mirror of
https://github.com/youngyangyang04/leetcode-master.git
synced 2026-06-28 16:07:10 +08:00
545
README.md
545
README.md
@@ -1,10 +1,11 @@
|
||||
|
||||
## 一些闲话:
|
||||
|
||||
> 1. **介绍**:本项目是一套完整的刷题计划,旨在帮助大家少走弯路,循序渐进学算法,[关注作者](#关于作者)
|
||||
> 2. **PDF版本** : [「代码随想录」算法精讲 PDF 版本](https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ) 。
|
||||
> 3. **知识星球** : 面试技巧/如何选择offer/大厂内推/职场规则/简历修改/技术分享/程序人生。欢迎加入[我的知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ) 。
|
||||
> 4. **转载须知** :以下所有文章如非文首说明皆为我([程序员Carl](https://github.com/youngyangyang04))的原创。引用本项目文章请注明出处,发现恶意抄袭或搬运,会动用法律武器维护自己的权益。让我们一起维护一个良好的技术创作环境!
|
||||
> 3. **刷题顺序** : README已经将刷题顺序排好了,按照顺序一道一道刷就可以。
|
||||
> 3. **学习社区** : 一起学习打卡/面试技巧/如何选择offer/大厂内推/职场规则/简历修改/技术分享/程序人生。欢迎加入[「代码随想录」学习社区](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ) 。
|
||||
> 4. **提交代码**:本项目统一使用C++语言进行讲解,但已经有Java、Python、Go、JavaScript等等多语言版本,感谢[这里的每一位贡献者](https://github.com/youngyangyang04/leetcode-master/graphs/contributors),如果你也想贡献代码点亮你的头像,[点击这里](https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A)了解提交代码的方式。
|
||||
> 5. **转载须知** :以下所有文章皆为我([程序员Carl](https://github.com/youngyangyang04))的原创。引用本项目文章请注明出处,发现恶意抄袭或搬运,会动用法律武器维护自己的权益。让我们一起维护一个良好的技术创作环境!
|
||||
|
||||
<p align="center">
|
||||
<a href="https://github.com/youngyangyang04/leetcode-master" target="_blank">
|
||||
@@ -12,30 +13,16 @@
|
||||
</a>
|
||||
|
||||
<p align="center">
|
||||
<a href="https://github.com/youngyangyang04/leetcode-master"><img src="https://img.shields.io/badge/Github-leetcode--master-lightgrey" alt=""></a>
|
||||
<a href="https://img-blog.csdnimg.cn/20201115103410182.png"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://img-blog.csdnimg.cn/20201210231711160.png"><img src="https://img.shields.io/badge/公众号-代码随想录-brightgreen" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://www.zhihu.com/people/sun-xiu-yang-64"><img src="https://img.shields.io/badge/知乎-代码随想录-blue" alt=""></a>
|
||||
<a href="https://www.toutiao.com/c/user/60356270818/#mid=1633692776932365"><img src="https://img.shields.io/badge/头条-代码随想录-red" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ" target="_blank">
|
||||
<img src="./pics/知识星球.png" width="600"/>
|
||||
</a>
|
||||
|
||||
# 算法面试思维导图
|
||||
|
||||

|
||||
|
||||
# B站算法视频讲解
|
||||
|
||||
以下为[B站「代码随想录」](https://space.bilibili.com/525438321)算法讲解视频:
|
||||
|
||||
* [帮你把KMP算法学个通透!(理论篇)](https://www.bilibili.com/video/BV1PD4y1o7nd)
|
||||
* [帮你把KMP算法学个通透!(代码篇)](https://www.bilibili.com/video/BV1M5411j7Xx)
|
||||
* [带你学透回溯算法(理论篇)](https://www.bilibili.com/video/BV1cy4y167mM)
|
||||
* [回溯算法之组合问题(力扣题目:77.组合)](https://www.bilibili.com/video/BV1ti4y1L7cv)
|
||||
* [组合问题的剪枝操作(对应力扣题目:77.组合)](https://www.bilibili.com/video/BV1wi4y157er)
|
||||
* [组合总和(对应力扣题目:39.组合总和)](https://www.bilibili.com/video/BV1KT4y1M7HJ/)
|
||||
|
||||
(持续更新中....)
|
||||
|
||||
# LeetCode 刷题攻略
|
||||
|
||||
@@ -43,191 +30,224 @@
|
||||
|
||||
很多刚开始刷题的同学都有一个困惑:面对leetcode上近两千道题目,从何刷起。
|
||||
|
||||
大家平时刷题感觉效率低,浪费的时间主要在三点:
|
||||
|
||||
* 找题
|
||||
* 找到了不应该现阶段做的题
|
||||
* 没有全套的优质题解可以参考
|
||||
|
||||
其实我之前在知乎上回答过这个问题,回答内容大概是按照如下类型来刷数组-> 链表-> 哈希表->字符串->栈与队列->树->回溯->贪心->动态规划->图论->高级数据结构,再从简单刷起,做了几个类型题目之后,再慢慢做中等题目、困难题目。
|
||||
|
||||
但我能设身处地的感受到:即使有这样一个整体规划,对于一位初学者甚至算法老手寻找合适自己的题目也是很困难,时间成本很高,而且题目还不一定就是经典题目。
|
||||
|
||||
对于刷题,我们都是想用最短的时间把经典题目都做一篇,这样效率才是最高的!
|
||||
对于刷题,我们都是想用最短的时间**按照循序渐进的难度顺序把经典题目都做一遍**,这样效率才是最高的!
|
||||
|
||||
所以我整理了leetcode刷题攻略:一个超级详细的刷题顺序,**每道题目都是我精心筛选,都是经典题目高频面试题**,大家只要按照这个顺序刷就可以了,**你没看错,就是题目顺序都排好了,文章顺序就是刷题顺序!挨个刷就可以,不用自己再去题海里选题了!**
|
||||
所以我整理了leetcode刷题攻略:一个超级详细的刷题顺序,**每道题目都是我精心筛选,都是经典题目高频面试题**,大家只要按照这个顺序刷就可以了,**你没看错,README已经把题目顺序都排好了,文章顺序就是刷题顺序!挨个刷就可以,不用自己再去题海里选题了!**
|
||||
|
||||
而且每道题目我都写了的详细题解(图文并茂,难点配有视频),力扣上我的题解都是排在对应题目的首页,质量是有目共睹的。
|
||||
|
||||
**那么今天我把这个刷题顺序整理出来,是为了帮助更多的学习算法的同学少走弯路!**
|
||||
**那么现在我把刷题顺序都整理出来,是为了帮助更多的学习算法的同学少走弯路!**
|
||||
|
||||
如果你在刷leetcode,强烈建议先按照本攻略刷题顺序来刷,刷完了你会发现对整个知识体系有一个质的飞跃,不用在题海茫然的寻找方向。
|
||||
|
||||
**文章会首发在公众号[「代码随想录」](https://img-blog.csdnimg.cn/20201124161234338.png),赶紧去看看吧,你一定会发现相见恨晚!**
|
||||
<div align="center"><strong>最新文章会首发在公众号「代码随想录」,扫码看看吧,你会发现相见恨晚!</strong></img></div>
|
||||
|
||||
<div align="center"><img src='./pics/公众号二维码.jpg' width=150 alt=''> </img></div>
|
||||
|
||||
## 如何使用该刷题攻略
|
||||
|
||||
电脑端还看不到留言,大家可以在公众号[「代码随想录」](https://img-blog.csdnimg.cn/20201124161234338.png),左下角有「算法汇总」,这是手机版刷题攻略,看完就会发现有很多录友(代码随想录的朋友们)在文章下留言打卡,这份刷题顺序和题解已经陪伴了上万录友了,同时也说明文章的质量是经过上万人的考验!
|
||||
电脑端还看不到留言,大家可以在公众号[「代码随想录」](https://img-blog.csdnimg.cn/20201124161234338.png),左下角有「刷题攻略」,这是手机版刷题攻略,看完就会发现有很多录友(代码随想录的朋友们)在文章下留言打卡,这份刷题顺序和题解已经陪伴了上万录友了,同时也说明文章的质量是经过上万人的考验!
|
||||
|
||||
欢迎每一位学习算法的小伙伴加入到这个学习阵营来!
|
||||
|
||||
**目前已经更新了,数组-> 链表-> 哈希表->字符串->栈与队列->树->回溯->贪心,八个专题了,正在讲解动态规划!**
|
||||
|
||||
在刷题指南中,每个专题开始都有理论基础篇,并不像是教科书般的理论介绍,而是从实战中归纳需要的基础知识。每个专题结束都有总结篇,最这个专题的归纳总结。
|
||||
在刷题攻略中,每个专题开始都有理论基础篇,并不像是教科书般的理论介绍,而是从实战中归纳需要的基础知识。每个专题结束都有总结篇,最这个专题的归纳总结。
|
||||
|
||||
如果你是算法老手,这篇攻略也是复习的最佳资料,如果把每个系列对应的总结篇,快速过一遍,整个算法知识体系以及各种解法就重现脑海了。
|
||||
|
||||
在按照如下顺序刷题的过程中,每一道题解一定要看对应文章下面的留言(留言目前只能在手机端查看)。
|
||||
|
||||
如果你有疑问或者发现文章哪里有不对的地方,都可以在留言区都能找到答案,还有很多录友的总结非常赞,看完之后也很有收获。
|
||||
目前「代码随想录」刷题攻略更新了:**200多篇文章,精讲了200道经典算法题目,共60w字的详细图解,部分难点题目还搭配了20分钟左右的视频讲解**。
|
||||
|
||||
目前「代码随想录」刷题指南更新了:**200篇文章,精讲了100多道经典算法题目,共50w字的详细图解,部分难点题目还搭配了20分钟左右的视频讲解**。
|
||||
**这里每一篇题解,都是精品,值得仔细琢磨**。
|
||||
|
||||
我在题目讲解中统一用C++语言,但你会发现下面几乎每篇题解都配有其他语言版本,Java、Python、Go、JavaScript等等,这正是热心小伙们的贡献的代码,当然我也会严格把控代码质量。
|
||||
|
||||
**所以也欢迎大家参与进来,完善题解的各个语言版本,拥抱开源,让更多小伙伴们收益**。
|
||||
|
||||
准备好了么,刷题攻略开始咯,go go go!
|
||||
|
||||
---------------------------------------------
|
||||
|
||||
## 前序
|
||||
|
||||
* [「代码随想录」后序安排](https://mp.weixin.qq.com/s/4eeGJREy6E-v6D7cR_5A4g)
|
||||
* [「代码随想录」学习社区](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
|
||||
|
||||
* 编程语言
|
||||
* [C++面试&C++学习指南知识点整理](https://github.com/youngyangyang04/TechCPP)
|
||||
* 项目
|
||||
* [基于跳表的轻量级KV存储引擎](https://github.com/youngyangyang04/Skiplist-CPP)
|
||||
|
||||
* 编程素养
|
||||
* [看了这么多代码,谈一谈代码风格!](https://mp.weixin.qq.com/s/UR9ztxz3AyL3qdHn_zMbqw)
|
||||
* [力扣上的代码想在本地编译运行?](https://mp.weixin.qq.com/s/r1696t8lvcw7Rz4gb_jacw)
|
||||
* [什么是核心代码模式,什么又是ACM模式?](https://mp.weixin.qq.com/s/TSEBJoeCB0dVVXFnlmES3A)
|
||||
* [看了这么多代码,谈一谈代码风格!](./problems/前序/代码风格.md)
|
||||
* [力扣上的代码想在本地编译运行?](./problems/前序/力扣上的代码想在本地编译运行?.md)
|
||||
* [什么是核心代码模式,什么又是ACM模式?](./problems/前序/什么是核心代码模式,什么又是ACM模式?.md)
|
||||
* 工具
|
||||
* [一站式vim配置](https://github.com/youngyangyang04/PowerVim)
|
||||
* [保姆级Git入门教程,万字详解](https://mp.weixin.qq.com/s/Q_O0ey4C9tryPZaZeJocbA)
|
||||
* [程序员应该用什么用具来写文档?](https://mp.weixin.qq.com/s/s_hig9nioq8nT-2F7AL0SQ)
|
||||
* [程序员应该用什么用具来写文档?](./problems/前序/程序员写文档工具.md)
|
||||
|
||||
* 求职
|
||||
* [程序员的简历应该这么写!!(附简历模板)](https://mp.weixin.qq.com/s/nCTUzuRTBo1_R_xagVszsA)
|
||||
* [BAT级别技术面试流程和注意事项都在这里了](https://mp.weixin.qq.com/s/815qCyFGVIxwut9I_7PNFw)
|
||||
* [北京有这些互联网公司,你都知道么?](https://mp.weixin.qq.com/s/BKrjK4myNB-FYbMqW9f3yw)
|
||||
* [上海有这些互联网公司,你都知道么?](https://mp.weixin.qq.com/s/iW4_rXQzc0fJDuSmPTUVdQ)
|
||||
* [深圳有这些互联网公司,你都知道么?](https://mp.weixin.qq.com/s/3VJHF2zNohBwDBxARFIn-Q)
|
||||
* [广州有这些互联网公司,你都知道么?](https://mp.weixin.qq.com/s/Ir_hQP0clbnvHrWzDL-qXg)
|
||||
* [成都有这些互联网公司,你都知道么?](https://mp.weixin.qq.com/s/Y9Qg22WEsBngs8B-K8acqQ)
|
||||
* [杭州有这些互联网公司,你都知道么?](https://mp.weixin.qq.com/s/33FmPJYrOU-ygovoxIaEUw)
|
||||
* [程序员的简历应该这么写!!(附简历模板)](./problems/前序/程序员简历.md)
|
||||
* [BAT级别技术面试流程和注意事项都在这里了](./problems/前序/BAT级别技术面试流程和注意事项都在这里了.md)
|
||||
* [北京有这些互联网公司,你都知道么?](./problems/前序/北京互联网公司总结.md)
|
||||
* [上海有这些互联网公司,你都知道么?](./problems/前序/上海互联网公司总结.md)
|
||||
* [深圳有这些互联网公司,你都知道么?](./problems/前序/深圳互联网公司总结.md)
|
||||
* [广州有这些互联网公司,你都知道么?](./problems/前序/广州互联网公司总结.md)
|
||||
* [成都有这些互联网公司,你都知道么?](./problems/前序/成都互联网公司总结.md)
|
||||
* [杭州有这些互联网公司,你都知道么?](./problems/前序/杭州互联网公司总结.md)
|
||||
|
||||
* 算法性能分析
|
||||
* [关于时间复杂度,你不知道的都在这里!](https://mp.weixin.qq.com/s/LWBfehW1gMuEnXtQjJo-sw)
|
||||
* [O(n)的算法居然超时了,此时的n究竟是多大?](https://mp.weixin.qq.com/s/73ryNsuPFvBQkt6BbhNzLA)
|
||||
* [通过一道面试题目,讲一讲递归算法的时间复杂度!](https://mp.weixin.qq.com/s/I6ZXFbw09NR31F5CJR_geQ)
|
||||
* [本周小结!(算法性能分析系列一)](https://mp.weixin.qq.com/s/5m8xDbGUeGgYJsESeg5ITQ)
|
||||
* [关于空间复杂度,可能有几个疑问?](https://mp.weixin.qq.com/s/IPv4pTD6UxKkFBkgeDCZyg)
|
||||
* [递归算法的时间与空间复杂度分析!](https://mp.weixin.qq.com/s/zLeRB-GPc3q4DG-a5cQLVw)
|
||||
* [刷了这么多题,你了解自己代码的内存消耗么?](https://mp.weixin.qq.com/s/IFZQCxJlI7-_dOC25xIOYQ)
|
||||
* [关于时间复杂度,你不知道的都在这里!](./problems/前序/关于时间复杂度,你不知道的都在这里!.md)
|
||||
* [O(n)的算法居然超时了,此时的n究竟是多大?](./problems/前序/On的算法居然超时了,此时的n究竟是多大?.md)
|
||||
* [通过一道面试题目,讲一讲递归算法的时间复杂度!](./problems/前序/通过一道面试题目,讲一讲递归算法的时间复杂度!.md)
|
||||
* [本周小结!(算法性能分析系列一)](./problems/周总结/20201210复杂度分析周末总结.md)
|
||||
* [关于空间复杂度,可能有几个疑问?](./problems/前序/关于空间复杂度,可能有几个疑问?.md)
|
||||
* [递归算法的时间与空间复杂度分析!](./problems/前序/递归算法的时间与空间复杂度分析.md)
|
||||
* [刷了这么多题,你了解自己代码的内存消耗么?](./problems/前序/刷了这么多题,你了解自己代码的内存消耗么?.md)
|
||||
|
||||
(持续更新中.....)
|
||||
|
||||
## 知识星球精选
|
||||
|
||||
1. [选择方向的时候,我也迷茫了](https://mp.weixin.qq.com/s/ZCzFiAHZHLqHPLJQXNm75g)
|
||||
2. [刷题就用库函数了,怎么了?](https://mp.weixin.qq.com/s/6K3_OSaudnHGq2Ey8vqYfg)
|
||||
3. [关于实习,大家可能有点迷茫!](https://mp.weixin.qq.com/s/xcxzi7c78kQGjvZ8hh7taA)
|
||||
4. [马上秋招了,慌得很!](https://mp.weixin.qq.com/s/7q7W8Cb2-a5U5atZdOnOFA)
|
||||
5. [Carl看了上百份简历,总结了这些!](https://mp.weixin.qq.com/s/sJa87MZD28piCOVMFkIbwQ)
|
||||
6. [面试中遇到了发散性问题.....](https://mp.weixin.qq.com/s/SSonDxi2pjkSVwHNzZswng)
|
||||
7. [英语到底重不重要!](https://mp.weixin.qq.com/s/1PRZiyF_-TVA-ipwDNjdKw)
|
||||
8. [计算机专业要不要读研!](https://mp.weixin.qq.com/s/c9v1L3IjqiXtkNH7sOMAdg)
|
||||
9. [秋招和提前批都越来越提前了....](https://mp.weixin.qq.com/s/SNFiRDx8CKyjhTPlys6ywQ)
|
||||
|
||||
|
||||
## 数组
|
||||
|
||||
1. [数组过于简单,但你该了解这些!](https://mp.weixin.qq.com/s/c2KABb-Qgg66HrGf8z-8Og)
|
||||
2. [数组:每次遇到二分法,都是一看就会,一写就废](https://mp.weixin.qq.com/s/fCf5QbPDtE6SSlZ1yh_q8Q)
|
||||
3. [数组:就移除个元素很难么?](https://mp.weixin.qq.com/s/wj0T-Xs88_FHJFwayElQlA)
|
||||
4. [数组:滑动窗口拯救了你](https://mp.weixin.qq.com/s/UrZynlqi4QpyLlLhBPglyg)
|
||||
5. [数组:这个循环可以转懵很多人!](https://mp.weixin.qq.com/s/KTPhaeqxbMK9CxHUUgFDmg)
|
||||
6. [数组:总结篇](https://mp.weixin.qq.com/s/LIfQFRJBH5ENTZpvixHEmg)
|
||||
1. [数组过于简单,但你该了解这些!](./problems/数组理论基础.md)
|
||||
2. [数组:每次遇到二分法,都是一看就会,一写就废](./problems/0704.二分查找.md)
|
||||
3. [数组:就移除个元素很难么?](./problems/0027.移除元素.md)
|
||||
4. [数组:有序数组的平方,还有序么?](./problems/0977.有序数组的平方.md)
|
||||
5. [数组:滑动窗口拯救了你](./problems/0209.长度最小的子数组.md)
|
||||
6. [数组:这个循环可以转懵很多人!](./problems/0059.螺旋矩阵II.md)
|
||||
7. [数组:总结篇](./problems/数组总结篇.md)
|
||||
|
||||
## 链表
|
||||
|
||||
1. [关于链表,你该了解这些!](https://mp.weixin.qq.com/s/ntlZbEdKgnFQKZkSUAOSpQ)
|
||||
2. [链表:听说用虚拟头节点会方便很多?](https://mp.weixin.qq.com/s/slM1CH5Ew9XzK93YOQYSjA)
|
||||
3. [链表:一道题目考察了常见的五个操作!](https://mp.weixin.qq.com/s/Cf95Lc6brKL4g2j8YyF3Mg)
|
||||
4. [链表:听说过两天反转链表又写不出来了?](https://mp.weixin.qq.com/s/pnvVP-0ZM7epB8y3w_Njwg)
|
||||
5. [链表:删除链表的倒数第 N 个结点](https://leetcode-cn.com/problems/remove-nth-node-from-end-of-list/solution/dai-ma-sui-xiang-lu-19-shan-chu-lian-bia-2hxt/)
|
||||
5. [链表:环找到了,那入口呢?](https://mp.weixin.qq.com/s/_QVP3IkRZWx9zIpQRgajzA)
|
||||
6. [链表:总结篇!](https://mp.weixin.qq.com/s/vK0JjSTHfpAbs8evz5hH8A)
|
||||
1. [关于链表,你该了解这些!](./problems/链表理论基础.md)
|
||||
2. [链表:听说用虚拟头节点会方便很多?](./problems/0203.移除链表元素.md)
|
||||
3. [链表:一道题目考察了常见的五个操作!](./problems/0707.设计链表.md)
|
||||
4. [链表:听说过两天反转链表又写不出来了?](./problems/0206.翻转链表.md)
|
||||
5. [链表:两两交换链表中的节点](./problems/0024.两两交换链表中的节点.md)
|
||||
6. [链表:删除链表的倒数第 N 个结点](./problems/0019.删除链表的倒数第N个节点.md)
|
||||
7. [链表:链表相交](./problems/面试题02.07.链表相交.md)
|
||||
8. [链表:环找到了,那入口呢?](./problems/0142.环形链表II.md)
|
||||
9. [链表:总结篇!](./problems/链表总结篇.md)
|
||||
|
||||
## 哈希表
|
||||
|
||||
1. [关于哈希表,你该了解这些!](https://mp.weixin.qq.com/s/g8N6WmoQmsCUw3_BaWxHZA)
|
||||
2. [哈希表:可以拿数组当哈希表来用,但哈希值不要太大](https://mp.weixin.qq.com/s/vM6OszkM6L1Mx2Ralm9Dig)
|
||||
3. [哈希表:哈希值太大了,还是得用set](https://mp.weixin.qq.com/s/N9iqAchXreSVW7zXUS4BVA)
|
||||
4. [哈希表:用set来判断快乐数](https://mp.weixin.qq.com/s/G4Q2Zfpfe706gLK7HpZHpA)
|
||||
5. [哈希表:map等候多时了](https://mp.weixin.qq.com/s/uVAtjOHSeqymV8FeQbliJQ)
|
||||
6. [哈希表:其实需要哈希的地方都能找到map的身影](https://mp.weixin.qq.com/s/Ue8pKKU5hw_m-jPgwlHcbA)
|
||||
7. [哈希表:这道题目我做过?](https://mp.weixin.qq.com/s/sYZIR4dFBrw_lr3eJJnteQ)
|
||||
8. [哈希表:解决了两数之和,那么能解决三数之和么?](https://mp.weixin.qq.com/s/r5cgZFu0tv4grBAexdcd8A)
|
||||
9. [双指针法:一样的道理,能解决四数之和](https://mp.weixin.qq.com/s/nQrcco8AZJV1pAOVjeIU_g)
|
||||
10. [哈希表:总结篇!(每逢总结必经典)](https://mp.weixin.qq.com/s/1s91yXtarL-PkX07BfnwLg)
|
||||
1. [关于哈希表,你该了解这些!](./problems/哈希表理论基础.md)
|
||||
2. [哈希表:可以拿数组当哈希表来用,但哈希值不要太大](./problems/0242.有效的字母异位词.md)
|
||||
3. [哈希表:哈希值太大了,还是得用set](./problems/0349.两个数组的交集.md)
|
||||
4. [哈希表:用set来判断快乐数](./problems/0202.快乐数.md)
|
||||
5. [哈希表:map等候多时了](./problems/0001.两数之和.md)
|
||||
6. [哈希表:其实需要哈希的地方都能找到map的身影](./problems/0454.四数相加II.md)
|
||||
7. [哈希表:这道题目我做过?](./problems/0383.赎金信.md)
|
||||
8. [哈希表:解决了两数之和,那么能解决三数之和么?](./problems/0015.三数之和.md)
|
||||
9. [双指针法:一样的道理,能解决四数之和](./problems/0018.四数之和.md)
|
||||
10. [哈希表:总结篇!(每逢总结必经典)](./problems/哈希表总结.md)
|
||||
|
||||
|
||||
## 字符串
|
||||
|
||||
1. [字符串:这道题目,使用库函数一行代码搞定](https://mp.weixin.qq.com/s/X02S61WCYiCEhaik6VUpFA)
|
||||
2. [字符串:简单的反转还不够!](https://mp.weixin.qq.com/s/XGSk1GyPWhfqj2g7Cb1Vgw)
|
||||
3. [字符串:替换空格](https://mp.weixin.qq.com/s/t0A9C44zgM-RysAQV3GZpg)
|
||||
4. [字符串:花式反转还不够!](https://mp.weixin.qq.com/s/X3qpi2v5RSp08mO-W5Vicw)
|
||||
5. [字符串:反转个字符串还有这个用处?](https://mp.weixin.qq.com/s/PmcdiWSmmccHAONzU0ScgQ)
|
||||
6. [帮你把KMP算法学个通透!(理论篇)B站视频](https://www.bilibili.com/video/BV1PD4y1o7nd)
|
||||
7. [帮你把KMP算法学个通透!(代码篇)B站视频](https://www.bilibili.com/video/BV1M5411j7Xx)
|
||||
8. [字符串:都来看看KMP的看家本领!](https://mp.weixin.qq.com/s/Gk9FKZ9_FSWLEkdGrkecyg)
|
||||
9. [字符串:KMP算法还能干这个!](https://mp.weixin.qq.com/s/lR2JPtsQSR2I_9yHbBmBuQ)
|
||||
10. [字符串:前缀表不右移,难道就写不出KMP了?](https://mp.weixin.qq.com/s/p3hXynQM2RRROK5c6X7xfw)
|
||||
11. [字符串:总结篇!](https://mp.weixin.qq.com/s/gtycjyDtblmytvBRFlCZJg)
|
||||
1. [字符串:这道题目,使用库函数一行代码搞定](./problems/0344.反转字符串.md)
|
||||
2. [字符串:简单的反转还不够!](./problems/0541.反转字符串II.md)
|
||||
3. [字符串:替换空格](./problems/剑指Offer05.替换空格.md)
|
||||
4. [字符串:花式反转还不够!](./problems/0151.翻转字符串里的单词.md)
|
||||
5. [字符串:反转个字符串还有这个用处?](./problems/剑指Offer58-II.左旋转字符串.md)
|
||||
6. [帮你把KMP算法学个通透](./problems/0028.实现strStr.md)
|
||||
8. [字符串:KMP算法还能干这个!](./problems/0459.重复的子字符串.md)
|
||||
9. [字符串:总结篇!](./problems/字符串总结.md)
|
||||
|
||||
## 双指针法
|
||||
|
||||
双指针法基本都是应用在数组,字符串与链表的题目上
|
||||
|
||||
1. [数组:就移除个元素很难么?](https://mp.weixin.qq.com/s/wj0T-Xs88_FHJFwayElQlA)
|
||||
2. [字符串:这道题目,使用库函数一行代码搞定](https://mp.weixin.qq.com/s/X02S61WCYiCEhaik6VUpFA)
|
||||
3. [字符串:替换空格](https://mp.weixin.qq.com/s/t0A9C44zgM-RysAQV3GZpg)
|
||||
4. [字符串:花式反转还不够!](https://mp.weixin.qq.com/s/X3qpi2v5RSp08mO-W5Vicw)
|
||||
5. [链表:听说过两天反转链表又写不出来了?](https://mp.weixin.qq.com/s/pnvVP-0ZM7epB8y3w_Njwg)
|
||||
6. [链表:环找到了,那入口呢?](https://mp.weixin.qq.com/s/_QVP3IkRZWx9zIpQRgajzA)
|
||||
7. [哈希表:解决了两数之和,那么能解决三数之和么?](https://mp.weixin.qq.com/s/r5cgZFu0tv4grBAexdcd8A)
|
||||
8. [双指针法:一样的道理,能解决四数之和](https://mp.weixin.qq.com/s/nQrcco8AZJV1pAOVjeIU_g)
|
||||
9. [双指针法:总结篇!](https://mp.weixin.qq.com/s/_p7grwjISfMh0U65uOyCjA)
|
||||
1. [数组:就移除个元素很难么?](./problems/0027.移除元素.md)
|
||||
2. [字符串:这道题目,使用库函数一行代码搞定](./problems/0344.反转字符串.md)
|
||||
3. [字符串:替换空格](./problems/剑指Offer05.替换空格.md)
|
||||
4. [字符串:花式反转还不够!](./problems/0151.翻转字符串里的单词.md)
|
||||
5. [链表:听说过两天反转链表又写不出来了?](./problems/0206.翻转链表.md)
|
||||
6. [链表:删除链表的倒数第 N 个结点](./problems/0019.删除链表的倒数第N个节点.md)
|
||||
7. [链表:链表相交](./problems/面试题02.07.链表相交.md)
|
||||
8. [链表:环找到了,那入口呢?](./problems/0142.环形链表II.md)
|
||||
9. [哈希表:解决了两数之和,那么能解决三数之和么?](./problems/0015.三数之和.md)
|
||||
10. [双指针法:一样的道理,能解决四数之和](./problems/0018.四数之和.md)
|
||||
11. [双指针法:总结篇!](./problems/双指针总结.md)
|
||||
|
||||
## 栈与队列
|
||||
|
||||
1. [栈与队列:来看看栈和队列不为人知的一面](https://mp.weixin.qq.com/s/VZRjOccyE09aE-MgLbCMjQ)
|
||||
2. [栈与队列:我用栈来实现队列怎么样?](https://mp.weixin.qq.com/s/P6tupDwRFi6Ay-L7DT4NVg)
|
||||
3. [栈与队列:用队列实现栈还有点别扭](https://mp.weixin.qq.com/s/yzn6ktUlL-vRG3-m5a8_Yw)
|
||||
4. [栈与队列:系统中处处都是栈的应用](https://mp.weixin.qq.com/s/nLlmPMsDCIWSqAtr0jbrpQ)
|
||||
5. [栈与队列:匹配问题都是栈的强项](https://mp.weixin.qq.com/s/eynAEbUbZoAWrk0ZlEugqg)
|
||||
6. [栈与队列:有没有想过计算机是如何处理表达式的?](https://mp.weixin.qq.com/s/hneh2nnLT91rR8ms2fm_kw)
|
||||
7. [栈与队列:滑动窗口里求最大值引出一个重要数据结构](https://mp.weixin.qq.com/s/8c6l2bO74xyMjph09gQtpA)
|
||||
8. [栈与队列:求前 K 个高频元素和队列有啥关系?](https://mp.weixin.qq.com/s/8hMwxoE_BQRbzCc7CA8rng)
|
||||
9. [栈与队列:总结篇!](https://mp.weixin.qq.com/s/xBcHyvHlWq4P13fzxEtkPg)
|
||||
1. [栈与队列:来看看栈和队列不为人知的一面](./problems/栈与队列理论基础.md)
|
||||
2. [栈与队列:我用栈来实现队列怎么样?](./problems/0232.用栈实现队列.md)
|
||||
3. [栈与队列:用队列实现栈还有点别扭](./problems/0225.用队列实现栈.md)
|
||||
4. [栈与队列:系统中处处都是栈的应用](./problems/0020.有效的括号.md)
|
||||
5. [栈与队列:匹配问题都是栈的强项](./problems/1047.删除字符串中的所有相邻重复项.md)
|
||||
6. [栈与队列:有没有想过计算机是如何处理表达式的?](./problems/0150.逆波兰表达式求值.md)
|
||||
7. [栈与队列:滑动窗口里求最大值引出一个重要数据结构](./problems/0239.滑动窗口最大值.md)
|
||||
8. [栈与队列:求前 K 个高频元素和队列有啥关系?](./problems/0347.前K个高频元素.md)
|
||||
9. [栈与队列:总结篇!](./problems/栈与队列总结.md)
|
||||
|
||||
## 二叉树
|
||||
|
||||
题目分类大纲如下:
|
||||
<img src='https://img-blog.csdnimg.cn/20210219190809451.png' width=600 alt='二叉树大纲'> </img></div>
|
||||
|
||||
1. [关于二叉树,你该了解这些!](https://mp.weixin.qq.com/s/_ymfWYvTNd2GvWvC5HOE4A)
|
||||
2. [二叉树:一入递归深似海,从此offer是路人](https://mp.weixin.qq.com/s/PwVIfxDlT3kRgMASWAMGhA)
|
||||
3. [二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg)
|
||||
4. [二叉树:前中后序迭代方式的写法就不能统一一下么?](https://mp.weixin.qq.com/s/WKg0Ty1_3SZkztpHubZPRg)
|
||||
5. [二叉树:层序遍历登场!](https://mp.weixin.qq.com/s/Gb3BjakIKGNpup2jYtTzog)
|
||||
6. [二叉树:你真的会翻转二叉树么?](https://mp.weixin.qq.com/s/6gY1MiXrnm-khAAJiIb5Bg)
|
||||
7. [本周小结!(二叉树)](https://mp.weixin.qq.com/s/JWmTeC7aKbBfGx4TY6uwuQ)
|
||||
8. [二叉树:我对称么?](https://mp.weixin.qq.com/s/Kgf0gjvlDlNDfKIH2b1Oxg)
|
||||
9. [二叉树:看看这些树的最大深度](https://mp.weixin.qq.com/s/guKwV-gSNbA1CcbvkMtHBg)
|
||||
10. [二叉树:看看这些树的最小深度](https://mp.weixin.qq.com/s/BH8-gPC3_QlqICDg7rGSGA)
|
||||
11. [二叉树:我有多少个节点?](https://mp.weixin.qq.com/s/2_eAjzw-D0va9y4RJgSmXw)
|
||||
12. [二叉树:我平衡么?](https://mp.weixin.qq.com/s/isUS-0HDYknmC0Rr4R8mww)
|
||||
13. [二叉树:找我的所有路径?](https://mp.weixin.qq.com/s/Osw4LQD2xVUnCJ-9jrYxJA)
|
||||
14. [还在玩耍的你,该总结啦!(本周小结之二叉树)](https://mp.weixin.qq.com/s/QMBUTYnoaNfsVHlUADEzKg)
|
||||
15. [二叉树:以为使用了递归,其实还隐藏着回溯](https://mp.weixin.qq.com/s/ivLkHzWdhjQQD1rQWe6zWA)
|
||||
16. [二叉树:做了这么多题目了,我的左叶子之和是多少?](https://mp.weixin.qq.com/s/gBAgmmFielojU5Wx3wqFTA)
|
||||
17. [二叉树:我的左下角的值是多少?](https://mp.weixin.qq.com/s/MH2gbLvzQ91jHPKqiub0Nw)
|
||||
18. [二叉树:递归函数究竟什么时候需要返回值,什么时候不要返回值?](https://mp.weixin.qq.com/s/6TWAVjxQ34kVqROWgcRFOg)
|
||||
19. [二叉树:构造二叉树登场!](https://mp.weixin.qq.com/s/7r66ap2s-shvVvlZxo59xg)
|
||||
20. [二叉树:构造一棵最大的二叉树](https://mp.weixin.qq.com/s/1iWJV6Aov23A7xCF4nV88w)
|
||||
21. [本周小结!(二叉树系列三)](https://mp.weixin.qq.com/s/JLLpx3a_8jurXcz6ovgxtg)
|
||||
22. [二叉树:合并两个二叉树](https://mp.weixin.qq.com/s/3f5fbjOFaOX_4MXzZ97LsQ)
|
||||
23. [二叉树:二叉搜索树登场!](https://mp.weixin.qq.com/s/vsKrWRlETxCVsiRr8v_hHg)
|
||||
24. [二叉树:我是不是一棵二叉搜索树](https://mp.weixin.qq.com/s/8odY9iUX5eSi0eRFSXFD4Q)
|
||||
25. [二叉树:搜索树的最小绝对差](https://mp.weixin.qq.com/s/Hwzml6698uP3qQCC1ctUQQ)
|
||||
26. [二叉树:我的众数是多少?](https://mp.weixin.qq.com/s/KSAr6OVQIMC-uZ8MEAnGHg)
|
||||
27. [二叉树:公共祖先问题](https://mp.weixin.qq.com/s/n6Rk3nc_X3TSkhXHrVmBTQ)
|
||||
28. [本周小结!(二叉树系列四)](https://mp.weixin.qq.com/s/CbdtOTP0N-HIP7DR203tSg)
|
||||
29. [二叉树:搜索树的公共祖先问题](https://mp.weixin.qq.com/s/Ja9dVw2QhBcg_vV-1fkiCg)
|
||||
30. [二叉树:搜索树中的插入操作](https://mp.weixin.qq.com/s/lwKkLQcfbCNX2W-5SOeZEA)
|
||||
31. [二叉树:搜索树中的删除操作](https://mp.weixin.qq.com/s/-p-Txvch1FFk3ygKLjPAKw)
|
||||
32. [二叉树:修剪一棵搜索树](https://mp.weixin.qq.com/s/QzmGfYUMUWGkbRj7-ozHoQ)
|
||||
33. [二叉树:构造一棵搜索树](https://mp.weixin.qq.com/s/sy3ygnouaZVJs8lhFgl9mw)
|
||||
34. [二叉树:搜索树转成累加树](https://mp.weixin.qq.com/s/hZtJh4T5lIGBarY-lZJf6Q)
|
||||
35. [二叉树:总结篇!(需要掌握的二叉树技能都在这里了)](https://mp.weixin.qq.com/s/-ZJn3jJVdF683ap90yIj4Q)
|
||||
1. [关于二叉树,你该了解这些!](./problems/二叉树理论基础.md)
|
||||
2. [二叉树:一入递归深似海,从此offer是路人](./problems/二叉树的递归遍历.md)
|
||||
3. [二叉树:听说递归能做的,栈也能做!](./problems/二叉树的迭代遍历.md)
|
||||
4. [二叉树:前中后序迭代方式的写法就不能统一一下么?](./problems/二叉树的统一迭代法.md)
|
||||
5. [二叉树:层序遍历登场!](./problems/0102.二叉树的层序遍历.md)
|
||||
6. [二叉树:你真的会翻转二叉树么?](./problems/0226.翻转二叉树.md)
|
||||
7. [本周小结!(二叉树)](./problems/周总结/20200927二叉树周末总结.md)
|
||||
8. [二叉树:我对称么?](./problems/0101.对称二叉树.md)
|
||||
9. [二叉树:看看这些树的最大深度](./problems/0104.二叉树的最大深度.md)
|
||||
10. [二叉树:看看这些树的最小深度](./problems/0111.二叉树的最小深度.md)
|
||||
11. [二叉树:我有多少个节点?](./problems/0222.完全二叉树的节点个数.md)
|
||||
12. [二叉树:我平衡么?](./problems/0110.平衡二叉树.md)
|
||||
13. [二叉树:找我的所有路径?](./problems/0257.二叉树的所有路径.md)
|
||||
14. [本周总结!二叉树系列二](./problems/周总结/20201003二叉树周末总结.md)
|
||||
15. [二叉树:以为使用了递归,其实还隐藏着回溯](./problems/二叉树中递归带着回溯.md)
|
||||
16. [二叉树:做了这么多题目了,我的左叶子之和是多少?](./problems/0404.左叶子之和.md)
|
||||
17. [二叉树:我的左下角的值是多少?](./problems/0513.找树左下角的值.md)
|
||||
18. [二叉树:递归函数究竟什么时候需要返回值,什么时候不要返回值?](./problems/0112.路径总和.md)
|
||||
19. [二叉树:构造二叉树登场!](./problems/0106.从中序与后序遍历序列构造二叉树.md)
|
||||
20. [二叉树:构造一棵最大的二叉树](./problems/0654.最大二叉树.md)
|
||||
21. [本周小结!(二叉树系列三)](./problems/周总结/20201010二叉树周末总结.md)
|
||||
22. [二叉树:合并两个二叉树](./problems/0617.合并二叉树.md)
|
||||
23. [二叉树:二叉搜索树登场!](./problems/0700.二叉搜索树中的搜索.md)
|
||||
24. [二叉树:我是不是一棵二叉搜索树](./problems/0098.验证二叉搜索树.md)
|
||||
25. [二叉树:搜索树的最小绝对差](./problems/0530.二叉搜索树的最小绝对差.md)
|
||||
26. [二叉树:我的众数是多少?](./problems/0501.二叉搜索树中的众数.md)
|
||||
27. [二叉树:公共祖先问题](./problems/0236.二叉树的最近公共祖先.md)
|
||||
28. [本周小结!(二叉树系列四)](./problems/周总结/20201017二叉树周末总结.md)
|
||||
29. [二叉树:搜索树的公共祖先问题](./problems/0235.二叉搜索树的最近公共祖先.md)
|
||||
30. [二叉树:搜索树中的插入操作](./problems/0701.二叉搜索树中的插入操作.md)
|
||||
31. [二叉树:搜索树中的删除操作](./problems/0450.删除二叉搜索树中的节点.md)
|
||||
32. [二叉树:修剪一棵搜索树](./problems/0669.修剪二叉搜索树.md)
|
||||
33. [二叉树:构造一棵搜索树](./problems/0108.将有序数组转换为二叉搜索树.md)
|
||||
34. [二叉树:搜索树转成累加树](./problems/0538.把二叉搜索树转换为累加树.md)
|
||||
35. [二叉树:总结篇!(需要掌握的二叉树技能都在这里了)](./problems/二叉树总结篇.md)
|
||||
|
||||
## 回溯算法
|
||||
|
||||
@@ -235,32 +255,28 @@
|
||||
|
||||
<img src='https://img-blog.csdnimg.cn/20210219192050666.png' width=600 alt='回溯算法大纲'> </img></div>
|
||||
|
||||
1. [关于回溯算法,你该了解这些!](https://mp.weixin.qq.com/s/gjSgJbNbd1eAA5WkA-HeWw)
|
||||
2. [回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)
|
||||
3. [回溯算法:组合问题再剪剪枝](https://mp.weixin.qq.com/s/Ri7spcJMUmph4c6XjPWXQA)
|
||||
4. [回溯算法:求组合总和!](https://mp.weixin.qq.com/s/HX7WW6ixbFZJASkRnCTC3w)
|
||||
5. [回溯算法:电话号码的字母组合](https://mp.weixin.qq.com/s/e2ua2cmkE_vpYjM3j6HY0A)
|
||||
6. [本周小结!(回溯算法系列一)](https://mp.weixin.qq.com/s/m2GnTJdkYhAamustbb6lmw)
|
||||
7. [回溯算法:求组合总和(二)](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)
|
||||
8. [回溯算法:求组合总和(三)](https://mp.weixin.qq.com/s/_1zPYk70NvHsdY8UWVGXmQ)
|
||||
9. [回溯算法:分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)
|
||||
10. [回溯算法:复原IP地址](https://mp.weixin.qq.com/s/v--VmA8tp9vs4bXCqHhBuA)
|
||||
11. [回溯算法:求子集问题!](https://mp.weixin.qq.com/s/NNRzX-vJ_pjK4qxohd_LtA)
|
||||
12. [本周小结!(回溯算法系列二)](https://mp.weixin.qq.com/s/uzDpjrrMCO8DOf-Tl5oBGw)
|
||||
13. [回溯算法:求子集问题(二)](https://mp.weixin.qq.com/s/WJ4JNDRJgsW3eUN72Hh3uQ)
|
||||
14. [回溯算法:递增子序列](https://mp.weixin.qq.com/s/ePxOtX1ATRYJb2Jq7urzHQ)
|
||||
15. [回溯算法:排列问题!](https://mp.weixin.qq.com/s/SCOjeMX1t41wcvJq49GhMw)
|
||||
16. [回溯算法:排列问题(二)](https://mp.weixin.qq.com/s/9L8h3WqRP_h8LLWNT34YlA)
|
||||
17. [本周小结!(回溯算法系列三)](https://mp.weixin.qq.com/s/tLkt9PSo42X60w8i94ViiA)
|
||||
18. [本周小结!(回溯算法系列三)续集](https://mp.weixin.qq.com/s/kSMGHc_YpsqL2j-jb_E_Ag)
|
||||
19. [视频来了!!带你学透回溯算法(理论篇)](https://www.bilibili.com/video/BV1cy4y167mM)
|
||||
20. [视频来了!!回溯算法(力扣题目:77.组合)](https://www.bilibili.com/video/BV1ti4y1L7cv)
|
||||
21. [视频来了!!回溯算法剪枝操作(力扣题目:77.组合)](https://www.bilibili.com/video/BV1wi4y157er)
|
||||
22. [视频来了!!回溯算法(力扣题目:39.组合总和)](https://www.bilibili.com/video/BV1KT4y1M7HJ/)
|
||||
23. [回溯算法:重新安排行程](https://mp.weixin.qq.com/s/3kmbS4qDsa6bkyxR92XCTA)
|
||||
24. [回溯算法:N皇后问题](https://mp.weixin.qq.com/s/lU_QwCMj6g60nh8m98GAWg)
|
||||
25. [回溯算法:解数独](https://mp.weixin.qq.com/s/eWE9TapVwm77yW9Q81xSZQ)
|
||||
26. [一篇总结带你彻底搞透回溯算法!](https://mp.weixin.qq.com/s/r73thpBnK1tXndFDtlsdCQ)
|
||||
1. [关于回溯算法,你该了解这些!](./problems/回溯算法理论基础.md)
|
||||
2. [回溯算法:组合问题](./problems/0077.组合.md)
|
||||
3. [回溯算法:组合问题再剪剪枝](./problems/0077.组合优化.md)
|
||||
4. [回溯算法:求组合总和!](./problems/0216.组合总和III.md)
|
||||
5. [回溯算法:电话号码的字母组合](./problems/0017.电话号码的字母组合.md)
|
||||
6. [本周小结!(回溯算法系列一)](./problems/周总结/20201030回溯周末总结.md)
|
||||
7. [回溯算法:求组合总和(二)](./problems/0039.组合总和.md)
|
||||
8. [回溯算法:求组合总和(三)](./problems/0040.组合总和II.md)
|
||||
9. [回溯算法:分割回文串](./problems/0131.分割回文串.md)
|
||||
10. [回溯算法:复原IP地址](./problems/0093.复原IP地址.md)
|
||||
11. [回溯算法:求子集问题!](./problems/0078.子集.md)
|
||||
12. [本周小结!(回溯算法系列二)](./problems/周总结/20201107回溯周末总结.md)
|
||||
13. [回溯算法:求子集问题(二)](./problems/0090.子集II.md)
|
||||
14. [回溯算法:递增子序列](./problems/0491.递增子序列.md)
|
||||
15. [回溯算法:排列问题!](./problems/0046.全排列.md)
|
||||
16. [回溯算法:排列问题(二)](./problems/0047.全排列II.md)
|
||||
17. [本周小结!(回溯算法系列三)](./problems/周总结/20201112回溯周末总结.md)
|
||||
18. [回溯算法去重问题的另一种写法](./problems/回溯算法去重问题的另一种写法.md)
|
||||
23. [回溯算法:重新安排行程](./problems/0332.重新安排行程.md)
|
||||
24. [回溯算法:N皇后问题](./problems/0051.N皇后.md)
|
||||
25. [回溯算法:解数独](./problems/0037.解数独.md)
|
||||
26. [一篇总结带你彻底搞透回溯算法!](./problems/回溯总结.md)
|
||||
|
||||
## 贪心算法
|
||||
|
||||
@@ -268,108 +284,119 @@
|
||||
|
||||
<img src='https://img-blog.csdnimg.cn/20210220152245584.png' width=600 alt='贪心算法大纲'> </img></div>
|
||||
|
||||
1. [关于贪心算法,你该了解这些!](https://mp.weixin.qq.com/s/O935TaoHE9Eexwe_vSbRAg)
|
||||
2. [贪心算法:分发饼干](https://mp.weixin.qq.com/s/YSuLIAYyRGlyxbp9BNC1uw)
|
||||
3. [贪心算法:摆动序列](https://mp.weixin.qq.com/s/Xytl05kX8LZZ1iWWqjMoHA)
|
||||
4. [贪心算法:最大子序和](https://mp.weixin.qq.com/s/DrjIQy6ouKbpletQr0g1Fg)
|
||||
5. [本周小结!(贪心算法系列一)](https://mp.weixin.qq.com/s/KQ2caT9GoVXgB1t2ExPncQ)
|
||||
6. [贪心算法:买卖股票的最佳时机II](https://mp.weixin.qq.com/s/VsTFA6U96l18Wntjcg3fcg)
|
||||
7. [贪心算法:跳跃游戏](https://mp.weixin.qq.com/s/606_N9j8ACKCODoCbV1lSA)
|
||||
8. [贪心算法:跳跃游戏II](https://mp.weixin.qq.com/s/kJBcsJ46DKCSjT19pxrNYg)
|
||||
9. [贪心算法:K次取反后最大化的数组和](https://mp.weixin.qq.com/s/dMTzBBVllRm_Z0aaWvYazA)
|
||||
10. [本周小结!(贪心算法系列二)](https://mp.weixin.qq.com/s/RiQri-4rP9abFmq_mlXNiQ)
|
||||
11. [贪心算法:加油站](https://mp.weixin.qq.com/s/aDbiNuEZIhy6YKgQXvKELw)
|
||||
12. [贪心算法:分发糖果](https://mp.weixin.qq.com/s/8MwlgFfvaNYmjGwjuMlETQ)
|
||||
13. [贪心算法:柠檬水找零](https://mp.weixin.qq.com/s/0kT4P-hzY7H6Ae0kjQqnZg)
|
||||
14. [贪心算法:根据身高重建队列](https://mp.weixin.qq.com/s/-2TgZVdOwS-DvtbjjDEbfw)
|
||||
15. [本周小结!(贪心算法系列三)](https://mp.weixin.qq.com/s/JfeuK6KgmifscXdpEyIm-g)
|
||||
16. [贪心算法:根据身高重建队列(续集)](https://mp.weixin.qq.com/s/K-pRN0lzR-iZhoi-1FgbSQ)
|
||||
17. [贪心算法:用最少数量的箭引爆气球](https://mp.weixin.qq.com/s/HxVAJ6INMfNKiGwI88-RFw)
|
||||
18. [贪心算法:无重叠区间](https://mp.weixin.qq.com/s/oFOEoW-13Bm4mik-aqAOmw)
|
||||
19. [贪心算法:划分字母区间](https://mp.weixin.qq.com/s/pdX4JwV1AOpc_m90EcO2Hw)
|
||||
20. [贪心算法:合并区间](https://mp.weixin.qq.com/s/royhzEM5tOkUFwUGrNStpw)
|
||||
21. [本周小结!(贪心算法系列四)](https://mp.weixin.qq.com/s/zAMHT6JfB19ZSJNP713CAQ)
|
||||
22. [贪心算法:单调递增的数字](https://mp.weixin.qq.com/s/TAKO9qPYiv6KdMlqNq_ncg)
|
||||
23. [贪心算法:买卖股票的最佳时机含手续费](https://mp.weixin.qq.com/s/olWrUuDEYw2Jx5rMeG7XAg)
|
||||
24. [贪心算法:我要监控二叉树!](https://mp.weixin.qq.com/s/kCxlLLjWKaE6nifHC3UL2Q)
|
||||
25. [贪心算法:总结篇!(每逢总结必经典)](https://mp.weixin.qq.com/s/ItyoYNr0moGEYeRtcjZL3Q)
|
||||
1. [关于贪心算法,你该了解这些!](./problems/贪心算法理论基础.md)
|
||||
2. [贪心算法:分发饼干](./problems/0455.分发饼干.md)
|
||||
3. [贪心算法:摆动序列](./problems/0376.摆动序列.md)
|
||||
4. [贪心算法:最大子序和](./problems/0053.最大子序和.md)
|
||||
5. [本周小结!(贪心算法系列一)](./problems/周总结/20201126贪心周末总结.md)
|
||||
6. [贪心算法:买卖股票的最佳时机II](./problems/0122.买卖股票的最佳时机II.md)
|
||||
7. [贪心算法:跳跃游戏](./problems/0055.跳跃游戏.md)
|
||||
8. [贪心算法:跳跃游戏II](./problems/0045.跳跃游戏II.md)
|
||||
9. [贪心算法:K次取反后最大化的数组和](./problems/1005.K次取反后最大化的数组和.md)
|
||||
10. [本周小结!(贪心算法系列二)](./problems/周总结/20201203贪心周末总结.md)
|
||||
11. [贪心算法:加油站](./problems/0134.加油站.md)
|
||||
12. [贪心算法:分发糖果](./problems/0135.分发糖果.md)
|
||||
13. [贪心算法:柠檬水找零](./problems/0860.柠檬水找零.md)
|
||||
14. [贪心算法:根据身高重建队列](./problems/0406.根据身高重建队列.md)
|
||||
15. [本周小结!(贪心算法系列三)](./problems/周总结/20201217贪心周末总结.md)
|
||||
16. [贪心算法:根据身高重建队列(续集)](./problems/根据身高重建队列(vector原理讲解).md)
|
||||
17. [贪心算法:用最少数量的箭引爆气球](./problems/0452.用最少数量的箭引爆气球.md)
|
||||
18. [贪心算法:无重叠区间](./problems/0435.无重叠区间.md)
|
||||
19. [贪心算法:划分字母区间](./problems/0763.划分字母区间.md)
|
||||
20. [贪心算法:合并区间](./problems/0056.合并区间.md)
|
||||
21. [本周小结!(贪心算法系列四)](./problems/周总结/20201224贪心周末总结.md)
|
||||
22. [贪心算法:单调递增的数字](./problems/0738.单调递增的数字.md)
|
||||
23. [贪心算法:买卖股票的最佳时机含手续费](./problems/0714.买卖股票的最佳时机含手续费.md)
|
||||
24. [贪心算法:我要监控二叉树!](./problems/0968.监控二叉树.md)
|
||||
25. [贪心算法:总结篇!(每逢总结必经典)](./problems/贪心算法总结篇.md)
|
||||
|
||||
## 动态规划
|
||||
|
||||
动态规划专题已经开始啦,来不及解释了,小伙伴们上车别掉队!
|
||||
|
||||
1. [关于动态规划,你该了解这些!](https://mp.weixin.qq.com/s/ocZwfPlCWrJtVGACqFNAag)
|
||||
2. [动态规划:斐波那契数](https://mp.weixin.qq.com/s/ko0zLJplF7n_4TysnPOa_w)
|
||||
3. [动态规划:爬楼梯](https://mp.weixin.qq.com/s/Ohop0jApSII9xxOMiFhGIw)
|
||||
4. [动态规划:使用最小花费爬楼梯](https://mp.weixin.qq.com/s/djZB9gkyLFAKcQcSvKDorA)
|
||||
5. [本周小结!(动态规划系列一)](https://mp.weixin.qq.com/s/95VqGEDhtBBBSb-rM4QSMA)
|
||||
6. [动态规划:不同路径](https://mp.weixin.qq.com/s/MGgGIt4QCpFMROE9X9he_A)
|
||||
7. [动态规划:不同路径还不够,要有障碍!](https://mp.weixin.qq.com/s/lhqF0O4le9-wvalptOVOww)
|
||||
8. [动态规划:整数拆分,你要怎么拆?](https://mp.weixin.qq.com/s/cVbyHrsWH_Rfzlj-ESr01A)
|
||||
9. [动态规划:不同的二叉搜索树](https://mp.weixin.qq.com/s/8VE8pDrGxTf8NEVYBDwONw)
|
||||
10. [本周小结!(动态规划系列二)](https://mp.weixin.qq.com/s/VVsDwTP57g1f9aVsg6wShw)
|
||||
<img src='https://code-thinking.cdn.bcebos.com/pics/动态规划-总结大纲1.jpg' width=500> </img></div>
|
||||
1. [关于动态规划,你该了解这些!](./problems/动态规划理论基础.md)
|
||||
2. [动态规划:斐波那契数](./problems/0509.斐波那契数.md)
|
||||
3. [动态规划:爬楼梯](./problems/0070.爬楼梯.md)
|
||||
4. [动态规划:使用最小花费爬楼梯](./problems/0746.使用最小花费爬楼梯.md)
|
||||
5. [本周小结!(动态规划系列一)](./problems/周总结/20210107动规周末总结.md)
|
||||
6. [动态规划:不同路径](./problems/0062.不同路径.md)
|
||||
7. [动态规划:不同路径还不够,要有障碍!](./problems/0063.不同路径II.md)
|
||||
8. [动态规划:整数拆分,你要怎么拆?](./problems/0343.整数拆分.md)
|
||||
9. [动态规划:不同的二叉搜索树](./problems/0096.不同的二叉搜索树.md)
|
||||
10. [本周小结!(动态规划系列二)](./problems/周总结/20210114动规周末总结.md)
|
||||
|
||||
背包问题系列:
|
||||
|
||||
<img src='https://img-blog.csdnimg.cn/202102261550480.png' width=500 alt='背包问题大纲'> </img></div>
|
||||
<img src='https://code-thinking.cdn.bcebos.com/pics/动态规划-背包问题总结.png' width=500 alt='背包问题大纲'> </img></div>
|
||||
|
||||
11. [动态规划:关于01背包问题,你该了解这些!](https://mp.weixin.qq.com/s/FwIiPPmR18_AJO5eiidT6w)
|
||||
12. [动态规划:关于01背包问题,你该了解这些!(滚动数组)](https://mp.weixin.qq.com/s/M4uHxNVKRKm5HPjkNZBnFA)
|
||||
13. [动态规划:分割等和子集可以用01背包!](https://mp.weixin.qq.com/s/sYw3QtPPQ5HMZCJcT4EaLQ)
|
||||
14. [动态规划:最后一块石头的重量 II](https://mp.weixin.qq.com/s/WbwAo3jaUaNJjvhHgq0BGg)
|
||||
15. [本周小结!(动态规划系列三)](https://mp.weixin.qq.com/s/7emRqR1O3scH63jbaE678A)
|
||||
16. [动态规划:目标和!](https://mp.weixin.qq.com/s/2pWmaohX75gwxvBENS-NCw)
|
||||
17. [动态规划:一和零!](https://mp.weixin.qq.com/s/x-u3Dsp76DlYqtCe0xEKJw)
|
||||
18. [动态规划:关于完全背包,你该了解这些!](https://mp.weixin.qq.com/s/akwyxlJ4TLvKcw26KB9uJw)
|
||||
19. [动态规划:给你一些零钱,你要怎么凑?](https://mp.weixin.qq.com/s/PlowDsI4WMBOzf3q80AksQ)
|
||||
20. [本周小结!(动态规划系列四)](https://mp.weixin.qq.com/s/vfEXwcOlrSBBcv9gg8VDJQ)
|
||||
21. [动态规划:Carl称它为排列总和!](https://mp.weixin.qq.com/s/Iixw0nahJWQgbqVNk8k6gA)
|
||||
22. [动态规划:以前我没得选,现在我选择再爬一次!](https://mp.weixin.qq.com/s/e_wacnELo-2PG76EjrUakA)
|
||||
23. [动态规划: 给我个机会,我再兑换一次零钱](https://mp.weixin.qq.com/s/dyk-xNilHzNtVdPPLObSeQ)
|
||||
24. [动态规划:一样的套路,再求一次完全平方数](https://mp.weixin.qq.com/s/VfJT78p7UGpDZsapKF_QJQ)
|
||||
25. [本周小结!(动态规划系列五)](https://mp.weixin.qq.com/s/znj-9j8mWymRFaPjJN2Qnw)
|
||||
26. [动态规划:单词拆分](https://mp.weixin.qq.com/s/3Spx1B6MbIYjS8YkVbByzA)
|
||||
27. [动态规划:关于多重背包,你该了解这些!](https://mp.weixin.qq.com/s/b-UUUmbvG7URWyCjQkiuuQ)
|
||||
28. [听说背包问题很难? 这篇总结篇来拯救你了](https://mp.weixin.qq.com/s/ZOehl3U1mDiyOQjFG1wNJA)
|
||||
|
||||
11. [动态规划:关于01背包问题,你该了解这些!](./problems/背包理论基础01背包-1.md)
|
||||
12. [动态规划:关于01背包问题,你该了解这些!(滚动数组)](./problems/背包理论基础01背包-2.md)
|
||||
13. [动态规划:分割等和子集可以用01背包!](./problems/0416.分割等和子集.md)
|
||||
14. [动态规划:最后一块石头的重量 II](./problems/1049.最后一块石头的重量II.md)
|
||||
15. [本周小结!(动态规划系列三)](./problems/周总结/20210121动规周末总结.md)
|
||||
16. [动态规划:目标和!](./problems/0494.目标和.md)
|
||||
17. [动态规划:一和零!](./problems/0474.一和零.md)
|
||||
18. [动态规划:关于完全背包,你该了解这些!](./problems/背包问题理论基础完全背包.md)
|
||||
19. [动态规划:给你一些零钱,你要怎么凑?](./problems/0518.零钱兑换II.md)
|
||||
20. [本周小结!(动态规划系列四)](./problems/周总结/20210128动规周末总结.md)
|
||||
21. [动态规划:Carl称它为排列总和!](./problems/0377.组合总和Ⅳ.md)
|
||||
22. [动态规划:以前我没得选,现在我选择再爬一次!](./problems/0070.爬楼梯完全背包版本.md)
|
||||
23. [动态规划: 给我个机会,我再兑换一次零钱](./problems/0322.零钱兑换.md)
|
||||
24. [动态规划:一样的套路,再求一次完全平方数](./problems/0279.完全平方数.md)
|
||||
25. [本周小结!(动态规划系列五)](./problems/周总结/20210204动规周末总结.md)
|
||||
26. [动态规划:单词拆分](./problems/0139.单词拆分.md)
|
||||
27. [动态规划:关于多重背包,你该了解这些!](./problems/背包问题理论基础多重背包.md)
|
||||
28. [听说背包问题很难? 这篇总结篇来拯救你了](./problems/背包总结篇.md)
|
||||
|
||||
打家劫舍系列:
|
||||
|
||||
29. [动态规划:开始打家劫舍!](https://mp.weixin.qq.com/s/UZ31WdLEEFmBegdgLkJ8Dw)
|
||||
30. [动态规划:继续打家劫舍!](https://mp.weixin.qq.com/s/kKPx4HpH3RArbRcxAVHbeQ)
|
||||
31. [动态规划:还要打家劫舍!](https://mp.weixin.qq.com/s/BOJ1lHsxbQxUZffXlgglEQ)
|
||||
29. [动态规划:开始打家劫舍!](./problems/0198.打家劫舍.md)
|
||||
30. [动态规划:继续打家劫舍!](./problems/0213.打家劫舍II.md)
|
||||
31. [动态规划:还要打家劫舍!](./problems/0337.打家劫舍III.md)
|
||||
|
||||
股票系列:
|
||||
|
||||
<img src='https://code-thinking.cdn.bcebos.com/pics/%E8%82%A1%E7%A5%A8%E9%97%AE%E9%A2%98%E6%80%BB%E7%BB%93.jpg' width=500 alt='股票问题总结'> </img></div>
|
||||
<img src='https://code-thinking.cdn.bcebos.com/pics/股票问题总结.jpg' width=500 alt='股票问题总结'> </img></div>
|
||||
|
||||
32. [动态规划:买卖股票的最佳时机](https://mp.weixin.qq.com/s/keWo5qYJY4zmHn3amfXdfQ)
|
||||
33. [动态规划:本周我们都讲了这些(系列六)](https://mp.weixin.qq.com/s/GVu-6eF0iNkpVDKRXTPOTA)
|
||||
33. [动态规划:买卖股票的最佳时机II](https://mp.weixin.qq.com/s/d4TRWFuhaY83HPa6t5ZL-w)
|
||||
34. [动态规划:买卖股票的最佳时机III](https://mp.weixin.qq.com/s/Sbs157mlVDtAR0gbLpdKzg)
|
||||
35. [动态规划:买卖股票的最佳时机IV](https://mp.weixin.qq.com/s/jtxZJWAo2y5sUsW647Z5cw)
|
||||
36. [动态规划:最佳买卖股票时机含冷冻期](https://mp.weixin.qq.com/s/TczJGFAPnkjH9ET8kwH1OA)
|
||||
37. [动态规划:本周我们都讲了这些(系列七)](https://mp.weixin.qq.com/s/vdzDlrEvhXWRzblTnOnzKg)
|
||||
38. [动态规划:买卖股票的最佳时机含手续费](https://mp.weixin.qq.com/s/2Cd_uINjerZ25VHH0K2IBQ)
|
||||
39. [动态规划:股票系列总结篇](https://mp.weixin.qq.com/s/sC5XyEtDQWkonKnbCvZhDw)
|
||||
|
||||
32. [动态规划:买卖股票的最佳时机](./problems/0121.买卖股票的最佳时机.md)
|
||||
33. [动态规划:本周我们都讲了这些(系列六)](./problems/周总结/20210225动规周末总结.md)
|
||||
33. [动态规划:买卖股票的最佳时机II](./problems/0122.买卖股票的最佳时机II(动态规划).md)
|
||||
34. [动态规划:买卖股票的最佳时机III](./problems/0123.买卖股票的最佳时机III.md)
|
||||
35. [动态规划:买卖股票的最佳时机IV](./problems/0188.买卖股票的最佳时机IV.md)
|
||||
36. [动态规划:最佳买卖股票时机含冷冻期](./problems/0309.最佳买卖股票时机含冷冻期.md)
|
||||
37. [动态规划:本周我们都讲了这些(系列七)](./problems/周总结/20210304动规周末总结.md)
|
||||
38. [动态规划:买卖股票的最佳时机含手续费](./problems/0714.买卖股票的最佳时机含手续费(动态规划).md)
|
||||
39. [动态规划:股票系列总结篇](./problems/动态规划-股票问题总结篇.md)
|
||||
|
||||
子序列系列:
|
||||
|
||||
40. [动态规划:最长递增子序列](https://mp.weixin.qq.com/s/f8nLO3JGfgriXep_gJQpqQ)
|
||||
41. [动态规划:最长连续递增序列](https://mp.weixin.qq.com/s/c0Nn0TtjkTISVdqRsyMmyA)
|
||||
42. [动态规划:最长重复子数组](https://mp.weixin.qq.com/s/U5WaWqBwdoxzQDotOdWqZg)
|
||||
43. [动态规划:最长公共子序列](https://mp.weixin.qq.com/s/Qq0q4HaE4TyasCTj2WGFOg)
|
||||
44. [动态规划:本周我们都讲了这些(系列八)](https://mp.weixin.qq.com/s/KJNNOzGxTYhr1ks7tHvk0g)
|
||||
45. [动态规划:不相交的线](https://mp.weixin.qq.com/s/krfYzSYEO8jIoVfyHzR0rw)
|
||||
46. [动态规划:最大子序和](https://mp.weixin.qq.com/s/2Xtyi2L4r8sM-BcxgUKmcA)
|
||||
47. [动态规划:判断子序列](https://mp.weixin.qq.com/s/2pjT4B4fjfOx5iB6N6xyng)
|
||||
48. [动态规划:不同的子序列](https://mp.weixin.qq.com/s/1SULY2XVSROtk_hsoVLu8A)
|
||||
49. [动态规划:两个字符串的删除操作](https://mp.weixin.qq.com/s/a8BerpqSf76DCqkPDJrpYg)
|
||||
|
||||
<img src='https://code-thinking.cdn.bcebos.com/pics/动态规划-子序列问题总结.jpg' width=500 alt=''> </img></div>
|
||||
|
||||
|
||||
40. [动态规划:最长递增子序列](./problems/0300.最长上升子序列.md)
|
||||
41. [动态规划:最长连续递增序列](./problems/0674.最长连续递增序列.md)
|
||||
42. [动态规划:最长重复子数组](./problems/0718.最长重复子数组.md)
|
||||
43. [动态规划:最长公共子序列](./problems/1143.最长公共子序列.md)
|
||||
45. [动态规划:不相交的线](./problems/1035.不相交的线.md)
|
||||
46. [动态规划:最大子序和](./problems/0053.最大子序和(动态规划).md)
|
||||
47. [动态规划:判断子序列](./problems/0392.判断子序列.md)
|
||||
48. [动态规划:不同的子序列](./problems/0115.不同的子序列.md)
|
||||
49. [动态规划:两个字符串的删除操作](./problems/0583.两个字符串的删除操作.md)
|
||||
51. [动态规划:编辑距离](./problems/0072.编辑距离.md)
|
||||
52. [为了绝杀编辑距离,Carl做了三步铺垫,你都知道么?](./problems/为了绝杀编辑距离,卡尔做了三步铺垫.md)
|
||||
53. [动态规划:回文子串](./problems/0647.回文子串.md)
|
||||
54. [动态规划:最长回文子序列](./problems/0516.最长回文子序列.md)
|
||||
55. [动态规划总结篇](./problems/动态规划总结篇.md)
|
||||
|
||||
(持续更新中....)
|
||||
|
||||
## 单调栈
|
||||
|
||||
1. [每日温度](./problems/0739.每日温度.md)
|
||||
|
||||
## 图论
|
||||
|
||||
## 十大排序
|
||||
@@ -391,22 +418,46 @@
|
||||
[各类基础算法模板](https://github.com/youngyangyang04/leetcode/blob/master/problems/算法模板.md)
|
||||
|
||||
|
||||
|
||||
# B站算法视频讲解
|
||||
|
||||
以下为[B站「代码随想录」](https://space.bilibili.com/525438321)算法讲解视频:
|
||||
|
||||
* [KMP算法(理论篇)](https://www.bilibili.com/video/BV1PD4y1o7nd)
|
||||
* [KMP算法(代码篇)](https://www.bilibili.com/video/BV1M5411j7Xx)
|
||||
* [回溯算法理论基础](https://www.bilibili.com/video/BV1cy4y167mM)
|
||||
* [回溯算法之组合问题(力扣题目:77.组合)](https://www.bilibili.com/video/BV1ti4y1L7cv)
|
||||
* [组合问题的剪枝操作(对应力扣题目:77.组合)](https://www.bilibili.com/video/BV1wi4y157er)
|
||||
* [组合总和(对应力扣题目:39.组合总和)](https://www.bilibili.com/video/BV1KT4y1M7HJ/)
|
||||
* [分割回文串(对应力扣题目:131.分割回文串)](https://www.bilibili.com/video/BV1c54y1e7k6)
|
||||
* [二叉树理论基础](https://www.bilibili.com/video/BV1Hy4y1t7ij)
|
||||
* [二叉树的递归遍历](https://www.bilibili.com/video/BV1Wh411S7xt)
|
||||
* [二叉树的非递归遍历(一)](https://www.bilibili.com/video/BV15f4y1W7i2)
|
||||
|
||||
(持续更新中....)
|
||||
|
||||
# 贡献者
|
||||
|
||||
你可以[点此链接](https://github.com/youngyangyang04/leetcode-master/graphs/contributors)查看LeetCode-Master的所有贡献者。感谢你们补充了LeetCode-Master的其他语言版本,让更多的读者收益于此项目。
|
||||
|
||||
# 关于作者
|
||||
|
||||
大家好,我是程序员Carl,哈工大师兄,ACM 校赛、黑龙江省赛、东北四省赛金牌、亚洲区域赛铜牌获得者,先后在腾讯和百度从事后端技术研发,CSDN博客专家。对算法和C++后端技术有一定的见解,利用工作之余重新刷leetcode。
|
||||
|
||||
**加我的微信,备注:「个人简单介绍」+「组队刷题」**, 拉你进刷题群,每天一道经典题目分析,而且题目不是孤立的,每一道题目之间都是有关系的,都是由浅入深一脉相承的,所以学习效果最好是每篇连续着看,也许之前你会某些知识点,但是一直没有把知识点串起来,这里每天一篇文章就会帮你把知识点串起来。
|
||||
加入刷题微信群,备注:「个人简单介绍」 + 组队刷题
|
||||
|
||||
也欢迎找我交流,加微信备注:「个人简单介绍」 + 交流
|
||||
也欢迎与我交流,备注:「个人简单介绍」 + 交流,围观朋友圈,做点赞之交(备注没有自我介绍不通过哦)
|
||||
|
||||
<a name="微信"></a>
|
||||
<img src="https://img-blog.csdnimg.cn/20200814140330894.png" data-img="1" width="175" height="175">
|
||||
|
||||
# 我的公众号
|
||||
# 公众号
|
||||
|
||||
更多精彩文章持续更新,微信搜索:「代码随想录」第一时间围观,关注后回复:「666」可以获得所有算法专题原创PDF。
|
||||
|
||||
**每天8:35准时为你推送一篇经典面试题目,帮你梳理算法知识体系,轻松学习算法!**,并且公众号里有大量学习资源,也有我自己的学习心得和方法总结,更有上万录友们在这里打卡学习,**来看看就你知道了,一定会发现相见恨晚!**
|
||||
**「代码随想录」每天准时为你推送一篇经典面试题目,帮你梳理算法知识体系,轻松学习算法!**,并且公众号里有大量学习资源,也有我自己的学习心得和方法总结,更有上万录友们在这里打卡学习。
|
||||
|
||||
**来看看就知道了,你会发现相见恨晚!**
|
||||
|
||||
<a name="公众号"></a>
|
||||
|
||||
|
||||
BIN
pics/公众号.png
BIN
pics/公众号.png
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 302 KiB After Width: | Height: | Size: 305 KiB |
BIN
pics/公众号二维码.jpg
Normal file
BIN
pics/公众号二维码.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 100 KiB |
BIN
pics/知识星球.png
Normal file
BIN
pics/知识星球.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 108 KiB |
213
problems/0001.两数之和.md
Normal file
213
problems/0001.两数之和.md
Normal file
@@ -0,0 +1,213 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 1. 两数之和
|
||||
|
||||
https://leetcode-cn.com/problems/two-sum/
|
||||
|
||||
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
|
||||
|
||||
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。
|
||||
|
||||
**示例:**
|
||||
|
||||
给定 nums = [2, 7, 11, 15], target = 9
|
||||
|
||||
因为 nums[0] + nums[1] = 2 + 7 = 9
|
||||
|
||||
所以返回 [0, 1]
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
很明显暴力的解法是两层for循环查找,时间复杂度是O(n^2)。
|
||||
|
||||
建议大家做这道题目之前,先做一下这两道
|
||||
* [242. 有效的字母异位词](https://mp.weixin.qq.com/s/ffS8jaVFNUWyfn_8T31IdA)
|
||||
* [349. 两个数组的交集](https://mp.weixin.qq.com/s/aMSA5zrp3jJcLjuSB0Es2Q)
|
||||
|
||||
[242. 有效的字母异位词](https://mp.weixin.qq.com/s/ffS8jaVFNUWyfn_8T31IdA) 这道题目是用数组作为哈希表来解决哈希问题,[349. 两个数组的交集](https://mp.weixin.qq.com/s/aMSA5zrp3jJcLjuSB0Es2Q)这道题目是通过set作为哈希表来解决哈希问题。
|
||||
|
||||
本题呢,则要使用map,那么来看一下使用数组和set来做哈希法的局限。
|
||||
|
||||
* 数组的大小是受限制的,而且如果元素很少,而哈希值太大会造成内存空间的浪费。
|
||||
* set是一个集合,里面放的元素只能是一个key,而两数之和这道题目,不仅要判断y是否存在而且还要记录y的下表位置,因为要返回x 和 y的下表。所以set 也不能用。
|
||||
|
||||
此时就要选择另一种数据结构:map ,map是一种key value的存储结构,可以用key保存数值,用value在保存数值所在的下表。
|
||||
|
||||
C++中map,有三种类型:
|
||||
|
||||
|映射 |底层实现 | 是否有序 |数值是否可以重复 | 能否更改数值|查询效率 |增删效率|
|
||||
|---|---| --- |---| --- | --- | ---|
|
||||
|std::map |红黑树 |key有序 |key不可重复 |key不可修改 | O(logn)|O(logn) |
|
||||
|std::multimap | 红黑树|key有序 | key可重复 | key不可修改|O(logn) |O(logn) |
|
||||
|std::unordered_map |哈希表 | key无序 |key不可重复 |key不可修改 |O(1) | O(1)|
|
||||
|
||||
std::unordered_map 底层实现为哈希表,std::map 和std::multimap 的底层实现是红黑树。
|
||||
|
||||
同理,std::map 和std::multimap 的key也是有序的(这个问题也经常作为面试题,考察对语言容器底层的理解)。 更多哈希表的理论知识请看[关于哈希表,你该了解这些!](https://mp.weixin.qq.com/s/RSUANESA_tkhKhYe3ZR8Jg)。
|
||||
|
||||
**这道题目中并不需要key有序,选择std::unordered_map 效率更高!**
|
||||
|
||||
解题思路动画如下:
|
||||
|
||||

|
||||
|
||||
|
||||
C++代码:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
vector<int> twoSum(vector<int>& nums, int target) {
|
||||
std::unordered_map <int,int> map;
|
||||
for(int i = 0; i < nums.size(); i++) {
|
||||
auto iter = map.find(target - nums[i]);
|
||||
if(iter != map.end()) {
|
||||
return {iter->second, i};
|
||||
}
|
||||
map.insert(pair<int, int>(nums[i], i));
|
||||
}
|
||||
return {};
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
public int[] twoSum(int[] nums, int target) {
|
||||
int[] res = new int[2];
|
||||
if(nums == null || nums.length == 0){
|
||||
return res;
|
||||
}
|
||||
Map<Integer, Integer> map = new HashMap<>();
|
||||
for(int i = 0; i < nums.length; i++){
|
||||
int temp = target - nums[i];
|
||||
if(map.containsKey(temp)){
|
||||
res[1] = i;
|
||||
res[0] = map.get(temp);
|
||||
}
|
||||
map.put(nums[i], i);
|
||||
}
|
||||
return res;
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def twoSum(self, nums: List[int], target: int) -> List[int]:
|
||||
hashmap={}
|
||||
for ind,num in enumerate(nums):
|
||||
hashmap[num] = ind
|
||||
for i,num in enumerate(nums):
|
||||
j = hashmap.get(target - num)
|
||||
if j is not None and i!=j:
|
||||
return [i,j]
|
||||
```
|
||||
|
||||
|
||||
Go:
|
||||
|
||||
```go
|
||||
func twoSum(nums []int, target int) []int {
|
||||
for k1, _ := range nums {
|
||||
for k2 := k1 + 1; k2 < len(nums); k2++ {
|
||||
if target == nums[k1] + nums[k2] {
|
||||
return []int{k1, k2}
|
||||
}
|
||||
}
|
||||
}
|
||||
return []int{}
|
||||
}
|
||||
```
|
||||
|
||||
```go
|
||||
// 使用map方式解题,降低时间复杂度
|
||||
func twoSum(nums []int, target int) []int {
|
||||
m := make(map[int]int)
|
||||
for index, val := range nums {
|
||||
if preIndex, ok := m[target-val]; ok {
|
||||
return []int{preIndex, index}
|
||||
} else {
|
||||
m[val] = index
|
||||
}
|
||||
}
|
||||
return []int{}
|
||||
}
|
||||
```
|
||||
|
||||
Rust
|
||||
|
||||
```rust
|
||||
use std::collections::HashMap;
|
||||
|
||||
impl Solution {
|
||||
pub fn two_sum(nums: Vec<i32>, target: i32) -> Vec<i32> {
|
||||
let mut map = HashMap::with_capacity(nums.len());
|
||||
|
||||
for i in 0..nums.len() {
|
||||
if let Some(k) = map.get(&(target - nums[i])) {
|
||||
if *k != i {
|
||||
return vec![*k as i32, i as i32];
|
||||
}
|
||||
}
|
||||
map.insert(nums[i], i);
|
||||
}
|
||||
panic!("not found")
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Javascript
|
||||
|
||||
```javascript
|
||||
var twoSum = function (nums, target) {
|
||||
let hash = {};
|
||||
for (let i = 0; i < nums.length; i++) {
|
||||
if (hash[target - nums[i]] !== undefined) {
|
||||
return [i, hash[target - nums[i]]];
|
||||
}
|
||||
hash[nums[i]] = i;
|
||||
}
|
||||
return [];
|
||||
};
|
||||
```
|
||||
|
||||
php
|
||||
|
||||
```php
|
||||
function twoSum(array $nums, int $target): array
|
||||
{
|
||||
for ($i = 0; $i < count($nums);$i++) {
|
||||
// 计算剩下的数
|
||||
$residue = $target - $nums[$i];
|
||||
// 匹配的index,有则返回index, 无则返回false
|
||||
$match_index = array_search($residue, $nums);
|
||||
if ($match_index !== false && $match_index != $i) {
|
||||
return array($i, $match_index);
|
||||
}
|
||||
}
|
||||
return [];
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
402
problems/0015.三数之和.md
Normal file
402
problems/0015.三数之和.md
Normal file
@@ -0,0 +1,402 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
|
||||
> 用哈希表解决了[两数之和](https://mp.weixin.qq.com/s/uVAtjOHSeqymV8FeQbliJQ),那么三数之和呢?
|
||||
|
||||
# 第15题. 三数之和
|
||||
|
||||
https://leetcode-cn.com/problems/3sum/
|
||||
|
||||
给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有满足条件且不重复的三元组。
|
||||
|
||||
**注意:** 答案中不可以包含重复的三元组。
|
||||
|
||||
示例:
|
||||
|
||||
给定数组 nums = [-1, 0, 1, 2, -1, -4],
|
||||
|
||||
满足要求的三元组集合为:
|
||||
[
|
||||
[-1, 0, 1],
|
||||
[-1, -1, 2]
|
||||
]
|
||||
|
||||
|
||||
# 思路
|
||||
|
||||
**注意[0, 0, 0, 0] 这组数据**
|
||||
|
||||
## 哈希解法
|
||||
|
||||
两层for循环就可以确定 a 和b 的数值了,可以使用哈希法来确定 0-(a+b) 是否在 数组里出现过,其实这个思路是正确的,但是我们有一个非常棘手的问题,就是题目中说的不可以包含重复的三元组。
|
||||
|
||||
把符合条件的三元组放进vector中,然后在去去重,这样是非常费时的,很容易超时,也是这道题目通过率如此之低的根源所在。
|
||||
|
||||
去重的过程不好处理,有很多小细节,如果在面试中很难想到位。
|
||||
|
||||
时间复杂度可以做到O(n^2),但还是比较费时的,因为不好做剪枝操作。
|
||||
|
||||
大家可以尝试使用哈希法写一写,就知道其困难的程度了。
|
||||
|
||||
哈希法C++代码:
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
vector<vector<int>> threeSum(vector<int>& nums) {
|
||||
vector<vector<int>> result;
|
||||
sort(nums.begin(), nums.end());
|
||||
// 找出a + b + c = 0
|
||||
// a = nums[i], b = nums[j], c = -(a + b)
|
||||
for (int i = 0; i < nums.size(); i++) {
|
||||
// 排序之后如果第一个元素已经大于零,那么不可能凑成三元组
|
||||
if (nums[i] > 0) {
|
||||
continue;
|
||||
}
|
||||
if (i > 0 && nums[i] == nums[i - 1]) { //三元组元素a去重
|
||||
continue;
|
||||
}
|
||||
unordered_set<int> set;
|
||||
for (int j = i + 1; j < nums.size(); j++) {
|
||||
if (j > i + 2
|
||||
&& nums[j] == nums[j-1]
|
||||
&& nums[j-1] == nums[j-2]) { // 三元组元素b去重
|
||||
continue;
|
||||
}
|
||||
int c = 0 - (nums[i] + nums[j]);
|
||||
if (set.find(c) != set.end()) {
|
||||
result.push_back({nums[i], nums[j], c});
|
||||
set.erase(c);// 三元组元素c去重
|
||||
} else {
|
||||
set.insert(nums[j]);
|
||||
}
|
||||
}
|
||||
}
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 双指针
|
||||
|
||||
**其实这道题目使用哈希法并不十分合适**,因为在去重的操作中有很多细节需要注意,在面试中很难直接写出没有bug的代码。
|
||||
|
||||
而且使用哈希法 在使用两层for循环的时候,能做的剪枝操作很有限,虽然时间复杂度是O(n^2),也是可以在leetcode上通过,但是程序的执行时间依然比较长 。
|
||||
|
||||
接下来我来介绍另一个解法:双指针法,**这道题目使用双指针法 要比哈希法高效一些**,那么来讲解一下具体实现的思路。
|
||||
|
||||
动画效果如下:
|
||||
|
||||
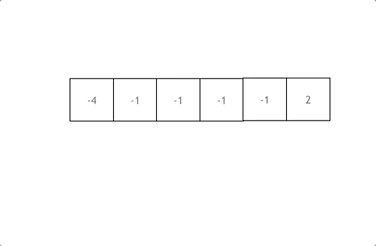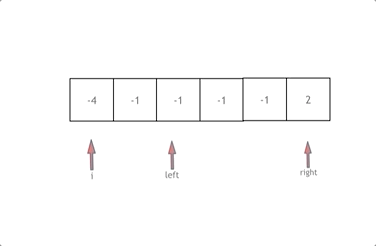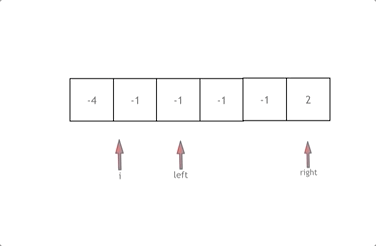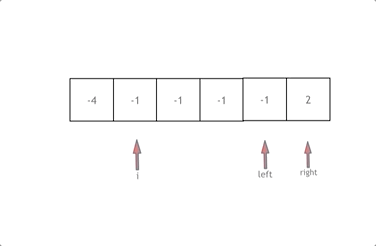
|
||||
|
||||
拿这个nums数组来举例,首先将数组排序,然后有一层for循环,i从下表0的地方开始,同时定一个下表left 定义在i+1的位置上,定义下表right 在数组结尾的位置上。
|
||||
|
||||
依然还是在数组中找到 abc 使得a + b +c =0,我们这里相当于 a = nums[i] b = nums[left] c = nums[right]。
|
||||
|
||||
接下来如何移动left 和right呢, 如果nums[i] + nums[left] + nums[right] > 0 就说明 此时三数之和大了,因为数组是排序后了,所以right下表就应该向左移动,这样才能让三数之和小一些。
|
||||
|
||||
如果 nums[i] + nums[left] + nums[right] < 0 说明 此时 三数之和小了,left 就向右移动,才能让三数之和大一些,直到left与right相遇为止。
|
||||
|
||||
时间复杂度:O(n^2)。
|
||||
|
||||
C++代码代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
vector<vector<int>> threeSum(vector<int>& nums) {
|
||||
vector<vector<int>> result;
|
||||
sort(nums.begin(), nums.end());
|
||||
// 找出a + b + c = 0
|
||||
// a = nums[i], b = nums[left], c = nums[right]
|
||||
for (int i = 0; i < nums.size(); i++) {
|
||||
// 排序之后如果第一个元素已经大于零,那么无论如何组合都不可能凑成三元组,直接返回结果就可以了
|
||||
if (nums[i] > 0) {
|
||||
return result;
|
||||
}
|
||||
// 错误去重方法,将会漏掉-1,-1,2 这种情况
|
||||
/*
|
||||
if (nums[i] == nums[i + 1]) {
|
||||
continue;
|
||||
}
|
||||
*/
|
||||
// 正确去重方法
|
||||
if (i > 0 && nums[i] == nums[i - 1]) {
|
||||
continue;
|
||||
}
|
||||
int left = i + 1;
|
||||
int right = nums.size() - 1;
|
||||
while (right > left) {
|
||||
// 去重复逻辑如果放在这里,0,0,0 的情况,可能直接导致 right<=left 了,从而漏掉了 0,0,0 这种三元组
|
||||
/*
|
||||
while (right > left && nums[right] == nums[right - 1]) right--;
|
||||
while (right > left && nums[left] == nums[left + 1]) left++;
|
||||
*/
|
||||
if (nums[i] + nums[left] + nums[right] > 0) {
|
||||
right--;
|
||||
} else if (nums[i] + nums[left] + nums[right] < 0) {
|
||||
left++;
|
||||
} else {
|
||||
result.push_back(vector<int>{nums[i], nums[left], nums[right]});
|
||||
// 去重逻辑应该放在找到一个三元组之后
|
||||
while (right > left && nums[right] == nums[right - 1]) right--;
|
||||
while (right > left && nums[left] == nums[left + 1]) left++;
|
||||
|
||||
// 找到答案时,双指针同时收缩
|
||||
right--;
|
||||
left++;
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
# 思考题
|
||||
|
||||
|
||||
既然三数之和可以使用双指针法,我们之前讲过的[1.两数之和](https://mp.weixin.qq.com/s/vaMsLnH-f7_9nEK4Cuu3KQ),可不可以使用双指针法呢?
|
||||
|
||||
如果不能,题意如何更改就可以使用双指针法呢? **大家留言说出自己的想法吧!**
|
||||
|
||||
两数之和 就不能使用双指针法,因为[1.两数之和](https://mp.weixin.qq.com/s/vaMsLnH-f7_9nEK4Cuu3KQ)要求返回的是索引下表, 而双指针法一定要排序,一旦排序之后原数组的索引就被改变了。
|
||||
|
||||
如果[1.两数之和](https://mp.weixin.qq.com/s/vaMsLnH-f7_9nEK4Cuu3KQ)要求返回的是数值的话,就可以使用双指针法了。
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
public List<List<Integer>> threeSum(int[] nums) {
|
||||
List<List<Integer>> result = new ArrayList<>();
|
||||
Arrays.sort(nums);
|
||||
|
||||
for (int i = 0; i < nums.length; i++) {
|
||||
if (nums[i] > 0) {
|
||||
return result;
|
||||
}
|
||||
|
||||
if (i > 0 && nums[i] == nums[i - 1]) {
|
||||
continue;
|
||||
}
|
||||
|
||||
int left = i + 1;
|
||||
int right = nums.length - 1;
|
||||
while (right > left) {
|
||||
int sum = nums[i] + nums[left] + nums[right];
|
||||
if (sum > 0) {
|
||||
right--;
|
||||
} else if (sum < 0) {
|
||||
left++;
|
||||
} else {
|
||||
result.add(Arrays.asList(nums[i], nums[left], nums[right]));
|
||||
|
||||
while (right > left && nums[right] == nums[right - 1]) right--;
|
||||
while (right > left && nums[left] == nums[left + 1]) left++;
|
||||
|
||||
right--;
|
||||
left++;
|
||||
}
|
||||
}
|
||||
}
|
||||
return result;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```Python
|
||||
class Solution:
|
||||
def threeSum(self, nums):
|
||||
ans = []
|
||||
n = len(nums)
|
||||
nums.sort()
|
||||
for i in range(n):
|
||||
left = i + 1
|
||||
right = n - 1
|
||||
if nums[i] > 0:
|
||||
break
|
||||
if i >= 1 and nums[i] == nums[i - 1]:
|
||||
continue
|
||||
while left < right:
|
||||
total = nums[i] + nums[left] + nums[right]
|
||||
if total > 0:
|
||||
right -= 1
|
||||
elif total < 0:
|
||||
left += 1
|
||||
else:
|
||||
ans.append([nums[i], nums[left], nums[right]])
|
||||
while left != right and nums[left] == nums[left + 1]: left += 1
|
||||
while left != right and nums[right] == nums[right - 1]: right -= 1
|
||||
left += 1
|
||||
right -= 1
|
||||
return ans
|
||||
```
|
||||
Go:
|
||||
```Go
|
||||
func threeSum(nums []int)[][]int{
|
||||
sort.Ints(nums)
|
||||
res:=[][]int{}
|
||||
|
||||
for i:=0;i<len(nums)-2;i++{
|
||||
n1:=nums[i]
|
||||
if n1>0{
|
||||
break
|
||||
}
|
||||
if i>0&&n1==nums[i-1]{
|
||||
continue
|
||||
}
|
||||
l,r:=i+1,len(nums)-1
|
||||
for l<r{
|
||||
n2,n3:=nums[l],nums[r]
|
||||
if n1+n2+n3==0{
|
||||
res=append(res,[]int{n1,n2,n3})
|
||||
for l<r&&nums[l]==n2{
|
||||
l++
|
||||
}
|
||||
for l<r&&nums[r]==n3{
|
||||
r--
|
||||
}
|
||||
}else if n1+n2+n3<0{
|
||||
l++
|
||||
}else {
|
||||
r--
|
||||
}
|
||||
}
|
||||
}
|
||||
return res
|
||||
}
|
||||
```
|
||||
|
||||
javaScript:
|
||||
|
||||
```js
|
||||
/**
|
||||
* @param {number[]} nums
|
||||
* @return {number[][]}
|
||||
*/
|
||||
|
||||
// 循环内不考虑去重
|
||||
var threeSum = function(nums) {
|
||||
const len = nums.length;
|
||||
if(len < 3) return [];
|
||||
nums.sort((a, b) => a - b);
|
||||
const resSet = new Set();
|
||||
for(let i = 0; i < len - 2; i++) {
|
||||
if(nums[i] > 0) break;
|
||||
let l = i + 1, r = len - 1;
|
||||
while(l < r) {
|
||||
const sum = nums[i] + nums[l] + nums[r];
|
||||
if(sum < 0) { l++; continue };
|
||||
if(sum > 0) { r--; continue };
|
||||
resSet.add(`${nums[i]},${nums[l]},${nums[r]}`);
|
||||
l++;
|
||||
r--;
|
||||
}
|
||||
}
|
||||
return Array.from(resSet).map(i => i.split(","));
|
||||
};
|
||||
|
||||
// 去重优化
|
||||
var threeSum = function(nums) {
|
||||
const len = nums.length;
|
||||
if(len < 3) return [];
|
||||
nums.sort((a, b) => a - b);
|
||||
const res = [];
|
||||
for(let i = 0; i < len - 2; i++) {
|
||||
if(nums[i] > 0) break;
|
||||
// a去重
|
||||
if(i > 0 && nums[i] === nums[i - 1]) continue;
|
||||
let l = i + 1, r = len - 1;
|
||||
while(l < r) {
|
||||
const sum = nums[i] + nums[l] + nums[r];
|
||||
if(sum < 0) { l++; continue };
|
||||
if(sum > 0) { r--; continue };
|
||||
res.push([nums[i], nums[l], nums[r]])
|
||||
// b c 去重
|
||||
while(l < r && nums[l] === nums[++l]);
|
||||
while(l < r && nums[r] === nums[--r]);
|
||||
}
|
||||
}
|
||||
return res;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
ruby:
|
||||
```ruby
|
||||
def is_valid(strs)
|
||||
symbol_map = {')' => '(', '}' => '{', ']' => '['}
|
||||
stack = []
|
||||
strs.size.times {|i|
|
||||
c = strs[i]
|
||||
if symbol_map.has_key?(c)
|
||||
top_e = stack.shift
|
||||
return false if symbol_map[c] != top_e
|
||||
else
|
||||
stack.unshift(c)
|
||||
end
|
||||
}
|
||||
stack.empty?
|
||||
end
|
||||
```
|
||||
|
||||
php:
|
||||
|
||||
```php
|
||||
function threeSum(array $nums): array
|
||||
{
|
||||
$result = [];
|
||||
$length = count($nums);
|
||||
if ($length < 3) {
|
||||
return [];
|
||||
}
|
||||
sort($nums);
|
||||
for ($i = 0; $i < $length; $i++) {
|
||||
// 如果大于0结束
|
||||
if ($nums[$i] > 0) break;
|
||||
// 去重
|
||||
if ($i > 0 && $nums[$i] == $nums[$i - 1]) continue;
|
||||
$left = $i + 1;
|
||||
$right = $length - 1;
|
||||
// 比较
|
||||
while ($left < $right) {
|
||||
$sum = $nums[$i] + $nums[$left] + $nums[$right];
|
||||
if ($sum < 0) {
|
||||
$left++;
|
||||
} elseif ($sum > 0) {
|
||||
$right--;
|
||||
} else {
|
||||
array_push($result, [$nums[$i], $nums[$left], $nums[$right]]);
|
||||
while ($left < $right && $nums[$left] == $nums[$left + 1]) $left++;
|
||||
while ($left < $right && $nums[$right - 1] == $nums[$right]) $right--;
|
||||
$left++;
|
||||
$right--;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return $result;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
419
problems/0017.电话号码的字母组合.md
Normal file
419
problems/0017.电话号码的字母组合.md
Normal file
@@ -0,0 +1,419 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
# 17.电话号码的字母组合
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/letter-combinations-of-a-phone-number/
|
||||
|
||||
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。
|
||||
|
||||
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
|
||||
|
||||
|
||||
|
||||
示例:
|
||||
输入:"23"
|
||||
输出:["ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf"].
|
||||
|
||||
说明:尽管上面的答案是按字典序排列的,但是你可以任意选择答案输出的顺序。
|
||||
|
||||
# 思路
|
||||
|
||||
从示例上来说,输入"23",最直接的想法就是两层for循环遍历了吧,正好把组合的情况都输出了。
|
||||
|
||||
如果输入"233"呢,那么就三层for循环,如果"2333"呢,就四层for循环.......
|
||||
|
||||
大家应该感觉出和[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)遇到的一样的问题,就是这for循环的层数如何写出来,此时又是回溯法登场的时候了。
|
||||
|
||||
理解本题后,要解决如下三个问题:
|
||||
|
||||
1. 数字和字母如何映射
|
||||
2. 两个字母就两个for循环,三个字符我就三个for循环,以此类推,然后发现代码根本写不出来
|
||||
3. 输入1 * #按键等等异常情况
|
||||
|
||||
## 数字和字母如何映射
|
||||
|
||||
可以使用map或者定义一个二位数组,例如:string letterMap[10],来做映射,我这里定义一个二维数组,代码如下:
|
||||
|
||||
```
|
||||
const string letterMap[10] = {
|
||||
"", // 0
|
||||
"", // 1
|
||||
"abc", // 2
|
||||
"def", // 3
|
||||
"ghi", // 4
|
||||
"jkl", // 5
|
||||
"mno", // 6
|
||||
"pqrs", // 7
|
||||
"tuv", // 8
|
||||
"wxyz", // 9
|
||||
};
|
||||
```
|
||||
|
||||
## 回溯法来解决n个for循环的问题
|
||||
|
||||
对于回溯法还不了解的同学看这篇:[关于回溯算法,你该了解这些!](https://mp.weixin.qq.com/s/gjSgJbNbd1eAA5WkA-HeWw)
|
||||
|
||||
|
||||
例如:输入:"23",抽象为树形结构,如图所示:
|
||||
|
||||
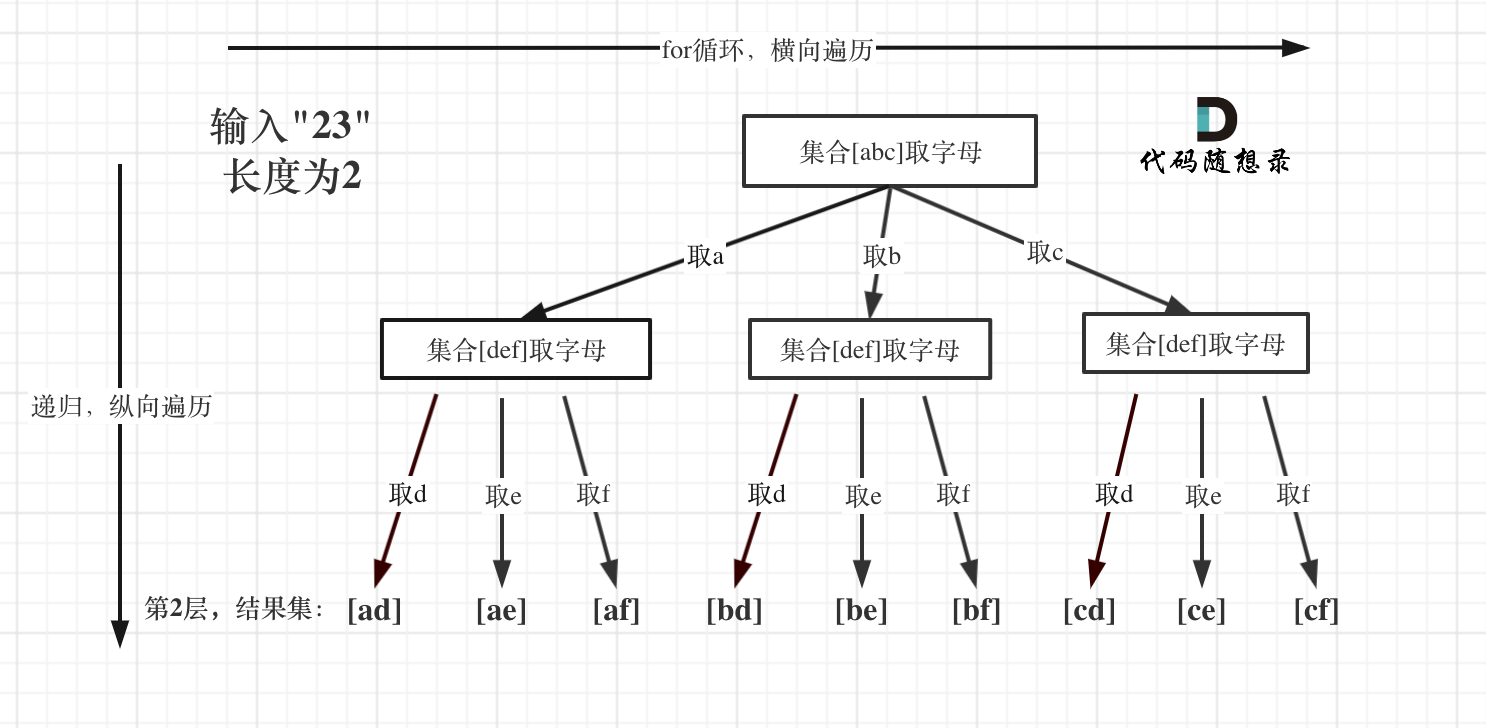
|
||||
|
||||
图中可以看出遍历的深度,就是输入"23"的长度,而叶子节点就是我们要收集的结果,输出["ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf"]。
|
||||
|
||||
回溯三部曲:
|
||||
|
||||
* 确定回溯函数参数
|
||||
|
||||
首先需要一个字符串s来收集叶子节点的结果,然后用一个字符串数组result保存起来,这两个变量我依然定义为全局。
|
||||
|
||||
再来看参数,参数指定是有题目中给的string digits,然后还要有一个参数就是int型的index。
|
||||
|
||||
注意这个index可不是 [回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)和[回溯算法:求组合总和!](https://mp.weixin.qq.com/s/HX7WW6ixbFZJASkRnCTC3w)中的startIndex了。
|
||||
|
||||
这个index是记录遍历第几个数字了,就是用来遍历digits的(题目中给出数字字符串),同时index也表示树的深度。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
vector<string> result;
|
||||
string s;
|
||||
void backtracking(const string& digits, int index)
|
||||
```
|
||||
|
||||
* 确定终止条件
|
||||
|
||||
例如输入用例"23",两个数字,那么根节点往下递归两层就可以了,叶子节点就是要收集的结果集。
|
||||
|
||||
那么终止条件就是如果index 等于 输入的数字个数(digits.size)了(本来index就是用来遍历digits的)。
|
||||
|
||||
然后收集结果,结束本层递归。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
if (index == digits.size()) {
|
||||
result.push_back(s);
|
||||
return;
|
||||
}
|
||||
```
|
||||
|
||||
* 确定单层遍历逻辑
|
||||
|
||||
首先要取index指向的数字,并找到对应的字符集(手机键盘的字符集)。
|
||||
|
||||
然后for循环来处理这个字符集,代码如下:
|
||||
|
||||
```
|
||||
int digit = digits[index] - '0'; // 将index指向的数字转为int
|
||||
string letters = letterMap[digit]; // 取数字对应的字符集
|
||||
for (int i = 0; i < letters.size(); i++) {
|
||||
s.push_back(letters[i]); // 处理
|
||||
backtracking(digits, index + 1); // 递归,注意index+1,一下层要处理下一个数字了
|
||||
s.pop_back(); // 回溯
|
||||
}
|
||||
```
|
||||
|
||||
**注意这里for循环,可不像是在[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)和[回溯算法:求组合总和!](https://mp.weixin.qq.com/s/HX7WW6ixbFZJASkRnCTC3w)中从startIndex开始遍历的**。
|
||||
|
||||
**因为本题每一个数字代表的是不同集合,也就是求不同集合之间的组合,而[77. 组合](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)和[216.组合总和III](https://mp.weixin.qq.com/s/HX7WW6ixbFZJASkRnCTC3w)都是是求同一个集合中的组合!**
|
||||
|
||||
|
||||
注意:输入1 * #按键等等异常情况
|
||||
|
||||
代码中最好考虑这些异常情况,但题目的测试数据中应该没有异常情况的数据,所以我就没有加了。
|
||||
|
||||
**但是要知道会有这些异常,如果是现场面试中,一定要考虑到!**
|
||||
|
||||
|
||||
## C++代码
|
||||
|
||||
关键地方都讲完了,按照[关于回溯算法,你该了解这些!](https://mp.weixin.qq.com/s/gjSgJbNbd1eAA5WkA-HeWw)中的回溯法模板,不难写出如下C++代码:
|
||||
|
||||
|
||||
```c++
|
||||
// 版本一
|
||||
class Solution {
|
||||
private:
|
||||
const string letterMap[10] = {
|
||||
"", // 0
|
||||
"", // 1
|
||||
"abc", // 2
|
||||
"def", // 3
|
||||
"ghi", // 4
|
||||
"jkl", // 5
|
||||
"mno", // 6
|
||||
"pqrs", // 7
|
||||
"tuv", // 8
|
||||
"wxyz", // 9
|
||||
};
|
||||
public:
|
||||
vector<string> result;
|
||||
string s;
|
||||
void backtracking(const string& digits, int index) {
|
||||
if (index == digits.size()) {
|
||||
result.push_back(s);
|
||||
return;
|
||||
}
|
||||
int digit = digits[index] - '0'; // 将index指向的数字转为int
|
||||
string letters = letterMap[digit]; // 取数字对应的字符集
|
||||
for (int i = 0; i < letters.size(); i++) {
|
||||
s.push_back(letters[i]); // 处理
|
||||
backtracking(digits, index + 1); // 递归,注意index+1,一下层要处理下一个数字了
|
||||
s.pop_back(); // 回溯
|
||||
}
|
||||
}
|
||||
vector<string> letterCombinations(string digits) {
|
||||
s.clear();
|
||||
result.clear();
|
||||
if (digits.size() == 0) {
|
||||
return result;
|
||||
}
|
||||
backtracking(digits, 0);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
一些写法,是把回溯的过程放在递归函数里了,例如如下代码,我可以写成这样:(注意注释中不一样的地方)
|
||||
|
||||
```c++
|
||||
// 版本二
|
||||
class Solution {
|
||||
private:
|
||||
const string letterMap[10] = {
|
||||
"", // 0
|
||||
"", // 1
|
||||
"abc", // 2
|
||||
"def", // 3
|
||||
"ghi", // 4
|
||||
"jkl", // 5
|
||||
"mno", // 6
|
||||
"pqrs", // 7
|
||||
"tuv", // 8
|
||||
"wxyz", // 9
|
||||
};
|
||||
public:
|
||||
vector<string> result;
|
||||
void getCombinations(const string& digits, int index, const string& s) { // 注意参数的不同
|
||||
if (index == digits.size()) {
|
||||
result.push_back(s);
|
||||
return;
|
||||
}
|
||||
int digit = digits[index] - '0';
|
||||
string letters = letterMap[digit];
|
||||
for (int i = 0; i < letters.size(); i++) {
|
||||
getCombinations(digits, index + 1, s + letters[i]); // 注意这里的不同
|
||||
}
|
||||
}
|
||||
vector<string> letterCombinations(string digits) {
|
||||
result.clear();
|
||||
if (digits.size() == 0) {
|
||||
return result;
|
||||
}
|
||||
getCombinations(digits, 0, "");
|
||||
return result;
|
||||
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
我不建议把回溯藏在递归的参数里这种写法,很不直观,我在[二叉树:以为使用了递归,其实还隐藏着回溯](https://mp.weixin.qq.com/s/ivLkHzWdhjQQD1rQWe6zWA)这篇文章中也深度分析了,回溯隐藏在了哪里。
|
||||
|
||||
所以大家可以按照版本一来写就可以了。
|
||||
|
||||
# 总结
|
||||
|
||||
本篇将题目的三个要点一一列出,并重点强调了和前面讲解过的[77. 组合](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)和[216.组合总和III](https://mp.weixin.qq.com/s/HX7WW6ixbFZJASkRnCTC3w)的区别,本题是多个集合求组合,所以在回溯的搜索过程中,都有一些细节需要注意的。
|
||||
|
||||
其实本题不算难,但也处处是细节,大家还要自己亲自动手写一写。
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
|
||||
//设置全局列表存储最后的结果
|
||||
List<String> list = new ArrayList<>();
|
||||
|
||||
public List<String> letterCombinations(String digits) {
|
||||
if (digits == null || digits.length() == 0) {
|
||||
return list;
|
||||
}
|
||||
//初始对应所有的数字,为了直接对应2-9,新增了两个无效的字符串""
|
||||
String[] numString = {"", "", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv", "wxyz"};
|
||||
//迭代处理
|
||||
backTracking(digits, numString, 0);
|
||||
return list;
|
||||
|
||||
}
|
||||
|
||||
//每次迭代获取一个字符串,所以会设计大量的字符串拼接,所以这里选择更为高效的 StringBuild
|
||||
StringBuilder temp = new StringBuilder();
|
||||
|
||||
//比如digits如果为"23",num 为0,则str表示2对应的 abc
|
||||
public void backTracking(String digits, String[] numString, int num) {
|
||||
//遍历全部一次记录一次得到的字符串
|
||||
if (num == digits.length()) {
|
||||
list.add(temp.toString());
|
||||
return;
|
||||
}
|
||||
//str 表示当前num对应的字符串
|
||||
String str = numString[digits.charAt(num) - '0'];
|
||||
for (int i = 0; i < str.length(); i++) {
|
||||
temp.append(str.charAt(i));
|
||||
//c
|
||||
backTracking(digits, numString, num + 1);
|
||||
//剔除末尾的继续尝试
|
||||
temp.deleteCharAt(temp.length() - 1);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
```Python
|
||||
class Solution:
|
||||
ans = []
|
||||
s = ''
|
||||
letterMap = {
|
||||
'2': 'abc',
|
||||
'3': 'def',
|
||||
'4': 'ghi',
|
||||
'5': 'jkl',
|
||||
'6': 'mno',
|
||||
'7': 'pqrs',
|
||||
'8': 'tuv',
|
||||
'9': 'wxyz'
|
||||
}
|
||||
|
||||
def letterCombinations(self, digits):
|
||||
self.ans.clear()
|
||||
if digits == '':
|
||||
return self.ans
|
||||
self.backtracking(digits, 0)
|
||||
return self.ans
|
||||
|
||||
def backtracking(self, digits, index):
|
||||
if index == len(digits):
|
||||
self.ans.append(self.s)
|
||||
return
|
||||
else:
|
||||
letters = self.letterMap[digits[index]] # 取出数字对应的字符集
|
||||
for letter in letters:
|
||||
self.s = self.s + letter # 处理
|
||||
self.backtracking(digits, index + 1)
|
||||
self.s = self.s[:-1] # 回溯
|
||||
```
|
||||
|
||||
python3:
|
||||
|
||||
```py
|
||||
class Solution:
|
||||
def letterCombinations(self, digits: str) -> List[str]:
|
||||
self.s = ""
|
||||
res = []
|
||||
letterMap = ["","","abc","def","ghi","jkl","mno","pqrs","tuv","wxyz"]
|
||||
if len(digits) == 0: return res
|
||||
def backtrack(digits,index):
|
||||
if index == len(digits):
|
||||
return res.append(self.s)
|
||||
digit = int(digits[index]) #将index指向的数字转为int
|
||||
letters = letterMap[digit] #取数字对应的字符集
|
||||
for i in range(len(letters)):
|
||||
self.s += letters[i]
|
||||
backtrack(digits,index + 1) #递归,注意index+1,一下层要处理下一个数字
|
||||
self.s = self.s[:-1] #回溯
|
||||
backtrack(digits,0)
|
||||
return res
|
||||
```
|
||||
|
||||
|
||||
Go:
|
||||
|
||||
|
||||
> 主要在于递归中传递下一个数字
|
||||
|
||||
```go
|
||||
func letterCombinations(digits string) []string {
|
||||
lenth:=len(digits)
|
||||
if lenth==0 ||lenth>4{
|
||||
return nil
|
||||
}
|
||||
digitsMap:= [10]string{
|
||||
"", // 0
|
||||
"", // 1
|
||||
"abc", // 2
|
||||
"def", // 3
|
||||
"ghi", // 4
|
||||
"jkl", // 5
|
||||
"mno", // 6
|
||||
"pqrs", // 7
|
||||
"tuv", // 8
|
||||
"wxyz", // 9
|
||||
}
|
||||
res:=make([]string,0)
|
||||
recursion("",digits,0,digitsMap,&res)
|
||||
return res
|
||||
}
|
||||
func recursion(tempString ,digits string, Index int,digitsMap [10]string, res *[]string) {//index表示第几个数字
|
||||
if len(tempString)==len(digits){//终止条件,字符串长度等于digits的长度
|
||||
*res=append(*res,tempString)
|
||||
return
|
||||
}
|
||||
tmpK:=digits[Index]-'0' // 将index指向的数字转为int(确定下一个数字)
|
||||
letter:=digitsMap[tmpK]// 取数字对应的字符集
|
||||
for i:=0;i<len(letter);i++{
|
||||
tempString=tempString+string(letter[i])//拼接结果
|
||||
recursion(tempString,digits,Index+1,digitsMap,res)
|
||||
tempString=tempString[:len(tempString)-1]//回溯
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
javaScript:
|
||||
|
||||
```js
|
||||
var letterCombinations = function(digits) {
|
||||
const k = digits.length;
|
||||
const map = ["","","abc","def","ghi","jkl","mno","pqrs","tuv","wxyz"];
|
||||
if(!k) return [];
|
||||
if(k === 1) return map[digits].split("");
|
||||
|
||||
const res = [], path = [];
|
||||
backtracking(digits, k, 0);
|
||||
return res;
|
||||
|
||||
function backtracking(n, k, a) {
|
||||
if(path.length === k) {
|
||||
res.push(path.join(""));
|
||||
return;
|
||||
}
|
||||
for(const v of map[n[a]]) {
|
||||
path.push(v);
|
||||
backtracking(n, k, a + 1);
|
||||
path.pop();
|
||||
}
|
||||
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
244
problems/0018.四数之和.md
Normal file
244
problems/0018.四数之和.md
Normal file
@@ -0,0 +1,244 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
> 一样的道理,能解决四数之和
|
||||
> 那么五数之和、六数之和、N数之和呢?
|
||||
|
||||
# 第18题. 四数之和
|
||||
|
||||
https://leetcode-cn.com/problems/4sum/
|
||||
|
||||
题意:给定一个包含 n 个整数的数组 nums 和一个目标值 target,判断 nums 中是否存在四个元素 a,b,c 和 d ,使得 a + b + c + d 的值与 target 相等?找出所有满足条件且不重复的四元组。
|
||||
|
||||
**注意:**
|
||||
|
||||
答案中不可以包含重复的四元组。
|
||||
|
||||
示例:
|
||||
给定数组 nums = [1, 0, -1, 0, -2, 2],和 target = 0。
|
||||
满足要求的四元组集合为:
|
||||
[
|
||||
[-1, 0, 0, 1],
|
||||
[-2, -1, 1, 2],
|
||||
[-2, 0, 0, 2]
|
||||
]
|
||||
|
||||
# 思路
|
||||
|
||||
四数之和,和[15.三数之和](https://mp.weixin.qq.com/s/QfTNEByq1YlNSXRKEumwHg)是一个思路,都是使用双指针法, 基本解法就是在[15.三数之和](https://mp.weixin.qq.com/s/QfTNEByq1YlNSXRKEumwHg) 的基础上再套一层for循环。
|
||||
|
||||
但是有一些细节需要注意,例如: 不要判断`nums[k] > target` 就返回了,三数之和 可以通过 `nums[i] > 0` 就返回了,因为 0 已经是确定的数了,四数之和这道题目 target是任意值。(大家亲自写代码就能感受出来)
|
||||
|
||||
[15.三数之和](https://mp.weixin.qq.com/s/QfTNEByq1YlNSXRKEumwHg)的双指针解法是一层for循环num[i]为确定值,然后循环内有left和right下表作为双指针,找到nums[i] + nums[left] + nums[right] == 0。
|
||||
|
||||
四数之和的双指针解法是两层for循环nums[k] + nums[i]为确定值,依然是循环内有left和right下表作为双指针,找出nums[k] + nums[i] + nums[left] + nums[right] == target的情况,三数之和的时间复杂度是O(n^2),四数之和的时间复杂度是O(n^3) 。
|
||||
|
||||
那么一样的道理,五数之和、六数之和等等都采用这种解法。
|
||||
|
||||
对于[15.三数之和](https://mp.weixin.qq.com/s/QfTNEByq1YlNSXRKEumwHg)双指针法就是将原本暴力O(n^3)的解法,降为O(n^2)的解法,四数之和的双指针解法就是将原本暴力O(n^4)的解法,降为O(n^3)的解法。
|
||||
|
||||
之前我们讲过哈希表的经典题目:[454.四数相加II](https://mp.weixin.qq.com/s/12g_w6RzHuEpFts1pT6BWw),相对于本题简单很多,因为本题是要求在一个集合中找出四个数相加等于target,同时四元组不能重复。
|
||||
|
||||
而[454.四数相加II](https://mp.weixin.qq.com/s/12g_w6RzHuEpFts1pT6BWw)是四个独立的数组,只要找到A[i] + B[j] + C[k] + D[l] = 0就可以,不用考虑有重复的四个元素相加等于0的情况,所以相对于本题还是简单了不少!
|
||||
|
||||
我们来回顾一下,几道题目使用了双指针法。
|
||||
|
||||
双指针法将时间复杂度O(n^2)的解法优化为 O(n)的解法。也就是降一个数量级,题目如下:
|
||||
|
||||
* [27.移除元素](https://mp.weixin.qq.com/s/RMkulE4NIb6XsSX83ra-Ww)
|
||||
* [15.三数之和](https://mp.weixin.qq.com/s/QfTNEByq1YlNSXRKEumwHg)
|
||||
* [18.四数之和](https://mp.weixin.qq.com/s/nQrcco8AZJV1pAOVjeIU_g)
|
||||
|
||||
|
||||
操作链表:
|
||||
|
||||
* [206.反转链表](https://mp.weixin.qq.com/s/ckEvIVGcNLfrz6OLOMoT0A)
|
||||
* [19.删除链表的倒数第N个节点](https://mp.weixin.qq.com/s/gxu65X1343xW_sBrkTz0Eg)
|
||||
* [面试题 02.07. 链表相交](https://mp.weixin.qq.com/s/BhfFfaGvt9Zs7UmH4YehZw)
|
||||
* [142题.环形链表II](https://mp.weixin.qq.com/s/gt_VH3hQTqNxyWcl1ECSbQ)
|
||||
|
||||
双指针法在字符串题目中还有很多应用,后面还会介绍到。
|
||||
|
||||
C++代码
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
vector<vector<int>> fourSum(vector<int>& nums, int target) {
|
||||
vector<vector<int>> result;
|
||||
sort(nums.begin(), nums.end());
|
||||
for (int k = 0; k < nums.size(); k++) {
|
||||
// 这种剪枝是错误的,这道题目target 是任意值
|
||||
// if (nums[k] > target) {
|
||||
// return result;
|
||||
// }
|
||||
// 去重
|
||||
if (k > 0 && nums[k] == nums[k - 1]) {
|
||||
continue;
|
||||
}
|
||||
for (int i = k + 1; i < nums.size(); i++) {
|
||||
// 正确去重方法
|
||||
if (i > k + 1 && nums[i] == nums[i - 1]) {
|
||||
continue;
|
||||
}
|
||||
int left = i + 1;
|
||||
int right = nums.size() - 1;
|
||||
while (right > left) {
|
||||
if (nums[k] + nums[i] + nums[left] + nums[right] > target) {
|
||||
right--;
|
||||
} else if (nums[k] + nums[i] + nums[left] + nums[right] < target) {
|
||||
left++;
|
||||
} else {
|
||||
result.push_back(vector<int>{nums[k], nums[i], nums[left], nums[right]});
|
||||
// 去重逻辑应该放在找到一个四元组之后
|
||||
while (right > left && nums[right] == nums[right - 1]) right--;
|
||||
while (right > left && nums[left] == nums[left + 1]) left++;
|
||||
|
||||
// 找到答案时,双指针同时收缩
|
||||
right--;
|
||||
left++;
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
return result;
|
||||
}
|
||||
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
public List<List<Integer>> fourSum(int[] nums, int target) {
|
||||
List<List<Integer>> result = new ArrayList<>();
|
||||
Arrays.sort(nums);
|
||||
|
||||
for (int i = 0; i < nums.length; i++) {
|
||||
|
||||
if (i > 0 && nums[i - 1] == nums[i]) {
|
||||
continue;
|
||||
}
|
||||
|
||||
for (int j = i + 1; j < nums.length; j++) {
|
||||
|
||||
if (j > i + 1 && nums[j - 1] == nums[j]) {
|
||||
continue;
|
||||
}
|
||||
|
||||
int left = j + 1;
|
||||
int right = nums.length - 1;
|
||||
while (right > left) {
|
||||
int sum = nums[i] + nums[j] + nums[left] + nums[right];
|
||||
if (sum > target) {
|
||||
right--;
|
||||
} else if (sum < target) {
|
||||
left++;
|
||||
} else {
|
||||
result.add(Arrays.asList(nums[i], nums[j], nums[left], nums[right]));
|
||||
|
||||
while (right > left && nums[right] == nums[right - 1]) right--;
|
||||
while (right > left && nums[left] == nums[left + 1]) left++;
|
||||
|
||||
left++;
|
||||
right--;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
return result;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
|
||||
class Solution(object):
|
||||
def fourSum(self, nums, target):
|
||||
"""
|
||||
:type nums: List[int]
|
||||
:type target: int
|
||||
:rtype: List[List[int]]
|
||||
"""
|
||||
# use a dict to store value:showtimes
|
||||
hashmap = dict()
|
||||
for n in nums:
|
||||
if n in hashmap:
|
||||
hashmap[n] += 1
|
||||
else:
|
||||
hashmap[n] = 1
|
||||
|
||||
# good thing about using python is you can use set to drop duplicates.
|
||||
ans = set()
|
||||
for i in range(len(nums)):
|
||||
for j in range(i + 1, len(nums)):
|
||||
for k in range(j + 1, len(nums)):
|
||||
val = target - (nums[i] + nums[j] + nums[k])
|
||||
if val in hashmap:
|
||||
# make sure no duplicates.
|
||||
count = (nums[i] == val) + (nums[j] == val) + (nums[k] == val)
|
||||
if hashmap[val] > count:
|
||||
ans.add(tuple(sorted([nums[i], nums[j], nums[k], val])))
|
||||
else:
|
||||
continue
|
||||
return ans
|
||||
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
javaScript:
|
||||
|
||||
```js
|
||||
/**
|
||||
* @param {number[]} nums
|
||||
* @param {number} target
|
||||
* @return {number[][]}
|
||||
*/
|
||||
var fourSum = function(nums, target) {
|
||||
const len = nums.length;
|
||||
if(len < 4) return [];
|
||||
nums.sort((a, b) => a - b);
|
||||
const res = [];
|
||||
for(let i = 0; i < len - 3; i++) {
|
||||
// 去重i
|
||||
if(i > 0 && nums[i] === nums[i - 1]) continue;
|
||||
for(let j = i + 1; j < len - 2; j++) {
|
||||
// 去重j
|
||||
if(j > i + 1 && nums[j] === nums[j - 1]) continue;
|
||||
let l = j + 1, r = len - 1;
|
||||
while(l < r) {
|
||||
const sum = nums[i] + nums[j] + nums[l] + nums[r];
|
||||
if(sum < target) { l++; continue}
|
||||
if(sum > target) { r--; continue}
|
||||
res.push([nums[i], nums[j], nums[l], nums[r]]);
|
||||
while(l < r && nums[l] === nums[++l]);
|
||||
while(l < r && nums[r] === nums[--r]);
|
||||
}
|
||||
}
|
||||
}
|
||||
return res;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
192
problems/0019.删除链表的倒数第N个节点.md
Normal file
192
problems/0019.删除链表的倒数第N个节点.md
Normal file
@@ -0,0 +1,192 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
|
||||
|
||||
## 19.删除链表的倒数第N个节点
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/remove-nth-node-from-end-of-list/
|
||||
|
||||
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
|
||||
|
||||
进阶:你能尝试使用一趟扫描实现吗?
|
||||
|
||||
示例 1:
|
||||
|
||||

|
||||
|
||||
输入:head = [1,2,3,4,5], n = 2
|
||||
输出:[1,2,3,5]
|
||||
示例 2:
|
||||
|
||||
输入:head = [1], n = 1
|
||||
输出:[]
|
||||
示例 3:
|
||||
|
||||
输入:head = [1,2], n = 1
|
||||
输出:[1]
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
双指针的经典应用,如果要删除倒数第n个节点,让fast移动n步,然后让fast和slow同时移动,直到fast指向链表末尾。删掉slow所指向的节点就可以了。
|
||||
|
||||
思路是这样的,但要注意一些细节。
|
||||
|
||||
分为如下几步:
|
||||
|
||||
* 首先这里我推荐大家使用虚拟头结点,这样方面处理删除实际头结点的逻辑,如果虚拟头结点不清楚,可以看这篇: [链表:听说用虚拟头节点会方便很多?](https://mp.weixin.qq.com/s/L5aanfALdLEwVWGvyXPDqA)
|
||||
|
||||
* 定义fast指针和slow指针,初始值为虚拟头结点,如图:
|
||||
|
||||
<img src='https://code-thinking.cdn.bcebos.com/pics/19.%E5%88%A0%E9%99%A4%E9%93%BE%E8%A1%A8%E7%9A%84%E5%80%92%E6%95%B0%E7%AC%ACN%E4%B8%AA%E8%8A%82%E7%82%B9.png' width=600> </img></div>
|
||||
|
||||
* fast首先走n + 1步 ,为什么是n+1呢,因为只有这样同时移动的时候slow才能指向删除节点的上一个节点(方便做删除操作),如图:
|
||||
<img src='https://code-thinking.cdn.bcebos.com/pics/19.%E5%88%A0%E9%99%A4%E9%93%BE%E8%A1%A8%E7%9A%84%E5%80%92%E6%95%B0%E7%AC%ACN%E4%B8%AA%E8%8A%82%E7%82%B91.png' width=600> </img></div>
|
||||
|
||||
* fast和slow同时移动,之道fast指向末尾,如题:
|
||||
<img src='https://code-thinking.cdn.bcebos.com/pics/19.%E5%88%A0%E9%99%A4%E9%93%BE%E8%A1%A8%E7%9A%84%E5%80%92%E6%95%B0%E7%AC%ACN%E4%B8%AA%E8%8A%82%E7%82%B92.png' width=600> </img></div>
|
||||
|
||||
* 删除slow指向的下一个节点,如图:
|
||||
<img src='https://code-thinking.cdn.bcebos.com/pics/19.%E5%88%A0%E9%99%A4%E9%93%BE%E8%A1%A8%E7%9A%84%E5%80%92%E6%95%B0%E7%AC%ACN%E4%B8%AA%E8%8A%82%E7%82%B93.png' width=600> </img></div>
|
||||
|
||||
此时不难写出如下C++代码:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
ListNode* removeNthFromEnd(ListNode* head, int n) {
|
||||
ListNode* dummyHead = new ListNode(0);
|
||||
dummyHead->next = head;
|
||||
ListNode* slow = dummyHead;
|
||||
ListNode* fast = dummyHead;
|
||||
while(n-- && fast != NULL) {
|
||||
fast = fast->next;
|
||||
}
|
||||
fast = fast->next; // fast再提前走一步,因为需要让slow指向删除节点的上一个节点
|
||||
while (fast != NULL) {
|
||||
fast = fast->next;
|
||||
slow = slow->next;
|
||||
}
|
||||
slow->next = slow->next->next;
|
||||
return dummyHead->next;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
java:
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
public ListNode removeNthFromEnd(ListNode head, int n) {
|
||||
ListNode dummy = new ListNode(-1);
|
||||
dummy.next = head;
|
||||
|
||||
ListNode slow = dummy;
|
||||
ListNode fast = dummy;
|
||||
while (n-- > 0) {
|
||||
fast = fast.next;
|
||||
}
|
||||
// 记住 待删除节点slow 的上一节点
|
||||
ListNode prev = null;
|
||||
while (fast != null) {
|
||||
prev = slow;
|
||||
slow = slow.next;
|
||||
fast = fast.next;
|
||||
}
|
||||
// 上一节点的next指针绕过 待删除节点slow 直接指向slow的下一节点
|
||||
prev.next = slow.next;
|
||||
// 释放 待删除节点slow 的next指针, 这句删掉也能AC
|
||||
slow.next = null;
|
||||
|
||||
return dummy.next;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
# Definition for singly-linked list.
|
||||
# class ListNode:
|
||||
# def __init__(self, val=0, next=None):
|
||||
# self.val = val
|
||||
# self.next = next
|
||||
class Solution:
|
||||
def removeNthFromEnd(self, head: ListNode, n: int) -> ListNode:
|
||||
head_dummy = ListNode()
|
||||
head_dummy.next = head
|
||||
|
||||
slow, fast = head_dummy, head_dummy
|
||||
while(n!=0): #fast先往前走n步
|
||||
fast = fast.next
|
||||
n -= 1
|
||||
while(fast.next!=None):
|
||||
slow = slow.next
|
||||
fast = fast.next
|
||||
#fast 走到结尾后,slow的下一个节点为倒数第N个节点
|
||||
slow.next = slow.next.next #删除
|
||||
return head_dummy.next
|
||||
```
|
||||
Go:
|
||||
```Go
|
||||
/**
|
||||
* Definition for singly-linked list.
|
||||
* type ListNode struct {
|
||||
* Val int
|
||||
* Next *ListNode
|
||||
* }
|
||||
*/
|
||||
func removeNthFromEnd(head *ListNode, n int) *ListNode {
|
||||
dummyHead := &ListNode{}
|
||||
dummyHead.Next = head
|
||||
cur := head
|
||||
prev := dummyHead
|
||||
i := 1
|
||||
for cur != nil {
|
||||
cur = cur.Next
|
||||
if i > n {
|
||||
prev = prev.Next
|
||||
}
|
||||
i++
|
||||
}
|
||||
prev.Next = prev.Next.Next
|
||||
return dummyHead.Next
|
||||
}
|
||||
```
|
||||
|
||||
JavaScript:
|
||||
|
||||
```js
|
||||
/**
|
||||
* @param {ListNode} head
|
||||
* @param {number} n
|
||||
* @return {ListNode}
|
||||
*/
|
||||
var removeNthFromEnd = function(head, n) {
|
||||
let ret = new ListNode(0, head),
|
||||
slow = fast = ret;
|
||||
while(n--) fast = fast.next;
|
||||
if(!fast) return ret.next;
|
||||
while (fast.next) {
|
||||
fast = fast.next;
|
||||
slow = slow.next
|
||||
};
|
||||
slow.next = slow.next.next;
|
||||
return ret.next;
|
||||
};
|
||||
```
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
267
problems/0020.有效的括号.md
Normal file
267
problems/0020.有效的括号.md
Normal file
@@ -0,0 +1,267 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
|
||||
> 数据结构与算法应用往往隐藏在我们看不到的地方
|
||||
|
||||
# 20. 有效的括号
|
||||
|
||||
https://leetcode-cn.com/problems/valid-parentheses/
|
||||
|
||||
给定一个只包括 '(',')','{','}','[',']' 的字符串,判断字符串是否有效。
|
||||
|
||||
有效字符串需满足:
|
||||
* 左括号必须用相同类型的右括号闭合。
|
||||
* 左括号必须以正确的顺序闭合。
|
||||
* 注意空字符串可被认为是有效字符串。
|
||||
|
||||
示例 1:
|
||||
* 输入: "()"
|
||||
* 输出: true
|
||||
|
||||
示例 2:
|
||||
* 输入: "()[]{}"
|
||||
* 输出: true
|
||||
|
||||
示例 3:
|
||||
* 输入: "(]"
|
||||
* 输出: false
|
||||
|
||||
示例 4:
|
||||
* 输入: "([)]"
|
||||
* 输出: false
|
||||
|
||||
示例 5:
|
||||
* 输入: "{[]}"
|
||||
* 输出: true
|
||||
|
||||
# 思路
|
||||
|
||||
## 题外话
|
||||
|
||||
**括号匹配是使用栈解决的经典问题。**
|
||||
|
||||
题意其实就像我们在写代码的过程中,要求括号的顺序是一样的,有左括号,相应的位置必须要有右括号。
|
||||
|
||||
如果还记得编译原理的话,编译器在 词法分析的过程中处理括号、花括号等这个符号的逻辑,也是使用了栈这种数据结构。
|
||||
|
||||
再举个例子,linux系统中,cd这个进入目录的命令我们应该再熟悉不过了。
|
||||
|
||||
```
|
||||
cd a/b/c/../../
|
||||
```
|
||||
|
||||
这个命令最后进入a目录,系统是如何知道进入了a目录呢 ,这就是栈的应用(其实可以出一道相应的面试题了)
|
||||
|
||||
所以栈在计算机领域中应用是非常广泛的。
|
||||
|
||||
有的同学经常会想学的这些数据结构有什么用,也开发不了什么软件,大多数同学说的软件应该都是可视化的软件例如APP、网站之类的,那都是非常上层的应用了,底层很多功能的实现都是基础的数据结构和算法。
|
||||
|
||||
**所以数据结构与算法的应用往往隐藏在我们看不到的地方!**
|
||||
|
||||
这里我就不过多展开了,先来看题。
|
||||
|
||||
## 进入正题
|
||||
|
||||
由于栈结构的特殊性,非常适合做对称匹配类的题目。
|
||||
|
||||
首先要弄清楚,字符串里的括号不匹配有几种情况。
|
||||
|
||||
**一些同学,在面试中看到这种题目上来就开始写代码,然后就越写越乱。**
|
||||
|
||||
建议要写代码之前要分析好有哪几种不匹配的情况,如果不动手之前分析好,写出的代码也会有很多问题。
|
||||
|
||||
先来分析一下 这里有三种不匹配的情况,
|
||||
|
||||
1. 第一种情况,字符串里左方向的括号多余了 ,所以不匹配。
|
||||
|
||||
2. 第二种情况,括号没有多余,但是 括号的类型没有匹配上。
|
||||
|
||||
3. 第三种情况,字符串里右方向的括号多余了,所以不匹配。
|
||||
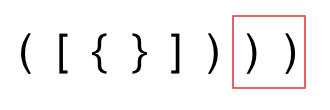
|
||||
|
||||
我们的代码只要覆盖了这三种不匹配的情况,就不会出问题,可以看出 动手之前分析好题目的重要性。
|
||||
|
||||
动画如下:
|
||||
|
||||
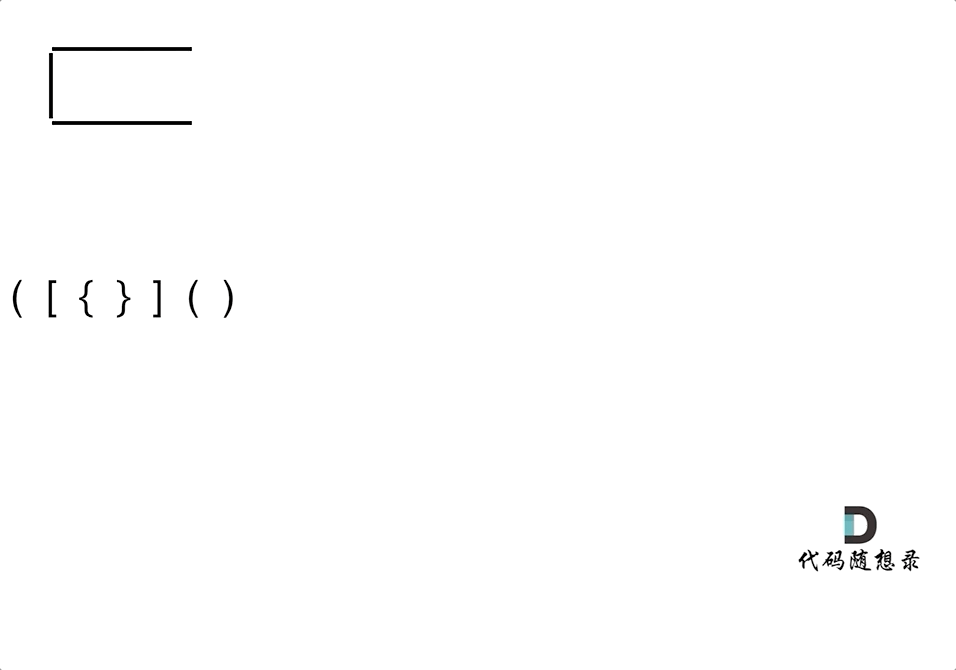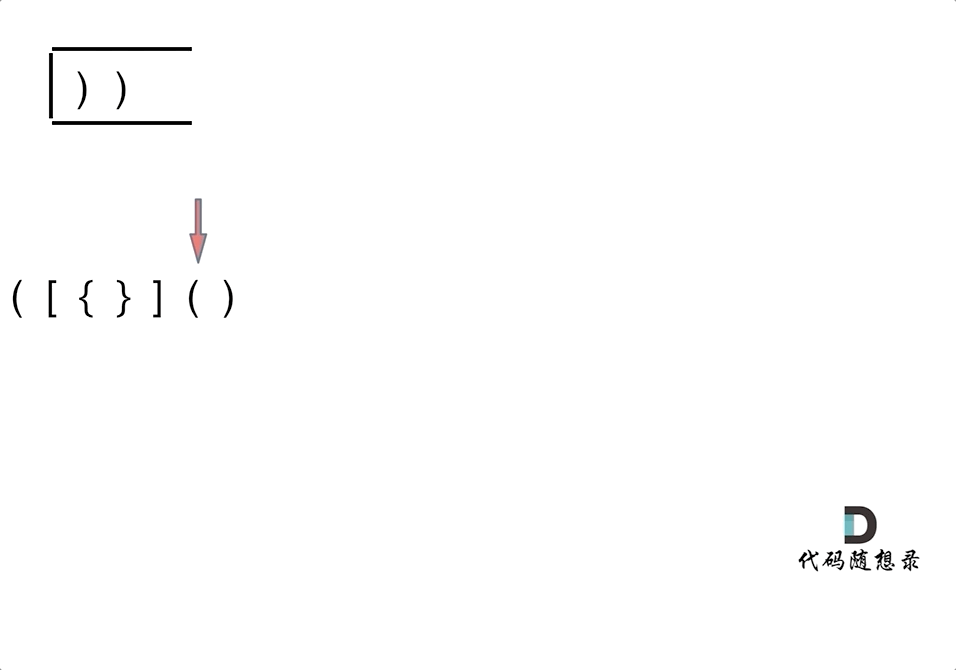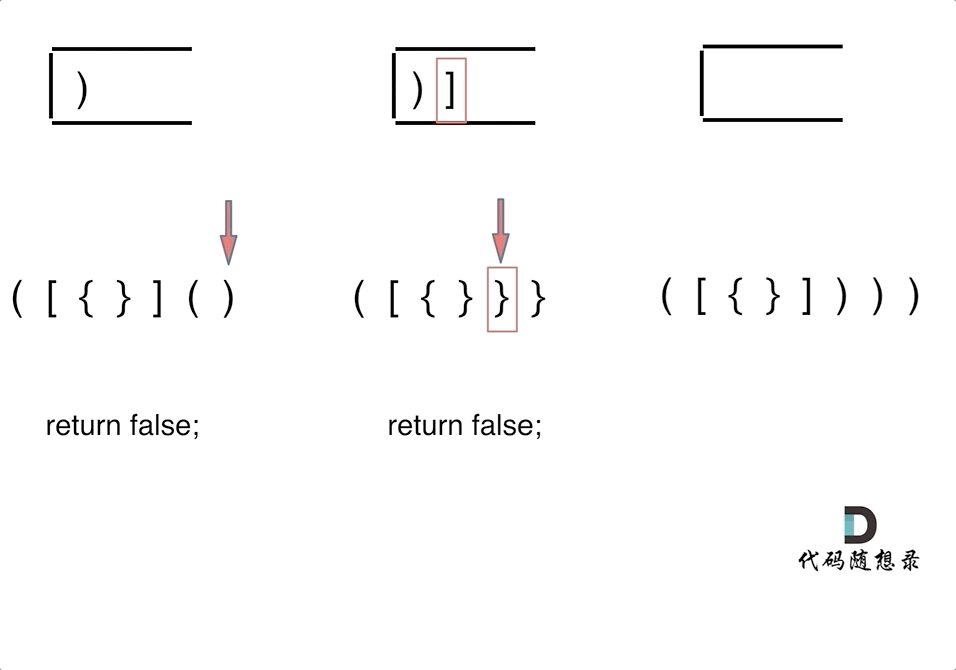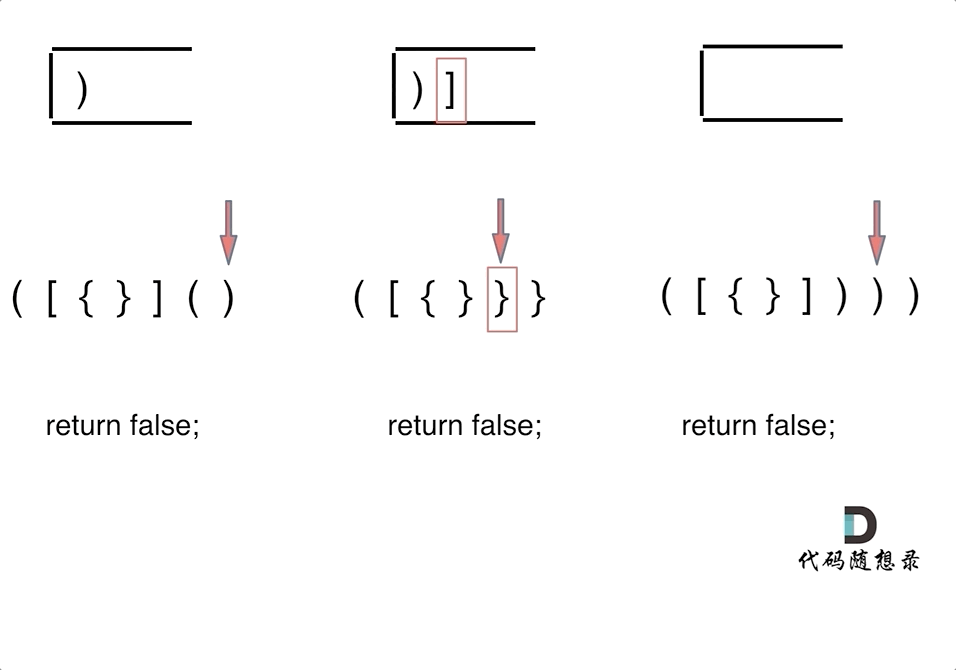
|
||||
|
||||
|
||||
第一种情况:已经遍历完了字符串,但是栈不为空,说明有相应的左括号没有右括号来匹配,所以return false
|
||||
|
||||
第二种情况:遍历字符串匹配的过程中,发现栈里没有要匹配的字符。所以return false
|
||||
|
||||
第三种情况:遍历字符串匹配的过程中,栈已经为空了,没有匹配的字符了,说明右括号没有找到对应的左括号return false
|
||||
|
||||
那么什么时候说明左括号和右括号全都匹配了呢,就是字符串遍历完之后,栈是空的,就说明全都匹配了。
|
||||
|
||||
分析完之后,代码其实就比较好写了,
|
||||
|
||||
但还有一些技巧,在匹配左括号的时候,右括号先入栈,就只需要比较当前元素和栈顶相不相等就可以了,比左括号先入栈代码实现要简单的多了!
|
||||
|
||||
实现C++代码如下:
|
||||
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
bool isValid(string s) {
|
||||
stack<int> st;
|
||||
for (int i = 0; i < s.size(); i++) {
|
||||
if (s[i] == '(') st.push(')');
|
||||
else if (s[i] == '{') st.push('}');
|
||||
else if (s[i] == '[') st.push(']');
|
||||
// 第三种情况:遍历字符串匹配的过程中,栈已经为空了,没有匹配的字符了,说明右括号没有找到对应的左括号 return false
|
||||
// 第二种情况:遍历字符串匹配的过程中,发现栈里没有我们要匹配的字符。所以return false
|
||||
else if (st.empty() || st.top() != s[i]) return false;
|
||||
else st.pop(); // st.top() 与 s[i]相等,栈弹出元素
|
||||
}
|
||||
// 第一种情况:此时我们已经遍历完了字符串,但是栈不为空,说明有相应的左括号没有右括号来匹配,所以return false,否则就return true
|
||||
return st.empty();
|
||||
}
|
||||
};
|
||||
```
|
||||
技巧性的东西没有固定的学习方法,还是要多看多练,自己总灵活运用了。
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
public boolean isValid(String s) {
|
||||
Deque<Character> deque = new LinkedList<>();
|
||||
char ch;
|
||||
for (int i = 0; i < s.length(); i++) {
|
||||
ch = s.charAt(i);
|
||||
//碰到左括号,就把相应的右括号入栈
|
||||
if (ch == '(') {
|
||||
deque.push(')');
|
||||
}else if (ch == '{') {
|
||||
deque.push('}');
|
||||
}else if (ch == '[') {
|
||||
deque.push(']');
|
||||
} else if (deque.isEmpty() || deque.peek() != ch) {
|
||||
return false;
|
||||
}else {//如果是右括号判断是否和栈顶元素匹配
|
||||
deque.pop();
|
||||
}
|
||||
}
|
||||
//最后判断栈中元素是否匹配
|
||||
return deque.isEmpty();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python3
|
||||
class Solution:
|
||||
def isValid(self, s: str) -> bool:
|
||||
stack = [] # 保存还未匹配的左括号
|
||||
mapping = {")": "(", "]": "[", "}": "{"}
|
||||
for i in s:
|
||||
if i in "([{": # 当前是左括号,则入栈
|
||||
stack.append(i)
|
||||
elif stack and stack[-1] == mapping[i]: # 当前是配对的右括号则出栈
|
||||
stack.pop()
|
||||
else: # 不是匹配的右括号或者没有左括号与之匹配,则返回false
|
||||
return False
|
||||
return stack == [] # 最后必须正好把左括号匹配完
|
||||
```
|
||||
|
||||
Go:
|
||||
```Go
|
||||
func isValid(s string) bool {
|
||||
hash := map[byte]byte{')':'(', ']':'[', '}':'{'}
|
||||
stack := make([]byte, 0)
|
||||
if s == "" {
|
||||
return true
|
||||
}
|
||||
|
||||
for i := 0; i < len(s); i++ {
|
||||
if s[i] == '(' || s[i] == '[' || s[i] == '{' {
|
||||
stack = append(stack, s[i])
|
||||
} else if len(stack) > 0 && stack[len(stack)-1] == hash[s[i]] {
|
||||
stack = stack[:len(stack)-1]
|
||||
} else {
|
||||
return false
|
||||
}
|
||||
}
|
||||
return len(stack) == 0
|
||||
}
|
||||
```
|
||||
|
||||
Ruby:
|
||||
```ruby
|
||||
def is_valid(strs)
|
||||
symbol_map = {')' => '(', '}' => '{', ']' => '['}
|
||||
stack = []
|
||||
strs.size.times {|i|
|
||||
c = strs[i]
|
||||
if symbol_map.has_key?(c)
|
||||
top_e = stack.shift
|
||||
return false if symbol_map[c] != top_e
|
||||
else
|
||||
stack.unshift(c)
|
||||
end
|
||||
}
|
||||
stack.empty?
|
||||
end
|
||||
```
|
||||
|
||||
Javascript:
|
||||
```javascript
|
||||
var isValid = function (s) {
|
||||
const stack = [];
|
||||
for (let i = 0; i < s.length; i++) {
|
||||
let c = s[i];
|
||||
switch (c) {
|
||||
case '(':
|
||||
stack.push(')');
|
||||
break;
|
||||
case '[':
|
||||
stack.push(']');
|
||||
break;
|
||||
case '{':
|
||||
stack.push('}');
|
||||
break;
|
||||
default:
|
||||
if (c !== stack.pop()) {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
}
|
||||
return stack.length === 0;
|
||||
};
|
||||
// 简化版本
|
||||
var isValid = function(s) {
|
||||
const stack = [],
|
||||
map = {
|
||||
"(":")",
|
||||
"{":"}",
|
||||
"[":"]"
|
||||
};
|
||||
for(const x of s) {
|
||||
if(x in map) {
|
||||
stack.push(x);
|
||||
continue;
|
||||
};
|
||||
if(map[stack.pop()] !== x) return false;
|
||||
}
|
||||
return !stack.length;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
206
problems/0024.两两交换链表中的节点.md
Normal file
206
problems/0024.两两交换链表中的节点.md
Normal file
@@ -0,0 +1,206 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 24. 两两交换链表中的节点
|
||||
|
||||
给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。
|
||||
|
||||
你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
|
||||
|
||||
|
||||
<img src='https://code-thinking.cdn.bcebos.com/pics/24.%E4%B8%A4%E4%B8%A4%E4%BA%A4%E6%8D%A2%E9%93%BE%E8%A1%A8%E4%B8%AD%E7%9A%84%E8%8A%82%E7%82%B9-%E9%A2%98%E6%84%8F.jpg' width=600 alt='24.两两交换链表中的节点-题意'> </img></div>
|
||||
|
||||
## 思路
|
||||
|
||||
这道题目正常模拟就可以了。
|
||||
|
||||
建议使用虚拟头结点,这样会方便很多,要不然每次针对头结点(没有前一个指针指向头结点),还要单独处理。
|
||||
|
||||
对虚拟头结点的操作,还不熟悉的话,可以看这篇[链表:听说用虚拟头节点会方便很多?](https://mp.weixin.qq.com/s/L5aanfALdLEwVWGvyXPDqA)。
|
||||
|
||||
接下来就是交换相邻两个元素了,**此时一定要画图,不画图,操作多个指针很容易乱,而且要操作的先后顺序**
|
||||
|
||||
初始时,cur指向虚拟头结点,然后进行如下三步:
|
||||
|
||||
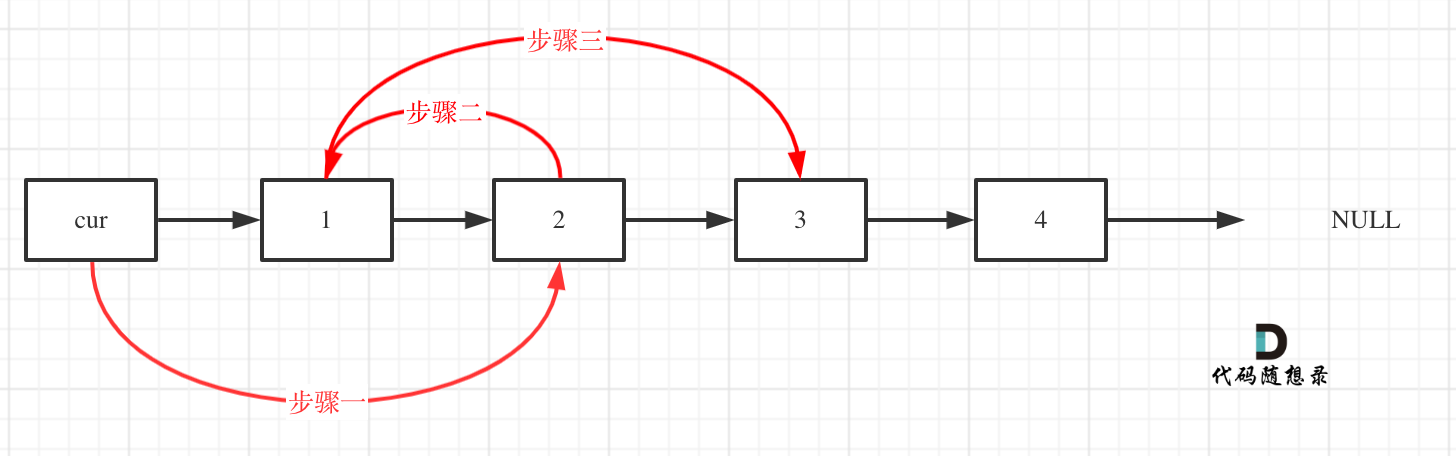
|
||||
|
||||
操作之后,链表如下:
|
||||
|
||||

|
||||
|
||||
看这个可能就更直观一些了:
|
||||
|
||||
|
||||

|
||||
|
||||
对应的C++代码实现如下: (注释中详细和如上图中的三步做对应)
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
ListNode* swapPairs(ListNode* head) {
|
||||
ListNode* dummyHead = new ListNode(0); // 设置一个虚拟头结点
|
||||
dummyHead->next = head; // 将虚拟头结点指向head,这样方面后面做删除操作
|
||||
ListNode* cur = dummyHead;
|
||||
while(cur->next != nullptr && cur->next->next != nullptr) {
|
||||
ListNode* tmp = cur->next; // 记录临时节点
|
||||
ListNode* tmp1 = cur->next->next->next; // 记录临时节点
|
||||
|
||||
cur->next = cur->next->next; // 步骤一
|
||||
cur->next->next = tmp; // 步骤二
|
||||
cur->next->next->next = tmp1; // 步骤三
|
||||
|
||||
cur = cur->next->next; // cur移动两位,准备下一轮交换
|
||||
}
|
||||
return dummyHead->next;
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度:$O(n)$
|
||||
* 空间复杂度:$O(1)$
|
||||
|
||||
## 拓展
|
||||
|
||||
**这里还是说一下,大家不必太在意力扣上执行用时,打败多少多少用户,这个统计不准确的。**
|
||||
|
||||
做题的时候自己能分析出来时间复杂度就可以了,至于力扣上执行用时,大概看一下就行。
|
||||
|
||||
上面的代码我第一次提交执行用时8ms,打败6.5%的用户,差点吓到我了。
|
||||
|
||||
心想应该没有更好的方法了吧,也就O(n)的时间复杂度,重复提交几次,这样了:
|
||||
|
||||

|
||||
|
||||
力扣上的统计如果两份代码是 100ms 和 300ms的耗时,其实是需要注意的。
|
||||
|
||||
如果一个是 4ms 一个是 12ms,看上去好像是一个打败了80%,一个打败了20%,其实是没有差别的。 只不过是力扣上统计的误差而已。
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
|
||||
```Java
|
||||
// 递归版本
|
||||
class Solution {
|
||||
public ListNode swapPairs(ListNode head) {
|
||||
// base case 退出提交
|
||||
if(head == null || head.next == null) return head;
|
||||
// 获取当前节点的下一个节点
|
||||
ListNode next = head.next;
|
||||
// 进行递归
|
||||
ListNode newNode = swapPairs(next.next);
|
||||
// 这里进行交换
|
||||
next.next = head;
|
||||
head.next = newNode;
|
||||
|
||||
return next;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
// 虚拟头结点
|
||||
class Solution {
|
||||
public ListNode swapPairs(ListNode head) {
|
||||
|
||||
ListNode dummyNode = new ListNode(0);
|
||||
dummyNode.next = head;
|
||||
ListNode prev = dummyNode;
|
||||
|
||||
while (prev.next != null && prev.next.next != null) {
|
||||
ListNode temp = head.next.next; // 缓存 next
|
||||
prev.next = head.next; // 将 prev 的 next 改为 head 的 next
|
||||
head.next.next = head; // 将 head.next(prev.next) 的next,指向 head
|
||||
head.next = temp; // 将head 的 next 接上缓存的temp
|
||||
prev = head; // 步进1位
|
||||
head = head.next; // 步进1位
|
||||
}
|
||||
return dummyNode.next;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def swapPairs(self, head: ListNode) -> ListNode:
|
||||
dummy = ListNode(0) #设置一个虚拟头结点
|
||||
dummy.next = head
|
||||
cur = dummy
|
||||
while cur.next and cur.next.next:
|
||||
tmp = cur.next #记录临时节点
|
||||
tmp1 = cur.next.next.next #记录临时节点
|
||||
|
||||
cur.next = cur.next.next #步骤一
|
||||
cur.next.next = tmp #步骤二
|
||||
cur.next.next.next = tmp1 #步骤三
|
||||
|
||||
cur = cur.next.next #cur移动两位,准备下一轮交换
|
||||
return dummy.next
|
||||
```
|
||||
|
||||
Go:
|
||||
```go
|
||||
func swapPairs(head *ListNode) *ListNode {
|
||||
dummy := &ListNode{
|
||||
Next: head,
|
||||
}
|
||||
//head=list[i]
|
||||
//pre=list[i-1]
|
||||
pre := dummy
|
||||
for head != nil && head.Next != nil {
|
||||
pre.Next = head.Next
|
||||
next := head.Next.Next
|
||||
head.Next.Next = head
|
||||
head.Next = next
|
||||
//pre=list[(i+2)-1]
|
||||
pre = head
|
||||
//head=list[(i+2)]
|
||||
head = next
|
||||
}
|
||||
return dummy.Next
|
||||
}
|
||||
```
|
||||
|
||||
```go
|
||||
// 递归版本
|
||||
func swapPairs(head *ListNode) *ListNode {
|
||||
if head == nil || head.Next == nil {
|
||||
return head
|
||||
}
|
||||
next := head.Next
|
||||
head.Next = swapPairs(next.Next)
|
||||
next.Next = head
|
||||
return next
|
||||
}
|
||||
```
|
||||
|
||||
Javascript:
|
||||
```javascript
|
||||
var swapPairs = function (head) {
|
||||
let ret = new ListNode(0, head), temp = ret;
|
||||
while (temp.next && temp.next.next) {
|
||||
let cur = temp.next.next, pre = temp.next;
|
||||
pre.next = cur.next;
|
||||
cur.next = pre;
|
||||
temp.next = cur;
|
||||
temp = pre;
|
||||
}
|
||||
return ret.next;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
223
problems/0027.移除元素.md
Normal file
223
problems/0027.移除元素.md
Normal file
@@ -0,0 +1,223 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 27. 移除元素
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/remove-element/
|
||||
|
||||
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
|
||||
|
||||
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并**原地**修改输入数组。
|
||||
|
||||
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
|
||||
|
||||
示例 1:
|
||||
给定 nums = [3,2,2,3], val = 3,
|
||||
函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。
|
||||
你不需要考虑数组中超出新长度后面的元素。
|
||||
|
||||
示例 2:
|
||||
给定 nums = [0,1,2,2,3,0,4,2], val = 2,
|
||||
函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。
|
||||
|
||||
**你不需要考虑数组中超出新长度后面的元素。**
|
||||
|
||||
## 思路
|
||||
|
||||
有的同学可能说了,多余的元素,删掉不就得了。
|
||||
|
||||
**要知道数组的元素在内存地址中是连续的,不能单独删除数组中的某个元素,只能覆盖。**
|
||||
|
||||
数组的基础知识可以看这里[程序员算法面试中,必须掌握的数组理论知识](https://mp.weixin.qq.com/s/c2KABb-Qgg66HrGf8z-8Og)。
|
||||
|
||||
### 暴力解法
|
||||
|
||||
这个题目暴力的解法就是两层for循环,一个for循环遍历数组元素 ,第二个for循环更新数组。
|
||||
|
||||
删除过程如下:
|
||||
|
||||

|
||||
|
||||
很明显暴力解法的时间复杂度是O(n^2),这道题目暴力解法在leetcode上是可以过的。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
// 时间复杂度:O(n^2)
|
||||
// 空间复杂度:O(1)
|
||||
class Solution {
|
||||
public:
|
||||
int removeElement(vector<int>& nums, int val) {
|
||||
int size = nums.size();
|
||||
for (int i = 0; i < size; i++) {
|
||||
if (nums[i] == val) { // 发现需要移除的元素,就将数组集体向前移动一位
|
||||
for (int j = i + 1; j < size; j++) {
|
||||
nums[j - 1] = nums[j];
|
||||
}
|
||||
i--; // 因为下表i以后的数值都向前移动了一位,所以i也向前移动一位
|
||||
size--; // 此时数组的大小-1
|
||||
}
|
||||
}
|
||||
return size;
|
||||
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
* 时间复杂度:$O(n^2)$
|
||||
* 空间复杂度:$O(1)$
|
||||
|
||||
### 双指针法
|
||||
|
||||
双指针法(快慢指针法): **通过一个快指针和慢指针在一个for循环下完成两个for循环的工作。**
|
||||
|
||||
删除过程如下:
|
||||
|
||||

|
||||
|
||||
**双指针法(快慢指针法)在数组和链表的操作中是非常常见的,很多考察数组、链表、字符串等操作的面试题,都使用双指针法。**
|
||||
|
||||
后序都会一一介绍到,本题代码如下:
|
||||
|
||||
```C++
|
||||
// 时间复杂度:O(n)
|
||||
// 空间复杂度:O(1)
|
||||
class Solution {
|
||||
public:
|
||||
int removeElement(vector<int>& nums, int val) {
|
||||
int slowIndex = 0;
|
||||
for (int fastIndex = 0; fastIndex < nums.size(); fastIndex++) {
|
||||
if (val != nums[fastIndex]) {
|
||||
nums[slowIndex++] = nums[fastIndex];
|
||||
}
|
||||
}
|
||||
return slowIndex;
|
||||
}
|
||||
};
|
||||
```
|
||||
注意这些实现方法并没有改变元素的相对位置!
|
||||
|
||||
* 时间复杂度:$O(n)$
|
||||
* 空间复杂度:$O(1)$
|
||||
|
||||
旧文链接:[数组:就移除个元素很难么?](https://mp.weixin.qq.com/s/wj0T-Xs88_FHJFwayElQlA)
|
||||
|
||||
## 相关题目推荐
|
||||
|
||||
* 26.删除排序数组中的重复项
|
||||
* 283.移动零
|
||||
* 844.比较含退格的字符串
|
||||
* 977.有序数组的平方
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
public int removeElement(int[] nums, int val) {
|
||||
|
||||
// 快慢指针
|
||||
int fastIndex = 0;
|
||||
int slowIndex;
|
||||
for (slowIndex = 0; fastIndex < nums.length; fastIndex++) {
|
||||
if (nums[fastIndex] != val) {
|
||||
nums[slowIndex] = nums[fastIndex];
|
||||
slowIndex++;
|
||||
}
|
||||
}
|
||||
return slowIndex;
|
||||
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def removeElement(self, nums: List[int], val: int) -> int:
|
||||
i,n = 0,len(nums)
|
||||
for j in range(n):
|
||||
if nums[j] != val:
|
||||
nums[i] = nums[j]
|
||||
i += 1
|
||||
return i
|
||||
```
|
||||
|
||||
|
||||
Go:
|
||||
```go
|
||||
func removeElement(nums []int, val int) int {
|
||||
length:=len(nums)
|
||||
res:=0
|
||||
for i:=0;i<length;i++{
|
||||
if nums[i]!=val {
|
||||
nums[res]=nums[i]
|
||||
res++
|
||||
}
|
||||
}
|
||||
return res
|
||||
}
|
||||
```
|
||||
|
||||
JavaScript:
|
||||
```
|
||||
//时间复杂度O(n)
|
||||
//空间复杂度O(1)
|
||||
var removeElement = (nums, val) => {
|
||||
let k = 0;
|
||||
for(let i = 0;i < nums.length;i++){
|
||||
if(nums[i] != val){
|
||||
nums[k++] = nums[i]
|
||||
}
|
||||
}
|
||||
return k;
|
||||
};
|
||||
```
|
||||
|
||||
Ruby:
|
||||
```ruby
|
||||
def remove_element(nums, val)
|
||||
i = 0
|
||||
nums.each_index do |j|
|
||||
if nums[j] != val
|
||||
nums[i] = nums[j]
|
||||
i+=1
|
||||
end
|
||||
end
|
||||
i
|
||||
end
|
||||
```
|
||||
Rust:
|
||||
```rust
|
||||
pub fn remove_element(nums: &mut Vec<i32>, val: i32) -> &mut Vec<i32> {
|
||||
let mut start: usize = 0;
|
||||
while start < nums.len() {
|
||||
if nums[start] == val {
|
||||
nums.remove(start);
|
||||
}
|
||||
start += 1;
|
||||
}
|
||||
nums
|
||||
}
|
||||
fn main() {
|
||||
let mut nums = vec![5,1,3,5,2,3,4,1];
|
||||
println!("{:?}",remove_element(&mut nums, 5));
|
||||
}
|
||||
```
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
819
problems/0028.实现strStr.md
Normal file
819
problems/0028.实现strStr.md
Normal file
@@ -0,0 +1,819 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
> 在一个串中查找是否出现过另一个串,这是KMP的看家本领。
|
||||
|
||||
# 28. 实现 strStr()
|
||||
|
||||
https://leetcode-cn.com/problems/implement-strstr/
|
||||
|
||||
实现 strStr() 函数。
|
||||
|
||||
给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。
|
||||
|
||||
示例 1:
|
||||
输入: haystack = "hello", needle = "ll"
|
||||
输出: 2
|
||||
|
||||
示例 2:
|
||||
输入: haystack = "aaaaa", needle = "bba"
|
||||
输出: -1
|
||||
|
||||
说明:
|
||||
当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。
|
||||
对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与C语言的 strstr() 以及 Java的 indexOf() 定义相符。
|
||||
|
||||
|
||||
# 思路
|
||||
|
||||
本题是KMP 经典题目。
|
||||
|
||||
以下文字如果看不进去,可以看我的B站视频:
|
||||
|
||||
* [帮你把KMP算法学个通透!B站(理论篇)](https://www.bilibili.com/video/BV1PD4y1o7nd/)
|
||||
* [帮你把KMP算法学个通透!(求next数组代码篇)](https://www.bilibili.com/video/BV1M5411j7Xx)
|
||||
|
||||
KMP的经典思想就是:**当出现字符串不匹配时,可以记录一部分之前已经匹配的文本内容,利用这些信息避免从头再去做匹配。**
|
||||
|
||||
本篇将以如下顺序来讲解KMP,
|
||||
|
||||
|
||||
* 什么是KMP
|
||||
* KMP有什么用
|
||||
* 什么是前缀表
|
||||
* 为什么一定要用前缀表
|
||||
* 如何计算前缀表
|
||||
* 前缀表与next数组
|
||||
* 使用next数组来匹配
|
||||
* 时间复杂度分析
|
||||
* 构造next数组
|
||||
* 使用next数组来做匹配
|
||||
* 前缀表统一减一 C++代码实现
|
||||
* 前缀表(不减一)C++实现
|
||||
* 总结
|
||||
|
||||
|
||||
读完本篇可以顺便把leetcode上28.实现strStr()题目做了。
|
||||
|
||||
|
||||
# 什么是KMP
|
||||
|
||||
说到KMP,先说一下KMP这个名字是怎么来的,为什么叫做KMP呢。
|
||||
|
||||
因为是由这三位学者发明的:Knuth,Morris和Pratt,所以取了三位学者名字的首字母。所以叫做KMP
|
||||
|
||||
# KMP有什么用
|
||||
|
||||
KMP主要应用在字符串匹配上。
|
||||
|
||||
KMP的主要思想是**当出现字符串不匹配时,可以知道一部分之前已经匹配的文本内容,可以利用这些信息避免从头再去做匹配了。**
|
||||
|
||||
所以如何记录已经匹配的文本内容,是KMP的重点,也是next数组肩负的重任。
|
||||
|
||||
其实KMP的代码不好理解,一些同学甚至直接把KMP代码的模板背下来。
|
||||
|
||||
没有彻底搞懂,懵懵懂懂就把代码背下来太容易忘了。
|
||||
|
||||
不仅面试的时候可能写不出来,如果面试官问:**next数组里的数字表示的是什么,为什么这么表示?**
|
||||
|
||||
估计大多数候选人都是懵逼的。
|
||||
|
||||
下面Carl就带大家把KMP的精髓,next数组弄清楚。
|
||||
|
||||
# 什么是前缀表
|
||||
|
||||
写过KMP的同学,一定都写过next数组,那么这个next数组究竟是个啥呢?
|
||||
|
||||
next数组就是一个前缀表(prefix table)。
|
||||
|
||||
前缀表有什么作用呢?
|
||||
|
||||
**前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配。**
|
||||
|
||||
为了清楚的了解前缀表的来历,我们来举一个例子:
|
||||
|
||||
要在文本串:aabaabaafa 中查找是否出现过一个模式串:aabaaf。
|
||||
|
||||
请记住文本串和模式串的作用,对于理解下文很重要,要不然容易看懵。所以说三遍:
|
||||
|
||||
要在文本串:aabaabaafa 中查找是否出现过一个模式串:aabaaf。
|
||||
|
||||
要在文本串:aabaabaafa 中查找是否出现过一个模式串:aabaaf。
|
||||
|
||||
要在文本串:aabaabaafa 中查找是否出现过一个模式串:aabaaf。
|
||||
|
||||
如动画所示:
|
||||
|
||||
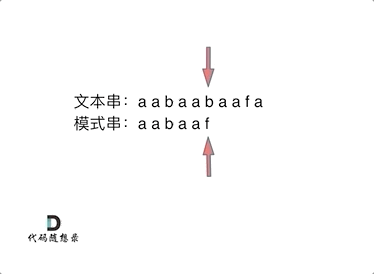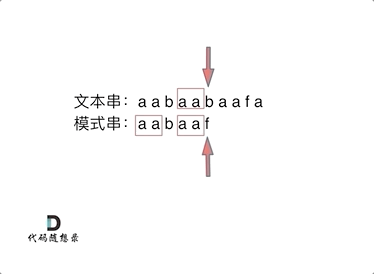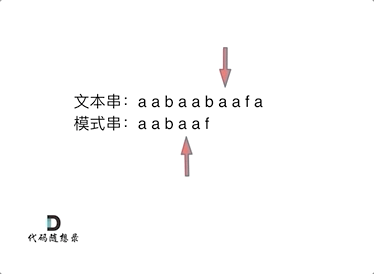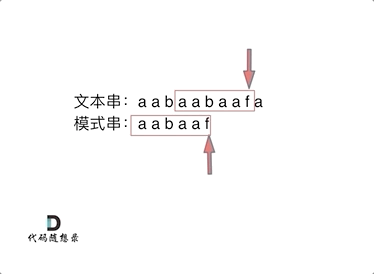
|
||||
|
||||
动画里,我特意把 子串`aa` 标记上了,这是有原因的,大家先注意一下,后面还会说道。
|
||||
|
||||
可以看出,文本串中第六个字符b 和 模式串的第六个字符f,不匹配了。如果暴力匹配,会发现不匹配,此时就要从头匹配了。
|
||||
|
||||
但如果使用前缀表,就不会从头匹配,而是从上次已经匹配的内容开始匹配,找到了模式串中第三个字符b继续开始匹配。
|
||||
|
||||
此时就要问了**前缀表是如何记录的呢?**
|
||||
|
||||
首先要知道前缀表的任务是当前位置匹配失败,找到之前已经匹配上的位置,在重新匹配,此也意味着在某个字符失配时,前缀表会告诉你下一步匹配中,模式串应该跳到哪个位置。
|
||||
|
||||
那么什么是前缀表:**记录下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。**
|
||||
|
||||
# 最长公共前后缀?
|
||||
|
||||
文章中字符串的**前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串**。
|
||||
|
||||
**后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串**。
|
||||
|
||||
**正确理解什么是前缀什么是后缀很重要**!
|
||||
|
||||
那么网上清一色都说 “kmp 最长公共前后缀” 又是什么回事呢?
|
||||
|
||||
我查了一遍 算法导论 和 算法4里KMP的章节,都没有提到 “最长公共前后缀”这个词,也不知道从哪里来了,我理解是用“最长相等前后缀” 更准确一些。
|
||||
|
||||
**因为前缀表要求的就是相同前后缀的长度。**
|
||||
|
||||
而最长公共前后缀里面的“公共”,更像是说前缀和后缀公共的长度。这其实并不是前缀表所需要的。
|
||||
|
||||
所以字符串a的最长相等前后缀为0。
|
||||
字符串aa的最长相等前后缀为1。
|
||||
字符串aaa的最长相等前后缀为2。
|
||||
等等.....。
|
||||
|
||||
|
||||
# 为什么一定要用前缀表
|
||||
|
||||
这就是前缀表那为啥就能告诉我们 上次匹配的位置,并跳过去呢?
|
||||
|
||||
回顾一下,刚刚匹配的过程在下标5的地方遇到不匹配,模式串是指向f,如图:
|
||||
<img src='https://code-thinking.cdn.bcebos.com/pics/KMP%E7%B2%BE%E8%AE%B21.png' width=600 alt='KMP精讲1'> </img></div>
|
||||
|
||||
|
||||
然后就找到了下标2,指向b,继续匹配:如图:
|
||||
<img src='https://code-thinking.cdn.bcebos.com/pics/KMP%E7%B2%BE%E8%AE%B22.png' width=600 alt='KMP精讲2'> </img></div>
|
||||
|
||||
以下这句话,对于理解为什么使用前缀表可以告诉我们匹配失败之后跳到哪里重新匹配 非常重要!
|
||||
|
||||
**下标5之前这部分的字符串(也就是字符串aabaa)的最长相等的前缀 和 后缀字符串是 子字符串aa ,因为找到了最长相等的前缀和后缀,匹配失败的位置是后缀子串的后面,那么我们找到与其相同的前缀的后面从新匹配就可以了。**
|
||||
|
||||
所以前缀表具有告诉我们当前位置匹配失败,跳到之前已经匹配过的地方的能力。
|
||||
|
||||
**很多介绍KMP的文章或者视频并没有把为什么要用前缀表?这个问题说清楚,而是直接默认使用前缀表。**
|
||||
|
||||
# 如何计算前缀表
|
||||
|
||||
接下来就要说一说怎么计算前缀表。
|
||||
|
||||
如图:
|
||||
|
||||
<img src='https://code-thinking.cdn.bcebos.com/pics/KMP%E7%B2%BE%E8%AE%B25.png' width=600 alt='KMP精讲5'> </img></div>
|
||||
|
||||
长度为前1个字符的子串`a`,最长相同前后缀的长度为0。(注意字符串的**前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串**;**后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串**。)
|
||||
|
||||
<img src='https://code-thinking.cdn.bcebos.com/pics/KMP%E7%B2%BE%E8%AE%B26.png' width=600 alt='KMP精讲6'> </img></div>
|
||||
长度为前2个字符的子串`aa`,最长相同前后缀的长度为1。
|
||||
|
||||
<img src='https://code-thinking.cdn.bcebos.com/pics/KMP%E7%B2%BE%E8%AE%B27.png' width=600 alt='KMP精讲7'> </img></div>
|
||||
长度为前3个字符的子串`aab`,最长相同前后缀的长度为0。
|
||||
|
||||
以此类推:
|
||||
长度为前4个字符的子串`aaba`,最长相同前后缀的长度为1。
|
||||
长度为前5个字符的子串`aabaa`,最长相同前后缀的长度为2。
|
||||
长度为前6个字符的子串`aabaaf`,最长相同前后缀的长度为0。
|
||||
|
||||
那么把求得的最长相同前后缀的长度就是对应前缀表的元素,如图:
|
||||
<img src='https://code-thinking.cdn.bcebos.com/pics/KMP%E7%B2%BE%E8%AE%B28.png' width=600 alt='KMP精讲8'> </img></div>
|
||||
|
||||
可以看出模式串与前缀表对应位置的数字表示的就是:**下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。**
|
||||
|
||||
再来看一下如何利用 前缀表找到 当字符不匹配的时候应该指针应该移动的位置。如动画所示:
|
||||
|
||||
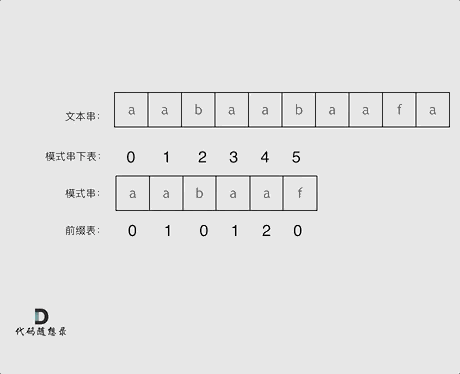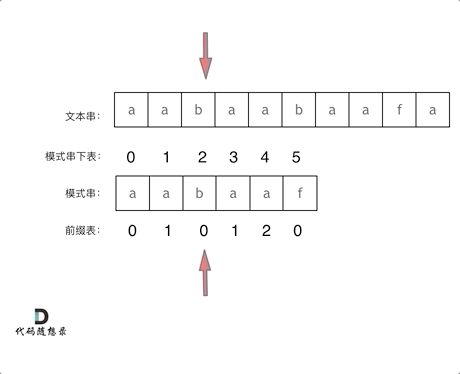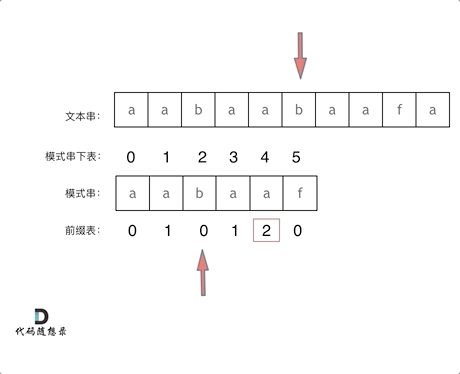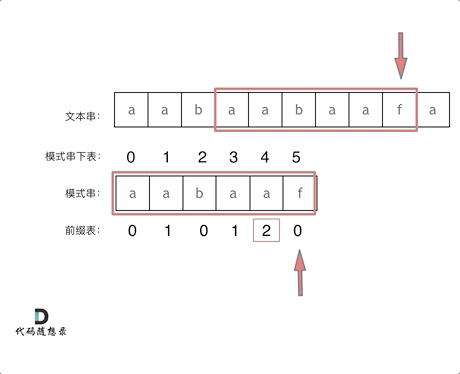
|
||||
|
||||
找到的不匹配的位置, 那么此时我们要看它的前一个字符的前缀表的数值是多少。
|
||||
|
||||
为什么要前一个字符的前缀表的数值呢,因为要找前面字符串的最长相同的前缀和后缀。
|
||||
|
||||
所以要看前一位的 前缀表的数值。
|
||||
|
||||
前一个字符的前缀表的数值是2, 所有把下标移动到下标2的位置继续比配。 可以再反复看一下上面的动画。
|
||||
|
||||
最后就在文本串中找到了和模式串匹配的子串了。
|
||||
|
||||
# 前缀表与next数组
|
||||
|
||||
很多KMP算法的时间都是使用next数组来做回退操作,那么next数组与前缀表有什么关系呢?
|
||||
|
||||
next数组就可以是前缀表,但是很多实现都是把前缀表统一减一(右移一位,初始位置为-1)之后作为next数组。
|
||||
|
||||
为什么这么做呢,其实也是很多文章视频没有解释清楚的地方。
|
||||
|
||||
其实**这并不涉及到KMP的原理,而是具体实现,next数组即可以就是前缀表,也可以是前缀表统一减一(右移一位,初始位置为-1)。**
|
||||
|
||||
后面我会提供两种不同的实现代码,大家就明白了了。
|
||||
|
||||
# 使用next数组来匹配
|
||||
|
||||
**以下我们以前缀表统一减一之后的next数组来做演示**。
|
||||
|
||||
有了next数组,就可以根据next数组来 匹配文本串s,和模式串t了。
|
||||
|
||||
注意next数组是新前缀表(旧前缀表统一减一了)。
|
||||
|
||||
匹配过程动画如下:
|
||||
|
||||
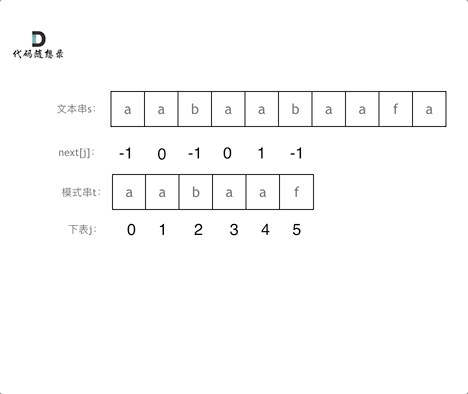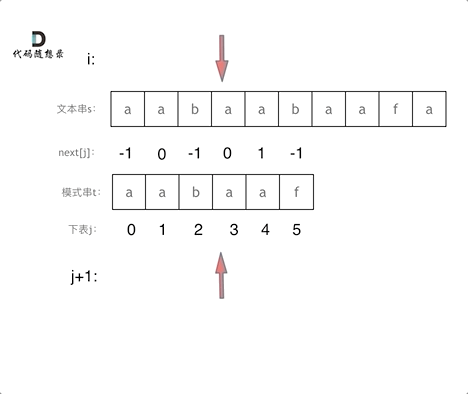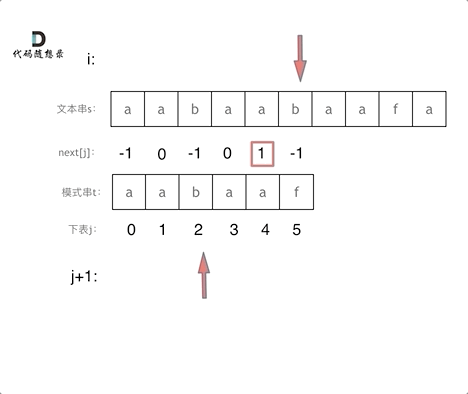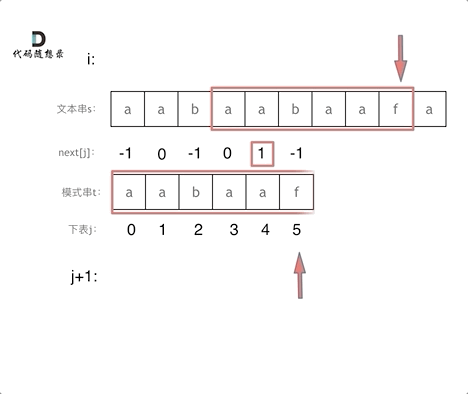
|
||||
|
||||
# 时间复杂度分析
|
||||
|
||||
其中n为文本串长度,m为模式串长度,因为在匹配的过程中,根据前缀表不断调整匹配的位置,可以看出匹配的过程是O(n),之前还要单独生成next数组,时间复杂度是O(m)。所以整个KMP算法的时间复杂度是O(n+m)的。
|
||||
|
||||
暴力的解法显而易见是O(n * m),所以**KMP在字符串匹配中极大的提高的搜索的效率。**
|
||||
|
||||
为了和力扣题目28.实现strStr保持一致,方便大家理解,以下文章统称haystack为文本串, needle为模式串。
|
||||
|
||||
都知道使用KMP算法,一定要构造next数组。
|
||||
|
||||
# 构造next数组
|
||||
|
||||
我们定义一个函数getNext来构建next数组,函数参数为指向next数组的指针,和一个字符串。 代码如下:
|
||||
|
||||
```
|
||||
void getNext(int* next, const string& s)
|
||||
```
|
||||
|
||||
**构造next数组其实就是计算模式串s,前缀表的过程。** 主要有如下三步:
|
||||
|
||||
1. 初始化
|
||||
2. 处理前后缀不相同的情况
|
||||
3. 处理前后缀相同的情况
|
||||
|
||||
接下来我们详解详解一下。
|
||||
|
||||
1. 初始化:
|
||||
|
||||
定义两个指针i和j,j指向前缀起始位置,i指向后缀起始位置。
|
||||
|
||||
然后还要对next数组进行初始化赋值,如下:
|
||||
|
||||
```
|
||||
int j = -1;
|
||||
next[0] = j;
|
||||
```
|
||||
|
||||
j 为什么要初始化为 -1呢,因为之前说过 前缀表要统一减一的操作仅仅是其中的一种实现,我们这里选择j初始化为-1,下文我还会给出j不初始化为-1的实现代码。
|
||||
|
||||
next[i] 表示 i(包括i)之前最长相等的前后缀长度(其实就是j)
|
||||
|
||||
所以初始化next[0] = j 。
|
||||
|
||||
|
||||
2. 处理前后缀不相同的情况
|
||||
|
||||
|
||||
因为j初始化为-1,那么i就从1开始,进行s[i] 与 s[j+1]的比较。
|
||||
|
||||
所以遍历模式串s的循环下标i 要从 1开始,代码如下:
|
||||
|
||||
```
|
||||
for(int i = 1; i < s.size(); i++) {
|
||||
```
|
||||
|
||||
如果 s[i] 与 s[j+1]不相同,也就是遇到 前后缀末尾不相同的情况,就要向前回退。
|
||||
|
||||
怎么回退呢?
|
||||
|
||||
next[j]就是记录着j(包括j)之前的子串的相同前后缀的长度。
|
||||
|
||||
那么 s[i] 与 s[j+1] 不相同,就要找 j+1前一个元素在next数组里的值(就是next[j])。
|
||||
|
||||
所以,处理前后缀不相同的情况代码如下:
|
||||
|
||||
```
|
||||
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
|
||||
j = next[j]; // 向前回退
|
||||
}
|
||||
```
|
||||
|
||||
3. 处理前后缀相同的情况
|
||||
|
||||
如果s[i] 与 s[j + 1] 相同,那么就同时向后移动i 和j 说明找到了相同的前后缀,同时还要将j(前缀的长度)赋给next[i], 因为next[i]要记录相同前后缀的长度。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
if (s[i] == s[j + 1]) { // 找到相同的前后缀
|
||||
j++;
|
||||
}
|
||||
next[i] = j;
|
||||
```
|
||||
|
||||
最后整体构建next数组的函数代码如下:
|
||||
|
||||
```C++
|
||||
void getNext(int* next, const string& s){
|
||||
int j = -1;
|
||||
next[0] = j;
|
||||
for(int i = 1; i < s.size(); i++) { // 注意i从1开始
|
||||
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
|
||||
j = next[j]; // 向前回退
|
||||
}
|
||||
if (s[i] == s[j + 1]) { // 找到相同的前后缀
|
||||
j++;
|
||||
}
|
||||
next[i] = j; // 将j(前缀的长度)赋给next[i]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
代码构造next数组的逻辑流程动画如下:
|
||||
|
||||
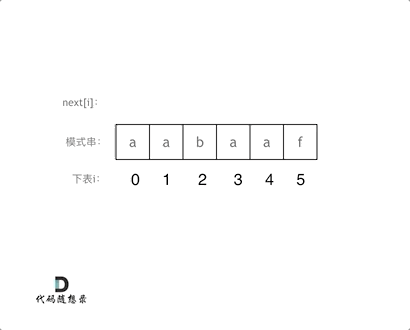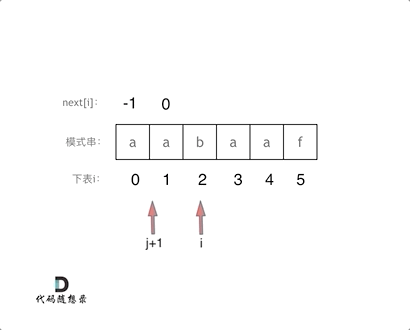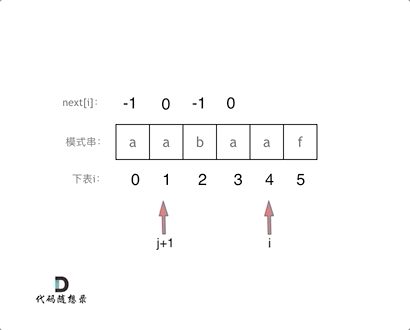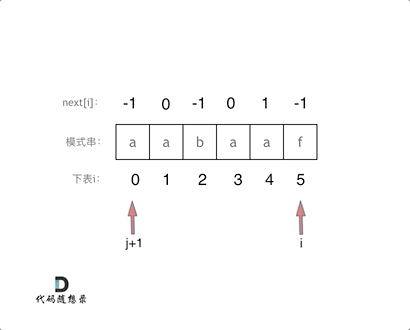
|
||||
|
||||
得到了next数组之后,就要用这个来做匹配了。
|
||||
|
||||
# 使用next数组来做匹配
|
||||
|
||||
在文本串s里 找是否出现过模式串t。
|
||||
|
||||
定义两个下标j 指向模式串起始位置,i指向文本串起始位置。
|
||||
|
||||
那么j初始值依然为-1,为什么呢? **依然因为next数组里记录的起始位置为-1。**
|
||||
|
||||
i就从0开始,遍历文本串,代码如下:
|
||||
|
||||
```
|
||||
for (int i = 0; i < s.size(); i++)
|
||||
```
|
||||
|
||||
接下来就是 s[i] 与 t[j + 1] (因为j从-1开始的) 进行比较。
|
||||
|
||||
如果 s[i] 与 t[j + 1] 不相同,j就要从next数组里寻找下一个匹配的位置。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
while(j >= 0 && s[i] != t[j + 1]) {
|
||||
j = next[j];
|
||||
}
|
||||
```
|
||||
|
||||
如果 s[i] 与 t[j + 1] 相同,那么i 和 j 同时向后移动, 代码如下:
|
||||
|
||||
```
|
||||
if (s[i] == t[j + 1]) {
|
||||
j++; // i的增加在for循环里
|
||||
}
|
||||
```
|
||||
|
||||
如何判断在文本串s里出现了模式串t呢,如果j指向了模式串t的末尾,那么就说明模式串t完全匹配文本串s里的某个子串了。
|
||||
|
||||
本题要在文本串字符串中找出模式串出现的第一个位置 (从0开始),所以返回当前在文本串匹配模式串的位置i 减去 模式串的长度,就是文本串字符串中出现模式串的第一个位置。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
if (j == (t.size() - 1) ) {
|
||||
return (i - t.size() + 1);
|
||||
}
|
||||
```
|
||||
|
||||
那么使用next数组,用模式串匹配文本串的整体代码如下:
|
||||
|
||||
```C++
|
||||
int j = -1; // 因为next数组里记录的起始位置为-1
|
||||
for (int i = 0; i < s.size(); i++) { // 注意i就从0开始
|
||||
while(j >= 0 && s[i] != t[j + 1]) { // 不匹配
|
||||
j = next[j]; // j 寻找之前匹配的位置
|
||||
}
|
||||
if (s[i] == t[j + 1]) { // 匹配,j和i同时向后移动
|
||||
j++; // i的增加在for循环里
|
||||
}
|
||||
if (j == (t.size() - 1) ) { // 文本串s里出现了模式串t
|
||||
return (i - t.size() + 1);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
此时所有逻辑的代码都已经写出来了,力扣 28.实现strStr 题目的整体代码如下:
|
||||
|
||||
# 前缀表统一减一 C++代码实现
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
void getNext(int* next, const string& s) {
|
||||
int j = -1;
|
||||
next[0] = j;
|
||||
for(int i = 1; i < s.size(); i++) { // 注意i从1开始
|
||||
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
|
||||
j = next[j]; // 向前回退
|
||||
}
|
||||
if (s[i] == s[j + 1]) { // 找到相同的前后缀
|
||||
j++;
|
||||
}
|
||||
next[i] = j; // 将j(前缀的长度)赋给next[i]
|
||||
}
|
||||
}
|
||||
int strStr(string haystack, string needle) {
|
||||
if (needle.size() == 0) {
|
||||
return 0;
|
||||
}
|
||||
int next[needle.size()];
|
||||
getNext(next, needle);
|
||||
int j = -1; // // 因为next数组里记录的起始位置为-1
|
||||
for (int i = 0; i < haystack.size(); i++) { // 注意i就从0开始
|
||||
while(j >= 0 && haystack[i] != needle[j + 1]) { // 不匹配
|
||||
j = next[j]; // j 寻找之前匹配的位置
|
||||
}
|
||||
if (haystack[i] == needle[j + 1]) { // 匹配,j和i同时向后移动
|
||||
j++; // i的增加在for循环里
|
||||
}
|
||||
if (j == (needle.size() - 1) ) { // 文本串s里出现了模式串t
|
||||
return (i - needle.size() + 1);
|
||||
}
|
||||
}
|
||||
return -1;
|
||||
}
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
# 前缀表(不减一)C++实现
|
||||
|
||||
那么前缀表就不减一了,也不右移的,到底行不行呢?
|
||||
|
||||
**行!**
|
||||
|
||||
我之前说过,这仅仅是KMP算法实现上的问题,如果就直接使用前缀表可以换一种回退方式,找j=next[j-1] 来进行回退。
|
||||
|
||||
主要就是j=next[x]这一步最为关键!
|
||||
|
||||
我给出的getNext的实现为:(前缀表统一减一)
|
||||
|
||||
```C++
|
||||
void getNext(int* next, const string& s) {
|
||||
int j = -1;
|
||||
next[0] = j;
|
||||
for(int i = 1; i < s.size(); i++) { // 注意i从1开始
|
||||
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
|
||||
j = next[j]; // 向前回退
|
||||
}
|
||||
if (s[i] == s[j + 1]) { // 找到相同的前后缀
|
||||
j++;
|
||||
}
|
||||
next[i] = j; // 将j(前缀的长度)赋给next[i]
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
此时如果输入的模式串为aabaaf,对应的next为-1 0 -1 0 1 -1。
|
||||
|
||||
这里j和next[0]初始化为-1,整个next数组是以 前缀表减一之后的效果来构建的。
|
||||
|
||||
那么前缀表不减一来构建next数组,代码如下:
|
||||
|
||||
```C++
|
||||
void getNext(int* next, const string& s) {
|
||||
int j = 0;
|
||||
next[0] = 0;
|
||||
for(int i = 1; i < s.size(); i++) {
|
||||
while (j > 0 && s[i] != s[j]) { // j要保证大于0,因为下面有取j-1作为数组下标的操作
|
||||
j = next[j - 1]; // 注意这里,是要找前一位的对应的回退位置了
|
||||
}
|
||||
if (s[i] == s[j]) {
|
||||
j++;
|
||||
}
|
||||
next[i] = j;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
此时如果输入的模式串为aabaaf,对应的next为 0 1 0 1 2 0,(其实这就是前缀表的数值了)。
|
||||
|
||||
那么用这样的next数组也可以用来做匹配,代码要有所改动。
|
||||
|
||||
实现代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
void getNext(int* next, const string& s) {
|
||||
int j = 0;
|
||||
next[0] = 0;
|
||||
for(int i = 1; i < s.size(); i++) {
|
||||
while (j > 0 && s[i] != s[j]) {
|
||||
j = next[j - 1];
|
||||
}
|
||||
if (s[i] == s[j]) {
|
||||
j++;
|
||||
}
|
||||
next[i] = j;
|
||||
}
|
||||
}
|
||||
int strStr(string haystack, string needle) {
|
||||
if (needle.size() == 0) {
|
||||
return 0;
|
||||
}
|
||||
int next[needle.size()];
|
||||
getNext(next, needle);
|
||||
int j = 0;
|
||||
for (int i = 0; i < haystack.size(); i++) {
|
||||
while(j > 0 && haystack[i] != needle[j]) {
|
||||
j = next[j - 1];
|
||||
}
|
||||
if (haystack[i] == needle[j]) {
|
||||
j++;
|
||||
}
|
||||
if (j == needle.size() ) {
|
||||
return (i - needle.size() + 1);
|
||||
}
|
||||
}
|
||||
return -1;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
# 总结
|
||||
|
||||
我们介绍了什么是KMP,KMP可以解决什么问题,然后分析KMP算法里的next数组,知道了next数组就是前缀表,再分析为什么要是前缀表而不是什么其他表。
|
||||
|
||||
接着从给出的模式串中,我们一步一步的推导出了前缀表,得出前缀表无论是统一减一还是不减一得到的next数组仅仅是kmp的实现方式的不同。
|
||||
|
||||
其中还分析了KMP算法的时间复杂度,并且和暴力方法做了对比。
|
||||
|
||||
然后先用前缀表统一减一得到的next数组,求得文本串s里是否出现过模式串t,并给出了具体分析代码。
|
||||
|
||||
又给出了直接用前缀表作为next数组,来做匹配的实现代码。
|
||||
|
||||
可以说把KMP的每一个细微的细节都扣了出来,毫无遮掩的展示给大家了!
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
|
||||
```Java
|
||||
class Solution {
|
||||
/**
|
||||
* 基于窗口滑动的算法
|
||||
* <p>
|
||||
* 时间复杂度:O(m*n)
|
||||
* 空间复杂度:O(1)
|
||||
* 注:n为haystack的长度,m为needle的长度
|
||||
*/
|
||||
public int strStr(String haystack, String needle) {
|
||||
int m = needle.length();
|
||||
// 当 needle 是空字符串时我们应当返回 0
|
||||
if (m == 0) {
|
||||
return 0;
|
||||
}
|
||||
int n = haystack.length();
|
||||
if (n < m) {
|
||||
return -1;
|
||||
}
|
||||
int i = 0;
|
||||
int j = 0;
|
||||
while (i < n - m + 1) {
|
||||
// 找到首字母相等
|
||||
while (i < n && haystack.charAt(i) != needle.charAt(j)) {
|
||||
i++;
|
||||
}
|
||||
if (i == n) {// 没有首字母相等的
|
||||
return -1;
|
||||
}
|
||||
// 遍历后续字符,判断是否相等
|
||||
i++;
|
||||
j++;
|
||||
while (i < n && j < m && haystack.charAt(i) == needle.charAt(j)) {
|
||||
i++;
|
||||
j++;
|
||||
}
|
||||
if (j == m) {// 找到
|
||||
return i - j;
|
||||
} else {// 未找到
|
||||
i -= j - 1;
|
||||
j = 0;
|
||||
}
|
||||
}
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
// 方法一
|
||||
class Solution {
|
||||
public void getNext(int[] next, String s){
|
||||
int j = -1;
|
||||
next[0] = j;
|
||||
for (int i = 1; i<s.length(); i++){
|
||||
while(j>=0 && s.charAt(i) != s.charAt(j+1)){
|
||||
j=next[j];
|
||||
}
|
||||
|
||||
if(s.charAt(i)==s.charAt(j+1)){
|
||||
j++;
|
||||
}
|
||||
next[i] = j;
|
||||
}
|
||||
}
|
||||
public int strStr(String haystack, String needle) {
|
||||
if(needle.length()==0){
|
||||
return 0;
|
||||
}
|
||||
|
||||
int[] next = new int[needle.length()];
|
||||
getNext(next, needle);
|
||||
int j = -1;
|
||||
for(int i = 0; i<haystack.length();i++){
|
||||
while(j>=0 && haystack.charAt(i) != needle.charAt(j+1)){
|
||||
j = next[j];
|
||||
}
|
||||
if(haystack.charAt(i)==needle.charAt(j+1)){
|
||||
j++;
|
||||
}
|
||||
if(j==needle.length()-1){
|
||||
return (i-needle.length()+1);
|
||||
}
|
||||
}
|
||||
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
```python
|
||||
// 方法一
|
||||
class Solution:
|
||||
def strStr(self, haystack: str, needle: str) -> int:
|
||||
a=len(needle)
|
||||
b=len(haystack)
|
||||
if a==0:
|
||||
return 0
|
||||
next=self.getnext(a,needle)
|
||||
p=-1
|
||||
for j in range(b):
|
||||
while p>=0 and needle[p+1]!=haystack[j]:
|
||||
p=next[p]
|
||||
if needle[p+1]==haystack[j]:
|
||||
p+=1
|
||||
if p==a-1:
|
||||
return j-a+1
|
||||
return -1
|
||||
|
||||
def getnext(self,a,needle):
|
||||
next=['' for i in range(a)]
|
||||
k=-1
|
||||
next[0]=k
|
||||
for i in range(1,len(needle)):
|
||||
while (k>-1 and needle[k+1]!=needle[i]):
|
||||
k=next[k]
|
||||
if needle[k+1]==needle[i]:
|
||||
k+=1
|
||||
next[i]=k
|
||||
return next
|
||||
```
|
||||
|
||||
```python
|
||||
// 方法二
|
||||
class Solution:
|
||||
def strStr(self, haystack: str, needle: str) -> int:
|
||||
a=len(needle)
|
||||
b=len(haystack)
|
||||
if a==0:
|
||||
return 0
|
||||
i=j=0
|
||||
next=self.getnext(a,needle)
|
||||
while(i<b and j<a):
|
||||
if j==-1 or needle[j]==haystack[i]:
|
||||
i+=1
|
||||
j+=1
|
||||
else:
|
||||
j=next[j]
|
||||
if j==a:
|
||||
return i-j
|
||||
else:
|
||||
return -1
|
||||
|
||||
def getnext(self,a,needle):
|
||||
next=['' for i in range(a)]
|
||||
j,k=0,-1
|
||||
next[0]=k
|
||||
while(j<a-1):
|
||||
if k==-1 or needle[k]==needle[j]:
|
||||
k+=1
|
||||
j+=1
|
||||
next[j]=k
|
||||
else:
|
||||
k=next[k]
|
||||
return next
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
```go
|
||||
// 方法一:前缀表使用减1实现
|
||||
|
||||
// getNext 构造前缀表next
|
||||
// params:
|
||||
// next 前缀表数组
|
||||
// s 模式串
|
||||
func getNext(next []int, s string) {
|
||||
j := -1 // j表示 最长相等前后缀长度
|
||||
next[0] = j
|
||||
|
||||
for i := 1; i < len(s); i++ {
|
||||
for j >= 0 && s[i] != s[j+1] {
|
||||
j = next[j] // 回退前一位
|
||||
}
|
||||
if s[i] == s[j+1] {
|
||||
j++
|
||||
}
|
||||
next[i] = j // next[i]是i(包括i)之前的最长相等前后缀长度
|
||||
}
|
||||
}
|
||||
func strStr(haystack string, needle string) int {
|
||||
if len(needle) == 0 {
|
||||
return 0
|
||||
}
|
||||
next := make([]int, len(needle))
|
||||
getNext(next, needle)
|
||||
j := -1 // 模式串的起始位置 next为-1 因此也为-1
|
||||
for i := 0; i < len(haystack); i++ {
|
||||
for j >= 0 && haystack[i] != needle[j+1] {
|
||||
j = next[j] // 寻找下一个匹配点
|
||||
}
|
||||
if haystack[i] == needle[j+1] {
|
||||
j++
|
||||
}
|
||||
if j == len(needle)-1 { // j指向了模式串的末尾
|
||||
return i - len(needle) + 1
|
||||
}
|
||||
}
|
||||
return -1
|
||||
}
|
||||
```
|
||||
|
||||
```go
|
||||
// 方法二: 前缀表无减一或者右移
|
||||
|
||||
// getNext 构造前缀表next
|
||||
// params:
|
||||
// next 前缀表数组
|
||||
// s 模式串
|
||||
func getNext(next []int, s string) {
|
||||
j := 0
|
||||
next[0] = j
|
||||
for i := 1; i < len(s); i++ {
|
||||
for j > 0 && s[i] != s[j] {
|
||||
j = next[j-1]
|
||||
}
|
||||
if s[i] == s[j] {
|
||||
j++
|
||||
}
|
||||
next[i] = j
|
||||
}
|
||||
}
|
||||
func strStr(haystack string, needle string) int {
|
||||
n := len(needle)
|
||||
if n == 0 {
|
||||
return 0
|
||||
}
|
||||
j := 0
|
||||
next := make([]int, n)
|
||||
getNext(next, needle)
|
||||
for i := 0; i < len(haystack); i++ {
|
||||
for j > 0 && haystack[i] != needle[j] {
|
||||
j = next[j-1] // 回退到j的前一位
|
||||
}
|
||||
if haystack[i] == needle[j] {
|
||||
j++
|
||||
}
|
||||
if j == n {
|
||||
return i - n + 1
|
||||
}
|
||||
}
|
||||
return -1
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
285
problems/0035.搜索插入位置.md
Normal file
285
problems/0035.搜索插入位置.md
Normal file
@@ -0,0 +1,285 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
|
||||
|
||||
# 35.搜索插入位置
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/search-insert-position/
|
||||
|
||||
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
|
||||
|
||||
你可以假设数组中无重复元素。
|
||||
|
||||
示例 1:
|
||||
输入: [1,3,5,6], 5
|
||||
输出: 2
|
||||
|
||||
示例 2:
|
||||
输入: [1,3,5,6], 2
|
||||
输出: 1
|
||||
|
||||
示例 3:
|
||||
输入: [1,3,5,6], 7
|
||||
输出: 4
|
||||
|
||||
示例 4:
|
||||
输入: [1,3,5,6], 0
|
||||
输出: 0
|
||||
|
||||
# 思路
|
||||
|
||||
这道题目不难,但是为什么通过率相对来说并不高呢,我理解是大家对边界处理的判断有所失误导致的。
|
||||
|
||||
这道题目,要在数组中插入目标值,无非是这四种情况。
|
||||
|
||||
|
||||
|
||||
* 目标值在数组所有元素之前
|
||||
* 目标值等于数组中某一个元素
|
||||
* 目标值插入数组中的位置
|
||||
* 目标值在数组所有元素之后
|
||||
|
||||
这四种情况确认清楚了,就可以尝试解题了。
|
||||
|
||||
接下来我将从暴力的解法和二分法来讲解此题,也借此好好讲一讲二分查找法。
|
||||
|
||||
## 暴力解法
|
||||
|
||||
暴力解题 不一定时间消耗就非常高,关键看实现的方式,就像是二分查找时间消耗不一定就很低,是一样的。
|
||||
|
||||
## 暴力解法C++代码
|
||||
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
int searchInsert(vector<int>& nums, int target) {
|
||||
for (int i = 0; i < nums.size(); i++) {
|
||||
// 分别处理如下三种情况
|
||||
// 目标值在数组所有元素之前
|
||||
// 目标值等于数组中某一个元素
|
||||
// 目标值插入数组中的位置
|
||||
if (nums[i] >= target) { // 一旦发现大于或者等于target的num[i],那么i就是我们要的结果
|
||||
return i;
|
||||
}
|
||||
}
|
||||
// 目标值在数组所有元素之后的情况
|
||||
return nums.size(); // 如果target是最大的,或者 nums为空,则返回nums的长度
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
时间复杂度:O(n)
|
||||
时间复杂度:O(1)
|
||||
|
||||
效率如下:
|
||||
|
||||

|
||||
|
||||
## 二分法
|
||||
|
||||
既然暴力解法的时间复杂度是O(n),就要尝试一下使用二分查找法。
|
||||
|
||||

|
||||
|
||||
大家注意这道题目的前提是数组是有序数组,这也是使用二分查找的基础条件。
|
||||
|
||||
以后大家**只要看到面试题里给出的数组是有序数组,都可以想一想是否可以使用二分法。**
|
||||
|
||||
同时题目还强调数组中无重复元素,因为一旦有重复元素,使用二分查找法返回的元素下表可能不是唯一的。
|
||||
|
||||
大体讲解一下二分法的思路,这里来举一个例子,例如在这个数组中,使用二分法寻找元素为5的位置,并返回其下标。
|
||||
|
||||
|
||||
|
||||
二分查找涉及的很多的边界条件,逻辑比较简单,就是写不好。
|
||||
|
||||
相信很多同学对二分查找法中边界条件处理不好。
|
||||
|
||||
例如到底是 `while(left < right)` 还是 `while(left <= right)`,到底是`right = middle`呢,还是要`right = middle - 1`呢?
|
||||
|
||||
这里弄不清楚主要是因为**对区间的定义没有想清楚,这就是不变量**。
|
||||
|
||||
要在二分查找的过程中,保持不变量,这也就是**循环不变量** (感兴趣的同学可以查一查)。
|
||||
|
||||
## 二分法第一种写法
|
||||
|
||||
以这道题目来举例,以下的代码中定义 target 是在一个在左闭右闭的区间里,**也就是[left, right] (这个很重要)**。
|
||||
|
||||
这就决定了这个二分法的代码如何去写,大家看如下代码:
|
||||
|
||||
**大家要仔细看注释,思考为什么要写while(left <= right), 为什么要写right = middle - 1**。
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int searchInsert(vector<int>& nums, int target) {
|
||||
int n = nums.size();
|
||||
int left = 0;
|
||||
int right = n - 1; // 定义target在左闭右闭的区间里,[left, right]
|
||||
while (left <= right) { // 当left==right,区间[left, right]依然有效
|
||||
int middle = left + ((right - left) / 2);// 防止溢出 等同于(left + right)/2
|
||||
if (nums[middle] > target) {
|
||||
right = middle - 1; // target 在左区间,所以[left, middle - 1]
|
||||
} else if (nums[middle] < target) {
|
||||
left = middle + 1; // target 在右区间,所以[middle + 1, right]
|
||||
} else { // nums[middle] == target
|
||||
return middle;
|
||||
}
|
||||
}
|
||||
// 分别处理如下四种情况
|
||||
// 目标值在数组所有元素之前 [0, -1]
|
||||
// 目标值等于数组中某一个元素 return middle;
|
||||
// 目标值插入数组中的位置 [left, right],return right + 1
|
||||
// 目标值在数组所有元素之后的情况 [left, right], return right + 1
|
||||
return right + 1;
|
||||
}
|
||||
};
|
||||
```
|
||||
时间复杂度:O(logn)
|
||||
时间复杂度:O(1)
|
||||
|
||||
效率如下:
|
||||

|
||||
|
||||
## 二分法第二种写法
|
||||
|
||||
如果说定义 target 是在一个在左闭右开的区间里,也就是[left, right) 。
|
||||
|
||||
那么二分法的边界处理方式则截然不同。
|
||||
|
||||
不变量是[left, right)的区间,如下代码可以看出是如何在循环中坚持不变量的。
|
||||
|
||||
**大家要仔细看注释,思考为什么要写while (left < right), 为什么要写right = middle**。
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int searchInsert(vector<int>& nums, int target) {
|
||||
int n = nums.size();
|
||||
int left = 0;
|
||||
int right = n; // 定义target在左闭右开的区间里,[left, right) target
|
||||
while (left < right) { // 因为left == right的时候,在[left, right)是无效的空间
|
||||
int middle = left + ((right - left) >> 1);
|
||||
if (nums[middle] > target) {
|
||||
right = middle; // target 在左区间,在[left, middle)中
|
||||
} else if (nums[middle] < target) {
|
||||
left = middle + 1; // target 在右区间,在 [middle+1, right)中
|
||||
} else { // nums[middle] == target
|
||||
return middle; // 数组中找到目标值的情况,直接返回下标
|
||||
}
|
||||
}
|
||||
// 分别处理如下四种情况
|
||||
// 目标值在数组所有元素之前 [0,0)
|
||||
// 目标值等于数组中某一个元素 return middle
|
||||
// 目标值插入数组中的位置 [left, right) ,return right 即可
|
||||
// 目标值在数组所有元素之后的情况 [left, right),return right 即可
|
||||
return right;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
时间复杂度:O(logn)
|
||||
时间复杂度:O(1)
|
||||
|
||||
# 总结
|
||||
|
||||
希望通过这道题目,大家会发现平时写二分法,为什么总写不好,就是因为对区间定义不清楚。
|
||||
|
||||
确定要查找的区间到底是左闭右开[left, right),还是左闭又闭[left, right],这就是不变量。
|
||||
|
||||
然后在**二分查找的循环中,坚持循环不变量的原则**,很多细节问题,自然会知道如何处理了。
|
||||
|
||||
**循序渐进学算法,认准「代码随想录」,Carl手把手带你过关斩将!**
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
Java:
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
public int searchInsert(int[] nums, int target) {
|
||||
int n = nums.length;
|
||||
|
||||
// 定义target在左闭右闭的区间,[low, high]
|
||||
int low = 0;
|
||||
int high = n - 1;
|
||||
|
||||
while (low <= high) { // 当low==high,区间[low, high]依然有效
|
||||
int mid = low + (high - low) / 2; // 防止溢出
|
||||
if (nums[mid] > target) {
|
||||
high = mid - 1; // target 在左区间,所以[low, mid - 1]
|
||||
} else if (nums[mid] < target) {
|
||||
low = mid + 1; // target 在右区间,所以[mid + 1, high]
|
||||
} else {
|
||||
// 1. 目标值等于数组中某一个元素 return mid;
|
||||
return mid;
|
||||
}
|
||||
}
|
||||
// 2.目标值在数组所有元素之前 3.目标值插入数组中 4.目标值在数组所有元素之后 return right + 1;
|
||||
return high + 1;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
Python:
|
||||
```python3
|
||||
class Solution:
|
||||
def searchInsert(self, nums: List[int], target: int) -> int:
|
||||
left, right = 0, len(nums) - 1
|
||||
|
||||
while left <= right:
|
||||
middle = (left + right) // 2
|
||||
|
||||
if nums[middle] < target:
|
||||
left = middle + 1
|
||||
elif nums[middle] > target:
|
||||
right = middle - 1
|
||||
else:
|
||||
return middle
|
||||
return right + 1
|
||||
```
|
||||
|
||||
|
||||
Go:
|
||||
|
||||
JavaScript:
|
||||
```js
|
||||
var searchInsert = function (nums, target) {
|
||||
let l = 0, r = nums.length - 1, ans = nums.length;
|
||||
|
||||
while (l <= r) {
|
||||
const mid = l + Math.floor((r - l) >> 1);
|
||||
|
||||
if (target > nums[mid]) {
|
||||
l = mid + 1;
|
||||
} else {
|
||||
ans = mid;
|
||||
r = mid - 1;
|
||||
}
|
||||
}
|
||||
|
||||
return ans;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
440
problems/0037.解数独.md
Normal file
440
problems/0037.解数独.md
Normal file
@@ -0,0 +1,440 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
如果对回溯法理论还不清楚的同学,可以先看这个视频[视频来了!!带你学透回溯算法(理论篇)](https://mp.weixin.qq.com/s/wDd5azGIYWjbU0fdua_qBg)
|
||||
|
||||
## 37. 解数独
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/sudoku-solver/
|
||||
|
||||
编写一个程序,通过填充空格来解决数独问题。
|
||||
|
||||
一个数独的解法需遵循如下规则:
|
||||
数字 1-9 在每一行只能出现一次。
|
||||
数字 1-9 在每一列只能出现一次。
|
||||
数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。
|
||||
空白格用 '.' 表示。
|
||||
|
||||
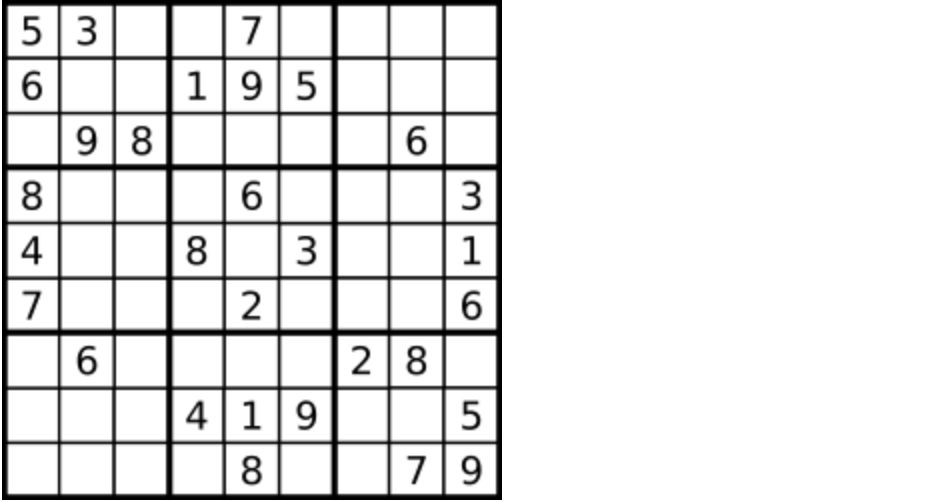
|
||||
|
||||
一个数独。
|
||||
|
||||
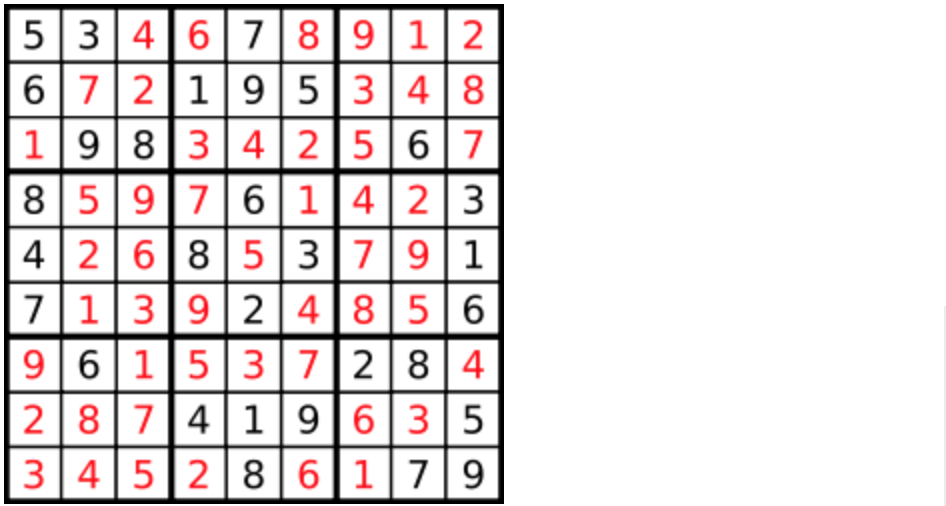
|
||||
|
||||
答案被标成红色。
|
||||
|
||||
提示:
|
||||
* 给定的数独序列只包含数字 1-9 和字符 '.' 。
|
||||
* 你可以假设给定的数独只有唯一解。
|
||||
* 给定数独永远是 9x9 形式的。
|
||||
|
||||
## 思路
|
||||
|
||||
棋盘搜索问题可以使用回溯法暴力搜索,只不过这次我们要做的是**二维递归**。
|
||||
|
||||
怎么做二维递归呢?
|
||||
|
||||
大家已经跟着「代码随想录」刷过了如下回溯法题目,例如:[77.组合(组合问题)](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ),[131.分割回文串(分割问题)](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q),[78.子集(子集问题)](https://mp.weixin.qq.com/s/NNRzX-vJ_pjK4qxohd_LtA),[46.全排列(排列问题)](https://mp.weixin.qq.com/s/SCOjeMX1t41wcvJq49GhMw),以及[51.N皇后(N皇后问题)](https://mp.weixin.qq.com/s/lU_QwCMj6g60nh8m98GAWg),其实这些题目都是一维递归。
|
||||
|
||||
**如果以上这几道题目没有做过的话,不建议上来就做这道题哈!**
|
||||
|
||||
[N皇后问题](https://mp.weixin.qq.com/s/lU_QwCMj6g60nh8m98GAWg)是因为每一行每一列只放一个皇后,只需要一层for循环遍历一行,递归来来遍历列,然后一行一列确定皇后的唯一位置。
|
||||
|
||||
本题就不一样了,**本题中棋盘的每一个位置都要放一个数字,并检查数字是否合法,解数独的树形结构要比N皇后更宽更深**。
|
||||
|
||||
因为这个树形结构太大了,我抽取一部分,如图所示:
|
||||
|
||||
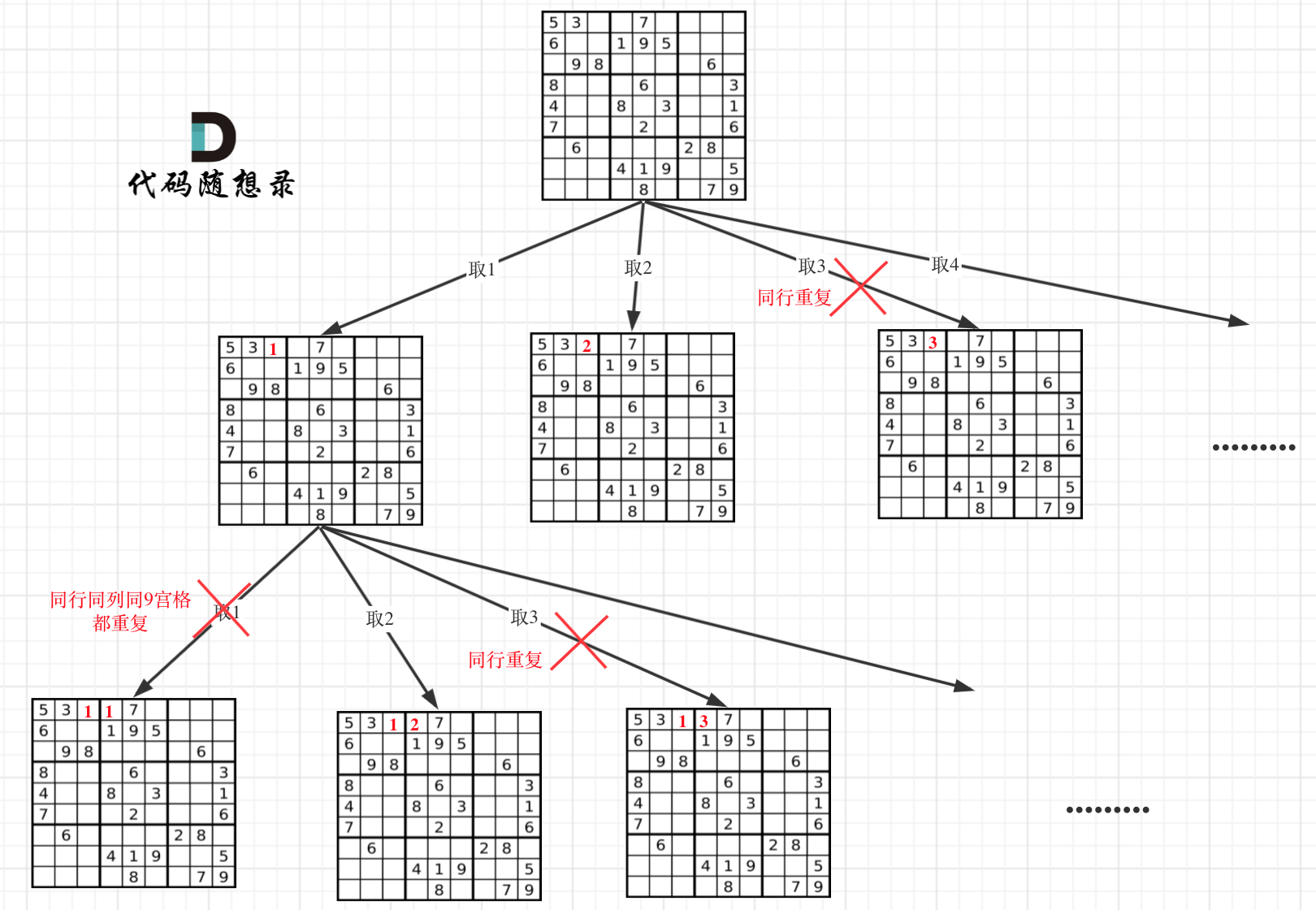
|
||||
|
||||
|
||||
## 回溯三部曲
|
||||
|
||||
* 递归函数以及参数
|
||||
|
||||
**递归函数的返回值需要是bool类型,为什么呢?**
|
||||
|
||||
因为解数独找到一个符合的条件(就在树的叶子节点上)立刻就返回,相当于找从根节点到叶子节点一条唯一路径,所以需要使用bool返回值,这一点在[回溯算法:N皇后问题](https://mp.weixin.qq.com/s/lU_QwCMj6g60nh8m98GAWg)中已经介绍过了,一样的道理。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
bool backtracking(vector<vector<char>>& board)
|
||||
```
|
||||
|
||||
* 递归终止条件
|
||||
|
||||
本题递归不用终止条件,解数独是要遍历整个树形结构寻找可能的叶子节点就立刻返回。
|
||||
|
||||
**不用终止条件会不会死循环?**
|
||||
|
||||
递归的下一层的棋盘一定比上一层的棋盘多一个数,等数填满了棋盘自然就终止(填满当然好了,说明找到结果了),所以不需要终止条件!
|
||||
|
||||
**那么有没有永远填不满的情况呢?**
|
||||
|
||||
这个问题我在递归单层搜索逻辑里在来讲!
|
||||
|
||||
* 递归单层搜索逻辑
|
||||
|
||||

|
||||
|
||||
在树形图中可以看出我们需要的是一个二维的递归(也就是两个for循环嵌套着递归)
|
||||
|
||||
**一个for循环遍历棋盘的行,一个for循环遍历棋盘的列,一行一列确定下来之后,递归遍历这个位置放9个数字的可能性!**
|
||||
|
||||
|
||||
代码如下:(**详细看注释**)
|
||||
|
||||
```C++
|
||||
bool backtracking(vector<vector<char>>& board) {
|
||||
for (int i = 0; i < board.size(); i++) { // 遍历行
|
||||
for (int j = 0; j < board[0].size(); j++) { // 遍历列
|
||||
if (board[i][j] != '.') continue;
|
||||
for (char k = '1'; k <= '9'; k++) { // (i, j) 这个位置放k是否合适
|
||||
if (isValid(i, j, k, board)) {
|
||||
board[i][j] = k; // 放置k
|
||||
if (backtracking(board)) return true; // 如果找到合适一组立刻返回
|
||||
board[i][j] = '.'; // 回溯,撤销k
|
||||
}
|
||||
}
|
||||
return false; // 9个数都试完了,都不行,那么就返回false
|
||||
}
|
||||
}
|
||||
return true; // 遍历完没有返回false,说明找到了合适棋盘位置了
|
||||
}
|
||||
```
|
||||
|
||||
**注意这里return false的地方,这里放return false 是有讲究的**。
|
||||
|
||||
因为如果一行一列确定下来了,这里尝试了9个数都不行,说明这个棋盘找不到解决数独问题的解!
|
||||
|
||||
那么会直接返回, **这也就是为什么没有终止条件也不会永远填不满棋盘而无限递归下去!**
|
||||
|
||||
## 判断棋盘是否合法
|
||||
|
||||
判断棋盘是否合法有如下三个维度:
|
||||
|
||||
* 同行是否重复
|
||||
* 同列是否重复
|
||||
* 9宫格里是否重复
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
bool isValid(int row, int col, char val, vector<vector<char>>& board) {
|
||||
for (int i = 0; i < 9; i++) { // 判断行里是否重复
|
||||
if (board[row][i] == val) {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
for (int j = 0; j < 9; j++) { // 判断列里是否重复
|
||||
if (board[j][col] == val) {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
int startRow = (row / 3) * 3;
|
||||
int startCol = (col / 3) * 3;
|
||||
for (int i = startRow; i < startRow + 3; i++) { // 判断9方格里是否重复
|
||||
for (int j = startCol; j < startCol + 3; j++) {
|
||||
if (board[i][j] == val ) {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
```
|
||||
|
||||
最后整体代码如下:
|
||||
|
||||
## C++代码
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
bool backtracking(vector<vector<char>>& board) {
|
||||
for (int i = 0; i < board.size(); i++) { // 遍历行
|
||||
for (int j = 0; j < board[0].size(); j++) { // 遍历列
|
||||
if (board[i][j] != '.') continue;
|
||||
for (char k = '1'; k <= '9'; k++) { // (i, j) 这个位置放k是否合适
|
||||
if (isValid(i, j, k, board)) {
|
||||
board[i][j] = k; // 放置k
|
||||
if (backtracking(board)) return true; // 如果找到合适一组立刻返回
|
||||
board[i][j] = '.'; // 回溯,撤销k
|
||||
}
|
||||
}
|
||||
return false; // 9个数都试完了,都不行,那么就返回false
|
||||
}
|
||||
}
|
||||
return true; // 遍历完没有返回false,说明找到了合适棋盘位置了
|
||||
}
|
||||
bool isValid(int row, int col, char val, vector<vector<char>>& board) {
|
||||
for (int i = 0; i < 9; i++) { // 判断行里是否重复
|
||||
if (board[row][i] == val) {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
for (int j = 0; j < 9; j++) { // 判断列里是否重复
|
||||
if (board[j][col] == val) {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
int startRow = (row / 3) * 3;
|
||||
int startCol = (col / 3) * 3;
|
||||
for (int i = startRow; i < startRow + 3; i++) { // 判断9方格里是否重复
|
||||
for (int j = startCol; j < startCol + 3; j++) {
|
||||
if (board[i][j] == val ) {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
public:
|
||||
void solveSudoku(vector<vector<char>>& board) {
|
||||
backtracking(board);
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
解数独可以说是非常难的题目了,如果还一直停留在单层递归的逻辑中,这道题目可以让大家瞬间崩溃。
|
||||
|
||||
所以我在开篇就提到了**二维递归**,这也是我自创词汇,希望可以帮助大家理解解数独的搜索过程。
|
||||
|
||||
一波分析之后,在看代码会发现其实也不难,唯一难点就是理解**二维递归**的思维逻辑。
|
||||
|
||||
**这样,解数独这么难的问题,也被我们攻克了**。
|
||||
|
||||
**恭喜一路上坚持打卡的录友们,回溯算法已经接近尾声了,接下来就是要一波总结了**。
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
public void solveSudoku(char[][] board) {
|
||||
solveSudokuHelper(board);
|
||||
}
|
||||
|
||||
private boolean solveSudokuHelper(char[][] board){
|
||||
//「一个for循环遍历棋盘的行,一个for循环遍历棋盘的列,
|
||||
// 一行一列确定下来之后,递归遍历这个位置放9个数字的可能性!」
|
||||
for (int i = 0; i < 9; i++){ // 遍历行
|
||||
for (int j = 0; j < 9; j++){ // 遍历列
|
||||
if (board[i][j] != '.'){ // 跳过原始数字
|
||||
continue;
|
||||
}
|
||||
for (char k = '1'; k <= '9'; k++){ // (i, j) 这个位置放k是否合适
|
||||
if (isValidSudoku(i, j, k, board)){
|
||||
board[i][j] = k;
|
||||
if (solveSudokuHelper(board)){ // 如果找到合适一组立刻返回
|
||||
return true;
|
||||
}
|
||||
board[i][j] = '.';
|
||||
}
|
||||
}
|
||||
// 9个数都试完了,都不行,那么就返回false
|
||||
return false;
|
||||
// 因为如果一行一列确定下来了,这里尝试了9个数都不行,说明这个棋盘找不到解决数独问题的解!
|
||||
// 那么会直接返回, 「这也就是为什么没有终止条件也不会永远填不满棋盘而无限递归下去!」
|
||||
}
|
||||
}
|
||||
// 遍历完没有返回false,说明找到了合适棋盘位置了
|
||||
return true;
|
||||
}
|
||||
|
||||
/**
|
||||
* 判断棋盘是否合法有如下三个维度:
|
||||
* 同行是否重复
|
||||
* 同列是否重复
|
||||
* 9宫格里是否重复
|
||||
*/
|
||||
private boolean isValidSudoku(int row, int col, char val, char[][] board){
|
||||
// 同行是否重复
|
||||
for (int i = 0; i < 9; i++){
|
||||
if (board[row][i] == val){
|
||||
return false;
|
||||
}
|
||||
}
|
||||
// 同列是否重复
|
||||
for (int j = 0; j < 9; j++){
|
||||
if (board[j][col] == val){
|
||||
return false;
|
||||
}
|
||||
}
|
||||
// 9宫格里是否重复
|
||||
int startRow = (row / 3) * 3;
|
||||
int startCol = (col / 3) * 3;
|
||||
for (int i = startRow; i < startRow + 3; i++){
|
||||
for (int j = startCol; j < startCol + 3; j++){
|
||||
if (board[i][j] == val){
|
||||
return false;
|
||||
}
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python3
|
||||
class Solution:
|
||||
def solveSudoku(self, board: List[List[str]]) -> None:
|
||||
"""
|
||||
Do not return anything, modify board in-place instead.
|
||||
"""
|
||||
def backtrack(board):
|
||||
for i in range(len(board)): #遍历行
|
||||
for j in range(len(board[0])): #遍历列
|
||||
if board[i][j] != ".": continue
|
||||
for k in range(1,10): #(i, j) 这个位置放k是否合适
|
||||
if isValid(i,j,k,board):
|
||||
board[i][j] = str(k) #放置k
|
||||
if backtrack(board): return True #如果找到合适一组立刻返回
|
||||
board[i][j] = "." #回溯,撤销k
|
||||
return False #9个数都试完了,都不行,那么就返回false
|
||||
return True #遍历完没有返回false,说明找到了合适棋盘位置了
|
||||
def isValid(row,col,val,board):
|
||||
for i in range(9): #判断行里是否重复
|
||||
if board[row][i] == str(val):
|
||||
return False
|
||||
for j in range(9): #判断列里是否重复
|
||||
if board[j][col] == str(val):
|
||||
return False
|
||||
startRow = (row // 3) * 3
|
||||
startcol = (col // 3) * 3
|
||||
for i in range(startRow,startRow + 3): #判断9方格里是否重复
|
||||
for j in range(startcol,startcol + 3):
|
||||
if board[i][j] == str(val):
|
||||
return False
|
||||
return True
|
||||
backtrack(board)
|
||||
```
|
||||
|
||||
Python3:
|
||||
|
||||
```python3
|
||||
class Solution:
|
||||
def __init__(self) -> None:
|
||||
self.board = []
|
||||
|
||||
def isValid(self, row: int, col: int, target: int) -> bool:
|
||||
for idx in range(len(self.board)):
|
||||
# 同列是否重复
|
||||
if self.board[idx][col] == str(target):
|
||||
return False
|
||||
# 同行是否重复
|
||||
if self.board[row][idx] == str(target):
|
||||
return False
|
||||
# 9宫格里是否重复
|
||||
box_row, box_col = (row // 3) * 3 + idx // 3, (col // 3) * 3 + idx % 3
|
||||
if self.board[box_row][box_col] == str(target):
|
||||
return False
|
||||
return True
|
||||
|
||||
def getPlace(self) -> List[int]:
|
||||
for row in range(len(self.board)):
|
||||
for col in range(len(self.board)):
|
||||
if self.board[row][col] == ".":
|
||||
return [row, col]
|
||||
return [-1, -1]
|
||||
|
||||
def isSolved(self) -> bool:
|
||||
row, col = self.getPlace() # 找个空位置
|
||||
|
||||
if row == -1 and col == -1: # 没有空位置,棋盘被填满的
|
||||
return True
|
||||
|
||||
for i in range(1, 10):
|
||||
if self.isValid(row, col, i): # 检查这个空位置放i,是否合适
|
||||
self.board[row][col] = str(i) # 放i
|
||||
if self.isSolved(): # 合适,立刻返回, 填下一个空位置。
|
||||
return True
|
||||
self.board[row][col] = "." # 不合适,回溯
|
||||
|
||||
return False # 空位置没法解决
|
||||
|
||||
def solveSudoku(self, board: List[List[str]]) -> None:
|
||||
"""
|
||||
Do not return anything, modify board in-place instead.
|
||||
"""
|
||||
if board is None or len(board) == 0:
|
||||
return
|
||||
self.board = board
|
||||
self.isSolved()
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
Javascript:
|
||||
```Javascript
|
||||
var solveSudoku = function(board) {
|
||||
function isValid(row, col, val, board) {
|
||||
let len = board.length
|
||||
// 行不能重复
|
||||
for(let i = 0; i < len; i++) {
|
||||
if(board[row][i] === val) {
|
||||
return false
|
||||
}
|
||||
}
|
||||
// 列不能重复
|
||||
for(let i = 0; i < len; i++) {
|
||||
if(board[i][col] === val) {
|
||||
return false
|
||||
}
|
||||
}
|
||||
let startRow = Math.floor(row / 3) * 3
|
||||
let startCol = Math.floor(col / 3) * 3
|
||||
|
||||
for(let i = startRow; i < startRow + 3; i++) {
|
||||
for(let j = startCol; j < startCol + 3; j++) {
|
||||
if(board[i][j] === val) {
|
||||
return false
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return true
|
||||
}
|
||||
|
||||
function backTracking() {
|
||||
for(let i = 0; i < board.length; i++) {
|
||||
for(let j = 0; j < board[0].length; j++) {
|
||||
if(board[i][j] !== '.') continue
|
||||
for(let val = 1; val <= 9; val++) {
|
||||
if(isValid(i, j, `${val}`, board)) {
|
||||
board[i][j] = `${val}`
|
||||
if (backTracking()) {
|
||||
return true
|
||||
}
|
||||
|
||||
board[i][j] = `.`
|
||||
}
|
||||
}
|
||||
return false
|
||||
}
|
||||
}
|
||||
return true
|
||||
}
|
||||
backTracking(board)
|
||||
return board
|
||||
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
354
problems/0039.组合总和.md
Normal file
354
problems/0039.组合总和.md
Normal file
@@ -0,0 +1,354 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 39. 组合总和
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/combination-sum/
|
||||
|
||||
给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
|
||||
|
||||
candidates 中的数字可以无限制重复被选取。
|
||||
|
||||
说明:
|
||||
|
||||
* 所有数字(包括 target)都是正整数。
|
||||
* 解集不能包含重复的组合。
|
||||
|
||||
示例 1:
|
||||
输入:candidates = [2,3,6,7], target = 7,
|
||||
所求解集为:
|
||||
[
|
||||
[7],
|
||||
[2,2,3]
|
||||
]
|
||||
|
||||
示例 2:
|
||||
输入:candidates = [2,3,5], target = 8,
|
||||
所求解集为:
|
||||
[
|
||||
[2,2,2,2],
|
||||
[2,3,3],
|
||||
[3,5]
|
||||
]
|
||||
|
||||
## 思路
|
||||
|
||||
[B站视频讲解-组合总和](https://www.bilibili.com/video/BV1KT4y1M7HJ)
|
||||
|
||||
|
||||
题目中的**无限制重复被选取,吓得我赶紧想想 出现0 可咋办**,然后看到下面提示:1 <= candidates[i] <= 200,我就放心了。
|
||||
|
||||
本题和[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ),[回溯算法:求组合总和!](https://mp.weixin.qq.com/s/HX7WW6ixbFZJASkRnCTC3w)和区别是:本题没有数量要求,可以无限重复,但是有总和的限制,所以间接的也是有个数的限制。
|
||||
|
||||
本题搜索的过程抽象成树形结构如下:
|
||||
|
||||
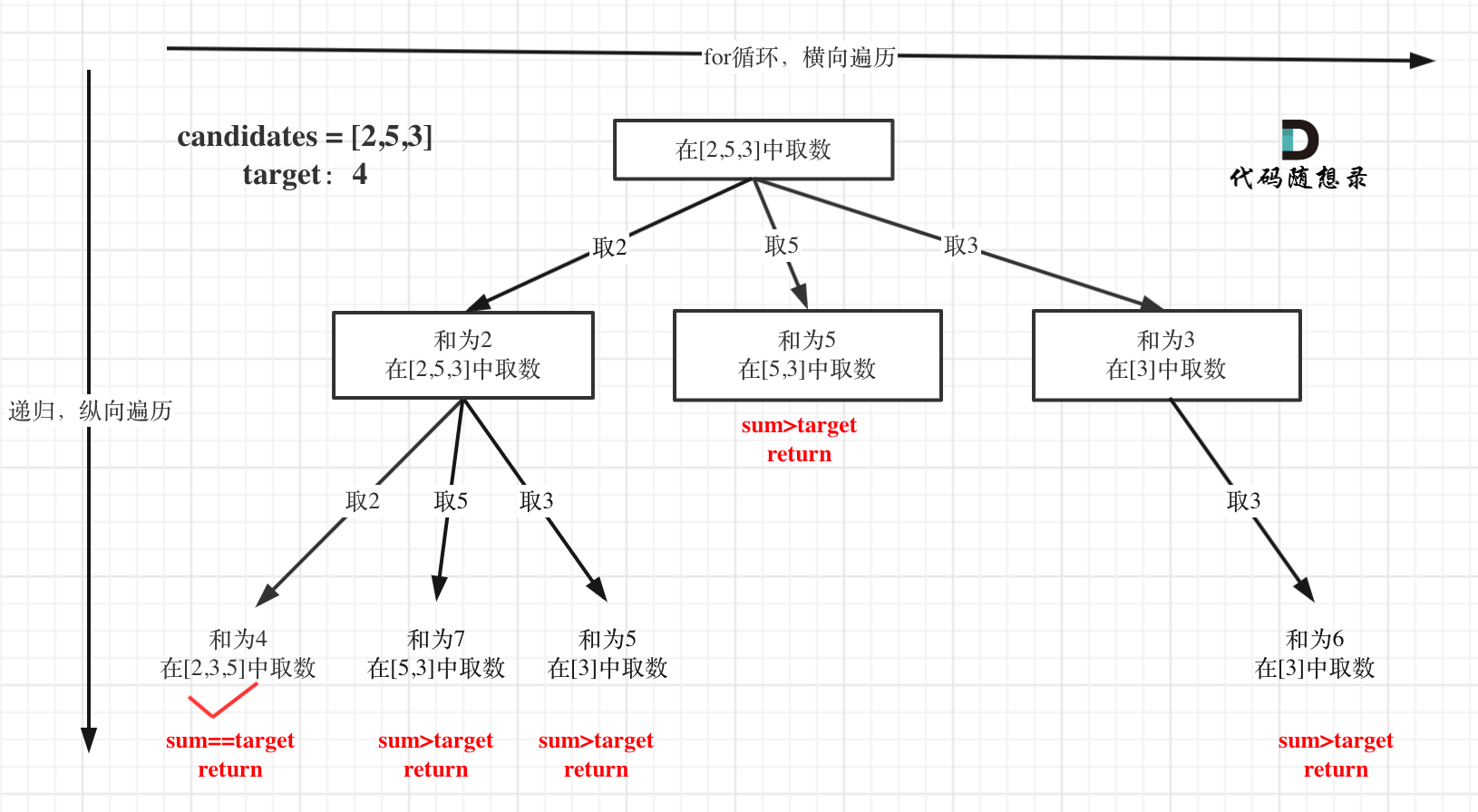
|
||||
注意图中叶子节点的返回条件,因为本题没有组合数量要求,仅仅是总和的限制,所以递归没有层数的限制,只要选取的元素总和超过target,就返回!
|
||||
|
||||
而在[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)和[回溯算法:求组合总和!](https://mp.weixin.qq.com/s/HX7WW6ixbFZJASkRnCTC3w) 中都可以知道要递归K层,因为要取k个元素的组合。
|
||||
|
||||
## 回溯三部曲
|
||||
|
||||
* 递归函数参数
|
||||
|
||||
这里依然是定义两个全局变量,二维数组result存放结果集,数组path存放符合条件的结果。(这两个变量可以作为函数参数传入)
|
||||
|
||||
首先是题目中给出的参数,集合candidates, 和目标值target。
|
||||
|
||||
此外我还定义了int型的sum变量来统计单一结果path里的总和,其实这个sum也可以不用,用target做相应的减法就可以了,最后如何target==0就说明找到符合的结果了,但为了代码逻辑清晰,我依然用了sum。
|
||||
|
||||
**本题还需要startIndex来控制for循环的起始位置,对于组合问题,什么时候需要startIndex呢?**
|
||||
|
||||
我举过例子,如果是一个集合来求组合的话,就需要startIndex,例如:[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ),[回溯算法:求组合总和!](https://mp.weixin.qq.com/s/HX7WW6ixbFZJASkRnCTC3w)。
|
||||
|
||||
如果是多个集合取组合,各个集合之间相互不影响,那么就不用startIndex,例如:[回溯算法:电话号码的字母组合](https://mp.weixin.qq.com/s/e2ua2cmkE_vpYjM3j6HY0A)
|
||||
|
||||
**注意以上我只是说求组合的情况,如果是排列问题,又是另一套分析的套路,后面我再讲解排列的时候就重点介绍**。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
vector<vector<int>> result;
|
||||
vector<int> path;
|
||||
void backtracking(vector<int>& candidates, int target, int sum, int startIndex)
|
||||
```
|
||||
|
||||
* 递归终止条件
|
||||
|
||||
在如下树形结构中:
|
||||
|
||||

|
||||
|
||||
从叶子节点可以清晰看到,终止只有两种情况,sum大于target和sum等于target。
|
||||
|
||||
sum等于target的时候,需要收集结果,代码如下:
|
||||
|
||||
```C++
|
||||
if (sum > target) {
|
||||
return;
|
||||
}
|
||||
if (sum == target) {
|
||||
result.push_back(path);
|
||||
return;
|
||||
}
|
||||
```
|
||||
|
||||
* 单层搜索的逻辑
|
||||
|
||||
单层for循环依然是从startIndex开始,搜索candidates集合。
|
||||
|
||||
**注意本题和[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)、[回溯算法:求组合总和!](https://mp.weixin.qq.com/s/HX7WW6ixbFZJASkRnCTC3w)的一个区别是:本题元素为可重复选取的**。
|
||||
|
||||
如何重复选取呢,看代码,注释部分:
|
||||
|
||||
```C++
|
||||
for (int i = startIndex; i < candidates.size(); i++) {
|
||||
sum += candidates[i];
|
||||
path.push_back(candidates[i]);
|
||||
backtracking(candidates, target, sum, i); // 关键点:不用i+1了,表示可以重复读取当前的数
|
||||
sum -= candidates[i]; // 回溯
|
||||
path.pop_back(); // 回溯
|
||||
}
|
||||
```
|
||||
|
||||
按照[关于回溯算法,你该了解这些!](https://mp.weixin.qq.com/s/gjSgJbNbd1eAA5WkA-HeWw)中给出的模板,不难写出如下C++完整代码:
|
||||
|
||||
```C++
|
||||
// 版本一
|
||||
class Solution {
|
||||
private:
|
||||
vector<vector<int>> result;
|
||||
vector<int> path;
|
||||
void backtracking(vector<int>& candidates, int target, int sum, int startIndex) {
|
||||
if (sum > target) {
|
||||
return;
|
||||
}
|
||||
if (sum == target) {
|
||||
result.push_back(path);
|
||||
return;
|
||||
}
|
||||
|
||||
for (int i = startIndex; i < candidates.size(); i++) {
|
||||
sum += candidates[i];
|
||||
path.push_back(candidates[i]);
|
||||
backtracking(candidates, target, sum, i); // 不用i+1了,表示可以重复读取当前的数
|
||||
sum -= candidates[i];
|
||||
path.pop_back();
|
||||
}
|
||||
}
|
||||
public:
|
||||
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
|
||||
result.clear();
|
||||
path.clear();
|
||||
backtracking(candidates, target, 0, 0);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 剪枝优化
|
||||
|
||||
在这个树形结构中:
|
||||
|
||||

|
||||
|
||||
以及上面的版本一的代码大家可以看到,对于sum已经大于target的情况,其实是依然进入了下一层递归,只是下一层递归结束判断的时候,会判断sum > target的话就返回。
|
||||
|
||||
其实如果已经知道下一层的sum会大于target,就没有必要进入下一层递归了。
|
||||
|
||||
那么可以在for循环的搜索范围上做做文章了。
|
||||
|
||||
**对总集合排序之后,如果下一层的sum(就是本层的 sum + candidates[i])已经大于target,就可以结束本轮for循环的遍历**。
|
||||
|
||||
如图:
|
||||
|
||||
|
||||
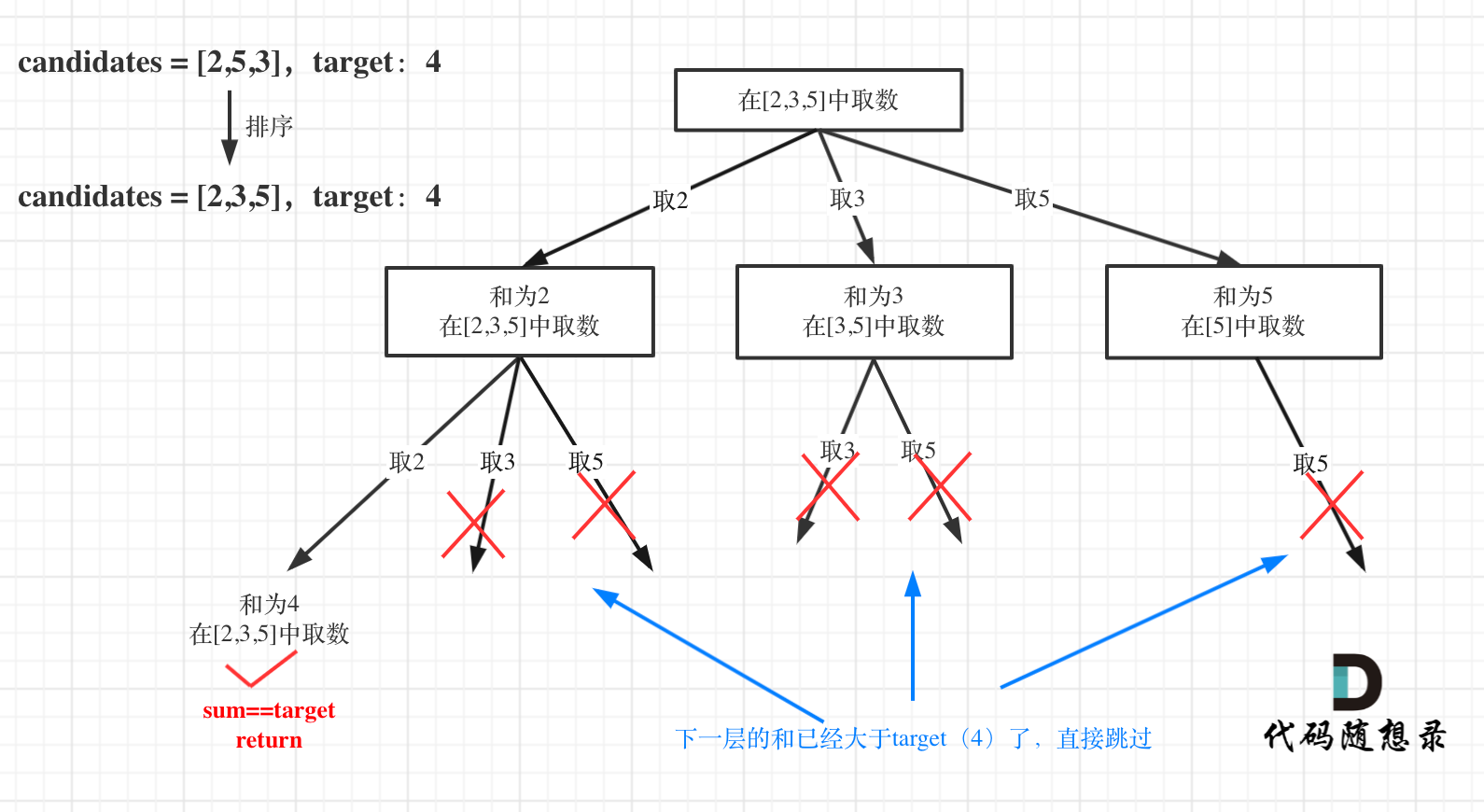
|
||||
|
||||
for循环剪枝代码如下:
|
||||
|
||||
```
|
||||
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++)
|
||||
```
|
||||
|
||||
整体代码如下:(注意注释的部分)
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
vector<vector<int>> result;
|
||||
vector<int> path;
|
||||
void backtracking(vector<int>& candidates, int target, int sum, int startIndex) {
|
||||
if (sum == target) {
|
||||
result.push_back(path);
|
||||
return;
|
||||
}
|
||||
|
||||
// 如果 sum + candidates[i] > target 就终止遍历
|
||||
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++) {
|
||||
sum += candidates[i];
|
||||
path.push_back(candidates[i]);
|
||||
backtracking(candidates, target, sum, i);
|
||||
sum -= candidates[i];
|
||||
path.pop_back();
|
||||
|
||||
}
|
||||
}
|
||||
public:
|
||||
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
|
||||
result.clear();
|
||||
path.clear();
|
||||
sort(candidates.begin(), candidates.end()); // 需要排序
|
||||
backtracking(candidates, target, 0, 0);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
本题和我们之前讲过的[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)、[回溯算法:求组合总和!](https://mp.weixin.qq.com/s/HX7WW6ixbFZJASkRnCTC3w)有两点不同:
|
||||
|
||||
* 组合没有数量要求
|
||||
* 元素可无限重复选取
|
||||
|
||||
针对这两个问题,我都做了详细的分析。
|
||||
|
||||
并且给出了对于组合问题,什么时候用startIndex,什么时候不用,并用[回溯算法:电话号码的字母组合](https://mp.weixin.qq.com/s/e2ua2cmkE_vpYjM3j6HY0A)做了对比。
|
||||
|
||||
最后还给出了本题的剪枝优化,这个优化如果是初学者的话并不容易想到。
|
||||
|
||||
**在求和问题中,排序之后加剪枝是常见的套路!**
|
||||
|
||||
可以看出我写的文章都会大量引用之前的文章,就是要不断作对比,分析其差异,然后给出代码解决的方法,这样才能彻底理解题目的本质与难点。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
// 剪枝优化
|
||||
class Solution {
|
||||
public List<List<Integer>> combinationSum(int[] candidates, int target) {
|
||||
List<List<Integer>> res = new ArrayList<>();
|
||||
Arrays.sort(candidates); // 先进行排序
|
||||
backtracking(res, new ArrayList<>(), candidates, target, 0, 0);
|
||||
return res;
|
||||
}
|
||||
|
||||
public void backtracking(List<List<Integer>> res, List<Integer> path, int[] candidates, int target, int sum, int idx) {
|
||||
// 找到了数字和为 target 的组合
|
||||
if (sum == target) {
|
||||
res.add(new ArrayList<>(path));
|
||||
return;
|
||||
}
|
||||
|
||||
for (int i = idx; i < candidates.length; i++) {
|
||||
// 如果 sum + candidates[i] > target 就终止遍历
|
||||
if (sum + candidates[i] > target) break;
|
||||
path.add(candidates[i]);
|
||||
backtracking(res, path, candidates, target, sum + candidates[i], i);
|
||||
path.remove(path.size() - 1); // 回溯,移除路径 path 最后一个元素
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python3
|
||||
class Solution:
|
||||
def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:
|
||||
res = []
|
||||
path = []
|
||||
def backtrack(candidates,target,sum,startIndex):
|
||||
if sum > target: return
|
||||
if sum == target: return res.append(path[:])
|
||||
for i in range(startIndex,len(candidates)):
|
||||
if sum + candidates[i] >target: return #如果 sum + candidates[i] > target 就终止遍历
|
||||
sum += candidates[i]
|
||||
path.append(candidates[i])
|
||||
backtrack(candidates,target,sum,i) #startIndex = i:表示可以重复读取当前的数
|
||||
sum -= candidates[i] #回溯
|
||||
path.pop() #回溯
|
||||
candidates = sorted(candidates) #需要排序
|
||||
backtrack(candidates,target,0,0)
|
||||
return res
|
||||
```
|
||||
Go:
|
||||
|
||||
|
||||
> 主要在于递归中传递下一个数字
|
||||
|
||||
```go
|
||||
func combinationSum(candidates []int, target int) [][]int {
|
||||
var trcak []int
|
||||
var res [][]int
|
||||
backtracking(0,0,target,candidates,trcak,&res)
|
||||
return res
|
||||
}
|
||||
func backtracking(startIndex,sum,target int,candidates,trcak []int,res *[][]int){
|
||||
//终止条件
|
||||
if sum==target{
|
||||
tmp:=make([]int,len(trcak))
|
||||
copy(tmp,trcak)//拷贝
|
||||
*res=append(*res,tmp)//放入结果集
|
||||
return
|
||||
}
|
||||
if sum>target{return}
|
||||
//回溯
|
||||
for i:=startIndex;i<len(candidates);i++{
|
||||
//更新路径集合和sum
|
||||
trcak=append(trcak,candidates[i])
|
||||
sum+=candidates[i]
|
||||
//递归
|
||||
backtracking(i,sum,target,candidates,trcak,res)
|
||||
//回溯
|
||||
trcak=trcak[:len(trcak)-1]
|
||||
sum-=candidates[i]
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
JavaScript:
|
||||
|
||||
```js
|
||||
var combinationSum = function(candidates, target) {
|
||||
const res = [], path = [];
|
||||
candidates.sort(); // 排序
|
||||
backtracking(0, 0);
|
||||
return res;
|
||||
function backtracking(j, sum) {
|
||||
if (sum > target) return;
|
||||
if (sum === target) {
|
||||
res.push(Array.from(path));
|
||||
return;
|
||||
}
|
||||
for(let i = j; i < candidates.length; i++ ) {
|
||||
const n = candidates[i];
|
||||
if(n > target - sum) continue;
|
||||
path.push(n);
|
||||
sum += n;
|
||||
backtracking(i, sum);
|
||||
path.pop();
|
||||
sum -= n;
|
||||
}
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
398
problems/0040.组合总和II.md
Normal file
398
problems/0040.组合总和II.md
Normal file
@@ -0,0 +1,398 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
> 这篇可以说是全网把组合问题如何去重,讲的最清晰的了!
|
||||
|
||||
## 40.组合总和II
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/combination-sum-ii/
|
||||
|
||||
给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
|
||||
|
||||
candidates 中的每个数字在每个组合中只能使用一次。
|
||||
|
||||
说明:
|
||||
所有数字(包括目标数)都是正整数。
|
||||
解集不能包含重复的组合。
|
||||
|
||||
示例 1:
|
||||
输入: candidates = [10,1,2,7,6,1,5], target = 8,
|
||||
所求解集为:
|
||||
[
|
||||
[1, 7],
|
||||
[1, 2, 5],
|
||||
[2, 6],
|
||||
[1, 1, 6]
|
||||
]
|
||||
|
||||
示例 2:
|
||||
输入: candidates = [2,5,2,1,2], target = 5,
|
||||
所求解集为:
|
||||
[
|
||||
[1,2,2],
|
||||
[5]
|
||||
]
|
||||
|
||||
## 思路
|
||||
|
||||
这道题目和[39.组合总和](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)如下区别:
|
||||
|
||||
1. 本题candidates 中的每个数字在每个组合中只能使用一次。
|
||||
2. 本题数组candidates的元素是有重复的,而[39.组合总和](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)是无重复元素的数组candidates
|
||||
|
||||
最后本题和[39.组合总和](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)要求一样,解集不能包含重复的组合。
|
||||
|
||||
**本题的难点在于区别2中:集合(数组candidates)有重复元素,但还不能有重复的组合**。
|
||||
|
||||
一些同学可能想了:我把所有组合求出来,再用set或者map去重,这么做很容易超时!
|
||||
|
||||
所以要在搜索的过程中就去掉重复组合。
|
||||
|
||||
很多同学在去重的问题上想不明白,其实很多题解也没有讲清楚,反正代码是能过的,感觉是那么回事,稀里糊涂的先把题目过了。
|
||||
|
||||
这个去重为什么很难理解呢,**所谓去重,其实就是使用过的元素不能重复选取。** 这么一说好像很简单!
|
||||
|
||||
都知道组合问题可以抽象为树形结构,那么“使用过”在这个树形结构上是有两个维度的,一个维度是同一树枝上使用过,一个维度是同一树层上使用过。**没有理解这两个层面上的“使用过” 是造成大家没有彻底理解去重的根本原因。**
|
||||
|
||||
那么问题来了,我们是要同一树层上使用过,还是统一树枝上使用过呢?
|
||||
|
||||
回看一下题目,元素在同一个组合内是可以重复的,怎么重复都没事,但两个组合不能相同。
|
||||
|
||||
|
||||
**所以我们要去重的是同一树层上的“使用过”,同一树枝上的都是一个组合里的元素,不用去重**。
|
||||
|
||||
为了理解去重我们来举一个例子,candidates = [1, 1, 2], target = 3,(方便起见candidates已经排序了)
|
||||
|
||||
**强调一下,树层去重的话,需要对数组排序!**
|
||||
|
||||
选择过程树形结构如图所示:
|
||||
|
||||
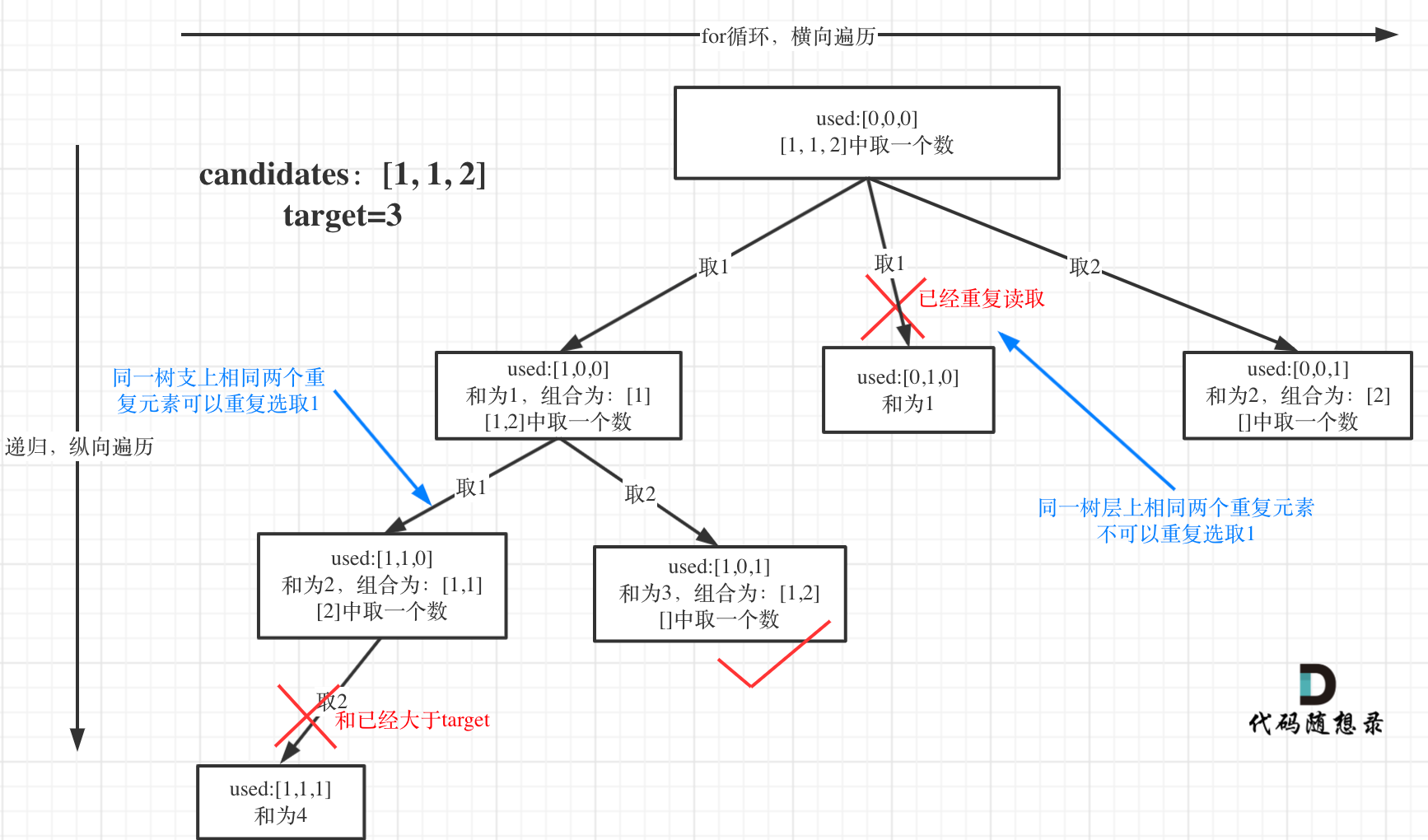
|
||||
|
||||
可以看到图中,每个节点相对于 [39.组合总和](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)我多加了used数组,这个used数组下面会重点介绍。
|
||||
|
||||
## 回溯三部曲
|
||||
|
||||
* **递归函数参数**
|
||||
|
||||
与[39.组合总和](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)套路相同,此题还需要加一个bool型数组used,用来记录同一树枝上的元素是否使用过。
|
||||
|
||||
这个集合去重的重任就是used来完成的。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
vector<vector<int>> result; // 存放组合集合
|
||||
vector<int> path; // 符合条件的组合
|
||||
void backtracking(vector<int>& candidates, int target, int sum, int startIndex, vector<bool>& used) {
|
||||
```
|
||||
|
||||
* **递归终止条件**
|
||||
|
||||
与[39.组合总和](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)相同,终止条件为 `sum > target` 和 `sum == target`。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
if (sum > target) { // 这个条件其实可以省略
|
||||
return;
|
||||
}
|
||||
if (sum == target) {
|
||||
result.push_back(path);
|
||||
return;
|
||||
}
|
||||
```
|
||||
|
||||
`sum > target` 这个条件其实可以省略,因为和在递归单层遍历的时候,会有剪枝的操作,下面会介绍到。
|
||||
|
||||
* **单层搜索的逻辑**
|
||||
|
||||
这里与[39.组合总和](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)最大的不同就是要去重了。
|
||||
|
||||
前面我们提到:要去重的是“同一树层上的使用过”,如果判断同一树层上元素(相同的元素)是否使用过了呢。
|
||||
|
||||
**如果`candidates[i] == candidates[i - 1]` 并且 `used[i - 1] == false`,就说明:前一个树枝,使用了candidates[i - 1],也就是说同一树层使用过candidates[i - 1]**。
|
||||
|
||||
此时for循环里就应该做continue的操作。
|
||||
|
||||
这块比较抽象,如图:
|
||||
|
||||
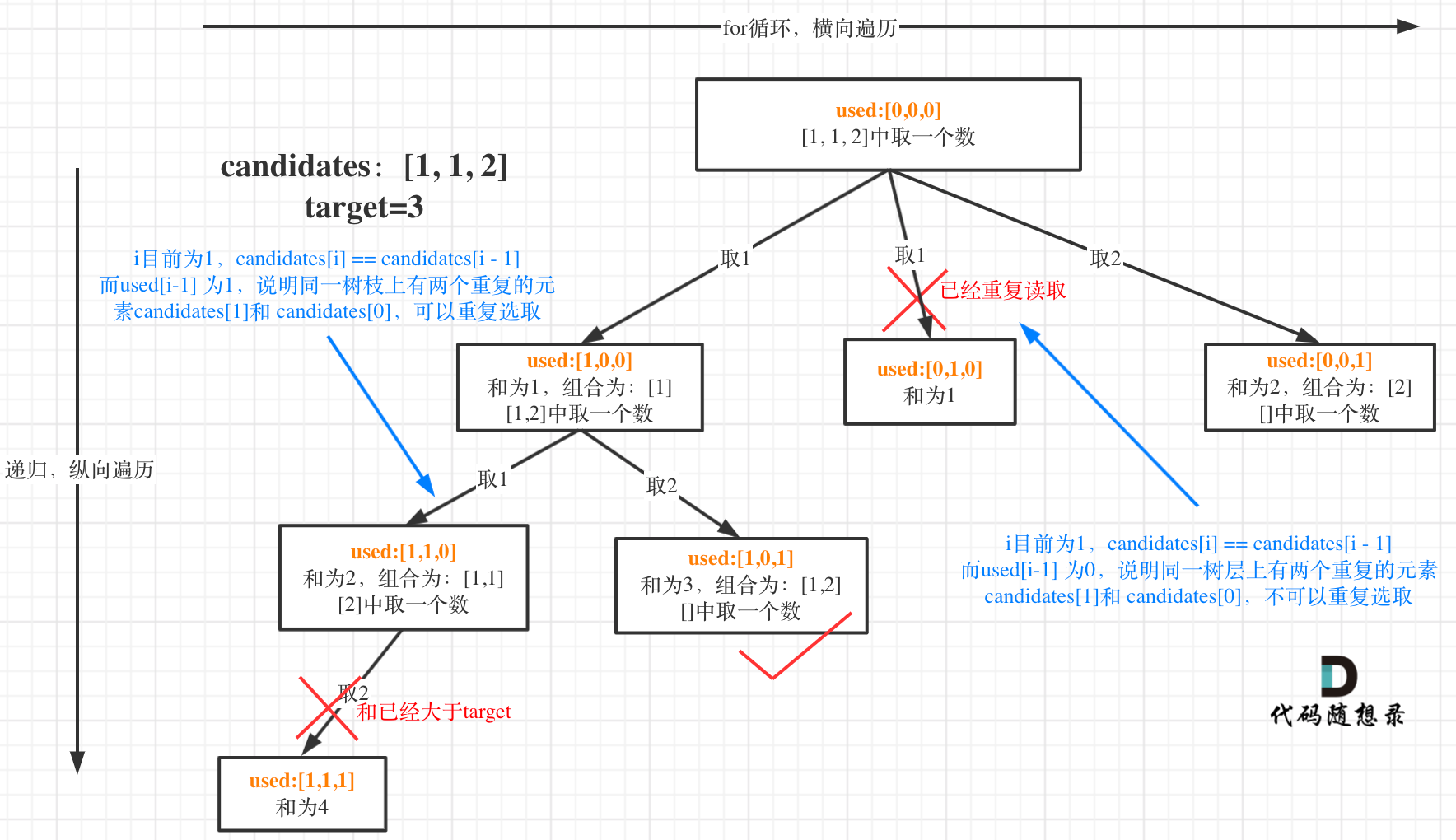
|
||||
|
||||
我在图中将used的变化用橘黄色标注上,可以看出在candidates[i] == candidates[i - 1]相同的情况下:
|
||||
|
||||
* used[i - 1] == true,说明同一树支candidates[i - 1]使用过
|
||||
* used[i - 1] == false,说明同一树层candidates[i - 1]使用过
|
||||
|
||||
**这块去重的逻辑很抽象,网上搜的题解基本没有能讲清楚的,如果大家之前思考过这个问题或者刷过这道题目,看到这里一定会感觉通透了很多!**
|
||||
|
||||
那么单层搜索的逻辑代码如下:
|
||||
|
||||
```C++
|
||||
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++) {
|
||||
// used[i - 1] == true,说明同一树支candidates[i - 1]使用过
|
||||
// used[i - 1] == false,说明同一树层candidates[i - 1]使用过
|
||||
// 要对同一树层使用过的元素进行跳过
|
||||
if (i > 0 && candidates[i] == candidates[i - 1] && used[i - 1] == false) {
|
||||
continue;
|
||||
}
|
||||
sum += candidates[i];
|
||||
path.push_back(candidates[i]);
|
||||
used[i] = true;
|
||||
backtracking(candidates, target, sum, i + 1, used); // 和39.组合总和的区别1:这里是i+1,每个数字在每个组合中只能使用一次
|
||||
used[i] = false;
|
||||
sum -= candidates[i];
|
||||
path.pop_back();
|
||||
}
|
||||
```
|
||||
|
||||
**注意sum + candidates[i] <= target为剪枝操作,在[39.组合总和](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)有讲解过!**
|
||||
|
||||
## C++代码
|
||||
|
||||
回溯三部曲分析完了,整体C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
vector<vector<int>> result;
|
||||
vector<int> path;
|
||||
void backtracking(vector<int>& candidates, int target, int sum, int startIndex, vector<bool>& used) {
|
||||
if (sum == target) {
|
||||
result.push_back(path);
|
||||
return;
|
||||
}
|
||||
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++) {
|
||||
// used[i - 1] == true,说明同一树支candidates[i - 1]使用过
|
||||
// used[i - 1] == false,说明同一树层candidates[i - 1]使用过
|
||||
// 要对同一树层使用过的元素进行跳过
|
||||
if (i > 0 && candidates[i] == candidates[i - 1] && used[i - 1] == false) {
|
||||
continue;
|
||||
}
|
||||
sum += candidates[i];
|
||||
path.push_back(candidates[i]);
|
||||
used[i] = true;
|
||||
backtracking(candidates, target, sum, i + 1, used); // 和39.组合总和的区别1,这里是i+1,每个数字在每个组合中只能使用一次
|
||||
used[i] = false;
|
||||
sum -= candidates[i];
|
||||
path.pop_back();
|
||||
}
|
||||
}
|
||||
|
||||
public:
|
||||
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
|
||||
vector<bool> used(candidates.size(), false);
|
||||
path.clear();
|
||||
result.clear();
|
||||
// 首先把给candidates排序,让其相同的元素都挨在一起。
|
||||
sort(candidates.begin(), candidates.end());
|
||||
backtracking(candidates, target, 0, 0, used);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
## 补充
|
||||
|
||||
这里直接用startIndex来去重也是可以的, 就不用used数组了。
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
vector<vector<int>> result;
|
||||
vector<int> path;
|
||||
void backtracking(vector<int>& candidates, int target, int sum, int startIndex) {
|
||||
if (sum == target) {
|
||||
result.push_back(path);
|
||||
return;
|
||||
}
|
||||
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++) {
|
||||
// 要对同一树层使用过的元素进行跳过
|
||||
if (i > startIndex && candidates[i] == candidates[i - 1]) {
|
||||
continue;
|
||||
}
|
||||
sum += candidates[i];
|
||||
path.push_back(candidates[i]);
|
||||
backtracking(candidates, target, sum, i + 1); // 和39.组合总和的区别1,这里是i+1,每个数字在每个组合中只能使用一次
|
||||
sum -= candidates[i];
|
||||
path.pop_back();
|
||||
}
|
||||
}
|
||||
|
||||
public:
|
||||
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
|
||||
path.clear();
|
||||
result.clear();
|
||||
// 首先把给candidates排序,让其相同的元素都挨在一起。
|
||||
sort(candidates.begin(), candidates.end());
|
||||
backtracking(candidates, target, 0, 0);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
本题同样是求组合总和,但就是因为其数组candidates有重复元素,而要求不能有重复的组合,所以相对于[39.组合总和](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)难度提升了不少。
|
||||
|
||||
**关键是去重的逻辑,代码很简单,网上一搜一大把,但几乎没有能把这块代码含义讲明白的,基本都是给出代码,然后说这就是去重了,究竟怎么个去重法也是模棱两可**。
|
||||
|
||||
所以Carl有必要把去重的这块彻彻底底的给大家讲清楚,**就连“树层去重”和“树枝去重”都是我自创的词汇,希望对大家理解有帮助!**
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
List<List<Integer>> lists = new ArrayList<>();
|
||||
Deque<Integer> deque = new LinkedList<>();
|
||||
int sum = 0;
|
||||
|
||||
public List<List<Integer>> combinationSum2(int[] candidates, int target) {
|
||||
//为了将重复的数字都放到一起,所以先进行排序
|
||||
Arrays.sort(candidates);
|
||||
//加标志数组,用来辅助判断同层节点是否已经遍历
|
||||
boolean[] flag = new boolean[candidates.length];
|
||||
backTracking(candidates, target, 0, flag);
|
||||
return lists;
|
||||
}
|
||||
|
||||
public void backTracking(int[] arr, int target, int index, boolean[] flag) {
|
||||
if (sum == target) {
|
||||
lists.add(new ArrayList(deque));
|
||||
return;
|
||||
}
|
||||
for (int i = index; i < arr.length && arr[i] + sum <= target; i++) {
|
||||
//出现重复节点,同层的第一个节点已经被访问过,所以直接跳过
|
||||
if (i > 0 && arr[i] == arr[i - 1] && !flag[i - 1]) {
|
||||
continue;
|
||||
}
|
||||
flag[i] = true;
|
||||
sum += arr[i];
|
||||
deque.push(arr[i]);
|
||||
//每个节点仅能选择一次,所以从下一位开始
|
||||
backTracking(arr, target, i + 1, flag);
|
||||
int temp = deque.pop();
|
||||
flag[i] = false;
|
||||
sum -= temp;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
Python:
|
||||
```py
|
||||
class Solution:
|
||||
def combinationSum2(self, candidates: List[int], target: int) -> List[List[int]]:
|
||||
res = []
|
||||
path = []
|
||||
def backtrack(candidates,target,sum,startIndex):
|
||||
if sum == target: res.append(path[:])
|
||||
for i in range(startIndex,len(candidates)): #要对同一树层使用过的元素进行跳过
|
||||
if sum + candidates[i] > target: return
|
||||
if i > startIndex and candidates[i] == candidates[i-1]: continue #直接用startIndex来去重,要对同一树层使用过的元素进行跳过
|
||||
sum += candidates[i]
|
||||
path.append(candidates[i])
|
||||
backtrack(candidates,target,sum,i+1) #i+1:每个数字在每个组合中只能使用一次
|
||||
sum -= candidates[i] #回溯
|
||||
path.pop() #回溯
|
||||
candidates = sorted(candidates) #首先把给candidates排序,让其相同的元素都挨在一起。
|
||||
backtrack(candidates,target,0,0)
|
||||
return res
|
||||
```
|
||||
Go:
|
||||
|
||||
|
||||
> 主要在于如何在回溯中去重
|
||||
|
||||
```go
|
||||
func combinationSum2(candidates []int, target int) [][]int {
|
||||
var trcak []int
|
||||
var res [][]int
|
||||
var history map[int]bool
|
||||
history=make(map[int]bool)
|
||||
sort.Ints(candidates)
|
||||
backtracking(0,0,target,candidates,trcak,&res,history)
|
||||
return res
|
||||
}
|
||||
func backtracking(startIndex,sum,target int,candidates,trcak []int,res *[][]int,history map[int]bool){
|
||||
//终止条件
|
||||
if sum==target{
|
||||
tmp:=make([]int,len(trcak))
|
||||
copy(tmp,trcak)//拷贝
|
||||
*res=append(*res,tmp)//放入结果集
|
||||
return
|
||||
}
|
||||
if sum>target{return}
|
||||
//回溯
|
||||
// used[i - 1] == true,说明同一树支candidates[i - 1]使用过
|
||||
// used[i - 1] == false,说明同一树层candidates[i - 1]使用过
|
||||
for i:=startIndex;i<len(candidates);i++{
|
||||
if i>0&&candidates[i]==candidates[i-1]&&history[i-1]==false{
|
||||
continue
|
||||
}
|
||||
//更新路径集合和sum
|
||||
trcak=append(trcak,candidates[i])
|
||||
sum+=candidates[i]
|
||||
history[i]=true
|
||||
//递归
|
||||
backtracking(i+1,sum,target,candidates,trcak,res,history)
|
||||
//回溯
|
||||
trcak=trcak[:len(trcak)-1]
|
||||
sum-=candidates[i]
|
||||
history[i]=false
|
||||
}
|
||||
}
|
||||
```
|
||||
javaScript:
|
||||
|
||||
```js
|
||||
/**
|
||||
* @param {number[]} candidates
|
||||
* @param {number} target
|
||||
* @return {number[][]}
|
||||
*/
|
||||
var combinationSum2 = function(candidates, target) {
|
||||
const res = []; path = [], len = candidates.length;
|
||||
candidates.sort();
|
||||
backtracking(0, 0);
|
||||
return res;
|
||||
function backtracking(sum, i) {
|
||||
if (sum > target) return;
|
||||
if (sum === target) {
|
||||
res.push(Array.from(path));
|
||||
return;
|
||||
}
|
||||
let f = -1;
|
||||
for(let j = i; j < len; j++) {
|
||||
const n = candidates[j];
|
||||
if(n > target - sum || n === f) continue;
|
||||
path.push(n);
|
||||
sum += n;
|
||||
f = n;
|
||||
backtracking(sum, j + 1);
|
||||
path.pop();
|
||||
sum -= n;
|
||||
}
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
244
problems/0045.跳跃游戏II.md
Normal file
244
problems/0045.跳跃游戏II.md
Normal file
@@ -0,0 +1,244 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
> 相对于[贪心算法:跳跃游戏](https://mp.weixin.qq.com/s/606_N9j8ACKCODoCbV1lSA)难了不少,做好心里准备!
|
||||
|
||||
## 45.跳跃游戏II
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/jump-game-ii/
|
||||
|
||||
给定一个非负整数数组,你最初位于数组的第一个位置。
|
||||
|
||||
数组中的每个元素代表你在该位置可以跳跃的最大长度。
|
||||
|
||||
你的目标是使用最少的跳跃次数到达数组的最后一个位置。
|
||||
|
||||
示例:
|
||||
输入: [2,3,1,1,4]
|
||||
输出: 2
|
||||
解释: 跳到最后一个位置的最小跳跃数是 2。从下标为 0 跳到下标为 1 的位置,跳 1 步,然后跳 3 步到达数组的最后一个位置。
|
||||
|
||||
说明:
|
||||
假设你总是可以到达数组的最后一个位置。
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
本题相对于[贪心算法:跳跃游戏](https://mp.weixin.qq.com/s/606_N9j8ACKCODoCbV1lSA)还是难了不少。
|
||||
|
||||
但思路是相似的,还是要看最大覆盖范围。
|
||||
|
||||
本题要计算最小步数,那么就要想清楚什么时候步数才一定要加一呢?
|
||||
|
||||
贪心的思路,局部最优:当前可移动距离尽可能多走,如果还没到终点,步数再加一。整体最优:一步尽可能多走,从而达到最小步数。
|
||||
|
||||
思路虽然是这样,但在写代码的时候还不能真的就能跳多远跳远,那样就不知道下一步最远能跳到哪里了。
|
||||
|
||||
**所以真正解题的时候,要从覆盖范围出发,不管怎么跳,覆盖范围内一定是可以跳到的,以最小的步数增加覆盖范围,覆盖范围一旦覆盖了终点,得到的就是最小步数!**
|
||||
|
||||
**这里需要统计两个覆盖范围,当前这一步的最大覆盖和下一步最大覆盖**。
|
||||
|
||||
如果移动下标达到了当前这一步的最大覆盖最远距离了,还没有到终点的话,那么就必须再走一步来增加覆盖范围,直到覆盖范围覆盖了终点。
|
||||
|
||||
如图:
|
||||
|
||||
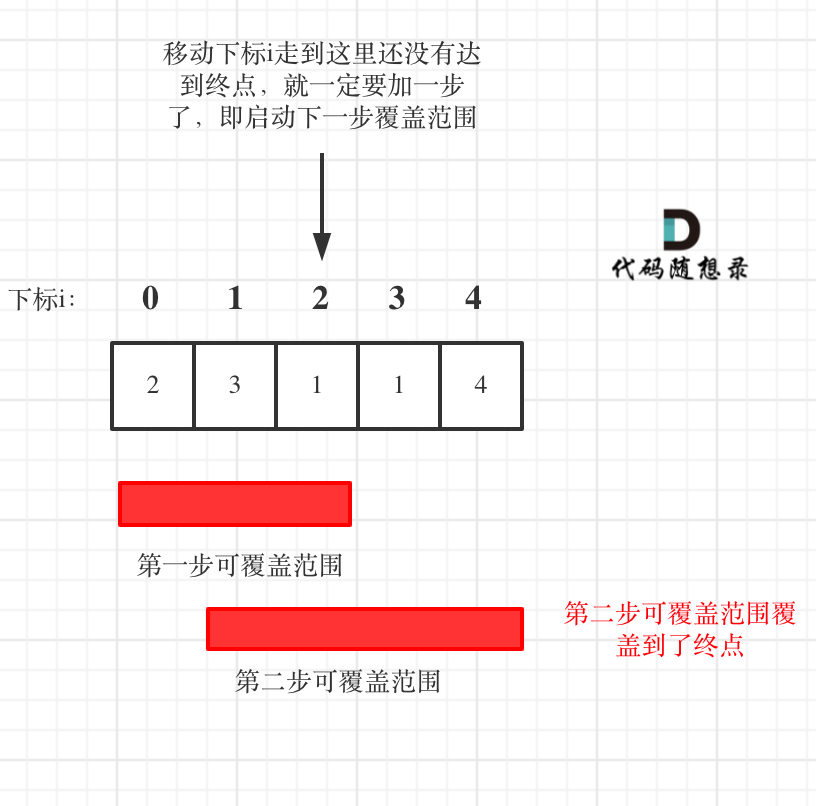
|
||||
|
||||
**图中覆盖范围的意义在于,只要红色的区域,最多两步一定可以到!(不用管具体怎么跳,反正一定可以跳到)**
|
||||
|
||||
## 方法一
|
||||
|
||||
从图中可以看出来,就是移动下标达到了当前覆盖的最远距离下标时,步数就要加一,来增加覆盖距离。最后的步数就是最少步数。
|
||||
|
||||
这里还是有个特殊情况需要考虑,当移动下标达到了当前覆盖的最远距离下标时
|
||||
|
||||
* 如果当前覆盖最远距离下标不是是集合终点,步数就加一,还需要继续走。
|
||||
* 如果当前覆盖最远距离下标就是是集合终点,步数不用加一,因为不能再往后走了。
|
||||
|
||||
C++代码如下:(详细注释)
|
||||
|
||||
```C++
|
||||
// 版本一
|
||||
class Solution {
|
||||
public:
|
||||
int jump(vector<int>& nums) {
|
||||
if (nums.size() == 1) return 0;
|
||||
int curDistance = 0; // 当前覆盖最远距离下标
|
||||
int ans = 0; // 记录走的最大步数
|
||||
int nextDistance = 0; // 下一步覆盖最远距离下标
|
||||
for (int i = 0; i < nums.size(); i++) {
|
||||
nextDistance = max(nums[i] + i, nextDistance); // 更新下一步覆盖最远距离下标
|
||||
if (i == curDistance) { // 遇到当前覆盖最远距离下标
|
||||
if (curDistance != nums.size() - 1) { // 如果当前覆盖最远距离下标不是终点
|
||||
ans++; // 需要走下一步
|
||||
curDistance = nextDistance; // 更新当前覆盖最远距离下标(相当于加油了)
|
||||
if (nextDistance >= nums.size() - 1) break; // 下一步的覆盖范围已经可以达到终点,结束循环
|
||||
} else break; // 当前覆盖最远距离下标是集合终点,不用做ans++操作了,直接结束
|
||||
}
|
||||
}
|
||||
return ans;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 方法二
|
||||
|
||||
依然是贪心,思路和方法一差不多,代码可以简洁一些。
|
||||
|
||||
**针对于方法一的特殊情况,可以统一处理**,即:移动下标只要遇到当前覆盖最远距离的下标,直接步数加一,不考虑是不是终点的情况。
|
||||
|
||||
想要达到这样的效果,只要让移动下标,最大只能移动到nums.size - 2的地方就可以了。
|
||||
|
||||
因为当移动下标指向nums.size - 2时:
|
||||
|
||||
* 如果移动下标等于当前覆盖最大距离下标, 需要再走一步(即ans++),因为最后一步一定是可以到的终点。(题目假设总是可以到达数组的最后一个位置),如图:
|
||||
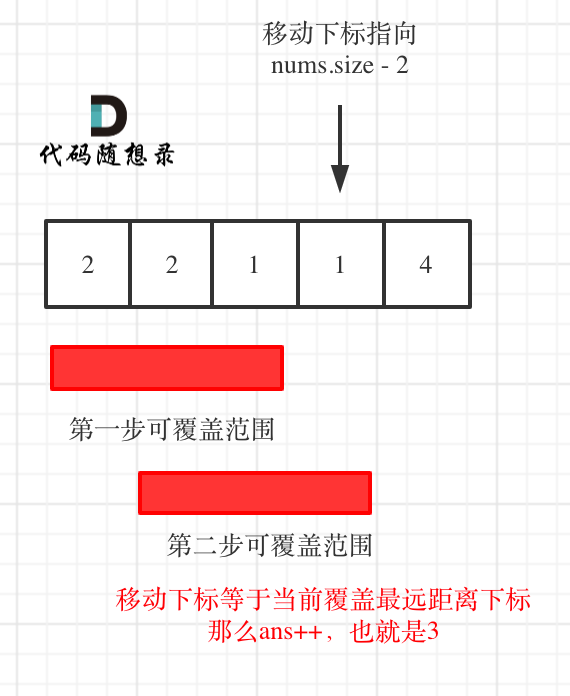
|
||||
|
||||
* 如果移动下标不等于当前覆盖最大距离下标,说明当前覆盖最远距离就可以直接达到终点了,不需要再走一步。如图:
|
||||
|
||||
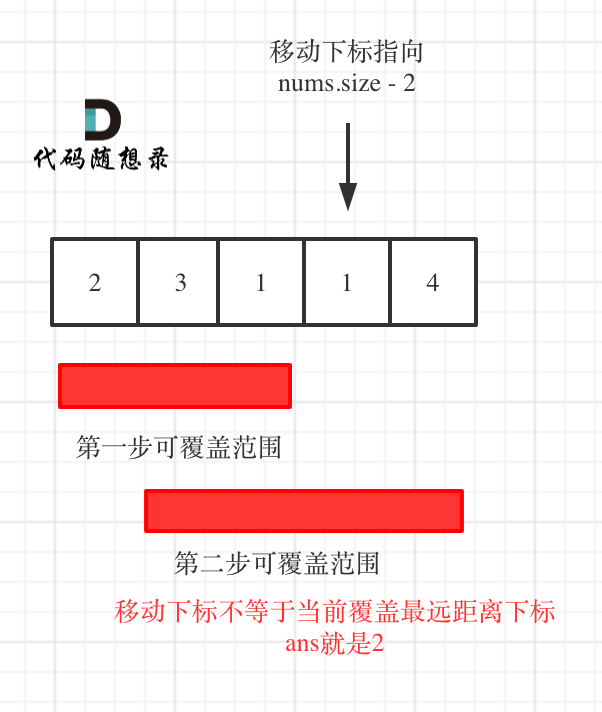
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
// 版本二
|
||||
class Solution {
|
||||
public:
|
||||
int jump(vector<int>& nums) {
|
||||
int curDistance = 0; // 当前覆盖的最远距离下标
|
||||
int ans = 0; // 记录走的最大步数
|
||||
int nextDistance = 0; // 下一步覆盖的最远距离下标
|
||||
for (int i = 0; i < nums.size() - 1; i++) { // 注意这里是小于nums.size() - 1,这是关键所在
|
||||
nextDistance = max(nums[i] + i, nextDistance); // 更新下一步覆盖的最远距离下标
|
||||
if (i == curDistance) { // 遇到当前覆盖的最远距离下标
|
||||
curDistance = nextDistance; // 更新当前覆盖的最远距离下标
|
||||
ans++;
|
||||
}
|
||||
}
|
||||
return ans;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
可以看出版本二的代码相对于版本一简化了不少!
|
||||
|
||||
其精髓在于控制移动下标i只移动到nums.size() - 2的位置,所以移动下标只要遇到当前覆盖最远距离的下标,直接步数加一,不用考虑别的了。
|
||||
|
||||
## 总结
|
||||
|
||||
相信大家可以发现,这道题目相当于[贪心算法:跳跃游戏](https://mp.weixin.qq.com/s/606_N9j8ACKCODoCbV1lSA)难了不止一点。
|
||||
|
||||
但代码又十分简单,贪心就是这么巧妙。
|
||||
|
||||
理解本题的关键在于:**以最小的步数增加最大的覆盖范围,直到覆盖范围覆盖了终点**,这个范围内最小步数一定可以跳到,不用管具体是怎么跳的,不纠结于一步究竟跳一个单位还是两个单位。
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
public int jump(int[] nums) {
|
||||
if (nums == null || nums.length == 0 || nums.length == 1) {
|
||||
return 0;
|
||||
}
|
||||
//记录跳跃的次数
|
||||
int count=0;
|
||||
//当前的覆盖最大区域
|
||||
int curDistance = 0;
|
||||
//最大的覆盖区域
|
||||
int maxDistance = 0;
|
||||
for (int i = 0; i < nums.length; i++) {
|
||||
//在可覆盖区域内更新最大的覆盖区域
|
||||
maxDistance = Math.max(maxDistance,i+nums[i]);
|
||||
//说明当前一步,再跳一步就到达了末尾
|
||||
if (maxDistance>=nums.length-1){
|
||||
count++;
|
||||
break;
|
||||
}
|
||||
//走到当前覆盖的最大区域时,更新下一步可达的最大区域
|
||||
if (i==curDistance){
|
||||
curDistance = maxDistance;
|
||||
count++;
|
||||
}
|
||||
}
|
||||
return count;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def jump(self, nums: List[int]) -> int:
|
||||
if len(nums) == 1: return 0
|
||||
ans = 0
|
||||
curDistance = 0
|
||||
nextDistance = 0
|
||||
for i in range(len(nums)):
|
||||
nextDistance = max(i + nums[i], nextDistance)
|
||||
if i == curDistance:
|
||||
if curDistance != len(nums) - 1:
|
||||
ans += 1
|
||||
curDistance = nextDistance
|
||||
if nextDistance >= len(nums) - 1: break
|
||||
return ans
|
||||
```
|
||||
|
||||
Go:
|
||||
```Go
|
||||
func jump(nums []int) int {
|
||||
dp:=make([]int ,len(nums))
|
||||
dp[0]=0
|
||||
|
||||
for i:=1;i<len(nums);i++{
|
||||
dp[i]=i
|
||||
for j:=0;j<i;j++{
|
||||
if nums[j]+j>i{
|
||||
dp[i]=min(dp[j]+1,dp[i])
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[len(nums)-1]
|
||||
}
|
||||
```
|
||||
|
||||
Javascript:
|
||||
```Javascript
|
||||
var jump = function(nums) {
|
||||
let curIndex = 0
|
||||
let nextIndex = 0
|
||||
let steps = 0
|
||||
for(let i = 0; i < nums.length - 1; i++) {
|
||||
nextIndex = Math.max(nums[i] + i, nextIndex)
|
||||
if(i === curIndex) {
|
||||
curIndex = nextIndex
|
||||
steps++
|
||||
}
|
||||
}
|
||||
|
||||
return steps
|
||||
};
|
||||
```
|
||||
|
||||
/*
|
||||
dp[i]表示从起点到当前位置的最小跳跃次数
|
||||
dp[i]=min(dp[j]+1,dp[i]) 表示从j位置用一步跳跃到当前位置,这个j位置可能有很多个,却最小一个就可以
|
||||
*/
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
286
problems/0046.全排列.md
Normal file
286
problems/0046.全排列.md
Normal file
@@ -0,0 +1,286 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 46.全排列
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/permutations/
|
||||
|
||||
给定一个 没有重复 数字的序列,返回其所有可能的全排列。
|
||||
|
||||
示例:
|
||||
输入: [1,2,3]
|
||||
输出:
|
||||
[
|
||||
[1,2,3],
|
||||
[1,3,2],
|
||||
[2,1,3],
|
||||
[2,3,1],
|
||||
[3,1,2],
|
||||
[3,2,1]
|
||||
]
|
||||
|
||||
## 思路
|
||||
|
||||
此时我们已经学习了[组合问题](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)、[切割问题](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)和[子集问题](https://mp.weixin.qq.com/s/NNRzX-vJ_pjK4qxohd_LtA),接下来看一看排列问题。
|
||||
|
||||
相信这个排列问题就算是让你用for循环暴力把结果搜索出来,这个暴力也不是很好写。
|
||||
|
||||
所以正如我们在[关于回溯算法,你该了解这些!](https://mp.weixin.qq.com/s/gjSgJbNbd1eAA5WkA-HeWw)所讲的为什么回溯法是暴力搜索,效率这么低,还要用它?
|
||||
|
||||
**因为一些问题能暴力搜出来就已经很不错了!**
|
||||
|
||||
我以[1,2,3]为例,抽象成树形结构如下:
|
||||
|
||||
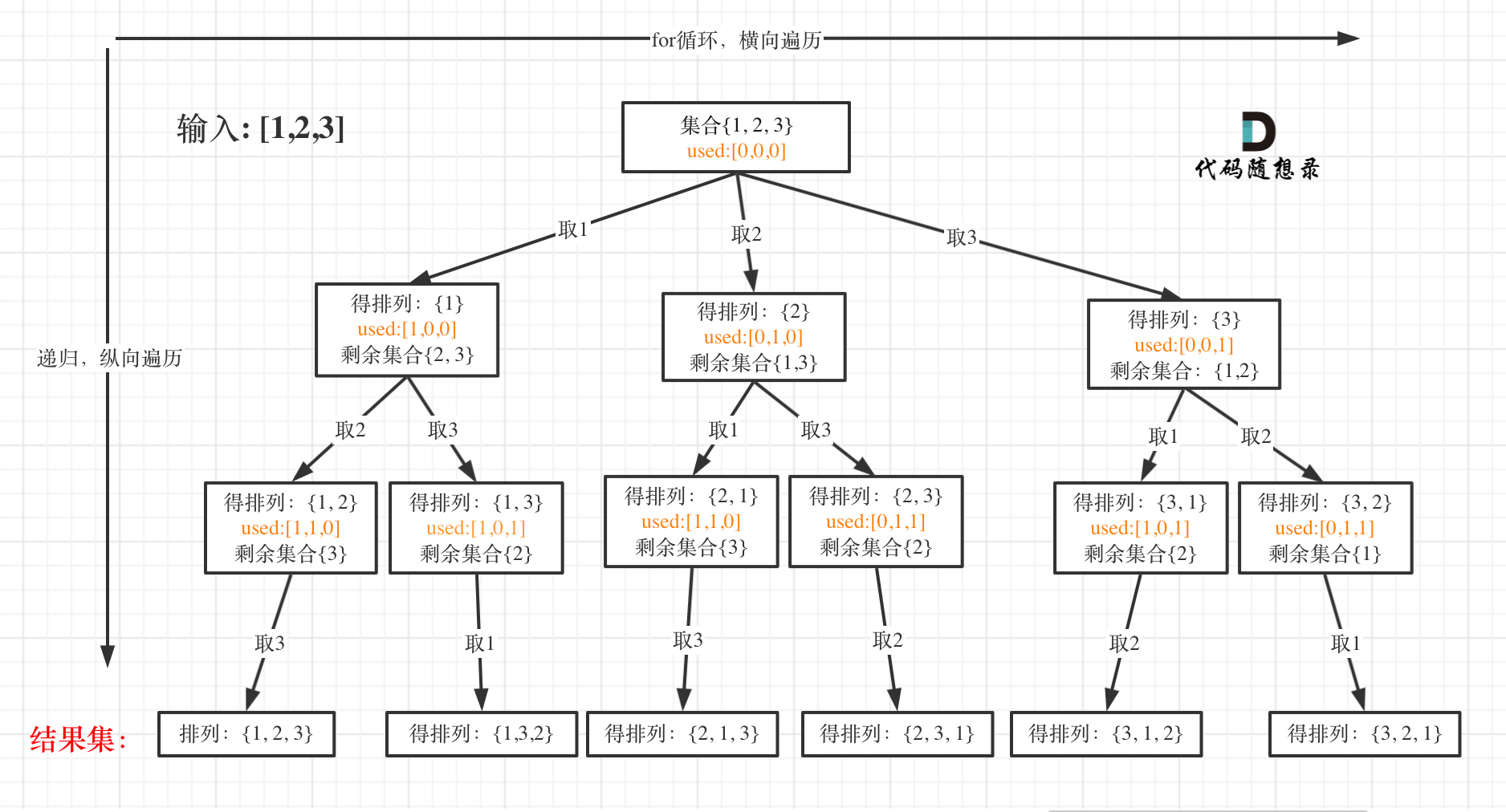
|
||||
|
||||
## 回溯三部曲
|
||||
|
||||
* 递归函数参数
|
||||
|
||||
**首先排列是有序的,也就是说[1,2] 和[2,1] 是两个集合,这和之前分析的子集以及组合所不同的地方**。
|
||||
|
||||
可以看出元素1在[1,2]中已经使用过了,但是在[2,1]中还要在使用一次1,所以处理排列问题就不用使用startIndex了。
|
||||
|
||||
但排列问题需要一个used数组,标记已经选择的元素,如图橘黄色部分所示:
|
||||
|
||||

|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
vector<vector<int>> result;
|
||||
vector<int> path;
|
||||
void backtracking (vector<int>& nums, vector<bool>& used)
|
||||
```
|
||||
|
||||
* 递归终止条件
|
||||
|
||||

|
||||
|
||||
可以看出叶子节点,就是收割结果的地方。
|
||||
|
||||
那么什么时候,算是到达叶子节点呢?
|
||||
|
||||
当收集元素的数组path的大小达到和nums数组一样大的时候,说明找到了一个全排列,也表示到达了叶子节点。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
// 此时说明找到了一组
|
||||
if (path.size() == nums.size()) {
|
||||
result.push_back(path);
|
||||
return;
|
||||
}
|
||||
```
|
||||
|
||||
* 单层搜索的逻辑
|
||||
|
||||
这里和[组合问题](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)、[切割问题](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)和[子集问题](https://mp.weixin.qq.com/s/NNRzX-vJ_pjK4qxohd_LtA)最大的不同就是for循环里不用startIndex了。
|
||||
|
||||
因为排列问题,每次都要从头开始搜索,例如元素1在[1,2]中已经使用过了,但是在[2,1]中还要再使用一次1。
|
||||
|
||||
**而used数组,其实就是记录此时path里都有哪些元素使用了,一个排列里一个元素只能使用一次**。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
for (int i = 0; i < nums.size(); i++) {
|
||||
if (used[i] == true) continue; // path里已经收录的元素,直接跳过
|
||||
used[i] = true;
|
||||
path.push_back(nums[i]);
|
||||
backtracking(nums, used);
|
||||
path.pop_back();
|
||||
used[i] = false;
|
||||
}
|
||||
```
|
||||
|
||||
整体C++代码如下:
|
||||
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
vector<vector<int>> result;
|
||||
vector<int> path;
|
||||
void backtracking (vector<int>& nums, vector<bool>& used) {
|
||||
// 此时说明找到了一组
|
||||
if (path.size() == nums.size()) {
|
||||
result.push_back(path);
|
||||
return;
|
||||
}
|
||||
for (int i = 0; i < nums.size(); i++) {
|
||||
if (used[i] == true) continue; // path里已经收录的元素,直接跳过
|
||||
used[i] = true;
|
||||
path.push_back(nums[i]);
|
||||
backtracking(nums, used);
|
||||
path.pop_back();
|
||||
used[i] = false;
|
||||
}
|
||||
}
|
||||
vector<vector<int>> permute(vector<int>& nums) {
|
||||
result.clear();
|
||||
path.clear();
|
||||
vector<bool> used(nums.size(), false);
|
||||
backtracking(nums, used);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
大家此时可以感受出排列问题的不同:
|
||||
|
||||
* 每层都是从0开始搜索而不是startIndex
|
||||
* 需要used数组记录path里都放了哪些元素了
|
||||
|
||||
排列问题是回溯算法解决的经典题目,大家可以好好体会体会。
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
|
||||
List<List<Integer>> result = new ArrayList<>();// 存放符合条件结果的集合
|
||||
LinkedList<Integer> path = new LinkedList<>();// 用来存放符合条件结果
|
||||
boolean[] used;
|
||||
public List<List<Integer>> permute(int[] nums) {
|
||||
if (nums.length == 0){
|
||||
return result;
|
||||
}
|
||||
used = new boolean[nums.length];
|
||||
permuteHelper(nums);
|
||||
return result;
|
||||
}
|
||||
|
||||
private void permuteHelper(int[] nums){
|
||||
if (path.size() == nums.length){
|
||||
result.add(new ArrayList<>(path));
|
||||
return;
|
||||
}
|
||||
for (int i = 0; i < nums.length; i++){
|
||||
if (used[i]){
|
||||
continue;
|
||||
}
|
||||
used[i] = true;
|
||||
path.add(nums[i]);
|
||||
permuteHelper(nums);
|
||||
path.removeLast();
|
||||
used[i] = false;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python3
|
||||
class Solution:
|
||||
def permute(self, nums: List[int]) -> List[List[int]]:
|
||||
res = [] #存放符合条件结果的集合
|
||||
path = [] #用来存放符合条件的结果
|
||||
used = [] #用来存放已经用过的数字
|
||||
def backtrack(nums,used):
|
||||
if len(path) == len(nums):
|
||||
return res.append(path[:]) #此时说明找到了一组
|
||||
for i in range(0,len(nums)):
|
||||
if nums[i] in used:
|
||||
continue #used里已经收录的元素,直接跳过
|
||||
path.append(nums[i])
|
||||
used.append(nums[i])
|
||||
backtrack(nums,used)
|
||||
used.pop()
|
||||
path.pop()
|
||||
backtrack(nums,used)
|
||||
return res
|
||||
```
|
||||
|
||||
Python(优化,不用used数组):
|
||||
```python3
|
||||
class Solution:
|
||||
def permute(self, nums: List[int]) -> List[List[int]]:
|
||||
res = [] #存放符合条件结果的集合
|
||||
path = [] #用来存放符合条件的结果
|
||||
def backtrack(nums):
|
||||
if len(path) == len(nums):
|
||||
return res.append(path[:]) #此时说明找到了一组
|
||||
for i in range(0,len(nums)):
|
||||
if nums[i] in path: #path里已经收录的元素,直接跳过
|
||||
continue
|
||||
path.append(nums[i])
|
||||
backtrack(nums) #递归
|
||||
path.pop() #回溯
|
||||
backtrack(nums)
|
||||
return res
|
||||
```
|
||||
|
||||
Go:
|
||||
```Go
|
||||
var result [][]int
|
||||
func backtrack(nums,pathNums []int,used []bool){
|
||||
if len(nums)==len(pathNums){
|
||||
tmp:=make([]int,len(nums))
|
||||
copy(tmp,pathNums)
|
||||
result=append(result,tmp)
|
||||
//result=append(result,pathNums)
|
||||
return
|
||||
}
|
||||
for i:=0;i<len(nums);i++{
|
||||
if !used[i]{
|
||||
used[i]=true
|
||||
pathNums=append(pathNums,nums[i])
|
||||
backtrack(nums,pathNums,used)
|
||||
pathNums=pathNums[:len(pathNums)-1]
|
||||
used[i]=false
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Javascript:
|
||||
|
||||
```js
|
||||
|
||||
/**
|
||||
* @param {number[]} nums
|
||||
* @return {number[][]}
|
||||
*/
|
||||
var permute = function(nums) {
|
||||
const res = [], path = [];
|
||||
backtracking(nums, nums.length, []);
|
||||
return res;
|
||||
|
||||
function backtracking(n, k, used) {
|
||||
if(path.length === k) {
|
||||
res.push(Array.from(path));
|
||||
return;
|
||||
}
|
||||
for (let i = 0; i < k; i++ ) {
|
||||
if(used[i]) continue;
|
||||
path.push(n[i]);
|
||||
used[i] = true; // 同支
|
||||
backtracking(n, k, used);
|
||||
path.pop();
|
||||
used[i] = false;
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
267
problems/0047.全排列II.md
Normal file
267
problems/0047.全排列II.md
Normal file
@@ -0,0 +1,267 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
# 排列问题(二)
|
||||
|
||||
## 47.全排列 II
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/permutations-ii/
|
||||
|
||||
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
|
||||
|
||||
示例 1:
|
||||
输入:nums = [1,1,2]
|
||||
输出:
|
||||
[[1,1,2],
|
||||
[1,2,1],
|
||||
[2,1,1]]
|
||||
|
||||
示例 2:
|
||||
输入:nums = [1,2,3]
|
||||
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
|
||||
|
||||
提示:
|
||||
* 1 <= nums.length <= 8
|
||||
* -10 <= nums[i] <= 10
|
||||
|
||||
## 思路
|
||||
|
||||
这道题目和[回溯算法:排列问题!](https://mp.weixin.qq.com/s/SCOjeMX1t41wcvJq49GhMw)的区别在与**给定一个可包含重复数字的序列**,要返回**所有不重复的全排列**。
|
||||
|
||||
这里又涉及到去重了。
|
||||
|
||||
在[回溯算法:求组合总和(三)](https://mp.weixin.qq.com/s/_1zPYk70NvHsdY8UWVGXmQ) 、[回溯算法:求子集问题(二)](https://mp.weixin.qq.com/s/WJ4JNDRJgsW3eUN72Hh3uQ)我们分别详细讲解了组合问题和子集问题如何去重。
|
||||
|
||||
那么排列问题其实也是一样的套路。
|
||||
|
||||
**还要强调的是去重一定要对元素经行排序,这样我们才方便通过相邻的节点来判断是否重复使用了**。
|
||||
|
||||
我以示例中的 [1,1,2]为例 (为了方便举例,已经排序)抽象为一棵树,去重过程如图:
|
||||
|
||||
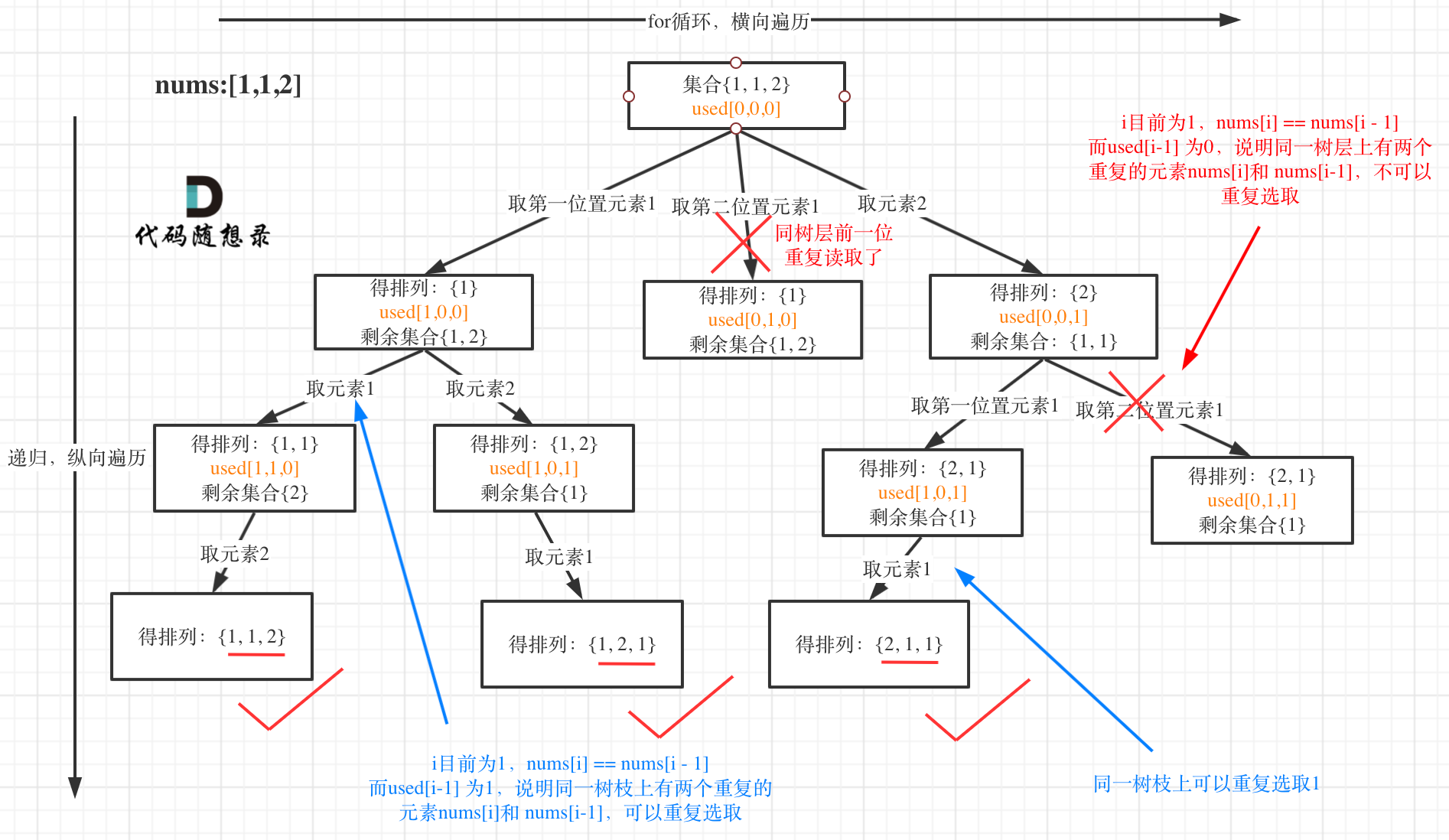
|
||||
|
||||
图中我们对同一树层,前一位(也就是nums[i-1])如果使用过,那么就进行去重。
|
||||
|
||||
**一般来说:组合问题和排列问题是在树形结构的叶子节点上收集结果,而子集问题就是取树上所有节点的结果**。
|
||||
|
||||
在[回溯算法:排列问题!](https://mp.weixin.qq.com/s/SCOjeMX1t41wcvJq49GhMw)中已经详解讲解了排列问题的写法,在[回溯算法:求组合总和(三)](https://mp.weixin.qq.com/s/_1zPYk70NvHsdY8UWVGXmQ) 、[回溯算法:求子集问题(二)](https://mp.weixin.qq.com/s/WJ4JNDRJgsW3eUN72Hh3uQ)中详细讲解的去重的写法,所以这次我就不用回溯三部曲分析了,直接给出代码,如下:
|
||||
|
||||
## C++代码
|
||||
|
||||
```
|
||||
class Solution {
|
||||
private:
|
||||
vector<vector<int>> result;
|
||||
vector<int> path;
|
||||
void backtracking (vector<int>& nums, vector<bool>& used) {
|
||||
// 此时说明找到了一组
|
||||
if (path.size() == nums.size()) {
|
||||
result.push_back(path);
|
||||
return;
|
||||
}
|
||||
for (int i = 0; i < nums.size(); i++) {
|
||||
// used[i - 1] == true,说明同一树支nums[i - 1]使用过
|
||||
// used[i - 1] == false,说明同一树层nums[i - 1]使用过
|
||||
// 如果同一树层nums[i - 1]使用过则直接跳过
|
||||
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) {
|
||||
continue;
|
||||
}
|
||||
if (used[i] == false) {
|
||||
used[i] = true;
|
||||
path.push_back(nums[i]);
|
||||
backtracking(nums, used);
|
||||
path.pop_back();
|
||||
used[i] = false;
|
||||
}
|
||||
}
|
||||
}
|
||||
public:
|
||||
vector<vector<int>> permuteUnique(vector<int>& nums) {
|
||||
result.clear();
|
||||
path.clear();
|
||||
sort(nums.begin(), nums.end()); // 排序
|
||||
vector<bool> used(nums.size(), false);
|
||||
backtracking(nums, used);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
## 拓展
|
||||
|
||||
大家发现,去重最为关键的代码为:
|
||||
|
||||
```
|
||||
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) {
|
||||
continue;
|
||||
}
|
||||
```
|
||||
|
||||
**如果改成 `used[i - 1] == true`, 也是正确的!**,去重代码如下:
|
||||
```
|
||||
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == true) {
|
||||
continue;
|
||||
}
|
||||
```
|
||||
|
||||
这是为什么呢,就是上面我刚说的,如果要对树层中前一位去重,就用`used[i - 1] == false`,如果要对树枝前一位去重用`used[i - 1] == true`。
|
||||
|
||||
**对于排列问题,树层上去重和树枝上去重,都是可以的,但是树层上去重效率更高!**
|
||||
|
||||
这么说是不是有点抽象?
|
||||
|
||||
来来来,我就用输入: [1,1,1] 来举一个例子。
|
||||
|
||||
树层上去重(used[i - 1] == false),的树形结构如下:
|
||||
|
||||
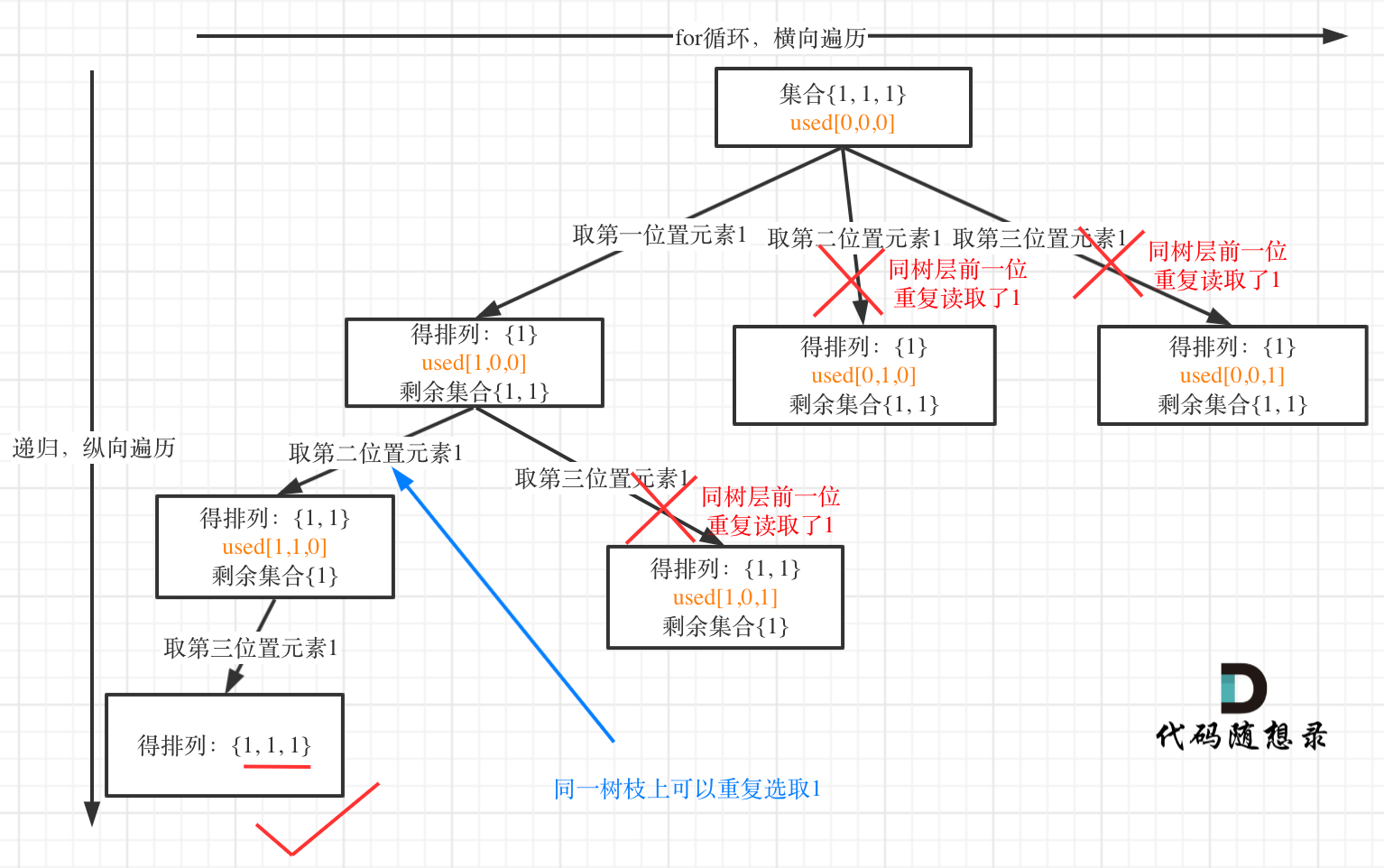
|
||||
|
||||
树枝上去重(used[i - 1] == true)的树型结构如下:
|
||||
|
||||
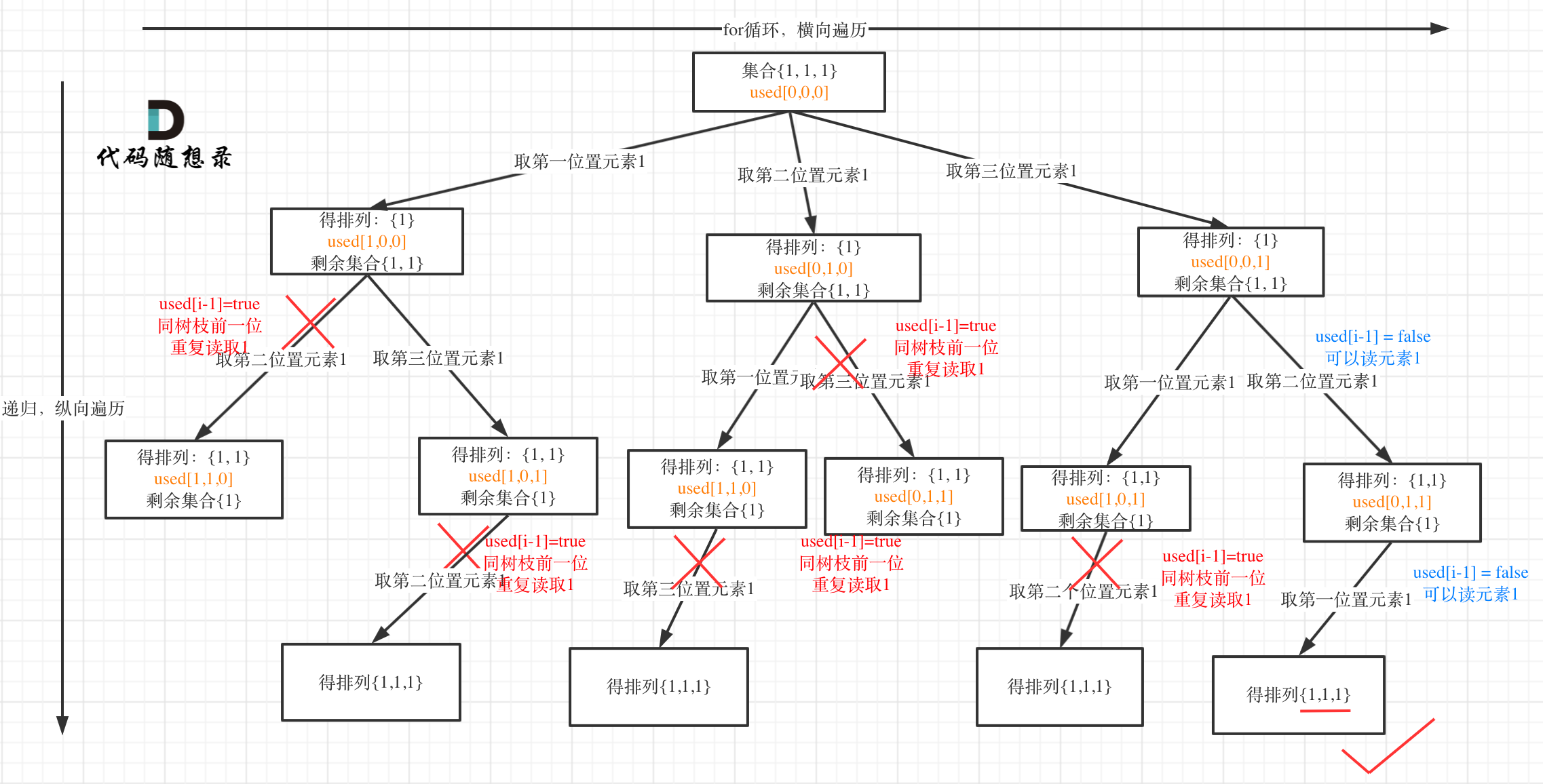
|
||||
|
||||
大家应该很清晰的看到,树层上对前一位去重非常彻底,效率很高,树枝上对前一位去重虽然最后可以得到答案,但是做了很多无用搜索。
|
||||
|
||||
## 总结
|
||||
|
||||
这道题其实还是用了我们之前讲过的去重思路,但有意思的是,去重的代码中,这么写:
|
||||
```
|
||||
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) {
|
||||
continue;
|
||||
}
|
||||
```
|
||||
和这么写:
|
||||
```
|
||||
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == true) {
|
||||
continue;
|
||||
}
|
||||
```
|
||||
|
||||
都是可以的,这也是很多同学做这道题目困惑的地方,知道`used[i - 1] == false`也行而`used[i - 1] == true`也行,但是就想不明白为啥。
|
||||
|
||||
所以我通过举[1,1,1]的例子,把这两个去重的逻辑分别抽象成树形结构,大家可以一目了然:为什么两种写法都可以以及哪一种效率更高!
|
||||
|
||||
是不是豁然开朗了!!
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
java:
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
//存放结果
|
||||
List<List<Integer>> result = new ArrayList<>();
|
||||
//暂存结果
|
||||
List<Integer> path = new ArrayList<>();
|
||||
|
||||
public List<List<Integer>> permuteUnique(int[] nums) {
|
||||
boolean[] used = new boolean[nums.length];
|
||||
Arrays.fill(used, false);
|
||||
Arrays.sort(nums);
|
||||
backTrack(nums, used);
|
||||
return result;
|
||||
}
|
||||
|
||||
private void backTrack(int[] nums, boolean[] used) {
|
||||
if (path.size() == nums.length) {
|
||||
result.add(new ArrayList<>(path));
|
||||
return;
|
||||
}
|
||||
for (int i = 0; i < nums.length; i++) {
|
||||
// used[i - 1] == true,说明同⼀树⽀nums[i - 1]使⽤过
|
||||
// used[i - 1] == false,说明同⼀树层nums[i - 1]使⽤过
|
||||
// 如果同⼀树层nums[i - 1]使⽤过则直接跳过
|
||||
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) {
|
||||
continue;
|
||||
}
|
||||
//如果同⼀树⽀nums[i]没使⽤过开始处理
|
||||
if (used[i] == false) {
|
||||
used[i] = true;//标记同⼀树⽀nums[i]使⽤过,防止同一树支重复使用
|
||||
path.add(nums[i]);
|
||||
backTrack(nums, used);
|
||||
path.remove(path.size() - 1);//回溯,说明同⼀树层nums[i]使⽤过,防止下一树层重复
|
||||
used[i] = false;//回溯
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
python:
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
|
||||
# res用来存放结果
|
||||
if not nums: return []
|
||||
res = []
|
||||
used = [0] * len(nums)
|
||||
def backtracking(nums, used, path):
|
||||
# 终止条件
|
||||
if len(path) == len(nums):
|
||||
res.append(path.copy())
|
||||
return
|
||||
for i in range(len(nums)):
|
||||
if not used[i]:
|
||||
if i>0 and nums[i] == nums[i-1] and not used[i-1]:
|
||||
continue
|
||||
used[i] = 1
|
||||
path.append(nums[i])
|
||||
backtracking(nums, used, path)
|
||||
path.pop()
|
||||
used[i] = 0
|
||||
# 记得给nums排序
|
||||
backtracking(sorted(nums),used,[])
|
||||
return res
|
||||
```
|
||||
|
||||
Javascript:
|
||||
|
||||
```javascript
|
||||
|
||||
var permuteUnique = function (nums) {
|
||||
nums.sort((a, b) => {
|
||||
return a - b
|
||||
})
|
||||
let result = []
|
||||
let path = []
|
||||
|
||||
function backtracing( used) {
|
||||
if (path.length === nums.length) {
|
||||
result.push(path.slice())
|
||||
return
|
||||
}
|
||||
for (let i = 0; i < nums.length; i++) {
|
||||
if (i > 0 && nums[i] === nums[i - 1] && !used[i - 1]) {
|
||||
continue
|
||||
}
|
||||
if (!used[i]) {
|
||||
used[i] = true
|
||||
path.push(nums[i])
|
||||
backtracing(used)
|
||||
path.pop()
|
||||
used[i] = false
|
||||
}
|
||||
|
||||
|
||||
}
|
||||
}
|
||||
backtracing([])
|
||||
return result
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
490
problems/0051.N皇后.md
Normal file
490
problems/0051.N皇后.md
Normal file
@@ -0,0 +1,490 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 第51题. N皇后
|
||||
|
||||
题目链接: https://leetcode-cn.com/problems/n-queens/
|
||||
|
||||
n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
|
||||
|
||||
上图为 8 皇后问题的一种解法。
|
||||
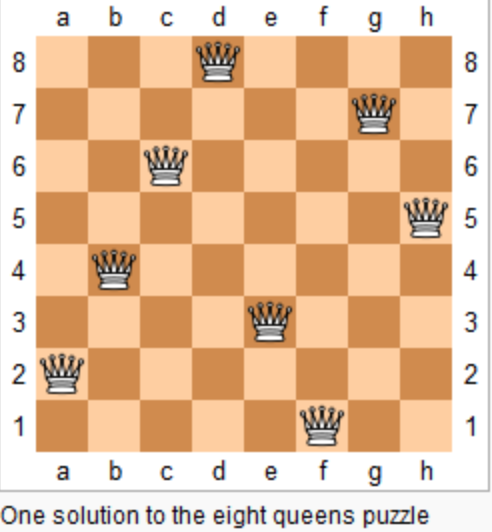
|
||||
|
||||
给定一个整数 n,返回所有不同的 n 皇后问题的解决方案。
|
||||
|
||||
每一种解法包含一个明确的 n 皇后问题的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
|
||||
|
||||
示例:
|
||||
输入: 4
|
||||
输出: [
|
||||
[".Q..", // 解法 1
|
||||
"...Q",
|
||||
"Q...",
|
||||
"..Q."],
|
||||
|
||||
["..Q.", // 解法 2
|
||||
"Q...",
|
||||
"...Q",
|
||||
".Q.."]
|
||||
]
|
||||
解释: 4 皇后问题存在两个不同的解法。
|
||||
|
||||
提示:
|
||||
> 皇后,是国际象棋中的棋子,意味着国王的妻子。皇后只做一件事,那就是“吃子”。当她遇见可以吃的棋子时,就迅速冲上去吃掉棋子。当然,她横、竖、斜都可走一到七步,可进可退。(引用自 百度百科 - 皇后 )
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
都知道n皇后问题是回溯算法解决的经典问题,但是用回溯解决多了组合、切割、子集、排列问题之后,遇到这种二位矩阵还会有点不知所措。
|
||||
|
||||
首先来看一下皇后们的约束条件:
|
||||
|
||||
1. 不能同行
|
||||
2. 不能同列
|
||||
3. 不能同斜线
|
||||
|
||||
确定完约束条件,来看看究竟要怎么去搜索皇后们的位置,其实搜索皇后的位置,可以抽象为一棵树。
|
||||
|
||||
下面我用一个3 * 3 的棋牌,将搜索过程抽象为一颗树,如图:
|
||||
|
||||
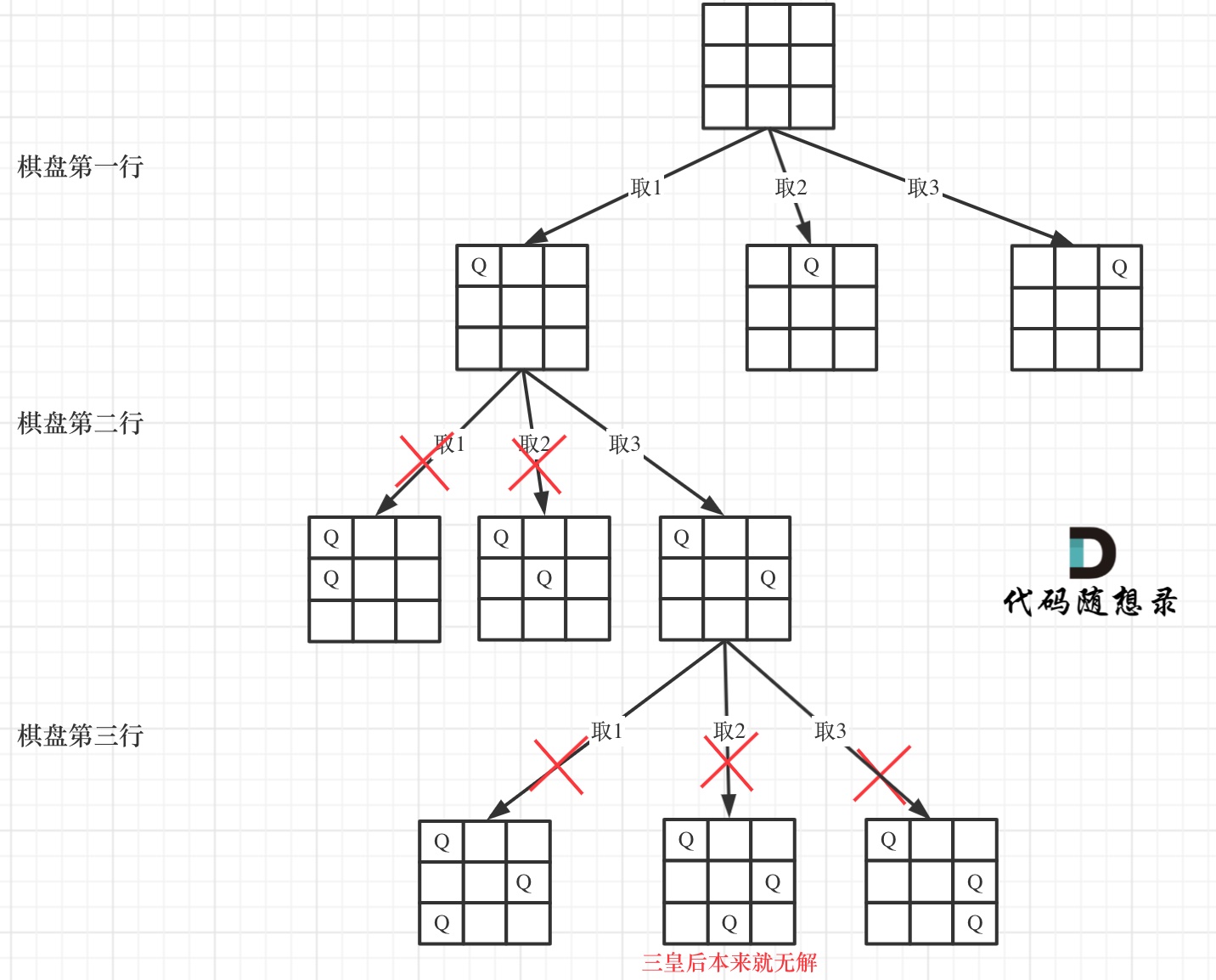
|
||||
|
||||
从图中,可以看出,二维矩阵中矩阵的高就是这颗树的高度,矩阵的宽就是树形结构中每一个节点的宽度。
|
||||
|
||||
那么我们用皇后们的约束条件,来回溯搜索这颗树,**只要搜索到了树的叶子节点,说明就找到了皇后们的合理位置了**。
|
||||
|
||||
## 回溯三部曲
|
||||
|
||||
按照我总结的如下回溯模板,我们来依次分析:
|
||||
|
||||
```
|
||||
void backtracking(参数) {
|
||||
if (终止条件) {
|
||||
存放结果;
|
||||
return;
|
||||
}
|
||||
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
|
||||
处理节点;
|
||||
backtracking(路径,选择列表); // 递归
|
||||
回溯,撤销处理结果
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
* 递归函数参数
|
||||
|
||||
我依然是定义全局变量二维数组result来记录最终结果。
|
||||
|
||||
参数n是棋牌的大小,然后用row来记录当前遍历到棋盘的第几层了。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
vector<vector<string>> result;
|
||||
void backtracking(int n, int row, vector<string>& chessboard) {
|
||||
```
|
||||
|
||||
* 递归终止条件
|
||||
|
||||
在如下树形结构中:
|
||||

|
||||
|
||||
|
||||
可以看出,当递归到棋盘最底层(也就是叶子节点)的时候,就可以收集结果并返回了。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
if (row == n) {
|
||||
result.push_back(chessboard);
|
||||
return;
|
||||
}
|
||||
```
|
||||
|
||||
* 单层搜索的逻辑
|
||||
|
||||
递归深度就是row控制棋盘的行,每一层里for循环的col控制棋盘的列,一行一列,确定了放置皇后的位置。
|
||||
|
||||
每次都是要从新的一行的起始位置开始搜,所以都是从0开始。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
for (int col = 0; col < n; col++) {
|
||||
if (isValid(row, col, chessboard, n)) { // 验证合法就可以放
|
||||
chessboard[row][col] = 'Q'; // 放置皇后
|
||||
backtracking(n, row + 1, chessboard);
|
||||
chessboard[row][col] = '.'; // 回溯,撤销皇后
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
* 验证棋牌是否合法
|
||||
|
||||
按照如下标准去重:
|
||||
|
||||
1. 不能同行
|
||||
2. 不能同列
|
||||
3. 不能同斜线 (45度和135度角)
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
bool isValid(int row, int col, vector<string>& chessboard, int n) {
|
||||
int count = 0;
|
||||
// 检查列
|
||||
for (int i = 0; i < row; i++) { // 这是一个剪枝
|
||||
if (chessboard[i][col] == 'Q') {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
// 检查 45度角是否有皇后
|
||||
for (int i = row - 1, j = col - 1; i >=0 && j >= 0; i--, j--) {
|
||||
if (chessboard[i][j] == 'Q') {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
// 检查 135度角是否有皇后
|
||||
for(int i = row - 1, j = col + 1; i >= 0 && j < n; i--, j++) {
|
||||
if (chessboard[i][j] == 'Q') {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
```
|
||||
|
||||
在这份代码中,细心的同学可以发现为什么没有在同行进行检查呢?
|
||||
|
||||
因为在单层搜索的过程中,每一层递归,只会选for循环(也就是同一行)里的一个元素,所以不用去重了。
|
||||
|
||||
那么按照这个模板不难写出如下C++代码:
|
||||
|
||||
## C++代码
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
vector<vector<string>> result;
|
||||
// n 为输入的棋盘大小
|
||||
// row 是当前递归到棋牌的第几行了
|
||||
void backtracking(int n, int row, vector<string>& chessboard) {
|
||||
if (row == n) {
|
||||
result.push_back(chessboard);
|
||||
return;
|
||||
}
|
||||
for (int col = 0; col < n; col++) {
|
||||
if (isValid(row, col, chessboard, n)) { // 验证合法就可以放
|
||||
chessboard[row][col] = 'Q'; // 放置皇后
|
||||
backtracking(n, row + 1, chessboard);
|
||||
chessboard[row][col] = '.'; // 回溯,撤销皇后
|
||||
}
|
||||
}
|
||||
}
|
||||
bool isValid(int row, int col, vector<string>& chessboard, int n) {
|
||||
int count = 0;
|
||||
// 检查列
|
||||
for (int i = 0; i < row; i++) { // 这是一个剪枝
|
||||
if (chessboard[i][col] == 'Q') {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
// 检查 45度角是否有皇后
|
||||
for (int i = row - 1, j = col - 1; i >=0 && j >= 0; i--, j--) {
|
||||
if (chessboard[i][j] == 'Q') {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
// 检查 135度角是否有皇后
|
||||
for(int i = row - 1, j = col + 1; i >= 0 && j < n; i--, j++) {
|
||||
if (chessboard[i][j] == 'Q') {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
public:
|
||||
vector<vector<string>> solveNQueens(int n) {
|
||||
result.clear();
|
||||
std::vector<std::string> chessboard(n, std::string(n, '.'));
|
||||
backtracking(n, 0, chessboard);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
可以看出,除了验证棋盘合法性的代码,省下来部分就是按照回溯法模板来的。
|
||||
|
||||
## 总结
|
||||
|
||||
本题是我们解决棋盘问题的第一道题目。
|
||||
|
||||
如果从来没有接触过N皇后问题的同学看着这样的题会感觉无从下手,可能知道要用回溯法,但也不知道该怎么去搜。
|
||||
|
||||
**这里我明确给出了棋盘的宽度就是for循环的长度,递归的深度就是棋盘的高度,这样就可以套进回溯法的模板里了**。
|
||||
|
||||
大家可以在仔细体会体会!
|
||||
|
||||
|
||||
## 其他语言补充
|
||||
|
||||
|
||||
Python:
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def solveNQueens(self, n: int) -> List[List[str]]:
|
||||
if not n: return []
|
||||
board = [['.'] * n for _ in range(n)]
|
||||
res = []
|
||||
def isVaild(board,row, col):
|
||||
#判断同一列是否冲突
|
||||
for i in range(len(board)):
|
||||
if board[i][col] == 'Q':
|
||||
return False
|
||||
# 判断左上角是否冲突
|
||||
i = row -1
|
||||
j = col -1
|
||||
while i>=0 and j>=0:
|
||||
if board[i][j] == 'Q':
|
||||
return False
|
||||
i -= 1
|
||||
j -= 1
|
||||
# 判断右上角是否冲突
|
||||
i = row - 1
|
||||
j = col + 1
|
||||
while i>=0 and j < len(board):
|
||||
if board[i][j] == 'Q':
|
||||
return False
|
||||
i -= 1
|
||||
j += 1
|
||||
return True
|
||||
|
||||
def backtracking(board, row, n):
|
||||
# 如果走到最后一行,说明已经找到一个解
|
||||
if row == n:
|
||||
temp_res = []
|
||||
for temp in board:
|
||||
temp_str = "".join(temp)
|
||||
temp_res.append(temp_str)
|
||||
res.append(temp_res)
|
||||
for col in range(n):
|
||||
if not isVaild(board, row, col):
|
||||
continue
|
||||
board[row][col] = 'Q'
|
||||
backtracking(board, row+1, n)
|
||||
board[row][col] = '.'
|
||||
backtracking(board, 0, n)
|
||||
return res
|
||||
```
|
||||
|
||||
Java:
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
List<List<String>> res = new ArrayList<>();
|
||||
|
||||
public List<List<String>> solveNQueens(int n) {
|
||||
char[][] chessboard = new char[n][n];
|
||||
for (char[] c : chessboard) {
|
||||
Arrays.fill(c, '.');
|
||||
}
|
||||
backTrack(n, 0, chessboard);
|
||||
return res;
|
||||
}
|
||||
|
||||
|
||||
public void backTrack(int n, int row, char[][] chessboard) {
|
||||
if (row == n) {
|
||||
res.add(Array2List(chessboard));
|
||||
return;
|
||||
}
|
||||
|
||||
for (int col = 0;col < n; ++col) {
|
||||
if (isValid (row, col, n, chessboard)) {
|
||||
chessboard[row][col] = 'Q';
|
||||
backTrack(n, row+1, chessboard);
|
||||
chessboard[row][col] = '.';
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
|
||||
public List Array2List(char[][] chessboard) {
|
||||
List<String> list = new ArrayList<>();
|
||||
|
||||
for (char[] c : chessboard) {
|
||||
list.add(String.copyValueOf(c));
|
||||
}
|
||||
return list;
|
||||
}
|
||||
|
||||
|
||||
public boolean isValid(int row, int col, int n, char[][] chessboard) {
|
||||
// 检查列
|
||||
for (int i=0; i<n; ++i) {
|
||||
if (chessboard[i][col] == 'Q') {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
// 检查45度对角线
|
||||
for (int i=row-1, j=col-1; i>=0 && j>=0; i--, j--) {
|
||||
if (chessboard[i][j] == 'Q') {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
// 检查135度对角线
|
||||
for (int i=row-1, j=col+1; i>=0 && j<=n-1; i--, j++) {
|
||||
if (chessboard[i][j] == 'Q') {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
Go:
|
||||
```Go
|
||||
import "strings"
|
||||
var res [][]string
|
||||
|
||||
func isValid(board [][]string, row, col int) (res bool){
|
||||
n := len(board)
|
||||
for i:=0; i < row; i++ {
|
||||
if board[i][col] == "Q" {
|
||||
return false
|
||||
}
|
||||
}
|
||||
for i := 0; i < n; i++{
|
||||
if board[row][i] == "Q" {
|
||||
return false
|
||||
}
|
||||
}
|
||||
|
||||
for i ,j := row, col; i >= 0 && j >=0 ; i, j = i - 1, j- 1{
|
||||
if board[i][j] == "Q"{
|
||||
return false
|
||||
}
|
||||
}
|
||||
for i, j := row, col; i >=0 && j < n; i,j = i-1, j+1 {
|
||||
if board[i][j] == "Q" {
|
||||
return false
|
||||
}
|
||||
}
|
||||
return true
|
||||
}
|
||||
|
||||
func backtrack(board [][]string, row int) {
|
||||
size := len(board)
|
||||
if row == size{
|
||||
temp := make([]string, size)
|
||||
for i := 0; i<size;i++{
|
||||
temp[i] = strings.Join(board[i],"")
|
||||
}
|
||||
res =append(res,temp)
|
||||
return
|
||||
}
|
||||
for col := 0; col < size; col++ {
|
||||
if !isValid(board, row, col){
|
||||
continue
|
||||
}
|
||||
board[row][col] = "Q"
|
||||
backtrack(board, row+1)
|
||||
board[row][col] = "."
|
||||
}
|
||||
}
|
||||
|
||||
func solveNQueens(n int) [][]string {
|
||||
res = [][]string{}
|
||||
board := make([][]string, n)
|
||||
for i := 0; i < n; i++{
|
||||
board[i] = make([]string, n)
|
||||
}
|
||||
for i := 0; i < n; i++{
|
||||
for j := 0; j<n;j++{
|
||||
board[i][j] = "."
|
||||
}
|
||||
}
|
||||
backtrack(board, 0)
|
||||
|
||||
return res
|
||||
}
|
||||
```
|
||||
|
||||
Javascript:
|
||||
```Javascript
|
||||
var solveNQueens = function(n) {
|
||||
function isValid(row, col, chessBoard, n) {
|
||||
|
||||
for(let i = 0; i < row; i++) {
|
||||
if(chessBoard[i][col] === 'Q') {
|
||||
return false
|
||||
}
|
||||
}
|
||||
|
||||
for(let i = row - 1, j = col - 1; i >= 0 && j >= 0; i--, j--) {
|
||||
if(chessBoard[i][j] === 'Q') {
|
||||
return false
|
||||
}
|
||||
}
|
||||
|
||||
for(let i = row - 1, j = col + 1; i >= 0 && j < n; i--, j++) {
|
||||
if(chessBoard[i][j] === 'Q') {
|
||||
return false
|
||||
}
|
||||
}
|
||||
return true
|
||||
}
|
||||
|
||||
function transformChessBoard(chessBoard) {
|
||||
let chessBoardBack = []
|
||||
chessBoard.forEach(row => {
|
||||
let rowStr = ''
|
||||
row.forEach(value => {
|
||||
rowStr += value
|
||||
})
|
||||
chessBoardBack.push(rowStr)
|
||||
})
|
||||
|
||||
return chessBoardBack
|
||||
}
|
||||
|
||||
let result = []
|
||||
function backtracing(row,chessBoard) {
|
||||
if(row === n) {
|
||||
result.push(transformChessBoard(chessBoard))
|
||||
return
|
||||
}
|
||||
for(let col = 0; col < n; col++) {
|
||||
if(isValid(row, col, chessBoard, n)) {
|
||||
chessBoard[row][col] = 'Q'
|
||||
backtracing(row + 1,chessBoard)
|
||||
chessBoard[row][col] = '.'
|
||||
}
|
||||
}
|
||||
}
|
||||
let chessBoard = new Array(n).fill([]).map(() => new Array(n).fill('.'))
|
||||
backtracing(0,chessBoard)
|
||||
return result
|
||||
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
217
problems/0053.最大子序和.md
Normal file
217
problems/0053.最大子序和.md
Normal file
@@ -0,0 +1,217 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 53. 最大子序和
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/maximum-subarray/
|
||||
|
||||
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
|
||||
|
||||
示例:
|
||||
输入: [-2,1,-3,4,-1,2,1,-5,4]
|
||||
输出: 6
|
||||
解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。
|
||||
|
||||
|
||||
## 暴力解法
|
||||
|
||||
暴力解法的思路,第一层for 就是设置起始位置,第二层for循环遍历数组寻找最大值
|
||||
|
||||
时间复杂度:O(n^2)
|
||||
空间复杂度:O(1)
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int maxSubArray(vector<int>& nums) {
|
||||
int result = INT32_MIN;
|
||||
int count = 0;
|
||||
for (int i = 0; i < nums.size(); i++) { // 设置起始位置
|
||||
count = 0;
|
||||
for (int j = i; j < nums.size(); j++) { // 每次从起始位置i开始遍历寻找最大值
|
||||
count += nums[j];
|
||||
result = count > result ? count : result;
|
||||
}
|
||||
}
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
以上暴力的解法C++勉强可以过,其他语言就不确定了。
|
||||
|
||||
## 贪心解法
|
||||
|
||||
**贪心贪的是哪里呢?**
|
||||
|
||||
如果 -2 1 在一起,计算起点的时候,一定是从1开始计算,因为负数只会拉低总和,这就是贪心贪的地方!
|
||||
|
||||
局部最优:当前“连续和”为负数的时候立刻放弃,从下一个元素重新计算“连续和”,因为负数加上下一个元素 “连续和”只会越来越小。
|
||||
|
||||
全局最优:选取最大“连续和”
|
||||
|
||||
**局部最优的情况下,并记录最大的“连续和”,可以推出全局最优**。
|
||||
|
||||
|
||||
从代码角度上来讲:遍历nums,从头开始用count累积,如果count一旦加上nums[i]变为负数,那么就应该从nums[i+1]开始从0累积count了,因为已经变为负数的count,只会拖累总和。
|
||||
|
||||
**这相当于是暴力解法中的不断调整最大子序和区间的起始位置**。
|
||||
|
||||
|
||||
**那有同学问了,区间终止位置不用调整么? 如何才能得到最大“连续和”呢?**
|
||||
|
||||
区间的终止位置,其实就是如果count取到最大值了,及时记录下来了。例如如下代码:
|
||||
|
||||
```
|
||||
if (count > result) result = count;
|
||||
```
|
||||
|
||||
**这样相当于是用result记录最大子序和区间和(变相的算是调整了终止位置)**。
|
||||
|
||||
如动画所示:
|
||||
|
||||
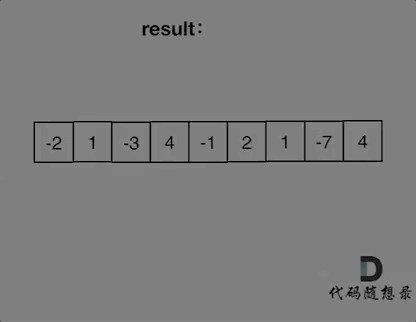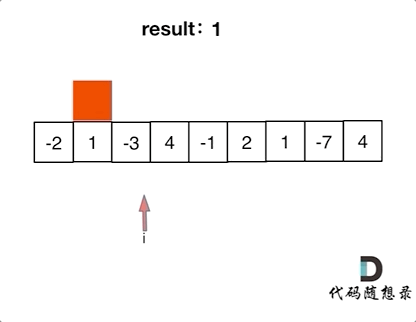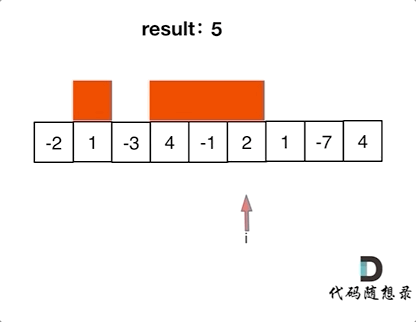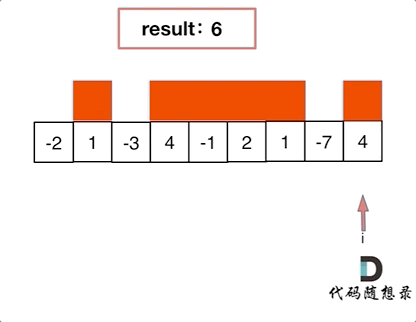
|
||||
|
||||
红色的起始位置就是贪心每次取count为正数的时候,开始一个区间的统计。
|
||||
|
||||
那么不难写出如下C++代码(关键地方已经注释)
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int maxSubArray(vector<int>& nums) {
|
||||
int result = INT32_MIN;
|
||||
int count = 0;
|
||||
for (int i = 0; i < nums.size(); i++) {
|
||||
count += nums[i];
|
||||
if (count > result) { // 取区间累计的最大值(相当于不断确定最大子序终止位置)
|
||||
result = count;
|
||||
}
|
||||
if (count <= 0) count = 0; // 相当于重置最大子序起始位置,因为遇到负数一定是拉低总和
|
||||
}
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
时间复杂度:O(n)
|
||||
空间复杂度:O(1)
|
||||
|
||||
当然题目没有说如果数组为空,应该返回什么,所以数组为空的话返回啥都可以了。
|
||||
|
||||
## 动态规划
|
||||
|
||||
当然本题还可以用动态规划来做,当前[「代码随想录」](https://img-blog.csdnimg.cn/20201124161234338.png)主要讲解贪心系列,后续到动态规划系列的时候会详细讲解本题的dp方法。
|
||||
|
||||
那么先给出我的dp代码如下,有时间的录友可以提前做一做:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int maxSubArray(vector<int>& nums) {
|
||||
if (nums.size() == 0) return 0;
|
||||
vector<int> dp(nums.size(), 0); // dp[i]表示包括i之前的最大连续子序列和
|
||||
dp[0] = nums[0];
|
||||
int result = dp[0];
|
||||
for (int i = 1; i < nums.size(); i++) {
|
||||
dp[i] = max(dp[i - 1] + nums[i], nums[i]); // 状态转移公式
|
||||
if (dp[i] > result) result = dp[i]; // result 保存dp[i]的最大值
|
||||
}
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
时间复杂度:O(n)
|
||||
空间复杂度:O(n)
|
||||
|
||||
## 总结
|
||||
|
||||
本题的贪心思路其实并不好想,这也进一步验证了,别看贪心理论很直白,有时候看似是常识,但贪心的题目一点都不简单!
|
||||
|
||||
后续将介绍的贪心题目都挺难的,哈哈,所以贪心很有意思,别小看贪心!
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
public int maxSubArray(int[] nums) {
|
||||
if (nums.length == 1){
|
||||
return nums[0];
|
||||
}
|
||||
int sum = Integer.MIN_VALUE;
|
||||
int count = 0;
|
||||
for (int i = 0; i < nums.length; i++){
|
||||
count += nums[i];
|
||||
sum = Math.max(sum, count); // 取区间累计的最大值(相当于不断确定最大子序终止位置)
|
||||
if (count <= 0){
|
||||
count = 0; // 相当于重置最大子序起始位置,因为遇到负数一定是拉低总和
|
||||
}
|
||||
}
|
||||
return sum;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def maxSubArray(self, nums: List[int]) -> int:
|
||||
result = -float('inf')
|
||||
count = 0
|
||||
for i in range(len(nums)):
|
||||
count += nums[i]
|
||||
if count > result:
|
||||
result = count
|
||||
if count <= 0:
|
||||
count = 0
|
||||
return result
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
```go
|
||||
func maxSubArray(nums []int) int {
|
||||
maxSum := nums[0]
|
||||
for i := 1; i < len(nums); i++ {
|
||||
if nums[i] + nums[i-1] > nums[i] {
|
||||
nums[i] += nums[i-1]
|
||||
}
|
||||
if nums[i] > maxSum {
|
||||
maxSum = nums[i]
|
||||
}
|
||||
}
|
||||
return maxSum
|
||||
}
|
||||
```
|
||||
Javascript:
|
||||
```Javascript
|
||||
var maxSubArray = function(nums) {
|
||||
let result = -Infinity
|
||||
let count = 0
|
||||
for(let i = 0; i < nums.length; i++) {
|
||||
count += nums[i]
|
||||
if(count > result) {
|
||||
result = count
|
||||
}
|
||||
if(count < 0) {
|
||||
count = 0
|
||||
}
|
||||
}
|
||||
return result
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
149
problems/0053.最大子序和(动态规划).md
Normal file
149
problems/0053.最大子序和(动态规划).md
Normal file
@@ -0,0 +1,149 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
## 53. 最大子序和
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/maximum-subarray/
|
||||
|
||||
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
|
||||
|
||||
示例:
|
||||
输入: [-2,1,-3,4,-1,2,1,-5,4]
|
||||
输出: 6
|
||||
解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。
|
||||
|
||||
## 思路
|
||||
|
||||
这道题之前我们在讲解贪心专题的时候用贪心算法解决过一次,[贪心算法:最大子序和](https://mp.weixin.qq.com/s/DrjIQy6ouKbpletQr0g1Fg)。
|
||||
|
||||
这次我们用动态规划的思路再来分析一次。
|
||||
|
||||
动规五部曲如下:
|
||||
|
||||
1. 确定dp数组(dp table)以及下标的含义
|
||||
|
||||
**dp[i]:包括下标i之前的最大连续子序列和为dp[i]**。
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
dp[i]只有两个方向可以推出来:
|
||||
|
||||
* dp[i - 1] + nums[i],即:nums[i]加入当前连续子序列和
|
||||
* nums[i],即:从头开始计算当前连续子序列和
|
||||
|
||||
一定是取最大的,所以dp[i] = max(dp[i - 1] + nums[i], nums[i]);
|
||||
|
||||
3. dp数组如何初始化
|
||||
|
||||
从递推公式可以看出来dp[i]是依赖于dp[i - 1]的状态,dp[0]就是递推公式的基础。
|
||||
|
||||
dp[0]应该是多少呢?
|
||||
|
||||
更具dp[i]的定义,很明显dp[0]因为为nums[0]即dp[0] = nums[0]。
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
递推公式中dp[i]依赖于dp[i - 1]的状态,需要从前向后遍历。
|
||||
|
||||
5. 举例推导dp数组
|
||||
|
||||
以示例一为例,输入:nums = [-2,1,-3,4,-1,2,1,-5,4],对应的dp状态如下:
|
||||
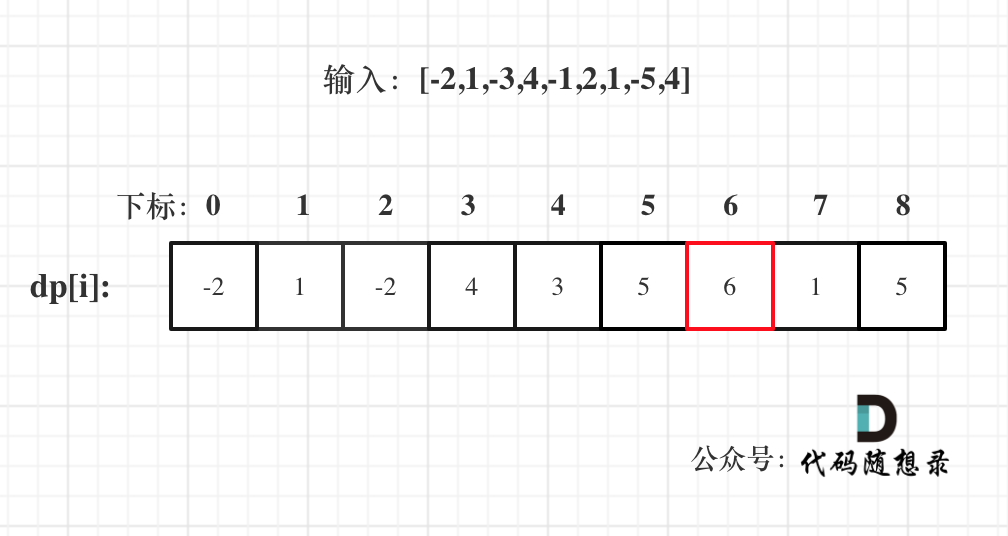
|
||||
|
||||
**注意最后的结果可不是dp[nums.size() - 1]!** ,而是dp[6]。
|
||||
|
||||
在回顾一下dp[i]的定义:包括下标i之前的最大连续子序列和为dp[i]。
|
||||
|
||||
那么我们要找最大的连续子序列,就应该找每一个i为终点的连续最大子序列。
|
||||
|
||||
所以在递推公式的时候,可以直接选出最大的dp[i]。
|
||||
|
||||
以上动规五部曲分析完毕,完整代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int maxSubArray(vector<int>& nums) {
|
||||
if (nums.size() == 0) return 0;
|
||||
vector<int> dp(nums.size());
|
||||
dp[0] = nums[0];
|
||||
int result = dp[0];
|
||||
for (int i = 1; i < nums.size(); i++) {
|
||||
dp[i] = max(dp[i - 1] + nums[i], nums[i]); // 状态转移公式
|
||||
if (dp[i] > result) result = dp[i]; // result 保存dp[i]的最大值
|
||||
}
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度:O(n)
|
||||
* 空间复杂度:O(n)
|
||||
|
||||
|
||||
## 总结
|
||||
|
||||
这道题目用贪心也很巧妙,但有一点绕,需要仔细想一想,如果想回顾一下贪心就看这里吧:[贪心算法:最大子序和](https://mp.weixin.qq.com/s/DrjIQy6ouKbpletQr0g1Fg)
|
||||
|
||||
动规的解法还是很直接的。
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
/**
|
||||
* 1.dp[i]代表当前下标对应的最大值
|
||||
* 2.递推公式 dp[i] = max (dp[i-1]+nums[i],nums[i]) res = max(res,dp[i])
|
||||
* 3.初始化 都为 0
|
||||
* 4.遍历方向,从前往后
|
||||
* 5.举例推导结果。。。
|
||||
*
|
||||
* @param nums
|
||||
* @return
|
||||
*/
|
||||
public static int maxSubArray(int[] nums) {
|
||||
if (nums.length == 0) {
|
||||
return 0;
|
||||
}
|
||||
|
||||
int res = nums[0];
|
||||
int[] dp = new int[nums.length];
|
||||
dp[0] = nums[0];
|
||||
for (int i = 1; i < nums.length; i++) {
|
||||
dp[i] = Math.max(dp[i - 1] + nums[i], nums[i]);
|
||||
res = res > dp[i] ? res : dp[i];
|
||||
}
|
||||
return res;
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def maxSubArray(self, nums: List[int]) -> int:
|
||||
if len(nums) == 0:
|
||||
return 0
|
||||
dp = [0] * len(nums)
|
||||
dp[0] = nums[0]
|
||||
result = dp[0]
|
||||
for i in range(1, len(nums)):
|
||||
dp[i] = max(dp[i-1] + nums[i], nums[i]) #状态转移公式
|
||||
result = max(result, dp[i]) #result 保存dp[i]的最大值
|
||||
return result
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
164
problems/0055.跳跃游戏.md
Normal file
164
problems/0055.跳跃游戏.md
Normal file
@@ -0,0 +1,164 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 55. 跳跃游戏
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/jump-game/
|
||||
|
||||
给定一个非负整数数组,你最初位于数组的第一个位置。
|
||||
|
||||
数组中的每个元素代表你在该位置可以跳跃的最大长度。
|
||||
|
||||
判断你是否能够到达最后一个位置。
|
||||
|
||||
示例 1:
|
||||
输入: [2,3,1,1,4]
|
||||
输出: true
|
||||
解释: 我们可以先跳 1 步,从位置 0 到达 位置 1, 然后再从位置 1 跳 3 步到达最后一个位置。
|
||||
|
||||
示例 2:
|
||||
输入: [3,2,1,0,4]
|
||||
输出: false
|
||||
解释: 无论怎样,你总会到达索引为 3 的位置。但该位置的最大跳跃长度是 0 , 所以你永远不可能到达最后一个位置。
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
刚看到本题一开始可能想:当前位置元素如果是3,我究竟是跳一步呢,还是两步呢,还是三步呢,究竟跳几步才是最优呢?
|
||||
|
||||
其实跳几步无所谓,关键在于可跳的覆盖范围!
|
||||
|
||||
不一定非要明确一次究竟跳几步,每次取最大的跳跃步数,这个就是可以跳跃的覆盖范围。
|
||||
|
||||
这个范围内,别管是怎么跳的,反正一定可以跳过来。
|
||||
|
||||
**那么这个问题就转化为跳跃覆盖范围究竟可不可以覆盖到终点!**
|
||||
|
||||
每次移动取最大跳跃步数(得到最大的覆盖范围),每移动一个单位,就更新最大覆盖范围。
|
||||
|
||||
**贪心算法局部最优解:每次取最大跳跃步数(取最大覆盖范围),整体最优解:最后得到整体最大覆盖范围,看是否能到终点**。
|
||||
|
||||
局部最优推出全局最优,找不出反例,试试贪心!
|
||||
|
||||
如图:
|
||||
|
||||

|
||||
|
||||
i每次移动只能在cover的范围内移动,每移动一个元素,cover得到该元素数值(新的覆盖范围)的补充,让i继续移动下去。
|
||||
|
||||
而cover每次只取 max(该元素数值补充后的范围, cover本身范围)。
|
||||
|
||||
如果cover大于等于了终点下标,直接return true就可以了。
|
||||
|
||||
C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
bool canJump(vector<int>& nums) {
|
||||
int cover = 0;
|
||||
if (nums.size() == 1) return true; // 只有一个元素,就是能达到
|
||||
for (int i = 0; i <= cover; i++) { // 注意这里是小于等于cover
|
||||
cover = max(i + nums[i], cover);
|
||||
if (cover >= nums.size() - 1) return true; // 说明可以覆盖到终点了
|
||||
}
|
||||
return false;
|
||||
}
|
||||
};
|
||||
```
|
||||
## 总结
|
||||
|
||||
这道题目关键点在于:不用拘泥于每次究竟跳跳几步,而是看覆盖范围,覆盖范围内一定是可以跳过来的,不用管是怎么跳的。
|
||||
|
||||
大家可以看出思路想出来了,代码还是非常简单的。
|
||||
|
||||
一些同学可能感觉,我在讲贪心系列的时候,题目和题目之间貌似没有什么联系?
|
||||
|
||||
**是真的就是没什么联系,因为贪心无套路!**没有个整体的贪心框架解决一些列问题,只能是接触各种类型的题目锻炼自己的贪心思维!
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
public boolean canJump(int[] nums) {
|
||||
if (nums.length == 1) {
|
||||
return true;
|
||||
}
|
||||
//覆盖范围
|
||||
int coverRange = nums[0];
|
||||
//在覆盖范围内更新最大的覆盖范围
|
||||
for (int i = 0; i <= coverRange; i++) {
|
||||
coverRange = Math.max(coverRange, i + nums[i]);
|
||||
if (coverRange >= nums.length - 1) {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
return false;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def canJump(self, nums: List[int]) -> bool:
|
||||
cover = 0
|
||||
if len(nums) == 1: return True
|
||||
i = 0
|
||||
# python不支持动态修改for循环中变量,使用while循环代替
|
||||
while i <= cover:
|
||||
cover = max(i + nums[i], cover)
|
||||
if cover >= len(nums) - 1: return True
|
||||
i += 1
|
||||
return False
|
||||
```
|
||||
|
||||
Go:
|
||||
```Go
|
||||
func canJUmp(nums []int) bool {
|
||||
if len(nums)<=1{
|
||||
return true
|
||||
}
|
||||
dp:=make([]bool,len(nums))
|
||||
dp[0]=true
|
||||
for i:=1;i<len(nums);i++{
|
||||
for j:=i-1;j>=0;j--{
|
||||
if dp[j]&&nums[j]+j>=i{
|
||||
dp[i]=true
|
||||
break
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[len(nums)-1]
|
||||
}
|
||||
```
|
||||
|
||||
Javascript:
|
||||
```Javascript
|
||||
var canJump = function(nums) {
|
||||
if(nums.length === 1) return true
|
||||
let cover = 0
|
||||
for(let i = 0; i <= cover; i++) {
|
||||
cover = Math.max(cover, i + nums[i])
|
||||
if(cover >= nums.length - 1) {
|
||||
return true
|
||||
}
|
||||
}
|
||||
return false
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
232
problems/0056.合并区间.md
Normal file
232
problems/0056.合并区间.md
Normal file
@@ -0,0 +1,232 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 56. 合并区间
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/merge-intervals/
|
||||
|
||||
给出一个区间的集合,请合并所有重叠的区间。
|
||||
|
||||
示例 1:
|
||||
输入: intervals = [[1,3],[2,6],[8,10],[15,18]]
|
||||
输出: [[1,6],[8,10],[15,18]]
|
||||
解释: 区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
|
||||
|
||||
示例 2:
|
||||
输入: intervals = [[1,4],[4,5]]
|
||||
输出: [[1,5]]
|
||||
解释: 区间 [1,4] 和 [4,5] 可被视为重叠区间。
|
||||
注意:输入类型已于2019年4月15日更改。 请重置默认代码定义以获取新方法签名。
|
||||
|
||||
提示:
|
||||
|
||||
* intervals[i][0] <= intervals[i][1]
|
||||
|
||||
## 思路
|
||||
|
||||
大家应该都感觉到了,此题一定要排序,那么按照左边界排序,还是右边界排序呢?
|
||||
|
||||
都可以!
|
||||
|
||||
那么我按照左边界排序,排序之后局部最优:每次合并都取最大的右边界,这样就可以合并更多的区间了,整体最优:合并所有重叠的区间。
|
||||
|
||||
局部最优可以推出全局最优,找不出反例,试试贪心。
|
||||
|
||||
那有同学问了,本来不就应该合并最大右边界么,这和贪心有啥关系?
|
||||
|
||||
有时候贪心就是常识!哈哈
|
||||
|
||||
按照左边界从小到大排序之后,如果 `intervals[i][0] < intervals[i - 1][1]` 即intervals[i]左边界 < intervals[i - 1]右边界,则一定有重复,因为intervals[i]的左边界一定是大于等于intervals[i - 1]的左边界。
|
||||
|
||||
即:intervals[i]的左边界在intervals[i - 1]左边界和右边界的范围内,那么一定有重复!
|
||||
|
||||
这么说有点抽象,看图:(**注意图中区间都是按照左边界排序之后了**)
|
||||
|
||||
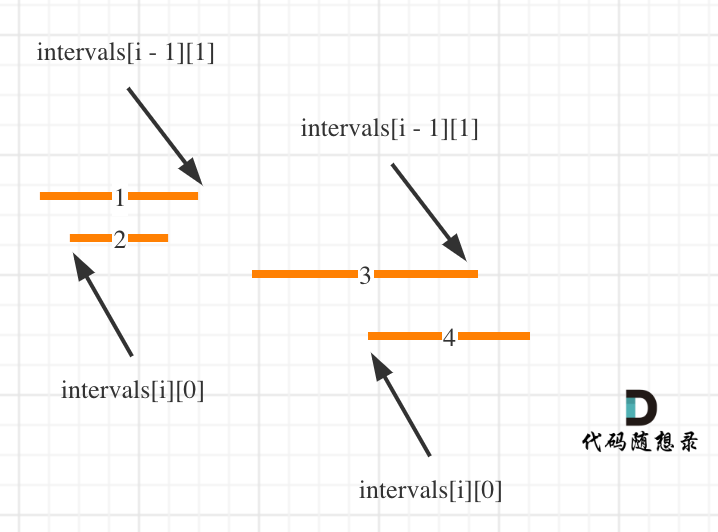
|
||||
|
||||
知道如何判断重复之后,剩下的就是合并了,如何去模拟合并区间呢?
|
||||
|
||||
其实就是用合并区间后左边界和右边界,作为一个新的区间,加入到result数组里就可以了。如果没有合并就把原区间加入到result数组。
|
||||
|
||||
C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
// 按照区间左边界从小到大排序
|
||||
static bool cmp (const vector<int>& a, const vector<int>& b) {
|
||||
return a[0] < b[0];
|
||||
}
|
||||
vector<vector<int>> merge(vector<vector<int>>& intervals) {
|
||||
vector<vector<int>> result;
|
||||
if (intervals.size() == 0) return result;
|
||||
sort(intervals.begin(), intervals.end(), cmp);
|
||||
bool flag = false; // 标记最后一个区间有没有合并
|
||||
int length = intervals.size();
|
||||
|
||||
for (int i = 1; i < length; i++) {
|
||||
int start = intervals[i - 1][0]; // 初始为i-1区间的左边界
|
||||
int end = intervals[i - 1][1]; // 初始i-1区间的右边界
|
||||
while (i < length && intervals[i][0] <= end) { // 合并区间
|
||||
end = max(end, intervals[i][1]); // 不断更新右区间
|
||||
if (i == length - 1) flag = true; // 最后一个区间也合并了
|
||||
i++; // 继续合并下一个区间
|
||||
}
|
||||
// start和end是表示intervals[i - 1]的左边界右边界,所以最优intervals[i]区间是否合并了要标记一下
|
||||
result.push_back({start, end});
|
||||
}
|
||||
// 如果最后一个区间没有合并,将其加入result
|
||||
if (flag == false) {
|
||||
result.push_back({intervals[length - 1][0], intervals[length - 1][1]});
|
||||
}
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
当然以上代码有冗余一些,可以优化一下,如下:(思路是一样的)
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
vector<vector<int>> merge(vector<vector<int>>& intervals) {
|
||||
vector<vector<int>> result;
|
||||
if (intervals.size() == 0) return result;
|
||||
// 排序的参数使用了lamda表达式
|
||||
sort(intervals.begin(), intervals.end(), [](const vector<int>& a, const vector<int>& b){return a[0] < b[0];});
|
||||
|
||||
result.push_back(intervals[0]);
|
||||
for (int i = 1; i < intervals.size(); i++) {
|
||||
if (result.back()[1] >= intervals[i][0]) { // 合并区间
|
||||
result.back()[1] = max(result.back()[1], intervals[i][1]);
|
||||
} else {
|
||||
result.push_back(intervals[i]);
|
||||
}
|
||||
}
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
* 时间复杂度:O(nlogn) ,有一个快排
|
||||
* 空间复杂度:O(1),我没有算result数组(返回值所需容器占的空间)
|
||||
|
||||
|
||||
## 总结
|
||||
|
||||
对于贪心算法,很多同学都是:**如果能凭常识直接做出来,就会感觉不到自己用了贪心, 一旦第一直觉想不出来, 可能就一直想不出来了**。
|
||||
|
||||
跟着「代码随想录」刷题的录友应该感受过,贪心难起来,真的难。
|
||||
|
||||
那应该怎么办呢?
|
||||
|
||||
正如我贪心系列开篇词[关于贪心算法,你该了解这些!](https://mp.weixin.qq.com/s/O935TaoHE9Eexwe_vSbRAg)中讲解的一样,贪心本来就没有套路,也没有框架,所以各种常规解法需要多接触多练习,自然而然才会想到。
|
||||
|
||||
「代码随想录」会把贪心常见的经典题目覆盖到,大家只要认真学习打卡就可以了。
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
public int[][] merge(int[][] intervals) {
|
||||
List<int[]> res = new LinkedList<>();
|
||||
Arrays.sort(intervals, (o1, o2) -> Integer.compare(o1[0], o2[0]));
|
||||
|
||||
int start = intervals[0][0];
|
||||
for (int i = 1; i < intervals.length; i++) {
|
||||
if (intervals[i][0] > intervals[i - 1][1]) {
|
||||
res.add(new int[]{start, intervals[i - 1][1]});
|
||||
start = intervals[i][0];
|
||||
} else {
|
||||
intervals[i][1] = Math.max(intervals[i][1], intervals[i - 1][1]);
|
||||
}
|
||||
}
|
||||
res.add(new int[]{start, intervals[intervals.length - 1][1]});
|
||||
return res.toArray(new int[res.size()][]);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def merge(self, intervals: List[List[int]]) -> List[List[int]]:
|
||||
if len(intervals) == 0: return intervals
|
||||
intervals.sort(key=lambda x: x[0])
|
||||
result = []
|
||||
result.append(intervals[0])
|
||||
for i in range(1, len(intervals)):
|
||||
last = result[-1]
|
||||
if last[1] >= intervals[i][0]:
|
||||
result[-1] = [last[0], max(last[1], intervals[i][1])]
|
||||
else:
|
||||
result.append(intervals[i])
|
||||
return result
|
||||
```
|
||||
|
||||
Go:
|
||||
```Go
|
||||
func merge(intervals [][]int) [][]int {
|
||||
sort.Slice(intervals, func(i, j int) bool {
|
||||
return intervals[i][0]<intervals[j][0]
|
||||
})
|
||||
|
||||
res:=[][]int{}
|
||||
prev:=intervals[0]
|
||||
|
||||
for i:=1;i<len(intervals);i++{
|
||||
cur :=intervals[i]
|
||||
if prev[1]<cur[0]{
|
||||
res=append(res,prev)
|
||||
prev=cur
|
||||
}else {
|
||||
prev[1]=max(prev[1],cur[1])
|
||||
}
|
||||
}
|
||||
res=append(res,prev)
|
||||
return res
|
||||
}
|
||||
func max(a, b int) int {
|
||||
if a > b { return a }
|
||||
return b
|
||||
}
|
||||
```
|
||||
|
||||
Javascript:
|
||||
```javascript
|
||||
var merge = function (intervals) {
|
||||
intervals.sort((a, b) => a[0] - b[0]);
|
||||
let prev = intervals[0]
|
||||
let result = []
|
||||
for(let i =0; i<intervals.length; i++){
|
||||
let cur = intervals[i]
|
||||
if(cur[0] > prev[1]){
|
||||
result.push(prev)
|
||||
prev = cur
|
||||
}else{
|
||||
prev[1] = Math.max(cur[1],prev[1])
|
||||
}
|
||||
}
|
||||
result.push(prev)
|
||||
return result
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
315
problems/0059.螺旋矩阵II.md
Normal file
315
problems/0059.螺旋矩阵II.md
Normal file
@@ -0,0 +1,315 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
|
||||
## 59.螺旋矩阵II
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/spiral-matrix-ii/
|
||||
给定一个正整数 n,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的正方形矩阵。
|
||||
|
||||
示例:
|
||||
|
||||
输入: 3
|
||||
输出:
|
||||
[
|
||||
[ 1, 2, 3 ],
|
||||
[ 8, 9, 4 ],
|
||||
[ 7, 6, 5 ]
|
||||
]
|
||||
|
||||
## 思路
|
||||
|
||||
这道题目可以说在面试中出现频率较高的题目,**本题并不涉及到什么算法,就是模拟过程,但却十分考察对代码的掌控能力。**
|
||||
|
||||
要如何画出这个螺旋排列的正方形矩阵呢?
|
||||
|
||||
相信很多同学刚开始做这种题目的时候,上来就是一波判断猛如虎。
|
||||
|
||||
结果运行的时候各种问题,然后开始各种修修补补,最后发现改了这里哪里有问题,改了那里这里又跑不起来了。
|
||||
|
||||
大家还记得我们在这篇文章[数组:每次遇到二分法,都是一看就会,一写就废](https://mp.weixin.qq.com/s/4X-8VRgnYRGd5LYGZ33m4w)中讲解了二分法,提到如果要写出正确的二分法一定要坚持**循环不变量原则**。
|
||||
|
||||
而求解本题依然是要坚持循环不变量原则。
|
||||
|
||||
模拟顺时针画矩阵的过程:
|
||||
|
||||
* 填充上行从左到右
|
||||
* 填充右列从上到下
|
||||
* 填充下行从右到左
|
||||
* 填充左列从下到上
|
||||
|
||||
由外向内一圈一圈这么画下去。
|
||||
|
||||
可以发现这里的边界条件非常多,在一个循环中,如此多的边界条件,如果不按照固定规则来遍历,那就是**一进循环深似海,从此offer是路人**。
|
||||
|
||||
这里一圈下来,我们要画每四条边,这四条边怎么画,每画一条边都要坚持一致的左闭右开,或者左开又闭的原则,这样这一圈才能按照统一的规则画下来。
|
||||
|
||||
那么我按照左闭右开的原则,来画一圈,大家看一下:
|
||||
|
||||
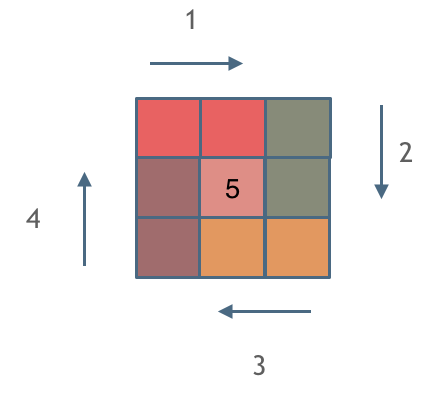
|
||||
|
||||
这里每一种颜色,代表一条边,我们遍历的长度,可以看出每一个拐角处的处理规则,拐角处让给新的一条边来继续画。
|
||||
|
||||
这也是坚持了每条边左闭右开的原则。
|
||||
|
||||
一些同学做这道题目之所以一直写不好,代码越写越乱。
|
||||
|
||||
就是因为在画每一条边的时候,一会左开又闭,一会左闭右闭,一会又来左闭右开,岂能不乱。
|
||||
|
||||
代码如下,已经详细注释了每一步的目的,可以看出while循环里判断的情况是很多的,代码里处理的原则也是统一的左闭右开。
|
||||
|
||||
整体C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
vector<vector<int>> generateMatrix(int n) {
|
||||
vector<vector<int>> res(n, vector<int>(n, 0)); // 使用vector定义一个二维数组
|
||||
int startx = 0, starty = 0; // 定义每循环一个圈的起始位置
|
||||
int loop = n / 2; // 每个圈循环几次,例如n为奇数3,那么loop = 1 只是循环一圈,矩阵中间的值需要单独处理
|
||||
int mid = n / 2; // 矩阵中间的位置,例如:n为3, 中间的位置就是(1,1),n为5,中间位置为(2, 2)
|
||||
int count = 1; // 用来给矩阵中每一个空格赋值
|
||||
int offset = 1; // 每一圈循环,需要控制每一条边遍历的长度
|
||||
int i,j;
|
||||
while (loop --) {
|
||||
i = startx;
|
||||
j = starty;
|
||||
|
||||
// 下面开始的四个for就是模拟转了一圈
|
||||
// 模拟填充上行从左到右(左闭右开)
|
||||
for (j = starty; j < starty + n - offset; j++) {
|
||||
res[startx][j] = count++;
|
||||
}
|
||||
// 模拟填充右列从上到下(左闭右开)
|
||||
for (i = startx; i < startx + n - offset; i++) {
|
||||
res[i][j] = count++;
|
||||
}
|
||||
// 模拟填充下行从右到左(左闭右开)
|
||||
for (; j > starty; j--) {
|
||||
res[i][j] = count++;
|
||||
}
|
||||
// 模拟填充左列从下到上(左闭右开)
|
||||
for (; i > startx; i--) {
|
||||
res[i][j] = count++;
|
||||
}
|
||||
|
||||
// 第二圈开始的时候,起始位置要各自加1, 例如:第一圈起始位置是(0, 0),第二圈起始位置是(1, 1)
|
||||
startx++;
|
||||
starty++;
|
||||
|
||||
// offset 控制每一圈里每一条边遍历的长度
|
||||
offset += 2;
|
||||
}
|
||||
|
||||
// 如果n为奇数的话,需要单独给矩阵最中间的位置赋值
|
||||
if (n % 2) {
|
||||
res[mid][mid] = count;
|
||||
}
|
||||
return res;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 类似题目
|
||||
|
||||
* 54.螺旋矩阵
|
||||
* 剑指Offer 29.顺时针打印矩阵
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
Java:
|
||||
|
||||
```Java
|
||||
class Solution {
|
||||
public int[][] generateMatrix(int n) {
|
||||
int[][] res = new int[n][n];
|
||||
|
||||
// 循环次数
|
||||
int loop = n / 2;
|
||||
|
||||
// 定义每次循环起始位置
|
||||
int startX = 0;
|
||||
int startY = 0;
|
||||
|
||||
// 定义偏移量
|
||||
int offset = 1;
|
||||
|
||||
// 定义填充数字
|
||||
int count = 1;
|
||||
|
||||
// 定义中间位置
|
||||
int mid = n / 2;
|
||||
|
||||
|
||||
while (loop > 0) {
|
||||
int i = startX;
|
||||
int j = startY;
|
||||
|
||||
// 模拟上侧从左到右
|
||||
for (; j<startY + n -offset; ++j) {
|
||||
res[startX][j] = count++;
|
||||
}
|
||||
|
||||
// 模拟右侧从上到下
|
||||
for (; i<startX + n -offset; ++i) {
|
||||
res[i][j] = count++;
|
||||
}
|
||||
|
||||
// 模拟下侧从右到左
|
||||
for (; j > startY; j--) {
|
||||
res[i][j] = count++;
|
||||
}
|
||||
|
||||
// 模拟左侧从下到上
|
||||
for (; i > startX; i--) {
|
||||
res[i][j] = count++;
|
||||
}
|
||||
|
||||
loop--;
|
||||
|
||||
startX += 1;
|
||||
startY += 1;
|
||||
|
||||
offset += 2;
|
||||
}
|
||||
|
||||
|
||||
if (n % 2 == 1) {
|
||||
res[mid][mid] = count;
|
||||
}
|
||||
|
||||
return res;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
python:
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def generateMatrix(self, n: int) -> List[List[int]]:
|
||||
left, right, up, down = 0, n-1, 0, n-1
|
||||
matrix = [ [0]*n for _ in range(n)]
|
||||
num = 1
|
||||
while left<=right and up<=down:
|
||||
# 填充左到右
|
||||
for i in range(left, right+1):
|
||||
matrix[up][i] = num
|
||||
num += 1
|
||||
up += 1
|
||||
# 填充上到下
|
||||
for i in range(up, down+1):
|
||||
matrix[i][right] = num
|
||||
num += 1
|
||||
right -= 1
|
||||
# 填充右到左
|
||||
for i in range(right, left-1, -1):
|
||||
matrix[down][i] = num
|
||||
num += 1
|
||||
down -= 1
|
||||
# 填充下到上
|
||||
for i in range(down, up-1, -1):
|
||||
matrix[i][left] = num
|
||||
num += 1
|
||||
left += 1
|
||||
return matrix
|
||||
```
|
||||
|
||||
javaScript
|
||||
|
||||
```js
|
||||
|
||||
/**
|
||||
* @param {number} n
|
||||
* @return {number[][]}
|
||||
*/
|
||||
var generateMatrix = function(n) {
|
||||
// new Array(n).fill(new Array(n))
|
||||
// 使用fill --> 填充的是同一个数组地址
|
||||
const res = Array.from({length: n}).map(() => new Array(n));
|
||||
let loop = n >> 1, i = 0, //循环次数
|
||||
count = 1,
|
||||
startX = startY = 0; // 起始位置
|
||||
while(++i <= loop) {
|
||||
// 定义行列
|
||||
let row = startX, column = startY;
|
||||
// [ startY, n - i)
|
||||
while(column < n - i) {
|
||||
res[row][column++] = count++;
|
||||
}
|
||||
// [ startX, n - i)
|
||||
while(row < n - i) {
|
||||
res[row++][column] = count++;
|
||||
}
|
||||
// [n - i , startY)
|
||||
while(column > startY) {
|
||||
res[row][column--] = count++;
|
||||
}
|
||||
// [n - i , startX)
|
||||
while(row > startX) {
|
||||
res[row--][column] = count++;
|
||||
}
|
||||
startX = ++startY;
|
||||
}
|
||||
if(n & 1) {
|
||||
res[startX][startY] = count;
|
||||
}
|
||||
return res;
|
||||
};
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
```go
|
||||
func generateMatrix(n int) [][]int {
|
||||
top, bottom := 0, n-1
|
||||
left, right := 0, n-1
|
||||
num := 1
|
||||
tar := n * n
|
||||
matrix := make([][]int, n)
|
||||
for i := 0; i < n; i++ {
|
||||
matrix[i] = make([]int, n)
|
||||
}
|
||||
for num <= tar {
|
||||
for i := left; i <= right; i++ {
|
||||
matrix[top][i] = num
|
||||
num++
|
||||
}
|
||||
top++
|
||||
for i := top; i <= bottom; i++ {
|
||||
matrix[i][right] = num
|
||||
num++
|
||||
}
|
||||
right--
|
||||
for i := right; i >= left; i-- {
|
||||
matrix[bottom][i] = num
|
||||
num++
|
||||
}
|
||||
bottom--
|
||||
for i := bottom; i >= top; i-- {
|
||||
matrix[i][left] = num
|
||||
num++
|
||||
}
|
||||
left++
|
||||
}
|
||||
return matrix
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
336
problems/0062.不同路径.md
Normal file
336
problems/0062.不同路径.md
Normal file
@@ -0,0 +1,336 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
## 62.不同路径
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/unique-paths/
|
||||
|
||||
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
|
||||
|
||||
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
|
||||
|
||||
问总共有多少条不同的路径?
|
||||
|
||||
示例 1:
|
||||
|
||||

|
||||
|
||||
输入:m = 3, n = 7
|
||||
输出:28
|
||||
|
||||
示例 2:
|
||||
输入:m = 2, n = 3
|
||||
输出:3
|
||||
解释:
|
||||
从左上角开始,总共有 3 条路径可以到达右下角。
|
||||
1. 向右 -> 向右 -> 向下
|
||||
2. 向右 -> 向下 -> 向右
|
||||
3. 向下 -> 向右 -> 向右
|
||||
|
||||
|
||||
示例 3:
|
||||
输入:m = 7, n = 3
|
||||
输出:28
|
||||
|
||||
示例 4:
|
||||
输入:m = 3, n = 3
|
||||
输出:6
|
||||
|
||||
提示:
|
||||
* 1 <= m, n <= 100
|
||||
* 题目数据保证答案小于等于 2 * 10^9
|
||||
|
||||
## 思路
|
||||
|
||||
### 深搜
|
||||
|
||||
这道题目,刚一看最直观的想法就是用图论里的深搜,来枚举出来有多少种路径。
|
||||
|
||||
注意题目中说机器人每次只能向下或者向右移动一步,那么其实**机器人走过的路径可以抽象为一颗二叉树,而叶子节点就是终点!**
|
||||
|
||||
如图举例:
|
||||
|
||||
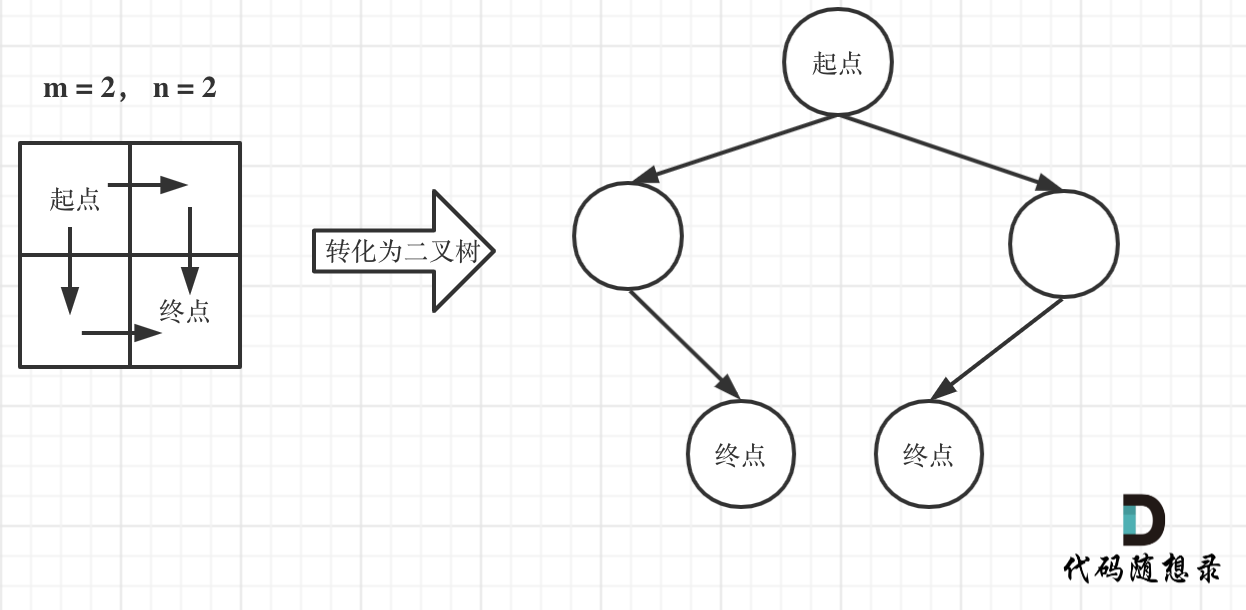
|
||||
|
||||
此时问题就可以转化为求二叉树叶子节点的个数,代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
int dfs(int i, int j, int m, int n) {
|
||||
if (i > m || j > n) return 0; // 越界了
|
||||
if (i == m && j == n) return 1; // 找到一种方法,相当于找到了叶子节点
|
||||
return dfs(i + 1, j, m, n) + dfs(i, j + 1, m, n);
|
||||
}
|
||||
public:
|
||||
int uniquePaths(int m, int n) {
|
||||
return dfs(1, 1, m, n);
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
**大家如果提交了代码就会发现超时了!**
|
||||
|
||||
来分析一下时间复杂度,这个深搜的算法,其实就是要遍历整个二叉树。
|
||||
|
||||
这颗树的深度其实就是m+n-1(深度按从1开始计算)。
|
||||
|
||||
那二叉树的节点个数就是 2^(m + n - 1) - 1。可以理解深搜的算法就是遍历了整个满二叉树(其实没有遍历整个满二叉树,只是近似而已)
|
||||
|
||||
所以上面深搜代码的时间复杂度为O(2^(m + n - 1) - 1),可以看出,这是指数级别的时间复杂度,是非常大的。
|
||||
|
||||
### 动态规划
|
||||
|
||||
机器人从(0 , 0) 位置出发,到(m - 1, n - 1)终点。
|
||||
|
||||
按照动规五部曲来分析:
|
||||
|
||||
1. 确定dp数组(dp table)以及下标的含义
|
||||
|
||||
dp[i][j] :表示从(0 ,0)出发,到(i, j) 有dp[i][j]条不同的路径。
|
||||
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
想要求dp[i][j],只能有两个方向来推导出来,即dp[i - 1][j] 和 dp[i][j - 1]。
|
||||
|
||||
此时在回顾一下 dp[i - 1][j] 表示啥,是从(0, 0)的位置到(i - 1, j)有几条路径,dp[i][j - 1]同理。
|
||||
|
||||
那么很自然,dp[i][j] = dp[i - 1][j] + dp[i][j - 1],因为dp[i][j]只有这两个方向过来。
|
||||
|
||||
3. dp数组的初始化
|
||||
|
||||
如何初始化呢,首先dp[i][0]一定都是1,因为从(0, 0)的位置到(i, 0)的路径只有一条,那么dp[0][j]也同理。
|
||||
|
||||
所以初始化代码为:
|
||||
|
||||
```
|
||||
for (int i = 0; i < m; i++) dp[i][0] = 1;
|
||||
for (int j = 0; j < n; j++) dp[0][j] = 1;
|
||||
```
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
这里要看一下递归公式dp[i][j] = dp[i - 1][j] + dp[i][j - 1],dp[i][j]都是从其上方和左方推导而来,那么从左到右一层一层遍历就可以了。
|
||||
|
||||
这样就可以保证推导dp[i][j]的时候,dp[i - 1][j] 和 dp[i][j - 1]一定是有数值的。
|
||||
|
||||
5. 举例推导dp数组
|
||||
|
||||
如图所示:
|
||||
|
||||

|
||||
|
||||
以上动规五部曲分析完毕,C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int uniquePaths(int m, int n) {
|
||||
vector<vector<int>> dp(m, vector<int>(n, 0));
|
||||
for (int i = 0; i < m; i++) dp[i][0] = 1;
|
||||
for (int j = 0; j < n; j++) dp[0][j] = 1;
|
||||
for (int i = 1; i < m; i++) {
|
||||
for (int j = 1; j < n; j++) {
|
||||
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
|
||||
}
|
||||
}
|
||||
return dp[m - 1][n - 1];
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度:O(m * n)
|
||||
* 空间复杂度:O(m * n)
|
||||
|
||||
其实用一个一维数组(也可以理解是滚动数组)就可以了,但是不利于理解,可以优化点空间,建议先理解了二维,在理解一维,C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int uniquePaths(int m, int n) {
|
||||
vector<int> dp(n);
|
||||
for (int i = 0; i < n; i++) dp[i] = 1;
|
||||
for (int j = 1; j < m; j++) {
|
||||
for (int i = 1; i < n; i++) {
|
||||
dp[i] += dp[i - 1];
|
||||
}
|
||||
}
|
||||
return dp[n - 1];
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度:O(m * n)
|
||||
* 空间复杂度:O(n)
|
||||
|
||||
### 数论方法
|
||||
|
||||
在这个图中,可以看出一共m,n的话,无论怎么走,走到终点都需要 m + n - 2 步。
|
||||
|
||||

|
||||
|
||||
在这m + n - 2 步中,一定有 m - 1 步是要向下走的,不用管什么时候向下走。
|
||||
|
||||
那么有几种走法呢? 可以转化为,给你m + n - 2个不同的数,随便取m - 1个数,有几种取法。
|
||||
|
||||
那么这就是一个组合问题了。
|
||||
|
||||
那么答案,如图所示:
|
||||
|
||||
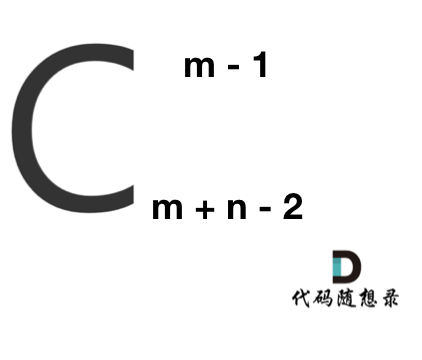
|
||||
|
||||
**求组合的时候,要防止两个int相乘溢出!** 所以不能把算式的分子都算出来,分母都算出来再做除法。
|
||||
|
||||
例如如下代码是不行的。
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int uniquePaths(int m, int n) {
|
||||
int numerator = 1, denominator = 1;
|
||||
int count = m - 1;
|
||||
int t = m + n - 2;
|
||||
while (count--) numerator *= (t--); // 计算分子,此时分子就会溢出
|
||||
for (int i = 1; i <= m - 1; i++) denominator *= i; // 计算分母
|
||||
return numerator / denominator;
|
||||
}
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
需要在计算分子的时候,不断除以分母,代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int uniquePaths(int m, int n) {
|
||||
long long numerator = 1; // 分子
|
||||
int denominator = m - 1; // 分母
|
||||
int count = m - 1;
|
||||
int t = m + n - 2;
|
||||
while (count--) {
|
||||
numerator *= (t--);
|
||||
while (denominator != 0 && numerator % denominator == 0) {
|
||||
numerator /= denominator;
|
||||
denominator--;
|
||||
}
|
||||
}
|
||||
return numerator;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
时间复杂度:O(m)
|
||||
空间复杂度:O(1)
|
||||
|
||||
**计算组合问题的代码还是有难度的,特别是处理溢出的情况!**
|
||||
|
||||
## 总结
|
||||
|
||||
本文分别给出了深搜,动规,数论三种方法。
|
||||
|
||||
深搜当然是超时了,顺便分析了一下使用深搜的时间复杂度,就可以看出为什么超时了。
|
||||
|
||||
然后在给出动规的方法,依然是使用动规五部曲,这次我们就要考虑如何正确的初始化了,初始化和遍历顺序其实也很重要!
|
||||
|
||||
就酱,循序渐进学算法,认准「代码随想录」!
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
/**
|
||||
* 1. 确定dp数组下表含义 dp[i][j] 到每一个坐标可能的路径种类
|
||||
* 2. 递推公式 dp[i][j] = dp[i-1][j] dp[i][j-1]
|
||||
* 3. 初始化 dp[i][0]=1 dp[0][i]=1 初始化横竖就可
|
||||
* 4. 遍历顺序 一行一行遍历
|
||||
* 5. 推导结果 。。。。。。。。
|
||||
*
|
||||
* @param m
|
||||
* @param n
|
||||
* @return
|
||||
*/
|
||||
public static int uniquePaths(int m, int n) {
|
||||
int[][] dp = new int[m][n];
|
||||
//初始化
|
||||
for (int i = 0; i < m; i++) {
|
||||
dp[i][0] = 1;
|
||||
}
|
||||
for (int i = 0; i < n; i++) {
|
||||
dp[0][i] = 1;
|
||||
}
|
||||
|
||||
for (int i = 1; i < m; i++) {
|
||||
for (int j = 1; j < n; j++) {
|
||||
dp[i][j] = dp[i-1][j]+dp[i][j-1];
|
||||
}
|
||||
}
|
||||
return dp[m-1][n-1];
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution: # 动态规划
|
||||
def uniquePaths(self, m: int, n: int) -> int:
|
||||
dp = [[1 for i in range(n)] for j in range(m)]
|
||||
for i in range(1, m):
|
||||
for j in range(1, n):
|
||||
dp[i][j] = dp[i][j - 1] + dp[i - 1][j]
|
||||
return dp[m - 1][n - 1]
|
||||
```
|
||||
|
||||
Go:
|
||||
```Go
|
||||
func uniquePaths(m int, n int) int {
|
||||
dp := make([][]int, m)
|
||||
for i := range dp {
|
||||
dp[i] = make([]int, n)
|
||||
dp[i][0] = 1
|
||||
}
|
||||
for j := 0; j < n; j++ {
|
||||
dp[0][j] = 1
|
||||
}
|
||||
for i := 1; i < m; i++ {
|
||||
for j := 1; j < n; j++ {
|
||||
dp[i][j] = dp[i-1][j] + dp[i][j-1]
|
||||
}
|
||||
}
|
||||
return dp[m-1][n-1]
|
||||
}
|
||||
```
|
||||
|
||||
Javascript:
|
||||
```Javascript
|
||||
var uniquePaths = function(m, n) {
|
||||
const dp = Array(m).fill().map(item => Array(n))
|
||||
|
||||
for (let i = 0; i < m; ++i) {
|
||||
dp[i][0] = 1
|
||||
}
|
||||
|
||||
for (let i = 0; i < n; ++i) {
|
||||
dp[0][i] = 1
|
||||
}
|
||||
|
||||
for (let i = 1; i < m; ++i) {
|
||||
for (let j = 1; j < n; ++j) {
|
||||
dp[i][j] = dp[i - 1][j] + dp[i][j - 1]
|
||||
}
|
||||
}
|
||||
return dp[m - 1][n - 1]
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
344
problems/0063.不同路径II.md
Normal file
344
problems/0063.不同路径II.md
Normal file
@@ -0,0 +1,344 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
## 63. 不同路径 II
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/unique-paths-ii/
|
||||
|
||||
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。
|
||||
|
||||
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。
|
||||
|
||||
现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
|
||||
|
||||

|
||||
|
||||
网格中的障碍物和空位置分别用 1 和 0 来表示。
|
||||
|
||||
示例 1:
|
||||
|
||||

|
||||
|
||||
输入:obstacleGrid = [[0,0,0],[0,1,0],[0,0,0]]
|
||||
输出:2
|
||||
解释:
|
||||
3x3 网格的正中间有一个障碍物。
|
||||
从左上角到右下角一共有 2 条不同的路径:
|
||||
1. 向右 -> 向右 -> 向下 -> 向下
|
||||
2. 向下 -> 向下 -> 向右 -> 向右
|
||||
|
||||
示例 2:
|
||||
|
||||

|
||||
|
||||
输入:obstacleGrid = [[0,1],[0,0]]
|
||||
输出:1
|
||||
|
||||
提示:
|
||||
|
||||
* m == obstacleGrid.length
|
||||
* n == obstacleGrid[i].length
|
||||
* 1 <= m, n <= 100
|
||||
* obstacleGrid[i][j] 为 0 或 1
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
这道题相对于[62.不同路径](https://mp.weixin.qq.com/s/MGgGIt4QCpFMROE9X9he_A) 就是有了障碍。
|
||||
|
||||
第一次接触这种题目的同学可能会有点懵,这有障碍了,应该怎么算呢?
|
||||
|
||||
[62.不同路径](https://mp.weixin.qq.com/s/MGgGIt4QCpFMROE9X9he_A)中我们已经详细分析了没有障碍的情况,有障碍的话,其实就是标记对应的dp table(dp数组)保持初始值(0)就可以了。
|
||||
|
||||
动规五部曲:
|
||||
|
||||
1. 确定dp数组(dp table)以及下标的含义
|
||||
|
||||
dp[i][j] :表示从(0 ,0)出发,到(i, j) 有dp[i][j]条不同的路径。
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
递推公式和62.不同路径一样,dp[i][j] = dp[i - 1][j] + dp[i][j - 1]。
|
||||
|
||||
但这里需要注意一点,因为有了障碍,(i, j)如果就是障碍的话应该就保持初始状态(初始状态为0)。
|
||||
|
||||
所以代码为:
|
||||
|
||||
```
|
||||
if (obstacleGrid[i][j] == 0) { // 当(i, j)没有障碍的时候,再推导dp[i][j]
|
||||
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
|
||||
}
|
||||
```
|
||||
|
||||
3. dp数组如何初始化
|
||||
|
||||
在[62.不同路径](https://mp.weixin.qq.com/s/MGgGIt4QCpFMROE9X9he_A)不同路径中我们给出如下的初始化:
|
||||
|
||||
```
|
||||
vector<vector<int>> dp(m, vector<int>(n, 0)); // 初始值为0
|
||||
for (int i = 0; i < m; i++) dp[i][0] = 1;
|
||||
for (int j = 0; j < n; j++) dp[0][j] = 1;
|
||||
```
|
||||
|
||||
因为从(0, 0)的位置到(i, 0)的路径只有一条,所以dp[i][0]一定为1,dp[0][j]也同理。
|
||||
|
||||
但如果(i, 0) 这条边有了障碍之后,障碍之后(包括障碍)都是走不到的位置了,所以障碍之后的dp[i][0]应该还是初始值0。
|
||||
|
||||
如图:
|
||||
|
||||
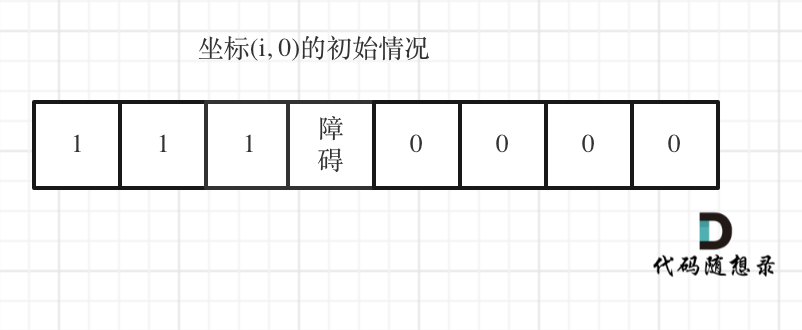
|
||||
|
||||
下标(0, j)的初始化情况同理。
|
||||
|
||||
所以本题初始化代码为:
|
||||
|
||||
```C++
|
||||
vector<vector<int>> dp(m, vector<int>(n, 0));
|
||||
for (int i = 0; i < m && obstacleGrid[i][0] == 0; i++) dp[i][0] = 1;
|
||||
for (int j = 0; j < n && obstacleGrid[0][j] == 0; j++) dp[0][j] = 1;
|
||||
```
|
||||
|
||||
**注意代码里for循环的终止条件,一旦遇到obstacleGrid[i][0] == 1的情况就停止dp[i][0]的赋值1的操作,dp[0][j]同理**
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
从递归公式dp[i][j] = dp[i - 1][j] + dp[i][j - 1] 中可以看出,一定是从左到右一层一层遍历,这样保证推导dp[i][j]的时候,dp[i - 1][j] 和 dp[i][j - 1]一定是有数值。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
for (int i = 1; i < m; i++) {
|
||||
for (int j = 1; j < n; j++) {
|
||||
if (obstacleGrid[i][j] == 1) continue;
|
||||
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
5. 举例推导dp数组
|
||||
|
||||
拿示例1来举例如题:
|
||||
|
||||
|
||||
|
||||
对应的dp table 如图:
|
||||
|
||||
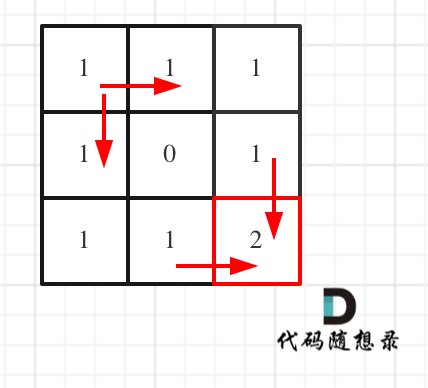
|
||||
|
||||
如果这个图看不同,建议在理解一下递归公式,然后照着文章中说的遍历顺序,自己推导一下!
|
||||
|
||||
动规五部分分析完毕,对应C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int uniquePathsWithObstacles(vector<vector<int>>& obstacleGrid) {
|
||||
int m = obstacleGrid.size();
|
||||
int n = obstacleGrid[0].size();
|
||||
vector<vector<int>> dp(m, vector<int>(n, 0));
|
||||
for (int i = 0; i < m && obstacleGrid[i][0] == 0; i++) dp[i][0] = 1;
|
||||
for (int j = 0; j < n && obstacleGrid[0][j] == 0; j++) dp[0][j] = 1;
|
||||
for (int i = 1; i < m; i++) {
|
||||
for (int j = 1; j < n; j++) {
|
||||
if (obstacleGrid[i][j] == 1) continue;
|
||||
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
|
||||
}
|
||||
}
|
||||
return dp[m - 1][n - 1];
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度O(n * m) n m 分别为obstacleGrid 长度和宽度
|
||||
* 空间复杂度O(n * m)
|
||||
|
||||
## 总结
|
||||
|
||||
本题是[62.不同路径](https://mp.weixin.qq.com/s/MGgGIt4QCpFMROE9X9he_A)的障碍版,整体思路大体一致。
|
||||
|
||||
但就算是做过62.不同路径,在做本题也会有感觉遇到障碍无从下手。
|
||||
|
||||
其实只要考虑到,遇到障碍dp[i][j]保持0就可以了。
|
||||
|
||||
也有一些小细节,例如:初始化的部分,很容易忽略了障碍之后应该都是0的情况。
|
||||
|
||||
就酱,「代码随想录」值得推荐给身边学算法的同学朋友们,关注后都会发现相见恨晚!
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
Java:
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
public int uniquePathsWithObstacles(int[][] obstacleGrid) {
|
||||
int n = obstacleGrid.length, m = obstacleGrid[0].length;
|
||||
int[][] dp = new int[n][m];
|
||||
dp[0][0] = 1 - obstacleGrid[0][0];
|
||||
for (int i = 1; i < m; i++) {
|
||||
if (obstacleGrid[0][i] == 0 && dp[0][i - 1] == 1) {
|
||||
dp[0][i] = 1;
|
||||
}
|
||||
}
|
||||
for (int i = 1; i < n; i++) {
|
||||
if (obstacleGrid[i][0] == 0 && dp[i - 1][0] == 1) {
|
||||
dp[i][0] = 1;
|
||||
}
|
||||
}
|
||||
for (int i = 1; i < n; i++) {
|
||||
for (int j = 1; j < m; j++) {
|
||||
if (obstacleGrid[i][j] == 1) continue;
|
||||
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
|
||||
}
|
||||
}
|
||||
return dp[n - 1][m - 1];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
Python:
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def uniquePathsWithObstacles(self, obstacleGrid: List[List[int]]) -> int:
|
||||
# 构造一个DP table
|
||||
row = len(obstacleGrid)
|
||||
col = len(obstacleGrid[0])
|
||||
dp = [[0 for _ in range(col)] for _ in range(row)]
|
||||
|
||||
dp[0][0] = 1 if obstacleGrid[0][0] != 1 else 0
|
||||
if dp[0][0] == 0: return 0 # 如果第一个格子就是障碍,return 0
|
||||
# 第一行
|
||||
for i in range(1, col):
|
||||
if obstacleGrid[0][i] != 1:
|
||||
dp[0][i] = dp[0][i-1]
|
||||
|
||||
# 第一列
|
||||
for i in range(1, row):
|
||||
if obstacleGrid[i][0] != 1:
|
||||
dp[i][0] = dp[i-1][0]
|
||||
print(dp)
|
||||
|
||||
for i in range(1, row):
|
||||
for j in range(1, col):
|
||||
if obstacleGrid[i][j] != 1:
|
||||
dp[i][j] = dp[i-1][j] + dp[i][j-1]
|
||||
return dp[-1][-1]
|
||||
```
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
"""
|
||||
使用一维dp数组
|
||||
"""
|
||||
|
||||
def uniquePathsWithObstacles(self, obstacleGrid: List[List[int]]) -> int:
|
||||
m, n = len(obstacleGrid), len(obstacleGrid[0])
|
||||
|
||||
# 初始化dp数组
|
||||
# 该数组缓存当前行
|
||||
curr = [0] * n
|
||||
for j in range(n):
|
||||
if obstacleGrid[0][j] == 1:
|
||||
break
|
||||
curr[j] = 1
|
||||
|
||||
for i in range(1, m): # 从第二行开始
|
||||
for j in range(n): # 从第一列开始,因为第一列可能有障碍物
|
||||
# 有障碍物处无法通行,状态就设成0
|
||||
if obstacleGrid[i][j] == 1:
|
||||
curr[j] = 0
|
||||
elif j > 0:
|
||||
# 等价于
|
||||
# dp[i][j] = dp[i - 1][j] + dp[i][j - 1]
|
||||
curr[j] = curr[j] + curr[j - 1]
|
||||
# 隐含的状态更新
|
||||
# dp[i][0] = dp[i - 1][0]
|
||||
|
||||
return curr[n - 1]
|
||||
```
|
||||
|
||||
|
||||
Go:
|
||||
|
||||
```go
|
||||
func uniquePathsWithObstacles(obstacleGrid [][]int) int {
|
||||
m,n:= len(obstacleGrid),len(obstacleGrid[0])
|
||||
// 定义一个dp数组
|
||||
dp := make([][]int,m)
|
||||
for i,_ := range dp {
|
||||
dp[i] = make([]int,n)
|
||||
}
|
||||
// 初始化
|
||||
for i:=0;i<m;i++ {
|
||||
// 如果是障碍物, 后面的就都是0, 不用循环了
|
||||
if obstacleGrid[i][0] == 1 {
|
||||
break
|
||||
}
|
||||
dp[i][0]=1
|
||||
}
|
||||
for i:=0;i<n;i++ {
|
||||
if obstacleGrid[0][i] == 1 {
|
||||
break
|
||||
}
|
||||
dp[0][i]=1
|
||||
}
|
||||
// dp数组推导过程
|
||||
for i:=1;i<m;i++ {
|
||||
for j:=1;j<n;j++ {
|
||||
// 如果obstacleGrid[i][j]这个点是障碍物, 那么我们的dp[i][j]保持为0
|
||||
if obstacleGrid[i][j] != 1 {
|
||||
// 否则我们需要计算当前点可以到达的路径数
|
||||
dp[i][j] = dp[i-1][j]+dp[i][j-1]
|
||||
}
|
||||
}
|
||||
}
|
||||
// debug遍历dp
|
||||
//for i,_ := range dp {
|
||||
// for j,_ := range dp[i] {
|
||||
// fmt.Printf("%.2v,",dp[i][j])
|
||||
// }
|
||||
// fmt.Println()
|
||||
//}
|
||||
return dp[m-1][n-1]
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Javascript
|
||||
``` Javascript
|
||||
var uniquePathsWithObstacles = function(obstacleGrid) {
|
||||
const m = obstacleGrid.length
|
||||
const n = obstacleGrid[0].length
|
||||
const dp = Array(m).fill().map(item => Array(n).fill(0))
|
||||
|
||||
for (let i = 0; i < m && obstacleGrid[i][0] === 0; ++i) {
|
||||
dp[i][0] = 1
|
||||
}
|
||||
|
||||
for (let i = 0; i < n && obstacleGrid[0][i] === 0; ++i) {
|
||||
dp[0][i] = 1
|
||||
}
|
||||
|
||||
for (let i = 1; i < m; ++i) {
|
||||
for (let j = 1; j < n; ++j) {
|
||||
dp[i][j] = obstacleGrid[i][j] === 1 ? 0 : dp[i - 1][j] + dp[i][j - 1]
|
||||
}
|
||||
}
|
||||
|
||||
return dp[m - 1][n - 1]
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
304
problems/0070.爬楼梯.md
Normal file
304
problems/0070.爬楼梯.md
Normal file
@@ -0,0 +1,304 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
## 70. 爬楼梯
|
||||
题目地址:https://leetcode-cn.com/problems/climbing-stairs/
|
||||
|
||||
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
|
||||
|
||||
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
|
||||
|
||||
注意:给定 n 是一个正整数。
|
||||
|
||||
示例 1:
|
||||
输入: 2
|
||||
输出: 2
|
||||
解释: 有两种方法可以爬到楼顶。
|
||||
1. 1 阶 + 1 阶
|
||||
2. 2 阶
|
||||
|
||||
示例 2:
|
||||
输入: 3
|
||||
输出: 3
|
||||
解释: 有三种方法可以爬到楼顶。
|
||||
1. 1 阶 + 1 阶 + 1 阶
|
||||
2. 1 阶 + 2 阶
|
||||
3. 2 阶 + 1 阶
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
本题大家如果没有接触过的话,会感觉比较难,多举几个例子,就可以发现其规律。
|
||||
|
||||
爬到第一层楼梯有一种方法,爬到二层楼梯有两种方法。
|
||||
|
||||
那么第一层楼梯再跨两步就到第三层 ,第二层楼梯再跨一步就到第三层。
|
||||
|
||||
所以到第三层楼梯的状态可以由第二层楼梯 和 到第一层楼梯状态推导出来,那么就可以想到动态规划了。
|
||||
|
||||
我们来分析一下,动规五部曲:
|
||||
|
||||
定义一个一维数组来记录不同楼层的状态
|
||||
|
||||
1. 确定dp数组以及下标的含义
|
||||
|
||||
dp[i]: 爬到第i层楼梯,有dp[i]种方法
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
如果可以推出dp[i]呢?
|
||||
|
||||
从dp[i]的定义可以看出,dp[i] 可以有两个方向推出来。
|
||||
|
||||
首先是dp[i - 1],上i-1层楼梯,有dp[i - 1]种方法,那么再一步跳一个台阶不就是dp[i]了么。
|
||||
|
||||
还有就是dp[i - 2],上i-2层楼梯,有dp[i - 2]种方法,那么再一步跳两个台阶不就是dp[i]了么。
|
||||
|
||||
那么dp[i]就是 dp[i - 1]与dp[i - 2]之和!
|
||||
|
||||
所以dp[i] = dp[i - 1] + dp[i - 2] 。
|
||||
|
||||
在推导dp[i]的时候,一定要时刻想着dp[i]的定义,否则容易跑偏。
|
||||
|
||||
这体现出确定dp数组以及下标的含义的重要性!
|
||||
|
||||
3. dp数组如何初始化
|
||||
|
||||
在回顾一下dp[i]的定义:爬到第i层楼梯,有dp[i]中方法。
|
||||
|
||||
那么i为0,dp[i]应该是多少呢,这个可以有很多解释,但都基本是直接奔着答案去解释的。
|
||||
|
||||
例如强行安慰自己爬到第0层,也有一种方法,什么都不做也就是一种方法即:dp[0] = 1,相当于直接站在楼顶。
|
||||
|
||||
但总有点牵强的成分。
|
||||
|
||||
那还这么理解呢:我就认为跑到第0层,方法就是0啊,一步只能走一个台阶或者两个台阶,然而楼层是0,直接站楼顶上了,就是不用方法,dp[0]就应该是0.
|
||||
|
||||
**其实这么争论下去没有意义,大部分解释说dp[0]应该为1的理由其实是因为dp[0]=1的话在递推的过程中i从2开始遍历本题就能过,然后就往结果上靠去解释dp[0] = 1**。
|
||||
|
||||
从dp数组定义的角度上来说,dp[0] = 0 也能说得通。
|
||||
|
||||
需要注意的是:题目中说了n是一个正整数,题目根本就没说n有为0的情况。
|
||||
|
||||
所以本题其实就不应该讨论dp[0]的初始化!
|
||||
|
||||
我相信dp[1] = 1,dp[2] = 2,这个初始化大家应该都没有争议的。
|
||||
|
||||
所以我的原则是:不考虑dp[0]如果初始化,只初始化dp[1] = 1,dp[2] = 2,然后从i = 3开始递推,这样才符合dp[i]的定义。
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
从递推公式dp[i] = dp[i - 1] + dp[i - 2];中可以看出,遍历顺序一定是从前向后遍历的
|
||||
|
||||
5. 举例推导dp数组
|
||||
|
||||
举例当n为5的时候,dp table(dp数组)应该是这样的
|
||||
|
||||
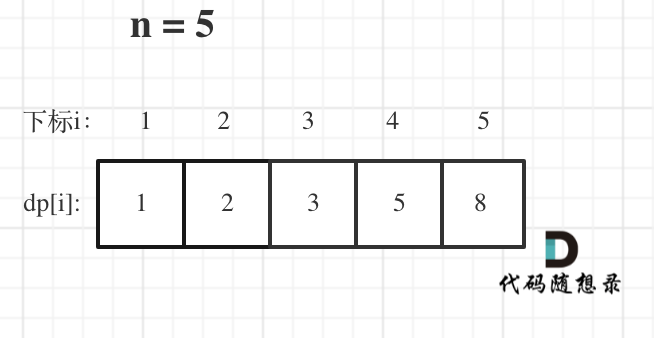
|
||||
|
||||
如果代码出问题了,就把dp table 打印出来,看看究竟是不是和自己推导的一样。
|
||||
|
||||
**此时大家应该发现了,这不就是斐波那契数列么!**
|
||||
|
||||
唯一的区别是,没有讨论dp[0]应该是什么,因为dp[0]在本题没有意义!
|
||||
|
||||
以上五部分析完之后,C++代码如下:
|
||||
|
||||
```C++
|
||||
// 版本一
|
||||
class Solution {
|
||||
public:
|
||||
int climbStairs(int n) {
|
||||
if (n <= 1) return n; // 因为下面直接对dp[2]操作了,防止空指针
|
||||
vector<int> dp(n + 1);
|
||||
dp[1] = 1;
|
||||
dp[2] = 2;
|
||||
for (int i = 3; i <= n; i++) { // 注意i是从3开始的
|
||||
dp[i] = dp[i - 1] + dp[i - 2];
|
||||
}
|
||||
return dp[n];
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度:O(n)
|
||||
* 空间复杂度:O(n)
|
||||
|
||||
当然依然也可以,优化一下空间复杂度,代码如下:
|
||||
|
||||
```C++
|
||||
// 版本二
|
||||
class Solution {
|
||||
public:
|
||||
int climbStairs(int n) {
|
||||
if (n <= 1) return n;
|
||||
int dp[3];
|
||||
dp[1] = 1;
|
||||
dp[2] = 2;
|
||||
for (int i = 3; i <= n; i++) {
|
||||
int sum = dp[1] + dp[2];
|
||||
dp[1] = dp[2];
|
||||
dp[2] = sum;
|
||||
}
|
||||
return dp[2];
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度:O(n)
|
||||
* 空间复杂度:O(1)
|
||||
|
||||
后面将讲解的很多动规的题目其实都是当前状态依赖前两个,或者前三个状态,都可以做空间上的优化,**但我个人认为面试中能写出版本一就够了哈,清晰明了,如果面试官要求进一步优化空间的话,我们再去优化**。
|
||||
|
||||
因为版本一才能体现出动规的思想精髓,递推的状态变化。
|
||||
|
||||
## 拓展
|
||||
|
||||
这道题目还可以继续深化,就是一步一个台阶,两个台阶,三个台阶,直到 m个台阶,有多少种方法爬到n阶楼顶。
|
||||
|
||||
这又有难度了,这其实是一个完全背包问题,但力扣上没有这种题目,所以后续我在讲解背包问题的时候,今天这道题还会拿从背包问题的角度上来再讲一遍。
|
||||
|
||||
这里我先给出我的实现代码:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int climbStairs(int n) {
|
||||
vector<int> dp(n + 1, 0);
|
||||
dp[0] = 1;
|
||||
for (int i = 1; i <= n; i++) {
|
||||
for (int j = 1; j <= m; j++) { // 把m换成2,就可以AC爬楼梯这道题
|
||||
if (i - j >= 0) dp[i] += dp[i - j];
|
||||
}
|
||||
}
|
||||
return dp[n];
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
代码中m表示最多可以爬m个台阶。
|
||||
|
||||
**以上代码不能运行哈,我主要是为了体现只要把m换成2,粘过去,就可以AC爬楼梯这道题,不信你就粘一下试试,哈哈**。
|
||||
|
||||
|
||||
**此时我就发现一个绝佳的大厂面试题**,第一道题就是单纯的爬楼梯,然后看候选人的代码实现,如果把dp[0]的定义成1了,就可以发难了,为什么dp[0]一定要初始化为1,此时可能候选人就要强行给dp[0]应该是1找各种理由。那这就是一个考察点了,对dp[i]的定义理解的不深入。
|
||||
|
||||
然后可以继续发难,如果一步一个台阶,两个台阶,三个台阶,直到 m个台阶,有多少种方法爬到n阶楼顶。这道题目leetcode上并没有原题,绝对是考察候选人算法能力的绝佳好题。
|
||||
|
||||
这一连套问下来,候选人算法能力如何,面试官心里就有数了。
|
||||
|
||||
**其实大厂面试最喜欢问题的就是这种简单题,然后慢慢变化,在小细节上考察候选人**。
|
||||
|
||||
|
||||
|
||||
## 总结
|
||||
|
||||
这道题目和[动态规划:斐波那契数](https://mp.weixin.qq.com/s/ko0zLJplF7n_4TysnPOa_w)题目基本是一样的,但是会发现本题相比[动态规划:斐波那契数](https://mp.weixin.qq.com/s/ko0zLJplF7n_4TysnPOa_w)难多了,为什么呢?
|
||||
|
||||
关键是 [动态规划:斐波那契数](https://mp.weixin.qq.com/s/ko0zLJplF7n_4TysnPOa_w) 题目描述就已经把动规五部曲里的递归公式和如何初始化都给出来了,剩下几部曲也自然而然的推出来了。
|
||||
|
||||
而本题,就需要逐个分析了,大家现在应该初步感受出[关于动态规划,你该了解这些!](https://leetcode-cn.com/circle/article/tNuNnM/)里给出的动规五部曲了。
|
||||
|
||||
简单题是用来掌握方法论的,例如昨天斐波那契的题目够简单了吧,但昨天和今天可以使用一套方法分析出来的,这就是方法论!
|
||||
|
||||
所以不要轻视简单题,那种凭感觉就刷过去了,其实和没掌握区别不大,只有掌握方法论并说清一二三,才能触类旁通,举一反三哈!
|
||||
|
||||
就酱,循序渐进学算法,认准「代码随想录」!
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
public int climbStairs(int n) {
|
||||
// 跟斐波那契数列一样
|
||||
if(n <= 2) return n;
|
||||
int a = 1, b = 2, sum = 0;
|
||||
|
||||
for(int i = 3; i <= n; i++){
|
||||
sum = a + b;
|
||||
a = b;
|
||||
b = sum;
|
||||
}
|
||||
return b;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
// 常规方式
|
||||
public int climbStairs(int n) {
|
||||
int[] dp = new int[n + 1];
|
||||
dp[0] = 1;
|
||||
dp[1] = 1;
|
||||
for (int i = 2; i <= n; i++) {
|
||||
dp[i] = dp[i - 1] + dp[i - 2];
|
||||
}
|
||||
return dp[n];
|
||||
}
|
||||
// 用变量记录代替数组
|
||||
public int climbStairs(int n) {
|
||||
int a = 0, b = 1, c = 0; // 默认需要1次
|
||||
for (int i = 1; i <= n; i++) {
|
||||
c = a + b; // f(i - 1) + f(n - 2)
|
||||
a = b; // 记录上一轮的值
|
||||
b = c; // 向后步进1个数
|
||||
}
|
||||
return c;
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def climbStairs(self, n: int) -> int:
|
||||
# dp[i]表示爬到第i级楼梯的种数, (1, 2) (2, 1)是两种不同的类型
|
||||
dp = [0] * (n + 1)
|
||||
dp[0] = 1
|
||||
for i in range(n+1):
|
||||
for j in range(1, 3):
|
||||
if i>=j:
|
||||
dp[i] += dp[i-j]
|
||||
return dp[-1]
|
||||
```
|
||||
|
||||
Go:
|
||||
```Go
|
||||
func climbStairs(n int) int {
|
||||
if n==1{
|
||||
return 1
|
||||
}
|
||||
dp:=make([]int,n+1)
|
||||
dp[1]=1
|
||||
dp[2]=2
|
||||
for i:=3;i<=n;i++{
|
||||
dp[i]=dp[i-1]+dp[i-2]
|
||||
}
|
||||
return dp[n]
|
||||
}
|
||||
```
|
||||
Javascript:
|
||||
```Javascript
|
||||
var climbStairs = function(n) {
|
||||
// dp[i] 为第 i 阶楼梯有多少种方法爬到楼顶
|
||||
// dp[i] = dp[i - 1] + dp[i - 2]
|
||||
let dp = [1 , 2]
|
||||
for(let i = 2; i < n; i++) {
|
||||
dp[i] = dp[i - 1] + dp[i - 2]
|
||||
}
|
||||
return dp[n - 1]
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
195
problems/0070.爬楼梯完全背包版本.md
Normal file
195
problems/0070.爬楼梯完全背包版本.md
Normal file
@@ -0,0 +1,195 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
# 动态规划:以前我没得选,现在我选择再爬一次!
|
||||
|
||||
之前讲这道题目的时候,因为还没有讲背包问题,所以就只是讲了一下爬楼梯最直接的动规方法(斐波那契)。
|
||||
|
||||
**这次终于讲到了背包问题,我选择带录友们再爬一次楼梯!**
|
||||
|
||||
## 70. 爬楼梯
|
||||
|
||||
链接:https://leetcode-cn.com/problems/climbing-stairs/
|
||||
|
||||
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
|
||||
|
||||
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
|
||||
|
||||
注意:给定 n 是一个正整数。
|
||||
|
||||
示例 1:
|
||||
输入: 2
|
||||
输出: 2
|
||||
解释: 有两种方法可以爬到楼顶。
|
||||
1. 1 阶 + 1 阶
|
||||
2. 2 阶
|
||||
|
||||
示例 2:
|
||||
输入: 3
|
||||
输出: 3
|
||||
解释: 有三种方法可以爬到楼顶。
|
||||
1. 1 阶 + 1 阶 + 1 阶
|
||||
2. 1 阶 + 2 阶
|
||||
3. 2 阶 + 1 阶
|
||||
|
||||
## 思路
|
||||
|
||||
这道题目 我们在[动态规划:爬楼梯](https://mp.weixin.qq.com/s/Ohop0jApSII9xxOMiFhGIw) 中已经讲过一次了,原题其实是一道简单动规的题目。
|
||||
|
||||
既然这么简单为什么还要讲呢,其实本题稍加改动就是一道面试好题。
|
||||
|
||||
**改为:一步一个台阶,两个台阶,三个台阶,.......,直到 m个台阶。问有多少种不同的方法可以爬到楼顶呢?**
|
||||
|
||||
1阶,2阶,.... m阶就是物品,楼顶就是背包。
|
||||
|
||||
每一阶可以重复使用,例如跳了1阶,还可以继续跳1阶。
|
||||
|
||||
问跳到楼顶有几种方法其实就是问装满背包有几种方法。
|
||||
|
||||
**此时大家应该发现这就是一个完全背包问题了!**
|
||||
|
||||
和昨天的题目[动态规划:377. 组合总和 Ⅳ](https://mp.weixin.qq.com/s/Iixw0nahJWQgbqVNk8k6gA)基本就是一道题了。
|
||||
|
||||
动规五部曲分析如下:
|
||||
|
||||
1. 确定dp数组以及下标的含义
|
||||
|
||||
**dp[i]:爬到有i个台阶的楼顶,有dp[i]种方法**。
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
在[动态规划:494.目标和](https://mp.weixin.qq.com/s/2pWmaohX75gwxvBENS-NCw) 、 [动态规划:518.零钱兑换II](https://mp.weixin.qq.com/s/PlowDsI4WMBOzf3q80AksQ)、[动态规划:377. 组合总和 Ⅳ](https://mp.weixin.qq.com/s/Iixw0nahJWQgbqVNk8k6gA)中我们都讲过了,求装满背包有几种方法,递推公式一般都是dp[i] += dp[i - nums[j]];
|
||||
|
||||
本题呢,dp[i]有几种来源,dp[i - 1],dp[i - 2],dp[i - 3] 等等,即:dp[i - j]
|
||||
|
||||
那么递推公式为:dp[i] += dp[i - j]
|
||||
|
||||
3. dp数组如何初始化
|
||||
|
||||
既然递归公式是 dp[i] += dp[i - j],那么dp[0] 一定为1,dp[0]是递归中一切数值的基础所在,如果dp[0]是0的话,其他数值都是0了。
|
||||
|
||||
下标非0的dp[i]初始化为0,因为dp[i]是靠dp[i-j]累计上来的,dp[i]本身为0这样才不会影响结果
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
这是背包里求排列问题,即:**1、2 步 和 2、1 步都是上三个台阶,但是这两种方法不一样!**
|
||||
|
||||
所以需将target放在外循环,将nums放在内循环。
|
||||
|
||||
每一步可以走多次,这是完全背包,内循环需要从前向后遍历。
|
||||
|
||||
5. 举例来推导dp数组
|
||||
|
||||
介于本题和[动态规划:377. 组合总和 Ⅳ](https://mp.weixin.qq.com/s/Iixw0nahJWQgbqVNk8k6gA)几乎是一样的,这里我就不再重复举例了。
|
||||
|
||||
|
||||
以上分析完毕,C++代码如下:
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
int climbStairs(int n) {
|
||||
vector<int> dp(n + 1, 0);
|
||||
dp[0] = 1;
|
||||
for (int i = 1; i <= n; i++) { // 遍历背包
|
||||
for (int j = 1; j <= m; j++) { // 遍历物品
|
||||
if (i - j >= 0) dp[i] += dp[i - j];
|
||||
}
|
||||
}
|
||||
return dp[n];
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
代码中m表示最多可以爬m个台阶,代码中把m改成2就是本题70.爬楼梯可以AC的代码了。
|
||||
|
||||
## 总结
|
||||
|
||||
**本题看起来是一道简单题目,稍稍进阶一下其实就是一个完全背包!**
|
||||
|
||||
如果我来面试的话,我就会先给候选人出一个 本题原题,看其表现,如果顺利写出来,进而在要求每次可以爬[1 - m]个台阶应该怎么写。
|
||||
|
||||
顺便再考察一下两个for循环的嵌套顺序,为什么target放外面,nums放里面。
|
||||
|
||||
这就能考察对背包问题本质的掌握程度,候选人是不是刷题背公式,一眼就看出来了。
|
||||
|
||||
这么一连套下来,如果候选人都能答出来,相信任何一位面试官都是非常满意的。
|
||||
|
||||
**本题代码不长,题目也很普通,但稍稍一进阶就可以考察完全背包,而且题目进阶的内容在leetcode上并没有原题,一定程度上就可以排除掉刷题党了,简直是面试题目的绝佳选择!**
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
public int climbStairs(int n) {
|
||||
int[] dp = new int[n + 1];
|
||||
int[] weight = {1,2};
|
||||
dp[0] = 1;
|
||||
|
||||
for (int i = 0; i <= n; i++) {
|
||||
for (int j = 0; j < weight.length; j++) {
|
||||
if (i >= weight[j]) dp[i] += dp[i - weight[j]];
|
||||
}
|
||||
}
|
||||
|
||||
return dp[n];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
|
||||
```python3
|
||||
class Solution:
|
||||
def climbStairs(self, n: int) -> int:
|
||||
dp = [0]*(n + 1)
|
||||
dp[0] = 1
|
||||
m = 2
|
||||
# 遍历背包
|
||||
for j in range(n + 1):
|
||||
# 遍历物品
|
||||
for step in range(1, m + 1):
|
||||
if j >= step:
|
||||
dp[j] += dp[j - step]
|
||||
return dp[n]
|
||||
```
|
||||
|
||||
|
||||
Go:
|
||||
```go
|
||||
func climbStairs(n int) int {
|
||||
//定义
|
||||
dp := make([]int, n+1)
|
||||
//初始化
|
||||
dp[0] = 1
|
||||
// 本题物品只有两个1,2
|
||||
m := 2
|
||||
// 遍历顺序
|
||||
for j := 1; j <= n; j++ { //先遍历背包
|
||||
for i := 1; i <= m; i++ { //再遍历物品
|
||||
if j >= i {
|
||||
dp[j] += dp[j-i]
|
||||
}
|
||||
//fmt.Println(dp)
|
||||
}
|
||||
}
|
||||
return dp[n]
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
315
problems/0072.编辑距离.md
Normal file
315
problems/0072.编辑距离.md
Normal file
@@ -0,0 +1,315 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
## 72. 编辑距离
|
||||
|
||||
https://leetcode-cn.com/problems/edit-distance/
|
||||
|
||||
给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数 。
|
||||
|
||||
你可以对一个单词进行如下三种操作:
|
||||
|
||||
* 插入一个字符
|
||||
* 删除一个字符
|
||||
* 替换一个字符
|
||||
|
||||
示例 1:
|
||||
输入:word1 = "horse", word2 = "ros"
|
||||
输出:3
|
||||
解释:
|
||||
horse -> rorse (将 'h' 替换为 'r')
|
||||
rorse -> rose (删除 'r')
|
||||
rose -> ros (删除 'e')
|
||||
|
||||
示例 2:
|
||||
输入:word1 = "intention", word2 = "execution"
|
||||
输出:5
|
||||
解释:
|
||||
intention -> inention (删除 't')
|
||||
inention -> enention (将 'i' 替换为 'e')
|
||||
enention -> exention (将 'n' 替换为 'x')
|
||||
exention -> exection (将 'n' 替换为 'c')
|
||||
exection -> execution (插入 'u')
|
||||
|
||||
|
||||
提示:
|
||||
|
||||
* 0 <= word1.length, word2.length <= 500
|
||||
* word1 和 word2 由小写英文字母组成
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
编辑距离终于来了,这道题目如果大家没有了解动态规划的话,会感觉超级复杂。
|
||||
|
||||
编辑距离是用动规来解决的经典题目,这道题目看上去好像很复杂,但用动规可以很巧妙的算出最少编辑距离。
|
||||
|
||||
接下来我依然使用动规五部曲,对本题做一个详细的分析:
|
||||
|
||||
-----------------------
|
||||
|
||||
### 1. 确定dp数组(dp table)以及下标的含义
|
||||
|
||||
**dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]**。
|
||||
|
||||
这里在强调一下:为啥要表示下标i-1为结尾的字符串呢,为啥不表示下标i为结尾的字符串呢?
|
||||
|
||||
用i来表示也可以! 但我统一以下标i-1为结尾的字符串,在下面的递归公式中会容易理解一点。
|
||||
|
||||
-----------------------
|
||||
|
||||
### 2. 确定递推公式
|
||||
|
||||
在确定递推公式的时候,首先要考虑清楚编辑的几种操作,整理如下:
|
||||
|
||||
```
|
||||
if (word1[i - 1] == word2[j - 1])
|
||||
不操作
|
||||
if (word1[i - 1] != word2[j - 1])
|
||||
增
|
||||
删
|
||||
换
|
||||
```
|
||||
|
||||
也就是如上4种情况。
|
||||
|
||||
`if (word1[i - 1] == word2[j - 1])` 那么说明不用任何编辑,`dp[i][j]` 就应该是 `dp[i - 1][j - 1]`,即`dp[i][j] = dp[i - 1][j - 1];`
|
||||
|
||||
此时可能有同学有点不明白,为啥要即`dp[i][j] = dp[i - 1][j - 1]`呢?
|
||||
|
||||
那么就在回顾上面讲过的`dp[i][j]`的定义,`word1[i - 1]` 与 `word2[j - 1]`相等了,那么就不用编辑了,以下标i-2为结尾的字符串word1和以下标j-2为结尾的字符串`word2`的最近编辑距离`dp[i - 1][j - 1]`就是 `dp[i][j]`了。
|
||||
|
||||
在下面的讲解中,如果哪里看不懂,就回想一下`dp[i][j]`的定义,就明白了。
|
||||
|
||||
**在整个动规的过程中,最为关键就是正确理解`dp[i][j]`的定义!**
|
||||
|
||||
|
||||
`if (word1[i - 1] != word2[j - 1])`,此时就需要编辑了,如何编辑呢?
|
||||
|
||||
操作一:word1增加一个元素,使其word1[i - 1]与word2[j - 1]相同,那么就是以下标i-2为结尾的word1 与 j-1为结尾的word2的最近编辑距离 加上一个增加元素的操作。
|
||||
|
||||
即 `dp[i][j] = dp[i - 1][j] + 1;`
|
||||
|
||||
|
||||
操作二:word2添加一个元素,使其word1[i - 1]与word2[j - 1]相同,那么就是以下标i-1为结尾的word1 与 j-2为结尾的word2的最近编辑距离 加上一个增加元素的操作。
|
||||
|
||||
即 `dp[i][j] = dp[i][j - 1] + 1;`
|
||||
|
||||
这里有同学发现了,怎么都是添加元素,删除元素去哪了。
|
||||
|
||||
**word2添加一个元素,相当于word1删除一个元素**,例如 `word1 = "ad" ,word2 = "a"`,`word1`删除元素`'d'`,`word2`添加一个元素`'d'`,变成`word1="a", word2="ad"`, 最终的操作数是一样! dp数组如下图所示意的:
|
||||
|
||||
```
|
||||
a a d
|
||||
+-----+-----+ +-----+-----+-----+
|
||||
| 0 | 1 | | 0 | 1 | 2 |
|
||||
+-----+-----+ ===> +-----+-----+-----+
|
||||
a | 1 | 0 | a | 1 | 0 | 1 |
|
||||
+-----+-----+ +-----+-----+-----+
|
||||
d | 2 | 1 |
|
||||
+-----+-----+
|
||||
```
|
||||
|
||||
操作三:替换元素,`word1`替换`word1[i - 1]`,使其与`word2[j - 1]`相同,此时不用增加元素,那么以下标`i-2`为结尾的`word1` 与 `j-2`为结尾的`word2`的最近编辑距离 加上一个替换元素的操作。
|
||||
|
||||
即 `dp[i][j] = dp[i - 1][j - 1] + 1;`
|
||||
|
||||
综上,当 `if (word1[i - 1] != word2[j - 1])` 时取最小的,即:`dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;`
|
||||
|
||||
递归公式代码如下:
|
||||
|
||||
```C++
|
||||
if (word1[i - 1] == word2[j - 1]) {
|
||||
dp[i][j] = dp[i - 1][j - 1];
|
||||
}
|
||||
else {
|
||||
dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 3. dp数组如何初始化
|
||||
|
||||
|
||||
再回顾一下dp[i][j]的定义:
|
||||
|
||||
**dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]**。
|
||||
|
||||
那么dp[i][0] 和 dp[0][j] 表示什么呢?
|
||||
|
||||
dp[i][0] :以下标i-1为结尾的字符串word1,和空字符串word2,最近编辑距离为dp[i][0]。
|
||||
|
||||
那么dp[i][0]就应该是i,对word1里的元素全部做删除操作,即:dp[i][0] = i;
|
||||
|
||||
同理dp[0][j] = j;
|
||||
|
||||
所以C++代码如下:
|
||||
|
||||
```C++
|
||||
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
|
||||
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
|
||||
```
|
||||
|
||||
-----------------------
|
||||
|
||||
### 4. 确定遍历顺序
|
||||
|
||||
从如下四个递推公式:
|
||||
|
||||
* `dp[i][j] = dp[i - 1][j - 1]`
|
||||
* `dp[i][j] = dp[i - 1][j - 1] + 1`
|
||||
* `dp[i][j] = dp[i][j - 1] + 1`
|
||||
* `dp[i][j] = dp[i - 1][j] + 1`
|
||||
|
||||
可以看出dp[i][j]是依赖左方,上方和左上方元素的,如图:
|
||||
|
||||
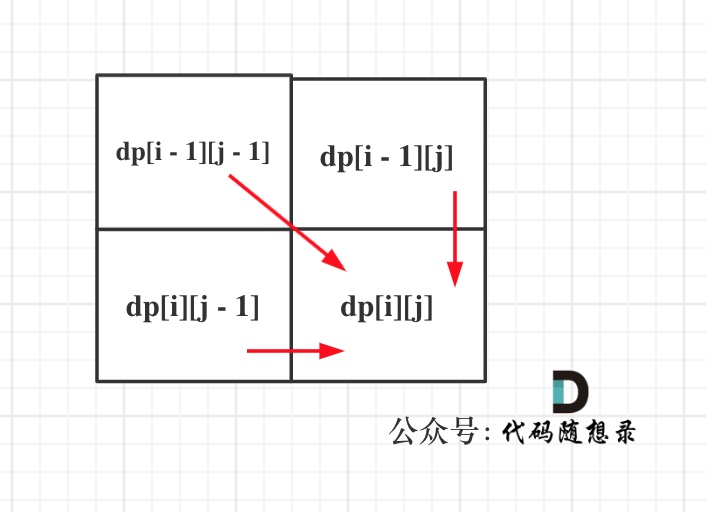
|
||||
|
||||
所以在dp矩阵中一定是从左到右从上到下去遍历。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
for (int i = 1; i <= word1.size(); i++) {
|
||||
for (int j = 1; j <= word2.size(); j++) {
|
||||
if (word1[i - 1] == word2[j - 1]) {
|
||||
dp[i][j] = dp[i - 1][j - 1];
|
||||
}
|
||||
else {
|
||||
dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
-----------------------
|
||||
|
||||
### 5. 举例推导dp数组
|
||||
|
||||
|
||||
以示例1为例,输入:`word1 = "horse", word2 = "ros"`为例,dp矩阵状态图如下:
|
||||
|
||||
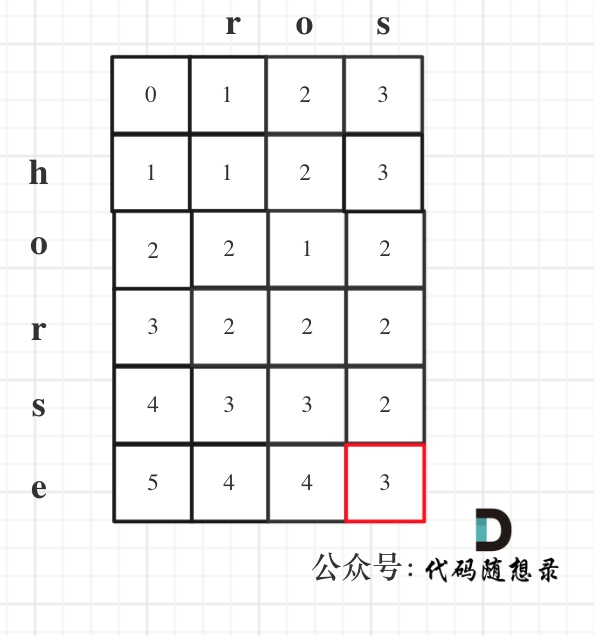
|
||||
|
||||
以上动规五部分析完毕,C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int minDistance(string word1, string word2) {
|
||||
vector<vector<int>> dp(word1.size() + 1, vector<int>(word2.size() + 1, 0));
|
||||
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
|
||||
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
|
||||
for (int i = 1; i <= word1.size(); i++) {
|
||||
for (int j = 1; j <= word2.size(); j++) {
|
||||
if (word1[i - 1] == word2[j - 1]) {
|
||||
dp[i][j] = dp[i - 1][j - 1];
|
||||
}
|
||||
else {
|
||||
dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[word1.size()][word2.size()];
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
-----------------------
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
public int minDistance(String word1, String word2) {
|
||||
int m = word1.length();
|
||||
int n = word2.length();
|
||||
int[][] dp = new int[m + 1][n + 1];
|
||||
// 初始化
|
||||
for (int i = 1; i <= m; i++) {
|
||||
dp[i][0] = i;
|
||||
}
|
||||
for (int j = 1; j <= n; j++) {
|
||||
dp[0][j] = j;
|
||||
}
|
||||
for (int i = 1; i <= m; i++) {
|
||||
for (int j = 1; j <= n; j++) {
|
||||
// 因为dp数组有效位从1开始
|
||||
// 所以当前遍历到的字符串的位置为i-1 | j-1
|
||||
if (word1.charAt(i - 1) == word2.charAt(j - 1)) {
|
||||
dp[i][j] = dp[i - 1][j - 1];
|
||||
} else {
|
||||
dp[i][j] = Math.min(Math.min(dp[i - 1][j - 1], dp[i][j - 1]), dp[i - 1][j]) + 1;
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[m][n];
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def minDistance(self, word1: str, word2: str) -> int:
|
||||
dp = [[0] * (len(word2)+1) for _ in range(len(word1)+1)]
|
||||
for i in range(len(word1)+1):
|
||||
dp[i][0] = i
|
||||
for j in range(len(word2)+1):
|
||||
dp[0][j] = j
|
||||
for i in range(1, len(word1)+1):
|
||||
for j in range(1, len(word2)+1):
|
||||
if word1[i-1] == word2[j-1]:
|
||||
dp[i][j] = dp[i-1][j-1]
|
||||
else:
|
||||
dp[i][j] = min(dp[i-1][j-1], dp[i-1][j], dp[i][j-1]) + 1
|
||||
return dp[-1][-1]
|
||||
```
|
||||
|
||||
Go:
|
||||
```Go
|
||||
func minDistance(word1 string, word2 string) int {
|
||||
m, n := len(word1), len(word2)
|
||||
dp := make([][]int, m+1)
|
||||
for i := range dp {
|
||||
dp[i] = make([]int, n+1)
|
||||
}
|
||||
for i := 0; i < m+1; i++ {
|
||||
dp[i][0] = i // word1[i] 变成 word2[0], 删掉 word1[i], 需要 i 部操作
|
||||
}
|
||||
for j := 0; j < n+1; j++ {
|
||||
dp[0][j] = j // word1[0] 变成 word2[j], 插入 word1[j],需要 j 部操作
|
||||
}
|
||||
for i := 1; i < m+1; i++ {
|
||||
for j := 1; j < n+1; j++ {
|
||||
if word1[i-1] == word2[j-1] {
|
||||
dp[i][j] = dp[i-1][j-1]
|
||||
} else { // Min(插入,删除,替换)
|
||||
dp[i][j] = Min(dp[i][j-1], dp[i-1][j], dp[i-1][j-1]) + 1
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[m][n]
|
||||
}
|
||||
func Min(args ...int) int {
|
||||
min := args[0]
|
||||
for _, item := range args {
|
||||
if item < min {
|
||||
min = item
|
||||
}
|
||||
}
|
||||
return min
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
443
problems/0077.组合.md
Normal file
443
problems/0077.组合.md
Normal file
@@ -0,0 +1,443 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
|
||||
|
||||
# 第77题. 组合
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/combinations/
|
||||
|
||||
给定两个整数 n 和 k,返回 1 ... n 中所有可能的 k 个数的组合。
|
||||
|
||||
示例:
|
||||
输入: n = 4, k = 2
|
||||
输出:
|
||||
[
|
||||
[2,4],
|
||||
[3,4],
|
||||
[2,3],
|
||||
[1,2],
|
||||
[1,3],
|
||||
[1,4],
|
||||
]
|
||||
|
||||
也可以直接看我的B站视频:[带你学透回溯算法-组合问题(对应力扣题目:77.组合)](https://www.bilibili.com/video/BV1ti4y1L7cv#reply3733925949)
|
||||
|
||||
## 思路
|
||||
|
||||
|
||||
本题这是回溯法的经典题目。
|
||||
|
||||
直接的解法当然是使用for循环,例如示例中k为2,很容易想到 用两个for循环,这样就可以输出 和示例中一样的结果。
|
||||
|
||||
代码如下:
|
||||
```
|
||||
int n = 4;
|
||||
for (int i = 1; i <= n; i++) {
|
||||
for (int j = i + 1; j <= n; j++) {
|
||||
cout << i << " " << j << endl;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
输入:n = 100, k = 3
|
||||
那么就三层for循环,代码如下:
|
||||
|
||||
```
|
||||
int n = 100;
|
||||
for (int i = 1; i <= n; i++) {
|
||||
for (int j = i + 1; j <= n; j++) {
|
||||
for (int u = j + 1; u <= n; n++) {
|
||||
cout << i << " " << j << " " << u << endl;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**如果n为100,k为50呢,那就50层for循环,是不是开始窒息**。
|
||||
|
||||
**此时就会发现虽然想暴力搜索,但是用for循环嵌套连暴力都写不出来!**
|
||||
|
||||
咋整?
|
||||
|
||||
回溯搜索法来了,虽然回溯法也是暴力,但至少能写出来,不像for循环嵌套k层让人绝望。
|
||||
|
||||
那么回溯法怎么暴力搜呢?
|
||||
|
||||
上面我们说了**要解决 n为100,k为50的情况,暴力写法需要嵌套50层for循环,那么回溯法就用递归来解决嵌套层数的问题**。
|
||||
|
||||
递归来做层叠嵌套(可以理解是开k层for循环),**每一次的递归中嵌套一个for循环,那么递归就可以用于解决多层嵌套循环的问题了**。
|
||||
|
||||
此时递归的层数大家应该知道了,例如:n为100,k为50的情况下,就是递归50层。
|
||||
|
||||
一些同学本来对递归就懵,回溯法中递归还要嵌套for循环,可能就直接晕倒了!
|
||||
|
||||
如果脑洞模拟回溯搜索的过程,绝对可以让人窒息,所以需要抽象图形结构来进一步理解。
|
||||
|
||||
**我们在[关于回溯算法,你该了解这些!](https://mp.weixin.qq.com/s/gjSgJbNbd1eAA5WkA-HeWw)中说道回溯法解决的问题都可以抽象为树形结构(N叉树),用树形结构来理解回溯就容易多了**。
|
||||
|
||||
那么我把组合问题抽象为如下树形结构:
|
||||
|
||||

|
||||
|
||||
可以看出这个棵树,一开始集合是 1,2,3,4, 从左向右取数,取过的数,不在重复取。
|
||||
|
||||
第一次取1,集合变为2,3,4 ,因为k为2,我们只需要再取一个数就可以了,分别取2,3,4,得到集合[1,2] [1,3] [1,4],以此类推。
|
||||
|
||||
**每次从集合中选取元素,可选择的范围随着选择的进行而收缩,调整可选择的范围**。
|
||||
|
||||
**图中可以发现n相当于树的宽度,k相当于树的深度**。
|
||||
|
||||
那么如何在这个树上遍历,然后收集到我们要的结果集呢?
|
||||
|
||||
**图中每次搜索到了叶子节点,我们就找到了一个结果**。
|
||||
|
||||
相当于只需要把达到叶子节点的结果收集起来,就可以求得 n个数中k个数的组合集合。
|
||||
|
||||
在[关于回溯算法,你该了解这些!](https://mp.weixin.qq.com/s/gjSgJbNbd1eAA5WkA-HeWw)中我们提到了回溯法三部曲,那么我们按照回溯法三部曲开始正式讲解代码了。
|
||||
|
||||
|
||||
## 回溯法三部曲
|
||||
|
||||
* 递归函数的返回值以及参数
|
||||
|
||||
在这里要定义两个全局变量,一个用来存放符合条件单一结果,一个用来存放符合条件结果的集合。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
vector<vector<int>> result; // 存放符合条件结果的集合
|
||||
vector<int> path; // 用来存放符合条件结果
|
||||
```
|
||||
|
||||
其实不定义这两个全局遍历也是可以的,把这两个变量放进递归函数的参数里,但函数里参数太多影响可读性,所以我定义全局变量了。
|
||||
|
||||
函数里一定有两个参数,既然是集合n里面取k的数,那么n和k是两个int型的参数。
|
||||
|
||||
然后还需要一个参数,为int型变量startIndex,这个参数用来记录本层递归的中,集合从哪里开始遍历(集合就是[1,...,n] )。
|
||||
|
||||
为什么要有这个startIndex呢?
|
||||
|
||||
**每次从集合中选取元素,可选择的范围随着选择的进行而收缩,调整可选择的范围,就是要靠startIndex**。
|
||||
|
||||
从下图中红线部分可以看出,在集合[1,2,3,4]取1之后,下一层递归,就要在[2,3,4]中取数了,那么下一层递归如何知道从[2,3,4]中取数呢,靠的就是startIndex。
|
||||
|
||||

|
||||
|
||||
所以需要startIndex来记录下一层递归,搜索的起始位置。
|
||||
|
||||
那么整体代码如下:
|
||||
|
||||
```
|
||||
vector<vector<int>> result; // 存放符合条件结果的集合
|
||||
vector<int> path; // 用来存放符合条件单一结果
|
||||
void backtracking(int n, int k, int startIndex)
|
||||
```
|
||||
|
||||
* 回溯函数终止条件
|
||||
|
||||
什么时候到达所谓的叶子节点了呢?
|
||||
|
||||
path这个数组的大小如果达到k,说明我们找到了一个子集大小为k的组合了,在图中path存的就是根节点到叶子节点的路径。
|
||||
|
||||
如图红色部分:
|
||||
|
||||

|
||||
|
||||
此时用result二维数组,把path保存起来,并终止本层递归。
|
||||
|
||||
所以终止条件代码如下:
|
||||
|
||||
```
|
||||
if (path.size() == k) {
|
||||
result.push_back(path);
|
||||
return;
|
||||
}
|
||||
```
|
||||
|
||||
* 单层搜索的过程
|
||||
|
||||
回溯法的搜索过程就是一个树型结构的遍历过程,在如下图中,可以看出for循环用来横向遍历,递归的过程是纵向遍历。
|
||||
|
||||

|
||||
|
||||
如此我们才遍历完图中的这棵树。
|
||||
|
||||
for循环每次从startIndex开始遍历,然后用path保存取到的节点i。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
for (int i = startIndex; i <= n; i++) { // 控制树的横向遍历
|
||||
path.push_back(i); // 处理节点
|
||||
backtracking(n, k, i + 1); // 递归:控制树的纵向遍历,注意下一层搜索要从i+1开始
|
||||
path.pop_back(); // 回溯,撤销处理的节点
|
||||
}
|
||||
```
|
||||
|
||||
可以看出backtracking(递归函数)通过不断调用自己一直往深处遍历,总会遇到叶子节点,遇到了叶子节点就要返回。
|
||||
|
||||
backtracking的下面部分就是回溯的操作了,撤销本次处理的结果。
|
||||
|
||||
关键地方都讲完了,组合问题C++完整代码如下:
|
||||
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
vector<vector<int>> result; // 存放符合条件结果的集合
|
||||
vector<int> path; // 用来存放符合条件结果
|
||||
void backtracking(int n, int k, int startIndex) {
|
||||
if (path.size() == k) {
|
||||
result.push_back(path);
|
||||
return;
|
||||
}
|
||||
for (int i = startIndex; i <= n; i++) {
|
||||
path.push_back(i); // 处理节点
|
||||
backtracking(n, k, i + 1); // 递归
|
||||
path.pop_back(); // 回溯,撤销处理的节点
|
||||
}
|
||||
}
|
||||
public:
|
||||
vector<vector<int>> combine(int n, int k) {
|
||||
result.clear(); // 可以不写
|
||||
path.clear(); // 可以不写
|
||||
backtracking(n, k, 1);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
还记得我们在[关于回溯算法,你该了解这些!](https://mp.weixin.qq.com/s/gjSgJbNbd1eAA5WkA-HeWw)中给出的回溯法模板么?
|
||||
|
||||
如下:
|
||||
```
|
||||
void backtracking(参数) {
|
||||
if (终止条件) {
|
||||
存放结果;
|
||||
return;
|
||||
}
|
||||
|
||||
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
|
||||
处理节点;
|
||||
backtracking(路径,选择列表); // 递归
|
||||
回溯,撤销处理结果
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**对比一下本题的代码,是不是发现有点像!** 所以有了这个模板,就有解题的大体方向,不至于毫无头绪。
|
||||
|
||||
# 总结
|
||||
|
||||
组合问题是回溯法解决的经典问题,我们开始的时候给大家列举一个很形象的例子,就是n为100,k为50的话,直接想法就需要50层for循环。
|
||||
|
||||
从而引出了回溯法就是解决这种k层for循环嵌套的问题。
|
||||
|
||||
然后进一步把回溯法的搜索过程抽象为树形结构,可以直观的看出搜索的过程。
|
||||
|
||||
接着用回溯法三部曲,逐步分析了函数参数、终止条件和单层搜索的过程。
|
||||
|
||||
# 剪枝优化
|
||||
|
||||
我们说过,回溯法虽然是暴力搜索,但也有时候可以有点剪枝优化一下的。
|
||||
|
||||
在遍历的过程中有如下代码:
|
||||
|
||||
```
|
||||
for (int i = startIndex; i <= n; i++) {
|
||||
path.push_back(i);
|
||||
backtracking(n, k, i + 1);
|
||||
path.pop_back();
|
||||
}
|
||||
```
|
||||
|
||||
这个遍历的范围是可以剪枝优化的,怎么优化呢?
|
||||
|
||||
来举一个例子,n = 4,k = 4的话,那么第一层for循环的时候,从元素2开始的遍历都没有意义了。 在第二层for循环,从元素3开始的遍历都没有意义了。
|
||||
|
||||
这么说有点抽象,如图所示:
|
||||
|
||||
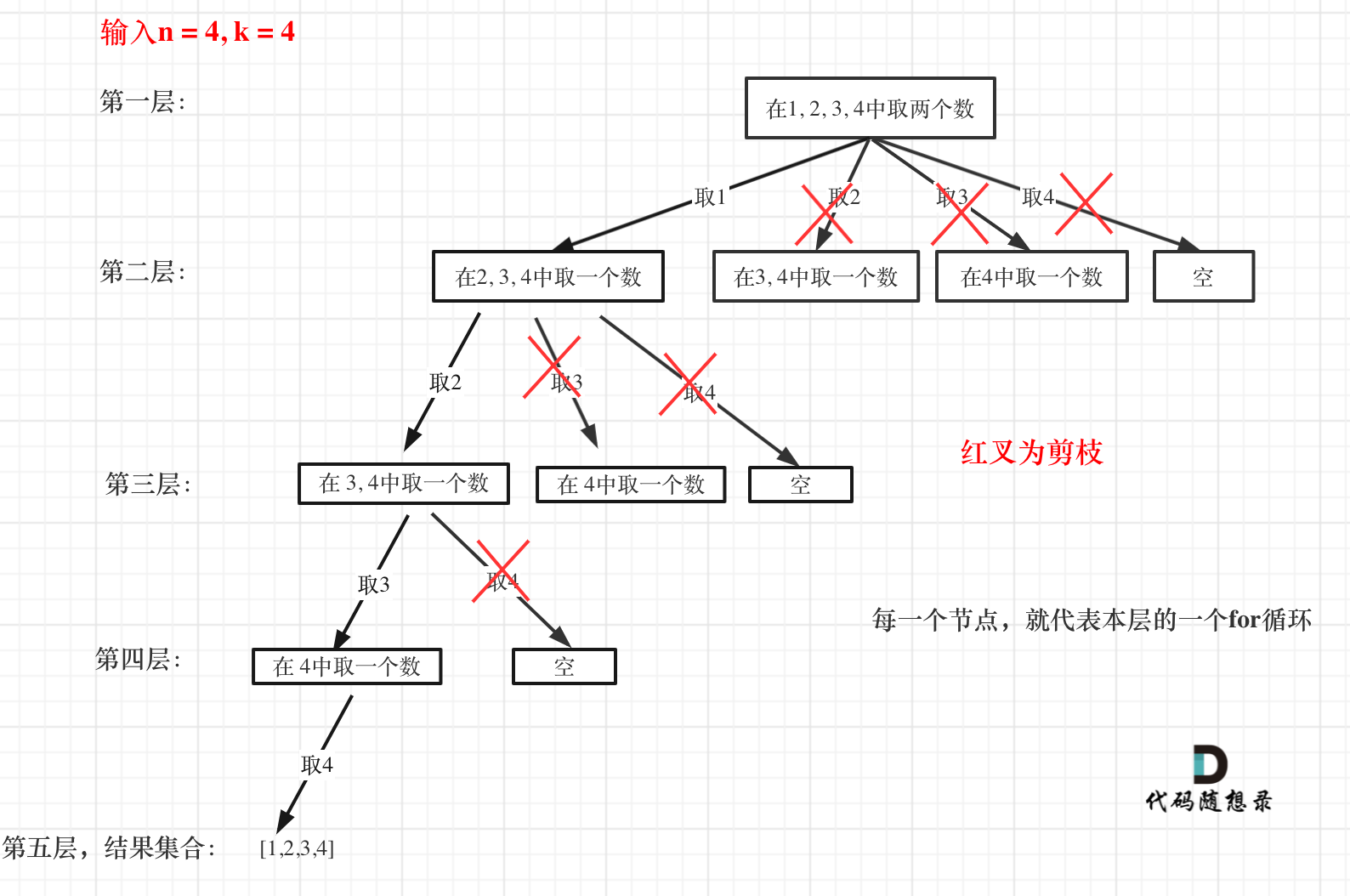
|
||||
|
||||
图中每一个节点(图中为矩形),就代表本层的一个for循环,那么每一层的for循环从第二个数开始遍历的话,都没有意义,都是无效遍历。
|
||||
|
||||
**所以,可以剪枝的地方就在递归中每一层的for循环所选择的起始位置**。
|
||||
|
||||
**如果for循环选择的起始位置之后的元素个数 已经不足 我们需要的元素个数了,那么就没有必要搜索了**。
|
||||
|
||||
注意代码中i,就是for循环里选择的起始位置。
|
||||
```
|
||||
for (int i = startIndex; i <= n; i++) {
|
||||
```
|
||||
|
||||
接下来看一下优化过程如下:
|
||||
|
||||
1. 已经选择的元素个数:path.size();
|
||||
|
||||
2. 还需要的元素个数为: k - path.size();
|
||||
|
||||
3. 在集合n中至多要从该起始位置 : n - (k - path.size()) + 1,开始遍历
|
||||
|
||||
为什么有个+1呢,因为包括起始位置,我们要是一个左闭的集合。
|
||||
|
||||
举个例子,n = 4,k = 3, 目前已经选取的元素为0(path.size为0),n - (k - 0) + 1 即 4 - ( 3 - 0) + 1 = 2。
|
||||
|
||||
从2开始搜索都是合理的,可以是组合[2, 3, 4]。
|
||||
|
||||
这里大家想不懂的话,建议也举一个例子,就知道是不是要+1了。
|
||||
|
||||
所以优化之后的for循环是:
|
||||
|
||||
```
|
||||
for (int i = startIndex; i <= n - (k - path.size()) + 1; i++) // i为本次搜索的起始位置
|
||||
```
|
||||
|
||||
优化后整体代码如下:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
private:
|
||||
vector<vector<int>> result;
|
||||
vector<int> path;
|
||||
void backtracking(int n, int k, int startIndex) {
|
||||
if (path.size() == k) {
|
||||
result.push_back(path);
|
||||
return;
|
||||
}
|
||||
for (int i = startIndex; i <= n - (k - path.size()) + 1; i++) { // 优化的地方
|
||||
path.push_back(i); // 处理节点
|
||||
backtracking(n, k, i + 1);
|
||||
path.pop_back(); // 回溯,撤销处理的节点
|
||||
}
|
||||
}
|
||||
public:
|
||||
|
||||
vector<vector<int>> combine(int n, int k) {
|
||||
backtracking(n, k, 1);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
# 剪枝总结
|
||||
|
||||
本篇我们准对求组合问题的回溯法代码做了剪枝优化,这个优化如果不画图的话,其实不好理解,也不好讲清楚。
|
||||
|
||||
所以我依然是把整个回溯过程抽象为一颗树形结构,然后可以直观的看出,剪枝究竟是剪的哪里。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
List<List<Integer>> result = new ArrayList<>();
|
||||
LinkedList<Integer> path = new LinkedList<>();
|
||||
public List<List<Integer>> combine(int n, int k) {
|
||||
combineHelper(n, k, 1);
|
||||
return result;
|
||||
}
|
||||
|
||||
/**
|
||||
* 每次从集合中选取元素,可选择的范围随着选择的进行而收缩,调整可选择的范围,就是要靠startIndex
|
||||
* @param startIndex 用来记录本层递归的中,集合从哪里开始遍历(集合就是[1,...,n] )。
|
||||
*/
|
||||
private void combineHelper(int n, int k, int startIndex){
|
||||
//终止条件
|
||||
if (path.size() == k){
|
||||
result.add(new ArrayList<>(path));
|
||||
return;
|
||||
}
|
||||
for (int i = startIndex; i <= n - (k - path.size()) + 1; i++){
|
||||
path.add(i);
|
||||
combineHelper(n, k, i + 1);
|
||||
path.removeLast();
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
Python:
|
||||
```python3
|
||||
class Solution:
|
||||
def combine(self, n: int, k: int) -> List[List[int]]:
|
||||
res=[] #存放符合条件结果的集合
|
||||
path=[] #用来存放符合条件结果
|
||||
def backtrack(n,k,startIndex):
|
||||
if len(path) == k:
|
||||
res.append(path[:])
|
||||
return
|
||||
for i in range(startIndex,n+1):
|
||||
path.append(i) #处理节点
|
||||
backtrack(n,k,i+1) #递归
|
||||
path.pop() #回溯,撤销处理的节点
|
||||
backtrack(n,k,1)
|
||||
return res
|
||||
```
|
||||
javascript
|
||||
```javascript
|
||||
let result = []
|
||||
let path = []
|
||||
var combine = function(n, k) {
|
||||
result = []
|
||||
combineHelper(n, k, 1)
|
||||
return result
|
||||
};
|
||||
const combineHelper = (n, k, startIndex) => {
|
||||
if (path.length === k) {
|
||||
result.push([...path])
|
||||
return
|
||||
}
|
||||
for (let i = startIndex; i <= n - (k - path.length) + 1; ++i) {
|
||||
path.push(i)
|
||||
combineHelper(n, k, i + 1)
|
||||
path.pop()
|
||||
}
|
||||
}
|
||||
```
|
||||
Go:
|
||||
```Go
|
||||
var res [][]int
|
||||
func combine(n int, k int) [][]int {
|
||||
res=[][]int{}
|
||||
if n <= 0 || k <= 0 || k > n {
|
||||
return res
|
||||
}
|
||||
backtrack(n, k, 1, []int{})
|
||||
return res
|
||||
}
|
||||
func backtrack(n,k,start int,track []int){
|
||||
if len(track)==k{
|
||||
temp:=make([]int,k)
|
||||
copy(temp,track)
|
||||
res=append(res,temp)
|
||||
}
|
||||
if len(track)+n-start+1 < k {
|
||||
return
|
||||
}
|
||||
for i:=start;i<=n;i++{
|
||||
track=append(track,i)
|
||||
backtrack(n,k,i+1,track)
|
||||
track=track[:len(track)-1]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
252
problems/0077.组合优化.md
Normal file
252
problems/0077.组合优化.md
Normal file
@@ -0,0 +1,252 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
在[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)中,我们通过回溯搜索法,解决了n个数中求k个数的组合问题。
|
||||
|
||||
> 可以直接看我的B栈视频讲解:[带你学透回溯算法-组合问题的剪枝操作](https://www.bilibili.com/video/BV1wi4y157er)
|
||||
|
||||
文中的回溯法是可以剪枝优化的,本篇我们继续来看一下题目77. 组合。
|
||||
|
||||
链接:https://leetcode-cn.com/problems/combinations/
|
||||
|
||||
**看本篇之前,需要先看[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)**。
|
||||
|
||||
大家先回忆一下[77. 组合]给出的回溯法的代码:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
private:
|
||||
vector<vector<int>> result; // 存放符合条件结果的集合
|
||||
vector<int> path; // 用来存放符合条件结果
|
||||
void backtracking(int n, int k, int startIndex) {
|
||||
if (path.size() == k) {
|
||||
result.push_back(path);
|
||||
return;
|
||||
}
|
||||
for (int i = startIndex; i <= n; i++) {
|
||||
path.push_back(i); // 处理节点
|
||||
backtracking(n, k, i + 1); // 递归
|
||||
path.pop_back(); // 回溯,撤销处理的节点
|
||||
}
|
||||
}
|
||||
public:
|
||||
vector<vector<int>> combine(int n, int k) {
|
||||
result.clear(); // 可以不写
|
||||
path.clear(); // 可以不写
|
||||
backtracking(n, k, 1);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
# 剪枝优化
|
||||
|
||||
我们说过,回溯法虽然是暴力搜索,但也有时候可以有点剪枝优化一下的。
|
||||
|
||||
在遍历的过程中有如下代码:
|
||||
|
||||
```
|
||||
for (int i = startIndex; i <= n; i++) {
|
||||
path.push_back(i);
|
||||
backtracking(n, k, i + 1);
|
||||
path.pop_back();
|
||||
}
|
||||
```
|
||||
|
||||
这个遍历的范围是可以剪枝优化的,怎么优化呢?
|
||||
|
||||
来举一个例子,n = 4,k = 4的话,那么第一层for循环的时候,从元素2开始的遍历都没有意义了。 在第二层for循环,从元素3开始的遍历都没有意义了。
|
||||
|
||||
这么说有点抽象,如图所示:
|
||||
|
||||

|
||||
|
||||
|
||||
图中每一个节点(图中为矩形),就代表本层的一个for循环,那么每一层的for循环从第二个数开始遍历的话,都没有意义,都是无效遍历。
|
||||
|
||||
**所以,可以剪枝的地方就在递归中每一层的for循环所选择的起始位置**。
|
||||
|
||||
**如果for循环选择的起始位置之后的元素个数 已经不足 我们需要的元素个数了,那么就没有必要搜索了**。
|
||||
|
||||
注意代码中i,就是for循环里选择的起始位置。
|
||||
```
|
||||
for (int i = startIndex; i <= n; i++) {
|
||||
```
|
||||
|
||||
接下来看一下优化过程如下:
|
||||
|
||||
1. 已经选择的元素个数:path.size();
|
||||
|
||||
2. 还需要的元素个数为: k - path.size();
|
||||
|
||||
3. 在集合n中至多要从该起始位置 : n - (k - path.size()) + 1,开始遍历
|
||||
|
||||
为什么有个+1呢,因为包括起始位置,我们要是一个左闭的集合。
|
||||
|
||||
举个例子,n = 4,k = 3, 目前已经选取的元素为0(path.size为0),n - (k - 0) + 1 即 4 - ( 3 - 0) + 1 = 2。
|
||||
|
||||
从2开始搜索都是合理的,可以是组合[2, 3, 4]。
|
||||
|
||||
这里大家想不懂的话,建议也举一个例子,就知道是不是要+1了。
|
||||
|
||||
所以优化之后的for循环是:
|
||||
|
||||
```
|
||||
for (int i = startIndex; i <= n - (k - path.size()) + 1; i++) // i为本次搜索的起始位置
|
||||
```
|
||||
|
||||
优化后整体代码如下:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
private:
|
||||
vector<vector<int>> result;
|
||||
vector<int> path;
|
||||
void backtracking(int n, int k, int startIndex) {
|
||||
if (path.size() == k) {
|
||||
result.push_back(path);
|
||||
return;
|
||||
}
|
||||
for (int i = startIndex; i <= n - (k - path.size()) + 1; i++) { // 优化的地方
|
||||
path.push_back(i); // 处理节点
|
||||
backtracking(n, k, i + 1);
|
||||
path.pop_back(); // 回溯,撤销处理的节点
|
||||
}
|
||||
}
|
||||
public:
|
||||
|
||||
vector<vector<int>> combine(int n, int k) {
|
||||
backtracking(n, k, 1);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
# 总结
|
||||
|
||||
本篇我们准对求组合问题的回溯法代码做了剪枝优化,这个优化如果不画图的话,其实不好理解,也不好讲清楚。
|
||||
|
||||
所以我依然是把整个回溯过程抽象为一颗树形结构,然后可以直观的看出,剪枝究竟是剪的哪里。
|
||||
|
||||
**就酱,学到了就帮Carl转发一下吧,让更多的同学知道这里!**
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
List<List<Integer>> result = new ArrayList<>();
|
||||
LinkedList<Integer> path = new LinkedList<>();
|
||||
public List<List<Integer>> combine(int n, int k) {
|
||||
combineHelper(n, k, 1);
|
||||
return result;
|
||||
}
|
||||
|
||||
/**
|
||||
* 每次从集合中选取元素,可选择的范围随着选择的进行而收缩,调整可选择的范围,就是要靠startIndex
|
||||
* @param startIndex 用来记录本层递归的中,集合从哪里开始遍历(集合就是[1,...,n] )。
|
||||
*/
|
||||
private void combineHelper(int n, int k, int startIndex){
|
||||
//终止条件
|
||||
if (path.size() == k){
|
||||
result.add(new ArrayList<>(path));
|
||||
return;
|
||||
}
|
||||
for (int i = startIndex; i <= n - (k - path.size()) + 1; i++){
|
||||
path.add(i);
|
||||
combineHelper(n, k, i + 1);
|
||||
path.removeLast();
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python3
|
||||
class Solution:
|
||||
def combine(self, n: int, k: int) -> List[List[int]]:
|
||||
res=[] #存放符合条件结果的集合
|
||||
path=[] #用来存放符合条件结果
|
||||
def backtrack(n,k,startIndex):
|
||||
if len(path) == k:
|
||||
res.append(path[:])
|
||||
return
|
||||
for i in range(startIndex,n-(k-len(path))+2): #优化的地方
|
||||
path.append(i) #处理节点
|
||||
backtrack(n,k,i+1) #递归
|
||||
path.pop() #回溯,撤销处理的节点
|
||||
backtrack(n,k,1)
|
||||
return res
|
||||
```
|
||||
Go:
|
||||
```Go
|
||||
var res [][]int
|
||||
func combine(n int, k int) [][]int {
|
||||
res=[][]int{}
|
||||
if n <= 0 || k <= 0 || k > n {
|
||||
return res
|
||||
}
|
||||
backtrack(n, k, 1, []int{})
|
||||
return res
|
||||
}
|
||||
func backtrack(n,k,start int,track []int){
|
||||
if len(track)==k{
|
||||
temp:=make([]int,k)
|
||||
copy(temp,track)
|
||||
res=append(res,temp)
|
||||
}
|
||||
if len(track)+n-start+1 < k {
|
||||
return
|
||||
}
|
||||
for i:=start;i<=n;i++{
|
||||
track=append(track,i)
|
||||
backtrack(n,k,i+1,track)
|
||||
track=track[:len(track)-1]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
javaScript:
|
||||
|
||||
```js
|
||||
var combine = function(n, k) {
|
||||
const res = [], path = [];
|
||||
backtracking(n, k, 1);
|
||||
return res;
|
||||
function backtracking (n, k, i){
|
||||
const len = path.length;
|
||||
if(len === k) {
|
||||
res.push(Array.from(path));
|
||||
return;
|
||||
}
|
||||
for(let a = i; a <= n + len - k + 1; a++) {
|
||||
path.push(a);
|
||||
backtracking(n, k, a + 1);
|
||||
path.pop();
|
||||
}
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
271
problems/0078.子集.md
Normal file
271
problems/0078.子集.md
Normal file
@@ -0,0 +1,271 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 第78题. 子集
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/subsets/
|
||||
|
||||
给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
|
||||
|
||||
说明:解集不能包含重复的子集。
|
||||
|
||||
示例:
|
||||
输入: nums = [1,2,3]
|
||||
输出:
|
||||
[
|
||||
[3],
|
||||
[1],
|
||||
[2],
|
||||
[1,2,3],
|
||||
[1,3],
|
||||
[2,3],
|
||||
[1,2],
|
||||
[]
|
||||
]
|
||||
|
||||
## 思路
|
||||
|
||||
求子集问题和[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)和[回溯算法:分割问题!](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)又不一样了。
|
||||
|
||||
如果把 子集问题、组合问题、分割问题都抽象为一棵树的话,**那么组合问题和分割问题都是收集树的叶子节点,而子集问题是找树的所有节点!**
|
||||
|
||||
其实子集也是一种组合问题,因为它的集合是无序的,子集{1,2} 和 子集{2,1}是一样的。
|
||||
|
||||
**那么既然是无序,取过的元素不会重复取,写回溯算法的时候,for就要从startIndex开始,而不是从0开始!**
|
||||
|
||||
有同学问了,什么时候for可以从0开始呢?
|
||||
|
||||
求排列问题的时候,就要从0开始,因为集合是有序的,{1, 2} 和{2, 1}是两个集合,排列问题我们后续的文章就会讲到的。
|
||||
|
||||
以示例中nums = [1,2,3]为例把求子集抽象为树型结构,如下:
|
||||
|
||||

|
||||
|
||||
从图中红线部分,可以看出**遍历这个树的时候,把所有节点都记录下来,就是要求的子集集合**。
|
||||
|
||||
## 回溯三部曲
|
||||
|
||||
* 递归函数参数
|
||||
|
||||
全局变量数组path为子集收集元素,二维数组result存放子集组合。(也可以放到递归函数参数里)
|
||||
|
||||
递归函数参数在上面讲到了,需要startIndex。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
vector<vector<int>> result;
|
||||
vector<int> path;
|
||||
void backtracking(vector<int>& nums, int startIndex) {
|
||||
```
|
||||
|
||||
* 递归终止条件
|
||||
|
||||
从图中可以看出:
|
||||
|
||||

|
||||
|
||||
剩余集合为空的时候,就是叶子节点。
|
||||
|
||||
那么什么时候剩余集合为空呢?
|
||||
|
||||
就是startIndex已经大于数组的长度了,就终止了,因为没有元素可取了,代码如下:
|
||||
|
||||
```
|
||||
if (startIndex >= nums.size()) {
|
||||
return;
|
||||
}
|
||||
```
|
||||
|
||||
**其实可以不需要加终止条件,因为startIndex >= nums.size(),本层for循环本来也结束了**。
|
||||
|
||||
* 单层搜索逻辑
|
||||
|
||||
**求取子集问题,不需要任何剪枝!因为子集就是要遍历整棵树**。
|
||||
|
||||
那么单层递归逻辑代码如下:
|
||||
|
||||
```
|
||||
for (int i = startIndex; i < nums.size(); i++) {
|
||||
path.push_back(nums[i]); // 子集收集元素
|
||||
backtracking(nums, i + 1); // 注意从i+1开始,元素不重复取
|
||||
path.pop_back(); // 回溯
|
||||
}
|
||||
```
|
||||
|
||||
## C++代码
|
||||
|
||||
根据[关于回溯算法,你该了解这些!](https://mp.weixin.qq.com/s/gjSgJbNbd1eAA5WkA-HeWw)给出的回溯算法模板:
|
||||
|
||||
```
|
||||
void backtracking(参数) {
|
||||
if (终止条件) {
|
||||
存放结果;
|
||||
return;
|
||||
}
|
||||
|
||||
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
|
||||
处理节点;
|
||||
backtracking(路径,选择列表); // 递归
|
||||
回溯,撤销处理结果
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
可以写出如下回溯算法C++代码:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
vector<vector<int>> result;
|
||||
vector<int> path;
|
||||
void backtracking(vector<int>& nums, int startIndex) {
|
||||
result.push_back(path); // 收集子集,要放在终止添加的上面,否则会漏掉自己
|
||||
if (startIndex >= nums.size()) { // 终止条件可以不加
|
||||
return;
|
||||
}
|
||||
for (int i = startIndex; i < nums.size(); i++) {
|
||||
path.push_back(nums[i]);
|
||||
backtracking(nums, i + 1);
|
||||
path.pop_back();
|
||||
}
|
||||
}
|
||||
public:
|
||||
vector<vector<int>> subsets(vector<int>& nums) {
|
||||
result.clear();
|
||||
path.clear();
|
||||
backtracking(nums, 0);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
在注释中,可以发现可以不写终止条件,因为本来我们就要遍历整颗树。
|
||||
|
||||
有的同学可能担心不写终止条件会不会无限递归?
|
||||
|
||||
并不会,因为每次递归的下一层就是从i+1开始的。
|
||||
|
||||
## 总结
|
||||
|
||||
相信大家经过了
|
||||
* 组合问题:
|
||||
* [回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)
|
||||
* [回溯算法:组合问题再剪剪枝](https://mp.weixin.qq.com/s/Ri7spcJMUmph4c6XjPWXQA)
|
||||
* [回溯算法:求组合总和!](https://mp.weixin.qq.com/s/HX7WW6ixbFZJASkRnCTC3w)
|
||||
* [回溯算法:电话号码的字母组合](https://mp.weixin.qq.com/s/e2ua2cmkE_vpYjM3j6HY0A)
|
||||
* [回溯算法:求组合总和(二)](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)
|
||||
* [回溯算法:求组合总和(三)](https://mp.weixin.qq.com/s/_1zPYk70NvHsdY8UWVGXmQ)
|
||||
* 分割问题:
|
||||
* [回溯算法:分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)
|
||||
* [回溯算法:复原IP地址](https://mp.weixin.qq.com/s/v--VmA8tp9vs4bXCqHhBuA)
|
||||
|
||||
洗礼之后,发现子集问题还真的有点简单了,其实这就是一道标准的模板题。
|
||||
|
||||
但是要清楚子集问题和组合问题、分割问题的的区别,**子集是收集树形结构中树的所有节点的结果**。
|
||||
|
||||
**而组合问题、分割问题是收集树形结构中叶子节点的结果**。
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
List<List<Integer>> result = new ArrayList<>();// 存放符合条件结果的集合
|
||||
LinkedList<Integer> path = new LinkedList<>();// 用来存放符合条件结果
|
||||
public List<List<Integer>> subsets(int[] nums) {
|
||||
if (nums.length == 0){
|
||||
result.add(new ArrayList<>());
|
||||
return result;
|
||||
}
|
||||
subsetsHelper(nums, 0);
|
||||
return result;
|
||||
}
|
||||
|
||||
private void subsetsHelper(int[] nums, int startIndex){
|
||||
result.add(new ArrayList<>(path));//「遍历这个树的时候,把所有节点都记录下来,就是要求的子集集合」。
|
||||
if (startIndex >= nums.length){ //终止条件可不加
|
||||
return;
|
||||
}
|
||||
for (int i = startIndex; i < nums.length; i++){
|
||||
path.add(nums[i]);
|
||||
subsetsHelper(nums, i + 1);
|
||||
path.removeLast();
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python3
|
||||
class Solution:
|
||||
def subsets(self, nums: List[int]) -> List[List[int]]:
|
||||
res = []
|
||||
path = []
|
||||
def backtrack(nums,startIndex):
|
||||
res.append(path[:]) #收集子集,要放在终止添加的上面,否则会漏掉自己
|
||||
for i in range(startIndex,len(nums)): #当startIndex已经大于数组的长度了,就终止了,for循环本来也结束了,所以不需要终止条件
|
||||
path.append(nums[i])
|
||||
backtrack(nums,i+1) #递归
|
||||
path.pop() #回溯
|
||||
backtrack(nums,0)
|
||||
return res
|
||||
```
|
||||
|
||||
Go:
|
||||
```Go
|
||||
var res [][]int
|
||||
func subset(nums []int) [][]int {
|
||||
res = make([][]int, 0)
|
||||
sort.Ints(nums)
|
||||
Dfs([]int{}, nums, 0)
|
||||
return res
|
||||
}
|
||||
func Dfs(temp, nums []int, start int){
|
||||
tmp := make([]int, len(temp))
|
||||
copy(tmp, temp)
|
||||
res = append(res, tmp)
|
||||
for i := start; i < len(nums); i++{
|
||||
//if i>start&&nums[i]==nums[i-1]{
|
||||
// continue
|
||||
//}
|
||||
temp = append(temp, nums[i])
|
||||
Dfs(temp, nums, i+1)
|
||||
temp = temp[:len(temp)-1]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Javascript:
|
||||
|
||||
```Javascript
|
||||
var subsets = function(nums) {
|
||||
let result = []
|
||||
let path = []
|
||||
function backtracking(startIndex) {
|
||||
result.push(path.slice())
|
||||
for(let i = startIndex; i < nums.length; i++) {
|
||||
path.push(nums[i])
|
||||
backtracking(i + 1)
|
||||
path.pop()
|
||||
}
|
||||
}
|
||||
backtracking(0)
|
||||
return result
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
291
problems/0090.子集II.md
Normal file
291
problems/0090.子集II.md
Normal file
@@ -0,0 +1,291 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 第90题.子集II
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/subsets-ii/
|
||||
|
||||
给定一个可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
|
||||
|
||||
说明:解集不能包含重复的子集。
|
||||
|
||||
示例:
|
||||
输入: [1,2,2]
|
||||
输出:
|
||||
[
|
||||
[2],
|
||||
[1],
|
||||
[1,2,2],
|
||||
[2,2],
|
||||
[1,2],
|
||||
[]
|
||||
]
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
做本题之前一定要先做[78.子集](https://mp.weixin.qq.com/s/NNRzX-vJ_pjK4qxohd_LtA)。
|
||||
|
||||
这道题目和[回溯算法:求子集问题!](https://mp.weixin.qq.com/s/NNRzX-vJ_pjK4qxohd_LtA)区别就是集合里有重复元素了,而且求取的子集要去重。
|
||||
|
||||
那么关于回溯算法中的去重问题,**在[40.组合总和II](https://mp.weixin.qq.com/s/_1zPYk70NvHsdY8UWVGXmQ)中已经详细讲解过了,和本题是一个套路**。
|
||||
|
||||
**剧透一下,后期要讲解的排列问题里去重也是这个套路,所以理解“树层去重”和“树枝去重”非常重要**。
|
||||
|
||||
用示例中的[1, 2, 2] 来举例,如图所示: (**注意去重需要先对集合排序**)
|
||||
|
||||
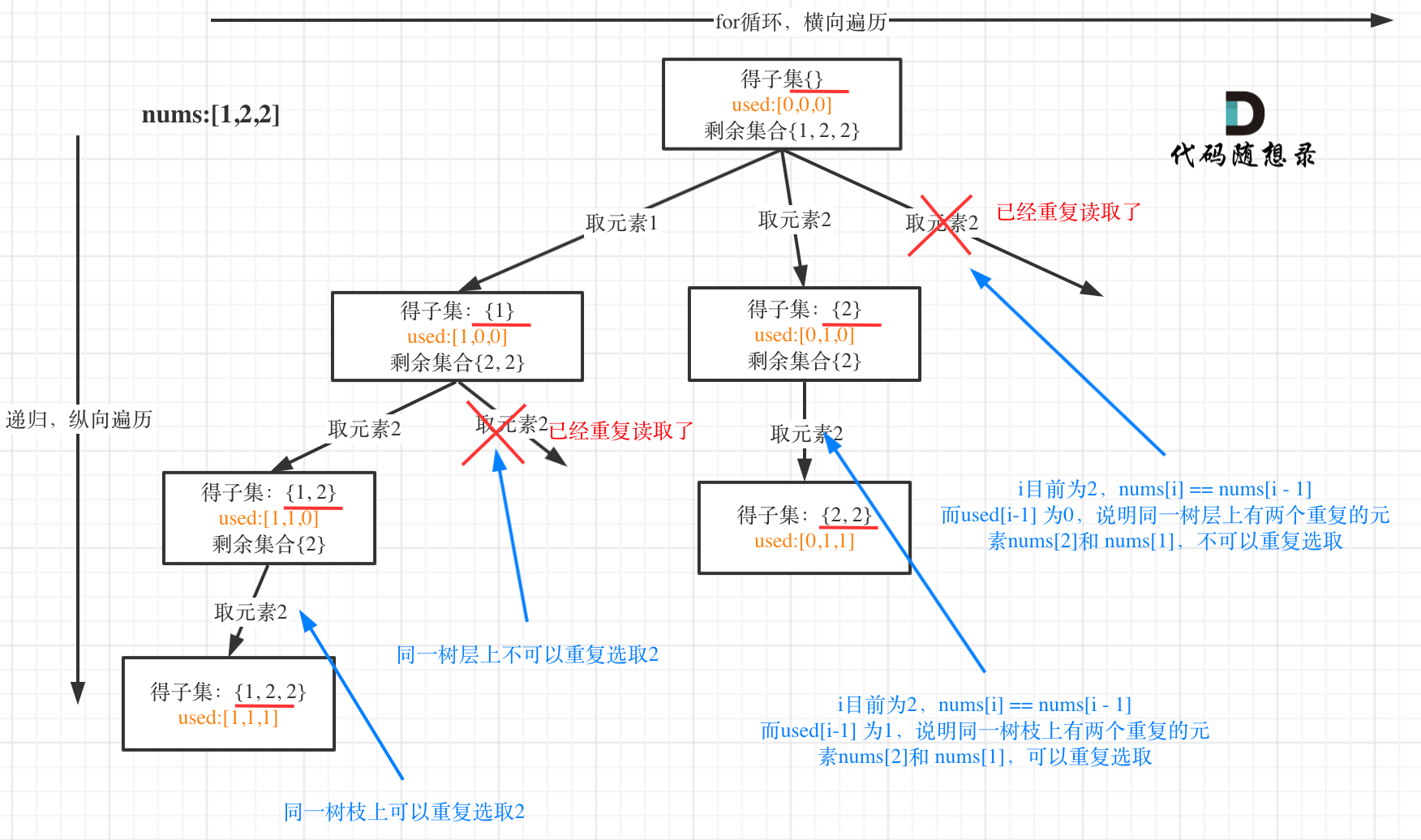
|
||||
|
||||
从图中可以看出,同一树层上重复取2 就要过滤掉,同一树枝上就可以重复取2,因为同一树枝上元素的集合才是唯一子集!
|
||||
|
||||
本题就是其实就是[回溯算法:求子集问题!](https://mp.weixin.qq.com/s/NNRzX-vJ_pjK4qxohd_LtA)的基础上加上了去重,去重我们在[回溯算法:求组合总和(三)](https://mp.weixin.qq.com/s/_1zPYk70NvHsdY8UWVGXmQ)也讲过了,所以我就直接给出代码了:
|
||||
|
||||
## C++代码
|
||||
|
||||
```
|
||||
class Solution {
|
||||
private:
|
||||
vector<vector<int>> result;
|
||||
vector<int> path;
|
||||
void backtracking(vector<int>& nums, int startIndex, vector<bool>& used) {
|
||||
result.push_back(path);
|
||||
for (int i = startIndex; i < nums.size(); i++) {
|
||||
// used[i - 1] == true,说明同一树支candidates[i - 1]使用过
|
||||
// used[i - 1] == false,说明同一树层candidates[i - 1]使用过
|
||||
// 而我们要对同一树层使用过的元素进行跳过
|
||||
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) {
|
||||
continue;
|
||||
}
|
||||
path.push_back(nums[i]);
|
||||
used[i] = true;
|
||||
backtracking(nums, i + 1, used);
|
||||
used[i] = false;
|
||||
path.pop_back();
|
||||
}
|
||||
}
|
||||
|
||||
public:
|
||||
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
|
||||
result.clear();
|
||||
path.clear();
|
||||
vector<bool> used(nums.size(), false);
|
||||
sort(nums.begin(), nums.end()); // 去重需要排序
|
||||
backtracking(nums, 0, used);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
使用set去重的版本。
|
||||
```
|
||||
class Solution {
|
||||
private:
|
||||
vector<vector<int>> result;
|
||||
vector<int> path;
|
||||
void backtracking(vector<int>& nums, int startIndex, vector<bool>& used) {
|
||||
result.push_back(path);
|
||||
unordered_set<int> uset;
|
||||
for (int i = startIndex; i < nums.size(); i++) {
|
||||
if (uset.find(nums[i]) != uset.end()) {
|
||||
continue;
|
||||
}
|
||||
uset.insert(nums[i]);
|
||||
path.push_back(nums[i]);
|
||||
backtracking(nums, i + 1, used);
|
||||
path.pop_back();
|
||||
}
|
||||
}
|
||||
|
||||
public:
|
||||
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
|
||||
result.clear();
|
||||
path.clear();
|
||||
vector<bool> used(nums.size(), false);
|
||||
sort(nums.begin(), nums.end()); // 去重需要排序
|
||||
backtracking(nums, 0, used);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
## 补充
|
||||
|
||||
本题也可以不适用used数组来去重,因为递归的时候下一个startIndex是i+1而不是0。
|
||||
|
||||
如果要是全排列的话,每次要从0开始遍历,为了跳过已入栈的元素,需要使用used。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
vector<vector<int>> result;
|
||||
vector<int> path;
|
||||
void backtracking(vector<int>& nums, int startIndex) {
|
||||
result.push_back(path);
|
||||
for (int i = startIndex; i < nums.size(); i++) {
|
||||
// 而我们要对同一树层使用过的元素进行跳过
|
||||
if (i > startIndex && nums[i] == nums[i - 1] ) { // 注意这里使用i > startIndex
|
||||
continue;
|
||||
}
|
||||
path.push_back(nums[i]);
|
||||
backtracking(nums, i + 1);
|
||||
path.pop_back();
|
||||
}
|
||||
}
|
||||
|
||||
public:
|
||||
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
|
||||
result.clear();
|
||||
path.clear();
|
||||
sort(nums.begin(), nums.end()); // 去重需要排序
|
||||
backtracking(nums, 0);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
其实这道题目的知识点,我们之前都讲过了,如果之前讲过的子集问题和去重问题都掌握的好,这道题目应该分分钟AC。
|
||||
|
||||
当然本题去重的逻辑,也可以这么写
|
||||
|
||||
```
|
||||
if (i > startIndex && nums[i] == nums[i - 1] ) {
|
||||
continue;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
List<List<Integer>> result = new ArrayList<>();// 存放符合条件结果的集合
|
||||
LinkedList<Integer> path = new LinkedList<>();// 用来存放符合条件结果
|
||||
boolean[] used;
|
||||
public List<List<Integer>> subsetsWithDup(int[] nums) {
|
||||
if (nums.length == 0){
|
||||
result.add(path);
|
||||
return result;
|
||||
}
|
||||
Arrays.sort(nums);
|
||||
used = new boolean[nums.length];
|
||||
subsetsWithDupHelper(nums, 0);
|
||||
return result;
|
||||
}
|
||||
|
||||
private void subsetsWithDupHelper(int[] nums, int startIndex){
|
||||
result.add(new ArrayList<>(path));
|
||||
if (startIndex >= nums.length){
|
||||
return;
|
||||
}
|
||||
for (int i = startIndex; i < nums.length; i++){
|
||||
if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]){
|
||||
continue;
|
||||
}
|
||||
path.add(nums[i]);
|
||||
used[i] = true;
|
||||
subsetsWithDupHelper(nums, i + 1);
|
||||
path.removeLast();
|
||||
used[i] = false;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python3
|
||||
class Solution:
|
||||
def subsetsWithDup(self, nums: List[int]) -> List[List[int]]:
|
||||
res = [] #存放符合条件结果的集合
|
||||
path = [] #用来存放符合条件结果
|
||||
def backtrack(nums,startIndex):
|
||||
res.append(path[:])
|
||||
for i in range(startIndex,len(nums)):
|
||||
if i > startIndex and nums[i] == nums[i - 1]: #我们要对同一树层使用过的元素进行跳过
|
||||
continue
|
||||
path.append(nums[i])
|
||||
backtrack(nums,i+1) #递归
|
||||
path.pop() #回溯
|
||||
nums = sorted(nums) #去重需要排序
|
||||
backtrack(nums,0)
|
||||
return res
|
||||
```
|
||||
|
||||
Go:
|
||||
```Go
|
||||
var res[][]int
|
||||
func subsetsWithDup(nums []int)[][]int {
|
||||
res=make([][]int,0)
|
||||
sort.Ints(nums)
|
||||
dfs([]int{},nums,0)
|
||||
return res
|
||||
}
|
||||
func dfs(temp, num []int, start int) {
|
||||
tmp:=make([]int,len(temp))
|
||||
copy(tmp,temp)
|
||||
|
||||
res=append(res,tmp)
|
||||
for i:=start;i<len(num);i++{
|
||||
if i>start&&num[i]==num[i-1]{
|
||||
continue
|
||||
}
|
||||
temp=append(temp,num[i])
|
||||
dfs(temp,num,i+1)
|
||||
temp=temp[:len(temp)-1]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
Javascript:
|
||||
|
||||
```Javascript
|
||||
|
||||
var subsetsWithDup = function(nums) {
|
||||
let result = []
|
||||
let path = []
|
||||
let sortNums = nums.sort((a, b) => {
|
||||
return a - b
|
||||
})
|
||||
function backtracing(startIndex, sortNums) {
|
||||
result.push(path.slice(0))
|
||||
if(startIndex > nums.length - 1) {
|
||||
return
|
||||
}
|
||||
for(let i = startIndex; i < nums.length; i++) {
|
||||
if(i > startIndex && nums[i] === nums[i - 1]) {
|
||||
continue
|
||||
}
|
||||
path.push(nums[i])
|
||||
backtracing(i + 1, sortNums)
|
||||
path.pop()
|
||||
}
|
||||
}
|
||||
backtracing(0, sortNums)
|
||||
return result
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
456
problems/0093.复原IP地址.md
Normal file
456
problems/0093.复原IP地址.md
Normal file
@@ -0,0 +1,456 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
|
||||
## 93.复原IP地址
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/restore-ip-addresses/
|
||||
|
||||
给定一个只包含数字的字符串,复原它并返回所有可能的 IP 地址格式。
|
||||
|
||||
有效的 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 '.' 分隔。
|
||||
|
||||
例如:"0.1.2.201" 和 "192.168.1.1" 是 有效的 IP 地址,但是 "0.011.255.245"、"192.168.1.312" 和 "192.168@1.1" 是 无效的 IP 地址。
|
||||
|
||||
示例 1:
|
||||
输入:s = "25525511135"
|
||||
输出:["255.255.11.135","255.255.111.35"]
|
||||
|
||||
示例 2:
|
||||
输入:s = "0000"
|
||||
输出:["0.0.0.0"]
|
||||
|
||||
示例 3:
|
||||
输入:s = "1111"
|
||||
输出:["1.1.1.1"]
|
||||
|
||||
示例 4:
|
||||
输入:s = "010010"
|
||||
输出:["0.10.0.10","0.100.1.0"]
|
||||
|
||||
示例 5:
|
||||
输入:s = "101023"
|
||||
输出:["1.0.10.23","1.0.102.3","10.1.0.23","10.10.2.3","101.0.2.3"]
|
||||
|
||||
提示:
|
||||
0 <= s.length <= 3000
|
||||
s 仅由数字组成
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
做这道题目之前,最好先把[回溯算法:分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)这个做了。
|
||||
|
||||
这道题目相信大家刚看的时候,应该会一脸茫然。
|
||||
|
||||
其实只要意识到这是切割问题,**切割问题就可以使用回溯搜索法把所有可能性搜出来**,和刚做过的[回溯算法:分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)就十分类似了。
|
||||
|
||||
切割问题可以抽象为树型结构,如图:
|
||||
|
||||

|
||||
|
||||
|
||||
## 回溯三部曲
|
||||
|
||||
* 递归参数
|
||||
|
||||
在[回溯算法:分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)中我们就提到切割问题类似组合问题。
|
||||
|
||||
startIndex一定是需要的,因为不能重复分割,记录下一层递归分割的起始位置。
|
||||
|
||||
本题我们还需要一个变量pointNum,记录添加逗点的数量。
|
||||
|
||||
所以代码如下:
|
||||
|
||||
```
|
||||
vector<string> result;// 记录结果
|
||||
// startIndex: 搜索的起始位置,pointNum:添加逗点的数量
|
||||
void backtracking(string& s, int startIndex, int pointNum) {
|
||||
```
|
||||
|
||||
* 递归终止条件
|
||||
|
||||
终止条件和[回溯算法:分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)情况就不同了,本题明确要求只会分成4段,所以不能用切割线切到最后作为终止条件,而是分割的段数作为终止条件。
|
||||
|
||||
pointNum表示逗点数量,pointNum为3说明字符串分成了4段了。
|
||||
|
||||
然后验证一下第四段是否合法,如果合法就加入到结果集里
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
if (pointNum == 3) { // 逗点数量为3时,分隔结束
|
||||
// 判断第四段子字符串是否合法,如果合法就放进result中
|
||||
if (isValid(s, startIndex, s.size() - 1)) {
|
||||
result.push_back(s);
|
||||
}
|
||||
return;
|
||||
}
|
||||
```
|
||||
|
||||
* 单层搜索的逻辑
|
||||
|
||||
在[回溯算法:分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)中已经讲过在循环遍历中如何截取子串。
|
||||
|
||||
在`for (int i = startIndex; i < s.size(); i++)`循环中 [startIndex, i]这个区间就是截取的子串,需要判断这个子串是否合法。
|
||||
|
||||
如果合法就在字符串后面加上符号`.`表示已经分割。
|
||||
|
||||
如果不合法就结束本层循环,如图中剪掉的分支:
|
||||
|
||||

|
||||
|
||||
然后就是递归和回溯的过程:
|
||||
|
||||
递归调用时,下一层递归的startIndex要从i+2开始(因为需要在字符串中加入了分隔符`.`),同时记录分割符的数量pointNum 要 +1。
|
||||
|
||||
回溯的时候,就将刚刚加入的分隔符`.` 删掉就可以了,pointNum也要-1。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
for (int i = startIndex; i < s.size(); i++) {
|
||||
if (isValid(s, startIndex, i)) { // 判断 [startIndex,i] 这个区间的子串是否合法
|
||||
s.insert(s.begin() + i + 1 , '.'); // 在i的后面插入一个逗点
|
||||
pointNum++;
|
||||
backtracking(s, i + 2, pointNum); // 插入逗点之后下一个子串的起始位置为i+2
|
||||
pointNum--; // 回溯
|
||||
s.erase(s.begin() + i + 1); // 回溯删掉逗点
|
||||
} else break; // 不合法,直接结束本层循环
|
||||
}
|
||||
```
|
||||
|
||||
## 判断子串是否合法
|
||||
|
||||
最后就是在写一个判断段位是否是有效段位了。
|
||||
|
||||
主要考虑到如下三点:
|
||||
|
||||
* 段位以0为开头的数字不合法
|
||||
* 段位里有非正整数字符不合法
|
||||
* 段位如果大于255了不合法
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
// 判断字符串s在左闭又闭区间[start, end]所组成的数字是否合法
|
||||
bool isValid(const string& s, int start, int end) {
|
||||
if (start > end) {
|
||||
return false;
|
||||
}
|
||||
if (s[start] == '0' && start != end) { // 0开头的数字不合法
|
||||
return false;
|
||||
}
|
||||
int num = 0;
|
||||
for (int i = start; i <= end; i++) {
|
||||
if (s[i] > '9' || s[i] < '0') { // 遇到非数字字符不合法
|
||||
return false;
|
||||
}
|
||||
num = num * 10 + (s[i] - '0');
|
||||
if (num > 255) { // 如果大于255了不合法
|
||||
return false;
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
```
|
||||
|
||||
## C++代码
|
||||
|
||||
|
||||
根据[关于回溯算法,你该了解这些!](https://mp.weixin.qq.com/s/gjSgJbNbd1eAA5WkA-HeWw)给出的回溯算法模板:
|
||||
|
||||
```
|
||||
void backtracking(参数) {
|
||||
if (终止条件) {
|
||||
存放结果;
|
||||
return;
|
||||
}
|
||||
|
||||
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
|
||||
处理节点;
|
||||
backtracking(路径,选择列表); // 递归
|
||||
回溯,撤销处理结果
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
可以写出如下回溯算法C++代码:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
vector<string> result;// 记录结果
|
||||
// startIndex: 搜索的起始位置,pointNum:添加逗点的数量
|
||||
void backtracking(string& s, int startIndex, int pointNum) {
|
||||
if (pointNum == 3) { // 逗点数量为3时,分隔结束
|
||||
// 判断第四段子字符串是否合法,如果合法就放进result中
|
||||
if (isValid(s, startIndex, s.size() - 1)) {
|
||||
result.push_back(s);
|
||||
}
|
||||
return;
|
||||
}
|
||||
for (int i = startIndex; i < s.size(); i++) {
|
||||
if (isValid(s, startIndex, i)) { // 判断 [startIndex,i] 这个区间的子串是否合法
|
||||
s.insert(s.begin() + i + 1 , '.'); // 在i的后面插入一个逗点
|
||||
pointNum++;
|
||||
backtracking(s, i + 2, pointNum); // 插入逗点之后下一个子串的起始位置为i+2
|
||||
pointNum--; // 回溯
|
||||
s.erase(s.begin() + i + 1); // 回溯删掉逗点
|
||||
} else break; // 不合法,直接结束本层循环
|
||||
}
|
||||
}
|
||||
// 判断字符串s在左闭又闭区间[start, end]所组成的数字是否合法
|
||||
bool isValid(const string& s, int start, int end) {
|
||||
if (start > end) {
|
||||
return false;
|
||||
}
|
||||
if (s[start] == '0' && start != end) { // 0开头的数字不合法
|
||||
return false;
|
||||
}
|
||||
int num = 0;
|
||||
for (int i = start; i <= end; i++) {
|
||||
if (s[i] > '9' || s[i] < '0') { // 遇到非数字字符不合法
|
||||
return false;
|
||||
}
|
||||
num = num * 10 + (s[i] - '0');
|
||||
if (num > 255) { // 如果大于255了不合法
|
||||
return false;
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
public:
|
||||
vector<string> restoreIpAddresses(string s) {
|
||||
result.clear();
|
||||
if (s.size() > 12) return result; // 算是剪枝了
|
||||
backtracking(s, 0, 0);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
在[回溯算法:分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)中我列举的分割字符串的难点,本题都覆盖了。
|
||||
|
||||
而且本题还需要操作字符串添加逗号作为分隔符,并验证区间的合法性。
|
||||
|
||||
可以说是[回溯算法:分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)的加强版。
|
||||
|
||||
在本文的树形结构图中,我已经把详细的分析思路都画了出来,相信大家看了之后一定会思路清晰不少!
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
java 版本:
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
List<String> result = new ArrayList<>();
|
||||
|
||||
public List<String> restoreIpAddresses(String s) {
|
||||
if (s.length() > 12) return result; // 算是剪枝了
|
||||
backTrack(s, 0, 0);
|
||||
return result;
|
||||
}
|
||||
|
||||
// startIndex: 搜索的起始位置, pointNum:添加逗点的数量
|
||||
private void backTrack(String s, int startIndex, int pointNum) {
|
||||
if (pointNum == 3) {// 逗点数量为3时,分隔结束
|
||||
// 判断第四段⼦字符串是否合法,如果合法就放进result中
|
||||
if (isValid(s,startIndex,s.length()-1)) {
|
||||
result.add(s);
|
||||
}
|
||||
return;
|
||||
}
|
||||
for (int i = startIndex; i < s.length(); i++) {
|
||||
if (isValid(s, startIndex, i)) {
|
||||
s = s.substring(0, i + 1) + "." + s.substring(i + 1); //在str的后⾯插⼊⼀个逗点
|
||||
pointNum++;
|
||||
backTrack(s, i + 2, pointNum);// 插⼊逗点之后下⼀个⼦串的起始位置为i+2
|
||||
pointNum--;// 回溯
|
||||
s = s.substring(0, i + 1) + s.substring(i + 2);// 回溯删掉逗点
|
||||
} else {
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// 判断字符串s在左闭⼜闭区间[start, end]所组成的数字是否合法
|
||||
private Boolean isValid(String s, int start, int end) {
|
||||
if (start > end) {
|
||||
return false;
|
||||
}
|
||||
if (s.charAt(start) == '0' && start != end) { // 0开头的数字不合法
|
||||
return false;
|
||||
}
|
||||
int num = 0;
|
||||
for (int i = start; i <= end; i++) {
|
||||
if (s.charAt(i) > '9' || s.charAt(i) < '0') { // 遇到⾮数字字符不合法
|
||||
return false;
|
||||
}
|
||||
num = num * 10 + (s.charAt(i) - '0');
|
||||
if (num > 255) { // 如果⼤于255了不合法
|
||||
return false;
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
python版本:
|
||||
|
||||
```python
|
||||
class Solution(object):
|
||||
def restoreIpAddresses(self, s):
|
||||
"""
|
||||
:type s: str
|
||||
:rtype: List[str]
|
||||
"""
|
||||
ans = []
|
||||
path = []
|
||||
def backtrack(path, startIndex):
|
||||
if len(path) == 4:
|
||||
if startIndex == len(s):
|
||||
ans.append(".".join(path[:]))
|
||||
return
|
||||
for i in range(startIndex+1, min(startIndex+4, len(s)+1)): # 剪枝
|
||||
string = s[startIndex:i]
|
||||
if not 0 <= int(string) <= 255:
|
||||
continue
|
||||
if not string == "0" and not string.lstrip('0') == string:
|
||||
continue
|
||||
path.append(string)
|
||||
backtrack(path, i)
|
||||
path.pop()
|
||||
|
||||
backtrack([], 0)
|
||||
return ans```
|
||||
```
|
||||
|
||||
```python3
|
||||
class Solution:
|
||||
def __init__(self) -> None:
|
||||
self.s = ""
|
||||
self.res = []
|
||||
|
||||
def isVaild(self, s: str) -> bool:
|
||||
if len(s) > 1 and s[0] == "0":
|
||||
return False
|
||||
|
||||
if 0 <= int(s) <= 255:
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
def backTrack(self, path: List[str], start: int) -> None:
|
||||
if start == len(self.s) and len(path) == 4:
|
||||
self.res.append(".".join(path))
|
||||
return
|
||||
|
||||
for end in range(start + 1, len(self.s) + 1):
|
||||
# 剪枝
|
||||
# 保证切割完,s没有剩余的字符。
|
||||
if len(self.s) - end > 3 * (4 - len(path) - 1):
|
||||
continue
|
||||
if self.isVaild(self.s[start:end]):
|
||||
# 在参数处,更新状态,实则创建一个新的变量
|
||||
# 不会影响当前的状态,当前的path变量没有改变
|
||||
# 因此递归完不用path.pop()
|
||||
self.backTrack(path + [self.s[start:end]], end)
|
||||
|
||||
def restoreIpAddresses(self, s: str) -> List[str]:
|
||||
# prune
|
||||
if len(s) > 3 * 4:
|
||||
return []
|
||||
self.s = s
|
||||
self.backTrack([], 0)
|
||||
return self.res
|
||||
```
|
||||
|
||||
JavaScript:
|
||||
|
||||
```js
|
||||
/**
|
||||
* @param {string} s
|
||||
* @return {string[]}
|
||||
*/
|
||||
var restoreIpAddresses = function(s) {
|
||||
const res = [], path = [];
|
||||
backtracking(0, 0)
|
||||
return res;
|
||||
function backtracking(i) {
|
||||
const len = path.length;
|
||||
if(len > 4) return;
|
||||
if(len === 4 && i === s.length) {
|
||||
res.push(path.join("."));
|
||||
return;
|
||||
}
|
||||
for(let j = i; j < s.length; j++) {
|
||||
const str = s.substr(i, j - i + 1);
|
||||
if(str.length > 3 || +str > 255) break;
|
||||
if(str.length > 1 && str[0] === "0") break;
|
||||
path.push(str);
|
||||
backtracking(j + 1);
|
||||
path.pop()
|
||||
}
|
||||
}
|
||||
};
|
||||
```
|
||||
Go:
|
||||
> 回溯(对于前导 0的IP(特别注意s[startIndex]=='0'的判断,不应该写成s[startIndex]==0,因为s截取出来不是数字))
|
||||
|
||||
```go
|
||||
func restoreIpAddresses(s string) []string {
|
||||
var res,path []string
|
||||
backTracking(s,path,0,&res)
|
||||
return res
|
||||
}
|
||||
func backTracking(s string,path []string,startIndex int,res *[]string){
|
||||
//终止条件
|
||||
if startIndex==len(s)&&len(path)==4{
|
||||
tmpIpString:=path[0]+"."+path[1]+"."+path[2]+"."+path[3]
|
||||
*res=append(*res,tmpIpString)
|
||||
}
|
||||
for i:=startIndex;i<len(s);i++{
|
||||
//处理
|
||||
path:=append(path,s[startIndex:i+1])
|
||||
if i-startIndex+1<=3&&len(path)<=4&&isNormalIp(s,startIndex,i){
|
||||
//递归
|
||||
backTracking(s,path,i+1,res)
|
||||
}else {//如果首尾超过了3个,或路径多余4个,或前导为0,或大于255,直接回退
|
||||
return
|
||||
}
|
||||
//回溯
|
||||
path=path[:len(path)-1]
|
||||
}
|
||||
}
|
||||
func isNormalIp(s string,startIndex,end int)bool{
|
||||
checkInt,_:=strconv.Atoi(s[startIndex:end+1])
|
||||
if end-startIndex+1>1&&s[startIndex]=='0'{//对于前导 0的IP(特别注意s[startIndex]=='0'的判断,不应该写成s[startIndex]==0,因为s截取出来不是数字)
|
||||
return false
|
||||
}
|
||||
if checkInt>255{
|
||||
return false
|
||||
}
|
||||
return true
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
237
problems/0096.不同的二叉搜索树.md
Normal file
237
problems/0096.不同的二叉搜索树.md
Normal file
@@ -0,0 +1,237 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
## 96.不同的二叉搜索树
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/unique-binary-search-trees/
|
||||
|
||||
给定一个整数 n,求以 1 ... n 为节点组成的二叉搜索树有多少种?
|
||||
|
||||
示例:
|
||||
|
||||

|
||||
|
||||
## 思路
|
||||
|
||||
这道题目描述很简短,但估计大部分同学看完都是懵懵的状态,这得怎么统计呢?
|
||||
|
||||
关于什么是二叉搜索树,我们之前在讲解二叉树专题的时候已经详细讲解过了,也可以看看这篇[二叉树:二叉搜索树登场!](https://mp.weixin.qq.com/s/vsKrWRlETxCVsiRr8v_hHg)在回顾一波。
|
||||
|
||||
了解了二叉搜索树之后,我们应该先举几个例子,画画图,看看有没有什么规律,如图:
|
||||
|
||||
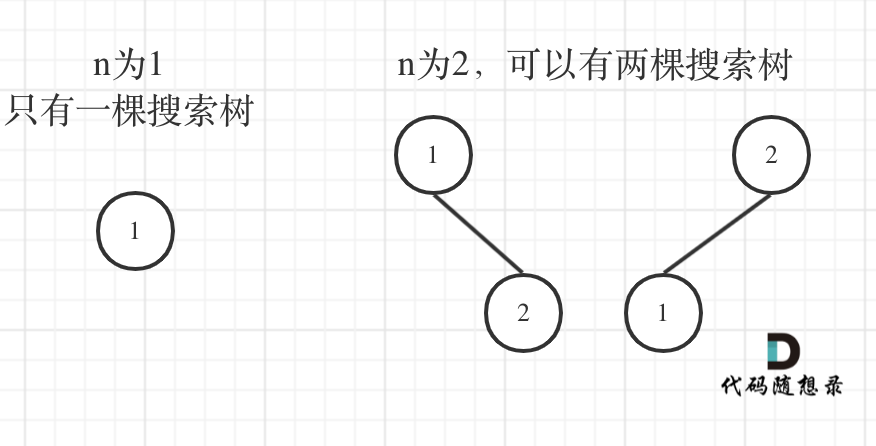
|
||||
|
||||
n为1的时候有一棵树,n为2有两棵树,这个是很直观的。
|
||||
|
||||
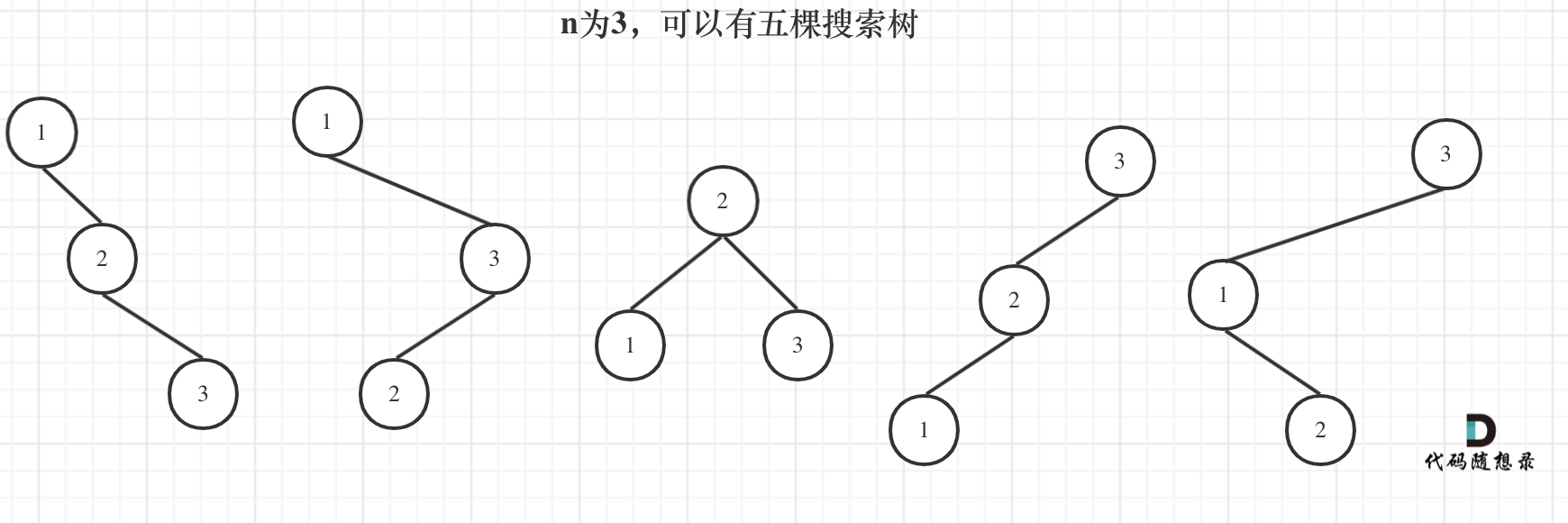
|
||||
|
||||
来看看n为3的时候,有哪几种情况。
|
||||
|
||||
当1为头结点的时候,其右子树有两个节点,看这两个节点的布局,是不是和 n 为2的时候两棵树的布局是一样的啊!
|
||||
|
||||
(可能有同学问了,这布局不一样啊,节点数值都不一样。别忘了我们就是求不同树的数量,并不用把搜索树都列出来,所以不用关心其具体数值的差异)
|
||||
|
||||
当3为头结点的时候,其左子树有两个节点,看这两个节点的布局,是不是和n为2的时候两棵树的布局也是一样的啊!
|
||||
|
||||
当2位头结点的时候,其左右子树都只有一个节点,布局是不是和n为1的时候只有一棵树的布局也是一样的啊!
|
||||
|
||||
发现到这里,其实我们就找到的重叠子问题了,其实也就是发现可以通过dp[1] 和 dp[2] 来推导出来dp[3]的某种方式。
|
||||
|
||||
思考到这里,这道题目就有眉目了。
|
||||
|
||||
dp[3],就是 元素1为头结点搜索树的数量 + 元素2为头结点搜索树的数量 + 元素3为头结点搜索树的数量
|
||||
|
||||
元素1为头结点搜索树的数量 = 右子树有2个元素的搜索树数量 * 左子树有0个元素的搜索树数量
|
||||
|
||||
元素2为头结点搜索树的数量 = 右子树有1个元素的搜索树数量 * 左子树有1个元素的搜索树数量
|
||||
|
||||
元素3为头结点搜索树的数量 = 右子树有0个元素的搜索树数量 * 左子树有2个元素的搜索树数量
|
||||
|
||||
有2个元素的搜索树数量就是dp[2]。
|
||||
|
||||
有1个元素的搜索树数量就是dp[1]。
|
||||
|
||||
有0个元素的搜索树数量就是dp[0]。
|
||||
|
||||
所以dp[3] = dp[2] * dp[0] + dp[1] * dp[1] + dp[0] * dp[2]
|
||||
|
||||
如图所示:
|
||||
|
||||
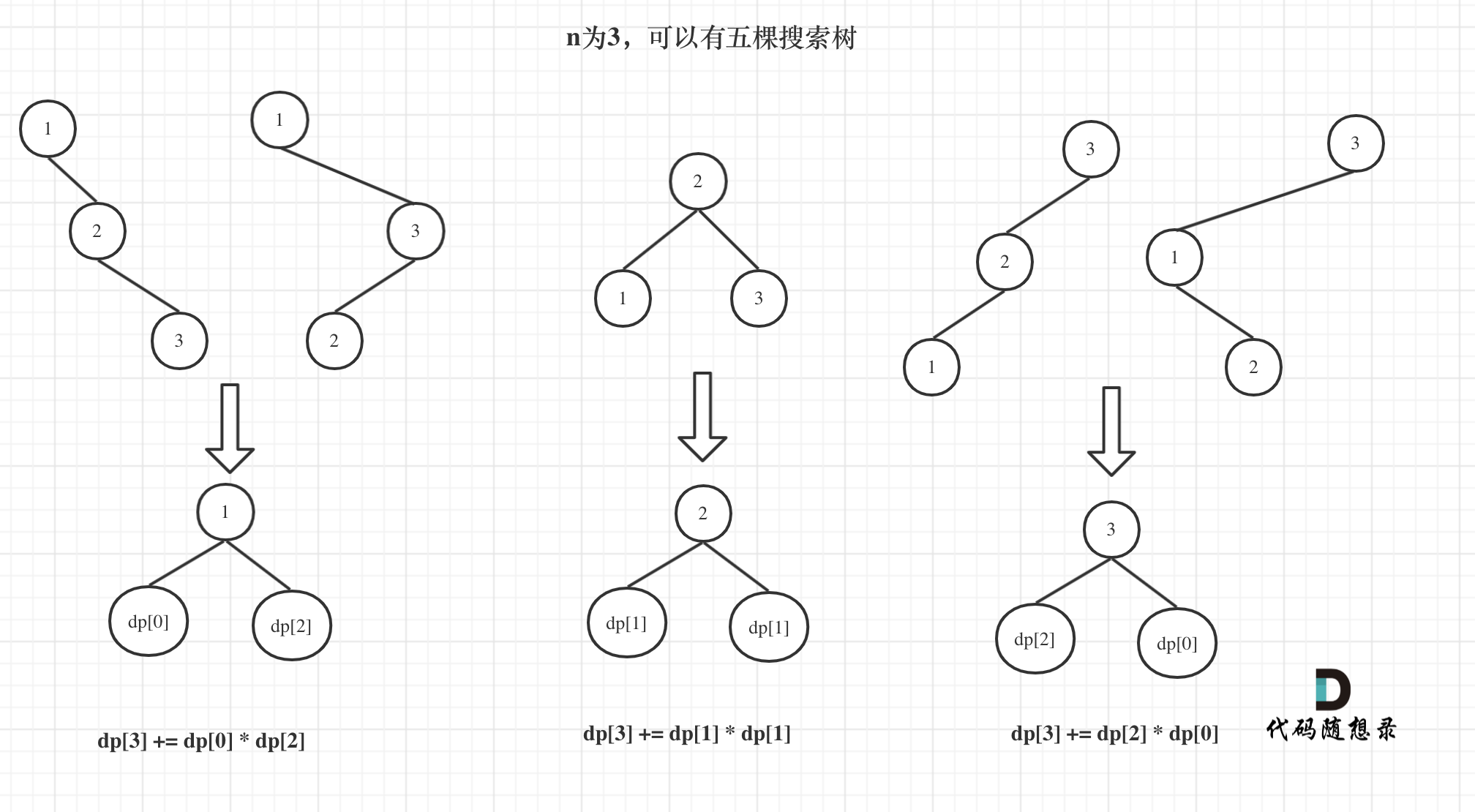
|
||||
|
||||
|
||||
此时我们已经找到的递推关系了,那么可以用动规五部曲在系统分析一遍。
|
||||
|
||||
1. 确定dp数组(dp table)以及下标的含义
|
||||
|
||||
**dp[i] : 1到i为节点组成的二叉搜索树的个数为dp[i]**。
|
||||
|
||||
也可以理解是i的不同元素节点组成的二叉搜索树的个数为dp[i] ,都是一样的。
|
||||
|
||||
以下分析如果想不清楚,就来回想一下dp[i]的定义
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
在上面的分析中,其实已经看出其递推关系, dp[i] += dp[以j为头结点左子树节点数量] * dp[以j为头结点右子树节点数量]
|
||||
|
||||
j相当于是头结点的元素,从1遍历到i为止。
|
||||
|
||||
所以递推公式:dp[i] += dp[j - 1] * dp[i - j]; ,j-1 为j为头结点左子树节点数量,i-j 为以j为头结点右子树节点数量
|
||||
|
||||
3. dp数组如何初始化
|
||||
|
||||
初始化,只需要初始化dp[0]就可以了,推导的基础,都是dp[0]。
|
||||
|
||||
那么dp[0]应该是多少呢?
|
||||
|
||||
从定义上来讲,空节点也是一颗二叉树,也是一颗二叉搜索树,这是可以说得通的。
|
||||
|
||||
从递归公式上来讲,dp[以j为头结点左子树节点数量] * dp[以j为头结点右子树节点数量] 中以j为头结点左子树节点数量为0,也需要dp[以j为头结点左子树节点数量] = 1, 否则乘法的结果就都变成0了。
|
||||
|
||||
所以初始化dp[0] = 1
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
首先一定是遍历节点数,从递归公式:dp[i] += dp[j - 1] * dp[i - j]可以看出,节点数为i的状态是依靠 i之前节点数的状态。
|
||||
|
||||
那么遍历i里面每一个数作为头结点的状态,用j来遍历。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
for (int i = 1; i <= n; i++) {
|
||||
for (int j = 1; j <= i; j++) {
|
||||
dp[i] += dp[j - 1] * dp[i - j];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
5. 举例推导dp数组
|
||||
|
||||
n为5时候的dp数组状态如图:
|
||||
|
||||
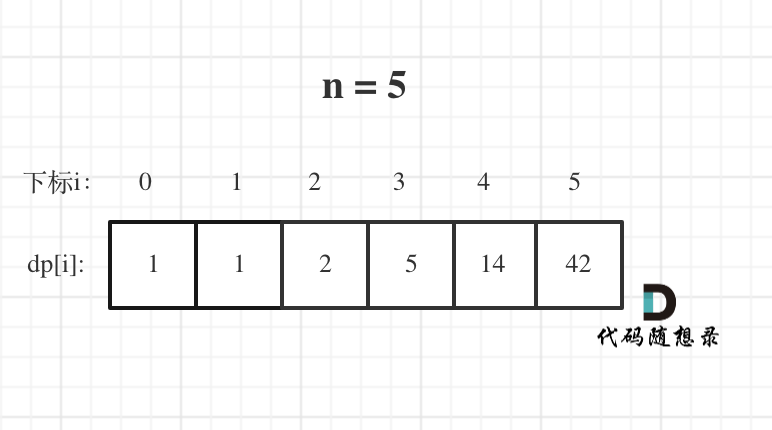
|
||||
|
||||
当然如果自己画图举例的话,基本举例到n为3就可以了,n为4的时候,画图已经比较麻烦了。
|
||||
|
||||
**我这里列到了n为5的情况,是为了方便大家 debug代码的时候,把dp数组打出来,看看哪里有问题**。
|
||||
|
||||
综上分析完毕,C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int numTrees(int n) {
|
||||
vector<int> dp(n + 1);
|
||||
dp[0] = 1;
|
||||
for (int i = 1; i <= n; i++) {
|
||||
for (int j = 1; j <= i; j++) {
|
||||
dp[i] += dp[j - 1] * dp[i - j];
|
||||
}
|
||||
}
|
||||
return dp[n];
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度O(n^2)
|
||||
* 空间复杂度O(n)
|
||||
|
||||
大家应该发现了,我们分析了这么多,最后代码却如此简单!
|
||||
|
||||
## 总结
|
||||
|
||||
这道题目虽然在力扣上标记是中等难度,但可以算是困难了!
|
||||
|
||||
首先这道题想到用动规的方法来解决,就不太好想,需要举例,画图,分析,才能找到递推的关系。
|
||||
|
||||
然后难点就是确定递推公式了,如果把递推公式想清楚了,遍历顺序和初始化,就是自然而然的事情了。
|
||||
|
||||
可以看出我依然还是用动规五部曲来进行分析,会把题目的方方面面都覆盖到!
|
||||
|
||||
**而且具体这五部分析是我自己平时总结的经验,找不出来第二个的,可能过一阵子 其他题解也会有动规五部曲了,哈哈**。
|
||||
|
||||
当时我在用动规五部曲讲解斐波那契的时候,一些录友和我反应,感觉讲复杂了。
|
||||
|
||||
其实当时我一直强调简单题是用来练习方法论的,并不能因为简单我就代码一甩,简单解释一下就完事了。
|
||||
|
||||
可能当时一些同学不理解,现在大家应该感受方法论的重要性了,加油💪
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
public int numTrees(int n) {
|
||||
//初始化 dp 数组
|
||||
int[] dp = new int[n + 1];
|
||||
//初始化0个节点和1个节点的情况
|
||||
dp[0] = 1;
|
||||
dp[1] = 1;
|
||||
for (int i = 2; i <= n; i++) {
|
||||
for (int j = 1; j <= i; j++) {
|
||||
//对于第i个节点,需要考虑1作为根节点直到i作为根节点的情况,所以需要累加
|
||||
//一共i个节点,对于根节点j时,左子树的节点个数为j-1,右子树的节点个数为i-j
|
||||
dp[i] += dp[j - 1] * dp[i - j];
|
||||
}
|
||||
}
|
||||
return dp[n];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def numTrees(self, n: int) -> int:
|
||||
dp = [0] * (n + 1)
|
||||
dp[0], dp[1] = 1, 1
|
||||
for i in range(2, n + 1):
|
||||
for j in range(1, i + 1):
|
||||
dp[i] += dp[j - 1] * dp[i - j]
|
||||
return dp[-1]
|
||||
```
|
||||
|
||||
Go:
|
||||
```Go
|
||||
func numTrees(n int)int{
|
||||
dp:=make([]int,n+1)
|
||||
dp[0]=1
|
||||
for i:=1;i<=n;i++{
|
||||
for j:=1;j<=i;j++{
|
||||
dp[i]+=dp[j-1]*dp[i-j]
|
||||
}
|
||||
}
|
||||
return dp[n]
|
||||
}
|
||||
```
|
||||
|
||||
Javascript:
|
||||
```Javascript
|
||||
const numTrees =(n) => {
|
||||
let dp = new Array(n+1).fill(0);
|
||||
dp[0] = 1;
|
||||
dp[1] = 1;
|
||||
|
||||
for(let i = 2; i <= n; i++) {
|
||||
for(let j = 1; j <= i; j++) {
|
||||
dp[i] += dp[j-1] * dp[i-j];
|
||||
}
|
||||
}
|
||||
|
||||
return dp[n];
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
477
problems/0098.验证二叉搜索树.md
Normal file
477
problems/0098.验证二叉搜索树.md
Normal file
@@ -0,0 +1,477 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 98.验证二叉搜索树
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/validate-binary-search-tree/
|
||||
|
||||
|
||||
给定一个二叉树,判断其是否是一个有效的二叉搜索树。
|
||||
|
||||
假设一个二叉搜索树具有如下特征:
|
||||
|
||||
* 节点的左子树只包含小于当前节点的数。
|
||||
* 节点的右子树只包含大于当前节点的数。
|
||||
* 所有左子树和右子树自身必须也是二叉搜索树。
|
||||
|
||||

|
||||
|
||||
## 思路
|
||||
|
||||
要知道中序遍历下,输出的二叉搜索树节点的数值是有序序列。
|
||||
|
||||
有了这个特性,**验证二叉搜索树,就相当于变成了判断一个序列是不是递增的了。**
|
||||
|
||||
## 递归法
|
||||
|
||||
可以递归中序遍历将二叉搜索树转变成一个数组,代码如下:
|
||||
|
||||
```
|
||||
vector<int> vec;
|
||||
void traversal(TreeNode* root) {
|
||||
if (root == NULL) return;
|
||||
traversal(root->left);
|
||||
vec.push_back(root->val); // 将二叉搜索树转换为有序数组
|
||||
traversal(root->right);
|
||||
}
|
||||
```
|
||||
|
||||
然后只要比较一下,这个数组是否是有序的,**注意二叉搜索树中不能有重复元素**。
|
||||
|
||||
```
|
||||
traversal(root);
|
||||
for (int i = 1; i < vec.size(); i++) {
|
||||
// 注意要小于等于,搜索树里不能有相同元素
|
||||
if (vec[i] <= vec[i - 1]) return false;
|
||||
}
|
||||
return true;
|
||||
```
|
||||
|
||||
整体代码如下:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
private:
|
||||
vector<int> vec;
|
||||
void traversal(TreeNode* root) {
|
||||
if (root == NULL) return;
|
||||
traversal(root->left);
|
||||
vec.push_back(root->val); // 将二叉搜索树转换为有序数组
|
||||
traversal(root->right);
|
||||
}
|
||||
public:
|
||||
bool isValidBST(TreeNode* root) {
|
||||
vec.clear(); // 不加这句在leetcode上也可以过,但最好加上
|
||||
traversal(root);
|
||||
for (int i = 1; i < vec.size(); i++) {
|
||||
// 注意要小于等于,搜索树里不能有相同元素
|
||||
if (vec[i] <= vec[i - 1]) return false;
|
||||
}
|
||||
return true;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
以上代码中,我们把二叉树转变为数组来判断,是最直观的,但其实不用转变成数组,可以在递归遍历的过程中直接判断是否有序。
|
||||
|
||||
|
||||
这道题目比较容易陷入两个陷阱:
|
||||
|
||||
* 陷阱1
|
||||
|
||||
**不能单纯的比较左节点小于中间节点,右节点大于中间节点就完事了**。
|
||||
|
||||
写出了类似这样的代码:
|
||||
|
||||
```
|
||||
if (root->val > root->left->val && root->val < root->right->val) {
|
||||
return true;
|
||||
} else {
|
||||
return false;
|
||||
}
|
||||
```
|
||||
|
||||
**我们要比较的是 左子树所有节点小于中间节点,右子树所有节点大于中间节点。**所以以上代码的判断逻辑是错误的。
|
||||
|
||||
例如: [10,5,15,null,null,6,20] 这个case:
|
||||
|
||||
|
||||
|
||||
节点10小于左节点5,大于右节点15,但右子树里出现了一个6 这就不符合了!
|
||||
|
||||
* 陷阱2
|
||||
|
||||
样例中最小节点 可能是int的最小值,如果这样使用最小的int来比较也是不行的。
|
||||
|
||||
此时可以初始化比较元素为longlong的最小值。
|
||||
|
||||
问题可以进一步演进:如果样例中根节点的val 可能是longlong的最小值 又要怎么办呢?文中会解答。
|
||||
|
||||
了解这些陷阱之后我们来看一下代码应该怎么写:
|
||||
|
||||
递归三部曲:
|
||||
|
||||
* 确定递归函数,返回值以及参数
|
||||
|
||||
要定义一个longlong的全局变量,用来比较遍历的节点是否有序,因为后台测试数据中有int最小值,所以定义为longlong的类型,初始化为longlong最小值。
|
||||
|
||||
注意递归函数要有bool类型的返回值, 我们在[二叉树:递归函数究竟什么时候需要返回值,什么时候不要返回值?](https://mp.weixin.qq.com/s/6TWAVjxQ34kVqROWgcRFOg) 中讲了,只有寻找某一条边(或者一个节点)的时候,递归函数会有bool类型的返回值。
|
||||
|
||||
其实本题是同样的道理,我们在寻找一个不符合条件的节点,如果没有找到这个节点就遍历了整个树,如果找到不符合的节点了,立刻返回。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
long long maxVal = LONG_MIN; // 因为后台测试数据中有int最小值
|
||||
bool isValidBST(TreeNode* root)
|
||||
```
|
||||
|
||||
* 确定终止条件
|
||||
|
||||
如果是空节点 是不是二叉搜索树呢?
|
||||
|
||||
是的,二叉搜索树也可以为空!
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
if (root == NULL) return true;
|
||||
```
|
||||
|
||||
* 确定单层递归的逻辑
|
||||
|
||||
中序遍历,一直更新maxVal,一旦发现maxVal >= root->val,就返回false,注意元素相同时候也要返回false。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
bool left = isValidBST(root->left); // 左
|
||||
|
||||
// 中序遍历,验证遍历的元素是不是从小到大
|
||||
if (maxVal < root->val) maxVal = root->val; // 中
|
||||
else return false;
|
||||
|
||||
bool right = isValidBST(root->right); // 右
|
||||
return left && right;
|
||||
```
|
||||
|
||||
整体代码如下:
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
long long maxVal = LONG_MIN; // 因为后台测试数据中有int最小值
|
||||
bool isValidBST(TreeNode* root) {
|
||||
if (root == NULL) return true;
|
||||
|
||||
bool left = isValidBST(root->left);
|
||||
// 中序遍历,验证遍历的元素是不是从小到大
|
||||
if (maxVal < root->val) maxVal = root->val;
|
||||
else return false;
|
||||
bool right = isValidBST(root->right);
|
||||
|
||||
return left && right;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
以上代码是因为后台数据有int最小值测试用例,所以都把maxVal改成了longlong最小值。
|
||||
|
||||
如果测试数据中有 longlong的最小值,怎么办?
|
||||
|
||||
不可能在初始化一个更小的值了吧。 建议避免 初始化最小值,如下方法取到最左面节点的数值来比较。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
TreeNode* pre = NULL; // 用来记录前一个节点
|
||||
bool isValidBST(TreeNode* root) {
|
||||
if (root == NULL) return true;
|
||||
bool left = isValidBST(root->left);
|
||||
|
||||
if (pre != NULL && pre->val >= root->val) return false;
|
||||
pre = root; // 记录前一个节点
|
||||
|
||||
bool right = isValidBST(root->right);
|
||||
return left && right;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
最后这份代码看上去整洁一些,思路也清晰。
|
||||
|
||||
## 迭代法
|
||||
|
||||
可以用迭代法模拟二叉树中序遍历,对前中后序迭代法生疏的同学可以看这两篇[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg),[二叉树:前中后序迭代方式统一写法](https://mp.weixin.qq.com/s/WKg0Ty1_3SZkztpHubZPRg)
|
||||
|
||||
迭代法中序遍历稍加改动就可以了,代码如下:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
bool isValidBST(TreeNode* root) {
|
||||
stack<TreeNode*> st;
|
||||
TreeNode* cur = root;
|
||||
TreeNode* pre = NULL; // 记录前一个节点
|
||||
while (cur != NULL || !st.empty()) {
|
||||
if (cur != NULL) {
|
||||
st.push(cur);
|
||||
cur = cur->left; // 左
|
||||
} else {
|
||||
cur = st.top(); // 中
|
||||
st.pop();
|
||||
if (pre != NULL && cur->val <= pre->val)
|
||||
return false;
|
||||
pre = cur; //保存前一个访问的结点
|
||||
|
||||
cur = cur->right; // 右
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
在[二叉树:二叉搜索树登场!](https://mp.weixin.qq.com/s/vsKrWRlETxCVsiRr8v_hHg)中我们分明写出了痛哭流涕的简洁迭代法,怎么在这里不行了呢,因为本题是要验证二叉搜索树啊。
|
||||
|
||||
## 总结
|
||||
|
||||
这道题目是一个简单题,但对于没接触过的同学还是有难度的。
|
||||
|
||||
所以初学者刚开始学习算法的时候,看到简单题目没有思路很正常,千万别怀疑自己智商,学习过程都是这样的,大家智商都差不多,哈哈。
|
||||
|
||||
只要把基本类型的题目都做过,总结过之后,思路自然就开阔了。
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
|
||||
```Java
|
||||
class Solution {
|
||||
// 递归
|
||||
TreeNode max;
|
||||
public boolean isValidBST(TreeNode root) {
|
||||
if (root == null) {
|
||||
return true;
|
||||
}
|
||||
// 左
|
||||
boolean left = isValidBST(root.left);
|
||||
if (!left) {
|
||||
return false;
|
||||
}
|
||||
// 中
|
||||
if (max != null && root.val <= max.val) {
|
||||
return false;
|
||||
}
|
||||
max = root;
|
||||
// 右
|
||||
boolean right = isValidBST(root.right);
|
||||
return right;
|
||||
}
|
||||
}
|
||||
|
||||
class Solution {
|
||||
// 迭代
|
||||
public boolean isValidBST(TreeNode root) {
|
||||
if (root == null) {
|
||||
return true;
|
||||
}
|
||||
Stack<TreeNode> stack = new Stack<>();
|
||||
TreeNode pre = null;
|
||||
while (root != null || !stack.isEmpty()) {
|
||||
while (root != null) {
|
||||
stack.push(root);
|
||||
root = root.left;// 左
|
||||
}
|
||||
// 中,处理
|
||||
TreeNode pop = stack.pop();
|
||||
if (pre != null && pop.val <= pre.val) {
|
||||
return false;
|
||||
}
|
||||
pre = pop;
|
||||
|
||||
root = pop.right;// 右
|
||||
}
|
||||
return true;
|
||||
}
|
||||
}
|
||||
|
||||
// 简洁实现·递归解法
|
||||
class Solution {
|
||||
public boolean isValidBST(TreeNode root) {
|
||||
return validBST(Long.MIN_VALUE, Long.MAX_VALUE, root);
|
||||
}
|
||||
boolean validBST(long lower, long upper, TreeNode root) {
|
||||
if (root == null) return true;
|
||||
if (root.val <= lower || root.val >= upper) return false;
|
||||
return validBST(lower, root.val, root.left) && validBST(root.val, upper, root.right);
|
||||
}
|
||||
}
|
||||
// 简洁实现·中序遍历
|
||||
class Solution {
|
||||
private long prev = Long.MIN_VALUE;
|
||||
public boolean isValidBST(TreeNode root) {
|
||||
if (root == null) {
|
||||
return true;
|
||||
}
|
||||
if (!isValidBST(root.left)) {
|
||||
return false;
|
||||
}
|
||||
if (root.val <= prev) { // 不满足二叉搜索树条件
|
||||
return false;
|
||||
}
|
||||
prev = root.val;
|
||||
return isValidBST(root.right);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
# Definition for a binary tree node.
|
||||
# class TreeNode:
|
||||
# def __init__(self, val=0, left=None, right=None):
|
||||
# self.val = val
|
||||
# self.left = left
|
||||
# self.right = right
|
||||
//递归法
|
||||
class Solution:
|
||||
def isValidBST(self, root: TreeNode) -> bool:
|
||||
res = [] //把二叉搜索树按中序遍历写成list
|
||||
def buildalist(root):
|
||||
if not root: return
|
||||
buildalist(root.left) //左
|
||||
res.append(root.val) //中
|
||||
buildalist(root.right) //右
|
||||
return res
|
||||
buildalist(root)
|
||||
return res == sorted(res) and len(set(res)) == len(res) //检查list里的数有没有重复元素,以及是否按从小到大排列
|
||||
```
|
||||
Go:
|
||||
```Go
|
||||
import "math"
|
||||
|
||||
func isValidBST(root *TreeNode) bool {
|
||||
if root == nil {
|
||||
return true
|
||||
}
|
||||
return isBST(root, math.MinInt64, math.MaxFloat64)
|
||||
}
|
||||
func isBST(root *TreeNode, min, max int) bool {
|
||||
if root == nil {
|
||||
return true
|
||||
}
|
||||
if min >= root.Val || max <= root.Val {
|
||||
return false
|
||||
}
|
||||
return isBST(root.Left, min, root.Val) && isBST(root.Right, root.Val, max)
|
||||
}
|
||||
```
|
||||
```go
|
||||
// 中序遍历解法
|
||||
func isValidBST(root *TreeNode) bool {
|
||||
// 保存上一个指针
|
||||
var prev *TreeNode
|
||||
var travel func(node *TreeNode) bool
|
||||
travel = func(node *TreeNode) bool {
|
||||
if node == nil {
|
||||
return true
|
||||
}
|
||||
leftRes := travel(node.Left)
|
||||
// 当前值小于等于前一个节点的值,返回false
|
||||
if prev != nil && node.Val <= prev.Val {
|
||||
return false
|
||||
}
|
||||
prev = node
|
||||
rightRes := travel(node.Right)
|
||||
return leftRes && rightRes
|
||||
}
|
||||
return travel(root)
|
||||
}
|
||||
```
|
||||
|
||||
JavaScript版本
|
||||
|
||||
> 辅助数组解决
|
||||
|
||||
```javascript
|
||||
/**
|
||||
* Definition for a binary tree node.
|
||||
* function TreeNode(val, left, right) {
|
||||
* this.val = (val===undefined ? 0 : val)
|
||||
* this.left = (left===undefined ? null : left)
|
||||
* this.right = (right===undefined ? null : right)
|
||||
* }
|
||||
*/
|
||||
/**
|
||||
* @param {TreeNode} root
|
||||
* @return {boolean}
|
||||
*/
|
||||
var isValidBST = function (root) {
|
||||
let arr = [];
|
||||
const buildArr = (root) => {
|
||||
if (root) {
|
||||
buildArr(root.left);
|
||||
arr.push(root.val);
|
||||
buildArr(root.right);
|
||||
}
|
||||
}
|
||||
buildArr(root);
|
||||
for (let i = 1; i < arr.length; ++i) {
|
||||
if (arr[i] <= arr[i - 1])
|
||||
return false;
|
||||
}
|
||||
return true;
|
||||
};
|
||||
```
|
||||
|
||||
> 递归中解决
|
||||
|
||||
```javascript
|
||||
/**
|
||||
* Definition for a binary tree node.
|
||||
* function TreeNode(val, left, right) {
|
||||
* this.val = (val===undefined ? 0 : val)
|
||||
* this.left = (left===undefined ? null : left)
|
||||
* this.right = (right===undefined ? null : right)
|
||||
* }
|
||||
*/
|
||||
/**
|
||||
* @param {TreeNode} root
|
||||
* @return {boolean}
|
||||
*/
|
||||
let pre = null;
|
||||
var isValidBST = function (root) {
|
||||
let pre = null;
|
||||
const inOrder = (root) => {
|
||||
if (root === null)
|
||||
return true;
|
||||
let left = inOrder(root.left);
|
||||
|
||||
if (pre !== null && pre.val >= root.val)
|
||||
return false;
|
||||
pre = root;
|
||||
|
||||
let right = inOrder(root.right);
|
||||
return left && right;
|
||||
}
|
||||
return inOrder(root);
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
592
problems/0101.对称二叉树.md
Normal file
592
problems/0101.对称二叉树.md
Normal file
@@ -0,0 +1,592 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 101. 对称二叉树
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/symmetric-tree/
|
||||
|
||||
给定一个二叉树,检查它是否是镜像对称的。
|
||||
|
||||

|
||||
|
||||
## 思路
|
||||
|
||||
**首先想清楚,判断对称二叉树要比较的是哪两个节点,要比较的可不是左右节点!**
|
||||
|
||||
对于二叉树是否对称,要比较的是根节点的左子树与右子树是不是相互翻转的,理解这一点就知道了**其实我们要比较的是两个树(这两个树是根节点的左右子树)**,所以在递归遍历的过程中,也是要同时遍历两棵树。
|
||||
|
||||
那么如果比较呢?
|
||||
|
||||
比较的是两个子树的里侧和外侧的元素是否相等。如图所示:
|
||||
|
||||

|
||||
|
||||
那么遍历的顺序应该是什么样的呢?
|
||||
|
||||
本题遍历只能是“后序遍历”,因为我们要通过递归函数的返回值来判断两个子树的内侧节点和外侧节点是否相等。
|
||||
|
||||
**正是因为要遍历两棵树而且要比较内侧和外侧节点,所以准确的来说是一个树的遍历顺序是左右中,一个树的遍历顺序是右左中。**
|
||||
|
||||
但都可以理解算是后序遍历,尽管已经不是严格上在一个树上进行遍历的后序遍历了。
|
||||
|
||||
其实后序也可以理解为是一种回溯,当然这是题外话,讲回溯的时候会重点讲的。
|
||||
|
||||
说到这大家可能感觉我有点啰嗦,哪有这么多道理,上来就干就完事了。别急,我说的这些在下面的代码讲解中都有身影。
|
||||
|
||||
那么我们先来看看递归法的代码应该怎么写。
|
||||
|
||||
## 递归法
|
||||
|
||||
递归三部曲
|
||||
|
||||
1. 确定递归函数的参数和返回值
|
||||
|
||||
因为我们要比较的是根节点的两个子树是否是相互翻转的,进而判断这个树是不是对称树,所以要比较的是两个树,参数自然也是左子树节点和右子树节点。
|
||||
|
||||
返回值自然是bool类型。
|
||||
|
||||
代码如下:
|
||||
```
|
||||
bool compare(TreeNode* left, TreeNode* right)
|
||||
```
|
||||
|
||||
2. 确定终止条件
|
||||
|
||||
要比较两个节点数值相不相同,首先要把两个节点为空的情况弄清楚!否则后面比较数值的时候就会操作空指针了。
|
||||
|
||||
节点为空的情况有:(**注意我们比较的其实不是左孩子和右孩子,所以如下我称之为左节点右节点**)
|
||||
|
||||
* 左节点为空,右节点不为空,不对称,return false
|
||||
* 左不为空,右为空,不对称 return false
|
||||
* 左右都为空,对称,返回true
|
||||
|
||||
此时已经排除掉了节点为空的情况,那么剩下的就是左右节点不为空:
|
||||
|
||||
* 左右都不为空,比较节点数值,不相同就return false
|
||||
|
||||
此时左右节点不为空,且数值也不相同的情况我们也处理了。
|
||||
|
||||
代码如下:
|
||||
```
|
||||
if (left == NULL && right != NULL) return false;
|
||||
else if (left != NULL && right == NULL) return false;
|
||||
else if (left == NULL && right == NULL) return true;
|
||||
else if (left->val != right->val) return false; // 注意这里我没有使用else
|
||||
```
|
||||
|
||||
注意上面最后一种情况,我没有使用else,而是elseif, 因为我们把以上情况都排除之后,剩下的就是 左右节点都不为空,且数值相同的情况。
|
||||
|
||||
3. 确定单层递归的逻辑
|
||||
|
||||
此时才进入单层递归的逻辑,单层递归的逻辑就是处理 右节点都不为空,且数值相同的情况。
|
||||
|
||||
|
||||
* 比较二叉树外侧是否对称:传入的是左节点的左孩子,右节点的右孩子。
|
||||
* 比较内测是否对称,传入左节点的右孩子,右节点的左孩子。
|
||||
* 如果左右都对称就返回true ,有一侧不对称就返回false 。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
bool outside = compare(left->left, right->right); // 左子树:左、 右子树:右
|
||||
bool inside = compare(left->right, right->left); // 左子树:右、 右子树:左
|
||||
bool isSame = outside && inside; // 左子树:中、 右子树:中(逻辑处理)
|
||||
return isSame;
|
||||
```
|
||||
|
||||
如上代码中,我们可以看出使用的遍历方式,左子树左右中,右子树右左中,所以我把这个遍历顺序也称之为“后序遍历”(尽管不是严格的后序遍历)。
|
||||
|
||||
最后递归的C++整体代码如下:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
bool compare(TreeNode* left, TreeNode* right) {
|
||||
// 首先排除空节点的情况
|
||||
if (left == NULL && right != NULL) return false;
|
||||
else if (left != NULL && right == NULL) return false;
|
||||
else if (left == NULL && right == NULL) return true;
|
||||
// 排除了空节点,再排除数值不相同的情况
|
||||
else if (left->val != right->val) return false;
|
||||
|
||||
// 此时就是:左右节点都不为空,且数值相同的情况
|
||||
// 此时才做递归,做下一层的判断
|
||||
bool outside = compare(left->left, right->right); // 左子树:左、 右子树:右
|
||||
bool inside = compare(left->right, right->left); // 左子树:右、 右子树:左
|
||||
bool isSame = outside && inside; // 左子树:中、 右子树:中 (逻辑处理)
|
||||
return isSame;
|
||||
|
||||
}
|
||||
bool isSymmetric(TreeNode* root) {
|
||||
if (root == NULL) return true;
|
||||
return compare(root->left, root->right);
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
**我给出的代码并不简洁,但是把每一步判断的逻辑都清楚的描绘出来了。**
|
||||
|
||||
如果上来就看网上各种简洁的代码,看起来真的很简单,但是很多逻辑都掩盖掉了,而题解可能也没有把掩盖掉的逻辑说清楚。
|
||||
|
||||
**盲目的照着抄,结果就是:发现这是一道“简单题”,稀里糊涂的就过了,但是真正的每一步判断逻辑未必想到清楚。**
|
||||
|
||||
当然我可以把如上代码整理如下:
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
bool compare(TreeNode* left, TreeNode* right) {
|
||||
if (left == NULL && right != NULL) return false;
|
||||
else if (left != NULL && right == NULL) return false;
|
||||
else if (left == NULL && right == NULL) return true;
|
||||
else if (left->val != right->val) return false;
|
||||
else return compare(left->left, right->right) && compare(left->right, right->left);
|
||||
|
||||
}
|
||||
bool isSymmetric(TreeNode* root) {
|
||||
if (root == NULL) return true;
|
||||
return compare(root->left, root->right);
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
**这个代码就很简洁了,但隐藏了很多逻辑,条理不清晰,而且递归三部曲,在这里完全体现不出来。**
|
||||
|
||||
**所以建议大家做题的时候,一定要想清楚逻辑,每一步做什么。把道题目所有情况想到位,相应的代码写出来之后,再去追求简洁代码的效果。**
|
||||
|
||||
## 迭代法
|
||||
|
||||
这道题目我们也可以使用迭代法,但要注意,这里的迭代法可不是前中后序的迭代写法,因为本题的本质是判断两个树是否是相互翻转的,其实已经不是所谓二叉树遍历的前中后序的关系了。
|
||||
|
||||
这里我们可以使用队列来比较两个树(根节点的左右子树)是否相互翻转,(**注意这不是层序遍历**)
|
||||
|
||||
### 使用队列
|
||||
|
||||
通过队列来判断根节点的左子树和右子树的内侧和外侧是否相等,如动画所示:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
如下的条件判断和递归的逻辑是一样的。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
bool isSymmetric(TreeNode* root) {
|
||||
if (root == NULL) return true;
|
||||
queue<TreeNode*> que;
|
||||
que.push(root->left); // 将左子树头结点加入队列
|
||||
que.push(root->right); // 将右子树头结点加入队列
|
||||
while (!que.empty()) { // 接下来就要判断这这两个树是否相互翻转
|
||||
TreeNode* leftNode = que.front(); que.pop();
|
||||
TreeNode* rightNode = que.front(); que.pop();
|
||||
if (!leftNode && !rightNode) { // 左节点为空、右节点为空,此时说明是对称的
|
||||
continue;
|
||||
}
|
||||
|
||||
// 左右一个节点不为空,或者都不为空但数值不相同,返回false
|
||||
if ((!leftNode || !rightNode || (leftNode->val != rightNode->val))) {
|
||||
return false;
|
||||
}
|
||||
que.push(leftNode->left); // 加入左节点左孩子
|
||||
que.push(rightNode->right); // 加入右节点右孩子
|
||||
que.push(leftNode->right); // 加入左节点右孩子
|
||||
que.push(rightNode->left); // 加入右节点左孩子
|
||||
}
|
||||
return true;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
### 使用栈
|
||||
|
||||
细心的话,其实可以发现,这个迭代法,其实是把左右两个子树要比较的元素顺序放进一个容器,然后成对成对的取出来进行比较,那么其实使用栈也是可以的。
|
||||
|
||||
只要把队列原封不动的改成栈就可以了,我下面也给出了代码。
|
||||
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
bool isSymmetric(TreeNode* root) {
|
||||
if (root == NULL) return true;
|
||||
stack<TreeNode*> st; // 这里改成了栈
|
||||
st.push(root->left);
|
||||
st.push(root->right);
|
||||
while (!st.empty()) {
|
||||
TreeNode* leftNode = st.top(); st.pop();
|
||||
TreeNode* rightNode = st.top(); st.pop();
|
||||
if (!leftNode && !rightNode) {
|
||||
continue;
|
||||
}
|
||||
if ((!leftNode || !rightNode || (leftNode->val != rightNode->val))) {
|
||||
return false;
|
||||
}
|
||||
st.push(leftNode->left);
|
||||
st.push(rightNode->right);
|
||||
st.push(leftNode->right);
|
||||
st.push(rightNode->left);
|
||||
}
|
||||
return true;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
这次我们又深度剖析了一道二叉树的“简单题”,大家会发现,真正的把题目搞清楚其实并不简单,leetcode上accept了和真正掌握了还是有距离的。
|
||||
|
||||
我们介绍了递归法和迭代法,递归依然通过递归三部曲来解决了这道题目,如果只看精简的代码根本看不出来递归三部曲是如果解题的。
|
||||
|
||||
在迭代法中我们使用了队列,需要注意的是这不是层序遍历,而且仅仅通过一个容器来成对的存放我们要比较的元素,知道这一本质之后就发现,用队列,用栈,甚至用数组,都是可以的。
|
||||
|
||||
如果已经做过这道题目的同学,读完文章可以再去看看这道题目,思考一下,会有不一样的发现!
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
Java:
|
||||
|
||||
```Java
|
||||
/**
|
||||
* 递归法
|
||||
*/
|
||||
public boolean isSymmetric1(TreeNode root) {
|
||||
return compare(root.left, root.right);
|
||||
}
|
||||
|
||||
private boolean compare(TreeNode left, TreeNode right) {
|
||||
|
||||
if (left == null && right != null) {
|
||||
return false;
|
||||
}
|
||||
if (left != null && right == null) {
|
||||
return false;
|
||||
}
|
||||
|
||||
if (left == null && right == null) {
|
||||
return true;
|
||||
}
|
||||
if (left.val != right.val) {
|
||||
return false;
|
||||
}
|
||||
// 比较外侧
|
||||
boolean compareOutside = compare(left.left, right.right);
|
||||
// 比较内侧
|
||||
boolean compareInside = compare(left.right, right.left);
|
||||
return compareOutside && compareInside;
|
||||
}
|
||||
|
||||
/**
|
||||
* 迭代法
|
||||
* 使用双端队列,相当于两个栈
|
||||
*/
|
||||
public boolean isSymmetric2(TreeNode root) {
|
||||
Deque<TreeNode> deque = new LinkedList<>();
|
||||
deque.offerFirst(root.left);
|
||||
deque.offerLast(root.right);
|
||||
while (!deque.isEmpty()) {
|
||||
TreeNode leftNode = deque.pollFirst();
|
||||
TreeNode rightNode = deque.pollLast();
|
||||
if (leftNode == null && rightNode == null) {
|
||||
continue;
|
||||
}
|
||||
// if (leftNode == null && rightNode != null) {
|
||||
// return false;
|
||||
// }
|
||||
// if (leftNode != null && rightNode == null) {
|
||||
// return false;
|
||||
// }
|
||||
// if (leftNode.val != rightNode.val) {
|
||||
// return false;
|
||||
// }
|
||||
// 以上三个判断条件合并
|
||||
if (leftNode == null || rightNode == null || leftNode.val != rightNode.val) {
|
||||
return false;
|
||||
}
|
||||
deque.offerFirst(leftNode.left);
|
||||
deque.offerFirst(leftNode.right);
|
||||
deque.offerLast(rightNode.right);
|
||||
deque.offerLast(rightNode.left);
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
/**
|
||||
* 迭代法
|
||||
* 使用普通队列
|
||||
*/
|
||||
public boolean isSymmetric3(TreeNode root) {
|
||||
Queue<TreeNode> deque = new LinkedList<>();
|
||||
deque.offer(root.left);
|
||||
deque.offer(root.right);
|
||||
while (!deque.isEmpty()) {
|
||||
TreeNode leftNode = deque.poll();
|
||||
TreeNode rightNode = deque.poll();
|
||||
if (leftNode == null && rightNode == null) {
|
||||
continue;
|
||||
}
|
||||
// if (leftNode == null && rightNode != null) {
|
||||
// return false;
|
||||
// }
|
||||
// if (leftNode != null && rightNode == null) {
|
||||
// return false;
|
||||
// }
|
||||
// if (leftNode.val != rightNode.val) {
|
||||
// return false;
|
||||
// }
|
||||
// 以上三个判断条件合并
|
||||
if (leftNode == null || rightNode == null || leftNode.val != rightNode.val) {
|
||||
return false;
|
||||
}
|
||||
// 这里顺序与使用Deque不同
|
||||
deque.offer(leftNode.left);
|
||||
deque.offer(rightNode.right);
|
||||
deque.offer(leftNode.right);
|
||||
deque.offer(rightNode.left);
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
> 递归法
|
||||
```python
|
||||
class Solution:
|
||||
def isSymmetric(self, root: TreeNode) -> bool:
|
||||
if not root:
|
||||
return True
|
||||
return self.compare(root.left, root.right)
|
||||
|
||||
def compare(self, left, right):
|
||||
#首先排除空节点的情况
|
||||
if left == None and right != None: return False
|
||||
elif left != None and right == None: return False
|
||||
elif left == None and right == None: return True
|
||||
#排除了空节点,再排除数值不相同的情况
|
||||
elif left.val != right.val: return False
|
||||
|
||||
#此时就是:左右节点都不为空,且数值相同的情况
|
||||
#此时才做递归,做下一层的判断
|
||||
outside = self.compare(left.left, right.right) #左子树:左、 右子树:右
|
||||
inside = self.compare(left.right, right.left) #左子树:右、 右子树:左
|
||||
isSame = outside and inside #左子树:中、 右子树:中 (逻辑处理)
|
||||
return isSame
|
||||
```
|
||||
|
||||
> 迭代法: 使用队列
|
||||
```python
|
||||
import collections
|
||||
class Solution:
|
||||
def isSymmetric(self, root: TreeNode) -> bool:
|
||||
if not root:
|
||||
return True
|
||||
queue = collections.deque()
|
||||
queue.append(root.left) #将左子树头结点加入队列
|
||||
queue.append(root.right) #将右子树头结点加入队列
|
||||
while queue: #接下来就要判断这这两个树是否相互翻转
|
||||
leftNode = queue.popleft()
|
||||
rightNode = queue.popleft()
|
||||
if not leftNode and not rightNode: #左节点为空、右节点为空,此时说明是对称的
|
||||
continue
|
||||
|
||||
#左右一个节点不为空,或者都不为空但数值不相同,返回false
|
||||
if not leftNode or not rightNode or leftNode.val != rightNode.val:
|
||||
return False
|
||||
queue.append(leftNode.left) #加入左节点左孩子
|
||||
queue.append(rightNode.right) #加入右节点右孩子
|
||||
queue.append(leftNode.right) #加入左节点右孩子
|
||||
queue.append(rightNode.left) #加入右节点左孩子
|
||||
return True
|
||||
```
|
||||
|
||||
> 迭代法:使用栈
|
||||
```python
|
||||
class Solution:
|
||||
def isSymmetric(self, root: TreeNode) -> bool:
|
||||
if not root:
|
||||
return True
|
||||
st = [] #这里改成了栈
|
||||
st.append(root.left)
|
||||
st.append(root.right)
|
||||
while st:
|
||||
leftNode = st.pop()
|
||||
rightNode = st.pop()
|
||||
if not leftNode and not rightNode:
|
||||
continue
|
||||
if not leftNode or not rightNode or leftNode.val != rightNode.val:
|
||||
return False
|
||||
st.append(leftNode.left)
|
||||
st.append(rightNode.right)
|
||||
st.append(leftNode.right)
|
||||
st.append(rightNode.left)
|
||||
return True
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
```go
|
||||
/**
|
||||
* Definition for a binary tree node.
|
||||
* type TreeNode struct {
|
||||
* Val int
|
||||
* Left *TreeNode
|
||||
* Right *TreeNode
|
||||
* }
|
||||
*/
|
||||
// 递归
|
||||
func defs(left *TreeNode, right *TreeNode) bool {
|
||||
if left == nil && right == nil {
|
||||
return true;
|
||||
};
|
||||
if left == nil || right == nil {
|
||||
return false;
|
||||
};
|
||||
if left.Val != right.Val {
|
||||
return false;
|
||||
}
|
||||
return defs(left.Left, right.Right) && defs(right.Left, left.Right);
|
||||
}
|
||||
func isSymmetric(root *TreeNode) bool {
|
||||
return defs(root.Left, root.Right);
|
||||
}
|
||||
|
||||
// 迭代
|
||||
func isSymmetric(root *TreeNode) bool {
|
||||
var queue []*TreeNode;
|
||||
if root != nil {
|
||||
queue = append(queue, root.Left, root.Right);
|
||||
}
|
||||
for len(queue) > 0 {
|
||||
left := queue[0];
|
||||
right := queue[1];
|
||||
queue = queue[2:];
|
||||
if left == nil && right == nil {
|
||||
continue;
|
||||
}
|
||||
if left == nil || right == nil || left.Val != right.Val {
|
||||
return false;
|
||||
};
|
||||
queue = append(queue, left.Left, right.Right, right.Left, left.Right);
|
||||
}
|
||||
return true;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
JavaScript
|
||||
```javascript
|
||||
var isSymmetric = function(root) {
|
||||
return check(root, root)
|
||||
};
|
||||
|
||||
const check = (leftPtr, rightPtr) => {
|
||||
// 如果只有根节点,返回true
|
||||
if (!leftPtr && !rightPtr) return true
|
||||
// 如果左右节点只存在一个,则返回false
|
||||
if (!leftPtr || !rightPtr) return false
|
||||
|
||||
return leftPtr.val === rightPtr.val && check(leftPtr.left, rightPtr.right) && check(leftPtr.right, rightPtr.left)
|
||||
}
|
||||
```
|
||||
JavaScript:
|
||||
|
||||
递归判断是否为对称二叉树:
|
||||
```javascript
|
||||
var isSymmetric = function(root) {
|
||||
//使用递归遍历左右子树 递归三部曲
|
||||
// 1. 确定递归的参数 root.left root.right和返回值true false
|
||||
const compareNode=function(left,right){
|
||||
//2. 确定终止条件 空的情况
|
||||
if(left===null&&right!==null||left!==null&&right===null){
|
||||
return false;
|
||||
}else if(left===null&&right===null){
|
||||
return true;
|
||||
}else if(left.val!==right.val){
|
||||
return false;
|
||||
}
|
||||
//3. 确定单层递归逻辑
|
||||
let outSide=compareNode(left.left,right.right);
|
||||
let inSide=compareNode(left.right,right.left);
|
||||
return outSide&&inSide;
|
||||
}
|
||||
if(root===null){
|
||||
return true;
|
||||
}
|
||||
return compareNode(root.left,root.right);
|
||||
};
|
||||
```
|
||||
队列实现迭代判断是否为对称二叉树:
|
||||
```javascript
|
||||
var isSymmetric = function(root) {
|
||||
//迭代方法判断是否是对称二叉树
|
||||
//首先判断root是否为空
|
||||
if(root===null){
|
||||
return true;
|
||||
}
|
||||
let queue=[];
|
||||
queue.push(root.left);
|
||||
queue.push(root.right);
|
||||
while(queue.length){
|
||||
let leftNode=queue.shift();//左节点
|
||||
let rightNode=queue.shift();//右节点
|
||||
if(leftNode===null&&rightNode===null){
|
||||
continue;
|
||||
}
|
||||
if(leftNode===null||rightNode===null||leftNode.val!==rightNode.val){
|
||||
return false;
|
||||
}
|
||||
queue.push(leftNode.left);//左节点左孩子入队
|
||||
queue.push(rightNode.right);//右节点右孩子入队
|
||||
queue.push(leftNode.right);//左节点右孩子入队
|
||||
queue.push(rightNode.left);//右节点左孩子入队
|
||||
}
|
||||
return true;
|
||||
};
|
||||
```
|
||||
栈实现迭代判断是否为对称二叉树:
|
||||
```javascript
|
||||
var isSymmetric = function(root) {
|
||||
//迭代方法判断是否是对称二叉树
|
||||
//首先判断root是否为空
|
||||
if(root===null){
|
||||
return true;
|
||||
}
|
||||
let stack=[];
|
||||
stack.push(root.left);
|
||||
stack.push(root.right);
|
||||
while(stack.length){
|
||||
let rightNode=stack.pop();//左节点
|
||||
let leftNode=stack.pop();//右节点
|
||||
if(leftNode===null&&rightNode===null){
|
||||
continue;
|
||||
}
|
||||
if(leftNode===null||rightNode===null||leftNode.val!==rightNode.val){
|
||||
return false;
|
||||
}
|
||||
stack.push(leftNode.left);//左节点左孩子入队
|
||||
stack.push(rightNode.right);//右节点右孩子入队
|
||||
stack.push(leftNode.right);//左节点右孩子入队
|
||||
stack.push(rightNode.left);//右节点左孩子入队
|
||||
}
|
||||
return true;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
1689
problems/0102.二叉树的层序遍历.md
Normal file
1689
problems/0102.二叉树的层序遍历.md
Normal file
File diff suppressed because it is too large
Load Diff
458
problems/0104.二叉树的最大深度.md
Normal file
458
problems/0104.二叉树的最大深度.md
Normal file
@@ -0,0 +1,458 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
看完本篇可以一起做了如下两道题目:
|
||||
* 104.二叉树的最大深度
|
||||
* 559.N叉树的最大深度
|
||||
|
||||
## 104.二叉树的最大深度
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/maximum-depth-of-binary-tree/
|
||||
|
||||
给定一个二叉树,找出其最大深度。
|
||||
|
||||
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
|
||||
|
||||
说明: 叶子节点是指没有子节点的节点。
|
||||
|
||||
示例:
|
||||
给定二叉树 [3,9,20,null,null,15,7],
|
||||
|
||||

|
||||
|
||||
返回它的最大深度 3 。
|
||||
|
||||
### 递归法
|
||||
|
||||
本题其实也要后序遍历(左右中),依然是因为要通过递归函数的返回值做计算树的高度。
|
||||
|
||||
按照递归三部曲,来看看如何来写。
|
||||
|
||||
1. 确定递归函数的参数和返回值:参数就是传入树的根节点,返回就返回这棵树的深度,所以返回值为int类型。
|
||||
|
||||
代码如下:
|
||||
```
|
||||
int getDepth(TreeNode* node)
|
||||
```
|
||||
|
||||
2. 确定终止条件:如果为空节点的话,就返回0,表示高度为0。
|
||||
|
||||
代码如下:
|
||||
```
|
||||
if (node == NULL) return 0;
|
||||
```
|
||||
|
||||
3. 确定单层递归的逻辑:先求它的左子树的深度,再求的右子树的深度,最后取左右深度最大的数值 再+1 (加1是因为算上当前中间节点)就是目前节点为根节点的树的深度。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
int leftDepth = getDepth(node->left); // 左
|
||||
int rightDepth = getDepth(node->right); // 右
|
||||
int depth = 1 + max(leftDepth, rightDepth); // 中
|
||||
return depth;
|
||||
```
|
||||
|
||||
所以整体C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int getDepth(TreeNode* node) {
|
||||
if (node == NULL) return 0;
|
||||
int leftDepth = getDepth(node->left); // 左
|
||||
int rightDepth = getDepth(node->right); // 右
|
||||
int depth = 1 + max(leftDepth, rightDepth); // 中
|
||||
return depth;
|
||||
}
|
||||
int maxDepth(TreeNode* root) {
|
||||
return getDepth(root);
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
代码精简之后C++代码如下:
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int maxDepth(TreeNode* root) {
|
||||
if (root == NULL) return 0;
|
||||
return 1 + max(maxDepth(root->left), maxDepth(root->right));
|
||||
}
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
**精简之后的代码根本看不出是哪种遍历方式,也看不出递归三部曲的步骤,所以如果对二叉树的操作还不熟练,尽量不要直接照着精简代码来学。**
|
||||
|
||||
|
||||
### 迭代法
|
||||
|
||||
使用迭代法的话,使用层序遍历是最为合适的,因为最大的深度就是二叉树的层数,和层序遍历的方式极其吻合。
|
||||
|
||||
在二叉树中,一层一层的来遍历二叉树,记录一下遍历的层数就是二叉树的深度,如图所示:
|
||||
|
||||
|
||||
|
||||
所以这道题的迭代法就是一道模板题,可以使用二叉树层序遍历的模板来解决的。
|
||||
|
||||
如果对层序遍历还不清楚的话,可以看这篇:[二叉树:层序遍历登场!](https://mp.weixin.qq.com/s/Gb3BjakIKGNpup2jYtTzog)
|
||||
|
||||
C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int maxDepth(TreeNode* root) {
|
||||
if (root == NULL) return 0;
|
||||
int depth = 0;
|
||||
queue<TreeNode*> que;
|
||||
que.push(root);
|
||||
while(!que.empty()) {
|
||||
int size = que.size();
|
||||
depth++; // 记录深度
|
||||
for (int i = 0; i < size; i++) {
|
||||
TreeNode* node = que.front();
|
||||
que.pop();
|
||||
if (node->left) que.push(node->left);
|
||||
if (node->right) que.push(node->right);
|
||||
}
|
||||
}
|
||||
return depth;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
那么我们可以顺便解决一下N叉树的最大深度问题
|
||||
|
||||
## 559.N叉树的最大深度
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/maximum-depth-of-n-ary-tree/
|
||||
|
||||
给定一个 N 叉树,找到其最大深度。
|
||||
|
||||
最大深度是指从根节点到最远叶子节点的最长路径上的节点总数。
|
||||
|
||||
例如,给定一个 3叉树 :
|
||||
|
||||

|
||||
|
||||
我们应返回其最大深度,3。
|
||||
|
||||
思路:
|
||||
|
||||
依然可以提供递归法和迭代法,来解决这个问题,思路是和二叉树思路一样的,直接给出代码如下:
|
||||
|
||||
### 递归法
|
||||
|
||||
C++代码:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int maxDepth(Node* root) {
|
||||
if (root == 0) return 0;
|
||||
int depth = 0;
|
||||
for (int i = 0; i < root->children.size(); i++) {
|
||||
depth = max (depth, maxDepth(root->children[i]));
|
||||
}
|
||||
return depth + 1;
|
||||
}
|
||||
};
|
||||
```
|
||||
### 迭代法
|
||||
|
||||
依然是层序遍历,代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int maxDepth(Node* root) {
|
||||
queue<Node*> que;
|
||||
if (root != NULL) que.push(root);
|
||||
int depth = 0;
|
||||
while (!que.empty()) {
|
||||
int size = que.size();
|
||||
depth++; // 记录深度
|
||||
for (int i = 0; i < size; i++) {
|
||||
Node* node = que.front();
|
||||
que.pop();
|
||||
for (int j = 0; j < node->children.size(); j++) {
|
||||
if (node->children[j]) que.push(node->children[j]);
|
||||
}
|
||||
}
|
||||
}
|
||||
return depth;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
|
||||
```Java
|
||||
class Solution {
|
||||
/**
|
||||
* 递归法
|
||||
*/
|
||||
public int maxDepth(TreeNode root) {
|
||||
if (root == null) {
|
||||
return 0;
|
||||
}
|
||||
int leftDepth = maxDepth(root.left);
|
||||
int rightDepth = maxDepth(root.right);
|
||||
return Math.max(leftDepth, rightDepth) + 1;
|
||||
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```Java
|
||||
class Solution {
|
||||
/**
|
||||
* 迭代法,使用层序遍历
|
||||
*/
|
||||
public int maxDepth(TreeNode root) {
|
||||
if(root == null) {
|
||||
return 0;
|
||||
}
|
||||
Deque<TreeNode> deque = new LinkedList<>();
|
||||
deque.offer(root);
|
||||
int depth = 0;
|
||||
while (!deque.isEmpty()) {
|
||||
int size = deque.size();
|
||||
depth++;
|
||||
for (int i = 0; i < size; i++) {
|
||||
TreeNode poll = deque.poll();
|
||||
if (poll.left != null) {
|
||||
deque.offer(poll.left);
|
||||
}
|
||||
if (poll.right != null) {
|
||||
deque.offer(poll.right);
|
||||
}
|
||||
}
|
||||
}
|
||||
return depth;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
104.二叉树的最大深度
|
||||
> 递归法:
|
||||
```python
|
||||
class Solution:
|
||||
def maxDepth(self, root: TreeNode) -> int:
|
||||
return self.getDepth(root)
|
||||
|
||||
def getDepth(self, node):
|
||||
if not node:
|
||||
return 0
|
||||
leftDepth = self.getDepth(node.left) #左
|
||||
rightDepth = self.getDepth(node.right) #右
|
||||
depth = 1 + max(leftDepth, rightDepth) #中
|
||||
return depth
|
||||
```
|
||||
> 递归法;精简代码
|
||||
```python
|
||||
class Solution:
|
||||
def maxDepth(self, root: TreeNode) -> int:
|
||||
if not root:
|
||||
return 0
|
||||
return 1 + max(self.maxDepth(root.left), self.maxDepth(root.right))
|
||||
```
|
||||
|
||||
> 迭代法:
|
||||
```python
|
||||
import collections
|
||||
class Solution:
|
||||
def maxDepth(self, root: TreeNode) -> int:
|
||||
if not root:
|
||||
return 0
|
||||
depth = 0 #记录深度
|
||||
queue = collections.deque()
|
||||
queue.append(root)
|
||||
while queue:
|
||||
size = len(queue)
|
||||
depth += 1
|
||||
for i in range(size):
|
||||
node = queue.popleft()
|
||||
if node.left:
|
||||
queue.append(node.left)
|
||||
if node.right:
|
||||
queue.append(node.right)
|
||||
return depth
|
||||
```
|
||||
|
||||
559.N叉树的最大深度
|
||||
> 递归法:
|
||||
```python
|
||||
class Solution:
|
||||
def maxDepth(self, root: 'Node') -> int:
|
||||
if not root:
|
||||
return 0
|
||||
depth = 0
|
||||
for i in range(len(root.children)):
|
||||
depth = max(depth, self.maxDepth(root.children[i]))
|
||||
return depth + 1
|
||||
```
|
||||
|
||||
> 迭代法:
|
||||
```python
|
||||
import collections
|
||||
class Solution:
|
||||
def maxDepth(self, root: 'Node') -> int:
|
||||
queue = collections.deque()
|
||||
if root:
|
||||
queue.append(root)
|
||||
depth = 0 #记录深度
|
||||
while queue:
|
||||
size = len(queue)
|
||||
depth += 1
|
||||
for i in range(size):
|
||||
node = queue.popleft()
|
||||
for j in range(len(node.children)):
|
||||
if node.children[j]:
|
||||
queue.append(node.children[j])
|
||||
return depth
|
||||
```
|
||||
|
||||
> 使用栈来模拟后序遍历依然可以
|
||||
```python
|
||||
class Solution:
|
||||
def maxDepth(self, root: 'Node') -> int:
|
||||
st = []
|
||||
if root:
|
||||
st.append(root)
|
||||
depth = 0
|
||||
result = 0
|
||||
while st:
|
||||
node = st.pop()
|
||||
if node != None:
|
||||
st.append(node) #中
|
||||
st.append(None)
|
||||
depth += 1
|
||||
for i in range(len(node.children)): #处理孩子
|
||||
if node.children[i]:
|
||||
st.append(node.children[i])
|
||||
|
||||
else:
|
||||
node = st.pop()
|
||||
depth -= 1
|
||||
result = max(result, depth)
|
||||
return result
|
||||
```
|
||||
|
||||
|
||||
Go:
|
||||
|
||||
```go
|
||||
/**
|
||||
* Definition for a binary tree node.
|
||||
* type TreeNode struct {
|
||||
* Val int
|
||||
* Left *TreeNode
|
||||
* Right *TreeNode
|
||||
* }
|
||||
*/
|
||||
func max (a, b int) int {
|
||||
if a > b {
|
||||
return a;
|
||||
}
|
||||
return b;
|
||||
}
|
||||
// 递归
|
||||
func maxDepth(root *TreeNode) int {
|
||||
if root == nil {
|
||||
return 0;
|
||||
}
|
||||
return max(maxDepth(root.Left), maxDepth(root.Right)) + 1;
|
||||
}
|
||||
|
||||
// 遍历
|
||||
func maxDepth(root *TreeNode) int {
|
||||
levl := 0;
|
||||
queue := make([]*TreeNode, 0);
|
||||
if root != nil {
|
||||
queue = append(queue, root);
|
||||
}
|
||||
for l := len(queue); l > 0; {
|
||||
for ;l > 0;l-- {
|
||||
node := queue[0];
|
||||
if node.Left != nil {
|
||||
queue = append(queue, node.Left);
|
||||
}
|
||||
if node.Right != nil {
|
||||
queue = append(queue, node.Right);
|
||||
}
|
||||
queue = queue[1:];
|
||||
}
|
||||
levl++;
|
||||
l = len(queue);
|
||||
}
|
||||
return levl;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
JavaScript
|
||||
```javascript
|
||||
var maxDepth = function(root) {
|
||||
if (!root) return root
|
||||
return 1 + Math.max(maxDepth(root.left), maxDepth(root.right))
|
||||
};
|
||||
```
|
||||
二叉树最大深度递归遍历
|
||||
```javascript
|
||||
var maxDepth = function(root) {
|
||||
//使用递归的方法 递归三部曲
|
||||
//1. 确定递归函数的参数和返回值
|
||||
const getDepth=function(node){
|
||||
//2. 确定终止条件
|
||||
if(node===null){
|
||||
return 0;
|
||||
}
|
||||
//3. 确定单层逻辑
|
||||
let leftDepth=getDepth(node.left);
|
||||
let rightDepth=getDepth(node.right);
|
||||
let depth=1+Math.max(leftDepth,rightDepth);
|
||||
return depth;
|
||||
}
|
||||
return getDepth(root);
|
||||
};
|
||||
```
|
||||
二叉树最大深度层级遍历
|
||||
```javascript
|
||||
var maxDepth = function(root) {
|
||||
//使用递归的方法 递归三部曲
|
||||
//1. 确定递归函数的参数和返回值
|
||||
const getDepth=function(node){
|
||||
//2. 确定终止条件
|
||||
if(node===null){
|
||||
return 0;
|
||||
}
|
||||
//3. 确定单层逻辑
|
||||
let leftDepth=getDepth(node.left);
|
||||
let rightDepth=getDepth(node.right);
|
||||
let depth=1+Math.max(leftDepth,rightDepth);
|
||||
return depth;
|
||||
}
|
||||
return getDepth(root);
|
||||
};
|
||||
```
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
796
problems/0106.从中序与后序遍历序列构造二叉树.md
Normal file
796
problems/0106.从中序与后序遍历序列构造二叉树.md
Normal file
@@ -0,0 +1,796 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
看完本文,可以一起解决如下两道题目
|
||||
|
||||
* 106.从中序与后序遍历序列构造二叉树
|
||||
* 105.从前序与中序遍历序列构造二叉树
|
||||
|
||||
## 106.从中序与后序遍历序列构造二叉树
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/construct-binary-tree-from-inorder-and-postorder-traversal/
|
||||
|
||||
根据一棵树的中序遍历与后序遍历构造二叉树。
|
||||
|
||||
注意:
|
||||
你可以假设树中没有重复的元素。
|
||||
|
||||
例如,给出
|
||||
|
||||
中序遍历 inorder = [9,3,15,20,7]
|
||||
后序遍历 postorder = [9,15,7,20,3]
|
||||
返回如下的二叉树:
|
||||
|
||||

|
||||
|
||||
### 思路
|
||||
|
||||
首先回忆一下如何根据两个顺序构造一个唯一的二叉树,相信理论知识大家应该都清楚,就是以 后序数组的最后一个元素为切割点,先切中序数组,根据中序数组,反过来在切后序数组。一层一层切下去,每次后序数组最后一个元素就是节点元素。
|
||||
|
||||
如果让我们肉眼看两个序列,画一颗二叉树的话,应该分分钟都可以画出来。
|
||||
|
||||
流程如图:
|
||||
|
||||
|
||||
|
||||
那么代码应该怎么写呢?
|
||||
|
||||
说到一层一层切割,就应该想到了递归。
|
||||
|
||||
来看一下一共分几步:
|
||||
|
||||
* 第一步:如果数组大小为零的话,说明是空节点了。
|
||||
|
||||
* 第二步:如果不为空,那么取后序数组最后一个元素作为节点元素。
|
||||
|
||||
* 第三步:找到后序数组最后一个元素在中序数组的位置,作为切割点
|
||||
|
||||
* 第四步:切割中序数组,切成中序左数组和中序右数组 (顺序别搞反了,一定是先切中序数组)
|
||||
|
||||
* 第五步:切割后序数组,切成后序左数组和后序右数组
|
||||
|
||||
* 第六步:递归处理左区间和右区间
|
||||
|
||||
不难写出如下代码:(先把框架写出来)
|
||||
|
||||
```C++
|
||||
TreeNode* traversal (vector<int>& inorder, vector<int>& postorder) {
|
||||
|
||||
// 第一步
|
||||
if (postorder.size() == 0) return NULL;
|
||||
|
||||
// 第二步:后序遍历数组最后一个元素,就是当前的中间节点
|
||||
int rootValue = postorder[postorder.size() - 1];
|
||||
TreeNode* root = new TreeNode(rootValue);
|
||||
|
||||
// 叶子节点
|
||||
if (postorder.size() == 1) return root;
|
||||
|
||||
// 第三步:找切割点
|
||||
int delimiterIndex;
|
||||
for (delimiterIndex = 0; delimiterIndex < inorder.size(); delimiterIndex++) {
|
||||
if (inorder[delimiterIndex] == rootValue) break;
|
||||
}
|
||||
|
||||
// 第四步:切割中序数组,得到 中序左数组和中序右数组
|
||||
// 第五步:切割后序数组,得到 后序左数组和后序右数组
|
||||
|
||||
// 第六步
|
||||
root->left = traversal(中序左数组, 后序左数组);
|
||||
root->right = traversal(中序右数组, 后序右数组);
|
||||
|
||||
return root;
|
||||
}
|
||||
```
|
||||
|
||||
**难点大家应该发现了,就是如何切割,以及边界值找不好很容易乱套。**
|
||||
|
||||
此时应该注意确定切割的标准,是左闭右开,还有左开又闭,还是左闭又闭,这个就是不变量,要在递归中保持这个不变量。
|
||||
|
||||
**在切割的过程中会产生四个区间,把握不好不变量的话,一会左闭右开,一会左闭又闭,必然乱套!**
|
||||
|
||||
我在[数组:每次遇到二分法,都是一看就会,一写就废](https://mp.weixin.qq.com/s/fCf5QbPDtE6SSlZ1yh_q8Q)和[数组:这个循环可以转懵很多人!](https://mp.weixin.qq.com/s/KTPhaeqxbMK9CxHUUgFDmg)中都强调过循环不变量的重要性,在二分查找以及螺旋矩阵的求解中,坚持循环不变量非常重要,本题也是。
|
||||
|
||||
|
||||
首先要切割中序数组,为什么先切割中序数组呢?
|
||||
|
||||
切割点在后序数组的最后一个元素,就是用这个元素来切割中序数组的,所以必要先切割中序数组。
|
||||
|
||||
中序数组相对比较好切,找到切割点(后序数组的最后一个元素)在中序数组的位置,然后切割,如下代码中我坚持左闭右开的原则:
|
||||
|
||||
|
||||
```
|
||||
// 找到中序遍历的切割点
|
||||
int delimiterIndex;
|
||||
for (delimiterIndex = 0; delimiterIndex < inorder.size(); delimiterIndex++) {
|
||||
if (inorder[delimiterIndex] == rootValue) break;
|
||||
}
|
||||
|
||||
// 左闭右开区间:[0, delimiterIndex)
|
||||
vector<int> leftInorder(inorder.begin(), inorder.begin() + delimiterIndex);
|
||||
// [delimiterIndex + 1, end)
|
||||
vector<int> rightInorder(inorder.begin() + delimiterIndex + 1, inorder.end() );
|
||||
```
|
||||
|
||||
接下来就要切割后序数组了。
|
||||
|
||||
首先后序数组的最后一个元素指定不能要了,这是切割点 也是 当前二叉树中间节点的元素,已经用了。
|
||||
|
||||
后序数组的切割点怎么找?
|
||||
|
||||
后序数组没有明确的切割元素来进行左右切割,不像中序数组有明确的切割点,切割点左右分开就可以了。
|
||||
|
||||
**此时有一个很重的点,就是中序数组大小一定是和后序数组的大小相同的(这是必然)。**
|
||||
|
||||
中序数组我们都切成了左中序数组和右中序数组了,那么后序数组就可以按照左中序数组的大小来切割,切成左后序数组和右后序数组。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
// postorder 舍弃末尾元素,因为这个元素就是中间节点,已经用过了
|
||||
postorder.resize(postorder.size() - 1);
|
||||
|
||||
// 左闭右开,注意这里使用了左中序数组大小作为切割点:[0, leftInorder.size)
|
||||
vector<int> leftPostorder(postorder.begin(), postorder.begin() + leftInorder.size());
|
||||
// [leftInorder.size(), end)
|
||||
vector<int> rightPostorder(postorder.begin() + leftInorder.size(), postorder.end());
|
||||
```
|
||||
|
||||
此时,中序数组切成了左中序数组和右中序数组,后序数组切割成左后序数组和右后序数组。
|
||||
|
||||
接下来可以递归了,代码如下:
|
||||
|
||||
```
|
||||
root->left = traversal(leftInorder, leftPostorder);
|
||||
root->right = traversal(rightInorder, rightPostorder);
|
||||
```
|
||||
|
||||
完整代码如下:
|
||||
|
||||
### C++完整代码
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
TreeNode* traversal (vector<int>& inorder, vector<int>& postorder) {
|
||||
if (postorder.size() == 0) return NULL;
|
||||
|
||||
// 后序遍历数组最后一个元素,就是当前的中间节点
|
||||
int rootValue = postorder[postorder.size() - 1];
|
||||
TreeNode* root = new TreeNode(rootValue);
|
||||
|
||||
// 叶子节点
|
||||
if (postorder.size() == 1) return root;
|
||||
|
||||
// 找到中序遍历的切割点
|
||||
int delimiterIndex;
|
||||
for (delimiterIndex = 0; delimiterIndex < inorder.size(); delimiterIndex++) {
|
||||
if (inorder[delimiterIndex] == rootValue) break;
|
||||
}
|
||||
|
||||
// 切割中序数组
|
||||
// 左闭右开区间:[0, delimiterIndex)
|
||||
vector<int> leftInorder(inorder.begin(), inorder.begin() + delimiterIndex);
|
||||
// [delimiterIndex + 1, end)
|
||||
vector<int> rightInorder(inorder.begin() + delimiterIndex + 1, inorder.end() );
|
||||
|
||||
// postorder 舍弃末尾元素
|
||||
postorder.resize(postorder.size() - 1);
|
||||
|
||||
// 切割后序数组
|
||||
// 依然左闭右开,注意这里使用了左中序数组大小作为切割点
|
||||
// [0, leftInorder.size)
|
||||
vector<int> leftPostorder(postorder.begin(), postorder.begin() + leftInorder.size());
|
||||
// [leftInorder.size(), end)
|
||||
vector<int> rightPostorder(postorder.begin() + leftInorder.size(), postorder.end());
|
||||
|
||||
root->left = traversal(leftInorder, leftPostorder);
|
||||
root->right = traversal(rightInorder, rightPostorder);
|
||||
|
||||
return root;
|
||||
}
|
||||
public:
|
||||
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
|
||||
if (inorder.size() == 0 || postorder.size() == 0) return NULL;
|
||||
return traversal(inorder, postorder);
|
||||
}
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
相信大家自己就算是思路清晰, 代码写出来一定是各种问题,所以一定要加日志来调试,看看是不是按照自己思路来切割的,不要大脑模拟,那样越想越糊涂。
|
||||
|
||||
加了日志的代码如下:(加了日志的代码不要在leetcode上提交,容易超时)
|
||||
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
TreeNode* traversal (vector<int>& inorder, vector<int>& postorder) {
|
||||
if (postorder.size() == 0) return NULL;
|
||||
|
||||
int rootValue = postorder[postorder.size() - 1];
|
||||
TreeNode* root = new TreeNode(rootValue);
|
||||
|
||||
if (postorder.size() == 1) return root;
|
||||
|
||||
int delimiterIndex;
|
||||
for (delimiterIndex = 0; delimiterIndex < inorder.size(); delimiterIndex++) {
|
||||
if (inorder[delimiterIndex] == rootValue) break;
|
||||
}
|
||||
|
||||
vector<int> leftInorder(inorder.begin(), inorder.begin() + delimiterIndex);
|
||||
vector<int> rightInorder(inorder.begin() + delimiterIndex + 1, inorder.end() );
|
||||
|
||||
postorder.resize(postorder.size() - 1);
|
||||
|
||||
vector<int> leftPostorder(postorder.begin(), postorder.begin() + leftInorder.size());
|
||||
vector<int> rightPostorder(postorder.begin() + leftInorder.size(), postorder.end());
|
||||
|
||||
// 一下为日志
|
||||
cout << "----------" << endl;
|
||||
|
||||
cout << "leftInorder :";
|
||||
for (int i : leftInorder) {
|
||||
cout << i << " ";
|
||||
}
|
||||
cout << endl;
|
||||
|
||||
cout << "rightInorder :";
|
||||
for (int i : rightInorder) {
|
||||
cout << i << " ";
|
||||
}
|
||||
cout << endl;
|
||||
|
||||
cout << "leftPostorder :";
|
||||
for (int i : leftPostorder) {
|
||||
cout << i << " ";
|
||||
}
|
||||
cout << endl;
|
||||
cout << "rightPostorder :";
|
||||
for (int i : rightPostorder) {
|
||||
cout << i << " ";
|
||||
}
|
||||
cout << endl;
|
||||
|
||||
root->left = traversal(leftInorder, leftPostorder);
|
||||
root->right = traversal(rightInorder, rightPostorder);
|
||||
|
||||
return root;
|
||||
}
|
||||
public:
|
||||
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
|
||||
if (inorder.size() == 0 || postorder.size() == 0) return NULL;
|
||||
return traversal(inorder, postorder);
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
**此时应该发现了,如上的代码性能并不好,应为每层递归定定义了新的vector(就是数组),既耗时又耗空间,但上面的代码是最好理解的,为了方便读者理解,所以用如上的代码来讲解。**
|
||||
|
||||
下面给出用下表索引写出的代码版本:(思路是一样的,只不过不用重复定义vector了,每次用下表索引来分割)
|
||||
|
||||
### C++优化版本
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
// 中序区间:[inorderBegin, inorderEnd),后序区间[postorderBegin, postorderEnd)
|
||||
TreeNode* traversal (vector<int>& inorder, int inorderBegin, int inorderEnd, vector<int>& postorder, int postorderBegin, int postorderEnd) {
|
||||
if (postorderBegin == postorderEnd) return NULL;
|
||||
|
||||
int rootValue = postorder[postorderEnd - 1];
|
||||
TreeNode* root = new TreeNode(rootValue);
|
||||
|
||||
if (postorderEnd - postorderBegin == 1) return root;
|
||||
|
||||
int delimiterIndex;
|
||||
for (delimiterIndex = inorderBegin; delimiterIndex < inorderEnd; delimiterIndex++) {
|
||||
if (inorder[delimiterIndex] == rootValue) break;
|
||||
}
|
||||
// 切割中序数组
|
||||
// 左中序区间,左闭右开[leftInorderBegin, leftInorderEnd)
|
||||
int leftInorderBegin = inorderBegin;
|
||||
int leftInorderEnd = delimiterIndex;
|
||||
// 右中序区间,左闭右开[rightInorderBegin, rightInorderEnd)
|
||||
int rightInorderBegin = delimiterIndex + 1;
|
||||
int rightInorderEnd = inorderEnd;
|
||||
|
||||
// 切割后序数组
|
||||
// 左后序区间,左闭右开[leftPostorderBegin, leftPostorderEnd)
|
||||
int leftPostorderBegin = postorderBegin;
|
||||
int leftPostorderEnd = postorderBegin + delimiterIndex - inorderBegin; // 终止位置是 需要加上 中序区间的大小size
|
||||
// 右后序区间,左闭右开[rightPostorderBegin, rightPostorderEnd)
|
||||
int rightPostorderBegin = postorderBegin + (delimiterIndex - inorderBegin);
|
||||
int rightPostorderEnd = postorderEnd - 1; // 排除最后一个元素,已经作为节点了
|
||||
|
||||
root->left = traversal(inorder, leftInorderBegin, leftInorderEnd, postorder, leftPostorderBegin, leftPostorderEnd);
|
||||
root->right = traversal(inorder, rightInorderBegin, rightInorderEnd, postorder, rightPostorderBegin, rightPostorderEnd);
|
||||
|
||||
return root;
|
||||
}
|
||||
public:
|
||||
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
|
||||
if (inorder.size() == 0 || postorder.size() == 0) return NULL;
|
||||
// 左闭右开的原则
|
||||
return traversal(inorder, 0, inorder.size(), postorder, 0, postorder.size());
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
那么这个版本写出来依然要打日志进行调试,打日志的版本如下:(**该版本不要在leetcode上提交,容易超时**)
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
TreeNode* traversal (vector<int>& inorder, int inorderBegin, int inorderEnd, vector<int>& postorder, int postorderBegin, int postorderEnd) {
|
||||
if (postorderBegin == postorderEnd) return NULL;
|
||||
|
||||
int rootValue = postorder[postorderEnd - 1];
|
||||
TreeNode* root = new TreeNode(rootValue);
|
||||
|
||||
if (postorderEnd - postorderBegin == 1) return root;
|
||||
|
||||
int delimiterIndex;
|
||||
for (delimiterIndex = inorderBegin; delimiterIndex < inorderEnd; delimiterIndex++) {
|
||||
if (inorder[delimiterIndex] == rootValue) break;
|
||||
}
|
||||
// 切割中序数组
|
||||
// 左中序区间,左闭右开[leftInorderBegin, leftInorderEnd)
|
||||
int leftInorderBegin = inorderBegin;
|
||||
int leftInorderEnd = delimiterIndex;
|
||||
// 右中序区间,左闭右开[rightInorderBegin, rightInorderEnd)
|
||||
int rightInorderBegin = delimiterIndex + 1;
|
||||
int rightInorderEnd = inorderEnd;
|
||||
|
||||
// 切割后序数组
|
||||
// 左后序区间,左闭右开[leftPostorderBegin, leftPostorderEnd)
|
||||
int leftPostorderBegin = postorderBegin;
|
||||
int leftPostorderEnd = postorderBegin + delimiterIndex - inorderBegin; // 终止位置是 需要加上 中序区间的大小size
|
||||
// 右后序区间,左闭右开[rightPostorderBegin, rightPostorderEnd)
|
||||
int rightPostorderBegin = postorderBegin + (delimiterIndex - inorderBegin);
|
||||
int rightPostorderEnd = postorderEnd - 1; // 排除最后一个元素,已经作为节点了
|
||||
|
||||
cout << "----------" << endl;
|
||||
cout << "leftInorder :";
|
||||
for (int i = leftInorderBegin; i < leftInorderEnd; i++) {
|
||||
cout << inorder[i] << " ";
|
||||
}
|
||||
cout << endl;
|
||||
|
||||
cout << "rightInorder :";
|
||||
for (int i = rightInorderBegin; i < rightInorderEnd; i++) {
|
||||
cout << inorder[i] << " ";
|
||||
}
|
||||
cout << endl;
|
||||
|
||||
cout << "leftpostorder :";
|
||||
for (int i = leftPostorderBegin; i < leftPostorderEnd; i++) {
|
||||
cout << postorder[i] << " ";
|
||||
}
|
||||
cout << endl;
|
||||
|
||||
cout << "rightpostorder :";
|
||||
for (int i = rightPostorderBegin; i < rightPostorderEnd; i++) {
|
||||
cout << postorder[i] << " ";
|
||||
}
|
||||
cout << endl;
|
||||
|
||||
root->left = traversal(inorder, leftInorderBegin, leftInorderEnd, postorder, leftPostorderBegin, leftPostorderEnd);
|
||||
root->right = traversal(inorder, rightInorderBegin, rightInorderEnd, postorder, rightPostorderBegin, rightPostorderEnd);
|
||||
|
||||
return root;
|
||||
}
|
||||
public:
|
||||
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
|
||||
if (inorder.size() == 0 || postorder.size() == 0) return NULL;
|
||||
return traversal(inorder, 0, inorder.size(), postorder, 0, postorder.size());
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 105.从前序与中序遍历序列构造二叉树
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/construct-binary-tree-from-preorder-and-inorder-traversal/
|
||||
|
||||
根据一棵树的前序遍历与中序遍历构造二叉树。
|
||||
|
||||
注意:
|
||||
你可以假设树中没有重复的元素。
|
||||
|
||||
例如,给出
|
||||
|
||||
前序遍历 preorder = [3,9,20,15,7]
|
||||
中序遍历 inorder = [9,3,15,20,7]
|
||||
返回如下的二叉树:
|
||||
|
||||

|
||||
|
||||
### 思路
|
||||
|
||||
本题和106是一样的道理。
|
||||
|
||||
我就直接给出代码了。
|
||||
|
||||
带日志的版本C++代码如下: (**带日志的版本仅用于调试,不要在leetcode上提交,会超时**)
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
TreeNode* traversal (vector<int>& inorder, int inorderBegin, int inorderEnd, vector<int>& preorder, int preorderBegin, int preorderEnd) {
|
||||
if (preorderBegin == preorderEnd) return NULL;
|
||||
|
||||
int rootValue = preorder[preorderBegin]; // 注意用preorderBegin 不要用0
|
||||
TreeNode* root = new TreeNode(rootValue);
|
||||
|
||||
if (preorderEnd - preorderBegin == 1) return root;
|
||||
|
||||
int delimiterIndex;
|
||||
for (delimiterIndex = inorderBegin; delimiterIndex < inorderEnd; delimiterIndex++) {
|
||||
if (inorder[delimiterIndex] == rootValue) break;
|
||||
}
|
||||
// 切割中序数组
|
||||
// 中序左区间,左闭右开[leftInorderBegin, leftInorderEnd)
|
||||
int leftInorderBegin = inorderBegin;
|
||||
int leftInorderEnd = delimiterIndex;
|
||||
// 中序右区间,左闭右开[rightInorderBegin, rightInorderEnd)
|
||||
int rightInorderBegin = delimiterIndex + 1;
|
||||
int rightInorderEnd = inorderEnd;
|
||||
|
||||
// 切割前序数组
|
||||
// 前序左区间,左闭右开[leftPreorderBegin, leftPreorderEnd)
|
||||
int leftPreorderBegin = preorderBegin + 1;
|
||||
int leftPreorderEnd = preorderBegin + 1 + delimiterIndex - inorderBegin; // 终止位置是起始位置加上中序左区间的大小size
|
||||
// 前序右区间, 左闭右开[rightPreorderBegin, rightPreorderEnd)
|
||||
int rightPreorderBegin = preorderBegin + 1 + (delimiterIndex - inorderBegin);
|
||||
int rightPreorderEnd = preorderEnd;
|
||||
|
||||
cout << "----------" << endl;
|
||||
cout << "leftInorder :";
|
||||
for (int i = leftInorderBegin; i < leftInorderEnd; i++) {
|
||||
cout << inorder[i] << " ";
|
||||
}
|
||||
cout << endl;
|
||||
|
||||
cout << "rightInorder :";
|
||||
for (int i = rightInorderBegin; i < rightInorderEnd; i++) {
|
||||
cout << inorder[i] << " ";
|
||||
}
|
||||
cout << endl;
|
||||
|
||||
cout << "leftPreorder :";
|
||||
for (int i = leftPreorderBegin; i < leftPreorderEnd; i++) {
|
||||
cout << preorder[i] << " ";
|
||||
}
|
||||
cout << endl;
|
||||
|
||||
cout << "rightPreorder :";
|
||||
for (int i = rightPreorderBegin; i < rightPreorderEnd; i++) {
|
||||
cout << preorder[i] << " ";
|
||||
}
|
||||
cout << endl;
|
||||
|
||||
|
||||
root->left = traversal(inorder, leftInorderBegin, leftInorderEnd, preorder, leftPreorderBegin, leftPreorderEnd);
|
||||
root->right = traversal(inorder, rightInorderBegin, rightInorderEnd, preorder, rightPreorderBegin, rightPreorderEnd);
|
||||
|
||||
return root;
|
||||
}
|
||||
|
||||
public:
|
||||
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
|
||||
if (inorder.size() == 0 || preorder.size() == 0) return NULL;
|
||||
return traversal(inorder, 0, inorder.size(), preorder, 0, preorder.size());
|
||||
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
105.从前序与中序遍历序列构造二叉树,最后版本,C++代码:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
TreeNode* traversal (vector<int>& inorder, int inorderBegin, int inorderEnd, vector<int>& preorder, int preorderBegin, int preorderEnd) {
|
||||
if (preorderBegin == preorderEnd) return NULL;
|
||||
|
||||
int rootValue = preorder[preorderBegin]; // 注意用preorderBegin 不要用0
|
||||
TreeNode* root = new TreeNode(rootValue);
|
||||
|
||||
if (preorderEnd - preorderBegin == 1) return root;
|
||||
|
||||
int delimiterIndex;
|
||||
for (delimiterIndex = inorderBegin; delimiterIndex < inorderEnd; delimiterIndex++) {
|
||||
if (inorder[delimiterIndex] == rootValue) break;
|
||||
}
|
||||
// 切割中序数组
|
||||
// 中序左区间,左闭右开[leftInorderBegin, leftInorderEnd)
|
||||
int leftInorderBegin = inorderBegin;
|
||||
int leftInorderEnd = delimiterIndex;
|
||||
// 中序右区间,左闭右开[rightInorderBegin, rightInorderEnd)
|
||||
int rightInorderBegin = delimiterIndex + 1;
|
||||
int rightInorderEnd = inorderEnd;
|
||||
|
||||
// 切割前序数组
|
||||
// 前序左区间,左闭右开[leftPreorderBegin, leftPreorderEnd)
|
||||
int leftPreorderBegin = preorderBegin + 1;
|
||||
int leftPreorderEnd = preorderBegin + 1 + delimiterIndex - inorderBegin; // 终止位置是起始位置加上中序左区间的大小size
|
||||
// 前序右区间, 左闭右开[rightPreorderBegin, rightPreorderEnd)
|
||||
int rightPreorderBegin = preorderBegin + 1 + (delimiterIndex - inorderBegin);
|
||||
int rightPreorderEnd = preorderEnd;
|
||||
|
||||
root->left = traversal(inorder, leftInorderBegin, leftInorderEnd, preorder, leftPreorderBegin, leftPreorderEnd);
|
||||
root->right = traversal(inorder, rightInorderBegin, rightInorderEnd, preorder, rightPreorderBegin, rightPreorderEnd);
|
||||
|
||||
return root;
|
||||
}
|
||||
|
||||
public:
|
||||
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
|
||||
if (inorder.size() == 0 || preorder.size() == 0) return NULL;
|
||||
|
||||
// 参数坚持左闭右开的原则
|
||||
return traversal(inorder, 0, inorder.size(), preorder, 0, preorder.size());
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 思考题
|
||||
|
||||
前序和中序可以唯一确定一颗二叉树。
|
||||
|
||||
后序和中序可以唯一确定一颗二叉树。
|
||||
|
||||
那么前序和后序可不可以唯一确定一颗二叉树呢?
|
||||
|
||||
**前序和后序不能唯一确定一颗二叉树!**,因为没有中序遍历无法确定左右部分,也就是无法分割。
|
||||
|
||||
举一个例子:
|
||||
|
||||
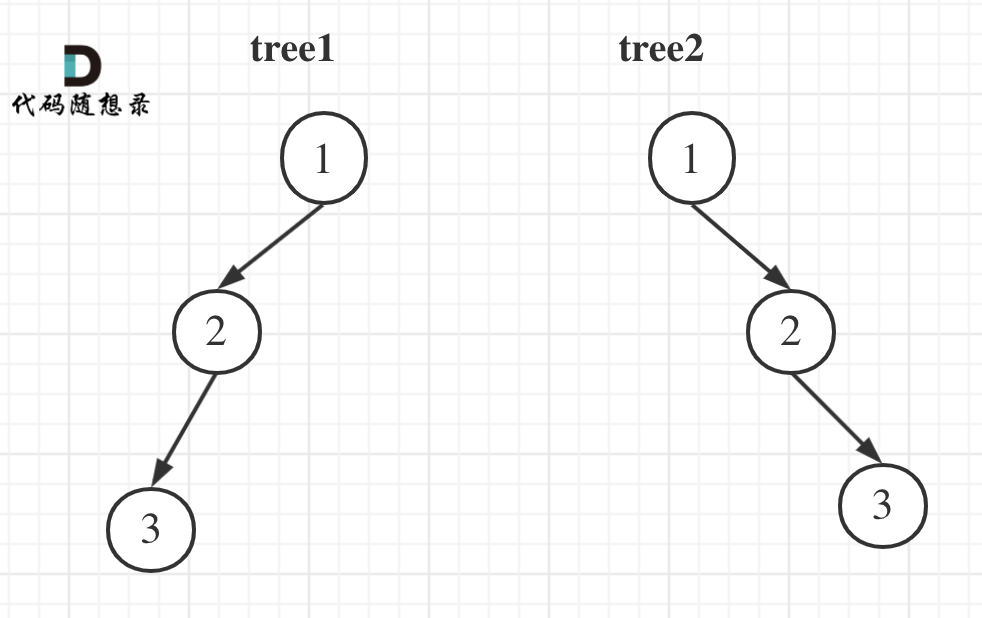
|
||||
|
||||
tree1 的前序遍历是[1 2 3], 后序遍历是[3 2 1]。
|
||||
|
||||
tree2 的前序遍历是[1 2 3], 后序遍历是[3 2 1]。
|
||||
|
||||
那么tree1 和 tree2 的前序和后序完全相同,这是一棵树么,很明显是两棵树!
|
||||
|
||||
所以前序和后序不能唯一确定一颗二叉树!
|
||||
|
||||
## 总结
|
||||
|
||||
之前我们讲的二叉树题目都是各种遍历二叉树,这次开始构造二叉树了,思路其实比较简单,但是真正代码实现出来并不容易。
|
||||
|
||||
所以要避免眼高手低,踏实的把代码写出来。
|
||||
|
||||
我同时给出了添加日志的代码版本,因为这种题目是不太容易写出来调一调就能过的,所以一定要把流程日志打出来,看看符不符合自己的思路。
|
||||
|
||||
大家遇到这种题目的时候,也要学会打日志来调试(如何打日志有时候也是个技术活),不要脑动模拟,脑动模拟很容易越想越乱。
|
||||
|
||||
最后我还给出了为什么前序和中序可以唯一确定一颗二叉树,后序和中序可以唯一确定一颗二叉树,而前序和后序却不行。
|
||||
|
||||
认真研究完本篇,相信大家对二叉树的构造会清晰很多。
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
Java:
|
||||
|
||||
106.从中序与后序遍历序列构造二叉树
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
public TreeNode buildTree(int[] inorder, int[] postorder) {
|
||||
return buildTree1(inorder, 0, inorder.length, postorder, 0, postorder.length);
|
||||
}
|
||||
public TreeNode buildTree1(int[] inorder, int inLeft, int inRight,
|
||||
int[] postorder, int postLeft, int postRight) {
|
||||
// 没有元素了
|
||||
if (inRight - inLeft < 1) {
|
||||
return null;
|
||||
}
|
||||
// 只有一个元素了
|
||||
if (inRight - inLeft == 1) {
|
||||
return new TreeNode(inorder[inLeft]);
|
||||
}
|
||||
// 后序数组postorder里最后一个即为根结点
|
||||
int rootVal = postorder[postRight - 1];
|
||||
TreeNode root = new TreeNode(rootVal);
|
||||
int rootIndex = 0;
|
||||
// 根据根结点的值找到该值在中序数组inorder里的位置
|
||||
for (int i = inLeft; i < inRight; i++) {
|
||||
if (inorder[i] == rootVal) {
|
||||
rootIndex = i;
|
||||
}
|
||||
}
|
||||
// 根据rootIndex划分左右子树
|
||||
root.left = buildTree1(inorder, inLeft, rootIndex,
|
||||
postorder, postLeft, postLeft + (rootIndex - inLeft));
|
||||
root.right = buildTree1(inorder, rootIndex + 1, inRight,
|
||||
postorder, postLeft + (rootIndex - inLeft), postRight - 1);
|
||||
return root;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
105.从前序与中序遍历序列构造二叉树
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
public TreeNode buildTree(int[] preorder, int[] inorder) {
|
||||
return helper(preorder, 0, preorder.length - 1, inorder, 0, inorder.length - 1);
|
||||
}
|
||||
|
||||
public TreeNode helper(int[] preorder, int preLeft, int preRight,
|
||||
int[] inorder, int inLeft, int inRight) {
|
||||
// 递归终止条件
|
||||
if (inLeft > inRight || preLeft > preRight) return null;
|
||||
|
||||
// val 为前序遍历第一个的值,也即是根节点的值
|
||||
// idx 为根据根节点的值来找中序遍历的下标
|
||||
int idx = inLeft, val = preorder[preLeft];
|
||||
TreeNode root = new TreeNode(val);
|
||||
for (int i = inLeft; i <= inRight; i++) {
|
||||
if (inorder[i] == val) {
|
||||
idx = i;
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
// 根据 idx 来递归找左右子树
|
||||
root.left = helper(preorder, preLeft + 1, preLeft + (idx - inLeft),
|
||||
inorder, inLeft, idx - 1);
|
||||
root.right = helper(preorder, preLeft + (idx - inLeft) + 1, preRight,
|
||||
inorder, idx + 1, inRight);
|
||||
return root;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
105.从前序与中序遍历序列构造二叉树
|
||||
|
||||
```python
|
||||
# Definition for a binary tree node.
|
||||
# class TreeNode:
|
||||
# def __init__(self, val=0, left=None, right=None):
|
||||
# self.val = val
|
||||
# self.left = left
|
||||
# self.right = right
|
||||
//递归法
|
||||
class Solution:
|
||||
def buildTree(self, preorder: List[int], inorder: List[int]) -> TreeNode:
|
||||
if not preorder: return None //特殊情况
|
||||
root = TreeNode(preorder[0]) //新建父节点
|
||||
p=inorder.index(preorder[0]) //找到父节点在中序遍历的位置(因为没有重复的元素,才可以这样找)
|
||||
root.left = self.buildTree(preorder[1:p+1],inorder[:p]) //注意左节点时分割中序数组和前续数组的开闭环
|
||||
root.right = self.buildTree(preorder[p+1:],inorder[p+1:]) //分割中序数组和前续数组
|
||||
return root
|
||||
```
|
||||
106.从中序与后序遍历序列构造二叉树
|
||||
|
||||
```python
|
||||
# Definition for a binary tree node.
|
||||
# class TreeNode:
|
||||
# def __init__(self, val=0, left=None, right=None):
|
||||
# self.val = val
|
||||
# self.left = left
|
||||
# self.right = right
|
||||
//递归法
|
||||
class Solution:
|
||||
def buildTree(self, inorder: List[int], postorder: List[int]) -> TreeNode:
|
||||
if not postorder: return None //特殊情况
|
||||
root = TreeNode(postorder[-1]) //新建父节点
|
||||
p=inorder.index(postorder[-1]) //找到父节点在中序遍历的位置*因为没有重复的元素,才可以这样找
|
||||
root.left = self.buildTree(inorder[:p],postorder[:p]) //分割中序数组和后续数组
|
||||
root.right = self.buildTree(inorder[p+1:],postorder[p:-1]) //注意右节点时分割中序数组和后续数组的开闭环
|
||||
return root
|
||||
```
|
||||
Go:
|
||||
> 106 从中序与后序遍历序列构造二叉树
|
||||
|
||||
```go
|
||||
/**
|
||||
* Definition for a binary tree node.
|
||||
* type TreeNode struct {
|
||||
* Val int
|
||||
* Left *TreeNode
|
||||
* Right *TreeNode
|
||||
* }
|
||||
*/
|
||||
func buildTree(inorder []int, postorder []int) *TreeNode {
|
||||
if len(inorder)<1||len(postorder)<1{return nil}
|
||||
//先找到根节点(后续遍历的最后一个就是根节点)
|
||||
nodeValue:=postorder[len(postorder)-1]
|
||||
//从中序遍历中找到一分为二的点,左边为左子树,右边为右子树
|
||||
left:=findRootIndex(inorder,nodeValue)
|
||||
//构造root
|
||||
root:=&TreeNode{Val: nodeValue,
|
||||
Left: buildTree(inorder[:left],postorder[:left]),//将后续遍历一分为二,左边为左子树,右边为右子树
|
||||
Right: buildTree(inorder[left+1:],postorder[left:len(postorder)-1])}
|
||||
return root
|
||||
}
|
||||
func findRootIndex(inorder []int,target int) (index int){
|
||||
for i:=0;i<len(inorder);i++{
|
||||
if target==inorder[i]{
|
||||
return i
|
||||
}
|
||||
}
|
||||
return -1
|
||||
}
|
||||
```
|
||||
|
||||
> 105 从前序与中序遍历序列构造二叉树
|
||||
|
||||
```go
|
||||
/**
|
||||
* Definition for a binary tree node.
|
||||
* type TreeNode struct {
|
||||
* Val int
|
||||
* Left *TreeNode
|
||||
* Right *TreeNode
|
||||
* }
|
||||
*/
|
||||
func buildTree(preorder []int, inorder []int) *TreeNode {
|
||||
if len(preorder)<1||len(inorder)<1{return nil}
|
||||
left:=findRootIndex(preorder[0],inorder)
|
||||
root:=&TreeNode{
|
||||
Val: preorder[0],
|
||||
Left: buildTree(preorder[1:left+1],inorder[:left]),
|
||||
Right: buildTree(preorder[left+1:],inorder[left+1:])}
|
||||
return root
|
||||
}
|
||||
func findRootIndex(target int,inorder []int) int{
|
||||
for i:=0;i<len(inorder);i++{
|
||||
if target==inorder[i]{
|
||||
return i
|
||||
}
|
||||
}
|
||||
return -1
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
JavaScript
|
||||
```javascript
|
||||
var buildTree = function(inorder, postorder) {
|
||||
if (!postorder.length) return null
|
||||
|
||||
let root = new TreeNode(postorder[postorder.length - 1])
|
||||
|
||||
let index = inorder.findIndex(number => number === root.val)
|
||||
|
||||
root.left = buildTree(inorder.slice(0, index), postorder.slice(0, index))
|
||||
root.right = buildTree(inorder.slice(index + 1, inorder.length), postorder.slice(index, postorder.length - 1))
|
||||
|
||||
return root
|
||||
};
|
||||
```
|
||||
|
||||
从前序与中序遍历序列构造二叉树
|
||||
|
||||
```javascript
|
||||
var buildTree = function(preorder, inorder) {
|
||||
if(!preorder.length)
|
||||
return null;
|
||||
let root = new TreeNode(preorder[0]);
|
||||
let mid = inorder.findIndex((number) => number === root.val);
|
||||
root.left = buildTree(preorder.slice(1, mid + 1), inorder.slice(0, mid));
|
||||
root.right = buildTree(preorder.slice(mid + 1, preorder.length), inorder.slice(mid + 1, inorder.length));
|
||||
return root;
|
||||
};
|
||||
```
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
391
problems/0108.将有序数组转换为二叉搜索树.md
Normal file
391
problems/0108.将有序数组转换为二叉搜索树.md
Normal file
@@ -0,0 +1,391 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
> 构造二叉搜索树,一不小心就平衡了
|
||||
|
||||
## 108.将有序数组转换为二叉搜索树
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/convert-sorted-array-to-binary-search-tree/
|
||||
|
||||
将一个按照升序排列的有序数组,转换为一棵高度平衡二叉搜索树。
|
||||
|
||||
本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
|
||||
|
||||
示例:
|
||||
|
||||

|
||||
|
||||
## 思路
|
||||
|
||||
做这道题目之前大家可以了解一下这几道:
|
||||
|
||||
* [106.从中序与后序遍历序列构造二叉树](https://mp.weixin.qq.com/s/7r66ap2s-shvVvlZxo59xg)
|
||||
* [654.最大二叉树](https://mp.weixin.qq.com/s/1iWJV6Aov23A7xCF4nV88w)中其实已经讲过了,如果根据数组构造一颗二叉树。
|
||||
* [701.二叉搜索树中的插入操作](https://mp.weixin.qq.com/s/lwKkLQcfbCNX2W-5SOeZEA)
|
||||
* [450.删除二叉搜索树中的节点](https://mp.weixin.qq.com/s/-p-Txvch1FFk3ygKLjPAKw)
|
||||
|
||||
|
||||
进入正题:
|
||||
|
||||
题目中说要转换为一棵高度平衡二叉搜索树。这和转换为一棵普通二叉搜索树有什么差别呢?
|
||||
|
||||
其实这里不用强调平衡二叉搜索树,数组构造二叉树,构成平衡树是自然而然的事情,因为大家默认都是从数组中间位置取值作为节点元素,一般不会随机取,**所以想构成不平衡的二叉树是自找麻烦**。
|
||||
|
||||
|
||||
在[二叉树:构造二叉树登场!](https://mp.weixin.qq.com/s/7r66ap2s-shvVvlZxo59xg)和[二叉树:构造一棵最大的二叉树](https://mp.weixin.qq.com/s/1iWJV6Aov23A7xCF4nV88w)中其实已经讲过了,如果根据数组构造一颗二叉树。
|
||||
|
||||
**本质就是寻找分割点,分割点作为当前节点,然后递归左区间和右区间**。
|
||||
|
||||
本题其实要比[二叉树:构造二叉树登场!](https://mp.weixin.qq.com/s/7r66ap2s-shvVvlZxo59xg) 和 [二叉树:构造一棵最大的二叉树](https://mp.weixin.qq.com/s/1iWJV6Aov23A7xCF4nV88w)简单一些,因为有序数组构造二叉搜索树,寻找分割点就比较容易了。
|
||||
|
||||
分割点就是数组中间位置的节点。
|
||||
|
||||
那么为问题来了,如果数组长度为偶数,中间节点有两个,取哪一个?
|
||||
|
||||
取哪一个都可以,只不过构成了不同的平衡二叉搜索树。
|
||||
|
||||
例如:输入:[-10,-3,0,5,9]
|
||||
|
||||
如下两棵树,都是这个数组的平衡二叉搜索树:
|
||||
|
||||
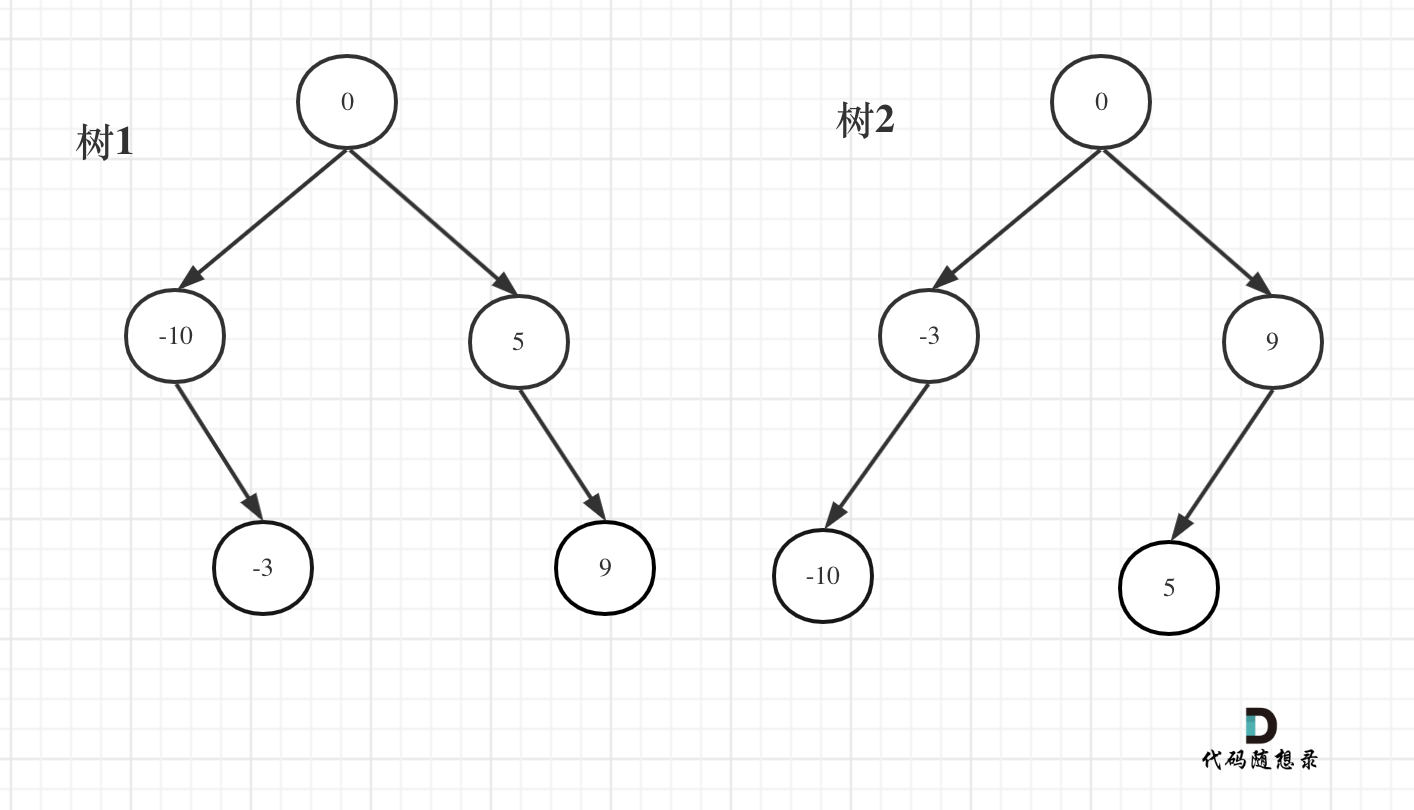
|
||||
|
||||
如果要分割的数组长度为偶数的时候,中间元素为两个,是取左边元素 就是树1,取右边元素就是树2。
|
||||
|
||||
**这也是题目中强调答案不是唯一的原因。 理解这一点,这道题目算是理解到位了**。
|
||||
|
||||
## 递归
|
||||
|
||||
递归三部曲:
|
||||
|
||||
* 确定递归函数返回值及其参数
|
||||
|
||||
删除二叉树节点,增加二叉树节点,都是用递归函数的返回值来完成,这样是比较方便的。
|
||||
|
||||
相信大家如果仔细看了[二叉树:搜索树中的插入操作](https://mp.weixin.qq.com/s/lwKkLQcfbCNX2W-5SOeZEA)和[二叉树:搜索树中的删除操作](https://mp.weixin.qq.com/s/-p-Txvch1FFk3ygKLjPAKw),一定会对递归函数返回值的作用深有感触。
|
||||
|
||||
那么本题要构造二叉树,依然用递归函数的返回值来构造中节点的左右孩子。
|
||||
|
||||
再来看参数,首先是传入数组,然后就是左下表left和右下表right,我们在[二叉树:构造二叉树登场!](https://mp.weixin.qq.com/s/7r66ap2s-shvVvlZxo59xg)中提过,在构造二叉树的时候尽量不要重新定义左右区间数组,而是用下表来操作原数组。
|
||||
|
||||
所以代码如下:
|
||||
|
||||
```
|
||||
// 左闭右闭区间[left, right]
|
||||
TreeNode* traversal(vector<int>& nums, int left, int right)
|
||||
```
|
||||
|
||||
这里注意,**我这里定义的是左闭右闭区间,在不断分割的过程中,也会坚持左闭右闭的区间,这又涉及到我们讲过的循环不变量**。
|
||||
|
||||
在[二叉树:构造二叉树登场!](https://mp.weixin.qq.com/s/7r66ap2s-shvVvlZxo59xg),[35.搜索插入位置](https://mp.weixin.qq.com/s/fCf5QbPDtE6SSlZ1yh_q8Q) 和[59.螺旋矩阵II](https://mp.weixin.qq.com/s/KTPhaeqxbMK9CxHUUgFDmg)都详细讲过循环不变量。
|
||||
|
||||
|
||||
* 确定递归终止条件
|
||||
|
||||
这里定义的是左闭右闭的区间,所以当区间 left > right的时候,就是空节点了。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
if (left > right) return nullptr;
|
||||
```
|
||||
|
||||
* 确定单层递归的逻辑
|
||||
|
||||
首先取数组中间元素的位置,不难写出`int mid = (left + right) / 2;`,**这么写其实有一个问题,就是数值越界,例如left和right都是最大int,这么操作就越界了,在[二分法](https://mp.weixin.qq.com/s/fCf5QbPDtE6SSlZ1yh_q8Q)中尤其需要注意!**
|
||||
|
||||
所以可以这么写:`int mid = left + ((right - left) / 2);`
|
||||
|
||||
但本题leetcode的测试数据并不会越界,所以怎么写都可以。但需要有这个意识!
|
||||
|
||||
取了中间位置,就开始以中间位置的元素构造节点,代码:`TreeNode* root = new TreeNode(nums[mid]);`。
|
||||
|
||||
接着划分区间,root的左孩子接住下一层左区间的构造节点,右孩子接住下一层右区间构造的节点。
|
||||
|
||||
最后返回root节点,单层递归整体代码如下:
|
||||
|
||||
```
|
||||
int mid = left + ((right - left) / 2);
|
||||
TreeNode* root = new TreeNode(nums[mid]);
|
||||
root->left = traversal(nums, left, mid - 1);
|
||||
root->right = traversal(nums, mid + 1, right);
|
||||
return root;
|
||||
```
|
||||
|
||||
这里`int mid = left + ((right - left) / 2);`的写法相当于是如果数组长度为偶数,中间位置有两个元素,取靠左边的。
|
||||
|
||||
* 递归整体代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
TreeNode* traversal(vector<int>& nums, int left, int right) {
|
||||
if (left > right) return nullptr;
|
||||
int mid = left + ((right - left) / 2);
|
||||
TreeNode* root = new TreeNode(nums[mid]);
|
||||
root->left = traversal(nums, left, mid - 1);
|
||||
root->right = traversal(nums, mid + 1, right);
|
||||
return root;
|
||||
}
|
||||
public:
|
||||
TreeNode* sortedArrayToBST(vector<int>& nums) {
|
||||
TreeNode* root = traversal(nums, 0, nums.size() - 1);
|
||||
return root;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
**注意:在调用traversal的时候为什么传入的left和right为什么是0和nums.size() - 1,因为定义的区间为左闭右闭**。
|
||||
|
||||
|
||||
## 迭代法
|
||||
|
||||
迭代法可以通过三个队列来模拟,一个队列放遍历的节点,一个队列放左区间下表,一个队列放右区间下表。
|
||||
|
||||
模拟的就是不断分割的过程,C++代码如下:(我已经详细注释)
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
TreeNode* sortedArrayToBST(vector<int>& nums) {
|
||||
if (nums.size() == 0) return nullptr;
|
||||
|
||||
TreeNode* root = new TreeNode(0); // 初始根节点
|
||||
queue<TreeNode*> nodeQue; // 放遍历的节点
|
||||
queue<int> leftQue; // 保存左区间下表
|
||||
queue<int> rightQue; // 保存右区间下表
|
||||
nodeQue.push(root); // 根节点入队列
|
||||
leftQue.push(0); // 0为左区间下表初始位置
|
||||
rightQue.push(nums.size() - 1); // nums.size() - 1为右区间下表初始位置
|
||||
|
||||
while (!nodeQue.empty()) {
|
||||
TreeNode* curNode = nodeQue.front();
|
||||
nodeQue.pop();
|
||||
int left = leftQue.front(); leftQue.pop();
|
||||
int right = rightQue.front(); rightQue.pop();
|
||||
int mid = left + ((right - left) / 2);
|
||||
|
||||
curNode->val = nums[mid]; // 将mid对应的元素给中间节点
|
||||
|
||||
if (left <= mid - 1) { // 处理左区间
|
||||
curNode->left = new TreeNode(0);
|
||||
nodeQue.push(curNode->left);
|
||||
leftQue.push(left);
|
||||
rightQue.push(mid - 1);
|
||||
}
|
||||
|
||||
if (right >= mid + 1) { // 处理右区间
|
||||
curNode->right = new TreeNode(0);
|
||||
nodeQue.push(curNode->right);
|
||||
leftQue.push(mid + 1);
|
||||
rightQue.push(right);
|
||||
}
|
||||
}
|
||||
return root;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
**在[二叉树:构造二叉树登场!](https://mp.weixin.qq.com/s/7r66ap2s-shvVvlZxo59xg) 和 [二叉树:构造一棵最大的二叉树](https://mp.weixin.qq.com/s/1iWJV6Aov23A7xCF4nV88w)之后,我们顺理成章的应该构造一下二叉搜索树了,一不小心还是一棵平衡二叉搜索树**。
|
||||
|
||||
其实思路也是一样的,不断中间分割,然后递归处理左区间,右区间,也可以说是分治。
|
||||
|
||||
此时相信大家应该对通过递归函数的返回值来增删二叉树很熟悉了,这也是常规操作。
|
||||
|
||||
在定义区间的过程中我们又一次强调了循环不变量的重要性。
|
||||
|
||||
最后依然给出迭代的方法,其实就是模拟取中间元素,然后不断分割去构造二叉树的过程。
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
|
||||
递归: 左闭右开 [left,right)
|
||||
```Java
|
||||
class Solution {
|
||||
public TreeNode sortedArrayToBST(int[] nums) {
|
||||
return sortedArrayToBST(nums, 0, nums.length);
|
||||
}
|
||||
|
||||
public TreeNode sortedArrayToBST(int[] nums, int left, int right) {
|
||||
if (left >= right) {
|
||||
return null;
|
||||
}
|
||||
if (right - left == 1) {
|
||||
return new TreeNode(nums[left]);
|
||||
}
|
||||
int mid = left + (right - left) / 2;
|
||||
TreeNode root = new TreeNode(nums[mid]);
|
||||
root.left = sortedArrayToBST(nums, left, mid);
|
||||
root.right = sortedArrayToBST(nums, mid + 1, right);
|
||||
return root;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
递归: 左闭右闭 [left,right]
|
||||
```java
|
||||
class Solution {
|
||||
public TreeNode sortedArrayToBST(int[] nums) {
|
||||
TreeNode root = traversal(nums, 0, nums.length - 1);
|
||||
return root;
|
||||
}
|
||||
|
||||
// 左闭右闭区间[left, right)
|
||||
private TreeNode traversal(int[] nums, int left, int right) {
|
||||
if (left > right) return null;
|
||||
|
||||
int mid = left + ((right - left) >> 1);
|
||||
TreeNode root = new TreeNode(nums[mid]);
|
||||
root.left = traversal(nums, left, mid - 1);
|
||||
root.right = traversal(nums, mid + 1, right);
|
||||
return root;
|
||||
}
|
||||
}
|
||||
```
|
||||
迭代: 左闭右闭 [left,right]
|
||||
```java
|
||||
class Solution {
|
||||
public TreeNode sortedArrayToBST(int[] nums) {
|
||||
if (nums.length == 0) return null;
|
||||
|
||||
//根节点初始化
|
||||
TreeNode root = new TreeNode(-1);
|
||||
Queue<TreeNode> nodeQueue = new LinkedList<>();
|
||||
Queue<Integer> leftQueue = new LinkedList<>();
|
||||
Queue<Integer> rightQueue = new LinkedList<>();
|
||||
|
||||
// 根节点入队列
|
||||
nodeQueue.offer(root);
|
||||
// 0为左区间下表初始位置
|
||||
leftQueue.offer(0);
|
||||
// nums.size() - 1为右区间下表初始位置
|
||||
rightQueue.offer(nums.length - 1);
|
||||
|
||||
while (!nodeQueue.isEmpty()) {
|
||||
TreeNode currNode = nodeQueue.poll();
|
||||
int left = leftQueue.poll();
|
||||
int right = rightQueue.poll();
|
||||
int mid = left + ((right - left) >> 1);
|
||||
|
||||
// 将mid对应的元素给中间节点
|
||||
currNode.val = nums[mid];
|
||||
|
||||
// 处理左区间
|
||||
if (left <= mid - 1) {
|
||||
currNode.left = new TreeNode(-1);
|
||||
nodeQueue.offer(currNode.left);
|
||||
leftQueue.offer(left);
|
||||
rightQueue.offer(mid - 1);
|
||||
}
|
||||
|
||||
// 处理右区间
|
||||
if (right >= mid + 1) {
|
||||
currNode.right = new TreeNode(-1);
|
||||
nodeQueue.offer(currNode.right);
|
||||
leftQueue.offer(mid + 1);
|
||||
rightQueue.offer(right);
|
||||
}
|
||||
}
|
||||
return root;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python3
|
||||
# Definition for a binary tree node.
|
||||
# class TreeNode:
|
||||
# def __init__(self, val=0, left=None, right=None):
|
||||
# self.val = val
|
||||
# self.left = left
|
||||
# self.right = right
|
||||
#递归法
|
||||
class Solution:
|
||||
def sortedArrayToBST(self, nums: List[int]) -> TreeNode:
|
||||
def buildaTree(left,right):
|
||||
if left > right: return None #左闭右闭的区间,当区间 left > right的时候,就是空节点,当left = right的时候,不为空
|
||||
mid = left + (right - left) // 2 #保证数据不会越界
|
||||
val = nums[mid]
|
||||
root = TreeNode(val)
|
||||
root.left = buildaTree(left,mid - 1)
|
||||
root.right = buildaTree(mid + 1,right)
|
||||
return root
|
||||
root = buildaTree(0,len(nums) - 1) #左闭右闭区间
|
||||
return root
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
|
||||
> 递归(隐含回溯)
|
||||
|
||||
```go
|
||||
/**
|
||||
* Definition for a binary tree node.
|
||||
* type TreeNode struct {
|
||||
* Val int
|
||||
* Left *TreeNode
|
||||
* Right *TreeNode
|
||||
* }
|
||||
*/
|
||||
//递归(隐含回溯)
|
||||
func sortedArrayToBST(nums []int) *TreeNode {
|
||||
if len(nums)==0{return nil}//终止条件,最后数组为空则可以返回
|
||||
root:=&TreeNode{nums[len(nums)/2],nil,nil}//按照BSL的特点,从中间构造节点
|
||||
root.Left=sortedArrayToBST(nums[:len(nums)/2])//数组的左边为左子树
|
||||
root.Right=sortedArrayToBST(nums[len(nums)/2+1:])//数字的右边为右子树
|
||||
return root
|
||||
}
|
||||
```
|
||||
|
||||
JavaScript版本
|
||||
|
||||
```javascript
|
||||
/**
|
||||
* Definition for a binary tree node.
|
||||
* function TreeNode(val, left, right) {
|
||||
* this.val = (val===undefined ? 0 : val)
|
||||
* this.left = (left===undefined ? null : left)
|
||||
* this.right = (right===undefined ? null : right)
|
||||
* }
|
||||
*/
|
||||
/**
|
||||
* @param {number[]} nums
|
||||
* @return {TreeNode}
|
||||
*/
|
||||
var sortedArrayToBST = function (nums) {
|
||||
const buildTree = (Arr, left, right) => {
|
||||
if (left > right)
|
||||
return null;
|
||||
|
||||
let mid = Math.floor(left + (right - left) / 2);
|
||||
|
||||
let root = new TreeNode(Arr[mid]);
|
||||
root.left = buildTree(Arr, left, mid - 1);
|
||||
root.right = buildTree(Arr, mid + 1, right);
|
||||
return root;
|
||||
}
|
||||
return buildTree(nums, 0, nums.length - 1);
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
627
problems/0110.平衡二叉树.md
Normal file
627
problems/0110.平衡二叉树.md
Normal file
@@ -0,0 +1,627 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
> 求高度还是求深度,你搞懂了不?
|
||||
|
||||
## 110.平衡二叉树
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/balanced-binary-tree/
|
||||
|
||||
给定一个二叉树,判断它是否是高度平衡的二叉树。
|
||||
|
||||
本题中,一棵高度平衡二叉树定义为:一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1。
|
||||
|
||||
示例 1:
|
||||
|
||||
给定二叉树 [3,9,20,null,null,15,7]
|
||||
|
||||

|
||||
|
||||
返回 true 。
|
||||
|
||||
示例 2:
|
||||
|
||||
给定二叉树 [1,2,2,3,3,null,null,4,4]
|
||||
|
||||

|
||||
|
||||
返回 false 。
|
||||
|
||||
## 题外话
|
||||
|
||||
咋眼一看这道题目和[二叉树:看看这些树的最大深度](https://mp.weixin.qq.com/s/guKwV-gSNbA1CcbvkMtHBg)很像,其实有很大区别。
|
||||
|
||||
这里强调一波概念:
|
||||
|
||||
* 二叉树节点的深度:指从根节点到该节点的最长简单路径边的条数。
|
||||
* 二叉树节点的高度:指从该节点到叶子节点的最长简单路径边的条数。
|
||||
|
||||
但leetcode中强调的深度和高度很明显是按照节点来计算的,如图:
|
||||
|
||||
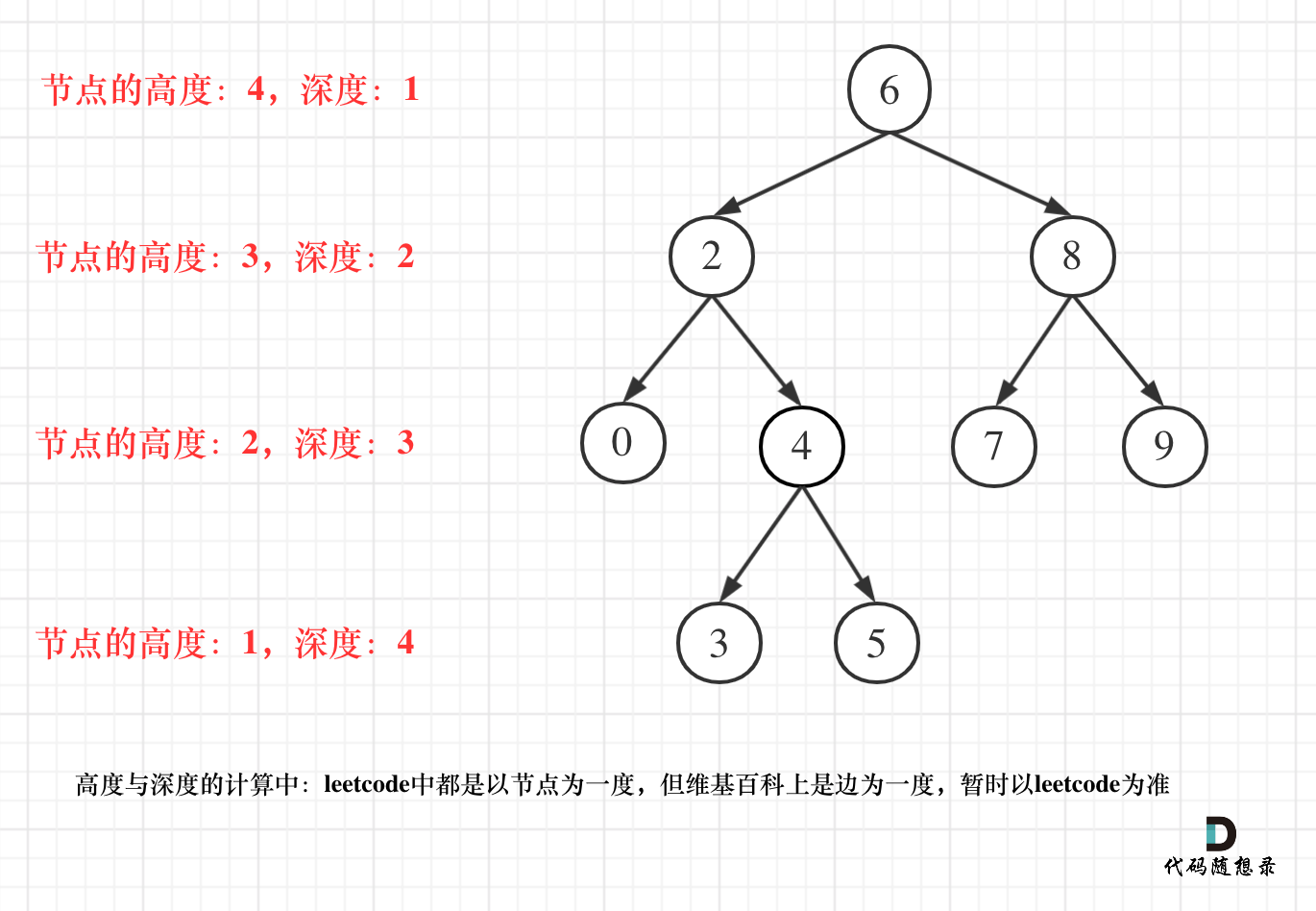
|
||||
|
||||
关于根节点的深度究竟是1 还是 0,不同的地方有不一样的标准,leetcode的题目中都是以节点为一度,即根节点深度是1。但维基百科上定义用边为一度,即根节点的深度是0,我们暂时以leetcode为准(毕竟要在这上面刷题)。
|
||||
|
||||
因为求深度可以从上到下去查 所以需要前序遍历(中左右),而高度只能从下到上去查,所以只能后序遍历(左右中)
|
||||
|
||||
有的同学一定疑惑,为什么[二叉树:看看这些树的最大深度](https://mp.weixin.qq.com/s/guKwV-gSNbA1CcbvkMtHBg)中求的是二叉树的最大深度,也用的是后序遍历。
|
||||
|
||||
**那是因为代码的逻辑其实是求的根节点的高度,而根节点的高度就是这颗树的最大深度,所以才可以使用后序遍历。**
|
||||
|
||||
在[二叉树:看看这些树的最大深度](https://mp.weixin.qq.com/s/guKwV-gSNbA1CcbvkMtHBg)中,如果真正求取二叉树的最大深度,代码应该写成如下:(前序遍历)
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int result;
|
||||
void getDepth(TreeNode* node, int depth) {
|
||||
result = depth > result ? depth : result; // 中
|
||||
|
||||
if (node->left == NULL && node->right == NULL) return ;
|
||||
|
||||
if (node->left) { // 左
|
||||
depth++; // 深度+1
|
||||
getDepth(node->left, depth);
|
||||
depth--; // 回溯,深度-1
|
||||
}
|
||||
if (node->right) { // 右
|
||||
depth++; // 深度+1
|
||||
getDepth(node->right, depth);
|
||||
depth--; // 回溯,深度-1
|
||||
}
|
||||
return ;
|
||||
}
|
||||
int maxDepth(TreeNode* root) {
|
||||
result = 0;
|
||||
if (root == 0) return result;
|
||||
getDepth(root, 1);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
**可以看出使用了前序(中左右)的遍历顺序,这才是真正求深度的逻辑!**
|
||||
|
||||
注意以上代码是为了把细节体现出来,简化一下代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int result;
|
||||
void getDepth(TreeNode* node, int depth) {
|
||||
result = depth > result ? depth : result; // 中
|
||||
if (node->left == NULL && node->right == NULL) return ;
|
||||
if (node->left) { // 左
|
||||
getDepth(node->left, depth + 1);
|
||||
}
|
||||
if (node->right) { // 右
|
||||
getDepth(node->right, depth + 1);
|
||||
}
|
||||
return ;
|
||||
}
|
||||
int maxDepth(TreeNode* root) {
|
||||
result = 0;
|
||||
if (root == 0) return result;
|
||||
getDepth(root, 1);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 本题思路
|
||||
|
||||
### 递归
|
||||
|
||||
此时大家应该明白了既然要求比较高度,必然是要后序遍历。
|
||||
|
||||
递归三步曲分析:
|
||||
|
||||
1. 明确递归函数的参数和返回值
|
||||
|
||||
参数的话为传入的节点指针,就没有其他参数需要传递了,返回值要返回传入节点为根节点树的深度。
|
||||
|
||||
那么如何标记左右子树是否差值大于1呢。
|
||||
|
||||
如果当前传入节点为根节点的二叉树已经不是二叉平衡树了,还返回高度的话就没有意义了。
|
||||
|
||||
所以如果已经不是二叉平衡树了,可以返回-1 来标记已经不符合平衡树的规则了。
|
||||
|
||||
代码如下:
|
||||
|
||||
|
||||
```
|
||||
// -1 表示已经不是平衡二叉树了,否则返回值是以该节点为根节点树的高度
|
||||
int getDepth(TreeNode* node)
|
||||
```
|
||||
|
||||
2. 明确终止条件
|
||||
|
||||
递归的过程中依然是遇到空节点了为终止,返回0,表示当前节点为根节点的树高度为0
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
if (node == NULL) {
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
3. 明确单层递归的逻辑
|
||||
|
||||
如何判断当前传入节点为根节点的二叉树是否是平衡二叉树呢,当然是左子树高度和右子树高度相差。
|
||||
|
||||
分别求出左右子树的高度,然后如果差值小于等于1,则返回当前二叉树的高度,否则则返回-1,表示已经不是二叉树了。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
int leftDepth = depth(node->left); // 左
|
||||
if (leftDepth == -1) return -1;
|
||||
int rightDepth = depth(node->right); // 右
|
||||
if (rightDepth == -1) return -1;
|
||||
|
||||
int result;
|
||||
if (abs(leftDepth - rightDepth) > 1) { // 中
|
||||
result = -1;
|
||||
} else {
|
||||
result = 1 + max(leftDepth, rightDepth); // 以当前节点为根节点的最大高度
|
||||
}
|
||||
|
||||
return result;
|
||||
```
|
||||
|
||||
代码精简之后如下:
|
||||
|
||||
```
|
||||
int leftDepth = getDepth(node->left);
|
||||
if (leftDepth == -1) return -1;
|
||||
int rightDepth = getDepth(node->right);
|
||||
if (rightDepth == -1) return -1;
|
||||
return abs(leftDepth - rightDepth) > 1 ? -1 : 1 + max(leftDepth, rightDepth);
|
||||
```
|
||||
|
||||
此时递归的函数就已经写出来了,这个递归的函数传入节点指针,返回以该节点为根节点的二叉树的高度,如果不是二叉平衡树,则返回-1。
|
||||
|
||||
getDepth整体代码如下:
|
||||
|
||||
```C++
|
||||
int getDepth(TreeNode* node) {
|
||||
if (node == NULL) {
|
||||
return 0;
|
||||
}
|
||||
int leftDepth = getDepth(node->left);
|
||||
if (leftDepth == -1) return -1;
|
||||
int rightDepth = getDepth(node->right);
|
||||
if (rightDepth == -1) return -1;
|
||||
return abs(leftDepth - rightDepth) > 1 ? -1 : 1 + max(leftDepth, rightDepth);
|
||||
}
|
||||
```
|
||||
|
||||
最后本题整体递归代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
// 返回以该节点为根节点的二叉树的高度,如果不是二叉搜索树了则返回-1
|
||||
int getDepth(TreeNode* node) {
|
||||
if (node == NULL) {
|
||||
return 0;
|
||||
}
|
||||
int leftDepth = getDepth(node->left);
|
||||
if (leftDepth == -1) return -1; // 说明左子树已经不是二叉平衡树
|
||||
int rightDepth = getDepth(node->right);
|
||||
if (rightDepth == -1) return -1; // 说明右子树已经不是二叉平衡树
|
||||
return abs(leftDepth - rightDepth) > 1 ? -1 : 1 + max(leftDepth, rightDepth);
|
||||
}
|
||||
bool isBalanced(TreeNode* root) {
|
||||
return getDepth(root) == -1 ? false : true;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
### 迭代
|
||||
|
||||
在[二叉树:看看这些树的最大深度](https://mp.weixin.qq.com/s/guKwV-gSNbA1CcbvkMtHBg)中我们可以使用层序遍历来求深度,但是就不能直接用层序遍历来求高度了,这就体现出求高度和求深度的不同。
|
||||
|
||||
本题的迭代方式可以先定义一个函数,专门用来求高度。
|
||||
|
||||
这个函数通过栈模拟的后序遍历找每一个节点的高度(其实是通过求传入节点为根节点的最大深度来求的高度)
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
// cur节点的最大深度,就是cur的高度
|
||||
int getDepth(TreeNode* cur) {
|
||||
stack<TreeNode*> st;
|
||||
if (cur != NULL) st.push(cur);
|
||||
int depth = 0; // 记录深度
|
||||
int result = 0;
|
||||
while (!st.empty()) {
|
||||
TreeNode* node = st.top();
|
||||
if (node != NULL) {
|
||||
st.pop();
|
||||
st.push(node); // 中
|
||||
st.push(NULL);
|
||||
depth++;
|
||||
if (node->right) st.push(node->right); // 右
|
||||
if (node->left) st.push(node->left); // 左
|
||||
|
||||
} else {
|
||||
st.pop();
|
||||
node = st.top();
|
||||
st.pop();
|
||||
depth--;
|
||||
}
|
||||
result = result > depth ? result : depth;
|
||||
}
|
||||
return result;
|
||||
}
|
||||
```
|
||||
|
||||
然后再用栈来模拟前序遍历,遍历每一个节点的时候,再去判断左右孩子的高度是否符合,代码如下:
|
||||
|
||||
```
|
||||
bool isBalanced(TreeNode* root) {
|
||||
stack<TreeNode*> st;
|
||||
if (root == NULL) return true;
|
||||
st.push(root);
|
||||
while (!st.empty()) {
|
||||
TreeNode* node = st.top(); // 中
|
||||
st.pop();
|
||||
if (abs(getDepth(node->left) - getDepth(node->right)) > 1) { // 判断左右孩子高度是否符合
|
||||
return false;
|
||||
}
|
||||
if (node->right) st.push(node->right); // 右(空节点不入栈)
|
||||
if (node->left) st.push(node->left); // 左(空节点不入栈)
|
||||
}
|
||||
return true;
|
||||
}
|
||||
```
|
||||
|
||||
整体代码如下:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
private:
|
||||
int getDepth(TreeNode* cur) {
|
||||
stack<TreeNode*> st;
|
||||
if (cur != NULL) st.push(cur);
|
||||
int depth = 0; // 记录深度
|
||||
int result = 0;
|
||||
while (!st.empty()) {
|
||||
TreeNode* node = st.top();
|
||||
if (node != NULL) {
|
||||
st.pop();
|
||||
st.push(node); // 中
|
||||
st.push(NULL);
|
||||
depth++;
|
||||
if (node->right) st.push(node->right); // 右
|
||||
if (node->left) st.push(node->left); // 左
|
||||
|
||||
} else {
|
||||
st.pop();
|
||||
node = st.top();
|
||||
st.pop();
|
||||
depth--;
|
||||
}
|
||||
result = result > depth ? result : depth;
|
||||
}
|
||||
return result;
|
||||
}
|
||||
|
||||
public:
|
||||
bool isBalanced(TreeNode* root) {
|
||||
stack<TreeNode*> st;
|
||||
if (root == NULL) return true;
|
||||
st.push(root);
|
||||
while (!st.empty()) {
|
||||
TreeNode* node = st.top(); // 中
|
||||
st.pop();
|
||||
if (abs(getDepth(node->left) - getDepth(node->right)) > 1) {
|
||||
return false;
|
||||
}
|
||||
if (node->right) st.push(node->right); // 右(空节点不入栈)
|
||||
if (node->left) st.push(node->left); // 左(空节点不入栈)
|
||||
}
|
||||
return true;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
当然此题用迭代法,其实效率很低,因为没有很好的模拟回溯的过程,所以迭代法有很多重复的计算。
|
||||
|
||||
虽然理论上所有的递归都可以用迭代来实现,但是有的场景难度可能比较大。
|
||||
|
||||
**例如:都知道回溯法其实就是递归,但是很少人用迭代的方式去实现回溯算法!**
|
||||
|
||||
因为对于回溯算法已经是非常复杂的递归了,如果在用迭代的话,就是自己给自己找麻烦,效率也并不一定高。
|
||||
|
||||
## 总结
|
||||
|
||||
通过本题可以了解求二叉树深度 和 二叉树高度的差异,求深度适合用前序遍历,而求高度适合用后序遍历。
|
||||
|
||||
本题迭代法其实有点复杂,大家可以有一个思路,也不一定说非要写出来。
|
||||
|
||||
但是递归方式是一定要掌握的!
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
Java:
|
||||
|
||||
```Java
|
||||
class Solution {
|
||||
/**
|
||||
* 递归法
|
||||
*/
|
||||
public boolean isBalanced(TreeNode root) {
|
||||
return getHeight(root) != -1;
|
||||
}
|
||||
|
||||
private int getHeight(TreeNode root) {
|
||||
if (root == null) {
|
||||
return 0;
|
||||
}
|
||||
int leftHeight = getHeight(root.left);
|
||||
if (leftHeight == -1) {
|
||||
return -1;
|
||||
}
|
||||
int rightHeight = getHeight(root.right);
|
||||
if (rightHeight == -1) {
|
||||
return -1;
|
||||
}
|
||||
// 左右子树高度差大于1,return -1表示已经不是平衡树了
|
||||
if (Math.abs(leftHeight - rightHeight) > 1) {
|
||||
return -1;
|
||||
}
|
||||
return Math.max(leftHeight, rightHeight) + 1;
|
||||
}
|
||||
}
|
||||
|
||||
class Solution {
|
||||
/**
|
||||
* 迭代法,效率较低,计算高度时会重复遍历
|
||||
* 时间复杂度:O(n^2)
|
||||
*/
|
||||
public boolean isBalanced(TreeNode root) {
|
||||
if (root == null) {
|
||||
return true;
|
||||
}
|
||||
Stack<TreeNode> stack = new Stack<>();
|
||||
TreeNode pre = null;
|
||||
while (root!= null || !stack.isEmpty()) {
|
||||
while (root != null) {
|
||||
stack.push(root);
|
||||
root = root.left;
|
||||
}
|
||||
TreeNode inNode = stack.peek();
|
||||
// 右结点为null或已经遍历过
|
||||
if (inNode.right == null || inNode.right == pre) {
|
||||
// 比较左右子树的高度差,输出
|
||||
if (Math.abs(getHeight(inNode.left) - getHeight(inNode.right)) > 1) {
|
||||
return false;
|
||||
}
|
||||
stack.pop();
|
||||
pre = inNode;
|
||||
root = null;// 当前结点下,没有要遍历的结点了
|
||||
} else {
|
||||
root = inNode.right;// 右结点还没遍历,遍历右结点
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
/**
|
||||
* 层序遍历,求结点的高度
|
||||
*/
|
||||
public int getHeight(TreeNode root) {
|
||||
if (root == null) {
|
||||
return 0;
|
||||
}
|
||||
Deque<TreeNode> deque = new LinkedList<>();
|
||||
deque.offer(root);
|
||||
int depth = 0;
|
||||
while (!deque.isEmpty()) {
|
||||
int size = deque.size();
|
||||
depth++;
|
||||
for (int i = 0; i < size; i++) {
|
||||
TreeNode poll = deque.poll();
|
||||
if (poll.left != null) {
|
||||
deque.offer(poll.left);
|
||||
}
|
||||
if (poll.right != null) {
|
||||
deque.offer(poll.right);
|
||||
}
|
||||
}
|
||||
}
|
||||
return depth;
|
||||
}
|
||||
}
|
||||
|
||||
class Solution {
|
||||
/**
|
||||
* 优化迭代法,针对暴力迭代法的getHeight方法做优化,利用TreeNode.val来保存当前结点的高度,这样就不会有重复遍历
|
||||
* 获取高度算法时间复杂度可以降到O(1),总的时间复杂度降为O(n)。
|
||||
* <p>
|
||||
* 时间复杂度:O(n)
|
||||
*/
|
||||
public boolean isBalanced(TreeNode root) {
|
||||
if (root == null) {
|
||||
return true;
|
||||
}
|
||||
Stack<TreeNode> stack = new Stack<>();
|
||||
TreeNode pre = null;
|
||||
while (root != null || !stack.isEmpty()) {
|
||||
while (root != null) {
|
||||
stack.push(root);
|
||||
root = root.left;
|
||||
}
|
||||
TreeNode inNode = stack.peek();
|
||||
// 右结点为null或已经遍历过
|
||||
if (inNode.right == null || inNode.right == pre) {
|
||||
// 输出
|
||||
if (Math.abs(getHeight(inNode.left) - getHeight(inNode.right)) > 1) {
|
||||
return false;
|
||||
}
|
||||
stack.pop();
|
||||
pre = inNode;
|
||||
root = null;// 当前结点下,没有要遍历的结点了
|
||||
} else {
|
||||
root = inNode.right;// 右结点还没遍历,遍历右结点
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
/**
|
||||
* 求结点的高度
|
||||
*/
|
||||
public int getHeight(TreeNode root) {
|
||||
if (root == null) {
|
||||
return 0;
|
||||
}
|
||||
int leftHeight = root.left != null ? root.left.val : 0;
|
||||
int rightHeight = root.right != null ? root.right.val : 0;
|
||||
int height = Math.max(leftHeight, rightHeight) + 1;
|
||||
root.val = height;// 用TreeNode.val来保存当前结点的高度
|
||||
return height;
|
||||
}
|
||||
}
|
||||
// LeetCode题解链接:https://leetcode-cn.com/problems/balanced-binary-tree/solution/110-ping-heng-er-cha-shu-di-gui-fa-bao-l-yqr3/
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
> 递归法:
|
||||
```python
|
||||
class Solution:
|
||||
def isBalanced(self, root: TreeNode) -> bool:
|
||||
return True if self.getDepth(root) != -1 else False
|
||||
|
||||
#返回以该节点为根节点的二叉树的高度,如果不是二叉搜索树了则返回-1
|
||||
def getDepth(self, node):
|
||||
if not node:
|
||||
return 0
|
||||
leftDepth = self.getDepth(node.left)
|
||||
if leftDepth == -1: return -1 #说明左子树已经不是二叉平衡树
|
||||
rightDepth = self.getDepth(node.right)
|
||||
if rightDepth == -1: return -1 #说明右子树已经不是二叉平衡树
|
||||
return -1 if abs(leftDepth - rightDepth)>1 else 1 + max(leftDepth, rightDepth)
|
||||
```
|
||||
|
||||
> 迭代法:
|
||||
```python
|
||||
class Solution:
|
||||
def isBalanced(self, root: TreeNode) -> bool:
|
||||
st = []
|
||||
if not root:
|
||||
return True
|
||||
st.append(root)
|
||||
while st:
|
||||
node = st.pop() #中
|
||||
if abs(self.getDepth(node.left) - self.getDepth(node.right)) > 1:
|
||||
return False
|
||||
if node.right:
|
||||
st.append(node.right) #右(空节点不入栈)
|
||||
if node.left:
|
||||
st.append(node.left) #左(空节点不入栈)
|
||||
return True
|
||||
|
||||
def getDepth(self, cur):
|
||||
st = []
|
||||
if cur:
|
||||
st.append(cur)
|
||||
depth = 0
|
||||
result = 0
|
||||
while st:
|
||||
node = st.pop()
|
||||
if node:
|
||||
st.append(node) #中
|
||||
st.append(None)
|
||||
depth += 1
|
||||
if node.right: st.append(node.right) #右
|
||||
if node.left: st.append(node.left) #左
|
||||
else:
|
||||
node = st.pop()
|
||||
depth -= 1
|
||||
result = max(result, depth)
|
||||
return result
|
||||
```
|
||||
|
||||
|
||||
Go:
|
||||
```Go
|
||||
func isBalanced(root *TreeNode) bool {
|
||||
if root==nil{
|
||||
return true
|
||||
}
|
||||
if !isBalanced(root.Left) || !isBalanced(root.Right){
|
||||
return false
|
||||
}
|
||||
LeftH:=maxdepth(root.Left)+1
|
||||
RightH:=maxdepth(root.Right)+1
|
||||
if abs(LeftH-RightH)>1{
|
||||
return false
|
||||
}
|
||||
return true
|
||||
}
|
||||
func maxdepth(root *TreeNode)int{
|
||||
if root==nil{
|
||||
return 0
|
||||
}
|
||||
return max(maxdepth(root.Left),maxdepth(root.Right))+1
|
||||
}
|
||||
func max(a,b int)int{
|
||||
if a>b{
|
||||
return a
|
||||
}
|
||||
return b
|
||||
}
|
||||
func abs(a int)int{
|
||||
if a<0{
|
||||
return -a
|
||||
}
|
||||
return a
|
||||
}
|
||||
```
|
||||
JavaScript:
|
||||
```javascript
|
||||
var isBalanced = function(root) {
|
||||
//还是用递归三部曲 + 后序遍历 左右中 当前左子树右子树高度相差大于1就返回-1
|
||||
// 1. 确定递归函数参数以及返回值
|
||||
const getDepth=function(node){
|
||||
// 2. 确定递归函数终止条件
|
||||
if(node===null){
|
||||
return 0;
|
||||
}
|
||||
// 3. 确定单层递归逻辑
|
||||
let leftDepth=getDepth(node.left);//左子树高度
|
||||
if(leftDepth===-1){
|
||||
return -1;
|
||||
}
|
||||
let rightDepth=getDepth(node.right);//右子树高度
|
||||
if(rightDepth===-1){
|
||||
return -1;
|
||||
}
|
||||
if(Math.abs(leftDepth-rightDepth)>1){
|
||||
return -1;
|
||||
}else{
|
||||
return 1+Math.max(leftDepth,rightDepth);
|
||||
}
|
||||
}
|
||||
return getDepth(root)===-1?false:true;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
416
problems/0111.二叉树的最小深度.md
Normal file
416
problems/0111.二叉树的最小深度.md
Normal file
@@ -0,0 +1,416 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
> 和求最大深度一个套路?
|
||||
|
||||
## 111.二叉树的最小深度
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/minimum-depth-of-binary-tree/
|
||||
|
||||
给定一个二叉树,找出其最小深度。
|
||||
|
||||
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
|
||||
|
||||
说明: 叶子节点是指没有子节点的节点。
|
||||
|
||||
示例:
|
||||
|
||||
给定二叉树 [3,9,20,null,null,15,7],
|
||||
|
||||

|
||||
|
||||
返回它的最小深度 2.
|
||||
|
||||
## 思路
|
||||
|
||||
看完了这篇[二叉树:看看这些树的最大深度](https://mp.weixin.qq.com/s/guKwV-gSNbA1CcbvkMtHBg),再来看看如何求最小深度。
|
||||
|
||||
直觉上好像和求最大深度差不多,其实还是差不少的。
|
||||
|
||||
遍历顺序上依然是后序遍历(因为要比较递归返回之后的结果),但在处理中间节点的逻辑上,最大深度很容易理解,最小深度可有一个误区,如图:
|
||||
|
||||
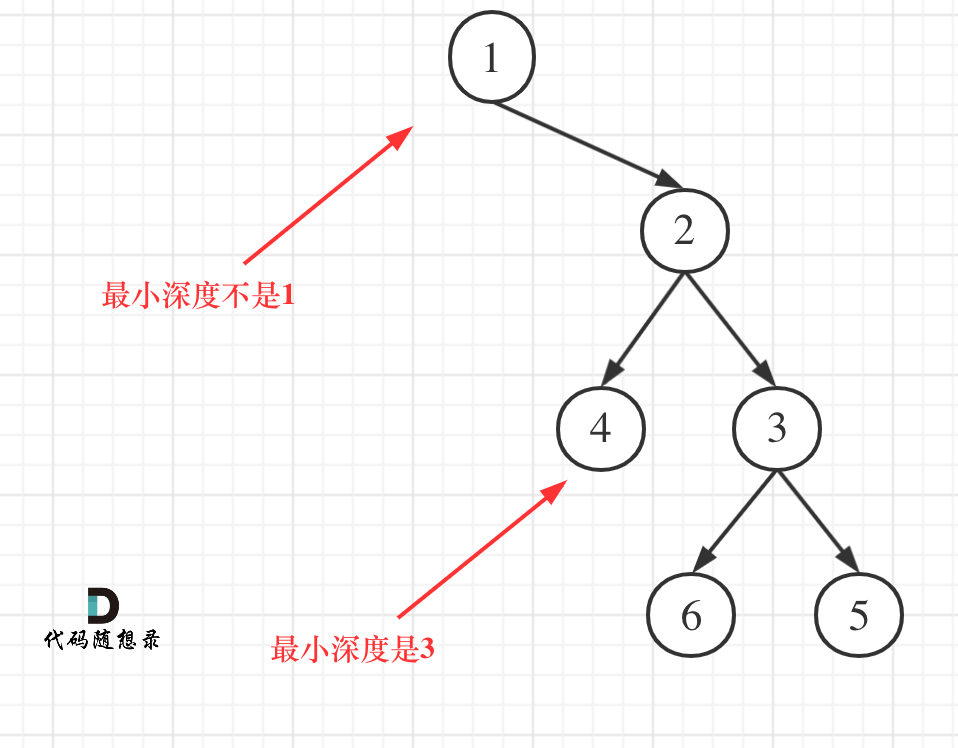
|
||||
|
||||
这就重新审题了,题目中说的是:**最小深度是从根节点到最近叶子节点的最短路径上的节点数量。**,注意是**叶子节点**。
|
||||
|
||||
什么是叶子节点,左右孩子都为空的节点才是叶子节点!
|
||||
|
||||
## 递归法
|
||||
|
||||
来来来,一起递归三部曲:
|
||||
|
||||
1. 确定递归函数的参数和返回值
|
||||
|
||||
参数为要传入的二叉树根节点,返回的是int类型的深度。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
int getDepth(TreeNode* node)
|
||||
```
|
||||
|
||||
2. 确定终止条件
|
||||
|
||||
终止条件也是遇到空节点返回0,表示当前节点的高度为0。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
if (node == NULL) return 0;
|
||||
```
|
||||
|
||||
3. 确定单层递归的逻辑
|
||||
|
||||
这块和求最大深度可就不一样了,一些同学可能会写如下代码:
|
||||
```
|
||||
int leftDepth = getDepth(node->left);
|
||||
int rightDepth = getDepth(node->right);
|
||||
int result = 1 + min(leftDepth, rightDepth);
|
||||
return result;
|
||||
```
|
||||
|
||||
这个代码就犯了此图中的误区:
|
||||
|
||||

|
||||
|
||||
如果这么求的话,没有左孩子的分支会算为最短深度。
|
||||
|
||||
所以,如果左子树为空,右子树不为空,说明最小深度是 1 + 右子树的深度。
|
||||
|
||||
反之,右子树为空,左子树不为空,最小深度是 1 + 左子树的深度。 最后如果左右子树都不为空,返回左右子树深度最小值 + 1 。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
int leftDepth = getDepth(node->left); // 左
|
||||
int rightDepth = getDepth(node->right); // 右
|
||||
// 中
|
||||
// 当一个左子树为空,右不为空,这时并不是最低点
|
||||
if (node->left == NULL && node->right != NULL) {
|
||||
return 1 + rightDepth;
|
||||
}
|
||||
// 当一个右子树为空,左不为空,这时并不是最低点
|
||||
if (node->left != NULL && node->right == NULL) {
|
||||
return 1 + leftDepth;
|
||||
}
|
||||
int result = 1 + min(leftDepth, rightDepth);
|
||||
return result;
|
||||
```
|
||||
|
||||
遍历的顺序为后序(左右中),可以看出:**求二叉树的最小深度和求二叉树的最大深度的差别主要在于处理左右孩子不为空的逻辑。**
|
||||
|
||||
整体递归代码如下:
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int getDepth(TreeNode* node) {
|
||||
if (node == NULL) return 0;
|
||||
int leftDepth = getDepth(node->left); // 左
|
||||
int rightDepth = getDepth(node->right); // 右
|
||||
// 中
|
||||
// 当一个左子树为空,右不为空,这时并不是最低点
|
||||
if (node->left == NULL && node->right != NULL) {
|
||||
return 1 + rightDepth;
|
||||
}
|
||||
// 当一个右子树为空,左不为空,这时并不是最低点
|
||||
if (node->left != NULL && node->right == NULL) {
|
||||
return 1 + leftDepth;
|
||||
}
|
||||
int result = 1 + min(leftDepth, rightDepth);
|
||||
return result;
|
||||
}
|
||||
|
||||
int minDepth(TreeNode* root) {
|
||||
return getDepth(root);
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
精简之后代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int minDepth(TreeNode* root) {
|
||||
if (root == NULL) return 0;
|
||||
if (root->left == NULL && root->right != NULL) {
|
||||
return 1 + minDepth(root->right);
|
||||
}
|
||||
if (root->left != NULL && root->right == NULL) {
|
||||
return 1 + minDepth(root->left);
|
||||
}
|
||||
return 1 + min(minDepth(root->left), minDepth(root->right));
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
**精简之后的代码根本看不出是哪种遍历方式,所以依然还要强调一波:如果对二叉树的操作还不熟练,尽量不要直接照着精简代码来学。**
|
||||
|
||||
## 迭代法
|
||||
|
||||
相对于[二叉树:看看这些树的最大深度](https://mp.weixin.qq.com/s/guKwV-gSNbA1CcbvkMtHBg),本题还可以使用层序遍历的方式来解决,思路是一样的。
|
||||
|
||||
如果对层序遍历还不清楚的话,可以看这篇:[二叉树:层序遍历登场!](https://mp.weixin.qq.com/s/Gb3BjakIKGNpup2jYtTzog)
|
||||
|
||||
**需要注意的是,只有当左右孩子都为空的时候,才说明遍历的最低点了。如果其中一个孩子为空则不是最低点**
|
||||
|
||||
代码如下:(详细注释)
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
|
||||
int minDepth(TreeNode* root) {
|
||||
if (root == NULL) return 0;
|
||||
int depth = 0;
|
||||
queue<TreeNode*> que;
|
||||
que.push(root);
|
||||
while(!que.empty()) {
|
||||
int size = que.size();
|
||||
depth++; // 记录最小深度
|
||||
for (int i = 0; i < size; i++) {
|
||||
TreeNode* node = que.front();
|
||||
que.pop();
|
||||
if (node->left) que.push(node->left);
|
||||
if (node->right) que.push(node->right);
|
||||
if (!node->left && !node->right) { // 当左右孩子都为空的时候,说明是最低点的一层了,退出
|
||||
return depth;
|
||||
}
|
||||
}
|
||||
}
|
||||
return depth;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
|
||||
```Java
|
||||
class Solution {
|
||||
/**
|
||||
* 递归法,相比求MaxDepth要复杂点
|
||||
* 因为最小深度是从根节点到最近**叶子节点**的最短路径上的节点数量
|
||||
*/
|
||||
public int minDepth(TreeNode root) {
|
||||
if (root == null) {
|
||||
return 0;
|
||||
}
|
||||
int leftDepth = minDepth(root.left);
|
||||
int rightDepth = minDepth(root.right);
|
||||
if (root.left == null) {
|
||||
return rightDepth + 1;
|
||||
}
|
||||
if (root.right == null) {
|
||||
return leftDepth + 1;
|
||||
}
|
||||
// 左右结点都不为null
|
||||
return Math.min(leftDepth, rightDepth) + 1;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```Java
|
||||
class Solution {
|
||||
/**
|
||||
* 迭代法,层序遍历
|
||||
*/
|
||||
public int minDepth(TreeNode root) {
|
||||
if (root == null) {
|
||||
return 0;
|
||||
}
|
||||
Deque<TreeNode> deque = new LinkedList<>();
|
||||
deque.offer(root);
|
||||
int depth = 0;
|
||||
while (!deque.isEmpty()) {
|
||||
int size = deque.size();
|
||||
depth++;
|
||||
for (int i = 0; i < size; i++) {
|
||||
TreeNode poll = deque.poll();
|
||||
if (poll.left == null && poll.right == null) {
|
||||
// 是叶子结点,直接返回depth,因为从上往下遍历,所以该值就是最小值
|
||||
return depth;
|
||||
}
|
||||
if (poll.left != null) {
|
||||
deque.offer(poll.left);
|
||||
}
|
||||
if (poll.right != null) {
|
||||
deque.offer(poll.right);
|
||||
}
|
||||
}
|
||||
}
|
||||
return depth;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
递归法:
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def minDepth(self, root: TreeNode) -> int:
|
||||
if not root:
|
||||
return 0
|
||||
if not root.left and not root.right:
|
||||
return 1
|
||||
|
||||
min_depth = 10**9
|
||||
if root.left:
|
||||
min_depth = min(self.minDepth(root.left), min_depth) # 获得左子树的最小高度
|
||||
if root.right:
|
||||
min_depth = min(self.minDepth(root.right), min_depth) # 获得右子树的最小高度
|
||||
return min_depth + 1
|
||||
```
|
||||
|
||||
迭代法:
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def minDepth(self, root: TreeNode) -> int:
|
||||
if not root:
|
||||
return 0
|
||||
que = deque()
|
||||
que.append(root)
|
||||
res = 1
|
||||
|
||||
while que:
|
||||
for _ in range(len(que)):
|
||||
node = que.popleft()
|
||||
# 当左右孩子都为空的时候,说明是最低点的一层了,退出
|
||||
if not node.left and not node.right:
|
||||
return res
|
||||
if node.left is not None:
|
||||
que.append(node.left)
|
||||
if node.right is not None:
|
||||
que.append(node.right)
|
||||
res += 1
|
||||
return res
|
||||
```
|
||||
|
||||
|
||||
Go:
|
||||
|
||||
```go
|
||||
/**
|
||||
* Definition for a binary tree node.
|
||||
* type TreeNode struct {
|
||||
* Val int
|
||||
* Left *TreeNode
|
||||
* Right *TreeNode
|
||||
* }
|
||||
*/
|
||||
func min(a, b int) int {
|
||||
if a < b {
|
||||
return a;
|
||||
}
|
||||
return b;
|
||||
}
|
||||
// 递归
|
||||
func minDepth(root *TreeNode) int {
|
||||
if root == nil {
|
||||
return 0;
|
||||
}
|
||||
if root.Left == nil && root.Right != nil {
|
||||
return 1 + minDepth(root.Right);
|
||||
}
|
||||
if root.Right == nil && root.Left != nil {
|
||||
return 1 + minDepth(root.Left);
|
||||
}
|
||||
return min(minDepth(root.Left), minDepth(root.Right)) + 1;
|
||||
}
|
||||
|
||||
// 迭代
|
||||
|
||||
func minDepth(root *TreeNode) int {
|
||||
dep := 0;
|
||||
queue := make([]*TreeNode, 0);
|
||||
if root != nil {
|
||||
queue = append(queue, root);
|
||||
}
|
||||
for l := len(queue); l > 0; {
|
||||
dep++;
|
||||
for ; l > 0; l-- {
|
||||
node := queue[0];
|
||||
if node.Left == nil && node.Right == nil {
|
||||
return dep;
|
||||
}
|
||||
if node.Left != nil {
|
||||
queue = append(queue, node.Left);
|
||||
}
|
||||
if node.Right != nil {
|
||||
queue = append(queue, node.Right);
|
||||
}
|
||||
queue = queue[1:];
|
||||
}
|
||||
l = len(queue);
|
||||
}
|
||||
return dep;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
JavaScript:
|
||||
|
||||
递归法:
|
||||
|
||||
```javascript
|
||||
/**
|
||||
* @param {TreeNode} root
|
||||
* @return {number}
|
||||
*/
|
||||
var minDepth1 = function(root) {
|
||||
if(!root) return 0;
|
||||
// 到叶子节点 返回 1
|
||||
if(!root.left && !root.right) return 1;
|
||||
// 只有右节点时 递归右节点
|
||||
if(!root.left) return 1 + minDepth(root.right);、
|
||||
// 只有左节点时 递归左节点
|
||||
if(!root.right) return 1 + minDepth(root.left);
|
||||
return Math.min(minDepth(root.left), minDepth(root.right)) + 1;
|
||||
};
|
||||
```
|
||||
|
||||
迭代法:
|
||||
|
||||
```javascript
|
||||
/**
|
||||
* @param {TreeNode} root
|
||||
* @return {number}
|
||||
*/
|
||||
var minDepth = function(root) {
|
||||
if(!root) return 0;
|
||||
const queue = [root];
|
||||
let dep = 0;
|
||||
while(true) {
|
||||
let size = queue.length;
|
||||
dep++;
|
||||
while(size--){
|
||||
const node = queue.shift();
|
||||
// 到第一个叶子节点 返回 当前深度
|
||||
if(!node.left && !node.right) return dep;
|
||||
node.left && queue.push(node.left);
|
||||
node.right && queue.push(node.right);
|
||||
}
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
706
problems/0112.路径总和.md
Normal file
706
problems/0112.路径总和.md
Normal file
@@ -0,0 +1,706 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
> 递归函数什么时候需要返回值
|
||||
|
||||
相信很多同学都会疑惑,递归函数什么时候要有返回值,什么时候没有返回值,特别是有的时候递归函数返回类型为bool类型。那么
|
||||
|
||||
接下来我通过详细讲解如下两道题,来回答这个问题:
|
||||
|
||||
* 112. 路径总和
|
||||
* 113. 路径总和II
|
||||
|
||||
## 112. 路径总和
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/path-sum/
|
||||
|
||||
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。
|
||||
|
||||
说明: 叶子节点是指没有子节点的节点。
|
||||
|
||||
示例:
|
||||
给定如下二叉树,以及目标和 sum = 22,
|
||||
|
||||
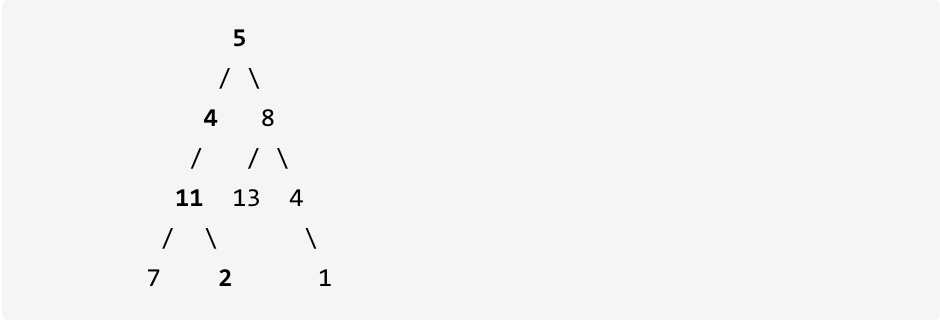
|
||||
|
||||
返回 true, 因为存在目标和为 22 的根节点到叶子节点的路径 5->4->11->2。
|
||||
|
||||
### 思路
|
||||
|
||||
这道题我们要遍历从根节点到叶子节点的的路径看看总和是不是目标和。
|
||||
|
||||
### 递归
|
||||
|
||||
可以使用深度优先遍历的方式(本题前中后序都可以,无所谓,因为中节点也没有处理逻辑)来遍历二叉树
|
||||
|
||||
1. 确定递归函数的参数和返回类型
|
||||
|
||||
参数:需要二叉树的根节点,还需要一个计数器,这个计数器用来计算二叉树的一条边之和是否正好是目标和,计数器为int型。
|
||||
|
||||
**再来看返回值,递归函数什么时候需要返回值?什么时候不需要返回值?**
|
||||
|
||||
在文章[二叉树:我的左下角的值是多少?](https://mp.weixin.qq.com/s/MH2gbLvzQ91jHPKqiub0Nw)中,我给出了一个结论:
|
||||
|
||||
**如果需要搜索整颗二叉树,那么递归函数就不要返回值,如果要搜索其中一条符合条件的路径,递归函数就需要返回值,因为遇到符合条件的路径了就要及时返回。**
|
||||
|
||||
在[二叉树:我的左下角的值是多少?](https://mp.weixin.qq.com/s/MH2gbLvzQ91jHPKqiub0Nw)中,因为要遍历树的所有路径,找出深度最深的叶子节点,所以递归函数不要返回值。
|
||||
|
||||
而本题我们要找一条符合条件的路径,所以递归函数需要返回值,及时返回,那么返回类型是什么呢?
|
||||
|
||||
如图所示:
|
||||
|
||||
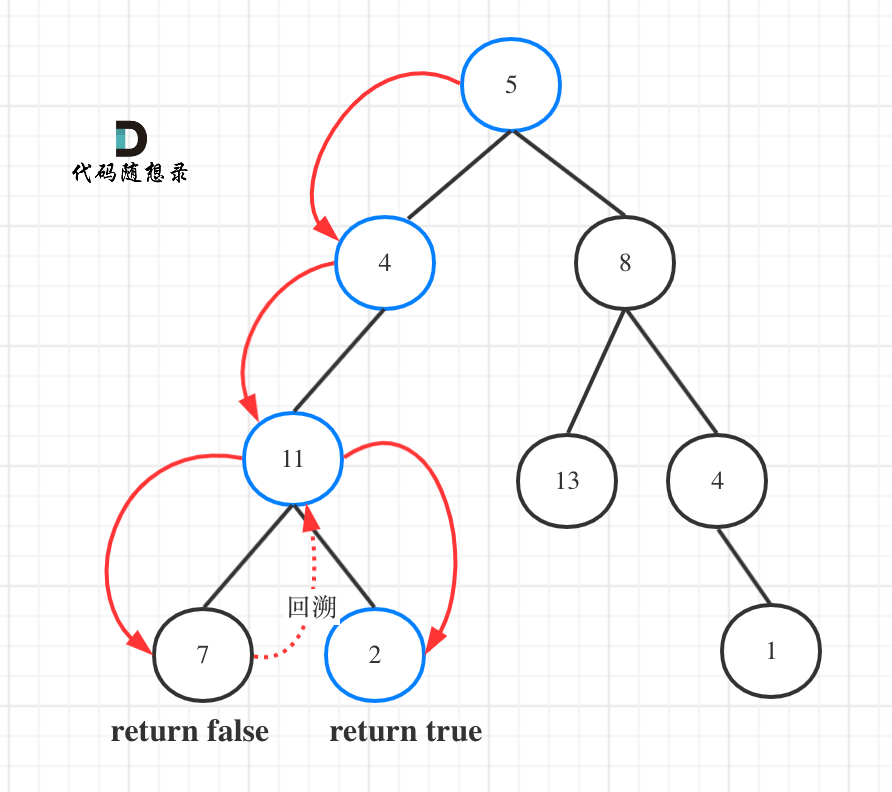
|
||||
|
||||
图中可以看出,遍历的路线,并不要遍历整棵树,所以递归函数需要返回值,可以用bool类型表示。
|
||||
|
||||
所以代码如下:
|
||||
|
||||
```
|
||||
bool traversal(TreeNode* cur, int count) // 注意函数的返回类型
|
||||
```
|
||||
|
||||
|
||||
2. 确定终止条件
|
||||
|
||||
首先计数器如何统计这一条路径的和呢?
|
||||
|
||||
不要去累加然后判断是否等于目标和,那么代码比较麻烦,可以用递减,让计数器count初始为目标和,然后每次减去遍历路径节点上的数值。
|
||||
|
||||
如果最后count == 0,同时到了叶子节点的话,说明找到了目标和。
|
||||
|
||||
如果遍历到了叶子节点,count不为0,就是没找到。
|
||||
|
||||
递归终止条件代码如下:
|
||||
|
||||
```
|
||||
if (!cur->left && !cur->right && count == 0) return true; // 遇到叶子节点,并且计数为0
|
||||
if (!cur->left && !cur->right) return false; // 遇到叶子节点而没有找到合适的边,直接返回
|
||||
```
|
||||
|
||||
3. 确定单层递归的逻辑
|
||||
|
||||
因为终止条件是判断叶子节点,所以递归的过程中就不要让空节点进入递归了。
|
||||
|
||||
递归函数是有返回值的,如果递归函数返回true,说明找到了合适的路径,应该立刻返回。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
if (cur->left) { // 左 (空节点不遍历)
|
||||
// 遇到叶子节点返回true,则直接返回true
|
||||
if (traversal(cur->left, count - cur->left->val)) return true; // 注意这里有回溯的逻辑
|
||||
}
|
||||
if (cur->right) { // 右 (空节点不遍历)
|
||||
// 遇到叶子节点返回true,则直接返回true
|
||||
if (traversal(cur->right, count - cur->right->val)) return true; // 注意这里有回溯的逻辑
|
||||
}
|
||||
return false;
|
||||
```
|
||||
|
||||
以上代码中是包含着回溯的,没有回溯,如何后撤重新找另一条路径呢。
|
||||
|
||||
回溯隐藏在`traversal(cur->left, count - cur->left->val)`这里, 因为把`count - cur->left->val` 直接作为参数传进去,函数结束,count的数值没有改变。
|
||||
|
||||
为了把回溯的过程体现出来,可以改为如下代码:
|
||||
|
||||
```C++
|
||||
if (cur->left) { // 左
|
||||
count -= cur->left->val; // 递归,处理节点;
|
||||
if (traversal(cur->left, count)) return true;
|
||||
count += cur->left->val; // 回溯,撤销处理结果
|
||||
}
|
||||
if (cur->right) { // 右
|
||||
count -= cur->right->val;
|
||||
if (traversal(cur->right, count)) return true;
|
||||
count += cur->right->val;
|
||||
}
|
||||
return false;
|
||||
```
|
||||
|
||||
|
||||
整体代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
bool traversal(TreeNode* cur, int count) {
|
||||
if (!cur->left && !cur->right && count == 0) return true; // 遇到叶子节点,并且计数为0
|
||||
if (!cur->left && !cur->right) return false; // 遇到叶子节点直接返回
|
||||
|
||||
if (cur->left) { // 左
|
||||
count -= cur->left->val; // 递归,处理节点;
|
||||
if (traversal(cur->left, count)) return true;
|
||||
count += cur->left->val; // 回溯,撤销处理结果
|
||||
}
|
||||
if (cur->right) { // 右
|
||||
count -= cur->right->val; // 递归,处理节点;
|
||||
if (traversal(cur->right, count)) return true;
|
||||
count += cur->right->val; // 回溯,撤销处理结果
|
||||
}
|
||||
return false;
|
||||
}
|
||||
|
||||
public:
|
||||
bool hasPathSum(TreeNode* root, int sum) {
|
||||
if (root == NULL) return false;
|
||||
return traversal(root, sum - root->val);
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
以上代码精简之后如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
bool hasPathSum(TreeNode* root, int sum) {
|
||||
if (root == NULL) return false;
|
||||
if (!root->left && !root->right && sum == root->val) {
|
||||
return true;
|
||||
}
|
||||
return hasPathSum(root->left, sum - root->val) || hasPathSum(root->right, sum - root->val);
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
**是不是发现精简之后的代码,已经完全看不出分析的过程了,所以我们要把题目分析清楚之后,在追求代码精简。** 这一点我已经强调很多次了!
|
||||
|
||||
|
||||
### 迭代
|
||||
|
||||
如果使用栈模拟递归的话,那么如果做回溯呢?
|
||||
|
||||
**此时栈里一个元素不仅要记录该节点指针,还要记录从头结点到该节点的路径数值总和。**
|
||||
|
||||
C++就我们用pair结构来存放这个栈里的元素。
|
||||
|
||||
定义为:`pair<TreeNode*, int>` pair<节点指针,路径数值>
|
||||
|
||||
这个为栈里的一个元素。
|
||||
|
||||
如下代码是使用栈模拟的前序遍历,如下:(详细注释)
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
|
||||
public:
|
||||
bool hasPathSum(TreeNode* root, int sum) {
|
||||
if (root == NULL) return false;
|
||||
// 此时栈里要放的是pair<节点指针,路径数值>
|
||||
stack<pair<TreeNode*, int>> st;
|
||||
st.push(pair<TreeNode*, int>(root, root->val));
|
||||
while (!st.empty()) {
|
||||
pair<TreeNode*, int> node = st.top();
|
||||
st.pop();
|
||||
// 如果该节点是叶子节点了,同时该节点的路径数值等于sum,那么就返回true
|
||||
if (!node.first->left && !node.first->right && sum == node.second) return true;
|
||||
|
||||
// 右节点,压进去一个节点的时候,将该节点的路径数值也记录下来
|
||||
if (node.first->right) {
|
||||
st.push(pair<TreeNode*, int>(node.first->right, node.second + node.first->right->val));
|
||||
}
|
||||
|
||||
// 左节点,压进去一个节点的时候,将该节点的路径数值也记录下来
|
||||
if (node.first->left) {
|
||||
st.push(pair<TreeNode*, int>(node.first->left, node.second + node.first->left->val));
|
||||
}
|
||||
}
|
||||
return false;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
如果大家完全理解了本地的递归方法之后,就可以顺便把leetcode上113. 路径总和II做了。
|
||||
|
||||
## 113. 路径总和II
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/path-sum-ii/
|
||||
|
||||
给定一个二叉树和一个目标和,找到所有从根节点到叶子节点路径总和等于给定目标和的路径。
|
||||
|
||||
说明: 叶子节点是指没有子节点的节点。
|
||||
|
||||
示例:
|
||||
给定如下二叉树,以及目标和 sum = 22,
|
||||
|
||||
|
||||
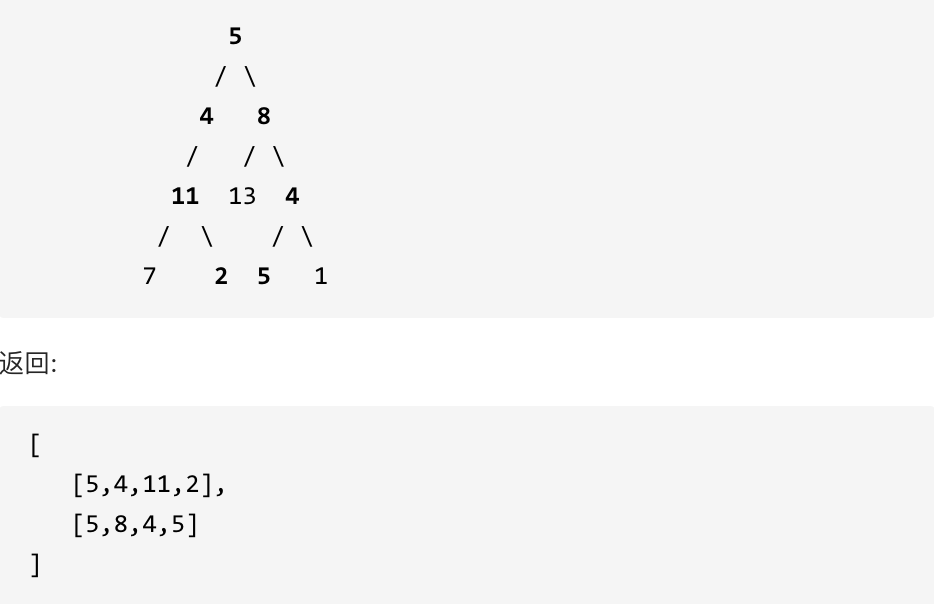
|
||||
|
||||
### 思路
|
||||
|
||||
113.路径总和II要遍历整个树,找到所有路径,**所以递归函数不要返回值!**
|
||||
|
||||
如图:
|
||||
|
||||
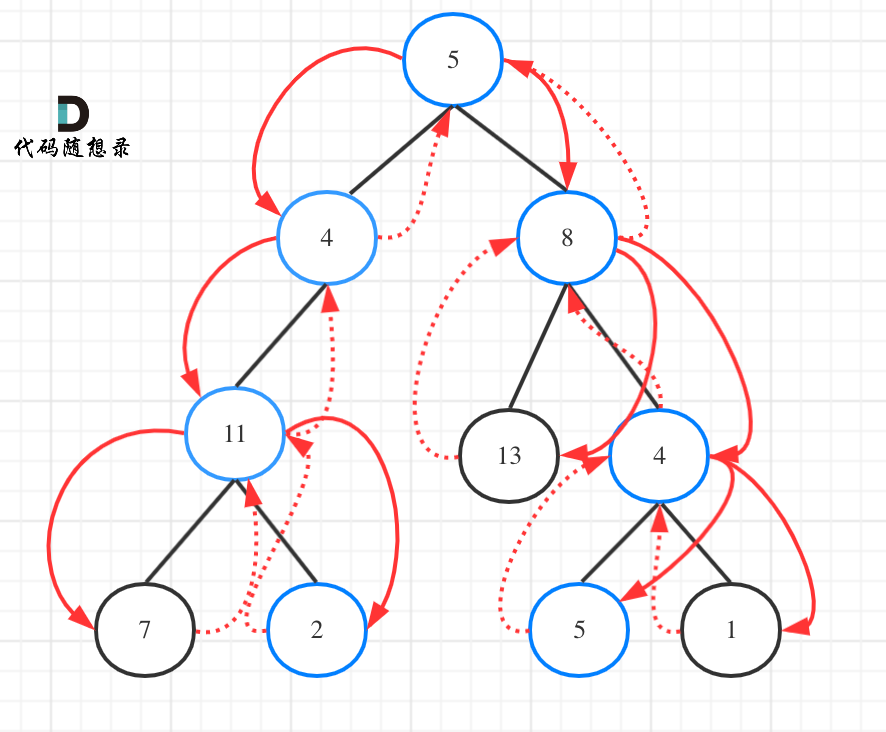
|
||||
|
||||
|
||||
为了尽可能的把细节体现出来,我写出如下代码(**这份代码并不简洁,但是逻辑非常清晰**)
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
vector<vector<int>> result;
|
||||
vector<int> path;
|
||||
// 递归函数不需要返回值,因为我们要遍历整个树
|
||||
void traversal(TreeNode* cur, int count) {
|
||||
if (!cur->left && !cur->right && count == 0) { // 遇到了叶子节点且找到了和为sum的路径
|
||||
result.push_back(path);
|
||||
return;
|
||||
}
|
||||
|
||||
if (!cur->left && !cur->right) return ; // 遇到叶子节点而没有找到合适的边,直接返回
|
||||
|
||||
if (cur->left) { // 左 (空节点不遍历)
|
||||
path.push_back(cur->left->val);
|
||||
count -= cur->left->val;
|
||||
traversal(cur->left, count); // 递归
|
||||
count += cur->left->val; // 回溯
|
||||
path.pop_back(); // 回溯
|
||||
}
|
||||
if (cur->right) { // 右 (空节点不遍历)
|
||||
path.push_back(cur->right->val);
|
||||
count -= cur->right->val;
|
||||
traversal(cur->right, count); // 递归
|
||||
count += cur->right->val; // 回溯
|
||||
path.pop_back(); // 回溯
|
||||
}
|
||||
return ;
|
||||
}
|
||||
|
||||
public:
|
||||
vector<vector<int>> pathSum(TreeNode* root, int sum) {
|
||||
result.clear();
|
||||
path.clear();
|
||||
if (root == NULL) return result;
|
||||
path.push_back(root->val); // 把根节点放进路径
|
||||
traversal(root, sum - root->val);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
至于113. 路径总和II 的迭代法我并没有写,用迭代方式记录所有路径比较麻烦,也没有必要,如果大家感兴趣的话,可以再深入研究研究。
|
||||
|
||||
## 总结
|
||||
|
||||
本篇通过leetcode上112. 路径总和 和 113. 路径总和II 详细的讲解了 递归函数什么时候需要返回值,什么不需要返回值。
|
||||
|
||||
这两道题目是掌握这一知识点非常好的题目,大家看完本篇文章再去做题,就会感受到搜索整棵树和搜索某一路径的差别。
|
||||
|
||||
对于112. 路径总和,我依然给出了递归法和迭代法,这种题目其实用迭代法会复杂一些,能掌握递归方式就够了!
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
public boolean hasPathSum(TreeNode root, int targetSum) {
|
||||
if (root == null) {
|
||||
return false;
|
||||
}
|
||||
targetSum -= root.val;
|
||||
// 叶子结点
|
||||
if (root.left == null && root.right == null) {
|
||||
return targetSum == 0;
|
||||
}
|
||||
if (root.left != null) {
|
||||
boolean left = hasPathSum(root.left, targetSum);
|
||||
if (left) {// 已经找到
|
||||
return true;
|
||||
}
|
||||
}
|
||||
if (root.right != null) {
|
||||
boolean right = hasPathSum(root.right, targetSum);
|
||||
if (right) {// 已经找到
|
||||
return true;
|
||||
}
|
||||
}
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
// LC112 简洁方法
|
||||
class Solution {
|
||||
public boolean hasPathSum(TreeNode root, int targetSum) {
|
||||
|
||||
if (root == null) return false; // 为空退出
|
||||
|
||||
// 叶子节点判断是否符合
|
||||
if (root.left == null && root.right == null) return root.val == targetSum;
|
||||
|
||||
// 求两侧分支的路径和
|
||||
return hasPathSum(root.left, targetSum - root.val) || hasPathSum(root.right, targetSum - root.val);
|
||||
}
|
||||
}
|
||||
```
|
||||
迭代
|
||||
```java
|
||||
class Solution {
|
||||
public boolean hasPathSum(TreeNode root, int targetSum) {
|
||||
if(root==null)return false;
|
||||
Stack<TreeNode> stack1 = new Stack<>();
|
||||
Stack<Integer> stack2 = new Stack<>();
|
||||
stack1.push(root);stack2.push(root.val);
|
||||
while(!stack1.isEmpty()){
|
||||
int size = stack1.size();
|
||||
for(int i=0;i<size;i++){
|
||||
TreeNode node = stack1.pop();int sum=stack2.pop();
|
||||
// 如果该节点是叶子节点了,同时该节点的路径数值等于sum,那么就返回true
|
||||
if(node.left==null && node.right==null && sum==targetSum)return true;
|
||||
// 右节点,压进去一个节点的时候,将该节点的路径数值也记录下来
|
||||
if(node.right!=null){
|
||||
stack1.push(node.right);stack2.push(sum+node.right.val);
|
||||
}
|
||||
// 左节点,压进去一个节点的时候,将该节点的路径数值也记录下来
|
||||
if(node.left!=null){
|
||||
stack1.push(node.left);stack2.push(sum+node.left.val);
|
||||
}
|
||||
}
|
||||
}
|
||||
return false;
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
0113.路径总和-ii
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
public List<List<Integer>> pathSum(TreeNode root, int targetSum) {
|
||||
List<List<Integer>> res = new ArrayList<>();
|
||||
if (root == null) return res; // 非空判断
|
||||
|
||||
List<Integer> path = new LinkedList<>();
|
||||
preorderDFS(root, targetSum, res, path);
|
||||
return res;
|
||||
}
|
||||
|
||||
public void preorderDFS(TreeNode root, int targetSum, List<List<Integer>> res, List<Integer> path) {
|
||||
path.add(root.val);
|
||||
// 遇到了叶子节点
|
||||
if (root.left == null && root.right == null) {
|
||||
// 找到了和为 targetSum 的路径
|
||||
if (targetSum - root.val == 0) {
|
||||
res.add(new ArrayList<>(path));
|
||||
}
|
||||
return; // 如果和不为 targetSum,返回
|
||||
}
|
||||
|
||||
if (root.left != null) {
|
||||
preorderDFS(root.left, targetSum - root.val, res, path);
|
||||
path.remove(path.size() - 1); // 回溯
|
||||
}
|
||||
if (root.right != null) {
|
||||
preorderDFS(root.right, targetSum - root.val, res, path);
|
||||
path.remove(path.size() - 1); // 回溯
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
0112.路径总和
|
||||
```python
|
||||
# Definition for a binary tree node.
|
||||
# class TreeNode:
|
||||
# def __init__(self, val=0, left=None, right=None):
|
||||
# self.val = val
|
||||
# self.left = left
|
||||
# self.right = right
|
||||
|
||||
// 递归法
|
||||
|
||||
class Solution:
|
||||
def hasPathSum(self, root: TreeNode, targetSum: int) -> bool:
|
||||
def isornot(root,targetSum)->bool:
|
||||
if (not root.left) and (not root.right) and targetSum == 0:return True // 遇到叶子节点,并且计数为0
|
||||
if (not root.left) and (not root.right):return False //遇到叶子节点,计数不为0
|
||||
if root.left:
|
||||
targetSum -= root.left.val //左节点
|
||||
if isornot(root.left,targetSum):return True //递归,处理左节点
|
||||
targetSum += root.left.val //回溯
|
||||
if root.right:
|
||||
targetSum -= root.right.val //右节点
|
||||
if isornot(root.right,targetSum):return True //递归,处理右节点
|
||||
targetSum += root.right.val //回溯
|
||||
return False
|
||||
|
||||
if root == None:return False //别忘记处理空TreeNode
|
||||
else:return isornot(root,targetSum-root.val)
|
||||
```
|
||||
|
||||
0113.路径总和-ii
|
||||
```python
|
||||
# Definition for a binary tree node.
|
||||
# class TreeNode:
|
||||
# def __init__(self, val=0, left=None, right=None):
|
||||
# self.val = val
|
||||
# self.left = left
|
||||
# self.right = right
|
||||
//递归法
|
||||
class Solution:
|
||||
def pathSum(self, root: TreeNode, targetSum: int) -> List[List[int]]:
|
||||
path=[]
|
||||
res=[]
|
||||
def pathes(root,targetSum):
|
||||
if (not root.left) and (not root.right) and targetSum == 0: // 遇到叶子节点,并且计数为0
|
||||
res.append(path[:]) //找到一种路径,记录到res中,注意必须是path[:]而不是path
|
||||
return
|
||||
if (not root.left) and (not root.right):return // 遇到叶子节点直接返回
|
||||
if root.left: //左
|
||||
targetSum -= root.left.val
|
||||
path.append(root.left.val) //递归前记录节点
|
||||
pathes(root.left,targetSum) //递归
|
||||
targetSum += root.left.val //回溯
|
||||
path.pop() //回溯
|
||||
if root.right: //右
|
||||
targetSum -= root.right.val
|
||||
path.append(root.right.val) //递归前记录节点
|
||||
pathes(root.right,targetSum) //递归
|
||||
targetSum += root.right.val //回溯
|
||||
path.pop() //回溯
|
||||
return
|
||||
|
||||
if root == None:return [] //处理空TreeNode
|
||||
else:
|
||||
path.append(root.val) //首先处理根节点
|
||||
pathes(root,targetSum-root.val)
|
||||
return res
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
> 112. 路径总和
|
||||
|
||||
```go
|
||||
//递归法
|
||||
/**
|
||||
* Definition for a binary tree node.
|
||||
* type TreeNode struct {
|
||||
* Val int
|
||||
* Left *TreeNode
|
||||
* Right *TreeNode
|
||||
* }
|
||||
*/
|
||||
func hasPathSum(root *TreeNode, targetSum int) bool {
|
||||
var flage bool //找没找到的标志
|
||||
if root==nil{
|
||||
return flage
|
||||
}
|
||||
pathSum(root,0,targetSum,&flage)
|
||||
return flage
|
||||
}
|
||||
func pathSum(root *TreeNode, sum int,targetSum int,flage *bool){
|
||||
sum+=root.Val
|
||||
if root.Left==nil&&root.Right==nil&&sum==targetSum{
|
||||
*flage=true
|
||||
return
|
||||
}
|
||||
if root.Left!=nil&&!(*flage){//左节点不为空且还没找到
|
||||
pathSum(root.Left,sum,targetSum,flage)
|
||||
}
|
||||
if root.Right!=nil&&!(*flage){//右节点不为空且没找到
|
||||
pathSum(root.Right,sum,targetSum,flage)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
> 113 递归法
|
||||
|
||||
```go
|
||||
/**
|
||||
* Definition for a binary tree node.
|
||||
* type TreeNode struct {
|
||||
* Val int
|
||||
* Left *TreeNode
|
||||
* Right *TreeNode
|
||||
* }
|
||||
*/
|
||||
func pathSum(root *TreeNode, targetSum int) [][]int {
|
||||
var result [][]int//最终结果
|
||||
if root==nil{
|
||||
return result
|
||||
}
|
||||
var sumNodes []int//经过路径的节点集合
|
||||
hasPathSum(root,&sumNodes,targetSum,&result)
|
||||
return result
|
||||
}
|
||||
func hasPathSum(root *TreeNode,sumNodes *[]int,targetSum int,result *[][]int){
|
||||
*sumNodes=append(*sumNodes,root.Val)
|
||||
if root.Left==nil&&root.Right==nil{//叶子节点
|
||||
fmt.Println(*sumNodes)
|
||||
var sum int
|
||||
var number int
|
||||
for k,v:=range *sumNodes{//求该路径节点的和
|
||||
sum+=v
|
||||
number=k
|
||||
}
|
||||
tempNodes:=make([]int,number+1)//新的nodes接受指针里的值,防止最终指针里的值发生变动,导致最后的结果都是最后一个sumNodes的值
|
||||
for k,v:=range *sumNodes{
|
||||
tempNodes[k]=v
|
||||
}
|
||||
if sum==targetSum{
|
||||
*result=append(*result,tempNodes)
|
||||
}
|
||||
}
|
||||
if root.Left!=nil{
|
||||
hasPathSum(root.Left,sumNodes,targetSum,result)
|
||||
*sumNodes=(*sumNodes)[:len(*sumNodes)-1]//回溯
|
||||
}
|
||||
if root.Right!=nil{
|
||||
hasPathSum(root.Right,sumNodes,targetSum,result)
|
||||
*sumNodes=(*sumNodes)[:len(*sumNodes)-1]//回溯
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
JavaScript:
|
||||
|
||||
0112.路径总和
|
||||
|
||||
```javascript
|
||||
/**
|
||||
* @param {TreeNode} root
|
||||
* @param {number} targetSum
|
||||
* @return {boolean}
|
||||
*/
|
||||
let hasPathSum = function (root, targetSum) {
|
||||
// 递归法
|
||||
const traversal = (node, cnt) => {
|
||||
// 遇到叶子节点,并且计数为0
|
||||
if (cnt === 0 && !node.left && !node.right) return true;
|
||||
// 遇到叶子节点而没有找到合适的边(计数不为0),直接返回
|
||||
if (!node.left && !node.right) return false;
|
||||
|
||||
// 左(空节点不遍历).遇到叶子节点返回true,则直接返回true
|
||||
if (node.left && traversal(node.left, cnt - node.left.val)) return true;
|
||||
// 右(空节点不遍历)
|
||||
if (node.right && traversal(node.right, cnt - node.right.val)) return true;
|
||||
return false;
|
||||
};
|
||||
if (!root) return false;
|
||||
return traversal(root, targetSum - root.val);
|
||||
|
||||
// 精简代码:
|
||||
// if (!root) return false;
|
||||
// if (!root.left && !root.right && targetSum === root.val) return true;
|
||||
// return hasPathSum(root.left, targetSum - root.val) || hasPathSum(root.right, targetSum - root.val);
|
||||
};
|
||||
```
|
||||
|
||||
0113.路径总和-ii
|
||||
|
||||
```javascript
|
||||
let pathSum = function (root, targetSum) {
|
||||
// 递归法
|
||||
// 要遍历整个树找到所有路径,所以递归函数不需要返回值, 与112不同
|
||||
const res = [];
|
||||
const travelsal = (node, cnt, path) => {
|
||||
// 遇到了叶子节点且找到了和为sum的路径
|
||||
if (cnt === 0 && !node.left && !node.right) {
|
||||
res.push([...path]); // 不能写res.push(path), 要深拷贝
|
||||
return;
|
||||
}
|
||||
if (!node.left && !node.right) return; // 遇到叶子节点而没有找到合适的边,直接返回
|
||||
// 左 (空节点不遍历)
|
||||
if (node.left) {
|
||||
path.push(node.left.val);
|
||||
travelsal(node.left, cnt - node.left.val, path); // 递归
|
||||
path.pop(); // 回溯
|
||||
}
|
||||
// 右 (空节点不遍历)
|
||||
if (node.right) {
|
||||
path.push(node.right.val);
|
||||
travelsal(node.right, cnt - node.right.val, path); // 递归
|
||||
path.pop(); // 回溯
|
||||
}
|
||||
return;
|
||||
};
|
||||
if (!root) return res;
|
||||
travelsal(root, targetSum - root.val, [root.val]); // 把根节点放进路径
|
||||
return res;
|
||||
};
|
||||
```
|
||||
|
||||
0112 路径总和
|
||||
```javascript
|
||||
var hasPathSum = function(root, targetSum) {
|
||||
//递归方法
|
||||
// 1. 确定函数参数
|
||||
const traversal = function(node,count){
|
||||
// 2. 确定终止条件
|
||||
if(node.left===null&&node.right===null&&count===0){
|
||||
return true;
|
||||
}
|
||||
if(node.left===null&&node.right===null){
|
||||
return false;
|
||||
}
|
||||
//3. 单层递归逻辑
|
||||
if(node.left){
|
||||
if(traversal(node.left,count-node.left.val)){
|
||||
return true;
|
||||
}
|
||||
}
|
||||
if(node.right){
|
||||
if(traversal(node.right,count-node.right.val)){
|
||||
return true;
|
||||
}
|
||||
}
|
||||
return false;
|
||||
}
|
||||
if(root===null){
|
||||
return false;
|
||||
}
|
||||
return traversal(root,targetSum-root.val);
|
||||
};
|
||||
```
|
||||
113 路径总和
|
||||
```javascript
|
||||
var pathSum = function(root, targetSum) {
|
||||
//递归方法
|
||||
let resPath = [],curPath = [];
|
||||
// 1. 确定递归函数参数
|
||||
const travelTree = function(node,count){
|
||||
curPath.push(node.val);
|
||||
count-=node.val;
|
||||
if(node.left===null&&node.right===null&&count===0){
|
||||
resPath.push([...curPath]);
|
||||
}
|
||||
node.left&&travelTree(node.left,count);
|
||||
node.right&&travelTree(node.right,count);
|
||||
let cur = curPath.pop();
|
||||
count-=cur;
|
||||
}
|
||||
if(root===null){
|
||||
return resPath;
|
||||
}
|
||||
travelTree(root,targetSum);
|
||||
return resPath;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
232
problems/0115.不同的子序列.md
Normal file
232
problems/0115.不同的子序列.md
Normal file
@@ -0,0 +1,232 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
## 115.不同的子序列
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/distinct-subsequences/
|
||||
|
||||
给定一个字符串 s 和一个字符串 t ,计算在 s 的子序列中 t 出现的个数。
|
||||
|
||||
字符串的一个 子序列 是指,通过删除一些(也可以不删除)字符且不干扰剩余字符相对位置所组成的新字符串。(例如,"ACE" 是 "ABCDE" 的一个子序列,而 "AEC" 不是)
|
||||
|
||||
题目数据保证答案符合 32 位带符号整数范围。
|
||||
|
||||

|
||||
|
||||
提示:
|
||||
|
||||
0 <= s.length, t.length <= 1000
|
||||
s 和 t 由英文字母组成
|
||||
|
||||
## 思路
|
||||
|
||||
这道题目如果不是子序列,而是要求连续序列的,那就可以考虑用KMP。
|
||||
|
||||
这道题目相对于72. 编辑距离,简单了不少,因为本题相当于只有删除操作,不用考虑替换增加之类的。
|
||||
|
||||
但相对于刚讲过的[动态规划:392.判断子序列](https://mp.weixin.qq.com/s/2pjT4B4fjfOx5iB6N6xyng)就有难度了,这道题目双指针法可就做不了了,来看看动规五部曲分析如下:
|
||||
|
||||
1. 确定dp数组(dp table)以及下标的含义
|
||||
|
||||
dp[i][j]:以i-1为结尾的s子序列中出现以j-1为结尾的t的个数为dp[i][j]。
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
这一类问题,基本是要分析两种情况
|
||||
|
||||
* s[i - 1] 与 t[j - 1]相等
|
||||
* s[i - 1] 与 t[j - 1] 不相等
|
||||
|
||||
当s[i - 1] 与 t[j - 1]相等时,dp[i][j]可以有两部分组成。
|
||||
|
||||
一部分是用s[i - 1]来匹配,那么个数为dp[i - 1][j - 1]。
|
||||
|
||||
一部分是不用s[i - 1]来匹配,个数为dp[i - 1][j]。
|
||||
|
||||
这里可能有同学不明白了,为什么还要考虑 不用s[i - 1]来匹配,都相同了指定要匹配啊。
|
||||
|
||||
例如: s:bagg 和 t:bag ,s[3] 和 t[2]是相同的,但是字符串s也可以不用s[3]来匹配,即用s[0]s[1]s[2]组成的bag。
|
||||
|
||||
当然也可以用s[3]来匹配,即:s[0]s[1]s[3]组成的bag。
|
||||
|
||||
所以当s[i - 1] 与 t[j - 1]相等时,dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
|
||||
|
||||
当s[i - 1] 与 t[j - 1]不相等时,dp[i][j]只有一部分组成,不用s[i - 1]来匹配,即:dp[i - 1][j]
|
||||
|
||||
所以递推公式为:dp[i][j] = dp[i - 1][j];
|
||||
|
||||
3. dp数组如何初始化
|
||||
|
||||
从递推公式dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j]; 和 dp[i][j] = dp[i - 1][j]; 中可以看出dp[i][0] 和dp[0][j]是一定要初始化的。
|
||||
|
||||
每次当初始化的时候,都要回顾一下dp[i][j]的定义,不要凭感觉初始化。
|
||||
|
||||
dp[i][0]表示什么呢?
|
||||
|
||||
dp[i][0] 表示:以i-1为结尾的s可以随便删除元素,出现空字符串的个数。
|
||||
|
||||
那么dp[i][0]一定都是1,因为也就是把以i-1为结尾的s,删除所有元素,出现空字符串的个数就是1。
|
||||
|
||||
再来看dp[0][j],dp[0][j]:空字符串s可以随便删除元素,出现以j-1为结尾的字符串t的个数。
|
||||
|
||||
那么dp[0][j]一定都是0,s如论如何也变成不了t。
|
||||
|
||||
最后就要看一个特殊位置了,即:dp[0][0] 应该是多少。
|
||||
|
||||
dp[0][0]应该是1,空字符串s,可以删除0个元素,变成空字符串t。
|
||||
|
||||
初始化分析完毕,代码如下:
|
||||
|
||||
```C++
|
||||
vector<vector<long long>> dp(s.size() + 1, vector<long long>(t.size() + 1));
|
||||
for (int i = 0; i <= s.size(); i++) dp[i][0] = 1;
|
||||
for (int j = 1; j <= t.size(); j++) dp[0][j] = 0; // 其实这行代码可以和dp数组初始化的时候放在一起,但我为了凸显初始化的逻辑,所以还是加上了。
|
||||
|
||||
```
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
从递推公式dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j]; 和 dp[i][j] = dp[i - 1][j]; 中可以看出dp[i][j]都是根据左上方和正上方推出来的。
|
||||
|
||||
所以遍历的时候一定是从上到下,从左到右,这样保证dp[i][j]可以根据之前计算出来的数值进行计算。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
for (int i = 1; i <= s.size(); i++) {
|
||||
for (int j = 1; j <= t.size(); j++) {
|
||||
if (s[i - 1] == t[j - 1]) {
|
||||
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
|
||||
} else {
|
||||
dp[i][j] = dp[i - 1][j];
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
5. 举例推导dp数组
|
||||
|
||||
以s:"baegg",t:"bag"为例,推导dp数组状态如下:
|
||||
|
||||
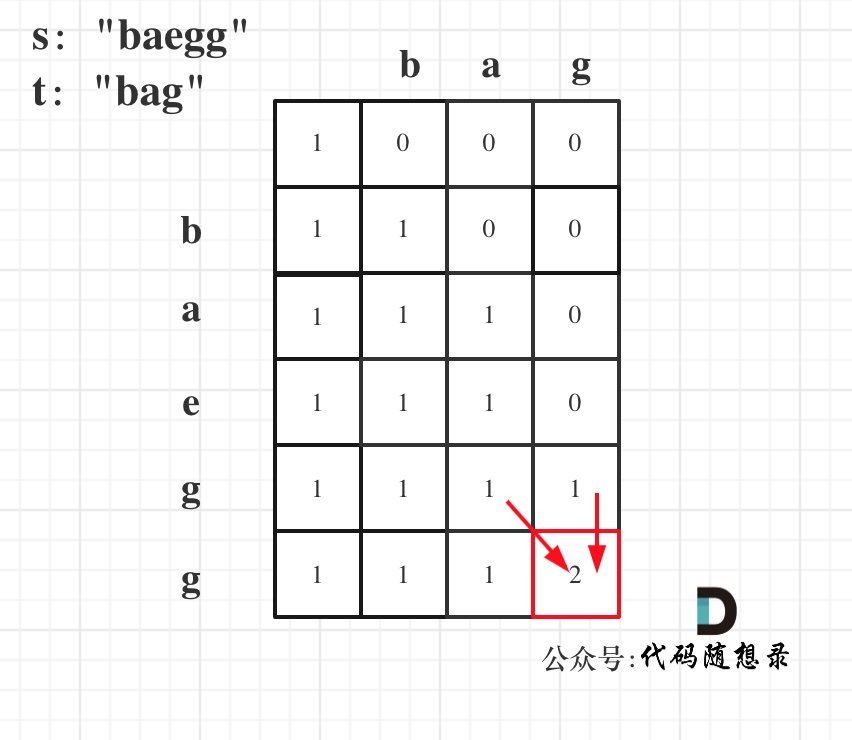
|
||||
|
||||
如果写出来的代码怎么改都通过不了,不妨把dp数组打印出来,看一看,是不是这样的。
|
||||
|
||||
|
||||
动规五部曲分析完毕,代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int numDistinct(string s, string t) {
|
||||
vector<vector<uint64_t>> dp(s.size() + 1, vector<uint64_t>(t.size() + 1));
|
||||
for (int i = 0; i < s.size(); i++) dp[i][0] = 1;
|
||||
for (int j = 1; j < t.size(); j++) dp[0][j] = 0;
|
||||
for (int i = 1; i <= s.size(); i++) {
|
||||
for (int j = 1; j <= t.size(); j++) {
|
||||
if (s[i - 1] == t[j - 1]) {
|
||||
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
|
||||
} else {
|
||||
dp[i][j] = dp[i - 1][j];
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[s.size()][t.size()];
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
public int numDistinct(String s, String t) {
|
||||
int[][] dp = new int[s.length() + 1][t.length() + 1];
|
||||
for (int i = 0; i < s.length() + 1; i++) {
|
||||
dp[i][0] = 1;
|
||||
}
|
||||
|
||||
for (int i = 1; i < s.length() + 1; i++) {
|
||||
for (int j = 1; j < t.length() + 1; j++) {
|
||||
if (s.charAt(i - 1) == t.charAt(j - 1)) {
|
||||
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
|
||||
}else{
|
||||
dp[i][j] = dp[i - 1][j];
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return dp[s.length()][t.length()];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def numDistinct(self, s: str, t: str) -> int:
|
||||
dp = [[0] * (len(t)+1) for _ in range(len(s)+1)]
|
||||
for i in range(len(s)):
|
||||
dp[i][0] = 1
|
||||
for j in range(1, len(t)):
|
||||
dp[0][j] = 0
|
||||
for i in range(1, len(s)+1):
|
||||
for j in range(1, len(t)+1):
|
||||
if s[i-1] == t[j-1]:
|
||||
dp[i][j] = dp[i-1][j-1] + dp[i-1][j]
|
||||
else:
|
||||
dp[i][j] = dp[i-1][j]
|
||||
return dp[-1][-1]
|
||||
```
|
||||
|
||||
Python3:
|
||||
```python
|
||||
class SolutionDP2:
|
||||
"""
|
||||
既然dp[i]只用到dp[i - 1]的状态,
|
||||
我们可以通过缓存dp[i - 1]的状态来对dp进行压缩,
|
||||
减少空间复杂度。
|
||||
(原理等同同于滚动数组)
|
||||
"""
|
||||
|
||||
def numDistinct(self, s: str, t: str) -> int:
|
||||
n1, n2 = len(s), len(t)
|
||||
if n1 < n2:
|
||||
return 0
|
||||
|
||||
dp = [0 for _ in range(n2 + 1)]
|
||||
dp[0] = 1
|
||||
|
||||
for i in range(1, n1 + 1):
|
||||
# 必须深拷贝
|
||||
# 不然prev[i]和dp[i]是同一个地址的引用
|
||||
prev = dp.copy()
|
||||
# 剪枝,保证s的长度大于等于t
|
||||
# 因为对于任意i,i > n1, dp[i] = 0
|
||||
# 没必要跟新状态。
|
||||
end = i if i < n2 else n2
|
||||
for j in range(1, end + 1):
|
||||
if s[i - 1] == t[j - 1]:
|
||||
dp[j] = prev[j - 1] + prev[j]
|
||||
else:
|
||||
dp[j] = prev[j]
|
||||
return dp[-1]
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
323
problems/0121.买卖股票的最佳时机.md
Normal file
323
problems/0121.买卖股票的最佳时机.md
Normal file
@@ -0,0 +1,323 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
## 121. 买卖股票的最佳时机
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock/
|
||||
|
||||
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
|
||||
|
||||
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
|
||||
|
||||
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
|
||||
|
||||
示例 1:
|
||||
输入:[7,1,5,3,6,4]
|
||||
输出:5
|
||||
解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
|
||||
|
||||
示例 2:
|
||||
输入:prices = [7,6,4,3,1]
|
||||
输出:0
|
||||
解释:在这种情况下, 没有交易完成, 所以最大利润为 0。
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
### 暴力
|
||||
|
||||
这道题目最直观的想法,就是暴力,找最优间距了。
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int maxProfit(vector<int>& prices) {
|
||||
int result = 0;
|
||||
for (int i = 0; i < prices.size(); i++) {
|
||||
for (int j = i + 1; j < prices.size(); j++){
|
||||
result = max(result, prices[j] - prices[i]);
|
||||
}
|
||||
}
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
* 时间复杂度:O(n^2)
|
||||
* 空间复杂度:O(1)
|
||||
|
||||
当然该方法超时了。
|
||||
|
||||
### 贪心
|
||||
|
||||
因为股票就买卖一次,那么贪心的想法很自然就是取最左最小值,取最右最大值,那么得到的差值就是最大利润。
|
||||
|
||||
C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int maxProfit(vector<int>& prices) {
|
||||
int low = INT_MAX;
|
||||
int result = 0;
|
||||
for (int i = 0; i < prices.size(); i++) {
|
||||
low = min(low, prices[i]); // 取最左最小价格
|
||||
result = max(result, prices[i] - low); // 直接取最大区间利润
|
||||
}
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度:O(n)
|
||||
* 空间复杂度:O(1)
|
||||
|
||||
### 动态规划
|
||||
|
||||
动规五部曲分析如下:
|
||||
|
||||
1. 确定dp数组(dp table)以及下标的含义
|
||||
|
||||
dp[i][0] 表示第i天持有股票所得最多现金 ,**这里可能有同学疑惑,本题中只能买卖一次,持有股票之后哪还有现金呢?**
|
||||
|
||||
其实一开始现金是0,那么加入第i天买入股票现金就是 -prices[i], 这是一个负数。
|
||||
|
||||
dp[i][1] 表示第i天不持有股票所得最多现金
|
||||
|
||||
**注意这里说的是“持有”,“持有”不代表就是当天“买入”!也有可能是昨天就买入了,今天保持持有的状态**
|
||||
|
||||
很多同学把“持有”和“买入”没分区分清楚。
|
||||
|
||||
在下面递推公式分析中,我会进一步讲解。
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
如果第i天持有股票即dp[i][0], 那么可以由两个状态推出来
|
||||
* 第i-1天就持有股票,那么就保持现状,所得现金就是昨天持有股票的所得现金 即:dp[i - 1][0]
|
||||
* 第i天买入股票,所得现金就是买入今天的股票后所得现金即:-prices[i]
|
||||
|
||||
那么dp[i][0]应该选所得现金最大的,所以dp[i][0] = max(dp[i - 1][0], -prices[i]);
|
||||
|
||||
如果第i天不持有股票即dp[i][1], 也可以由两个状态推出来
|
||||
* 第i-1天就不持有股票,那么就保持现状,所得现金就是昨天不持有股票的所得现金 即:dp[i - 1][1]
|
||||
* 第i天卖出股票,所得现金就是按照今天股票佳价格卖出后所得现金即:prices[i] + dp[i - 1][0]
|
||||
|
||||
同样dp[i][1]取最大的,dp[i][1] = max(dp[i - 1][1], prices[i] + dp[i - 1][0]);
|
||||
|
||||
这样递归公式我们就分析完了
|
||||
|
||||
3. dp数组如何初始化
|
||||
|
||||
由递推公式 dp[i][0] = max(dp[i - 1][0], -prices[i]); 和 dp[i][1] = max(dp[i - 1][1], prices[i] + dp[i - 1][0]);可以看出
|
||||
|
||||
其基础都是要从dp[0][0]和dp[0][1]推导出来。
|
||||
|
||||
那么dp[0][0]表示第0天持有股票,此时的持有股票就一定是买入股票了,因为不可能有前一天推出来,所以dp[0][0] -= prices[0];
|
||||
|
||||
dp[0][1]表示第0天不持有股票,不持有股票那么现金就是0,所以dp[0][1] = 0;
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
从递推公式可以看出dp[i]都是有dp[i - 1]推导出来的,那么一定是从前向后遍历。
|
||||
|
||||
5. 举例推导dp数组
|
||||
|
||||
以示例1,输入:[7,1,5,3,6,4]为例,dp数组状态如下:
|
||||
|
||||
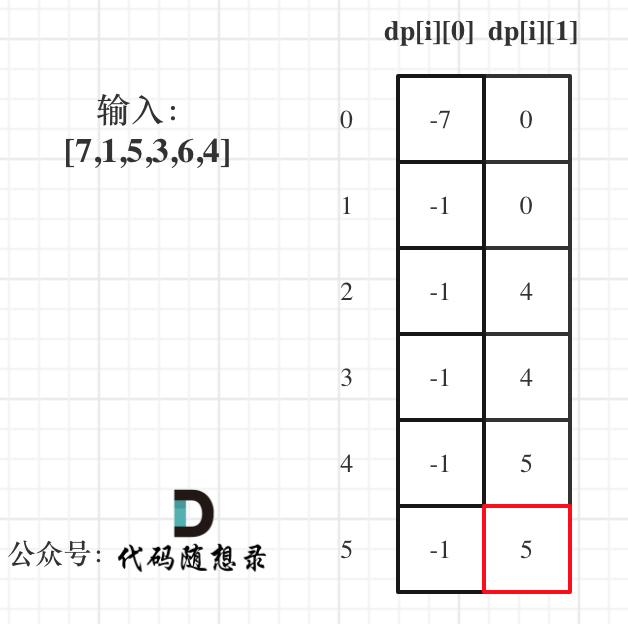
|
||||
|
||||
|
||||
dp[5][1]就是最终结果。
|
||||
|
||||
为什么不是dp[5][0]呢?
|
||||
|
||||
**因为本题中不持有股票状态所得金钱一定比持有股票状态得到的多!**
|
||||
|
||||
以上分析完毕,C++代码如下:
|
||||
|
||||
```C++
|
||||
// 版本一
|
||||
class Solution {
|
||||
public:
|
||||
int maxProfit(vector<int>& prices) {
|
||||
int len = prices.size();
|
||||
if (len == 0) return 0;
|
||||
vector<vector<int>> dp(len, vector<int>(2));
|
||||
dp[0][0] -= prices[0];
|
||||
dp[0][1] = 0;
|
||||
for (int i = 1; i < len; i++) {
|
||||
dp[i][0] = max(dp[i - 1][0], -prices[i]);
|
||||
dp[i][1] = max(dp[i - 1][1], prices[i] + dp[i - 1][0]);
|
||||
}
|
||||
return dp[len - 1][1];
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度:O(n)
|
||||
* 空间复杂度:O(n)
|
||||
|
||||
从递推公式可以看出,dp[i]只是依赖于dp[i - 1]的状态。
|
||||
|
||||
```
|
||||
dp[i][0] = max(dp[i - 1][0], -prices[i]);
|
||||
dp[i][1] = max(dp[i - 1][1], prices[i] + dp[i - 1][0]);
|
||||
```
|
||||
|
||||
那么我们只需要记录 当前天的dp状态和前一天的dp状态就可以了,可以使用滚动数组来节省空间,代码如下:
|
||||
|
||||
```C++
|
||||
// 版本二
|
||||
class Solution {
|
||||
public:
|
||||
int maxProfit(vector<int>& prices) {
|
||||
int len = prices.size();
|
||||
vector<vector<int>> dp(2, vector<int>(2)); // 注意这里只开辟了一个2 * 2大小的二维数组
|
||||
dp[0][0] -= prices[0];
|
||||
dp[0][1] = 0;
|
||||
for (int i = 1; i < len; i++) {
|
||||
dp[i % 2][0] = max(dp[(i - 1) % 2][0], -prices[i]);
|
||||
dp[i % 2][1] = max(dp[(i - 1) % 2][1], prices[i] + dp[(i - 1) % 2][0]);
|
||||
}
|
||||
return dp[(len - 1) % 2][1];
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
* 时间复杂度:O(n)
|
||||
* 空间复杂度:O(1)
|
||||
|
||||
这里能写出版本一就可以了,版本二虽然原理都一样,但是想直接写出版本二还是有点麻烦,容易自己给自己找bug。
|
||||
|
||||
所以建议是先写出版本一,然后在版本一的基础上优化成版本二,而不是直接就写出版本二。
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
Java:
|
||||
```java
|
||||
// 贪心思路
|
||||
class Solution {
|
||||
public int maxProfit(int[] prices) {
|
||||
int minprice = Integer.MAX_VALUE;
|
||||
int maxprofit = 0;
|
||||
for (int i = 0; i < prices.length; i++) {
|
||||
if (prices[i] < minprice) {
|
||||
minprice = prices[i];
|
||||
} else if (prices[i] - minprice > maxprofit) {
|
||||
maxprofit = prices[i] - minprice;
|
||||
}
|
||||
}
|
||||
return maxprofit;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
``` java
|
||||
class Solution { // 动态规划解法
|
||||
public int maxProfit(int[] prices) {
|
||||
// 可交易次数
|
||||
int k = 1;
|
||||
// [天数][交易次数][是否持有股票]
|
||||
int[][][] dp = new int[prices.length][k + 1][2];
|
||||
|
||||
// bad case
|
||||
dp[0][0][0] = 0;
|
||||
dp[0][0][1] = Integer.MIN_VALUE;
|
||||
dp[0][1][0] = Integer.MIN_VALUE;
|
||||
dp[0][1][1] = -prices[0];
|
||||
|
||||
for (int i = 1; i < prices.length; i++) {
|
||||
for (int j = k; j >= 1; j--) {
|
||||
// dp公式
|
||||
dp[i][j][0] = Math.max(dp[i - 1][j][0], dp[i - 1][j][1] + prices[i]);
|
||||
dp[i][j][1] = Math.max(dp[i - 1][j][1], dp[i - 1][j - 1][0] - prices[i]);
|
||||
}
|
||||
}
|
||||
|
||||
return dp[prices.length - 1][k][0] > 0 ? dp[prices.length - 1][k][0] : 0;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
> 贪心法:
|
||||
```python
|
||||
class Solution:
|
||||
def maxProfit(self, prices: List[int]) -> int:
|
||||
low = float("inf")
|
||||
result = 0
|
||||
for i in range(len(prices)):
|
||||
low = min(low, prices[i]) #取最左最小价格
|
||||
result = max(result, prices[i] - low) #直接取最大区间利润
|
||||
return result
|
||||
```
|
||||
|
||||
> 动态规划:版本一
|
||||
```python
|
||||
class Solution:
|
||||
def maxProfit(self, prices: List[int]) -> int:
|
||||
length = len(prices)
|
||||
if len == 0:
|
||||
return 0
|
||||
dp = [[0] * 2 for _ in range(length)]
|
||||
dp[0][0] = -prices[0]
|
||||
dp[0][1] = 0
|
||||
for i in range(1, length):
|
||||
dp[i][0] = max(dp[i-1][0], -prices[i])
|
||||
dp[i][1] = max(dp[i-1][1], prices[i] + dp[i-1][0])
|
||||
return dp[-1][1]
|
||||
```
|
||||
|
||||
> 动态规划:版本二
|
||||
```python
|
||||
class Solution:
|
||||
def maxProfit(self, prices: List[int]) -> int:
|
||||
length = len(prices)
|
||||
dp = [[0] * 2 for _ in range(2)] #注意这里只开辟了一个2 * 2大小的二维数组
|
||||
dp[0][0] = -prices[0]
|
||||
dp[0][1] = 0
|
||||
for i in range(1, length):
|
||||
dp[i % 2][0] = max(dp[(i-1) % 2][0], -prices[i])
|
||||
dp[i % 2][1] = max(dp[(i-1) % 2][1], prices[i] + dp[(i-1) % 2][0])
|
||||
return dp[(length-1) % 2][1]
|
||||
```
|
||||
|
||||
Go:
|
||||
```Go
|
||||
func maxProfit(prices []int) int {
|
||||
length:=len(prices)
|
||||
if length==0{return 0}
|
||||
dp:=make([][]int,length)
|
||||
for i:=0;i<length;i++{
|
||||
dp[i]=make([]int,2)
|
||||
}
|
||||
|
||||
dp[0][0]=-prices[0]
|
||||
dp[0][1]=0
|
||||
for i:=1;i<length;i++{
|
||||
dp[i][0]=max(dp[i-1][0],-prices[i])
|
||||
dp[i][1]=max(dp[i-1][1],dp[i-1][0]+prices[i])
|
||||
}
|
||||
return dp[length-1][1]
|
||||
}
|
||||
|
||||
func max(a,b int)int {
|
||||
if a>b{
|
||||
return a
|
||||
}
|
||||
return b
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
209
problems/0122.买卖股票的最佳时机II.md
Normal file
209
problems/0122.买卖股票的最佳时机II.md
Normal file
@@ -0,0 +1,209 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 122.买卖股票的最佳时机II
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-ii/
|
||||
|
||||
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
|
||||
|
||||
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
|
||||
|
||||
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
|
||||
|
||||
|
||||
示例 1:
|
||||
输入: [7,1,5,3,6,4]
|
||||
输出: 7
|
||||
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4。随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。
|
||||
|
||||
示例 2:
|
||||
输入: [1,2,3,4,5]
|
||||
输出: 4
|
||||
解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。
|
||||
|
||||
示例 3:
|
||||
输入: [7,6,4,3,1]
|
||||
输出: 0
|
||||
解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。
|
||||
|
||||
提示:
|
||||
* 1 <= prices.length <= 3 * 10 ^ 4
|
||||
* 0 <= prices[i] <= 10 ^ 4
|
||||
|
||||
## 思路
|
||||
|
||||
本题首先要清楚两点:
|
||||
|
||||
* 只有一只股票!
|
||||
* 当前只有买股票或者买股票的操作
|
||||
|
||||
想获得利润至少要两天为一个交易单元。
|
||||
|
||||
## 贪心算法
|
||||
|
||||
这道题目可能我们只会想,选一个低的买入,在选个高的卖,在选一个低的买入.....循环反复。
|
||||
|
||||
**如果想到其实最终利润是可以分解的,那么本题就很容易了!**
|
||||
|
||||
如果分解呢?
|
||||
|
||||
假如第0天买入,第3天卖出,那么利润为:prices[3] - prices[0]。
|
||||
|
||||
相当于(prices[3] - prices[2]) + (prices[2] - prices[1]) + (prices[1] - prices[0])。
|
||||
|
||||
**此时就是把利润分解为每天为单位的维度,而不是从0天到第3天整体去考虑!**
|
||||
|
||||
那么根据prices可以得到每天的利润序列:(prices[i] - prices[i - 1]).....(prices[1] - prices[0])。
|
||||
|
||||
如图:
|
||||
|
||||

|
||||
|
||||
一些同学陷入:第一天怎么就没有利润呢,第一天到底算不算的困惑中。
|
||||
|
||||
第一天当然没有利润,至少要第二天才会有利润,所以利润的序列比股票序列少一天!
|
||||
|
||||
从图中可以发现,其实我们需要收集每天的正利润就可以,**收集正利润的区间,就是股票买卖的区间,而我们只需要关注最终利润,不需要记录区间**。
|
||||
|
||||
那么只收集正利润就是贪心所贪的地方!
|
||||
|
||||
**局部最优:收集每天的正利润,全局最优:求得最大利润**。
|
||||
|
||||
局部最优可以推出全局最优,找不出反例,试一试贪心!
|
||||
|
||||
对应C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int maxProfit(vector<int>& prices) {
|
||||
int result = 0;
|
||||
for (int i = 1; i < prices.size(); i++) {
|
||||
result += max(prices[i] - prices[i - 1], 0);
|
||||
}
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度O(n)
|
||||
* 空间复杂度O(1)
|
||||
|
||||
## 动态规划
|
||||
|
||||
动态规划将在下一个系列详细讲解,本题解先给出我的C++代码(带详细注释),感兴趣的同学可以自己先学习一下。
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int maxProfit(vector<int>& prices) {
|
||||
// dp[i][1]第i天持有的最多现金
|
||||
// dp[i][0]第i天持有股票后的最多现金
|
||||
int n = prices.size();
|
||||
vector<vector<int>> dp(n, vector<int>(2, 0));
|
||||
dp[0][0] -= prices[0]; // 持股票
|
||||
for (int i = 1; i < n; i++) {
|
||||
// 第i天持股票所剩最多现金 = max(第i-1天持股票所剩现金, 第i-1天持现金-买第i天的股票)
|
||||
dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]);
|
||||
// 第i天持有最多现金 = max(第i-1天持有的最多现金,第i-1天持有股票的最多现金+第i天卖出股票)
|
||||
dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] + prices[i]);
|
||||
}
|
||||
return max(dp[n - 1][0], dp[n - 1][1]);
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度O(n)
|
||||
* 空间复杂度O(n)
|
||||
|
||||
## 总结
|
||||
|
||||
股票问题其实是一个系列的,属于动态规划的范畴,因为目前在讲解贪心系列,所以股票问题会在之后的动态规划系列中详细讲解。
|
||||
|
||||
**可以看出有时候,贪心往往比动态规划更巧妙,更好用,所以别小看了贪心算法**。
|
||||
|
||||
**本题中理解利润拆分是关键点!** 不要整块的去看,而是把整体利润拆为每天的利润。
|
||||
|
||||
一旦想到这里了,很自然就会想到贪心了,即:只收集每天的正利润,最后稳稳的就是最大利润了。
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
Java:
|
||||
|
||||
```java
|
||||
// 贪心思路
|
||||
class Solution {
|
||||
public int maxProfit(int[] prices) {
|
||||
int sum = 0;
|
||||
int profit = 0;
|
||||
int buy = prices[0];
|
||||
for (int i = 1; i < prices.length; i++) {
|
||||
profit = prices[i] - buy;
|
||||
if (profit > 0) {
|
||||
sum += profit;
|
||||
}
|
||||
buy = prices[i];
|
||||
}
|
||||
return sum;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
class Solution { // 动态规划
|
||||
public int maxProfit(int[] prices) {
|
||||
// [天数][是否持有股票]
|
||||
int[][] dp = new int[prices.length][2];
|
||||
|
||||
// bad case
|
||||
dp[0][0] = 0;
|
||||
dp[0][1] = -prices[0];
|
||||
|
||||
for (int i = 1; i < prices.length; i++) {
|
||||
// dp公式
|
||||
dp[i][0] = Math.max(dp[i - 1][0], dp[i - 1][1] + prices[i]);
|
||||
dp[i][1] = Math.max(dp[i - 1][1], dp[i - 1][0] - prices[i]);
|
||||
}
|
||||
|
||||
return dp[prices.length - 1][0];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def maxProfit(self, prices: List[int]) -> int:
|
||||
result = 0
|
||||
for i in range(1, len(prices)):
|
||||
result += max(prices[i] - prices[i - 1], 0)
|
||||
return result
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
|
||||
Javascript:
|
||||
```Javascript
|
||||
// 贪心
|
||||
var maxProfit = function(prices) {
|
||||
let result = 0
|
||||
for(let i = 1; i < prices.length; i++) {
|
||||
result += Math.max(prices[i] - prices[i - 1], 0)
|
||||
}
|
||||
return result
|
||||
};
|
||||
```
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
211
problems/0122.买卖股票的最佳时机II(动态规划).md
Normal file
211
problems/0122.买卖股票的最佳时机II(动态规划).md
Normal file
@@ -0,0 +1,211 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
## 122.买卖股票的最佳时机II
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-ii/
|
||||
|
||||
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
|
||||
|
||||
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
|
||||
|
||||
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
|
||||
|
||||
|
||||
示例 1:
|
||||
输入: [7,1,5,3,6,4]
|
||||
输出: 7
|
||||
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4。随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。
|
||||
|
||||
示例 2:
|
||||
输入: [1,2,3,4,5]
|
||||
输出: 4
|
||||
解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。
|
||||
|
||||
示例 3:
|
||||
输入: [7,6,4,3,1]
|
||||
输出: 0
|
||||
解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。
|
||||
|
||||
提示:
|
||||
* 1 <= prices.length <= 3 * 10 ^ 4
|
||||
* 0 <= prices[i] <= 10 ^ 4
|
||||
|
||||
## 思路
|
||||
|
||||
本题我们在讲解贪心专题的时候就已经讲解过了[贪心算法:买卖股票的最佳时机II](https://mp.weixin.qq.com/s/VsTFA6U96l18Wntjcg3fcg),只不过没有深入讲解动态规划的解法,那么这次我们再好好分析一下动规的解法。
|
||||
|
||||
|
||||
本题和[121. 买卖股票的最佳时机](https://mp.weixin.qq.com/s/keWo5qYJY4zmHn3amfXdfQ)的唯一区别本题股票可以买卖多次了(注意只有一只股票,所以再次购买前要出售掉之前的股票)
|
||||
|
||||
**在动规五部曲中,这个区别主要是体现在递推公式上,其他都和[121. 买卖股票的最佳时机](https://mp.weixin.qq.com/s/keWo5qYJY4zmHn3amfXdfQ)一样一样的**。
|
||||
|
||||
所以我们重点讲一讲递推公式。
|
||||
|
||||
这里重申一下dp数组的含义:
|
||||
|
||||
* dp[i][0] 表示第i天持有股票所得现金。
|
||||
* dp[i][1] 表示第i天不持有股票所得最多现金
|
||||
|
||||
|
||||
如果第i天持有股票即dp[i][0], 那么可以由两个状态推出来
|
||||
* 第i-1天就持有股票,那么就保持现状,所得现金就是昨天持有股票的所得现金 即:dp[i - 1][0]
|
||||
* 第i天买入股票,所得现金就是昨天不持有股票的所得现金减去 今天的股票价格 即:dp[i - 1][1] - prices[i]
|
||||
|
||||
|
||||
**注意这里和[121. 买卖股票的最佳时机](https://mp.weixin.qq.com/s/keWo5qYJY4zmHn3amfXdfQ)唯一不同的地方,就是推导dp[i][0]的时候,第i天买入股票的情况**。
|
||||
|
||||
在[121. 买卖股票的最佳时机](https://mp.weixin.qq.com/s/keWo5qYJY4zmHn3amfXdfQ)中,因为股票全程只能买卖一次,所以如果买入股票,那么第i天持有股票即dp[i][0]一定就是 -prices[i]。
|
||||
|
||||
而本题,因为一只股票可以买卖多次,所以当第i天买入股票的时候,所持有的现金可能有之前买卖过的利润。
|
||||
|
||||
那么第i天持有股票即dp[i][0],如果是第i天买入股票,所得现金就是昨天不持有股票的所得现金 减去 今天的股票价格 即:dp[i - 1][1] - prices[i]。
|
||||
|
||||
在来看看如果第i天不持有股票即dp[i][1]的情况, 依然可以由两个状态推出来
|
||||
* 第i-1天就不持有股票,那么就保持现状,所得现金就是昨天不持有股票的所得现金 即:dp[i - 1][1]
|
||||
* 第i天卖出股票,所得现金就是按照今天股票佳价格卖出后所得现金即:prices[i] + dp[i - 1][0]
|
||||
|
||||
**注意这里和[121. 买卖股票的最佳时机](https://mp.weixin.qq.com/s/keWo5qYJY4zmHn3amfXdfQ)就是一样的逻辑,卖出股票收获利润(可能是负值)天经地义!**
|
||||
|
||||
代码如下:(注意代码中的注释,标记了和121.买卖股票的最佳时机唯一不同的地方)
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int maxProfit(vector<int>& prices) {
|
||||
int len = prices.size();
|
||||
vector<vector<int>> dp(len, vector<int>(2, 0));
|
||||
dp[0][0] -= prices[0];
|
||||
dp[0][1] = 0;
|
||||
for (int i = 1; i < len; i++) {
|
||||
dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]); // 注意这里是和121. 买卖股票的最佳时机唯一不同的地方。
|
||||
dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] + prices[i]);
|
||||
}
|
||||
return dp[len - 1][1];
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
* 时间复杂度:O(n)
|
||||
* 空间复杂度:O(n)
|
||||
|
||||
大家可以本题和[121. 买卖股票的最佳时机](https://mp.weixin.qq.com/s/keWo5qYJY4zmHn3amfXdfQ)的代码几乎一样,唯一的区别在:
|
||||
|
||||
```
|
||||
dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]);
|
||||
```
|
||||
|
||||
**这正是因为本题的股票可以买卖多次!** 所以买入股票的时候,可能会有之前买卖的利润即:dp[i - 1][1],所以dp[i - 1][1] - prices[i]。
|
||||
|
||||
想到到这一点,对这两道题理解的比较深刻了。
|
||||
|
||||
这里我依然给出滚动数组的版本,C++代码如下:
|
||||
|
||||
```C++
|
||||
// 版本二
|
||||
class Solution {
|
||||
public:
|
||||
int maxProfit(vector<int>& prices) {
|
||||
int len = prices.size();
|
||||
vector<vector<int>> dp(2, vector<int>(2)); // 注意这里只开辟了一个2 * 2大小的二维数组
|
||||
dp[0][0] -= prices[0];
|
||||
dp[0][1] = 0;
|
||||
for (int i = 1; i < len; i++) {
|
||||
dp[i % 2][0] = max(dp[(i - 1) % 2][0], dp[(i - 1) % 2][1] - prices[i]);
|
||||
dp[i % 2][1] = max(dp[(i - 1) % 2][1], prices[i] + dp[(i - 1) % 2][0]);
|
||||
}
|
||||
return dp[(len - 1) % 2][1];
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
* 时间复杂度:O(n)
|
||||
* 空间复杂度:O(1)
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
// 动态规划
|
||||
class Solution
|
||||
// 实现1:二维数组存储
|
||||
// 可以将每天持有与否的情况分别用 dp[i][0] 和 dp[i][1] 来进行存储
|
||||
// 时间复杂度:O(n),空间复杂度O(n)
|
||||
public int maxProfit(int[] prices) {
|
||||
int n = prices.length;
|
||||
int[][] dp = new int[n][2]; // 创建二维数组存储状态
|
||||
dp[0][0] = 0; // 初始状态
|
||||
dp[0][1] = -prices[0];
|
||||
for (int i = 1; i < n; ++i) {
|
||||
dp[i][0] = Math.max(dp[i - 1][0], dp[i - 1][1] + prices[i]); // 第 i 天,没有股票
|
||||
dp[i][1] = Math.max(dp[i - 1][1], dp[i - 1][0] - prices[i]); // 第 i 天,持有股票
|
||||
}
|
||||
return dp[n - 1][0]; // 卖出股票收益高于持有股票收益,因此取[0]
|
||||
}
|
||||
|
||||
// 实现2:变量存储
|
||||
// 第一种方法需要用二维数组存储,有空间开销,其实关心的仅仅是前一天的状态,不关注更多的历史信息
|
||||
// 因此,可以仅保存前一天的信息存入 dp0、dp1 这 2 个变量即可
|
||||
// 时间复杂度:O(n),空间复杂度O(1)
|
||||
public int maxProfit(int[] prices) {
|
||||
int n = prices.length;
|
||||
int dp0 = 0, dp1 = -prices[0]; // 定义变量,存储初始状态
|
||||
for (int i = 1; i < n; ++i) {
|
||||
int newDp0 = Math.max(dp0, dp1 + prices[i]); // 第 i 天,没有股票
|
||||
int newDp1 = Math.max(dp1, dp0 - prices[i]); // 第 i 天,持有股票
|
||||
dp0 = newDp0;
|
||||
dp1 = newDp1;
|
||||
}
|
||||
return dp0;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
> 版本一:
|
||||
```python
|
||||
class Solution:
|
||||
def maxProfit(self, prices: List[int]) -> int:
|
||||
length = len(prices)
|
||||
dp = [[0] * 2 for _ in range(length)]
|
||||
dp[0][0] = -prices[0]
|
||||
dp[0][1] = 0
|
||||
for i in range(1, length):
|
||||
dp[i][0] = max(dp[i-1][0], dp[i-1][1] - prices[i]) #注意这里是和121. 买卖股票的最佳时机唯一不同的地方
|
||||
dp[i][1] = max(dp[i-1][1], dp[i-1][0] + prices[i])
|
||||
return dp[-1][1]
|
||||
```
|
||||
|
||||
> 版本二:
|
||||
```python
|
||||
class Solution:
|
||||
def maxProfit(self, prices: List[int]) -> int:
|
||||
length = len(prices)
|
||||
dp = [[0] * 2 for _ in range(2)] #注意这里只开辟了一个2 * 2大小的二维数组
|
||||
dp[0][0] = -prices[0]
|
||||
dp[0][1] = 0
|
||||
for i in range(1, length):
|
||||
dp[i % 2][0] = max(dp[(i-1) % 2][0], dp[(i-1) % 2][1] - prices[i])
|
||||
dp[i % 2][1] = max(dp[(i-1) % 2][1], dp[(i-1) % 2][0] + prices[i])
|
||||
return dp[(length-1) % 2][1]
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
276
problems/0123.买卖股票的最佳时机III.md
Normal file
276
problems/0123.买卖股票的最佳时机III.md
Normal file
@@ -0,0 +1,276 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
## 123.买卖股票的最佳时机III
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-iii/
|
||||
|
||||
|
||||
给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。
|
||||
|
||||
设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。
|
||||
|
||||
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
|
||||
|
||||
示例 1:
|
||||
输入:prices = [3,3,5,0,0,3,1,4]
|
||||
输出:6
|
||||
解释:在第 4 天(股票价格 = 0)的时候买入,在第 6 天(股票价格 = 3)的时候卖出,这笔交易所能获得利润 = 3-0 = 3 。随后,在第 7 天(股票价格 = 1)的时候买入,在第 8 天 (股票价格 = 4)的时候卖出,这笔交易所能获得利润 = 4-1 = 3。
|
||||
|
||||
示例 2:
|
||||
输入:prices = [1,2,3,4,5]
|
||||
输出:4
|
||||
解释:在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4。注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。
|
||||
|
||||
示例 3:
|
||||
输入:prices = [7,6,4,3,1]
|
||||
输出:0
|
||||
解释:在这个情况下, 没有交易完成, 所以最大利润为0。
|
||||
|
||||
示例 4:
|
||||
输入:prices = [1]
|
||||
输出:0
|
||||
|
||||
提示:
|
||||
|
||||
* 1 <= prices.length <= 10^5
|
||||
* 0 <= prices[i] <= 10^5
|
||||
|
||||
## 思路
|
||||
|
||||
|
||||
这道题目相对 [121.买卖股票的最佳时机](https://mp.weixin.qq.com/s/keWo5qYJY4zmHn3amfXdfQ) 和 [122.买卖股票的最佳时机II](https://mp.weixin.qq.com/s/d4TRWFuhaY83HPa6t5ZL-w) 难了不少。
|
||||
|
||||
关键在于至多买卖两次,这意味着可以买卖一次,可以买卖两次,也可以不买卖。
|
||||
|
||||
接来下我用动态规划五部曲详细分析一下:
|
||||
|
||||
1. 确定dp数组以及下标的含义
|
||||
|
||||
一天一共就有五个状态,
|
||||
0. 没有操作
|
||||
1. 第一次买入
|
||||
2. 第一次卖出
|
||||
3. 第二次买入
|
||||
4. 第二次卖出
|
||||
|
||||
dp[i][j]中 i表示第i天,j为 [0 - 4] 五个状态,dp[i][j]表示第i天状态j所剩最大现金。
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
需要注意:dp[i][1],**表示的是第i天,买入股票的状态,并不是说一定要第i天买入股票,这是很多同学容易陷入的误区**。
|
||||
|
||||
达到dp[i][1]状态,有两个具体操作:
|
||||
|
||||
* 操作一:第i天买入股票了,那么dp[i][1] = dp[i-1][0] - prices[i]
|
||||
* 操作二:第i天没有操作,而是沿用前一天买入的状态,即:dp[i][1] = dp[i - 1][1]
|
||||
|
||||
那么dp[i][1]究竟选 dp[i-1][0] - prices[i],还是dp[i - 1][1]呢?
|
||||
|
||||
一定是选最大的,所以 dp[i][1] = max(dp[i-1][0] - prices[i], dp[i - 1][1]);
|
||||
|
||||
同理dp[i][2]也有两个操作:
|
||||
|
||||
* 操作一:第i天卖出股票了,那么dp[i][2] = dp[i - 1][1] + prices[i]
|
||||
* 操作二:第i天没有操作,沿用前一天卖出股票的状态,即:dp[i][2] = dp[i - 1][2]
|
||||
|
||||
所以dp[i][2] = max(dp[i - 1][1] + prices[i], dp[i - 1][2])
|
||||
|
||||
同理可推出剩下状态部分:
|
||||
|
||||
dp[i][3] = max(dp[i - 1][3], dp[i - 1][2] - prices[i]);
|
||||
dp[i][4] = max(dp[i - 1][4], dp[i - 1][3] + prices[i]);
|
||||
|
||||
|
||||
3. dp数组如何初始化
|
||||
|
||||
第0天没有操作,这个最容易想到,就是0,即:dp[0][0] = 0;
|
||||
|
||||
第0天做第一次买入的操作,dp[0][1] = -prices[0];
|
||||
|
||||
第0天做第一次卖出的操作,这个初始值应该是多少呢?
|
||||
|
||||
首先卖出的操作一定是收获利润,整个股票买卖最差情况也就是没有盈利即全程无操作现金为0,
|
||||
|
||||
从递推公式中可以看出每次是取最大值,那么既然是收获利润如果比0还小了就没有必要收获这个利润了。
|
||||
|
||||
所以dp[0][2] = 0;
|
||||
|
||||
第0天第二次买入操作,初始值应该是多少呢?应该不少同学疑惑,第一次还没买入呢,怎么初始化第二次买入呢?
|
||||
|
||||
第二次买入依赖于第一次卖出的状态,其实相当于第0天第一次买入了,第一次卖出了,然后在买入一次(第二次买入),那么现在手头上没有现金,只要买入,现金就做相应的减少。
|
||||
|
||||
所以第二次买入操作,初始化为:dp[0][3] = -prices[0];
|
||||
|
||||
同理第二次卖出初始化dp[0][4] = 0;
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
从递归公式其实已经可以看出,一定是从前向后遍历,因为dp[i],依靠dp[i - 1]的数值。
|
||||
|
||||
5. 举例推导dp数组
|
||||
|
||||
以输入[1,2,3,4,5]为例
|
||||
|
||||
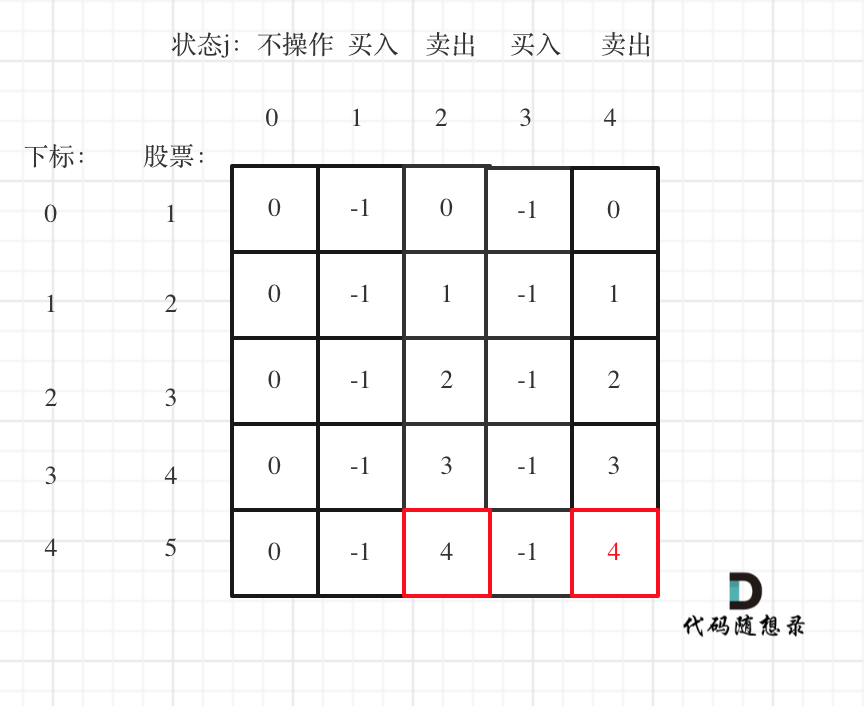
|
||||
|
||||
大家可以看到红色框为最后两次卖出的状态。
|
||||
|
||||
现在最大的时候一定是卖出的状态,而两次卖出的状态现金最大一定是最后一次卖出。
|
||||
|
||||
所以最终最大利润是dp[4][4]
|
||||
|
||||
以上五部都分析完了,不难写出如下代码:
|
||||
|
||||
```C++
|
||||
// 版本一
|
||||
class Solution {
|
||||
public:
|
||||
int maxProfit(vector<int>& prices) {
|
||||
if (prices.size() == 0) return 0;
|
||||
vector<vector<int>> dp(prices.size(), vector<int>(5, 0));
|
||||
dp[0][1] = -prices[0];
|
||||
dp[0][3] = -prices[0];
|
||||
for (int i = 1; i < prices.size(); i++) {
|
||||
dp[i][0] = dp[i - 1][0];
|
||||
dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] - prices[i]);
|
||||
dp[i][2] = max(dp[i - 1][2], dp[i - 1][1] + prices[i]);
|
||||
dp[i][3] = max(dp[i - 1][3], dp[i - 1][2] - prices[i]);
|
||||
dp[i][4] = max(dp[i - 1][4], dp[i - 1][3] + prices[i]);
|
||||
}
|
||||
return dp[prices.size() - 1][4];
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
* 时间复杂度:O(n)
|
||||
* 空间复杂度:O(n * 5)
|
||||
|
||||
当然,大家可以看到力扣官方题解里的一种优化空间写法,我这里给出对应的C++版本:
|
||||
|
||||
```C++
|
||||
// 版本二
|
||||
class Solution {
|
||||
public:
|
||||
int maxProfit(vector<int>& prices) {
|
||||
if (prices.size() == 0) return 0;
|
||||
vector<int> dp(5, 0);
|
||||
dp[1] = -prices[0];
|
||||
dp[3] = -prices[0];
|
||||
for (int i = 1; i < prices.size(); i++) {
|
||||
dp[1] = max(dp[1], dp[0] - prices[i]);
|
||||
dp[2] = max(dp[2], dp[1] + prices[i]);
|
||||
dp[3] = max(dp[3], dp[2] - prices[i]);
|
||||
dp[4] = max(dp[4], dp[3] + prices[i]);
|
||||
}
|
||||
return dp[4];
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
* 时间复杂度:O(n)
|
||||
* 空间复杂度:O(1)
|
||||
|
||||
大家会发现dp[2]利用的是当天的dp[1]。 但结果也是对的。
|
||||
|
||||
我来简单解释一下:
|
||||
|
||||
dp[1] = max(dp[1], dp[0] - prices[i]); 如果dp[1]取dp[1],即保持买入股票的状态,那么 dp[2] = max(dp[2], dp[1] + prices[i]);中dp[1] + prices[i] 就是今天卖出。
|
||||
|
||||
如果dp[1]取dp[0] - prices[i],今天买入股票,那么dp[2] = max(dp[2], dp[1] + prices[i]);中的dp[1] + prices[i]相当于是尽在再卖出股票,一买一卖收益为0,对所得现金没有影响。相当于今天买入股票又卖出股票,等于没有操作,保持昨天卖出股票的状态了。
|
||||
|
||||
**这种写法看上去简单,其实思路很绕,不建议大家这么写,这么思考,很容易把自己绕进去!**
|
||||
|
||||
对于本题,把版本一的写法研究明白,足以!
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
Java:
|
||||
|
||||
```java
|
||||
class Solution { // 动态规划
|
||||
public int maxProfit(int[] prices) {
|
||||
// 可交易次数
|
||||
int k = 2;
|
||||
|
||||
// [天数][交易次数][是否持有股票]
|
||||
int[][][] dp = new int[prices.length][k + 1][2];
|
||||
|
||||
// badcase
|
||||
dp[0][0][0] = 0;
|
||||
dp[0][0][1] = Integer.MIN_VALUE;
|
||||
dp[0][1][0] = 0;
|
||||
dp[0][1][1] = -prices[0];
|
||||
dp[0][2][0] = 0;
|
||||
dp[0][2][1] = Integer.MIN_VALUE;
|
||||
|
||||
for (int i = 1; i < prices.length; i++) {
|
||||
for (int j = 2; j >= 1; j--) {
|
||||
// dp公式
|
||||
dp[i][j][0] = Math.max(dp[i - 1][j][0], dp[i - 1][j][1] + prices[i]);
|
||||
dp[i][j][1] = Math.max(dp[i - 1][j][1], dp[i - 1][j - 1][0] - prices[i]);
|
||||
}
|
||||
}
|
||||
|
||||
int res = 0;
|
||||
for (int i = 1; i < 3; i++) {
|
||||
res = Math.max(res, dp[prices.length - 1][i][0]);
|
||||
}
|
||||
return res;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
Python:
|
||||
|
||||
> 版本一:
|
||||
```python
|
||||
class Solution:
|
||||
def maxProfit(self, prices: List[int]) -> int:
|
||||
if len(prices) == 0:
|
||||
return 0
|
||||
dp = [[0] * 5 for _ in range(len(prices))]
|
||||
dp[0][1] = -prices[0]
|
||||
dp[0][3] = -prices[0]
|
||||
for i in range(1, len(prices)):
|
||||
dp[i][0] = dp[i-1][0]
|
||||
dp[i][1] = max(dp[i-1][1], dp[i-1][0] - prices[i])
|
||||
dp[i][2] = max(dp[i-1][2], dp[i-1][1] + prices[i])
|
||||
dp[i][3] = max(dp[i-1][3], dp[i-1][2] - prices[i])
|
||||
dp[i][4] = max(dp[i-1][4], dp[i-1][3] + prices[i])
|
||||
return dp[-1][4]
|
||||
```
|
||||
|
||||
> 版本二:
|
||||
```python
|
||||
class Solution:
|
||||
def maxProfit(self, prices: List[int]) -> int:
|
||||
if len(prices) == 0:
|
||||
return 0
|
||||
dp = [0] * 5
|
||||
dp[1] = -prices[0]
|
||||
dp[3] = -prices[0]
|
||||
for i in range(1, len(prices)):
|
||||
dp[1] = max(dp[1], dp[0] - prices[i])
|
||||
dp[2] = max(dp[2], dp[1] + prices[i])
|
||||
dp[3] = max(dp[3], dp[2] - prices[i])
|
||||
dp[4] = max(dp[4], dp[3] + prices[i])
|
||||
return dp[4]
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
398
problems/0131.分割回文串.md
Normal file
398
problems/0131.分割回文串.md
Normal file
@@ -0,0 +1,398 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
> 切割问题其实是一种组合问题!
|
||||
|
||||
## 131.分割回文串
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/palindrome-partitioning/
|
||||
|
||||
给定一个字符串 s,将 s 分割成一些子串,使每个子串都是回文串。
|
||||
|
||||
返回 s 所有可能的分割方案。
|
||||
|
||||
示例:
|
||||
输入: "aab"
|
||||
输出:
|
||||
[
|
||||
["aa","b"],
|
||||
["a","a","b"]
|
||||
]
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
关于本题,大家也可以看我在B站的视频讲解:[131.分割回文串(B站视频)](https://www.bilibili.com/video/BV1c54y1e7k6)
|
||||
|
||||
本题这涉及到两个关键问题:
|
||||
|
||||
1. 切割问题,有不同的切割方式
|
||||
2. 判断回文
|
||||
|
||||
相信这里不同的切割方式可以搞懵很多同学了。
|
||||
|
||||
这种题目,想用for循环暴力解法,可能都不那么容易写出来,所以要换一种暴力的方式,就是回溯。
|
||||
|
||||
一些同学可能想不清楚 回溯究竟是如何切割字符串呢?
|
||||
|
||||
我们来分析一下切割,**其实切割问题类似组合问题**。
|
||||
|
||||
例如对于字符串abcdef:
|
||||
|
||||
* 组合问题:选取一个a之后,在bcdef中再去选取第二个,选取b之后在cdef中在选组第三个.....。
|
||||
* 切割问题:切割一个a之后,在bcdef中再去切割第二段,切割b之后在cdef中在切割第三段.....。
|
||||
|
||||
感受出来了不?
|
||||
|
||||
所以切割问题,也可以抽象为一颗树形结构,如图:
|
||||
|
||||
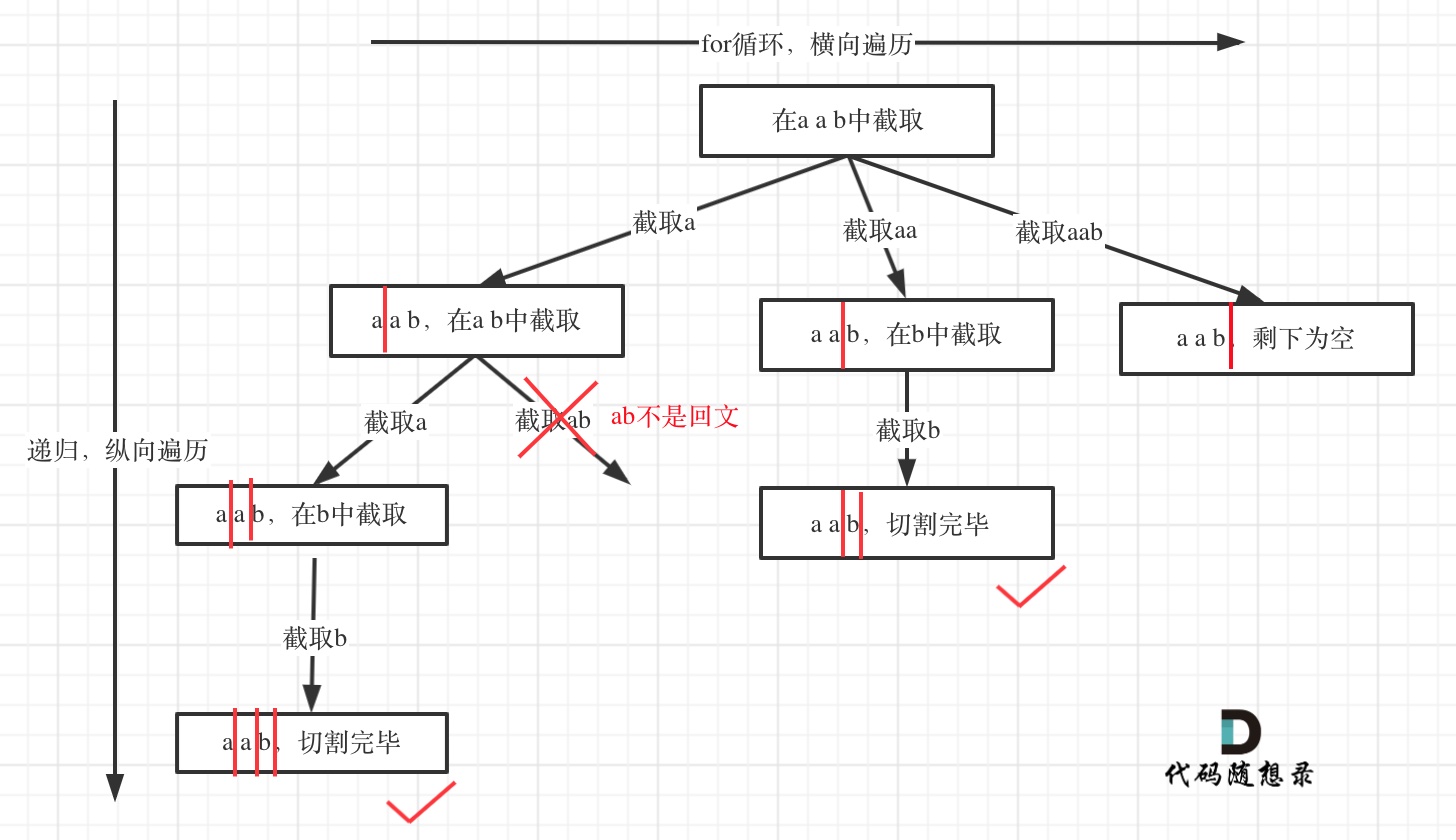
|
||||
|
||||
递归用来纵向遍历,for循环用来横向遍历,切割线(就是图中的红线)切割到字符串的结尾位置,说明找到了一个切割方法。
|
||||
|
||||
此时可以发现,切割问题的回溯搜索的过程和组合问题的回溯搜索的过程是差不多的。
|
||||
|
||||
## 回溯三部曲
|
||||
|
||||
* 递归函数参数
|
||||
|
||||
全局变量数组path存放切割后回文的子串,二维数组result存放结果集。 (这两个参数可以放到函数参数里)
|
||||
|
||||
本题递归函数参数还需要startIndex,因为切割过的地方,不能重复切割,和组合问题也是保持一致的。
|
||||
|
||||
在[回溯算法:求组合总和(二)](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)中我们深入探讨了组合问题什么时候需要startIndex,什么时候不需要startIndex。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
vector<vector<string>> result;
|
||||
vector<string> path; // 放已经回文的子串
|
||||
void backtracking (const string& s, int startIndex) {
|
||||
```
|
||||
|
||||
* 递归函数终止条件
|
||||
|
||||

|
||||
|
||||
从树形结构的图中可以看出:切割线切到了字符串最后面,说明找到了一种切割方法,此时就是本层递归的终止终止条件。
|
||||
|
||||
**那么在代码里什么是切割线呢?**
|
||||
|
||||
在处理组合问题的时候,递归参数需要传入startIndex,表示下一轮递归遍历的起始位置,这个startIndex就是切割线。
|
||||
|
||||
所以终止条件代码如下:
|
||||
|
||||
```C++
|
||||
void backtracking (const string& s, int startIndex) {
|
||||
// 如果起始位置已经大于s的大小,说明已经找到了一组分割方案了
|
||||
if (startIndex >= s.size()) {
|
||||
result.push_back(path);
|
||||
return;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
* 单层搜索的逻辑
|
||||
|
||||
**来看看在递归循环,中如何截取子串呢?**
|
||||
|
||||
在`for (int i = startIndex; i < s.size(); i++)`循环中,我们 定义了起始位置startIndex,那么 [startIndex, i] 就是要截取的子串。
|
||||
|
||||
首先判断这个子串是不是回文,如果是回文,就加入在`vector<string> path`中,path用来记录切割过的回文子串。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
for (int i = startIndex; i < s.size(); i++) {
|
||||
if (isPalindrome(s, startIndex, i)) { // 是回文子串
|
||||
// 获取[startIndex,i]在s中的子串
|
||||
string str = s.substr(startIndex, i - startIndex + 1);
|
||||
path.push_back(str);
|
||||
} else { // 如果不是则直接跳过
|
||||
continue;
|
||||
}
|
||||
backtracking(s, i + 1); // 寻找i+1为起始位置的子串
|
||||
path.pop_back(); // 回溯过程,弹出本次已经填在的子串
|
||||
}
|
||||
```
|
||||
|
||||
**注意切割过的位置,不能重复切割,所以,backtracking(s, i + 1); 传入下一层的起始位置为i + 1**。
|
||||
|
||||
## 判断回文子串
|
||||
|
||||
最后我们看一下回文子串要如何判断了,判断一个字符串是否是回文。
|
||||
|
||||
可以使用双指针法,一个指针从前向后,一个指针从后先前,如果前后指针所指向的元素是相等的,就是回文字符串了。
|
||||
|
||||
那么判断回文的C++代码如下:
|
||||
|
||||
```C++
|
||||
bool isPalindrome(const string& s, int start, int end) {
|
||||
for (int i = start, j = end; i < j; i++, j--) {
|
||||
if (s[i] != s[j]) {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
```
|
||||
|
||||
如果大家对双指针法有生疏了,传送门:[双指针法:总结篇!](https://mp.weixin.qq.com/s/_p7grwjISfMh0U65uOyCjA)
|
||||
|
||||
此时关键代码已经讲解完毕,整体代码如下(详细注释了)
|
||||
|
||||
## C++整体代码
|
||||
|
||||
根据Carl给出的回溯算法模板:
|
||||
|
||||
```C++
|
||||
void backtracking(参数) {
|
||||
if (终止条件) {
|
||||
存放结果;
|
||||
return;
|
||||
}
|
||||
|
||||
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
|
||||
处理节点;
|
||||
backtracking(路径,选择列表); // 递归
|
||||
回溯,撤销处理结果
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
不难写出如下代码:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
vector<vector<string>> result;
|
||||
vector<string> path; // 放已经回文的子串
|
||||
void backtracking (const string& s, int startIndex) {
|
||||
// 如果起始位置已经大于s的大小,说明已经找到了一组分割方案了
|
||||
if (startIndex >= s.size()) {
|
||||
result.push_back(path);
|
||||
return;
|
||||
}
|
||||
for (int i = startIndex; i < s.size(); i++) {
|
||||
if (isPalindrome(s, startIndex, i)) { // 是回文子串
|
||||
// 获取[startIndex,i]在s中的子串
|
||||
string str = s.substr(startIndex, i - startIndex + 1);
|
||||
path.push_back(str);
|
||||
} else { // 不是回文,跳过
|
||||
continue;
|
||||
}
|
||||
backtracking(s, i + 1); // 寻找i+1为起始位置的子串
|
||||
path.pop_back(); // 回溯过程,弹出本次已经填在的子串
|
||||
}
|
||||
}
|
||||
bool isPalindrome(const string& s, int start, int end) {
|
||||
for (int i = start, j = end; i < j; i++, j--) {
|
||||
if (s[i] != s[j]) {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
public:
|
||||
vector<vector<string>> partition(string s) {
|
||||
result.clear();
|
||||
path.clear();
|
||||
backtracking(s, 0);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
这道题目在leetcode上是中等,但可以说是hard的题目了,但是代码其实就是按照模板的样子来的。
|
||||
|
||||
那么难究竟难在什么地方呢?
|
||||
|
||||
**我列出如下几个难点:**
|
||||
|
||||
* 切割问题可以抽象为组合问题
|
||||
* 如何模拟那些切割线
|
||||
* 切割问题中递归如何终止
|
||||
* 在递归循环中如何截取子串
|
||||
* 如何判断回文
|
||||
|
||||
**我们平时在做难题的时候,总结出来难究竟难在哪里也是一种需要锻炼的能力**。
|
||||
|
||||
一些同学可能遇到题目比较难,但是不知道题目难在哪里,反正就是很难。其实这样还是思维不够清晰,这种总结的能力需要多接触多锻炼。
|
||||
|
||||
**本题我相信很多同学主要卡在了第一个难点上:就是不知道如何切割,甚至知道要用回溯法,也不知道如何用。也就是没有体会到按照求组合问题的套路就可以解决切割**。
|
||||
|
||||
如果意识到这一点,算是重大突破了。接下来就可以对着模板照葫芦画瓢。
|
||||
|
||||
**但接下来如何模拟切割线,如何终止,如何截取子串,其实都不好想,最后判断回文算是最简单的了**。
|
||||
|
||||
关于模拟切割线,其实就是index是上一层已经确定了的分割线,i是这一层试图寻找的新分割线
|
||||
|
||||
除了这些难点,**本题还有细节,例如:切割过的地方不能重复切割所以递归函数需要传入i + 1**。
|
||||
|
||||
所以本题应该是一个道hard题目了。
|
||||
|
||||
**可能刷过这道题目的录友都没感受到自己原来克服了这么多难点,就把这道题目AC了**,这应该叫做无招胜有招,人码合一,哈哈哈。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
List<List<String>> lists = new ArrayList<>();
|
||||
Deque<String> deque = new LinkedList<>();
|
||||
|
||||
public List<List<String>> partition(String s) {
|
||||
backTracking(s, 0);
|
||||
return lists;
|
||||
}
|
||||
|
||||
private void backTracking(String s, int startIndex) {
|
||||
//如果起始位置大于s的大小,说明找到了一组分割方案
|
||||
if (startIndex >= s.length()) {
|
||||
lists.add(new ArrayList(deque));
|
||||
return;
|
||||
}
|
||||
for (int i = startIndex; i < s.length(); i++) {
|
||||
//如果是回文子串,则记录
|
||||
if (isPalindrome(s, startIndex, i)) {
|
||||
String str = s.substring(startIndex, i + 1);
|
||||
deque.addLast(str);
|
||||
} else {
|
||||
continue;
|
||||
}
|
||||
//起始位置后移,保证不重复
|
||||
backTracking(s, i + 1);
|
||||
deque.removeLast();
|
||||
}
|
||||
}
|
||||
//判断是否是回文串
|
||||
private boolean isPalindrome(String s, int startIndex, int end) {
|
||||
for (int i = startIndex, j = end; i < j; i++, j--) {
|
||||
if (s.charAt(i) != s.charAt(j)) {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```py
|
||||
class Solution:
|
||||
def partition(self, s: str) -> List[List[str]]:
|
||||
res = []
|
||||
path = [] #放已经回文的子串
|
||||
def backtrack(s,startIndex):
|
||||
if startIndex >= len(s): #如果起始位置已经大于s的大小,说明已经找到了一组分割方案了
|
||||
return res.append(path[:])
|
||||
for i in range(startIndex,len(s)):
|
||||
p = s[startIndex:i+1] #获取[startIndex,i+1]在s中的子串
|
||||
if p == p[::-1]: path.append(p) #是回文子串
|
||||
else: continue #不是回文,跳过
|
||||
backtrack(s,i+1) #寻找i+1为起始位置的子串
|
||||
path.pop() #回溯过程,弹出本次已经填在path的子串
|
||||
backtrack(s,0)
|
||||
return res
|
||||
|
||||
```
|
||||
|
||||
Go:
|
||||
> 注意切片(go切片是披着值类型外衣的引用类型)
|
||||
|
||||
```go
|
||||
func partition(s string) [][]string {
|
||||
var tmpString []string//切割字符串集合
|
||||
var res [][]string//结果集合
|
||||
backTracking(s,tmpString,0,&res)
|
||||
return res
|
||||
}
|
||||
func backTracking(s string,tmpString []string,startIndex int,res *[][]string){
|
||||
if startIndex==len(s){//到达字符串末尾了
|
||||
//进行一次切片拷贝,怕之后的操作影响tmpString切片内的值
|
||||
t := make([]string, len(tmpString))
|
||||
copy(t, tmpString)
|
||||
*res=append(*res,t)
|
||||
}
|
||||
for i:=startIndex;i<len(s);i++{
|
||||
//处理(首先通过startIndex和i判断切割的区间,进而判断该区间的字符串是否为回文,若为回文,则加入到tmpString,否则继续后移,找到回文区间)(这里为一层处理)
|
||||
if isPartition(s,startIndex,i){
|
||||
tmpString=append(tmpString,s[startIndex:i+1])
|
||||
}else{
|
||||
continue
|
||||
}
|
||||
//递归
|
||||
backTracking(s,tmpString,i+1,res)
|
||||
//回溯
|
||||
tmpString=tmpString[:len(tmpString)-1]
|
||||
}
|
||||
}
|
||||
//判断是否为回文
|
||||
func isPartition(s string,startIndex,end int)bool{
|
||||
left:=startIndex
|
||||
right:=end
|
||||
for ;left<right;{
|
||||
if s[left]!=s[right]{
|
||||
return false
|
||||
}
|
||||
//移动左右指针
|
||||
left++
|
||||
right--
|
||||
}
|
||||
return true
|
||||
}
|
||||
```
|
||||
|
||||
javaScript:
|
||||
|
||||
```js
|
||||
/**
|
||||
* @param {string} s
|
||||
* @return {string[][]}
|
||||
*/
|
||||
const isPalindrome = (s, l, r) => {
|
||||
for (let i = l, j = r; i < j; i++, j--) {
|
||||
if(s[i] !== s[j]) return false;
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
var partition = function(s) {
|
||||
const res = [], path = [], len = s.length;
|
||||
backtracking(0);
|
||||
return res;
|
||||
function backtracking(i) {
|
||||
if(i >= len) {
|
||||
res.push(Array.from(path));
|
||||
return;
|
||||
}
|
||||
for(let j = i; j < len; j++) {
|
||||
if(!isPalindrome(s, i, j)) continue;
|
||||
path.push(s.substr(i, j - i + 1));
|
||||
backtracking(j + 1);
|
||||
path.pop();
|
||||
}
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
291
problems/0134.加油站.md
Normal file
291
problems/0134.加油站.md
Normal file
@@ -0,0 +1,291 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 134. 加油站
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/gas-station/
|
||||
|
||||
在一条环路上有 N 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
|
||||
|
||||
你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
|
||||
|
||||
如果你可以绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1。
|
||||
|
||||
说明:
|
||||
|
||||
* 如果题目有解,该答案即为唯一答案。
|
||||
* 输入数组均为非空数组,且长度相同。
|
||||
* 输入数组中的元素均为非负数。
|
||||
|
||||
示例 1:
|
||||
输入:
|
||||
gas = [1,2,3,4,5]
|
||||
cost = [3,4,5,1,2]
|
||||
|
||||
输出: 3
|
||||
解释:
|
||||
从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油
|
||||
开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油
|
||||
开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油
|
||||
开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油
|
||||
开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油
|
||||
开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。
|
||||
因此,3 可为起始索引。
|
||||
|
||||
示例 2:
|
||||
输入:
|
||||
gas = [2,3,4]
|
||||
cost = [3,4,3]
|
||||
|
||||
输出: -1
|
||||
解释:
|
||||
你不能从 0 号或 1 号加油站出发,因为没有足够的汽油可以让你行驶到下一个加油站。
|
||||
我们从 2 号加油站出发,可以获得 4 升汽油。 此时油箱有 = 0 + 4 = 4 升汽油
|
||||
开往 0 号加油站,此时油箱有 4 - 3 + 2 = 3 升汽油
|
||||
开往 1 号加油站,此时油箱有 3 - 3 + 3 = 3 升汽油
|
||||
你无法返回 2 号加油站,因为返程需要消耗 4 升汽油,但是你的油箱只有 3 升汽油。
|
||||
因此,无论怎样,你都不可能绕环路行驶一周。
|
||||
|
||||
|
||||
## 暴力方法
|
||||
|
||||
暴力的方法很明显就是O(n^2)的,遍历每一个加油站为起点的情况,模拟一圈。
|
||||
|
||||
如果跑了一圈,中途没有断油,而且最后油量大于等于0,说明这个起点是ok的。
|
||||
|
||||
暴力的方法思路比较简单,但代码写起来也不是很容易,关键是要模拟跑一圈的过程。
|
||||
|
||||
**for循环适合模拟从头到尾的遍历,而while循环适合模拟环形遍历,要善于使用while!**
|
||||
|
||||
C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {
|
||||
for (int i = 0; i < cost.size(); i++) {
|
||||
int rest = gas[i] - cost[i]; // 记录剩余油量
|
||||
int index = (i + 1) % cost.size();
|
||||
while (rest > 0 && index != i) { // 模拟以i为起点行驶一圈
|
||||
rest += gas[index] - cost[index];
|
||||
index = (index + 1) % cost.size();
|
||||
}
|
||||
// 如果以i为起点跑一圈,剩余油量>=0,返回该起始位置
|
||||
if (rest >= 0 && index == i) return i;
|
||||
}
|
||||
return -1;
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度O(n^2)
|
||||
* 空间复杂度O(n)
|
||||
|
||||
C++暴力解法在leetcode上提交也可以过。
|
||||
|
||||
## 贪心算法(方法一)
|
||||
|
||||
直接从全局进行贪心选择,情况如下:
|
||||
|
||||
* 情况一:如果gas的总和小于cost总和,那么无论从哪里出发,一定是跑不了一圈的
|
||||
* 情况二:rest[i] = gas[i]-cost[i]为一天剩下的油,i从0开始计算累加到最后一站,如果累加没有出现负数,说明从0出发,油就没有断过,那么0就是起点。
|
||||
|
||||
* 情况三:如果累加的最小值是负数,汽车就要从非0节点出发,从后向前,看哪个节点能这个负数填平,能把这个负数填平的节点就是出发节点。
|
||||
|
||||
C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {
|
||||
int curSum = 0;
|
||||
int min = INT_MAX; // 从起点出发,油箱里的油量最小值
|
||||
for (int i = 0; i < gas.size(); i++) {
|
||||
int rest = gas[i] - cost[i];
|
||||
curSum += rest;
|
||||
if (curSum < min) {
|
||||
min = curSum;
|
||||
}
|
||||
}
|
||||
if (curSum < 0) return -1; // 情况1
|
||||
if (min >= 0) return 0; // 情况2
|
||||
// 情况3
|
||||
for (int i = gas.size() - 1; i >= 0; i--) {
|
||||
int rest = gas[i] - cost[i];
|
||||
min += rest;
|
||||
if (min >= 0) {
|
||||
return i;
|
||||
}
|
||||
}
|
||||
return -1;
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度:O(n)
|
||||
* 空间复杂度:O(1)
|
||||
|
||||
**其实我不认为这种方式是贪心算法,因为没有找出局部最优,而是直接从全局最优的角度上思考问题**。
|
||||
|
||||
但这种解法又说不出是什么方法,这就是一个从全局角度选取最优解的模拟操作。
|
||||
|
||||
所以对于本解法是贪心,我持保留意见!
|
||||
|
||||
但不管怎么说,解法毕竟还是巧妙的,不用过于执着于其名字称呼。
|
||||
|
||||
## 贪心算法(方法二)
|
||||
|
||||
可以换一个思路,首先如果总油量减去总消耗大于等于零那么一定可以跑完一圈,说明 各个站点的加油站 剩油量rest[i]相加一定是大于等于零的。
|
||||
|
||||
每个加油站的剩余量rest[i]为gas[i] - cost[i]。
|
||||
|
||||
i从0开始累加rest[i],和记为curSum,一旦curSum小于零,说明[0, i]区间都不能作为起始位置,起始位置从i+1算起,再从0计算curSum。
|
||||
|
||||
如图:
|
||||
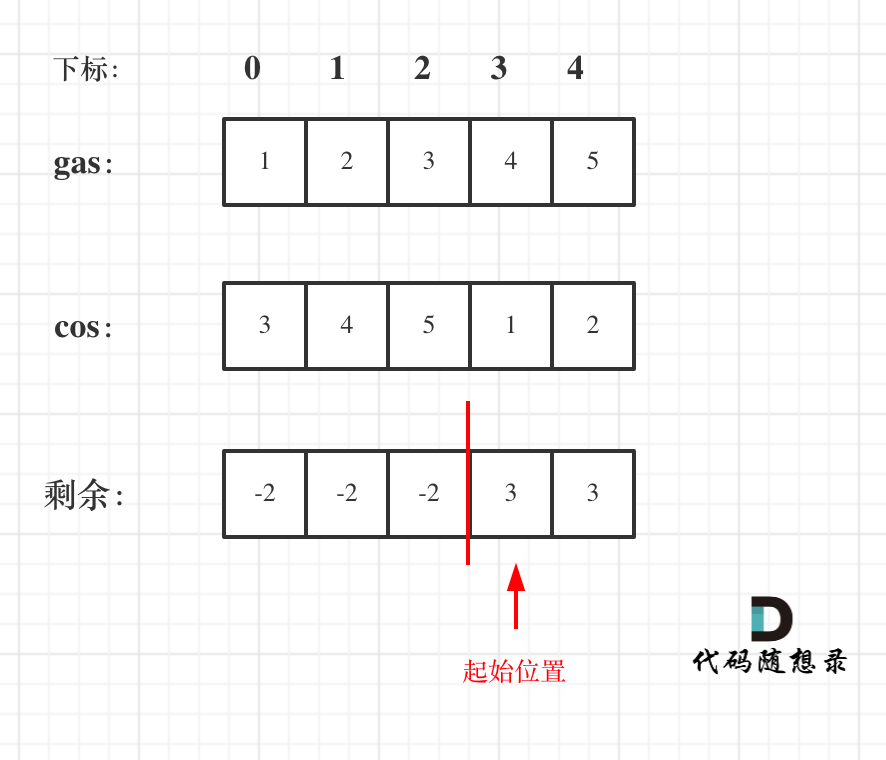
|
||||
|
||||
那么为什么一旦[i,j] 区间和为负数,起始位置就可以是j+1呢,j+1后面就不会出现更大的负数?
|
||||
|
||||
如果出现更大的负数,就是更新j,那么起始位置又变成新的j+1了。
|
||||
|
||||
而且j之前出现了多少负数,j后面就会出现多少正数,因为耗油总和是大于零的(前提我们已经确定了一定可以跑完全程)。
|
||||
|
||||
**那么局部最优:当前累加rest[j]的和curSum一旦小于0,起始位置至少要是j+1,因为从j开始一定不行。全局最优:找到可以跑一圈的起始位置**。
|
||||
|
||||
局部最优可以推出全局最优,找不出反例,试试贪心!
|
||||
|
||||
C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {
|
||||
int curSum = 0;
|
||||
int totalSum = 0;
|
||||
int start = 0;
|
||||
for (int i = 0; i < gas.size(); i++) {
|
||||
curSum += gas[i] - cost[i];
|
||||
totalSum += gas[i] - cost[i];
|
||||
if (curSum < 0) { // 当前累加rest[i]和 curSum一旦小于0
|
||||
start = i + 1; // 起始位置更新为i+1
|
||||
curSum = 0; // curSum从0开始
|
||||
}
|
||||
}
|
||||
if (totalSum < 0) return -1; // 说明怎么走都不可能跑一圈了
|
||||
return start;
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度:O(n)
|
||||
* 空间复杂度:O(1)
|
||||
|
||||
**说这种解法为贪心算法,才是是有理有据的,因为全局最优解是根据局部最优推导出来的**。
|
||||
|
||||
## 总结
|
||||
|
||||
对于本题首先给出了暴力解法,暴力解法模拟跑一圈的过程其实比较考验代码技巧的,要对while使用的很熟练。
|
||||
|
||||
然后给出了两种贪心算法,对于第一种贪心方法,其实我认为就是一种直接从全局选取最优的模拟操作,思路还是好巧妙的,值得学习一下。
|
||||
|
||||
对于第二种贪心方法,才真正体现出贪心的精髓,用局部最优可以推出全局最优,进而求得起始位置。
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
public int canCompleteCircuit(int[] gas, int[] cost) {
|
||||
int sum = 0;
|
||||
int min = 0;
|
||||
for (int i = 0; i < gas.length; i++) {
|
||||
sum += (gas[i] - cost[i]);
|
||||
min = Math.min(sum, min);
|
||||
}
|
||||
|
||||
if (sum < 0) return -1;
|
||||
if (min >= 0) return 0;
|
||||
|
||||
for (int i = gas.length - 1; i > 0; i--) {
|
||||
min += (gas[i] - cost[i]);
|
||||
if (min >= 0) return i;
|
||||
}
|
||||
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def canCompleteCircuit(self, gas: List[int], cost: List[int]) -> int:
|
||||
start = 0
|
||||
curSum = 0
|
||||
totalSum = 0
|
||||
for i in range(len(gas)):
|
||||
curSum += gas[i] - cost[i]
|
||||
totalSum += gas[i] - cost[i]
|
||||
if curSum < 0:
|
||||
curSum = 0
|
||||
start = i + 1
|
||||
if totalSum < 0: return -1
|
||||
return start
|
||||
```
|
||||
|
||||
Go:
|
||||
```go
|
||||
func canCompleteCircuit(gas []int, cost []int) int {
|
||||
curSum := 0
|
||||
totalSum := 0
|
||||
start := 0
|
||||
for i := 0; i < len(gas); i++ {
|
||||
curSum += gas[i] - cost[i]
|
||||
totalSum += gas[i] - cost[i]
|
||||
if curSum < 0 {
|
||||
start = i+1
|
||||
curSum = 0
|
||||
}
|
||||
}
|
||||
if totalSum < 0 {
|
||||
return -1
|
||||
}
|
||||
return start
|
||||
}
|
||||
```
|
||||
|
||||
Javascript:
|
||||
```Javascript
|
||||
var canCompleteCircuit = function(gas, cost) {
|
||||
const gasLen = gas.length
|
||||
let start = 0
|
||||
let curSum = 0
|
||||
let totalSum = 0
|
||||
|
||||
for(let i = 0; i < gasLen; i++) {
|
||||
curSum += gas[i] - cost[i]
|
||||
totalSum += gas[i] - cost[i]
|
||||
if(curSum < 0) {
|
||||
curSum = 0
|
||||
start = i + 1
|
||||
}
|
||||
}
|
||||
|
||||
if(totalSum < 0) return -1
|
||||
|
||||
return start
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
209
problems/0135.分发糖果.md
Normal file
209
problems/0135.分发糖果.md
Normal file
@@ -0,0 +1,209 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 135. 分发糖果
|
||||
|
||||
链接:https://leetcode-cn.com/problems/candy/
|
||||
|
||||
老师想给孩子们分发糖果,有 N 个孩子站成了一条直线,老师会根据每个孩子的表现,预先给他们评分。
|
||||
|
||||
你需要按照以下要求,帮助老师给这些孩子分发糖果:
|
||||
|
||||
* 每个孩子至少分配到 1 个糖果。
|
||||
* 相邻的孩子中,评分高的孩子必须获得更多的糖果。
|
||||
|
||||
那么这样下来,老师至少需要准备多少颗糖果呢?
|
||||
|
||||
示例 1:
|
||||
输入: [1,0,2]
|
||||
输出: 5
|
||||
解释: 你可以分别给这三个孩子分发 2、1、2 颗糖果。
|
||||
|
||||
示例 2:
|
||||
输入: [1,2,2]
|
||||
输出: 4
|
||||
解释: 你可以分别给这三个孩子分发 1、2、1 颗糖果。
|
||||
第三个孩子只得到 1 颗糖果,这已满足上述两个条件。
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
这道题目一定是要确定一边之后,再确定另一边,例如比较每一个孩子的左边,然后再比较右边,**如果两边一起考虑一定会顾此失彼**。
|
||||
|
||||
|
||||
先确定右边评分大于左边的情况(也就是从前向后遍历)
|
||||
|
||||
此时局部最优:只要右边评分比左边大,右边的孩子就多一个糖果,全局最优:相邻的孩子中,评分高的右孩子获得比左边孩子更多的糖果
|
||||
|
||||
局部最优可以推出全局最优。
|
||||
|
||||
如果ratings[i] > ratings[i - 1] 那么[i]的糖 一定要比[i - 1]的糖多一个,所以贪心:candyVec[i] = candyVec[i - 1] + 1
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
// 从前向后
|
||||
for (int i = 1; i < ratings.size(); i++) {
|
||||
if (ratings[i] > ratings[i - 1]) candyVec[i] = candyVec[i - 1] + 1;
|
||||
}
|
||||
```
|
||||
|
||||
如图:
|
||||
|
||||
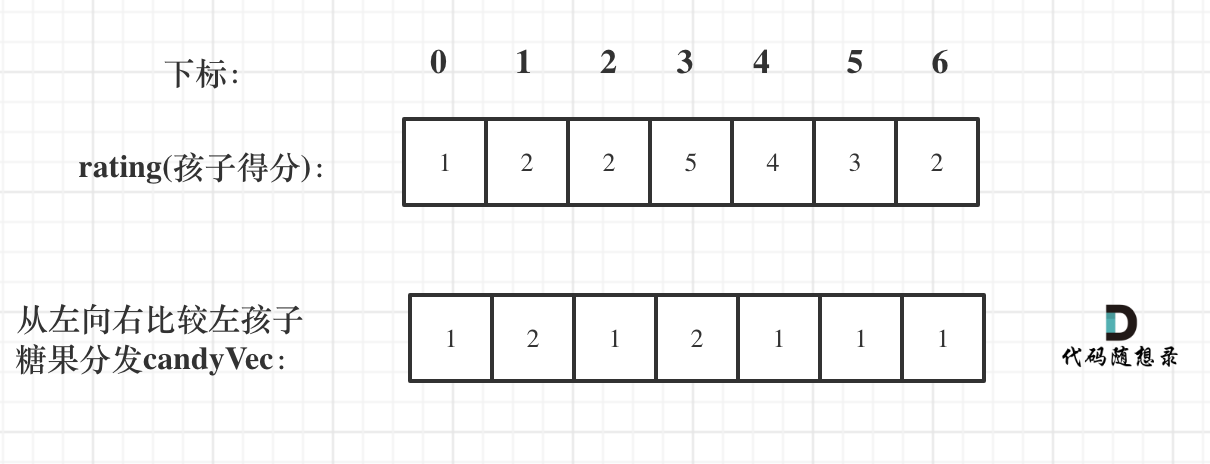
|
||||
|
||||
再确定左孩子大于右孩子的情况(从后向前遍历)
|
||||
|
||||
遍历顺序这里有同学可能会有疑问,为什么不能从前向后遍历呢?
|
||||
|
||||
因为如果从前向后遍历,根据 ratings[i + 1] 来确定 ratings[i] 对应的糖果,那么每次都不能利用上前一次的比较结果了。
|
||||
|
||||
**所以确定左孩子大于右孩子的情况一定要从后向前遍历!**
|
||||
|
||||
如果 ratings[i] > ratings[i + 1],此时candyVec[i](第i个小孩的糖果数量)就有两个选择了,一个是candyVec[i + 1] + 1(从右边这个加1得到的糖果数量),一个是candyVec[i](之前比较右孩子大于左孩子得到的糖果数量)。
|
||||
|
||||
那么又要贪心了,局部最优:取candyVec[i + 1] + 1 和 candyVec[i] 最大的糖果数量,保证第i个小孩的糖果数量即大于左边的也大于右边的。全局最优:相邻的孩子中,评分高的孩子获得更多的糖果。
|
||||
|
||||
局部最优可以推出全局最优。
|
||||
|
||||
所以就取candyVec[i + 1] + 1 和 candyVec[i] 最大的糖果数量,**candyVec[i]只有取最大的才能既保持对左边candyVec[i - 1]的糖果多,也比右边candyVec[i + 1]的糖果多**。
|
||||
|
||||
如图:
|
||||
|
||||
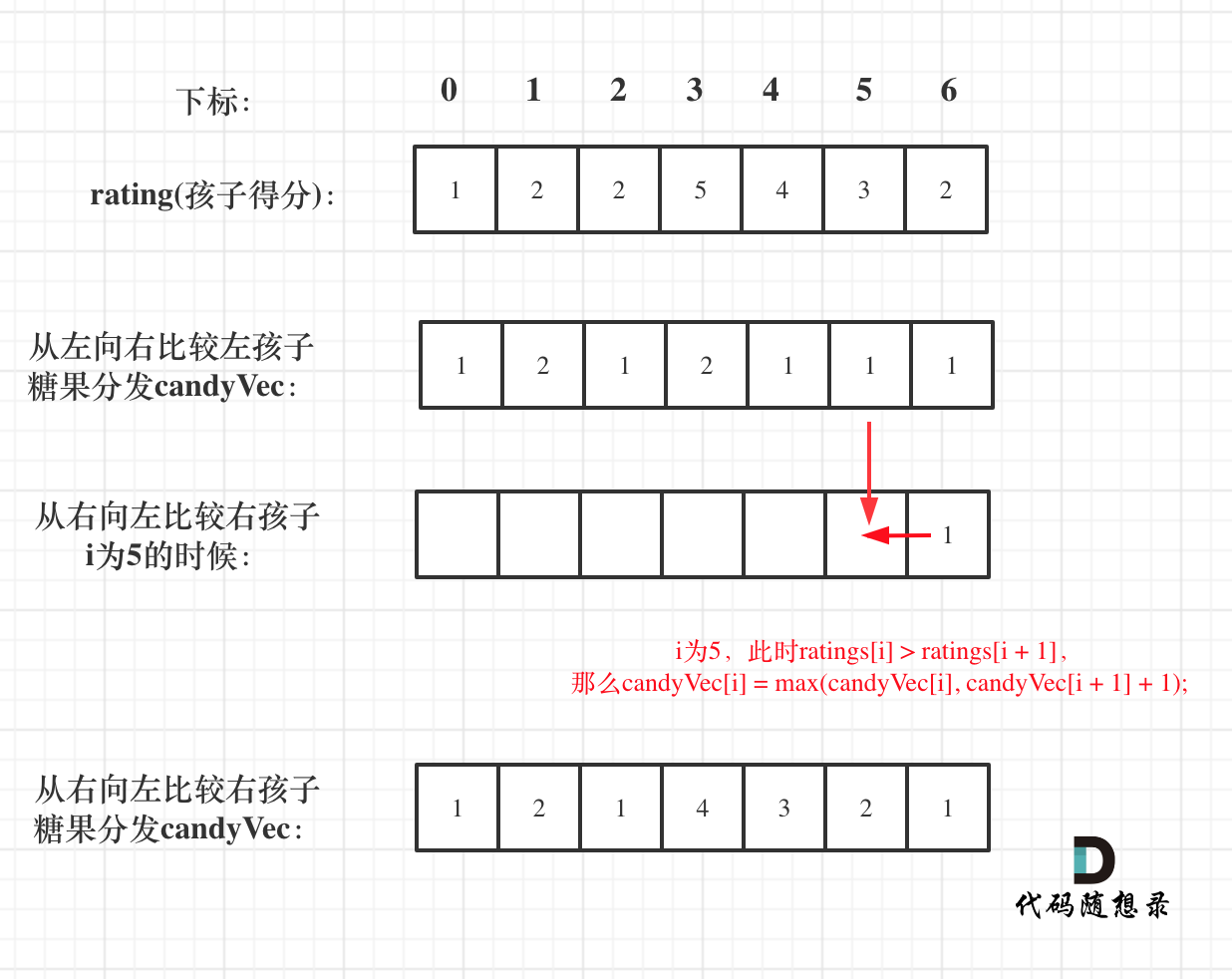
|
||||
|
||||
所以该过程代码如下:
|
||||
|
||||
```C++
|
||||
// 从后向前
|
||||
for (int i = ratings.size() - 2; i >= 0; i--) {
|
||||
if (ratings[i] > ratings[i + 1] ) {
|
||||
candyVec[i] = max(candyVec[i], candyVec[i + 1] + 1);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
整体代码如下:
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int candy(vector<int>& ratings) {
|
||||
vector<int> candyVec(ratings.size(), 1);
|
||||
// 从前向后
|
||||
for (int i = 1; i < ratings.size(); i++) {
|
||||
if (ratings[i] > ratings[i - 1]) candyVec[i] = candyVec[i - 1] + 1;
|
||||
}
|
||||
// 从后向前
|
||||
for (int i = ratings.size() - 2; i >= 0; i--) {
|
||||
if (ratings[i] > ratings[i + 1] ) {
|
||||
candyVec[i] = max(candyVec[i], candyVec[i + 1] + 1);
|
||||
}
|
||||
}
|
||||
// 统计结果
|
||||
int result = 0;
|
||||
for (int i = 0; i < candyVec.size(); i++) result += candyVec[i];
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
这在leetcode上是一道困难的题目,其难点就在于贪心的策略,如果在考虑局部的时候想两边兼顾,就会顾此失彼。
|
||||
|
||||
那么本题我采用了两次贪心的策略:
|
||||
|
||||
* 一次是从左到右遍历,只比较右边孩子评分比左边大的情况。
|
||||
* 一次是从右到左遍历,只比较左边孩子评分比右边大的情况。
|
||||
|
||||
这样从局部最优推出了全局最优,即:相邻的孩子中,评分高的孩子获得更多的糖果。
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
public int candy(int[] ratings) {
|
||||
int[] candy = new int[ratings.length];
|
||||
for (int i = 0; i < candy.length; i++) {
|
||||
candy[i] = 1;
|
||||
}
|
||||
|
||||
for (int i = 1; i < ratings.length; i++) {
|
||||
if (ratings[i] > ratings[i - 1]) {
|
||||
candy[i] = candy[i - 1] + 1;
|
||||
}
|
||||
}
|
||||
|
||||
for (int i = ratings.length - 2; i >= 0; i--) {
|
||||
if (ratings[i] > ratings[i + 1]) {
|
||||
candy[i] = Math.max(candy[i],candy[i + 1] + 1);
|
||||
}
|
||||
}
|
||||
|
||||
int count = 0;
|
||||
for (int i = 0; i < candy.length; i++) {
|
||||
count += candy[i];
|
||||
}
|
||||
|
||||
return count;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def candy(self, ratings: List[int]) -> int:
|
||||
candyVec = [1] * len(ratings)
|
||||
for i in range(1, len(ratings)):
|
||||
if ratings[i] > ratings[i - 1]:
|
||||
candyVec[i] = candyVec[i - 1] + 1
|
||||
for j in range(len(ratings) - 2, -1, -1):
|
||||
if ratings[j] > ratings[j + 1]:
|
||||
candyVec[j] = max(candyVec[j], candyVec[j + 1] + 1)
|
||||
return sum(candyVec)
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
Javascript:
|
||||
```Javascript
|
||||
var candy = function(ratings) {
|
||||
let candys = new Array(ratings.length).fill(1)
|
||||
|
||||
for(let i = 1; i < ratings.length; i++) {
|
||||
if(ratings[i] > ratings[i - 1]) {
|
||||
candys[i] = candys[i - 1] + 1
|
||||
}
|
||||
}
|
||||
|
||||
for(let i = ratings.length - 2; i >= 0; i--) {
|
||||
if(ratings[i] > ratings[i + 1]) {
|
||||
candys[i] = Math.max(candys[i], candys[i + 1] + 1)
|
||||
}
|
||||
}
|
||||
|
||||
let count = candys.reduce((a, b) => {
|
||||
return a + b
|
||||
})
|
||||
|
||||
return count
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
300
problems/0139.单词拆分.md
Normal file
300
problems/0139.单词拆分.md
Normal file
@@ -0,0 +1,300 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
# 动态规划:单词拆分
|
||||
|
||||
## 139.单词拆分
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/word-break/
|
||||
|
||||
给定一个非空字符串 s 和一个包含非空单词的列表 wordDict,判定 s 是否可以被空格拆分为一个或多个在字典中出现的单词。
|
||||
|
||||
说明:
|
||||
|
||||
拆分时可以重复使用字典中的单词。
|
||||
|
||||
你可以假设字典中没有重复的单词。
|
||||
|
||||
示例 1:
|
||||
输入: s = "leetcode", wordDict = ["leet", "code"]
|
||||
输出: true
|
||||
解释: 返回 true 因为 "leetcode" 可以被拆分成 "leet code"。
|
||||
|
||||
示例 2:
|
||||
输入: s = "applepenapple", wordDict = ["apple", "pen"]
|
||||
输出: true
|
||||
解释: 返回 true 因为 "applepenapple" 可以被拆分成 "apple pen apple"。
|
||||
注意你可以重复使用字典中的单词。
|
||||
|
||||
示例 3:
|
||||
输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"]
|
||||
输出: false
|
||||
|
||||
## 思路
|
||||
|
||||
看到这道题目的时候,大家应该回想起我们之前讲解回溯法专题的时候,讲过的一道题目[回溯算法:分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q),就是枚举字符串的所有分割情况。
|
||||
|
||||
[回溯算法:分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q):是枚举分割后的所有子串,判断是否回文。
|
||||
|
||||
本道是枚举分割所有字符串,判断是否在字典里出现过。
|
||||
|
||||
那么这里我也给出回溯法C++代码:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
bool backtracking (const string& s, const unordered_set<string>& wordSet, int startIndex) {
|
||||
if (startIndex >= s.size()) {
|
||||
return true;
|
||||
}
|
||||
for (int i = startIndex; i < s.size(); i++) {
|
||||
string word = s.substr(startIndex, i - startIndex + 1);
|
||||
if (wordSet.find(word) != wordSet.end() && backtracking(s, wordSet, i + 1)) {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
return false;
|
||||
}
|
||||
public:
|
||||
bool wordBreak(string s, vector<string>& wordDict) {
|
||||
unordered_set<string> wordSet(wordDict.begin(), wordDict.end());
|
||||
return backtracking(s, wordSet, 0);
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
* 时间复杂度:O(2^n),因为每一个单词都有两个状态,切割和不切割
|
||||
* 空间复杂度:O(n),算法递归系统调用栈的空间
|
||||
|
||||
那么以上代码很明显要超时了,超时的数据如下:
|
||||
|
||||
```
|
||||
"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaab"
|
||||
["a","aa","aaa","aaaa","aaaaa","aaaaaa","aaaaaaa","aaaaaaaa","aaaaaaaaa","aaaaaaaaaa"]
|
||||
```
|
||||
|
||||
递归的过程中有很多重复计算,可以使用数组保存一下递归过程中计算的结果。
|
||||
|
||||
这个叫做记忆化递归,这种方法我们之前已经提过很多次了。
|
||||
|
||||
使用memory数组保存每次计算的以startIndex起始的计算结果,如果memory[startIndex]里已经被赋值了,直接用memory[startIndex]的结果。
|
||||
|
||||
C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
bool backtracking (const string& s,
|
||||
const unordered_set<string>& wordSet,
|
||||
vector<int>& memory,
|
||||
int startIndex) {
|
||||
if (startIndex >= s.size()) {
|
||||
return true;
|
||||
}
|
||||
// 如果memory[startIndex]不是初始值了,直接使用memory[startIndex]的结果
|
||||
if (memory[startIndex] != -1) return memory[startIndex];
|
||||
for (int i = startIndex; i < s.size(); i++) {
|
||||
string word = s.substr(startIndex, i - startIndex + 1);
|
||||
if (wordSet.find(word) != wordSet.end() && backtracking(s, wordSet, memory, i + 1)) {
|
||||
memory[startIndex] = 1; // 记录以startIndex开始的子串是可以被拆分的
|
||||
return true;
|
||||
}
|
||||
}
|
||||
memory[startIndex] = 0; // 记录以startIndex开始的子串是不可以被拆分的
|
||||
return false;
|
||||
}
|
||||
public:
|
||||
bool wordBreak(string s, vector<string>& wordDict) {
|
||||
unordered_set<string> wordSet(wordDict.begin(), wordDict.end());
|
||||
vector<int> memory(s.size(), -1); // -1 表示初始化状态
|
||||
return backtracking(s, wordSet, memory, 0);
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
这个时间复杂度其实也是:O(2^n)。只不过对于上面那个超时测试用例优化效果特别明显。
|
||||
|
||||
**这个代码就可以AC了,当然回溯算法不是本题的主菜,背包才是!**
|
||||
|
||||
## 背包问题
|
||||
|
||||
单词就是物品,字符串s就是背包,单词能否组成字符串s,就是问物品能不能把背包装满。
|
||||
|
||||
拆分时可以重复使用字典中的单词,说明就是一个完全背包!
|
||||
|
||||
动规五部曲分析如下:
|
||||
|
||||
1. 确定dp数组以及下标的含义
|
||||
|
||||
**dp[i] : 字符串长度为i的话,dp[i]为true,表示可以拆分为一个或多个在字典中出现的单词**。
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
如果确定dp[j] 是true,且 [j, i] 这个区间的子串出现在字典里,那么dp[i]一定是true。(j < i )。
|
||||
|
||||
所以递推公式是 if([j, i] 这个区间的子串出现在字典里 && dp[j]是true) 那么 dp[i] = true。
|
||||
|
||||
3. dp数组如何初始化
|
||||
|
||||
从递归公式中可以看出,dp[i] 的状态依靠 dp[j]是否为true,那么dp[0]就是递归的根基,dp[0]一定要为true,否则递归下去后面都都是false了。
|
||||
|
||||
那么dp[0]有没有意义呢?
|
||||
|
||||
dp[0]表示如果字符串为空的话,说明出现在字典里。
|
||||
|
||||
但题目中说了“给定一个非空字符串 s” 所以测试数据中不会出现i为0的情况,那么dp[0]初始为true完全就是为了推导公式。
|
||||
|
||||
下标非0的dp[i]初始化为false,只要没有被覆盖说明都是不可拆分为一个或多个在字典中出现的单词。
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
题目中说是拆分为一个或多个在字典中出现的单词,所以这是完全背包。
|
||||
|
||||
还要讨论两层for循环的前后循序。
|
||||
|
||||
**如果求组合数就是外层for循环遍历物品,内层for遍历背包**。
|
||||
|
||||
**如果求排列数就是外层for遍历背包,内层for循环遍历物品**。
|
||||
|
||||
对这个结论还有疑问的同学可以看这篇[本周小结!(动态规划系列五)](https://mp.weixin.qq.com/s/znj-9j8mWymRFaPjJN2Qnw),这篇本周小节中,我做了如下总结:
|
||||
|
||||
求组合数:[动态规划:518.零钱兑换II](https://mp.weixin.qq.com/s/PlowDsI4WMBOzf3q80AksQ)
|
||||
求排列数:[动态规划:377. 组合总和 Ⅳ](https://mp.weixin.qq.com/s/Iixw0nahJWQgbqVNk8k6gA)、[动态规划:70. 爬楼梯进阶版(完全背包)](https://mp.weixin.qq.com/s/e_wacnELo-2PG76EjrUakA)
|
||||
求最小数:[动态规划:322. 零钱兑换](https://mp.weixin.qq.com/s/dyk-xNilHzNtVdPPLObSeQ)、[动态规划:279.完全平方数](https://mp.weixin.qq.com/s/VfJT78p7UGpDZsapKF_QJQ)
|
||||
|
||||
本题最终要求的是是否都出现过,所以对出现单词集合里的元素是组合还是排列,并不在意!
|
||||
|
||||
**那么本题使用求排列的方式,还是求组合的方式都可以**。
|
||||
|
||||
即:外层for循环遍历物品,内层for遍历背包 或者 外层for遍历背包,内层for循环遍历物品 都是可以的。
|
||||
|
||||
但本题还有特殊性,因为是要求子串,最好是遍历背包放在外循环,将遍历物品放在内循环。
|
||||
|
||||
如果要是外层for循环遍历物品,内层for遍历背包,就需要把所有的子串都预先放在一个容器里。(如果不理解的话,可以自己尝试这么写一写就理解了)
|
||||
|
||||
**所以最终我选择的遍历顺序为:遍历背包放在外循环,将遍历物品放在内循环。内循环从前到后**。
|
||||
|
||||
|
||||
5. 举例推导dp[i]
|
||||
|
||||
以输入: s = "leetcode", wordDict = ["leet", "code"]为例,dp状态如图:
|
||||
|
||||
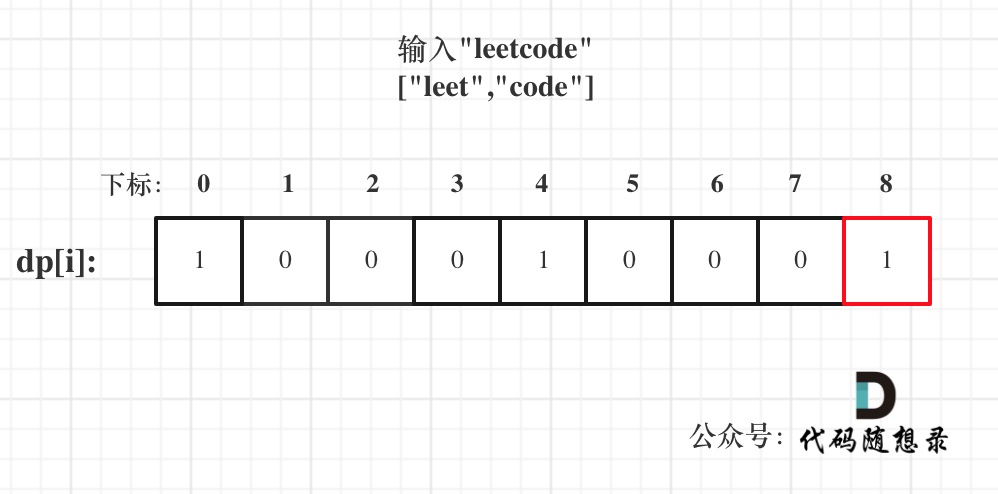
|
||||
|
||||
dp[s.size()]就是最终结果。
|
||||
|
||||
动规五部曲分析完毕,C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
bool wordBreak(string s, vector<string>& wordDict) {
|
||||
unordered_set<string> wordSet(wordDict.begin(), wordDict.end());
|
||||
vector<bool> dp(s.size() + 1, false);
|
||||
dp[0] = true;
|
||||
for (int i = 1; i <= s.size(); i++) { // 遍历背包
|
||||
for (int j = 0; j < i; j++) { // 遍历物品
|
||||
string word = s.substr(j, i - j); //substr(起始位置,截取的个数)
|
||||
if (wordSet.find(word) != wordSet.end() && dp[j]) {
|
||||
dp[i] = true;
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[s.size()];
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度:O(n^3),因为substr返回子串的副本是O(n)的复杂度(这里的n是substring的长度)
|
||||
* 空间复杂度:O(n)
|
||||
|
||||
|
||||
## 总结
|
||||
|
||||
本题和我们之前讲解回溯专题的[回溯算法:分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)非常像,所以我也给出了对应的回溯解法。
|
||||
|
||||
稍加分析,便可知道本题是完全背包,而且是求能否组成背包,所以遍历顺序理论上来讲 两层for循环谁先谁后都可以!
|
||||
|
||||
但因为分割子串的特殊性,遍历背包放在外循环,将遍历物品放在内循环更方便一些。
|
||||
|
||||
本题其实递推公式都不是重点,遍历顺序才是重点,如果我直接把代码贴出来,估计同学们也会想两个for循环的顺序理所当然就是这样,甚至都不会想为什么遍历背包的for循环为什么在外层。
|
||||
|
||||
不分析透彻不是Carl的风格啊,哈哈
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
public boolean wordBreak(String s, List<String> wordDict) {
|
||||
boolean[] valid = new boolean[s.length() + 1];
|
||||
valid[0] = true;
|
||||
for (int i = 1; i <= s.length(); i++) {
|
||||
for (int j = 0; j < i; j++) {
|
||||
if (wordDict.contains(s.substring(j,i)) && valid[j]) {
|
||||
valid[i] = true;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return valid[s.length()];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
```python3
|
||||
class Solution:
|
||||
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
|
||||
'''排列'''
|
||||
dp = [False]*(len(s) + 1)
|
||||
dp[0] = True
|
||||
# 遍历背包
|
||||
for j in range(1, len(s) + 1):
|
||||
# 遍历单词
|
||||
for word in wordDict:
|
||||
if j >= len(word):
|
||||
dp[j] = dp[j] or (dp[j - len(word)] and word == s[j - len(word):j])
|
||||
return dp[len(s)]
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
Go:
|
||||
```Go
|
||||
func wordBreak(s string,wordDict []string) bool {
|
||||
wordDictSet:=make(map[string]bool)
|
||||
for _,w:=range wordDict{
|
||||
wordDictSet[w]=true
|
||||
}
|
||||
dp:=make([]bool,len(s)+1)
|
||||
dp[0]=true
|
||||
for i:=1;i<=len(s);i++{
|
||||
for j:=0;j<i;j++{
|
||||
if dp[j]&& wordDictSet[s[j:i]]{
|
||||
dp[i]=true
|
||||
break
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[len(s)]
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
304
problems/0142.环形链表II.md
Normal file
304
problems/0142.环形链表II.md
Normal file
@@ -0,0 +1,304 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
|
||||
> 找到有没有环已经很不容易了,还要让我找到环的入口?
|
||||
|
||||
|
||||
## 142.环形链表II
|
||||
|
||||
https://leetcode-cn.com/problems/linked-list-cycle-ii/
|
||||
|
||||
题意:
|
||||
给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
|
||||
|
||||
为了表示给定链表中的环,使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
|
||||
|
||||
**说明**:不允许修改给定的链表。
|
||||
|
||||
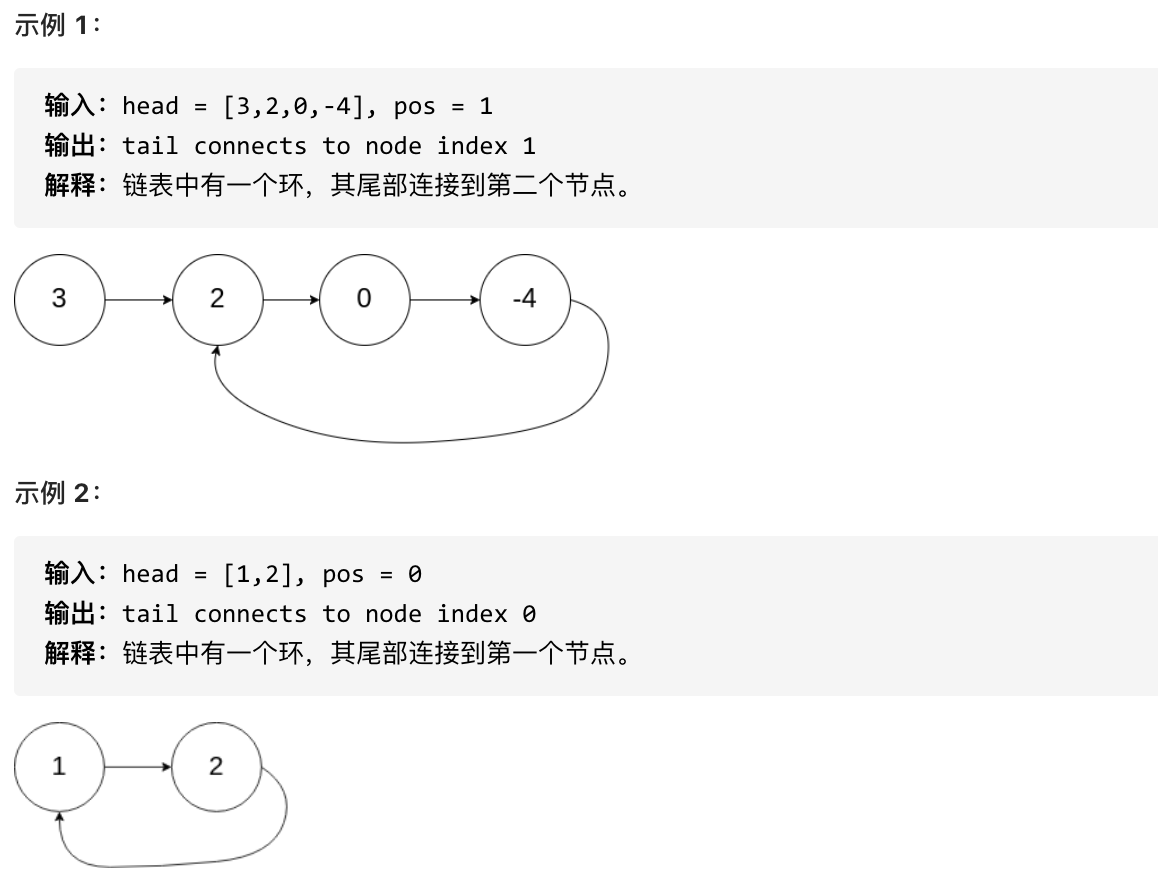
|
||||
|
||||
## 思路
|
||||
|
||||
这道题目,不仅考察对链表的操作,而且还需要一些数学运算。
|
||||
|
||||
主要考察两知识点:
|
||||
|
||||
* 判断链表是否环
|
||||
* 如果有环,如何找到这个环的入口
|
||||
|
||||
### 判断链表是否有环
|
||||
|
||||
可以使用快慢指针法, 分别定义 fast 和 slow指针,从头结点出发,fast指针每次移动两个节点,slow指针每次移动一个节点,如果 fast 和 slow指针在途中相遇 ,说明这个链表有环。
|
||||
|
||||
为什么fast 走两个节点,slow走一个节点,有环的话,一定会在环内相遇呢,而不是永远的错开呢
|
||||
|
||||
首先第一点: **fast指针一定先进入环中,如果fast 指针和slow指针相遇的话,一定是在环中相遇,这是毋庸置疑的。**
|
||||
|
||||
那么来看一下,**为什么fast指针和slow指针一定会相遇呢?**
|
||||
|
||||
可以画一个环,然后让 fast指针在任意一个节点开始追赶slow指针。
|
||||
|
||||
会发现最终都是这种情况, 如下图:
|
||||
|
||||
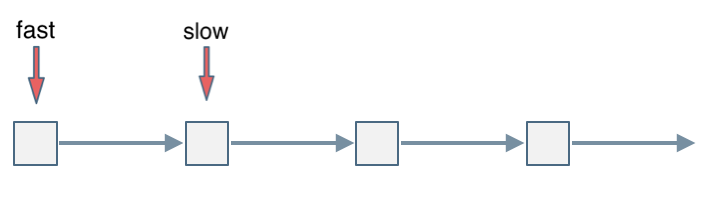
|
||||
|
||||
|
||||
fast和slow各自再走一步, fast和slow就相遇了
|
||||
|
||||
这是因为fast是走两步,slow是走一步,**其实相对于slow来说,fast是一个节点一个节点的靠近slow的**,所以fast一定可以和slow重合。
|
||||
|
||||
动画如下:
|
||||
|
||||

|
||||
|
||||
|
||||
### 如果有环,如何找到这个环的入口
|
||||
|
||||
**此时已经可以判断链表是否有环了,那么接下来要找这个环的入口了。**
|
||||
|
||||
假设从头结点到环形入口节点 的节点数为x。
|
||||
环形入口节点到 fast指针与slow指针相遇节点 节点数为y。
|
||||
从相遇节点 再到环形入口节点节点数为 z。 如图所示:
|
||||
|
||||
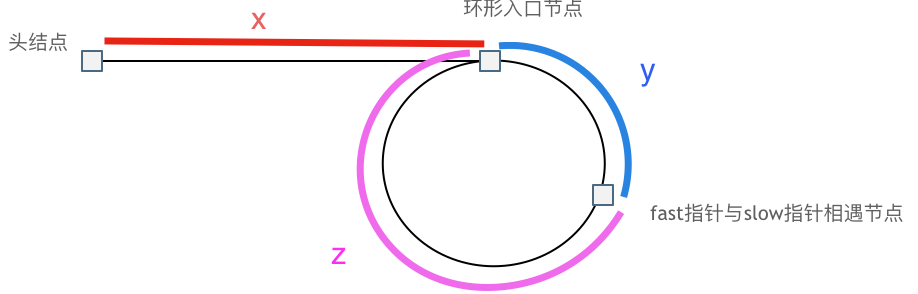
|
||||
|
||||
那么相遇时:
|
||||
slow指针走过的节点数为: `x + y`,
|
||||
fast指针走过的节点数:` x + y + n (y + z)`,n为fast指针在环内走了n圈才遇到slow指针, (y+z)为 一圈内节点的个数A。
|
||||
|
||||
因为fast指针是一步走两个节点,slow指针一步走一个节点, 所以 fast指针走过的节点数 = slow指针走过的节点数 * 2:
|
||||
|
||||
`(x + y) * 2 = x + y + n (y + z)`
|
||||
|
||||
两边消掉一个(x+y): `x + y = n (y + z) `
|
||||
|
||||
因为要找环形的入口,那么要求的是x,因为x表示 头结点到 环形入口节点的的距离。
|
||||
|
||||
所以要求x ,将x单独放在左面:`x = n (y + z) - y` ,
|
||||
|
||||
再从n(y+z)中提出一个 (y+z)来,整理公式之后为如下公式:`x = (n - 1) (y + z) + z ` 注意这里n一定是大于等于1的,因为 fast指针至少要多走一圈才能相遇slow指针。
|
||||
|
||||
这个公式说明什么呢?
|
||||
|
||||
先拿n为1的情况来举例,意味着fast指针在环形里转了一圈之后,就遇到了 slow指针了。
|
||||
|
||||
当 n为1的时候,公式就化解为 `x = z`,
|
||||
|
||||
这就意味着,**从头结点出发一个指针,从相遇节点 也出发一个指针,这两个指针每次只走一个节点, 那么当这两个指针相遇的时候就是 环形入口的节点**。
|
||||
|
||||
|
||||
也就是在相遇节点处,定义一个指针index1,在头结点处定一个指针index2。
|
||||
|
||||
让index1和index2同时移动,每次移动一个节点, 那么他们相遇的地方就是 环形入口的节点。
|
||||
|
||||
动画如下:
|
||||
|
||||

|
||||
|
||||
|
||||
那么 n如果大于1是什么情况呢,就是fast指针在环形转n圈之后才遇到 slow指针。
|
||||
|
||||
其实这种情况和n为1的时候 效果是一样的,一样可以通过这个方法找到 环形的入口节点,只不过,index1 指针在环里 多转了(n-1)圈,然后再遇到index2,相遇点依然是环形的入口节点。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
/**
|
||||
* Definition for singly-linked list.
|
||||
* struct ListNode {
|
||||
* int val;
|
||||
* ListNode *next;
|
||||
* ListNode(int x) : val(x), next(NULL) {}
|
||||
* };
|
||||
*/
|
||||
class Solution {
|
||||
public:
|
||||
ListNode *detectCycle(ListNode *head) {
|
||||
ListNode* fast = head;
|
||||
ListNode* slow = head;
|
||||
while(fast != NULL && fast->next != NULL) {
|
||||
slow = slow->next;
|
||||
fast = fast->next->next;
|
||||
// 快慢指针相遇,此时从head 和 相遇点,同时查找直至相遇
|
||||
if (slow == fast) {
|
||||
ListNode* index1 = fast;
|
||||
ListNode* index2 = head;
|
||||
while (index1 != index2) {
|
||||
index1 = index1->next;
|
||||
index2 = index2->next;
|
||||
}
|
||||
return index2; // 返回环的入口
|
||||
}
|
||||
}
|
||||
return NULL;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 补充
|
||||
|
||||
在推理过程中,大家可能有一个疑问就是:**为什么第一次在环中相遇,slow的 步数 是 x+y 而不是 x + 若干环的长度 + y 呢?**
|
||||
|
||||
即文章[链表:环找到了,那入口呢?](https://mp.weixin.qq.com/s/_QVP3IkRZWx9zIpQRgajzA)中如下的地方:
|
||||
|
||||

|
||||
|
||||
|
||||
首先slow进环的时候,fast一定是先进环来了。
|
||||
|
||||
如果slow进环入口,fast也在环入口,那么把这个环展开成直线,就是如下图的样子:
|
||||
|
||||

|
||||
|
||||
可以看出如果slow 和 fast同时在环入口开始走,一定会在环入口3相遇,slow走了一圈,fast走了两圈。
|
||||
|
||||
重点来了,slow进环的时候,fast一定是在环的任意一个位置,如图:
|
||||
|
||||

|
||||
|
||||
那么fast指针走到环入口3的时候,已经走了k + n 个节点,slow相应的应该走了(k + n) / 2 个节点。
|
||||
|
||||
因为k是小于n的(图中可以看出),所以(k + n) / 2 一定小于n。
|
||||
|
||||
**也就是说slow一定没有走到环入口3,而fast已经到环入口3了**。
|
||||
|
||||
这说明什么呢?
|
||||
|
||||
**在slow开始走的那一环已经和fast相遇了**。
|
||||
|
||||
那有同学又说了,为什么fast不能跳过去呢? 在刚刚已经说过一次了,**fast相对于slow是一次移动一个节点,所以不可能跳过去**。
|
||||
|
||||
好了,这次把为什么第一次在环中相遇,slow的 步数 是 x+y 而不是 x + 若干环的长度 + y ,用数学推理了一下,算是对[链表:环找到了,那入口呢?](https://mp.weixin.qq.com/s/_QVP3IkRZWx9zIpQRgajzA)的补充。
|
||||
|
||||
## 总结
|
||||
|
||||
这次可以说把环形链表这道题目的各个细节,完完整整的证明了一遍,说这是全网最详细讲解不为过吧,哈哈。
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
public class Solution {
|
||||
public ListNode detectCycle(ListNode head) {
|
||||
ListNode slow = head;
|
||||
ListNode fast = head;
|
||||
while (fast != null && fast.next != null) {
|
||||
slow = slow.next;
|
||||
fast = fast.next.next;
|
||||
if (slow == fast) {// 有环
|
||||
ListNode index1 = fast;
|
||||
ListNode index2 = head;
|
||||
// 两个指针,从头结点和相遇结点,各走一步,直到相遇,相遇点即为环入口
|
||||
while (index1 != index2) {
|
||||
index1 = index1.next;
|
||||
index2 = index2.next;
|
||||
}
|
||||
return index1;
|
||||
}
|
||||
}
|
||||
return null;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
Python:
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def detectCycle(self, head: ListNode) -> ListNode:
|
||||
slow, fast = head, head
|
||||
while fast and fast.next:
|
||||
slow = slow.next
|
||||
fast = fast.next.next
|
||||
# 如果相遇
|
||||
if slow == fast:
|
||||
p = head
|
||||
q = slow
|
||||
while p!=q:
|
||||
p = p.next
|
||||
q = q.next
|
||||
#你也可以return q
|
||||
return p
|
||||
|
||||
return None
|
||||
```
|
||||
|
||||
Go:
|
||||
```go
|
||||
func detectCycle(head *ListNode) *ListNode {
|
||||
slow, fast := head, head
|
||||
for fast != nil && fast.Next != nil {
|
||||
slow = slow.Next
|
||||
fast = fast.Next.Next
|
||||
if slow == fast {
|
||||
for slow != head {
|
||||
slow = slow.Next
|
||||
head = head.Next
|
||||
}
|
||||
return head
|
||||
}
|
||||
}
|
||||
return nil
|
||||
}
|
||||
```
|
||||
|
||||
javaScript
|
||||
|
||||
```js
|
||||
// 两种循环实现方式
|
||||
/**
|
||||
* @param {ListNode} head
|
||||
* @return {ListNode}
|
||||
*/
|
||||
// 先判断是否是环形链表
|
||||
var detectCycle = function(head) {
|
||||
if(!head || !head.next) return null;
|
||||
let slow =head.next, fast = head.next.next;
|
||||
while(fast && fast.next && fast!== slow) {
|
||||
slow = slow.next;
|
||||
fast = fast.next.next;
|
||||
}
|
||||
if(!fast || !fast.next ) return null;
|
||||
slow = head;
|
||||
while (fast !== slow) {
|
||||
slow = slow.next;
|
||||
fast = fast.next;
|
||||
}
|
||||
return slow;
|
||||
};
|
||||
|
||||
var detectCycle = function(head) {
|
||||
if(!head || !head.next) return null;
|
||||
let slow =head.next, fast = head.next.next;
|
||||
while(fast && fast.next) {
|
||||
slow = slow.next;
|
||||
fast = fast.next.next;
|
||||
if(fast == slow) {
|
||||
slow = head;
|
||||
while (fast !== slow) {
|
||||
slow = slow.next;
|
||||
fast = fast.next;
|
||||
}
|
||||
return slow;
|
||||
}
|
||||
}
|
||||
return null;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
248
problems/0150.逆波兰表达式求值.md
Normal file
248
problems/0150.逆波兰表达式求值.md
Normal file
@@ -0,0 +1,248 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
|
||||
|
||||
> 这不仅仅是一道好题,也展现出计算机的思考方式
|
||||
|
||||
# 150. 逆波兰表达式求值
|
||||
|
||||
https://leetcode-cn.com/problems/evaluate-reverse-polish-notation/
|
||||
|
||||
根据 逆波兰表示法,求表达式的值。
|
||||
|
||||
有效的运算符包括 + , - , * , / 。每个运算对象可以是整数,也可以是另一个逆波兰表达式。
|
||||
|
||||
说明:
|
||||
|
||||
整数除法只保留整数部分。
|
||||
给定逆波兰表达式总是有效的。换句话说,表达式总会得出有效数值且不存在除数为 0 的情况。
|
||||
|
||||
|
||||
示例 1:
|
||||
输入: ["2", "1", "+", "3", " * "]
|
||||
输出: 9
|
||||
解释: 该算式转化为常见的中缀算术表达式为:((2 + 1) * 3) = 9
|
||||
|
||||
示例 2:
|
||||
输入: ["4", "13", "5", "/", "+"]
|
||||
输出: 6
|
||||
解释: 该算式转化为常见的中缀算术表达式为:(4 + (13 / 5)) = 6
|
||||
|
||||
示例 3:
|
||||
输入: ["10", "6", "9", "3", "+", "-11", " * ", "/", " * ", "17", "+", "5", "+"]
|
||||
输出: 22
|
||||
解释:
|
||||
该算式转化为常见的中缀算术表达式为:
|
||||
((10 * (6 / ((9 + 3) * -11))) + 17) + 5
|
||||
= ((10 * (6 / (12 * -11))) + 17) + 5
|
||||
= ((10 * (6 / -132)) + 17) + 5
|
||||
= ((10 * 0) + 17) + 5
|
||||
= (0 + 17) + 5
|
||||
= 17 + 5
|
||||
= 22
|
||||
|
||||
|
||||
逆波兰表达式:是一种后缀表达式,所谓后缀就是指算符写在后面。
|
||||
|
||||
平常使用的算式则是一种中缀表达式,如 ( 1 + 2 ) * ( 3 + 4 ) 。
|
||||
|
||||
该算式的逆波兰表达式写法为 ( ( 1 2 + ) ( 3 4 + ) * ) 。
|
||||
|
||||
逆波兰表达式主要有以下两个优点:
|
||||
|
||||
* 去掉括号后表达式无歧义,上式即便写成 1 2 + 3 4 + * 也可以依据次序计算出正确结果。
|
||||
|
||||
* 适合用栈操作运算:遇到数字则入栈;遇到算符则取出栈顶两个数字进行计算,并将结果压入栈中。
|
||||
|
||||
# 思路
|
||||
|
||||
在上一篇文章中[栈与队列:匹配问题都是栈的强项](https://mp.weixin.qq.com/s/eynAEbUbZoAWrk0ZlEugqg)提到了 递归就是用栈来实现的。
|
||||
|
||||
所以**栈与递归之间在某种程度上是可以转换的!**这一点我们在后续讲解二叉树的时候,会更详细的讲解到。
|
||||
|
||||
那么来看一下本题,**其实逆波兰表达式相当于是二叉树中的后序遍历**。 大家可以把运算符作为中间节点,按照后序遍历的规则画出一个二叉树。
|
||||
|
||||
但我们没有必要从二叉树的角度去解决这个问题,只要知道逆波兰表达式是用后续遍历的方式把二叉树序列化了,就可以了。
|
||||
|
||||
在进一步看,本题中每一个子表达式要得出一个结果,然后拿这个结果再进行运算,那么**这岂不就是一个相邻字符串消除的过程,和[栈与队列:匹配问题都是栈的强项](https://mp.weixin.qq.com/s/eynAEbUbZoAWrk0ZlEugqg)中的对对碰游戏是不是就非常像了。**
|
||||
|
||||
如动画所示:
|
||||
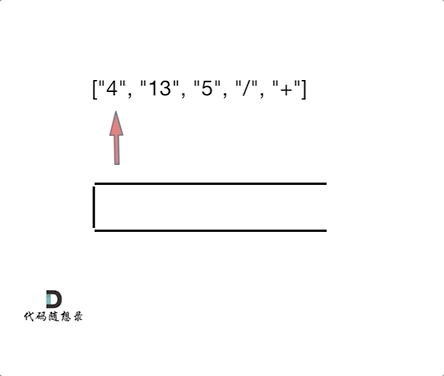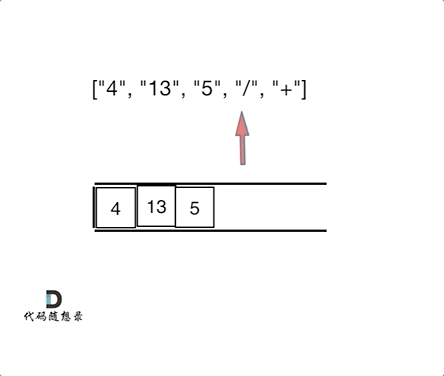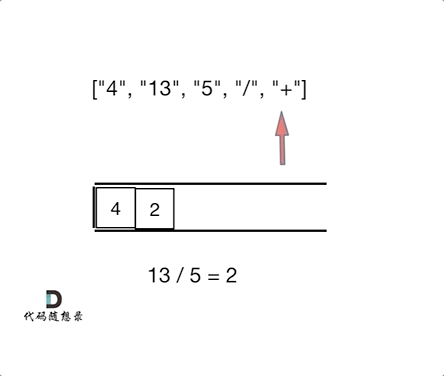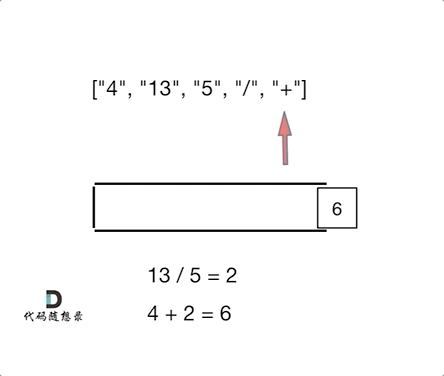
|
||||
|
||||
相信看完动画大家应该知道,这和[1047. 删除字符串中的所有相邻重复项](https://mp.weixin.qq.com/s/eynAEbUbZoAWrk0ZlEugqg)是差不错的,只不过本题不要相邻元素做消除了,而是做运算!
|
||||
|
||||
C++代码如下:
|
||||
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int evalRPN(vector<string>& tokens) {
|
||||
stack<int> st;
|
||||
for (int i = 0; i < tokens.size(); i++) {
|
||||
if (tokens[i] == "+" || tokens[i] == "-" || tokens[i] == "*" || tokens[i] == "/") {
|
||||
int num1 = st.top();
|
||||
st.pop();
|
||||
int num2 = st.top();
|
||||
st.pop();
|
||||
if (tokens[i] == "+") st.push(num2 + num1);
|
||||
if (tokens[i] == "-") st.push(num2 - num1);
|
||||
if (tokens[i] == "*") st.push(num2 * num1);
|
||||
if (tokens[i] == "/") st.push(num2 / num1);
|
||||
} else {
|
||||
st.push(stoi(tokens[i]));
|
||||
}
|
||||
}
|
||||
int result = st.top();
|
||||
st.pop(); // 把栈里最后一个元素弹出(其实不弹出也没事)
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
# 题外话
|
||||
|
||||
我们习惯看到的表达式都是中缀表达式,因为符合我们的习惯,但是中缀表达式对于计算机来说就不是很友好了。
|
||||
|
||||
例如:4 + 13 / 5,这就是中缀表达式,计算机从左到右去扫描的话,扫到13,还要判断13后面是什么运算法,还要比较一下优先级,然后13还和后面的5做运算,做完运算之后,还要向前回退到 4 的位置,继续做加法,你说麻不麻烦!
|
||||
|
||||
那么将中缀表达式,转化为后缀表达式之后:["4", "13", "5", "/", "+"] ,就不一样了,计算机可以利用栈里顺序处理,不需要考虑优先级了。也不用回退了, **所以后缀表达式对计算机来说是非常友好的。**
|
||||
|
||||
可以说本题不仅仅是一道好题,也展现出计算机的思考方式。
|
||||
|
||||
在1970年代和1980年代,惠普在其所有台式和手持式计算器中都使用了RPN(后缀表达式),直到2020年代仍在某些模型中使用了RPN。
|
||||
|
||||
参考维基百科如下:
|
||||
|
||||
> During the 1970s and 1980s, Hewlett-Packard used RPN in all of their desktop and hand-held calculators, and continued to use it in some models into the 2020s.
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
java:
|
||||
|
||||
```Java
|
||||
public class EvalRPN {
|
||||
|
||||
public int evalRPN(String[] tokens) {
|
||||
Deque<Integer> stack = new LinkedList();
|
||||
for (String token : tokens) {
|
||||
char c = token.charAt(0);
|
||||
if (!isOpe(token)) {
|
||||
stack.addFirst(stoi(token));
|
||||
} else if (c == '+') {
|
||||
stack.push(stack.pop() + stack.pop());
|
||||
} else if (c == '-') {
|
||||
stack.push(- stack.pop() + stack.pop());
|
||||
} else if (c == '*') {
|
||||
stack.push( stack.pop() * stack.pop());
|
||||
} else {
|
||||
int num1 = stack.pop();
|
||||
int num2 = stack.pop();
|
||||
stack.push( num2/num1);
|
||||
}
|
||||
}
|
||||
return stack.pop();
|
||||
}
|
||||
|
||||
|
||||
private boolean isOpe(String s) {
|
||||
return s.length() == 1 && s.charAt(0) <'0' || s.charAt(0) >'9';
|
||||
}
|
||||
|
||||
private int stoi(String s) {
|
||||
return Integer.valueOf(s);
|
||||
}
|
||||
|
||||
|
||||
public static void main(String[] args) {
|
||||
new EvalRPN().evalRPN(new String[] {"10","6","9","3","+","-11","*","/","*","17","+","5","+"});
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
Go:
|
||||
```Go
|
||||
func evalRPN(tokens []string) int {
|
||||
stack := []int{}
|
||||
for _, token := range tokens {
|
||||
val, err := strconv.Atoi(token)
|
||||
if err == nil {
|
||||
stack = append(stack, val)
|
||||
} else {
|
||||
num1, num2 := stack[len(stack)-2], stack[(len(stack))-1]
|
||||
stack = stack[:len(stack)-2]
|
||||
switch token {
|
||||
case "+":
|
||||
stack = append(stack, num1+num2)
|
||||
case "-":
|
||||
stack = append(stack, num1-num2)
|
||||
case "*":
|
||||
stack = append(stack, num1*num2)
|
||||
case "/":
|
||||
stack = append(stack, num1/num2)
|
||||
}
|
||||
}
|
||||
}
|
||||
return stack[0]
|
||||
}
|
||||
```
|
||||
|
||||
javaScript:
|
||||
|
||||
```js
|
||||
|
||||
/**
|
||||
* @param {string[]} tokens
|
||||
* @return {number}
|
||||
*/
|
||||
var evalRPN = function(tokens) {
|
||||
const s = new Map([
|
||||
["+", (a, b) => a * 1 + b * 1],
|
||||
["-", (a, b) => b - a],
|
||||
["*", (a, b) => b * a],
|
||||
["/", (a, b) => (b / a) | 0]
|
||||
]);
|
||||
const stack = [];
|
||||
for (const i of tokens) {
|
||||
if(!s.has(i)) {
|
||||
stack.push(i);
|
||||
continue;
|
||||
}
|
||||
stack.push(s.get(i)(stack.pop(),stack.pop()))
|
||||
}
|
||||
return stack.pop();
|
||||
};
|
||||
```
|
||||
|
||||
python3
|
||||
|
||||
```python
|
||||
def evalRPN(tokens) -> int:
|
||||
stack = list()
|
||||
for i in range(len(tokens)):
|
||||
if tokens[i] not in ["+", "-", "*", "/"]:
|
||||
stack.append(tokens[i])
|
||||
else:
|
||||
tmp1 = stack.pop()
|
||||
tmp2 = stack.pop()
|
||||
res = eval(tmp2+tokens[i]+tmp1)
|
||||
stack.append(str(int(res)))
|
||||
return stack[-1]
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
417
problems/0151.翻转字符串里的单词.md
Normal file
417
problems/0151.翻转字符串里的单词.md
Normal file
@@ -0,0 +1,417 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
|
||||
> 综合考察字符串操作的好题。
|
||||
|
||||
# 151.翻转字符串里的单词
|
||||
|
||||
https://leetcode-cn.com/problems/reverse-words-in-a-string/
|
||||
|
||||
给定一个字符串,逐个翻转字符串中的每个单词。
|
||||
|
||||
示例 1:
|
||||
输入: "the sky is blue"
|
||||
输出: "blue is sky the"
|
||||
|
||||
示例 2:
|
||||
输入: " hello world! "
|
||||
输出: "world! hello"
|
||||
解释: 输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。
|
||||
|
||||
示例 3:
|
||||
输入: "a good example"
|
||||
输出: "example good a"
|
||||
解释: 如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。
|
||||
|
||||
|
||||
# 思路
|
||||
|
||||
**这道题目可以说是综合考察了字符串的多种操作。**
|
||||
|
||||
|
||||
一些同学会使用split库函数,分隔单词,然后定义一个新的string字符串,最后再把单词倒序相加,那么这道题题目就是一道水题了,失去了它的意义。
|
||||
|
||||
所以这里我还是提高一下本题的难度:**不要使用辅助空间,空间复杂度要求为O(1)。**
|
||||
|
||||
不能使用辅助空间之后,那么只能在原字符串上下功夫了。
|
||||
|
||||
想一下,我们将整个字符串都反转过来,那么单词的顺序指定是倒序了,只不过单词本身也倒叙了,那么再把单词反转一下,单词不就正过来了。
|
||||
|
||||
所以解题思路如下:
|
||||
|
||||
* 移除多余空格
|
||||
* 将整个字符串反转
|
||||
* 将每个单词反转
|
||||
|
||||
举个例子,源字符串为:"the sky is blue "
|
||||
|
||||
* 移除多余空格 : "the sky is blue"
|
||||
* 字符串反转:"eulb si yks eht"
|
||||
* 单词反转:"blue is sky the"
|
||||
|
||||
这样我们就完成了翻转字符串里的单词。
|
||||
|
||||
|
||||
思路很明确了,我们说一说代码的实现细节,就拿移除多余空格来说,一些同学会上来写如下代码:
|
||||
|
||||
```C++
|
||||
void removeExtraSpaces(string& s) {
|
||||
for (int i = s.size() - 1; i > 0; i--) {
|
||||
if (s[i] == s[i - 1] && s[i] == ' ') {
|
||||
s.erase(s.begin() + i);
|
||||
}
|
||||
}
|
||||
// 删除字符串最后面的空格
|
||||
if (s.size() > 0 && s[s.size() - 1] == ' ') {
|
||||
s.erase(s.begin() + s.size() - 1);
|
||||
}
|
||||
// 删除字符串最前面的空格
|
||||
if (s.size() > 0 && s[0] == ' ') {
|
||||
s.erase(s.begin());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
逻辑很简单,从前向后遍历,遇到空格了就erase。
|
||||
|
||||
如果不仔细琢磨一下erase的时间复杂读,还以为以上的代码是O(n)的时间复杂度呢。
|
||||
|
||||
想一下真正的时间复杂度是多少,一个erase本来就是O(n)的操作,erase实现原理题目:[数组:就移除个元素很难么?](https://mp.weixin.qq.com/s/RMkulE4NIb6XsSX83ra-Ww),最优的算法来移除元素也要O(n)。
|
||||
|
||||
erase操作上面还套了一个for循环,那么以上代码移除冗余空格的代码时间复杂度为O(n^2)。
|
||||
|
||||
那么使用双指针法来去移除空格,最后resize(重新设置)一下字符串的大小,就可以做到O(n)的时间复杂度。
|
||||
|
||||
如果对这个操作比较生疏了,可以再看一下这篇文章:[数组:就移除个元素很难么?](https://mp.weixin.qq.com/s/RMkulE4NIb6XsSX83ra-Ww)是如何移除元素的。
|
||||
|
||||
那么使用双指针来移除冗余空格代码如下: fastIndex走的快,slowIndex走的慢,最后slowIndex就标记着移除多余空格后新字符串的长度。
|
||||
|
||||
```C++
|
||||
void removeExtraSpaces(string& s) {
|
||||
int slowIndex = 0, fastIndex = 0; // 定义快指针,慢指针
|
||||
// 去掉字符串前面的空格
|
||||
while (s.size() > 0 && fastIndex < s.size() && s[fastIndex] == ' ') {
|
||||
fastIndex++;
|
||||
}
|
||||
for (; fastIndex < s.size(); fastIndex++) {
|
||||
// 去掉字符串中间部分的冗余空格
|
||||
if (fastIndex - 1 > 0
|
||||
&& s[fastIndex - 1] == s[fastIndex]
|
||||
&& s[fastIndex] == ' ') {
|
||||
continue;
|
||||
} else {
|
||||
s[slowIndex++] = s[fastIndex];
|
||||
}
|
||||
}
|
||||
if (slowIndex - 1 > 0 && s[slowIndex - 1] == ' ') { // 去掉字符串末尾的空格
|
||||
s.resize(slowIndex - 1);
|
||||
} else {
|
||||
s.resize(slowIndex); // 重新设置字符串大小
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
有的同学可能发现用erase来移除空格,在leetcode上性能也还行。主要是以下几点;:
|
||||
|
||||
1. leetcode上的测试集里,字符串的长度不够长,如果足够长,性能差距会非常明显。
|
||||
2. leetcode的测程序耗时不是很准确的。
|
||||
|
||||
此时我们已经实现了removeExtraSpaces函数来移除冗余空格。
|
||||
|
||||
还做实现反转字符串的功能,支持反转字符串子区间,这个实现我们分别在[344.反转字符串](https://mp.weixin.qq.com/s/_rNm66OJVl92gBDIbGpA3w)和[541.反转字符串II](https://mp.weixin.qq.com/s/pzXt6PQ029y7bJ9YZB2mVQ)里已经讲过了。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
// 反转字符串s中左闭又闭的区间[start, end]
|
||||
void reverse(string& s, int start, int end) {
|
||||
for (int i = start, j = end; i < j; i++, j--) {
|
||||
swap(s[i], s[j]);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
本题C++整体代码
|
||||
|
||||
|
||||
```C++
|
||||
// 版本一
|
||||
class Solution {
|
||||
public:
|
||||
// 反转字符串s中左闭又闭的区间[start, end]
|
||||
void reverse(string& s, int start, int end) {
|
||||
for (int i = start, j = end; i < j; i++, j--) {
|
||||
swap(s[i], s[j]);
|
||||
}
|
||||
}
|
||||
|
||||
// 移除冗余空格:使用双指针(快慢指针法)O(n)的算法
|
||||
void removeExtraSpaces(string& s) {
|
||||
int slowIndex = 0, fastIndex = 0; // 定义快指针,慢指针
|
||||
// 去掉字符串前面的空格
|
||||
while (s.size() > 0 && fastIndex < s.size() && s[fastIndex] == ' ') {
|
||||
fastIndex++;
|
||||
}
|
||||
for (; fastIndex < s.size(); fastIndex++) {
|
||||
// 去掉字符串中间部分的冗余空格
|
||||
if (fastIndex - 1 > 0
|
||||
&& s[fastIndex - 1] == s[fastIndex]
|
||||
&& s[fastIndex] == ' ') {
|
||||
continue;
|
||||
} else {
|
||||
s[slowIndex++] = s[fastIndex];
|
||||
}
|
||||
}
|
||||
if (slowIndex - 1 > 0 && s[slowIndex - 1] == ' ') { // 去掉字符串末尾的空格
|
||||
s.resize(slowIndex - 1);
|
||||
} else {
|
||||
s.resize(slowIndex); // 重新设置字符串大小
|
||||
}
|
||||
}
|
||||
|
||||
string reverseWords(string s) {
|
||||
removeExtraSpaces(s); // 去掉冗余空格
|
||||
reverse(s, 0, s.size() - 1); // 将字符串全部反转
|
||||
int start = 0; // 反转的单词在字符串里起始位置
|
||||
int end = 0; // 反转的单词在字符串里终止位置
|
||||
bool entry = false; // 标记枚举字符串的过程中是否已经进入了单词区间
|
||||
for (int i = 0; i < s.size(); i++) { // 开始反转单词
|
||||
if (!entry) {
|
||||
start = i; // 确定单词起始位置
|
||||
entry = true; // 进入单词区间
|
||||
}
|
||||
// 单词后面有空格的情况,空格就是分词符
|
||||
if (entry && s[i] == ' ' && s[i - 1] != ' ') {
|
||||
end = i - 1; // 确定单词终止位置
|
||||
entry = false; // 结束单词区间
|
||||
reverse(s, start, end);
|
||||
}
|
||||
// 最后一个结尾单词之后没有空格的情况
|
||||
if (entry && (i == (s.size() - 1)) && s[i] != ' ' ) {
|
||||
end = i;// 确定单词终止位置
|
||||
entry = false; // 结束单词区间
|
||||
reverse(s, start, end);
|
||||
}
|
||||
}
|
||||
return s;
|
||||
}
|
||||
|
||||
// 当然这里的主函数reverseWords写的有一些冗余的,可以精简一些,精简之后的主函数为:
|
||||
/* 主函数简单写法
|
||||
string reverseWords(string s) {
|
||||
removeExtraSpaces(s);
|
||||
reverse(s, 0, s.size() - 1);
|
||||
for(int i = 0; i < s.size(); i++) {
|
||||
int j = i;
|
||||
// 查找单词间的空格,翻转单词
|
||||
while(j < s.size() && s[j] != ' ') j++;
|
||||
reverse(s, i, j - 1);
|
||||
i = j;
|
||||
}
|
||||
return s;
|
||||
}
|
||||
*/
|
||||
};
|
||||
```
|
||||
|
||||
效率:
|
||||
<img src='https://code-thinking.cdn.bcebos.com/pics/151_翻转字符串里的单词.png' width=600> </img></div>
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
|
||||
```Java
|
||||
class Solution {
|
||||
/**
|
||||
* 不使用Java内置方法实现
|
||||
* <p>
|
||||
* 1.去除首尾以及中间多余空格
|
||||
* 2.反转整个字符串
|
||||
* 3.反转各个单词
|
||||
*/
|
||||
public String reverseWords(String s) {
|
||||
// System.out.println("ReverseWords.reverseWords2() called with: s = [" + s + "]");
|
||||
// 1.去除首尾以及中间多余空格
|
||||
StringBuilder sb = removeSpace(s);
|
||||
// 2.反转整个字符串
|
||||
reverseString(sb, 0, sb.length() - 1);
|
||||
// 3.反转各个单词
|
||||
reverseEachWord(sb);
|
||||
return sb.toString();
|
||||
}
|
||||
|
||||
private StringBuilder removeSpace(String s) {
|
||||
// System.out.println("ReverseWords.removeSpace() called with: s = [" + s + "]");
|
||||
int start = 0;
|
||||
int end = s.length() - 1;
|
||||
while (s.charAt(start) == ' ') start++;
|
||||
while (s.charAt(end) == ' ') end--;
|
||||
StringBuilder sb = new StringBuilder();
|
||||
while (start <= end) {
|
||||
char c = s.charAt(start);
|
||||
if (c != ' ' || sb.charAt(sb.length() - 1) != ' ') {
|
||||
sb.append(c);
|
||||
}
|
||||
start++;
|
||||
}
|
||||
// System.out.println("ReverseWords.removeSpace returned: sb = [" + sb + "]");
|
||||
return sb;
|
||||
}
|
||||
|
||||
/**
|
||||
* 反转字符串指定区间[start, end]的字符
|
||||
*/
|
||||
public void reverseString(StringBuilder sb, int start, int end) {
|
||||
// System.out.println("ReverseWords.reverseString() called with: sb = [" + sb + "], start = [" + start + "], end = [" + end + "]");
|
||||
while (start < end) {
|
||||
char temp = sb.charAt(start);
|
||||
sb.setCharAt(start, sb.charAt(end));
|
||||
sb.setCharAt(end, temp);
|
||||
start++;
|
||||
end--;
|
||||
}
|
||||
// System.out.println("ReverseWords.reverseString returned: sb = [" + sb + "]");
|
||||
}
|
||||
|
||||
private void reverseEachWord(StringBuilder sb) {
|
||||
int start = 0;
|
||||
int end = 1;
|
||||
int n = sb.length();
|
||||
while (start < n) {
|
||||
while (end < n && sb.charAt(end) != ' ') {
|
||||
end++;
|
||||
}
|
||||
reverseString(sb, start, end - 1);
|
||||
start = end + 1;
|
||||
end = start + 1;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
```Python3
|
||||
class Solution:
|
||||
#1.去除多余的空格
|
||||
def trim_spaces(self,s):
|
||||
n=len(s)
|
||||
left=0
|
||||
right=n-1
|
||||
|
||||
while left<=right and s[left]==' ': #去除开头的空格
|
||||
left+=1
|
||||
while left<=right and s[right]==' ': #去除结尾的空格
|
||||
right=right-1
|
||||
tmp=[]
|
||||
while left<=right: #去除单词中间多余的空格
|
||||
if s[left]!=' ':
|
||||
tmp.append(s[left])
|
||||
elif tmp[-1]!=' ': #当前位置是空格,但是相邻的上一个位置不是空格,则该空格是合理的
|
||||
tmp.append(s[left])
|
||||
left+=1
|
||||
return tmp
|
||||
#2.翻转字符数组
|
||||
def reverse_string(self,nums,left,right):
|
||||
while left<right:
|
||||
nums[left], nums[right]=nums[right],nums[left]
|
||||
left+=1
|
||||
right-=1
|
||||
return None
|
||||
#3.翻转每个单词
|
||||
def reverse_each_word(self, nums):
|
||||
start=0
|
||||
end=0
|
||||
n=len(nums)
|
||||
while start<n:
|
||||
while end<n and nums[end]!=' ':
|
||||
end+=1
|
||||
self.reverse_string(nums,start,end-1)
|
||||
start=end+1
|
||||
end+=1
|
||||
return None
|
||||
|
||||
#4.翻转字符串里的单词
|
||||
def reverseWords(self, s): #测试用例:"the sky is blue"
|
||||
l = self.trim_spaces(s) #输出:['t', 'h', 'e', ' ', 's', 'k', 'y', ' ', 'i', 's', ' ', 'b', 'l', 'u', 'e'
|
||||
self.reverse_string( l, 0, len(l) - 1) #输出:['e', 'u', 'l', 'b', ' ', 's', 'i', ' ', 'y', 'k', 's', ' ', 'e', 'h', 't']
|
||||
self.reverse_each_word(l) #输出:['b', 'l', 'u', 'e', ' ', 'i', 's', ' ', 's', 'k', 'y', ' ', 't', 'h', 'e']
|
||||
return ''.join(l) #输出:blue is sky the
|
||||
|
||||
|
||||
'''
|
||||
|
||||
|
||||
Go:
|
||||
|
||||
```go
|
||||
import (
|
||||
"fmt"
|
||||
)
|
||||
|
||||
func reverseWords(s string) string {
|
||||
//1.使用双指针删除冗余的空格
|
||||
slowIndex, fastIndex := 0, 0
|
||||
b := []byte(s)
|
||||
//删除头部冗余空格
|
||||
for len(b) > 0 && fastIndex < len(b) && b[fastIndex] == ' ' {
|
||||
fastIndex++
|
||||
}
|
||||
//删除单词间冗余空格
|
||||
for ; fastIndex < len(b); fastIndex++ {
|
||||
if fastIndex-1 > 0 && b[fastIndex-1] == b[fastIndex] && b[fastIndex] == ' ' {
|
||||
continue
|
||||
}
|
||||
b[slowIndex] = b[fastIndex]
|
||||
slowIndex++
|
||||
}
|
||||
//删除尾部冗余空格
|
||||
if slowIndex-1 > 0 && b[slowIndex-1] == ' ' {
|
||||
b = b[:slowIndex-1]
|
||||
} else {
|
||||
b = b[:slowIndex]
|
||||
}
|
||||
//2.反转整个字符串
|
||||
reverse(&b, 0, len(b)-1)
|
||||
//3.反转单个单词 i单词开始位置,j单词结束位置
|
||||
i := 0
|
||||
for i < len(b) {
|
||||
j := i
|
||||
for ; j < len(b) && b[j] != ' '; j++ {
|
||||
}
|
||||
reverse(&b, i, j-1)
|
||||
i = j
|
||||
i++
|
||||
}
|
||||
return string(b)
|
||||
}
|
||||
|
||||
func reverse(b *[]byte, left, right int) {
|
||||
for left < right {
|
||||
(*b)[left], (*b)[right] = (*b)[right], (*b)[left]
|
||||
left++
|
||||
right--
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
2
problems/0160.相交链表.md
Normal file
2
problems/0160.相交链表.md
Normal file
@@ -0,0 +1,2 @@
|
||||
|
||||
同:[链表:链表相交](./面试题02.07.链表相交.md)
|
||||
239
problems/0188.买卖股票的最佳时机IV.md
Normal file
239
problems/0188.买卖股票的最佳时机IV.md
Normal file
@@ -0,0 +1,239 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
## 188.买卖股票的最佳时机IV
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-iv/
|
||||
|
||||
给定一个整数数组 prices ,它的第 i 个元素 prices[i] 是一支给定的股票在第 i 天的价格。
|
||||
|
||||
设计一个算法来计算你所能获取的最大利润。你最多可以完成 k 笔交易。
|
||||
|
||||
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
|
||||
|
||||
示例 1:
|
||||
输入:k = 2, prices = [2,4,1]
|
||||
输出:2
|
||||
解释:在第 1 天 (股票价格 = 2) 的时候买入,在第 2 天 (股票价格 = 4) 的时候卖出,这笔交易所能获得利润 = 4-2 = 2。
|
||||
|
||||
示例 2:
|
||||
输入:k = 2, prices = [3,2,6,5,0,3]
|
||||
输出:7
|
||||
解释:在第 2 天 (股票价格 = 2) 的时候买入,在第 3 天 (股票价格 = 6) 的时候卖出, 这笔交易所能获得利润 = 6-2 = 4。随后,在第 5 天 (股票价格 = 0) 的时候买入,在第 6 天 (股票价格 = 3) 的时候卖出, 这笔交易所能获得利润 = 3-0 = 3 。
|
||||
|
||||
|
||||
提示:
|
||||
|
||||
* 0 <= k <= 100
|
||||
* 0 <= prices.length <= 1000
|
||||
* 0 <= prices[i] <= 1000
|
||||
|
||||
## 思路
|
||||
|
||||
这道题目可以说是[动态规划:123.买卖股票的最佳时机III](https://mp.weixin.qq.com/s/Sbs157mlVDtAR0gbLpdKzg)的进阶版,这里要求至多有k次交易。
|
||||
|
||||
动规五部曲,分析如下:
|
||||
|
||||
1. 确定dp数组以及下标的含义
|
||||
|
||||
在[动态规划:123.买卖股票的最佳时机III](https://mp.weixin.qq.com/s/Sbs157mlVDtAR0gbLpdKzg)中,我是定义了一个二维dp数组,本题其实依然可以用一个二维dp数组。
|
||||
|
||||
使用二维数组 dp[i][j] :第i天的状态为j,所剩下的最大现金是dp[i][j]
|
||||
|
||||
j的状态表示为:
|
||||
|
||||
* 0 表示不操作
|
||||
* 1 第一次买入
|
||||
* 2 第一次卖出
|
||||
* 3 第二次买入
|
||||
* 4 第二次卖出
|
||||
* .....
|
||||
|
||||
**大家应该发现规律了吧 ,除了0以外,偶数就是卖出,奇数就是买入**。
|
||||
|
||||
题目要求是至多有K笔交易,那么j的范围就定义为 2 * k + 1 就可以了。
|
||||
|
||||
所以二维dp数组的C++定义为:
|
||||
|
||||
```
|
||||
vector<vector<int>> dp(prices.size(), vector<int>(2 * k + 1, 0));
|
||||
```
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
还要强调一下:dp[i][1],**表示的是第i天,买入股票的状态,并不是说一定要第i天买入股票,这是很多同学容易陷入的误区**。
|
||||
|
||||
达到dp[i][1]状态,有两个具体操作:
|
||||
|
||||
* 操作一:第i天买入股票了,那么dp[i][1] = dp[i - 1][0] - prices[i]
|
||||
* 操作二:第i天没有操作,而是沿用前一天买入的状态,即:dp[i][1] = dp[i - 1][1]
|
||||
|
||||
选最大的,所以 dp[i][1] = max(dp[i - 1][0] - prices[i], dp[i - 1][0]);
|
||||
|
||||
同理dp[i][2]也有两个操作:
|
||||
|
||||
* 操作一:第i天卖出股票了,那么dp[i][2] = dp[i - 1][1] + prices[i]
|
||||
* 操作二:第i天没有操作,沿用前一天卖出股票的状态,即:dp[i][2] = dp[i - 1][2]
|
||||
|
||||
所以dp[i][2] = max(dp[i - 1][i] + prices[i], dp[i][2])
|
||||
|
||||
同理可以类比剩下的状态,代码如下:
|
||||
|
||||
```C++
|
||||
for (int j = 0; j < 2 * k - 1; j += 2) {
|
||||
dp[i][j + 1] = max(dp[i - 1][j + 1], dp[i - 1][j] - prices[i]);
|
||||
dp[i][j + 2] = max(dp[i - 1][j + 2], dp[i - 1][j + 1] + prices[i]);
|
||||
}
|
||||
```
|
||||
|
||||
**本题和[动态规划:123.买卖股票的最佳时机III](https://mp.weixin.qq.com/s/Sbs157mlVDtAR0gbLpdKzg)最大的区别就是这里要类比j为奇数是买,偶数是卖剩的状态**。
|
||||
|
||||
3. dp数组如何初始化
|
||||
|
||||
第0天没有操作,这个最容易想到,就是0,即:dp[0][0] = 0;
|
||||
|
||||
第0天做第一次买入的操作,dp[0][1] = -prices[0];
|
||||
|
||||
第0天做第一次卖出的操作,这个初始值应该是多少呢?
|
||||
|
||||
首先卖出的操作一定是收获利润,整个股票买卖最差情况也就是没有盈利即全程无操作现金为0,
|
||||
|
||||
从递推公式中可以看出每次是取最大值,那么既然是收获利润如果比0还小了就没有必要收获这个利润了。
|
||||
|
||||
所以dp[0][2] = 0;
|
||||
|
||||
第0天第二次买入操作,初始值应该是多少呢?
|
||||
|
||||
不用管第几次,现在手头上没有现金,只要买入,现金就做相应的减少。
|
||||
|
||||
第二次买入操作,初始化为:dp[0][3] = -prices[0];
|
||||
|
||||
**所以同理可以推出dp[0][j]当j为奇数的时候都初始化为 -prices[0]**
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
for (int j = 1; j < 2 * k; j += 2) {
|
||||
dp[0][j] = -prices[0];
|
||||
}
|
||||
```
|
||||
|
||||
**在初始化的地方同样要类比j为偶数是卖、奇数是买的状态**。
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
从递归公式其实已经可以看出,一定是从前向后遍历,因为dp[i],依靠dp[i - 1]的数值。
|
||||
|
||||
5. 举例推导dp数组
|
||||
|
||||
以输入[1,2,3,4,5],k=2为例。
|
||||
|
||||
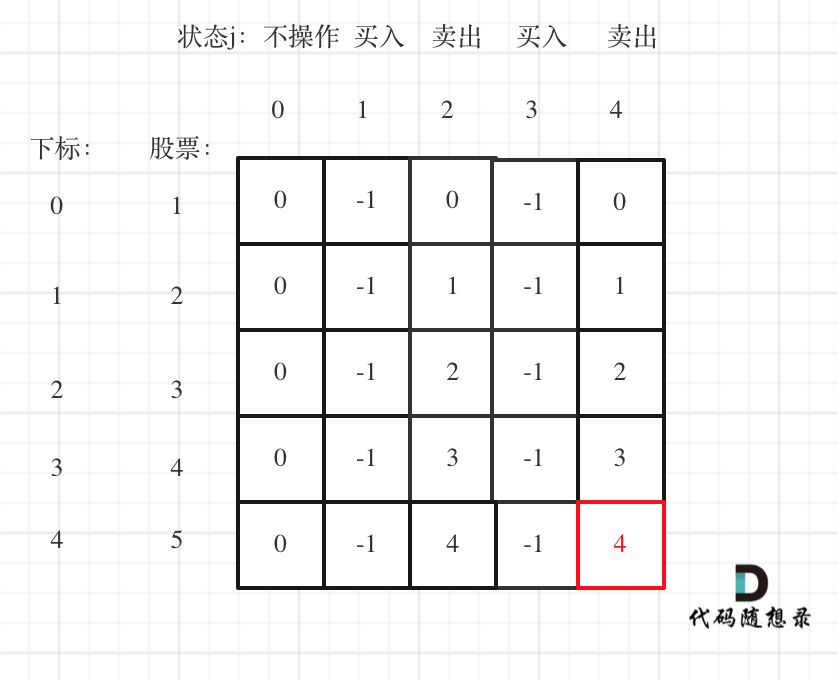
|
||||
|
||||
最后一次卖出,一定是利润最大的,dp[prices.size() - 1][2 * k]即红色部分就是最后求解。
|
||||
|
||||
以上分析完毕,C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int maxProfit(int k, vector<int>& prices) {
|
||||
|
||||
if (prices.size() == 0) return 0;
|
||||
vector<vector<int>> dp(prices.size(), vector<int>(2 * k + 1, 0));
|
||||
for (int j = 1; j < 2 * k; j += 2) {
|
||||
dp[0][j] = -prices[0];
|
||||
}
|
||||
for (int i = 1;i < prices.size(); i++) {
|
||||
for (int j = 0; j < 2 * k - 1; j += 2) {
|
||||
dp[i][j + 1] = max(dp[i - 1][j + 1], dp[i - 1][j] - prices[i]);
|
||||
dp[i][j + 2] = max(dp[i - 1][j + 2], dp[i - 1][j + 1] + prices[i]);
|
||||
}
|
||||
}
|
||||
return dp[prices.size() - 1][2 * k];
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
当然有的解法是定义一个三维数组dp[i][j][k],第i天,第j次买卖,k表示买还是卖的状态,从定义上来讲是比较直观。
|
||||
|
||||
但感觉三维数组操作起来有些麻烦,我是直接用二维数组来模拟三位数组的情况,代码看起来也清爽一些。
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
Java:
|
||||
|
||||
```java
|
||||
class Solution { //动态规划
|
||||
public int maxProfit(int k, int[] prices) {
|
||||
if (prices == null || prices.length < 2 || k == 0) {
|
||||
return 0;
|
||||
}
|
||||
|
||||
// [天数][交易次数][是否持有股票]
|
||||
int[][][] dp = new int[prices.length][k + 1][2];
|
||||
|
||||
// bad case
|
||||
dp[0][0][0] = 0;
|
||||
dp[0][0][1] = Integer.MIN_VALUE;
|
||||
dp[0][1][0] = 0;
|
||||
dp[0][1][1] = -prices[0];
|
||||
// dp[0][j][0] 都均为0
|
||||
// dp[0][j][1] 异常值都取Integer.MIN_VALUE;
|
||||
for (int i = 2; i < k + 1; i++) {
|
||||
dp[0][i][0] = 0;
|
||||
dp[0][i][1] = Integer.MIN_VALUE;
|
||||
}
|
||||
|
||||
for (int i = 1; i < prices.length; i++) {
|
||||
for (int j = k; j >= 1; j--) {
|
||||
// dp公式
|
||||
dp[i][j][0] = Math.max(dp[i - 1][j][0], dp[i - 1][j][1] + prices[i]);
|
||||
dp[i][j][1] = Math.max(dp[i - 1][j][1], dp[i - 1][j - 1][0] - prices[i]);
|
||||
}
|
||||
}
|
||||
|
||||
int res = 0;
|
||||
for (int i = 1; i < k + 1; i++) {
|
||||
res = Math.max(res, dp[prices.length - 1][i][0]);
|
||||
}
|
||||
|
||||
return res;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
Python:
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def maxProfit(self, k: int, prices: List[int]) -> int:
|
||||
if len(prices) == 0:
|
||||
return 0
|
||||
dp = [[0] * (2*k+1) for _ in range(len(prices))]
|
||||
for j in range(1, 2*k, 2):
|
||||
dp[0][j] = -prices[0]
|
||||
for i in range(1, len(prices)):
|
||||
for j in range(0, 2*k-1, 2):
|
||||
dp[i][j+1] = max(dp[i-1][j+1], dp[i-1][j] - prices[i])
|
||||
dp[i][j+2] = max(dp[i-1][j+2], dp[i-1][j+1] + prices[i])
|
||||
return dp[-1][2*k]
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
185
problems/0198.打家劫舍.md
Normal file
185
problems/0198.打家劫舍.md
Normal file
@@ -0,0 +1,185 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
## 198.打家劫舍
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/house-robber/
|
||||
|
||||
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
|
||||
|
||||
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
|
||||
|
||||
示例 1:
|
||||
输入:[1,2,3,1]
|
||||
输出:4
|
||||
解释:偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。
|
||||
偷窃到的最高金额 = 1 + 3 = 4 。
|
||||
|
||||
示例 2:
|
||||
输入:[2,7,9,3,1]
|
||||
输出:12
|
||||
解释:偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。
|
||||
偷窃到的最高金额 = 2 + 9 + 1 = 12 。
|
||||
|
||||
|
||||
提示:
|
||||
|
||||
* 0 <= nums.length <= 100
|
||||
* 0 <= nums[i] <= 400
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
打家劫舍是dp解决的经典问题,动规五部曲分析如下:
|
||||
|
||||
1. 确定dp数组(dp table)以及下标的含义
|
||||
|
||||
**dp[i]:考虑下标i(包括i)以内的房屋,最多可以偷窃的金额为dp[i]**。
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
决定dp[i]的因素就是第i房间偷还是不偷。
|
||||
|
||||
如果偷第i房间,那么dp[i] = dp[i - 2] + nums[i] ,即:第i-1房一定是不考虑的,找出 下标i-2(包括i-2)以内的房屋,最多可以偷窃的金额为dp[i-2] 加上第i房间偷到的钱。
|
||||
|
||||
如果不偷第i房间,那么dp[i] = dp[i - 1],即考虑i-1房,(**注意这里是考虑,并不是一定要偷i-1房,这是很多同学容易混淆的点**)
|
||||
|
||||
然后dp[i]取最大值,即dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);
|
||||
|
||||
3. dp数组如何初始化
|
||||
|
||||
从递推公式dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);可以看出,递推公式的基础就是dp[0] 和 dp[1]
|
||||
|
||||
从dp[i]的定义上来讲,dp[0] 一定是 nums[0],dp[1]就是nums[0]和nums[1]的最大值即:dp[1] = max(nums[0], nums[1]);
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
vector<int> dp(nums.size());
|
||||
dp[0] = nums[0];
|
||||
dp[1] = max(nums[0], nums[1]);
|
||||
```
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
dp[i] 是根据dp[i - 2] 和 dp[i - 1] 推导出来的,那么一定是从前到后遍历!
|
||||
|
||||
代码如下:
|
||||
```C++
|
||||
for (int i = 2; i < nums.size(); i++) {
|
||||
dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);
|
||||
}
|
||||
```
|
||||
|
||||
5. 举例推导dp数组
|
||||
|
||||
以示例二,输入[2,7,9,3,1]为例。
|
||||
|
||||
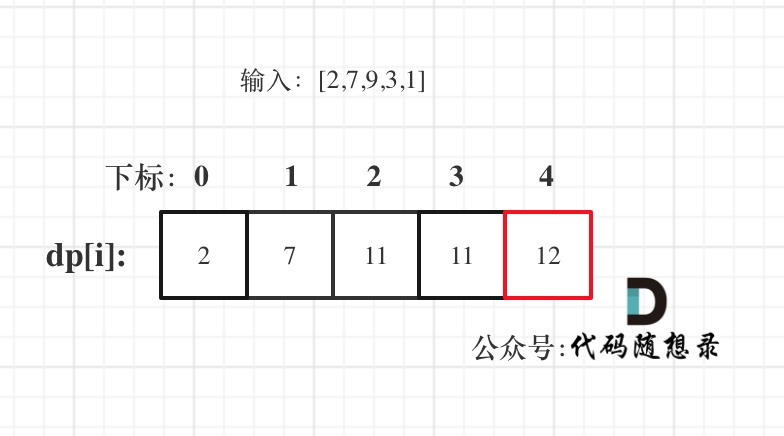
|
||||
|
||||
红框dp[nums.size() - 1]为结果。
|
||||
|
||||
以上分析完毕,C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int rob(vector<int>& nums) {
|
||||
if (nums.size() == 0) return 0;
|
||||
if (nums.size() == 1) return nums[0];
|
||||
vector<int> dp(nums.size());
|
||||
dp[0] = nums[0];
|
||||
dp[1] = max(nums[0], nums[1]);
|
||||
for (int i = 2; i < nums.size(); i++) {
|
||||
dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);
|
||||
}
|
||||
return dp[nums.size() - 1];
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
打家劫舍是DP解决的经典题目,这道题也是打家劫舍入门级题目,后面我们还会变种方式来打劫的。
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
// 动态规划
|
||||
class Solution {
|
||||
public int rob(int[] nums) {
|
||||
if (nums == null || nums.length == 0) return 0;
|
||||
if (nums.length == 1) return nums[0];
|
||||
|
||||
int[] dp = new int[nums.length];
|
||||
dp[0] = nums[0];
|
||||
dp[1] = Math.max(dp[0], nums[1]);
|
||||
for (int i = 2; i < nums.length; i++) {
|
||||
dp[i] = Math.max(dp[i - 1], dp[i - 2] + nums[i]);
|
||||
}
|
||||
|
||||
return dp[nums.length - 1];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def rob(self, nums: List[int]) -> int:
|
||||
if len(nums) == 0:
|
||||
return 0
|
||||
if len(nums) == 1:
|
||||
return nums[0]
|
||||
dp = [0] * len(nums)
|
||||
dp[0] = nums[0]
|
||||
dp[1] = max(nums[0], nums[1])
|
||||
for i in range(2, len(nums)):
|
||||
dp[i] = max(dp[i-2]+nums[i], dp[i-1])
|
||||
return dp[-1]
|
||||
```
|
||||
|
||||
Go:
|
||||
```Go
|
||||
func rob(nums []int) int {
|
||||
if len(nums)<1{
|
||||
return 0
|
||||
}
|
||||
if len(nums)==1{
|
||||
return nums[0]
|
||||
}
|
||||
if len(nums)==2{
|
||||
return max(nums[0],nums[1])
|
||||
}
|
||||
dp :=make([]int,len(nums))
|
||||
dp[0]=nums[0]
|
||||
dp[1]=max(nums[0],nums[1])
|
||||
for i:=2;i<len(nums);i++{
|
||||
dp[i]=max(dp[i-2]+nums[i],dp[i-1])
|
||||
}
|
||||
return dp[len(dp)-1]
|
||||
}
|
||||
|
||||
func max(a, b int) int {
|
||||
if a>b{
|
||||
return a
|
||||
}
|
||||
return b
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
196
problems/0202.快乐数.md
Normal file
196
problems/0202.快乐数.md
Normal file
@@ -0,0 +1,196 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
|
||||
> 该用set的时候,还是得用set
|
||||
|
||||
# 第202题. 快乐数
|
||||
|
||||
https://leetcode-cn.com/problems/happy-number/
|
||||
|
||||
编写一个算法来判断一个数 n 是不是快乐数。
|
||||
|
||||
「快乐数」定义为:对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和,然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。如果 可以变为 1,那么这个数就是快乐数。
|
||||
|
||||
如果 n 是快乐数就返回 True ;不是,则返回 False 。
|
||||
|
||||
**示例:**
|
||||
|
||||
输入:19
|
||||
输出:true
|
||||
解释:
|
||||
1^2 + 9^2 = 82
|
||||
8^2 + 2^2 = 68
|
||||
6^2 + 8^2 = 100
|
||||
1^2 + 0^2 + 0^2 = 1
|
||||
|
||||
# 思路
|
||||
|
||||
这道题目看上去貌似一道数学问题,其实并不是!
|
||||
|
||||
题目中说了会 **无限循环**,那么也就是说**求和的过程中,sum会重复出现,这对解题很重要!**
|
||||
|
||||
正如:[关于哈希表,你该了解这些!](https://mp.weixin.qq.com/s/RSUANESA_tkhKhYe3ZR8Jg)中所说,**当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法了。**
|
||||
|
||||
所以这道题目使用哈希法,来判断这个sum是否重复出现,如果重复了就是return false, 否则一直找到sum为1为止。
|
||||
|
||||
判断sum是否重复出现就可以使用unordered_set。
|
||||
|
||||
**还有一个难点就是求和的过程,如果对取数值各个位上的单数操作不熟悉的话,做这道题也会比较艰难。**
|
||||
|
||||
C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
// 取数值各个位上的单数之和
|
||||
int getSum(int n) {
|
||||
int sum = 0;
|
||||
while (n) {
|
||||
sum += (n % 10) * (n % 10);
|
||||
n /= 10;
|
||||
}
|
||||
return sum;
|
||||
}
|
||||
bool isHappy(int n) {
|
||||
unordered_set<int> set;
|
||||
while(1) {
|
||||
int sum = getSum(n);
|
||||
if (sum == 1) {
|
||||
return true;
|
||||
}
|
||||
// 如果这个sum曾经出现过,说明已经陷入了无限循环了,立刻return false
|
||||
if (set.find(sum) != set.end()) {
|
||||
return false;
|
||||
} else {
|
||||
set.insert(sum);
|
||||
}
|
||||
n = sum;
|
||||
}
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
# 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
public boolean isHappy(int n) {
|
||||
Set<Integer> record = new HashSet<>();
|
||||
while (n != 1 && !record.contains(n)) {
|
||||
record.add(n);
|
||||
n = getNextNumber(n);
|
||||
}
|
||||
return n == 1;
|
||||
}
|
||||
|
||||
private int getNextNumber(int n) {
|
||||
int res = 0;
|
||||
while (n > 0) {
|
||||
int temp = n % 10;
|
||||
res += temp * temp;
|
||||
n = n / 10;
|
||||
}
|
||||
return res;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def isHappy(self, n: int) -> bool:
|
||||
set_ = set()
|
||||
while 1:
|
||||
sum_ = self.getSum(n)
|
||||
if sum_ == 1:
|
||||
return True
|
||||
#如果这个sum曾经出现过,说明已经陷入了无限循环了,立刻return false
|
||||
if sum_ in set_:
|
||||
return False
|
||||
else:
|
||||
set_.add(sum_)
|
||||
n = sum_
|
||||
|
||||
#取数值各个位上的单数之和
|
||||
def getSum(self, n):
|
||||
sum_ = 0
|
||||
while n > 0:
|
||||
sum_ += (n%10) * (n%10)
|
||||
n //= 10
|
||||
return sum_
|
||||
```
|
||||
|
||||
Go:
|
||||
```go
|
||||
func isHappy(n int) bool {
|
||||
m := make(map[int]bool)
|
||||
for n != 1 && !m[n] {
|
||||
n, m[n] = getSum(n), true
|
||||
}
|
||||
return n == 1
|
||||
}
|
||||
|
||||
func getSum(n int) int {
|
||||
sum := 0
|
||||
for n > 0 {
|
||||
sum += (n % 10) * (n % 10)
|
||||
n = n / 10
|
||||
}
|
||||
return sum
|
||||
}
|
||||
```
|
||||
|
||||
javaScript:
|
||||
|
||||
```js
|
||||
function getN(n) {
|
||||
if (n == 1 || n == 0) return n;
|
||||
let res = 0;
|
||||
while (n) {
|
||||
res += (n % 10) * (n % 10);
|
||||
n = parseInt(n / 10);
|
||||
}
|
||||
return res;
|
||||
}
|
||||
|
||||
var isHappy = function(n) {
|
||||
const sumSet = new Set();
|
||||
while (n != 1 && !sumSet.has(n)) {
|
||||
sumSet.add(n);
|
||||
n = getN(n);
|
||||
}
|
||||
return n == 1;
|
||||
};
|
||||
|
||||
// 使用环形链表的思想 说明出现闭环 退出循环
|
||||
var isHappy = function(n) {
|
||||
if (getN(n) == 1) return true;
|
||||
let a = getN(n), b = getN(getN(n));
|
||||
// 如果 a === b
|
||||
while (b !== 1 && getN(b) !== 1 && a !== b) {
|
||||
a = getN(a);
|
||||
b = getN(getN(b));
|
||||
}
|
||||
return b === 1 || getN(b) === 1 ;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
283
problems/0203.移除链表元素.md
Normal file
283
problems/0203.移除链表元素.md
Normal file
@@ -0,0 +1,283 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
> 链表操作中,可以使用原链表来直接进行删除操作,也可以设置一个虚拟头结点在进行删除操作,接下来看一看哪种方式更方便。
|
||||
|
||||
# 203.移除链表元素
|
||||
|
||||
https://leetcode-cn.com/problems/remove-linked-list-elements/
|
||||
|
||||
题意:删除链表中等于给定值 val 的所有节点。
|
||||
|
||||
示例 1:
|
||||
输入:head = [1,2,6,3,4,5,6], val = 6
|
||||
输出:[1,2,3,4,5]
|
||||
|
||||
示例 2:
|
||||
输入:head = [], val = 1
|
||||
输出:[]
|
||||
|
||||
示例 3:
|
||||
输入:head = [7,7,7,7], val = 7
|
||||
输出:[]
|
||||
|
||||
|
||||
# 思路
|
||||
|
||||
这里以链表 1 4 2 4 来举例,移除元素4。
|
||||
|
||||
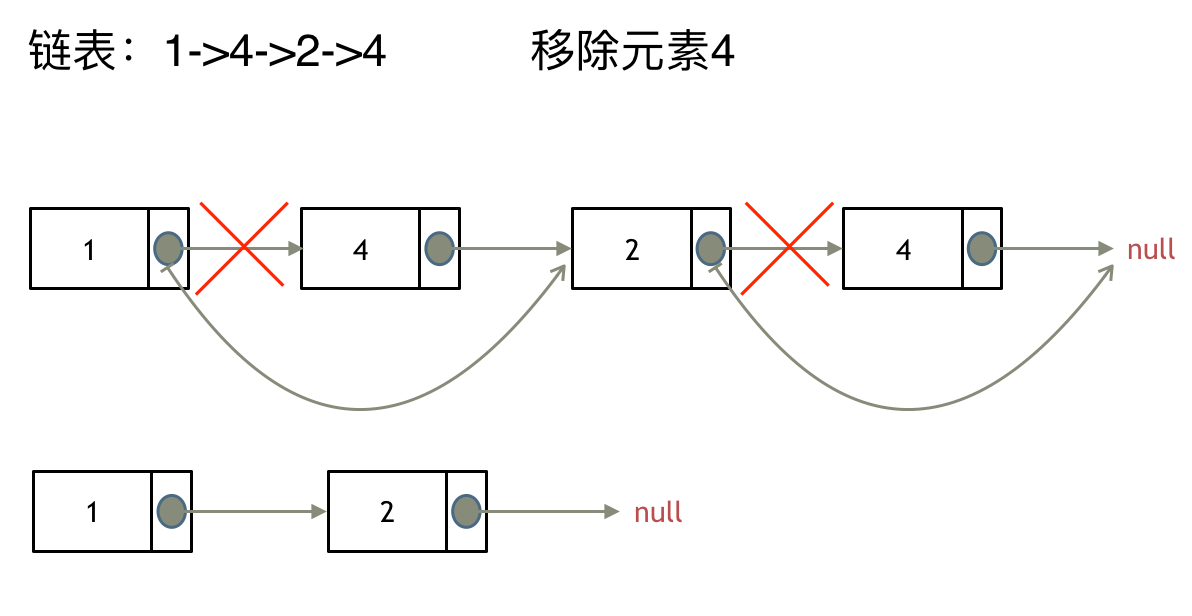
|
||||
|
||||
如果使用C,C++编程语言的话,不要忘了还要从内存中删除这两个移除的节点, 清理节点内存之后如图:
|
||||
|
||||
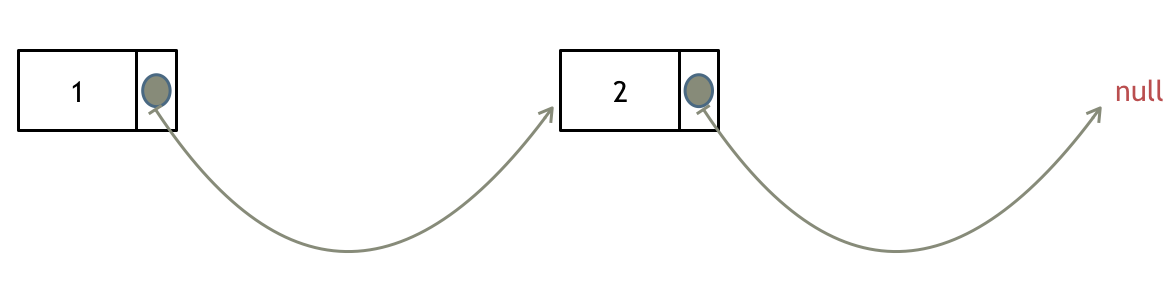
|
||||
|
||||
**当然如果使用java ,python的话就不用手动管理内存了。**
|
||||
|
||||
还要说明一下,就算使用C++来做leetcode,如果移除一个节点之后,没有手动在内存中删除这个节点,leetcode依然也是可以通过的,只不过,内存使用的空间大一些而已,但建议依然要养生手动清理内存的习惯。
|
||||
|
||||
这种情况下的移除操作,就是让节点next指针直接指向下下一个节点就可以了,
|
||||
|
||||
那么因为单链表的特殊性,只能指向下一个节点,刚刚删除的是链表的中第二个,和第四个节点,那么如果删除的是头结点又该怎么办呢?
|
||||
|
||||
这里就涉及如下链表操作的两种方式:
|
||||
* **直接使用原来的链表来进行删除操作。**
|
||||
* **设置一个虚拟头结点在进行删除操作。**
|
||||
|
||||
|
||||
来看第一种操作:直接使用原来的链表来进行移除。
|
||||
|
||||
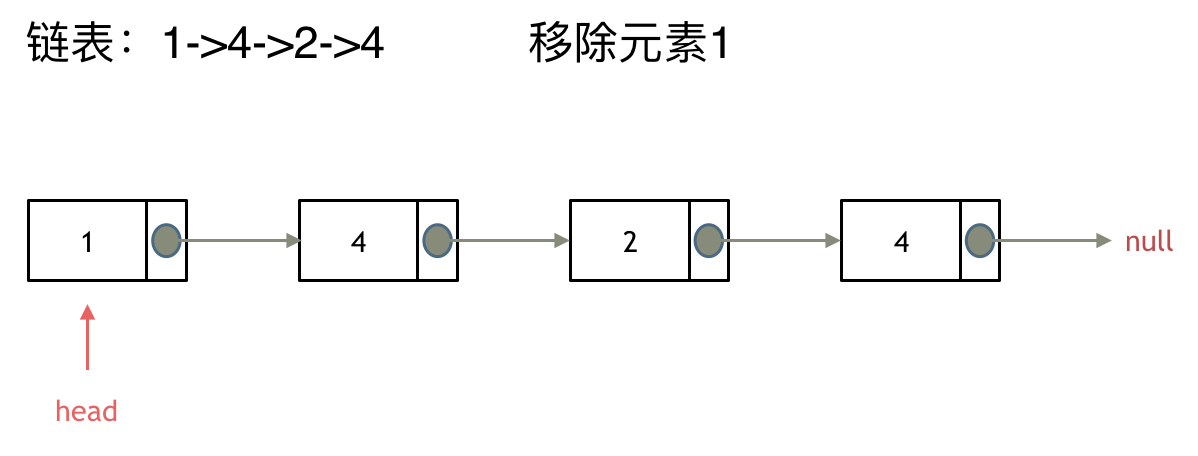
|
||||
|
||||
移除头结点和移除其他节点的操作是不一样的,因为链表的其他节点都是通过前一个节点来移除当前节点,而头结点没有前一个节点。
|
||||
|
||||
所以头结点如何移除呢,其实只要将头结点向后移动一位就可以,这样就从链表中移除了一个头结点。
|
||||
|
||||

|
||||
|
||||
|
||||
依然别忘将原头结点从内存中删掉。
|
||||

|
||||
|
||||
|
||||
这样移除了一个头结点,是不是发现,在单链表中移除头结点 和 移除其他节点的操作方式是不一样,其实在写代码的时候也会发现,需要单独写一段逻辑来处理移除头结点的情况。
|
||||
|
||||
那么可不可以 以一种统一的逻辑来移除 链表的节点呢。
|
||||
|
||||
其实**可以设置一个虚拟头结点**,这样原链表的所有节点就都可以按照统一的方式进行移除了。
|
||||
|
||||
来看看如何设置一个虚拟头。依然还是在这个链表中,移除元素1。
|
||||
|
||||
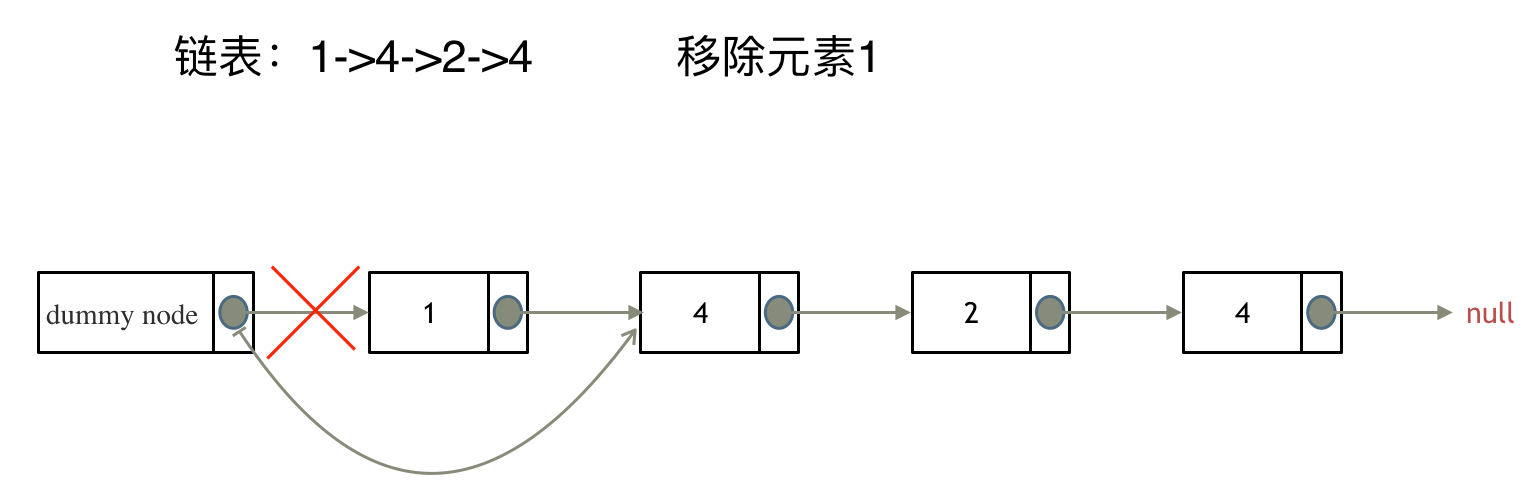
|
||||
|
||||
这里来给链表添加一个虚拟头结点为新的头结点,此时要移除这个旧头结点元素1。
|
||||
|
||||
这样是不是就可以使用和移除链表其他节点的方式统一了呢?
|
||||
|
||||
来看一下,如何移除元素1 呢,还是熟悉的方式,然后从内存中删除元素1。
|
||||
|
||||
最后呢在题目中,return 头结点的时候,别忘了 `return dummyNode->next;`, 这才是新的头结点
|
||||
|
||||
|
||||
# C++代码
|
||||
|
||||
**直接使用原来的链表来进行移除节点操作:**
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
ListNode* removeElements(ListNode* head, int val) {
|
||||
// 删除头结点
|
||||
while (head != NULL && head->val == val) { // 注意这里不是if
|
||||
ListNode* tmp = head;
|
||||
head = head->next;
|
||||
delete tmp;
|
||||
}
|
||||
|
||||
// 删除非头结点
|
||||
ListNode* cur = head;
|
||||
while (cur != NULL && cur->next!= NULL) {
|
||||
if (cur->next->val == val) {
|
||||
ListNode* tmp = cur->next;
|
||||
cur->next = cur->next->next;
|
||||
delete tmp;
|
||||
} else {
|
||||
cur = cur->next;
|
||||
}
|
||||
}
|
||||
return head;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
**设置一个虚拟头结点在进行移除节点操作:**
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
ListNode* removeElements(ListNode* head, int val) {
|
||||
ListNode* dummyHead = new ListNode(0); // 设置一个虚拟头结点
|
||||
dummyHead->next = head; // 将虚拟头结点指向head,这样方面后面做删除操作
|
||||
ListNode* cur = dummyHead;
|
||||
while (cur->next != NULL) {
|
||||
if(cur->next->val == val) {
|
||||
ListNode* tmp = cur->next;
|
||||
cur->next = cur->next->next;
|
||||
delete tmp;
|
||||
} else {
|
||||
cur = cur->next;
|
||||
}
|
||||
}
|
||||
head = dummyHead->next;
|
||||
delete dummyHead;
|
||||
return head;
|
||||
}
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
/**
|
||||
* 添加虚节点方式
|
||||
* 时间复杂度 O(n)
|
||||
* 空间复杂度 O(1)
|
||||
* @param head
|
||||
* @param val
|
||||
* @return
|
||||
*/
|
||||
public ListNode removeElements(ListNode head, int val) {
|
||||
if (head == null) {
|
||||
return head;
|
||||
}
|
||||
// 因为删除可能涉及到头节点,所以设置dummy节点,统一操作
|
||||
ListNode dummy = new ListNode(-1, head);
|
||||
ListNode pre = dummy;
|
||||
ListNode cur = head;
|
||||
while (cur != null) {
|
||||
if (cur.val == val) {
|
||||
pre.next = cur.next;
|
||||
} else {
|
||||
pre = cur;
|
||||
}
|
||||
cur = cur.next;
|
||||
}
|
||||
return dummy.next;
|
||||
}
|
||||
/**
|
||||
* 不添加虚拟节点方式
|
||||
* 时间复杂度 O(n)
|
||||
* 空间复杂度 O(1)
|
||||
* @param head
|
||||
* @param val
|
||||
* @return
|
||||
*/
|
||||
public ListNode removeElements(ListNode head, int val) {
|
||||
while (head != null && head.val == val) {
|
||||
head = head.next;
|
||||
}
|
||||
// 已经为null,提前退出
|
||||
if (head == null) {
|
||||
return head;
|
||||
}
|
||||
// 已确定当前head.val != val
|
||||
ListNode pre = head;
|
||||
ListNode cur = head.next;
|
||||
while (cur != null) {
|
||||
if (cur.val == val) {
|
||||
pre.next = cur.next;
|
||||
} else {
|
||||
pre = cur;
|
||||
}
|
||||
cur = cur.next;
|
||||
}
|
||||
return head;
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
# Definition for singly-linked list.
|
||||
# class ListNode:
|
||||
# def __init__(self, val=0, next=None):
|
||||
# self.val = val
|
||||
# self.next = next
|
||||
class Solution:
|
||||
def removeElements(self, head: ListNode, val: int) -> ListNode:
|
||||
dummy_head = ListNode(next=head) #添加一个虚拟节点
|
||||
cur = dummy_head
|
||||
while(cur.next!=None):
|
||||
if(cur.next.val == val):
|
||||
cur.next = cur.next.next #删除cur.next节点
|
||||
else:
|
||||
cur = cur.next
|
||||
return dummy_head.next
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
```go
|
||||
/**
|
||||
* Definition for singly-linked list.
|
||||
* type ListNode struct {
|
||||
* Val int
|
||||
* Next *ListNode
|
||||
* }
|
||||
*/
|
||||
func removeElements(head *ListNode, val int) *ListNode {
|
||||
dummyHead := &ListNode{}
|
||||
dummyHead.Next = head
|
||||
cur := dummyHead
|
||||
for cur != nil && cur.Next != nil {
|
||||
if cur.Next.Val == val {
|
||||
cur.Next = cur.Next.Next
|
||||
} else {
|
||||
cur = cur.Next
|
||||
}
|
||||
}
|
||||
return dummyHead.Next
|
||||
}
|
||||
```
|
||||
|
||||
javaScript:
|
||||
|
||||
```js
|
||||
/**
|
||||
* @param {ListNode} head
|
||||
* @param {number} val
|
||||
* @return {ListNode}
|
||||
*/
|
||||
var removeElements = function(head, val) {
|
||||
const ret = new ListNode(0, head);
|
||||
let cur = ret;
|
||||
while(cur.next) {
|
||||
if(cur.next.val === val) {
|
||||
cur.next = cur.next.next;
|
||||
continue;
|
||||
}
|
||||
cur = cur.next;
|
||||
}
|
||||
return ret.next;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
285
problems/0206.翻转链表.md
Normal file
285
problems/0206.翻转链表.md
Normal file
@@ -0,0 +1,285 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
> 反转链表的写法很简单,一些同学甚至可以背下来但过一阵就忘了该咋写,主要是因为没有理解真正的反转过程。
|
||||
|
||||
# 206.反转链表
|
||||
|
||||
https://leetcode-cn.com/problems/reverse-linked-list/
|
||||
|
||||
题意:反转一个单链表。
|
||||
|
||||
示例:
|
||||
输入: 1->2->3->4->5->NULL
|
||||
输出: 5->4->3->2->1->NULL
|
||||
|
||||
# 思路
|
||||
|
||||
如果再定义一个新的链表,实现链表元素的反转,其实这是对内存空间的浪费。
|
||||
|
||||
其实只需要改变链表的next指针的指向,直接将链表反转 ,而不用重新定义一个新的链表,如图所示:
|
||||
|
||||
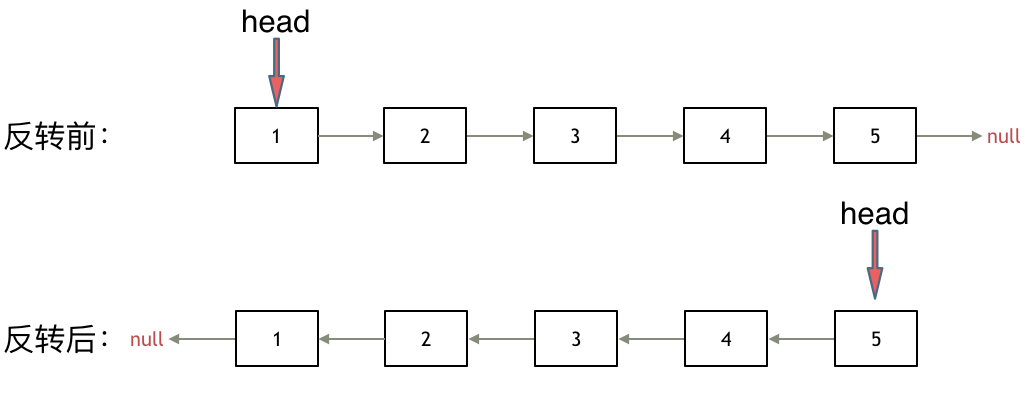
|
||||
|
||||
之前链表的头节点是元素1, 反转之后头结点就是元素5 ,这里并没有添加或者删除节点,仅仅是改表next指针的方向。
|
||||
|
||||
那么接下来看一看是如何反转呢?
|
||||
|
||||
我们拿有示例中的链表来举例,如动画所示:
|
||||
|
||||

|
||||
|
||||
首先定义一个cur指针,指向头结点,再定义一个pre指针,初始化为null。
|
||||
|
||||
然后就要开始反转了,首先要把 cur->next 节点用tmp指针保存一下,也就是保存一下这个节点。
|
||||
|
||||
为什么要保存一下这个节点呢,因为接下来要改变 cur->next 的指向了,将cur->next 指向pre ,此时已经反转了第一个节点了。
|
||||
|
||||
接下来,就是循环走如下代码逻辑了,继续移动pre和cur指针。
|
||||
|
||||
最后,cur 指针已经指向了null,循环结束,链表也反转完毕了。 此时我们return pre指针就可以了,pre指针就指向了新的头结点。
|
||||
|
||||
# C++代码
|
||||
|
||||
## 双指针法
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
ListNode* reverseList(ListNode* head) {
|
||||
ListNode* temp; // 保存cur的下一个节点
|
||||
ListNode* cur = head;
|
||||
ListNode* pre = NULL;
|
||||
while(cur) {
|
||||
temp = cur->next; // 保存一下 cur的下一个节点,因为接下来要改变cur->next
|
||||
cur->next = pre; // 翻转操作
|
||||
// 更新pre 和 cur指针
|
||||
pre = cur;
|
||||
cur = temp;
|
||||
}
|
||||
return pre;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 递归法
|
||||
|
||||
递归法相对抽象一些,但是其实和双指针法是一样的逻辑,同样是当cur为空的时候循环结束,不断将cur指向pre的过程。
|
||||
|
||||
关键是初始化的地方,可能有的同学会不理解, 可以看到双指针法中初始化 cur = head,pre = NULL,在递归法中可以从如下代码看出初始化的逻辑也是一样的,只不过写法变了。
|
||||
|
||||
具体可以看代码(已经详细注释),**双指针法写出来之后,理解如下递归写法就不难了,代码逻辑都是一样的。**
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
ListNode* reverse(ListNode* pre,ListNode* cur){
|
||||
if(cur == NULL) return pre;
|
||||
ListNode* temp = cur->next;
|
||||
cur->next = pre;
|
||||
// 可以和双指针法的代码进行对比,如下递归的写法,其实就是做了这两步
|
||||
// pre = cur;
|
||||
// cur = temp;
|
||||
return reverse(cur,temp);
|
||||
}
|
||||
ListNode* reverseList(ListNode* head) {
|
||||
// 和双指针法初始化是一样的逻辑
|
||||
// ListNode* cur = head;
|
||||
// ListNode* pre = NULL;
|
||||
return reverse(NULL, head);
|
||||
}
|
||||
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
// 双指针
|
||||
class Solution {
|
||||
public ListNode reverseList(ListNode head) {
|
||||
ListNode prev = null;
|
||||
ListNode cur = head;
|
||||
ListNode temp = null;
|
||||
while (cur != null) {
|
||||
temp = cur.next;// 保存下一个节点
|
||||
cur.next = prev;
|
||||
prev = cur;
|
||||
cur = temp;
|
||||
}
|
||||
return prev;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
// 递归
|
||||
class Solution {
|
||||
public ListNode reverseList(ListNode head) {
|
||||
return reverse(null, head);
|
||||
}
|
||||
|
||||
private ListNode reverse(ListNode prev, ListNode cur) {
|
||||
if (cur == null) {
|
||||
return prev;
|
||||
}
|
||||
ListNode temp = null;
|
||||
temp = cur.next;// 先保存下一个节点
|
||||
cur.next = prev;// 反转
|
||||
// 更新prev、cur位置
|
||||
prev = cur;
|
||||
cur = temp;
|
||||
return reverse(prev, cur);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python迭代法:
|
||||
```python
|
||||
#双指针
|
||||
# Definition for singly-linked list.
|
||||
# class ListNode:
|
||||
# def __init__(self, val=0, next=None):
|
||||
# self.val = val
|
||||
# self.next = next
|
||||
class Solution:
|
||||
def reverseList(self, head: ListNode) -> ListNode:
|
||||
cur = head
|
||||
pre = None
|
||||
while(cur!=None):
|
||||
temp = cur.next # 保存一下 cur的下一个节点,因为接下来要改变cur->next
|
||||
cur.next = pre #反转
|
||||
#更新pre、cur指针
|
||||
pre = cur
|
||||
cur = temp
|
||||
return pre
|
||||
```
|
||||
|
||||
Python递归法:
|
||||
|
||||
```python
|
||||
# Definition for singly-linked list.
|
||||
# class ListNode:
|
||||
# def __init__(self, val=0, next=None):
|
||||
# self.val = val
|
||||
# self.next = next
|
||||
class Solution:
|
||||
def reverseList(self, head: ListNode) -> ListNode:
|
||||
|
||||
def reverse(pre,cur):
|
||||
if not cur:
|
||||
return pre
|
||||
|
||||
tmp = cur.next
|
||||
cur.next = pre
|
||||
|
||||
return reverse(cur,tmp)
|
||||
|
||||
return reverse(None,head)
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
Go:
|
||||
|
||||
```go
|
||||
//双指针
|
||||
func reverseList(head *ListNode) *ListNode {
|
||||
var pre *ListNode
|
||||
cur := head
|
||||
for cur != nil {
|
||||
next := cur.Next
|
||||
cur.Next = pre
|
||||
pre = cur
|
||||
cur = next
|
||||
}
|
||||
return pre
|
||||
}
|
||||
|
||||
//递归
|
||||
func reverseList(head *ListNode) *ListNode {
|
||||
return help(nil, head)
|
||||
}
|
||||
|
||||
func help(pre, head *ListNode)*ListNode{
|
||||
if head == nil {
|
||||
return pre
|
||||
}
|
||||
next := head.Next
|
||||
head.Next = pre
|
||||
return help(head, next)
|
||||
}
|
||||
|
||||
```
|
||||
javaScript:
|
||||
|
||||
```js
|
||||
/**
|
||||
* @param {ListNode} head
|
||||
* @return {ListNode}
|
||||
*/
|
||||
|
||||
// 双指针:
|
||||
var reverseList = function(head) {
|
||||
if(!head || !head.next) return head;
|
||||
let temp = null, pre = null, cur = head;
|
||||
while(cur) {
|
||||
temp = cur.next;
|
||||
cur.next = pre;
|
||||
pre = cur;
|
||||
cur = temp;
|
||||
}
|
||||
// temp = cur = null;
|
||||
return pre;
|
||||
};
|
||||
|
||||
// 递归:
|
||||
var reverse = function(pre, head) {
|
||||
if(!head) return pre;
|
||||
const temp = head.next;
|
||||
head.next = pre;
|
||||
pre = head
|
||||
return reverse(pre, temp);
|
||||
}
|
||||
|
||||
var reverseList = function(head) {
|
||||
return reverse(null, head);
|
||||
};
|
||||
|
||||
// 递归2
|
||||
var reverse = function(head) {
|
||||
if(!head || !head.next) return head;
|
||||
// 从后往前翻
|
||||
const pre = reverse(head.next);
|
||||
head.next = pre.next;
|
||||
pre.next = head;
|
||||
return head;
|
||||
}
|
||||
|
||||
var reverseList = function(head) {
|
||||
let cur = head;
|
||||
while(cur && cur.next) {
|
||||
cur = cur.next;
|
||||
}
|
||||
reverse(head);
|
||||
return cur;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
223
problems/0209.长度最小的子数组.md
Normal file
223
problems/0209.长度最小的子数组.md
Normal file
@@ -0,0 +1,223 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 209.长度最小的子数组
|
||||
|
||||
题目链接: https://leetcode-cn.com/problems/minimum-size-subarray-sum/
|
||||
|
||||
给定一个含有 n 个正整数的数组和一个正整数 s ,找出该数组中满足其和 ≥ s 的长度最小的 连续 子数组,并返回其长度。如果不存在符合条件的子数组,返回 0。
|
||||
|
||||
示例:
|
||||
|
||||
输入:s = 7, nums = [2,3,1,2,4,3]
|
||||
输出:2
|
||||
解释:子数组 [4,3] 是该条件下的长度最小的子数组。
|
||||
|
||||
|
||||
## 暴力解法
|
||||
|
||||
这道题目暴力解法当然是 两个for循环,然后不断的寻找符合条件的子序列,时间复杂度很明显是O(n^2) 。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int minSubArrayLen(int s, vector<int>& nums) {
|
||||
int result = INT32_MAX; // 最终的结果
|
||||
int sum = 0; // 子序列的数值之和
|
||||
int subLength = 0; // 子序列的长度
|
||||
for (int i = 0; i < nums.size(); i++) { // 设置子序列起点为i
|
||||
sum = 0;
|
||||
for (int j = i; j < nums.size(); j++) { // 设置子序列终止位置为j
|
||||
sum += nums[j];
|
||||
if (sum >= s) { // 一旦发现子序列和超过了s,更新result
|
||||
subLength = j - i + 1; // 取子序列的长度
|
||||
result = result < subLength ? result : subLength;
|
||||
break; // 因为我们是找符合条件最短的子序列,所以一旦符合条件就break
|
||||
}
|
||||
}
|
||||
}
|
||||
// 如果result没有被赋值的话,就返回0,说明没有符合条件的子序列
|
||||
return result == INT32_MAX ? 0 : result;
|
||||
}
|
||||
};
|
||||
```
|
||||
时间复杂度:$O(n^2)$
|
||||
空间复杂度:$O(1)$
|
||||
|
||||
## 滑动窗口
|
||||
|
||||
接下来就开始介绍数组操作中另一个重要的方法:**滑动窗口**。
|
||||
|
||||
所谓滑动窗口,**就是不断的调节子序列的起始位置和终止位置,从而得出我们要想的结果**。
|
||||
|
||||
这里还是以题目中的示例来举例,s=7, 数组是 2,3,1,2,4,3,来看一下查找的过程:
|
||||
|
||||
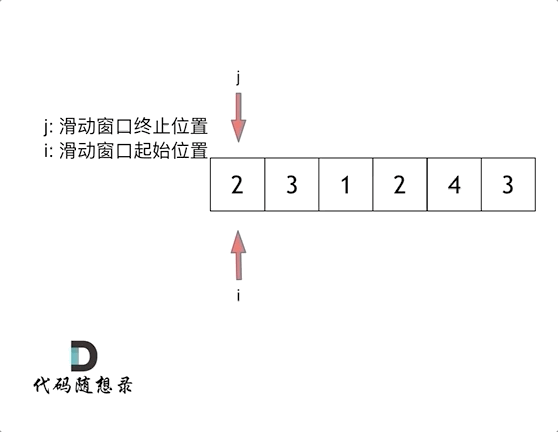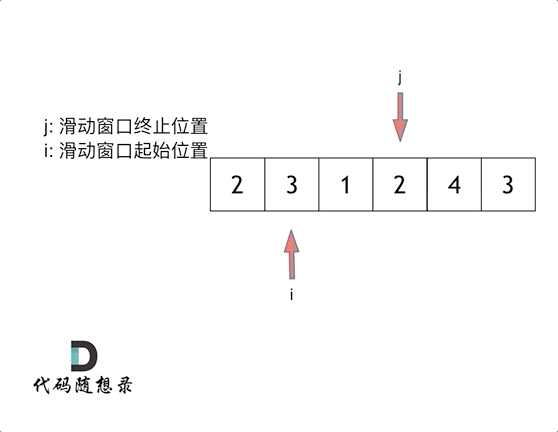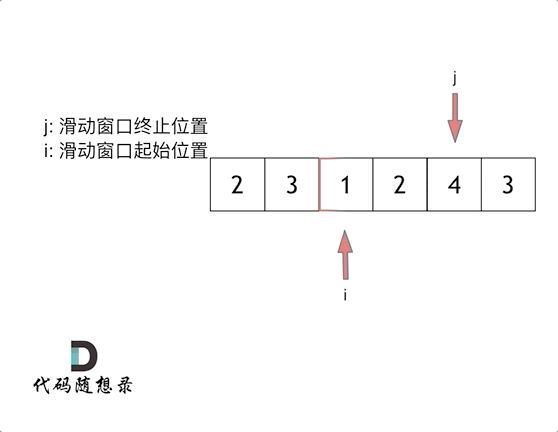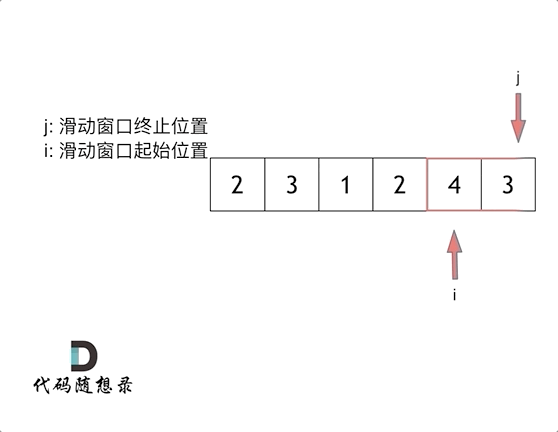
|
||||
|
||||
最后找到 4,3 是最短距离。
|
||||
|
||||
其实从动画中可以发现滑动窗口也可以理解为双指针法的一种!只不过这种解法更像是一个窗口的移动,所以叫做滑动窗口更适合一些。
|
||||
|
||||
在本题中实现滑动窗口,主要确定如下三点:
|
||||
|
||||
* 窗口内是什么?
|
||||
* 如何移动窗口的起始位置?
|
||||
* 如何移动窗口的结束位置?
|
||||
|
||||
窗口就是 满足其和 ≥ s 的长度最小的 连续 子数组。
|
||||
|
||||
窗口的起始位置如何移动:如果当前窗口的值大于s了,窗口就要向前移动了(也就是该缩小了)。
|
||||
|
||||
窗口的结束位置如何移动:窗口的结束位置就是遍历数组的指针,窗口的起始位置设置为数组的起始位置就可以了。
|
||||
|
||||
解题的关键在于 窗口的起始位置如何移动,如图所示:
|
||||
|
||||
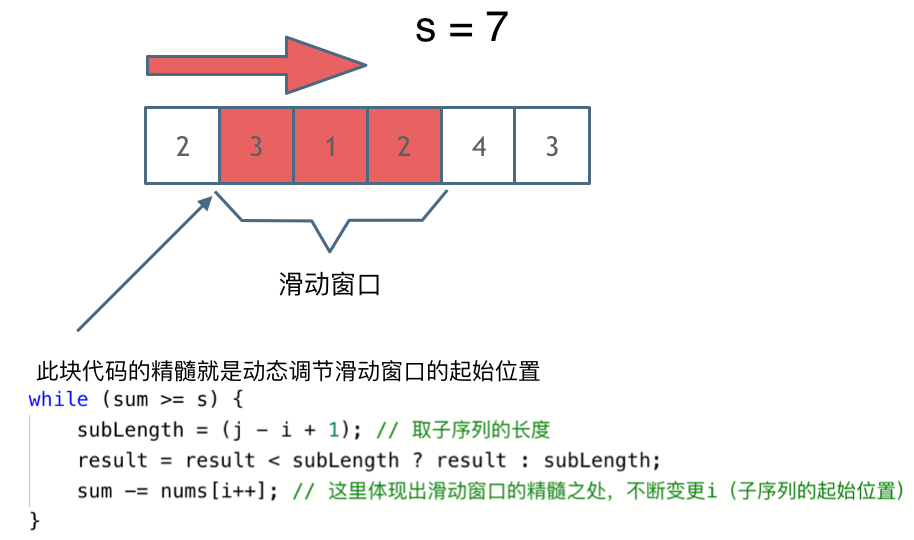
|
||||
|
||||
可以发现**滑动窗口的精妙之处在于根据当前子序列和大小的情况,不断调节子序列的起始位置。从而将O(n^2)的暴力解法降为O(n)。**
|
||||
|
||||
C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int minSubArrayLen(int s, vector<int>& nums) {
|
||||
int result = INT32_MAX;
|
||||
int sum = 0; // 滑动窗口数值之和
|
||||
int i = 0; // 滑动窗口起始位置
|
||||
int subLength = 0; // 滑动窗口的长度
|
||||
for (int j = 0; j < nums.size(); j++) {
|
||||
sum += nums[j];
|
||||
// 注意这里使用while,每次更新 i(起始位置),并不断比较子序列是否符合条件
|
||||
while (sum >= s) {
|
||||
subLength = (j - i + 1); // 取子序列的长度
|
||||
result = result < subLength ? result : subLength;
|
||||
sum -= nums[i++]; // 这里体现出滑动窗口的精髓之处,不断变更i(子序列的起始位置)
|
||||
}
|
||||
}
|
||||
// 如果result没有被赋值的话,就返回0,说明没有符合条件的子序列
|
||||
return result == INT32_MAX ? 0 : result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
时间复杂度:$O(n)$
|
||||
空间复杂度:$O(1)$
|
||||
|
||||
**一些录友会疑惑为什么时间复杂度是O(n)**。
|
||||
|
||||
不要以为for里放一个while就以为是$O(n^2)$啊, 主要是看每一个元素被操作的次数,每个元素在滑动窗后进来操作一次,出去操作一次,每个元素都是被被操作两次,所以时间复杂度是2 * n 也就是$O(n)$。
|
||||
|
||||
## 相关题目推荐
|
||||
|
||||
* [904.水果成篮](https://leetcode-cn.com/problems/fruit-into-baskets/)
|
||||
* [76.最小覆盖子串](https://leetcode-cn.com/problems/minimum-window-substring/)
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
|
||||
// 滑动窗口
|
||||
public int minSubArrayLen(int s, int[] nums) {
|
||||
int left = 0;
|
||||
int sum = 0;
|
||||
int result = Integer.MAX_VALUE;
|
||||
for (int right = 0; right < nums.length; right++) {
|
||||
sum += nums[right];
|
||||
while (sum >= s) {
|
||||
result = Math.min(result, right - left + 1);
|
||||
sum -= nums[left++];
|
||||
}
|
||||
}
|
||||
return result == Integer.MAX_VALUE ? 0 : result;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def minSubArrayLen(self, s: int, nums: List[int]) -> int:
|
||||
# 定义一个无限大的数
|
||||
res = float("inf")
|
||||
Sum = 0
|
||||
index = 0
|
||||
for i in range(len(nums)):
|
||||
Sum += nums[i]
|
||||
while Sum >= s:
|
||||
res = min(res, i-index+1)
|
||||
Sum -= nums[index]
|
||||
index += 1
|
||||
return 0 if res==float("inf") else res
|
||||
```
|
||||
|
||||
|
||||
Go:
|
||||
```go
|
||||
func minSubArrayLen(target int, nums []int) int {
|
||||
i := 0
|
||||
l := len(nums) // 数组长度
|
||||
sum := 0 // 子数组之和
|
||||
result := l + 1 // 初始化返回长度为l+1,目的是为了判断“不存在符合条件的子数组,返回0”的情况
|
||||
for j := 0; j < l; j++ {
|
||||
sum += nums[j]
|
||||
for sum >= target {
|
||||
subLength := j - i + 1
|
||||
if subLength < result {
|
||||
result = subLength
|
||||
}
|
||||
sum -= nums[i]
|
||||
i++
|
||||
}
|
||||
}
|
||||
if result == l+1 {
|
||||
return 0
|
||||
} else {
|
||||
return result
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
JavaScript:
|
||||
|
||||
```js
|
||||
|
||||
var minSubArrayLen = function(target, nums) {
|
||||
// 长度计算一次
|
||||
const len = nums.length;
|
||||
let l = r = sum = 0,
|
||||
res = len + 1; // 子数组最大不会超过自身
|
||||
while(r < len) {
|
||||
sum += nums[r++];
|
||||
// 窗口滑动
|
||||
while(sum >= target) {
|
||||
// r始终为开区间 [l, r)
|
||||
res = res < r - l ? res : r - l;
|
||||
sum-=nums[l++];
|
||||
}
|
||||
}
|
||||
return res > len ? 0 : res;
|
||||
};
|
||||
```
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
177
problems/0213.打家劫舍II.md
Normal file
177
problems/0213.打家劫舍II.md
Normal file
@@ -0,0 +1,177 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
## 213.打家劫舍II
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/house-robber-ii/
|
||||
|
||||
你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金。这个地方所有的房屋都 围成一圈 ,这意味着第一个房屋和最后一个房屋是紧挨着的。同时,相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警 。
|
||||
|
||||
给定一个代表每个房屋存放金额的非负整数数组,计算你 在不触动警报装置的情况下 ,能够偷窃到的最高金额。
|
||||
|
||||
示例 1:
|
||||
|
||||
输入:nums = [2,3,2]
|
||||
输出:3
|
||||
解释:你不能先偷窃 1 号房屋(金额 = 2),然后偷窃 3 号房屋(金额 = 2), 因为他们是相邻的。
|
||||
|
||||
示例 2:
|
||||
输入:nums = [1,2,3,1]
|
||||
输出:4
|
||||
解释:你可以先偷窃 1 号房屋(金额 = 1),然后偷窃 3 号房屋(金额 = 3)。偷窃到的最高金额 = 1 + 3 = 4 。
|
||||
|
||||
示例 3:
|
||||
输入:nums = [0]
|
||||
输出:0
|
||||
|
||||
提示:
|
||||
* 1 <= nums.length <= 100
|
||||
* 0 <= nums[i] <= 1000
|
||||
|
||||
## 思路
|
||||
|
||||
这道题目和[198.打家劫舍](https://mp.weixin.qq.com/s/UZ31WdLEEFmBegdgLkJ8Dw)是差不多的,唯一区别就是成环了。
|
||||
|
||||
对于一个数组,成环的话主要有如下三种情况:
|
||||
|
||||
* 情况一:考虑不包含首尾元素
|
||||
|
||||
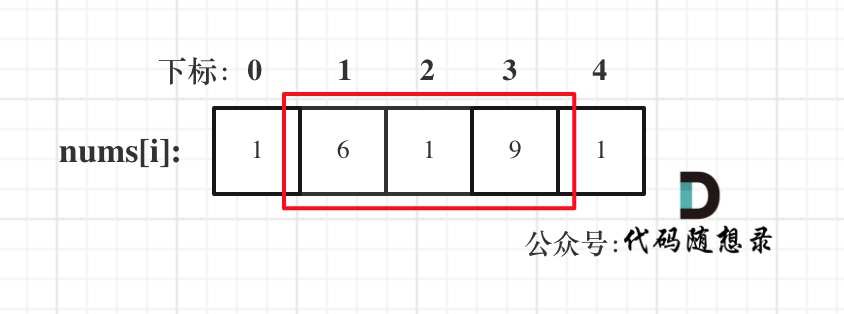
|
||||
|
||||
* 情况二:考虑包含首元素,不包含尾元素
|
||||
|
||||
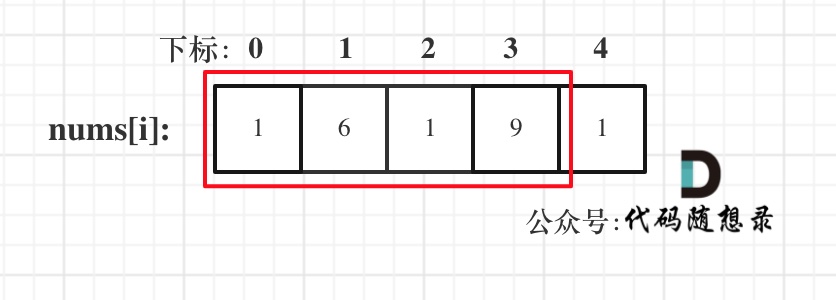
|
||||
|
||||
* 情况三:考虑包含尾元素,不包含首元素
|
||||
|
||||
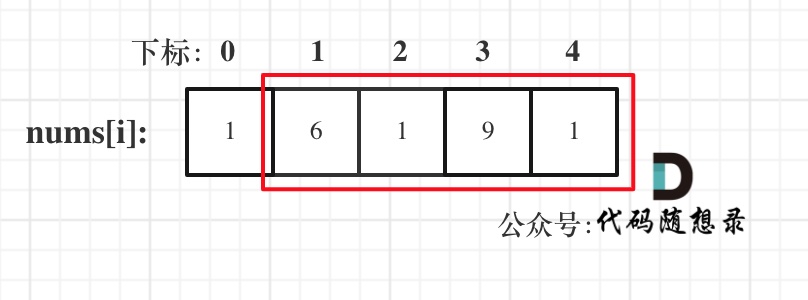
|
||||
|
||||
**注意我这里用的是"考虑"**,例如情况三,虽然是考虑包含尾元素,但不一定要选尾部元素! 对于情况三,取nums[1] 和 nums[3]就是最大的。
|
||||
|
||||
**而情况二 和 情况三 都包含了情况一了,所以只考虑情况二和情况三就可以了**。
|
||||
|
||||
分析到这里,本题其实比较简单了。 剩下的和[198.打家劫舍](https://mp.weixin.qq.com/s/UZ31WdLEEFmBegdgLkJ8Dw)就是一样的了。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
// 注意注释中的情况二情况三,以及把198.打家劫舍的代码抽离出来了
|
||||
class Solution {
|
||||
public:
|
||||
int rob(vector<int>& nums) {
|
||||
if (nums.size() == 0) return 0;
|
||||
if (nums.size() == 1) return nums[0];
|
||||
int result1 = robRange(nums, 0, nums.size() - 2); // 情况二
|
||||
int result2 = robRange(nums, 1, nums.size() - 1); // 情况三
|
||||
return max(result1, result2);
|
||||
}
|
||||
// 198.打家劫舍的逻辑
|
||||
int robRange(vector<int>& nums, int start, int end) {
|
||||
if (end == start) return nums[start];
|
||||
vector<int> dp(nums.size());
|
||||
dp[start] = nums[start];
|
||||
dp[start + 1] = max(nums[start], nums[start + 1]);
|
||||
for (int i = start + 2; i <= end; i++) {
|
||||
dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);
|
||||
}
|
||||
return dp[end];
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
成环之后还是难了一些的, 不少题解没有把“考虑房间”和“偷房间”说清楚。
|
||||
|
||||
这就导致大家会有这样的困惑:情况三怎么就包含了情况一了呢? 本文图中最后一间房不能偷啊,偷了一定不是最优结果。
|
||||
|
||||
所以我在本文重点强调了情况一二三是“考虑”的范围,而具体房间偷与不偷交给递推公式去抉择。
|
||||
|
||||
这样大家就不难理解情况二和情况三包含了情况一了。
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
public int rob(int[] nums) {
|
||||
if (nums == null || nums.length == 0)
|
||||
return 0;
|
||||
int len = nums.length;
|
||||
if (len == 1)
|
||||
return nums[0];
|
||||
return Math.max(robAction(nums, 0, len - 1), robAction(nums, 1, len));
|
||||
}
|
||||
|
||||
int robAction(int[] nums, int start, int end) {
|
||||
int x = 0, y = 0, z = 0;
|
||||
for (int i = start; i < end; i++) {
|
||||
y = z;
|
||||
z = Math.max(y, x + nums[i]);
|
||||
x = y;
|
||||
}
|
||||
return z;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```Python
|
||||
class Solution:
|
||||
def rob(self, nums: List[int]) -> int:
|
||||
if (n := len(nums)) == 0:
|
||||
return 0
|
||||
if n == 1:
|
||||
return nums[0]
|
||||
result1 = self.robRange(nums, 0, n - 2)
|
||||
result2 = self.robRange(nums, 1, n - 1)
|
||||
return max(result1 , result2)
|
||||
|
||||
def robRange(self, nums: List[int], start: int, end: int) -> int:
|
||||
if end == start: return nums[start]
|
||||
dp = [0] * len(nums)
|
||||
dp[start] = nums[start]
|
||||
dp[start + 1] = max(nums[start], nums[start + 1])
|
||||
for i in range(start + 2, end + 1):
|
||||
dp[i] = max(dp[i -2] + nums[i], dp[i - 1])
|
||||
return dp[end]
|
||||
```
|
||||
|
||||
javascipt:
|
||||
```javascript
|
||||
var rob = function(nums) {
|
||||
const n = nums.length
|
||||
if (n === 0) return 0
|
||||
if (n === 1) return nums[0]
|
||||
const result1 = robRange(nums, 0, n - 2)
|
||||
const result2 = robRange(nums, 1, n - 1)
|
||||
return Math.max(result1, result2)
|
||||
};
|
||||
|
||||
const robRange = (nums, start, end) => {
|
||||
if (end === start) return nums[start]
|
||||
const dp = Array(nums.length).fill(0)
|
||||
dp[start] = nums[start]
|
||||
dp[start + 1] = Math.max(nums[start], nums[start + 1])
|
||||
for (let i = start + 2; i <= end; i++) {
|
||||
dp[i] = Math.max(dp[i - 2] + nums[i], dp[i - 1])
|
||||
}
|
||||
return dp[end]
|
||||
}
|
||||
```
|
||||
Go:
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
363
problems/0216.组合总和III.md
Normal file
363
problems/0216.组合总和III.md
Normal file
@@ -0,0 +1,363 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
|
||||
|
||||
> 别看本篇选的是组合总和III,而不是组合总和,本题和上一篇[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)相比难度刚刚好!
|
||||
|
||||
# 216.组合总和III
|
||||
|
||||
链接:https://leetcode-cn.com/problems/combination-sum-iii/
|
||||
|
||||
找出所有相加之和为 n 的 k 个数的组合。组合中只允许含有 1 - 9 的正整数,并且每种组合中不存在重复的数字。
|
||||
|
||||
说明:
|
||||
* 所有数字都是正整数。
|
||||
* 解集不能包含重复的组合。
|
||||
|
||||
示例 1:
|
||||
输入: k = 3, n = 7
|
||||
输出: [[1,2,4]]
|
||||
|
||||
示例 2:
|
||||
输入: k = 3, n = 9
|
||||
输出: [[1,2,6], [1,3,5], [2,3,4]]
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
本题就是在[1,2,3,4,5,6,7,8,9]这个集合中找到和为n的k个数的组合。
|
||||
|
||||
相对于[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ),无非就是多了一个限制,本题是要找到和为n的k个数的组合,而整个集合已经是固定的了[1,...,9]。
|
||||
|
||||
想到这一点了,做过[77. 组合](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)之后,本题是简单一些了。
|
||||
|
||||
本题k相当于了树的深度,9(因为整个集合就是9个数)就是树的宽度。
|
||||
|
||||
例如 k = 2,n = 4的话,就是在集合[1,2,3,4,5,6,7,8,9]中求 k(个数) = 2, n(和) = 4的组合。
|
||||
|
||||
选取过程如图:
|
||||
|
||||
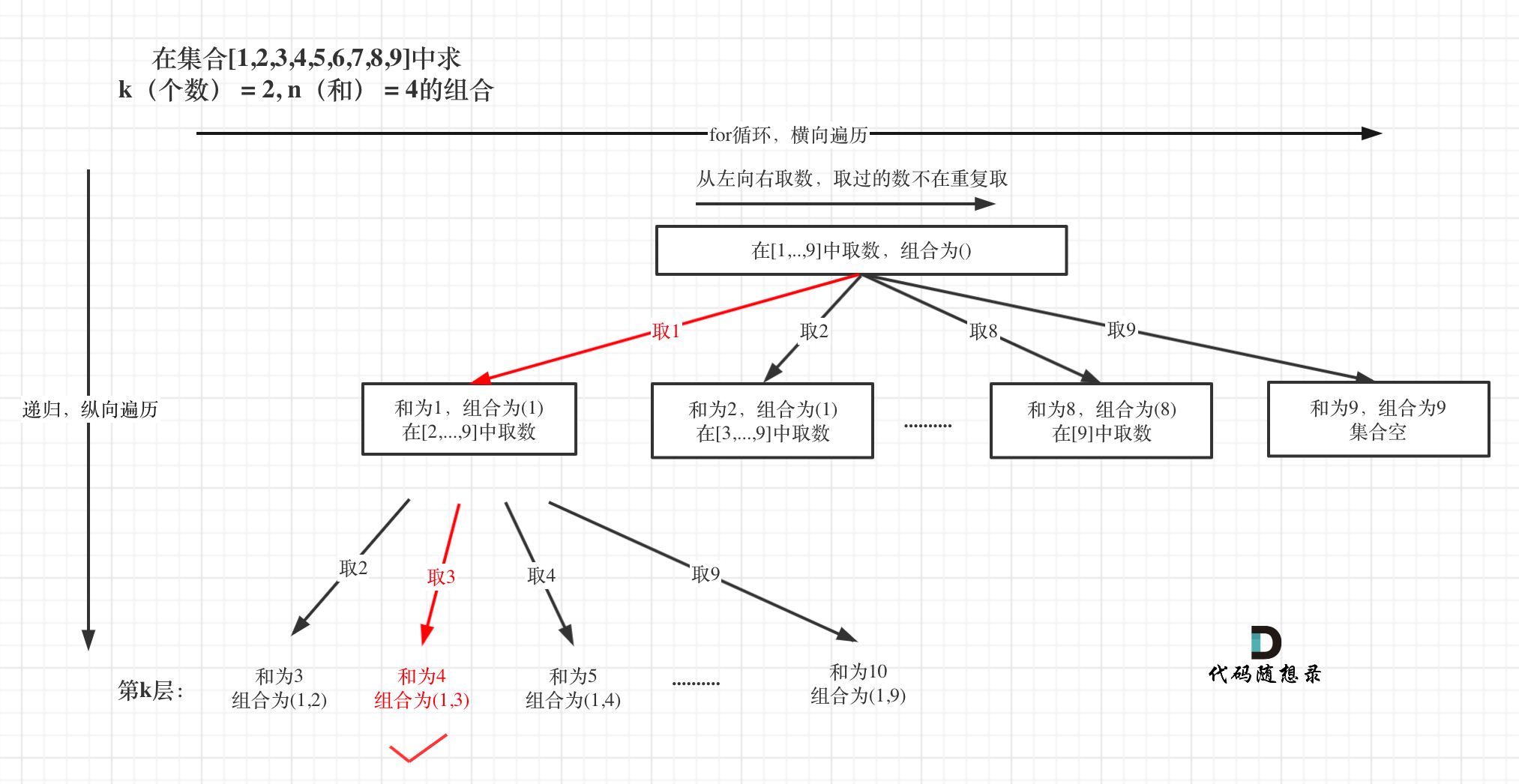
|
||||
|
||||
图中,可以看出,只有最后取到集合(1,3)和为4 符合条件。
|
||||
|
||||
|
||||
## 回溯三部曲
|
||||
|
||||
* **确定递归函数参数**
|
||||
|
||||
和[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)一样,依然需要一维数组path来存放符合条件的结果,二维数组result来存放结果集。
|
||||
|
||||
这里我依然定义path 和 result为全局变量。
|
||||
|
||||
至于为什么取名为path?从上面树形结构中,可以看出,结果其实就是一条根节点到叶子节点的路径。
|
||||
|
||||
```
|
||||
vector<vector<int>> result; // 存放结果集
|
||||
vector<int> path; // 符合条件的结果
|
||||
```
|
||||
|
||||
接下来还需要如下参数:
|
||||
|
||||
* targetSum(int)目标和,也就是题目中的n。
|
||||
* k(int)就是题目中要求k个数的集合。
|
||||
* sum(int)为已经收集的元素的总和,也就是path里元素的总和。
|
||||
* startIndex(int)为下一层for循环搜索的起始位置。
|
||||
|
||||
所以代码如下:
|
||||
|
||||
```
|
||||
vector<vector<int>> result;
|
||||
vector<int> path;
|
||||
void backtracking(int targetSum, int k, int sum, int startIndex)
|
||||
```
|
||||
其实这里sum这个参数也可以省略,每次targetSum减去选取的元素数值,然后判断如果targetSum为0了,说明收集到符合条件的结果了,我这里为了直观便于理解,还是加一个sum参数。
|
||||
|
||||
还要强调一下,回溯法中递归函数参数很难一次性确定下来,一般先写逻辑,需要啥参数了,填什么参数。
|
||||
|
||||
* 确定终止条件
|
||||
|
||||
什么时候终止呢?
|
||||
|
||||
在上面已经说了,k其实就已经限制树的深度,因为就取k个元素,树再往下深了没有意义。
|
||||
|
||||
所以如果path.size() 和 k相等了,就终止。
|
||||
|
||||
如果此时path里收集到的元素和(sum) 和targetSum(就是题目描述的n)相同了,就用result收集当前的结果。
|
||||
|
||||
所以 终止代码如下:
|
||||
|
||||
```C++
|
||||
if (path.size() == k) {
|
||||
if (sum == targetSum) result.push_back(path);
|
||||
return; // 如果path.size() == k 但sum != targetSum 直接返回
|
||||
}
|
||||
```
|
||||
|
||||
* **单层搜索过程**
|
||||
|
||||
本题和[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)区别之一就是集合固定的就是9个数[1,...,9],所以for循环固定i<=9
|
||||
|
||||
如图:
|
||||

|
||||
|
||||
处理过程就是 path收集每次选取的元素,相当于树型结构里的边,sum来统计path里元素的总和。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
for (int i = startIndex; i <= 9; i++) {
|
||||
sum += i;
|
||||
path.push_back(i);
|
||||
backtracking(targetSum, k, sum, i + 1); // 注意i+1调整startIndex
|
||||
sum -= i; // 回溯
|
||||
path.pop_back(); // 回溯
|
||||
}
|
||||
```
|
||||
|
||||
**别忘了处理过程 和 回溯过程是一一对应的,处理有加,回溯就要有减!**
|
||||
|
||||
参照[关于回溯算法,你该了解这些!](https://mp.weixin.qq.com/s/gjSgJbNbd1eAA5WkA-HeWw)中的模板,不难写出如下C++代码:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
vector<vector<int>> result; // 存放结果集
|
||||
vector<int> path; // 符合条件的结果
|
||||
// targetSum:目标和,也就是题目中的n。
|
||||
// k:题目中要求k个数的集合。
|
||||
// sum:已经收集的元素的总和,也就是path里元素的总和。
|
||||
// startIndex:下一层for循环搜索的起始位置。
|
||||
void backtracking(int targetSum, int k, int sum, int startIndex) {
|
||||
if (path.size() == k) {
|
||||
if (sum == targetSum) result.push_back(path);
|
||||
return; // 如果path.size() == k 但sum != targetSum 直接返回
|
||||
}
|
||||
for (int i = startIndex; i <= 9; i++) {
|
||||
sum += i; // 处理
|
||||
path.push_back(i); // 处理
|
||||
backtracking(targetSum, k, sum, i + 1); // 注意i+1调整startIndex
|
||||
sum -= i; // 回溯
|
||||
path.pop_back(); // 回溯
|
||||
}
|
||||
}
|
||||
|
||||
public:
|
||||
vector<vector<int>> combinationSum3(int k, int n) {
|
||||
result.clear(); // 可以不加
|
||||
path.clear(); // 可以不加
|
||||
backtracking(n, k, 0, 1);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 剪枝
|
||||
|
||||
这道题目,剪枝操作其实是很容易想到了,想必大家看上面的树形图的时候已经想到了。
|
||||
|
||||
如图:
|
||||
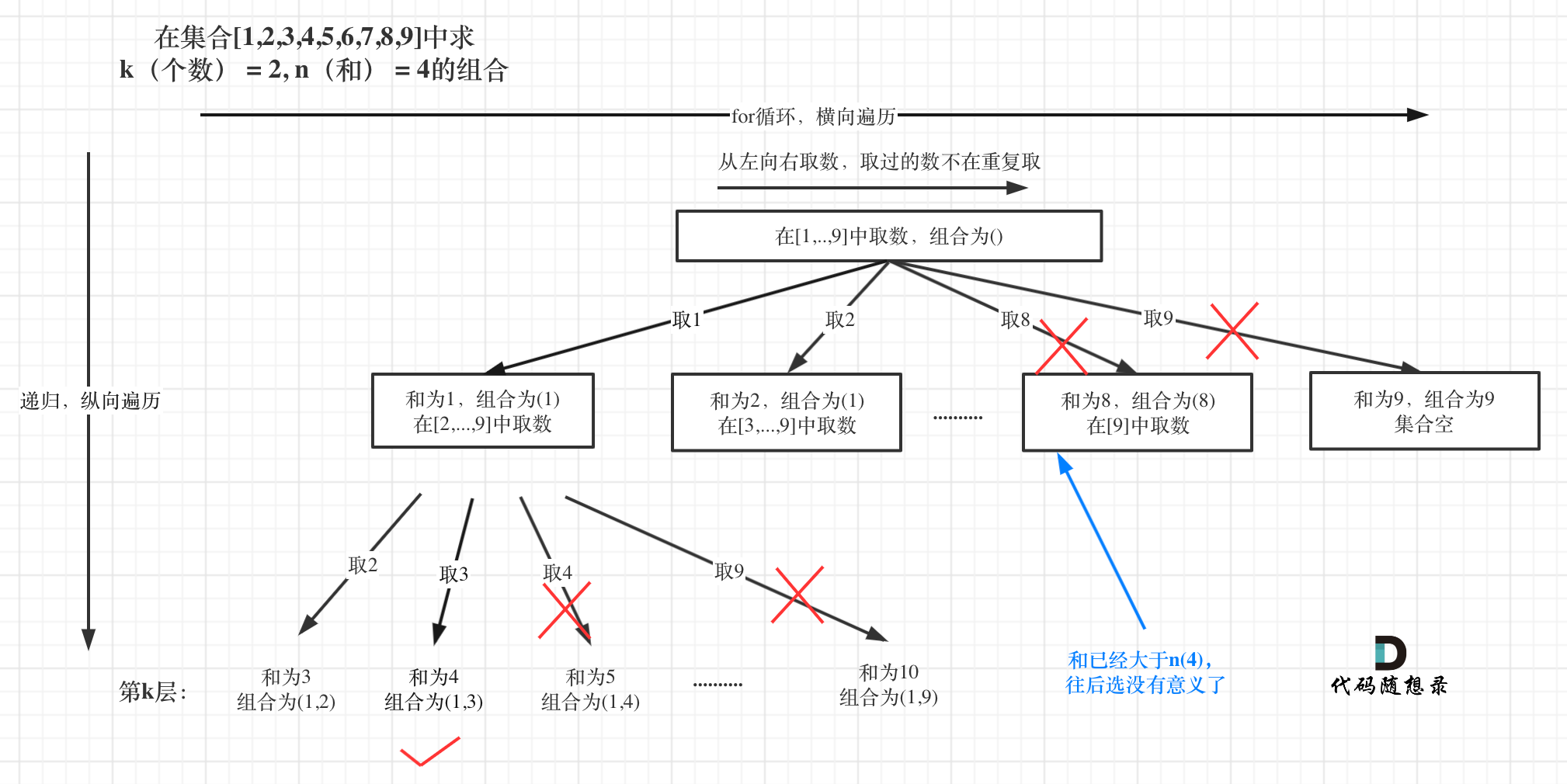
|
||||
|
||||
已选元素总和如果已经大于n(图中数值为4)了,那么往后遍历就没有意义了,直接剪掉。
|
||||
|
||||
那么剪枝的地方一定是在递归终止的地方剪,剪枝代码如下:
|
||||
|
||||
```
|
||||
if (sum > targetSum) { // 剪枝操作
|
||||
return;
|
||||
}
|
||||
```
|
||||
|
||||
和[回溯算法:组合问题再剪剪枝](https://mp.weixin.qq.com/s/Ri7spcJMUmph4c6XjPWXQA) 一样,for循环的范围也可以剪枝,i <= 9 - (k - path.size()) + 1就可以了。
|
||||
|
||||
最后C++代码如下:
|
||||
|
||||
```c++
|
||||
class Solution {
|
||||
private:
|
||||
vector<vector<int>> result; // 存放结果集
|
||||
vector<int> path; // 符合条件的结果
|
||||
void backtracking(int targetSum, int k, int sum, int startIndex) {
|
||||
if (sum > targetSum) { // 剪枝操作
|
||||
return; // 如果path.size() == k 但sum != targetSum 直接返回
|
||||
}
|
||||
if (path.size() == k) {
|
||||
if (sum == targetSum) result.push_back(path);
|
||||
return;
|
||||
}
|
||||
for (int i = startIndex; i <= 9 - (k - path.size()) + 1; i++) { // 剪枝
|
||||
sum += i; // 处理
|
||||
path.push_back(i); // 处理
|
||||
backtracking(targetSum, k, sum, i + 1); // 注意i+1调整startIndex
|
||||
sum -= i; // 回溯
|
||||
path.pop_back(); // 回溯
|
||||
}
|
||||
}
|
||||
|
||||
public:
|
||||
vector<vector<int>> combinationSum3(int k, int n) {
|
||||
result.clear(); // 可以不加
|
||||
path.clear(); // 可以不加
|
||||
backtracking(n, k, 0, 1);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
# 总结
|
||||
|
||||
开篇就介绍了本题与[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)的区别,相对来说加了元素总和的限制,如果做完[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)再做本题在合适不过。
|
||||
|
||||
分析完区别,依然把问题抽象为树形结构,按照回溯三部曲进行讲解,最后给出剪枝的优化。
|
||||
|
||||
相信做完本题,大家对组合问题应该有初步了解了。
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
List<List<Integer>> res = new ArrayList<>();
|
||||
List<Integer> list = new ArrayList<>();
|
||||
|
||||
public List<List<Integer>> combinationSum3(int k, int n) {
|
||||
res.clear();
|
||||
list.clear();
|
||||
backtracking(k, n, 9);
|
||||
return res;
|
||||
}
|
||||
|
||||
private void backtracking(int k, int n, int maxNum) {
|
||||
if (k == 0 && n == 0) {
|
||||
res.add(new ArrayList<>(list));
|
||||
return;
|
||||
}
|
||||
|
||||
// 因为不能重复,并且单个数字最大值是maxNum,所以sum最大值为
|
||||
// (maxNum + (maxNum - 1) + ... + (maxNum - k + 1)) == k * maxNum - k*(k - 1) / 2
|
||||
if (maxNum == 0
|
||||
|| n > k * maxNum - k * (k - 1) / 2
|
||||
|| n < (1 + k) * k / 2) {
|
||||
return;
|
||||
}
|
||||
list.add(maxNum);
|
||||
backtracking(k - 1, n - maxNum, maxNum - 1);
|
||||
list.remove(list.size() - 1);
|
||||
backtracking(k, n, maxNum - 1);
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```py
|
||||
class Solution:
|
||||
def combinationSum3(self, k: int, n: int) -> List[List[int]]:
|
||||
res = [] #存放结果集
|
||||
path = [] #符合条件的结果
|
||||
def findallPath(n,k,sum,startIndex):
|
||||
if sum > n: return #剪枝操作
|
||||
if sum == n and len(path) == k: #如果path.size() == k 但sum != n 直接返回
|
||||
return res.append(path[:])
|
||||
for i in range(startIndex,9-(k-len(path))+2): #剪枝操作
|
||||
path.append(i)
|
||||
sum += i
|
||||
findallPath(n,k,sum,i+1) #注意i+1调整startIndex
|
||||
sum -= i #回溯
|
||||
path.pop() #回溯
|
||||
|
||||
findallPath(n,k,0,1)
|
||||
return res
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
|
||||
> 回溯+减枝
|
||||
|
||||
```go
|
||||
func combinationSum3(k int, n int) [][]int {
|
||||
var track []int// 遍历路径
|
||||
var result [][]int// 存放结果集
|
||||
backTree(n,k,1,&track,&result)
|
||||
return result
|
||||
}
|
||||
func backTree(n,k,startIndex int,track *[]int,result *[][]int){
|
||||
if len(*track)==k{
|
||||
var sum int
|
||||
tmp:=make([]int,k)
|
||||
for k,v:=range *track{
|
||||
sum+=v
|
||||
tmp[k]=v
|
||||
}
|
||||
if sum==n{
|
||||
*result=append(*result,tmp)
|
||||
}
|
||||
return
|
||||
}
|
||||
for i:=startIndex;i<=9-(k-len(*track))+1;i++{//减枝(k-len(*track)表示还剩多少个可填充的元素)
|
||||
*track=append(*track,i)//记录路径
|
||||
backTree(n,k,i+1,track,result)//递归
|
||||
*track=(*track)[:len(*track)-1]//回溯
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
javaScript:
|
||||
|
||||
```js
|
||||
// 等差数列
|
||||
var maxV = k => k * (9 + 10 - k) / 2;
|
||||
var minV = k => k * (1 + k) / 2;
|
||||
var combinationSum3 = function(k, n) {
|
||||
if (k > 9 || k < 1) return [];
|
||||
// if (n > maxV(k) || n < minV(k)) return [];
|
||||
// if (n === maxV(k)) return [Array.from({length: k}).map((v, i) => 9 - i)];
|
||||
// if (n === minV(k)) return [Array.from({length: k}).map((v, i) => i + 1)];
|
||||
|
||||
const res = [], path = [];
|
||||
backtracking(k, n, 1, 0);
|
||||
return res;
|
||||
function backtracking(k, n, i, sum){
|
||||
const len = path.length;
|
||||
if (len > k || sum > n) return;
|
||||
if (maxV(k - len) < n - sum) return;
|
||||
if (minV(k - len) > n - sum) return;
|
||||
|
||||
if(len === k && sum == n) {
|
||||
res.push(Array.from(path));
|
||||
return;
|
||||
}
|
||||
|
||||
const min = Math.min(n - sum, 9 + len - k + 1);
|
||||
|
||||
for(let a = i; a <= min; a++) {
|
||||
path.push(a);
|
||||
sum += a;
|
||||
backtracking(k, n, a + 1, sum);
|
||||
path.pop();
|
||||
sum -= a;
|
||||
}
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
439
problems/0222.完全二叉树的节点个数.md
Normal file
439
problems/0222.完全二叉树的节点个数.md
Normal file
@@ -0,0 +1,439 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 222.完全二叉树的节点个数
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/count-complete-tree-nodes/
|
||||
|
||||
给出一个完全二叉树,求出该树的节点个数。
|
||||
|
||||
示例:
|
||||
示例 1:
|
||||
输入:root = [1,2,3,4,5,6]
|
||||
输出:6
|
||||
|
||||
示例 2:
|
||||
输入:root = []
|
||||
输出:0
|
||||
|
||||
示例 3:
|
||||
输入:root = [1]
|
||||
输出:1
|
||||
|
||||
提示:
|
||||
|
||||
* 树中节点的数目范围是[0, 5 * 10^4]
|
||||
* 0 <= Node.val <= 5 * 10^4
|
||||
* 题目数据保证输入的树是 完全二叉树
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
本篇给出按照普通二叉树的求法以及利用完全二叉树性质的求法。
|
||||
|
||||
## 普通二叉树
|
||||
|
||||
首先按照普通二叉树的逻辑来求。
|
||||
|
||||
这道题目的递归法和求二叉树的深度写法类似, 而迭代法,[二叉树:层序遍历登场!](https://mp.weixin.qq.com/s/Gb3BjakIKGNpup2jYtTzog)遍历模板稍稍修改一下,记录遍历的节点数量就可以了。
|
||||
|
||||
递归遍历的顺序依然是后序(左右中)。
|
||||
|
||||
### 递归
|
||||
|
||||
如果对求二叉树深度还不熟悉的话,看这篇:[二叉树:看看这些树的最大深度](https://mp.weixin.qq.com/s/guKwV-gSNbA1CcbvkMtHBg)。
|
||||
|
||||
1. 确定递归函数的参数和返回值:参数就是传入树的根节点,返回就返回以该节点为根节点二叉树的节点数量,所以返回值为int类型。
|
||||
|
||||
代码如下:
|
||||
```
|
||||
int getNodesNum(TreeNode* cur) {
|
||||
```
|
||||
|
||||
2. 确定终止条件:如果为空节点的话,就返回0,表示节点数为0。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
if (cur == NULL) return 0;
|
||||
```
|
||||
|
||||
3. 确定单层递归的逻辑:先求它的左子树的节点数量,再求的右子树的节点数量,最后取总和再加一 (加1是因为算上当前中间节点)就是目前节点为根节点的节点数量。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
int leftNum = getNodesNum(cur->left); // 左
|
||||
int rightNum = getNodesNum(cur->right); // 右
|
||||
int treeNum = leftNum + rightNum + 1; // 中
|
||||
return treeNum;
|
||||
```
|
||||
|
||||
所以整体C++代码如下:
|
||||
|
||||
```C++
|
||||
// 版本一
|
||||
class Solution {
|
||||
private:
|
||||
int getNodesNum(TreeNode* cur) {
|
||||
if (cur == 0) return 0;
|
||||
int leftNum = getNodesNum(cur->left); // 左
|
||||
int rightNum = getNodesNum(cur->right); // 右
|
||||
int treeNum = leftNum + rightNum + 1; // 中
|
||||
return treeNum;
|
||||
}
|
||||
public:
|
||||
int countNodes(TreeNode* root) {
|
||||
return getNodesNum(root);
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
代码精简之后C++代码如下:
|
||||
```C++
|
||||
// 版本二
|
||||
class Solution {
|
||||
public:
|
||||
int countNodes(TreeNode* root) {
|
||||
if (root == NULL) return 0;
|
||||
return 1 + countNodes(root->left) + countNodes(root->right);
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
时间复杂度:O(n)
|
||||
空间复杂度:O(logn),算上了递归系统栈占用的空间
|
||||
|
||||
**网上基本都是这个精简的代码版本,其实不建议大家照着这个来写,代码确实精简,但隐藏了一些内容,连遍历的顺序都看不出来,所以初学者建议学习版本一的代码,稳稳的打基础**。
|
||||
|
||||
|
||||
### 迭代法
|
||||
|
||||
如果对求二叉树层序遍历还不熟悉的话,看这篇:[二叉树:层序遍历登场!](https://mp.weixin.qq.com/s/Gb3BjakIKGNpup2jYtTzog)。
|
||||
|
||||
那么只要模板少做改动,加一个变量result,统计节点数量就可以了
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int countNodes(TreeNode* root) {
|
||||
queue<TreeNode*> que;
|
||||
if (root != NULL) que.push(root);
|
||||
int result = 0;
|
||||
while (!que.empty()) {
|
||||
int size = que.size();
|
||||
for (int i = 0; i < size; i++) {
|
||||
TreeNode* node = que.front();
|
||||
que.pop();
|
||||
result++; // 记录节点数量
|
||||
if (node->left) que.push(node->left);
|
||||
if (node->right) que.push(node->right);
|
||||
}
|
||||
}
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
时间复杂度:O(n)
|
||||
空间复杂度:O(n)
|
||||
|
||||
## 完全二叉树
|
||||
|
||||
以上方法都是按照普通二叉树来做的,对于完全二叉树特性不了解的同学可以看这篇 [关于二叉树,你该了解这些!](https://mp.weixin.qq.com/s/_ymfWYvTNd2GvWvC5HOE4A),这篇详细介绍了各种二叉树的特性。
|
||||
|
||||
完全二叉树只有两种情况,情况一:就是满二叉树,情况二:最后一层叶子节点没有满。
|
||||
|
||||
对于情况一,可以直接用 2^树深度 - 1 来计算,注意这里根节点深度为1。
|
||||
|
||||
对于情况二,分别递归左孩子,和右孩子,递归到某一深度一定会有左孩子或者右孩子为满二叉树,然后依然可以按照情况1来计算。
|
||||
|
||||
完全二叉树(一)如图:
|
||||
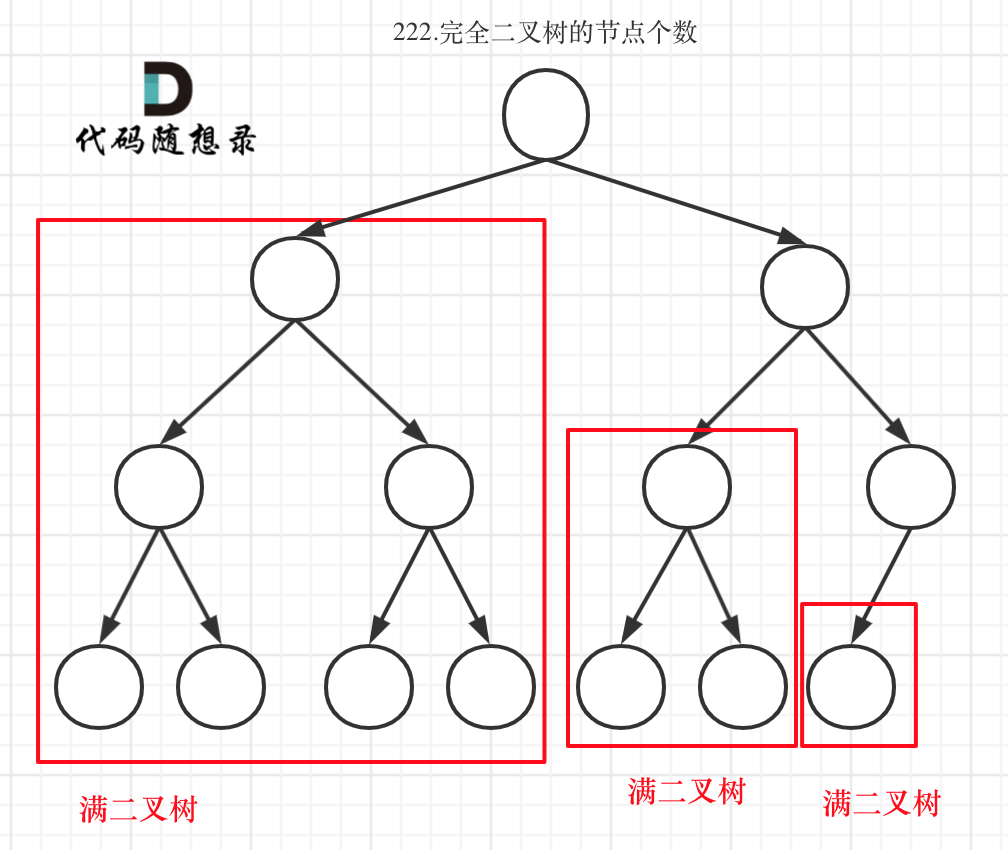
|
||||
|
||||
完全二叉树(二)如图:
|
||||

|
||||
|
||||
可以看出如果整个树不是满二叉树,就递归其左右孩子,直到遇到满二叉树为止,用公式计算这个子树(满二叉树)的节点数量。
|
||||
|
||||
C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int countNodes(TreeNode* root) {
|
||||
if (root == nullptr) return 0;
|
||||
TreeNode* left = root->left;
|
||||
TreeNode* right = root->right;
|
||||
int leftHeight = 0, rightHeight = 0; // 这里初始为0是有目的的,为了下面求指数方便
|
||||
while (left) { // 求左子树深度
|
||||
left = left->left;
|
||||
leftHeight++;
|
||||
}
|
||||
while (right) { // 求右子树深度
|
||||
right = right->right;
|
||||
rightHeight++;
|
||||
}
|
||||
if (leftHeight == rightHeight) {
|
||||
return (2 << leftHeight) - 1; // 注意(2<<1) 相当于2^2,所以leftHeight初始为0
|
||||
}
|
||||
return countNodes(root->left) + countNodes(root->right) + 1;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
时间复杂度:O(logn * logn)
|
||||
空间复杂度:O(logn)
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
// 通用递归解法
|
||||
public int countNodes(TreeNode root) {
|
||||
if(root == null) {
|
||||
return 0;
|
||||
}
|
||||
return countNodes(root.left) + countNodes(root.right) + 1;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
/**
|
||||
* 针对完全二叉树的解法
|
||||
*
|
||||
* 满二叉树的结点数为:2^depth - 1
|
||||
*/
|
||||
public int countNodes(TreeNode root) {
|
||||
if(root == null) {
|
||||
return 0;
|
||||
}
|
||||
int leftDepth = getDepth(root.left);
|
||||
int rightDepth = getDepth(root.right);
|
||||
if (leftDepth == rightDepth) {// 左子树是满二叉树
|
||||
// 2^leftDepth其实是 (2^leftDepth - 1) + 1 ,左子树 + 根结点
|
||||
return (1 << leftDepth) + countNodes(root.right);
|
||||
} else {// 右子树是满二叉树
|
||||
return (1 << rightDepth) + countNodes(root.left);
|
||||
}
|
||||
}
|
||||
|
||||
private int getDepth(TreeNode root) {
|
||||
int depth = 0;
|
||||
while (root != null) {
|
||||
root = root.left;
|
||||
depth++;
|
||||
}
|
||||
return depth;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
> 递归法:
|
||||
```python
|
||||
class Solution:
|
||||
def countNodes(self, root: TreeNode) -> int:
|
||||
return self.getNodesNum(root)
|
||||
|
||||
def getNodesNum(self, cur):
|
||||
if not cur:
|
||||
return 0
|
||||
leftNum = self.getNodesNum(cur.left) #左
|
||||
rightNum = self.getNodesNum(cur.right) #右
|
||||
treeNum = leftNum + rightNum + 1 #中
|
||||
return treeNum
|
||||
```
|
||||
|
||||
> 递归法:精简版
|
||||
```python
|
||||
class Solution:
|
||||
def countNodes(self, root: TreeNode) -> int:
|
||||
if not root:
|
||||
return 0
|
||||
return 1 + self.countNodes(root.left) + self.countNodes(root.right)
|
||||
```
|
||||
|
||||
> 迭代法:
|
||||
```python
|
||||
import collections
|
||||
class Solution:
|
||||
def countNodes(self, root: TreeNode) -> int:
|
||||
queue = collections.deque()
|
||||
if root:
|
||||
queue.append(root)
|
||||
result = 0
|
||||
while queue:
|
||||
size = len(queue)
|
||||
for i in range(size):
|
||||
node = queue.popleft()
|
||||
result += 1 #记录节点数量
|
||||
if node.left:
|
||||
queue.append(node.left)
|
||||
if node.right:
|
||||
queue.append(node.right)
|
||||
return result
|
||||
```
|
||||
|
||||
> 完全二叉树
|
||||
```python
|
||||
class Solution:
|
||||
def countNodes(self, root: TreeNode) -> int:
|
||||
if not root:
|
||||
return 0
|
||||
left = root.left
|
||||
right = root.right
|
||||
leftHeight = 0 #这里初始为0是有目的的,为了下面求指数方便
|
||||
rightHeight = 0
|
||||
while left: #求左子树深度
|
||||
left = left.left
|
||||
leftHeight += 1
|
||||
while right: #求右子树深度
|
||||
right = right.right
|
||||
rightHeight += 1
|
||||
if leftHeight == rightHeight:
|
||||
return (2 << leftHeight) - 1 #注意(2<<1) 相当于2^2,所以leftHeight初始为0
|
||||
return self.countNodes(root.left) + self.countNodes(root.right) + 1
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
递归版本
|
||||
|
||||
```go
|
||||
/**
|
||||
* Definition for a binary tree node.
|
||||
* type TreeNode struct {
|
||||
* Val int
|
||||
* Left *TreeNode
|
||||
* Right *TreeNode
|
||||
* }
|
||||
*/
|
||||
//本题直接就是求有多少个节点,无脑存进数组算长度就行了。
|
||||
func countNodes(root *TreeNode) int {
|
||||
if root == nil {
|
||||
return 0
|
||||
}
|
||||
res := 1
|
||||
if root.Right != nil {
|
||||
res += countNodes(root.Right)
|
||||
}
|
||||
if root.Left != nil {
|
||||
res += countNodes(root.Left)
|
||||
}
|
||||
return res
|
||||
}
|
||||
```
|
||||
|
||||
利用完全二叉树特性的递归解法
|
||||
```go
|
||||
func countNodes(root *TreeNode) int {
|
||||
if root == nil {
|
||||
return 0
|
||||
}
|
||||
leftH, rightH := 0, 0
|
||||
leftNode := root.Left
|
||||
rightNode := root.Right
|
||||
for leftNode != nil {
|
||||
leftNode = leftNode.Left
|
||||
leftH++
|
||||
}
|
||||
for rightNode != nil {
|
||||
rightNode = rightNode.Right
|
||||
rightH++
|
||||
}
|
||||
if leftH == rightH {
|
||||
return (2 << leftH) - 1
|
||||
}
|
||||
return countNodes(root.Left) + countNodes(root.Right) + 1
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
JavaScript:
|
||||
|
||||
递归版本
|
||||
```javascript
|
||||
var countNodes = function(root) {
|
||||
//递归法计算二叉树节点数
|
||||
// 1. 确定递归函数参数
|
||||
const getNodeSum=function(node){
|
||||
//2. 确定终止条件
|
||||
if(node===null){
|
||||
return 0;
|
||||
}
|
||||
//3. 确定单层递归逻辑
|
||||
let leftNum=getNodeSum(node.left);
|
||||
let rightNum=getNodeSum(node.right);
|
||||
return leftNum+rightNum+1;
|
||||
}
|
||||
return getNodeSum(root);
|
||||
};
|
||||
```
|
||||
|
||||
迭代(层序遍历)版本
|
||||
```javascript
|
||||
var countNodes = function(root) {
|
||||
//层序遍历
|
||||
let queue=[];
|
||||
if(root===null){
|
||||
return 0;
|
||||
}
|
||||
queue.push(root);
|
||||
let nodeNums=0;
|
||||
while(queue.length){
|
||||
let length=queue.length;
|
||||
while(length--){
|
||||
let node=queue.shift();
|
||||
nodeNums++;
|
||||
node.left&&queue.push(node.left);
|
||||
node.right&&queue.push(node.right);
|
||||
}
|
||||
}
|
||||
return nodeNums;
|
||||
};
|
||||
```
|
||||
|
||||
利用完全二叉树性质
|
||||
```javascript
|
||||
var countNodes = function(root) {
|
||||
//利用完全二叉树的特点
|
||||
if(root===null){
|
||||
return 0;
|
||||
}
|
||||
let left=root.left;
|
||||
let right=root.right;
|
||||
let leftHeight=0,rightHeight=0;
|
||||
while(left){
|
||||
left=left.left;
|
||||
leftHeight++;
|
||||
}
|
||||
while(right){
|
||||
right=right.right;
|
||||
rightHeight++;
|
||||
}
|
||||
if(leftHeight==rightHeight){
|
||||
return Math.pow(2,leftHeight+1)-1;
|
||||
}
|
||||
return countNodes(root.left)+countNodes(root.right)+1;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
477
problems/0225.用队列实现栈.md
Normal file
477
problems/0225.用队列实现栈.md
Normal file
@@ -0,0 +1,477 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
|
||||
> 用队列实现栈还是有点别扭。
|
||||
|
||||
# 225. 用队列实现栈
|
||||
|
||||
https://leetcode-cn.com/problems/implement-stack-using-queues/
|
||||
|
||||
使用队列实现栈的下列操作:
|
||||
|
||||
* push(x) -- 元素 x 入栈
|
||||
* pop() -- 移除栈顶元素
|
||||
* top() -- 获取栈顶元素
|
||||
* empty() -- 返回栈是否为空
|
||||
|
||||
注意:
|
||||
|
||||
* 你只能使用队列的基本操作-- 也就是 push to back, peek/pop from front, size, 和 is empty 这些操作是合法的。
|
||||
* 你所使用的语言也许不支持队列。 你可以使用 list 或者 deque(双端队列)来模拟一个队列 , 只要是标准的队列操作即可。
|
||||
* 你可以假设所有操作都是有效的(例如, 对一个空的栈不会调用 pop 或者 top 操作)。
|
||||
|
||||
|
||||
# 思路
|
||||
|
||||
(这里要强调是单向队列)
|
||||
|
||||
有的同学可能疑惑这种题目有什么实际工程意义,**其实很多算法题目主要是对知识点的考察和教学意义远大于其工程实践的意义,所以面试题也是这样!**
|
||||
|
||||
刚刚做过[栈与队列:我用栈来实现队列怎么样?](https://mp.weixin.qq.com/s/Cj6R0qu8rFA7Et9V_ZMjCA)的同学可能依然想着用一个输入队列,一个输出队列,就可以模拟栈的功能,仔细想一下还真不行!
|
||||
|
||||
**队列模拟栈,其实一个队列就够了**,那么我们先说一说两个队列来实现栈的思路。
|
||||
|
||||
**队列是先进先出的规则,把一个队列中的数据导入另一个队列中,数据的顺序并没有变,并有变成先进后出的顺序。**
|
||||
|
||||
所以用栈实现队列, 和用队列实现栈的思路还是不一样的,这取决于这两个数据结构的性质。
|
||||
|
||||
但是依然还是要用两个队列来模拟栈,只不过没有输入和输出的关系,而是另一个队列完全用又来备份的!
|
||||
|
||||
如下面动画所示,**用两个队列que1和que2实现队列的功能,que2其实完全就是一个备份的作用**,把que1最后面的元素以外的元素都备份到que2,然后弹出最后面的元素,再把其他元素从que2导回que1。
|
||||
|
||||
模拟的队列执行语句如下:
|
||||
|
||||
```
|
||||
queue.push(1);
|
||||
queue.push(2);
|
||||
queue.pop(); // 注意弹出的操作
|
||||
queue.push(3);
|
||||
queue.push(4);
|
||||
queue.pop(); // 注意弹出的操作
|
||||
queue.pop();
|
||||
queue.pop();
|
||||
queue.empty();
|
||||
```
|
||||
|
||||
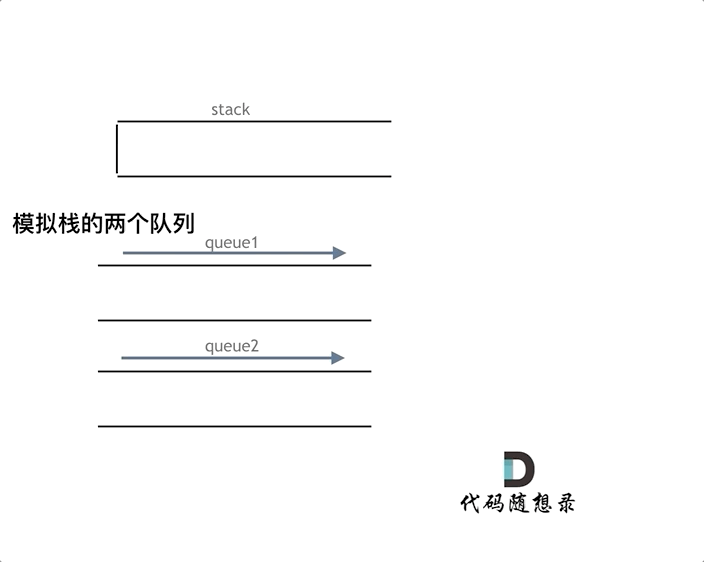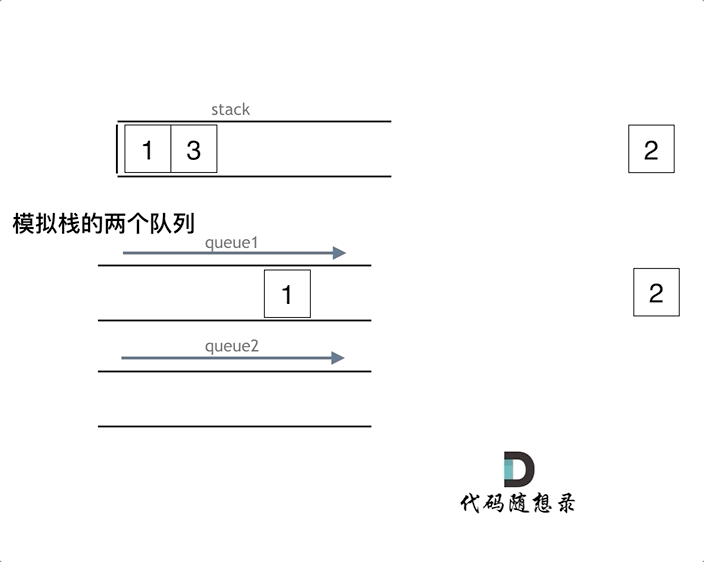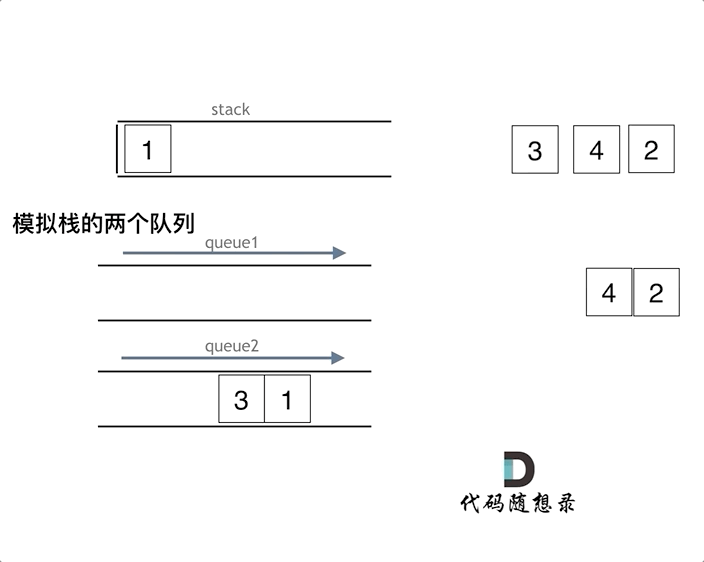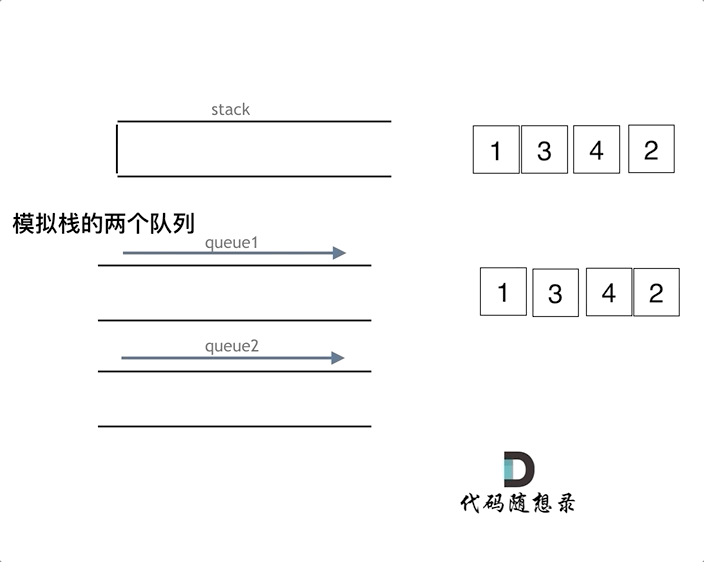
|
||||
|
||||
详细如代码注释所示:
|
||||
|
||||
|
||||
```C++
|
||||
class MyStack {
|
||||
public:
|
||||
queue<int> que1;
|
||||
queue<int> que2; // 辅助队列,用来备份
|
||||
/** Initialize your data structure here. */
|
||||
MyStack() {
|
||||
|
||||
}
|
||||
|
||||
/** Push element x onto stack. */
|
||||
void push(int x) {
|
||||
que1.push(x);
|
||||
}
|
||||
|
||||
/** Removes the element on top of the stack and returns that element. */
|
||||
int pop() {
|
||||
int size = que1.size();
|
||||
size--;
|
||||
while (size--) { // 将que1 导入que2,但要留下最后一个元素
|
||||
que2.push(que1.front());
|
||||
que1.pop();
|
||||
}
|
||||
|
||||
int result = que1.front(); // 留下的最后一个元素就是要返回的值
|
||||
que1.pop();
|
||||
que1 = que2; // 再将que2赋值给que1
|
||||
while (!que2.empty()) { // 清空que2
|
||||
que2.pop();
|
||||
}
|
||||
return result;
|
||||
}
|
||||
|
||||
/** Get the top element. */
|
||||
int top() {
|
||||
return que1.back();
|
||||
}
|
||||
|
||||
/** Returns whether the stack is empty. */
|
||||
bool empty() {
|
||||
return que1.empty();
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
# 优化
|
||||
|
||||
其实这道题目就是用一个队里就够了。
|
||||
|
||||
**一个队列在模拟栈弹出元素的时候只要将队列头部的元素(除了最后一个元素外) 重新添加到队列尾部,此时在去弹出元素就是栈的顺序了。**
|
||||
|
||||
C++优化代码
|
||||
|
||||
```C++
|
||||
class MyStack {
|
||||
public:
|
||||
queue<int> que;
|
||||
/** Initialize your data structure here. */
|
||||
MyStack() {
|
||||
|
||||
}
|
||||
/** Push element x onto stack. */
|
||||
void push(int x) {
|
||||
que.push(x);
|
||||
}
|
||||
/** Removes the element on top of the stack and returns that element. */
|
||||
int pop() {
|
||||
int size = que.size();
|
||||
size--;
|
||||
while (size--) { // 将队列头部的元素(除了最后一个元素外) 重新添加到队列尾部
|
||||
que.push(que.front());
|
||||
que.pop();
|
||||
}
|
||||
int result = que.front(); // 此时弹出的元素顺序就是栈的顺序了
|
||||
que.pop();
|
||||
return result;
|
||||
}
|
||||
|
||||
/** Get the top element. */
|
||||
int top() {
|
||||
return que.back();
|
||||
}
|
||||
|
||||
/** Returns whether the stack is empty. */
|
||||
bool empty() {
|
||||
return que.empty();
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
# 其他语言版本
|
||||
|
||||
Java:
|
||||
|
||||
使用两个 Queue 实现
|
||||
```java
|
||||
class MyStack {
|
||||
|
||||
Queue<Integer> queue1; // 和栈中保持一样元素的队列
|
||||
Queue<Integer> queue2; // 辅助队列
|
||||
|
||||
/** Initialize your data structure here. */
|
||||
public MyStack() {
|
||||
queue1 = new LinkedList<>();
|
||||
queue2 = new LinkedList<>();
|
||||
}
|
||||
|
||||
/** Push element x onto stack. */
|
||||
public void push(int x) {
|
||||
queue2.offer(x); // 先放在辅助队列中
|
||||
while (!queue1.isEmpty()){
|
||||
queue2.offer(queue1.poll());
|
||||
}
|
||||
Queue<Integer> queueTemp;
|
||||
queueTemp = queue1;
|
||||
queue1 = queue2;
|
||||
queue2 = queueTemp; // 最后交换queue1和queue2,将元素都放到queue1中
|
||||
}
|
||||
|
||||
/** Removes the element on top of the stack and returns that element. */
|
||||
public int pop() {
|
||||
return queue1.poll(); // 因为queue1中的元素和栈中的保持一致,所以这个和下面两个的操作只看queue1即可
|
||||
}
|
||||
|
||||
/** Get the top element. */
|
||||
public int top() {
|
||||
return queue1.peek();
|
||||
}
|
||||
|
||||
/** Returns whether the stack is empty. */
|
||||
public boolean empty() {
|
||||
return queue1.isEmpty();
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Your MyQueue object will be instantiated and called as such:
|
||||
* MyQueue obj = new MyQueue();
|
||||
* obj.push(x);
|
||||
* int param_2 = obj.pop();
|
||||
* int param_3 = obj.peek();
|
||||
* boolean param_4 = obj.empty();
|
||||
*/
|
||||
```
|
||||
使用两个 Deque 实现
|
||||
```java
|
||||
class MyStack {
|
||||
// Deque 接口继承了 Queue 接口
|
||||
// 所以 Queue 中的 add、poll、peek等效于 Deque 中的 addLast、pollFirst、peekFirst
|
||||
Deque<Integer> que1; // 和栈中保持一样元素的队列
|
||||
Deque<Integer> que2; // 辅助队列
|
||||
/** Initialize your data structure here. */
|
||||
public MyStack() {
|
||||
que1 = new ArrayDeque<>();
|
||||
que2 = new ArrayDeque<>();
|
||||
}
|
||||
|
||||
/** Push element x onto stack. */
|
||||
public void push(int x) {
|
||||
que1.addLast(x);
|
||||
}
|
||||
|
||||
/** Removes the element on top of the stack and returns that element. */
|
||||
public int pop() {
|
||||
int size = que1.size();
|
||||
size--;
|
||||
// 将 que1 导入 que2 ,但留下最后一个值
|
||||
while (size-- > 0) {
|
||||
que2.addLast(que1.peekFirst());
|
||||
que1.pollFirst();
|
||||
}
|
||||
|
||||
int res = que1.pollFirst();
|
||||
// 将 que2 对象的引用赋给了 que1 ,此时 que1,que2 指向同一个队列
|
||||
que1 = que2;
|
||||
// 如果直接操作 que2,que1 也会受到影响,所以为 que2 分配一个新的空间
|
||||
que2 = new ArrayDeque<>();
|
||||
return res;
|
||||
}
|
||||
|
||||
/** Get the top element. */
|
||||
public int top() {
|
||||
return que1.peekLast();
|
||||
}
|
||||
|
||||
/** Returns whether the stack is empty. */
|
||||
public boolean empty() {
|
||||
return que1.isEmpty();
|
||||
}
|
||||
}
|
||||
```
|
||||
优化,使用一个 Deque 实现
|
||||
```java
|
||||
class MyStack {
|
||||
// Deque 接口继承了 Queue 接口
|
||||
// 所以 Queue 中的 add、poll、peek等效于 Deque 中的 addLast、pollFirst、peekFirst
|
||||
Deque<Integer> que1;
|
||||
/** Initialize your data structure here. */
|
||||
public MyStack() {
|
||||
que1 = new ArrayDeque<>();
|
||||
}
|
||||
|
||||
/** Push element x onto stack. */
|
||||
public void push(int x) {
|
||||
que1.addLast(x);
|
||||
}
|
||||
|
||||
/** Removes the element on top of the stack and returns that element. */
|
||||
public int pop() {
|
||||
int size = que1.size();
|
||||
size--;
|
||||
// 将 que1 导入 que2 ,但留下最后一个值
|
||||
while (size-- > 0) {
|
||||
que1.addLast(que1.peekFirst());
|
||||
que1.pollFirst();
|
||||
}
|
||||
|
||||
int res = que1.pollFirst();
|
||||
return res;
|
||||
}
|
||||
|
||||
/** Get the top element. */
|
||||
public int top() {
|
||||
return que1.peekLast();
|
||||
}
|
||||
|
||||
/** Returns whether the stack is empty. */
|
||||
public boolean empty() {
|
||||
return que1.isEmpty();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
```python
|
||||
from collections import deque
|
||||
class MyStack:
|
||||
def __init__(self):
|
||||
"""
|
||||
Initialize your data structure here.
|
||||
"""
|
||||
#使用两个队列来实现
|
||||
self.que1 = deque()
|
||||
self.que2 = deque()
|
||||
|
||||
def push(self, x: int) -> None:
|
||||
"""
|
||||
Push element x onto stack.
|
||||
"""
|
||||
self.que1.append(x)
|
||||
|
||||
def pop(self) -> int:
|
||||
"""
|
||||
Removes the element on top of the stack and returns that element.
|
||||
"""
|
||||
size = len(self.que1)
|
||||
size -= 1#这里先减一是为了保证最后面的元素
|
||||
while size > 0:
|
||||
size -= 1
|
||||
self.que2.append(self.que1.popleft())
|
||||
|
||||
|
||||
result = self.que1.popleft()
|
||||
self.que1, self.que2= self.que2, self.que1#将que2和que1交换 que1经过之前的操作应该是空了
|
||||
#一定注意不能直接使用que1 = que2 这样que2的改变会影响que1 可以用浅拷贝
|
||||
return result
|
||||
|
||||
def top(self) -> int:
|
||||
"""
|
||||
Get the top element.
|
||||
"""
|
||||
return self.que1[-1]
|
||||
|
||||
def empty(self) -> bool:
|
||||
"""
|
||||
Returns whether the stack is empty.
|
||||
"""
|
||||
#print(self.que1)
|
||||
if len(self.que1) == 0:
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
|
||||
# Your MyStack object will be instantiated and called as such:
|
||||
# obj = MyStack()
|
||||
# obj.push(x)
|
||||
# param_2 = obj.pop()
|
||||
# param_3 = obj.top()
|
||||
# param_4 = obj.empty()
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
javaScript:
|
||||
|
||||
使用数组(push, shift)模拟队列
|
||||
|
||||
```js
|
||||
|
||||
// 使用两个队列实现
|
||||
/**
|
||||
* Initialize your data structure here.
|
||||
*/
|
||||
var MyStack = function() {
|
||||
this.queue1 = [];
|
||||
this.queue2 = [];
|
||||
};
|
||||
|
||||
/**
|
||||
* Push element x onto stack.
|
||||
* @param {number} x
|
||||
* @return {void}
|
||||
*/
|
||||
MyStack.prototype.push = function(x) {
|
||||
this.queue1.push(x);
|
||||
};
|
||||
|
||||
/**
|
||||
* Removes the element on top of the stack and returns that element.
|
||||
* @return {number}
|
||||
*/
|
||||
MyStack.prototype.pop = function() {
|
||||
// 减少两个队列交换的次数, 只有当queue1为空时,交换两个队列
|
||||
if(!this.queue1.length) {
|
||||
[this.queue1, this.queue2] = [this.queue2, this.queue1];
|
||||
}
|
||||
while(this.queue1.length > 1) {
|
||||
this.queue2.push(this.queue1.shift());
|
||||
}
|
||||
return this.queue1.shift();
|
||||
};
|
||||
|
||||
/**
|
||||
* Get the top element.
|
||||
* @return {number}
|
||||
*/
|
||||
MyStack.prototype.top = function() {
|
||||
const x = this.pop();
|
||||
this.queue1.push(x);
|
||||
return x;
|
||||
};
|
||||
|
||||
/**
|
||||
* Returns whether the stack is empty.
|
||||
* @return {boolean}
|
||||
*/
|
||||
MyStack.prototype.empty = function() {
|
||||
return !this.queue1.length && !this.queue2.length;
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
```js
|
||||
|
||||
// 使用一个队列实现
|
||||
/**
|
||||
* Initialize your data structure here.
|
||||
*/
|
||||
var MyStack = function() {
|
||||
this.queue = [];
|
||||
};
|
||||
|
||||
/**
|
||||
* Push element x onto stack.
|
||||
* @param {number} x
|
||||
* @return {void}
|
||||
*/
|
||||
MyStack.prototype.push = function(x) {
|
||||
this.queue.push(x);
|
||||
};
|
||||
|
||||
/**
|
||||
* Removes the element on top of the stack and returns that element.
|
||||
* @return {number}
|
||||
*/
|
||||
MyStack.prototype.pop = function() {
|
||||
let size = this.queue.length;
|
||||
while(size-- > 1) {
|
||||
this.queue.push(this.queue.shift());
|
||||
}
|
||||
return this.queue.shift();
|
||||
};
|
||||
|
||||
/**
|
||||
* Get the top element.
|
||||
* @return {number}
|
||||
*/
|
||||
MyStack.prototype.top = function() {
|
||||
const x = this.pop();
|
||||
this.queue.push(x);
|
||||
return x;
|
||||
};
|
||||
|
||||
/**
|
||||
* Returns whether the stack is empty.
|
||||
* @return {boolean}
|
||||
*/
|
||||
MyStack.prototype.empty = function() {
|
||||
return !this.queue.length;
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
422
problems/0226.翻转二叉树.md
Normal file
422
problems/0226.翻转二叉树.md
Normal file
@@ -0,0 +1,422 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 226.翻转二叉树
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/invert-binary-tree/
|
||||
|
||||
翻转一棵二叉树。
|
||||
|
||||

|
||||
|
||||
这道题目背后有一个让程序员心酸的故事,听说 Homebrew的作者Max Howell,就是因为没在白板上写出翻转二叉树,最后被Google拒绝了。(真假不做判断,权当一个乐子哈)
|
||||
|
||||
## 题外话
|
||||
|
||||
这道题目是非常经典的题目,也是比较简单的题目(至少一看就会)。
|
||||
|
||||
但正是因为这道题太简单,一看就会,一些同学都没有抓住起本质,稀里糊涂的就把这道题目过了。
|
||||
|
||||
如果做过这道题的同学也建议认真看完,相信一定有所收获!
|
||||
|
||||
## 思路
|
||||
|
||||
我们之前介绍的都是各种方式遍历二叉树,这次要翻转了,感觉还是有点懵逼。
|
||||
|
||||
这得怎么翻转呢?
|
||||
|
||||
如果要从整个树来看,翻转还真的挺复杂,整个树以中间分割线进行翻转,如图:
|
||||
|
||||
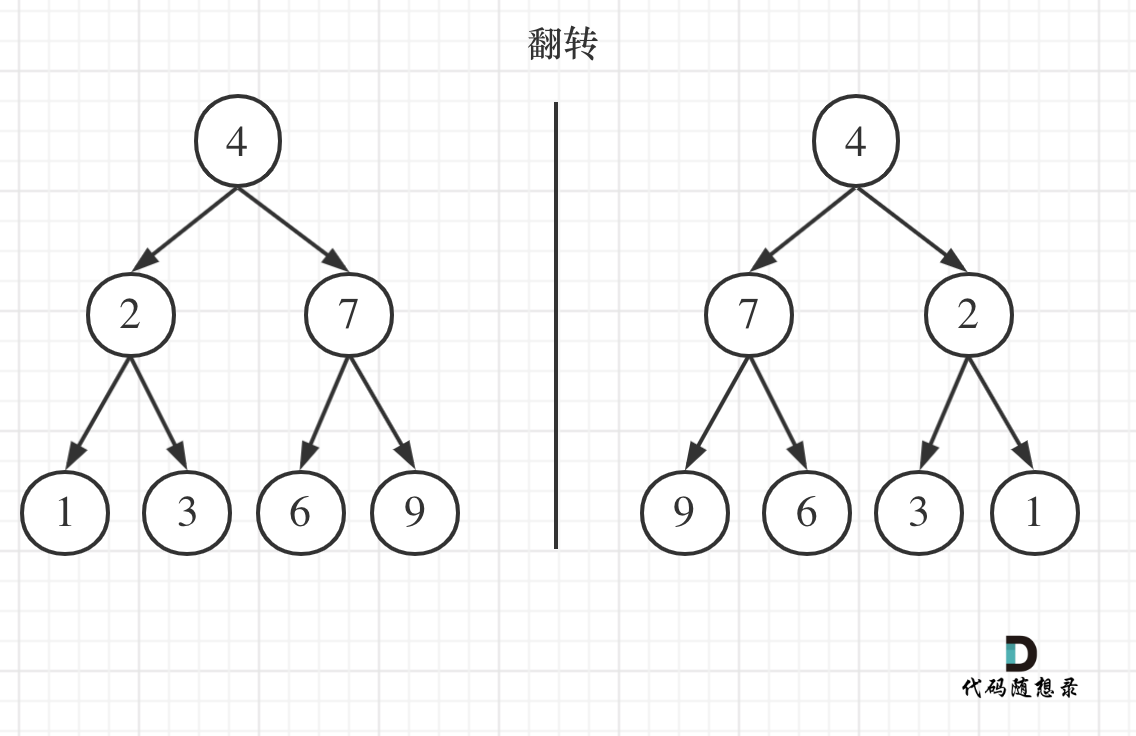
|
||||
|
||||
可以发现想要翻转它,其实就把每一个节点的左右孩子交换一下就可以了。
|
||||
|
||||
关键在于遍历顺序,前中后序应该选哪一种遍历顺序? (一些同学这道题都过了,但是不知道自己用的是什么顺序)
|
||||
|
||||
遍历的过程中去翻转每一个节点的左右孩子就可以达到整体翻转的效果。
|
||||
|
||||
**注意只要把每一个节点的左右孩子翻转一下,就可以达到整体翻转的效果**
|
||||
|
||||
**这道题目使用前序遍历和后序遍历都可以,唯独中序遍历不行,因为中序遍历会把某些节点的左右孩子翻转了两次!建议拿纸画一画,就理解了**
|
||||
|
||||
那么层序遍历可以不可以呢?**依然可以的!只要把每一个节点的左右孩子翻转一下的遍历方式都是可以的!**
|
||||
|
||||
## 递归法
|
||||
|
||||
对于二叉树的递归法的前中后序遍历,已经在[二叉树:前中后序递归遍历](https://mp.weixin.qq.com/s/PwVIfxDlT3kRgMASWAMGhA)详细讲解了。
|
||||
|
||||
我们下文以前序遍历为例,通过动画来看一下翻转的过程:
|
||||
|
||||

|
||||
|
||||
我们来看一下递归三部曲:
|
||||
|
||||
1. 确定递归函数的参数和返回值
|
||||
|
||||
参数就是要传入节点的指针,不需要其他参数了,通常此时定下来主要参数,如果在写递归的逻辑中发现还需要其他参数的时候,随时补充。
|
||||
|
||||
返回值的话其实也不需要,但是题目中给出的要返回root节点的指针,可以直接使用题目定义好的函数,所以就函数的返回类型为`TreeNode*`。
|
||||
|
||||
```
|
||||
TreeNode* invertTree(TreeNode* root)
|
||||
```
|
||||
|
||||
2. 确定终止条件
|
||||
|
||||
当前节点为空的时候,就返回
|
||||
|
||||
```
|
||||
if (root == NULL) return root;
|
||||
```
|
||||
|
||||
3. 确定单层递归的逻辑
|
||||
|
||||
因为是先前序遍历,所以先进行交换左右孩子节点,然后反转左子树,反转右子树。
|
||||
|
||||
```
|
||||
swap(root->left, root->right);
|
||||
invertTree(root->left);
|
||||
invertTree(root->right);
|
||||
```
|
||||
|
||||
基于这递归三步法,代码基本写完,C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
TreeNode* invertTree(TreeNode* root) {
|
||||
if (root == NULL) return root;
|
||||
swap(root->left, root->right); // 中
|
||||
invertTree(root->left); // 左
|
||||
invertTree(root->right); // 右
|
||||
return root;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 迭代法
|
||||
|
||||
### 深度优先遍历
|
||||
|
||||
[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg)中给出了前中后序迭代方式的写法,所以本地可以很轻松的切出如下迭代法的代码:
|
||||
|
||||
C++代码迭代法(前序遍历)
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
TreeNode* invertTree(TreeNode* root) {
|
||||
if (root == NULL) return root;
|
||||
stack<TreeNode*> st;
|
||||
st.push(root);
|
||||
while(!st.empty()) {
|
||||
TreeNode* node = st.top(); // 中
|
||||
st.pop();
|
||||
swap(node->left, node->right);
|
||||
if(node->right) st.push(node->right); // 右
|
||||
if(node->left) st.push(node->left); // 左
|
||||
}
|
||||
return root;
|
||||
}
|
||||
};
|
||||
```
|
||||
如果这个代码看不懂的话可以在回顾一下[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg)。
|
||||
|
||||
|
||||
我们在[二叉树:前中后序迭代方式的统一写法](https://mp.weixin.qq.com/s/WKg0Ty1_3SZkztpHubZPRg)中介绍了统一的写法,所以,本题也只需将文中的代码少做修改便可。
|
||||
|
||||
C++代码如下迭代法(前序遍历)
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
TreeNode* invertTree(TreeNode* root) {
|
||||
stack<TreeNode*> st;
|
||||
if (root != NULL) st.push(root);
|
||||
while (!st.empty()) {
|
||||
TreeNode* node = st.top();
|
||||
if (node != NULL) {
|
||||
st.pop();
|
||||
if (node->right) st.push(node->right); // 右
|
||||
if (node->left) st.push(node->left); // 左
|
||||
st.push(node); // 中
|
||||
st.push(NULL);
|
||||
} else {
|
||||
st.pop();
|
||||
node = st.top();
|
||||
st.pop();
|
||||
swap(node->left, node->right); // 节点处理逻辑
|
||||
}
|
||||
}
|
||||
return root;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
如果上面这个代码看不懂,回顾一下文章[二叉树:前中后序迭代方式的统一写法](https://mp.weixin.qq.com/s/WKg0Ty1_3SZkztpHubZPRg)。
|
||||
|
||||
### 广度优先遍历
|
||||
|
||||
也就是层序遍历,层数遍历也是可以翻转这棵树的,因为层序遍历也可以把每个节点的左右孩子都翻转一遍,代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
TreeNode* invertTree(TreeNode* root) {
|
||||
queue<TreeNode*> que;
|
||||
if (root != NULL) que.push(root);
|
||||
while (!que.empty()) {
|
||||
int size = que.size();
|
||||
for (int i = 0; i < size; i++) {
|
||||
TreeNode* node = que.front();
|
||||
que.pop();
|
||||
swap(node->left, node->right); // 节点处理
|
||||
if (node->left) que.push(node->left);
|
||||
if (node->right) que.push(node->right);
|
||||
}
|
||||
}
|
||||
return root;
|
||||
}
|
||||
};
|
||||
```
|
||||
如果对以上代码不理解,或者不清楚二叉树的层序遍历,可以看这篇[二叉树:层序遍历登场!](https://mp.weixin.qq.com/s/Gb3BjakIKGNpup2jYtTzog)
|
||||
|
||||
## 总结
|
||||
|
||||
针对二叉树的问题,解题之前一定要想清楚究竟是前中后序遍历,还是层序遍历。
|
||||
|
||||
**二叉树解题的大忌就是自己稀里糊涂的过了(因为这道题相对简单),但是也不知道自己是怎么遍历的。**
|
||||
|
||||
这也是造成了二叉树的题目“一看就会,一写就废”的原因。
|
||||
|
||||
**针对翻转二叉树,我给出了一种递归,三种迭代(两种模拟深度优先遍历,一种层序遍历)的写法,都是之前我们讲过的写法,融汇贯通一下而已。**
|
||||
|
||||
大家一定也有自己的解法,但一定要成方法论,这样才能通用,才能举一反三!
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
|
||||
```Java
|
||||
//DFS递归
|
||||
class Solution {
|
||||
/**
|
||||
* 前后序遍历都可以
|
||||
* 中序不行,因为先左孩子交换孩子,再根交换孩子(做完后,右孩子已经变成了原来的左孩子),再右孩子交换孩子(此时其实是对原来的左孩子做交换)
|
||||
*/
|
||||
public TreeNode invertTree(TreeNode root) {
|
||||
if (root == null) {
|
||||
return null;
|
||||
}
|
||||
invertTree(root.left);
|
||||
invertTree(root.right);
|
||||
swapChildren(root);
|
||||
return root;
|
||||
}
|
||||
|
||||
private void swapChildren(TreeNode root) {
|
||||
TreeNode tmp = root.left;
|
||||
root.left = root.right;
|
||||
root.right = tmp;
|
||||
}
|
||||
}
|
||||
|
||||
//BFS
|
||||
class Solution {
|
||||
public TreeNode invertTree(TreeNode root) {
|
||||
if (root == null) {return null;}
|
||||
ArrayDeque<TreeNode> deque = new ArrayDeque<>();
|
||||
deque.offer(root);
|
||||
while (!deque.isEmpty()) {
|
||||
int size = deque.size();
|
||||
while (size-- > 0) {
|
||||
TreeNode node = deque.poll();
|
||||
swap(node);
|
||||
if (node.left != null) {deque.offer(node.left);}
|
||||
if (node.right != null) {deque.offer(node.right);}
|
||||
}
|
||||
}
|
||||
return root;
|
||||
}
|
||||
|
||||
public void swap(TreeNode root) {
|
||||
TreeNode temp = root.left;
|
||||
root.left = root.right;
|
||||
root.right = temp;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
> 递归法:前序遍历
|
||||
```python
|
||||
class Solution:
|
||||
def invertTree(self, root: TreeNode) -> TreeNode:
|
||||
if not root:
|
||||
return None
|
||||
root.left, root.right = root.right, root.left #中
|
||||
self.invertTree(root.left) #左
|
||||
self.invertTree(root.right) #右
|
||||
return root
|
||||
```
|
||||
|
||||
> 迭代法:深度优先遍历(前序遍历)
|
||||
```python
|
||||
class Solution:
|
||||
def invertTree(self, root: TreeNode) -> TreeNode:
|
||||
if not root:
|
||||
return root
|
||||
st = []
|
||||
st.append(root)
|
||||
while st:
|
||||
node = st.pop()
|
||||
node.left, node.right = node.right, node.left #中
|
||||
if node.right:
|
||||
st.append(node.right) #右
|
||||
if node.left:
|
||||
st.append(node.left) #左
|
||||
return root
|
||||
```
|
||||
|
||||
> 迭代法:广度优先遍历(层序遍历)
|
||||
```python
|
||||
import collections
|
||||
class Solution:
|
||||
def invertTree(self, root: TreeNode) -> TreeNode:
|
||||
queue = collections.deque() #使用deque()
|
||||
if root:
|
||||
queue.append(root)
|
||||
while queue:
|
||||
size = len(queue)
|
||||
for i in range(size):
|
||||
node = queue.popleft()
|
||||
node.left, node.right = node.right, node.left #节点处理
|
||||
if node.left:
|
||||
queue.append(node.left)
|
||||
if node.right:
|
||||
queue.append(node.right)
|
||||
return root
|
||||
```
|
||||
|
||||
Go:
|
||||
```Go
|
||||
func invertTree(root *TreeNode) *TreeNode {
|
||||
if root ==nil{
|
||||
return nil
|
||||
}
|
||||
temp:=root.Left
|
||||
root.Left=root.Right
|
||||
root.Right=temp
|
||||
|
||||
invertTree(root.Left)
|
||||
invertTree(root.Right)
|
||||
|
||||
return root
|
||||
}
|
||||
```
|
||||
|
||||
JavaScript:
|
||||
|
||||
使用递归版本的前序遍历
|
||||
```javascript
|
||||
var invertTree = function(root) {
|
||||
//1. 首先使用递归版本的前序遍历实现二叉树翻转
|
||||
//交换节点函数
|
||||
const inverNode=function(left,right){
|
||||
let temp=left;
|
||||
left=right;
|
||||
right=temp;
|
||||
//需要重新给root赋值一下
|
||||
root.left=left;
|
||||
root.right=right;
|
||||
}
|
||||
//确定递归函数的参数和返回值inverTree=function(root)
|
||||
//确定终止条件
|
||||
if(root===null){
|
||||
return root;
|
||||
}
|
||||
//确定节点处理逻辑 交换
|
||||
inverNode(root.left,root.right);
|
||||
invertTree(root.left);
|
||||
invertTree(root.right);
|
||||
return root;
|
||||
};
|
||||
```
|
||||
使用迭代版本(统一模板))的前序遍历:
|
||||
```javascript
|
||||
var invertTree = function(root) {
|
||||
//我们先定义节点交换函数
|
||||
const invertNode=function(root,left,right){
|
||||
let temp=left;
|
||||
left=right;
|
||||
right=temp;
|
||||
root.left=left;
|
||||
root.right=right;
|
||||
}
|
||||
//使用迭代方法的前序遍历
|
||||
let stack=[];
|
||||
if(root===null){
|
||||
return root;
|
||||
}
|
||||
stack.push(root);
|
||||
while(stack.length){
|
||||
let node=stack.pop();
|
||||
if(node!==null){
|
||||
//前序遍历顺序中左右 入栈顺序是前序遍历的倒序右左中
|
||||
node.right&&stack.push(node.right);
|
||||
node.left&&stack.push(node.left);
|
||||
stack.push(node);
|
||||
stack.push(null);
|
||||
}else{
|
||||
node=stack.pop();
|
||||
//节点处理逻辑
|
||||
invertNode(node,node.left,node.right);
|
||||
}
|
||||
}
|
||||
return root;
|
||||
};
|
||||
```
|
||||
使用层序遍历:
|
||||
```javascript
|
||||
var invertTree = function(root) {
|
||||
//我们先定义节点交换函数
|
||||
const invertNode=function(root,left,right){
|
||||
let temp=left;
|
||||
left=right;
|
||||
right=temp;
|
||||
root.left=left;
|
||||
root.right=right;
|
||||
}
|
||||
//使用层序遍历
|
||||
let queue=[];
|
||||
if(root===null){
|
||||
return root;
|
||||
}
|
||||
queue.push(root);
|
||||
while(queue.length){
|
||||
let length=queue.length;
|
||||
while(length--){
|
||||
let node=queue.shift();
|
||||
//节点处理逻辑
|
||||
invertNode(node,node.left,node.right);
|
||||
node.left&&queue.push(node.left);
|
||||
node.right&&queue.push(node.right);
|
||||
}
|
||||
}
|
||||
return root;
|
||||
};
|
||||
```
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
460
problems/0232.用栈实现队列.md
Normal file
460
problems/0232.用栈实现队列.md
Normal file
@@ -0,0 +1,460 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
> 工作上一定没人这么搞,但是考察对栈、队列理解程度的好题
|
||||
|
||||
# 232.用栈实现队列
|
||||
|
||||
https://leetcode-cn.com/problems/implement-queue-using-stacks/
|
||||
|
||||
使用栈实现队列的下列操作:
|
||||
|
||||
push(x) -- 将一个元素放入队列的尾部。
|
||||
pop() -- 从队列首部移除元素。
|
||||
peek() -- 返回队列首部的元素。
|
||||
empty() -- 返回队列是否为空。
|
||||
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
MyQueue queue = new MyQueue();
|
||||
queue.push(1);
|
||||
queue.push(2);
|
||||
queue.peek(); // 返回 1
|
||||
queue.pop(); // 返回 1
|
||||
queue.empty(); // 返回 false
|
||||
```
|
||||
|
||||
说明:
|
||||
|
||||
* 你只能使用标准的栈操作 -- 也就是只有 push to top, peek/pop from top, size, 和 is empty 操作是合法的。
|
||||
* 你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。
|
||||
* 假设所有操作都是有效的 (例如,一个空的队列不会调用 pop 或者 peek 操作)。
|
||||
|
||||
## 思路
|
||||
|
||||
这是一道模拟题,不涉及到具体算法,考察的就是对栈和队列的掌握程度。
|
||||
|
||||
使用栈来模式队列的行为,如果仅仅用一个栈,是一定不行的,所以需要两个栈**一个输入栈,一个输出栈**,这里要注意输入栈和输出栈的关系。
|
||||
|
||||
下面动画模拟以下队列的执行过程如下:
|
||||
|
||||
执行语句:
|
||||
queue.push(1);
|
||||
queue.push(2);
|
||||
queue.pop(); **注意此时的输出栈的操作**
|
||||
queue.push(3);
|
||||
queue.push(4);
|
||||
queue.pop();
|
||||
queue.pop();**注意此时的输出栈的操作**
|
||||
queue.pop();
|
||||
queue.empty();
|
||||
|
||||
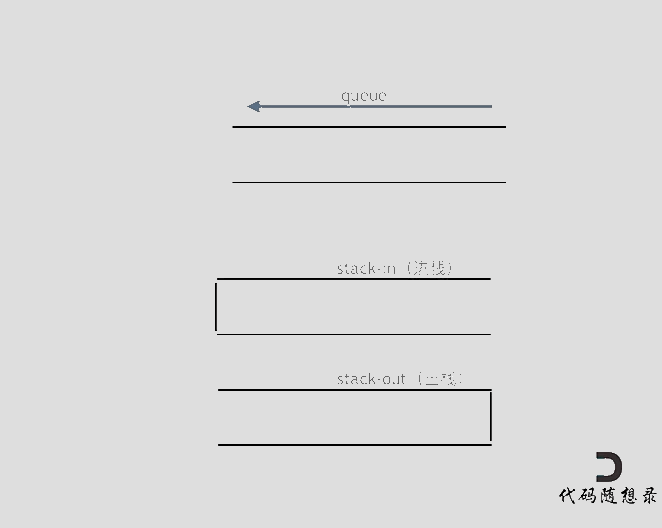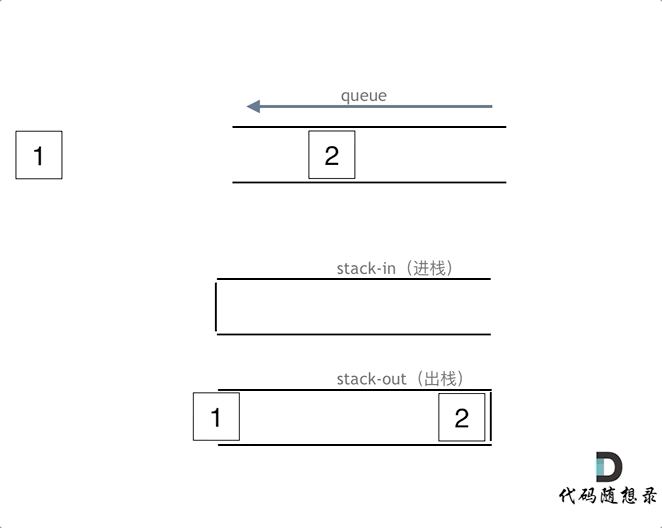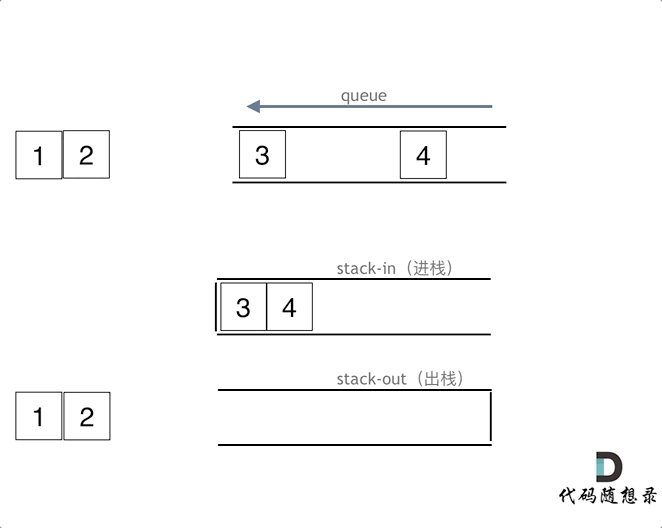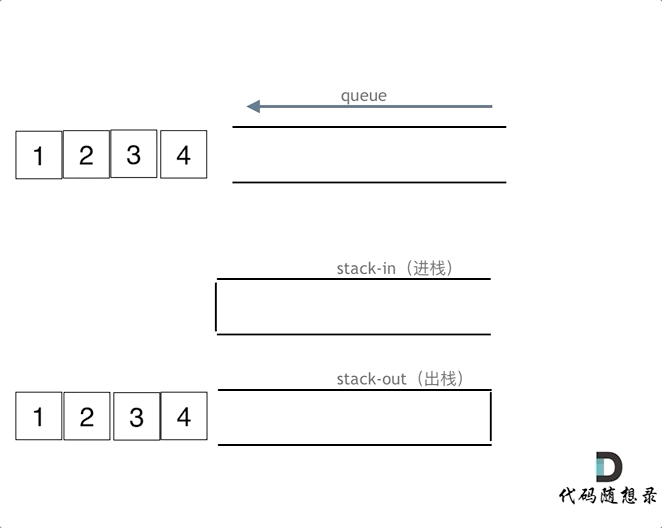
|
||||
|
||||
在push数据的时候,只要数据放进输入栈就好,**但在pop的时候,操作就复杂一些,输出栈如果为空,就把进栈数据全部导入进来(注意是全部导入)**,再从出栈弹出数据,如果输出栈不为空,则直接从出栈弹出数据就可以了。
|
||||
|
||||
最后如何判断队列为空呢?**如果进栈和出栈都为空的话,说明模拟的队列为空了。**
|
||||
|
||||
在代码实现的时候,会发现pop() 和 peek()两个函数功能类似,代码实现上也是类似的,可以思考一下如何把代码抽象一下。
|
||||
|
||||
C++代码如下:
|
||||
|
||||
```C++
|
||||
class MyQueue {
|
||||
public:
|
||||
stack<int> stIn;
|
||||
stack<int> stOut;
|
||||
/** Initialize your data structure here. */
|
||||
MyQueue() {
|
||||
|
||||
}
|
||||
/** Push element x to the back of queue. */
|
||||
void push(int x) {
|
||||
stIn.push(x);
|
||||
}
|
||||
|
||||
/** Removes the element from in front of queue and returns that element. */
|
||||
int pop() {
|
||||
// 只有当stOut为空的时候,再从stIn里导入数据(导入stIn全部数据)
|
||||
if (stOut.empty()) {
|
||||
// 从stIn导入数据直到stIn为空
|
||||
while(!stIn.empty()) {
|
||||
stOut.push(stIn.top());
|
||||
stIn.pop();
|
||||
}
|
||||
}
|
||||
int result = stOut.top();
|
||||
stOut.pop();
|
||||
return result;
|
||||
}
|
||||
|
||||
/** Get the front element. */
|
||||
int peek() {
|
||||
int res = this->pop(); // 直接使用已有的pop函数
|
||||
stOut.push(res); // 因为pop函数弹出了元素res,所以再添加回去
|
||||
return res;
|
||||
}
|
||||
|
||||
/** Returns whether the queue is empty. */
|
||||
bool empty() {
|
||||
return stIn.empty() && stOut.empty();
|
||||
}
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
## 拓展
|
||||
|
||||
可以看出peek()的实现,直接复用了pop()。
|
||||
|
||||
再多说一些代码开发上的习惯问题,在工业级别代码开发中,最忌讳的就是 实现一个类似的函数,直接把代码粘过来改一改就完事了。
|
||||
|
||||
这样的项目代码会越来越乱,**一定要懂得复用,功能相近的函数要抽象出来,不要大量的复制粘贴,很容易出问题!(踩过坑的人自然懂)**
|
||||
|
||||
工作中如果发现某一个功能自己要经常用,同事们可能也会用到,自己就花点时间把这个功能抽象成一个好用的函数或者工具类,不仅自己方便,也方面了同事们。
|
||||
|
||||
同事们就会逐渐认可你的工作态度和工作能力,自己的口碑都是这么一点一点积累起来的!在同事圈里口碑起来了之后,你就发现自己走上了一个正循环,以后的升职加薪才少不了你!哈哈哈
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
Java:
|
||||
|
||||
使用Stack(堆栈)同名方法:
|
||||
```java
|
||||
class MyQueue {
|
||||
// java中的 Stack 有设计上的缺陷,官方推荐使用 Deque(双端队列) 代替 Stack
|
||||
Deque<Integer> stIn;
|
||||
Deque<Integer> stOut;
|
||||
/** Initialize your data structure here. */
|
||||
public MyQueue() {
|
||||
stIn = new ArrayDeque<>();
|
||||
stOut = new ArrayDeque<>();
|
||||
}
|
||||
|
||||
/** Push element x to the back of queue. */
|
||||
public void push(int x) {
|
||||
stIn.push(x);
|
||||
}
|
||||
|
||||
/** Removes the element from in front of queue and returns that element. */
|
||||
public int pop() {
|
||||
// 只要 stOut 为空,那么就应该将 stIn 中所有的元素倒腾到 stOut 中
|
||||
if (stOut.isEmpty()) {
|
||||
while (!stIn.isEmpty()) {
|
||||
stOut.push(stIn.pop());
|
||||
}
|
||||
}
|
||||
// 再返回 stOut 中的元素
|
||||
return stOut.pop();
|
||||
}
|
||||
|
||||
/** Get the front element. */
|
||||
public int peek() {
|
||||
// 直接使用已有的pop函数
|
||||
int res = this.pop();
|
||||
// 因为pop函数弹出了元素res,所以再添加回去
|
||||
stOut.push(res);
|
||||
return res;
|
||||
}
|
||||
|
||||
/** Returns whether the queue is empty. */
|
||||
public boolean empty() {
|
||||
// 当 stIn 栈为空时,说明没有元素可以倒腾到 stOut 栈了
|
||||
// 并且 stOut 栈也为空时,说明没有以前从 stIn 中倒腾到的元素了
|
||||
return stIn.isEmpty() && stOut.isEmpty();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
个人习惯写法,使用Deque通用api:
|
||||
```java
|
||||
class MyQueue {
|
||||
// java中的 Stack 有设计上的缺陷,官方推荐使用 Deque(双端队列) 代替 Stack
|
||||
// Deque 中的 addFirst、removeFirst、peekFirst 等方法等效于 Stack(堆栈) 中的 push、pop、peek
|
||||
Deque<Integer> stIn;
|
||||
Deque<Integer> stOut;
|
||||
/** Initialize your data structure here. */
|
||||
public MyQueue() {
|
||||
stIn = new ArrayDeque<>();
|
||||
stOut = new ArrayDeque<>();
|
||||
}
|
||||
|
||||
/** Push element x to the back of queue. */
|
||||
public void push(int x) {
|
||||
stIn.addLast(x);
|
||||
}
|
||||
|
||||
/** Removes the element from in front of queue and returns that element. */
|
||||
public int pop() {
|
||||
// 只要 stOut 为空,那么就应该将 stIn 中所有的元素倒腾到 stOut 中
|
||||
if (stOut.isEmpty()) {
|
||||
while (!stIn.isEmpty()) {
|
||||
stOut.addLast(stIn.pollLast());
|
||||
}
|
||||
}
|
||||
// 再返回 stOut 中的元素
|
||||
return stOut.pollLast();
|
||||
}
|
||||
|
||||
/** Get the front element. */
|
||||
public int peek() {
|
||||
// 直接使用已有的pop函数
|
||||
int res = this.pop();
|
||||
// 因为pop函数弹出了元素res,所以再添加回去
|
||||
stOut.addLast(res);
|
||||
return res;
|
||||
}
|
||||
|
||||
/** Returns whether the queue is empty. */
|
||||
public boolean empty() {
|
||||
// 当 stIn 栈为空时,说明没有元素可以倒腾到 stOut 栈了
|
||||
// 并且 stOut 栈也为空时,说明没有以前从 stIn 中倒腾到的元素了
|
||||
return stIn.isEmpty() && stOut.isEmpty();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
class MyQueue {
|
||||
|
||||
Stack<Integer> stack1;
|
||||
Stack<Integer> stack2;
|
||||
|
||||
/** Initialize your data structure here. */
|
||||
public MyQueue() {
|
||||
stack1 = new Stack<>(); // 负责进栈
|
||||
stack2 = new Stack<>(); // 负责出栈
|
||||
}
|
||||
|
||||
/** Push element x to the back of queue. */
|
||||
public void push(int x) {
|
||||
stack1.push(x);
|
||||
}
|
||||
|
||||
/** Removes the element from in front of queue and returns that element. */
|
||||
public int pop() {
|
||||
dumpStack1();
|
||||
return stack2.pop();
|
||||
}
|
||||
|
||||
/** Get the front element. */
|
||||
public int peek() {
|
||||
dumpStack1();
|
||||
return stack2.peek();
|
||||
}
|
||||
|
||||
/** Returns whether the queue is empty. */
|
||||
public boolean empty() {
|
||||
return stack1.isEmpty() && stack2.isEmpty();
|
||||
}
|
||||
|
||||
// 如果stack2为空,那么将stack1中的元素全部放到stack2中
|
||||
private void dumpStack1(){
|
||||
if (stack2.isEmpty()){
|
||||
while (!stack1.isEmpty()){
|
||||
stack2.push(stack1.pop());
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Your MyQueue object will be instantiated and called as such:
|
||||
* MyQueue obj = new MyQueue();
|
||||
* obj.push(x);
|
||||
* int param_2 = obj.pop();
|
||||
* int param_3 = obj.peek();
|
||||
* boolean param_4 = obj.empty();
|
||||
*/
|
||||
```
|
||||
|
||||
|
||||
Python:
|
||||
```python
|
||||
# 使用两个栈实现先进先出的队列
|
||||
class MyQueue:
|
||||
def __init__(self):
|
||||
"""
|
||||
Initialize your data structure here.
|
||||
"""
|
||||
self.stack1 = list()
|
||||
self.stack2 = list()
|
||||
|
||||
def push(self, x: int) -> None:
|
||||
"""
|
||||
Push element x to the back of queue.
|
||||
"""
|
||||
# self.stack1用于接受元素
|
||||
self.stack1.append(x)
|
||||
|
||||
def pop(self) -> int:
|
||||
"""
|
||||
Removes the element from in front of queue and returns that element.
|
||||
"""
|
||||
# self.stack2用于弹出元素,如果self.stack2为[],则将self.stack1中元素全部弹出给self.stack2
|
||||
if self.stack2 == []:
|
||||
while self.stack1:
|
||||
tmp = self.stack1.pop()
|
||||
self.stack2.append(tmp)
|
||||
return self.stack2.pop()
|
||||
|
||||
def peek(self) -> int:
|
||||
"""
|
||||
Get the front element.
|
||||
"""
|
||||
if self.stack2 == []:
|
||||
while self.stack1:
|
||||
tmp = self.stack1.pop()
|
||||
self.stack2.append(tmp)
|
||||
return self.stack2[-1]
|
||||
|
||||
def empty(self) -> bool:
|
||||
"""
|
||||
Returns whether the queue is empty.
|
||||
"""
|
||||
return self.stack1 == [] and self.stack2 == []
|
||||
```
|
||||
|
||||
|
||||
Go:
|
||||
```Go
|
||||
type MyQueue struct {
|
||||
stack []int
|
||||
back []int
|
||||
}
|
||||
|
||||
/** Initialize your data structure here. */
|
||||
func Constructor() MyQueue {
|
||||
return MyQueue{
|
||||
stack: make([]int, 0),
|
||||
back: make([]int, 0),
|
||||
}
|
||||
}
|
||||
|
||||
/** Push element x to the back of queue. */
|
||||
func (this *MyQueue) Push(x int) {
|
||||
for len(this.back) != 0 {
|
||||
val := this.back[len(this.back)-1]
|
||||
this.back = this.back[:len(this.back)-1]
|
||||
this.stack = append(this.stack, val)
|
||||
}
|
||||
this.stack = append(this.stack, x)
|
||||
}
|
||||
|
||||
/** Removes the element from in front of queue and returns that element. */
|
||||
func (this *MyQueue) Pop() int {
|
||||
for len(this.stack) != 0 {
|
||||
val := this.stack[len(this.stack)-1]
|
||||
this.stack = this.stack[:len(this.stack)-1]
|
||||
this.back = append(this.back, val)
|
||||
}
|
||||
if len(this.back) == 0 {
|
||||
return 0
|
||||
}
|
||||
val := this.back[len(this.back)-1]
|
||||
this.back = this.back[:len(this.back)-1]
|
||||
return val
|
||||
}
|
||||
|
||||
/** Get the front element. */
|
||||
func (this *MyQueue) Peek() int {
|
||||
for len(this.stack) != 0 {
|
||||
val := this.stack[len(this.stack)-1]
|
||||
this.stack = this.stack[:len(this.stack)-1]
|
||||
this.back = append(this.back, val)
|
||||
}
|
||||
if len(this.back) == 0 {
|
||||
return 0
|
||||
}
|
||||
val := this.back[len(this.back)-1]
|
||||
return val
|
||||
}
|
||||
|
||||
/** Returns whether the queue is empty. */
|
||||
func (this *MyQueue) Empty() bool {
|
||||
return len(this.stack) == 0 && len(this.back) == 0
|
||||
}
|
||||
|
||||
/**
|
||||
* Your MyQueue object will be instantiated and called as such:
|
||||
* obj := Constructor();
|
||||
* obj.Push(x);
|
||||
* param_2 := obj.Pop();
|
||||
* param_3 := obj.Peek();
|
||||
* param_4 := obj.Empty();
|
||||
*/
|
||||
```
|
||||
|
||||
javaScript:
|
||||
|
||||
```js
|
||||
// 使用两个数组的栈方法(push, pop) 实现队列
|
||||
/**
|
||||
* Initialize your data structure here.
|
||||
*/
|
||||
var MyQueue = function() {
|
||||
this.stack1 = [];
|
||||
this.stack2 = [];
|
||||
};
|
||||
|
||||
/**
|
||||
* Push element x to the back of queue.
|
||||
* @param {number} x
|
||||
* @return {void}
|
||||
*/
|
||||
MyQueue.prototype.push = function(x) {
|
||||
this.stack1.push(x);
|
||||
};
|
||||
|
||||
/**
|
||||
* Removes the element from in front of queue and returns that element.
|
||||
* @return {number}
|
||||
*/
|
||||
MyQueue.prototype.pop = function() {
|
||||
const size = this.stack2.length;
|
||||
if(size) {
|
||||
return this.stack2.pop();
|
||||
}
|
||||
while(this.stack1.length) {
|
||||
this.stack2.push(this.stack1.pop());
|
||||
}
|
||||
return this.stack2.pop();
|
||||
};
|
||||
|
||||
/**
|
||||
* Get the front element.
|
||||
* @return {number}
|
||||
*/
|
||||
MyQueue.prototype.peek = function() {
|
||||
const x = this.pop();
|
||||
this.stack2.push(x);
|
||||
return x;
|
||||
};
|
||||
|
||||
/**
|
||||
* Returns whether the queue is empty.
|
||||
* @return {boolean}
|
||||
*/
|
||||
MyQueue.prototype.empty = function() {
|
||||
return !this.stack1.length && !this.stack2.length
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
363
problems/0235.二叉搜索树的最近公共祖先.md
Normal file
363
problems/0235.二叉搜索树的最近公共祖先.md
Normal file
@@ -0,0 +1,363 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 235. 二叉搜索树的最近公共祖先
|
||||
|
||||
链接:https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-search-tree/
|
||||
|
||||
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
|
||||
|
||||
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
|
||||
|
||||
例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]
|
||||
|
||||
|
||||
|
||||
示例 1:
|
||||
|
||||
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8
|
||||
输出: 6
|
||||
解释: 节点 2 和节点 8 的最近公共祖先是 6。
|
||||
示例 2:
|
||||
|
||||
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4
|
||||
输出: 2
|
||||
解释: 节点 2 和节点 4 的最近公共祖先是 2, 因为根据定义最近公共祖先节点可以为节点本身。
|
||||
|
||||
|
||||
说明:
|
||||
|
||||
* 所有节点的值都是唯一的。
|
||||
* p、q 为不同节点且均存在于给定的二叉搜索树中。
|
||||
|
||||
## 思路
|
||||
|
||||
做过[二叉树:公共祖先问题](https://mp.weixin.qq.com/s/n6Rk3nc_X3TSkhXHrVmBTQ)题目的同学应该知道,利用回溯从底向上搜索,遇到一个节点的左子树里有p,右子树里有q,那么当前节点就是最近公共祖先。
|
||||
|
||||
那么本题是二叉搜索树,二叉搜索树是有序的,那得好好利用一下这个特点。
|
||||
|
||||
在有序树里,如果判断一个节点的左子树里有p,右子树里有q呢?
|
||||
|
||||
其实只要从上到下遍历的时候,cur节点是数值在[p, q]区间中则说明该节点cur就是最近公共祖先了。
|
||||
|
||||
理解这一点,本题就很好解了。
|
||||
|
||||
和[二叉树:公共祖先问题](https://mp.weixin.qq.com/s/n6Rk3nc_X3TSkhXHrVmBTQ)不同,普通二叉树求最近公共祖先需要使用回溯,从底向上来查找,二叉搜索树就不用了,因为搜索树有序(相当于自带方向),那么只要从上向下遍历就可以了。
|
||||
|
||||
那么我们可以采用前序遍历(其实这里没有中节点的处理逻辑,遍历顺序无所谓了)。
|
||||
|
||||
如图所示:p为节点3,q为节点5
|
||||
|
||||
|
||||
|
||||
可以看出直接按照指定的方向,就可以找到节点4,为最近公共祖先,而且不需要遍历整棵树,找到结果直接返回!
|
||||
|
||||
|
||||
递归三部曲如下:
|
||||
|
||||
* 确定递归函数返回值以及参数
|
||||
|
||||
参数就是当前节点,以及两个结点 p、q。
|
||||
|
||||
返回值是要返回最近公共祖先,所以是TreeNode * 。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
TreeNode* traversal(TreeNode* cur, TreeNode* p, TreeNode* q)
|
||||
```
|
||||
|
||||
* 确定终止条件
|
||||
|
||||
遇到空返回就可以了,代码如下:
|
||||
|
||||
```
|
||||
if (cur == NULL) return cur;
|
||||
```
|
||||
|
||||
其实都不需要这个终止条件,因为题目中说了p、q 为不同节点且均存在于给定的二叉搜索树中。也就是说一定会找到公共祖先的,所以并不存在遇到空的情况。
|
||||
|
||||
* 确定单层递归的逻辑
|
||||
|
||||
在遍历二叉搜索树的时候就是寻找区间[p->val, q->val](注意这里是左闭又闭)
|
||||
|
||||
那么如果 cur->val 大于 p->val,同时 cur->val 大于q->val,那么就应该向左遍历(说明目标区间在左子树上)。
|
||||
|
||||
**需要注意的是此时不知道p和q谁大,所以两个都要判断**
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
if (cur->val > p->val && cur->val > q->val) {
|
||||
TreeNode* left = traversal(cur->left, p, q);
|
||||
if (left != NULL) {
|
||||
return left;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**细心的同学会发现,在这里调用递归函数的地方,把递归函数的返回值left,直接return**。
|
||||
|
||||
|
||||
在[二叉树:公共祖先问题](https://mp.weixin.qq.com/s/n6Rk3nc_X3TSkhXHrVmBTQ)中,如果递归函数有返回值,如何区分要搜索一条边,还是搜索整个树。
|
||||
|
||||
搜索一条边的写法:
|
||||
|
||||
```
|
||||
if (递归函数(root->left)) return ;
|
||||
|
||||
if (递归函数(root->right)) return ;
|
||||
```
|
||||
|
||||
搜索整个树写法:
|
||||
|
||||
```
|
||||
left = 递归函数(root->left);
|
||||
right = 递归函数(root->right);
|
||||
left与right的逻辑处理;
|
||||
```
|
||||
|
||||
本题就是标准的搜索一条边的写法,遇到递归函数的返回值,如果不为空,立刻返回。
|
||||
|
||||
|
||||
如果 cur->val 小于 p->val,同时 cur->val 小于 q->val,那么就应该向右遍历(目标区间在右子树)。
|
||||
|
||||
```
|
||||
if (cur->val < p->val && cur->val < q->val) {
|
||||
TreeNode* right = traversal(cur->right, p, q);
|
||||
if (right != NULL) {
|
||||
return right;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
剩下的情况,就是cur节点在区间(p->val <= cur->val && cur->val <= q->val)或者 (q->val <= cur->val && cur->val <= p->val)中,那么cur就是最近公共祖先了,直接返回cur。
|
||||
|
||||
代码如下:
|
||||
```
|
||||
return cur;
|
||||
|
||||
```
|
||||
|
||||
那么整体递归代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
TreeNode* traversal(TreeNode* cur, TreeNode* p, TreeNode* q) {
|
||||
if (cur == NULL) return cur;
|
||||
// 中
|
||||
if (cur->val > p->val && cur->val > q->val) { // 左
|
||||
TreeNode* left = traversal(cur->left, p, q);
|
||||
if (left != NULL) {
|
||||
return left;
|
||||
}
|
||||
}
|
||||
|
||||
if (cur->val < p->val && cur->val < q->val) { // 右
|
||||
TreeNode* right = traversal(cur->right, p, q);
|
||||
if (right != NULL) {
|
||||
return right;
|
||||
}
|
||||
}
|
||||
return cur;
|
||||
}
|
||||
public:
|
||||
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
|
||||
return traversal(root, p, q);
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
精简后代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
|
||||
if (root->val > p->val && root->val > q->val) {
|
||||
return lowestCommonAncestor(root->left, p, q);
|
||||
} else if (root->val < p->val && root->val < q->val) {
|
||||
return lowestCommonAncestor(root->right, p, q);
|
||||
} else return root;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 迭代法
|
||||
|
||||
对于二叉搜索树的迭代法,大家应该在[二叉树:二叉搜索树登场!](https://mp.weixin.qq.com/s/vsKrWRlETxCVsiRr8v_hHg)就了解了。
|
||||
|
||||
利用其有序性,迭代的方式还是比较简单的,解题思路在递归中已经分析了。
|
||||
|
||||
迭代代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
|
||||
while(root) {
|
||||
if (root->val > p->val && root->val > q->val) {
|
||||
root = root->left;
|
||||
} else if (root->val < p->val && root->val < q->val) {
|
||||
root = root->right;
|
||||
} else return root;
|
||||
}
|
||||
return NULL;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
灵魂拷问:是不是又被简单的迭代法感动到痛哭流涕?
|
||||
|
||||
## 总结
|
||||
|
||||
对于二叉搜索树的最近祖先问题,其实要比[普通二叉树公共祖先问题](https://mp.weixin.qq.com/s/n6Rk3nc_X3TSkhXHrVmBTQ)简单的多。
|
||||
|
||||
不用使用回溯,二叉搜索树自带方向性,可以方便的从上向下查找目标区间,遇到目标区间内的节点,直接返回。
|
||||
|
||||
最后给出了对应的迭代法,二叉搜索树的迭代法甚至比递归更容易理解,也是因为其有序性(自带方向性),按照目标区间找就行了。
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
|
||||
while (true) {
|
||||
if (root.val > p.val && root.val > q.val) {
|
||||
root = root.left;
|
||||
} else if (root.val < p.val && root.val < q.val) {
|
||||
root = root.right;
|
||||
} else {
|
||||
break;
|
||||
}
|
||||
}
|
||||
return root;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
# Definition for a binary tree node.
|
||||
# class TreeNode:
|
||||
# def __init__(self, x):
|
||||
# self.val = x
|
||||
# self.left = None
|
||||
# self.right = None
|
||||
|
||||
class Solution:
|
||||
def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':
|
||||
if not root: return root //中
|
||||
if root.val >p.val and root.val > q.val:
|
||||
return self.lowestCommonAncestor(root.left,p,q) //左
|
||||
elif root.val < p.val and root.val < q.val:
|
||||
return self.lowestCommonAncestor(root.right,p,q) //右
|
||||
else: return root
|
||||
```
|
||||
Go:
|
||||
> BSL法
|
||||
|
||||
```go
|
||||
/**
|
||||
* Definition for a binary tree node.
|
||||
* type TreeNode struct {
|
||||
* Val int
|
||||
* Left *TreeNode
|
||||
* Right *TreeNode
|
||||
* }
|
||||
*/
|
||||
//利用BSL的性质(前序遍历有序)
|
||||
func lowestCommonAncestor(root, p, q *TreeNode) *TreeNode {
|
||||
if root==nil{return nil}
|
||||
if root.Val>p.Val&&root.Val>q.Val{//当前节点的值大于给定的值,则说明满足条件的在左边
|
||||
return lowestCommonAncestor(root.Left,p,q)
|
||||
}else if root.Val<p.Val&&root.Val<q.Val{//当前节点的值小于各点的值,则说明满足条件的在右边
|
||||
return lowestCommonAncestor(root.Right,p,q)
|
||||
}else {return root}//当前节点的值在给定值的中间(或者等于),即为最深的祖先
|
||||
}
|
||||
```
|
||||
|
||||
> 普通法
|
||||
|
||||
```go
|
||||
/**
|
||||
* Definition for a binary tree node.
|
||||
* type TreeNode struct {
|
||||
* Val int
|
||||
* Left *TreeNode
|
||||
* Right *TreeNode
|
||||
* }
|
||||
*/
|
||||
//递归会将值层层返回
|
||||
func lowestCommonAncestor(root, p, q *TreeNode) *TreeNode {
|
||||
//终止条件
|
||||
if root==nil||root.Val==p.Val||root.Val==q.Val{return root}//最后为空或者找到一个值时,就返回这个值
|
||||
//后序遍历
|
||||
findLeft:=lowestCommonAncestor(root.Left,p,q)
|
||||
findRight:=lowestCommonAncestor(root.Right,p,q)
|
||||
//处理单层逻辑
|
||||
if findLeft!=nil&&findRight!=nil{return root}//说明在root节点的两边
|
||||
if findLeft==nil{//左边没找到,就说明在右边找到了
|
||||
return findRight
|
||||
}else {return findLeft}
|
||||
}
|
||||
```
|
||||
|
||||
JavaScript版本:
|
||||
1. 使用递归的方法
|
||||
```javascript
|
||||
var lowestCommonAncestor = function(root, p, q) {
|
||||
// 使用递归的方法
|
||||
// 1. 使用给定的递归函数lowestCommonAncestor
|
||||
// 2. 确定递归终止条件
|
||||
if(root === null) {
|
||||
return root;
|
||||
}
|
||||
if(root.val>p.val&&root.val>q.val) {
|
||||
// 向左子树查询
|
||||
let left = lowestCommonAncestor(root.left,p,q);
|
||||
return left !== null&&left;
|
||||
}
|
||||
if(root.val<p.val&&root.val<q.val) {
|
||||
// 向右子树查询
|
||||
let right = lowestCommonAncestor(root.right,p,q);
|
||||
return right !== null&&right;
|
||||
}
|
||||
return root;
|
||||
};
|
||||
```
|
||||
2. 使用迭代的方法
|
||||
```javascript
|
||||
var lowestCommonAncestor = function(root, p, q) {
|
||||
// 使用迭代的方法
|
||||
while(root) {
|
||||
if(root.val>p.val&&root.val>q.val) {
|
||||
root = root.left;
|
||||
}else if(root.val<p.val&&root.val<q.val) {
|
||||
root = root.right;
|
||||
}else {
|
||||
return root;
|
||||
}
|
||||
|
||||
}
|
||||
return null;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
346
problems/0236.二叉树的最近公共祖先.md
Normal file
346
problems/0236.二叉树的最近公共祖先.md
Normal file
@@ -0,0 +1,346 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
> 本来是打算将二叉树和二叉搜索树的公共祖先问题一起讲,后来发现篇幅过长了,只能先说一说二叉树的公共祖先问题。
|
||||
|
||||
## 236. 二叉树的最近公共祖先
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/
|
||||
|
||||
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
|
||||
|
||||
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
|
||||
|
||||
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]
|
||||
|
||||
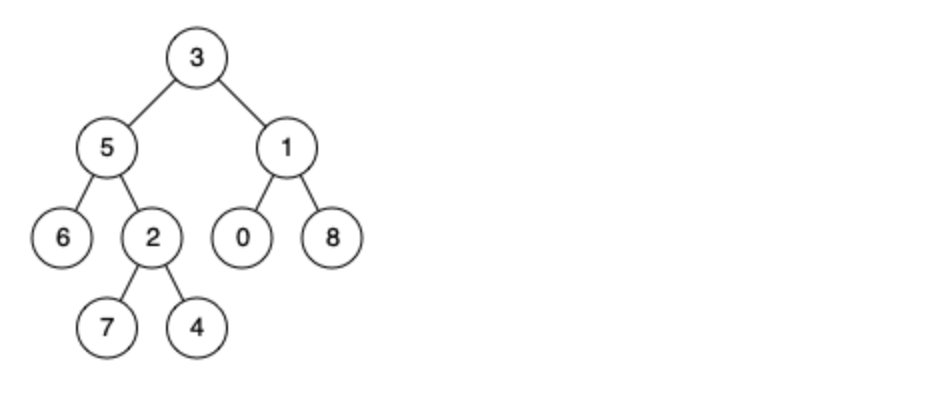
|
||||
|
||||
示例 1:
|
||||
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
|
||||
输出: 3
|
||||
解释: 节点 5 和节点 1 的最近公共祖先是节点 3。
|
||||
|
||||
示例 2:
|
||||
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
|
||||
输出: 5
|
||||
解释: 节点 5 和节点 4 的最近公共祖先是节点 5。因为根据定义最近公共祖先节点可以为节点本身。
|
||||
|
||||
说明:
|
||||
* 所有节点的值都是唯一的。
|
||||
* p、q 为不同节点且均存在于给定的二叉树中。
|
||||
|
||||
## 思路
|
||||
|
||||
遇到这个题目首先想的是要是能自底向上查找就好了,这样就可以找到公共祖先了。
|
||||
|
||||
那么二叉树如何可以自底向上查找呢?
|
||||
|
||||
回溯啊,二叉树回溯的过程就是从低到上。
|
||||
|
||||
后序遍历就是天然的回溯过程,最先处理的一定是叶子节点。
|
||||
|
||||
接下来就看如何判断一个节点是节点q和节点p的公共公共祖先呢。
|
||||
|
||||
**如果找到一个节点,发现左子树出现结点p,右子树出现节点q,或者 左子树出现结点q,右子树出现节点p,那么该节点就是节点p和q的最近公共祖先。**
|
||||
|
||||
使用后序遍历,回溯的过程,就是从低向上遍历节点,一旦发现如何这个条件的节点,就是最近公共节点了。
|
||||
|
||||
递归三部曲:
|
||||
|
||||
* 确定递归函数返回值以及参数
|
||||
|
||||
需要递归函数返回值,来告诉我们是否找到节点q或者p,那么返回值为bool类型就可以了。
|
||||
|
||||
但我们还要返回最近公共节点,可以利用上题目中返回值是TreeNode * ,那么如果遇到p或者q,就把q或者p返回,返回值不为空,就说明找到了q或者p。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q)
|
||||
```
|
||||
|
||||
* 确定终止条件
|
||||
|
||||
如果找到了 节点p或者q,或者遇到空节点,就返回。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
if (root == q || root == p || root == NULL) return root;
|
||||
```
|
||||
|
||||
* 确定单层递归逻辑
|
||||
|
||||
值得注意的是 本题函数有返回值,是因为回溯的过程需要递归函数的返回值做判断,但本题我们依然要遍历树的所有节点。
|
||||
|
||||
我们在[二叉树:递归函数究竟什么时候需要返回值,什么时候不要返回值?](https://mp.weixin.qq.com/s/6TWAVjxQ34kVqROWgcRFOg)中说了 递归函数有返回值就是要遍历某一条边,但有返回值也要看如何处理返回值!
|
||||
|
||||
如果递归函数有返回值,如何区分要搜索一条边,还是搜索整个树呢?
|
||||
|
||||
搜索一条边的写法:
|
||||
|
||||
```
|
||||
if (递归函数(root->left)) return ;
|
||||
|
||||
if (递归函数(root->right)) return ;
|
||||
```
|
||||
|
||||
搜索整个树写法:
|
||||
|
||||
```
|
||||
left = 递归函数(root->left);
|
||||
right = 递归函数(root->right);
|
||||
left与right的逻辑处理;
|
||||
```
|
||||
|
||||
看出区别了没?
|
||||
|
||||
**在递归函数有返回值的情况下:如果要搜索一条边,递归函数返回值不为空的时候,立刻返回,如果搜索整个树,直接用一个变量left、right接住返回值,这个left、right后序还有逻辑处理的需要,也就是后序遍历中处理中间节点的逻辑(也是回溯)**。
|
||||
|
||||
那么为什么要遍历整颗树呢?直观上来看,找到最近公共祖先,直接一路返回就可以了。
|
||||
|
||||
如图:
|
||||
|
||||
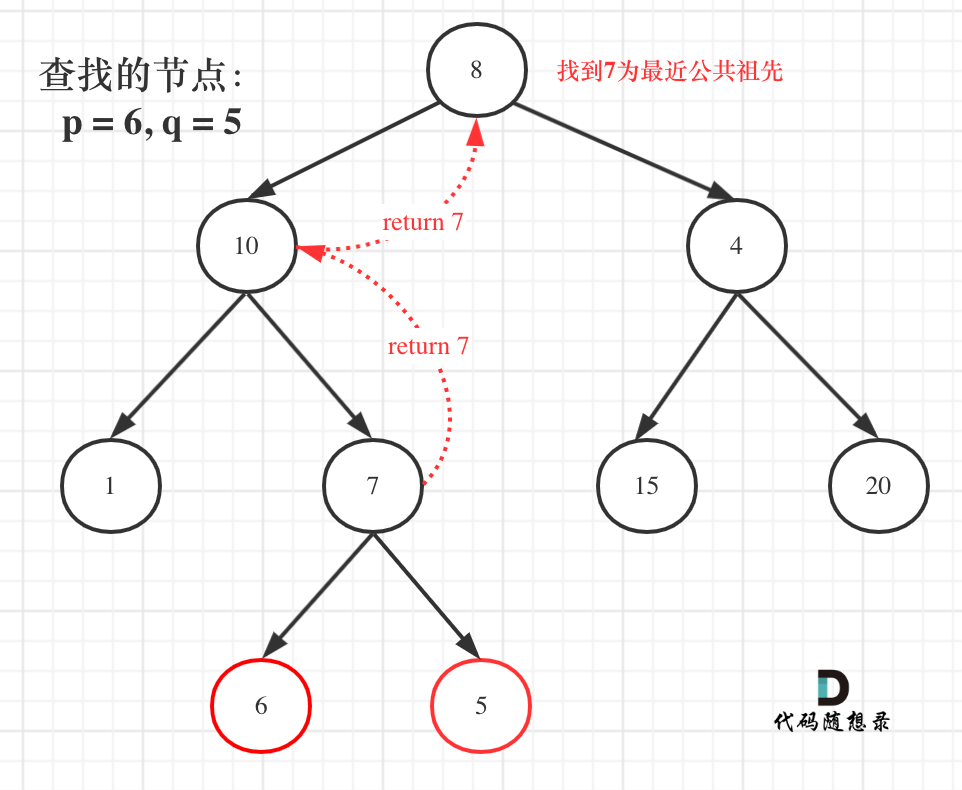
|
||||
|
||||
就像图中一样直接返回7,多美滋滋。
|
||||
|
||||
但事实上还要遍历根节点右子树(即使此时已经找到了目标节点了),也就是图中的节点4、15、20。
|
||||
|
||||
因为在如下代码的后序遍历中,如果想利用left和right做逻辑处理, 不能立刻返回,而是要等left与right逻辑处理完之后才能返回。
|
||||
|
||||
```
|
||||
left = 递归函数(root->left);
|
||||
right = 递归函数(root->right);
|
||||
left与right的逻辑处理;
|
||||
```
|
||||
|
||||
所以此时大家要知道我们要遍历整棵树。知道这一点,对本题就有一定深度的理解了。
|
||||
|
||||
|
||||
那么先用left和right接住左子树和右子树的返回值,代码如下:
|
||||
|
||||
```
|
||||
TreeNode* left = lowestCommonAncestor(root->left, p, q);
|
||||
TreeNode* right = lowestCommonAncestor(root->right, p, q);
|
||||
|
||||
```
|
||||
|
||||
**如果left 和 right都不为空,说明此时root就是最近公共节点。这个比较好理解**
|
||||
|
||||
**如果left为空,right不为空,就返回right,说明目标节点是通过right返回的,反之依然**。
|
||||
|
||||
这里有的同学就理解不了了,为什么left为空,right不为空,目标节点通过right返回呢?
|
||||
|
||||
如图:
|
||||
|
||||
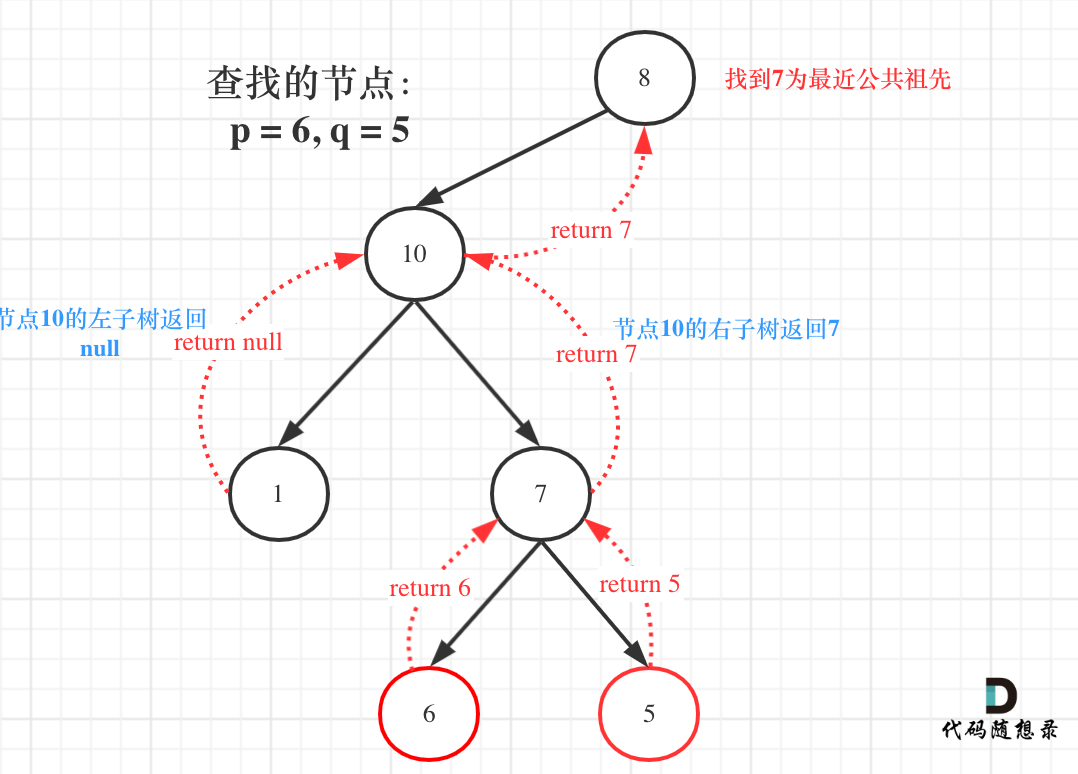
|
||||
|
||||
图中节点10的左子树返回null,右子树返回目标值7,那么此时节点10的处理逻辑就是把右子树的返回值(最近公共祖先7)返回上去!
|
||||
|
||||
这里点也很重要,可能刷过这道题目的同学,都不清楚结果究竟是如何从底层一层一层传到头结点的。
|
||||
|
||||
那么如果left和right都为空,则返回left或者right都是可以的,也就是返回空。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
if (left == NULL && right != NULL) return right;
|
||||
else if (left != NULL && right == NULL) return left;
|
||||
else { // (left == NULL && right == NULL)
|
||||
return NULL;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
那么寻找最小公共祖先,完整流程图如下:
|
||||
|
||||
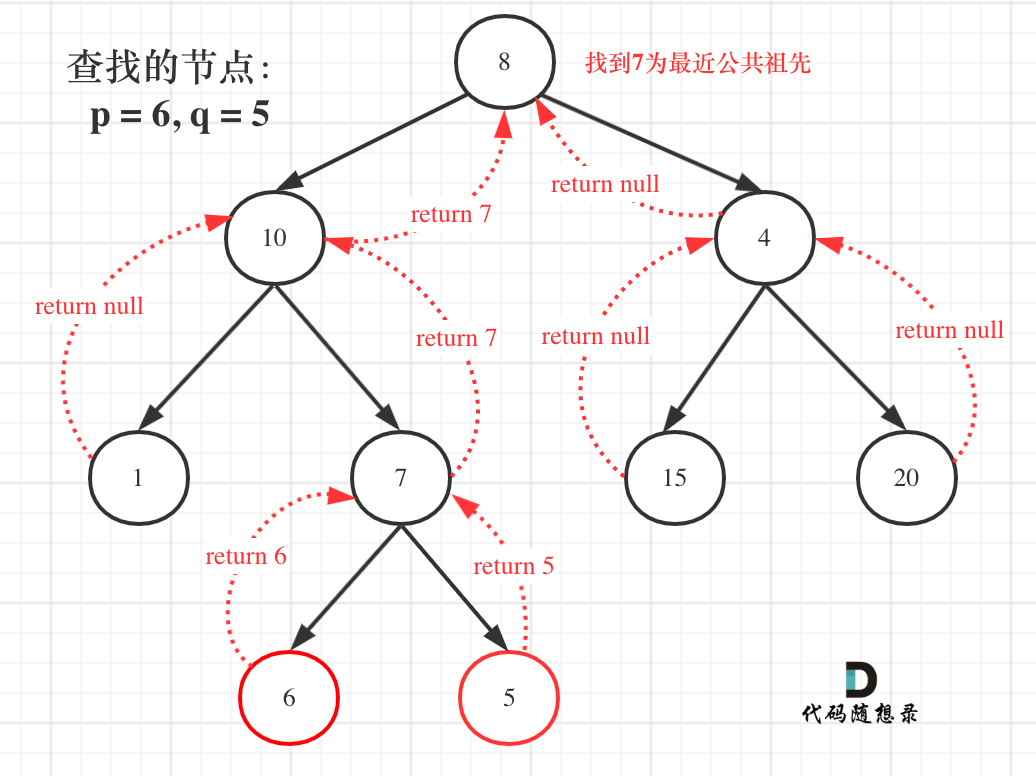
|
||||
|
||||
**从图中,大家可以看到,我们是如何回溯遍历整颗二叉树,将结果返回给头结点的!**
|
||||
|
||||
整体代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
|
||||
if (root == q || root == p || root == NULL) return root;
|
||||
TreeNode* left = lowestCommonAncestor(root->left, p, q);
|
||||
TreeNode* right = lowestCommonAncestor(root->right, p, q);
|
||||
if (left != NULL && right != NULL) return root;
|
||||
|
||||
if (left == NULL && right != NULL) return right;
|
||||
else if (left != NULL && right == NULL) return left;
|
||||
else { // (left == NULL && right == NULL)
|
||||
return NULL;
|
||||
}
|
||||
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
稍加精简,代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
|
||||
if (root == q || root == p || root == NULL) return root;
|
||||
TreeNode* left = lowestCommonAncestor(root->left, p, q);
|
||||
TreeNode* right = lowestCommonAncestor(root->right, p, q);
|
||||
if (left != NULL && right != NULL) return root;
|
||||
if (left == NULL) return right;
|
||||
return left;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
这道题目刷过的同学未必真正了解这里面回溯的过程,以及结果是如何一层一层传上去的。
|
||||
|
||||
**那么我给大家归纳如下三点**:
|
||||
|
||||
1. 求最小公共祖先,需要从底向上遍历,那么二叉树,只能通过后序遍历(即:回溯)实现从低向上的遍历方式。
|
||||
|
||||
2. 在回溯的过程中,必然要遍历整颗二叉树,即使已经找到结果了,依然要把其他节点遍历完,因为要使用递归函数的返回值(也就是代码中的left和right)做逻辑判断。
|
||||
|
||||
3. 要理解如果返回值left为空,right不为空为什么要返回right,为什么可以用返回right传给上一层结果。
|
||||
|
||||
可以说这里每一步,都是有难度的,都需要对二叉树,递归和回溯有一定的理解。
|
||||
|
||||
本题没有给出迭代法,因为迭代法不适合模拟回溯的过程。理解递归的解法就够了。
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
|
||||
return lowestCommonAncestor1(root, p, q);
|
||||
}
|
||||
public TreeNode lowestCommonAncestor1(TreeNode root, TreeNode p, TreeNode q) {
|
||||
if (root == null || root == p || root == q) {
|
||||
return root;
|
||||
}
|
||||
TreeNode left = lowestCommonAncestor1(root.left, p, q);
|
||||
TreeNode right = lowestCommonAncestor1(root.right, p, q);
|
||||
if (left != null && right != null) {// 左右子树分别找到了,说明此时的root就是要求的结果
|
||||
return root;
|
||||
}
|
||||
if (left == null) {
|
||||
return right;
|
||||
}
|
||||
return left;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
```java
|
||||
// 代码精简版
|
||||
class Solution {
|
||||
TreeNode pre;
|
||||
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
|
||||
if (root == null || root.val == p.val ||root.val == q.val) return root;
|
||||
TreeNode left = lowestCommonAncestor(root.left,p,q);
|
||||
TreeNode right = lowestCommonAncestor(root.right,p,q);
|
||||
if (left != null && right != null) return root;
|
||||
else if (left == null && right != null) return right;
|
||||
else if (left != null && right == null) return left;
|
||||
else return null;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
# Definition for a binary tree node.
|
||||
# class TreeNode:
|
||||
# def __init__(self, x):
|
||||
# self.val = x
|
||||
# self.left = None
|
||||
# self.right = None
|
||||
//递归
|
||||
class Solution:
|
||||
def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':
|
||||
if not root or root == p or root == q: return root //找到了节点p或者q,或者遇到空节点
|
||||
left = self.lowestCommonAncestor(root.left,p,q) //左
|
||||
right = self.lowestCommonAncestor(root.right,p,q) //右
|
||||
if left and right: return root //中: left和right不为空,root就是最近公共节点
|
||||
elif left and not right: return left //目标节点是通过left返回的
|
||||
elif not left and right: return right //目标节点是通过right返回的
|
||||
else: return None //没找到
|
||||
```
|
||||
Go:
|
||||
```Go
|
||||
func lowestCommonAncestor(root, p, q *TreeNode) *TreeNode {
|
||||
// check
|
||||
if root == nil {
|
||||
return root
|
||||
}
|
||||
// 相等 直接返回root节点即可
|
||||
if root == p || root == q {
|
||||
return root
|
||||
}
|
||||
// Divide
|
||||
left := lowestCommonAncestor(root.Left, p, q)
|
||||
right := lowestCommonAncestor(root.Right, p, q)
|
||||
|
||||
// Conquer
|
||||
// 左右两边都不为空,则根节点为祖先
|
||||
if left != nil && right != nil {
|
||||
return root
|
||||
}
|
||||
if left != nil {
|
||||
return left
|
||||
}
|
||||
if right != nil {
|
||||
return right
|
||||
}
|
||||
return nil
|
||||
}
|
||||
```
|
||||
|
||||
JavaScript版本:
|
||||
```javascript
|
||||
var lowestCommonAncestor = function(root, p, q) {
|
||||
// 使用递归的方法
|
||||
// 需要从下到上,所以使用后序遍历
|
||||
// 1. 确定递归的函数
|
||||
const travelTree = function(root,p,q) {
|
||||
// 2. 确定递归终止条件
|
||||
if(root === null || root === p||root === q) {
|
||||
return root;
|
||||
}
|
||||
// 3. 确定递归单层逻辑
|
||||
let left = travelTree(root.left,p,q);
|
||||
let right = travelTree(root.right,p,q);
|
||||
if(left !== null&&right !== null) {
|
||||
return root;
|
||||
}
|
||||
if(left ===null) {
|
||||
return right;
|
||||
}
|
||||
return left;
|
||||
}
|
||||
return travelTree(root,p,q);
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
460
problems/0239.滑动窗口最大值.md
Normal file
460
problems/0239.滑动窗口最大值.md
Normal file
@@ -0,0 +1,460 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
|
||||
> 要用啥数据结构呢?
|
||||
|
||||
# 239. 滑动窗口最大值
|
||||
|
||||
https://leetcode-cn.com/problems/sliding-window-maximum/
|
||||
|
||||
给定一个数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
|
||||
|
||||
返回滑动窗口中的最大值。
|
||||
|
||||
进阶:
|
||||
|
||||
你能在线性时间复杂度内解决此题吗?
|
||||
|
||||
<img src='https://code-thinking.cdn.bcebos.com/pics/239.%E6%BB%91%E5%8A%A8%E7%AA%97%E5%8F%A3%E6%9C%80%E5%A4%A7%E5%80%BC.png' width=600> </img></div>
|
||||
|
||||
提示:
|
||||
|
||||
1 <= nums.length <= 10^5
|
||||
-10^4 <= nums[i] <= 10^4
|
||||
1 <= k <= nums.length
|
||||
|
||||
|
||||
|
||||
# 思路
|
||||
|
||||
这是使用单调队列的经典题目。
|
||||
|
||||
难点是如何求一个区间里的最大值呢? (这好像是废话),暴力一下不就得了。
|
||||
|
||||
暴力方法,遍历一遍的过程中每次从窗口中在找到最大的数值,这样很明显是O(n * k)的算法。
|
||||
|
||||
有的同学可能会想用一个大顶堆(优先级队列)来存放这个窗口里的k个数字,这样就可以知道最大的最大值是多少了, **但是问题是这个窗口是移动的,而大顶堆每次只能弹出最大值,我们无法移除其他数值,这样就造成大顶堆维护的不是滑动窗口里面的数值了。所以不能用大顶堆。**
|
||||
|
||||
此时我们需要一个队列,这个队列呢,放进去窗口里的元素,然后随着窗口的移动,队列也一进一出,每次移动之后,队列告诉我们里面的最大值是什么。
|
||||
|
||||
|
||||
这个队列应该长这个样子:
|
||||
|
||||
```
|
||||
class MyQueue {
|
||||
public:
|
||||
void pop(int value) {
|
||||
}
|
||||
void push(int value) {
|
||||
}
|
||||
int front() {
|
||||
return que.front();
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
每次窗口移动的时候,调用que.pop(滑动窗口中移除元素的数值),que.push(滑动窗口添加元素的数值),然后que.front()就返回我们要的最大值。
|
||||
|
||||
这么个队列香不香,要是有现成的这种数据结构是不是更香了!
|
||||
|
||||
**可惜了,没有! 我们需要自己实现这么个队列。**
|
||||
|
||||
然后在分析一下,队列里的元素一定是要排序的,而且要最大值放在出队口,要不然怎么知道最大值呢。
|
||||
|
||||
但如果把窗口里的元素都放进队列里,窗口移动的时候,队列需要弹出元素。
|
||||
|
||||
那么问题来了,已经排序之后的队列 怎么能把窗口要移除的元素(这个元素可不一定是最大值)弹出呢。
|
||||
|
||||
大家此时应该陷入深思.....
|
||||
|
||||
**其实队列没有必要维护窗口里的所有元素,只需要维护有可能成为窗口里最大值的元素就可以了,同时保证队里里的元素数值是由大到小的。**
|
||||
|
||||
那么这个维护元素单调递减的队列就叫做**单调队列,即单调递减或单调递增的队列。C++中没有直接支持单调队列,需要我们自己来一个单调队列**
|
||||
|
||||
**不要以为实现的单调队列就是 对窗口里面的数进行排序,如果排序的话,那和优先级队列又有什么区别了呢。**
|
||||
|
||||
来看一下单调队列如何维护队列里的元素。
|
||||
|
||||
动画如下:
|
||||
|
||||
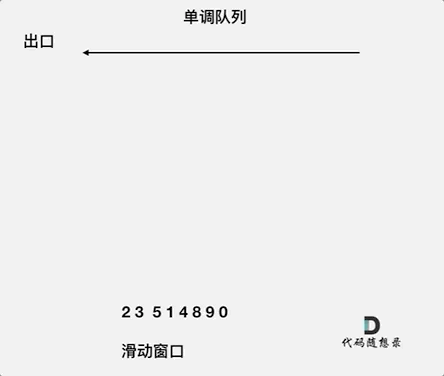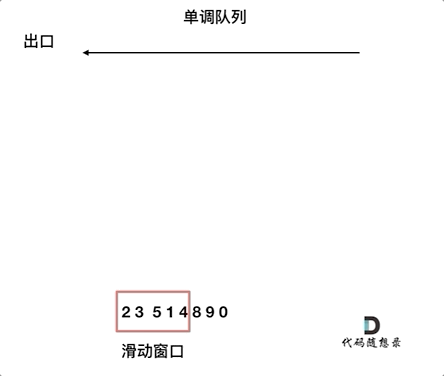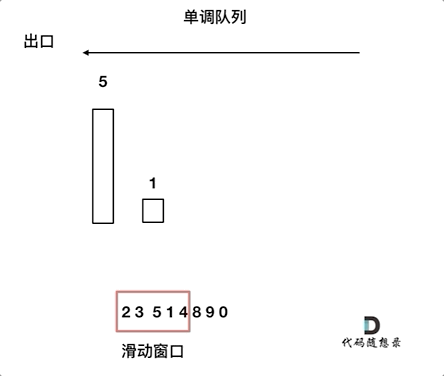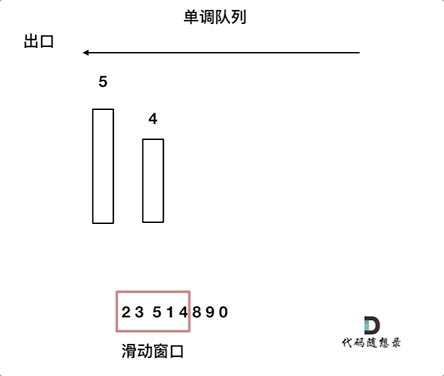
|
||||
|
||||
对于窗口里的元素{2, 3, 5, 1 ,4},单调队列里只维护{5, 4} 就够了,保持单调队列里单调递减,此时队列出口元素就是窗口里最大元素。
|
||||
|
||||
此时大家应该怀疑单调队列里维护着{5, 4} 怎么配合窗口经行滑动呢?
|
||||
|
||||
设计单调队列的时候,pop,和push操作要保持如下规则:
|
||||
|
||||
1. pop(value):如果窗口移除的元素value等于单调队列的出口元素,那么队列弹出元素,否则不用任何操作
|
||||
2. push(value):如果push的元素value大于入口元素的数值,那么就将队列入口的元素弹出,直到push元素的数值小于等于队列入口元素的数值为止
|
||||
|
||||
保持如上规则,每次窗口移动的时候,只要问que.front()就可以返回当前窗口的最大值。
|
||||
|
||||
为了更直观的感受到单调队列的工作过程,以题目示例为例,输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3,动画如下:
|
||||
|
||||
|
||||
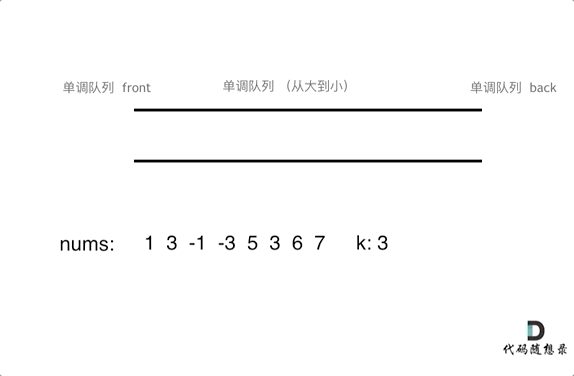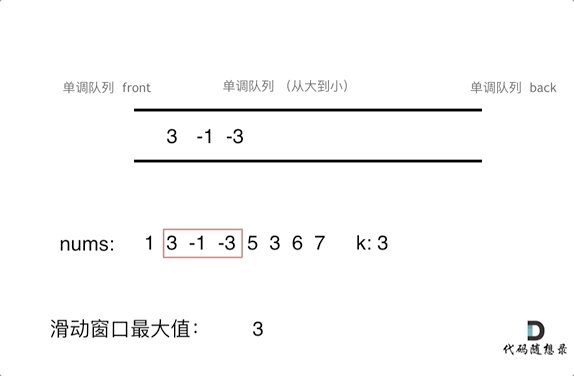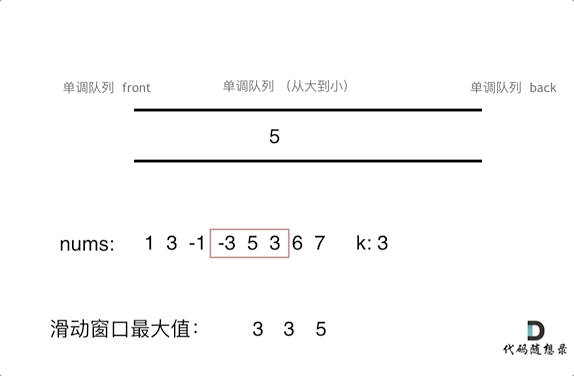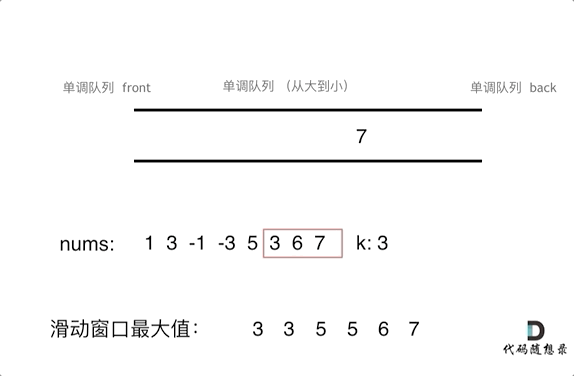
|
||||
|
||||
那么我们用什么数据结构来实现这个单调队列呢?
|
||||
|
||||
使用deque最为合适,在文章[栈与队列:来看看栈和队列不为人知的一面](https://mp.weixin.qq.com/s/VZRjOccyE09aE-MgLbCMjQ)中,我们就提到了常用的queue在没有指定容器的情况下,deque就是默认底层容器。
|
||||
|
||||
基于刚刚说过的单调队列pop和push的规则,代码不难实现,如下:
|
||||
|
||||
```C++
|
||||
class MyQueue { //单调队列(从大到小)
|
||||
public:
|
||||
deque<int> que; // 使用deque来实现单调队列
|
||||
// 每次弹出的时候,比较当前要弹出的数值是否等于队列出口元素的数值,如果相等则弹出。
|
||||
// 同时pop之前判断队列当前是否为空。
|
||||
void pop(int value) {
|
||||
if (!que.empty() && value == que.front()) {
|
||||
que.pop_front();
|
||||
}
|
||||
}
|
||||
// 如果push的数值大于入口元素的数值,那么就将队列后端的数值弹出,直到push的数值小于等于队列入口元素的数值为止。
|
||||
// 这样就保持了队列里的数值是单调从大到小的了。
|
||||
void push(int value) {
|
||||
while (!que.empty() && value > que.back()) {
|
||||
que.pop_back();
|
||||
}
|
||||
que.push_back(value);
|
||||
|
||||
}
|
||||
// 查询当前队列里的最大值 直接返回队列前端也就是front就可以了。
|
||||
int front() {
|
||||
return que.front();
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
这样我们就用deque实现了一个单调队列,接下来解决滑动窗口最大值的问题就很简单了,直接看代码吧。
|
||||
|
||||
C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
class MyQueue { //单调队列(从大到小)
|
||||
public:
|
||||
deque<int> que; // 使用deque来实现单调队列
|
||||
// 每次弹出的时候,比较当前要弹出的数值是否等于队列出口元素的数值,如果相等则弹出。
|
||||
// 同时pop之前判断队列当前是否为空。
|
||||
void pop(int value) {
|
||||
if (!que.empty() && value == que.front()) {
|
||||
que.pop_front();
|
||||
}
|
||||
}
|
||||
// 如果push的数值大于入口元素的数值,那么就将队列后端的数值弹出,直到push的数值小于等于队列入口元素的数值为止。
|
||||
// 这样就保持了队列里的数值是单调从大到小的了。
|
||||
void push(int value) {
|
||||
while (!que.empty() && value > que.back()) {
|
||||
que.pop_back();
|
||||
}
|
||||
que.push_back(value);
|
||||
|
||||
}
|
||||
// 查询当前队列里的最大值 直接返回队列前端也就是front就可以了。
|
||||
int front() {
|
||||
return que.front();
|
||||
}
|
||||
};
|
||||
public:
|
||||
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
|
||||
MyQueue que;
|
||||
vector<int> result;
|
||||
for (int i = 0; i < k; i++) { // 先将前k的元素放进队列
|
||||
que.push(nums[i]);
|
||||
}
|
||||
result.push_back(que.front()); // result 记录前k的元素的最大值
|
||||
for (int i = k; i < nums.size(); i++) {
|
||||
que.pop(nums[i - k]); // 滑动窗口移除最前面元素
|
||||
que.push(nums[i]); // 滑动窗口前加入最后面的元素
|
||||
result.push_back(que.front()); // 记录对应的最大值
|
||||
}
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
在来看一下时间复杂度,使用单调队列的时间复杂度是 O(n)。
|
||||
|
||||
有的同学可能想了,在队列中 push元素的过程中,还有pop操作呢,感觉不是纯粹的O(n)。
|
||||
|
||||
其实,大家可以自己观察一下单调队列的实现,nums 中的每个元素最多也就被 push_back 和 pop_back 各一次,没有任何多余操作,所以整体的复杂度还是 O(n)。
|
||||
|
||||
空间复杂度因为我们定义一个辅助队列,所以是O(k)。
|
||||
|
||||
# 扩展
|
||||
|
||||
大家貌似对单调队列 都有一些疑惑,首先要明确的是,题解中单调队列里的pop和push接口,仅适用于本题哈。单调队列不是一成不变的,而是不同场景不同写法,总之要保证队列里单调递减或递增的原则,所以叫做单调队列。 不要以为本地中的单调队列实现就是固定的写法哈。
|
||||
|
||||
大家貌似对deque也有一些疑惑,C++中deque是stack和queue默认的底层实现容器(这个我们之前已经讲过啦),deque是可以两边扩展的,而且deque里元素并不是严格的连续分布的。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
//解法一
|
||||
//自定义数组
|
||||
class MyQueue {
|
||||
Deque<Integer> deque = new LinkedList<>();
|
||||
//弹出元素时,比较当前要弹出的数值是否等于队列出口的数值,如果相等则弹出
|
||||
//同时判断队列当前是否为空
|
||||
void poll(int val) {
|
||||
if (!deque.isEmpty() && val == deque.peek()) {
|
||||
deque.poll();
|
||||
}
|
||||
}
|
||||
//添加元素时,如果要添加的元素大于入口处的元素,就将入口元素弹出
|
||||
//保证队列元素单调递减
|
||||
//比如此时队列元素3,1,2将要入队,比1大,所以1弹出,此时队列:3,2
|
||||
void add(int val) {
|
||||
while (!deque.isEmpty() && val > deque.getLast()) {
|
||||
deque.removeLast();
|
||||
}
|
||||
deque.add(val);
|
||||
}
|
||||
//队列队顶元素始终为最大值
|
||||
int peek() {
|
||||
return deque.peek();
|
||||
}
|
||||
}
|
||||
|
||||
class Solution {
|
||||
public int[] maxSlidingWindow(int[] nums, int k) {
|
||||
if (nums.length == 1) {
|
||||
return nums;
|
||||
}
|
||||
int len = nums.length - k + 1;
|
||||
//存放结果元素的数组
|
||||
int[] res = new int[len];
|
||||
int num = 0;
|
||||
//自定义队列
|
||||
MyQueue myQueue = new MyQueue();
|
||||
//先将前k的元素放入队列
|
||||
for (int i = 0; i < k; i++) {
|
||||
myQueue.add(nums[i]);
|
||||
}
|
||||
res[num++] = myQueue.peek();
|
||||
for (int i = k; i < nums.length; i++) {
|
||||
//滑动窗口移除最前面的元素,移除是判断该元素是否放入队列
|
||||
myQueue.poll(nums[i - k]);
|
||||
//滑动窗口加入最后面的元素
|
||||
myQueue.add(nums[i]);
|
||||
//记录对应的最大值
|
||||
res[num++] = myQueue.peek();
|
||||
}
|
||||
return res;
|
||||
}
|
||||
}
|
||||
|
||||
//解法二
|
||||
//利用双端队列手动实现单调队列
|
||||
/**
|
||||
* 用一个单调队列来存储对应的下标,每当窗口滑动的时候,直接取队列的头部指针对应的值放入结果集即可
|
||||
* 单调队列类似 (tail -->) 3 --> 2 --> 1 --> 0 (--> head) (右边为头结点,元素存的是下标)
|
||||
*/
|
||||
class Solution {
|
||||
public int[] maxSlidingWindow(int[] nums, int k) {
|
||||
ArrayDeque<Integer> deque = new ArrayDeque<>();
|
||||
int n = nums.length;
|
||||
int[] res = new int[n - k + 1];
|
||||
int idx = 0;
|
||||
for(int i = 0; i < n; i++) {
|
||||
// 根据题意,i为nums下标,是要在[i - k + 1, k] 中选到最大值,只需要保证两点
|
||||
// 1.队列头结点需要在[i - k + 1, k]范围内,不符合则要弹出
|
||||
while(!deque.isEmpty() && deque.peek() < i - k + 1){
|
||||
deque.poll();
|
||||
}
|
||||
// 2.既然是单调,就要保证每次放进去的数字要比末尾的都大,否则也弹出
|
||||
while(!deque.isEmpty() && nums[deque.peekLast()] < nums[i]) {
|
||||
deque.pollLast();
|
||||
}
|
||||
|
||||
deque.offer(i);
|
||||
|
||||
// 因为单调,当i增长到符合第一个k范围的时候,每滑动一步都将队列头节点放入结果就行了
|
||||
if(i >= k - 1){
|
||||
res[idx++] = nums[deque.peek()];
|
||||
}
|
||||
}
|
||||
return res;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class MyQueue: #单调队列(从大到小
|
||||
def __init__(self):
|
||||
self.queue = [] #使用list来实现单调队列
|
||||
|
||||
#每次弹出的时候,比较当前要弹出的数值是否等于队列出口元素的数值,如果相等则弹出。
|
||||
#同时pop之前判断队列当前是否为空。
|
||||
def pop(self, value):
|
||||
if self.queue and value == self.queue[0]:
|
||||
self.queue.pop(0)#list.pop()时间复杂度为O(n),这里可以使用collections.deque()
|
||||
|
||||
#如果push的数值大于入口元素的数值,那么就将队列后端的数值弹出,直到push的数值小于等于队列入口元素的数值为止。
|
||||
#这样就保持了队列里的数值是单调从大到小的了。
|
||||
def push(self, value):
|
||||
while self.queue and value > self.queue[-1]:
|
||||
self.queue.pop()
|
||||
self.queue.append(value)
|
||||
|
||||
#查询当前队列里的最大值 直接返回队列前端也就是front就可以了。
|
||||
def front(self):
|
||||
return self.queue[0]
|
||||
|
||||
class Solution:
|
||||
def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]:
|
||||
que = MyQueue()
|
||||
result = []
|
||||
for i in range(k): #先将前k的元素放进队列
|
||||
que.push(nums[i])
|
||||
result.append(que.front()) #result 记录前k的元素的最大值
|
||||
for i in range(k, len(nums)):
|
||||
que.pop(nums[i - k]) #滑动窗口移除最前面元素
|
||||
que.push(nums[i]) #滑动窗口前加入最后面的元素
|
||||
result.append(que.front()) #记录对应的最大值
|
||||
return result
|
||||
```
|
||||
|
||||
|
||||
Go:
|
||||
|
||||
```go
|
||||
func maxSlidingWindow(nums []int, k int) []int {
|
||||
var queue []int
|
||||
var rtn []int
|
||||
|
||||
for f := 0; f < len(nums); f++ {
|
||||
//维持队列递减, 将 k 插入合适的位置, queue中 <=k 的 元素都不可能是窗口中的最大值, 直接弹出
|
||||
for len(queue) > 0 && nums[f] > nums[queue[len(queue)-1]] {
|
||||
queue = queue[:len(queue)-1]
|
||||
}
|
||||
// 等大的后来者也应入队
|
||||
if len(queue) == 0 || nums[f] <= nums[queue[len(queue)-1]] {
|
||||
queue = append(queue, f)
|
||||
}
|
||||
|
||||
if f >= k - 1 {
|
||||
rtn = append(rtn, nums[queue[0]])
|
||||
//弹出离开窗口的队首
|
||||
if f - k + 1 == queue[0] {
|
||||
queue = queue[1:]
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return rtn
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
```go
|
||||
// 封装单调队列的方式解题
|
||||
type MyQueue struct {
|
||||
queue []int
|
||||
}
|
||||
|
||||
func NewMyQueue() *MyQueue {
|
||||
return &MyQueue{
|
||||
queue: make([]int, 0),
|
||||
}
|
||||
}
|
||||
|
||||
func (m *MyQueue) Front() int {
|
||||
return m.queue[0]
|
||||
}
|
||||
|
||||
func (m *MyQueue) Back() int {
|
||||
return m.queue[len(m.queue)-1]
|
||||
}
|
||||
|
||||
func (m *MyQueue) Empty() bool {
|
||||
return len(m.queue) == 0
|
||||
}
|
||||
|
||||
func (m *MyQueue) Push(val int) {
|
||||
for !m.Empty() && val > m.Back() {
|
||||
m.queue = m.queue[:len(m.queue)-1]
|
||||
}
|
||||
m.queue = append(m.queue, val)
|
||||
}
|
||||
|
||||
func (m *MyQueue) Pop(val int) {
|
||||
if !m.Empty() && val == m.Front() {
|
||||
m.queue = m.queue[1:]
|
||||
}
|
||||
}
|
||||
|
||||
func maxSlidingWindow(nums []int, k int) []int {
|
||||
queue := NewMyQueue()
|
||||
length := len(nums)
|
||||
res := make([]int, 0)
|
||||
// 先将前k个元素放入队列
|
||||
for i := 0; i < k; i++ {
|
||||
queue.Push(nums[i])
|
||||
}
|
||||
// 记录前k个元素的最大值
|
||||
res = append(res, queue.Front())
|
||||
|
||||
for i := k; i < length; i++ {
|
||||
// 滑动窗口移除最前面的元素
|
||||
queue.Pop(nums[i-k])
|
||||
// 滑动窗口添加最后面的元素
|
||||
queue.Push(nums[i])
|
||||
// 记录最大值
|
||||
res = append(res, queue.Front())
|
||||
}
|
||||
return res
|
||||
}
|
||||
```
|
||||
|
||||
Javascript:
|
||||
```javascript
|
||||
var maxSlidingWindow = function (nums, k) {
|
||||
// 队列数组(存放的是元素下标,为了取值方便)
|
||||
const q = [];
|
||||
// 结果数组
|
||||
const ans = [];
|
||||
for (let i = 0; i < nums.length; i++) {
|
||||
// 若队列不为空,且当前元素大于等于队尾所存下标的元素,则弹出队尾
|
||||
while (q.length && nums[i] >= nums[q[q.length - 1]]) {
|
||||
q.pop();
|
||||
}
|
||||
// 入队当前元素下标
|
||||
q.push(i);
|
||||
// 判断当前最大值(即队首元素)是否在窗口中,若不在便将其出队
|
||||
while (q[0] <= i - k) {
|
||||
q.shift();
|
||||
}
|
||||
// 当达到窗口大小时便开始向结果中添加数据
|
||||
if (i >= k - 1) ans.push(nums[q[0]]);
|
||||
}
|
||||
return ans;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
212
problems/0242.有效的字母异位词.md
Normal file
212
problems/0242.有效的字母异位词.md
Normal file
@@ -0,0 +1,212 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
> 数组就是简单的哈希表,但是数组的大小可不是无限开辟的
|
||||
|
||||
## 242.有效的字母异位词
|
||||
|
||||
https://leetcode-cn.com/problems/valid-anagram/
|
||||
|
||||
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
|
||||
|
||||
示例 1:
|
||||
输入: s = "anagram", t = "nagaram"
|
||||
输出: true
|
||||
|
||||
示例 2:
|
||||
输入: s = "rat", t = "car"
|
||||
输出: false
|
||||
|
||||
|
||||
**说明:**
|
||||
你可以假设字符串只包含小写字母。
|
||||
|
||||
## 思路
|
||||
|
||||
先看暴力的解法,两层for循环,同时还要记录字符是否重复出现,很明显时间复杂度是 O(n^2)。
|
||||
|
||||
暴力的方法这里就不做介绍了,直接看一下有没有更优的方式。
|
||||
|
||||
**数组其实就是一个简单哈希表**,而且这道题目中字符串只有小写字符,那么就可以定义一个数组,来记录字符串s里字符出现的次数。
|
||||
|
||||
如果对哈希表的理论基础关于数组,set,map不了解的话可以看这篇:[关于哈希表,你该了解这些!](https://mp.weixin.qq.com/s/g8N6WmoQmsCUw3_BaWxHZA)
|
||||
|
||||
需要定义一个多大的数组呢,定一个数组叫做record,大小为26 就可以了,初始化为0,因为字符a到字符z的ASCII也是26个连续的数值。
|
||||
|
||||
为了方便举例,判断一下字符串s= "aee", t = "eae"。
|
||||
|
||||
操作动画如下:
|
||||
|
||||

|
||||
|
||||
定义一个数组叫做record用来上记录字符串s里字符出现的次数。
|
||||
|
||||
需要把字符映射到数组也就是哈希表的索引下表上,**因为字符a到字符z的ASCII是26个连续的数值,所以字符a映射为下表0,相应的字符z映射为下表25。**
|
||||
|
||||
再遍历 字符串s的时候,**只需要将 s[i] - ‘a’ 所在的元素做+1 操作即可,并不需要记住字符a的ASCII,只要求出一个相对数值就可以了。** 这样就将字符串s中字符出现的次数,统计出来了。
|
||||
|
||||
那看一下如何检查字符串t中是否出现了这些字符,同样在遍历字符串t的时候,对t中出现的字符映射哈希表索引上的数值再做-1的操作。
|
||||
|
||||
那么最后检查一下,**record数组如果有的元素不为零0,说明字符串s和t一定是谁多了字符或者谁少了字符,return false。**
|
||||
|
||||
最后如果record数组所有元素都为零0,说明字符串s和t是字母异位词,return true。
|
||||
|
||||
时间复杂度为O(n),空间上因为定义是的一个常量大小的辅助数组,所以空间复杂度为O(1)。
|
||||
|
||||
|
||||
C++ 代码如下:
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
bool isAnagram(string s, string t) {
|
||||
int record[26] = {0};
|
||||
for (int i = 0; i < s.size(); i++) {
|
||||
// 并不需要记住字符a的ASCII,只要求出一个相对数值就可以了
|
||||
record[s[i] - 'a']++;
|
||||
}
|
||||
for (int i = 0; i < t.size(); i++) {
|
||||
record[t[i] - 'a']--;
|
||||
}
|
||||
for (int i = 0; i < 26; i++) {
|
||||
if (record[i] != 0) {
|
||||
// record数组如果有的元素不为零0,说明字符串s和t 一定是谁多了字符或者谁少了字符。
|
||||
return false;
|
||||
}
|
||||
}
|
||||
// record数组所有元素都为零0,说明字符串s和t是字母异位词
|
||||
return true;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
public boolean isAnagram(String s, String t) {
|
||||
|
||||
int[] record = new int[26];
|
||||
for (char c : s.toCharArray()) {
|
||||
record[c - 'a'] += 1;
|
||||
}
|
||||
for (char c : t.toCharArray()) {
|
||||
record[c - 'a'] -= 1;
|
||||
}
|
||||
for (int i : record) {
|
||||
if (i != 0) {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def isAnagram(self, s: str, t: str) -> bool:
|
||||
record = [0] * 26
|
||||
for i in range(len(s)):
|
||||
#并不需要记住字符a的ASCII,只要求出一个相对数值就可以了
|
||||
record[ord(s[i]) - ord("a")] += 1
|
||||
print(record)
|
||||
for i in range(len(t)):
|
||||
record[ord(t[i]) - ord("a")] -= 1
|
||||
for i in range(26):
|
||||
if record[i] != 0:
|
||||
#record数组如果有的元素不为零0,说明字符串s和t 一定是谁多了字符或者谁少了字符。
|
||||
return False
|
||||
return True
|
||||
```
|
||||
|
||||
Python写法二(没有使用数组作为哈希表,只是介绍defaultdict这样一种解题思路):
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def isAnagram(self, s: str, t: str) -> bool:
|
||||
from collections import defaultdict
|
||||
|
||||
s_dict = defaultdict(int)
|
||||
t_dict = defaultdict(int)
|
||||
|
||||
for x in s:
|
||||
s_dict[x] += 1
|
||||
|
||||
for x in t:
|
||||
t_dict[x] += 1
|
||||
|
||||
return s_dict == t_dict
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
```go
|
||||
func isAnagram(s string, t string) bool {
|
||||
if len(s)!=len(t){
|
||||
return false
|
||||
}
|
||||
exists := make(map[byte]int)
|
||||
for i:=0;i<len(s);i++{
|
||||
if v,ok:=exists[s[i]];v>=0&&ok{
|
||||
exists[s[i]]=v+1
|
||||
}else{
|
||||
exists[s[i]]=1
|
||||
}
|
||||
}
|
||||
for i:=0;i<len(t);i++{
|
||||
if v,ok:=exists[t[i]];v>=1&&ok{
|
||||
exists[t[i]]=v-1
|
||||
}else{
|
||||
return false
|
||||
}
|
||||
}
|
||||
return true
|
||||
}
|
||||
```
|
||||
|
||||
javaScript:
|
||||
|
||||
```js
|
||||
/**
|
||||
* @param {string} s
|
||||
* @param {string} t
|
||||
* @return {boolean}
|
||||
*/
|
||||
var isAnagram = function(s, t) {
|
||||
if(s.length !== t.length) return false;
|
||||
const resSet = new Array(26).fill(0);
|
||||
const base = "a".charCodeAt();
|
||||
for(const i of s) {
|
||||
resSet[i.charCodeAt() - base]++;
|
||||
}
|
||||
for(const i of t) {
|
||||
if(!resSet[i.charCodeAt() - base]) return false;
|
||||
resSet[i.charCodeAt() - base]--;
|
||||
}
|
||||
return true;
|
||||
};
|
||||
```
|
||||
|
||||
## 相关题目
|
||||
|
||||
* 383.赎金信
|
||||
* 49.字母异位词分组
|
||||
* 438.找到字符串中所有字母异位词
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
455
problems/0257.二叉树的所有路径.md
Normal file
455
problems/0257.二叉树的所有路径.md
Normal file
@@ -0,0 +1,455 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
> 以为只用了递归,其实还用了回溯
|
||||
|
||||
## 257. 二叉树的所有路径
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/binary-tree-paths/
|
||||
|
||||
给定一个二叉树,返回所有从根节点到叶子节点的路径。
|
||||
|
||||
说明: 叶子节点是指没有子节点的节点。
|
||||
|
||||
示例:
|
||||

|
||||
|
||||
## 思路
|
||||
|
||||
这道题目要求从根节点到叶子的路径,所以需要前序遍历,这样才方便让父节点指向孩子节点,找到对应的路径。
|
||||
|
||||
在这道题目中将第一次涉及到回溯,因为我们要把路径记录下来,需要回溯来回退一一个路径在进入另一个路径。
|
||||
|
||||
前序遍历以及回溯的过程如图:
|
||||
|
||||
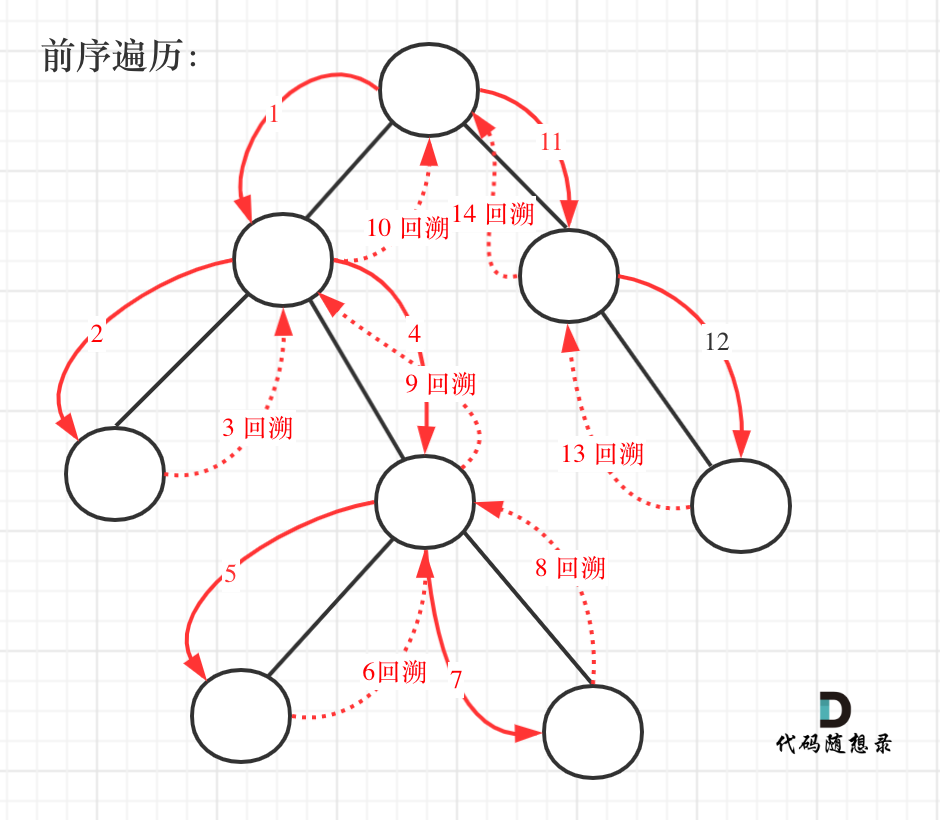
|
||||
|
||||
我们先使用递归的方式,来做前序遍历。**要知道递归和回溯就是一家的,本题也需要回溯。**
|
||||
|
||||
## 递归
|
||||
|
||||
1. 递归函数函数参数以及返回值
|
||||
|
||||
要传入根节点,记录每一条路径的path,和存放结果集的result,这里递归不需要返回值,代码如下:
|
||||
|
||||
```
|
||||
void traversal(TreeNode* cur, vector<int>& path, vector<string>& result)
|
||||
```
|
||||
|
||||
2. 确定递归终止条件
|
||||
|
||||
再写递归的时候都习惯了这么写:
|
||||
|
||||
```
|
||||
if (cur == NULL) {
|
||||
终止处理逻辑
|
||||
}
|
||||
```
|
||||
|
||||
但是本题的终止条件这样写会很麻烦,因为本题要找到叶子节点,就开始结束的处理逻辑了(把路径放进result里)。
|
||||
|
||||
**那么什么时候算是找到了叶子节点?** 是当 cur不为空,其左右孩子都为空的时候,就找到叶子节点。
|
||||
|
||||
所以本题的终止条件是:
|
||||
```
|
||||
if (cur->left == NULL && cur->right == NULL) {
|
||||
终止处理逻辑
|
||||
}
|
||||
```
|
||||
|
||||
为什么没有判断cur是否为空呢,因为下面的逻辑可以控制空节点不入循环。
|
||||
|
||||
再来看一下终止处理的逻辑。
|
||||
|
||||
这里使用vector<int> 结构path来记录路径,所以要把vector<int> 结构的path转为string格式,在把这个string 放进 result里。
|
||||
|
||||
**那么为什么使用了vector<int> 结构来记录路径呢?** 因为在下面处理单层递归逻辑的时候,要做回溯,使用vector方便来做回溯。
|
||||
|
||||
可能有的同学问了,我看有些人的代码也没有回溯啊。
|
||||
|
||||
**其实是有回溯的,只不过隐藏在函数调用时的参数赋值里**,下文我还会提到。
|
||||
|
||||
这里我们先使用vector<int>结构的path容器来记录路径,那么终止处理逻辑如下:
|
||||
|
||||
```C++
|
||||
if (cur->left == NULL && cur->right == NULL) { // 遇到叶子节点
|
||||
string sPath;
|
||||
for (int i = 0; i < path.size() - 1; i++) { // 将path里记录的路径转为string格式
|
||||
sPath += to_string(path[i]);
|
||||
sPath += "->";
|
||||
}
|
||||
sPath += to_string(path[path.size() - 1]); // 记录最后一个节点(叶子节点)
|
||||
result.push_back(sPath); // 收集一个路径
|
||||
return;
|
||||
}
|
||||
```
|
||||
|
||||
3. 确定单层递归逻辑
|
||||
|
||||
因为是前序遍历,需要先处理中间节点,中间节点就是我们要记录路径上的节点,先放进path中。
|
||||
|
||||
`path.push_back(cur->val);`
|
||||
|
||||
然后是递归和回溯的过程,上面说过没有判断cur是否为空,那么在这里递归的时候,如果为空就不进行下一层递归了。
|
||||
|
||||
所以递归前要加上判断语句,下面要递归的节点是否为空,如下
|
||||
|
||||
```
|
||||
if (cur->left) {
|
||||
traversal(cur->left, path, result);
|
||||
}
|
||||
if (cur->right) {
|
||||
traversal(cur->right, path, result);
|
||||
}
|
||||
```
|
||||
|
||||
此时还没完,递归完,要做回溯啊,因为path 不能一直加入节点,它还要删节点,然后才能加入新的节点。
|
||||
|
||||
那么回溯要怎么回溯呢,一些同学会这么写,如下:
|
||||
|
||||
```C++
|
||||
if (cur->left) {
|
||||
traversal(cur->left, path, result);
|
||||
}
|
||||
if (cur->right) {
|
||||
traversal(cur->right, path, result);
|
||||
}
|
||||
path.pop_back();
|
||||
```
|
||||
|
||||
这个回溯就要很大的问题,我们知道,**回溯和递归是一一对应的,有一个递归,就要有一个回溯**,这么写的话相当于把递归和回溯拆开了, 一个在花括号里,一个在花括号外。
|
||||
|
||||
**所以回溯要和递归永远在一起,世界上最遥远的距离是你在花括号里,而我在花括号外!**
|
||||
|
||||
那么代码应该这么写:
|
||||
|
||||
```C++
|
||||
if (cur->left) {
|
||||
traversal(cur->left, path, result);
|
||||
path.pop_back(); // 回溯
|
||||
}
|
||||
if (cur->right) {
|
||||
traversal(cur->right, path, result);
|
||||
path.pop_back(); // 回溯
|
||||
}
|
||||
```
|
||||
|
||||
那么本题整体代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
|
||||
void traversal(TreeNode* cur, vector<int>& path, vector<string>& result) {
|
||||
path.push_back(cur->val);
|
||||
// 这才到了叶子节点
|
||||
if (cur->left == NULL && cur->right == NULL) {
|
||||
string sPath;
|
||||
for (int i = 0; i < path.size() - 1; i++) {
|
||||
sPath += to_string(path[i]);
|
||||
sPath += "->";
|
||||
}
|
||||
sPath += to_string(path[path.size() - 1]);
|
||||
result.push_back(sPath);
|
||||
return;
|
||||
}
|
||||
if (cur->left) {
|
||||
traversal(cur->left, path, result);
|
||||
path.pop_back(); // 回溯
|
||||
}
|
||||
if (cur->right) {
|
||||
traversal(cur->right, path, result);
|
||||
path.pop_back(); // 回溯
|
||||
}
|
||||
}
|
||||
|
||||
public:
|
||||
vector<string> binaryTreePaths(TreeNode* root) {
|
||||
vector<string> result;
|
||||
vector<int> path;
|
||||
if (root == NULL) return result;
|
||||
traversal(root, path, result);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
如上的C++代码充分体现了回溯。
|
||||
|
||||
那么如上代码可以精简成如下代码:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
|
||||
void traversal(TreeNode* cur, string path, vector<string>& result) {
|
||||
path += to_string(cur->val); // 中
|
||||
if (cur->left == NULL && cur->right == NULL) {
|
||||
result.push_back(path);
|
||||
return;
|
||||
}
|
||||
if (cur->left) traversal(cur->left, path + "->", result); // 左
|
||||
if (cur->right) traversal(cur->right, path + "->", result); // 右
|
||||
}
|
||||
|
||||
public:
|
||||
vector<string> binaryTreePaths(TreeNode* root) {
|
||||
vector<string> result;
|
||||
string path;
|
||||
if (root == NULL) return result;
|
||||
traversal(root, path, result);
|
||||
return result;
|
||||
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
如上代码精简了不少,也隐藏了不少东西。
|
||||
|
||||
注意在函数定义的时候`void traversal(TreeNode* cur, string path, vector<string>& result)` ,定义的是`string path`,每次都是复制赋值,不用使用引用,否则就无法做到回溯的效果。
|
||||
|
||||
那么在如上代码中,**貌似没有看到回溯的逻辑,其实不然,回溯就隐藏在`traversal(cur->left, path + "->", result);`中的 `path + "->"`。** 每次函数调用完,path依然是没有加上"->" 的,这就是回溯了。
|
||||
|
||||
**如果这里还不理解的话,可以看这篇[二叉树:以为使用了递归,其实还隐藏着回溯](https://mp.weixin.qq.com/s/ivLkHzWdhjQQD1rQWe6zWA),我这这篇中详细的解释了递归中如何隐藏着回溯。 **
|
||||
|
||||
|
||||
|
||||
**综合以上,第二种递归的代码虽然精简但把很多重要的点隐藏在了代码细节里,第一种递归写法虽然代码多一些,但是把每一个逻辑处理都完整的展现了出来了。**
|
||||
|
||||
|
||||
|
||||
## 迭代法
|
||||
|
||||
至于非递归的方式,我们可以依然可以使用前序遍历的迭代方式来模拟遍历路径的过程,对该迭代方式不了解的同学,可以看文章[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg)和[二叉树:前中后序迭代方式的写法就不能统一一下么?](https://mp.weixin.qq.com/s/WKg0Ty1_3SZkztpHubZPRg)。
|
||||
|
||||
这里除了模拟递归需要一个栈,同时还需要一个栈来存放对应的遍历路径。
|
||||
|
||||
C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
vector<string> binaryTreePaths(TreeNode* root) {
|
||||
stack<TreeNode*> treeSt;// 保存树的遍历节点
|
||||
stack<string> pathSt; // 保存遍历路径的节点
|
||||
vector<string> result; // 保存最终路径集合
|
||||
if (root == NULL) return result;
|
||||
treeSt.push(root);
|
||||
pathSt.push(to_string(root->val));
|
||||
while (!treeSt.empty()) {
|
||||
TreeNode* node = treeSt.top(); treeSt.pop(); // 取出节点 中
|
||||
string path = pathSt.top();pathSt.pop(); // 取出该节点对应的路径
|
||||
if (node->left == NULL && node->right == NULL) { // 遇到叶子节点
|
||||
result.push_back(path);
|
||||
}
|
||||
if (node->right) { // 右
|
||||
treeSt.push(node->right);
|
||||
pathSt.push(path + "->" + to_string(node->right->val));
|
||||
}
|
||||
if (node->left) { // 左
|
||||
treeSt.push(node->left);
|
||||
pathSt.push(path + "->" + to_string(node->left->val));
|
||||
}
|
||||
}
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
当然,使用java的同学,可以直接定义一个成员变量为object的栈`Stack<Object> stack = new Stack<>();`,这样就不用定义两个栈了,都放到一个栈里就可以了。
|
||||
|
||||
## 总结
|
||||
|
||||
**本文我们开始初步涉及到了回溯,很多同学过了这道题目,可能都不知道自己其实使用了回溯,回溯和递归都是相伴相生的。**
|
||||
|
||||
我在第一版递归代码中,把递归与回溯的细节都充分的展现了出来,大家可以自己感受一下。
|
||||
|
||||
第二版递归代码对于初学者其实非常不友好,代码看上去简单,但是隐藏细节于无形。
|
||||
|
||||
最后我依然给出了迭代法。
|
||||
|
||||
对于本地充分了解递归与回溯的过程之后,有精力的同学可以在去实现迭代法。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
Java:
|
||||
|
||||
```Java
|
||||
//解法一
|
||||
class Solution {
|
||||
/**
|
||||
* 递归法
|
||||
*/
|
||||
public List<String> binaryTreePaths(TreeNode root) {
|
||||
List<String> res = new ArrayList<>();
|
||||
if (root == null) {
|
||||
return res;
|
||||
}
|
||||
List<Integer> paths = new ArrayList<>();
|
||||
traversal(root, paths, res);
|
||||
return res;
|
||||
}
|
||||
|
||||
private void traversal(TreeNode root, List<Integer> paths, List<String> res) {
|
||||
paths.add(root.val);
|
||||
// 叶子结点
|
||||
if (root.left == null && root.right == null) {
|
||||
// 输出
|
||||
StringBuilder sb = new StringBuilder();
|
||||
for (int i = 0; i < paths.size() - 1; i++) {
|
||||
sb.append(paths.get(i)).append("->");
|
||||
}
|
||||
sb.append(paths.get(paths.size() - 1));
|
||||
res.add(sb.toString());
|
||||
return;
|
||||
}
|
||||
if (root.left != null) {
|
||||
traversal(root.left, paths, res);
|
||||
paths.remove(paths.size() - 1);// 回溯
|
||||
}
|
||||
if (root.right != null) {
|
||||
traversal(root.right, paths, res);
|
||||
paths.remove(paths.size() - 1);// 回溯
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
//解法二(常规前序遍历,不用回溯),更容易理解
|
||||
class Solution {
|
||||
public List<String> binaryTreePaths(TreeNode root) {
|
||||
List<String> res = new ArrayList<>();
|
||||
helper(root, new StringBuilder(), res);
|
||||
return res;
|
||||
}
|
||||
|
||||
public void helper(TreeNode root, StringBuilder sb, List<String> res) {
|
||||
if (root == null) {return;}
|
||||
// 遇到叶子结点就放入当前路径到res集合中
|
||||
if (root.left == null && root.right ==null) {
|
||||
sb.append(root.val);
|
||||
res.add(sb.toString());
|
||||
// 记得结束当前方法
|
||||
return;
|
||||
}
|
||||
helper(root.left,new StringBuilder(sb).append(root.val + "->"),res);
|
||||
helper(root.right,new StringBuilder(sb).append(root.val + "->"),res);
|
||||
}
|
||||
}
|
||||
|
||||
//针对解法二优化,思路本质是一样的
|
||||
class Solution {
|
||||
public List<String> binaryTreePaths(TreeNode root) {
|
||||
List<String> res = new ArrayList<>();
|
||||
helper(root, "", res);
|
||||
return res;
|
||||
}
|
||||
|
||||
public void helper(TreeNode root, String path, List<String> res) {
|
||||
if (root == null) {return;}
|
||||
// 由原始解法二可以知道,root的值肯定会下面某一个条件加入到path中,那么干脆直接在这一步加入即可
|
||||
StringBuilder sb = new StringBuilder(path);
|
||||
sb.append(root.val);
|
||||
if (root.left == null && root.right ==null) {
|
||||
res.add(sb.toString());
|
||||
}else{
|
||||
// 如果是非叶子结点则还需要跟上一个 “->”
|
||||
sb.append("->");
|
||||
helper(root.left,sb.toString(),res);
|
||||
helper(root.right,sb.toString(),res);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Python:
|
||||
```Python
|
||||
# class TreeNode:
|
||||
# def __init__(self, val=0, left=None, right=None):
|
||||
# self.val = val
|
||||
# self.left = left
|
||||
# self.right = right
|
||||
class Solution:
|
||||
def binaryTreePaths(self, root: TreeNode) -> List[str]:
|
||||
path=[]
|
||||
res=[]
|
||||
def backtrace(root, path):
|
||||
if not root:return
|
||||
path.append(root.val)
|
||||
if (not root.left)and (not root.right):
|
||||
res.append(path[:])
|
||||
ways=[]
|
||||
if root.left:ways.append(root.left)
|
||||
if root.right:ways.append(root.right)
|
||||
for way in ways:
|
||||
backtrace(way,path)
|
||||
path.pop()
|
||||
backtrace(root,path)
|
||||
return ["->".join(list(map(str,i))) for i in res]
|
||||
|
||||
```
|
||||
Go:
|
||||
|
||||
```go
|
||||
func binaryTreePaths(root *TreeNode) []string {
|
||||
res := make([]string, 0)
|
||||
var travel func(node *TreeNode, s string)
|
||||
travel = func(node *TreeNode, s string) {
|
||||
if node.Left == nil && node.Right == nil {
|
||||
v := s + strconv.Itoa(node.Val)
|
||||
res = append(res, v)
|
||||
return
|
||||
}
|
||||
s = s + strconv.Itoa(node.Val) + "->"
|
||||
if node.Left != nil {
|
||||
travel(node.Left, s)
|
||||
}
|
||||
if node.Right != nil {
|
||||
travel(node.Right, s)
|
||||
}
|
||||
}
|
||||
travel(root, "")
|
||||
return res
|
||||
}
|
||||
```
|
||||
|
||||
JavaScript:
|
||||
1.递归版本
|
||||
```javascript
|
||||
var binaryTreePaths = function(root) {
|
||||
//递归遍历+递归三部曲
|
||||
let res=[];
|
||||
//1. 确定递归函数 函数参数
|
||||
const getPath=function(node,curPath){
|
||||
//2. 确定终止条件,到叶子节点就终止
|
||||
if(node.left===null&&node.right===null){
|
||||
curPath+=node.val;
|
||||
res.push(curPath);
|
||||
return ;
|
||||
}
|
||||
//3. 确定单层递归逻辑
|
||||
curPath+=node.val+'->';
|
||||
node.left&&getPath(node.left,curPath);
|
||||
node.right&&getPath(node.right,curPath);
|
||||
}
|
||||
getPath(root,'');
|
||||
return res;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
295
problems/0279.完全平方数.md
Normal file
295
problems/0279.完全平方数.md
Normal file
@@ -0,0 +1,295 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
# 动态规划:一样的套路,再求一次完全平方数
|
||||
|
||||
## 279.完全平方数
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/perfect-squares/
|
||||
|
||||
给定正整数 n,找到若干个完全平方数(比如 1, 4, 9, 16, ...)使得它们的和等于 n。你需要让组成和的完全平方数的个数最少。
|
||||
|
||||
给你一个整数 n ,返回和为 n 的完全平方数的 最少数量 。
|
||||
|
||||
完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 和 11 不是。
|
||||
|
||||
示例 1:
|
||||
输入:n = 12
|
||||
输出:3
|
||||
解释:12 = 4 + 4 + 4
|
||||
|
||||
示例 2:
|
||||
输入:n = 13
|
||||
输出:2
|
||||
解释:13 = 4 + 9
|
||||
|
||||
提示:
|
||||
* 1 <= n <= 10^4
|
||||
|
||||
## 思路
|
||||
|
||||
可能刚看这种题感觉没啥思路,又平方和的,又最小数的。
|
||||
|
||||
**我来把题目翻译一下:完全平方数就是物品(可以无限件使用),凑个正整数n就是背包,问凑满这个背包最少有多少物品?**
|
||||
|
||||
感受出来了没,这么浓厚的完全背包氛围,而且和昨天的题目[动态规划:322. 零钱兑换](https://mp.weixin.qq.com/s/dyk-xNilHzNtVdPPLObSeQ)就是一样一样的!
|
||||
|
||||
动规五部曲分析如下:
|
||||
|
||||
1. 确定dp数组(dp table)以及下标的含义
|
||||
|
||||
**dp[i]:和为i的完全平方数的最少数量为dp[i]**
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
dp[j] 可以由dp[j - i * i]推出, dp[j - i * i] + 1 便可以凑成dp[j]。
|
||||
|
||||
此时我们要选择最小的dp[j],所以递推公式:dp[j] = min(dp[j - i * i] + 1, dp[j]);
|
||||
|
||||
3. dp数组如何初始化
|
||||
|
||||
dp[0]表示 和为0的完全平方数的最小数量,那么dp[0]一定是0。
|
||||
|
||||
有同学问题,那0 * 0 也算是一种啊,为啥dp[0] 就是 0呢?
|
||||
|
||||
看题目描述,找到若干个完全平方数(比如 1, 4, 9, 16, ...),题目描述中可没说要从0开始,dp[0]=0完全是为了递推公式。
|
||||
|
||||
非0下标的dp[j]应该是多少呢?
|
||||
|
||||
从递归公式dp[j] = min(dp[j - i * i] + 1, dp[j]);中可以看出每次dp[j]都要选最小的,**所以非0下标的dp[i]一定要初始为最大值,这样dp[j]在递推的时候才不会被初始值覆盖**。
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
我们知道这是完全背包,
|
||||
|
||||
如果求组合数就是外层for循环遍历物品,内层for遍历背包。
|
||||
|
||||
如果求排列数就是外层for遍历背包,内层for循环遍历物品。
|
||||
|
||||
在[动态规划:322. 零钱兑换](https://mp.weixin.qq.com/s/dyk-xNilHzNtVdPPLObSeQ)中我们就深入探讨了这个问题,本题也是一样的,是求最小数!
|
||||
|
||||
**所以本题外层for遍历背包,里层for遍历物品,还是外层for遍历物品,内层for遍历背包,都是可以的!**
|
||||
|
||||
我这里先给出外层遍历背包,里层遍历物品的代码:
|
||||
|
||||
```C++
|
||||
vector<int> dp(n + 1, INT_MAX);
|
||||
dp[0] = 0;
|
||||
for (int i = 0; i <= n; i++) { // 遍历背包
|
||||
for (int j = 1; j * j <= i; j++) { // 遍历物品
|
||||
dp[i] = min(dp[i - j * j] + 1, dp[i]);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
5. 举例推导dp数组
|
||||
|
||||
已输入n为5例,dp状态图如下:
|
||||
|
||||

|
||||
|
||||
dp[0] = 0
|
||||
dp[1] = min(dp[0] + 1) = 1
|
||||
dp[2] = min(dp[1] + 1) = 2
|
||||
dp[3] = min(dp[2] + 1) = 3
|
||||
dp[4] = min(dp[3] + 1, dp[0] + 1) = 1
|
||||
dp[5] = min(dp[4] + 1, dp[1] + 1) = 2
|
||||
|
||||
最后的dp[n]为最终结果。
|
||||
|
||||
## C++代码
|
||||
|
||||
以上动规五部曲分析完毕C++代码如下:
|
||||
|
||||
```C++
|
||||
// 版本一
|
||||
class Solution {
|
||||
public:
|
||||
int numSquares(int n) {
|
||||
vector<int> dp(n + 1, INT_MAX);
|
||||
dp[0] = 0;
|
||||
for (int i = 0; i <= n; i++) { // 遍历背包
|
||||
for (int j = 1; j * j <= i; j++) { // 遍历物品
|
||||
dp[i] = min(dp[i - j * j] + 1, dp[i]);
|
||||
}
|
||||
}
|
||||
return dp[n];
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
同样我在给出先遍历物品,在遍历背包的代码,一样的可以AC的。
|
||||
|
||||
```C++
|
||||
// 版本二
|
||||
class Solution {
|
||||
public:
|
||||
int numSquares(int n) {
|
||||
vector<int> dp(n + 1, INT_MAX);
|
||||
dp[0] = 0;
|
||||
for (int i = 1; i * i <= n; i++) { // 遍历物品
|
||||
for (int j = 1; j <= n; j++) { // 遍历背包
|
||||
if (j - i * i >= 0) {
|
||||
dp[j] = min(dp[j - i * i] + 1, dp[j]);
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[n];
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
如果大家认真做了昨天的题目[动态规划:322. 零钱兑换](https://mp.weixin.qq.com/s/dyk-xNilHzNtVdPPLObSeQ),今天这道就非常简单了,一样的套路一样的味道。
|
||||
|
||||
但如果没有按照「代码随想录」的题目顺序来做的话,做动态规划或者做背包问题,上来就做这道题,那还是挺难的!
|
||||
|
||||
经过前面的训练这道题已经是简单题了,哈哈哈
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
public int numSquares(int n) {
|
||||
int max = Integer.MAX_VALUE;
|
||||
int[] dp = new int[n + 1];
|
||||
//初始化
|
||||
for (int j = 0; j <= n; j++) {
|
||||
dp[j] = max;
|
||||
}
|
||||
//当和为0时,组合的个数为0
|
||||
dp[0] = 0;
|
||||
for (int i = 1; i * i <= n; i++) {
|
||||
for (int j = i * i; j <= n; j++) {
|
||||
if (dp[j - i * i] != max) {
|
||||
dp[j] = Math.min(dp[j], dp[j - i * i] + 1);
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[n];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
```python3
|
||||
class Solution:
|
||||
def numSquares(self, n: int) -> int:
|
||||
'''版本一'''
|
||||
# 初始化
|
||||
nums = [i**2 for i in range(1, n + 1) if i**2 <= n]
|
||||
dp = [10**4]*(n + 1)
|
||||
dp[0] = 0
|
||||
# 遍历背包
|
||||
for j in range(1, n + 1):
|
||||
# 遍历物品
|
||||
for num in nums:
|
||||
if j >= num:
|
||||
dp[j] = min(dp[j], dp[j - num] + 1)
|
||||
return dp[n]
|
||||
|
||||
def numSquares1(self, n: int) -> int:
|
||||
'''版本二'''
|
||||
# 初始化
|
||||
nums = [i**2 for i in range(1, n + 1) if i**2 <= n]
|
||||
dp = [10**4]*(n + 1)
|
||||
dp[0] = 0
|
||||
# 遍历物品
|
||||
for num in nums:
|
||||
# 遍历背包
|
||||
for j in range(num, n + 1)
|
||||
dp[j] = min(dp[j], dp[j - num] + 1)
|
||||
return dp[n]
|
||||
```
|
||||
|
||||
Python3:
|
||||
```python
|
||||
class Solution:
|
||||
def numSquares(self, n: int) -> int:
|
||||
# 初始化
|
||||
# 组成和的完全平方数的最多个数,就是只用1构成
|
||||
# 因此,dp[i] = i
|
||||
dp = [i for i in range(n + 1)]
|
||||
# dp[0] = 0 无意义,只是为了方便记录特殊情况:
|
||||
# n本身就是完全平方数,dp[n] = min(dp[n], dp[n - n] + 1) = 1
|
||||
|
||||
for i in range(1, n): # 遍历物品
|
||||
if i * i > n:
|
||||
break
|
||||
num = i * i
|
||||
for j in range(num, n + 1): # 遍历背包
|
||||
dp[j] = min(dp[j], dp[j - num] + 1)
|
||||
|
||||
return dp[n]
|
||||
```
|
||||
|
||||
Go:
|
||||
```go
|
||||
// 版本一,先遍历物品, 再遍历背包
|
||||
func numSquares1(n int) int {
|
||||
//定义
|
||||
dp := make([]int, n+1)
|
||||
// 初始化
|
||||
dp[0] = 0
|
||||
for i := 1; i <= n; i++ {
|
||||
dp[i] = math.MaxInt32
|
||||
}
|
||||
// 遍历物品
|
||||
for i := 1; i <= n; i++ {
|
||||
// 遍历背包
|
||||
for j := i*i; j <= n; j++ {
|
||||
dp[j] = min(dp[j], dp[j-i*i]+1)
|
||||
}
|
||||
}
|
||||
|
||||
return dp[n]
|
||||
}
|
||||
|
||||
// 版本二,先遍历背包, 再遍历物品
|
||||
func numSquares2(n int) int {
|
||||
//定义
|
||||
dp := make([]int, n+1)
|
||||
// 初始化
|
||||
dp[0] = 0
|
||||
// 遍历背包
|
||||
for j := 1; j <= n; j++ {
|
||||
//初始化
|
||||
dp[j] = math.MaxInt32
|
||||
// 遍历物品
|
||||
for i := 1; i <= n; i++ {
|
||||
if j >= i*i {
|
||||
dp[j] = min(dp[j], dp[j-i*i]+1)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return dp[n]
|
||||
}
|
||||
|
||||
func min(a, b int) int {
|
||||
if a < b {
|
||||
return a
|
||||
}
|
||||
return b
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
182
problems/0300.最长上升子序列.md
Normal file
182
problems/0300.最长上升子序列.md
Normal file
@@ -0,0 +1,182 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
## 300.最长递增子序列
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/longest-increasing-subsequence/
|
||||
|
||||
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。
|
||||
|
||||
子序列是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。
|
||||
|
||||
|
||||
示例 1:
|
||||
输入:nums = [10,9,2,5,3,7,101,18]
|
||||
输出:4
|
||||
解释:最长递增子序列是 [2,3,7,101],因此长度为 4 。
|
||||
|
||||
示例 2:
|
||||
输入:nums = [0,1,0,3,2,3]
|
||||
输出:4
|
||||
|
||||
示例 3:
|
||||
输入:nums = [7,7,7,7,7,7,7]
|
||||
输出:1
|
||||
|
||||
提示:
|
||||
|
||||
* 1 <= nums.length <= 2500
|
||||
* -10^4 <= nums[i] <= 104
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
最长上升子序列是动规的经典题目,这里dp[i]是可以根据dp[j] (j < i)推导出来的,那么依然用动规五部曲来分析详细一波:
|
||||
|
||||
1. dp[i]的定义
|
||||
|
||||
**dp[i]表示i之前包括i的最长上升子序列**。
|
||||
|
||||
2. 状态转移方程
|
||||
|
||||
位置i的最长升序子序列等于j从0到i-1各个位置的最长升序子序列 + 1 的最大值。
|
||||
|
||||
所以:if (nums[i] > nums[j]) dp[i] = max(dp[i], dp[j] + 1);
|
||||
|
||||
**注意这里不是要dp[i] 与 dp[j] + 1进行比较,而是我们要取dp[j] + 1的最大值**。
|
||||
|
||||
3. dp[i]的初始化
|
||||
|
||||
每一个i,对应的dp[i](即最长上升子序列)起始大小至少都是是1.
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
dp[i] 是有0到i-1各个位置的最长升序子序列 推导而来,那么遍历i一定是从前向后遍历。
|
||||
|
||||
j其实就是0到i-1,遍历i的循环里外层,遍历j则在内层,代码如下:
|
||||
|
||||
```C++
|
||||
for (int i = 1; i < nums.size(); i++) {
|
||||
for (int j = 0; j < i; j++) {
|
||||
if (nums[i] > nums[j]) dp[i] = max(dp[i], dp[j] + 1);
|
||||
}
|
||||
if (dp[i] > result) result = dp[i]; // 取长的子序列
|
||||
}
|
||||
```
|
||||
|
||||
5. 举例推导dp数组
|
||||
|
||||
输入:[0,1,0,3,2],dp数组的变化如下:
|
||||
|
||||
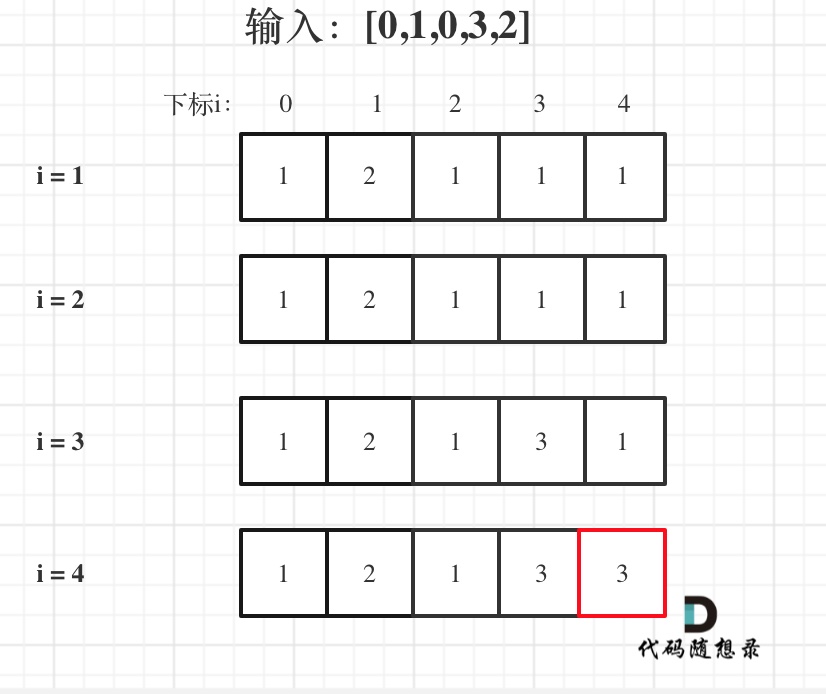
|
||||
|
||||
|
||||
如果代码写出来,但一直AC不了,那么就把dp数组打印出来,看看对不对!
|
||||
|
||||
以上五部分析完毕,C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int lengthOfLIS(vector<int>& nums) {
|
||||
if (nums.size() <= 1) return nums.size();
|
||||
vector<int> dp(nums.size(), 1);
|
||||
int result = 0;
|
||||
for (int i = 1; i < nums.size(); i++) {
|
||||
for (int j = 0; j < i; j++) {
|
||||
if (nums[i] > nums[j]) dp[i] = max(dp[i], dp[j] + 1);
|
||||
}
|
||||
if (dp[i] > result) result = dp[i]; // 取长的子序列
|
||||
}
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
本题最关键的是要想到dp[i]由哪些状态可以推出来,并取最大值,那么很自然就能想到递推公式:dp[i] = max(dp[i], dp[j] + 1);
|
||||
|
||||
子序列问题是动态规划的一个重要系列,本题算是入门题目,好戏刚刚开始!
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
public int lengthOfLIS(int[] nums) {
|
||||
int[] dp = new int[nums.length];
|
||||
Arrays.fill(dp, 1);
|
||||
for (int i = 0; i < dp.length; i++) {
|
||||
for (int j = 0; j < i; j++) {
|
||||
if (nums[i] > nums[j]) {
|
||||
dp[i] = Math.max(dp[i], dp[j] + 1);
|
||||
}
|
||||
}
|
||||
}
|
||||
int res = 0;
|
||||
for (int i = 0; i < dp.length; i++) {
|
||||
res = Math.max(res, dp[i]);
|
||||
}
|
||||
return res;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def lengthOfLIS(self, nums: List[int]) -> int:
|
||||
if len(nums) <= 1:
|
||||
return len(nums)
|
||||
dp = [1] * len(nums)
|
||||
result = 0
|
||||
for i in range(1, len(nums)):
|
||||
for j in range(0, i):
|
||||
if nums[i] > nums[j]:
|
||||
dp[i] = max(dp[i], dp[j] + 1)
|
||||
result = max(result, dp[i]) #取长的子序列
|
||||
return result
|
||||
```
|
||||
|
||||
Go:
|
||||
```go
|
||||
func lengthOfLIS(nums []int ) int {
|
||||
dp := []int{}
|
||||
for _, num := range nums {
|
||||
if len(dp) ==0 || dp[len(dp) - 1] < num {
|
||||
dp = append(dp, num)
|
||||
} else {
|
||||
l, r := 0, len(dp) - 1
|
||||
pos := r
|
||||
for l <= r {
|
||||
mid := (l + r) >> 1
|
||||
if dp[mid] >= num {
|
||||
pos = mid;
|
||||
r = mid - 1
|
||||
} else {
|
||||
l = mid + 1
|
||||
}
|
||||
}
|
||||
dp[pos] = num
|
||||
}//二分查找
|
||||
}
|
||||
return len(dp)
|
||||
}
|
||||
```
|
||||
*复杂度分析*
|
||||
- 时间复杂度:O(nlogn)。数组 nums 的长度为 n,我们依次用数组中的元素去更新 dp 数组,相当于插入最后递增的元素,而更新 dp 数组时需要进行 O(logn) 的二分搜索,所以总时间复杂度为 O(nlogn)。
|
||||
- 空间复杂度:O(n),需要额外使用长度为 n 的 dp 数组。
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
217
problems/0309.最佳买卖股票时机含冷冻期.md
Normal file
217
problems/0309.最佳买卖股票时机含冷冻期.md
Normal file
@@ -0,0 +1,217 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
## 309.最佳买卖股票时机含冷冻期
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-with-cooldown/
|
||||
|
||||
给定一个整数数组,其中第 i 个元素代表了第 i 天的股票价格 。
|
||||
|
||||
设计一个算法计算出最大利润。在满足以下约束条件下,你可以尽可能地完成更多的交易(多次买卖一支股票):
|
||||
|
||||
* 你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
|
||||
* 卖出股票后,你无法在第二天买入股票 (即冷冻期为 1 天)。
|
||||
|
||||
示例:
|
||||
输入: [1,2,3,0,2]
|
||||
输出: 3
|
||||
解释: 对应的交易状态为: [买入, 卖出, 冷冻期, 买入, 卖出]
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
> 之前我们在[动态规划:最佳买卖股票时机含冷冻期](https://mp.weixin.qq.com/s/IgC0iWWCDpYL9ZbTHGHgfw)讲过一次这道题目,讲解的过程感觉不是很严谨,和录友们也聊过这个问题,本着对大家负责的态度,有问题的地方我都会及时纠正,所以重新发文讲解一下。
|
||||
|
||||
相对于[动态规划:122.买卖股票的最佳时机II](https://mp.weixin.qq.com/s/d4TRWFuhaY83HPa6t5ZL-w),本题加上了一个冷冻期
|
||||
|
||||
|
||||
在[动态规划:122.买卖股票的最佳时机II](https://mp.weixin.qq.com/s/d4TRWFuhaY83HPa6t5ZL-w) 中有两个状态,持有股票后的最多现金,和不持有股票的最多现金。
|
||||
|
||||
动规五部曲,分析如下:
|
||||
|
||||
1. 确定dp数组以及下标的含义
|
||||
|
||||
dp[i][j],第i天状态为j,所剩的最多现金为dp[i][j]。
|
||||
|
||||
**其实本题很多同学搞的比较懵,是因为出现冷冻期之后,状态其实是比较复杂度**,例如今天买入股票、今天卖出股票、今天是冷冻期,都是不能操作股票的。
|
||||
具体可以区分出如下四个状态:
|
||||
|
||||
* 状态一:买入股票状态(今天买入股票,或者是之前就买入了股票然后没有操作)
|
||||
* 卖出股票状态,这里就有两种卖出股票状态
|
||||
* 状态二:两天前就卖出了股票,度过了冷冻期,一直没操作,今天保持卖出股票状态
|
||||
* 状态三:今天卖出了股票
|
||||
* 状态四:今天为冷冻期状态,但冷冻期状态不可持续,只有一天!
|
||||
|
||||
j的状态为:
|
||||
|
||||
* 0:状态一
|
||||
* 1:状态二
|
||||
* 2:状态三
|
||||
* 3:状态四
|
||||
|
||||
很多题解为什么讲的比较模糊,是因为把这四个状态合并成三个状态了,其实就是把状态二和状态四合并在一起了。
|
||||
|
||||
从代码上来看确实可以合并,但从逻辑上分析合并之后就很难理解了,所以我下面的讲解是按照这四个状态来的,把每一个状态分析清楚。
|
||||
|
||||
**注意这里的每一个状态,例如状态一,是买入股票状态并不是说今天已经就买入股票,而是说保存买入股票的状态即:可能是前几天买入的,之后一直没操作,所以保持买入股票的状态**。
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
|
||||
达到买入股票状态(状态一)即:dp[i][0],有两个具体操作:
|
||||
|
||||
* 操作一:前一天就是持有股票状态(状态一),dp[i][0] = dp[i - 1][0]
|
||||
* 操作二:今天买入了,有两种情况
|
||||
* 前一天是冷冻期(状态四),dp[i - 1][3] - prices[i]
|
||||
* 前一天是保持卖出股票状态(状态二),dp[i - 1][1] - prices[i]
|
||||
|
||||
所以操作二取最大值,即:max(dp[i - 1][3], dp[i - 1][1]) - prices[i]
|
||||
|
||||
那么dp[i][0] = max(dp[i - 1][0], max(dp[i - 1][3], dp[i - 1][1]) - prices[i]);
|
||||
|
||||
达到保持卖出股票状态(状态二)即:dp[i][1],有两个具体操作:
|
||||
|
||||
* 操作一:前一天就是状态二
|
||||
* 操作二:前一天是冷冻期(状态四)
|
||||
|
||||
dp[i][1] = max(dp[i - 1][1], dp[i - 1][3]);
|
||||
|
||||
达到今天就卖出股票状态(状态三),即:dp[i][2] ,只有一个操作:
|
||||
|
||||
* 操作一:昨天一定是买入股票状态(状态一),今天卖出
|
||||
|
||||
即:dp[i][2] = dp[i - 1][0] + prices[i];
|
||||
|
||||
达到冷冻期状态(状态四),即:dp[i][3],只有一个操作:
|
||||
|
||||
* 操作一:昨天卖出了股票(状态三)
|
||||
|
||||
p[i][3] = dp[i - 1][2];
|
||||
|
||||
综上分析,递推代码如下:
|
||||
|
||||
```C++
|
||||
dp[i][0] = max(dp[i - 1][0], max(dp[i - 1][3], dp[i - 1][1]) - prices[i];
|
||||
dp[i][1] = max(dp[i - 1][1], dp[i - 1][3]);
|
||||
dp[i][2] = dp[i - 1][0] + prices[i];
|
||||
dp[i][3] = dp[i - 1][2];
|
||||
```
|
||||
|
||||
3. dp数组如何初始化
|
||||
|
||||
这里主要讨论一下第0天如何初始化。
|
||||
|
||||
如果是持有股票状态(状态一)那么:dp[0][0] = -prices[0],买入股票所省现金为负数。
|
||||
|
||||
保持卖出股票状态(状态二),第0天没有卖出dp[0][1]初始化为0就行,
|
||||
|
||||
今天卖出了股票(状态三),同样dp[0][2]初始化为0,因为最少收益就是0,绝不会是负数。
|
||||
|
||||
同理dp[0][3]也初始为0。
|
||||
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
从递归公式上可以看出,dp[i] 依赖于 dp[i-1],所以是从前向后遍历。
|
||||
|
||||
5. 举例推导dp数组
|
||||
|
||||
以 [1,2,3,0,2] 为例,dp数组如下:
|
||||
|
||||
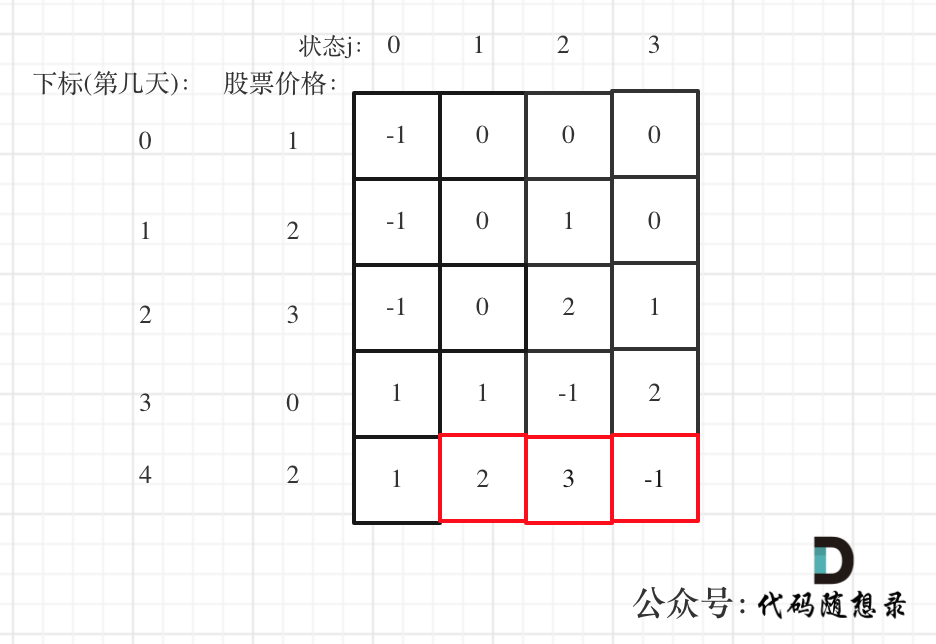
|
||||
|
||||
最后结果去是 状态二,状态三,和状态四的最大值,不少同学会把状态四忘了,状态四是冷冻期,最后一天如果是冷冻期也可能是最大值。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int maxProfit(vector<int>& prices) {
|
||||
int n = prices.size();
|
||||
if (n == 0) return 0;
|
||||
vector<vector<int>> dp(n, vector<int>(4, 0));
|
||||
dp[0][0] -= prices[0]; // 持股票
|
||||
for (int i = 1; i < n; i++) {
|
||||
dp[i][0] = max(dp[i - 1][0], max(dp[i - 1][3], dp[i - 1][1]) - prices[i]);
|
||||
dp[i][1] = max(dp[i - 1][1], dp[i - 1][3]);
|
||||
dp[i][2] = dp[i - 1][0] + prices[i];
|
||||
dp[i][3] = dp[i - 1][2];
|
||||
}
|
||||
return max(dp[n - 1][3],max(dp[n - 1][1], dp[n - 1][2]));
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
* 时间复杂度:O(n)
|
||||
* 空间复杂度:O(n)
|
||||
|
||||
当然,空间复杂度可以优化,定义一个dp[2][4]大小的数组就可以了,就保存前一天的当前的状态,感兴趣的同学可以自己去写一写,思路是一样的。
|
||||
|
||||
## 总结
|
||||
|
||||
这次把冷冻期这道题目,讲的很透彻了,细分为四个状态,其状态转移也十分清晰,建议大家都按照四个状态来分析,如果只划分三个状态确实很容易给自己绕进去。
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
Java:
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
public int maxProfit(int[] prices) {
|
||||
if (prices == null || prices.length < 2) {
|
||||
return 0;
|
||||
}
|
||||
int[][] dp = new int[prices.length][2];
|
||||
|
||||
// bad case
|
||||
dp[0][0] = 0;
|
||||
dp[0][1] = -prices[0];
|
||||
dp[1][0] = Math.max(dp[0][0], dp[0][1] + prices[1]);
|
||||
dp[1][1] = Math.max(dp[0][1], -prices[1]);
|
||||
|
||||
for (int i = 2; i < prices.length; i++) {
|
||||
// dp公式
|
||||
dp[i][0] = Math.max(dp[i - 1][0], dp[i - 1][1] + prices[i]);
|
||||
dp[i][1] = Math.max(dp[i - 1][1], dp[i - 2][0] - prices[i]);
|
||||
}
|
||||
|
||||
return dp[prices.length - 1][0];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
Python:
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def maxProfit(self, prices: List[int]) -> int:
|
||||
n = len(prices)
|
||||
if n == 0:
|
||||
return 0
|
||||
dp = [[0] * 4 for _ in range(n)]
|
||||
dp[0][0] = -prices[0] #持股票
|
||||
for i in range(1, n):
|
||||
dp[i][0] = max(dp[i-1][0], max(dp[i-1][3], dp[i-1][1]) - prices[i])
|
||||
dp[i][1] = max(dp[i-1][1], dp[i-1][3])
|
||||
dp[i][2] = dp[i-1][0] + prices[i]
|
||||
dp[i][3] = dp[i-1][2]
|
||||
return max(dp[n-1][3], dp[n-1][1], dp[n-1][2])
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
313
problems/0322.零钱兑换.md
Normal file
313
problems/0322.零钱兑换.md
Normal file
@@ -0,0 +1,313 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
# 动态规划: 给我个机会,我再兑换一次零钱
|
||||
|
||||
## 322. 零钱兑换
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/coin-change/
|
||||
|
||||
给定不同面额的硬币 coins 和一个总金额 amount。编写一个函数来计算可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回 -1。
|
||||
|
||||
你可以认为每种硬币的数量是无限的。
|
||||
|
||||
示例 1:
|
||||
输入:coins = [1, 2, 5], amount = 11
|
||||
输出:3
|
||||
解释:11 = 5 + 5 + 1
|
||||
|
||||
示例 2:
|
||||
输入:coins = [2], amount = 3
|
||||
输出:-1
|
||||
|
||||
示例 3:
|
||||
输入:coins = [1], amount = 0
|
||||
输出:0
|
||||
|
||||
示例 4:
|
||||
输入:coins = [1], amount = 1
|
||||
输出:1
|
||||
|
||||
示例 5:
|
||||
输入:coins = [1], amount = 2
|
||||
输出:2
|
||||
|
||||
提示:
|
||||
|
||||
* 1 <= coins.length <= 12
|
||||
* 1 <= coins[i] <= 2^31 - 1
|
||||
* 0 <= amount <= 10^4
|
||||
|
||||
## 思路
|
||||
|
||||
在[动态规划:518.零钱兑换II](https://mp.weixin.qq.com/s/PlowDsI4WMBOzf3q80AksQ)中我们已经兑换一次零钱了,这次又要兑换,套路不一样!
|
||||
|
||||
题目中说每种硬币的数量是无限的,可以看出是典型的完全背包问题。
|
||||
|
||||
动规五部曲分析如下:
|
||||
|
||||
1. 确定dp数组以及下标的含义
|
||||
|
||||
**dp[j]:凑足总额为j所需钱币的最少个数为dp[j]**
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
得到dp[j](考虑coins[i]),只有一个来源,dp[j - coins[i]](没有考虑coins[i])。
|
||||
|
||||
凑足总额为j - coins[i]的最少个数为dp[j - coins[i]],那么只需要加上一个钱币coins[i]即dp[j - coins[i]] + 1就是dp[j](考虑coins[i])
|
||||
|
||||
所以dp[j] 要取所有 dp[j - coins[i]] + 1 中最小的。
|
||||
|
||||
递推公式:dp[j] = min(dp[j - coins[i]] + 1, dp[j]);
|
||||
|
||||
3. dp数组如何初始化
|
||||
|
||||
首先凑足总金额为0所需钱币的个数一定是0,那么dp[0] = 0;
|
||||
|
||||
其他下标对应的数值呢?
|
||||
|
||||
考虑到递推公式的特性,dp[j]必须初始化为一个最大的数,否则就会在min(dp[j - coins[i]] + 1, dp[j])比较的过程中被初始值覆盖。
|
||||
|
||||
所以下标非0的元素都是应该是最大值。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
vector<int> dp(amount + 1, INT_MAX);
|
||||
dp[0] = 0;
|
||||
```
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
本题求钱币最小个数,**那么钱币有顺序和没有顺序都可以,都不影响钱币的最小个数。**。
|
||||
|
||||
所以本题并不强调集合是组合还是排列。
|
||||
|
||||
**如果求组合数就是外层for循环遍历物品,内层for遍历背包**。
|
||||
|
||||
**如果求排列数就是外层for遍历背包,内层for循环遍历物品**。
|
||||
|
||||
在动态规划专题我们讲过了求组合数是[动态规划:518.零钱兑换II](https://mp.weixin.qq.com/s/PlowDsI4WMBOzf3q80AksQ),求排列数是[动态规划:377. 组合总和 Ⅳ](https://mp.weixin.qq.com/s/Iixw0nahJWQgbqVNk8k6gA)。
|
||||
|
||||
**所以本题的两个for循环的关系是:外层for循环遍历物品,内层for遍历背包或者外层for遍历背包,内层for循环遍历物品都是可以的!**
|
||||
|
||||
那么我采用coins放在外循环,target在内循环的方式。
|
||||
|
||||
本题钱币数量可以无限使用,那么是完全背包。所以遍历的内循环是正序
|
||||
|
||||
综上所述,遍历顺序为:coins(物品)放在外循环,target(背包)在内循环。且内循环正序。
|
||||
|
||||
5. 举例推导dp数组
|
||||
|
||||
以输入:coins = [1, 2, 5], amount = 5为例
|
||||
|
||||
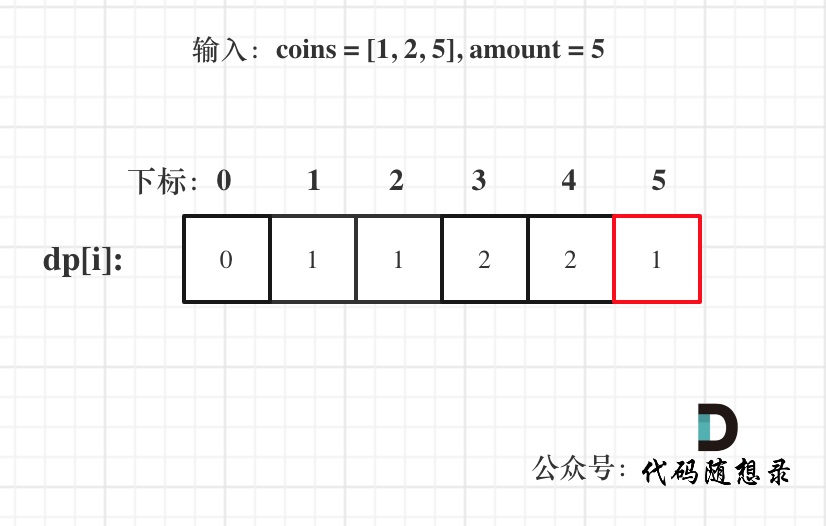
|
||||
|
||||
dp[amount]为最终结果。
|
||||
|
||||
## C++代码
|
||||
以上分析完毕,C++ 代码如下:
|
||||
|
||||
```C++
|
||||
// 版本一
|
||||
class Solution {
|
||||
public:
|
||||
int coinChange(vector<int>& coins, int amount) {
|
||||
vector<int> dp(amount + 1, INT_MAX);
|
||||
dp[0] = 0;
|
||||
for (int i = 0; i < coins.size(); i++) { // 遍历物品
|
||||
for (int j = coins[i]; j <= amount; j++) { // 遍历背包
|
||||
if (dp[j - coins[i]] != INT_MAX) { // 如果dp[j - coins[i]]是初始值则跳过
|
||||
dp[j] = min(dp[j - coins[i]] + 1, dp[j]);
|
||||
}
|
||||
}
|
||||
}
|
||||
if (dp[amount] == INT_MAX) return -1;
|
||||
return dp[amount];
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
对于遍历方式遍历背包放在外循环,遍历物品放在内循环也是可以的,我就直接给出代码了
|
||||
|
||||
```C++
|
||||
// 版本二
|
||||
class Solution {
|
||||
public:
|
||||
int coinChange(vector<int>& coins, int amount) {
|
||||
vector<int> dp(amount + 1, INT_MAX);
|
||||
dp[0] = 0;
|
||||
for (int i = 1; i <= amount; i++) { // 遍历背包
|
||||
for (int j = 0; j < coins.size(); j++) { // 遍历物品
|
||||
if (i - coins[j] >= 0 && dp[i - coins[j]] != INT_MAX ) {
|
||||
dp[i] = min(dp[i - coins[j]] + 1, dp[i]);
|
||||
}
|
||||
}
|
||||
}
|
||||
if (dp[amount] == INT_MAX) return -1;
|
||||
return dp[amount];
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
细心的同学看网上的题解,**可能看一篇是遍历背包的for循环放外面,看一篇又是遍历背包的for循环放里面,看多了都看晕了**,到底两个for循环应该是什么先后关系。
|
||||
|
||||
能把遍历顺序讲明白的文章几乎找不到!
|
||||
|
||||
这也是大多数同学学习动态规划的苦恼所在,有的时候递推公式很简单,难在遍历顺序上!
|
||||
|
||||
但最终又可以稀里糊涂的把题目过了,也不知道为什么这样可以过,反正就是过了,哈哈
|
||||
|
||||
那么这篇文章就把遍历顺序分析的清清楚楚。
|
||||
|
||||
[动态规划:518.零钱兑换II](https://mp.weixin.qq.com/s/PlowDsI4WMBOzf3q80AksQ)中求的是组合数,[动态规划:377. 组合总和 Ⅳ](https://mp.weixin.qq.com/s/Iixw0nahJWQgbqVNk8k6gA)中求的是排列数。
|
||||
|
||||
**而本题是要求最少硬币数量,硬币是组合数还是排列数都无所谓!所以两个for循环先后顺序怎样都可以!**
|
||||
|
||||
这也是我为什么要先讲518.零钱兑换II 然后再讲本题即:322.零钱兑换,这是Carl的良苦用心那。
|
||||
|
||||
相信大家看完之后,对背包问题中的遍历顺序又了更深的理解了。
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
public int coinChange(int[] coins, int amount) {
|
||||
int max = Integer.MAX_VALUE;
|
||||
int[] dp = new int[amount + 1];
|
||||
//初始化dp数组为最大值
|
||||
for (int j = 0; j < dp.length; j++) {
|
||||
dp[j] = max;
|
||||
}
|
||||
//当金额为0时需要的硬币数目为0
|
||||
dp[0] = 0;
|
||||
for (int i = 0; i < coins.length; i++) {
|
||||
//正序遍历:完全背包每个硬币可以选择多次
|
||||
for (int j = coins[i]; j <= amount; j++) {
|
||||
//只有dp[j-coins[i]]不是初始最大值时,该位才有选择的必要
|
||||
if (dp[j - coins[i]] != max) {
|
||||
//选择硬币数目最小的情况
|
||||
dp[j] = Math.min(dp[j], dp[j - coins[i]] + 1);
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[amount] == max ? -1 : dp[amount];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
```python3
|
||||
class Solution:
|
||||
def coinChange(self, coins: List[int], amount: int) -> int:
|
||||
'''版本一'''
|
||||
# 初始化
|
||||
dp = [amount + 1]*(amount + 1)
|
||||
dp[0] = 0
|
||||
# 遍历物品
|
||||
for coin in coins:
|
||||
# 遍历背包
|
||||
for j in range(coin, amount + 1):
|
||||
dp[j] = min(dp[j], dp[j - coin] + 1)
|
||||
return dp[amount] if dp[amount] < amount + 1 else -1
|
||||
|
||||
def coinChange1(self, coins: List[int], amount: int) -> int:
|
||||
'''版本二'''
|
||||
# 初始化
|
||||
dp = [amount + 1]*(amount + 1)
|
||||
dp[0] = 0
|
||||
# 遍历物品
|
||||
for j in range(1, amount + 1):
|
||||
# 遍历背包
|
||||
for coin in coins:
|
||||
if j >= coin:
|
||||
dp[j] = min(dp[j], dp[j - coin] + 1)
|
||||
return dp[amount] if dp[amount] < amount + 1 else -1
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
Go:
|
||||
```go
|
||||
// 版本一, 先遍历物品,再遍历背包
|
||||
func coinChange1(coins []int, amount int) int {
|
||||
dp := make([]int, amount+1)
|
||||
// 初始化dp[0]
|
||||
dp[0] = 0
|
||||
// 初始化为math.MaxInt32
|
||||
for j := 1; j <= amount; j++ {
|
||||
dp[j] = math.MaxInt32
|
||||
}
|
||||
|
||||
// 遍历物品
|
||||
for i := 0; i < len(coins); i++ {
|
||||
// 遍历背包
|
||||
for j := coins[i]; j <= amount; j++ {
|
||||
if dp[j-coins[i]] != math.MaxInt32 {
|
||||
// 推导公式
|
||||
dp[j] = min(dp[j], dp[j-coins[i]]+1)
|
||||
//fmt.Println(dp,j,i)
|
||||
}
|
||||
}
|
||||
}
|
||||
// 没找到能装满背包的, 就返回-1
|
||||
if dp[amount] == math.MaxInt32 {
|
||||
return -1
|
||||
}
|
||||
return dp[amount]
|
||||
}
|
||||
|
||||
// 版本二,先遍历背包,再遍历物品
|
||||
func coinChange2(coins []int, amount int) int {
|
||||
dp := make([]int, amount+1)
|
||||
// 初始化dp[0]
|
||||
dp[0] = 0
|
||||
// 遍历背包,从1开始
|
||||
for j := 1; j <= amount; j++ {
|
||||
// 初始化为math.MaxInt32
|
||||
dp[j] = math.MaxInt32
|
||||
// 遍历物品
|
||||
for i := 0; i < len(coins); i++ {
|
||||
if j >= coins[i] && dp[j-coins[i]] != math.MaxInt32 {
|
||||
// 推导公式
|
||||
dp[j] = min(dp[j], dp[j-coins[i]]+1)
|
||||
//fmt.Println(dp)
|
||||
}
|
||||
}
|
||||
}
|
||||
// 没找到能装满背包的, 就返回-1
|
||||
if dp[amount] == math.MaxInt32 {
|
||||
return -1
|
||||
}
|
||||
return dp[amount]
|
||||
}
|
||||
|
||||
func min(a, b int) int {
|
||||
if a < b {
|
||||
return a
|
||||
}
|
||||
return b
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
450
problems/0332.重新安排行程.md
Normal file
450
problems/0332.重新安排行程.md
Normal file
@@ -0,0 +1,450 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
> 这也可以用回溯法? 其实深搜和回溯也是相辅相成的,毕竟都用递归。
|
||||
|
||||
## 332.重新安排行程
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/reconstruct-itinerary/
|
||||
|
||||
给定一个机票的字符串二维数组 [from, to],子数组中的两个成员分别表示飞机出发和降落的机场地点,对该行程进行重新规划排序。所有这些机票都属于一个从 JFK(肯尼迪国际机场)出发的先生,所以该行程必须从 JFK 开始。
|
||||
|
||||
提示:
|
||||
* 如果存在多种有效的行程,请你按字符自然排序返回最小的行程组合。例如,行程 ["JFK", "LGA"] 与 ["JFK", "LGB"] 相比就更小,排序更靠前
|
||||
* 所有的机场都用三个大写字母表示(机场代码)。
|
||||
* 假定所有机票至少存在一种合理的行程。
|
||||
* 所有的机票必须都用一次 且 只能用一次。
|
||||
|
||||
|
||||
示例 1:
|
||||
输入:[["MUC", "LHR"], ["JFK", "MUC"], ["SFO", "SJC"], ["LHR", "SFO"]]
|
||||
输出:["JFK", "MUC", "LHR", "SFO", "SJC"]
|
||||
|
||||
示例 2:
|
||||
输入:[["JFK","SFO"],["JFK","ATL"],["SFO","ATL"],["ATL","JFK"],["ATL","SFO"]]
|
||||
输出:["JFK","ATL","JFK","SFO","ATL","SFO"]
|
||||
解释:另一种有效的行程是 ["JFK","SFO","ATL","JFK","ATL","SFO"]。但是它自然排序更大更靠后。
|
||||
|
||||
## 思路
|
||||
|
||||
这道题目还是很难的,之前我们用回溯法解决了如下问题:[组合问题](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ),[分割问题](https://mp.weixin.qq.com/s/v--VmA8tp9vs4bXCqHhBuA),[子集问题](https://mp.weixin.qq.com/s/NNRzX-vJ_pjK4qxohd_LtA),[排列问题](https://mp.weixin.qq.com/s/SCOjeMX1t41wcvJq49GhMw)。
|
||||
|
||||
直觉上来看 这道题和回溯法没有什么关系,更像是图论中的深度优先搜索。
|
||||
|
||||
实际上确实是深搜,但这是深搜中使用了回溯的例子,在查找路径的时候,如果不回溯,怎么能查到目标路径呢。
|
||||
|
||||
所以我倾向于说本题应该使用回溯法,那么我也用回溯法的思路来讲解本题,其实深搜一般都使用了回溯法的思路,在图论系列中我会再详细讲解深搜。
|
||||
|
||||
**这里就是先给大家拓展一下,原来回溯法还可以这么玩!**
|
||||
|
||||
**这道题目有几个难点:**
|
||||
|
||||
1. 一个行程中,如果航班处理不好容易变成一个圈,成为死循环
|
||||
2. 有多种解法,字母序靠前排在前面,让很多同学望而退步,如何该记录映射关系呢 ?
|
||||
3. 使用回溯法(也可以说深搜) 的话,那么终止条件是什么呢?
|
||||
4. 搜索的过程中,如何遍历一个机场所对应的所有机场。
|
||||
|
||||
针对以上问题我来逐一解答!
|
||||
|
||||
## 如何理解死循环
|
||||
|
||||
对于死循环,我来举一个有重复机场的例子:
|
||||
|
||||
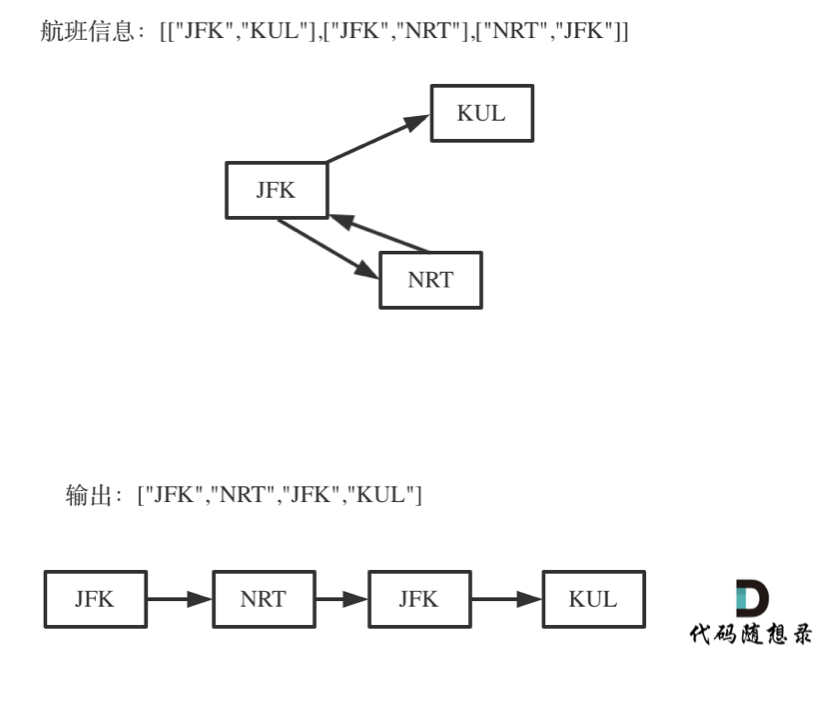
|
||||
|
||||
为什么要举这个例子呢,就是告诉大家,出发机场和到达机场也会重复的,**如果在解题的过程中没有对集合元素处理好,就会死循环。**
|
||||
|
||||
## 该记录映射关系
|
||||
|
||||
有多种解法,字母序靠前排在前面,让很多同学望而退步,如何该记录映射关系呢 ?
|
||||
|
||||
一个机场映射多个机场,机场之间要靠字母序排列,一个机场映射多个机场,可以使用std::unordered_map,如果让多个机场之间再有顺序的话,就是用std::map 或者std::multimap 或者 std::multiset。
|
||||
|
||||
如果对map 和 set 的实现机制不太了解,也不清楚为什么 map、multimap就是有序的同学,可以看这篇文章[关于哈希表,你该了解这些!](https://mp.weixin.qq.com/s/g8N6WmoQmsCUw3_BaWxHZA)。
|
||||
|
||||
这样存放映射关系可以定义为 `unordered_map<string, multiset<string>> targets` 或者 `unordered_map<string, map<string, int>> targets`。
|
||||
|
||||
含义如下:
|
||||
|
||||
`unordered_map<string, multiset<string>> targets`:`unordered_map<出发机场, 到达机场的集合> targets`
|
||||
`unordered_map<string, map<string, int>> targets`:`unordered_map<出发机场, map<到达机场, 航班次数>> targets`
|
||||
|
||||
这两个结构,我选择了后者,因为如果使用`unordered_map<string, multiset<string>> targets` 遍历multiset的时候,不能删除元素,一旦删除元素,迭代器就失效了。
|
||||
|
||||
**再说一下为什么一定要增删元素呢,正如开篇我给出的图中所示,出发机场和到达机场是会重复的,搜索的过程没及时删除目的机场就会死循环。**
|
||||
|
||||
所以搜索的过程中就是要不断的删multiset里的元素,那么推荐使用`unordered_map<string, map<string, int>> targets`。
|
||||
|
||||
在遍历 `unordered_map<出发机场, map<到达机场, 航班次数>> targets`的过程中,**可以使用"航班次数"这个字段的数字做相应的增减,来标记到达机场是否使用过了。**
|
||||
|
||||
|
||||
如果“航班次数”大于零,说明目的地还可以飞,如果如果“航班次数”等于零说明目的地不能飞了,而不用对集合做删除元素或者增加元素的操作。
|
||||
|
||||
**相当于说我不删,我就做一个标记!**
|
||||
|
||||
## 回溯法
|
||||
|
||||
这道题目我使用回溯法,那么下面按照我总结的回溯模板来:
|
||||
|
||||
```
|
||||
void backtracking(参数) {
|
||||
if (终止条件) {
|
||||
存放结果;
|
||||
return;
|
||||
}
|
||||
|
||||
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
|
||||
处理节点;
|
||||
backtracking(路径,选择列表); // 递归
|
||||
回溯,撤销处理结果
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
本题以输入:[["JFK", "KUL"], ["JFK", "NRT"], ["NRT", "JFK"]为例,抽象为树形结构如下:
|
||||
|
||||
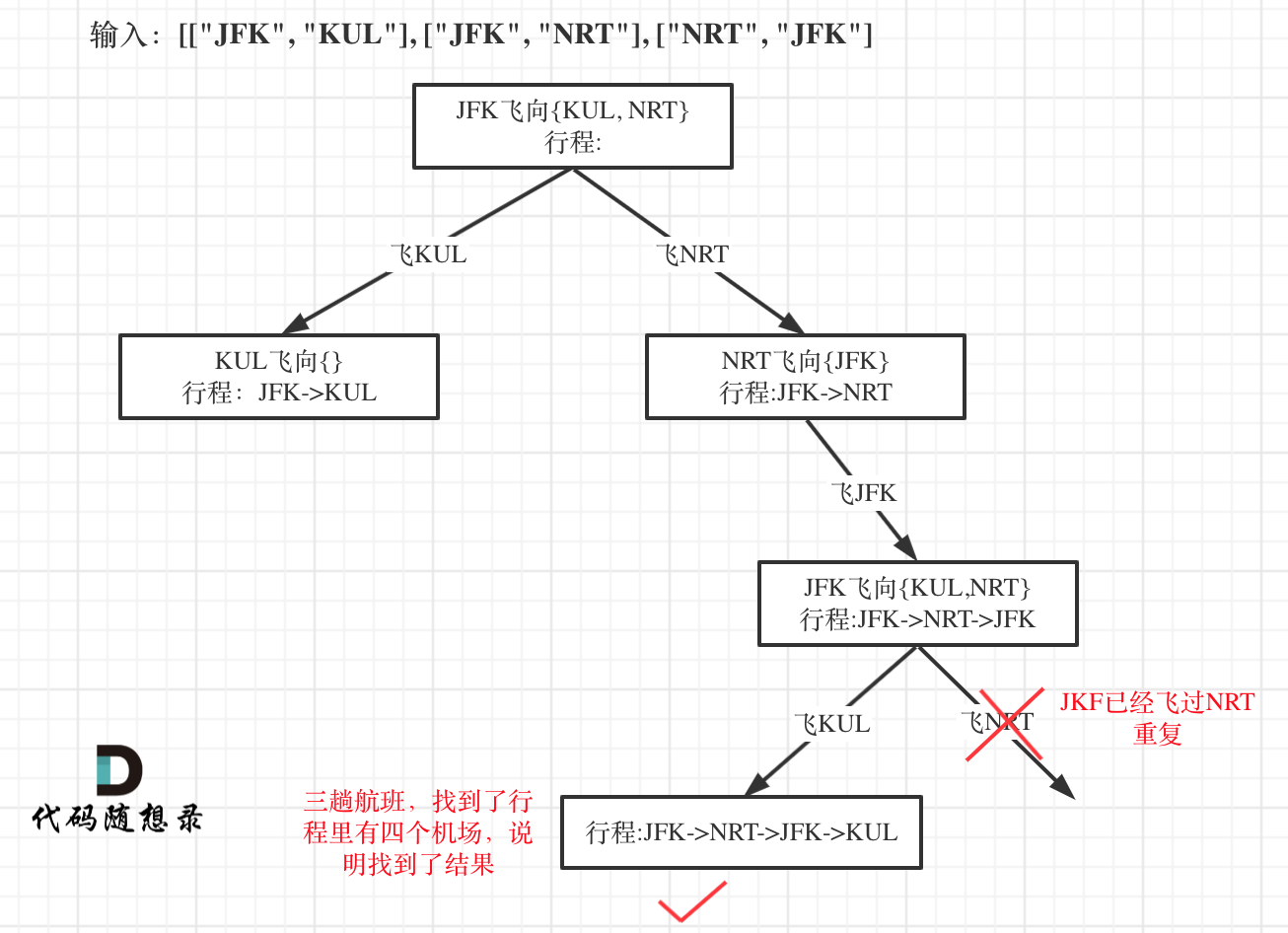
|
||||
|
||||
开始回溯三部曲讲解:
|
||||
|
||||
* 递归函数参数
|
||||
|
||||
在讲解映射关系的时候,已经讲过了,使用`unordered_map<string, map<string, int>> targets;` 来记录航班的映射关系,我定义为全局变量。
|
||||
|
||||
当然把参数放进函数里传进去也是可以的,我是尽量控制函数里参数的长度。
|
||||
|
||||
参数里还需要ticketNum,表示有多少个航班(终止条件会用上)。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
// unordered_map<出发机场, map<到达机场, 航班次数>> targets
|
||||
unordered_map<string, map<string, int>> targets;
|
||||
bool backtracking(int ticketNum, vector<string>& result) {
|
||||
```
|
||||
|
||||
**注意函数返回值我用的是bool!**
|
||||
|
||||
我们之前讲解回溯算法的时候,一般函数返回值都是void,这次为什么是bool呢?
|
||||
|
||||
因为我们只需要找到一个行程,就是在树形结构中唯一的一条通向叶子节点的路线,如图:
|
||||
|
||||

|
||||
|
||||
所以找到了这个叶子节点了直接返回,这个递归函数的返回值问题我们在讲解二叉树的系列的时候,在这篇[二叉树:递归函数究竟什么时候需要返回值,什么时候不要返回值?](https://mp.weixin.qq.com/s/6TWAVjxQ34kVqROWgcRFOg)详细介绍过。
|
||||
|
||||
当然本题的targets和result都需要初始化,代码如下:
|
||||
```
|
||||
for (const vector<string>& vec : tickets) {
|
||||
targets[vec[0]][vec[1]]++; // 记录映射关系
|
||||
}
|
||||
result.push_back("JFK"); // 起始机场
|
||||
```
|
||||
|
||||
* 递归终止条件
|
||||
|
||||
拿题目中的示例为例,输入: [["MUC", "LHR"], ["JFK", "MUC"], ["SFO", "SJC"], ["LHR", "SFO"]] ,这是有4个航班,那么只要找出一种行程,行程里的机场个数是5就可以了。
|
||||
|
||||
所以终止条件是:我们回溯遍历的过程中,遇到的机场个数,如果达到了(航班数量+1),那么我们就找到了一个行程,把所有航班串在一起了。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
if (result.size() == ticketNum + 1) {
|
||||
return true;
|
||||
}
|
||||
```
|
||||
|
||||
已经看习惯回溯法代码的同学,到叶子节点了习惯性的想要收集结果,但发现并不需要,本题的result相当于 [回溯算法:求组合总和!](https://mp.weixin.qq.com/s/HX7WW6ixbFZJASkRnCTC3w)中的path,也就是本题的result就是记录路径的(就一条),在如下单层搜索的逻辑中result就添加元素了。
|
||||
|
||||
* 单层搜索的逻辑
|
||||
|
||||
回溯的过程中,如何遍历一个机场所对应的所有机场呢?
|
||||
|
||||
这里刚刚说过,在选择映射函数的时候,不能选择`unordered_map<string, multiset<string>> targets`, 因为一旦有元素增删multiset的迭代器就会失效,当然可能有牛逼的容器删除元素迭代器不会失效,这里就不在讨论了。
|
||||
|
||||
**可以说本题既要找到一个对数据进行排序的容器,而且还要容易增删元素,迭代器还不能失效**。
|
||||
|
||||
所以我选择了`unordered_map<string, map<string, int>> targets` 来做机场之间的映射。
|
||||
|
||||
遍历过程如下:
|
||||
|
||||
```C++
|
||||
for (pair<const string, int>& target : targets[result[result.size() - 1]]) {
|
||||
if (target.second > 0 ) { // 记录到达机场是否飞过了
|
||||
result.push_back(target.first);
|
||||
target.second--;
|
||||
if (backtracking(ticketNum, result)) return true;
|
||||
result.pop_back();
|
||||
target.second++;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
可以看出 通过`unordered_map<string, map<string, int>> targets`里的int字段来判断 这个集合里的机场是否使用过,这样避免了直接去删元素。
|
||||
|
||||
分析完毕,此时完整C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
// unordered_map<出发机场, map<到达机场, 航班次数>> targets
|
||||
unordered_map<string, map<string, int>> targets;
|
||||
bool backtracking(int ticketNum, vector<string>& result) {
|
||||
if (result.size() == ticketNum + 1) {
|
||||
return true;
|
||||
}
|
||||
for (pair<const string, int>& target : targets[result[result.size() - 1]]) {
|
||||
if (target.second > 0 ) { // 记录到达机场是否飞过了
|
||||
result.push_back(target.first);
|
||||
target.second--;
|
||||
if (backtracking(ticketNum, result)) return true;
|
||||
result.pop_back();
|
||||
target.second++;
|
||||
}
|
||||
}
|
||||
return false;
|
||||
}
|
||||
public:
|
||||
vector<string> findItinerary(vector<vector<string>>& tickets) {
|
||||
targets.clear();
|
||||
vector<string> result;
|
||||
for (const vector<string>& vec : tickets) {
|
||||
targets[vec[0]][vec[1]]++; // 记录映射关系
|
||||
}
|
||||
result.push_back("JFK"); // 起始机场
|
||||
backtracking(tickets.size(), result);
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
一波分析之后,可以看出我就是按照回溯算法的模板来的。
|
||||
|
||||
代码中
|
||||
```
|
||||
for (pair<const string, int>& target : targets[result[result.size() - 1]])
|
||||
```
|
||||
pair里要有const,因为map中的key是不可修改的,所以是`pair<const string, int>`。
|
||||
|
||||
如果不加const,也可以复制一份pair,例如这么写:
|
||||
```
|
||||
for (pair<string, int>target : targets[result[result.size() - 1]])
|
||||
```
|
||||
|
||||
|
||||
## 总结
|
||||
|
||||
本题其实可以算是一道hard的题目了,关于本题的难点我在文中已经列出了。
|
||||
|
||||
**如果单纯的回溯搜索(深搜)并不难,难还难在容器的选择和使用上**。
|
||||
|
||||
本题其实是一道深度优先搜索的题目,但是我完全使用回溯法的思路来讲解这道题题目,**算是给大家拓展一下思维方式,其实深搜和回溯也是分不开的,毕竟最终都是用递归**。
|
||||
|
||||
如果最终代码,发现照着回溯法模板画的话好像也能画出来,但难就难如何知道可以使用回溯,以及如果套进去,所以我再写了这么长的一篇来详细讲解。
|
||||
|
||||
就酱,很多录友表示和「代码随想录」相见恨晚,那么帮Carl宣传一波吧,让更多同学知道这里!
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
java 版本:
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
private Deque<String> res;
|
||||
private Map<String, Map<String, Integer>> map;
|
||||
|
||||
private boolean backTracking(int ticketNum){
|
||||
if(res.size() == ticketNum + 1){
|
||||
return true;
|
||||
}
|
||||
String last = res.getLast();
|
||||
if(map.containsKey(last)){//防止出现null
|
||||
for(Map.Entry<String, Integer> target : map.get(last).entrySet()){
|
||||
int count = target.getValue();
|
||||
if(count > 0){
|
||||
res.add(target.getKey());
|
||||
target.setValue(count - 1);
|
||||
if(backTracking(ticketNum)) return true;
|
||||
res.removeLast();
|
||||
target.setValue(count);
|
||||
}
|
||||
}
|
||||
}
|
||||
return false;
|
||||
}
|
||||
|
||||
public List<String> findItinerary(List<List<String>> tickets) {
|
||||
map = new HashMap<String, Map<String, Integer>>();
|
||||
res = new LinkedList<>();
|
||||
for(List<String> t : tickets){
|
||||
Map<String, Integer> temp;
|
||||
if(map.containsKey(t.get(0))){
|
||||
temp = map.get(t.get(0));
|
||||
temp.put(t.get(1), temp.getOrDefault(t.get(1), 0) + 1);
|
||||
}else{
|
||||
temp = new TreeMap<>();//升序Map
|
||||
temp.put(t.get(1), 1);
|
||||
}
|
||||
map.put(t.get(0), temp);
|
||||
|
||||
}
|
||||
res.add("JFK");
|
||||
backTracking(tickets.size());
|
||||
return new ArrayList<>(res);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
python:
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def findItinerary(self, tickets: List[List[str]]) -> List[str]:
|
||||
# defaultdic(list) 是为了方便直接append
|
||||
tickets_dict = defaultdict(list)
|
||||
for item in tickets:
|
||||
tickets_dict[item[0]].append(item[1])
|
||||
'''
|
||||
tickets_dict里面的内容是这样的
|
||||
{'JFK': ['SFO', 'ATL'], 'SFO': ['ATL'], 'ATL': ['JFK', 'SFO']})
|
||||
'''
|
||||
path = ["JFK"]
|
||||
def backtracking(start_point):
|
||||
# 终止条件
|
||||
if len(path) == len(tickets) + 1:
|
||||
return True
|
||||
tickets_dict[start_point].sort()
|
||||
for _ in tickets_dict[start_point]:
|
||||
#必须及时删除,避免出现死循环
|
||||
end_point = tickets_dict[start_point].pop(0)
|
||||
path.append(end_point)
|
||||
# 只要找到一个就可以返回了
|
||||
if backtracking(end_point):
|
||||
return True
|
||||
path.pop()
|
||||
tickets_dict[start_point].append(end_point)
|
||||
|
||||
backtracking("JFK")
|
||||
return path
|
||||
```
|
||||
|
||||
C语言版本:
|
||||
|
||||
```C
|
||||
char **result;
|
||||
bool *used;
|
||||
int g_found;
|
||||
|
||||
int cmp(const void *str1, const void *str2)
|
||||
{
|
||||
const char **tmp1 = *(char**)str1;
|
||||
const char **tmp2 = *(char**)str2;
|
||||
int ret = strcmp(tmp1[0], tmp2[0]);
|
||||
if (ret == 0) {
|
||||
return strcmp(tmp1[1], tmp2[1]);
|
||||
}
|
||||
return ret;
|
||||
}
|
||||
|
||||
void backtracting(char *** tickets, int ticketsSize, int* returnSize, char *start, char **result, bool *used)
|
||||
{
|
||||
if (*returnSize == ticketsSize + 1) {
|
||||
g_found = 1;
|
||||
return;
|
||||
}
|
||||
for (int i = 0; i < ticketsSize; i++) {
|
||||
if ((used[i] == false) && (strcmp(start, tickets[i][0]) == 0)) {
|
||||
result[*returnSize] = (char*)malloc(sizeof(char) * 4);
|
||||
memcpy(result[*returnSize], tickets[i][1], sizeof(char) * 4);
|
||||
(*returnSize)++;
|
||||
used[i] = true;
|
||||
/*if ((*returnSize) == ticketsSize + 1) {
|
||||
return;
|
||||
}*/
|
||||
backtracting(tickets, ticketsSize, returnSize, tickets[i][1], result, used);
|
||||
if (g_found) {
|
||||
return;
|
||||
}
|
||||
(*returnSize)--;
|
||||
used[i] = false;
|
||||
}
|
||||
}
|
||||
return;
|
||||
}
|
||||
|
||||
char ** findItinerary(char *** tickets, int ticketsSize, int* ticketsColSize, int* returnSize){
|
||||
if (tickets == NULL || ticketsSize <= 0) {
|
||||
return NULL;
|
||||
}
|
||||
result = malloc(sizeof(char*) * (ticketsSize + 1));
|
||||
used = malloc(sizeof(bool) * ticketsSize);
|
||||
memset(used, false, sizeof(bool) * ticketsSize);
|
||||
result[0] = malloc(sizeof(char) * 4);
|
||||
memcpy(result[0], "JFK", sizeof(char) * 4);
|
||||
g_found = 0;
|
||||
*returnSize = 1;
|
||||
qsort(tickets, ticketsSize, sizeof(tickets[0]), cmp);
|
||||
backtracting(tickets, ticketsSize, returnSize, "JFK", result, used);
|
||||
*returnSize = ticketsSize + 1;
|
||||
return result;
|
||||
}
|
||||
```
|
||||
|
||||
Javascript:
|
||||
```Javascript
|
||||
|
||||
var findItinerary = function(tickets) {
|
||||
let result = ['JFK']
|
||||
let map = {}
|
||||
|
||||
for (const tickt of tickets) {
|
||||
const [from, to] = tickt
|
||||
if (!map[from]) {
|
||||
map[from] = []
|
||||
}
|
||||
map[from].push(to)
|
||||
}
|
||||
|
||||
for (const city in map) {
|
||||
// 对到达城市列表排序
|
||||
map[city].sort()
|
||||
}
|
||||
function backtracing() {
|
||||
if (result.length === tickets.length + 1) {
|
||||
return true
|
||||
}
|
||||
if (!map[result[result.length - 1]] || !map[result[result.length - 1]].length) {
|
||||
return false
|
||||
}
|
||||
for(let i = 0 ; i < map[result[result.length - 1]].length; i++) {
|
||||
let city = map[result[result.length - 1]][i]
|
||||
// 删除已走过航线,防止死循环
|
||||
map[result[result.length - 1]].splice(i, 1)
|
||||
result.push(city)
|
||||
if (backtracing()) {
|
||||
return true
|
||||
}
|
||||
result.pop()
|
||||
map[result[result.length - 1]].splice(i, 0, city)
|
||||
}
|
||||
}
|
||||
backtracing()
|
||||
return result
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
380
problems/0337.打家劫舍III.md
Normal file
380
problems/0337.打家劫舍III.md
Normal file
@@ -0,0 +1,380 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 337.打家劫舍 III
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/house-robber-iii/
|
||||
|
||||
在上次打劫完一条街道之后和一圈房屋后,小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为“根”。 除了“根”之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果两个直接相连的房子在同一天晚上被打劫,房屋将自动报警。
|
||||
|
||||
计算在不触动警报的情况下,小偷一晚能够盗取的最高金额。
|
||||
|
||||

|
||||
|
||||
## 思路
|
||||
|
||||
这道题目和 [198.打家劫舍](https://mp.weixin.qq.com/s/UZ31WdLEEFmBegdgLkJ8Dw),[213.打家劫舍II](https://mp.weixin.qq.com/s/kKPx4HpH3RArbRcxAVHbeQ)也是如出一辙,只不过这个换成了树。
|
||||
|
||||
如果对树的遍历不够熟悉的话,那本题就有难度了。
|
||||
|
||||
对于树的话,首先就要想到遍历方式,前中后序(深度优先搜索)还是层序遍历(广度优先搜索)。
|
||||
|
||||
**本题一定是要后序遍历,因为通过递归函数的返回值来做下一步计算**。
|
||||
|
||||
与198.打家劫舍,213.打家劫舍II一样,关键是要讨论当前节点抢还是不抢。
|
||||
|
||||
如果抢了当前节点,两个孩子就不是动,如果没抢当前节点,就可以考虑抢左右孩子(**注意这里说的是“考虑”**)
|
||||
|
||||
### 暴力递归
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int rob(TreeNode* root) {
|
||||
if (root == NULL) return 0;
|
||||
if (root->left == NULL && root->right == NULL) return root->val;
|
||||
// 偷父节点
|
||||
int val1 = root->val;
|
||||
if (root->left) val1 += rob(root->left->left) + rob(root->left->right); // 跳过root->left,相当于不考虑左孩子了
|
||||
if (root->right) val1 += rob(root->right->left) + rob(root->right->right); // 跳过root->right,相当于不考虑右孩子了
|
||||
// 不偷父节点
|
||||
int val2 = rob(root->left) + rob(root->right); // 考虑root的左右孩子
|
||||
return max(val1, val2);
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
* 时间复杂度:O(n^2) 这个时间复杂度不太标准,也不容易准确化,例如越往下的节点重复计算次数就越多
|
||||
* 空间复杂度:O(logn) 算上递推系统栈的空间
|
||||
|
||||
当然以上代码超时了,这个递归的过程中其实是有重复计算了。
|
||||
|
||||
我们计算了root的四个孙子(左右孩子的孩子)为头结点的子树的情况,又计算了root的左右孩子为头结点的子树的情况,计算左右孩子的时候其实又把孙子计算了一遍。
|
||||
|
||||
### 记忆化递推
|
||||
|
||||
所以可以使用一个map把计算过的结果保存一下,这样如果计算过孙子了,那么计算孩子的时候可以复用孙子节点的结果。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
unordered_map<TreeNode* , int> umap; // 记录计算过的结果
|
||||
int rob(TreeNode* root) {
|
||||
if (root == NULL) return 0;
|
||||
if (root->left == NULL && root->right == NULL) return root->val;
|
||||
if (umap[root]) return umap[root]; // 如果umap里已经有记录则直接返回
|
||||
// 偷父节点
|
||||
int val1 = root->val;
|
||||
if (root->left) val1 += rob(root->left->left) + rob(root->left->right); // 跳过root->left
|
||||
if (root->right) val1 += rob(root->right->left) + rob(root->right->right); // 跳过root->right
|
||||
// 不偷父节点
|
||||
int val2 = rob(root->left) + rob(root->right); // 考虑root的左右孩子
|
||||
umap[root] = max(val1, val2); // umap记录一下结果
|
||||
return max(val1, val2);
|
||||
}
|
||||
};
|
||||
|
||||
```
|
||||
* 时间复杂度:O(n)
|
||||
* 空间复杂度:O(logn) 算上递推系统栈的空间
|
||||
|
||||
|
||||
### 动态规划
|
||||
|
||||
在上面两种方法,其实对一个节点 投与不投得到的最大金钱都没有做记录,而是需要实时计算。
|
||||
|
||||
而动态规划其实就是使用状态转移容器来记录状态的变化,这里可以使用一个长度为2的数组,记录当前节点偷与不偷所得到的的最大金钱。
|
||||
|
||||
**这道题目算是树形dp的入门题目,因为是在树上进行状态转移,我们在讲解二叉树的时候说过递归三部曲,那么下面我以递归三部曲为框架,其中融合动规五部曲的内容来进行讲解**。
|
||||
|
||||
1. 确定递归函数的参数和返回值
|
||||
|
||||
这里我们要求一个节点 偷与不偷的两个状态所得到的金钱,那么返回值就是一个长度为2的数组。
|
||||
|
||||
参数为当前节点,代码如下:
|
||||
|
||||
```C++
|
||||
vector<int> robTree(TreeNode* cur) {
|
||||
```
|
||||
|
||||
其实这里的返回数组就是dp数组。
|
||||
|
||||
所以dp数组(dp table)以及下标的含义:下标为0记录不偷该节点所得到的的最大金钱,下标为1记录偷该节点所得到的的最大金钱。
|
||||
|
||||
**所以本题dp数组就是一个长度为2的数组!**
|
||||
|
||||
那么有同学可能疑惑,长度为2的数组怎么标记树中每个节点的状态呢?
|
||||
|
||||
**别忘了在递归的过程中,系统栈会保存每一层递归的参数**。
|
||||
|
||||
如果还不理解的话,就接着往下看,看到代码就理解了哈。
|
||||
|
||||
2. 确定终止条件
|
||||
|
||||
在遍历的过程中,如果遇到空间点的话,很明显,无论偷还是不偷都是0,所以就返回
|
||||
```
|
||||
if (cur == NULL) return vector<int>{0, 0};
|
||||
```
|
||||
这也相当于dp数组的初始化
|
||||
|
||||
|
||||
3. 确定遍历顺序
|
||||
|
||||
首先明确的是使用后序遍历。 因为通过递归函数的返回值来做下一步计算。
|
||||
|
||||
通过递归左节点,得到左节点偷与不偷的金钱。
|
||||
|
||||
通过递归右节点,得到右节点偷与不偷的金钱。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
// 下标0:不偷,下标1:偷
|
||||
vector<int> left = robTree(cur->left); // 左
|
||||
vector<int> right = robTree(cur->right); // 右
|
||||
// 中
|
||||
|
||||
```
|
||||
|
||||
4. 确定单层递归的逻辑
|
||||
|
||||
如果是偷当前节点,那么左右孩子就不能偷,val1 = cur->val + left[0] + right[0]; (**如果对下标含义不理解就在回顾一下dp数组的含义**)
|
||||
|
||||
如果不偷当前节点,那么左右孩子就可以偷,至于到底偷不偷一定是选一个最大的,所以:val2 = max(left[0], left[1]) + max(right[0], right[1]);
|
||||
|
||||
最后当前节点的状态就是{val2, val1}; 即:{不偷当前节点得到的最大金钱,偷当前节点得到的最大金钱}
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
vector<int> left = robTree(cur->left); // 左
|
||||
vector<int> right = robTree(cur->right); // 右
|
||||
|
||||
// 偷cur
|
||||
int val1 = cur->val + left[0] + right[0];
|
||||
// 不偷cur
|
||||
int val2 = max(left[0], left[1]) + max(right[0], right[1]);
|
||||
return {val2, val1};
|
||||
```
|
||||
|
||||
|
||||
|
||||
5. 举例推导dp数组
|
||||
|
||||
以示例1为例,dp数组状态如下:(**注意用后序遍历的方式推导**)
|
||||
|
||||
|
||||
|
||||
**最后头结点就是 取下标0 和 下标1的最大值就是偷得的最大金钱**。
|
||||
|
||||
递归三部曲与动规五部曲分析完毕,C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int rob(TreeNode* root) {
|
||||
vector<int> result = robTree(root);
|
||||
return max(result[0], result[1]);
|
||||
}
|
||||
// 长度为2的数组,0:不偷,1:偷
|
||||
vector<int> robTree(TreeNode* cur) {
|
||||
if (cur == NULL) return vector<int>{0, 0};
|
||||
vector<int> left = robTree(cur->left);
|
||||
vector<int> right = robTree(cur->right);
|
||||
// 偷cur
|
||||
int val1 = cur->val + left[0] + right[0];
|
||||
// 不偷cur
|
||||
int val2 = max(left[0], left[1]) + max(right[0], right[1]);
|
||||
return {val2, val1};
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度:O(n) 每个节点只遍历了一次
|
||||
* 空间复杂度:O(logn) 算上递推系统栈的空间
|
||||
|
||||
## 总结
|
||||
|
||||
这道题是树形DP的入门题目,通过这道题目大家应该也了解了,所谓树形DP就是在树上进行递归公式的推导。
|
||||
|
||||
**所以树形DP也没有那么神秘!**
|
||||
|
||||
只不过平时我们习惯了在一维数组或者二维数组上推导公式,一下子换成了树,就需要对树的遍历方式足够了解!
|
||||
|
||||
大家还记不记得我在讲解贪心专题的时候,讲到这道题目:[贪心算法:我要监控二叉树!](https://mp.weixin.qq.com/s/kCxlLLjWKaE6nifHC3UL2Q),这也是贪心算法在树上的应用。**那我也可以把这个算法起一个名字,叫做树形贪心**,哈哈哈
|
||||
|
||||
“树形贪心”词汇从此诞生,来自「代码随想录」
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
// 1.递归去偷,超时
|
||||
public int rob(TreeNode root) {
|
||||
if (root == null)
|
||||
return 0;
|
||||
int money = root.val;
|
||||
if (root.left != null) {
|
||||
money += rob(root.left.left) + rob(root.left.right);
|
||||
}
|
||||
if (root.right != null) {
|
||||
money += rob(root.right.left) + rob(root.right.right);
|
||||
}
|
||||
return Math.max(money, rob(root.left) + rob(root.right));
|
||||
}
|
||||
|
||||
// 2.递归去偷,记录状态
|
||||
// 执行用时:3 ms , 在所有 Java 提交中击败了 56.24% 的用户
|
||||
public int rob1(TreeNode root) {
|
||||
Map<TreeNode, Integer> memo = new HashMap<>();
|
||||
return robAction(root, memo);
|
||||
}
|
||||
|
||||
int robAction(TreeNode root, Map<TreeNode, Integer> memo) {
|
||||
if (root == null)
|
||||
return 0;
|
||||
if (memo.containsKey(root))
|
||||
return memo.get(root);
|
||||
int money = root.val;
|
||||
if (root.left != null) {
|
||||
money += robAction(root.left.left, memo) + robAction(root.left.right, memo);
|
||||
}
|
||||
if (root.right != null) {
|
||||
money += robAction(root.right.left, memo) + robAction(root.right.right, memo);
|
||||
}
|
||||
int res = Math.max(money, robAction(root.left, memo) + robAction(root.right, memo));
|
||||
memo.put(root, res);
|
||||
return res;
|
||||
}
|
||||
|
||||
// 3.状态标记递归
|
||||
// 执行用时:0 ms , 在所有 Java 提交中击败了 100% 的用户
|
||||
// 不偷:Max(左孩子不偷,左孩子偷) + Max(又孩子不偷,右孩子偷)
|
||||
// root[0] = Math.max(rob(root.left)[0], rob(root.left)[1]) +
|
||||
// Math.max(rob(root.right)[0], rob(root.right)[1])
|
||||
// 偷:左孩子不偷+ 右孩子不偷 + 当前节点偷
|
||||
// root[1] = rob(root.left)[0] + rob(root.right)[0] + root.val;
|
||||
public int rob3(TreeNode root) {
|
||||
int[] res = robAction1(root);
|
||||
return Math.max(res[0], res[1]);
|
||||
}
|
||||
|
||||
int[] robAction1(TreeNode root) {
|
||||
int res[] = new int[2];
|
||||
if (root == null)
|
||||
return res;
|
||||
|
||||
int[] left = robAction1(root.left);
|
||||
int[] right = robAction1(root.right);
|
||||
|
||||
res[0] = Math.max(left[0], left[1]) + Math.max(right[0], right[1]);
|
||||
res[1] = root.val + left[0] + right[0];
|
||||
return res;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
> 暴力递归
|
||||
|
||||
```python3
|
||||
|
||||
# Definition for a binary tree node.
|
||||
# class TreeNode:
|
||||
# def __init__(self, val=0, left=None, right=None):
|
||||
# self.val = val
|
||||
# self.left = left
|
||||
# self.right = right
|
||||
class Solution:
|
||||
def rob(self, root: TreeNode) -> int:
|
||||
if root is None:
|
||||
return 0
|
||||
if root.left is None and root.right is None:
|
||||
return root.val
|
||||
# 偷父节点
|
||||
val1 = root.val
|
||||
if root.left:
|
||||
val1 += self.rob(root.left.left) + self.rob(root.left.right)
|
||||
if root.right:
|
||||
val1 += self.rob(root.right.left) + self.rob(root.right.right)
|
||||
# 不偷父节点
|
||||
val2 = self.rob(root.left) + self.rob(root.right)
|
||||
return max(val1, val2)
|
||||
```
|
||||
|
||||
> 记忆化递归
|
||||
|
||||
```python3
|
||||
|
||||
# Definition for a binary tree node.
|
||||
# class TreeNode:
|
||||
# def __init__(self, val=0, left=None, right=None):
|
||||
# self.val = val
|
||||
# self.left = left
|
||||
# self.right = right
|
||||
class Solution:
|
||||
memory = {}
|
||||
def rob(self, root: TreeNode) -> int:
|
||||
if root is None:
|
||||
return 0
|
||||
if root.left is None and root.right is None:
|
||||
return root.val
|
||||
if self.memory.get(root) is not None:
|
||||
return self.memory[root]
|
||||
# 偷父节点
|
||||
val1 = root.val
|
||||
if root.left:
|
||||
val1 += self.rob(root.left.left) + self.rob(root.left.right)
|
||||
if root.right:
|
||||
val1 += self.rob(root.right.left) + self.rob(root.right.right)
|
||||
# 不偷父节点
|
||||
val2 = self.rob(root.left) + self.rob(root.right)
|
||||
self.memory[root] = max(val1, val2)
|
||||
return max(val1, val2)
|
||||
```
|
||||
|
||||
> 动态规划
|
||||
```python3
|
||||
# Definition for a binary tree node.
|
||||
# class TreeNode:
|
||||
# def __init__(self, val=0, left=None, right=None):
|
||||
# self.val = val
|
||||
# self.left = left
|
||||
# self.right = right
|
||||
class Solution:
|
||||
def rob(self, root: TreeNode) -> int:
|
||||
result = self.rob_tree(root)
|
||||
return max(result[0], result[1])
|
||||
|
||||
def rob_tree(self, node):
|
||||
if node is None:
|
||||
return (0, 0) # (偷当前节点金额,不偷当前节点金额)
|
||||
left = self.rob_tree(node.left)
|
||||
right = self.rob_tree(node.right)
|
||||
val1 = node.val + left[1] + right[1] # 偷当前节点,不能偷子节点
|
||||
val2 = max(left[0], left[1]) + max(right[0], right[1]) # 不偷当前节点,可偷可不偷子节点
|
||||
return (val1, val2)
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
247
problems/0343.整数拆分.md
Normal file
247
problems/0343.整数拆分.md
Normal file
@@ -0,0 +1,247 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
## 343. 整数拆分
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/integer-break/
|
||||
|
||||
给定一个正整数 n,将其拆分为至少两个正整数的和,并使这些整数的乘积最大化。 返回你可以获得的最大乘积。
|
||||
|
||||
示例 1:
|
||||
输入: 2
|
||||
输出: 1
|
||||
解释: 2 = 1 + 1, 1 × 1 = 1。
|
||||
|
||||
示例 2:
|
||||
输入: 10
|
||||
输出: 36
|
||||
解释: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36。
|
||||
说明: 你可以假设 n 不小于 2 且不大于 58。
|
||||
|
||||
## 思路
|
||||
|
||||
看到这道题目,都会想拆成两个呢,还是三个呢,还是四个....
|
||||
|
||||
我们来看一下如何使用动规来解决。
|
||||
|
||||
### 动态规划
|
||||
|
||||
动规五部曲,分析如下:
|
||||
|
||||
1. 确定dp数组(dp table)以及下标的含义
|
||||
|
||||
dp[i]:分拆数字i,可以得到的最大乘积为dp[i]。
|
||||
|
||||
dp[i]的定义讲贯彻整个解题过程,下面哪一步想不懂了,就想想dp[i]究竟表示的是啥!
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
可以想 dp[i]最大乘积是怎么得到的呢?
|
||||
|
||||
其实可以从1遍历j,然后有两种渠道得到dp[i].
|
||||
|
||||
一个是j * (i - j) 直接相乘。
|
||||
|
||||
一个是j * dp[i - j],相当于是拆分(i - j),对这个拆分不理解的话,可以回想dp数组的定义。
|
||||
|
||||
**那有同学问了,j怎么就不拆分呢?**
|
||||
|
||||
j是从1开始遍历,拆分j的情况,在遍历j的过程中其实都计算过了。那么从1遍历j,比较(i - j) * j和dp[i - j] * j 取最大的。递推公式:dp[i] = max(dp[i], max((i - j) * j, dp[i - j] * j));
|
||||
|
||||
也可以这么理解,j * (i - j) 是单纯的把整数拆分为两个数相乘,而j * dp[i - j]是拆分成两个以及两个以上的个数相乘。
|
||||
|
||||
如果定义dp[i - j] * dp[j] 也是默认将一个数强制拆成4份以及4份以上了。
|
||||
|
||||
所以递推公式:dp[i] = max({dp[i], (i - j) * j, dp[i - j] * j});
|
||||
|
||||
|
||||
3. dp的初始化
|
||||
|
||||
不少同学应该疑惑,dp[0] dp[1]应该初始化多少呢?
|
||||
|
||||
有的题解里会给出dp[0] = 1,dp[1] = 1的初始化,但解释比较牵强,主要还是因为这么初始化可以把题目过了。
|
||||
|
||||
严格从dp[i]的定义来说,dp[0] dp[1] 就不应该初始化,也就是没有意义的数值。
|
||||
|
||||
拆分0和拆分1的最大乘积是多少?
|
||||
|
||||
这是无解的。
|
||||
|
||||
这里我只初始化dp[2] = 1,从dp[i]的定义来说,拆分数字2,得到的最大乘积是1,这个没有任何异议!
|
||||
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
确定遍历顺序,先来看看递归公式:dp[i] = max(dp[i], max((i - j) * j, dp[i - j] * j));
|
||||
|
||||
|
||||
dp[i] 是依靠 dp[i - j]的状态,所以遍历i一定是从前向后遍历,先有dp[i - j]再有dp[i]。
|
||||
|
||||
枚举j的时候,是从1开始的。i是从3开始,这样dp[i - j]就是dp[2]正好可以通过我们初始化的数值求出来。
|
||||
|
||||
所以遍历顺序为:
|
||||
```
|
||||
for (int i = 3; i <= n ; i++) {
|
||||
for (int j = 1; j < i - 1; j++) {
|
||||
dp[i] = max(dp[i], max((i - j) * j, dp[i - j] * j));
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
5. 举例推导dp数组
|
||||
|
||||
举例当n为10 的时候,dp数组里的数值,如下:
|
||||
|
||||
|
||||
|
||||
以上动规五部曲分析完毕,C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int integerBreak(int n) {
|
||||
vector<int> dp(n + 1);
|
||||
dp[2] = 1;
|
||||
for (int i = 3; i <= n ; i++) {
|
||||
for (int j = 1; j < i - 1; j++) {
|
||||
dp[i] = max(dp[i], max((i - j) * j, dp[i - j] * j));
|
||||
}
|
||||
}
|
||||
return dp[n];
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
* 时间复杂度:O(n^2)
|
||||
* 空间复杂度:O(n)
|
||||
|
||||
### 贪心
|
||||
|
||||
本题也可以用贪心,每次拆成n个3,如果剩下是4,则保留4,然后相乘,**但是这个结论需要数学证明其合理性!**
|
||||
|
||||
我没有证明,而是直接用了结论。感兴趣的同学可以自己再去研究研究数学证明哈。
|
||||
|
||||
给出我的C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int integerBreak(int n) {
|
||||
if (n == 2) return 1;
|
||||
if (n == 3) return 2;
|
||||
if (n == 4) return 4;
|
||||
int result = 1;
|
||||
while (n > 4) {
|
||||
result *= 3;
|
||||
n -= 3;
|
||||
}
|
||||
result *= n;
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度O(n)
|
||||
* 空间复杂度O(1)
|
||||
|
||||
## 总结
|
||||
|
||||
本题掌握其动规的方法,就可以了,贪心的解法确实简单,但需要有数学证明,如果能自圆其说也是可以的。
|
||||
|
||||
其实这道题目的递推公式并不好想,而且初始化的地方也很有讲究,我在写本题的时候一开始写的代码是这样的:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int integerBreak(int n) {
|
||||
if (n <= 3) return 1 * (n - 1);
|
||||
vector<int> dp(n + 1, 0);
|
||||
dp[1] = 1;
|
||||
dp[2] = 2;
|
||||
dp[3] = 3;
|
||||
for (int i = 4; i <= n ; i++) {
|
||||
for (int j = 1; j < i - 1; j++) {
|
||||
dp[i] = max(dp[i], dp[i - j] * dp[j]);
|
||||
}
|
||||
}
|
||||
return dp[n];
|
||||
}
|
||||
};
|
||||
```
|
||||
**这个代码也是可以过的!**
|
||||
|
||||
在解释递推公式的时候,也可以解释通,dp[i] 就等于 拆解i - j的最大乘积 * 拆解j的最大乘积。 看起来没毛病!
|
||||
|
||||
但是在解释初始化的时候,就发现自相矛盾了,dp[1]为什么一定是1呢?根据dp[i]的定义,dp[2]也不应该是2啊。
|
||||
|
||||
但如果递归公式是 dp[i] = max(dp[i], dp[i - j] * dp[j]);,就一定要这么初始化。递推公式没毛病,但初始化解释不通!
|
||||
|
||||
虽然代码在初始位置有一个判断if (n <= 3) return 1 * (n - 1);,保证n<=3 结果是正确的,但代码后面又要给dp[1]赋值1 和 dp[2] 赋值 2,**这其实就是自相矛盾的代码,违背了dp[i]的定义!**
|
||||
|
||||
我举这个例子,其实就说做题的严谨性,上面这个代码也可以AC,大体上一看好像也没有毛病,递推公式也说得过去,但是仅仅是恰巧过了而已。
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
public int integerBreak(int n) {
|
||||
//dp[i]为正整数i拆分结果的最大乘积
|
||||
int[] dp = new int[n+1];
|
||||
dp[2] = 1;
|
||||
for (int i = 3; i <= n; ++i) {
|
||||
for (int j = 1; j < i - 1; ++j) {
|
||||
//j*(i-j)代表把i拆分为j和i-j两个数相乘
|
||||
//j*dp[i-j]代表把i拆分成j和继续把(i-j)这个数拆分,取(i-j)拆分结果中的最大乘积与j相乘
|
||||
dp[i] = Math.max(dp[i], Math.max(j * (i - j), j * dp[i - j]));
|
||||
}
|
||||
}
|
||||
return dp[n];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def integerBreak(self, n: int) -> int:
|
||||
dp = [0] * (n + 1)
|
||||
dp[2] = 1
|
||||
for i in range(3, n + 1):
|
||||
# 假设对正整数 i 拆分出的第一个正整数是 j(1 <= j < i),则有以下两种方案:
|
||||
# 1) 将 i 拆分成 j 和 i−j 的和,且 i−j 不再拆分成多个正整数,此时的乘积是 j * (i-j)
|
||||
# 2) 将 i 拆分成 j 和 i−j 的和,且 i−j 继续拆分成多个正整数,此时的乘积是 j * dp[i-j]
|
||||
for j in range(1, i - 1):
|
||||
dp[i] = max(dp[i], max(j * (i - j), j * dp[i - j]))
|
||||
return dp[n]
|
||||
```
|
||||
Go:
|
||||
|
||||
|
||||
Javascript:
|
||||
```Javascript
|
||||
var integerBreak = function(n) {
|
||||
let dp = new Array(n + 1).fill(0)
|
||||
dp[2] = 1
|
||||
|
||||
for(let i = 3; i <= n; i++) {
|
||||
for(let j = 1; j < i; j++) {
|
||||
dp[i] = Math.max(dp[i], dp[i - j] * j, (i - j) * j)
|
||||
}
|
||||
}
|
||||
return dp[n]
|
||||
};
|
||||
```
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
222
problems/0344.反转字符串.md
Normal file
222
problems/0344.反转字符串.md
Normal file
@@ -0,0 +1,222 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
|
||||
> 打基础的时候,不要太迷恋于库函数。
|
||||
|
||||
# 344.反转字符串
|
||||
|
||||
https://leetcode-cn.com/problems/reverse-string/
|
||||
|
||||
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 char[] 的形式给出。
|
||||
|
||||
不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。
|
||||
|
||||
你可以假设数组中的所有字符都是 ASCII 码表中的可打印字符。
|
||||
|
||||
示例 1:
|
||||
输入:["h","e","l","l","o"]
|
||||
输出:["o","l","l","e","h"]
|
||||
|
||||
示例 2:
|
||||
输入:["H","a","n","n","a","h"]
|
||||
输出:["h","a","n","n","a","H"]
|
||||
|
||||
|
||||
# 思路
|
||||
|
||||
先说一说题外话:
|
||||
|
||||
对于这道题目一些同学直接用C++里的一个库函数 reverse,调一下直接完事了, 相信每一门编程语言都有这样的库函数。
|
||||
|
||||
如果这么做题的话,这样大家不会清楚反转字符串的实现原理了。
|
||||
|
||||
但是也不是说库函数就不能用,是要分场景的。
|
||||
|
||||
如果在现场面试中,我们什么时候使用库函数,什么时候不要用库函数呢?
|
||||
|
||||
**如果题目关键的部分直接用库函数就可以解决,建议不要使用库函数。**
|
||||
|
||||
毕竟面试官一定不是考察你对库函数的熟悉程度, 如果使用python和java 的同学更需要注意这一点,因为python、java提供的库函数十分丰富。
|
||||
|
||||
**如果库函数仅仅是 解题过程中的一小部分,并且你已经很清楚这个库函数的内部实现原理的话,可以考虑使用库函数。**
|
||||
|
||||
建议大家平时在leetcode上练习算法的时候本着这样的原则去练习,这样才有助于我们对算法的理解。
|
||||
|
||||
不要沉迷于使用库函数一行代码解决题目之类的技巧,不是说这些技巧不好,而是说这些技巧可以用来娱乐一下。
|
||||
|
||||
真正自己写的时候,要保证理解可以实现是相应的功能。
|
||||
|
||||
接下来再来讲一下如何解决反转字符串的问题。
|
||||
|
||||
大家应该还记得,我们已经讲过了[206.反转链表](https://mp.weixin.qq.com/s/ckEvIVGcNLfrz6OLOMoT0A)。
|
||||
|
||||
在反转链表中,使用了双指针的方法。
|
||||
|
||||
那么反转字符串依然是使用双指针的方法,只不过对于字符串的反转,其实要比链表简单一些。
|
||||
|
||||
因为字符串也是一种数组,所以元素在内存中是连续分布,这就决定了反转链表和反转字符串方式上还是有所差异的。
|
||||
|
||||
如果对数组和链表原理不清楚的同学,可以看这两篇,[关于链表,你该了解这些!](https://mp.weixin.qq.com/s/fDGMmLrW7ZHlzkzlf_dZkw),[必须掌握的数组理论知识](https://mp.weixin.qq.com/s/c2KABb-Qgg66HrGf8z-8Og)。
|
||||
|
||||
对于字符串,我们定义两个指针(也可以说是索引下表),一个从字符串前面,一个从字符串后面,两个指针同时向中间移动,并交换元素。
|
||||
|
||||
以字符串`hello`为例,过程如下:
|
||||
|
||||

|
||||
|
||||
|
||||
不难写出如下C++代码:
|
||||
|
||||
```C++
|
||||
void reverseString(vector<char>& s) {
|
||||
for (int i = 0, j = s.size() - 1; i < s.size()/2; i++, j--) {
|
||||
swap(s[i],s[j]);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
循环里只要做交换s[i] 和s[j]操作就可以了,那么我这里使用了swap 这个库函数。大家可以使用。
|
||||
|
||||
因为相信大家都知道交换函数如何实现,而且这个库函数仅仅是解题中的一部分, 所以这里使用库函数也是可以的。
|
||||
|
||||
swap可以有两种实现。
|
||||
|
||||
一种就是常见的交换数值:
|
||||
|
||||
```C++
|
||||
int tmp = s[i];
|
||||
s[i] = s[j];
|
||||
s[j] = tmp;
|
||||
|
||||
```
|
||||
|
||||
一种就是通过位运算:
|
||||
|
||||
```C++
|
||||
s[i] ^= s[j];
|
||||
s[j] ^= s[i];
|
||||
s[i] ^= s[j];
|
||||
|
||||
```
|
||||
|
||||
这道题目还是比较简单的,但是我正好可以通过这道题目说一说在刷题的时候,使用库函数的原则。
|
||||
|
||||
如果题目关键的部分直接用库函数就可以解决,建议不要使用库函数。
|
||||
|
||||
如果库函数仅仅是 解题过程中的一小部分,并且你已经很清楚这个库函数的内部实现原理的话,可以考虑使用库函数。
|
||||
|
||||
本着这样的原则,我没有使用reverse库函数,而使用swap库函数。
|
||||
|
||||
**在字符串相关的题目中,库函数对大家的诱惑力是非常大的,因为会有各种反转,切割取词之类的操作**,这也是为什么字符串的库函数这么丰富的原因。
|
||||
|
||||
相信大家本着我所讲述的原则来做字符串相关的题目,在选择库函数的角度上会有所原则,也会有所收获。
|
||||
|
||||
C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
void reverseString(vector<char>& s) {
|
||||
for (int i = 0, j = s.size() - 1; i < s.size()/2; i++, j--) {
|
||||
swap(s[i],s[j]);
|
||||
}
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
public void reverseString(char[] s) {
|
||||
int l = 0;
|
||||
int r = s.length - 1;
|
||||
while (l < r) {
|
||||
s[l] ^= s[r]; //构造 a ^ b 的结果,并放在 a 中
|
||||
s[r] ^= s[l]; //将 a ^ b 这一结果再 ^ b ,存入b中,此时 b = a, a = a ^ b
|
||||
s[l] ^= s[r]; //a ^ b 的结果再 ^ a ,存入 a 中,此时 b = a, a = b 完成交换
|
||||
l++;
|
||||
r--;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def reverseString(self, s: List[str]) -> None:
|
||||
"""
|
||||
Do not return anything, modify s in-place instead.
|
||||
"""
|
||||
left, right = 0, len(s) - 1
|
||||
while(left < right):
|
||||
s[left], s[right] = s[right], s[left]
|
||||
left += 1
|
||||
right -= 1
|
||||
|
||||
# 下面的写法更加简洁,但是都是同样的算法
|
||||
# class Solution:
|
||||
# def reverseString(self, s: List[str]) -> None:
|
||||
# """
|
||||
# Do not return anything, modify s in-place instead.
|
||||
# """
|
||||
# 不需要判别是偶数个还是奇数个序列,因为奇数个的时候,中间那个不需要交换就可
|
||||
# for i in range(len(s)//2):
|
||||
# s[i], s[len(s)-1-i] = s[len(s)-1-i], s[i]
|
||||
# return s
|
||||
```
|
||||
|
||||
Go:
|
||||
```Go
|
||||
func reverseString(s []byte) {
|
||||
left:=0
|
||||
right:=len(s)-1
|
||||
for left<right{
|
||||
s[left],s[right]=s[right],s[left]
|
||||
left++
|
||||
right--
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
javaScript:
|
||||
|
||||
```js
|
||||
/**
|
||||
* @param {character[]} s
|
||||
* @return {void} Do not return anything, modify s in-place instead.
|
||||
*/
|
||||
var reverseString = function(s) {
|
||||
return s.reverse();
|
||||
};
|
||||
|
||||
var reverseString = function(s) {
|
||||
let l = -1, r = s.length;
|
||||
while(++l < --r) [s[l], s[r]] = [s[r], s[l]];
|
||||
return s;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
202
problems/0347.前K个高频元素.md
Normal file
202
problems/0347.前K个高频元素.md
Normal file
@@ -0,0 +1,202 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
|
||||
|
||||
> 前K个大数问题,老生常谈,不得不谈
|
||||
|
||||
# 347.前 K 个高频元素
|
||||
|
||||
https://leetcode-cn.com/problems/top-k-frequent-elements/
|
||||
|
||||
给定一个非空的整数数组,返回其中出现频率前 k 高的元素。
|
||||
|
||||
示例 1:
|
||||
输入: nums = [1,1,1,2,2,3], k = 2
|
||||
输出: [1,2]
|
||||
|
||||
示例 2:
|
||||
输入: nums = [1], k = 1
|
||||
输出: [1]
|
||||
|
||||
提示:
|
||||
你可以假设给定的 k 总是合理的,且 1 ≤ k ≤ 数组中不相同的元素的个数。
|
||||
你的算法的时间复杂度必须优于 O(n log n) , n 是数组的大小。
|
||||
题目数据保证答案唯一,换句话说,数组中前 k 个高频元素的集合是唯一的。
|
||||
你可以按任意顺序返回答案。
|
||||
|
||||
# 思路
|
||||
|
||||
这道题目主要涉及到如下三块内容:
|
||||
1. 要统计元素出现频率
|
||||
2. 对频率排序
|
||||
3. 找出前K个高频元素
|
||||
|
||||
首先统计元素出现的频率,这一类的问题可以使用map来进行统计。
|
||||
|
||||
然后是对频率进行排序,这里我们可以使用一种 容器适配器就是**优先级队列**。
|
||||
|
||||
什么是优先级队列呢?
|
||||
|
||||
其实**就是一个披着队列外衣的堆**,因为优先级队列对外接口只是从队头取元素,从队尾添加元素,再无其他取元素的方式,看起来就是一个队列。
|
||||
|
||||
而且优先级队列内部元素是自动依照元素的权值排列。那么它是如何有序排列的呢?
|
||||
|
||||
缺省情况下priority_queue利用max-heap(大顶堆)完成对元素的排序,这个大顶堆是以vector为表现形式的complete binary tree(完全二叉树)。
|
||||
|
||||
什么是堆呢?
|
||||
|
||||
**堆是一颗完全二叉树,树中每个结点的值都不小于(或不大于)其左右孩子的值。** 如果父亲结点是大于等于左右孩子就是大顶堆,小于等于左右孩子就是小顶堆。
|
||||
|
||||
所以大家经常说的大顶堆(堆头是最大元素),小顶堆(堆头是最小元素),如果懒得自己实现的话,就直接用priority_queue(优先级队列)就可以了,底层实现都是一样的,从小到大排就是小顶堆,从大到小排就是大顶堆。
|
||||
|
||||
本题我们就要使用优先级队列来对部分频率进行排序。
|
||||
|
||||
为什么不用快排呢, 使用快排要将map转换为vector的结构,然后对整个数组进行排序, 而这种场景下,我们其实只需要维护k个有序的序列就可以了,所以使用优先级队列是最优的。
|
||||
|
||||
此时要思考一下,是使用小顶堆呢,还是大顶堆?
|
||||
|
||||
有的同学一想,题目要求前 K 个高频元素,那么果断用大顶堆啊。
|
||||
|
||||
那么问题来了,定义一个大小为k的大顶堆,在每次移动更新大顶堆的时候,每次弹出都把最大的元素弹出去了,那么怎么保留下来前K个高频元素呢。
|
||||
|
||||
**所以我们要用小顶堆,因为要统计最大前k个元素,只有小顶堆每次将最小的元素弹出,最后小顶堆里积累的才是前k个最大元素。**
|
||||
|
||||
寻找前k个最大元素流程如图所示:(图中的频率只有三个,所以正好构成一个大小为3的小顶堆,如果频率更多一些,则用这个小顶堆进行扫描)
|
||||
|
||||
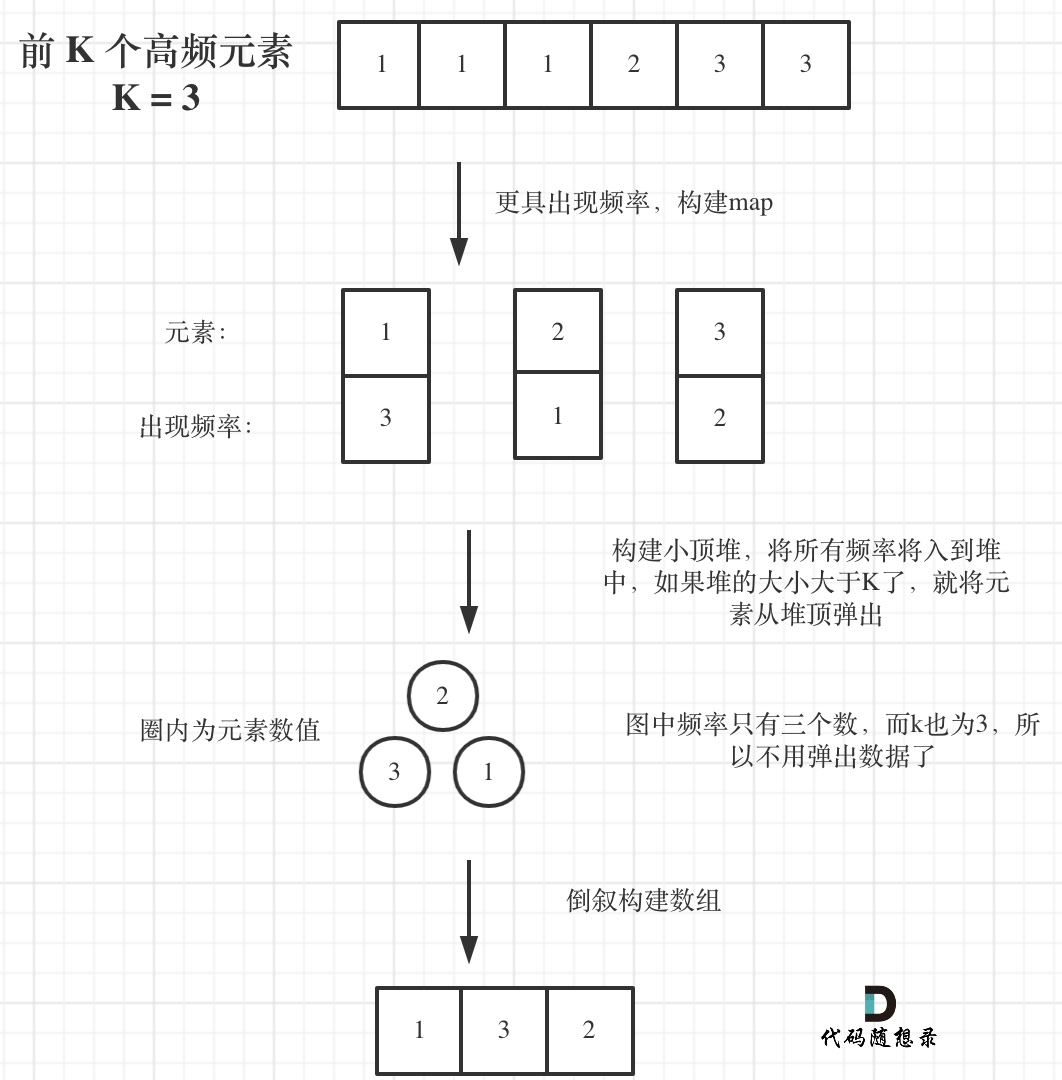
|
||||
|
||||
|
||||
我们来看一下C++代码:
|
||||
|
||||
|
||||
```C++
|
||||
// 时间复杂度:O(nlogk)
|
||||
// 空间复杂度:O(n)
|
||||
class Solution {
|
||||
public:
|
||||
// 小顶堆
|
||||
class mycomparison {
|
||||
public:
|
||||
bool operator()(const pair<int, int>& lhs, const pair<int, int>& rhs) {
|
||||
return lhs.second > rhs.second;
|
||||
}
|
||||
};
|
||||
vector<int> topKFrequent(vector<int>& nums, int k) {
|
||||
// 要统计元素出现频率
|
||||
unordered_map<int, int> map; // map<nums[i],对应出现的次数>
|
||||
for (int i = 0; i < nums.size(); i++) {
|
||||
map[nums[i]]++;
|
||||
}
|
||||
|
||||
// 对频率排序
|
||||
// 定义一个小顶堆,大小为k
|
||||
priority_queue<pair<int, int>, vector<pair<int, int>>, mycomparison> pri_que;
|
||||
|
||||
// 用固定大小为k的小顶堆,扫面所有频率的数值
|
||||
for (unordered_map<int, int>::iterator it = map.begin(); it != map.end(); it++) {
|
||||
pri_que.push(*it);
|
||||
if (pri_que.size() > k) { // 如果堆的大小大于了K,则队列弹出,保证堆的大小一直为k
|
||||
pri_que.pop();
|
||||
}
|
||||
}
|
||||
|
||||
// 找出前K个高频元素,因为小顶堆先弹出的是最小的,所以倒叙来输出到数组
|
||||
vector<int> result(k);
|
||||
for (int i = k - 1; i >= 0; i--) {
|
||||
result[i] = pri_que.top().first;
|
||||
pri_que.pop();
|
||||
}
|
||||
return result;
|
||||
|
||||
}
|
||||
};
|
||||
```
|
||||
# 拓展
|
||||
大家对这个比较运算在建堆时是如何应用的,为什么左大于右就会建立小顶堆,反而建立大顶堆比较困惑。
|
||||
|
||||
确实 例如我们在写快排的cmp函数的时候,`return left>right` 就是从大到小,`return left<right` 就是从小到大。
|
||||
|
||||
优先级队列的定义正好反过来了,可能和优先级队列的源码实现有关(我没有仔细研究),我估计是底层实现上优先队列队首指向后面,队尾指向最前面的缘故!
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
|
||||
class Solution {
|
||||
public int[] topKFrequent(int[] nums, int k) {
|
||||
int[] result = new int[k];
|
||||
HashMap<Integer, Integer> map = new HashMap<>();
|
||||
for (int num : nums) {
|
||||
map.put(num, map.getOrDefault(num, 0) + 1);
|
||||
}
|
||||
|
||||
Set<Map.Entry<Integer, Integer>> entries = map.entrySet();
|
||||
// 根据map的value值正序排,相当于一个小顶堆
|
||||
PriorityQueue<Map.Entry<Integer, Integer>> queue = new PriorityQueue<>((o1, o2) -> o1.getValue() - o2.getValue());
|
||||
for (Map.Entry<Integer, Integer> entry : entries) {
|
||||
queue.offer(entry);
|
||||
if (queue.size() > k) {
|
||||
queue.poll();
|
||||
}
|
||||
}
|
||||
for (int i = k - 1; i >= 0; i--) {
|
||||
result[i] = queue.poll().getKey();
|
||||
}
|
||||
return result;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
Python:
|
||||
```python
|
||||
#时间复杂度:O(nlogk)
|
||||
#空间复杂度:O(n)
|
||||
import heapq
|
||||
class Solution:
|
||||
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
|
||||
#要统计元素出现频率
|
||||
map_ = {} #nums[i]:对应出现的次数
|
||||
for i in range(len(nums)):
|
||||
map_[nums[i]] = map_.get(nums[i], 0) + 1
|
||||
|
||||
#对频率排序
|
||||
#定义一个小顶堆,大小为k
|
||||
pri_que = [] #小顶堆
|
||||
|
||||
#用固定大小为k的小顶堆,扫面所有频率的数值
|
||||
for key, freq in map_.items():
|
||||
heapq.heappush(pri_que, (freq, key))
|
||||
if len(pri_que) > k: #如果堆的大小大于了K,则队列弹出,保证堆的大小一直为k
|
||||
heapq.heappop(pri_que)
|
||||
|
||||
#找出前K个高频元素,因为小顶堆先弹出的是最小的,所以倒叙来输出到数组
|
||||
result = [0] * k
|
||||
for i in range(k-1, -1, -1):
|
||||
result[i] = heapq.heappop(pri_que)[1]
|
||||
return result
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
191
problems/0349.两个数组的交集.md
Normal file
191
problems/0349.两个数组的交集.md
Normal file
@@ -0,0 +1,191 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
|
||||
|
||||
> 如果哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费!
|
||||
|
||||
|
||||
## 349. 两个数组的交集
|
||||
|
||||
https://leetcode-cn.com/problems/intersection-of-two-arrays/
|
||||
|
||||
题意:给定两个数组,编写一个函数来计算它们的交集。
|
||||
|
||||

|
||||
|
||||
**说明:**
|
||||
输出结果中的每个元素一定是唯一的。
|
||||
我们可以不考虑输出结果的顺序。
|
||||
|
||||
## 思路
|
||||
|
||||
这道题目,主要要学会使用一种哈希数据结构:unordered_set,这个数据结构可以解决很多类似的问题。
|
||||
|
||||
注意题目特意说明:**输出结果中的每个元素一定是唯一的,也就是说输出的结果的去重的, 同时可以不考虑输出结果的顺序**
|
||||
|
||||
这道题用暴力的解法时间复杂度是O(n^2),那来看看使用哈希法进一步优化。
|
||||
|
||||
那么用数组来做哈希表也是不错的选择,例如[242. 有效的字母异位词](https://mp.weixin.qq.com/s/ffS8jaVFNUWyfn_8T31IdA)
|
||||
|
||||
但是要注意,**使用数组来做哈希的题目,是因为题目都限制了数值的大小。**
|
||||
|
||||
而这道题目没有限制数值的大小,就无法使用数组来做哈希表了。
|
||||
|
||||
**而且如果哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费。**
|
||||
|
||||
此时就要使用另一种结构体了,set ,关于set,C++ 给提供了如下三种可用的数据结构:
|
||||
|
||||
* std::set
|
||||
* std::multiset
|
||||
* std::unordered_set
|
||||
|
||||
std::set和std::multiset底层实现都是红黑树,std::unordered_set的底层实现是哈希表, 使用unordered_set 读写效率是最高的,并不需要对数据进行排序,而且还不要让数据重复,所以选择unordered_set。
|
||||
|
||||
思路如图所示:
|
||||
|
||||

|
||||
|
||||
C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
|
||||
unordered_set<int> result_set; // 存放结果
|
||||
unordered_set<int> nums_set(nums1.begin(), nums1.end());
|
||||
for (int num : nums2) {
|
||||
// 发现nums2的元素 在nums_set里又出现过
|
||||
if (nums_set.find(num) != nums_set.end()) {
|
||||
result_set.insert(num);
|
||||
}
|
||||
}
|
||||
return vector<int>(result_set.begin(), result_set.end());
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 拓展
|
||||
|
||||
那有同学可能问了,遇到哈希问题我直接都用set不就得了,用什么数组啊。
|
||||
|
||||
直接使用set 不仅占用空间比数组大,而且速度要比数组慢,set把数值映射到key上都要做hash计算的。
|
||||
|
||||
不要小瞧 这个耗时,在数据量大的情况,差距是很明显的。
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
|
||||
```Java
|
||||
import java.util.HashSet;
|
||||
import java.util.Set;
|
||||
|
||||
class Solution {
|
||||
public int[] intersection(int[] nums1, int[] nums2) {
|
||||
if (nums1 == null || nums1.length == 0 || nums2 == null || nums2.length == 0) {
|
||||
return new int[0];
|
||||
}
|
||||
Set<Integer> set1 = new HashSet<>();
|
||||
Set<Integer> resSet = new HashSet<>();
|
||||
//遍历数组1
|
||||
for (int i : nums1) {
|
||||
set1.add(i);
|
||||
}
|
||||
//遍历数组2的过程中判断哈希表中是否存在该元素
|
||||
for (int i : nums2) {
|
||||
if (set1.contains(i)) {
|
||||
resSet.add(i);
|
||||
}
|
||||
}
|
||||
int[] resArr = new int[resSet.size()];
|
||||
int index = 0;
|
||||
//将结果几何转为数组
|
||||
for (int i : resSet) {
|
||||
resArr[index++] = i;
|
||||
}
|
||||
return resArr;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
|
||||
result_set = set()
|
||||
|
||||
set1 = set(nums1)
|
||||
for num in nums2:
|
||||
if num in set1:
|
||||
result_set.add(num) # set1里出现的nums2元素 存放到结果
|
||||
return result_set
|
||||
```
|
||||
|
||||
|
||||
Go:
|
||||
```go
|
||||
func intersection(nums1 []int, nums2 []int) []int {
|
||||
m := make(map[int]int)
|
||||
for _, v := range nums1 {
|
||||
m[v] = 1
|
||||
}
|
||||
var res []int
|
||||
// 利用count>0,实现重复值只拿一次放入返回结果中
|
||||
for _, v := range nums2 {
|
||||
if count, ok := m[v]; ok && count > 0 {
|
||||
res = append(res, v)
|
||||
m[v]--
|
||||
}
|
||||
}
|
||||
return res
|
||||
}
|
||||
```
|
||||
|
||||
javaScript:
|
||||
|
||||
```js
|
||||
/**
|
||||
* @param {number[]} nums1
|
||||
* @param {number[]} nums2
|
||||
* @return {number[]}
|
||||
*/
|
||||
var intersection = function(nums1, nums2) {
|
||||
// 根据数组大小交换操作的数组
|
||||
if(nums1.length < nums2.length) {
|
||||
const _ = nums1;
|
||||
nums1 = nums2;
|
||||
nums2 = _;
|
||||
}
|
||||
const nums1Set = new Set(nums1);
|
||||
const resSet = new Set();
|
||||
// for(const n of nums2) {
|
||||
// nums1Set.has(n) && resSet.add(n);
|
||||
// }
|
||||
// 循环 比 迭代器快
|
||||
for(let i = nums2.length - 1; i >= 0; i--) {
|
||||
nums1Set.has(nums2[i]) && resSet.add(nums2[i]);
|
||||
}
|
||||
return Array.from(resSet);
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
## 相关题目
|
||||
|
||||
* 350.两个数组的交集 II
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
178
problems/0376.摆动序列.md
Normal file
178
problems/0376.摆动序列.md
Normal file
@@ -0,0 +1,178 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
> 本周讲解了[贪心理论基础](https://mp.weixin.qq.com/s/O935TaoHE9Eexwe_vSbRAg),以及第一道贪心的题目:[贪心算法:分发饼干](https://mp.weixin.qq.com/s/YSuLIAYyRGlyxbp9BNC1uw),可能会给大家一种贪心算法比较简单的错觉,好了,接下来几天的题目难度要上来了,哈哈。
|
||||
|
||||
## 376. 摆动序列
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/wiggle-subsequence/
|
||||
|
||||
如果连续数字之间的差严格地在正数和负数之间交替,则数字序列称为摆动序列。第一个差(如果存在的话)可能是正数或负数。少于两个元素的序列也是摆动序列。
|
||||
|
||||
例如, [1,7,4,9,2,5] 是一个摆动序列,因为差值 (6,-3,5,-7,3) 是正负交替出现的。相反, [1,4,7,2,5] 和 [1,7,4,5,5] 不是摆动序列,第一个序列是因为它的前两个差值都是正数,第二个序列是因为它的最后一个差值为零。
|
||||
|
||||
给定一个整数序列,返回作为摆动序列的最长子序列的长度。 通过从原始序列中删除一些(也可以不删除)元素来获得子序列,剩下的元素保持其原始顺序。
|
||||
|
||||
示例 1:
|
||||
输入: [1,7,4,9,2,5]
|
||||
输出: 6
|
||||
解释: 整个序列均为摆动序列。
|
||||
|
||||
示例 2:
|
||||
输入: [1,17,5,10,13,15,10,5,16,8]
|
||||
输出: 7
|
||||
解释: 这个序列包含几个长度为 7 摆动序列,其中一个可为[1,17,10,13,10,16,8]。
|
||||
|
||||
示例 3:
|
||||
输入: [1,2,3,4,5,6,7,8,9]
|
||||
输出: 2
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
本题要求通过从原始序列中删除一些(也可以不删除)元素来获得子序列,剩下的元素保持其原始顺序。
|
||||
|
||||
相信这么一说吓退不少同学,这要求最大摆动序列又可以修改数组,这得如何修改呢?
|
||||
|
||||
来分析一下,要求删除元素使其达到最大摆动序列,应该删除什么元素呢?
|
||||
|
||||
用示例二来举例,如图所示:
|
||||
|
||||
|
||||
|
||||
**局部最优:删除单调坡度上的节点(不包括单调坡度两端的节点),那么这个坡度就可以有两个局部峰值**。
|
||||
|
||||
**整体最优:整个序列有最多的局部峰值,从而达到最长摆动序列**。
|
||||
|
||||
局部最优推出全局最优,并举不出反例,那么试试贪心!
|
||||
|
||||
(为方便表述,以下说的峰值都是指局部峰值)
|
||||
|
||||
**实际操作上,其实连删除的操作都不用做,因为题目要求的是最长摆动子序列的长度,所以只需要统计数组的峰值数量就可以了(相当于是删除单一坡度上的节点,然后统计长度)**
|
||||
|
||||
**这就是贪心所贪的地方,让峰值尽可能的保持峰值,然后删除单一坡度上的节点**。
|
||||
|
||||
本题代码实现中,还有一些技巧,例如统计峰值的时候,数组最左面和最右面是最不好统计的。
|
||||
|
||||
例如序列[2,5],它的峰值数量是2,如果靠统计差值来计算峰值个数就需要考虑数组最左面和最右面的特殊情况。
|
||||
|
||||
所以可以针对序列[2,5],可以假设为[2,2,5],这样它就有坡度了即preDiff = 0,如图:
|
||||
|
||||
|
||||
|
||||
针对以上情形,result初始为1(默认最右面有一个峰值),此时curDiff > 0 && preDiff <= 0,那么result++(计算了左面的峰值),最后得到的result就是2(峰值个数为2即摆动序列长度为2)
|
||||
|
||||
C++代码如下(和上图是对应的逻辑):
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int wiggleMaxLength(vector<int>& nums) {
|
||||
if (nums.size() <= 1) return nums.size();
|
||||
int curDiff = 0; // 当前一对差值
|
||||
int preDiff = 0; // 前一对差值
|
||||
int result = 1; // 记录峰值个数,序列默认序列最右边有一个峰值
|
||||
for (int i = 0; i < nums.size() - 1; i++) {
|
||||
curDiff = nums[i + 1] - nums[i];
|
||||
// 出现峰值
|
||||
if ((curDiff > 0 && preDiff <= 0) || (preDiff >= 0 && curDiff < 0)) {
|
||||
result++;
|
||||
preDiff = curDiff;
|
||||
}
|
||||
}
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
时间复杂度O(n)
|
||||
空间复杂度O(1)
|
||||
|
||||
## 总结
|
||||
|
||||
**贪心的题目说简单有的时候就是常识,说难就难在都不知道该怎么用贪心**。
|
||||
|
||||
本题大家如果要去模拟删除元素达到最长摆动子序列的过程,那指定绕里面去了,一时半会拔不出来。
|
||||
|
||||
而这道题目有什么技巧说一下子能想到贪心么?
|
||||
|
||||
其实也没有,类似的题目做过了就会想到。
|
||||
|
||||
此时大家就应该了解了:保持区间波动,只需要把单调区间上的元素移除就可以了。
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
public int wiggleMaxLength(int[] nums) {
|
||||
if (nums == null || nums.length <= 1) {
|
||||
return nums.length;
|
||||
}
|
||||
//当前差值
|
||||
int curDiff = 0;
|
||||
//上一个差值
|
||||
int preDiff = 0;
|
||||
int count = 1;
|
||||
for (int i = 1; i < nums.length; i++) {
|
||||
//得到当前差值
|
||||
curDiff = nums[i] - nums[i - 1];
|
||||
//如果当前差值和上一个差值为一正一负
|
||||
//等于0的情况表示初始时的preDiff
|
||||
if ((curDiff > 0 && preDiff <= 0) || (curDiff < 0 && preDiff >= 0)) {
|
||||
count++;
|
||||
preDiff = curDiff;
|
||||
}
|
||||
}
|
||||
return count;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python3
|
||||
class Solution:
|
||||
def wiggleMaxLength(self, nums: List[int]) -> int:
|
||||
preC,curC,res = 0,0,1 #题目里nums长度大于等于1,当长度为1时,其实到不了for循环里去,所以不用考虑nums长度
|
||||
for i in range(len(nums) - 1):
|
||||
curC = nums[i + 1] - nums[i]
|
||||
if curC * preC <= 0 and curC !=0: #差值为0时,不算摆动
|
||||
res += 1
|
||||
preC = curC #如果当前差值和上一个差值为一正一负时,才需要用当前差值替代上一个差值
|
||||
return res
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
|
||||
Javascript:
|
||||
```Javascript
|
||||
var wiggleMaxLength = function(nums) {
|
||||
if(nums.length <= 1) return nums.length
|
||||
let result = 1
|
||||
let preDiff = 0
|
||||
let curDiff = 0
|
||||
for(let i = 0; i <= nums.length; i++) {
|
||||
curDiff = nums[i + 1] - nums[i]
|
||||
if((curDiff > 0 && preDiff <= 0) || (curDiff < 0 && preDiff >= 0)) {
|
||||
result++
|
||||
preDiff = curDiff
|
||||
}
|
||||
}
|
||||
return result
|
||||
};
|
||||
```
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
210
problems/0377.组合总和Ⅳ.md
Normal file
210
problems/0377.组合总和Ⅳ.md
Normal file
@@ -0,0 +1,210 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
# 动态规划:Carl称它为排列总和!
|
||||
|
||||
## 377. 组合总和 Ⅳ
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/combination-sum-iv/
|
||||
|
||||
难度:中等
|
||||
|
||||
给定一个由正整数组成且不存在重复数字的数组,找出和为给定目标正整数的组合的个数。
|
||||
|
||||
示例:
|
||||
|
||||
nums = [1, 2, 3]
|
||||
target = 4
|
||||
|
||||
所有可能的组合为:
|
||||
(1, 1, 1, 1)
|
||||
(1, 1, 2)
|
||||
(1, 2, 1)
|
||||
(1, 3)
|
||||
(2, 1, 1)
|
||||
(2, 2)
|
||||
(3, 1)
|
||||
|
||||
请注意,顺序不同的序列被视作不同的组合。
|
||||
|
||||
因此输出为 7。
|
||||
|
||||
## 思路
|
||||
|
||||
本题题目描述说是求组合,但又说是可以元素相同顺序不同的组合算两个组合,**其实就是求排列!**
|
||||
|
||||
弄清什么是组合,什么是排列很重要。
|
||||
|
||||
组合不强调顺序,(1,5)和(5,1)是同一个组合。
|
||||
|
||||
排列强调顺序,(1,5)和(5,1)是两个不同的排列。
|
||||
|
||||
大家在公众号里学习回溯算法专题的时候,一定做过这两道题目[回溯算法:39.组合总和](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)和[回溯算法:40.组合总和II](https://mp.weixin.qq.com/s/_1zPYk70NvHsdY8UWVGXmQ)会感觉这两题和本题很像!
|
||||
|
||||
但其本质是本题求的是排列总和,而且仅仅是求排列总和的个数,并不是把所有的排列都列出来。
|
||||
|
||||
**如果本题要把排列都列出来的话,只能使用回溯算法爆搜**。
|
||||
|
||||
动规五部曲分析如下:
|
||||
|
||||
1. 确定dp数组以及下标的含义
|
||||
|
||||
**dp[i]: 凑成目标正整数为i的排列个数为dp[i]**
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
dp[i](考虑nums[j])可以由 dp[i - nums[j]](不考虑nums[j]) 推导出来。
|
||||
|
||||
因为只要得到nums[j],排列个数dp[i - nums[j]],就是dp[i]的一部分。
|
||||
|
||||
在[动态规划:494.目标和](https://mp.weixin.qq.com/s/2pWmaohX75gwxvBENS-NCw) 和 [动态规划:518.零钱兑换II](https://mp.weixin.qq.com/s/PlowDsI4WMBOzf3q80AksQ)中我们已经讲过了,求装满背包有几种方法,递推公式一般都是dp[i] += dp[i - nums[j]];
|
||||
|
||||
本题也一样。
|
||||
|
||||
3. dp数组如何初始化
|
||||
|
||||
因为递推公式dp[i] += dp[i - nums[j]]的缘故,dp[0]要初始化为1,这样递归其他dp[i]的时候才会有数值基础。
|
||||
|
||||
至于dp[0] = 1 有没有意义呢?
|
||||
|
||||
其实没有意义,所以我也不去强行解释它的意义了,因为题目中也说了:给定目标值是正整数! 所以dp[0] = 1是没有意义的,仅仅是为了推导递推公式。
|
||||
|
||||
至于非0下标的dp[i]应该初始为多少呢?
|
||||
|
||||
初始化为0,这样才不会影响dp[i]累加所有的dp[i - nums[j]]。
|
||||
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
个数可以不限使用,说明这是一个完全背包。
|
||||
|
||||
得到的集合是排列,说明需要考虑元素之间的顺序。
|
||||
|
||||
|
||||
本题要求的是排列,那么这个for循环嵌套的顺序可以有说法了。
|
||||
|
||||
在[动态规划:518.零钱兑换II](https://mp.weixin.qq.com/s/PlowDsI4WMBOzf3q80AksQ) 中就已经讲过了。
|
||||
|
||||
**如果求组合数就是外层for循环遍历物品,内层for遍历背包**。
|
||||
|
||||
**如果求排列数就是外层for遍历背包,内层for循环遍历物品**。
|
||||
|
||||
如果把遍历nums(物品)放在外循环,遍历target的作为内循环的话,举一个例子:计算dp[4]的时候,结果集只有 {1,3} 这样的集合,不会有{3,1}这样的集合,因为nums遍历放在外层,3只能出现在1后面!
|
||||
|
||||
所以本题遍历顺序最终遍历顺序:**target(背包)放在外循环,将nums(物品)放在内循环,内循环从前到后遍历**。
|
||||
|
||||
5. 举例来推导dp数组
|
||||
|
||||
我们再来用示例中的例子推导一下:
|
||||
|
||||

|
||||
|
||||
如果代码运行处的结果不是想要的结果,就把dp[i]都打出来,看看和我们推导的一不一样。
|
||||
|
||||
以上分析完毕,C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int combinationSum4(vector<int>& nums, int target) {
|
||||
vector<int> dp(target + 1, 0);
|
||||
dp[0] = 1;
|
||||
for (int i = 0; i <= target; i++) { // 遍历背包
|
||||
for (int j = 0; j < nums.size(); j++) { // 遍历物品
|
||||
if (i - nums[j] >= 0 && dp[i] < INT_MAX - dp[i - nums[j]]) {
|
||||
dp[i] += dp[i - nums[j]];
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[target];
|
||||
}
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
C++测试用例有超过两个树相加超过int的数据,所以需要在if里加上dp[i] < INT_MAX - dp[i - num]。
|
||||
|
||||
但java就不用考虑这个限制,java里的int也是四个字节吧,也有可能leetcode后台对不同语言的测试数据不一样。
|
||||
|
||||
## 总结
|
||||
|
||||
**求装满背包有几种方法,递归公式都是一样的,没有什么差别,但关键在于遍历顺序!**
|
||||
|
||||
本题与[动态规划:518.零钱兑换II](https://mp.weixin.qq.com/s/PlowDsI4WMBOzf3q80AksQ)就是一个鲜明的对比,一个是求排列,一个是求组合,遍历顺序完全不同。
|
||||
|
||||
如果对遍历顺序没有深度理解的话,做这种完全背包的题目会很懵逼,即使题目刷过了可能也不太清楚具体是怎么过的。
|
||||
|
||||
此时大家应该对动态规划中的遍历顺序又有更深的理解了。
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
|
||||
```Java
|
||||
class Solution {
|
||||
public int combinationSum4(int[] nums, int target) {
|
||||
int[] dp = new int[target + 1];
|
||||
dp[0] = 1;
|
||||
for (int i = 0; i <= target; i++) {
|
||||
for (int j = 0; j < nums.length; j++) {
|
||||
if (i >= nums[j]) {
|
||||
dp[i] += dp[i - nums[j]];
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[target];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def combinationSum4(self, nums, target):
|
||||
dp = [0] * (target + 1)
|
||||
dp[0] = 1
|
||||
|
||||
for i in range(1, target+1):
|
||||
for j in nums:
|
||||
if i >= j:
|
||||
dp[i] += dp[i - j]
|
||||
|
||||
return dp[-1]
|
||||
```
|
||||
|
||||
|
||||
Go:
|
||||
```go
|
||||
func combinationSum4(nums []int, target int) int {
|
||||
//定义dp数组
|
||||
dp := make([]int, target+1)
|
||||
// 初始化
|
||||
dp[0] = 1
|
||||
// 遍历顺序, 先遍历背包,再循环遍历物品
|
||||
for j:=0;j<=target;j++ {
|
||||
for i:=0 ;i < len(nums);i++ {
|
||||
if j >= nums[i] {
|
||||
dp[j] += dp[j-nums[i]]
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[target]
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
259
problems/0383.赎金信.md
Normal file
259
problems/0383.赎金信.md
Normal file
@@ -0,0 +1,259 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
|
||||
> 在哈希法中有一些场景就是为数组量身定做的。
|
||||
|
||||
# 383. 赎金信
|
||||
|
||||
https://leetcode-cn.com/problems/ransom-note/
|
||||
|
||||
给定一个赎金信 (ransom) 字符串和一个杂志(magazine)字符串,判断第一个字符串 ransom 能不能由第二个字符串 magazines 里面的字符构成。如果可以构成,返回 true ;否则返回 false。
|
||||
|
||||
(题目说明:为了不暴露赎金信字迹,要从杂志上搜索各个需要的字母,组成单词来表达意思。杂志字符串中的每个字符只能在赎金信字符串中使用一次。)
|
||||
|
||||
**注意:**
|
||||
|
||||
你可以假设两个字符串均只含有小写字母。
|
||||
|
||||
canConstruct("a", "b") -> false
|
||||
canConstruct("aa", "ab") -> false
|
||||
canConstruct("aa", "aab") -> true
|
||||
|
||||
## 思路
|
||||
|
||||
这道题目和[242.有效的字母异位词](https://mp.weixin.qq.com/s/ffS8jaVFNUWyfn_8T31IdA)很像,[242.有效的字母异位词](https://mp.weixin.qq.com/s/ffS8jaVFNUWyfn_8T31IdA)相当于求 字符串a 和 字符串b 是否可以相互组成 ,而这道题目是求 字符串a能否组成字符串b,而不用管字符串b 能不能组成字符串a。
|
||||
|
||||
本题判断第一个字符串ransom能不能由第二个字符串magazines里面的字符构成,但是这里需要注意两点。
|
||||
|
||||
* 第一点“为了不暴露赎金信字迹,要从杂志上搜索各个需要的字母,组成单词来表达意思” 这里*说明杂志里面的字母不可重复使用。*
|
||||
|
||||
* 第二点 “你可以假设两个字符串均只含有小写字母。” *说明只有小写字母*,这一点很重要
|
||||
|
||||
## 暴力解法
|
||||
|
||||
那么第一个思路其实就是暴力枚举了,两层for循环,不断去寻找,代码如下:
|
||||
|
||||
```C++
|
||||
// 时间复杂度: O(n^2)
|
||||
// 空间复杂度:O(1)
|
||||
class Solution {
|
||||
public:
|
||||
bool canConstruct(string ransomNote, string magazine) {
|
||||
for (int i = 0; i < magazine.length(); i++) {
|
||||
for (int j = 0; j < ransomNote.length(); j++) {
|
||||
// 在ransomNote中找到和magazine相同的字符
|
||||
if (magazine[i] == ransomNote[j]) {
|
||||
ransomNote.erase(ransomNote.begin() + j); // ransomNote删除这个字符
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
// 如果ransomNote为空,则说明magazine的字符可以组成ransomNote
|
||||
if (ransomNote.length() == 0) {
|
||||
return true;
|
||||
}
|
||||
return false;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
这里时间复杂度是比较高的,而且里面还有一个字符串删除也就是erase的操作,也是费时的,当然这段代码也可以过这道题。
|
||||
|
||||
|
||||
## 哈希解法
|
||||
|
||||
因为题目所只有小写字母,那可以采用空间换取时间的哈希策略, 用一个长度为26的数组还记录magazine里字母出现的次数。
|
||||
|
||||
然后再用ransomNote去验证这个数组是否包含了ransomNote所需要的所有字母。
|
||||
|
||||
依然是数组在哈希法中的应用。
|
||||
|
||||
一些同学可能想,用数组干啥,都用map完事了,**其实在本题的情况下,使用map的空间消耗要比数组大一些的,因为map要维护红黑树或者哈希表,而且还要做哈希函数,是费时的!数据量大的话就能体现出来差别了。 所以数组更加简单直接有效!**
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
// 时间复杂度: O(n)
|
||||
// 空间复杂度:O(1)
|
||||
class Solution {
|
||||
public:
|
||||
bool canConstruct(string ransomNote, string magazine) {
|
||||
int record[26] = {0};
|
||||
for (int i = 0; i < magazine.length(); i++) {
|
||||
// 通过recode数据记录 magazine里各个字符出现次数
|
||||
record[magazine[i]-'a'] ++;
|
||||
}
|
||||
for (int j = 0; j < ransomNote.length(); j++) {
|
||||
// 遍历ransomNote,在record里对应的字符个数做--操作
|
||||
record[ransomNote[j]-'a']--;
|
||||
// 如果小于零说明ransomNote里出现的字符,magazine没有
|
||||
if(record[ransomNote[j]-'a'] < 0) {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
public boolean canConstruct(String ransomNote, String magazine) {
|
||||
//记录杂志字符串出现的次数
|
||||
int[] arr = new int[26];
|
||||
int temp;
|
||||
for (int i = 0; i < magazine.length(); i++) {
|
||||
temp = magazine.charAt(i) - 'a';
|
||||
arr[temp]++;
|
||||
}
|
||||
for (int i = 0; i < ransomNote.length(); i++) {
|
||||
temp = ransomNote.charAt(i) - 'a';
|
||||
//对于金信中的每一个字符都在数组中查找
|
||||
//找到相应位减一,否则找不到返回false
|
||||
if (arr[temp] > 0) {
|
||||
arr[temp]--;
|
||||
} else {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Python写法一(使用数组作为哈希表):
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def canConstruct(self, ransomNote: str, magazine: str) -> bool:
|
||||
|
||||
arr = [0] * 26
|
||||
|
||||
for x in magazine:
|
||||
arr[ord(x) - ord('a')] += 1
|
||||
|
||||
for x in ransomNote:
|
||||
if arr[ord(x) - ord('a')] == 0:
|
||||
return False
|
||||
else:
|
||||
arr[ord(x) - ord('a')] -= 1
|
||||
|
||||
return True
|
||||
```
|
||||
|
||||
Python写法二(使用defaultdict):
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def canConstruct(self, ransomNote: str, magazine: str) -> bool:
|
||||
|
||||
from collections import defaultdict
|
||||
|
||||
hashmap = defaultdict(int)
|
||||
|
||||
for x in magazine:
|
||||
hashmap[x] += 1
|
||||
|
||||
for x in ransomNote:
|
||||
value = hashmap.get(x)
|
||||
if value is None or value == 0:
|
||||
return False
|
||||
else:
|
||||
hashmap[x] -= 1
|
||||
|
||||
return True
|
||||
```
|
||||
|
||||
Python写法三:
|
||||
|
||||
```python
|
||||
class Solution(object):
|
||||
def canConstruct(self, ransomNote, magazine):
|
||||
"""
|
||||
:type ransomNote: str
|
||||
:type magazine: str
|
||||
:rtype: bool
|
||||
"""
|
||||
|
||||
# use a dict to store the number of letter occurance in ransomNote
|
||||
hashmap = dict()
|
||||
for s in ransomNote:
|
||||
if s in hashmap:
|
||||
hashmap[s] += 1
|
||||
else:
|
||||
hashmap[s] = 1
|
||||
|
||||
# check if the letter we need can be found in magazine
|
||||
for l in magazine:
|
||||
if l in hashmap:
|
||||
hashmap[l] -= 1
|
||||
|
||||
for key in hashmap:
|
||||
if hashmap[key] > 0:
|
||||
return False
|
||||
|
||||
return True
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
```go
|
||||
func canConstruct(ransomNote string, magazine string) bool {
|
||||
record := make([]int, 26)
|
||||
for _, v := range magazine {
|
||||
record[v-'a']++
|
||||
}
|
||||
for _, v := range ransomNote {
|
||||
record[v-'a']--
|
||||
if record[v-'a'] < 0 {
|
||||
return false
|
||||
}
|
||||
}
|
||||
return true
|
||||
}
|
||||
```
|
||||
|
||||
javaScript:
|
||||
|
||||
```js
|
||||
/**
|
||||
* @param {string} ransomNote
|
||||
* @param {string} magazine
|
||||
* @return {boolean}
|
||||
*/
|
||||
var canConstruct = function(ransomNote, magazine) {
|
||||
const strArr = new Array(26).fill(0),
|
||||
base = "a".charCodeAt();
|
||||
for(const s of magazine) {
|
||||
strArr[s.charCodeAt() - base]++;
|
||||
}
|
||||
for(const s of ransomNote) {
|
||||
const index = s.charCodeAt() - base;
|
||||
if(!strArr[index]) return false;
|
||||
strArr[index]--;
|
||||
}
|
||||
return true;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
192
problems/0392.判断子序列.md
Normal file
192
problems/0392.判断子序列.md
Normal file
@@ -0,0 +1,192 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 392.判断子序列
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/is-subsequence/
|
||||
|
||||
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
|
||||
|
||||
字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"的一个子序列,而"aec"不是)。
|
||||
|
||||
示例 1:
|
||||
输入:s = "abc", t = "ahbgdc"
|
||||
输出:true
|
||||
|
||||
示例 2:
|
||||
输入:s = "axc", t = "ahbgdc"
|
||||
输出:false
|
||||
|
||||
提示:
|
||||
|
||||
* 0 <= s.length <= 100
|
||||
* 0 <= t.length <= 10^4
|
||||
|
||||
两个字符串都只由小写字符组成。
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
(这道题可以用双指针的思路来实现,时间复杂度就是O(n))
|
||||
|
||||
这道题应该算是编辑距离的入门题目,因为从题意中我们也可以发现,只需要计算删除的情况,不用考虑增加和替换的情况。
|
||||
|
||||
**所以掌握本题也是对后面要讲解的编辑距离的题目打下基础**。
|
||||
|
||||
动态规划五部曲分析如下:
|
||||
|
||||
1. 确定dp数组(dp table)以及下标的含义
|
||||
|
||||
**dp[i][j] 表示以下标i-1为结尾的字符串s,和以下标j-1为结尾的字符串t,相同子序列的长度为dp[i][j]**。
|
||||
|
||||
注意这里是判断s是否为t的子序列。即t的长度是大于等于s的。
|
||||
|
||||
有同学问了,为啥要表示下标i-1为结尾的字符串呢,为啥不表示下标i为结尾的字符串呢?
|
||||
|
||||
用i来表示也可以!
|
||||
|
||||
但我统一以下标i-1为结尾的字符串来计算,这样在下面的递归公式中会容易理解一些,如果还有疑惑,可以继续往下看。
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
在确定递推公式的时候,首先要考虑如下两种操作,整理如下:
|
||||
|
||||
* if (s[i - 1] == t[j - 1])
|
||||
* t中找到了一个字符在s中也出现了
|
||||
* if (s[i - 1] != t[j - 1])
|
||||
* 相当于t要删除元素,继续匹配
|
||||
|
||||
if (s[i - 1] == t[j - 1]),那么dp[i][j] = dp[i - 1][j - 1] + 1;,因为找到了一个相同的字符,相同子序列长度自然要在dp[i-1][j-1]的基础上加1(**如果不理解,在回看一下dp[i][j]的定义**)
|
||||
|
||||
if (s[i - 1] != t[j - 1]),此时相当于t要删除元素,t如果把当前元素t[j - 1]删除,那么dp[i][j] 的数值就是 看s[i - 1]与 t[j - 2]的比较结果了,即:dp[i][j] = dp[i][j - 1];
|
||||
|
||||
|
||||
3. dp数组如何初始化
|
||||
|
||||
从递推公式可以看出dp[i][j]都是依赖于dp[i - 1][j - 1] 和 dp[i][j - 1],所以dp[0][0]和dp[i][0]是一定要初始化的。
|
||||
|
||||
这里大家已经可以发现,在定义dp[i][j]含义的时候为什么要**表示以下标i-1为结尾的字符串s,和以下标j-1为结尾的字符串t,相同子序列的长度为dp[i][j]**。
|
||||
|
||||
因为这样的定义在dp二维矩阵中可以留出初始化的区间,如图:
|
||||
|
||||
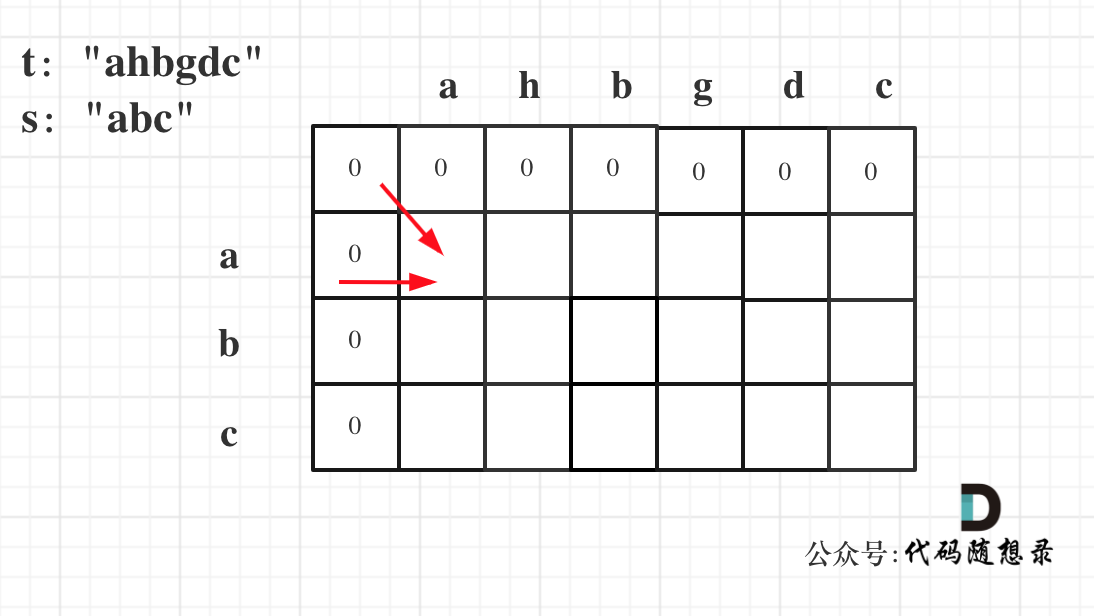
|
||||
|
||||
如果要是定义的dp[i][j]是以下标i为结尾的字符串s和以下标j为结尾的字符串t,初始化就比较麻烦了。
|
||||
|
||||
这里dp[i][0]和dp[0][j]是没有含义的,仅仅是为了给递推公式做前期铺垫,所以初始化为0。
|
||||
|
||||
**其实这里只初始化dp[i][0]就够了,但一起初始化也方便,所以就一起操作了**,代码如下:
|
||||
|
||||
```
|
||||
vector<vector<int>> dp(s.size() + 1, vector<int>(t.size() + 1, 0));
|
||||
```
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
同理从从递推公式可以看出dp[i][j]都是依赖于dp[i - 1][j - 1] 和 dp[i][j - 1],那么遍历顺序也应该是从上到下,从左到右
|
||||
|
||||
如图所示:
|
||||
|
||||
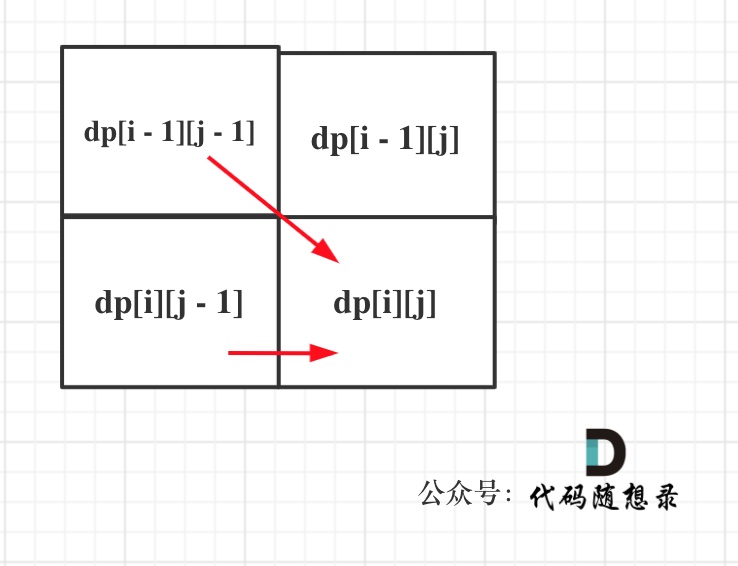
|
||||
|
||||
5. 举例推导dp数组
|
||||
|
||||
以示例一为例,输入:s = "abc", t = "ahbgdc",dp状态转移图如下:
|
||||
|
||||
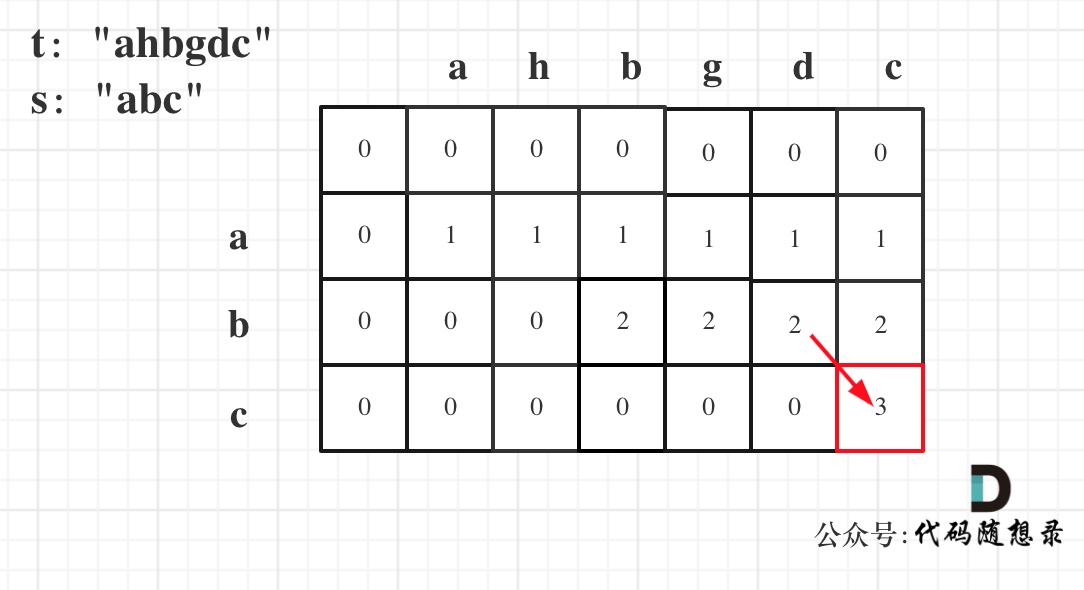
|
||||
|
||||
dp[i][j]表示以下标i-1为结尾的字符串s和以下标j-1为结尾的字符串t 相同子序列的长度,所以如果dp[s.size()][t.size()] 与 字符串s的长度相同说明:s与t的最长相同子序列就是s,那么s 就是 t 的子序列。
|
||||
|
||||
图中dp[s.size()][t.size()] = 3, 而s.size() 也为3。所以s是t 的子序列,返回true。
|
||||
|
||||
动规五部曲分析完毕,C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
bool isSubsequence(string s, string t) {
|
||||
vector<vector<int>> dp(s.size() + 1, vector<int>(t.size() + 1, 0));
|
||||
for (int i = 1; i <= s.size(); i++) {
|
||||
for (int j = 1; j <= t.size(); j++) {
|
||||
if (s[i - 1] == t[j - 1]) dp[i][j] = dp[i - 1][j - 1] + 1;
|
||||
else dp[i][j] = dp[i][j - 1];
|
||||
}
|
||||
}
|
||||
if (dp[s.size()][t.size()] == s.size()) return true;
|
||||
return false;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
* 时间复杂度:O(n * m)
|
||||
* 空间复杂度:O(n * m)
|
||||
|
||||
## 总结
|
||||
|
||||
这道题目算是编辑距离的入门题目(毕竟这里只是涉及到减法),也是动态规划解决的经典题型。
|
||||
|
||||
这一类题都是题目读上去感觉很复杂,模拟一下也发现很复杂,用动规分析完了也感觉很复杂,但是最终代码却很简短。
|
||||
|
||||
编辑距离的题目最能体现出动规精髓和巧妙之处,大家可以好好体会一下。
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```
|
||||
class Solution {
|
||||
public boolean isSubsequence(String s, String t) {
|
||||
int length1 = s.length(); int length2 = t.length();
|
||||
int[][] dp = new int[length1+1][length2+1];
|
||||
for(int i = 1; i <= length1; i++){
|
||||
for(int j = 1; j <= length2; j++){
|
||||
if(s.charAt(i-1) == t.charAt(j-1)){
|
||||
dp[i][j] = dp[i-1][j-1] + 1;
|
||||
}else{
|
||||
dp[i][j] = dp[i][j-1];
|
||||
}
|
||||
}
|
||||
}
|
||||
if(dp[length1][length2] == length1){
|
||||
return true;
|
||||
}else{
|
||||
return false;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def isSubsequence(self, s: str, t: str) -> bool:
|
||||
dp = [[0] * (len(t)+1) for _ in range(len(s)+1)]
|
||||
for i in range(1, len(s)+1):
|
||||
for j in range(1, len(t)+1):
|
||||
if s[i-1] == t[j-1]:
|
||||
dp[i][j] = dp[i-1][j-1] + 1
|
||||
else:
|
||||
dp[i][j] = dp[i][j-1]
|
||||
if dp[-1][-1] == len(s):
|
||||
return True
|
||||
return False
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
348
problems/0404.左叶子之和.md
Normal file
348
problems/0404.左叶子之和.md
Normal file
@@ -0,0 +1,348 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 404.左叶子之和
|
||||
|
||||
题目地址:https://leetcode-cn.com/problems/sum-of-left-leaves/
|
||||
|
||||
计算给定二叉树的所有左叶子之和。
|
||||
|
||||
示例:
|
||||
|
||||

|
||||
|
||||
## 思路
|
||||
|
||||
**首先要注意是判断左叶子,不是二叉树左侧节点,所以不要上来想着层序遍历。**
|
||||
|
||||
因为题目中其实没有说清楚左叶子究竟是什么节点,那么我来给出左叶子的明确定义:**如果左节点不为空,且左节点没有左右孩子,那么这个节点就是左叶子**
|
||||
|
||||
大家思考一下如下图中二叉树,左叶子之和究竟是多少?
|
||||
|
||||
|
||||
|
||||
**其实是0,因为这棵树根本没有左叶子!**
|
||||
|
||||
那么**判断当前节点是不是左叶子是无法判断的,必须要通过节点的父节点来判断其左孩子是不是左叶子。**
|
||||
|
||||
|
||||
如果该节点的左节点不为空,该节点的左节点的左节点为空,该节点的左节点的右节点为空,则找到了一个左叶子,判断代码如下:
|
||||
|
||||
```
|
||||
if (node->left != NULL && node->left->left == NULL && node->left->right == NULL) {
|
||||
左叶子节点处理逻辑
|
||||
}
|
||||
```
|
||||
|
||||
## 递归法
|
||||
|
||||
递归的遍历顺序为后序遍历(左右中),是因为要通过递归函数的返回值来累加求取左叶子数值之和。。
|
||||
|
||||
递归三部曲:
|
||||
|
||||
1. 确定递归函数的参数和返回值
|
||||
|
||||
判断一个树的左叶子节点之和,那么一定要传入树的根节点,递归函数的返回值为数值之和,所以为int
|
||||
|
||||
使用题目中给出的函数就可以了。
|
||||
|
||||
2. 确定终止条件
|
||||
|
||||
依然是
|
||||
```
|
||||
if (root == NULL) return 0;
|
||||
```
|
||||
|
||||
3. 确定单层递归的逻辑
|
||||
|
||||
当遇到左叶子节点的时候,记录数值,然后通过递归求取左子树左叶子之和,和 右子树左叶子之和,相加便是整个树的左叶子之和。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
int leftValue = sumOfLeftLeaves(root->left); // 左
|
||||
int rightValue = sumOfLeftLeaves(root->right); // 右
|
||||
// 中
|
||||
int midValue = 0;
|
||||
if (root->left && !root->left->left && !root->left->right) {
|
||||
midValue = root->left->val;
|
||||
}
|
||||
int sum = midValue + leftValue + rightValue;
|
||||
return sum;
|
||||
|
||||
```
|
||||
|
||||
|
||||
整体递归代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int sumOfLeftLeaves(TreeNode* root) {
|
||||
if (root == NULL) return 0;
|
||||
|
||||
int leftValue = sumOfLeftLeaves(root->left); // 左
|
||||
int rightValue = sumOfLeftLeaves(root->right); // 右
|
||||
// 中
|
||||
int midValue = 0;
|
||||
if (root->left && !root->left->left && !root->left->right) { // 中
|
||||
midValue = root->left->val;
|
||||
}
|
||||
int sum = midValue + leftValue + rightValue;
|
||||
return sum;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
以上代码精简之后如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int sumOfLeftLeaves(TreeNode* root) {
|
||||
if (root == NULL) return 0;
|
||||
int midValue = 0;
|
||||
if (root->left != NULL && root->left->left == NULL && root->left->right == NULL) {
|
||||
midValue = root->left->val;
|
||||
}
|
||||
return midValue + sumOfLeftLeaves(root->left) + sumOfLeftLeaves(root->right);
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 迭代法
|
||||
|
||||
|
||||
本题迭代法使用前中后序都是可以的,只要把左叶子节点统计出来,就可以了,那么参考文章 [二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg)和[二叉树:前中后序迭代方式的写法就不能统一一下么?](https://mp.weixin.qq.com/s/WKg0Ty1_3SZkztpHubZPRg)中的写法,可以写出一个前序遍历的迭代法。
|
||||
|
||||
判断条件都是一样的,代码如下:
|
||||
|
||||
```C++
|
||||
|
||||
class Solution {
|
||||
public:
|
||||
int sumOfLeftLeaves(TreeNode* root) {
|
||||
stack<TreeNode*> st;
|
||||
if (root == NULL) return 0;
|
||||
st.push(root);
|
||||
int result = 0;
|
||||
while (!st.empty()) {
|
||||
TreeNode* node = st.top();
|
||||
st.pop();
|
||||
if (node->left != NULL && node->left->left == NULL && node->left->right == NULL) {
|
||||
result += node->left->val;
|
||||
}
|
||||
if (node->right) st.push(node->right);
|
||||
if (node->left) st.push(node->left);
|
||||
}
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
这道题目要求左叶子之和,其实是比较绕的,因为不能判断本节点是不是左叶子节点。
|
||||
|
||||
此时就要通过节点的父节点来判断其左孩子是不是左叶子了。
|
||||
|
||||
**平时我们解二叉树的题目时,已经习惯了通过节点的左右孩子判断本节点的属性,而本题我们要通过节点的父节点判断本节点的属性。**
|
||||
|
||||
希望通过这道题目,可以扩展大家对二叉树的解题思路。
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
Java:
|
||||
|
||||
**递归**
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
public int sumOfLeftLeaves(TreeNode root) {
|
||||
if (root == null) return 0;
|
||||
int leftValue = sumOfLeftLeaves(root.left); // 左
|
||||
int rightValue = sumOfLeftLeaves(root.right); // 右
|
||||
|
||||
int midValue = 0;
|
||||
if (root.left != null && root.left.left == null && root.left.right == null) { // 中
|
||||
midValue = root.left.val;
|
||||
}
|
||||
int sum = midValue + leftValue + rightValue;
|
||||
return sum;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**迭代**
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
public int sumOfLeftLeaves(TreeNode root) {
|
||||
if (root == null) return 0;
|
||||
Stack<TreeNode> stack = new Stack<> ();
|
||||
stack.add(root);
|
||||
int result = 0;
|
||||
while (!stack.isEmpty()) {
|
||||
TreeNode node = stack.pop();
|
||||
if (node.left != null && node.left.left == null && node.left.right == null) {
|
||||
result += node.left.val;
|
||||
}
|
||||
if (node.right != null) stack.add(node.right);
|
||||
if (node.left != null) stack.add(node.left);
|
||||
}
|
||||
return result;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
Python:
|
||||
```Python
|
||||
**递归**
|
||||
# Definition for a binary tree node.
|
||||
# class TreeNode:
|
||||
# def __init__(self, val=0, left=None, right=None):
|
||||
# self.val = val
|
||||
# self.left = left
|
||||
# self.right = right
|
||||
class Solution:
|
||||
def sumOfLeftLeaves(self, root: TreeNode) -> int:
|
||||
self.res=0
|
||||
def areleftleaves(root):
|
||||
if not root:return
|
||||
if root.left and (not root.left.left) and (not root.left.right):self.res+=root.left.val
|
||||
areleftleaves(root.left)
|
||||
areleftleaves(root.right)
|
||||
areleftleaves(root)
|
||||
return self.res
|
||||
```
|
||||
Go:
|
||||
|
||||
> 递归法
|
||||
|
||||
```go
|
||||
/**
|
||||
* Definition for a binary tree node.
|
||||
* type TreeNode struct {
|
||||
* Val int
|
||||
* Left *TreeNode
|
||||
* Right *TreeNode
|
||||
* }
|
||||
*/
|
||||
func sumOfLeftLeaves(root *TreeNode) int {
|
||||
var res int
|
||||
findLeft(root,&res)
|
||||
return res
|
||||
}
|
||||
func findLeft(root *TreeNode,res *int){
|
||||
//左节点
|
||||
if root.Left!=nil&&root.Left.Left==nil&&root.Left.Right==nil{
|
||||
*res=*res+root.Left.Val
|
||||
}
|
||||
if root.Left!=nil{
|
||||
findLeft(root.Left,res)
|
||||
}
|
||||
if root.Right!=nil{
|
||||
findLeft(root.Right,res)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
> 迭代法
|
||||
|
||||
```go
|
||||
/**
|
||||
* Definition for a binary tree node.
|
||||
* type TreeNode struct {
|
||||
* Val int
|
||||
* Left *TreeNode
|
||||
* Right *TreeNode
|
||||
* }
|
||||
*/
|
||||
func sumOfLeftLeaves(root *TreeNode) int {
|
||||
var res int
|
||||
queue:=list.New()
|
||||
queue.PushBack(root)
|
||||
for queue.Len()>0{
|
||||
length:=queue.Len()
|
||||
for i:=0;i<length;i++{
|
||||
node:=queue.Remove(queue.Front()).(*TreeNode)
|
||||
if node.Left!=nil&&node.Left.Left==nil&&node.Left.Right==nil{
|
||||
res=res+node.Left.Val
|
||||
}
|
||||
if node.Left!=nil{
|
||||
queue.PushBack(node.Left)
|
||||
}
|
||||
if node.Right!=nil{
|
||||
queue.PushBack(node.Right)
|
||||
}
|
||||
}
|
||||
}
|
||||
return res
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
JavaScript:
|
||||
递归版本
|
||||
```javascript
|
||||
var sumOfLeftLeaves = function(root) {
|
||||
//采用后序遍历 递归遍历
|
||||
// 1. 确定递归函数参数
|
||||
const nodesSum = function(node){
|
||||
// 2. 确定终止条件
|
||||
if(node===null){
|
||||
return 0;
|
||||
}
|
||||
let leftValue = sumOfLeftLeaves(node.left);
|
||||
let rightValue = sumOfLeftLeaves(node.right);
|
||||
// 3. 单层递归逻辑
|
||||
let midValue = 0;
|
||||
if(node.left&&node.left.left===null&&node.left.right===null){
|
||||
midValue = node.left.val;
|
||||
}
|
||||
let sum = midValue + leftValue + rightValue;
|
||||
return sum;
|
||||
}
|
||||
return nodesSum(root);
|
||||
};
|
||||
```
|
||||
迭代版本
|
||||
```javascript
|
||||
var sumOfLeftLeaves = function(root) {
|
||||
//采用层序遍历
|
||||
if(root===null){
|
||||
return null;
|
||||
}
|
||||
let queue = [];
|
||||
let sum = 0;
|
||||
queue.push(root);
|
||||
while(queue.length){
|
||||
let node = queue.shift();
|
||||
if(node.left!==null&&node.left.left===null&&node.left.right===null){
|
||||
sum+=node.left.val;
|
||||
}
|
||||
node.left&&queue.push(node.left);
|
||||
node.right&&queue.push(node.right);
|
||||
}
|
||||
return sum;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
251
problems/0406.根据身高重建队列.md
Normal file
251
problems/0406.根据身高重建队列.md
Normal file
@@ -0,0 +1,251 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 406.根据身高重建队列
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/queue-reconstruction-by-height/
|
||||
|
||||
假设有打乱顺序的一群人站成一个队列,数组 people 表示队列中一些人的属性(不一定按顺序)。每个 people[i] = [hi, ki] 表示第 i 个人的身高为 hi ,前面 正好 有 ki 个身高大于或等于 hi 的人。
|
||||
|
||||
请你重新构造并返回输入数组 people 所表示的队列。返回的队列应该格式化为数组 queue ,其中 queue[j] = [hj, kj] 是队列中第 j 个人的属性(queue[0] 是排在队列前面的人)。
|
||||
|
||||
示例 1:
|
||||
输入:people = [[7,0],[4,4],[7,1],[5,0],[6,1],[5,2]]
|
||||
输出:[[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]]
|
||||
解释:
|
||||
编号为 0 的人身高为 5 ,没有身高更高或者相同的人排在他前面。
|
||||
编号为 1 的人身高为 7 ,没有身高更高或者相同的人排在他前面。
|
||||
编号为 2 的人身高为 5 ,有 2 个身高更高或者相同的人排在他前面,即编号为 0 和 1 的人。
|
||||
编号为 3 的人身高为 6 ,有 1 个身高更高或者相同的人排在他前面,即编号为 1 的人。
|
||||
编号为 4 的人身高为 4 ,有 4 个身高更高或者相同的人排在他前面,即编号为 0、1、2、3 的人。
|
||||
编号为 5 的人身高为 7 ,有 1 个身高更高或者相同的人排在他前面,即编号为 1 的人。
|
||||
因此 [[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]] 是重新构造后的队列。
|
||||
|
||||
示例 2:
|
||||
输入:people = [[6,0],[5,0],[4,0],[3,2],[2,2],[1,4]]
|
||||
输出:[[4,0],[5,0],[2,2],[3,2],[1,4],[6,0]]
|
||||
|
||||
提示:
|
||||
|
||||
* 1 <= people.length <= 2000
|
||||
* 0 <= hi <= 10^6
|
||||
* 0 <= ki < people.length
|
||||
|
||||
题目数据确保队列可以被重建
|
||||
|
||||
## 思路
|
||||
|
||||
本题有两个维度,h和k,看到这种题目一定要想如何确定一个维度,然后在按照另一个维度重新排列。
|
||||
|
||||
其实如果大家认真做了[贪心算法:分发糖果](https://mp.weixin.qq.com/s/8MwlgFfvaNYmjGwjuMlETQ),就会发现和此题有点点的像。
|
||||
|
||||
在[贪心算法:分发糖果](https://mp.weixin.qq.com/s/8MwlgFfvaNYmjGwjuMlETQ)我就强调过一次,遇到两个维度权衡的时候,一定要先确定一个维度,再确定另一个维度。
|
||||
|
||||
**如果两个维度一起考虑一定会顾此失彼**。
|
||||
|
||||
对于本题相信大家困惑的点是先确定k还是先确定h呢,也就是究竟先按h排序呢,还先按照k排序呢?
|
||||
|
||||
如果按照k来从小到大排序,排完之后,会发现k的排列并不符合条件,身高也不符合条件,两个维度哪一个都没确定下来。
|
||||
|
||||
那么按照身高h来排序呢,身高一定是从大到小排(身高相同的话则k小的站前面),让高个子在前面。
|
||||
|
||||
**此时我们可以确定一个维度了,就是身高,前面的节点一定都比本节点高!**
|
||||
|
||||
那么只需要按照k为下标重新插入队列就可以了,为什么呢?
|
||||
|
||||
以图中{5,2} 为例:
|
||||
|
||||

|
||||
|
||||
|
||||
按照身高排序之后,优先按身高高的people的k来插入,后序插入节点也不会影响前面已经插入的节点,最终按照k的规则完成了队列。
|
||||
|
||||
所以在按照身高从大到小排序后:
|
||||
|
||||
**局部最优:优先按身高高的people的k来插入。插入操作过后的people满足队列属性**
|
||||
|
||||
**全局最优:最后都做完插入操作,整个队列满足题目队列属性**
|
||||
|
||||
局部最优可推出全局最优,找不出反例,那就试试贪心。
|
||||
|
||||
一些同学可能也会疑惑,你怎么知道局部最优就可以推出全局最优呢? 有数学证明么?
|
||||
|
||||
在贪心系列开篇词[关于贪心算法,你该了解这些!](https://mp.weixin.qq.com/s/O935TaoHE9Eexwe_vSbRAg)中,我已经讲过了这个问题了。
|
||||
|
||||
刷题或者面试的时候,手动模拟一下感觉可以局部最优推出整体最优,而且想不到反例,那么就试一试贪心,至于严格的数学证明,就不在讨论范围内了。
|
||||
|
||||
如果没有读过[关于贪心算法,你该了解这些!](https://mp.weixin.qq.com/s/O935TaoHE9Eexwe_vSbRAg)的同学建议读一下,相信对贪心就有初步的了解了。
|
||||
|
||||
回归本题,整个插入过程如下:
|
||||
|
||||
排序完的people:
|
||||
[[7,0], [7,1], [6,1], [5,0], [5,2],[4,4]]
|
||||
|
||||
插入的过程:
|
||||
插入[7,0]:[[7,0]]
|
||||
插入[7,1]:[[7,0],[7,1]]
|
||||
插入[6,1]:[[7,0],[6,1],[7,1]]
|
||||
插入[5,0]:[[5,0],[7,0],[6,1],[7,1]]
|
||||
插入[5,2]:[[5,0],[7,0],[5,2],[6,1],[7,1]]
|
||||
插入[4,4]:[[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]]
|
||||
|
||||
此时就按照题目的要求完成了重新排列。
|
||||
|
||||
C++代码如下:
|
||||
|
||||
```C++
|
||||
// 版本一
|
||||
class Solution {
|
||||
public:
|
||||
static bool cmp(const vector<int> a, const vector<int> b) {
|
||||
if (a[0] == b[0]) return a[1] < b[1];
|
||||
return a[0] > b[0];
|
||||
}
|
||||
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
|
||||
sort (people.begin(), people.end(), cmp);
|
||||
vector<vector<int>> que;
|
||||
for (int i = 0; i < people.size(); i++) {
|
||||
int position = people[i][1];
|
||||
que.insert(que.begin() + position, people[i]);
|
||||
}
|
||||
return que;
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度O(nlogn + n^2)
|
||||
* 空间复杂度O(n)
|
||||
|
||||
但使用vector是非常费时的,C++中vector(可以理解是一个动态数组,底层是普通数组实现的)如果插入元素大于预先普通数组大小,vector底部会有一个扩容的操作,即申请两倍于原先普通数组的大小,然后把数据拷贝到另一个更大的数组上。
|
||||
|
||||
所以使用vector(动态数组)来insert,是费时的,插入再拷贝的话,单纯一个插入的操作就是O(n^2)了,甚至可能拷贝好几次,就不止O(n^2)了。
|
||||
|
||||
改成链表之后,C++代码如下:
|
||||
|
||||
```C++
|
||||
// 版本二
|
||||
class Solution {
|
||||
public:
|
||||
// 身高从大到小排(身高相同k小的站前面)
|
||||
static bool cmp(const vector<int> a, const vector<int> b) {
|
||||
if (a[0] == b[0]) return a[1] < b[1];
|
||||
return a[0] > b[0];
|
||||
}
|
||||
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
|
||||
sort (people.begin(), people.end(), cmp);
|
||||
list<vector<int>> que; // list底层是链表实现,插入效率比vector高的多
|
||||
for (int i = 0; i < people.size(); i++) {
|
||||
int position = people[i][1]; // 插入到下标为position的位置
|
||||
std::list<vector<int>>::iterator it = que.begin();
|
||||
while (position--) { // 寻找在插入位置
|
||||
it++;
|
||||
}
|
||||
que.insert(it, people[i]);
|
||||
}
|
||||
return vector<vector<int>>(que.begin(), que.end());
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
* 时间复杂度O(nlogn + n^2)
|
||||
* 空间复杂度O(n)
|
||||
|
||||
大家可以把两个版本的代码提交一下试试,就可以发现其差别了!
|
||||
|
||||
关于本题使用数组还是使用链表的性能差异,我在[贪心算法:根据身高重建队列(续集)](https://mp.weixin.qq.com/s/K-pRN0lzR-iZhoi-1FgbSQ)中详细讲解了一波
|
||||
|
||||
## 总结
|
||||
|
||||
关于出现两个维度一起考虑的情况,我们已经做过两道题目了,另一道就是[贪心算法:分发糖果](https://mp.weixin.qq.com/s/8MwlgFfvaNYmjGwjuMlETQ)。
|
||||
|
||||
**其技巧都是确定一边然后贪心另一边,两边一起考虑,就会顾此失彼**。
|
||||
|
||||
这道题目可以说比[贪心算法:分发糖果](https://mp.weixin.qq.com/s/8MwlgFfvaNYmjGwjuMlETQ)难不少,其贪心的策略也是比较巧妙。
|
||||
|
||||
最后我给出了两个版本的代码,可以明显看是使用C++中的list(底层链表实现)比vector(数组)效率高得多。
|
||||
|
||||
**对使用某一种语言容器的使用,特性的选择都会不同程度上影响效率**。
|
||||
|
||||
所以很多人都说写算法题用什么语言都可以,主要体现在算法思维上,其实我是同意的但也不同意。
|
||||
|
||||
对于看别人题解的同学,题解用什么语言其实影响不大,只要题解把所使用语言特性优化的点讲出来,大家都可以看懂,并使用自己语言的时候注意一下。
|
||||
|
||||
对于写题解的同学,刷题用什么语言影响就非常大,如果自己语言没有学好而强调算法和编程语言没关系,其实是会误伤别人的。
|
||||
|
||||
**这也是我为什么统一使用C++写题解的原因**,其实用其他语言java、python、php、go啥的,我也能写,我的Github上也有用这些语言写的小项目,但写题解的话,我就不能保证把语言特性这块讲清楚,所以我始终坚持使用最熟悉的C++写题解。
|
||||
|
||||
**而且我在写题解的时候涉及语言特性,一般都会后面加上括号说明一下。没办法,认真负责就是我,哈哈**。
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
public int[][] reconstructQueue(int[][] people) {
|
||||
Arrays.sort(people, new Comparator<int[]>() {
|
||||
@Override
|
||||
public int compare(int[] o1, int[] o2) {
|
||||
if (o1[0] != o2[0]) {
|
||||
return Integer.compare(o2[0],o1[0]);
|
||||
} else {
|
||||
return Integer.compare(o1[1],o2[1]);
|
||||
}
|
||||
}
|
||||
});
|
||||
|
||||
LinkedList<int[]> que = new LinkedList<>();
|
||||
|
||||
for (int[] p : people) {
|
||||
que.add(p[1],p);
|
||||
}
|
||||
|
||||
return que.toArray(new int[people.length][]);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def reconstructQueue(self, people: List[List[int]]) -> List[List[int]]:
|
||||
people.sort(key=lambda x: (-x[0], x[1]))
|
||||
que = []
|
||||
for p in people:
|
||||
que.insert(p[1], p)
|
||||
return que
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
Javascript:
|
||||
```Javascript
|
||||
var reconstructQueue = function(people) {
|
||||
let queue = []
|
||||
people.sort((a, b ) => {
|
||||
if(b[0] !== a[0]) {
|
||||
return b[0] - a[0]
|
||||
} else {
|
||||
return a[1] - b[1]
|
||||
}
|
||||
|
||||
})
|
||||
|
||||
for(let i = 0; i < people.length; i++) {
|
||||
queue.splice(people[i][1], 0, people[i])
|
||||
}
|
||||
return queue
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
269
problems/0416.分割等和子集.md
Normal file
269
problems/0416.分割等和子集.md
Normal file
@@ -0,0 +1,269 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
## 416. 分割等和子集
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/partition-equal-subset-sum/
|
||||
|
||||
题目难易:中等
|
||||
|
||||
给定一个只包含正整数的非空数组。是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。
|
||||
|
||||
注意:
|
||||
每个数组中的元素不会超过 100
|
||||
数组的大小不会超过 200
|
||||
|
||||
示例 1:
|
||||
输入: [1, 5, 11, 5]
|
||||
输出: true
|
||||
解释: 数组可以分割成 [1, 5, 5] 和 [11].
|
||||
|
||||
示例 2:
|
||||
输入: [1, 2, 3, 5]
|
||||
输出: false
|
||||
解释: 数组不能分割成两个元素和相等的子集.
|
||||
|
||||
提示:
|
||||
* 1 <= nums.length <= 200
|
||||
* 1 <= nums[i] <= 100
|
||||
|
||||
## 思路
|
||||
|
||||
这道题目初步看,是如下两题几乎是一样的,大家可以用回溯法,解决如下两题
|
||||
|
||||
* 698.划分为k个相等的子集
|
||||
* 473.火柴拼正方形
|
||||
|
||||
这道题目是要找是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。
|
||||
|
||||
那么只要找到集合里能够出现 sum / 2 的子集总和,就算是可以分割成两个相同元素和子集了。
|
||||
|
||||
本题是可以用回溯暴力搜索出所有答案的,但最后超时了,也不想再优化了,放弃回溯,直接上01背包吧。
|
||||
|
||||
如果对01背包不够了解,建议仔细看完如下两篇:
|
||||
|
||||
* [动态规划:关于01背包问题,你该了解这些!](https://mp.weixin.qq.com/s/FwIiPPmR18_AJO5eiidT6w)
|
||||
* [动态规划:关于01背包问题,你该了解这些!(滚动数组)](https://mp.weixin.qq.com/s/M4uHxNVKRKm5HPjkNZBnFA)
|
||||
|
||||
## 01背包问题
|
||||
|
||||
背包问题,大家都知道,有N件物品和一个最多能被重量为W 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品只能用一次,求解将哪些物品装入背包里物品价值总和最大。
|
||||
|
||||
**背包问题有多种背包方式,常见的有:01背包、完全背包、多重背包、分组背包和混合背包等等。**
|
||||
|
||||
要注意题目描述中商品是不是可以重复放入。
|
||||
|
||||
**即一个商品如果可以重复多次放入是完全背包,而只能放入一次是01背包,写法还是不一样的。**
|
||||
|
||||
**要明确本题中我们要使用的是01背包,因为元素我们只能用一次。**
|
||||
|
||||
回归主题:首先,本题要求集合里能否出现总和为 sum / 2 的子集。
|
||||
|
||||
那么来一一对应一下本题,看看背包问题如果来解决。
|
||||
|
||||
**只有确定了如下四点,才能把01背包问题套到本题上来。**
|
||||
|
||||
* 背包的体积为sum / 2
|
||||
* 背包要放入的商品(集合里的元素)重量为 元素的数值,价值也为元素的数值
|
||||
* 背包如何正好装满,说明找到了总和为 sum / 2 的子集。
|
||||
* 背包中每一个元素是不可重复放入。
|
||||
|
||||
以上分析完,我们就可以套用01背包,来解决这个问题了。
|
||||
|
||||
动规五部曲分析如下:
|
||||
|
||||
1. 确定dp数组以及下标的含义
|
||||
|
||||
01背包中,dp[i] 表示: 容量为j的背包,所背的物品价值可以最大为dp[j]。
|
||||
|
||||
**套到本题,dp[i]表示 背包总容量是i,最大可以凑成i的子集总和为dp[i]**。
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
01背包的递推公式为:dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
|
||||
|
||||
本题,相当于背包里放入数值,那么物品i的重量是nums[i],其价值也是nums[i]。
|
||||
|
||||
所以递推公式:dp[j] = max(dp[j], dp[j - nums[i]] + nums[i]);
|
||||
|
||||
|
||||
3. dp数组如何初始化
|
||||
|
||||
在01背包,一维dp如何初始化,已经讲过,
|
||||
|
||||
从dp[j]的定义来看,首先dp[0]一定是0。
|
||||
|
||||
如果如果题目给的价值都是正整数那么非0下标都初始化为0就可以了,如果题目给的价值有负数,那么非0下标就要初始化为负无穷。
|
||||
|
||||
**这样才能让dp数组在递归公式的过程中取的最大的价值,而不是被初始值覆盖了**。
|
||||
|
||||
本题题目中 只包含正整数的非空数组,所以非0下标的元素初始化为0就可以了。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
// 题目中说:每个数组中的元素不会超过 100,数组的大小不会超过 200
|
||||
// 总和不会大于20000,背包最大只需要其中一半,所以10001大小就可以了
|
||||
vector<int> dp(10001, 0);
|
||||
```
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
在[动态规划:关于01背包问题,你该了解这些!(滚动数组)](https://mp.weixin.qq.com/s/M4uHxNVKRKm5HPjkNZBnFA)中就已经说明:如果使用一维dp数组,物品遍历的for循环放在外层,遍历背包的for循环放在内层,且内层for循环倒叙遍历!
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
// 开始 01背包
|
||||
for(int i = 0; i < nums.size(); i++) {
|
||||
for(int j = target; j >= nums[i]; j--) { // 每一个元素一定是不可重复放入,所以从大到小遍历
|
||||
dp[j] = max(dp[j], dp[j - nums[i]] + nums[i]);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
5. 举例推导dp数组
|
||||
|
||||
dp[i]的数值一定是小于等于i的。
|
||||
|
||||
**如果dp[i] == i 说明,集合中的子集总和正好可以凑成总和i,理解这一点很重要。**
|
||||
|
||||
用例1,输入[1,5,11,5] 为例,如图:
|
||||
|
||||
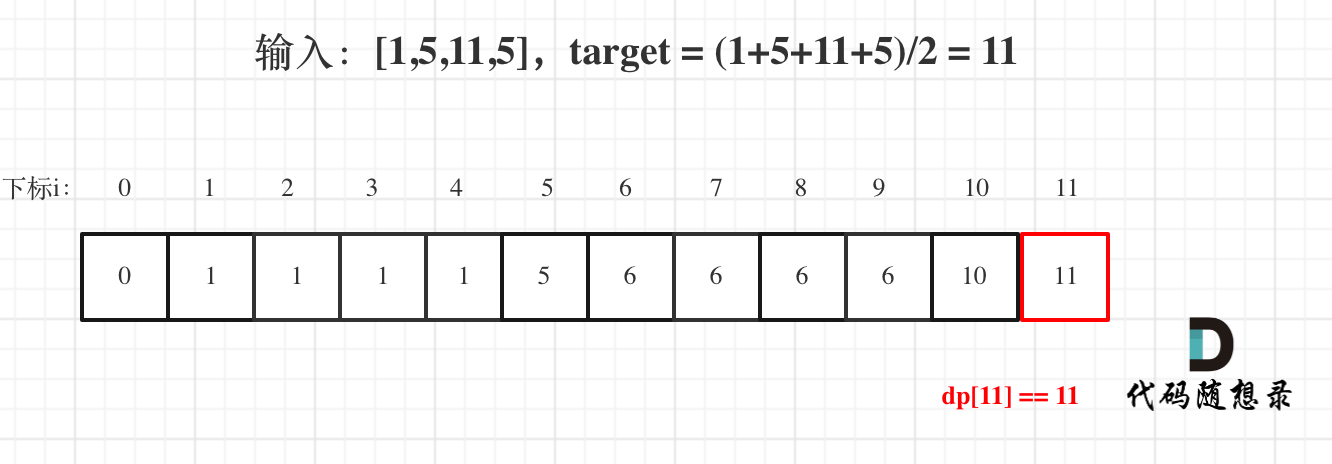
|
||||
|
||||
最后dp[11] == 11,说明可以将这个数组分割成两个子集,使得两个子集的元素和相等。
|
||||
|
||||
综上分析完毕,C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
bool canPartition(vector<int>& nums) {
|
||||
int sum = 0;
|
||||
|
||||
// dp[i]中的i表示背包内总和
|
||||
// 题目中说:每个数组中的元素不会超过 100,数组的大小不会超过 200
|
||||
// 总和不会大于20000,背包最大只需要其中一半,所以10001大小就可以了
|
||||
vector<int> dp(10001, 0);
|
||||
for (int i = 0; i < nums.size(); i++) {
|
||||
sum += nums[i];
|
||||
}
|
||||
if (sum % 2 == 1) return false;
|
||||
int target = sum / 2;
|
||||
|
||||
// 开始 01背包
|
||||
for(int i = 0; i < nums.size(); i++) {
|
||||
for(int j = target; j >= nums[i]; j--) { // 每一个元素一定是不可重复放入,所以从大到小遍历
|
||||
dp[j] = max(dp[j], dp[j - nums[i]] + nums[i]);
|
||||
}
|
||||
}
|
||||
// 集合中的元素正好可以凑成总和target
|
||||
if (dp[target] == target) return true;
|
||||
return false;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
* 时间复杂度:O(n^2)
|
||||
* 空间复杂度:O(n),虽然dp数组大小为一个常数,但是大常数
|
||||
|
||||
## 总结
|
||||
|
||||
这道题目就是一道01背包应用类的题目,需要我们拆解题目,然后套入01背包的场景。
|
||||
|
||||
01背包相对于本题,主要要理解,题目中物品是nums[i],重量是nums[i],价值也是nums[i],背包体积是sum/2。
|
||||
|
||||
看代码的话,就可以发现,基本就是按照01背包的写法来的。
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
public boolean canPartition(int[] nums) {
|
||||
int sum = 0;
|
||||
for (int i : nums) {
|
||||
sum += i;
|
||||
}
|
||||
if ((sum & 1) == 1) {
|
||||
return false;
|
||||
}
|
||||
int length = nums.length;
|
||||
int target = sum >> 1;
|
||||
//dp[j]表示前i个元素可以找到相加等于j情况
|
||||
boolean[] dp = new boolean[target + 1];
|
||||
//对于第一个元素,只有当j=nums[0]时,才恰好填充满
|
||||
if (nums[0] <= target) {
|
||||
dp[nums[0]] = true;
|
||||
}
|
||||
|
||||
for (int i = 1; i < length; i++) {
|
||||
//j由右往左直到nums[i]
|
||||
for (int j = target; j >= nums[i]; j--) {
|
||||
//只有两种情况,要么放,要么不放
|
||||
//取其中的TRUE值
|
||||
dp[j] = dp[j] || dp[j - nums[i]];
|
||||
}
|
||||
//一旦满足,结束,因为只需要找到一组值即可
|
||||
if (dp[target]) {
|
||||
return dp[target];
|
||||
}
|
||||
}
|
||||
return dp[target];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def canPartition(self, nums: List[int]) -> bool:
|
||||
taraget = sum(nums)
|
||||
if taraget % 2 == 1: return False
|
||||
taraget //= 2
|
||||
dp = [0] * 10001
|
||||
for i in range(len(nums)):
|
||||
for j in range(taraget, nums[i] - 1, -1):
|
||||
dp[j] = max(dp[j], dp[j - nums[i]] + nums[i])
|
||||
return taraget == dp[taraget]
|
||||
```
|
||||
Go:
|
||||
|
||||
|
||||
javaScript:
|
||||
|
||||
```js
|
||||
var canPartition = function(nums) {
|
||||
const sum = (nums.reduce((p, v) => p + v));
|
||||
if (sum & 1) return false;
|
||||
const dp = Array(sum / 2 + 1).fill(0);
|
||||
for(let i = 0; i < nums.length; i++) {
|
||||
for(let j = sum / 2; j >= nums[i]; j--) {
|
||||
dp[j] = Math.max(dp[j], dp[j - nums[i]] + nums[i]);
|
||||
if (dp[j] === sum / 2) {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[sum / 2] === sum / 2;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
258
problems/0435.无重叠区间.md
Normal file
258
problems/0435.无重叠区间.md
Normal file
@@ -0,0 +1,258 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 435. 无重叠区间
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/non-overlapping-intervals/
|
||||
|
||||
给定一个区间的集合,找到需要移除区间的最小数量,使剩余区间互不重叠。
|
||||
|
||||
注意:
|
||||
可以认为区间的终点总是大于它的起点。
|
||||
区间 [1,2] 和 [2,3] 的边界相互“接触”,但没有相互重叠。
|
||||
|
||||
示例 1:
|
||||
输入: [ [1,2], [2,3], [3,4], [1,3] ]
|
||||
输出: 1
|
||||
解释: 移除 [1,3] 后,剩下的区间没有重叠。
|
||||
|
||||
示例 2:
|
||||
输入: [ [1,2], [1,2], [1,2] ]
|
||||
输出: 2
|
||||
解释: 你需要移除两个 [1,2] 来使剩下的区间没有重叠。
|
||||
|
||||
示例 3:
|
||||
输入: [ [1,2], [2,3] ]
|
||||
输出: 0
|
||||
解释: 你不需要移除任何区间,因为它们已经是无重叠的了。
|
||||
|
||||
## 思路
|
||||
|
||||
**相信很多同学看到这道题目都冥冥之中感觉要排序,但是究竟是按照右边界排序,还是按照左边界排序呢?**
|
||||
|
||||
这其实是一个难点!
|
||||
|
||||
按照右边界排序,就要从左向右遍历,因为右边界越小越好,只要右边界越小,留给下一个区间的空间就越大,所以从左向右遍历,优先选右边界小的。
|
||||
|
||||
按照左边界排序,就要从右向左遍历,因为左边界数值越大越好(越靠右),这样就给前一个区间的空间就越大,所以可以从右向左遍历。
|
||||
|
||||
如果按照左边界排序,还从左向右遍历的话,其实也可以,逻辑会有所不同。
|
||||
|
||||
一些同学做这道题目可能真的去模拟去重复区间的行为,这是比较麻烦的,还要去删除区间。
|
||||
|
||||
题目只是要求移除区间的个数,没有必要去真实的模拟删除区间!
|
||||
|
||||
**我来按照右边界排序,从左向右记录非交叉区间的个数。最后用区间总数减去非交叉区间的个数就是需要移除的区间个数了**。
|
||||
|
||||
此时问题就是要求非交叉区间的最大个数。
|
||||
|
||||
右边界排序之后,局部最优:优先选右边界小的区间,所以从左向右遍历,留给下一个区间的空间大一些,从而尽量避免交叉。全局最优:选取最多的非交叉区间。
|
||||
|
||||
局部最优推出全局最优,试试贪心!
|
||||
|
||||
这里记录非交叉区间的个数还是有技巧的,如图:
|
||||
|
||||

|
||||
|
||||
区间,1,2,3,4,5,6都按照右边界排好序。
|
||||
|
||||
每次取非交叉区间的时候,都是可右边界最小的来做分割点(这样留给下一个区间的空间就越大),所以第一条分割线就是区间1结束的位置。
|
||||
|
||||
接下来就是找大于区间1结束位置的区间,是从区间4开始。**那有同学问了为什么不从区间5开始?别忘已经是按照右边界排序的了**。
|
||||
|
||||
区间4结束之后,在找到区间6,所以一共记录非交叉区间的个数是三个。
|
||||
|
||||
总共区间个数为6,减去非交叉区间的个数3。移除区间的最小数量就是3。
|
||||
|
||||
C++代码如下:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
// 按照区间右边界排序
|
||||
static bool cmp (const vector<int>& a, const vector<int>& b) {
|
||||
return a[1] < b[1];
|
||||
}
|
||||
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
|
||||
if (intervals.size() == 0) return 0;
|
||||
sort(intervals.begin(), intervals.end(), cmp);
|
||||
int count = 1; // 记录非交叉区间的个数
|
||||
int end = intervals[0][1]; // 记录区间分割点
|
||||
for (int i = 1; i < intervals.size(); i++) {
|
||||
if (end <= intervals[i][0]) {
|
||||
end = intervals[i][1];
|
||||
count++;
|
||||
}
|
||||
}
|
||||
return intervals.size() - count;
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度:O(nlogn) ,有一个快排
|
||||
* 空间复杂度:O(1)
|
||||
|
||||
大家此时会发现如此复杂的一个问题,代码实现却这么简单!
|
||||
|
||||
## 总结
|
||||
|
||||
本题我认为难度级别可以算是hard级别的!
|
||||
|
||||
总结如下难点:
|
||||
|
||||
* 难点一:一看题就有感觉需要排序,但究竟怎么排序,按左边界排还是右边界排。
|
||||
* 难点二:排完序之后如何遍历,如果没有分析好遍历顺序,那么排序就没有意义了。
|
||||
* 难点三:直接求重复的区间是复杂的,转而求最大非重复区间个数。
|
||||
* 难点四:求最大非重复区间个数时,需要一个分割点来做标记。
|
||||
|
||||
**这四个难点都不好想,但任何一个没想到位,这道题就解不了**。
|
||||
|
||||
一些录友可能看网上的题解代码很简单,照葫芦画瓢稀里糊涂的就过了,但是其题解可能并没有把问题难点讲清楚,然后自己再没有钻研的话,那么一道贪心经典区间问题就这么浪费掉了。
|
||||
|
||||
贪心就是这样,代码有时候很简单(不是指代码短,而是逻辑简单),但想法是真的难!
|
||||
|
||||
这和动态规划还不一样,动规的代码有个递推公式,可能就看不懂了,而贪心往往是直白的代码,但想法读不懂,哈哈。
|
||||
|
||||
**所以我把本题的难点也一一列出,帮大家不仅代码看的懂,想法也理解的透彻!**
|
||||
|
||||
## 补充
|
||||
|
||||
本题其实和[贪心算法:用最少数量的箭引爆气球](https://mp.weixin.qq.com/s/HxVAJ6INMfNKiGwI88-RFw)非常像,弓箭的数量就相当于是非交叉区间的数量,只要把弓箭那道题目代码里射爆气球的判断条件加个等号(认为[0,1][1,2]不是相邻区间),然后用总区间数减去弓箭数量 就是要移除的区间数量了。
|
||||
|
||||
把[贪心算法:用最少数量的箭引爆气球](https://mp.weixin.qq.com/s/HxVAJ6INMfNKiGwI88-RFw)代码稍做修改,就可以AC本题。
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
// 按照区间右边界排序
|
||||
static bool cmp (const vector<int>& a, const vector<int>& b) {
|
||||
return a[1] < b[1];
|
||||
}
|
||||
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
|
||||
if (intervals.size() == 0) return 0;
|
||||
sort(intervals.begin(), intervals.end(), cmp);
|
||||
|
||||
int result = 1; // points 不为空至少需要一支箭
|
||||
for (int i = 1; i < intervals.size(); i++) {
|
||||
if (intervals[i][0] >= intervals[i - 1][1]) {
|
||||
result++; // 需要一支箭
|
||||
}
|
||||
else { // 气球i和气球i-1挨着
|
||||
intervals[i][1] = min(intervals[i - 1][1], intervals[i][1]); // 更新重叠气球最小右边界
|
||||
}
|
||||
}
|
||||
return intervals.size() - result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
这里按照 左区间遍历,或者按照右边界遍历,都可以AC,具体原因我还没有仔细看,后面有空再补充。
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
// 按照区间左边界排序
|
||||
static bool cmp (const vector<int>& a, const vector<int>& b) {
|
||||
return a[0] < b[0];
|
||||
}
|
||||
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
|
||||
if (intervals.size() == 0) return 0;
|
||||
sort(intervals.begin(), intervals.end(), cmp);
|
||||
|
||||
int result = 1; // points 不为空至少需要一支箭
|
||||
for (int i = 1; i < intervals.size(); i++) {
|
||||
if (intervals[i][0] >= intervals[i - 1][1]) {
|
||||
result++; // 需要一支箭
|
||||
}
|
||||
else { // 气球i和气球i-1挨着
|
||||
intervals[i][1] = min(intervals[i - 1][1], intervals[i][1]); // 更新重叠气球最小右边界
|
||||
}
|
||||
}
|
||||
return intervals.size() - result;
|
||||
}
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
public int eraseOverlapIntervals(int[][] intervals) {
|
||||
if (intervals.length < 2) return 0;
|
||||
Arrays.sort(intervals, new Comparator<int[]>() {
|
||||
@Override
|
||||
public int compare(int[] o1, int[] o2) {
|
||||
if (o1[0] != o2[0]) {
|
||||
return Integer.compare(o1[1],o2[1]);
|
||||
} else {
|
||||
return Integer.compare(o2[0],o1[0]);
|
||||
}
|
||||
}
|
||||
});
|
||||
|
||||
int count = 0;
|
||||
int edge = intervals[0][1];
|
||||
for (int i = 1; i < intervals.length; i++) {
|
||||
if (intervals[i][0] < edge) {
|
||||
count++;
|
||||
} else {
|
||||
edge = intervals[i][1];
|
||||
}
|
||||
}
|
||||
return count;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:
|
||||
if len(intervals) == 0: return 0
|
||||
intervals.sort(key=lambda x: x[1])
|
||||
count = 1 # 记录非交叉区间的个数
|
||||
end = intervals[0][1] # 记录区间分割点
|
||||
for i in range(1, len(intervals)):
|
||||
if end <= intervals[i][0]:
|
||||
count += 1
|
||||
end = intervals[i][1]
|
||||
return len(intervals) - count
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
Javascript:
|
||||
```Javascript
|
||||
var eraseOverlapIntervals = function(intervals) {
|
||||
intervals.sort((a, b) => {
|
||||
return a[1] - b[1]
|
||||
})
|
||||
|
||||
let count = 1
|
||||
let end = intervals[0][1]
|
||||
|
||||
for(let i = 1; i < intervals.length; i++) {
|
||||
let interval = intervals[i]
|
||||
if(interval[0] >= right) {
|
||||
end = interval[1]
|
||||
count += 1
|
||||
}
|
||||
}
|
||||
|
||||
return intervals.length - count
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
413
problems/0450.删除二叉搜索树中的节点.md
Normal file
413
problems/0450.删除二叉搜索树中的节点.md
Normal file
@@ -0,0 +1,413 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
> 二叉搜索树删除节点就涉及到结构调整了
|
||||
|
||||
## 450.删除二叉搜索树中的节点
|
||||
|
||||
题目链接: https://leetcode-cn.com/problems/delete-node-in-a-bst/
|
||||
|
||||
给定一个二叉搜索树的根节点 root 和一个值 key,删除二叉搜索树中的 key 对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用。
|
||||
|
||||
一般来说,删除节点可分为两个步骤:
|
||||
|
||||
首先找到需要删除的节点;
|
||||
如果找到了,删除它。
|
||||
说明: 要求算法时间复杂度为 O(h),h 为树的高度。
|
||||
|
||||
示例:
|
||||
|
||||

|
||||
|
||||
## 思路
|
||||
|
||||
搜索树的节点删除要比节点增加复杂的多,有很多情况需要考虑,做好心里准备。
|
||||
|
||||
## 递归
|
||||
|
||||
递归三部曲:
|
||||
|
||||
* 确定递归函数参数以及返回值
|
||||
|
||||
说道递归函数的返回值,在[二叉树:搜索树中的插入操作](https://mp.weixin.qq.com/s/lwKkLQcfbCNX2W-5SOeZEA)中通过递归返回值来加入新节点, 这里也可以通过递归返回值删除节点。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
TreeNode* deleteNode(TreeNode* root, int key)
|
||||
```
|
||||
|
||||
* 确定终止条件
|
||||
|
||||
遇到空返回,其实这也说明没找到删除的节点,遍历到空节点直接返回了
|
||||
|
||||
```
|
||||
if (root == nullptr) return root;
|
||||
```
|
||||
|
||||
* 确定单层递归的逻辑
|
||||
|
||||
这里就把平衡二叉树中删除节点遇到的情况都搞清楚。
|
||||
|
||||
有以下五种情况:
|
||||
|
||||
* 第一种情况:没找到删除的节点,遍历到空节点直接返回了
|
||||
* 找到删除的节点
|
||||
* 第二种情况:左右孩子都为空(叶子节点),直接删除节点, 返回NULL为根节点
|
||||
* 第三种情况:删除节点的左孩子为空,右孩子不为空,删除节点,右孩子补位,返回右孩子为根节点
|
||||
* 第四种情况:删除节点的右孩子为空,左孩子不为空,删除节点,左孩子补位,返回左孩子为根节点
|
||||
* 第五种情况:左右孩子节点都不为空,则将删除节点的左子树头结点(左孩子)放到删除节点的右子树的最左面节点的左孩子上,返回删除节点右孩子为新的根节点。
|
||||
|
||||
第五种情况有点难以理解,看下面动画:
|
||||
|
||||

|
||||
|
||||
动画中颗二叉搜索树中,删除元素7, 那么删除节点(元素7)的左孩子就是5,删除节点(元素7)的右子树的最左面节点是元素8。
|
||||
|
||||
将删除节点(元素7)的左孩子放到删除节点(元素7)的右子树的最左面节点(元素8)的左孩子上,就是把5为根节点的子树移到了8的左孩子的位置。
|
||||
|
||||
要删除的节点(元素7)的右孩子(元素9)为新的根节点。.
|
||||
|
||||
这样就完成删除元素7的逻辑,最好动手画一个图,尝试删除一个节点试试。
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
if (root->val == key) {
|
||||
// 第二种情况:左右孩子都为空(叶子节点),直接删除节点, 返回NULL为根节点
|
||||
// 第三种情况:其左孩子为空,右孩子不为空,删除节点,右孩子补位 ,返回右孩子为根节点
|
||||
if (root->left == nullptr) return root->right;
|
||||
// 第四种情况:其右孩子为空,左孩子不为空,删除节点,左孩子补位,返回左孩子为根节点
|
||||
else if (root->right == nullptr) return root->left;
|
||||
// 第五种情况:左右孩子节点都不为空,则将删除节点的左子树放到删除节点的右子树的最左面节点的左孩子的位置
|
||||
// 并返回删除节点右孩子为新的根节点。
|
||||
else {
|
||||
TreeNode* cur = root->right; // 找右子树最左面的节点
|
||||
while(cur->left != nullptr) {
|
||||
cur = cur->left;
|
||||
}
|
||||
cur->left = root->left; // 把要删除的节点(root)左子树放在cur的左孩子的位置
|
||||
TreeNode* tmp = root; // 把root节点保存一下,下面来删除
|
||||
root = root->right; // 返回旧root的右孩子作为新root
|
||||
delete tmp; // 释放节点内存(这里不写也可以,但C++最好手动释放一下吧)
|
||||
return root;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这里相当于把新的节点返回给上一层,上一层就要用 root->left 或者 root->right接住,代码如下:
|
||||
|
||||
```
|
||||
if (root->val > key) root->left = deleteNode(root->left, key);
|
||||
if (root->val < key) root->right = deleteNode(root->right, key);
|
||||
return root;
|
||||
```
|
||||
|
||||
**整体代码如下:(注释中:情况1,2,3,4,5和上面分析严格对应)**
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
TreeNode* deleteNode(TreeNode* root, int key) {
|
||||
if (root == nullptr) return root; // 第一种情况:没找到删除的节点,遍历到空节点直接返回了
|
||||
if (root->val == key) {
|
||||
// 第二种情况:左右孩子都为空(叶子节点),直接删除节点, 返回NULL为根节点
|
||||
// 第三种情况:其左孩子为空,右孩子不为空,删除节点,右孩子补位 ,返回右孩子为根节点
|
||||
if (root->left == nullptr) return root->right;
|
||||
// 第四种情况:其右孩子为空,左孩子不为空,删除节点,左孩子补位,返回左孩子为根节点
|
||||
else if (root->right == nullptr) return root->left;
|
||||
// 第五种情况:左右孩子节点都不为空,则将删除节点的左子树放到删除节点的右子树的最左面节点的左孩子的位置
|
||||
// 并返回删除节点右孩子为新的根节点。
|
||||
else {
|
||||
TreeNode* cur = root->right; // 找右子树最左面的节点
|
||||
while(cur->left != nullptr) {
|
||||
cur = cur->left;
|
||||
}
|
||||
cur->left = root->left; // 把要删除的节点(root)左子树放在cur的左孩子的位置
|
||||
TreeNode* tmp = root; // 把root节点保存一下,下面来删除
|
||||
root = root->right; // 返回旧root的右孩子作为新root
|
||||
delete tmp; // 释放节点内存(这里不写也可以,但C++最好手动释放一下吧)
|
||||
return root;
|
||||
}
|
||||
}
|
||||
if (root->val > key) root->left = deleteNode(root->left, key);
|
||||
if (root->val < key) root->right = deleteNode(root->right, key);
|
||||
return root;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 普通二叉树的删除方式
|
||||
|
||||
这里我在介绍一种通用的删除,普通二叉树的删除方式(没有使用搜索树的特性,遍历整棵树),用交换值的操作来删除目标节点。
|
||||
|
||||
代码中目标节点(要删除的节点)被操作了两次:
|
||||
|
||||
* 第一次是和目标节点的右子树最左面节点交换。
|
||||
* 第二次直接被NULL覆盖了。
|
||||
|
||||
思路有点绕,感兴趣的同学可以画图自己理解一下。
|
||||
|
||||
代码如下:(关键部分已经注释)
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
TreeNode* deleteNode(TreeNode* root, int key) {
|
||||
if (root == nullptr) return root;
|
||||
if (root->val == key) {
|
||||
if (root->right == nullptr) { // 这里第二次操作目标值:最终删除的作用
|
||||
return root->left;
|
||||
}
|
||||
TreeNode *cur = root->right;
|
||||
while (cur->left) {
|
||||
cur = cur->left;
|
||||
}
|
||||
swap(root->val, cur->val); // 这里第一次操作目标值:交换目标值其右子树最左面节点。
|
||||
}
|
||||
root->left = deleteNode(root->left, key);
|
||||
root->right = deleteNode(root->right, key);
|
||||
return root;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
这个代码是简短一些,思路也巧妙,但是不太好想,实操性不强,推荐第一种写法!
|
||||
|
||||
## 迭代法
|
||||
|
||||
删除节点的迭代法还是复杂一些的,但其本质我在递归法里都介绍了,最关键就是删除节点的操作(动画模拟的过程)
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
// 将目标节点(删除节点)的左子树放到 目标节点的右子树的最左面节点的左孩子位置上
|
||||
// 并返回目标节点右孩子为新的根节点
|
||||
// 是动画里模拟的过程
|
||||
TreeNode* deleteOneNode(TreeNode* target) {
|
||||
if (target == nullptr) return target;
|
||||
if (target->right == nullptr) return target->left;
|
||||
TreeNode* cur = target->right;
|
||||
while (cur->left) {
|
||||
cur = cur->left;
|
||||
}
|
||||
cur->left = target->left;
|
||||
return target->right;
|
||||
}
|
||||
public:
|
||||
TreeNode* deleteNode(TreeNode* root, int key) {
|
||||
if (root == nullptr) return root;
|
||||
TreeNode* cur = root;
|
||||
TreeNode* pre = nullptr; // 记录cur的父节点,用来删除cur
|
||||
while (cur) {
|
||||
if (cur->val == key) break;
|
||||
pre = cur;
|
||||
if (cur->val > key) cur = cur->left;
|
||||
else cur = cur->right;
|
||||
}
|
||||
if (pre == nullptr) { // 如果搜索树只有头结点
|
||||
return deleteOneNode(cur);
|
||||
}
|
||||
// pre 要知道是删左孩子还是右孩子
|
||||
if (pre->left && pre->left->val == key) {
|
||||
pre->left = deleteOneNode(cur);
|
||||
}
|
||||
if (pre->right && pre->right->val == key) {
|
||||
pre->right = deleteOneNode(cur);
|
||||
}
|
||||
return root;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
读完本篇,大家会发现二叉搜索树删除节点比增加节点复杂的多。
|
||||
|
||||
**因为二叉搜索树添加节点只需要在叶子上添加就可以的,不涉及到结构的调整,而删除节点操作涉及到结构的调整**。
|
||||
|
||||
这里我们依然使用递归函数的返回值来完成把节点从二叉树中移除的操作。
|
||||
|
||||
**这里最关键的逻辑就是第五种情况(删除一个左右孩子都不为空的节点),这种情况一定要想清楚**。
|
||||
|
||||
而且就算想清楚了,对应的代码也未必可以写出来,所以**这道题目即考察思维逻辑,也考察代码能力**。
|
||||
|
||||
递归中我给出了两种写法,推荐大家学会第一种(利用搜索树的特性)就可以了,第二种递归写法其实是比较绕的。
|
||||
|
||||
最后我也给出了相应的迭代法,就是模拟递归法中的逻辑来删除节点,但需要一个pre记录cur的父节点,方便做删除操作。
|
||||
|
||||
迭代法其实不太容易写出来,所以如果是初学者的话,彻底掌握第一种递归写法就够了。
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
public TreeNode deleteNode(TreeNode root, int key) {
|
||||
root = delete(root,key);
|
||||
return root;
|
||||
}
|
||||
|
||||
private TreeNode delete(TreeNode root, int key) {
|
||||
if (root == null) return null;
|
||||
|
||||
if (root.val > key) {
|
||||
root.left = delete(root.left,key);
|
||||
} else if (root.val < key) {
|
||||
root.right = delete(root.right,key);
|
||||
} else {
|
||||
if (root.left == null) return root.right;
|
||||
if (root.right == null) return root.left;
|
||||
TreeNode tmp = root.right;
|
||||
while (tmp.left != null) {
|
||||
tmp = tmp.left;
|
||||
}
|
||||
root.val = tmp.val;
|
||||
root.right = delete(root.right,tmp.val);
|
||||
}
|
||||
return root;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
# Definition for a binary tree node.
|
||||
# class TreeNode:
|
||||
# def __init__(self, val=0, left=None, right=None):
|
||||
# self.val = val
|
||||
# self.left = left
|
||||
# self.right = right
|
||||
class Solution:
|
||||
def deleteNode(self, root: TreeNode, key: int) -> TreeNode:
|
||||
if not root: return root #第一种情况:没找到删除的节点,遍历到空节点直接返回了
|
||||
if root.val == key:
|
||||
if not root.left and not root.right: #第二种情况:左右孩子都为空(叶子节点),直接删除节点, 返回NULL为根节点
|
||||
del root
|
||||
return None
|
||||
if not root.left and root.right: #第三种情况:其左孩子为空,右孩子不为空,删除节点,右孩子补位 ,返回右孩子为根节点
|
||||
tmp = root
|
||||
root = root.right
|
||||
del tmp
|
||||
return root
|
||||
if root.left and not root.right: #第四种情况:其右孩子为空,左孩子不为空,删除节点,左孩子补位,返回左孩子为根节点
|
||||
tmp = root
|
||||
root = root.left
|
||||
del tmp
|
||||
return root
|
||||
else: #第五种情况:左右孩子节点都不为空,则将删除节点的左子树放到删除节点的右子树的最左面节点的左孩子的位置
|
||||
v = root.right
|
||||
while v.left:
|
||||
v = v.left
|
||||
v.left = root.left
|
||||
tmp = root
|
||||
root = root.right
|
||||
del tmp
|
||||
return root
|
||||
if root.val > key: root.left = self.deleteNode(root.left,key) #左递归
|
||||
if root.val < key: root.right = self.deleteNode(root.right,key) #右递归
|
||||
return root
|
||||
```
|
||||
|
||||
Go:
|
||||
```Go
|
||||
func deleteNode(root *TreeNode, key int) *TreeNode {
|
||||
if root==nil{
|
||||
return nil
|
||||
}
|
||||
if key<root.Val{
|
||||
root.Left=deleteNode(root.Left,key)
|
||||
return root
|
||||
}
|
||||
if key>root.Val{
|
||||
root.Right=deleteNode(root.Right,key)
|
||||
return root
|
||||
}
|
||||
if root.Right==nil{
|
||||
return root.Left
|
||||
}
|
||||
if root.Left==nil{
|
||||
return root.Right
|
||||
}
|
||||
minnode:=root.Right
|
||||
for minnode.Left!=nil{
|
||||
minnode=minnode.Left
|
||||
}
|
||||
root.Val=minnode.Val
|
||||
root.Right=deleteNode1(root.Right)
|
||||
return root
|
||||
}
|
||||
|
||||
func deleteNode1(root *TreeNode)*TreeNode{
|
||||
if root.Left==nil{
|
||||
pRight:=root.Right
|
||||
root.Right=nil
|
||||
return pRight
|
||||
}
|
||||
root.Left=deleteNode1(root.Left)
|
||||
return root
|
||||
}
|
||||
```
|
||||
|
||||
JavaScript版本
|
||||
|
||||
> 递归
|
||||
|
||||
```javascript
|
||||
/**
|
||||
* Definition for a binary tree node.
|
||||
* function TreeNode(val, left, right) {
|
||||
* this.val = (val===undefined ? 0 : val)
|
||||
* this.left = (left===undefined ? null : left)
|
||||
* this.right = (right===undefined ? null : right)
|
||||
* }
|
||||
*/
|
||||
/**
|
||||
* @param {TreeNode} root
|
||||
* @param {number} key
|
||||
* @return {TreeNode}
|
||||
*/
|
||||
var deleteNode = function (root, key) {
|
||||
if (root === null)
|
||||
return root;
|
||||
if (root.val === key) {
|
||||
if (!root.left)
|
||||
return root.right;
|
||||
else if (!root.right)
|
||||
return root.left;
|
||||
else {
|
||||
let cur = root.right;
|
||||
while (cur.left) {
|
||||
cur = cur.left;
|
||||
}
|
||||
cur.left = root.left;
|
||||
let temp = root;
|
||||
root = root.right;
|
||||
delete root;
|
||||
return root;
|
||||
}
|
||||
}
|
||||
if (root.val > key)
|
||||
root.left = deleteNode(root.left, key);
|
||||
if (root.val < key)
|
||||
root.right = deleteNode(root.right, key);
|
||||
return root;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
202
problems/0452.用最少数量的箭引爆气球.md
Normal file
202
problems/0452.用最少数量的箭引爆气球.md
Normal file
@@ -0,0 +1,202 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 452. 用最少数量的箭引爆气球
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/minimum-number-of-arrows-to-burst-balloons/
|
||||
|
||||
在二维空间中有许多球形的气球。对于每个气球,提供的输入是水平方向上,气球直径的开始和结束坐标。由于它是水平的,所以纵坐标并不重要,因此只要知道开始和结束的横坐标就足够了。开始坐标总是小于结束坐标。
|
||||
|
||||
一支弓箭可以沿着 x 轴从不同点完全垂直地射出。在坐标 x 处射出一支箭,若有一个气球的直径的开始和结束坐标为 xstart,xend, 且满足 xstart ≤ x ≤ xend,则该气球会被引爆。可以射出的弓箭的数量没有限制。 弓箭一旦被射出之后,可以无限地前进。我们想找到使得所有气球全部被引爆,所需的弓箭的最小数量。
|
||||
|
||||
给你一个数组 points ,其中 points [i] = [xstart,xend] ,返回引爆所有气球所必须射出的最小弓箭数。
|
||||
|
||||
|
||||
示例 1:
|
||||
输入:points = [[10,16],[2,8],[1,6],[7,12]]
|
||||
|
||||
输出:2
|
||||
解释:对于该样例,x = 6 可以射爆 [2,8],[1,6] 两个气球,以及 x = 11 射爆另外两个气球
|
||||
|
||||
示例 2:
|
||||
输入:points = [[1,2],[3,4],[5,6],[7,8]]
|
||||
输出:4
|
||||
|
||||
示例 3:
|
||||
输入:points = [[1,2],[2,3],[3,4],[4,5]]
|
||||
输出:2
|
||||
|
||||
示例 4:
|
||||
输入:points = [[1,2]]
|
||||
输出:1
|
||||
|
||||
示例 5:
|
||||
输入:points = [[2,3],[2,3]]
|
||||
输出:1
|
||||
|
||||
提示:
|
||||
|
||||
* 0 <= points.length <= 10^4
|
||||
* points[i].length == 2
|
||||
* -2^31 <= xstart < xend <= 2^31 - 1
|
||||
|
||||
## 思路
|
||||
|
||||
如何使用最少的弓箭呢?
|
||||
|
||||
直觉上来看,貌似只射重叠最多的气球,用的弓箭一定最少,那么有没有当前重叠了三个气球,我射两个,留下一个和后面的一起射这样弓箭用的更少的情况呢?
|
||||
|
||||
尝试一下举反例,发现没有这种情况。
|
||||
|
||||
那么就试一试贪心吧!局部最优:当气球出现重叠,一起射,所用弓箭最少。全局最优:把所有气球射爆所用弓箭最少。
|
||||
|
||||
**算法确定下来了,那么如何模拟气球射爆的过程呢?是在数组中移除元素还是做标记呢?**
|
||||
|
||||
如果真实的模拟射气球的过程,应该射一个,气球数组就remove一个元素,这样最直观,毕竟气球被射了。
|
||||
|
||||
但仔细思考一下就发现:如果把气球排序之后,从前到后遍历气球,被射过的气球仅仅跳过就行了,没有必要让气球数组remote气球,只要记录一下箭的数量就可以了。
|
||||
|
||||
以上为思考过程,已经确定下来使用贪心了,那么开始解题。
|
||||
|
||||
**为了让气球尽可能的重叠,需要对数组进行排序**。
|
||||
|
||||
那么按照气球起始位置排序,还是按照气球终止位置排序呢?
|
||||
|
||||
其实都可以!只不过对应的遍历顺序不同,我就按照气球的起始位置排序了。
|
||||
|
||||
既然按照起始位置排序,那么就从前向后遍历气球数组,靠左尽可能让气球重复。
|
||||
|
||||
从前向后遍历遇到重叠的气球了怎么办?
|
||||
|
||||
**如果气球重叠了,重叠气球中右边边界的最小值 之前的区间一定需要一个弓箭**。
|
||||
|
||||
以题目示例: [[10,16],[2,8],[1,6],[7,12]]为例,如图:(方便起见,已经排序)
|
||||
|
||||
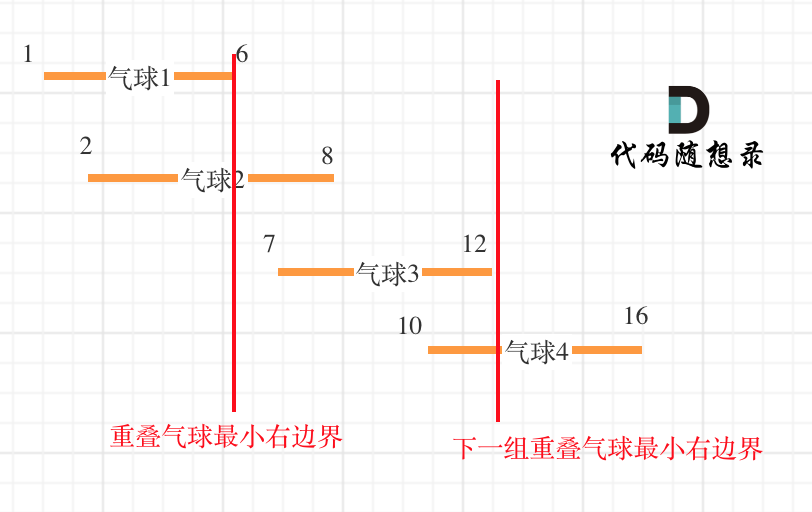
|
||||
|
||||
可以看出首先第一组重叠气球,一定是需要一个箭,气球3,的左边界大于了 第一组重叠气球的最小右边界,所以再需要一支箭来射气球3了。
|
||||
|
||||
C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
private:
|
||||
static bool cmp(const vector<int>& a, const vector<int>& b) {
|
||||
return a[0] < b[0];
|
||||
}
|
||||
public:
|
||||
int findMinArrowShots(vector<vector<int>>& points) {
|
||||
if (points.size() == 0) return 0;
|
||||
sort(points.begin(), points.end(), cmp);
|
||||
|
||||
int result = 1; // points 不为空至少需要一支箭
|
||||
for (int i = 1; i < points.size(); i++) {
|
||||
if (points[i][0] > points[i - 1][1]) { // 气球i和气球i-1不挨着,注意这里不是>=
|
||||
result++; // 需要一支箭
|
||||
}
|
||||
else { // 气球i和气球i-1挨着
|
||||
points[i][1] = min(points[i - 1][1], points[i][1]); // 更新重叠气球最小右边界
|
||||
}
|
||||
}
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
* 时间复杂度O(nlogn),因为有一个快排
|
||||
* 空间复杂度O(1)
|
||||
|
||||
可以看出代码并不复杂。
|
||||
|
||||
## 注意事项
|
||||
|
||||
注意题目中说的是:满足 xstart ≤ x ≤ xend,则该气球会被引爆。那么说明两个气球挨在一起不重叠也可以一起射爆,
|
||||
|
||||
所以代码中 `if (points[i][0] > points[i - 1][1])` 不能是>=
|
||||
|
||||
## 总结
|
||||
|
||||
这道题目贪心的思路很简单也很直接,就是重复的一起射了,但本题我认为是有难度的。
|
||||
|
||||
就算思路都想好了,模拟射气球的过程,很多同学真的要去模拟了,实时把气球从数组中移走,这么写的话就复杂了。
|
||||
|
||||
而且寻找重复的气球,寻找重叠气球最小右边界,其实都有代码技巧。
|
||||
|
||||
贪心题目有时候就是这样,看起来很简单,思路很直接,但是一写代码就感觉贼复杂无从下手。
|
||||
|
||||
这里其实是需要代码功底的,那代码功底怎么练?
|
||||
|
||||
**多看多写多总结!**
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
public int findMinArrowShots(int[][] points) {
|
||||
if (points.length == 0) return 0;
|
||||
Arrays.sort(points, (o1, o2) -> Integer.compare(o1[0], o2[0]));
|
||||
|
||||
int count = 1;
|
||||
for (int i = 1; i < points.length; i++) {
|
||||
if (points[i][0] > points[i - 1][1]) {
|
||||
count++;
|
||||
} else {
|
||||
points[i][1] = Math.min(points[i][1],points[i - 1][1]);
|
||||
}
|
||||
}
|
||||
return count;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python
|
||||
class Solution:
|
||||
def findMinArrowShots(self, points: List[List[int]]) -> int:
|
||||
if len(points) == 0: return 0
|
||||
points.sort(key=lambda x: x[0])
|
||||
result = 1
|
||||
for i in range(1, len(points)):
|
||||
if points[i][0] > points[i - 1][1]: # 气球i和气球i-1不挨着,注意这里不是>=
|
||||
result += 1
|
||||
else:
|
||||
points[i][1] = min(points[i - 1][1], points[i][1]) # 更新重叠气球最小右边界
|
||||
return result
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
Javascript:
|
||||
```Javascript
|
||||
var findMinArrowShots = function(points) {
|
||||
points.sort((a, b) => {
|
||||
return a[0] - b[0]
|
||||
})
|
||||
let result = 1
|
||||
for(let i = 1; i < points.length; i++) {
|
||||
if(points[i][0] > points[i - 1][1]) {
|
||||
result++
|
||||
} else {
|
||||
points[i][1] = Math.min(points[i - 1][1], points[i][1])
|
||||
}
|
||||
}
|
||||
|
||||
return result
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
237
problems/0454.四数相加II.md
Normal file
237
problems/0454.四数相加II.md
Normal file
@@ -0,0 +1,237 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
> 需要哈希的地方都能找到map的身影
|
||||
|
||||
# 第454题.四数相加II
|
||||
|
||||
|
||||
https://leetcode-cn.com/problems/4sum-ii/
|
||||
|
||||
给定四个包含整数的数组列表 A , B , C , D ,计算有多少个元组 (i, j, k, l) ,使得 A[i] + B[j] + C[k] + D[l] = 0。
|
||||
|
||||
为了使问题简单化,所有的 A, B, C, D 具有相同的长度 N,且 0 ≤ N ≤ 500 。所有整数的范围在 -2^28 到 2^28 - 1 之间,最终结果不会超过 2^31 - 1 。
|
||||
|
||||
**例如:**
|
||||
|
||||
输入:
|
||||
A = [ 1, 2]
|
||||
B = [-2,-1]
|
||||
C = [-1, 2]
|
||||
D = [ 0, 2]
|
||||
输出:
|
||||
2
|
||||
**解释:**
|
||||
两个元组如下:
|
||||
1. (0, 0, 0, 1) -> A[0] + B[0] + C[0] + D[1] = 1 + (-2) + (-1) + 2 = 0
|
||||
2. (1, 1, 0, 0) -> A[1] + B[1] + C[0] + D[0] = 2 + (-1) + (-1) + 0 = 0
|
||||
|
||||
|
||||
# 思路
|
||||
|
||||
本题咋眼一看好像和[0015.三数之和](https://mp.weixin.qq.com/s/r5cgZFu0tv4grBAexdcd8A),[0018.四数之和](https://mp.weixin.qq.com/s/nQrcco8AZJV1pAOVjeIU_g)差不多,其实差很多。
|
||||
|
||||
**本题是使用哈希法的经典题目,而[0015.三数之和](https://mp.weixin.qq.com/s/r5cgZFu0tv4grBAexdcd8A),[0018.四数之和](https://mp.weixin.qq.com/s/nQrcco8AZJV1pAOVjeIU_g)并不合适使用哈希法**,因为三数之和和四数之和这两道题目使用哈希法在不超时的情况下做到对结果去重是很困难的,很有多细节需要处理。
|
||||
|
||||
**而这道题目是四个独立的数组,只要找到A[i] + B[j] + C[k] + D[l] = 0就可以,不用考虑有重复的四个元素相加等于0的情况,所以相对于题目18. 四数之和,题目15.三数之和,还是简单了不少!**
|
||||
|
||||
如果本题想难度升级:就是给出一个数组(而不是四个数组),在这里找出四个元素相加等于0,答案中不可以包含重复的四元组,大家可以思考一下,后续的文章我也会讲到的。
|
||||
|
||||
本题解题步骤:
|
||||
|
||||
1. 首先定义 一个unordered_map,key放a和b两数之和,value 放a和b两数之和出现的次数。
|
||||
2. 遍历大A和大B数组,统计两个数组元素之和,和出现的次数,放到map中。
|
||||
3. 定义int变量count,用来统计a+b+c+d = 0 出现的次数。
|
||||
4. 在遍历大C和大D数组,找到如果 0-(c+d) 在map中出现过的话,就用count把map中key对应的value也就是出现次数统计出来。
|
||||
5. 最后返回统计值 count 就可以了
|
||||
|
||||
C++代码:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int fourSumCount(vector<int>& A, vector<int>& B, vector<int>& C, vector<int>& D) {
|
||||
unordered_map<int, int> umap; //key:a+b的数值,value:a+b数值出现的次数
|
||||
// 遍历大A和大B数组,统计两个数组元素之和,和出现的次数,放到map中
|
||||
for (int a : A) {
|
||||
for (int b : B) {
|
||||
umap[a + b]++;
|
||||
}
|
||||
}
|
||||
int count = 0; // 统计a+b+c+d = 0 出现的次数
|
||||
// 在遍历大C和大D数组,找到如果 0-(c+d) 在map中出现过的话,就把map中key对应的value也就是出现次数统计出来。
|
||||
for (int c : C) {
|
||||
for (int d : D) {
|
||||
if (umap.find(0 - (c + d)) != umap.end()) {
|
||||
count += umap[0 - (c + d)];
|
||||
}
|
||||
}
|
||||
}
|
||||
return count;
|
||||
}
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
public int fourSumCount(int[] nums1, int[] nums2, int[] nums3, int[] nums4) {
|
||||
Map<Integer, Integer> map = new HashMap<>();
|
||||
int temp;
|
||||
int res = 0;
|
||||
//统计两个数组中的元素之和,同时统计出现的次数,放入map
|
||||
for (int i : nums1) {
|
||||
for (int j : nums2) {
|
||||
temp = i + j;
|
||||
if (map.containsKey(temp)) {
|
||||
map.put(temp, map.get(temp) + 1);
|
||||
} else {
|
||||
map.put(temp, 1);
|
||||
}
|
||||
}
|
||||
}
|
||||
//统计剩余的两个元素的和,在map中找是否存在相加为0的情况,同时记录次数
|
||||
for (int i : nums3) {
|
||||
for (int j : nums4) {
|
||||
temp = i + j;
|
||||
if (map.containsKey(0 - temp)) {
|
||||
res += map.get(0 - temp);
|
||||
}
|
||||
}
|
||||
}
|
||||
return res;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
```python
|
||||
class Solution(object):
|
||||
def fourSumCount(self, nums1, nums2, nums3, nums4):
|
||||
"""
|
||||
:type nums1: List[int]
|
||||
:type nums2: List[int]
|
||||
:type nums3: List[int]
|
||||
:type nums4: List[int]
|
||||
:rtype: int
|
||||
"""
|
||||
# use a dict to store the elements in nums1 and nums2 and their sum
|
||||
hashmap = dict()
|
||||
for n1 in nums1:
|
||||
for n2 in nums2:
|
||||
if n1 + n2 in hashmap:
|
||||
hashmap[n1+n2] += 1
|
||||
else:
|
||||
hashmap[n1+n2] = 1
|
||||
|
||||
# if the -(a+b) exists in nums3 and nums4, we shall add the count
|
||||
count = 0
|
||||
for n3 in nums3:
|
||||
for n4 in nums4:
|
||||
key = - n3 - n4
|
||||
if key in hashmap:
|
||||
count += hashmap[key]
|
||||
return count
|
||||
|
||||
# 下面这个写法更为简洁,但是表达的是同样的算法
|
||||
# class Solution:
|
||||
# def fourSumCount(self, nums1: List[int], nums2: List[int], nums3: List[int], nums4: List[int]) -> int:
|
||||
# from collections import defaultdict
|
||||
|
||||
# hashmap = defaultdict(int)
|
||||
|
||||
# for x1 in nums1:
|
||||
# for x2 in nums2:
|
||||
# hashmap[x1+x2] += 1
|
||||
|
||||
# count=0
|
||||
# for x3 in nums3:
|
||||
# for x4 in nums4:
|
||||
# key = -x3-x4
|
||||
# value = hashmap.get(key)
|
||||
|
||||
# dict的get方法会返回None(key不存在)或者key对应的value
|
||||
# 所以如果value==0,就会继续执行or,count+0,否则就会直接加value
|
||||
# 这样就不用去写if判断了
|
||||
|
||||
# count += value or 0
|
||||
|
||||
# return count
|
||||
|
||||
```
|
||||
|
||||
|
||||
Go:
|
||||
```go
|
||||
func fourSumCount(nums1 []int, nums2 []int, nums3 []int, nums4 []int) int {
|
||||
m := make(map[int]int)
|
||||
count := 0
|
||||
for _, v1 := range nums1 {
|
||||
for _, v2 := range nums2 {
|
||||
m[v1+v2]++
|
||||
}
|
||||
}
|
||||
for _, v3 := range nums3 {
|
||||
for _, v4 := range nums4 {
|
||||
count += m[-v3-v4]
|
||||
}
|
||||
}
|
||||
return count
|
||||
}
|
||||
```
|
||||
|
||||
javaScript:
|
||||
|
||||
```js
|
||||
/**
|
||||
* @param {number[]} nums1
|
||||
* @param {number[]} nums2
|
||||
* @param {number[]} nums3
|
||||
* @param {number[]} nums4
|
||||
* @return {number}
|
||||
*/
|
||||
var fourSumCount = function(nums1, nums2, nums3, nums4) {
|
||||
const twoSumMap = new Map();
|
||||
let count = 0;
|
||||
|
||||
for(const n1 of nums1) {
|
||||
for(const n2 of nums2) {
|
||||
const sum = n1 + n2;
|
||||
twoSumMap.set(sum, (twoSumMap.get(sum) || 0) + 1)
|
||||
}
|
||||
}
|
||||
|
||||
for(const n3 of nums3) {
|
||||
for(const n4 of nums4) {
|
||||
const sum = n3 + n4;
|
||||
count += (twoSumMap.get(0 - sum) || 0)
|
||||
}
|
||||
}
|
||||
|
||||
return count;
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
174
problems/0455.分发饼干.md
Normal file
174
problems/0455.分发饼干.md
Normal file
@@ -0,0 +1,174 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
## 455.分发饼干
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/assign-cookies/
|
||||
|
||||
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。
|
||||
|
||||
对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
|
||||
|
||||
示例 1:
|
||||
输入: g = [1,2,3], s = [1,1]
|
||||
输出: 1
|
||||
解释:
|
||||
你有三个孩子和两块小饼干,3个孩子的胃口值分别是:1,2,3。
|
||||
虽然你有两块小饼干,由于他们的尺寸都是1,你只能让胃口值是1的孩子满足。
|
||||
所以你应该输出1。
|
||||
|
||||
示例 2:
|
||||
输入: g = [1,2], s = [1,2,3]
|
||||
输出: 2
|
||||
解释:
|
||||
你有两个孩子和三块小饼干,2个孩子的胃口值分别是1,2。
|
||||
你拥有的饼干数量和尺寸都足以让所有孩子满足。
|
||||
所以你应该输出2.
|
||||
|
||||
|
||||
提示:
|
||||
* 1 <= g.length <= 3 * 10^4
|
||||
* 0 <= s.length <= 3 * 10^4
|
||||
* 1 <= g[i], s[j] <= 2^31 - 1
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
为了了满足更多的小孩,就不要造成饼干尺寸的浪费。
|
||||
|
||||
大尺寸的饼干既可以满足胃口大的孩子也可以满足胃口小的孩子,那么就应该优先满足胃口大的。
|
||||
|
||||
**这里的局部最优就是大饼干喂给胃口大的,充分利用饼干尺寸喂饱一个,全局最优就是喂饱尽可能多的小孩**。
|
||||
|
||||
可以尝试使用贪心策略,先将饼干数组和小孩数组排序。
|
||||
|
||||
然后从后向前遍历小孩数组,用大饼干优先满足胃口大的,并统计满足小孩数量。
|
||||
|
||||
如图:
|
||||
|
||||
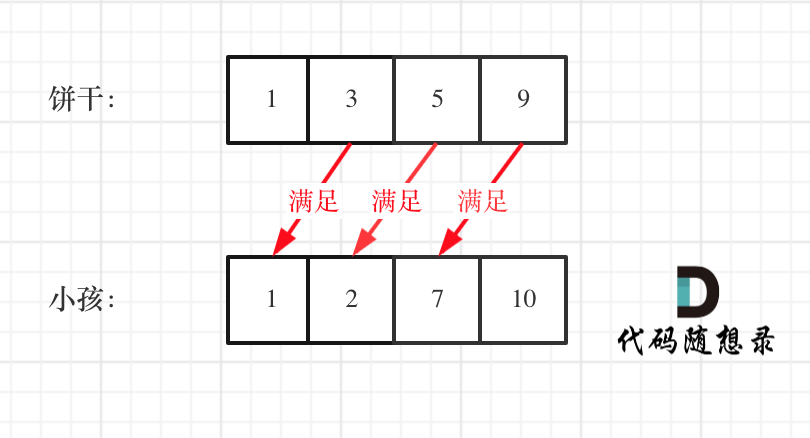
|
||||
|
||||
这个例子可以看出饼干9只有喂给胃口为7的小孩,这样才是整体最优解,并想不出反例,那么就可以撸代码了。
|
||||
|
||||
|
||||
C++代码整体如下:
|
||||
|
||||
```C++
|
||||
// 时间复杂度:O(nlogn)
|
||||
// 空间复杂度:O(1)
|
||||
class Solution {
|
||||
public:
|
||||
int findContentChildren(vector<int>& g, vector<int>& s) {
|
||||
sort(g.begin(), g.end());
|
||||
sort(s.begin(), s.end());
|
||||
int index = s.size() - 1; // 饼干数组的下表
|
||||
int result = 0;
|
||||
for (int i = g.size() - 1; i >= 0; i--) {
|
||||
if (index >= 0 && s[index] >= g[i]) {
|
||||
result++;
|
||||
index--;
|
||||
}
|
||||
}
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
从代码中可以看出我用了一个index来控制饼干数组的遍历,遍历饼干并没有再起一个for循环,而是采用自减的方式,这也是常用的技巧。
|
||||
|
||||
有的同学看到要遍历两个数组,就想到用两个for循环,那样逻辑其实就复杂了。
|
||||
|
||||
**也可以换一个思路,小饼干先喂饱小胃口**
|
||||
|
||||
代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int findContentChildren(vector<int>& g, vector<int>& s) {
|
||||
sort(g.begin(),g.end());
|
||||
sort(s.begin(),s.end());
|
||||
int index = 0;
|
||||
for(int i = 0;i < s.size();++i){
|
||||
if(index < g.size() && g[index] <= s[i]){
|
||||
index++;
|
||||
}
|
||||
}
|
||||
return index;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
这道题是贪心很好的一道入门题目,思路还是比较容易想到的。
|
||||
|
||||
文中详细介绍了思考的过程,**想清楚局部最优,想清楚全局最优,感觉局部最优是可以推出全局最优,并想不出反例,那么就试一试贪心**。
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```java
|
||||
class Solution {
|
||||
public int findContentChildren(int[] g, int[] s) {
|
||||
Arrays.sort(g);
|
||||
Arrays.sort(s);
|
||||
int start = 0;
|
||||
int count = 0;
|
||||
for (int i = 0; i < s.length && start < g.length; i++) {
|
||||
if (s[i] >= g[start]) {
|
||||
start++;
|
||||
count++;
|
||||
}
|
||||
}
|
||||
return count;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python3
|
||||
class Solution:
|
||||
def findContentChildren(self, g: List[int], s: List[int]) -> int:
|
||||
g.sort()
|
||||
s.sort()
|
||||
res = 0
|
||||
for i in range(len(s)):
|
||||
if res <len(g) and s[i] >= g[res]: #小饼干先喂饱小胃口
|
||||
res += 1
|
||||
return res
|
||||
```
|
||||
Go:
|
||||
|
||||
Javascript:
|
||||
```Javascript
|
||||
|
||||
var findContentChildren = function(g, s) {
|
||||
g = g.sort((a, b) => a - b)
|
||||
s = s.sort((a, b) => a - b)
|
||||
let result = 0
|
||||
let index = s.length - 1
|
||||
for(let i = g.length - 1; i >= 0; i--) {
|
||||
if(index >= 0 && s[index] >= g[i]) {
|
||||
result++
|
||||
index--
|
||||
}
|
||||
}
|
||||
return result
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
301
problems/0459.重复的子字符串.md
Normal file
301
problems/0459.重复的子字符串.md
Normal file
@@ -0,0 +1,301 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
|
||||
|
||||
> KMP算法还能干这个
|
||||
|
||||
# 459.重复的子字符串
|
||||
|
||||
https://leetcode-cn.com/problems/repeated-substring-pattern/
|
||||
|
||||
给定一个非空的字符串,判断它是否可以由它的一个子串重复多次构成。给定的字符串只含有小写英文字母,并且长度不超过10000。
|
||||
|
||||
示例 1:
|
||||
输入: "abab"
|
||||
输出: True
|
||||
解释: 可由子字符串 "ab" 重复两次构成。
|
||||
|
||||
示例 2:
|
||||
输入: "aba"
|
||||
输出: False
|
||||
|
||||
示例 3:
|
||||
输入: "abcabcabcabc"
|
||||
输出: True
|
||||
解释: 可由子字符串 "abc" 重复四次构成。 (或者子字符串 "abcabc" 重复两次构成。)
|
||||
|
||||
# 思路
|
||||
|
||||
这又是一道标准的KMP的题目。
|
||||
|
||||
如果KMP还不够了解,可以看我的B站:
|
||||
|
||||
* [帮你把KMP算法学个通透!B站(理论篇)](https://www.bilibili.com/video/BV1PD4y1o7nd/)
|
||||
* [帮你把KMP算法学个通透!(求next数组代码篇)](https://www.bilibili.com/video/BV1M5411j7Xx)
|
||||
|
||||
|
||||
我们在[字符串:KMP算法精讲](https://mp.weixin.qq.com/s/MoRBHbS4hQXn7LcPdmHmIg)里提到了,在一个串中查找是否出现过另一个串,这是KMP的看家本领。
|
||||
|
||||
那么寻找重复子串怎么也涉及到KMP算法了呢?
|
||||
|
||||
这里就要说一说next数组了,next 数组记录的就是最长相同前后缀( [字符串:KMP算法精讲](https://mp.weixin.qq.com/s/MoRBHbS4hQXn7LcPdmHmIg) 这里介绍了什么是前缀,什么是后缀,什么又是最长相同前后缀), 如果 next[len - 1] != -1,则说明字符串有最长相同的前后缀(就是字符串里的前缀子串和后缀子串相同的最长长度)。
|
||||
|
||||
最长相等前后缀的长度为:next[len - 1] + 1。
|
||||
|
||||
数组长度为:len。
|
||||
|
||||
如果len % (len - (next[len - 1] + 1)) == 0 ,则说明 (数组长度-最长相等前后缀的长度) 正好可以被 数组的长度整除,说明有该字符串有重复的子字符串。
|
||||
|
||||
**数组长度减去最长相同前后缀的长度相当于是第一个周期的长度,也就是一个周期的长度,如果这个周期可以被整除,就说明整个数组就是这个周期的循环。**
|
||||
|
||||
|
||||
**强烈建议大家把next数组打印出来,看看next数组里的规律,有助于理解KMP算法**
|
||||
|
||||
如图:
|
||||
|
||||
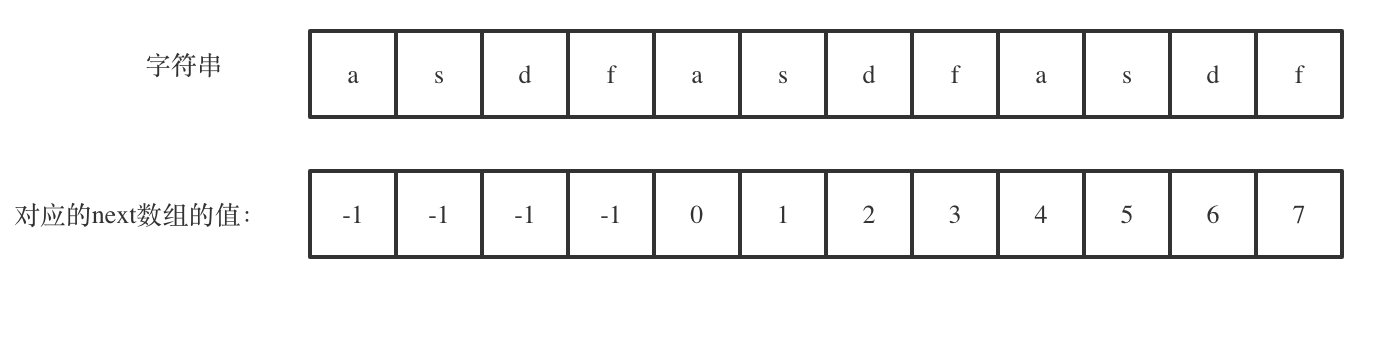
|
||||
|
||||
next[len - 1] = 7,next[len - 1] + 1 = 8,8就是此时字符串asdfasdfasdf的最长相同前后缀的长度。
|
||||
|
||||
|
||||
(len - (next[len - 1] + 1)) 也就是: 12(字符串的长度) - 8(最长公共前后缀的长度) = 4, 4正好可以被 12(字符串的长度) 整除,所以说明有重复的子字符串(asdf)。
|
||||
|
||||
|
||||
C++代码如下:(这里使用了前缀表统一减一的实现方式)
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
void getNext (int* next, const string& s){
|
||||
next[0] = -1;
|
||||
int j = -1;
|
||||
for(int i = 1;i < s.size(); i++){
|
||||
while(j >= 0 && s[i] != s[j+1]) {
|
||||
j = next[j];
|
||||
}
|
||||
if(s[i] == s[j+1]) {
|
||||
j++;
|
||||
}
|
||||
next[i] = j;
|
||||
}
|
||||
}
|
||||
bool repeatedSubstringPattern (string s) {
|
||||
if (s.size() == 0) {
|
||||
return false;
|
||||
}
|
||||
int next[s.size()];
|
||||
getNext(next, s);
|
||||
int len = s.size();
|
||||
if (next[len - 1] != -1 && len % (len - (next[len - 1] + 1)) == 0) {
|
||||
return true;
|
||||
}
|
||||
return false;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
前缀表(不减一)的C++代码实现
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
void getNext (int* next, const string& s){
|
||||
next[0] = 0;
|
||||
int j = 0;
|
||||
for(int i = 1;i < s.size(); i++){
|
||||
while(j > 0 && s[i] != s[j]) {
|
||||
j = next[j - 1];
|
||||
}
|
||||
if(s[i] == s[j]) {
|
||||
j++;
|
||||
}
|
||||
next[i] = j;
|
||||
}
|
||||
}
|
||||
bool repeatedSubstringPattern (string s) {
|
||||
if (s.size() == 0) {
|
||||
return false;
|
||||
}
|
||||
int next[s.size()];
|
||||
getNext(next, s);
|
||||
int len = s.size();
|
||||
if (next[len - 1] != 0 && len % (len - (next[len - 1] )) == 0) {
|
||||
return true;
|
||||
}
|
||||
return false;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
# 拓展
|
||||
|
||||
在[字符串:KMP算法精讲](https://mp.weixin.qq.com/s/MoRBHbS4hQXn7LcPdmHmIg)中讲解KMP算法的基础理论,给出next数组究竟是如何来了,前缀表又是怎么回事,为什么要选择前缀表。
|
||||
|
||||
讲解一道KMP的经典题目,力扣:28. 实现 strStr(),判断文本串里是否出现过模式串,这里涉及到构造next数组的代码实现,以及使用next数组完成模式串与文本串的匹配过程。
|
||||
|
||||
后来很多同学反馈说:搞不懂前后缀,什么又是最长相同前后缀(最长公共前后缀我认为这个用词不准确),以及为什么前缀表要统一减一(右移)呢,不减一行不行?针对这些问题,我在[字符串:KMP算法精讲](https://mp.weixin.qq.com/s/MoRBHbS4hQXn7LcPdmHmIg)给出了详细的讲解。
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
Java:
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
public boolean repeatedSubstringPattern(String s) {
|
||||
if (s.equals("")) return false;
|
||||
|
||||
int len = s.length();
|
||||
// 原串加个空格(哨兵),使下标从1开始,这样j从0开始,也不用初始化了
|
||||
s = " " + s;
|
||||
char[] chars = s.toCharArray();
|
||||
int[] next = new int[len + 1];
|
||||
|
||||
// 构造 next 数组过程,j从0开始(空格),i从2开始
|
||||
for (int i = 2, j = 0; i <= len; i++) {
|
||||
// 匹配不成功,j回到前一位置 next 数组所对应的值
|
||||
while (j > 0 && chars[i] != chars[j + 1]) j = next[j];
|
||||
// 匹配成功,j往后移
|
||||
if (chars[i] == chars[j + 1]) j++;
|
||||
// 更新 next 数组的值
|
||||
next[i] = j;
|
||||
}
|
||||
|
||||
// 最后判断是否是重复的子字符串,这里 next[len] 即代表next数组末尾的值
|
||||
if (next[len] > 0 && len % (len - next[len]) == 0) {
|
||||
return true;
|
||||
}
|
||||
return false;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
Python:
|
||||
|
||||
这里使用了前缀表统一减一的实现方式
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def repeatedSubstringPattern(self, s: str) -> bool:
|
||||
if len(s) == 0:
|
||||
return False
|
||||
nxt = [0] * len(s)
|
||||
self.getNext(nxt, s)
|
||||
if nxt[-1] != -1 and len(s) % (len(s) - (nxt[-1] + 1)) == 0:
|
||||
return True
|
||||
return False
|
||||
|
||||
def getNext(self, nxt, s):
|
||||
nxt[0] = -1
|
||||
j = -1
|
||||
for i in range(1, len(s)):
|
||||
while j >= 0 and s[i] != s[j+1]:
|
||||
j = nxt[j]
|
||||
if s[i] == s[j+1]:
|
||||
j += 1
|
||||
nxt[i] = j
|
||||
return nxt
|
||||
```
|
||||
|
||||
前缀表(不减一)的代码实现
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def repeatedSubstringPattern(self, s: str) -> bool:
|
||||
if len(s) == 0:
|
||||
return False
|
||||
nxt = [0] * len(s)
|
||||
self.getNext(nxt, s)
|
||||
if nxt[-1] != 0 and len(s) % (len(s) - nxt[-1]) == 0:
|
||||
return True
|
||||
return False
|
||||
|
||||
def getNext(self, nxt, s):
|
||||
nxt[0] = 0
|
||||
j = 0
|
||||
for i in range(1, len(s)):
|
||||
while j > 0 and s[i] != s[j]:
|
||||
j = nxt[j - 1]
|
||||
if s[i] == s[j]:
|
||||
j += 1
|
||||
nxt[i] = j
|
||||
return nxt
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
这里使用了前缀表统一减一的实现方式
|
||||
|
||||
```go
|
||||
func repeatedSubstringPattern(s string) bool {
|
||||
n := len(s)
|
||||
if n == 0 {
|
||||
return false
|
||||
}
|
||||
next := make([]int, n)
|
||||
j := -1
|
||||
next[0] = j
|
||||
for i := 1; i < n; i++ {
|
||||
for j >= 0 && s[i] != s[j+1] {
|
||||
j = next[j]
|
||||
}
|
||||
if s[i] == s[j+1] {
|
||||
j++
|
||||
}
|
||||
next[i] = j
|
||||
}
|
||||
// next[n-1]+1 最长相同前后缀的长度
|
||||
if next[n-1] != -1 && n%(n-(next[n-1]+1)) == 0 {
|
||||
return true
|
||||
}
|
||||
return false
|
||||
}
|
||||
```
|
||||
|
||||
前缀表(不减一)的代码实现
|
||||
|
||||
```go
|
||||
func repeatedSubstringPattern(s string) bool {
|
||||
n := len(s)
|
||||
if n == 0 {
|
||||
return false
|
||||
}
|
||||
j := 0
|
||||
next := make([]int, n)
|
||||
next[0] = j
|
||||
for i := 1; i < n; i++ {
|
||||
for j > 0 && s[i] != s[j] {
|
||||
j = next[j-1]
|
||||
}
|
||||
if s[i] == s[j] {
|
||||
j++
|
||||
}
|
||||
next[i] = j
|
||||
}
|
||||
// next[n-1] 最长相同前后缀的长度
|
||||
if next[n-1] != 0 && n%(n-next[n-1]) == 0 {
|
||||
return true
|
||||
}
|
||||
return false
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
253
problems/0474.一和零.md
Normal file
253
problems/0474.一和零.md
Normal file
@@ -0,0 +1,253 @@
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
# 动态规划:一和零!
|
||||
|
||||
## 474.一和零
|
||||
|
||||
题目链接:https://leetcode-cn.com/problems/ones-and-zeroes/
|
||||
|
||||
给你一个二进制字符串数组 strs 和两个整数 m 和 n 。
|
||||
|
||||
请你找出并返回 strs 的最大子集的大小,该子集中 最多 有 m 个 0 和 n 个 1 。
|
||||
|
||||
如果 x 的所有元素也是 y 的元素,集合 x 是集合 y 的 子集 。
|
||||
|
||||
示例 1:
|
||||
|
||||
输入:strs = ["10", "0001", "111001", "1", "0"], m = 5, n = 3
|
||||
输出:4
|
||||
|
||||
解释:最多有 5 个 0 和 3 个 1 的最大子集是 {"10","0001","1","0"} ,因此答案是 4 。
|
||||
其他满足题意但较小的子集包括 {"0001","1"} 和 {"10","1","0"} 。{"111001"} 不满足题意,因为它含 4 个 1 ,大于 n 的值 3 。
|
||||
|
||||
示例 2:
|
||||
输入:strs = ["10", "0", "1"], m = 1, n = 1
|
||||
输出:2
|
||||
解释:最大的子集是 {"0", "1"} ,所以答案是 2 。
|
||||
|
||||
提示:
|
||||
|
||||
* 1 <= strs.length <= 600
|
||||
* 1 <= strs[i].length <= 100
|
||||
* strs[i] 仅由 '0' 和 '1' 组成
|
||||
* 1 <= m, n <= 100
|
||||
|
||||
## 思路
|
||||
|
||||
这道题目,还是比较难的,也有点像程序员自己给自己出个脑筋急转弯,程序员何苦为难程序员呢哈哈。
|
||||
|
||||
来说题,本题不少同学会认为是多重背包,一些题解也是这么写的。
|
||||
|
||||
其实本题并不是多重背包,再来看一下这个图,捋清几种背包的关系
|
||||
|
||||
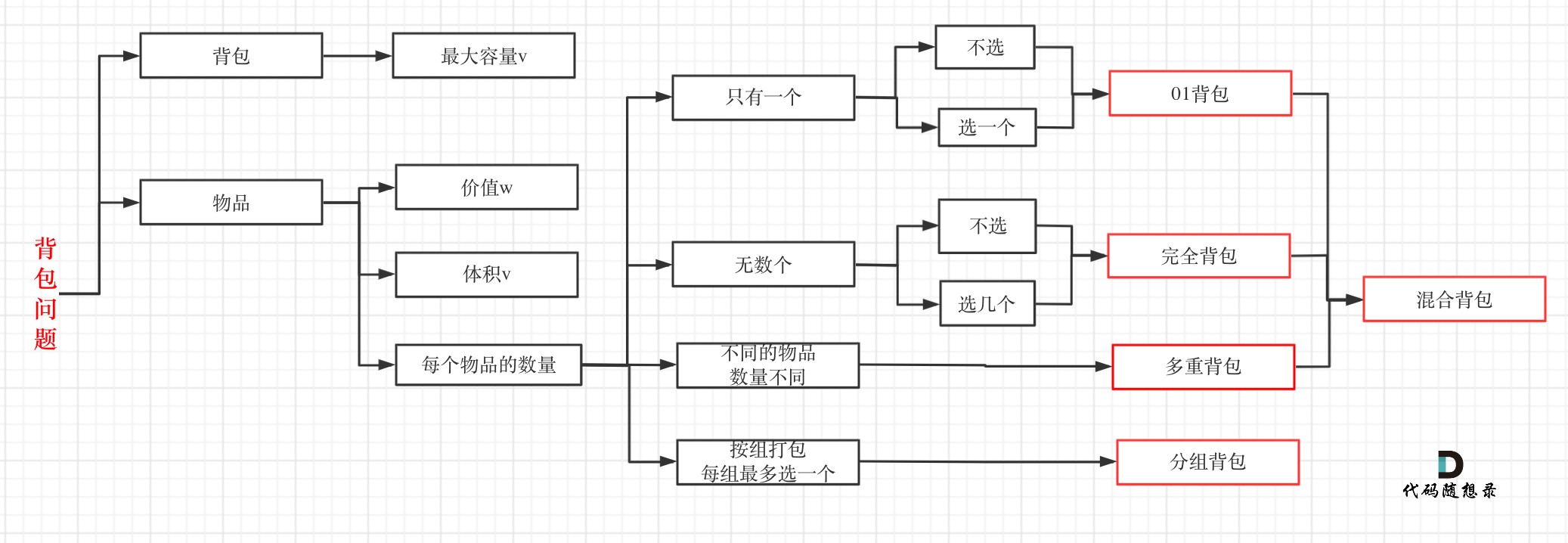
|
||||
|
||||
多重背包是每个物品,数量不同的情况。
|
||||
|
||||
**本题中strs 数组里的元素就是物品,每个物品都是一个!**
|
||||
|
||||
**而m 和 n相当于是一个背包,两个维度的背包**。
|
||||
|
||||
理解成多重背包的同学主要是把m和n混淆为物品了,感觉这是不同数量的物品,所以以为是多重背包。
|
||||
|
||||
但本题其实是01背包问题!
|
||||
|
||||
这不过这个背包有两个维度,一个是m 一个是n,而不同长度的字符串就是不同大小的待装物品。
|
||||
|
||||
开始动规五部曲:
|
||||
|
||||
1. 确定dp数组(dp table)以及下标的含义
|
||||
|
||||
**dp[i][j]:最多有i个0和j个1的strs的最大子集的大小为dp[i][j]**。
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
dp[i][j] 可以由前一个strs里的字符串推导出来,strs里的字符串有zeroNum个0,oneNum个1。
|
||||
|
||||
dp[i][j] 就可以是 dp[i - zeroNum][j - oneNum] + 1。
|
||||
|
||||
然后我们在遍历的过程中,取dp[i][j]的最大值。
|
||||
|
||||
所以递推公式:dp[i][j] = max(dp[i][j], dp[i - zeroNum][j - oneNum] + 1);
|
||||
|
||||
此时大家可以回想一下01背包的递推公式:dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
|
||||
|
||||
对比一下就会发现,字符串的zeroNum和oneNum相当于物品的重量(weight[i]),字符串本身的个数相当于物品的价值(value[i])。
|
||||
|
||||
**这就是一个典型的01背包!** 只不过物品的重量有了两个维度而已。
|
||||
|
||||
|
||||
3. dp数组如何初始化
|
||||
|
||||
在[动态规划:关于01背包问题,你该了解这些!(滚动数组)](https://mp.weixin.qq.com/s/M4uHxNVKRKm5HPjkNZBnFA)中已经讲解了,01背包的dp数组初始化为0就可以。
|
||||
|
||||
因为物品价值不会是负数,初始为0,保证递推的时候dp[i][j]不会被初始值覆盖。
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
在[动态规划:关于01背包问题,你该了解这些!(滚动数组)](https://mp.weixin.qq.com/s/M4uHxNVKRKm5HPjkNZBnFA)中,我们讲到了01背包为什么一定是外层for循环遍历物品,内层for循环遍历背包容量且从后向前遍历!
|
||||
|
||||
那么本题也是,物品就是strs里的字符串,背包容量就是题目描述中的m和n。
|
||||
|
||||
代码如下:
|
||||
```C++
|
||||
for (string str : strs) { // 遍历物品
|
||||
int oneNum = 0, zeroNum = 0;
|
||||
for (char c : str) {
|
||||
if (c == '0') zeroNum++;
|
||||
else oneNum++;
|
||||
}
|
||||
for (int i = m; i >= zeroNum; i--) { // 遍历背包容量且从后向前遍历!
|
||||
for (int j = n; j >= oneNum; j--) {
|
||||
dp[i][j] = max(dp[i][j], dp[i - zeroNum][j - oneNum] + 1);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
有同学可能想,那个遍历背包容量的两层for循环先后循序有没有什么讲究?
|
||||
|
||||
没讲究,都是物品重量的一个维度,先遍历那个都行!
|
||||
|
||||
5. 举例推导dp数组
|
||||
|
||||
以输入:["10","0001","111001","1","0"],m = 3,n = 3为例
|
||||
|
||||
最后dp数组的状态如下所示:
|
||||
|
||||
|
||||
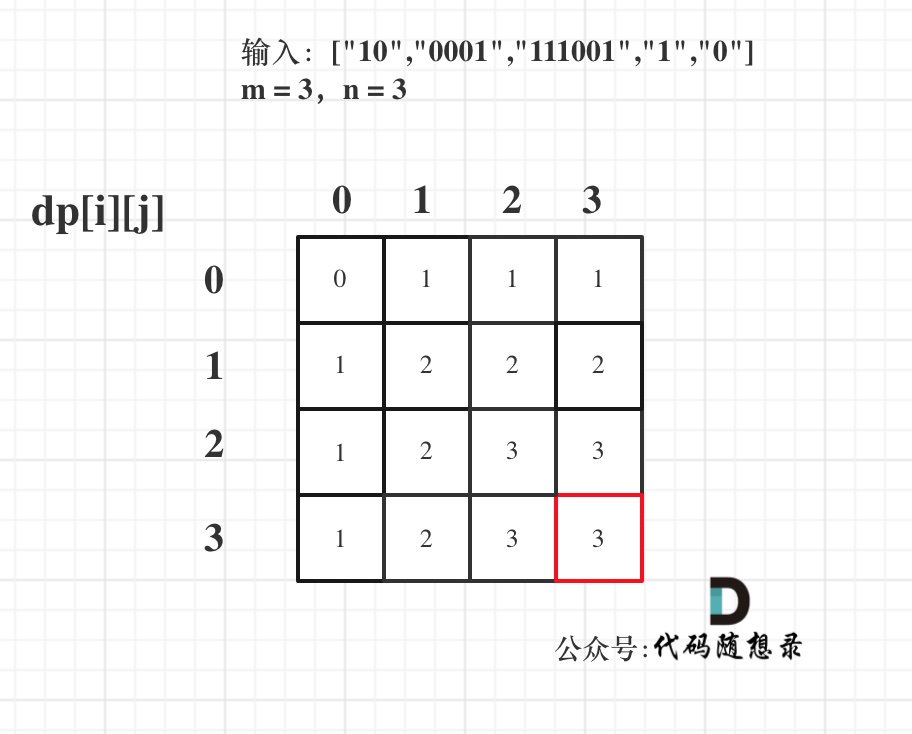
|
||||
|
||||
|
||||
以上动规五部曲分析完毕,C++代码如下:
|
||||
|
||||
```C++
|
||||
class Solution {
|
||||
public:
|
||||
int findMaxForm(vector<string>& strs, int m, int n) {
|
||||
vector<vector<int>> dp(m + 1, vector<int> (n + 1, 0)); // 默认初始化0
|
||||
for (string str : strs) { // 遍历物品
|
||||
int oneNum = 0, zeroNum = 0;
|
||||
for (char c : str) {
|
||||
if (c == '0') zeroNum++;
|
||||
else oneNum++;
|
||||
}
|
||||
for (int i = m; i >= zeroNum; i--) { // 遍历背包容量且从后向前遍历!
|
||||
for (int j = n; j >= oneNum; j--) {
|
||||
dp[i][j] = max(dp[i][j], dp[i - zeroNum][j - oneNum] + 1);
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[m][n];
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
不少同学刷过这道提,可能没有总结这究竟是什么背包。
|
||||
|
||||
这道题的本质是有两个维度的01背包,如果大家认识到这一点,对这道题的理解就比较深入了。
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
```Java
|
||||
class Solution {
|
||||
public int findMaxForm(String[] strs, int m, int n) {
|
||||
//dp[i][j]表示i个0和j个1时的最大子集
|
||||
int[][] dp = new int[m + 1][n + 1];
|
||||
int oneNum, zeroNum;
|
||||
for (String str : strs) {
|
||||
oneNum = 0;
|
||||
zeroNum = 0;
|
||||
for (char ch : str.toCharArray()) {
|
||||
if (ch == '0') {
|
||||
zeroNum++;
|
||||
} else {
|
||||
oneNum++;
|
||||
}
|
||||
}
|
||||
//倒序遍历
|
||||
for (int i = m; i >= zeroNum; i--) {
|
||||
for (int j = n; j >= oneNum; j--) {
|
||||
dp[i][j] = Math.max(dp[i][j], dp[i - zeroNum][j - oneNum] + 1);
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[m][n];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
```python3
|
||||
class Solution:
|
||||
def findMaxForm(self, strs: List[str], m: int, n: int) -> int:
|
||||
dp = [[0] * (n + 1) for _ in range(m + 1)] # 默认初始化0
|
||||
# 遍历物品
|
||||
for str in strs:
|
||||
ones = str.count('1')
|
||||
zeros = str.count('0')
|
||||
# 遍历背包容量且从后向前遍历!
|
||||
for i in range(m, zeros - 1, -1):
|
||||
for j in range(n, ones - 1, -1):
|
||||
dp[i][j] = max(dp[i][j], dp[i - zeros][j - ones] + 1)
|
||||
return dp[m][n]
|
||||
```
|
||||
|
||||
Go:
|
||||
```go
|
||||
func findMaxForm(strs []string, m int, n int) int {
|
||||
// 定义数组
|
||||
dp := make([][]int, m+1)
|
||||
for i,_ := range dp {
|
||||
dp[i] = make([]int, n+1 )
|
||||
}
|
||||
// 遍历
|
||||
for i:=0;i<len(strs);i++ {
|
||||
zeroNum,oneNum := 0 , 0
|
||||
//计算0,1 个数
|
||||
//或者直接strings.Count(strs[i],"0")
|
||||
for _,v := range strs[i] {
|
||||
if v == '0' {
|
||||
zeroNum++
|
||||
}
|
||||
}
|
||||
oneNum = len(strs[i])-zeroNum
|
||||
// 从后往前 遍历背包容量
|
||||
for j:= m ; j >= zeroNum;j-- {
|
||||
for k:=n ; k >= oneNum;k-- {
|
||||
// 推导公式
|
||||
dp[j][k] = max(dp[j][k],dp[j-zeroNum][k-oneNum]+1)
|
||||
}
|
||||
}
|
||||
//fmt.Println(dp)
|
||||
}
|
||||
return dp[m][n]
|
||||
}
|
||||
|
||||
func max(a,b int) int {
|
||||
if a > b {
|
||||
return a
|
||||
}
|
||||
return b
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=../pics/公众号.png width=450 alt=> </img></div>
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user