mirror of
https://github.com/riba2534/TCP-IP-NetworkNote.git
synced 2026-06-29 17:36:05 +08:00
@@ -24,7 +24,7 @@
|
||||
|
||||
#### 10.1.3 进程 ID
|
||||
|
||||
在说进程创建方法之前,先要简要说明进程 ID。无论进程是如何创建的,所有的进程都会被操作系统分配一个 ID。此 ID 被称为「进程ID」,其值为大于 2 的证书。1 要分配给操作系统启动后的(用于协助操作系统)首个进程,因此用户无法得到 ID 值为 1 。接下来观察在 Linux 中运行的进程。
|
||||
在说进程创建方法之前,先要简要说明进程 ID。无论进程是如何创建的,所有的进程都会被操作系统分配一个 ID。此 ID 被称为「进程ID」,其值为大于 2 的整数。1 要分配给操作系统启动后的(用于协助操作系统)首个进程,因此用户无法得到 ID 值为 1 。接下来观察在 Linux 中运行的进程。
|
||||
|
||||
```shell
|
||||
ps au
|
||||
@@ -123,9 +123,9 @@ gcc fork.c -o fork
|
||||
- 传递参数并调用 exit() 函数
|
||||
- main 函数中执行 return 语句并返回值
|
||||
|
||||
**向 exit 函数传递的参数值和 main 函数的 return 语句返回的值都回传递给操作系统。而操作系统不会销毁子进程,直到把这些值传递给产生该子进程的父进程。处在这种状态下的进程就是僵尸进程。**也就是说将子进程变成僵尸进程的正是操作系统。既然如此,僵尸进程何时被销毁呢?
|
||||
**向 exit 函数传递的参数值和 main 函数的 return 语句返回的值都会传递给操作系统。而操作系统不会销毁子进程,直到把这些值传递给产生该子进程的父进程。处在这种状态下的进程就是僵尸进程。**也就是说将子进程变成僵尸进程的正是操作系统。既然如此,僵尸进程何时被销毁呢?
|
||||
|
||||
> 应该向创建子进程册父进程传递子进程的 exit 参数值或 return 语句的返回值。
|
||||
> 应该向创建子进程的父进程传递子进程的 exit 参数值或 return 语句的返回值。
|
||||
|
||||
如何向父进程传递这些值呢?操作系统不会主动把这些值传递给父进程。只有父进程主动发起请求(函数调用)的时候,操作系统才会传递该值。换言之,如果父进程未主动要求获得子进程结束状态值,操作系统将一直保存,并让子进程长时间处于僵尸进程状态。也就是说,父母要负责收回自己生的孩子。接下来的示例是创建僵尸进程:
|
||||
|
||||
@@ -327,7 +327,7 @@ gcc waitpid.c -o waitpid
|
||||
|
||||
#### 10.3.1 向操作系统求助
|
||||
|
||||
子进程终止的识别主题是操作系统,因此,若操作系统能把如下信息告诉正忙于工作的父进程,将有助于构建更高效的程序
|
||||
子进程终止的识别主题是操作系统,因此,若操作系统能把子进程结束的信息告诉正忙于工作的父进程,将有助于构建更高效的程序
|
||||
|
||||
为了实现上述的功能,引入信号处理机制(Signal Handing)。此处「信号」是在特定事件发生时由操作系统向进程发送的消息。另外,为了响应该消息,执行与消息相关的自定义操作的过程被称为「处理」或「信号处理」。
|
||||
|
||||
@@ -337,7 +337,7 @@ gcc waitpid.c -o waitpid
|
||||
|
||||
> 进程:操作系统,如果我之前创建的子进程终止,就帮我调用 zombie_handler 函数。
|
||||
>
|
||||
> 操作系统:好的,如果你的子进程终止,我舅帮你调用 zombie_handler 函数,你先把要函数要执行的语句写好。
|
||||
> 操作系统:好的,如果你的子进程终止,我就帮你调用 zombie_handler 函数,你先把函数要执行的语句写好。
|
||||
|
||||
上述的对话,相当于「注册信号」的过程。即进程发现自己的子进程结束时,请求操作系统调用的特定函数。该请求可以通过如下函数调用完成:
|
||||
|
||||
@@ -362,7 +362,7 @@ void (*signal(int signo, void (*func)(int)))(int);
|
||||
|
||||
> 「子进程终止则调用 mychild 函数」
|
||||
|
||||
此时 mychild 函数的参数应为 int ,返回值类型应为 void 。只有这样才能称为 signal 函数的第二个参数。另外,常数 SIGCHLD 定义了子进程终止的情况,应成为 signal 函数的第一个参数。也就是说,signal 函数调用语句如下:
|
||||
此时 mychild 函数的参数应为 int ,返回值类型应为 void 。只有这样才能成为 signal 函数的第二个参数。另外,常数 SIGCHLD 定义了子进程终止的情况,应成为 signal 函数的第一个参数。也就是说,signal 函数调用语句如下:
|
||||
|
||||
```c
|
||||
signal(SIGCHLD , mychild);
|
||||
@@ -442,7 +442,7 @@ gcc signal.c -o signal
|
||||
|
||||
> 发生信号时将唤醒由于调用 sleep 函数而进入阻塞状态的进程。
|
||||
|
||||
调用函数的主题的确是操作系统,但是进程处于睡眠状态时无法调用函数,因此,产生信号时,为了调用信号处理器,将唤醒由于调用 sleep 函数而进入阻塞状态的进程。而且,进程一旦被唤醒,就不会再进入睡眠状态。即使还未到 sleep 中规定的时间也是如此。所以上述示例运行不到 10 秒后就会结束,连续输入 CTRL+C 可能连一秒都不到。
|
||||
调用函数的主体的确是操作系统,但是进程处于睡眠状态时无法调用函数,因此,产生信号时,为了调用信号处理器,将唤醒由于调用 sleep 函数而进入阻塞状态的进程。而且,进程一旦被唤醒,就不会再进入睡眠状态。即使还未到 sleep 中规定的时间也是如此。所以上述示例运行不到 10 秒后就会结束,连续输入 CTRL+C 可能连一秒都不到。
|
||||
|
||||
**简言之,就是本来系统要睡眠100秒,但是到了 alarm(2) 规定的两秒之后,就会唤醒睡眠的进程,进程被唤醒了就不会再进入睡眠状态了,所以就不用等待100秒。如果把 timeout() 函数中的 alarm(2) 注释掉,就会先输出`wait...`,然后再输出`Time out!` (这时已经跳过了第一次的 sleep(100) 秒),然后就真的会睡眠100秒,因为没有再发出 alarm(2) 的信号。**
|
||||
|
||||
@@ -499,7 +499,7 @@ int main(int argc, char *argv[])
|
||||
int i;
|
||||
struct sigaction act;
|
||||
act.sa_handler = timeout; //保存函数指针
|
||||
sigemptyset(&act.sa_mask); //将 sa_mask 函数的所有位初始化成0
|
||||
sigemptyset(&act.sa_mask); //将 sa_mask 成员的所有位初始化成0
|
||||
act.sa_flags = 0; //sa_flags 同样初始化成 0
|
||||
sigaction(SIGALRM, &act, 0); //注册 SIGALRM 信号的处理器。
|
||||
|
||||
@@ -670,7 +670,7 @@ gcc echo_mpserv.c -o eserver
|
||||
|
||||

|
||||
|
||||
如图所示,1 个套接字存在 2 个文件描述符时,只有 2 个文件描述符都终止(销毁)后,才能销毁套接字。如果维持图中的状态,即使子进程销毁了与客户端连接的套接字文件描述符,也无法销毁套接字(服务器套接字同样如此)。因此调用 fork 函数候,要将无关紧要的套接字文件描述符关掉,如图所示:
|
||||
如图所示,1 个套接字存在 2 个文件描述符时,只有 2 个文件描述符都终止(销毁)后,才能销毁套接字。如果维持图中的状态,即使子进程销毁了与客户端连接的套接字文件描述符,也无法销毁套接字(服务器套接字同样如此)。因此调用 fork 函数后,要将无关紧要的套接字文件描述符关掉,如图所示:
|
||||
|
||||

|
||||
|
||||
@@ -688,13 +688,13 @@ gcc echo_mpserv.c -o eserver
|
||||
|
||||
从图中可以看出,客户端的父进程负责接收数据,额外创建的子进程负责发送数据,分割后,不同进程分别负责输入输出,这样,无论客户端是否从服务器端接收完数据都可以进程传输。
|
||||
|
||||
分割 I/O 程序的另外一个好处是,可以提高频繁交换数据的程序性能,图下图所示:
|
||||
分割 I/O 程序的另外一个好处是,可以提高频繁交换数据的程序性能,如下图所示:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
根据上图显示可以看出,再网络不好的情况下,明显提升速度。
|
||||
根据上图显示可以看出,在网络不好的情况下,明显提升速度。
|
||||
|
||||
#### 10.5.2 回声客户端的 I/O 程序分割
|
||||
|
||||
|
||||
@@ -24,7 +24,7 @@ filedes[1]: 通过管道传输数据时使用的文件描述符,即管道入
|
||||
*/
|
||||
```
|
||||
|
||||
父进程创建函数时将创建管道,同时获取对应于出入口的文件描述符,此时父进程可以读写同一管道。但父进程的目的是与子进程进行数据交换,因此需要将入口或出口中的 1 个文件描述符传递给子进程。下面的例子是关于该函数的使用方法:
|
||||
父进程调用函数时将创建管道,同时获取对应于出入口的文件描述符,此时父进程可以读写同一管道。但父进程的目的是与子进程进行数据交换,因此需要将入口或出口中的 1 个文件描述符传递给子进程。下面的例子是关于该函数的使用方法:
|
||||
|
||||
- [pipe1.c](https://github.com/riba2534/TCP-IP-NetworkNote/blob/master/ch11/pipe1.c)
|
||||
|
||||
|
||||
@@ -83,7 +83,7 @@ select 函数的使用方法与一般函数的区别并不大,更准确的说
|
||||
|
||||
- `FD_ZERO(fd_set *fdset)`:将 fd_set 变量所指的位全部初始化成0
|
||||
- `FD_SET(int fd,fd_set *fdset)`:在参数 fdset 指向的变量中注册文件描述符 fd 的信息
|
||||
- `FD_SLR(int fd,fd_set *fdset)`:从参数 fdset 指向的变量中清除文件描述符 fd 的信息
|
||||
- `FD_CLR(int fd,fd_set *fdset)`:从参数 fdset 指向的变量中清除文件描述符 fd 的信息
|
||||
- `FD_ISSET(int fd,fd_set *fdset)`:若参数 fdset 指向的变量中包含文件描述符 fd 的信息,则返回「真」
|
||||
|
||||
上述函数中,FD_ISSET 用于验证 select 函数的调用结果,通过下图解释这些函数的功能:
|
||||
@@ -128,7 +128,7 @@ struct timeval
|
||||
};
|
||||
```
|
||||
|
||||
本来 select 函数只有在监视文件描述符发生变化时才返回。如果未发生变化,就会进入阻塞状态。指定超时时间就是为了防止这种情况的发生。通过上述结构体变量,将秒数填入 tv_sec 的成员,将微妙数填入 tv_usec 的成员,然后将结构体的地址值传递到 select 函数的最后一个参数。此时,即使文件描述符未发生变化,只要过了指定时间,也可以从函数中返回。不过这种情况下, select 函数返回 0 。因此,可以通过返回值了解原因。如果不向设置超时,则传递 NULL 参数。
|
||||
本来 select 函数只有在监视文件描述符发生变化时才返回。如果未发生变化,就会进入阻塞状态。指定超时时间就是为了防止这种情况的发生。通过上述结构体变量,将秒数填入 tv_sec 的成员,将微妙数填入 tv_usec 的成员,然后将结构体的地址值传递到 select 函数的最后一个参数。此时,即使文件描述符未发生变化,只要过了指定时间,也可以从函数中返回。不过这种情况下, select 函数返回 0 。因此,可以通过返回值了解原因。如果不想设置超时,则传递 NULL 参数。
|
||||
|
||||
#### 12.2.4 调用 select 函数查看结果
|
||||
|
||||
@@ -136,7 +136,7 @@ select 返回正整数时,怎样获知哪些文件描述符发生了变化?
|
||||
|
||||

|
||||
|
||||
由图可知,select 函数调用完成候,向其传递的 fd_set 变量将发生变化。原来为 1 的所有位将变成 0,但是发生了变化的文件描述符除外。因此,可以认为值仍为 1 的位置上的文件描述符发生了变化。
|
||||
由图可知,select 函数调用完成后,向其传递的 fd_set 变量将发生变化。原来为 1 的所有位将变成 0,但是发生了变化的文件描述符除外。因此,可以认为值仍为 1 的位置上的文件描述符发生了变化。
|
||||
|
||||
#### 12.2.5 select 函数调用示例
|
||||
|
||||
|
||||
@@ -14,7 +14,7 @@ ssize_t send(int sockfd, const void *buf, size_t nbytes, int flags);
|
||||
/*
|
||||
成功时返回发送的字节数,失败时返回 -1
|
||||
sockfd: 表示与数据传输对象的连接的套接字和文件描述符
|
||||
buf: 保存带传输数据的缓冲地址值
|
||||
buf: 保存待传输数据的缓冲地址值
|
||||
nbytes: 待传输字节数
|
||||
flags: 传输数据时指定的可选项信息
|
||||
*/
|
||||
@@ -34,7 +34,7 @@ flags: 接收数据时指定的可选项参数
|
||||
*/
|
||||
```
|
||||
|
||||
send 和 recv 函数都是最后一个参数是收发数据的可选项,该选项可以用位或(bit OR)运算符(| 运算符)同时传递多个信息。
|
||||
send 和 recv 函数的最后一个参数是收发数据的可选项,该选项可以用位或(bit OR)运算符(| 运算符)同时传递多个信息。
|
||||
|
||||
send & recv 函数的可选项意义:
|
||||
|
||||
@@ -86,7 +86,7 @@ fcntl(recv_sock, F_SETOWN, getpid());
|
||||
|
||||
的确,通过 MSG_OOB 并不会加快传输速度,而通过信号处理函数 urg_handler 也只能读取一个字节。剩余数据只能通过未设置 MSG_OOB 可选项的普通输入函数读取。因为 TCP 不存在真正意义上的「外带数据」。实际上,MSG_OOB 中的 OOB 指的是 Out-of-band ,而「外带数据」的含义是:
|
||||
|
||||
> 通过去完全不同的通信路径传输的数据
|
||||
> 通过完全不同的通信路径传输的数据
|
||||
|
||||
即真正意义上的 Out-of-band 需要通过单独的通信路径高速传输数据,但是 TCP 不另外提供,只利用 TCP 的紧急模式(Urgent mode)进行传输。
|
||||
|
||||
@@ -102,7 +102,7 @@ MSG_OOB 的真正意义在于督促数据接收对象尽快处理数据。这是
|
||||
send(sock, "890", strlen("890"), MSG_OOB);
|
||||
```
|
||||
|
||||
图上是调用这个函数的缓冲状态。如果缓冲最左端的位置视作偏移量 0 。字符 0 保存于偏移量 2 的位置。另外,字符 0 右侧偏移量为 3 的位置存有紧急指针(Urgent Pointer)。紧急指针指向紧急消息的下一个位置(偏移量加一),同时向对方主机传递一下信息:
|
||||
图上是调用这个函数的缓冲状态。如果缓冲最左端的位置视作偏移量 0 。字符 0 保存于偏移量 2 的位置。另外,字符 0 右侧偏移量为 3 的位置存有紧急指针(Urgent Pointer)。紧急指针指向紧急消息的下一个位置(偏移量加一),同时向对方主机传递以下信息:
|
||||
|
||||
> 紧急指针指向的偏移量为 3 之前的部分就是紧急消息。
|
||||
|
||||
@@ -121,7 +121,7 @@ TCP 数据包实际包含更多信息。TCP 头部包含如下两种信息:
|
||||
|
||||
#### 13.1.4 检查输入缓冲
|
||||
|
||||
同时设置 MSG_PEEK 选项和 MSG_DONTWAIT 选项,以验证输入缓冲是否存在接收的数据。设置 MSG_PEEK 选项并调用 recv 函数时,即使读取了输入缓冲的数据也不会删除。因此,该选项通常与 MSG_DONTWAIT 合作,用于调用以非阻塞方式验证待读数据存与否的函数。下面的示例是二者的含义:
|
||||
同时设置 MSG_PEEK 选项和 MSG_DONTWAIT 选项,以验证输入缓冲是否存在接收的数据。设置 MSG_PEEK 选项并调用 recv 函数时,即使读取了输入缓冲的数据也不会删除。因此,该选项通常与 MSG_DONTWAIT 合作,用于以非阻塞方式验证待读数据存在与否。下面的示例是二者的含义:
|
||||
|
||||
- [peek_recv.c](https://github.com/riba2534/TCP-IP-NetworkNote/blob/master/ch13/peek_recv.c)
|
||||
- [peek_send.c](https://github.com/riba2534/TCP-IP-NetworkNote/blob/master/ch13/peek_send.c)
|
||||
@@ -225,9 +225,9 @@ Write bytes: 7
|
||||
ssize_t readv(int filedes, const struct iovc *iov, int iovcnt);
|
||||
/*
|
||||
成功时返回接收的字节数,失败时返回 -1
|
||||
filedes: 表示数据传输对象的套接字文件描述符。但该函数并不仅限于套接字,因此,可以像 read 一样向向其传递文件或标准输出描述符.
|
||||
iov: iovec 结构体数组的地址值,结构体 iovec 中包含待发送数据的位置和大小信息
|
||||
iovcnt: 向第二个参数传递数组长度
|
||||
filedes: 表示数据传输对象的套接字文件描述符。但该函数并不仅限于套接字,因此,可以像 write 一样向向其传递文件或标准输出描述符.
|
||||
iov: iovec 结构体数组的地址值,结构体 iovec 中包含待数据保存的位置和大小信息
|
||||
iovcnt: 第二个参数中数组的长度
|
||||
*/
|
||||
```
|
||||
|
||||
|
||||
@@ -43,7 +43,7 @@ setsockopt(send_sock,IPPROTO_IP,IP_MULTICAST_TTL,(void*)&time_live,sizeof(time_l
|
||||
...
|
||||
```
|
||||
|
||||
加入多播组也通过设置设置套接字可选项来完成。加入多播组相关的协议层为 IPPROTO_IP,选项名为 IP_ADD_MEMBERSHIP 。可通过如下代码加入多播组:
|
||||
加入多播组也通过设置套接字可选项来完成。加入多播组相关的协议层为 IPPROTO_IP,选项名为 IP_ADD_MEMBERSHIP 。可通过如下代码加入多播组:
|
||||
|
||||
```c
|
||||
int recv_sock;
|
||||
@@ -53,7 +53,7 @@ recv_sock=socket(PF_INET,SOCK_DGRAM,0);
|
||||
...
|
||||
join_adr.imr_multiaddr.s_addr="多播组地址信息";
|
||||
join_adr.imr_interface.s_addr="加入多播组的主机地址信息";
|
||||
setsockopt(recv_sock,IPPROTO_IP,IP_ADD_MEMBERSHIP,(void*)&join_adr,sizeof(time_live);
|
||||
setsockopt(recv_sock,IPPROTO_IP,IP_ADD_MEMBERSHIP,(void*)&join_adr,sizeof(join_adr);
|
||||
...
|
||||
```
|
||||
|
||||
|
||||
@@ -6,7 +6,7 @@
|
||||
|
||||
#### 15.1.1 标准 I/O 函数的两个优点
|
||||
|
||||
下面是标准 I/O 函数的两个优点:
|
||||
除了使用 read 和 write 函数收发数据外,还能使用标准 I/O 函数收发数据。下面是标准 I/O 函数的两个优点:
|
||||
|
||||
- 标准 I/O 函数具有良好的移植性
|
||||
- 标准 I/O 函数可以利用缓冲提高性能
|
||||
@@ -22,7 +22,7 @@
|
||||
- 传输的数据量
|
||||
- 数据向输出缓冲移动的次数。
|
||||
|
||||
比较 1 个字节的数据发送 10 次的情况和 10 个数据包发送 1 次的情况。发送数据时,数据包中含有头信息。头信与数据大小无关,是按照一定的格式填入的。假设头信息占 40 个字节,需要传输的数据量也存在较大区别:
|
||||
比较 1 个字节的数据发送 10 次的情况和 10 个字节发送 1 次的情况。发送数据时,数据包中含有头信息。头信与数据大小无关,是按照一定的格式填入的。假设头信息占 40 个字节,需要传输的数据量也存在较大区别:
|
||||
|
||||
- 1 个字节 10 次:40*10=400 字节
|
||||
- 10个字节 1 次:40*1=40 字节。
|
||||
@@ -80,7 +80,7 @@ int main()
|
||||
fputs("file open error", stdout);
|
||||
return -1;
|
||||
}
|
||||
fd = fdopen(fd, "w"); //返回 写 模式的 FILE 指针
|
||||
fp = fdopen(fd, "w"); //返回 写 模式的 FILE 指针
|
||||
fputs("NetWork C programming \n", fp);
|
||||
fclose(fp);
|
||||
return 0;
|
||||
|
||||
@@ -19,11 +19,11 @@ select 性能上最大的弱点是:每次传递监视对象信息,准确的
|
||||
|
||||
> 仅向操作系统传递一次监视对象,监视范围或内容发生变化时只通知发生变化的事项
|
||||
|
||||
这样就无需每次调用 select 函数时都想操作系统传递监视对象信息,但是前提操作系统支持这种处理方式。Linux 的支持方式是 epoll ,Windows 的支持方式是 IOCP。
|
||||
这样就无需每次调用 select 函数时都向操作系统传递监视对象信息,但是前提操作系统支持这种处理方式。Linux 的支持方式是 epoll ,Windows 的支持方式是 IOCP。
|
||||
|
||||
#### 17.1.2 select 也有有点
|
||||
|
||||
select 的兼容性比较高,这样就可以支持很多的操作系统,不受平台的限制,使用 select 函数满足以下两个条件:
|
||||
select 的兼容性比较高,这样就可以支持很多的操作系统,不受平台的限制,满足以下两个条件使可以使用 select 函数:
|
||||
|
||||
- 服务器接入者少
|
||||
- 程序应该具有兼容性
|
||||
@@ -83,7 +83,7 @@ size:epoll 实例的大小
|
||||
|
||||
调用 epoll_create 函数时创建的文件描述符保存空间称为「epoll 例程」,但有些情况下名称不同,需要稍加注意。通过参数 size 传递的值决定 epoll 例程的大小,但该值只是向操作系统提出的建议。换言之,size 并不用来决定 epoll 的大小,而仅供操作系统参考。
|
||||
|
||||
> Linux 2.6.8 之后的内核将完全传入 epoll_create 函数的 size 函数,因此内核会根据情况调整 epoll 例程大小。但是本书程序并没有忽略 size
|
||||
> Linux 2.6.8 之后的内核将完全忽略传入 epoll_create 函数的 size 函数,因此内核会根据情况调整 epoll 例程大小。但是本书程序并没有忽略 size
|
||||
|
||||
epoll_create 函数创建的资源与套接字相同,也由操作系统管理。因此,该函数和创建套接字的情况相同,也会返回文件描述符,也就是说返回的文件描述符主要用于区分 epoll 例程。需要终止时,与其他文件描述符相同,也要调用 close 函数
|
||||
|
||||
@@ -97,7 +97,7 @@ int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
|
||||
/*
|
||||
成功时返回 0 ,失败时返回 -1
|
||||
epfd:用于注册监视对象的 epoll 例程的文件描述符
|
||||
op:用于制定监视对象的添加、删除或更改等操作
|
||||
op:用于指定监视对象的添加、删除或更改等操作
|
||||
fd:需要注册的监视对象文件描述符
|
||||
event:监视对象的事件类型
|
||||
*/
|
||||
@@ -119,7 +119,7 @@ epoll_ctl(A,EPOLL_CTL_ADD,B,C);
|
||||
epoll_ctl(A,EPOLL_CTL_DEL,B,NULL);
|
||||
```
|
||||
|
||||
上述语句中第二个参数意味这「删除」,有以下含义:
|
||||
上述语句中第二个参数意味着「删除」,有以下含义:
|
||||
|
||||
> 从 epoll 例程 A 中删除文件描述符 B
|
||||
|
||||
@@ -131,7 +131,7 @@ epoll_ctl(A,EPOLL_CTL_DEL,B,NULL);
|
||||
- EPOLL_CTL_DEL:从 epoll 例程中删除文件描述符
|
||||
- EPOLL_CTL_MOD:更改注册的文件描述符的关注事件发生情况
|
||||
|
||||
epoll_event 结构体用于保存事件的文件描述符结合。但也可以在 epoll 例程中注册文件描述符时,用于注册关注的事件。该函数中 epoll_event 结构体的定义并不显眼,因此通过掉英语剧说明该结构体在 epoll_ctl 函数中的应用。
|
||||
epoll_event 结构体用于保存事件的文件描述符结合。但也可以在 epoll 例程中注册文件描述符时,用于注册关注的事件。该函数中 epoll_event 结构体的定义并不显眼,因此通过调用语句说明该结构体在 epoll_ctl 函数中的应用。
|
||||
|
||||
```c
|
||||
struct epoll_event event;
|
||||
@@ -152,7 +152,7 @@ epoll_ctl(epfd,EPOLL_CTL_ADD,sockfd,&event);
|
||||
- EPOLLET:以边缘触发的方式得到事件通知
|
||||
- EPOLLONESHOT:发生一次事件后,相应文件描述符不再收到事件通知。因此需要向 epoll_ctl 函数的第二个参数传递 EPOLL_CTL_MOD ,再次设置事件。
|
||||
|
||||
可通过位运算同事传递多个上述参数。
|
||||
可通过位或运算同时传递多个上述参数。
|
||||
|
||||
#### 17.1.6 epoll_wait
|
||||
|
||||
@@ -162,7 +162,7 @@ epoll_ctl(epfd,EPOLL_CTL_ADD,sockfd,&event);
|
||||
#include <sys/epoll.h>
|
||||
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
|
||||
/*
|
||||
成功时返回发生事件的文件描述符,失败时返回 -1
|
||||
成功时返回发生事件的文件描述符个数,失败时返回 -1
|
||||
epfd : 表示事件发生监视范围的 epoll 例程的文件描述符
|
||||
events : 保存发生事件的文件描述符集合的结构体地址值
|
||||
maxevents : 第二个参数中可以保存的最大事件数
|
||||
@@ -182,7 +182,7 @@ event_cnt=epoll_wait(epfd,ep_events,EPOLL_SIZE,-1);
|
||||
...
|
||||
```
|
||||
|
||||
调用函数后,返回发生事件的文件描述符,同时在第二个参数指向的缓冲中保存发生事件的文件描述符集合。因此,无需像 select 一样插入针对所有文件描述符的循环。
|
||||
调用函数后,返回发生事件的文件描述符个数,同时在第二个参数指向的缓冲中保存发生事件的文件描述符集合。因此,无需像 select 一样插入针对所有文件描述符的循环。
|
||||
|
||||
#### 17.1.7 基于 epoll 的回声服务器端
|
||||
|
||||
@@ -252,7 +252,7 @@ gcc echo_EPLTserv.c -o serv
|
||||
|
||||
|
||||
|
||||
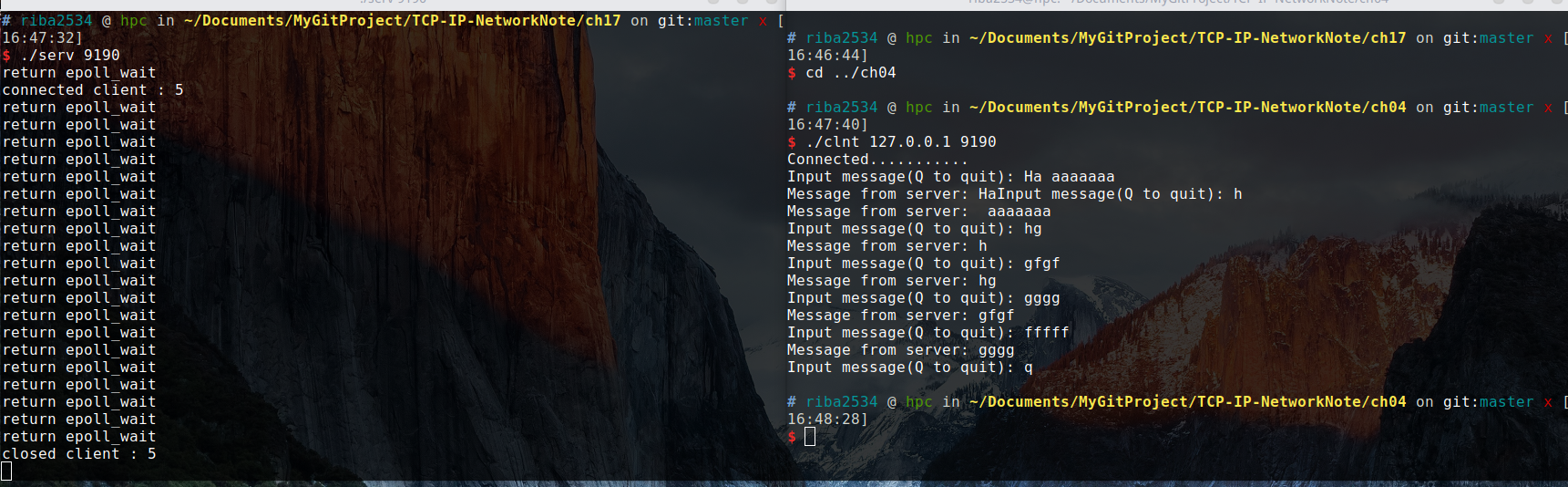
从结果可以看出,每当收到客户端数据时,都回注册该事件,并因此调用 epoll_wait 函数。
|
||||
从结果可以看出,每当收到客户端数据时,都会注册该事件,并因此调用 epoll_wait 函数。
|
||||
|
||||
下面的代码是修改后的边缘触发方式的代码,仅仅是把上面的代码改为:
|
||||
|
||||
@@ -310,7 +310,7 @@ cmd : 表示函数调用目的
|
||||
|
||||
```C
|
||||
int flag = fcntl(fd,F_GETFL,0);
|
||||
fcntl(fd,F_SETFL | O_NONBLOCK)
|
||||
fcntl(fd, F_SETFL, flag | O_NONBLOCK);
|
||||
```
|
||||
|
||||
通过第一条语句,获取之前设置的属性信息,通过第二条语句在此基础上添加非阻塞 O_NONBLOCK 标志。调用 read/write 函数时,无论是否存在数据,都会形成非阻塞文件(套接字)。fcntl 函数的适用范围很广。
|
||||
|
||||
@@ -757,7 +757,7 @@ gcc chat_clnt.c -D_REENTRANT -o cclnt -lpthread
|
||||
|
||||
1. **单 CPU 系统中如何同时执行多个进程?请解释该过程中发生的上下文切换**。
|
||||
|
||||
答:系统将 CPU 时间分成多个微笑的块后分配给了多个进程。为了分时使用 CPU ,需要「上下文切换」过程。运行程序前需要将相应进程信息读入内存,如果运行进程 A 后需要紧接着运行进程 B ,就应该将进程 A 相关今夕移出内存,并读入进程 B 的信息。这就是上下文切换
|
||||
答:系统将 CPU 时间分成多个微小的时间块后分配给了多个进程。为了分时使用 CPU ,需要「上下文切换」过程。运行程序前需要将相应进程信息读入内存,如果运行进程 A 后需要紧接着运行进程 B ,就应该将进程 A 相关信息移出内存,并读入进程 B 的信息。这就是上下文切换
|
||||
|
||||
2. **为何线程的上下文切换速度相对更快?线程间数据交换为何不需要类似 IPC 特别技术**。
|
||||
|
||||
|
||||
Reference in New Issue
Block a user