||
>
|
||||
> *C++ 中常称为字符串字面值,或称为常值,或称为字面量。有些 C 语言的书中称之为字串*
|
||||
|
||||
#### 1. 字符串字面量中的转义序列
|
||||
|
||||
字符串字面量可以包含转义序列。比如:
|
||||
|
||||
```c
|
||||
printf("Hello World\n");
|
||||
```
|
||||
|
||||
虽然字符串字面量中的八进制数和十六进制数的转义序列也是合法的,但是字符转义序列更为常见。
|
||||
|
||||
**注意:在字符串字面量中慎用八进制数和十六进制数的转义序列**
|
||||
|
||||
- 八进制数的转义序列在三个数字后 或者 在第一个非八进制数字符 处结束。如:`\1234`包含两个字符`\123`和`4`
|
||||
|
||||
- 十六进制数的转义序列则不限制 3 个数字,而是直到第一个非十六进制数字符处结束。如:`Z\xfcrich` 表示 6 个字符(`Z`,`\xfc`,`r`,`i`,`c`,`h`)
|
||||
|
||||
十六进制转义序列的通常范围是`\x0 ~ \xff`,所以 `\xfcber`本应是两个字符(`\xfcbe`,`r`)但是这个十六进制数对字符来说太大了。
|
||||
|
||||
#### 2. 延续字符串字面量
|
||||
|
||||
如果发现字符串字面量太长而无法放置在单独一行内,有下面几种办法解决这个问题。这个问题在前面详细讲过了,有兴趣可以看我之前的文章。下面我就不细说了。
|
||||
|
||||
1. 使用 `\`
|
||||
|
||||
```c
|
||||
printf("Hello \
|
||||
World\n");
|
||||
```
|
||||
|
||||
但是字符串字面量必须从下一行最左边继续,这样会破坏程序的缩进结。
|
||||
|
||||
2. ```c
|
||||
printf("Hello"
|
||||
" World\n");
|
||||
```
|
||||
|
||||
3. ```c
|
||||
printf("Hello ");
|
||||
printf(" World\n");
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 3. 字符串字面量的存储
|
||||
|
||||
本质上而言,C 语言把字符串字面量作为字符数组来处理。当 C 语言编译器在程序中遇到了长度为 n 的字符串字面量时,它会为字符串字面量分配长度为 n + 1 的内存空间。额外的 1 个空间用来存放一个**空字符**来标识字符串末尾。空字符是所有位都为 0 的字节,因此用转义序列`\0`来表示。
|
||||
|
||||
**注意:不要混淆空字符`'\0'`和零字符`'0'`。**
|
||||
|
||||
`'\0'`的 ASCII 码值为 0;`'0'`的 ASCII 码值为 48
|
||||
|
||||
`"abc"`使用 4 个字符的数组来存储的:
|
||||
|
||||

|
||||
|
||||
字符串字面量可以为空:`""`表示单独存储一个空字符
|
||||
|
||||
|
||||
|
||||
既然字符串字面量是作为数组来存储的,那么编译器会把它看作是 `char*`类型的指针。
|
||||
|
||||
`printf`和`scanf`函数都接收 `char*`类型的值作为它们的第一个参数。思考下面的例子:
|
||||
|
||||
```c
|
||||
printf("abc");
|
||||
```
|
||||
|
||||
当调用 printf 函数时,会传递 "abc" 的地址。(即指向存储字母 a 的内存单元的指针)
|
||||
|
||||
#### 4. 字符串字面量的操作
|
||||
|
||||
> 通常情况下,可以在任何C语言允许使用 char* 指针的地方使用字符串字面量。例如,字符串字面量可以出现在赋值运算符的右边。
|
||||
|
||||
```c
|
||||
char* p;
|
||||
p = "abc";
|
||||
```
|
||||
|
||||
这个操作不是复制 "abc" 中的字符,而是使 p 指向字符串的第一个字符。
|
||||
|
||||
C 语言允许对指针取下标,所以可以对字符串字面量取下标:
|
||||
|
||||
```c
|
||||
char ch;
|
||||
ch = "abc"[1];
|
||||
```
|
||||
|
||||
ch 的新值是 'b' 。甚至可以:
|
||||
|
||||
```c
|
||||
ch = "abc"[3];// ch is now '\0'
|
||||
```
|
||||
|
||||
字符串字面量的这种特性并不常用,但有时也很方便:这个函数将 0 ~ 15 的数转换成等价的十六进制的字符形式:
|
||||
|
||||
```c
|
||||
char digit_to_hex_char(int digit){
|
||||
return "0123456789ABCDEF"[digit];
|
||||
}
|
||||
```
|
||||
|
||||
**注意:试图改变字符串字面量会导致未定义行为**
|
||||
|
||||
```c
|
||||
char* p = "abc";
|
||||
*p = 'd'; // wrong
|
||||
```
|
||||
|
||||
改变字符串字面量会导致程序崩溃或运行不稳定。
|
||||
|
||||
|
||||
|
||||
#### 5. 字符串字面量与字符常量
|
||||
|
||||
**只包含一个字符的字符串字面量不同于字符常量**。字符串字面量`"a"`是用**指针**来表示的,这个指针指向存放字符"a"(后面紧跟空字符)的内存单元。字符常量`'a'`是用**整数**(字符集的数值码)来表示的。
|
||||
|
||||
**注意:不要再需要字符串的时候使用字符(反之亦然)**
|
||||
|
||||
函数调用:
|
||||
|
||||
```c
|
||||
printf("\n");
|
||||
```
|
||||
|
||||
是合法的。然而使用字符则是非法的:
|
||||
|
||||
```c
|
||||
printf('\n');
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 二 字符串变量
|
||||
|
||||
> 一些编程语言专门为声明字符串变量提供了专门的 string 类型。C 语言采用了不同的方式:只要保证字符串是以空字符结尾的,任何一维的字符数组都可以用来存储字符串。
|
||||
|
||||
假设需要用一个变量来存储最多有 80 个字符的字符串。由于字符串末尾有空字符,我们需要声明含有 81 个字符的数组:
|
||||
|
||||
```c
|
||||
#define STR_LEN 80
|
||||
|
||||
char str[STR_LEN + 1];
|
||||
```
|
||||
|
||||
这里把 `STR_LEN`定义为 80 而不是 81,强调的是 str 最多可以存储 80 个字符;然后才在 str 的声明中对 STR_LEN 加 1 。这是 C 程序员常用的方式。
|
||||
|
||||
**注意:声明用于存放字符串的数组时,要始终保证数组长度比字符串长度多一个字符**
|
||||
|
||||
这是因为 C 语言规定每个字符串都已 `\0` 结尾。如果没有空字符预留位置,可能导致运行时出现未定义行为。因为C函数库中的函数假设字符串都以空字符结尾。
|
||||
|
||||
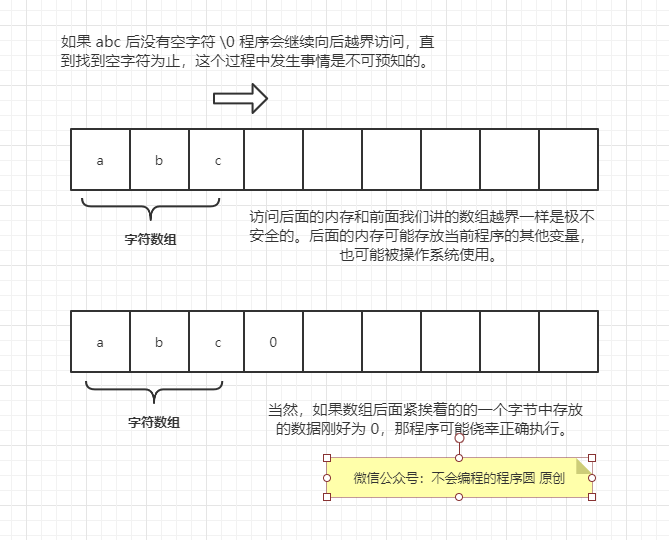
|
||||
|
||||
|
||||
|
||||
声明长度为 `STR_LEN + 1`的字符数组并不意味着总是存放长度为 STR_LEN 的字符串。字符串长度取决于 `\0`出现的位置。
|
||||
|
||||
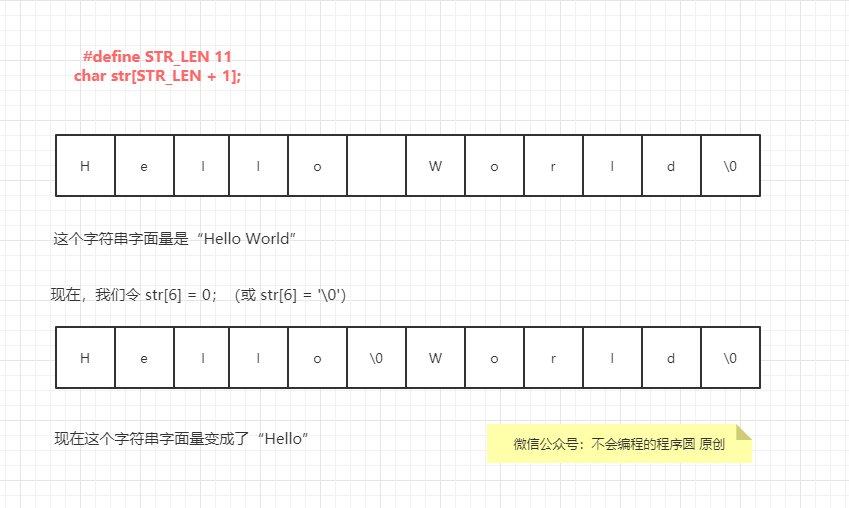
|
||||
|
||||
|
||||
|
||||
#### 1. 初始化字符串变量
|
||||
|
||||
字符串变量可以在声明时进行初始化:
|
||||
|
||||
```c
|
||||
char date1[8] = "June 14";
|
||||
```
|
||||
|
||||
编辑器将把字符串 "June 14" 中的字符复制到数组 data1 中,然后追加一个空字符:
|
||||
|
||||
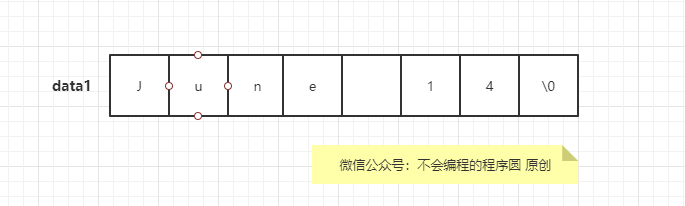
|
||||
|
||||
"June 14" 看起来像是字符串字面量,但其实不然。C 编译器会把它看成是数组初始化式的缩写形式。实际上我们可以写成:
|
||||
|
||||
```c
|
||||
char date1[8] = {'J', 'u', 'n', 'e', ' ', '1', '4', '\0'};
|
||||
```
|
||||
|
||||
不管是编写还是阅读,后者都不是好的选择。使用数组的初始化式时,切记要手动**加上 '\0'**
|
||||
|
||||
|
||||
|
||||
如果初始化式太短以致于不能填满字符串变量将会如何呢?在这种情况下,编译器会**添加空的字符**。因此,在声明:
|
||||
|
||||
```c
|
||||
char date2[9] = "June 14";
|
||||
```
|
||||
|
||||
之后,data2 将如下图所示:
|
||||
|
||||
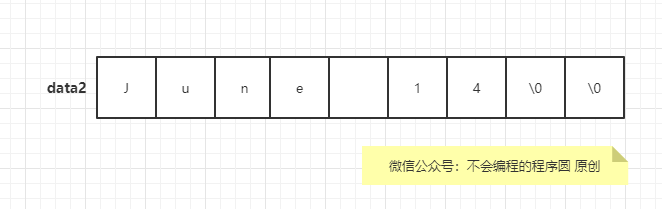
|
||||
|
||||
|
||||
|
||||
如果初始化式比字符串变量长会怎样?这对字符串而言是非法的,就如同对数组而言是非法的一样。然而,C 语言允许初始化式(不包括空字符)与变量有完全相同的长度。
|
||||
|
||||
```c
|
||||
char data3[7] = "June 14";
|
||||
```
|
||||
|
||||
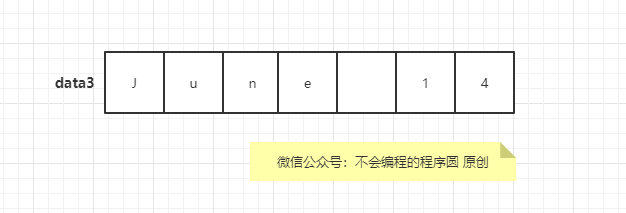
|
||||
|
||||
由于没有给空字符留出空间,所以编译器不会试图存储空字符。因此,data3 无法作为字符串使用。
|
||||
|
||||
|
||||
|
||||
字符串变量的声明中可以省略它的长度。这种情况下,编译器会自动计算长度:
|
||||
|
||||
```c
|
||||
char date4[] = "June 14";
|
||||
```
|
||||
|
||||
编译器会为 date4 分配 8 个字符的空间。
|
||||
|
||||
如果初始化式很长,那么省略字符串变量的长度是特别有效的,因为手工计算长度很容易出错。
|
||||
|
||||
|
||||
|
||||
#### 2. 字符数组与字符指针
|
||||
|
||||
```c
|
||||
char date[] = "June 14";
|
||||
char* date = "June 14";
|
||||
```
|
||||
|
||||
前者声明 date 是一个字符数组,或者声明 date 是一个指针。
|
||||
|
||||
它们的相同点类似数组和指针,现在我们看一下不同点:
|
||||
|
||||
- 声明为数组,可以修改存储在 date 中的元素;声明为指针,date 指向字符串字面量,前面我们已经讲过字符串字面量是不能被修改的。
|
||||
- 声明为数组,date 是数组名。声明为指针,date 是变量,这个变量可以在程序执行期间指向其他字符串。
|
||||
|
||||
如果我们希望可以修改字符串,那么应该建立字符数组存储字符串。
|
||||
|
||||
如果我们声明了一个`char*`类型的指针,在使用它之前应让它指向字符串字面量或者字符串变量。
|
||||
|
||||
**注意:使用未初始化的指针变量作为字符串是严重的错误**
|
||||
|
||||
```c
|
||||
char *p;
|
||||
|
||||
p[0] = 'a'; // wrong
|
||||
p[1] = 'b'; // wrong
|
||||
p[2] = 'c'; // wrong
|
||||
p[3] = '\0'; // wrong
|
||||
```
|
||||
|
||||
这个程序试图创建一个字符串。因为 p 没有被初始化,所以我们不知道它指向哪里。直接解引用属于非法内存访问。
|
||||
|
||||
|
||||
|
||||
### 三 字符串的读和写
|
||||
|
||||
#### 1. 用 printf 函数和 puts 函数写字符串
|
||||
|
||||
使用转换说明:`%s`
|
||||
|
||||
```c
|
||||
char str[] = "Are you happy?";
|
||||
printf("%s\n", str);
|
||||
```
|
||||
|
||||
输出会是:
|
||||
|
||||
```c
|
||||
Are you happy?
|
||||
```
|
||||
|
||||
printf 函数会逐个写字符串中的字符,直到遇到空字符为止。如果空字符丢失,printf 函数会越过字符串的末尾继续写,直到最终在内存的某个地方找到空字符为止。
|
||||
|
||||
如果只想显示字符串的一部分,可以使用转换说明`%.ps`这里 p 是要显示的字符数量。
|
||||
|
||||
```c
|
||||
printf("%.3", str);
|
||||
//输出:
|
||||
Are
|
||||
```
|
||||
|
||||
字符串跟数一样,可以指定字段内显示。转换说明`%ms`会在大小为 m 的字段内显示字符串。(对于超过 m 个字符的字符串,printf 函数会显示整个字符串,而不会截断。)如果字符串少于 m 个字符,则会在字段内右对齐输出。如果要前置左对齐,可以在 m 前加一个 - 号。m 和 p 可以组合使用:转换说明`%m.ps`会使字符串的前 p 个字符在大小为 m 的字段内输出。
|
||||
|
||||
比如:
|
||||
|
||||
```c
|
||||
printf("%.3s\n", str);
|
||||
printf("%10s\n", str);
|
||||
printf("%20s\n", str);
|
||||
printf("%-20s\n", str);
|
||||
printf("%5.3s\n", str);
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```c
|
||||
Are
|
||||
Are you happy?
|
||||
Are you happy?
|
||||
Are you happy?
|
||||
Are
|
||||
```
|
||||
|
||||
|
||||
|
||||
还可以使用 `puts`函数输出字符串。
|
||||
|
||||
```c
|
||||
puts(str);
|
||||
```
|
||||
|
||||
puts 函数只有一个参数,即需要显示的字符串。写完字符串后,puts 函数总会添加一个额外的换行符:
|
||||
|
||||
```c
|
||||
puts(str);
|
||||
puts(str);
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```c
|
||||
Are you happy?
|
||||
Are you happy?
|
||||
```
|
||||
|
||||
|
||||
|
||||
**puts 函数**
|
||||
|
||||
> `int puts( const char *str )`
|
||||
>
|
||||
> **头文件:**<stdio.h>
|
||||
>
|
||||
> **参数:**`str` - 要写入的参数
|
||||
>
|
||||
> **返回值:**
|
||||
>
|
||||
> 成功时返回非负值
|
||||
>
|
||||
> 失败时,返回 EOF 并设置 stdout 的错误指示器
|
||||
>
|
||||
> **定义:**
|
||||
>
|
||||
> 写入每个来自空终止字符串 `str` 的字符及附加换行符 '**\n**' 到输出流 `stdout` ,如同以重复执行 [putc](https://zh.cppreference.com/w/c/io/fputc) 写入。
|
||||
>
|
||||
> 不写入来自 `str` 的空终止字符。
|
||||
|
||||
|
||||
|
||||
#### 2. 用 scanf 函数和 gets 函数读字符串
|
||||
|
||||
转换说明 `%s`
|
||||
|
||||
```c
|
||||
scanf("%s", str);
|
||||
```
|
||||
|
||||
在 scanf 函数调用中,**不需要**在 str 前加 & 运算符,因为 str 是数组名,编译器在把他传给函数时会把它当作指针来处理。
|
||||
|
||||
调用时,scanf 函数会**跳过空白字符**,然后读入字符并存储到 str 中,直到遇到**空白字符**为止。scanf 函数始终会**在字符串末尾存储一个空字符**。
|
||||
|
||||
用 scanf 函数读入字符串永远不会包括空白字符。因此,scanf 函数通常不会读入一整行输入。换行符,空格符和制表符都会使 scanf 函数停止读入。为了一次读入一整行输入,可使用 `gets`函数。
|
||||
|
||||
**gets 函数**
|
||||
|
||||
> `char * gets(char * str)`
|
||||
>
|
||||
> **head:**<stdio.h>
|
||||
>
|
||||
> **Parameters:**`str` - Pointer to a block of memory (array of char) where the string read is copied as a C string.
|
||||
>
|
||||
> **Return Value:** On success, the function returns *str*.
|
||||
>
|
||||
> **Description:**
|
||||
>
|
||||
> Reads characters from the *standard input* ([stdin](http://www.cplusplus.com/stdin)) and stores them as a C string into *str* until a newline character or the *end-of-file* is reached.
|
||||
>
|
||||
> The newline character, if found, is not copied into *str*.
|
||||
>
|
||||
> A terminating null character is automatically appended after the characters copied to *str*.
|
||||
|
||||
总结一下重点就是:
|
||||
|
||||
- gets 函数**不会**在开始读字符串之前跳过空白字符。
|
||||
- gets 函数会持续读入直到找到**换行符**才停止。**换行符会被忽略**,不会存储到数组中,在字符串**末尾追加空字符**。
|
||||
|
||||
我们用程序来比较一下 scanf 和 gets :
|
||||
|
||||
先来测试 scanf:
|
||||
|
||||
```c
|
||||
char str[20];
|
||||
scanf("%s", str);// 输入 Are you ok?
|
||||
puts(str);
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```c
|
||||
Are
|
||||
```
|
||||
|
||||
只有 "Are" 被存储到了 str 中
|
||||
|
||||
测试 gets:
|
||||
|
||||
```c
|
||||
char str[20];
|
||||
gets(str); // 输入 Are you ok?
|
||||
puts(str);
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```c
|
||||
Are you ok?
|
||||
```
|
||||
|
||||
"Are you ok?" 一整行被存入 str 中
|
||||
|
||||
**注意:**
|
||||
|
||||
把字符读入数组时,scanf 函数和 gets 函数都无法检测数组何时被填满。因此,它们存储字符时可能会越过数组的边界,这会导致未定义行为。
|
||||
|
||||
通过转换说明 `%ns`代替`%s`可以使 scanf 更加安全。这里 n 指出可以存储的最多字符数。可惜的是,gets 天生就是不安全的,`fgets`函数则是好的多的选择(后面会讲)。
|
||||
|
||||
|
||||
|
||||
#### 3. 逐个字符读取字符串
|
||||
|
||||
因为对许多程序而言,scanf 函数和 gets 函数都有风险而且不够灵活,C 程序员经常会自己编写输入函数。通过每次读一个字符的方式读取字符串。
|
||||
|
||||
如果决定自己设计输入函数,那么需要考虑以下问题:
|
||||
|
||||
- 在开始存储字符串之前,函数应该跳过空白字符吗?
|
||||
- 什么字符导致函数停止读取:换行符,任意空白字符,还是其他某种字符?需要存储这些字符还是忽略掉?
|
||||
- 如果输入的字符串太长以至于无法存储,那么函数应该忽略额外的字符还是把它们留给下一次输入操作?
|
||||
|
||||
示例中,我们选择:不跳过空白字符,换行符结束,不存储换行符,忽略掉额外字符。
|
||||
|
||||
函数原型如下:
|
||||
|
||||
```c
|
||||
int read_line(char str[], int read_num);
|
||||
```
|
||||
|
||||
参数:str 表示存储输入的数组,read_num 表示读入字符的最大数量。
|
||||
|
||||
返回值:返回读入字符的个数。
|
||||
|
||||
使用 getchar 实现按字符读入。(按理来说,getchar 函数读入字符失败,也应该结束循环,但这里暂时忽略这种情况)
|
||||
|
||||
```c
|
||||
int read_line(char str[], int read_num) {
|
||||
|
||||
int ch, i = 0;
|
||||
|
||||
while ((ch = getchar()) != '\n') {
|
||||
// i 大于 read_num 不执行操作,跳过后面的字符
|
||||
if (i < read_num)
|
||||
str[i++] = ch;
|
||||
}
|
||||
|
||||
str[i] = '\0';
|
||||
|
||||
return i;
|
||||
}
|
||||
```
|
||||
|
||||
**注意:**
|
||||
|
||||
ch 的类型是 int 而不是 char ,只是因为 getchar 把它读入的字符作为 int 类型的值返回。
|
||||
|
||||
|
||||
|
||||
### 四 访问字符串中的字符
|
||||
|
||||
编写一个函数统计字符串中空格的数量:
|
||||
|
||||
```c
|
||||
int count_spaces(const char s[]){
|
||||
int i, count = 0;
|
||||
|
||||
for(i = 0; s[i] != '\0'; i++)
|
||||
if(s[i] == ' ')
|
||||
count++;
|
||||
|
||||
return count;
|
||||
}
|
||||
```
|
||||
|
||||
声明中 `const` 表明此函数不能改变数组元素。因为 s 是字符串,所以不需要传入数组的大小,遍历中如果出现 `\0` 就表示字符串结束。
|
||||
|
||||
C 程序员更喜欢用指针来跟踪字符串当前的位置:
|
||||
|
||||
```c
|
||||
int count_spaces(const char* s){
|
||||
int count = 0;
|
||||
|
||||
while(*s != '\0'){
|
||||
if(*s == ' ')
|
||||
count++;
|
||||
s++;
|
||||
}
|
||||
|
||||
return count;
|
||||
}
|
||||
```
|
||||
|
||||
**注意:**
|
||||
|
||||
关于字符串数组用数组取下标还是用指针访问字符,形参声明为数组还是指针,这和上一讲中数组和指针的问题是一样的。
|
||||
|
||||
|
||||
|
||||
### 五 C 语言字符串库
|
||||
|
||||
一些编程语言提供的运算符可以对字符串进行复制,比较,拼接,选择字串等操作,但 C 语言的运算符根本无法操作字符串。所以我们需要常用到一些`<string.h>`中的库函数,当然你自己写也是可以的。
|
||||
|
||||
**注意:**
|
||||
|
||||
对于两个字符串数组:
|
||||
|
||||
```c
|
||||
char str1[] = "Hello";
|
||||
char str2[] = "World";
|
||||
```
|
||||
|
||||
如果你这样复制字符串:
|
||||
|
||||
``` c
|
||||
str1 = str2;// wrong
|
||||
str1 = "abc"; // wrong
|
||||
```
|
||||
|
||||
如果想这样比较字符串的内容:
|
||||
|
||||
```c
|
||||
if(str1 == str2){ // wrong
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
上面这样的行为都是不能达到你的预期的。
|
||||
|
||||
|
||||
|
||||
如果你要使用 string.h 中的函数,需要包含它的头文件:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
```
|
||||
|
||||
我们这里介绍几种最基本的函数。
|
||||
|
||||
- `strcpy`
|
||||
- `strlen`
|
||||
- `strcat`
|
||||
- `strcmp`
|
||||
|
||||
***
|
||||
|
||||
**程序圆寄语**:
|
||||
|
||||
这些函数在我的【C必知必会】的【慕课】篇和【C进阶】篇中各一篇文章详细的讲了这些函数的原理和实现。链接如下:
|
||||
|
||||
[基础](https://mp.weixin.qq.com/s/CrInWDeD5k_XNvPzcgI06Q)
|
||||
|
||||
[进阶](https://mp.weixin.qq.com/s/oOMvQaup_Phw1bfF3fIzrg)
|
||||
|
||||
如果你是初学者只需要看上面列举出来的那几个函数即可,甚至可以不用去实现它们。先把它们用起来。
|
||||
|
||||
***
|
||||
|
||||
|
||||
|
||||
#### 程序:显示一个月的提醒列表
|
||||
|
||||
此程序会显示每一个月的每日提醒列表。用户需要输入一系列提醒,每条提醒都要有一个前缀来说明是那一个月中的那一天。当用户输入的是 0 而不是有效日期时,程序会显示出录入的全部提醒列表(按日期排序)。下面是会话示例:
|
||||
|
||||
```c
|
||||
Enter day and reminder: 24 Suan's birstday
|
||||
Enter day and reminder: 5 6:00 - Dinner with Marge
|
||||
Enter day and reminder: 7 10:30 - Movie - "Chinatown"
|
||||
Enter day and reminder: 0
|
||||
Day Reminder:
|
||||
5 6:00 - Dinner with Marge
|
||||
7 10:30 - Movie - "Chinatown"
|
||||
24 Suan's birstday
|
||||
```
|
||||
|
||||
- 读入提醒使用我们写的 read_line 函数
|
||||
- 将提醒存放在二维数组中,数组的每一行看作一个字符串。日期和提示消息都要放进去 。
|
||||
- 日期我们用整型输入,然后转换为字符串放入二维数组的前面。
|
||||
- 每次读入新的日期和提示消息后,将转为字符串的当前日期和二维数组每行前面表示日期的部分比较。如果当前日期字符串小于二维数组当前行的字符串,说明当前日期较小,应当插入到当前数组的行前一行。我们可以将二维数组从当前行到存放提示的最后一行每行依次向后移动一行,从而使得当前日期和提示可以插入二维数组的当前行。
|
||||
- 打印二维数组
|
||||
|
||||
结合着程序一起看吧:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<string.h>
|
||||
|
||||
#define MAX_REMIND 50
|
||||
#define MSG_LEN 100
|
||||
|
||||
|
||||
int read_line(char str[], int read_num);
|
||||
|
||||
int main(void) {
|
||||
|
||||
char reminders[MAX_REMIND][MSG_LEN + 3]; // 存放提示的数组
|
||||
// 如何使用这个二维数组呢?我们将它的每一行当作一个字符串,reminders[i] 就是每个字符串的指针,如果你不理解可以去前面看看我们的数组的二维数组中的行如何访问;本节第七部分也会讨论二维数组存放字符串的问题。
|
||||
char day_str[3];//当前日期转换为字符串
|
||||
char msg_str[MSG_LEN + 1]; //当前输入的提示消息
|
||||
int day, num_remind = 0; // 日期和当前提示数
|
||||
int i, j;
|
||||
|
||||
|
||||
for (;;) {
|
||||
|
||||
if (num_remind == MAX_REMIND) {
|
||||
printf("-- No space left --\n");
|
||||
break;
|
||||
}
|
||||
|
||||
printf("Enter day and reminder:");
|
||||
|
||||
scanf("%2d", &day); //每月的日期只用两个数表示即可,只读 2 个字段
|
||||
|
||||
if (day == 0)
|
||||
break;
|
||||
|
||||
sprintf(day_str, "%2d", day); // 将 day 以 "%2d" 的格式写入 day_str 字符数组中。"%2d" 保证小于10的天占两位右对齐
|
||||
read_line(msg_str, MSG_LEN);
|
||||
|
||||
// 寻找当前输入的提示应该放到提示数组的那个位置
|
||||
for (i = 0; i < num_remind; i++) {
|
||||
// 说明当前输入的日期应该排在此行前
|
||||
if(strcmp(day_str, reminders[i]) < 0)
|
||||
break;
|
||||
}
|
||||
|
||||
// 将当前输入的提示插入到正确的位置
|
||||
for (j = num_remind; j > i; j--) {
|
||||
strcpy(reminders[j], reminders[j - 1]);
|
||||
}
|
||||
|
||||
strcpy(reminders[i], day_str);
|
||||
strcat(reminders[i], msg_str);// 刚好将 day_str 复制进去的空字符覆盖掉了
|
||||
|
||||
num_remind++;
|
||||
}
|
||||
|
||||
printf("Day Reminder: \n");
|
||||
for (i = 0; i < num_remind; i++)
|
||||
printf("%s\n", reminders[i]);
|
||||
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
|
||||
int read_line(char str[], int read_num) {
|
||||
|
||||
int ch, count = 0;
|
||||
|
||||
while ((ch = getchar()) != '\n') {
|
||||
if (count < read_num) {
|
||||
str[count++] = ch;
|
||||
}
|
||||
}
|
||||
|
||||
str[count] = '\0';
|
||||
|
||||
return count;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
当然了,这个程序也是可以定义一个结构体来写的。我们就不展示这种写法了。
|
||||
|
||||
|
||||
|
||||
### 六 字符串惯用法
|
||||
|
||||
#### 1. 搜索字符串结尾
|
||||
|
||||
我们来看一下 strlen 的一种模拟实现:
|
||||
|
||||
```c
|
||||
size_t my_strlen(const char* s){
|
||||
|
||||
const char* end = s;
|
||||
|
||||
while(*end++)
|
||||
;
|
||||
return end - s - 1;
|
||||
}
|
||||
```
|
||||
|
||||
**惯用法:**
|
||||
|
||||
```c
|
||||
while(*s)
|
||||
s++;
|
||||
```
|
||||
|
||||
循环结束后 s 指向空字符。
|
||||
|
||||
```c
|
||||
while(*s++)
|
||||
;
|
||||
```
|
||||
|
||||
循环结束 s 正好指向空字符后面的位置。所以上面返回值需要减去 1
|
||||
|
||||
|
||||
|
||||
#### 2. 复制字符串
|
||||
|
||||
strcat 第一种模拟实现:
|
||||
|
||||
```c
|
||||
char* my_strcat(char* s1, const char* s2){
|
||||
|
||||
char* ret = s1;
|
||||
|
||||
while(*s1 != '\0')
|
||||
s1++;
|
||||
|
||||
while(*s2 != '\0'){
|
||||
*s1 = *s2;
|
||||
s1++;
|
||||
s2++;
|
||||
}
|
||||
*s1 = '\0';
|
||||
|
||||
return ret;
|
||||
}
|
||||
```
|
||||
|
||||
另一种更为简便的方法:
|
||||
|
||||
```c
|
||||
char* my_strcat(char* s1, const char* s2){
|
||||
|
||||
char* ret = s1;
|
||||
|
||||
while(*s1)
|
||||
s1++;
|
||||
|
||||
while(*s1++ = *s2++)
|
||||
;
|
||||
|
||||
return ret;
|
||||
}
|
||||
```
|
||||
|
||||
第二个循环结束时:s2 将其空字符赋值给 s1 ,所以不需要最后再用单独的一条语句在新字符串的末尾加上空字符。
|
||||
|
||||
|
||||
|
||||
**惯用法:**
|
||||
|
||||
```c
|
||||
while(*s1++ = *s2++)
|
||||
;
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 七 字符串数组
|
||||
|
||||
存储字符串数组的最佳方式是什么?最明显的解决方案是创建一个二维字符数组,然后按照每行一个字符串来存储。
|
||||
|
||||
```c
|
||||
char planets[][8] = {
|
||||
"Mercury", "Venus", "Earth",
|
||||
"Mars", "Jupiter", "Saturn",
|
||||
"Uranus", "Neptune", "Pluto"
|
||||
};
|
||||
```
|
||||
|
||||
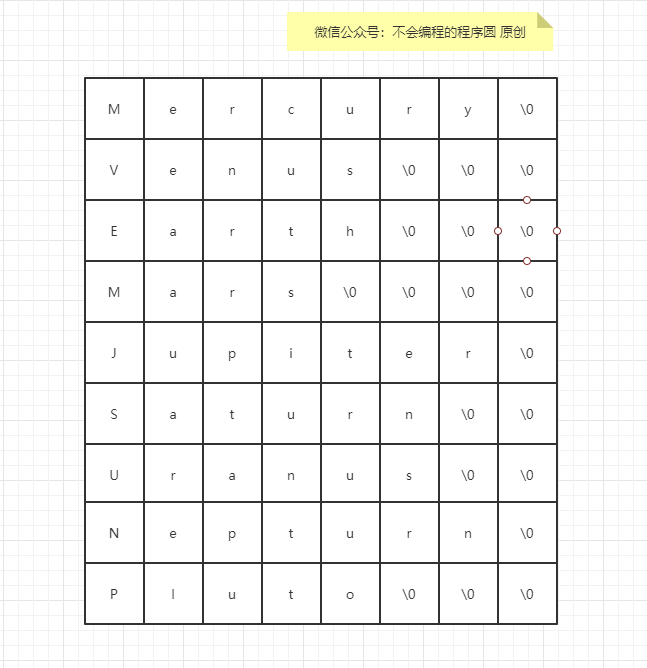
|
||||
|
||||
因为只有 3 个行星的名字填满了一行,所以这样的数组有一点浪费空间。remind.c 程序就是这种浪费的的代表。
|
||||
|
||||
我们需要的是**参差不齐的数组**(ragged array),即每一行有不同长度的二维数组。C 语言本身不提供这样的数组类型。但是我们可以创建一个**指针数组**,数组的每个元素都是一个指向字符串的指针。声明方式:
|
||||
|
||||
```c
|
||||
char* planets[] = {
|
||||
"Mercury", "Venus", "Earth",
|
||||
"Mars", "Jupiter", "Saturn",
|
||||
"Uranus", "Neptune", "Pluto"
|
||||
};
|
||||
```
|
||||
|
||||
现在 planets 的存储方式变为:
|
||||
|
||||
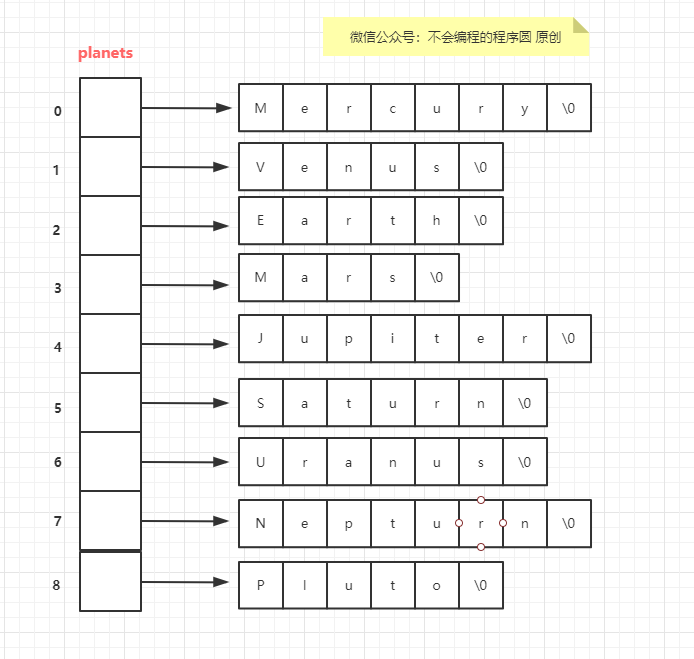
|
||||
|
||||
|
||||
|
||||
planets 中的每个元素都是指向以空字符结尾的字符串的指针。虽然必须为 planets 数组中的指针分配空间,但是字符串中不再有任何浪费的字符。
|
||||
|
||||
获取字符串和普通数组访问一样。由于数组和指针的特殊关系,我们可以这样访问字符串中的字符:
|
||||
|
||||
```c
|
||||
for(i = 0; i < 9; i++)
|
||||
if(planets[i][0] == 'M')
|
||||
printf("%s begins with M\n", planets[i]);
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 1. 命令行参数
|
||||
|
||||
命令行信息不仅对操作系统命令可用,它对所有程序都是可用的。为了可以访问这些**命令行参数**(C 标准中称为**程序参数**),必须把 main 函数定义为含有两个参数的函数。写法如下:
|
||||
|
||||
```c
|
||||
int main(int argc, char* argv[]){
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
> `argc` - 参数计数,是命令行参数的数量(包括程序名本身)
|
||||
>
|
||||
> `argv` - 参数向量,是指向命令行参数的指针数组,这些命令行参数以字符串形式存储。
|
||||
>
|
||||
> `argv[0]`指向程序名,而从 `argv[1] `到 `argv[argc - 1]`则指向余下命令行参数。
|
||||
>
|
||||
> `argv[argc]`是附加元素,这个元素始终是一个空指针 `NULL` 。空指针是一种不指向任何地方的特殊指针。后面我们会讨论空指针问题。
|
||||
>
|
||||
> `NULL` 是一个宏,VS 中我们发现对这个宏的定义:`#define NULL ((void*)0)`
|
||||
|
||||
如果用户输入命令行:
|
||||
|
||||
```c
|
||||
ls -l remind.c
|
||||
```
|
||||
|
||||
argc 将为 3:
|
||||
|
||||
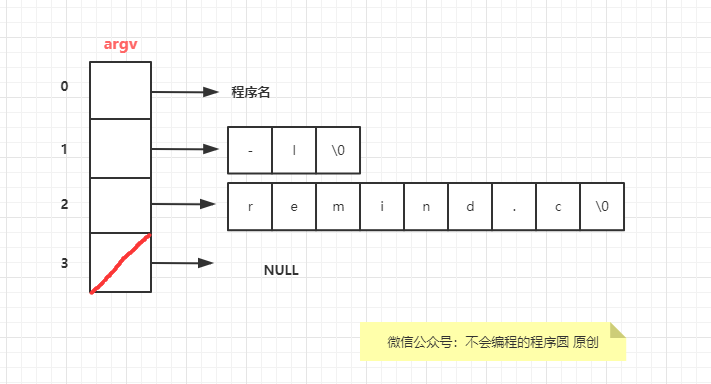
|
||||
|
||||
程序名因操作系统而异。如果程序名不可用,那么 argv[0] 将为 NULL
|
||||
|
||||
**访问命令行参数的方法:**
|
||||
|
||||
```c
|
||||
int i;
|
||||
for(i = 1; i < argc, i++)
|
||||
printf("%s\n", argv[i]);
|
||||
```
|
||||
|
||||
另一种方法是构造一个指向 argv[1] 的指针,然后对指针重复自增来逐个访问数组中的字符串指针。因为 argv[1] 是指针,所以我们要构造一个指向指针的指针:
|
||||
|
||||
```c
|
||||
char** p;
|
||||
for(p = &argc[1]; p != NULL; p++){
|
||||
printf("%s\n", *p);
|
||||
}
|
||||
```
|
||||
|
||||
因为 p 是指向指针的指针,所以 *p 就是指向参数字符串的指针
|
||||
|
||||
|
||||
|
||||
#### 程序:核对行星的名字
|
||||
|
||||
设计一个程序检查一系列字符串,从而找出那些字符串是行星的名字。执行程序时,用户把待测试的字符串放置在命令行中:
|
||||
|
||||
```c
|
||||
planet Mercury Aotoman Pluto Thebug Earth
|
||||
```
|
||||
|
||||
程序会指出每个字符串是否为行星名。如果是,程序还将显示行星的编号:
|
||||
|
||||
```c
|
||||
Mercury is a planet 1
|
||||
Aotoman is not a planet
|
||||
Pluto is a planet 9
|
||||
Thebug is not a planet
|
||||
Earth is a planet 3
|
||||
```
|
||||
|
||||
**注意:**命令行输入的第一个参数 planet 是 c 程序编译出的可执行程序名。一般一个叫 x.c 的程序编译后的可执行程序就叫做 x 。
|
||||
|
||||
我们命名这个 c 程序为 planet.c 所以编译后的可执行文件应该叫做 planet (在 Windows 上后缀应该为 .exe)
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<string.h>
|
||||
|
||||
#define NUM_PLANETS 9
|
||||
|
||||
int main(int argc, char* argv[]) {
|
||||
|
||||
int i, j;
|
||||
char* planets[NUM_PLANETS] = {
|
||||
"Mercury", "Venus", "Earth",
|
||||
"Mars", "Jupiter", "Saturn",
|
||||
"Uranus", "Neptune", "Pluto"
|
||||
};
|
||||
|
||||
for (i = 1; i < argc; i++) {
|
||||
for (j = 0; j < NUM_PLANETS; j++)
|
||||
if (strcmp(argv[i], planets[j]) == 0) {
|
||||
printf("%s is a planet %d\n", argv[i], j + 1);
|
||||
break;
|
||||
}
|
||||
if (j == NUM_PLANETS)
|
||||
printf("%s is not a planet\n", argv[i]);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
程序会依次访问每个命令行参数,把它与 planets 中的字符串进行比较,直到找到匹配的名字或到了数组末尾才停止。
|
||||
|
||||
|
||||
|
||||
我们来看一下如何在 Windows 上测试我们写出的程序。打开 cmd 窗口,找到编译后的可执行程序的位置。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
*参考资料:cplusplus.com cppreference.com 《C语言程序设计:现代方法》*
|
||||
|
||||
[^1]: 凡事都应该自顶向下,除了第一次。
|
||||
1038
content/c-mordern-approch/15-预处理器.md
Normal file
1038
content/c-mordern-approch/15-预处理器.md
Normal file
File diff suppressed because it is too large
Load Diff
624
content/c-mordern-approch/16-编写大型程序.md
Normal file
624
content/c-mordern-approch/16-编写大型程序.md
Normal file
@@ -0,0 +1,624 @@
|
||||
## 编写大型程序
|
||||
|
||||
*If a listener nods his head when you're explaining your program, wake him up.* [^1]
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 目录
|
||||
|
||||
***
|
||||
|
||||
[TOC]
|
||||
|
||||
|
||||
|
||||
## 编写大型程序
|
||||
|
||||
***
|
||||
|
||||
|
||||
|
||||
### 零 源文件
|
||||
|
||||
到现在为止一直假设 C 程序是由单独一个文件组成的。事实上,可以把程序分割为任意数量的**源文件**。根据惯例,源文件的扩展名为`.c`。每个源文件包含程序的部分内容,主要是函数的定义和变量的定义。其中源文件必须包含一个 `main`函数作为程序的起始点。
|
||||
|
||||
把程序分为多个源文件有许多**优点**:
|
||||
|
||||
- **把相关的函数和变量分组放在同一个文件中可以使程序的结构清晰**
|
||||
- **可以分别对每一个源文件进行编译**
|
||||
- **把函数分组放在不同的源文件中更利于复用**
|
||||
|
||||
|
||||
|
||||
### 一 头文件
|
||||
|
||||
当把程序分割为几个源文件时,问题也随之产生了:某文件中的函数如何调用定义在其他文件中的函数呢?函数如何访问其他文件中的外部变量呢?两个文件如何共享一个宏定义或类型定义呢?答案就是使用 `#include`指令
|
||||
|
||||
`#include`指令告诉预处理器打开指定的文件,并把此文件的内容插入到当前文件中。按照此种方式包含的文件称为**头文件**(有时称为包含文件)。
|
||||
|
||||
注意:C 标准使用术语“源文件”来只是程序员编写的全部文件,包括`.c`和`.h`文件。前面说的源文件指`.c`文件。
|
||||
|
||||
|
||||
|
||||
#### 0. `#include`指令
|
||||
|
||||
#include 指令主要有两种书写格式,这两种格式之间的差异在于编译器定位头文件的方式。
|
||||
|
||||
- 用于属于 C 语言自身库的头文件:
|
||||
|
||||
```c
|
||||
#include <文件名>
|
||||
```
|
||||
|
||||
搜寻系统头文件所在的目录(或多个目录)。
|
||||
|
||||
- 用于所有其他头文件(包含自己编写的):
|
||||
|
||||
```c
|
||||
#include"文件名"
|
||||
```
|
||||
|
||||
先搜寻当前目录,然后再搜寻系统头文件所在的目录。
|
||||
|
||||
|
||||
|
||||
在 #include 指令中的文件名可以含有帮助定位文件的信息,比如目录的路径或驱动器号:
|
||||
|
||||
```c
|
||||
#include"c:\VScode\myhead.h" // Windows path
|
||||
```
|
||||
|
||||
|
||||
|
||||
**注意:**
|
||||
|
||||
- 预处理器不会将 #include 指令中的双引号部分当作字符串字面量来处理。(否则,上例中的`\v`和`\m`会被当作转义序列处理)
|
||||
- 最好在 #include 指令中不包含路径和驱动器信息(相对路径要好于绝对路径),这样可以提高可移植性。
|
||||
|
||||
|
||||
|
||||
#include 指令还有一种格式:
|
||||
|
||||
```c
|
||||
#include 记号
|
||||
```
|
||||
|
||||
应用场景:
|
||||
|
||||
```c
|
||||
#if defined(IA32)
|
||||
#define CPU_FILE "ia32.h"
|
||||
#elif defined(IA64)
|
||||
#define CPU_FILE "ia64.h"
|
||||
#elif defined(AMD64)
|
||||
#define CPU_FILE "amd64.h"
|
||||
#endif
|
||||
|
||||
#include CPU_FILE
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 2. 共享宏定义和类型定义
|
||||
|
||||
#### 3. 共享函数原型
|
||||
|
||||
#### 4. 共享变量声明
|
||||
|
||||
上面这三部分的内容本质上差不多,后面我们会用一个程序来向大家演示如何完成。
|
||||
|
||||
需要注意的是:**含有函数和变量定义的`.c`文件需要包含有相应声明的头文件,这样编译器可以检查声明与定义是否匹配。**
|
||||
|
||||
|
||||
|
||||
***
|
||||
|
||||
在头文件中这样写:
|
||||
|
||||
```c
|
||||
int i;
|
||||
```
|
||||
|
||||
这样不仅声明 i 是 int 类型变量,而且也对 i 进行了定义,从而使编译器为 i 留出了空间。为了声明变量 i 而不是定义它,可以这样做:
|
||||
|
||||
```c
|
||||
extern int i;
|
||||
```
|
||||
|
||||
`extern`告诉编译器,变量 i 是在程序中的其他位置定义的,因此不需要为 i 分配空间。
|
||||
|
||||
extern 可以用于所有类型变量的声明中。在数组的声明中使用 extern 时,可以省略数组长度:
|
||||
|
||||
```c
|
||||
extern int a[];
|
||||
```
|
||||
|
||||
因为此刻编译器不用为数组分配空间,所以不需要知道数组长度。
|
||||
|
||||
|
||||
|
||||
说了这么多我是没看懂 extern 怎么用,反正用的不多,不懂没事。
|
||||
|
||||
***
|
||||
|
||||
|
||||
|
||||
#### 5. 嵌套包含
|
||||
|
||||
#### 6. 保护头文件
|
||||
|
||||
如果源文件包含同一个头文件两次,那么可能产生编译错误。
|
||||
|
||||
比如 file1.h 包含 file3.h ,file2.h 包含 file3.h 如果 foo.c 同时包含 file1.h 和 file2.h,那么 file3.h 会被该源文件包含两次。(头文件包含另一个头文件就是所谓的嵌套包含,简单吧。)
|
||||
|
||||
保护头文件的**好处**:
|
||||
|
||||
- **安全**
|
||||
- **减少重复,提高效率**
|
||||
|
||||
比如:
|
||||
|
||||
```c
|
||||
#ifndef BOOLEAN_H
|
||||
#define BOOLEAN_H
|
||||
#
|
||||
#define TRUE 1
|
||||
#define FALSE 0
|
||||
typedef int bool;
|
||||
#
|
||||
#endif;
|
||||
```
|
||||
|
||||
在 boolean.h 中定义宏 BOOLEAN_H ,首次包含这个头文件时,该宏没有被定义。另外,这种情况下,这样定义宏是一个不错的选择。
|
||||
|
||||
|
||||
|
||||
#### 7. 头文件中的 `#error`指令
|
||||
|
||||
`#error`指令经常放置在头文件中,用来检查不应该包含该头文件的条件。例如:如果一个头文件中用到了一个在最初的 C89 前不存在的特性,为了避免把头文件用于旧的非标准编译器,检查 `__STDC__`宏是否存在:
|
||||
|
||||
```c
|
||||
#ifndef __STDC__
|
||||
#error This header requires a Standard C compiler
|
||||
#endif
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 二 把程序划分成多个文件
|
||||
|
||||
#### 程序:文本格式化
|
||||
|
||||
输入未格式化的引语:来自 Dennis M. Ritchie 写的"The Development of the C programming language" 一文:
|
||||
|
||||
```c
|
||||
C is quirky, flawed, and an
|
||||
enormous success. Although accidents of history
|
||||
surely helped, it evidently satisfied a need
|
||||
|
||||
for a system implementation language efficient
|
||||
enough to displace assembly language,
|
||||
yet sufficiently abstract and fluent to describe
|
||||
algorithms and interactions in a wide variety
|
||||
of environments.
|
||||
-- Dennis M. Ritchie
|
||||
```
|
||||
|
||||
程序完成对这段文字的调整:
|
||||
|
||||
```c
|
||||
C is quirky, flawed, and an enormous success. Although
|
||||
accidents of history surely helped, it evidently satisfied a
|
||||
need for a system implementation language efficient enough
|
||||
to displace assembly language, yet sufficiently abstract and
|
||||
fluent to describe algorithms and interactions in a wide
|
||||
variety of environments. -- Dennis M. Ritchie
|
||||
```
|
||||
|
||||
程序分析:
|
||||
|
||||
完成这个程序需要两步:读入和输出。
|
||||
|
||||
读入我们选择按单词读入到当前行中,然后按当前行输出。注意输出的每一行最后“对”的很齐,我们 write_line 函数对这种格式做了特殊处理。
|
||||
|
||||
按单词读入我们创建 word.h 和 word.c
|
||||
|
||||
按行输出我们创建 line.h 和 line.c
|
||||
|
||||
最后用 justify.c 包含 main 函数
|
||||
|
||||
参考程序:
|
||||
|
||||
**word.h**
|
||||
|
||||
```c
|
||||
#ifndef WORD_H
|
||||
#define WORD_H
|
||||
|
||||
/***********************************************************************
|
||||
*
|
||||
* read_word: Read the next word from the input and stores it in word.
|
||||
* Make word empty if no word could be read because of EOF.
|
||||
* Truncates the word if its length exceeds len.
|
||||
*
|
||||
************************************************************************/
|
||||
|
||||
void read_word(char* word, int len);
|
||||
|
||||
#endif
|
||||
```
|
||||
|
||||
**line.h**
|
||||
|
||||
```c
|
||||
#ifndef LINE_H
|
||||
#define LINE_H
|
||||
|
||||
/********************************************************
|
||||
*
|
||||
* clear_line: Clears the current line.
|
||||
*
|
||||
*********************************************************/
|
||||
void clear_line();
|
||||
|
||||
|
||||
/********************************************************
|
||||
*
|
||||
* add_word: Adds word to the end of current line.
|
||||
* If this is not the first word on the line,
|
||||
* puts one space before word.
|
||||
*
|
||||
*********************************************************/
|
||||
void add_word(const char* word);
|
||||
|
||||
|
||||
/********************************************************
|
||||
*
|
||||
* space_remaining: Returns the number of characters left
|
||||
* in the current line.
|
||||
*
|
||||
*********************************************************/
|
||||
int space_remaining();
|
||||
|
||||
|
||||
/********************************************************
|
||||
*
|
||||
* write_line: Writes the current line with justification.
|
||||
*
|
||||
*********************************************************/
|
||||
void write_line();
|
||||
|
||||
|
||||
/********************************************************
|
||||
*
|
||||
* flush_line: Write the current line without
|
||||
* justification.If the line is empty,
|
||||
* does nothing.
|
||||
*
|
||||
*********************************************************/
|
||||
void flush_line(void);
|
||||
|
||||
#endif
|
||||
```
|
||||
|
||||
**word.c**
|
||||
|
||||
```c
|
||||
#define _CRT_SECURE_NO_WARNINGS 1
|
||||
|
||||
#include<stdio.h>
|
||||
#include"word.h"
|
||||
|
||||
// 解决换行符和制表符问题
|
||||
int read_char(void) {
|
||||
|
||||
int ch = getchar();
|
||||
|
||||
if (ch == '\n' || ch == '\t')
|
||||
return ' ';
|
||||
|
||||
return ch;
|
||||
}
|
||||
|
||||
void read_word(char* word, int len) {
|
||||
|
||||
int ch, i;
|
||||
|
||||
while ((ch = read_char()) == ' ')
|
||||
;
|
||||
|
||||
i = 0;
|
||||
while (ch != ' ' && ch != EOF) {
|
||||
if (i < len)
|
||||
word[i++] = ch;
|
||||
|
||||
ch = read_char();
|
||||
}
|
||||
|
||||
word[i] = '\0';
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
**line.c**
|
||||
|
||||
```c
|
||||
#define _CRT_SECURE_NO_WARNINGS 1
|
||||
|
||||
#include<stdio.h>
|
||||
#include<string.h>
|
||||
#include"line.h"
|
||||
|
||||
#define MAX_LINE_LEN 60 // 每行的最大字符数
|
||||
|
||||
char line[MAX_LINE_LEN + 1];
|
||||
int line_len = 0; // 当前行长度
|
||||
int num_words = 0; // 当前行的单词数
|
||||
|
||||
void clear_line() {
|
||||
|
||||
line[0] = '\0';
|
||||
line_len = 0;
|
||||
num_words = 0;
|
||||
}
|
||||
|
||||
void add_word(const char* word) {
|
||||
|
||||
// 非首个单词,需要在上一个单词后添加空格
|
||||
if (num_words > 0) {
|
||||
line[line_len] = ' ';
|
||||
line[line_len + 1] = '\0';
|
||||
line_len++;
|
||||
}
|
||||
|
||||
strcat(line, word);
|
||||
line_len += strlen(word);
|
||||
num_words++;
|
||||
}
|
||||
|
||||
int space_remaining() {
|
||||
|
||||
return MAX_LINE_LEN - line_len;
|
||||
}
|
||||
|
||||
|
||||
void write_line() {
|
||||
|
||||
int extra_space, spaces_to_insert, i, j;
|
||||
|
||||
extra_space = MAX_LINE_LEN - line_len; // 当前行未被填满的字符数
|
||||
for (i = 0; i < line_len; i++) {
|
||||
if (line[i] != ' ')
|
||||
putchar(line[i]);
|
||||
else {
|
||||
spaces_to_insert = extra_space / num_words; // 遵循这个公式来增加空格
|
||||
for (j = 0; j <= spaces_to_insert; j++) // 使用 = 确保至少打印一个
|
||||
putchar(' ');
|
||||
extra_space -= spaces_to_insert;
|
||||
num_words--;
|
||||
}
|
||||
}
|
||||
putchar('\n');
|
||||
}
|
||||
|
||||
void flush_line(void) {
|
||||
|
||||
if (line_len > 0)
|
||||
puts(line);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
**justify.c**
|
||||
|
||||
```c
|
||||
#define _CRT_SECURE_NO_WARNINGS 1
|
||||
|
||||
#include<stdio.h>
|
||||
#include<string.h>
|
||||
#include"word.h"
|
||||
#include"line.h"
|
||||
|
||||
#define MAX_WORD_LEN 20 //每个单词的最大长度
|
||||
|
||||
int main(void) {
|
||||
|
||||
char word[MAX_WORD_LEN + 2];
|
||||
int word_len;
|
||||
|
||||
clear_line();
|
||||
for (;;) {
|
||||
// 允许 read_word 函数多读 1 个字符,多读则代表单词长度超过 20,需要截断
|
||||
read_word(word, MAX_WORD_LEN + 1);
|
||||
word_len = strlen(word);
|
||||
if (word_len == 0) {
|
||||
flush_line();
|
||||
return 0;
|
||||
}
|
||||
// 截断超过 20 个字符的单词
|
||||
if (word_len > MAX_WORD_LEN)
|
||||
word[MAX_WORD_LEN] = '*';
|
||||
// + 1 是因为需要在上一个单词后添加空格。
|
||||
// 如果满足条件,则需要输出当前行并清空当前行
|
||||
if (word_len + 1 > space_remaining()) {
|
||||
write_line();
|
||||
clear_line();
|
||||
}
|
||||
add_word(word);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
### 三 构建多文件程序
|
||||
|
||||
- **编译** 必须对程序中的每个源文件分别进行编译。(**不需要编译头文件。**编译包含头文件的源文件时会自动编译头文件的内容。)对于每个源文件,编译器会产生一个包含目标代码的文件。这些文件称为**目标文件**(object file),在 UNIX 中扩展名为 `.o`,Windows 中为 `.obj`
|
||||
- **链接** 连接器把上一步产生的目标文件和库函数的代码结合起来在一起生成可执行的程序。链接器的一个职责是解决编译器遗留的外部引用问题。(外部引用发生在一个文件中的函数调用另一个文件中定义的函数或访问另一个文件中定义的变量时。)
|
||||
|
||||
编译我们可以用命令:`gcc -c 文件名`
|
||||
|
||||
大多数编译器允许一部构建:`gcc -o justify justify.c word.c line.c `
|
||||
|
||||
选项 `-o` 表明我们希望的可执行文件名为: justify
|
||||
|
||||
|
||||
|
||||
#### 0. makefile
|
||||
|
||||
makefile 过于复杂,以后可能会单独处一起教学。
|
||||
|
||||
|
||||
|
||||
#### 1. 链接期间的错误
|
||||
|
||||
如果程序丢失了函数的定义或变量定义,那么链接器将无法解析外部引用,从而导致`undefined symbol`或`undefined referece` 的消息。
|
||||
|
||||
下面是一些最常见的错误起因:
|
||||
|
||||
- **变量名或函数名拼写错误**。
|
||||
- **缺失文件** 如果编译器不能找到 foo.c 中的函数,那么可能不知道此文件。需要检查是否列出了 foo.c 文件
|
||||
- **缺失库** 链接器不可能找到程序中用到的全部库函数。Linux/Unix 中使用头`<math.h>`可能需要在链接程序时指明选项`-lm`,这会导致链接器去搜索一个包含<math.h>函数编译版本的系统文件。(命令为 `gcc -lm 文件名` )
|
||||
|
||||
|
||||
|
||||
#### 2. 重新构建程序
|
||||
|
||||
程序开发期间,极少需要编译全部文件。为了节约时间,重新构建的过程应该只对那些可能受到上次修改影响的文件进行重新编译。
|
||||
|
||||
需要重新编译的文件有两种可能性:
|
||||
|
||||
- **源文件被改**
|
||||
- **源文件包含的头文件被改**
|
||||
|
||||
|
||||
|
||||
比如我们需要对**程序:文本格式化**中的程序做出一些修改:
|
||||
|
||||
修改 **word.c** 中的 read_char 函数:
|
||||
|
||||
```c
|
||||
int read_char(){
|
||||
|
||||
int ch = getchar();
|
||||
|
||||
return (ch == '\n' || ch == '\t') ? ' ' : ch;
|
||||
}
|
||||
```
|
||||
|
||||
为了避免在 justify.c 中使用 strlen ,我们可以修改 **word.c** 中的 read_word 函数的返回值:
|
||||
|
||||
```c
|
||||
int read_word(char* word, int len) {
|
||||
|
||||
int ch, i;
|
||||
|
||||
while ((ch = read_char()) == ' ')
|
||||
;
|
||||
|
||||
i = 0;
|
||||
while (ch != ' ' && ch != EOF) {
|
||||
if (i < len)
|
||||
word[i++] = ch;
|
||||
|
||||
ch = read_char();
|
||||
}
|
||||
|
||||
word[i] = '\0';
|
||||
|
||||
return i; // 直接返回 i
|
||||
}
|
||||
```
|
||||
|
||||
与此同时,我们需要改变 read_word 在 **word.h** 中的声明:
|
||||
|
||||
```c
|
||||
int read_word(char* word, int len);
|
||||
```
|
||||
|
||||
然后改变 **justify.c** 函数对 read_word 的调用:
|
||||
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
char word[MAX_WORD_LEN + 2];
|
||||
int word_len;
|
||||
|
||||
clear_line();
|
||||
for (;;) {
|
||||
|
||||
word_len = read_word(word, MAX_WORD_LEN + 1); // 利用返回值
|
||||
if (word_len == 0) {
|
||||
flush_line();
|
||||
return 0;
|
||||
}
|
||||
|
||||
if (word_len > MAX_WORD_LEN)
|
||||
word[MAX_WORD_LEN] = '*';
|
||||
|
||||
if (word_len + 1 > space_remaining()) {
|
||||
write_line();
|
||||
clear_line();
|
||||
}
|
||||
add_word(word);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
如此一来,我们改变了 word.c , word.h 和 justify.c ,在重新构建可执行程序 justify 时,我们需要重新编译 word.c 和 justify.c 然后再重新链接。注意,我们不需要重新编译 line.c ,因为它没有被修改也没有包含 word.h 。所以,对于 GCC 编译器,可以使用下面的指令进行重构:`gcc -o justify justify.c word.c line.o`
|
||||
|
||||
|
||||
|
||||
#### 3. 在程序外定义宏
|
||||
|
||||
命令:`gcc -D` 比如:
|
||||
|
||||
```c
|
||||
gcc -DDEBUG=1 foo.c
|
||||
```
|
||||
|
||||
其效果相当于在 foo.c 的开始处这样写:
|
||||
|
||||
```c
|
||||
#define DEBUG 1
|
||||
```
|
||||
|
||||
如果 -D 选项没有指定值,那么这个值被设为 1
|
||||
|
||||
许多编译器也支持`-U`选项,用于删除宏,效果相当于`#undef`
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
[^1]: 如果有人听你讲解程序时点头了,把他叫醒。 [Epigrams on Programming 编程警句 ](https://epigrams-on-programming.readthedocs.io/zh_CN/latest/epigrams.html)
|
||||
|
||||
*参考资料:《C语言程序设计:现代方法》*
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
1029
content/c-mordern-approch/17-结构&联合&枚举.md
Normal file
1029
content/c-mordern-approch/17-结构&联合&枚举.md
Normal file
File diff suppressed because it is too large
Load Diff
807
content/c-mordern-approch/18-指针的高级应用.md
Normal file
807
content/c-mordern-approch/18-指针的高级应用.md
Normal file
@@ -0,0 +1,807 @@
|
||||
## 指针的高级应用
|
||||
|
||||
*A language that doesn't affect the way you think about programming, is
|
||||
not worth knowing.* [^1]
|
||||
|
||||
|
||||
|
||||
## 目录
|
||||
|
||||
***
|
||||
|
||||
[TOC]
|
||||
|
||||
## 指针的高级应用
|
||||
|
||||
***
|
||||
|
||||
### 零 前言
|
||||
|
||||
相关文章参考:
|
||||
|
||||
https://mp.weixin.qq.com/s/9nXO9i8AXbMZ5fyckLjp5A
|
||||
|
||||
https://mp.weixin.qq.com/s/FfNI5ooT75VyIdM9dmiq-A
|
||||
|
||||
参考这两篇文章对你理解这部分知识很有帮助。
|
||||
|
||||
### 一 动态存储分配
|
||||
|
||||
C 语言的数据结构通常是固定大小的。例如,一旦程序完成编译,数组元素的数组就固定了。(C99 中,变长数组的长度在运行时确定,但是数组的声明周期内仍然是固定长度的。)因为在编写程序时强制选择了大小,在不修改程序并且再次编译程序的情况下无法改变数据结构的大小。
|
||||
|
||||
为了扩大数据结构(前面我们通常用到的是数组)的大小,可以增加数组大小并重新编译程序。但是,无论如何增大数组,始终有可能填满数组。幸运的是,C 语言支持**动态存储分配**,即在程序执行期间分配内存单元的能力。利用动态存储分配,可以设计出根据需要扩大(和缩小)的数据结构。
|
||||
|
||||
|
||||
|
||||
#### 0. 内存分配函数
|
||||
|
||||
为了动态地分配存储空间,需要调用三种内存分配函数的一种,这些函数都是声明在头`<stdlib.h>`中的。
|
||||
|
||||
- `malloc`函数 —— 分配内存块,但是不对内存块进行初始化
|
||||
- `calloc` 函数 —— 分配内存块,并对内存块进行清零
|
||||
- `realloc` 函数 —— 调整先前分配的内存块的大小
|
||||
|
||||
这三种函数中,`malloc`函数是最常用的。因为 malloc 不需要对分配的内存块进行清零,所以它比 calloc 函数**效率更高**。
|
||||
|
||||
当为申请内存块而调用内存分配函数时,由于函数无法知道计划存储在内存块中的数据是什么类型的,所以它不能返回 `int` 类型,`char`类型等普通类型的指针。取而代之的是,函数返回`void*`类型的值。`void*`类型的值是“通用”指针,本质上它只是内存地址。
|
||||
|
||||
|
||||
|
||||
#### 1. 空指针
|
||||
|
||||
当调用内存分配函数中时,总存在这样的可能性:找不到满足我们需要的足够大的内存块。如果真的发生了这类问题,函数会返回**空指针**(null pointer)。空指针是“不指向任何地方的指针”,这是一个区别于所有有效指针的特殊值。
|
||||
|
||||
**注意:试图通过空指针访问内存的效果是未定义的,程序可能出现崩溃或者出现不可预测的行为。**因此,在把内存分配函数的返回值存储到指针变量中以后,需要判断该指针变量是否为空指针。
|
||||
|
||||
空指针用名为 `NULL` 的宏来表示,所以可以使用下列方式测试 malloc 函数的返回值:
|
||||
|
||||
```c
|
||||
p = malloc(10000);
|
||||
if(p == NULL){
|
||||
// allocation failed; take approriate action
|
||||
}
|
||||
```
|
||||
|
||||
一些程序员把 malloc 函数的调用和 NULL 的测试组合起来:
|
||||
|
||||
```c
|
||||
if((p == malloc(10000)) == NULL){
|
||||
// allocation failed; take approriate action
|
||||
}
|
||||
```
|
||||
|
||||
名为 `NULL`的宏在 6 个头`<locale.h> <stddef.h> <stdio.h> <stdlib.h> <string.h> <time.h>`中都有定义。
|
||||
|
||||
语句:
|
||||
|
||||
```c
|
||||
if(p == NULL) ...
|
||||
```
|
||||
|
||||
可以写成:
|
||||
|
||||
```c
|
||||
if(!p) ...
|
||||
```
|
||||
|
||||
而语句:
|
||||
|
||||
```c
|
||||
if(p != NULL) ...
|
||||
```
|
||||
|
||||
可以写成:
|
||||
|
||||
```c
|
||||
if(p) ...
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 二 动态分配字符串
|
||||
|
||||
#### 0. 使用 malloc 函数为字符串分配内存
|
||||
|
||||
`malloc`函数具有如下原型:
|
||||
|
||||
```c
|
||||
void* malloc(size_t size);
|
||||
```
|
||||
|
||||
`size_t`是 C 语言库定义的无符号整数类型,除非分配的空间巨大,否则可以用 `int`型。
|
||||
|
||||
为长度为 n 的字符串分配内存空间:
|
||||
```c
|
||||
char* p = malloc(n + 1);
|
||||
```
|
||||
|
||||
`n + 1`为空字符留出空间。执行赋值操作时会把 malloc 函数返回的通用指针转化为`char*`类型,而不需要强制类型转换。然后,一般我们都会进行强制类型转换:
|
||||
|
||||
```c
|
||||
p = (char*)malloc(n + 1);
|
||||
```
|
||||
|
||||
**注意:为字符串分配内存空间时,不要忘记包含空字符的空间**
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### 1. 在字符串函数中使用动态存储分配
|
||||
|
||||
我们自行编写一个函数将两个字符串连接起来而不改变其中任何一个字符串。先调用 malloc 分配适当大小的内存空间。接下来函数把第一个字符串复制到新的内存空间中,然后调用 `strcat`函数来拼接第二个字符串:
|
||||
|
||||
```c
|
||||
char* concat(const char* s1, const char* s2){
|
||||
|
||||
char* ret = (char*)malloc(strlen(s1) + strlen(s2) + 1);
|
||||
|
||||
if(ret == NULL){
|
||||
printf("Error:malloc failed in concat.\n");
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
strcpy(ret, s1);
|
||||
strcat(ret, s2);
|
||||
|
||||
return ret;
|
||||
}
|
||||
```
|
||||
|
||||
如果 malloc 函数返回 NULL,函数显示出错信息并终止程序。这并不是正确的措施。
|
||||
|
||||
下面时可能的 concat 函数调用方式:
|
||||
|
||||
```c
|
||||
p = concat("abc", "def");
|
||||
```
|
||||
|
||||
这个调用后,p 将指向字符串"abcdef",此字符串存储在动态内存分配的数组中。数组包含结尾的空字符一共 7 个字符长。
|
||||
|
||||
|
||||
|
||||
**注意:注意最后调用 free 函数释放申请的空间**
|
||||
|
||||
|
||||
|
||||
#### 3. 动态分配字符串的数组
|
||||
|
||||
#### 程序:显示一个月的提醒列表
|
||||
|
||||
前面我们把字符串存储在二维数组中,但是这可能会浪费空间。后面的教学中我们设想使用指针数组存储字符串,让一维数组的每个元素都指向一个字符串字面量。如果数组元素是指向动态分配的字符串的指针,那么是可以实现我们的设想的。
|
||||
|
||||
下面的程序对之前的程序作了小部分修改,修改的地方后面用注释注明了。
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<string.h>
|
||||
#include<stdlib.h>
|
||||
|
||||
#define MAX_REMIND 50
|
||||
#define MSG_LEN 100
|
||||
|
||||
|
||||
int read_line(char str[], int read_num);
|
||||
|
||||
int main(void) {
|
||||
|
||||
char* reminders[MAX_REMIND]; // 存放提示的数组 // change
|
||||
char day_str[3];//当前日期转换为字符串
|
||||
char msg_str[MSG_LEN + 1]; //当前输入的提示消息
|
||||
int day, num_remind = 0; // 日期和当前提示数
|
||||
int i, j;
|
||||
|
||||
|
||||
for (;;) {
|
||||
|
||||
if (num_remind == MAX_REMIND) {
|
||||
printf("-- No space left --\n");
|
||||
break;
|
||||
}
|
||||
|
||||
printf("Enter day and reminder:");
|
||||
|
||||
scanf("%2d", &day); //每月的日期只用两个数表示即可,只读 2 个字段
|
||||
|
||||
if (day == 0)
|
||||
break;
|
||||
|
||||
sprintf(day_str, "%2d", day); // 将 day 以 "%2d" 的格式写入 day_str 字符数组中。"%2d" 保证小于10的天占两位右对齐
|
||||
read_line(msg_str, MSG_LEN);
|
||||
|
||||
|
||||
// 寻找当前输入的提示应该放到提示数组的那个位置
|
||||
for (i = 0; i < num_remind; i++) {
|
||||
// 说明当前输入的日期应该排在此行前
|
||||
if (strcmp(day_str, reminders[i]) < 0)
|
||||
break;
|
||||
}
|
||||
|
||||
// 将当前输入的提示插入到正确的位置
|
||||
for (j = num_remind; j > i; j--) {
|
||||
reminders[j] = reminders[j - 1]; // change
|
||||
}
|
||||
|
||||
reminders[i] = (char*)malloc(sizeof(msg_str) + sizeof(day_str) + 1); // change
|
||||
|
||||
// change
|
||||
if (reminders[i] == NULL) {
|
||||
printf("-- No space left --\n");
|
||||
break;
|
||||
}
|
||||
|
||||
strcpy(reminders[i], day_str);
|
||||
strcat(reminders[i], msg_str);// 刚好将 day_str 复制进去的空字符覆盖掉了
|
||||
|
||||
num_remind++;
|
||||
}
|
||||
|
||||
printf("Day Reminder: \n");
|
||||
for (i = 0; i < num_remind; i++)
|
||||
printf("%s\n", reminders[i]);
|
||||
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
|
||||
int read_line(char str[], int read_num) {
|
||||
|
||||
int ch, count = 0;
|
||||
|
||||
while ((ch = getchar()) != '\n') {
|
||||
if (count < read_num) {
|
||||
str[count++] = ch;
|
||||
}
|
||||
}
|
||||
|
||||
str[count] = '\0';
|
||||
|
||||
return count;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 三 动态分配数组
|
||||
|
||||
当编写程序时,常常很难为数组估计合适的大小。前面我们是用宏来定义数组的大小;现在我们可以在程序执行期间为数组动态分配内存空间。
|
||||
|
||||
|
||||
|
||||
#### 0. 使用 malloc 函数为数组分配存储空间
|
||||
|
||||
分配一个`int[n]`大小的数组:
|
||||
|
||||
```c
|
||||
int* a = (int*)malloc(sizeof(int) * n);
|
||||
```
|
||||
|
||||
对 a 指向的数组进行初始化:
|
||||
|
||||
```c
|
||||
for(i = 0; i < n; i++)
|
||||
a[i] = 0;
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 1. `calloc` 函数
|
||||
|
||||
**函数原型:**
|
||||
|
||||
```c
|
||||
void* calloc(size_t nmemb, size_t size);
|
||||
```
|
||||
|
||||
下面 calloc 函数调用为 n 个整数的数组分配存储空间,并且初始化所有整数为 0:
|
||||
|
||||
```c
|
||||
a = calloc(n, sizeof(int));
|
||||
```
|
||||
|
||||
调用以 1 作为第一个实参的 calloc 函数,可以为任何类型的数据分配空间:
|
||||
|
||||
```c
|
||||
struct point {int x, y}*p;
|
||||
p = calloc(1, sizeof(struct point));
|
||||
```
|
||||
|
||||
执行完此语句后,p 将指向一个结构,且此结构的成员 x 和 y 都会被设为 0 。
|
||||
|
||||
|
||||
|
||||
#### 2. `realloc` 函数
|
||||
|
||||
一旦为数组分配完内存,稍后可能会发现数组过大或过小。realloc 函数可以调整数组的大小使它更适合需要。
|
||||
|
||||
**函数原型**
|
||||
|
||||
```c
|
||||
void* realloc(void* ptr, size_t size);
|
||||
```
|
||||
|
||||
当调用`realloc`函数时,ptr 必须指向先前通过 malloc,calloc 或 realloc 的调用获得的内存块。size 表示内存块的新尺寸,新尺寸可能大于或小于原有尺寸。
|
||||
|
||||
**注意:要确定传递给 realloc 函数的指针来自于先前 malloc,calloc 或 realloc 的调用。如果不是这样的指针,程序可能会行为异常**
|
||||
|
||||
|
||||
|
||||
C 标准列出了几条关于 realloc 函数的规则:
|
||||
|
||||
- 当扩展内存块时,realloc 不会对添加进内存块的字节进行初始化
|
||||
- 如果 realloc 函数不能按要求扩大内存块,那么它会返回空指针,并且原有的内存块中的数据不会发生改变
|
||||
- 如果 realloc 函数调用时以空指针作为第一个参数,那么它的行为就像 malloc 函数一样
|
||||
- 如果 realloc 函数被调用时以 0 作为第二个实参,那么它会释放掉内存块
|
||||
|
||||
如果无法扩大内存块(因为内存块后面的字节已经用于其他目的),realloc 函数会在别处分配新的内存块,然后把旧块中的内容复制到新块中。
|
||||
|
||||
**注意:一旦 realloc 函数返回,请一定要对指向内存块的所有指针进行更新,因为 realloc 函数可能会使内存块移动到了其他地方。**
|
||||
|
||||
|
||||
|
||||
### 四 释放存储空间
|
||||
|
||||
动态存储分配函数所获得的内存都来自一个称为**堆**(heap)的存储池。过于频繁地调用这些函数(或者让这些函数申请大内存块)可能会耗尽堆,这回导致函数返回空指针。
|
||||
|
||||
更糟的是,程序可能分配了内存块,然后又丢失了对这些块的记录,因而浪费了空间。请思考下例:
|
||||
|
||||
```c
|
||||
p = malloc(...);
|
||||
q = malloc(...);
|
||||
p = q;
|
||||
```
|
||||
|
||||
如图:
|
||||
|
||||
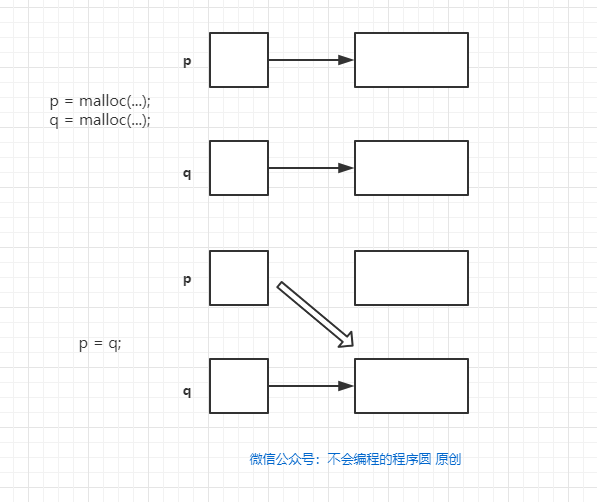
|
||||
|
||||
|
||||
|
||||
因为没有指针指向第一个内存块,所以再也不能使用此块内存了。
|
||||
|
||||
|
||||
|
||||
对于程序而言,不可再访问到的内存称为**垃圾**(garbage)。留有垃圾的程序存在**内存泄漏**(memory leak)现象。一些语言提供**垃圾收集器**(garbage collector)用于垃圾的自动定位和回收,但是 C 语言不提供。所以我们使用 `free`函数来释放不需要的内存。
|
||||
|
||||
#### 0. `free`函数
|
||||
|
||||
**函数原型:**
|
||||
|
||||
```c
|
||||
void* free(void* ptr);
|
||||
```
|
||||
|
||||
使用 free 函数很简单,将指向不再需要的内存块的指针传递给 free 函数即可:
|
||||
|
||||
```c
|
||||
p = malloc(...);
|
||||
q = malloc(...);
|
||||
free(p);
|
||||
p = q;
|
||||
```
|
||||
|
||||
调用 free 函数会释放 p 指向的内存块。然后此内存块可以被后续的 malloc 函数或其他内存分配函数的调用重新使用。
|
||||
|
||||
**注意:**
|
||||
|
||||
- free 函数实参必须是先前由内存分配函数返回的指针,如果参数是指向其他对象的指针,可能会导致未定义行为。
|
||||
- 实参可以空指针,此时 free 调用不起作用
|
||||
|
||||
#### 1. “悬空指针”问题
|
||||
|
||||
虽然 free 函数允许收回不再需要的内存,但会导致一个新的问题:**悬空指针**(dangling pointer)。调用 `free(p)`函数会释放 p 指向的内存块,但是不会改变 p 本身。如果忘记了 p 不再指向有效内存块:
|
||||
|
||||
```c
|
||||
char* p = malloc(4);
|
||||
...
|
||||
free(p);
|
||||
...
|
||||
strcpy(p, "abc"); // wrong
|
||||
```
|
||||
|
||||
修改 p 指向的内存是严重的错误,因为程序不再对此内存由任何控制权了。
|
||||
|
||||
**注意:试图访问或修改释放掉的内存块会导致未定义行为。**
|
||||
|
||||
|
||||
|
||||
### 五 链表
|
||||
|
||||
链表这部分请参考【数据结构轻松学】部分。
|
||||
|
||||
|
||||
|
||||
#### 程序:维护零件数据库
|
||||
|
||||
下面重做前面的程序,这次把数据库存储在链表中。链表代替数组主要有两个好处:
|
||||
|
||||
1. 不需要事先限制数据库的大小
|
||||
2. 可以很容易地按零件编号对数据库排序(本程序采用默认升序排序)
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<stdlib.h>
|
||||
#include"readline.h"
|
||||
|
||||
#define NAME_LEN 20
|
||||
|
||||
typedef struct part {
|
||||
int number;
|
||||
char name[NAME_LEN + 1];
|
||||
int on_hand;
|
||||
struct part* next;
|
||||
}part;
|
||||
|
||||
|
||||
void menu();
|
||||
part* find_part(part* head, int number);
|
||||
void insert(part* head);
|
||||
void search(part* head);
|
||||
void update(part* head);
|
||||
void print(part* head);
|
||||
|
||||
|
||||
int main(void) {
|
||||
|
||||
char code = 'a';
|
||||
part* head = (part*)malloc(sizeof(part));
|
||||
head->next = NULL;
|
||||
|
||||
if (head == NULL) {
|
||||
printf("Database establish failed\n");
|
||||
exit(EXIT_SUCCESS);
|
||||
}
|
||||
|
||||
menu();
|
||||
|
||||
for (;;) {
|
||||
printf("Enter operation code: ");
|
||||
scanf(" %c", &code);
|
||||
while (getchar() != '\n') // skips to end of line
|
||||
;
|
||||
switch (code) {
|
||||
case 'i': insert(head); break;
|
||||
case 's': search(head); break;
|
||||
case 'u': update(head); break;
|
||||
case 'p': print(head); break;
|
||||
case 'q': return 0;
|
||||
default: printf("Illegal code.\n"); break;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
void menu() {
|
||||
|
||||
printf(" ==================================\n");
|
||||
printf(" * *\n");
|
||||
printf(" * i: insert *\n");
|
||||
printf(" * s: search *\n");
|
||||
printf(" * u: undate *\n");
|
||||
printf(" * p: print *\n");
|
||||
printf(" * q: quit *\n");
|
||||
printf(" * *\n");
|
||||
printf(" ==================================\n");
|
||||
}
|
||||
|
||||
|
||||
/**********************************************************
|
||||
*
|
||||
* find_part: Looks up a part number in the inventory
|
||||
* array.Returns the array index if the part
|
||||
* number is found;otherwise,return -1
|
||||
*
|
||||
***********************************************************/
|
||||
part* find_part(part* head, int number) {
|
||||
|
||||
part* cur;
|
||||
|
||||
// 链表是按照编号升序排序的
|
||||
for (cur = head->next; cur != NULL && cur->number > number;
|
||||
cur = cur->next)
|
||||
;
|
||||
|
||||
if (cur == NULL)
|
||||
return NULL;
|
||||
|
||||
if (cur->number == number)
|
||||
return cur;
|
||||
|
||||
}
|
||||
|
||||
|
||||
/**********************************************************
|
||||
*
|
||||
* insert: Inserts the part into the database.Prints
|
||||
* an error message and returns prematurely
|
||||
* if the part already exists or the database
|
||||
* is full.
|
||||
*
|
||||
***********************************************************/
|
||||
void insert(part* head) {
|
||||
|
||||
int part_number;
|
||||
part* cur, * prev, *new_part;
|
||||
|
||||
|
||||
printf("Enter part number: ");
|
||||
scanf("%d", &part_number);
|
||||
|
||||
// 寻找 part_number 所应插入的位置,我们需要 cur 遍历链表,但是应该保留 cur 前面的结点 prev
|
||||
// 退出循环条件:cur == NULL 说明是头插或尾插
|
||||
// cur->number > part_number 说明 输入的编号重复
|
||||
// 应该在 cur 和 prev 之间插入新的零件 或 头插
|
||||
for (cur = head->next, prev = NULL;cur != NULL && cur->number < part_number ;
|
||||
prev = cur, cur = cur->next)
|
||||
;
|
||||
|
||||
// 判断输入的编号是否于数据库中的现有重复
|
||||
if (cur != NULL && cur->number == part_number) {
|
||||
printf("Part already exists.\n");
|
||||
return;
|
||||
}
|
||||
|
||||
// 申请新结点
|
||||
new_part = (part*)malloc(sizeof(part));
|
||||
|
||||
// 判断申请是否成功
|
||||
if (new_part == NULL) {
|
||||
printf("Database is full; can't add more parts.\n");
|
||||
return;
|
||||
}
|
||||
|
||||
|
||||
new_part->number = part_number;
|
||||
printf("Enter part name: ");
|
||||
read_line(new_part->name, NAME_LEN);
|
||||
printf("Enter quantity on hand: ");
|
||||
scanf("%d", &new_part->on_hand);
|
||||
|
||||
// 插入的方式:
|
||||
// 链表为空时:对 head 进行操作(prev == NULL, cur == NULL)
|
||||
// 链表不为空:
|
||||
// 头插:对 head 操作 (prev == NULL, cur != NULL)
|
||||
// 尾插:对 prev 操作 (prev != NULL, cur == NULL)
|
||||
// 普通位置插入:对 prev 操作(prev,cur 都不为 NULL)
|
||||
new_part->next = cur;
|
||||
|
||||
if (prev == NULL)
|
||||
head->next = new_part;
|
||||
else
|
||||
prev->next = new_part;
|
||||
|
||||
}
|
||||
|
||||
|
||||
/************************************************************
|
||||
*
|
||||
* search: Look up a part by the number user enters.
|
||||
* If the part exists, prints the name and quantity
|
||||
* on hand;if not, print an error message.
|
||||
*
|
||||
************************************************************/
|
||||
void search(part* head) {
|
||||
|
||||
int number;
|
||||
part* trg;
|
||||
|
||||
printf("Enter part number: ");
|
||||
scanf("%d", &number);
|
||||
|
||||
trg = find_part(head, number);
|
||||
|
||||
if (trg == NULL) {
|
||||
printf("Part not found.\n");
|
||||
return;
|
||||
}
|
||||
|
||||
printf("Part name: %s\n", trg->name);
|
||||
printf("Quantity on hand: %d\n", trg->on_hand);
|
||||
|
||||
}
|
||||
|
||||
|
||||
/************************************************************
|
||||
*
|
||||
* update: Prompts user to enter a number.
|
||||
* Print an error message if the part doesn't exist;
|
||||
* otherwise,prompts the user to enter change in
|
||||
* quantity on hand and updates the database.
|
||||
*
|
||||
************************************************************/
|
||||
|
||||
void update(part* head) {
|
||||
|
||||
int number, change;
|
||||
part* trg;
|
||||
|
||||
printf("Enter part number: ");
|
||||
scanf("%d", &number);
|
||||
|
||||
trg = find_part(head, number);
|
||||
|
||||
if (trg == NULL) {
|
||||
printf("Part not found.\n");
|
||||
return;
|
||||
}
|
||||
|
||||
printf("Enter change in quantity on hand(- means minus): ");
|
||||
scanf("%d", &change);
|
||||
trg->on_hand += change;
|
||||
|
||||
}
|
||||
|
||||
|
||||
/************************************************************
|
||||
*
|
||||
* print: Print a listing of all parts in the database,
|
||||
* showing the part number,part name and quantity
|
||||
* on hand.Parts are printed in the order in which
|
||||
* they were entered into the database.
|
||||
*
|
||||
************************************************************/
|
||||
|
||||
void print(part* head) {
|
||||
|
||||
|
||||
printf("Part Number Part Name Quantity on Hand\n");
|
||||
for (part* cur = head->next; cur != NULL; cur = cur->next) {
|
||||
printf("%6d%20s%15d\n", cur->number, cur->name, cur->on_hand);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 六 指向指针的指针
|
||||
|
||||
前面我们使用元素类型为`char*`的数组,指向数组元素的指针的类型为`char**`。下面我们以链表的头插为应用场景,帮助大家了解指向指针的指针应该如何应用。
|
||||
|
||||
我们知道,链表的头插需要改变头指针。传递给函数的`list`为头指针(指向首节点的指针),函数返回指向新的首结点的指针。
|
||||
|
||||
```c
|
||||
struct node* add_to_list(struct node* list, int n){
|
||||
struct node* new_node;
|
||||
|
||||
new_node = malloc(sizeof(struct node));
|
||||
if(new_code == NULL){
|
||||
printf("Error: mallloc failed in add_to_list.\n");
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
new_node->val = n;
|
||||
new_node->next = list;
|
||||
return new_node;
|
||||
}
|
||||
```
|
||||
|
||||
假如我们将 return 语句删除,然后添加下面的语句:
|
||||
|
||||
```c
|
||||
list = new_node;
|
||||
```
|
||||
|
||||
可惜的是,这个想法无法实现。假设以此方法调用函数 add_to_list:
|
||||
|
||||
```c
|
||||
add_to_list(first, 10);
|
||||
```
|
||||
|
||||
在调用点,会把 first 复制给 list 。(像所有其他参数一样,指针也是按值传递的。)函数最后一行改变了 list 的值,使它指向了新的结点。但是此复制操作对 first 没有影响。
|
||||
|
||||
让函数修改 first 是可能的,但是需要给函数 add_to_first 传递一个指向 first 的指针。下面是函数的正确形式:
|
||||
|
||||
```c
|
||||
void add_to_list(struct node** list, int n){
|
||||
struct node* new_node;
|
||||
|
||||
new_node = malloc(sizeof(struct node));
|
||||
if(new_code == NULL){
|
||||
printf("Error: mallloc failed in add_to_list.\n");
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
new_node->val = n;
|
||||
new_node->next = *list;
|
||||
|
||||
*list = new_node;
|
||||
}
|
||||
```
|
||||
|
||||
调用此函数,第一个实参为 first 的地址:
|
||||
|
||||
```c
|
||||
add_to_list(&first, 10);
|
||||
```
|
||||
|
||||
使用`*list`作为 first 的别名,修改它是可以改变 first 的内容的。
|
||||
|
||||
|
||||
|
||||
### 七 指向函数的指针
|
||||
|
||||
指向函数的指针(函数指针),不像人们想的那么奇怪。毕竟函数占用内存单元,所以每个函数都有地址,就像每个变量都有地址一样。
|
||||
|
||||
|
||||
|
||||
[^1]: 没有影响你思考编程的语言不值得学。[Epigrams on Programming 编程警句 ](https://epigrams-on-programming.readthedocs.io/zh_CN/latest/epigrams.html)
|
||||
|
||||
*参考资料:《C语言程序设计:现代方法》*
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
486
content/c-mordern-approch/19-声明.md
Normal file
486
content/c-mordern-approch/19-声明.md
Normal file
@@ -0,0 +1,486 @@
|
||||
|
||||
|
||||
## 声明
|
||||
|
||||
*Wherever there is modularity there is the potential for misunderstanding: Hiding information implies a need to check communication.* [^1]
|
||||
|
||||
|
||||
|
||||
## 目录
|
||||
|
||||
***
|
||||
|
||||
[TOC]
|
||||
|
||||
## 声明
|
||||
|
||||
***
|
||||
|
||||
### 零 前言
|
||||
|
||||
声明在 C 语言编程中起着核心的作用。通过声明变量和函数,可以检查程序潜在的错误以及把程序翻译成目标代码两方面为编译器提供至关重要的信息。
|
||||
|
||||
|
||||
|
||||
### 一 声明的语法
|
||||
|
||||
```c
|
||||
声明说明符 声明符;
|
||||
```
|
||||
|
||||
**声明说明符**(declaration specifier):描述声明的变量或函数的性质。**声明符**(declarator)给出了它们单独名字,并且提供了关于其他性质的额外信息。
|
||||
|
||||
声明说明符分为以下 3 大类:
|
||||
|
||||
- **存储类型**。`auto`,`static`,`extern`和`register`。在声明中最多可以出现**一种**存储类型。
|
||||
- **类型限定符**。C89 :`const`,`volatile` 。C99:`restrict`。声明可以包含**多个**类型限定符。
|
||||
- **类型说明符**。关键字 int, double, char 等。类型说明符也包含结构,联合和枚举。
|
||||
|
||||
C99 中还有一种说明符,**函数说明符**,它只用于函数声明。这类说明符只有一个:`inline`
|
||||
|
||||
声明符包括**标识符**,可以组合`*`, `[]`, `()`
|
||||
|
||||
一起看一些说明这些规则的例子:
|
||||
|
||||
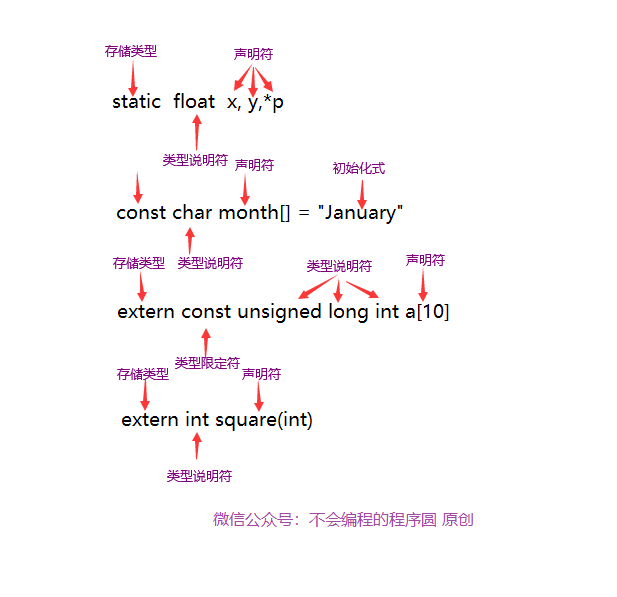
|
||||
|
||||
### 二 存储类型
|
||||
|
||||
这一部分集中讨论**变量**的存储类型。
|
||||
|
||||
**块**(block),表示函数体或者复合语句(可以理解为使用花括号的地方)。C99 中,选择语句和循环语句也被视为块,尽管本质上有些区别。
|
||||
|
||||
#### 1. 变量的性质
|
||||
|
||||
C 程序中的每个变量都具有以下 3 个性质:
|
||||
|
||||
- **存储期限**。变量的存储期限决定了为变量预留和内存被释放的时间。
|
||||
- **自动存储期限**:变量在所属块被执行时获得内存单元,并在程序终止时释放内存单元,从而导致变量失去值。
|
||||
- **静态存储期限**:程序运行期间占有同一个的存储单元,也就允许变量无限期地保留它的值。
|
||||
|
||||
- **作用域**。变量的作用域是指可以引用变量的那部分程序文本。
|
||||
|
||||
- **块作用域**:变量从声明的地方一直到所在块的末尾都是可见的。
|
||||
- **文件作用域**:变量从声明的地方一直到所在文件的末尾都是可见的。
|
||||
|
||||
- **链接**。变量的链接确定了程序的不同部分可以共享此变量的范围。
|
||||
|
||||
- **外部链接**:变量可以被程序中的几个(或全部)文件共享。
|
||||
- **内部链接**:变量只能属于单独的一个文件,但是此文件中的函数可以共享这个变量。
|
||||
- **无连接**:变量属于单独一个函数,而且根本不能被共享。
|
||||
|
||||
变量的默认存储期限,作用域和链接都依赖于变量声明的位置:
|
||||
|
||||
- 在块内声明的变量(如图)
|
||||
- 在程序外层(任意块外部)声明的变量(如图)
|
||||
|
||||

|
||||
|
||||
#### 2. `auto` 存储类型
|
||||
|
||||
`auto`存储类型只对属于块的变量有效。auto 变量具有自动存储期限,块作用域,无链接。auto 存储类型几乎从来不用明确的指明,因为在块内部声明的变量,它是默认的。
|
||||
|
||||
#### 3. `static` 存储类型
|
||||
|
||||
`static`作用于块外部和块内部的变量效果不同。如图:
|
||||
|
||||

|
||||
|
||||
下面的例子中,函数 f1 和 f2 可以访问变量 i,但是其他文件中的函数不可以:
|
||||
|
||||
```c
|
||||
static int i;
|
||||
|
||||
void f1(){
|
||||
...;
|
||||
}
|
||||
void f2(){
|
||||
...;
|
||||
}
|
||||
```
|
||||
|
||||
`static`的此用法可以用来实现一种称为**信息隐藏**的技术。
|
||||
|
||||
块内声明的 static 变量在程序执行期间驻留在同意存储单元内。和每次程序离开所在块就会丢失值的自动变量不同, static 变量会无限期地保留值。static 变量具有以下性质:
|
||||
|
||||
- 块内声明的 `static` 变量只在程序执行前进行一次初始化,而 `auto` 变量则会在每次出现时进行初始化。(当然,假设它有初始化式)
|
||||
- 含有 static 变量的函数全部调用共享这个 static 变量。
|
||||
- 虽然函数不应该返回指向 `auto`变量的指针,但是函数返回指向`static`变量的指针是没有错误的。
|
||||
|
||||
声明函数中的一个变量为 static,这样做允许函数在“隐藏区域”的调用之间保留信息。隐藏区域是程序其他部分无法访问到的地方。思考下列函数:
|
||||
|
||||
```c
|
||||
char digit_to_hex_char(int digit){
|
||||
|
||||
const char hex_chars[16] = "0123456789ABCDEF";
|
||||
|
||||
return hex_chars[digit];
|
||||
}
|
||||
```
|
||||
|
||||
每次调用 digit_to_hex_char 函数时,都会把字符串字面量"0123456789ABCDEF"赋值给数组 hex_chars[16] 来对其初始化。现在,把数组设为 static:
|
||||
|
||||
```c
|
||||
char digit_to_hex_char(int digit){
|
||||
|
||||
static const char hex_chars[16] = "0123456789ABCDEF";
|
||||
|
||||
return hex_chars[digit];
|
||||
}
|
||||
```
|
||||
|
||||
由于 static 变量只进行一次初始化,这样就改进了 digit_to_hex_char 函数的速度。
|
||||
|
||||
#### 4. `extern`存储类型
|
||||
|
||||
`extern` 存储类型可以使几个源文件可以共享同一个变量。前面我们也讲过它,这里不再重复。
|
||||
|
||||
下列声明给编译器提供的信息是 i 是 int 型变量:
|
||||
|
||||
```c
|
||||
extern int i;
|
||||
```
|
||||
|
||||
但是这样不会导致编译器为变量 i 分配存储单元。用 C 的术语来说,上述声明不是变量 i 的定义,他只是提示编译器需要访问定义在别处的变量。(可能稍后在同一文件中,更常见的是在另一个文件中。)变量在程序中可以有多次声明,但是定义只能有一次。
|
||||
|
||||
对变量进行初始化的 extern 声明是变量的定义。例如:
|
||||
|
||||
```c
|
||||
extern int i = 0;
|
||||
```
|
||||
|
||||
等效于:
|
||||
|
||||
```c
|
||||
int i = 0;
|
||||
```
|
||||
|
||||
|
||||
|
||||
extern 声明中的变量始终具有静态存储期限。变量的作用域依赖于声明的位置。如图:
|
||||
|
||||

|
||||
|
||||
确定 extern 型变量的链接有一定难度。如果变量在文件中较早的位置(任何函数外部)声明为 static ,那么它具有内部链接;否则(通常情况下),变量具有外部链接。
|
||||
|
||||
如何理解上面这段话呢,请看下面的程序:
|
||||
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
extern int n;
|
||||
|
||||
n++;
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
int n = 0;
|
||||
```
|
||||
|
||||
编译运行这个程序,没有编译错误和链接错误。程序执行结束,n 会被增加 1 。
|
||||
|
||||
如果我们在另一个文件的函数中想访问 n:
|
||||
|
||||
**file1.c**
|
||||
|
||||
```c
|
||||
void f();
|
||||
|
||||
int main(void) {
|
||||
|
||||
f();
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
int n = 0;
|
||||
```
|
||||
|
||||
**file2.c**
|
||||
|
||||
```c
|
||||
void f() {
|
||||
|
||||
extern int n;
|
||||
|
||||
n++;
|
||||
}
|
||||
```
|
||||
|
||||
编译运行这个程序,也没有编译错误和链接错误。程序执行结束,n 会被增加 1 。
|
||||
|
||||
**这时,n 具有外部链接**
|
||||
|
||||
|
||||
|
||||
我们对程序稍作修改:
|
||||
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
extern int n;
|
||||
|
||||
n++;
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
static int n = 0;
|
||||
```
|
||||
|
||||
编译运行这个程序,出现链接错误。我们需要将 n 的定义放在调用前:
|
||||
|
||||
```c
|
||||
static int n = 0;
|
||||
|
||||
int main(void) {
|
||||
|
||||
extern int n;
|
||||
|
||||
n++;
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
编译运行这个程序,没有编译错误和链接错误。程序执行结束,n 会被增加 1 。
|
||||
|
||||
这时,如果我们想在另一个文件中访问 n,可以实现吗?
|
||||
|
||||
**file1.c**
|
||||
|
||||
```c
|
||||
void f();
|
||||
|
||||
static int n = 0;
|
||||
|
||||
int main(void) {
|
||||
|
||||
n++;
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
**file2.c**
|
||||
|
||||
```c
|
||||
void f() {
|
||||
|
||||
extern int n;
|
||||
|
||||
n++;
|
||||
}
|
||||
```
|
||||
|
||||
编译运行这个程序,出现链接错误。
|
||||
|
||||
**此时,n 具有内部链接**。
|
||||
|
||||
|
||||
|
||||
#### 5. `register` 存储类型
|
||||
|
||||
声明变量具有`register`类型就要求编译器把变量存储在**寄存器**中,而不是像其他变量一样保留在内存中。(寄存器是驻留在 计算机 CPU 中的存储单元。存储在寄存器中的数据会比存储在普通内存中的数据访问和更新速度更快。指明变量的存储类型是 register 是一种**请求**,而不是命令。编译器可以选择把 register 类型的变量存储在内存中。
|
||||
|
||||
register 存储类型只对声明在块内的变量有效。register 变量具有和 auto 变量一样的存储期限,作用域和链接。但是,由于**寄存器没有地址**,所以对 register 变量取地址`&`是非法的。即使编译器选择将其存储在内存中,这一限制仍然适用。
|
||||
|
||||
register 存储类型最好用于需要**频繁进行访问或更新**的变量。例如:
|
||||
|
||||
```c
|
||||
for(register int i = 0; i < N; i++){
|
||||
sum += a[i];
|
||||
}
|
||||
```
|
||||
|
||||
现在 register **不像以前那么流行**了。当今的编译器比早期的 C 语言编译器复杂多了,许多编译器可以**自动确定**哪些变量保存在寄存器中可以获得最大好处。
|
||||
|
||||
|
||||
|
||||
#### 6. 函数的存储类型
|
||||
|
||||
函数声明或定义存储类型选项只有:`extern`和 `static`
|
||||
|
||||
在函数声明开始处的单词`extern`说明函数具有外部链接,也就是允许其他文件调用此函数(默认情况下);`static`说明是内部链接,也就是说只有在定义函数的文件内调用此函数。思考下面的函数声明:
|
||||
|
||||
```c
|
||||
extern int f(int i);// same as: int f(int i);
|
||||
static int g(int i);
|
||||
```
|
||||
|
||||
把 g 声明为 static 不能完全阻止在别的文件中对它的调用,通过**函数指针**进行间接调用仍然是可能的。
|
||||
|
||||
|
||||
|
||||
使用 static 的好处:
|
||||
|
||||
- **更容易维护**。把函数声明为 static 存储类型保证在函数定义出现的文件之外函数 f 都是不可见的。因此,以后修改程序的人可以知道对函数 f 的变化不会影响其他文件中的函数。(另一个文件中如果传入了指向函数 f 的指针,它可能会收到函数 f 变化的影响。幸运的是,这种问题很容易通过检查定义函数 f 的文件来发现,因为传递 f 的函数一定也定义在此文件中。)
|
||||
- **减少了“名字空间污染”**。用于声明 static 的函数具有内部链接,所以可以在其他文件中重新使用这些函数名。虽然我们不太可能会为一些其他目的故意使用相同的函数名,但是在大规模程序中这种现象是难以避免的。
|
||||
|
||||
|
||||
|
||||
### 三 类型限定符
|
||||
|
||||
C 语言中一共有两种类型限定符:`const`和`volatile`(C99 中还有第三种:`restrict`,它只用于指针。)因为 `volatile`只用于底层编程中,我们会在后面的章节中进行讨论。
|
||||
|
||||
`const`用来声明一些类似于变量的对象。但这些变量是“只读”的。程序可以访问 const 型对象的值,但是无法改变它的值。例如:
|
||||
|
||||
```c
|
||||
const int n = 10;
|
||||
const int a[] = {1, 2, 3, 4 ,5};
|
||||
```
|
||||
|
||||
把对象声明为 const 有以下几个好处:
|
||||
|
||||
- **const 是文档格式**。声明对象是 const 类型可以提示阅读程序的人,该对象的值不会改变。
|
||||
- **编译器可以检查程序没有特意地试图改变该对象的值**。
|
||||
|
||||
const 与 #define 之间的差异:
|
||||
|
||||
- `#define`指令为数值,字符或字符串常量创建名字;`const`可用于产生任何类型的只读对象,包括数组,指针,结构或联合。
|
||||
|
||||
- const 对象遵循与变量相同的作用域规则;#define 创建的常量不受这些规则的限制。特别是,不能用 #define 创建具有块作用域的常量。
|
||||
|
||||
- 和宏的值不同,const 对象的值可以在调试器中看到。
|
||||
|
||||
- 不同于宏,**const 对象的值不可用于常量表达式**。比如:
|
||||
|
||||
```c
|
||||
const int n = 10;
|
||||
int a[n]; //wrong
|
||||
```
|
||||
在 C99 中,如果 a 具有自动存储期限,那么这个例子是合法的——它会被视为变长数组;但是如果 a 具有静态存储期限,那么这个例子是不合法的。
|
||||
|
||||
- 对 const 对象应用取地址运算符`&`是合法的,因为它有地址。宏没有地址。
|
||||
|
||||
|
||||
|
||||
### 四 声明符
|
||||
|
||||
声明符包含标识符,符号(`*`,`[]`,`()`)
|
||||
|
||||
|
||||
|
||||
#### 1. 解释复杂声明
|
||||
|
||||
下面这个声明符是什么意思呢?
|
||||
|
||||
```c
|
||||
int *(*x[10])(void);
|
||||
```
|
||||
|
||||
理解声明符的规则:
|
||||
|
||||
- **从内向外读声明符**。定位声明的标识符,并且从此处开始解释声明。
|
||||
- **在做选择时,使用使`[]`和`()`优先于`*`**。
|
||||
|
||||
先看一些简单的声明:
|
||||
|
||||
```c
|
||||
int *ap[10];
|
||||
```
|
||||
|
||||
ap 是标识符,[] 优先级高于 *,所以 ap 是指针数组。
|
||||
|
||||
```c
|
||||
float *fp(float);
|
||||
```
|
||||
|
||||
fp 是标识符,() 优先于 *,所以 fp 是返回指针的函数。
|
||||
|
||||
```c
|
||||
void (*pf)(int);
|
||||
```
|
||||
|
||||
由于 *pf 包含在圆括号内,所以 pf 一定是一个函数指针,此函数返回值类型为 void ,参数为 int 类型。
|
||||
|
||||
再来看前面的这个声明:
|
||||
|
||||
```c
|
||||
int *(*x[10])(void);
|
||||
```
|
||||
|
||||
找到 x,`x[10]`表示数组,`*x[10]`表示指针数组,`(*[x10])`表示这是一个元素都是指向函数的指针数组,此函数返回值类型是 `int*` ,没有参数。
|
||||
|
||||
|
||||
|
||||
### 五 初始化式
|
||||
|
||||
初始化式我们并不陌生,现在我们来看一些控制初始化式的额外规则:
|
||||
|
||||
- 具有静态存储期限的变量的初始化式必须是常量:
|
||||
|
||||
```c
|
||||
#define FIRST 1
|
||||
#define LAST 100
|
||||
|
||||
static int i = LAST - FIRST + 1;
|
||||
```
|
||||
|
||||
- 如果变量具有自动存储期限,那么它的初始化式不需要式常量:
|
||||
|
||||
```c
|
||||
int f(int i){
|
||||
int last = n - 1;
|
||||
}
|
||||
```
|
||||
|
||||
- 包含在花括号中的数组,结构和联合的初始化式必须只包含常量表达式,允许有变量或函数调用:
|
||||
|
||||
```c
|
||||
#define N 2
|
||||
int powers[5] = {1, N, N * N, N * N * N, N * N * N * N};
|
||||
```
|
||||
|
||||
C99 中,仅当变量具有静态存储期限时,这一限制才生效。
|
||||
|
||||
- 自动类型的结构或联合的初始化式可以是另一个结构或联合:
|
||||
|
||||
```c
|
||||
struct part part2 = part1;
|
||||
```
|
||||
|
||||
初始化式不一定非要是变量。比如:
|
||||
|
||||
```c
|
||||
struct part part2 = *p;//p 指向 struct part 类型变量
|
||||
struct part part2 = f(part1); // f 返回值为 struct part 类型
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 1. 未初始化的变量
|
||||
|
||||
变量的默认初始化依赖于变量的**存储类型**:
|
||||
|
||||
- 具有**自动存储期限**的变量没有默认初始值。不能预测自动变量的初始值,每次变量变为有效时只可能不同。
|
||||
- 具有**静态存储期限**的变量默认情况下为 0 。整型变量初始化为 0,符点变量初始化为 0.0,指针初始化为 NULL(空指针)。
|
||||
|
||||
出于书写风格和可读性的考虑,**最好为静态类型的变量提供初始化式**。
|
||||
|
||||
|
||||
|
||||
### 六 内联函数(C99)
|
||||
|
||||
略
|
||||
|
||||
|
||||
|
||||
[^1]: 模块是误解之源;信息隐藏预示沟通的必要。[Epigrams on Programming 编程警句 ](https://epigrams-on-programming.readthedocs.io/zh_CN/latest/epigrams.html)
|
||||
|
||||
*参考资料:《C语言程序设计:现代方法》*
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
862
content/c-mordern-approch/20-程序设计.md
Normal file
862
content/c-mordern-approch/20-程序设计.md
Normal file
@@ -0,0 +1,862 @@
|
||||
## 程序设计
|
||||
|
||||
*Optimization hinders evolution.* [^1]
|
||||
|
||||
## 目录
|
||||
|
||||
***
|
||||
|
||||
[TOC]
|
||||
|
||||
## 程序设计
|
||||
|
||||
***
|
||||
|
||||
### 零 前言
|
||||
|
||||
实际应用中的程序显然比本系列教学的例子要大,但是你可能不会意识到会大多少。如今,大多数功能完整的程序至少有十万行代码,百万行级的程序已经很常见。
|
||||
|
||||
虽然 C 语言不是专门用来编写大型程序的,但许多大型程序的确是用 C 编写的。
|
||||
|
||||
编写大型程序(通常称为“大规模程序设计”)与编写小程序有很大的不同——就如同写一篇学期论文与写一本长篇小说之间的差别一样。大型程序需要更加注意编写风格,因为会有很多人一起工作。需要有正规的文档,同时还需要对维护进行规划,因为程序可能会多次修改。
|
||||
|
||||
尤其是,相对于小型程序,编写大型程序需要更仔细的设计和更详细的计划。
|
||||
|
||||
### 一 模块
|
||||
|
||||
> 设计 C 程序(或其他任何语言的程序)时,最好将它看作是一些独立的**模块**。模块是一组服务的集合,其中一些服务可以被程序的其他部分(称为**客户**)使用。每个模块都有一个**接口**来描述所提供的服务。模块的细节(包括这些服务自身的源代码)都包含在模块的**实现**中。
|
||||
|
||||
在 C 语言环境下,这些“服务”就是函数。模块的接口就是**头文件**,头文件包含那些可以被程序其他文件调用的函数的原型。模块的实现就是包含该模块中函数的定义的**源文件**。
|
||||
|
||||
比如,前面我们写的**程序:文本格式化** 中 line.h 和 word.h 就是接口,line.c 和 word.c 就是实现,包含 main 函数的 justify.c 为客户。
|
||||
|
||||
|
||||
|
||||
将程序分割成模块有一系列好处。
|
||||
|
||||
- **抽象**。 我们知道模块会做什么,但是不需要知道这些功能的实现细节。我们不必为了修改部分程序而了解整个程序是如何工作的。
|
||||
- **可复用性**。任何一个提供服务的模块都有可能在其他程序中复用。
|
||||
- **可维护性**。将程序模块化后,程序中的错误通常只会影响一个模块实现,因而更容易找到错误并修正错误。在修正了错误之后,重建程序只需要重新编译该模块实现(然后重新链接整个程序)。
|
||||
|
||||
比如我们以 inventory 程序为例。最初将零件记录存储在一个数组中。假设在程序使用一段时间后,客户不同意对零件存储数量设置固定的上限。为了满足客户需求,我们可能会改用链表。为了这个修改,需要仔细检查整个程序,找出所有依赖于零件存储方式的地方。如果一开始就采用了不同的方式来设计程序,我们可能只需要重写这一个模块的实现,而不需要重写整个程序。
|
||||
|
||||
一旦我们确定了要进行模块设计,设计程序的过程就变成了确定 需要哪些模块,每个模块应该提供哪些服务,各个模块之间的相互关系是什么。
|
||||
|
||||
|
||||
|
||||
### 二 信息隐藏
|
||||
|
||||
设计良好的模块经常会对它的客户隐藏一些信息。例如,我们的栈模块的客户就不需要知道栈是用数组,链表还是其他形式存储的。这种故意对客户隐藏信息的方法称为信息隐藏。信息隐藏有两大优点:
|
||||
|
||||
- **安全性**。如果客户不知道栈是如何存储的,就不可能通过栈的内部机制擅自修改栈的数据。
|
||||
- **灵活性**。无论对模块的内部机制进行多大的改动,都不会很复杂。
|
||||
|
||||
C 语言中,强制信息隐藏的主要工具是 static 存储类型。将具有文件作用域的变量声明称 static 可以使其具有内部链接,从而避免它被其他文件(包含模块的客户)访问;将函数声明成 static 也可以使其具有内部链接,这样函数只能被同一文件中的其他函数直接调用。
|
||||
|
||||
|
||||
|
||||
#### 1. 栈模块
|
||||
|
||||
为了清楚地看到信息隐藏所带来的好处,下面我们来看看栈模块的两种实现。一种使用数组,一种使用链表。我们假设模块的头文件如下所示:
|
||||
|
||||
**stack.h**
|
||||
|
||||
```c
|
||||
#ifndef STACK_H
|
||||
#define STACK_H
|
||||
|
||||
#include<stdbool.h> //C99 only
|
||||
|
||||
void make_empty();
|
||||
bool is_empty();
|
||||
bool is_full();
|
||||
void push(int i);
|
||||
int pop();
|
||||
|
||||
#endif
|
||||
|
||||
```
|
||||
|
||||
数组实现:
|
||||
|
||||
**stack1.c**
|
||||
|
||||
```c
|
||||
#define _CRT_SECURE_NO_WARNINGS
|
||||
|
||||
#include<stdio.h>
|
||||
#include<stdlib.h>
|
||||
#include"stack.h"
|
||||
|
||||
#define STACK_SIZE 100
|
||||
|
||||
static int contents[STACK_SIZE];
|
||||
static int top = 0;
|
||||
|
||||
static void terminate(const char* message) {
|
||||
printf("%s\n", message);
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
|
||||
void make_empty() {
|
||||
top = 0;
|
||||
}
|
||||
|
||||
bool is_empty() {
|
||||
return top == 0;
|
||||
}
|
||||
|
||||
bool is_full() {
|
||||
return top == STACK_SIZE;
|
||||
}
|
||||
|
||||
void push(int i) {
|
||||
if (is_full())
|
||||
terminate("Error in push: stack is full\n");
|
||||
contents[top++] = i;
|
||||
}
|
||||
|
||||
int pop() {
|
||||
if (is_empty())
|
||||
printf("Error in pop: stack is empty\n");
|
||||
return contents[--top];
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
组成栈的变量(contents 和 top)都被声明为 static 了,因为没有理由让程序的其他部分直接访问它们。terminate 函数也声明为 static 。这个函数不属于模块的接口;相反,它只能在模块的实现内使用。
|
||||
|
||||
我们可以用宏来指明那些函数和变量是公有的(程序的任何地方可以访问)或私有的(一个文件内访问):
|
||||
|
||||
```c
|
||||
#define PRIVATE static
|
||||
#define PUBLIC //empty
|
||||
```
|
||||
|
||||
下面是使用 PUBLIC 和 PRIVATE 栈实现的样子:
|
||||
|
||||
```c
|
||||
PRIVATE int contents[STACK_SIZE];
|
||||
PRIVATE int top = 0;
|
||||
|
||||
PRIVATE void terminate(const char* message) { ... }
|
||||
PUBLIC void make_empty(){...}
|
||||
PUBLIC bool is_empty() { ... }
|
||||
PUBLIC bool is_full() { ... }
|
||||
PUBLIC void push(int i) { ... }
|
||||
PUBLIC int pop() { ... }
|
||||
```
|
||||
|
||||
链表实现:
|
||||
|
||||
**stack2.c**
|
||||
|
||||
```c
|
||||
#define _CRT_SECURE_NO_WARNINGS 1
|
||||
|
||||
#include<stdio.h>
|
||||
#include<stdlib.h>
|
||||
#include"stack.h"
|
||||
|
||||
typedef struct node {
|
||||
int data;
|
||||
struct node* next;
|
||||
}node;
|
||||
|
||||
static node* top = NULL;
|
||||
|
||||
static void terminate(char* message) {
|
||||
printf("%s\n", message);
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
|
||||
void make_empty() {
|
||||
while (!is_empty())
|
||||
pop();
|
||||
}
|
||||
|
||||
bool is_empty() {
|
||||
return top == NULL;
|
||||
}
|
||||
|
||||
bool is_full() {
|
||||
return false;
|
||||
}
|
||||
|
||||
void push(int i) {
|
||||
|
||||
node* new_node = (node*)malloc(sizeof(node));
|
||||
if (new_node == NULL)
|
||||
terminate("Error in push: stack is full.\n");
|
||||
|
||||
new_node->data = i;
|
||||
new_node->next = top;
|
||||
top = new_node;
|
||||
}
|
||||
|
||||
int pop() {
|
||||
|
||||
if (is_empty())
|
||||
terminate("Error in pop: stack is empty.\n");
|
||||
|
||||
int data = top->data;
|
||||
|
||||
node* del = top;
|
||||
top = top->next;
|
||||
free(del);
|
||||
|
||||
return data;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 三 抽象数据类型
|
||||
|
||||
作为抽象对象的模块(比如上面的栈模块)有一个严重的缺点:无法拥有该对象的多个实例(本例中指多个栈)。为了达到这个目的,我们需要进一步创建一个新的类型。
|
||||
|
||||
```c
|
||||
Stack s1, s2;
|
||||
|
||||
make_empty(s1);
|
||||
make_empty(s2);
|
||||
...
|
||||
```
|
||||
|
||||
我们不知道 s1 和 s2 究竟是什么(结构?指针?),但这并不重要。对于栈模块的客户,s1 和 s2 是抽象,它只响应特定的操作。
|
||||
|
||||
修改头文件:
|
||||
|
||||
**stack2.h**
|
||||
|
||||
```c
|
||||
#ifndef STACK2_H
|
||||
#define STACK2_H
|
||||
|
||||
#define STACK_SIZE 100
|
||||
|
||||
typedef struct{
|
||||
int contents[STACK_SIZE];
|
||||
int top;
|
||||
}Stack;
|
||||
|
||||
void make_empty(Stack* s);
|
||||
bool is_empty(const Stack* s);
|
||||
bool is_full(const Stack* s);
|
||||
void push(Stack* s, int i);
|
||||
int pop(Stack* s);
|
||||
|
||||
#endif
|
||||
```
|
||||
|
||||
函数 make_empty, push 和 pop 参数的栈变量需要为指针,因为这些函数会改变栈的内容。is_empty 和 is_full 函数的参数并不需要为指针,但我们依然使用指针,因为传递 Stack 值会导致整个数据结构被复制。
|
||||
|
||||
#### 1. 封装
|
||||
|
||||
遗憾的是,上面的 Stack 不是抽象数据类型,因为 stack2.h 暴露了 Stack 类型的具体实现方式,因此无法阻止客户将 Stack 变量作为结构直接使用:
|
||||
|
||||
```c
|
||||
Stack s1;
|
||||
|
||||
s1.top = 0;
|
||||
s1.contents[top++] = 1;
|
||||
```
|
||||
|
||||
所以,我们真正需要的是一种组织客户知道 Stack 类型具体实现的方式。C 语言对于封装类型的支持有限。新的基于 C 的语言(Java,C++ 和 C#)对于封装的支持更好一些。
|
||||
|
||||
|
||||
|
||||
#### 2. 不完整类型
|
||||
|
||||
C 语言提供的唯一的封装工具为**不完整类型**(incomplete type)。C 标准对不完整类型的描述为:描述了对象但缺少定义对象大小所需的信息。例如,声明:
|
||||
|
||||
```c
|
||||
struct t;
|
||||
```
|
||||
|
||||
告诉编译器 t 是一个结构标记,但没有描述结构的成员。所以编译器没有足够的信息去确定该结构的大小。这样做的意图是:不完整类型将会在程序的其他地方将信息补充完整。
|
||||
|
||||
不完整类型的使用是受限的。因为编译器不知道不完整类型的大小,所以它不能用于变量达到声明:
|
||||
|
||||
```c
|
||||
struct t s;// wrong
|
||||
```
|
||||
|
||||
但是完全可以定义一个指针类型引用不完整的类型:
|
||||
|
||||
```c
|
||||
typedef struct t* T;
|
||||
```
|
||||
|
||||
可以声明类型 T 的变量,将其作为函数的参数传递,并可以执行合法的指针运算(指针的大小不依赖于它所指向的对象,这就解释了为什么 C 语言允许这种行为。)。但是我们不能使用 `->` 运算符。
|
||||
|
||||
|
||||
|
||||
### 四 栈抽象数据类型
|
||||
|
||||
为了说明怎么利用不完整数据类型进行封装,我们需要开发一个基于前面描述的栈模块的栈抽象数据类型(Abstract Data Type,ADT)。这一过程中,我们将用 3 种不同的方法实现栈。
|
||||
|
||||
#### 1. 为栈抽象数据类型定义接口
|
||||
|
||||
Stack 类型作为指针指向 stack_type 结构。这个结构是一个不完整类型,在实现栈的文件中信息将变得完整。
|
||||
|
||||
**stackADT.h**
|
||||
|
||||
```c
|
||||
#ifndef STACKADT_H
|
||||
#define STACKADT_H
|
||||
|
||||
#include<stdbool.h>
|
||||
|
||||
typedef struct stack_type* Stack;
|
||||
|
||||
Stack create(); // 自动给栈分配内存,同时把栈化位空状态
|
||||
void destory(Stack s);// 释放栈的动态内存分配
|
||||
void make_empty(Stack s);
|
||||
bool is_empty(const Stack s);
|
||||
bool is_full(const Stack s);
|
||||
void push(Stack s, int i);
|
||||
int pop(Stack s);
|
||||
|
||||
#endif
|
||||
```
|
||||
|
||||
包含头文件 stackADT.h 的客户就可以声明 Stack 类型的变量,这些变量都可以指向 stack_type 结构。之后客户就可以调用在 stackADT.h 中的函数来对栈进行操作。但是客户不能访问 stack_type 结构的成员,因为该结构定义在另一个文件中。
|
||||
|
||||
下面的客户文件可以用于测试栈抽象数据类型。
|
||||
|
||||
**stackclient.c**
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include"stackADT.h"
|
||||
|
||||
int main(void) {
|
||||
|
||||
Stack s1, s2;
|
||||
|
||||
s1 = create();
|
||||
s2 = create();
|
||||
|
||||
push(s1, 1);
|
||||
push(s1, 2);
|
||||
|
||||
printf("%d\n", pop(s1));
|
||||
printf("%d\n", pop(s1));
|
||||
|
||||
destory(s1);
|
||||
destory(s2);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```c
|
||||
2
|
||||
1
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 2. 使用定长数组实现栈抽象数据类型
|
||||
|
||||
**stackADT.c**
|
||||
|
||||
```c
|
||||
#define _CRT_SECURE_NO_WARNINGS 1
|
||||
|
||||
#include<stdio.h>
|
||||
#include<stdlib.h>
|
||||
#include"stackADT.h"
|
||||
|
||||
#define STACK_SIZE 100
|
||||
|
||||
typedef struct stack_type {
|
||||
int contents[STACK_SIZE];
|
||||
int top;
|
||||
}stack_type;
|
||||
|
||||
|
||||
|
||||
static void terminate(char* message) {
|
||||
printf("%s\n", message);
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
|
||||
Stack create() {
|
||||
|
||||
Stack s = (Stack)malloc(sizeof(stack_type));
|
||||
if (s == NULL) {
|
||||
terminate("Error in create: stack could not be created.\n");
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
s->top = 0;
|
||||
|
||||
return s;
|
||||
}
|
||||
|
||||
|
||||
void destory(Stack s) {
|
||||
|
||||
free(s);
|
||||
}
|
||||
|
||||
|
||||
void make_empty(Stack s) {
|
||||
|
||||
s->top = 0;
|
||||
}
|
||||
|
||||
bool is_empty(Stack s) {
|
||||
return s->top == 0;
|
||||
}
|
||||
|
||||
bool is_full(Stack s) {
|
||||
return s->top == STACK_SIZE;
|
||||
}
|
||||
|
||||
void push(Stack s, int i) {
|
||||
|
||||
if (is_full(s)) {
|
||||
terminate("Error in push: stack is full.\n");
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
|
||||
s->contents[s->top++] = i;
|
||||
}
|
||||
|
||||
int pop(Stack s) {
|
||||
|
||||
if (is_empty(s)) {
|
||||
terminate("Error in pop: stack is empty.\n");
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
|
||||
return s->contents[--s->top];
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 3. 改变栈抽象数据类型中的数据的类型
|
||||
|
||||
栈中的项都是整数,太具有局限性了。为了使栈抽象数据类更易于针对不同的数据项类型进行修改,我们在 stackADT.h 中增加了一行类型定义。现在用类型名 Item 表示存储到栈中的数据的类型。
|
||||
|
||||
**stackADT2.h**
|
||||
|
||||
```c
|
||||
#ifndef STACKADT2_H
|
||||
#define STACKADT2_H
|
||||
|
||||
#include<stdbool.h>
|
||||
|
||||
typedef int Item;
|
||||
|
||||
typedef struct stack_type* Stack;
|
||||
|
||||
Stack create();
|
||||
void destory(Stack s);
|
||||
void make_empty(Stack s);
|
||||
bool is_empty(const Stack s);
|
||||
bool is_full(const Stack s);
|
||||
void push(Stack s, Item i);
|
||||
Item pop(Stack s);
|
||||
|
||||
#endif
|
||||
```
|
||||
|
||||
修改 stackADT.c : 我们只需将 int 出现的地方换为 Item 即可:
|
||||
|
||||
```c
|
||||
typedef struct stack_type {
|
||||
Item contents[STACK_SIZE];
|
||||
int top; // 这个 int 无需修改
|
||||
}stack_type;
|
||||
|
||||
void push(Stack s, Item i) {
|
||||
|
||||
if (is_full(s)) {
|
||||
terminate("Error in push: stack is full.\n");
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
|
||||
s->contents[s->top++] = i;
|
||||
}
|
||||
|
||||
Item pop(Stack s) {
|
||||
|
||||
if (is_empty(s)) {
|
||||
terminate("Error in pop: stack is empty.\n");
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
|
||||
return s->contents[--s->top];
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 4. 用动态数组实现栈抽象数据类型
|
||||
|
||||
修改 stack_type 结构:
|
||||
|
||||
```c
|
||||
typedef struct stack_type {
|
||||
int top;
|
||||
int size;
|
||||
Item contents[]; // 柔性数组
|
||||
}stack_type;
|
||||
```
|
||||
|
||||
使 contents 成员为指向数据项所在数组的指针,而不是数组本身;增加 size 成员来存储栈的最大容量(contents 数组长度)。使用这个成员检测“栈满”情况。使用柔性数组可以减少 create 函数中的一次 malloc。(什么是柔性数组?https://mp.weixin.qq.com/s/FfNI5ooT75VyIdM9dmiq-A)
|
||||
|
||||
**stackADT3.h**
|
||||
|
||||
```c
|
||||
#ifndef STACKADT3_H
|
||||
#define STACKADT3_H
|
||||
|
||||
#include<stdbool.h>
|
||||
|
||||
typedef int Item;
|
||||
|
||||
typedef struct stack_type* Stack;
|
||||
|
||||
Stack create(int size); // change
|
||||
void destory(Stack s);
|
||||
void make_empty(Stack s);
|
||||
bool is_empty(const Stack s);
|
||||
bool is_full(const Stack s);
|
||||
void push(Stack s, Item i);
|
||||
Item pop(Stack s);
|
||||
|
||||
#endif
|
||||
```
|
||||
|
||||
**stackADT3.c**
|
||||
|
||||
修改的地方不多:
|
||||
|
||||
```c
|
||||
#define _CRT_SECURE_NO_WARNINGS 1
|
||||
|
||||
#include<stdio.h>
|
||||
#include<stdlib.h>
|
||||
#include"stackADT3.h"
|
||||
|
||||
|
||||
typedef struct stack_type {
|
||||
int top;
|
||||
int size;
|
||||
Item contents[]; // 柔性数组
|
||||
}stack_type;
|
||||
|
||||
|
||||
|
||||
static void terminate(char* message) {
|
||||
printf("%s\n", message);
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
|
||||
Stack create(int size) {
|
||||
|
||||
// sizeof(stack_type) 的大小不含有柔性数组
|
||||
Stack s = (Stack)malloc(sizeof(stack_type) + sizeof(Item) * size);
|
||||
if (s == NULL) {
|
||||
terminate("Error in create: stack could not be created.\n");
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
s->top = 0;
|
||||
s->size = size;
|
||||
|
||||
return s;
|
||||
}
|
||||
|
||||
|
||||
void destory(Stack s) {
|
||||
|
||||
free(s); // 柔性数组只需要释放一次
|
||||
}
|
||||
|
||||
|
||||
void make_empty(Stack s) {
|
||||
|
||||
s->top = 0;
|
||||
}
|
||||
|
||||
bool is_empty(Stack s) {
|
||||
return s->top == 0;
|
||||
}
|
||||
|
||||
bool is_full(Stack s) {
|
||||
return s->top == s->size;// change
|
||||
}
|
||||
|
||||
void push(Stack s, Item i) {
|
||||
|
||||
if (is_full(s)) {
|
||||
terminate("Error in push: stack is full.\n");
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
|
||||
s->contents[s->top++] = i;
|
||||
}
|
||||
|
||||
Item pop(Stack s) {
|
||||
|
||||
if (is_empty(s)) {
|
||||
terminate("Error in pop: stack is empty.\n");
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
|
||||
return s->contents[--s->top];
|
||||
}
|
||||
```
|
||||
|
||||
事实上,你可以不使用柔性数组:create 函数先为结构变量整体 malloc,然后再为表示栈的数组 malloc 。同样,释放时也需要 2 次分步释放。
|
||||
|
||||
客户文件在调用 create 时需要给出栈的大小:
|
||||
|
||||
```c
|
||||
s1 = create(2);
|
||||
s2 = create(2);
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 5. 使用链表实现栈抽象数据类型
|
||||
|
||||
链表中的结点用如下结构表示:
|
||||
|
||||
```c
|
||||
typedef struct node{
|
||||
int data;
|
||||
struct node* next;
|
||||
}node;
|
||||
```
|
||||
|
||||
为了使栈的接口不变,我们需要再定义一个包含指向链表首节点的结构:
|
||||
|
||||
```c
|
||||
typedef struct stack_type{
|
||||
node* top;
|
||||
}stack_type;
|
||||
```
|
||||
|
||||
**stackADT4.h**
|
||||
|
||||
```c
|
||||
#ifndef STACKADT4_H
|
||||
#define STACKADT4_H
|
||||
|
||||
#include<stdbool.h>
|
||||
|
||||
typedef int Item;
|
||||
|
||||
typedef struct stack_type* Stack;
|
||||
|
||||
Stack create();
|
||||
void destory(Stack s);
|
||||
void make_empty(Stack s);
|
||||
bool is_empty(const Stack s);
|
||||
bool is_full(const Stack s);
|
||||
void push(Stack s, Item i);
|
||||
Item pop(Stack s);
|
||||
|
||||
#endif
|
||||
```
|
||||
|
||||
**stackADT4.c**
|
||||
|
||||
```c
|
||||
#define _CRT_SECURE_NO_WARNINGS 1
|
||||
|
||||
#include<stdio.h>
|
||||
#include<stdlib.h>
|
||||
#include"stackADT4.h"
|
||||
|
||||
typedef struct node{
|
||||
Item data;
|
||||
struct node* next;
|
||||
}node;
|
||||
|
||||
typedef struct stack_type {
|
||||
node* top;
|
||||
}stack_type;
|
||||
|
||||
|
||||
static void terminate(char* message) {
|
||||
printf("%s\n", message);
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
|
||||
Stack create() {
|
||||
Stack s = (Stack)malloc(sizeof(stack_type));
|
||||
if (s == NULL) {
|
||||
terminate("Error in create: stack could not be created.\n");
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
s->top = NULL;
|
||||
|
||||
return s;
|
||||
}
|
||||
|
||||
void destory(Stack s) {
|
||||
|
||||
make_empty(s);
|
||||
free(s);
|
||||
}
|
||||
|
||||
|
||||
|
||||
void make_empty(Stack s) {
|
||||
while (!is_empty(s))
|
||||
pop(s);
|
||||
}
|
||||
|
||||
bool is_empty(Stack s) {
|
||||
return s->top == NULL;
|
||||
}
|
||||
|
||||
bool is_full(Stack s) {
|
||||
return false;
|
||||
}
|
||||
|
||||
void push(Stack s, Item i) {
|
||||
|
||||
node* new_node = (node*)malloc(sizeof(node));
|
||||
if (new_node == NULL) {
|
||||
terminate("Error in push: stack is full.\n");
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
|
||||
new_node->data = i;
|
||||
new_node->next = s->top;
|
||||
s->top = new_node;
|
||||
}
|
||||
|
||||
Item pop(Stack s) {
|
||||
|
||||
if (is_empty(s))
|
||||
terminate("Error in pop: stack is empty.\n");
|
||||
|
||||
int data = s->top->data;
|
||||
|
||||
node* del = s->top;
|
||||
s->top = s->top->next;
|
||||
free(del);
|
||||
|
||||
return data;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 五 抽象数据类型的设计问题
|
||||
|
||||
前面描述了栈的抽象数据类型,并介绍了几种实现方法。遗憾的是,这里的抽象数据类型存储一些问题,使其达不到工业级强度。
|
||||
|
||||
#### 1. 命名惯例
|
||||
|
||||
目前的栈抽象数据类型函数都采用简短,便于记忆的名字:create,destroy 等。如果一个程序中有多个抽象数据类型,两个模块中很可能具有同名函数,这样就出现了名字冲突。所以,我们可能需要在函数名中加入抽象数据类型本身的名字。
|
||||
|
||||
下面是修改后的部分头文件:
|
||||
|
||||
```c
|
||||
Stack stack_create();
|
||||
void stack_destory(Stack s);
|
||||
void stack_make_empty(Stack s);
|
||||
bool stack_is_empty(const Stack s);
|
||||
bool stack_is_full(const Stack s);
|
||||
void stack_push(Stack s, Item i);
|
||||
Item stack_pop(Stack s);
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 2. 错误处理
|
||||
|
||||
栈抽象数据类型通过显示出错误消息或终止程序的方式来处理错误。这是一个不错的方式,但是,我们希望为程序提供一种从这些错误中恢复的途径,而不是简单的终止程序。
|
||||
|
||||
一种方式是让 push 和 pop 函数返回一个 bool 类型的值说明函数调用是否成功。push 返回类型为 void,所以很容易改为成功时返回 true,失败时返回 false;但是修改 pop 就没那么简单了,因为目前 pop 是返回 Item 类型的值。如果让 pop 返回指向弹出的值的指针而不是数值,我们可以让 pop 返回 NULL 表示栈为空 。
|
||||
|
||||
修改后的函数定义如下:
|
||||
|
||||
```c
|
||||
PUBLIC bool stack_push(Stack s, Item i) {
|
||||
|
||||
node* new_node = (node*)malloc(sizeof(node));
|
||||
if (new_node == NULL)
|
||||
return false;
|
||||
|
||||
new_node->data = i;
|
||||
new_node->next = s->top;
|
||||
s->top = new_node;
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
PUBLIC Item* stack_pop(Stack s) {
|
||||
|
||||
if (stack_is_empty(s))
|
||||
return NULL;
|
||||
|
||||
node* del = s->top;
|
||||
s->pop_val = del->data;
|
||||
s->top = s->top->next;
|
||||
free(del);
|
||||
|
||||
return &s->pop_val;
|
||||
}
|
||||
```
|
||||
|
||||
最后,C 库包含 assert 宏,可以在指定条件不满足时终止程序。我们可以用改宏的调用取代目前使用的 if 语句和 terminate 函数。
|
||||
|
||||
|
||||
|
||||
#### 3. 通用抽象数据类型
|
||||
|
||||
现在的抽象数据类型栈还存在一个严重问题:程序不能创建两个数据类型不同的栈。
|
||||
|
||||
为了允许多个栈具有不同数据类型,我们可以复制栈抽象数据类型的头文件和源文件,并改变 Item 的类型定义,然后使 Stack 类型以及相关函数具有不同的名字。
|
||||
|
||||
我们希望有一个“通用”的栈类型。C 语言有很多不同的途径做到这一点,但是没有一个是令人满意的。最常见的一种方法是使用`void*`作为数据项类型,这样就可以使用各种类型的指针了。
|
||||
|
||||
只需要修改接口中的 push 和 pop 函数:
|
||||
|
||||
```c
|
||||
bool stack_push(Stack s, void* i);
|
||||
void* stack_pop(Stack s);
|
||||
```
|
||||
|
||||
那么程序应该如何改写呢?这个问题留给大家吧。
|
||||
|
||||
使用 void* 作为 数据项类型有两个缺点:
|
||||
|
||||
- 这种方法不适用于无法用指针形式表示的数据
|
||||
- 不能进行函数参数的错误检查
|
||||
|
||||
#### 4. 新语言中的抽象数据类型
|
||||
|
||||
上面的问题在新的基于 C 的语言(C++,Java,C#)中处理的更好。
|
||||
|
||||
- 通过在类中定义函数可以避免名字冲突问题
|
||||
- 这些语言都提供了一种称为**异常处理**的特性
|
||||
- 专门提供了定义通用数据类型的特性。例如,在 C++ 中我们可以定义一个**模板**,而不是指定数据项的类型。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
[^1]: 优化阻碍进化。[Epigrams on Programming 编程警句 ](https://epigrams-on-programming.readthedocs.io/zh_CN/latest/epigrams.html)
|
||||
|
||||
*参考资料:《C语言程序设计:现代方法》*
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
693
content/c-mordern-approch/21-底层程序设计.md
Normal file
693
content/c-mordern-approch/21-底层程序设计.md
Normal file
@@ -0,0 +1,693 @@
|
||||
## 底层程序设计
|
||||
|
||||
*A good system can't have a weak command language.* [^1]
|
||||
|
||||
## 目录
|
||||
|
||||
***
|
||||
|
||||
[TOC]
|
||||
|
||||
## 底层程序设计
|
||||
|
||||
***
|
||||
|
||||
### 零 前言
|
||||
|
||||
有些程序需要进行位级别的操作。位操作和其他一些底层运算在编写系统程序(包括编译器和操作系统),加密程序,图形程序以及一些其他需要高执行速度或高效利用空间的程序非常有用。
|
||||
|
||||
|
||||
|
||||
### 一 位运算符
|
||||
|
||||
C 语言提供了 6 个位运算符。
|
||||
|
||||
关于位运算符参考文章:https://mp.weixin.qq.com/s/rWFUortJu0JAw1kIwSegRQ
|
||||
|
||||
#### 1. 移位运算符
|
||||
|
||||
> `<<` 左移位
|
||||
>
|
||||
> `>>` 右移位
|
||||
|
||||
操作数可以为任意整数类型(包括 char型)。对两个操作数都会进行整数提升,返回值的类型是左操作数提升后的类型。
|
||||
|
||||
- `i << j`将 i 中的位左移 j 位后的结果。每次从 i 最左端溢出一位,在 i 的最右端补 0
|
||||
- `i >> j `将 i 中的位右移 j 位后的结果。每次从 i 的最右端溢出一位。如果 i 是无符号数或非负值,在 i 左端补 0;如果 i 是 负值,其结果是由实现定义的:一些实现会在左端补 0,其他实现会在保留符号位而补 1 。
|
||||
|
||||
**可移植性技巧:**仅对无符号数进行位运算。
|
||||
|
||||
例:
|
||||
|
||||
```c
|
||||
unsigned short i, j;
|
||||
|
||||
i = 13;// i is now 13(binary 0000 0000 0000 1101)
|
||||
j = j << 2; // i is now 52(binary 0000 0000 0011 0100)
|
||||
j = j >> 2; // i is now 3(binary 0000 0000 0000 0011)
|
||||
```
|
||||
|
||||
如上面所示,两个运算符都不会改变他它的操作数。如果想要改变:
|
||||
|
||||
```c
|
||||
i <<= 2;
|
||||
i >>= 2;
|
||||
```
|
||||
|
||||
位移运算符的优先级比算数运算符的优先级**低**,所以:
|
||||
|
||||
```c
|
||||
i << 2 + 1;
|
||||
```
|
||||
|
||||
等价于:
|
||||
|
||||
```c
|
||||
i << (2 + 1);
|
||||
```
|
||||
|
||||
而不是:
|
||||
|
||||
```c
|
||||
(i << 2) + 1;
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 2. 其他位运算符
|
||||
|
||||
> `~` 按位求反
|
||||
>
|
||||
> `&` 按位与
|
||||
>
|
||||
> `|` 按位或
|
||||
>
|
||||
> `^` 按位异或
|
||||
|
||||
`~`是一元运算符,对操作数进行整数提升;其他是二元运算符,对操作数进行常用的算术转换。
|
||||
|
||||
它们对操作数的每一位进行布尔运算。
|
||||
|
||||
**注意:不要混淆 `&` 与`&&`, `|`与 `||`,它们绝不相同。**
|
||||
|
||||
例:
|
||||
|
||||
```c
|
||||
unsigned short i, j, k;
|
||||
|
||||
i = 21; // i is now 21 (binary 0000 0000 0001 0101)
|
||||
j = 56; // j is now 56 (binary 0000 0000 0011 1000)
|
||||
k = ~i; // k is now 65514(binary 1111 1111 1110 1010)
|
||||
k = i & j;// k is now 16 (binary 0000 0000 0001 0000)
|
||||
k = i | j;// k is now 61 (binary 0000 0000 0011 1101)
|
||||
k = i ^ j;// k is now 45 (binary 0000 0000 0010 1101)
|
||||
```
|
||||
|
||||
其中对 `~i` 是基于 unsigned short 类型的值占有 16 位的假设。
|
||||
|
||||
运算符可以帮助我们使底层程序的可移植性更好。比如我们需要一个整数,它的所有位都为 1,写成`~0`;如果我们需要一个整数,除了最后 5 位其他位数都为 1,写成`~0x1f`
|
||||
|
||||
**优先级:**
|
||||
|
||||
```c
|
||||
最高 ~
|
||||
&
|
||||
^
|
||||
最低 |
|
||||
```
|
||||
|
||||
复合赋值运算符:
|
||||
|
||||
```c
|
||||
i &= j;
|
||||
i |= j;
|
||||
i ^= j;
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 3. 用位运算符访问位
|
||||
|
||||
```c
|
||||
unsigned short i;
|
||||
```
|
||||
|
||||
- **位的设置。**假设我们需要设置 i 的第 4 位(我们假定最高有效位为第15位,最低有效位为 0 位。)。将 i 的值与 0x0010(一个在第 4 位上为 1 的“掩码”)进行**或**运算:
|
||||
|
||||
```c
|
||||
i = 0x0000; // i is now 0000 0000 0000 0000
|
||||
i |= 0x0010;// i is now 0000 0000 0000 1000
|
||||
```
|
||||
|
||||
如果需要设置的位存储在 j 中,可以用移位运算符构造掩码:
|
||||
|
||||
```c
|
||||
i |= 1 << j;// sets bit j
|
||||
```
|
||||
|
||||
如果 j 的值为 3,`1 << j`是 0x0008
|
||||
|
||||
- **位的清除**。要清除 i 的第 4 位,可以使用第 4 位为 0 ,其他位为 1 的掩码:
|
||||
|
||||
```c
|
||||
i = 0x00ff; // i is now 0000 0000 1111 1111
|
||||
i &= ~0x0010; // i is now 0000 0000 1110 1111
|
||||
```
|
||||
|
||||
按照相同的思路,得出惯用法:
|
||||
|
||||
```c
|
||||
i &= ~(1 << j);//clear bit j
|
||||
```
|
||||
|
||||
- **位的测试**。下面的 if 语句测试 i 的第4位是否被设置:
|
||||
|
||||
```c
|
||||
if(i & 0x0010) ...
|
||||
```
|
||||
|
||||
测试第 j 位是否被设置,使用惯用法:
|
||||
|
||||
```c
|
||||
if(i & 1 << j) ...
|
||||
```
|
||||
|
||||
|
||||
|
||||
为了使位的操作更容易,经常会给他们起名字,给第 0,1,2 位定义名字:
|
||||
|
||||
```c
|
||||
#define BLUE 1
|
||||
#define GREEN 2
|
||||
#define RED 4
|
||||
```
|
||||
|
||||
设置,清除或测试 BLUE 可以如下进行:
|
||||
|
||||
```c
|
||||
i |= BLUE;
|
||||
i &= ~BLUE;
|
||||
if(i & BULE) ...
|
||||
```
|
||||
|
||||
同时对几个位操作也一样简单:
|
||||
|
||||
```c
|
||||
i |= (BLUE | GREEN);
|
||||
i &= ~(BLUE | GREEN);
|
||||
if(i & (BLUE | GREEN)) ...
|
||||
```
|
||||
|
||||
if 语句测试 BLUE 位或 GREEN 位是否被设置了。
|
||||
|
||||
|
||||
|
||||
#### 4. 用位运算符访问位域
|
||||
|
||||
处理一组连续的位(**位域**)比处理单个位要复杂一点。下面是两种最常见的位域操作的例子。
|
||||
|
||||
- **修改位域**。修改位域需要先使用**按位与**(清除位域),再使用**按位或**(存入位域)。
|
||||
|
||||
将二进制的 101 存入 i 的 4~6 位:
|
||||
|
||||
```c
|
||||
i = i & ~0x0070 | 0x0050;
|
||||
```
|
||||
|
||||
注意:使用 `i |= 0x0050 `并不总是可行,这只会设置第 6 位和第 4 位,但是不会改变第 5 位。
|
||||
|
||||
假设 j 包含了需要存储到 i 的第 4 位到第 6 位的值。我们需要在执行按位或操作之前将 j 移位至相应的位置:
|
||||
|
||||
```c
|
||||
i = i & ~0x0070 | j << 4;
|
||||
```
|
||||
|
||||
因为 `<<` 优先级高于 `| `,我们可以省略括号(加上也没问题)。
|
||||
|
||||
- **获取位域**。当位域处在数的最右端(最低有效位)时,获取它十分简单。例如,获取变量 i 的第 0~2 位:
|
||||
|
||||
```c
|
||||
j = i & 0x0007;
|
||||
```
|
||||
|
||||
如果位域不在 i 的右端,那么需要先将位域移位至右端,在使用 & 提取位域。例如,获取 i 的第 4~6 位:
|
||||
|
||||
```c
|
||||
j = (i >> 4) & 0x0007;
|
||||
```
|
||||
|
||||
#### 程序:XOR 加密
|
||||
|
||||
对数据加密的一种最简单的方法就是,将每个字符与一个密钥进行异或(XOR)运算。假设密钥时一个 & 字符。如果将它与字符 z 异或,我们会得到 \ 字符(假定字符集为 ACSII 字符集)。具体计算如下:
|
||||
|
||||
```c
|
||||
00100110 (& 的 ASCII 码)
|
||||
XOR 01111010 (z 的 ASCII 码)
|
||||
01011100 (\ 的 ASCII 码)
|
||||
```
|
||||
|
||||
要将消息解密,只需要采用相同的算法。例如,如果将 & 与 \ 异或就可以得到 &:
|
||||
|
||||
```c
|
||||
00100110 (& 的 ASCII 码)
|
||||
XOR 01011100 (\ 的 ASCII 码)
|
||||
01111010 (z 的 ASCII 码)
|
||||
```
|
||||
|
||||
下面的程序 xor.c 通过每个字符于 & 字符进行异或来加密消息。原始消息可以由用户输入也可以输入重定向从文件读入。加密后的消息可以在屏幕上显示也可以通过输出重定向存入到文件中。例如 msg 文件包含以下内容:
|
||||
|
||||
```
|
||||
If two people write exactly the same program, each should be put in
|
||||
micro-code and then they certainly won't be the same.
|
||||
-- epigrams-on-programming
|
||||
Time:4/21/2020
|
||||
```
|
||||
|
||||
为了对文件 msg 加密并将加密后的消息存入文件 newmsg 中,输入以下命令:
|
||||
|
||||
```c
|
||||
xor <msg >newmsg
|
||||
```
|
||||
|
||||
文件 newmsg 将包含下面的内容:
|
||||
|
||||
```
|
||||
o@ RQI VCIVJC QTORC C^GERJ_ RNC UGKC VTIATGK, CGEN UNISJB DC VSR OH
|
||||
KOETI-EIBC GHB RNCH RNC_ ECTRGOHJ_ QIH'R DC RNC UGKC.
|
||||
-- CVOATGKU-IH-VTIATGKKOHA
|
||||
rOKC:4/21/2020
|
||||
```
|
||||
|
||||
要恢复原始消息,需要命令:
|
||||
|
||||
```c
|
||||
xor <newmsg
|
||||
```
|
||||
|
||||
将原始消息显示在屏幕上。
|
||||
|
||||
正如例子中看到的那样,程序不会改变一些字符,包括数字。将这些字符于 & 异或会产生不可见的控制字符,这在一些操作系统中会引发问题。在这里,为了安全起见,我们使用 `isprint`函数来确保原始字符和新字符都是可打印字符(即不是控制字符)。如果不满足,让程序写原始字符,而不是新字符。
|
||||
|
||||
**xor.c**
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<ctype.h>
|
||||
|
||||
#define KEY '&'
|
||||
|
||||
int main(void) {
|
||||
|
||||
int orig_ch, new_ch;
|
||||
|
||||
while ((orig_ch = getchar()) != EOF) {
|
||||
new_ch = orig_ch ^ KEY;
|
||||
if (isprint(orig_ch) && isprint(new_ch))
|
||||
putchar(new_ch);
|
||||
else
|
||||
putchar(orig_ch);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 二 结构中的位域
|
||||
|
||||
声明其成员表示位域的结构。
|
||||
|
||||
例如,我们来看看 MS-DOS 操作系统(通常简称 DOS)是如何存储文件的创建和最后修改日期的。由于日期,月和年都是很小的数,将它们按整数存储会浪费空间。DOS 只为日期分配了 16 位,5 位用于日,4 位用于 月,7 位用于年。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
利用位域,我们可以定义相同形式的 C 结构:
|
||||
|
||||
```c
|
||||
struct file_data{
|
||||
unsigned int day: 5;
|
||||
unsigned int month: 4;
|
||||
unsigned int year: 7;
|
||||
}
|
||||
```
|
||||
|
||||
每个成员后面指定了它所含用的长度。因为所有成员类型一样,我们可以简化声明:
|
||||
|
||||
```c
|
||||
struct file_data{
|
||||
unsigned int day: 5, month: 4, year: 7;
|
||||
}
|
||||
```
|
||||
|
||||
位域的类型必须是`int`, `unsigned int`, `signed int`。使用 int 会引发二义性,因为一些编译器将位域的最高位作为符号位,而其他一些编译器不会。
|
||||
|
||||
**可移植性技巧**:将所有的位域声明为:`unsigned int`或`signed int`
|
||||
|
||||
C99 中,位域也可以具有类型`_Bool`。
|
||||
|
||||
|
||||
|
||||
我们可以将位域像结构的其他成员一样使用:
|
||||
|
||||
```c
|
||||
struct file_data fd;
|
||||
|
||||
fd.day = 28;
|
||||
fd.month = 12;
|
||||
fd.year = 8; // represents 1988
|
||||
```
|
||||
|
||||
注意:year 成员相对于 1980 年(根据微软的描述,这是 DOS 出现的时间)存储的。在这些赋值语句之后,变量 fd 的形式如下所示:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
使用位运算可以达到同样的效果,使用位运算甚至可以更快。但是,让程序更易度通常比节省几微妙更重要一些。
|
||||
|
||||
通常意义上讲,**位域没有地址**,C 语言不允许讲 & 运算符用于位域。由于这条规则的限制,像 scanf 这样的函数无法直接向位域中存储数据:
|
||||
|
||||
```c
|
||||
scanf("%d", &fd.day);// wrong
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 1. 位域是如何存储的
|
||||
|
||||
C 标准在如何存储位域方面给编译器保留了相当的自由度。
|
||||
|
||||
“存储单元”的大小是由实现定义的,通常为 8 位,16 位或 32 位。当编译器处理结构的声明时,会将位域逐个放入存储单元,位域之间没有空隙,直到剩下的空间不够存放下一个位域了。这时,一些编译器会跳到下一个存储单元的开始,而另一些则会将位域拆开夸存储单元存放。位域存放的顺序(从左至右,还是从右至左)也是由实现定义的。
|
||||
|
||||
前面的 file_data 例子假设存储单元是 16 位长的。我们也假设位域是从右向左存储的。(第一个位域占据低序号位)
|
||||
|
||||
|
||||
|
||||
C 语言允许省略位域的名字。未命名的位域经常作为字段之间的“填充”,以保证其他位于存储在适当的位置。考虑与 DOS 文件关联的时间,存储方式如下:
|
||||
```c
|
||||
struct file_time{
|
||||
unsigned int seconds: 5;
|
||||
unsigned int minutes: 6;
|
||||
unsigned int hours: 5;
|
||||
};
|
||||
```
|
||||
|
||||
你可能会奇怪将秒 —— 0 ~ 59 之间的数存放在一个 5 位字段中呢。实际上,DOS 将描述除以 2,因此 seconds 成员实际存储的是 0 ~ 29 的数。如果我们不关心 seconds 字段,可以不给它命名:
|
||||
|
||||
```c
|
||||
struct file_time{
|
||||
unsigned int : 5;
|
||||
unsigned int minutes: 6;
|
||||
unsigned int hours: 5;
|
||||
};
|
||||
```
|
||||
|
||||
其他位域仍会正常对齐。
|
||||
|
||||
另一个用来控制位于存储的技巧是指明未命名字段长度为 0:
|
||||
|
||||
```c
|
||||
struct s{
|
||||
unsigned int a : 4;
|
||||
unsigned int : 0;
|
||||
unsigned int b : 8;
|
||||
};
|
||||
```
|
||||
|
||||
长度为 0 的位域是给编译器的一个信号,告诉编译器将下一个位域在一个存储单元的起始位置对齐。假设存储单元是 8 位长的,编译器会给成员 a 分配 4 位,接着跳过余下的 4 位到下一个存储单元,然后给成员 b 分配 8 位。如果存储单元是 16 位,则会在 a 分配 4 位后跳过余下的 12 位分配 b。
|
||||
|
||||
|
||||
|
||||
### 三 其他底层技术
|
||||
|
||||
|
||||
|
||||
#### 1. 定义依赖机器的类型
|
||||
|
||||
依据定义,char 类型占据一个字节,所以我们有时当字符是字节,并用它们存储一些并不一定是字符形式的数据。但这时候最好定义一个 BYTE 类型:
|
||||
|
||||
```c
|
||||
typedef unsigned char BYTE;
|
||||
```
|
||||
|
||||
x86 体系结构大量使用了 16 位的字,我们可以定义:
|
||||
|
||||
```c
|
||||
typedef unsigned short WORD;
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 2. 用联合提供数据多个视角
|
||||
|
||||
在 C 语言中,联合经常被用于**从两个或更多的角度看代内存块**。
|
||||
|
||||
前面我们知道 file_date 结构正好可以放入两个字节,我们可以将任何两个字节的数据当作是一个 file_date 结构。下面定义一个联合可以使我们很方便的将一个短整数与文件日期相互转换:
|
||||
|
||||
```c
|
||||
union int_date{
|
||||
unsigned short i;
|
||||
struct file_date fd;
|
||||
};
|
||||
```
|
||||
|
||||
通过这个联合,我们可以以两个字节的形式获取磁盘文件中的日期,然后提取出其中的 month, day, year 字段的值。相反的,我们可以以 file_date 结构构造一个日期,然后作为两个字节写入磁盘中。例如:
|
||||
|
||||
```c
|
||||
void print_date(unsigned short n){
|
||||
union int_date u;
|
||||
|
||||
u.i = n;
|
||||
printf("%d/%d/%d\n", u.fd.month, u.fd.day, u.fd.year + 1980);
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
x86 处理器包含 16 位寄存器 ——AX,BX,CX 和 DX 。每一个寄存器都可以看作是两个 8 位的寄存器。例如,AX 可以被划分为 AH 和 AL 两个寄存器。
|
||||
|
||||
当针对于 x86 的计算机编写底层程序时,可能会用到寄存器中的值的变量。我们需要对 16 位寄存器和 8 位寄存器进行访问,同时要考虑到它们之间的关系(改变 AX 会改变 AH 和 AL;反之同理)。所以我们可以构造一个联合包含两个结构(分别存储 16 位和 8 位的寄存器):
|
||||
|
||||
```c
|
||||
union {
|
||||
struct {
|
||||
WORD ax, bx, cx, dx;
|
||||
}word;
|
||||
struct {
|
||||
BYTE al, ah, bl, bh, cl, ch, dl, dh;
|
||||
}byte;
|
||||
}regs;
|
||||
```
|
||||
|
||||
下面时是一个使用 regs 联合的例子:
|
||||
|
||||
```c
|
||||
regs.byte.ah = 0x12;
|
||||
regs.byte.al = 0x34;
|
||||
printf("AX: %hx\n", regs.word.ax);
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```c
|
||||
AX: 1234
|
||||
```
|
||||
|
||||
注意,尽管 AL 寄存器是 AX 寄存器的“低位”部分而 AH 是“高位”部分,但在 byte 结构中 al 在 ah 之前。原因是,当数据项多于一个字节时,在内存中有两种存储方式:**大端**(big-endian) 和 **小端**(small-endian) 。小端代表:低位内存(al 是最低位)存储数的低位(34 是低位),大端则相反(可以记小端为:小小小)。C 对存储的的顺序没有要求,因为这取决于程序执行时所使用的 CPU。x86 处理器假设数据按小段方式存储。
|
||||
|
||||
**在底层对内存进行操作的程序必须注意字节的存储顺序**。处理含有非字符数据的文件时也要当心字节的存储顺序。
|
||||
|
||||
|
||||
|
||||
#### 3. 将指针作为地址使用
|
||||
|
||||
指针实际上就是一种内存地址。地址所包含的位的个数与整数(或长整数)一致。构造一个指针来表示某个特定的地址是十分方便的:只需要将整数强转为指针就行。比如,将地址 1000 存入一个指针变量:
|
||||
|
||||
```c
|
||||
BYTE* p;
|
||||
p = (BYTE*)0x1000;
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 程序:查看内存单元
|
||||
|
||||
这个程序允许用户查看计算机内存段,这主要得益于 C 允许把整数用作指针。大多数 CPU 执行程序时都是处于“保护模式”,这就意味着程序只能访问那些分配给它的内存。这种方式还可以阻止对其他应用程序和操作系统本身所占用的内存的访问。因此我们只能看到程序本身分配到的内存,如果要对其他内存地址进行访问将导致程序崩溃。
|
||||
|
||||
程序 veiw_memory.c 先显示了该程序主函数和主函数中第一个变量的地址,这样可以给用户一个线索去了解那个内存可以被探测。程序接下来提示用户输入地址(16 进制格式)和需要查看的字节数,然后从指定地址开始显示指定字节内存块的内容。
|
||||
|
||||
字节按 10 个一组的方式显示(最后一组可能达不到 10 个)。每组字节的首地址显示在一行的开头,然后是该组的字节(16 进制格式),再后面为该组字节的字符显示。只有打印字符(使用 `isprint`函数判断)会被显示,其余的被显示为 `.`。
|
||||
|
||||
假设 int 类型大小为 32 位,地址也是 32 位长。
|
||||
|
||||
格式如下:
|
||||
|
||||
```
|
||||
Address of main function: 5712bc
|
||||
Address of addr variable: bcf784
|
||||
|
||||
Enter a (hex)address: 5712bc
|
||||
Enter number of bytes to view: 40
|
||||
|
||||
Address Bytes Characters
|
||||
----------------------------------------------------
|
||||
5712BC E9 6F 06 00 00 E9 EA 04 00 00 .o........
|
||||
5712C6 E9 45 22 00 00 E9 50 3F 00 00 .E"...P?..
|
||||
5712D0 E9 FB 0C 00 00 E9 A6 27 00 00 .......'..
|
||||
5712DA E9 14 3E 00 00 E9 AC 1E 00 00 ..>.......
|
||||
```
|
||||
|
||||
.
|
||||
|
||||
```
|
||||
Address of main function: 5712bc
|
||||
Address of addr variable: effbc8
|
||||
|
||||
Enter a (hex)address: effbc8
|
||||
Enter number of bytes to view: 64
|
||||
|
||||
Address Bytes Characters
|
||||
----------------------------------------------------
|
||||
EFFBC8 C8 FB EF 00 CC CC CC CC 99 76 .........v
|
||||
EFFBD2 90 86 F4 FB EF 00 63 24 57 00 ......c$W.
|
||||
EFFBDC 01 00 00 00 F8 4F 2E 01 B0 70 .....O...p
|
||||
EFFBE6 2E 01 01 00 00 00 F8 4F 2E 01 .......O..
|
||||
EFFBF0 B0 70 2E 01 50 FC EF 00 B7 22 .p..P...."
|
||||
EFFBFA 57 00 1D 71 90 86 48 13 57 00 W..q..H.W.
|
||||
EFFC04 48 13 57 00 H.W.
|
||||
|
||||
```
|
||||
|
||||
(前 4 个字节是我们输入的表示地址的整数,注意它的每个字节存储顺序)
|
||||
|
||||
**view_memory.c**
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<ctype.h>
|
||||
|
||||
typedef unsigned char BYTE;
|
||||
|
||||
int main(void) {
|
||||
|
||||
unsigned int addr;
|
||||
int i, n;
|
||||
BYTE* ptr;
|
||||
|
||||
printf("Address of main function: %x\n", (unsigned int)main);
|
||||
printf("Address of addr variable: %x\n", (unsigned int)&addr);
|
||||
printf("\nEnter a (hex)address: ");
|
||||
scanf("%x", &addr);
|
||||
printf("Enter number of bytes to view: ");
|
||||
scanf("%d", &n);
|
||||
|
||||
printf("\n");
|
||||
printf(" Address Bytes Characters\n");
|
||||
printf("----------------------------------------------------\n");
|
||||
|
||||
ptr = (BYTE*)addr;
|
||||
for (; n > 0; n -= 10) {
|
||||
printf("%8X ", (unsigned int)ptr);
|
||||
// 考虑到最后一组不满 10 个字节
|
||||
for (i = 0; i < 10 && i < n; i++) {
|
||||
printf("%.2X ", *(ptr + i)); // 转换说明:%.2X 相当于 %02hhX
|
||||
}
|
||||
// 最后一组不够 10 用空格凑满
|
||||
for (; i < 10; i++) {
|
||||
printf(" ");
|
||||
}
|
||||
printf(" ");
|
||||
for (i = 0; i < 10 && i < n; i++) {
|
||||
BYTE ch = *(ptr + i);
|
||||
if (!(isprint(ch)))
|
||||
ch = '.';
|
||||
printf("%c", ch);
|
||||
}
|
||||
printf("\n");
|
||||
ptr += 10;
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 4. `volatile`类型限定符
|
||||
|
||||
在一些计算机中,一部分内存空间是“易变”的,保存在这些内存空间的值可能在程序运行期间发生改变,即使程序自身并未试图存放新值。例如,一些内存空间可能被用于保存直接来自输入设备的数据。
|
||||
|
||||
`volatile`类型限定符使我们可以通知编译器,程序中的某些数据是“易变”的。所以,它常用于声明指向易变空间的指针:
|
||||
|
||||
```c
|
||||
volatile BYTE* p;
|
||||
```
|
||||
|
||||
为了了解为什么需要使用 volatile ,我们假设指针 p 指向的内存空间用于存放用户通过键盘输入的最近一个字符。这个空间是易变的:用户每输入一个新字符,这里的值都会发生改变。我们可能通过下面的循环获取键盘输入的字符,并将它们存储到一个缓冲区中:
|
||||
|
||||
```c
|
||||
while(缓冲区未满){
|
||||
等待输入;
|
||||
buffer[i] = *p;
|
||||
if(buffer[i++] == '\n')
|
||||
break;
|
||||
}
|
||||
```
|
||||
|
||||
比较好的编译器可能会注意到这个循环没有改变 p,也没有改变 *p,因此编译器可能会对程序进行优化,使 *p 只被取一次:
|
||||
|
||||
```c
|
||||
在寄存器中存储 *p;
|
||||
while(缓冲区未满){
|
||||
等待输入;
|
||||
buffer[i] = 在寄存器中存储的值;
|
||||
if(buffer[i++] == '\n')
|
||||
break;
|
||||
}
|
||||
```
|
||||
|
||||
优化后的程序会不断重复复制同一个字符到缓冲区中,这不是我们期望的。需要将 p 声明为 volatile 类型可以避免这种问题。
|
||||
|
||||
|
||||
|
||||
[^1]: 好系统无坏指令。[Epigrams on Programming 编程警句 ](https://epigrams-on-programming.readthedocs.io/zh_CN/latest/epigrams.html)
|
||||
|
||||
*参考资料:《C语言程序设计:现代方法》*
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
1464
content/c-mordern-approch/22-输出&输出.md
Normal file
1464
content/c-mordern-approch/22-输出&输出.md
Normal file
File diff suppressed because it is too large
Load Diff
200
content/c-mordern-approch/23-标准库.md
Normal file
200
content/c-mordern-approch/23-标准库.md
Normal file
@@ -0,0 +1,200 @@
|
||||
|
||||
|
||||
## 标准库
|
||||
|
||||
*Perhaps if we wrote programs from childhood on, as adults we'd be able to read them.* [^1]
|
||||
|
||||
## 目录
|
||||
|
||||
[TOC]
|
||||
|
||||
|
||||
|
||||
### 一 标准库的使用
|
||||
|
||||
C89 标准库总共划分成 15 个部分,每个部分用一个头描述。C99 新增了 9 个头,总共有 24 个。
|
||||
|
||||
| C89 | | |
|
||||
| ------------ | ------------ | ------------ |
|
||||
| `<assert.h>` | `<locale.h>` | `<stddef.h>` |
|
||||
| `<ctype.h>` | `<math.h>` | `<stdio.h>` |
|
||||
| `<errno.h>` | `<setjmp.h>` | `<stdlib.h>` |
|
||||
| `<float.h>` | `<signal.h>` | `<string.h>` |
|
||||
| `<limits.h>` | `<stdarg.h>` | `<time.h>` |
|
||||
|
||||
| C99 新增 | |
|
||||
| ------------- | ------------ |
|
||||
| `<complex.h>` | `<stdint.h>` |
|
||||
| `<fenv.h>` | `<tgmath.h>` |
|
||||
| `<inttype.h>` | `<wchar.h>` |
|
||||
| `<iso646.h>` | `<wctype.h>` |
|
||||
| `<stdbool.h>` | |
|
||||
|
||||
|
||||
|
||||
大多数编译器都会使用更大的库,其中包含很多上表中没有的头。额外添加的头当然不属于标准库的范畴,所以我们不能假设其他的编译器也支持这些头。这类头通常提供些针对特定机型或特定操作系统的函数(这也解释了为什么它们不属于标准库),它们可能会提供允许对屏幕或键盘做更多控制的函数。用于支持图形或窗口界面的头也是很常见的。
|
||||
|
||||
标准头主要由**函数原型、类型定义以及宏定义**组成。如果我们的文件中调用了头中声明的函数,或是使用了头中定义的类型或宏,就需要在文件开头将相应的头包含进来。当一个文件包含多个标准头时,`#include`指令的顺序无关紧要。多次包含同一个标准头也是合法的。
|
||||
|
||||
#### 1. 对标准库 中所用名字的限制
|
||||
任何包含了标准头的文件都必须遵守两条规则。
|
||||
|
||||
- 第一,**该文件不能将头中定义过的宏的名字用于其他目的**。例如,如果某个文件包含了<stdio.h>,就不能重新定义NULL了,因为使用这个名字的宏已经在<stdio.h>中定义过了。
|
||||
- 第二,**具有文件作用域的库名(尤其是typedef名)也不可以在文件层次重定义**。因此,一旦文件包含了<stdio.h>,由于<stdio.h>中已经将size_ t定义为typedef名,那么在文件作用域内都不能将size_ t重定义为任何标识符。
|
||||
|
||||
上述这些限制是显而易见的,但C语言还有一些其他的限制,可能是你想不到的。
|
||||
|
||||
- **由一个下划线和一个大写字母开头或由两个下划线开头的标识符**是为标准库保留的标识符。程序不允许为任何目的使用这种形式的标识符。
|
||||
|
||||
- **由一个下划线开头的标识符被保留用作具有文件作用域的标识符和标记**。除非在函数内部声明,否则不应该使用这类标识符。
|
||||
|
||||
- **在标准库中所有具有外部链接的标识符被保留用作具有外部链接的标识符**。特别是所有标准库函数的名字都被保留。因此,即使文件没有包含<stdio.h>,也不应该定义名为printf的外部函数,因为在标准库中已经有一个同名的函数了。这些规则对程序的所有文件都起作用,不论文件包含了哪个头。虽然这些规则并不总是强制性的,但不遵守这些规则可能会导致程序不具有可移植性。
|
||||
|
||||
|
||||
|
||||
上面列出的规则不仅适用于库中现有的名字,也适用于留作未来使用的名字。至于哪些名字是保留的,完整的描述太冗长了,你可以在C标准的 “future library directions" 中找到。例如,C保留了以str和一个小写字母开头的标识符,从而具有这类名字的函数就可以被添加到 <string.h> 头中。
|
||||
|
||||
#### 2. 使用宏隐藏的函数
|
||||
|
||||
C 程序员经常会用带参数的宏来替代小的函数,这在标准库中同样很常见。C 标准允许在头中定义与库函数同名的宏,为了起到保护作用,还要求有实际的函数存在。因此,对于库的头,声明一个函数并同时定义一个有相同名字的宏的情况并不少见。
|
||||
|
||||
我们已经见过宏与库函数同名的例子。getchar 是声明在<stdio.h>中的库函数,它具有如下原型:
|
||||
|
||||
```c
|
||||
int getchar (void);
|
||||
```
|
||||
|
||||
<stdio .h> 通常也把 getchar 定义为一一个宏:
|
||||
|
||||
```c
|
||||
#define getchar() getc (stdin)
|
||||
```
|
||||
|
||||
在默认情况下,对 getchar 的调用会被看作宏调用(因为宏名会在预处理时被替换)。在大多数情况下,我们喜欢使用宏来替代实际的函数,因为这样可能会提高程序的运行速度。然而在某些情况下,我们可能需要的是一个真实的函数,可能是为了尽量缩小可执行代码的大小。
|
||||
|
||||
如果确实存在这种需求,我们可以使用`#undef`指令来删除宏定义。例如,我们可以在包含了<stdio.h>后删除宏getchar的定义:
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#undef getchar
|
||||
```
|
||||
|
||||
即使 getchar 不是宏,这样的做法也不会带来任何坏处,因为当给定的名字没有被定义成宏时,#undef指令不会起任何作用。
|
||||
|
||||
此外,我们也可以通过给名字加圆括号来禁用个别宏调用:
|
||||
|
||||
```c
|
||||
ch = (getchar)(); /* instead of ch= getchar(); */
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 三 C89 & C99 标准宏概状
|
||||
|
||||
大家可以下去自行去看一看上面标准头表中的头都是主要用来做什么的,它们都有什么函数原型,类型定义或宏定义。
|
||||
|
||||
|
||||
|
||||
### 四 了解两个简单的头
|
||||
|
||||
前面我们已经了解了 `<string.h>`,`<stdio.h>` 大部分函数和`<stdlib.h>`中的一些函数。现在开始,我们就要继续了解一些常用的头中的函数。今天我们要学习的头是`<stddef.h>`和`<stdbool.h>`。
|
||||
|
||||
#### 1. `<stddef.h>`常用定义
|
||||
|
||||
stddef.h 头提供了常用类型定义,但没有声明任何函数。定义的类型包括一下几个:
|
||||
|
||||
- `ptrdiff_t` 当进行指针相减运算时,其结果的类型。
|
||||
- `size_t` sizeof 运算符返回的类型
|
||||
- `wchar_t` 一种足够强大的,可以用于表示所有支持的地区所有字符的类型。
|
||||
|
||||
stddef.h 头中还定义了两个宏。
|
||||
|
||||
- 一个是 `NULL`,用来表示空指针。
|
||||
- 另一个宏是 `offsetof`需要两个参数:类型(结构类型)和成员指示符(结构的一个成员)。offsetof 会计算计算结构起点到指定成员间的字节数。
|
||||
|
||||
考虑下面的结构:
|
||||
|
||||
```c
|
||||
struct S {
|
||||
char a;
|
||||
int b[2];
|
||||
float c;
|
||||
}
|
||||
```
|
||||
|
||||
`offsetof(struct s, a)`的值一定是0,C 语言确保结构的第一个成员的地址与结构自身地址相同。我们无法确定地说出 b 和 c 的偏移量是多少。一种可能是`offsetof(structs, b)`是1 (因为 a 的长度是一个字节), 而`offsetof(struct s, c)`是9 (假设整数是32位)。然而,一些编译器会在结构中留下一些空洞,从而会影响到 offsetof 产生的值。例如,如果编译器在a后面留下了3个字节的空洞,那么 b 和 c 的偏移量分别是4和12。但这正是offsetof宏的魅力所在:对任意编译器,它都能返回正确的偏移量,从而
|
||||
使我们可以编写可移植的程序。
|
||||
|
||||
offsetof有很多用途。例如,假如我们需要将结构 s 的前两个成员写入文件,但忽略成员 c。我们不使用 fwrite 函数来写 sizeof(struct s)个字节,因为这样会将整个结构写入,而只要写`offsetof(struct s, c)`个字节。
|
||||
|
||||
最后一点:一些在 <stddef .h> 中定义的类型和宏在其他头中也会出现。(例如, NULL宏不仅在C99的头<wchar .h>中定义,在<locale.h>、<stdio.h>、<stdlib.h>、<string.h>和<time.h>中也有定义。)因此,只有少数程序真的需要包含<stddef .h>)
|
||||
|
||||
|
||||
|
||||
#### 2. `stdbool.h` 布尔类型和值
|
||||
|
||||
stdbool.h 头定义了 4 个宏:
|
||||
|
||||
- `bool` (定义为`_Bool`)
|
||||
- `true`(定义为 1)
|
||||
- `false`(定义为 0)
|
||||
- `__bool_true_false_are_defined`(定义为 1)
|
||||
|
||||
在自己定义 bool,true,false 之前可以使用预处理指令(#if 或 #endif)来测试这个宏。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
[^1]: 从童年开始写程序,长大了就能读懂了。[Epigrams on Programming 编程警句 ](https://epigrams-on-programming.readthedocs.io/zh_CN/latest/epigrams.html)
|
||||
|
||||
*参考资料:《C语言程序设计:现代方法》*
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
458
content/c-mordern-approch/24-错误处理.md
Normal file
458
content/c-mordern-approch/24-错误处理.md
Normal file
@@ -0,0 +1,458 @@
|
||||
## 错误处理
|
||||
|
||||
*There will always be things we wish to say in our programs that in all known languages can only be said poorly.* [^1]
|
||||
|
||||
|
||||
|
||||
## 目录
|
||||
|
||||
[TOC]
|
||||
|
||||
|
||||
|
||||
## 错误处理
|
||||
|
||||
### 零 前言
|
||||
|
||||
编写无错程序的方法有两种,但只有第三种写程序的方法才行得通。学习 C 语言的学生所编写的程序在遇到异常输入时经常无法正常运行,但真正商业用途的程序却必须“非常强壮”能够从错误中恢复正常而不至于崩溃。 为了使程序非常强壮,我们需要能够预见程序执行时可能遇到的错误,包括对每个错误进行检测,并提供错误发生时的合适行为。
|
||||
|
||||
本章讲述两种在程序中检测错误的方法:调用`assert`宏以及测试`errno`变量;如何检测并处理称为信号的条件,一些信号用于表示错误;最后探讨 `setjmp/longjmp` 机制,它们经常用于响应错误。
|
||||
|
||||
错误的检测和处理并不是C语言的强项。C语言对运行时错误以多种形式表示,而没有提供一种统一的方式。而且,在 C 程序中,需要由程序员编写检测错误的代码。因此,很容易忽略一些可能发生的错误。一 旦发生某个被略掉的错误,程序经常可以继续运行,虽然不是很好。C++、 Java 和 C# 等较新的语言具有“异常处理"特性,可以更容易地检测和响应错误。
|
||||
|
||||
|
||||
|
||||
### 一 `<assert.h>`诊断
|
||||
|
||||
```c
|
||||
void assert (scalar expression) ;
|
||||
```
|
||||
|
||||
`assert` 定义在`<assert.h>`中。它使程序可以监控自己的行为,并尽早发现可能会发生的错误。
|
||||
|
||||
虽然 assert 实际上是一个宏, 但它是按照函数的使用方式设计的。assert有一个参数,这个参数必须是一种“断言”一个我们认为在正常情况 下定为真的表达式。 每次执行 assert时,它都会检查其参数的值。如果参数的值不为 0, assert什么也不做;如果参数
|
||||
的值为 0, assert 会向`stderr` (标准错误流) 写条消息, 并调用 `abort` 函数 终止程序执行。
|
||||
|
||||
例如,假定文件 demo.c 声明了一个长度为 10 的数组 a,我们关心的是 demo.c 程序中的语句:
|
||||
|
||||
```c
|
||||
ali] = 0;
|
||||
```
|
||||
|
||||
可能会由于 i 不在 0- 9 之间而导致程序失败。可以在给`a[i]`赋值前使用 assert 宏检查这种情况:
|
||||
|
||||
```c
|
||||
assert(0 <= i && i < 10); /* checks subscript first */
|
||||
a[i] = 0; /* now does the assignment */
|
||||
```
|
||||
|
||||
如果的值小于0或者大于等于10,程序在显出类似下面的消息后会终止:
|
||||
|
||||
```
|
||||
Assertion failed: 0 <= i && i < 10, file demo.c, line 109
|
||||
```
|
||||
|
||||
C99 对asset做了两处小修改。C89 标准指出,assert 的参数必须是 int 类型的。C99 放宽了要求,允许参数为任意标量类型(C99 的原型中出现了单词 scalar)。例如,现在参数可以为浮点数或指针。 此外, C99 要求失败的 assert 显示其所在的函数名。(C89只要求 assert 以文本格式显示参数,源文件及源文件中的行号。) C99 建议的消息格式为:
|
||||
|
||||
```
|
||||
Assertion failed: expression , function xxx, file xxx,line xxx.
|
||||
```
|
||||
|
||||
根据编译器的不同,assert 生成的消息格式也不尽相问,但它们都应包含标准要求的信息。例如,GCC编译器在上述情况下给出如下的消息:
|
||||
|
||||
```
|
||||
a.out: demo.c: 109 main: Assertion `0 <= i && i < 10` failed.
|
||||
```
|
||||
|
||||
|
||||
|
||||
assert 有个缺点: 因为它引入了额外的检查, 因此会增加程序的运行时间。偶尔使用一下 assert 可能对程序的运行速度没有很大影响,但在实时程序中,这么小的运行时间增加可能也是无法接受的。因此许多程序员在测过程中会使用 assert,但当程序最终完成时就会禁止 assert 。要禁止 assert 很容易,只需要在包含 <assert.h> 之前定义宏 `NDEBUC` 即可。
|
||||
|
||||
```
|
||||
#define NDEBUG
|
||||
#include <assert.h>
|
||||
```
|
||||
|
||||
|
||||
|
||||
NDEBUC的值不重要,只要定义了 NDEDG 宏即可。一旦之后程序又有错误发生,可以去掉 NDEBUG 宏的定义来重新启用 assert 。
|
||||
信号的
|
||||
|
||||
**注意:**
|
||||
不要在 assert 中使用有副作用的表达式(包括函数调用)。一旦后来某天禁止了 assert ,这些表达式将不再会被求值。考虑下面的例子:
|
||||
|
||||
```c
|
||||
assert((p = malloc(n)) != NULL);
|
||||
```
|
||||
|
||||
一旦定义了 NDEBUG, assert 会被忽略并且 malloc 不会被调用。
|
||||
|
||||
|
||||
|
||||
### 二 `<errno.h>`:错误
|
||||
|
||||
|
||||
|
||||
标准库中的一些函数通过向 <errno . h> 中声明的 int 类型 `errno `变量存储一个错误码(正整数)来表示有错误发生。(errno可能实际上是个宏。如果确实是宏,C标准要求它表示左值,以便可以像变量一样使用。) 大部分使用 errno 变量的函数集中在 <math.h> ,但也有一些在标准库的其他部分。
|
||||
|
||||
假设我们需要使用一个库函数,该库函数通过给 errno 赋值来产生程序运行出错的信号。在调用这个函数之后,我们可以检查errno的值是否为零。如果不为零,则表示在函数调用过程中有错误发生。举例来说,假如需要检查 sqrt 函数的调用是否出错,可以使用类 似下面的代码:
|
||||
|
||||
```c
|
||||
errno = 0;
|
||||
y = sqrt(x);
|
||||
if (errno != 0 ) {
|
||||
fprintf (stderr, "sqrt error; program terminated.\n");
|
||||
exit (EXIT_ FAILURE);
|
||||
}
|
||||
```
|
||||
|
||||
当使用 errno 来检测库的数调用中的错误时,在**函数调用前将 errno 置零**非常重要。虽然在程序刚开始运行时 errno 的值为零,但有可能在随后的函数调用中已经被改动了。 库函数不会将 errno 清零,这是程序需要做的事情。
|
||||
|
||||
当错误发生时,向 errno 中存储的值通常是 EDOM 或 ERANGE. (这两个宏都定义在 <errno.h> 中。) 这两个值代表调用数学函数时可能发生的两种错误:
|
||||
|
||||
- **定义域错误(EDOM):**传递给函数的一个参数超出了函数的定义域。例如,用负数作为 sqrt 的参数就会导致定义域错误。
|
||||
- **取值范围错误(ERANGE):** 函数返回值太大,无法用返回类型表示。
|
||||
|
||||
一些函数可能会同时导致这两种错误。我们可以用 errno 分别与 EDOM 和 ERANGE 比较,然后确定究竟发生了那种错误。
|
||||
|
||||
|
||||
|
||||
##### `perror`函数和 `strerror`函数
|
||||
|
||||
> `void perror(const char* s);` <stdio.h>
|
||||
>
|
||||
> `char *stderror(int errnum);`<string.h>
|
||||
|
||||
这两个函数都不属于 <errno.h> 。
|
||||
|
||||
当库函数向 errno 存储了一个非零值时,可能希望显示一条描述这种错误的信息。
|
||||
|
||||
一种实现方式是调用 `perror` 函数,他会按顺序显示一下信息:
|
||||
|
||||
1. 调用 perror 的参数
|
||||
2. 一个冒号
|
||||
3. 一个空格
|
||||
4. 一条出错消息,消息内容根据 errno 的值决定
|
||||
5. 一个换行符。perror 函数会输出到 stderr 流而不是标准输出。
|
||||
|
||||
下面是一个使用 perror 的例子:
|
||||
|
||||
```c
|
||||
errno = 0;
|
||||
y = sqrt(x);
|
||||
if(errno != 0){
|
||||
perror("sqrt error");
|
||||
exit(EXIT_FAILUARE);
|
||||
}
|
||||
```
|
||||
|
||||
如果 sqrt 调用因为定义域错误而失败,perror 会打印如下输出:
|
||||
|
||||
```c
|
||||
sqrt error: Numerical argument out of domain
|
||||
```
|
||||
|
||||
perror 函数在 sqrt error 后显示处的错误消息是由实现定义的。在这个例子中,Numerical argument out of domain. 是与 EDOM 错误相对应的消息。ERANGE 错误通常会对应不同的消息。
|
||||
|
||||
|
||||
|
||||
`stderror`函数属 <string.h>。当以错误码为参数调用 stderror 时,函数会返回一个指针,它指向一个描述这个错误的字符串。例如,调用:
|
||||
|
||||
```c
|
||||
puts(stderror(EDOM));
|
||||
```
|
||||
|
||||
可能会显示:
|
||||
|
||||
```c
|
||||
Numerical argument out of domain
|
||||
```
|
||||
|
||||
stderror 的值通常是 errno 的值,但以任意整数作为参数时 stderror 都能返回一个字符串。
|
||||
|
||||
stderror 和 perror 紧密相关。如果 stderror 的参数为 errno,那么 perror 所显示的出错消息与 stderror 所返回的消息相同。
|
||||
|
||||
|
||||
|
||||
##### 更多例子
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main(void)
|
||||
{
|
||||
FILE *f = fopen("non_existent", "r");
|
||||
if (f == NULL) {
|
||||
perror("fopen() failed");
|
||||
} else {
|
||||
fclose(f);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
fopen() failed: No such file or directory
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 三 `<signal.h>`:信号处理
|
||||
|
||||
<signal.h> 提供了处理异常情况(称为信号)的工具。信号有两种类型:**运行时错误**(例如除以0)和**发生在程序以外的事件**。例如,许多操作系统都允许用户中断或终止正在运行的程序,C语言把这些事件视为信号。当有错误或外部事件发生时,我们称产生了一个信号。大多数信号是异步的:它们可以在程序执行过程中的任意时刻发生,而不仅是在程序员所知道的特定时刻发生。由于信号可能会在任何意想不到的时刻发生,因此必须用一种独特的方式来处理它们。
|
||||
|
||||
本节按 C 标准中的描述来介绍信号。这里对信号谈得很有限,但实际上信号在UNIX中的作用很大。有关UNIX信号的信息,见参考文献中列出的UNIX编程书。
|
||||
|
||||
|
||||
|
||||
#### 1. 信号宏
|
||||
|
||||
<signal.h> 中定义了一系列的宏,用于表示不同的信号。每个宏的值都是正整数常量。C 语言的实现可以提供更多的信号宏,只要宏的名字以 SIG 和一个大写字母开头即可。
|
||||
|
||||
| 常量 | 解释 |
|
||||
| --------- | ------------------------------------------------------------ |
|
||||
| `SIGTERM` | 发送给程序的终止请求 |
|
||||
| `SIGSEGV` | 非法内存访问(段错误) |
|
||||
| `SIGINT` | 外部中断,通常为用户所发动 |
|
||||
| `SIGILL` | 非法程序映像,例如非法指令 |
|
||||
| `SIGABRT` | 异常终止条件,例如 [abort()](https://zh.cppreference.com/w/c/program/abort) 所起始的 |
|
||||
| `SIGFPE` | 错误的算术运算,如除以零 |
|
||||
|
||||
C 标准不要求表中的信号都自动产生,因为对于某个特定的计算机或操作系统,不是所有信号都是有意义的。大多数 C 的实现都支持其中的一部分。
|
||||
|
||||
|
||||
|
||||
#### 2. `signal`函数
|
||||
|
||||
> `void (*signal( int sig, void (*handler) (int))) (int);`
|
||||
|
||||
<signal.h> 提供了两个函数:`raise` 和 `signal`。 这里先讨论 signal 函数,它会安装一个信号处理函数,以便将来给定的信号发生时使用。signal函数的使用比它的原型看起来要简单得多。它的第一个参数是特定信号的编码,第二个参数是一个指向会在信号发生时处理这信号的函数的指针。例如,下面的signal 函数调用为SIGINT信号安装了一个处理函数:
|
||||
|
||||
```c
|
||||
signal (SIGINT, handler);
|
||||
```
|
||||
|
||||
handler 就是信号处理函数的函数名。一旦随后在程序执行过程中出现了 SIGINT 信号,handler 函数就会自动被调用。
|
||||
|
||||
每个信号处理函数都必须有一个 int 类型的参数,且返回类型为void。当个特定的信号产生并调用相应的处理函数时,信号的编码会作为参数传递给处理函数。知道是哪种信号导致了处理函数被调用是十分有用的,尤其是,它允许我们对多个信号使用同一个处理函数。
|
||||
|
||||
信号处理函数可以做许多事。这可能包含忽略该信号、执行一些错误恢复或终止程序。然而,除非信号是由调用 abort 函数或 raise函数引发的,否则信号处理函数不应该调用库函数或试图使用具有静态存储期限的变量。(但这些规则也有例外。)
|
||||
|
||||
一旦信号处理函数返回,程序会从信号发生点恢复并继续执行,但有两种例外情况: (1)如果信号是 SIGABRT ,当处理函数返回时程序会(异常地)终止: (2)如果处理的信号是 SIGFPE ,那么处理函数返回的结果是未定义的。(也就是说,不要处理它。)
|
||||
|
||||
虽然 signal 函数有返回值,但经常被丢弃。返回值是指向指定信号的前一个处理函数的指针。如果需要,可以将它保存在变量中。特别是,如果打算恢复原来的处理函数,那么就需要保留 signal 函数的返回值:
|
||||
|
||||
```c
|
||||
void (*orig_handler)(int); /* function pointer variable */
|
||||
...;
|
||||
orig_handler = signal (SIGINT, handler);
|
||||
```
|
||||
|
||||
这条语句将 handler 函数安装为 SIGINT 的处理函数,并将指向原来的处理函数的指针保存在变量 orig_handler 中。如果要恢复原来的处理函数,我们需要使用下面的代码:
|
||||
|
||||
```c
|
||||
signal (SIGINT, orig_handler);/* restores original handler */
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 3. 预定义的信号处理函数
|
||||
|
||||
除了编写自己的信号处理函数,还可以选择使用 <signal .h> 提供的预定义的处理函数。有两个这样的函数,每个都是用宏表示的。
|
||||
|
||||
- `SIG_DFL`: SIG_DFL 按“默认”方式处理信号。可以使用下面的调用安装 SIG_DFL:
|
||||
|
||||
```c
|
||||
signal(SIGIT, SIG_DFL); /* use default handler */
|
||||
```
|
||||
|
||||
调用 SIG_DFL 的结果是由实现定义的,但大多数情况下会导致程序终止。
|
||||
|
||||
- `SIG_IGN`:调用
|
||||
|
||||
```c
|
||||
signal(SIGINT, SIG_IGN); /* ignore SIGINT signal */
|
||||
```
|
||||
|
||||
指明随后当信号 SIGINT 产生时,忽略该信号。
|
||||
|
||||
|
||||
|
||||
除了 SIG_DFL 和 SIG_IGN, <signal .h> 可能还会提供其他的信号处理函数;其函数名必须是以`SIG_`和一个大写字母开头。当程序刚开始执行时,根据不同的实现,每个信号的处理函数都会被初始化为 SIG_ DFL 或 SIG_ IGN。
|
||||
|
||||
<signal.h> 还定义了另一个宏:SIG_ ERR,它看起来像是个信号处理函数。实际上,SIG_ERR 是用来在安装处理函数时检测是否发生错误的。如果一个 signal 调用失败(即不能对所指定的信号安装处理函数),就会返回 SIG_ERR 并在 errno 中存入一个正值。因此,为了测试 signal 调用是否失败,可以使用如下代码:
|
||||
|
||||
```c
|
||||
if (signal(SIGINT, handler) == SIG_ERR) {
|
||||
perror ("signal (SIGINT, handler) failed");
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
在整个信号处理机制中,有一个棘手的问题:如果信号是由处理这个信号的函数引发的会怎样呢?为了避免无限递归,C89标准为程序员安装的信号处理函数引发信号的情况规定了一个两步的过程。首先,要么把该信号对应的处理函数重置为 SIG_DFL (默认处理函数),要么在处理函数执行的时候阻塞该信号。(SIGILL是 一个特殊情况,当 SIGILL发生时这两种行为都不需要。) 然后,再调用程序员提供的处理函数。
|
||||
|
||||
信号处理完之后,处理函数是否需要重新安装是由实现定义的。UNIX实现通常会在使用处理函数之后保持其安装状态,但其他实现可能会把处理函数重置为SIG_DFL。在后一种情况下,处理函数可以通过在其返回前调用 signal 函数来实现自身的重新安装。
|
||||
|
||||
C99 对信号处理过程做了一些小的改动。 当信号发生时,实现不仅可以禁用该信号,还可以禁用别的信号。对于处理 SIGILL或SIGSEGV 信号( 以及SIGFPE信号)的信号处理函数,函数返回的结果是未定义的。C99还增加了一条限制:如果信号是因为调用 abort函数或 raise函数而产生的,信号处理函数本身一定不能调用raise函数。
|
||||
|
||||
|
||||
|
||||
#### 4. `raise`函数
|
||||
|
||||
> `int raise( int sig );`
|
||||
|
||||
通常信号都是由于运行时错误或外部事件产生的,但是有时候如果程序可以触发信号会非常方便。raise 函数就可以用于这一目的。raise 函数的参数指定所需信号的编码:
|
||||
|
||||
```c
|
||||
raise(SIGABRT);
|
||||
```
|
||||
|
||||
raise 函数的返回值:成功时为 0 ,失败时为非零。
|
||||
|
||||
|
||||
|
||||
#### 程序:测试信号
|
||||
|
||||
下面的程序说明了如何使用信号。首先,给 SIGINT 信号安装了一个惯用的处理函数(并小心地保存了原先的处理函数),然后调用`raise_sig` 产生该信号:接下来,程序将 SIG_IGN设置为SIGINT的处理函数并再次调用 raise_sig;最后,它重新安装信号 SIGINT原先的处理函数,并最后调用一次 raise_sig。
|
||||
|
||||
**tsignal.c**
|
||||
|
||||
```c
|
||||
#include <signal.h>
|
||||
#include <stdio.h>
|
||||
|
||||
void handler(int sig) ;
|
||||
void raise_sig(void) ;
|
||||
|
||||
int main(void){
|
||||
|
||||
void (*orig_handler) (int);
|
||||
|
||||
printf("Installing handler for signal %d\n", SIGINT) ;
|
||||
|
||||
orig_ handler = signal(SIGINT, handler);
|
||||
raise_sig();
|
||||
|
||||
printf("Changing handler to SIG_IGN\n");
|
||||
signal (SIGINT, SIG_IGN) ;
|
||||
raise_ sig();
|
||||
|
||||
printf("Restoring original handler\n");
|
||||
signal (SIGINT, orig_handler);
|
||||
raise_ sig();
|
||||
|
||||
printf("Program terminates normally\n");
|
||||
return 0
|
||||
}
|
||||
|
||||
void handler(int sig){
|
||||
printf("Handler called for signal ad\n", sig);
|
||||
}
|
||||
|
||||
void raise_sig(void){
|
||||
raise (SIGINT);
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
当然,调用 raise 并不需要在单独的函数中。这里定义 raise_sig 函数只是为了说明一点:无论信号是从哪里产生的(无论是在main函数中还是在其他函数中),它都会被最近安装的该信号的处理函数捕获。
|
||||
|
||||
这段程序的输出可能会有多种。下面是一 种可能的输出形式:
|
||||
|
||||
```
|
||||
Installing handler for signal 2
|
||||
Handler called for signal 2
|
||||
Changing handler to SIG_IGN
|
||||
Restoring original handler
|
||||
```
|
||||
|
||||
这个输出结果表明,我们的实现把 SIGINT 的值定义为 2,而且 SIGIN原先的处理函数一定是 SIG_DFL。(如果是 SIG_IGN,应该会看到信息 Program terminates normally) 最后, 我们注意到 SIG_DFL 会导致程序终止,但不会显示出错消息。
|
||||
|
||||
|
||||
|
||||
|
||||
### 四 `<setjmp.h>`:非局跳转
|
||||
|
||||
> `int set jmp(jmp_buf env);
|
||||
> void longimp(jmp_buf env, int val);`
|
||||
|
||||
通常情况下,函数会返回到它被调用的位置。我们无法使用 goto语句使它转到其他地方,因为 goto 只能跳转到同一函数内的某个标号处。但是 <setjmp.h> 可以使一个函数直接跳转到另一个函数,而不需要返回。
|
||||
|
||||
在 `<setjmp.h>` 中最重要的内容就是 `setjmp`宏和`1ongjmp`函数。setjmp宏 “标记”程序中的一个位置:随后可以使用 longjmp跳转到该位置。虽然这一强大的机制可以有多种潜在的用途,但它主要被用于错误处理。
|
||||
|
||||
如果要为将来的跳转标记一个位置, 可以调用 setjmp 宏,调用的参数是一个 `jmp_buf`类型 (在<set imp . h>中声明) 的变量。setjmp 宏会将当前“环境”(包括一个 指向 setjmp 宏自身位置的指针) 保存到该变量中以便将来可以在调用 longjmp 函数时使用,然后**返回 0**。
|
||||
|
||||
要返回 setjmp 宏所标记的位置可以调用 1ongjmp 函数,调用的参数是调用 setjmp宏时使用的同一个 jmp_buf 类型的变量。longjmp函数会首先根据 jmp_buf 变量的内容恢复当前环境,然后从 setjmp 宏调用中返回。这是最难以理解的。这次 setjmp宏的返回值是 val,就是调用 longjmp 函数时的第 2 个参数。 (如果val的值为0, 那么set jmp宏会返回 1 。)
|
||||
|
||||
一定要确保作为 1ongjmp 函数的参数之前已经被 setjmp 调用初始化了。还有一点很重要:包含 setjmp 最初调用的函数一定不能在调用 longjmp 之前返回。如果两个条件都不满足,调用longjmp会导致未定义的行为。( 程序很可能会崩溃。)
|
||||
|
||||
总而言之,setjmp 会在第一次调用时返回 0; 随后,longjmp将控制权重新转给最初的 setjmp 宏调用,而setjmp在这次调用时会返回一个非零值。明白了吗?我们可能需要一个例子。
|
||||
|
||||
|
||||
|
||||
#### 程序测试setjmp和1ongjmp
|
||||
下面的程序使用 setjmp 宏在 main 函数中标记一个位置,然后函数 f2 通过调用 1ongjmp 函数返回到这个位置。
|
||||
|
||||
**tsetjmp.c**
|
||||
|
||||
```c
|
||||
/* Tests setjmp/1ongjmp */
|
||||
#include<setjmp.h>
|
||||
#include<stdio.h>
|
||||
|
||||
jmp_buf env;
|
||||
|
||||
void f1(void);
|
||||
void f2(void);
|
||||
|
||||
int main(void) {
|
||||
|
||||
if (setjmp(env) == 0)
|
||||
printf("setjmp returned 0\n");
|
||||
else {
|
||||
printf("Program terminates: longjmp called\n");
|
||||
return 0;
|
||||
}
|
||||
|
||||
f1();
|
||||
printf("Program terminates normally\n");
|
||||
|
||||
return 0;
|
||||
}
|
||||
void f1(void) {
|
||||
printf("f1 begins\n");
|
||||
f2();
|
||||
printf("f1 returs\n");
|
||||
}
|
||||
void f2(void) {
|
||||
printf("f2 begins\n");
|
||||
longjmp(env, 1);
|
||||
printf("f2 returns\n");
|
||||
}
|
||||
```
|
||||
|
||||
这段程序的输出如下:
|
||||
|
||||
```
|
||||
setjmp returned 0
|
||||
f1 begins
|
||||
f2 begins
|
||||
Program terminates: longjmp called
|
||||
```
|
||||
|
||||
setjmp 宏的最初调用返回 0,因此main函数会调用 f1。接着,f1 调用 f2,f2 使用1ongjmp 函数将控制权重新转给 main 函数,而不是返回到 f1 。当 longjmp 函数被执行时,控制权重新回到 setjmp 宏调用。这次 setjmp宏返回 1 (就是在longjmp函数调用时所指定的值)。
|
||||
|
||||
|
||||
|
||||
[^1]: 程序中总有些话,所有已知的语言都不能很好的表达。[Epigrams on Programming 编程警句 ](https://epigrams-on-programming.readthedocs.io/zh_CN/latest/epigrams.html)
|
||||
|
||||
*参考资料:《C语言程序设计:现代方法》*
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
290
content/c-review/1-数据类型和变量.md
Normal file
290
content/c-review/1-数据类型和变量.md
Normal file
@@ -0,0 +1,290 @@
|
||||
## 数据类型及大小
|
||||
|
||||
char 字符型 1 byte
|
||||
|
||||
short 短整型 2 byte
|
||||
|
||||
int 整型 4 byte
|
||||
|
||||
long 长整型 4 byte
|
||||
|
||||
long long 更长的整型 8 byte
|
||||
|
||||
float 单精度浮点型 4 byte
|
||||
|
||||
double 双精度浮点型 8 byte
|
||||
|
||||
long double 16 byte
|
||||
|
||||
### 看大小的程序:
|
||||
|
||||
```
|
||||
#include<stdio.h>
|
||||
int main(){
|
||||
printf("%d\n",sizeof(long));
|
||||
printf("%d\n",sizeof(long double));
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
## 定义变量的位置
|
||||
|
||||
```c
|
||||
int main()
|
||||
{
|
||||
int num1 = 0;
|
||||
int num2 = 0;
|
||||
printf("请输入两个数字:>");
|
||||
scanf("%d%d", &num1, &num2);
|
||||
int sum = num1+num2;
|
||||
printf("sum = %d\n", sum);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
有的编译器会在这里提示错误,因为c规定对变量的声明应该在函数的开头。
|
||||
|
||||
修改后:
|
||||
|
||||
```
|
||||
int main()
|
||||
{
|
||||
int num1 = 0;
|
||||
int num2 = 0;
|
||||
int sum = 0;
|
||||
printf("请输入两个数字:>");
|
||||
scanf("%d%d", &num1, &num2);
|
||||
sum = num1+num2;
|
||||
printf("sum = %d\n", sum);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
这样应该就不会有问题了
|
||||
|
||||
## 关于变量的作用域和生存期
|
||||
|
||||
注意变量的作用域
|
||||
|
||||
```
|
||||
int main()
|
||||
{
|
||||
{
|
||||
int a = 10; //对变量a的声明再括号内,所以a的作用域仅在括号内
|
||||
}
|
||||
printf("a = %d\n", a);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
外部变量引用
|
||||
|
||||
```
|
||||
//声明外部符号(仅需要再同一个项目的另一个c文件中声明这个变量即可,可以直接调用)
|
||||
extern int g_val;
|
||||
|
||||
int main()
|
||||
{
|
||||
printf("g_val = %d\n", g_val);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 全局变量的注意事项:先声明,后引用
|
||||
|
||||
大家思考下面这个代码sum函数是否可以算出a+b的和
|
||||
|
||||
```
|
||||
#include<stdio.h>
|
||||
|
||||
int sum(int x){
|
||||
|
||||
return x+a;
|
||||
}
|
||||
int a=2; //a 声明在sum函数后
|
||||
int main(){
|
||||
int b=2;
|
||||
|
||||
printf("%d",sum(b));
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
运算结果并不是我们像要的,应该如何修改呢?
|
||||
|
||||
只需要将对 a的声明放在要调用a的sum函数前即可
|
||||
|
||||
|
||||
|
||||
```
|
||||
#include<stdio.h>
|
||||
int a=2; //
|
||||
int sum(int x){
|
||||
|
||||
return x+a;
|
||||
}
|
||||
|
||||
int main(){
|
||||
int b=2;
|
||||
|
||||
printf("%d",sum(b));
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
也有例外,供大家思考
|
||||
|
||||
```
|
||||
#include<stdio.h>
|
||||
int sum(int x,int y){
|
||||
return x+y;
|
||||
}
|
||||
int a=2;
|
||||
int main(){
|
||||
int b=2;
|
||||
|
||||
printf("%d",sum(a,b));
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
## 总而言之,一定要在引用变量前声明变量,就算是全局变量
|
||||
|
||||
##
|
||||
|
||||
## 常量的类型
|
||||
|
||||
### 1.字面常量
|
||||
|
||||
如:3.14,"abc" ,'a'
|
||||
|
||||
### 2.const 修饰的常变量
|
||||
|
||||
声明方式const int num = 10
|
||||
|
||||
一般来说常变量无法再赋其他值
|
||||
|
||||
常变量依然是变量,并不是常量(int arr[num] = {0};这个语句是有错误提示的,证明num并不是常量)
|
||||
|
||||
### 3.#define定义的标识符常量
|
||||
|
||||
```
|
||||
#include<stdio.h>
|
||||
#define MAX 10
|
||||
int main(){
|
||||
int a=MAX;
|
||||
printf("%d",a);
|
||||
}
|
||||
|
||||
//输出结果为10
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 4. 枚举常量
|
||||
|
||||
```
|
||||
enum Sex
|
||||
{
|
||||
MALE,
|
||||
FEMALE=5,
|
||||
SECRET
|
||||
};
|
||||
#include<stdio.h>
|
||||
int main(){
|
||||
printf("%d\n", MALE);
|
||||
printf("%d\n", FEMALE);
|
||||
printf("%d\n", SECRET);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
enum 枚举类型常量 如果没有赋予其他处置默认从0开始递增。
|
||||
|
||||
## 字符串的一个重要问题
|
||||
|
||||
```c
|
||||
char arr1[] = "abc";
|
||||
char arr2[] = {'a', 'b', 'c'};
|
||||
printf("%s\n", arr1);
|
||||
printf("%s\n", arr2);
|
||||
```
|
||||
|
||||
|
||||
|
||||
思考一下上述两个printf函数会输出什么?是否一样?
|
||||
|
||||
结果是
|
||||
|
||||
arr1可以正常输出
|
||||
|
||||
但是arr2却在输出abc后出现了乱码(这个乱码是随机的,可能出现也可能不出现)
|
||||
|
||||
为什么会这样?
|
||||
|
||||
因为c语言中会在字符串后面自动加上空字符'\0',它代表着字符串的结束
|
||||
|
||||
再输出arr2过程中由于后面没有终止符,系统会继续向下搜寻,而后面是什么内容是未知的,因此会出现乱码。
|
||||
|
||||
```c
|
||||
printf("%d\n", strlen(arr1));//string length
|
||||
printf("%d\n", strlen(arr2));
|
||||
```
|
||||
|
||||
|
||||
|
||||
字符串的长度都是3
|
||||
|
||||
## 转义字符的重要用法
|
||||
|
||||
如果我想输出目录“ c:\test\090\test.c”用下面代码输出是否可以?
|
||||
|
||||
```
|
||||
#include<stdio.h>
|
||||
int main(){
|
||||
printf("c:\test\070\test.c");
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
输出结果竟然是:c: est8 est.c
|
||||
|
||||
为什么会这样?因为‘\’是一个转义字符,‘\t’为水平制表符 会进行缩进
|
||||
|
||||
那么应该正确的输出我们想要的结果呢?
|
||||
|
||||
我们只需要再'\'之前再加上一个'\'再次进行转义就好了
|
||||
|
||||
### \ddd ddd表示1~3个八进制的数字
|
||||
|
||||
### \xdd dd表示2个十六进制数字
|
||||
|
||||
注:八进制数位上最大值为7
|
||||
|
||||
|
||||
|
||||
以上就是本次关于c语言要点的归纳,感谢观看
|
||||
|
||||
231
content/c-review/2-数组.md
Normal file
231
content/c-review/2-数组.md
Normal file
@@ -0,0 +1,231 @@
|
||||
|
||||
|
||||
## 数组
|
||||
|
||||
### 1.数组的赋值
|
||||
|
||||
int arr[10]={1,2}的意义为将数组arr前2个元素初始化为1,2后面的元素初始化为0。
|
||||
|
||||
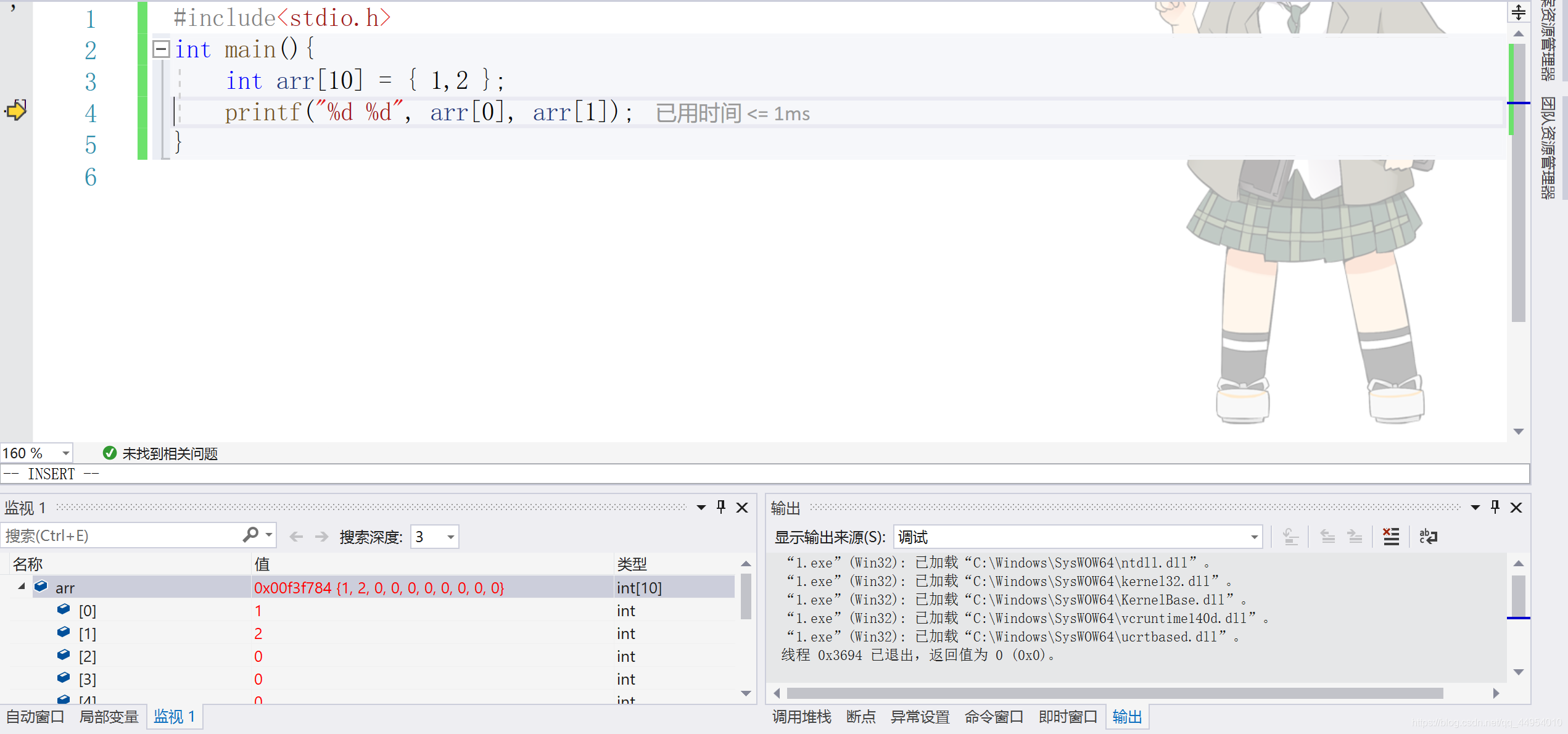
|
||||
|
||||

|
||||
|
||||
------
|
||||
|
||||
|
||||
|
||||
## 操作符
|
||||
|
||||
### 1.算数操作符
|
||||
|
||||
> \+ - * / %
|
||||
|
||||
" / "除法运算 向下取整
|
||||
|
||||
" % "求余运算 计算余数
|
||||
|
||||
### 2.移位操作符
|
||||
|
||||
> \>> <<
|
||||
|
||||
\>> 左移 << 右移 表示2进制位左移右移
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
为方便理解,可以参考下图:
|
||||
|
||||

|
||||
|
||||
### 3.位操作符
|
||||
|
||||
> & | ^
|
||||
|
||||
a.按位与
|
||||
|
||||
与的原理等同于数学中的且
|
||||
|
||||
按位就是按照变量的2进制位
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
b.按位或
|
||||
|
||||
101 5
|
||||
|
||||
011 3
|
||||
|
||||
111 7
|
||||
|
||||

|
||||
|
||||
c.按位异或
|
||||
|
||||
101 5
|
||||
|
||||
011 3
|
||||
|
||||
110 6
|
||||
|
||||

|
||||
|
||||
### 赋值操作符
|
||||
|
||||
> ### = += -= *= /= &= ^= |= >>= <<=
|
||||
|
||||
### 单目操作符
|
||||
|
||||
> ! 逻辑反操作
|
||||
>
|
||||
> \- 负值
|
||||
>
|
||||
> \+ 正值
|
||||
>
|
||||
> & 取地址
|
||||
>
|
||||
> sizeof() 操作数的类型长度(以字节为单位)
|
||||
>
|
||||
> ++
|
||||
>
|
||||
> \--
|
||||
>
|
||||
> \* 间接访问操作符(解引用操作符)
|
||||
>
|
||||
> (类型) 强制类型转换
|
||||
>
|
||||
> ~ 对一个数的二进制按位取反
|
||||
|
||||
### 关系操作符
|
||||
|
||||
> \> >= < <= != ==(不要写成=)
|
||||
|
||||
### 逻辑操作符
|
||||
|
||||
> && ||
|
||||
|
||||

|
||||
|
||||
### 条件操作符
|
||||
|
||||
> exp1 ? exp2 : exp3
|
||||
|
||||
### 逗号表达式
|
||||
|
||||
> exp1, exp2, exp3, …expN
|
||||
|
||||
从左到右依次计算,最终值等于最后一个表达式
|
||||
|
||||
### 下标引用、函数调用和结构成员
|
||||
|
||||
> [] () . ->
|
||||
|
||||
## 常见关键字
|
||||
|
||||
> auto break case char const continue default do double else enum exte
|
||||
>
|
||||
> rn float for goto if int long register return short signed sizeof static struct switch typedef union unsigned void volatile while
|
||||
|
||||
### 1.typedef
|
||||
|
||||
类型重命名
|
||||
|
||||
```c
|
||||
//将unsigned int 重命名为uint_32, 所以uint_32也是一个类型名
|
||||
typedef unsigned int uint_32;
|
||||
|
||||
int main() {
|
||||
//观察num1和num2,这两个变量的类型是一样的
|
||||
unsigned int num1 = 0;
|
||||
uint_32 num2 = 0;
|
||||
return 0;
|
||||
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 2.static
|
||||
|
||||
```c
|
||||
//代码1
|
||||
#include <stdio.h>
|
||||
void test() {
|
||||
int i = 0;
|
||||
i++;
|
||||
printf("%d ", i);
|
||||
}
|
||||
int main() {
|
||||
int i = 0;
|
||||
for(i=0; i<10; i++){
|
||||
test();
|
||||
}
|
||||
return 0;
|
||||
}
|
||||
//代码2
|
||||
#include <stdio.h>
|
||||
void test() {
|
||||
//static修饰局部变量
|
||||
static int i = 0;
|
||||
i++;
|
||||
printf("%d ", i);
|
||||
}
|
||||
int main(){
|
||||
int i = 0;
|
||||
for(i=0; i<10; i++){
|
||||
test();
|
||||
}
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
代码1 中会输出十个2。而代码2种则会输出0~9
|
||||
|
||||
------
|
||||
|
||||
关于static 的思考
|
||||
|
||||

|
||||
|
||||
对于静态变量的声明应该在static语句中声明
|
||||
|
||||
|
||||
|
||||
a)*一个全局变量被statica修饰,使得这个全局变量只能在本源文件内使用,不能在其他源文件内使用。
|
||||
extern int a (所要执行的源文件内声明)*
|
||||
|
||||
*static int a (包含a的源文件内声明)*
|
||||
|
||||
b)*一个函数被static修饰,使得这个函数只能在本源文件内使用,不能在其他源文件内使用*。
|
||||
extern int add(int x,int y)
|
||||
|
||||
### 3.define定义的常量和宏
|
||||
|
||||
```
|
||||
#define MAX 100//定义常量
|
||||
#define Add(x,y) (x+y)//定义函数
|
||||
#define Max(x,y) (x>y?x:y)
|
||||
```
|
||||
|
||||

|
||||
|
||||
## 指针
|
||||
|
||||

|
||||
|
||||
指针变量也需要地址存放。
|
||||
|
||||

|
||||
|
||||
*结论:指针大小在32位平台是4个字节,64位平台是8个字节。*
|
||||
|
||||
*printf("%p\n", p) 输出地址*
|
||||
|
||||
## 结构体
|
||||
|
||||

|
||||
|
||||
337
content/c-review/3-分支和循环.md
Normal file
337
content/c-review/3-分支和循环.md
Normal file
@@ -0,0 +1,337 @@
|
||||
**目录**
|
||||
|
||||
[分支和循环语句](#分支和循环语句)
|
||||
|
||||
|
||||
|
||||
[顺序结构](#顺序结构)
|
||||
|
||||
[分支语句(选择结构)](#分支语句(循环结构))
|
||||
|
||||
[if语句](#if语句)
|
||||
|
||||
[if语句建议以以下两种方式书写:](#if语句建议以以下两种方式书写:)
|
||||
|
||||
[ 表达式内的关系操作符与逻辑操作符:](# 表达式内的关系操作符与逻辑操作符:)
|
||||
|
||||
[ else:](# else:)
|
||||
|
||||
[switch语句:](#switch语句:)
|
||||
|
||||
[ 循环语句:](# 循环语句:)
|
||||
|
||||
[while语句:](#while语句:)
|
||||
|
||||
[while语句中的break与continue:](#while语句中的break与continue:)
|
||||
|
||||
[ do...while语句](# do...while语句)
|
||||
|
||||
[ for语句:](# for语句:)
|
||||
|
||||
[答案:](#答案:)
|
||||
|
||||
------
|
||||
|
||||
# 分支和循环语句
|
||||
|
||||
#
|
||||
|
||||
------
|
||||
|
||||
|
||||
|
||||
# 顺序结构
|
||||
|
||||
|
||||
|
||||
# 分支语句(选择结构)
|
||||
|
||||
##
|
||||
|
||||
## if语句
|
||||
|
||||
> 语法结构:
|
||||
>
|
||||
> 1.if(表达式)
|
||||
>
|
||||
> 语句;
|
||||
>
|
||||
> 2.if(表达式)
|
||||
>
|
||||
> 语句1;
|
||||
>
|
||||
> else
|
||||
>
|
||||
> 语句2;
|
||||
>
|
||||
> 3.if(表达式)
|
||||
>
|
||||
> 语句1;
|
||||
>
|
||||
> else if(表达式)
|
||||
>
|
||||
> 语句2;
|
||||
>
|
||||
> else
|
||||
>
|
||||
> 语句3;
|
||||
>
|
||||
> **表达式结果为非0(真)则执行语句*
|
||||
>
|
||||
> *{ }代表代码块*
|
||||
|
||||
|
||||
|
||||
### if语句建议以以下两种方式书写:
|
||||
|
||||
```c
|
||||
if(5 == a ){//这么写if结构更加清晰明了
|
||||
...; //变量放在右侧可以避免少写=
|
||||
}
|
||||
else{
|
||||
...;
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
> 注意:“==”与“=”的区别
|
||||
|
||||
### 表达式内的关系操作符与逻辑操作符:
|
||||
|
||||
示例:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
18 <= age <= 30的程序中判断过程是:
|
||||
|
||||
18 <= age (40) 为真 所以左边部分变为1
|
||||
|
||||
1 <= 30 为真 值为 1
|
||||
|
||||
所以if内的语句可以被执行
|
||||
|
||||
正确写法:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### else:
|
||||
|
||||
> else 与相邻最近的if匹配(就近)
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
else会与第二个if匹配而不是第一个
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
正确的写代码规范十分重要,如下这样写就不会有问题:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
当然也是可以简化的:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
## switch语句:
|
||||
|
||||
> switch(整型常量表达式){
|
||||
>
|
||||
> case 1:
|
||||
>
|
||||
> ........;
|
||||
>
|
||||
> break;
|
||||
>
|
||||
> case 2:
|
||||
>
|
||||
> ........;
|
||||
>
|
||||
> break;
|
||||
>
|
||||
> case 3:
|
||||
>
|
||||
> ........;
|
||||
>
|
||||
> break;
|
||||
>
|
||||
> ...
|
||||
>
|
||||
> case n:
|
||||
>
|
||||
> ........;
|
||||
>
|
||||
> break;
|
||||
>
|
||||
> default:
|
||||
>
|
||||
> ........;
|
||||
>
|
||||
> break;
|
||||
>
|
||||
> }
|
||||
|
||||
1.*switch中必须为整型的常量表达式*
|
||||
|
||||
*2**.break语句建议在每个case后加上,避免以后修改时忘记添加*
|
||||
|
||||
3.default只能出现一次
|
||||
|
||||
思考:
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
int main() {
|
||||
int n = 1;
|
||||
int m = 2;
|
||||
switch (n) {
|
||||
case 1:
|
||||
m++;
|
||||
case 2:
|
||||
n++;
|
||||
case 3:
|
||||
switch (n) {//switch允许嵌套使用
|
||||
case 1:
|
||||
n++;
|
||||
case 2:
|
||||
m++;
|
||||
n++;
|
||||
break;
|
||||
}
|
||||
case 4:
|
||||
m++;
|
||||
break;
|
||||
default:
|
||||
break;
|
||||
}
|
||||
printf("m = %d, n = %d\n", m, n);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
# 循环语句:
|
||||
|
||||
## while语句:
|
||||
|
||||
> while(表达式){
|
||||
>
|
||||
> 循环语句;
|
||||
>
|
||||
> }
|
||||
|
||||
### while语句中的break与continue:
|
||||
|
||||
以下给出三个示例
|
||||
|
||||
示例1:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
示例2:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
程序没有结束,这是一个死循环
|
||||
|
||||
示例3:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
------
|
||||
|
||||
## do...while语句
|
||||
|
||||
> do{
|
||||
>
|
||||
> 循环语句;
|
||||
>
|
||||
> }while(表达式);//分号不要忘记
|
||||
|
||||
------
|
||||
|
||||
|
||||
|
||||
## for语句:
|
||||
|
||||
> for( 初始化部分;条件判断部分;调整部分 ){
|
||||
>
|
||||
> 循环语句;
|
||||
>
|
||||
> }
|
||||
>
|
||||
> 1. 不可在for 循环体内修改循环变量,防止 for 循环失去控制。
|
||||
> 2. 建议for语句的循环控制变量的取值采用“前闭后开区间”写法。
|
||||
>
|
||||
|
||||
\1. 请问下面的代码中循环体执行几次?
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
int main() {
|
||||
int i = 0;
|
||||
int k = 0;
|
||||
for(i =0,k=0; k=0; i++,k++)
|
||||
k++;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
2.下面的代码会输出什么?
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
int main(){
|
||||
int i = 0;
|
||||
int j = 0;
|
||||
for(; i < 10; i++)
|
||||
for(; j < 10; j++)
|
||||
printf("%d ",j);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
代码应该书写规范:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
int main(){
|
||||
int i = 0;
|
||||
int j = 0;
|
||||
for(i = 0; i < 10; i++)
|
||||
for(j = 0; j < 10; j++)
|
||||
printf("%d ",j);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
# 答案:
|
||||
|
||||
> m=5,n=3
|
||||
>
|
||||
> 0 1 2 3 4 5 6 7 8 9(因为在第一次大循环中j已经变为10 后面的大循环中第二个循环是没有输出的)
|
||||
246
content/c-review/4-函数.md
Normal file
246
content/c-review/4-函数.md
Normal file
@@ -0,0 +1,246 @@
|
||||
# 什么是函数?
|
||||
|
||||
这个大家自己思考吧(没必要去复制粘贴百度的定义到这里来。每个人有自己的理解,这个东西多用就会了)
|
||||
|
||||
函数(function) 通过实参(argument)初始 形参(parameter) 执行完函数体(function body) 返回(return value)一个值。(或者不返回)
|
||||
|
||||
# 函数类型
|
||||
|
||||
## 1.库函数
|
||||
|
||||
提供给大家一个学习库函数的网站:http://www.cplusplus.com/reference/
|
||||
|
||||
## 2.自定义函数
|
||||
|
||||
比如我们常用的
|
||||
|
||||
int main(){
|
||||
|
||||
}
|
||||
|
||||
1.这个 int 就是返回值的类型 我们一般在main函数最后一行加 return 0
|
||||
|
||||
2.main 是函数名 可以自己起
|
||||
|
||||
3.()括号内 可以放形式参数 也可以不写
|
||||
|
||||
4.大括号内就是函数体 写函数的功能 定义函数
|
||||
|
||||
### 强调一下函数的声明与定义不一样!
|
||||
|
||||
声明就像你在main函数开头初始化变量 它的作用就是让main函数顺序执行到调用语句时知道这个你在前面说过,不至于让main函数很懵逼 只用写上面的1,2,3
|
||||
|
||||
如:int Max(int a, int b);
|
||||
|
||||
定义就需要具体实现这个函数的功能 1,2,3,4都需要写完
|
||||
|
||||
```c
|
||||
int Max(int a,int b){
|
||||
|
||||
return (a>b)?a:b;//返回a,b中较大的数
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
# 形参与实参
|
||||
|
||||
这个不同大家自己百度就行。
|
||||
|
||||
自己可以在vs里调试看看你设置的形参与实参的地址(形参与实参地址时不一样的)
|
||||
|
||||
# 嵌套调用
|
||||
|
||||
可以类比数学的复合函数f(g(x))
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<math.h>
|
||||
#define e 2.7
|
||||
float g(int x){
|
||||
return pow(e,x);
|
||||
}
|
||||
float f(int x){
|
||||
return 2*g(x)-1;
|
||||
}
|
||||
int main(){
|
||||
int x = 0;
|
||||
printf("计算2*e^x-1\n请输入 x:\n");
|
||||
scanf("%d",&x);
|
||||
printf("f(%d) = %.2f",x,f(x));
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
# 链式访问
|
||||
|
||||
例1:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<string.h>
|
||||
int main() {
|
||||
char arr[20] = "hello ";
|
||||
int ret = strlen(strcat(arr, "world"));
|
||||
printf("%d\n", ret);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
arr数组在经过strcat后变成了"hello world"
|
||||
|
||||
我们知道strlen读取的长度是11(不懂为什么可以按照我给的网站去查strlen ,strcat的用法,里面说的很到位)
|
||||
|
||||
例2:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
int Max(int a,int b){
|
||||
return (a>b)?a:b;
|
||||
}
|
||||
int main(){
|
||||
int max = 0;
|
||||
max = Max(Max(7,Max(1,2)),6);
|
||||
printf("%d",max);
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
最后输出是7(其实直接看谁最大就好了,不知道原理也没事)
|
||||
|
||||
例3:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
int main(){
|
||||
printf("%d",printf("%d",printf("%d",printf("%d",43))));
|
||||
//printf返回打印字符的个数
|
||||
//最里面的printf 打印43 返回2
|
||||
// 打印2 返回1
|
||||
// 打印1 返回1
|
||||
//最外面的 。。 。。。
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
我们从最内层开始看起:
|
||||
|
||||
printf("%d,43")它会输出 43
|
||||
|
||||
printf函数会返回它打印的字符数 所以它返回 2
|
||||
|
||||
我们看下一层:
|
||||
|
||||
printf("%d",2);
|
||||
|
||||
这时打印 2 返回 1
|
||||
|
||||
继续下一层:
|
||||
|
||||
printf("%d",1);
|
||||
|
||||
打印 1 返回 1
|
||||
|
||||
同理最外层会打印1
|
||||
|
||||
所以最总结果是:43211
|
||||
|
||||
总结一下:链式访问需要关注函数的返回值
|
||||
|
||||
# 递归
|
||||
|
||||
## 什么是递归?
|
||||
|
||||
程序调用自身的编程技巧称为递归( recursion)
|
||||
|
||||
## 递归的两个必要条件
|
||||
|
||||
1.存在限制条件,当满足这个限制条件的时候,递归便不再继续。
|
||||
|
||||
2.每次递归调用之后越来越接近这个限制条件
|
||||
|
||||
举个例子:
|
||||
|
||||
求第 n 个斐波那契数列
|
||||
|
||||
先用数组法
|
||||
|
||||
以我的经验 普通的做法往往能给递归法找到规律
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
int main(){
|
||||
int arr[50] = {0};
|
||||
int i = 0;
|
||||
int n = 0;
|
||||
arr[0] = 1;
|
||||
arr[1] = 1;
|
||||
printf("你想知道斐波那契而数列的第几个数:\n");
|
||||
scanf("%d",&n);
|
||||
if(n==1 || n==2)
|
||||
printf("第 %d 个斐波那锲数列是 %d",n,1);//两类情况分开讨论一下
|
||||
else {
|
||||
for(i = 2; i<n; i++){
|
||||
arr[i] = arr[i-1] + arr[i-2];
|
||||
}
|
||||
printf("第 %d 个斐波那锲数列是 %d",n,arr[i-1]);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
递归法:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
int Fibonacci(int n){
|
||||
if(n==1 || n==2)
|
||||
return 1;
|
||||
else
|
||||
return (Fibonacci(n-1)+Fibonacci(n-2));
|
||||
}
|
||||
int main(){
|
||||
int n = 0;
|
||||
printf("你想知道斐波那契数列的第几个:\n");
|
||||
scanf("%d",&n);
|
||||
printf("%d",Fibonacci(n));
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
但是递归法做有的问题并不聪明==(比如这个问题)
|
||||
|
||||
因为如果给的n很大它会重复计算很多次,不断调用意味着更大的空间。可能造成栈溢出(stack overflow)
|
||||
|
||||
所以下面这个做法也许是解决这一类问题的好做法
|
||||
|
||||
迭代法:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
int main(){
|
||||
int Fir = 1;
|
||||
int Sec = 1;
|
||||
int Thi = 1;
|
||||
int N = 0;
|
||||
printf("请输入你想知道第几个斐波那契数列:\n");
|
||||
scanf("%d",&N);
|
||||
while(N>2){
|
||||
Thi = Fir + Sec;
|
||||
Fir = Sec;
|
||||
Sec = Thi;
|
||||
N--;
|
||||
}
|
||||
printf("%d",Thi);
|
||||
}
|
||||
```
|
||||
|
||||
215
content/c-review/5-指针.md
Normal file
215
content/c-review/5-指针.md
Normal file
@@ -0,0 +1,215 @@
|
||||
|
||||
|
||||
这一节带大家简单了解一下与指针,希望对大家有帮助
|
||||
|
||||
------
|
||||
|
||||
|
||||
|
||||
# 指针
|
||||
|
||||
## 1.什么是指针?
|
||||
|
||||
> 在计算机科学中,指针(Pointer)是编程语言中的一个对象,利用地址,它的值直接指向 (points to)存在电脑存储器中另一个地方的值。由于通过地址能找到所需的变量单元,可以说,地址指向该变量单元。因此,将地址形象化的称为“指针”。意思是通过它能找到以它为地址 的内存单元。
|
||||
|
||||
|
||||
|
||||
### 指针的大小:
|
||||
|
||||
1.指针是用来存放地址的,地址是唯一标示一块地址空间的。
|
||||
|
||||
2.**指针的大小在32位平台是4个字节,在64位平台是8个字节。**
|
||||
|
||||
### 指针类型:
|
||||
|
||||
> char *p = NULL;
|
||||
>
|
||||
> short *p = NULL;
|
||||
>
|
||||
> int *p = NULL;
|
||||
>
|
||||
> long *p = NULL;
|
||||
>
|
||||
> double *p = NULL;
|
||||
>
|
||||
> .......
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
null 是什么我后面会解释给大家
|
||||
|
||||
既然指针大小已经固定的,那么要这么多指针类型有什么用呢?或者说我们可不可以有char*来表示所有的指针类型?
|
||||
|
||||
## 指针类型的作用
|
||||
|
||||
### 1.指针的类型决定了指针向前或者向后走一步有多大
|
||||
|
||||

|
||||
|
||||
可以看到:字符指针加一只增加了一个字节;而整型指针增加了四个字节
|
||||
|
||||
(char*)为强制类型转换 因为n是整型所以n的指针应该是int*
|
||||
|
||||
### 2.指针的类型决定了,对指针解引用的时候有多大的权限(能操作几个字节)。
|
||||
|
||||
比如: char* 的 指针解引用就只能访问一个字节,而 int* 的指针的解引用就能访问四个字节。
|
||||
|
||||

|
||||
|
||||
0x11223344是16进制数 16进制数一位就是四个二进制位
|
||||
|
||||
所以16进制数 每两位就代表一个字节
|
||||
|
||||
所以地址一般有16进制位表示 也就是四个字节
|
||||
|
||||
## 野指针
|
||||
|
||||
> 概念: 野指针就是指针指向的位置是不可知的(随机的、不正确的、没有明确限制的)指针变量 在定义时如果未初始化,其值是随机的,指针变量的值是别的变量的地址,意味着指针指向了一 个地址是不确定的变量,此时去解引用就是去访问了一个不确定的地址,所以结果是不可知的。
|
||||
|
||||
### 1.野指针成因
|
||||
|
||||
**1.指针未初始化**
|
||||
|
||||

|
||||
|
||||
**2. 指针越界访问**
|
||||
|
||||

|
||||
|
||||
**3. 指针指向的空间释放**
|
||||
举个简单例子
|
||||
|
||||

|
||||
|
||||
test被调用完之后临时变量a已经被释放,所以*p就是野指针。
|
||||
|
||||
动态空间开辟会详细讲。
|
||||
|
||||
> **如何规避野指针**
|
||||
> \1. 指针初始化
|
||||
>
|
||||
> \2. 小心指针越界
|
||||
>
|
||||
> \3. 指针指向空间释放即使置NULL
|
||||
>
|
||||
> \4. 指针使用之前检查有效性
|
||||
|
||||
防止指针为初始化我们可以这样做:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
int main() {
|
||||
int *p = NULL;//NULL 值为0
|
||||
int a = 10;
|
||||
p = &a;
|
||||
if (p != NULL)//如果p为NUL说明指针p没有经过初始化
|
||||
{
|
||||
*p = 20;
|
||||
}
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
## 指针运算
|
||||
|
||||
### 1.指针+-整数
|
||||
|
||||
```
|
||||
eg:
|
||||
double arr[5] = {1.1,2,3,4,5};
|
||||
double * p = arr;
|
||||
for(p = &arr[0];p<&arr[5];)
|
||||
*(p++) = 0;
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 2.指针减指针
|
||||
|
||||
这里介绍strlen实现:
|
||||
|
||||
方法1:
|
||||
|
||||

|
||||
|
||||
方法2:
|
||||
|
||||

|
||||
|
||||
方法3:
|
||||
|
||||

|
||||
|
||||
方法4:
|
||||
|
||||

|
||||
|
||||
我们来看一下vs strlen库函数是如何写的,它的路径如下:
|
||||
|
||||
```
|
||||
size_t __cdecl strlen (
|
||||
const char * str
|
||||
)
|
||||
{
|
||||
const char *eos = str;
|
||||
|
||||
while( *eos++ ) ;
|
||||
|
||||
return( eos - str - 1 );
|
||||
```
|
||||
|
||||

|
||||
|
||||
是不是和方法4差不多呀
|
||||
|
||||
### 3.指针关系运算
|
||||
|
||||
以初始化数组为例
|
||||
|
||||
方法1:
|
||||
|
||||

|
||||
|
||||
方法2:
|
||||
|
||||

|
||||
|
||||
实际在绝大部分的编译器上是可以顺利完成任务的,然而我们还是应该避免这样写,因为标准并不保证 它可行。
|
||||
|
||||
大家可以根据上面的例子细品一下这句话:
|
||||
|
||||
> 标准规定:
|
||||
> 允许指向数组元素的指针与指向数组最后一个元素后面的那个内存位置的指针比较,但是不允许 与指向第一个元素之前的那个内存位置的指针进行比较。
|
||||
|
||||
## 二级指针
|
||||
|
||||
## 
|
||||
|
||||
## 指针数组
|
||||
|
||||

|
||||
|
||||
例1:
|
||||
|
||||
## 
|
||||
|
||||
12 = 3*4(指针大小)
|
||||
|
||||
例2:
|
||||
|
||||

|
||||
|
||||
练习:
|
||||
|
||||
1:
|
||||
|
||||

|
||||
|
||||
2:
|
||||
|
||||

|
||||
|
||||
632
content/c-review/6-操作符.md
Normal file
632
content/c-review/6-操作符.md
Normal file
@@ -0,0 +1,632 @@
|
||||
|
||||
|
||||
## 目录
|
||||
|
||||
***
|
||||
|
||||
[TOC]
|
||||
|
||||
|
||||
|
||||
## 正文
|
||||
|
||||
***
|
||||
|
||||
### 一 算数操作符
|
||||
|
||||
>`+`
|
||||
>
|
||||
>`-`
|
||||
>
|
||||
>`*`
|
||||
>
|
||||
>`/`
|
||||
>
|
||||
>`%`: % 左右两边的数必须都为整数
|
||||
|
||||
|
||||
|
||||
### 二 移位操作符
|
||||
|
||||
> `>>` : 右移
|
||||
>
|
||||
> `<<`: 左移
|
||||
|
||||
**例1:b = 20**
|
||||
|
||||
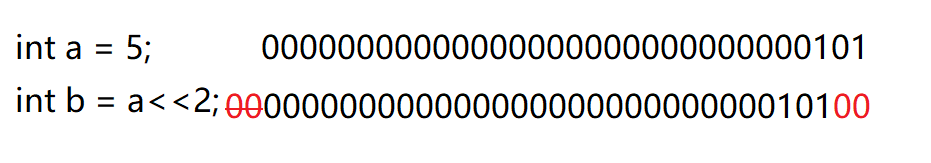
|
||||
|
||||
**例2:b = -4**
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
>注意1:
|
||||
>
|
||||
>左移直接在空的地方补0 如例1
|
||||
>
|
||||
>右移有两种情况:
|
||||
>
|
||||
>1.逻辑位移 补0
|
||||
>
|
||||
>2.算数位移 补1 如例2(一般都是这种情况)
|
||||
>
|
||||
>注意2:
|
||||
>
|
||||
>移位操作符,不要移动负数位,这是标准未定义。
|
||||
>
|
||||
>如:num >> -1//error
|
||||
|
||||
|
||||
|
||||
### 三 位操作符
|
||||
|
||||
> `&` (按位与) `|` (按位或) `^`(按位异或)
|
||||
|
||||
|
||||
|
||||
例3:按位与
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
例4:按位或
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
例5:按位异或
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
例6:异或的应用——交换两个值的内容
|
||||
|
||||
方法1:
|
||||
|
||||
```
|
||||
int a,b,c;
|
||||
c = a;
|
||||
a = b;
|
||||
b = c;
|
||||
```
|
||||
|
||||

|
||||
|
||||
方法2:(如果a,b很大可能会溢出)
|
||||
|
||||
```
|
||||
int a,b;
|
||||
a = a + b;
|
||||
b = a - b;
|
||||
a = a - b;
|
||||
```
|
||||
|
||||

|
||||
|
||||
方法3(异或法):
|
||||
|
||||
```
|
||||
int a, b;
|
||||
a = a^b;
|
||||
b = a^b;
|
||||
a = a^b;
|
||||
```
|
||||
|
||||

|
||||
|
||||
例7:怎么求一个二进制位中1的个数
|
||||
|
||||
```
|
||||
#include<stdio.h>
|
||||
int CountOneBit(unsigned int n){//解决负数无法计算问题,这种运算运算的是补码
|
||||
int count = 0;
|
||||
while(n){//类比十进制中每位数的求法
|
||||
if(n%2 == 1)
|
||||
count++;
|
||||
n/=2;
|
||||
}
|
||||
return count;
|
||||
}
|
||||
int main(){
|
||||
int n = 0;
|
||||
int num_1 = 0;
|
||||
printf("请输入一个数:");
|
||||
scanf("%d",&n);
|
||||
num_1 = CountOneBit(n);
|
||||
printf("%d的二进制序列中有%d个 1",n,num_1);
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
> **unsigned的作用:**
|
||||
>
|
||||
> unsigned就是将这个二进制数最高位的符号位变成计数位。下面我们举个例子帮大家理解一下
|
||||
>
|
||||
> 如果我们输入的是-1
|
||||
>
|
||||
> -1%2 == -1
|
||||
>
|
||||
> -1/2 = 0
|
||||
>
|
||||
> 这样输出的count为0
|
||||
>
|
||||
> 但是我们知道-1的补码是11111111111111111111111111111111
|
||||
>
|
||||
> 这样我们的代码就局限在正整数
|
||||
>
|
||||
> 如果加上unsigned 虽然我们输入的是-1 但是程序计算是是按照 unsigned int 的最大值,这样就避免了这个问题
|
||||
|
||||
更多位运算相关示例: [https://github.com/hairrrrr/linux.ccode/tree/master/Bit/ClassCode/2020-1-7%EF%BC%888%EF%BC%89](https://github.com/hairrrrr/linux.ccode/tree/master/Bit/ClassCode/2020-1-7(8))
|
||||
|
||||
|
||||
|
||||
### 四 赋值操作符
|
||||
|
||||
> `=`
|
||||
|
||||
a = b = c
|
||||
|
||||
它的意义是将c的值赋给b,再将b的值赋给a。其实这样理解不够准确,其实应该这么写:
|
||||
|
||||
a = (b = c)
|
||||
|
||||
先将c的值赋给b 然后将这个整体,即b的值赋给a
|
||||
|
||||
|
||||
|
||||
### 五 复合赋值符
|
||||
|
||||
> `+= -= *= \= %= >>= <<= &= |= ^=`
|
||||
|
||||
|
||||
|
||||
### 六 单目操作符
|
||||
|
||||
> `!`
|
||||
>
|
||||
> ` \- `
|
||||
>
|
||||
> `= `
|
||||
>
|
||||
> **`&`**(取地址)
|
||||
>
|
||||
> **`sizeof`**(操作数的类型长度)
|
||||
>
|
||||
> **`~`** (对一个数的二进制位按位取反)
|
||||
>
|
||||
> `--` ` ++ `(前置,后置)
|
||||
>
|
||||
> **`*`** (解引用)
|
||||
>
|
||||
> **`(类型)`**(强制类型转换)
|
||||
|
||||
**例8:!的应用**
|
||||
|
||||
应用!与flag来判断情况做出选择
|
||||
|
||||
if(flag){
|
||||
|
||||
flag为真进入循环;
|
||||
|
||||
}
|
||||
|
||||
if(!flag){
|
||||
|
||||
flag为假进入循环;
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
**printf函数打印格式**
|
||||
|
||||
> %#p 0XCCCCCC
|
||||
>
|
||||
> %p 00CCCCCCC
|
||||
>
|
||||
> %x cccccc
|
||||
>
|
||||
> %X CCCCCC
|
||||
|
||||
```c
|
||||
1
|
||||
|
||||
int a = 0;
|
||||
|
||||
sizeof(a)=4
|
||||
|
||||
sizeof(int) = 4
|
||||
|
||||
sizeof a √
|
||||
|
||||
sizeof int ×
|
||||
|
||||
2
|
||||
|
||||
sizeof求数组大小 sizeof(arr)
|
||||
|
||||
sizeof求数组元素个数 sizeof(arr)/sizeof(arr[0])
|
||||
|
||||
切记!!!sizeof不能再函数内部求指针数组的大小
|
||||
|
||||
3
|
||||
|
||||
int a = 10;
|
||||
|
||||
short s =3;
|
||||
|
||||
printf('%d\n",sizeof(s = a+4));
|
||||
|
||||
printf("%d\n",a);
|
||||
|
||||
printf("%d\n",s);
|
||||
|
||||
输出: 2 10 3
|
||||
|
||||
赋值并不会将类型一同赋予左值
|
||||
|
||||
sizeof在编译阶段就已经运行结束了(sizeof 被 换成 2)
|
||||
|
||||
而s = a + 4要到生成可执行文件之后才会完成
|
||||
|
||||
编译(.c) -- 链接(.exe)
|
||||
|
||||
4
|
||||
|
||||
小心细节问题。进入函数后 ch实际上变成了指针变量。
|
||||
```
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
**例9:~ 的应用**
|
||||
|
||||
```c
|
||||
若想完成一下操作:
|
||||
|
||||
15 00001111
|
||||
|
||||
将从右数第4位变成0 ,应该如何操作?
|
||||
|
||||
a = (1<<4-1) 00001000
|
||||
|
||||
b = ~(a) 11110111
|
||||
|
||||
b&15 00000111
|
||||
|
||||
所以可以这么写:
|
||||
|
||||
a &= (~(1<<4-1));
|
||||
|
||||
如何变回来呢?
|
||||
|
||||
00001000 1<<4-1
|
||||
|
||||
00000111 | (1<<4-1) 即可
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 七 关系操作符
|
||||
|
||||
>`>`
|
||||
>
|
||||
>`>=`
|
||||
>
|
||||
>`<=`
|
||||
>
|
||||
>`!=`
|
||||
>
|
||||
>`==`
|
||||
|
||||
**注意:不要将 ‘ == ’ 写成 ‘ = ’**
|
||||
|
||||
|
||||
|
||||
### 八 逻辑操作符
|
||||
|
||||
>`&&`
|
||||
>
|
||||
>`||`
|
||||
|
||||
**例11 &与&&的差异:**
|
||||
|
||||

|
||||
|
||||
**例12 这个题值得思考**
|
||||
|
||||

|
||||
|
||||
**在&&的判断中如果一边位假(0)那么程序就会停止向后面判断**。所以++b与d++并没有执行
|
||||
|
||||
**在 || 的判断中如果一边为真,则停止继续向下判断。**(如:++a || b++ || c)
|
||||
|
||||
补充:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### 九 条件操作符
|
||||
|
||||
> `a > b ? a : b`
|
||||
|
||||
|
||||
|
||||
### 十 逗号表达式
|
||||
|
||||
> `a,b,c,d,.....n`
|
||||
|
||||
|
||||
|
||||
**逗号表达式整体的值等于最后一个表达式的值**
|
||||
|
||||
例13 思考题
|
||||
|
||||
```
|
||||
int main() {
|
||||
int a = 0;
|
||||
int b = 1, c = 2;
|
||||
a = (a = b, b += c, c--);
|
||||
printf("case1:%d\n", a);
|
||||
|
||||
a = 0,b = 1, c = 2;
|
||||
a = (a < 0, a++, b = a);
|
||||
printf("case2:%d\n", a);
|
||||
|
||||
a = 0, b = 1, c = 2;
|
||||
a = (a<0, b<a);
|
||||
printf("case3:%d\n", a);
|
||||
|
||||
a = 0, b = 1, c = 2;
|
||||
if (a = b + 1, c = a / 2 - 1, c == 0)
|
||||
printf("case4:%d\n", c);
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
另一种代码书写方式:
|
||||
|
||||
```
|
||||
//一般情况
|
||||
a = get_val();
|
||||
count_val(a);
|
||||
while (a > 0) {
|
||||
//业务处理
|
||||
a = get_val();
|
||||
count_val(a);
|
||||
}
|
||||
//应用逗号表达式
|
||||
while (a = get_val(), count_val(a), a > 0) {
|
||||
//业务处理
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
合理应用逗号表达式可以简化代码。
|
||||
|
||||
|
||||
|
||||
### 11 其他
|
||||
|
||||
#### 1. [] 下标引用操作符
|
||||
|
||||
对于数组 arr[5] = {1,2,3,4,5}
|
||||
|
||||
我们一般的用法是:
|
||||
|
||||
arr[0],arr[1],arr[2].....其中arr[0]就代表访问数组中第一个元素,arr[1]代表访问第二个以此类推
|
||||
|
||||
学习了指针之后我们知道:
|
||||
|
||||
arr代表数组首元素的地址。
|
||||
|
||||
arr[0],arr[1],arr[2]...我们可以改写成:*arr,*(arr+1),*(arr+2)..... (*arr可以理解为*(arr+0))
|
||||
|
||||
进一步思考:
|
||||
|
||||
(arr+1)可以改写成(1+arr)
|
||||
|
||||
那么arr[1]可否写成1[arr]呢?答案是肯定的。
|
||||
|
||||
所以我们就有了一下结论:
|
||||
|
||||
> `1[arr] == arr[1] == *(arr+1) == *(1+arr)`
|
||||
|
||||
**事实上,无论哪一种写法,程序再最终编译的时候都会转化为:\*( arr+1)**
|
||||
|
||||
|
||||
|
||||
#### 2. ( ) 函数调用操作符
|
||||
|
||||
例14.有参数调用
|
||||
|
||||
```c
|
||||
int add(int x, int y){
|
||||
return x+y;
|
||||
}
|
||||
int main(){
|
||||
int a = 1;
|
||||
int b = 2;
|
||||
printf("%d",add(a,b));
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
例15.无参数调用
|
||||
|
||||
```c
|
||||
void test(){
|
||||
printf("看到这里的都是人才!!!\n");
|
||||
}
|
||||
int main(){
|
||||
test();
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
c
|
||||
|
||||
#### 3.访问一个结构的成员
|
||||
|
||||
> **`.`** (结构体.成员名)
|
||||
>
|
||||
> **`->`** (结构体指针 -> 成员名)
|
||||
|
||||
例16.
|
||||
|
||||
```c
|
||||
struct Stu{
|
||||
char name[20];
|
||||
int age;
|
||||
}stu;
|
||||
int main(){
|
||||
stu = {"张三",20};
|
||||
struct Stu *ps = &stu;c
|
||||
//下面三种写法都是正确的
|
||||
printf("%s %d\n",stu.name,stu.age);
|
||||
printf("%s %d\n",(*ps).name,(*ps).age);
|
||||
printf("%s %d\n",ps->name,ps->age);
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 12 表达式求值
|
||||
|
||||
#### 1. 隐式类型转换
|
||||
|
||||
> - C的整型算术运算总是至少以缺省整型类型的精度来进行的。
|
||||
> - 为了获得这个精度,表达式中的字符和短整型操作数在使用之前被转换为普通整型,这种转换称为**整型提升**。
|
||||
|
||||
> **整型提升的意义:**
|
||||
> 表达式的整型运算要在CPU的相应运算器件内执行,CPU内整型运算器(ALU)的操作数的字节长度 一般就是int的字节长度,同时也是CPU的通用寄存器的长度。
|
||||
> 因此,即使两个char类型的相加,在CPU执行时实际上也要先转换为CPU内整型操作数的标准长 度。
|
||||
> 通用CPU(general-purpose CPU)是难以直接实现两个8比特字节直接相加运算(虽然机器指令 中可能有这种字节相加指令)。所以,表达式中各种长度可能小于int长度的整型值,都必须先转 换为int或unsigned int,然后才能送入CPU去执行运算。
|
||||
|
||||
> 整型提升方法:
|
||||
>
|
||||
> **正数的整型高位补充0 负数补充1**
|
||||
|
||||
例17.整型提升示例
|
||||
|
||||
注:char是有符号的
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
补充:字符类型的反码(1字节)及其表示的值
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
> 总结:
|
||||
>
|
||||
> **char** 的值范围是:**-128 ~ 127**
|
||||
>
|
||||
> **unsigned char** 值的范围是:**0 ~ 255**
|
||||
|
||||
**例18.整型提升在程序中的证明**
|
||||
|
||||
```
|
||||
int main()
|
||||
{
|
||||
char a = 0x41;
|
||||
char b = 0xFF;//0xFF -> 255 11111111
|
||||
int c = 0xb6000000;
|
||||
if (a == 0x41) {//正数原码补码一致,整型提升补码不变
|
||||
printf("a\n");
|
||||
printf("%d %c\n", a, a);
|
||||
}
|
||||
if (b == 0xFF) {
|
||||
printf("b\n");
|
||||
}
|
||||
//在判断 b==0xFF 时 要对b进行整型提升
|
||||
//b 11111111 -> 11111111 11111111 11111111 11111111 而 0xEF的补码依然是11111111 所以这两个补码时不同的
|
||||
printf("%d %c\n", b, b);
|
||||
//输出时 依然要对b进行整型提升
|
||||
// 11111111 -> 补码:11111111 11111111 11111111 11111111
|
||||
//反码:11111111 11111111 11111111 11111110
|
||||
//原码:10000000 00000000 00000000 00000001 即:-1
|
||||
if(c==0xb6000000)
|
||||
printf("c\n");
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
**例子20.整型提升的再一次证明**
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
#### 2. 算数转换
|
||||
|
||||
> 如果某个操作符的各个操作数属于不同的类型,那么除非其中一个操作数的转换为另一个操作数的类 型,否则操作就无法进行。下面的层次体系称为寻常算术转换。
|
||||
|
||||
> **long double** 8byte
|
||||
>
|
||||
> **double** 8byte
|
||||
>
|
||||
> **float** 4byte
|
||||
>
|
||||
> **unsigned long int** 4byte
|
||||
>
|
||||
> **long int** 4byte
|
||||
>
|
||||
> **unsigned int** 4byte
|
||||
>
|
||||
> **int** 4byte
|
||||
|
||||
> **如果某个操作数的类型在上面这个列表中排名较低,那么首先要转换为另外一个操作数的类型后执行运算**。
|
||||
|
||||
**附:各类型变量在内存中占的字节**(32位)
|
||||
|
||||
```c
|
||||
int main() {
|
||||
printf("%d\n", sizeof(char));//1
|
||||
printf("%d\n", sizeof(int));//4
|
||||
printf("%d\n", sizeof(unsigned int));//4
|
||||
printf("%d\n", sizeof(long));//4
|
||||
printf("%d\n", sizeof(unsigned long));//4
|
||||
printf("%d\n", sizeof(long long int));//8
|
||||
printf("%d\n", sizeof(float));//4
|
||||
printf("%d\n", sizeof(double));//8
|
||||
printf("%d\n", sizeof(long double));//8
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 3. 操作符属性
|
||||
|
||||
> 1. 操作符的优先级
|
||||
>
|
||||
> 2. 操作符的结合性
|
||||
>
|
||||
> 3. 是否控制求值顺序
|
||||
|
||||
|
||||
240
content/c-traps-and-pitfalls/01 词法陷阱.md
Normal file
240
content/c-traps-and-pitfalls/01 词法陷阱.md
Normal file
@@ -0,0 +1,240 @@
|
||||
## 【C 陷阱与缺陷 】(一)词法陷阱
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 一 内容
|
||||
|
||||
#### 0. `=`不同于`==`
|
||||
|
||||
当程序员本意是作比较运算时,却可能无意中误写成了赋值运算。
|
||||
|
||||
1.本意是检查 x 与 y 是否相等:
|
||||
|
||||
```c
|
||||
if(x = y)
|
||||
break;
|
||||
```
|
||||
|
||||
实际上是将 y 的值赋值给了 x ,然后再检查该值是否为 0 。
|
||||
|
||||
2.本意是跳过文件中的空白字符:
|
||||
|
||||
```c
|
||||
while(c = '' || c == '\t' || c == '\n')
|
||||
c = getc(f);
|
||||
```
|
||||
|
||||
因为 `' '`不等于 0 (`' '`的 ASCII 码值为 32),那么无论变量为何值,上述表达式求值的结果都为 1,因此循环将进行下去直到整个文件结束。
|
||||
|
||||
|
||||
|
||||
C 编译器发现形如 x = y 的表达式出现在选择语句,循环语句的条件判断部分时,会给出警告。当确实需要对变量进行赋值时,为了避免警告,我们应该这样处理:
|
||||
|
||||
```c
|
||||
if((x = y) != 0)
|
||||
foo();
|
||||
```
|
||||
|
||||
|
||||
|
||||
如果将赋值写成了比较,也会造成混淆:
|
||||
```c
|
||||
if((filedesc == open(argv[i], 0)) < 0)
|
||||
error();
|
||||
```
|
||||
|
||||
本例中,open 执行成功返回非零值,失败返回 -1。本意是将 open 函数的返回值存储在变量 filedesc 中,然后将其和 0 比较大小,判断 open 执行是否成功 。`==`运算符的结果只可能是 1 或 0,永远不会小于 0,所以 error() 将没有机会被调用。
|
||||
|
||||
|
||||
|
||||
#### 1. `&`和`|`不同于`&&`和`||`
|
||||
|
||||
比较 `i & j` 和 `i && j` ,只要 i 和 j 是 0 或 1 ,两个表达式的值是一样的(`|` 和 `||` 同理。)。然而,一旦 i 和 j 的值为其他,两个表达式的值不会始终一致。
|
||||
|
||||
另一个区别是操作数带有自增自减的运算:
|
||||
|
||||
`i & j++`, j 始终会自增;但是 `i && j++` 有时 j 不会自增。
|
||||
|
||||
|
||||
|
||||
#### 2. 词法分析中的“贪心法”
|
||||
|
||||
当 C 的编译器读入一个字符`/`后跟着一个字符`*`时,那么编译器就必须做出判断:时将其作为两个符号对待,还是合起来作为一个符号对待。这类问题的规则:**每个符号应该包含尽可能多的符号**。
|
||||
|
||||
例如:`a---b`和`(a--) - b`含义相同,而与`a - (--b)`含义不同。
|
||||
|
||||
又如:下面的语句本意是 x 除以 p 指向的值然后将结果赋值给 y
|
||||
|
||||
```c
|
||||
y = x/*p;
|
||||
```
|
||||
|
||||
但是,实际上 `/*`被编译器理解为一段注释的开始。
|
||||
|
||||
将上面的语句重写如下:
|
||||
|
||||
```c
|
||||
y = x / *p;
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```c
|
||||
y = x/(*p);
|
||||
```
|
||||
|
||||
老版本的编译器允许使用`=+`来代表现在`+=`的含义,这种编译器会将:
|
||||
|
||||
```c
|
||||
a=-1;
|
||||
```
|
||||
|
||||
理解为:
|
||||
|
||||
```c
|
||||
a =- 1;
|
||||
```
|
||||
|
||||
即为:
|
||||
|
||||
```c
|
||||
a = a - 1;
|
||||
```
|
||||
|
||||
因此,如果程序员的原意为:
|
||||
|
||||
```c
|
||||
a = -1;
|
||||
```
|
||||
|
||||
那么结果会让其大吃一惊。
|
||||
|
||||
再如:
|
||||
|
||||
```c
|
||||
a=/*b;
|
||||
```
|
||||
|
||||
在老版本的编译器会将其当作:
|
||||
|
||||
```c
|
||||
a =/ *b;
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 3. 整型常量
|
||||
|
||||
许多编译器会把 8 和 9 作为把八进制的数字处理,这种处理方式来源于八进制数的定义。例如:0195 的含义是`1x8^2 + 9x8 + 5x8^0`也就是 141(十进制)或 0215(八进制)。**ANSI C 标准中禁止这种用法。**
|
||||
|
||||
|
||||
|
||||
#### 4. 字符与字符串
|
||||
|
||||
**单引号引起的一个字符实际上代表一个整数**。整数值对应于该字符在编译器采用的字符集中的序列值。因此,对于采用 ASCII 字符集的编译器而言,`'a'`的含义与 97 (十进制)严格一致。
|
||||
|
||||
**用双引号引起的字符串,代表的确实一个指向无名数组起始字符的指针**。该数组被双引号之间的字符以及一个额外的二进制值为 0 的字符`\0`初始化。
|
||||
|
||||
比如,下面的这个语句:
|
||||
|
||||
```c
|
||||
printf("Hello World\n");
|
||||
```
|
||||
|
||||
等价于:
|
||||
|
||||
```c
|
||||
char hello[] = {'H', 'e', 'l', 'l', 'o', ' ', 'W', 'o', 'r', 'l', 'd', '\n', 0};
|
||||
printf(hello);
|
||||
```
|
||||
|
||||
|
||||
|
||||
整数型(一般为 16 或 32 位)的存储空间可以容纳多个字符(一般为 8 位),因此有的编译器允许在一个字符常量(以及字符串常量)中包含多个字符。也就是说:用`'yes'`代替`"yes"`不会被该编译器检测到。前者的含义大多数编译器理解为一个整数值,由`'y','e','s'`所代表的整数值按照特定编译器实现中的定义方式组合得到。
|
||||
|
||||
|
||||
|
||||
### 二 练习
|
||||
|
||||
#### 练习 1
|
||||
|
||||
某些 C 编译器允许嵌套注释。请写一个测试程序,要求:无论编译器是否允许嵌套注释,该程序都能正常通过编译,但是两种情况下程序执行结果不同。
|
||||
|
||||
对于符号序列:
|
||||
|
||||
```c
|
||||
/*/**/"*/"
|
||||
```
|
||||
|
||||
如果允许嵌套注释,上面的符号序列表示:一个单独的双引号`"`,因为最后的注释符前出现的符号都会被当作注释的一部分。
|
||||
|
||||
如果不允许嵌套注释,上面的符号就表示一个字符串:`"*/"`
|
||||
|
||||
Doug Mcllroy 发现了下面这个令人拍案叫绝的解法:
|
||||
|
||||
```c
|
||||
/*/*/0 */**/1
|
||||
```
|
||||
|
||||
这个解法主要利用了编译器作词发分析时的“贪心法”规则。
|
||||
|
||||
如果编译器允许嵌套注释,则将上式解释为:
|
||||
|
||||
```c
|
||||
/* /*/0 */ * */ 1
|
||||
```
|
||||
|
||||
上式的值为 1
|
||||
|
||||
如果编译器不允许嵌套注释,则解释为:
|
||||
|
||||
```c
|
||||
/* / */ 0 * /**/ 1
|
||||
```
|
||||
|
||||
也就是 `0*1`,值为 0
|
||||
|
||||
|
||||
|
||||
#### 练习 2
|
||||
|
||||
`a+++++b` 的含义是什么?
|
||||
|
||||
上式唯一有意义的解析方式就是:
|
||||
|
||||
```c
|
||||
a++ + ++b
|
||||
```
|
||||
|
||||
可是,根据“贪心法”的规则,上式应该被解释为:
|
||||
|
||||
```c
|
||||
a++ ++ + b
|
||||
```
|
||||
|
||||
等价于:
|
||||
|
||||
```c
|
||||
(a++)++ + b;
|
||||
```
|
||||
|
||||
但是 `a++`的值不能作为左值,因此编译器不会接受 a++ 作为后面 ++ 运算的操作数。
|
||||
|
||||
|
||||
|
||||
**参考资料**:*《C 缺陷与陷阱》*
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
384
content/c-traps-and-pitfalls/02 语法陷阱.md
Normal file
384
content/c-traps-and-pitfalls/02 语法陷阱.md
Normal file
@@ -0,0 +1,384 @@
|
||||
## 【C 陷阱与缺陷 】(二)语法“陷阱”
|
||||
|
||||
|
||||
|
||||
### 零
|
||||
|
||||
#### 0. 理解函数声明
|
||||
|
||||
请思考下面语句的含义:
|
||||
|
||||
```c
|
||||
(*(void(*)())0)()
|
||||
```
|
||||
|
||||
前面我们说过 C 语言的声明包含两个部分:类型和类似表达式的声明符。
|
||||
|
||||
最简单的声明符就是单个变量:
|
||||
|
||||
```c
|
||||
float f, g;
|
||||
```
|
||||
|
||||
由于声明符和表达式的相似,我们可以在声明符中任意使用括号:
|
||||
|
||||
```c
|
||||
float ((f));
|
||||
```
|
||||
|
||||
这个声明的含义是:当对 f 求值时,`((f))`的类型为 float 类型,可以推知 `f` 也是浮点类型。
|
||||
|
||||
同样的,我们可以声明函数:
|
||||
|
||||
```c
|
||||
float ff();
|
||||
```
|
||||
|
||||
这个声明的含义是:表达式 `ff()`求值结果是 float 类型,也就是返回 float 类型的函数。
|
||||
|
||||
类似的:
|
||||
|
||||
```c
|
||||
float *pf;
|
||||
```
|
||||
|
||||
这个声明的含义是:`*pf`是一个 float 类型的数,也就是说 pf 是指向 float 类型的指针。
|
||||
|
||||
以上的声明可以结合起来:
|
||||
|
||||
```c
|
||||
float *g(), (*h)();
|
||||
```
|
||||
|
||||
`*g()`和`(*h)()`是浮点表达式。因为`()`(和`[]`)的优先级高于`*`。`*g()`也就是`*(g())`:g 是一个函数,该函数返回一个指向浮点数的指针。同理,可以得到 h 是一个函数指针,h 所指向的函数返回值为浮点类型。
|
||||
|
||||
|
||||
|
||||
一旦我们知道如何声明一个给定类型的变量,那么该类型的类型转换符就很容易得到:**只需要把声明中的变量名和声明末尾的分号去掉,再用括号整体括起来**。
|
||||
|
||||
比如:
|
||||
|
||||
```c
|
||||
float (*h)();
|
||||
|
||||
(float (*)())p;
|
||||
```
|
||||
|
||||
|
||||
|
||||
假定变量 fp 是一个函数指针,那么如何调用 fp 所指向的函数呢?调用方法如下:
|
||||
|
||||
```c
|
||||
(*fp)();
|
||||
```
|
||||
|
||||
*fp 就是该指针所指向的函数。ANSI C 标准允许将上式简写为:
|
||||
|
||||
```c
|
||||
fp();
|
||||
```
|
||||
|
||||
但是要记住这是一种简写方法。
|
||||
|
||||
注意:`(*fp)()`和`*fp()`的含义完全不同,不要省略 *fp 两侧的分号。
|
||||
|
||||
|
||||
|
||||
现在我们声明一个返回值为 void 类型的函数指针:
|
||||
|
||||
```c
|
||||
void (*fp)();
|
||||
```
|
||||
|
||||
如果我们现在要调用存储位置为 0 的子例程,我们是否可以这样写:
|
||||
|
||||
```c
|
||||
(*0)();
|
||||
```
|
||||
|
||||
上式并不能生效,因为运算符 * 需要一个函数指针作为操作数。我们需要对 0 进行类型转换:
|
||||
|
||||
```c
|
||||
(* (void (*)())0 )();
|
||||
```
|
||||
|
||||
|
||||
|
||||
我们可以使用 `typedef`来使表述更加清晰:
|
||||
|
||||
```c
|
||||
typedef void (*funcptr)();
|
||||
(*(funcptr)0)();
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 1. 运算符优先级问题
|
||||
|
||||
```c
|
||||
if(FLAG & flags != 0){
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
FLAG 是一个已经定义的常量,FLAG 是一个整数,该数的二进制表示中只有某一位是 1,其余的位都为 0 ,也就是 2 的某次幂。为了判断整数 flags 的某一位是否也是 1,并且将结果与 0 作比较,我们写出了上面 if 的判断表达式。
|
||||
|
||||
但是`!=`的优先级高于`&`,上面的式子被解释为:
|
||||
|
||||
```c
|
||||
if(FLAG & (flags != 0)){
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
这显然不是我们想要的。
|
||||
|
||||
high 和 low 是两个 0 ~ 15 的数,r 是一个八位整数,且 r 的低 4 位与 low 一致,高 4 位与 high 一致,很自然想到:
|
||||
|
||||
```c
|
||||
r = high<<4 + low;
|
||||
```
|
||||
|
||||
但是,加法的优先级高于移位运算,本例相当于:
|
||||
|
||||
```c
|
||||
r = high<<(4 + low);
|
||||
```
|
||||
|
||||
对于这种情况,有两种更正方法:
|
||||
|
||||
```c
|
||||
r = (high<<4) + low;
|
||||
```
|
||||
|
||||
或利用移位运算的优先级高于逻辑运算:
|
||||
|
||||
```c
|
||||
r = high<<4 | low;
|
||||
```
|
||||
|
||||
|
||||
|
||||
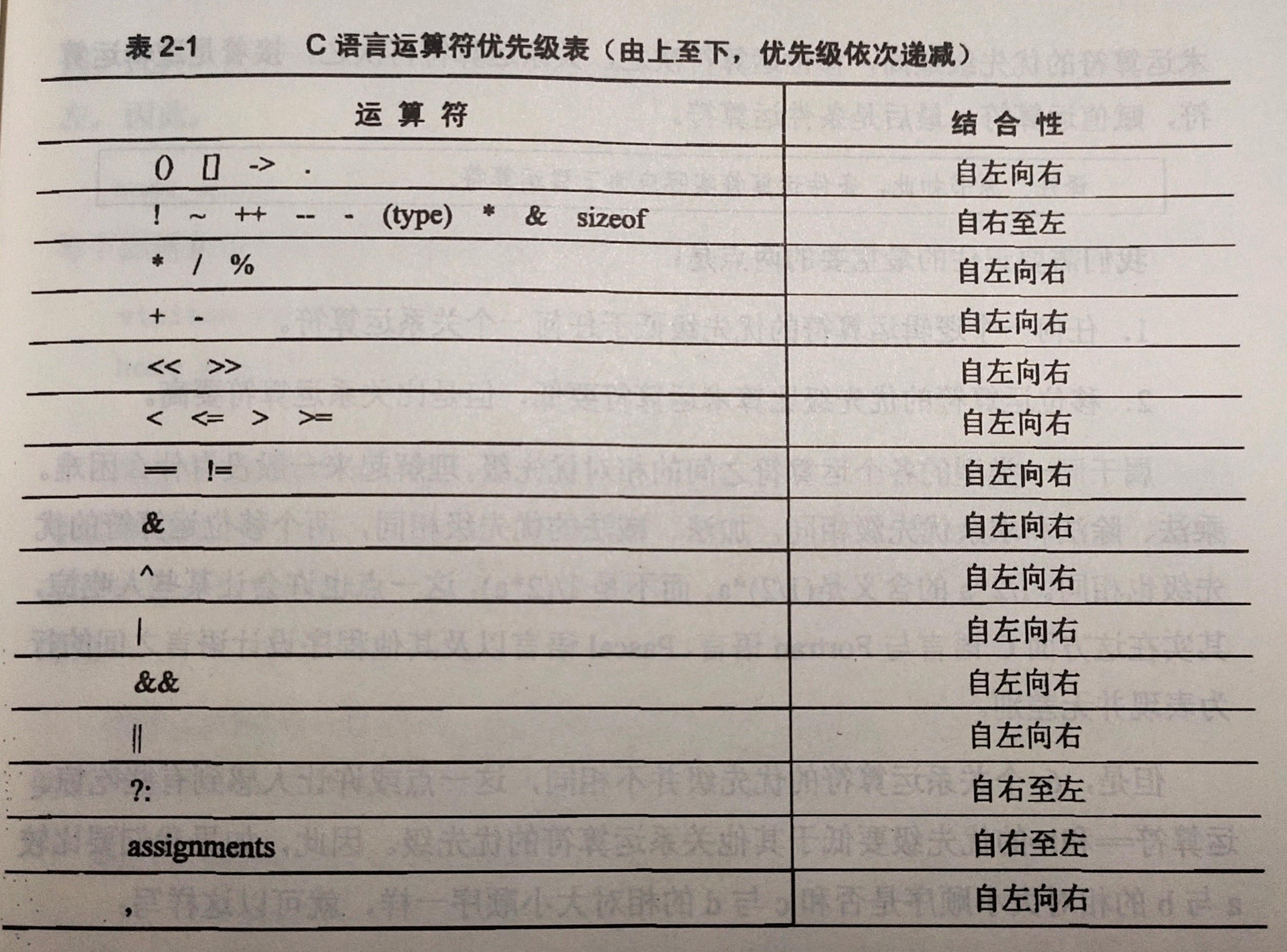
|
||||
|
||||
|
||||
|
||||
下面我们说几个比较常见的运算符的用法:
|
||||
|
||||
- `a.b.c`的含义是`(a.b).c`而不是`a.(b.c)`
|
||||
|
||||
- 函数指针要写成:`(*p)()`,如果写成了`*p()`,编译器会解释为:`*(p())`
|
||||
|
||||
- `*p++`会解释为:`*(p++)`而不是`(*p)++`
|
||||
|
||||
- 记住两点:
|
||||
|
||||
- 任何一个逻辑运算符的优先级低于任何一个关系运算符。
|
||||
- 移位运算符的优先级比算数运算符要低,但是高于关系运算符。
|
||||
|
||||
- 赋值运算符结合方式从右到左,因此:
|
||||
|
||||
```c
|
||||
a = b = 0;
|
||||
```
|
||||
|
||||
等价于:
|
||||
|
||||
```c
|
||||
b = 0;
|
||||
a = b;
|
||||
```
|
||||
|
||||
- 关于涉及赋值运算时优先级的混淆:
|
||||
|
||||
复制一个文件到另一个文件中:
|
||||
|
||||
```c
|
||||
while(c = getc(in) != EOF)
|
||||
putc(c, out);
|
||||
```
|
||||
|
||||
但是上式被解释为:
|
||||
|
||||
```c
|
||||
while(c = (getc(in) != EOF))
|
||||
putc(c, out);
|
||||
```
|
||||
|
||||
关系运算符的结果只有 0 或 1 两种可能。最后得到的文件副本中只包含了一组二进制为 1 的字节流。
|
||||
|
||||
|
||||
|
||||
#### 2. 注意作为语句结束标志的分号
|
||||
|
||||
考虑下面的例子:
|
||||
|
||||
```c
|
||||
if(x[i] > big);
|
||||
big = x[i];
|
||||
```
|
||||
|
||||
这与:
|
||||
|
||||
```c
|
||||
if(x[i] > big)
|
||||
big = x[i];
|
||||
```
|
||||
|
||||
大不相同。
|
||||
|
||||
前面的例子相当于:
|
||||
|
||||
```c
|
||||
if(x[i] > big) {}
|
||||
big = x[i];
|
||||
```
|
||||
|
||||
无论 x[i] 是否大于 big,赋值都会被执行。
|
||||
|
||||
|
||||
|
||||
如果不是多写了分号,而是遗漏了分号,一样会招致麻烦:
|
||||
|
||||
```c
|
||||
if( n < 3)
|
||||
return
|
||||
logrec.date = x[0];
|
||||
logrec.time = x[1];
|
||||
logrec.code = x[2];
|
||||
```
|
||||
|
||||
遗漏了 return 后的分号,这段程序仍然会顺利通过编译而不会报错,它等价于:
|
||||
|
||||
```c
|
||||
if( n < 3)
|
||||
return logrec.date = x[0];
|
||||
logrec.time = x[1];
|
||||
logrec.code = x[2];
|
||||
```
|
||||
|
||||
|
||||
|
||||
还有一种情形,也是有分号与没有分号实际效果相差极为不同。那就是当一个声明的结尾紧跟一个函数定义时,如果声明结尾的分号被省略,编译器可能会把声明的类型视作函数的返回值类型。考虑下例:
|
||||
|
||||
```c
|
||||
struct logrec{
|
||||
int date;
|
||||
int time;
|
||||
int code;
|
||||
}
|
||||
main(){
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
上面代码段的实际效果是声明函数 main 返回值是结构 logrec 类型。
|
||||
|
||||
如果分号没有被省略,函数 main 的返回值类型会缺省定义为 int 类型。
|
||||
|
||||
|
||||
|
||||
#### 3. switch 语句
|
||||
|
||||
```c
|
||||
switch(color){
|
||||
case 1: printf("red");
|
||||
break;
|
||||
case 2: printf("blue");
|
||||
break;
|
||||
case 3: printf("yellow");
|
||||
break;
|
||||
}
|
||||
```
|
||||
|
||||
如果稍作改动:
|
||||
|
||||
```c
|
||||
switch(color){
|
||||
case 1: printf("red");
|
||||
case 2: printf("blue");
|
||||
case 3: printf("yellow");
|
||||
}
|
||||
```
|
||||
|
||||
假定 color 的值为 2,那么将会输出:
|
||||
|
||||
```c
|
||||
blueyellow
|
||||
```
|
||||
|
||||
因为程序的控制流程在执行了第二个 printf 函数的调用后,会自然地顺序执行下去。第三个 printf 函数也会被调用。
|
||||
|
||||
|
||||
|
||||
switch 的这种特性,即使它的弱点,也是它的优势所在。
|
||||
|
||||
对于两个操作数的加减运算,我们可以将操作数变号来取代减法:
|
||||
|
||||
```c
|
||||
case SUBTRACT:
|
||||
opnd2 = -opnd2;
|
||||
case ADD:
|
||||
...
|
||||
```
|
||||
|
||||
在这里,我们是有意省略 break 语句。
|
||||
|
||||
|
||||
|
||||
#### 4. 函数调用
|
||||
|
||||
C 语言要求:在函数调用时,即使函数不带参数,也应该包含参数列表。如果,f 是一个函数:
|
||||
|
||||
```c
|
||||
f();
|
||||
```
|
||||
|
||||
是一个函数调用语句,而:
|
||||
|
||||
```c
|
||||
f;
|
||||
```
|
||||
|
||||
却是一个什么也不作的语句,f 表示函数的地址。
|
||||
|
||||
|
||||
|
||||
#### 5. 悬挂 else 引发的问题
|
||||
|
||||
这个相信大家学习 C 的时候老师都会讲,在我的 【C 必知必会】系列教程中也有详细讲解,不懂可以去参考相关。
|
||||
|
||||
这里说一点,写 if 语句时,不要省略括号是一种可以学习的习惯。
|
||||
|
||||
|
||||
|
||||
**参考资料**:*《C 缺陷与陷阱》*
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
596
content/c-traps-and-pitfalls/03 语义陷阱.md
Normal file
596
content/c-traps-and-pitfalls/03 语义陷阱.md
Normal file
@@ -0,0 +1,596 @@
|
||||
## 【C 陷阱与缺陷】(三)语义陷阱
|
||||
|
||||
|
||||
|
||||
#### 0. 指针与数组
|
||||
|
||||
> C 语言中数组与指针这两个概念之间的联系密不可分。
|
||||
|
||||
##### 关于数组:
|
||||
|
||||
- C 语言中只有一维数组,而且数组大小必须在编译期就作为一个常数确定下来。数组元素可以是任何类型的对象,也可以是另外一个数组。(C99 允许变长数组)
|
||||
- 对于一个数组,我们只能够做两件事:确定该数组的大小,以及获得指向该数组下标为 0 的元素的指针。
|
||||
|
||||
任何一个数组下标运算都等同于一个对应的指针运算。
|
||||
|
||||
|
||||
|
||||
**声明数组**
|
||||
|
||||
```c
|
||||
int a[3];
|
||||
```
|
||||
|
||||
声明了一个拥有 3 个整型元素的数组。
|
||||
|
||||
```c
|
||||
struct{
|
||||
int p[4];
|
||||
double x;
|
||||
}b[14];
|
||||
```
|
||||
|
||||
声明了一个拥有 17 个元素的数组,且每个元素都是一个结构。
|
||||
|
||||
```c
|
||||
int calendar[12][31];
|
||||
```
|
||||
|
||||
声明了拥有 12 个数组类型的元素,其中每个元素都是拥有 31 个整型元素的数组。因此 `sizeof(calendar)`的值是 12x31 与 `sizeof(int)`的乘积。
|
||||
|
||||
|
||||
|
||||
##### 关于指针
|
||||
|
||||
任何指针都是指向某种类型的变量。
|
||||
|
||||
```c
|
||||
int *ip;
|
||||
```
|
||||
|
||||
表明 ip 是一个指向整型变量的指针。
|
||||
|
||||
我们可以将整型变量 i 的地址赋值给指针 ip :
|
||||
|
||||
```c
|
||||
int i;
|
||||
ip = &i;
|
||||
```
|
||||
|
||||
如果我们给 *ip 赋值,就可以改变 i 的取值:
|
||||
|
||||
```c
|
||||
*ip = 17;
|
||||
```
|
||||
|
||||
|
||||
|
||||
##### 数组与指针
|
||||
|
||||
如果一个指针指向的是数组中的一个元素,那么我们只要给这个指针加 1,就能够得到指向该数组中下一个元素的指针。减法同理。
|
||||
|
||||
如果两个指针指向的是同一个数组中的元素,那么两个指针相减是有意义的:
|
||||
|
||||
```c
|
||||
int *q = p + i;
|
||||
```
|
||||
|
||||
我们可以通过 q - p 得到 i 的值。
|
||||
|
||||
|
||||
|
||||
```c
|
||||
int a[3];
|
||||
int* p = a;
|
||||
```
|
||||
|
||||
数组名被当作指向数组下标为 0 的元素的地址。
|
||||
|
||||
注意,我们没有写成:
|
||||
|
||||
```c
|
||||
p = &a;
|
||||
```
|
||||
|
||||
这样的写法在 ANSI C 中是非法的,因为 `&a`是一个指向数组的指针,而 p 是指向整型变量的指针,它们了类型并不匹配。
|
||||
|
||||
继续我们的讨论,现在 p 指向数组 a 中下标为 0 的元素,p + 1 指向下标为 1 的元素,以此类推。如果希望 p 指向下标为 1 的元素,可以这样写:
|
||||
|
||||
```c
|
||||
p = p + 1;
|
||||
```
|
||||
|
||||
当然,也可以这样写:
|
||||
|
||||
```c
|
||||
p++;
|
||||
```
|
||||
|
||||
`*a` 是数组 a 中下标为 0 的元素的引用。同理,`*(a + 1)`是数组中下标为 1 的元素的引用,`*(a + i)`是数组中下标为 i 的元素的引用,简写为 `a[i]`。
|
||||
|
||||
由于 `a + i` 和 `i + a`的含义一致,因此`a[i]`和`i[a]`也具有相同的含义。但我们绝不推荐这种写法。
|
||||
|
||||
|
||||
|
||||
##### 二维数组
|
||||
|
||||
```c
|
||||
int calendar[12][31];
|
||||
```
|
||||
|
||||
请思考,`calendar[4]`含义是什么?
|
||||
|
||||
`calender[4]`是 calendar 数组第 5 个元素,是 calendar 数组 12 个拥有着 31 个整型元素的数组之一。`sizeof(calendar[4])`大小为 31 与 `sizeof(int)`的乘积。
|
||||
|
||||
```c
|
||||
p = calendar[4];
|
||||
```
|
||||
|
||||
这个语句使 p 指向了数组 calendar 下标为 0 的元素。
|
||||
|
||||
如果 calendar 是数组,我们可以:
|
||||
|
||||
```c
|
||||
i = calender[4][7];
|
||||
```
|
||||
|
||||
上式等价于:
|
||||
|
||||
```c
|
||||
i = *(calender[4] + 7);
|
||||
```
|
||||
|
||||
等价于:
|
||||
|
||||
```c
|
||||
i = *(*(calender + 4) + 7);
|
||||
```
|
||||
|
||||
下面我们再看:
|
||||
|
||||
```c
|
||||
p = calender;
|
||||
```
|
||||
|
||||
这个语句是非法的。因为 calendar 是一个二维数组,即数组的数组,calendar 是一个指向数组的指针,而 p 是指向整型变量的指针。
|
||||
|
||||
我们需要声明一种指向数组的指针,经过上一章的讨论,我们不难得出:
|
||||
|
||||
```c
|
||||
int (*ap)[31];
|
||||
```
|
||||
|
||||
这个语句的效果是:声明了 *ap 是一个拥有 31 个元素的数组,所以,ap 就是指向这样的数组的指针。因此,我们可以这样写:
|
||||
|
||||
```c
|
||||
int calender[12][31];
|
||||
int (*monthp)[31];
|
||||
monthp = calendar;
|
||||
```
|
||||
|
||||
这样 monthp 指向 calendar 数组的第一个元素,也就是 calendar 的 12 个拥有 31 个整型变量的数组类型的元素之一。
|
||||
|
||||
假定在新的一年开始时,我们需要清空 calendar 数组,用下标的形式可以很容易的做到:
|
||||
|
||||
```c
|
||||
int month;
|
||||
for(month = 0; month < 12; month++){
|
||||
int day;
|
||||
for(day = 0; day < 31; day++)
|
||||
calendar[month][day] = 0;
|
||||
}
|
||||
```
|
||||
|
||||
上面的代码用指针应该如何表示?
|
||||
|
||||
```c
|
||||
int (*month)[31] = calander;
|
||||
for(;month < calendar + 12; month++){
|
||||
int *day = *month;
|
||||
for(; day < *month + 31; day++)
|
||||
*day = 0;
|
||||
}
|
||||
```
|
||||
|
||||
原书中的代码为:
|
||||
|
||||
```c
|
||||
int (*monthp)[31];
|
||||
for(monthp = calendar; monthp < &calendar[12]; monthp++){
|
||||
int *dayp;
|
||||
for(dayp = *monthp; dayp < &(*monthp)[31]; dayp++)
|
||||
*dayp = 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### 1. 非数组的指针
|
||||
|
||||
假定我们两个这样的字符串 s 和 t,我们希望将这两个字符串连接成单个字符串 r :
|
||||
|
||||
```c
|
||||
char* r;
|
||||
strcpy(r, s);
|
||||
strcat(r, t);
|
||||
```
|
||||
|
||||
我们不确定 r 指向何处,而且 r 所指向的地址处不一定有内存空间可供容纳字符串。这一次,我们为 r 分配空间:
|
||||
|
||||
```c
|
||||
char r[100];
|
||||
strcpy(r, s);
|
||||
strcat(r, t);
|
||||
```
|
||||
|
||||
C 语言强制要求我们必须声明数组大小为一个常量,因此我们不能保证 r 足够大。这时,我们可以利用库函数 malloc :
|
||||
|
||||
```c
|
||||
char *r, *malloc();
|
||||
r = malloc(strlen(s) + strlen(t));
|
||||
strcpy(r, s);
|
||||
strcat(r, t);
|
||||
```
|
||||
|
||||
这个例子还是错的,原因有 3 :
|
||||
|
||||
1. malloc 函数可能无法提供请求的内存
|
||||
2. 给 r 分配的内存在使用完后应该及时释放
|
||||
3. strlen(s) 的值如果是 n ,那么字符串 s 的实际长度为 n + 1,因为,strlen 会忽略作为结束标志的空字符。所以,malloc 时,切记给字符串结尾的空字符留有空间。
|
||||
|
||||
修改:
|
||||
|
||||
```c
|
||||
char *r, *malloc();
|
||||
r = malloc(strlen(s) + strlen(t) + 1);
|
||||
if(!r){
|
||||
complain();
|
||||
exit(1);
|
||||
}
|
||||
strcpy(r, s);
|
||||
strcat(r, t);
|
||||
|
||||
//一段时间后再使用
|
||||
free(r);
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 2. 作为参数的数组声明
|
||||
|
||||
C 语言中,我们没有办法可以将一个数组作为函数参数直接传递。如果我们使用数组名作为参数,那么数组名会立刻被转换为指向该数组第 1 个元素的指针。例如:
|
||||
|
||||
```c
|
||||
char hello[] = "hello";
|
||||
printf("%s\n", hello);
|
||||
```
|
||||
|
||||
printf 函数调用等价于:
|
||||
|
||||
```c
|
||||
printf("%s\n", &hello[0]);
|
||||
```
|
||||
|
||||
所以,C 语言中会自动的将作为参数的数组声明转换为相应的指针声明。也就是像这样的写法:
|
||||
|
||||
```c
|
||||
int strlen(char s[]){
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
或:
|
||||
|
||||
```c
|
||||
int strlen(char* s){
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
C 程序员经常错误的假设,在其他情况下也会有这种自动的转换。后面我们会说到:
|
||||
|
||||
```c
|
||||
extern char* hello;
|
||||
```
|
||||
|
||||
和下面的语句有着天壤之别:
|
||||
|
||||
```c
|
||||
extern char hello[];
|
||||
```
|
||||
|
||||
|
||||
|
||||
另一个常见的例子就是 main 函数的参数:
|
||||
|
||||
```c
|
||||
int main(int argc, char* argv[]){
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
等价于:
|
||||
|
||||
```c
|
||||
int main(int argc, char** argv){
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
需要注意的是,前一种写法强调 argv 是一个指向某数组元素为字符指针的起始元素的指针。因为这两种写法是等价的,所以可以任选一种最能清晰反应自己意图的写法。
|
||||
|
||||
|
||||
|
||||
#### 3. 避免“举隅法”
|
||||
|
||||
**指针的复制并不同时复制指针所指向的数据。**
|
||||
|
||||
```c
|
||||
char *p, *q;
|
||||
p = "xyz";
|
||||
```
|
||||
|
||||
p 的值并不是字符串 `"xyz"`,而是指向该字符串起始元素的指针。因此,如果我们执行下面的语句:
|
||||
|
||||
```c
|
||||
q = p;
|
||||
```
|
||||
|
||||
现在 p 和 q 是两个指向内存中同一地址的指针。如图:
|
||||
|
||||
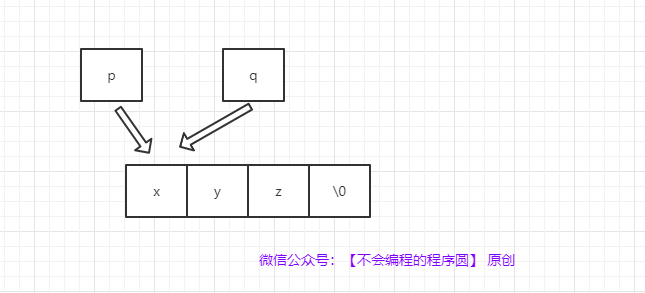
|
||||
|
||||
|
||||
|
||||
因此,当我们执行完语句:
|
||||
|
||||
```c
|
||||
q[1] = 'Y';
|
||||
```
|
||||
|
||||
q 所指向的内存存储的字符串是"xYz",p 所指向的内存中存储的当然也是字符串"xYz" 。
|
||||
|
||||
**注意**:ANSI C 中禁止对 string literal (字符串字面量)作出修改。K&R 对这一行为的说明是:试图修改字符串常量的行为是未定义的。
|
||||
|
||||
#### 4. 空指针并非空字符串
|
||||
|
||||
常数 0 转换而来的指针不等于任何有效的指针。
|
||||
|
||||
```c
|
||||
#define NULL 0
|
||||
```
|
||||
|
||||
无论是用 0 还是符号 NULL,效果都是完全相同的。**空指针绝不能被解引用**。
|
||||
|
||||
下面的写法是合法的:
|
||||
|
||||
```c
|
||||
if(p == (char*)0){...}
|
||||
```
|
||||
|
||||
但是如果写成这样:
|
||||
|
||||
```c
|
||||
if(strcmp(p, (char*)0) == 0){...}
|
||||
```
|
||||
|
||||
就是非法的了。因为库函数 strcmp 的实现中会查看它的指针参数所指向的内存中的内容。
|
||||
|
||||
如果 p 是一个空指针,即使
|
||||
|
||||
```c
|
||||
printf(p);
|
||||
```
|
||||
|
||||
和
|
||||
|
||||
```c
|
||||
printf("%s\n", p);
|
||||
```
|
||||
|
||||
的行为也是未定义的。
|
||||
|
||||
|
||||
|
||||
#### 5.边界计算与不对称边界
|
||||
|
||||
如果一个数组有 10 个元素,那么这个数组下标允许取值范围是什么呢?
|
||||
|
||||
在 C 语言中,这个数组下标的范围是 0 ~ 9 。
|
||||
|
||||
|
||||
|
||||
##### 栏杆错误
|
||||
|
||||
也称**差一错误**(off-by-one error)。
|
||||
|
||||
解决这种问题的通用原则:
|
||||
|
||||
- 首先考虑最简单情况下的特例,然后将得到的结果外推。
|
||||
- 仔细计算边界,绝不掉以轻心。
|
||||
|
||||
|
||||
|
||||
##### 不对称边界
|
||||
|
||||
解决差一错误的一个方法是使用不对称边界的思想。
|
||||
|
||||
比如,一个字符串中由下标为 16 到下标为 37 的字符元素组成的字串,如何表示这个范围?
|
||||
|
||||
我们采用不对称边界:`x >= 16 && x <38`而不是采用`x >= 16 && x <= 37`。这样,这个字串的长度明显就是 38 - 16,也就是 22 。
|
||||
|
||||
用 for 循环遍历一个大小为 10 的数组:
|
||||
|
||||
```c
|
||||
for(i = 0; i < 10; i++){
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
而非:
|
||||
|
||||
```c
|
||||
for(i = 0; i <= 9; i++){
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 6. 求值顺序
|
||||
|
||||
C 语言中只有 4 个运算符(`&&`,`||`,`?:`,`,`)存在规定的求值顺序。
|
||||
|
||||
- 运算符 && 和 || 首先对左操作数求值,只有在需要时才对右操作数求值。
|
||||
- 运算符 ?: 有 3 个操作数:在 `a ? b : c`中,首先对 a 求值,根据 a 的值再对操作数 b 或 操作数 c 求值。
|
||||
- 逗号运算符从左向右一次求值。(求值然后丢弃再继续求值。)
|
||||
|
||||
运算符 && 和 || 对于保证检查操作按照正确的顺序执行至关重要。例如在语句
|
||||
|
||||
```c
|
||||
if(y != 0 && x / y > tolerance)
|
||||
complain();
|
||||
```
|
||||
|
||||
中,就必须保证仅当 y 非 0 时才对 x / y 求值。
|
||||
|
||||
|
||||
|
||||
下面这种从数组 x 中复制前 n 个元素到数组 y 中的做法是不正确的:
|
||||
|
||||
```c
|
||||
i = 0;
|
||||
while(i < n)
|
||||
y[i] = x[i++];
|
||||
```
|
||||
|
||||
问题出在哪里呢?上面的代码假设 `y[i]`的地址在 i 的自增操作指向前被求值,这一点并没有任何保证。
|
||||
|
||||
同样的道理,下面的代码也是错误的:
|
||||
|
||||
```c
|
||||
i = 0;
|
||||
while(i < n)
|
||||
y[i++] = x[i];
|
||||
```
|
||||
|
||||
应该使用这一种写法:
|
||||
|
||||
```c
|
||||
i = 0;
|
||||
while(i < n){
|
||||
y[i] = x[i];
|
||||
i++;
|
||||
}
|
||||
```
|
||||
|
||||
或:
|
||||
|
||||
```c
|
||||
for(i = 0; i < n; i++){
|
||||
y[i] = x[i];
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 7. 运算符 && 和 || 与 运算符 & 和 |
|
||||
|
||||
按位运算 &,|,^ ,~ 对操作数的处理方式是将其视为一个二进制的位序列,分别对其每一位进行操作。
|
||||
|
||||
逻辑运算 &&,||,! 对操作数的处理方式是将其视为要么是“真” 要么是“假”。通常将 0 视为 假,非 0 视为 真。它们的结果只可能是 1 或 0 。
|
||||
|
||||
需要注意的是逻辑运算中的 && 和 || 是有求值顺序的。
|
||||
|
||||
|
||||
|
||||
考虑下面的代码段,其作用是在表中查询一个特定的元素:
|
||||
|
||||
```c
|
||||
i = 0;
|
||||
while(i < tabsize && tab[i] != x)
|
||||
i++;
|
||||
```
|
||||
|
||||
假定我们无意中用 & 替换了 &&:
|
||||
|
||||
```c
|
||||
i = 0;
|
||||
while(i < tabsize & tab[i] != x)
|
||||
i++;
|
||||
```
|
||||
|
||||
这个循环也可能正常工作,但这仅仅是因为两个侥幸的原因:
|
||||
|
||||
1. while 循环中的表达式 & 两侧都是比较运算,其结果只会是 1 或 0 。因此 x && y 和 x & y 会具有相同的结果。然而,如果两个比较运算中的任意一个使用除 1 之外的非 0 的数表示“真”,那么这个循环就不能正常个工作了。
|
||||
2. 对于数组结尾后的下一个元素(实际上是不存在的),只要程序不去修改该元素的值,而仅仅读取它的值,一般情况下是不会有什么危害的。运算符 && 和 & 不同,& 要求 两侧的操作数都必须被求值。因此,在后一个代码中,最后一次循环当 i 等于 tabsize 时,尽管 tab[i] 并不存在,程序依然会查看 tab[i] 的值。
|
||||
|
||||
|
||||
|
||||
#### 8. 整数溢出
|
||||
|
||||
C 语言中存在两类整数算术运算,有符号运算与无符号运算。在无符号运算中,没有所谓“溢出”一说:所有无符号运算都是以 2 的 n 次方为模,这里 n 是结果中的位数。
|
||||
|
||||
如果算数运算符中的一个操作数是无符号整数一个是有符号整数,有符号整数会被转换为无符号整数。“溢出”同样不会发生。
|
||||
|
||||
但是当两个操作数都为有符号整数时,溢出就可能发生,而且“溢出”的结果是未定义的。
|
||||
|
||||
例如,假定 a 和 b 为连个非负整形变量,我们要检查 a + b 是否会“溢出”,一种想当然的方式:
|
||||
|
||||
```c
|
||||
if(a + b < 0)
|
||||
complain();
|
||||
```
|
||||
|
||||
这并不能正常运行。当 a + b 确实发生“溢出”时,所有关于结果如何的假设都是不可靠的。例如,有的计算机上,加法运算将设置内部寄存器为四种状态之一:正,负,零和溢出。在这种机器上,上面 if 语句的检测就会失效。
|
||||
|
||||
一种正确的方式为将 a 和 b 强转为无符号整数:
|
||||
|
||||
```c
|
||||
if((unsigned)a + (unsigned)b > INT_MAX)
|
||||
complain();
|
||||
```
|
||||
|
||||
此处的 INT_MAX 是一个已定义常量,代表可能的最大整数值。ANSI C 标准在<limits.h>中定义了 INT_MAX 。
|
||||
|
||||
不需要用到无符号整数运算的另一种可行的办法是:
|
||||
|
||||
```c
|
||||
if(a > INT_MAX - b)
|
||||
complain();
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 9. 为 main 函数提供返回值
|
||||
|
||||
已在 【C 必知必会】系列详细讲解过。不再赘述。
|
||||
|
||||
|
||||
|
||||
**参考资料**:*《C 缺陷与陷阱》*
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
497
content/c-traps-and-pitfalls/04 连接.md
Normal file
497
content/c-traps-and-pitfalls/04 连接.md
Normal file
@@ -0,0 +1,497 @@
|
||||
## 【C 陷阱与缺陷】(四)连接
|
||||
|
||||
|
||||
|
||||
### 一 链接
|
||||
|
||||
#### 0. 什么是连接器
|
||||
|
||||
C 语言的一个重要思想就是分别编译(separate compilation),即若干个源程序可以在不同的时候单独进行编译,然后在恰当的时候整合在一起。但是,连接器一般是与 C 编译器分离的,它不可能了解 C 语言的诸多细节。
|
||||
|
||||
**连接器的工作原理:**连接器的输入是一组目标模块和库文件。连接器的输出是一个载入摸块。连接器读入目标模块和库文件同时生皮载入模块。对每个目标核块中的每个外部对象,链接器都要检查载入模块。查看是否有同名的外部对象。如果没有,连接器就将该外部对象添加到入模块中,如果有,连接器就要开始处理命名冲突。
|
||||
|
||||
**外部对象:**程序中的每个函数和每个外部变量,如果没有被声明为 static,就都是一个外部对象。
|
||||
|
||||
除了外部对象之外,目标模块中还可能包括了对其他模块中的外部对象的引用。例如一个调用了函数 printf 的 C 程序所生成的目标模块,就包括了一个对库函数 printf 的引用。可以推测得出,该引用指向的是一个位于某个库文件中的外部对象。在连接器生成载入模块的过程中,它必须同时记录这些外部对象的应用。当连接器读入一个目标模块时,它必须解析出这个目标模块中定义的所有外部对象的引用,并标记这些外部对象不再是未定义的。
|
||||
|
||||
|
||||
|
||||
#### 1. 声明与定义
|
||||
|
||||
声明语句:
|
||||
|
||||
```c
|
||||
int a;
|
||||
```
|
||||
|
||||
如果其位置出现在所有函数体之外,那么它就被称为外部对象 a 的定义。这个语句说明了 a 是一个外部整型变量,同时为 a 分配内存空间。它的初始值默认为 0 。
|
||||
|
||||
下面的声明语句:
|
||||
|
||||
```c
|
||||
int a = 7;
|
||||
```
|
||||
|
||||
不仅为 a 分配了内存空间,而且说明了在该内存中应该存储的值。
|
||||
|
||||
下面的声明语句:
|
||||
|
||||
```c
|
||||
extern int a;
|
||||
```
|
||||
|
||||
并不是对 a 的定义。这个语句仍然说明了 a 是一个外部整型变量,但是 a 的存储空间是在程序的其他地方分配的。从连接器的角度来看,上面的声明是对 a 的引用,而不是定义。
|
||||
|
||||
```c
|
||||
void srand(int n){
|
||||
extern int random_seed;
|
||||
random_seed = n;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
**每个外部对象都必须在某个地方进行定义**。因此,如果程序中包括了语句:
|
||||
|
||||
```c
|
||||
extern int a;
|
||||
```
|
||||
|
||||
那么,这个程序就必须在别的某个地方包括语句:
|
||||
|
||||
```c
|
||||
int a;
|
||||
```
|
||||
|
||||
这两个语句既可以是在同一个源文件中,也可以位于程序的不同源文件中。
|
||||
|
||||
|
||||
|
||||
严格的规则是,**每个外部变量都只能被定义一次**。
|
||||
|
||||
|
||||
|
||||
#### 2. 命名冲突与 static 修饰符
|
||||
|
||||
两个具有相同名称的外部对象实际上代表的是同一个对象,即使编程者的本意并非如此,但系统却会如此处理。因此,如果在两个不同的源文件中都包括了定义:
|
||||
|
||||
```c
|
||||
int a;
|
||||
```
|
||||
|
||||
那么,它或者表示程序错误(如果连接器禁止外部变量重复定义的话),或者在两个源文件中共享 a 的同一个实例(无论两个源文件中的外部变量 a 是否应该共享)。
|
||||
|
||||
即使其中 a 的一个定义是出现在系统提供的库文件中,也仍然进行同样的处理。当然,一个设计良好的函数库不至于定义 a 作外部名称。但是,要了解函数库中定义的所有外部对象名称却也并非易事。类似于read 和 write 这样的名称不难猜到,但其他的名称就没有这么容易了。
|
||||
|
||||
|
||||
|
||||
static 修饰符是一个能够减少此类命名冲突的有用工具。例如,以下声明语句:
|
||||
```c
|
||||
static int a;
|
||||
```
|
||||
|
||||
其含义与下面的语句相同
|
||||
|
||||
```c
|
||||
int a;
|
||||
```
|
||||
|
||||
只不过,a 的作用域限制在一个源文件内,对于其他源文件,a是不可见的。因此,如果若干个函数需要共享一组外部对象,可以将这些函数放到一个源文件中,把它们需要用到的对象也都在同一一个源文件中以 static 修饰符声明。
|
||||
|
||||
static修饰符不仅适用于变量,也适用于函数。如果函数 f 需要调用另一个函数 g ,而且只有函数 f 需要调用函数 g ,我们可以把函数 g 和 f 放到同一个源文件中,并声明函数 g 为 static:
|
||||
|
||||
```c
|
||||
static int g(int x){
|
||||
// 函数体
|
||||
}
|
||||
int f(){
|
||||
// 其他内容
|
||||
b = g(a);
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
我们可以在多个源文件中定义同名的函数 g,只要所有的函数 g 都被定义为 static,或者仅仅只有其中一个函数 g 不是static 。因此,为了避免可能出现的命名冲突,如果一个函数仅仅被同一个源文件中的其他函数调用,我们就应该声明该函数为 static。
|
||||
|
||||
|
||||
|
||||
#### 3. 形参,实参与返回值
|
||||
|
||||
如果任何一个函数在调用它的每个文件中,都在第一次被调用之前进行了声明或定义,那么就不会有任何与返回类型相关的麻烦。
|
||||
|
||||
比如一个调用 square 函数的程序:
|
||||
|
||||
```c
|
||||
main(){
|
||||
printf("%g\n", square(3.0));
|
||||
}
|
||||
```
|
||||
|
||||
要使这个程序能够运行,函数 square 必须要么在 main 函数之前进行定义:
|
||||
|
||||
```c
|
||||
double
|
||||
square(double x){
|
||||
return x * x;
|
||||
}
|
||||
|
||||
main(){
|
||||
printf("%g\n", square(3.0));
|
||||
}
|
||||
```
|
||||
|
||||
要么在 main 函数前进行声明:
|
||||
```c
|
||||
double square(double);
|
||||
|
||||
main(){
|
||||
printf("%g\n", square(3.0));
|
||||
}
|
||||
|
||||
double
|
||||
square(double x){
|
||||
return x * x;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
如果一个函数在被定义或声明之前被调用,那么它的返回类型就**默认为整型**。比如将上面的 main 函数放到一个独立的源文件中:
|
||||
|
||||
```c
|
||||
main(){
|
||||
printf("%g\n", square(3.0));
|
||||
}
|
||||
```
|
||||
|
||||
main 函数假定函数 square 返回类型为整型,而函数 square 返回类型实际上是双精度类型,当他与 square 函数连接时就会得出错误的结果。
|
||||
|
||||
|
||||
|
||||
如果我们需要在两个不同的源文件中分别定义函数 main 和函数 square ,那么应该在**调用 square 函数的文件中声明 square 函数**。比如:
|
||||
|
||||
```c
|
||||
double square(double);
|
||||
|
||||
main(){
|
||||
printf("%g\n", square(3.0));
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
ANSI C 允许程序员在声明时指定函数的参数类型(省略也是可以的,但是在函数定义时是不能省略参数类型的说明)。
|
||||
|
||||
```c
|
||||
double square(double);
|
||||
```
|
||||
|
||||
像下面这样声明也是可以的:
|
||||
|
||||
```c
|
||||
double square();
|
||||
```
|
||||
|
||||
|
||||
|
||||
**默认实参提升**:
|
||||
|
||||
- float 类型参数会转换为 double 类型
|
||||
- char 类型,short 类型参数会转换为 int 类型
|
||||
|
||||
对于声明:
|
||||
|
||||
```c
|
||||
int isvowel(char);
|
||||
```
|
||||
|
||||
如果在使用 isvowel 函数前没有这样声明,调用者将把传递给 isvowel 函数实参自动转换为 int 类型。
|
||||
|
||||
|
||||
|
||||
```c
|
||||
main(){
|
||||
double s;
|
||||
s = sqrt(2);
|
||||
printf("%g\n", s);
|
||||
}
|
||||
```
|
||||
|
||||
上面的程序不能正常运行,原因有两个:
|
||||
|
||||
- sqrt 函数本该接受一个双精度的值作为实参,而实际上被传递了一个整型
|
||||
- sqrt 函数的返回类型是双精度类型,但却没有这样声明。
|
||||
|
||||
一种更正方式是:
|
||||
|
||||
```c
|
||||
double sqrt(double);
|
||||
|
||||
main(){
|
||||
double s;
|
||||
s = sqrt(2.0);
|
||||
printf("%g\n", s);
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
当然,最好的更正的方式是这样:
|
||||
|
||||
```c
|
||||
#include<math.h>
|
||||
|
||||
main(){
|
||||
double s;
|
||||
s = sqrt(2.0);
|
||||
printf("%g\n", s);
|
||||
}
|
||||
```
|
||||
|
||||
上面 sqrt 的实参已经修改为 2.0,然而即使仍然写成 2,在符合 ANSI C 的编译器上,这个程序也能确保实参会被转换为恰当的类型。
|
||||
|
||||
|
||||
|
||||
因为函数 printf 和函数 scanf 在不同情形下可以接受不同类型的参数,所以它们特别容易出错。这里有个值得注意的例子:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main() {
|
||||
|
||||
int i;
|
||||
char c;
|
||||
for (i = 0; i < 5; i++) {
|
||||
scanf("%d", &c);
|
||||
printf("%d ", i);
|
||||
}
|
||||
printf("\n");
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
表面上,这个程序从标准输入设备读入 5 个数,在标准输出设备上写 5 个数:0 1 2 3 4
|
||||
|
||||
实际上,这个程序并不是一定得到上面的结果。例如,在某个编译器上,它的输出是:0 0 0 0 0 1 2 3 4
|
||||
|
||||
为什么呢?问题的关键在于,这里 c 被声明为 char 类型,而不是 int 类型。当程序要求 scanf 读入一个整数,应该传递给它一个指向整数的指针。而程序中scanf函数得到的却是一一个指向字符的指针,scanf 函数并不能分辨这种情况,它只是将这个指向字符的指针作为指向整数的指针而接受,并且在指针指向的位置存储一个整数。因为整数所占的存储空间要大于字符所占的存储空间,所以字符 c 附近的内存将被覆盖。
|
||||
|
||||
字符 c 附近的内存中存储的内容是由编译器决定的,本例中它存放的是整数 i 的低端部分。因此,每次读入一个数值到 c 时,都会将i的低端部分覆盖为 0 ,而 i 的高端部分本来就是 0 ,相当于 i 每次被重新设置为 0, 循环将一直进行。当到达文件的结束位置后,scanf 函数不再试图读入新的数值到 c 。这时,i 才可以正常地递增,最后终止循环。
|
||||
|
||||
|
||||
|
||||
#### 4. 检查外部类型
|
||||
|
||||
假定我们有一个 C 程序,它由两个源文件组成。一个文件包含外部变量 n 的声明:
|
||||
|
||||
```c
|
||||
extern int n;
|
||||
```
|
||||
|
||||
另一个文件中包含外部变量 n 的定义:
|
||||
|
||||
```c
|
||||
long n;
|
||||
```
|
||||
|
||||
这是一个无效的 C 程序,因为同一个外部变量在两个文件中不能被声明为不同类型。然而编译器和连接器可能检查不出这种错误。
|
||||
|
||||
当这个程序运行时,究竟会发生什么情况呢?存在很多的可能情况:
|
||||
|
||||
1. C 语言编译器足够“聪明”,能够检测到这类型冲突。编程者将会得到一条诊断消息,报告变量 n 在两个不同的文件中被给定了不同的类型。
|
||||
2. 读者使用的C语言实现对 int 类型的数值与 long 类型的数值在内部表示上是样的。尤其是在32位计算机上,一般都是如此处理。在这种情况下,程序很可能正常工作,就好像 n 在两个文件中都被声明为long (或int)类型一样。 本来错误的程序因为某种巧合却能够工作,这是一个很好的例子。
|
||||
3. 变量 n 的两个实例虽然要求的存储空间的大小不同,但是它们共享存储空间的方式却恰好能够满足这样的条件:赋给其中一个的值,对另一个也是有效的。这是有可能发生的。举例来说,如果连接器安排 int 类型的 n 与 long 类型的 n 的低端部分共享存储空间,这样给每个long类型的 n 赋值,恰好相当于把其低端部分赋给了 int 类型的 n。本来错误的程序因为某种巧合却能够作,这是一个比第 2 种情况更能说明问题的例子。
|
||||
4. 变量 n 的两个实例共享存储空间的方式,使得对其中一个赋值时,其效果相当于同时给另一个赋了 完全不同的值。在这种情况下,程序将不能正常工作。
|
||||
|
||||
因此,保证一个特定的名称的所有外部定义在每个目标模块中都有相同的类型,一般来说是程序员的责任。
|
||||
|
||||
|
||||
|
||||
考虑下面的例子,在一个文件中包含定义:
|
||||
|
||||
```c
|
||||
char filename[] = "/etc/passwd";
|
||||
```
|
||||
|
||||
而在另一个文件中包含声明:
|
||||
|
||||
```c
|
||||
extern char* filename;
|
||||
```
|
||||
|
||||
|
||||
|
||||
第一个例子中字符数组 filename 的内存布局大致如图:
|
||||
|
||||
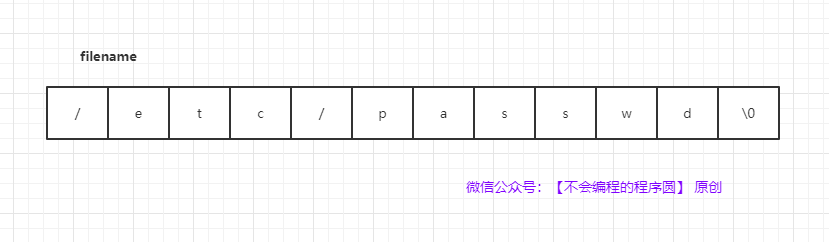
|
||||
|
||||
第二个例子中字符指针 filename 的内存布局大致如图:
|
||||
|
||||
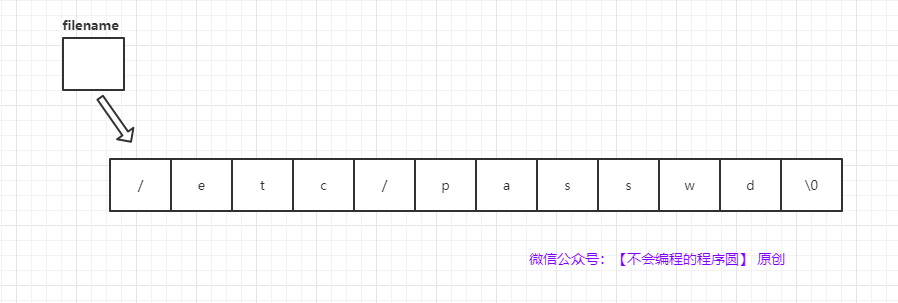
|
||||
|
||||
|
||||
|
||||
要更正本例,改法如下:
|
||||
|
||||
```c
|
||||
char filename[] = "/etc/passwd";// 文件 1
|
||||
|
||||
extern char filename[]; // 文件 2
|
||||
```
|
||||
|
||||
或:
|
||||
|
||||
```c
|
||||
char* filename = "/etc/passwd";// 文件 1
|
||||
|
||||
extern char* filename; // 文件 2
|
||||
```
|
||||
|
||||
|
||||
|
||||
现在我们回顾前面的程序:
|
||||
|
||||
```c
|
||||
main(){
|
||||
double s;
|
||||
s = sqrt(2);
|
||||
printf("%g\n", s);
|
||||
}
|
||||
```
|
||||
|
||||
这个程序在调用函数 sqrt 前没有对函数 sqrt 进行声明或定义。因此,这个程序完全等同于下面的程序:
|
||||
```c
|
||||
extern int sqrt();
|
||||
|
||||
main(){
|
||||
double s;
|
||||
s = sqrt(2);
|
||||
printf("%g\n", s);
|
||||
}
|
||||
```
|
||||
|
||||
这样的写法当然是错误的。
|
||||
|
||||
|
||||
|
||||
#### 5. 头文件
|
||||
|
||||
有一个好方法可以避免大部分此类问题,这个方法只需要我们接受一个简单的规则:每个外部对象只在一个地方声明。这个声明的地方一般就在一个头文件中,需要用到该外部对象的所有模块都应该包括这个头文件。特别需要指出的是,定义该外部对象的模块也应该包括这个头文件。
|
||||
|
||||
例如,创建一个文件叫 file.h,它包含声明:
|
||||
|
||||
```c
|
||||
extern char filename[];
|
||||
```
|
||||
|
||||
需要用到外部对象 filename 的每个 C 文件都应该加上这样的一个语句:
|
||||
|
||||
```c
|
||||
#include "file.h"
|
||||
```
|
||||
|
||||
最后我们选择一个 C 源文件,在其中给出 filename 的初始值。
|
||||
|
||||
**file.c**
|
||||
|
||||
```c
|
||||
#include "file.h"
|
||||
char filename[] = "/etc/passwd";
|
||||
```
|
||||
|
||||
|
||||
|
||||
注意,源文件 file.c 中实际上包含了 filename 的两个声明,这一点只要把 include 语句展开就可以看出:
|
||||
|
||||
```c
|
||||
extern char filename[];
|
||||
char filename[] = "/etc/passwd";
|
||||
```
|
||||
|
||||
只要源文件 file.c 中 filename 的各个声明是一致的,而且这些声明中最多只有 1 个是 filename 的定义,这样写就是合法的。
|
||||
|
||||
|
||||
|
||||
### 二 练习
|
||||
|
||||
#### 练习4-1.
|
||||
|
||||
假定一个程序在一个源文件中包含了声明:
|
||||
|
||||
```c
|
||||
long foo;
|
||||
```
|
||||
|
||||
而在另一个源文件中包含了:
|
||||
|
||||
```c
|
||||
extern short foo;
|
||||
```
|
||||
|
||||
又进一步假定,如果给long类型的 foo 赋一个较小的值,例如37,那么short类型的foo就同时获得了一个值37。我们能够对运行该程序的硬件作出什么样的推断?如果short类型的foo得到的值不是37而是0,我们又能够作出什么样的推断?
|
||||
|
||||
如果把值 37 赋给 long 型的 foo,相当于同时把值 37 也赋给了short型的foo,那么这意昧着 short 型的 foo,与 long 型的foo中包含了值37的有效位的部分,两者在内存中占用的是同一区域。long 型的 foo 的低位部分与 short 型的 foo 共享了相同的内存空间,因此我们的一个可能推论就是,运行该程序的硬件是一个低位优先(little-endian:小端) 的机器。
|
||||
|
||||
同样道理,如果在 long 型的 foo 中存储,了值 37,而 short 型的 foo 的值却是 0,我们所用的硬件可能是一个高位优先(big-endian:大端)的机器。
|
||||
|
||||
注:小端就是将数字的低位放在低地址;大端则相反。
|
||||
|
||||
#### 练习4-2
|
||||
|
||||
.本章第 4节中讨论的错误程序,经过适当简化后如下所示:
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
main()
|
||||
{
|
||||
printf("qg\n",sqrt(2) ) ;
|
||||
}
|
||||
```
|
||||
|
||||
在某些系统中,打印出的结果是 `%g` 请问这是为什么?
|
||||
|
||||
在某些 C 语言实现中,存在着两种不同版本的 printf 函数:其中一-种实现了用于表示浮点格式的项,如 %e、%f、%g 等;而另一种却没有实现这些浮点格式。库文件中同时提供了printf 函数的两种版本,这样的话,那些没有用到浮点运算的程序,就可以使用不提供浮点格式支持的版本,从而节省程序空间、减少程序大小。
|
||||
|
||||
在某些系统上,编程者必须显式地通知连接器是否用到了浮点运算。而另一些系统,则是通过编译器来告知连接器在程序中是否出现了浮点运算,以自动地作出决定。
|
||||
|
||||
上面的程序没有进行任何浮点运算!它既没有包含 math.h 头文件,也没有声明 sqrt 函数,因此编译器无从得知 sqrt 是一个浮点函数。这个程序甚至都没有传送一个浮点参数给sqrt 函数。所以,编译器“自认合理”地通知连接器,该程序没有进行浮点运算。
|
||||
|
||||
那 sqrt 函数又怎么解释呢?难道 sqrt 函数是从库文件中取出的这个事实,还不足以证明该程序用到了浮点运算? 当然,sqrt 函数是从库文件中取出的这一点没错;但是,连接器可能在从库文件中取出 sqrt 函数之前,就已经作出了使用何种版本的printf 函数的决定。
|
||||
|
||||
注:其实 %g 被 printf 函数当作了字符串输出,后面的参数被舍弃掉了,你可以用下面这个例子来理解:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
printf("Hello World\n", 123);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
**参考资料**:*《C 缺陷与陷阱》*
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
272
content/c-traps-and-pitfalls/05 库函数.md
Normal file
272
content/c-traps-and-pitfalls/05 库函数.md
Normal file
@@ -0,0 +1,272 @@
|
||||
|
||||
|
||||
## [C 陷阱与缺陷] (五) 库函数
|
||||
|
||||
|
||||
|
||||
C语言中没有定义输入/输出语句,任何一个有用的 C 程序(起码必须接受零个或多个输入,生成一个或多个输出)都必须调用库函数来完成最基本的输入和输出操作。ANSI C 标准毫无疑问地意识到了这一点, 因而定义了一个包含大量标准库函数的集合。从理论上说,任何一个 C 语言实现都应该提供这些标准库函数。
|
||||
|
||||
有关库函数的使用,我们能给出的最好建议是尽量使用系统头文件。
|
||||
|
||||
### 一 库函数
|
||||
|
||||
#### 1. 返回整数的 getchar 函数
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
main(void){
|
||||
char c;
|
||||
|
||||
while((c = getchar()) != EOF)
|
||||
putchar(c);
|
||||
}
|
||||
```
|
||||
|
||||
getchar 函数在一般情况下返回的是标准输入文件中的下一个字符,当没有输入时返回EOF (一个在头文件stdio.h 中被定义的值,不同于任何一个字符)。这个程序乍一看似乎是把标准输入复制到标准输出,实则不然。
|
||||
|
||||
原因在于程序中的变量 c 被声明为 char 类型,而不是 int 类型。这意味着c无法容下所有可能的字符,特别是,可能无法容下 EOF 。
|
||||
|
||||
因此,最终结果存在两种可能。一种可能是,某些合法的输入字符在被“截断”后使得 c 的取值与 EOF 相同;另一种可能是, c 根本不可能取到EOF这个值。对于前一种情况,程序将在文件复制的中途终止;对于后一种情况,程序将陷入一个死循环。
|
||||
|
||||
实际上,还有可能存在第三种情况:程序表面上似乎能够正常工作,但完全是因为巧合。尽管函数 getchar 的返回结果在赋给 char 类型的变量 c 时会发生“截断”操作,尽管 while 语句中比较运算的操作数不是函数 getchar 的返回值,而是被“截断”的值 c,然而令人惊讶地是许多编译器对上述表达式的实现并不正确。这些编译器确实对函数 getchar 的返回值作了“截断”处理,并把低端字节部分赋给了变量c。但是,它们在比较表达式中并不是比较 c 与 EOF,而是比较 getchar 函数的返回值与 EOF ! 编译器如果采取的是这种做法,上面的例子程序看 上去就能够“正常”运行了。
|
||||
|
||||
|
||||
|
||||
#### 2. 更新顺序文件
|
||||
|
||||
许多系统中的标准输入/输出库都允许程序打开一个文件,同时进行写入和读出的操作:
|
||||
|
||||
```c
|
||||
FILE *fp;
|
||||
fp = open(file, "r+");
|
||||
```
|
||||
|
||||
上面的例子代码打开了文件名由变量file 指定的文件,对于存取权限的设定表明程序希望对这个文件进行输入和输出操作。
|
||||
|
||||
编程者也许认为,程序一旦执行上述操作完毕,就可以自由地交错进行读出和写入的操作。遗憾的是,事实总难遂人所愿,为了保持与过去不能同时进行读写操作的程序的向下兼容性,一个输入操作不能随后直接紧跟一个输出操作,反之亦然。如果要同时进行输入和输出操作,必须在其中插入fseek 函数的调用。
|
||||
|
||||
下面的程序片段似乎更新了一个顺序文件中选定的记录:.
|
||||
|
||||
```c
|
||||
FILE *fp;
|
||||
|
||||
struct record rec;
|
||||
|
||||
...
|
||||
|
||||
while(fread((char*)&rec), sizeof(rec), 1, fp) == 1 ){
|
||||
/* 对 rec 执行某些操纵 */
|
||||
if(/* rec 必须被重新写入 */){
|
||||
fseek(fp, -(long)sizeof(rec), 1);
|
||||
fwrite( (char*)&rec, sizeof(rec), 1, fp );
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
这段代码乍看上去毫无问题: `&rec` 在传入 fread 和fwrite 函数时被小心翼翼地转换为字符指针类型,`sizeof(rec)` 被转换为 长整型(fseek 函数要求第二个参数是 long 类型,因为 int类型的整数可能无法包含一个文件的大小;sizeof 返回一个unsigned 值,因此首先必须将其转换为有符号类型才有可能将其反号)。但是这段代码仍然可能运行失败,而且出错的方式非常难于察觉。
|
||||
|
||||
问题出在:如果一个记录需要被重新写入文件,也就是说,fwrite 函数得到执行,对这个文件执行的下一个操作将是循环开始的 fread 函数。因为在fwrite函数调用与fread函数调用之,间缺少了一个fseek函数调用,所以无法进行上述操作。解决的办法是把这段代码改写为:
|
||||
|
||||
```c
|
||||
while(fread((char*)&rec), sizeof(rec), 1, fp) == 1 ){
|
||||
/* 对 rec 执行某些操纵 */
|
||||
if(/* rec 必须被重新写入 */){
|
||||
fseek(fp, -(long)sizeof(rec), 1);
|
||||
fwrite( (char*)&rec, sizeof(rec), 1, fp );
|
||||
fseek(fp, 0L, 1);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
第二个fseek函数虽然看上去什么也没做,但它改变了文件的状态,使得文件现在可以正常地进行读取了。
|
||||
|
||||
**程序圆帮你理解**:
|
||||
|
||||
- **`&rec`为何要强转成 `char*`类型**:这就要理解 fread 函数(`size_t fread ( void * ptr, size_t size, size_t count, FILE * stream )`):fread 函数的参数有四个,简单的来说就是:从 stream 中读 count 个 size 大小的元素到 ptr 指向的内存中。而 fread 内部在读取一个 size 大小的元素时会调用 size 次 fputc 函数,所以我猜测是每次用 fputc 函数读一个字节然后将该值赋给 ptr 指向的那个地址。既然 fputc 每次只能读一个,那也应该将 ptr 强转为 char* 类型。(但是函数原型是 `void*` 类型,会发生实参提升,转成 `void*`,这又是个问题了)。
|
||||
|
||||
- 其实上面的程序可以简化为:
|
||||
|
||||
```c
|
||||
fread();
|
||||
fseek();
|
||||
fwrite();
|
||||
fread();
|
||||
```
|
||||
|
||||
我们知道,读写之间需要调用一次 fseek,这就是为什么要在 fwrite 后调用 fseek 了。
|
||||
|
||||
|
||||
|
||||
#### 3.缓冲输出 与内存分配
|
||||
|
||||
当一个程序生成输出时,是否有必要将输出立即展示给用户?这个问题的答案根据不同的程序而定。
|
||||
|
||||
程序输出有两种方式:一种是即时处理方式,另一种是先暂存起来,然后再大块写入的方式,前者往往造成较高的系统负担。因此,C语言实现通常都允许程序员进行实际的写操作之前控制产生的输出数据量。
|
||||
|
||||
这种控制能力一般是通过库函数 setbuf 实现的。如果buf是一个大小适当的字符数组,那么
|
||||
|
||||
```c
|
||||
setbuf(stdout, buf);
|
||||
```
|
||||
|
||||
语句将通知输入/输出库,所有写入到 stdout 的输出都应该使用 buf 作为输出缓冲区,直到 buf 缓冲区被填满或者程序员直接调用 flush (译注:对于由写操作打开的文件,调用 fflush 将导致输出缓冲区的内容被实际地写入该文件),buf 缓冲区中的内容才实际写入到stdout 中。缓冲区的大小由系统头文件<stdio.h>中的 BUFSIZ 定义。
|
||||
|
||||
**程序圆帮你理解:** setbuf 比较老,现在可以用 C99 引入的函数 `setvbuf`
|
||||
|
||||
下面的程序的作用是把标准输入的内容复制到标准输出中,演示了setbuf 库函数最显而易见的用法:
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
main()
|
||||
int C;
|
||||
|
||||
char buf [BUFSIZ];
|
||||
setbuf(stdout, buf) ;
|
||||
|
||||
while((c = getchar()) != EOF)
|
||||
putchar(c) ;
|
||||
|
||||
)
|
||||
```
|
||||
|
||||
遗憾的是,这个程序是错误的,仅仅是因为一个细微的原因。程序中对库函数 setbuf 的调用,通知了输入输出库所有字符的标准输出应该首先缓存在 buf 中。要找到问题出自何处,我们不妨思考一下buf缓冲区最后一次被清空是在什么时候?答案是在 main 函数结束之后,作为程序交回控制给操作系统之前 C 运行时库所必须进行的清理工作的一部分。但是,在此之前 buf 字符数组已经被释放!
|
||||
|
||||
要避免这种类型的错误有两种办法。第一种办法是让缓冲数组成为静态数组,即可以直接显式声明 buf 为静态:
|
||||
|
||||
```c
|
||||
static char buf[BUFSIZ];
|
||||
```
|
||||
|
||||
也可以把 buf 声明完全移到 main 函数之外。
|
||||
|
||||
第二种办法是动态分配缓冲区,在程序中并不主动释放分配的缓冲区(译注:由于缓冲区是动态分配的,所以 main 函数结束时并不会释放该缓冲区,这样 C 运行时库进行清理工作时就不会发生缓冲区已释放的情况):
|
||||
|
||||
```c
|
||||
char *malloc() ;
|
||||
|
||||
setbuf(stdout, malloc(BUFSIZ));
|
||||
```
|
||||
|
||||
如果读者关心一些编程“小技巧”,也许会注意到这里其实并不需要检查 malloc 函数调用是否成功。如果 malloc 函数调用失败,将返回一个 NULL 指针。setbuf 函数的第二个参数取值可以为 NULL,此时标准输出不需要进行缓冲。这种情况下,
|
||||
程序仍然能够工作,只不过速度较慢而已。
|
||||
|
||||
#### 4. 使用errno检测错误
|
||||
|
||||
很多库函数,特别是那些与操作系统有关的,当执行失败时会通过一个名称为 `errno` 的外部变量,通知程序该函数调用失败。下面的代码利用这一 特性进行错误处理,似乎再清楚明白不过,然而却是错误的:
|
||||
|
||||
```c
|
||||
/*调用库函数*/
|
||||
if (errno)
|
||||
/*处理错误*/
|
||||
```
|
||||
|
||||
出错原因在于,在库函数调用没有失败的情况下,并没有强制要求库函数一定要设置 errno 为0,这样errno 的值就可能是前一个执行失败的库函数设置的值。
|
||||
|
||||
下面的代码作了更正,似乎能够工作,很可惜还是错误的:
|
||||
|
||||
```c
|
||||
errno = 0;
|
||||
/*调用库函数*/
|
||||
if (errno)
|
||||
/*处理错误*/
|
||||
```
|
||||
|
||||
库函数在调用成功时,既没有强制要求对 errno 清零,但同时也没有禁止设置 errno。既然库函数已经调用成功,为什么还有可能设置 errno 呢? 要理解这一点,我们不妨假想一下库函数 fopen 在调用时可能会发生什么情况。
|
||||
|
||||
当 fopen 函数被要求新建一个文件以供程序输出时,如果已经存在一个同名文件,fopen 函数将先删除它,然后新建一个文件。 这样,fopen 函数可能需要调用其他的库函数,以检测同名文件是否已经存在。(译注:假设用于检测文件的库函数在文件不存在时,会设置 errno 。那么,fopen 函数每次新建一个事先并不存在的文件时,即使没有任何程序错误发生,errmo 也仍然可能被设置。)
|
||||
|
||||
因此,在调用库函数时,我们应该首先检测作为错误指示的返回值,确定程序执行已经失败。然后,再检查 errno,来搞清楚出错原因:
|
||||
|
||||
```c
|
||||
/*调用库函数*/
|
||||
if (返回的错误值)
|
||||
/* 检查errno */
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 5. 库函数 signal
|
||||
|
||||
关于 signal 函数使用需要避免的情况:
|
||||
|
||||
- **信号处理函数不应该调用复杂的库函数**(例如:malloc)
|
||||
|
||||
例如,假设malloc函数的执行过程被一个信号中断。 此时,malloc 函数用来跟踪可用内存的数据结构很可能只有部分被更新。如果 signal 处理函数再调用 malloc 函数,结果可能是 malloc 函数用到的数据结构完全崩溃,后果不堪设想!
|
||||
|
||||
- **从 siganl 函数中使用 longjup 退出**
|
||||
|
||||
基于同样的原因,从 signal 处理函数中使用 longjmp 退出,通常情况下也是不安全的:因为信号可能发生在 malloc 或者其他库函数开始更新某个数据结构,却又没有最后完成的过程中。因此,signal 处理函数能够做的安全的事情,似乎就只有设置一个标志然后返回,期待以后主程序能够检查到这个标志,发现一个信号已经发生。
|
||||
|
||||
- **算数运算错误**
|
||||
|
||||
然而,就算这样做也并不总是安全的。当一个算术运算错误(例如溢出或者零作除数)引发一个信号时,某些机器在signal 处理函数返回后还将重新执行失败的操作。而当这个算术运算重新执行时,我们并没有一个可移植的办法来改变操作数。这种情况下,最可能的结果就是马上又引发一个同样的信号。因此,对于算术运算错误,signal 处理函数的惟一安全、 可移植的操作就是打印一条出错消息,然后使用 longjmp 或 exit 立即退出程序。
|
||||
|
||||
由此,我们得到的结论是:信号非常复杂棘手,而且具有一些从本质上而言不可移植的特性。解决这个问题我们最好采取“守势”,让signal处理函数尽可能地简单,并将它们组织在一起。这样,当需要适应一个新系统时,我们可以很容易地进行修改。
|
||||
|
||||
|
||||
|
||||
### 练习
|
||||
|
||||
#### 练习5-1
|
||||
|
||||
当一个程序异常终止时,程序输出的最后几行常常会去失,原因是什么?我们能够采取怎样的措施来解决这个问题?
|
||||
|
||||
一个异常终止的程序可能没有机会来清空其输出缓冲区。
|
||||
|
||||
解决方案就是在调试时强制不允许对输出进行缓冲。要做到这一点,不同的系统有不同的做法,这些做法虽然存在细微差别,但大致如下:
|
||||
|
||||
```c
|
||||
setbuf(stdout, (char *)0);
|
||||
```
|
||||
|
||||
这个语句必须在任何输出被写入到 stdout(包括任何对 printf 函数的调用)之前执行。该语句最恰当的位置就是作为main函数的第一个语句。
|
||||
|
||||
|
||||
|
||||
#### 练习5-2
|
||||
|
||||
下 面程序的作用是把它的输入复制到输出:
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
main()
|
||||
register int c;
|
||||
|
||||
while ((c = getchar()) != EOF)
|
||||
putchar(c);
|
||||
}
|
||||
```
|
||||
|
||||
从这个程序中去掉 `#include` 语句,将导致程序不能通过编译,因为这时 EOF 是未定义的。假定我们手工定义了EOF (当然,这是一种不好的做法):
|
||||
|
||||
```c
|
||||
#define EOP -1
|
||||
main()
|
||||
{
|
||||
register int c;
|
||||
|
||||
while ((c = getchar()) != EOF)
|
||||
putchar (c) ;
|
||||
}
|
||||
```
|
||||
|
||||
这个程序在许多系统中仍然能够运行,但是在某些系统运行起来却慢得多。这是为什么?
|
||||
|
||||
函数调用需要花费较长的程序执行时间,因此getchar经常被实现为宏。这个宏在stdio.h头文件中定义,因此如果一个程序没有包含 stdio.h 头文件,编译器对 getchar 的定义就一无所知。 在这种情况下,编译器会假定 getchar 是一个返回类型为整型的函数。
|
||||
|
||||
实际上,很多C语言实现在库文件中都包括有 getchar 函数,原因部分是预防编程者粗心大意,部分是为了方便那些需要得到 getchar 地址的编程者。因此,程序中忘记包含 stdio.h 头文件的效果就是,在所有 getchar 宏出现的地方,都getchar 函数调用来替换 getchar 宏。这个程序之所以运行变慢,就是因为函数调用所导致的开销增多。同样的依据也完全适用于putchar 。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**参考资料**:*《C 缺陷与陷阱》*
|
||||
|
||||
412
content/c-traps-and-pitfalls/06 预处理器.md
Normal file
412
content/c-traps-and-pitfalls/06 预处理器.md
Normal file
@@ -0,0 +1,412 @@
|
||||
## [C 陷阱与缺陷] (六) 预处理器
|
||||
|
||||
|
||||
|
||||
### 一 预处理器
|
||||
|
||||
在严格意义上的编译过程开始之前,C 语言预处理器首先对程序代码作了必要的转换处理。因此,我们运行的程序实际上并不是我们所写的程序。预处理器使得编程者可以简化某些工作,它的重要性可以由两个主要的原因说明(当然还有一些次要原因,此处就不赘述了)。
|
||||
|
||||
第一个原因是,我们也许会遇到这样的情况,需要将某个特定数量(例如,某个数据表的大小)在程序中出现的所有实例统统加以修改。我们希望能够通过在程序中,只改动一处数值,然后重新编译就可以实现。预处理器要做到这一点可以说是轻而易举,即使这个数值在程序中的很多地方出现。我们只需要将这个数值定义为一个显式常量(manifest constant), 然后在程序中需要的地方使用这个常量即可。而且,预处理器还能够很容易地把所有常量定义都集中在一起, 这样要找到这些常量也非常容易。
|
||||
|
||||
第二个原因是,大多数 C 语言实现在函数调用时都会带来重大的系统开销。因此,我们也许希望有这样一种程序块, 它看上去像一个函数, 但却没有函数调用的开销。举例来说,getchar 和 putchar 经常被实现为宏,以避免在每次执行输入或者输出一个字符这样简单的操作时,都要调用相应的函数而造成系统效率的下降。
|
||||
|
||||
虽然宏非常有用,但如果程序员没有认识到宏只是对程序的文本起作用,那么他们很容易对宏的作用感到迷惑。也就是说,宏提供了一种对组成 C 程序的字符进行变换的方式,而并不作用于程序中的对象。因而,宏既可以使一段看上去完全不合语法的代码成为一个有效的 C 程序,也能使一段看 上去无害的代码成为一个可怕的怪物。
|
||||
|
||||
|
||||
|
||||
#### 1. 不能忽视宏定义中的空格
|
||||
|
||||
一个函数如果不带参数,在调用时只需在函数名后加上--对括号即可加以调用了。而一个宏如果不带参数,则只需要使用宏名即可,括号无关紧要。只要宏已经定义过了,就不会带来什么问题:预处理器从宏定义中就可以知道宏调用时是否需要参数。与宏调用相比,宏定义显得有些“暗藏机关”。例如,下面的宏定义中f是否带了一个参数呢?
|
||||
|
||||
```c
|
||||
#define f (x) ((x)-1)
|
||||
```
|
||||
|
||||
答案只可能有两种:
|
||||
|
||||
或者 `f(x)` 代表 `((x)-1)`
|
||||
|
||||
或者 f 代表 `(x) ((x)-1)`
|
||||
|
||||
在上述宏定义中,第二个答案是正确的,因为在 f 和后面的 (x) 之间多了一个空格!所以,如果希望定义 f(x) 为 ((x)-1),必须像下面这样写:
|
||||
|
||||
```c
|
||||
#define f(x) ((x)-1)
|
||||
```
|
||||
|
||||
这一规则不适用于宏调用,而只对宏定义适用。因此,在上面完成宏定义后,f(3) 与 f (3) 求值后 都等于 2。
|
||||
|
||||
|
||||
|
||||
#### 2. 宏并不是函数
|
||||
|
||||
因为宏从表面上看其行为与函数非常相似,程序员有时会禁不住把两者视为完全等同。因此,我们常常可以看到类似下面的写法:
|
||||
|
||||
```c
|
||||
#define abs(x) (((x)>=0)?(x) :-(x))
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```c
|
||||
#define max(a,b) ((a)>(b)?(a):(b))
|
||||
```
|
||||
|
||||
请注意宏定义中出现的所有这些括号,它们的作用是预防引起与优先级有关的问题。例如,假设宏 abs 被定义成了这个样子:
|
||||
|
||||
```c
|
||||
#define abs(x) x>0?x:-x
|
||||
```
|
||||
|
||||
让我们来看 abs(a-b) 求值后会得到怎样的结果。表达式
|
||||
|
||||
```c
|
||||
abs(a-b)
|
||||
```
|
||||
|
||||
会被展开为
|
||||
|
||||
```c
|
||||
a-b>0?a-b:-a-b
|
||||
```
|
||||
|
||||
这里的子表达式 -a-b 相当于 (-a)-b,而不是我们期望的 -(a-b),因此上式无疑会得到一个错误的结果。因此,我们最好在宏定义中把每个参数都用括号括起来。同样,整个结果表达式也应该用括号括起来,以防止当宏用于一个更大一些的表
|
||||
达式中可能出现的问题。如果不这样,
|
||||
|
||||
```c
|
||||
abs(a)+1
|
||||
```
|
||||
|
||||
展开后的结果为:
|
||||
|
||||
```c
|
||||
a>0?a:-a+1
|
||||
```
|
||||
|
||||
这个表达式很显然是错误的,我们期望得到的是 -a,而不是 -a+1! abs 的正确定义应该是这样的:
|
||||
|
||||
```c
|
||||
#define abs(x) (((x)>=0)?(x):-(x))
|
||||
```
|
||||
|
||||
这时,abs (a-b) 才会被正确地展开为: `((a-b)>0? (a-b):-(a-b))`,
|
||||
而 abs (a)+1 也会被正确地展开为: `((a)>0?(a):-(a))+1`
|
||||
|
||||
即使宏定义中的各个参数与整个结果表达式都被括号括起来,也仍然还可能有其他问题存在,比如说,一个操作数如果在两处被用到,就会被求值两次。例如,在表达式 max(a,b )中,如果 a 大于 b,那么 a 将被求值两次:第一次是在 a 与 b 比较期间,第二次是在计算 max 应该得到的结果值时。
|
||||
|
||||
这种做法不但效率低下,而且可能是错误的:.
|
||||
|
||||
```c
|
||||
biggest = x[0];
|
||||
i = 1;
|
||||
while (i < n)
|
||||
biggest = max(biggest, x[i++]);
|
||||
```
|
||||
|
||||
如果max是一个真正的函数,上面的代码可以正常工作;而如果max是一个宏,那么就不能正常工作。要看清楚这一点,我们首先初始化数组x中的一些元素:
|
||||
|
||||
```c
|
||||
x[0] = 2;
|
||||
x[1] = 3;
|
||||
x[2] = 1;
|
||||
```
|
||||
|
||||
然后考察在循环的第一次迭代时会发生什么。上面代码中的赋值语句将被扩展为:
|
||||
|
||||
```c
|
||||
biggest = ( (biggest)>(x[i++])?(biggest):(x[i++]));
|
||||
```
|
||||
|
||||
首先,变量 `biggest` 将与 `x[i++]` 比较。因为 i 此时的值是 1, `x[1]` 的值是 3,而变量 `biggest` 此时的值是 `x[0]` 即 2,所以关系运算的结果为 false (假)。 这里,因为 `i++` 的副作用,在比较后 i 递增为2。
|
||||
|
||||
因为关系运算的结果为 false (假),所以 `x[i++]` 的值将被赋给变量 `biggest` 。然而,经过 `i++` 的递增运算后,i 此时的值是 2。所以,实际上赋给变量 `biggest` 的值是 `x[2]` ,即 1。这时,又因为 `i++` 的副作用,i 的值成为 3 。
|
||||
|
||||
解决这类问题的一个办法是,确保宏 max 中的参数没有副作用:
|
||||
|
||||
```c
|
||||
biggest = x[0];
|
||||
for(i = 1; i < n; i++)
|
||||
biggest = max(biggest, x[i]);
|
||||
```
|
||||
|
||||
另一个办法是让 max 作为函数而不是宏,或者直接编写比较两数取较大者的运算的代码:
|
||||
|
||||
```c
|
||||
biggest = x[0];
|
||||
for(i = 1; i < n; i++)
|
||||
if(x[i] > biggest)
|
||||
biggest = x[i];
|
||||
```
|
||||
|
||||
下面是另外一个例子,其中因为混合了宏和递增运算的副作用,使代码显得岌岌可危。这个例子是宏 putc 的一个典型定义:
|
||||
|
||||
```c
|
||||
#define putc(x,p) \
|
||||
(--(p)->_cnt>=0?(*(p)->_ ptr++=(x)):_ flsbuf(X,p))
|
||||
```
|
||||
|
||||
宏 putc 的第一个参数是将要写入文件的字符,第二个参数是一个指针,指向一个用于描述文件的内部数据结构。请注意这里的第一个参数 x,它极有可能是类似于 `*z++` 这样的表达式。尽管 x 在宏 putc 的定义中两个不同的地方出现了两次,
|
||||
但是因为这两次出现的地方是在运算符 `:` 的两侧,所以 x 只会被求值一次。
|
||||
|
||||
第二个参数 p 则恰恰相反,它代表将要写入字符的文件,总是会被求值两次。因为文件参数 p 一般不需要作递增递减之类有副作用的操作,所以这很少引起麻烦。不过, ANSI C 标准中还是提出了警告: putc 的第二个参数可能会被求值两次。
|
||||
|
||||
某些 C 语言实现对宏 putc 的定义也许不会像上面的定义那样小心翼翼,putc 的第一个参数很可能被不止一次求值,这样实现是可能的。编程者在给 putc 一个可能有副作用的参数时,应该考虑一下正在使用的 C 语言实现是否足够周密。
|
||||
|
||||
再举一个例子,考虑许多 C 库文件中都有的 toupper 函数,该函数的作用是将所有的小写字母转换为相应的大写字母,而其他的字符则保持原状。如果我们假定所有的小写字母和所有的大写字母在机器字符集中都是连续排列的(在大小写字母之间可能有一个固定的间隔),那么我们可以这样实现toupper函数:
|
||||
|
||||
```c
|
||||
toupper (int c)
|
||||
{
|
||||
if(c >= 'a' && c <= 'z')
|
||||
c += 'A' - 'a';
|
||||
|
||||
return c;
|
||||
}
|
||||
```
|
||||
|
||||
在大多数 C 语言实现中, toupper 的数在调用时造成的系统开销要大大多于函数体内的实际计算操作。因此,实现者很可能禁不住要把 toupper 实现为宏:
|
||||
|
||||
```c
|
||||
#define toupper(c) \
|
||||
((c)>='a' && (c)<='z')? ((c) - 'a' + 'A') : (c))
|
||||
```
|
||||
|
||||
在许多情况下,这样做确实比把 toupper 实现为函数要快得多。然而,如果编程者试图这样使用
|
||||
|
||||
`toupper (*p++)`
|
||||
|
||||
则最后的结果会让所有人都大吃一惊!
|
||||
|
||||
使用宏的另一个危险是,宏展开可能产生非常庞大的表达式,占用的空间远远超过了编程者所期望的空间。例如,让我们再看宏max的定义:
|
||||
|
||||
`#define max(a,b) ((a)>(b)?(a):(b))`
|
||||
|
||||
假定我们需要使用上面定义的宏 max,来找到 a、b、 c、 d 四个数的最大者,最显而易见的写法是:
|
||||
|
||||
`max(a, max (b, max(c, d)))`
|
||||
|
||||
上面的式子展开后就是:
|
||||
|
||||
```c
|
||||
((a)>(((b)>(((c)>(d)?(c):(d)))?(b):(((c)>(d)?(C):()))))?
|
||||
(a):(((b)>(((c)>(d)?(c): (d))?(b):((c)>(d)?(C):())))))
|
||||
```
|
||||
|
||||
确实,这个式子太长了!如果我们调整一下,使上式中操作数左右平衡:
|
||||
|
||||
`max (max(a,b) ,max(c,d) )`
|
||||
|
||||
现在这个式子展开后还是较长: .
|
||||
|
||||
```c
|
||||
((((a)>(b)?(a):(b)))>(({c)>(d)?(c):(d)))?
|
||||
(((a)>(b)?(a):(b))):(((c)>(d)?(C):(d))))
|
||||
```
|
||||
|
||||
其实,写成以下代码似乎更容易一些:
|
||||
|
||||
```c
|
||||
biggest = a;
|
||||
if (biggest < b) biggest = b;
|
||||
if (biggest < c) biggest = c;
|
||||
if (biggest < d) biggest = d;
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 3. 宏并不是语句
|
||||
|
||||
编程者有时会试图定义宏的行为与语句类似,但这样做的实际困难往往令人吃惊! 举例来说,考虑一下assert 宏,它的参数是一个表达式,如果该表达式为 0,就使程序终止执行,并给出一条适当的出错消息。把 assert 作为宏来处理,这
|
||||
样就使得我们可以在出错信息中包括有文件名和断言失败处的行号。也就是说,
|
||||
|
||||
`assert (x>y);`
|
||||
|
||||
在x大于y时什么也不做,其他情况下则会终止程序。
|
||||
|
||||
下面是我们定义 assert 宏的第一次尝试:
|
||||
|
||||
```c
|
||||
#define assert(e) if (!e) assert_ error(_ FILE_, _ LINE__ )
|
||||
```
|
||||
|
||||
因为考虑到宏 assert 的使用者会加上一个分号,所以在宏定义中并没有包括分号。`__FILE__` 和`__LINE__` 是内建于 C语言预处理器中的宏,它们会被扩展为所在文件的文件名和所处代码行的行号。
|
||||
|
||||
宏 assert 的这个定义,即使用在一个再明白直接不过的情形中,也会有一些难于察觉的错误:
|
||||
|
||||
```c
|
||||
if(x > 0 && y > 0)
|
||||
assert(x > y);
|
||||
else
|
||||
assert(y > x) ;
|
||||
```
|
||||
|
||||
上面的写法似乎很合理,但是它展开之后就是这个样子:
|
||||
|
||||
```c
|
||||
if(x>0&&y>0)
|
||||
if(!(x > y)) assert_error("foo.c", 37);
|
||||
else
|
||||
if(!(y > x)) assert_error("foo.c", 39);
|
||||
```
|
||||
|
||||
把上面的代码作适当的缩排处理,我们就能够看清它实际的流程结构与我们期望的结构有怎样的区别:
|
||||
|
||||
```c
|
||||
if(x>0&&y>0)
|
||||
if(!(x > y))
|
||||
assert_error("foo.c", 37);
|
||||
else
|
||||
if(!(y > x))
|
||||
assert_error("foo.c", 39) ;
|
||||
```
|
||||
|
||||
读者也许会想到,在宏 assert 的定义中用大括号把宏体整个给“括”起来,就能避免这样的问题产生:
|
||||
|
||||
```c
|
||||
#define assert(e)\
|
||||
{ if (!e) assert_error(__FILE__, __LINE__ ); }
|
||||
```
|
||||
|
||||
然而,这样做又带来了一个新的问题。我们上面提到的例子展开后就成了:
|
||||
|
||||
```c
|
||||
if(x>0&&y> 0)
|
||||
{ if(!(x > y)) assert_error("foo.c", 37);};
|
||||
else
|
||||
{ if(!(y > x)) assert_error ("foo.c", 39);};
|
||||
```
|
||||
|
||||
在else之前的分号是一个语法错误。要解决这个问题,一个办法是对 assert 的调用后面都不再跟一个分号,但这样的用法显得有些“怪异”:
|
||||
|
||||
```c
|
||||
y = distance(p, q) ;
|
||||
assert(y > 0)
|
||||
x = sqrt(y);
|
||||
```
|
||||
|
||||
宏 assert 的正确定义很不直观,编程者很难想到这个定义不是类似于一个语句,而是类似一个表达式
|
||||
|
||||
```c
|
||||
#define assert(e) \
|
||||
((void) ((e) || assert_error(__FILE__, __LINE__ ))
|
||||
```
|
||||
|
||||
这个定义实际上利用了 `||` 运算符对两侧的操作数依次顺序求值的性质。
|
||||
|
||||
如果 e 为真,|| 后半部分语句不会被执行。
|
||||
|
||||
|
||||
|
||||
#### 4. 宏不是类型定义
|
||||
|
||||
宏的类型定义:
|
||||
|
||||
```c
|
||||
#define FOOTYPE struct foo
|
||||
|
||||
FOOTYPE a;
|
||||
FOOTYPE b, c;
|
||||
```
|
||||
|
||||
宏的这种用法有一个优点——可移植性,得到了所有 C 编译器的支持。
|
||||
|
||||
但是我们最好还是使用类型定义:
|
||||
|
||||
```c
|
||||
typedef struct foo FOOTYPE;
|
||||
```
|
||||
|
||||
这个语句定义了 FOOTYPE 为一个新的类型,与 struct foo 完全等效。
|
||||
|
||||
这两种命名类型的方式似乎都差不多,但是使用typedef的方式要更加通用一些。例如,考虑下面的代码:
|
||||
|
||||
```c
|
||||
#define T1 struct foo *
|
||||
typedef struct foo *T2;
|
||||
```
|
||||
|
||||
从上面两个定义来看,T1 和 T2 从概念上完全符同,都是指向结构foo的指针。但是,当我们试图用它们来声明多个变量时,问题就来了:
|
||||
|
||||
```c
|
||||
T1 a, b;
|
||||
T2 a, b;
|
||||
```
|
||||
|
||||
第一个声明被扩展为:
|
||||
|
||||
`struct foo * a,b;`
|
||||
|
||||
这个语句中 a 被定义为一个指向结构的指针,而 b 却被定义为一个结构(而不是指针)。
|
||||
|
||||
第二个声明则不同,它定义了 a 和 b 都是指向结构的指针,因为这里 T2 的行为完全与一个真实的类型相同。
|
||||
|
||||
|
||||
|
||||
### 二 练习
|
||||
|
||||
#### 1. 练习6-1
|
||||
|
||||
请使用宏来实现max的一个版本,其中max的参数都是整数,要求在宏 max 的定义中这些整型参数只被求值一次。
|
||||
|
||||
max宏的每个参数的值都有可能使用两次: 一次是在两个参数作比较时;一次是在把它作为结果返回时。因此,我们有必要把每个参数存储在一个临时变量中。
|
||||
|
||||
遗憾的是,我们没有直接的办法可以在一个 C表达式的内部声明一个临时变量。因此,如果我们要在一个表达式中使用 max宏,那么我们就必须在其他地方声明这些临时变量,比如说可以在宏定义之后,但不是将这些变量作为宏定义的一部分进行声明。如果 max 宏用于不止一个程序文件,我们应该把这些临时变量声明为 static, 以避免命名冲突。不妨假定,这些定义将出现在某个头文件中:
|
||||
|
||||
```c
|
||||
static int max__ temp1, max_ temp2;
|
||||
#define max(p,q) (max_temp1=(p), max_temp2=(q),\
|
||||
max_temp1>max_temp2? max_temp1 : max_temp2)
|
||||
```
|
||||
|
||||
只要对max宏不是嵌套调用,上面的定义都能正常工作;在 max 宏嵌套调用的情况下,我们不可能做到让它正常工作。
|
||||
|
||||
#### 2. 练习6-2
|
||||
|
||||
本章第1节中提到的“表达式”
|
||||
|
||||
`(x) ((x)-1)`
|
||||
|
||||
能否成为一个合法的C表达式?
|
||||
|
||||
一种可能是,如果 x 是类型名,例如 x 被这样定义:
|
||||
|
||||
`typedef int x;`
|
||||
|
||||
在这种情况下,
|
||||
|
||||
`(x) ((x)-1)`
|
||||
|
||||
等价于
|
||||
|
||||
`(int) ((int)-1)`
|
||||
|
||||
这个式子的含义是把常数 -1 转换为 int 类型两次。我们也可以通过预处理指令来定义 x 为一种类型,以达到同样的效果:
|
||||
|
||||
`#define x int`
|
||||
|
||||
另一种可能是当 x 为函数指针时。回忆一下,如果某个上下文中本应需要函数而实际上却用了函数指针,那么该指针所指向的函数将会自动地被取得并替换这个函数指针。因此,本题中的表达式可以被解释为调用 x 所指向的函数,这个函数的参数是 `(x)-1`。为了保证 `(x)-1` 是一个合法的表达式,x 必须实际地指向一个函数指针数组中的某个元素。
|
||||
|
||||
x 的完整类型是什么呢?为了讨论问题方便起见,我们假定 x 的类型是 T, 因此可以如下声明 x:
|
||||
|
||||
`T x;`
|
||||
|
||||
显而易见,x 必须是一个指针,所指向的函数的参数类型是 T 。这一点让 T 比较难以定义。下面是最容易想到的办法,但却没有用:
|
||||
|
||||
```c
|
||||
typedef void (*T)(T) ;
|
||||
```
|
||||
|
||||
因为只有当 T 已经被声明之后,才能这样定义 T! 不过,x 所指向的函数的参数类型并不一定要是 T,而可以是任何 T 可以被转换成的类型。具体来说,void * 类型就完全可以:
|
||||
|
||||
```c
|
||||
typedef void (*T) (void *) ;
|
||||
```
|
||||
|
||||
这个练习的用意在于说明,对于那些看上去无从着手、形式“怪异”的结构, 我们不应该轻率地一律将其作为错误来处理。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**参考资料**:*《C 缺陷与陷阱》*
|
||||
|
||||
486
content/c-traps-and-pitfalls/07 可移植性缺陷.md
Normal file
486
content/c-traps-and-pitfalls/07 可移植性缺陷.md
Normal file
@@ -0,0 +1,486 @@
|
||||
## [C 陷阱与缺陷] (七) 可移植性缺陷
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
了解更多有关可移植可以参考《How to Write Portable Software in C》(Prentice-Hall)。
|
||||
|
||||
本章主要讨论几个常见的错误来源,重点放在语言属性上,而非函数库属性上。
|
||||
|
||||
|
||||
|
||||
### 一 可移植性缺陷
|
||||
|
||||
#### 1. 应对 C 语言标准变更
|
||||
|
||||
这种语言标准的变更使得 C 程序的编写者面临一个两难境地:程序中是否应该用到新的特性呢? 如果使用它们,程序无疑更加容易编写,而且不大容易出错,但是那样做也有代价,那就是这些程序在较早的编译器上将无法工作。
|
||||
|
||||
本书的 4.4节讨论了一个这类例子:函数原型的概念。让我们回想一下 4.4 节中提到的 square 函数:
|
||||
|
||||
```c
|
||||
double
|
||||
square (double x){
|
||||
return x * x;
|
||||
}
|
||||
```
|
||||
|
||||
如果这样写,这个函数在很多编译器上都不能通过编译。如果我们按照旧风格来重写这个函数,因为 ANSI 标准为了保持和以前的用法兼容也允许这种形式,这就增强了它的可移植性:
|
||||
|
||||
```c
|
||||
double
|
||||
square (x)
|
||||
double x;
|
||||
{
|
||||
return x*x;
|
||||
}
|
||||
```
|
||||
|
||||
这种可移植性的获得当然也付出了代价。为了与旧用法保持一致, 我们必须在调用了 square 函数的程序中作如下声明:
|
||||
|
||||
```c
|
||||
double square();
|
||||
```
|
||||
|
||||
函数声明中略去参数类型的说明,这在 ANSI C 标准中也是合法的。因为这样的声明并没有对参数类型做出任何说明,就意味着如果在函数调用时传入了错误类型的参数,函数调用就会不声不响地失败:
|
||||
|
||||
```c
|
||||
double square();
|
||||
|
||||
main(){
|
||||
printf("%g\n",square(3));
|
||||
}
|
||||
```
|
||||
|
||||
函数square的声明中并没有对参数类型做出说明,因此在编译 main 函数时,编译器无法得知函数 square 的参数类型应该是 double,而不是 int 。这样,程序打印出的将是一堆 “垃圾信息”。要检测这类问题,有一个办法就是使用 lint 程序,前提是编程者的 C 语言实现提供了这一工具。
|
||||
|
||||
如果上面的程序被写成了这样:
|
||||
|
||||
```c
|
||||
double square (double);
|
||||
main(){
|
||||
printf("%g\n", square(3));
|
||||
}
|
||||
```
|
||||
|
||||
这里,3 会被自动转换为double类型。
|
||||
|
||||
另种改写的方式是,在这个程序中显式地给函数 square 传入一个 double 类型的参数:
|
||||
|
||||
```c
|
||||
double square() ;
|
||||
|
||||
main()
|
||||
{
|
||||
printf ("%g\n", square(3.0));
|
||||
}
|
||||
```
|
||||
|
||||
这样做程序就能得到正确的结果。即使是对于那些不允许在函数声明中包括参数类型的旧编译器,第二种写法也仍然能够使程序照常工作。
|
||||
|
||||
许多有关可移植性的决策都有类似的特点。一个程序员是否应该使用某个新的或特定的特性?使用该特性也许能给编程带来巨大的方便,但代价却是使程序失去了一部分潜在用户。
|
||||
|
||||
#### 2. 标识符名称的限制
|
||||
|
||||
某些 C 语言实现把一个标识符中出现的所有字符都作为有效字符处理,而另一些 C实 现却会自动地截断一个长标识符名称的尾部。连接器也会对它们能够处理的名称强加限制,例如外部名称中只允许使用大写字母。C实现者在面对这样的限制时,一个合理的选择就是强制所有的外部名称必须是大写。事实上,**ANSI C标准所能保证的只是,C实现必须能够区别出前 6 个字符不同的外部名称。而且,这个定义中并没有区分大写字母与其对应的小写字母**。
|
||||
|
||||
因为这个原因,为了保证程序的可移植性,谨慎地选择外部标识符的名称是重要的。比方说,两个函数的名称分别为 `print_fields` 与 `print_float` 这样的命名方式就不恰当;同理, 使用 State 与 STATE 这样的命名方式也不明智。
|
||||
|
||||
考虑以下函数:
|
||||
|
||||
```c
|
||||
char*
|
||||
Malloc (unsigned n)
|
||||
{
|
||||
char *p, *malloc (unsigned) ;
|
||||
p = malloc(n) ;
|
||||
if (p == NULL)
|
||||
panic("out of memory") ;
|
||||
return p;
|
||||
}
|
||||
```
|
||||
|
||||
上面的例子程序演示了一个确保检测到内存耗尽的异常情况的简单办法。编程者的想法是,在程序中应该调用 malloc 函数分配内存的地方,改为调用 Malloc 函数。如果 malloc 函数调用失败,则 panic 函数将被调用,panic 函数终止程序,并打印出一条恰当的出错消息。这样,客户程序就不必在每次调用malloc函数时都要进行检查。
|
||||
|
||||
然而,考虑一下如果这个函数的编译环境是不区分外部名称大小写的 C 语言实现,将会发生怎样的情况呢? 此时,函数malloc 与Malloc 实际上是等同的。也就是说,库函数 malloc将被上面的 Malloc 函数等效替换。当在 Malloc 函数中调用库函数 malloc 时,实际上调用的却是 Malloc 函数自身!当然,尽管函数 Malloc 在那些区分大小写的C语言实现上仍然能够正常工作,但在这种情况下结果却是:程序在第一次试图分配内存时对 Malloc 函数的调用将引起一系列的递归调用, 而这些递归调用又不存在一个返回点,最后引发灾难性的后果!
|
||||
|
||||
#### 3. 整数的大小
|
||||
|
||||
C语言中为编程者提供了3种不同长度的整数: `short` 型、`int` 型和 `long` 型,C 语言中的字符行为方式与小整数相似。C语言的定义中对各种不同类型整数的相对长度作了一些规定:
|
||||
|
||||
1. **3种类型的整数其长度是非递减的**。也就是说,short 型整数容纳的值肯定能够被 int 型整数容纳,int 型整数容纳的值也肯定能够被 long 型整数容纳。对于一个特定的 C 语言实现来说,并不需要实际支持 3 种不同长度的整数,但可能不会让 short 型整数大于 int 型整数,而 int 型整数大于 long 型整数。
|
||||
|
||||
2. 一个普通(int 类型)整数足够大以容纳任何数组下标。
|
||||
|
||||
3. 字符长度由硬件特性决定。
|
||||
|
||||
ANSI 标准要求 long 型整数的长度至少应该是 32 位,而 short 型和 int 型整数的长度至少应该是 16 位。因为大多数机器中字符长度是8位,对这些机器而言最方便的整数长度是 16 位和 32 位,因此所有早期的C编译器也都能够满足这些限制条件。
|
||||
|
||||
程序员当然可以用一个 int 型整数来表示一个数据表格的大小或者数组的下标。但如果一个变量需要存放可能是千万数量级的数值,又该如何呢?
|
||||
|
||||
要定义这样一个变量,可移植性最好的办法就是声明该变量为 long 型,但在这种情况下我们定义一个“新的”类型无疑更为清晰:
|
||||
|
||||
```c
|
||||
typedef long tenmil;
|
||||
```
|
||||
|
||||
而且,程序员可以用这个新类型来声明所有此类变量,最坏的情形也不过是我们只需要改动类型定义,所有这些变量的类型就自动变为正确的了。
|
||||
|
||||
|
||||
|
||||
#### 4. 字符是有符号整数还是无符号整数
|
||||
|
||||
现代大多数计算机都支持 8 位字符,因此大多数现代 C 编译器都把字符实现为 8 位整数。然而,并非所有的编译器都按照同样的方式来解释这些8 位数值。
|
||||
|
||||
只有在我们需要把一个字符值转换为一个较大的整数时,这个问题才变得重要起来。而在其他情况下,结果都是已定义的:多余的位将被简单地“丢弃”。编译器在转换 char 类型到 int 类型时,需要做出选择:应该将字符作为有符号数还是应该无符号数处理?如果是前一种情况,编译器在将 char 类型的数扩展到 int 类型时,应该同时复制符号位:而如果是后一种情况,编译器只需在多余的位上直接填充 0 即可。
|
||||
|
||||
如果一个字符的最高位是1,编译器是将该字符当作有符号数,还是无符号数呢?对于任何一个需要处理该字符的程序员来说,上述选择的结果非常重要。它决定着一个 8 位字符的取值范围是从 -128 到 127 ,还是从 0 到 255。而这一点,又反过来影响到程序员对哈希表或转换表等的设计方式。
|
||||
|
||||
如果编程者关注一个最高位是1的字符其数值究竟是正还是负,可以将这个字符声明为无符号字符(unsigned char)。这样,无论是什么编译器,在将该字符转换为整数时都只需将多余的位填充为 0 即可。而如果声明为一般的字符变量,那么在某些编译器上可能会作为有符号数处理,在另一些编译器上又会作为无符号数处理。
|
||||
|
||||
与此相关的一个常见错误认识是:如果 c 是一个字符变量,使用 `(unsigned)c` 就可得到与 c 等价的无符号整数。这是会失败的,因为在将字符 c 转换为无符号整数时,c 将首先被转换为 int 型整数,而此时可能得到非预期的结果。正确的方式是使用语句 `(unsigned char)c`,因为一个 `unsigned char` 类型的字符在转换为无符号整数时无需首先转换为int型整数,而是直接进行转换。
|
||||
|
||||
#### 5. 移位运算符
|
||||
|
||||
使用移位运算符的程序员经常对这样两个问题感到困惑:
|
||||
|
||||
1. 在向右移位时,空出的位是由 0 填充,还是由符号位的副本填充?
|
||||
2. 移位计数(即移位操作的位数)允许的取值范围是什么?
|
||||
|
||||
第一个问题的答案很简单,但有时却是与具体的 C 语言实现有关。如果被移位的对象是无符号数,那么空出的位将被0填充。如果被移位的对象是有符号数,那么 C 语言实现既可以用 0 填充空出的位,也可以用符号位的副本填充空出的位。编程者如果关注向右移位时空出的位,那么可以将操作的变量声明为无符号类型,那么空出的位都会被设置为0。
|
||||
|
||||
第二个问题的答案同样也很简单:如果被移位的对象长度是 n 位,那么移位计数必须大于或等于 0,而严格小于 n。因此,不可能做到在单次操作中将某个数值中的所有位都移出。为什么要有这个限制呢?因为只要加上了这个限制条件, 我们就能够在硬件上高效地实现移位运算。举例来说,如果一个 int 型整数是 32 位,n 是一个 int 型整数,那么 `n<<31`
|
||||
和 `n<<0` 这样写是合法的,而 `n<<32` 和 `n<<-1` 这样写是非法的。
|
||||
|
||||
需要注意的是,即使 C 实现将符号位复制到空出的位中,有符号整数的向右移位运算也并不等同于除以 2 的某次幂。要证明这一点, 让我们考虑 `(-1)>>1`,这个操作的结果一般不可 能为 0,但是 `(-1)/2` 在大多数 C 实现上求值结果都是 0。这意味着以除法运算来代替移位运算,将可能导致程序运行速度大大减慢。举例而言,如果已知下面表达式中的 `low+high` 为非负,那么
|
||||
|
||||
```c
|
||||
mid = (1ow + high) >> 1;
|
||||
```
|
||||
|
||||
与下式
|
||||
|
||||
```c
|
||||
mid = (low + high) / 2;
|
||||
```
|
||||
|
||||
完全等效,而且前者的执行速度也要快得多。
|
||||
|
||||
|
||||
|
||||
#### 6. 内存位置 0
|
||||
|
||||
null 指针并不指向任何对象。因此,除非是用于赋值或比较运算,出于其他任何目的使用 null 指针都是非法的。例如,如果 p 或 q 是一个 null 指针,那么 `strcmp(p, q)` 的值就是未定义的。
|
||||
|
||||
在这种情况下究竟会得到什么结果呢?不同的编译器有不同的结果。某些 C 语言实现对内存位置 0 强加了硬件级的读保护,在其上工作的程序如果错误使用了一个 null 指针,将立即终止执行。其他一些 C 语言实现对内存位置 0 只允许读,不允许写。在这种情况下,一个 null 指针似乎指向的是某个字符串,但其内容通常不过是一堆“垃圾信息”。还有一些 C 语言实现对内存位置0既允许读,也允许写。在这种实现上面工作的程序如果错误使用了一个 null 指针,则很可能覆盖了操作系统的部分内容,造成彻底的灾难!
|
||||
|
||||
严格说来,这并非一个可移植性问题:在所有的C程序中,误用 null 指针的效果都是未定义的。然而,这样的程序有可能在某个 C 语言实现上“似乎”能够工作,只有当该程序转移到另一台机器上运行时才会暴露出问题来。要检查出这类问题的最简单办法就是,把程序移到不允许读取内存位置 0 的机器上运行。下面的程序将揭示出某个 C 语言实现是如何处理内存地址 0 的:
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
main{)
|
||||
char *p;
|
||||
p = NULL;
|
||||
printf("Location 0 contains %d\n", *p) ;
|
||||
}
|
||||
```
|
||||
|
||||
在禁止读取内存地址 0 的机器上,这个程序将会执行失败。在其他机器上,这个程序将会以 10 进制的格式打印出内存位置 0 中存储的字符内容。
|
||||
|
||||
|
||||
|
||||
#### 7. 除法运算时发生的截断
|
||||
|
||||
假定我们让a除以b,商为q,余数为r :
|
||||
|
||||
```c
|
||||
q = a / b;
|
||||
r = a % b;
|
||||
```
|
||||
|
||||
这里,不妨假定 b 大于 0。我们希望a、b、q、r之间维持怎样的关系呢?
|
||||
|
||||
1. 最重要的一点,我们希望 `q * b + r == a`, 因为这是定义余数的关系。
|
||||
2. 如果我们改变 a 的正负号,我们希望这会改变 q 的符号,但这不会改变 q 的绝对值。
|
||||
3. 当 `b > 0`时,我们希望保证 `r >= 0` 且 `r < b` 。例如,如果余数用于哈希表的索引。确保它是一个有效的索引值很重要。
|
||||
|
||||
这三条性质是我们认为整数除法和余数操作所应该具备的。很不幸的是,它们不可能同时成立。
|
||||
|
||||
考虑一个简单的例子: 3 / 2, 商为 1,余数也为 1。此时,第 1 条性质得到了满足。(-3)/2 的值应该是多少呢?如果要满足第 2 条性质,答案应该是 -1,但如果是这样,余数就必定是 -1,这样第 3 条性质就无法满足了。如果我们首先满足第 3 条性质,即余数是 1,这种情况下根据第 1 条性质则商是 -2,那么第 2 条性质又无法满足了。
|
||||
|
||||
因此,C 语言或者其他语言在实现整数除法截断运算时,必须放弃上述三条原则中的至少一条。 大多数程序设计语言选择了放弃第 3 条,而改为要求余数与被除数的正负号相同。这样,性质 1 和性质 2 就可以得到满足。大多数C编译器在实践中也都是这样做的。
|
||||
|
||||
然而,C语言的定义只保证了性质 1,以及当 `a >= 0` 且 `b > 0` 时,保证 `|r| < |b|` 以及 `|r >= 0|`。后面部分的保证与性质 2 或者性质 3 比较起来,限制性要弱得多。
|
||||
|
||||
C 语言的定义虽然有时候会带来不需要的灵活性,但大多数时候,只要编程者清楚地知道要做什么、该做什么,这个定义对让整数除法运算满足其需要来说还是够用了的。例如,假定我们有一个数 n ,它代表标识符中的字符经过某种函数运算后的结果,我们希望通过除法运算得到哈希表的条目 h,满足 `0 <= h < HASHSIZE`。又如果已知 n 恒为非负,那么我们只需要像下面一样简单地写:
|
||||
|
||||
`h = n % HASHSIZE;`
|
||||
|
||||
然而,如果 n 有可能为负数,而此时 h 也有可能为负,那么这样做就不一定总是合适的了。不过,我们已知 `h >= -HASHSIZE`,因此我们可以这样写:
|
||||
|
||||
```c
|
||||
h = n % HASHSIZE;
|
||||
if(h < 0)
|
||||
h += HASHSIZE;
|
||||
```
|
||||
|
||||
更好的做法是,程序在设计时就应该避免 n 的值为负这样的情形,并且声明 n 为无符号数。
|
||||
|
||||
|
||||
#### 8. 随机数的大小
|
||||
|
||||
最早的C语言实现运行于 PDP-11 计算机上,它提供了一个称为 rand 的函数,该函数的作用是产生一个(伪)随机非负整数。PDP-11 计算机上的整数长度为16位(包括了符号位),因此 rand 函数将返回一个介于 0 到2^15 - 1 之间的整数。
|
||||
|
||||
当在 VAX-11 计算机上实现 C 语言时,因为该种机器上整数的长度为 32 位,这就带来了一个实现方面的问题: VAX-11 计算机上 rand 函数的返回值范围应该是多少呢?
|
||||
|
||||
当时有两组人员同时分别在 VAX-11 计算机上实现 C 语言,他们做出的选择互不相同。一组人员在加州大学伯克利分校,他们认为 rand 函数的返回值范围应该包括该机器上所有可能的非负整数取值,因此他们设计版本的 rand 函数返回一
|
||||
个介于 0 到 2^31 - 1 的整数。另一组人员在 AT&T,他们认为如果 VAX-11计算机上的 rand 函数返回值范围与 PDP-11计算机上的一样,即介于 0 到 2^15 - 1之间的整数,那么在PDP-11计算机上所写的程序就能够较为容易移植到 VAX-11 计算机上。
|
||||
|
||||
这样造成的后果是,如果我们的程序中用到了 rand 函数,在移植时就必须根据特定的C语言实现作出“剪裁”。ANSI C 标准中定义了一个常数 `RAND_ MAX`, 它的值等于随机数的最大取值,但是早期的 C 实现通常都没有包含这个常数。
|
||||
|
||||
#### 9. 大小写转换
|
||||
|
||||
库函数 `toupper` 和 `tolower` 也有与随机数类似的历史。他们起初被实现为宏:
|
||||
|
||||
```c
|
||||
#define toupper(c) ((c) - 'a' + 'A')
|
||||
#define tolower(c) ((c) - 'A' + 'a')
|
||||
```
|
||||
|
||||
然而,这些宏确实有一个不足之处:如果输入的字母大小写不对,那么它们返回的就都是无用的垃圾信息。考虑下面的程序段,其作用是把一个文件中的大写字母全部转换为小写字母,这个程序段看上去没什么问题,但实际上却无法工作:
|
||||
|
||||
```c
|
||||
int c;
|
||||
|
||||
while((c = getchar()) != EOF)
|
||||
putchar(tolower(c));
|
||||
```
|
||||
|
||||
我们应该写成这样才对:
|
||||
|
||||
```c
|
||||
int c;
|
||||
|
||||
while((c = getchar()) != EOF)
|
||||
putchar(isupper(c) ? tolower(c) : c);
|
||||
```
|
||||
|
||||
有一次, AT&T 软件开发部门的一一个极具创新精神的人注意到,大多数 toupper 和 tolower 的使用都需要首先进行检查以保证参数是合适的。慎重考虑之后,他决定把这些宏重写如下:
|
||||
|
||||
```c
|
||||
#define toupper(c) ( (c) >= 'a' && (c) <= 'z' ? ((c) - 'a' + 'A') : (c) )
|
||||
#define tolower(c) ( (c) >= 'A' && (c) <= 'Z' ? ((c) - 'A' + 'a') : (c) )
|
||||
```
|
||||
|
||||
他又意识到这样做有可能在每次宏调用时,致使 c 被求值 1 到 3 次。如果遇到类似 `toupper(*p++)` 这样的表达式,可能造成不良后果。因此,他决定重写 `toupper`和 `tolower` 为函数,重写后的 `toupper` 函数看上去大致像这样:
|
||||
|
||||
```c
|
||||
int
|
||||
toupper(int c)
|
||||
{
|
||||
if(c >= 'a' && c <= 'z')
|
||||
return c - 'a' + 'A';
|
||||
return c;
|
||||
}
|
||||
```
|
||||
|
||||
这样改动之后程序的健壮性无疑得到了增强,而代价是每次使用这些函数时却又引入了函数调用的开销。他意识到某些人也许不愿意付出效率方面损失的代价,因此他又重新引入了这些宏,不过使用了新的宏名:
|
||||
|
||||
```c
|
||||
#define _toupper (c) ((c) + 'A' - 'a')
|
||||
#define _tolower(c) ((c) + 'a' - 'A')
|
||||
```
|
||||
|
||||
这样,宏的使用者就可以在速度与方便之间自由选择。
|
||||
|
||||
|
||||
|
||||
#### 10. 首先释放,然后重新分配
|
||||
|
||||
Unix 系统参考手册第七版中描述 realloc :
|
||||
|
||||
> `Realloc` 函数把指针 `ptr` 所指向内存块的大小调整为 size 字节,返回一个指向调整后内存块(可能该内存块已经被移动过了)的指针。假定这块内存原来大小为 oldsize,新的大小为 newsize ,这两个数之间较小者为`min(oldsize, newsize)`,那么内存块中 `min(oldsize,newsize)` 部分存储的内容将保持不变。
|
||||
>
|
||||
> 如果 ptr 指向的是一块最近一次调用 `malloc`, `realloc` 或 `calloc` 分配的内存,即使这块内存已被释放, `realloc` 函数仍然可以工作。因此,可以通过调节 `free`, `malloc` 和 `realloc` 的调用顺序,充分利用 `malloc` 函数的搜索策略来压缩存储空间。
|
||||
|
||||
也就是说,这一实现允许在某内存块被释放之后重新分配其大小,前提是内存重分配(reallocation) 操作执行得必须足够早。因此,在符合第7版参考手册描述的系统中,下面的代码就是合法的:
|
||||
|
||||
```c
|
||||
free(p) ;
|
||||
p = realloc(p, newsize);
|
||||
```
|
||||
|
||||
在一个有这样特殊性质的系统中,我们可以用下面这个多少有些“怪异”的办法,来释放一个链表中的所有元素:
|
||||
|
||||
```c
|
||||
for (p = head; p != NULL; p = p->next)
|
||||
free( (char *) p) ;
|
||||
```
|
||||
|
||||
这里,我们不必担心调用 free 之后,会使 `p->next `变得无效。
|
||||
|
||||
当然,这种技巧不值得推荐,因为并非所有的 C 实现在某块内存被释放后还能较长时间的保留之。不过,第7版参考手册还有一点没有提到:早期的realloc 函数的实现要求待重新分配的内存区域必须首先被释放。因为这个原因,仍然还
|
||||
有一些较老的C程序是首先释放某块内存,然后再重新分配这块内存。当我们移植这样一个较老的C程序到一个新的实现中时,必须注意到这一点。
|
||||
|
||||
#### 11 可移植性问题的一个例子
|
||||
|
||||
让我们来看这样一个问题,这个问题许多人都遇到过,也被解决过许多次,因此非常具有代表性。下面的程序接受两个参数: 一个 long 型整数和一个函数指针。这段程序的作用是把给出的long 型整数转换为其10进制表示,并且对10进制表示中的每个字符都调用函数指针所指向的函数:
|
||||
|
||||
```c
|
||||
void printnum(long n, void (*p)())
|
||||
{
|
||||
if(n < 0){
|
||||
(*p)('-');
|
||||
n = -n;
|
||||
}
|
||||
|
||||
if(n >= 10){
|
||||
printnum(n / 10, p);
|
||||
}
|
||||
|
||||
(*p)((int)(n % 10) + '0');
|
||||
}
|
||||
```
|
||||
|
||||
这段程序写得非常明白直接。首先,我们检查n是否为负;如果是负数,就打印出一个负号,然后让 n 反号,即 -n。接着,我们检查n是否大于等于 10;如果是的,那么 n 的 10 进制表示要包含两个或两个以上数字,然后我们递归调用 printnum函数打印出 n 的 10 进制表示中除最后一位以外的所有数字。最后,我们打印出 n 的 10 进制表示中的末位数字。为了使*p 能够处理正确参数类型,这里把表达式 n%10 的类型转换为 int 类型。这一点在 ANSI C 标准中其实并不必要,之所以进行类型转换主要是为了避免某些人可能只是简单地改写一下 printnum 的函数头,就将程序移植到早期的C实现上。
|
||||
|
||||
这个程序尽管简单,却存在几个可移植性方面的问题。第一个问题出在该程序把 n 的 10 进制表示的末位数字转换为字符形式时所用的方法。通过 n%10 来得到末位数字的值,这一点没有什么问题;但是给它加上 0 来得到对应的字符表示却不一定合适。程序中的加法操作实际上假定了在机器的字符集中数字是顺序排列、没有间隔的,这样才有 '0' + 5 的值与 '5' 的值相同,依次类推。这种假定,对 ASCII 字符集和 EBCDIC 字符集是正确的,对符合 ANSI 的 C 实现也是正确的,但对某些机器却有可能出错。要避免这个问题,解决办法是使用一张代表数字的字符表。因为一个字符串常量可以用来表示一个字符数组,所以在数组名出现的地方都可以用字符串常量来替换。下面例子中 printnum 函数的这个表达式虽然有些令人吃惊,却是合法的:
|
||||
|
||||
```c
|
||||
"0123456789" [n % 10]
|
||||
```
|
||||
|
||||
我们把前面的程序进行如下改写,就解决了第一个可移植性问题:
|
||||
|
||||
```c
|
||||
void printnum(long n, void (*p)())
|
||||
{
|
||||
if(n < 0){
|
||||
(*p)('-');
|
||||
n = -n;
|
||||
}
|
||||
|
||||
if(n >= 10){
|
||||
printnum(n / 10, p);
|
||||
}
|
||||
|
||||
(*p)("0123456789"[n % 10]);
|
||||
}
|
||||
```
|
||||
|
||||
第二个问题与 n<0 时的情形有关。上面的程序首先打印出一个负号, 然后把 n 设置为 -n。这个赋值操作有可能发生溢出,因为基于 2 的补码的计算机一般允许表示的负数取值范围要大于正数的取值范围。具体来说,就是如果一个 long 型整数有 k 位以及一个符号位,该 long 型整数能够表示 -2^k 却不能表示 2^k。要解决这个问题,有好几种办法。最明显的一种办法是把 -n 赋给一个 unsigned long 型的变量,然后对这个变量进行操作。但是,我们不能对 -n 求值,因为这样做将引起溢出!无论是对基于 1 的补码还是基于 2 的补码 ( 1's complement and 2'scomplement) 的机器,改变一个正整数的符号都可以确保不会发生溢出。惟一的麻烦来自于当改变一个负数的符号的时候。因此,如果我们能够保证不将 n 转换为对应的正数,那么我们就能避免这一问题。
|
||||
|
||||
我们当然可以做到以同样的方式来处理正数和负数,只不过 n 为负数时需要打印出一个负号。要做到这一点,程序在打印负号之后强制 n 为负数,并且让所有的算术运算都是针对负数进行的。也就是说,我们必须保证打印负号的操作所对应的程序只被执行一次,最简单的办法就是把程序分解为两个函数。现在,printnum 函数只是检查 n 是否为负,如果是的就打印一个负号。无论 n 为正为负,printnum 函数都将调用 printne g函数,以 n 的绝对值的相反数为参数。这样, printneg 函数就满足了 n 总为负数或零的条件:
|
||||
|
||||
```c
|
||||
void printneg(long n, void (*p)())
|
||||
{
|
||||
if (n <= -10) {
|
||||
printneg(n / 10, p);
|
||||
}
|
||||
|
||||
(*p)("0123456789"[-(n % 10)]);
|
||||
}
|
||||
|
||||
|
||||
void printnum(long n, void (*p)())
|
||||
{
|
||||
if (n < 0) {
|
||||
(*p)('-');
|
||||
printneg(n, p);
|
||||
}
|
||||
else
|
||||
printneg(-n, p);
|
||||
}
|
||||
```
|
||||
|
||||
这样写还是有在可移植性方面的问题。我们曾经在程序中使用 n/10 和 n%10 来分别表示 n 的首位数字与末位数字,当然还需要适当改变符号。回忆一下, 本章前面提到了:当整数除法运算中的一个操作数为负时,它的行为表现与具体的实现有关。因此,当 n 为负数时,n%10 完全有可能是一个正数!此时,`-(n % 10)` 就是一个负数,`"0123456789"[-(n % 10)]`就不在数字数组之中。要解决这个问题,我们可以创建两个临时变量来分别保存商和余数。在除法运算完成之后,检查余数是否在合理的范围内:如果不是,则适当调整两个变量。printnum 函数不需要进行修改,需要改动的是 printneg 函数,因此下面我们只写出了printneg 函数:函数就满足了 n 总为负数或零的条件:
|
||||
|
||||
```c
|
||||
void printneg(long n, void (*p)())
|
||||
{
|
||||
long q;
|
||||
int r;
|
||||
|
||||
q = n / 10;
|
||||
r = n % 10;
|
||||
|
||||
if (r > 0) {
|
||||
r -= 10;
|
||||
q++;
|
||||
}
|
||||
|
||||
if (n <= 10)
|
||||
printneg(q, p);
|
||||
|
||||
(*p)("0123456789"[-r]);
|
||||
}
|
||||
```
|
||||
|
||||
我们为什么要如此不辞劳苦地精益求精地修改呢?因为我们所处的是一个编程环境不断改变的世界,尽管软件看上去不像硬件那么实在,但大多数软件的生命期却要长于它运行其上的硬件。而且,我们很难预言未来硬件的特性。因此,努力
|
||||
提高软件的可移植性,实际上是延长了软件的生命期。
|
||||
|
||||
可移植性强的软件比较不容易出错。本例中的代码改动看上去是提高软件的可移植性,实际上大多数工作是确保边界条件的正确,即保证当 printnum 函数的参数是可能取到的最小负数时,它仍然能够正常工作。
|
||||
|
||||
|
||||
|
||||
### 二 练习
|
||||
|
||||
#### 练习7-1
|
||||
本章第 3 节中说,如果一个机器的字符长度为 8 位,那么其整数长度很可能是 16 位或 32 位。请问原因是什么?
|
||||
|
||||
某些计算机为每个字符分配一个惟一的内存地址, 而另一些机器却是按字来对内存寻址。按字寻址的机器通常都存在不能有效处理字符数据的问题,因为要从内存中取得一个字符, 就必须读取整个字的内容,然后把不需要用到的部分都丢弃。
|
||||
|
||||
由于按字符寻址的机型在字符处理方面的效率优势,它们相对于按字寻址的机型,近年来要更为流行。然而,即使对于按字符寻址的机器,字的概念在进行整数运算的时候也仍然是重要的。因为字符在内存中的存储位置是连续的,所以一个字中包含的字符数,将决定在内存中连续存放的字的地址。
|
||||
|
||||
如果一个字中包含的字符数是 2 的某次幂,因为乘以 2 的某次幂的运算可以转换为移位运算,所以计算机硬件就能很容易地完成从字符地址到字地址的转换。因此,我们可以合理地预期,字的长度是字符长度的 2 的某次冪。
|
||||
|
||||
那么整数的长度为什么不是 64 位呢?当然,某些时候这样做无疑是有用的。但是,对于那些支持浮点运算的硬件的机器,这样做的意义就不大了;而且考虑:到我们并不经常需要用到 64 位整数这样的精度,实现 64 位整数的代价就过于昂贵。如果只是偶尔用到,我们完全可以用软件来仿真 64 位(或者更长)的整数,而且丝毫不影响效率。
|
||||
|
||||
#### 练习7-2
|
||||
|
||||
函数 `atol` 的作用是,接受一个指向以 null 结尾的字符串的指针作为参数,返回一个对应的 long 型整数值。假定:
|
||||
|
||||
- 作为输入参数的指针,指向的字符串总是代表一个 合法的 long 型整数值,因此 atol 函数无须检查该输入是否越界。
|
||||
- 惟一合法的输入字符是数字和正负号。输入字符串在遇到第一个非法字符时结束。
|
||||
|
||||
请写出atol函数的一个可移植版本。
|
||||
|
||||
我们不妨假定在机器的排序序列中,数字是连续排列的:任何一种现代计算机都是这样实现的,而且 ANSI C 标准中也是这样要求的。因此,我们面临的主要问题就是避免中间结果发生溢出,即使最终的结果在取值范围之内也是如此。
|
||||
|
||||
正如 printum 函数中的情形,如果 long 型负数的最小可能取值与正数的最大可能取值并不相匹配,问题就变得棘手了。特别地,如果我们首先把一个值作为正数处理,然后再使它为负,对于负数的最大可能取值的情况,在很多机器上都会发生溢出。
|
||||
|
||||
下面这个版本的 atol 函数,只使用负数(和零)来得到函数的结果,从而避免了溢出:
|
||||
|
||||
```c
|
||||
long atol(char* str) {
|
||||
|
||||
long l;
|
||||
int neg = 0;
|
||||
|
||||
switch (*str) {
|
||||
case '-':
|
||||
neg = 1;
|
||||
case '+':
|
||||
str++;
|
||||
break;
|
||||
}
|
||||
|
||||
while (*str >= '0' && *str <= '9') {
|
||||
int n = *str++ - '0';
|
||||
if (neg) {
|
||||
n = -n;
|
||||
}
|
||||
l = l * 10 + n;
|
||||
}
|
||||
|
||||
return l;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**参考资料**:*《C 缺陷与陷阱》*
|
||||
|
||||
106
content/c-traps-and-pitfalls/08 建议.md
Normal file
106
content/c-traps-and-pitfalls/08 建议.md
Normal file
@@ -0,0 +1,106 @@
|
||||
## 【C 陷阱与缺陷】(八)建议
|
||||
|
||||
|
||||
|
||||
#### 1. 不要说服自己相信“皇帝的新装”
|
||||
|
||||
有的错误极具伪装性和欺骗性。比如,第一章原来的例子是这样写的:
|
||||
|
||||
```c
|
||||
while (c == '\t' || c = ' ' || c == '\n')
|
||||
c = getc(f) ;
|
||||
```
|
||||
|
||||
如上,这个例子在 C 语言中是非法的。因为赋值运算符 = 的优先级比 while 子句中其他运算符的优先级都要低,因此上例可以这样解释:
|
||||
|
||||
```c
|
||||
while ( (c == '\t' || c) = (' ' || c == '\n') )
|
||||
c = getc(f) ;
|
||||
```
|
||||
|
||||
当然,这是非法的:
|
||||
|
||||
`(c == '\t' || c)`不能出现在赋值运算的左侧。
|
||||
|
||||
|
||||
|
||||
#### 2. 直截了当地表明意图
|
||||
|
||||
当你编写代码的本意是希望表达某个意思,但这些代码有可能被误解为另一种意思时,请使用括号或者其他方式让你的意图尽可能清楚明了。这样做不仅有助于你日后重读程序时能够更好地理解自己的用意,也方便了其他程序员日后维护你的代码。
|
||||
|
||||
有时候我们还应该预料哪些错误有可能出现,在代码的编写方式上做到事先预防,一旦错误真正发生能够马上捕获。例如,有的程序员把常量放在判断相等的比较表达式的左侧。换言之,不是按照习惯的写法:
|
||||
|
||||
```c
|
||||
while (c == '\t' || c == ' '|| c == '\n')
|
||||
c = getc(f) ;
|
||||
```
|
||||
|
||||
而是写作:
|
||||
|
||||
```c
|
||||
while('\t' == c || ' ' == c || '\n' == c)
|
||||
c = getc(f) ;
|
||||
```
|
||||
|
||||
这样,如果程序员不小心把比较运算符 `==` 写成了赋值运算符 `=`,编译器将会捕获到这种错误,并给出一条编译器诊断信息:
|
||||
|
||||
```c
|
||||
while('\t'= c || ' ' == c || '\n' == c)
|
||||
c = getc(f) ;
|
||||
```
|
||||
|
||||
上面的代码试图给字符常量 `'\t'` 赋值,因而是非法的。
|
||||
|
||||
|
||||
|
||||
#### 3. 考查最简单的特例
|
||||
|
||||
无论是构思程序的工作方式,还是测试程序的工作情况,这一原则都是适用的。当部分输入数据为空或者只有一个元素时,很多程序都会执行失败,其实这些情况应该是一早就应该考虑到的。这一原则还适用于程序的设计。在设计程序时,我们可以首先考虑一组输入数据全为空的情形,从最简单的特例获得启发。
|
||||
|
||||
#### 4. 使用不对称边界
|
||||
|
||||
本系列第三章节关于如何表示取值范围的讨论,值得一读再读。C 语言中数组下标取值从 0 开始,各种计数错误的产生与这一点或多或少有关系。
|
||||
|
||||
我们一旦理解了这个事实,处理这些计数错误就变得不那么困难了。
|
||||
|
||||
#### 5. 注意潜伏在暗处的Bug
|
||||
|
||||
各种C语言实现之间,都存在着或多或少的细微差别。我们应该坚持只使用C语言中众所周知的部分,而避免使用那些“生僻”的语言特性。这样做,我们能够很方便地将程序移植到一个新的机器或编译器,而且“遭遇”到编译器Bug的可能性也会大大降低。
|
||||
|
||||
#### 6. 防御性编程
|
||||
|
||||
对程序用户和编译器的假设不要太多!
|
||||
|
||||
如果 C 编译器能够捕获到更多的编程错误,这当然不错。不幸的是,因为几方面的原因,要做到这一点很困难。最重要的原因也许是历史因素:长期以来,人们惯于用C语言来完成以前用汇编语言做的工作。因此,许多C程序中总有这样的部分,刻意去做那些严格说来在 C 语言所允许范围以外的工作。最明显的例子就是类似操作系统的东西。这样,一个C编译器要做到严格检测程序中的各种错误,就要对程序中本意是可移植的部分做到严格检测,同时对程序中那些需要完成与特定机器相关工作的部分网开一面。
|
||||
|
||||
另一个原因是,某些类型的错误从本质上说是难于检测的。考虑下面的函数:
|
||||
|
||||
```c
|
||||
void set(int *p, int n) {
|
||||
*p = n;
|
||||
```
|
||||
|
||||
这个函数是合法还是非法?离开一定的上下文,我们当然不可能知道答案。
|
||||
|
||||
如果像下面的代码一样调用这个函数:
|
||||
|
||||
```c
|
||||
int a[10];
|
||||
set (a+5,37) ;
|
||||
```
|
||||
|
||||
这当然是合法的,但如果这样来调用 set 函数:
|
||||
|
||||
```c
|
||||
int a[10] ;
|
||||
set (a+10,37) ;
|
||||
```
|
||||
|
||||
上面的代码就是非法的了。ANSI C 标准允许程序得到数组尾端出界的第一个位置的地址,因此上面的后一个代码段从它本身来说并没有什么错误。C编译器要想捕获到这样的错误,就必须非常地“聪明”。
|
||||
|
||||
|
||||
|
||||
**参考资料**:*《C 缺陷与陷阱》*
|
||||
|
||||
|
||||
|
||||
0
content/other/Q&A.md
Normal file
0
content/other/Q&A.md
Normal file
Reference in New Issue
Block a user