mirror of
https://github.com/hairrrrr/C-CrashCourse.git
synced 2026-06-28 09:36:27 +08:00
add
This commit is contained in:
142
content/c-games/猜数字.md
Normal file
142
content/c-games/猜数字.md
Normal file
@@ -0,0 +1,142 @@
|
||||
# C语言——猜数字小游戏
|
||||
|
||||
## 如何用rand,srand,time来完成随机数发生
|
||||
|
||||
------
|
||||
|
||||
这是这款小游戏的简单玩法。期待着与你一同完善,改进这个小游戏!
|
||||
|
||||
------
|
||||
|
||||
接下来我们看一下如何来实现这样一个游戏。
|
||||
纵观这个游戏,我们发现,这个游戏的难点其实就是**如何生成一个随机数**。
|
||||
生成随机数我们这里用到了三个个函数分别是:
|
||||
|
||||
- `rand()`
|
||||
- `srand()`
|
||||
- `time()`
|
||||
|
||||
由于生成随机数是我们这个游戏的核心,我们把这三个函数在这里细讲一下
|
||||
|
||||
------
|
||||
|
||||
> **`int rand()`**
|
||||
> **头文件**:stdlib.h
|
||||
> **定义**:srand() 播种 rand() 所用的伪随机数生成器。若在任何对 srand() 的调用前使用 rand() ,则 rand() 表现如同它以 srand(1) 播种。每次以 srand() 播种 rand() 时,它必须产生相同的值数列。
|
||||
> **返回值**:返回 0 与 RAND_MAX 间的随机整数值(包含 0 与 RAND_MAX )。
|
||||
> **`void srand( unsigned seed )`**
|
||||
> **头文件**:stdlib.h
|
||||
> **定义**:以值 seed 播种 rand() 所用的随机数生成器。若在任何到 srand() 的调用前使用 rand() ,则 rand() 表现为如同它被以 srand(1) 播种。每次以同一 seed 播种 rand() 时,它必须产生相同的值数列。
|
||||
> **返回值**:无
|
||||
|
||||
是不是听了之后很懵逼?没关系,请看下面的例子
|
||||
|
||||
```
|
||||
//大家可以用自己的编译器反复运行下面的代码,可以发现,每次产生的五个数都是一样的。
|
||||
#include<stdio.h>
|
||||
#include<stdlib.h>
|
||||
int main() {
|
||||
int x = 0;
|
||||
int test = 5;
|
||||
int i = 0;
|
||||
i = test;
|
||||
//srand(1);//不写srand函数是默认srand内参数为1
|
||||
while (i--) {
|
||||
x = rand()%10 + 1;
|
||||
printf("%d ", x);
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
```
|
||||
//这时候我们调用srand函数并且改变参数,再次观察产生的随机序列,会发现这次的五个数和之前的不同了
|
||||
#include<stdio.h>
|
||||
#include<stdlib.h>
|
||||
int main() {
|
||||
int x = 0;
|
||||
int test = 5;
|
||||
int i = 0;
|
||||
i = test;
|
||||
srand(2);
|
||||
while (i--) {
|
||||
x = rand() % 10 + 1;
|
||||
printf("%d ", x);
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
//这就说明了srand内的参数可以让rand函数产生不同的序列,但是这些序列并不是随机的。
|
||||
//如果我们要产生随机数,就必须不断改变srand函数内的参数,这时我们就需要引入time函数。
|
||||
```
|
||||
|
||||

|
||||
|
||||
> **`time_t time( time_t \*arg )`**
|
||||
> **头文件**:time.h
|
||||
> **定义**:返回编码成 time_t 对象的当前日历时间,并将其存储于 arg 指向的 time_t 对象(除非 arg 为空指针)
|
||||
> **参数**:arg - 指向将存储时间的 time_t 对象的指针,或空指针
|
||||
> **返回值**:成功时返回编码成 time_t 对象的当前日历时间。错误时返回 (time_t)(-1) 。若arg不是空指针,则返回值也会存储于 arg 所指向的对象。
|
||||
>
|
||||
> ------
|
||||
>
|
||||
> 需要注意的是,在我的32位的vs2019编译器上,time_t的类型是long long
|
||||
|
||||
对于time的用法请看下例
|
||||
|
||||
```
|
||||
#include<stdio.h>
|
||||
#include<stdlib.h>
|
||||
#include<time.h>
|
||||
int main() {
|
||||
time_t t1, t2;
|
||||
t1 = time(NULL);//传入空指针,需要用t1接收返回的时间
|
||||
time(&t2);//传入指针,当前的时间戳写入t2
|
||||
printf("%lld\n",t1);
|
||||
printf("%lld\n",t2);
|
||||
}
|
||||
//两个printf输出的数相同
|
||||
```
|
||||
|
||||

|
||||
|
||||
------
|
||||
|
||||
**综上所述,我们把time函数返回的随时变化的时间戳(从1970年1月1日至今)当作srand函数的参数,这样就可以让rand每次产生的数列都是不同的,随机的**
|
||||
**切记要在使用rand函数前先调用srand函数哦!**
|
||||
|
||||
------
|
||||
|
||||
它们组合起来怎么写呢?我们可以这么来写:
|
||||
|
||||
```
|
||||
#include<stdio.h>
|
||||
#include<stdlib.h>
|
||||
#include<time.h>
|
||||
int main() {
|
||||
srand((unsigned)time(NULL));//关注一下srand函数的参数类型
|
||||
int i = 0;
|
||||
int random = 0;
|
||||
for (; i < 5; i++) {
|
||||
random = rand();
|
||||
printf("%d ", random);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
------
|
||||
|
||||
想必大家看到了我的程序还有一个让你选择猜数范围的功能,那么它又是怎么实现的呢?
|
||||
其实也很简单,核心就是**求余**
|
||||
假如你想猜数的范围是1~10
|
||||
rand函数产生数是随机数,用 `rand() % 10` 得到的范围是 0~9 那就再给它加上1就好了,其他范围都是这个道理
|
||||
|
||||
------
|
||||
|
||||
|
||||
|
||||
[猜数字游戏完整源代码](https://github.com/hairrrrr/project/tree/master/C games/guessing-number)
|
||||
|
||||
250
content/c-notes/5分钟看懂什么是 malloc.md
Normal file
250
content/c-notes/5分钟看懂什么是 malloc.md
Normal file
@@ -0,0 +1,250 @@
|
||||
|
||||
|
||||
# 初识 动态内存分配
|
||||
### 动态内存分配的引入
|
||||
初学数组的时候,有一个问题经常困扰着我,就是:我们可不可以**自己在程序里定义一个数组的大小**而不是在函数开头先声明一个很大的数组,然后仅仅使用它的一小部分?
|
||||
|
||||
请看下面的程序:
|
||||
我们需要一个大小为 N ( N < 1000)的数组,我们通常这么写:
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
int arr[1000] = { 0 };
|
||||
int N = 0;
|
||||
int i = 0;
|
||||
|
||||
printf("请输入数组的大小\n");
|
||||
scanf("%d", &N);
|
||||
|
||||
printf("请输入%d个数\n", N);
|
||||
for (i = 0; i < N; i++)
|
||||
scanf("%d", &arr[i]);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
每次这么写我都觉得自己在绕远路,为什么就不能直接把输入的变量 N 当作数组的大小直接使用?
|
||||
比如这样:`arr[N]`,但是很遗憾,每次编译器都把你扼杀在程序编译之前!
|
||||

|
||||
>C99才可以用变量做数组定义的大小
|
||||
>并且可以在程序中随时声明变量。(C99前我们需要在函数的最前面的区域对所有变量进行声明)
|
||||
|
||||
如果我不想用上面那种笨笨的办法,又没有支持C99的编译器,我该怎么办?
|
||||
|
||||
可以这么做:
|
||||
`int* arr = (int*)malloc(sizeof(int) * N)`
|
||||
|
||||
`sizeof(int)` 代表数组中每个元素的类型
|
||||
`N` 代表数组的元素个数
|
||||
|
||||
所以malloc的意义是向 堆区 要了一块`sizeof(int) * N` 这么大的空间
|
||||
|
||||
### malloc 与 free ——好哥俩
|
||||
#### malloc
|
||||
>**头文件**:`stdlib`
|
||||
>**原型**:`void* malloc(size_t size)`
|
||||
>所以需要根据实际你需要的类型对其强制类型转换
|
||||
>**返回值**:
|
||||
>成功时,返回指向新分配内存的指针。为避免内存泄漏,必须用 free() 或 realloc() 解分配返回的指针。
|
||||
>失败时,返回空指针(NULL)
|
||||
>**参数**:size - 要分配的字节数
|
||||
>***
|
||||
>**定义**
|
||||
>分配 size 字节的未初始化内存。
|
||||
>若分配成功,则返回为任何拥有基础对齐的对象类型对齐的指针。
|
||||
> ——
|
||||
>若 size 为零,则 malloc 的行为是实现定义的。例如可返回空指针。亦可返回非空指针;但不应当解引用这种指针,而且应将它传递给 free 以避免内存泄漏。
|
||||
>[更多关于malloc](https://zh.cppreference.com/w/c/memory/malloc)
|
||||
|
||||
|
||||
#### free
|
||||
>**头文件**:`stdlib`
|
||||
>**原型**:`void free( void* ptr );`
|
||||
>**参数**:指向要解分配的内存的指针
|
||||
>**返回值**:无
|
||||
>**此函数接收空指针(并对其不处理)以减少特例的数量。不管分配成功与否,分配函数返回的指针都能传递给 free()**
|
||||
>——
|
||||
>这是什么意思?意思就是malloc与free成对出现,不要忘记写free哦。
|
||||
>***
|
||||
>定义:
|
||||
>解分配之前由 malloc() 、 calloc() 、 aligned_alloc (C11 起) 或 realloc() 分配的空间。
|
||||
>——
|
||||
>**若 ptr 为空指针,则函数不进行操作**。[^1]
|
||||
>——
|
||||
>**若 ptr 的值 不等于之前从 malloc() 、 calloc() 、 realloc() 或 aligned_alloc() (C11 起) 返回的值**[^2],则行为未定义。
|
||||
>——
|
||||
>**若 ptr 所指代的内存区域已经被解分配[^3]**,则行为未定义,即是说已经以ptr 为参数调用 free() 或 realloc() ,而且没有后继的 malloc() 、 calloc() 或 realloc() 调用以 ptr 为结果。
|
||||
>——
|
||||
>**若在 free() 返回后通过指针 ptr 访问内存[^4]**,则行为未定义(除非另一个分配函数恰好返回等于 ptr 的值)。
|
||||
>[更多关于free](https://zh.cppreference.com/w/c/memory/free)
|
||||
|
||||
|
||||
**free()**:将申请来的空间的 **首地址** 还给“系统”,只要申请到了空间就**一定要归还**
|
||||
|
||||
毕竟有借有还,再借不难嘛
|
||||
<br/>
|
||||
#### 解读 free
|
||||
|
||||
注释1:释放空指针有何意义?
|
||||
>我们在声明一个指针时,一般把它初始化为0,也就是NULL。
|
||||
>——
|
||||
>这样做的好处是,如果我们在后面的程序中没有让这个指针指向一块具体的空间,这个指针不会是野指针,方便我们用来判断。比如`if(p != NULL)`
|
||||
>——
|
||||
>我们还知道,当malloc失败时返回的是 NULL
|
||||
>所以我们一开始写上free是好习惯,因为我们不知道我们会不会用到我们声明的指针,也不知道malloc能不能成功
|
||||
>这时候,free空指针就是有意义的了
|
||||
|
||||
注释2:molloc申请到的指针 与 free要释放的指针保持一致
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main() {
|
||||
|
||||
int* p;
|
||||
|
||||
p = (int*)malloc(100 * 1024);
|
||||
|
||||
p++; //改变了 p 的首地址;
|
||||
|
||||
free(p);//free 没有得到 malloc时 分配给p的首地址,程序崩溃
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
注释3:free释放空间后,被释放的指针成为野指针,不能直接使用它
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main() {
|
||||
|
||||
int* p;
|
||||
|
||||
p = (int*)malloc(100 * 1024);
|
||||
|
||||
p++;
|
||||
|
||||
free(p);
|
||||
p++;//free 释放后 p 成为了野指针,程序崩溃
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
注释4:不能多次释放同一次malloc申请的地址
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
int main() {
|
||||
|
||||
int* p;
|
||||
|
||||
p = (int*)malloc(100 * 1024);
|
||||
|
||||
p++;
|
||||
|
||||
free(p);
|
||||
free(p);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
<br/>
|
||||
|
||||
**现在我们就可以改进我们上面的程序啦!**
|
||||
```c
|
||||
#include<stdlib.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
int i = 0;
|
||||
int N = 0;
|
||||
int* arr;
|
||||
|
||||
printf("请输入数组的大小\n");
|
||||
scanf("%d", &N);
|
||||
|
||||
arr = (int*)malloc(sizeof(int) * N);
|
||||
|
||||
printf("请输入%d个数\n", N);
|
||||
for (i = 0; i < N; i++)
|
||||
scanf("%d", &arr[i]);
|
||||
|
||||
free(arr);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
<br/>
|
||||
|
||||
什么?不是改进吗?怎么行数反而变多了?
|
||||

|
||||
|
||||
|
||||
#### 测测你能给系统分配多大空间?
|
||||
```c
|
||||
#include<stdlib.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
void* p;
|
||||
int i = 0;
|
||||
|
||||
//每次申请100M,失败返回空指针0,退出循环
|
||||
while ((p = malloc(1024 * 1024 * 100)))
|
||||
i++;
|
||||
|
||||
printf("最多分配%d00M内存", i);
|
||||
|
||||
return 0;
|
||||
|
||||
}
|
||||
```
|
||||
#### 如果忘记了free?
|
||||
我们一次程序中可以申请的内存是有限的。
|
||||
|
||||
如果你只是平时写简单的程序,写完就关闭,退出去了,这时忘记了free的话,不会对任何人造成影响,因为操作系统有清除曾使用的内存的机制
|
||||
|
||||
但是如果是一个持续运行的服务器呢?堆区中所有的空间都被你申请了呢?
|
||||
|
||||
###### free的常见问题
|
||||
>- 申请了没有free -> 长时间运行内存逐渐下降
|
||||
>- free 后再free
|
||||
>- 地址变更后,直接去free
|
||||
|
||||
***
|
||||
###### 小测试:
|
||||
1.对于以下的代码段,正确的说法是:
|
||||
```c
|
||||
char *p;
|
||||
while(1){
|
||||
p = malloc(1);
|
||||
*p = 0;
|
||||
}
|
||||
```
|
||||
A:最终程序会因为没有空间了而退出
|
||||
B:最终程序会因为向0地址写入而退出
|
||||
C:程序会一直运行下去
|
||||
D:程序不能被编译
|
||||
|
||||
2.对于以下代码段:
|
||||
```c
|
||||
int a[] = {1, 2, 3, 4, 5};
|
||||
int *p = a;
|
||||
int *q = &a[5];
|
||||
printf("%d",q-p);
|
||||
```
|
||||
当 `sizeof(int) = 4`时,以下说法正确的是:
|
||||
A:因为第三行的错误不能编译
|
||||
B:因为第三行的的错误运行时崩溃
|
||||
C:输出5
|
||||
D:输出20
|
||||
|
||||
3.使用malloc就可以做出运行时可以随时改变大小的数组
|
||||
A:√
|
||||
B:❌
|
||||
|
||||
查看答案可在后台回复:**2020 0204**查看答案哦
|
||||
***
|
||||
欢迎各位与我交流讨论!
|
||||
173
content/c-notes/C 语言还值得学习吗?C 语言会过时吗?C 语言解惑.md
Normal file
173
content/c-notes/C 语言还值得学习吗?C 语言会过时吗?C 语言解惑.md
Normal file
@@ -0,0 +1,173 @@
|
||||
### C 语言还值得学吗?
|
||||
|
||||
答案是肯定的。
|
||||
|
||||
第一,学习C有助于更好的理解C++,Java,C#,Perl以及其他基于C的特性的语言。第一开始就学习其他语言的程序员往往不能很好的掌握继承自C语言的基本特性。
|
||||
|
||||
第二,目前仍有许多C程序,我们需要读懂并维护这些代码。
|
||||
|
||||
第三,C语言仍广泛应用于新软件的开发,特别是在内存或处理能力受限的情况下以及需要使用C语言简单特性的地方。
|
||||
|
||||
### C 语言会过时吗?
|
||||
|
||||
> 对所有的编程语言,他们的最后的目的其实就是两种:**提高硬件的运行效率和提高程序员的开发效率**。遗憾的是,这两点是不可能并存的!你只能选一样。在提高硬件的运行效率这一方面,C语言没有竞争者!举个简单的例子,实现一个列表,C语言用数组int a[3],经过编译以后变成了(基地址+偏移量)的方式。对于计算机来说,没有运算比加法更快,没有任何一种方法比(基地址+偏移量)的存取方法更快。C语言已经把硬件的运行效率压缩到了极致。这种设计思想带来的问题就是易用性和安全性的缺失。例如,你不能在数组中混合保存不同的类型,否则编译器没有办法计算正确的偏移量。同时C语言对于错误的偏移量也不闻不问,这就是C语言中臭名昭著的越界问题。C语言自诩的“相信程序员”都是漂亮的说辞,它的唯一目的就是快,要么飞速的运行,要么飞速的崩溃。C语言只关心程序飞的高不高,不关心程序猿飞的累不累。就是这样!
|
||||
|
||||
|
||||
|
||||
>伴随着嵌入和实时系统的兴起,AI,机器人,自动驾驶等。这些都是C语言的核心应用,而且在这种应用上面,C语言没有竞争者。所以我感觉C语言会稳定在自己核心的应用中,并开始逐步回升。但是Java语言我个人不乐观。小型和灵活性上,Python更胜一筹。一行python代码后,你根本不知道自己还是不是duck类型?平台领域,每个平台都推出自己专属的语言。Windows会继续支持C#,苹果偏爱Swift, Android推出Kotlin,Google用go。Java宣称自己可以自由到每家做客,但是无论是到谁家,都会发现客厅里面坐着一个亲儿子,这个时候自己这个干儿子多多少少有点尴尬。所以我猜测,最后Java会稳定在对跨平台有严格要求的,大型非实时应用上。
|
||||
|
||||
> 最后说点闲话,C++不会淘汰C语言。有了对象后你会发现再简朴的对象也耗费资源,而且有了对象以后,总是不由自主的去想继承这个事,一但继承实现了,你会发现继承带来的麻烦远超过你的想象。Java的发明人James被问到如果可以从新设计Java语言的话,第一个要做什么事?他说:“去掉对象”!作为一个已婚,有两个孩子的程序猿,我感同身受。如果大家感兴趣,我可以再写一个博客,聊聊C++和C的真实区别所在。
|
||||
|
||||
> 如果你看到这里,还什么都没记住。那就只记住一点:没人能预测未来。
|
||||
> --------------------------
|
||||
> 全世界只需要五台电脑 -IBM创始人
|
||||
> 640K内存足够了 -微软创始人
|
||||
> 没必要在家里用电脑-DEC创始人
|
||||
> --------------------------
|
||||
> 如果再有人对你说C语言已经过时了,最好自己思考一下,能求真最好,如果不能,至少要做到存疑。
|
||||
|
||||
### C 语言的前世今生
|
||||
|
||||
#### 1. 起源
|
||||
|
||||
C语言是贝尔实验室的 Ken Thompson, Dennis Ritchie 等人开发的 UNIX 操作系统的“副产品”。
|
||||
|
||||
与同时代的其他操作系统一样,UNIX 系统最初也是用汇编语言写的。用汇编语言编写的程序往往难以调试和改进,UNIX 操作系统也不例外。Thompson 意识到需要用一种高级的编程语言来完成 UNIX 系统未来的开发,于是他设计了一种小型的 B语言。Thompson 的 B语言是在 BCPL语言(20世纪60年代中期产生的一种系统编程语言)的基础上开发的,而 BCPL语言又可以追溯到最早(且影响深远)的语言之一——Algol 60语言。
|
||||
|
||||
1970年,贝尔实验室为 UNIX 项目争取到了一台 PDP-11 计算机。当 B语言经过改进并能够在 PDP-11 计算机上成功运行后,Thompson 用 B语言重新编写了部分 UNIX 代码。
|
||||
|
||||
到了1971年,B语言已经明显不适合 PDP-11 计算机了,于是 Ritchie 着手开发 B语言的升级版。最初他将新开发的语言命名为 NB语言(意味New B),但是后来新语言越来越偏离 B语言,于是他将其改名为 C语言。
|
||||
|
||||
到1973年,C语言已经足够稳定,可以用来重新编写 UNIX 系统了。
|
||||
|
||||
#### 2. 标准化
|
||||
|
||||
C语言在20世纪七十年代(尤其是1977年到1979)持续发展。这一时期出现了第一本有关 C语言的书。Brian Kernighan 和 Dennis Ritchie 合作编写的 *The C Programming Language* 于1978年出版,并迅速成为 C程序员必读的“圣经”。由于当时没有 C语言的正式标准,这本书就成为了事实上的标准,编程爱好者把它称为“K&R”或者“白皮书”。
|
||||
|
||||
随着C语言的迅速普及,一系列问题也接踵而至。首先, K&R 对一些语言特性描述得非常模糊,以至于不同编译器对这些特性会做出不同的处理。而且,K&R 也没有对属于 C语言的特性和属于 UNIX 系统的的特性进行明确的区分。更糟糕的是,K&R 出版后 C语言仍然在不断变化,增加了一些新特性并除去了一些旧特性。很快,C语言需要一个全面,准确的最新描述开始成为共识。
|
||||
|
||||
##### C89/C90
|
||||
|
||||
1983年,在美国国家标准协会(ANSI)的推动下(ANSI 于此年组建了一个委员会称为 X3Jll),美国开始制定本国的 C语言标准。
|
||||
|
||||
1988年完成并于1989年12月正式通过的 C语言标准成为 ANSI 标准 X3.159-1989。
|
||||
|
||||
1990年,国际标准化组织(ISO)通过了此项标准,将其作为 ISO/IEC 9899:1990 国际标准(中国国家标准为 GB/T 15272—1994)。
|
||||
|
||||
我们把这一C语言版本称为 **C89** 或 **C90**,以区别原始的 C语言版本。
|
||||
|
||||
委员会在制定的指导原则中的一条写道:保持 C 的精神。委员会在描述这一精神时列出了一下几点:
|
||||
|
||||
- 信任程序员
|
||||
- 不要妨碍程序员做需要做的事
|
||||
- 保持语言精炼简单
|
||||
- 只提供一种方法执行一项操作
|
||||
- 让程序运行更快,即使不能保持其可移植性
|
||||
|
||||
在最后一点上,标准委员会的用意是:作为实现,应该针对目标计算机来定义最合适的某特定操作,而不是强加一个抽象,统一的定义。在学习 C语言的过程中,许多方面都反映了这一哲学思想。
|
||||
|
||||
##### C99
|
||||
|
||||
1995 年,C语言发生了一些改变。
|
||||
|
||||
1999年通过的 ISO/IEC 9899:1999 新标准中包含了一些更重要的改变,这一标准所描述的语言通常称为 **C99**
|
||||
|
||||
此次改变,委员会的用意不是在C语言中添加新的特性,而是为了达到新的目标。
|
||||
|
||||
1. **支持国际化编程**。如:提供多种方法处理国际字符集
|
||||
2. **调整现有实践致力于解决明显的缺陷**。因此,在遇到需要将 C移至64位处理器时,委员会根据现实生活中处理问题的经验来添加标准。
|
||||
3. 为**适应科学和工程项目中的关键计算**,提高 C 的适应性,让 C 比 FORTRAN 更有竞争力。
|
||||
|
||||
其他方面的改变则更为保守,如,尽量让C90,C++兼容,让语言在概念上保持简单。
|
||||
|
||||
虽然改标准已经发布了很长时间,但**并非所有编译器都完全支持C99**的所有改动。因此,你有可能发现 C99 的一些改动在自己的系统中不可用,或者需要改变编译器的设置才可用。
|
||||
|
||||
##### C11
|
||||
|
||||
2011年,**C11**标准问世。
|
||||
|
||||
|
||||
|
||||
### 那些基于 C 的语言,你知道吗?
|
||||
|
||||
- C++:包含所有C的特性
|
||||
- Java:基于C++,所以也继承了C的许多特性
|
||||
- C#:由C++于java发展起来的较新的语言
|
||||
- Perl:最初是一种简单的脚本语言,在发展过程中采用了C的许多特性
|
||||
- Python
|
||||
- ...
|
||||
|
||||
|
||||
|
||||
### C 语言的优缺点
|
||||
|
||||
与其他任何一种编程语言一样,C语言也有自己的优缺点。这些优缺点都源于该语言的最初用途(编写操作系统和其它系统软件)和它自身的基础理论体系。
|
||||
|
||||
- **C语言是一种底层语言** 为了适应系统编程的需要,C语言提供了对机器级概念(例如,字节和地址)的访问,而这些都是其他编程语言试图隐藏的内容。
|
||||
- **C语言是一种小型语言** 与许多其他编程语言相比,C语言提供了一套更有限特性集合。(在K&R第二版的参考手册中仅用49页就描述了整个C语言。)为了使特性较少,C语言在很大程度上依赖一个标准函数的“库”。
|
||||
- **C是一种包容性语言** C假设用户知道自己在干什么,因此它提供了比其他许多语言更广阔的自由度。此外,C语言不像其他语言那样强制进行详细的错误检查。
|
||||
|
||||
#### 1. C语言的优点
|
||||
|
||||
C语言的众多优点解释了C语言为何如此流行。
|
||||
|
||||
- **高效** 高效性是C语言与生俱来的优点之一。发明C语言就是为了编写那些以往由汇编语言编写的程序,所以对C语言来说,能够在有限的内存空间快速运行就显得至关重要。
|
||||
|
||||
- **可移植** 当程序必须在多种机型(从个人计算机到超级计算机)上运行时,常常会用C语言来编写。
|
||||
|
||||
原因一:C语言没有分裂成不兼容的多种分支。这主要归功于C语言早期与UNIX系统的结合以及后来的ANSI/ISO标准。
|
||||
|
||||
原因二:C语言编译器规模小且容易编写,这使得它们得以广泛应用。
|
||||
|
||||
原因三:C语言的自身特性也支持可移植性(尽管它没有阻止程序员编写不可移植的程序)。
|
||||
|
||||
- **功能强大** C语言拥有一个庞大的数据类型和运算符集合,这个集合使得C语言具有强大的表达能力,往往寥寥几行代码就可以实现许多功能。
|
||||
|
||||
- **灵活** C语言最初设计是为了系统编程,但没有固有的约束将其限制在此范围内。C语言现在可以用于编写从嵌入式系统到商业数据处理的各种应用程序。
|
||||
|
||||
- **标准库** C语言的突出优点就是它具有标准库,该标准库包括了数百个可以用于输入/输出,字符串处理,储存分配以及其他实用操作的函数。
|
||||
|
||||
- **与UNIX的集成** C语言在与UNIX系统(包括Linux)结合方面特别强大。事实上,一些UNIX工具甚至假设用户是了解C语言的。
|
||||
|
||||
#### 2. C语言的缺点
|
||||
|
||||
- **C语言容易隐藏错误** C语言的灵活性使得用它编程出错的概率极高。在用其他语言时可以发现的错误,C语言的编译器却无法检查到。更糟糕的是,C语言还包含大量不易察觉的隐患。
|
||||
- **C程序可能难以理解** C程序的简明扼要与灵活性,可能导致程序员编写出除了自己别人无法读懂的代码。
|
||||
- **C程序可能难以修改** 如果在设计中没有考虑到维护的问题,那么C编写的大型程序可能很难修改。现代的编程语言通常提供“类”和“包”之类的语言特性,这样的特性可以把大的程序分解成许多更容易管理的模块。遗憾的是,C语言恰恰缺少这样的特性。
|
||||
|
||||
#### 3. 高效的使用C语言
|
||||
|
||||
要高效的使用C语言,就需要利用C语言优点的同时尽量避免它的缺点,一下给出一些建议。
|
||||
|
||||
- **学习如何规避C语言的缺陷**
|
||||
- **使用软件工具使程序更可靠**
|
||||
- **利用现有的代码库** 使用C语言的一个好处是其他许多人也在使用C。把别人编写好的代码用于自己的程序是一个非常好多主意。C代码通常被打包成库(函数的集合)。获取适当的库既可以大大减少错误,也可以节省很多编程工作。
|
||||
- **采用一套切合实际的编码规范** 良好的编码习惯和规范易于自己和他人对自己代码的阅读和修改。
|
||||
- **避免“投机取巧”和极度复杂的代码**。C语言鼓励使用编程技巧。但是,过犹不及,不要对技巧毫无节制,最简单的解决方案往往也是最难理解的。
|
||||
- **紧贴标准** 大多数编译器都提供不属于 C89/C99 标准的特征和库函数。为了程序的可移植性,若非确有必要,最好避免这些特性和库函数。
|
||||
|
||||
### 为什么 C 语言难学?
|
||||
|
||||
>不同与JAVA和python,C语言面临的任务几乎都是要求实时,高速或者是嵌入的。例如医疗,军事,飞控,航天,金融等领域。举个栗子,NASA大部分软件要基于三个不同的时钟系统,自转(公转)时间,CPU的晶振时间和原子钟时间。一秒要分成500份,基于2毫秒的基础进行操作同步;同时用全球的原子钟时间均值对所有时钟系统调整。在这种环境下,JAVA那种“大约一分钟以后”的虚拟机管理方式一定是不行的。 所以我在NASA工作所接触的软件,几乎都是C语言编写的。可想而之,这种软件的开发难度,当你阅读这种程序代码的时候,你说C语言太难了,这是否有点不公平?
|
||||
|
||||
> 其次是开发环境难。C语言一开始就和UNIX(LINUX)有不解之缘,它们是伴生的系统。所以要想发挥C语言的全部威力,最好的开发环境就是UNIX(LINUX)系统。但是问题来了,UNIX(LINUX)系统里的各种开发工具,每一个都不是省油的灯。它们设计的最初目的就是效率,而不是易学性。再举个栗子,gcc的各种编译开关就很复杂了,make系统为了解决gcc的部分问题,自己随之带来了更大的问题。git目的就是帮你保存历史备份,但是你会发现你经常会串改历史,或者干脆迷失在历史中。就连最简单的一个编辑器VIM,头一个月内,你最多的使用体验就是“恨不得拽自己的头发把自己提溜起来。”
|
||||
|
||||
> 好吧,外面的世界太凶险!让我们回到Windows妈妈哪里。虽然Windows的大部分内核都是C语言写的,但是它对C语言的支持缺最差。Why?如果你用Window的编译器去编译C语言,你会发现变量必须要写到函数的开头。它是唯一一个只支持到C89标准的编译器。Windows本身不想去抢这份实时,高速,嵌入的市场,老老实实做消费电子市场就好,这种市场要求开发容易,发布快。所以C#语言和后面的.Net平台才是它发展的重心。像玩LEGO那样的编程,你需要做的就是把一个个控件拽到窗口上,用鼠标来编程!所以还是算了吧,毕竟你也不想你在做飞机的时候,飞机上控制降落的电脑突然蓝屏了吧!所以如果你是一个C程序员,你唯一能做的就是在linux下使用哪些臭名昭彰的难学的工具。这笔账难到也要算到C语言的头上吗?
|
||||
|
||||
> 最后是底层难。这必须要要聊聊C语言两个最受诟病的特性,位操作和指针。这两个概念本身很简单。但是通过这两个概念,它把很多底层操作系统的知识和体系结构的知识都暴露了出来。指针指向地址后,马上引入了一大堆内存管理知识。什么是堆?什么是栈?这个地址在内存的那个区域?这个区域可以修改吗?这个区域自动回收吗?指针指向函数后,又引入了一堆操作系统知识,什么是回调函数啊?什么是事件驱动啊?以及位操作后面的二进制,溢出,浮点数精度等等一系列的问题。我用手指指向了一本《相对论》,然后就有人跑过来对我说,你这个手指头太难了!
|
||||
|
||||
> 如果编程只是你的业余爱好,使用那种语言真的无所谓。大部分初学者面临的任务规模下,三种语言的开发难度都差不多。 就是打个招呼,英语的“hello”,中文的“你好”,或者是日语的‘牙买碟’,我实在看不出这有什么难度上的区别。但是如果你立志要当一名高水准的程序员,C语言你是逃避不开的。或者编程序是你的饭碗,你也要认真考虑一下C语言。语言的易学性在就业上是一把双刃剑。如果一个公司招聘C程序员,你第一个反应就是他为什么不去招聘满大街的JAVA程序员?你面临的一定不是什么图书管理系统,也一定不是一个什么网站。想明白了这一点,就完全有理由要一个高价钱!
|
||||
|
||||
> C语言很难,要逃避这种难,却很难!C语言很简单,要理解这种简单,却不简单(文章排比对账,我只服自己!)
|
||||
|
||||
|
||||
|
||||
***
|
||||
|
||||
|
||||
|
||||
参考资料:
|
||||
|
||||
赵岩的博客(http://zhaoyan.website/blog)
|
||||
|
||||
《C 语言程序设计 —— 现代方法》
|
||||
106
content/c-notes/C语言 3 道面试题,不会还敢说你C学的好?带详解.md
Normal file
106
content/c-notes/C语言 3 道面试题,不会还敢说你C学的好?带详解.md
Normal file
@@ -0,0 +1,106 @@
|
||||
|
||||
|
||||
## 关于整数类型存储的面试问题
|
||||
|
||||
以下三个问题大家可以先独立思考一下,看看如果真的面试官问你,你能不能正确的回答并清晰的讲出其中的原理。
|
||||
|
||||
###
|
||||
|
||||
### 问题 1
|
||||
|
||||
请问,printf 函数会打印出什么内容?并解释原因。
|
||||
|
||||
```
|
||||
char a = -1;
|
||||
signed char b = -1;
|
||||
unsigned char c = -1;
|
||||
printf("a = %d, b = %d, c = %d\n", a, b, c);
|
||||
```
|
||||
|
||||

|
||||
|
||||
```
|
||||
a = -1, b = -1, c = 255
|
||||
```
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
signed char 与 char 表示同一种类型,原理一样
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
###
|
||||
|
||||
### 问题 2
|
||||
|
||||
请问,printf 函数会打印出什么内容?并解释原因。
|
||||
|
||||
```
|
||||
char a = -128; printf("%u\n", a);
|
||||
```
|
||||
|
||||

|
||||
|
||||
```
|
||||
4294967168
|
||||
```
|
||||
|
||||

|
||||
|
||||
你想到了吗?
|
||||
|
||||
|
||||
|
||||
我们还是按照上面的思路分析:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
###
|
||||
|
||||
### 问题 3
|
||||
|
||||
请问,printf 函数会打印出什么内容?并解释原因。
|
||||
|
||||
```
|
||||
char a = 128; printf("%u\n", a);
|
||||
```
|
||||
|
||||

|
||||
|
||||
```
|
||||
4294967168
|
||||
```
|
||||
|
||||

|
||||
|
||||
神奇吗?并不神奇。
|
||||
|
||||
原因就在于“截断”时得到的二进制序列是一模一样的,后面的操做是相同的。
|
||||
|
||||
另外说一句,char 的范围是 -128 ~ 127,所以上面的 char 型变量 a 溢出了。
|
||||
|
||||
|
||||
|
||||
试着想想下面的 printf 函数又会输出什么呢?
|
||||
|
||||
```
|
||||
unsigned char a = -128;
|
||||
unsigned char b = 128;
|
||||
printf("a = %u, b = %u\n", a, b);
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 推荐阅读:
|
||||
|
||||
[给你三个必须要学C语言的理由!](https://blog.csdn.net/qq_44954010/article/details/104334319)
|
||||
498
content/c-notes/C语言 文件 看这一篇就够了.md
Normal file
498
content/c-notes/C语言 文件 看这一篇就够了.md
Normal file
@@ -0,0 +1,498 @@
|
||||
**想看更好排版,可以看原文**
|
||||
[点击看原文](https://mp.weixin.qq.com/s/H1Yp5miEf8NP4HdP8OECqg)
|
||||
|
||||
|
||||
### 文件
|
||||
#### 格式化的输入输出
|
||||
> `printf`
|
||||
> % [flag] [width] [.prec] [hlL] type
|
||||
> `scanf`
|
||||
> % [flag] type
|
||||
|
||||
##### printf
|
||||
###### **flag 属性一般与 width 属性结合**
|
||||
| Flag | 含义 |
|
||||
| ---- | ------------ |
|
||||
| - | 左对齐 |
|
||||
| + | 在正数放 + |
|
||||
| 0 | 在前面填充 0 |
|
||||
|
||||
例1
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
printf("%9d\n", 123);
|
||||
printf("%-9d\n", 123);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
```
|
||||
123
|
||||
123
|
||||
```
|
||||
例2
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
printf("%+9d\n", 123);
|
||||
printf("%-9d\n", -123);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
```
|
||||
+123
|
||||
-123
|
||||
```
|
||||
**`+` 可以让正数打印出符号,负数的符号自动会打印出来**
|
||||
|
||||
例3
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
printf("%+09d\n", 123);
|
||||
printf("%-09d\n", -123);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
```
|
||||
+00000123
|
||||
-123
|
||||
```
|
||||
*有的编译器不允许 `- 0`*这样的语法,因为 `-` 已经表示左对齐了,`0` 就没有意义了
|
||||
|
||||
###### width.prec
|
||||
| width.prec | 含义 |
|
||||
| --------------- | ---------------------------------- |
|
||||
| number . number | 总共的输出占几位 . 小数点后占几位 |
|
||||
| `*.*` | 下一个参数是字符数或小数点后的位数 |
|
||||
|
||||
例1
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
printf("%9.2f\n", 12.3);
|
||||
printf("%8.4f\n", -12.3);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
```
|
||||
12.30
|
||||
-12.3000
|
||||
```
|
||||
例2:融合一下
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
printf("%+09.2f\n", 12.3);
|
||||
printf("%-8.3f\n", -12.3);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
```
|
||||
+00012.30
|
||||
-12.300
|
||||
```
|
||||
**小数点 `.` 也是占位数的**
|
||||
|
||||
例3:
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
int len = 5;
|
||||
int dec = 2;
|
||||
printf("%*.*f\n",5, 2, 12.3);
|
||||
printf("%*.*f\n",len, dec, 12.3);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
```
|
||||
12.30
|
||||
12.30
|
||||
```
|
||||
**给了我们用参数控制格式的途径,可以用变量来改变输出的格式**
|
||||
|
||||
###### hlL 格式
|
||||
| 修饰类型 | 含义 |
|
||||
| -------- | ----------- |
|
||||
| hh | 单个字节 |
|
||||
| h | short |
|
||||
| l | long |
|
||||
| ll | long long |
|
||||
| L | long double |
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
printf("%hhd\n", (char)12345);//当作 1 个字节输出(最低为作为 char 输出)
|
||||
printf("%hd\n", 12345);//当作 short 输出
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
12345 的 16 进制数是:3039
|
||||
39 的十进制是 57
|
||||
```
|
||||
57
|
||||
12345
|
||||
```
|
||||
##### 格式
|
||||
| type | 表示 | type | 表示 |
|
||||
| ---- | -------------- | ---- | --------------- |
|
||||
| i&d | int | g | float |
|
||||
| u | unsigned int | G | float |
|
||||
| o | 八进制 | a&A | 十六进制浮点 |
|
||||
| x | 十六进制 | c | char |
|
||||
| X | 大写的十六进制 | s | 字符串 |
|
||||
| f&F | float | p | 指针 |
|
||||
| e&E | 指数 | n | 读入/写出的个数 |
|
||||
|
||||
##### scanf :% [flag] type
|
||||
**flag 属性**
|
||||
| flag | 含义 |
|
||||
| ---- | ------------ |
|
||||
| * | 跳过 |
|
||||
| 数字 | 最大字符数 |
|
||||
| hh | char |
|
||||
| h | short |
|
||||
| l | long ,double |
|
||||
| ll | long long |
|
||||
| L | long double |
|
||||
|
||||
例:
|
||||
```c
|
||||
int main() {
|
||||
|
||||
int num;
|
||||
scanf("%*d %d", &num);
|
||||
printf("%d\n", num);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
程序输出如下:
|
||||
输入:123 456
|
||||
```c
|
||||
456
|
||||
```
|
||||
|
||||
**type属性**
|
||||
| type | 用于 |
|
||||
| ------- | ----------------------------- |
|
||||
| d | int |
|
||||
| i | 整数(10进制,8进制或16进制) |
|
||||
| u | unsigned int |
|
||||
| o | 八进制 |
|
||||
| x | 十六进制 |
|
||||
| a,e,f,g | float |
|
||||
| c | char |
|
||||
| s | 字符串 |
|
||||
| [...] | 允许的字符 |
|
||||
| p | 指针 |
|
||||
|
||||
#### printf 与 scanf 的返回值
|
||||
>`scanf`:读入的项目(item)数
|
||||
>`printf`: 输出的字符数
|
||||
|
||||
有什么用?
|
||||
**再由严格要求的程序中,应该判断每次调用 scanf 或 printf 的返回值,从而了解运行中的程序是否出现了问题**
|
||||
|
||||
例如:
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
int num = 0;
|
||||
int return_scanf = 0;
|
||||
int return_printf = 0;
|
||||
|
||||
return_scanf = scanf("%d", &num);
|
||||
return_printf = printf("%d\n", num);
|
||||
|
||||
printf("%d:%d\n", return_scanf, return_printf);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
```c
|
||||
//输入
|
||||
1234
|
||||
//输出
|
||||
1234
|
||||
1:5 //回车键要算进去
|
||||
```
|
||||
### 文件输入输出
|
||||
**< 与 > 来重定向**
|
||||
- `< `重定向输入
|
||||
- `>` 重定向输出
|
||||
|
||||
我们用 linux 操作系统为例:
|
||||
|
||||
|
||||
<div align = "center" font style = "font-size:100px" >
|
||||
<img src ="https://img-blog.csdnimg.cn/20200211220335414.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ0OTU0MDEw,size_16,color_FFFFFF,t_70" width = "600" height = "250" ></img>
|
||||
<p >1.写一个c文件并完成编译</p>
|
||||
</div>
|
||||
|
||||
<div align = "center" font style = "font-size:100px" >
|
||||
<img src ="https://img-blog.csdnimg.cn/20200211220423492.png" width = "600" height = "200" ></img>
|
||||
<p >2.这是标准的输入输出</p>
|
||||
</div>
|
||||
|
||||
<div align = "center" font style = "font-size:100px" >
|
||||
<img src ="https://img-blog.csdnimg.cn/20200211222935631.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ0OTU0MDEw,size_16,color_FFFFFF,t_70" width = "600" height = "200" ></img>
|
||||
<p >3.我们先创建一个文件 read.out,并写入 1234</p>
|
||||
</div>
|
||||
|
||||
<div align = "center" font style = "font-size:100px" >
|
||||
<img src ="https://img-blog.csdnimg.cn/20200211223231641.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ0OTU0MDEw,size_16,color_FFFFFF,t_70" width = "600" height = "200" ></img>
|
||||
<p >4.用 read.out 作为输入,向 write.out 中写入程序运行结果</p>
|
||||
</div>
|
||||
|
||||
###### 用程序打开文件
|
||||
#### fopen
|
||||
>`FILE *fopen( const char *filename, const char *mode )`;(C99 前)
|
||||
>`FILE *fopen( const char *restrict filename, const char *restrict mode )`;(C99 起)
|
||||
>**头文件**:stdio.h
|
||||
>**参数**:
|
||||
>filename - 关联到文件系统的文件名
|
||||
>mode - 确定访问模式的空终止字符串
|
||||
>**返回值**:
|
||||
>若成功,则返回指向新文件流的指针。流为完全缓冲,除非 filename 表示一个交互设备。错误时,返回空指针
|
||||
|
||||

|
||||
**简单理解**
|
||||
|
||||
| r | 打开只读 |
|
||||
| ---- | ------------------------------------------------------ |
|
||||
| r+ | 打开读写,从文件头开始 |
|
||||
| w | 打开只写。如果不存在则新建,如果存在就清空 |
|
||||
| w+ | 打开读写。如果不存在则新建,如果存在清空 |
|
||||
| a | 打开追加。如果不存在则新建,如果存在则从文件尾开始追加 |
|
||||
| x | 后附于上面。表示如果文件已存在则不能打开 |
|
||||
|
||||
#### fclose
|
||||
>`int fclose( FILE *stream )`
|
||||
>**头文件:**stdio.h
|
||||
>**参数:**
|
||||
>stream - 需要关闭的文件流
|
||||
>**返回值:**
|
||||
>成功时为 0 ,否则为 EOF 。
|
||||
>***
|
||||
>**定义:**
|
||||
>关闭给定的文件流。冲入任何未写入的缓冲数据到 OS 。舍弃任何未读取的缓冲数据。
|
||||
>
|
||||
>无论操作是否成功,流都不再关联到文件,且由 setbuf 或 setvbuf 分配的缓冲区若存在,则亦被解除关联,并且若使用自动分配则被解分配。
|
||||
>
|
||||
>若在 fclose 返回后使用指针 stream 的值则行为未定义。
|
||||
|
||||
#### scanf系
|
||||
>·`int scanf( const char *format, ... )`;(C99 前)
|
||||
>
|
||||
>`int scanf( const char *restrict format, ... )`;(C99 起)
|
||||
>(2)
|
||||
>`int fscanf( FILE *stream, const char *format, ... )`;(C99 前)
|
||||
>
|
||||
>`int fscanf( FILE *restrict stream, const char *restrict format, ... )`;(C99 起)
|
||||
>(3)
|
||||
>`int sscanf( const char *buffer, const char *format, ... )`;(C99 前)
|
||||
>
|
||||
>`int sscanf( const char *restrict buffer, const char *restrict format, ... )`;(C99 起)
|
||||
>**定义**
|
||||
>从各种资源读取数据,按照 format 转译,并将结果存储到指定位置。
|
||||
>
|
||||
>1) 从 stdin 读取数据
|
||||
>
|
||||
>2) 从文件流 stream 读取数据
|
||||
>
|
||||
>3) 从空终止字符串 buffer 读取数据。抵达字符串结尾等价于 fscanf 的抵达文件尾条件
|
||||
>
|
||||
>**参数:**
|
||||
>stream - 要读取的输入文件流
|
||||
>
|
||||
>buffer - 指向要读取的空终止字符串的指针
|
||||
>
|
||||
>format - 指向指定读取输入方式的空终止字符串的指针。
|
||||
>
|
||||
>**返回值:**
|
||||
>成功赋值的接收参数的数量(可以为零,在首个接收用参数赋值前匹配失败的情况下),者若输入在首个接收用参数赋值前发生失败,则为EOF。
|
||||
|
||||
#### printf系
|
||||
>**头文件:** stdio.h
|
||||
>(1)
|
||||
>`int printf( const char *format, ... )`(C99 前)
|
||||
>
|
||||
>`int printf( const char *restrict format, ... )`;(C99 起)
|
||||
>
|
||||
>(2)
|
||||
>
|
||||
>`int fprintf( FILE *stream, const char *format, ... )`;(C99 前)
|
||||
>
|
||||
>`int fprintf( FILE *restrict stream, const char *restrict format, ... );`(C99 起)
|
||||
>
|
||||
>(3)
|
||||
>
|
||||
>`int sprintf( char *buffer, const char *format, ... )`;(C99 前)
|
||||
>
|
||||
>`int sprintf( char *restrict buffer, const char *restrict format, ... )`;(C99 起)
|
||||
>
|
||||
>(4)
|
||||
>
|
||||
>`int snprintf( char *restrict buffer, int bufsz, const char *restrict format, ... )`;(C99 起)
|
||||
>
|
||||
>**定义:**
|
||||
>从给定位置加载数据,转换为字符串等价物,并写结果到各种池。
|
||||
>
|
||||
>1) 写结果到 stdout 。
|
||||
>
|
||||
>2) 写结果到文件流 stream 。
|
||||
>
|
||||
>3) 写结果到字符串 buffer 。
|
||||
>
|
||||
>4) 写结果到字符串 buffer 。至多写 buf_size - 1 个字符。产生的字符串会以空字符终止,除非 buf_size 为零。若 buf_size 为零,则不写入任何内容,且 buffer 可以是空指针,然而依旧计算返回值(会写入的字符数,不包含空终止符)并返回。
|
||||
>
|
||||
>**参数:**
|
||||
>stream - 要写入的输出文件流
|
||||
>
|
||||
>buffer - 指向要写入的字符串的指针
|
||||
>
|
||||
>bufsz - 最多会写入 bufsz - 1 个字符,再加空终止符
|
||||
>
|
||||
>format - 指向指定数据转译方式的空终止多字节字符串的指针。
|
||||
>
|
||||
>**返回值:**
|
||||
>1,2) 传输到输出流的字符数,或若出现输出错误或编码错误(对于字符串和字符转换指定符)则为负值。
|
||||
>
|
||||
>3) 写入到 buffer 的字符数(不计空终止字符),或若输出错误或编码错误(对于字符串和字符转换指定符)发生则为负值。
|
||||
>
|
||||
>4) 假如忽略 bufsz 则本应写入到 buffer 的字符数(不计空终止字符),或若出现输出错误或编码错误(对于字符串和字符转换指定符)则为负值。
|
||||
|
||||
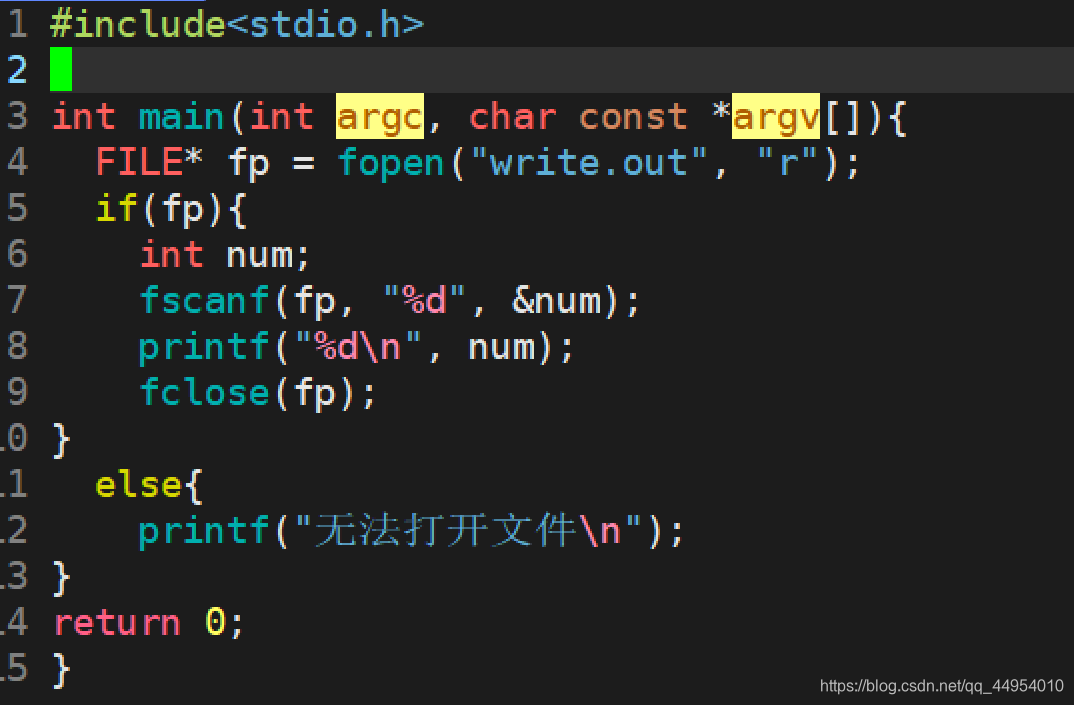
标准代码:
|
||||
```c
|
||||
FILE* fp = fopen("file", "r");
|
||||
|
||||
if (fp) {
|
||||
fscanf(fp, ...);
|
||||
fclose(fp);
|
||||
}
|
||||
else {
|
||||
...
|
||||
}
|
||||
```
|
||||
例:
|
||||
|
||||
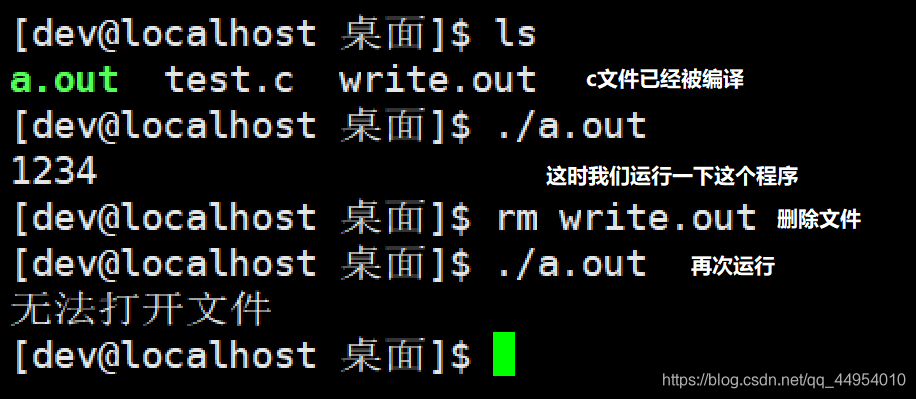
|
||||
|
||||
|
||||
|
||||
#### 二进制文件
|
||||
##### fread
|
||||
>`size_t fread( void *restrict buffer, size_t size, size_t count, FILE *restrict stream );`
|
||||
>定义于头文件 <stdio.h>
|
||||
>**参数**:
|
||||
>buffer - 指向要读取的数组中首个对象的指针
|
||||
>size - 每个对象的字节大小
|
||||
>count - 要读取的对象数
|
||||
>stream - 读取来源的输入文件流
|
||||
>**返回值**:
|
||||
>成功读取的对象数,若出现错误或文件尾条件,则可能小于 count 。
|
||||
>若 size 或 count 为零,则 fread 返回零且不进行其他动作。
|
||||
>fread 不区别文件尾和错误,而调用者必须用 feof 和 ferror 鉴别出现者为何。
|
||||
>***
|
||||
>**定义**:
|
||||
>从给定输入流 stream 读取至多 count 个对象到数组 buffer 中,如同以对每个对象调用 size 次 fgetc ,并按顺序存储结果到转译为 unsigned char 数组的 buffer 中的相继位置。流的文件位置指示器前进读取的字符数。
|
||||
>若出现错误,则流的文件位置指示器的结果值不确定。若读入部分的元素,则元素值不确定。
|
||||
|
||||
直白点说就是从 一个流(文件)种读取 count 个 size 大小 的对象到 buffer 数组中
|
||||
|
||||
成功返回读取的对象数( <= count), 失败返回 0
|
||||
|
||||
##### fwrite
|
||||
>`size_t fwrite( const void *restrict buffer, size_t size, size_t count,
|
||||
> FILE *restrict stream );`
|
||||
>定义于头文件 <stdio.h>
|
||||
>**参数**:
|
||||
>buffer - 指向数组中要被写入的首个对象的指针
|
||||
>size - 每个对象的大小
|
||||
>count - 要被写入的对象数
|
||||
>stream - 指向输出流的指针
|
||||
>**返回值**:
|
||||
>成功写入的对象数,若错误发生则可能小于 count 。
|
||||
>若 size 或 count 为零,则 fwrite 返回零并不进行其他行动。
|
||||
>***
|
||||
>**定义**
|
||||
>写 count 个来自给定数组 buffer 的对象到输出流stream。如同转译每个对象为 unsigned char 数组,并对每个对象调用 size 次 fputc 以将那些 unsigned char 按顺序写入 stream 一般写入。文件位置指示器前进写入的字节数。
|
||||
|
||||
###### 程序演示
|
||||
现在我们想将学生的信息以二进制文本写入到 student.data 文件中
|
||||
|
||||
应该如何写这个程序呢?
|
||||
|
||||
关注公众号: 不会编程的程序圆 回复[0212 1]
|
||||
获取程序演示以及程序的详细注释!
|
||||
|
||||
#### ftell
|
||||
>`long ftell( FILE *stream );`
|
||||
>定义于头文件 <stdio.h>
|
||||
>**参数**:stream - 要检验的文件流
|
||||
>**返回值**:
|
||||
>成功时为文件位置指示器,若失败发生则为 -1L 。
|
||||
>失败时,设 errno 对象为实现定义的正值。
|
||||
>***
|
||||
>**定义**:
|
||||
>返回流 stream 的文件位置指示器。
|
||||
>若流以二进制模式打开,则由此函数获得的值是从文件开始的字节数。
|
||||
>若流以文本模式打开,则由此函数返回的值未指定,且仅若作为 fseek() 的输入才有意义。
|
||||
|
||||
#### fseek
|
||||
>`int fseek( FILE *stream, long offset, int origin );`
|
||||
>定义于头文件 <stdio.h>
|
||||
>**参数**:
|
||||
>stream - 要修改的文件流
|
||||
>offset - 相对 origin 迁移的字符数
|
||||
>origin - offset 所加上的位置。它能拥有下列值之一: SEEK_SET 、 SEEK_CUR 、 SEEK_END
|
||||
>**返回值**:
|
||||
>成功时为 0 ,否则为非零。
|
||||
>***
|
||||
>**定义**:
|
||||
>设置文件流 stream 的文件位置指示器为 offset 所指向的值。
|
||||
>
|
||||
>若 stream 以二进制模式打开,则新位置准确地是文件起始后(若 origin 为 SEEK_SET )或当前文件位置后(若 origin 为 SEEK_CUR ),或文件结尾后(若 origin 为 SEEK_END )的 offset 字节。不要求二进制流支持 SEEK_END ,尤其是是否输出附加的空字节。
|
||||
>
|
||||
>若 stream 以文本模式打开,则仅有的受支持 offset 值为零(可用于任何 origin )和先前在关联到同一个文件的流上对 ftell 的调用的返回值(仅可用于 SEEK_SET 的 origin )。
|
||||
>
|
||||
>若 stream 为宽面向,则一同应用对文本和二进制流的限制(允许 ftell 的结果与 SEEK_SET 一同使用,并允许零 offset 以 SEEK_SET 和 SEEK_CUR 但非 SEEK_END 为基准)。
|
||||
>
|
||||
>除了更改文件位置指示器, fseek 还撤销 ungetc 的效果并清除文件尾状态,若可应用。
|
||||
>
|
||||
>若发生读或写错误,则设置流的错误指示器( ferror )而不影响文件位置。
|
||||
|
||||
>SEEK_SET 从头开始
|
||||
>SEEK_CUR 从当前位置开始
|
||||
>SEEK_END 从尾开始
|
||||
|
||||
简单的理解:将 stream 指针,从 origin 开始,移动 offset 个字节
|
||||
|
||||
比如:`fseek(fp, 100L, SEEK_SET)`
|
||||
|
||||
它的意义时,将 fp 指针从 文件头开始移动100个字节
|
||||
|
||||
###### 程序演示
|
||||
上面一个程序我们将学生信息以二进制形式写入到了 student.data 文件中
|
||||
|
||||
如何打开这个二进制文件呢?
|
||||
|
||||
关注公众号: 不会编程的程序圆 回复[0212 1]
|
||||
获取程序演示以及程序的详细注释!
|
||||
|
||||
###### 可移植性
|
||||
这一节,我们看了到各种比较复杂的函数,
|
||||
|
||||
如`fprintf` `fscanf` `sprintf` `fopen` `fclose` `fread` `fwrite`
|
||||
|
||||
我们也看到了文本文件的一些操作和二进制文件比较复杂的读写,而且你也不能直接从windows 上读我们到底以二进制的形式向文件内写了什么
|
||||
>这样的二进制文件不具备可移植性,因为在int 为32为的机器上写成的数据文件无法直接在int为64位的机器上正确读出
|
||||
>
|
||||
>解决方案之一是放弃使用int,用typedef具有明确大小的类型
|
||||
>
|
||||
>更好的方案是用文本
|
||||
|
||||
时至今日,我们已经很少用c语言这种最底层的文件读写方式了,要么用数据库,要么用第三方库
|
||||
|
||||
*参考网站:https://zh.cppreference.com/*
|
||||
|
||||
460
content/c-notes/C语言指针笔试题这么变态?我可能白学C语言了!带详解!.md
Normal file
460
content/c-notes/C语言指针笔试题这么变态?我可能白学C语言了!带详解!.md
Normal file
@@ -0,0 +1,460 @@
|
||||
### 6.指针和数组笔试题
|
||||
|
||||
环境:**32 位机器**
|
||||
|
||||
#### 第一组
|
||||
|
||||
```c
|
||||
int a[] = {1,2,3,4};
|
||||
printf("%d\n",sizeof(a));
|
||||
printf("%d\n",sizeof(a+0));
|
||||
printf("%d\n",sizeof(*a));
|
||||
printf("%d\n",sizeof(a+1));
|
||||
printf("%d\n",sizeof(a[1]));
|
||||
printf("%d\n",sizeof(&a));
|
||||
printf("%d\n",sizeof(*&a));
|
||||
printf("%d\n",sizeof(&a+1));
|
||||
printf("%d\n",sizeof(&a[0]));
|
||||
printf("%d\n",sizeof(&a[0]+1));
|
||||
```
|
||||
|
||||
答案:
|
||||
|
||||
```c
|
||||
printf("%d\n",sizeof(a));// 16
|
||||
printf("%d\n",sizeof(a+0));// 4 (a + 0 这个操作使得编译器将 a 看为指针)
|
||||
printf("%d\n",sizeof(*a));// 4
|
||||
printf("%d\n",sizeof(a+1));// 4
|
||||
printf("%d\n",sizeof(a[1]));// 4
|
||||
printf("%d\n",sizeof(&a));// 4
|
||||
printf("%d\n",sizeof(*&a));// 16 (&a 是数组指针。再次用 * 解引用,是从这个地址开始取 int(*)[4] 类型对应的字节数)
|
||||
printf("%d\n",sizeof(&a+1));// 4 (&a 得到的是 int(*)[4] 类型的指针,只要是指针大小就是 4)
|
||||
printf("%d\n",sizeof(&a[0]));// 4
|
||||
printf("%d\n",sizeof(&a[0]+1));// 4
|
||||
```
|
||||
|
||||
#### 第二组
|
||||
|
||||
```c
|
||||
char arr[] = {'a','b','c','d','e','f'};
|
||||
printf("%d\n", sizeof(arr));
|
||||
printf("%d\n", sizeof(arr+0));
|
||||
printf("%d\n", sizeof(*arr));
|
||||
printf("%d\n", sizeof(arr[1]));
|
||||
printf("%d\n", sizeof(&arr));
|
||||
printf("%d\n", sizeof(&arr+1));
|
||||
printf("%d\n", sizeof(&arr[0]+1));
|
||||
|
||||
printf("%d\n", strlen(arr));
|
||||
printf("%d\n", strlen(arr+0));
|
||||
printf("%d\n", strlen(*arr));
|
||||
printf("%d\n", strlen(arr[1]));
|
||||
printf("%d\n", strlen(&arr));
|
||||
printf("%d\n", strlen(&arr+1));
|
||||
printf("%d\n", strlen(&arr[0]+1));
|
||||
```
|
||||
|
||||
答案:
|
||||
|
||||
```c
|
||||
printf("%d\n", sizeof(arr));// 6
|
||||
printf("%d\n", sizeof(arr+0));// 4
|
||||
printf("%d\n", sizeof(*arr));// 1
|
||||
printf("%d\n", sizeof(arr[1]));// 1
|
||||
printf("%d\n", sizeof(&arr));// 4 (char (*)[6] 类型的指针)
|
||||
printf("%d\n", sizeof(&arr+1));// 4
|
||||
printf("%d\n", sizeof(&arr[0]+1));//4
|
||||
|
||||
printf("%d\n", strlen(arr));// 未定义 (arr 字符数组没有 '\0',有可能会出现一个随机值,程序也有可能会崩溃。)
|
||||
printf("%d\n", strlen(arr+0));// 未定义
|
||||
printf("%d\n", strlen(*arr)); // 错误的参数类型 (strlen 要的是 char* 类型,但是 *arr 是 char类型。*arr 是字符 a,也就是 97,编译器有可能将 97 当成一个 16 进制的地址。所以,这样的代码一定是不对的)
|
||||
printf("%d\n", strlen(arr[1]));//同上
|
||||
printf("%d\n", strlen(&arr));// 未定义
|
||||
printf("%d\n", strlen(&arr+1)); // 未定义
|
||||
printf("%d\n", strlen(&arr[0]+1));// 未定义
|
||||
```
|
||||
|
||||
#### 第三组
|
||||
|
||||
```c
|
||||
char arr[] = "abcdef";
|
||||
printf("%d\n", sizeof(arr));
|
||||
printf("%d\n", sizeof(arr+0));
|
||||
printf("%d\n", sizeof(*arr));
|
||||
printf("%d\n", sizeof(arr[1]));
|
||||
printf("%d\n", sizeof(&arr));
|
||||
printf("%d\n", sizeof(&arr+1));
|
||||
printf("%d\n", sizeof(&arr[0]+1));
|
||||
|
||||
printf("%d\n", strlen(arr));
|
||||
printf("%d\n", strlen(arr+0));
|
||||
printf("%d\n", strlen(*arr));
|
||||
printf("%d\n", strlen(arr[1]));
|
||||
printf("%d\n", strlen(&arr));
|
||||
printf("%d\n", strlen(&arr+1));
|
||||
printf("%d\n", strlen(&arr[0]+1));
|
||||
```
|
||||
|
||||
答案:
|
||||
|
||||
```c
|
||||
char arr[] = "abcdef";
|
||||
printf("%d\n", sizeof(arr));//7
|
||||
printf("%d\n", sizeof(arr+0));//7
|
||||
printf("%d\n", sizeof(*arr));//1
|
||||
printf("%d\n", sizeof(arr[1]));//1
|
||||
printf("%d\n", sizeof(&arr));//4 (char (*)[7])
|
||||
printf("%d\n", sizeof(&arr+1));//4 (char (*)[7])
|
||||
printf("%d\n", sizeof(&arr[0]+1));//4 (char*)
|
||||
|
||||
printf("%d\n", strlen(arr));// 6
|
||||
printf("%d\n", strlen(arr+0));// 6
|
||||
printf("%d\n", strlen(*arr));// 错误的参数类型
|
||||
printf("%d\n", strlen(arr[1]));// 同上
|
||||
printf("%d\n", strlen(&arr));// 6 (&arr 的类型是 char (*)[7] 与 char* 类型不一致,但是 &arr 与 arr 是相同的,所以恰巧能得出正确结果,但是这是错误的写法。)
|
||||
printf("%d\n", strlen(&arr+1)); // 未定义 (&arr + 1,跳过了整个数组,访问数组后面的空间,非法内存访问)
|
||||
printf("%d\n", strlen(&arr[0]+1)); // 5 (&arr[0] -> char* ,加以跳过一个数组元素)
|
||||
```
|
||||
|
||||
#### 第四组
|
||||
|
||||
```c
|
||||
char *p = "abcdef";
|
||||
printf("%d\n", sizeof(p));
|
||||
printf("%d\n", sizeof(p+1));
|
||||
printf("%d\n", sizeof(*p));
|
||||
printf("%d\n", sizeof(p[0]));
|
||||
printf("%d\n", sizeof(&p));
|
||||
printf("%d\n", sizeof(&p+1));
|
||||
printf("%d\n", sizeof(&p[0]+1));
|
||||
|
||||
printf("%d\n", strlen(p));
|
||||
printf("%d\n", strlen(p+1));
|
||||
printf("%d\n", strlen(*p));
|
||||
printf("%d\n", strlen(p[0]));
|
||||
printf("%d\n", strlen(&p));
|
||||
printf("%d\n", strlen(&p+1));
|
||||
printf("%d\n", strlen(&p[0]+1));
|
||||
```
|
||||
|
||||
答案:
|
||||
|
||||
```c
|
||||
char *p = "abcdef";
|
||||
printf("%d\n", sizeof(p));// 4
|
||||
printf("%d\n", sizeof(p+1));// 4
|
||||
printf("%d\n", sizeof(*p));// 1
|
||||
printf("%d\n", sizeof(p[0]));// 1
|
||||
printf("%d\n", sizeof(&p));// 4 (char**)
|
||||
printf("%d\n", sizeof(&p+1));// 4 (char**)
|
||||
printf("%d\n", sizeof(&p[0]+1));// 4
|
||||
|
||||
printf("%d\n", strlen(p));// 6
|
||||
printf("%d\n", strlen(p+1));// 5
|
||||
printf("%d\n", strlen(*p));// 错误的参数类型
|
||||
printf("%d\n", strlen(p[0]));// 错误的参数类型
|
||||
printf("%d\n", strlen(&p));// 同上 (&p 的类型是 char**,将char** 强转成的 char* 并不是一个字符串)
|
||||
printf("%d\n", strlen(&p+1));// 未定义
|
||||
printf("%d\n", strlen(&p[0]+1));// 5 (对于 &p[0] 来说,p 先与 [] 结合)
|
||||
```
|
||||
|
||||
|
||||
|
||||
> 指针为什么也可以用 `[]`运算符?
|
||||
>
|
||||
> 对于指针 int* p = "abc";
|
||||
>
|
||||
> `p[1]` 等价于 `*(p + 1)`
|
||||
>
|
||||
> 这是因为数组很多时候可以隐式转换成指针。
|
||||
|
||||
|
||||
|
||||
重点注意:`printf("%d\n", strlen(&p));`
|
||||
|
||||
`&p`的类型是 `char**`,但是C语言会将其隐式类型转换成 `char*`,但是 strlen 访问的是地址p的内存空间,那这其实是未定义行为。
|
||||
|
||||
|
||||
|
||||
#### 第五组
|
||||
|
||||
```c
|
||||
int a[3][4] = {0};
|
||||
printf("%d\n",sizeof(a));
|
||||
printf("%d\n",sizeof(a[0][0]));
|
||||
printf("%d\n",sizeof(a[0]));
|
||||
printf("%d\n",sizeof(a[0]+1));
|
||||
printf("%d\n",sizeof(*(a[0]+1)));
|
||||
printf("%d\n",sizeof(a+1));
|
||||
printf("%d\n",sizeof(*(a+1)));
|
||||
printf("%d\n",sizeof(&a[0]+1));
|
||||
printf("%d\n",sizeof(*(&a[0]+1)));
|
||||
printf("%d\n",sizeof(*a));
|
||||
printf("%d\n",sizeof(a[3]));
|
||||
```
|
||||
|
||||
答案:
|
||||
|
||||
```c
|
||||
int a[3][4] = {0};
|
||||
//所谓二维数组本质是一维数组。里面的每个元素又是一个一维数组。
|
||||
//本例是一个长度为 3 的一维数组,每个元素又是长度为 4 的一维数组。(VS 中可以用调试来测试)
|
||||
printf("%d\n",sizeof(a));// 48
|
||||
printf("%d\n",sizeof(a[0][0]));// 4
|
||||
printf("%d\n",sizeof(a[0]));// 16 (a[0] 的类型是 int[4])
|
||||
printf("%d\n",sizeof(a[0]+1));// 4 (a[0]->int[4]相当于一个一维数组,a[0] + 1 隐式转换为指针 int*)
|
||||
printf("%d\n",sizeof(*(a[0]+1)));// 4 (a[0] + 1 -> a[0][1])
|
||||
printf("%d\n",sizeof(a+1));// 4
|
||||
printf("%d\n",sizeof(*(a+1)));// 4
|
||||
printf("%d\n",sizeof(&a[0]+1));// 4 (a[0] -> int[4],&a[0] -> int (*)[4],再加1还是数组指针)
|
||||
printf("%d\n",sizeof(*(&a[0]+1)));// 16 (int (*)[4] 解引用变为 int[4])
|
||||
printf("%d\n",sizeof(*a));// 16 (*a -> *(a + 0) -> a[0])
|
||||
printf("%d\n",sizeof(a[3]));// 16
|
||||
```
|
||||
|
||||
重点注意:
|
||||
|
||||
`printf("%d\n",sizeof(a[0]+1))`
|
||||
|
||||
`printf("%d\n",sizeof(&a[0]+1))`
|
||||
|
||||
a[0] 与 &a[0] 的差异比较:
|
||||
|
||||
```c
|
||||
int a[3][4] = {
|
||||
{1, 2, 3, 4},
|
||||
{5, 6, 7, 8},
|
||||
{5, 10, 11, 12},
|
||||
};
|
||||
|
||||
printf("%d\n", *(a[0] + 1));// 2
|
||||
printf("%d\n", **(&a[0] + 1));//5
|
||||
```
|
||||
|
||||
|
||||
|
||||
`printf("%d\n",sizeof(*(&a[0]+1)));`
|
||||
|
||||
我们来一步一步分析:
|
||||
|
||||
`a[0] -> int[4] ; &a[0] -> int (\*)[4] ; &a[0] + 1 -> int (\*)[4] ; *(&a[0] + 1) -> int[4]`
|
||||
|
||||
|
||||
|
||||
`printf("%d\n",sizeof(a[3]))`
|
||||
|
||||
`sizeof`是一个运算符,并不是函数。它在预编译时期替换。而我们说的“数组下标访问越界”前提条件是 **内存**访问越界,这个时期是程序运行时。a[3] 就是 int[4] 类型,所以就是 16。哪怕你写 a[100]都可以。
|
||||
|
||||
`printf("%d\n", 16)`是程序运行时执行的语句。
|
||||
|
||||
#### 关于 const
|
||||
|
||||
```c
|
||||
int num;
|
||||
const int* p = #
|
||||
int const* p = #// 这样的写法不科学,int* 应该当成一个整体,不过它的含义与上面的相同。
|
||||
int* const p = #
|
||||
```
|
||||
|
||||
对于第一种写法,*p 是不能改变的;对于第三种写法,地址 p 是不能被改变的。
|
||||
|
||||
|
||||
|
||||
### 7. 指针笔试题
|
||||
|
||||
#### Ⅰ
|
||||
|
||||
```c
|
||||
int main(void)
|
||||
{
|
||||
int a[5] = { 1, 2, 3, 4, 5 };
|
||||
int *ptr = (int *)(&a + 1);
|
||||
printf( "%d,%d", *(a + 1), *(ptr - 1));
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
`a + 1`:a 隐式转换成 指针,指向 首地址后移 4 个字节。(a 隐式转换后是 int* 类型,它指向的 int 大小是 4 个字节,所以后移 4 个字节)
|
||||
|
||||
`&a` 的类型是 `int(*)[5]` ,所以 `&a + 1` 后移 int[5] 的长度
|
||||
|
||||
|
||||
|
||||
所以最后输出的是:2,5
|
||||
|
||||
#### Ⅱ
|
||||
|
||||
```c
|
||||
//由于还没学习结构体,这里告知结构体的大小是20个字节
|
||||
struct Test
|
||||
{
|
||||
int Num;
|
||||
char *pcName;
|
||||
short sDate;
|
||||
char cha[2];
|
||||
short sBa[4];
|
||||
}*p;
|
||||
//假设p 的值为0x100000。 如下表表达式的值分别为多少?
|
||||
int main(void)
|
||||
{
|
||||
printf("%p\n", p + 0x1);
|
||||
printf("%p\n", (unsigned long)p + 0x1);
|
||||
printf("%p\n", (unsigned int*)p + 0x1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
`p + 0x1` p 加十六进制的 1,p 所指向的结构体大小是 20,所以 p 会增加 20 。但是注意 `%p` 输出的是 16 进制的地址,所以输出的是 0x100014
|
||||
|
||||
`(unsigned long)p + 0x1` p 被强转成了一个数,所以输出的就是 0x100001
|
||||
|
||||
`(unsigned int*)p + 0x1` p 被强转成了一个 int* 类型的指针,所以输出的是 0x100004
|
||||
|
||||
#### Ⅲ
|
||||
|
||||
```c
|
||||
int main(void)
|
||||
{
|
||||
int a[4] = { 1, 2, 3, 4 };
|
||||
int *ptr1 = (int *)(&a + 1);
|
||||
int *ptr2 = (int *)((int)a + 1);
|
||||
printf( "%x,%x", ptr1[-1], *ptr2);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
`ptr1[-1]`: 前面我们说过,这个操作相当于 `*(ptr1 - 1)`
|
||||
|
||||
`(int)a + 1` 是将 a 先强转为 int 然后再加 1,所以 a 仅仅增加了 1 个字节
|
||||
|
||||
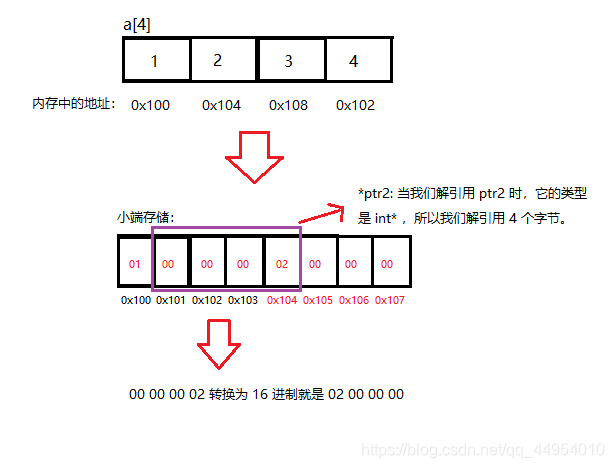
|
||||
|
||||
#### Ⅳ
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
int main(void)
|
||||
{
|
||||
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
|
||||
int *p;
|
||||
p = a[0];
|
||||
printf( "%d", p[0]);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
p[0] -> a[0] [0] ,所以输出的是 0 吗?
|
||||
|
||||
并不是,注意看 a[3] [2]大括号内的内容,里面是圆括号而不是大括号,这是**逗号表达式**。
|
||||
|
||||
所以,a[0] [0] == 1
|
||||
|
||||
|
||||
|
||||
#### Ⅴ
|
||||
|
||||
```c
|
||||
int main(void){
|
||||
int a[5][5];
|
||||
int(*p)[4];
|
||||
p = a;
|
||||
printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
指针(同类型)相减的意义是**两个指针之间间隔的元素个数**
|
||||
|
||||
`&p[4][2]` -> 数组中的第 19 个元素(4 * 4 + 3)
|
||||
|
||||
`&a[4][2]` -> 数组中的第 23 个元素 (4 * 5 + 3)
|
||||
|
||||
|
||||
|
||||
答案:FFFFFFFC,-4
|
||||
|
||||
|
||||
|
||||
#### Ⅵ
|
||||
|
||||
```c
|
||||
int main(void)
|
||||
{
|
||||
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
|
||||
int *ptr1 = (int *)(&aa + 1);
|
||||
int *ptr2 = (int *)(*(aa + 1));
|
||||
printf( "%d,%d", *(ptr1 - 1), *(ptr2 - 1));
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
`&aa` 的类型是 `int(*)[2][5]`,所以 `&aa + 1` 指向的是整个数组后面的内存 。所以 `*(ptr1 - 1)` 的值是 10
|
||||
|
||||
`aa` aa + 1 让 aa 隐式转换为 `int(*)[5]` ,所以 `aa + 1` 指向的是元素 6 所在的地址。所以 `*(ptr2 - 1)` 的值是 5
|
||||
|
||||
|
||||
|
||||
#### Ⅶ
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
int main(void)
|
||||
{
|
||||
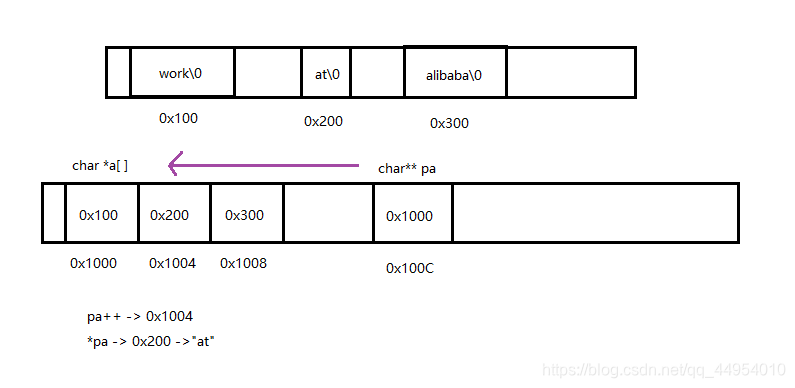
char *a[] = {"work","at","alibaba"};
|
||||
char**pa = a;
|
||||
pa++;
|
||||
printf("%s\n", *pa);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### Ⅷ
|
||||
|
||||
```c
|
||||
int main(void)
|
||||
{
|
||||
char *c[] = {"ENTER","NEW","POINT","FIRST"};
|
||||
char** cp[] = {c+3,c+2,c+1,c};
|
||||
char***cpp = cp;
|
||||
printf("%s\n", **++cpp);// ++cpp 会改变 cpp 的值
|
||||
printf("%s\n", *--*++cpp+3);//
|
||||
printf("%s\n", *cpp[-2]+3);//-2 并没有改变 cpp
|
||||
printf("%s\n", cpp[-1][-1]+1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
单目运算符从右向左依次运算。
|
||||
|
||||
```c
|
||||
char* p = "ENTER";
|
||||
printf("%s", p + 3);// 输出 ER,p + 3 增加 3 个字节,因为 p 指向的类型是 char 大小是 1 个字节。
|
||||
```
|
||||
|
||||
|
||||
91
content/c-notes/if-else语句详解.md
Normal file
91
content/c-notes/if-else语句详解.md
Normal file
@@ -0,0 +1,91 @@
|
||||
|
||||
**关于 if else 选择结构 的两种写法:**
|
||||
```c
|
||||
if () {
|
||||
;
|
||||
}
|
||||
if () {
|
||||
;
|
||||
}
|
||||
if () {
|
||||
;
|
||||
}
|
||||
else {
|
||||
;
|
||||
}
|
||||
|
||||
|
||||
if () {
|
||||
;
|
||||
}
|
||||
else if () {
|
||||
;
|
||||
}
|
||||
else if () {
|
||||
;
|
||||
}
|
||||
else {
|
||||
;
|
||||
}
|
||||
```
|
||||
上面两种写法有区别吗?
|
||||
|
||||
直接看程序吧:
|
||||
#### 多个if 直接并列
|
||||
```c
|
||||
int main() {
|
||||
|
||||
int a = 5;
|
||||
|
||||
if (a > 0)
|
||||
printf("a > 0\n");
|
||||
if (a > 2)
|
||||
printf("a > 2\n");
|
||||
if (a > 4)
|
||||
printf("a > 4\n");
|
||||
if (a > 5)
|
||||
printf("a > 5\n");
|
||||
else
|
||||
printf("a < 5\n");
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
输出:
|
||||
```c
|
||||
a > 0
|
||||
a > 2
|
||||
a > 4
|
||||
a < 5
|
||||
```
|
||||
#### 多个else if 并列
|
||||
```c
|
||||
int main() {
|
||||
|
||||
int a = 0;
|
||||
|
||||
if (a > 0)
|
||||
printf("a > 0\n");
|
||||
else if (a > 2)
|
||||
printf("a > 2\n");
|
||||
else if (a > 4)
|
||||
printf("a > 4\n");
|
||||
else if (a > 5)
|
||||
printf("a > 5\n");
|
||||
else
|
||||
printf("a < 5\n");
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
输出:
|
||||
```c
|
||||
a > 0
|
||||
```
|
||||
|
||||
### 总结
|
||||
- 多个if 并列 程序会遍历所有的 if 条件。最后一个 else 与最后一个 if 配对,两者必有一个为真
|
||||
- 多个 else if 并列 程序只要找到一个 真,就会退出整个 “条件体”。最后一个else 与 前面的任意一个语句 必有一个为真。
|
||||
- 关于else:
|
||||
* 第一种:else 与 最后一个 if 形成对立
|
||||
* 第二种:else 与 除 else 外的整体形成对立
|
||||
638
content/c-notes/一篇看懂 C语言常用 字符串函数,全网最全整理!.md
Normal file
638
content/c-notes/一篇看懂 C语言常用 字符串函数,全网最全整理!.md
Normal file
@@ -0,0 +1,638 @@
|
||||
字符串函数 指的是头文件 ` stdio.h ` 中的输入输出函数 和 头文件`string.h`里定义的我们平时直接使用的函数。
|
||||
一下是本节重点讲解的 10 个函数。对于生僻点的字符串函数我们以后再讲。
|
||||
|
||||
- putchar & getchar
|
||||
- strlen & strnlen_s
|
||||
- strcmp & strncmp
|
||||
- strcpy & strncpy
|
||||
- strcat & strncat
|
||||
|
||||
这些函数我们到处在用,可你有没有想过,究竟这些函数是怎么声明和定义的?他们远没有你想的那么简单。
|
||||
|
||||
**以下被划掉的部分如果你理解,那是最好。不理解不可以不用纠结,~~慢慢来~~**
|
||||

|
||||
### (一)putchar & getchar
|
||||
#### putchar
|
||||
>`int putchar( int ch )`
|
||||
>**头文件**:stdio.h
|
||||
>**定义**:写字符 ch 到 stdout 。在内部,字符于写入前被转换到 unsigned char 。
|
||||
>*stdout:标准输出 我们后面会单独讲*
|
||||
>意思就是:向标准输出写入一个字符
|
||||
>~~等价于 putc(ch, stdout) 。~~
|
||||
>**参数**: `ch` 要被写入的字符串
|
||||
>**返回值**:
|
||||
>成功时返回写入的字符。
|
||||
>失败时返回 EOF ~~并设置 stdout 上的错误指示器~~
|
||||
>*EOF(end of file)是一个宏,值为 -1*
|
||||
|
||||
第一次看到这个函数的 返回类型 和 参数类型 我其实很懵:
|
||||
嗯?
|
||||
我输入的不是 char 类型的吗? 怎么参数类型是 int ?
|
||||
我看到的不是 char 类型的 `A` 吗?怎么返回类型是 int?
|
||||
|
||||

|
||||
其实,输出是什么不代表返回就是什么。scanf还返回整数呢,照样可以输出汉字。
|
||||
|
||||
下面的程序帮助大家理解:
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
char ch = 'A';
|
||||
|
||||
int a = 0;
|
||||
|
||||
a = putchar(ch);
|
||||
|
||||
printf("\n%d", a);
|
||||
|
||||
return 0;
|
||||
|
||||
}
|
||||
```
|
||||
输出:
|
||||
```c
|
||||
A
|
||||
65
|
||||
```
|
||||
|
||||
上面我说慢慢来的时候也许有同学不屑:“这还用慢慢来?早会了!”
|
||||
那好吧,`putchar` 的上面的定义中说它等价于 `putc`
|
||||
要不我们再来看看 putc 是怎么定义的?与 putc 类似的还有个 `fputc`
|
||||
要想真正理解它们还得看看 `ferror`,一个个来呗?
|
||||

|
||||
A watched pot never boils —— 心急吃不了热豆腐
|
||||
#### getchar
|
||||
>`int getchar(void)`
|
||||
>**头文件**:stdio.h
|
||||
>**定义**:
|
||||
>从 stdin 读取下一个字符。
|
||||
>~~等价于 getc(stdin) 。~~
|
||||
>也就是 从标准输入读入一个字符
|
||||
>**参数**:无
|
||||
>**返回值**:
|
||||
>成功时为获得的字符
|
||||
>失败时为 EOF 。
|
||||
|
||||
#### getchar的返回值有什么用?
|
||||
如何退出下面程序中的 while循环?
|
||||
可以自己打出来先测试一下。
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
int ch;
|
||||
|
||||
while ((ch = getchar()) != EOF) {
|
||||
putchar(ch);
|
||||
}
|
||||
|
||||
printf("EOF\n");
|
||||
//退出循环的方式可能有两种:
|
||||
//1.程序被关闭。EOF不会输出
|
||||
//2.退出了循环,程序继续向下运行。EOF会被输出
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
后面还会继续详细讲解 这部分知识。可以自行思考一下,也可以查阅资料看看。
|
||||
我做了一个便于理解的图示,如果现在就想看,在公众号回复[0206]查看。
|
||||
|
||||
*为了减少冗余,下面的程序我只写 main 函数部分,
|
||||
但是在你写程序到时候你要记得引用头文件 string.h*
|
||||
|
||||
### (二)strlen & strnlen_s
|
||||
帮你理解:
|
||||
strlen: string lenth
|
||||
#### strlen
|
||||
>`size_t strlen( const char *str )`
|
||||
>**头文件**:`string.h`
|
||||
>**参数**:str - 指向要检测的空终止字符串的指针
|
||||
>**返回值**: 空终止字节字符串 str 的长度。
|
||||
>***
|
||||
>**定义**:返回给定空终止字符串的长度,即首元素为 str 所指,且不包含首个空字符的字符数组中的字符数。
|
||||
> 若 str 不是指向空终止字节字符串的指针则行为未定义。
|
||||
|
||||
*什么是 空终止字节字符串?
|
||||
空终止字节字符串( NTBS )是尾随零值字节(空终止字符)的非零字节序列。字节字符串中的每个字节都是一些字符集的编码。例如,字符数组 {'\x63','\x61','\x74','\0'} 是一个以 ASCII 编码表示字符串 "cat" 的 NTBS 。*
|
||||
|
||||
#### strnlen_s
|
||||
>`size_t strnlen_s( const char *str, size_t strsz )`
|
||||
>**头文件**:`string.h`
|
||||
>**参数**:
|
||||
>str - 指向要检测的空终止字符串的指针
|
||||
>strsz - 要检测的最大字符数量
|
||||
>**返回值**:
|
||||
>成功时为空终止字节字符串 str 的长度,若 str 是空指针则为零,若找不到空字符则为 strsz 。
|
||||
>***
|
||||
>**定义**:
|
||||
>除了若 str 为空指针则返回零,而若在 str 的首 strsz 个字节找不到空字符则返回 strsz 。
|
||||
>若 str 指向缺少空字符的字符数组且该字符数组的大小 < strsz 则行为未定义;~~换言之, strsz 的错误值不会暴露行将来临的缓冲区溢出。~~
|
||||
|
||||
#### strlen 与 strnlen_s 的区别与用法
|
||||
**1.空指针**
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char* str = NULL;
|
||||
|
||||
//str为空指针,行为未定义。程序会崩溃
|
||||
printf("%d\n", strlen(str));
|
||||
|
||||
//str为空指针,返回 0
|
||||
printf("%d\n", strnlen_s(str, 1));
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
**2.没有终止符的字符串数组当作函数参数**
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char str[] = { 'H', 'E', 'L', 'L', 'O', };
|
||||
|
||||
printf("%d\n", strlen(str));
|
||||
|
||||
printf("%d\n", strnlen_s(str, (size_t)sizeof(str)));
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
猜一猜会输出什么?
|
||||
```c
|
||||
19
|
||||
5
|
||||
```
|
||||
**当我们不清楚字符串中有没有 '\0' 时,我们要小心使用 strlen**
|
||||
strlen 只有遇到 '\0' 才会停止,这造成的潜在的数组越界风险。
|
||||
|
||||
**3. 当 strsz > str的大小 时**
|
||||
1)若 str 有终止符
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char str[] = { 'H', 'I', '!', 0 };
|
||||
|
||||
printf("%d\n", strnlen_s(str, 5));
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
```c
|
||||
3
|
||||
```
|
||||
2) 若 str 无终止符, 行为未定义
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char str[] = { 'H', 'I', '!'};
|
||||
|
||||
printf("%d\n", strnlen_s(str, 5));
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
```c
|
||||
5
|
||||
```
|
||||
最后,对于 `strnlen_s `来说**如果 strsz < str数组大小**,直接返回 strsz
|
||||
|
||||
#### strlen 详解
|
||||
###### const的作用
|
||||
`size_t strlen( const char *str )`
|
||||
|
||||
const 的作用是什么?
|
||||
简单来说,如果你不希望这个函数改变你传入的数组,const 具有保护作用,使得 strlen 函数内部无法改变 str 数组每个元素的值。
|
||||
|
||||
const详解可以参考这篇文章:
|
||||
[点击查看](https://mp.weixin.qq.com/s/Fc-sAgpXmJ1eVKufZCvN8A)
|
||||
|
||||
#### mystrlen
|
||||
mystrlen 的写法有很多,如果你的编译器是 VS,你甚至可以直接看编译器是如何去写的。
|
||||
一下提供一种比较简洁的写法供大家参考:
|
||||
|
||||
不难(你细品
|
||||
|
||||
```c
|
||||
int mystrlen(const char* str) {
|
||||
|
||||
char* end = str;
|
||||
|
||||
while ( *end++ );
|
||||
|
||||
//退出while循环时,多加了一次 1
|
||||
return (end - start - 1);
|
||||
|
||||
}
|
||||
|
||||
int main() {
|
||||
|
||||
char* str = "Hello World!";
|
||||
|
||||
printf("%d\n", mystrlen(str));
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||

|
||||
### (三) strcmp & strncmp
|
||||
如何记忆?
|
||||
strcmp:string compare
|
||||
lhs:left-hand side
|
||||
rhs:right-hand side
|
||||
#### strcmp
|
||||
>`int strcmp( const char *lhs, const char *rhs )`
|
||||
>**头文件**:`string.h`
|
||||
>**参数**:
|
||||
>lhs, rhs - 指向要比较的空终止字节字符串的指针
|
||||
>**返回值**:
|
||||
>若字典序中 lhs 先出现于 rhs 则为负值。
|
||||
>若 lhs 与 rhs 比较相等则为零。
|
||||
>若字典序中 lhs 后出现于 rhs 则为正值。
|
||||
>***
|
||||
>*什么是字典序?*
|
||||
>*简单理解就是在字母表中出现的顺序。*
|
||||
>*记法小窍门:*
|
||||
>*lhs ASCII码值大 就为正 否则为负*
|
||||
>*解释:ASCII值大在字典序中肯定靠后,是后出现的*
|
||||
>***
|
||||
>**定义**:
|
||||
>以字典序比较二个空终止字节字符串。
|
||||
>结果的符号是被比较的字符串中首对不同字符(都转译成 unsigned char )的值间的差的符号。
|
||||
>若 lhs 或 rhs 不是指向空终止字节字符串的指针,则行为未定义。
|
||||
|
||||
### strncmp
|
||||
>`int strncmp( const char *lhs, const char *rhs, size_t count )`
|
||||
>**头文件**:`string.h`
|
||||
>**参数**:
|
||||
>lhs, rhs - 指向要比较的可能空终止的数组的指针
|
||||
>count - 要比较的最大字符数
|
||||
>**返回值**:
|
||||
>若字典序中 lhs 先出现于 rhs 则为负值。
|
||||
>若 lhs 与 rhs 比较相等,或若 count 为零,则为零。
|
||||
>若字典序中 lhs 后出现于 rhs 则为正值。
|
||||
>***
|
||||
>**定义**:
|
||||
>比较二个可能空终止的数组的至多 count 个字符。按字典序进行比较。不比较后随空字符的字符。
|
||||
>结果的符号是被比较的数组中首对字符(都转译成 unsigned char )的值间的差的符号。
|
||||
>若出现越过 lhs 或 rhs 结尾的访问,则行为未定义。若 lhs 或 rhs 为空指针,则行为未定义。
|
||||
#### strcmp 与 strncmp 比较
|
||||
**1. lhs 或 rhs 为非空终止字符字符串**
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char str2[3] = { 'J', 'I', 'M' };
|
||||
//'M' 后的字符是不可预测的。但是肯定都比0大,所以输出 0 或 1
|
||||
//你可以试试将 str1 也改为 str2 的数组形式, 试试结果会不会为 -1
|
||||
char str1[3] = "JIM";
|
||||
|
||||
printf("%d\n", strcmp(str1, str2));
|
||||
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
**2. count 的作用**
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char* str1 = "Helloa";
|
||||
char* str2 = "HelloA";
|
||||
|
||||
printf("%d\n", strcmp(str1, str2));
|
||||
//输出 1, str1 > str2
|
||||
|
||||
printf("%d\n", strncmp(str1, str2, 5));
|
||||
//输出 0, str1 = str2
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
**3. "Hello" 与 "Hello " 的区别?**
|
||||
字符串 "Hello" 是小于字符串 "Hello " 的。(用strcmp函数检测)
|
||||
因为最后一次字符比较是 '\0' 与 ' '比较,
|
||||
'\0' ASCII码值为 0, ' ' ASCII码值为 32
|
||||
如图:
|
||||

|
||||
```c
|
||||
int main() {
|
||||
|
||||
char* str1 = "Hello";
|
||||
char* str2 = "Hello ";
|
||||
|
||||
printf("%d\n", strcmp(str1, str2));
|
||||
printf("%d\n", strncmp(str1, str2, 10));
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
输出:
|
||||
```c
|
||||
-1
|
||||
-1
|
||||
```
|
||||
|
||||
#### mystrcmp
|
||||
先想后做,事半功倍:
|
||||
1. 按字符比较,都相等返回0;
|
||||
出现不相等,返回 *lhs - *rhs 的差值
|
||||
2. *lhs 或 *rhs 遇到 '\0' 退出循环返回 差值
|
||||
|
||||
```c
|
||||
int mystrcmp(char* str1, char* str2) {
|
||||
|
||||
while (1) {
|
||||
if (*str1 != *str2)
|
||||
break;
|
||||
else if (*str1 == 0)
|
||||
break;
|
||||
else
|
||||
++str1, ++str2;
|
||||
}
|
||||
|
||||
return (*str1 - *str2);
|
||||
}
|
||||
|
||||
int main() {
|
||||
|
||||
char* str1 = "Hello";
|
||||
char* str2 = "Hello";
|
||||
|
||||
printf("%d\n", mystrcmp(str1, str2));
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
上面的 mystrcmp 看着很笨,当然是可以改进的。
|
||||
自己思考一下。
|
||||
答案放在了我的GitHub上。[点击查看](https://github.com/hairrrrr/C-CrashCourse/tree/master/C%20Crash%20Course/13%20String/Prelesson/code/mystrcmp)
|
||||
对你有帮助,麻烦给我点个小星星哦,方便下次查看。
|
||||
如果你有更好的解法,欢迎 pull request !
|
||||
|
||||

|
||||
### (四) strcpy & strncpy
|
||||
帮助理解:
|
||||
strcpy:string copy
|
||||
dest:destination
|
||||
src:source
|
||||
#### strcpy
|
||||
>`char *strcpy( char *dest, const char *src )`
|
||||
>**头文件**:`string.h`
|
||||
>**参数**:
|
||||
>dest - 指向要写入的字符数组的指针
|
||||
>src - 指向要复制的空终止字节字符串的指针
|
||||
>**返回值**:
|
||||
>返回 dest 的副本
|
||||
>***
|
||||
>**定义**:
|
||||
>复制 src 所指向的空终止字节字符串,包含空终止符,到首元素为 dest 所指的字符数组。
|
||||
> 若 dest 数组长度不足则行为未定义。
|
||||
> 若字符串覆盖则行为未定义。
|
||||
> 若 dest 不是指向字符数组的指针或 src 不是指向空终止字节字符串的指针则行为未定义。
|
||||
|
||||
#### strncpy
|
||||
>`char *strncpy( char *dest, const char *src, size_t count )`
|
||||
>**头文件**:`string.h`
|
||||
>**参数**:
|
||||
>dest - 指向要复制到的字符数组的指针
|
||||
>src - 指向复制来源的字符数组的指针
|
||||
>count - 要复制的最大字符数
|
||||
>**返回值**:
|
||||
>返回 dest 的副本
|
||||
>
|
||||
>***
|
||||
>**定义**:
|
||||
>复制 src 所指向的字符数组的至多 count 个字符(包含空终止字符,但不包含后随空字符的任何字符)到 dest 所指向的字符数组。
|
||||
>**若在完全复制整个 src 数组前抵达 count ,则结果的字符数组不是空终止的。**
|
||||
> 若在复制来自 src 的空终止字符后未抵达 count ,则写入额外的空字符到 dest ,直至写入总共 count 个字符。
|
||||
> 若字符数组重叠,
|
||||
> 若 dest 或 src 不是指向字符数组的指针(包含若 dest 或 src 为空指针),
|
||||
> 若 dest 所指向的数组大小小于 count ,
|
||||
> 或若 src 所指向的数组大小小于 count 且它不含空字符,
|
||||
> 则行为未定义。
|
||||
|
||||
#### strcpy 与 strncpy 的未定义行为
|
||||
**1. dest 和 src 一定不能是空终止字节字符串, 且要指向字符串**
|
||||
**2. dest 与 src 覆盖**
|
||||
从 C99起 strcpy函数原型变成了这样:
|
||||
`char *strcpy( char *restrict dest, const char *restrict src )`
|
||||
`restrict` 表示两个字符串是不重叠的
|
||||
重叠并不是重复一样的意思。这一点我们目前不去深入。
|
||||
|
||||
**3. dest 长度小于 src**
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char* str1 = "Hello";
|
||||
char* str2 = "Hello World";
|
||||
|
||||
strcpy(str1, str2);
|
||||
strncpy(str1, str2, 12);
|
||||
|
||||
puts(str1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
这样写是可以通过编译的,但是你要知道这样做实际上已经越界了。
|
||||
|
||||
如果用数组的形式定义字符串,编译器才会报错。
|
||||
可以看出,在这种情况下。编译器对数组更为敏感,数组的写法也更加安全。
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char str1[] = "hello";
|
||||
char str2[] = "hello world";
|
||||
|
||||
//两个函数都会报错
|
||||
strcpy(str1, str2);
|
||||
//strncpy(str1, str2, 12);
|
||||
|
||||
puts(str1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
**4. strncpy:dest 大小小于 count**
|
||||
这点其实 3 也说明了。
|
||||
对于 strcpy 来说, dest 的大小不能小于 src
|
||||
而 strncpy 只需要 dest 的大小不小于 count 即可
|
||||
|
||||
**5. src 大小小于 count 且 src 不含空字符**
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char str1[] = "Hello World";
|
||||
char str2[] = { 'H', 'e', 'l','l', 'o' };
|
||||
|
||||
strncpy(str1, str2, 10);
|
||||
|
||||
puts(str1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
输出:
|
||||
```c
|
||||
Hello烫烫蘢
|
||||
```
|
||||
其实这也不难理解,strncpy 需要 '\0' 来判断 src 是否写完。
|
||||
如果有 src 结尾有'\0' ,这时如果 count 还没有写满
|
||||
函数会向 dest 中写入 '\0' 直到写满 count
|
||||
但是如果 src 没有 '\0' 那么函数不知道 src 已经结束,而继续写入后面的内容,结果可想而知,是不可预测的。
|
||||
|
||||
#### mystrcpy
|
||||
```c
|
||||
#include<assert.h>
|
||||
|
||||
char* mystrcpy(char* str1, char* str2) {
|
||||
|
||||
assert(str1 != NULL && str2 != NULL);
|
||||
assert(strlen(str1) >= strlen(str2));
|
||||
|
||||
//核心代码从这里开始, 上面的不懂可以加QQ群问我(群在我公众号关注回复的消息里)
|
||||
char* after = str1;
|
||||
|
||||
while (*str1++ = *str2++);
|
||||
|
||||
return after;
|
||||
}
|
||||
|
||||
int main() {
|
||||
|
||||
char* str1 = "HI!!!";
|
||||
char* str2 = "Hello";
|
||||
|
||||
mystrcpy(str1, str2);
|
||||
puts(str1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
### (五)strcat & strncat
|
||||
帮你理解:
|
||||
strcat:string catenate 字符串连接
|
||||
|
||||
#### strcat
|
||||
>`char *strcat( char *dest, const char *src )`
|
||||
>**头文件**:`string.h`
|
||||
>**参数**:
|
||||
>dest - 指向要后附到的空终止字节字符串的指针
|
||||
>src - 指向作为复制来源的空终止字节字符串的指针
|
||||
>**返回值**:
|
||||
>返回 dest 的副本
|
||||
>***
|
||||
>**定义**:
|
||||
>后附 src 所指向的空终止字节字符串的副本到 dest 所指向的空终止字节字符串的结尾。字符 src[0] 替换 dest 末尾的空终止符。产生的字节字符串是空终止的。
|
||||
> 若目标数组对于 src 和 dest 的内容以及空终止符不够大,则行为未定义。
|
||||
> 若字符串重叠,则行为未定义。
|
||||
> 若 dest 或 src 不是指向空终止字节字符串的指针,则行为未定义。
|
||||
|
||||
#### strncat
|
||||
>`char *strncat( char *dest, const char *src, size_t count )`
|
||||
>**头文件**:`string.h`
|
||||
>**参数**:
|
||||
>dest - 指向要后附到的空终止字节字符串的指针
|
||||
>src - 指向作为复制来源的字符数组的指针
|
||||
>count - 要复制的最大字符数
|
||||
>**反回值**:
|
||||
>返回 dest 的副本
|
||||
>***
|
||||
>**定义**:
|
||||
>后附来自 src 所指向的字符数组的至多 count 个字符,到 dest 所指向的空终止字节字符串的末尾,若找到空字符则停止。字符 src[0] 替换位于 dest 末尾的空终止符。始终后附终止空字符到末尾(故函数可写入的最大字节数是 count+1 )。
|
||||
> 若目标数组没有对于 dest 和 src 的首 count 个字符加上终止空字符的足够空间,则行为未定义。
|
||||
> 若源与目标对象重叠,则行为未定义。
|
||||
> 若 dest 不是指向空终止字节字符串的指针,或 src 不是指向字符数组的指针,则行为未定义。
|
||||
>
|
||||
|
||||
#### strcat 与 strncat 用法解读
|
||||
**1. strcat:dest >= dest + src + '\0'**
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char str1[11] = "Hello";
|
||||
char* str2 = " World";
|
||||
|
||||
//11刚好可以放下"Hello World",但是因为没有'\0' 的位置,程序崩溃。
|
||||
strcat(str1, str2);
|
||||
puts(str1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
**2. strcpy:dest 或 src 不是 空终止字节字符串**
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char str1[11] = "Hello";
|
||||
char str2[3] = {'J', 'I', 'M'};//程序崩溃
|
||||
|
||||
strcat(str1, str2);
|
||||
puts(str1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
**3. strncpy:dest 不是空终止字节字符串?**
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char str1[11] = {'H', 'I'};
|
||||
char str2[3] = { 'J', 'I', 'M' };
|
||||
|
||||
strncat(str1, str2, 3);
|
||||
puts(str1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
正确地输出了:
|
||||
```c
|
||||
HIJIM
|
||||
```
|
||||
可以看出 strncpy 具有某种优化,即使 dest 没有空字符,它也能正确找到正确的后缀位置
|
||||
即使 src 没有空字符,也可以在新的 dest 后加上空字符
|
||||
|
||||
|
||||
#### mystrcat
|
||||
```c
|
||||
char* mystrcat(char* str1, char* str2) {
|
||||
//这一步请细品
|
||||
while (str1[strlen(str1)] = *str2++);
|
||||
|
||||
return str1;
|
||||
}
|
||||
|
||||
int main() {
|
||||
|
||||
char str1[8] = "Hi";
|
||||
char str2[4] = "YOU";
|
||||
|
||||
mystrcat(str1, str2);
|
||||
puts(str1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
***
|
||||
|
||||
### 写在后面
|
||||

|
||||
说了半天,其实就是想带大家过一遍我们常用的字符串函数。
|
||||
里面肯定有你忽略的知识点,希望大家**一定不要放过一些细节**,**一定要多想**,**一定要多写代码**。
|
||||
重要的事说三遍。
|
||||
再有就是,不要嫌麻烦。
|
||||
毕竟你看完可能只要 10 分钟,我写要写好几个小时。
|
||||
|
||||
其实这也只是入门的基础概念,真的要学会还是要拿来用。
|
||||
具体使用有机会再总结吧。
|
||||
|
||||
***
|
||||
**更多精彩内容:**
|
||||
|
||||
[指针入门](https://mp.weixin.qq.com/s/0DD10hQQ4411ycbKSpghTw)
|
||||
[你不知道的素数判断方法](https://mp.weixin.qq.com/s/T-ovU-PIunKFrgH1ZVLOLw)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
参考资料:cppreference.com
|
||||
76
content/c-notes/两个数组为何不能赋值.md
Normal file
76
content/c-notes/两个数组为何不能赋值.md
Normal file
@@ -0,0 +1,76 @@
|
||||
# 指针 关于const
|
||||
### 关于const
|
||||
#### 数组变量 是 const 的指针
|
||||
在初学数组时,我们都有这样的思考:既然变量可以互相赋值,那么 数组 可以相互赋值吗?
|
||||
比如说:
|
||||
```C
|
||||
int a = 1;
|
||||
int b = 2;
|
||||
int arr1[3] = {1, 2, 3};
|
||||
int arr2[3] = {0};
|
||||
b = a;//ok
|
||||
arr2 = arr1;//error
|
||||
```
|
||||
一但这么些程序就会报错,为什么会这样呢?
|
||||
>这是因为,以上面的为例:`int arr2[3] = {0}`在编译器看来其实是这样的:`int* const arr2 ` 上一篇我们也学到了,const在 * 后 const 修饰的是地址 arr2,因此arr2是不能被改变的
|
||||
|
||||
#### `int* const arr` 与 `int arr[]`是否可以划等号?
|
||||
我们先来看下面这个程序:
|
||||
```C
|
||||
int main() {
|
||||
|
||||
int arr[3] = { 1, 2, 3 };
|
||||
int* const q = arr;
|
||||
|
||||
printf("arr = %p\n", arr);
|
||||
printf("&arr = %p\n", &arr);
|
||||
|
||||
printf("q = %p\n", q);
|
||||
printf("&q = %p\n", &q);
|
||||
|
||||
}
|
||||
```
|
||||
这个程序里,arr 的值与 q 的值相同我们应该是提前都会想到的。问题就是 这个 arr 的地址 与 q 的地址问题。他们会相同吗?虽然他们都指向 arr,但是这是两个不同的指针变量,所以他们的地址肯定是不会相同的。请看在我的机器上输出结果:
|
||||
```C
|
||||
arr = 004FF824
|
||||
&arr = 004FF824
|
||||
q = 004FF824
|
||||
&q = 004FF818
|
||||
```
|
||||
`&arr` 竟然与 `arr` 与 `q` 是一样的! 为什么会 这样?`&arr` 与 `arr` 有什么区别?请看下面的程序:
|
||||
```C
|
||||
int main() {
|
||||
|
||||
int arr[3] = { 1, 2, 3 };
|
||||
int* const q = arr;
|
||||
|
||||
printf("arr = %p\n", arr);
|
||||
printf("&arr = %p\n", &arr);
|
||||
|
||||
printf("arr + 1 = %p\n", arr + 1);
|
||||
printf("&arr + 1 = %p\n", &arr + 1);
|
||||
|
||||
printf("%d\n", ((int)(&arr + 1) - (int)(&arr)));//将指针转变为int,看地址相差多少
|
||||
|
||||
printf("q = %p\n", q);
|
||||
printf("&q = %p\n", &q);
|
||||
|
||||
printf("&q + 1 = %p\n", &q + 1);
|
||||
|
||||
}
|
||||
```
|
||||
```C
|
||||
arr = 0020F860
|
||||
&arr = 0020F860
|
||||
arr + 1 = 0020F864
|
||||
&arr + 1 = 0020F86C
|
||||
12
|
||||
q = 0020F860
|
||||
&q = 0020F854
|
||||
&q + 1 = 0020F858
|
||||
```
|
||||
`&arr + 1` 和 `arr + 1`差了 12 个字节, 刚好是一整个arr数组的长度。这意味着什么?
|
||||
>取数组的地址 实际上 取走的是 ==整个数组==的 地址,它将整个数组视为整体,对它进行加减,大小是整个数组的大小
|
||||
>而`&q + 1`得值仅仅变化了 4 个字节 ,就是一个指针的大小
|
||||
|
||||
<关于const 在程序中的使用教学 后续会在本编中加上 ,敬请期待 !>
|
||||
683
content/c-notes/什么 是 枚举 & 结构 & 联合,看这一篇就够了.md
Normal file
683
content/c-notes/什么 是 枚举 & 结构 & 联合,看这一篇就够了.md
Normal file
@@ -0,0 +1,683 @@
|
||||
### 枚举 Enum
|
||||
>枚举:
|
||||
>关键字:`enum`(enumeration)
|
||||
>用法:
|
||||
>enum 枚举类型名 {名字 0, 名字 1 ...., 名字 n};
|
||||
>注意:
|
||||
>枚举类型名通常不使用,用的是大括号内的名字,它们就是常量符号,**类型是 `int`**,**值依次从 0 到 n**
|
||||
|
||||
如:
|
||||
```c
|
||||
enum color {
|
||||
red, yellow, blue
|
||||
};
|
||||
```
|
||||
**注意**:
|
||||
- 大括号内每个常量符号以 **逗号** 间隔
|
||||
- 大括号后有 **分号**
|
||||
|
||||
**用法示例**:
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
enum color {
|
||||
red, yellow, blue
|
||||
};
|
||||
|
||||
void f(enum color x) {
|
||||
printf("%d\n", x);
|
||||
}
|
||||
|
||||
int main(void) {
|
||||
|
||||
// 变量 t 的类型是 enum color
|
||||
enum color t = yellow;
|
||||
|
||||
scanf("%d", &t);//可以当作整数输入输出
|
||||
|
||||
f(t);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
- `enum color` 作为变量类型应该写完整
|
||||
- 变量 t 虽然是 enum color 类型,但可以当作整型来进行内部计算和外部输入输出。
|
||||
|
||||
**自动计数的枚举**
|
||||
|
||||
```c
|
||||
enum color {
|
||||
red, yellow, blue, NumColors
|
||||
};
|
||||
```
|
||||
>**原理**:像上面这样,在 枚举 的所有元素后增加一个 Num<内容> 表示 枚举 元素的总数
|
||||
>比如上例:
|
||||
>red 值为 0
|
||||
>blue 值为 2
|
||||
>那么 NumColors 值为 3
|
||||
>NumColors 其实 表示的就是这个枚举的总个数
|
||||
>**好处:** 定义数组大小 和 遍历数组的时候就很方便
|
||||
|
||||
示例:
|
||||
```c
|
||||
enum color {
|
||||
red, yellow, blue, NumColors
|
||||
};
|
||||
|
||||
int main(void) {
|
||||
|
||||
char* ColorNames[NumColors] = {
|
||||
"red", "yellow", "blue",
|
||||
};
|
||||
|
||||
char* colorName = NULL;
|
||||
int color = 0;
|
||||
|
||||
printf("输入你喜欢的颜色所对应的代码:\n");
|
||||
scanf("%d", &color);
|
||||
|
||||
if (color >= 0 && color < NumColors)
|
||||
colorName = ColorNames[color];
|
||||
else
|
||||
colorName = "Unknowe";
|
||||
|
||||
printf("%s\n", colorName);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
**枚举量**
|
||||
>声明枚举量的时候可以指定值
|
||||
>如:`enum COLOR {RED = 1,YELLOW , GREEN = 5 };`
|
||||
|
||||
例如:
|
||||
```c
|
||||
enum COLOR { RED = 1, YELLOW, GREEN = 5, NumColors, };
|
||||
|
||||
int main(void) {
|
||||
|
||||
printf("%d\n%d", YELLOW, NumColors);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
输出:
|
||||
```c
|
||||
2
|
||||
6
|
||||
```
|
||||

|
||||
**枚举是不是 int 类型?**
|
||||
```c
|
||||
enum color {
|
||||
red = 1, greem, yellow
|
||||
};
|
||||
|
||||
int main(void) {
|
||||
|
||||
enum color t = 0;
|
||||
|
||||
printf("%d\n", t);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
如果我们让编译器将 `int` 类型的 0 赋给 `enum color` 类型的 t
|
||||
编译器不但不会报错,而且连 warning 都没有
|
||||
但是我们知道 `enum color` 其实是一个我们定义出来的新的类型
|
||||
|
||||
可能现在你对此理解不深刻,等你学了 C++/Java 知道了 类与对象,你就明白了
|
||||
|
||||
因此,我们总结出:
|
||||
|
||||
**枚举的特点**
|
||||
- 枚举 的类型很少使用
|
||||
- 某种情况下,用 枚举 比用 很多`const int`方便
|
||||
- 枚举 比 宏 好,因为它有 int 类型
|
||||
|
||||
### 结构 Struct
|
||||
|
||||
**写在前面**:
|
||||
想理解结构体,不去多看代码,不去自己写是不可能的。
|
||||
|
||||
结构和数组,函数,指针混在一起就导致代码可能很长很乱。这没办法,一定要熬过去,要知道这才是 C语言的精髓 ,也是C++的基础。这里我们用的代码还不是很难。希望大家一定要攻克这里。实在想不通了可以后台私信我或者加入QQ群询问。
|
||||
|
||||
我写这篇文章看多了这些代码也有点头晕,为了小伙伴们,我也是拼了。
|
||||
加油。
|
||||

|
||||
***
|
||||
#### 认识结构体
|
||||
**声明与使用**
|
||||
```c
|
||||
struct date {
|
||||
int year;
|
||||
int month;
|
||||
int day;
|
||||
};
|
||||
|
||||
int main(void) {
|
||||
|
||||
struct date today;
|
||||
|
||||
today.year = 2020;
|
||||
today.month = 2;
|
||||
today.day = 9;
|
||||
|
||||
printf("%d年 - %d月 - %d日\n", today.year, today.month, today.day);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
**声明的三种方式**
|
||||
|
||||
新手法
|
||||
```c
|
||||
struct point {
|
||||
int x;
|
||||
int y;
|
||||
};
|
||||
|
||||
struct point p1, p2;
|
||||
```
|
||||
狠人法
|
||||
```c
|
||||
struct {
|
||||
int x;
|
||||
int y;
|
||||
}p1, p2;
|
||||
//用这种方式后面就无法继续声明 struct 变量了,struct绝种了
|
||||
```
|
||||
常用方法
|
||||
```c
|
||||
struct date {
|
||||
int x;
|
||||
int y;
|
||||
}p1, p2;
|
||||
```
|
||||
###### 从 数组 看 结构体
|
||||
**结构体的初始化**
|
||||
```c
|
||||
struct date {
|
||||
int year;
|
||||
int month;
|
||||
int day;
|
||||
};
|
||||
|
||||
int main(void) {
|
||||
|
||||
struct date today = { 2020, 2, 9 };
|
||||
struct date tomorrow = { .month = 2, .day = 9 };
|
||||
|
||||
printf("%d - %d - %d\n", today.year, today.month, today.day);
|
||||
printf("%d - %d - %d\n", tomorrow.year, tomorrow.month, tomorrow.day);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
输出:
|
||||
```c
|
||||
2020 - 2 - 9
|
||||
0 - 2 - 9
|
||||
```
|
||||
可以看到,有两种初始化方法:
|
||||
当你要初始化 struct 内的所有成员时:
|
||||
1.`struct date today = { 2020, 2, 9 };`
|
||||
当你只想给 struct 内的某几个成员赋值时:
|
||||
2.`struct date tomorrow = { .month = 2, .day = 9 };`
|
||||
|
||||
**没有被赋值的成员被初始化为 0**(类似数组)
|
||||
|
||||
###### 结构运算
|
||||
```c
|
||||
struct date {
|
||||
int year;
|
||||
int month;
|
||||
int day;
|
||||
}p1, p2;
|
||||
|
||||
int main(void) {
|
||||
|
||||
p1 = (struct date){ 2020, 2, 9 };
|
||||
p2 = (struct date){ 1010, 1, 5 };
|
||||
|
||||
p2 = p1;
|
||||
|
||||
printf("%d - %d - %d\n", p2.year, p2.month, p2.day);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
输出:
|
||||
```c
|
||||
2020 - 2 -9
|
||||
```
|
||||
`p1 = (struct date){2020, 2, 9}`
|
||||
等价于 p1.year = 2020,p1.month = 2,p1.day = 9;
|
||||
`p1 = p2 `
|
||||
等价于 p1.year = p2.year ....
|
||||
|
||||
数组是无法无法做这两种运算的
|
||||
|
||||
**指针: 结构体需要取地址**
|
||||
```c
|
||||
struct date today;
|
||||
struct date* ptoday = &today;
|
||||
```
|
||||
数组名本身就是地址,所以数组可以不用 & 符号
|
||||
|
||||
***
|
||||
#### 结构体作为函数参数
|
||||
**明天的日期**
|
||||
*写一个程序:输入今天的日期,求明天的日期*
|
||||

|
||||
看着这个问题简单,实际上稍微有点技巧.
|
||||
给出下面四个特殊日期,大家可以思考一下:
|
||||
|
||||
>2020 - 1 -31
|
||||
>2020 - 11 - 31
|
||||
>2020 - 12 - 31
|
||||
>2000 - 2 - 28
|
||||
|
||||
目测下面这个代码会被我这种喜欢空行的选手写的将近100行,
|
||||
放在文中会影响阅读, 辛苦一下大家,**公众号后台回复 [0209] **获取代码
|
||||
*附:我觉得这个代码不难,不会的加Q群问吧,Q群关注我的公众号即可看到*
|
||||
|
||||
#### 结构指针作为参数
|
||||
>K & R 说过 (p.131)
|
||||
>"if a large structure is to be passed to a function,in is generally more efficent to pass a pointer than to copy the whole structure"
|
||||
>大的结构体指针传参更为高效
|
||||
|
||||
**指针所指的结构变量的成员访问**
|
||||
```c
|
||||
struct date {
|
||||
int month;
|
||||
int day;
|
||||
int year;
|
||||
}myday;
|
||||
|
||||
int main(void) {
|
||||
|
||||
struct date* p = &myday;
|
||||
|
||||
//两种访问指针结构体变量成员方式
|
||||
(*p).month = 12;
|
||||
|
||||
p->month = 12;
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
通常我们用第二种方法,即:
|
||||
>`p->month`
|
||||
>读作 p 所指的 month (英文读作 arrow 箭头)
|
||||
|
||||
来实操一下吧,请听题:
|
||||
>问题描述:
|
||||
>我们 输入整型,浮点型可以直接用
|
||||
>`scanf("%d")`或者`scanf("%lf")`
|
||||
>那么我们可以直接像这样输入一个结构体吗?
|
||||
>答案是我们需要自己写一个函数。
|
||||
>下面程序提供一个思路,可以自己改善/创造你的函数
|
||||
```c
|
||||
struct point {
|
||||
int month;
|
||||
int day;
|
||||
int year;
|
||||
};
|
||||
|
||||
struct point* getStruct(struct point* p);//输入结构体函数
|
||||
|
||||
void outputStruct(struct point p);//输出结构体函数
|
||||
|
||||
void printStruct(const struct point* p);//输出结构体函数
|
||||
|
||||
int main(void) {
|
||||
|
||||
struct point y = { 0, 0, 0 };
|
||||
|
||||
*getStruct(&y);
|
||||
// *getStruct(&y) = (struct point){ 0, 0, 0 };
|
||||
|
||||
outputStruct(y);
|
||||
outputStruct(*getStruct(&y));
|
||||
|
||||
printStruct(&y);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
struct point* getStruct(struct point* p) {
|
||||
|
||||
printf("Input a date\n");
|
||||
scanf("%d", &p->month);
|
||||
scanf("%d", &p->day);
|
||||
scanf("%d", &p->year);
|
||||
|
||||
return p;
|
||||
}
|
||||
|
||||
void outputStruct(struct point p) {
|
||||
|
||||
printf("outputStruct:\n");
|
||||
printf("%d - %d - %d\n", p.month, p.day, p.year);
|
||||
}
|
||||
|
||||
void printStruct(const struct point* p) {
|
||||
|
||||
printf("printStruct:\n");
|
||||
printf("%d - %d - %d\n", p->month, p->day, p->year);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
#### 结构数组
|
||||
**初始化方法**
|
||||
```c
|
||||
struct date {
|
||||
int month;
|
||||
int day;
|
||||
int year;
|
||||
};
|
||||
|
||||
struct date dates[100];
|
||||
struct date datess[2] = { {2, 9, 2020}, {2, 10, 2020} };
|
||||
```
|
||||
>问题描述:
|
||||
>用一个结构数组记录 5 组时间,请求出这组时间下一秒的时间。
|
||||
>和上面年的问题一样,需要考虑进制问题。请思考一下,尝试自己写出。
|
||||
```c
|
||||
struct time {
|
||||
int hour;
|
||||
int minute;
|
||||
int second;
|
||||
};
|
||||
|
||||
struct time* timeUpdate(struct time* p) {
|
||||
|
||||
if (p->second != 59) {
|
||||
p->second++;
|
||||
}
|
||||
else if (p->minute != 59) {
|
||||
p->second = 0;
|
||||
p->minute++;
|
||||
}
|
||||
else if(p->hour != 23){
|
||||
p->second = 0;
|
||||
p->minute = 0;
|
||||
p->hour++;
|
||||
}
|
||||
else {
|
||||
p->second = 0;
|
||||
p->minute = 0;
|
||||
p->hour = 0;
|
||||
}
|
||||
return p;
|
||||
}
|
||||
|
||||
int main(void) {
|
||||
|
||||
struct time testTimes[5] = {
|
||||
{11, 59, 59}, {12, 0, 0}, {1, 29, 59}, {23, 59, 59}, {19, 12, 27}
|
||||
};
|
||||
int i = 0;
|
||||
|
||||
for (i = 0; i < 5; i++) {
|
||||
|
||||
printf("Now the time is:%d - %d - %d\n",
|
||||
testTimes[i].hour, testTimes[i].minute, testTimes[i].second);
|
||||
|
||||
testTimes[i] = *timeUpdate(&testTimes[i]);
|
||||
|
||||
printf("one second letter:%d - %d - %d\n",
|
||||
testTimes[i].hour, testTimes[i].minute, testTimes[i].second);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
#### 嵌套的结构
|
||||
**嵌套的结构引入**
|
||||
```c
|
||||
//这个结构体表示 二维坐标系中点的坐标
|
||||
struct point {
|
||||
int x;
|
||||
int y;
|
||||
};
|
||||
|
||||
//这个结构体表示一个矩形 (两点确定一个矩形)
|
||||
struct rectangle {
|
||||
struct point p1;
|
||||
struct point p2;
|
||||
};
|
||||
|
||||
int main(void) {
|
||||
|
||||
struct rectangle r;
|
||||
r.p1.x;
|
||||
r.p2.y;
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
**嵌套的结构的成员访问**
|
||||
```c
|
||||
struct point {
|
||||
int x;
|
||||
int y;
|
||||
};
|
||||
|
||||
struct rectangle {
|
||||
struct point p1;
|
||||
struct point p2;
|
||||
struct point* p3;
|
||||
};
|
||||
|
||||
int main(void) {
|
||||
|
||||
struct rectangle r, *pr;
|
||||
|
||||
r.p1.x;
|
||||
(r.p1).x;
|
||||
|
||||
pr->p1.x;
|
||||
(pr->p1).x;
|
||||
//为什么访问 point 不需要用 -> 呢?
|
||||
//因为在 rectangle 中 point 并不是指针结构体
|
||||
|
||||
pr->p3->x;
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
**结构中有结构的数组**
|
||||

|
||||
```c
|
||||
struct point {
|
||||
int x;
|
||||
int y;
|
||||
};
|
||||
|
||||
struct rectangle {
|
||||
struct point p1;
|
||||
struct point p2;
|
||||
|
||||
};
|
||||
|
||||
void printStruct(struct rectangle* p, int len) {
|
||||
|
||||
int i = 0;
|
||||
|
||||
for (i = 0; i < len; i++) {
|
||||
|
||||
printf("(%d, %d) (%d, %d)\n", p[i].p1.x, p[i].p1.y, p[i].p2.x, p[i].p2.y);
|
||||
}
|
||||
}
|
||||
|
||||
int main(void) {
|
||||
|
||||
struct rectangle rects[] = {
|
||||
{{2, 2}, {4, 4} },
|
||||
{{5, 6}, {7, 8} }
|
||||
};
|
||||
int len = sizeof(rects) / sizeof(rects[0]);
|
||||
|
||||
printStruct(rects, len);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
***
|
||||
**测试一下:**
|
||||
1.有下列代码段,则输出结果为:
|
||||
```c
|
||||
struct {
|
||||
int x, y;
|
||||
} s[2] = {
|
||||
{1, 3},
|
||||
{2, 7}
|
||||
};
|
||||
|
||||
printf("%d\n",s[0].y / s[1].x);
|
||||
```
|
||||
A: 0
|
||||
B: 1
|
||||
C: 2
|
||||
D: 3
|
||||
|
||||
2.有如下变量定义,则对data中的a的正确引用是:
|
||||
```c
|
||||
struct sk {
|
||||
int a;
|
||||
float b;
|
||||
}data , *p = & data;
|
||||
```
|
||||
A: (*p).data.a;
|
||||
B: (*p).a;
|
||||
C: p->data.a;
|
||||
D: p.data.a;
|
||||
|
||||
3.以下两行代码是否出现在一起?
|
||||
```c
|
||||
struct { int x; int y; }x;
|
||||
struct { int x; int y; }y;
|
||||
```
|
||||
A: √
|
||||
B: ×
|
||||
|
||||
公众号回复[0209 2]获取答案。
|
||||
***
|
||||
**关于结构体的内存对齐等问题我们以后再说**
|
||||
|
||||
### 联合
|
||||
#### typedef 关键字
|
||||
**自定义类型**
|
||||
>**关键字**:`typedef`
|
||||
|
||||
例如:
|
||||
```c
|
||||
typedef long int64_t;
|
||||
|
||||
typedef struct Adate {
|
||||
int month;
|
||||
int day;
|
||||
int year;
|
||||
}date;
|
||||
|
||||
int main(void) {
|
||||
|
||||
int64_t i = (int64_t)1e+10;
|
||||
date d = { 2, 10, 2020 };
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
- 新的名字是某种类型的别名
|
||||
- 改善了程序的可读性
|
||||
|
||||
请看下面这两段代码,你能分别出他们的意思是什么吗?
|
||||
```c
|
||||
struct {
|
||||
int month;
|
||||
int day;
|
||||
int year;
|
||||
}Date;
|
||||
```
|
||||
```c
|
||||
typedef struct {
|
||||
int month;
|
||||
int day;
|
||||
int year;
|
||||
}Date;
|
||||
```
|
||||
第一个表示:一个没有名字的结构体类型 它有一个结构体变量 Date
|
||||
第二个表示:将这个结构体类型重定义为 Date
|
||||
如果你用你的编译器敲一下这段代码,会发现这两段代码的 Date 的颜色是不一样的
|
||||
|
||||
#### 认识 联合
|
||||
**特点:**
|
||||
- 所有成员共享一个空间
|
||||
- 同一时间只有一个成员是有效的
|
||||
- union的大小是其最大的成员
|
||||
|
||||
怎么去理解?请看下面程序,以32位机器为例
|
||||
```c
|
||||
union AnEit {
|
||||
int i;
|
||||
char c;
|
||||
}elt1, elt2;
|
||||
|
||||
int main(void) {
|
||||
|
||||
elt1.i = 4;
|
||||
elt2.c = 'a';
|
||||
elt2.i = 0xDEADBEEF;
|
||||
//程序运行到这里,union 所占内存中存储的内容如下:
|
||||
//1. 可以看出 union 的大小为 4 个字节(int 的大小)
|
||||
//2. elt2 中的 char c 已经被后面赋值 的int i所覆盖
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
#### union 的常用场景
|
||||
先看一下这段程序:
|
||||
```c
|
||||
typedef union {
|
||||
int i;
|
||||
char ch[sizeof(int)];
|
||||
}CHI;
|
||||
|
||||
int main(void) {
|
||||
|
||||
CHI chi;
|
||||
int i;
|
||||
chi.i = 1234;
|
||||
for (i = 0; i < sizeof(int); i++) {
|
||||
printf("%02hhx", chi.ch[i]);
|
||||
//"%02x",是以0补齐2位数,如果超过2位就显示实际的数;
|
||||
//"%hhx" 是只输出2位数,即便超了,也只显示低两位
|
||||
}
|
||||
printf("\n");
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
它的输出是:
|
||||
```c
|
||||
d2040000
|
||||
```
|
||||
这说明了chi的内存存储情况:
|
||||
|
||||
我们用计算机看一下 16 进制的 1234 是什么样子:
|
||||

|
||||
chi的大小是 4个字节,我们可以表示 chi.i 为
|
||||
00 00 04 D2
|
||||
|
||||
**这种 高位(d2) 放在 低地址; 低位 (00)放在 高地址**的存储模式叫做 **小端**
|
||||
我们现在用的 x86 的机器 基本都是这种存储方式。
|
||||
|
||||
**我们可以利用 union 得到一个 int 或者 double 等等的内部的字节**
|
||||
这是一个有用的工具。当我们讲到文件时候,大家就对它的功能有更熟悉的理解了。
|
||||
|
||||
626
content/c-notes/什么是 全局变量 & 宏 & 大程序怎么写,看这一篇就够了.md
Normal file
626
content/c-notes/什么是 全局变量 & 宏 & 大程序怎么写,看这一篇就够了.md
Normal file
@@ -0,0 +1,626 @@
|
||||
### 全局变量
|
||||
#### 认识 全局变量
|
||||
- 定义在函数外的变量就是全局变量
|
||||
- 全局变量具有全局的生存期和作用域
|
||||
- 它们与任何函数无关
|
||||
- 任何函数(定义在全局变量后的的函数)内部都可以使用它们
|
||||
|
||||
例如:
|
||||
```c
|
||||
int f(void);
|
||||
|
||||
int gAll = 12;
|
||||
|
||||
int main(void){
|
||||
|
||||
//__func__ 可以打印出当前函数的函数名,下划线一边是两个
|
||||
printf("in %s gAll = %d\n", __func__, gAll);
|
||||
//全局变量可以直接使用,不需要再声明
|
||||
f();
|
||||
printf("again in %s gAll = %d\n", __func__, gAll);
|
||||
//函数内对全局变量值的改变在 main函数中依然存在
|
||||
return 0;
|
||||
}
|
||||
|
||||
int f(void) {
|
||||
|
||||
printf("in %s gAll = %d\n", __func__, gAll);
|
||||
gAll += 2;
|
||||
printf("again in %s gAll = %d\n", __func__, gAll);
|
||||
|
||||
return gAll;
|
||||
}
|
||||
```
|
||||
输出:
|
||||
```c
|
||||
in main gAll = 12
|
||||
in f gAll = 12
|
||||
again in f gAll = 14
|
||||
again in main gAll = 14
|
||||
```
|
||||
###### 全局变量的初始化
|
||||
- 没有初始化的全局变量**默认值为 0**
|
||||
- 指针默认为 **NULL**
|
||||
- 只能用**编译时刻已知**[^1]的值来初始化全局变量
|
||||
- 全局变量的初始化发生在main函数之前
|
||||
|
||||
注释1:
|
||||
```c
|
||||
int gAll = 12;
|
||||
int g = gAll;//报错
|
||||
|
||||
int main(void) {
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
下面这段代码在某些编译器(dev c++)上是可以编译的,但是在 vs 上是不能编译的
|
||||
```c
|
||||
const int gAll = 12;
|
||||
int g = gAll;
|
||||
|
||||
int main(void) {
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
**但是,这种方式是不推荐的**
|
||||
|
||||
###### 被隐藏的全局变量
|
||||
- 如果函数内部存在与全局变量同名的变量,则全局变量被隐藏。
|
||||
|
||||
```c
|
||||
int f(void);
|
||||
|
||||
int gAll = 12;
|
||||
|
||||
int main(void) {
|
||||
|
||||
printf("in %s gAll = %d\n", __func__, gAll);
|
||||
|
||||
f();
|
||||
|
||||
printf("again in %s gAll = %d\n", __func__, gAll);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
int f(void) {
|
||||
|
||||
int gAll = 2;//仅在这个范围内适用
|
||||
printf("in %s gAll = %d\n", __func__, gAll);
|
||||
gAll += 2;
|
||||
printf("again in %s gAll = %d\n", __func__, gAll);
|
||||
|
||||
return gAll;
|
||||
}
|
||||
```
|
||||
输出:
|
||||
```c
|
||||
in main gAll = 12
|
||||
in f gAll = 2
|
||||
again in f gAll = 4
|
||||
again in main gAll = 12
|
||||
```
|
||||
即使 gAll 在 main 函数中被覆盖,f 函数中的 gAll 也是不会被该改变的
|
||||
|
||||
为什么会这样?自己思考一下。
|
||||
|
||||
#### 静态本地变量
|
||||
- 在本地变量定义时加上 static 修饰符就成为静态本地变量
|
||||
- 当离开函数的生存期后,静态本地变量会继续存在并保持其值
|
||||
- 静态本地变量的初始化只会在第一次进入这个函数时进行,以后进入函数时会保持上次离开时的值。
|
||||
|
||||
例:
|
||||
**不用static**的情况
|
||||
```c
|
||||
int f(void);
|
||||
|
||||
int main(void) {
|
||||
|
||||
f();
|
||||
f();
|
||||
f();
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
int f(void) {
|
||||
|
||||
int All = 1;
|
||||
printf("in %s All = %d\n", __func__, All);
|
||||
All += 2;
|
||||
printf("again in %s All = %d\n", __func__, All);
|
||||
|
||||
return All;
|
||||
}
|
||||
```
|
||||
输出:
|
||||
```c
|
||||
in f All = 1
|
||||
again in f All = 3
|
||||
in f All = 1
|
||||
again in f All = 3
|
||||
in f All = 1
|
||||
again in f All = 3
|
||||
```
|
||||
|
||||
**使用static**:
|
||||
```c
|
||||
int f(void);
|
||||
|
||||
int main(void) {
|
||||
|
||||
f();
|
||||
f();
|
||||
f();
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
int f(void) {
|
||||
|
||||
static int All = 1;//只添加 static
|
||||
printf("in %s All = %d\n", __func__, All);
|
||||
All += 2;
|
||||
printf("again in %s All = %d\n", __func__, All);
|
||||
|
||||
return All;
|
||||
}
|
||||
```
|
||||
输出:
|
||||
```c
|
||||
in f All = 1
|
||||
again in f All = 3
|
||||
in f All = 3
|
||||
again in f All = 5
|
||||
in f All = 5
|
||||
again in f All = 7
|
||||
```
|
||||
**看看地址**
|
||||
```c
|
||||
int f(void);
|
||||
|
||||
int gAll = 12;
|
||||
|
||||
int main(void) {
|
||||
|
||||
printf("1 st\n");
|
||||
f();
|
||||
printf("2 nd\n");
|
||||
f();
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
int f(void) {
|
||||
|
||||
int a = 0;
|
||||
int b = 0;
|
||||
static int All = 1;
|
||||
|
||||
printf("&All : %p\n", &All);
|
||||
printf("&gAll: %p\n", &gAll);
|
||||
printf("&a : %p\n", &a);
|
||||
printf("&b : %p\n", &b);
|
||||
|
||||
return All;
|
||||
}
|
||||
```
|
||||
输出:
|
||||
```c
|
||||
1 st
|
||||
&All : 00007FF6A9ECC054
|
||||
&gAll: 00007FF6A9ECC050
|
||||
&a : 000000E8815CF8B4
|
||||
&b : 000000E8815CF8D4
|
||||
2 nd
|
||||
&All : 00007FF6A9ECC054
|
||||
&gAll: 00007FF6A9ECC050
|
||||
&a : 000000E8815CF8B4
|
||||
&b : 000000E8815CF8D4
|
||||
```
|
||||
全局变量 gAll 与 静态局部变量 All 在内存中相邻
|
||||
|
||||
**总结**
|
||||
- 静态本地变量实际上是特殊的全局变量
|
||||
- 它们位于相同的内存区域
|
||||
- 静态本地变量具有全局的生存期,函数内的局部作用域
|
||||
|
||||
#### 返回指针的函数
|
||||
请同学们先看一下下面这个程序:
|
||||
|
||||
```c
|
||||
int* f(void);
|
||||
void g(void);
|
||||
|
||||
int main(void) {
|
||||
|
||||
int* p = f();
|
||||
printf("*p = %d\n", *p);
|
||||
g();
|
||||
printf("*p = %d\n", *p);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
int* f(void) {
|
||||
|
||||
int i = 12;
|
||||
|
||||
return &i;
|
||||
}
|
||||
void g(void) {
|
||||
|
||||
int k = 24;
|
||||
|
||||
printf("k = %d\n", k);
|
||||
|
||||
return k;
|
||||
}
|
||||
```
|
||||
输出:
|
||||
```c
|
||||
*p = 12
|
||||
k = 24
|
||||
*p = 24
|
||||
```
|
||||
**i 和 k 的内存其实是同一块空间**
|
||||
|
||||
**总结**
|
||||
|
||||
- 返回 **本地变量** 的地址是危险的
|
||||
- 返回 **全局变量** 或 **静态局部变量** 的地址是安全的
|
||||
- 返回函数内 malloc 的内存是安全的,但是容易造成问题
|
||||
- 最好的做法是**返回传入的指针**
|
||||
|
||||
说了这么多,总结一句话
|
||||
###### 尽量避免使用 全局变量 和 静态本地变量
|
||||

|
||||
为什么这里就不深讲了,有兴趣的朋友可以下来自己查查。
|
||||
|
||||
***
|
||||
### 编译预处理 与 宏
|
||||
|
||||
#### 编译预处理指令
|
||||
- `#` 开头的是编译预处理指令
|
||||
- 它们不是 C语言的一部分,但是 C语言离不开他们
|
||||
- `#define` 用来定义一个宏
|
||||
|
||||
#### define 关键字
|
||||
回想我们刚学 double 的时候,是不是计算过圆的面积。当时我们可能是这样写的:
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
const double PI = 3.14159;
|
||||
|
||||
int main(void) {
|
||||
|
||||
printf("%f\n", 2 * PI * 3.0);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
现在我们用 宏 就不需要用 const 修饰的全局变量了,我们也说过,全局变量最好不用。
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
#define PI 3.14159
|
||||
//注意:不写分号 不写等于号
|
||||
|
||||
int main(void) {
|
||||
|
||||
printf("%f\n", 2 * PI * 3.0);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
现在,我们打开我们的虚拟机,进入 Linux 系统。
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||

|
||||
现在多出来了 4 个文件,蓝色的是文件夹,我们不去管它,绿色的是可执行文件,类似 windows 的 .exe 文件
|
||||
现在我们主要关注这 3 个中间文件
|
||||
|
||||

|
||||
一个 c文件编译的过程文件变化是这样的:
|
||||
>`.c `(处理编译预处理指令)-> `.i `(产生汇编代码)-> `.s`(汇编生成目标文件) -> `.o`(链接等) -> `a.out `
|
||||
>
|
||||
|
||||
可以看到 .i 文件时很大
|
||||

|
||||

|
||||
**我们发现程序中的宏 PI 被换成了它所表示的 数字**
|
||||
|
||||
这种替换是**简单的文本替换**,我们再试试其他的替换方式:
|
||||
|
||||

|
||||

|
||||
我们再试试这样,定义宏的时候 不带双引号:
|
||||

|
||||

|
||||
因此可知,**被 `" "`扩起来的字符串 宏 是不会替换的**
|
||||
|
||||
###### 总结
|
||||
- 格式: `#define <名字> <值>`
|
||||
- 注意结尾没有分号,因为不是 C 的语句
|
||||
- 名字必须是一个单词,值可以是任何(注意字符串替换定义时需要带引号)
|
||||
- 在 **C语言的编译器开始编译之前**,编译预处理程序(cpp)会把程序中的宏的名字替换为值
|
||||
- linux/unix
|
||||
- 编译并保留中间文件指令:`gcc --save-temps`
|
||||
- 查看文件结尾:`tail`
|
||||
|
||||
###### 宏
|
||||
- 如果在一个宏的值中有其他宏的名字,这些宏也是会被替换的
|
||||
- 如果一个宏的值超过一行,最后一行之前的行末需要加 \
|
||||
- 宏的值后面出现的注释不会被当作宏的值的一部分
|
||||
|
||||
###### 没有值的宏
|
||||
- `#define _DEBUG`
|
||||
- ` #define _CRT_SECURE_NO_WARNINGS` 用 VS 的应该都知道这个吧,加上这个你就可以直接用`scanf`而不是`scanf_s`了
|
||||
>这类宏是用来做条件编译的,后面有其他编译预处理指令来检查这个宏是否已经被定义过了。
|
||||
>比如有这个宏执行这部分代码,没有则执行另外一部分
|
||||
|
||||
###### 预定义的宏
|
||||
- `__LINE__`
|
||||
- `__FILE__`
|
||||
- `__DATE__`
|
||||
- `__TIME__`
|
||||
- `__STDC__`
|
||||
|
||||
我们来试着用一下:
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
printf("%s : %d\n", __FILE__, __LINE__);
|
||||
printf("%s %s\n", __DATE__, __TIME__);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
输出:
|
||||
```c
|
||||
D:\vscode\练习\12-31\Project1\oj.c : 174
|
||||
Feb 11 2020 04:12:57
|
||||
```
|
||||
值得注意的是,`__LINE__`表示的是它自己所在的行数
|
||||
|
||||
你们在熟睡,而我还在给你们写教学,关注我/点个赞/转发 不过分吧~
|
||||
|
||||

|
||||
#### 带参数的宏
|
||||
- `#define cube(x) ( (x) * (x) * (x) )`
|
||||
|
||||
例如:
|
||||
```c
|
||||
#define cube(x) ((x) * (x) * (x))
|
||||
|
||||
int main(void) {
|
||||
|
||||
printf("%d\n", cube(5));
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
输出:
|
||||
```c
|
||||
125
|
||||
```
|
||||
**容易犯的错误**
|
||||
|
||||
一下这两种写法在程序中会不会有问题?
|
||||
- `#define ERROR(1x) (x * 57)`
|
||||
- `#define ERROR2(x) (x) * 57`
|
||||
|
||||
思考一下这个程序会的到你想要的结果吗?
|
||||
```c
|
||||
#define ERROR1(x) (x * 57)
|
||||
#define ERROR2(x) (x) * 57
|
||||
|
||||
int main(void) {
|
||||
|
||||
printf("%d\n", ERROR(1 + 2));
|
||||
printf("%d\n", 300 / ERROR(1));
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
输出:
|
||||
```c
|
||||
115
|
||||
17100
|
||||
```
|
||||
为什么会这样呢?我们不妨来看一下,`.i`文件内部:
|
||||
|
||||

|
||||
**定义带参数的宏的原则**
|
||||
- 一切都要有括号
|
||||
- 整个值有括号
|
||||
- 每个参数都有括号
|
||||
|
||||
所以,上面错误的例子的正确的写法就是:
|
||||
`#define ERROR ( (x) * 57 )`
|
||||
|
||||
**带参数的宏的更多用法**:
|
||||
- `#define MIN(a, b) ((a) > (b) ? (b) : (a))`
|
||||
|
||||
**定义宏切记不要加分号**
|
||||
|
||||
错误示范:
|
||||
```c
|
||||
#define PRETTY_PRINT(msg) printf(msg);
|
||||
|
||||
int main(void) {
|
||||
|
||||
int n = 0;
|
||||
|
||||
printf("Input an number\n");
|
||||
scanf("%d", &n);
|
||||
|
||||
if (n < 10)
|
||||
PRETTY_PRINT("less than 10\n");
|
||||
else
|
||||
PRETTY_PRINT("more than 10\n");
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
VS 会报错 :没有匹配 if 的非法 else,为什么呢?
|
||||
|
||||
因为如果你在宏后面加了 `;`,你又在 if 内的语句后加了`;`
|
||||
这样在`.i`的阶段,if 后的语句有了两个 `;`,即:
|
||||
`PRETTY_PRINT("less than 10\n");;`
|
||||
第二个`;`表示 一个空语句,这样 else 前面就没有对象可以匹配了
|
||||
|
||||
###### 总结
|
||||
- **#开头的预处理指令并不是 C语言独有的内容**
|
||||
- **宏的参数时没有类型的**
|
||||
- 大型程序中宏的使用很常见
|
||||
- 宏可以很复杂,可以产生函数
|
||||
- 使用运算符 `#` 和 `##`
|
||||
- 部分宏会被 `inline`函数取代
|
||||
- 中西方差异(国人少用)
|
||||
|
||||
***
|
||||
Quiz:
|
||||
请看下面的代码片段,判断这段程序会输出什么?
|
||||
```c
|
||||
|
||||
#define TOUPPER(c) ('a' <= (c) && (c) <= 'z' ? (c) - 'a' + 'A' : (c))
|
||||
|
||||
int i = 0;
|
||||
char s[1000];
|
||||
|
||||
strcpy(s, "abcd");
|
||||
|
||||
putchar(TOUPPER(s[++i]));
|
||||
|
||||
```
|
||||
A: B
|
||||
B: C
|
||||
C: D
|
||||
D: E
|
||||
|
||||
*这道题是需要都脑子的呦!*
|
||||
公众号后台回复:**0211 1** 查看答案和解析
|
||||
***
|
||||
### 大程序结构
|
||||
#### 多个源代码文件
|
||||
###### 多个源文件`.c`
|
||||
**引入**
|
||||
回想我们学习的过程,开始是 main()里的代码太长了,我们学习了函数,将其分开
|
||||
现在如果 一个源文件太长了,我们就可以将其分成几个源文件
|
||||
|
||||
**怎么让多个源文件联系起来?**
|
||||
在编译器上创建一个项目,将你想操作的 .c 文件放到同一个项目中
|
||||
|
||||
#### 头文件 `.h`
|
||||
###### **`" " ` 还是 `< >` ?**
|
||||
- `#include`有两种形式来指出要插入的文件
|
||||
- `" "`要求编译器首先在当前目录(.c 文件所在目录)寻找这个文件;如果没有,再去编译器指定的目录寻找。**自己的头文件用**
|
||||
- `< >`让编译器只在指定位置寻找 **。系统的头文件用**
|
||||
- 编译器知道自己的标准库的头文件在哪里
|
||||
- 环境变量 和 编译器命令行参数也可以指定寻找头文件的目录
|
||||
|
||||
###### **`#include`的误区**
|
||||
- `#include`不是用来引入库的
|
||||
- `stdio.h ` 中只有函数的声明,函数的定义在其他的地方
|
||||
- C语言编译器默认会引入所有标准库
|
||||
- `#include<stdio.h>`的作用其实就是将 这个头文件的所有内容 插入到这个文件中来。目的是让编译器知道你使用的函数时所给的参数是否正确。(类似函数的声明)
|
||||
|
||||
**为什么不引用 `stdlib.h` 依然可以使用 `malloc ` ?**
|
||||
这时因为在你调用函数前没有声明函数(引入头文件),编译器回去猜测 参数 和 函数返回类型都为 `int`型
|
||||
恰好 `malloc` 的参数 `size_t` 是 `long int` ,返回值是个指针,也可以看作是 16进制的 整型。
|
||||
|
||||
*[为什么?可以参考我的另一篇文章,点击跳转](https://mp.weixin.qq.com/s/JEalmGOwNXp9IM0W7B7YJw
|
||||
)*
|
||||
|
||||
###### 头文件
|
||||
- 使用和定义函数的地方都应该包含这个头文件
|
||||
- 将 函数声明 全局变量 放入 `.h`文件
|
||||
|
||||
###### 不对外公开的 函数&变量
|
||||
函数&全局变量前加上 `static`就使得这个 函数/变量 只能在当前文件中被使用
|
||||
|
||||
### 声明
|
||||
###### extern
|
||||
当一个c 文件想调用另一个 c文件中定义的全局变量时
|
||||
需要在头文件中加上 `extern <类型> <变量名>` 来声明这个变量
|
||||
|
||||
例如:
|
||||
```c
|
||||
<1.c>
|
||||
int gAll = 12;
|
||||
|
||||
<2.c>
|
||||
printf("%d\n", gAll);
|
||||
|
||||
<1.h>
|
||||
extern int gAll;
|
||||
```
|
||||
**声明不产生代码**
|
||||
|
||||
###### 避免重复声明
|
||||
请看下例:
|
||||
```c
|
||||
<1.h>
|
||||
int a ;
|
||||
|
||||
<2.h>
|
||||
#include"1.h"
|
||||
|
||||
<3.h>
|
||||
#include"1.h"
|
||||
//相当于
|
||||
//int a
|
||||
|
||||
#include"2.h"
|
||||
//相当于
|
||||
//#include"1.h"
|
||||
//相当于
|
||||
//int a ;
|
||||
|
||||
//可以看到, int a 被重定义的
|
||||
```
|
||||
如何避免上述这种重定义情况?
|
||||
|
||||
###### 条件编译和宏
|
||||
- 运用条件编译和宏,保证这个头文件在一个编译单元中只会被 include 一次
|
||||
- `#pragma once`也能起到相同作用,但不是所有的编译器都支持
|
||||
```c
|
||||
#ifdef _MAIN_H_//先看 这个宏是否定义过,是:继续 不是:跳过这个结构。跳过的意思是编译时将不再向 .i 文件中插入这段代码
|
||||
#define _MAIN_H_//没有定义,则定义
|
||||
|
||||
#endif
|
||||
```
|
||||
这就是我们前面说的预定义的宏的一种使用方法。
|
||||
应用这种方法我们再看上例
|
||||
|
||||
```c
|
||||
<1.h>
|
||||
#ifdef _FIRST_H_
|
||||
#define _FIRST_H_
|
||||
|
||||
int a ;
|
||||
|
||||
#endif
|
||||
<2.h>
|
||||
#include"1.h"
|
||||
|
||||
<3.h>
|
||||
#include"1.h"
|
||||
//相当于:
|
||||
//#ifdef _FIRST_H
|
||||
//#define _FIRST_H
|
||||
//int a ;
|
||||
//#endif
|
||||
#include"2.h"
|
||||
//相当于:
|
||||
//#include"1.h"
|
||||
//这时,_FIRST_H 已经被定义,则跳过
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
232
content/c-notes/关于字符串你不知道的知识点.md
Normal file
232
content/c-notes/关于字符串你不知道的知识点.md
Normal file
@@ -0,0 +1,232 @@
|
||||
# 字符串入门
|
||||
### 字符串基础:
|
||||
#### 基本概念:
|
||||
- 以 0 结尾的一串字符
|
||||
- 0 和 '\0' 是一样的,但是与 ’0‘ 不同
|
||||
- 0标志着字符串的结束,但它不是字符串的一部分
|
||||
- 计算字符串长度不包括这个0
|
||||
- 字符串以数组的形式存在,以数组或指针的形式访问(更多以指针形式)
|
||||
- 头文件 string.h
|
||||
|
||||
#### 表示方法
|
||||
```c
|
||||
char* str = "Hello";
|
||||
char string[] = "Hello";
|
||||
char line[10] = "Hello";
|
||||
```
|
||||
#### 字符串常量
|
||||
- 形如"Hello"这样**被双引号引起来的字符串**就叫字符串常量(字面量)
|
||||
- **字符串常量**:"Hello"
|
||||
**大小** 6 加上结尾表示结束的0
|
||||
- C的编译器会将**两个连续的字符串连接起来**
|
||||
- 字符串常量通常放在 `代码段`,这个区域的数据通常是只读的
|
||||
|
||||
比如:
|
||||
```c
|
||||
printf("Hello","world");
|
||||
```
|
||||
这样会输出
|
||||
```c
|
||||
Hello World
|
||||
```
|
||||
**或者你也可以这样写:**
|
||||
这种写法在我的计算机上提示有语法错误,那位大佬能指导一下?(翁恺老师可以在这样写,难道是C99语法。。。)
|
||||
```c
|
||||
printf("Hello \
|
||||
World");
|
||||
```
|
||||
#### 注意
|
||||
- 不能对字符串做运算
|
||||
- 可通过数组方式遍历字符串
|
||||
- 可以通过字符串常量来初始化字符串数组
|
||||
|
||||
### 字符串输入输出
|
||||
```c
|
||||
char* str = "Hello";
|
||||
//输入
|
||||
scanf("%s",string);
|
||||
//输出
|
||||
printf("%s",string);
|
||||
```
|
||||
**读取方式**
|
||||
|
||||
可以用以下程序测试:
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char str1[4];
|
||||
char str2[4];
|
||||
|
||||
scanf("%s", str1);
|
||||
scanf("%s", str2);
|
||||
|
||||
printf("%s##%s", str1, str2);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
- `scanf`读入一个单词(遇到 **空格**,**tab**,**回车** 结束)
|
||||
- `scanf`不安全,因为不知道读入的内容的长度
|
||||
|
||||
**安全的输入**
|
||||
>`scanf("%3s",str1)`
|
||||
>% 与 s 之间的数字表示,最多允许读入的字符数量,这个数的最大值应该等于 `数组大小 - 1`
|
||||
|
||||
请看下面的程序:
|
||||
分别输入以下两组值,会输出什么?
|
||||
1234 1234
|
||||
123 123
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char str1[4];
|
||||
char str2[4];
|
||||
|
||||
scanf("%3s", str1);
|
||||
scanf("%s", str2);
|
||||
|
||||
printf("%s##%s", str1, str2);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
```c
|
||||
//1
|
||||
123 4
|
||||
//2
|
||||
123 123
|
||||
```
|
||||

|
||||
**注意**
|
||||
`char buffer[100] = ""`(""是紧挨的,下同)
|
||||
它的意思是 `buffer[0] == '\0'` 表示空字符串
|
||||
`char buffer[] = ""`
|
||||
它表示字符串长度为1
|
||||
|
||||
我们不妨来测试一下:
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char buffer1[100] = "";
|
||||
char buffer2[] = "";
|
||||
|
||||
printf("%c %d\n", buffer1[0], sizeof(buffer1));
|
||||
printf("%c %d\n", buffer2[0], sizeof(buffer2));
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
输出
|
||||
```c
|
||||
100
|
||||
1
|
||||
```
|
||||
**0 用%c 的格式输出为空格**
|
||||
|
||||
### 字符串数组 — 指针数组的一类
|
||||
这里我们重点介绍 字符串数组。什么是指针数组,可以参考我CSDN上的这篇文章:
|
||||
[[C语言复习巩固]指针(入门)](https://blog.csdn.net/qq_44954010/article/details/103742120)
|
||||
|
||||
#### char* str1[5] 与char str2[5][10]
|
||||
![char* a[] 与char a[][10]在栈中的不同](https://img-blog.csdnimg.cn/20200205151248503.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ0OTU0MDEw,size_16,color_FFFFFF,t_70)
|
||||
从上图可以看出,char* str1[5] 内存放的是**字符串的指针**,指向了一个地址
|
||||
而char str2[5][10]则是在栈中开辟了50char大小的空间来存放这些字符
|
||||
|
||||
下面的程序通过初始方式来帮助你理解两者的不同:
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char Str1[10] = "Hello";
|
||||
char Str2[10];
|
||||
char Str3[10];
|
||||
char Str4[10];
|
||||
char Str5[10] = "World";
|
||||
|
||||
char* str1[5] = {Str1, Str2, Str3, Str4, Str5};
|
||||
char str2[5][10] = {
|
||||
"Hello",//注意写逗号
|
||||
"",
|
||||
"",
|
||||
"",
|
||||
"World"};
|
||||
|
||||
str1[1] = " Goodbye";
|
||||
//str2[1] = " Goodbye";//报错:表达式必须是可修改的左值
|
||||
scanf("%s", str2[1]);
|
||||
|
||||
printf("%s", str1[0]);
|
||||
printf("%s\n", str1[4]);
|
||||
printf("%s ", str2[0]);
|
||||
printf("%s\n", str2[4]);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
#### 字符串数组的一个应用
|
||||
**写一个程序。输入一个数代表月份,输出这个月的英语单词。**
|
||||
|
||||
我们可以用 if else 来做也可以用 switch 来做。但是今天学习了字符串数组,我们有了更简单的方式来完成。
|
||||
|
||||
请看下面的程序:
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char* str[12] = { "January", "February", "March", "April", "May", "June",
|
||||
"July", "August", "September", "October", "November", "Decenmber",
|
||||
};
|
||||
int month = 0;
|
||||
|
||||
while (1) {
|
||||
printf("input a month\n");
|
||||
scanf("%d", &month);
|
||||
|
||||
if (month >= 1 && month <= 12)
|
||||
printf("%s\n", str[month - 1]);
|
||||
else
|
||||
printf("invalid input\n");
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
这样写代码被大大缩短了
|
||||
|
||||
#### main函数的参数?
|
||||
通常我们写 main 函数会这样写:
|
||||
`int main()` ,这样写其实并不严谨。
|
||||
但这并不是大家的错,是谭老师没教好。
|
||||
如果你的main函数没有参数,从今天起我们都这样写`int main(void)`,为什么呢?
|
||||
首先你的main函数和大多初学者不一样,可以装一装大佬。
|
||||

|
||||
其次,我们知道,main函数也是函数,是被其他函数调用的。这个在我函数的文章中讲解过。感兴趣的朋友可以看一下。[点击查看](https://mp.weixin.qq.com/s/JEalmGOwNXp9IM0W7B7YJw)
|
||||
|
||||
这是mian函数有参数的形式(我们在这里简化了一下,方便理解)
|
||||
`int main(int argc, char* argv[])`
|
||||

|
||||
>`int argc` 是字符串数组`char* argv[]`的大小 (也称“参数计数” ,是命令行参数的数量)
|
||||
>`int argv[]` 也称“参数向量” 是指向命令行参数的指针数组
|
||||
>`argv[0]`指向可执行程序的名称(.exe)
|
||||
>`argv[1] ~ argv[argc - 1]` 指向实际参数,也就是命令行
|
||||
>`argv[argc]`是空指针NULL
|
||||
|
||||
如果你不知道我上面写的是什么,那么就要注意啦!其他的都是开玩笑,这里才是这一节的重点。
|
||||
***
|
||||
一下内容面向小白,大佬可以跳过这一段
|
||||
|
||||
什么是命令行?
|
||||
|
||||
看完这篇文章后,去搜索一下linux是什么以及linux对程序员有什么用相关问题。如果你有收获,分享一下这篇文章不过分吧
|
||||
|
||||
命令行说白了就是一个替代你鼠标的东西,它可以让你更加高效的去做很多事情。
|
||||
比如在win10下你在键盘上按下 `win + R` 然后再跳出的窗口里输入 `cmd` 打开的小黑窗口其实就是命令行窗口。在这个窗口里你可以输入指令,来完成各种事情。比如基础的`dir` 展示当前目录下内容 `cd`进入文件夹
|
||||
`cd .. `退出文件夹等等。
|
||||
***
|
||||
为了更深入的了解mian函数的参数有什么用,我们在实际的程序中来感受一下。
|
||||
|
||||
**用main函数的参数实现的 命令行中 两个整数的 四则运算**
|
||||
|
||||
先看一下程序运行的效果:
|
||||
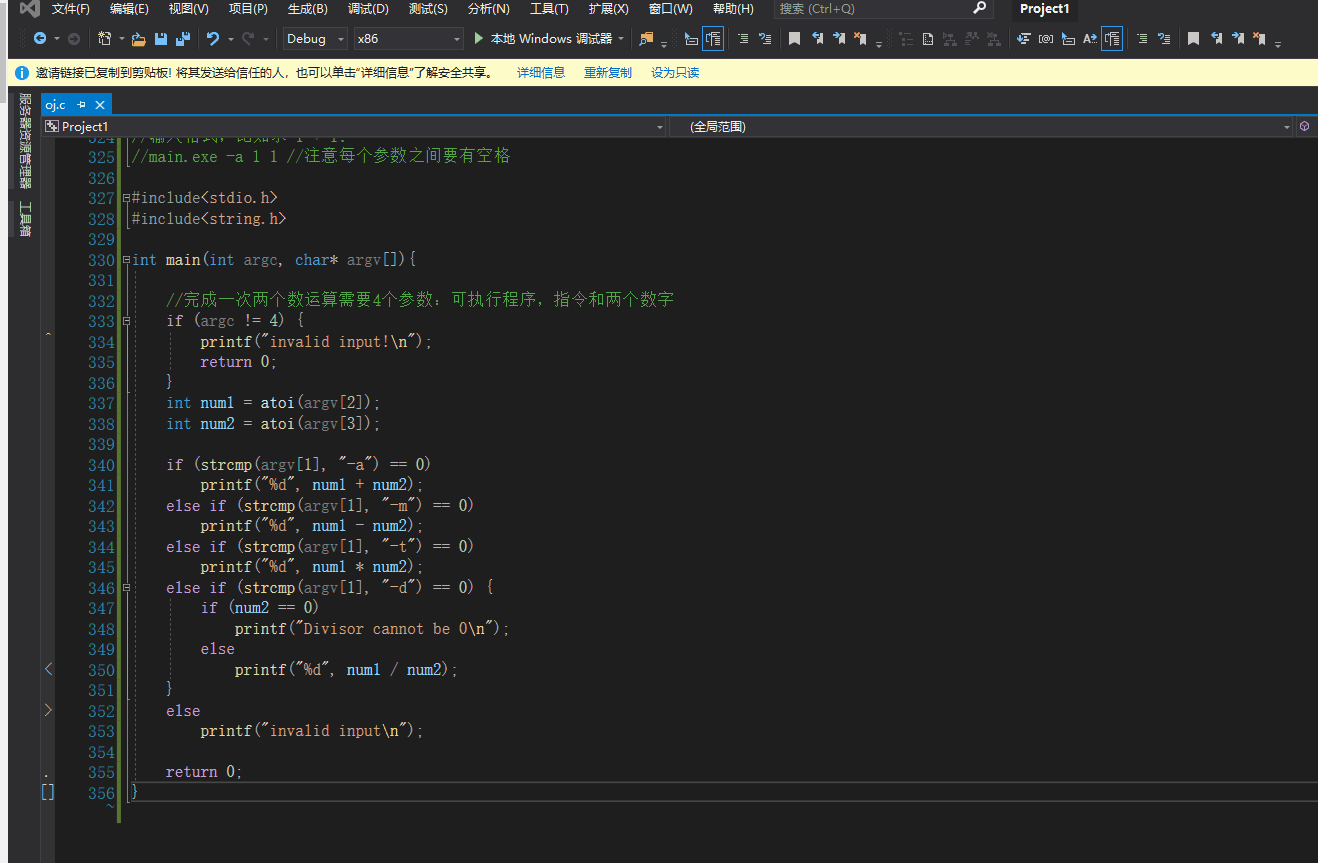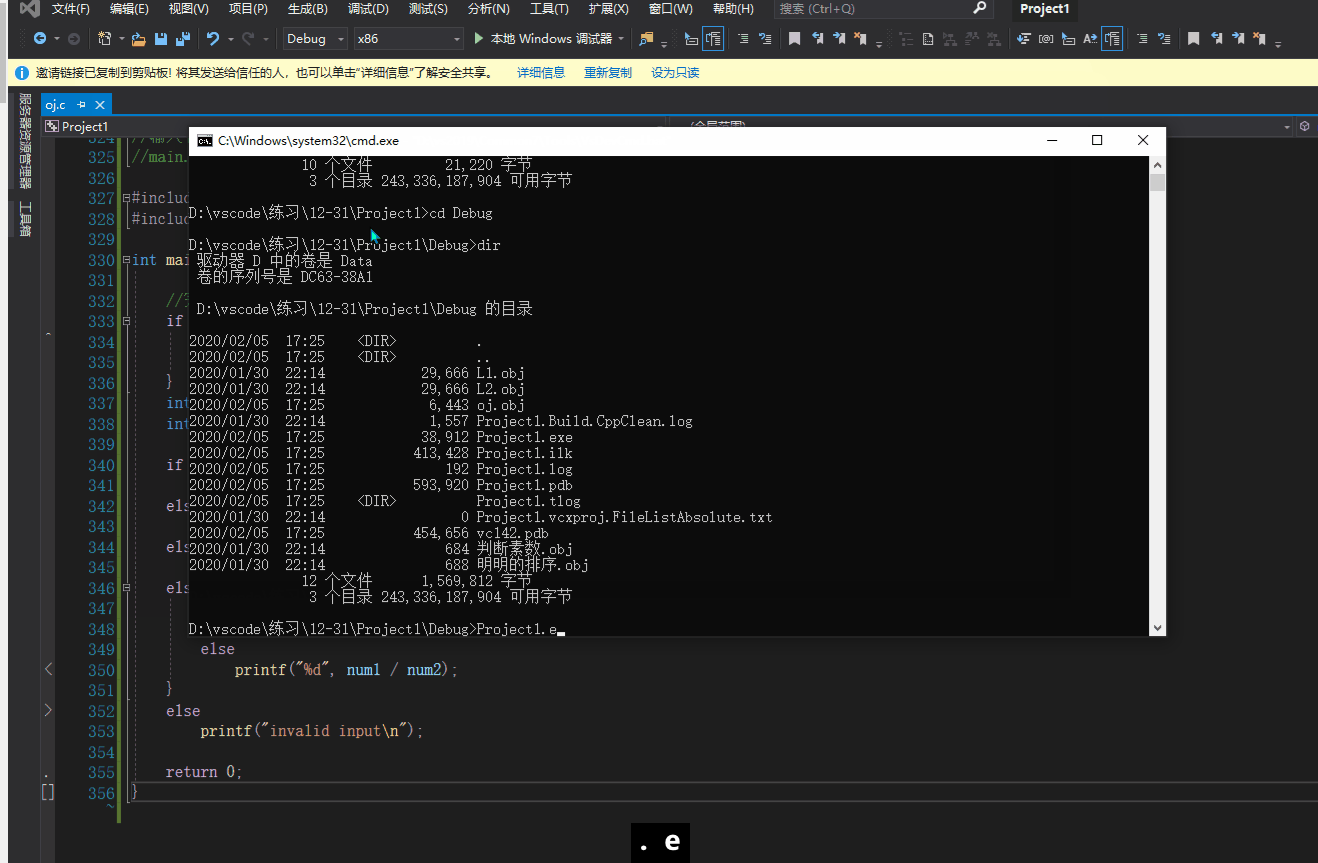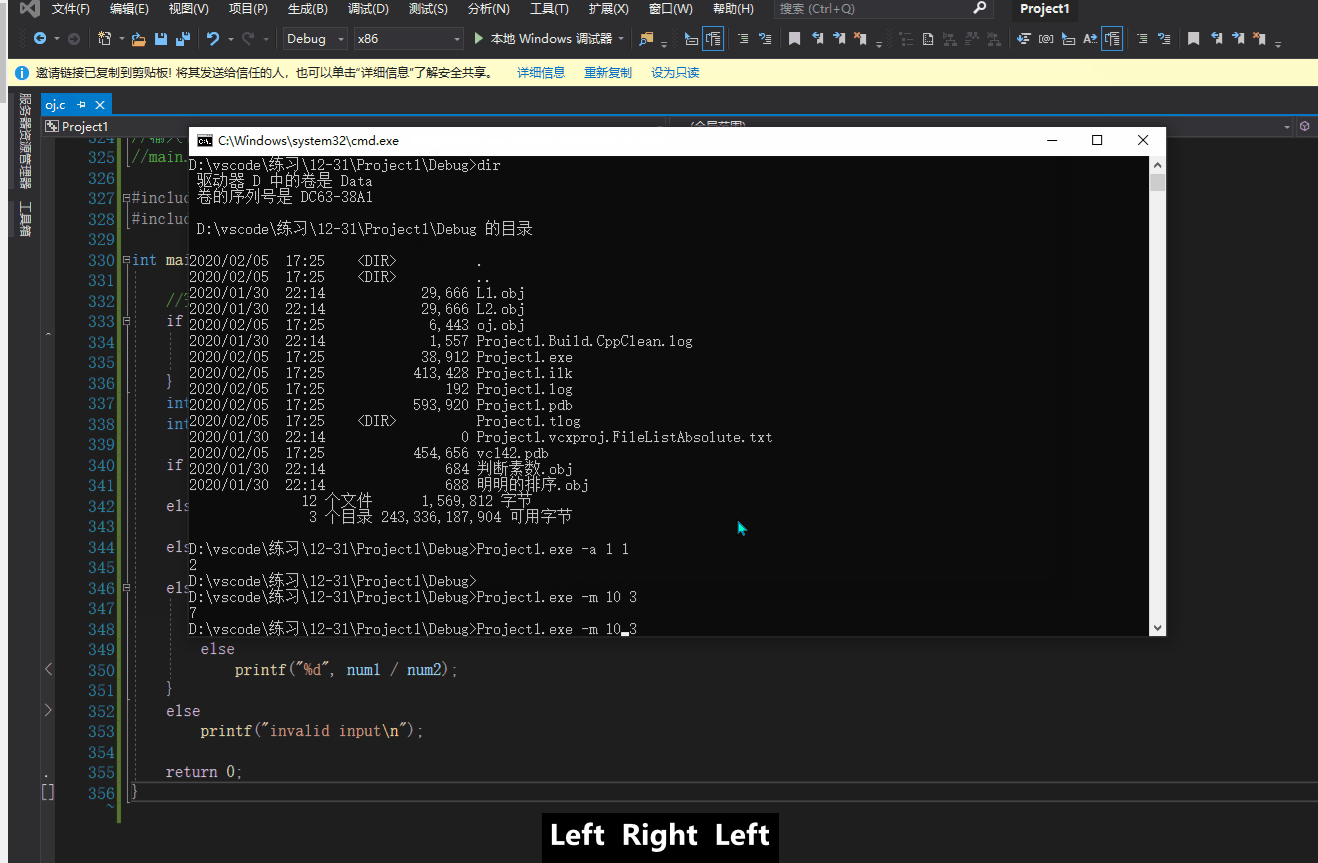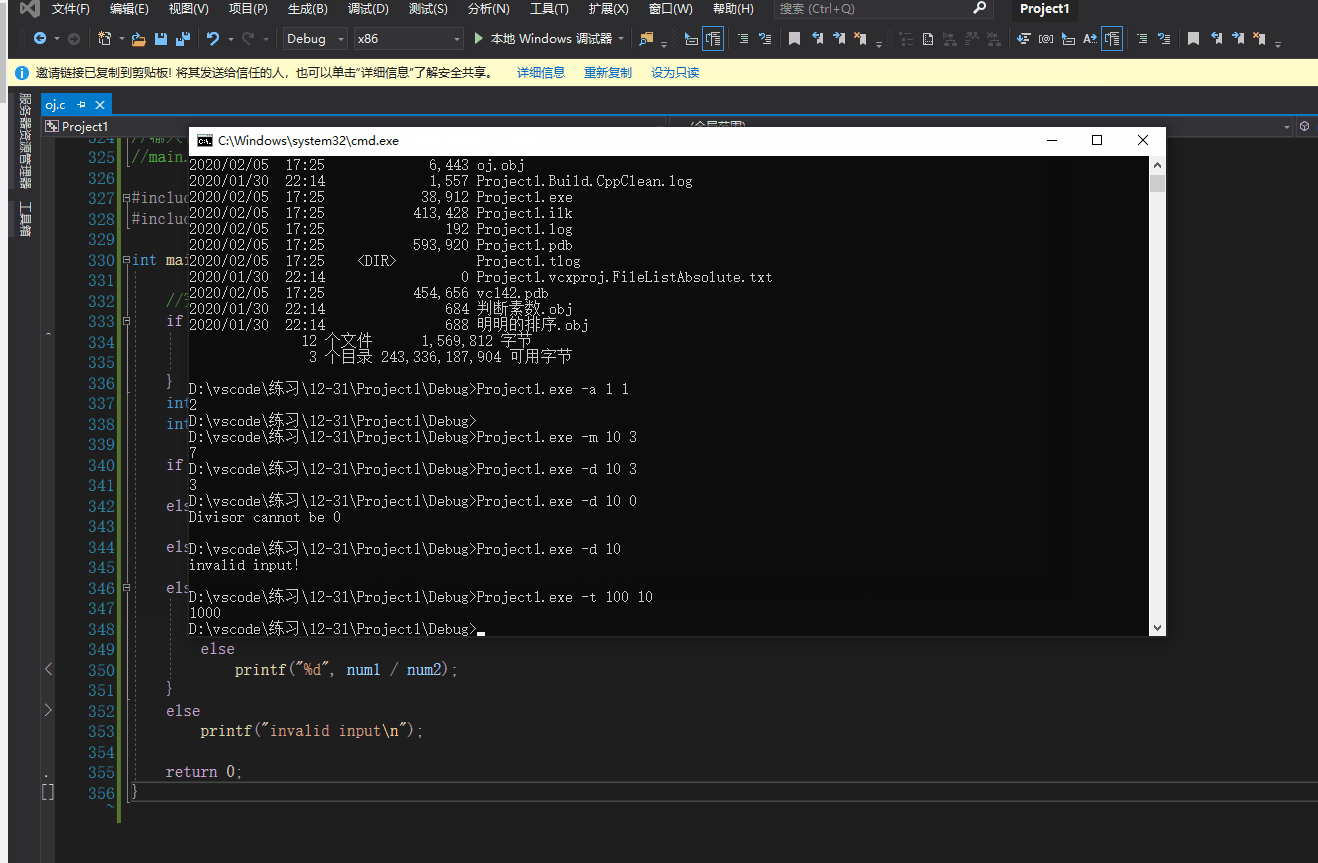
|
||||
关注公众号后台回复 【2020 0205】获得源码以及详细讲解
|
||||
213
content/c-notes/内存对齐.md
Normal file
213
content/c-notes/内存对齐.md
Normal file
@@ -0,0 +1,213 @@
|
||||
|
||||
|
||||
### 零 前言
|
||||
|
||||
自定义类型也就是:结构体,联合和枚举。这部分的基础知识在前面的文章中我们也详细的讲过。[点击阅读](https://mp.weixin.qq.com/s/NkXZSdM-gnAuG7_jAM8ZiA)
|
||||
|
||||
我们这一节主要来讲一相关的些比较重要的知识。
|
||||
|
||||
|
||||
|
||||
### 一 结构体
|
||||
|
||||
#### 1. 内存对齐
|
||||
|
||||
##### Ⅰ)引入
|
||||
|
||||
```c
|
||||
struct S1
|
||||
{
|
||||
char c1;
|
||||
int i;
|
||||
char c2;
|
||||
};
|
||||
```
|
||||
|
||||
上面是一个结构体,也是我们自定义的一种类型。我们知道,任何类型都有大小,那么结构体 S1 的大小是多少?
|
||||
|
||||
是结构体各成员变量大小的和吗?如果是的话,那结构体 S1 的大小就是 6
|
||||
|
||||
那我们设计一个程序验证一下:
|
||||
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
printf("%d", sizeof(struct S1));
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
**输出是:12**,这个 12 是怎么得来的呢?
|
||||
|
||||
想要知道这个问题答案,那我们就要了解一下 **内存对齐**。
|
||||
|
||||
##### Ⅱ)为什么要内存对齐?
|
||||
|
||||
内存对齐关系到 CPU 读取数据的效率 和 一些其他原因。我们这里不做展开,有兴趣可以自己查一下。
|
||||
|
||||
##### Ⅲ)规则
|
||||
|
||||
>- 第一个成员在与结构体变量偏移量为0的地址处。
|
||||
>
|
||||
>- 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
|
||||
>
|
||||
>**对齐数** = 编译器默认的一个对齐数 与 该成员大小的**较小值**。
|
||||
>VS中默认的值为8
|
||||
>
|
||||
>- 结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
|
||||
>
|
||||
>- 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
|
||||
|
||||
|
||||
|
||||
##### 四)练习
|
||||
|
||||
判断下面结构体的大小:
|
||||
|
||||
VS 默认的对齐数是 8,32 位机器
|
||||
|
||||
**1**
|
||||
|
||||
```c
|
||||
struct S1
|
||||
{
|
||||
char c1;
|
||||
int i;
|
||||
char c2;
|
||||
};
|
||||
```
|
||||
|
||||
解析:`1(char)` (+` 3`(int 应该对齐到 4 的整数倍上,也就是 4,所以应该给 1 加上 3 凑成 4)) +` 4(int)` +` 1(char)` (+` 3`最后整个结构体大小为最大对齐数(也就是 4)的整数倍处,所以结构体的大小不是 9 而是 12 )(最大对齐数是最大成员的对齐数,这个是前面算过的(成员大小和默认对齐数取小))
|
||||
|
||||
答案:12
|
||||
|
||||
**2**
|
||||
|
||||
```c
|
||||
struct S2
|
||||
{
|
||||
char c1;
|
||||
char c2;
|
||||
int i;
|
||||
};
|
||||
```
|
||||
|
||||
第一个例题已经详细的分析了判断结构体大小的步骤,下面不再赘述。
|
||||
|
||||
`1 (char)`+ `1 (char)` (+`2`) + `4 (int)`
|
||||
|
||||
答案:8
|
||||
|
||||
**3**
|
||||
|
||||
```c
|
||||
struct S3
|
||||
{
|
||||
double d;
|
||||
char c;
|
||||
int i;
|
||||
}
|
||||
```
|
||||
|
||||
`8 (double)` + `1 (char)` (+`3`) + `4 (int)`
|
||||
|
||||
答案:16
|
||||
|
||||
**4**
|
||||
|
||||
```c
|
||||
struct S3
|
||||
{
|
||||
double d;
|
||||
char c;
|
||||
int i;
|
||||
};
|
||||
|
||||
struct S4
|
||||
{
|
||||
char c1;
|
||||
struct S3 s3;
|
||||
double d;
|
||||
};
|
||||
```
|
||||
|
||||
例 3 中,我们已经知道了 S3 的大小是 16
|
||||
|
||||
`1 (char)` (+ `7`(结构体大小是 16 和 编译器默认对齐数 8 取较小值,所以结构体要对齐的整数倍是 8)) + `16 (S3)` + `8 (double)`
|
||||
|
||||
答案:32
|
||||
|
||||
|
||||
|
||||
不确定你可以自己在你的编译器上敲一下,看看运行结构,前提是编译器的默认对齐数是 8 ,如果不是,结果可能会不一样,那么编译器的默认对齐数可以修改吗?
|
||||
|
||||
|
||||
|
||||
#### 2. 修改默认对齐数
|
||||
|
||||
只需要加上一条指令即可:
|
||||
|
||||
```c
|
||||
#pragma pack(4)//设置默认对齐数为4
|
||||
```
|
||||
|
||||
如果你想取消设置的默认对齐数,还原为默认:
|
||||
|
||||
```c
|
||||
#pragma pack()
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 二 位段
|
||||
|
||||
#### 1.了解位段
|
||||
|
||||
位段的声明和结构是类似的,有两个不同:
|
||||
|
||||
1. 位段的成员必须是 int、unsigned int 或signed int 。
|
||||
2. 位段的成员名后边有一个冒号和一个数字。
|
||||
|
||||
<br>
|
||||
|
||||
```c
|
||||
struct S
|
||||
{
|
||||
char a : 3;// a 的大小为 3 个比特位
|
||||
char b : 4;
|
||||
char c : 5;
|
||||
char d : 4;
|
||||
};
|
||||
int main(void) {
|
||||
|
||||
struct S s = { 0 };
|
||||
|
||||
// 可以像一般的结构体成员访问一样访问它们
|
||||
s.a = -4;// 3 个字节存储数的范围是 -4 ~ 3
|
||||
s.b = 7;
|
||||
s.c = 3;
|
||||
s.d = 4;
|
||||
|
||||
|
||||
printf("%d\n", s.a);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
**存储方式:**
|
||||
|
||||
1. 位段的成员可以是 int unsigned int signed int 或者是 char (属于整形家族)类型
|
||||
2. 位段的空间上是按照需要以4个字节( int )或者1个字节( char )的方式来开辟的。
|
||||
3. 位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使用位段
|
||||
|
||||
|
||||
|
||||
**位段的应用:**
|
||||
|
||||
可以自行了解**IP数据报格式**。
|
||||
|
||||
|
||||
681
content/c-notes/动态内存管理.md
Normal file
681
content/c-notes/动态内存管理.md
Normal file
@@ -0,0 +1,681 @@
|
||||
**想看更好的排版可以阅读原文**
|
||||
[点击阅读原文](https://mp.weixin.qq.com/s/FfNI5ooT75VyIdM9dmiq-A)
|
||||
|
||||
## 思维导图
|
||||
|
||||
***
|
||||
|
||||

|
||||
|
||||
## 目录
|
||||
|
||||
***
|
||||
|
||||
@[toc]
|
||||
## 正文
|
||||
|
||||
***
|
||||
|
||||
### 零 简单了解内存区域划分
|
||||
|
||||

|
||||
### 一 动态内存函数
|
||||
|
||||
#### 1.1 malloc
|
||||
|
||||
malloc -> memory allocate
|
||||
|
||||
> `void* malloc (size_t size)`
|
||||
>
|
||||
> size_t 类型就是 unsigned long
|
||||
>
|
||||
> **库函数:**`stdlib.h`
|
||||
>
|
||||
> **解释:**
|
||||
>
|
||||
> 分配 `size` 字节的未初始化内存。
|
||||
>
|
||||
> 若分配成功,则返回为任何拥有[基础对齐](https://zh.cppreference.com/w/c/language/object#.E5.AF.B9.E9.BD.90)的对象类型对齐的指针。
|
||||
>
|
||||
> 若 `size` 为零,则 `malloc` 的行为是实现定义的。例如可返回空指针。亦可返回非空指针;但不应当**解引用**这种指针,而且应将它传递给 [free](https://zh.cppreference.com/w/c/memory/free) 以避免内存泄漏。
|
||||
>
|
||||
> **参数:**size - 要分配的字节数
|
||||
>
|
||||
> **返回值:**
|
||||
>
|
||||
> 成功时,返回指向新分配内存的指针。为避免内存泄漏,必须用 [free()](https://zh.cppreference.com/w/c/memory/free) 或 [realloc()](https://zh.cppreference.com/w/c/memory/realloc) 解分配返回的指针。
|
||||
>
|
||||
> 失败时,返回空指针。
|
||||
|
||||
英文文档:
|
||||
|
||||
>Allocate memory block
|
||||
>
|
||||
>Allocates a block of size bytes of memory, returning a pointer to the beginning of the block.
|
||||
>
|
||||
>The content of the newly allocated block of memory is not initialized, remaining with indeterminate values.
|
||||
>
|
||||
>If size is zero, the return value depends on the particular library implementation (it may or may not be a *null pointer*), but the returned pointer shall not be dereferenced.
|
||||
>
|
||||
>**Parameters**
|
||||
>
|
||||
>`size`
|
||||
>
|
||||
>Size of the memory block, in bytes.
|
||||
>[size_t](http://www.cplusplus.com/cstdlib:size_t) is an unsigned integral type.
|
||||
>
|
||||
>**Return Value**
|
||||
>
|
||||
>On success, a pointer to the memory block allocated by the function.
|
||||
>
|
||||
>The type of this pointer is always `void*`, which can be cast to the desired type of data pointer in order to be dereferenceable.
|
||||
>
|
||||
>If the function failed to allocate the requested block of memory, a *null pointer* is returned.
|
||||
|
||||
###### 例1:malloc
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<stdlib.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
int size;
|
||||
printf("请输入元素个数:");
|
||||
scanf("%d", &size);
|
||||
int* arr = (int*)malloc(size * sizeof(int));
|
||||
//内存申请失败返回 空指针
|
||||
if (arr == NULL) {
|
||||
printf("内存申请失败!\n");
|
||||
return 0;
|
||||
}
|
||||
for (int i = 0; i < size; i++) {
|
||||
arr[i] = i;
|
||||
printf("%d\n", i);
|
||||
}
|
||||
|
||||
free(arr);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 1.2 free
|
||||
|
||||
>`void free( void* ptr )`
|
||||
>
|
||||
>**头文件:**stdlib.h
|
||||
>
|
||||
>**解释:**
|
||||
>
|
||||
>解分配之前由 [malloc()](https://zh.cppreference.com/w/c/memory/malloc) 、 [calloc()](https://zh.cppreference.com/w/c/memory/calloc) 或 [realloc()](https://zh.cppreference.com/w/c/memory/realloc) 分配的空间
|
||||
>
|
||||
>若 `ptr` 为空指针,则函数不进行操作。
|
||||
>
|
||||
>若 `ptr` 的值不等于之前从 [malloc()](https://zh.cppreference.com/w/c/memory/malloc) 、 [calloc()](https://zh.cppreference.com/w/c/memory/calloc) 、 [realloc()](https://zh.cppreference.com/w/c/memory/realloc) 返回的值,则行为未定义。
|
||||
>
|
||||
>若 `ptr` 所指代的内存区域已经被解分配,则行为未定义,即是说已经以`ptr` 为参数调用 `free()` 或 [realloc()](https://zh.cppreference.com/w/c/memory/realloc) ,而且没有后继的 [malloc()](https://zh.cppreference.com/w/c/memory/malloc) 、 [calloc()](https://zh.cppreference.com/w/c/memory/calloc) 或 [realloc()](https://zh.cppreference.com/w/c/memory/realloc) 调用以 `ptr` 为结果。
|
||||
>
|
||||
>若在 `free()` 返回后通过指针 `ptr` 访问内存,则行为未定义(除非另一个分配函数恰好返回等于 `ptr` 的值)。
|
||||
>
|
||||
>**参数:** ptr - 指向要解分配的内存的指针
|
||||
>
|
||||
>**返回值:** 无
|
||||
>
|
||||
>**注意:**此函数接收空指针(并对其不处理)以减少特例的数量。不管分配成功与否,分配函数返回的指针都能传递给 `free()` 。
|
||||
|
||||
英文文档
|
||||
|
||||
>Deallocate memory block
|
||||
>
|
||||
>A block of memory previously allocated by a call to [malloc](http://www.cplusplus.com/malloc), [calloc](http://www.cplusplus.com/calloc) or [realloc](http://www.cplusplus.com/realloc) is deallocated, making it available again for further allocations.
|
||||
>
|
||||
>If ptr does not point to a block of memory allocated with the above functions, it causes *undefined behavior*.
|
||||
>
|
||||
>If ptr is a *null pointer*, the function does nothing.
|
||||
>
|
||||
>Notice that this function does not change the value of ptr itself, hence it still points to the same (now invalid) location.
|
||||
>
|
||||
>**Paramaters**
|
||||
>
|
||||
>`ptr`
|
||||
>
|
||||
>Pointer to a memory block previously allocated with [malloc](http://www.cplusplus.com/malloc), [calloc](http://www.cplusplus.com/calloc) or [realloc](http://www.cplusplus.com/realloc).
|
||||
>
|
||||
>**Return Value**
|
||||
>
|
||||
>none
|
||||
>
|
||||
>If ptr does not point to a memory block previously allocated with [malloc](http://www.cplusplus.com/malloc), [calloc](http://www.cplusplus.com/calloc) or [realloc](http://www.cplusplus.com/realloc), and is not a *null pointer*, it causes *undefined behavior*.
|
||||
|
||||
|
||||
|
||||
#### 1.3 calloc
|
||||
|
||||
> void* calloc( [size_t](http://zh.cppreference.com/w/c/types/size_t) num, [size_t](http://zh.cppreference.com/w/c/types/size_t) size )
|
||||
>
|
||||
> **头文件:**stdlib.h
|
||||
>
|
||||
> **解释:**
|
||||
>
|
||||
> 为 `num` 个对象的数组分配内存,并初始化所有分配存储中的字节为零。
|
||||
>
|
||||
> 若分配成功,会返回指向分配内存块最低位(首位)字节的指针,它为任何类型适当地对齐。
|
||||
>
|
||||
> 若 `size` 为零,则行为是实现定义的(可返回空指针,或返回不可用于访问存储的非空指针)。
|
||||
>
|
||||
> **参数:**
|
||||
>
|
||||
> num - 对象数目
|
||||
>
|
||||
> size - 每个对象的大小
|
||||
>
|
||||
> **返回值:**
|
||||
>
|
||||
> 成功时,返回指向新分配内存的指针。为避免内存泄漏,必须用 [free()](https://zh.cppreference.com/w/c/memory/free) 或 `realloc()` 解分配返回的指针。
|
||||
>
|
||||
> 失败时,返回空指针。
|
||||
>
|
||||
> **注意:**
|
||||
>
|
||||
> 因为对齐需求的缘故,分配的字节数不必等于 `num*size` 。
|
||||
>
|
||||
> 初始化所有位为零不保证浮点数或指针被各种初始化为 0.0 或空指针(尽管这在所有常见平台上为真)。
|
||||
|
||||
英文文档:
|
||||
|
||||
>```c
|
||||
>void* calloc (size_t num, size_t size);
|
||||
>```
|
||||
>
|
||||
>Allocate and zero-initialize array
|
||||
>
|
||||
>Allocates a block of memory for an array of num elements, each of them size bytes long, and initializes all its bits to zero.
|
||||
>
|
||||
>The effective result is the allocation of a zero-initialized memory block of `(num*size)` bytes.
|
||||
>
|
||||
>If size is zero, the return value depends on the particular library implementation (it may or may not be a *null pointer*), but the returned pointer shall not be dereferenced.
|
||||
>
|
||||
>**Parameters**
|
||||
>
|
||||
>- num
|
||||
>
|
||||
>Number of elements to allocate.
|
||||
>
|
||||
>- size
|
||||
>
|
||||
>Size of each element.
|
||||
>
|
||||
>size_t - is an unsigned integral type.
|
||||
>
|
||||
>**Return Value**
|
||||
>
|
||||
>On success, a pointer to the memory block allocated by the function.
|
||||
>
|
||||
>The type of this pointer is always `void*`, which can be cast to the desired type of data pointer in order to be dereferenceable.
|
||||
>
|
||||
>If the function failed to allocate the requested block of memory, a *null pointer* is returned.
|
||||
|
||||
|
||||
|
||||
###### 例2:calloc
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<stdlib.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
int* p1 = (int*)calloc(4, sizeof(int));//分配并清零 4 个 int 的数组
|
||||
int* p2 = (int*)calloc(1, sizeof(int[4]));//等价,直接命名数组类型
|
||||
int* p3 = (int*)calloc(4, sizeof *p3);//等价,免去重复类型名
|
||||
|
||||
if (p2) {
|
||||
for (int n = 0; n < 4; n++)
|
||||
printf("p2[%d] == %d\n", n, p2[n]);
|
||||
}
|
||||
|
||||
free(p1);
|
||||
free(p2);
|
||||
free(p3);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 1.4 realloc
|
||||
|
||||
英文文档:
|
||||
|
||||
> ```c
|
||||
> void* realloc (void* ptr, size_t size)
|
||||
> ```
|
||||
>
|
||||
> **Reallocate memory block**
|
||||
>
|
||||
> Changes the size of the memory block pointed to by ptr.
|
||||
>
|
||||
> The function may move the memory block to a new location (whose address is returned by the function).
|
||||
>
|
||||
> The content of the memory block is preserved up to the lesser of the new and old sizes, even if the block is moved to a new location. If the new size is larger, the value of the newly allocated portion is indeterminate.
|
||||
>
|
||||
> In case that ptr is a null pointer, the function behaves like [malloc](http://www.cplusplus.com/malloc), assigning a new block of size bytes and returning a pointer to its beginning.
|
||||
>
|
||||
> C90:
|
||||
>
|
||||
> Otherwise, if size is zero, the memory previously allocated at ptr is deallocated as if a call to [free](http://www.cplusplus.com/free) was made, and a *null pointer* is returned.
|
||||
>
|
||||
> C99/C11:
|
||||
>
|
||||
> If size is zero, the return value depends on the particular library implementation: it may either be a *null pointer* or some other location that shall not be dereferenced.
|
||||
>
|
||||
> If the function fails to allocate the requested block of memory, a null pointer is returned, and the memory block pointed to by argument ptr is not deallocated (it is still valid, and with its contents unchanged).
|
||||
>
|
||||
> **Parameter**
|
||||
>
|
||||
> ptr
|
||||
>
|
||||
> Pointer to a memory block previously allocated with [malloc](http://www.cplusplus.com/malloc), [calloc](http://www.cplusplus.com/calloc) or [realloc](http://www.cplusplus.com/realloc).
|
||||
> Alternatively, this can be a *null pointer*, in which case a new block is allocated (as if [malloc](http://www.cplusplus.com/malloc) was called).
|
||||
>
|
||||
> size
|
||||
>
|
||||
> New size for the memory block, in bytes.
|
||||
> [size_t](http://www.cplusplus.com/cstdlib:size_t) is an unsigned integral type.
|
||||
>
|
||||
> **Return Value**
|
||||
>
|
||||
> A pointer to the reallocated memory block, which may be either the same as ptr or a new location.
|
||||
> The type of this pointer is `void*`, which can be cast to the desired type of data pointer in order to be dereferenceable.
|
||||
>
|
||||
> C90:
|
||||
>
|
||||
> A *null-pointer* indicates either that size was zero (an thus ptr was deallocated), or that the function did not allocate storage (and thus the block pointed by ptr was not modified).
|
||||
>
|
||||
> C99:
|
||||
>
|
||||
> A *null-pointer* indicates that the function failed to allocate storage, and thus the block pointed by ptr was not modified.
|
||||
|
||||
|
||||
|
||||
###### 例3:realloc
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<stdlib.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
int* pa = (int*)malloc(3 * sizeof(int));
|
||||
if (pa) {
|
||||
printf("%zu bytes allocated. Storing ints:\n", 3 * sizeof(int));
|
||||
for (int i = 0; i < 3; i++)
|
||||
printf("%d\n", pa[i] = i);
|
||||
}
|
||||
|
||||
int* pb = (int*)malloc(10 * sizeof(int));
|
||||
if (pb) {
|
||||
printf("%zu bytes allocated. First 3 ints:\n", 10 * sizeof(int));
|
||||
for (int i = 0; i < 3; i++)
|
||||
printf("%d\n", pb[i] = i);
|
||||
}
|
||||
else { // 如果 realloc 返回 NULL,表示扩容失败,我们需要 free pa指向的地址
|
||||
free(pa);
|
||||
}
|
||||
//如果成功,free pb即可,如果 pb 与 pa 指向的内容不同,那么 pa 就已经被释放过了
|
||||
free(pb);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
###### 例3.1:realloc
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<stdlib.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
int input, i;
|
||||
int count = 0;
|
||||
int* numbers = NULL;
|
||||
|
||||
do {
|
||||
printf("Ener a number: ");
|
||||
scanf("%d", &input);
|
||||
count++;
|
||||
|
||||
numbers = (int*)realloc(numbers, count * sizeof(int));
|
||||
|
||||
if (numbers != NULL) {
|
||||
numbers[count - 1] = input;
|
||||
}
|
||||
else {
|
||||
free(numbers);
|
||||
printf("Error reallocating memory\n");
|
||||
exit (1);
|
||||
}
|
||||
|
||||
} while (input != 0);
|
||||
|
||||
printf("%zu bytes allocated. Elements as follow:\n", count * sizeof(int));
|
||||
for (i = 0; i < count; i++) {
|
||||
printf("%d ", numbers[i]);
|
||||
}
|
||||
|
||||
free(numbers);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 1.5 malloc 造成内存泄漏的典例
|
||||
|
||||
###### 典例1:由 return 造成的没有 free
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<stdlib.h>
|
||||
|
||||
int* Func() {
|
||||
|
||||
int* p = (int*)malloc(sizeof(int) * 10);
|
||||
if (p == NULL) {
|
||||
return NULL;
|
||||
}
|
||||
//下面是业务逻辑代码:
|
||||
if (cond1) {
|
||||
return p;//满足条件就return ,p 没有 free
|
||||
}
|
||||
if (cond2) {
|
||||
return p;//同上
|
||||
}
|
||||
//执行一些操作
|
||||
do_something;
|
||||
|
||||
free(p);
|
||||
|
||||
}
|
||||
|
||||
int main(void) {
|
||||
|
||||
int* a = Func();
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
###### 典例2:malloc 后没有 free,再次 malloc
|
||||
|
||||
```c
|
||||
int* Func() {
|
||||
|
||||
int* p = (int*)malloc(sizeof(int) * 10);
|
||||
p = (int*)malloc(sizeof(int*) * 20);//第一次 malloc 的内存没有 free
|
||||
if (p) {
|
||||
return NULL;
|
||||
}
|
||||
do_something;
|
||||
|
||||
free(p);
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
###### 典例3:指针运算后改变造成 free 失败
|
||||
|
||||
```c
|
||||
void test(){
|
||||
int* p = (int*)malloc(4 * sizeof(int));
|
||||
p++;
|
||||
free(p);
|
||||
}
|
||||
```
|
||||
|
||||
###### 典例4:多次 free 同一块内存
|
||||
|
||||
```c
|
||||
void test(){
|
||||
int* p = (int*)malloc(4 * sizeof(int));
|
||||
free(p);
|
||||
free(p);
|
||||
}
|
||||
```
|
||||
|
||||
###### 典例5:对 NULL 进行解引用操作
|
||||
|
||||
```c
|
||||
void test(){
|
||||
int *p = (int *)malloc(INT_MAX/4);
|
||||
*p = 20;//如果p的值是NULL,就会有问题
|
||||
free(p);
|
||||
}
|
||||
```
|
||||
|
||||
###### 典例6:对动态开辟空间的越界访问
|
||||
|
||||
```c
|
||||
void test(){
|
||||
int i = 0;
|
||||
int *p = (int *)malloc(10*sizeof(int));
|
||||
if(NULL == p){
|
||||
exit(EXIT_FAILURE);
|
||||
}
|
||||
for(i=0; i<=10; i++){
|
||||
*(p+i) = i;//当i是10的时候越界访问
|
||||
}
|
||||
free(p);
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 二 笔试题
|
||||
|
||||
#### 1
|
||||
|
||||
```c
|
||||
void GetMemory(char* p)
|
||||
{
|
||||
//形参是实参的拷贝,形参指针不会改变实参指针的指向
|
||||
p = (char*)malloc(100);
|
||||
}
|
||||
void Test(void)
|
||||
{
|
||||
char* str = NULL;
|
||||
GetMemory(str);
|
||||
strcpy(str, "hello world");
|
||||
printf("%s", str);
|
||||
}
|
||||
//请问运行Test 函数会有什么样的结果?
|
||||
程序崩溃
|
||||
```
|
||||
|
||||
|
||||
|
||||
1. malloc 之后要判空
|
||||
2. 没有 free
|
||||
|
||||
|
||||
|
||||
#### 2
|
||||
|
||||
```c
|
||||
char* GetMemory(void)
|
||||
{
|
||||
char p[] = "hello world";
|
||||
return p;
|
||||
//函数结束,p 的地址内的内容是未知的
|
||||
}
|
||||
void Test(void)
|
||||
{
|
||||
char* str = NULL;
|
||||
str = GetMemory();
|
||||
printf("%s", str);
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 3
|
||||
|
||||
```c
|
||||
void GetMemory(char** p, int num)
|
||||
{
|
||||
*p = (char*)malloc(num);
|
||||
}
|
||||
void Test(void)
|
||||
{
|
||||
char* str = NULL;
|
||||
GetMemory(&str, 100);
|
||||
strcpy(str, "hello");
|
||||
printf("%s", str);
|
||||
}
|
||||
//没有 free
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 4
|
||||
|
||||
```c
|
||||
void Test(void)
|
||||
{
|
||||
char* str = (char*)malloc(100);
|
||||
strcpy(str, "hello");
|
||||
free(str);
|
||||
if (str != NULL)
|
||||
{
|
||||
strcpy(str, "world");
|
||||
printf(str);
|
||||
}
|
||||
}
|
||||
// 访问非法内存
|
||||
// free 操作不会改变 str 内容
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 三 柔性数组
|
||||
|
||||
>**柔性数组**(flexible array):C99 中,结构中的最后一个元素允许是未知大小的数组,这就叫做『柔性数组』成员。
|
||||
|
||||
#### 1. 特点
|
||||
|
||||
- 结构中的柔性数组成员前面必须至少一个其他成员。
|
||||
- sizeof 返回的这种结构大小不包括柔性数组的内存。
|
||||
- 包含柔性数组成员的结构用malloc ()函数进行内存的动态分配,并且分配的内存应该大于结构的大小,以适应柔性数组的预期大小
|
||||
|
||||
#### 2. 使用方法
|
||||
|
||||
##### 1. 定义结构体
|
||||
|
||||
```c
|
||||
typedef struct Test {
|
||||
int i;
|
||||
int a[];// 也可写成 int a[0]
|
||||
}Test;
|
||||
```
|
||||
|
||||
##### 2. 使用
|
||||
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
Test* test = (Test*)malloc(sizeof(Test) + sizeof(int) * 100);
|
||||
|
||||
for (int i = 0; i < 100; i++) {
|
||||
test->a[i] = i;
|
||||
}
|
||||
free(test);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
##### 3. 反例
|
||||
|
||||
如果我们不用 “柔性数组”,而这样 定义结构体和使用 可不可以实现自定义数组大小呢?
|
||||
|
||||
```c
|
||||
typedef struct Test {
|
||||
int i;
|
||||
int* a;// 修改
|
||||
}Test;
|
||||
|
||||
int main(void) {
|
||||
|
||||
Test* test = (Test*)malloc(sizeof(Test) + sizeof(int) * 100);
|
||||
|
||||
for (int i = 0; i < 100; i++) {
|
||||
test->a[i] = i;
|
||||
}
|
||||
|
||||
free(test);
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这样显然是不行的,那我们应该如何写呢?
|
||||
|
||||
正确的写法是 malloc 两次
|
||||
|
||||
```c
|
||||
typedef struct Test {
|
||||
int i;
|
||||
int* a;
|
||||
}Test;
|
||||
|
||||
int main(void) {
|
||||
|
||||
Test* test = (Test*)malloc(sizeof(Test));
|
||||
test->a = (int*)malloc(sizeof(int) * 100);
|
||||
|
||||
for (int i = 0; i < 100; i++) {
|
||||
test->a[i] = i;
|
||||
}
|
||||
|
||||
free(test->a);
|
||||
free(test);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
malloc 两次 free 也得两次,所以这种写法还是十分麻烦的。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 补:printf(str)
|
||||
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
char* str = "Hello";
|
||||
|
||||
printf(str);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这个程序会正常输出 str 的内容。因为 char* 的类型,而 printf format 的格式是 char const* const ,C语言的对类型之间的标准比较模糊,所以没有报错,起始这种写法类似于:
|
||||
|
||||
```c
|
||||
printf("Hello");
|
||||
```
|
||||
|
||||
|
||||
|
||||
<br>
|
||||
|
||||
*参考资料:cppreference.com cplusplus.com*
|
||||
654
content/c-notes/字符串函数与内存函数.md
Normal file
654
content/c-notes/字符串函数与内存函数.md
Normal file
@@ -0,0 +1,654 @@
|
||||
## 思维导图
|
||||
|
||||
***
|
||||

|
||||
|
||||
## 目录
|
||||
|
||||
***
|
||||
|
||||
@[toc]
|
||||
## 正文
|
||||
|
||||
***
|
||||
|
||||
- strlen & strlen_s
|
||||
- getchar() & putchar()
|
||||
- strcmp & strncmp()
|
||||
- strcpy() & strncpy()
|
||||
- strcat & strncat()
|
||||
|
||||
以上这几个函数在我的另一篇文章中我已经详细讲过了。[文章链接](https://mp.weixin.qq.com/s/CrInWDeD5k_XNvPzcgI06Q)
|
||||
|
||||
<br>
|
||||
|
||||
这篇文章中,我们先主要来简单实现一下这几个函数,然后再讨论其他函数。
|
||||
|
||||
### 序 老朋友们
|
||||
|
||||
#### myStrlen & myStrcat & myStrcpy
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<assert.h>
|
||||
|
||||
int myStrlen(const char* str);
|
||||
char* myStrcat(char* dest, const char* src);
|
||||
char* myStrcpy(char* dest, const char* src);
|
||||
|
||||
int main(void) {
|
||||
|
||||
char str1[12] = "Today ";
|
||||
char str2[6] = "sucks";
|
||||
|
||||
//str1 和 str2 不是空指针
|
||||
if (str1 && str2) {
|
||||
|
||||
printf("str1 is :%s str2 is :%s\n", str1, str2);
|
||||
printf("str1 has %d characters, str2 has %d characters\n", myStrlen(str1), myStrlen(str2));
|
||||
printf("str1 + str2 = %s\n", myStrcat(str1, str2));
|
||||
printf("Copy str2 to str1,now str1 is:%s\n", myStrcpy(str1, str2));
|
||||
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
int myStrlen(const char* str) {
|
||||
|
||||
assert(str != NULL);
|
||||
|
||||
const char* start = str;
|
||||
|
||||
while (*++str);
|
||||
|
||||
return str - start;
|
||||
|
||||
}
|
||||
|
||||
char* myStrcat(char* dest, const char* src) {
|
||||
|
||||
assert(dest && src);
|
||||
|
||||
char* ret = dest;
|
||||
|
||||
//找到 dest 中 '\0' 的位置
|
||||
while (*++dest);
|
||||
|
||||
while (*dest++ = *src++);
|
||||
|
||||
return ret;
|
||||
}
|
||||
|
||||
char* myStrcpy(char* dest, const char* src) {
|
||||
|
||||
assert(dest && src);
|
||||
|
||||
char* ret = dest;
|
||||
|
||||
while (*dest++ = *src++);
|
||||
|
||||
return ret;
|
||||
}
|
||||
```
|
||||
|
||||
***
|
||||
|
||||
#### MyStrcmp
|
||||
|
||||
```c
|
||||
#define _CRT_SECURE_NO_WARNINGS 1
|
||||
|
||||
#include<stdio.h>
|
||||
#include<string.h>
|
||||
#include<assert.h>
|
||||
|
||||
// strcmp 返回值:
|
||||
// 如果 str1 > str2, 返回的是一个比 0 大的数(不一定是 1)
|
||||
// 如果 str1 < str2, 返回的是一个比 0 小的数(不一定是 -1)
|
||||
// str1 > str2 在 VS 上可能是 1,在 linux gcc 中不一定是 1
|
||||
// 为了方便实现,我们就选择返回 -1 和 1
|
||||
|
||||
int MyStrcmp(char* str1, char* str2) {
|
||||
|
||||
assert(str1 != NULL && str2 != NULL);
|
||||
|
||||
while (*str1 != '\0' && *str2 != '\0') {
|
||||
|
||||
if (*str1 > *str2) {
|
||||
return 1;
|
||||
}
|
||||
else if (*str1 < *str2) {
|
||||
return -1;
|
||||
}
|
||||
str1++;
|
||||
str2++;
|
||||
}
|
||||
|
||||
// 当循环退出时,str1 或 str2 达到字符串末尾 '\0'
|
||||
// 对于 strcmp 来说,如果前面的字符都相同,那么,短的字符串就小
|
||||
// 因为 '\0' 的 ASCII 值是 0,它是最小的(达到字符串结尾的字符串用'\0'来进行最后一次比较)
|
||||
|
||||
if (*str1 > * str2) {
|
||||
return 1;
|
||||
}
|
||||
else if (*str1 < *str2) {
|
||||
return -1;
|
||||
}
|
||||
else {
|
||||
return 0;
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
int main(void) {
|
||||
|
||||
char str1[] = "haha";
|
||||
char str2[] = "haha";
|
||||
|
||||
int ret = MyStrcmp(str1, str2);
|
||||
|
||||
if (ret > 0) {
|
||||
printf("str1 > str2\n");
|
||||
}
|
||||
else if (ret < 0) {
|
||||
printf("str1 < str2\n");
|
||||
}
|
||||
else {
|
||||
printf("str1 == str2\n");
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 始 新朋友们
|
||||
|
||||
#### 1. strstr
|
||||
|
||||
> `char *strstr( const char* str, const char* substr );`
|
||||
>
|
||||
> 定义于头文件:<string.h>
|
||||
>
|
||||
> 查找 `substr` 所指的空终止字节字符串在 `str` 所指的空终止字节字符串中的首次出现。不比较空终止字符。
|
||||
>
|
||||
> 若 `str` 或 `substr` 不是指向空终止字节字符串的指针,则行为未定义。
|
||||
>
|
||||
> **参数:**
|
||||
>
|
||||
> str - 指向要检验的空终止字节字符串的指针
|
||||
> substr - 指向要查找的空终止字节字符串的指针
|
||||
>
|
||||
> **返回值:**
|
||||
>
|
||||
> 指向于 `str` 中找到的子串首字符的指针,或若找不到该子串则为 [NULL](https://zh.cppreference.com/w/c/types/NULL) 。若 `substr` 指向空字符串,则返回 `str` 。
|
||||
|
||||
|
||||
|
||||
想象实现 MyStrstr 是我们产品经理的需求,先来看看他的需求是什么:
|
||||
|
||||
1. 查找 字符串 substr 在字符串 str 中首次出现的位置(返回找到的字串的首字符的指针)
|
||||
|
||||
思路
|
||||
|
||||
1. 我们先在 str 中找到 substr 的第一个元素
|
||||
2. 比较 str 的下一个字符与 substr 的下一个字符是否相等(可以循环实现)
|
||||
3. 如果 substr 中有一个字符与 str 中的是不一样的,那么 substr 应该从首个元素开始重新在 str 中继续向下寻找,直到找到或者 str 结束
|
||||
4. 我忽略了一个条件:当 substr 重新从第一个元素开始在 str 中寻找时,str 应该重置为 上一次 str 所在位置的下一个字符处(比如 "cacacat" 中寻找 "cacat")
|
||||
|
||||
##### 实现
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<string.h>
|
||||
#include<assert.h>
|
||||
|
||||
char* MyStrstr(const char* str, const char* substr) {
|
||||
|
||||
const char* substr_begin = substr;
|
||||
const char* str_next = str;
|
||||
|
||||
assert(str != NULL && substr != NULL);
|
||||
|
||||
if (*str == '\0' || *substr == '\0') {
|
||||
return NULL;
|
||||
}
|
||||
|
||||
while (*str_next != '\0') {
|
||||
|
||||
// substr 从头开始
|
||||
substr = substr_begin;
|
||||
str = str_next;
|
||||
|
||||
if (*str == *substr) {
|
||||
while (*str == *substr && *str != '\0' && *substr != '\0') {
|
||||
str++;
|
||||
substr++;
|
||||
}
|
||||
// 循环退出三种情况
|
||||
if (*substr == '\0') {
|
||||
return str_next;
|
||||
}
|
||||
if (*str == '\0') {
|
||||
return NULL;
|
||||
}
|
||||
// 剩下的一种就是 str 的字串 和 substr 不是完全匹配的,重新找 substr 的第一个元素
|
||||
}
|
||||
|
||||
str_next++;
|
||||
}
|
||||
}
|
||||
|
||||
int main(void) {
|
||||
|
||||
char str1[] = "Hello World";
|
||||
char str2[] = "lo";
|
||||
|
||||
char* ptr = MyStrstr(str1, str2);
|
||||
|
||||
if (MyStrstr != NULL) {
|
||||
printf("%s\n", ptr);
|
||||
}
|
||||
else {
|
||||
printf("str2 在 str1 中不存在\n");
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 2. strtok
|
||||
|
||||
了解这个函数即可。
|
||||
|
||||
>`char *strtok( char *str, const char *delim )`
|
||||
>
|
||||
>定义于头文件 < string.h >
|
||||
>
|
||||
>**参数:**
|
||||
>
|
||||
>| str | - | 指向要记号化的空终止字节字符串的指针 |
|
||||
>| ----- | ---- | -------------------------------------- |
|
||||
>| delim | - | 指向标识分隔符的空终止字节字符串的指针 |
|
||||
>
|
||||
>**返回值:**
|
||||
>
|
||||
>返回指向下个记号起始的指针,或若无更多记号则返回 [NULL](https://zh.cppreference.com/w/c/types/NULL) 。
|
||||
>
|
||||
>**注意:**
|
||||
>
|
||||
>此函数是破坏性的:它写入 '**\0**' 字符于字符串 `str` 的元素。特别是,字符串字面量不能用作 `strtok` 的首参数。
|
||||
>
|
||||
>每次对 `strtok` 的调用都会修改静态对象:它不是线程安全的。
|
||||
|
||||
strtok 中有个 static 修饰的变量记录下来上次位置
|
||||
|
||||
|
||||
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
char str[] = "World is so beautiful!Hi,Look!";
|
||||
char* pch;
|
||||
|
||||
pch = strtok(str, ",. !");
|
||||
while (pch != NULL) {
|
||||
printf("%s\n", pch);
|
||||
pch = strtok(NULL, ",. !");
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
// 输出:
|
||||
World
|
||||
is
|
||||
so
|
||||
beautiful
|
||||
Hi
|
||||
Look
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 3. memcpy
|
||||
|
||||
> `void* memcpy( void *dest, const void *src, size_t count );`
|
||||
>
|
||||
> 定义于头文件 :<string.h>
|
||||
>
|
||||
> 从 `src` 所指向的对象复制 `count` 个字符到 `dest` 所指向的对象。两个对象都被转译成 unsigned char 的数组。
|
||||
>
|
||||
> 若访问发生在 dest 数组结尾后则行为未定义。若对象重叠(这违背 [`restrict`](https://zh.cppreference.com/w/c/language/restrict) 契约) (C99 起),则行为未定义。若 `dest` 或 `src` 为非法或空指针则行为未定义。
|
||||
>
|
||||
> **参数:**
|
||||
>
|
||||
> | dest | - | 指向要复制的对象的指针 |
|
||||
> | ----- | ---- | ---------------------- |
|
||||
> | src | - | 指向复制来源对象的指针 |
|
||||
> | count | - | 复制的字节数 |
|
||||
>
|
||||
> **返回值:**
|
||||
>
|
||||
> 返回 `dest` 的副本,本质为更底层操作的临时内存地址,在实际操作中不建议直接使用此地址,操作完成以后,真正有意义的地址是dest本身。
|
||||
>
|
||||
> **注意:**
|
||||
>
|
||||
> `memcpy` 可用于设置分配函数所获得对象的[有效类型](https://zh.cppreference.com/w/c/language/object#.E6.9C.89.E6.95.88.E7.B1.BB.E5.9E.8B)。
|
||||
>
|
||||
> `memcpy` 是最快的内存到内存复制子程序。它通常比必须扫描其所复制数据的 [strcpy](https://zh.cppreference.com/w/c/string/byte/strcpy) ,或必须预防以处理重叠输入的 [memmove](https://zh.cppreference.com/w/c/string/byte/memmove) 更高效。
|
||||
>
|
||||
> 许多 C 编译器将适合的内存复制循环变换为 `memcpy` 调用。
|
||||
>
|
||||
> 在[严格别名使用](https://zh.cppreference.com/w/c/language/object#.E4.B8.A5.E6.A0.BC.E5.88.AB.E5.90.8D.E4.BD.BF.E7.94.A8)禁止检验同一内存为二个不同类型的值处,可用 `memcpy` 转换值。
|
||||
|
||||
|
||||
|
||||
**注:**
|
||||
|
||||
void* 只包含地址,没有内存空间大小这样的信息,所以 void* 不能解引用,也不能进行运算
|
||||
|
||||
void* 是为了兼容各种类型的指针,算是一种简单的“泛型编程”。
|
||||
|
||||
|
||||
|
||||
**简单的用法:**
|
||||
|
||||
```c
|
||||
int main(void) {
|
||||
|
||||
char src[] = "Once upon a midnight dreary", dest[4];
|
||||
memcpy(dest, src, sizeof dest);
|
||||
for (size_t i = 0; i < sizeof dest; i++)
|
||||
putchar(dest[i]);
|
||||
|
||||
int* p = malloc(3 * sizeof(int));// 分配的内存没有有效类型
|
||||
int arr[3] = { 1, 2, 3 };
|
||||
memcpy(p, arr, 3 * sizeof(int));// 分配到内存有了有效类型 int
|
||||
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
##### 实现
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<assert.h>
|
||||
|
||||
void* MyMemcpy(void* dest, const void* src, size_t count) {
|
||||
|
||||
assert(dest != NULL && src != NULL);
|
||||
|
||||
void* ret = dest;
|
||||
|
||||
for (size_t i = 0; i < count; i++) {
|
||||
*(char*)dest = *(char*)src;// 逐字节复制
|
||||
dest = (char*)dest + 1;
|
||||
src = (char*)src + 1;
|
||||
}
|
||||
|
||||
return dest;
|
||||
}
|
||||
|
||||
int main(void) {
|
||||
|
||||
char src[] = "Once upon a midnight dreary", dest[4];
|
||||
MyMemcpy(dest, src, sizeof dest);
|
||||
for (size_t i = 0; i < sizeof dest; i++)
|
||||
putchar(dest[i]);
|
||||
|
||||
int* p = malloc(3 * sizeof(int));// 分配的内存没有有效类型
|
||||
int arr[3] = { 1, 2, 3 };
|
||||
MyMemcpy(p, arr, 3 * sizeof(int));// 分配到内存有了有效类型 int
|
||||
for (int i = 0; i < 3; i++) {
|
||||
printf("%d ", *(p + i));
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
##### 思考
|
||||
|
||||
请看下例:
|
||||
|
||||
```c
|
||||
#include<stdint.h>
|
||||
#include<inttypes.h>
|
||||
#include<stdio.h>
|
||||
#include<string.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
double d = 1.0;
|
||||
int64_t i = 1;
|
||||
|
||||
i = d;
|
||||
// 输出:0.000000 5509945
|
||||
|
||||
printf("%f %d\n", i, i);
|
||||
|
||||
memcpy(&i, &d, sizeof d);
|
||||
|
||||
printf("%f %"PRId64" ", i, i);//#define PRId64 "lld"
|
||||
//输出:1.000000 4607182418800017408
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
memcpy 该表了 i 作为整型的内存布局,所以 i 可以直接用 %f 输出
|
||||
|
||||
#### 4. memmove
|
||||
|
||||
> `void* memmove( void* dest, const void* src, size_t count )`
|
||||
>
|
||||
> 定义于头文件 :< string.h >
|
||||
>
|
||||
> 从 `src` 所指向的对象复制 `count` 个字节到 `dest` 所指向的对象。两个对象都被转译成 unsigned char 的数组。对象可以重叠:如同复制字符到临时数组,再从该数组到 `dest` 一般发生复制。
|
||||
>
|
||||
> 若出现 dest 数组末尾后的访问则行为未定义。若 `dest` 或 `src` 为非法或空指针则行为未定义。
|
||||
>
|
||||
> **参数:**
|
||||
>
|
||||
> | dest | - | 指向复制目的对象的指针 |
|
||||
> | ----- | ---- | ---------------------- |
|
||||
> | src | - | 指向复制来源对象的指针 |
|
||||
> | count | - | 要复制的字节数 |
|
||||
>
|
||||
> **返回值:**
|
||||
>
|
||||
> 返回 `dest` 的副本,本质为更底层操作的临时内存地址,在实际操作中不建议直接使用此地址,操作完成以后,真正有意义的地址是dest本身。
|
||||
>
|
||||
> **注意:**
|
||||
>
|
||||
> `memmove` 可用于设置由分配函数获得的对象的[有效类型](https://zh.cppreference.com/w/c/language/object#.E6.9C.89.E6.95.88.E7.B1.BB.E5.9E.8B)。
|
||||
>
|
||||
> 尽管说明了“如同”使用临时缓冲区,此函数的实际实现不会带来二次复制或额外内存的开销。常用方法( glibc 和 bsd libc )是若目标在源之前开始,则从缓冲区开始正向复制,否则从末尾反向复制,**完全无重叠时回落到更高效的 memcpy**。
|
||||
>
|
||||
> 在[严格别名时用](https://zh.cppreference.com/w/c/language/object#.E4.B8.A5.E6.A0.BC.E5.88.AB.E5.90.8D.E4.BD.BF.E7.94.A8)禁止检验同一内存为二个不同类型的值时,可使用 `memmove` 转换值。
|
||||
|
||||
##### 重叠的含义
|
||||
|
||||

|
||||
|
||||
##### 实现
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<assert.h>
|
||||
|
||||
void* MyMemcpy(void* dest, const void* src, size_t count) {
|
||||
|
||||
assert(dest != NULL && src != NULL);
|
||||
|
||||
void* ret = dest;
|
||||
|
||||
for (size_t i = 0; i < count; i++) {
|
||||
*(char*)dest = *(char*)src;// 逐字节复制
|
||||
dest = (char*)dest + 1;
|
||||
src = (char*)src + 1;
|
||||
}
|
||||
|
||||
return dest;
|
||||
}
|
||||
|
||||
void* MyMemmove(void* dest, const void* src, size_t count) {
|
||||
|
||||
assert(dest != NULL && src != NULL);
|
||||
|
||||
void* ret = dest;
|
||||
char* pdest = (char*)dest;
|
||||
char* psrc = (char*)src;
|
||||
|
||||
// 先判断有没有重叠
|
||||
|
||||
// 如果没有重叠,应该用更为高效的 memcpy
|
||||
if (dest >= (char*)src + count || src >= dest) {
|
||||
MyMemcpy(dest, src, count);
|
||||
}
|
||||
else {
|
||||
// 分别指向 dest 和 src 的最后一个字符
|
||||
pdest = pdest + count - 1;
|
||||
psrc = psrc + count - 1;
|
||||
|
||||
while (count--) {
|
||||
*pdest = *psrc;
|
||||
pdest--;
|
||||
psrc--;
|
||||
}
|
||||
return dest;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
int main(void) {
|
||||
|
||||
char str[] = "123456789";
|
||||
puts(str + 1);
|
||||
MyMemcpy(str + 1, str, 3);
|
||||
puts(str + 1);
|
||||
MyMemcpy(str, "123456789", sizeof(str));
|
||||
MyMemmove(str + 1, str, 3);
|
||||
puts(str + 1);
|
||||
|
||||
return 0;
|
||||
}
|
||||
//输出:
|
||||
23456789
|
||||
11156789
|
||||
12356789
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 5. memcmp
|
||||
|
||||
> `int memcmp( const void* lhs, const void* rhs, size_t count );`
|
||||
>
|
||||
> **参数:**
|
||||
>
|
||||
> | lhs, rhs | - | 指向要比较的对象的指针 |
|
||||
> | -------- | ---- | ---------------------- |
|
||||
> | count | - | 要检验的字节数 |
|
||||
>
|
||||
> **返回值:**
|
||||
>
|
||||
> 若 `lhs` 以字典序出现前于 `rhs` 则为负值。
|
||||
>
|
||||
> 若 `lhs` 与 `rhs` 比较相等,或 count 为零则为零。
|
||||
>
|
||||
> 若 `lhs` 以字典序出现后于 `rhs` 则为正值。
|
||||
>
|
||||
> **注意:**
|
||||
>
|
||||
> 此函数读取[对象表示](https://zh.cppreference.com/w/c/language/object),而非对象值,而且典型地只对字节数组有意义:结构体可以含有填充字节而其值不确定,存储于联合体最近存储成员后的任何字节的值是不确定的,且一个类型可以对相同值拥有二种或多种表示(对于 +0 和 -0 或 +0.0 和 –0.0 的相异编码、类型中不确定填充位)。
|
||||
|
||||
|
||||
|
||||
简单的应用:
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<string.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
int arr1[] = { 0, 1, 2, 3 };
|
||||
int arr2[] = { 0, 1, 2, 3 };
|
||||
int arr3[] = { -0, 1, 2, 3 };
|
||||
|
||||
if(memcmp(arr1, arr2, sizeof arr1) == 0){
|
||||
printf("arr1 == arr2\n");
|
||||
}
|
||||
else {
|
||||
printf("arr1 != arr2\n");
|
||||
}
|
||||
|
||||
if (memcmp(arr1, arr3, sizeof arr1) == 0) {
|
||||
printf("arr1 == arr3\n");
|
||||
}
|
||||
else {
|
||||
printf("arr1 != arr3\n");
|
||||
}
|
||||
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 6. memset
|
||||
|
||||
>`void *memset( void *dest, int ch, size_t count );`
|
||||
>
|
||||
>定义于头文件 <string.h>
|
||||
>
|
||||
>复制值 `ch` (如同以 (unsigned char)ch 转换到 unsigned char 后)到 `dest` 所指向对象的首 `count` 个字节。
|
||||
>
|
||||
>若出现 dest 数组结尾后的访问则行为未定义。若 `dest` 为空指针则行为未定义。
|
||||
>
|
||||
>**参数:**
|
||||
>
|
||||
>| dest | - | 指向要填充的对象的指针 |
|
||||
>| ----- | ---- | ---------------------- |
|
||||
>| ch | - | 填充字节 |
|
||||
>| count | - | 要填充的字节数 |
|
||||
>
|
||||
>**返回值:**
|
||||
>
|
||||
>1) `dest` 的副本,本质为更底层操作的临时内存地址,在实际操作中不建议直接使用此地址,操作完成以后,真正有意义的地址是dest本身。
|
||||
|
||||
<br>
|
||||
|
||||
**简单应用:**
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<string.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
char str[] = "Hello World";
|
||||
|
||||
memset(str, '\0', sizeof str);
|
||||
|
||||
puts(str);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
101
content/c-notes/教你用简单的程序判断你的电脑是大端还是小端.md
Normal file
101
content/c-notes/教你用简单的程序判断你的电脑是大端还是小端.md
Normal file
@@ -0,0 +1,101 @@
|
||||
### **如何用程序判断自己的机器是大端还是小端?**
|
||||
|
||||
通常情况下,我们的计算机都是小端存储模式。
|
||||
|
||||
> 小端:数字的低位存储到内存的低地址上。
|
||||
> 大端:数字的低位存储到内存的高地址上。
|
||||
|
||||
我们在 VS 中创建一个临时变脸
|
||||
|
||||
```
|
||||
int a = 0x11223344;// 十六进制数
|
||||
```
|
||||
|
||||

|
||||
|
||||
然后打开调试器,看到变量 a 在内存中是这样存储的:
|
||||
|
||||
```
|
||||
0x0133FC50 44 33 22 11
|
||||
```
|
||||
|
||||

|
||||
|
||||
对于 Vs 调试中内存窗口的这行信息应该如何理解呢?它就表示:
|
||||
|
||||

|
||||
|
||||
十六进制数每两位表示一个字节,地址也是十六进制数;int 类型在 32 位机器上大小为 4 个字节。
|
||||
|
||||
|
||||
|
||||
**如何理解十六进制数每两位表示一个字节?**
|
||||
|
||||
十六进制数每一位的取值范围是 0 ~ 15,表示 16 种不同可能,对应 4 个二进制位(0000 ~ 1111),所以每一位十六进制可以表示 4 个二进制位,那么两个十六进制位就表示 8 个二进制位,也就是 1 个字节。
|
||||
|
||||
|
||||
|
||||
可以看到,在我的机器上,低位 44 存储在 低地址(0x0133FC50)上,所以我的机器是 小端存储模式。
|
||||
|
||||
|
||||
|
||||
如果是大端存储模式,变量 a 在内存中的存储应该如下图所示:
|
||||
|
||||

|
||||
|
||||
现在,让我们用程序来验证一下我们的机器到底是大端还是小端。
|
||||
|
||||
|
||||
|
||||
### **方法一**
|
||||
|
||||
```
|
||||
#include<stdio.h>
|
||||
|
||||
int main(void) {
|
||||
|
||||
int a = 0x11223344;
|
||||
int* pi = &a;
|
||||
char* pc = (char*)pi;//指针强转
|
||||
|
||||
printf("%x\n", *pc);//输出 44 ,得到证实
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
### **方法二**
|
||||
|
||||
```
|
||||
#include<stdio.h>
|
||||
|
||||
typedef union {
|
||||
int a;
|
||||
char ch[sizeof(int)];
|
||||
}BOS;//big or small
|
||||
|
||||
int main(void) {
|
||||
|
||||
BOS bos;
|
||||
bos.a = 0x11223344;
|
||||
|
||||
printf("%x", (unsigned int)bos.ch[0]);//输出 44
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
**如果本文你有地方没有看懂,推荐阅读以下文章,可以帮助你理解**:
|
||||
|
||||
- [一文看懂枚举&结构&联合](https://mp.weixin.qq.com/s/NkXZSdM-gnAuG7_jAM8ZiA)
|
||||
|
||||
|
||||
|
||||
172
content/c-notes/有关指针.md
Normal file
172
content/c-notes/有关指针.md
Normal file
@@ -0,0 +1,172 @@
|
||||
# 指针的运算 详解
|
||||
### 指针的运算
|
||||
### 指针加减 常量
|
||||
请看下面的程序,猜测一下结果:
|
||||
|
||||
```c
|
||||
int main() {
|
||||
|
||||
int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
|
||||
int* a = &arr;
|
||||
|
||||
printf("a = %p\n", a);
|
||||
printf("a + 1 = %p\n", a + 1);
|
||||
printf("a - 1 = %p\n", a - 1);
|
||||
|
||||
}
|
||||
```
|
||||
运行结果:
|
||||
```c
|
||||
a = 00AFF82C
|
||||
a + 1 = 00AFF830
|
||||
a - 1 = 00AFF828
|
||||
```
|
||||
可以看到, a 与 a + 1 和 a - 1 都差了四个字节
|
||||
>**指针加减常量** 加减的大小为 **`sizeof(类型) * 常量 `**
|
||||
|
||||
再试试 char 类型?
|
||||
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char arr[10] = { ' 1', '2', '3', '4', '5', '6', '7', '8', '9', '10',};
|
||||
char* a = &arr;
|
||||
|
||||
printf("a = %p\n", a);
|
||||
printf("a + 1 = %p\n", a + 1);
|
||||
printf("a - 1 = %p\n", a - 1);
|
||||
|
||||
}
|
||||
```
|
||||
结果如我们所料:
|
||||
|
||||
```c
|
||||
a = 0095F9E0
|
||||
a + 1 = 0095F9E1
|
||||
a - 1 = 0095F9DF
|
||||
```
|
||||
相差大小 为 1
|
||||
|
||||
#### 指针 - 指针
|
||||
先来看一段程序吧:
|
||||
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char arr1[10] = { ' 1', '2', '3', '4', '5', '6', '7', '8', '9', '10', };
|
||||
int arr2[5] = { 1, 2, 3, 4, 5 };
|
||||
|
||||
char* ch1 = &arr1[4];
|
||||
char* ch2 = &arr1;
|
||||
int* i1 = &arr2[4];
|
||||
int* i2 = &arr2;
|
||||
|
||||
printf("ch1 - ch2 = %d\n", ch1 - ch2);
|
||||
printf("ch2 - ch1 = %d\n", ch2 - ch1);
|
||||
printf("\ni1 - i2 = %d\n", i1 - i2);
|
||||
printf("i2 - i1 = %d\n", i2 - i1);
|
||||
|
||||
}
|
||||
```
|
||||
指针相减 结果会是 指针相差的大小吗?看结果:
|
||||
|
||||
```c
|
||||
ch1 - ch2 = 4
|
||||
ch2 - ch1 = -4
|
||||
|
||||
i1 - i2 = 4
|
||||
i2 - i1 = -4
|
||||
```
|
||||
>指针 减 指针 意义是 **两个地址之间相隔的单元格数**
|
||||
>也可以理解为:指针相差的大小 / sizeof(类型)
|
||||
|
||||
如果想输出两个指针 相差的距离(大小)只需要将变量类型 更改成普通类型,如下:
|
||||
```c
|
||||
int main() {
|
||||
|
||||
char arr1[10] = { ' 1', '2', '3', '4', '5', '6', '7', '8', '9', '10', };
|
||||
int arr2[5] = { 1, 2, 3, 4, 5 };
|
||||
|
||||
//变量不再是指针变量
|
||||
char ch1 = &arr1[4];
|
||||
char ch2 = &arr1;
|
||||
int i1 = &arr2[4];
|
||||
int i2 = &arr2;
|
||||
|
||||
printf("ch1 - ch2 = %d\n", ch1 - ch2);
|
||||
printf("ch2 - ch1 = %d\n", ch2 - ch1);
|
||||
printf("\n");
|
||||
printf("i1 - i2 = %d\n", i1 - i2);
|
||||
printf("i2 - i1 = %d\n", i2 - i1);
|
||||
|
||||
}
|
||||
```
|
||||
输出结果:
|
||||
|
||||
```c
|
||||
ch1 - ch2 = 4
|
||||
ch2 - ch1 = -4
|
||||
|
||||
i1 - i2 = 16
|
||||
i2 - i1 = -16
|
||||
```
|
||||
**普通类型是无法进行解引用操作的**
|
||||
##### 总结一下
|
||||
>指针 可以 加减常数,指针之间可以相减,可以比较(如:> == < >=等)
|
||||
>但是指针不能乘除,相加 **这是没有意义的**
|
||||
>举个很简单的例子,时间可以相减,但是时间乘除或者相加有什么意义呢?
|
||||
|
||||
#### NULL
|
||||
>通过前面的学习,我们知道:内存中的地址有很多编号。如果你的机器是 32 位,
|
||||
>那么内存范围是:`0 ~ 2^32 -1`(32位2进制数全1) 最大值大约为 4GB
|
||||
>**NULL其实就表示 0地址**
|
||||
>补充个小知识点:
|
||||
> 1kB=1024B =2^10(次方是二进制形式)
|
||||
> 1MB=1024kB =2^20
|
||||
> 1GB=1024MB =2^30
|
||||
> 1TB=1024GB =2^40
|
||||
|
||||
##### NULL有什么用?
|
||||
0地址规定为我们不能写入的地址,你的指针不指向 0地址,如果你的指针指向了 0地址 那么程序运行时会崩溃。基于这个特点,0地址 也就是NULL有了很重要的功能:
|
||||
> - 函数返回 NULL指示错误
|
||||
> - 防止野指针(什么是野指针?参考 [C语言复习巩固(五) 指针(初阶)](https://blog.csdn.net/qq_44954010/article/details/103742120))。用NULL初始化指针,如果指针使用时没有指向任何实际地址,程序崩溃。
|
||||
|
||||
**NULL类型时 void * 可以设置任何类型为NULL**
|
||||
下面的程序是官网上讲NULL时给出的例子:
|
||||
```c
|
||||
#include <stdlib.h>
|
||||
#include <stdio.h>
|
||||
int main(void)
|
||||
{
|
||||
// 能设置任何类型指针为 NULL
|
||||
int* p = NULL;
|
||||
struct S* s = NULL;
|
||||
void(*f)(int, double) = NULL;
|
||||
|
||||
// 多数返回指针的函数用空指针指示错误
|
||||
char* ptr = malloc(10);
|
||||
if (ptr == NULL) printf("Out of memory");
|
||||
free(ptr);
|
||||
}
|
||||
```
|
||||
|
||||
#### void*
|
||||
void* 表示 不知道指向什么类型的 指针
|
||||
比如:
|
||||
|
||||
```c
|
||||
int i = 1;
|
||||
int* p = &i;
|
||||
void* q = (void*)p;
|
||||
```
|
||||
这么写并没有改变 p 所指向的变量的类型, 而是可以让程序用不同的眼光通过 p看它所指的变量。
|
||||
#### 指针类型的作用
|
||||
>1. 指针的类型决定了指针向前或者向后走一步有多大
|
||||
>2. 指针的类型决定了,对指针解引用的时候有多大的权限(能操作几个字节)
|
||||
|
||||
(具体示例参考 [C语言复习巩固(五) 指针(初阶)](https://blog.csdn.net/qq_44954010/article/details/103742120))
|
||||
|
||||
***
|
||||
更多关于指针的可以参考我的其他篇文章:
|
||||
[C语言复习巩固(五) 指针(初阶)](https://blog.csdn.net/qq_44954010/article/details/103742120)
|
||||
[指针运算详解,const详解,NULL?void* 指针基础](https://mp.weixin.qq.com/s/x3un4tnaHSISUfP8n3V_6g)
|
||||
289
content/c-notes/浅谈 C 语言实现重载,多态和模板.md
Normal file
289
content/c-notes/浅谈 C 语言实现重载,多态和模板.md
Normal file
@@ -0,0 +1,289 @@
|
||||
### C 语言实现重载,多态和模板
|
||||
|
||||
#### 为什么 C 语言不支持重载
|
||||
|
||||
这和 C 和 C++ 的函数名称修饰有关。编译(并汇编)一个 C 和 Cpp 程序,使用 `objdump -dS `命令查看 ELF 格式文件发现:
|
||||
|
||||
```
|
||||
[root@SuperhandsomeChuan ~]# objdump -dS test.o
|
||||
|
||||
0000000000000000 <main>:
|
||||
|
||||
[root@SuperhandsomeChuan ~]# objdump -dS testcpp.o
|
||||
|
||||
0000000000000000 <_Z3sumii>:
|
||||
|
||||
0000000000000014 <_Z3sumdd>:
|
||||
```
|
||||
|
||||
`gcc` 编译器下,C 程序的函数名没有变化,但是 Cpp 程序的函数名称有了参数相关的后缀,这使得重载的 sum 函数底层的函数名称不同,编译器可以区分。
|
||||
|
||||
#### C 语言实现重载
|
||||
|
||||
| 函数 | 描述 |
|
||||
| ----------------------- | ------------------------------------------------------------ |
|
||||
| col 3 is | right-aligned |
|
||||
| va_list arg_ptr | 定义一个可变参数列表指针 |
|
||||
| va_start(arg_ptr, argN) | 让arg_ptr指向参数argN |
|
||||
| va_arg(arg_ptr, type) | 返回类型为type的参数指针,并指向下一个参数 |
|
||||
| va_copy(dest, src) | 拷贝参数列表指针,src->dest, |
|
||||
| va_end(arg_ptr) | 清空参数列表,并置参数指针arg_ptr无效。每个va_start()必须与一个va_end()对应 |
|
||||
|
||||
参考文章:http://locklessinc.com/articles/overloading/
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<stdarg.h>
|
||||
|
||||
void va_overload2(int p1, int p2)
|
||||
{
|
||||
printf("va_overload2 %d %d\n", p1, p2);
|
||||
}
|
||||
|
||||
void va_overload3(int p1, int p2, int p3)
|
||||
{
|
||||
printf("va_overload3 %d %d %d\n", p1, p2, p3);
|
||||
}
|
||||
|
||||
static void va_overload(int p1, int p2, ...)
|
||||
{
|
||||
if(p2 == 7)
|
||||
{
|
||||
va_list v;
|
||||
va_start(v, p2);
|
||||
|
||||
int p3 = va_arg(v, int);
|
||||
va_end(v);
|
||||
va_overload3(p1, p2, p3);
|
||||
|
||||
return;
|
||||
}
|
||||
va_overload2(p1, p2);
|
||||
}
|
||||
|
||||
int main(void)
|
||||
{
|
||||
va_overload(1, 2);
|
||||
va_overload(1, 7, 4);
|
||||
|
||||
return 0;
|
||||
}
|
||||
//输出:
|
||||
va_overload2 1 2
|
||||
va_overload3 1 7 4
|
||||
```
|
||||
|
||||
上面的代码,我们可以解析函数参数,然后选择调用 `va_overload2()` 或 `va_overload3()` 。POSIX 的 `open()` 函数在你的机器上也许有着类似的实现方式。
|
||||
|
||||
另一种 `va_args`常见的用法是接受数量没有限制参数,没有直接的可接受数量的说明符。通过 NULL 来结束参数列表,我们可以解析任意对我们函数的输入。
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<stdarg.h>
|
||||
|
||||
static void print_nt_strings(const char* s, ...)
|
||||
{
|
||||
va_list v;
|
||||
va_start(v, s);
|
||||
|
||||
/* Stop on NULL */
|
||||
while(s)
|
||||
{
|
||||
printf("%s\n", s);
|
||||
/* Grab next parameter */
|
||||
s = va_arg(v, const char*);
|
||||
}
|
||||
|
||||
va_end(v);
|
||||
}
|
||||
|
||||
int main(void)
|
||||
{
|
||||
|
||||
print_nt_strings("Hello", "World", "brrrrr~~~", NULL);
|
||||
|
||||
return 0;
|
||||
}
|
||||
// 输出
|
||||
Hello
|
||||
World
|
||||
brrrrr~~~
|
||||
```
|
||||
|
||||
|
||||
|
||||
上面的函数将会打印传递给他的 C 字符串。无论最后一个指针是否是 NULL 。这里的问题是需要记得最后在参数列表后加上 NULL 。如果它丢掉了,上面的函数将会把栈上的值当作 `const char*` 指针然后尝试将其打印出来。这回引发未定义行为,这可能会使这个程序崩溃。
|
||||
|
||||
一种解决办法是明确的说明有多少参数存在,将最后的参数 NULL 删除。 让用户人为的确定个数是不便且易错的。
|
||||
|
||||
*这段我感觉自己翻译的不是很好,有兴趣可以自己去看原文*
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
#include<stdarg.h>
|
||||
|
||||
static void print_nt_strings(int n, ...)
|
||||
{
|
||||
va_list v;
|
||||
va_start(v, n);
|
||||
int i;
|
||||
for(i = 0; i < n; i++)
|
||||
{
|
||||
const char* s = va_arg(v, const char*);
|
||||
|
||||
printf("%s\n", s);
|
||||
}
|
||||
|
||||
va_end(v);
|
||||
}
|
||||
|
||||
int main(void)
|
||||
{
|
||||
|
||||
print_nt_strings(3, "Hello", "World", "brrr~~");
|
||||
print_nt_strings(2, "Gooble", "World");
|
||||
|
||||
return 0;
|
||||
}
|
||||
//输出
|
||||
Hello
|
||||
World
|
||||
brrr~~
|
||||
Gooble
|
||||
World
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### C 语言实现多态
|
||||
|
||||
下面程序的本质就是 C++ 多态的实现
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
typedef void (*Func1)();
|
||||
typedef void (*Func2)();
|
||||
|
||||
// 虚函数表
|
||||
typedef struct VFunTable
|
||||
{
|
||||
Func1 eat;
|
||||
Func2 sleep;
|
||||
}VFunTable;
|
||||
|
||||
// 基类
|
||||
typedef struct base
|
||||
{
|
||||
VFunTable vptr;
|
||||
const char kind[20];
|
||||
}Base;
|
||||
|
||||
// 派生类
|
||||
typedef struct derive
|
||||
{
|
||||
Base base;
|
||||
const char kind[20];
|
||||
}Derive;
|
||||
|
||||
void base_eat()
|
||||
{
|
||||
printf("base eat\n");
|
||||
}
|
||||
|
||||
void base_sleep()
|
||||
{
|
||||
printf("base sleep\n");
|
||||
}
|
||||
|
||||
void derive_eat()
|
||||
{
|
||||
printf("derive eat\n");
|
||||
}
|
||||
|
||||
void derive_sleep()
|
||||
{
|
||||
printf("derive sleep\n");
|
||||
}
|
||||
|
||||
void init(Base* b, Derive* d)
|
||||
{
|
||||
b->vptr.eat = base_eat;
|
||||
b->vptr.sleep = base_sleep;
|
||||
|
||||
d->base.vptr.eat = derive_eat;
|
||||
d->base.vptr.sleep = derive_sleep;
|
||||
}
|
||||
|
||||
int main(void)
|
||||
{
|
||||
struct base b;
|
||||
Derive d;
|
||||
init(&b, &d);
|
||||
|
||||
Base* pb = &b;
|
||||
Base* pb2 = (Base*)&d;
|
||||
|
||||
pb->vptr.eat();
|
||||
pb2->vptr.eat();
|
||||
|
||||
return 0;
|
||||
}
|
||||
//输出
|
||||
base eat
|
||||
derive eat
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### C 语言实现模板
|
||||
|
||||
`##` 运算符可以将两个表达式“拼”起来
|
||||
|
||||
```c
|
||||
#include<stdio.h>
|
||||
|
||||
#define GENERATE(type) \
|
||||
type type##_max(type A, type B) \
|
||||
{ \
|
||||
return (A > B ? A : B); \
|
||||
} \
|
||||
|
||||
GENERATE(int);
|
||||
GENERATE(double);
|
||||
|
||||
int main(void)
|
||||
{
|
||||
|
||||
printf("%d\n", int_max(3, 5));
|
||||
printf("%f\n", double_max(3.0, 5.0));
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
看一下预处理后的代码:
|
||||
|
||||
```c
|
||||
int int_max(int A, int B) { return (A > B ? A : B); };
|
||||
double double_max(double A, double B) { return (A > B ? A : B); };
|
||||
|
||||
int main(void)
|
||||
{
|
||||
|
||||
printf("%d\n", int_max(3, 5));
|
||||
printf("%f\n", double_max(3.0, 5.0));
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
参考资料:
|
||||
|
||||
《C 语言程序设计 —— 现代方法》
|
||||
|
||||
http://locklessinc.com/articles/overloading/
|
||||
|
||||
https://blog.csdn.net/gatieme/article/details/50921577
|
||||
|
||||
https://www.cnblogs.com/qingergege/p/9594432.html
|
||||
282
content/c-notes/这些关于数组的基础知识点你都知道吗.md
Normal file
282
content/c-notes/这些关于数组的基础知识点你都知道吗.md
Normal file
@@ -0,0 +1,282 @@
|
||||
各位同学,你觉得你数组学会了吗?不妨看看下面的问题,你能看一眼程序就回答上来吗?
|
||||
|
||||
引子:观察下面的程序,这个程序有安全隐患吗?
|
||||
|
||||
```
|
||||
#include<stdio.h>
|
||||
|
||||
int main() {
|
||||
|
||||
int x = 0;
|
||||
double sum = 0;
|
||||
int number[100] = { 0 };
|
||||
int cnt = 0;
|
||||
|
||||
scanf("%d", &x);
|
||||
while (x != -1) {
|
||||
number[cnt] = x;
|
||||
sum += x;
|
||||
cnt++;
|
||||
scanf("%d", &x);
|
||||
}
|
||||
|
||||
if (cnt > 0) {
|
||||
int i = 0;
|
||||
double average = sum / cnt;
|
||||
for (i = 0; i < cnt; i++) {
|
||||
if (number[i] > average)
|
||||
printf("number %d: %d\n", i, number[i]);
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
> 答案是有的 `while`循环种没有限制 `cnt` 有可能导致 **数组越界**!
|
||||
|
||||
**不能快速找到错误和找不到错误其实是一样的**,因为不能快速找到这个错误说明你没有深刻的理解数组。这种基础的概念如果没有渗透到你的脑中,并不能说自己学好了数组吧!我学了一学期C,课设1000行代码都是自己独立完成的。依然没有立刻看出这个问题来,我也是自愧没有学好啊!
|
||||
|
||||
### 数组特性与一个注意
|
||||
|
||||
> 1.数组是一种容器(放东西的东西)
|
||||
> 2.基本特点是:
|
||||
>
|
||||
> - 其中所有元素具有相同的数据类型
|
||||
> - 一旦创建,不能改变大小
|
||||
> - 在内存中连续依次排列
|
||||
>
|
||||
> ------
|
||||
>
|
||||
> 3.注意:
|
||||
> **数组作为函数参数时,往往必须再用另一个参数来传入数组的大小**
|
||||
> 我们常用`sizeof(arr) / sizeof(arr[0])`来判断数组元素个数
|
||||
> 但是这种情况下不能在函数中用`sizeof(arr)`判断数组大小
|
||||
|
||||
例1
|
||||
|
||||
//写一个程序,输入数量不确定的【0 ~ 9】范围内的整数,统计每一种数字出现的次数,输入 -1 表示结束
|
||||
|
||||
方法一:先看一个基础做法
|
||||
|
||||
```
|
||||
#include<stdio.h>
|
||||
|
||||
int main() {
|
||||
|
||||
const int number = 10;//记录数组元素。用const修饰,数组大小规定后不可改变
|
||||
int count[10] = { 0 };
|
||||
int i = 0;
|
||||
int input = 1;
|
||||
|
||||
while (input + 1) {//避免输入0时退出,-1 + 1 = 0 刚好满足退出要求
|
||||
printf("input a number\n");
|
||||
scanf("%d",&input);
|
||||
switch (input) {
|
||||
case 0:
|
||||
count[0]++;
|
||||
break;
|
||||
case 1:
|
||||
count[1]++;
|
||||
break;
|
||||
case 2:
|
||||
count[2]++;
|
||||
break;
|
||||
case 3:
|
||||
count[3]++;
|
||||
break;
|
||||
case 4:
|
||||
count[4]++;
|
||||
break;
|
||||
case 5:
|
||||
count[5]++;
|
||||
break;
|
||||
case 6:
|
||||
count[6]++;
|
||||
break;
|
||||
case 7:
|
||||
count[7]++;
|
||||
break;
|
||||
case 8:
|
||||
count[8]++;
|
||||
break;
|
||||
case 9:
|
||||
count[9]++;
|
||||
break;
|
||||
default:
|
||||
break;
|
||||
}
|
||||
|
||||
|
||||
|
||||
for (i = 0; i < 10; i++)
|
||||
printf("%d:%d times\n", i, count[i]);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
方法2
|
||||
|
||||
当我们要统计的数是像 0 ~ 9 这样连续的数时,我们可以把数组下标与这些数一一对应起来,可以更方便,快捷
|
||||
|
||||
```
|
||||
#include<stdio.h>
|
||||
|
||||
int main() {
|
||||
|
||||
int count[10] = { 0 };
|
||||
int i = 0;
|
||||
int input = 1;
|
||||
int error = 0;
|
||||
|
||||
|
||||
//更简单的方法:
|
||||
while (input + 1) {
|
||||
printf("input a number\n");
|
||||
scanf("%d", &input);
|
||||
if (input >= 0 && input <= 9)
|
||||
count[input]++;
|
||||
if (input == -1)
|
||||
break;
|
||||
}
|
||||
|
||||
for (i = 0; i < 10; i++) {
|
||||
printf("%d:%d times\n", i, count[i]);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
------
|
||||
|
||||
> **思考一下:字符常量可以做数组下标吗?**
|
||||
> 例如,形如arr['a'] 可以吗?
|
||||
|
||||
如果可以,那么当我们想要统计字符串种某个字母(或者任何ASCII码表上存在的字符)的具体个数时,就会很方便。可以自己尝试着写一下哦~思路和上面的数字判断差不多。
|
||||
我写的供大家参考:[代码](https://github.com/hairrrrr/win.ccode/blob/master/Pactise/2020WinterVacation/Array/%E7%BB%9F%E8%AE%A1%E6%AF%8F%E4%B8%AA%E5%AD%97%E6%AF%8D%E5%87%BA%E7%8E%B0%E7%9A%84%E6%AC%A1%E6%95%B0%EF%BC%88%E5%8F%AF%E6%8B%93%E5%B1%95%E5%88%B0%E7%BB%9F%E8%AE%A1%E6%89%80%E6%9C%89ascii%E8%A1%A8%E5%86%85%E5%87%BA%E7%8E%B0%E7%9A%84%E5%AD%97%E7%AC%A6%E6%AC%A1%E6%95%B0%EF%BC%89.c)
|
||||
|
||||
------
|
||||
|
||||
例2
|
||||
|
||||
```
|
||||
#include<stdio.h>
|
||||
|
||||
#define N 10 //数组元素个数
|
||||
|
||||
int search(int want, int lenth, int* arr) {
|
||||
|
||||
int right = lenth - 1;
|
||||
int left = 0;
|
||||
int mid = 0;
|
||||
int ret = 0;
|
||||
|
||||
while (right >= left) {
|
||||
mid = (right + left) / 2;
|
||||
if (want > arr[mid])
|
||||
left = mid + 1;
|
||||
if (want < arr[mid])
|
||||
right = mid - 1;
|
||||
if (want == arr[mid]) {
|
||||
ret = mid;
|
||||
break;
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
if (right < left)
|
||||
return -1;
|
||||
else
|
||||
return ret;
|
||||
}
|
||||
|
||||
int main() {
|
||||
|
||||
int arr[N] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
|
||||
int lenth = sizeof(arr) / sizeof(arr[0]);//计算数组大小
|
||||
int want = 0;
|
||||
int index = 0;
|
||||
|
||||
printf("input the number you want to search\n");
|
||||
scanf("%d", &want);
|
||||
|
||||
index = search(want, lenth, arr);//切记:数组作为函数参数时,往往必须再用另一个参数来传入数组的大小
|
||||
|
||||
if (index == -1)
|
||||
printf("Can't find!\n");
|
||||
else
|
||||
printf("the index of %d: %d\n", want, index);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
------
|
||||
|
||||
### 二维数组
|
||||
|
||||
1.初始化
|
||||
|
||||
> `int a[][3] = {{1, 1, 1}, {2, 2, 2}, {3},}`
|
||||
> 1.列数必须给出,行数可以空出
|
||||
> 2.每行都有有一个单独的大括号 `{ }`(可以不写,建议写上)
|
||||
> 3.最后的逗号可以写上,老一代程序员们约定俗成的经验(如果你写上,可以装装逼)
|
||||
> 4.缺省表示补零
|
||||
> 5.强烈推荐的另一种书写方式:
|
||||
>
|
||||
> ```html
|
||||
> int a[][3] = {
|
||||
> {1, 1, 1},
|
||||
> {2, 2, 2},
|
||||
> {3},
|
||||
> }
|
||||
> ```
|
||||
>
|
||||
> 
|
||||
>
|
||||
> 这样写的好处不言而喻,更加形象立体
|
||||
|
||||
### 练习题
|
||||
|
||||
1.
|
||||
|
||||
若有定义:int a[2][3].则下列不越界的正确访问有:
|
||||
A: a[2][0]
|
||||
B: a[2][3]
|
||||
C: a[1 > 2][0]
|
||||
D: a[0][3]
|
||||
|
||||
2.
|
||||
|
||||
以下程序片段输出的结果是:
|
||||
|
||||
```
|
||||
int m[][3] = {1, 4, 7, 2, 5, 8, 3, 6, 9,}
|
||||
int i, j, k = 2;
|
||||
for( i = 0; i < 3; i++){
|
||||
printf("%d",m[k][j]);
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
A: 369
|
||||
B: 不能通过编译
|
||||
C:789
|
||||
D:能编译,但是数组下标越界了
|
||||
|
||||
3
|
||||
|
||||
若有int a[][3] = {{0}, {1}, {2}};
|
||||
a[1][2] 的值是?
|
||||
|
||||
> 答案:C A 0
|
||||
211
content/c-notes/那些关于函数我们容易忽略的基础知识.md
Normal file
211
content/c-notes/那些关于函数我们容易忽略的基础知识.md
Normal file
@@ -0,0 +1,211 @@
|
||||
|
||||
|
||||
------
|
||||
|
||||
相信在学校同学们看谭老师的教材的时候已经对函数有了“初步的认识”。
|
||||
但是,如果你没有理解下面这几个例子,那并不能说你对函数入门了。
|
||||
|
||||
------
|
||||
|
||||
## 1.为什么要声明函数?
|
||||
|
||||
```
|
||||
#include<stdio.h>
|
||||
|
||||
void swap();
|
||||
|
||||
int main() {
|
||||
|
||||
int a = 0;
|
||||
int b = 1;
|
||||
swap(a, b);
|
||||
return 0;
|
||||
|
||||
}
|
||||
|
||||
void swap(double x, double y) {
|
||||
|
||||
double tep = x;
|
||||
x = y;
|
||||
y = tep;
|
||||
printf("a = %f b = %f\n", x, y);
|
||||
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
上面代码`void swap();`就是swap函数的声明
|
||||
|
||||
> 把对swap的声明写在main函数的上面是因为:
|
||||
> C的编译器从main函数的第一行开始,自上而下的分析你的代码。
|
||||
> 在看到`swap(a, b)`时,它需要知道`swap()`的样子
|
||||
> 也就是swap()的**返回类型**,**参数类型**,**参数个数**
|
||||
> 这样它才能检查你对swap()的调用是否正确
|
||||
|
||||
接下来我们讨论,如果编译器不知道函数的返回类型,参数类型,参数个数的话,编译能否继续进行?
|
||||
下面我们看两个例子,分析编译器能否正确执行我们的代码
|
||||
|
||||
```
|
||||
#include<stdio.h>
|
||||
|
||||
int main() {
|
||||
|
||||
int a = 0;
|
||||
int b = 1;
|
||||
swap(a, b);
|
||||
return 0;
|
||||
|
||||
}
|
||||
|
||||
int swap(int x, int y) {
|
||||
|
||||
int tep = x;
|
||||
x = y;
|
||||
y = tep;
|
||||
printf("a = %d b = %d\n", x, y);
|
||||
return 0;
|
||||
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
------
|
||||
|
||||
```
|
||||
#include<stdio.h>
|
||||
|
||||
int main() {
|
||||
|
||||
int a = 0;
|
||||
int b = 1;
|
||||
swap(a, b);
|
||||
return 0;
|
||||
|
||||
}
|
||||
|
||||
double swap(int x, int y) {
|
||||
|
||||
int tep = x;
|
||||
x = y;
|
||||
y = tep;
|
||||
printf("a = %d b = %d\n", x, y);
|
||||
return 0;
|
||||
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
第二种情况会报错:
|
||||
“swap”未定义,假设外部返回int
|
||||
“swap”重定义,不同的基类型
|
||||
|
||||
> 在没有对函数进行声明的情况下
|
||||
> 旧标准会假设你所调用的函数所有的参数和返回类型都是int类型。
|
||||
> 如果不是,就会发生上述的问题
|
||||
|
||||
## 2.定义函数的方式
|
||||
|
||||

|
||||
|
||||
请观察下面三种函数声明,这三种写法哪些是正确的?
|
||||
|
||||
```
|
||||
//写法1:
|
||||
void swap(int x, int y);
|
||||
//写法2:
|
||||
void swap(int w, int z);
|
||||
//写法3:
|
||||
void swap(int,int);
|
||||
```
|
||||
|
||||

|
||||
|
||||
> **答案是,这三种写法都是可以的。**
|
||||
> **事实上,编译器看的是第三种写法。而我们常用的第一种写法是为了让我们自己和别人更好的理解我们写的代码,这是良好的写代码习惯。**
|
||||
|
||||
然而还有这样一种声明方式,大家想一下,编译器可以识别吗?
|
||||
|
||||
```
|
||||
void swap();
|
||||
```
|
||||
|
||||

|
||||
|
||||
> 答案是可以的。
|
||||
|
||||
这种写法可以说是这几种写法中最方便的写法,那么这种写法是不是无懈可击的呢?
|
||||
如果我改变了临时变量a,b的类型再试试呢?
|
||||
|
||||
```
|
||||
#include<stdio.h>
|
||||
|
||||
void swap();
|
||||
|
||||
int main() {
|
||||
|
||||
int a = 0;
|
||||
int b = 1;
|
||||
swap(a, b);
|
||||
return 0;
|
||||
|
||||
}
|
||||
|
||||
void swap(double x, double y) {
|
||||
|
||||
double tep = x;
|
||||
x = y;
|
||||
y = tep;
|
||||
printf("a = %f b = %f\n", x, y);
|
||||
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
这回,输出的x,y就不我们所期望的了。为什么会这样?我在这里给出简单解释:
|
||||
|
||||
> `main函数`执行到调用swap函数的地方的时候,由于我们在声明`swap函数`的时候并没有指定参数的类型,所以程序会猜测这两个变量的类型为`int`类型。而在函数定义的时候类型却为`double`,所以程序就有点“疑惑”了。
|
||||
> **所以,这种类型的写法是错误的!**
|
||||
|
||||
## 3.了解概念:块(block)
|
||||
|
||||
简单的来说,一个大括号`{ }`就是一个块
|
||||
|
||||
## 4.作用域和生存期的关系
|
||||
|
||||
如果变量在作用域内,那么它的生存期一定存在
|
||||
如果变量的生存期还没结束,它不一定在作用域内
|
||||
|
||||
## 5.没有参数时
|
||||
|
||||
当一个函数没有参数,应如何表示呢?
|
||||
`void f(void)`还是`void f()`?
|
||||
|
||||
> `void f(void)`表示函数没有参数
|
||||
> `void f()`表示参数未知
|
||||
|
||||
## 6.函数括号内的逗号与逗号运算符
|
||||
|
||||
我们思考一下,`f(a,b)`会不会引发歧义?
|
||||
如果有人认为这个逗号表示的是逗号运算符怎么办?
|
||||
|
||||
> `f(a,b)`表示函数f有a,b两个参数
|
||||
> `f((a,b))`这个逗号才是逗号运算符,表示函数f只有一个参数b
|
||||
|
||||
## 7.函数内是否可以定义函数
|
||||
|
||||
C语言不允许函数内嵌套定义
|
||||
|
||||
## 8.return(i)
|
||||
|
||||
这样写会引起歧义,它的意思究竟是返回i还是调用return函数?
|
||||
|
||||
## 9.关于main函数
|
||||
|
||||
- main函数也是函数,是被其函数调用的
|
||||
- main函数返回值是有意义的
|
||||
- `int main()`还是`int main(void)`?
|
||||
|
||||
Reference in New Issue
Block a user