mirror of
https://github.com/youngyangyang04/leetcode-master.git
synced 2026-02-02 18:39:09 +08:00
377 lines
12 KiB
Markdown
Executable File
377 lines
12 KiB
Markdown
Executable File
* [做项目(多个C++、Java、Go、测开、前端项目)](https://www.programmercarl.com/other/kstar.html)
|
||
* [刷算法(两个月高强度学算法)](https://www.programmercarl.com/xunlian/xunlianying.html)
|
||
* [背八股(40天挑战高频面试题)](https://www.programmercarl.com/xunlian/bagu.html)
|
||
|
||
# 115.不同的子序列
|
||
|
||
[力扣题目链接](https://leetcode.cn/problems/distinct-subsequences/)
|
||
|
||
给定一个字符串 s 和一个字符串 t ,计算在 s 的子序列中 t 出现的个数。
|
||
|
||
字符串的一个 子序列 是指,通过删除一些(也可以不删除)字符且不干扰剩余字符相对位置所组成的新字符串。(例如,"ACE" 是 "ABCDE" 的一个子序列,而 "AEC" 不是)
|
||
|
||
题目数据保证答案符合 32 位带符号整数范围。
|
||
|
||

|
||
|
||
提示:
|
||
|
||
* 0 <= s.length, t.length <= 1000
|
||
* s 和 t 由英文字母组成
|
||
|
||
## 算法公开课
|
||
|
||
**[《代码随想录》算法视频公开课](https://programmercarl.com/other/gongkaike.html):[动态规划之子序列,为了编辑距离做铺垫 | LeetCode:115.不同的子序列](https://www.bilibili.com/video/BV1fG4y1m75Q/),相信结合视频在看本篇题解,更有助于大家对本题的理解**。
|
||
|
||
## 思路
|
||
|
||
这道题目如果不是子序列,而是要求连续序列的,那就可以考虑用KMP。
|
||
|
||
这道题目相对于72. 编辑距离,简单了不少,因为本题相当于只有删除操作,不用考虑替换增加之类的。
|
||
|
||
但相对于刚讲过的[动态规划:392.判断子序列](https://programmercarl.com/0392.判断子序列.html)就有难度了,这道题目双指针法可就做不了了,来看看动规五部曲分析如下:
|
||
|
||
1. 确定dp数组(dp table)以及下标的含义
|
||
|
||
dp[i][j]:以i-1为结尾的s子序列中出现以j-1为结尾的t的个数为dp[i][j]。
|
||
|
||
为什么i-1,j-1 这么定义我在 [718. 最长重复子数组](https://programmercarl.com/0718.最长重复子数组.html) 中做了详细的讲解。
|
||
|
||
2. 确定递推公式
|
||
|
||
这一类问题,基本是要分析两种情况
|
||
|
||
* s[i - 1] 与 t[j - 1]相等
|
||
* s[i - 1] 与 t[j - 1] 不相等
|
||
|
||
当s[i - 1] 与 t[j - 1]相等时,dp[i][j]可以有两部分组成。
|
||
|
||
一部分是用s[i - 1]来匹配,那么个数为dp[i - 1][j - 1]。即不需要考虑当前s子串和t子串的最后一位字母,所以只需要 dp[i-1][j-1]。
|
||
|
||
一部分是不用s[i - 1]来匹配,个数为dp[i - 1][j]。
|
||
|
||
**这里可能有录友不明白了,为什么还要考虑 不用s[i - 1]来匹配,都相同了指定要匹配啊**。
|
||
|
||
例如: s:bagg 和 t:bag ,s[3] 和 t[2]是相同的,但是字符串s也可以不用s[3]来匹配,即用s[0]s[1]s[2]组成的bag。
|
||
|
||
当然也可以用s[3]来匹配,即:s[0]s[1]s[3]组成的bag。
|
||
|
||
所以当s[i - 1] 与 t[j - 1]相等时,dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
|
||
|
||
当s[i - 1] 与 t[j - 1]不相等时,dp[i][j]只有一部分组成,不用s[i - 1]来匹配(就是模拟在s中删除这个元素),即:dp[i - 1][j]
|
||
|
||
所以递推公式为:dp[i][j] = dp[i - 1][j];
|
||
|
||
这里可能有录友还疑惑,为什么只考虑 “不用s[i - 1]来匹配” 这种情况, 不考虑 “不用t[j - 1]来匹配” 的情况呢。
|
||
|
||
这里大家要明确,我们求的是 s 中有多少个 t,而不是 求t中有多少个s,所以只考虑 s中删除元素的情况,即 不用s[i - 1]来匹配 的情况。
|
||
|
||
3. dp数组如何初始化
|
||
|
||
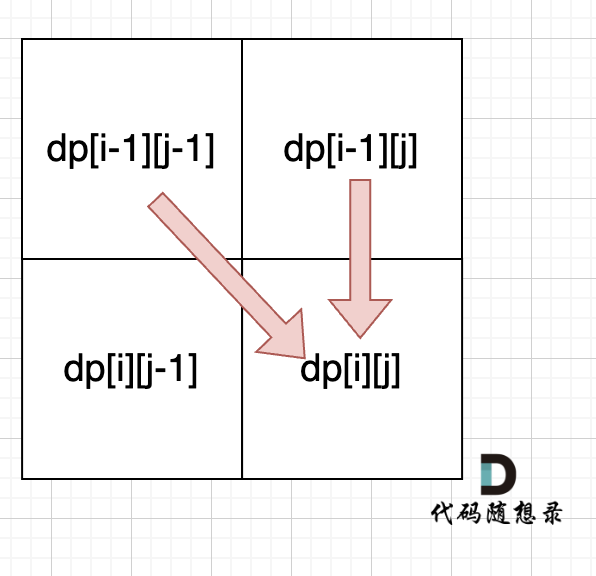
从递推公式dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j]; 和 dp[i][j] = dp[i - 1][j]; 中可以看出dp[i][j] 是从上方和左上方推导而来,如图:,那么 dp[i][0] 和dp[0][j]是一定要初始化的。
|
||
|
||
|
||
|
||
每次当初始化的时候,都要回顾一下dp[i][j]的定义,不要凭感觉初始化。
|
||
|
||
dp[i][0]表示什么呢?
|
||
|
||
dp[i][0] 表示:以i-1为结尾的s可以随便删除元素,出现空字符串的个数。
|
||
|
||
那么dp[i][0]一定都是1,因为也就是把以i-1为结尾的s,删除所有元素,出现空字符串的个数就是1。
|
||
|
||
再来看dp[0][j],dp[0][j]:空字符串s可以随便删除元素,出现以j-1为结尾的字符串t的个数。
|
||
|
||
那么dp[0][j]一定都是0,s如论如何也变成不了t。
|
||
|
||
最后就要看一个特殊位置了,即:dp[0][0] 应该是多少。
|
||
|
||
dp[0][0]应该是1,空字符串s,可以删除0个元素,变成空字符串t。
|
||
|
||
初始化分析完毕,代码如下:
|
||
|
||
```CPP
|
||
vector<vector<long long>> dp(s.size() + 1, vector<long long>(t.size() + 1));
|
||
for (int i = 0; i <= s.size(); i++) dp[i][0] = 1;
|
||
for (int j = 1; j <= t.size(); j++) dp[0][j] = 0; // 其实这行代码可以和dp数组初始化的时候放在一起,但我为了凸显初始化的逻辑,所以还是加上了。
|
||
|
||
```
|
||
|
||
4. 确定遍历顺序
|
||
|
||
从递推公式dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j]; 和 dp[i][j] = dp[i - 1][j]; 中可以看出dp[i][j]都是根据左上方和正上方推出来的。
|
||
|
||

|
||
|
||
所以遍历的时候一定是从上到下,从左到右,这样保证dp[i][j]可以根据之前计算出来的数值进行计算。
|
||
|
||
代码如下:
|
||
|
||
```CPP
|
||
for (int i = 1; i <= s.size(); i++) {
|
||
for (int j = 1; j <= t.size(); j++) {
|
||
if (s[i - 1] == t[j - 1]) {
|
||
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
|
||
} else {
|
||
dp[i][j] = dp[i - 1][j];
|
||
}
|
||
}
|
||
}
|
||
```
|
||
|
||
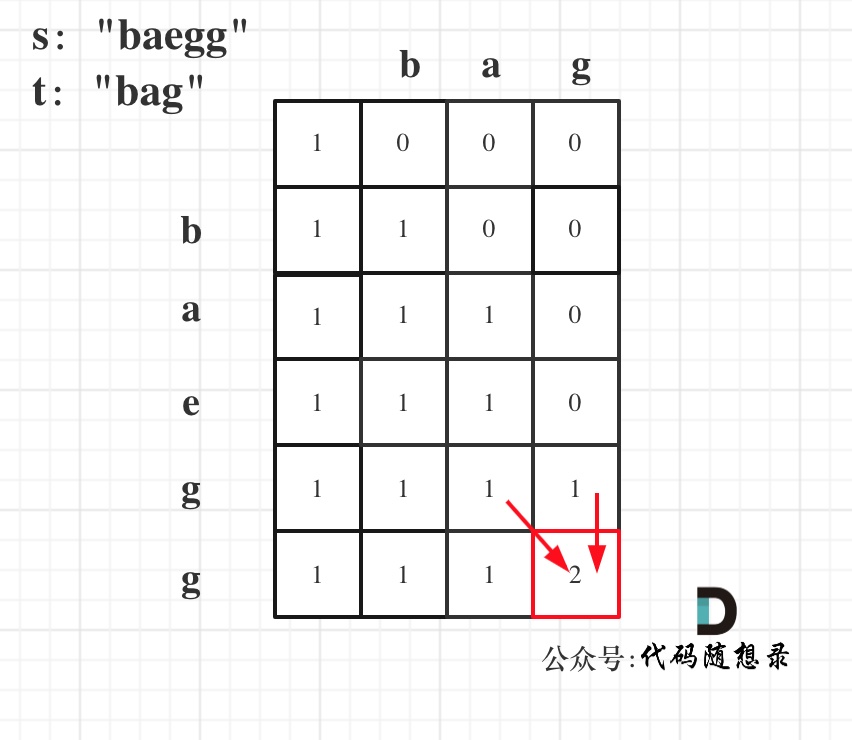
5. 举例推导dp数组
|
||
|
||
以s:"baegg",t:"bag"为例,推导dp数组状态如下:
|
||
|
||
|
||
|
||
如果写出来的代码怎么改都通过不了,不妨把dp数组打印出来,看一看,是不是这样的。
|
||
|
||
|
||
动规五部曲分析完毕,代码如下:
|
||
|
||
```CPP
|
||
class Solution {
|
||
public:
|
||
int numDistinct(string s, string t) {
|
||
vector<vector<uint64_t>> dp(s.size() + 1, vector<uint64_t>(t.size() + 1));
|
||
for (int i = 0; i < s.size(); i++) dp[i][0] = 1;
|
||
for (int j = 1; j < t.size(); j++) dp[0][j] = 0;
|
||
for (int i = 1; i <= s.size(); i++) {
|
||
for (int j = 1; j <= t.size(); j++) {
|
||
if (s[i - 1] == t[j - 1]) {
|
||
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
|
||
} else {
|
||
dp[i][j] = dp[i - 1][j];
|
||
}
|
||
}
|
||
}
|
||
return dp[s.size()][t.size()];
|
||
}
|
||
};
|
||
```
|
||
|
||
* 时间复杂度: O(n * m)
|
||
* 空间复杂度: O(n * m)
|
||
|
||
|
||
|
||
## 其他语言版本
|
||
|
||
### Java:
|
||
|
||
```java
|
||
class Solution {
|
||
public int numDistinct(String s, String t) {
|
||
int[][] dp = new int[s.length() + 1][t.length() + 1];
|
||
for (int i = 0; i < s.length() + 1; i++) {
|
||
dp[i][0] = 1;
|
||
}
|
||
|
||
for (int i = 1; i < s.length() + 1; i++) {
|
||
for (int j = 1; j < t.length() + 1; j++) {
|
||
if (s.charAt(i - 1) == t.charAt(j - 1)) {
|
||
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
|
||
}else{
|
||
dp[i][j] = dp[i - 1][j];
|
||
}
|
||
}
|
||
}
|
||
|
||
return dp[s.length()][t.length()];
|
||
}
|
||
}
|
||
```
|
||
|
||
### Python:
|
||
|
||
```python
|
||
class Solution:
|
||
def numDistinct(self, s: str, t: str) -> int:
|
||
dp = [[0] * (len(t)+1) for _ in range(len(s)+1)]
|
||
for i in range(len(s)):
|
||
dp[i][0] = 1
|
||
for j in range(1, len(t)):
|
||
dp[0][j] = 0
|
||
for i in range(1, len(s)+1):
|
||
for j in range(1, len(t)+1):
|
||
if s[i-1] == t[j-1]:
|
||
dp[i][j] = dp[i-1][j-1] + dp[i-1][j]
|
||
else:
|
||
dp[i][j] = dp[i-1][j]
|
||
return dp[-1][-1]
|
||
```
|
||
|
||
### Python3:
|
||
|
||
```python
|
||
class SolutionDP2:
|
||
"""
|
||
既然dp[i]只用到dp[i - 1]的状态,
|
||
我们可以通过缓存dp[i - 1]的状态来对dp进行压缩,
|
||
减少空间复杂度。
|
||
(原理等同同于滚动数组)
|
||
"""
|
||
|
||
def numDistinct(self, s: str, t: str) -> int:
|
||
n1, n2 = len(s), len(t)
|
||
if n1 < n2:
|
||
return 0
|
||
|
||
dp = [0 for _ in range(n2 + 1)]
|
||
dp[0] = 1
|
||
|
||
for i in range(1, n1 + 1):
|
||
# 必须深拷贝
|
||
# 不然prev[i]和dp[i]是同一个地址的引用
|
||
prev = dp.copy()
|
||
# 剪枝,保证s的长度大于等于t
|
||
# 因为对于任意i,i > n1, dp[i] = 0
|
||
# 没必要跟新状态。
|
||
end = i if i < n2 else n2
|
||
for j in range(1, end + 1):
|
||
if s[i - 1] == t[j - 1]:
|
||
dp[j] = prev[j - 1] + prev[j]
|
||
else:
|
||
dp[j] = prev[j]
|
||
return dp[-1]
|
||
```
|
||
|
||
### Go:
|
||
|
||
```go
|
||
func numDistinct(s string, t string) int {
|
||
dp:= make([][]int,len(s)+1)
|
||
for i:=0;i<len(dp);i++{
|
||
dp[i] = make([]int,len(t)+1)
|
||
}
|
||
// 初始化
|
||
for i:=0;i<len(dp);i++{
|
||
dp[i][0] = 1
|
||
}
|
||
// dp[0][j] 为 0,默认值,因此不需要初始化
|
||
for i:=1;i<len(dp);i++{
|
||
for j:=1;j<len(dp[i]);j++{
|
||
if s[i-1] == t[j-1]{
|
||
dp[i][j] = dp[i-1][j-1] + dp[i-1][j]
|
||
}else{
|
||
dp[i][j] = dp[i-1][j]
|
||
}
|
||
}
|
||
}
|
||
return dp[len(dp)-1][len(dp[0])-1]
|
||
}
|
||
```
|
||
|
||
### JavaScript:
|
||
|
||
```javascript
|
||
const numDistinct = (s, t) => {
|
||
let dp = Array.from(Array(s.length + 1), () => Array(t.length +1).fill(0));
|
||
|
||
for(let i = 0; i <=s.length; i++) {
|
||
dp[i][0] = 1;
|
||
}
|
||
|
||
for(let i = 1; i <= s.length; i++) {
|
||
for(let j = 1; j<= t.length; j++) {
|
||
if(s[i-1] === t[j-1]) {
|
||
dp[i][j] = dp[i-1][j-1] + dp[i-1][j];
|
||
} else {
|
||
dp[i][j] = dp[i-1][j]
|
||
}
|
||
}
|
||
}
|
||
|
||
return dp[s.length][t.length];
|
||
};
|
||
```
|
||
|
||
### TypeScript:
|
||
|
||
```typescript
|
||
function numDistinct(s: string, t: string): number {
|
||
/**
|
||
dp[i][j]: s前i个字符,t前j个字符,s子序列中t出现的个数
|
||
dp[0][0]=1, 表示s前0个字符为'',t前0个字符为''
|
||
*/
|
||
const sLen: number = s.length,
|
||
tLen: number = t.length;
|
||
const dp: number[][] = new Array(sLen + 1).fill(0)
|
||
.map(_ => new Array(tLen + 1).fill(0));
|
||
for (let m = 0; m < sLen; m++) {
|
||
dp[m][0] = 1;
|
||
}
|
||
for (let i = 1; i <= sLen; i++) {
|
||
for (let j = 1; j <= tLen; j++) {
|
||
if (s[i - 1] === t[j - 1]) {
|
||
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
|
||
} else {
|
||
dp[i][j] = dp[i - 1][j];
|
||
}
|
||
}
|
||
}
|
||
return dp[sLen][tLen];
|
||
};
|
||
```
|
||
|
||
### Rust:
|
||
|
||
```rust
|
||
impl Solution {
|
||
pub fn num_distinct(s: String, t: String) -> i32 {
|
||
if s.len() < t.len() {
|
||
return 0;
|
||
}
|
||
let mut dp = vec![vec![0; s.len() + 1]; t.len() + 1];
|
||
// i = 0, t 为空字符串,s 作为子序列的个数为 1(删除 s 所有元素)
|
||
dp[0] = vec![1; s.len() + 1];
|
||
for (i, char_t) in t.chars().enumerate() {
|
||
for (j, char_s) in s.chars().enumerate() {
|
||
if char_t == char_s {
|
||
// t 的前 i 个字符在 s 的前 j 个字符中作为子序列的个数
|
||
dp[i + 1][j + 1] = dp[i][j] + dp[i + 1][j];
|
||
continue;
|
||
}
|
||
dp[i + 1][j + 1] = dp[i + 1][j];
|
||
}
|
||
}
|
||
dp[t.len()][s.len()]
|
||
}
|
||
}
|
||
```
|
||
|
||
> 滚动数组
|
||
|
||
```rust
|
||
impl Solution {
|
||
pub fn num_distinct(s: String, t: String) -> i32 {
|
||
if s.len() < t.len() {
|
||
return 0;
|
||
}
|
||
let (s, t) = (s.into_bytes(), t.into_bytes());
|
||
// 对于 t 为空字符串,s 作为子序列的个数为 1(删除 s 所有元素)
|
||
let mut dp = vec![1; s.len() + 1];
|
||
for char_t in t {
|
||
// dp[i - 1][j - 1],dp[j + 1] 更新之前的值
|
||
let mut pre = dp[0];
|
||
// 当开始遍历 t,s 的前 0 个字符无法包含任意子序列
|
||
dp[0] = 0;
|
||
for (j, &char_s) in s.iter().enumerate() {
|
||
let temp = dp[j + 1];
|
||
if char_t == char_s {
|
||
dp[j + 1] = pre + dp[j];
|
||
} else {
|
||
dp[j + 1] = dp[j];
|
||
}
|
||
pre = temp;
|
||
}
|
||
}
|
||
dp[s.len()]
|
||
}
|
||
}
|
||
```
|
||
|
||
|
||
|